
Оптимізація мережевого стеку Linux для високонавантажених застосунків: від ядра до eBPF
TL;DR
- Комплексний підхід: Оптимізація мережевого стеку для високонавантажених систем вимагає уваги до всіх рівнів – від драйверів мережевих карт (NIC) і параметрів ядра до просторів користувачів і просунутих технологій, таких як eBPF.
- Вимірювання – ключ до успіху: Перед внесенням будь-яких змін необхідно встановити базові метрики продуктивності та постійно моніторити вплив оптимізацій, використовуючи такі інструменти, як
iperf3,netstat,ss,perfіbcc-tools. - Тонке налаштування ядра: Параметри
sysctl(наприклад,net.core.somaxconn,net.ipv4.tcp_tw_reuse,net.ipv4.tcp_rmem/wmem) критично важливі для керування з'єднаннями, буферами і поведінкою TCP, але вимагають обережного підходу. - Використання можливостей NIC: Сучасні мережеві карти пропонують апаратні розвантаження (TSO, GSO, GRO, RSS, LRO), які значно знижують навантаження на CPU, і їх активація через
ethtoolє першим кроком до підвищення продуктивності. - eBPF як революційний інструмент: Extended Berkeley Packet Filter (eBPF) дозволяє програмувати мережевий стек на рівні ядра без його перекомпіляції, надаючи безпрецедентні можливості для фільтрації пакетів (XDP), балансування навантаження, моніторингу і створення кастомних мережевих функцій з мінімальними накладними витратами.
- Важливість стратегії TCP-перевантаження: Вибір алгоритму керування перевантаженням TCP (BBR, CUBIC) може суттєво впливати на пропускну здатність і затримку, особливо в мережах з високою затримкою або втратами.
- Ітеративний підхід і тестування: Застосовуйте зміни поступово, тестуйте їх під реальним навантаженням і будьте готові до відкату. Неправильна оптимізація може призвести до нестабільності або зниження продуктивності.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Вступ
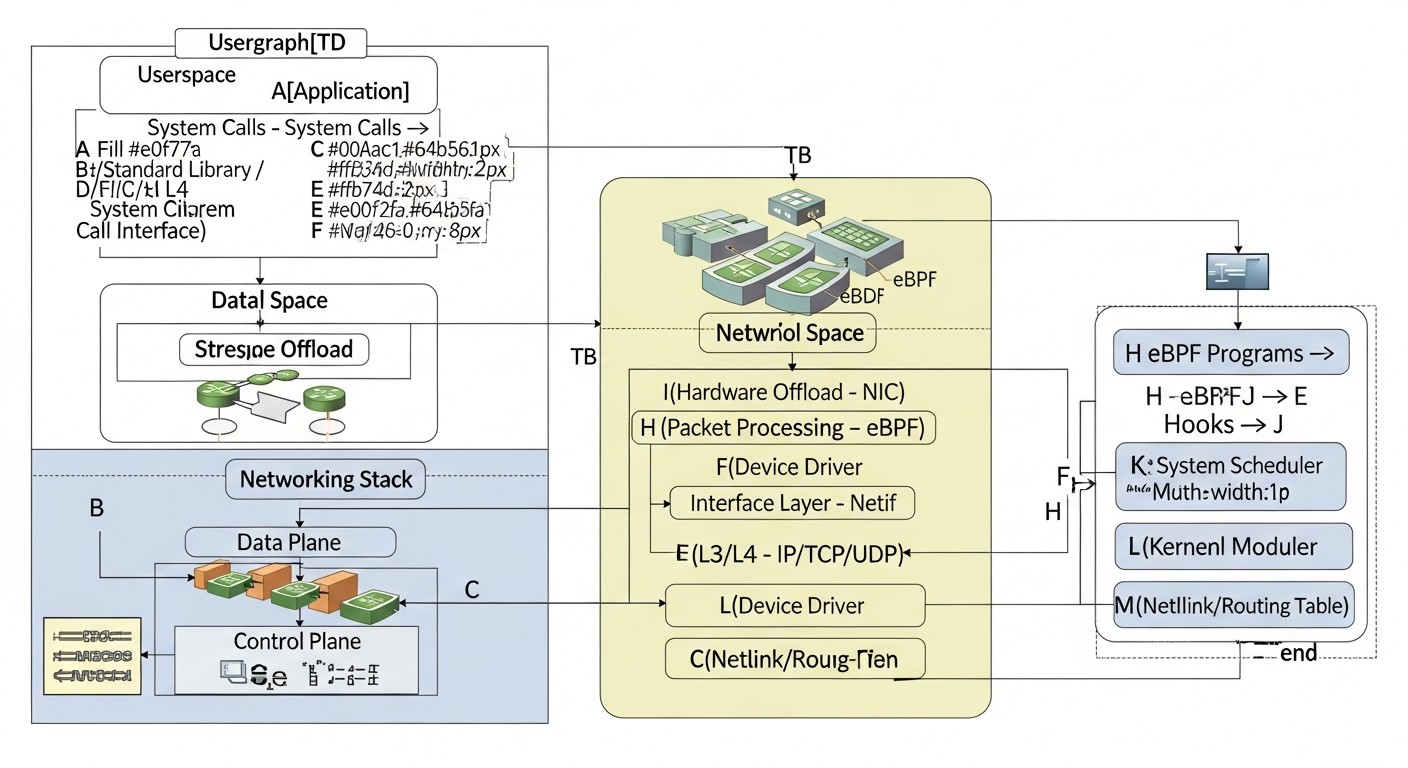
У світі 2026 року, що стрімко розвивається, де домінують хмарні технології, мікросервісна архітектура, штучний інтелект, машинне навчання та повсюдний IoT, продуктивність мережевого стеку Linux стає не просто важливим аспектом, а критичним фактором успіху для будь-якого високонавантаженого застосунку. Відгук API-шлюзів, швидкість обробки транзакцій у фінансових системах, плавність потокової передачі даних у реальному часі, ефективність роботи баз даних і розподілених систем — все це безпосередньо залежить від того, наскільки ефективно Linux справляється з мережевим трафіком. Стандартні налаштування ядра, розроблені для широкого спектра завдань, часто не здатні забезпечити оптимальну продуктивність в умовах екстремальних навантажень, характерних для сучасних SaaS-проєктів, висономасштабованих бекендів та інфраструктур DevOps.
Ця стаття покликана стати вичерпним посібником для DevOps-інженерів, бекенд-розробників, фаундерів SaaS-проєктів, системних адміністраторів та технічних директорів стартапів. Ми зануримось у глибини мережевого стеку Linux, починаючи з базових параметрів ядра та апаратних можливостей мережевих карт (NIC), і закінчуючи передовими технологіями, такими як eBPF. Мета — надати не просто набір команд, а глибоке розуміння принципів роботи, конкретні приклади, практичні поради та реальні кейси, які дозволять вам приймати обґрунтовані рішення та досягати максимальної продуктивності своїх систем.
Ми розглянемо, як правильно діагностувати вузькі місця, які параметри ядра Linux можна і потрібно налаштовувати, як використовувати апаратні розвантаження мережевих карт, і як eBPF відкриває нові горизонти для динамічної, безпечної та високопродуктивної маніпуляції мережевим трафіком безпосередньо в ядрі. Відповімо на питання, пов'язані з вибором стратегій управління перевантаженнями TCP, оптимізацією буферів, масштабуванням обробки переривань та багатьом іншим. У 2026 році, коли кожна мілісекунда затримки і кожен відсоток використання CPU можуть коштувати реальних грошей або репутації, розуміння та застосування цих технік є не розкішшю, а необхідністю. Приготуйтеся до глибокого занурення у світ високопродуктивних мереж Linux.
Основні критерії та фактори оптимізації
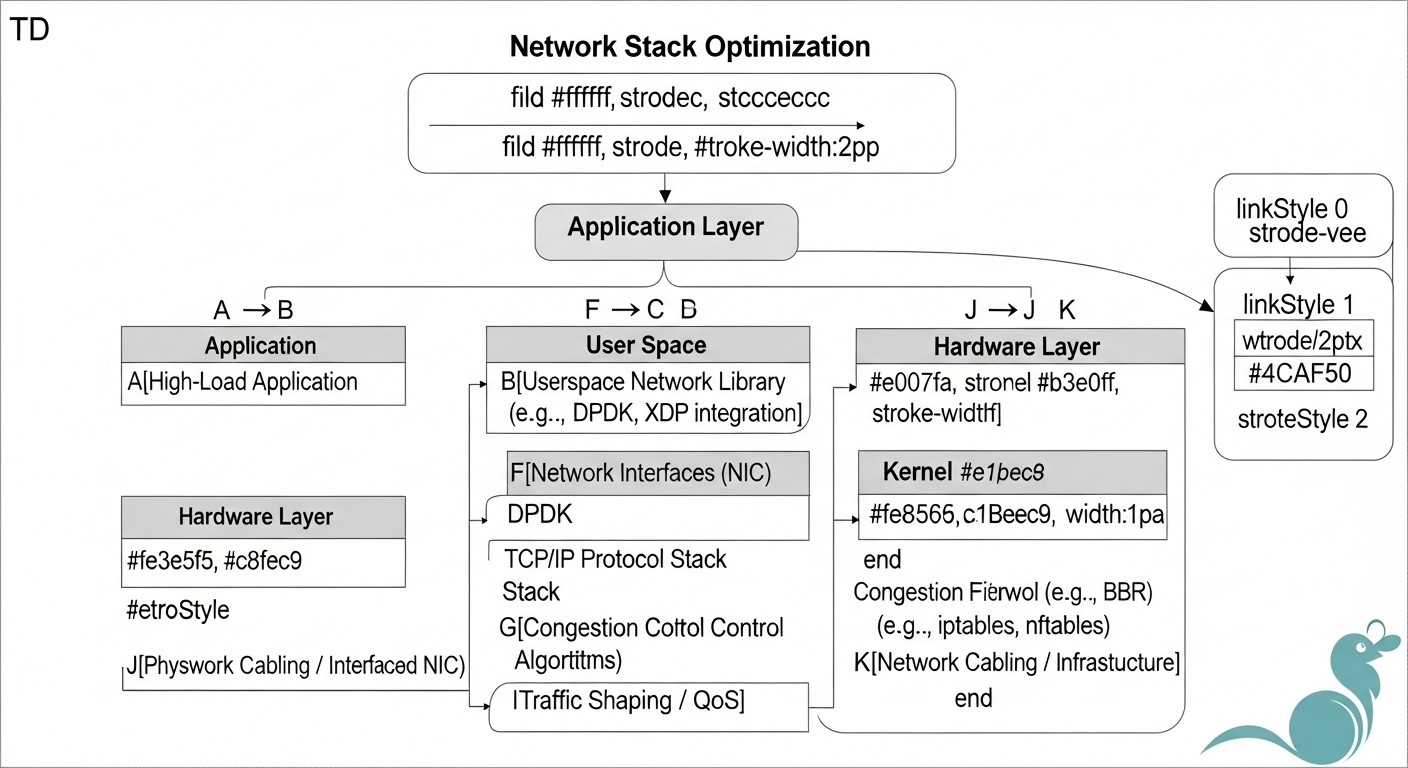
Перш ніж приступати до оптимізації, необхідно чітко розуміти, які метрики та фактори визначають продуктивність мережевого стеку і як їх оцінювати. Без цього будь-які зміни будуть випадковими і можуть принести більше шкоди, ніж користі. У 2026 році, з урахуванням експоненціального зростання обсягів даних і вимог до низької затримки, ці критерії стають ще більш актуальними.
