Розширені стратегії деплою Docker-застосунків на VPS: Blue/Green та Canary оновлення
TL;DR
- Безшовний деплой на VPS: Освоїте стратегії Blue/Green та Canary для мінімізації даунтайму та ризиків під час оновлення Docker-застосунків на віртуальних серверах.
- Blue/Green для простоти та безпеки: Ідеально для застосунків, де повне перемикання трафіку прийнятне; забезпечує швидкий відкат, але вимагає подвоєння ресурсів на час деплою.
- Canary для поступового впровадження: Дозволяє тестувати нову версію на невеликій частині користувачів, мінімізуючи вплив можливих помилок та збираючи зворотний зв'язок перед повним розгортанням.
- Автоматизація — ключ до успіху: Використовуйте CI/CD пайплайни з Ansible, Jenkins, GitLab CI або GitHub Actions для автоматизації всіх етапів деплою та моніторингу.
- Моніторинг та логування критичні: Впровадьте Prometheus, Grafana, ELK-стек або Loki/Promtail для відстеження метрик, помилок та продуктивності обох версій застосунку в реальному часі.
- Оптимізація ресурсів та витрат: За допомогою грамотного вибору VPS, використання ефективних образів Docker та продуманих стратегій, можна значно скоротити витрати, незважаючи на тимчасове подвоєння ресурсів.
- Конкретні приклади та інструменти 2026 року: Стаття містить актуальні для 2026 року рекомендації щодо інструментів, конфігурацій та практичних кейсів для успішного впровадження.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
1. Вступ
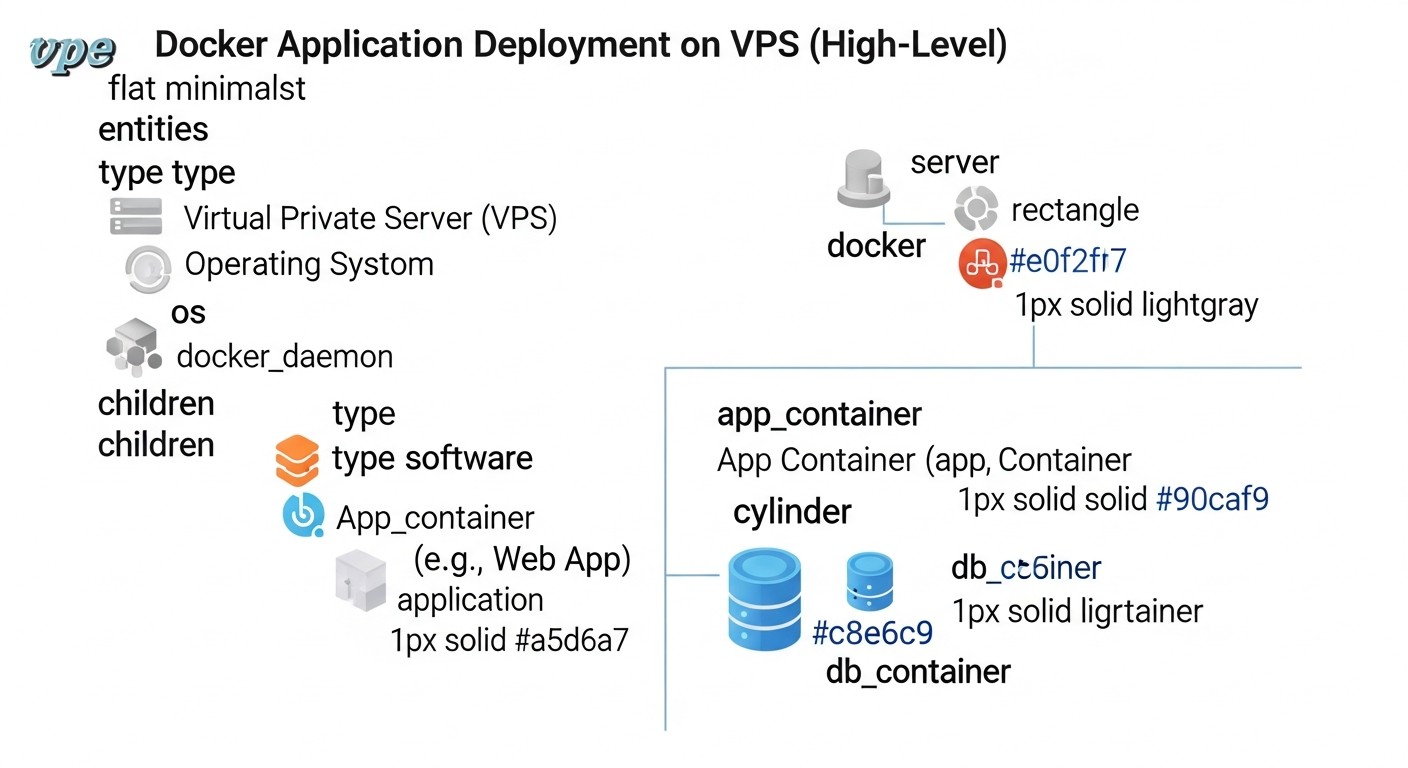 Схема: 1. Вступ
Схема: 1. Вступ
У світі DevOps та хмарних технологій, що стрімко розвивається, де кожна хвилина простою обходиться бізнесу в тисячі, а то й мільйони доларів, забезпечення безперебійної роботи застосунків стає не просто бажанням, а критичною необхідністю. Особливо це актуально для SaaS-проєктів, де доступність сервісу безпосередньо впливає на задоволеність клієнтів, репутацію і, в кінцевому підсумку, на прибуток. У 2026 році, коли мікросервісна архітектура та контейнеризація за допомогою Docker стали де-факто стандартом, а VPS-хостинги пропонують безпрецедентну гнучкість та продуктивність за доступною ціною, питання ефективного та безпечного деплою виходить на перший план.
