
SRE-практики для стартапів та малих SaaS-команд на VPS/Dedicated: від SLO до Post-Mortem
TL;DR
- Впровадження SRE-практик критично важливе для виживання та масштабування стартапів на VPS/Dedicated, забезпечуючи стабільність та передбачуваність роботи.
- Почніть з визначення ключових метрик (SLI) та реалістичних цілей (SLO) для ваших критичних сервісів, не прагнучи до ідеальних "дев'яток".
- Ефективний моніторинг та алертинг — основа SRE; використовуйте опенсорсні рішення на кшталт Prometheus/Grafana для економії та контролю.
- Розробіть прості, але дієві процеси реагування на інциденти та проводьте "беззвинувачувальні" Post-Mortem для безперервного навчання.
- Автоматизуйте рутинні завдання (розгортання, оновлення, резервне копіювання), щоб скоротити "toil" та мінімізувати людський фактор.
- SRE не вимагає великих бюджетів; фокус на практичності, ітеративному підході та використанні доступних інструментів дозволить досягти значних результатів.
- Інвестиції в SRE окупаються зниженням downtime, покращенням репутації, зменшенням стресу в команді та прискоренням розробки.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Вступ
У стрімкому ландшафті технологій 2026 року, де користувацькі очікування стабільності та швидкості роботи сервісів досягли безпрецедентного рівня, а конкуренція серед стартапів та SaaS-проєктів продовжує посилюватися, здатність підтримувати високу доступність та продуктивність стає не просто перевагою, а життєвою необхідністю. Для багатьох молодих компаній та невеликих команд, що оперують на VPS або виділених серверах, впровадження складних методологій рівня Google може здаватися нездійсненною мрією. Однак, саме тут на допомогу приходять адаптовані SRE-практики (Site Reliability Engineering).
Ця стаття створена, щоб розвіяти міф про те, що SRE — це доля лише технологічних гігантів. Ми покажемо, як принципи SRE, такі як визначення SLI/SLO, управління бюджетом помилок, ефективний моніторинг, оперативне реагування на інциденти та проведення Post-Mortem, можуть бути успішно застосовані навіть в умовах обмежених ресурсів та невеликих команд. Ми сфокусуємось на практичних аспектах, застосовних до інфраструктури на VPS/Dedicated, де кожен цент та кожна хвилина мають значення.
Чому ця тема важлива саме зараз, у 2026 році? З одного боку, вартість хмарних ресурсів продовжує зростати, роблячи VPS та виділені сервери більш привабливими з точки зору капітальних витрат для багатьох стартапів. З іншого боку, складність сучасних додатків не зменшується, а очікування користувачів від якості сервісу лише зростають. Це створює дилему: як забезпечити надійність та масштабованість на "залізі", не маючи армій інженерів та необмежених бюджетів? SRE пропонує відповідь, фокусуючись на автоматизації, вимірюванні та культурі безперервного поліпшення.
Які проблеми вирішує ця стаття? Ми допоможемо вам:
- Подолати хаотичне реагування на проблеми та перейти до проактивного управління надійністю.
- Визначити, що дійсно важливо для вашого бізнесу з точки зору доступності та продуктивності.
- Скоротити час простою (downtime) та мінімізувати його вплив на бізнес.
- Зменшити стрес та вигорання в команді за рахунок автоматизації та чітких процесів.
- Створити культуру навчання на помилках, а не пошуку винних.
- Оптимізувати витрати на інфраструктуру та інструменти, вибираючи найбільш ефективні рішення для вашого середовища.
Для кого написано цей посібник? Він буде безцінним ресурсом для:
- DevOps-інженерів, які прагнуть систематизувати свою роботу та впровадити найкращі практики.
- Backend-розробників (на Python, Node.js, Go, PHP), які хочуть краще розуміти операційні аспекти своїх додатків та брати участь у їх надійності.
- Фаундерів SaaS-проєктів, яким необхідно забезпечити стабільність свого продукту для утримання клієнтів та зростання.
- Системних адміністраторів, які шукають способи підвищення ефективності управління серверами та додатками.
- Технічних директорів стартапів, перед якими стоїть завдання побудови надійної та масштабованої інфраструктури з обмеженими ресурсами.
Приготуйтеся до занурення у світ практичного SRE, де кожна порада перевірена реальним досвідом та спрямована на досягнення відчутних результатів.
Основні критерії та фактори SRE для малих команд
В основі будь-якої ефективної SRE-стратегії лежить розуміння ключових метрик та принципів. Для стартапів та малих SaaS-команд на VPS/Dedicated важливо не просто скопіювати підходи гігантів, а адаптувати їх до своїх реалій, фокусуючись на максимальній віддачі при мінімальних витратах. Розглянемо основні критерії та фактори, які стануть вашими орієнтирами.
1. Service Level Indicators (SLI) – Індикатори рівня сервісу
SLI — це кількісні метрики, які показують, наскільки добре працює ваш сервіс. Для малих команд вибір правильних SLI критичний, оскільки їх буде небагато, і вони повинні бути максимально інформативними. Чому важливі: SLI служать основою для вимірювання продуктивності та надійності. Як оцінювати: Вони повинні бути вимірювані, зрозумілі та безпосередньо пов'язані з користувацьким досвідом.
- Затримка (Latency): Час відповіді від сервера на запит користувача. Для веб-застосунків це може бути час завантаження сторінки або API-відповіді. Приклад: 95% запитів до API повинні виконуватися менш ніж за 300 мс.
- Частота помилок (Error Rate): Відсоток запитів, які завершились помилкою (наприклад, HTTP 5xx). Це прямо вказує на проблеми в роботі застосунку або інфраструктури. Приклад: менше 0.1% запитів до основного сервісу повинні повертати помилки 5xx.
- Доступність (Availability): Відсоток часу, протягом якого сервіс доступний і працездатний. Часто вимірюється як (загальний час - час простою) / загальний час. Приклад: 99.9% доступності основного веб-сервісу.
- Пропускна здатність (Throughput): Кількість запитів, оброблених за одиницю часу. Важливо для оцінки масштабованості та продуктивності під навантаженням. Приклад: обробка не менше 1000 запитів/сек при піковому навантаженні.
Наш досвід показує, що починати слід з 2-3 найбільш критичних SLI для вашого основного користувацького сценарію. Наприклад, для SaaS-платформи це може бути доступність API та затримка відповіді при аутентифікації.
2. Service Level Objectives (SLO) – Цілі рівня сервісу
SLO — це конкретні цільові значення для ваших SLI, виражені у відсотках або абсолютних числах за певний період. Чому важливі: SLO переводять абстрактні метрики в конкретні, вимірювані цілі, навколо яких будується вся робота із забезпечення надійності. Вони допомагають команді зрозуміти, коли сервіс "достатньо хороший". Як оцінювати: SLO повинні бути реалістичними та досяжними, а не ідеалістичними. Занадто амбітні SLO призведуть до вигорання, занадто низькі — до невдоволення користувачів.
- Приклад SLO для доступності: "Доступність основного API повинна бути не менше 99.9% за календарний місяць." Це означає, що допустимий простій становить близько 43 хвилин на місяць.
- Приклад SLO для затримки: "99-й перцентиль затримки відповіді для критично важливих запитів бази даних повинен бути менше 200 мс."
Для стартапів важливо не гнатися за "п'ятьма дев'ятками" (99.999%), які вимагають величезних витрат. Часто 99.5% або 99.9% — це більш ніж достатньо, особливо на початкових етапах. Реальний кейс: Ми одного разу зіткнулися з тим, що команда встановила SLO 99.99% для нового сервісу, що працює на одному VPS. Це призвело до постійного стресу та переробок, поки ми не скоригували його до 99.5%, що виявилося цілком прийнятним для користувачів і значно знизило навантаження на команду.
3. Service Level Agreement (SLA) – Угода про рівень сервісу
SLA — це формальний договір між постачальником послуг (вами) і клієнтом, який описує очікуваний рівень сервісу та наслідки його невиконання (наприклад, фінансові компенсації). Чому важливі: SLA — це юридичне зобов'язання, яке ґрунтується на ваших SLO. Як оцінювати: Воно повинно бути реалістичним і відповідати вашим внутрішнім можливостям, продиктованим SLO.
Для малих SaaS-команд SLA може бути частиною умов використання. Важливо, щоб SLA було менш суворим, ніж ваше внутрішнє SLO, щоб у вас був "запас міцності". Наприклад, якщо ваше SLO 99.9%, то SLA може бути 99.5%.
4. Error Budgets – Бюджет помилок
Бюджет помилок — це допустима кількість "ненадійності" або "простою" за певний період, яку ви готові прийняти, не порушуючи SLO. Якщо ваше SLO 99.9% доступності, то 0.1% часу (приблизно 43 хвилини на місяць) — це ваш бюджет помилок. Чому важливі: Бюджет помилок — потужний інструмент для балансування між надійністю та швидкістю розробки. Якщо бюджет помилок вичерпано, команда повинна призупинити випуск нових функцій і зосередитися на підвищенні надійності. Як оцінювати: Відстежуйте використання бюджету помилок щодня або щотижня. Коли він наближається до нуля, це сигнал до дії.
Це допомагає уникнути вічної дилеми "фічі проти стабільності". Реальний приклад: Одного разу, після серії інцидентів, наш бюджет помилок був практично вичерпаний. Ми прийняли рішення на два тижні повністю зупинити розробку нових функцій, щоб зосередитися на рефакторингу проблемних місць, поліпшенні моніторингу та автоматизації розгортання. Це дозволило нам стабілізувати сервіс і повернути довіру користувачів.
5. Моніторинг і Алерт (Monitoring & Alerting)
Моніторинг — це збір і аналіз даних про стан вашої системи. Алерт — це повідомлення про те, що щось пішло не так або виходить за рамки допустимих значень. Чому важливі: Це очі та вуха вашої SRE-практики. Без них неможливо відстежувати SLI, контролювати SLO та реагувати на проблеми. Як оцінювати: Моніторинг повинен бути всеосяжним (інфраструктура, застосунок, користувацький досвід), а алерти — дієвими, що не викликають "втоми від сповіщень".
- Метрики інфраструктури: CPU, RAM, Disk I/O, Network I/O для VPS.
- Метрики застосунку: Кількість запитів, затримка відповідей, кількість помилок, стан пулів з'єднань (БД, кеш).
- Логи: Централізований збір і аналіз логів для швидкого пошуку причин проблем.
- Трасування (Tracing): Для розподілених систем, дозволяє відстежити шлях запиту через різні компоненти. Для VPS це може бути складніше, але корисно для розуміння взаємодій між вашими сервісами.
Для малих команд на VPS, самохостинг Prometheus + Grafana є золотим стандартом, надаючи потужні можливості при мінімальних витратах.
