
Развертывание Ollama и Open WebUI на VPS: пошаговое руководство по созданию приватного AI-чата
TL;DR
В данном руководстве описывается процесс развертывания полностью автономной и приватной экосистемы искусственного интеллекта на базе Ollama (бэкенд для запуска LLM) и Open WebUI (современный интерфейс в стиле ChatGPT) на виртуальном сервере (VPS). Это решение позволяет исключить передачу данных сторонним компаниям, обойти цензурные ограничения облачных моделей и получить полный контроль над своими данными и вычислительными ресурсами.
- Полная приватность: Ваши запросы и документы для RAG не покидают пределы вашего сервера.
- Экономия: Отсутствие ежемесячных подписок (ChatGPT Plus, Claude Pro) при использовании собственных мощностей.
- Гибкость: Возможность запускать любые открытые модели: Llama 3.x, Mistral, DeepSeek, Gemma и специализированные кодинг-ассистенты.
- Интеграция: Готовая API-совместимость с OpenAI API для подключения сторонних приложений к вашему серверу.
- Масштабируемость: Легкий переход от CPU-инференса к полноценному использованию GPU при росте нагрузки.
Ищете сервер, который просто работает?
Valebyte VPS — NVMe, поддержка 24/7, развёртывание за 60 секунд.
1. Что мы настраиваем и зачем: Эволюция Self-hosted AI
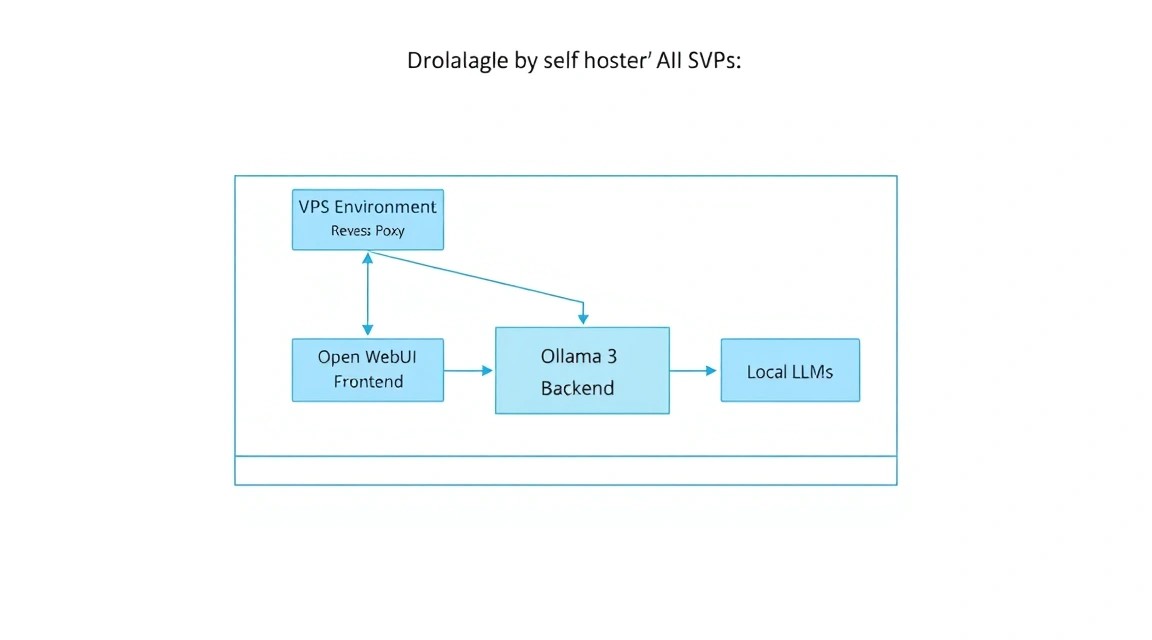
К 2026 году индустрия больших языковых моделей (LLM) разделилась на два четких лагеря: проприетарные облачные решения (OpenAI, Anthropic, Google) и открытые модели (Meta, Mistral AI, DeepSeek). Несмотря на удобство первых, профессиональные разработчики и компании все чаще выбирают self-hosted путь. Основная причина — суверенитет данных. Когда вы используете облачный чат, каждое ваше слово становится частью обучающей выборки или хранится в логах, доступных третьим лицам.
Мы будем использовать связку из двух мощных инструментов:
- Ollama: Это эффективный движок (инференс-сервер), который берет на себя всю тяжелую работу по загрузке весов моделей, управлению памятью и выполнению вычислений. Он оптимизирован для работы как на GPU, так и на CPU, используя современные наборы инструкций (AVX-512, AMX).
