
Глобальна балансування навантаження та DNS-файловер: Архітектура відмовостійких SaaS-застосунків
TL;DR
- Мультирегіональна архітектура — основа відмовостійкості. Розгортання SaaS-застосунків у кількох географічних регіонах критично важливе для мінімізації простоїв та підвищення доступності.
- Глобальна балансування навантаження (GLB) — ваш диригент трафіку. Використовуйте DNS-провайдерів з розширеними функціями (Route 53, Azure DNS Traffic Manager, Google Cloud DNS з GLB) для інтелектуальної маршрутизації користувачів до найближчих і здорових інстансів.
- DNS-файловер — рятівне коло у разі катастрофи. Автоматичне перемикання трафіку на резервний регіон у разі збою основного, мінімізуючи RTO (Recovery Time Objective).
- Активні перевірки здоров'я (Health Checks) — очі та вуха вашої системи. Налаштуйте глибокі, багаторівневі перевірки для моніторингу доступності та продуктивності сервісів, а не тільки мережевого рівня.
- Стратегія даних — найскладніша частина головоломки. Реплікація баз даних (Active-Active, Active-Passive) і синхронізація кешів — ключові аспекти для збереження цілісності даних під час перемикання.
- Тестування та автоматизація — не розкіш, а необхідність. Регулярно проводьте навчання з аварійного відновлення та автоматизуйте процеси перемикання для впевненості у працездатності архітектури.
- Вартість — значний фактор, який потребує оптимізації. Мультирегіональність збільшує витрати, але правильно спроєктована система може забезпечити оптимальний баланс між доступністю та витратами.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Вступ
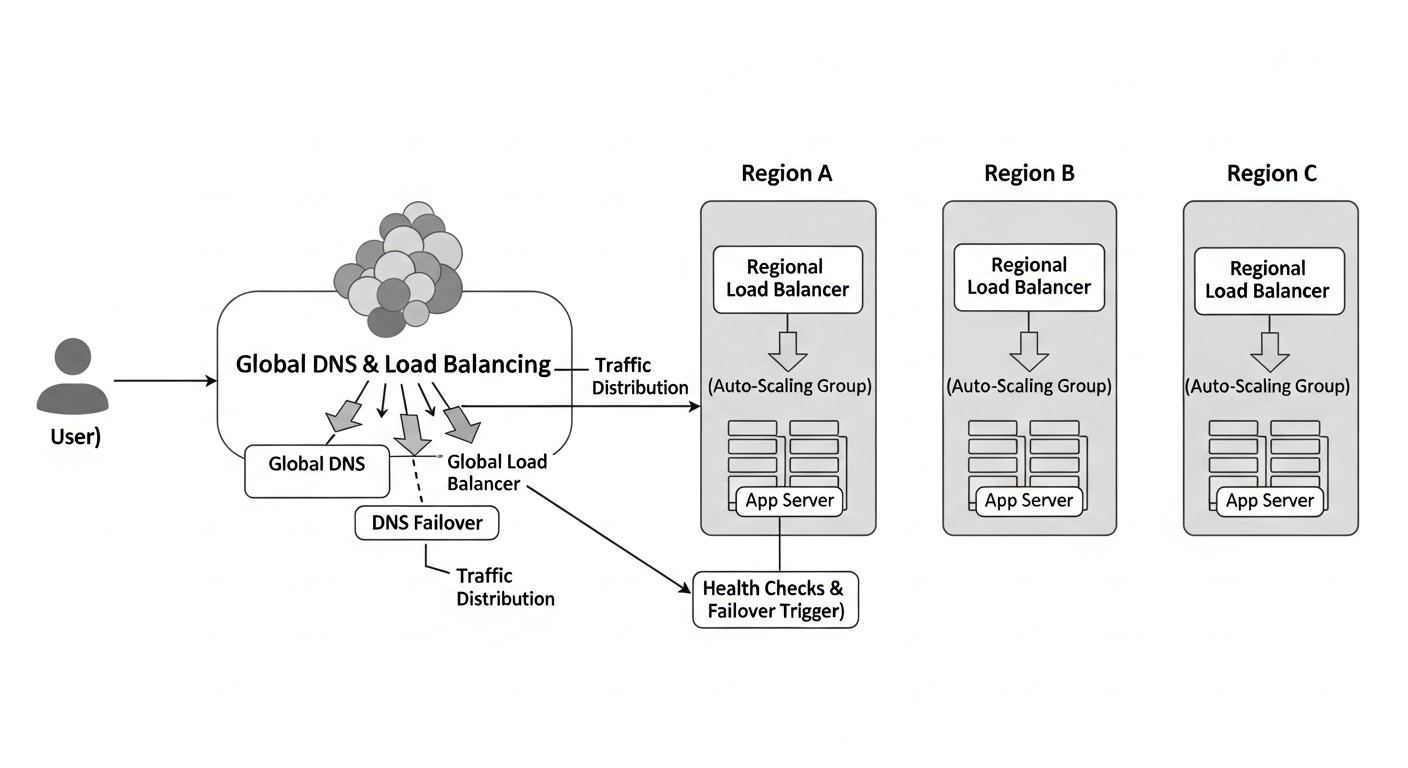
У сучасному світі, де цифровізація проникла у всі сфери бізнесу, а очікування користувачів від доступності сервісів прагнуть до 100%, архітектура високонадійних SaaS-застосунків перестала бути опцією і перетворилася на абсолютну необхідність. До 2026 року компанії, які не зможуть забезпечити безперервність роботи своїх сервісів, ризикують втратити клієнтів, репутацію і, в кінцевому підсумку, частку ринку. Простій у кілька хвилин може обернутися мільйонними збитками та непоправною шкодою для бренду.
Ця стаття присвячена двом наріжним каменям побудови відмовостійких SaaS-застосунків: глобальній балансуванню навантаження (Global Load Balancing, GLB) і DNS-файловеру. Ми глибоко поринемо в механізми, що дозволяють розподіляти трафік між географічно рознесеними центрами обробки даних і автоматично перемикатися на резервні системи у разі виникнення проблем. Це не просто технічні концепції; це фундаментальні елементи стратегії виживання будь-якого SaaS-проєкту в умовах постійно зростаючих вимог до доступності та продуктивності.
Ми розглянемо, чому ці технології важливі не тільки для великих корпорацій, але і для стартапів, які прагнуть до масштабування та глобальної присутності. Стаття охоплює практичні аспекти реалізації, починаючи від вибору відповідних провайдерів і закінчуючи тонкими нюансами налаштування та моніторингу. Вона написана для DevOps-інженерів, backend-розробників, фаундерів SaaS-проєктів, системних адміністраторів і технічних директорів, які стикаються з викликами забезпечення високої доступності, катастрофостійкості та оптимальної продуктивності своїх застосунків.
Основна проблема, яку вирішує даний гайд — це побудова архітектури, здатної витримати регіональні збої, мережеві проблеми або навіть цілі катастрофи в одному з дата-центрів, при цьому мінімізуючи час простою та втрату даних. Ми покажемо, як за допомогою GLB і DNS-файловера можна не тільки знизити ризики, але й поліпшити користувацький досвід, направляючи трафік до найближчих серверів, тим самим зменшуючи затримки. Готуйтеся до глибокого занурення у світ розподілених систем, де кожен байт даних і кожна мілісекунда затримки мають значення.
Основні критерії та фактори
При проєктуванні архітектури глобального балансування навантаження і DNS-файловера необхідно враховувати безліч факторів, які безпосередньо впливають на надійність, продуктивність і вартість вашої SaaS-платформи. Вибір правильного рішення залежить від специфіки вашого застосунку, цільової аудиторії та бізнес-вимог. Давайте розглянемо ключові критерії, які допоможуть вам прийняти обґрунтоване рішення.
Доступність (Availability) і Відмовостійкість (Resilience)
Це найочевидніший і, мабуть, найважливіший критерій. Доступність вимірюється відсотком часу, протягом якого сервіс доступний для користувачів (наприклад, 99.99% — це всього 52 хвилини простою в рік). Відмовостійкість же характеризує здатність системи відновлюватися після збоїв. Для GLB і DNS-файловера це означає здатність швидко й автоматично перемикати трафік на здорові ресурси в іншому регіоні у разі відмови основного. Важливо оцінити:
- RTO (Recovery Time Objective): Максимальний допустимий час простою після збою. Чим нижче RTO, тим складніше і дорожче архітектура. Для критичних SaaS-застосунків RTO може бути в межах секунд або навіть мілісекунд.
- RPO (Recovery Point Objective): Максимальний допустимий обсяг втрати даних, вимірюваний у часі. Для багатьох SaaS RPO має прагнути до нуля, що вимагає синхронної або асинхронної реплікації даних між регіонами.
- Механізми виявлення збоїв: Наскільки швидко і точно система GLB може виявити збій в регіоні або конкретному сервісі? Це включає в себе різні типи health checks (HTTP, TCP, ICMP, користувацькі скрипти).
- Швидкість перемикання (Failover Speed): Час, необхідний для перенаправлення трафіку після виявлення збою. Для DNS-файловера це сильно залежить від TTL (Time To Live) DNS-записів і кешування на стороні клієнтів і провайдерів.
Продуктивність і Затримка (Latency)
Користувачі очікують швидкої роботи застосунків. Розміщення ресурсів ближче до користувачів значно знижує затримку. GLB може використовувати гео-маршрутизацію або маршрутизацію на основі затримки, щоб направляти запити до найближчого або найбільш продуктивного дата-центру. Оцініть:
- Географічний розподіл користувачів: Де знаходяться ваші основні користувачі? Це допоможе визначити оптимальне розташування регіонів.
- Механізми маршрутизації: Чи підтримує вибране GLB-рішення маршрутизацію за географічним принципом, за затримкою, за вагою або комбінацію цих методів?
- Вплив на CDN: Як GLB буде взаємодіяти з вашою Content Delivery Network? Оптимізація цієї зв'язки критична для статичного контенту.
Масштабованість (Scalability)
SaaS-застосунки повинні бути готові до росту навантаження. GLB і DNS-файловер повинні дозволяти легко додавати нові регіони або збільшувати ресурси в існуючих, не порушуючи роботу системи. Важливі аспекти:
- Горизонтальна масштабованість: Можливість легко додавати нові інстанси або навіть цілі регіони.
- Інтеграція з хмарними сервісами: Наскільки добре GLB-рішення інтегрується з автоматичним масштабуванням у хмарі (Auto Scaling Groups, VM Scale Sets).
- Управління конфігурацією: Наскільки просто управляти конфігурацією GLB у міру зростання інфраструктури.
Вартість (Cost)
Мультирегіональна архітектура за замовчуванням дорожча, ніж однорегіональна. Важливо ретельно оцінити всі компоненти витрат:
- Вартість сервісів GLB/DNS: Плата за запити, за health checks, за зони.
- Вартість інфраструктури в декількох регіонах: Віртуальні машини, бази даних, сховища, мережеві компоненти.
- Трафік між регіонами (Egress/Ingress): Міжрегіональний трафік часто є одним з найдорожчих пунктів у хмарних рахунках.
- Вартість розробки та експлуатації: Додаткові години інженерів на проєктування, впровадження та підтримку складної архітектури.
- Приховані витрати: Наприклад, ліцензії на ПЗ, додаткові інструменти моніторингу.
Складність реалізації та управління (Complexity)
Чим складніша система, тим вищий ризик помилок і тим дорожче її обслуговування. Простота налаштування, управління і моніторингу відіграє велику роль. Оцініть:
- Крива навчання: Наскільки швидко ваша команда зможе освоїти вибране рішення.
- Інтеграція: Наскільки легко інтегрувати GLB з існуючою CI/CD, системами моніторингу та оповіщення.
- Документація та підтримка: Якість документації та доступність технічної підтримки від провайдера.
Залежність від постачальника (Vendor Lock-in)
Використання специфічних сервісів одного хмарного провайдера може ускладнити міграцію або використання мультихмарної стратегії в майбутньому. Оцініть:
- Стандартизація: Чи використовує рішення стандартні протоколи (DNS) або пропрієтарні API?
- Переносимість: Наскільки легко буде перенести вашу GLB-конфігурацію або навіть весь застосунок до іншого провайдера.
Відповідність нормативним вимогам (Compliance)
Для деяких галузей або типів даних існують суворі вимоги до місцезнаходження даних і обробки. GLB повинно дозволяти дотримуватися цих вимог.
- Суверенітет даних: Можливість гарантувати, що дані користувачів з певного регіону залишаються в цьому регіоні.
- Регуляторні норми: Відповідність GDPR, HIPAA, PCI DSS та іншим стандартам.
Ретельний аналіз цих критеріїв на ранніх етапах проєктування дозволить уникнути дорогих помилок і побудувати надійну, масштабовану та економічно ефективну архітектуру для вашого SaaS-застосунку.
