Стратегії Disaster Recovery (DR) для SaaS-застосунків на VPS і хмарі: планування, автоматизація та тестування
TL;DR
- DR — це не просто бекапи: Це комплексний план з відновлення працездатності SaaS-застосунку після збою, що мінімізує простої та втрати даних.
- RTO та RPO — ваші головні метрики: Визначте цільовий час відновлення (RTO) та допустиму втрату даних (RPO) на основі бізнес-вимог і вартості простою.
- Автоматизація — ключ до успіху: Ручні процедури DR повільні, схильні до помилок і не масштабуються. Інвестуйте в IaC, скрипти та оркестрацію для швидкого та надійного відновлення.
- Тестування — не розкіш, а необхідність: Регулярно тестуйте ваш DR-план (від настільних навчань до повного перемикання), щоб переконатися в його працездатності та актуальності.
- Гібридні стратегії — оптимальний баланс: Комбінування VPS і хмарних рішень часто пропонує кращий компроміс між вартістю, продуктивністю та стійкістю.
- Приховані витрати: Враховуйте не лише прямі витрати на інфраструктуру, а й вартість простою, втрати репутації, трудовитрати на відновлення та тестування.
- 2026 рік: ШІ та ML все активніше використовуються для предиктивного DR, оптимізації ресурсів і автоматичного аналізу логів при збоях.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
Вступ
 Схема: Введення
Схема: Введення
У світі SaaS-застосунків, що стрімко розвивається, де кожна хвилина простою може коштувати компанії не лише значних фінансових втрат, а й непоправної шкоди репутації, питання забезпечення безперервності бізнесу стає критично важливим. До 2026 року користувачі очікують від сервісів 24/7 доступності та миттєвого відгуку, а збої сприймаються як пряме порушення довіри. Кібератаки стають все більш витонченими, інфраструктурні відмови — хоч і рідкісні, але катастрофічні, а людський фактор, як і раніше, залишається однією з головних причин інцидентів.
Ця стаття покликана стати вичерпним посібником з розробки, впровадження та тестування стратегій Disaster Recovery (DR) для SaaS-застосунків, що працюють як на класичних VPS, так і в сучасних хмарних середовищах. Ми розглянемо, чому DR — це не просто "хороша практика", а життєва необхідність, особливо для фаундерів SaaS-проектів, які часто недооцінюють його важливість на ранніх етапах, а також для DevOps-інженерів і системних адміністраторів, на чиї плечі лягає завдання реалізації.
У 2026 році ландшафт технологій пропонує безпрецедентні можливості для створення відмовостійких систем. Від автоматизованих інструментів Infrastructure as Code (IaC) до інтелектуальних систем моніторингу на базі ШІ, здатних передбачати потенційні збої. Однак, незважаючи на ці досягнення, багато компаній, як і раніше, стикаються з проблемами при реалізації ефективних DR-планів. Причина часто криється у відсутності системного підходу, нестачі тестування та нерозумінні реальних бізнес-вимог до відновлення.
Даний посібник створено для того, щоб допомогти вам:
- Зрозуміти фундаментальні принципи Disaster Recovery.
- Вибрати оптимальну DR-стратегію, виходячи з ваших RTO (Recovery Time Objective) та RPO (Recovery Point Objective).
- Освоїти методи автоматизації DR-процесів для підвищення швидкості та надійності відновлення.
- Навчитися ефективно тестувати ваш DR-план, виявляючи та усуваючи слабкі місця до настання реального інциденту.
- Оцінити економічну доцільність різних підходів до DR та оптимізувати витрати.
- Уникнути поширених помилок, які можуть призвести до провалу відновлення.
Ми говоритимемо технічною, але зрозумілою мовою, підкріплюючи кожне твердження конкретними прикладами, конфігураціями та рекомендаціями, заснованими на реальному досвіді. Приготуйтеся заглибитися у світ стійкості, де підготовка до найгіршого сценарію — це найкраща інвестиція в майбутнє вашого SaaS.
Основні критерії/фактори вибору DR-стратегії
 Схема: Основні критерії/фактори вибору DR-стратегії
Схема: Основні критерії/фактори вибору DR-стратегії
Вибір оптимальної стратегії Disaster Recovery — це не просто технічне рішення, а стратегічне бізнес-рішення, яке має враховувати безліч факторів. Правильне розуміння та оцінка цих критеріїв допоможуть вам побудувати DR-план, який відповідатиме як технічним вимогам, так і фінансовим можливостям вашої компанії.
RTO (Recovery Time Objective) — Цільовий час відновлення
Що це: Максимально допустимий час, протягом якого програма або сервіс може бути недоступним після збою. Це метрика часу простою, яку визначає бізнес.
Чому важливо: Визначає швидкість, з якою ваш бізнес має бути готовий відновити роботу. Чим нижче RTO, тим дорожче та складніше DR-стратегія. Наприклад, для фінансового застосунку RTO може бути 1-5 хвилин, для внутрішньої CRM — 4-8 годин.
Як оцінювати: Проведіть аналіз впливу на бізнес (Business Impact Analysis, BIA). Оцініть фінансові втрати за кожну годину простою, збитки репутації, штрафи за недотримання SLA. Це допоможе визначити, скільки ви готові інвестувати у швидке відновлення.
RPO (Recovery Point Objective) — Цільова точка відновлення
Що це: Максимально допустимий обсяг даних, який може бути втрачено в результаті збою. Це метрика втрати даних, що вимірюється в часі (наприклад, 15 хвилин, 1 година).
Чому важливо: Визначає частоту резервного копіювання або реплікації даних. Чим нижче RPO, тим частіше мають синхронізуватися дані між основною та резервною системами. Нульове RPO означає відсутність втрати даних (вимагає синхронної реплікації).
Як оцінювати: BIA також допоможе тут. Які дані є критичними? Яка вартість відновлення або відтворення втрачених даних? Чи можуть користувачі повторно ввести дані? Для більшості SaaS RPO 5-15 хвилин вважається хорошим балансом.
Вартість (Cost)
Що це: Загальні витрати на реалізацію та підтримку DR-стратегії. Включає прямі та приховані витрати.
Чому важливо: DR-план має бути економічно доцільним. Немає сенсу витрачати мільйони на DR, якщо потенційна шкода від простою в десятки разів менша. Вартість включає: інфраструктуру (сервери, сховища, мережа), програмне забезпечення (ліцензії, інструменти), персонал (розробка, підтримка), тестування, передачу даних.
Як оцінювати: Детальний розрахунок Total Cost of Ownership (TCO) для кожного варіанту DR. Враховуйте капітальні (CAPEX) та операційні (OPEX) витрати. Не забудьте про приховані витрати, такі як вартість навчання персоналу, час на розробку та налагодження DR-скриптів, а також вартість простою під час тестування.
Складність реалізації та підтримки (Complexity)
Що це: Рівень зусиль, необхідних для проектування, розгортання, налаштування та подальшого обслуговування DR-рішення.
Чому важливо: Більш складні системи вимагають більше часу на розробку, вищої кваліфікації персоналу та більш частих перевірок. Висока складність збільшує ймовірність помилок як під час впровадження, так і під час реального відновлення.
Як оцінювати: Оцініть обсяг роботи з IaC, налаштування реплікації, розробки скриптів failover/failback, інтеграції з моніторингом. Враховуйте доступність готових рішень та експертизу вашої команди.
Рівень автоматизації (Automation Level)
Що це: Ступінь, в якій процеси резервного копіювання, реплікації, моніторингу, перемикання (failover) та повернення (failback) виконуються без ручного втручання.
Чому важливо: Автоматизація значно скорочує RTO, мінімізує людський фактор та підвищує надійність. У 2026 році ручні DR-процедури вважаються анахронізмом для критично важливих систем.
Як оцінювати: Розробіть сценарії DR та оцініть, скільки кроків можна автоматизувати. Використовуйте IaC (Terraform, Ansible), CI/CD-пайплайни для розгортання DR-інфраструктури та скрипти для оркестрації перемикання.
Масштабованість (Scalability)
Що це: Здатність DR-рішення адаптуватися до зростання вашого SaaS-додатку (збільшення трафіку, даних, користувачів) без суттєвого перепроектування.
Чому важливо: Ваша DR-стратегія повинна рости разом з вашим бізнесом. Немасштабоване рішення швидко застаріє та стане вузьким місцем.
Як оцінювати: Розгляньте, як DR-інфраструктура буде справлятися з X2 або X10 навантаженням. Хмарні рішення часто виграють тут завдяки еластичності ресурсів.
Безпека (Security)
Що це: Захист даних та інфраструктури DR від несанкціонованого доступу, компрометації та втрати.
Чому важливо: DR-інфраструктура містить копії ваших критично важливих даних, тому вона є привабливою мішенню для зловмисників. Недостатня безпека DR може призвести до витоку даних або їх знищення.
Як оцінювати: Застосовуйте ті ж самі або навіть більш суворі заходи безпеки до DR-ресурсів: шифрування даних (у стані спокою та в дорозі), управління доступом (IAM, MFA), мережева ізоляція, регулярні аудити безпеки.
Відповідність нормативним вимогам (Compliance)
Що це: Здатність DR-плану задовольняти вимоги законодавства (GDPR, HIPAA, PCI DSS і т.д.) та галузевих стандартів.
Чому важливо: Недотримання вимог може призвести до величезних штрафів, втрати ліцензій та репутаційної шкоди.
Як оцінювати: Проконсультуйтеся з юристами та фахівцями з комплаєнсу. Переконайтеся, що ваш DR-план охоплює всі аспекти зберігання, обробки та відновлення чутливих даних відповідно до регуляцій.
Частота та якість тестування (Testing Frequency and Quality)
Що це: Регулярність проведення DR-тестів та їх глибина (від настільних навчань до повного перемикання).
Чому важливо: Непротестований DR-план — це не план, а набір припущень. Тільки регулярне тестування виявляє помилки, вузькі місця та забезпечує впевненість у працездатності системи.
Як оцінювати: Розробіть графік тестування (наприклад, раз на квартал для повного перемикання, щомісяця для перевірки бекапів). Використовуйте автоматизовані фреймворки тестування та Chaos Engineering для імітації різних збоїв.
Гравітація даних та географічне розташування (Data Gravity and Geographical Location)
Що це: Фізичне розташування даних та вплив цього на затримки (latency) та вартість передачі.
Чому важливо: Для додатків з низькою RPO та високою пропускною здатністю даних, географічна близькість DR-сайту до основного є критичною. Передача великих обсягів даних між континентами може бути дорогою та повільною.
Як оцінювати: Розгляньте розташування ваших користувачів, вимоги до суверенітету даних (якщо є), а також вартість міжрегіонального трафіку у провайдерів.
Ретельний аналіз цих критеріїв дозволить вам обрати найбільш підходящу DR-стратегію, яка буде не тільки технічно надійною, але й економічно обґрунтованою, а також відповідатиме бізнес-цілям вашого SaaS-додатку.
