Instalación y configuración de LiteLLM Proxy en un VPS: una interfaz API única para gestionar todos sus LLM
TL;DR
En esta guía, analizaremos el proceso de despliegue de LiteLLM Proxy en un servidor virtual: una potente herramienta que une decenas de proveedores de inteligencia artificial diferentes (OpenAI, Anthropic, Google, Azure, Ollama) en una interfaz API unificada, totalmente compatible con el formato de OpenAI. Esto permite a los desarrolladores y empresas gestionar de forma centralizada las claves, los límites, el registro y la tolerancia a fallos de sus servicios de IA.
- Unificación: Un único endpoint para todos los modelos (GPT-4, Claude 3.5, Gemini, Llama 3).
- Ahorro: Caché de consultas integrada mediante Redis y monitorización detallada de costes.
- Fiabilidad: Reintentos automáticos y conmutación a modelos de reserva (fallback) en caso de fallos del proveedor.
- Seguridad: Gestión de acceso mediante claves virtuales con límites de tokens y presupuesto.
- Self-hosted: Control total sobre los datos y registros en su propio VPS.
1. Qué estamos configurando y por qué: el problema de la fragmentación de los servicios de IA
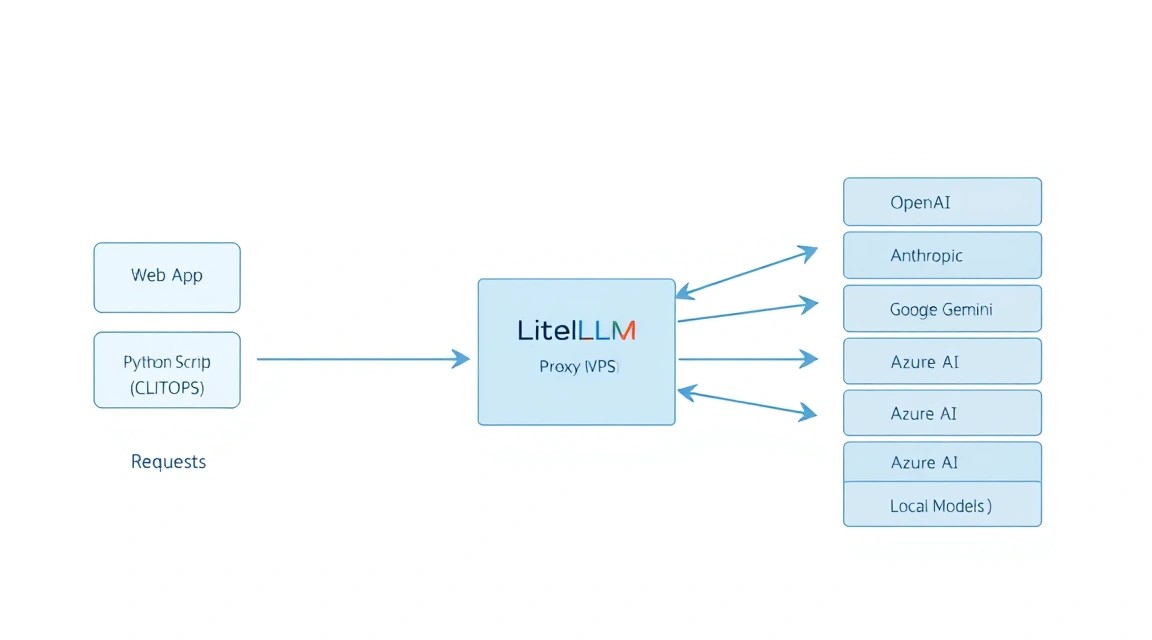
Para 2026, el panorama de los grandes modelos de lenguaje (LLM) se ha vuelto extremadamente fragmentado. Los desarrolladores tienen que integrar APIs de OpenAI para GPT-5, Anthropic para Claude 4, Google para Gemini 2.0, así como modelos locales a través de vLLM u Ollama para garantizar la privacidad. Cada proveedor tiene sus propios formatos de solicitud, métodos de autenticación y sistemas de límites.
