
Развертывание Tabby на VPS: создание собственного AI-ассистента для кодинга (Self-hosted GitHub Copilot alternative)
TL;DR
В этом руководстве мы развернем Tabby — современную self-hosted альтернативу GitHub Copilot — на выделенном виртуальном сервере. Это позволит вам получить мощный инструмент автодополнения кода на базе больших языковых моделей (LLM), сохраняя при этом полный контроль над вашими исходными кодами и приватностью. Мы настроим Docker-контейнеры, обеспечим безопасность через SSL-шифрование и подключим ассистента к популярным IDE.
- Конфиденциальность: Ваш код никогда не покидает ваш сервер.
- Экономия: Отсутствие ежемесячных подписок за каждого пользователя.
- Гибкость: Возможность выбора моделей (StarCoder, DeepSeek, CodeLlama) под конкретные задачи.
- Производительность: Оптимизация под CPU и GPU архитектуры актуальные в 2026 году.
- Интеграция: Поддержка VS Code, JetBrains, Vim/Neovim через официальные расширения.
Ищете сервер, который просто работает?
Valebyte VPS — NVMe, поддержка 24/7, развёртывание за 60 секунд.
1. Что мы настраиваем и зачем
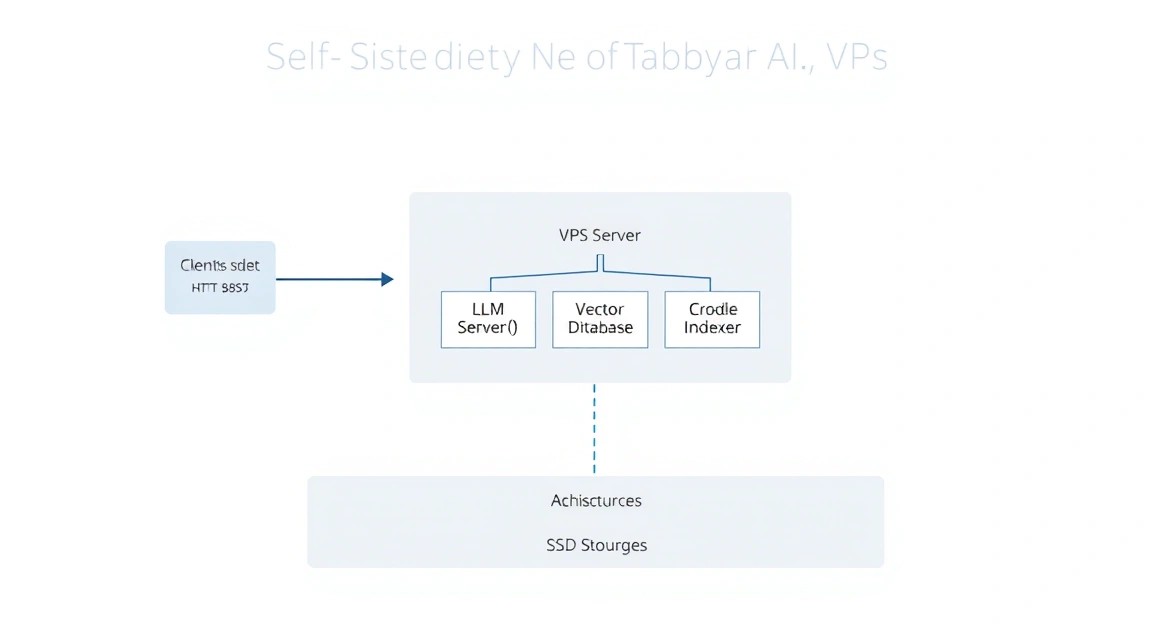
Программирование в 2026 году немыслимо без AI-ассистентов. Однако использование облачных решений вроде GitHub Copilot или ChatGPT сопряжено с рисками: утечка проприетарного кода, зависимость от стабильности внешних сервисов и постоянно растущая стоимость подписки. Tabby решает эти проблемы, предлагая open-source движок для запуска LLM (Large Language Models), оптимизированных специально для написания кода.
