
Мультихмарне та гібридне управління ресурсами з Terraform: Від VPS до Kubernetes
TL;DR
- Стратегічна необхідність: Мультихмарні та гібридні підходи стають стандартом до 2026 року для забезпечення відмовостійкості, оптимізації витрат і зниження ризиків вендор-локу.
- Terraform як фундамент: Terraform є де-факто стандартом для Infrastructure as Code (IaC), дозволяючи уніфікувати управління ресурсами на будь-якій платформі — від локальних VPS до складних кластерів Kubernetes в декількох хмарах.
- Ключові вигоди: Пришвидшене розгортання, автоматизація операцій, зниження людського фактору, консистентність конфігурацій та ефективне управління життєвим циклом інфраструктури.
- Складнощі та рішення: Управління станом, мережева зв'язність, безпека та оптимізація витрат вимагають продуманої архітектури, використання модулів, віддаленого стану та інструментів на зразок Terragrunt.
- Економія та ефективність: Грамотне застосування Terraform у мультихмарному середовищі дозволяє не тільки уникнути переплат, але й забезпечити гнучкість для швидкого масштабування та адаптації до мінливих бізнес-вимог.
- Майбутнє вже тут: Інтеграція з GitOps, автоматизоване тестування та просунутий моніторинг перетворюють Terraform на центральний елемент сучасної DevOps-стратегії.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Вступ
До 2026 року ландшафт ІТ-інфраструктури зазнав значних змін. Монолітні застосунки, що живуть на одному сервері, поступилися місцем розподіленим мікросервісним архітектурам, розгорнутим у хмарах. Однак просте переміщення в одну хмару вже не є панацеєю. Бізнес вимагає максимальної відмовостійкості, гнучкості, оптимізації витрат та незалежності від одного постачальника. Саме тут на сцену виходять концепції мультихмарності та гібридних інфраструктур.
Мультихмарність передбачає використання кількох публічних хмарних провайдерів (наприклад, AWS, Azure, Google Cloud, Yandex.Cloud) для різних частин однієї системи або для різних систем, в той час як гібридний підхід комбінує публічні хмари з власною онпремісною інфраструктурою (приватною хмарою або традиційними серверами). Це дозволяє компаніям використовувати найкращі риси кожного підходу: масштабованість та інновації публічних хмар у поєднанні з контролем, безпекою та низькою затримкою власної інфраструктури.
Однак управління такою складною, розподіленою інфраструктурою без адекватних інструментів швидко перетворюється на хаос. Ручні налаштування, різнорідні API, розрізнені скрипти – все це веде до помилок, затримок та величезних операційних витрат. Тут на допомогу приходить Infrastructure as Code (IaC), і його флагман – Terraform від HashiCorp.
Ця стаття адресована DevOps-інженерам, backend-розробникам, фаундерам SaaS-проектів, системним адміністраторам та технічним директорам стартапів, які прагнуть ефективно управляти своєю інфраструктурою у 2026 році. Ми розглянемо, як Terraform дозволяє уніфікувати розгортання та управління ресурсами на всіх рівнях: від простих віртуальних приватних серверів (VPS) до високодоступних кластерів Kubernetes, охоплюючи як публічні, так і приватні хмари. Ми заглибимося в практичні аспекти, розберемо типові помилки та запропонуємо конкретні рішення, засновані на реальному досвіді.
Мета цієї статті — не просто розповісти про можливості Terraform, а дати вичерпне практичне керівництво, яке дозволить читачеві впевнено проектувати, розгортати та підтримувати свою мультихмарну або гібридну інфраструктуру, мінімізуючи ризики та максимізуючи вигоди.
Основні критерії та фактори вибору стратегії мультихмарності та гібридного підходу
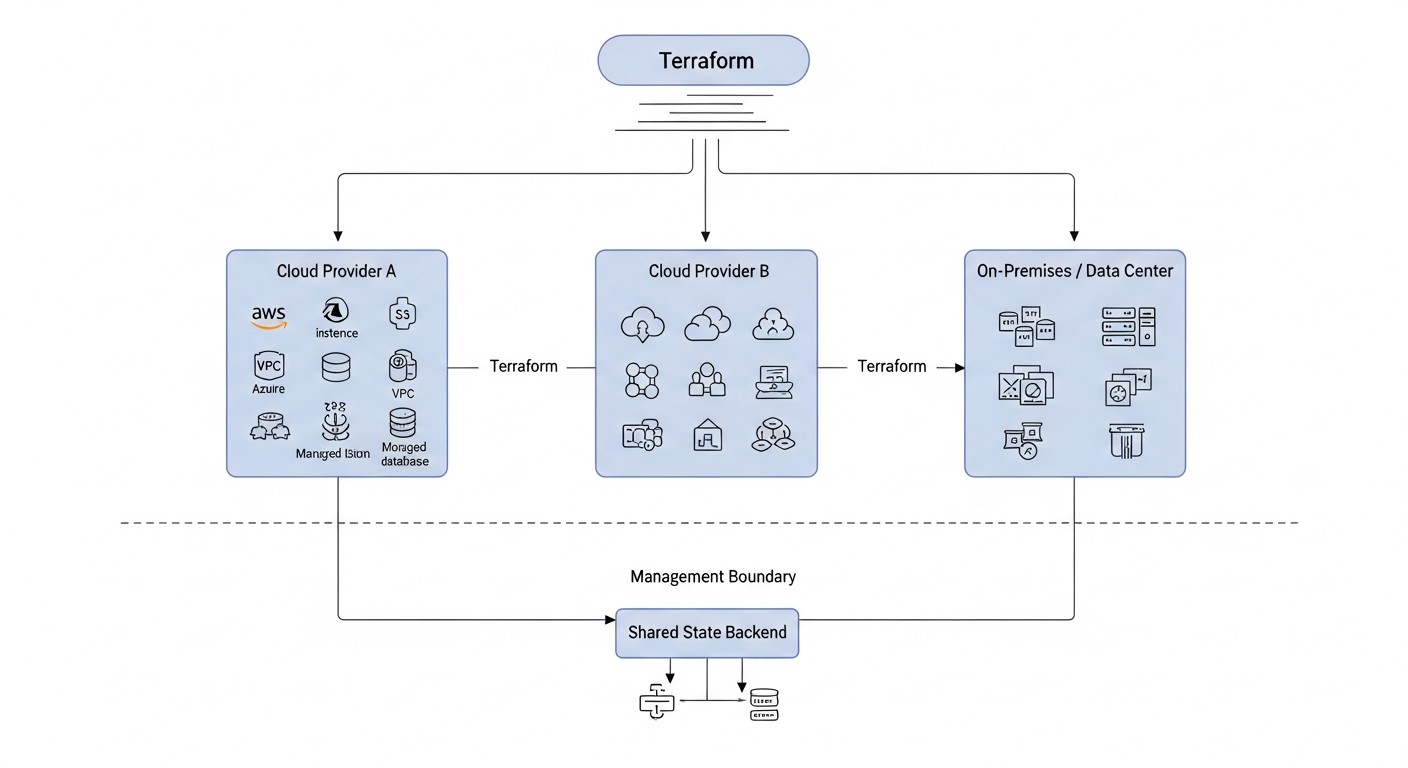
Вибір оптимальної стратегії для мультихмарної або гібридної інфраструктури — це не просто технічне рішення, а стратегічне. Воно має бути глибоко інтегровано з бізнес-цілями, вимогами до продуктивності, безпеки та бюджетом. Нижче представлені ключові критерії, які необхідно враховувати при плануванні.
1. Зниження вендор-локу (Vendor Lock-in)
Чому важливий: Залежність від одного хмарного провайдера може призвести до складнощів при міграції, високих витрат у довгостроковій перспективі та обмежень у використанні інноваційних сервісів інших провайдерів. У 2026 році, коли хмарні ринки стали ще більш конкурентними, здатність легко перемикатися між провайдерами або розподіляти робочі навантаження є критично важливою.
Як оцінювати: Оцініть ступінь абстракції ваших застосунків від специфічних хмарних сервісів. Чи використовуєте ви стандартні API (наприклад, Kubernetes, SQL) або глибоко інтегровані з пропрієтарними PaaS-рішеннями? Terraform, використовуючи декларативний підхід, дозволяє абстрагуватися від низькорівневих API кожного провайдера, але сам код Terraform все ще прив'язаний до провайдерів. Важливо використовувати загальні абстракції (наприклад, Kubernetes) і уникати глибокої прив'язки до специфічних managed-сервісів.
2. Відмовостійкість та аварійне відновлення (Disaster Recovery, DR)
Чому важливо: Бізнес-критичні додатки мають бути доступні 24/7. Відмова цілого регіону в одного провайдера, хоч і рідкісна, може призвести до катастрофічних наслідків. Мульти-хмарна стратегія DR (наприклад, active-passive або active-active) забезпечує безперервність роботи.
Як оцінювати: Визначте цільові показники RTO (Recovery Time Objective) та RPO (Recovery Point Objective). Який час простою допустимий? Скільки даних можна втратити? Для active-passive DR Terraform може розгорнути мінімальний набір ресурсів у резервній хмарі, готовий до активації. Для active-active потрібна складніша синхронізація даних та маршрутизація трафіку.