Традиційні методи деплою, такі як "rip-and-replace" (зупинка старої версії, розгортання нової), давно показали свою неспроможність. Вони призводять до неминучого даунтайму, високого ризику помилок та складнощів з відкотом у разі проблем. Саме тому індустрія прийшла до необхідності використання розширених стратегій, таких як Blue/Green та Canary оновлення. Ці підходи дозволяють мінімізувати або повністю виключити простій застосунку, значно знизити ризики при впровадженні нових функцій та забезпечити швидкий та безпечний відкат до попередньої версії.
Ця стаття призначена для широкого кола технічних фахівців: від досвідчених DevOps-інженерів та системних адміністраторів, які прагнуть оптимізувати свої пайплайни, до backend-розробників (Python, Node.js, Go, PHP), які бажають краще розуміти інфраструктурні аспекти деплою. Фаундери SaaS-проєктів та технічні директори стартапів знайдуть тут практичні рекомендації щодо зниження операційних ризиків та підвищення надійності своїх сервісів. Ми заглибимося в деталі Blue/Green та Canary стратегій, розглянемо їх переваги та недоліки, наведемо конкретні приклади реалізації на VPS з використанням Docker, а також обговоримо актуальні інструменти та найкращі практики, актуальні на 2026 рік.
Ми не будемо продавати вам "чарівні пігулки" або "срібні кулі". Натомість ви отримаєте експертний, практичний гайд, заснований на реальному досвіді та перевірених рішеннях. Ми розберемо, як ці стратегії допомагають вирішувати такі проблеми, як:
- Мінімізація даунтайму: Забезпечення безперервної роботи сервісу під час оновлення.
- Зниження ризиків деплою: Можливість швидкого відкату або поступового впровадження нової версії.
- Покращення якості релізів: Тестування нової версії в реальному виробничому середовищі на обмеженій аудиторії.
- Підвищення довіри до команди: Демонстрація стабільності та надійності сервісу навіть при частих оновленнях.