6. Incident Response – Реагування на інциденти
Incident Response — це процес, який команда використовує для виявлення, оцінки, вирішення та документування інцидентів, що впливають на сервіс. Чому важливі: Навіть з найкращими SRE-практиками інциденти неминучі. Ефективний процес реагування мінімізує час простою (MTTR - Mean Time To Recover) і його вплив на бізнес. Як оцінювати: Вимірюйте MTTR і кількість інцидентів. Мета — скоротити MTTR і запобігти повторенню інцидентів.
Малим командам потрібен чіткий, але простий план: хто на чергуванні, як сповіщається, де документується, які кроки робляться. Важливо мати "runbooks" — покрокові інструкції для вирішення типових проблем.
7. Post-Mortem (Blameless) – Беззвинувачувальний аналіз інцидентів
Post-Mortem — це процес аналізу інциденту після його вирішення з метою вилучення уроків і запобігання його повторенню. "Беззвинувачувальний" означає, що фокус робиться на системних проблемах, а не на пошуку винних. Чому важливі: Це ключовий механізм для безперервного поліпшення надійності. Без Post-Mortem команда приречена наступати на одні й ті ж граблі. Як оцінювати: Кількість і якість виявлених "action items" (дій щодо поліпшення), їх виконання та вплив на метрики надійності.
Для стартапів це може бути проста нарада на 30-60 хвилин після кожного серйозного інциденту, де обговорюються: що сталося, чому, що ми зробили, щоб виправити, що ми можемо зробити, щоб запобігти повторенню. Важливо документувати висновки.
8. Автоматизація (Automation)
Автоматизація — це усунення рутинних, повторюваних завдань (toil) за допомогою скриптів та інструментів. Чому важливі: Автоматизація скорочує людські помилки, прискорює операції, звільняє час інженерів для більш цінної роботи та підвищує передбачуваність системи. Як оцінювати: Кількість автоматизованих завдань, скорочення "toil", швидкість розгортання, зниження кількості помилок, пов'язаних з ручними операціями.
Для VPS/Dedicated це може бути автоматизація розгортання (CI/CD), резервного копіювання, оновлення ОС та залежностей, масштабування (якщо можливо), налаштування серверів (Infrastructure as Code з Ansible). Навіть прості bash-скрипти можуть дати величезний ефект.
9. Observability – Спостережуваність
Спостережуваність — це здатність зрозуміти внутрішній стан системи, просто досліджуючи дані, які вона генерує (метрики, логи, трасування). Чому важливо: Observability дозволяє не просто знати, що щось зламалось, але й зрозуміти, *чому* це сталося, без необхідності додаткового дебагінгу або доступу до машини. Як оцінювати: Швидкість діагностики та вирішення невідомих проблем, глибина розуміння поведінки системи.
Для малих команд це може бути складним завданням через обмеженість ресурсів. Почніть з хорошого збору метрик та централізованого логування. Трасування може бути впроваджено пізніше, по мірі росту складності та ресурсів. Loki для логів і Tempo для трасувань (у зв'язці з Grafana) можуть бути хорошим опенсорсним вибором.
10. Capacity Planning – Планування потужностей
Capacity Planning — це процес прогнозування майбутніх потреб в ресурсах (CPU, RAM, диск, мережа) та відповідного планування інфраструктури. Чому важливо: Дозволяє уникнути деградації сервісу через нестачу ресурсів та оптимізувати витрати, купуючи тільки необхідні потужності. Як оцінювати: Точність прогнозів, відсутність інцидентів, пов'язаних з нестачею ресурсів, оптимальне використання поточних потужностей.
На VPS/Dedicated це зазвичай зводиться до моніторингу поточного використання ресурсів та прогнозування на основі трендів росту. Якщо ви бачите, що CPU постійно завантажений на 80-90%, це сигнал до апгрейду VPS або оптимізації програми. Для стартапів цей процес часто більш реактивний, ніж проактивний, але постійний моніторинг дозволяє приймати обґрунтовані рішення про масштабування.
Порівняльна таблиця інструментів для SRE
Вибір правильних інструментів критично важливий для ефективного впровадження SRE-практик, особливо при обмежених бюджетах VPS/Dedicated. У 2026 році ринок пропонує як зрілі опенсорсні рішення, так і комерційні SaaS-продукти з тарифами для малих команд. Ця таблиця допоможе порівняти деякі з них за ключовими параметрами.
| Критерій | Prometheus + Grafana | Zabbix | Datadog (Starter/Pro) | New Relic (Standard) | ELK Stack (self-hosted) | Loki + Grafana |
|---|---|---|---|---|---|---|
| Тип рішення | Open-source, self-hosted | Open-source, self-hosted | SaaS | SaaS | Open-source, self-hosted | Open-source, self-hosted |
| Основні функції | Метрики, алерти, дашборди | Метрики, алерти, дашборди, інвентаризація | APM, інфраструктура, логи, синтетика, RUM | APM, інфраструктура, логи, синтетика, RUM | Логи, метрики, трасування (через APM) | Логи (з метриками та трасуваннями через Grafana) |
| Складність впровадження (для VPS) | Середня (потребує налаштування) | Середня (потребує налаштування) | Низька (встановлення агента) | Низька (встановлення агента) | Висока (багато компонентів) | Низька-середня (простіше ELK) |
| Приблизна вартість (2026, $/міс) | 0 (тільки ресурси VPS) | 0 (тільки ресурси VPS) | $30-100+ (залежить від об'єму) | $25-75+ (залежить від об'єму) | 0 (тільки ресурси VPS) | 0 (тільки ресурси VPS) |
| Вимоги до ресурсів VPS | Середні | Середні | Низькі (агент) | Низькі (агент) | Високі (особливо Elasticsearch) | Низькі-середні |
| Масштабованість | Хороша (federation) | Хороша | Відмінна (SaaS) | Відмінна (SaaS) | Середня-хороша (кластер) | Відмінна (cloud-native) |
| Ідеально для | Малих команд, бюджетних проєктів, гнучкості | Традиційних SysOps, комплексного моніторингу інфраструктури | Швидкого старту, комплексного APM, готових рішень | Швидкого старту, комплексного APM, готових рішень | Глибокого аналізу логів, великих об'ємів даних | Економічного логування, інтеграції з Grafana |
| Підтримка | Спільнота, платні вендори | Спільнота, платні вендори | Вендор | Вендор | Спільнота, Elastic Inc. | Спільнота, Grafana Labs |
Коментарі до таблиці:
- Prometheus + Grafana: Це "золотий стандарт" для багатьох стартапів на VPS. Prometheus збирає метрики, Grafana візуалізує їх. Обидва інструменти дуже потужні, гнучкі та мають величезну спільноту. Потребують деякого часу на вивчення та налаштування, але окупаються повною свободою та відсутністю щомісячних платежів за функціонал.
- Zabbix: Більш традиційна система моніторингу, часто використовується системними адміністраторами. Відмінна для моніторингу серверів, мережевого обладнання, але може бути менш гнучка для моніторингу сучасних мікросервісних додатків у порівнянні з Prometheus.
- Datadog / New Relic: Це потужні комерційні платформи "все в одному". Вони пропонують APM (Application Performance Monitoring), моніторинг інфраструктури, логи, трасування, синтетичний моніторинг та багато іншого. Їх головна перевага — простота впровадження та глибока аналітика з коробки. Однак, для стартапів на VPS їх вартість може швидко стати значною, особливо при рості об'ємів даних. Для дуже маленьких команд можуть бути безкоштовні або дуже дешеві тарифи, але з обмеженнями.
- ELK Stack: Elasticsearch, Logstash, Kibana — це потужний стек для збору, зберігання, аналізу та візуалізації логів. Він надає глибокі можливості для пошуку та аналізу текстових даних. Однак, Elasticsearch дуже вимогливий до ресурсів, і його розгортання на одному VPS може бути складним і ресурсоємним. Часто вимагає окремого виділеного сервера або кластера.
- Loki + Grafana: Loki — це система агрегації логів, розроблена Grafana Labs. Вона набагато менш ресурсоємна, ніж Elasticsearch, оскільки індексує тільки метадані логів, а не весь їх контент. Це робить її відмінним вибором для централізованого логування на VPS, особливо в зв'язці з Grafana. Дозволяє ефективно шукати і аналізувати логи, інтегруючи їх з метриками.
Вибір інструменту багато в чому залежить від ваших поточних потреб, розміру команди, бюджету і готовності інвестувати час в налаштування. Для більшості стартапів на VPS/Dedicated комбінація Prometheus + Grafana для метрик і Loki + Grafana для логів є найбільш збалансованим і економічно вигідним рішенням.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Детальний огляд ключових SRE-практик
Впровадження SRE в умовах стартапу або малої команди на VPS/Dedicated вимагає прагматичного підходу. Тут ми заглибимося в деталі кожної ключової практики, пояснюючи, як її ефективно адаптувати до ваших реалій.
1. SLI, SLO і Бюджет помилок для малих команд
SLI (Service Level Indicators) — це ваші очі на стан системи. Для початку, зосередьтеся на тому, що безпосередньо впливає на користувача і легко вимірюється. Для типового SaaS-застосунку на VPS це:
- Доступність основного API/Веб-інтерфейсу: Відсоток успішних HTTP-запитів (2xx, 3xx) від загального числа запитів. Використовуйте зовнішні пінги (UptimeRobot, Healthchecks.io) і внутрішні метрики (Prometheus HTTP_exporter) для збору.
- Затримка критичних операцій: Час відповіді для найбільш частих або важливих запитів (наприклад, вхід в систему, завантаження панелі управління, збереження даних). Відстежуйте 95-й і 99-й перцентилі, щоб зрозуміти не тільки середнє, але і гірші сценарії.
- Частота помилок: Відсоток запитів, що повертають HTTP 5xx. Також важливо відстежувати помилки в логах застосунку, які можуть не приводити до 5xx, але впливають на функціональність.
SLO (Service Level Objectives) — це ваші обіцянки самим собі і користувачам. Не прагніть до нереалістичних 99.999%. Для стартапу, що починає з VPS, 99.5% або 99.9% доступності — це відмінна мета, яка означає всього 43 хвилини простою в місяць для 99.9%. Це дає простір для маневру, оновлень і навіть невеликих інцидентів. Приклад: "Доступність API для клієнтів повинна бути ≥99.9% за останні 30 днів", "95% запитів до бази даних повинні виконуватися ≤100 мс". Важливо, щоб SLO були узгоджені з бізнес-цілями і можливостями команди.
Бюджет помилок (Error Budget) — це ваш "кредит" на ненадійність. Якщо ваше SLO 99.9%, то у вас є 0.1% від загального часу роботи сервісу, яке ви можете "витратити" на інциденти, планові роботи або експерименти. Як використовувати: Якщо бюджет помилок починає швидко скорочуватися, це сигнал для команди призупинити розробку нових функцій і зосередитися на підвищенні надійності. Наприклад, якщо за тиждень ви "витратили" половину місячного бюджету помилок, можливо, варто відкласти реліз нової фічі і провести рефакторинг проблемного компонента. Цей механізм допомагає збалансувати швидкість розробки і стабільність.