Порівняльна таблиця рішень для GLB і DNS-файловеру
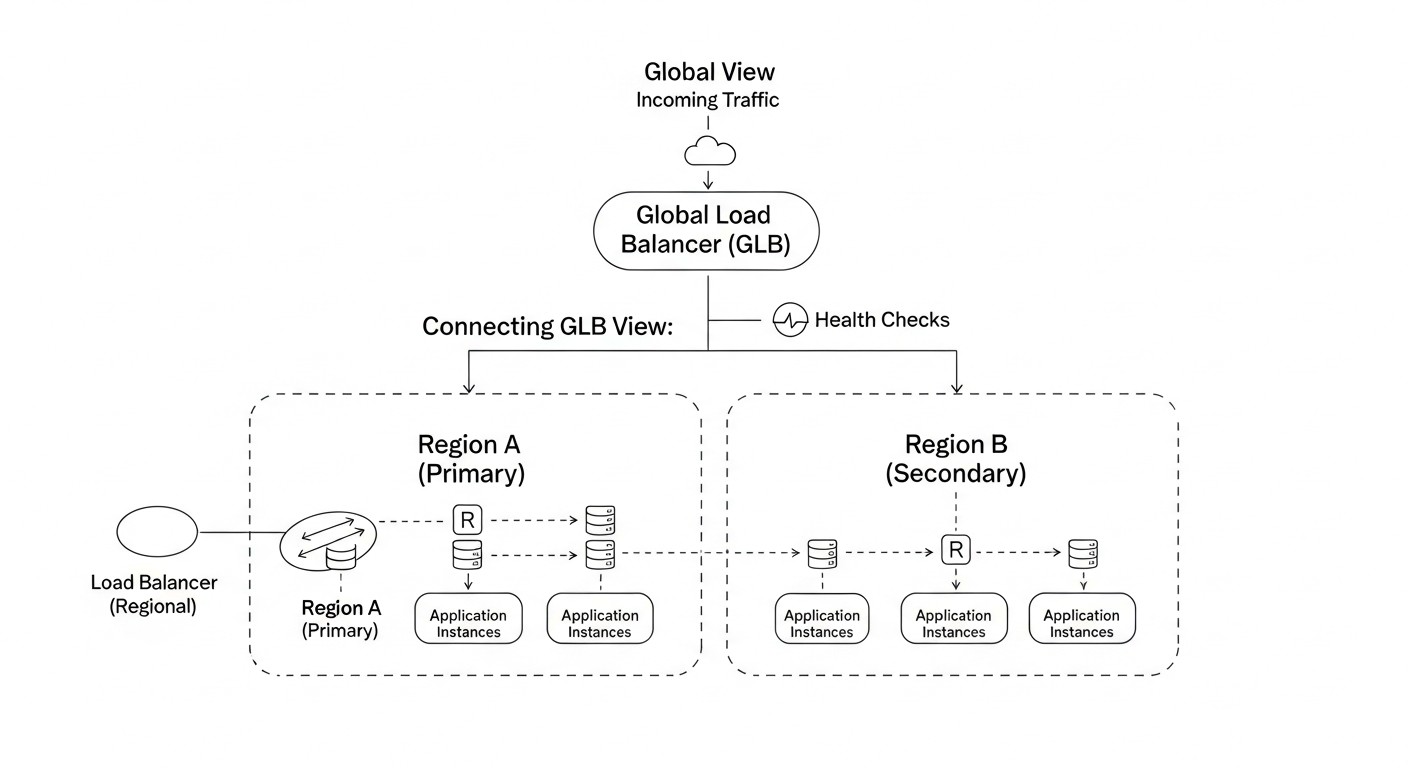
Вибір конкретного рішення для глобального балансування навантаження і DNS-файловеру залежить від безлічі факторів, включаючи ваш бюджет, вимоги до продуктивності, складність інфраструктури і ступінь залежності від хмарного провайдера. У цій таблиці ми порівняємо найбільш популярні підходи і сервіси, актуальні для 2026 року, з урахуванням їх можливостей, вартості та застосовності.
| Критерій | Керований DNS GLB (AWS Route 53 Traffic Flow, Azure Traffic Manager, Google Cloud DNS з Health Checks) | CDN з GLB (Cloudflare, Akamai, AWS CloudFront з Origin Failover) | Програмний GLB (Nginx Plus, HAProxy Enterprise + Consul/Zookeeper) | Anycast DNS (Cloudflare DNS, Google Public DNS, спеціалізовані провайдери) | Мультихмарний/Гібридний GLB (VMware NSX ALB, F5 BIG-IP DNS, NetScaler GSLB) |
|---|---|---|---|---|---|
| Тип рішення | Хмарний сервіс DNS з розширеними можливостями маршрутизації і health checks. | Глобальна мережа доставки контенту з функцією маршрутизації запитів до кращих Origin-серверів. | Програмне забезпечення, що розгортається на вашій інфраструктурі (VMs, контейнери). | Спеціалізована мережева технологія маршрутизації DNS-запитів до найближчого сервера. | Комплексне рішення для балансування навантаження в гібридних і мультихмарних середовищах. |
| Механізм маршрутизації | DNS-записи (A, CNAME) з гео-таргетингом, на основі затримки, зважені, за health check. | HTTP(S) проксі, L7-балансування, гео-маршрутизація, на основі продуктивності Origin. | L4/L7 балансування, гео-таргетинг (через DNS або IP-адреси), на основі health checks. | BGP-маршрутизація IP-адрес, направляє UDP-запити до найближчого вузла. | DNS-балансування (GSLB), інтелектуальна маршрутизація, L4/L7, інтеграція з хмарами. |
| Швидкість файловеру (RTO) | Залежить від TTL DNS-записів (від 30-60 сек до 5-10 хв). Health checks до 10-30 сек. | Миттєво (кілька секунд) за рахунок проксіювання і постійних health checks Origin-серверів. | Миттєво (кілька секунд) за рахунок локальних health checks і перемикання на рівні L4/L7. | Миттєво на рівні DNS-запиту (не впливає на активні з'єднання). | Від 5 секунд (L7) до 1-2 хвилин (DNS GSLB) в залежності від конфігурації. |
| RPO (втрата даних) | Залежить від стратегії реплікації баз даних, не від GLB. | Залежить від стратегії реплікації баз даних, не від CDN. | Залежить від стратегії реплікації баз даних, не від GLB. | Залежить від стратегії реплікації баз даних, не від DNS. | Залежить від стратегії реплікації баз даних, не від GSLB. |
| Приблизна вартість (2026) | $0.50-$1.00 за зону/місяць + $0.005-$0.007 за 1M запитів + $0.70-$1.00 за health check/місяць. | Від $20/міс (Pro) до $2000+/міс (Enterprise), залежить від трафіку та функцій. Включає CDN. | Ліцензії від $1000-$5000+ за інстанс/рік. Потрібні VM/сервери. Високі експлуатаційні витрати. | Часто входить у базові тарифи DNS-провайдерів (Cloudflare Free/Pro). Для великих від $200/міс. | Ліцензії від $5000-$20000+ за пристрій/рік. Високі експлуатаційні витрати. |
| Складність впровадження | Середня. Потрібне розуміння DNS, health checks та регіональних розгортань. | Низька-Середня. Просте налаштування DNS, але складна оптимізація CDN та Origin. | Висока. Потрібне глибоке знання мережевих технологій, ОС, скриптингу та кластеризації. | Низька. Проста зміна NS-записів. Налаштування специфічне для провайдера. | Дуже висока. Потребує експертних знань мережевих технологій, апаратних рішень та інтеграції. |
| Гнучкість та кастомізація | Висока. Гнучкі політики маршрутизації, інтеграція з іншими хмарними сервісами. | Середня. Кастомізація правил кешування, WAF, але обмежена в маршрутизації Origin. | Дуже висока. Повний контроль над логікою балансування, скрипти, модулі. | Низька. Фокусується на маршрутизації DNS-запитів, не трафіку додатків. | Дуже висока. Повний контроль над усіма аспектами балансування та маршрутизації. |
| Управління даними | Не управляє даними, лише трафіком. | Кешує статичний контент, може впливати на динамічний. | Не управляє даними, лише трафіком. | Не управляє даними, лише трафіком. | Не управляє даними, лише трафіком. |
| Сценарії використання | Більшість SaaS-додатків, мультирегіональні розгортання, A/B-тестування, Blue/Green деплой. | SaaS з великим об'ємом статичного/динамічного контенту, API-сервіси, захист від DDoS. | Додатки з високою продуктивністю, специфічні вимоги до L4/L7, on-premise, гібридні хмари. | Покращення продуктивності DNS-запитів, розподіл низькорівневого трафіку, DDoS-захист DNS. | Великі підприємства, гібридні хмари, мультихмарні стратегії, комплексні вимоги до безпеки та продуктивності. |
Ця таблиця дає загальне уявлення про доступні варіанти. У 2026 році очікується подальша конвергенція цих рішень, коли хмарні провайдери пропонуватимуть глибшу інтеграцію CDN та GLB, а програмні рішення стануть ще більш гнучкими за рахунок контейнеризації та оркестрації.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Детальний огляд кожного пункту/варіанту
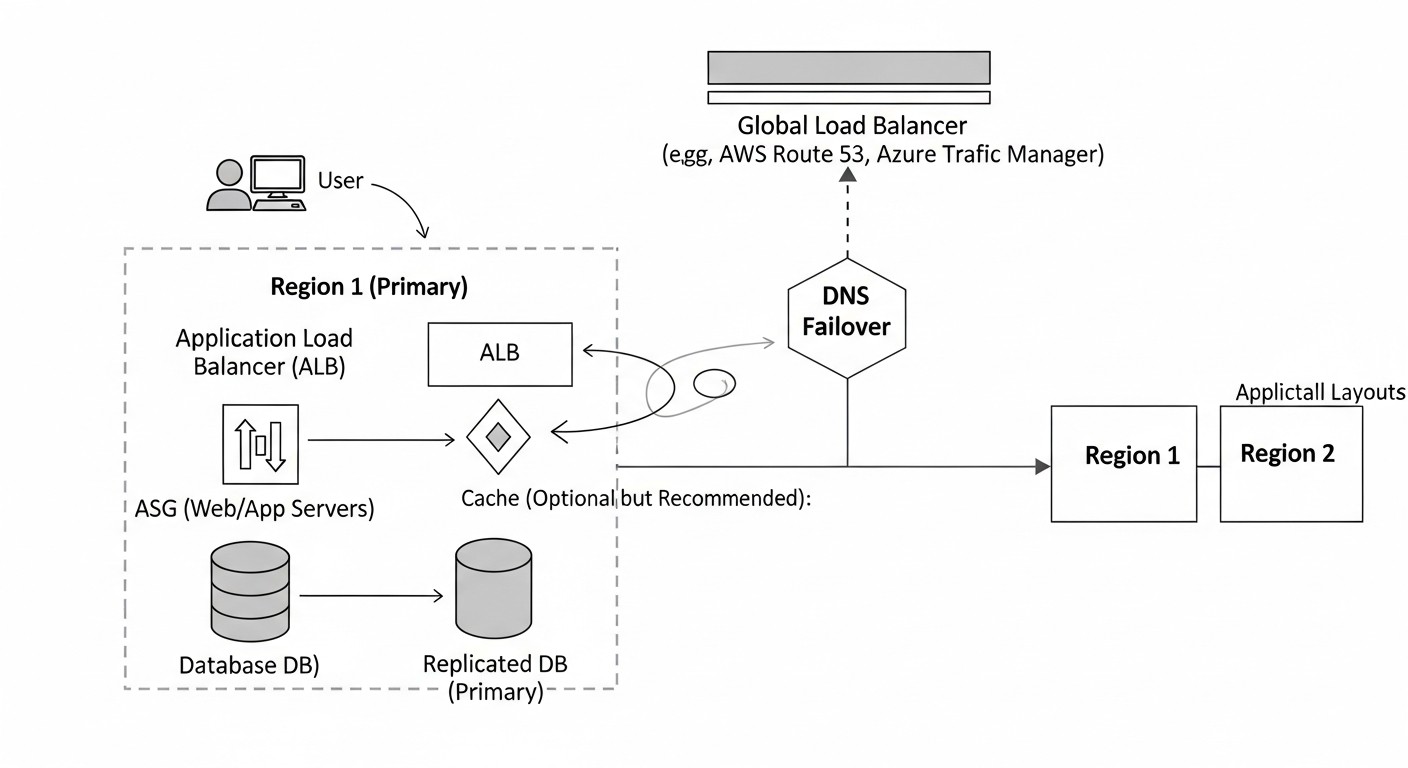
Після загального порівняння, давайте заглибимося в деталі кожного з представлених рішень, розглянемо їх архітектурні особливості, плюси, мінуси та оптимальні сценарії використання. Розуміння цих нюансів є критично важливим для прийняття обґрунтованого рішення.