Порівняльна таблиця DR-стратегій
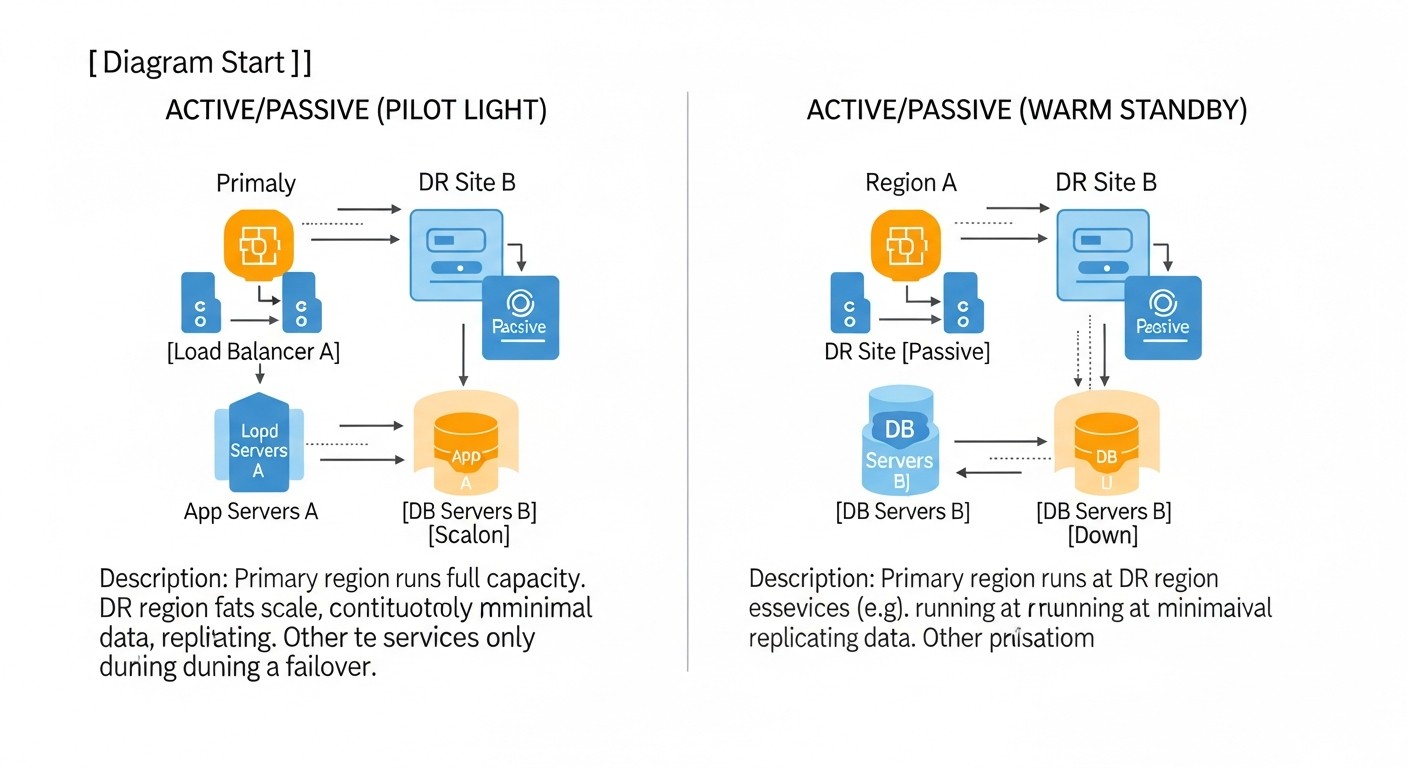 Схема: Порівняльна таблиця DR-стратегій
Схема: Порівняльна таблиця DR-стратегій
Вибір DR-стратегії — це завжди компроміс між вартістю, складністю, RTO та RPO. Нижче представлена порівняльна таблиця найбільш поширених підходів, актуальна для 2026 року, з урахуванням тенденцій у хмарних та VPS-технологіях. Ціни наведені орієнтовно для середнього SaaS-додатку (наприклад, 3-5 серверів додатків, 1-2 сервера БД, 100-500 ГБ даних), без урахування вартості персоналу та ліцензій спеціалізованого ПЗ.
| Критерій |
Cold Standby (VPS/Хмара) |
Warm Standby (VPS/Хмара) |
Hot Standby (Хмара/Мульти-AZ) |
Multi-Region Active/Active (Хмара) |
Гібридний DR (VPS + Хмара) |
| RTO (Цільовий час відновлення) |
4-24 години |
15 хвилин - 4 години |
< 5 хвилин |
0 - кілька секунд |
30 хвилин - 2 години |
| RPO (Допустима втрата даних) |
1-24 години (за останньою резервною копією) |
5 хвилин - 1 година (за останньою реплікацією/резервною копією) |
0-5 хвилин (синхронна/асинхронна реплікація) |
0-1 хвилина (практично нульова) |
10-30 хвилин |
| Вартість (щомісячно, 2026 р., USD) |
$50 - $300 (тільки зберігання резервних копій + мінімальний VPS) |
$200 - $1000 (кілька VPS/VM + сховище + трафік) |
$1000 - $5000+ (дубльована інфраструктура) |
$5000 - $20000+ (географічно розподілена інфраструктура) |
$300 - $2000 (комбінація, залежить від використовуваних хмарних ресурсів) |
| Складність реалізації |
Низька (налаштування резервних копій, ручний запуск) |
Середня (налаштування реплікації, скрипти запуску) |
Висока (автоматичний failover, синхронізація) |
Дуже висока (глобальний балансувальник, розподілені БД) |
Середня-Висока (інтеграція різнорідних середовищ) |
| Рівень автоматизації |
Низький (тільки резервні копії, відновлення вручну) |
Середній (автоматична реплікація, скрипти активації) |
Високий (автоматичний моніторинг, failover/failback) |
Дуже високий (повністю автоматизоване управління трафіком і даними) |
Середній (автоматизація в хмарній частині, ручні кроки на VPS) |
| Масштабованість |
Низька (вимагає ручного масштабування при відновленні) |
Середня (можна передбачити шаблони для масштабування) |
Висока (використовує хмарні можливості автомасштабування) |
Дуже висока (глобальне автомасштабування) |
Середня (хмарна частина масштабується, VPS — ні) |
| Приклади технологій |
rsync, pg_dump, S3/Object Storage, Cron |
PostgreSQL Streaming Replication, MySQL GTID, rsync, DRBD, Terraform, Ansible |
AWS RDS Multi-AZ, Azure SQL Geo-replication, GCP Cloud Spanner, Kubernetes Operators, Route 53, ALB |
AWS Global Accelerator, Azure Front Door, GCP Global Load Balancer, CockroachDB, Cassandra, DynamoDB Global Tables |
VPN-тунелі, rsync, S3/Object Storage, CloudFlare, Hybrid Cloud Connectors |
| Для кого підходить |
Малі стартапи, некритичні сервіси, внутрішні утиліти |
Середні SaaS-проекти з помірними вимогами до RTO/RPO |
Великі SaaS, критично важливі програми, фінансові сервіси |
Глобальні SaaS, сервіси з вкрай високими вимогами до доступності (99.999%) |
SaaS-проекти, які бажають оптимізувати витрати, але використовувати переваги хмари для DR |
Ця таблиця дає загальне уявлення. Реальні цифри і складність можуть значно варіюватися в залежності від архітектури вашої програми, обраних технологій і рівня експертизи команди. Важливо пам'ятати, що інвестиції в DR - це страховка, яка окупається в момент катастрофи.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
Детальний огляд кожної DR-стратегії
 Схема: Детальний огляд кожної DR-стратегії
Схема: Детальний огляд кожної DR-стратегії
Кожна з представлених DR-стратегій має свої особливості, переваги та недоліки. Вибір конкретного підходу повинен ґрунтуватися на ретельному аналізі бізнес-вимог, бюджету і технічних можливостей. Розглянемо кожну стратегію докладніше.
1. Cold Standby (Холодний резерв)
Опис: Це найменш витратна і найбільш проста стратегія. На резервному сайті (чи то інший VPS або хмарна VM) немає постійно запущених ресурсів програми. Замість цього, регулярно створюються резервні копії даних (бази даних, файли, конфігурації) з основного сайту і зберігаються на віддаленому, незалежному сховищі (наприклад, S3-сумісне сховище, інший VPS з великим диском). У разі катастрофи, резервний сервер або VM розгортається "з нуля" або з заздалегідь підготовленого образу, на нього завантажуються останні резервні копії даних, і програма запускається. DNS-записи перемикаються на нову IP-адресу.
Плюси:
- Низька вартість: Основні витрати пов'язані тільки зі зберіганням резервних копій і, можливо, оплатою мінімального VPS або VM, який знаходиться у вимкненому стані і оплачується за фактом використання (якщо хмара).
- Простота реалізації: Вимагає базових навичок з налаштування резервних копій і розгортання серверів.
- Добре підходить для некритичних даних: Якщо RPO і RTO можуть бути в межах декількох годин, це прийнятний варіант.
Мінуси:
- Високі RTO: Час відновлення може становити від 4 до 24 годин, так як включає розгортання інфраструктури, завантаження даних і налаштування програми.
- Високі RPO: Втрата даних обмежена частотою створення резервних копій (наприклад, 1-24 години).
- Ручне втручання: Процес відновлення часто вимагає значного ручного втручання, що збільшує ймовірність помилок.
- Не масштабується: Швидке відновлення великої і складної програми в ручному режимі практично неможливо.
Для кого підходить: Малі стартапи на ранніх стадіях, внутрішні інструменти, тестові середовища, некритичні SaaS-додатки, де простій в кілька годин не призводить до катастрофічних втрат. Фаундери SaaS-проектів з обмеженим бюджетом можуть почати з цього, але повинні планувати перехід до більш надійних стратегій по мірі зростання.
Приклади використання: SaaS для ведення блогів, невеликі CRM, особисті кабінети, де бізнес-процеси не страждають критично від декількох годин простою. Наприклад, ваш SaaS-додаток — це таск-трекер для фрілансерів, і втрата даних за останні 12 годин або простій на 8 годин не є фатальним для бізнесу.
2. Warm Standby (Теплий резерв)
Опис: Ця стратегія передбачає наявність резервного сайту, який частково або повністю запущений і готовий до прийому трафіку, але не є активним. Інфраструктура (сервери, бази даних) на резервному сайті вже розгорнута та налаштована. Дані з основного сайту регулярно реплікуються або синхронізуються на резервний сайт. У разі збою на основному сайті, резервний сайт активується, і DNS-записи перемикаються. Це може включати запуск додаткових сервісів, масштабування потужностей і перемикання балансувальників навантаження.
Плюси:
- Помірні RTO: Час відновлення значно скорочується до 15 хвилин - 4 годин, оскільки більша частина інфраструктури вже готова.
- Помірні RPO: Втрата даних може бути скорочена до хвилин або десятків хвилин завдяки частій реплікації.
- Баланс вартості та надійності: Дорожчий, ніж Cold Standby, але значно дешевший за Hot Standby.
- Можливість часткової автоматизації: Процеси реплікації та часткового перемикання можуть бути автоматизовані.
Мінуси:
- Вимагає більше ресурсів: Постійно працююча, хоча і неповноцінно завантажена, інфраструктура на резервному сайті.
- Складність налаштування: Налаштування реплікації баз даних і синхронізації файлів вимагає певних знань.
- Ризик застарівання конфігурацій: Якщо резервний сайт не використовується активно, його конфігурації можуть відставати від основного.
- Неповна автоматизація: Часто вимагає ручного втручання для фінальної активації та перевірки.
Для кого підходить: Зростаючі SaaS-проєкти з середніми вимогами до доступності, де простій в декілька годин вже відчутний, але не критичний. Backend-розробники та DevOps-інженери можуть реалізувати цю стратегію, використовуючи стандартні засоби реплікації БД та IaC для розгортання інфраструктури.
