
Despliegue de Tabby en VPS: creación de su propio asistente de IA para codificación (Alternativa a GitHub Copilot auto-hospedada)
TL;DR
En esta guía, desplegaremos Tabby —una alternativa moderna y auto-hospedada a GitHub Copilot— en un servidor virtual dedicado. Esto le permitirá obtener una potente herramienta de autocompletado de código basada en grandes modelos de lenguaje (LLM), manteniendo al mismo tiempo el control total sobre su código fuente y su privacidad. Configuraremos contenedores Docker, garantizaremos la seguridad mediante cifrado SSL y conectaremos el asistente a los IDE más populares.
- Privacidad: Su código nunca sale de su servidor.
- Ahorro: Sin suscripciones mensuales por cada usuario.
- Flexibilidad: Posibilidad de elegir modelos (StarCoder, DeepSeek, CodeLlama) para tareas específicas.
- Rendimiento: Optimización para arquitecturas de CPU y GPU actuales en 2026.
- Integración: Soporte para VS Code, JetBrains, Vim/Neovim a través de extensiones oficiales.
¿Buscas un servidor que simplemente funcione?
Valebyte VPS — NVMe, soporte 24/7, despliegue en 60 segundos.
1. Qué estamos configurando y por qué
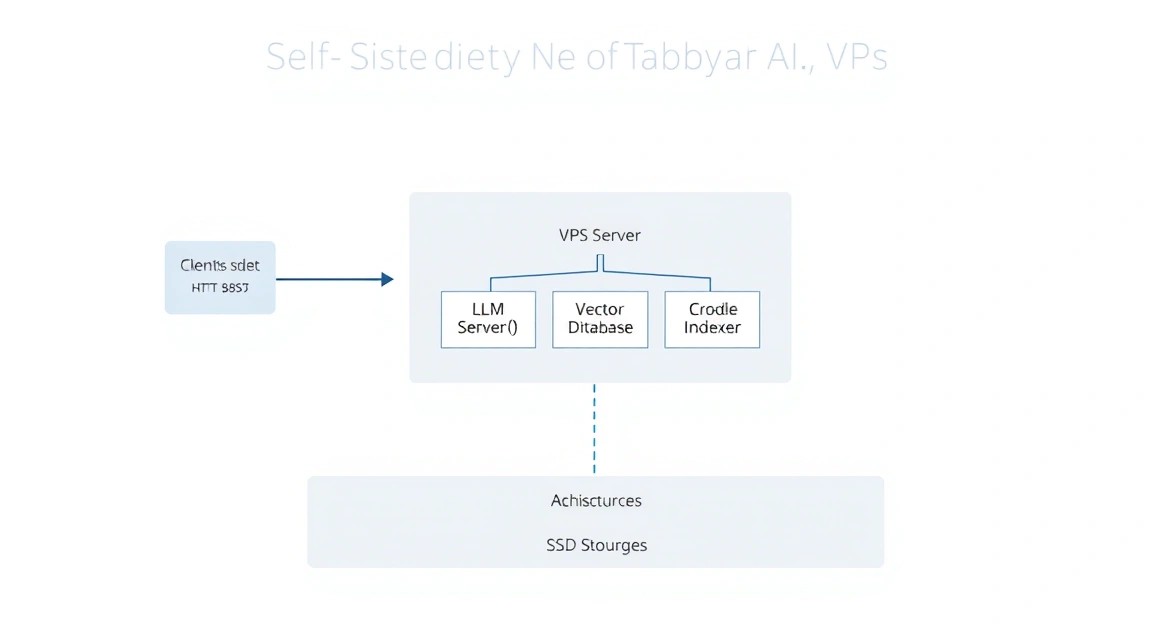
La programación en 2026 es impensable sin asistentes de IA. Sin embargo, el uso de soluciones en la nube como GitHub Copilot o ChatGPT conlleva riesgos: filtración de código propietario, dependencia de la estabilidad de servicios externos y el costo en constante aumento de la suscripción. Tabby resuelve estos problemas ofreciendo un motor de código abierto para ejecutar LLM (Large Language Models), optimizados específicamente para escribir código.
