
Оптимізація продуктивності I/O на Linux з io_uring для високонавантажених застосунків
TL;DR
- io_uring — це сучасний асинхронний I/O інтерфейс ядра Linux, що уніфікує дискові, мережеві та файлові операції, значно перевершує традиційні методи у високонавантажених сценаріях.
- Він усуває накладні витрати на системні виклики та перемикання контексту, використовуючи кільцеві буфери для обміну даними між ядром і простором користувача.
- Ключові переваги: зниження затримок, збільшення пропускної здатності, суттєве зменшення утилізації CPU для I/O-інтенсивних задач.
- Актуальний для 2026 року як стандарт де-факто для високопродуктивних баз даних, проксі-серверів, ігрових серверів і будь-яких застосунків з екстремальними вимогами до I/O.
- Вимагає глибокого розуміння низькорівневого програмування та специфіки ядра Linux, але надає безпрецедентний контроль і ефективність.
- Починати використовувати io_uring рекомендується з ядра Linux 5.10+, оптимально — з версій 6.x для максимальної стабільності та функціональності.
- Економічно вигідний за рахунок зниження вимог до апаратних ресурсів і оптимізації хмарних витрат, незважаючи на більш високу початкову вартість розробки.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
1. Вступ
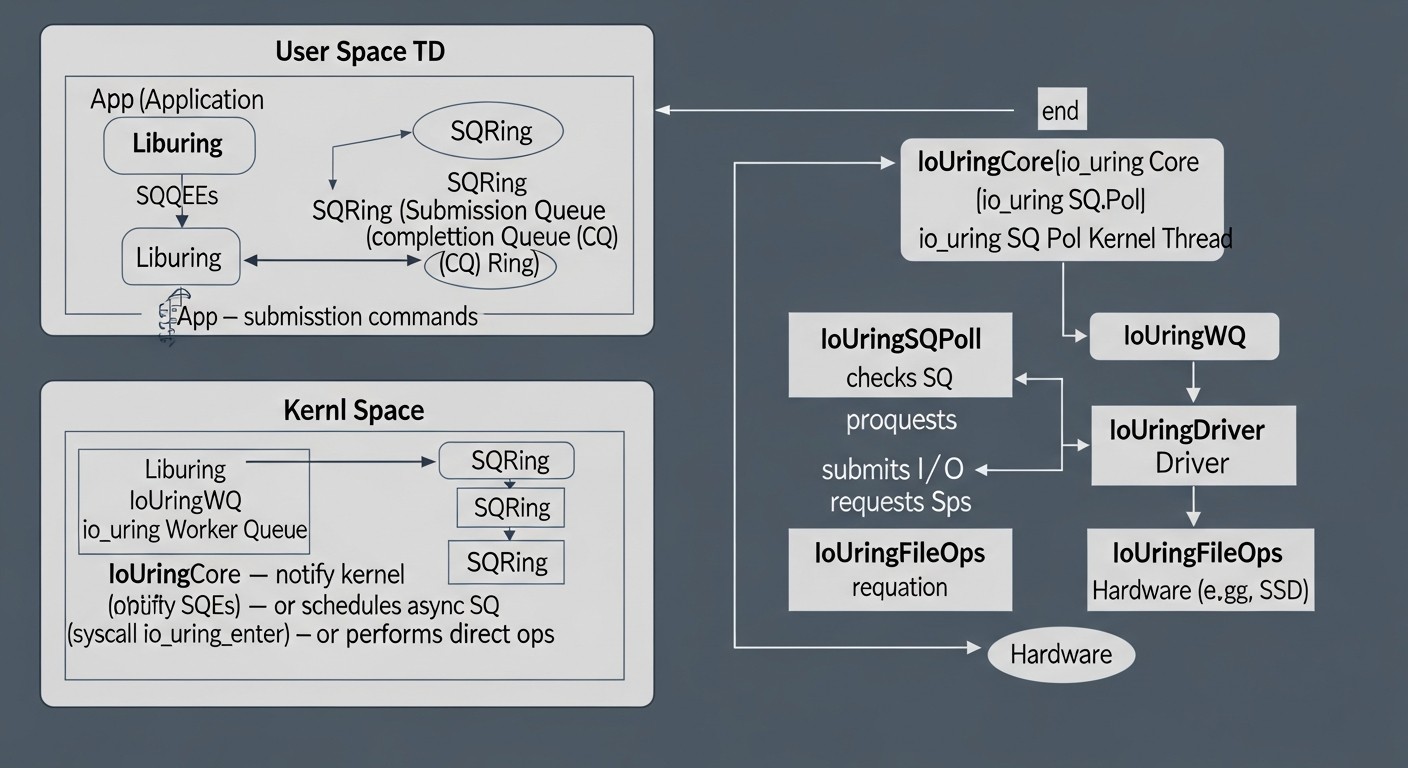
В умовах експоненційного зростання обсягів даних, повсюдного поширення мікросервісної архітектури та вимог до обробки транзакцій в реальному часі, продуктивність підсистеми введення-виведення (I/O) стає критичним фактором успіху для будь-якого високонавантаженого застосунку. До 2026 року цей тренд лише посилюється, оскільки користувачі очікують миттєвого відгуку, а бізнес-процеси вимагають обробки петабайтів інформації з мінімальними затримками.
Традиційні підходи до управління I/O в Linux, такі як блокуючі виклики, select()/poll()/epoll() для мережевих операцій та libaio для дискових, демонструють свої обмеження. Вони страждають від високих накладних витрат на системні виклики (syscalls), частих перемикань контексту між простором користувача та ядром, а також фрагментації API для різних типів I/O. Ці недоліки призводять до неефективного використання ресурсів CPU, збільшення затримок та обмеження масштабованості.
Саме тут на сцену виходить io_uring — революційний асинхронний I/O інтерфейс ядра Linux, представлений у версії 5.1 ядра. io_uring покликаний вирішити фундаментальні проблеми продуктивності I/O, уніфікуючи операції з файлами, дисками та мережею під єдиним, високоефективним API. Він дозволяє застосункам виконувати тисячі I/O операцій без жодного системного виклику після ініціалізації, значно скорочуючи накладні витрати та вивільняючи CPU для корисної роботи.
Дана стаття призначена для широкого кола технічних фахівців, які стикаються з викликами високонавантажених систем: DevOps-інженерів, які прагнуть оптимізувати інфраструктуру; Backend-розробників (особливо на Python, Node.js, Go, PHP), що працюють над продуктивністю своїх сервісів; Фаундерів SaaS-проєктів, яким важлива економічна ефективність та масштабованість; Системних адміністраторів, які відповідають за стабільність та швидкість роботи серверів; і Технічних директорів стартапів, які приймають архітектурні рішення. Ми заглибимося в деталі io_uring, розглянемо його переваги, недоліки, практичні аспекти застосування та економічну доцільність, щоб допомогти вам приймати обґрунтовані рішення у світі високопродуктивних систем 2026 року.
2. Основні критерії та фактори продуктивності I/O
Для ефективної оптимізації продуктивності I/O необхідно чітко розуміти, які метрики та фактори є ключовими. Однобокий підхід може призвести до невірних висновків та неефективних рішень. У 2026 році, коли апаратні можливості продовжують зростати, а вимоги до швидкості обробки даних посилюються, детальний аналіз цих критеріїв стає ще важливішим.
2.1. Затримка (Latency)
Що це: Час, необхідний для завершення однієї I/O операції, від моменту запиту до моменту отримання результату. Вимірюється в мілісекундах (мс), мікросекундах (мкс) або навіть наносекундах (нс) для критично важливих систем. Розрізняють середню затримку, а також затримки на перцентилях (P90, P99, P99.9), які показують, скільки часу займає операція для 90%, 99% або 99.9% запитів відповідно. Високі значення на P99 або P99.9 вказують на "хвостові" затримки, які можуть сильно псувати користувацький досвід.
Чому важливо: Безпосередньо впливає на швидкість відгуку застосунку. Для інтерактивних систем (веб-сервери, бази даних, ігрові сервери) низька затримка критична для забезпечення плавного користувацького досвіду. Високі затримки можуть призвести до таймаутів, зниження задоволеності клієнтів та втрати доходу.
Як оцінювати: Використовуйте утиліти типу fio, iostat, а також спеціалізовані інструменти моніторингу застосунків та інфраструктури, які збирають метрики затримки. Важливо вимірювати затримку як на рівні операційної системи, так і на рівні самого застосунку.
2.2. Пропускна здатність (Throughput)
Що це: Обсяг даних або кількість операцій, які система може обробити за одиницю часу. Для дискових операцій це може бути МБ/с або ГБ/с, для мережевих — пакети/с або Гбіт/с, для баз даних — IOPS (операцій вводу/виводу в секунду) або транзакцій/с. IOPS особливо важливий для баз даних з великою кількістю дрібних випадкових операцій.
Чому важливо: Визначає загальну продуктивність системи під час обробки великих обсягів даних. Висока пропускна здатність дозволяє обробляти більше запитів, зберігати лог-файли, передавати потокове відео або виконувати аналітичні задачі швидше.
Як оцінювати: Аналогічно до затримки, за допомогою fio, iostat, sar, а також мережевих аналізаторів та моніторингу продуктивності баз даних. Важливо розрізняти послідовну та випадкову пропускну здатність, а також пропускну здатність для читання та запису.
2.3. Утилізація CPU (CPU Utilization)
Що це: Частка процесорного часу, що використовується для виконання I/O операцій та пов'язаних з ними системних викликів, перемикань контексту та обробки переривань. Висока утилізація CPU для I/O вказує на неефективність.
Чому важливо: Кожен цикл CPU, витрачений на обробку I/O, не може бути використаний для виконання корисної бізнес-логіки. Зниження утилізації CPU для I/O дозволяє додатку виконувати більше роботи на тому ж обладнанні, зменшуючи потребу в масштабуванні і, як наслідок, витрати.
Як оцінювати: Використовуйте top, htop, vmstat, perf, bpftrace для детального аналізу профілю CPU. Звертайте увагу на %sy (системний час) та %wa (час очікування I/O).