Приклади використання: E-commerce платформи, SaaS для управління проєктами, CRM-системи, де втрата години-двох даних або простою на 30 хвилин прийнятна. Наприклад, SaaS для управління інвентаризацією, де синхронізація раз на 15 хвилин дозволяє мінімізувати втрати.
3. Hot Standby (Гарячий резерв) / Multi-AZ в хмарі
Опис: Ця стратегія передбачає наявність повністю функціонального та постійно запущеного резервного сайту, який є дзеркалом основного. Обидві системи (основна та резервна) працюють паралельно, і дані синхронізуються практично в реальному часі. У хмарних середовищах це часто реалізується через Multi-AZ (Multi-Availability Zone) розгортання, де додаток і база даних дублюються в різних фізично ізольованих датацентрах (AZ) одного регіону. Трафік направляється на активну систему, а в разі збою відбувається автоматичне перемикання (failover) на резервну систему з мінімальним або нульовим простоєм.
Плюси:
- Низькі RTO: Час відновлення становить хвилини або навіть секунди, оскільки резервна система вже працює.
- Низькі RPO: Втрата даних мінімальна або відсутня завдяки синхронній або дуже частій асинхронній реплікації.
- Висока доступність: Забезпечує практично безперервну роботу сервісу.
- Високий ступінь автоматизації: Процеси моніторингу, виявлення збоїв і перемикання повністю автоматизовані.
Мінуси:
- Висока вартість: Вимагає дублювання всієї виробничої інфраструктури, що значно збільшує витрати.
- Висока складність: Налаштування синхронної реплікації, автоматичного failover, балансування навантаження та забезпечення консистентності даних вимагає високої кваліфікації.
- Ризик "Split-brain": Неправильне налаштування може призвести до ситуації, коли обидві системи вважають себе активними, що викликає втрату даних.
- Не захищає від регіональних збоїв: Multi-AZ захищає від збоїв в одній AZ, але не від збою всього регіону (хоча ймовірність такої події вкрай мала).
Для кого підходить: Великі SaaS-проєкти, критично важливі застосунки, фінансові сервіси, E-commerce з високим обсягом транзакцій, де кожна хвилина простою обходиться у величезні суми. Системні адміністратори та DevOps-інженери з досвідом роботи в хмарі та з розподіленими системами є ключовими для реалізації.
Приклади використання: Платіжні системи, платформи онлайн-банкінгу, глобальні ігрові сервіси, SaaS для охорони здоров'я, де безперервність і цілісність даних абсолютно критичні.
4. Multi-Region Active/Active (Мультирегіональний активний/активний)
Опис: Це найвищий рівень DR і високої доступності. Додаток розгорнуто і активно працює одночасно в декількох географічно віддалених регіонах (наприклад, в Європі та Північній Америці). Користувачі направляються в найближчий або найменш завантажений регіон за допомогою глобальних балансувальників навантаження (наприклад, AWS Route 53, Azure Front Door, GCP Global Load Balancer). Дані реплікуються між регіонами, часто з використанням розподілених баз даних, здатних працювати в режимі Active/Active. У разі відмови цілого регіону, трафік автоматично перенаправляється на регіони, що залишилися, без будь-якого простою для кінцевого користувача.
Плюси:
- Практично нульові RTO і RPO: Користувачі можуть не помітити збою, оскільки трафік миттєво перемикається на інший активний регіон. Втрата даних мінімальна або відсутня.
- Максимальна стійкість: Захищає від збоїв цілих регіонів, що вкрай рідко, але можливо.
- Глобальна продуктивність: Користувачі обслуговуються з найближчого регіону, що знижує затримки.
- Найвищий рівень доступності: Досягнення 99.999% і вище.
Мінуси:
- Екстремально висока вартість: Вимагає повного дублювання інфраструктури в декількох регіонах, а також дорогих глобальних сервісів і розподілених баз даних.
- Виключно висока складність: Проєктування та підтримка такої системи — це надзвичайно складна інженерна задача. Управління консистентністю даних між регіонами є серйозним викликом.
- Проблема "Eventual Consistency": Для багатьох розподілених баз даних характерна eventual consistency, що може бути неприйнятно для деяких додатків.
- Вимагає спеціалізованих інструментів і експертизи: Команда повинна володіти глибокими знаннями в галузі розподілених систем.
Для кого підходить: Глобальні SaaS-проєкти, соціальні мережі, критично важливі сервіси з мільйонами користувачів по всьому світу, для яких будь-яка хвилина простою неприпустима. CTO і провідні архітектори повинні ретельно зважити всі "за" і "проти", перш ніж приймати рішення про таку дорогу та складну стратегію.
Приклади використання: Google, Facebook, Netflix, великі банківські системи, глобальні SaaS-платформи, де доступність по всьому світу і нульовий простій є ключовими для бізнесу.
5. Гібридний DR (VPS + Хмара)
Опис: Ця стратегія поєднує в собі переваги і VPS, і хмарних середовищ. Основний застосунок може працювати на VPS (для контролю витрат або специфічних вимог), а DR-сайт розгортається в хмарі. Наприклад, дані з VPS реплікуються в хмарне сховище (S3, GCS, Azure Blob Storage) або в хмарну базу даних (RDS, Cloud SQL). У разі збою основного VPS, в хмарі автоматично або напівавтоматично розгортається інфраструктура (VMs, контейнери, безсерверні функції) з заздалегідь підготовлених образів і конфігурацій, і застосунок запускається з використанням реплікованих даних. DNS-записи перемикаються на хмарні ресурси.
Плюси:
- Оптимізація вартості: Дозволяє використовувати дешевші VPS для основної роботи, а платити за хмарні ресурси DR тільки при необхідності (модель "pay-as-you-go" для DR-інфраструктури).
- Гнучкість: Поєднує контроль і передбачуваність VPS з еластичністю і багатим набором сервісів хмари.
- Помірні RTO і RPO: Залежно від рівня автоматизації та реплікації, можна досягти RTO від 30 хвилин до 2 годин, і RPO від 10 до 30 хвилин.
- Захист від збоїв провайдера: Якщо основний VPS-провайдер виходить з ладу, хмарний DR-сайт залишається доступним.
Мінуси:
- Складність інтеграції: Потребує налаштування мережевої взаємодії (VPN), синхронізації даних і конфігурацій між двома різними середовищами.
- Додаткові інструменти: Потрібні інструменти для оркестрації розгортання в хмарі (IaC) та управління даними.
- Передача даних: Вартість і затримки при передачі даних між VPS і хмарою можуть бути значними.
- Потрібна експертиза в обох середовищах: Команда повинна розбиратися як в VPS, так і в хмарних технологіях.
Для кого підходить: SaaS-проєкти, які хочуть отримати переваги хмарного DR, не переносячи всю свою основну інфраструктуру в хмару. Фаундери SaaS, які хочуть контролювати бюджет, але при цьому забезпечити надійний DR. Системні адміністратори і DevOps-інженери, здатні працювати з обома платформами і налаштовувати гібридні рішення.
Приклади використання: SaaS-застосунки, які виросли на VPS, але хочуть отримати більш надійний і автоматизований DR, ніж можуть запропонувати інші VPS-провайдери. Наприклад, SaaS-платформа для бухгалтерії, яка зберігає дані на VPS, але використовує AWS S3 для бекапів і AWS EC2/RDS для DR-сайту.
Обираючи стратегію, завжди починайте з визначення ваших RTO і RPO, потім оцініть доступний бюджет і експертизу команди. Пам'ятайте, що DR - це еволюційний процес, і ви можете почати з більш простого рішення, поступово ускладнюючи його по мірі росту бізнесу і збільшення вимог до доступності.
Практичні поради та рекомендації щодо впровадження DR
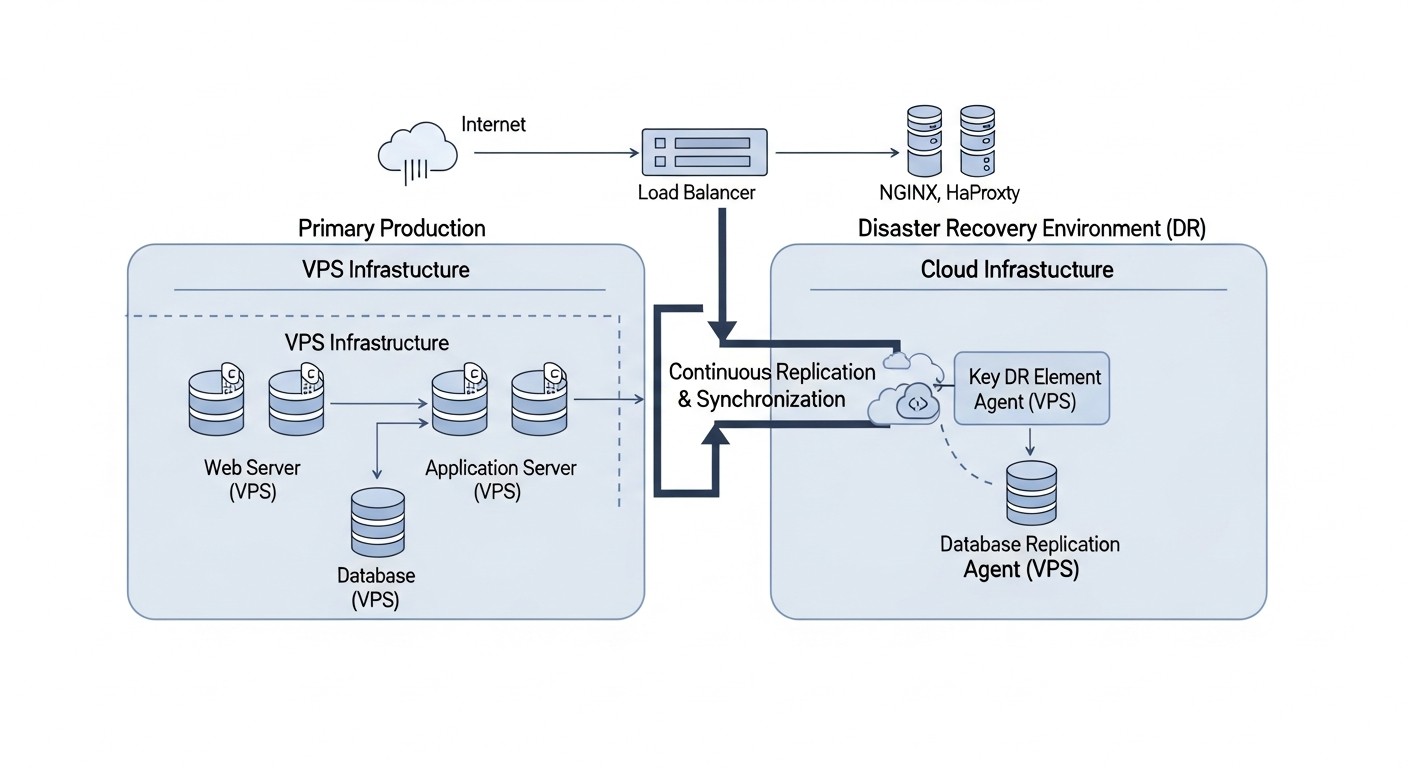 Схема: Практичні поради та рекомендації щодо впровадження DR
Схема: Практичні поради та рекомендації щодо впровадження DR
Впровадження ефективної стратегії Disaster Recovery вимагає системного підходу та уваги до деталей. Наступні практичні поради та команди допоможуть вам у цьому процесі.
