
Despliegue de Ollama y Open WebUI en un VPS: guía paso a paso para crear un chat de IA privado
TL;DR
Esta guía describe el proceso de despliegue de un ecosistema de inteligencia artificial totalmente autónomo y privado basado en Ollama (backend para ejecutar LLM) y Open WebUI (interfaz moderna al estilo ChatGPT) en un servidor virtual (VPS). Esta solución permite eliminar la transferencia de datos a terceras empresas, evitar las restricciones de censura de los modelos en la nube y obtener un control total sobre sus datos y recursos computacionales.
- Privacidad total: Sus consultas y documentos para RAG no salen de los límites de su servidor.
- Ahorro: Sin suscripciones mensuales (ChatGPT Plus, Claude Pro) al utilizar sus propias capacidades.
- Flexibilidad: Posibilidad de ejecutar cualquier modelo abierto: Llama 3.x, Mistral, DeepSeek, Gemma y asistentes de codificación especializados.
- Integración: Compatibilidad con la API de OpenAI lista para conectar aplicaciones de terceros a su servidor.
- Escalabilidad: Transición fácil de la inferencia por CPU al uso completo de GPU a medida que crece la carga.
¿Buscas un servidor que simplemente funcione?
Valebyte VPS — NVMe, soporte 24/7, despliegue en 60 segundos.
1. Qué estamos configurando y por qué: La evolución de la IA self-hosted
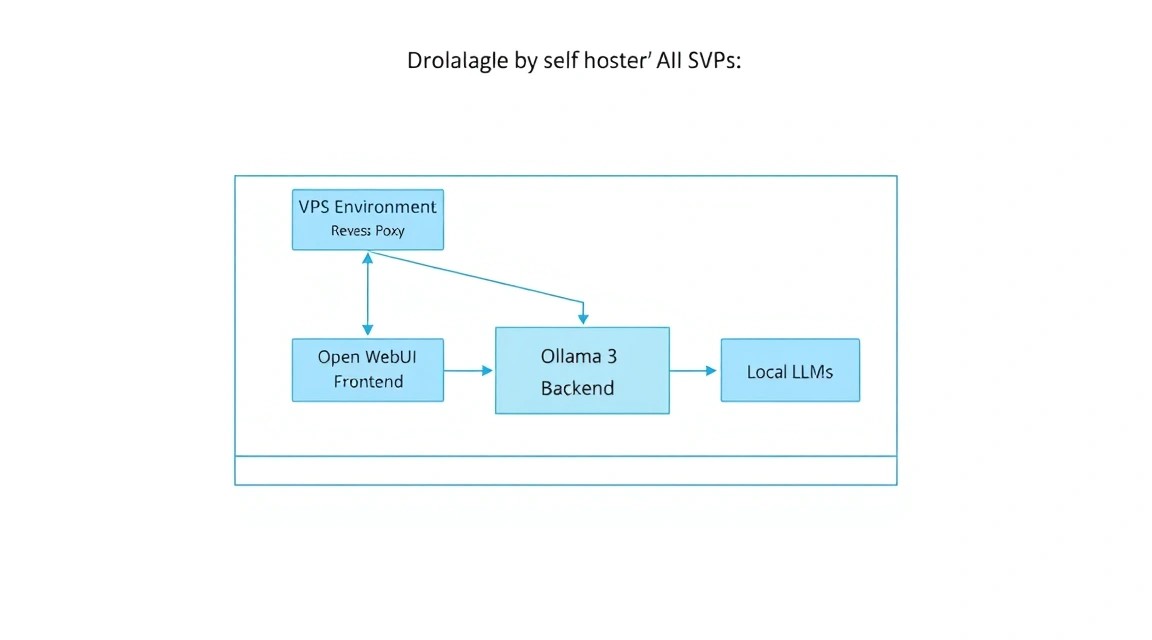
Para 2026, la industria de los grandes modelos de lenguaje (LLM) se ha dividido en dos campos claros: soluciones propietarias en la nube (OpenAI, Anthropic, Google) y modelos abiertos (Meta, Mistral AI, DeepSeek). A pesar de la comodidad de los primeros, los desarrolladores profesionales y las empresas eligen cada vez más el camino del self-hosted. La razón principal es la soberanía de los datos. Cuando utiliza un chat en la nube, cada una de sus palabras se convierte en parte del conjunto de entrenamiento o se almacena en registros accesibles a terceros.