2.4. Паралелізм (Concurrency)
Що це: Кількість I/O операцій, які можуть виконуватися одночасно. Сучасні додатки часто обробляють тисячі або мільйони паралельних запитів.
Чому важливо: Прямо впливає на здатність системи обслуговувати безліч клієнтів або внутрішніх процесів без деградації продуктивності. Традиційні блокуючі I/O моделі погано масштабуються за паралелізмом, вимагаючи великої кількості потоків або процесів, що збільшує накладні витрати.
Як оцінювати: Навантажувальне тестування зі збільшенням числа одночасних клієнтів/запитів. Моніторинг кількості активних з'єднань, потоків або запитів в очікуванні.
2.5. Масштабованість (Scalability)
Що це: Здатність системи ефективно збільшувати свою продуктивність при додаванні додаткових ресурсів (CPU, RAM, диски, мережеві адаптери) або при збільшенні навантаження. Ідеально, якщо продуктивність зростає лінійно з ресурсами.
Чому важливо: Дозволяє додатку рости разом з потребами бізнесу, уникаючи дорогих переробок архітектури або лімітів продуктивності. Хороша масштабованість знижує ризики та забезпечує гнучкість.
Як оцінювати: Проведення навантажувального тестування на різних конфігураціях обладнання, аналіз продуктивності при збільшенні числа вузлів в кластері або ресурсів на одному вузлі.
2.6. Ефективність використання ресурсів (Resource Efficiency)
Що це: Наскільки ефективно система використовує доступні CPU, RAM, пропускну здатність мережі та диска. Менше ресурсів для тієї ж роботи — вища ефективність.
Чому важливо: Безпосередньо впливає на операційні витрати (OpEx), особливо в хмарних середовищах, де кожен гігабайт RAM та кожна година CPU оплачуються. Оптимізація I/O може призвести до істотної економії.
Як оцінювати: Комплексний моніторинг всіх системних ресурсів, зіставлення їх утилізації з досягнутою пропускною здатністю та затримкою.
2.7. Джитер (Jitter)
Що це: Варіабельність або флуктуації затримки I/O операцій. Навіть при низькій середній затримці, високий джитер (великі розкиди в P99.9 у порівнянні з P50) може створювати проблеми.
Чому важливо: Непередбачуваність затримок може бути гірше, ніж стабільно висока затримка. Вона ускладнює планування, призводить до непередбачуваних таймаутів і може викликати каскадні збої в розподілених системах.
Як оцінювати: Аналіз перцентилів затримки (P90, P99, P99.9), побудова гістограм розподілу затримок.
Розуміння цих критеріїв дозволяє не тільки діагностувати проблеми продуктивності, але й вибирати найбільш відповідні технології та підходи, такі як io_uring, для досягнення оптимальних результатів у конкретних сценаріях.
3. Порівняльна таблиця методів I/O
У світі Linux існує безліч підходів до управління вводом-виводом, кожен зі своїми сильними та слабкими сторонами. io_uring не є універсальним рішенням для всіх задач, але в певних сценаріях він демонструє безпрецедентну ефективність. У цій таблиці ми порівняємо ключові методи I/O, актуальні на 2026 рік, щоб дати уявлення про їх застосовність та продуктивність.
| Критерій | Блокуючий I/O (read()/write()) |
Мультиплексування (epoll/select) |
Linux Native AIO (libaio) |
io_uring (з SQPOLL) |
io_uring (без SQPOLL) |
|---|---|---|---|---|---|
| Рік появи / Актуальність | 1970-ті / Все ще базовий | 1990-ті (select), 2002 (epoll) / Широко використовується |
2002 / Вузькоспеціалізований | 2019 (Linux 5.1) / Стандарт для high-perf (2026) | 2019 (Linux 5.1) / Стандарт для high-perf (2026) |
| Складність API | Дуже низька | Середня | Висока | Дуже висока | Висока |
| Накладні витрати (syscalls на операцію) | 1-2 (очікування + читання/запис) | 1 (epoll_wait) + N (read/write) |
2 (io_submit, io_getevents) |
~0 (після ініціалізації) | 1 (io_uring_enter) на батч |
| Підтримка мережевих операцій | Так | Так (основне застосування) | Ні | Повна (accept, connect, recvmsg, sendmsg) |
Повна (accept, connect, recvmsg, sendmsg) |
| Підтримка дискових операцій | Так | Ні (тільки готовність FD) | Так (тільки O_DIRECT) | Повна (включаючи кешований I/O) | Повна (включаючи кешований I/O) |
| Підтримка файлових операцій (загальні) | Так | Ні | Обмежена (open, close) |
Повна (openat, close, statx, fadvise) |
Повна (openat, close, statx, fadvise) |
| Асинхронність | Ні (блокуючий) | Псевдо-асинхронний (готовність до I/O) | Так (справжній асинхронний) | Так (справжній асинхронний, kernel-side polling) | Так (справжній асинхронний, user-side polling) |
| Рекомендовані сценарії | Прості скрипти, низьконавантажені застосунки | Високонавантажені мережеві застосунки (веб-сервери, проксі) | СУБД, спеціалізовані сховища (O_DIRECT) | Екстремально високонавантажені застосунки (СУБД, кеші, брокери повідомлень, проксі) | Високонавантажені застосунки, де SQPOLL не критичний або небажаний |
| Типова затримка (нс) при високому навантаженні (P99) | 20000+ | 5000-10000 | 3000-7000 | 500-1500 | 1000-3000 |
| Макс. QPS (IOPS) на 1 ядро (K) (умов.) | 10-20 | 50-150 | 80-200 | 500-1500+ | 200-800 |
| Утилізація CPU при 100K IOPS (%) | ~50-70 | ~30-40 | ~20-30 | ~5-15 | ~15-25 |
| Вартість розробки (умовні одиниці, 2026) | 1 | 2-3 | 4-5 | 8-10 | 6-8 |
Примітка: Зазначені цифри є приблизними оцінками для високонавантажених сценаріїв на сучасному обладнанні (процесори Intel Xeon/AMD EPYC 2024-2026 років, NVMe SSDs, 100GbE мережі) і можуть сильно варіюватися в залежності від конкретного застосунку, типу I/O, розміру блоків і конфігурації системи. "Вартість розробки" відображає відносну складність освоєння та інтеграції.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
4. Детальний огляд кожного пункту/варіанту I/O
Давайте заглибимося в особливості кожного методу I/O, щоб зрозуміти, коли і чому вони використовуються, і чому io_uring стає кращим вибором для високопродуктивних систем.
4.1. Блокуючий I/O (read()/write())
Це найпростіший та інтуїтивно зрозумілий спосіб виконання операцій введення-виведення. Коли застосунок викликає read() або write(), він блокується до тих пір, поки операція не буде завершена ядром. В цей час потік, який ініціював I/O, переходить в стан очікування, і планувальник ядра може переключитися на інший потік або процес. Простота API робить його ідеальним для простих застосунків і скриптів, де продуктивність I/O не є вузьким місцем. Однак для високонавантажених застосунків така модель призводить до серйозних проблем масштабованості. Кожна I/O операція вимагає системного виклику, перемикання контексту та очікування, що породжує величезні накладні витрати при великій кількості паралельних запитів. Для обробки паралелізму доводиться запускати безліч потоків або процесів, кожен з яких може бути заблокований, що призводить до "пробуксовки" CPU на перемиканнях контексту та неефективного використання ресурсів. У 2026 році цей метод залишається базовим, але абсолютно непридатний для систем, де потрібно обробляти десятки та сотні тисяч I/O операцій в секунду.
4.2. Мультиплексування I/O (select(), poll(), epoll())
Ці механізми були розроблені для вирішення проблеми блокуючого I/O в мережевих застосунках. Замість того, щоб блокувати на кожній операції читання/запису, застосунок може "запитати" ядро, які з безлічі відкритих файлових дескрипторів (сокети, пайпи) готові до читання або запису. select() та poll() страждають від масштабування за кількістю файлових дескрипторів (O(N) сканування списку), тоді як epoll() (представлений в Linux 2.5.44) значно ефективніший, працюючи в режимі O(1) за рахунок використання зворотних викликів ядра та кільцевих буферів подій. epoll дозволяє застосунку ефективно обробляти тисячі та мільйони паралельних мережевих з'єднань з мінімальними накладними витратами. Він є наріжним каменем більшості сучасних веб-серверів, проксі та брокерів повідомлень. Однак epoll не є істинно асинхронним I/O для дискових операцій; він лише повідомляє про готовність файлового дескриптора. Самі операції read()/write() після отримання події все ще можуть блокувати, якщо дані ще не готові або буфер заповнений, або якщо операція виконується з диском, а не з мережею. Це обмежує його застосування в сценаріях з інтенсивним дисковим I/O, таких як бази даних.
4.3. Linux Native AIO (libaio)
libaio (або Linux Native AIO) був розроблений спеціально для вирішення проблем асинхронного дискового I/O, особливо для баз даних, яким потрібен прямий доступ до диску (O_DIRECT) без втручання кешу сторінки ядра. Він дозволяє застосунку відправляти ядру пачку I/O запитів і потім асинхронно отримувати повідомлення про їх завершення. Це усуває блокування викликаючого потоку і дозволяє ефективно використовувати переваги високопродуктивних сховищ (наприклад, NVMe SSD). API libaio досить складний і низькорівневий, вимагаючи ручного управління iocb (I/O control blocks) та io_event. Основні обмеження libaio полягають в його фокусі виключно на дискових операціях (і тільки з O_DIRECT для асинхронності) і відсутності підтримки мережевого I/O. Крім того, навіть з libaio, кожна пачка операцій вимагає системних викликів io_submit() та io_getevents(), що, хоча і краще, ніж по одному виклику, все ж створює накладні витрати, які io_uring прагне усунути. До 2026 року libaio здебільшого витіснений io_uring в нових високопродуктивних проєктах, хоча все ще присутній в старих, перевірених часом системах.