3. Оптимізація витрат
Чому важливо: Ціни на хмарні ресурси постійно змінюються, і провайдери пропонують різні знижки та моделі ціноутворення. Мульти-хмара дозволяє вибирати найбільш економічно вигідного провайдера для конкретного робочого навантаження або навіть динамічно перемикатися між ними. Гібрид може бути вигідний для стабільних, передбачуваних навантажень на власному обладнанні.
Як оцінювати: Проведіть детальний аналіз TCO (Total Cost of Ownership) для кожного варіанта. Враховуйте не тільки вартість обчислювальних ресурсів, але й мережевий трафік (особливо вихідний та міжхмарний), зберігання даних, managed-сервіси, ліцензії та операційні витрати. У 2026 році вартість вихідного трафіку, як і раніше, залишається одним із прихованих "податків" хмари.
4. Продуктивність та затримка (Latency)
Чому важливо: Для додатків, чутливих до затримок (наприклад, онлайн-ігри, фінансові транзакції, IoT), розташування ресурсів має першорядне значення. Розміщення сервісів ближче до кінцевих користувачів або до джерел даних покращує користувацький досвід.
Як оцінювати: Виміряйте затримки між різними регіонами та провайдерами, а також між вашою онпремісною інфраструктурою та хмарами. Для гібридних сценаріїв критична пропускна здатність та стабільність VPN/Direct Connect з'єднань. Terraform може допомогти у розгортанні CDN або Edge-сервісів для мінімізації затримок.
5. Відповідність вимогам та безпека (Compliance & Security)
Чому важливо: Регулюючі органи (GDPR, HIPAA, PCI DSS та ін.) часто накладають суворі вимоги на зберігання та обробку даних, а також на їх географічне розташування. Різні провайдери можуть пропонувати різні сертифікації та рівні безпеки.
Як оцінювати: Проаналізуйте вимоги до даних: де вони можуть зберігатися, хто має до них доступ. Оцініть сертифікації кожного провайдера та їхні можливості щодо забезпечення відповідності. Terraform дозволяє автоматизувати розгортання ресурсів із заданими політиками безпеки (наприклад, IAM, мережеві правила, шифрування даних).
6. Операційна складність та навички команди
Чому важливо: Управління кількома хмарами або гібридним середовищем значно складніше, ніж управління однією хмарою. Потрібні спеціалізовані знання та інструменти. Недооцінка цього фактора може призвести до збільшення операційних витрат та вигоряння команди.
Як оцінювати: Оцініть поточний рівень компетенції вашої команди. Чи мають вони досвід роботи з кількома хмарами? Чи готові вони вивчати нові API та інструменти? Terraform стандартизує процес розгортання, але вимагає глибокого розуміння провайдерів, з якими він працює. Використання модулів Terraform може значно знизити складність.
7. Гравітація даних (Data Gravity)
Чому важливо: Великі обсяги даних мають "гравітацію" – їх переміщення дороге та повільне. Часто додатки мігрують до даних, а не навпаки. Це особливо актуально для гібридних сценаріїв, де масиви даних можуть залишатися онпреміс.
Як оцінювати: Визначте, де знаходяться ваші основні сховища даних і наскільки часто потрібна їх синхронізація або доступ до них із різних середовищ. Якщо дані критично важливі та їх обсяг величезний, можливо, гібридний підхід із збереженням даних онпреміс або в одній хмарі, а обчислювальних ресурсів в іншій, буде оптимальним.
Ретельний аналіз цих критеріїв дозволить вашій команді прийняти обґрунтоване рішення щодо вибору стратегії мульти-хмари або гібридного підходу, а Terraform стане потужним інструментом для її реалізації.
Порівняльна таблиця стратегій мульти-хмарного та гібридного управління з Terraform (Актуально для 2026 року)

У цій таблиці ми порівняємо різні стратегії впровадження мульти-хмарних та гібридних підходів, оцінюючи їх за ключовими параметрами, актуальними для 2026 року. Передбачається, що у всіх сценаріях використовується Terraform для управління інфраструктурою.
| Критерій | Моно-хмара (для порівняння) | Мульти-хмара: Активно-пасивне DR | Мульти-хмара: Активно-активне | Гібрид: Хмара + Онпреміс (дані онпреміс) | Гібрид: Хмара + Онпреміс (розширення потужностей) |
|---|---|---|---|---|---|
| Зниження вендор-лока | Низьке (висока прив'язка) | Середнє (можливість міграції) | Високе (розподіл навантаження) | Середнє (залежність від онпреміс) | Середнє (залежність від онпреміс) |
| Відмовостійкість (DR) | Низька (вразливість до відмов регіону) | Висока (перемикання на резервну хмару) | Дуже висока (миттєве перемикання) | Середня (залежить від онпреміс DR) | Середня (залежить від онпреміс DR) |
| Оптимізація витрат | Середня (залежить від знижок) | Середня (резервні ресурси) | Висока (вибір найкращого провайдера) | Висока (стабільні навантаження онпреміс) | Висока (динамічне масштабування) |
| Продуктивність/Затримка | Висока (в рамках регіону) | Висока (в рамках активного регіону) | Дуже висока (найближчий регіон до користувача) | Низька (міжхмарні затримки) | Середня (міжхмарні затримки) |
| Складність впровадження (Terraform) | Низька | Середня (два провайдери, синхронізація) | Висока (кілька провайдерів, балансування, дані) | Висока (інтеграція з онпреміс, мережа) | Висока (автомасштабування, мережа) |
| Операційні витрати (OpEx) | Низькі | Середні | Високі (моніторинг, балансування) | Середні (підтримка онпреміс) | Середні (підтримка онпреміс, хмари) |
| Застосовність для даних | Локально | Реплікація в резерв | Розподілені бази даних/синхронізація | Переважно онпреміс (Data Gravity) | Розширення сховищ у хмару |
| Типова вартість (умовні одиниці, 2026) | X | 1.3X - 1.8X | 1.5X - 2.5X | 0.8X - 1.5X | 0.9X - 1.7X |
| Рекомендовані інструменти Terraform | Core, Providers | Core, Providers, Modules, Remote State | Core, Providers, Modules, Terragrunt, Cross-Cloud Networking | Core, Providers (vSphere/OpenStack), VPN/Direct Connect | Core, Providers (vSphere/OpenStack), Kubernetes Provider |
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Детальний огляд кожної стратегії
Кожна з розглянутих стратегій має свої унікальні переваги та недоліки. Вибір залежить від специфічних вимог бізнесу, технічної зрілості команди та бюджету. Terraform є ключовим інструментом для реалізації будь-якої з цих стратегій, забезпечуючи консистентність та автоматизацію.
1. Моно-хмара (для порівняння)
Хоча ця стаття присвячена мульти-хмарі та гібридним підходам, важливо розуміти базову стратегію моно-хмари для контрасту. У цьому сценарії вся інфраструктура розгорнута в одного хмарного провайдера (наприклад, AWS, Azure, Google Cloud). Terraform активно використовується для управління всіма ресурсами в рамках цієї хмари.
- Плюси:
- Простота: Менше провайдерів, менше API, менше інструментів для вивчення. Команда фокусується на одній екосистемі.
- Інтеграція: Глибока інтеграція між сервісами одного провайдера, часто з низькою затримкою та високою пропускною здатністю.
- Вартість: Потенційно нижча за рахунок оптових знижок та уніфікованого білінгу, особливо для стабільних навантажень.
- Мінуси:
- Вендор-лок: Висока прив'язка до одного провайдера, що ускладнює міграцію та обмежує можливості вибору.
- Відмовостійкість: Вразливість до глобальних збоїв у регіоні провайдера. DR можливий тільки в рамках однієї хмари.
- Обмеження: Неможливість використовувати кращі сервіси від різних провайдерів.
- Для кого підходить: Стартапи на ранніх стадіях, невеликі проєкти з обмеженим бюджетом, компанії без суворих вимог до DR або з готовністю прийняти ризик вендор-лока.
- Приклад використання: SaaS-проєкт, розгорнутий повністю в AWS, що використовує EC2, RDS, S3 та EKS, яким керують через один Terraform-репозиторій.
2. Мульти-хмара: Активно-пасивне DR
У цій стратегії основне робоче навантаження працює в одній хмарі (активне), а в іншій хмарі (пасивне) підтримується мінімальний набір ресурсів, готових до активації у випадку збою основного. Дані реплікуються між хмарами.
- Плюси:
- Висока відмовостійкість: Захист від глобальної відмови одного хмарного провайдера. Швидке перемикання (в залежності від RTO).
- Зниження вендор-лока: Дозволяє при необхідності мігрувати на резервну хмару або використовувати її для нових проєктів.
- Відносно низькі витрати на DR: Пасивна хмара містить тільки необхідний мінімум ресурсів, що знижує OpEx у порівнянні з актив-актив.
- Мінуси:
- Складність реплікації даних: Забезпечення консистентності даних між хмарами може бути складною задачею, особливо для великих обсягів.