Utilizaremos una combinación de dos potentes herramientas:
- Ollama: Es un motor eficiente (servidor de inferencia) que se encarga de todo el trabajo pesado de cargar los pesos de los modelos, gestionar la memoria y realizar los cálculos. Está optimizado para funcionar tanto en GPU como en CPU, utilizando conjuntos de instrucciones modernos (AVX-512, AMX).
- Open WebUI: Anteriormente conocido como Ollama WebUI, es la interfaz más avanzada para trabajar con modelos locales. Soporta multimodalidad (análisis de imágenes), RAG (Retrieval Augmented Generation — comunicación con sus PDF/documentos), gestión de usuarios e integración con búsqueda web.
Una solución self-hosted en un VPS le otorga independencia de las claves de API, de los límites de mensajes por hora y de la "lobotomía" de los modelos, que ocurre cuando los desarrolladores restringen excesivamente las respuestas de la IA por razones de seguridad. Su servidor, sus reglas.
2. Qué configuración de VPS se necesita para esta tarea: Cálculo de recursos
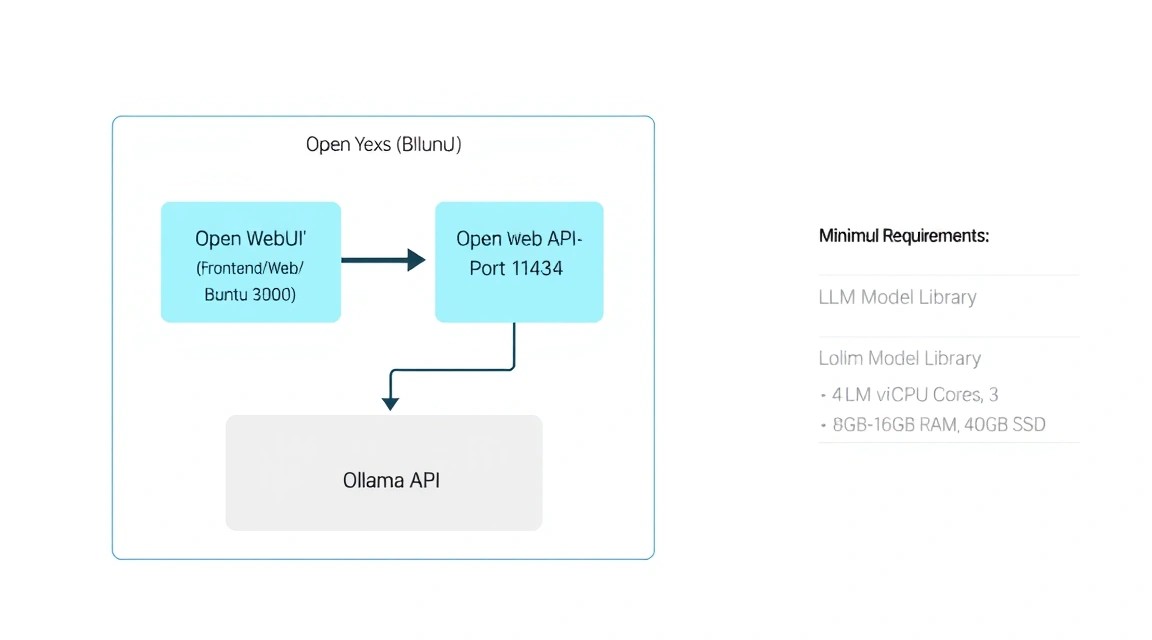
La elección de las características del servidor depende directamente de los modelos que planee ejecutar. En 2026, el estándar para un chat "inteligente" son los modelos con entre 7 y 14 mil millones de parámetros (7B-14B), cuantizados a 4 u 8 bits.