1. Затримка (Latency)
Затримка — це час, необхідний пакету даних для проходження від відправника до одержувача і назад (Round Trip Time, RTT) або в один бік (One-Way Latency). У контексті мережевого стеку Linux, це час, який потрібен ядру для обробки вхідного пакета і відправки вихідного. Висока затримка безпосередньо впливає на чутливість застосунків, особливо для інтерактивних сервісів, ігрових платформ, фінансових транзакцій і будь-яких систем, чутливих до часу відгуку. Для SaaS-проєктів, де важливий користувацький досвід, кожна мілісекунда затримки може призводити до втрати конверсії або відтоку клієнтів. Наприклад, дослідження Google показало, що збільшення затримки на 500 мс призводить до падіння трафіку на 20%.
- Чому важлива: Впливає на UX, продуктивність розподілених систем, швидкість транзакцій.
- Як оцінювати: Інструменти
ping,traceroute,hping3, а також спеціалізовані моніторингові системи, що збирають RTT для TCP-з'єднань. Важливо вимірювати затримку не тільки до зовнішніх ресурсів, а й усередині кластера, між мікросервісами. - Оптимізація: Мінімізація обробки пакетів у ядрі, використання апаратних розвантажень, правильне налаштування буферів, XDP.
2. Пропускна здатність (Throughput)
Пропускна здатність — це обсяг даних, який може бути переданий за одиницю часу (наприклад, мегабіти в секунду, Мбіт/с або гігабіти в секунду, Гбіт/с). Це критичний фактор для застосунків, що працюють з великими обсягами даних: стримінгові сервіси, системи резервного копіювання, аналітичні платформи, бази даних. У 2026 році, з появою 400GbE і навіть 800GbE мережевих карт, здатність ядра ефективно обробляти такі потоки даних стає ключовою. Недостатня пропускна здатність може призвести до "голодування" застосунків за даними, збільшення часу обробки завдань і зниження загальної продуктивності системи.
- Чому важлива: Визначає швидкість передачі великих обсягів даних, впливає на час виконання пакетних завдань.
- Як оцінювати: Інструменти
iperf3,netperf, а також метрики мережевих інтерфейсів (rx_bytes_per_sec,tx_bytes_per_sec) з/proc/net/devабо систем моніторингу. - Оптимізація: Збільшення буферів TCP/UDP, активація Jumbo Frames, використання TSO/GSO/GRO, правильне налаштування IRQ балансування та RSS.
3. Втрати пакетів (Packet Loss)
Втрати пакетів відбуваються, коли пакети даних не досягають місця призначення. Це може бути викликано переповненням буферів, помилками в мережі, проблемами з апаратним забезпеченням або неправильною конфігурацією. Втрати пакетів катастрофічно впливають на продуктивність, оскільки призводять до повторної передачі даних (retransmissions), що збільшує затримку, знижує пропускну здатність і навантажує CPU. Для протоколів реального часу (VoIP, відеоконференції) втрати пакетів призводять до погіршення якості зв'язку. У сценаріях IoT або Edge Computing, де стабільність з'єднання критична, втрати пакетів можуть бути неприпустимі.
- Чому важлива: Призводить до повторної передачі даних, збільшує затримку, знижує пропускну здатність, навантажує CPU.
- Як оцінювати: Метрики
rx_dropped,tx_droppedз/proc/net/dev,ss -s(втрати для TCP),netstat -s,tcpdumpдля аналізу retransmissions. - Оптимізація: Збільшення буферів (
net.core.netdev_max_backlog,tcp_rmem/wmem), управління чергами (QoS), XDP для швидкого відбраковування небажаного трафіку.
4. Використання CPU (CPU Utilization)
Обробка мережевого трафіку в Linux вимагає ресурсів CPU. Це включає обробку переривань (IRQs), копіювання даних між користувацьким і ядерним простором, виконання мережевих протоколів (TCP/IP), маршрутизацію і фільтрацію. Високе навантаження на CPU, особливо в контексті ksoftirqd або kworker, часто вказує на вузькі місця в мережевому стеку. Надмірне використання CPU мережею забирає ресурси у застосунків, що знижує їх продуктивність і загальну ефективність сервера. У 2026 році, коли вартість кожного ядра CPU в хмарі продовжує зростати, ефективне використання CPU стає прямим фактором економії.
- Чому важлива: Впливає на доступність CPU для застосунків, загальну продуктивність системи.
- Як оцінювати: Інструменти
top,htop,perf,mpstatдля моніторингу використання CPU, особливо в режимахsoftirqіsi. - Оптимізація: Апаратні розвантаження NIC (TSO, GSO, GRO, RSS), RPS/RFS, XDP, eBPF для зміщення логіки з користувацького простору в ядро з мінімальними накладними витратами.
5. Використання пам'яті (Memory Usage)
Мережевий стек використовує пам'ять для буферів (сокетні буфери, буфери мережевих карт), таблиць маршрутизації, ARP-кешу та інших структур даних. Нестача пам'яті для буферів може призвести до втрат пакетів, особливо при пікових навантаженнях. Надлишкове виділення пам'яті може бути неефективним, але найчастіше проблемою є саме нестача. Для високонавантажених систем з великою кількістю одночасних з'єднань або високою пропускною здатністю, правильне налаштування буферів пам'яті критичне для запобігання втрат і підтримки стабільної продуктивності. У контейнеризованих і безсерверних середовищах 2026 року, де ресурси часто обмежені, ефективне управління пам'яттю для мережевих операцій має першорядне значення.
- Чому важлива: Нестача буферів призводить до втрат пакетів, надлишок — до неефективного використання ресурсів.
- Як оцінювати:
/proc/meminfo(Buffers,Cached), метрики сокетів (ss -m),vmstat. - Оптимізація: Налаштування
net.core.rmem_max,net.core.wmem_max,net.ipv4.tcp_rmem,net.ipv4.tcp_wmem,net.core.netdev_max_backlog.
6. Масштабованість (Scalability)
Масштабованість мережевого стека означає його здатність ефективно обробляти зростаючу кількість з'єднань, пакетів або пропускної здатності без деградації продуктивності. Це включає в себе ефективний розподіл навантаження між ядрами CPU, управління великою кількістю файлових дескрипторів і оптимізацію структур даних ядра для паралельної обробки. Для сучасних мікросервісних архітектур і розподілених систем, де кількість мережевих взаємодій може обчислюватися мільйонами в секунду, масштабованість мережевого стека є основою стабільності та чуйності всієї системи. Здатність обробляти "вибуховий" трафік і адаптуватися до змінних навантажень — це наріжний камінь надійної інфраструктури в 2026 році.
- Чому важлива: Дозволяє системі справлятися зі зростаючими навантаженнями без деградації.
- Як оцінювати: Тестування під навантаженням зі збільшенням кількості клієнтів/з'єднань, моніторинг метрик CPU, пам'яті та затримки при зростанні навантаження.
- Оптимізація: RSS/RPS/RFS,
net.core.somaxconn,net.ipv4.tcp_max_syn_backlog,net.ipv4.ip_local_port_range, eBPF для більш ефективного розподілу трафіку.
7. Джитер (Jitter)
Джитер — це варіація затримки пакетів. Навіть якщо середня затримка низька, висока варіативність може бути проблемою, особливо для застосунків реального часу (VoIP, відео, онлайн-ігри) або високочастотного трейдингу. Непередбачувані затримки можуть призводити до буферизації, пропусків кадрів або помилок синхронізації. У 2026 році, зі зростанням популярності інтерактивних і AR/VR застосунків, мінімізація джитера стає все більш критичною для забезпечення безшовного користувацького досвіду.
- Чому важлива: Впливає на якість застосунків реального часу, стабільність потоків даних.
- Як оцінювати: Спеціалізовані інструменти для вимірювання RTT з відстеженням варіацій, аналіз розподілу затримок.
- Оптимізація: Пріоритизація трафіку (QoS), мінімізація черг, стабільність обробки переривань, eBPF для більш точного управління потоками.
8. Вплив на безпеку (Security Implications)
Будь-які зміни в мережевому стеку можуть мати наслідки для безпеки. Наприклад, послаблення деяких параметрів TCP для підвищення продуктивності може зробити систему більш вразливою до SYN-флуду або інших видів атак. Активація певних функцій (наприклад, tcp_tw_reuse без належного розуміння) може призвести до небажаних наслідків. Використання eBPF, хоча і безпечне за своєю природою (програми верифікуються ядром), вимагає уважності при написанні коду, щоб уникнути логічних вразливостей або ненавмисних побічних ефектів. У 2026 році, коли загрози стають все більш витонченими, безпека повинна бути невід'ємною частиною будь-якої стратегії оптимізації.
- Чому важлива: Оптимізація не повинна призводити до створення нових вразливостей.
- Як оцінювати: Аудит змін, тестування на проникнення, аналіз векторів атак.
- Оптимізація: Уважне вивчення документації, використання перевірених практик, eBPF для реалізації фаєрволів і систем виявлення вторгнень на рівні ядра.
Порівняльна таблиця методів оптимізації
Вибір відповідного методу оптимізації мережевого стека Linux залежить від конкретних вимог програми, апаратної конфігурації і бюджету. У цій таблиці ми порівняємо ключові підходи, актуальні для 2026 року, за кількома важливими критеріями. Ціни та характеристики є орієнтовними і можуть варіюватися.