Tabby no es solo un envoltorio para un modelo, es un backend completo que indexa sus repositorios locales para proporcionar autocompletado contextual. Admite técnicas modernas de cuantificación, lo que permite ejecutar modelos pesados incluso en hardware de consumo o VPS económicos sin tarjetas gráficas dedicadas (utilizando solo CPU e instrucciones rápidas AVX-512).
Lo que obtendrá al final:
- Su propio servidor de API, compatible con los protocolos de las extensiones de IA modernas.
- Una interfaz web para la gestión de modelos y el monitoreo de la carga.
- Independencia total de los proveedores de la nube occidentales.
- Posibilidad de reentrenamiento (fine-tuning) del modelo en la base de código de su empresa.
2. Qué configuración de VPS se necesita para esta tarea
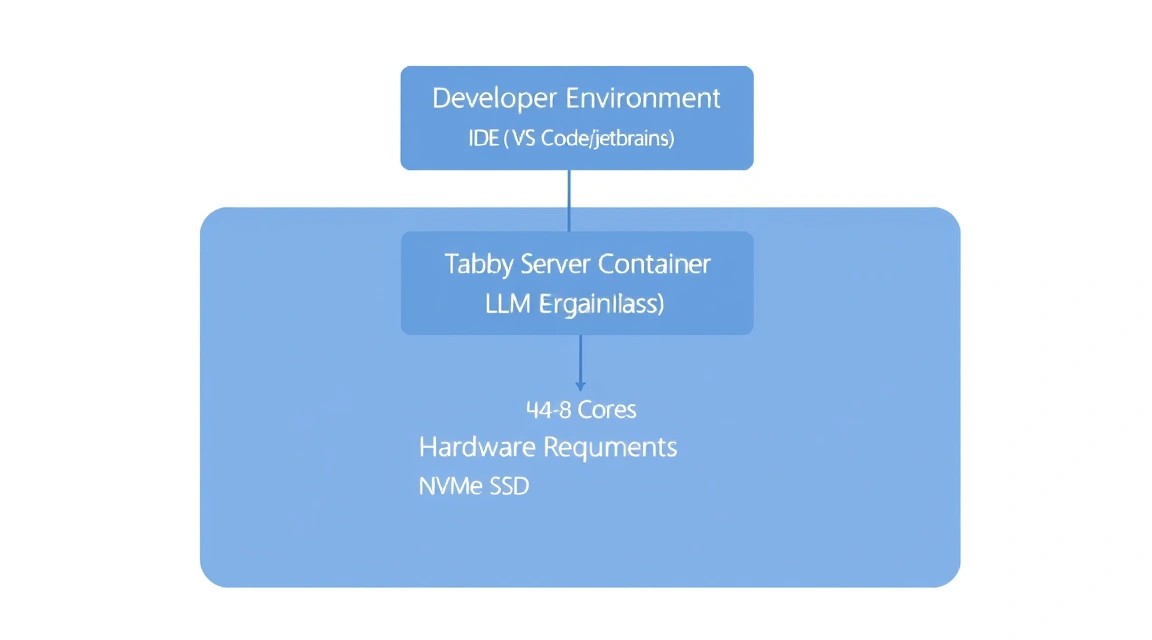
La elección del hardware para Tabby es críticamente importante, ya que el funcionamiento de los LLM depende directamente de la velocidad de acceso a la memoria y de la potencia de procesamiento del procesador. En 2026, el estándar para un trabajo cómodo son los modelos con un volumen de 3B a 7B parámetros en forma cuantificada (4-bit u 8-bit).