| Tipo de tarea | Modelo (ejemplo) | RAM mínima | CPU recomendado | Disco (NVMe) |
|---|---|---|---|---|
| Chat ligero / Código | Llama 3.2 3B / Phi-4 | 8 GB | 4 Cores | 40 GB |
| IA universal | Llama 3.1 8B / Mistral 7B | 16 GB | 8 Cores | 80 GB |
| Analítica compleja | Gemma 2 27B / Command R | 32-48 GB | 12+ Cores | 160 GB |
| Enterprise / RAG | Llama 3.1 70B (Q4) | 64 GB+ | 16+ Cores | 300 GB |
Es importante entender la diferencia entre la inferencia por CPU y GPU. En un VPS convencional, utilizará la CPU. Gracias a la librería llama.cpp, en la que se basa Ollama, la velocidad de generación en procesadores de servidor modernos alcanza los 3-7 tokens por segundo para modelos 8B, lo cual es bastante cómodo para la lectura humana en tiempo real. Si necesita una generación instantánea o atender a más de 10 usuarios simultáneos, debería considerar un servidor dedicado con GPU (NVIDIA A2000, A4000 o H100/L40).
Para un trabajo cómodo con modelos de nivel medio (8B-14B), puede alquilar un VPS adecuado con 16 GB de memoria RAM y discos NVMe rápidos, ya que la velocidad de carga de los pesos del modelo en la memoria es crítica para la capacidad de respuesta de la interfaz.
Ubicación del servidor: Dado que transmitirá y recibirá volúmenes significativos de datos de texto, elija una ubicación con el mínimo ping hacia usted. Sin embargo, para tareas de IA, el rendimiento físico del procesador es más importante que una latencia de red de 20-30 ms.
3. Preparación del servidor: Seguridad y entorno básico
Tras obtener acceso al servidor por SSH, lo primero que debe hacer es garantizar su seguridad. Los servicios de IA consumen muchos recursos y usted no querrá que su servidor se convierta en parte de una botnet.
# Actualizamos la lista de paquetes y el sistema
sudo apt update && sudo apt upgrade -y
# Creamos un nuevo usuario con privilegios sudo (reemplace 'aiuser' con su nombre)
adduser aiuser
usermod -aG sudo aiuser
# Configuramos SSH: prohibimos el acceso por contraseña y bajo el usuario root (opcional, pero recomendado)
# Antes de esto, asegúrese de haber añadido su clave SSH en ~/.ssh/authorized_keys
# sudo nano /etc/ssh/sshd_config
# Cambiar: PermitRootLogin no, PasswordAuthentication no
# sudo systemctl restart ssh
Configuración del cortafuegos (UFW). Necesitaremos los puertos 22 (SSH), 80 (HTTP) y 443 (HTTPS). Dejaremos cerrados al mundo exterior los puertos de Ollama (11434) y Open WebUI (8080), ya que el acceso a ellos se realizará a través de un proxy inverso.
sudo ufw allow 22/tcp
sudo ufw allow 80/tcp
sudo ufw allow 443/tcp
sudo ufw enable
Instalación de utilidades básicas que serán necesarias para el monitoreo de recursos y el trabajo con archivos:
sudo apt install -y curl wget git htop fastfetch build-essential
¿Buscas un servidor que simplemente funcione?
Valebyte VPS — NVMe, soporte 24/7, despliegue en 60 segundos.
4. Instalación de Docker y Docker Compose (Versión 2026)
La mejor manera de desplegar Open WebUI es mediante el uso de la contenerización. Esto aisla las dependencias y permite actualizar el sistema fácilmente. En 2026, Docker Compose es una parte integrada de la CLI de Docker.