- Open WebUI: Ранее известный как Ollama WebUI, это самый продвинутый интерфейс для работы с локальными моделями. Он поддерживает мультимодальность (анализ изображений), RAG (Retrieval Augmented Generation — общение с вашими PDF/документами), управление пользователями и интеграцию с веб-поиском.
Self-hosted решение на VPS дает вам независимость от API-ключей, лимитов на количество сообщений в час и "лоботомии" моделей, когда разработчики чрезмерно ограничивают ответы ИИ из соображений безопасности. Ваш сервер — ваши правила.
2. Какой VPS-конфиг нужен под эту задачу: Расчет ресурсов
Выбор характеристик сервера напрямую зависит от того, какие модели вы планируете запускать. В 2026 году стандартом для "умного" чата являются модели с 7-14 миллиардами параметров (7B-14B), квантованные до 4 или 8 бит.
| Тип задачи | Модель (пример) | Минимальная RAM | Рекомендуемый CPU | Диск (NVMe) |
|---|---|---|---|---|
| Легкий чат / Код | Llama 3.2 3B / Phi-4 | 8 GB | 4 Cores | 40 GB |
| Универсальный ИИ | Llama 3.1 8B / Mistral 7B | 16 GB | 8 Cores | 80 GB |
| Сложная аналитика | Gemma 2 27B / Command R | 32-48 GB | 12+ Cores | 160 GB |
| Enterprise / RAG | Llama 3.1 70B (Q4) | 64 GB+ | 16+ Cores | 300 GB |
Важно понимать разницу между CPU и GPU инференсом. На обычном VPS вы будете использовать CPU. Благодаря библиотеке llama.cpp, на которой базируется Ollama, скорость генерации на современных серверных процессорах достигает 3-7 токенов в секунду для моделей 8B, что вполне комфортно для чтения человеком в реальном времени. Если же вам нужна мгновенная генерация или обслуживание 10+ одновременных пользователей, стоит рассмотреть выделенный сервер с GPU (NVIDIA A2000, A4000 или H100/L40).
Для комфортной работы с моделями среднего уровня (8B-14B) можно арендовать подходящий VPS с 16 ГБ оперативной памяти и быстрыми NVMe дисками, так как скорость загрузки весов модели в память критически важна для отзывчивости интерфейса.
Локация сервера: Поскольку вы будете передавать и получать значительные объемы текстовых данных, выбирайте локацию с минимальным пингом до вас. Однако для AI-задач важнее физическая производительность процессора, чем задержка сети в 20-30 мс.
3. Подготовка сервера: Безопасность и базовое окружение
После получения доступа к серверу по SSH, первым делом необходимо обеспечить его безопасность. AI-сервисы потребляют много ресурсов, и вы не хотите, чтобы ваш сервер стал частью ботнета.
# Обновляем список пакетов и систему
sudo apt update && sudo apt upgrade -y
# Создаем нового пользователя с правами sudo (замените 'aiuser' на ваше имя)
adduser aiuser
usermod -aG sudo aiuser
# Настраиваем SSH: запрещаем вход по паролю и под пользователем root (опционально, но рекомендуется)
# Перед этим убедитесь, что вы добавили свой SSH-ключ в ~/.ssh/authorized_keys
# sudo nano /etc/ssh/sshd_config
# Изменить: PermitRootLogin no, PasswordAuthentication no
# sudo systemctl restart ssh
Настройка брандмауэра (UFW). Нам понадобятся порты 22 (SSH), 80 (HTTP) и 443 (HTTPS). Порты Ollama (11434) и Open WebUI (8080) мы оставим закрытыми от внешнего мира, так как доступ к ним будет осуществляться через реверс-прокси.
sudo ufw allow 22/tcp
sudo ufw allow 80/tcp
sudo ufw allow 443/tcp
sudo ufw enable
Установка базовых утилит, которые понадобятся для мониторинга ресурсов и работы с файлами:
sudo apt install -y curl wget git htop fastfetch build-essential
Ищете сервер, который просто работает?
Valebyte VPS — NVMe, поддержка 24/7, развёртывание за 60 секунд.
4. Установка Docker и Docker Compose (Версии 2026)
Наилучший способ развертывания Open WebUI — использование контейнеризации. Это изолирует зависимости и позволяет легко обновлять систему. В 2026 году Docker Compose является встроенной частью Docker CLI.