| Característica | Mínimos (1 usuario) | Recomendados (equipo 3-5 pers) | Máximos (aceleración por GPU) |
|---|---|---|---|
| CPU | 2-4 vCPU (con soporte AVX2) | 8+ vCPU (Modernos AMD/Intel) | 4+ vCPU + NVIDIA GPU (8GB+ VRAM) |
| RAM | 8 GB DDR4/DDR5 | 16-32 GB DDR5 | 16 GB + VRAM de la tarjeta de video |
| Disco | 40 GB NVMe SSD | 100 GB NVMe SSD | 200 GB NVMe SSD |
| SO | Ubuntu 24.04 / 26.04 LTS | Ubuntu 24.04 / 26.04 LTS | Ubuntu + NVIDIA Drivers |
Para un funcionamiento estable sin retrasos (latency) al generar código, es extremadamente importante utilizar unidades NVMe, ya que los pesos de los modelos se cargan rápidamente en la memoria, pero la indexación de repositorios crea una alta carga de E/S. Si planea utilizar modelos del nivel de DeepSeek-Coder-7B, apunte a una cantidad de memoria RAM de al menos 16 GB.
Para la mayoría de los desarrolladores individuales y equipos pequeños, la opción óptima será un VPS adecuado con 4-8 núcleos y un disco NVMe rápido. Si su base de código se cuenta por millones de líneas, vale la pena considerar un servidor dedicado adecuado para evitar "vecinos ruidosos" y utilizar toda la potencia de la CPU para la inferencia.
Ubicación del servidor: Elija un centro de datos con el ping mínimo a su lugar de trabajo. Un retraso de 100-150 ms con cada pulsación de tecla puede hacer que el uso del asistente de IA sea incómodo.
3. Preparación del servidor
Después de obtener acceso al servidor, es necesario realizar una configuración básica de seguridad. Crearemos un usuario separado, configuraremos el firewall y actualizaremos los paquetes del sistema.
Nos conectamos por SSH:
ssh root@your_server_ip
Actualizamos el sistema al estado actual:
apt update && apt upgrade -y
Creamos un usuario para trabajar con Tabby (ejecutar servicios de IA como root es una mala práctica):
adduser tabbyuser
usermod -aG sudo tabbyuser
Configuramos el firewall básico (UFW). Necesitaremos los puertos 22 (SSH), 80 (HTTP) y 443 (HTTPS):
ufw allow 22/tcp
ufw allow 80/tcp
ufw allow 443/tcp
ufw enable
Instalamos la zona horaria y utilidades útiles:
timedatectl set-timezone Europe/Moscow
apt install -y curl git vim htop fail2ban
¿Buscas un servidor que simplemente funcione?
Valebyte VPS — NVMe, soporte 24/7, despliegue en 60 segundos.
4. Instalación de Docker y utilidades necesarias
Tabby se distribuye oficialmente en forma de imágenes de Docker. Este es el método de despliegue más estable, ya que aís
7. Configuración del IDE (VS Code y JetBrains)

Una vez que el servidor esté en funcionamiento, debe conectarlo a su editor de código. Tabby cuenta con extensiones oficiales para la mayoría de las herramientas populares.
Visual Studio Code
- Abra Extensions (Ctrl+Shift+X).
- Busque e instale la extensión Tabby.
- Haga clic en el icono de Tabby en la barra de estado (abajo a la derecha).
- En el campo Server Endpoint, ingrese
https://ai.yourdomain.com. - Si ha configurado la autorización, ingrese su API Token (puede encontrarlo en la interfaz web de Tabby en la sección Settings -> Auth).
JetBrains (IntelliJ IDEA, PyCharm, WebStorm)
- Settings -> Plugins -> Marketplace.
- Instale el complemento Tabby.
- Settings -> Tools -> Tabby.
- Especifique la dirección de su servidor y la clave API.
Verificación: Comience a escribir una función, por ejemplo def get_weather(city):. En un segundo, Tabby debería sugerir la continuación del código en texto gris. Presione Tab para aceptar la sugerencia.