- Вартість: Незважаючи на "пасивність", резервна хмара все одно вимагає деяких ресурсів та витрат на реплікацію.
- RTO: Час перемикання може бути значним, в залежності від автоматизації та обсягу розгортання ресурсів.
- Для кого підходить: Компанії, яким потрібна висока відмовостійкість, але немає суворих вимог до RTO в секундах. Бізнес-критичні програми, де допустимо кілька хвилин або годин простою при катастрофі.
- Приклад використання: Основний кластер Kubernetes в GKE (Google Cloud), резервний набір ресурсів (VPC, балансувальник, пустий кластер AKS) в Azure, дані реплікуються через S3-compatible сховища або спеціалізовані інструменти для баз даних. Terraform розгортає обидва набори ресурсів.
3. Мульти-хмара: Активно-активне
У цьому сценарії робоче навантаження активно розподіляється між кількома хмарами, кожна з яких обробляє частину трафіку. Це забезпечує максимальну відмовостійкість та продуктивність, але значно збільшує складність.
- Плюси:
- Максимальна відмовостійкість: Відмова однієї хмари не впливає на доступність сервісу, так як трафік просто перенаправляється на інші активні хмари.
- Оптимізація продуктивності: Розміщення ресурсів ближче до користувачів по всьому світу, зниження затримок.
- Оптимізація витрат: Можливість динамічно розподіляти навантаження між провайдерами, вибираючи найбільш вигідні ціни в даний момент.
- Нульовий вендор-лок: Максимальна незалежність, можливість легко перемикатися.
- Мінуси:
- Найвища складність: Потрібна дуже складна архітектура для синхронізації даних, глобального балансування навантаження, розподіленого стану та моніторингу.
- Високі витрати: Утримання декількох повністю активних середовищ, а також витрати на міжхмарний трафік та інструменти синхронізації.
- Складність розробки: Додатки повинні бути спроєктовані для роботи в розподіленому середовищі, з урахуванням eventual consistency та інших патернів.
- Для кого підходить: Глобальні SaaS-платформи, високонавантажені сервіси, що потребують максимальної доступності та мінімальної затримки, фінансові системи, e-commerce з міжнародною аудиторією.
- Приклад використання: Глобальна розподілена система, де фронтенд та stateless-мікросервіси розгорнуті в EKS (AWS) та GKE (Google Cloud), а дані синхронізуються через розподілену базу даних (наприклад, CockroachDB або Cassandra). Глобальне балансування трафіку здійснюється через DNS (Route 53, Cloud DNS) або спеціалізовані сервіси. Terraform управляє всіма компонентами в обох хмарах.
4. Гібрид: Хмара + Онпреміс (дані онпреміс)
Ця стратегія передбачає розміщення чутливих даних або застарілих систем у власній онпреміс інфраструктурі, в той час як обчислювальні ресурси або менш чутливі програми розгортаються в публічній хмарі. Хмара використовується як розширення дата-центру.
- Переваги:
- Відповідність вимогам: Ідеально для компаній зі строгими регуляторними вимогами до зберігання даних (наприклад, державні установи, банки).
- Контроль: Повний контроль над даними та інфраструктурою онпреміс.
- Використання застарілих систем: Дозволяє поступово модернізувати інфраструктуру, не переносячи відразу всі "моноліти" в хмару.
- Зниження витрат: Для стабільних, передбачуваних навантажень онпреміс може бути дешевшим за хмару в довгостроковій перспективі.
- Недоліки:
- Складність інтеграції: Забезпечення надійного та безпечного мережевого з'єднання (VPN, Direct Connect) між хмарою та онпреміс.
- Затримки: Високі затримки при доступі хмарних додатків до онпремісних даних.
- Управління: Потребує управління двома різними середовищами з різними наборами інструментів (хоча Terraform може допомогти).
- Для кого підходить: Великі підприємства, фінансові організації, державні структури, компанії з великими обсягами даних, які не можуть бути легко переміщені в хмару.
- Приклад використання: Корпоративна ERP-система та бази даних залишаються на онпреміс-серверах, а нові мікросервіси та API розгортаються в публічній хмарі (наприклад, Yandex.Cloud) і отримують доступ до даних через захищене VPN-з'єднання. Terraform управляє хмарною частиною інфраструктури та конфігурацією VPN-шлюзів.
5. Гібрид: Хмара + Онпреміс (розширення потужностей)
Цей підхід використовує публічну хмару для "розширення" онпремісної інфраструктури, коли потрібна додаткова обчислювальна потужність для пікових навантажень (bursting) або для розгортання нових, некритичних сервісів. Хмара виступає в ролі "зовнішнього" ЦОД.
- Переваги:
- Гнучкість масштабування: Можливість швидко масштабувати обчислювальні ресурси в хмарі для обробки пікових навантажень, не вкладаючись у надлишкове онпремісне обладнання.
- Економія: Оплата хмарних ресурсів тільки за фактом використання, що знижує капітальні витрати.
- Швидке розгортання: Нові проєкти можна швидко запускати в хмарі, не чекаючи закупівлі обладнання.
- Недоліки:
- Складність управління: Необхідно ефективно управляти розподілом навантаження між онпреміс та хмарою, а також мережевою зв'язністю.
- Витрати на трафік: Можуть бути значними при частій передачі даних між онпреміс та хмарою.
- Консистентність: Підтримання єдиного середовища розробки та розгортання між двома платформами.
- Для кого підходить: Компанії зі змінним, непередбачуваним навантаженням, медіа-компанії, ритейлери (для розпродажів), розробники ігор.
- Приклад використання: Онпремісний кластер Kubernetes використовується для базового навантаження, а при збільшенні трафіку автоматично масштабується в хмарний EKS/AKS/GKE за допомогою Kubernetes Federation або схожих технологій. Terraform управляє розгортанням кластерів в обох середовищах та їх інтеграцією.
Практичні поради та рекомендації щодо роботи з Terraform у мульти-хмарних та гібридних середовищах
Ефективне використання Terraform у складних архітектурах вимагає не тільки знання синтаксису, але й розуміння кращих практик. Нижче представлені конкретні рекомендації, підкріплені прикладами коду, які допоможуть вам уникнути поширених пасток.
1. Використовуйте модулі для абстракції та перевикористання
Модулі — це наріжний камінь ефективного Terraform. Вони дозволяють інкапсулювати конфігурації ресурсів, створюючи блоки, що перевикористовуються. У мульти-хмарному середовищі це критично важливо для забезпечення консистентності та зниження дублювання коду.
Порада: Створюйте модулі, які абстрагують специфіку хмарного провайдера. Наприклад, модуль network може приймати параметри для створення VPC в AWS або VNet в Azure, а всередині використовувати відповідний провайдер.
# modules/vpc_network/main.tf
variable "cloud_provider" {
description = "Хмарний провайдер (aws, azure, gcp)"
type = string
}
variable "region" {
description = "Регіон хмари"
type = string
}
variable "cidr_block" {
description = "CIDR блок для мережі"
type = string
}
variable "name_prefix" {
description = "Префікс для імен ресурсів"
type = string
}
# AWS VPC
resource "aws_vpc" "main" {
count = var.cloud_provider == "aws" ? 1 : 0
cidr_block = var.cidr_block
tags = {
Name = "${var.name_prefix}-vpc-aws"
}
}
# Azure VNet
resource "azurerm_virtual_network" "main" {
count = var.cloud_provider == "azure" ? 1 : 0
name = "${var.name_prefix}-vnet-azure"
address_space = [var.cidr_block]
location = var.region
resource_group_name = "rg-${var.name_prefix}" # Припускаємо, що RG вже створено або буде створено окремо
}
output "vpc_id" {
value = var.cloud_provider == "aws" ? aws_vpc.main[0].id : (var.cloud_provider == "azure" ? azurerm_virtual_network.main[0].id : null)
}
Потім ви можете викликати цей модуль для різних хмар:
# main.tf (для AWS)
module "aws_network" {
source = "./modules/vpc_network"
cloud_provider = "aws"
region = "eu-central-1"
cidr_block = "10.0.0.0/16"
name_prefix = "prod"
}
# main.tf (для Azure)
module "azure_network" {
source = "./modules/vpc_network"
cloud_provider = "azure"
region = "West Europe"
cidr_block = "10.1.0.0/16"
name_prefix = "prod"
}
2. Використовуйте віддалений стан (Remote State)
Локальне зберігання стану Terraform в мультихмарному середовищі — це рецепт катастрофи. Віддалений стан забезпечує спільну роботу, блокування стану та історію змін.
Порада: Завжди використовуйте віддалений стан. S3 для AWS, Azure Blob Storage для Azure, GCS для Google Cloud або Terraform Cloud/Enterprise для централізованого управління. У 2026 році Terraform Cloud/Enterprise пропонують найбільш просунуті функції для командної роботи та управління політиками.
