
Створення Високодоступного PostgreSQL Кластера на VPS та Виділених Серверах
TL;DR
- Висока доступність PostgreSQL критична для безперервності бізнесу, мінімізуючи простої та втрати даних.
- Ключові рішення включають Patroni, pg_auto_failover та нативну потокову реплікацію із зовнішніми інструментами.
- Вибір залежить від RPO, RTO, бюджету, складності та рівня автоматизації, який ви готові підтримувати.
- Автоматичний failover та грамотний моніторинг — основа надійного кластера.
- Регулярне тестування механізмів відновлення та резервного копіювання абсолютно обов'язкове.
- Ефективне управління витратами вимагає оптимізації ресурсів та вибору відповідної архітектури.
- Ця стаття — ваш покроковий гайд з проєктування, розгортання та обслуговування відмовостійкого PostgreSQL.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Вступ: Навіщо вашому бізнесу високодоступний PostgreSQL у 2026 році?
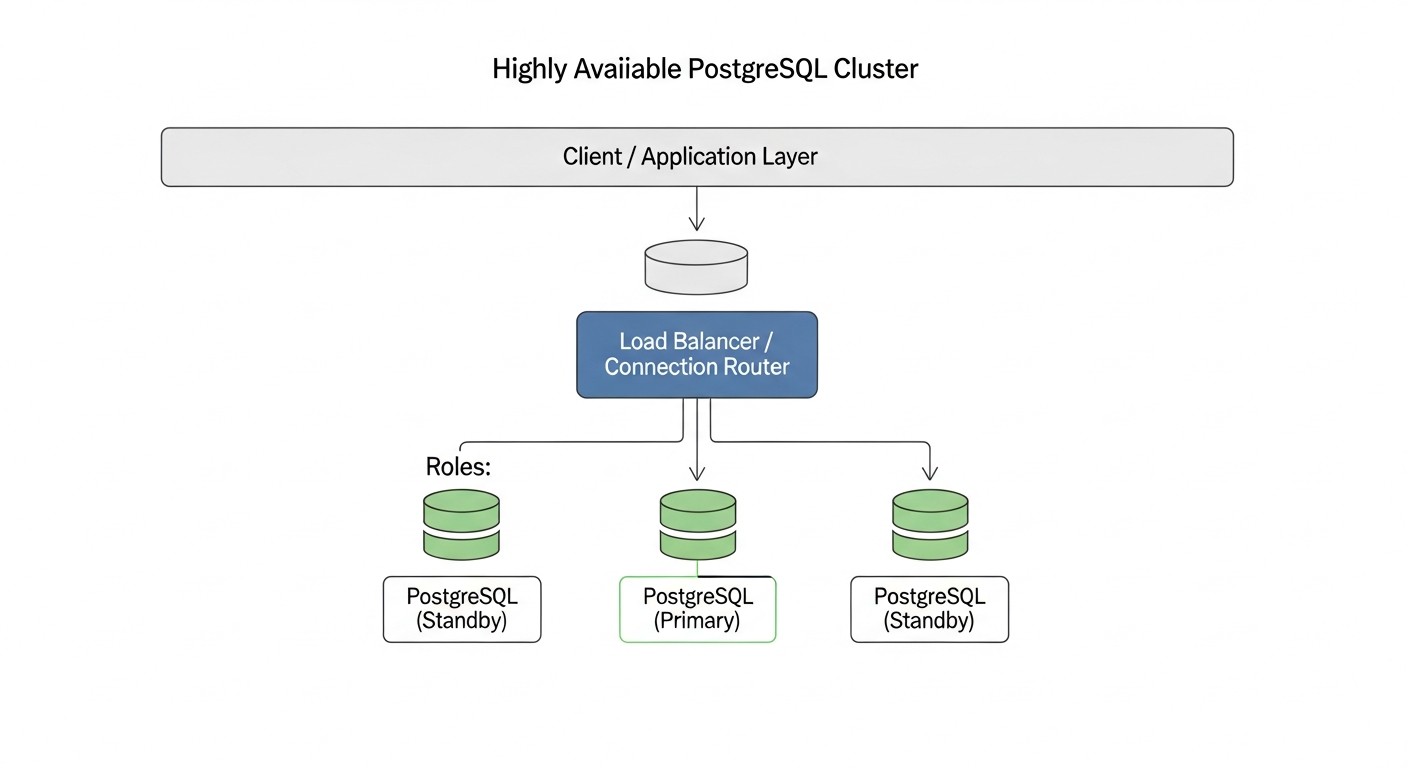
У сучасному світі, де цифровізація проникла в усі сфери бізнесу, а користувачі очікують цілодобового доступу до сервісів, безперервність роботи критично важлива. Простій навіть на кілька хвилин може обернутися не лише фінансовими втратами, але й серйозною шкодою для репутації компанії. Особливо це актуально для проєктів, де дані є центральним активом — будь то SaaS-платформа, фінансовий сервіс чи великий інтернет-магазин. PostgreSQL, як одна з найнадійніших та функціональних реляційних баз даних, є наріжним каменем для безлічі таких систем. Однак сам по собі PostgreSQL не забезпечує високу доступність з коробки. Відмова єдиного сервера баз даних може призвести до повної зупинки роботи застосунку, що неприпустимо для будь-якого сучасного бізнесу.
Саме тому створення високодоступного PostgreSQL кластера стає не просто "приємною опцією", а обов'язковою вимогою. У 2026 році, на тлі постійно зростаючих обсягів даних, посилення вимог до SLA та повсюдного поширення мікросервісної архітектури, завдання забезпечення відмовостійкості баз даних виходить на перший план. Компанії, які не приділяють цьому належної уваги, ризикують втратити клієнтів, доходи та конкурентні переваги. Ми спостерігаємо тренд, коли навіть стартапи на ранніх стадіях розвитку закладають архітектуру високої доступності, розуміючи, що виправлення проблем "на льоту" в продакшені обходиться значно дорожче, ніж правильне проєктування з самого початку. Більш того, зі збільшенням складності систем та розподілених навантажень, ручне втручання у разі відмови стає все менш ефективним та більш ризикованим.
Ця стаття покликана стати вашим вичерпним посібником зі створення надійного та ефективного PostgreSQL кластера на VPS та виділених серверах. Ми розглянемо різні підходи, інструменти та найкращі практики, актуальні на 2026 рік, щоб ви могли вибрати оптимальне рішення для своїх потреб. Незалежно від того, чи є ви DevOps-інженером, Backend-розробником, фаундером SaaS-проєкту, системним адміністратором чи технічним директором стартапу, тут ви знайдете практичні поради та конкретні інструкції. Ми глибоко зануримось у технічні деталі, розберемо типові помилки та дамо рекомендації, засновані на реальному досвіді. Наша мета — не просто розповісти "як", а й пояснити "чому", щоб ви могли приймати обґрунтовані архітектурні рішення та впевнено будувати стійкі системи, здатні витримувати будь-які випробування.
В рамках цього матеріалу ми сфокусуємось на рішеннях, які можна розгорнути та контролювати самостійно на VPS або виділених серверах, що особливо актуально для проєктів, які потребують повного контролю над інфраструктурою, оптимізації витрат або специфічних вимог до безпеки. Ми не будемо заглиблюватись в хмарні керовані сервіси, такі як AWS RDS/Aurora або Google Cloud SQL, оскільки вони надають HA "з коробки" та мають свої особливості управління, відмінні від підходів для самостійного хостингу. Замість цього ми зосередимось на інструментах та методиках, які дозволяють досягти схожого рівня надійності, використовуючи доступні та гнучкі ресурси.
Основні критерії та фактори вибору HA-рішення для PostgreSQL
Вибір оптимального рішення для забезпечення високої доступності PostgreSQL — це багатогранний процес, який вимагає глибокого розуміння як бізнес-вимог, так і технічних можливостей. Не існує універсального "найкращого" рішення; ідеальний вибір завжди є компромісом між різними факторами. Розглянемо ключові критерії, які необхідно врахувати:
Recovery Point Objective (RPO) — Допустима втрата даних
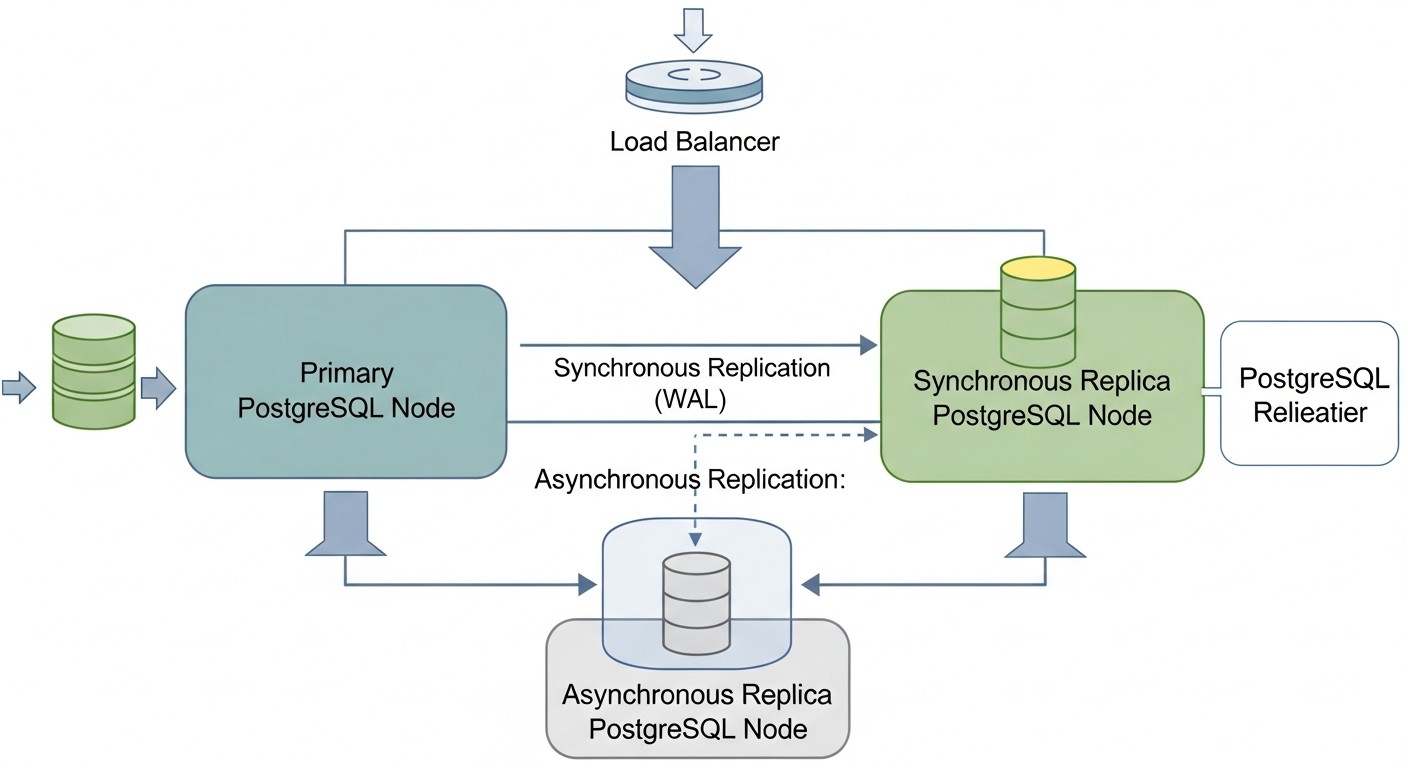
RPO визначає максимально допустимий обсяг даних, який може бути втрачено у випадку збою. Він вимірюється в часі, наприклад, "RPO = 5 хвилин" означає, що ви готові втратити не більше 5 хвилин останніх транзакцій. Для критично важливих систем, таких як фінансові додатки або системи обробки платежів, RPO може бути близьким до нуля (нульова втрата даних). Це досягається за допомогою синхронної реплікації, де транзакція вважається завершеною тільки після того, як вона була записана і підтверджена як мінімум на двох вузлах. Однак синхронна реплікація збільшує затримки запису і може знижувати загальну продуктивність. Для менш критичних систем можна використовувати асинхронну реплікацію, яка пропонує кращі показники продуктивності, але при цьому RPO буде ненульовим (зазвичай кілька секунд або хвилин, в залежності від затримки реплікації). Оцінка RPO вимагає детального аналізу бізнес-процесів і вартості втрати даних.