1. Розробка Плану Disaster Recovery (DRP)
DRP — це не просто документ, це живий посібник до дії. Він повинен бути детальним, актуальним і доступним для всіх причетних. Ключові компоненти DRP:
- Цілі RTO/RPO: Чітко визначені для кожного критичного сервісу.
- Сценарії катастроф: Список можливих збоїв (відмова сервера, ЦОД, кібератака, людський фактор).
- Ролі та обов'язки: Хто за що відповідає під час інциденту.
- Процедури активації DR: Покрокові інструкції з перемикання на резервний сайт.
- Процедури Failback: Як повернутися на основний сайт після усунення проблеми.
- Контакти: Внутрішні команди, зовнішні провайдери, клієнти.
- Комунікаційний план: Хто, коли і як інформує зацікавлені сторони.
- Місце зберігання: DRP повинен зберігатися поза основною інфраструктурою (наприклад, в Google Docs, роздрукований екземпляр).
2. Визначення RTO і RPO з Бізнес-Власниками
Це не технічне завдання, а бізнес-завдання. Проведіть зустрічі з керівниками відділів, щоб зрозуміти, скільки часу простою або втрати даних вони можуть собі дозволити. Використовуйте ці дані для вибору DR-стратегії. Наприклад, для фінансового модуля RPO може бути 1 хвилина, а для аналітичного звіту — 4 години.
3. Вибір Правильної Стратегії Резервного Копіювання (Backup Strategy)
Бекапи — основа будь-якого DR. Використовуйте правило 3-2-1:
- 3 копії даних: Основна і дві резервні.
- 2 різних носія: Наприклад, локальний диск і хмарне сховище.
- 1 віддалене сховище: Географічно відокремлене від основного сайту.
Типи бекапів: повні, інкрементальні, диференціальні. Використовуйте снапшоти для швидкого створення точок відновлення VM і дисків.
# Пример бэкапа PostgreSQL в S3-совместимое хранилище
# Установите aws-cli или s3cmd
# pg_dump -Fc -Z9 -h localhost -U youruser yourdatabase > /tmp/yourdatabase_$(date +%F).dump
# aws s3 cp /tmp/yourdatabase_$(date +%F).dump s3://your-backup-bucket/db/
# rm /tmp/yourdatabase_$(date +%F).dump
# Пример бэкапа файлов с помощью rsync
# rsync -avz --delete /var/www/your_app/ s3://your-backup-bucket/app_files/
4. Налаштування Реплікації Даних
Для досягнення низьких RPO необхідна реплікація баз даних і, можливо, файлових систем.
- Бази даних:
- PostgreSQL: Використовуйте Streaming Replication (WAL shipping) для асинхронної або синхронної реплікації.
- MySQL: Binary Log Replication (GTID-based) для асинхронної реплікації.
- MongoDB: Replica Sets.
- Облачні БД: Використовуйте Multi-AZ або Geo-replication функції (AWS RDS, Azure SQL, GCP Cloud SQL).
- Файлові системи:
rsync для періодичної синхронізації.DRBD (Distributed Replicated Block Device) для синхронної блочної реплікації між двома Linux-серверами.- Облачні рішення: AWS EFS, Azure Files, GCP Filestore з реплікацією або синхронізацією.
# Пример настройки PostgreSQL Streaming Replication (на мастере)
# В postgresql.conf:
# wal_level = replica
# max_wal_senders = 10
# max_replication_slots = 10
# hot_standby = on
# listen_addresses = ''
# В pg_hba.conf:
# host replication all 0.0.0.0/0 md5
# Приклад створення базової копії для репліки
# sudo -u postgres pg_basebackup -h master_ip -D /var/lib/postgresql/16/main/ -U replicator -P -R -W
5. Автоматизація DR-процесів (IaC, Скрипти, Оркестрація)
Автоматизація — це серце сучасного DR. Ручні дії повільні та схильні до помилок.
- Infrastructure as Code (IaC): Використовуйте Terraform, Ansible, CloudFormation (AWS), ARM Templates (Azure), Deployment Manager (GCP) для опису всієї вашої інфраструктури (включаючи DR-сайт). Це дозволяє швидко розгорнути або відновити оточення.
- Скрипти Failover: Напишіть скрипти на Bash, Python або PowerShell для автоматичного перемикання. Вони повинні включати:
- Визначення збою (моніторинг).
- Активація резервних ресурсів.
- Оновлення DNS-записів або перемикання балансувальника.
- Перевірка працездатності.
- Сповіщення.
- Оркестрація контейнерів: Для додатків у Kubernetes використовуйте оператори (наприклад, Velero для бекапів, Strimzi для Kafka DR) та рішення для Multi-Cluster DR.
- CI/CD для DR: Інтегруйте розгортання та тестування DR-інфраструктури у ваш CI/CD пайплайн.
# Приклад Terraform для розгортання EC2 інстанса в AWS (DR-сайт)
resource "aws_instance" "dr_app_server" {
ami = "ami-0abcdef1234567890" # Вкажіть актуальний AMI
instance_type = "t3.medium"
key_name = "my-ssh-key"
vpc_security_group_ids = [aws_security_group.dr_sg.id]
subnet_id = aws_subnet.dr_subnet.id
tags = {
Name = "DR-App-Server"
Environment = "DR"
}
# ... інші налаштування, наприклад, EBS-томи для даних
}
6. Моніторинг та Сповіщення
Надійний моніторинг критично важливий для своєчасного виявлення збоїв та активації DR-плану. Моніторте не тільки основну, але і DR-інфраструктуру.
- Метрики: CPU, RAM, Disk I/O, Network I/O, latency, health checks додатку, статуси реплікації БД, доступність DNS.
- Інструменти: Prometheus/Grafana, Zabbix, Datadog, New Relic, ELK Stack.
- Сповіщення: Налаштуйте сповіщення (SMS, дзвінки через PagerDuty, Slack, Email) для критичних подій, які вимагають негайного втручання або запуску DR-процедур.
7. Регулярне Тестування DR-плану
Як вже згадувалося, неперевірений DRP марний. Розробіть стратегію тестування:
- Настільні навчання (Tabletop Exercises): Обговорення DRP з командою, проробка сценаріїв без реальних дій.
- Симульовані тести: Імітація відмови компонента (наприклад, зупинка БД) без повного перемикання.
- Повний Failover Test: Перемикання на резервний сайт та робота з нього протягом певного часу. Це найбільш реалістичний тест, але вимагає ретельного планування, щоб не зачепити реальних користувачів.
- Failback Test: Перевірка процедури повернення на основний сайт.
- Chaos Engineering: Використовуйте інструменти (Gremlin, Chaos Mesh) для контрольованого впровадження збоїв у продакшн або DR-середовище, щоб виявити слабкі місця.
Важливо: Завжди документуйте результати тестування, помилки та їх рішення. Оновлюйте DRP після кожного тесту.
8. Актуальна Документація
Детальна та актуальна документація — це ваша "рятувальна шлюпка" під час катастрофи. В ній повинно бути описано все: архітектура, залежності, процедури розгортання, налаштування, процедури DR, контакти. Зберігайте її в легкодоступному, але безпечному місці.
9. Управління Конфігураціями
Використовуйте системи управління конфігураціями (Ansible, Chef, Puppet, SaltStack) для одноманітного розгортання та налаштування серверів на основному та DR-сайтах. Це гарантує, що DR-інфраструктура буде ідентична основній.
10. Мережева Ізоляція та Безпека DR-сайту
DR-сайт повинен бути максимально ізольований від основної мережі, але при цьому мати можливість отримувати дані. Використовуйте VPN-тунелі для безпечної реплікації. Застосовуйте строгі правила фаєрволів, IAM-політики, шифрування даних у стані спокою та в дорозі. Пам'ятайте, що DR-сайт — це потенційна точка входу для зловмисників, якщо він не захищений належним чином.
Застосовуючи ці рекомендації, ви зможете значно підвищити стійкість вашого SaaS-додатку до різних видів збоїв та забезпечити безперервність бізнесу навіть у найскладніших ситуаціях.
Типові помилки при розробці та реалізації DR-плану
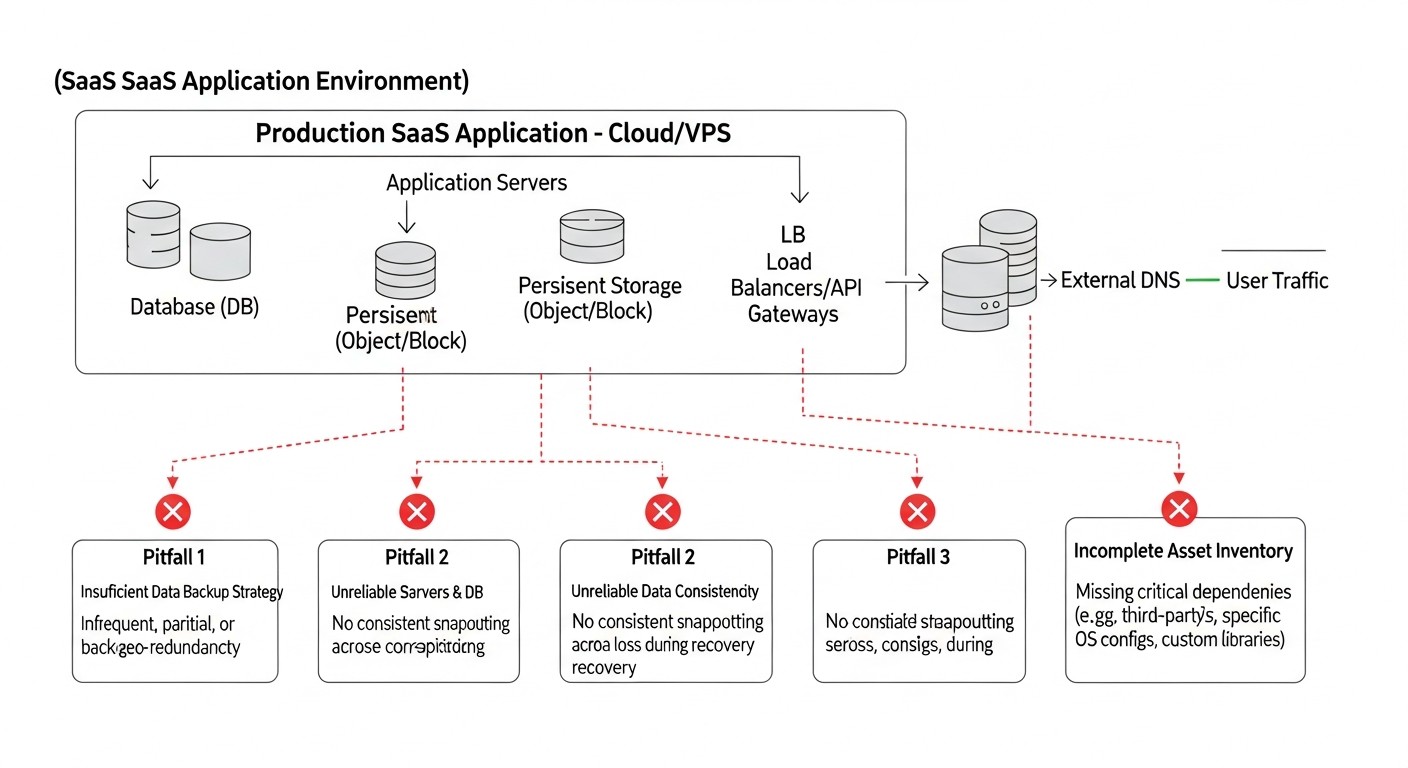 Схема: Типові помилки при розробці та реалізації DR-плану
Схема: Типові помилки при розробці та реалізації DR-плану
Навіть найдосвідченіші команди можуть робити помилки при плануванні та реалізації Disaster Recovery. Знання цих підводних каменів допоможе вам уникнути дорогих провалів.