# backend.tf (для S3)
terraform {
backend "s3" {
bucket = "my-tf-state-bucket-prod"
key = "prod/network.tfstate"
region = "eu-central-1"
encrypt = true
dynamodb_table = "my-tf-state-lock" # Для блокування стану
}
}
# backend.tf (для Azure Blob Storage)
terraform {
backend "azurerm" {
resource_group_name = "tfstate-rg"
storage_account_name = "tfstatesa2026"
container_name = "tfstate"
key = "prod/network.tfstate"
}
}
3. Організуйте код за допомогою Workspaces або Terragrunt
Управління різними середовищами (dev, staging, prod) та хмарами вимагає чіткої структури. Terraform workspaces можуть допомогти, але Terragrunt пропонує більш потужні можливості для DRY (Don't Repeat Yourself) та ієрархічної організації.
Порада: Для простих проєктів можна використовувати Terraform workspaces. Для складних мультихмарних/гібридних сценаріїв з великою кількістю середовищ та модулів, Terragrunt є кращим вибором.
# Приклад використання Terraform Workspaces
terraform workspace new prod
terraform workspace select prod
terraform apply
# Приклад структури з Terragrunt
# live/prod/aws/eu-central-1/network/terragrunt.hcl
# live/prod/azure/west-europe/network/terragrunt.hcl
# live/dev/aws/eu-west-1/network/terragrunt.hcl
# terragrunt.hcl
include {
path = find_in_parent_folders()
}
terraform {
source = "../../modules/vpc_network" # Шлях до вашого модуля
}
inputs = {
cloud_provider = "aws" # або "azure"
region = "eu-central-1"
cidr_block = "10.0.0.0/16"
name_prefix = "prod"
}
4. Проєктуйте міжхмарну та гібридну мережеву зв'язність
Мережева зв'язність — одна з найскладніших частин мультихмарної та гібридної архітектури. Використовуйте VPN, Direct Connect/ExpressRoute/Cloud Interconnect для забезпечення безпечного та високопродуктивного з'єднання.
Порада: Завжди використовуйте приватні IP-адреси для внутрішньої комунікації. Уникайте публічного інтернету для міжхмарного трафіку. Terraform дозволяє автоматизувати створення VPN-шлюзів та пірингових з'єднань.
# Приклад створення VPN між AWS та Azure (спрощено)
resource "aws_vpn_connection" "main" {
customer_gateway_id = aws_customer_gateway.main.id
transit_gateway_id = aws_ec2_transit_gateway.main.id # Якщо використовується TGW
type = "ipsec.1"
static_routes_only = true
tunnel1_inside_cidr = "169.254.10.0/30"
tunnel2_inside_cidr = "169.254.11.0/30"
}
resource "azurerm_vpn_gateway" "main" {
name = "my-vpngw"
location = azurerm_resource_group.main.location
resource_group_name = azurerm_resource_group.main.name
virtual_network_id = azurerm_virtual_network.main.id
sku = "VpnGw1"
}
5. Безпечне управління секретами
Ніколи не зберігайте секрети (паролі, API-ключі) в коді Terraform або у файлах стану. Використовуйте спеціалізовані інструменти.
Порада: Інтегруйте Terraform з системами управління секретами, такими як HashiCorp Vault, AWS Secrets Manager, Azure Key Vault, Google Secret Manager. Використовуйте змінні оточення для передачі чутливих даних під час виконання Terraform.
# Отримання секрета з AWS Secrets Manager
data "aws_secretsmanager_secret" "db_password" {
name = "prod/db/password"
}
resource "aws_db_instance" "main" {
# ...
password = data.aws_secretsmanager_secret.db_password.secret_string
}
6. Управління Kubernetes з Terraform
Terraform може напряму управляти ресурсами Kubernetes за допомогою провайдера Kubernetes. Це особливо корисно для розгортання базових компонентів кластера (наприклад, Ingress-контролерів, CRD, namespace'ів) або для забезпечення консистентності розгортань між різними кластерами.
Порада: Використовуйте провайдер Kubernetes для інфраструктурних компонентів K8s, а Helm/GitOps (FluxCD, ArgoCD) для розгортання застосунків. Це розділення відповідальності робить систему більш керованою.
# main.tf (всередині модуля для Kubernetes кластера)
resource "kubernetes_namespace" "app_ns" {
metadata {
name = "my-application"
}
}
resource "kubernetes_deployment" "nginx" {
metadata {
name = "nginx-deployment"
namespace = kubernetes_namespace.app_ns.metadata[0].name
}
spec {
replicas = 3
selector {
match_labels = {
app = "nginx"
}
}
template {
metadata {
labels = {
app = "nginx"
}
}
spec {
container {
name = "nginx"
image = "nginx:1.21"
port {
container_port = 80
}
}
}
}
}
}
7. Інтеграція з CI/CD
Автоматизуйте виконання Terraform через CI/CD пайплайни (GitHub Actions, GitLab CI, Jenkins, Azure DevOps). Це забезпечує узгодженість, безпеку та прискорює розгортання.
Порада: Впровадьте terraform plan на етапі Pull Request для перевірки змін. terraform apply повинен виконуватися тільки після рев'ю та схвалення. Використовуйте спеціалізовані інструменти, такі як Atlantis, для управління Terraform через Pull Requests.
# .github/workflows/terraform.yml
name: 'Terraform CI/CD'
on:
push:
branches:
- main
pull_request:
jobs:
terraform:
name: 'Terraform'
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v3
- name: Setup Terraform
uses: hashicorp/setup-terraform@v2
with:
terraform_version: 1.5.7 # Актуальна версія для 2026 року
- name: Terraform Init
run: terraform init
- name: Terraform Format
run: terraform fmt -check
- name: Terraform Plan
if: github.event_name == 'pull_request'
run: terraform plan -no-color
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
- name: Terraform Apply
if: github.ref == 'refs/heads/main' && github.event_name == 'push'
run: terraform apply -auto-approve
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
Ці рекомендації допоможуть вам побудувати стійку, масштабовану та керовану інфраструктуру, використовуючи Terraform у найскладніших мульти-хмарних та гібридних сценаріях.
Типові помилки при впровадженні мульти-хмар та гібридних середовищ з Terraform
Впровадження складних інфраструктурних рішень завжди пов'язане з ризиками. Мульти-хмарні та гібридні підходи, незважаючи на всі свої переваги, можуть стати джерелом головного болю, якщо не враховувати типові помилки. Ось найпоширеніші з них, з порадами щодо їх запобігання.
1. Неправильне керування станом Terraform
Помилка: Зберігання файлу .tfstate локально, відсутність блокування стану, використання одного файлу стану для занадто великої або різнорідної інфраструктури.
Наслідки: Конфлікти при паралельній роботі кількох інженерів, втрата даних про стан, неможливість відновлення інфраструктури після збою, складнощі при масштабуванні команд.
Як уникнути:
- Завжди використовуйте віддалене сховище стану (S3, Azure Blob, GCS, Terraform Cloud).
- Налаштуйте блокування стану (DynamoDB для S3, вбудовані механізми для Azure/GCS/Terraform Cloud).
- Розділяйте стан за логічними межами (наприклад, окремий стан для мережі, для баз даних, для Kubernetes кластера). Використовуйте Terragrunt або модулі для керування безліччю невеликих файлів стану.
- Регулярно робіть бекапи стану (більшість віддалених бекендів це роблять автоматично, але перевірте).
2. Ігнорування безпеки та управління секретами
Помилка: Хардкодинг паролів, API-ключів, токенів у HCL-коді або в змінних Terraform. Відсутність належного управління доступом до Terraform-стану.
Наслідки: Витік конфіденційних даних, несанкціонований доступ до інфраструктури, компрометація систем, порушення вимог безпеки та комплаєнсу.
Як уникнути:
- Використовуйте спеціалізовані системи управління секретами (Vault, AWS Secrets Manager, Azure Key Vault, Google Secret Manager).
- Передавайте секрети в Terraform через змінні оточення або динамічно отримуйте їх з систем управління секретами.
- Обмежуйте доступ до файлів стану Terraform (через IAM-політики для хмарних сховищ, RBAC для Terraform Cloud).
- Впровадьте принцип мінімальних привілеїв для облікових записів, які використовуються Terraform.
3. Недооцінка складності мережевої інтеграції
Помилка: Неправильне планування IP-адрес, відсутність обліку міжхмарного трафіку та затримок, ігнорування проблем маршрутизації між хмарами та онпреміс.
Наслідки: Проблеми з комунікацією між сервісами, високі витрати на вихідний трафік, низька продуктивність додатків, складнощі з усуненням неполадок.
Як уникнути:
- Ретельно плануйте CIDR-блоки для кожної хмари та онпреміс, уникайте перетинів.
- Використовуйте приватні з'єднання (VPN, Direct Connect/ExpressRoute/Cloud Interconnect) для критично важливого міжхмарного/гібридного трафіку.
- Оптимізуйте маршрутизацію: використовуйте Transit Gateway, Virtual WAN або аналогічні рішення для централізованого управління мережею.
- Регулярно моніторьте мережевий трафік та затримки.
4. Відсутність або неправильне використання модулів Terraform
Помилка: Копіювання та вставка коду Terraform, створення монолітних конфігурацій, відсутність абстракції для багаторазово використовуваних ресурсів.
