Впровадження Zero Trust принципів для інфраструктури на VPS та виділених серверах: Практичний посібник 2026
TL;DR
- Не довіряйте нікому, завжди перевіряйте: Відмовтеся від периметрового захисту на користь верифікації кожного запиту, користувача та пристрою, незалежно від їх місцезнаходження.
- Мікросегментація — ваш найкращий друг: Розділіть інфраструктуру на найдрібніші, ізольовані домени безпеки, щоб обмежити горизонтальне переміщення зловмисника.
- Посилена автентифікація всюди: Впровадьте багатофакторну автентифікацію (MFA) та паролі без пароля (passwordless) для всіх облікових записів, а також безперервну верифікацію ідентифікації.
- Принцип найменших привілеїв: Надавайте доступ тільки до необхідних ресурсів і тільки на необхідний час, автоматизуючи управління привілеями.
- Безперервний моніторинг та автоматизація: Впровадьте системи моніторингу поведінки, виявлення аномалій та автоматизованого реагування на загрози в реальному часі.
- Припускайте злам: Проєктуйте системи з урахуванням того, що рано чи пізно відбудеться компрометація, і мінімізуйте її наслідки.
- 2026 рік вимагає проактивності: З урахуванням зростання ІІ-атак та складності загроз, Zero Trust — це не опція, а необхідність для виживання бізнесу.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
Вступ: Чому Zero Trust критичний у 2026 році
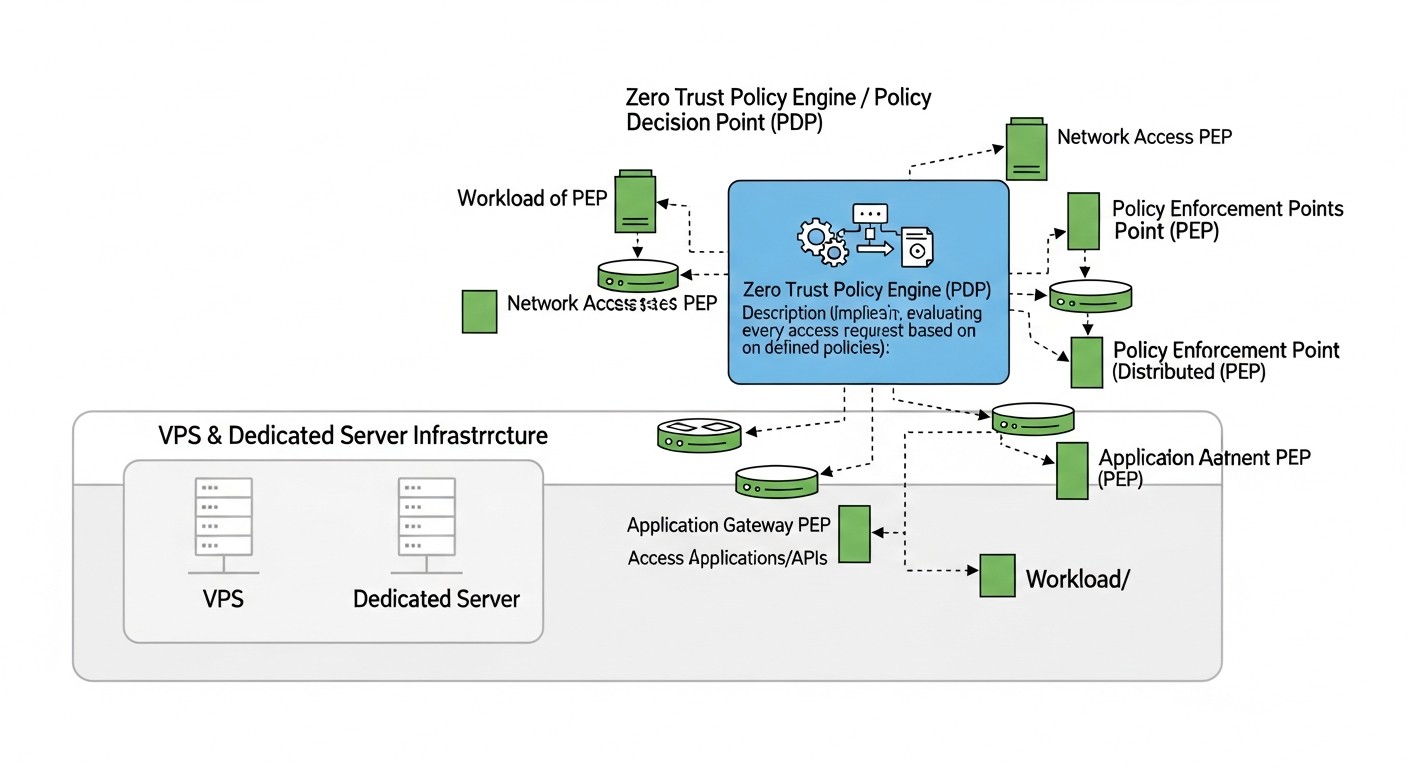 Схема: Вступ: Чому Zero Trust критичний у 2026 році
Схема: Вступ: Чому Zero Trust критичний у 2026 році
У 2026 році ландшафт кіберзагроз продовжує стрімко еволюціонувати, стаючи все більш складним та витонченим. Традиційні моделі безпеки, засновані на концепції "захищеного периметра", де всередині мережі вважається довіреним, виявилися неспроможними перед обличчям цільових атак, внутрішніх загроз та зростаючої складності розподілених систем. Окремі VPS та виділені сервери, часто сприймаються як "острівок безпеки" через їхню відносну ізоляцію, насправді піддаються не меншим, а іноді й більшим ризикам, оскільки не мають вбудованих механізмів захисту, властивих великим хмарним провайдерам.
Ми живемо в епоху, коли штучний інтелект активно використовується не тільки для захисту, а й для автоматизації атак, створення переконливих фішингових кампаній та прискореного пошуку вразливостей. Компрометація одного облікового запису або одного сервісу може стати точкою входу для зловмисника, який потім безперешкодно переміщається по "довіреній" внутрішній мережі. Саме тут на сцену виходить концепція Zero Trust — "нульової довіри".
Zero Trust — це не конкретний продукт або технологія, а стратегічний підхід до безпеки, заснований на принципі "нікому не довіряй, завжди перевіряй". Він вимагає суворої перевірки кожного користувача, пристрою та програми, що намагається отримати доступ до ресурсів, незалежно від того, чи знаходяться вони всередині чи поза традиційним мережевим периметром. У контексті VPS та виділених серверів, де немає такого поняття, як "корпоративна мережа" в традиційному сенсі, Zero Trust стає ще більш актуальним. Він дозволяє створити віртуальний "периметр" навколо кожного ресурсу, кожної служби, кожного користувача.
Ця стаття адресована DevOps-інженерам, backend-розробникам, фаундерам SaaS-проєктів, системним адміністраторам та технічним директорам стартапів, які керують інфраструктурою на VPS або виділених серверах. Ми розглянемо, як застосувати принципи Zero Trust в умовах обмежених ресурсів та без дорогих корпоративних рішень. Наша мета — надати практичний посібник, наповнений конкретними прикладами, конфігураціями та рекомендаціями, які допоможуть вам значно підвищити рівень безпеки вашої інфраструктури у 2026 році та підготуватися до викликів майбутнього. Ми зануримося в деталі, покажемо, як уникнути поширених помилок, та дамо чіткий план дій для створення по-справжньому захищеного середовища.
Основні критерії та фактори впровадження Zero Trust
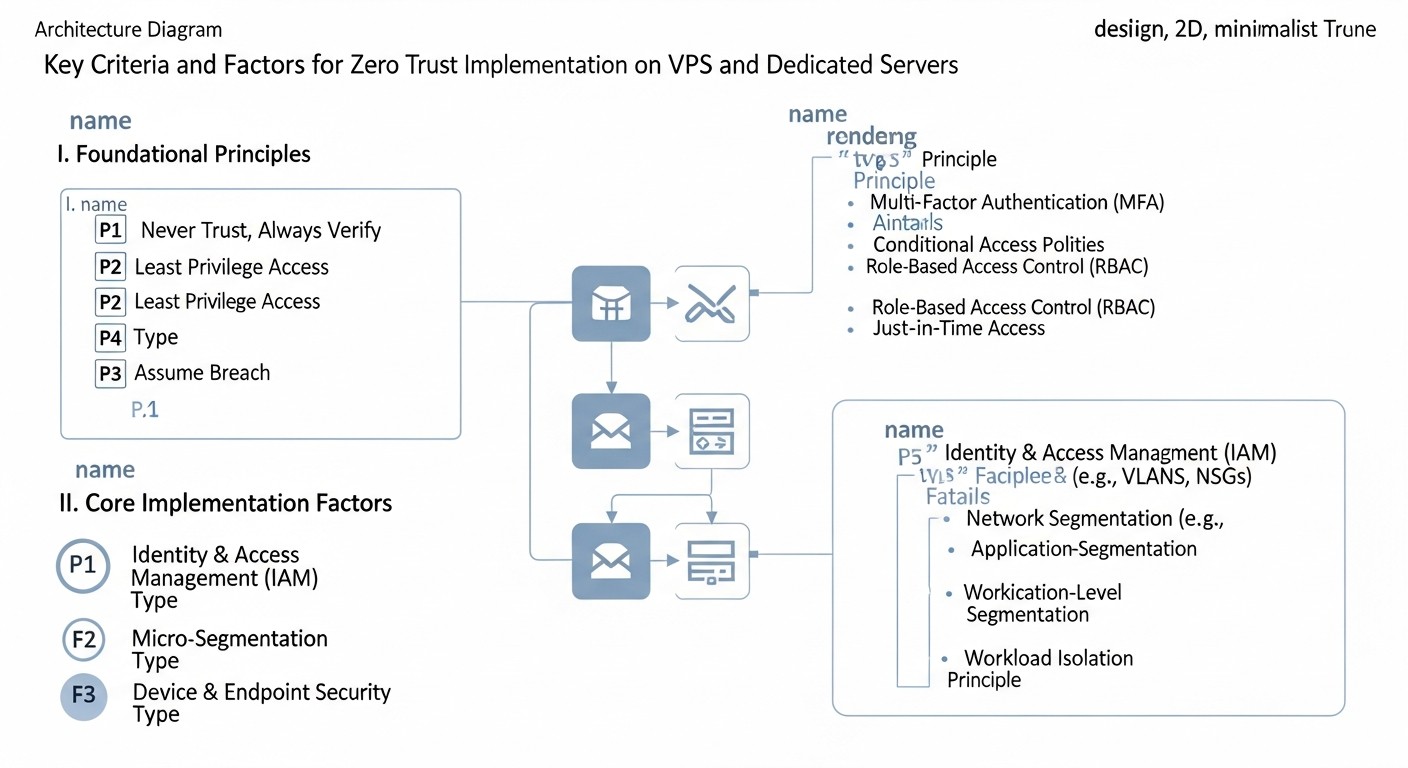 Схема: Основні критерії та фактори впровадження Zero Trust
Схема: Основні критерії та фактори впровадження Zero Trust
Впровадження Zero Trust на VPS та виділених серверах вимагає глибокого розуміння ключових принципів та їх адаптації до вашої унікальної інфраструктури. Ці критерії формують основу будь-якої стратегії Zero Trust і мають бути ретельно опрацьовані.