8. Copias de seguridad y mantenimiento
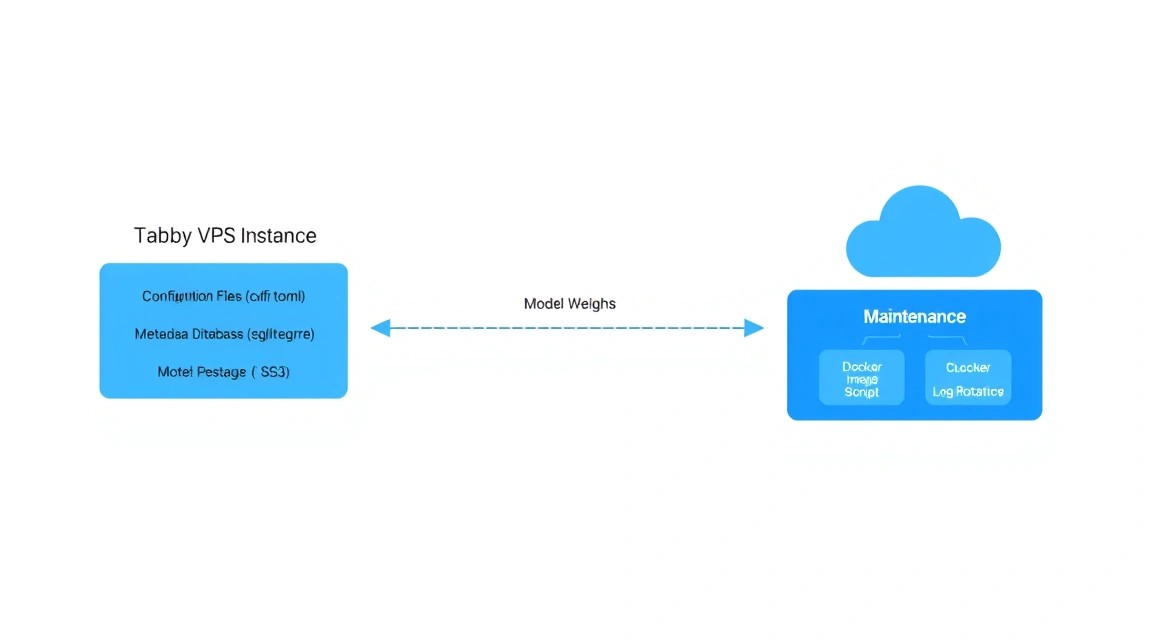
El servidor de IA requiere un mantenimiento regular. Los datos principales de Tabby se almacenan en la carpeta ./data, que hemos montado en el contenedor. Allí se encuentran los índices de sus repositorios, la configuración de los usuarios y los modelos descargados.
Qué se debe respaldar:
- El archivo
docker-compose.ymlyCaddyfile. - El directorio
./data/config(donde se encuentran los tokens y la configuración). - La base de datos SQLite (normalmente
./data/tabby.db).
Un script sencillo para realizar una copia de seguridad diaria en una carpeta local:
#!/bin/bash
BACKUP_DIR="/home/tabbyuser/backups"
TIMESTAMP=$(date +"%Y%m%d_%H%M%S")
mkdir -p $BACKUP_DIR
# Detenemos el contenedor para la consistencia de la BD
cd /home/tabbyuser/tabby-server
docker compose stop
# Creamos el archivo
tar -czf $BACKUP_DIR/tabby_backup_$TIMESTAMP.tar.gz ./data Caddyfile docker-compose.yml
# Iniciamos de nuevo
docker compose start
# Eliminamos copias de seguridad de más de 7 días
find $BACKUP_DIR -type f -mtime +7 -name "*.gz" -delete
Agregue este script a crontab -e para la automatización:
0 3 * * * /home/tabbyuser/tabby-server/backup.shActualización de Tabby: Los desarrolladores lanzan actualizaciones con optimizaciones con frecuencia. Para actualizar, ejecute:
docker compose pull
docker compose up -d
¿Buscas un servidor que simplemente funcione?