Tabby — это не просто обертка над моделью, это полноценный бэкенд, который индексирует ваши локальные репозитории для обеспечения контекстного автодополнения. Он поддерживает современные техники квантования, что позволяет запускать тяжелые модели даже на потребительском железе или недорогих VPS без выделенных видеокарт (используя только CPU и быстрые инструкции AVX-512).
Что вы получите в итоге:
- Собственный API-сервер, совместимый с протоколами современных AI-расширений.
- Веб-интерфейс для управления моделями и мониторинга нагрузки.
- Полную независимость от западных облачных провайдеров.
- Возможность дообучения (fine-tuning) модели на кодовой базе вашей компании.
2. Какой VPS-конфиг нужен под эту задачу
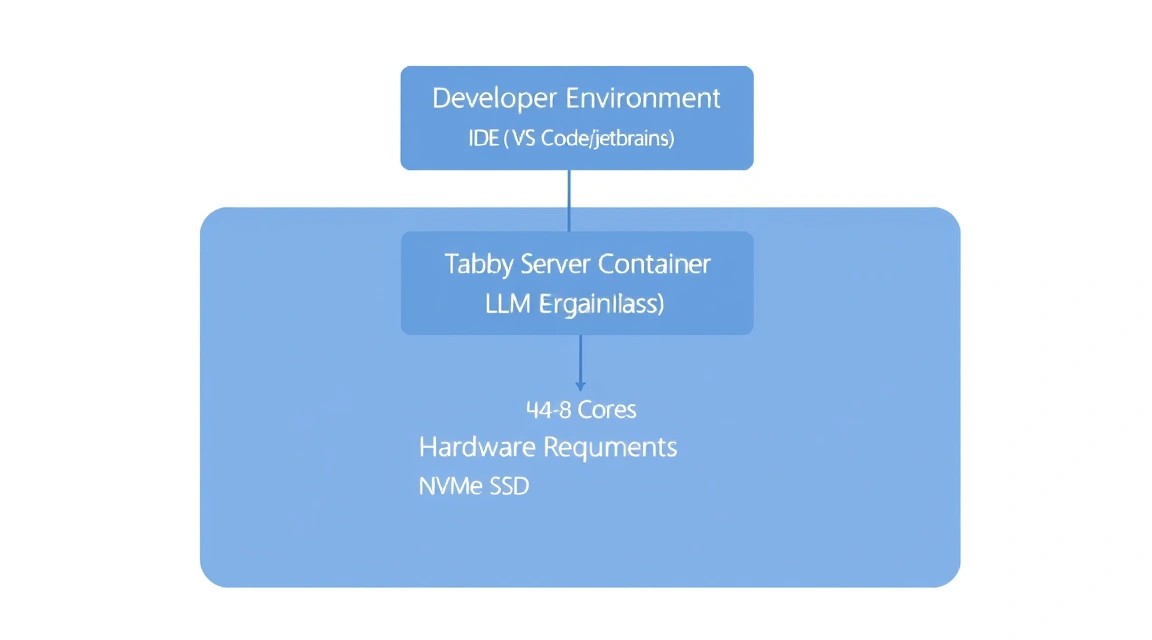
Выбор железа для Tabby критически важен, так как работа LLM напрямую зависит от скорости доступа к памяти и вычислительной мощности процессора. В 2026 году стандартом для комфортной работы являются модели объемом от 3B до 7B параметров в квантованном виде (4-bit или 8-bit).