2. Практичний моніторинг і алертинг
Для VPS/Dedicated, моніторинг є наріжним каменем SRE. Ваша мета — бачити, що відбувається з сервером і застосунком, і отримувати повідомлення до того, як користувачі помітять проблему.
- Моніторинг інфраструктури: Встановіть Node Exporter на кожен VPS для збору метрик CPU, RAM, диска, мережі. Для контейнерів використовуйте cAdvisor.
- Моніторинг застосунку: Інтегруйте бібліотеки для експорту метрик (наприклад, Prometheus client libraries) в ваш код. Відстежуйте кількість запитів, затримку, помилки, стан черги, використання пам'яті JVM/Go/Node.js.
- Моніторинг логів: Використовуйте Loki + Promtail для збору логів з ваших серверів і застосунків. Це дозволить централізовано шукати і аналізувати події, а також створювати алерти на основі патернів в логах.
- Синтетичний моніторинг: Використовуйте зовнішні сервіси (UptimeRobot, Healthchecks.io) або Blackbox Exporter для Prometheus, щоб регулярно перевіряти доступність і коректність відповідей ваших публічних ендпоінтів ззовні.
Алертинг: Налаштуйте Alertmanager для обробки алертів від Prometheus. Ключові принципи:
- Конкретика: Алерти повинні бути максимально інформативними: що зламалося, де, коли, і що робити.
- Дієвість: Алерти повинні вимагати негайної дії. Якщо алерт не вимагає дії, це шум.
- Пріоритети: Розділіть алерти за критичністю. Високопріоритетні (сервіс недоступний) повинні будити команду. Низькопріоритетні (використання диска 80%) можуть відправлятися в Slack/Telegram.
- "Runbooks": До кожного алерту прив'яжіть посилання на "runbook" — коротку інструкцію, що робити при спрацюванні цього алерту.
Реальний кейс: Ми скоротили кількість "помилкових" алертів на 70% після того, як ввели правило: "Якщо алерт спрацьовує більше 3 разів за тиждень і не приводить до реального інциденту, він підлягає перегляду або відключенню". Це змусило команду налаштовувати більш точні пороги і фокусуватися на дійсно важливих проблемах.
3. Ефективний Incident Response для малих команд
Навіть з кращим моніторингом інциденти трапляються. Ваша мета — мінімізувати Mean Time To Recover (MTTR). Для невеликої команди це означає:
- Чітке чергування (On-Call Rotation): Навіть якщо вас всього двоє, визначте, хто чергує в неробочий час. Використовуйте прості інструменти: PagerDuty (є безкоштовний/дешевий тариф для малих команд), Opsgenie, або навіть самописний скрипт, що відправляє повідомлення в Telegram/Slack за розкладом.
- Канали комунікації: Виділіть окремий канал в Slack/Telegram для інцидентів. Вся комунікація повинна бути там.
- Runbooks: Це покрокові інструкції для вирішення типових проблем. Зберігайте їх в Wiki або Git-репозиторії. Приклад: "Сервер X не відповідає: 1) Перевірити пінг. 2) Перевірити SSH. 3) Перезапустити сервіс Y. 4) Перезавантажити VPS."
- Інцидент-менеджер: Призначте одну людину, яка буде координувати дії під час інциденту, навіть якщо це всього 2-3 людини. Вона відповідає за комунікацію, а не за технічне рішення.
- Швидка діагностика: Переконайтеся, що у кожного чергового є доступ до моніторингу, логів та можливість виконувати діагностичні команди на серверах.
Секрет успіху — практика. Регулярно проводьте "навчання", моделюючи невеликі інциденти, щоб команда знала, що робити.
4. Культура Post-Mortem (Blameless)
Post-Mortem — це не пошук винних, а системний аналіз для запобігання майбутнім проблемам. Для стартапів:
- Проводьте Post-Mortem для кожного значущого інциденту: Визначте "значущий" як будь-який інцидент, що порушив SLO або викликав суттєве невдоволення клієнтів.
- Фокус на системі, а не на людях: Питання "Що відбулося?", "Чому?", "Як ми це виявили?", "Що ми зробили?", "Що ми могли б зробити краще?", "Які системні зміни необхідні?".
- Документуйте: Записуйте висновки, хронологію, прийняті рішення і, найголовніше, "action items" — конкретні завдання з покращення (наприклад, "Додати алерт на заповнення диска", "Оновити документацію з розгортання", "Провести тренування з Incident Response").
- Призначайте відповідальних і терміни: Переконайтеся, що у кожного "action item" є відповідальний і реалістичний термін виконання.
- Діліться уроками: Розповідайте про висновки всій команді, щоб усі вчилися на чужих помилках.
Це допомагає створити культуру довіри та безперервного навчання, що особливо важливо у швидкозростаючих командах.
5. Автоматизація рутини та Toil
Toil (рутинна, повторювана, робота, що не приносить довгострокової користі) — ворог SRE. Автоматизація — ваш найкращий друг на VPS/Dedicated:
- Розгортання (CI/CD): Використовуйте GitLab CI, GitHub Actions (з self-hosted runner на вашому VPS) або Jenkins для автоматичного тестування та розгортання коду при кожному коміті. Це зменшує помилки та прискорює релізи.
- Управління конфігурацією (IaC): Використовуйте Ansible для автоматичного налаштування серверів, встановлення ПЗ, управління файлами конфігурації. Навіть для одного VPS це заощадить час та забезпечить консистентність.
- Резервне копіювання: Налаштуйте автоматичне резервне копіювання бази даних та важливих файлів на віддалене сховище (S3-сумісне сховище, Rsync.net). Використовуйте скрипти, cron-завдання.
- Оновлення: Автоматизуйте встановлення патчів безпеки для ОС (наприклад, за допомогою
unattended-upgradesв Debian/Ubuntu) та залежностей програми. - Перевірка стану: Скрипти, що перевіряють стан сервісів, вільне місце на диску, доступність портів, та надсилають звіти.
Почніть з малого: автоматизуйте те, що ви робите найчастіше і що найбільше схильне до помилок. Наприклад, процес розгортання нового мікросервісу або налаштування нового VPS.
6. Observability на VPS/Dedicated
Навіть на одному сервері, Observability дозволяє глибше зрозуміти, що відбувається.
- Метрики: Як вже згадувалося, Prometheus + Grafana. Збирайте метрики не тільки з ОС, але і з самої програми.
- Логи: Loki + Promtail + Grafana. Переконайтеся, що ваша програма логує достатньо інформації (рівні, контекст, User ID, Request ID).
- Трасування (Tracing): Для більш складних програм, де є кілька сервісів, навіть на одному VPS, трасування може бути корисним. Grafana Tempo — опенсорсне рішення, яке може бути розгорнуте на тому ж VPS, що і Loki/Prometheus. Інтегруйте OpenTelemetry SDK у ваш додаток для відправки трасувань.
Почніть з метрик та логів. Це дасть вам 80% необхідної інформації. Трасування — це наступний крок, коли у вас є ресурси та потреба у глибшому аналізі розподілених транзакцій.
Практичні поради та рекомендації щодо впровадження
Переходимо від теорії до конкретних кроків. Тут ви знайдете покрокові інструкції, приклади команд і конфігурацій, які можна застосувати прямо зараз.
1. Встановлення базового стеку моніторингу (Prometheus + Grafana + Node Exporter) на VPS
Це "must-have" для будь-якої команди на VPS. Припускаємо, що у вас є VPS з Ubuntu 22.04.
Крок 1: Встановлення Prometheus
# Створюємо користувача та директорії
sudo useradd --no-create-home --shell /bin/false prometheus
sudo mkdir /etc/prometheus
sudo mkdir /var/lib/prometheus
# Завантажуємо та розпаковуємо Prometheus (актуальна версія на 2026 рік може відрізнятися)
wget https://github.com/prometheus/prometheus/releases/download/v2.x.x/prometheus-2.x.x.linux-amd64.tar.gz
tar xvfz prometheus-2.x.x.linux-amd64.tar.gz
cd prometheus-2.x.x.linux-amd64
# Копіюємо бінарники та конфіг
sudo cp prometheus /usr/local/bin/
sudo cp promtool /usr/local/bin/
sudo cp -r consoles /etc/prometheus
sudo cp -r console_libraries /etc/prometheus
sudo cp prometheus.yml /etc/prometheus/prometheus.yml # Це буде базовий конфіг
# Встановлюємо права
sudo chown -R prometheus:prometheus /etc/prometheus
sudo chown -R prometheus:prometheus /var/lib/prometheus
sudo chown prometheus:prometheus /usr/local/bin/prometheus
sudo chown prometheus:prometheus /usr/local/bin/promtool
# Створюємо systemd-сервіс для Prometheus
sudo nano /etc/systemd/system/prometheus.service
Вміст файлу /etc/systemd/system/prometheus.service:
[Unit]
Description=Prometheus
Wants=network-online.target
After=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/usr/local/bin/prometheus \
--config.file /etc/prometheus/prometheus.yml \
--storage.tsdb.path /var/lib/prometheus \
--web.console.templates=/etc/prometheus/consoles \
--web.console.libraries=/etc/prometheus/console_libraries \
--web.listen-address="0.0.0.0:9090" \
--storage.tsdb.retention.time=30d # Зберігати дані 30 днів
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
# Перезавантажуємо systemd та запускаємо Prometheus
sudo systemctl daemon-reload
sudo systemctl start prometheus
sudo systemctl enable prometheus
sudo systemctl status prometheus # Перевіряємо статус
Крок 2: Встановлення Node Exporter
# Створюємо користувача
sudo useradd --no-create-home --shell /bin/false node_exporter
# Завантажуємо та розпаковуємо Node Exporter
wget https://github.com/prometheus/node_exporter/releases/download/v1.x.x/node_exporter-1.x.x.linux-amd64.tar.gz
tar xvfz node_exporter-1.x.x.linux-amd64.tar.gz
cd node_exporter-1.x.x.linux-amd64
# Копіюємо бінарник
sudo cp node_exporter /usr/local/bin
sudo chown node_exporter:node_exporter /usr/local/bin/node_exporter
# Створюємо systemd-сервіс для Node Exporter
sudo nano /etc/systemd/system/node_exporter.service
Вміст файлу /etc/systemd/system/node_exporter.service:
[Unit]
Description=Node Exporter
Wants=network-online.target
After=network-online.target
[Service]
User=node_exporter
Group=node_exporter
Type=simple
ExecStart=/usr/local/bin/node_exporter
[Install]
WantedBy=multi-user.target
# Перезавантажуємо systemd та запускаємо Node Exporter
sudo systemctl daemon-reload
sudo systemctl start node_exporter
sudo systemctl enable node_exporter
sudo systemctl status node_exporter
Крок 3: Налаштування Prometheus для збору метрик з Node Exporter
Відредагуйте /etc/prometheus/prometheus.yml, додавши job для Node Exporter:
# ... (решта конфігу)
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090'] # Сам Prometheus
- job_name: 'node_exporter'
static_configs:
- targets: ['localhost:9100'] # Node Exporter на цьому ж сервері
# Перезавантажуємо Prometheus, щоб застосувати зміни
sudo systemctl reload prometheus
Крок 4: Встановлення Grafana
# Додаємо ключ GPG
sudo apt install -y apt-transport-https software-properties-common wget
wget -q -O - https://apt.grafana.com/gpg.key | sudo gpg --dearmor | sudo tee /etc/apt/keyrings/grafana.gpg > /dev/null
# Додаємо репозиторій Grafana
echo "deb [signed-by=/etc/apt/keyrings/grafana.gpg] https://apt.grafana.com stable main" | sudo tee /etc/apt/sources.list.d/grafana.list
# Оновлюємо список пакетів та встановлюємо Grafana
sudo apt update
sudo apt install grafana -y
# Запускаємо та вмикаємо Grafana
sudo systemctl start grafana-server
sudo systemctl enable grafana-server
sudo systemctl status grafana-server
Grafana буде доступна за адресою http://ВАШ_IP:3000. Логін/пароль за замовчуванням: admin/admin (змініть одразу!). Додайте Prometheus як джерело даних (Data Source) та імпортуйте готові дашборди для Node Exporter (наприклад, ID 1860, 11074).