1. Експліцитна верифікація (Verify Explicitly)
Це наріжний камінь Zero Trust. Замість того щоб покладатися на неявну довіру, необхідно явно автентифікувати та авторизувати кожного користувача, кожен пристрій та кожну службу при кожному запиті доступу. У 2026 році це означає не тільки перевірку логіна та пароля, але й використання безлічі контекстних факторів.
- Ідентифікація користувача: Не просто логін/пароль, а MFA (багатофакторна автентифікація) або навіть passwordless-рішення (FIDO2-ключі, біометрія). Важлива безперервна автентифікація, коли система періодично перевіряє ідентичність користувача протягом сесії.
- Ідентифікація пристрою: Перевірка стану пристрою (чи встановлені оновлення, чи активний антивірус, чи відповідає конфігурація політикам безпеки). У випадку VPS/виділених серверів, це може бути перевірка відбитків SSH-ключів, сертифікатів для VPN-клієнтів або навіть моніторинг активності агентів безпеки на самому сервері.
- Контекст запиту: Де знаходиться користувач (геолокація)? Який час доби? Яка звичайна поведінка цього користувача/пристрою? Чи є аномалії в запиті? Наприклад, спроба доступу до критичної бази даних з нової країни о 3 годині ночі повинна викликати підвищену увагу.
- Авторизація за принципом найменших привілеїв: Після успішної аутентифікації, система повинна надати доступ лише до тих ресурсів, які необхідні для виконання поточної задачі, і тільки на обмежений час.
Чому це важливо: Це запобігає атакам, заснованим на компрометації облікових даних або пристроїв, оскільки навіть при отриманні доступу зловмиснику доведеться пройти додаткові перевірки. Це значно ускладнює горизонтальне переміщення всередині скомпрометованої мережі.
Як оцінювати: Наявність централізованої системи управління ідентифікацією та доступом (IAM), повсюдне впровадження MFA, наявність політик умовного доступу, здатність системи реагувати на зміни контексту в реальному часі.
2. Мікросегментація мережі (Micro-segmentation)
Замість однієї великої "внутрішньої" мережі, де всі спілкуються з усіма, мікросегментація розділяє вашу інфраструктуру на дрібні, ізольовані зони безпеки. Кожна служба, кожна програма, кожен сервер отримує свій власний "міні-периметр".
- Ізоляція робочих навантажень: Розділення фронтенду, бекенду, бази даних, кешу, черг повідомлень та інших компонентів на окремі логічні або фізичні сегменти.
- Політики "білого списку": Дозвіл тільки явно дозволеного трафіку між сегментами. Все інше блокується за замовчуванням. Наприклад, фронтенд може спілкуватися тільки з API-сервером, а API-сервер — тільки з базою даних та кешем.
- Хостові фаєрволи: Використання
iptables, nftables або firewalld на кожному VPS/виділеному сервері для контролю трафіку на рівні хоста.
- VLAN/підмережі: Використання логічного розділення мережі на рівні провайдера (якщо доступно) або за допомогою програмних рішень, таких як VPN-тунелі між серверами.
Чому це важливо: Якщо зловмисник скомпрометує один сегмент, він не зможе легко переміститися в інші. Це значно обмежує область потенційної шкоди і дає більше часу на виявлення та реагування.
Як оцінювати: Наявність чіткої карти мережевих взаємодій, мінімальна кількість дозволених правил фаєрвола, використання принципу "deny by default", регулярний аудит правил мережевої безпеки.
3. Принцип найменших привілеїв (Least Privilege Access)
Надавайте користувачам, процесам і пристроям тільки той доступ, який абсолютно необхідний для виконання їх поточних задач, і тільки на той термін, який потрібен. Ні більше, ні на довше.
- Role-Based Access Control (RBAC): Визначення ролей і призначення їм мінімально необхідних прав доступу. Наприклад, розробник може мати доступ до тестових серверів, але не до продакшену, а адміністратор бази даних — тільки до самої БД, але не до файлової системи сервера додатків.
- Just-in-Time (JIT) Access: Надання підвищених привілеїв тільки на короткий, чітко визначений період часу (наприклад, 30 хвилин для виконання термінової задачі), після чого привілеї автоматично відкликаються.
- Сегрегація обов'язків: Розділення критично важливих задач між кількома співробітниками, щоб жодна людина не мала повного контролю над усією системою.
- Автоматизація управління привілеями: Використання інструментів для автоматичного надання та відкликання доступу на основі робочих процесів.
Чому це важливо: Мінімізує потенційну шкоду в разі компрометації облікового запису або пристрою. Якщо зловмисник отримає доступ до облікового запису з обмеженими привілеями, він не зможе виконати критично важливі дії або отримати доступ до чутливих даних.
Як оцінювати: Наявність централізованої системи управління привілеями, регулярний аудит прав доступу, відсутність "постійних" адміністративних привілеїв, автоматизація відкликання прав.
4. Постійний моніторинг та аналіз (Continuous Monitoring & Analytics)
В Zero Trust немає поняття "довіреної" зони, тому вся активність повинна безперервно відстежуватися і аналізуватися на предмет аномалій і потенційних загроз.
- Централізоване логування: Збір логів з усіх серверів, додатків, фаєрволів та систем аутентифікації в єдину систему (наприклад, ELK Stack, Graylog, Splunk).
- Моніторинг поведінки користувачів та сутностей (UEBA): Аналіз патернів доступу та активності для виявлення відхилень від норми. Наприклад, якщо користувач зазвичай входить з Москви і раптом намагається увійти з Нью-Йорка, це може бути підозріло.
- Виявлення вторгнень (IDS/IPS): Використання хостових (HIDS, наприклад, OSSEC, Wazuh) та/або мережевих (NIDS) систем для виявлення та запобігання атакам.
- Аналіз вразливостей: Регулярне сканування системи на предмет відомих вразливостей і неправильних конфігурацій.
- Метрики продуктивності та безпеки: Відстеження показників, які можуть вказувати на компрометацію (наприклад, незвично високий трафік, підвищене завантаження ЦПУ, помилки доступу).
Чому це важливо: Дозволяє швидко виявити і відреагувати на інциденти безпеки, навіть якщо зловмисник зміг обійти початкові заходи захисту. У 2026 році, коли атаки стають все більш прихованими, безперервний моніторинг є єдиним способом залишатися на крок попереду.
Як оцінювати: Наявність працюючої SIEM-системи, автоматизовані алерти на аномалії, регулярні звіти про стан безпеки, здатність швидко реагувати на інциденти.
5. Автоматизація та оркестрація (Automation & Orchestration)
Впровадження Zero Trust без автоматизації стає непосильним завданням. Автоматизація необхідна для масштабування, підтримки консистентності політик та швидкого реагування.
- Автоматичне розгортання та управління конфігураціями: Використання Ansible, Puppet, Chef або Terraform для забезпечення однорідності конфігурацій безпеки на всіх серверах.
- Автоматичне управління доступом: Інтеграція IAM-систем з CI/CD-пайплайнами для автоматичного надання та відкликання доступу.
- Автоматичне реагування на інциденти (SOAR): Скрипти або системи, які автоматично блокують підозрілий трафік, ізолюють скомпрометовані вузли або повідомляють адміністраторів при виявленні загрози.
- Автоматичне оновлення та патчінг: Системи, які гарантують своєчасне застосування оновлень безпеки до всіх компонентів інфраструктури.
Чому це важливо: Зменшує ймовірність людських помилок, прискорює розгортання безпечних конфігурацій, забезпечує швидке та ефективне реагування на інциденти, що критично важливо в умовах загроз 2026 року, які швидко змінюються.
Як оцінювати: Високий рівень автоматизації в управлінні інфраструктурою, наявність playbook'ів для реагування на інциденти, мінімальна кількість ручних операцій, пов'язаних з безпекою.
6. Припущення про злам (Assume Breach)
Цей принцип означає, що ви завжди повинні проєктувати та експлуатувати свою інфраструктуру, виходячи з припущення, що рано чи пізно відбудеться компрометація. Мета — мінімізувати наслідки цього зламу.
- Ізоляція та сегментація: Згадана вище мікросегментація є ключовим елементом цього принципу.
- Шифрування всюди: Шифрування даних у стані спокою (at rest) та при передачі (in transit). Це включає дискове шифрування, SSL/TLS для всіх комунікацій, шифрування баз даних.
- Регулярне резервне копіювання та відновлення: Перевірені та ізольовані резервні копії, які можуть бути швидко відновлені у разі компрометації або вимагання.
- Плани реагування на інциденти: Чітко визначені процедури на випадок зламу, включаючи виявлення, локалізацію, усунення та відновлення.
- Тестування на проникнення (Pentesting) та Red Teaming: Регулярні симуляції атак для виявлення слабких місць та перевірки ефективності захисних заходів.
Чому це важливо: Дозволяє підготуватися до найгіршого сценарію та забезпечити стійкість бізнесу навіть після успішної атаки, що стає все більш актуальним у 2026 році зі зростанням числа цілеспрямованих та руйнівних кібератак.
Як оцінювати: Наявність актуальних планів реагування на інциденти, регулярні навчання з відновлення після катастроф, використання шифрування за замовчуванням, проведення регулярних пентестів.