| Характеристика | Минимальные (1 пользователь) | Рекомендуемые (команда 3-5 чел) | Максимальные (GPU-ускорение) |
|---|---|---|---|
| CPU | 2-4 vCPU (с поддержкой AVX2) | 8+ vCPU (Modern AMD/Intel) | 4+ vCPU + NVIDIA GPU (8GB+ VRAM) |
| RAM | 8 GB DDR4/DDR5 | 16-32 GB DDR5 | 16 GB + VRAM видеокарты |
| Диск | 40 GB NVMe SSD | 100 GB NVMe SSD | 200 GB NVMe SSD |
| ОС | Ubuntu 24.04 / 26.04 LTS | Ubuntu 24.04 / 26.04 LTS | Ubuntu + NVIDIA Drivers |
Для стабильной работы без задержек (latency) при генерации кода крайне важно использовать NVMe накопители, так как веса моделей подгружаются в память быстро, но индексация репозиториев создает высокую нагрузку на I/O. Если вы планируете использовать модели уровня DeepSeek-Coder-7B, ориентируйтесь на объем оперативной памяти не менее 16 ГБ.
Для большинства индивидуальных разработчиков и небольших команд оптимальным выбором будет подходящий VPS с 4-8 ядрами и быстрым NVMe диском. Если же ваша кодовая база исчисляется миллионами строк, стоит рассмотреть подходящий dedicated сервер, чтобы избежать "шумных соседей" и использовать всю мощность CPU для инференса.
Локация сервера: Выбирайте дата-центр с минимальным пингом до вашего рабочего места. Задержка в 100-150 мс при каждом нажатии клавиши может сделать использование AI-ассистента некомфортным.
3. Подготовка сервера
После получения доступа к серверу необходимо выполнить базовую настройку безопасности. Мы создадим отдельного пользователя, настроим брандмауэр и обновим пакеты системы.
Подключаемся по SSH:
ssh root@your_server_ip
Обновляем систему до актуального состояния:
apt update && apt upgrade -y
Создаем пользователя для работы с Tabby (запуск AI-сервисов от root — плохая практика):
adduser tabbyuser
usermod -aG sudo tabbyuser
Настраиваем базовый брандмауэр (UFW). Нам понадобятся порты 22 (SSH), 80 (HTTP) и 443 (HTTPS):
ufw allow 22/tcp
ufw allow 80/tcp
ufw allow 443/tcp
ufw enable
Устанавливаем часовой пояс и полезные утилиты:
timedatectl set-timezone Europe/Moscow
apt install -y curl git vim htop fail2ban
Ищете сервер, который просто работает?
Valebyte VPS — NVMe, поддержка 24/7, развёртывание за 60 секунд.
4. Установка Docker и необходимых утилит
Tabby официально распространяется в виде Docker-образов. Это наиболее стабильный способ развертывания, так как он изолирует зависимости моделей и библиотеки инференса.
Устанавливаем Docker через официальный скрипт:
curl -fsSL https://get.docker.com -o get-docker.sh
sudo sh get-docker.sh
Добавляем нашего пользователя в группу docker, чтобы не использовать sudo постоянно:
sudo usermod -aG docker tabbyuser
Важно: Перезайдите в терминал (logout/login), чтобы права применились.