Recovery Time Objective (RTO) — Допустимий час відновлення
RTO визначає максимально допустимий час, протягом якого система може бути недоступною після збою. Наприклад, "RTO = 30 секунд" означає, що ваш кластер повинен відновитися і бути готовим приймати запити протягом півхвилини. Чим нижче RTO, тим складніше і дорожче рішення. Автоматичний failover з миттєвим перемиканням на резервний вузол забезпечує низький RTO, часто вимірюваний секундами. Ручний failover, навпаки, збільшує RTO, так як вимагає людського втручання. Для критичних систем з низьким RTO необхідні інструменти автоматичного виявлення збоїв і координації failover, такі як Patroni або pg_auto_failover. Необхідно враховувати не тільки час перезапуску БД, а й час перемикання мережевих адрес, оновлення DNS і перепідключення клієнтських додатків.
Масштабованість (Scalability)
Масштабованість відноситься до здатності системи ефективно обробляти зростаючі обсяги навантаження. У контексті HA PostgreSQL це може означати як горизонтальне масштабування (додавання більшої кількості вузлів для розподілу навантаження), так і вертикальне (збільшення ресурсів одного вузла). Для масштабування читання зазвичай використовуються репліки (standby servers), на які направляються запити SELECT. Масштабування запису складніше і часто вимагає більш складних рішень, таких як шардування або використання спеціалізованих розширень. Важливо оцінити поточні та прогнозовані потреби в масштабуванні, щоб вибрати рішення, яке не стане "вузьким горлом" в майбутньому. Деякі HA-рішення (наприклад, Patroni) спочатку добре інтегруються з механізмами горизонтального масштабування читання, дозволяючи легко додавати нові репліки.
Узгодженість даних (Consistency)
Узгодженість даних гарантує, що всі вузли кластера бачать одні й ті ж дані в один і той же момент часу. У розподілених системах досягти строгої узгодженості при високій доступності і продуктивності - завдання нетривіальне (CAP-теорема). PostgreSQL за замовчуванням забезпечує строгу узгодженість на основному вузлі. При використанні реплікації важливо розуміти, який рівень узгодженості вона надає. Асинхронна реплікація може мати невелику затримку, що означає, що репліка може "відставати" від майстра на кілька мілісекунд або секунд. Синхронна реплікація забезпечує більш високий рівень узгодженості, але, як вже згадувалося, впливає на продуктивність. Для більшості додатків потрібна строга узгодженість для операцій запису і прийнятна (eventual consistency) для операцій читання з реплік. Вибір HA-рішення повинен враховувати, як воно управляє узгодженістю даних при перемиканні вузлів і при звичайній роботі.
Вартість (Cost)
Вартість включає в себе не тільки прямі витрати на обладнання або VPS, але і ліцензії (хоча PostgreSQL безкоштовний), витрати на софт (системи моніторингу, оркестратори), а також непрямі витрати, такі як час інженерів на розгортання, підтримку та навчання. Для VPS і виділених серверів вартість буде залежати від кількості серверів, їх конфігурації (CPU, RAM, SSD) і мережевого трафіку. Рішення, що вимагають більшої кількості вузлів (наприклад, для кворуму), або більш складної настройки, будуть дорожчими в експлуатації. Важливо провести детальний розрахунок TCO (Total Cost of Ownership) на кілька років вперед, враховуючи потенційні витрати на аварійне відновлення і простої.
Складність (Complexity)
Складність рішення впливає на час розгортання, ймовірність помилок і трудовитрати на підтримку. Прості рішення можуть бути легко налаштовані, але можуть мати обмежені можливості. Складні рішення, такі як Patroni з розподіленим сховищем конфігурації (etcd/Consul), пропонують більше функціональності та автоматизації, але вимагають глибоких знань для правильного налаштування і налагодження. Необхідно оцінити рівень експертизи вашої команди. Якщо ресурсів і досвіду мало, варто почати з більш простих рішень або інвестувати в навчання. Занадто складне рішення може стати джерелом проблем, а не їх вирішенням.
Простота управління та моніторингу (Ease of Management & Monitoring)
Гарне HA-рішення має бути не тільки надійним, але і зручним в управлінні. Це включає в себе інструменти для моніторингу стану кластера, логування, оповіщень, а також можливість легко виконувати рутинні операції, такі як додавання нових реплік, оновлення PostgreSQL або тестування failover. Рішення з хорошою документацією, активною спільнотою і вбудованими CLI-утилітами значно спрощують життя. Важливо інтегрувати HA-кластер в існуючу систему моніторингу та оповіщень, щоб оперативно реагувати на будь-які проблеми. Відсутність адекватного моніторингу - прямий шлях до несподіваних простоїв.
Порівняльна таблиця популярних рішень для HA PostgreSQL
На ринку існує кілька зрілих підходів до побудови високонадійних PostgreSQL кластерів на VPS і виділених серверах. Кожен з них має свої особливості, переваги і недоліки. У цій таблиці ми порівняємо найбільш популярні і перевірені рішення, актуальні для 2026 року, щоб допомогти вам зробити поінформований вибір.
| Критерій | Patroni + etcd/Consul | pg_auto_failover | Нативна потокова реплікація + Keepalived/HAProxy | Pgpool-II (HA-режим) |
|---|---|---|---|---|
| Тип рішення | Оркестратор на базі розподіленого сховища (DCS) | Інтегрований інструмент автоматичного failover | Ручний/напівавтоматичний failover з зовнішніми інструментами | Проксі-сервер з функціями HA і балансування |
| RPO (Допустима втрата даних) | 0-кілька секунд (залежить від синхронності реплікації) | 0-кілька секунд (залежить від синхронності реплікації) | Декілька секунд/хвилин (асинхронна реплікація) | Декілька секунд/хвилин (асинхронна реплікація) |
| RTO (Допустимий час відновлення) | 5-30 секунд (автоматичний failover) | 10-60 секунд (автоматичний failover) | 30 секунд - 5 хвилин (потребує скриптів/ручного втручання) | 10-60 секунд (автоматичний failover на рівні Pgpool) |
| Складність налаштування | Висока (DCS, Patroni, PostgreSQL) | Середня (спеціалізований інструмент) | Середня (PostgreSQL, Keepalived/HAProxy, скрипти) | Середня (Pgpool-II, PostgreSQL) |
| Вимоги до серверів (мін.) | 3 вузли (1 мастер, 2 репліки) + 3 вузли для DCS (можна поєднувати) | 2 вузли (1 мастер, 1 репліка) + 1 монітор | 2 вузли (1 мастер, 1 репліка) | 2-3 вузли (1 мастер, 1-2 репліки) + 2 вузли Pgpool-II |
| Автоматичний Failover | Так (повністю автоматичний, з урахуванням кворуму) | Так (автоматичний, за допомогою монітора) | Ні (потребує зовнішніх скриптів і Keepalived/Corosync) | Так (на рівні Pgpool-II, для бекендів) |
| Масштабування читання | Відмінні можливості (легко додавати репліки) | Хороші можливості (легко додавати репліки) | Базове (ручне управління підключенням) | Відмінні можливості (балансування запитів) |
| Підтримка синхронної реплікації | Так (через Patroni API) | Так | Так (нативна функція PostgreSQL) | Так |
| Орієнтовна вартість (VPS, 2026, USD/міс) | $90-150 (3 VPS x $30-50, 4vCPU/8GB RAM/160GB NVMe) | $60-100 (2 VPS x $30-50, 4vCPU/8GB RAM/160GB NVMe) | $60-100 (2 VPS x $30-50, 4vCPU/8GB RAM/160GB NVMe) | $90-150 (3 VPS x $30-50, 4vCPU/8GB RAM/160GB NVMe) |
| Ключові особливості | Повна автоматизація, API, інтеграція з DCS, самовідновлення. | Простота розгортання, вбудований монітор, спеціалізований для PostgreSQL. | Базове, повний контроль, потребує кастомних скриптів, гнучкість. | Балансування навантаження, кешування, пулінг з'єднань, HA. |
| Найкращий сценарій використання | Критичні додатки, вимогливі до RPO/RTO, DevOps-орієнтовані команди. | Середні проєкти, де потрібна простота та автоматизація без високої складності. | Невеликі проєкти, обмежений бюджет, високий рівень контролю, досвідчена команда. | Проєкти з високим навантаженням читання, де потрібен пулінг і кешування, а також HA. |
*Примітка: Ціни на VPS є орієнтовними для 2026 року та можуть варіюватися в залежності від провайдера, регіону та поточних ринкових умов. Зазначені конфігурації (4vCPU/8GB RAM/160GB NVMe) передбачають середнє навантаження для продакшн-системи.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Детальний огляд кожного пункту/варіанту HA-рішення
Давайте детальніше розглянемо кожне згадане рішення, щоб зрозуміти їх внутрішню механіку, переваги та недоліки. Це дозволить вам прийняти більш обґрунтоване рішення, виходячи зі специфіки вашого проєкту та ресурсів команди.
Patroni + Розподілене сховище конфігурації (etcd/Consul/ZooKeeper)
Patroni — це потужний Python-демон, розроблений компанією Zalando, який надає надійне та повністю автоматизоване рішення для створення високодоступних кластерів PostgreSQL. Він діє як оркестратор, керуючи життєвим циклом екземплярів PostgreSQL, реплікацією, failover та switchover операціями. Ключова особливість Patroni — використання розподіленого сховища конфігурації (DCS) для зберігання стану кластера, такого як etcd, Consul або Apache ZooKeeper. DCS відіграє роль джерела істини для всіх вузлів кластера, забезпечуючи консистентність інформації про поточного майстра, статус реплік та налаштування.
Як це працює: Кожен вузол PostgreSQL, керований Patroni, регулярно оновлює свій статус в DCS. Patroni на кожному вузлі моніторить стан інших вузлів та самого DCS. Якщо поточний мастер падає, Patroni автоматично ініціює процедуру failover: він обирає нового майстра з числа здорових реплік, використовуючи алгоритм на основі кворуму та пріоритетів. Після вибору нового майстра, Patroni перемикає решту реплік на нового майстра і, за необхідності, запускає старий мастер як репліку після відновлення. Patroni також надає REST API для управління кластером, моніторингу та виконання операцій, таких як switchover (планове переключення майстра).
Плюси:
- Повна автоматизація: Автоматичний failover, switchover, відновлення реплік, додавання нових вузлів.