# Instalación del repositorio oficial de Docker
sudo apt install -y ca-certificates curl gnupg
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
# Adición del repositorio a las fuentes de apt
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt update
sudo apt install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# Adición del usuario al grupo docker para no usar sudo constantemente
sudo usermod -aG docker $USER
# IMPORTANTE: Vuelva a iniciar sesión en la sesión SSH para que se actualicen los permisos
5. Despliegue de Ollama: El corazón de su servidor de IA
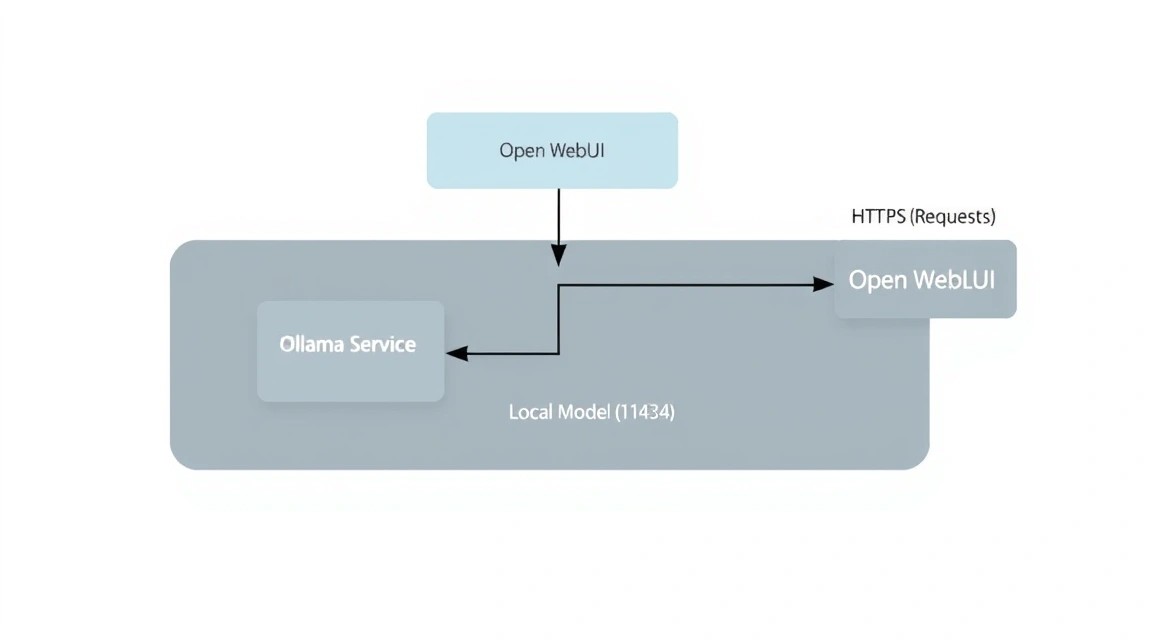
Ollama se puede instalar tanto de forma nativa como en Docker. Para obtener el máximo rendimiento en Linux, a menudo se recomienda la instalación nativa, ya que tiene acceso directo a las instrucciones del procesador sin las capas de la contenerización.
# Instalación nativa de Ollama con un solo comando
curl -fsSL https://ollama.com/install.sh | sh
Después de la instalación, Ollama se inicia como un servicio del sistema. Comprobemos su estado:
sudo systemctl status ollama
Ahora descarguemos nuestro primer modelo. Llama 3.1 8B es una excelente opción para empezar. Está equilibrada en cuanto a velocidad y calidad de respuestas.
ollama run llama3.1:8b
Una vez finalizada la descarga, podrá conversar con el modelo directamente en la consola. Para salir, escriba /bye. El modelo permanecerá en la memoria del servidor o se cargará automáticamente en la primera llamada a través de la API.
Consejo: Si su servidor tiene una RAM limitada, utilice modelos con el sufijo :q4_k_m (cuantización de 4 bits), consumen casi la mitad de memoria con una pérdida mínima de calidad.
