Установка и настройка LiteLLM Proxy на VPS: единый API интерфейс для управления всеми вашими LLM
TL;DR
В данном руководстве мы разберем процесс развертывания LiteLLM Proxy на виртуальном сервере — мощного инструмента, который объединяет десятки различных провайдеров искусственного интеллекта (OpenAI, Anthropic, Google, Azure, Ollama) в один унифицированный API-интерфейс, полностью совместимый с форматом OpenAI. Это позволяет разработчикам и компаниям централизованно управлять ключами, лимитами, логированием и отказоустойчивостью своих ИИ-сервисов.
- Унификация: Один эндпоинт для всех моделей (GPT-4, Claude 3.5, Gemini, Llama 3).
- Экономия: Встроенное кэширование запросов через Redis и детальный мониторинг затрат.
- Надежность: Автоматические ретраи и переключение на резервные модели (fallback) при сбоях провайдера.
- Безопасность: Управление доступом через виртуальные ключи с лимитами по токенам и бюджету.
- Self-hosted: Полный контроль над данными и логами на вашем собственном VPS.
1. Что мы настраиваем и зачем: проблема фрагментации ИИ-сервисов
К 2026 году ландшафт больших языковых моделей (LLM) стал крайне фрагментированным. Разработчикам приходится интегрировать API от OpenAI для GPT-5, Anthropic для Claude 4, Google для Gemini 2.0, а также локальные модели через vLLM или Ollama для обеспечения приватности. Каждый провайдер имеет свои форматы запросов, методы аутентификации и системы лимитов.
LiteLLM Proxy решает эту проблему, выступая в роли интеллектуального шлюза. Он принимает запросы в стандартном формате OpenAI и "переводит" их на язык нужного провайдера. Но это не просто прокси-сервер. Это полноценная платформа управления (Governance Layer), которая позволяет:
- Создавать виртуальные ключи для разных отделов или приложений, ограничивая их бюджет (например, не более 10$ в день).
- Настраивать "умную" маршрутизацию: если OpenAI вернул ошибку 500, запрос автоматически уходит на Anthropic.
- Логировать каждый запрос и ответ в базу данных PostgreSQL для последующего анализа качества и затрат.
- Использовать семантическое кэширование, чтобы не платить дважды за идентичные вопросы пользователей.
Выбор self-hosted решения на VPS вместо использования облачных агрегаторов (типа OpenRouter) продиктован требованиями безопасности и желанием избежать дополнительной наценки на токены. Имея собственный прокси, вы платите провайдерам напрямую и полностью контролируете, куда уходят ваши данные.
2. Какой VPS-конфиг нужен под эту задачу
LiteLLM Proxy сам по себе является легковесным приложением на Python, но его требования растут в зависимости от объема трафика, использования базы данных для логов и кэширования в Redis.
| Компонент | Минимальные (1-5 польз.) | Рекомендуемые (Production) |
|---|---|---|
| CPU | 1 Core (Shared) | 2-4 Cores (Dedicated) |
| RAM | 2 GB | 4-8 GB |
| Disk | 20 GB SSD | 50 GB NVMe (для логов БД) |
| OS | Ubuntu 24.04 LTS | Ubuntu 24.04 / 26.04 LTS |
Для стабильной работы системы с учетом базы данных PostgreSQL и кэша Redis, оптимальным выбором будет подходящий VPS с 4 ГБ оперативной памяти. Это обеспечит достаточный запас для обработки параллельных запросов без задержек.
Когда нужен Dedicated сервер? Если вы планируете запускать локальные модели (например, Llama 3 70B) прямо на этом же сервере через Ollama. В этом случае вам потребуются мощности с GPU (NVIDIA A100/H100) или огромный объем RAM для CPU-инференса. Для самого же прокси-слоя обычного VPS более чем достаточно.
Локация: Выбирайте дата-центр, максимально близкий к вашим основным серверам приложений или к эндпоинтам провайдеров (обычно это США или Европа), чтобы минимизировать сетевые задержки (TTFT — Time To First Token).