- Висока надійність: Використовує DCS для кворуму та запобігання split-brain.
- Гнучкість: Підтримує різні типи реплікації (асинхронна, синхронна), інтеграцію з проксі (HAProxy, PgBouncer).
- API та CLI: Зручні інструменти для управління та інтеграції з іншими системами.
- Активна спільнота: Підтримується Zalando та великою спільнотою розробників.
Мінуси:
- Висока складність: Потребує розуміння роботи PostgreSQL, Patroni та DCS. Налаштування може бути трудомістким.
- Додаткова інфраструктура: Необхідний окремий кластер DCS (мінімум 3 вузли для etcd/Consul).
- Споживання ресурсів: Patroni та DCS споживають свої ресурси, хоч і невеликі.
Для кого підходить: Для середніх та великих проєктів, SaaS-платформ, де критичні RPO та RTO, і є команда з досвідом у DevOps та адмініструванні баз даних. Ідеально для тих, хто шукає максимально автоматизоване та надійне рішення.
pg_auto_failover
pg_auto_failover — це інструмент, розроблений компанією Citus Data (тепер частина Microsoft), який спрощує розгортання та управління високодоступними кластерами PostgreSQL. Він фокусується на простоті використання та автоматизації, надаючи єдиний бінарник для всіх компонентів кластера: координатора (монітора), майстра та реплік.
Як це працює: pg_auto_failover створює кластер з як мінімум двох вузлів PostgreSQL (майстер і репліка) та окремого вузла-монітора. Монітор постійно опитує стан всіх вузлів і приймає рішення про failover. Якщо майстер стає недоступним, монітор ініціює failover, вибираючи одну з реплік як нового майстра і перемикаючи на неї клієнтські з'єднання. Він також може управляти синхронною реплікацією, забезпечуючи нульовий RPO в більшості випадків. Монітор сам по собі може бути налаштований на високу доступність, але це додає складності.
Плюси:
- Простота розгортання: Значно простіше в налаштуванні порівняно з Patroni.
- Автоматичний Failover: Повністю автоматизоване виявлення збоїв і перемикання.
- Вбудований монітор: Єдиний інструмент для всіх функцій HA.
- Підтримка синхронної реплікації: Легко налаштовується для нульового RPO.
- Спеціалізований для PostgreSQL: Глибока інтеграція з особливостями PostgreSQL.
Мінуси:
- Залежність від монітора: Монітор є єдиною точкою відмови, якщо не налаштований на HA.
- Менша гнучкість: Менше можливостей для тонкого налаштування в порівнянні з Patroni.
- Менш зріла спільнота: Хоча підтримується Microsoft, спільнота менша, ніж у Patroni.
Для кого підходить: Для проєктів середнього розміру, стартапів, де важлива простота розгортання та управління, але при цьому потрібен високий рівень автоматизації та надійності. Відмінно підходить для команд, які хочуть мінімізувати час на налаштування HA і зосередитися на розробці.
Нативна потокова реплікація PostgreSQL + Keepalived/HAProxy
Цей підхід використовує вбудовані можливості PostgreSQL для потокової реплікації (streaming replication) в поєднанні з зовнішніми інструментами для виявлення збоїв і управління IP-адресами або балансування навантаження. Потокова реплікація дозволяє постійно передавати зміни з майстер-сервера на один або кілька реплік, підтримуючи їх в актуальному стані.
Як це працює: Ви налаштовуєте один PostgreSQL сервер як майстер і один або кілька як репліки. Репліки постійно отримують WAL-файли (Write-Ahead Log) від майстра і застосовують їх. Для автоматичного виявлення збоїв і перемикання використовується Keepalived: він моніторить стан майстер-сервера і, в разі його відмови, автоматично переносить віртуальний IP-адрес (VIP) на одну з реплік, роблячи її новим майстром. HAProxy або Nginx можуть використовуватися для балансування навантаження читання між репліками і перенаправлення запису на поточний майстер. Для автоматизації промоуту репліки в майстер і переналаштування інших реплік потрібні кастомні скрипти, які будуть запускатися Keepalived.
Плюси:
- Повний контроль: Ви повністю контролюєте кожен компонент і скрипт.
- Низька вартість: Використовує тільки Open Source компоненти без додаткових ліцензій.
- Гнучкість: Можна налаштувати під дуже специфічні вимоги.
- Простота базової реплікації: Налаштування потокової реплікації досить просте.
Мінуси:
- Висока складність автоматизації: Написання і налагодження надійних скриптів для failover, switchover і відновлення — дуже трудомістка задача, схильна до помилок.
- Ризик split-brain: Без надійного механізму кворуму (який Keepalived сам по собі не надає) є ризик одночасного промоуту кількох майстрів.
- Високий RTO: Час відновлення може бути вище через ручне/скриптове втручання.
- Підтримка: Залежить від кваліфікації вашої команди, немає централізованої підтримки.
Для кого підходить: Для невеликих проєктів з обмеженим бюджетом, де є дуже досвідчена команда DBA/DevOps, готова витратити час на розробку і підтримку кастомних скриптів. Також може бути варіантом, коли потрібно максимально "полегшене" рішення без додаткових залежностей.
Pgpool-II (HA-режим)
Pgpool-II — це проміжне ПЗ (middleware) для PostgreSQL, яке надає ряд корисних функцій, включаючи пулінг з'єднань, балансування навантаження, кешування запитів і, що важливо для нас, функції високої доступності. Pgpool-II працює як проксі між клієнтськими застосунками і серверами PostgreSQL.
Як це працює: Pgpool-II розміщується перед кластером PostgreSQL і управляє з'єднаннями клієнтів. В режимі високої доступності він моніторить стан бекенд-серверів PostgreSQL. Якщо майстер-сервер виходить з ладу, Pgpool-II може автоматично переключити трафік на одну з реплік, зробивши її новим майстром. Він також може управляти перемиканням віртуального IP-адреси за допомогою watchdog-функцій, які інтегруються з такими інструментами, як `pcp_attach_node` і `pcp_detach_node` для зміни стану вузлів. Для забезпечення HA самого Pgpool-II зазвичай розгортають два екземпляри Pgpool-II з Keepalived для перемикання VIP.
Плюси:
- Багатофункціональність: Крім HA, надає пулінг з'єднань, балансування читання, кешування.
- Поліпшення продуктивності: Пулінг і кешування можуть значно знизити навантаження на БД.
- Автоматичний Failover: Здатний автоматично перемикати майстер.
- Прозорість для застосунків: Застосунки підключаються до Pgpool-II, не знаючи про топологію кластера.
Мінуси:
- Єдина точка відмови: Сам Pgpool-II може стати нею, якщо не налаштований на HA (що ускладнює архітектуру).
- Додаткова затримка: Вносить невеликий оверхед через проксіювання.
- Складність налаштування: Конфігурація Pgpool-II може бути досить складною, особливо з HA і watchdog.
- Не управляє PostgreSQL: Pgpool-II управляє тільки перемиканням, але не оркеструє сам PostgreSQL (наприклад, не відновлює репліки).
Для кого підходить: Для проєктів, де крім високої доступності потрібна також оптимізація продуктивності за рахунок пулінгу з'єднань і балансування читання. Підходить для команд, готових інвестувати у вивчення і підтримку Pgpool-II як ключового компонента інфраструктури.
Практичні поради та рекомендації щодо впровадження Patroni
Patroni є одним із найпотужніших і гнучких рішень для HA PostgreSQL, тому ми зосередимося на його практичному впровадженні. Цей розділ надасть покрокові інструкції та рекомендації, засновані на реальному досвіді.
1. Планування інфраструктури
Для мінімального HA-кластера Patroni з надійним кворумом вам знадобиться як мінімум 3 сервери. Це можуть бути VPS або виділені сервери. Рекомендується наступна конфігурація:
- 3 вузли PostgreSQL: Кожен вузол запускатиме Patroni та PostgreSQL. Один буде майстром, інші - репліками.
- 3 вузли для Distributed Configuration Store (DCS): etcd або Consul. У невеликих кластерах (3 вузли) DCS можна розмістити на тих же серверах, що й PostgreSQL/Patroni. У більших або дуже критичних системах рекомендується виносити DCS на окремі сервери.
Приклад конфігурації VPS (2026 рік):
- CPU: 4 vCPU
- RAM: 8-16 GB
- Диск: 160-320 GB NVMe SSD (для даних PostgreSQL)
- Мережа: 1 Гбіт/с
- ОС: Ubuntu 24.04 LTS або Debian 13
Переконайтеся, що у всіх серверів є статичні IP-адреси та відкриті необхідні порти (PostgreSQL: 5432, Patroni API: 8008, etcd: 2379/2380, Consul: 8300/8301/8302/8500/8600).
2. Підготовка операційної системи
На кожному з трьох серверів виконайте базове налаштування:
# Оновлення системи
sudo apt update && sudo apt upgrade -y
# Встановлення необхідних пакетів
sudo apt install -y python3 python3-pip python3-psycopg2 python3-yaml postgresql-client-16
# Створення користувача postgres (якщо його немає або потрібне специфічне налаштування)
# За замовчуванням PostgreSQL створює користувача postgres, використовуйте його.
# Налаштування файрвола (приклад для UFW)
sudo ufw allow 22/tcp
sudo ufw allow 5432/tcp
sudo ufw allow 8008/tcp # Patroni API
sudo ufw allow 2379/tcp # etcd client
sudo ufw allow 2380/tcp # etcd server
sudo ufw enable
3. Встановлення та налаштування DCS (etcd)
На кожному з трьох серверів встановіть та налаштуйте etcd. У production-середовищі etcd краще розгортати на виділених вузлах, але для початку можна поєднати.
# Встановлення etcd (приклад для Ubuntu/Debian)
# Завантажте останній реліз з GitHub: https://github.com/etcd-io/etcd/releases
ETCD_VERSION="v3.5.12" # Актуально на 2026 рік, перевірте
wget "https://github.com/etcd-io/etcd/releases/download/${ETCD_VERSION}/etcd-${ETCD_VERSION}-linux-amd64.tar.gz"
tar xzvf etcd-${ETCD_VERSION}-linux-amd64.tar.gz
sudo mv etcd-${ETCD_VERSION}-linux-amd64/etcd /usr/local/bin/
sudo mv etcd-${ETCD_VERSION}-linux-amd64/etcdctl /usr/local/bin/
# Створення директорій для даних etcd
sudo mkdir -p /var/lib/etcd
sudo mkdir -p /etc/etcd
# Створення systemd-сервісу для etcd (на кожному вузлі)
# Замініть IP-адреси та імена вузлів на свої
# NODE_1_IP, NODE_2_IP, NODE_3_IP
# NODE_1_NAME, NODE_2_NAME, NODE_3_NAME
# Приклад для node1:
sudo nano /etc/systemd/system/etcd.service
Вміст файлу `/etc/systemd/system/etcd.service` для `node1` (з IP 192.168.1.1):
[Unit]
Description=etcd - Highly-available key value store
Documentation=https://github.com/etcd-io/etcd
After=network.target
[Service]
Type=notify
Restart=always
RestartSec=5s
LimitNOFILE=40000
TimeoutStartSec=0
ExecStart=/usr/local/bin/etcd \\
--name node1 \\
--data-dir /var/lib/etcd \\
--initial-advertise-peer-urls http://192.168.1.1:2380 \\
--listen-peer-urls http://192.168.1.1:2380 \\
--listen-client-urls http://192.168.1.1:2379,http://127.0.0.1:2379 \\
--advertise-client-urls http://192.168.1.1:2379 \\
--initial-cluster-token etcd-cluster-1 \\
--initial-cluster node1=http://192.168.1.1:2380,node2=http://192.168.1.2:2380,node3=http://192.168.1.3:2380 \\
--initial-cluster-state new \\
--heartbeat-interval 100 \\
--election-timeout 500
[Install]
WantedBy=multi-user.target
Повторіть для `node2` (192.168.1.2) та `node3` (192.168.1.3), змінюючи `--name`, `--initial-advertise-peer-urls`, `--listen-peer-urls`, `--listen-client-urls`, `--advertise-client-urls` на відповідні IP-адреси. Після створення файлу на всіх вузлах:
sudo systemctl daemon-reload
sudo systemctl enable etcd
sudo systemctl start etcd
# Перевірка статусу кластера etcd на будь-якому вузлі
etcdctl --endpoints=http://192.168.1.1:2379,http://192.168.1.2:2379,http://192.168.1.3:2379 member list
4. Встановлення Patroni
На кожному вузлі встановіть Patroni через pip:
sudo pip3 install patroni[etcd]
5. Налаштування Patroni
Створіть конфігураційний файл Patroni на кожному вузлі. Використовуйте один і той же шаблон, змінюючи лише `name` та `listen` IP-адреси.