LiteLLM Proxy resuelve este problema actuando como una pasarela inteligente. Acepta solicitudes en el formato estándar de OpenAI y las "traduce" al lenguaje del proveedor correspondiente. Pero no es solo un servidor proxy. Es una plataforma de gestión completa (Governance Layer) que permite:
- Crear claves virtuales para diferentes departamentos o aplicaciones, limitando su presupuesto (por ejemplo, no más de 10$ al día).
- Configurar un enrutamiento "inteligente": si OpenAI devuelve un error 500, la solicitud se dirige automáticamente a Anthropic.
- Registrar cada solicitud y respuesta en una base de datos PostgreSQL para el análisis posterior de calidad y costes.
- Utilizar caché semántica para no pagar dos veces por preguntas idénticas de los usuarios.
La elección de una solución self-hosted en un VPS en lugar de utilizar agregadores en la nube (como OpenRouter) está dictada por los requisitos de seguridad y el deseo de evitar recargos adicionales en los tokens. Al tener su propio proxy, usted paga directamente a los proveedores y controla totalmente a dónde van sus datos.
2. Qué configuración de VPS se necesita para esta tarea
LiteLLM Proxy es en sí misma una aplicación ligera en Python, pero sus requisitos crecen en función del volumen de tráfico, el uso de la base de datos para registros y el almacenamiento en caché en Redis.
| Componente | Mínimos (1-5 usuarios) | Recomendados (Production) |
|---|---|---|
| CPU | 1 Core (Shared) | 2-4 Cores (Dedicated) |
| RAM | 2 GB | 4-8 GB |
| Disk | 20 GB SSD | 50 GB NVMe (para registros de BD) |
| OS | Ubuntu 24.04 LTS | Ubuntu 24.04 / 26.04 LTS |
Para un funcionamiento estable del sistema, teniendo en cuenta la base de datos PostgreSQL y la caché de Redis, la opción óptima será un VPS adecuado con 4 GB de memoria RAM. Esto proporcionará un margen suficiente para procesar solicitudes paralelas sin retardos.
¿Cuándo se necesita un servidor dedicado? Si planea ejecutar modelos locales (por ejemplo, Llama 3 70B) directamente en el mismo servidor a través de Ollama. En este caso, necesitará potencia con GPU (NVIDIA A100/H100) o una gran cantidad de RAM para la inferencia por CPU. Para la capa de proxy en sí, un VPS convencional es más que suficiente.
Ubicación: Elija un centro de datos lo más cercano posible a sus servidores de aplicaciones principales o a los endpoints de los proveedores (generalmente en EE. UU. o Europa) para minimizar la latencia de red (TTFT — Time To First Token).
3. Preparación del servidor: seguridad y software básico