| Критерій | Тонке налаштування sysctl | Апаратні розвантаження NIC | RSS/RPS/RFS | eBPF (XDP/TC) | Userspace Networking (DPDK) | TCP Congestion Control (BBR) |
|---|---|---|---|---|---|---|
| Складність впровадження | Низька-Середня | Низька-Середня | Середня | Висока | Дуже висока | Низька |
| Потенційний приріст продуктивності (2026) | 5-20% (залежить від сценарію) | 10-30% зниження CPU навантаження | До 20% збільшення PPS | До 70% зниження CPU для L3/L4, 10-30% загальна | 100-300% збільшення PPS (обхід ядра) | 10-50% збільшення пропускної здатності на WAN |
| Вплив на CPU | Знижує/перерозподіляє | Значно знижує | Перерозподіляє, знижує softirq | Значно знижує (особливо XDP) | Повністю обходить CPU ядра | Мінімальний |
| Вплив на затримку | Може знизити | Знижує | Знижує | Значно знижує (XDP) | Значно знижує | Може знизити (BBR) |
| Вимоги до обладнання | Стандартний Linux сервер | Сучасна NIC з підтримкою offload | Багатоядерний CPU | Ядро Linux 4.x+ (краще 5.x+), сучасний CPU | Спеціалізована NIC, багатоядерний CPU, підтримка IOMMU | Стандартний Linux сервер |
| Типові сценарії використання | Веб-сервери, бази даних, проксі | Будь-які високонавантажені мережеві додатки | Високопродуктивні мережеві шлюзи, балансувальники | DDoS-захист, кастомні фаєрволи, балансувальники, моніторинг, телеметрія | Телеком, HFT, NFV, високошвидкісна пакетна обробка | WAN-оптимізація, хмарні середовища, CDN |
| Приблизна вартість впровадження (Dev Time) | Низька (години) | Низька (години) | Середня (дні) | Висока (тижні/місяці) | Дуже висока (місяці) | Низька (хвилини) |
| Ризики/Побічні ефекти | Неправильне налаштування може погіршити | Конфлікти з драйверами, несумісність | Неправильне налаштування може викликати дисбаланс | Складність налагодження, ризик нестабільності при помилках | Повний обхід ядра, вимагає спеціалізованих додатків | Може бути агресивним в деяких мережах |
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Детальний огляд кожного пункту/варіанту
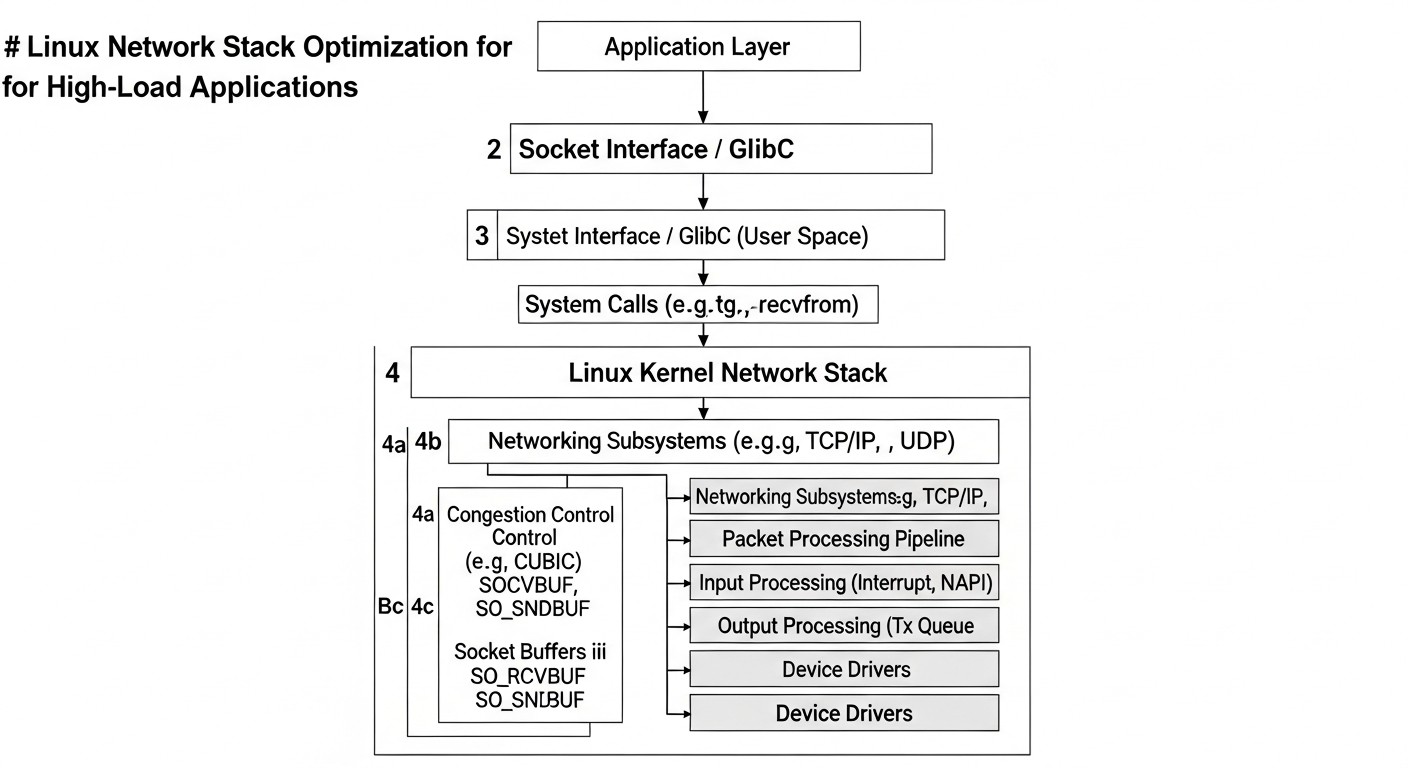
Кожен метод оптимізації мережевого стека Linux має свої особливості, переваги і недоліки. Розуміння цих нюансів дозволяє вибрати найбільш підходящі інструменти для конкретної задачі і досягти максимальної ефективності.
1. Тонке налаштування параметрів ядра (sysctl)
Параметри ядра Linux, доступні через інтерфейс sysctl, є першим і найбільш доступним рівнем оптимізації. Вони дозволяють налаштувати поведінку мережевого стека, управляючи розмірами буферів, таймаутами, механізмами управління перевантаженнями та іншими аспектами. Незважаючи на уявну простоту, їх налаштування вимагає глибокого розуміння, оскільки невірні значення можуть призвести до деградації продуктивності або навіть до нестабільності системи. У 2026 році, коли більшість систем працюють в контейнерах або віртуальних машинах, ці параметри залишаються актуальними, хоча деякі з них можуть бути обмежені середовищем.
net.core.somaxconn: Визначає максимальну кількість з'єднань, які можуть знаходитися в стані LISTEN-backlog. Для високонавантажених веб-серверів або балансувальників навантаження, що обробляють тисячі нових з'єднань за секунду, значення за замовчуванням (зазвичай 128) часто недостатньо. Його збільшення до 4096 або навіть 65535 може значно зменшити кількість скинутих з'єднань (connection refused) під час пікового навантаження. Наприклад, для API-шлюзу, що приймає 10 000 RPS, збільшенняsomaxconnз 128 до 8192 може запобігти до 5% помилок з'єднання в пікові моменти, покращуючи користувацький досвід і стабільність сервісу.net.ipv4.tcp_tw_reuseіnet.ipv4.tcp_fin_timeout:tcp_tw_reuseдозволяє повторно використовувати сокети в станіTIME_WAITдля нових вихідних з'єднань. Це критично важливо для клієнтів, які швидко відкривають і закривають безліч з'єднань. У поєднанні зtcp_fin_timeout(зменшення часу перебування в станіFIN_WAIT2), це допомагає запобігти вичерпанню портів і знижує навантаження на систему при інтенсивному створенні/закритті з'єднань. Однакtcp_tw_reuseслід використовувати з обережністю на серверах, оскільки це може призвести до проблем при взаємодії з деякими NAT-пристроями, які відправляють пакети із застарілими номерами послідовності. Для вихідних проксі або мікросервісів, які ініціюють безліч запитів, активаціяtcp_tw_reuseможе скоротити кількість портів у станіTIME_WAITна 30-50%, вивільняючи ресурси.net.core.rmem_max/net.core.wmem_maxіnet.ipv4.tcp_rmem/net.ipv4.tcp_wmem: Ці параметри контролюють максимальні розміри буферів отримання та відправлення для всіх сокетів (net.core.) і для TCP-сокетів (net.ipv4.tcp_). Збільшення цих значень дозволяє TCP-вікнам бути більшими, що особливо важливо для високошвидкісних мереж з великою затримкою (High-Bandwidth Delay Product, BDP). Для серверів, що передають великі файли або працюють з високошвидкісними базами даних, збільшення буферів до 16MB (16777216) або навіть 32MB може значно підвищити пропускну здатність, знижуючи кількість повторних передач і покращуючи ефективність використання каналу. Наприклад, на каналі 10 Гбіт/с з RTT 50 мс, оптимальний розмір буфера становить близько 625 КБ. Якщо буфер менший, канал буде недовикористаний.net.ipv4.tcp_max_syn_backlog: Максимальна кількість TCP-з'єднань, для яких отримані пакети SYN, але ще не завершено тристороннє рукостискання. Збільшення цього значення (наприклад, до 8192 або 16384) допомагає захиститися від SYN-флуду і запобігає втраті з'єднань при високому навантаженні на встановлення з'єднань.net.ipv4.tcp_timestamps: Включення тимчасових міток TCP (RFC 1323) допомагає ядру більш точно вимірювати RTT і захищає від застарілих сегментів, але додає 12 байт до кожного TCP-заголовку. Для високошвидкісних LAN з дуже великою кількістю маленьких пакетів це може бути накладним. У більшості випадків для WAN його варто залишити включеним.
Плюси: Легкість застосування, не вимагає зміни коду програми, універсальність.
Мінуси: Вимагає перезавантаження для деяких параметрів, може призвести до нестабільності при неправильному налаштуванні, не вирішує фундаментальних проблем продуктивності на дуже високих навантаженнях.
Для кого підходить: Більшість серверів, де потрібна загальна оптимізація продуктивності мережі без глибоких змін архітектури.
Приклади: Збільшення somaxconn для веб-серверів, налаштування буферів для файлових серверів, оптимізація tcp_tw_reuse для клієнтських додатків або проксі.
2. Апаратні розвантаження мережевих карт (NIC Offloads)
Сучасні мережеві карти (NIC) — це не просто трансивери, а потужні співпроцесори, здатні виконувати частину мережевої обробки, яка традиційно лягає на CPU ядра. Використання цих апаратних розвантажень (offloads) дозволяє значно знизити навантаження на центральний процесор, вивільняючи його для виконання прикладних завдань, і тим самим підвищити загальну продуктивність системи. У 2026 році, з повсюдним поширенням 10/25/40/100GbE NIC, активація цих функцій є обов'язковим першим кроком.
- TSO (TCP Segmentation Offload) / GSO (Generic Segmentation Offload): Дозволяють ядру відправляти дуже великі TCP-сегменти (до 64 КБ) драйверу NIC, який потім самостійно ділить їх на пакети, що відповідають MTU мережі. Це значно знижує кількість операцій, виконуваних CPU, так як ядро обробляє менше пакетів, але більше даних за один раз. Особливо корисно для високошвидкісної передачі великих файлів.
- GRO (Generic Receive Offload) / LRO (Large Receive Offload): Зворотний бік TSO/GSO. NIC або драйвер об'єднує кілька вхідних пакетів в один великий сегмент перед передачею його ядру. Це зменшує кількість переривань і кількість пакетів, які ядро має обробляти, тим самим знижуючи навантаження на CPU. GRO є більш універсальною версією LRO і краща.
- RSS (Receive Side Scaling): Дозволяє розподіляти обробку вхідних мережевих переривань і пакетів між декількома ядрами CPU. NIC використовує хеш-функцію для визначення, яке ядро має обробляти конкретний пакет, тим самим запобігаючи перевантаженню одного ядра і підвищуючи загальну пропускну здатність. Для багатоядерних систем з високошвидкісними NIC це критично важливо. Наприклад, 100GbE NIC без RSS може призвести до того, що одне ядро CPU буде повністю завантажене обробкою мережевого трафіку, в той час як інші простоюють.
- RPS (Receive Packet Steering) / RFS (Receive Flow Steering): Програмні реалізації RSS, коли NIC не підтримує апаратний RSS або коли потрібне більш тонке управління. RPS розподіляє пакети між ядрами CPU після того, як вони були прийняті NIC. RFS додатково намагається направити пакети на те ядро, де працює додаток, який буде їх обробляти, покращуючи кеш-ефективність.
- SR-IOV (Single Root I/O Virtualization): Технологія віртуалізації, яка дозволяє віртуальним машинам безпосередньо отримувати доступ до апаратних функцій NIC, минаючи гіпервізор. Це забезпечує майже нативну продуктивність мережі для ВМ, значно знижуючи затримку і збільшуючи пропускну здатність. Критично важливо для NFV (Network Function Virtualization) і високопродуктивних хмарних інстансів.
Плюси: Значне зниження навантаження на CPU, збільшення пропускної здатності і зменшення затримки, не вимагає зміни коду програми.
Мінуси: Залежить від апаратної підтримки NIC і драйверів, може бути складним в налаштуванні (особливо SR-IOV), іноді може викликати проблеми з сумісністю або налагодженням.
Для кого підходить: Будь-які високонавантажені сервери, особливо з 10GbE+ NIC, віртуалізовані середовища.
Приклади: Активація TSO/GSO/GRO для файлових серверів, налаштування RSS для балансувальників навантаження, використання SR-IOV для віртуальних мережевих функцій.
3. eBPF (Extended Berkeley Packet Filter)
eBPF — це революційна технологія, яка дозволяє виконувати програми на рівні ядра Linux без необхідності його перекомпіляції або завантаження модулів. Ці програми, написані обмеженою підмножиною C та скомпільовані в байткод, верифікуються ядром на безпеку і потім запускаються в ізольованій пісочниці. eBPF надає безпрецедентні можливості для моніторингу, трасування, безпеки та, що особливо важливо для нас, для високопродуктивної мережевої обробки. У 2026 році eBPF є одним з найпотужніших інструментів для оптимізації мережевого стека, дозволяючи реалізовувати логіку, яка раніше була можливою тільки в просторі користувача або вимагала модифікації ядра.