Порівняльна таблиця підходів до Zero Trust на VPS/виділених серверах
 Схема: Порівняльна таблиця підходів до Zero Trust на VPS/виділених серверах
Схема: Порівняльна таблиця підходів до Zero Trust на VPS/виділених серверах
Вибір конкретних інструментів та підходів для реалізації принципів Zero Trust на VPS та виділених серверах може бути непростим завданням. У таблиці нижче ми порівняємо декілька поширених стратегій та технологій, актуальних для 2026 року, з точки зору їхньої застосовності, вартості та складності впровадження.
| Критерій |
Нативний підхід (OS + Open Source) |
Мережевий Zero Trust (SDP/ZTNA) |
Ідентифікаційний Zero Trust (IAM + PAM) |
Контейнерний/Service Mesh Zero Trust |
AI-посилений моніторинг (2026 тренд) |
| Ключові технології / Інструменти |
iptables/nftables, WireGuard/OpenVPN, FreeIPA/OpenLDAP, OSSEC/Wazuh, Vault (HashiCorp), Ansible, ELK Stack. |
Cloudflare Zero Trust, Tailscale, ZeroTier, OpenZiti, Twingate. |
Keycloak, FreeIPA, HashiCorp Vault, Apache Syncope, Teleport (Proxy/PAM). |
Docker/Podman, Kubernetes (K3s), Istio/Linkerd, Cilium. |
Elastic Security (SIEM з ML), Wazuh (AI-модулі), CrowdStrike Falcon (EDR), Vectra AI, користувацькі ML-моделі на логах. |
| Принцип Zero Trust, який посилює |
Мікросегментація, Експліцитна верифікація (базова), Найменші привілеї (базова), Моніторинг. |
Експліцитна верифікація, Найменші привілеї, Припущення про злам (ізоляція). |
Експліцитна верифікація, Найменші привілеї, Автоматизація. |
Мікросегментація, Експліцитна верифікація (для сервісів), Припущення про злам. |
Безперервний моніторинг, Автоматизація (реагування), Експліцитна верифікація (поведінковий аналіз). |
| Складність впровадження (1-5, 5-складно) |
3 (вимагає глибоких знань OS та мережі) |
2 (відносно просто для невеликих команд, SaaS-рішення) |
4 (значні зусилля для інтеграції та налаштування) |
4-5 (вимагає освоєння контейнеризації та оркестрації) |
3-5 (залежить від глибини інтеграції та кастомізації ML) |
| Приблизна вартість (на місяць на 5-10 серверів, 2026) |
0 - 150 USD (залежить від платних розширень/підтримки для Open Source) |
50 - 500 USD (SaaS-підписки, залежить від числа користувачів/трафіку) |
0 - 300 USD (Open Source безкоштовно, але може знадобитися платна підтримка/комерційні версії) |
0 - 200 USD (Open Source безкоштовно, але витрати на обчислювальні ресурси) |
200 - 1500 USD (SaaS-платформи, ліцензії на SIEM з ML, експертні послуги) |
| Основні переваги |
Повний контроль, гнучкість, низькі прямі витрати, незалежність від вендора. |
Швидке розгортання, простота управління, приховування інфраструктури, ефективний віддалений доступ. |
Централізоване управління доступом, сильна аутентифікація, JIT-доступ, аудит. |
Гранулярна ізоляція сервісів, управління трафіком між мікросервісами, вбудовані політики безпеки. |
Раннє виявлення аномалій, зниження хибних спрацьовувань, автоматичне виявлення складних загроз. |
| Основні недоліки |
Високий поріг входу, вимагає експертів, потенційні помилки конфігурації, ручне масштабування. |
Залежність від стороннього провайдера, потенційна затримка трафіку, не завжди повний контроль над мережею. |
Складність початкового налаштування, необхідність інтеграції з усіма програмами. |
Складність архітектури, високий поріг входу, додаткові накладні витрати на ресурси. |
Висока вартість, вимагає великих обсягів даних для навчання, може давати хибні спрацьовування на початковому етапі. |
| Для кого підходить |
Малі та середні команди з сильною технічною експертизою, обмеженим бюджетом. |
Команди, які потребують швидкого та безпечного віддаленого доступу, приховування публічних сервісів. |
Будь-які команди, які серйозно ставляться до управління доступом та ідентифікацією. |
Проєкти, які використовують мікросервіси та контейнеризацію, DevOps-орієнтовані команди. |
Середні та великі проєкти, готові інвестувати в просунутий моніторинг та проактивний захист. |
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
Детальний огляд кожного пункту/варіанту Zero Trust
 Схема: Детальний огляд кожного пункту/варіанту Zero Trust
Схема: Детальний огляд кожного пункту/варіанту Zero Trust
Давайте заглибимось в кожен з підходів, представлених в порівняльній таблиці, щоб зрозуміти їхні сильні та слабкі сторони, а також сценарії застосування в 2026 році.
1. Нативний підхід (OS + Open Source)
Цей підхід передбачає використання вбудованих механізмів операційної системи (Linux) і зрілих Open Source рішень. Він забезпечує максимальний контроль і гнучкість, але вимагає глибоких знань і значних зусиль з налаштування та підтримки.
Плюси: Повна незалежність від вендорів та їх ліцензійної політики. Відсутність прямих витрат на ліцензії. Максимальна кастомізація під специфічні вимоги. Висока продуктивність, оскільки немає зайвих абстракцій. Глибоке розуміння роботи системи на низькому рівні, що сприяє більш ефективному усуненню неполадок. У 2026 році багато Open Source проєктів досягли зрілості та пропонують стабільні, безпечні рішення, які активно підтримуються спільнотою. Це дозволяє створювати дійсно robustні системи безпеки, якщо у команди є достатня експертиза.
Мінуси: Високий поріг входу. Потрібна команда з глибокими знаннями Linux, мережевих технологій, криптографії та безпеки. Ручне управління може призвести до помилок конфігурації, особливо за відсутності автоматизації. Масштабування вимагає серйозних зусиль з автоматизації (наприклад, за допомогою Ansible). Час на розгортання та налаштування значно вищий, ніж при використанні SaaS-рішень. Підтримка та оновлення всіх компонентів лягає на плечі команди, що може бути ресурсоємним.
Для кого підходить: Невеликі та середні стартапи з сильною командою DevOps/SysAdmin, які готові інвестувати час у вивчення та налаштування. Проєкти з дуже чутливими даними, де потрібен повний контроль над кожним аспектом безпеки. Компанії, які хочуть уникнути залежності від хмарних провайдерів або комерційних рішень. Наприклад, якщо ви розробляєте свій власний SaaS і хочете мати максимальний контроль над своєю інфраструктурою з мінімальними операційними витратами на сторонні сервіси, цей підхід може бути ідеальним.
Приклади використання:
- Використання
nftables для мікросегментації між сервісами на одному сервері або між кількома VPS.
- Налаштування WireGuard VPN для безпечного доступу до внутрішньої мережі серверів.
- Впровадження FreeIPA для централізованого управління користувачами та SSH-ключами.
- Розгортання HashiCorp Vault для управління секретами та динамічними обліковими даними.
- Збір логів за допомогою
rsyslog та їх агрегація в ELK Stack для моніторингу.
2. Мережевий Zero Trust (SDP/ZTNA)
Software-Defined Perimeter (SDP) або Zero Trust Network Access (ZTNA) — це підхід, при якому доступ до ресурсів надається тільки після суворої аутентифікації користувача та пристрою, і тільки до конкретних додатків, а не до всієї мережі. Інфраструктура стає "невидимою" для неавторизованих користувачів.
Плюси: Значно спрощує віддалений доступ і робить його більш безпечним, ніж традиційні VPN. Приховує інфраструктуру від публічного інтернету, зменшуючи поверхню атаки. Швидке розгортання (особливо у SaaS-провайдерів). Централізоване управління політиками доступу. Підтримка умовного доступу (наприклад, доступ тільки з корпоративних пристроїв). У 2026 році ці рішення стали ще більш зрілими, пропонуючи глибоку інтеграцію з IAM і EDR системами, а також покращену продуктивність.
Мінуси: Залежність від стороннього провайдера (якщо це SaaS-рішення), що може викликати питання про конфіденційність даних і доступність сервісу. Потенційні затримки трафіку через проходження через проксі-сервери провайдера. Може бути дорожчим, ніж Open Source рішення, особливо при великій кількості користувачів або високому обсязі трафіку. Не завжди надає повний контроль над мережевим рівнем, що може бути обмеженням для дуже специфічних конфігурацій. Деякі рішення можуть бути менш гнучкими в інтеграції з унікальними внутрішніми системами.
Для кого підходить: Команди з розподіленими співробітниками, яким потрібен безпечний доступ до внутрішніх ресурсів. SaaS-проєкти, які хочуть максимально приховати свою інфраструктуру від публічного інтернету та спростити управління доступом. Компанії, які хочуть швидко впровадити Zero Trust без глибоких інвестицій у власну розробку та підтримку. Наприклад, стартап, який активно наймає віддалених співробітників по всьому світу, може використовувати Cloudflare Zero Trust для забезпечення безпечного доступу до своїх серверів і внутрішніх інструментів, не турбуючись про налаштування та підтримку складної VPN-інфраструктури.
Приклади використання:
- Використання Cloudflare Zero Trust Tunnel для підключення серверів до Cloudflare мережі та надання доступу до них через браузер або SSH після аутентифікації.
- Впровадження Tailscale для створення mesh-мережі між всіма VPS, розробниками і навіть мобільними пристроями, використовуючи WireGuard.
- Використання Twingate для створення безпечного доступу до внутрішніх додатків без необхідності відкриття портів в інтернет.
3. Ідентифікаційний Zero Trust (IAM + PAM)
Цей підхід фокусується на управлінні ідентифікацією та доступом (IAM) і управлінні привілейованим доступом (PAM). Він гарантує, що тільки авторизовані користувачі можуть отримати доступ до критично важливих ресурсів, і тільки з мінімально необхідними привілеями.
Плюси: Централізоване управління всіма обліковими записами та правами доступу, що значно спрощує аудит і дотримання комплаєнсу. Примусове застосування суворих політик паролів, MFA і JIT-доступу. Зменшення ризику зловживання привілеями. Підвищена безпека для адміністративних облікових записів. У 2026 році IAM/PAM системи пропонують просунуті функції, такі як адаптивна аутентифікація на основі ризиків, інтеграція з поведінковою аналітикою та автоматичне управління життєвим циклом облікових записів.
Мінуси: Складність початкового налаштування та інтеграції з усіма існуючими додатками та сервісами. Вимагає зміни робочих процесів для використання JIT-доступу та інших функцій. Може бути дорогим, якщо використовувати комерційні рішення. Підтримання актуальності ролей та привілеїв вимагає постійних зусиль. Якщо система IAM/PAM скомпрометована, це може мати катастрофічні наслідки, тому її захист має бути пріоритетом.
```html
Для кого підходить: Будь-які компанії, які серйозно ставляться до управління доступом і хочуть мінімізувати ризики, пов'язані з привілейованими обліковими записами. Особливо актуально для команд з великою кількістю співробітників або підрядників, яким потрібен доступ до чутливих систем. Приклад: SaaS-компанія з кількома десятками розробників і системних адміністраторів, яким потрібен доступ до продакшен-серверів, баз даних та інструментів моніторингу. Впровадження Keycloak для SSO і централізованої аутентифікації, а також HashiCorp Vault для управління секретами і динамічними обліковими даними, значно підвищить безпеку.