3. Подготовка сервера: безопасность и базовое ПО
Прежде чем устанавливать LiteLLM, необходимо подготовить среду. Безопасность критична, так как через этот сервер будут проходить ваши API-ключи от платных сервисов.
Обновим пакеты и установим базовые утилиты:
sudo apt update && sudo apt upgrade -y
sudo apt install -y curl git wget build-essential software-properties-common
Создадим отдельного пользователя для запуска сервисов, чтобы не использовать root:
sudo adduser litellm-admin
sudo usermod -aG sudo litellm-admin
# Переключаемся на нового пользователя
su - litellm-admin
Настроим базовый фаервол UFW. Нам понадобятся порты 22 (SSH), 80 (HTTP) и 443 (HTTPS):
sudo ufw allow 22/tcp
sudo ufw allow 80/tcp
sudo ufw allow 443/tcp
sudo ufw enable
Для защиты от брутфорса SSH установим fail2ban:
sudo apt install -y fail2ban
sudo systemctl enable fail2ban
sudo systemctl start fail2ban
4. Установка Docker и необходимых компонентов
В 2026 году самым надежным способом развертывания LiteLLM Proxy остается Docker. Это изолирует зависимости Python и упрощает обновление.
Устанавливаем Docker Engine и Docker Compose:
# Добавляем официальный GPG ключ Docker
sudo install -m 0755 -d /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
sudo chmod a+r /etc/apt/keyrings/docker.gpg
# Добавляем репозиторий
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu $(. /etc/os-release && echo "$VERSION_CODENAME") stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt update
sudo apt install -y docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
# Добавляем пользователя в группу docker
sudo usermod -aG docker $USER
# Примените изменения групп без перезагрузки
newgrp docker
Проверим установку:
docker --version && docker compose version
5. Пошаговая установка LiteLLM Proxy
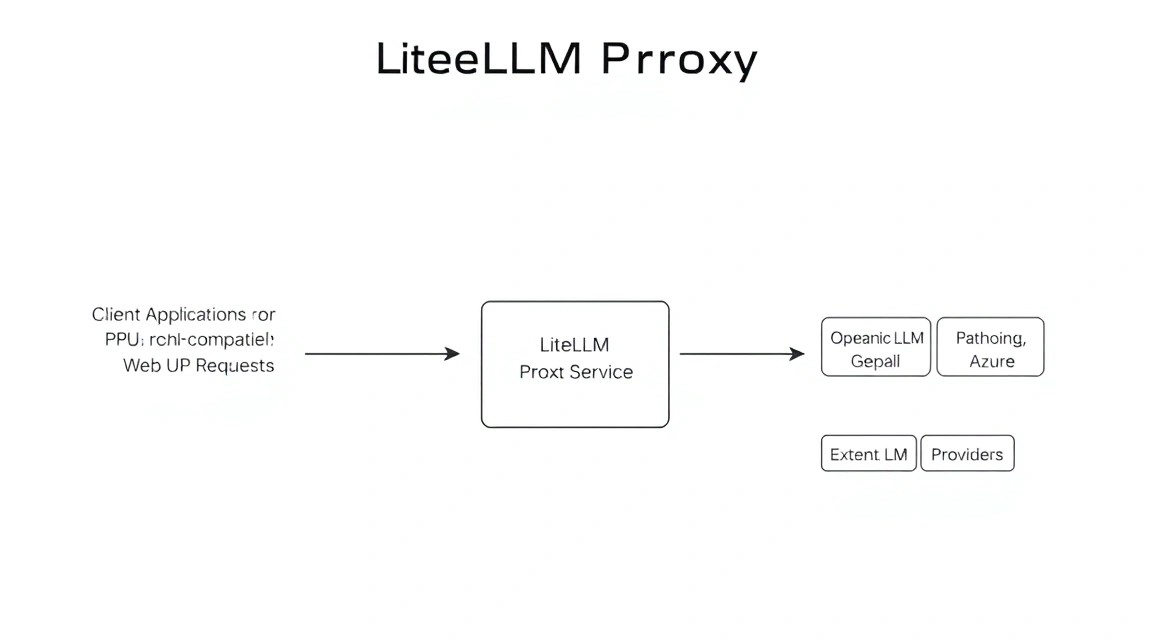
Мы будем использовать связку из трех контейнеров: сам LiteLLM, PostgreSQL (для хранения ключей и логов) и Redis (для кэширования запросов и rate limiting).