- XDP (eXpress Data Path): Найшвидший шлях обробки пакетів в Linux. XDP-програми запускаються безпосередньо в драйвері мережевої карти, до того як пакет потрапляє в звичайний мережевий стек. Це дозволяє виконувати такі операції, як фільтрація DDoS-трафіку, балансування навантаження, швидка маршрутизація або перенаправлення пакетів з мінімальною затримкою та навантаженням на CPU. XDP дозволяє відкинути небажаний трафік або перенаправити його на інші інтерфейси/CPU до того, як він буде повністю оброблений ядром. В реальних кейсах XDP може обробляти мільйони пакетів в секунду на одному ядрі CPU, знижуючи навантаження на CPU на 50-70% в порівнянні з традиційними методами для певних задач.
- TC eBPF (Traffic Control eBPF): Програми eBPF, які прикріплюються до точок входу в підсистемі управління трафіком Linux. Вони дозволяють реалізовувати більш складні політики фільтрації, класифікації та модифікації пакетів, ніж XDP, але з трохи більшою затримкою, оскільки вони працюють глибше в стеку. TC eBPF використовується для створення просунутих фаєрволів, QoS-політик, мережевих функцій, таких як проксування або тунелювання, і навіть для реалізації частини SDN-контролерів.
- Socket Filters: eBPF-програми, які прикріплюються до сокетів. Вони дозволяють фільтрувати вхідні пакети до того, як вони будуть доставлені додатку. Це може бути використано для реалізації кастомних протоколів, оптимізації обробки специфічного трафіку або для більш тонкої безпеки на рівні додатку.
- Cilium, Calico та інші: У 2026 році eBPF активно використовується в хмарних та контейнерних середовищах для реалізації мережевих політик, балансування навантаження та забезпечення безпеки. Проєкти на кшталт Cilium повністю перебудовані на eBPF, надаючи високопродуктивну та безпечну мережу для Kubernetes.
Плюси: Безпрецедентна продуктивність та гнучкість, виконання коду на рівні ядра без його модифікації, безпека (верифікатор ядра), потужні можливості для моніторингу та налагодження, активний розвиток спільнотою.
Мінуси: Високий поріг входу (вимагає знань C, специфічного API eBPF), складність налагодження, не всі драйвери NIC підтримують XDP, програми обмежені за розміром та складністю.
Для кого підходить: DevOps-інженери та розробники, які працюють з екстремально високими навантаженнями, які потребують кастомної логіки обробки пакетів, DDoS-захисту, високопродуктивного балансування навантаження, просунутого моніторингу.
Приклади: XDP для відкидання DDoS-трафіку, TC eBPF для створення кастомних балансувальників L4, eBPF для глибокої телеметрії мережевого трафіку.
4. Простір користувача (Userspace Networking - DPDK)
Для найекстремальніших навантажень, коли навіть XDP недостатньо, існують рішення, які повністю обходять мережевий стек ядра та обробляють пакети безпосередньо в просторі користувача. Найвідомішим з них є DPDK (Data Plane Development Kit). DPDK надає набір бібліотек та драйверів, які дозволяють додаткам напряму взаємодіяти з мережевою картою, минаючи ядро Linux. Це досягається за рахунок використання режиму "poll mode driver" (PMD), де CPU постійно опитує NIC на предмет нових пакетів, уникаючи накладних витрат на переривання. DPDK вимагає виділення ядер CPU та великих сторінок пам'яті, але натомість пропонує продуктивність, яка вимірюється десятками мільйонів пакетів в секунду (Mpps) на одному ядрі.
- Принцип роботи: DPDK-додатки отримують ексклюзивний доступ до NIC. Драйвери DPDK працюють в просторі користувача та постійно опитують черги NIC на наявність пакетів. Це усуває перемикання контексту, копіювання даних між ядром та простором користувача, а також обробку переривань, які є основними джерелами накладних витрат в традиційному мережевому стеку.
- Застосування: Використовується в телекомунікаційній індустрії (NFV), високочастотному трейдингу (HFT), спеціалізованих маршрутизаторах, фаєрволах, IDS/IPS системах, де потрібна максимальна пропускна здатність та мінімальна затримка.
Плюси: Максимальна продуктивність (десятки Mpps), мінімальна затримка, повний контроль над обробкою пакетів.
Мінуси: Вкрай висока складність розробки та впровадження (вимагає переписування або адаптації додатків), повний обхід мережевого стека ядра (втрачаються стандартні функції Linux), вимагає виділених ядер CPU та специфічної конфігурації, немає стандартних утиліт.
Для кого підходить: Тільки для найвимогливіших сценаріїв, де стандартний мережевий стек (навіть з eBPF) не справляється, і є ресурси для глибокої розробки.
Приклади: Комерційні NFV-рішення (віртуальні маршрутизатори, фаєрволи), HFT-платформи, спеціалізовані мережеві пристрої.
5. Алгоритми управління перевантаженнями TCP
Алгоритм управління перевантаженнями TCP визначає, як TCP-з'єднання реагує на перевантаження мережі, контролюючи розмір вікна перевантаження. Вибір правильного алгоритму може суттєво вплинути на пропускну здатність, затримку та справедливість розподілу смуги пропускання. У 2026 році, коли мережі стають все більш різноманітними (від високошвидкісних дата-центрів до супутникових каналів), вибір алгоритму має велике значення.
- CUBIC: Алгоритм за замовчуванням в більшості сучасних ядер Linux. Добре працює у високошвидкісних мережах з високою затримкою, але може бути менш агресивним та повільніше реагувати на зміни, ніж деякі інші алгоритми.
- BBR (Bottleneck Bandwidth and RTT): Розроблений Google, BBR фокусується на вимірюванні пропускної здатності "вузького горла" та мінімальної затримки RTT для визначення оптимального вікна перевантаження. На відміну від CUBIC, який реагує на втрати пакетів (що часто є пізнім індикатором перевантаження), BBR активно шукає вільну смугу пропускання, що часто призводить до значного збільшення пропускної здатності та зниження затримки, особливо на каналах з високою затримкою та/або втратами. Для хмарних середовищ, міжрегіональних з'єднань та CDN BBR часто демонструє чудові результати. Його використання може збільшити пропускну здатність на 10-50% та знизити затримку на 5-10% в певних сценаріях.
- Reno/NewReno: Більш старі алгоритми, які все ще використовуються, але зазвичай поступаються CUBIC та BBR в сучасних високошвидкісних мережах.
Переваги: Легко налаштовується (sysctl), значний приріст продуктивності для BBR у WAN-мережах.
Недоліки: BBR може бути занадто агресивним у деяких мережах, що може призвести до витіснення трафіку, який використовує інші алгоритми.
Для кого підходить: Усі сервери, особливо ті, які взаємодіють через WAN або хмарні мережі. BBR рекомендовано для більшості сценаріїв.
Приклади: Активація BBR для веб-серверів, CDN-нод, файлових серверів, що працюють через інтернет.
6. Балансування переривань (IRQ Balancing)
Мережеві карти генерують переривання (IRQs) для кожного прийнятого або відправленого пакета. На високошвидкісних NIC кількість переривань може бути величезною, що призводить до значного навантаження на CPU, якщо всі вони обробляються одним ядром. Балансування переривань розподіляє ці IRQs між кількома ядрами CPU, що дозволяє паралельно обробляти мережевий трафік і запобігати перевантаженню окремих ядер.
irqbalance: Демон, який автоматично розподіляє IRQs між доступними ядрами CPU. Це просте рішення для більшості систем.- Ручне налаштування
/proc/irq/<IRQ_NUMBER>/smp_affinity: Для максимальної продуктивності та передбачуваності, особливо у виділених системах, можна вручну прив'язати IRQs мережевих карт до певних ядер CPU. Це дозволяє уникнути конкуренції з іншими процесами та оптимізувати кеш-ефективність. Наприклад, для 100GbE NIC з 16 чергами, можна прив'язати кожну чергу до окремого ядра CPU, забезпечуючи максимальне розпаралелювання.
Переваги: Знижує навантаження на CPU, покращує масштабованість і пропускну здатність.
Недоліки: Ручне налаштування може бути складним, вимагає розуміння топології NUMA.
Для кого підходить: Будь-які багатоядерні сервери з високошвидкісними NIC, особливо мережеві шлюзи та балансувальники навантаження.
Приклади: Налаштування irqbalance на стандартних серверах, ручна прив'язка IRQs для високопродуктивних мережевих пристроїв.
Практичні поради та рекомендації
Застосування теоретичних знань на практиці вимагає конкретних кроків і команд. Нижче представлені покрокові інструкції та приклади конфігурацій, які допоможуть вам оптимізувати мережевий стек Linux в реальних умовах 2026 року.
1. Встановлення базових метрик і моніторинг
Перш ніж що-небудь змінювати, виміряйте поточну продуктивність. Це дозволить вам оцінити ефект від внесених змін.
- Використання
iperf3для вимірювання пропускної здатності:
# На сервері (приймаюча сторона)
iperf3 -s
# На клієнті (відправляюча сторона)
iperf3 -c <server_ip> -t 60 -P 10 # 60 секунд, 10 паралельних потоків
# Загальна статистика мережевих інтерфейсів
ip -s link show eth0
# Статистика TCP/UDP сокетів
ss -s
# Детальна статистика за мережевими протоколами
netstat -s
# Моніторинг використання CPU, особливо softirq
mpstat -P ALL 1
# Перевірка дропів пакетів у драйвері NIC
ethtool -S eth0 | grep "drop"
2. Налаштування параметрів ядра (sysctl)
Зміни через sysctl застосовуються негайно, але не зберігаються після перезавантаження. Для постійності їх потрібно додати в /etc/sysctl.conf або в файли в /etc/sysctl.d/.
- Приклад конфігурації
/etc/sysctl.d/99-network-optimizations.conf:
# Збільшуємо backlog для LISTEN-сокетів
net.core.somaxconn = 65535
net.ipv4.tcp_max_syn_backlog = 16384
# Збільшуємо розміри буферів для всіх сокетів
net.core.rmem_max = 33554432
net.core.wmem_max = 33554432
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
# Збільшуємо розміри буферів для TCP-сокетів
# Формат: min default max
net.ipv4.tcp_rmem = 4096 87380 33554432
net.ipv4.tcp_wmem = 4096 65536 33554432
# Дозволяємо перевикористання сокетів у стані TIME_WAIT
net.ipv4.tcp_tw_reuse = 1
# Зменшуємо таймаут для FIN-WAIT2
net.ipv4.tcp_fin_timeout = 30
# Використовуємо алгоритм управління перевантаженнями BBR
net.ipv4.tcp_congestion_control = bbr
# Збільшуємо максимальну кількість портів для вихідних з'єднань
net.ipv4.ip_local_port_range = 1024 65535
# Відключаємо SACK (Selective Acknowledgement) - може бути корисним у деяких випадках, але частіше краще залишити включеним
# net.ipv4.tcp_sack = 0
# Відключаємо TCP Slow Start після простою (може бути корисним для коротких з'єднань)
net.ipv4.tcp_slow_start_after_idle = 0
# Збільшуємо чергу вхідних пакетів на рівні драйвера
net.core.netdev_max_backlog = 16384
sudo sysctl -p /etc/sysctl.d/99-network-optimizations.conf
3. Налаштування апаратних розвантажень NIC
Використовуйте ethtool для перевірки та налаштування можливостей вашої мережевої карти. Замініть eth0 на ім'я вашого інтерфейсу.