2. Визначення перших SLO та SLI
Не намагайтеся одразу охопити все. Виберіть 1-2 найбільш критичних сервіси та 1-2 SLI для кожного.
- Сервіс: Основний API вашого SaaS-продукту.
- SLI 1: Доступність (кількість HTTP 2xx/3xx від загальної кількості запитів до API).
- SLO 1: 99.9% доступності за 30 днів.
- Бюджет помилок: 0.1% від загального часу роботи (приблизно 43.2 хвилини на місяць).
- SLI 2: Затримка відповіді (95-й перцентиль для запитів типу POST /login).
- SLO 2: 95% запитів POST /login повинні виконуватися за менш ніж 500 мс за 7 днів.
- Бюджет помилок: 5% запитів можуть перевищувати 500 мс.
Використовуйте Prometheus Alertmanager для створення алертів, які спрацьовують, коли ви наближаєтеся до вичерпання бюджету помилок, а не тільки коли SLO вже порушено. Це дає вам час на реакцію.
# Приклад правила для Prometheus Alertmanager
groups:
- name: service_availability
rules:
- alert: HighAvailabilityErrorRate
expr: |
sum(rate(http_requests_total{job="my_api", status=~"5.."}[5m])) by (job) / sum(rate(http_requests_total{job="my_api"}[5m])) by (job) > 0.001
for: 5m
labels:
severity: critical
annotations:
summary: "Високий рівень помилок 5xx на API {{ $labels.job }}"
description: "Більше 0.1% запитів до API {{ $labels.job }} повертають 5xx помилки протягом 5 хвилин. Це загрожує нашому SLO 99.9%."
runbook: "https://your-wiki.com/runbooks/api_5xx_errors"
3. Приклад простого Runbook для інциденту "Високе завантаження CPU на VPS"
Це може бути простий файл в Git-репозиторії або сторінка в Wiki.
# Runbook: Високе завантаження CPU на VPS
Назва інцидента: Високе завантаження CPU (більше 90% протягом 5 хвилин) на VPS {{ $labels.instance }}
Пріоритет: P1 (Критичний), негайне реагування
Мета: Ідентифікувати та усунути причину високого завантаження CPU, відновити нормальну роботу.
Відповідальний: Черговий інженер
---
Кроки з діагностики та усунення:
1. Підтвердження інциденту:
* Перевірте поточне завантаження CPU через Grafana (дашборд Node Exporter).
* Підключіться до VPS по SSH: ssh user@{{ $labels.instance }}
2. Ідентифікація процесу-винуватця:
* Виконайте top або htop для перегляду процесів, які споживають найбільше CPU.
* Зверніть увагу на PID та COMMAND процесів з високим споживанням.
3. Аналіз логів:
* Якщо винуватець - ваш додаток, перевірте його логи на наявність помилок або аномалій:
journalctl -u your_app_service.service -f
(або перегляд логів через Loki/Grafana, якщо налаштовано).
* Перевірте системні логи: journalctl -f
4. Спроба відновлення (неруйнівна):
* Якщо винуватець - ваш додаток, спробуйте його перезапустити:
sudo systemctl restart your_app_service.service
* Якщо це відомий баг або тимчасове навантаження, розгляньте можливість тимчасового масштабування (якщо можливо) або зниження навантаження.
5. Спроба відновлення (руйнівна):
* Якщо перезапуск сервісу не допоміг, і VPS залишається перевантаженим, розгляньте перезавантаження всього VPS:
sudo reboot (попередньо переконайтеся, що це не призведе до втрати даних та сповістіть команду).
6. Документування:
* Запишіть всі вжиті кроки, знайдені причини та результати в трекер інцидентів (Jira, Notion).
* Зберіть команду для Post-Mortem, якщо інцидент був серйозним або повторюваним.
---
Додаткові команди діагностики:
* sudo dmesg -T - повідомлення ядра
* free -h - використання RAM
* df -h - використання диска
* netstat -tunlp - відкриті порти та з'єднання
4. Приклад автоматизації розгортання з GitLab CI (для VPS)
Припустимо, у вас є NodeJS додаток і ви хочете розгортати його на VPS при кожному комміті в гілку main.
Файл .gitlab-ci.yml в корені вашого репозиторію:
stages:
- build
- deploy
variables:
# Налаштуйте SSH-ключ для доступу до VPS в GitLab CI/CD Variables
# SSH_PRIVATE_KEY: ваш приватний ключ SSH
# SSH_USER: користувач на VPS (наприклад, deploy_user)
# SSH_HOST: IP або домен вашого VPS
build_job:
stage: build
image: node:18-alpine
script:
- npm install
- npm test
- npm run build # Якщо у вас є етап збірки (наприклад, для React/Vue фронтенда)
artifacts:
paths:
- node_modules/
- dist/ # Або build/
only:
- main
deploy_job:
stage: deploy
image: alpine/git # Легкий образ з Git та SSH
before_script:
- apk add openssh-client # Встановлюємо SSH-клієнт
- eval $(ssh-agent -s)
- echo "$SSH_PRIVATE_KEY" | tr -d '\r' | ssh-add - # Додаємо приватний ключ
- mkdir -p ~/.ssh
- chmod 700 ~/.ssh
- ssh-keyscan -H "$SSH_HOST" >> ~/.ssh/known_hosts # Додаємо хост в known_hosts
- chmod 644 ~/.ssh/known_hosts
script:
- echo "Deploying to $SSH_USER@$SSH_HOST..."
- ssh "$SSH_USER@$SSH_HOST" "mkdir -p /var/www/my-app" # Створюємо директорію, якщо немає
- scp -r node_modules/ "$SSH_USER@$SSH_HOST:/var/www/my-app/"
- scp -r dist/ "$SSH_USER@$SSH_HOST:/var/www/my-app/" # Копіюємо зібрані файли
- scp package.json "$SSH_USER@$SSH_HOST:/var/www/my-app/"
- scp app.js "$SSH_USER@$SSH_HOST:/var/www/my-app/" # Копіюємо основні файли програми
- ssh "$SSH_USER@$SSH_HOST" "cd /var/www/my-app && sudo systemctl restart my-app-service" # Перезапускаємо сервіс
- echo "Deployment completed!"
only:
- main
На вашому VPS має бути користувач (наприклад, deploy_user) з SSH-доступом та налаштований sudo для перезапуску сервісу без пароля. Також переконайтеся, що ваша програма працює як systemd-сервіс.
5. Оптимізація витрат на моніторинг
- Використовуйте опенсорс: Prometheus, Grafana, Loki, Alertmanager, Node Exporter — все це безкоштовно. Ваші витрати — це ресурси VPS.
- Економте дисковий простір: Налаштуйте короткий термін зберігання даних в Prometheus (наприклад, 30 днів за допомогою
--storage.tsdb.retention.time=30d). Для логів в Loki також можна налаштувати TTL. - Обмежте кардинальність метрик: Уникайте створення метрик з дуже великою кількістю унікальних лейблів (наприклад, з User ID в якості лейбла), це роздуває базу даних Prometheus.
- Оптимізуйте запити: У Grafana намагайтеся використовувати агрегуючі функції та запити з меншою роздільною здатністю для тривалих періодів.
- Розгляньте невеликі VPS для моніторингу: Якщо ваш основний VPS вже навантажений, виділіть окремий, менш потужний VPS спеціально для Prometheus, Grafana і Loki. Це рознесе навантаження та підвищить відмовостійкість самого моніторингу.
Наш досвід показує, що навіть базовий набір з Prometheus, Grafana і Loki на окремому VPS з 2 CPU, 4GB RAM і 80GB SSD може комфортно обслуговувати моніторинг і логування для декількох невеликих SaaS-сервісів.
Типові помилки при впровадженні SRE в стартапах
Впровадження SRE — це шлях, повний підводних каменів, особливо коли ресурси обмежені. Знання типових помилок допоможе вам уникнути їх та заощадити час, нерви та гроші.
1. Ігнорування або невірне визначення SLI/SLO
Помилка: Або не визначати SLI/SLO взагалі, або копіювати їх у великих компаній (наприклад, прагнути до 99.999% доступності), або вибирати метрики, які не відображають реальний досвід користувача.
Як уникнути: Почніть з 1-2 найбільш критичних SLI, які безпосередньо впливають на дохід або утримання клієнтів (наприклад, доступність основного API, швидкість завантаження ключової сторінки). Встановіть реалістичні SLO (99.5%-99.9% для початку) та регулярно переглядайте їх. Залучайте бізнес до процесу визначення SLO, щоб вони розуміли компроміси між надійністю та швидкістю розробки.
Наслідки: Відсутність чітких цілей призводить до хаотичних пріоритетів, постійного стресу від "гасіння пожеж" та неможливості виміряти реальний прогрес у надійності. Нереалістичні SLO призводять до вигорання команди та постійного відчуття провалу.
2. Alert Fatigue (Втома від сповіщень)
Помилка: Налаштування занадто великої кількості алертів, алертів на некритичні події, алертів без чіткого "runbook" або алертів, які спрацьовують занадто часто без реальної проблеми.