6. Instalación de Open WebUI: Interfaz y funcionalidad
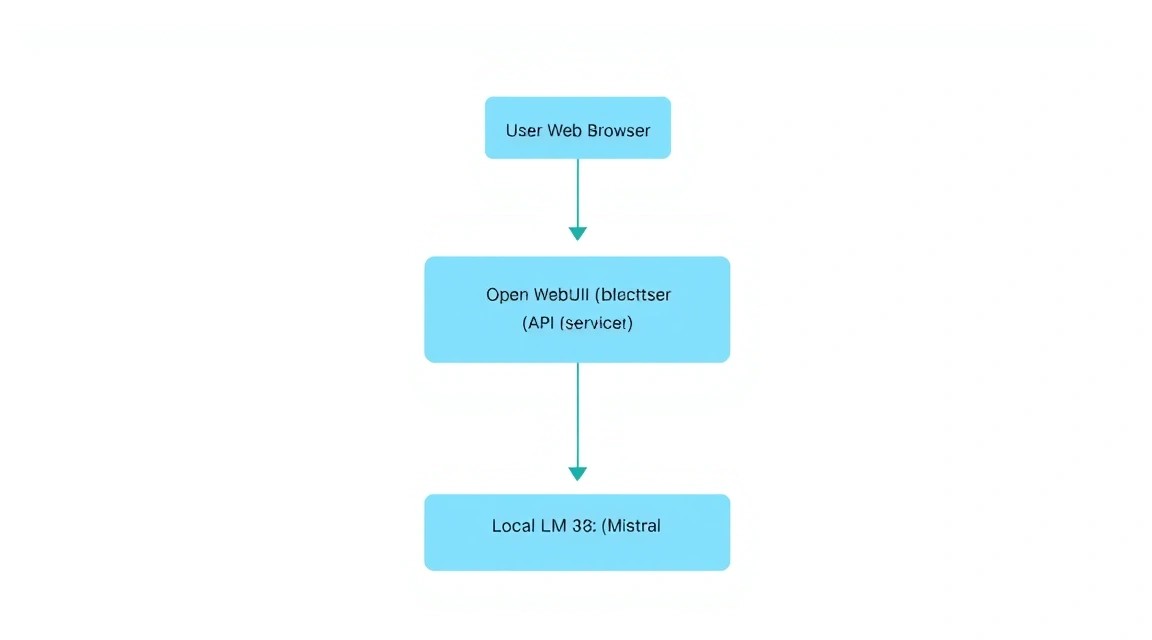
Open WebUI no es solo un chat, es una plataforma completa. La desplegaremos usando Docker Compose para vincular la interfaz con Ollama y asegurar el almacenamiento de datos en un volumen persistente (volume).
Crearemos un directorio de trabajo:
mkdir ~/ai-stack && cd ~/ai-stack
nano docker-compose.yaml
Inserte el siguiente contenido en el archivo docker-compose.yaml:
services:
open-webui:
image: ghcr.io/open-webui/open-webui:main
container_name: open-webui
restart: always
ports:
- "8080:8080"
extra_hosts:
- "host.docker.internal:host-gateway"
environment:
- 'OLLAMA_BASE_URL=http://host.docker.internal:11434'
- 'WEBUI_SECRET_KEY=super_secret_key_change_me'
volumes:
- open-webui:/app/backend/data
volumes:
open-webui:
Desplegamos el stack:
docker compose up -d
Ahora la interfaz está disponible en la dirección http://IP_DE_SU_SERVIDOR:8080. El primer usuario que se registre se convertirá automáticamente en administrador.
¿Buscas un servidor que simplemente funcione?
Valebyte VPS — NVMe, soporte 24/7, despliegue en 60 segundos.
7. Configuración de red, SSL y seguridad (Caddy/Nginx)
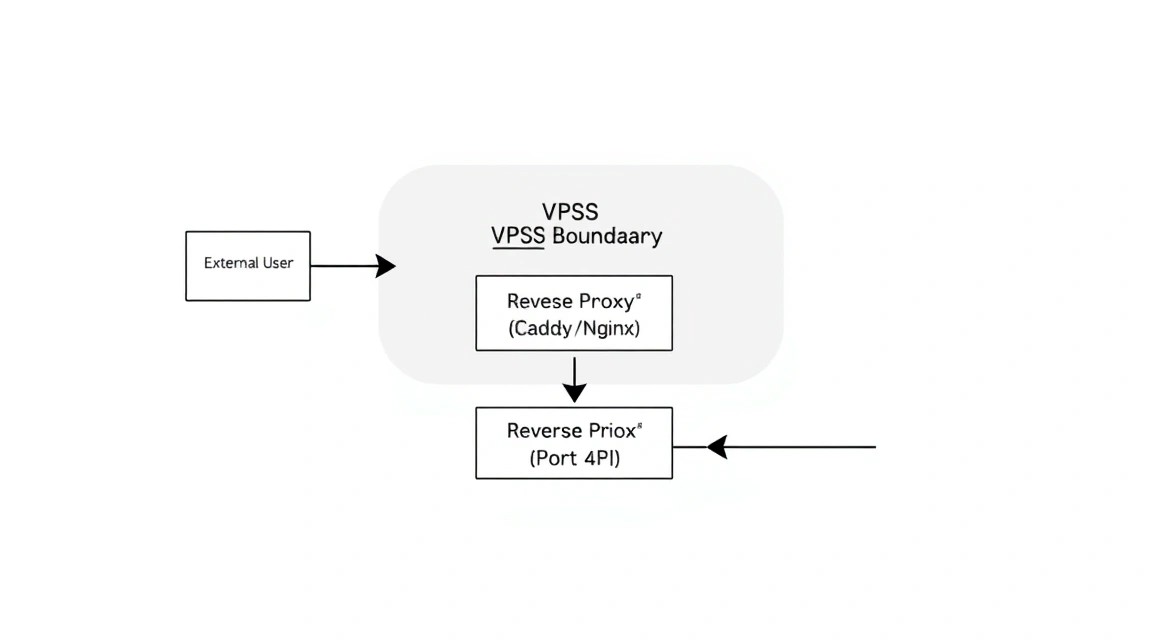
Abrir el puerto 8080 directamente es una mala idea. Necesitamos HTTPS para proteger el tráfico y un dominio atractivo. Utilizaremos Caddy, ya que obtiene y renueva automáticamente los certificados SSL de Let's Encrypt.