1. Відсутність DR-плану або його застарілість
Помилка: Багато компаній або взагалі не мають формалізованого DRP, або він існує "для галочки" і не оновлюється роками. В умовах інфраструктури та архітектури SaaS, що швидко змінюється, такий план швидко стає неактуальним.
Як уникнути: Розробіть DRP, який включає всі ключові компоненти: RTO/RPO, сценарії, ролі, покрокові інструкції. Зробіть його живим документом, який регулярно переглядається та оновлюється (наприклад, щоквартально або після кожної значної зміни архітектури). Зберігайте його в доступному, але захищеному місці, а також у кількох копіях (включаючи офлайн).
Реальні приклади наслідків: Під час масштабного збою команда панікує, витрачає години на пошук актуальної інформації, не може визначити, хто за що відповідає, і в результаті процес відновлення затягується на невизначений термін, багаторазово перевищуючи допустимі RTO.
2. Непротестовані бекапи та DR-план
Помилка: Одна з найпоширеніших і найнебезпечніших помилок. Компанії налаштовують бекапи, вважають, що DR "є", але ніколи не перевіряють, чи можна з цих бекапів реально відновитися, і чи працює процедура перемикання.
Як уникнути: Зробіть тестування DR обов'язковою та регулярною процедурою. Почніть з перевірки цілісності бекапів (наприклад, спроба відновлення на тестовому сервері). Проводьте повні DR-навчання (failover/failback) не рідше одного разу на півроку. Документуйте кожен тест, виявляйте проблеми та негайно їх усувайте. Автоматизуйте тестування, де це можливо.
Реальні приклади наслідків: Під час реальної катастрофи з'ясовується, що бекапи пошкоджені, неповні, або процедура відновлення містить критичні помилки. Це призводить до повної втрати даних або до неможливості відновлення сервісу в принципі, що може бути фатальним для SaaS-бізнесу.
3. Недооцінка RTO та RPO
Помилка: Технічні фахівці часто встановлюють RTO та RPO, виходячи з технічних можливостей, а не з реальних бізнес-вимог. Або, навпаки, бізнес запитує нульові RTO/RPO, не розуміючи астрономічної вартості їх реалізації.
Як уникнути: Проводьте ретельний Business Impact Analysis (BIA) за участю всіх зацікавлених сторін. Визначте фінансові та репутаційні втрати від простою та втрати даних для кожного критичного компонента. Зіставте ці втрати з витратами на досягнення різних RTO/RPO. Знайдіть оптимальний баланс. Документуйте прийняті рішення та їх обґрунтування.
Реальні приклади наслідків: При збої з'ясовується, що заявлене RTO в 4 години насправді є 8-12 годинами, що призводить до багатомільйонних втрат і розриву клієнтських договорів. Або, навпаки, компанія вклала величезні кошти в Hot Standby, коли Warm Standby був би цілком достатнім і набагато дешевшим.
4. Ігнорування людського фактору
Помилка: Передбачається, що в умовах стресу команда буде діяти ідеально за написаними інструкціями. Забувається про втому, паніку, нестачу знань у конкретного співробітника.
Як уникнути: Навчайте команду DR-процедурам. Проводьте регулярні навчання, щоб кожен знав свою роль і міг діяти без паніки. Автоматизуйте якомога більше кроків, щоб мінімізувати ручне втручання. Забезпечте чіткі канали комунікації. Переконайтеся, що DRP зрозумілий навіть новачкові. Розгляньте можливість використання зовнішніх експертів для аудиту або допомоги при складних інцидентах.
Реальні приклади наслідків: Під час інциденту співробітник помилково видаляє критично важливі дані, або не може знайти потрібну команду в DRP, або просто панікує і не діє, що погіршує ситуацію і збільшує час простою.
5. Єдина точка відмови в DR-інфраструктурі
Помилка: При проектуванні DR-рішення команда може ненавмисно створити нову єдину точку відмови. Наприклад, DR-сайт використовує того ж DNS-провайдера, що і основний, або бекапи зберігаються в тому ж регіоні хмари, що і основний сервіс.
Як уникнути: Завжди проєктуйте DR з урахуванням повної незалежності від основної інфраструктури. Використовуйте різних провайдерів (для VPS, DNS), різні регіони хмари, різні апаратні платформи. Проводьте ретельний аудит архітектури DR для виявлення прихованих залежностей. Для критично важливих компонентів розгляньте мультирегіональні рішення.
Реальні приклади наслідків: Відмова DNS-провайдера робить недоступними як основний, так і DR-сайт. Або регіональний збій в хмарі виводить з ладу обидві системи, тому що DR-рішення було розгорнуто в тій же області, але в іншій AZ, яка виявилася зачеплена загальним збоєм регіону.
6. Недостатня увага до безпеки DR-сайту
Помилка: DR-інфраструктура часто розглядається як "другорядна" і отримує менше уваги до безпеки, ніж основний продакшн. Однак вона містить копії всіх ваших даних і може стати легкою мішенню для зловмисників.
Як уникнути: Застосовуйте ті ж або навіть більш суворі стандарти безпеки до DR-інфраструктури. Шифруйте дані в стані спокою і в дорозі. Використовуйте суворі правила контролю доступу (IAM, MFA). Регулярно проводите аудити безпеки і пентести для DR-сайту. Ізолюйте DR-мережу від публічного доступу. Переконайтеся, що резервні копії також захищені від компрометації.
Реальні приклади наслідків: Зловмисник отримує доступ до DR-сайту через погано захищений сервіс, який був розгорнутий "про всяк випадок", і знищує або краде всі резервні копії даних, роблячи відновлення неможливим.
7. Забування про дані, що не належать до БД
Помилка: Часто фокус DR зміщується виключно на базу даних, забуваючи про файли користувача, логи, конфігурації, статичний контент, кеші та інші нереляційні дані, які також важливі для функціонування SaaS.
Як уникнути: Включіть в DRP всі типи даних, необхідні для повного відновлення програми. Розробіть стратегію бекапів і реплікації для кожного з них. Використовуйте об'єктні сховища (S3) для файлів, централізовані системи логування (ELK, Splunk) з реплікацією, системи управління конфігураціями (Git) для всіх налаштувань.
Реальні приклади наслідків: Після відновлення БД додаток не може запуститися, тому що відсутні файли завантажень користувачів або критичні конфігураційні файли. Це призводить до додаткового простою і зусиль по відновленню.
Уникаючи цих поширених помилок, ви значно підвищите шанси на успішне відновлення вашого SaaS-додатку після будь-якої катастрофи.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
Чекліст для практичного застосування DR-стратегій
Цей чеклист допоможе вам систематизувати процес планування, впровадження і тестування Disaster Recovery для вашого SaaS-додатку.
-
Визначення бізнес-вимог:
- Чи проведено Business Impact Analysis (BIA) для всіх критично важливих компонентів SaaS?
- Чи визначені цільові RTO (Recovery Time Objective) для кожного сервісу?
- Чи визначені цільові RPO (Recovery Point Objective) для кожного сервісу?
- Чи узгоджені ці метрики з бізнес-власниками?
-
Розробка DR-плану (DRP):
- Чи створено формальний документ DRP?
- Чи описані в DRP всі сценарії катастроф?
- Чи чітко визначені ролі та обов'язки команди в разі інциденту?
- Чи є покрокові інструкції для активації DR і повернення (failover/failback)?
- Чи містить DRP актуальні контактні дані всіх учасників і провайдерів?
- Чи розроблено комунікаційний план для інформування клієнтів і стейкхолдерів?
- Чи зберігається DRP в безпечному, але доступному місці, окремо від основної інфраструктури?
-
Вибір і проектування DR-стратегії:
- Чи вибрано оптимальну DR-стратегію (Cold/Warm/Hot Standby, Multi-Region, Hybrid), що відповідає RTO/RPO і бюджету?
- Чи спроектована DR-архітектура, що забезпечує незалежність від основної інфраструктури?
- Чи враховані географічні фактори і вимоги до суверенітету даних?
- Чи визначені технології для бекапів, реплікації і автоматизації?
-
Впровадження бекапів і реплікації:
- Чи реалізована стратегія резервного копіювання 3-2-1 для всіх критичних даних?
- Чи налаштована регулярна перевірка цілісності бекапів?
- Чи налаштована реплікація баз даних (streaming replication, replica sets і т.д.)?
- Чи забезпечена синхронізація файлових систем та інших нереляційних даних?
- Чи зашифровані всі резервні копії і дані в дорозі?
-
Автоматизація DR-процесів:
- Чи розроблена інфраструктура DR за допомогою IaC (Terraform, CloudFormation і т.д.)?
- Чи створені скрипти для автоматичного виявлення збоїв і перемикання (failover)?
- Чи автоматизовано процес оновлення DNS-записів або перемикання балансувальників навантаження?
- Чи інтегровані DR-процеси в CI/CD пайплайн?
-
Моніторинг та оповіщення:
- Чи налаштовано комплексний моніторинг основної та DR-інфраструктури (метрики, логи, health checks)?
- Чи створені оповіщення для критичних подій, що вимагають активації DR?
- Чи забезпечена доставка оповіщень по декількох каналах (SMS, дзвінки, Slack, email)?
-
Тестування та перевірка:
- Чи розроблено графік регулярного тестування DR-плану?
- Чи проведені настільні навчання (Tabletop Exercises) з командою?
- Чи виконувались симульовані тести без повного перемикання?
- Чи проводились повні тести Failover і Failback?
- Чи використовувались елементи Chaos Engineering для виявлення слабких місць?
- Чи документуються всі результати тестування, виявлені проблеми та їх вирішення?
- Чи оновлюється DRP після кожного тесту та виявлених змін?
-
Безпека та відповідність:
- Чи застосовані суворі заходи безпеки до DR-інфраструктури (IAM, фаєрволи, шифрування)?
- Чи відповідає DR-план всім застосовним нормативним вимогам (GDPR, HIPAA, PCI DSS)?
- Чи проводився аудит безпеки DR-рішення?
-
Документація та навчання:
- Чи є вся документація (архітектура, конфігурації, DRP) актуальною та доступною?
- Чи навчена команда всім аспектам DR-плану та процедурам?
- Чи є резервні співробітники, здатні виконувати DR-процедури?
-
Оптимізація вартості:
- Чи проведено аналіз TCO для DR-рішення?
- Чи використовуються можливості оптимізації витрат (резервні екземпляри, спотові інстанси, tiering зберігання)?
- Чи регулярно переглядаються витрати на DR?
Дотримуючись цього чеклисту, ви зможете побудувати стійку та надійну систему Disaster Recovery, яка захистить ваш SaaS-бізнес від непередбачених збоїв.
Розрахунок вартості / Економіка Disaster Recovery
 Схема: Розрахунок вартості / Економіка Disaster Recovery
Схема: Розрахунок вартості / Економіка Disaster Recovery
Економіка Disaster Recovery — це не тільки прямі витрати на інфраструктуру, але й приховані витрати, а також вартість потенційних втрат від збоїв. Правильний розрахунок TCO (Total Cost of Ownership) і ROI (Return on Investment) DR-рішення критично важливий для прийняття обґрунтованих рішень.