Приклади використання:
- Використання Keycloak в якості централізованого IdP для всіх внутрішніх і зовнішніх додатків, з підтримкою MFA.
- Впровадження FreeIPA для централізованого управління SSH-ключами, LDAP-аутентифікацією для сервісів і Kerberos для міжсервісної аутентифікації.
- Використання Teleport для забезпечення Just-in-Time доступу до серверів, баз даних і Kubernetes-кластерів з повним аудитом сесій.
- Налаштування HashiCorp Vault для видачі тимчасових SSH-сертифікатів і динамічних облікових даних для баз даних.
4. Контейнерне/Service Mesh Zero Trust
Цей підхід орієнтований на мікросервісні архітектури, розгорнуті в контейнерах (Docker, Podman) і керовані оркестраторами (Kubernetes, K3s). Service Mesh (Istio, Linkerd) додає рівень управління трафіком і безпекою між сервісами.
Плюси: Дуже гранулярна мікросегментація на рівні окремих мікросервісів. Автоматичне взаємне TLS-шифрування між сервісами (mTLS). Централізоване управління політиками трафіку і безпеки. Вбудовані можливості для спостереження (метрики, логи, трасування). Спрощення впровадження політик "білого списку" для міжсервісної взаємодії. У 2026 році контейнеризація і оркестрація стали стандартом, і Service Mesh рішення пропонують більш зрілі і продуктивні функції безпеки, включаючи автоматичне застосування Zero Trust політик.
Мінуси: Висока складність архітектури і значний поріг входу. Вимагає освоєння Kubernetes і обраного Service Mesh. Додає накладні витрати на ресурси (пам'ять, ЦПУ) через проксі-контейнери (sidecars). Усунення неполадок може бути складним через безліч шарів абстракції. Не завжди застосовний для "монолітних" додатків або простих VPS, де немає необхідності в оркестрації. Для VPS і виділених серверів це зазвичай означає розгортання легковажного Kubernetes-кластера, такого як K3s.
Для кого підходить: Команди, які розробляють і розгортають мікросервіси. Проєкти, які вже використовують контейнеризацію і розглядають перехід на Kubernetes (або вже використовують його). Компанії, яким потрібна дуже гранулярна безпека на рівні окремих сервісів. Приклад: SaaS-проєкт, який переходить від монолітної архітектури до мікросервісної, розгорнутої на декількох VPS за допомогою K3s. Впровадження Linkerd дозволить забезпечити безпечну mTLS-взаємодію між усіма мікросервісами, гарантуючи, що тільки авторизовані сервіси можуть спілкуватися один з одним.
Приклади використання:
- Розгортання K3s на декількох VPS для створення легковажного Kubernetes-кластера.
- Впровадження Linkerd для автоматичного mTLS між мікросервісами і застосування політик авторизації.
- Використання Cilium для мережевої політики на рівні CNI, забезпечуючи гранулярну мікросегментацію на основі ідентифікаторів сервісів.
- Налаштування Docker/Podman з жорсткими політиками безпеки (AppArmor/SELinux) для ізоляції контейнерів.
5. AI-посилений моніторинг (2026 тренд)
Цей підхід використовує можливості штучного інтелекту і машинного навчання для аналізу величезних обсягів даних безпеки (логи, метрики, мережевий трафік) з метою виявлення аномалій, загроз і підозрілої поведінки, які можуть бути непомітні для людини або традиційних правил.
Плюси: Значно підвищує ефективність виявлення складних і "нульових" атак. Знижує кількість помилкових спрацьовувань завдяки навчанню на реальних даних. Автоматизує аналіз і кореляцію подій, що скорочує час на виявлення і реагування. Дозволяє виявляти приховані патерни поведінки зловмисників. У 2026 році AI-системи моніторингу стали більш доступними і точними, здатними аналізувати поведінкові аномалії користувачів і систем в реальному часі, передбачаючи потенційні загрози до їх повного розвитку.
Мінуси: Висока вартість впровадження і підтримки, особливо для комерційних рішень. Вимагає великих обсягів якісних даних для навчання моделей. Може давати помилкові спрацьовування на початкових етапах або при зміні нормальної поведінки системи. Вимагає експертів для налаштування, калібрування та інтерпретації результатів. Складність інтеграції з існуючою інфраструктурою. Залежність від якості вхідних даних — "сміття на вході, сміття на виході".
Для кого підходить: Середні і великі проєкти з великим обсягом трафіку і складною інфраструктурою, які готові інвестувати в передові засоби захисту. Компанії, які стикаються з висококваліфікованими і цільовими атаками. Для SaaS-проєктів, чия репутація і дані клієнтів є критично важливими. Приклад: SaaS-платформа, що обробляє чутливі фінансові дані клієнтів, використовує Elastic Security з модулями машинного навчання для аналізу логів і виявлення аномалій в поведінці користувачів і систем. Це допомагає виявити інсайдерські загрози або спроби обходу захисту, які не були б помічені стандартними правилами.
Приклади використання:
- Використання Elastic Security (або іншої SIEM з ML-модулями) для аналізу логів і мережевого трафіку на предмет аномалій.
- Інтеграція Wazuh HIDS з поведінковим аналізом для виявлення відхилень в активності на хостах.
- Розробка власних ML-моделей для аналізу специфічних для програми логів і виявлення аномальної поведінки API-запитів.
- Застосування EDR-рішень (Endpoint Detection and Response) з функціями AI, такими як CrowdStrike Falcon, для глибокого моніторингу і реагування на загрози на рівні кожного сервера.
Практичні поради та рекомендації щодо впровадження Zero Trust
 Схема: Практичні поради та рекомендації щодо впровадження Zero Trust
Схема: Практичні поради та рекомендації щодо впровадження Zero Trust
Впровадження Zero Trust — це не одноразовий проєкт, а безперервний процес. Ось покрокові інструкції, команди та приклади конфігурацій, які допоможуть вам почати.
1. Інвентаризація та картування
Перш ніж що-небудь змінювати, ви повинні точно знати, що у вас є.
Крок 1: Створіть повний список всіх серверів, сервісів, додатків, баз даних, облікових записів і їх взаємозв'язків.
Крок 2: Визначте, які дані зберігаються на кожному сервері і яка їх чутливість.
```
Крок 3: Намалюйте карту потоків даних і мережевих взаємодій. Це критично важливо для планування мікросегментації.
# Пример команды для инвентаризации открытых портов на Linux
sudo netstat -tulpn | grep LISTEN
# или
sudo ss -tulpn | grep LISTEN
# Пример для просмотра установленных пакетов
dpkg -l # Debian/Ubuntu
rpm -qa # CentOS/RHEL
Практичний приклад: Використовуйте інструменти типу nmap для сканування власної інфраструктури ззовні та зсередини, щоб зрозуміти, які порти дійсно відкриті. Задокументуйте кожен сервіс, його призначення і хто до нього звертається.
2. Посилення аутентифікації та авторизації
Впровадження MFA та суворих політик доступу - перший і найважливіший крок.
Крок 1: Увімкніть MFA для всіх облікових записів, що мають доступ до серверів (SSH, панель управління VPS, Git-репозиторії, CI/CD).
Крок 2: Використовуйте SSH-ключі замість паролів для доступу до серверів. Захистіть ключі парольною фразою.
Крок 3: Налаштуйте централізовану систему управління ідентифікацією (IAM) для всіх користувачів та сервісів. FreeIPA або Keycloak - чудові Open Source варіанти.
# Пример настройки SSH для отключения парольной аутентификации
# Отредактируйте /etc/ssh/sshd_config
PasswordAuthentication no
ChallengeResponseAuthentication no
UsePAM yes # Если вы используете PAM для MFA
AuthenticationMethods publickey,keyboard-interactive # publickey ИЛИ keyboard-interactive (для MFA)
KbdInteractiveAuthentication yes # Для PAM-based MFA
# Перезапустите SSH-сервис
sudo systemctl restart sshd
Практичний приклад: Інтегруйте Google Authenticator (або FreeOTP) з PAM для SSH-доступу. Встановіть libpam-google-authenticator та налаштуйте його для кожного користувача. Це забезпечить двофакторну аутентифікацію при вході по SSH.
3. Мікросегментація за допомогою фаєрволів
Розділіть вашу мережу на логічні сегменти та застосовуйте суворі правила фаєрволу.
Крок 1: Визначте, які сервіси повинні спілкуватися один з одним.
Крок 2: Налаштуйте nftables або iptables на кожному сервері, дозволяючи тільки необхідний трафік.
# Пример правил nftables для микросегментации
# Предположим, у вас есть веб-сервер (80/443), который общается с базой данных (3306)
# и сервер базы данных, который принимает только от веб-сервера.
# На веб-сервере:
sudo nft add table ip filter
sudo nft add chain ip filter input { type filter hook input priority 0; policy drop; }
sudo nft add chain ip filter output { type filter hook output priority 0; policy accept; } # Открываем исходящий
sudo nft add rule ip filter input ip saddr { 127.0.0.1/8, } accept
sudo nft add rule ip filter input tcp dport { 80, 443 } accept # Разрешаем HTTP/HTTPS извне
sudo nft add rule ip filter input ct state established,related accept # Разрешаем ответы на исходящие
sudo nft add rule ip filter input drop # Все остальное дропаем
# На сервере базы данных (предположим, IP веб-сервера 192.168.1.10):
sudo nft add table ip filter
sudo nft add chain ip filter input { type filter hook input priority 0; policy drop; }
sudo nft add chain ip filter output { type filter hook output priority 0; policy accept; }
sudo nft add rule ip filter input ip saddr { 127.0.0.1/8, } accept
sudo nft add rule ip filter input ip saddr 192.168.1.10 tcp dport 3306 accept # Разрешаем только от веб-сервера
sudo nft add rule ip filter input ct state established,related accept
sudo nft add rule ip filter input drop
Практичний приклад: Використовуйте Ansible для автоматичного розгортання та управління правилами nftables на всіх ваших серверах, забезпечуючи консистентність та знижуючи ризик помилок.
4. Впровадження принципу найменших привілеїв
Нікому не давайте більше прав, ніж йому потрібно.
Крок 1: Створіть окремі системні облікові записи для кожного додатку/сервісу.
Крок 2: Використовуйте sudo з мінімально необхідними правами замість прямого використання root.
Крок 3: Налаштуйте JIT-доступ для адміністративних задач, використовуючи, наприклад, Teleport або HashiCorp Vault.