Проверяем работоспособность:
docker --version && docker compose version
5. Развертывание Tabby: пошаговая установка
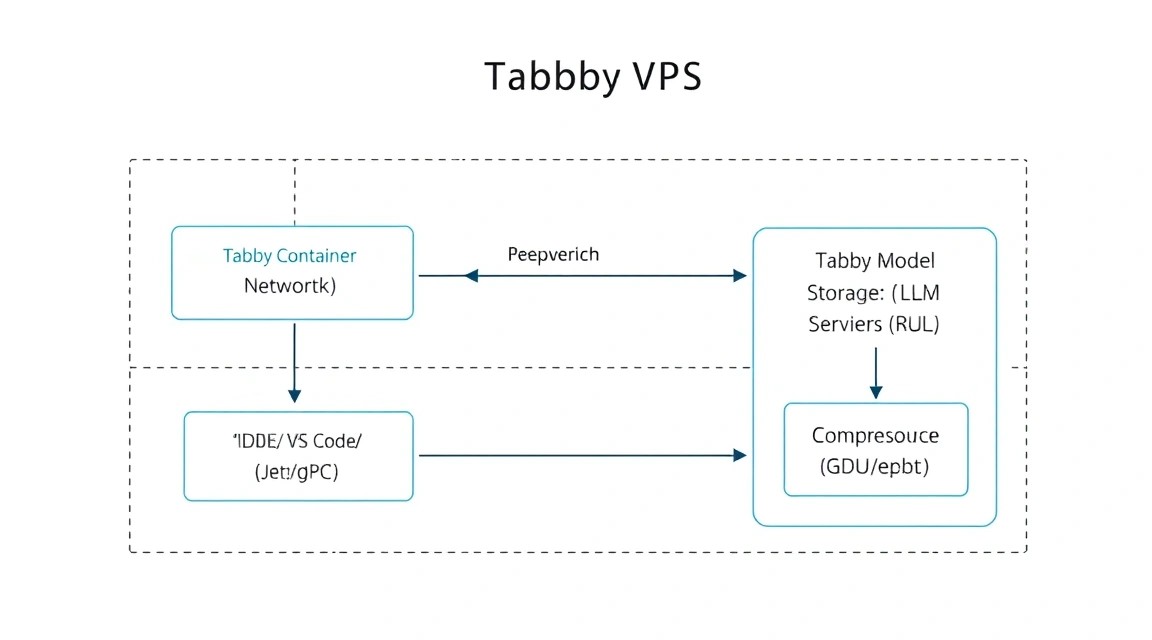
Мы будем использовать Docker Compose для управления контейнером Tabby. Это позволит легко обновлять модель и сохранять конфигурацию.
Создаем директорию для проекта:
mkdir ~/tabby-server && cd ~/tabby-server
Создаем файл docker-compose.yml. В данном примере мы используем конфигурацию для CPU-инференса, которая подходит для большинства VPS. Мы выберем модель StarCoder2-3B, которая отлично сбалансирована по скорости и качеству.
cat < docker-compose.yml
version: '3.8'
services:
tabby:
image: tabbyml/tabby:latest
container_name: tabby
restart: always
ports:
- "8080:8080"
volumes:
- ./data:/data
command: serve --model StarCoder2-3B --device cpu
EOF
Разберем параметры команды запуска:
--model StarCoder2-3B: Указывает Tabby автоматически скачать и использовать эту модель.--device cpu: Явное указание использовать центральный процессор. Если у вас есть GPU, замените наcuda.--port 8080: Внутренний порт сервера.
Запускаем сервер (первый запуск займет время, так как скачивается образ и веса модели — около 2-5 ГБ):
docker compose up -d
Проверить статус загрузки модели можно через логи:
docker compose logs -f
Когда вы увидите сообщение Listening at 0.0.0.0:8080, сервер готов к работе.