Як уникнути: Дотримуйтесь принципу "кожний алерт повинен вимагати дії". Якщо алерт спрацьовує, але не вимагає негайного втручання (наприклад, "використання диска 70%"), переведіть його в інформаційне повідомлення в Slack або змініть поріг спрацювання. Налаштуйте ескалацію: спочатку в загальний чат, потім черговому. Переконайтеся, що кожен алерт має пов'язаний "runbook".
Наслідки: Команда починає ігнорувати алерти, що призводить до пропуску реальних інцидентів та збільшення часу простою. Це також сильно підриває моральний дух та викликає вигорання.
3. Відсутність або неефективний процес Post-Mortem
Помилка: Не проводити Post-Mortem взагалі, або проводити їх з метою знайти винного, або проводити, але не документувати висновки та не виконувати "action items".
Як уникнути: Зробіть Post-Mortem обов'язковою практикою після кожного значущого інциденту. Підкреслюйте беззвинувачувальний характер процесу, фокусуючись на системних причинах. Чітко документуйте хронологію, причини, вжиті заходи та, найголовніше, конкретні "action items" з відповідальними та термінами. Регулярно відстежуйте виконання цих завдань.
Наслідки: Команда постійно наступає на одні й ті самі граблі, інциденти повторюються, а культура пошуку винних пригнічує ініціативу та чесність, перешкоджаючи навчанню та покращенню.
4. Переускладнення та "золота клітка"
Помилка: Намагатися впровадити всі "модні" SRE-інструменти та практики відразу, не враховуючи поточний розмір команди, бюджет та складність системи. Наприклад, впроваджувати повноцінний розподілений трейсинг для моноліту на одному VPS.
Як уникнути: Почніть з основ: базовий моніторинг, централізовані логи, прості SLO. Впроваджуйте SRE ітеративно, додаючи нові практики та інструменти в міру зростання потреб та ресурсів. Фокусуйтесь на "достатньо хороших" рішеннях, а не на "ідеальних". Використовуйте опенсорс та прості рішення, поки не виникне реальна потреба в комерційних продуктах.
Наслідки: Надмірна складність призводить до повільного впровадження, високих витрат, труднощів у підтримці та не дає реальної користі, викликаючи фрустрацію та відторгнення SRE-практик.
5. Ігнорування автоматизації та технічного боргу
Помилка: Відкладати автоматизацію "на потім" або вважати, що "ручками швидше". Ігнорувати накопичення технічного боргу в інфраструктурі та коді, що робить систему крихкою та важко підтримуваною.
Як уникнути: Виділіть час на автоматизацію рутинних завдань (розгортання, резервне копіювання, оновлення). Навіть невеликі скрипти можуть заощадити години. Включіть роботу з технічним боргом у регулярне планування (наприклад, 10-20% спринту). Використовуйте результати Post-Mortem для виявлення критичного технічного боргу.
Наслідки: Збільшення "toil", людські помилки, повільні та непередбачувані релізи, висока вартість підтримки та постійна загроза стабільності системи. Накопичений техборг в підсумку сповільнює розробку нових функцій.
6. Відсутність чіткого плану реагування на інциденти
Помилка: Припускати, що "хтось розбереться", коли щось зламається, або відсутність чіткої процедури оповіщення та дій.
Як уникнути: Створіть простий, але чіткий план Incident Response: хто чергує, як оповіщається, хто головний по інциденту, де ведеться комунікація, де зберігаються "runbooks". Проводьте регулярні "навчання", щоб команда знала свої ролі.
Наслідки: Хаос під час інциденту, паніка, повільне відновлення, що призводить до тривалих простоїв, втрати клієнтів та репутаційного збитку.
7. Відсутність резервного копіювання або його неефективність
Помилка: Повна відсутність резервного копіювання, або наявність резервних копій, які ніколи не перевірялися на працездатність, або зберігання їх на тому ж сервері, що й основний сервіс.
Як уникнути: Впровадьте регулярне автоматичне резервне копіювання всіх критично важливих даних (бази даних, конфігурації, файли користувачів). Зберігайте копії на віддаленому, незалежному сховищі (наприклад, S3-сумісна хмара). Регулярно (хоча б раз на квартал) перевіряйте працездатність відновлення з резервних копій.
Наслідки: Втрата даних у разі збою сервера, атаки або людської помилки, що може бути катастрофічним для SaaS-бізнесу та призвести до його закриття.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Чекліст для практичного застосування SRE
Цей покроковий алгоритм допоможе вам систематизувати впровадження SRE-практик у вашій малій команді на VPS/Dedicated. Проходьте по пунктах та відмічайте прогрес.
Фаза 1: Підготовка та планування
- Визначте критичні сервіси:
- Складіть список 1-3 ключових сервісів вашого SaaS-продукту, від яких напряму залежить користувацька цінність та дохід.
- Приклад: API бекенду, веб-інтерфейс, сервіс авторизації.
- Оберіть ключові SLI:
- Для кожного критичного сервісу оберіть 1-2 найбільш важливих SLI (доступність, затримка, частота помилок), які легко виміряти та які відображають користувацький досвід.
- Приклад: Доступність API, 95-й перцентиль затримки POST /login.
- Встановіть реалістичні SLO:
- Для кожного SLI визначте реалістичну ціль (наприклад, 99.9% доступності, 95% запитів < 500мс). Обговоріть та узгодьте їх з командою та стейкхолдерами.
- Приклад: SLO доступності API = 99.9% за 30 днів.
- Визначте бюджет помилок:
- Розрахуйте допустимий час простою або кількість помилок, що відповідає вашим SLO.
- Приклад: Бюджет помилок для 99.9% доступності = 43.2 хвилини на місяць.
- Оберіть інструменти моніторингу та логування:
- Для VPS/Dedicated розгляньте Prometheus + Grafana для метрик та Loki + Promtail для логів.
- Приклад: Вирішено використовувати Prometheus, Grafana, Node Exporter, Loki, Promtail.
Фаза 2: Впровадження базових практик
- Розгорніть стек моніторингу:
- Встановіть Prometheus, Node Exporter та Grafana на ваш основний або окремий VPS.
- Налаштуйте Prometheus для збору метрик з Node Exporter та, при необхідності, з вашого застосунку.
- Налаштуйте централізоване логування:
- Встановіть Loki та Promtail. Налаштуйте Promtail для збору логів вашого застосунку та системних логів.
- Підключіть Loki як джерело даних в Grafana.
- Створіть перші дашборди:
- В Grafana імпортуйте готові дашборди для Node Exporter.
- Створіть власні дашборди для моніторингу ваших SLI (доступність, затримка, помилки застосунку).
- Налаштуйте базовий алертінг:
- Встановіть та налаштуйте Alertmanager.
- Створіть алерти для критичних подій (наприклад, сервіс недоступний, висока частота помилок, вичерпання бюджету помилок).
- Налаштуйте повідомлення в Slack/Telegram або через PagerDuty/Opsgenie.
- Розробіть прості Runbooks:
- Для кожного критичного алерта створіть коротку, покрокову інструкцію з діагностики та усунення проблеми.
- Зберігайте їх в легкодоступному місці (Wiki, Git-репозиторій).
- Налаштуйте автоматичне резервне копіювання:
- Впровадьте скрипти для автоматичного бекапу бази даних та важливих файлів.
- Налаштуйте зберігання бекапів на віддаленому, незалежному ресурсі.
- Перевірте процедуру відновлення з бекапа.
Фаза 3: Розвиток та оптимізація
- Впровадьте автоматизацію розгортання (CI/CD):
- Налаштуйте GitLab CI/GitHub Actions з self-hosted runner або Jenkins для автоматичного тестування та деплою вашого застосунку.
- Почніть проводити Post-Mortem:
- Після кожного значущого інциденту проводьте безобвинувальний Post-Mortem.
- Документуйте висновки та створюйте "action items" з відповідальними та термінами.
- Оптимізуйте алерти:
- Регулярно переглядайте алерти, усувайте "шум", налаштовуйте більш точні пороги.
- Переконайтеся, що кожен алерт дійсно вимагає дії.
- Документуйте інфраструктуру та процеси:
- Створіть просту схему вашої інфраструктури.
- Опишіть ключові процеси (розгортання, реагування на інциденти, оновлення).
- Регулярно переглядайте SLO та SLI:
- Щоквартально або при значних змінах в продукті переглядайте актуальність та досяжність ваших цілей.
- Інвестуйте в навчання команди:
- Заохочуйте вивчення SRE-принципів та інструментів.
- Проводьте внутрішні "навчання" з реагування на інциденти.
Розрахунок вартості / Економіка SRE

Одна з основних причин, чому стартапи та малі команди на VPS/Dedicated обирають цей шлях, — це прагнення до оптимізації витрат. SRE, на перший погляд, може здатися додатковою статтею витрат, але насправді це інвестиція, яка багаторазово окуповується. Давайте розберемо економіку SRE.
1. Вартість простою (Cost of Downtime)
Перш ніж говорити про витрати на SRE, необхідно зрозуміти, скільки коштує відсутність SRE. Кожна година простою вашого SaaS-продукту — це не просто технічний збій, це прямі та непрямі втрати для бізнесу.
- Прямі втрати доходу: Якщо ваш продукт не працює, клієнти не можуть ним користуватися, а значить, ви втрачаєте потенційні продажі, підписки, транзакції.
- Приклад: SaaS-проєкт з 1000 активними платними користувачами, кожен з яких приносить $20/місяць. Щоденний дохід = (1000 * $20) / 30 = ~$667. Погодинний дохід = ~$28. Якщо простій триває 4 години, прямі втрати складуть $112.
- Втрата репутації та довіри клієнтів: Це важчий для вимірювання, але часто більш руйнівний фактор. Ненадійний сервіс відлякує нових клієнтів і змушує йти старих.
- Приклад: Після 4-годинного простою 5% клієнтів можуть скасувати підписку. Це 50 клієнтів * $20/місяць = $1000/місяць втраченого доходу, помноженого на термін життя клієнта.
- Штрафи за SLA: Якщо у вас є SLA з клієнтами, кожна година простою може спричинити фінансові компенсації.
- Приклад: SLA передбачає 10% повернення коштів за місяць, якщо доступність падає нижче 99.5%. Один серйозний інцидент може коштувати вам значної частини місячної виручки.
- Операційні витрати: Час, витрачений командою на "гасіння пожежі", замість роботи над новими функціями. Це втрачена вигода та зниження продуктивності.
- Приклад: 3 інженери витратили по 4 години на усунення інциденту. Якщо середня вартість години інженера $50, це $600.
Підсумок: Навіть невеликий простій у 4 години може коштувати стартапу сотні або тисячі доларів прямих втрат, не кажучи вже про довгострокову шкоду репутації та відтік клієнтів. Інвестиції в SRE — це страховка від цих втрат.
2. Розрахунок витрат на SRE для VPS/Dedicated
Хороша новина в тому, що SRE-практики не обов'язково дорогі. Основні витрати припадають на:
- Ресурси VPS/Dedicated: Для хостингу SRE-інструментів (Prometheus, Grafana, Loki).