# Пример настройки sudoers для JIT-доступа (часть конфига /etc/sudoers.d/devops)
# Разрешает пользователю 'devops_user' выполнять service restart для nginx без пароля
devops_user ALL=(ALL) NOPASSWD: /usr/sbin/service nginx restart
# Более безопасный подход с использованием Teleport (через proxy)
# Пользователь запрашивает доступ к серверу через Teleport,
# Teleport выдает временный SSH-сертификат с ограниченными правами.
tsh login --proxy=teleport.example.com --auth=github
tsh ssh --request-roles=admin-role web-01.example.com # Запрос роли администратора
Практичний приклад: Для баз даних створюйте окремі облікові записи для кожного мікросервісу з правами тільки на ті таблиці, з якими він працює. Наприклад, мікросервіс "Замовлення" має доступ тільки до таблиць orders та order_items, а не до всієї бази даних.
5. Безперервний моніторинг та логування
Збирайте, аналізуйте та реагуйте на всі події безпеки.
Крок 1: Впровадьте централізовану систему логування (ELK Stack, Graylog).
Крок 2: Використовуйте HIDS (OSSEC, Wazuh) для моніторингу цілісності файлів, системних викликів та активності користувачів на кожному сервері.
Крок 3: Налаштуйте алерти на критичні події (спроби входу з невідомих IP, зміна критично важливих файлів, незвичайний мережевий трафік).
# Пример настройки rsyslog для отправки логов на центральный сервер
# Отредактируйте /etc/rsyslog.conf на каждом клиенте
. @192.168.1.20:514 # Отправка всех логов на SIEM-сервер 192.168.1.20 по UDP 514
# Пример установки Wazuh Agent
# Скачайте и установите агент согласно документации Wazuh для вашей ОС
# После установки отредактируйте /var/ossec/etc/ossec.conf
192.168.1.20 # IP вашего Wazuh Manager
# Перезапустите Wazuh Agent
sudo systemctl restart wazuh-agent
Практичний приклад: Налаштуйте Grafana для візуалізації метрик безпеки (спроби входу, заблоковані фаєрволом пакети) та інтегруйте її з Prometheus. Створіть дашборди, які показують аномалії в реальному часі.
6. Шифрування даних
Шифруйте все: дані в стані спокою та при передачі.
Крок 1: Використовуйте HTTPS (Let's Encrypt) для всіх веб-сервісів.
Крок 2: Шифруйте диски на серверах (LUKS).
Крок 3: Використовуйте mTLS для міжсервісної взаємодії, якщо це можливо (наприклад, з Service Mesh).
# Пример команды для шифрования раздела диска с LUKS (на этапе установки или с осторожностью на живой системе)
# Это пример, требует понимания работы с дисками
sudo cryptsetup luksFormat /dev/vdb1 # Форматирование раздела
sudo cryptsetup luksOpen /dev/vdb1 my_encrypted_data # Открытие раздела
sudo mkfs.ext4 /dev/mapper/my_encrypted_data # Создание файловой системы
sudo mount /dev/mapper/my_encrypted_data /mnt/data # Монтирование
# Пример получения Let's Encrypt сертификата с certbot
sudo apt install certbot python3-certbot-nginx # Установка для Nginx
sudo certbot --nginx -d yourdomain.com -d www.yourdomain.com # Получение и настройка
Практичний приклад: Під час розгортання нового VPS завжди вибирайте опцію шифрування диска, якщо вона доступна. Якщо ні, розгляньте можливість використання dm-crypt/LUKS для шифрування даних перед їх записом на диск, особливо для критично важливих даних і баз даних.
7. Автоматизація та Infrastructure as Code (IaC)
Автоматизуйте все, що можна, щоб забезпечити консистентність і швидкість.
Крок 1: Використовуйте Ansible, Terraform або Puppet для управління конфігураціями серверів і розгортання застосунків.
Крок 2: Впровадьте CI/CD пайплайни для автоматичного тестування та розгортання коду.
Крок 3: Автоматизуйте оновлення пакетів і застосування патчів безпеки.
# Пример Ansible playbook для настройки фаервола
# file: firewall.yml
- name: Configure nftables for web server
hosts: webservers
become: yes
tasks:
- name: Ensure nftables is installed
ansible.builtin.apt:
name: nftables
state: present
- name: Copy nftables configuration
ansible.builtin.copy:
src: files/nftables.conf
dest: /etc/nftables.conf
mode: '0640'
notify: Restart nftables
- name: Enable and start nftables service
ansible.builtin.service:
name: nftables
state: started
enabled: yes
handlers:
- name: Restart nftables
ansible.builtin.service:
name: nftables
state: restarted
Практичний приклад: Використовуйте Terraform для опису вашої інфраструктури (VPS, мережеві правила у провайдера) та Ansible для конфігурації операційної системи та встановлення застосунків. Це гарантує, що кожен новий сервер буде розгорнуто з однаковими політиками безпеки.
Типові помилки при реалізації Zero Trust
 Схема: Типові помилки при реалізації Zero Trust
Схема: Типові помилки при реалізації Zero Trust
Впровадження Zero Trust — це складний процес, і на цьому шляху легко зробити помилки, які можуть підірвати всі зусилля з підвищення безпеки. Ось мінімум 5 поширених помилок і способи їх уникнути.
1. Підхід "все або нічого"
Помилка: Спроба впровадити всі принципи Zero Trust відразу по всій інфраструктурі. Це призводить до перевантаження команди, тривалих простоїв, конфліктів і, в кінцевому підсумку, до провалу проєкту через його складність.
Як уникнути: Застосовуйте ітеративний підхід. Почніть з найбільш критично важливих активів або з найменш складних для реалізації компонентів. Наприклад, спочатку впровадьте MFA для адміністративного доступу, потім мікросегментацію для одного критичного сервісу, потім JIT-доступ. Розбийте проєкт на маленькі, керовані етапи. Відзначайте малі перемоги і поступово розширюйте сферу застосування. У 2026 році цей підхід став ще більш актуальним, оскільки складність систем зростає, і "великий вибух" впроваджень практично завжди приречений на провал.
Реальний приклад наслідків: Одна SaaS-компанія спробувала впровадити повноцінний Zero Trust з Service Mesh, новим IAM і повною мікросегментацією за 6 місяців. Проєкт затягнувся на 1,5 року, викликав вигорання команди, численні збої у продакшені через неправильну конфігурацію і в підсумку був згорнутий, так і не досягнувши всіх цілей. В результаті, вони повернулися до менш амбітних, але більш керованих етапів.
2. Забути про інвентаризацію та картування
Помилка: Починати впровадження Zero Trust без повного розуміння поточного стану інфраструктури, всіх активів, їх взаємозв'язків і потоків даних. Це призводить до створення "сліпих зон", неправильних політик безпеки і потенційних прогалин.
Як уникнути: Проведіть ретельну інвентаризацію всіх активів (сервери, застосунки, бази даних, API, облікові записи), їх ролей, власників і чутливості даних. Створіть докладні карти мережевих взаємодій і потоків даних. Використовуйте автоматизовані інструменти для виявлення активів і залежностей. Регулярно оновлюйте цю документацію. У 2026 році існує безліч інструментів для автоматичного виявлення і картування залежностей в динамічних середовищах.
Реальний приклад наслідків: Стартап впроваджував мікросегментацію, не знаючи про існування старого, рідко використовуваного API-сервера, який спілкувався з базою даних за нестандартним портом. Цей сервер залишився без захисту, став точкою входу для зловмисників і призвів до витоку даних, попри всі зусилля із захисту основної інфраструктури.
3. Ігнорування користувацького досвіду
Помилка: Впровадження суворих політик безпеки (наприклад, часта переаутентифікація, складні MFA, JIT-доступ) без урахування зручності для кінцевих користувачів (розробників, системних адміністраторів). Це призводить до обходу політик, використання "тіньових" методів доступу і опору змінам.
Як уникнути: Залучайте користувачів в процес проєктування. Пояснюйте їм переваги Zero Trust. Шукайте баланс між безпекою і зручністю. Використовуйте сучасні, зручні для користувача MFA-рішення (наприклад, FIDO2-ключі, біометрія). Автоматизуйте процеси, щоб мінімізувати ручні дії. У 2026 році рішення для безпарольної аутентифікації та адаптивного доступу стали набагато більш зрілими, що дозволяє поліпшити UX без шкоди для безпеки.
Реальний приклад наслідків: Команда DevOps впровадила MFA для SSH, яке вимагало введення довгого коду з телефону кожні 15 хвилин. Розробники, втомлені від постійних переривань, почали обмінюватися SSH-ключами або використовувати VNC для віддаленого доступу, повністю обходячи нові політики і створюючи ще більші ризики безпеки.
4. Недостатній моніторинг і логування
Помилка: Впровадження Zero Trust без адекватних систем моніторингу, агрегації логів і аналітики. Без цього неможливо виявити аномалії, оцінити ефективність політик або оперативно реагувати на інциденти. Zero Trust — це не тільки запобігання, але і швидке виявлення.
Як уникнути: З самого початку плануйте централізоване логування з усіх джерел (фаєрволи, системи аутентифікації, застосунки, OS). Впровадьте SIEM-систему (Elastic Security, Graylog, Splunk) і налаштуйте алерти на ключові події і аномалії. Використовуйте HIDS/NIDS для додаткового рівня виявлення. Регулярно переглядайте логи і звіти. У 2026 році активно використовуйте AI/ML для аналізу логів, щоб виявляти приховані загрози, які людське око або прості правила не помітять.
Реальний приклад наслідків: Компанія впровадила мікросегментацію і суворі політики доступу, але не налаштувала адекватний моніторинг. Коли один з серверів був скомпрометований через уразливість в старому ПЗ, зловмисник зміг довгий час переміщатися по обмеженому сегменту, перш ніж його виявили, тому що ніхто не відстежував аномальні мережеві з'єднання зсередини сегмента.
5. Відсутність автоматизації та застарілі політики
Помилка: Ручне керування політиками Zero Trust, конфігураціями фаєрволів і привілеями. У динамічному середовищі це призводить до швидкого застарівання політик, помилок і "дрейфу конфігурації", коли реальний стан відрізняється від бажаного.
Як уникнути: Впровадьте Infrastructure as Code (IaC) за допомогою Terraform, Ansible або Puppet для управління всією інфраструктурою та політиками безпеки. Автоматизуйте розгортання, оновлення та відкликання привілеїв. Інтегруйте політики безпеки в CI/CD пайплайни. Регулярно проводьте аудит відповідності конфігурацій. Використовуйте автоматизовані інструменти для перевірки актуальності політик. У 2026 році ручне управління інфраструктурою та безпекою вважається антипатерном.