4.4. io_uring: Єдиний асинхронний I/O для Linux
io_uring — це кульмінація десятиліть розвитку I/O в Linux. Його головна мета — надати єдиний, високоефективний, асинхронний інтерфейс для всіх типів I/O операцій: дискових, файлових, мережевих, а також для ряду інших системних операцій. На відміну від попередніх методів, io_uring працює за принципом "запитав і забув" з мінімальною взаємодією з ядром після початкового налаштування.
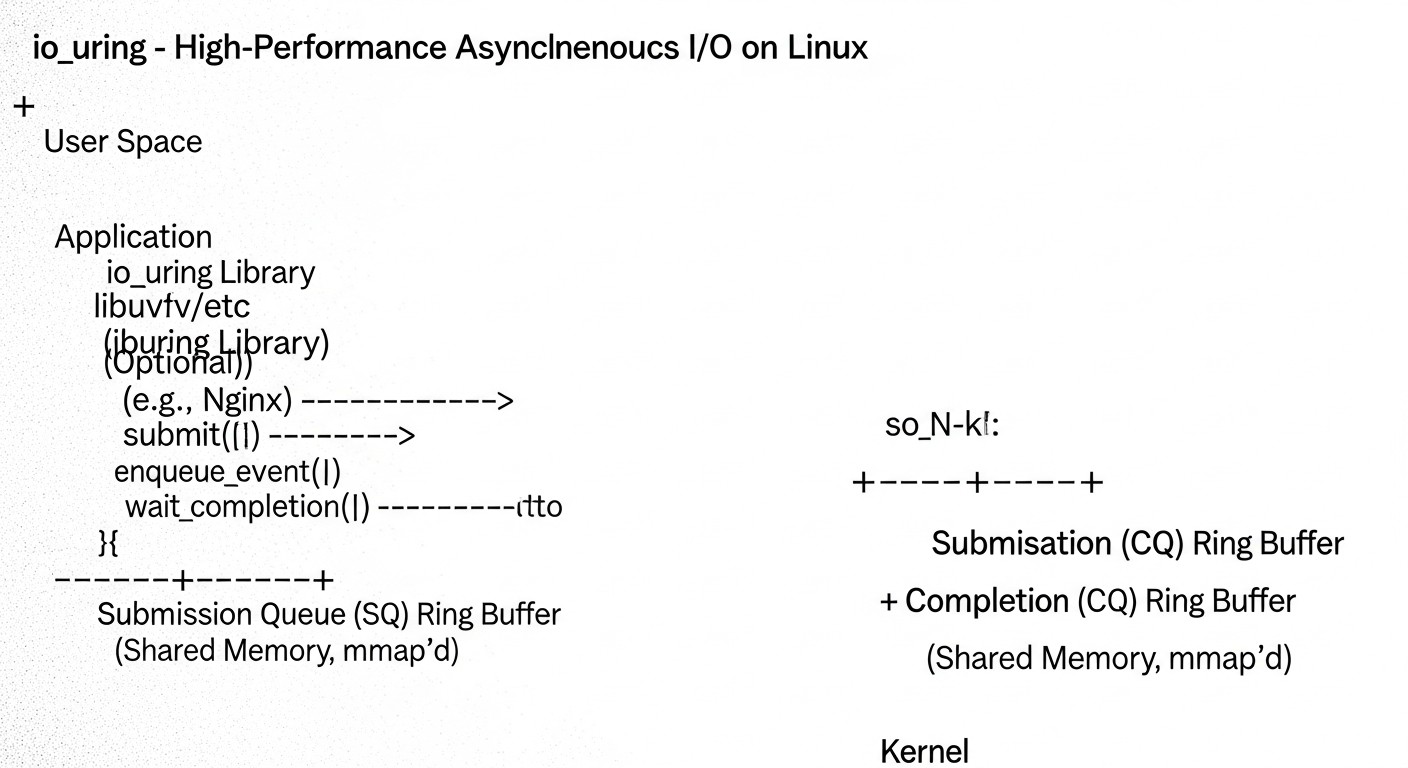
Архітектура io_uring:
- Кільцеві буфери (Ring Buffers): В основі io_uring лежать два кільцевих буфера, що відображаються в пам'ять користувацького простору:
- Submission Queue (SQ): Черга запитів. Додаток поміщає сюди дескриптори операцій (Submission Queue Entries, SKE), що описують, що потрібно зробити (наприклад, прочитати файл, відправити дані по сокету).
- Completion Queue (CQ): Черга завершень. Ядро поміщає сюди результати виконаних операцій (Completion Queue Entries, CQE), повідомляючи додаток про статус і результат кожної операції.
- Мінімальна кількість системних викликів: Після ініціалізації io_uring, додаток може відправляти тисячі операцій, просто записуючи їх в SQ. Ядро бере їх з SQ і виконує асинхронно. Коли операції завершуються, результати поміщаються в CQ. Додаток періодично перевіряє CQ на наявність завершених операцій. Системний виклик
io_uring_enter()потрібен тільки для "пробудження" ядра, якщо воно неактивне, або для відправки великого батча запитів, якщо SQ заповнений. Це радикально скорочує накладні витрати на системні виклики. - Уніфікація: io_uring підтримує широкий спектр операцій, включаючи:
- Дисковий/файловий I/O:
read,write,fsync,openat,close,statx,fadvise. Підтримує як кешований, так і прямий I/O (O_DIRECT). - Мережевий I/O:
accept,connect,recvmsg,sendmsg. Це дозволяє створювати високопродуктивні мережеві сервери, які раніше покладалися наepoll. - Інші операції:
link_timeout(асинхронні таймери),async_cancel(скасування операцій),io_uring_cmd(розширювані команди для драйверів).
- Дисковий/файловий I/O:
- SQPOLL (Submission Queue Polling): Це опціональний режим, при якому окремий потік ядра постійно опитує SQ на наявність нових запитів. Це повністю виключає необхідність системного виклику
io_uring_enter()для відправки запитів, доводячи накладні витрати до абсолютного мінімуму. Ідеально підходить для екстремально високих навантажень, але споживає одне ядро CPU для потоку-опитувача. - IORING_SETUP_IOPOLL: Це режим, коли ядро не генерує переривання по завершенню I/O, а користувацький додаток сам опитує CQ на предмет завершених операцій. Вимагає активного циклу опитування в користувацькому просторі. Використовується в сценаріях з дуже низькими затримками, коли навіть переривання занадто дорогі.
- Реєстрація ресурсів: io_uring дозволяє попередньо реєструвати буфери пам'яті та файлові дескриптори в ядрі. Це усуває необхідність дорогих системних викликів
mmap/munmapабо перевірок дескрипторів при кожній операції, додатково знижуючи накладні витрати та дозволяючи ядру виконувати операції більш ефективно (наприклад, уникаючи копіювання даних між користувацьким і ядром).
Переваги: io_uring значно знижує затримки, збільшує пропускну здатність і зменшує утилізацію CPU для I/O-інтенсивних задач. Він дозволяє обробляти мільйони IOPS на одному ядрі CPU, що було немислимо з попередніми методами. Це досягається за рахунок мінімізації системних викликів, перемикань контексту і використання ядра для виконання асинхронних операцій.
Недоліки: Складний і низькорівневий API, що вимагає глибокого розуміння роботи ядра і ретельного управління пам'яттю. Високий поріг входу для розробників. Помилки в роботі з io_uring можуть призвести до важкодіагностованих проблем.
Для кого підходить: io_uring є ідеальним рішенням для розробників високопродуктивних баз даних, key-value сховищ, брокерів повідомлень, проксі-серверів, ігрових серверів, високонавантажених веб-серверів і будь-яких інших додатків, де I/O є вузьким місцем і потрібна максимальна ефективність використання апаратних ресурсів. У 2026 році він стає стандартом для таких систем.
5. Практичні поради та рекомендації щодо io_uring
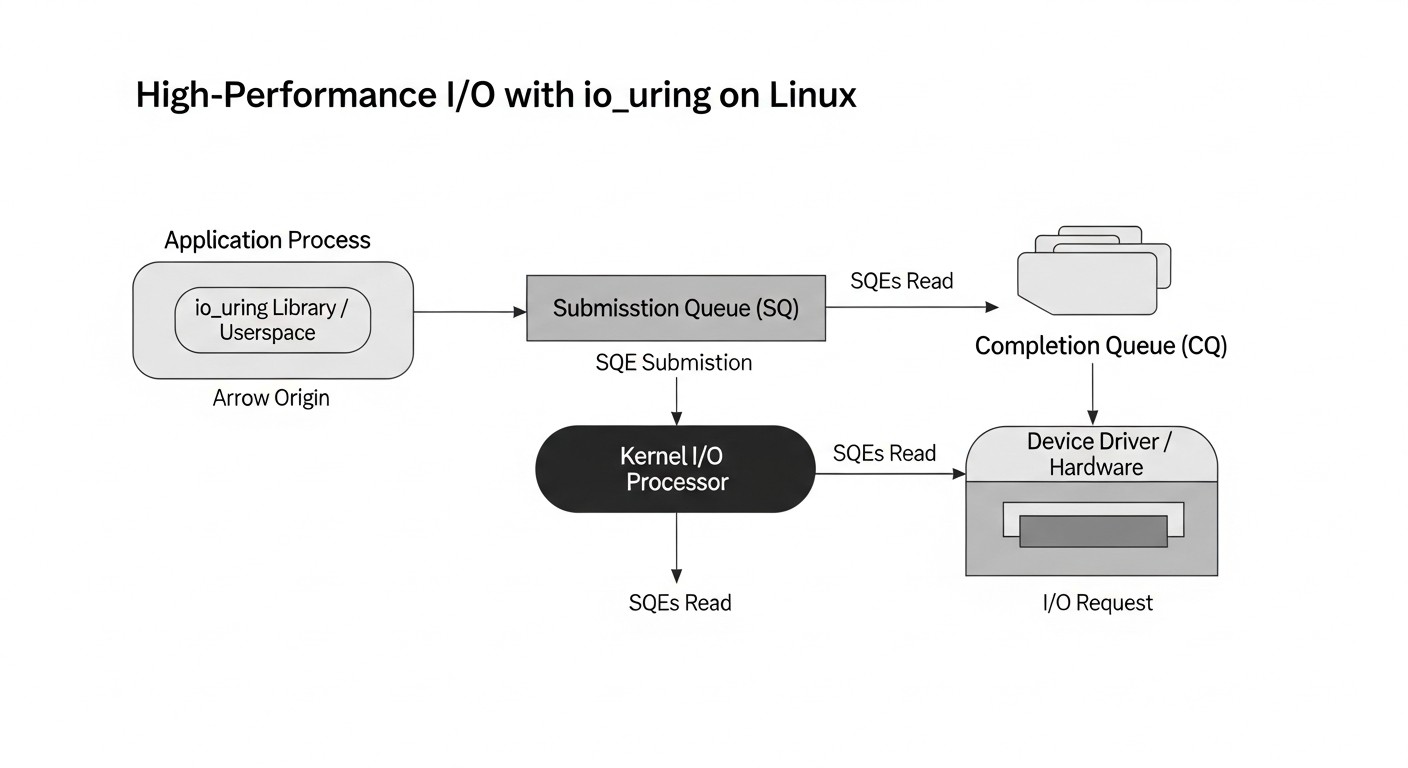
Інтеграція io_uring у високонавантажений додаток — це нетривіальне завдання, що вимагає уважності та глибокого розуміння. Ось ряд практичних порад і покрокових рекомендацій, заснованих на реальному досвіді.