Компоненти вартості DR
- Інфраструктура:
- Обчислювальні ресурси: VPS, хмарні VM (EC2, Azure VMs, GCP Compute Engine), контейнери, безсерверні функції. Вартість залежить від обраної стратегії (Cold/Warm/Hot Standby).
- Зберігання даних: Диски (EBS, Azure Disks, GCP Persistent Disks), об'єктне сховище (S3, Azure Blob, GCS) для бекапів і холодних даних. Вартість залежить від обсягу, типу зберігання (Standard, Infrequent Access, Archive).
- Мережеві ресурси: Трафік на реплікацію даних, вихідний трафік при перемиканні, VPN-тунелі, балансувальники навантаження, DNS-сервіси. Міжрегіональний трафік може бути дорогим.
- Керовані сервіси: Керовані бази даних (RDS, Azure SQL, Cloud SQL), черги повідомлень, кеші, CDN.
- Програмне забезпечення:
- Ліцензії на спеціалізоване DR-ПО (Veeam, Zerto).
- Ліцензії на ОС та інше ПЗ (якщо не використовуються open-source або безкоштовні версії).
- Персонал:
- Час інженерів на проєктування, реалізацію, тестування та підтримку DR-рішення.
- Навчання команди.
- Час на реальне відновлення при інциденті.
- Тестування:
- Ресурси, що виділяються для DR-тестів (тимчасове розгортання тестових середовищ).
- Трудовитрати команди на планування та проведення тестів.
- Приховані витрати та втрати:
- Втрата доходу: Прямі фінансові втрати від недоступності сервісу.
- Втрата продуктивності: Співробітники не можуть працювати через недоступність внутрішніх інструментів.
- Збитки репутації: Втрата довіри клієнтів, негативні відгуки, відтік користувачів.
- Штрафи: За недотримання SLA або регуляторних вимог.
- Вартість відновлення даних: Якщо дані були втрачені та їх потрібно відтворювати вручну.
- Юридичні витрати: Судові позови від постраждалих клієнтів.
Приклади розрахунків для різних сценаріїв (орієнтовні ціни 2026 р.)
Припустимо, у нас SaaS-додаток з 3 серверами додатків (CPU, RAM), 1 сервером БД (PostgreSQL), 200 ГБ даних, 500 ГБ файлів, 1 ТБ щомісячного трафіку.
Сценарій 1: Малий SaaS (Warm Standby на VPS)
- Основна інфраструктура: 3 x VPS (4vCPU, 8GB RAM, 100GB SSD) + 1 x VPS (8vCPU, 16GB RAM, 200GB SSD) = $200/міс.
- DR-інфраструктура (Warm Standby):
- 1 x VPS (2vCPU, 4GB RAM, 50GB SSD) для репліки БД: $30/міс.
- 2 x VPS (2vCPU, 4GB RAM, 50GB SSD) у вимкненому стані (оплата за зберігання диска): $20/міс.
- Об'єктне сховище (S3-сумісне) для бекапів (1 ТБ): $20/міс.
- Трафік на реплікацію і бекапи (500 ГБ): $25/міс.
- Керований DNS (наприклад, Cloudflare): $5/міс.
- Всього прямі DR-витрати: ~$100/міс.
- Трудовитрати (інженер 0.1 FTE): $500/міс.
- Загальний TCO DR: ~$600/міс.
- Потенційні збитки від простою (12 годин, $1000/година): $12000. DR окупається, якщо запобігає 1-2 великих простої в рік.
Сценарій 2: Середній SaaS (Hot Standby в хмарі, Multi-AZ)
- Основна інфраструктура (AWS):
- 3 x EC2 (t3.medium) = $150/міс.
- 1 x RDS PostgreSQL (db.t3.large, Multi-AZ) = $200/міс.
- S3 (500GB) + EBS (200GB) = $40/міс.
- ALB, Route 53, VPC, трафік = $100/міс.
- Разом основна: ~$490/міс.
- DR-інфраструктура (майже дзеркало, Multi-AZ):
- RDS Multi-AZ вже включений у вартість, забезпечує DR для БД.
- EC2 (Auto Scaling Group в 2 AZ) = $150/міс.
- S3 для бекапів (1 ТБ) = $20/міс.
- EBS для EC2 (200GB) = $20/міс.
- ALB, Route 53, VPC, трафік (включаючи між-AZ) = $120/міс.
- Разом прямі DR-витрати: ~$310/міс (поверх базової інфраструктури, яка вже відмовостійка в рамках AZ).
- Трудовитрати (інженер 0.2 FTE): $1000/міс.
- Загальний TCO DR: ~$1310/міс.
- Потенційні збитки від простою (1 година, $5000/година): $5000. DR окупається, запобігаючи 3-4 великим простоям на рік.
Сценарій 3: Великий SaaS (Multi-Region Active/Active в хмарі)
Тут вартість значно зростає через повне дублювання інфраструктури в декількох регіонах і використання глобальних сервісів. Основна інфраструктура множиться на кількість регіонів, додаються витрати на міжрегіональну реплікацію даних і глобальний балансувальник.
- Два повноцінних регіони (наприклад, US-East і EU-West): Подвоює вартість основної інфраструктури, плюс додаткові витрати.
- Інфраструктура в кожному регіоні: ~$490/міс 2 = $980/міс.
- Міжрегіональна реплікація даних: Для 200 ГБ БД і 500 ГБ файлів, при активному використанні, трафік може бути 1-2 ТБ/міс, плюс вартість читання/запису. Орієнтовно: $200-$500/міс.
- Глобальний балансувальник (AWS Global Accelerator/Route 53): ~$100/міс.
- Разом прямі DR-витрати: ~$500/міс (поверх вартості дублювання інфраструктури).
- Трудовитрати (інженер 0.5 FTE): $2500/міс.
- Загальний TCO DR: ~$3980/міс ($980 + $500 + $2500).
- Потенційні збитки від простою (10 хвилин, $20000/хвилина): $200000. DR критично важливий і окупається при запобіганні навіть одного такого інциденту.
Таблиця з прикладами розрахунків (усереднені значення для 2026 р.)
| Компонент / Стратегія |
Cold Standby (VPS) |
Warm Standby (VPS/Cloud) |
Hot Standby (Cloud Multi-AZ) |
Multi-Region A/A (Cloud) |
| Інфраструктура DR (міс.) |
$50 - $150 |
$150 - $500 |
$300 - $1000 |
$1000 - $5000+ |
| Зберігання бекапів (міс.) |
$10 - $30 |
$15 - $50 |
$20 - $70 |
$50 - $200 |
| Трафік реплікації/бекапів (міс.) |
$5 - $20 |
$20 - $100 |
$50 - $200 |
$200 - $1000+ |
| Ліцензії ПЗ (міс.) |
$0 - $50 |
$0 - $100 |
$0 - $200 |
$0 - $500+ |
| Трудовитрати інженерів (міс.) |
$200 - $500 |
$500 - $1500 |
$1000 - $3000 |
$2000 - $5000+ |
| Разом TCO DR (міс.) |
$265 - $750 |
$685 - $2150 |
$1370 - $4470 |
$3250 - $11700+ |
| Потенційні збитки від 1 години простою |
$500 - $5000 |
$2000 - $15000 |
$10000 - $50000 |
$50000 - $500000+ |
Як оптимізувати витрати
- Резервні екземпляри (Reserved Instances) / Ощадні плани (Savings Plans): Для стабільної частини DR-інфраструктури в хмарі можна значно знизити вартість.
- Спотові інстанси (Spot Instances): Можуть використовуватися для некритичних частин DR-інфраструктури або для тимчасових тестових розгортань, але вимагають стійкості до переривань.
- Тірінг зберігання даних (Storage Tiering): Переміщуйте старі бекапи в дешевші архівні класи зберігання (Glacier, Deep Archive).
- Open-source інструменти: Використовуйте безкоштовні та потужні open-source рішення для бекапів, реплікації та автоматизації, щоб уникнути ліцензійних платежів.
- Автоматичне вимкнення/ввімкнення: Для Warm Standby можна вимикати неактивні ресурси DR-сайту в неробочий час (якщо RTO дозволяє).
- Оптимізація трафіку: Компресія даних перед передачею, використання приватних мереж (VPN) для реплікації, вибір провайдера з вигідними тарифами на вихідний трафік.
- DR-as-a-Service: Розгляньте сторонні рішення DRaaS, які можуть бути економічно вигіднішими для деяких компаній, ніж створення власного DR-центру.
Економіка DR - це постійний процес оцінки та оптимізації. Важливо не просто скорочувати витрати, а знаходити оптимальний баланс між вартістю, надійністю та відповідністю бізнес-вимогам.
Кейси та приклади впровадження DR
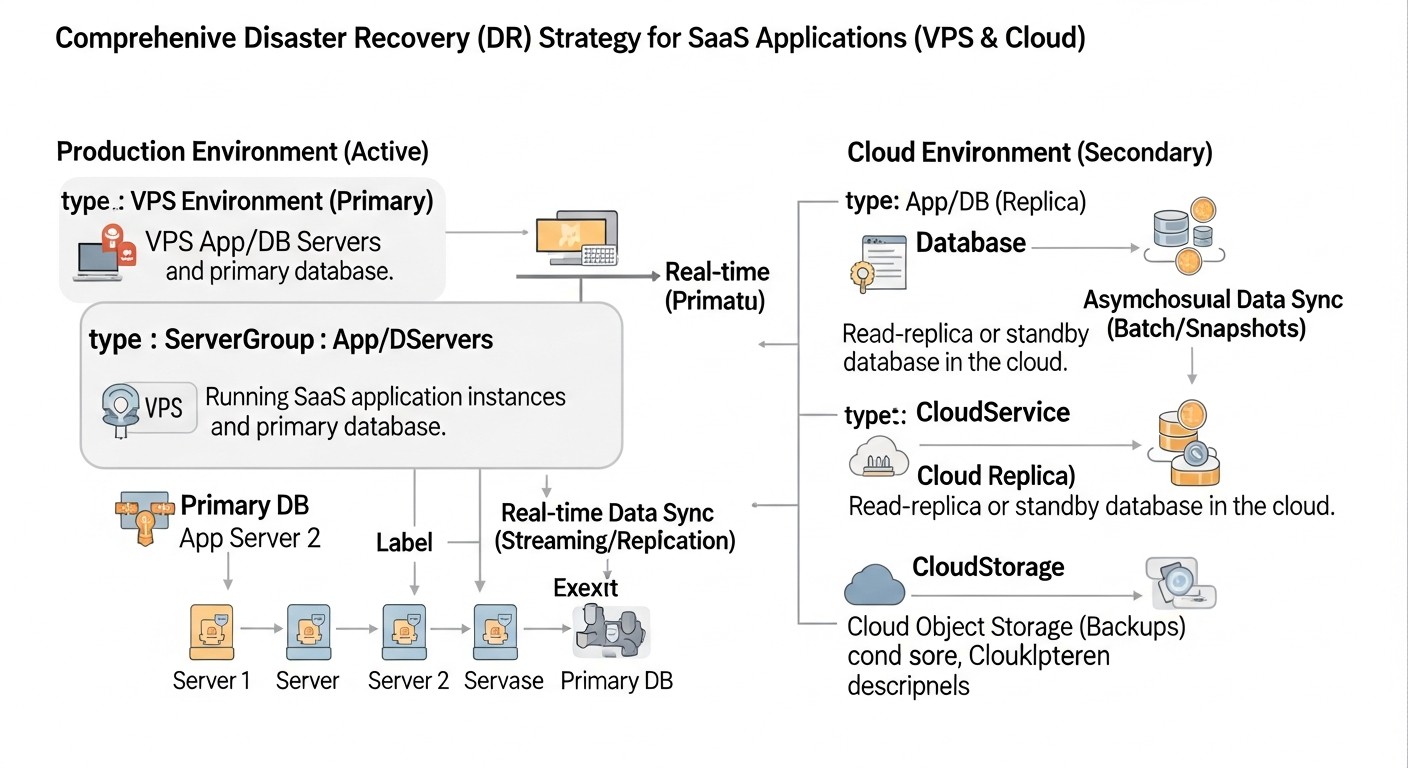 Схема: Кейси та приклади впровадження DR
Схема: Кейси та приклади впровадження DR
Реальні приклади допоможуть краще зрозуміти, як різні стратегії DR застосовуються на практиці та які результати вони приносять.