sudo mkdir -p /etc/patroni
sudo nano /etc/patroni/patroni.yml
Приклад файлу `patroni.yml` для `node1`:
scope: my_pg_cluster
name: node1 # Унікальне ім'я для кожного вузла
restapi:
listen: 0.0.0.0:8008
connect_address: 192.168.1.1:8008 # IP-адреса поточного вузла
etcd:
host: 192.168.1.1:2379,192.168.1.2:2379,192.168.1.3:2379
postgresql:
listen: 0.0.0.0:5432
connect_address: 192.168.1.1:5432 # IP-адреса поточного вузла
data_dir: /var/lib/postgresql/data # Шлях до даних PG
bin_dir: /usr/lib/postgresql/16/bin # Шлях до бінарників PG (перевірте версію)
authentication:
replication:
username: repl_user
password: repl_password
superuser:
username: postgres
password: superuser_password
parameters:
wal_level: replica
hot_standby: on
max_wal_senders: 10
max_replication_slots: 10
archive_mode: on
archive_command: 'cd . && test ! -f %p && cp %p %l' # Приклад, для продакшена потрібна система архівації
log_destination: stderr
logging_collector: on
log_directory: pg_log
log_filename: 'postgresql-%Y-%m-%d_%H%M%S.log'
log_file_mode: 0600
log_truncate_on_rotation: on
log_rotation_age: 1d
log_rotation_size: 10MB
max_connections: 100
# Налаштування для автоматичного відновлення
bootstrap:
dcs:
ttl: 30 # Time-to-live для ключів в DCS
loop_wait: 10 # Затримка між ітераціями Patroni
retry_timeout: 10 # Таймаут для повторних спроб
maximum_lag_on_failover: 1048576 # Максимальний лаг реплікації для failover (1MB)
initdb:
- encoding: UTF8
- locale: en_US.UTF-8
- data-checksums
pg_hba:
- host replication repl_user 0.0.0.0/0 md5
- host all all 0.0.0.0/0 md5
- host all all ::/0 md5
users:
admin_user:
password: admin_password
options:
- createrole
- createdb
repl_user:
password: repl_password
options:
- replication
- bypassrls
Важливо:
- Замініть `192.168.1.1`, `192.168.1.2`, `192.168.1.3` на актуальні IP-адреси ваших серверів.
- Вкажіть коректний `bin_dir` для вашої версії PostgreSQL (наприклад, `/usr/lib/postgresql/16/bin`).
- Встановіть надійні паролі для `repl_user`, `postgres` та `admin_user`.
- Параметр `archive_command` в production-середовищі має бути налаштований на реальну систему архівації WAL (наприклад, S3, NFS), а не на локальне копіювання.
6. Створення systemd-сервісу для Patroni
Створіть unit-файл для Patroni на кожному вузлі:
sudo nano /etc/systemd/system/patroni.service
Вміст `patroni.service`:
[Unit]
Description=Patroni - A Template for PostgreSQL High Availability
After=network.target etcd.service # Додайте etcd.service якщо etcd на тому ж вузлі
[Service]
Type=simple
User=postgres
Group=postgres
ExecStart=/usr/bin/python3 -m patroni -c /etc/patroni/patroni.yml
Restart=on-failure
TimeoutStopSec=60
LimitNOFILE=131072
[Install]
WantedBy=multi-user.target
Після створення файлу на всіх вузлах:
sudo systemctl daemon-reload
sudo systemctl enable patroni
sudo systemctl start patroni
7. Ініціалізація кластера
Patroni автоматично ініціалізує PostgreSQL на першому запущеному вузлі, який стане майстром. Решта вузлів приєднаються до нього як репліки. Зачекайте декілька хвилин, поки всі вузли запустяться та синхронізуються.
8. Перевірка стану кластера
Використовуйте утиліту `patronictl` для перевірки стану кластера на будь-якому вузлі:
patronictl -c /etc/patroni/patroni.yml list
Вивід повинен показати один майстер і дві репліки. Приклад:
+ Cluster: my_pg_cluster (6909873467941793393) ---+----+-----------+----+-----------+
| Member | Host | Role | State | Lag in MB |
+--------+--------------+---------+----------+-----------+
| node1 | 192.168.1.1 | Leader | running | 0 |
| node2 | 192.168.1.2 | Replica | running | 0 |
| node3 | 192.168.1.3 | Replica | running | 0 |
+--------+--------------+---------+----------+-----------+
9. Тестування Failover
Це критично важливий крок. Ви повинні регулярно тестувати failover, щоб переконатися, що кластер працює, як очікується. Найпростіший спосіб — зупинити Patroni на поточному майстрі:
# На поточному майстер-вузлі
sudo systemctl stop patroni
Patroni на решті вузлів виявить, що майстер недоступний, та ініціює failover. Через 5-30 секунд одна з реплік повинна стати новим майстром. Перевірте це за допомогою `patronictl list` на іншому вузлі. Потім запустіть Patroni на старому майстрі, і він повинен приєднатися як репліка.
10. Налаштування балансувальника навантаження (HAProxy)
Для клієнтських застосунків рекомендується використовувати балансувальник навантаження (наприклад, HAProxy), який буде направляти запити запису на поточний майстер, а запити читання — на репліки. HAProxy може бути налаштований на моніторинг Patroni API для визначення ролі кожного вузла.
Приклад конфігурації HAProxy (на окремому сервері, або на кожному вузлі, якщо використовується Keepalived для HAProxy):
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats socket /run/haproxy/admin.sock mode 660 level admin expose-fd listeners
stats timeout 30s
user haproxy
group haproxy
daemon
defaults
log global
mode tcp
option tcplog
option dontlognull
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
listen stats
bind *:8080
mode http
stats enable
stats uri /haproxy_stats
stats refresh 10s
stats auth admin:password
listen postgres_primary
bind *:5432
mode tcp
option httpchk GET /primary # Використовуємо Patroni API для перевірки ролі
balance roundrobin
server node1 192.168.1.1:5432 check port 8008 inter 1s fall 3 rise 2 weight 10 on-marked-down shutdown-sessions
server node2 192.168.1.2:5432 check port 8008 inter 1s fall 3 rise 2 weight 10 on-marked-down shutdown-sessions
server node3 192.168.1.3:5432 check port 8008 inter 1s fall 3 rise 2 weight 10 on-marked-down shutdown-sessions
listen postgres_replicas
bind *:5433 # Окремий порт для читання з реплік
mode tcp
option httpchk GET /replica # Використовуємо Patroni API для перевірки ролі
balance leastconn
server node1 192.168.1.1:5432 check port 8008 inter 1s fall 3 rise 2 weight 10 on-marked-down shutdown-sessions
server node2 192.168.1.2:5432 check port 8008 inter 1s fall 3 rise 2 weight 10 on-marked-down shutdown-sessions
server node3 192.168.1.3:5432 check port 8008 inter 1s fall 3 rise 2 weight 10 on-marked-down shutdown-sessions
У цьому прикладі HAProxy буде направляти трафік на порт 5432 тільки на той вузол, який Patroni визначив як майстер (`/primary`). На порт 5433 він буде направляти запити на читання на всі вузли, які Patroni визначив як репліки (`/replica`), включаючи майстра (який також може обробляти запити читання).
Ці практичні поради допоможуть вам успішно розгорнути та налаштувати базовий HA-кластер PostgreSQL з використанням Patroni. Пам'ятайте, що кожен крок вимагає уважності, а тестування - це ключ до впевненості в роботі вашої системи.
Типові помилки при побудові HA кластера PostgreSQL

Навіть досвідчені інженери можуть допускати помилки при проєктуванні та розгортанні високонадійних систем. Розуміння цих поширених проблем допоможе вам уникнути дорогих простоїв і головного болю. Ось п'ять найбільш частих помилок:
1. Недостатній або неправильно налаштований кворум (Split-Brain)
Опис: Кворум — це мінімальна кількість вузлів, яка має бути доступна для прийняття рішень у кластері. Якщо кворум не налаштований або налаштований неправильно, у разі мережевого розділення (network partition) два або більше вузла можуть вирішити, що вони є майстрами. Цей стан називається "split-brain" і призводить до розсинхронізації даних, коли кожен "майстер" приймає записи незалежно, що робить відновлення дуже складним і чреватим втратою даних.
Як уникнути: Завжди використовуйте непарну кількість вузлів для вашого DCS (Distributed Configuration Store), наприклад, 3 або 5. Це гарантує, що в разі відмови одного або двох вузлів завжди буде більшість, здатна прийняти рішення про вибір майстра. Patroni і pg_auto_failover за замовчуванням використовують механізми кворуму. Переконайтеся, що конфігурація DCS (etcd/Consul) коректна і стійка до відмов. Регулярно перевіряйте стан кворуму.
Реальні наслідки: "В одній компанії, через неправильне налаштування etcd-кластера, під час тимчасового збою мережі два вузли порахували себе майстрами. Застосунки продовжували писати дані на обидва вузли. Коли мережа відновилася, дані розійшлися. Відновлення зайняло понад 12 годин, вимагало ручного аналізу логів і вибору 'правильного' майстра, що призвело до втрати частини транзакцій і серйозних репутаційних витрат."
2. Відсутність або недостатнє тестування Failover і Recovery
Опис: Багато інженерів розгортають HA-кластер, бачать, що він працює, і на цьому заспокоюються. Однак механізми failover і recovery можуть бути складними, і їхня поведінка в реальних умовах (наприклад, при специфічному типі збою або під навантаженням) може відрізнятися від очікуваної. Неперевірений failover — це непрацюючий failover.
Як уникнути: Регулярно, як мінімум раз на квартал, проводьте "навчання" з аварійного відновлення. Це включає в себе штучне відключення майстер-вузла, імітацію мережевих проблем, повну зупинку DCS. Заміряйте RTO, перевіряйте цілісність даних після відновлення. Автоматизуйте ці тести, якщо це можливо. Переконайтеся, що ваша команда знає, як діяти в разі реального збою.