6. Конфигурация: домен, SSL и безопасность
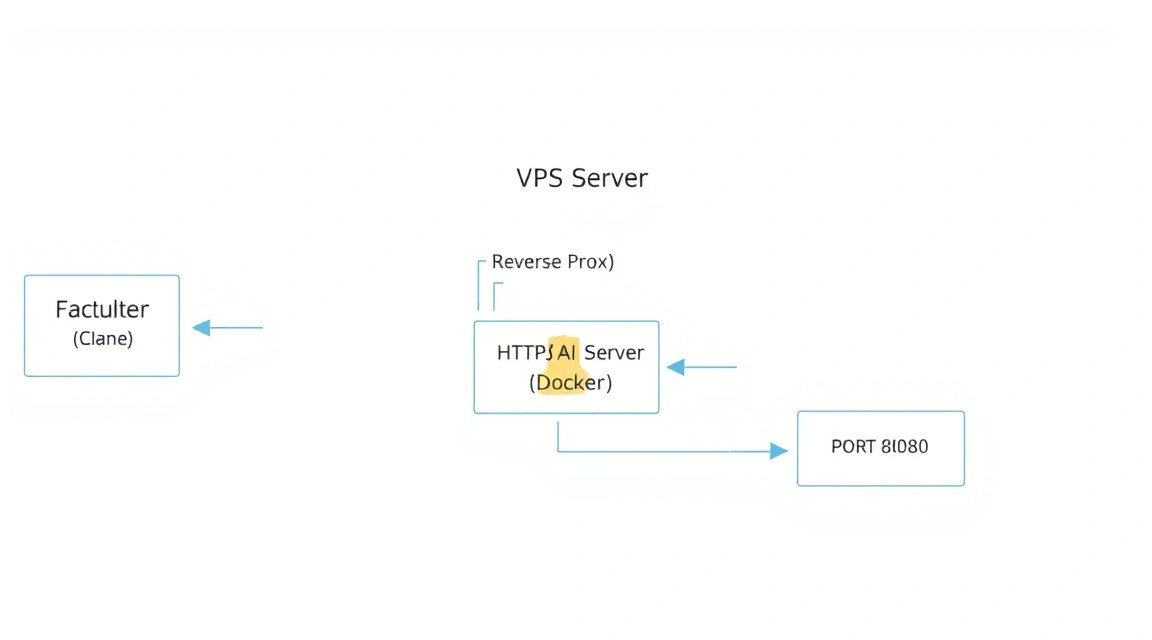
Открывать порт 8080 напрямую в интернет небезопасно. Мы настроим реверс-прокси с помощью Caddy. Caddy автоматически получит SSL-сертификаты от Let's Encrypt и настроит HTTPS.
Создаем Caddyfile в той же директории:
cat < Caddyfile
ai.yourdomain.com {
reverse_proxy tabby:8080
header {
Strict-Transport-Security max-age=31536000
}
}
EOF
Замените ai.yourdomain.com на ваш реальный домен или поддомен.
Обновим docker-compose.yml, добавив сервис Caddy:
cat < docker-compose.yml
version: '3.8'
services:
tabby:
image: tabbyml/tabby:latest
container_name: tabby
restart: always
volumes:
- ./data:/data
command: serve --model StarCoder2-3B --device cpu
caddy:
image: caddy:latest
container_name: caddy
restart: always
ports:
- "80:80"
- "443:443"
volumes:
- ./Caddyfile:/etc/caddy/Caddyfile
- caddy_data:/data
- caddy_config:/config
depends_on:
- tabby
volumes:
caddy_data:
caddy_config:
EOF
Перезапускаем стек:
docker compose up -d
Теперь ваш AI-ассистент доступен по защищенному протоколу HTTPS. Перейдите в браузере на https://ai.yourdomain.com. При первом входе Tabby предложит создать аккаунт администратора. Это критически важно для защиты вашего API от несанкционированного доступа.
Ищете сервер, который просто работает?
Valebyte VPS — NVMe, поддержка 24/7, развёртывание за 60 секунд.
7. Настройка IDE (VS Code и JetBrains)

После того как сервер запущен, его нужно подключить к вашему редактору кода. Tabby имеет официальные расширения для большинства популярных инструментов.
Visual Studio Code
- Откройте Extensions (Ctrl+Shift+X).
- Найдите и установите расширение Tabby.
- Нажмите на иконку Tabby в статус-баре (внизу справа).
- В поле Server Endpoint введите
https://ai.yourdomain.com. - Если вы настроили авторизацию, введите ваш API Token (его можно найти в веб-интерфейсе Tabby в разделе Settings -> Auth).
JetBrains (IntelliJ IDEA, PyCharm, WebStorm)
- Settings -> Plugins -> Marketplace.