Valebyte VPS — NVMe, soporte 24/7, despliegue en 60 segundos.
9. Solución de problemas + FAQ
¿Por qué la generación de código es demasiado lenta?
La razón principal es la falta de potencia de la CPU o la ausencia de soporte para las instrucciones AVX-512. Asegúrese de que su VPS no esté sobrecargado con otros procesos. También intente cambiar a un modelo más ligero, por ejemplo, de 7B a 1.1B o 3B. Si utiliza Docker, asegúrese de no haber limitado los recursos del contenedor en la configuración.
Error "Out of Memory" (OOM) al iniciar
Los modelos LLM se cargan por completo en la RAM. Un modelo 7B con cuantificación de 4 bits requiere aproximadamente 5-6 GB de memoria libre + un margen para el funcionamiento del sistema. Si tiene 8 GB de RAM, cierre los servicios innecesarios o agregue un archivo Swap (aunque esto ralentizará significativamente el rendimiento).
¿Cómo conectar mis repositorios privados para el contexto?
En la interfaz web de Tabby, vaya a la sección "Repositories". Puede agregar enlaces a repositorios Git. Tabby los clonará localmente y los indexará. Después de esto, el asistente conocerá sus bibliotecas internas y su estilo de código.
¿Qué configuración de VPS es la mínima adecuada?
Para un funcionamiento mínimamente cómodo (modelo 1.1B o 3B), 4 GB de RAM y 2 núcleos de CPU son suficientes. Sin embargo, para el desarrollo profesional, recomendamos encarecidamente comenzar con 8-16 GB de RAM, ya que esto permitirá utilizar modelos más "inteligentes" como DeepSeek-Coder.
¿Qué elegir: VPS o dedicado para esta tarea?
Si trabaja solo, un VPS de calidad será suficiente. Si está implementando Tabby para un equipo de más de 10 personas, es mejor optar por un servidor dedicado. La inferencia de LLM es una tarea intensiva de CPU y en un VPS podría experimentar una degradación del rendimiento debido a los vecinos en el hipervisor.
¿Es seguro almacenar el código en Tabby?
Sí, esta es una de las razones principales para cambiar a self-hosted. Todo el código se almacena en un volumen de Docker en su servidor. Si ha configurado HTTPS y una contraseña de administrador compleja, solo usted tendrá acceso a los datos. Tabby no envía telemetría con su código a servidores externos.
Tabby no ofrece sugerencias de código en el IDE, ¿qué hacer?
Verifique: 1. El estado del servidor (debe estar Online). 2. La validez de la clave API. 3. Los registros del contenedor (docker logs tabby): si hay errores de autenticación o problemas al cargar el modelo. 4. El firewall: si se permite el acceso al puerto 443.
10. Conclusiones y próximos pasos
Hemos implementado con éxito nuestro propio asistente de IA Tabby en un VPS, garantizando la privacidad y una alta velocidad de funcionamiento. Ahora tiene una herramienta potente que no depende de suscripciones ni de API externas. Esta es la base para crear un entorno de desarrollo verdaderamente eficiente.
Qué hacer a continuación:
- Experimente con modelos: Pruebe
DeepSeek-Coder-6.7B-Instructsi los recursos del servidor lo permiten; se considera una de las mejores en 2026 para Python y JS. - Configure la indexación: Agregue todos los proyectos principales de su empresa a Tabby para que sugiera código teniendo en cuenta su especificidad.
- Monitoreo: Instale Prometheus y Grafana para realizar un seguimiento de la carga de la CPU y el tiempo de respuesta (latency) de su servidor de IA.
El self-hosting de IA no se trata solo de ahorro, sino también de higiene digital. En un mundo donde el código es el principal activo de una empresa, el control sobre las herramientas para escribirlo se convierte en una ventaja estratégica.