Керований DNS GLB (AWS Route 53 Traffic Flow, Azure Traffic Manager, Google Cloud DNS з Health Checks)
Ці сервіси пропонують DNS-кероване глобальне балансування навантаження. Основний принцип роботи полягає в тому, що DNS-сервери провайдера відповідають на запити клієнтів, видаючи IP-адреси найближчих або найбільш здорових ресурсів, ґрунтуючись на налаштованих політиках маршрутизації та результатах health checks. Клієнтський браузер або додаток потім напряму підключається до цієї IP-адреси.
Як це працює: Ви створюєте декілька DNS-записів (наприклад, A-записи) для вашого домену, кожна з яких вказує на IP-адресу вашого додатку в різних регіонах. Потім ви застосовуєте політики маршрутизації (наприклад, гео-маршрутизація, маршрутизація на основі затримки, зважена маршрутизація) і прив'язуєте до кожного запису health checks. Коли користувач запитує ваш домен, DNS-провайдер перевіряє політики та результати health checks, а потім повертає найбільш підходящу IP-адресу. Якщо один регіон виходить з ладу, health check це виявить, і DNS-провайдер перестане видавати його IP-адресу, перенаправляючи трафік на здоровий регіон.
Плюси:
- Простота реалізації: Відносно легко налаштувати, особливо якщо ви вже використовуєте хмарного провайдера.
- Ефективність за вартістю: Зазвичай дешевше, ніж комплексні L7-рішення, особливо для невеликих і середніх навантажень.
- Гео-маршрутизація та маршрутизація за затримкою: Дозволяє направляти користувачів до найближчих серверів, покращуючи UX.
- Інтеграція з хмарною інфраструктурою: Глибока інтеграція з іншими сервісами хмарного провайдера (EC2, Load Balancers, VMs).
Мінуси:
- Залежність від TTL: Час перемикання при файловері обмежений TTL DNS-записів. Якщо TTL високий (наприклад, 5 хвилин), клієнти можуть продовжувати отримувати IP несправного регіону до закінчення кешу.
- Кешування DNS: Проміжні DNS-сервери та користувацькі пристрої можуть кешувати записи, ігноруючи швидкі зміни.
- Тільки L4-балансування: DNS-рішення працюють на рівні IP-адрес. Вони не можуть інспектувати HTTP-заголовки або виконувати складне L7-балансування.
- Складність для мультихмарних сценаріїв: Використання GLB одного провайдера для балансування між різними хмарами може бути скрутним або вимагати додаткових рішень.
Для кого підходить: Більшість SaaS-застосунків, які хочуть забезпечити мультирегіональну відмовостійкість та оптимізувати затримки, особливо якщо вони вже тісно інтегровані в одного хмарного провайдера. Ідеально для A/B-тестування та Blue/Green деплою на рівні регіонів.
CDN з GLB (Cloudflare, Akamai, AWS CloudFront з Origin Failover)
CDN (Content Delivery Network) спочатку призначені для кешування та доставки статичного контенту. Однак сучасні CDN-провайдери значно розширили свій функціонал, пропонуючи просунуті можливості балансування навантаження, файловеру та захисту. Вони діють як зворотні проксі, приймаючи весь трафік на свої граничні вузли по всьому світу, а потім перенаправляючи його до ваших Origin-серверів.
Як це працює: Ви налаштовуєте свій домен так, щоб він вказував на CDN (зазвичай через CNAME). CDN, у свою чергу, знає про ваші Origin-сервери в різних регіонах. Вона постійно перевіряє їх здоров'я та продуктивність. Коли користувач робить запит, CDN направляє його до найближчого граничного вузла, який потім вибирає найбільш оптимальний Origin-сервер (за гео-принципом, затримкою, навантаженням) для отримання контенту або обробки динамічного запиту. У разі збою Origin-сервера CDN миттєво перемикається на інший здоровий Origin, оскільки вона контролює весь трафік.
Плюси:
- Миттєвий файловер: Оскільки CDN виступає в ролі проксі, вона може миттєво перемкнути трафік на здоровий Origin, не чекаючи закінчення TTL.
- Покращена продуктивність: Крім GLB, CDN кешує контент, знижує затримки та розвантажує ваші Origin-сервери.
- DDoS-захист: Більшість CDN надають потужний захист від DDoS-атак на граничних вузлах.
- L7-балансування: Можливість маршрутизації на основі HTTP-заголовків, URL-шляхів, методів запиту.
- WAF (Web Application Firewall): Захист від поширених веб-вразливостей.
Мінуси:
- Вартість: Може бути значно дорожче, ніж чистий DNS GLB, особливо при великому обсязі трафіку.
- Складність налаштування: Оптимізація кешування, правил WAF та маршрутизації Origin може бути складною.
- Додаткова точка відмови: CDN стає єдиною точкою відмови (хоча великі CDN дуже надійні).
- Затримка для динамічного контенту: Незважаючи на оптимізації, проксування через CDN може додати невелику затримку для повністю динамічних запитів, які не кешуються.
Для кого підходить: SaaS-застосунки з високим обсягом трафіку, що вимагають максимальної відмовостійкості, низької затримки для статичного та динамічного контенту, а також вбудованого захисту від DDoS та інших веб-атак. Ідеально для e-commerce, медіа-платформ, API-сервісів.
Програмний GLB (Nginx Plus, HAProxy Enterprise + Consul/Zookeeper)
Цей підхід передбачає розгортання та управління власними програмними балансувальниками навантаження в кожному регіоні. Ці балансувальники можуть бути налаштовані для роботи як на L4, так і на L7 рівнях, і часто використовують зовнішні сервіси для виявлення сервісів (Service Discovery) та управління конфігурацією.
Як це працює: У кожному регіоні ви розгортаєте кластер Nginx Plus або HAProxy Enterprise. Ці балансувальники налаштовані для розподілу трафіку між внутрішніми інстансами вашого застосунку. Для глобального балансування ви використовуєте DNS GLB (як у першому варіанті), який вказує на IP-адреси ваших балансувальників у різних регіонах. Всередині кожного регіону балансувальники постійно моніторять здоров'я бекенд-серверів. Для забезпечення відмовостійкості та синхронізації конфігурації між балансувальниками та регіонами часто використовуються такі інструменти, як Consul, ZooKeeper або etcd.
Плюси:
- Повний контроль та гнучкість: Максимальна кастомізація логіки балансування, правил маршрутизації, обробки запитів.
- Висока продуктивність: Можливість тонкого налаштування для досягнення максимальної пропускної здатності та мінімальної затримки.
- Відсутність vendor lock-in: Ви не прив'язані до конкретного хмарного провайдера для GLB-функцій.
- Безпека: Можливість глибокої інтеграції з вашою власною стратегією безпеки.
Мінуси:
- Висока складність: Вимагає значних інженерних зусиль для розгортання, налаштування, моніторингу та підтримки.
- Експлуатаційні витрати: Необхідно управляти серверами, ОС, оновленнями, кластеризацією.
- RTO залежить від DNS: Глобальний файловер все одно залежатиме від TTL DNS-записів, якщо ви використовуєте DNS GLB для перемикання між регіонами.
- Складнощі з гео-маршрутизацією: Самостійна реалізація гео-маршрутизації без зовнішнього DNS GLB може бути дуже складною.
Для кого підходить: Великі компанії зі специфічними вимогами до продуктивності, безпеки або функціоналу, які мають сильні DevOps-команди та готові інвестувати у власну інфраструктуру. Також підходить для гібридних хмар або on-premise розгортань, де хмарні GLB-сервіси не застосовні.
Anycast DNS (Cloudflare DNS, Google Public DNS, спеціалізовані провайдери)
Anycast — це мережева технологія, при якій одна й та сама IP-адреса маршрутизується в кількох географічних точках. Коли клієнт відправляє пакет на Anycast IP, мережева інфраструктура (BGP) направляє його до найближчої точки присутності (PoP), яка анонсує цю IP-адресу. Anycast DNS означає, що DNS-сервери провайдера доступні за однією й тією ж IP-адресою в десятках або сотнях PoP по всьому світу.
Як це працює: Ваш домен налаштовується на використання NS-записів, які вказують на Anycast IP-адреси DNS-серверів провайдера. Коли користувач робить DNS-запит, його запит автоматично направляється до найближчого Anycast PoP, який потім обробляє запит. Це значно прискорює розв'язання DNS-імен, оскільки запит не повинен перетинати півсвіту. Важливо зазначити, що Anycast працює на рівні DNS-запитів, а не на рівні трафіку вашого застосунку. Він прискорює процес отримання IP-адреси, але сам трафік застосунку все одно піде звичайним маршрутом до отриманої IP.
Плюси:
- Низька затримка DNS-запитів: Значно прискорює розв'язання доменних імен, оскільки запит обробляється найближчим сервером.
- Підвищена доступність DNS: У разі відмови одного PoP, DNS-запити автоматично перенаправляються до наступного найближчого PoP, забезпечуючи високу відмовостійкість самого DNS-сервісу.
- DDoS-захист DNS: Розподілена природа Anycast допомагає поглинати DDoS-атаки на DNS, оскільки трафік розсіюється по безлічі вузлів.
- Простота налаштування: Зазвичай зводиться до зміни NS-записів домену.
Мінуси:
- Тільки для DNS: Anycast DNS не балансує трафік вашого застосунку. Він лише прискорює та робить більш відмовостійким сам процес розв'язання доменних імен. Для балансування трафіку застосунку вам все одно знадобиться GLB (DNS GLB або CDN).
- Немає L7-функцій: Не надає функціоналу балансування на рівні застосунків, WAF або кешування.
- Вартість: Хоча деякі провайдери пропонують Anycast DNS безкоштовно (Cloudflare Free), для більш просунутих функцій та SLA може знадобитися платна підписка.
Для кого підходить: Усім SaaS-застосункам для покращення продуктивності та відмовостійкості DNS-запитів. Є відмінним доповненням до будь-якого з перерахованих вище GLB-рішень, але не замінює їх. Обов'язковий для глобальних SaaS-проєктів.
Мультихмарний/Гібридний GLB (VMware NSX ALB, F5 BIG-IP DNS, NetScaler GSLB)
Ці рішення є корпоративними системами балансування навантаження, які призначені для роботи в складних, гетерогенних середовищах, включаючи мультихмарні, гібридні та on-premise інфраструктури. Вони пропонують централізоване управління глобальним балансуванням навантаження, файловером, а також розширені можливості L4/L7 балансування та безпеки.
Як це працює: Ці системи розгортаються як віртуальні або апаратні пристрої в кожному з ваших центрів обробки даних або хмарних регіонів. Вони можуть використовувати як DNS-методи (GSLB – Global Server Load Balancing), так і прямі проксі-методи для маршрутизації трафіку. Вони мають власні механізми health checks і можуть інтегруватися з різними хмарними API для виявлення сервісів і автоматичного масштабування. Центральна консоль управління дозволяє вам визначати політики маршрутизації, моніторити стан всіх ресурсів і управляти файловером між регіонами і хмарами.
Плюси:
- Комплексне рішення: Об'єднує GLB, L4/L7 балансування, WAF, SSL/TLS offloading та інші функції в одному продукті.
- Мультихмарна та гібридна підтримка: Ідеально підходить для компаній, які використовують кілька хмар або поєднують хмарні та on-premise ресурси.
- Висока продуктивність та масштабованість: Розроблені для роботи з дуже великими обсягами трафіку.
- Централізоване управління: Єдина точка управління для всієї глобальної інфраструктури балансування.
- Глибока інтеграція: Можливість глибокої інтеграції з корпоративними системами моніторингу, безпеки та оркестрації.
Мінуси:
- Дуже висока вартість: Ліцензії та підтримка цих систем значно дорожчі за хмарні аналоги.
- Складність впровадження та обслуговування: Вимагає висококваліфікованих фахівців і значних інженерних ресурсів.
- Експлуатаційні витрати: Крім ліцензій, необхідно управляти самою інфраструктурою, на якій розгорнуті ці рішення.
- Надмірність функціоналу: Для невеликих та середніх SaaS-проєктів функціонал може бути надмірним.
Для кого підходить: Великі підприємства та корпорації з комплексними, гетерогенними інфраструктурами, суворими вимогами до безпеки та продуктивності, які готові інвестувати в потужні, централізовано керовані рішення. Рідко використовується стартапами або невеликими SaaS-проєктами.
Вибір конкретного рішення повинен ґрунтуватися на ретельному аналізі ваших поточних і майбутніх потреб, бюджету та доступних інженерних ресурсів. Часто оптимальним є гібридний підхід, наприклад, використання керованого DNS GLB у поєднанні з CDN для кешування та захисту, і Anycast DNS для прискорення DNS-запитів.