- Оптимізація використання ресурсів: Ефективне управління інфраструктурою VPS для підтримки декількох версій застосунку.
Приготуйтеся до занурення у світ розширених стратегій деплою, які змінять ваше уявлення про те, як повинні оновлюватися Docker-застосунки на VPS. Давайте почнемо.
2. Основні критерії вибору стратегії деплою
 Схема: 2. Основні критерії вибору стратегії деплою
Схема: 2. Основні критерії вибору стратегії деплою
Вибір відповідної стратегії деплою — це не просто технічне рішення, а стратегічний вибір, який безпосередньо впливає на стабільність, надійність та економічну ефективність вашого застосунку. У 2026 році, коли вимоги до швидкості та якості релізів тільки ростуть, важливо враховувати безліч факторів. Давайте детально розберемо ключові критерії, які допоможуть вам визначити, яка стратегія — Blue/Green або Canary — найкращим чином відповідає вашим потребам.
2.1. Допустимий даунтайм (Downtime Tolerance)
Чому важливо: Це, мабуть, найочевидніший і найкритичніший фактор. Для деяких сервісів (наприклад, банківських систем, медичних платформ, E-commerce у пікові години) будь-який простій неприйнятний. Для інших (внутрішні інструменти, блоги з некритичним трафіком) кілька хвилин простою можуть бути допустимими. Даунтайм безпосередньо впливає на користувацький досвід, фінансові втрати та репутацію бренду. Стратегії Blue/Green і Canary створені для мінімізації або повного виключення даунтайму.
Як оцінювати: Визначте SLA (Service Level Agreement) вашого застосунку. Який максимально допустимий час простою на рік, місяць чи тиждень? Які фінансові та репутаційні втрати спричинить простій? Якщо даунтайм має бути нульовим або прагнути до нуля, то Blue/Green або Canary — ваш єдиний вибір.
2.2. Швидкість відкату (Rollback Speed)
Чому важливо: Помилки трапляються. І коли вони трапляються в продакшені, здатність швидко повернутися до стабільної версії стає життєво важливою. Чим швидше ви можете відкотитися, тим меншим буде вплив на користувачів і бізнес. Повільний відкат може призвести до тривалого простою та погіршення проблем.
Як оцінювати: Виміряйте час, необхідний для розгортання попередньої версії застосунку. В ідеалі, відкат має займати секунди або хвилини. Blue/Green дозволяє виконати відкат практично миттєво, просто переключивши трафік назад на "синю" (стару) середу. Canary вимагає складнішого відкату, можливо, поетапного виведення "канарейки" з експлуатації та повернення трафіку на стабільну версію.
2.3. Складність реалізації та управління (Implementation Complexity & Management Overhead)
Чому важливо: Кожна стратегія деплою має свою криву навчання і вимагає певних навичок та інструментів. Складна стратегія може потребувати більше часу на налаштування, більше ресурсів для підтримки та збільшити ймовірність помилок при ручному управлінні. В умовах обмежених ресурсів VPS і невеликої команди це може бути критично.
Як оцінювати: Оцініть рівень вашої команди. Чи є у вас досвід роботи з балансувальниками навантаження, динамічним DNS, CI/CD пайплайнами? Чи готові ви інвестувати час у вивчення та налаштування? Blue/Green відносно простий в концепції, але вимагає ретельного управління трафіком. Canary складніший, оскільки передбачає тонке налаштування маршрутизації трафіку (користувачі, відсоток) і складніший моніторинг.
2.4. Споживання ресурсів (Resource Consumption)
Чому важливо: Деплой на VPS часто пов'язаний з обмеженими ресурсами. Blue/Green стратегія, за своєю суттю, вимагає як мінімум подвоєння ресурсів на короткий період (стара і нова версії працюють паралельно). Canary може бути більш економною, якщо ви поступово замінюєте старі інстанси новими, але для повноцінного A/B тестування або паралельної роботи двох версій все одно знадобляться додаткові ресурси.