- Перевірка поточних можливостей:
sudo ethtool -k eth0
sudo ethtool -K eth0 rx on tx on sg on tso on gso on gro on lro off
# lro часто конфліктує з gro, тому краще залишити gro
# Перевірити кількість черг та їх розподіл
sudo ethtool -l eth0
# Встановити максимальну кількість черг RX/TX, доступну для NIC (якщо NIC підтримує)
sudo ethtool -L eth0 rx 16 tx 16
Для автоматичного балансування IRQs переконайтеся, що служба irqbalance запущена:
sudo systemctl enable irqbalance
sudo systemctl start irqbalance
Для ручної прив'язки IRQs (для просунутих сценаріїв):
# Визначити IRQ номери для eth0
grep eth0 /proc/interrupts
# Приклад: прив'язати IRQ 123 (перша черга eth0) до CPU 1
echo 2 > /proc/irq/123/smp_affinity_list
# (2 в бітовій масці відповідає CPU 1. Для CPU 0 це 1, для CPU 0 і 1 це 3 і т.д.)
4. Налаштування eBPF (XDP)
Налаштування eBPF зазвичай включає написання C-програми та завантаження її в ядро за допомогою утиліт з bcc-tools або libbpf. Це більш складний процес.
- Приклад найпростішої XDP-програми (відкидання всього трафіку):
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
SEC("xdp")
int xdp_drop_all(struct xdp_md *ctx)
{
// Ця програма просто відкидає всі вхідні пакети
// Реальні XDP програми мають складну логіку фільтрації
return XDP_DROP;
}
char _license[] SEC("license") = "GPL";
ip link):
# Скомпілювати C-код в об'єктний файл (потребує clang та llvm)
clang -O2 -target bpf -c xdp_drop_all.c -o xdp_drop_all.o
# Завантажити XDP-програму на інтерфейс eth0
sudo ip link set dev eth0 xdp obj xdp_drop_all.o section xdp
# Перевірити статус XDP
sudo ip link show dev eth0
# Відключити XDP
sudo ip link set dev eth0 xdp off
Примітка: Використання eBPF вимагає глибокого розуміння та обережності. Почніть з вивчення bcc-tools і прикладів на GitHub bcc та XDP Tutorial.
5. Налаштування Jumbo Frames
Якщо вся ваша мережа (NIC, комутатори, маршрутизатори) підтримує Jumbo Frames (MTU > 1500), їх активація може значно підвищити пропускну здатність за рахунок зменшення кількості пакетів. Типове значення для Jumbo Frames — 9000 байт.
- Зміна MTU:
sudo ip link set dev eth0 mtu 9000
Важливо: Усі пристрої на шляху повинні підтримувати і бути налаштовані на використання Jumbo Frames. В іншому випадку це призведе до фрагментації та зниження продуктивності.
6. Рекомендації щодо вибору стека TCP/IP
- IPv6 First: У 2026 році IPv6 стає стандартом. Переконайтеся, що ваші застосунки та інфраструктура повністю підтримують IPv6. Іноді це може дати невеликі переваги у продуктивності за рахунок більш ефективної маршрутизації та відсутності NAT.
- TCP Fast Open (TFO): Для коротких, частих TCP-з'єднань TFO може значно скоротити затримку, дозволяючи відправляти дані в першому SYN-пакеті. Активуйте його на сервері та клієнті:
net.ipv4.tcp_fastopen = 3 # 1 для клієнта, 2 для сервера, 3 для обох
Застосовуйте ці рекомендації та команди поступово, тестуючи кожен крок і спостерігаючи за метриками продуктивності. Документуйте всі зміни і будьте готові до відкату, якщо щось піде не так.
Типові помилки при оптимізації мережевого стека
Оптимізація мережевого стека — це тонке мистецтво, і помилки можуть дорого коштувати. У 2026 році, коли системи стають все більш складними і взаємопов'язаними, наслідки неправильного налаштування можуть бути катастрофічними. Ось п'ять найпоширеніших помилок, яких слід уникати:
1. Оптимізація без попереднього вимірювання та бенчмаркінгу
Помилка: Застосування "загальних" рекомендацій з оптимізації (наприклад, зі статті в інтернеті або від колеги) без розуміння поточних вузьких місць і без вимірювання базової продуктивності.
Як уникнути: Завжди починайте з ретельної діагностики. Використовуйте iperf3, netstat, ss, mpstat, ethtool для збору метрик до будь-яких змін. Створіть навантажувальні тести, що імітують реальну поведінку вашого застосунку. Тільки так ви зможете точно визначити, що саме потребує оптимізації, і оцінити ефективність ваших дій. Без базових метрик ви не зможете довести, що оптимізація спрацювала, або зрозуміти, що вона погіршила ситуацію.
Приклад наслідків: Збільшення net.core.somaxconn до 65535 на сервері, який ніколи не відчував проблем з LISTEN-backlog, не принесе жодної користі, але може створити хибне відчуття оптимізації. У той же час, якщо реальною проблемою є нестача буферів TCP, а ви налаштовуєте irqbalance, ви не тільки не вирішите проблему, але й змарнуєте час.
2. Сліпе копіювання конфігурацій без розуміння контексту
Помилка: Застосування налаштувань, знайдених в інтернеті або використовуваних в іншій системі, без урахування специфіки вашої інфраструктури, застосунку та апаратного забезпечення.
Як уникнути: Розумійте, що робить кожен параметр. Параметри, оптимальні для одного типу навантаження (наприклад, високошвидкісна передача файлів), можуть бути абсолютно неефективними або навіть шкідливими для іншого (наприклад, безліч коротких HTTP-запитів). Враховуйте тип NIC, кількість ядер CPU, топологію NUMA, версію ядра Linux і специфіку мережевого середовища (LAN/WAN).
Приклад наслідків: Активація tcp_tw_reuse на публічному сервері без розуміння його взаємодії з NAT-пристроями клієнтів може призвести до помилкового прийому "старих" пакетів і нестабільності з'єднань для частини користувачів. Або, наприклад, відключення tcp_timestamps для "економії" 12 байт заголовка може негативно позначитися на точності вимірювання RTT та захисті від застарілих сегментів, що більш критично для WAN-з'єднань.
3. Ігнорування апаратних можливостей NIC
Помилка: Спроби оптимізувати мережевий стек виключно програмними методами, ігноруючи апаратні розвантаження, що надаються сучасною мережевою картою.
Як уникнути: Завжди перевіряйте можливості вашої NIC за допомогою ethtool -k <interface> і ethtool -S <interface>. Переконайтеся, що TSO, GSO, GRO, RSS та інші підтримувані розвантаження активовані. Для високошвидкісних NIC (10GbE і вище) це критично важливо.
Приклад наслідків: Завантаження CPU на 50% через обробку мережевих переривань на 25GbE NIC, в той час як апаратний RSS відключений. Активація RSS могла б знизити це навантаження до 5-10%, вивільняючи CPU для застосунків і значно збільшуючи пропускну здатність без будь-яких змін у ядрі або застосунку.
4. Недостатнє тестування під навантаженням і відсутність моніторингу після змін
Помилка: Внесення змін в продакшн без попереднього тестування в тестовому середовищі, що імітує реальне навантаження, або відсутність постійного моніторингу після впровадження змін.
Як уникнути: Завжди тестуйте зміни в ізольованому середовищі, яке максимально наближене до продакшну. Використовуйте інструменти для навантажувального тестування (wrk, locust, JMeter) і переконайтеся, що система стабільна і продуктивність покращилася. Після розгортання в продакшні, уважно стежте за ключовими метриками (CPU, пам'ять, затримка, втрати пакетів, помилки) за допомогою систем моніторингу (Prometheus, Grafana, ELK).
Приклад наслідків: Зміна параметра net.ipv4.tcp_max_orphans на дуже велике значення може призвести до того, що система буде тримати занадто багато "сирітських" сокетів, що в кінцевому підсумку може вичерпати пам'ять і викликати падіння сервера при певних пікових навантаженнях, які не були враховані в тестовому середовищі.
5. Ігнорування впливу на безпеку та стабільність
Помилка: Фокусування виключно на продуктивності, забуваючи про потенційні ризики для безпеки та загальної стабільності системи.
Як уникнути: Деякі оптимізації можуть послабити захисні механізми ядра. Наприклад, деякі параметри, спрямовані на скорочення часу очікування або повторного використання з'єднань, можуть бути використані зловмисниками. Завжди оцінюйте ризики безпеки. При роботі з eBPF, переконайтеся, що програми ретельно протестовані та верифіковані, щоб уникнути ненавмисних помилок або вразливостей. Завжди плануйте стратегію відкату.
Приклад наслідків: Відключення SYN Cookies (net.ipv4.tcp_syncookies = 0) для підвищення продуктивності встановлення з'єднань під дуже високим навантаженням може зробити сервер вкрай вразливим до SYN-флуд атак, що призведе до повної недоступності сервісу.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Чекліст для практичного застосування
Цей покроковий чекліст допоможе вам систематизувати процес оптимізації мережевого стеку Linux для ваших високонавантажених додатків. Дотримуйтесь його, щоб забезпечити всебічний і безпечний підхід.
- Визначте мету оптимізації:
- Що саме ви хочете покращити? (Знизити затримку, збільшити пропускну здатність, зменшити використання CPU, запобігти втратам пакетів, поліпшити масштабованість?)
- Які ваші поточні ліміти та вузькі місця?
- Встановіть базові метрики продуктивності:
- Проведіть навантажувальне тестування в поточній конфігурації.
- Зафіксуйте ключові показники: RTT, пропускна здатність (
iperf3), PPS (pktgen), використання CPU (mpstat,top), помилки та дропи пакетів (netstat -s,ss -s,ethtool -S). - Створіть графіки у вашій системі моніторингу (Prometheus/Grafana) для відстеження цих метрик.
- Перевірте апаратні можливості NIC:
- Виконайте
sudo ethtool -k <interface>іsudo ethtool -l <interface>. - Переконайтеся, що TSO, GSO, GRO, RSS активовані, якщо підтримуються.
- Налаштуйте максимальну кількість черг RX/TX, якщо це можливо (
sudo ethtool -L <interface> rx <N> tx <N>). - Розгляньте використання Jumbo Frames, якщо вся мережа підтримує (
sudo ip link set dev <interface> mtu 9000).
- Виконайте
- Оптимізуйте параметри ядра (sysctl):
- Створіть або відредагуйте файл
/etc/sysctl.d/99-network-optimizations.conf. - Встановіть адекватні значення для
net.core.somaxconn,net.ipv4.tcp_max_syn_backlog,net.core.rmem_max,net.core.wmem_max,net.ipv4.tcp_rmem,net.ipv4.tcp_wmem. - Увімкніть
net.ipv4.tcp_tw_reuse = 1(якщо можливо для вашої ролі сервера). - Встановіть
net.ipv4.tcp_congestion_control = bbr. - Застосуйте зміни:
sudo sysctl -p /etc/sysctl.d/99-network-optimizations.conf.
- Створіть або відредагуйте файл
- Налаштуйте балансування переривань (IRQ Balancing):
- Переконайтеся, що служба
irqbalanceзапущена та активна. - Для екстремальних навантажень розгляньте ручне прив'язування IRQs до CPU (
/proc/irq/<IRQ_NUMBER>/smp_affinity_list), особливо для NUMA-систем.
- Переконайтеся, що служба
- Розгляньте застосування eBPF:
- Вивчіть можливості XDP для фільтрації DDoS, швидкої маршрутизації або балансування навантаження.
- Використовуйте
bcc-toolsдля моніторингу та трасування мережевого стеку. - Якщо потрібна кастомна логіка, розробіть і протестуйте eBPF-програми.
- Проведіть тестування після кожного етапу оптимізації:
- Повторіть навантажувальні тести та порівняйте результати з базовими метриками.
- Оцініть вплив на CPU, пам'ять, затримку та пропускну здатність.
- Переконайтеся в стабільності системи.
- Перевірте вплив на безпеку:
- Переконайтеся, що оптимізації не відкрили нові вектори атак або не послабили існуючі захисти.
- Проведіть аудит змін, особливо якщо вони зачіпають фаєрвол або мережеві політики.
- Документуйте всі зміни:
- Записуйте всі внесені зміни, їх обґрунтування та результати.
- Зберігайте конфігурації в системі контролю версій.
- Плануйте стратегію відкату:
- Завжди майте чіткий план дій на випадок, якщо оптимізації призведуть до проблем.