- Установите плагин Tabby.
- Settings -> Tools -> Tabby.
- Укажите адрес вашего сервера и API ключ.
Проверка: Начните писать функцию, например def get_weather(city):. Через секунду Tabby должен предложить серым текстом продолжение кода. Нажмите Tab для принятия предложения.
8. Бэкапы и обслуживание
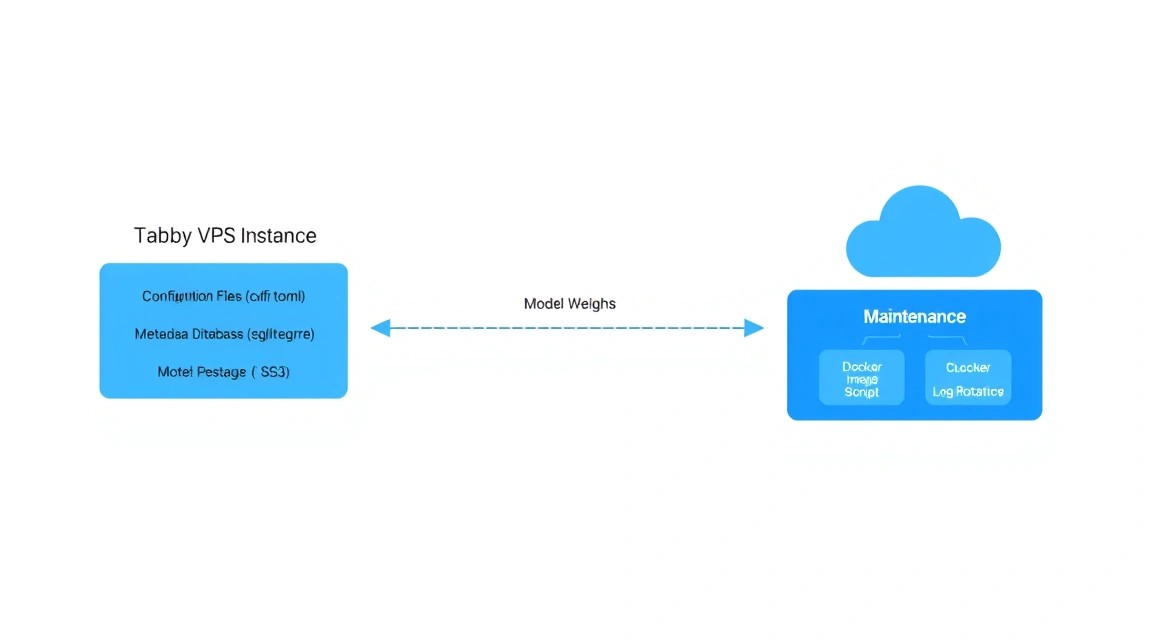
AI-сервер требует регулярного ухода. Основные данные Tabby хранятся в папке ./data, которую мы примонтировали в контейнер. Там находятся индексы ваших репозиториев, настройки пользователей и скачанные модели.
Что нужно бэкапить:
- Файл
docker-compose.ymlиCaddyfile. - Директорию
./data/config(там лежат токены и настройки). - Базу данных SQLite (обычно
./data/tabby.db).
Простой скрипт для ежедневного бэкапа в локальную папку:
#!/bin/bash
BACKUP_DIR="/home/tabbyuser/backups"
TIMESTAMP=$(date +"%Y%m%d_%H%M%S")
mkdir -p $BACKUP_DIR
# Останавливаем контейнер для консистентности БД
cd /home/tabbyuser/tabby-server
docker compose stop
# Создаем архив
tar -czf $BACKUP_DIR/tabby_backup_$TIMESTAMP.tar.gz ./data Caddyfile docker-compose.yml
# Запускаем обратно
docker compose start
# Удаляем бэкапы старше 7 дней
find $BACKUP_DIR -type f -mtime +7 -name ".gz" -delete
Добавьте этот скрипт в crontab -e для автоматизации:
0 3 /home/tabbyuser/tabby-server/backup.shОбновление Tabby: Разработчики часто выпускают обновления с оптимизациями. Чтобы обновиться, выполните:
docker compose pull
docker compose up -d
9. Troubleshooting + FAQ
Почему генерация кода происходит слишком медленно?