Як оцінювати: Проаналізуйте поточне завантаження вашого VPS. Чи є у вас запас по CPU, RAM, дисковому простору? Чи готові ви тимчасово масштабувати VPS або використовувати додаткові інстанси? Вартість ресурсів на VPS у 2026 році, хоча і знизилася, все ще є значущим фактором. Оцініть, чи можете ви дозволити собі подвоїти ресурси на 10-30 хвилин під час деплою.
2.5. Можливості тестування та валідації (Testing & Validation Capabilities)
Чому важливо: Чим раніше ви виявите помилку, тим дешевше вона обійдеться. Стратегії деплою повинні надавати можливості для тестування нової версії в максимально наближених до продакшену умовах, перш ніж вона стане доступна всім користувачам. Це включає функціональне тестування, навантажувальне тестування, моніторинг продуктивності та збір метрик.
Як оцінювати: Blue/Green дозволяє провести повне тестування нового "зеленого" середовища перед переключенням трафіку. Canary йде далі, дозволяючи тестувати нову версію на реальних користувачах, збираючи метрики та зворотний зв'язок, перш ніж повністю розгорнути її. Це особливо цінно для оцінки користувацького досвіду та продуктивності в реальних умовах.
2.6. Сумісність з базами даних і міграціями (Database & Data Migration Compatibility)
Чому важливо: Оновлення застосунку часто тягне за собою зміни в схемі бази даних. Це одна з найскладніших частин деплою, оскільки вона може порушити роботу як старої, так і нової версії застосунку. Важливо переконатися, що ваша стратегія деплою підтримує зворотну і пряму сумісність зі змінами бази даних.
Як оцінювати: Плануйте міграції бази даних так, щоб вони були неблокуючими і зворотно сумісними. Наприклад, при додаванні нової колонки, спочатку розгорніть нову версію застосунку, яка вміє працювати з новою колонкою (але не вимагає її). Потім виконайте міграцію БД, а після цього переключіть трафік. При видаленні колонки, спочатку переконайтеся, що всі старі версії, які використовують цю колонку, виведені з експлуатації. Це вимагає ретельного планування і, можливо, використання патернів, таких як "Two-Phase Schema Migration".
2.7. Вимоги до відмовостійкості (Fault Tolerance Requirements)
Чому важливо: Навіть при найбільш продуманих стратегіях, збої можуть відбуватися. Ваша система повинна бути спроектована так, щоб витримувати відмови окремих компонентів або цілих версій застосунку. Це включає в себе автоматичне виявлення проблем, переключення на резервні ресурси та ізоляцію несправних частин.
Як оцінювати: Оцініть, наскільки критично для вашого бізнесу, щоб система продовжувала працювати навіть при частковому збої. Blue/Green забезпечує високу відмовостійкість при відкаті, так як стара версія залишається доступною. Canary, завдяки поступовому розгортанню, обмежує вплив збою лише на частину користувачів, що підвищує загальну відмовостійкість системи в процесі деплою.
Ретельний аналіз цих критеріїв дозволить вам вибрати найбільш підходящу стратегію деплою, яка не тільки мінімізує ризики і даунтайм, але і буде економічно виправданою і керованою для вашої команди та інфраструктури VPS.