Создадим рабочую директорию:
mkdir ~/litellm-stack && cd ~/litellm-stack
Создадим файл docker-compose.yaml. Этот конфиг актуален для версий 2026 года и включает автоматический перезапуск и проверку здоровья контейнеров:
cat < docker-compose.yaml
services:
db:
image: postgres:16-alpine
volumes:
- ./postgres_data:/var/lib/postgresql/data
environment:
POSTGRES_DB: litellm
POSTGRES_USER: litellm_user
POSTGRES_PASSWORD: your_strong_password
healthcheck:
test: ["CMD-SHELL", "pg_isready -U litellm_user -d litellm"]
interval: 5s
timeout: 5s
retries: 5
redis:
image: redis:7-alpine
command: redis-server --appendonly yes
volumes:
- ./redis_data:/data
healthcheck:
test: ["CMD", "redis-cli", "ping"]
interval: 5s
timeout: 5s
retries: 5
litellm:
image: ghcr.io/berriai/litellm:main-latest
ports:
- "4000:4000"
volumes:
- ./config.yaml:/app/config.yaml
environment:
- DATABASE_URL=postgresql://litellm_user:your_strong_password@db:5432/litellm
- REDIS_HOST=redis
- REDIS_PORT=6379
- LITELLM_MASTER_KEY=sk-master-key-2026-very-secret
- UI_USERNAME=admin
- UI_PASSWORD=admin-password-change-me
depends_on:
db:
condition: service_healthy
redis:
condition: service_healthy
command: ["--config", "/app/config.yaml", "--port", "4000", "--detailed_debug"]
EOF
Примечание: Обязательно заменитеyour_strong_passwordиLITELLM_MASTER_KEYна свои уникальные значения. Мастер-ключ будет использоваться для первичного доступа к админ-панели и создания виртуальных ключей.
6. Глубокая настройка: модели, секреты и маршрутизация
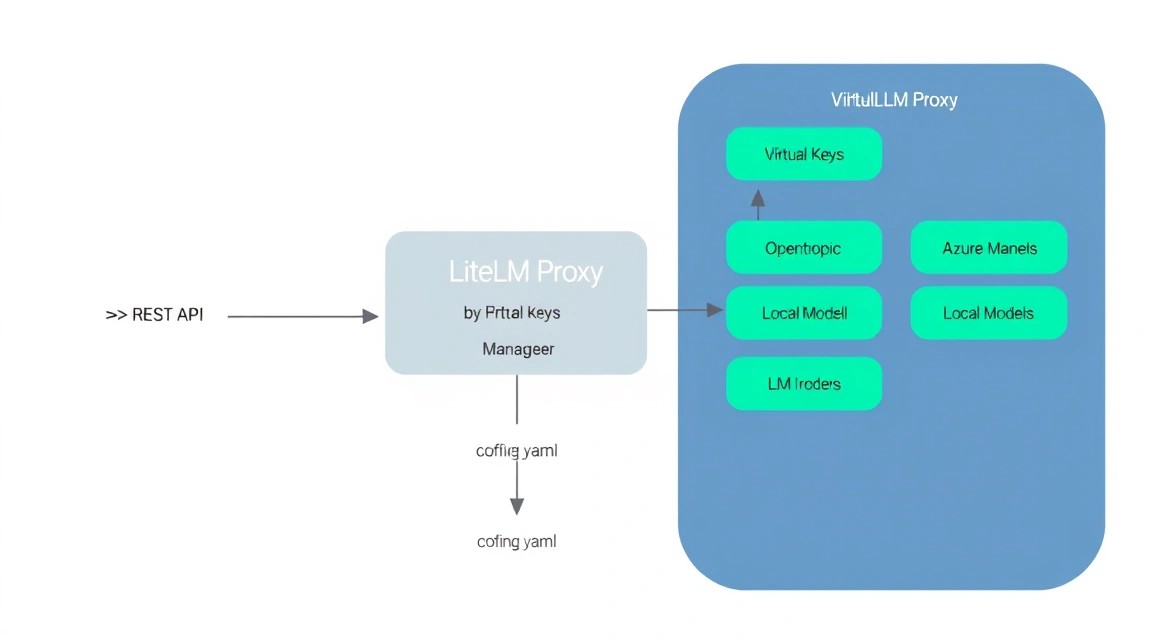
Сердце LiteLLM — это файл config.yaml. Здесь мы определяем список моделей и правила их работы.