Наслідки: Дублювання коду, складнощі з підтримкою та оновленням, високий ризик помилок, повільне розгортання, непослідовність інфраструктури між середовищами.
Як уникнути:
- Створюйте модулі для будь-яких повторюваних блоків інфраструктури (VPC, кластер Kubernetes, база даних, група безпеки).
- Робіть модулі максимально гнучкими через змінні, але з розумними значеннями за замовчуванням.
- Використовуйте реєстр модулів (публічний або приватний) для централізованого зберігання та управління версіями.
- Дотримуйтесь принципів DRY.
5. Відсутність CI/CD для Terraform
Помилка: Ручне виконання terraform apply з локальної машини інженера, відсутність рев'ю змін в інфраструктурі.
Наслідки: Людські помилки, неконсистентність середовищ, відсутність аудиту змін, повільне розгортання, неможливість відкату до попередньої версії.
Як уникнути:
- Впровадьте CI/CD пайплайн для кожного репозиторію Terraform.
- Автоматизуйте
terraform planна етапі Pull Request/Merge Request. - Вимагайте схвалення для
terraform apply, особливо для продакшн-середовищ. - Використовуйте спеціальні інструменти для GitOps-підходу до Terraform, такі як Atlantis або інтеграція з Terraform Cloud/Enterprise.
- Переконайтеся, що CI/CD агенти мають необхідні права доступу та використовують безпечні методи аутентифікації.
6. Неврахування міжхмарних витрат та економіки
Помилка: Фокусування тільки на вартості обчислювальних ресурсів, ігнорування витрат на вихідний трафік, managed-сервіси, ліцензії, а також операційних витрат на підтримку складного середовища.
Наслідки: Несподівано високі рахунки за хмарні послуги, перевищення бюджету, зниження рентабельності проєкту, складнощі з обґрунтуванням інвестицій у мульти-хмару.
Як уникнути:
- Проводьте ретельний TCO-аналіз для кожного сценарію, включаючи всі компоненти: обчислення, зберігання, мережу, managed-сервіси, ліцензії, підтримку.
- Особливу увагу приділіть вартості вихідного трафіку між хмарами — це може бути значною статтею витрат.
- Використовуйте хмарні інструменти для моніторингу витрат та бюджетування.
- Впровадьте політики для автоматичного вимкнення невикористаних ресурсів (наприклад, dev-середовища в неробочий час).
- Регулярно переглядайте та оптимізуйте свої хмарні витрати.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Чекліст для практичного застосування мульти-хмар та гібридного управління з Terraform
Цей чеклист допоможе вам структурувати процес впровадження та переконатися, що ви врахували всі важливі аспекти при роботі з Terraform в мульти-хмарних та гібридних середовищах.
- Визначення стратегії та вимог:
- Чи визначили ви бізнес-цілі для мульти-хмари/гібрида (DR, Cost Opt, Compliance, Performance)?
- Чи проаналізували ви вимоги до RTO/RPO для критично важливих програм?
- Чи оцінили ви поточні навички команди та готовність до навчання?
- Чи вибрали ви конкретних хмарних провайдерів та/або онпремісні платформи?
- Проєктування архітектури:
- Чи спроєктували ви топологію мережі (CIDR, VPN/Direct Connect, маршрутизація) для всіх середовищ?
- Чи визначили ви, які програми/сервіси будуть розміщені в кожній хмарі/онпреміс?
- Чи розробили ви стратегію реплікації/синхронізації даних між середовищами?
- Чи визначили ви, які сервіси будуть використовуватися (Managed K8s, PaaS, IaaS)?
- Підготовка Terraform-репозиторію:
- Чи створили ви структуру репозиторію (наприклад, по хмарах, по середовищах, по компонентах)?
- Чи налаштували ви віддалене сховище стану Terraform з блокуванням?
- Чи впровадили ви Terragrunt для DRY та управління безліччю файлів стану?
- Чи налаштували ви провайдери Terraform для всіх цільових хмар/платформ?
- Розробка модулів Terraform:
- Чи розробили ви модулі для спільного використання для загальних компонентів (VPC, K8s, DB, Security Groups)?
- Чи абстрагували ви специфіку провайдерів всередині модулів, де це можливо?
- Чи забезпечили ви версіонування модулів?
- Чи документували ви змінні та висновки модулів?
- Управління секретами та безпекою:
- Чи інтегрували ви Terraform з системою управління секретами (Vault, Secrets Manager, Key Vault)?
- Чи застосовуєте ви принцип мінімальних привілеїв для облікових записів Terraform?
- Чи налаштували ви політики безпеки (IAM, Firewall, Security Groups) через Terraform?
- Чи включено шифрування даних у спокої та під час передавання?
- Впровадження CI/CD:
- Чи налаштували ви CI/CD пайплайни для автоматичного виконання
terraform planтаapply? - Чи включили ви перевірку формату та лінтинг коду Terraform?
- Чи налаштували ви рев'ю та схвалення змін перед
apply? - Чи використовуєте ви інструменти для GitOps-підходу до IaC (Atlantis, Terraform Cloud)?
- Чи налаштували ви CI/CD пайплайни для автоматичного виконання
- Моніторинг та оповіщення:
- Чи налаштували ви уніфіковану систему моніторингу для всіх хмар та онпреміс?
- Чи створили ви дашборди для відстеження стану інфраструктури та програм?
- Чи налаштували ви оповіщення про критичні події та аномалії?
- Чи моніторите ви витрати та споживання ресурсів?
- Тестування та валідація:
- Чи розробили ви стратегію тестування інфраструктури (unit, integration, end-to-end)?
- Чи проводите ви регулярні тренування з аварійного відновлення (DR drills)?
- Чи тестуєте ви продуктивність та масштабованість у мульти-хмарному/гібридному середовищі?
- Документація та навчання:
- Чи створили ви детальну документацію з архітектури та процесів?
- Чи навчили ви команду працювати з новими інструментами та процедурами?
- Чи включили ви Terraform в onboarding нових співробітників?
- Оптимізація та рефакторинг:
- Чи плануєте ви регулярний аудит та оптимізацію витрат?
- Чи є у вас процес для рефакторингу Terraform-коду та оновлення версій провайдерів/модулів?
- Чи збираєте ви зворотний зв'язок від команд розробки та операцій для поліпшення інфраструктури?
Розрахунок вартості / Економіка мульти-хмарних та гібридних рішень з Terraform
Економіка мульти-хмарних та гібридних рішень значно складніша, ніж здається на перший погляд. Крім очевидних витрат на обчислювальні ресурси, існують приховані витрати, які можуть суттєво вплинути на підсумковий бюджет. У 2026 році хмарні провайдери продовжують вдосконалювати свої моделі ціноутворення, але основні принципи залишаються незмінними.
Приклади розрахунків для різних сценаріїв (умовні цифри 2026 року)
Припустимо, у нас є середній SaaS-додаток, що працює на 10 інстансах K8s (4 vCPU, 16 GB RAM кожен) та керованій базі даних (16 vCPU, 64 GB RAM, 1TB SSD). Щомісячний вихідний трафік — 5TB.
Сценарій 1: Моно-хмара (AWS, регіон eu-central-1)
- Managed Kubernetes (EKS): 10 інстансів по $180/міс = $1800
- Managed DB (RDS PostgreSQL): $1500/міс
- Вихідний трафік (5TB): $0.08/GB 5000 GB = $400
- Балансувальник, Storage, Monitoring: $300
- Підсумкова щомісячна вартість: $1800 + $1500 + $400 + $300 = $4000
Сценарій 2: Мульти-хмара Активно-пасивне DR (AWS + Azure)
Основне навантаження в AWS. В Azure розгорнуто "холодний" DR: мінімальний кластер K8s (2 інстанса), мінімальна DB (без активної реплікації, тільки зберігання бекапів), мережева інфраструктура. Щоденна реплікація 100GB даних між хмарами.
- AWS (основна): $4000 (як у Сценарії 1)
- Azure (резервна):
- Managed Kubernetes (AKS): 2 інстанса по $150/міс = $300
- Managed DB (Azure Database for PostgreSQL): $400/міс (тільки зберігання)
- Мережева інфраструктура, Load Balancer: $100
- Міжхмарний трафік (реплікація 100GB 30 днів = 3TB): $0.10/GB 3000 GB = $300
- Підсумкова щомісячна вартість: $4000 + $300 + $400 + $100 + $300 = $5100 (+27.5% до моно-хмари)
Сценарій 3: Гібрид (Онпреміс + Yandex.Cloud)
Базове навантаження (5 інстансів K8s, DB) онпреміс. Пікове навантаження (додаткові 5 інстансів K8s) у Yandex.Cloud. 2TB вихідного трафіку онпреміс, 3TB з хмари. VPN-з'єднання.