3. Порівняльна таблиця: Blue/Green vs. Canary оновлення
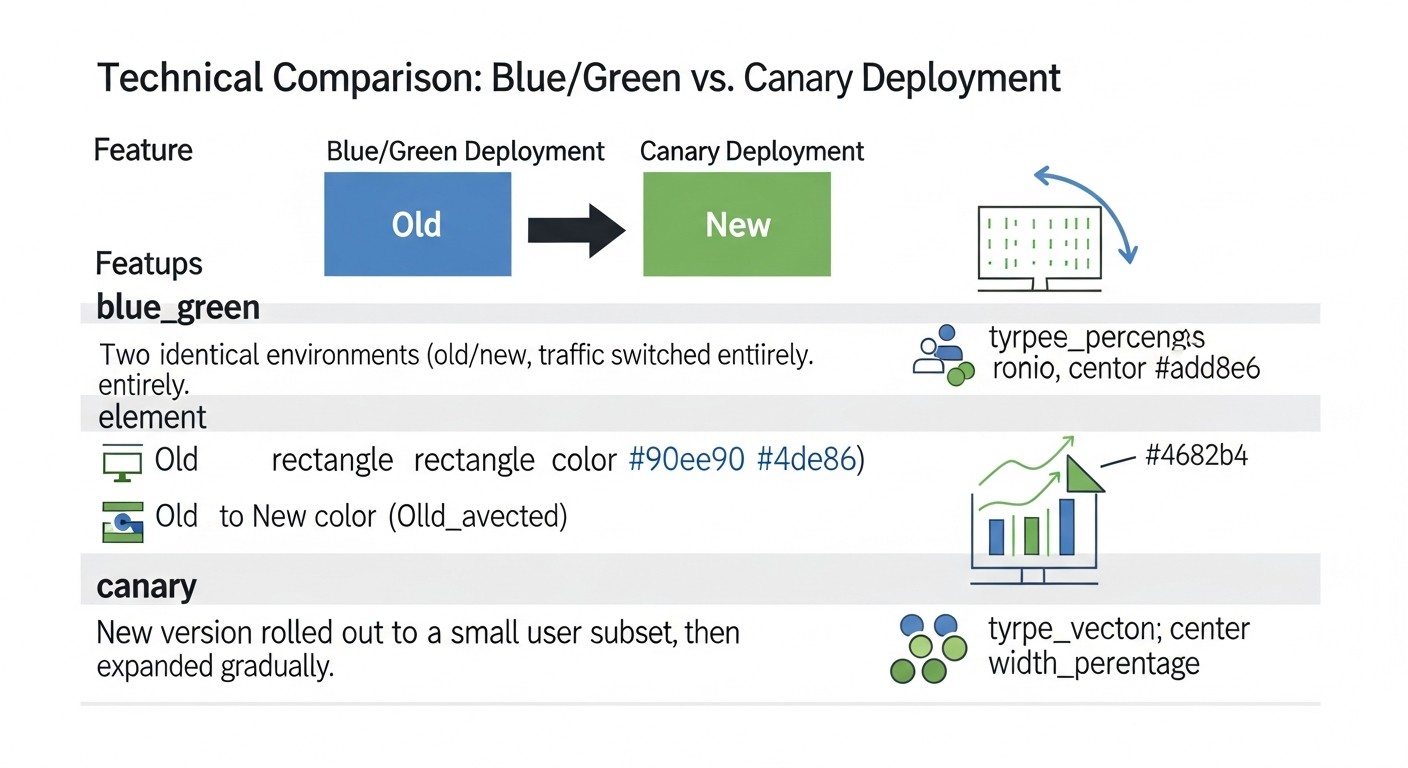 Схема: 3. Порівняльна таблиця: Blue/Green vs. Canary оновлення
Схема: 3. Порівняльна таблиця: Blue/Green vs. Canary оновлення
Вибір між Blue/Green і Canary стратегіями деплою часто зводиться до компромісу між простотою, швидкістю відкату і можливістю тестування на реальних користувачах. У цій таблиці ми представимо детальне порівняння обох стратегій, враховуючи актуальні реалії та очікування 2026 року, включаючи приблизні витрати і технічні особливості.