# Instalación de Caddy
sudo apt install -y debian-keyring debian-archive-keyring apt-transport-https
curl -1G 'https://dl.cloudsmith.io/public/caddy/stable/gpg.key' | sudo gpg --dearmor -o /usr/share/keyrings/caddy-stable-archive-keyring.gpg
curl -1G 'https://dl.cloudsmith.io/public/caddy/stable/debian.deb.txt' | sudo tee /etc/apt/sources.list.d/caddy-stable.list
sudo apt update
sudo apt install caddy
Ajuste de la configuración de Caddy:
sudo nano /etc/caddy/Caddyfile
Añada las siguientes líneas (reemplace ai.yourdomain.com por su dominio real):
ai.yourdomain.com {
reverse_proxy localhost:8080
header {
# Protección contra clickjacking
X-Frame-Options DENY
# Protección contra XSS
X-XSS-Protection "1; mode=block"
Strict-Transport-Security "max-age=31536000;"
}
}
Reinicie Caddy:
sudo systemctl restart caddy
Ahora su chat privado está disponible a través del protocolo seguro HTTPS.
8. Configuración de RAG y trabajo con documentos
Una de las funciones más potentes de Open WebUI es RAG (Retrieval-Augmented Generation). Esto le permite cargar archivos PDF, archivos de texto o proporcionar enlaces a sitios web para que la IA responda preguntas basándose en esa información.
En 2026, Open WebUI incluye por defecto una base de datos vectorial (ChromaDB o similar). Para que RAG funcione de manera eficiente en un VPS:
- Selección del modelo de Embedding: Vaya a la configuración de administrador -> Documents. Por defecto se utiliza
sentence-transformers, que funciona bien en CPU. - Carga de documentos: En la ventana del chat, haga clic en el icono "+" o simplemente arrastre el archivo.
- Uso: Introduzca el símbolo
#en la línea de mensaje para seleccionar el documento cargado para el contexto.
Esto convierte su VPS en una base de conocimientos personal. Puede cargar documentación de proyectos, contratos legales o libros de texto, y hacer preguntas sobre su contenido sin riesgo de que estos documentos se filtren a nubes públicas.
9. Backups, actualización de modelos y mantenimiento del sistema
Un servidor con IA requiere un mantenimiento regular, ya que los modelos y el software se actualizan casi todas las semanas.
Actualización de componentes
# Actualización de Ollama
curl -fsSL https://ollama.com/install.sh | sh
# Actualización de Open WebUI
cd ~/ai-stack
docker compose pull
docker compose up -d --remove-orphans
Script de copia de seguridad
Lo más importante es la base de datos de usuarios y sus chats. En Open WebUI, se almacena en un Docker volume. Crearemos un script de backup sencillo:
#!/bin/bash
BACKUP_DIR="/home/aiuser/backups"
TIMESTAMP=$(date +"%Y%m%d_%H%M%S")
mkdir -p $BACKUP_DIR
# Detención del contenedor para la consistencia de los datos
docker stop open-webui
# Creación del archivo de datos
tar -czf $BACKUP_DIR/webui_data_$TIMESTAMP.tar.gz -C /var/lib/docker/volumes/ai-stack_open-webui/_data .