- Онпреміс (базове):
- Амортизація обладнання, електроенергія, підтримка (еквівалент 5 інстансів K8s + DB): $2500/міс (довгостроково може бути нижче)
- Вихідний трафік (2TB): $0
- Yandex.Cloud (пікове):
- Managed Kubernetes: 5 інстансів по $160/міс = $800
- Managed DB (Yandex Managed Service for PostgreSQL): $700/міс (тільки репліка)
- Вихідний трафік (3TB): $0.06/GB 3000 GB = $180
- VPN-шлюз і трафік: $100
- Підсумкова щомісячна вартість: $2500 + $800 + $700 + $180 + $100 = $4280 (+7% до моно-хмари)
Приховані витрати
- Міжхмарний/вихідний трафік: Часто недооцінюється. Провайдери беруть плату за вихідний трафік, а також за трафік між регіонами. У 2026 році це, як і раніше, значна стаття витрат.
- Операційні витрати (OpEx): Управління складнішим середовищем вимагає більше часу та кваліфікації від команди. Інструменти моніторингу, безпеки, CI/CD, а також навчання персоналу - все це OpEx.
- Ліцензії: Деякі PaaS-сервіси або спеціалізоване ПЗ можуть мати додаткові ліцензійні платежі.
- Інструменти: Вартість Terraform Cloud/Enterprise, Terragrunt, систем управління секретами, просунутих систем моніторингу.
- Складність міграції даних: Переміщення великих обсягів даних між хмарами або онпреміс може бути дорогим і таким, що потребує багато часу.
- Утилізація ресурсів: У мультихмарному середовищі складніше відстежувати та оптимізувати невикористовувані ресурси.
Як оптимізувати витрати
- Ретельне планування архітектури: Мінімізуйте міжхмарний трафік, розміщуючи пов'язані сервіси поруч.
- Використання зарезервованих інстансів/економічних планів: Для передбачуваних навантажень купіть зарезервовані інстанси або використовуйте ощадні плани (Savings Plans), що може знизити вартість до 60%.
- Автоматичне масштабування: Використовуйте автомасштабування (HPA, Cluster Autoscaler) для K8s, щоб платити тільки за необхідні ресурси.
- Моніторинг та оптимізація: Регулярно аналізуйте споживання ресурсів та витрати. Вимикайте невикористовувані середовища (dev/staging) у неробочий час.
- Використання Spot-інстансів: Для відмовостійких, некритичних навантажень можна використовувати Spot-інстанси (до 90% дешевше).
- Стиснення даних: Зменшуйте обсяги даних, що передаються, використовуючи стиснення.
- CDN: Використовуйте Content Delivery Networks для кешування статичного контенту ближче до користувачів, знижуючи навантаження на основні хмари та вихідний трафік.
- Terraform для політики: Використовуйте Sentinel (Terraform Enterprise) або Open Policy Agent для впровадження політик, які запобігають розгортанню дорогих або неоптимальних ресурсів.
Таблиця з прикладами розрахунків (умовні значення)
| Компонент витрат | Моно-хмара ($/міс) | Мульти-хмара DR ($/міс) | Гібрид ($/міс) | Коментар |
|---|---|---|---|---|
| Обчислення (K8s/VMs) | 1800 | 1800 (основне) + 300 (резерв) | 800 (хмара) + 1500 (онпреміс) | Основна стаття витрат, залежить від розміру та кількості інстансів. |
| Бази даних (Managed DB) | 1500 | 1500 (основне) + 400 (резерв) | 700 (хмара) + 1000 (онпреміс) | Вартість ліцензій, зберігання, реплікації. |
| Мережевий трафік (Вихідний) | 400 | 400 (основне) + 300 (міжхмарний) | 180 (хмара) + 0 (онпреміс) | Одна з найпідступніших статей, особливо міжхмарний. |
| Мережева інфраструктура (LB, VPN) | 100 | 100 (основне) + 100 (резерв) | 100 (хмара) + 50 (онпреміс) | Балансувальники, шлюзи, піринги. |
| Зберігання даних (S3/Blob) | 50 | 50 (основне) + 20 (резерв) | 20 (хмара) + 30 (онпреміс) | Бекапи, статичні файли. |
| Моніторинг/Логування | 100 | 150 | 120 | Єдина система моніторингу для всіх середовищ. |
| CI/CD та IaC інструменти | 50 | 80 | 80 | Terraform Cloud, Atlantis, CI-runner-и. |
| РАЗОМ (місяць) | 4000 | 4300 + 1270 = 5570 | 2000 + 2500 = 4500 |
Примітка: Онпреміс витрати на "обчислення" та "бази даних" включають амортизацію обладнання, електроенергію, обслуговування. Вони можуть бути значно нижчими за хмарні для стабільних, довгострокових навантажень, але вимагають великих CAPEX.
Кейси та приклади з реальної практики (2026 рік)
Розглянемо кілька гіпотетичних, але реалістичних сценаріїв, які демонструють застосування Terraform у мультихмарних та гібридних середовищах, з урахуванням актуальних трендів 2026 року.
Кейс 1: SaaS-стартап з глобальною аудиторією та вимогою до DR
Компанія: "GlobalConnect SaaS" – швидкозростаючий стартап, що надає платформу для управління розподіленими командами. Аудиторія по всьому світу, критично важлива доступність 24/7 та низька затримка. Спочатку все було в AWS.
Проблема: Ризик вендор-локу, потенційні збої в одному регіоні AWS можуть зупинити весь бізнес. Високі затримки для користувачів з Європи та Азії, оскільки основний регіон – us-east-1.
Мета: Впровадити мульти-хмарну стратегію active-active для підвищення відмовостійкості, зниження затримок і диверсифікації ризиків, використовуючи AWS і Google Cloud.
Рішення з Terraform:
- Інфраструктура як код: Вся інфраструктура (VPC, EKS/GKE кластери, балансувальники, бази даних) описана в Terraform. Використано модулі для абстракції спільних компонентів.
- Дві хмари, два регіони: Розгорнуто два незалежних, але функціонально ідентичних стеки в AWS (us-east-1) і GCP (europe-west1). Для цього використано окремі Terraform-репозиторії зі спільними модулями, але різними змінними провайдерів.
- Глобальне балансування: DNS-записи (AWS Route 53, GCP Cloud DNS) налаштовані з політиками маршрутизації за геолокацією та затримкою, направляючи користувачів на найближчий активний стек.
- Розподілена база даних: Замість традиційної реляційної БД, яка складно синхронізується між хмарами, обрано CockroachDB (SQL-сумісна розподілена БД), розгорнута на EKS і GKE з реплікацією між кластерами. Terraform управляє розгортанням кластерів CockroachDB.
- Синхронізація даних: Для некритичних даних (наприклад, користувацькі аватари) використовуються S3-сумісні сховища з крос-хмарною реплікацією, керованою Lambda/Cloud Functions.
- CI/CD: Всі зміни в Terraform-коді проходять через GitLab CI з
terraform planна MR і автоматичнимterraform applyпісля успішного злиття вmain.
Результат: За 6 місяців компанія перейшла на fully active-active мульти-хмарну архітектуру. Середня затримка для користувачів знизилася на 40%, а час відновлення після гіпотетичної відмови цілої хмари скоротився до майже нуля (автоматичне перенаправлення трафіку). Вартість збільшилася на 20%, але це було виправдано бізнес-критичністю.
Кейс 2: Велике підприємство зі успадкованою системою та вимогами комплаєнсу
Компанія: "SecureBank Inc." – великий банк з багаторічною історією. Основні банківські системи та дані клієнтів зберігаються у власному дата-центрі (онпреміс) на базі VMware vSphere. Нові фінтех-сервіси та аналітика даних вимагають гнучкості та масштабованості публічної хмари.
Проблема: Неможливо перенести всі дані клієнтів у публічну хмару через суворі регуляторні вимоги та політику безпеки. Розробка нових сервісів на онпреміс надто повільна та дорога.
Мета: Впровадити гібридну стратегію, використовуючи Yandex.Cloud для нових сервісів, зберігаючи критичні дані онпреміс, і забезпечивши безпечну інтеграцію.
Рішення з Terraform:
- Інфраструктура як код (гібрид): Terraform використовується для управління ресурсами як в Yandex.Cloud, так і для віртуальних машин і мереж на VMware vSphere.
- Мережева зв'язність: Встановлено високопродуктивне та безпечне Direct Connect-з'єднання між онпреміс-дата-центром і Yandex.Cloud. Terraform налаштував VPN-шлюзи та маршрутизацію в хмарі.
- Розділення навантаження:
- Онпреміс: Основні транзакційні системи, бази даних клієнтів, системи обліку. Управляються Terraform-провайдером для vSphere.
- Yandex.Cloud: Нові мікросервіси для мобільного банкінгу, рекомендаційні системи на базі ML, аналітичні платформи. Розгорнуті на Yandex Managed Kubernetes (Yandex.Cloud) і отримують доступ до онпреміс-даних через захищені API.
- Управління доступом: Єдина система IAM (Active Directory Federation Services) для обох середовищ. Terraform управляє ролями та політиками доступу в Yandex.Cloud, інтегруючись з корпоративним LDAP.
- Секрети: HashiCorp Vault розгорнутий онпреміс, але доступний для хмарних сервісів через захищений канал, забезпечуючи централізоване управління секретами.