Реальні наслідки: "Одного разу в стартапі, де я консультував, кластер Patroni був налаштований більше року тому. При першому реальному збої виявилося, що через оновлення операційної системи змінилися шляхи до бінарників PostgreSQL, і Patroni не міг коректно запустити новий майстер. Простій тривав кілька годин, поки інженери з'ясовували причину і вручну коригували конфігурацію. Якби вони регулярно тестували failover, ця проблема була б виявлена задовго до продакшена."
3. Ігнорування моніторингу та оповіщень
Опис: HA-кластери за своєю природою більш складні, ніж поодинокі сервери. Без адекватного моніторингу неможливо оперативно дізнатися про проблеми, такі як відставання реплікації, вичерпання дискового простору, високе навантаження на DCS або проблеми з мережею. Відсутність оповіщень означає, що ви дізнаєтеся про проблему тільки тоді, коли вона вже призвела до простою.
Як уникнути: Впровадьте комплексну систему моніторингу (Prometheus+Grafana, Zabbix, Datadog) для всіх компонентів кластера: PostgreSQL (метрики, реплікація, WAL), Patroni (API), DCS (etcd/Consul), операційна система (CPU, RAM, диск, мережа). Налаштуйте оповіщення (Alertmanager, Slack, Telegram, PagerDuty) на критичні метрики: RPO > X секунд, дисковий простір < Y%, кількість вузлів у кластері < Z, недоступність Patroni API. Регулярно переглядайте пороги оповіщень.
Реальні наслідки: "У клієнта був налаштований Patroni, але моніторинг реплікації був базовим. Через помилку в мережі між дата-центрами реплікація почала відставати на кілька годин. Жодних оповіщень не було, тому що пороги були занадто високі. Коли стався збій майстра, failover пройшов, але новий майстер мав дані, що відставали на 3 години, що призвело до відкату частини транзакцій і довелося відновлювати дані з бекапу, що зайняло майже добу."
4. Неправильна конфігурація мережі та DNS
Опис: Мережа є основою будь-якого розподіленого кластера. Некоректне налаштування DNS, проблеми з роздільною здатністю імен, неправильні правила файрвола, а також асиметрична маршрутизація можуть призвести до того, що вузли не зможуть "бачити" один одного, або програми не зможуть підключитися до актуального майстра після failover.
Як уникнути: Переконайтеся, що всі вузли можуть звертатися один до одного по всіх необхідних портах. Використовуйте статичні IP-адреси. Налаштуйте DNS таким чином, щоб ім'я хоста вашого кластера (наприклад, `pg-cluster.mydomain.com`) завжди вказувало на актуальний майстер (через балансувальник або динамічне оновлення DNS). Перевіряйте правила файрвола на кожному вузлі. Використовуйте внутрішні мережі для трафіку реплікації та DCS, якщо це можливо.
Реальні наслідки: "В одному проекті, після автоматичного failover, програми не могли підключитися до нового майстра. Проблема виявилася в кешуванні DNS на клієнтській стороні та занадто довгому TTL для запису A-запису. Довелося вручну очищати кеші та перезапускати програми, що збільшило RTO в кілька разів. З тих пір ми використовуємо дуже низький TTL для DNS-записів кластера і рекомендуємо використовувати балансувальник навантаження з перевіркою здоров'я вузлів."
5. Зневага бекапами та їх тестуванням
Опис: Висока доступність захищає від простоїв, але не від втрати даних через логічні помилки (наприклад, випадкове видалення таблиці) або катастрофічні збої (наприклад, одночасна відмова всіх вузлів в дата-центрі). Бекапи — це ваша остання лінія оборони. Якщо бекапи не робляться регулярно, не зберігаються безпечно або, що ще гірше, не тестуються на можливість відновлення, вони марні.
Як уникнути: Впровадьте надійну стратегію резервного копіювання (наприклад, за допомогою pgBackRest або Barman) з регулярним повним та інкрементальним резервуванням. Зберігайте бекапи у віддаленому, географічно розподіленому сховищі (наприклад, S3-сумісне сховище). Найголовніше: регулярно відновлюйте бекапи на тестовому стенді, щоб переконатися в їх цілісності та працездатності. Це єдиний спосіб переконатися, що в разі чого ви дійсно зможете відновити дані.
Реальні наслідки: "В одній компанії сталася логічна помилка в додатку, яка призвела до масового видалення даних. HA-кластер продовжував працювати, але дані були втрачені. Коли спробували відновитися з бекапу, з'ясувалося, що через помилку конфігурації останні 3 місяці бекапи були пошкоджені та не підлягали відновленню. Компанії довелося відновлювати дані зі старіших бекапів і вручну переносити частину інформації, що призвело до значних втрат і штрафів від регуляторів."
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Чекліст для практичного застосування: Розгортання HA PostgreSQL
Цей покроковий чекліст допоможе вам систематизувати процес розгортання високонадійного PostgreSQL кластера, мінімізуючи ймовірність помилок і забезпечуючи комплексний підхід.
Фаза 1: Планування і Проектування
- Визначення вимог RPO і RTO: Чітко встановіть, скільки даних ви готові втратити і як швидко повинні відновитися після збою. Це ключові параметри для вибору архітектури.
- Вибір HA-рішення: На основі RPO, RTO, бюджету, складності та експертизи команди виберіть оптимальне рішення (Patroni, pg_auto_failover, нативна реплікація + скрипти, Pgpool-II).
- Проектування архітектури кластера:
- Визначте кількість вузлів (мінімум 3 для Patroni/etcd, 2+монітор для pg_auto_failover).
- Розподіліть вузли по різних дата-центрах/стійках/провайдерах для підвищення стійкості (якщо дозволяє бюджет).
- Сплануйте розміщення DCS (etcd/Consul) — спільно з БД або на окремих вузлах.
- Оцінка ресурсів серверів: Визначте необхідну конфігурацію CPU, RAM, SSD і мережевих ресурсів для кожного вузла, виходячи з очікуваного навантаження.
- Планування мережевої інфраструктури:
- Призначте статичні IP-адреси для всіх вузлів.
- Визначте порти для PostgreSQL (5432), Patroni API (8008), DCS (etcd: 2379/2380, Consul: 8500), балансувальника (5432, 5433).
- Налаштуйте правила файрвола (UFW, firewalld, мережеві ACL провайдера) для дозволу необхідного трафіку.
- Розробка стратегії резервного копіювання та відновлення: Виберіть інструмент (pgBackRest, Barman), визначте частоту, місце зберігання (віддалене, географічно розподілене) і процедури відновлення.
- Планування моніторингу та оповіщень: Оберіть інструменти (Prometheus, Grafana, Alertmanager) та визначте ключові метрики та пороги для оповіщень.
- Документація: Створіть детальну документацію з архітектури, налаштування, процедур failover/switchover та аварійного відновлення.
Фаза 2: Підготовка Інфраструктури
- Замовлення/виділення серверів: Розгорніть необхідну кількість VPS або виділених серверів.
- Базове налаштування ОС: Встановіть обрану ОС (Ubuntu LTS, Debian), оновіть систему, налаштуйте SSH-доступ, часовий пояс, NTP.
- Встановлення PostgreSQL: Встановіть PostgreSQL на всіх вузлах, але не ініціалізуйте його вручну (це зробить Patroni/pg_auto_failover).
- Встановлення залежностей: Встановіть Python, pip, psycopg2, PyYAML та інші залежності для Patroni/pg_auto_failover.
- Налаштування файрволу: Відкрийте необхідні порти на кожному вузлі.
- Налаштування DNS: Переконайтеся, що імена хостів розпізнаються коректно і, за потреби, налаштуйте динамічне оновлення DNS або використовуйте балансувальник.
Фаза 3: Розгортання HA-рішення
- Встановлення та налаштування DCS (якщо потрібно): Розгорніть etcd/Consul на всіх вузлах, переконайтеся в працездатності кластера DCS.
- Встановлення та налаштування Patroni/pg_auto_failover:
- Встановіть обраний інструмент.
- Створіть конфігураційні файли на кожному вузлі, адаптуючи під специфіку кожного сервера (ім'я, IP-адреси).
- Налаштуйте параметри PostgreSQL в конфігурації HA-інструменту (wal_level, max_wal_senders і т.д.).
- Налаштуйте користувачів для реплікації та суперкористувача з надійними паролями.
- Створення systemd-сервісів: Створіть та налаштуйте systemd-сервіси для Patroni/pg_auto_failover на кожному вузлі.
- Запуск кластера: Запустіть сервіси DCS (якщо окремі), потім Patroni/pg_auto_failover на всіх вузлах.
- Ініціалізація кластера: Дочекайтеся автоматичної ініціалізації майстра та приєднання реплік.
- Перевірка стану кластера: Використовуйте `patronictl list` або `pg_auto_failover show state` для підтвердження коректної роботи.
Фаза 4: Тестування та Моніторинг
- Налаштування балансувальника навантаження: Розгорніть та налаштуйте HAProxy/PgBouncer для маршрутизації трафіку до майстра та реплік.
- Налаштування моніторингу: Інтегруйте кластер у вашу систему моніторингу, налаштуйте збір метрик та оповіщення.
- Тестування Failover: Ініціюйте штучну відмову майстра та перевірте автоматичне перемикання на репліку, виміряйте RTO.
- Тестування Switchover: Проведіть планове перемикання майстра на репліку.
- Тестування відновлення з бекапу: Відновіть тестову БД з бекапу на окремому стенді.
- Тестування продуктивності: Проведіть навантажувальне тестування кластера в різних сценаріях.
- Оновлення документації: Актуалізуйте всю документацію після розгортання та тестування.
Фаза 5: Експлуатація та Обслуговування
- Регулярний моніторинг: Постійно слідкуйте за станом кластера, реагуйте на оповіщення.
- Регулярне тестування: Продовжуйте періодично тестувати failover та відновлення бекапів.
- Оновлення ПЗ: Плануйте та виконуйте оновлення PostgreSQL, Patroni/pg_auto_failover, DCS та ОС відповідно до best practices для HA-систем.
- Аналіз логів: Регулярно переглядайте логи PostgreSQL, Patroni та DCS для виявлення потенційних проблем.
- Оптимізація: Аналізуйте продуктивність та, за потреби, оптимізуйте конфігурацію PostgreSQL та HA-рішення.