Практичні поради та рекомендації
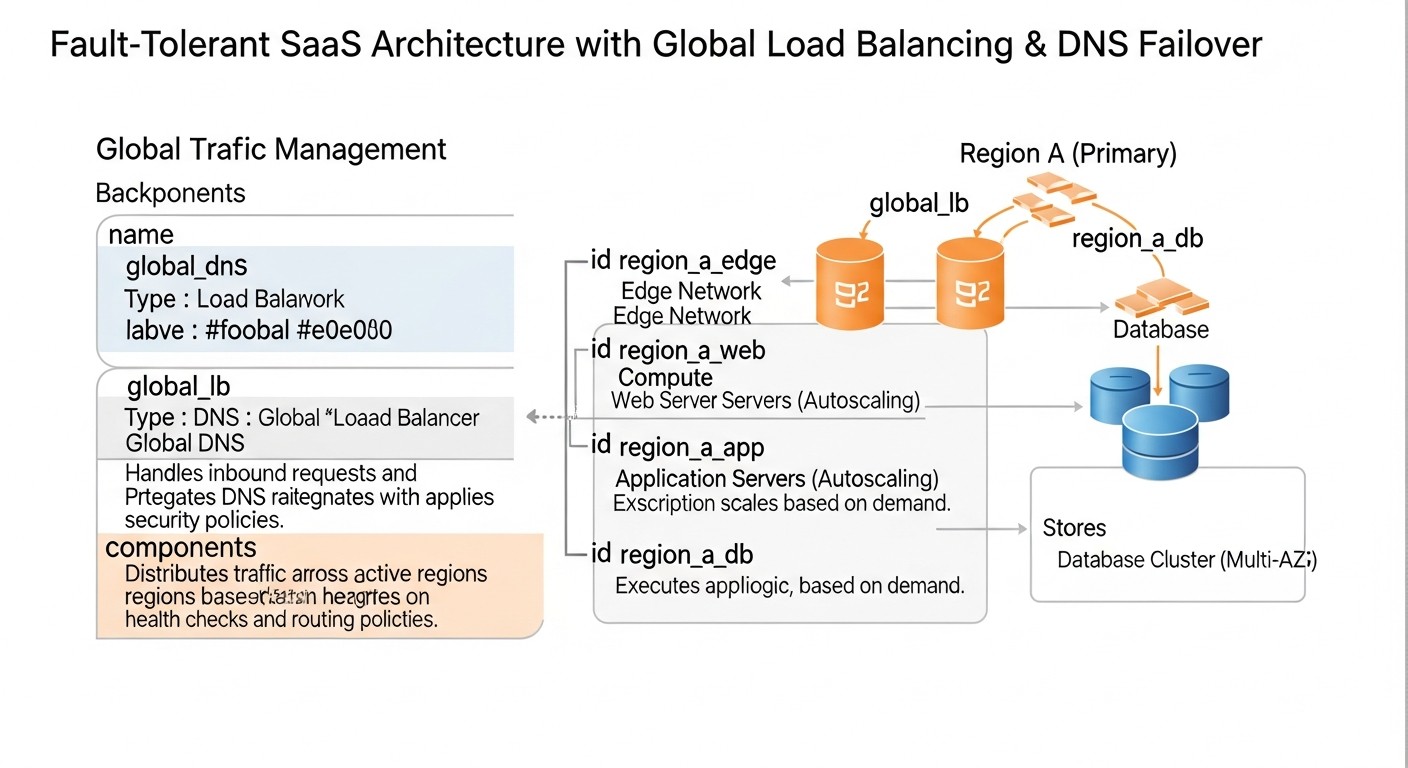
Теорія — це добре, але без практичних кроків вона марна. У цьому розділі ми розглянемо конкретні рекомендації, покрокові інструкції та приклади конфігурацій, які допоможуть вам впровадити глобальне балансування навантаження та DNS-файловер у ваш SaaS-застосунок.
1. Плануйте мультирегіональну архітектуру з самого початку
Не намагайтеся прикрутити мультирегіональність до моноліту, спочатку спроєктованого для одного ЦОД. Заздалегідь продумайте, як будуть взаємодіяти компоненти в різних регіонах. Це стосується не тільки мережевого рівня, а й баз даних, черг повідомлень, кешів і сховищ файлів.
- Визначте регіони: Виберіть 2-3 регіони, де зосереджені ваші користувачі або де є стратегічні переваги (наприклад, дотримання регуляторних вимог). Рекомендується вибирати регіони на різних континентах для максимальної відмовостійкості.
- Ізоляція ресурсів: Кожен регіон повинен бути максимально незалежним. Збій в одному регіоні не повинен впливати на роботу іншого.
- Реплікація даних: Це найскладніший аспект. Для баз даних розгляньте:
- Active-Passive: Один регіон активний, інший — резервний. Дані реплікуються асинхронно або напівсинхронно. Простіше в реалізації, але RPO > 0. Приклад: PostgreSQL з WAL shipping, MySQL з реплікацією.
- Active-Active: Обидва регіони приймають запис. Вимагає розподілених баз даних (Cassandra, CockroachDB, Spanner) або складних схем вирішення конфліктів. RPO = 0, але дуже висока складність.
- Гео-партиціонування: Дані користувачів зберігаються в найближчому до них регіоні. Спрощує реплікацію, але ускладнює запити, що охоплюють кілька регіонів.
2. Налаштуйте DNS-провайдера з підтримкою GLB та Health Checks
Використовуйте сервіси типу AWS Route 53 Traffic Flow, Azure Traffic Manager або Google Cloud DNS з політиками маршрутизації. Для прикладу розглянемо AWS Route 53.
Крок 1: Створіть Health Checks
Health checks повинні бути максимально глибокими. Недостатньо перевіряти тільки доступність порту 80. Переконайтеся, що ваш застосунок здатний відповісти на запит, обробити його та взаємодіяти з базою даних.
# Пример URL для Health Check, который проверяет не только доступность, но и работоспособность DB
# GET /healthz - возвращает 200 OK, если приложение и его зависимости (DB, Redis) живы.
# Создание Health Check для основного региона (например, us-east-1)
aws route53 create-health-check \
--caller-reference "my-saas-app-us-east-1-health-check-$(date +%s)" \
--health-check-config '{"IPAddress": "1.2.3.4", "Port": 80, "Type": "HTTP", "ResourcePath": "/healthz", "RequestInterval": 10, "FailureThreshold": 3}'
# Создание Health Check для резервного региона (например, eu-west-1)
aws route53 create-health-check \
--caller-reference "my-saas-app-eu-west-1-health-check-$(date +%s)" \
--health-check-config '{"IPAddress": "5.6.7.8", "Port": 80, "Type": "HTTP", "ResourcePath": "/healthz", "RequestInterval": 10, "FailureThreshold": 3}'
Крок 2: Налаштуйте Record Sets з політиками маршрутизації
Використовуйте політику Failover або Latency-based Routing для автоматичного перемикання.
# Приклад створення Failover Record Set для домену app.example.com
# Основний регіон (Primary)
{
"Comment": "Primary record for app.example.com in us-east-1",
"Changes": [
{
"Action": "CREATE",
"ResourceRecordSet": {
"Name": "app.example.com",
"Type": "A",
"SetIdentifier": "us-east-1-primary",
"Failover": "PRIMARY",
"HealthCheckId": "YOUR_US_EAST_1_HEALTH_CHECK_ID",
"TTL": 60,
"ResourceRecords": [
{ "Value": "IP_OF_US_EAST_1_LOAD_BALANCER" }
]
}
}
]
}
# Резервний регіон (Secondary)
{
"Comment": "Secondary record for app.example.com in eu-west-1",
"Changes": [
{
"Action": "CREATE",
"ResourceRecordSet": {
"Name": "app.example.com",
"Type": "A",
"SetIdentifier": "eu-west-1-secondary",
"Failover": "SECONDARY",
"HealthCheckId": "YOUR_EU_WEST_1_HEALTH_CHECK_ID",
"TTL": 60,
"ResourceRecords": [
{ "Value": "IP_OF_EU_WEST_1_LOAD_BALANCER" }
]
}
}
]
}
Крок 3: Встановіть низький TTL
Для критично важливих сервісів встановіть TTL на 60-300 секунд (1-5 хвилин). Занадто низький TTL (наприклад, 5 секунд) може збільшити навантаження на DNS-сервери, але значно прискорить файловер. Знайдіть золоту середину.
3. Інтегруйте CDN для підвищення продуктивності та захисту
Навіть якщо ви використовуєте DNS GLB, CDN може значно покращити досвід користувача та забезпечити додатковий рівень захисту.
- Налаштуйте Origin Failover: У Cloudflare або AWS CloudFront ви можете вказати декілька Origin-серверів (ваших регіональних балансувальників) та налаштувати правила перемикання між ними.
- Оптимізуйте кешування: Переконайтеся, що статичний контент кешується максимально ефективно.
- Увімкніть WAF та DDoS-захист: Використовуйте можливості CDN для захисту вашого додатку на рівні Edge.
4. Розгорніть комплексний моніторинг та оповіщення
Ви повинні знати про проблеми раніше своїх клієнтів. Моніторинг повинен охоплювати:
- Health Checks GLB: Моніторинг статусу ваших DNS health checks.
- Метрики додатку: Затримка, помилки, пропускна здатність, завантаження CPU/RAM в кожному регіоні.
- Метрики бази даних: Реплікація, затримки, помилки, використання диска.
- Мережеві метрики: Затримка між регіонами, втрати пакетів.
Налаштуйте оповіщення (Slack, PagerDuty, email) на критичні події, такі як збій health check, збільшення помилок або затримки.
5. Регулярно проводьте навчання з аварійного відновлення (DR Drills)
Єдиний спосіб переконатися, що ваша архітектура працює, — це регулярно її тестувати. Імітуйте збої в одному з регіонів і перевіряйте, як система реагує.
- Ініціюйте збій Health Check: Тимчасово заблокуйте доступ до
/healthzв одному регіоні або зупиніть сервіс, щоб перевірити, як GLB перемикає трафік. - Вимкніть регіон: Використовуйте AWS Fault Injection Simulator або аналогічні інструменти для імітації повного збою регіону.
- Документуйте RTO та RPO: Заміряйте фактичний час відновлення та потенційну втрату даних.
- Автоматизуйте тестування: Увімкніть перевірку файловеру у ваші CI/CD пайплайни.
6. Використовуйте Infrastructure as Code (IaC)
Всі ваші налаштування інфраструктури, включаючи GLB, DNS, health checks, повинні бути описані в коді (Terraform, CloudFormation, Pulumi). Це забезпечує повторюваність, версіонування та спрощує управління.
# Приклад Terraform для AWS Route 53 Health Check
resource "aws_route53_health_check" "us_east_1_app_health" {
fqdn = "app.example.com"
port = 80
type = "HTTP"
resource_path = "/healthz"
request_interval = 10
failure_threshold = 3
tags = {
Name = "app-us-east-1-health"
}
}
# Приклад Terraform для AWS Route 53 Failover A Record Set
resource "aws_route53_record" "app_primary" {
zone_id = aws_route53_zone.main.zone_id
name = "app.example.com"
type = "A"
ttl = 60
set_identifier = "us-east-1-primary"
failover_routing_policy {
type = "PRIMARY"
}
health_check_id = aws_route53_health_check.us_east_1_app_health.id
records = ["IP_OF_US_EAST_1_LOAD_BALANCER"]
}
resource "aws_route53_record" "app_secondary" {
zone_id = aws_route53_zone.main.zone_id
name = "app.example.com"
type = "A"
ttl = 60
set_identifier = "eu-west-1-secondary"
failover_routing_policy {
type = "SECONDARY"
}
health_check_id = aws_route53_health_check.eu_west_1_app_health.id # Припускаємо, що є health check для eu-west-1
records = ["IP_OF_EU_WEST_1_LOAD_BALANCER"]
}
7. Забезпечте консистентність даних
При файловері на інший регіон, дані повинні бути актуальними. Для реляційних баз даних розгляньте:
- PostgreSQL з Logical Replication: Дозволяє реплікувати дані між регіонами.
- Aurora Global Database (AWS): Повністю кероване рішення для глобальної реплікації PostgreSQL/MySQL.
- Cassandra/MongoDB Atlas Global Clusters: Для NoSQL баз даних, спочатку розроблених для розподілених середовищ.
Пам'ятайте про кеші. При перемиканні регіону, кеші в новому активному регіоні можуть бути холодними або містити застарілі дані. Продумайте стратегію інвалідації або прогріву кешу.
8. Враховуйте автентифікацію та сесії
Якщо користувачі авторизовані в одному регіоні, при перемиканні на інший регіон їм не повинно вимагатися повторна авторизація. Використовуйте розподілені сховища сесій (наприклад, Redis Cluster, DynamoDB) або JWT-токени, які не прив'язані до конкретного серверу або регіону.
Типові помилки
Впровадження глобального балансування навантаження і DNS-файловеру — складний процес, і помилки на цьому шляху можуть призвести до тривалих простоїв, втрати даних і значних фінансових втрат. Знання типових помилок допоможе вам їх уникнути.
1. Занадто високий TTL для DNS-записів
Помилка: Встановлення TTL (Time To Live) DNS-записів на години або навіть дні (наприклад, 24 години).