- Переконайтеся, що ви можете швидко повернутися до попередньої робочої конфігурації.
Розрахунок вартості / Економіка оптимізації
Оптимізація мережевого стеку Linux — це не просто технічне завдання, але й економічне рішення. У 2026 році, коли хмарні ресурси стають все дорожчими, а вимоги до продуктивності зростають, правильна оптимізація може принести суттєву економію та підвищити конкурентоспроможність. Однак вона також вимагає інвестицій. Давайте розглянемо основні економічні аспекти.
Прямі та приховані витрати
- Вартість апаратного забезпечення:
- NIC з просунутими розвантаженнями: Сучасні 25/50/100GbE NIC з підтримкою SR-IOV, розширеними offload-функціями та більш потужними апаратними хешуваннями можуть коштувати від $300 до $2000+ за карту. Це значні інвестиції, але вони окупаються зниженням навантаження на CPU.
- CPU: Іноді для обробки дуже високих PPS потрібен більш потужний CPU або сервер з більшою кількістю ядер. Однак мета оптимізації часто полягає в тому, щоб уникнути покупки більш потужного CPU за рахунок ефективного використання існуючого.
- Вартість інженерного часу:
- Вивчення та планування: Час, витрачений на вивчення документації, бенчмаркінг, аналіз вузьких місць.
- Впровадження та тестування: Налаштування
sysctl,ethtool, написання та налагодження eBPF-програм, проведення навантажувального тестування. Це може бути від кількох годин для базових налаштувань до кількох тижнів або навіть місяців для складних eBPF-рішень або DPDK. - Підтримка та моніторинг: Постійний моніторинг продуктивності та адаптація налаштувань до мінливих навантажень.
- Вартість інструментів:
- Більшість інструментів (
iperf3,netstat,bcc-tools) безкоштовні та з відкритим вихідним кодом. - Системи моніторингу (Prometheus, Grafana) також безкоштовні, але їх розгортання та підтримка потребують ресурсів.
- Більшість інструментів (
- Приховані витрати неоптимізованої системи:
- Збільшені хмарні рахунки: Неефективне використання CPU через мережевий стек означає, що ви платите за невикористані потужності або змушені масштабувати інстанси раніше, ніж це необхідно. Наприклад, якщо мережевий стек споживає 30% CPU, це еквівалентно 30% переплати за CPU.
- Втрати доходу через низьку продуктивність: Висока затримка або низька пропускна здатність можуть призвести до погіршення користувацького досвіду, відтоку клієнтів, зниження конверсії або пропущених бізнес-можливостей (наприклад, у HFT).
- Втрати через нестабільність: Перевантаження, втрати пакетів і падіння сервісів через неоптимізовану мережу призводять до простоїв та репутаційних втрат.
- Додаткові витрати на ПЗ: Іноді неоптимізований мережевий стек змушує купувати дорожчі ліцензії на мережеве ПЗ або балансувальники навантаження, які могли б бути замінені eBPF-рішеннями.
Приклади розрахунків для різних сценаріїв (2026)
Припустимо, вартість години роботи кваліфікованого DevOps-інженера становить $100.
| Сценарій | Метод оптимізації | Інвестиції (Dev Time) | Інвестиції (Hardware) | Потенційна економія/прибуток | ROI (окупність) |
|---|---|---|---|---|---|
| Малий SaaS (1000 RPS) | Базові sysctl, BBR, перевірка offloads |
4-8 годин ($400-$800) | $0 (використання поточних NIC) | Зниження CPU на 5-10%, економія $50-$100/міс на хмарі, покращення UX. | 1-2 місяці |
| Середній Backend (100k RPS) | Просунуті sysctl, RSS/RPS, ethtool, irqbalance |
20-40 годин ($2000-$4000) | $0-$600 (оновлення NIC) | Зниження CPU на 10-20%, економія $200-$500/міс на хмарі, підвищення стабільності. | 2-6 місяців |
| Великий Data Center (1M+ PPS) | eBPF (XDP/TC), SR-IOV, DPDK (якщо необхідно), глибоке налаштування ядра | 80-320 годин ($8000-$32000) | $1000-$5000 (високопродуктивні NIC) | Зниження CPU на 20-50%, можливість консолідації серверів (економія $1000-$5000/міс), нові можливості (DDoS-захист, кастомний LB). | 3-12 місяців (залежить від складності) |
| HFT/Real-time (мікросекунди) | DPDK, спеціалізовані NIC, CPU affinity, kernel bypass | 320+ годин ($32000+) | $5000-$10000+ (спец. NIC, FPGA) | Мінімальна затримка (мкс), конкурентна перевага, прямі фінансові вигоди. | 1-3 місяці (за рахунок прямих доходів) |
Як оптимізувати витрати
- Почніть з простого: Спочатку застосуйте найдешевші та найпростіші методи (
sysctl,ethtool). Вони часто дають значний приріст. - Використовуйте Open Source: Більшість інструментів і технологій (Linux, eBPF, Prometheus, Grafana) безкоштовні, що знижує вартість ПЗ.
- Поступове впровадження: Не намагайтеся впровадити все й одразу. Ітераційний підхід з постійним моніторингом дозволяє уникнути дорогих помилок.
- Навчання команди: Інвестиції в навчання інженерів eBPF і глибокому розумінню мережевого стека окупляться багатократно, знижуючи залежність від зовнішніх консультантів.
- Автоматизація: Використовуйте Ansible, Terraform або інші інструменти IaC для автоматизації розгортання та управління конфігураціями, що знижує ручні помилки та час на впровадження.
Економіка оптимізації мережевого стека — це баланс між інвестиціями в інженерний час та обладнання, і потенційною економією на хмарних ресурсах, підвищенням доходів за рахунок кращого UX і зниженням ризиків простою. У 2026 році цей баланс все більше зміщується в бік активної оптимізації, оскільки вартість неефективності зростає.
Кейси та приклади з реальної практики
Теорія важлива, але реальні приклади застосування оптимізацій демонструють їхню справжню цінність. Ось кілька сценаріїв з практики 2026 року, які показують, як різні підходи до оптимізації мережевого стека Linux допомагають вирішувати конкретні бізнес-завдання.
Кейс 1: Оптимізація API-шлюзу для хмарного SaaS-сервісу
Проблема: Великий SaaS-сервіс, що надає API для мобільних і веб-додатків, зіткнувся з високою затримкою і випадковими помилками Connection Refused під піковим навантаженням (до 50 000 RPS). Моніторинг показав, що CPU API-шлюзів (на основі Nginx і Envoy) було завантажено на 70-80%, а в логах ядра з'являлися повідомлення про переповнення LISTEN-backlog. Сервери працювали на інстансах AWS c5n.xlarge (4 vCPU, 10 Gbps NIC).
Рішення:
- Налаштування
sysctl:- Збільшено
net.core.somaxconnз 128 до 16384, аnet.ipv4.tcp_max_syn_backlogз 1024 до 8192. Це дозволило ядру обробляти більше одночасних спроб з'єднання. - Активовано
net.ipv4.tcp_tw_reuse = 1і зменшеноnet.ipv4.tcp_fin_timeout = 30, щоб швидше очищати порти після коротких HTTP-з'єднань. - Встановлено
net.ipv4.tcp_congestion_control = bbrдля кращої продуктивності через WAN.
- Збільшено
- Апаратні розвантаження NIC:
- Перевірено та активовано TSO, GSO, GRO за допомогою
ethtool -K eth0 rx on tx on sg on tso on gso on gro on. Це значно знизило навантаження на CPU, пов'язане з сегментацією та збиранням пакетів. - Налаштовано балансування IRQ за допомогою
irqbalanceта додатково вручну прив'язано черги RSS до різних vCPU, щоб рівномірно розподілити обробку переривань.
- Перевірено та активовано TSO, GSO, GRO за допомогою
- XDP для DDoS-захисту:
- Розгорнуто просту XDP-програму, яка на рівні драйвера NIC відкидає пакети з відомими сигнатурами DDoS-атак (наприклад, SYN-флуд з аномальними прапорами або джерелами) до того, як вони досягнуть основного мережевого стека та Nginx.
Результати:
- Помилки
Connection Refusedповністю зникли. - Середня затримка API знизилася на 15% (з 40 мс до 34 мс).
- Використання CPU на API-шлюзах впало з 70-80% до 40-50% під тим же навантаженням, що дозволило обробляти на 30% більше RPS на одному інстансі.
- Економія на хмарних ресурсах склала близько $1500 на місяць за рахунок скорочення кількості необхідних інстансів.
Кейс 2: Оптимізація платформи для потокової обробки даних в реальному часі
Проблема: Компанія, що займається аналізом фінансових даних в реальному часі, використовувала Kafka-кластер для прийому та обробки величезних обсягів даних (до 20 Гбіт/с вхідного трафіку на ноду). Виникали проблеми з втратою пакетів, що призводило до затримок в обробці та неточностей в аналітиці. Моніторинг показував високі значення rx_dropped та net.core.netdev_max_backlog переповнення.
Рішення:
- Збільшення буферів ядра:
- Значно збільшено
net.core.netdev_max_backlogдо 65535, а такожnet.core.rmem_maxтаnet.ipv4.tcp_rmemдо 32 МБ. Це дозволило ядру буферизувати більше вхідних пакетів в пікові моменти, запобігаючи їх втраті. - Налаштовано
net.ipv4.tcp_wmemдля Kafka-продюсерів для забезпечення більш ефективної відправки.
- Значно збільшено
- Оптимізація NIC:
- Використано 100GbE NIC з підтримкою SR-IOV для віртуальних машин, на яких працювали Kafka-брокери, що забезпечило майже нативну продуктивність мережі.
- Налаштовано черги RSS на максимальну кількість, що відповідає кількості ядер CPU, і вручну прив'язано IRQs, щоб уникнути конкуренції.
- eBPF для кастомної маршрутизації:
- Розроблено TC eBPF-програму, яка на основі заголовків повідомлень Kafka (або інших метаданих) перенаправляла певні потоки даних на спеціалізовані Kafka-топіки або навіть на інші вузли кластера, минаючи стандартну маршрутизацію ядра для "гарячих" даних. Це дозволило знизити навантаження на CPU стандартного мережевого стека та забезпечити більш прямий шлях для критично важливого трафіку.
Результати:
- Втрати пакетів скоротилися практично до нуля.
- Пропускна здатність кластера збільшилася на 25%, що дозволило обробляти пікові навантаження без деградації.
- Затримка обробки даних знизилася на 10%, що критично важливо для фінансових додатків.
- Зменшилася кількість ретрансмісій TCP, що знизило навантаження на CPU Kafka-брокерів.
Кейс 3: Зниження вартості інфраструктури для CDN-провайдера
Проблема: Великий CDN-провайдер зіткнувся з постійно зростаючими витратами на інфраструктуру через необхідність масштабувати кількість серверів для обслуговування пікового трафіку. Основне навантаження припадало на видачу статичного контенту (відео, зображення), що вимагало високої пропускної здатності та ефективного використання CPU для обслуговування великої кількості одночасних з'єднань.
Рішення:
- Вибір алгоритму TCP-перевантаження:
- На всіх CDN-нодах було активовано
net.ipv4.tcp_congestion_control = bbr. Це дозволило значно поліпшити пропускну здатність і знизити затримку для клієнтів, що знаходяться на великих відстанях або використовують мережі з високою затримкою, що особливо важливо для CDN.
- На всіх CDN-нодах було активовано
- Оптимізація буферів і
TIME_WAIT:- Буфери TCP були налаштовані на оптимальні значення для кожного типу серверів (для файлових серверів - великі, для проксі - середні).
net.ipv4.tcp_tw_reuse = 1було активовано на всіх проксі-серверах і серверах-джерелах, щоб уникнути вичерпання портів.