Создадим пример конфигурации:
cat < config.yaml
model_list:
- model_name: gpt-4
litellm_params:
model: openai/gpt-4-turbo
api_key: "os.environ/OPENAI_API_KEY"
- model_name: claude-3-5
litellm_params:
model: anthropic/claude-3-5-sonnet-20240620
api_key: "os.environ/ANTHROPIC_API_KEY"
- model_name: global-llm
model_info:
base_model: gpt-4
litellm_params:
model: openai/gpt-4
api_key: "os.environ/OPENAI_API_KEY"
tpm: 10000
rpm: 500
- model_name: global-llm
model_info:
base_model: claude-3-5
litellm_params:
model: anthropic/claude-3-5-sonnet
api_key: "os.environ/ANTHROPIC_API_KEY"
router_settings:
routing_strategy: usage-based-routing-v2
enable_pre_call_checks: true
litellm_settings:
drop_params: true
set_verbose: false
cache: true
cache_type: redis
success_callback: ["database"]
failure_callback: ["database"]
EOF
В данном примере мы настроили:
- Прямые модели: Обращение к конкретным GPT-4 или Claude.
- Группу моделей (Load Balancing): При запросе к
global-llm, прокси сам выберет менее загруженную модель или переключится на альтернативу при сбое. - Redis Caching: Повторные запросы не будут отправляться провайдеру, экономя деньги.
- Database Logging: Все успешные и неудачные вызовы сохраняются в PostgreSQL.
Для передачи API-ключей создадим файл .env:
cat < .env
OPENAI_API_KEY=sk-proj-xxxx...
ANTHROPIC_API_KEY=sk-ant-xxxx...
EOF
Теперь обновим docker-compose.yaml, чтобы он подхватывал переменные окружения из .env (добавьте секцию env_file: .env в сервис litellm).
Запускаем стек:
docker compose up -d
7. Настройка HTTPS через Caddy для защиты API
Открывать порт 4000 напрямую в интернет небезопасно. Нам нужен обратный прокси с автоматическим получением SSL-сертификатов. Caddy — идеальный выбор для 2026 года благодаря простоте настройки.
sudo apt install -y debian-keyring debian-archive-keyring apt-transport-https
curl -1sLf 'https://dl.cloudsmith.io/public/caddy/stable/gpg.key' | sudo gpg --dearmor -o /usr/share/keyrings/caddy-stable-archive-keyring.gpg
curl -1sLf 'https://dl.cloudsmith.io/public/caddy/stable/debian.deb.txt' | sudo tee /etc/apt/sources.list.d/caddy-stable.list
sudo apt update
sudo apt install caddy
Настроим Caddyfile (замените api.yourdomain.com на ваш реальный домен, направленный на IP сервера):
sudo nano /etc/caddy/Caddyfile
Содержимое файла:
api.yourdomain.com {
reverse_proxy localhost:4000
header {
# Базовая защита
Strict-Transport-Security "max-age=31536000;"
X-Content-Type-Options nosniff
X-Frame-Options DENY
Referrer-Policy no-referrer-when-downgrade
}
}
Перезапустим Caddy:
sudo systemctl restart caddy
8. Бэкапы, мониторинг и обслуживание
Ваш прокси теперь хранит критические данные: виртуальные ключи пользователей и историю затрат. Потеря базы данных PostgreSQL будет болезненной.