Наслідки: У разі збою основного регіону, DNS-кеші по всьому світу продовжуватимуть вказувати на непрацюючу IP-адресу протягом усього терміну TTL. Це означає, що навіть після того, як ваш GLB виявить збій та оновить записи, користувачі не зможуть отримати доступ до вашого додатку протягом тривалого часу (RTO буде дуже високим). Приклад: у SaaS-компанії з TTL 1 день стався збій в AWS us-east-1. Незважаючи на наявність резервного регіону, користувачі не могли підключитися до сервісу протягом 12-24 годин, поки їх локальні DNS-кеші не оновилися. Це призвело до втрати мільйонів доларів та масового відтоку клієнтів.
Як уникнути: Для критично важливих записів, що використовуються GLB, встановіть TTL в діапазоні від 60 до 300 секунд (1-5 хвилин). Це забезпечить розумний компроміс між швидкістю файловеру та навантаженням на DNS-сервери.
2. Поверхневі Health Checks
Помилка: Налаштування Health Checks, які перевіряють лише доступність порту (наприклад, TCP 80/443), але не працездатність самого додатку або його залежностей.
Наслідки: Балансувальник навантаження може вважати регіон здоровим, тому що веб-сервер відповідає, але насправді додаток може бути непрацездатним (наприклад, через проблеми з базою даних, Redis, зовнішніми API). Це призводить до того, що трафік направляється в регіон, який не може обслуговувати запити, що викликає помилки у користувачів. Приклад: Health Check перевіряв тільки Nginx. Nginx працював, але бекенд-додаток впав через проблеми з базою даних. GLB продовжував направляти трафік на Nginx, який повертав 502 Bad Gateway, замість того щоб переключитися на резервний регіон.
Як уникнути: Створюйте глибокі Health Checks, які перевіряють стан всіх критично важливих компонентів додатку (API, база даних, кеш, черги). Реалізуйте спеціальний ендпоінт /healthz або /status, який виконує ці перевірки і повертає HTTP 200 OK тільки у випадку повної працездатності.
3. Непротестований механізм файловеру
Помилка: Розгортання архітектури з GLB та DNS-файловером без регулярного тестування сценаріїв збоїв.
Наслідки: В реальній ситуації збою система може не спрацювати так, як очікувалося. Процес переключення може бути повільним, неповним або зовсім не відбутися через помилки в конфігурації, забуті залежності або проблеми з реплікацією даних. Приклад: Великий банк розгорнув мультирегіональну архітектуру, але ніколи не проводив повноцінних навчань. Під час регіонального збою з'ясувалося, що один з критичних мікросервісів не був налаштований на реплікацію в резервний регіон, і процес відновлення зайняв години замість хвилин.
Як уникнути: Включіть регулярні навчання з аварійного відновлення (DR Drills) в свою операційну практику. Імітуйте збої в одному регіоні (відключення сервісів, ізоляція мережі) і перевіряйте, як швидко і коректно система переключається. Автоматизуйте ці тести, якщо це можливо.
4. Неузгодженість даних між регіонами
Помилка: Відсутність або неправильне налаштування реплікації даних між регіонами.
Наслідки: При переключенні на резервний регіон користувачі можуть зіткнутися з застарілими або відсутніми даними. Це може призвести до втрати користувацьких даних, порушення бізнес-логіки та серйозних проблем з довірою. Приклад: SaaS-платформа для управління проектами використовувала асинхронну реплікацію бази даних. Під час файловеру, останні 5 хвилин даних (створені в основному регіоні) були втрачені, що призвело до зникнення нещодавно створених задач і коментарів у користувачів.
Як уникнути: Ретельно сплануйте стратегію реплікації даних. Для критично важливих даних прагніть до RPO, близького до нуля, використовуючи синхронну або напівсинхронну реплікацію (наприклад, AWS Aurora Global Database, CockroachDB). Пам'ятайте про кеші та файлові сховища; вони також повинні бути репліковані або мати стратегію відновлення.
5. Ігнорування вартості міжрегіонального трафіку
Помилка: Недооцінка вартості трафіку, що передається між регіонами (egress/ingress).
Наслідки: Мультирегіональна архітектура за замовчуванням дорожча, але міжрегіональний трафік може стати прихованим "пожирачем" бюджету. Якщо ваші сервіси в різних регіонах активно обмінюються даними, рахунки за хмару можуть швидко вийти з-під контролю. Приклад: Стартап розгорнув Active-Active архітектуру з двома регіонами, але не врахував, що їх мікросервіси постійно обмінювалися великим об'ємом даних один з одним, навіть якщо користувацький трафік йшов в найближчий регіон. Це призвело до того, що рахунок за трафік між регіонами перевищив вартість всіх інших ресурсів.
Як уникнути: Мінімізуйте міжрегіональний трафік. Проектуйте сервіси так, щоб вони були максимально автономні в рамках свого регіону. Якщо міжрегіональна взаємодія необхідна, використовуйте ефективні протоколи, стиснення даних і розгляньте можливість використання приватних з'єднань (VPC Peering, Direct Connect) для зниження вартості трафіку.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Чекліст для практичного застосування
Цей чеклист допоможе вам систематизувати процес проектування та впровадження глобального балансування навантаження та DNS-файловеру для вашого SaaS-додатку. Пройдіться по кожному пункту, щоб переконатися, що ви нічого не пропустили.
- Визначення вимог:
- Чи визначено цільовий RTO (Recovery Time Objective) для вашого додатку (наприклад, 30 секунд, 5 хвилин)?
- Чи визначено цільовий RPO (Recovery Point Objective) для вашого додатку (наприклад, 0 секунд, 1 хвилина)?
- Чи визначено ключові регіони, де будуть розміщені ресурси, виходячи з географії користувачів і регуляторних вимог?
- Чи проведено аналіз критичних компонентів додатку, які вимагають максимальної відмовостійкості?
- Архітектурне проектування:
- Чи вибрано стратегію реплікації даних (Active-Passive, Active-Active, гео-партиціонування) і відповідні технології баз даних?
- Чи спроектовано архітектуру додатку з урахуванням відсутності стану (stateless) для легкої переносності між регіонами?
- Чи розроблено стратегію для кешів і сховищ файлів (наприклад, S3 Cross-Region Replication)?
- Чи продумано, як будуть оброблятися користувацькі сесії та аутентифікація при переключенні між регіонами?
- Вибір і налаштування GLB/DNS:
- Чи вибрано основного GLB/DNS-провайдера (AWS Route 53, Azure Traffic Manager, Google Cloud DNS) або CDN з GLB (Cloudflare, Akamai)?
- Чи налаштовано NS-записи вашого домену для використання вибраного DNS-провайдера?
- Чи створено Health Checks для кожного регіону, що перевіряють глибоку працездатність додатку та його залежностей (HTTP
/healthz)? - Чи налаштовано DNS-записи (A/CNAME) з відповідними політиками маршрутизації (Failover, Latency, Geo) і чи прив'язано до них Health Checks?
- Чи встановлено оптимальний TTL (наприклад, 60-300 секунд) для критично важливих DNS-записів?
- (Опціонально) Чи інтегрована CDN для кешування, DDoS-захисту та додаткового рівня файловеру?
- (Опціонально) Чи використовується Anycast DNS для підвищення відмовостійкості та швидкості розв'язання DNS-запитів?
- Впровадження інфраструктури:
- Чи розгорнута ідентична (або максимально схожа) інфраструктура в кожному з вибраних регіонів?
- Чи налаштовано реплікацію баз даних та інших постійних сховищ між регіонами?
- Чи використовується Infrastructure as Code (Terraform, CloudFormation) для управління всією інфраструктурою, включно з GLB та DNS?
- Чи налаштовані регіональні балансувальники навантаження (ALB, Nginx) для розподілу трафіку всередині кожного регіону?
- Моніторинг та оповіщення:
- Чи налаштовано моніторинг статусу GLB Health Checks та метрик перемикання?
- Чи налаштовано моніторинг ключових метрик застосунку (помилки, затримки, пропускна здатність) в кожному регіоні?
- Чи налаштовано моніторинг стану реплікації даних між регіонами?
- Чи налаштовано оповіщення для ключових подій (збій Health Check, регіональний збій, проблеми з реплікацією)?
- Тестування та оптимізація:
- Чи проведені навчання з аварійного відновлення (DR Drills) з імітацією збою основного регіону?
- Чи виміряні фактичні RTO та RPO під час навчань?
- Чи оптимізовано витрати на міжрегіональний трафік та ресурси в резервних регіонах?
- Чи документовані всі процедури файловеру та відновлення?
- Чи включено тестування файловеру в CI/CD пайплайн, де це можливо?
Розрахунок вартості / Економіка
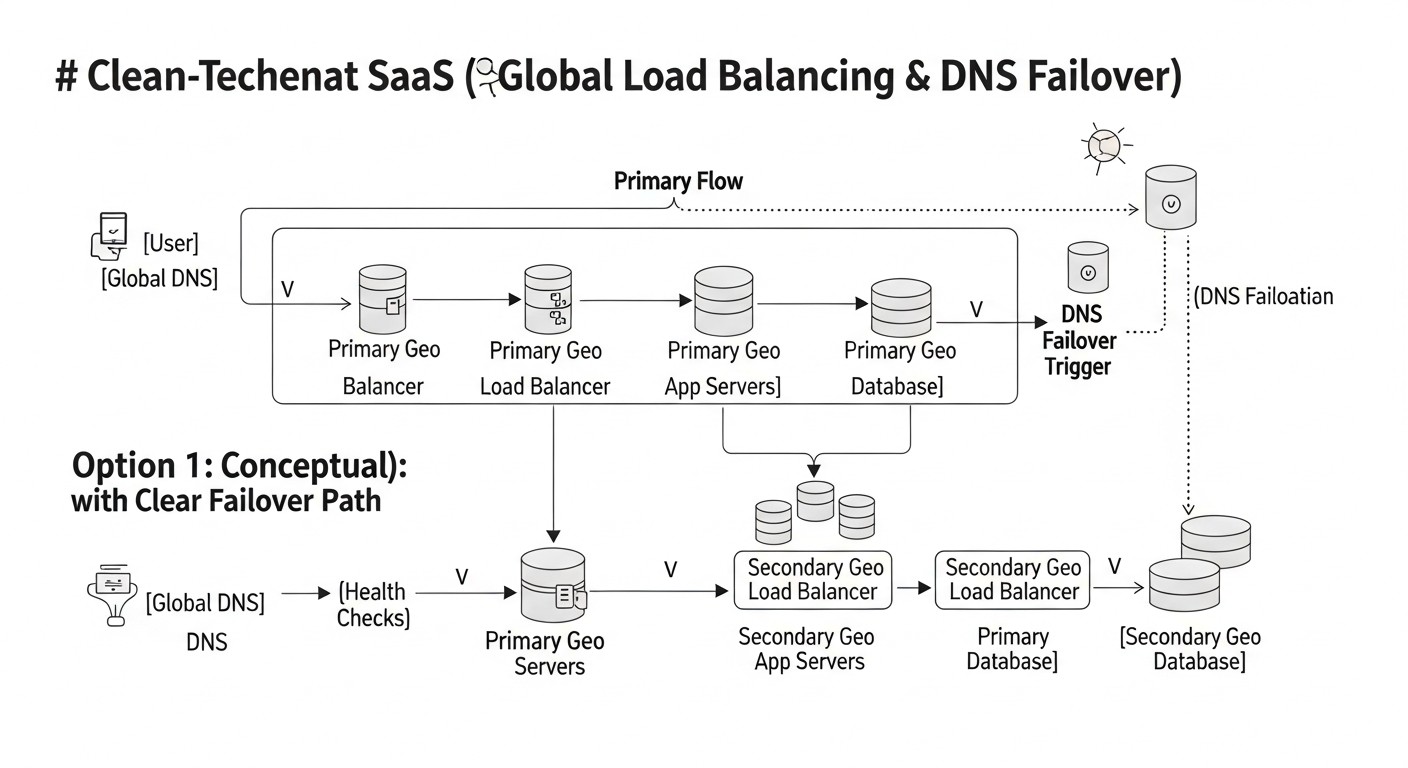
Впровадження глобального балансування навантаження та DNS-файловеру значно збільшує відмовостійкість, але також суттєво впливає на бюджет. Важливо розуміти, з чого складаються витрати і як їх оптимізувати. Розглянемо приклади розрахунків для різних сценаріїв, актуальні для 2026 року.
Основні компоненти витрат
- GLB/DNS-сервіси: Плата за DNS-зони, запити, Health Checks.
- AWS Route 53: $0.50/зона/міс, $0.005/1M запитів, $0.70/Health Check/міс.
- Azure Traffic Manager: $0.50/1M DNS-запитів, $1.00/Health Check/міс.
- Google Cloud DNS: $0.20/зона/міс, $0.40/1M запитів. Health checks інтегровані з Cloud Load Balancing.
- Інфраструктура в резервному регіоні:
- Active-Passive: Резервний регіон працює в "гарячому" (завжди включеному), "теплому" (включені тільки критичні компоненти) або "холодному" (розгортання за вимогою) режимі. Вартість залежить від вибраного режиму.
- Active-Active: Повна інфраструктура в кожному регіоні.