- Jumbo Frames:
- Всередині дата-центру, де це було можливо, налаштовано Jumbo Frames (MTU 9000) на всіх мережевих інтерфейсах і комутаторах. Це дозволило передавати більше даних за один пакет, знижуючи накладні витрати на заголовки і кількість пакетів, оброблюваних CPU.
- eBPF для L4-балансування:
- Замість використання дорогих апаратних балансувальників навантаження або більш ресурсоємних програмних рішень на основі Nginx, було розроблено XDP-програму для L4-балансування вхідного трафіку. Ця програма, що працює на граничних маршрутизаторах, розподіляла вхідні з'єднання по внутрішніх CDN-нодах з мінімальними накладними витратами і затримкою.
Результати:
- Загальна пропускна здатність CDN збільшилася на 20-30% без додавання нових серверів.
- Кількість серверів, необхідних для обслуговування пікового навантаження, скоротилася на 15%, що призвело до прямої економії на хмарних/колокейшн витратах в розмірі $5000-$8000 на місяць.
- Середня затримка доставки контенту для кінцевих користувачів знизилася.
- Значно знизилося навантаження на CPU на граничних серверах, що використовують XDP-балансування.
Ці кейси демонструють, що комплексний підхід до оптимізації мережевого стека Linux, що включає налаштування ядра, використання апаратних розвантажень і застосування eBPF, може привести до значних поліпшень продуктивності і істотної економії ресурсів в самих різних сценаріях.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Інструменти та ресурси для оптимізації та моніторингу
Для успішної оптимізації мережевого стеку Linux необхідний правильний набір інструментів для діагностики, тестування, моніторингу та налагодження. У 2026 році існує безліч потужних утиліт, багато з яких є частиною стандартного дистрибутива Linux або доступні як Open Source проєкти.
Утиліти для діагностики та налаштування
ip(iproute2): Сучасна замінаifconfigтаroute. Дозволяє керувати мережевими інтерфейсами, маршрутами, ARP-таблицями, а також переглядати детальну статистику.ip a show eth0 # Показати інформацію про інтерфейс ip -s link show eth0 # Показати статистику інтерфейсу (помилки, дропи) ip route show # Показати таблицю маршрутизаціїss(socket statistics): Більш швидка та потужна замінаnetstatдля перегляду інформації про сокети.ss -s # Загальна статистика по сокетах ss -tuna # Всі TCP/UDP сокети, що прослуховують та встановлені ss -tuna | grep ESTAB # Тільки встановлені TCP з'єднання ss -tuna | grep TIME-WAIT # Сокети в стані TIME_WAIT ss -m # Показати статистику по пам'яті, що використовується сокетамиnetstat: Класичний інструмент для мережевої статистики. Хочаssє кращим для нових систем,netstat -sнадає велику статистику по протоколах (TCP, UDP, IP).netstat -s # Загальна статистика по протоколахethtool: Утиліта для керування параметрами мережевих карт, включаючи апаратні розвантаження, швидкість, дуплекс, RSS та інші.ethtool eth0 # Загальна інформація про NIC ethtool -k eth0 # Стан апаратних розвантажень ethtool -S eth0 # Статистика драйвера NIC (включаючи помилки та дропи) ethtool -L eth0 # Кількість RX/TX чергsysctl: Утиліта для перегляду та зміни параметрів ядра Linux.sysctl -a | grep net.ipv4 # Всі параметри net.ipv4 sysctl -w net.core.somaxconn=4096 # Встановити параметрmpstat/top/htop: Для моніторингу використання CPU, особливо категорійsoftirq(si) таsystem, які часто вказують на мережеву активність ядра.mpstat -P ALL 1 # Використання CPU по ядрах, кожну секундуtcpdump/wireshark: Для захоплення та аналізу мережевого трафіку на рівні пакетів. Незамінні для глибокої діагностики.tcpdump -i eth0 -n -s 0 -w capture.pcap # Захоплення всього трафіку на eth0
Інструменти для моніторингу та тестування
iperf3: Стандарт для вимірювання пропускної здатності TCP та UDP. Дозволяє тестувати продуктивність між двома точками.iperf3 -s # Сервер iperf3 -c <server_ip> -P 10 -t 30 # Клієнт, 10 потоків, 30 секундnetperf: Більш просунутий інструмент для вимірювання продуктивності мережі, включаючи запити/відповіді, транзакції і т.д.wrk/locust/JMeter: Інструменти для навантажувального тестування веб-додатків та API. Допомагають імітувати реальне навантаження та виявляти вузькі місця.hping3: Інструмент для створення та аналізу TCP/IP пакетів, корисний для тестування фаєрволів, сканування портів та вимірювання затримки.- Prometheus + Grafana: Стандартна зв'язка для збору, зберігання та візуалізації метрик. За допомогою
node_exporterможна збирати всі системні метрики, включаючи мережеві. - ELK Stack (Elasticsearch, Logstash, Kibana): Для збору, аналізу та візуалізації логів, що допомагає виявляти мережеві помилки та аномалії.
Інструменти для eBPF
bcc-tools(BPF Compiler Collection): Набір потужних інструментів на основі eBPF для трасування, моніторингу та налагодження ядра Linux, включаючи мережевий стек. Дозволяє бачити, що відбувається з пакетами на різних рівнях.tcplife: Відображає час життя TCP-з'єднань.tcpconnect/tcpaccept: Відстежує встановлення TCP-з'єднань.dropwatch: Відстежує, де ядро відкидає пакети.xdp_stats: Статистика по XDP-програмах.
bpftool: Офіційна утиліта для керування eBPF-програмами, картами та об'єктами. Дозволяє завантажувати, вивантажувати програми, переглядати їх статус, отримувати статистику.bpftool prog show # Показати всі завантажені eBPF-програми bpftool map show # Показати всі eBPF-картиlibbpf: Бібліотека для розробки eBPF-додатків, спрощує взаємодію з ядром.
Корисні посилання та документація
- Документація ядра Linux по мережі: Офіційні документи по мережевому стеку.
- IO Visor Project та eBPF.io: Основні ресурси по eBPF, туторіали, приклади, документація.
- BCC GitHub Repository: Вихідний код та приклади
bcc-tools. - LWN.net: Відмінний ресурс для глибоких технічних статей про розвиток ядра Linux, включаючи мережевий стек та eBPF.
- TCP Documentation: Детальна інформація про параметри TCP в ядрі.
- DPDK.org: Офіційний сайт Data Plane Development Kit.
Використання цих інструментів та ресурсів дозволить вам не тільки ефективно оптимізувати мережевий стек, але й глибоко розуміти його поведінку, що критично важливо для підтримки високопродуктивних систем у 2026 році.
Troubleshooting: вирішення типових проблем

Навіть з самими ретельними налаштуваннями, проблеми в мережевому стеку можуть виникнути. Вміння швидко діагностувати та усувати їх - найважливіший навик. У цьому розділі ми розглянемо типові проблеми та запропонуємо діагностичні команди та рішення, актуальні для 2026 року.
1. Високе завантаження CPU (ksoftirqd / softirq)
Опис: Якщо top або mpstat показують високе завантаження CPU в категорії si (softirq) або процес ksoftirqd споживає багато ресурсів, це часто вказує на те, що ядро витрачає багато часу на обробку мережевих переривань.
Діагностика:
mpstat -P ALL 1: Подивитися завантаженняsoftirqпо кожному ядру. Якщо одне ядро сильно перевантажене, це може вказувати на проблему з балансуванням IRQ./proc/interrupts: Подивитися розподіл IRQ по ядрам. Шукайте IRQ, пов'язані з вашою NIC.ethtool -S <interface> | grep rx_queue: Перевірити кількість пакетів, прийнятих кожною чергою RX. Якщо одна черга приймає значно більше пакетів, це проблема.
Рішення:
- Активуйте RSS/RPS/RFS: Переконайтеся, що апаратний RSS включений на NIC (
ethtool -k <interface>). Якщо ні, або на додаток, налаштуйте RPS/RFS (/sys/class/net/<interface>/queues/rx-<N>/rps_cpus). - Налаштуйте
irqbalance: Переконайтеся, що службаirqbalanceзапущена. Для більш точного контролю розгляньте ручне прив'язування IRQ до CPU. - Перевірте offloads: Переконайтеся, що TSO, GSO, GRO включені (
ethtool -k <interface>). - Розгляньте XDP: Для дуже високих PPS, XDP може значно знизити навантаження на CPU, відкидаючи або перенаправляючи трафік на ранній стадії.
2. Втрати пакетів (Packet Drops)
Опис: Додатки повідомляють про тайм-аути, повільну роботу, або netstat -s показує зростаючі лічильники packet receive errors, dropped, overruns.
Діагностика:
ip -s link show <interface>: Перевірити лічильникиrx_dropped,tx_dropped,overruns.netstat -s: Перевірити статистику TCP (segments retransmited), UDP (packet receive errors).ss -s: Перевіритиrecv-Qіsend-Qдля сокетів, а також глобальні лічильники.ethtool -S <interface>: Перевірити лічильники помилок і дропів на рівні драйвера NIC (наприклад,rx_dropped_by_nic,rx_fifo_errors).dmesg | grep "tx ring": Пошукати повідомлення про переповнення буферів NIC.
Рішення:
- Збільште буфери ядра:
net.core.netdev_max_backlog,net.core.rmem_max,net.ipv4.tcp_rmem,net.ipv4.tcp_wmem. - Збільште TX-чергу NIC:
ip link set dev <interface> txqueuelen <value>(наприклад, 10000). - Перевірте фізичний рівень: Несправний кабель, порт комутатора, або несумісність швидкості/дуплексу можуть викликати дропи.
- Усуньте перевантаження CPU: Якщо дропи пов'язані з високим завантаженням CPU, застосуйте рішення з пункту 1.
- XDP для раннього відкидання: Якщо дропи викликані небажаним трафіком (DDoS), XDP може відкидати його до переповнення буферів.
3. Повільні з'єднання або висока затримка
Опис: Додатки відповідають повільно, ping показує високий RTT, traceroute виявляє затримки на мережевому шляху.
Діагностика:
ping <destination>: Виміряйте RTT.traceroute <destination>: Визначте, на якому хості/маршрутизаторі виникає затримка.ss -tin: Перевірити RTT для встановлених TCP-з'єднань.netstat -s | grep "retransmited": Висока кількість ретрансмісій вказує на втрати пакетів, які збільшують затримку.
Рішення:
- Перевірте алгоритм управління перевантаженнями: Встановіть
net.ipv4.tcp_congestion_control = bbr, особливо для WAN-з'єднань. - Налаштуйте буфери: Переконайтеся, що
tcp_rmemіtcp_wmemдостатньо великі для вашої смуги пропускання і затримки. - Увімкніть TCP Fast Open:
net.ipv4.tcp_fastopen = 3для скорочення затримки встановлення з'єднань. - Усуньте втрати пакетів: Якщо затримка викликана ретрансмісіями, вирішіть проблему втрат пакетів.
- Перевірте MTU: Неузгоджене MTU може призводити до фрагментації і зниження продуктивності.
4. "Connection refused" або "Too many open files"
Опис: Додатки не можуть встановити нові з'єднання, сервери відмовляються приймати з'єднання.
Діагностика:
ss -s | grep -i "listen": Перевірити кількість сокетів в стані LISTEN і їх backlog.dmesg | grep "TCP: request_sock_TCP: dropped": Повідомлення про скинуті SYN-пакети.ulimit -n: Перевірити ліміт на кількість відкритих файлових дескрипторів для процесу.cat /proc/sys/fs/file-nr: Загальна кількість відкритих файлових дескрипторів в системі.
Рішення:
- Збільште
somaxconnіtcp_max_syn_backlog:net.core.somaxconn,net.ipv4.tcp_max_syn_backlog. - Збільште ліміт файлових дескрипторів: Налаштуйте
ulimit -nдля користувача/додатка і системний лімітfs.file-maxвsysctl. - Перевірте
TIME_WAITсокети: Якщо багато сокетів вTIME_WAIT, активуйтеnet.ipv4.tcp_tw_reuse = 1. - Перевірте фаєрвол: Переконайтеся, що фаєрвол (
iptables,nftables) не блокує вхідні з'єднання.