5.1. Вибір правильної версії ядра Linux
Для повноцінного використання io_uring суворо рекомендується використовувати ядро Linux версії 5.10 або новіше. У версіях 5.1-5.9 функціональність була обмеженою, були баги і відсутні багато важливих операцій (наприклад, мережеві). Оптимальний вибір для production-середовища у 2026 році — це ядра серії 6.x (наприклад, 6.6 LTS або новіше), які пропонують максимальну стабільність, продуктивність і повний набір функцій, включаючи розширену підтримку файлових операцій, таймерів і скасування запитів.
# Перевірка версії ядра
uname -r
# Очікуваний вивід: 6.6.10-amd64 або новіше
5.2. Використання бібліотеки liburing
Хоча можна працювати з io_uring безпосередньо через системні виклики, настійно рекомендується використовувати користувацьку бібліотеку liburing. Вона надає зручний і безпечний високорівневий API, що абстрагує від низькорівневих деталей роботи з кільцевими буферами і системними викликами, значно спрощуючи розробку і знижуючи ймовірність помилок.
# Встановлення liburing (приклад для Debian/Ubuntu)
sudo apt update
sudo apt install liburing-dev
# Для інших дистрибутивів використовуйте відповідний менеджер пакетів (dnf, pacman)
5.3. Ініціалізація контексту io_uring
Перший крок — створення екземпляра io_uring. Необхідно визначити розмір кільцевих буферів (кількість записів SQE). Чим більший розмір, тим більше операцій можна поставити в чергу без системного виклику io_uring_enter.
#include <liburing.h>
#include <stdio.h>
#include <stdlib.h>
#define QUEUE_DEPTH 4096 // Рекомендована глибина черги для високонавантажених систем
struct io_uring ring;
int main() {
struct io_uring_params p = {};
// Можна додати прапорці, наприклад, IORING_SETUP_SQPOLL
// p.flags |= IORING_SETUP_SQPOLL;
// p.sq_thread_cpu = 0; // Прив'язати SQPOLL до конкретного ядра
int ret = io_uring_queue_init_params(QUEUE_DEPTH, &ring, &p);
if (ret < 0) {
fprintf(stderr, "io_uring_queue_init: %s\n", strerror(-ret));
return 1;
}
printf("io_uring ініціалізовано успішно з глибиною черги %d\n", QUEUE_DEPTH);
// ... ваш код роботи з io_uring ...
io_uring_queue_exit(&ring);
return 0;
}
5.4. Реєстрація буферів та файлових дескрипторів
Для досягнення максимальної продуктивності обов'язково реєструйте буфери пам'яті та файлові дескриптори. Це дозволяє ядру уникнути дорогих перевірок та копіювання даних, а також використовувати оптимізації, такі як I/O з нульовим копіюванням (zero-copy) в деяких сценаріях.
// Приклад реєстрації буферів
char buffer_pool[NUM_BUFFERS]; // Попередньо виділені буфери
// ... ініціалізація buffer_pool ...
int ret = io_uring_register_buffers(&ring, buffer_pool, NUM_BUFFERS, BUFFER_SIZE);
if (ret < 0) {
fprintf(stderr, "io_uring_register_buffers: %s\n", strerror(-ret));
// Обробка помилки
}
// Приклад реєстрації файлових дескрипторів
int files[NUM_FILES]; // Масив відкритих FD
// ... ініціалізація files ...
ret = io_uring_register_files(&ring, files, NUM_FILES);
if (ret < 0) {
fprintf(stderr, "io_uring_register_files: %s\n", strerror(-ret));
// Обробка помилки
}
5.5. Пакетування операцій (Batching)
Один з головних принципів io_uring — відправка максимально можливої кількості операцій за один системний виклик. Замість того щоб викликати io_uring_submit() після кожної операції, накопичуйте SQE в черзі та відправляйте їх пачкою. Це різко скорочує кількість перемикань контексту.
// Приклад пакетування операцій читання
for (int i = 0; i < batch_size; ++i) {
struct io_uring_sqe sqe = io_uring_get_sqe(&ring);
if (!sqe) {
// Черга SQ заповнена, відправляємо поточні та пробуємо знову
io_uring_submit(&ring);
sqe = io_uring_get_sqe(&ring); // Повторна спроба
if (!sqe) {
fprintf(stderr, "Failed to get SQE even after submit\n");
break;
}
}
io_uring_prep_read(sqe, file_descriptors[i], buffers[i], BUFFER_SIZE, offsets[i]);
io_uring_sqe_set_data(sqe, (void)(long)request_id[i]); // Користувацькі дані для ідентифікації
}
io_uring_submit(&ring); // Відправляємо залишок операцій
5.6. Обробка завершених операцій
Після відправки запитів необхідно періодично перевіряти Completion Queue на наявність завершених операцій. Це можна робити як блокуючим (io_uring_wait_cqe), так і неблокуючим (io_uring_peek_cqe, io_uring_for_each_cqe) способом.
struct io_uring_cqe cqe;
unsigned head;
unsigned count = 0;
// Неблокуюче опитування CQ
io_uring_for_each_cqe(&ring, head, cqe) {
long request_id = (long)io_uring_cqe_get_data(cqe);
int res = cqe->res; // Результат операції (кількість байт або код помилки)
if (res < 0) {
fprintf(stderr, "I/O error for request %ld: %s\n", request_id, strerror(-res));
} else {
printf("Request %ld completed successfully, bytes: %d\n", request_id, res);
}
count++;
}
io_uring_cq_advance(&ring, count); // Відмітити оброблені CQE
5.7. Використання IORING_SETUP_SQPOLL
Для самих екстремальних навантажень розгляньте використання IORING_SETUP_SQPOLL. Цей прапорець при ініціалізації io_uring створює потік ядра, який постійно опитує SQ. Це усуває необхідність в системному виклику io_uring_enter() для відправки запитів, але споживає одне ядро CPU. Прив'язка цього потоку до конкретного ядра (sq_thread_cpu) може покращити кешування.
struct io_uring_params p = {};
p.flags |= IORING_SETUP_SQPOLL;
p.sq_thread_cpu = 0; // Прив'язати до CPU 0
int ret = io_uring_queue_init_params(QUEUE_DEPTH, &ring, &p);
// ...
5.8. Асинхронні мережеві операції
io_uring повністю підтримує асинхронні мережеві операції, замінюючи epoll у високопродуктивних мережевих серверах.
// Приклад асинхронного accept
struct io_uring_sqe sqe = io_uring_get_sqe(&ring);
io_uring_prep_accept(sqe, listen_fd, (struct sockaddr )&client_addr, &client_addr_len, 0);
io_uring_sqe_set_data(sqe, (void)(long)ACCEPT_REQ_ID);
io_uring_submit(&ring);
// Приклад асинхронного recv
sqe = io_uring_get_sqe(&ring);
io_uring_prep_recv(sqe, client_fd, buffer, BUFFER_SIZE, 0);
io_uring_sqe_set_data(sqe, (void)(long)RECV_REQ_ID);
io_uring_submit(&ring);
5.9. Управління життєвим циклом буферів
При використанні зареєстрованих буферів, переконайтеся, що вони залишаються валідними до тих пір, поки ядро не завершить всі операції з ними. Використання "user_data" в SQE для передачі вказівників на структури запитів або ідентифікаторів допомагає коректно управляти буферами та ресурсами після завершення операції.
5.10. Ретельне тестування та бенчмаркінг
Після впровадження io_uring, обов'язково проводьте навантажувальне тестування за допомогою fio (з рушієм io_uring), wrk, ab або спеціалізованих бенчмарків. Порівнюйте продуктивність з попередніми реалізаціями, аналізуйте метрики затримки, пропускної здатності та утилізації CPU. io_uring не завжди дає виграш для всіх типів навантажень, тому важливо переконатися, що він дійсно вирішує вашу проблему.
6. Типові помилки при роботі з io_uring
io_uring — потужний, але складний інструмент. Помилки при його використанні можуть призвести до непередбачуваної поведінки, витоків пам'яті, або, що іронічно, до зниження продуктивності. Ось найбільш поширені помилки, з якими стикаються розробники:
6.1. Ігнорування версії ядра Linux
Помилка: Спроба використовувати io_uring на старих ядрах (до 5.10) або очікування повної функціональності на ранніх версіях (5.1-5.9).
Наслідки: Відсутність підтримки потрібних операцій (наприклад, мережевих), наявність багів, нестабільність, неможливість використання ключових оптимізацій. Додаток може компілюватися, але падати в рантаймі або працювати некоректно.
Як уникнути: Завжди перевіряйте версію ядра за допомогою uname -r. У 2026 році для серйозних проектів використовуйте ядра 6.x LTS. Включайте перевірку версії ядра на старті додатку або в скриптах деплою.