- Віртуальні машини/контейнери, бази даних, сховища, балансувальники навантаження.
- Трафік між регіонами:
- Міжрегіональна реплікація даних (баз даних, сховищ).
- Міжсервісна взаємодія.
- Часто це найдорожчий компонент, наприклад, $0.02-$0.09 за ГБ.
- CDN: Якщо використовується, то плата за трафік, запити, WAF, DDoS-захист.
- Розробка та експлуатація: Зарплати інженерів, час на проєктування, впровадження, тестування, моніторинг та підтримку.
- Ліцензії: Якщо використовуються сторонні програмні GLB або корпоративні рішення.
Приклади розрахунків для різних сценаріїв (2026 рік)
Припустимо, у нас є SaaS-застосунок зі 100 000 активних користувачів, який генерує 500 млн DNS-запитів на місяць і 10 ТБ вихідного трафіку на місяць (без CDN). База даних генерує 500 ГБ реплікаційного трафіку між регіонами на місяць.
Сценарій 1: Active-Passive з AWS Route 53 (2 регіони)
Основний регіон (us-east-1) працює на повну потужність, резервний (eu-west-1) в "гарячому" режимі (тобто вся інфраструктура запущена, але простоює або обслуговує мінімальний трафік).
- AWS Route 53:
- 1 Hosted Zone: $0.50
- 500 млн DNS-запитів: 500 $0.005 = $2500
- 2 Health Checks: 2 $0.70 = $1.40
- Всього Route 53: ~$2502
- Інфраструктура:
- Основний регіон: $5000/міс (віртуальні машини, бази даних, балансувальники)
- Резервний регіон (гарячий): $5000/міс (повністю дублююча інфраструктура)
- Всього інфраструктура: ~$10000
- Трафік:
- 10 ТБ вихідного трафіку (з основного регіону): $0.05/ГБ 10240 ГБ = $512
- 500 ГБ міжрегіонального трафіку (реплікація DB): $0.02/ГБ 500 ГБ = $10
- Всього трафік: ~$522
- Загальна орієнтовна вартість: ~$13024/міс
Сценарій 2: Active-Active з Cloudflare та AWS Route 53 (2 регіони)
Обидва регіони обслуговують трафік. Cloudflare виступає як основний GLB та CDN, Route 53 використовується для DNS-розв'язання домену Cloudflare.
- Cloudflare (Enterprise): Орієнтовно $2000/міс (включає CDN, WAF, GLB, 50 ТБ трафіку).
- AWS Route 53:
- 1 Hosted Zone: $0.50
- 500 млн DNS-запитів (до Cloudflare): $2500 (якщо Route 53 використовується для балансування DNS-запитів до Cloudflare, але зазвичай Cloudflare бере на себе DNS). Якщо Cloudflare DNS, то $0.
- 2 Health Checks (для Origin-серверів Cloudflare): 2 $0.70 = $1.40
- Всього Route 53: ~$1.90 (якщо Cloudflare DNS) або ~$2502 (якщо Route 53 DNS)
- Інфраструктура:
- Основний регіон: $5000/міс
- Другий активний регіон: $5000/міс
- Всього інфраструктура: ~$10000
- Трафік:
- Трафік від Cloudflare до Origin (10 ТБ): $0.01/ГБ 10240 ГБ = $102.40 (Cloudflare зазвичай має нижчі ціни на egress до Origin).
- 500 ГБ міжрегіонального трафіку (реплікація DB): $0.02/ГБ * 500 ГБ = $10
- Разом трафік: ~$112.40
- Загальна орієнтовна вартість: ~$12114/міс (з Cloudflare DNS) або ~$14614/міс (з Route 53 DNS)
- Неефективне використання ресурсів: Запуск повної інфраструктури в резервному регіоні, яка не використовується (в Active-Passive).
- Data Transfer Out (Egress): Передача даних з хмари завжди найдорожча. Міжрегіональний трафік може бути в кілька разів дорожчим, ніж внутрішньорегіональний.
- Складність управління: Додаткові години інженерів на налаштування, моніторинг, тестування та усунення проблем у більш складній системі.
- Ліцензії на стороннє ПЗ: Якщо ви використовуєте Nginx Plus, HAProxy Enterprise або інші комерційні рішення.
- Аудит і комплаєнс: Для забезпечення відповідності регуляторним вимогам у різних регіонах.
Як оптимізувати витрати
- Оптимізація режиму резервного регіону: Замість "гарячого" Active-Passive розгляньте "теплий" (запущені тільки мінімальні сервіси, масштабування за вимогою) або "холодний" (розгортання інфраструктури з нуля при збої) режими. Це знижує витрати на простіюючі ресурси, але збільшує RTO.
- Мінімізація міжрегіонального трафіку:
- Розміщуйте дані та сервіси поруч з користувачами (гео-партиціонування).
- Використовуйте стиснення даних при передачі.
- Оптимізуйте протоколи взаємодії.
- Використовуйте приватні з'єднання (VPC Peering, Direct Connect) для зниження вартості трафіку між хмарними обліковими записами або регіонами.
- Використання Spot Instances/Preemptible VMs: Для некритичних або масштабованих робочих навантажень в резервному регіоні можна використовувати дешевші інстанси, які можуть бути перервані.
- Резервування (Reserved Instances/Savings Plans): Якщо ви впевнені в довгостроковому використанні ресурсів, покупка Reserved Instances або Savings Plans може значно знизити вартість віртуальних машин і баз даних.
- Ефективне використання CDN: Максимально кешуйте статичний контент, щоб знизити навантаження і трафік на ваші Origin-сервери.
- Автоматизація: Автоматизуйте розгортання, масштабування і файловер, щоб знизити операційні витрати.
Таблиця з прикладами розрахунків для різних режимів резервування (на базі сценарію 1, інфраструктура):
| Режим резервного регіону | Опис | Орієнтовні витрати на інфраструктуру (2 регіони) | Орієнтовний RTO | Приклади використання |
|---|---|---|---|---|
| Гарячий (Hot Standby) | Повністю розгорнута і працююча інфраструктура в резервному регіоні. | $10000/міс (2 x $5000) | Секунди-Хвилини | Критично важливі SaaS з низьким RTO, фінансові, медичні додатки. |
| Теплий (Warm Standby) | Мінімальний набір ресурсів запущений в резервному регіоні, масштабування за вимогою. | $6000-$8000/міс (1 x $5000 + 1 x $1000-$3000) | Хвилини-Десятки хвилин | Більшість SaaS, де допустимий невеликий простій. |
| Холодний (Cold Standby) | Інфраструктура розгортається з нуля або з образів при збої. | $5000-$5500/міс (1 x $5000 + зберігання образів) | Години | Некритичні додатки, де високий RTO допустимий. |
Економіка мультирегіональної архітектури - це баланс між доступністю, продуктивністю і вартістю. Ретельне планування і постійна оптимізація необхідні для досягнення найкращого результату.
Кейси та приклади
Щоб краще зрозуміти, як глобальне балансування навантаження і DNS-файловер працюють на практиці, розглянемо кілька реалістичних сценаріїв з досвіду SaaS-компаній.
Кейс 1: Глобальна E-commerce платформа з піковими навантаженнями
Проблема: Велика e-commerce платформа, що працює на світовому ринку, стикалася з двома основними проблемами: високою затримкою для користувачів, що знаходяться далеко від основного ЦОД в США, і ризиком повного простою під час великих розпродажів (наприклад, Чорна п'ятниця) через регіональні збої. Потрібно було забезпечити RTO менше 5 хвилин і RPO, близьке до нуля, для транзакційних даних.
Рішення:
- Мультирегіональна архітектура Active-Active: Платформа була розгорнута в трьох регіонах AWS:
us-east-1(Північна Америка),eu-central-1(Європа) іap-southeast-2(Азія/Тихий океан). У кожному регіоні розгорнуті повні стеки програми (веб-сервери, API-сервіси, кеші). - AWS Route 53 з Latency-based Routing і Failover:
- Для домену
shop.example.comбули налаштовані A-записи, що вказують на регіональні Application Load Balancers (ALB) в кожному з трьох регіонів. - Використовувалася політика маршрутизації Latency-based Routing, щоб направляти користувачів до регіону з найменшою затримкою.
- До кожної A-запису був прив'язаний Health Check, який перевіряв доступність і працездатність не тільки ALB, але і ключових API-сервісів і з'єднання з базою даних в кожному регіоні (через ендпоінт
/healthz-deep). - TTL для A-записів був встановлений на 60 секунд.
- Додатково, для критичних внутрішніх сервісів, були налаштовані Failover Routing Policies, де один регіон був Primary, а два інших Secondary.
- Для домену
- Cloudflare CDN і WAF: Весь користувацький трафік проходив через Cloudflare для кешування статичного контенту, зниження затримок, DDoS-захисту і використання WAF. Cloudflare був налаштований з декількома Origin-серверами (регіональними ALB) і функцією Origin Failover, що забезпечувало миттєве перемикання на рівні L7.
- База даних: Використовувалася AWS Aurora Global Database (PostgreSQL-сумісна), яка забезпечувала асинхронну реплікацію з низькою затримкою між усіма трьома регіонами. У кожному регіоні був свій кластер Aurora, при цьому один регіон був Primary (для запису), а решта Secondary (для читання і швидкого просування до Primary при файловері). Механізм Aurora Global Database забезпечував RPO < 5 секунд.
- Сесії та кеші: Сесії зберігалися в розподіленому Redis Cluster, розгорнутому в кожному регіоні, з асинхронною реплікацією між регіонами для мінімізації втрати сесій при файловері. Кеші були регіональними, з можливістю швидкого прогріву при переключенні.
Результати:
- Значне зниження затримки для користувачів по всьому світу (на 30-50% в залежності від регіону).
- Під час великого збою в
us-east-1, система автоматично переключила весь трафік Північної Америки наeu-central-1протягом 90 секунд. Користувачі відчули короткочасні проблеми, але сервіс залишився доступним. Втрата даних склала менше 5 секунд (RPO). - Платформа успішно витримувала пікові навантаження, розподіляючи їх між регіонами.
- Значне підвищення безпеки завдяки Cloudflare WAF і DDoS-захисту.
Кейс 2: SaaS-платформа для аналітики даних із чутливими даними
Проблема: SaaS-компанія надавала платформу для аналітики фінансових даних, що вимагало суворих вимог до суверенітету даних (дані європейських клієнтів повинні залишатися в Європі) і високої доступності (RTO < 10 хвилин, RPO < 1 хвилина). В основному ЦОД (eu-west-1) стався серйозний збій, і компанія зазнала збитків.
Рішення:
- Гео-партиціонована архітектура Active-Passive: Було створено два незалежних "стеки" додатка: один в
eu-west-1(Ірландія) для європейських клієнтів і один вus-east-1(США) для американських клієнтів. Кожен стек був Active-Passive в рамках свого регіону, але глобально вони працювали як Active-Active для різних груп користувачів. - Azure Traffic Manager з Geo-routing і Priority Failover:
- Для домену
app.example.comбули налаштовані профілі Traffic Manager. - Використовувалася політика Geographic Routing, щоб направляти європейських користувачів на
eu-west-1, а американських — наus-east-1. - Всередині кожного географічного профілю була налаштована політика Priority Failover:
eu-west-1був Primary, аeu-west-2(Лондон) був Secondary для європейських клієнтів. Аналогічно для США. - Endpoint Monitoring перевіряв доступність і працездатність регіональних Application Gateways (L7-балансувальників) і ключових API.
- TTL для DNS-записів було встановлено на 120 секунд.
- Для домену
- База даних: Використовувалася PostgreSQL з Logical Replication для асинхронної реплікації даних між
eu-west-1іeu-west-2(і аналогічно для США). Для кожного клієнта дані зберігалися тільки в його географічному регіоні, забезпечуючи суверенітет даних. RPO був налаштований на 30 секунд. - Файлове сховище: Azure Blob Storage з гео-надмірністю (GRS) в рамках кожного географічного кластера.
Результати:
- Повна відповідність вимогам суверенітету даних.
- Під час імітації збою в
eu-west-1, Traffic Manager успішно переключив європейський трафік наeu-west-2протягом 5 хвилин. Втрата даних склала менше 30 секунд. - Значно покращено продуктивність для європейських і американських користувачів за рахунок локалізації даних і сервісів.
- Знижені ризики глобальних збоїв, так як проблеми в одному географічному кластері не впливають на інший.
Кейс 3: IoT-платформа з розподіленими вузлами
Проблема: IoT-платформа збирала дані з тисяч пристроїв по всьому світу. Важливо було забезпечити максимально низьку затримку для прийому даних і високу доступність для API управління пристроями. Збої в передачі даних або недоступність API могли призвести до втрати критично важливих показань.
Рішення:
- Розподілена мікросервісна архітектура з Edge Computing: Основні хаби обробки даних були розгорнуті в трьох регіонах GCP:
us-central1,europe-west1,asia-east1. У кожному регіоні працювали мікросервіси для прийому, обробки та зберігання даних. - Google Cloud Load Balancer (Global External HTTP(S) Load Balancer) з Cross-Region Failover:
- Це L7-балансувальник, який надає єдину глобальну IP-адресу. Він автоматично направляє трафік до найближчого бекенд-сервісу.