Antes de instalar LiteLLM, es necesario preparar el entorno. La seguridad es crítica, ya que a través de este servidor pasarán sus claves API de servicios de pago.
Actualizaremos los paquetes e instalaremos las utilidades básicas:
sudo apt update && sudo apt upgrade -y
sudo apt install -y curl git wget build-essential software-properties-common
Crearemos un usuario independiente para ejecutar los servicios, para no utilizar root:
sudo adduser litellm-admin
sudo usermod -aG sudo litellm-admin
# Cambiamos al nuevo usuario
su - litellm-admin
Configuraremos el firewall básico UFW. Necesitaremos los puertos 22 (SSH), 80 (HTTP) y 443 (HTTPS):
sudo ufw allow 22/tcp
sudo ufw allow 80/tcp
sudo ufw allow 443/tcp
sudo ufw enable
Para protegerse contra ataques de fuerza bruta en SSH, instalaremos fail2ban:
sudo apt install -y fail2ban
sudo systemctl enable fail2ban
sudo systemctl start fail2ban
4. Instalación de Docker y componentes necesarios
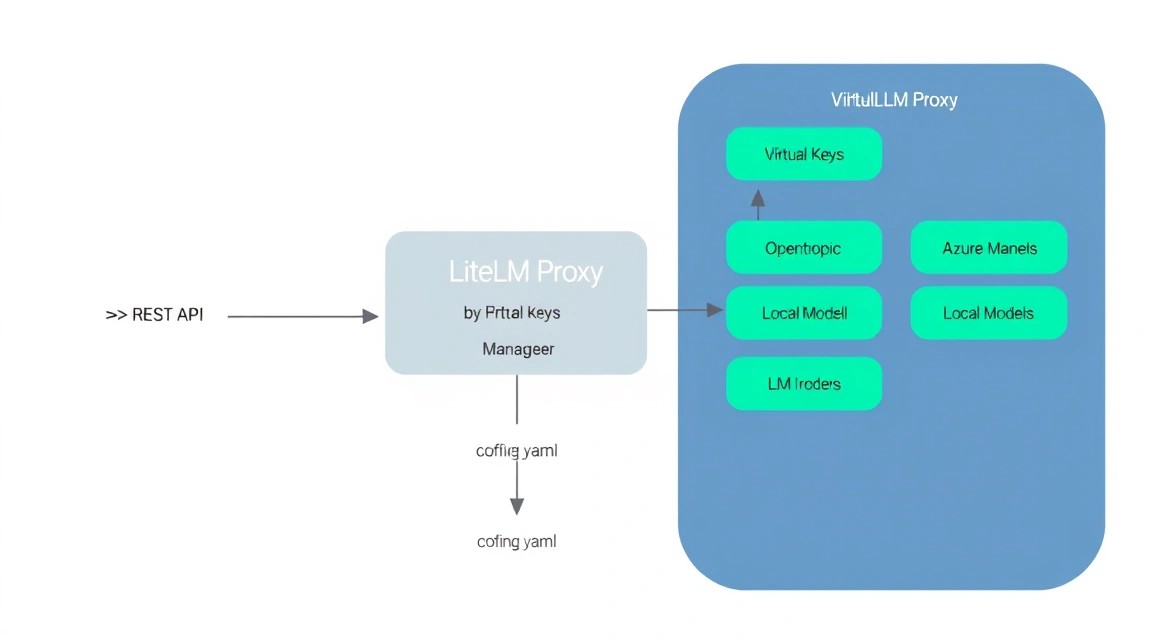
El corazón de LiteLLM es el archivo config.yaml. Aquí definimos la lista de modelos y sus reglas de funcionamiento.
Creemos un ejemplo de configuración:
cat < config.yaml
model_list:
- model_name: gpt-4
litellm_params:
model: openai/gpt-4-turbo
api_key: "os.environ/OPENAI_API_KEY"
- model_name: claude-3-5
litellm_params:
model: anthropic/claude-3-5-sonnet-20240620
api_key: "os.environ/ANTHROPIC_API_KEY"
- model_name: global-llm
model_info:
base_model: gpt-4
litellm_params:
model: openai/gpt-4
api_key: "os.environ/OPENAI_API_KEY"
tpm: 10000
rpm: 500
- model_name: global-llm
model_info:
base_model: claude-3-5
litellm_params:
model: anthropic/claude-3-5-sonnet
api_key: "os.environ/ANTHROPIC_API_KEY"
router_settings:
routing_strategy: usage-based-routing-v2
enable_pre_call_checks: true
litellm_settings:
drop_params: true
set_verbose: false
cache: true
cache_type: redis
success_callback: ["database"]
failure_callback: ["database"]
EOF
En este ejemplo, hemos configurado:
- Modelos directos: Acceso a GPT-4 o Claude específicos.
- Grupo de modelos (Load Balancing): Al solicitar
global-llm, el proxy seleccionará automáticamente el modelo menos cargado o cambiará a una alternativa en caso de fallo. - Redis Caching: Las solicitudes repetidas no se enviarán al proveedor, ahorrando dinero.
- Database Logging: Todas las llamadas exitosas y fallidas se guardan en PostgreSQL.
Para pasar las claves API, crearemos un archivo .env:
cat < .env
OPENAI_API_KEY=sk-proj-xxxx...
ANTHROPIC_API_KEY=sk-ant-xxxx...
EOF
Ahora actualizaremos docker-compose.yaml para que tome las variables de entorno del .env (añada la sección env_file: .env al servicio litellm).