Кейс 1: Малий SaaS-проект на VPS — "TaskFlow" (Warm Standby)
Проект: "TaskFlow" — SaaS для управління задачами та проектами для невеликих команд. Заснований на Python/Django з PostgreSQL, розгорнутий на 3 VPS у одного провайдера.
Проблема: Зростаючі ризики втрати даних і тривалого простою. RTO = 3 години, RPO = 15 хвилин.
Рішення: Впровадження стратегії Warm Standby з використанням другого VPS-провайдера та хмарного сховища.
- База даних (PostgreSQL): На основному VPS налаштовано асинхронну потокову реплікацію (streaming replication) на окремий, постійно працюючий VPS у іншого провайдера. WAL-логи копіюються кожні 5 хвилин в об'єктне сховище (S3-сумісне).
- Файли застосунку та статика: Щогодинна синхронізація всіх користувацьких файлів (завантаження, вкладення) та статики з основного VPS в об'єктне сховище за допомогою
rsync.
- Код та конфігурації: Зберігаються в Git-репозиторії.
- DR-сайт: У другого провайдера встановлено образи VPS з операційною системою та базовим ПЗ. У разі збою основного, активуються два нових VPS з образів (для застосунку і для БД, якщо репліка не може бути підвищена до майстра), на них завантажуються останні файли з S3, і застосунок запускається.
- Автоматизація: Розроблено Bash-скрипти для моніторингу стану основного сервера, перемикання DNS-записів (через API DNS-провайдера) та запуску застосунку на DR-сайті. Процес активації напівавтоматичний, вимагає підтвердження інженера.
- Тестування: Повний Failover Test проводиться раз на 3 місяці в неробочий час.
Результати:
- RTO: Скорочено до 45-60 хвилин (включаючи ручне підтвердження та перевірку).
- RPO: До 5-15 хвилин завдяки потоковій реплікації та частій синхронізації WAL-логів.
- Вартість: Додаткові ~$150/міс на DR-VPS, сховище та трафік, що було прийнятно для бюджету.
- Значно підвищено стійкість до збоїв одного VPS-провайдера.
Кейс 2: Середній SaaS-проєкт в AWS — "AnalyticsPro" (Hot Standby Multi-AZ)
Проєкт: "AnalyticsPro" — SaaS-платформа для глибокої аналітики даних, розгорнута в AWS. Використовує Node.js на EC2 (в Auto Scaling Group), MongoDB Atlas (managed service) та S3 для зберігання сирих даних.
Проблема: Високі вимоги до доступності (99.99%) та мінімальна втрата даних (RPO < 1 хвилини). Простій в 15 хвилин вже критичний.
Рішення: Впровадження стратегії Hot Standby з використанням AWS Multi-AZ можливостей та MongoDB Atlas.
- База даних (MongoDB Atlas): Використовується Multi-Region Replica Set, який по суті є Active/Passive DR-рішенням в рамках провайдера. MongoDB Atlas автоматично управляє реплікацією та failover між AZ.
- Застосунок (Node.js на EC2): Розгорнуто в Auto Scaling Group, яка розподіляє інстанси по двом Availability Zones (AZ) в одному регіоні. Перед ASG стоїть Application Load Balancer (ALB), що також працює в декількох AZ.
- Сховище даних (S3): S3 за своєю природою є високодоступним та гео-реплікованим всередині регіону.
- Автоматизація:
- Інфраструктура описана за допомогою AWS CloudFormation.
- Health checks на ALB і в ASG автоматично виявляють непрацездатні інстанси та замінюють їх.
- DNS-записи (Route 53) вказують на ALB, який сам управляє трафіком між AZ.
- Lambda-функції моніторять стан реплікації MongoDB та відправляють сповіщення.
- Тестування: Регулярно проводяться імітації збоїв AZ (наприклад, зупинка інстансів в одній AZ) для перевірки автоматичного перемикання.
Результати:
- RTO: Менше 1-2 хвилин (час перемикання ALB та запуску нових інстансів ASG). Для БД практично нульове.
- RPO: Практично нульове для всіх критичних даних.
- Вартість: Збільшилась приблизно на 40-50% у порівнянні з однозонним розгортанням, але це було виправдано бізнес-вимогами та відверненими збитками.
- Забезпечено високу доступність та стійкість до збоїв на рівні AZ.
Кейс 3: Великий SaaS-проєкт з гібридною інфраструктурою — "EnterpriseConnect" (Hybrid DR)
Проєкт: "EnterpriseConnect" — SaaS для управління корпоративними комунікаціями, спочатку розгорнутий у власному датацентрі (On-Premise) через вимоги до суверенітету даних та високої продуктивності. Частина сервісів (наприклад, аналітика, звітність) вже винесена в хмару.
Проблема: Високі RTO (8-12 годин) та RPO (4 години) для критично важливих компонентів у власному ЦОД. Необхідно забезпечити нижчі RTO/RPO без повного перенесення в хмару.
Рішення: Впровадження гібридної DR-стратегії з використанням публічної хмари (Azure) як резервного сайту.
- База даних (SQL Server): Налаштовано Geo-replication в Azure SQL Database. Локальна БД постійно реплікується в хмарну керовану БД.
- Файлові сервери: Критично важливі файли синхронізуються в Azure Blob Storage.
- Застосунок (ASP.NET Core): Образи VM з застосунком та базовим ПЗ зберігаються в Azure Image Gallery. Конфігурації зберігаються в Azure Key Vault.
- DR-сайт в Azure:
- Налаштовано VPN-тунель між локальним ЦОД та Azure VNet.
- В Azure VNet заздалегідь підготовлені підмережі, групи безпеки, балансувальники навантаження (Azure Application Gateway).
- Розгорнуті мінімальні, але постійно працюючі VM для моніторингу та підтримки VPN-тунелю.
- Автоматизація:
- Вся DR-інфраструктура в Azure описана за допомогою Azure Resource Manager (ARM) шаблонів.
- Розроблено PowerShell скрипти для автоматичної активації DR: запуск VM з образів, підключення дисків, налаштування застосунку, перемикання DNS-записів (через Azure DNS).
- Моніторинг основного ЦОД налаштовано в Azure Monitor, який при виявленні збою запускає сповіщення та ініціює скрипт активації DR.
- Тестування: Щоквартольний повний Failover Test з переключенням частини трафіку на Azure.
Результати:
- RTO: Скорочено до 1-2 годин.
- RPO: Скорочено до 15-30 хвилин для БД та файлів.
- Вартість: Значні інвестиції в розробку та підтримку, але операційні витрати на хмарну інфраструктуру в режимі "standby" були оптимізовані.
- Забезпечено надійний захист від збоїв всього локального датацентра.
Ці кейси демонструють, що ефективна стратегія DR не є універсальним рішенням, а вимагає індивідуального підходу, заснованого на специфіці проєкту, його вимогах та доступних ресурсах.
Troubleshooting: Вирішення типових проблем DR
 Схема: Troubleshooting: Вирішення типових проблем DR
Схема: Troubleshooting: Вирішення типових проблем DR
Навіть при найретельнішому плануванні та автоматизації, в процесі Disaster Recovery можуть виникати проблеми. Знання типових сценаріїв та підходів до їх вирішення значно скорочує час відновлення.
1. Проблема: Збої резервного копіювання або реплікації
Симптоми: Відсутність свіжих бекапів, відставання репліки БД, помилки в логах бекап-скриптів.
Діагностика:
- Перевірте логи бекап-процесів та сервісів реплікації (наприклад,
tail -f /var/log/syslog, логи PostgreSQL/MySQL).
- Перевірте дисковий простір на серверах та в цільовому сховищі (
df -h, моніторинг хмарного сховища).
- Перевірте мережеве з'єднання між основним та резервним сайтами (
ping, traceroute, netstat -tulnp).
- Перевірте права доступу користувача, від імені якого запускаються бекапи/реплікація.
- Для баз даних:
- PostgreSQL:
SELECT * FROM pg_stat_replication; на майстрі, SELECT pg_is_in_recovery(); на репліці.
- MySQL:
SHOW SLAVE STATUS\G; на репліці.
Рішення:
- Усуньте проблеми з дисковим простором, мережею або правами.
- Перезапустіть сервіси реплікації.
- При значному відставанні репліки, можливо, потрібно перестворити її з нуля (
pg_basebackup для PostgreSQL, mysqldump з подальшим імпортом для MySQL, rsync для файлових систем).
- Налаштуйте агресивний моніторинг та оповіщення про збої бекапів/реплікації.
2. Проблема: Неузгодженість даних після failover
Симптоми: Частина даних відсутня, транзакції втрачені, додаток поводиться непередбачувано після перемикання на DR-сайт.
Діагностика:
- Перевірте RPO, яке було досягнуто на момент збою. Чи відповідає воно очікуванням?
- Порівняйте контрольні суми файлів або кількість записів в таблицях БД між основним та DR-сайтами (якщо можливо).
- Проаналізуйте логи реплікації на предмет помилок або пропущених транзакцій.
- Перевірте налаштування реплікації: чи була вона синхронною або асинхронною?
Рішення:
- Якщо RPO було порушено, і дані дійсно втрачені, оцініть можливість відновлення з більш старих бекапів (якщо це допустимо) або ручного відновлення даних.
- Для майбутніх інцидентів: перегляньте RPO та стратегію реплікації. Можливо, потрібна більш сувора синхронна реплікація або використання розподілених баз даних з гарантованою консистентністю.
- Впровадьте додаткові перевірки консистентності даних в DR-план.
3. Проблема: Повільне або невдале перемикання (Failover)
Симптоми: DR-сайт активується довше, ніж очікувалось, скрипти failover зависають, додаток не запускається коректно на DR-сайті.
Діагностика:
- Перевірте логи скриптів failover. На якому кроці сталася затримка або помилка?
- Перевірте доступність зовнішніх сервісів, від яких залежить DR-сайт (DNS-провайдер, хмарні API).
- Перевірте стан ресурсів на DR-сайті: чи достатньо CPU/RAM/IOPS? Чи не "замерзли" VM?
- Перевірте мережеві налаштування на DR-сайті (фаєрволи, маршрутизація).
- Переконайтеся, що всі залежності додатку (черги, кеші, сторонні API) доступні або правильно сконфігуровані на DR-сайті.
Рішення:
- Оптимізуйте скрипти failover: зробіть їх більш робастними, додайте таймаути та повторні спроби.
- Попередньо "розігрійте" (pre-warm) інстанси на DR-сайті, якщо це Warm Standby, щоб скоротити час завантаження.