- Для API управління пристроями був налаштований Global External HTTP(S) Load Balancer, що вказує на групи інстансів (Managed Instance Groups) в кожному регіоні.
- GCP Load Balancer сам виконує Health Checks для груп інстансів і автоматично виключає несправні інстанси або навіть цілі регіони з пулу.
- Автоматичне перемикання відбувається миттєво на рівні L7, без залежності від TTL DNS.
- Google Cloud DNS з Anycast: Використовувався для швидкого розв'язання імен для IoT-пристроїв, хоча основну балансування виконував Global Load Balancer.
- База даних: Використовувалася Google Cloud Spanner — глобально розподілена, горизонтально масштабована реляційна база даних, що забезпечує сильну консистентність і RPO=0 в декількох регіонах.
- Черги повідомлень: Google Cloud Pub/Sub для прийому даних з пристроїв, що забезпечує глобальну доступність і високу пропускну здатність.
Результати:
- Максимально низька затримка для IoT-пристроїв, оскільки трафік завжди направлявся до найближчого хабу.
- Висока доступність API управління пристроями з миттєвим файловером при збоях в регіонах.
- RPO=0 завдяки Cloud Spanner, що виключило втрату даних пристроїв.
- Система легко масштабувалася для обробки зростаючої кількості пристроїв і обсягів даних.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Інструменти та ресурси
Для успішної реалізації та підтримки глобального балансування навантаження та DNS-файловеру необхідний набір перевірених інструментів. Цей розділ надає огляд ключових утиліт, сервісів моніторингу та корисних посилань, які будуть актуальними і в 2026 році.
1. Провайдери GLB та DNS-сервісів
- AWS Route 53: Комплексний DNS-сервіс із широкими можливостями GLB (Latency, Geo, Weighted, Failover Routing), Health Checks та інтеграцією з іншими сервісами AWS. Обов'язковий для користувачів AWS.
- Azure Traffic Manager: Аналогічний сервіс від Microsoft Azure, що пропонує різні методи маршрутизації трафіку (Priority, Weighted, Performance, Geographic, Multivalue) та Health Checks.
- Google Cloud DNS: Швидкий та масштабований DNS-сервіс. Для GLB зазвичай використовується у зв'язці з Google Cloud Load Balancing (External HTTP(S) Load Balancer, Internal Load Balancer), який надає глобальний IP та автоматичне перемикання між регіонами.
- Cloudflare: Крім CDN, пропонує потужні DNS-сервіси (Anycast DNS), Global Load Balancing (L7), WAF, DDoS-захист. Відмінний вибір для мультихмарних стратегій та підвищення продуктивності.
- Akamai, Fastly: Інші великі CDN-провайдери з розширеними можливостями GLB та Edge Computing.
- F5 BIG-IP DNS (GSLB), VMware NSX ALB (Avi Networks): Корпоративні рішення для складних гібридних та мультихмарних середовищ.
2. Інструменти Infrastructure as Code (IaC)
Для автоматизації розгортання та управління інфраструктурою GLB та DNS:
- Terraform: Найбільш популярний інструмент для IaC, що підтримує всіх великих хмарних провайдерів та багато інших сервісів. Дозволяє описувати DNS-записи, Health Checks, балансувальники навантаження та всю іншу інфраструктуру в декларативному вигляді.
- AWS CloudFormation, Azure Resource Manager (ARM), Google Cloud Deployment Manager: Нативні IaC-інструменти відповідних хмарних провайдерів. Добре інтегровані з екосистемою, але прив'язані до одного провайдера.
- Pulumi: Дозволяє описувати інфраструктуру звичними мовами програмування (Python, TypeScript, Go, C#).
# Пример установки Terraform
sudo apt update
sudo apt install -y curl unzip
curl -fsSL https://apt.releases.hashicorp.com/gpg | sudo apt-key add -
sudo apt-add-repository "deb [arch=amd64] https://apt.releases.hashicorp.com $(lsb_release -cs) main"
sudo apt update
sudo apt install terraform
3. Моніторинг та оповіщення
Критично важливі для відстеження стану GLB та файловеру:
- Prometheus + Grafana: Відкриті інструменти для збору метрик та візуалізації. Prometheus може збирати метрики з ваших Health Checks, балансувальників та додатків. Grafana забезпечує потужні дашборди.
- Datadog, New Relic, Dynatrace: Комерційні APM (Application Performance Monitoring) рішення, що пропонують комплексний моніторинг хмарних ресурсів, додатків, баз даних та мережевого трафіку.
- AWS CloudWatch, Azure Monitor, Google Cloud Monitoring: Нативні хмарні сервіси моніторингу. Надають метрики та логи для всіх ресурсів у хмарі, включаючи GLB та Health Checks.
- PagerDuty, Opsgenie: Інструменти для управління інцидентами та оповіщеннями, що забезпечують надійну доставку повідомлень DevOps-командам.
4. Інструменти для діагностики та Troubleshooting
dig,nslookup: Стандартні утиліти для запитів до DNS-серверів, дозволяють перевірити, які IP-адреси повертає ваш GLB.dig app.example.com dig @8.8.8.8 app.example.com # Проверить через Google Public DNS nslookup app.example.comtraceroute,mtr: Для відстеження маршруту пакетів та виявлення мережевих затримок або втрат.traceroute app.example.com mtr -rwc 10 app.example.comcurl,wget: Для перевірки доступності HTTP/HTTPS ендпоінтів, включаючи Health Checks.curl -v https://app.example.com/healthz- Онлайн-інструменти DNS-перевірки: Наприклад, dnschecker.org, whatsmydns.net для перевірки розповсюдження DNS-записів по світу.
5. Бази даних для глобальних розгортань
- AWS Aurora Global Database: Керована, високопродуктивна, гео-розподілена база даних (PostgreSQL/MySQL).
- Google Cloud Spanner: Глобально розподілена, горизонтально масштабована реляційна база даних із сильною консистентністю.
- CockroachDB: Розподілена SQL-база даних, розроблена для мультирегіональних розгортань та сильної консистентності.
- Cassandra, MongoDB Atlas Global Clusters: NoSQL бази даних, що добре підходять для розподілених середовищ (але з компромісами по консистентності).
6. Корисні посилання та документація
- AWS Route 53 Documentation
- Azure Traffic Manager Documentation
- Google Cloud DNS Documentation
- Cloudflare DNS Traffic Management
- Terraform AWS Route 53 Record Documentation
- Microservices by Martin Fowler (для розуміння розподілених систем)
- Building Highly Available Applications on AWS (загальні принципи)
Використання цих інструментів у поєднанні з продуманою архітектурою та регулярним тестуванням дозволить вам побудувати та підтримувати надійну та відмовостійку інфраструктуру.
Troubleshooting (вирішення проблем)
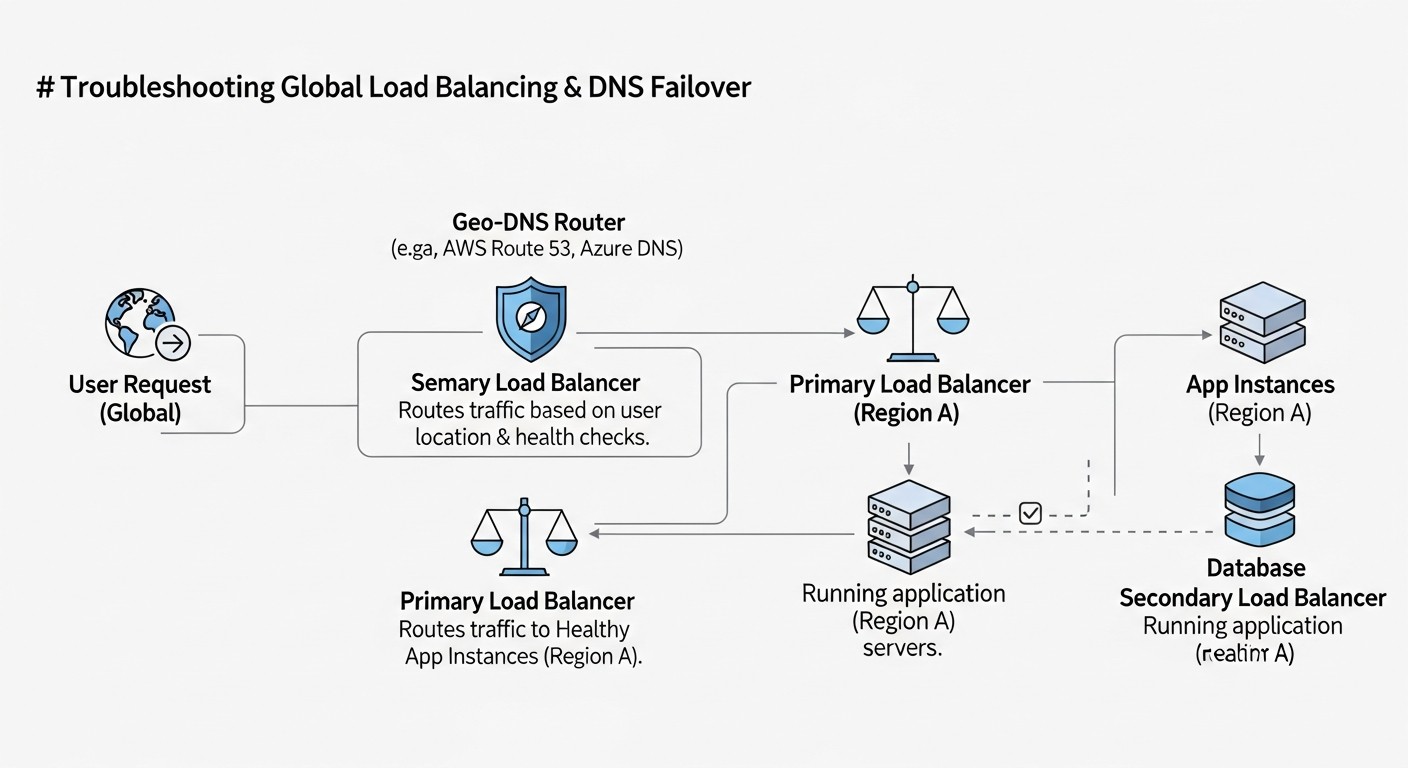
Навіть з найбільш продуманою архітектурою, проблеми неминучі. Уміння швидко діагностувати та усувати збої в системі глобального балансування навантаження та DNS-файловеру є критично важливим навиком. Нижче описані типові проблеми та підходи до їх вирішення.
1. Трафік не перемикається на резервний регіон
Опис проблеми: Основний регіон вийшов з ладу, але користувачі, як і раніше, направляються туди, або перемикання відбувається дуже повільно.
```Діагностика:
- Перевірте Health Checks: Переконайтеся, що ваш GLB-провайдер (Route 53, Traffic Manager) дійсно бачить основний регіон як "нездоровий".
Перевірте логи Health Check (якщо доступні), щоб зрозуміти, чому він вважає регіон нездоровим. Можливо, проблема глибша, ніж здається.# AWS Route 53: Перевірити статус Health Check aws route53 list-health-checks --query "HealthChecks[?Id=='YOUR_HEALTH_CHECK_ID'].HealthCheckObservations" - Перевірте TTL DNS-записів: Використовуйте
digабо онлайн-інструменти (dnschecker.org) для перевірки поточного TTL і IP-адрес, які видає ваш DNS-сервер. Можливо, клієнти або проміжні DNS-сервери кешують старі записи.dig +trace app.example.com - Перевірте конфігурацію GLB: Переконайтеся, що політики маршрутизації (Failover, Latency) налаштовані коректно і прив'язані до правильних Health Checks. Іноді буває, що Health Check налаштовано, але не прив'язано до DNS-запису.
- Перевірте мережеву взаємодію: Переконайтеся, що Health Check-сервери GLB-провайдера можуть достукатися до вашого ендпоінта. Можливо, є проблеми з мережевими ACL, фаєрволами або групами безпеки.
Рішення: Знизити TTL для критичних записів (якщо він був високим). Виправити помилки в конфігурації Health Checks або політик маршрутизації. Відкрити необхідні порти/IP-адреси для Health Check-серверів.
2. Неузгоджені або застарілі дані після файловеру
Опис проблеми: Після перемикання на резервний регіон, користувачі бачать старі дані або стикаються з помилками, пов'язаними з відсутністю даних.
Діагностика:
- Перевірте статус реплікації бази даних: Переконайтеся, що реплікація працює і відставання мінімальне.
Для хмарних баз даних використовуйте їх нативні метрики реплікації (наприклад, Aurora Global Database Lag).-- Пример для PostgreSQL: проверить WAL replay lag SELECT pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), (pg_last_wal_receive_lsn() - pg_last_wal_replay_lsn()) AS replay_lag; - Перевірте кеші: Можливо, кеші в новому активному регіоні "холодні" або містять застарілі дані.