Реальний приклад наслідків: В одній з компаній правила фаєрвола на 50 VPS управлялися вручну. Коли потрібно було відкрити новий порт для нового сервісу, адміністратор забув закрити його після тестування. Пізніше, коли сервіс було розгорнуто на іншому порту, старе правило так і не було видалено, залишивши відкриту вразливість, яка використовувалася для DDoS-атаки.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
Чекліст для практичного застосування Zero Trust
Цей чеклист допоможе вам структурувати процес впровадження Zero Trust принципів на вашій інфраструктурі VPS та виділених серверах. Проходьте по пунктах послідовно, відмічаючи виконані задачі.
- Підготовка та планування:
- [ ] Провести повну інвентаризацію всіх активів (сервери, додатки, бази даних, користувачі, API).
- [ ] Скласти карту мережевих взаємодій та потоків даних між всіма компонентами інфраструктури.
- [ ] Визначити критично важливі активи та дані, які потребують першочергового захисту.
- [ ] Сформувати команду по впровадженню Zero Trust та виділити відповідальних.
- [ ] Розробити поетапний план впровадження, починаючи з малих, керованих кроків.
- Управління ідентифікацією та доступом (IAM):
- [ ] Впровадити централізовану систему управління ідентифікацією (наприклад, FreeIPA, Keycloak, LDAP).
- [ ] Забезпечити багатофакторну аутентифікацію (MFA) для всіх адміністративних облікових записів (SSH, панелі управління, CI/CD).
- [ ] Налаштувати MFA для всіх користувачів, які мають доступ до внутрішніх ресурсів.
- [ ] Відключити парольну аутентифікацію для SSH, використовувати тільки SSH-ключі (захищені парольною фразою).
- [ ] Впровадити принцип найменших привілеїв (RBAC) для всіх користувачів та сервісів.
- [ ] Розглянути впровадження Just-in-Time (JIT) доступу для привілейованих операцій (наприклад, через Teleport).
- [ ] Автоматизувати управління життєвим циклом облікових записів (створення, зміна, видалення).
- Мікросегментація мережі:
- [ ] Визначити логічні групи сервісів та їх залежності.
- [ ] Налаштувати хостові фаєрволи (
nftables/iptables) на всіх серверах з політикою "deny by default".
- [ ] Дозволити тільки явно необхідний трафік між сегментами/сервісами.
- [ ] Ізолювати критично важливі сервіси (бази даних, адміністративні панелі) в окремих мережевих сегментах.
- [ ] Використовувати VPN (WireGuard, OpenVPN) або ZTNA-рішення (Tailscale, Cloudflare Zero Trust) для безпечного віддаленого доступу до внутрішньої мережі.
- [ ] Розглянути використання Service Mesh (Istio, Linkerd) для мікросегментації на рівні мікросервісів, якщо використовується контейнеризація.
- Моніторинг, логування та реагування:
- [ ] Впровадити централізовану систему збору логів (SIEM: ELK Stack, Graylog, Splunk).
- [ ] Налаштувати збір логів зі всіх серверів, додатків, фаєрволів та систем аутентифікації.
- [ ] Розгорнути систему виявлення вторгнень на хості (HIDS: OSSEC, Wazuh) на всіх серверах.
- [ ] Налаштувати алерти на ключові події безпеки та аномалії (спроби брутфорсу, зміна критичних файлів, незвичайний трафік).
- [ ] Регулярно проводити аналіз вразливостей та сканування безпеки.
- [ ] Розробити та протестувати план реагування на інциденти безпеки.
- [ ] Розглянути впровадження AI/ML-аналітики для виявлення складних загроз (UEBA).
- Захист даних та шифрування:
- [ ] Забезпечити шифрування всіх даних при передачі (TLS/HTTPS для всіх веб-сервісів, mTLS для міжсервісних комунікацій).
- [ ] Впровадити шифрування даних у стані спокою (дискове шифрування LUKS для критичних серверів, шифрування баз даних).
- [ ] Використовувати HashiCorp Vault або аналоги для безпечного зберігання та управління секретами (API-ключі, облікові дані).
- [ ] Регулярно створювати та тестувати резервні копії даних, зберігати їх ізольовано та з шифруванням.
- Автоматизація та Infrastructure as Code (IaC):
- [ ] Використовувати інструменти IaC (Terraform, Ansible) для управління всією інфраструктурою та конфігураціями безпеки.
- [ ] Інтегрувати політики безпеки в CI/CD пайплайни.
- [ ] Автоматизувати розгортання та налаштування фаєрволів, агентів моніторингу та IAM-компонентів.
- [ ] Автоматизувати процес оновлення пакетів та застосування патчів безпеки.
- [ ] Впровадити регулярний аудит конфігурацій для запобігання "дрейфу".
- Тестування та аудит:
- [ ] Проводити регулярні внутрішні та зовнішні сканування вразливостей.
- [ ] Організувати періодичні тести на проникнення (пентести) для оцінки ефективності захисних заходів.
- [ ] Регулярно аудитувати права доступу та політики безпеки.
- [ ] Проводити навчання з реагування на інциденти.
Розрахунок вартості / Економіка впровадження Zero Trust
 Схема: Розрахунок вартості / Економіка впровадження Zero Trust
Схема: Розрахунок вартості / Економіка впровадження Zero Trust
Впровадження Zero Trust, особливо на VPS і виділених серверах, часто сприймається як дороге підприємство. Однак, в 2026 році, вартість бездіяльності перед лицем кіберзагроз значно перевищує інвестиції в безпеку. Важливо розуміти, що "вартість" включає не тільки прямі фінансові витрати, але і час, ресурси команди і потенційні приховані витрати.
Прямі витрати
- Ліцензії та підписки:
- SaaS-рішення ZTNA/SDP: Cloudflare Zero Trust, Tailscale, Twingate — від 50 до 500 USD/місяць для команди з 10-20 осіб та 5-10 серверів. Ціни залежать від кількості користувачів, трафіку та функціоналу.
- Комерційні IAM/PAM системи: Якщо не використовуються Open Source, то ліцензії можуть коштувати від кількох сотень до тисяч USD на місяць, залежно від масштабу.
- SIEM/EDR з AI/ML: Комерційні SIEM-рішення (Splunk, Elastic Security Enterprise з ML) або EDR-платформи (CrowdStrike, SentinelOne) можуть коштувати від 200 USD до 1500 USD і вище на місяць, залежно від обсягу даних/кількості кінцевих точок.
- Інфраструктурні витрати:
- Додаткові VPS/виділені сервери: Для розгортання Open Source рішень (FreeIPA, Keycloak, ELK Stack, Wazuh Manager, Vault) можуть знадобитися окремі сервери. Наприклад, виділений VPS для SIEM, ще один для IAM. Вартість одного VPS може варіюватися від 10 до 100 USD/місяць.
- Мережевий трафік: Якщо використовуються хмарні ZTNA-рішення, можливі додаткові витрати на вихідний трафік.
- Сторонні послуги:
- Консалтинг: Залучення експертів з Zero Trust для аудиту, проєктування та впровадження. Погодинна ставка може становити від 100 до 300 USD і вище.
- Пентести та аудит безпеки: Від 2000 до 10000 USD і вище за один повноцінний тест. Рекомендується проводити щорічно.
Приховані витрати та "ціна" команди
- Час команди:
- Навчання: Команді потрібен час на вивчення нових концепцій, інструментів і технологій. Це може бути еквівалентно кільком тижням роботи інженера.
- Впровадження та налаштування: Найбільш значна прихована витрата. Розробка політик, написання скриптів автоматизації, інтеграція систем, тестування. Для повноцінного впровадження на Open Source це може зайняти від 3 до 12 місяців роботи 1-2 інженерів.
- Підтримка та обслуговування: Постійний моніторинг, оновлення політик, реагування на інциденти, оновлення ПЗ. Zero Trust — це безперервний процес.
- Зниження продуктивності:
- Початковий етап: У процесі впровадження можливі тимчасові простої або уповільнення роботи сервісів через неправильну конфігурацію або нові шари безпеки.
- Накладні витрати: Деякі рішення (наприклад, Service Mesh) додають невеликі накладні витрати на ЦПУ/пам'ять, що може вимагати незначного збільшення ресурсів серверів.
- Ризик помилок:
- Людський фактор: Неправильна конфігурація може створити нові вразливості або викликати збої.
- Складність: Чим складніша система, тим вища ймовірність помилок.
Як оптимізувати витрати
- Починайте з Open Source: Багато ключових компонентів Zero Trust (фаєрволи, IAM, HIDS, SIEM) мають потужні та безплатні Open Source аналоги. Це дозволяє значно знизити прямі витрати, переносячи акцент на інвестиції в час та експертизу команди.
- Ітеративний підхід: Не намагайтеся впровадити все відразу. Почніть з найбільш критичних областей і поступово розширюйте. Це дозволяє розподілити навантаження на команду та бюджет.
- Автоматизація з першого дня: Інвестуйте в Infrastructure as Code (IaC) та CI/CD. Це скоротить час на розгортання, зменшить кількість помилок та знизить операційні витрати в довгостроковій перспективі.
- Використовуйте гібридний підхід: Комбінуйте Open Source для базових компонентів з комерційними SaaS-рішеннями для специфічних задач (наприклад, ZTNA для віддаленого доступу), де це економічно виправдано та спрощує управління.
- Навчайте команду: Інвестуйте в навчання своїх інженерів. Висока кваліфікація команди дозволить ефективно використовувати Open Source рішення та знизити потребу в дорогому зовнішньому консалтингу.
- Оцінюйте TCO (Total Cost of Ownership): При порівнянні рішень враховуйте не тільки прямі ліцензійні платежі, але й витрати на впровадження, підтримку, навчання, а також потенційні ризики та збитки від інцидентів безпеки.