Iniciamos el stack:
docker compose up -d
7. Configuración de HTTPS a través de Caddy para proteger la API
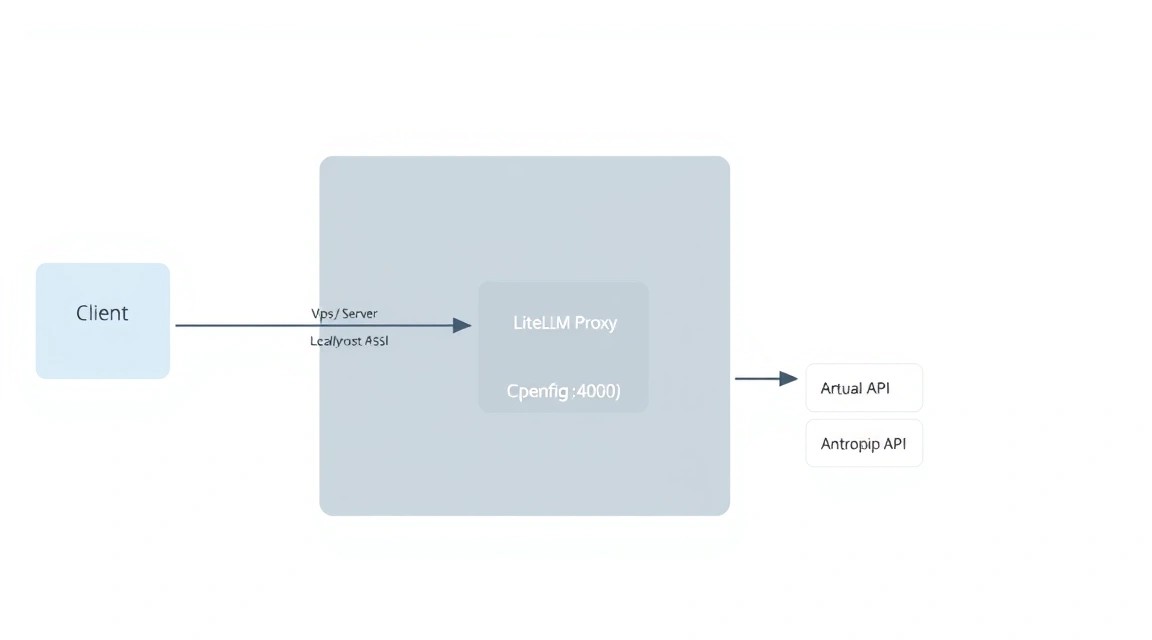
Abrir el puerto 4000 directamente a Internet no es seguro. Necesitamos un proxy inverso con obtención automática de certificados SSL. Caddy es la elección ideal para 2026 gracias a su sencillez de configuración.
sudo apt install -y debian-keyring debian-archive-keyring apt-transport-https
curl -1sLf 'https://dl.cloudsmith.io/public/caddy/stable/gpg.key' | sudo gpg --dearmor -o /usr/share/keyrings/caddy-stable-archive-keyring.gpg
curl -1sLf 'https://dl.cloudsmith.io/public/caddy/stable/debian.deb.txt' | sudo tee /etc/apt/sources.list.d/caddy-stable.list
sudo apt update
sudo apt install caddy
Configuraremos el Caddyfile (reemplace api.yourdomain.com con su dominio real, apuntando a la IP del servidor):
sudo nano /etc/caddy/Caddyfile
Contenido del archivo:
api.yourdomain.com {
reverse_proxy localhost:4000
header {
# Protección básica
Strict-Transport-Security "max-age=31536000;"
X-Content-Type-Options nosniff
X-Frame-Options DENY
Referrer-Policy no-referrer-when-downgrade
}
}
Reiniciamos Caddy:
sudo systemctl restart caddy
8. Backups, monitoreo y mantenimiento
Su proxy ahora almacena datos críticos: claves virtuales de usuarios e historial de costes. La pérdida de la base de datos PostgreSQL sería dolorosa.