- Моніторинг: Єдина платформа моніторингу (Prometheus + Grafana) збирає метрики з обох середовищ, забезпечуючи повний огляд.
Результат: "SecureBank Inc." значно прискорив випуск нових продуктів, скоротивши час від ідеї до продакшна з 6-12 місяців до 2-3 місяців. Витрати на розробку нових сервісів знизилися на 30% за рахунок використання хмарних PaaS. Комплаєнс повністю дотримано, оскільки чутливі дані не покидають периметр банку. Terraform забезпечив консистентність і автоматизацію розгортання гібридної інфраструктури.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Інструменти та ресурси для мульти-хмарного та гібридного управління з Terraform
Побудова та управління складною інфраструктурою вимагає не тільки Terraform, але й цілого стеку допоміжних інструментів. До 2026 року екосистема навколо Terraform стала ще більш зрілою та пропонує безліч рішень для підвищення ефективності, безпеки та автоматизації.
1. Інструменти Infrastructure as Code (IaC)
- Terraform Core: Основа всього. Дозволяє декларативно описувати інфраструктуру.
- Terraform Providers: Розширення для роботи з різними хмарами (AWS, Azure, GCP, Yandex.Cloud), онпреміс-платформами (vSphere, OpenStack), Kubernetes, Helm, а також з SaaS-сервісами (Datadog, Cloudflare).
- Terraform Modules: Готові, блоки конфігурації, які можна повторно використовувати, для типових ресурсів. Використовуйте Terraform Registry або створюйте власні приватні реєстри.
- Terragrunt: Обгортка навколо Terraform, яка допомагає підтримувати DRY-принцип, управляти кількома модулями, віддаленим станом і змінними. Незамінний для великих проектів.
- Packer (HashiCorp): Для створення золотих образів VM (AMI, VHD, VMDK) в різних хмарах. Забезпечує консистентність базових образів для ваших VPS/VM.
2. Управління станом і секретами
- Terraform Cloud / Terraform Enterprise: Централізована платформа для управління Terraform-робочими процесами. Пропонує віддалений стан, блокування, аудит, інтеграцію з VCS, політики (Sentinel) та UI для командної роботи.
- HashiCorp Vault: Універсальне рішення для безпечного зберігання та управління секретами, ключами API, паролями та сертифікатами. Глибоко інтегрується з Terraform.
- Хмарні сервіси для секретів: AWS Secrets Manager, Azure Key Vault, Google Secret Manager. Можуть використовуватися як альтернатива або доповнення до Vault.
- Git: Система контролю версій (GitHub, GitLab, Bitbucket, Azure Repos) для зберігання Terraform-коду.
3. CI/CD та GitOps
- GitHub Actions / GitLab CI / Azure DevOps / Jenkins: Інструменти для автоматизації виконання Terraform-операцій (
plan,apply) в рамках CI/CD пайплайнів. - Atlantis: GitOps-інструмент для Terraform, який дозволяє запускати
terraform planтаapplyбезпосередньо з Pull Request'ів/Merge Request'ів, забезпечуючи рев'ю та контроль. - FluxCD / ArgoCD: GitOps-інструменти для Kubernetes, які можуть розгортати додатки після того, як Terraform підготував кластер.
4. Моніторинг та тестування
- Prometheus / Grafana: Відкриті рішення для збору метрик та візуалізації стану інфраструктури. Можуть збирати дані з різних хмар та онпреміс.
- Datadog / New Relic / Splunk: Комерційні APM- та моніторингові платформи, що пропонують уніфікований погляд на гібридне та мульти-хмарне середовище.
- Terraform Validate / TFLint: Вбудовані та сторонні інструменти для перевірки синтаксису та стилю коду Terraform.
- Terratest: Бібліотека Go для написання автоматизованих тестів для інфраструктури, розгорнутої за допомогою Terraform. Дозволяє перевіряти працездатність ресурсів після їх розгортання.
- Open Policy Agent (OPA) / Sentinel (Terraform Enterprise): Інструменти для визначення та примусового застосування політик безпеки, відповідності та вартості на етапі
terraform plan.
5. Мережеві інструменти
- AWS Transit Gateway / Azure Virtual WAN / Google Cloud Network Connectivity Center: Хмарні сервіси для централізованого управління мережевою зв'язністю між VPC, онпреміс та іншими хмарами.
- OpenVPN / WireGuard: Програмні VPN-рішення для створення захищених каналів між онпреміс та хмарою, якщо немає можливості використовувати Direct Connect.
6. Корисні посилання та документація
- Офіційна документація Terraform
- Terraform Registry (модулі та провайдери)
- Документація Terragrunt
- Блог HashiCorp (новини та кращі практики)
- Google Cloud Terraform Docs
- Azure Terraform Docs
- AWS Terraform Docs
- Yandex.Cloud Terraform Docs
Troubleshooting (вирішення проблем) у мульти-хмарних та гібридних середовищах з Terraform
Робота зі складними розподіленими системами неминуче призводить до виникнення проблем. Уміння швидко діагностувати та усувати їх критично важливо. Terraform, хоча і спрощує управління, не позбавляє від необхідності розуміти, що відбувається "під капотом".
1. Розбіжність стану (State Drift)
Проблема: Реальний стан інфраструктури відрізняється від того, що записано у файлі .tfstate. Це може статися через ручні зміни в консолі хмари, помилки в коді Terraform або використання інших інструментів.
Діагностика:
terraform plan
Команда terraform plan покаже всі розбіжності між поточним станом та бажаним, описаним в HCL-коді.
Рішення:
- Якщо зміни були внесені вручну і їх потрібно зберегти: використовуйте
terraform importдля додавання некерованих ресурсів до стану або оновіть HCL-код, щоб він відповідав ручним змінам. - Якщо зміни небажані: виконайте
terraform apply, щоб Terraform повернув інфраструктуру до бажаного стану. - Для запобігання: впровадьте суворі політики IAM, що забороняють ручні зміни, та використовуйте CI/CD для виконання всіх змін через Terraform.
2. Проблеми з автентифікацією провайдера
Проблема: Terraform не може автентифікуватися в одному або декількох хмарних провайдерах.
Діагностика: Повідомлення про помилку типу "Access Denied", "Invalid Credentials", "Unauthorized". Перевірте змінні оточення (AWS_ACCESS_KEY_ID, AZURE_CLIENT_ID і т.д.), файли конфігурації (~/.aws/credentials), ролі IAM, які Terraform намагається використовувати.
Рішення:
- Переконайтеся, що змінні оточення встановлені правильно, особливо в CI/CD пайплайнах.
- Перевірте термін дії ключів та токенів.
- Переконайтеся, що IAM-роль або користувач, який використовується Terraform, має достатні права для створення, читання, оновлення та видалення всіх необхідних ресурсів.
- Для мульти-хмари переконайтеся, що кожен провайдер налаштований правильно та автентифікується незалежно.
3. Проблеми з міжхмарною/гібридною мережевою зв'язністю
Проблема: Сервіси в одній хмарі не можуть зв'язатися з сервісами в іншій хмарі або онпреміс. Висока затримка, втрата пакетів.
Діагностика:
- Перевірте таблиці маршрутизації в VPC/VNet кожної хмари та на онпреміс-маршрутизаторах.
- Перевірте правила Firewall/Security Groups/Network ACL на всіх рівнях.
- Використовуйте
ping,traceroute,tcpdumpз тестових інстансів в кожному середовищі. - Перевірте стан VPN-тунелів або Direct Connect/ExpressRoute-з'єднань в консолях провайдерів.
- Переконайтеся, що CIDR-блоки не перетинаються.
Рішення:
- Коригування правил безпеки для дозволу трафіку між потрібними IP-діапазонами.
- Виправлення маршрутів, додавання відсутніх записів.
- Перезапуск VPN-шлюзів або звернення до підтримки провайдера, якщо з'єднання не піднімається.
- Використання Cloud Watch (AWS), Azure Monitor, Google Cloud Monitoring для аналізу мережевих метрик.
4. Обмеження ресурсів (Service Limits)
Проблема: Terraform не може створити ресурс через перевищення лімітів провайдера (наприклад, кількість VPC, інстансів, IP-адрес).
Діагностика: Повідомлення про помилку типу "Service Limit Exceeded", "Quota Exceeded".
Рішення:
- Перевірте поточні ліміти в консолі хмарного провайдера.
- Відправте запит на збільшення лімітів через службу підтримки провайдера.
- Оптимізуйте використання ресурсів, видаляючи непотрібні.
5. Проблеми при оновленні версій Terraform або провайдерів
Проблема: Після оновлення Terraform Core або версії провайдера, існуючий код починає видавати помилки або поводиться непередбачувано.
Діагностика: Уважно читайте changelog'и та release notes нових версій Terraform і провайдерів. Вони часто містять інформацію про breaking changes.
Рішення:
- Завжди тестуйте оновлення в невиробничому середовищі.
- Виправляйте код Terraform у відповідності до змін в API провайдера або синтаксисі HCL.