Таблиця з прикладами розрахунків для різних сценаріїв (на 2026 рік, на 5-10 серверів та 10-20 користувачів)
Представлені цифри є орієнтовними і можуть сильно варіюватися в залежності від конкретних вимог, обраних провайдерів та кваліфікації команди.
| Категорія витрат |
Сценарій 1: Мінімум витрат (Open Source + час команди) |
Сценарій 2: Збалансований (Гібридний) |
Сценарій 3: Розширений (Комерційні + AI/ML) |
| Ліцензії/Підписки ZTNA/SDP |
0 USD (тільки WireGuard/OpenVPN) |
50-200 USD/міс (Tailscale/Twingate) |
200-500 USD/міс (Cloudflare ZTNA Business) |
| Ліцензії/Підписки IAM/PAM |
0 USD (FreeIPA/Keycloak) |
0-100 USD/міс (HashiCorp Vault Open Source з плагінами) |
300-800 USD/міс (Teleport Enterprise / комерційні PAM) |
| Ліцензії/Підписки SIEM/EDR/AI |
0 USD (ELK/Wazuh Open Source) |
100-300 USD/міс (Elastic Security Basic / Wazuh Cloud) |
500-1500 USD/міс (CrowdStrike Falcon / Splunk Cloud) |
| Додаткові VPS для інфраструктури безпеки |
20-40 USD/міс (1-2 VPS для FreeIPA/ELK/Wazuh Manager) |
20-40 USD/міс (1-2 VPS, якщо частина сервісів в SaaS) |
0-20 USD/міс (більше SaaS, менше своїх VPS) |
| Пентести/Аудит (щорічно, розділити на 12) |
150-400 USD/міс (2000-5000 USD/рік) |
400-800 USD/міс (5000-10000 USD/рік) |
800-1200 USD/міс (10000-15000 USD/рік) |
| Час команди (в еквіваленті зарплати інженера) |
2000-4000 USD/міс (високі трудовитрати на впровадження та підтримку) |
1000-2000 USD/міс (середні трудовитрати) |
500-1000 USD/міс (низькі трудовитрати завдяки SaaS та автоматизації) |
| Підсумкова орієнтовна вартість на місяць |
2170-4440 USD/міс |
1670-3440 USD/міс |
2320-5170 USD/міс |
Як видно з таблиці, прямі витрати на ліцензії можуть бути низькими у Open Source сценарії, але це компенсується високими трудовитратами команди. Комерційні рішення знижують навантаження на команду, але збільшують прямі платежі. Оптимальний вибір залежить від розміру вашої команди, її кваліфікації та бюджету.
Кейси та приклади впровадження Zero Trust
 Схема: Кейси та приклади впровадження Zero Trust
Схема: Кейси та приклади впровадження Zero Trust
Розглянемо декілька реалістичних сценаріїв, які демонструють застосування принципів Zero Trust на VPS та виділених серверах у 2026 році.
Кейс 1: Стартап "Alpha SaaS" — захист внутрішньої інфраструктури та віддаленого доступу
Проблема: "Alpha SaaS" (15 розробників, 5 DevOps-інженерів) розробляє критично важливу B2B-платформу, розгорнуту на 10 VPS у різних провайдерів. Раніше використовувалася традиційна VPN для доступу до серверів, що створювало "широкий" доступ до внутрішньої мережі. Облікові дані зберігалися локально, MFA не було повсюдним. Виникла необхідність посилити безпеку, особливо для віддалених співробітників, та забезпечити відповідність новим регуляторним вимогам 2026 року.
Рішення Zero Trust:
- ZTNA для віддаленого доступу: Відмовилися від традиційного VPN на користь Cloudflare Zero Trust. Всі VPS були підключені до Cloudflare Tunnel, що зробило їх недоступними з публічного інтернету напряму. Доступ до SSH, Grafana, Jenkins та внутрішніх API тепер здійснювався тільки через Cloudflare Gateway після аутентифікації користувача.
- Централізоване IAM та MFA: Впроваджено Keycloak як центральний IdP. Всі розробники та DevOps тепер аутентифікуються через Keycloak з обов'язковим MFA (FIDO2-ключі). Keycloak інтегрований з Cloudflare Zero Trust для верифікації ідентичності.
- Принцип найменших привілеїв (PAM): Для доступу до SSH на серверах використовується Teleport. Користувачі запитують доступ до конкретного серверу на певний час (JIT Access), Teleport видає тимчасовий SSH-сертифікат з мінімально необхідними правами. Всі SSH-сесії записуються та аудіюються.
- Мікросегментація на хостах: На кожному VPS налаштовані
nftables, що дозволяють вхідні з'єднання тільки від Cloudflare Tunnel та вихідні тільки до необхідних зовнішніх сервісів (бази даних, API-шлюзи). Міжсервісна взаємодія між VPS суворо обмежена за IP та портами, використовуючи політики "білого списку".
- Моніторинг: Розгорнуто ELK Stack на окремому VPS для централізованого збору логів з усіх серверів, фаєрволів, Keycloak та Teleport. Налаштовані алерти на аномальну поведінку (наприклад, спроби входу з невідомих пристроїв, незвичайні SSH-команди).
Результати:
- Значно знижено поверхню атаки, так як сервери більше не мають публічних IP.
- Покращено безпеку віддаленого доступу та управління привілеями.
- Підвищено прозорість та аудіюваність всіх адміністративних дій.
- Успішно пройдено сертифікацію за новими стандартами безпеки, що вимагають принципів Zero Trust.
- Час реагування на потенційні інциденти скоротився на 40% завдяки централізованому моніторингу.
Кейс 2: Фінтех-компанія "SecurePay" — захист чутливих даних та міжсервісної взаємодії
Проблема: "SecurePay" (30+ інженерів) управляє платіжною системою, розгорнутою на декількох виділених серверах. Інфраструктура складається з мікросервісів, що працюють у контейнерах. Чутливі дані клієнтів вимагають максимально можливого захисту. Існували ризики горизонтального переміщення зловмисника у випадку компрометації одного мікросервісу. Потрібно було забезпечити mTLS між всіма сервісами та гранулярний контроль доступу до баз даних.
Рішення Zero Trust:
- Контейнерна оркестрація та Service Mesh: На виділених серверах розгорнуто легковагий Kubernetes-кластер (K3s). Впроваджено Linkerd як Service Mesh. Це автоматично забезпечило взаємну TLS-аутентифікацію (mTLS) та шифрування всього трафіку між мікросервісами.
- Гранулярні політики авторизації: За допомогою Linkerd налаштовані політики авторизації, які явно дозволяють, наприклад, мікросервісу "Платежі" звертатися до мікросервісу "Облікові записи" тільки за певним API-шляхом, та блокують всі інші взаємодії.
- Управління секретами та динамічними обліковими даними: Розгорнуто HashiCorp Vault. Всі чутливі дані (API-ключі, облікові дані баз даних) зберігаються у Vault. Мікросервіси отримують тимчасові, динамічно генеровані облікові дані для баз даних при кожному запуску, які автоматично відкликаються після закінчення терміну дії.
- Шифрування даних у спокої: Всі диски на виділених серверах зашифровані за допомогою LUKS. Бази даних використовують вбудоване шифрування для чутливих полів.
- HIDS та поведінковий аналіз: На кожному вузлі K3s встановлено Wazuh Agent, інтегрований з Wazuh Manager, який збирає логи контейнерів та хостів, відстежує цілісність файлів та виявляє аномалії у поведінці процесів. У Wazuh Manager налаштовані правила для виявлення незвичайних мережевих підключень або модифікацій файлів всередині контейнерів.
Результати:
- Забезпечено повне mTLS-шифрування та сувора авторизація для міжсервісної взаємодії.
- Мінімізовано ризик витоку облікових даних завдяки динамічному управлінню секретами.
- Значно обмежено горизонтальне переміщення зловмисника у випадку компрометації окремого мікросервісу.
- Збільшено прозорість та можливість аудиту всіх операцій всередині кластера.
- Система успішно пройшла аудит PCI DSS, що було критично для бізнесу.
Troubleshooting: Розв'язання типових проблем Zero Trust
Впровадження Zero Trust може бути пов'язане з різними проблемами. Нижче наведено типові сценарії та підходи до їх розв'язання.
1. Проблеми з доступом після налаштування фаєрволів (мікросегментація)
Симптом: Сервіси не можуть спілкуватися один з одним, користувачі не можуть підключитися до серверів після налаштування nftables/iptables.
Діагностика:
- Перевірте логи фаєрвола: Переконайтеся, що фаєрвол логує відкинуті пакети. Якщо ні, тимчасово додайте правила логування (наприклад,
nft add rule ip filter input drop counter log prefix "NFT_DROP: ").
- Перевірте стан фаєрвола:
sudo nft list ruleset # Для nftables
sudo iptables -nvL # Для iptables
- Використовуйте
tcpdump: Запустіть tcpdump на обох вузлах (джерелі та отримувачі) для аналізу трафіку.
sudo tcpdump -i any host <IP_іншого_сервера> and port <PORT> -vn
- Перевірте мережеве підключення: Використовуйте
ping, telnet або nc для перевірки базового мережевого підключення до застосування фаєрвола або з мінімальними правилами.
telnet <IP_сервера> <PORT>
nc -vz <IP_сервера> <PORT>
Рішення:
- Тимчасово послабте правила: Для діагностики можна тимчасово дозволити весь трафік між двома проблемними вузлами, щоб переконатися, що проблема саме у фаєрволі. Потім поступово звужуйте правила.
- Перевірте порядок правил: У фаєрволах правила обробляються послідовно. Переконайтеся, що дозволяючі правила стоять до блокуючих.
- Враховуйте
RELATED,ESTABLISHED: Не забудьте дозволити вхідний трафік для вже встановлених з'єднань (ct state established,related accept в nftables або -m state --state RELATED,ESTABLISHED -j ACCEPT в iptables).
- Перевірте обидва напрямки: Фаєрвол працює в обидві сторони. Переконайтеся, що дозволено як вхідний, так і вихідний трафік для необхідних портів.
2. Проблеми з MFA/JIT-доступом (аутентифікація)
Симптом: Користувачі не можуть пройти аутентифікацію з MFA, JIT-доступ не працює або не видаються тимчасові сертифікати.
Діагностика:
- Перевірте системні логи: Логи
auth.log, syslog, логи PAM (/var/log/auth.log на Debian/Ubuntu, /var/log/secure на CentOS/RHEL) можуть містити повідомлення про помилки аутентифікації.
- Перевірте логи IAM/PAM системи: Keycloak, FreeIPA, Teleport мають свої власні логи, які можуть вказати на причину відмови.
- Перевірте синхронізацію часу: MFA-токени на основі часу (TOTP) дуже чутливі до синхронізації часу між клієнтом і сервером.
timedatectl # Перевірити час на сервері
- Перевірте конфігурацію PAM: Переконайтеся, що модулі PAM налаштовані правильно (наприклад,
/etc/pam.d/sshd для SSH).
Рішення:
- Синхронізуйте час: Налаштуйте NTP-синхронізацію на всіх серверах.
- Перевірте секрети MFA: Переконайтеся, що секрет MFA правильно введено на клієнті (наприклад, в Google Authenticator) і відповідає тому, що на сервері.
- Перегляньте політики: Якщо JIT-доступ не видається, переконайтеся, що політики авторизації в Teleport або Vault правильно налаштовані і користувач має право запитувати дану роль/сертифікат.
- Тестуйте з мінімальними налаштуваннями: Тимчасово вимкніть один з факторів MFA, щоб ізолювати проблему.
3. Проблеми з продуктивністю після впровадження Zero Trust
Симптом: Помітне зниження продуктивності додатків, високе завантаження ЦП/пам'яті на серверах після впровадження нових компонентів Zero Trust (наприклад, Service Mesh, SIEM-агенти).