Automatización de backups
Crearemos un script sencillo para el volcado diario de la base de datos a un almacenamiento compatible con S3 o a otro servidor:
#!/bin/bash
# backup-db.sh
BACKUP_DIR="/home/litellm-admin/backups"
TIMESTAMP=$(date +"%Y%m%d_%H%M%S")
mkdir -p $BACKUP_DIR
docker exec litellm-stack-db-1 pg_dump -U litellm_user litellm > $BACKUP_DIR/litellm_backup_$TIMESTAMP.sql
# Eliminamos los backups con más de 30 días
find $BACKUP_DIR -type f -mtime +30 -name "*.sql" -delete
Añádalo al cron (crontab -e):
0 3 * * * /bin/bash /home/litellm-admin/backup-db.shActualización de LiteLLM
Los desarrolladores de LiteLLM lanzan actualizaciones casi a diario. Para actualizar sin perder datos:
cd ~/litellm-stack
docker compose pull
docker compose up -d
Monitoreo
LiteLLM proporciona un panel de control integrado. Tras la instalación, está disponible en https://api.yourdomain.com/ui. Utilice el usuario y la contraseña especificados en docker-compose.yaml. Allí verá gráficos de uso, claves activas y errores de los proveedores en tiempo real.
9. Solución de problemas + FAQ
1. ¿Error "Connection refused" al intentar acceder a la API?
Compruebe si los contenedores se están ejecutando: docker compose ps. Si el contenedor litellm se reinicia constantemente, consulte los logs: docker compose logs litellm. Lo más común es que el problema sea un formato incorrecto en config.yaml o la falta de DATABASE_URL.
2. ¿Cómo añadir un nuevo modelo sin reiniciar todo el stack?
LiteLLM admite la recarga en caliente de la configuración. Edite config.yaml y envíe una señal SIGHUP al contenedor o simplemente ejecute docker compose up -d; Docker reiniciará solo el servicio modificado con un tiempo de inactividad mínimo.
3. ¿Qué configuración de VPS es la mínima adecuada para uso personal?
Para un solo usuario, 1 vCPU y 2 GB de RAM son suficientes. Sin embargo, si activa el registro detallado en PostgreSQL y comienza a usar activamente el panel UI, el sistema podría empezar a usar "swap". 4 GB es el "estándar de oro" para un funcionamiento fluido.
4. ¿Qué elegir: VPS o dedicado para esta tarea?
En el 95% de los casos, un VPS es la mejor opción. Un servidor dedicado solo es necesario en dos escenarios: 1) Tiene un tráfico enorme (millones de solicitudes al día) que requiere recursos de CPU garantizados. 2) Desea ejecutar modelos de código abierto localmente (Llama, Mistral) en el mismo hardware.
5. ¿Cómo limitar el presupuesto para una clave API específica?
Esto se hace a través de la Admin UI o la API. Al crear una clave, puede especificar los parámetros max_budget y budget_duration (por ejemplo, 50$ al mes). LiteLLM bloqueará automáticamente la clave al alcanzar el límite.
6. ¿Admite LiteLLM la transmisión por secuencias (streaming)?
Sí, LiteLLM admite totalmente stream: true. Esto es fundamental para los chatbots, para que el usuario vea el texto a medida que se genera. El proxy reenvía correctamente los fragmentos (chunks) de datos del proveedor al cliente.
10. Conclusiones y próximos pasos
Hemos desplegado una pasarela tolerante a fallos, escalable y segura para trabajar con inteligencia artificial. Ahora dispone de un punto de entrada único para todos los LLM, protegido por HTTPS y controlado a través de una base de datos.
Qué hacer a continuación:
- Integración: Redirija sus aplicaciones (LangChain, AutoGPT o scripts personalizados) al nuevo endpoint
https://api.yourdomain.com/v1. - Optimización: Configure
fallbacksenconfig.yamlpara que sus servicios no fallen cuando OpenAI tenga labores de mantenimiento técnico. - Analítica: Tras una semana de funcionamiento, examine el panel de LiteLLM para entender qué modelos le resultan más costosos y dónde puede ahorrar cambiando a alternativas más económicas (por ejemplo, de GPT-4 a Claude Haiku para tareas sencillas).
El uso de un servidor proxy propio es un paso importante hacia una infraestructura de IA madura, que proporciona independencia de las políticas de un único proveedor y un control total sobre los gastos.