Розрахунок вартості / Економіка високодоступного PostgreSQL кластера
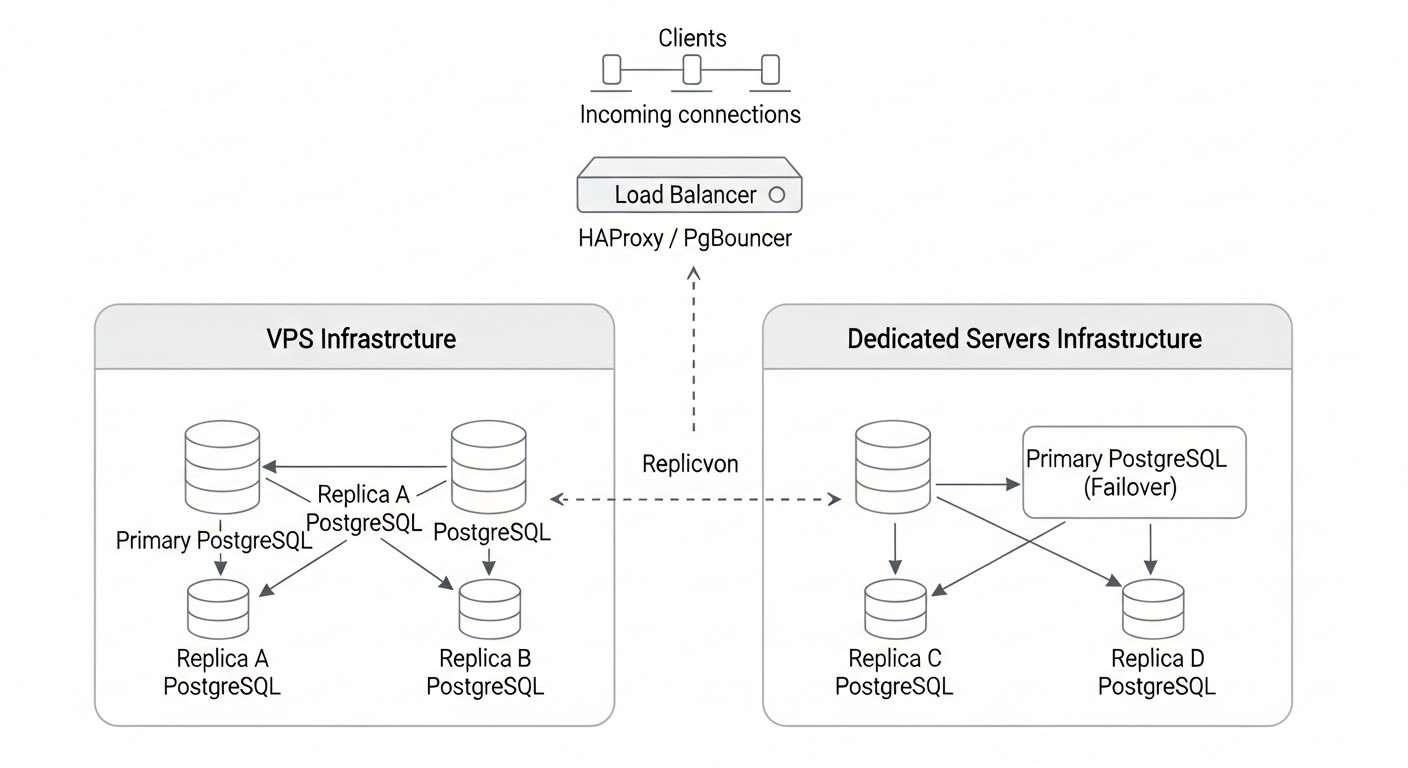
Створення та підтримка високодоступного PostgreSQL кластера на VPS або виділених серверах тягне за собою певні витрати. Важливо розуміти не лише прямі, але й приховані витрати, щоб отримати повне уявлення про TCO (Total Cost of Ownership) та ефективно управляти бюджетом. Наведені нижче цифри є орієнтовними для 2026 року і можуть варіюватися в залежності від провайдера, регіону та конкретних вимог.
Основні статті витрат
- Вартість серверів (VPS/Dedicated): Це основна та найбільш очевидна стаття витрат. Для HA-кластера потрібно мінімум 3 вузли для забезпечення кворуму та відмовостійкості (наприклад, 1 майстер, 2 репліки).
- VPS: Більш гнучкі, масштабовані та часто дешевші для невеликих та середніх навантажень. Вартість залежить від vCPU, RAM, SSD та мережевого трафіку.
- Виділені сервери: Забезпечують максимальну продуктивність та контроль, але дорожчі та потребують більше зусиль з управління.
- Вартість зберігання даних (Storage): Крім базового диску ОС, вам знадобиться достатньо швидке та об'ємне сховище для даних PostgreSQL (WAL-логи, бази даних). NVMe SSD є стандартом для продакшн-систем.
- Мережевий трафік: Вхідний трафік зазвичай безкоштовний, але вихідний може тарифікуватися, особливо при великих обсягах реплікації між дата-центрами або при частих бекапах в хмарне сховище.
- Системи моніторингу та логування: Хоча багато рішень Open Source (Prometheus, Grafana, ELK), їх розгортання та підтримка вимагають ресурсів. Комерційні рішення (Datadog, New Relic) значно спрощують життя, але мають свою вартість.
- Резервне копіювання та DR: Зберігання бекапів (S3-сумісні сховища, NFS), а також витрати на тестові стенди для відновлення.
- Інженерний час (Human Capital): Це часто недооцінена, але одна з найбільш значних статей витрат. Час інженерів на проектування, розгортання, налаштування, тестування, моніторинг, обслуговування, усунення проблем та навчання. HA-системи складніші, ніж одиночні сервери, і вимагають більш високої кваліфікації.
- Ліцензії ПЗ: PostgreSQL та більшість HA-інструментів (Patroni, pg_auto_failover, HAProxy, etcd, Consul) є Open Source та безкоштовні. Однак, якщо ви використовуєте комерційні ОС або спеціалізоване ПЗ, можуть бути ліцензійні збори.
Приховані витрати
- Простої: Вартість простою може бути величезною (втрата доходу, репутаційна шкода, штрафи за SLA). Інвестиції в HA – це страховка від цих втрат.
- Упущена вигода: Повільна БД або часті збої можуть відлякувати клієнтів, знижувати конверсію та заважати зростанню бізнесу.
- Навчання команди: Підтримка кваліфікації інженерів для роботи зі складними HA-системами.
- Масштабування: Невдало обрана архітектура може потребувати повного перепроектування при зростанні навантаження.
- Технічний борг: Недостатня увага до HA на ранніх етапах призводить до накопичення технічного боргу, який потім коштуватиме дорожче.
Як оптимізувати витрати
- Оптимальний вибір VPS/серверів: Не переплачуйте за надлишкові ресурси, але й не економте на критично важливих компонентах (SSD, RAM). Почніть з мінімально достатньої конфігурації та масштабуйте по мірі зростання.
- Використання Open Source: Максимально використовуйте безкоштовні Open Source рішення для всіх компонентів (ОС, БД, HA-інструменти, моніторинг).
- Автоматизація: Інвестуйте в автоматизацію розгортання (Ansible, Terraform) та операцій. Це знизить витрати на інженерний час в довгостроковій перспективі.
- Грамотний моніторинг: Раннє виявлення проблем запобігає дорогим простоям.
- Ефективна стратегія бекапу: Використовуйте інкрементальні бекапи, стиснення, та зберігайте тільки необхідну кількість копій, щоб знизити витрати на зберігання.
- Мережева архітектура: Використовуйте внутрішні мережі провайдера для трафіку реплікації та DCS, щоб уникнути плати за вихідний трафік.
- Навчання та документація: Інвестиції в знання команди та хорошу документацію знижують ризики та час на вирішення проблем.
Таблиця з прикладами розрахунків для різних сценаріїв (2026 рік, USD/місяць)
Передбачається використання 3-х VPS вузлів для кластера PostgreSQL (Patroni + etcd) та одного VPS для балансувальника HAProxy/PgBouncer, а також віддаленого сховища для бекапів.
| Стаття витрат | Малий проект (3 VPS x 2vCPU/4GB RAM/80GB NVMe) | Середній проект (3 VPS x 4vCPU/8GB RAM/160GB NVMe) | Великий проект (3 VPS x 8vCPU/16GB RAM/320GB NVMe) |
|---|---|---|---|
| VPS для PostgreSQL (3 шт) | 3 x $15 = $45 | 3 x $35 = $105 | 3 x $70 = $210 |
| VPS для HAProxy/PgBouncer (1 шт) | 1 x $10 = $10 | 1 x $15 = $15 | 1 x $20 = $20 |
| Віддалене сховище для бекапів (S3-сумісне) | $5 (500 GB) | $10 (1 TB) | $25 (2.5 TB) |
| Мережевий трафік (вихідний) | $5 | $10 | $25 |
| Моніторинг (Open Source, витрати на VPS) | $0 (спільно з HAProxy) | $10 (окремий VPS) | $20 (окремий VPS) |
| РАЗОМ прямі витрати (USD/міс) | $65 | $150 | $300 |
| Інженерний час (орієнтовно, USD/міс)* | $200-500 | $500-1500 | $1500-3000+ |
| РАЗОМ TCO (прямі + інж. час) | $265-565 | $650-1650 | $1800-3300+ |
*Примітка щодо інженерного часу: Це дуже приблизна оцінка, яка сильно залежить від кваліфікації команди, рівня автоматизації та складності проєкту. Вона включає час на розгортання, підтримку, моніторинг, усунення проблем та тестування. На початку проєкту витрати на інженерний час будуть значно вищими.
Як видно з таблиці, прямі витрати на інфраструктуру для HA-кластера цілком доступні навіть для невеликих проєктів. Однак, значно більшою статтею витрат є інженерний час, особливо на етапі впровадження та при низькому рівні автоматизації. Правильний вибір рішення та інвестиції в автоматизацію окупаються за рахунок зниження TCO в довгостроковій перспективі та підвищення надійності системи.
Кейси та приклади реальних впроваджень HA PostgreSQL
Теорія важлива, але реальні кейси дають краще розуміння того, як HA-рішення працюють на практиці та які виклики вони допомагають подолати. Ось декілька сценаріїв з нашої практики та досвіду колег.
Кейс 1: SaaS-платформа для управління проєктами (Patroni + etcd)
Проблема: Молода SaaS-компанія активно росла, і їх єдина інстанція PostgreSQL на виділеному сервері стала критичною точкою відмови. Будь-який простій призводив до недоступності сервісу для тисяч клієнтів, що напряму впливало на репутацію та доходи. RPO було встановлено в 0 секунд (синхронна реплікація), RTO — не більше 30 секунд.
Рішення: Було прийнято рішення розгорнути кластер Patroni з etcd.
- Архітектура: 3 виділених сервери (8vCPU, 32GB RAM, 500GB NVMe SSD) в одному дата-центрі, але в різних стійках, щоб мінімізувати ризики відмови обладнання. Кожен сервер запускав PostgreSQL 16, Patroni та etcd.
- Конфігурація Patroni: Налаштовано синхронну реплікацію з одним `synchronous_standby_names`, що забезпечувало нульовий RPO. Використовувався HAProxy на окремому VPS для маршрутизації трафіку: запис на майстер (порт 5432), читання на репліки (порт 5433).
- Моніторинг: Prometheus з `postgres_exporter` та `patroni_exporter`, Grafana для візуалізації, Alertmanager для оповіщень в Slack та PagerDuty.
- Бекапи: pgBackRest для інкрементальних бекапів в S3-сумісне сховище.
Результати:
- RTO 15 секунд: При імітації відмови майстра (вимикання сервера) Patroni автоматично перемикав роль на репліку за 15-20 секунд.
- Нульовий RPO: Завдяки синхронній реплікації не було зафіксовано втрати даних при збоях.
- Покращення SLA: Компанія змогла гарантувати клієнтам 99.99% доступності сервісу.
- Зниження операційного стресу: Автоматизація failover дозволила команді DevOps зосередитися на розвитку, а не на ручному відновленні.
Кейс 2: E-commerce платформа з високим навантаженням читання (pg_auto_failover + PgBouncer)
Проблема: Великий інтернет-магазин відчував пікові навантаження під час розпродажів, що призводило до деградації продуктивності БД і іноді до короткочасних простоїв. Основна проблема була в масштабуванні читання і необхідності швидкого відновлення після збоїв. RPO був прийнятним у кілька секунд, RTO — до 1 хвилини.