- Використовуйте
terraform state rmтаterraform importдля ручної корекції стану, якщо це необхідно після міграції. - Зафіксуйте версії Terraform і провайдерів у файлі
versions.tf, щоб уникнути несподіваних оновлень.
6. Проблеми з інтеграцією Terraform і Kubernetes
Проблема: Terraform не може розгорнути ресурси Kubernetes, або Kubernetes-ресурси, створені Terraform, не працюють належним чином.
Діагностика:
- Переконайтеся, що контекст
kubectlналаштовано правильно і Terraform має доступ до кластера. - Перевірте логи контролерів Kubernetes і подів, які Terraform намагається створити.
- Використовуйте
kubectl describeдля отримання детальної інформації про стан ресурсів. - Переконайтеся, що провайдер Kubernetes в Terraform має необхідний доступ до API кластера.
Рішення:
- Виправте помилки в маніфестах Kubernetes, якщо вони були причиною.
- Перевірте мережеву зв'язність між Terraform-ранером і API-сервером Kubernetes.
- Переконайтеся, що кластер Kubernetes здоровий і його компоненти працюють.
- Для мульти-хмарних кластерів: переконайтеся, що кожен кластер доступний і налаштований правильно.
Коли звертатися до підтримки:
- При системних збоях хмарного провайдера, які не вдається усунути самостійно.
- При проблемах з Direct Connect/ExpressRoute-з'єднаннями, які виходять за рамки вашої компетенції.
- При виявленні помилок в роботі хмарних сервісів, які здаються багами провайдера.
- Коли ви вичерпали всі свої внутрішні ресурси і знання.
У 2026 році служби підтримки хмарних провайдерів стали ще більш інтегрованими і часто пропонують спеціалізовані команди для гібридних і мульти-хмарних сценаріїв. Не соромтеся звертатися до них при серйозних проблемах.
FAQ (Часті запитання)
Q1: Чи обов'язково використовувати Terraform для мульти-хмари/гібриду?
A1: Строго кажучи, ні. Можна використовувати CloudFormation, ARM Templates, Cloud Deployment Manager або навіть ручні скрипти. Однак Terraform є де-факто стандартом для IaC в мульти-хмарному середовищі завдяки своїй універсальності та підтримці величезної кількості провайдерів. Він забезпечує єдину мову для опису інфраструктури, що значно знижує складність і прискорює розгортання.
Q2: Наскільки складно мігрувати існуючу інфраструктуру в Terraform?
A2: Це може бути досить трудомістким процесом, особливо для великих і складних систем. Terraform надає команду terraform import, яка дозволяє імпортувати існуючі ресурси в стан Terraform. Однак після імпорту вам все одно доведеться вручну написати HCL-код, який відповідає імпортованим ресурсам. Рекомендується починати з нових проектів або невеликих, ізольованих компонентів.
Q3: Як керувати секретами в Terraform без їх хардкодингу?
A3: Ніколи не хардкодьте секрети. Використовуйте спеціалізовані системи управління секретами, такі як HashiCorp Vault, AWS Secrets Manager, Azure Key Vault або Google Secret Manager. Terraform може динамічно отримувати секрети з цих систем під час виконання, або вони можуть бути передані через змінні оточення CI/CD пайплайна. Важливо, щоб доступ до цих систем також був суворо контрольований.
Q4: Чи можна використовувати один файл стану Terraform для всієї мульти-хмарної інфраструктури?
A4: Категорично не рекомендується. Один файл стану для всієї інфраструктури призведе до величезних розмірів, повільної роботи, частих конфліктів при спільній роботі і високого ризику помилок. Краща практика — розділяти стан за логічними межами: по хмарах, по регіонах, по середовищах (dev/prod), по компонентах (мережа, K8s, БД). Terragrunt дуже допомагає в цьому.
Q5: Як забезпечити консистентність конфігурацій між різними хмарами?
A5: Основний спосіб — використання модулів Terraform. Створюйте модулі, які абстрагують специфіку провайдера і дозволяють вам визначити загальну логіку (наприклад, "створити VPC", "розгорнути кластер K8s"). Ці модулі потім можуть бути викликані з різними параметрами для кожної хмари. Також допомагають інструменти на кшталт Terragrunt, які дозволяють перевикористовувати код модулів з мінімальним дублюванням.
Q6: Що таке "гравітація даних" і як вона впливає на вибір стратегії?
A6: Гравітація даних — це концепція, згідно з якою великі обсяги даних притягують до себе додатки і сервіси, тому що переміщення цих даних між різними місцями розташування (наприклад, між хмарами або онпреміс) дорого, повільно і складно. Якщо у вас є масивні бази даних, які не можуть бути легко репліковані або переміщені, вони можуть диктувати, де буде розміщене ваше основне робоче навантаження, що часто призводить до гібридних сценаріїв.
Q7: Які ризики пов'язані з використанням мульти-хмари?
A7: Основні ризики включають: збільшення операційної складності, потенційно більш високі витрати (особливо на вихідний трафік та інструменти), складність у забезпеченні єдиної безпеки та комплаєнсу, а також необхідність у висококваліфікованій команді. Однак ці ризики можуть бути мінімізовані при ретельному плануванні і використанні правильних інструментів, таких як Terraform.
Q8: Як Terraform допомагає в управлінні Kubernetes в мульти-хмарі?
A8: Terraform може розгортати самі кластери Kubernetes (EKS, AKS, GKE) за допомогою відповідних хмарних провайдерів. Потім, використовуючи провайдер Kubernetes, Terraform може керувати базовими ресурсами всередині кластера (namespaces, service accounts, CRD, ingress controllers). Це дозволяє уніфікувати розгортання кластерів і їх основних компонентів, забезпечуючи консистентність між різними хмарами.
Q9: Що таке "Infrastructure as Code Drift" і як його запобігти?
A9: IaC Drift (розбіжність стану IaC) — це ситуація, коли фактичний стан інфраструктури відрізняється від того, що описано у вашому коді IaC (Terraform). Це відбувається через ручні зміни, зроблені поза Terraform. Запобігти цьому можна, встановивши суворі політики (наприклад, через IAM), які забороняють ручні зміни, і використовуючи CI/CD пайплайни, які гарантують, що всі зміни проходять через Terraform. Регулярні terraform plan також допомагають виявляти дрифт.
Q10: Як керувати версіями Terraform-коду та провайдерів?
A10: Завжди використовуйте систему контролю версій (Git) для вашого Terraform-коду. У файлі versions.tf (або main.tf) явно вказуйте необхідні версії Terraform Core та кожного провайдера. Наприклад, required_version = "~> 1.5" і version = "~> 4.0" для провайдера. Це запобігає несподіваним змінам у поведінці при оновленні та забезпечує відтворюваність розгортань.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Висновок
У 2026 році мульти-хмарні та гібридні стратегії перестали бути екзотикою і стали невід'ємною частиною архітектури більшості зрілих компаній. Вони пропонують безпрецедентний рівень відмовостійкості, гнучкості та оптимізації витрат, але при цьому привносять значну складність в управління інфраструктурою. Саме тут Terraform проявляє себе як незамінний інструмент.
Наша подорож від VPS до Kubernetes через різні хмари та онпреміс-середовища показала, що Terraform здатний уніфікувати управління будь-якими ресурсами. Завдяки декларативному підходу, потужній екосистемі провайдерів, модулям та інтеграції з CI/CD, він дозволяє командам ефективно розгортати, масштабувати та підтримувати складну, розподілену інфраструктуру. Ми розглянули ключові критерії вибору, детально розібрали різні стратегії, дали практичні поради, вказали на типові помилки та запропонували шляхи оптимізації вартості.
Пам'ятайте, що успіх в мульти-хмарному та гібридному середовищі залежить не тільки від інструментів, але й від культури вашої команди. Принципи Infrastructure as Code, GitOps, автоматизації та постійного навчання повинні бути глибоко інтегровані у ваші робочі процеси. Технології розвиваються, і Terraform не стоїть на місці, постійно пропонуючи нові можливості для управління все більш складними системами.
Наступні кроки для читача:
- Почніть з малого: Не намагайтеся перенести всю інфраструктуру відразу. Виберіть невеликий, некритичний проєкт або компонент для пілотного впровадження Terraform в мульти-хмарному/гібридному середовищі.
- Вивчіть Terraform глибше: Пройдіть офіційні курси, вивчіть документацію та спробуйте різні провайдери. Експериментуйте з модулями та Terragrunt.
- Плануйте мережеве з'єднання: Мережа — це основа. Ретельно продумайте IP-схеми, VPN/Direct Connect та правила безпеки.
- Впровадьте CI/CD: Автоматизуйте розгортання Terraform з самого початку. Це знизить ризики та прискорить процеси.
- Освойте управління секретами: Безпека повинна бути пріоритетом. Інтегруйте системи управління секретами.
- Моніторьте та оптимізуйте: Постійно відстежуйте продуктивність, доступність і, що важливо, вартість вашої інфраструктури. Шукайте можливості для оптимізації.
Мульти-хмарне та гібридне майбутнє вже тут. З Terraform у вашому арсеналі ви готові до його викликів та можливостей.