6.2. Відсутність пакетування операцій
Помилка: Відправка кожного I/O запиту в ядро через io_uring_submit() (або io_uring_enter()) по окремо, замість об'єднання їх в пачки.
Наслідки: Зниження продуктивності, оскільки кожен виклик io_uring_submit() — це системний виклик, який спричиняє перемикання контексту. Це зводить нанівець одну з головних переваг io_uring, роблячи його не набагато кращим за традиційний AIO або навіть epoll для великої кількості дрібних операцій.
Як уникнути: Максимально батчіть запити. Накопичуйте SQE в Submission Queue до певного порогу (наприклад, 64, 128, 256 операцій) або до закінчення короткого таймауту, перш ніж викликати io_uring_submit(). Використовуйте флаг IOSQE_IO_DRAIN для операцій, які повинні бути виконані до наступних, але це рідко потрібно.
6.3. Некоректне управління життєвим циклом буферів і файлових дескрипторів
Помилка: Звільнення буферів пам'яті або закриття файлових дескрипторів до того, як ядро завершило всі операції з ними. Або навпаки, не звільнення ресурсів після їх використання.
Наслідки: Витоки пам'яті, помилки "use-after-free", краші застосунку, пошкодження даних. Ядро працює з вказівниками на ваші буфери; якщо вони стають недійсними, виникає невизначена поведінка.
Як уникнути:
- Використовуйте
user_dataв SQE для зв'язування запиту з контекстом (наприклад, вказівником на структуру запиту, що включає буфери). - Звільняйте або перевикористовуйте буфери тільки після отримання відповідного CQE (Completion Queue Entry) про завершення операції.
- Реєструйте буфери і файлові дескриптори за допомогою
io_uring_register_buffers()іio_uring_register_files(). Це допомагає ядру більш безпечно управляти ресурсами і знижує накладні витрати.
6.4. Неправильна обробка завершених операцій
Помилка: Неправильне читання Completion Queue (CQ) або ігнорування кодів помилок в CQE.
Наслідки: Зависання застосунку (якщо CQ переповнюється і нові операції не можуть бути завершені), втрата даних, некоректний стан застосунку, пропуск помилок I/O.
Як уникнути:
- Завжди перевіряйте
cqe->resна предмет помилок (від'ємні значення). Використовуйтеstrerror(-cqe->res)для отримання текстового опису помилки. - Регулярно опитуйте CQ і просувайте вказівник
headза допомогоюio_uring_cq_advance()після обробки CQE. - Використовуйте
io_uring_wait_cqe()з обережністю, щоб не блокувати основний цикл обробки занадто довго, якщо є інші завдання.
6.5. Неправильне використання або ігнорування IORING_SETUP_SQPOLL
Помилка: Увімкнення IORING_SETUP_SQPOLL без розуміння його наслідків (споживання ядра CPU) або його невикористання в сценаріях, де він міг би дати значний приріст продуктивності.
Наслідки: Якщо SQPOLL увімкнений без потреби, ви даремно витрачаєте ядро CPU. Якщо він не використовується там, де потрібен, застосунок страждає від зайвих системних викликів io_uring_enter().
Як уникнути: SQPOLL призначений для екстремальних навантажень, де кожен системний виклик критичний. Застосовуйте його тільки після ретельного бенчмаркінгу. Переконайтеся, що ви прив'язуєте SQPOLL-потік до конкретного CPU (p.sq_thread_cpu), щоб уникнути проблем з кешуванням та ізоляцією.
6.6. Відсутність обробки скасування операцій
Помилка: Нездатність скасувати завислі або неактуальні I/O операції, особливо в довготривалих мережевих з'єднаннях або при роботі з повільними дисками.
Наслідки: Зависання ресурсів, таймаути, споживання пам'яті і CPU ядром на операції, які вже не потрібні застосунку.
Як уникнути: Використовуйте IORING_OP_ASYNC_CANCEL. Зберігайте user_data для кожного запиту, щоб можна було ідентифікувати і скасувати конкретну операцію. Це особливо важливо для мережевих операцій з таймаутами або при закритті клієнтських з'єднань.
6.7. Недостатнє логування і моніторинг
Помилка: Відсутність детального логування помилок і метрик продуктивності io_uring.
Наслідки: Труднощі в діагностиці проблем в production-середовищі, неможливість виявити вузькі місця, неоптимальна робота системи.
Як уникнути: Логуйте всі помилки, що повертаються io_uring. Моніторьте кількість SQE, CQE, затримки операцій, кількість системних викликів io_uring_enter(), утилізацію CPU (особливо %sy і %wa) за допомогою інструментів, таких як bpftrace, perf, iostat. Використовуйте /proc/sys/fs/io_uring/ для отримання статистики про поточні контексти io_uring.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
7. Чекліст для практичного застосування io_uring
Цей чеклист допоможе вам систематизувати процес впровадження та оптимізації io_uring у вашому застосунку, мінімізуючи ризики та максимізуючи продуктивність.
7.1. Підготовка та планування
- Визначити I/O профіль застосунку:
- Який тип I/O домінує: дисковий (випадковий/послідовний, дрібні/великі блоки), мережевий (багато з'єднань/мало трафіку, мало з'єднань/багато трафіку)?
- Які поточні метрики: затримка (P99, P99.9), пропускна здатність (IOPS/МБ/с), утилізація CPU?
- Які поточні I/O методи використовуються?
- Перевірити версію ядра Linux: Переконайтеся, що використовується ядро 5.10+ (рекомендується 6.x LTS). Якщо ні, заплануйте оновлення.
- Оцінити складність інтеграції: io_uring вимагає значних зусиль з розробки. Оцініть, чи виправдані ці зусилля потенційним приростом продуктивності.
7.2. Ініціалізація io_uring
- Використовувати
liburing: Включіть бібліотекуliburingу ваш проєкт для спрощення роботи з API. - Ініціалізувати io_uring контекст:
- Визначте оптимальну глибину черги (
QUEUE_DEPTH) для SQ і CQ, виходячи з очікуваного паралелізму. - Виберіть флаги ініціалізації:
IORING_SETUP_SQPOLL: Якщо потрібна екстремально низька затримка і ви готові пожертвувати ядром CPU. Прив'яжіть потік SQPOLL до конкретного ядра (p.sq_thread_cpu).IORING_SETUP_IOPOLL: Для пристроїв, що підтримують опитування на стороні ядра (наприклад, NVMe).IORING_SETUP_SQ_AFF: Прив'язка SQ до певного ядра.
- Визначте оптимальну глибину черги (
- Зареєструвати ресурси:
- Зареєструйте буфери пам'яті (
io_uring_register_buffers), якщо ви будете використовувати фіксовані буфери. - Зареєструйте файлові дескриптори (
io_uring_register_files), якщо ви працюєте з постійним набором файлів/сокетів. - Пам'ятайте про правильне управління життєвим циклом зареєстрованих ресурсів.
- Зареєструйте буфери пам'яті (
7.3. Реалізація I/O логіки
- Реалізувати батчинг операцій:
- Накопичуйте SQE в Submission Queue.
- Викликайте
io_uring_submit()тільки коли SQ заповнений або минув короткий таймаут.
- Спроектувати структуру запитів: Використовуйте
io_uring_sqe_set_data()для прив'язки користувацьких даних (вказівників на буфери, ідентифікатори запитів, коллбеки) до кожного SQE. - Реалізувати обробку завершень:
- Періодично опитуйте Completion Queue.
- Використовуйте
io_uring_for_each_cqe()для ефективної обробки всіх завершених подій. - Завжди перевіряйте
cqe->resна помилки та логуйте їх. - Після обробки всіх CQE, просувайте вказівник
headза допомогоюio_uring_cq_advance().
- Обробити скасування операцій: Впровадьте механізм скасування завислих або неактуальних запитів за допомогою
IORING_OP_ASYNC_CANCEL.
7.4. Тестування, моніторинг та оптимізація
- Провести бенчмаркінг:
- Використовуйте
fio(з рушієм io_uring) для дискових операцій. - Використовуйте
wrk,ab, або користувацькі бенчмарки для мережевих операцій. - Порівняйте продуктивність з попередньою реалізацією та з іншими I/O методами.
- Використовуйте
- Налаштувати моніторинг:
- Відстежуйте метрики I/O (IOPS, throughput, latency) за допомогою
iostat,vmstat. - Моніторте утилізацію CPU (
top,htop), особливо системний час та час очікування I/O. - Використовуйте
bpftraceабоperfдля глибокого аналізу поведінки io_uring в ядрі.
- Відстежуйте метрики I/O (IOPS, throughput, latency) за допомогою
- Ізолювати CPU: Для критично важливих I/O-потоків розгляньте ізоляцію CPU за допомогою параметрів ядра (
isolcpus,nohz_full) та прив'язки процесів/потоків до конкретних ядер (taskset). - Тонке налаштування: Експериментуйте з розмірами кільцевих буферів, кількістю батчів, прапорами ініціалізації та налаштуваннями реєстрації буферів для досягнення оптимальної продуктивності для вашого конкретного сценарію.
8. Розрахунок вартості / Економіка використання io_uring
Впровадження io_uring — це інвестиція, яка окупається не тільки у вигляді приросту продуктивності, але й у вигляді значної економії операційних витрат (OpEx) та підвищення бізнес-цінності. До 2026 року, коли хмарні сервіси продовжують дорожчати, а вимоги до ефективності ростуть, економічний аспект io_uring стає все більш очевидним.
8.1. Зниження вимог до апаратних ресурсів
Головна економічна перевага io_uring полягає в його здатності виконувати набагато більший обсяг I/O операцій з меншою кількістю ресурсів CPU. Це означає, що для того ж робочого навантаження вам знадобиться:
- Менше CPU-ядер: io_uring значно скорочує системні виклики та перемикання контексту, звільняючи CPU для корисної роботи програми. Це дозволяє обслуговувати те ж навантаження на серверах з меншою кількістю ядер або на меншій кількості інстансів у хмарі.