Автоматизация бэкапов
Создадим простой скрипт для ежедневного дампа базы в S3-совместимое хранилище или на другой сервер:
#!/bin/bash
# backup-db.sh
BACKUP_DIR="/home/litellm-admin/backups"
TIMESTAMP=$(date +"%Y%m%d_%H%M%S")
mkdir -p $BACKUP_DIR
docker exec litellm-stack-db-1 pg_dump -U litellm_user litellm > $BACKUP_DIR/litellm_backup_$TIMESTAMP.sql
# Удаляем бэкапы старше 30 дней
find $BACKUP_DIR -type f -mtime +30 -name ".sql" -delete
Добавьте его в cron (crontab -e):
0 3 /bin/bash /home/litellm-admin/backup-db.shОбновление LiteLLM
Разработчики LiteLLM выпускают обновления почти ежедневно. Чтобы обновиться без потери данных:
cd ~/litellm-stack
docker compose pull
docker compose up -d
Мониторинг
LiteLLM предоставляет встроенный дашборд. После установки он доступен по адресу https://api.yourdomain.com/ui. Используйте логин и пароль, указанные в docker-compose.yaml. Там вы увидите графики использования, активные ключи и ошибки провайдеров в реальном времени.
9. Troubleshooting + FAQ
1. Ошибка "Connection refused" при попытке доступа к API?
Проверьте, запущены ли контейнеры: docker compose ps. Если контейнер litellm постоянно перезагружается, посмотрите логи: docker compose logs litellm. Чаще всего проблема в неправильном формате config.yaml или отсутствующем DATABASE_URL.
2. Как добавить новую модель без перезагрузки всего стека?
LiteLLM поддерживает горячую перезагрузку конфигурации. Отредактируйте config.yaml и отправьте сигнал SIGHUP контейнеру или просто выполните docker compose up -d — Docker перезапустит только изменившийся сервис с минимальным простоем.
3. Какой VPS-конфиг минимально подойдёт для личного использования?
Для одного пользователя достаточно 1 vCPU и 2 ГБ RAM. Однако, если вы включите подробное логирование в PostgreSQL и начнете активно использовать UI-панель, система может начать "свопиться". 4 ГБ — это "золотой стандарт" для комфортной работы.
4. Что выбрать — VPS или dedicated для этой задачи?
В 95% случаев VPS — лучший выбор. Dedicated сервер нужен только в двух сценариях: 1) У вас огромный трафик (миллионы запросов в день), требующий гарантированных ресурсов CPU. 2) Вы хотите запускать open-source модели локально (Llama, Mistral) на этом же железе.
5. Как ограничить бюджет для конкретного API-ключа?
Это делается через Admin UI или API. При создании ключа вы можете указать параметр max_budget и budget_duration (например, 50$ в месяц). LiteLLM автоматически заблокирует ключ при достижении лимита.
6. Поддерживает ли LiteLLM потоковую передачу (streaming)?
Да, LiteLLM полностью поддерживает stream: true. Это критично для чат-ботов, чтобы пользователь видел текст по мере его генерации. Прокси корректно пробрасывает чанки данных от провайдера к клиенту.
10. Выводы и следующие шаги
Мы развернули отказоустойчивый, масштабируемый и безопасный шлюз для работы с искусственным интеллектом. Теперь у вас есть единая точка входа для всех LLM, защищенная HTTPS и контролируемая через базу данных.
Что делать дальше:
- Интеграция: Перенаправьте свои приложения (LangChain, AutoGPT или кастомные скрипты) на новый эндпоинт
https://api.yourdomain.com/v1. - Оптимизация: Настройте
fallbacksвconfig.yaml, чтобы ваши сервисы не падали, когда у OpenAI случаются технические работы. - Аналитика: Через неделю работы изучите дашборд LiteLLM, чтобы понять, какие модели обходятся вам дороже всего и где можно сэкономить, перейдя на более дешевые аналоги (например, с GPT-4 на Claude Haiku для простых задач).
Использование собственного прокси-сервера — это важный шаг к зрелой ИИ-инфраструктуре, который дает независимость от политики одного провайдера и полный контроль над расходами.