- Оцінка: Окремий невеликий VPS (2 CPU, 4GB RAM, 80GB SSD) для моніторингу та логування може коштувати $15-30/місяць у 2026 році. Якщо розміщувати на основному сервері, то "вартість" — це частина його ресурсів.
- Час команди: На впровадження, налаштування та підтримку SRE-інструментів і процесів. Це найбільш значна "прихована" вартість.
- Оцінка: На початкове впровадження SRE (базовий моніторинг, алерти, Post-Mortem) може знадобитися 10-20% робочого часу одного інженера протягом 1-2 місяців. Далі — 5-10% часу на підтримку та покращення.
- Платні сторонні сервіси (опціонально): Для алертингу (PagerDuty, Opsgenie), зовнішнього моніторингу (UptimeRobot Pro), віддаленого бекапу (S3-сумісні сховища).
- Оцінка: PagerDuty/Opsgenie (Starter) $10-25/місяць, UptimeRobot Pro $10-20/місяць, S3-сховище $5-15/місяць (залежить від обсягу).
Приблизний розрахунок щомісячних витрат для малого SaaS на VPS (2026 рік):
| Категорія витрат | Опис | Приблизна вартість ($/місяць) | Примітки |
|---|---|---|---|
| VPS для основного застосунку | 1x VPS (4 CPU, 8GB RAM, 160GB SSD) | $40-70 | Для хостингу застосунку |
| VPS для SRE-інструментів | 1x VPS (2 CPU, 4GB RAM, 80GB SSD) | $15-30 | Для Prometheus, Grafana, Loki, Alertmanager |
| Віддалене сховище для бекапів | S3-сумісне сховище (500GB) | $5-15 | Важливо для відновлення даних |
| Сервіс оповіщень (опціонально) | PagerDuty/Opsgenie (Starter Plan) | $10-25 | Для on-call ротації та ескалації |
| Зовнішній моніторинг (опціонально) | UptimeRobot Pro | $10-20 | Для перевірки доступності ззовні |
| Час інженера (частка) | 10% часу одного інженера ($50/година * 160 годин * 0.1) | $800 | Найбільша "вартість", але це інвестиція в стабільність |
| Підсумкова приблизна вартість | $880 - $980 | Включаючи вартість ресурсів і часу інженера |
Як видно, більша частина витрат припадає на час інженера. Однак, це час, який в іншому випадку було б витрачено на "гасіння пожеж", рутинну роботу або вирішення проблем, які можна було б запобігти. SRE переводить ці реактивні витрати в проактивні інвестиції.
3. Як оптимізувати витрати
- Максимально використовуйте опенсорс: Prometheus, Grafana, Loki, Ansible, GitLab CI (self-hosted runner) — все це безкоштовно.
- Консолідуйте ресурси: Якщо ваш основний VPS має запас по ресурсах, можна розмістити Prometheus, Grafana і Loki на ньому ж, заощадивши на окремому VPS. Однак це знижує відмовостійкість моніторингу.
- Ітеративне впровадження: Не намагайтеся впровадити все й одразу. Почніть з найдешевших і найефективніших практик (базовий моніторинг, алерти, Post-Mortem) і поступово розширюйте.
- Автоматизація Toil: Чим більше рутинних завдань ви автоматизуєте, тим менше часу інженери витрачають на "toil", звільняючи його для більш цінної роботи.
- Навчання команди: Інвестиції в навчання команди SRE-принципам підвищують їх ефективність і знижують потребу в наймі дорогих вузьких фахівців.
Економіка SRE для стартапу на VPS/Dedicated полягає в тому, що ці практики дозволяють вам отримувати переваги великого бізнесу (стабільність, надійність, передбачуваність) при набагато менших витратах, запобігаючи набагато дорожчим наслідкам простою і втрати клієнтів.
Кейси та приклади з практики
Теорія важлива, але реальні приклади допомагають краще зрозуміти, як SRE-практики застосовні в житті. Ось 2-3 реалістичних сценарії з нашого досвіду роботи зі стартапами та малими SaaS-командами на VPS/Dedicated.
Кейс 1: Підвищення доступності та зниження стресу в SaaS-стартапі "TaskFlow"
Проблема: "TaskFlow" — SaaS-платформа для управління проєктами, що працює на одному потужному VPS. Команда з 3 розробників постійно стикалася з непередбачуваними простоями (2-3 рази на місяць по 1-2 години), викликаними піковими навантаженнями або помилками в нових релізах. Моніторинг був мінімальним (тільки uptime-пінги), а реагування на інциденти — хаотичним і стресовим. Це призводило до втрати клієнтів і вигорання команди.
Рішення:
- Впровадження SLI/SLO: Визначили, що критичними SLI є доступність основного API (створення/редагування задач) і затримка відповіді на головній панелі. Встановили SLO: 99.8% доступності API і 95% запитів до панелі < 800мс.
- Стек моніторингу: Розгорнули Prometheus + Grafana + Node Exporter на тому ж VPS. Інтегрували Prometheus client library в Node.js бекенд для збору метрик застосунку (кількість запитів, помилки, затримки).
- Алертинг: Налаштували Alertmanager для відправки критичних алертів у спеціально виділений Telegram-канал. Алерти спрацьовували, якщо доступність падала нижче 99.5% або затримка перевищувала 1.5 секунди.
- Інцидент-менеджмент: Створили простий графік чергувань (по черзі на тиждень). Розробили 5 базових "runbooks" для найчастіших проблем (високий CPU, помилка БД, недоступність сервісу).
- Post-Mortem: Після кожного інциденту проводили 30-хвилинний "беззвинувачувальний" Post-Mortem, документуючи хронологію та "action items".
Результати:
- Доступність: За 3 місяці доступність API виросла з 97-98% до стабільних 99.9%.
- MTTR: Середній час відновлення скоротився з 1-2 годин до 15-30 хвилин.
- Зниження стресу: Команда стала почувати себе впевненіше, маючи чіткий план дій. Кількість нічних пробуджень через хибні алерти скоротилася на 80%.
- Покращення продукту: "Action items" з Post-Mortem привели до оптимізації кількох "вузьких" місць у коді та налаштуванні бази даних, що покращило загальну продуктивність.
Цей кейс демонструє, як навіть на одному VPS, базові SRE-практики можуть значно покращити надійність та якість роботи команди.
Кейс 2: Управління бюджетом помилок та оптимізація релізного циклу в e-commerce проєкті "ShopBoost"
Проблема: "ShopBoost" — малий e-commerce проєкт на виділеному сервері, часто випускав нові функції. Однак, кожен новий реліз ніс ризик деградації продуктивності або появи багів, що призводило до втрат продажів. Команда розробників була під тиском з боку бізнесу, який вимагав нових фіч, але й постійно скаржився на нестабільність.
Рішення:
- Бюджет помилок: Після визначення SLO доступності (99.9%) і частоти помилок (менше 0.2%), команда встановила бюджет помилок. Якщо за тиждень більше 50% місячного бюджету помилок було "витрачено", нові релізи призупинялися.
- Покращений моніторинг: На додаток до Prometheus/Grafana, впровадили Loki для централізованого збору логів застосунку та веб-сервера. Це дозволило швидко шукати помилки, пов'язані з новими релізами.
- Автоматизація CI/CD: Налаштували GitLab CI з self-hosted runner на сервері для автоматичного розгортання. Кожен комміт проходив базові тести, а потім автоматично деплоївся на staging, і після ручного тестування — на production.
- Post-Mortem з фокусом на релізи: Кожен інцидент, пов'язаний з релізом, ретельно аналізувався. Особлива увага приділялася тому, як можна було б запобігти проблемі на етапі розробки або тестування.
Результати:
- Баланс "фічі vs. стабільність": Бюджет помилок став чітким індикатором, коли потрібно "гальмувати" з новими функціями і фокусуватися на стабільності. Це знизило конфлікти між розробкою та бізнесом.
- Якість релізів: Кількість критичних багів, що потрапляють у продакшн, скоротилася на 60% завдяки покращеному тестуванню та контролю якості.
- Швидкість розгортання: Час від комміта до продакшна скоротився з кількох годин (ручний деплой) до 15-20 хвилин (автоматичний деплой).
- Культура якості: Розробники стали більш уважно ставитися до тестування та моніторингу своїх змін, розуміючи, що це напряму впливає на їх здатність випускати нові фічі.
Цей кейс показує, як SRE допомагає управляти ризиками та оптимізувати цикл розробки, знаходячи баланс між інноваціями та стабільністю.
Кейс 3: Масштабування та оптимізація ресурсів для аналітичного сервісу "DataInsight"
Проблема: "DataInsight" — стартап, що надає аналітику даних для малого бізнесу, зіткнувся з проблемою росту. Їх сервіс, що працює на двох VPS, періодично сповільнювався або падав через нестачу ресурсів (особливо RAM і CPU) при обробці великих звітів. Команда не розуміла, коли і які ресурси потрібно масштабувати, і часто діяла реактивно, купуючи більш потужні VPS "на всякий випадок".
Рішення:
- Capacity Planning: Впроваджено детальний моніторинг використання ресурсів (CPU, RAM, Disk I/O) за допомогою Prometheus + Grafana. Метрики збиралися кожні 15 секунд.
- SLI/SLO на основі ресурсів: Визначили SLI для використання CPU (< 80% протягом 10 хвилин) і RAM (< 90% вільної пам'яті). Встановили SLO на основі цих метрик.
- Проактивні алерти: Налаштували алерти в Alertmanager, які спрацьовували, коли використання ресурсів наближалося до критичних порогів (наприклад, CPU > 70% більше 5 хвилин).
- Аналіз трендів: Регулярно аналізували графіки використання ресурсів в Grafana, щоб прогнозувати майбутні потреби. Наприклад, якщо споживання RAM стабільно росло на 10% на місяць, планували апгрейд VPS через 2-3 місяці.
- Оптимізація коду: Post-Mortem після інцидентів з нестачею ресурсів привели до виявлення "важких" запитів до БД і неефективних алгоритмів обробки даних, які були оптимізовані.
Результати:
- Оптимізація витрат: Замість реактивної покупки більш потужних VPS, команда стала приймати обґрунтовані рішення. Наприклад, замість апгрейду всього сервера, вони змогли оптимізувати запити до БД, що відклало необхідність покупки більш дорогого обладнання на 6 місяців, заощадивши до $300 на місяць.
- Стабільність: Кількість інцидентів, пов'язаних з нестачею ресурсів, скоротилася на 90%.
- Проактивність: Команда почала заздалегідь планувати апгрейди або оптимізації, уникаючи сюрпризів.