Основная причина — нехватка мощностей CPU или отсутствие поддержки инструкций AVX-512. Убедитесь, что ваш VPS не перегружен другими процессами. Также попробуйте сменить модель на более легкую, например, с 7B на 1.1B или 3B. Если вы используете Docker, убедитесь, что вы не ограничили ресурсы контейнера в конфиге.
Ошибка "Out of Memory" (OOM) при запуске
Модели LLM загружаются целиком в RAM. Модель 7B в квантовании 4-bit требует около 5-6 ГБ свободной памяти + запас для работы самой системы. Если у вас 8 ГБ RAM, закройте лишние сервисы или добавьте Swap-файл (хотя это сильно замедлит работу).
Как подключить свои приватные репозитории для контекста?
В веб-интерфейсе Tabby перейдите в раздел "Repositories". Вы можете добавить ссылки на Git-репозитории. Tabby склонирует их локально и проиндексирует. После этого ассистент будет знать о ваших внутренних библиотеках и стилистике кода.
Какой VPS-конфиг минимально подойдёт?
Для минимально комфортной работы (модель 1.1B или 3B) достаточно 4 ГБ ОЗУ и 2 ядра CPU. Однако для профессиональной разработки мы настоятельно рекомендуем начинать с 8-16 ГБ ОЗУ, так как это позволит использовать более "умные" модели уровня DeepSeek-Coder.
Что выбрать — VPS или dedicated для этой задачи?
Если вы работаете один — качественного VPS будет достаточно. Если вы разворачиваете Tabby на команду из 10+ человек, лучше взять dedicated сервер. LLM-инференс — это CPU-интенсивная задача, и на VPS вы можете столкнуться с деградацией производительности из-за соседей по гипервизору.
Безопасно ли хранить код в Tabby?
Да, это одна из главных причин перехода на self-hosted. Весь код хранится в Docker-волюме на вашем сервере. Если вы настроили HTTPS и сложный пароль администратора, доступ к данным будет только у вас. Tabby не отправляет телеметрию с вашим кодом на внешние сервера.
Tabby не предлагает варианты кода в IDE, что делать?
Проверьте: 1. Статус сервера (должен быть Online). 2. Правильность API ключа. 3. Логи контейнера (docker logs tabby) — нет ли там ошибок аутентификации или проблем с загрузкой модели. 4. Брандмауэр — разрешен ли доступ к порту 443.
Ищете сервер, который просто работает?
Valebyte VPS — NVMe, поддержка 24/7, развёртывание за 60 секунд.
10. Выводы и следующие шаги
Мы успешно развернули собственный AI-ассистент Tabby на VPS, обеспечив приватность и высокую скорость работы. Теперь у вас есть мощный инструмент, который не зависит от подписок и внешних API. Это фундамент для создания по-настоящему эффективной среды разработки.
Что делать дальше:
- Экспериментируйте с моделями: Попробуйте
DeepSeek-Coder-6.7B-Instruct, если ресурсы сервера позволяют — она считается одной из лучших в 2026 году для Python и JS. - Настройте индексацию: Добавьте все основные проекты вашей компании в Tabby, чтобы он предлагал код, учитывающий вашу специфику.
- Мониторинг: Установите Prometheus и Grafana для отслеживания нагрузки на CPU и времени отклика (latency) вашего AI-сервера.
Self-hosting AI — это не только про экономию, но и про цифровую гигиену. В мире, где код является главным активом компании, контроль над инструментами его написания становится стратегическим преимуществом.