# Inicio del contenedor
docker start open-webui
# Eliminación de backups con más de 30 días de antigüedad
find $BACKUP_DIR -type f -mtime +30 -name "*.gz" -delete
Añada este script a crontab -e para su ejecución diaria a las 3 de la mañana.
¿Buscas un servidor que simplemente funcione?
Valebyte VPS — NVMe, soporte 24/7, despliegue en 60 segundos.
10. Troubleshooting + FAQ: Resolución de problemas comunes
¿Por qué la generación de texto es muy lenta?
La causa principal es la falta de memoria RAM. Si al modelo le falta RAM, el sistema comienza a usar swap (intercambio en el disco), lo que ralentiza el trabajo cientos de veces. Verifique el consumo de memoria con el comando htop. También asegúrese de no estar ejecutando un modelo cuyo tamaño exceda la RAM disponible. Para un modelo 8B se necesitan al menos 8-10 GB de memoria libre.
Error "Connection refused" al conectar WebUI a Ollama
Verifique si Ollama está escuchando en el puerto 11434 en todas las interfaces. Por defecto, puede que solo escuche en 127.0.0.1. En el Docker-compose utilizamos host.docker.internal, lo cual es correcto para la comunicación del contenedor con el host. Asegúrese de que la variable de entorno OLLAMA_HOST=0.0.0.0 esté configurada en el sistema si utiliza una configuración de red compleja.
¿Qué configuración de VPS es la mínima adecuada?
Para ejecutar los modelos más pequeños como Phi-3 o Llama 3.2 3B, es suficiente con 4-8 GB de RAM y 2-4 núcleos de CPU. Sin embargo, para una experiencia completa con modelos del nivel de Llama 3.1 8B, recomendamos encarecidamente 16 GB de RAM. Esto proporcionará un margen para el funcionamiento del SO, Docker y el almacenamiento en caché del contexto.
¿Qué elegir: VPS o dedicado para esta tarea?
Un VPS es ideal para uso personal y experimentos. Si planea implementar la IA en los procesos de negocio de una empresa, donde el chat será utilizado por más de 20 empleados simultáneamente, o si necesita entrenar modelos (fine-tuning), definitivamente vale la pena elegir un servidor dedicado (dedicated) con un potente procesador multinúcleo o GPU.
¿Cómo restringir el acceso al chat?
En los ajustes de Open WebUI (Admin Settings -> General) puede desactivar "New Signups". Una vez que haya creado las cuentas para usted y su equipo, desactive el registro para que personas ajenas no puedan utilizar los recursos de su servidor.
¿Puedo usar una GPU en un VPS?
Sí, si el proveedor ofrece aceleración por GPU y el paso del dispositivo a la máquina virtual. En este caso, necesitará instalar nvidia-container-toolkit y añadir deploy.resources.reservations.devices a su docker-compose.yaml. La velocidad de generación aumentará entre 10 y 50 veces.
11. Conclusiones y próximos pasos: El camino hacia un agente personal
Hemos desplegado con éxito un entorno de inteligencia artificial totalmente privado y funcional. Ahora tiene su propio análogo de ChatGPT, que no está sujeto a censura, no comercia con sus datos y está disponible para usted las 24 horas, los 7 días de la semana, por un precio fijo de alquiler del servidor.
¿Hacia dónde seguir?
- Integración con API: Utilice la dirección de su servidor como sustituto de la API de OpenAI en aplicaciones como Cursor u Obsidian.
- Modelos personalizados: Pruebe modelos especializados para programación (CodeLlama, DeepSeek-Coder) o modelos médicos/legales.
- Automatización: Configure la integración con su calendario o correo electrónico a través de la API de Open WebUI, convirtiendo el chat en un asistente digital completo.
Recuerde que el campo de los LLM locales se desarrolla rápidamente. Siga las actualizaciones de Ollama y Open WebUI, ya que las nuevas versiones suelen traer optimizaciones de velocidad significativas, permitiendo ejecutar modelos cada vez más complejos en el mismo hardware.