Цей кейс підкреслює, як SRE-підхід до моніторингу та планування потужностей дозволяє стартапам ефективно масштабуватися, уникаючи непотрібних витрат та забезпечуючи стабільність сервісу.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Інструменти та ресурси
Для успішного впровадження SRE-практик, навіть на VPS/Dedicated, вам знадобиться арсенал надійних та ефективних інструментів. Ми зосередимося на рішеннях, які довели свою цінність для малих команд, пропонуючи відмінний баланс функціональності та вартості.
1. Моніторинг та візуалізація метрик
- Prometheus: Система збору та зберігання часових рядів метрик. Є стандартом де-факто для хмарного та контейнерного моніторингу, але чудово підходить і для VPS.
- Grafana: Потужна платформа для візуалізації метрик. Дозволяє створювати інформативні дашборди, налаштовувати алерти та досліджувати дані з різних джерел (Prometheus, Loki, бази даних).
- Node Exporter: Експортер метрик для Prometheus, який збирає дані про стан операційної системи (CPU, RAM, диск, мережа). Повинен бути встановлений на кожному VPS.
- cAdvisor: Експортер метрик для Prometheus, який збирає дані про контейнери (Docker). Корисно, якщо ваш додаток працює в контейнерах на VPS.
- Blackbox Exporter: Експортер для Prometheus, який дозволяє перевіряти доступність та коректність HTTP/HTTPS, TCP, ICMP ендпоінтів зсередини вашої інфраструктури.
- UptimeRobot / Healthchecks.io: Зовнішні сервіси для моніторингу доступності ваших публічних ендпоінтів з різних географічних точок. У UptimeRobot є щедрий безкоштовний тариф.
2. Логування та трасування
- Loki: Система агрегації логів, розроблена Grafana Labs. Менш ресурсомістка, ніж Elasticsearch, оскільки індексує лише метадані логів. Відмінно інтегрується з Grafana.
- Promtail: Агент для Loki, який збирає логи з ваших серверів та відправляє їх в Loki.
- Grafana Tempo: Розподілена система трасування, також від Grafana Labs. Дозволяє збирати та зберігати трасування OpenTelemetry, інтегруючись з метриками та логами в Grafana.
- OpenTelemetry: Набір інструментів, API та SDK для інструментування вашого додатку, що дозволяє генерувати метрики, логи та трасування в єдиному форматі.
3. Алерт-менеджмент та On-Call
- Alertmanager: Компонент Prometheus, який обробляє алерти, дедуплікує їх, групує та відправляє в потрібні канали (Slack, Telegram, PagerDuty, email).
- PagerDuty / Opsgenie: Професійні сервіси для управління on-call ротаціями, ескалацією алертів та плануванням чергувань. Пропонують безкоштовні або недорогі тарифи для малих команд.
- Telegram / Slack: Прості та безкоштовні канали для відправки алертів. Alertmanager легко інтегрується з ними.
4. Автоматизація та Infrastructure as Code (IaC)
- Ansible: Простий, але потужний інструмент для управління конфігурацією, розгортання додатків та оркестрації задач. Не вимагає агентів на керованих серверах. Ідеальний для VPS/Dedicated.
- GitLab CI / GitHub Actions: Системи безперервної інтеграції/безперервного розгортання (CI/CD). Дозволяють автоматизувати тестування та деплой коду. Можуть використовувати self-hosted runner на вашому VPS.
- Bash / Python скрипти: Недооцінені, але надзвичайно потужні інструменти для автоматизації специфічних задач на VPS.
5. Документація та управління знаннями
- Wiki (Confluence, Notion, DokuWiki): Для зберігання runbooks, Post-Mortem звітів, документації по інфраструктурі та процесам.
- Git-репозиторії: Для зберігання конфігурацій (IaC), скриптів, runbooks у вигляді Markdown-файлів.
6. Корисні книги та ресурси
- "Site Reliability Engineering: How Google Runs Production Systems" та "The Site Reliability Workbook": Класичні книги від Google, хоча і орієнтовані на масштабні системи, базові принципи придатні всюди.
- Блоги Grafana Labs, Prometheus, Incident.io: Регулярно публікують корисні статті та кейси.
- Спільноти DevOps та SRE: Telegram-чати, Discord-сервери, Stack Overflow.
Почніть з освоєння Prometheus та Grafana, потім додайте Loki. Поступово впроваджуйте автоматизацію з Ansible та CI/CD. Пам'ятайте, що інструменти — це лише засоби; головне — принципи та культура SRE.
Troubleshooting: вирішення типових проблем
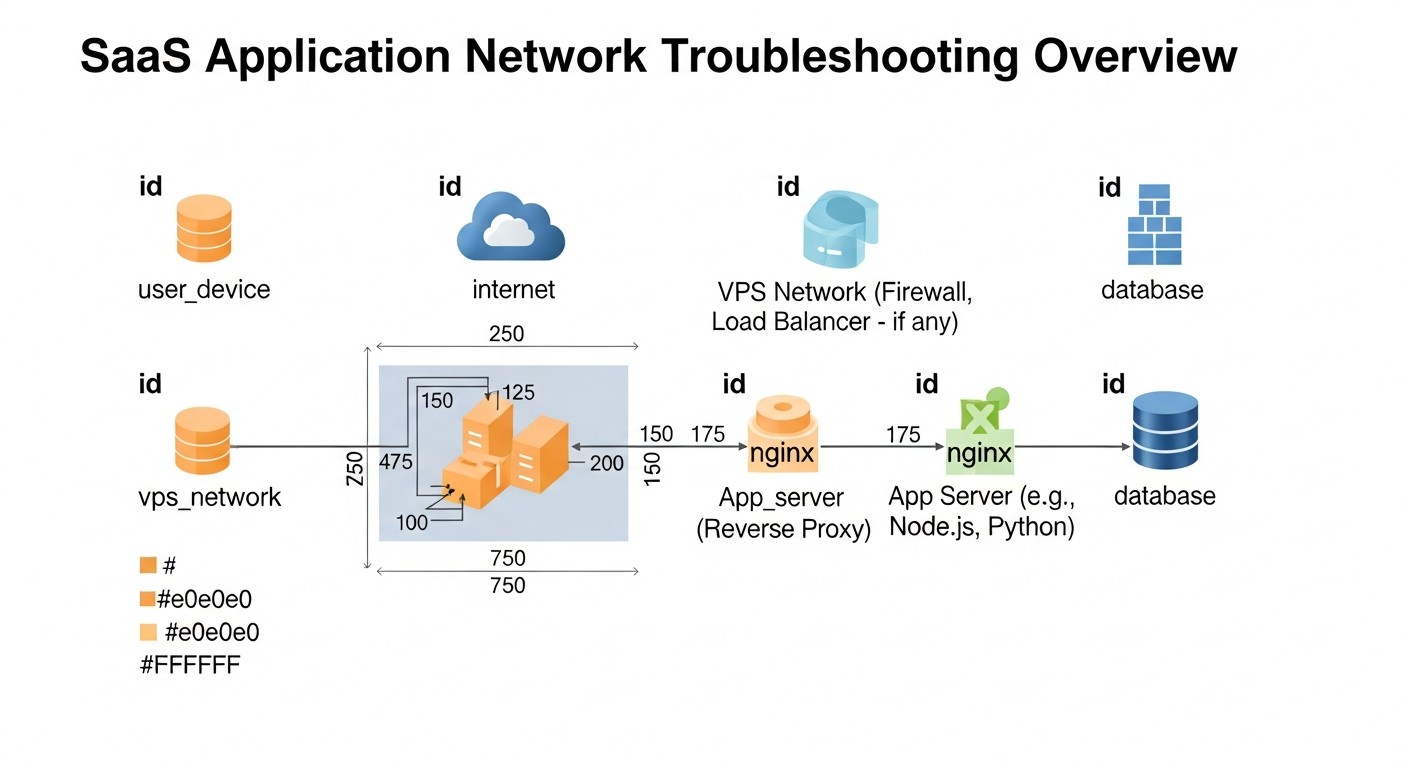
Навіть з найкращими SRE-практиками, проблеми у продакшені неминучі. Вміння швидко діагностувати та усувати їх — ключова навичка. Нижче представлені типові проблеми, з якими стикаються малі SaaS-команди на VPS/Dedicated, та практичні команди для їх вирішення.
1. Високе завантаження CPU
Симптоми: Повільна робота застосунку, затримки у відповідях, алерти про високий CPU.
Діагностика:
topабоhtop: Показує процеси, відсортовані за споживанням CPU. Шукайте процеси, що споживають >80-90% CPU.uptime: Показує середнє завантаження системи за 1, 5 та 15 хвилин. Якщо load average вище кількості ядер CPU, система перевантажена.- Grafana (Node Exporter dashboard): Візуальний аналіз трендів CPU-використання.
- Логи застосунку: Шукайте помилки, "важкі" запити до БД, нескінченні цикли або ресурсоємні операції.
Вирішення:
- Якщо винуватець — ваш застосунок:
- Перезапустіть сервіс:
sudo systemctl restart your_app_service.service - Якщо це тимчасовий пік, можливо, варто оптимізувати код або базу даних.
- Якщо проблема постійна, розгляньте апгрейд VPS або масштабування на декілька серверів.
- Перезапустіть сервіс:
- Якщо винуватець — інший процес (наприклад, якийсь скрипт, cron-задача):
- Ідентифікуйте, що це за процес, і чому він споживає багато ресурсів.
- Оптимізуйте скрипт або змініть розклад його запуску.
2. Нестача оперативної пам'яті (RAM)
Симптоми: Застосунок "падає" з помилками Out Of Memory, повільна робота, активне використання swap-розділу.
Діагностика:
free -h: Показує загальну кількість RAM, використану та вільну, а також використання swap.htop: Показує споживання RAM кожним процесом.- Grafana (Node Exporter dashboard): Моніторинг використання RAM та swap.
- Логи застосунку: Шукайте помилки Out Of Memory.
Вирішення:
- Якщо ваш застосунок споживає занадто багато RAM:
- Оптимізуйте код (наприклад, уникайте завантаження великих об'ємів даних в пам'ять, використовуйте потокову обробку).
- Збільште ліміти пам'яті для вашого застосунку (якщо це можливо, наприклад, JVM-параметри).
- Розгляньте апгрейд VPS з більшим об'ємом RAM.
- Якщо інші процеси споживають RAM:
- Зупиніть непотрібні сервіси.
- Оптимізуйте конфігурацію інших сервісів (наприклад, зменште кількість worker-процесів веб-сервера).
3. Заповнення дискового простору
Симптоми: Помилки запису файлів, збої застосунків, неможливість встановлення нових пакетів.
Діагностика:
df -h: Показує використання дискового простору по розділам. Шукайте розділи, заповнені на 90% і більше.du -sh /path/to/directory: Показує розмір конкретної директорії. Використовуйте це для пошуку "важких" директорій (наприклад,/var/log,/var/lib/docker,/tmp).- Grafana (Node Exporter dashboard): Моніторинг використання диску.