# Установка официального репозитория Docker
sudo apt install -y ca-certificates curl gnupg
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
# Добавление репозитория в источники apt
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt update
sudo apt install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# Добавление пользователя в группу docker, чтобы не использовать sudo постоянно
sudo usermod -aG docker $USER
# ВАЖНО: Перезайдите в SSH-сессию, чтобы права обновились
5. Развертывание Ollama: Сердце вашего AI-сервера
Ollama можно установить как нативно, так и в Docker. Для максимальной производительности на Linux часто рекомендуют нативную установку, так как она имеет прямой доступ к инструкциям процессора без прослоек контейнеризации.
# Нативная установка Ollama одной командой
curl -fsSL https://ollama.com/install.sh | sh
После установки Ollama запускается как системная служба. Проверим ее статус:
sudo systemctl status ollama
Теперь загрузим нашу первую модель. Llama 3.1 8B — отличный выбор для начала. Она сбалансирована по скорости и качеству ответов.
ollama run llama3.1:8b
После завершения загрузки вы сможете пообщаться с моделью прямо в консоли. Для выхода введите /bye. Модель останется в памяти сервера или будет загружена автоматически при первом обращении через API.
Совет: Если ваш сервер имеет ограниченный объем RAM, используйте модели с припиской :q4_k_m (4-битное квантование), они потребляют почти в два раза меньше памяти при минимальной потере качества.
6. Установка Open WebUI: Интерфейс и функциональность
Open WebUI — это не просто чат, это полноценная платформа. Мы развернем ее с помощью Docker Compose, чтобы связать интерфейс с Ollama и обеспечить хранение данных в постоянном томе (volume).
Создадим рабочую директорию:
mkdir ~/ai-stack && cd ~/ai-stack
nano docker-compose.yaml
Вставьте следующее содержимое в файл docker-compose.yaml:
services:
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
restart: always
ports:
- "8080:8080"
extra_hosts:
- "host.docker.internal:host-gateway"
environment:
- 'OLLAMA_BASE_URL=http://host.docker.internal:11434'
- 'WEBUI_SECRET_KEY=super_secret_key_change_me'
volumes:
- open-webui:/app/backend/data
volumes:
open-webui:
Развертываем стек:
docker compose up -d
Теперь интерфейс доступен по адресу http://IP_ВАШЕГО_СЕРВЕРА:8080. Первый зарегистрировавшийся пользователь автоматически станет администратором.
Ищете сервер, который просто работает?
Valebyte VPS — NVMe, поддержка 24/7, развёртывание за 60 секунд.
7. Настройка сети, SSL и безопасности (Caddy/Nginx)
Открывать порт 8080 напрямую — плохая идея. Нам нужен HTTPS для защиты трафика и красивый домен. Мы будем использовать Caddy, так как он автоматически получает и обновляет SSL-сертификаты от Let's Encrypt.
# Установка Caddy
sudo apt install -y debian-keyring debian-archive-keyring apt-transport-https
curl -1G 'https://dl.cloudsmith.io/public/caddy/stable/gpg.key' | sudo gpg --dearmor -o /usr/share/keyrings/caddy-stable-archive-keyring.gpg
curl -1G 'https://dl.cloudsmith.io/public/caddy/stable/debian.deb.txt' | sudo tee /etc/apt/sources.list.d/caddy-stable.list
sudo apt update
sudo apt install caddy
Настройка конфигурации Caddy:
sudo nano /etc/caddy/Caddyfile
Добавьте следующие строки (замените ai.yourdomain.com на ваш реальный домен):
ai.yourdomain.com {
reverse_proxy localhost:8080
header {
# Защита от кликджекинга
X-Frame-Options DENY
# Защита от XSS
X-XSS-Protection "1; mode=block"
Strict-Transport-Security "max-age=31536000;"
}
}
Перезапустите Caddy:
sudo systemctl restart caddy
Теперь ваш приватный чат доступен по безопасному протоколу HTTPS.
8. Настройка RAG и работа с документами
Одной из самых мощных функций Open WebUI является RAG (Retrieval-Augmented Generation). Это позволяет вам загружать PDF, текстовые файлы или давать ссылки на сайты, чтобы ИИ отвечал на вопросы, основываясь на этой информации.
В 2026 году Open WebUI по умолчанию включает в себя векторную базу данных (ChromaDB или аналоги). Чтобы RAG работал эффективно на VPS:
- Выбор Embedding-модели: Перейдите в настройки администратора -> Documents. По умолчанию используется
sentence-transformers, которая хорошо работает на CPU. - Загрузка документов: В окне чата нажмите на иконку "+" или просто перетащите файл.
- Использование: Введите символ
#в строке сообщения, чтобы выбрать загруженный документ для контекста.
Это превращает ваш VPS в персональную базу знаний. Вы можете загрузить документацию по проекту, юридические договоры или учебники, и задавать вопросы по их содержанию без риска утечки этих документов в публичные облака.