Рішення: Впровадження pg_auto_failover у поєднанні з PgBouncer для пулінгу з'єднань і HAProxy для балансування.
- Архітектура: 2 виділених сервера (16vCPU, 64GB RAM, 1TB NVMe SSD) для PostgreSQL (майстер і репліка) і 1 VPS для монітора pg_auto_failover. Додатково 2 VPS для PgBouncer і HAProxy в режимі active/passive з Keepalived.
- Конфігурація pg_auto_failover: Асинхронна реплікація для кращої продуктивності, але з налаштуваннями `wal_level = replica` і `hot_standby = on`. Монітор pg_auto_failover розміщений на окремому вузлі для підвищення надійності.
- PgBouncer: Розгорнутий на двох вузлах (HAProxy перед ними), щоб управляти сотнями тисяч клієнтських з'єднань, знижуючи навантаження на PostgreSQL.
- HAProxy: Налаштований для направлення запитів запису на поточний майстер (через PgBouncer) і балансування запитів читання між майстром і реплікою (також через PgBouncer).
- Бекапи: Barman для потокових бекапів і point-in-time recovery.
Результати:
- RTO ~45 секунд: При збої майстра pg_auto_failover успішно перемикався, а HAProxy і PgBouncer швидко перенаправляли трафік.
- Масштабування читання: PgBouncer і HAProxy ефективно розподіляли навантаження читання, дозволяючи кластеру витримувати піки до 100 000 RPS.
- Стабільність: Значно скоротилася кількість простоїв і деградацій продуктивності під час високих навантажень.
- Спрощене управління: pg_auto_failover спростив завдання з управління HA в порівнянні з кастомними скриптами.
Кейс 3: Стартап з мікросервісною архітектурою (Patroni в контейнерах на VPS)
Проблема: Невеликий стартап розробляв нову мікросервісну платформу і потребував високонадійної БД, яка легко інтегрувалася б з контейнерним середовищем (Docker/Kubernetes). Бюджет був обмежений, тому використовувалися VPS. Потрібен був швидкий failover і гнучкість в управлінні.
Рішення: Розгортання Patroni в Docker-контейнерах на 3 VPS з etcd, також запущеним в контейнерах.
- Архітектура: 3 VPS (4vCPU, 8GB RAM, 160GB NVMe SSD). На кожному VPS запущений Docker. У кожному VPS запущені контейнери для PostgreSQL, Patroni і etcd.
- Конфігурація: Використовувалися офіційні Docker-образи PostgreSQL і Patroni. Конфігурація Patroni була адаптована для роботи в контейнерах, з монтуванням томів для даних PostgreSQL і etcd. Мережа контейнерів налаштована для взаємодії через внутрішні IP-адреси VPS.
- Взаємодія з мікросервісами: Мікросервіси підключалися до кластера через HAProxy, запущений на окремому VPS, який моніторив Patroni API для визначення майстра.
- CICD: Розгортання і оновлення кластера Patroni було автоматизовано за допомогою GitLab CI/CD і Ansible.
Результати:
- Швидке розгортання: Завдяки контейнеризації і автоматизації, розгортання нового кластера займало лічені хвилини.
- Висока доступність: Кластер успішно переживав відмови окремих VPS, автоматично перемикаючи майстра.
- Економічність: Використання VPS і Open Source рішень дозволило вкластися в обмежений бюджет.
- Гнучкість: Легко масштабувати кластер, додаючи нові VPS і запускаючи на них контейнери.
Ці кейси демонструють, що з правильним вибором інструментів і підходом, можна досягти високого рівня доступності PostgreSQL навіть на відносно недорогих VPS і виділених серверах, задовольняючи різні бізнес-вимоги.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Інструменти та ресурси для управління HA PostgreSQL кластером
Успішне розгортання і підтримка високонадійного PostgreSQL кластера неможливе без правильного набору інструментів. Тут ми перерахуємо ключові утиліти і ресурси, які допоможуть вам на кожному етапі.
1. Інструменти для створення HA-кластера
- Patroni: (Zalando) — Оркестратор для PostgreSQL, який використовує DCS для координації HA. Must-have для автоматизованих і надійних кластерів.
- pg_auto_failover: (Citus Data / Microsoft) — Спрощене рішення для автоматичного failover, інтегроване з PostgreSQL.
- Pgpool-II: Проксі-сервер з пулінгом з'єднань, балансуванням навантаження і функціями HA.
2. Розподілені сховища конфігурації (DCS)
Необхідні для Patroni, забезпечують кворум і зберігають стан кластера.
- etcd: Високонадійне розподілене сховище ключ/значення, яке часто використовується в Kubernetes.
- Consul: Сервіс-меш і розподілене сховище ключ/значення від HashiCorp.
- Apache ZooKeeper: Ще одне зріле рішення для розподіленої координації.
3. Балансувальники навантаження та проксі
- HAProxy: Високопродуктивний TCP/HTTP балансувальник навантаження. Ідеальний для розподілу клієнтських запитів між майстром та репліками.
- PgBouncer: Легкий пулер з'єднань для PostgreSQL. Зменшує навантаження на сервер БД від великої кількості клієнтських з'єднань.
- Keepalived: Використовується для забезпечення високої доступності IP-адрес (Virtual IP) та сервісів за допомогою протоколу VRRP. Часто використовується з HAProxy.
4. Інструменти резервного копіювання та відновлення
- pgBackRest: Потужний та гнучкий інструмент для резервного копіювання та відновлення PostgreSQL, що підтримує інкрементальні бекапи, стиснення та віддалене зберігання.
- Офіційна документація pgBackRest
- Barman: (Backup and Recovery Manager) — Ще один популярний інструмент для централізованого керування бекапами PostgreSQL, включаючи Point-in-Time Recovery.
5. Інструменти моніторингу та логування
- Prometheus: Система моніторингу та сповіщень з потужною мовою запитів PromQL.
- Grafana: Платформа для візуалізації даних моніторингу.
- postgres_exporter: Експортер метрик PostgreSQL для Prometheus.
- patroni_exporter: Експортер метрик Patroni для Prometheus.
- pgBadger: Потужний аналізатор логів PostgreSQL, який генерує детальні HTML-звіти.
- ELK Stack (Elasticsearch, Logstash, Kibana): Для централізованого збору, зберігання, індексації та візуалізації логів.
6. Автоматизація розгортання
- Ansible: Інструмент для автоматизації налаштування та розгортання ПЗ. Ідеальний для управління конфігурацією кластера.
- Terraform: Інструмент для управління інфраструктурою як кодом (IaC). Дозволяє автоматизувати створення VPS та їх базове налаштування.
7. Корисні посилання та документація
- Офіційна документація PostgreSQL — Завжди актуальне та повне джерело інформації про саму СУБД.
- PostgreSQL Wiki: High Availability and Load Balancing — Огляд різних HA-рішень та підходів.
- Блоги та спільноти: Planet PostgreSQL, PostgreSQL.ru, Хабр, різні Telegram-канали по PostgreSQL та DevOps — чудові джерела для вивчення кейсів та вирішення проблем.
Troubleshooting: Вирішення типових проблем у HA PostgreSQL
Навіть при самому ретельному налаштуванні у високодоступних системах можуть виникати проблеми. Важливо вміти швидко діагностувати та усувати їх. Ось деякі типові проблеми та підходи до їх вирішення.
1. Проблеми з реплікацією (Replication Lag)
Симптоми: Репліки значно відстають від майстра, що видно по метриках моніторингу або по запитах.
Діагностика:
-- На майстрі
SELECT client_addr, state, sync_state, pg_wal_lsn_diff(pg_current_wal_lsn(), replay_lsn) AS lag_bytes
FROM pg_stat_replication;
-- На репліці
SELECT pg_wal_lsn_diff(pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn()); -- Lag в байтах
Можливі причини та рішення:
- Мережеві проблеми: Повільне або нестабільне мережеве з'єднання між майстром та реплікою.
- Рішення: Перевірте пропускну здатність (`iperf3`) та затримку (`ping`, `mtr`) між вузлами. Переконайтеся, що немає втрати пакетів. Можливо, потрібно оптимізувати мережеву інфраструктуру або використовувати більш швидкі VPS/виділені сервери.
- Навантаження на репліку: Репліка перевантажена запитами читання, що заважає застосуванню WAL-файлів.
- Рішення: Оптимізуйте запити читання, додайте більше реплік для розподілу навантаження, розгляньте використання PgBouncer для ефективного управління з'єднаннями.
- Повільний диск на репліці: Дискова підсистема репліки не справляється із записом WAL-файлів.
- Рішення: Перевірте метрики I/O (iostat, fio). Можливо, потрібен більш швидкий SSD (NVMe) або оптимізація дискової підсистеми.
- Недостатні ресурси на майстрі: Майстер не встигає генерувати WAL-файли або у нього мало `wal_senders`.
- Рішення: Збільште `max_wal_senders` та перевірте спільні ресурси майстра.
2. Проблеми з Failover (Patroni/pg_auto_failover не перемикає майстра)
Симптоми: Майстер недоступний, але автоматичний failover не відбувається або займає занадто багато часу.
Діагностика:
# Для Patroni
patronictl -c /etc/patroni/patroni.yml list
# Перевірте логи Patroni на всіх вузлах
sudo journalctl -u patroni -f
# Для pg_auto_failover
pg_auto_failover show state
# Перевірте логи pg_auto_failover monitor і вузлів
sudo journalctl -u pg_auto_failover_monitor -f
sudo journalctl -u pg_auto_failover_node -f
Можливі причини та рішення:
- Проблеми з DCS (etcd/Consul): DCS недоступний або не має кворуму. Patroni не може оновити стан.
- Рішення: Перевірте статус DCS (`etcdctl member list`). Переконайтеся, що всі вузли DCS працюють і мають кворум. Можливо, потрібно перезапустити DCS або вручну відновити кворум.
- Мережеві проблеми: Вузли Patroni/pg_auto_failover не можуть "бачити" один одного або DCS.
- Рішення: Перевірте мережеву зв'язність (ping, telnet на порти) між усіма вузлами та DCS. Переконайтеся в коректній роботі файрволів.
- Неправильна конфігурація Patroni/pg_auto_failover: Помилки в `patroni.yml` або в налаштуваннях pg_auto_failover.
- Рішення: Уважно перевірте конфігураційні файли на всіх вузлах. Особливо параметри `ttl`, `loop_wait`, `retry_timeout`, `maximum_lag_on_failover`.
- Проблеми з ресурсами: Вузли перевантажені (CPU, RAM), що заважає нормальній роботі Patroni/pg_auto_failover.
- Рішення: Перевірте утилізацію ресурсів на всіх вузлах. Можливо, потрібно збільшити ресурси або оптимізувати навантаження.
- Replication Lag занадто великий: Якщо `maximum_lag_on_failover` занадто низький, а репліка відстає, Patroni може не вибрати її як кандидата на майстра.
- Рішення: Збільште значення `maximum_lag_on_failover` або усуньте причину відставання реплікації.
3. Проблеми з підключенням клієнтів після Failover
Симптоми: Після успішного failover клієнтські застосунки не можуть підключитися до нового майстра.
Діагностика:
- Перевірте, куди вказує DNS-запис для вашого кластера.
- Перевірте статус балансувальника навантаження (HAProxy) та його бекендів.
- Спробуйте підключитися до нового майстра напряму з клієнтського хоста (`psql -h
-p 5432 -U `).