| Критерій |
Blue/Green Деплой |
Canary Деплой |
| Основна ідея |
Два ідентичні середовища (Blue - старе, Green - нове). Трафік перемикається цілком на Green після успішного тестування. |
Поступове впровадження нової версії (Canary) для невеликої частини користувачів, потім збільшення відсотка. |
| Даунтайм при деплої |
Практично нульовий (час перемикання трафіку). |
Нульовий, оскільки стара версія продовжує обслуговувати більшість користувачів. |
| Швидкість відкату |
Миттєвий (перемикання трафіку назад на Blue). |
Займає більше часу, оскільки потрібно вивести Canary з експлуатації та перенаправити трафік. |
| Споживання ресурсів (VPS) |
Тимчасово подвоює споживання (Blue + Green середовища). Наприклад, 2x VPS або 2x набір контейнерів. |
Може бути ефективнішим, якщо Canary займає невелику частину ресурсів. На піку може бути 1.1x - 1.5x від звичайного. |
| Складність реалізації |
Середня. Вимагає управління двома середовищами та балансувальником навантаження. |
Висока. Вимагає складної маршрутизації трафіку, просунутого моніторингу та автоматизації. |
| Можливості тестування |
Повне тестування нової версії перед запуском. |
Тестування на реальних користувачах, A/B тестування, збір метрик продуктивності та помилок у продакшені. |
| Виявлення помилок |
Помилки виявляються до перемикання трафіку (в Green). |
Помилки виявляються на невеликій частині користувачів, мінімізуючи загальний вплив. |
| Управління базами даних |
Вимагає ретельного планування міграцій зі зворотною сумісністю. |
Ще більш сувора вимога до зворотної сумісності, оскільки обидві версії можуть одночасно працювати з БД. |
| Ідеально підходить для |
Критичних додатків з високим SLA, де потрібен швидкий відкат і повне тестування перед релізом. |
Додатків, де важливо мінімізувати ризик, тестувати нові функції на живій аудиторії, поступово впроваджувати зміни. |
| Приблизні додаткові витрати на VPS (2026) |
Короткочасно +100%: Якщо ваш сервіс працює на 2 VPS по $20/міс, то на час деплою потрібно 4 VPS, тобто $80/міс замість $40/міс (на кілька хвилин/годин). У довгостроковій перспективі, це може бути +$5-10/міс на більш потужний VPS або додатковий інстанс на кілька годин. |