- Менше RAM: Хоча io_uring сам по собі може вимагати виділення буферів, загальна ефективність може дозволити скоротити обсяг RAM, необхідний для підтримки великої кількості потоків або процесів, кожен з яких вимагає свого стеку та контексту.
- Менше серверів/інстансів: Якщо одна машина може обробляти в 2-3 рази більше I/O, ви можете скоротити кількість фізичних серверів або хмарних інстансів, необхідних для кластера.
8.2. Оптимізація хмарних витрат
У хмарних середовищах (AWS, GCP, Azure), де вартість інстансів безпосередньо залежить від кількості vCPU та обсягу RAM, економія може бути драматичною. Наприклад, перехід з інстансів типу m6a.xlarge на m6a.large або навіть m6a.medium для тієї ж I/O-інтенсивної задачі може скоротити щомісячні рахунки на десятки відсотків. Крім того, менша кількість інстансів означає менші витрати на мережевий трафік (ingress/egress), IP-адреси та управління.
8.3. Підвищення бізнес-цінності
- Покращений користувацький досвід: Зниження затримок I/O безпосередньо веде до більш швидкої відповіді програми, що підвищує задоволеність клієнтів, знижує відтік та сприяє росту бізнесу.
- Збільшення пропускної здатності: Можливість обробляти більше запитів або даних за одиницю часу дозволяє розширювати функціональність, впроваджувати нові сервіси та підтримувати більший обсяг бізнесу без перепроектування інфраструктури.
- Конкурентна перевага: Програми, що використовують io_uring, можуть перевершувати конкурентів за продуктивністю та вартістю, що є критично важливим фактором на висококонкурентних ринках SaaS та онлайн-сервісів.
8.4. Приховані витрати
- Висока вартість розробки: API io_uring складний та низькорівневий. Розробникам знадобиться значний час на вивчення та інтеграцію, що збільшує початкові витрати на розробку. Потрібні висококваліфіковані фахівці.
- Складність налагодження: Помилки в роботі з io_uring можуть бути важкодіагностованими, що збільшує час на пошук та усунення проблем.
- Залежність від версії ядра: Вимога до нової версії ядра Linux може бути проблемою для компаній з консервативною політикою оновлень.
- Споживання CPU для SQPOLL: Якщо використовується
IORING_SETUP_SQPOLL, одне ядро CPU буде постійно зайняте потоком ядра, що може бути неефективно для низьконавантажених систем.
8.5. Таблиця з прикладами розрахунків для різних сценаріїв (2026 рік)
Припустимо, у нас є SaaS-додаток, якому потрібно обробляти 1 мільйон IOPS для своєї основної бази даних або кешу.
| Параметр | Традиційний I/O (epoll + блокуючий read/write) |
io_uring (без SQPOLL) |
io_uring (з SQPOLL) |
|---|---|---|---|
| Необхідна кількість CPU-ядер (для 1M IOPS) | ~16-24 ядра | ~4-8 ядер | ~2-4 ядра (+1 ядро для SQPOLL) |
| Необхідний обсяг RAM (для 1M IOPS) | ~64-128 GB | ~32-64 GB | ~32-64 GB |
| Тип інстанса (приклад, 2026) | 2 x m7g.8xlarge (16 vCPU, 64GB RAM) |
1 x m7g.4xlarge (8 vCPU, 32GB RAM) |
1 x m7g.2xlarge (4 vCPU, 16GB RAM) + 1 ядро для SQPOLL |
| Вартість інстансів (міс, 2026, умов.) | ~$2000 - $3000 | ~$500 - $800 | ~$250 - $400 |
| Енергоспоживання (кВт/год, міс) | ~1000 кВт/год | ~300 кВт/год | ~150 кВт/год |
| Вартість розробки (умовні одиниці, 2026) | 10 | 25 | 30 |
| Вартість підтримки (умовні одиниці, 2026) | 5 | 8 | 10 |
| Загальна TCO за 3 роки (умовні одиниці) | ~1000 | ~400 | ~300 |
Примітка: Умовні одиниці та ціни інстансів є гіпотетичними для 2026 року і служать для ілюстрації відносної економії. Реальні цифри залежатимуть від конкретного провайдера, регіону, знижок та робочого навантаження. TCO (Total Cost of Ownership) включає розробку, підтримку та 3 роки експлуатації.
Як видно з таблиці, незважаючи на більш високі початкові витрати на розробку, io_uring забезпечує значну економію на операційних витратах у довгостроковій перспективі, особливо для високонавантажених систем. Це робить його вкрай привабливою інвестицією для SaaS-проектів та інших I/O-інтенсивних додатків.
9. Кейси та приклади впровадження io_uring
io_uring вже зарекомендував себе в реальних високонавантажених проектах. Наведемо кілька реалістичних сценаріїв, що демонструють його трансформаційний потенціал.
9.1. Кейс 1: Високопродуктивна Key-Value база даних (аналог Redis/Memcached)
Проблема: Стартап розробляв розподілену Key-Value базу даних з низькими затримками для ігрових додатків. Спочатку використовувався epoll для мережевого I/O і libaio для збереження даних на NVMe SSD (з O_DIRECT). При досягненні 500 000 IOPS на одному вузлі, утилізація CPU досягала 70-80%, а P99 затримка операцій запису зростала до 10-15 мс через часті системні виклики та перемикання контексту між мережевим та дисковим I/O. Масштабування вимагало додавання великої кількості вузлів, що призводило до високих хмарних витрат.
Рішення з io_uring: Команда переписала I/O-підсистему, повністю перейшовши на io_uring. Усі мережеві операції (accept, recvmsg, sendmsg) і дискові операції (read, write, fsync) були уніфіковані під єдиний цикл обробки io_uring. Були впроваджені наступні оптимізації:
- Використання
IORING_SETUP_SQPOLL, прив'язаного до окремого ядра CPU. - Реєстрація буферів пам'яті для уникнення копіювання даних.
- Реєстрація файлових дескрипторів для відкритих файлів даних.
- Агресивний батчинг операцій (до 256 SQE за один
io_uring_submit(), при необхідності).
Результати:
- Пропускна здатність: Збільшилась до 1.5 мільйона IOPS на одному вузлі (300% приріст).
- Затримка (P99): Знизилась з 10-15 мс до 1.5-3 мс для операцій запису.
- Утилізація CPU: При 1 мільйоні IOPS знизилась з 70-80% до 20-25% (включаючи ядро для SQPOLL).
- Економія: Кількість необхідних хмарних інстансів скоротилася в 3 рази, що призвело до економії понад 60% на щомісячних операційних витратах інфраструктури.
Цей кейс показав, як io_uring дозволив стартапу досягти продуктивності, раніше доступної тільки з дуже дорогим апаратним забезпеченням або складними спеціалізованими рішеннями.
9.2. Кейс 2: Високонавантажений Проксі-сервер / Балансувальник навантаження
Проблема: Великий онлайн-сервіс використовував NGINX як основний проксі-сервер і балансувальник навантаження. У пікові години, при обробці мільйонів активних TCP-з'єднань і тисяч запитів в секунду, NGINX (на основі epoll) починав споживати значні ресурси CPU, а затримки проксування зростали. Це вимагало масштабування шляхом додавання безлічі проксі-інстансів, що збільшувало вартість і складність управління.
Рішення з io_uring: Команда вирішила розробити кастомний, легковагий проксі-сервер на C++ з використанням io_uring. Метою було не замінити NGINX повністю, а створити спеціалізований компонент для найбільш критичних шляхів даних. Були використані асинхронні accept, connect, recvmsg, sendmsg операції io_uring. Основний акцент було зроблено на мінімізації копіювання даних.
- Використання зареєстрованих буферів для вхідних і вихідних даних, щоб уникнути
memcpyміж користувацьким простором і ядром. - Застосування
IORING_OP_SPLICEдля прямого копіювання даних між сокетами без копіювання в користувацький простір (zero-copy). - Оптимізація циклу обробки CQ для миттєвої реакції на мережеві події.
Результати:
- Обробка з'єднань: Кастомний проксі зміг обробляти в 2-2.5 рази більше активних TCP-з'єднань на одному ядрі CPU в порівнянні з NGINX.
- Затримка (P99): Середня затримка проксування знизилася на 30-40% при високих навантаженнях.
- Утилізація CPU: Для того ж обсягу трафіку утилізація CPU знизилася на 50-60%.
- Економія: Дозволило скоротити кількість проксі-інстансів на 40%, значно зменшивши хмарні витрати і спростивши архітектуру.
Цей кейс підкреслює ефективність io_uring в мережевих сценаріях, особливо коли потрібна обробка величезної кількості з'єднань і мінімізація затримок.
9.3. Кейс 3: Система логування і збору метрик
Проблема: Велика система моніторингу та збору логів зіштовхувалася з проблемою запису величезних обсягів даних на диск. Сервери агрегації логів постійно працювали з високим навантаженням I/O, що призводило до високих затримок запису, переповнення буферів і втрати деяких логів у пікові моменти. Використовувалися стандартні блокуючі виклики write() з періодичним fsync().
Рішення з io_uring: Розробники переробили компонент запису логів, використовуючи io_uring для всіх дискових операцій. Вони реалізували механізм асинхронного запису та асинхронної синхронізації (IORING_OP_FSYNC).
- Пул попередньо виділених і зареєстрованих буферів для вхідних логів.
- Батчинг операцій
IORING_OP_WRITEдля запису декількох блоків логів за один раз. - Використання
IORING_OP_FSYNCдля асинхронного примусового запису даних на диск через певні інтервали або після накопичення певного обсягу даних.
Результати:
- Пропускна здатність запису: Збільшилася на 50-70%, дозволяючи системі обробляти пікові навантаження без втрати даних.
- Затримка запису (P99): Знизилася на 20-30%, забезпечуючи більш стабільну роботу.
- Утилізація CPU: Витрати CPU на операції запису значно скоротилися, вивільняючи ресурси для обробки та фільтрації логів.
- Надійність: Система стала більш стійкою до пікових навантажень I/O, зменшилась кількість випадків "backpressure" і втрати даних.