Можливі причини та рішення:
- Кешування DNS: Клієнтські застосунки або ОС кешують старий DNS-запис.
- Рішення: Використовуйте низький TTL для DNS-запису кластера (наприклад, 30-60 секунд). Рекомендується використовувати балансувальник навантаження, який не залежить від DNS-перемикань.
- Балансувальник навантаження не оновив стан: HAProxy або інший балансувальник не переключив трафік на нового майстра.
- Рішення: Перевірте логи HAProxy, переконайтеся, що його health checks коректно працюють з Patroni API (`/primary`, `/replica`). Перезапустіть HAProxy, якщо необхідно.
- Файрвол: Файрвол блокує підключення до нового майстра.
- Рішення: Переконайтеся, що порт 5432 відкрито на новому майстер-вузлі для клієнтських підключень.
4. Проблеми з продуктивністю
Симптоми: Повільні запити, високе завантаження CPU/RAM/IO, довгі транзакції.
Діагностика:
-- Перевірка активних запитів
SELECT pid, usename, client_addr, application_name, backend_start, state, query_start, query
FROM pg_stat_activity
WHERE state != 'idle' ORDER BY query_start;
-- Перевірка повільних запитів (якщо включено log_min_duration_statement)
-- Аналіз логів PostgreSQL через pgBadger
-- Моніторинг ресурсів ОС
top, htop, iostat, vmstat, netstat
Можливі причини та рішення:
- Неоптимізовані запити: Погано написані запити, відсутність індексів.
- Рішення: Використовуйте `EXPLAIN ANALYZE` для аналізу запитів, створіть необхідні індекси, оптимізуйте схему БД.
- Недостатньо ресурсів: Нестача CPU, RAM або повільний диск.
- Рішення: Збільште ресурси VPS/виділеного сервера.
- Неправильна конфігурація PostgreSQL: Неоптимальні значення `work_mem`, `shared_buffers`, `effective_cache_size` і т.д.
- Рішення: Налаштуйте параметри PostgreSQL відповідно до рекомендацій для вашого навантаження та доступних ресурсів.
- Блокування: Довгі транзакції або блокування, що заважають іншим запитам.
- Рішення: Ідентифікуйте та усуньте джерело блокувань. Оптимізуйте транзакції.
Коли звертатися в підтримку
Якщо ви вичерпали всі можливості з діагностики та усунення проблеми, або якщо проблема критична і викликає тривалий простій, не соромтеся звертатися за допомогою:
- Спільнота PostgreSQL: Форуми, mailing lists, Telegram-чати.
- Розробники Patroni/pg_auto_failover: GitHub Issues або спеціалізовані канали.
- Професійна підтримка: Компанії, що спеціалізуються на PostgreSQL або DevOps-консалтингу.
Важливо надати максимально повну інформацію: логи, конфігураційні файли, метрики моніторингу, кроки з відтворення проблеми.
FAQ: Часті запитання про високонадійний PostgreSQL
Чи можу я використовувати лише два вузли для HA PostgreSQL?
Теоретично, так, але це вкрай не рекомендується для продакшн-середовища. З двома вузлами ви не зможете забезпечити кворум. У разі мережевого розділення (network split-brain) обидва вузли можуть вирішити, що інший вузол недоступний, і кожен спробує стати майстром, що призведе до розсинхронізації даних. Для надійного кворуму та запобігання split-brain завжди використовуйте непарну кількість вузлів (мінімум три) для голосування або для вашого розподіленого сховища конфігурації (etcd/Consul).
Як оновити PostgreSQL в HA кластері без простою?
Для оновлення PostgreSQL в HA-кластері рекомендується використовувати метод "rolling upgrade". Спочатку оновіть репліки, по одній, потім виконайте плановий switchover (перемикання майстра) на одну з оновлених реплік. Після цього оновіть залишок старого майстра. Patroni надає зручні інструменти для виконання switchover. Важливо ретельно протестувати процес оновлення на тестовому стенді перед застосуванням у продакшені.
Що щодо бекапів? Вони, як і раніше, потрібні, якщо у мене є HA?
Абсолютно! Висока доступність захищає від простоїв, але не від втрати даних через логічні помилки (наприклад, випадкове видалення даних додатком), апаратних збоїв усіх вузлів одночасно (наприклад, пожежа в дата-центрі) або людських помилок. Бекапи — це ваша остання лінія оборони. Завжди робіть регулярні, тестовані бекапи та зберігайте їх віддалено від основного кластера.
Як масштабувати читання в HA кластері?
Масштабування читання в HA кластері PostgreSQL досягається шляхом додавання додаткових реплік. Ви можете направляти запити SELECT на ці репліки, використовуючи балансувальник навантаження (наприклад, HAProxy, Pgpool-II), який розподілятиме трафік. Patroni та pg_auto_failover дозволяють легко додавати нові репліки до кластера. Переконайтеся, що ваш додаток коректно розділяє запити читання та запису.
У чому різниця між синхронною та асинхронною реплікацією?
При асинхронній реплікації майстер-сервер підтверджує транзакцію клієнту відразу після того, як вона записана в WAL на майстрі, не чекаючи підтвердження від репліки. Це забезпечує високу продуктивність, але у разі збою майстра ви можете втратити останні транзакції, які ще не були передані або застосовані на репліці (ненульовий RPO). При синхронній реплікації майстер чекає підтвердження від однієї або кількох реплік про те, що транзакція успішно записана на їхні диски, перш ніж підтвердити її клієнту. Це гарантує нульовий RPO (немає втрати даних), але збільшує затримку запису та знижує продуктивність.
Що таке "кворум" у контексті HA PostgreSQL?
Кворум — це мінімальна кількість вузлів, яка має бути доступна та одностайна у своєму рішенні для виконання певної операції (наприклад, вибору нового майстра або підтвердження транзакції). У розподілених системах кворум запобігає сценарію split-brain. Наприклад, у кластері з 3 вузлів кворум зазвичай становить 2 вузли. Якщо 2 вузли бачать один одного, але не бачать третій, вони можуть прийняти рішення про вибір майстра. Якщо ж кожен з двох вузлів бачить тільки себе, кворум не досягається, і жоден з них не стане майстром, запобігаючи конфлікту.
Як впоратися з мережевими розділами (Network Partitions) у кластері?
Мережеві розділи — це сценарії, коли частина вузлів кластера втрачає зв'язок з іншою частиною. Правильно налаштований механізм кворуму (наприклад, через etcd/Consul в Patroni) є ключовим. Він гарантує, що лише більшість вузлів (які мають кворум) зможе продовжити роботу як майстер, в той час як меншість перейде в режим очікування або повністю зупиниться, щоб запобігти split-brain. Важливо ретельно планувати розміщення вузлів (наприклад, у різних стійках або навіть дата-центрах) і мати надійний моніторинг мережі.
Чи можна змішувати VPS і виділені сервери в одному HA кластері?
Технічно це можливо, але не рекомендується для критично важливих систем. Різні типи серверів можуть мати різну продуктивність, затримки мережі та надійність, що ускладнює прогнозування поведінки кластера і може призвести до асиметричних проблем. Якщо ви все ж вирішите це зробити, переконайтеся, що найповільніший компонент не стане "вузьким місцем" і що у вас є чітка стратегія управління неоднорідністю.
Що таке Point-in-Time Recovery (PITR) і як воно пов'язане з HA?
Point-in-Time Recovery (PITR) — це можливість відновити базу даних до будь-якого моменту часу в минулому (в межах доступних бекапів та WAL-файлів). Це критично важлива функція для відновлення після логічних помилок або пошкодження даних. Хоча PITR не є частиною HA-рішення напряму, воно доповнює HA, забезпечуючи повне відновлення даних у випадках, коли HA не може допомогти (наприклад, після випадкового DELETE). Інструменти на кшталт pgBackRest та Barman надають можливості PITR.
Чи є повністю безкоштовне рішення для HA PostgreSQL?
Так, більшість згаданих рішень, таких як Patroni, pg_auto_failover, Pgpool-II, а також сам PostgreSQL, є Open Source та безкоштовні. Однак "безкоштовність" відноситься лише до вартості ліцензій. Вам все одно доведеться платити за інфраструктуру (VPS/сервери), а також за інженерний час на проєктування, розгортання, налаштування, моніторинг та підтримку, що є суттєвою частиною загальних витрат.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Висновок: Ваш шлях до надійного PostgreSQL
Створення високодоступного PostgreSQL кластера на VPS або виділених серверах — це не просто технічне завдання, а стратегічне рішення, яке безпосередньо впливає на безперервність вашого бізнесу, репутацію та доходи. У 2026 році, коли простої неприпустимі, а дані є золотом, інвестиції в відмовостійку базу даних окупаються багаторазово.
Ми розглянули різні підходи, від потужного оркестратора Patroni до простішого pg_auto_failover та ручних рішень з нативною реплікацією. Кожен з них має свої сильні та слабкі сторони, і вибір завжди повинен ґрунтуватися на ретельному аналізі ваших вимог до RPO та RTO, доступного бюджету та рівня експертизи вашої команди. Пам'ятайте, що не існує універсального рішення, яке підходить усім. Ваше завдання — знайти баланс між складністю, вартістю та рівнем надійності, який відповідає вашим бізнес-цілям.
Ключові висновки, які ви повинні винести з цього майстер-промту:
- Планування — це все: Детальне проєктування архітектури, оцінка ресурсів та чітке визначення бізнес-вимог — фундамент успіху.
- Тестування — ваша страховка: Регулярне тестування механізмів failover, switchover та відновлення з бекапів абсолютно критичне. Неперевірена HA-система — це ілюзія безпеки.
- Моніторинг — ваші очі та вуха: Без всебічного моніторингу всіх компонентів кластера ви будете сліпі до потенційних проблем. Налаштуйте сповіщення на критичні метрики.
- Автоматизація — ваш найкращий друг: Інвестуйте в автоматизацію розгортання та рутинних операцій. Це знизить ризик людських помилок та звільнить час інженерів для складніших задач.
- Бекапи — остання лінія оборони: Ніколи не забувайте про надійні, тестовані бекапи, які доповнюють HA-стратегію та захищають від логічних помилок та катастрофічних збоїв.
Побудова надійного HA-кластера PostgreSQL — це безперервний процес, який вимагає постійної уваги, навчання та адаптації до мінливих умов. Але з правильними інструментами, знаннями та підходом ваша база даних стане не просто сховищем даних, а надійним та стійким серцем вашої цифрової інфраструктури.
Наступні кроки для читача:
- Виберіть рішення: Визначтеся з HA-рішенням, яке найкращим чином відповідає вашим потребам.
- Розробіть пілотний проєкт: Почніть з невеликого тестового кластера на кількох VPS, щоб освоїти вибраний інструмент та відпрацювати всі кроки.
- Автоматизуйте: Використовуйте Ansible або Terraform для створення повторюваного процесу розгортання.
- Впроваджуйте моніторинг: Налаштуйте Prometheus/Grafana для відстеження стану вашого кластера.
- Тренуйтеся: Регулярно проводьте навчання з аварійного відновлення та тестуйте failover.
- Продовжуйте навчатися: Активно беріть участь у спільноті PostgreSQL, читайте блоги та документацію, щоб бути в курсі останніх розробок та найкращих практик.
Нехай ваш PostgreSQL кластер буде завжди доступний та надійний!