Діагностика:
- Моніторинг ресурсів: Використовуйте
top, htop, Prometheus/Grafana для виявлення процесів, які споживають найбільше ресурсів.
- Перевірте логи: Висока активність логування може навантажувати диск і ЦП.
- Тестування з вимкненням компонентів: Спробуйте тимчасово вимкнути один з нових компонентів Zero Trust (наприклад, агент HIDS, sidecar Service Mesh), щоб визначити джерело проблеми.
- Проаналізуйте мережеві затримки: Використовуйте
mtr або traceroute для виявлення вузьких місць у мережі, особливо якщо використовується ZTNA-рішення.
Рішення:
- Оптимізуйте конфігурацію: Для HIDS-агентів зменште частоту сканування або виключіть некритичні шляхи. Для Service Mesh перевірте конфігурацію проксі-серверів.
- Збільште ресурси: Якщо один з компонентів (наприклад, Elasticsearch в ELK Stack) постійно споживає багато ресурсів, можливо, йому потрібно більше ЦП, пам'яті або швидший диск.
- Оптимізуйте логування: Відфільтруйте менш важливі логи, агрегуйте їх, використовуйте більш ефективні транспортні протоколи (наприклад, UDP для syslog, якщо втрати не критичні).
- Вибір більш легковажних альтернатив: Якщо комерційне рішення занадто ресурсоємне, розгляньте Open Source аналоги.
4. "Дрейф конфігурації" та неактуальні політики
Симптом: Конфігурації серверів або правила безпеки відрізняються від очікуваних, політики застарівають, з'являються незадокументовані зміни.
Діагностика:
- Аудит конфігурацій: Використовуйте Ansible (режим
--check) або інші IaC-інструменти для регулярної перевірки відповідності фактичного стану бажаному.
- Моніторинг змін файлів: HIDS-системи (Wazuh, OSSEC) можуть відстежувати зміни критично важливих конфігураційних файлів.
- Регулярні сканування: Сканери вразливостей і конфігурацій можуть виявити відхилення від базових ліній безпеки.
Рішення:
- Впровадьте IaC: Використовуйте Terraform/Ansible для управління всіма аспектами інфраструктури.
- Автоматизуйте застосування політик: Налаштуйте CI/CD для автоматичного застосування змін конфігурації.
- Регулярний аудит: Заплануйте автоматичні або ручні аудити відповідності, як мінімум щоквартально.
- Навчайте команду: Переконайтеся, що всі інженери дотримуються принципів IaC і не вносять зміни вручну без фіксації в системі контролю версій.
Коли звертатися в підтримку або до експертів:
- Якщо після всіх діагностичних кроків ви не можете визначити причину проблеми.
- Якщо проблема стосується критично важливої системи і викликає тривалий простій.
- Якщо ви підозрюєте активну атаку або компрометацію, і ваша команда не має достатнього досвіду в реагуванні на інциденти.
- При впровадженні складних компонентів (наприклад, налаштування Service Mesh, кастомних політик IAM) без достатньої внутрішньої експертизи.
- Для проведення незалежного аудиту безпеки або пентесту, щоб отримати погляд з боку.
FAQ: Часті питання про Zero Trust
Що таке Zero Trust і чим він відрізняється від традиційної безпеки?
Zero Trust — це стратегічний підхід до безпеки, заснований на принципі "нікому не довіряй, завжди перевіряй". На відміну від традиційної моделі, яка довіряє всьому всередині периметра мережі, Zero Trust явно перевіряє кожного користувача, пристрій і запит доступу, незалежно від їх місцезнаходження. Це означає, що навіть якщо користувач знаходиться "всередині" вашої мережі, його доступ буде суворо контролюватися і верифікуватися.
Чи можна впровадити Zero Trust на одному VPS або це тільки для великих компаній?
Так, безумовно. Zero Trust — це принципи, які застосовні до будь-якої інфраструктури. Навіть на одному VPS можна впровадити мікросегментацію за допомогою nftables, посилити аутентифікацію SSH з MFA, використовувати HashiCorp Vault для секретів та налаштувати централізоване логування. Масштаб реалізації буде меншим, але принципи залишаються тими ж, і їх впровадження значно підвищить безпеку.
Які перші кроки слід зробити для впровадження Zero Trust?
Почніть з інвентаризації всіх ваших активів та їх взаємозв'язків. Потім зосередьтесь на посиленні аутентифікації: впровадьте MFA для всіх адміністративних облікових записів та використовуйте SSH-ключі. Паралельно почніть з мікросегментації найбільш критичних сервісів, застосовуючи політики "deny by default" на рівні хостових фаєрволів.
Чи потрібно повністю відмовлятися від VPN при переході на Zero Trust?
Не обов'язково. Традиційні VPN, що надають широкий доступ до мережі, можуть бути замінені на ZTNA-рішення, які надають доступ лише до конкретних застосунків. Однак, WireGuard або OpenVPN можуть бути використані для створення безпечних тунелів між серверами або для створення базової мережі, поверх якої вже будуть будуватися Zero Trust політики доступу до застосунків.
Як Zero Trust допомагає у боротьбі з внутрішніми загрозами?
Zero Trust ефективно бореться з внутрішніми загрозами, оскільки він не довіряє "внутрішнім" користувачам або системам за замовчуванням. Принцип найменших привілеїв, JIT-доступ, мікросегментація та безперервний моніторинг гарантують, що навіть скомпрометований внутрішній обліковий запис або зловмисний інсайдер матиме обмежений доступ і його дії будуть швидко виявлені.
Які інструменти Open Source найбільш корисні для Zero Trust?
Для IAM: Keycloak, FreeIPA. Для управління секретами: HashiCorp Vault. Для мережевої безпеки: nftables/iptables, WireGuard. Для моніторингу: ELK Stack, Graylog, Wazuh, Prometheus/Grafana. Для автоматизації: Ansible, Terraform. Ці інструменти дозволяють побудувати потужну Zero Trust інфраструктуру з мінімальними прямими витратами.
Скільки часу займає впровадження Zero Trust?
Впровадження Zero Trust — це безперервний процес, а не одноразовий проєкт. Перші значущі результати (наприклад, MFA для SSH та базова мікросегментація) можуть бути досягнуті за 3-6 місяців. Повне перетворення інфраструктури може зайняти від 1 до 3 років, в залежності від розміру та складності вашої системи, а також від ресурсів команди.
Чи потрібно переписувати всі застосунки для Zero Trust?
Ні, не обов'язково. Багато принципів Zero Trust (MFA, фаєрволи, моніторинг) можуть бути застосовані на рівні інфраструктури без зміни коду застосунків. Однак, для досягнення максимального ефекту (наприклад, для гранулярної авторизації на рівні API або mTLS для мікросервісів), може знадобитися певна адаптація або використання Service Mesh, що може вимагати змін у розгортанні застосунків.
Як виміряти ефективність впровадження Zero Trust?
Ефективність можна виміряти за кількома показниками: зниження кількості інцидентів безпеки, скорочення часу виявлення та реагування на загрози (MTTD/MTTR), зменшення поверхні атаки, успішне проходження аудитів та пентестів, а також покращення відповідності регуляторним вимогам. Важливо відстежувати метрики, такі як кількість заблокованих фаєрволом атак, кількість спроб несанкціонованого доступу та активність HIDS.
Яка роль AI та ML в Zero Trust у 2026 році?
У 2026 році AI та ML відіграють критично важливу роль в Zero Trust, особливо в області безперервного моніторингу та виявлення загроз. Вони використовуються для аналізу величезних обсягів логів та мережевого трафіку, виявлення аномалій у поведінці користувачів та систем, прогнозування загроз та автоматизації реагування. AI допомагає знаходити приховані атаки, які не можуть бути виявлені традиційними сигнатурними методами, роблячи захист більш проактивним та адаптивним.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
Висновок: Наступні кроки до безпечного майбутнього
У 2026 році концепція Zero Trust перестала бути просто модним терміном і стала абсолютною необхідністю для будь-якої інфраструктури, особливо для тих, хто управляє VPS та виділеними серверами. Враховуючи експоненціальне зростання складності кіберзагроз, посилене можливостями штучного інтелекту, традиційні підходи до безпеки вже не здатні забезпечити адекватний захист. Принципи "нікому не довіряй, завжди перевіряй", мікросегментація, принцип найменших привілеїв, безперервний моніторинг та автоматизація — це не просто кращі практики, це фундамент для побудови стійкого та безпечного цифрового середовища.
Ми розглянули, як застосовувати ці принципи в умовах обмежених ресурсів, використовуючи міць Open Source рішень та стратегічно впроваджуючи комерційні продукти там, де це виправдано. Ключовим висновком є те, що Zero Trust — це не продукт, який можна купити та встановити, а стратегічний підхід, що вимагає змін у мисленні, процесах та архітектурі. Це безперервна подорож, що вимагає постійної адаптації та вдосконалення.
Наступні кроки для читача:
- Почніть з аудиту: Використовуйте наш чекліст, щоб оцінити поточний стан вашої інфраструктури. Виявіть найкритичніші активи та найбільш очевидні прогалини в безпеці.
- Пріоритезуйте MFA: Це найшвидший та найефективніший спосіб значно підвищити безпеку. Впровадьте багатофакторну аутентифікацію для всіх адміністративних облікових записів і, за можливості, для всіх користувачів.
- Плануйте мікросегментацію: Почніть з картування мережевих взаємодій та поступово впроваджуйте хостові фаєрволи з політикою "deny by default" для ізоляції критичних сервісів.
- Інвестуйте в автоматизацію: Використовуйте IaC-інструменти, такі як Ansible та Terraform, для управління конфігураціями та розгортаннями. Це не тільки підвищить безпеку, але й значно спростить операції.
- Впровадьте централізований моніторинг: Налаштуйте ELK Stack або Wazuh для збору та аналізу логів з усіх ваших серверів. Налаштуйте алерти на аномалії. Без моніторингу Zero Trust буде неповним.
- Навчайте команду: Ваші інженери — ваша перша лінія оборони. Інвестуйте в їх навчання принципам Zero Trust та роботі з відповідними інструментами.
- Проводьте регулярні аудити та пентести: Тільки зовнішній погляд або симуляція атаки може виявити реальні слабкі місця вашої системи.
Пам'ятайте, що шлях до повної реалізації Zero Trust може бути довгим, але кожен зроблений крок наближає вас до більш безпечної та стійкої інфраструктури. В умовах постійно мінливого ландшафту загроз 2026 року, інвестиції в Zero Trust — це інвестиції в майбутнє вашого бізнесу.
Поділитися цим записом:
внедрение zero trust принципов для инфраструктуры на vps и выделенных серверах: практическое руководство 2026