Вирішення:
- Очищення логів:
sudo journalctl --vacuum-size=1G(для systemd journal)- Вручну видаліть старі логи вашого застосунку або налаштуйте logrotate.
- Очищення кешів:
sudo apt clean(для Debian/Ubuntu)- Очистіть кеші вашого застосунку.
- Видалення непотрібних файлів:
- Старі резервні копії, тимчасові файли, невикористовувані образи Docker.
- Якщо проблема постійна, розгляньте апгрейд диску VPS або перенесення великих даних на зовнішнє сховище.
4. Проблеми з мережею
Симптоми: Повільні з'єднання, помилки таймауту, неможливість підключення до сервісів.
Діагностика:
ping google.com: Перевірка доступності зовнішніх ресурсів.ping localhost: Перевірка мережевої карти.netstat -tunlp: Показує відкриті порти та активні з'єднання. Переконайтеся, що ваш застосунок слухає потрібний порт.ss -tulpn: Аналог netstat, часто швидший.ip a: Показує мережеві інтерфейси та їх IP-адреси.traceroute example.com: Відстеження маршруту до віддаленого хоста.- Grafana (Node Exporter dashboard): Моніторинг мережевого трафіку.
Вирішення:
- Перевірте фаєрвол (
sudo ufw statusабо правила iptables). - Переконайтеся, що застосунок слухає на
0.0.0.0або правильній IP, якщо він має бути доступним ззовні. - Перевірте конфігурацію DNS (
cat /etc/resolv.conf). - Якщо проблема на стороні VPS-провайдера, зв'яжіться з їх підтримкою.
5. Збої застосунку / Помилки HTTP 5xx
Симптоми: Користувачі бачать сторінки помилок, API повертає 5xx, застосунок не запускається.
Діагностика:
- Логи застосунку: Це ваше основне джерело інформації. Шукайте трасування стека, повідомлення про помилки, попередження. Використовуйте Loki/Grafana для швидкого пошуку.
sudo systemctl status your_app_service.service: Перевіряє статус systemd-сервісу.sudo journalctl -u your_app_service.service -f: Показує логи вашого сервісу в реальному часі.- Моніторинг метрик: Аномалії в кількості запитів, затримці, помилках.
Вирішення:
- Перезапустіть сервіс:
sudo systemctl restart your_app_service.service. - Якщо проблема повторюється, проаналізуйте логи, щоб знайти першопричину (баг в коді, проблема з БД, зовнішнім сервісом).
- Перевірте конфігураційні файли застосунку.
- Відкотіться до попередньої стабільної версії, якщо проблема з'явилася після релізу.
Коли звертатися до підтримки VPS-провайдера
Не соромтеся звертатися до підтримки, якщо:
- Ви не можете підключитися до VPS через SSH, і проблема не у ваших мережевих налаштуваннях.
- Ваш VPS не відповідає на пінги, але застосунок має бути запущений.
- Спостерігаються проблеми з мережею, які явно не пов'язані з вашою конфігурацією (наприклад, втрата пакетів до вашого VPS).
- Обладнання (диск, RAM) показує ознаки фізичного збою.
- Ваш VPS був атакований або потрапив до чорного списку.
Завжди надавайте провайдеру максимум інформації: точний час початку проблеми, симптоми, що спостерігаються, результати ваших діагностичних команд.
Часті запитання (FAQ)
Чи потрібен мені повноцінний SRE-інженер у стартапі?
На початковому етапі, коли команда складається з кількох людей, виділений SRE-інженер, швидше за все, не потрібен. Функції SRE можуть виконувати DevOps-інженери або навіть бекенд-розробники з операційним ухилом. Важливо, щоб принципи SRE були інтегровані в культуру команди, і кожен ніс відповідальність за надійність. Повноцінний SRE-інженер стає актуальним, коли команда зростає до 10-15+ осіб, а складність системи значно збільшується.
Як вибрати перші SLI/SLO?
Почніть з того, що найбільш критичне для вашого бізнесу і безпосередньо впливає на користувача. Для більшості SaaS це доступність основного API/веб-інтерфейсу та затримка ключових користувацьких операцій (наприклад, вхід, збереження даних). Встановіть реалістичні SLO (наприклад, 99.9% доступності), а не ідеальні "п'ять дев'яток", які вимагатимуть невиправданих зусиль і витрат.
Скільки коштує впровадження SRE?
Прямі витрати на SRE для VPS/Dedicated можуть бути мінімальними, якщо використовувати опенсорсні інструменти (Prometheus, Grafana, Loki). Основна "вартість" — це час вашої команди на впровадження і підтримку цих практик. Це інвестиція, яка окупається зниженням простою, поліпшенням репутації та запобіганням втрати клієнтів. Для базового стека моніторингу на окремому VPS можна вкластися в $15-30/місяць за сам сервер, плюс частка зарплати інженера.
Чи можна обійтися без платних інструментів?
Абсолютно. Для стартапів на VPS/Dedicated опенсорсні рішення (Prometheus, Grafana, Loki, Ansible) є ідеальним вибором. Вони надають потужний функціонал, гнучкість і не вимагають щомісячних платежів. Платні сервіси (наприклад, PagerDuty, Datadog) можуть спростити деякі аспекти, але не є обов'язковими для початку.
Як боротися з 'alert fatigue'?
Ключ до боротьби з 'alert fatigue' — це якість, а не кількість алертів. Кожен алерт має бути дієвим, вимагати негайного втручання і мати чіткий "runbook". Регулярно переглядайте алерти, відключайте ті, які не приносять користі, і налаштовуйте більш точні пороги. Використовуйте різні канали для алертів різної критичності (наприклад, PagerDuty для критичних, Slack для інформаційних).
Чим відрізняється SRE від DevOps?
DevOps — це ширша культурна і методологічна філософія, спрямована на поліпшення співпраці між розробкою та операціями. SRE — це конкретна реалізація принципів DevOps, сфокусована на застосуванні інженерних підходів до проблем експлуатації. SRE використовує метрики, автоматизацію та управління ризиками для досягнення певних цілей надійності (SLO), тоді як DevOps охоплює весь життєвий цикл розробки та розгортання.
Що робити, якщо у мене всього один сервер?
Навіть для одного сервера SRE-практики дуже корисні. Почніть з базового моніторингу (Prometheus + Node Exporter + Grafana на тому ж сервері), централізованого логування (Loki + Promtail), автоматичного резервного копіювання і простих SLO. Це допоможе вам краще розуміти стан сервера, швидко реагувати на проблеми і запобігати їх. Наявність одного сервера робить SRE ще більш критичним, так як немає надмірності.
Як переконати команду витрачати час на SRE?
Покажіть команді пряму вигоду: менше "пожеж", менше нічних пробуджень, більш стабільний продукт, який подобається клієнтам. Поясніть, що SRE — це не додаткова робота, а систематизація і автоматизація того, що вони вже роблять, але більш ефективно. Залучайте команду до визначення SLO і Post-Mortem, щоб вони відчували свою причетність і бачили результати.
Які метрики найважливіші для SaaS?
Для SaaS найбільш важливі метрики, безпосередньо пов'язані з користувацьким досвідом і бізнес-цілями:
- Доступність (сервіс працює і доступний).
- Затримка (швидкість відповіді застосунку).
- Частота помилок (кількість помилок, видимих користувачам).
- Пропускна здатність (здатність обробляти навантаження).
- Метрики ресурсів (CPU, RAM, диск) для планування потужностей.
Як часто проводити Post-Mortem?
Post-Mortem слід проводити після кожного інциденту, який порушив ваше SLO або викликав значне невдоволення клієнтів. Для стартапу це може бути 1-2 рази на місяць, а іноді й частіше. Важливіше не частота, а якість: фокусуйтеся на вилученні уроків і створенні конкретних "action items", які будуть виконані.
Як почати автоматизацію?
Почніть з найбільш рутинних і схильних до помилок завдань. Це може бути автоматизація розгортання коду (CI/CD), резервного копіювання, установки оновлень або налаштування нового сервера. Використовуйте прості інструменти, такі як Bash-скрипти або Ansible. Поступово автоматизуйте більше процесів, звільняючи час для більш складної роботи.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Висновок
Впровадження SRE-практик для стартапів і малих SaaS-команд на VPS/Dedicated — це не розкіш, а стратегічна необхідність в умовах сучасного висококонкурентного ринку 2026 року. Ми переконалися, що принципи Site Reliability Engineering, спочатку розроблені для масштабів Google, можуть бути успішно адаптовані і застосовані навіть при обмежених ресурсах, приносячи значні вигоди.
Ключові висновки, які ви повинні винести з цієї статті:
- Прагматизм — ваш найкращий друг: Не прагніть до ідеалу відразу. Почніть з малого, виберіть 1-2 критичних SLI і реалістичних SLO, поступово розширюючи охоплення.
- Моніторинг — основа всього: Без надійного моніторингу ви будете "гасити пожежі" наосліп. Опенсорсні рішення на кшталт Prometheus і Grafana надають потужні можливості при мінімальних витратах.
- Автоматизація — шлях до ефективності: Скорочуйте "toil" (рутинну роботу) за допомогою скриптів, Ansible і CI/CD. Це звільнить час інженерів і зменшить кількість людських помилок.
- Культура навчання, а не звинувачення: Беззвинувачувальні Post-Mortem є потужним інструментом для безперервного поліпшення і запобігання повторенню інцидентів.
- SRE — це інвестиція: Час і ресурси, вкладені в SRE, окупаються зниженням downtime, поліпшенням репутації, зменшенням стресу в команді і прискоренням розробки нових функцій.
Наступні кроки для читача:
- Оцініть поточний стан: Проведіть аудит вашої поточної інфраструктури та процесів. Де "вузькі місця"? Які проблеми виникають найчастіше?
- Виберіть перший "пілотний" сервіс: Почніть з найбільш критичного або найбільш проблемного сервісу.
- Визначте перші SLI та SLO: Узгодьте їх з командою та бізнесом.
- Впровадьте базовий стек моніторингу: Встановіть Prometheus, Node Exporter, Grafana та Loki. Налаштуйте дашборди для ваших SLI.
- Налаштуйте алерти: Створіть кілька критичних алертів, які будуть спрацьовувати до того, як SLO буде порушено.
- Розробіть перший Runbook: Для одного з ваших критичних алертів.
- Проведіть перший Post-Mortem: Після наступного значущого інциденту, навіть якщо він невеликий.
- Автоматизуйте одне рутинне завдання: Наприклад, резервне копіювання або деплой.
Пам'ятайте, SRE — це не одноразовий проект, а безперервний процес вдосконалення. Почніть з малого, ітеративно покращуйте, і ви побачите, як ваш стартап стає більш надійним, передбачуваним та успішним. Удачі!
Чи був цей гайд корисним?
Ваш відгук допомагає нам покращувати гайди.