- Перевірте файлові сховища: Якщо використовуються S3, Azure Blob Storage або Google Cloud Storage, переконайтеся, що файли репліковані між регіонами (наприклад, S3 Cross-Region Replication).
Рішення: Оптимізувати реплікацію бази даних (можливо, перейти на більш продуктивний тип реплікації або збільшити пропускну здатність мережі). Реалізувати стратегію прогріву кешу після файловеру або використовувати розподілені кеші. Переконатися в коректному налаштуванні реплікації файлових сховищ.
3. Погіршення продуктивності після файловеру
Опис проблеми: Сервіс доступний, але працює повільніше, ніж зазвичай, після перемикання регіону.
Діагностика:
- Перевірте ресурси резервного регіону: Чи достатньо потужності (CPU, RAM, IOPS) у віртуальних машин і баз даних в резервному регіоні, щоб прийняти все навантаження? Можливо, він був налаштований як "теплий" стендбай з меншою кількістю ресурсів.
- Перевірте мережеву затримку: Можливо, новий активний регіон знаходиться далі від більшості користувачів, що збільшує мережеву затримку. Використовуйте
traceroute. - Перевірте "холодні" кеші: Якщо кеші в новому регіоні були порожні, це може призвести до додаткового навантаження на базу даних і уповільнення роботи.
Рішення: Збільшити ресурси в резервному регіоні. Оптимізувати масштабування. Розробити стратегію "прогріву" кешів. Розглянути гео-маршрутизацію або Anycast DNS для мінімізації мережевої затримки для користувачів.
4. Проблема "Split-Brain" (роздвоєння свідомості)
Опис проблеми: Обидва регіони вважають себе "активними" і намагаються приймати запити на запис, що призводить до конфліктів даних і непередбачуваної поведінки.
Діагностика:
- Перевірте логи GLB: Переконайтеся, що GLB коректно виключив несправний регіон.
- Перевірте стан баз даних: Переконайтеся, що тільки один регіон вважається Primary для запису.
- Моніторинг конфліктів: Відстежуйте метрики конфліктів запису у вашій базі даних.
Рішення: Це серйозна проблема, що вимагає ретельного проєктування. Використовуйте кворумні механізми (наприклад, в розподілених базах даних) або суворі правила для визначення "Primary" регіону. В Active-Passive архітектурах переконайтеся, що резервний регіон ніколи не стає Primary, поки основний явно не буде оголошений мертвим або не буде проведено ручне перемикання. Автоматизація файловеру повинна бути дуже добре протестована, щоб уникнути цієї ситуації.
5. DDoS-атака, що впливає на GLB
Опис проблеми: Ваш додаток піддається DDoS-атаці, яка перевантажує GLB або DNS-сервери, роблячи сервіс недоступним.
Діагностика:
- Моніторинг DNS-запитів: Раптовий сплеск DNS-запитів або запитів до GLB.
- Моніторинг трафіку: Аномальний обсяг трафіку.
Рішення: Використовуйте CDN-провайдерів (Cloudflare, Akamai) з вбудованим DDoS-захистом, які можуть поглинати атаки на рівні Edge. Використовуйте Anycast DNS для розподілу навантаження DNS-запитів. Включіть нативні хмарні сервіси DDoS-захисту (AWS Shield Advanced, Azure DDoS Protection, Google Cloud Armor).
Коли звертатися в підтримку
- Якщо ви підозрюєте глобальний збій на стороні вашого хмарного провайдера (перевірте сторінки статусу).
- Якщо Health Checks показують, що ваш ресурс "нездоровий", але ви впевнені, що він працює (можливо, проблема в самому Health Check-сервісі).
- Якщо ви зіткнулися з проблемами, пов'язаними з маршрутизацією BGP або Anycast, які знаходяться поза вашим контролем.
- Якщо ви не можете зрозуміти причину аномальної поведінки GLB або DNS, незважаючи на всі внутрішні перевірки.
Головне в troubleshooting — це систематичний підхід, використання всіх доступних інструментів моніторингу і логування, а також добре документовані процедури.
FAQ
Навіщо мені глобальне балансування навантаження, якщо у мене є регіональний балансувальник?
Регіональний балансувальник навантаження (наприклад, AWS ALB, Azure Application Gateway) розподіляє трафік лише всередині одного регіону або зони доступності. Глобальне балансування навантаження (GLB) працює на вищому рівні, направляючи користувачів у найбільш підходящий географічний регіон. Воно забезпечує відмовостійкість на рівні регіону, перемикаючи трафік на інший регіон у разі збою, та оптимізує затримку, направляючи користувачів до найближчого доступного ЦОД. Це два різних, але взаємодоповнюючих рівні балансування.
Як правильно вибрати TTL для DNS-записів?
Вибір TTL — це компроміс між швидкістю файловеру та навантаженням на DNS-сервери. Для критично важливих записів, які використовуються в GLB-архітектурі, рекомендується встановлювати TTL в діапазоні від 60 до 300 секунд (1-5 хвилин). Це досить низько, щоб забезпечити відносно швидкий файловер (в межах декількох хвилин), але не настільки низько, щоб викликати надмірне навантаження на DNS-інфраструктуру. Для записів, які рідко змінюються (наприклад, NS-записи), можна використовувати більш високий TTL (1 година і більше).
В чому різниця між Active-Active та Active-Passive архітектурами?
Active-Active: Обидва (або всі) регіони активно обслуговують трафік. Переваги: висока доступність, низькі затримки, ефективне використання ресурсів. Недоліки: висока складність управління даними (потрібна розподілена база даних з вирішенням конфліктів), вища вартість. Active-Passive: Один регіон активний, інший (або інші) знаходиться в режимі очікування. Переваги: простіше в реалізації, легше управляти даними. Недоліки: простійні ресурси в резервному регіоні, потенційно більш високий RTO та RPO. Вибір залежить від вимог до RTO/RPO та бюджету.
Як забезпечити консистентність даних при мультирегіональному розгортанні?
Це одна з найскладніших задач. Для реляційних баз даних можна використовувати асинхронну реплікацію (наприклад, PostgreSQL Logical Replication, MySQL Replication) для Active-Passive, або спеціалізовані глобальні бази даних (AWS Aurora Global Database, Google Cloud Spanner) для Active-Active з сильною консистентністю. Для NoSQL баз даних (Cassandra, MongoDB) використовуйте їх вбудовані механізми розподілу даних. Важливо також продумати реплікацію файлових сховищ (S3 Cross-Region Replication) та управління розподіленими кешами.
Чи може CDN повністю замінити GLB?
Сучасні CDN (наприклад, Cloudflare, Akamai) пропонують потужні функції GLB на рівні L7 (HTTP/HTTPS), включаючи маршрутизацію за гео-принципом, затримкою та файловером. Для багатьох SaaS-додатків CDN може виконувати функції GLB, особливо якщо основний трафік — HTTP/HTTPS. Однак, якщо у вас є трафік, який не відноситься до HTTP (наприклад, TCP, UDP), або вам потрібен більш низькорівневий контроль на рівні DNS, то чистий DNS GLB (Route 53, Traffic Manager) або гібридний підхід з використанням обох рішень буде більш підходящим.
Які Health Checks вважаються "глибокими"?
Глибокі Health Checks не просто перевіряють доступність порту або базовий HTTP 200 OK. Вони повинні імітувати реальний користувацький запит або перевіряти працездатність всіх критичних залежностей додатку. Наприклад, ендпоінт /healthz може спробувати підключитися до бази даних, запросити дані з кешу, перевірити доступність зовнішніх API і тільки після успішного виконання всіх цих кроків повернути HTTP 200 OK. Це гарантує, що GLB переключить трафік тільки тоді, коли додаток дійсно готовий обслуговувати запити.
Як часто потрібно тестувати файловер?
Рекомендується проводити навчання з аварійного відновлення (DR Drills) не рідше одного разу на квартал, а для критично важливих систем — щомісяця. Це дозволяє виявляти помилки в конфігурації, проблеми з реплікацією та інші несподівані нюанси до того, як вони призведуть до реального простою. Автоматизовані тести файловеру можна запускати ще частіше, наприклад, як частину CI/CD пайплайну при кожній значній зміні інфраструктури.
Як скоротити витрати на мультирегіональну архітектуру?
Основні способи:
- Використовувати "теплий" або "холодний" режим резервного регіону замість "гарячого" для економії на простійних ресурсах.
- Мінімізувати міжрегіональний трафік, оптимізуючи архітектуру сервісів і реплікації даних.
- Використовувати резервування (Reserved Instances, Savings Plans) для стабільних навантажень.
- Максимально використовувати CDN для кешування та зниження навантаження на Origin-сервери.
- Оптимізувати Health Checks, щоб вони не генерували надлишкових запитів.
Як боротися з локальним кешуванням DNS на стороні клієнта?
Локальне кешування DNS на клієнтських пристроях і проміжних DNS-серверах (провайдерів) є основною причиною повільного файловеру при використанні DNS GLB. Повністю уникнути його неможливо, але можна мінімізувати ефект:
- Встановити низький TTL (60-300 секунд) для критичних DNS-записів.
- Використовувати CDN: CDN виступає в ролі проксі, і переключення на рівні CDN відбувається миттєво, оскільки клієнти взаємодіють тільки з CDN, а не напряму з вашими Origin-серверами.
- Навчити користувачів скидати DNS-кеш на своїх пристроях (хоча це не завжди практично).
Чи варто використовувати мультихмарну стратегію для GLB?
Мультихмарна стратегія (розміщення додатку в декількох різних хмарах) може підвищити відмовостійкість, захистивши від збоїв цілого хмарного провайдера. Однак вона значно збільшує складність, вартість і операційне навантаження. Для більшості SaaS-проектів достатньо мультирегіонального розгортання в одній хмарі. Мультихмару варто розглядати тільки при дуже суворих вимогах до доступності (наприклад, 5 дев'яток), жорстких регуляторних нормах або для уникнення vendor lock-in. В цьому випадку потрібні спеціалізовані мультихмарні GLB-рішення.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Висновок
Побудова відмовостійкої архітектури для SaaS-додатків з використанням глобального балансування навантаження і DNS-файловеру — це не просто набір технічних рішень, а стратегічний імператив для будь-якого бізнесу, який прагне до успіху в цифровій економіці 2026 року. Ми розглянули, як ці концепції дозволяють не тільки мінімізувати час простою і втрату даних в разі катастроф, але і значно поліпшити користувацький досвід за рахунок зниження затримок і підвищення продуктивності.
Ключові висновки, які ми можемо зробити з цього глибокого занурення, зводяться до кількох фундаментальних принципів:
- Планування — це половина успіху: Починайте проектування з урахуванням мультирегіональності, продумуючи не тільки мережевий рівень, але і стратегії роботи з даними, сесіями та кешами.
- Глибокі Health Checks рятують життя: Не покладайтеся на поверхневі перевірки. Переконайтеся, що ваш GLB бачить реальний стан додатку і його залежностей.
- Дані — ваш головний актив: Виберіть і налаштуйте стратегію реплікації даних, яка відповідає вашим RPO-вимогам, пам'ятаючи про баланс між консистентністю і продуктивністю.
- Тестування — ваша страховка: Регулярні навчання з аварійного відновлення та автоматизовані тести файловеру — єдиний спосіб переконатися, що ваша система працює так, як задумано.
- Оптимізація витрат — постійний процес: Мультирегіональність дорога, але правильний вибір архітектури, режиму резервування та мінімізація міжрегіонального трафіку допоможуть утримати бюджет в розумних рамках.
- Інструменти прискорюють роботу: Використовуйте IaC для автоматизації, потужні системи моніторингу для контролю та спеціалізовані інструменти для діагностики.
Світ SaaS постійно змінюється, і вимоги до доступності будуть тільки рости. Інвестиції в надійну архітектуру сьогодні окупляться сторицею, захищаючи вашу репутацію, лояльність клієнтів і, в кінцевому підсумку, ваш дохід. Нехай ці знання стануть вашим компасом у створенні архітектури, яка не просто виживає, але й процвітає в умовах будь-яких викликів.
Наступні кроки для читача:
- Проведіть аудит поточної архітектури: Оцініть її вразливості та відповідність вимогам RTO/RPO.
- Виберіть стратегію: Визначте, який підхід до GLB і реплікації даних найкраще підходить для вашого SaaS.
- Почніть з малого: Якщо ви тільки починаєте, розгляньте Active-Passive у двох регіонах як відправну точку, поступово ускладнюючи архітектуру.
- Автоматизуйте: Переведіть всі налаштування GLB, DNS та інфраструктури в Infrastructure as Code.
- Практикуйтеся: Заплануйте і проведіть свої перші навчання з аварійного відновлення.
- Моніторьте та оптимізуйте: Постійно відстежуйте продуктивність, доступність і витрати, вносите корективи.
Успіхів у побудові вашої глобально розподіленої та відмовостійкої SaaS-платформи!