Довготривало +10-50%: Наприклад, якщо ваш сервіс працює на 2 VPS по $20/міс, то для Canary може знадобитися 2 основних + 1 додатковий VPS (для Canary), або більш потужні VPS для розміщення більшої кількості контейнерів. Це може бути +$20/міс постійно, якщо Canary інстанси працюють довго. |
| Основні інструменти (2026) |
Docker Compose, Nginx/Caddy, HAProxy, Ansible, GitLab CI/GitHub Actions, Prometheus, Grafana. |
Docker Compose, Nginx/Caddy, HAProxy, Traefik, Istio (для більш складних сценаріїв), Kubernetes, Ansible, GitLab CI/GitHub Actions, Prometheus, Grafana, OpenTelemetry. |
Ця таблиця наочно демонструє, що немає "найкращої" стратегії; є та, яка краще підходить для конкретного сценарію, бюджету та рівня зрілості команди. Blue/Green забезпечує простоту та безпеку повного перемикання, в той час як Canary пропонує неперевершені можливості для поступового впровадження та тестування в реальному часі, але ціною більшої складності та можливих постійних витрат на ресурси.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
4. Детальний огляд Blue/Green деплою
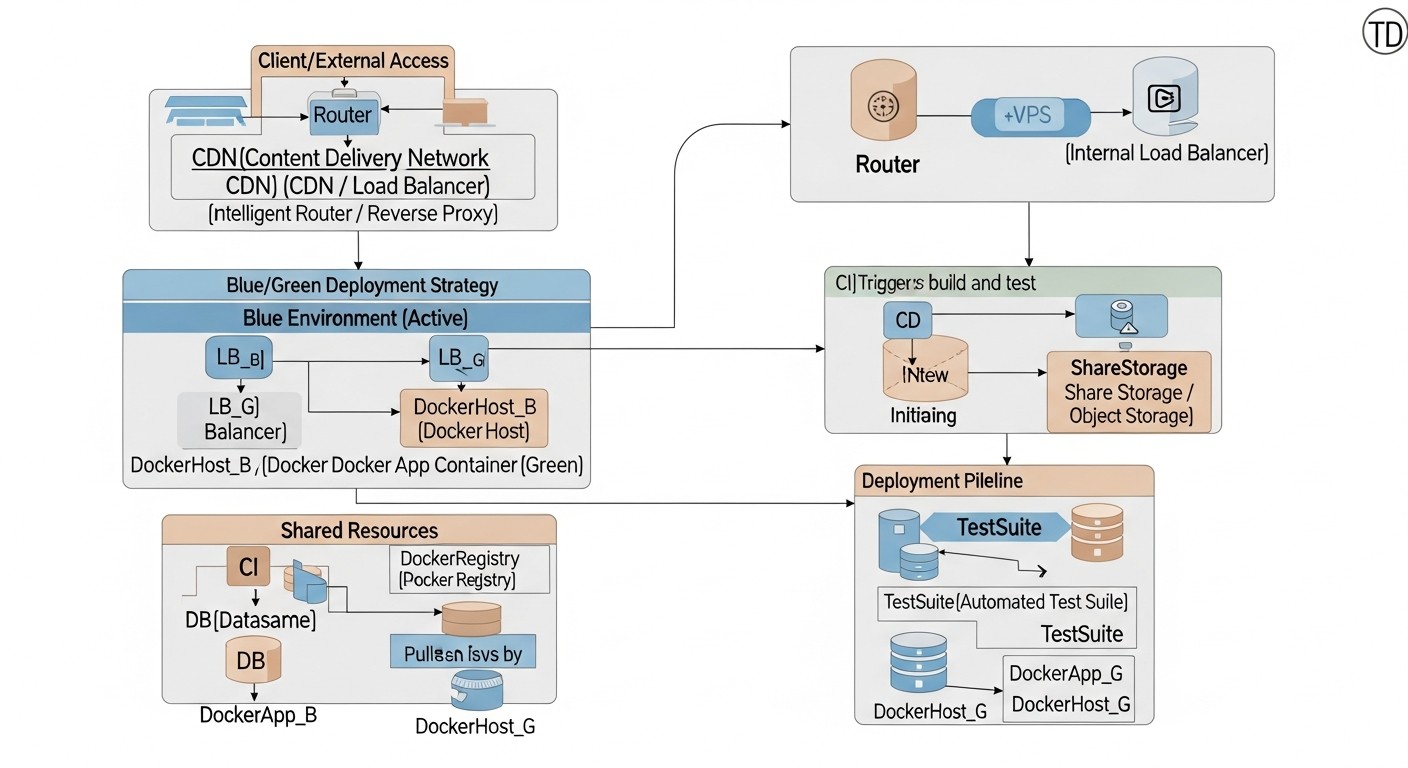 Схема: 4. Детальний огляд Blue/Green деплою
Схема: 4. Детальний огляд Blue/Green деплою
Стратегія Blue/Green деплою є одним з найбільш популярних та ефективних методів забезпечення безшовних оновлень додатків з мінімальним даунтаймом. Її ключова ідея полягає в підтримці двох ідентичних виробничих середовищ, які ми умовно називаємо "синім" (Blue) та "зеленим" (Green). В будь-який момент часу лише одне з цих середовищ активне та обслуговує весь користувацький трафік. Давайте заглибимось в деталі цієї стратегії.
4.1. Принцип роботи Blue/Green
Уявіть, що у вас є дві повністю ідентичні інфраструктури або набори ресурсів на вашому VPS. Одна з них, скажімо, "синя", містить поточну, стабільну версію вашого Docker-додатку та обслуговує весь вхідний трафік. Коли приходить час оновити додаток, ви розгортаєте нову версію на "зеленому" середовищі, яке до цього моменту було неактивним або містило стару версію, але без трафіку.