Цей приклад показує, що io_uring корисний не тільки для баз даних, але і для будь-яких систем, де потрібен ефективний і надійний запис великих обсягів даних на диск.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
10. Інструменти та ресурси для роботи з io_uring
Робота з io_uring вимагає не тільки розуміння концепцій, але й уміння використовувати правильні інструменти для розробки, тестування та моніторингу. До 2026 року екосистема навколо io_uring значно розширилася, надаючи розробникам потужні засоби.
10.1. Бібліотеки та фреймворки
liburing(офіційна користувацька бібліотека):- Опис: Стандартна, підтримувана ядром бібліотека, що надає високорівневий C API для io_uring. Значно спрощує взаємодію з кільцевими буферами та системними викликами io_uring. Це ваш основний інструмент для розробки на C/C++.
- Посилання: https://github.com/axboe/liburing
- Мовні біндинги:
- Go: Проєкт iouring-go та інші.
- Rust: Проєкт io-uring (частина екосистеми Tokio).
- Python: Біндинги через
ctypesабо спеціалізовані бібліотеки. - Node.js: Експериментальні біндинги.
- Опис: Дозволяють використовувати io_uring з високорівневих мов програмування, хоча й з невеликими накладними витратами в порівнянні з C/C++.
iouring-by-example:- Опис: Відмінний ресурс з набором простих, але показових прикладів використання різних функцій io_uring. Незамінний для вивчення.
- Посилання: https://unixism.net/loti/
10.2. Утиліти для тестування та бенчмаркінгу I/O
fio(Flexible I/O Tester):- Опис: Промисловий стандарт для тестування продуктивності I/O. Підтримує рушій
io_uring, дозволяючи бенчмаркати дискові операції з його використанням. - Використання:
fio --name=test --ioengine=iouring --direct=1 --rw=randread --bs=4k --size=1G --numjobs=1 --iodepth=64 - Посилання: https://github.com/axboe/fio
- Опис: Промисловий стандарт для тестування продуктивності I/O. Підтримує рушій
wrk/ab(HTTP Benchmarking tools):- Опис: Для тестування мережевих застосунків, що використовують io_uring для HTTP-серверів або проксі.
- Використання:
wrk -t4 -c100 -d30s http://localhost:8080/
10.3. Інструменти моніторингу та налагодження
perf(Linux Performance Tools):- Опис: Потужний інструмент для профілювання ядра та користувацького простору. Дозволяє аналізувати системні виклики, переривання, кешування CPU та багато іншого, що критично для виявлення вузьких місць I/O.
- Використання:
perf record -g -F 99 -a sleep 10, потімperf report
bpftrace/bcc-tools(eBPF-based tools):- Опис: Надають безпрецедентний рівень видимості в роботу ядра Linux без модифікації коду. Дозволяють трасувати системні виклики io_uring, аналізувати поведінку кільцевих буферів, відстежувати затримки I/O та багато іншого.
- Приклади:
bpftrace -e 'tracepoint:io_uring:* { @[probe] = count(); }' - Посилання: https://github.com/iovisor/bpftrace, https://github.com/iovisor/bcc
iostat/vmstat/sar:- Опис: Стандартні утиліти Linux для моніторингу I/O та системних ресурсів. Допомагають оцінити загальне завантаження дисків, мережі та CPU.
- Використання:
iostat -xz 1,vmstat 1,sar -d 1
strace:- Опис: Хоча
straceне показує деталі роботи всередині io_uring (так як операції виконуються без системних викликів), він корисний для налагодження ініціалізації io_uring контексту та системних викликівio_uring_enter(). - Використання:
strace -f -e io_uring_enter,io_uring_setup ./your_app
- Опис: Хоча
10.4. Корисні посилання та документація
- Офіційна документація ядра Linux щодо io_uring:
- Опис: Найнадійніше джерело інформації. Містить детальний опис системних викликів, прапорів та операцій.
- Посилання: https://www.kernel.org/doc/html/latest/core-api/io_uring.html
- Блог та презентації Єнса Аксьбо (Jens Axboe):
- Опис: Єнс Аксьбо — основний розробник io_uring. Його статті та презентації містять цінні інсайти та практичні поради.
- Посилання: Пошук за "Jens Axboe io_uring" на конференціях (наприклад, FOSDEM, Linux Plumbers Conference) та в його блозі.
- Статті та гайди від спільноти:
- Опис: Безліч технічних блогів та статей від інженерів, які використовують io_uring у продакшені.
- Пошук: Використовуйте пошукові запити типу "io_uring performance", "io_uring tutorial", "io_uring examples".
Озброївшись цими інструментами та ресурсами, ви зможете ефективно розробляти, налагоджувати, тестувати та моніторити застосунки, які використовують io_uring, максимально розкриваючи його потенціал.
11. Troubleshooting: Вирішення проблем з io_uring
Попри свою міць, io_uring може бути джерелом складних проблем, які потребують глибокого розуміння системи. Ось типові проблеми та підходи до їх вирішення.
11.1. Проблеми з ініціалізацією io_uring
Симптоми: io_uring_queue_init() або io_uring_queue_init_params() повертає від'ємне значення (код помилки).
- Помилка
-EPERM(Operation not permitted) або-EINVAL(Invalid argument):- Причина 1: Занадто стара версія ядра Linux. io_uring вимагає ядро 5.1+, а для повної функціональності 5.10+ (оптимально 6.x).
- Рішення: Оновіть ядро.
- Причина 2: Спроба використовувати прапори ініціалізації (наприклад,
IORING_SETUP_SQPOLL), які не підтримуються вашою версією ядра або несумісні з поточною конфігурацією. - Рішення: Перевірте документацію ядра для вашої версії. Приберіть прапори по одному, щоб визначити проблемний.
- Причина 3: Недостатні права. Хоча io_uring зазвичай не вимагає root-прав, деякі прапори або операції можуть бути обмежені.
- Рішення: Спробуйте запустити застосунок з
sudoдля діагностики. Якщо це працює, можливо, потрібно налаштувати можливості (capabilities) або використовувати прапори, які не вимагають підвищених привілеїв.
- Помилка
-ENOMEM(Out of memory):- Причина: Занадто велика глибина черги (
queue_depth) або система відчуває нестачу пам'яті. - Рішення: Зменште
queue_depth. Перевірте вільну пам'ять в системі.
- Причина: Занадто велика глибина черги (
11.2. Операції io_uring зависають або не завершуються
Симптоми: Запити відправляються в SQ, але відповідні CQE ніколи не з'являються. Застосунок блокується або зависає.
- Причина 1: Недостатній або відсутній виклик
io_uring_submit()(абоio_uring_enter()). Ядро не знає, що в SQ з'явились нові запити. - Рішення: Переконайтеся, що ви регулярно викликаєте
io_uring_submit()після додавання SQE. Якщо ви використовуєтеIORING_SETUP_SQPOLL, переконайтеся, що потік SQPOLL активний і не заблокований. - Причина 2: Помилки в SQE (некоректні файлові дескриптори, буфери, зміщення). Ядро може мовчки ігнорувати некоректні запити або повертати помилки, які ви не обробляєте.
- Рішення: Уважно перевіряйте параметри кожного SQE. Використовуйте
io_uring_sqe_set_data()для прив'язки контексту та налагоджувальної інформації до кожного запиту, щоб при отриманні CQE можна було зрозуміти, який запит завис. - Причина 3: Неправильне керування буферами або файловими дескрипторами (див. розділ "Типові помилки").
- Рішення: Переконайтеся, що буфери та FD залишаються валідними протягом всієї операції. Використовуйте зареєстровані буфери/FD.
- Причина 4: Зависання або блокування на рівні ядра/драйвера.
- Рішення: Перевірте
dmesgна наявність помилок ядра. Використовуйтеbpftraceдля трасування системних викликів io_uring та пов'язаних з ними функцій ядра, щоб побачити, де відбувається затримка.
11.3. Погана продуктивність або висока утилізація CPU
Симптоми: Застосунок використовує io_uring, але продуктивність не покращується або навіть погіршується в порівнянні з попередніми методами. Утилізація CPU залишається високою.
- Причина 1: Відсутність батчингу операцій. Занадто часті виклики
io_uring_submit(). - Рішення: Впровадьте ефективний батчинг (див. розділ "Практичні поради").
- Причина 2: Невикористання зареєстрованих буферів/файлових дескрипторів. Ядро витрачає час на перевірку та копіювання даних.
- Рішення: Зареєструйте буфери та FD, якщо це можливо для вашого сценарію.
- Причина 3: Неправильне використання
IORING_SETUP_SQPOLL. Наприклад, якщо навантаження низьке, потік SQPOLL може даремно споживати ядро CPU. - Рішення: Вимкніть SQPOLL для низьконавантажених сценаріїв. Переконайтеся, що потік SQPOLL прив'язаний до ізольованого ядра CPU, щоб мінімізувати вплив на інші процеси.
- Причина 4: Неефективний цикл обробки завершень (CQ). Наприклад, блокуючий виклик
io_uring_wait_cqe(), коли очікується багато подій, або занадто часті неблокуючі опитування. - Рішення: Оптимізуйте цикл обробки CQ. Використовуйте
io_uring_for_each_cqe()для обробки пачки подій. - Причина 5: Проблема не в I/O. io_uring оптимізує I/O, але якщо вузьке місце в іншому місці (наприклад, CPU-інтенсивні обчислення, блокування м'ютексів, неефективні алгоритми), то io_uring не допоможе.
- Рішення: Проведіть повне профілювання застосунку за допомогою
perfабоbpftrace, щоб визначити справжнє вузьке місце.
11.4. Витоки пам'яті
Симптоми: Споживання пам'яті застосунком постійно зростає.
- Причина: Неправильне керування буферами пам'яті або контекстами запитів після завершення операцій.
- Рішення: Переконайтеся, що кожен буфер або структура запиту, виділена для SQE, звільняється або перевикористовується рівно один раз після отримання відповідного CQE. Використовуйте інструменти на кшталт Valgrind для виявлення витоків.