- Усуньте мережеві проблеми.
- Актуалізуйте конфігурації DR-сайту. Він має бути ідентичним основному.
- Проведіть ретельне тестування failover, щоб виявити всі вузькі місця.
4. Проблема: Помилки при поверненні (Failback)
Симптоми: Неможливо переключитися назад на основний сайт, дані на основному сайті застаріли, виникають конфлікти даних.
Діагностика:
- Перевірте, чи був основний сайт повністю відновлений та готовий до прийому трафіку.
- Переконайтеся, що дані з DR-сайту були коректно репліковані назад на основний сайт.
- Перевірте логи failback-скриптів.
- Оцініть, чи є конфлікти даних, які могли виникнути в процесі роботи DR-сайту.
Рішення:
- Процедура failback часто складніша, ніж failover, і вимагає ще більш ретельного планування.
- Забезпечте повну синхронізацію даних з DR-сайту на основний перед перемиканням.
- Розробіть стратегію вирішення конфліктів даних, якщо вони виникли.
- Тестуйте failback так само ретельно, як і failover.
5. Проблема: Людський фактор
Симптоми: Помилки при виконанні ручних кроків DR, паніка, відсутність чіткого розуміння ролей.
Діагностика:
- Аналіз інциденту: який крок було виконано неправильно, чому?
- Оцінка рівня стресу та втоми команди.
- Перевірка актуальності та зрозумілості DRP.
Рішення:
- Максимально автоматизуйте всі можливі кроки.
- Проводьте регулярні тренування та навчання, щоб команда звикла до процедур.
- Покращіть DRP, зробіть його більш деталізованим та зрозумілим.
- Забезпечте наявність декількох навчених співробітників, здатних виконати DR-процедури.
- Впровадьте чек-листи для критичних ручних операцій.
Коли звертатися в підтримку
- Проблеми з базовою інфраструктурою: Якщо ви впевнені, що проблема не у вашій конфігурації, а в роботі VPS-провайдера або хмарної платформи (недоступність мережі, збої дисків, недоступність регіону).
- Складні проблеми з керованими сервісами: Якщо керована база даних або інший хмарний сервіс поводиться непередбачувано, і документація не допомагає.
- Неможливість відновлення: Якщо, незважаючи на всі зусилля, ви не можете відновити дані або запустити додаток, і всі внутрішні ресурси вичерпані.
- Питання безпеки: Якщо ви підозрюєте компрометацію DR-інфраструктури або даних.
Завжди майте під рукою контакти служби підтримки ваших провайдерів та SLA з ними.
FAQ: Часті запитання про Disaster Recovery
Що таке RTO та RPO і чому вони такі важливі?
RTO (Recovery Time Objective) — це максимально допустимий час, протягом якого ваш SaaS-додаток може бути недоступним після збою. RPO (Recovery Point Objective) — це максимально допустимий обсяг даних, який може бути втрачений в результаті збою, вимірюваний в часі. Ці метрики критично важливі, тому що вони визначають, наскільки швидко і з якою мірою повноти ваш бізнес повинен відновитися. Вони є основою для вибору DR-стратегії і безпосередньо впливають на її вартість і складність.
Чим відрізняється Disaster Recovery від простого резервного копіювання (бекапів)?
Резервне копіювання — це лише один з компонентів Disaster Recovery. Бекапи дозволяють відновити дані до певної точки в часі. DR — це комплексний план, який включає не тільки бекапи, але й механізми реплікації даних, автоматизацію розгортання інфраструктури, процедури перемикання на резервний сайт (failover), відновлення роботи (failback), моніторинг, оповіщення та регулярне тестування. DR спрямований на повне відновлення працездатності всього застосунку, а не тільки даних.
Чи потрібен DR для малого SaaS-проєкту з невеликим бюджетом?
Так, абсолютно. Навіть для малого SaaS-проєкту втрата даних або тривалий простій може бути катастрофічним. Почати можна з базової, але ефективної стратегії Cold Standby, яка відносно недорога. Головне — це мати план, регулярно робити бекапи і тестувати можливість відновлення з них. У міру зростання проєкту і збільшення вимог до доступності, можна поступово переходити до більш складних і дорогих стратегій DR.
Як часто потрібно тестувати DR-план?
Частота тестування залежить від критичності вашого SaaS-застосунку і швидкості змін в інфраструктурі. Для критично важливих систем рекомендується проводити повний Failover Test не рідше одного разу на квартал. Перевірку цілісності бекапів і реплікації слід виконувати щотижня або щодня. Настільні навчання (Tabletop Exercises) можна проводити щомісяця. Головне правило: тестуйте ваш DR-план так часто, щоб бути впевненим в його працездатності, і завжди після значних змін в архітектурі або конфігурації.
Які основні типи DR-стратегій існують?
Основні типи DR-стратегій включають: Cold Standby (холодний резерв, найдешевший, високі RTO/RPO), Warm Standby (теплий резерв, помірні RTO/RPO), Hot Standby (гарячий резерв, низькі RTO/RPO, дорогий), Multi-Region Active/Active (найвища доступність, дуже дорогий і складний), і Гібридний DR (поєднання VPS і хмари для оптимізації). Вибір залежить від ваших RTO, RPO, бюджету і складності застосунку.
Чи можна автоматизувати весь процес Disaster Recovery?
Для більшості сучасних SaaS-застосунків, особливо тих, що розгорнуті в хмарі, значну частину DR-процесів можна і потрібно автоматизувати. За допомогою Infrastructure as Code (IaC), скриптів, CI/CD пайплайнів, хмарних сервісів та інструментів оркестрації можна автоматизувати виявлення збоїв, розгортання ресурсів, перемикання DNS і запуск застосунку. Однак, повністю виключити людську участь, особливо на етапі прийняття рішень і контролю, поки складно, хоча ШІ і ML активно розвиваються в цьому напрямку.
Які хмарні сервіси допомагають з Disaster Recovery?
Практично всі великі хмарні провайдери (AWS, Azure, Google Cloud) пропонують широкий спектр сервісів для DR: Multi-AZ/Multi-Region розгортання для VM і БД, керовані бази даних (RDS, Azure SQL, Cloud SQL) з вбудованою реплікацією, об'єктні сховища (S3, Blob Storage, GCS) для бекапів, IaC-інструменти (CloudFormation, ARM Templates, Deployment Manager), DNS-сервіси (Route 53, Azure DNS, Cloud DNS) з функціями failover, глобальні балансувальники навантаження (Global Accelerator, Front Door, Global Load Balancer) і сервіси моніторингу та оповіщення (CloudWatch, Azure Monitor, Cloud Monitoring).
Як вибрати між VPS і хмарою для DR?
Вибір залежить від вашого бюджету, RTO/RPO і експертизи команди. VPS може бути дешевше для Cold/Warm Standby, особливо якщо у вас вже є інфраструктура на VPS і ви хочете зберегти контроль. Однак масштабованість і автоматизація на VPS часто складніша. Хмара пропонує високу гнучкість, еластичність, багатий набір DR-сервісів і більш легку автоматизацію, але може бути дорожче, особливо для Hot Standby і Multi-Region рішень. Гібридний підхід (VPS для основної роботи, хмара для DR) часто є хорошим компромісом.
Що таке Chaos Engineering і як він пов'язаний з DR?
Chaos Engineering — це практика контрольованого впровадження збоїв в розподілені системи з метою виявлення слабких місць і перевірки стійкості. Він безпосередньо пов'язаний з DR, тому що дозволяє активно тестувати ваш DR-план в реальних умовах, імітуючи відмови серверів, мережі, баз даних або навіть цілих AZ. Це допомагає виявити приховані залежності і вузькі місця, які можуть привести до провалу DR, перш ніж вони відбудуться в реальній катастрофі.
Яка роль ШІ в DR 2026 року?
У 2026 році ШІ і машинне навчання відіграють все більш важливу роль в DR. Вони використовуються для предиктивного аналізу: ШІ може аналізувати патерни в логах і метриках, щоб передбачати потенційні збої до їх виникнення. Також ШІ допомагає в автоматичному аналізі інцидентів, швидко виявляючи першопричини проблем. У майбутньому можна очікувати автоматизованого прийняття рішень про failover на основі ШІ, який буде враховувати безліч факторів, мінімізуючи людське втручання і скорочуючи RTO.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
Висновок
Disaster Recovery — це не просто технічне завдання, а фундаментальна складова стійкості будь-якого SaaS-бізнесу в 2026 році. В умовах постійно зростаючих очікувань користувачів, посилення регуляторних вимог і збільшення складності інфраструктур, ефективний DR-план стає не розкішшю, а критичною необхідністю. Відсутність такого плану або його неефективність може призвести до катастрофічних фінансових втрат, незворотної шкоди репутації і втрати довіри клієнтів.
Ми розглянули широкий спектр стратегій — від бюджетного Cold Standby для невеликих проєктів до складних Multi-Region Active/Active систем для глобальних SaaS-гігантів. Ключовим висновком є те, що не існує універсального рішення. Вибір оптимальної стратегії завжди повинен ґрунтуватися на ретельному аналізі ваших RTO (цільового часу відновлення) і RPO (допустимої втрати даних), які, в свою чергу, визначаються бізнес-вимогами і вартістю простою для вашої компанії.
Головні рекомендації, які ви повинні винести з цієї статті:
- Плануйте системно: Розробіть докладний і актуальний Disaster Recovery Plan (DRP), який охоплює всі аспекти: від сценаріїв збоїв до комунікаційного плану.
- Автоматизуйте максимально: Використовуйте Infrastructure as Code (IaC), скрипти та інструменти оркестрації для мінімізації ручної праці, скорочення RTO і виключення людського фактора.
- Тестуйте безжально: Непротестований DR-план — це ілюзія безпеки. Регулярно проводите навчання і тести, аж до повного перемикання, щоб виявити і усунути всі слабкі місця.
- Інвестуйте в правильні інструменти: Сучасні хмарні сервіси та open-source інструменти пропонують потужні можливості для побудови відмовостійких систем.
- Враховуйте економіку: Завжди зіставляйте витрати на DR з потенційним збитком від збою. Шукайте оптимальний баланс, використовуючи можливості оптимізації вартості.
- Навчайте команду: Ваші інженери повинні бути добре знайомі з DRP і процедурами, щоб діяти ефективно в умовах стресу.
- Будьте готові до гібридності: Комбінування VPS і хмарних рішень часто дає найкращий результат за співвідношенням "ціна/якість" для багатьох SaaS-проєктів.
Наступні кроки для читача:
- Почніть з BIA: Визначте критичність ваших сервісів та встановіть реалістичні RTO та RPO.
- Розробіть або оновіть DRP: Формалізуйте ваш план.
- Впровадьте базові бекапи: Переконайтеся, що всі критичні дані регулярно бекапляться і зберігаються за правилом 3-2-1.
- Проведіть перший тест: Спробуйте відновити дані з бекапів на тестовому сервері. Це дасть вам безцінний досвід.
- Поступово автоматизуйте: Почніть з автоматизації бекапів, потім переходьте до розгортання інфраструктури за допомогою IaC.
Пам'ятайте, що Disaster Recovery — це безперервний процес. Ваша інфраструктура змінюється, бізнес-вимоги еволюціонують, і ваш DR-план повинен розвиватися разом з ними. Інвестиції в DR — це інвестиції в стабільність, довіру клієнтів і довгостроковий успіх вашого SaaS-проєкту.