5. Неефективне використання CPU на NUMA-системах
Опис: На серверах з архітектурою NUMA (Non-Uniform Memory Access) спостерігається нерівномірне завантаження CPU, або додатки відчувають затримки при доступі до пам'яті, хоча загальне завантаження CPU невисоке.
Діагностика:
numactl --hardware: Перевірити топологію NUMA.numastat: Статистика використання пам'яті по NUMA-вузлах.mpstat -N ALL: Завантаження CPU по NUMA-вузлах.
Рішення:
- Прив'язка IRQ до NUMA-вузлів: Прив'яжіть IRQ мережевої карти до CPU, що знаходяться на тому ж NUMA-вузлі, що і NIC.
- Прив'язка процесів до NUMA-вузлів: Використовуйте
numactl --cpunodebind=<node> --membind=<node> <command>для запуску мережевих додатків на тому ж NUMA-вузлі, що і відповідна NIC. - Налаштування RPS/RFS з урахуванням NUMA: При налаштуванні RPS/RFS переконайтеся, що пакети направляються на CPU, які знаходяться на тому ж NUMA-вузлі, де і обробник додатка.
Коли звертатися до підтримки:
- Якщо проблеми виникають після оновлення ядра або драйвера NIC, і ви не можете знайти рішення.
- Якщо ви підозрюєте апаратну несправність NIC, але не можете її підтвердити.
- Якщо ви зіткнулися з незрозумілими падіннями або зависаннями системи, пов'язаними з мережевим стеком.
- Якщо ви не можете досягти очікуваної продуктивності після всіх застосованих оптимізацій і вичерпали свої знання.
FAQ: Часті запитання
1. Чи eBPF завжди є найкращим рішенням для оптимізації мережі?
Ні, не завжди. eBPF — це потужний інструмент, який пропонує безпрецедентну гнучкість і продуктивність для певних задач, таких як DDoS-захист, кастомне балансування навантаження або розширений моніторинг. Однак його впровадження вимагає високої кваліфікації та значних інженерних зусиль. Для більшості стандартних високонавантажених застосунків, таких як веб-сервери або бази даних, достатніми та простішими у реалізації будуть тонке налаштування sysctl, активація апаратних розвантажень NIC і правильний вибір алгоритму TCP-перевантаження. eBPF слід розглядати, коли інші методи вичерпано або потрібна дуже специфічна, низькорівнева логіка обробки пакетів.
2. Чи варто вимикати всі TCP-таймстампи (tcp_timestamps) для підвищення продуктивності?
tcp_timestamps) для підвищення продуктивності?У більшості випадків ні. Хоча вимкнення tcp_timestamps заощаджує 12 байт у кожному TCP-заголовку, це несуттєва економія для сучасних високошвидкісних мереж. Тимчасові мітки відіграють важливу роль у захисті від застарілих сегментів (PAWS - Protection Against Wrapped Sequence numbers) і в більш точному вимірюванні RTT. Їх вимкнення може призвести до проблем зі стабільністю з'єднань, особливо в мережах з високою затримкою або при дуже швидкому створенні/закритті з'єднань. Рекомендується залишати їх увімкненими, якщо немає конкретних доказів того, що вони спричиняють проблеми.
3. Як часто слід переглядати налаштування мережевого стека?
Налаштування мережевого стека не є статичними. Їх слід переглядати при значних змінах:
- Оновлення ядра Linux: Нові версії можуть приносити нові параметри або змінювати поведінку існуючих.
- Оновлення апаратного забезпечення: Нові NIC можуть мати інші можливості розвантаження.
- Зміна профілю навантаження застосунку: Зростання трафіку, зміна типів запитів, збільшення кількості з'єднань.
- Виникнення нових мережевих проблем: Втрати пакетів, висока затримка, перевантаження CPU.
4. Який вплив tcp_tw_reuse на безпеку?
tcp_tw_reuse на безпеку?tcp_tw_reuse дозволяє повторно використовувати сокети в стані TIME_WAIT для нових вихідних з'єднань. Це безпечно для клієнтів або проксі, які ініціюють безліч з'єднань. Однак на сервері, який приймає вхідні з'єднання, активація tcp_tw_reuse може бути ризикованою, якщо цей сервер знаходиться за NAT, який не дотримується RFC 1323 (TCP Timestamps). У такому випадку, сервер може прийняти пакет з застарілим номером послідовності від нового з'єднання, помилково прийнявши його за частину старого, що може призвести до пошкодження даних або нестабільності. Тому tcp_tw_reuse зазвичай рекомендується активувати тільки на клієнтських машинах або на серверах, які не знаходяться за NAT і не приймають вхідні з'єднання.
5. Чи можуть ці оптимізації порушити роботу мого застосунку?
Так, неправильна оптимізація може призвести до нестабільності, зниження продуктивності або навіть падіння системи. Наприклад, занадто великі буфери можуть призвести до збільшення затримки (bufferbloat), а занадто маленькі — до втрат пакетів. Неправильне налаштування IRQ або RSS може викликати дисбаланс навантаження на CPU. Саме тому вкрай важливий ітеративний підхід: вносьте зміни по одній, тестуйте їх у контрольованому середовищі, моніторте ефект і будьте готові до відкату. Ніколи не застосовуйте зміни в продакшн без попереднього тестування.
6. Яка роль systemd-networkd і NetworkManager в контексті цих оптимізацій?
systemd-networkd і NetworkManager в контексті цих оптимізацій?systemd-networkd і NetworkManager — це служби, які керують мережевими інтерфейсами та їх конфігурацією на більш високому рівні. Вони відповідають за призначення IP-адрес, налаштування DNS, маршрутизацію та інші базові мережеві параметри. Більшість описаних тут оптимізацій (sysctl, ethtool) діють на більш низькому рівні ядра або драйвера NIC і, як правило, не конфліктують з цими службами. Однак важливо переконатися, що ці служби не перевизначають ваші ручні налаштування (наприклад, MTU, або деякі параметри ethtool). Для збереження налаштувань ethtool після перезавантаження часто потрібні додаткові скрипти або конфігураційні файли, специфічні для вашої системи ініціалізації.
7. Як хмарні середовища впливають на ці оптимізації?
У хмарних середовищах (AWS, GCP, Azure) ви працюєте з віртуалізованим обладнанням. Деякі апаратні розвантаження NIC (наприклад, SR-IOV) можуть бути доступні тільки на певних типах інстансів. Можливості налаштування ядра залишаються, але можуть бути обмеження на зміну деяких параметрів в контейнерних середовищах (наприклад, в Kubernetes, де деякі sysctl можуть бути заблоковані). Часто хмарні провайдери вже застосовують базові оптимізації на рівні гіпервізора. Важливо консультуватися з документацією вашого хмарного провайдера щодо доступних мережевих функцій і рекомендацій щодо оптимізації для їх платформи.
8. Коли слід розглядати користувацький простір (DPDK) замість eBPF?
DPDK слід розглядати тільки в самих екстремальних сценаріях, коли навіть XDP-оптимізації не забезпечують необхідної продуктивності. Це зазвичай відноситься до телекомунікаційних систем, високочастотного трейдингу (HFT), спеціалізованих маршрутизаторів/фаєрволів і NFV, де потрібна обробка десятків мільйонів пакетів в секунду з мікросекундними затримками. Впровадження DPDK вимагає повного обходу мережевого стека ядра, що означає, що ваш застосунок повинен бути написаний або переписаний для роботи з бібліотеками DPDK. Це значно збільшує складність розробки, підтримки і втрачає переваги стандартних мережевих утиліт Linux.
9. Яке майбутнє мережевої оптимізації за межами eBPF?
Майбутнє мережевої оптимізації в 2026 році і далі обіцяє бути захоплюючим. Продовжиться розвиток eBPF, з'являться нові типи програм і точки прикріплення, розширяться можливості апаратних розвантажень. Ми побачимо більше інтеграції зі штучним інтелектом і машинним навчанням для адаптивної оптимізації мережі в реальному часі, передбачення перевантажень і автоматичного застосування налаштувань. Також будуть розвиватися технології, такі як SmartNICs (програмовані мережеві карти з власними CPU/FPGA), які будуть брати на себе ще більше мережевої логіки. Квантові мережі і нові протоколи також можуть внести свої корективи, але базові принципи ефективної обробки пакетів залишаться актуальними.
10. Чи безпечно використовувати BBR на продакшені?
Так, BBR вважається безпечним для використання на продакшені та часто рекомендується. Він був розроблений Google і широко використовується в їхній інфраструктурі, а також у багатьох CDN та хмарних сервісах. BBR зазвичай забезпечує кращу пропускну здатність і меншу затримку порівняно з CUBIC, особливо на WAN-з'єднаннях. Однак, як і будь-який алгоритм управління перевантаженнями, BBR може бути більш агресивним у певних мережевих умовах, що потенційно може витісняти трафік, який використовує старіші алгоритми. У більшості випадків це не є проблемою, але в дуже специфічних, сильно перевантажених мережах з різнорідним трафіком, може знадобитися додатковий моніторинг.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Висновок
В умовах постійно зростаючих вимог до продуктивності та масштабованості сучасних застосунків, оптимізація мережевого стеку Linux перестала бути опціональною задачею і перетворилася на критично важливий елемент успішної інфраструктури. У 2026 році, коли кожна мілісекунда затримки і кожен відсоток використання CPU можуть напряму впливати на бізнес-метрики, глибоке розуміння і вміле застосування технік оптимізації є конкурентною перевагою.
Ми пройшли шлях від базових налаштувань ядра за допомогою sysctl, які залишаються фундаментом для більшості систем, до використання передових апаратних розвантажень мережевих карт, здатних значно знизити навантаження на CPU. Особливу увагу було приділено eBPF — технології, яка революціонізує мережеву обробку, надаючи безпрецедентні можливості для програмування ядра без його модифікації, відкриваючи двері для високопродуктивних фаєрволів, балансувальників навантаження та систем моніторингу, які працюють зі швидкістю лінії. Ми також розглянули екстремальні рішення, такі як DPDK, для найвимогливіших сценаріїв.
Ключові висновки, які ви повинні засвоїти:
- Вимірювання — це все: Ніколи не оптимізуйте наосліп. Завжди починайте з бенчмаркінгу і постійно моніторте вплив змін.
- Комплексний підхід: Оптимізація — це багаторівневий процес, який зачіпає ядро, драйвери, апаратне забезпечення і навіть застосунки.
- Ітеративність і обережність: Вносьте зміни поступово, тестуйте в ізольованому середовищі і завжди майте план відкату.
- Розуміння контексту: Немає універсальних "найкращих" налаштувань. Оптимальна конфігурація залежить від вашого специфічного навантаження, апаратного забезпечення і мережевого середовища.
- eBPF — майбутнє, але не панацея: Потужний інструмент, що вимагає глибоких знань, але не завжди необхідний. Почніть з простіших методів.
Наступні кроки для читача:
Почніть з аудиту вашої поточної інфраструктури. Визначте вузькі місця, використовуючи інструменти діагностики, описані в цій статті. Потім, застосовуючи чекліст, почніть з базових налаштувань sysctl і ethtool. Постійно вимірюйте і порівнюйте результати. У міру поглиблення в проблеми продуктивності, розгляньте більш просунуті методи, такі як eBPF. Інвестуйте в навчання вашої команди, щоб вони могли ефективно використовувати ці потужні інструменти.
Світ мережевих технологій Linux постійно розвивається. Залишайтеся допитливими, експериментуйте і не бійтеся занурюватися в глибини ядра. Тільки так ви зможете побудувати по-справжньому високопродуктивні та відмовостійкі системи, здатні витримати будь-які навантаження 2026 року і далі.