9. Бэкапы, обновление моделей и обслуживание системы
Сервер с AI требует регулярного обслуживания, так как модели и софт обновляются почти каждую неделю.
Обновление компонентов
# Обновление Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Обновление Open WebUI
cd ~/ai-stack
docker compose pull
docker compose up -d --remove-orphans
Скрипт резервного копирования
Самое важное — это база данных пользователей и их чатов. В Open WebUI она хранится в Docker volume. Создадим простой скрипт бэкапа:
#!/bin/bash
BACKUP_DIR="/home/aiuser/backups"
TIMESTAMP=$(date +"%Y%m%d_%H%M%S")
mkdir -p $BACKUP_DIR
# Остановка контейнера для консистентности данных
docker stop open-webui
# Создание архива данных
tar -czf $BACKUP_DIR/webui_data_$TIMESTAMP.tar.gz -C /var/lib/docker/volumes/ai-stack_open-webui/_data .
# Запуск контейнера
docker start open-webui
# Удаление бэкапов старше 30 дней
find $BACKUP_DIR -type f -mtime +30 -name "*.gz" -delete
Добавьте этот скрипт в crontab -e для ежедневного запуска в 3 часа ночи.
Ищете сервер, который просто работает?
Valebyte VPS — NVMe, поддержка 24/7, развёртывание за 60 секунд.
10. Troubleshooting + FAQ: Решение типичных проблем
Почему генерация текста идет очень медленно?
Основная причина — нехватка оперативной памяти. Если модели не хватает RAM, система начинает использовать swap (подкачку на диске), что замедляет работу в сотни раз. Проверьте потребление памяти командой htop. Также убедитесь, что вы не запускаете модель, размер которой превышает доступную RAM. Для модели 8B нужно минимум 8-10 ГБ свободной памяти.
Ошибка "Connection refused" при подключении WebUI к Ollama
Проверьте, слушает ли Ollama порт 11434 на всех интерфейсах. По умолчанию она может слушать только 127.0.0.1. В Docker-compose мы использовали host.docker.internal, что правильно для связи контейнера с хостом. Убедитесь, что переменная окружения OLLAMA_HOST=0.0.0.0 установлена в системе, если используете сложную сетевую конфигурацию.
Какой VPS-конфиг минимально подойдёт?
Для запуска самых маленьких моделей вроде Phi-3 или Llama 3.2 3B достаточно 4-8 ГБ RAM и 2-4 ядер CPU. Однако для полноценного опыта с моделями уровня Llama 3.1 8B мы настоятельно рекомендуем 16 ГБ RAM. Это обеспечит запас для работы ОС, Docker и кэширования контекста.
Что выбрать — VPS или dedicated для этой задачи?
VPS идеально подходит для личного использования и экспериментов. Если же вы планируете внедрять AI в бизнес-процессы компании, где чатом будут пользоваться 20+ сотрудников одновременно, или вам нужно обучать модели (fine-tuning), однозначно стоит выбрать выделенный сервер (dedicated) с мощным многоядерным процессором или GPU.
Как ограничить доступ к чату?
В настройках Open WebUI (Admin Settings -> General) можно отключить "New Signups". После того как вы создадите аккаунты для себя и своей команды, выключите регистрацию, чтобы посторонние не могли использовать ресурсы вашего сервера.
Могу ли я использовать GPU на VPS?
Да, если провайдер предоставляет GPU-ускорение и проброс устройства в виртуальную машину. В этом случае вам потребуется установить nvidia-container-toolkit и добавить deploy.resources.reservations.devices в ваш docker-compose.yaml. Скорость генерации вырастет в 10-50 раз.
11. Выводы и следующие шаги: Путь к персональному агенту
Мы успешно развернули полностью приватную и функциональную среду искусственного интеллекта. Теперь у вас есть собственный аналог ChatGPT, который не подвержен цензуре, не торгует вашими данными и доступен вам 24/7 по фиксированной цене аренды сервера.
Куда двигаться дальше?
- Интеграция с API: Используйте адрес вашего сервера в качестве замены OpenAI API в таких приложениях, как Cursor или Obsidian.
- Кастомные модели: Попробуйте специализированные модели для программирования (CodeLlama, DeepSeek-Coder) или медицинские/юридические модели.
- Автоматизация: Настройте интеграцию с вашим календарем или почтой через API Open WebUI, превращая чат в полноценного цифрового ассистента.
Помните, что сфера локальных LLM развивается стремительно. Следите за обновлениями Ollama и Open WebUI, так как новые версии часто приносят значительные оптимизации скорости, позволяя запускать всё более сложные модели на том же железе.