11.5. Діагностичні команди
dmesg: Перевіряйте логи ядра на наявність помилок, пов'язаних з io_uring або дисковою підсистемою./proc/sys/fs/io_uring/: В цій директорії знаходяться файли з інформацією про поточні активні контексти io_uring, їх параметри та статистику. Наприклад,/proc/sys/fs/io_uring/max_filesабо/proc/sys/fs/io_uring/max_sq_entries.bpftrace: Створюйте власні скрипти для трасування конкретних функцій ядра, пов'язаних з io_uring, та аналізу їх поведінки.perf: Профілювання застосунку та ядра для виявлення гарячих точок CPU.strace -e trace=io_uring ./app: Допоможе побачити системні викликиio_uring_setupтаio_uring_enter, але не внутрішні операції.
11.6. Коли звертатися в підтримку або до спільноти
Якщо ви вичерпали всі можливості самостійної діагностики та впевнені, що проблема пов'язана з ядром Linux або специфікою io_uring, не соромтеся звертатися:
- Linux Kernel Mailing List (LKML): Для повідомлень про потенційні баги в ядрі або запитів на нові функції io_uring.
- GitHub репозиторій
liburing: Для питань, пов'язаних з використанням бібліотеки. - Спеціалізовані форуми та спільноти: Stack Overflow, Reddit (r/linux, r/kernel, r/programming), або спільноти вашої мови програмування.
Надавайте максимально детальну інформацію: версія ядра, код, кроки для відтворення, логи помилок, результати бенчмарків та профілювання.
12. FAQ: Питання, що часто задаються про io_uring
1. Чи завжди io_uring швидший, ніж традиційні методи I/O?
Відповідь: Ні, не завжди. io_uring розроблено для високонавантажених асинхронних I/O-інтенсивних задач, де він значно знижує накладні витрати на системні виклики та перемикання контексту. Для простих, низьконавантажених або переважно CPU-інтенсивних застосунків, накладні витрати на більш складний API io_uring можуть переважити потенційні вигоди, і традиційні блокуючі виклики або epoll можуть бути більш придатними або навіть трохи швидшими через свою простоту.
2. Яка мінімальна версія ядра Linux потрібна для io_uring?
Відповідь: io_uring був представлений в ядрі Linux 5.1. Однак для повноцінного використання всіх функцій, включаючи мережеві операції та безліч оптимізацій, настійно рекомендується використовувати ядро Linux 5.10 або новіше. Оптимальним вибором для production-середовища у 2026 році є ядра серії 6.x LTS, які забезпечують максимальну стабільність та продуктивність.
3. io_uring призначений тільки для дискового I/O або для мережевого теж?
Відповідь: io_uring уніфікує обидва типи I/O. Він надає асинхронний інтерфейс як для дискових та файлових операцій (read, write, fsync, openat), так і для мережевих операцій (accept, connect, recvmsg, sendmsg). Це одна з його ключових переваг, що дозволяє створювати високопродуктивні системи, які обробляють всі види I/O під єдиним API.
4. Наскільки складно освоїти та використовувати io_uring?
Відповідь: io_uring має досить круту криву навчання. Його API низькорівневий та вимагає глибокого розуміння принципів роботи ядра Linux, керування пам'яттю та асинхронного програмування. Він значно складніший, ніж epoll або libaio. Однак використання користувацької бібліотеки liburing значно спрощує процес, абстрагуючи від багатьох низькорівневих деталей.
5. Чи можу я використовувати io_uring з високорівневими мовами, такими як Python, Node.js, Go або Rust?
Відповідь: Так, це можливо. Для Go та Rust існують досить зрілі біндинги та бібліотеки, які інтегрують io_uring в їх асинхронні рантайми (наприклад, io-uring для Rust/Tokio). Для Python та Node.js існують експериментальні біндинги, які зазвичай використовують FFI (Foreign Function Interface) для взаємодії з liburing. Однак накладні витрати на FFI можуть знизити частину переваг io_uring, і повний потенціал розкривається в C/C++.
6. Чи є epoll застарілим тепер, коли є io_uring?
Відповідь: Ні, epoll не застарів. Він залишається ефективним та широко використовуваним механізмом для подієвого мережевого I/O. io_uring є більш потужною та універсальною заміною, особливо для сценаріїв, що вимагають максимальної продуктивності та уніфікації дискового та мережевого I/O. Для багатьох застосунків, де epoll вже працює добре, перехід на io_uring може бути зайвим, враховуючи його складність.
7. Чи підтримує io_uring zero-copy I/O?
Відповідь: Так, io_uring розроблений з урахуванням оптимізацій zero-copy. Шляхом реєстрації буферів пам'яті (io_uring_register_buffers) ядро може виконувати операції I/O безпосередньо в ці буфери, минаючи копіювання даних між простором ядра та користувацьким простором. Крім того, операції на кшталт IORING_OP_SPLICE дозволяють безпосередньо передавати дані між файловими дескрипторами (наприклад, сокетами), також без копіювання в користувацький буфер.
8. Що таке SQPOLL і коли його слід використовувати?
Відповідь: SQPOLL (Submission Queue Polling) — це опціональний режим io_uring, що активується прапором IORING_SETUP_SQPOLL під час ініціалізації. В цьому режимі ядро створює спеціальний потік, який постійно опитує Submission Queue на наявність нових запитів. Це повністю виключає необхідність системного виклику io_uring_enter() для відправки запитів, що знижує накладні витрати до абсолютного мінімуму. Його слід використовувати тільки в екстремально високонавантажених сценаріях, де кожен системний виклик критичний, оскільки SQPOLL споживає одне ядро CPU.
9. В яких випадках не варто використовувати io_uring?
Відповідь: io_uring не рекомендується для:
- Низьконавантажених застосунків, де I/O не є вузьким місцем.
- Проектів з жорсткими часовими рамками та обмеженими ресурсами на розробку.
- Застосунків, де основне вузьке місце знаходиться в CPU-інтенсивних обчисленнях, а не в I/O.
- Систем, що працюють на дуже старих версіях ядра Linux без можливості оновлення.
У цих випадках складність io_uring може принести більше проблем, ніж користі.
10. Як io_uring співвідноситься з DPDK?
Відповідь: io_uring і DPDK (Data Plane Development Kit) вирішують схожі проблеми продуктивності I/O, але на різних рівнях і з різними підходами. io_uring — це інтерфейс ядра Linux, який надає асинхронний I/O з мінімальними накладними витратами, залишаючись при цьому в рамках стандартної мережевої та дискової підсистеми ядра. DPDK, у свою чергу, є користувацьким фреймворком, який "обходить" ядро Linux, напряму керуючи мережевими картами та обробляючи пакети в користувацькому просторі. DPDK забезпечує ще нижчі затримки та вищу пропускну здатність для мережевих задач, але вимагає спеціалізованого обладнання, складнішої архітектури та не підтримує дисковий I/O. io_uring більш універсальний та інтегрований в ядро, тоді як DPDK — це нішеве рішення для найбільш вимогливих мережевих задач.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
13. Висновок
io_uring — це не просто чергове оновлення в ядрі Linux; це фундаментальний зсув у парадигмі асинхронного введення-виведення, який до 2026 року стає де-факто стандартом для високонавантажених застосунків. Він надає безпрецедентний рівень контролю та ефективності, дозволяючи застосункам досягати мільйонів I/O операцій в секунду з мінімальною утилізацією CPU.
Ми розглянули, як io_uring вирішує больові точки традиційних I/O методів, уніфікуючи дискові, файлові та мережеві операції під єдиним, високоефективним API. Його ключові особливості — кільцеві буфери, мінімізація системних викликів, підтримка SQPOLL та реєстрація ресурсів — відкривають шлях до створення систем з екстремально низькими затримками та колосальною пропускною здатністю.
Економічний аналіз показав, що, незважаючи на вищу початкову вартість розробки через складність API, io_uring забезпечує значну довгострокову економію. Скорочення вимог до апаратних ресурсів напряму транслюється в зменшення хмарних витрат та підвищення конкурентоспроможності продукту на ринку. Реальні кейси підтверджують ці висновки, демонструючи вражаючі прирости продуктивності в базах даних, проксі-серверах та системах логування.
Проте, як і будь-який потужний інструмент, io_uring вимагає глибокого розуміння та обережності. Типові помилки, такі як відсутність батчингу, неправильне керування буферами або ігнорування версії ядра, можуть звести нанівець усі його переваги. Використання бібліотеки liburing, ретельне тестування, моніторинг за допомогою perf та bpftrace, а також дотримання кращих практик є ключем до успішного впровадження.
Підсумкові рекомендації:
- Оцініть ваше навантаження: Якщо ваш застосунок відчуває I/O-вузькі місця, а вимоги до затримок та пропускної здатності високі, io_uring — ваш кандидат №1.
- Оновіть ядро: Переконайтеся, що ваша система працює на Linux 5.10+ (ідеально 6.x LTS).
- Використовуйте
liburing: Почніть з цієї бібліотеки, щоб спростити розробку. - Батчте операції: Це критично важливо для продуктивності io_uring.
- Реєструйте ресурси: Для максимальної ефективності використовуйте зареєстровані буфери та файлові дескриптори.
- Ретельно тестуйте та моніторте: Вимірюйте реальні метрики та профілюйте ваш застосунок.
Наступні кроки для читача:
Якщо ви дочитали до цього моменту, значить, ви готові до глибокого занурення в io_uring. Ваші наступні кроки повинні включати:
- Вивчення
iouring-by-example: Опрацюйте приклади, щоб отримати практичний досвід. - Експерименти з
fio: Проведіть бенчмаркінг вашої поточної системи зfio, а потім спробуйте використовувати рушійio_uring. - Пілотний проєкт: Почніть з невеликого, але I/O-інтенсивного компонента вашого застосунку, щоб оцінити складність та потенційні вигоди у вашому середовищі.
- Глибоке вивчення документації: Регулярно звертайтеся до офіційної документації ядра Linux та статей Єнса Аксбо.
У світі, де дані — це нова нафта, а швидкість — це валюта, io_uring надає вам інструменти для створення по-справжньому конкурентоспроможних та ефективних високонавантажених застосунків. Освойте його, і ви відкриєте нові горизонти продуктивності для ваших проєктів у 2026 році та далі.