- Підготовка "зеленого" середовища: Ви розгортаєте нову версію Docker-образу вашого додатку на "зеленій" інфраструктурі. Це може бути окремий Docker-контейнер, група контейнерів, або навіть окремий VPS, налаштований ідентично "синьому".
- Тестування "зеленого" середовища: Після розгортання нової версії на "зеленому" середовищі, ви проводите всі необхідні тести: функціональні, інтеграційні, навантажувальні. Це дає вам впевненість, що нова версія працює коректно в виробничих умовах, але ще не зачіпає реальних користувачів.
- Перемикання трафіку: Якщо тести пройшли успішно, ви перемикаєте весь вхідний користувацький трафік з "синього" середовища на "зелене". Це зазвичай робиться шляхом зміни конфігурації балансувальника навантаження (наприклад, Nginx, HAProxy, Caddy) або DNS-запису. Це перемикання відбувається практично миттєво.
- Моніторинг "зеленого" середовища: Після перемикання трафіку, ви уважно відстежуєте роботу нового "зеленого" середовища, збираючи метрики продуктивності, помилки та логи.
- Відкат (Rollback): Якщо в "зеленому" середовищі виявляються критичні проблеми, ви можете моментально відкотитися, просто перемкнувши трафік назад на стабільне "синє" середовище. Це відбувається дуже швидко та безпечно, оскільки "синє" середовище залишалось недоторканим.
- Очистка або повторне використання: Якщо "зелене" середовище стабільне, "синє" середовище може бути або знищене (для економії ресурсів), або оновлене до нової версії та стати наступним "зеленим" середовищем для майбутнього деплою.
4.2. Переваги Blue/Green деплою
- Нульовий даунтайм: Перемикання трафіку відбувається дуже швидко, зазвичай впродовж секунд, що мінімізує або повністю виключає простій для користувачів.
- Швидкий та безпечний відкат: У разі проблем, повернення до попередньої стабільної версії відбувається миттєво, просто шляхом перемикання трафіку назад на "синю" середу. Це дає високий ступінь впевненості в процесі деплою.
- Простота тестування: Нова версія може бути повністю протестована у виробничому середовищі перед тим, як стати доступною для користувачів, що знижує ризик виведення помилок у продакшен.
- Ізоляція середовищ: "Синя" та "зелена" середи повністю ізольовані, що запобігає конфліктам та спрощує управління.
- Впевненість у релізах: Можливість швидкого відкату знижує стрес та підвищує впевненість команди в кожному новому релізі.
4.3. Недоліки Blue/Green деплою
- Подвоєння ресурсів: На час деплою потрібне подвоєння обчислювальних ресурсів (CPU, RAM, дисковий простір), оскільки обидва середовища (Blue та Green) працюють паралельно. На VPS це може означати тимчасове масштабування або використання більш потужного сервера.
- Управління станом: Якщо додаток має стан (наприклад, сесії користувачів, кеші), необхідно забезпечити їх коректну обробку при перемиканні. Це може вимагати використання спільних сховищ стану (Redis, Memcached) або ретельного проектування сесій.
- Міграції баз даних: Зміни в схемі бази даних вимагають особливої уваги. Міграції повинні бути зворотно сумісними, щоб обидві версії додатка (стара та нова) могли працювати з однією і тією ж базою даних під час перехідного періоду.
- Складність для дуже великих додатків: Для монолітних додатків з великою кількістю залежностей або дуже складною інфраструктурою, створення двох повністю ідентичних середовищ може бути дорогим та трудомістким.
4.4. Для кого підходить Blue/Green
Blue/Green деплой ідеально підходить для:
- SaaS-проектів з високим SLA: Де критично важливий нульовий даунтайм та швидкий відкат.
- Додатків з частими, але передбачуваними релізами: Коли ви впевнені в якості коду після внутрішнього тестування, але хочете додаткову страховку в продакшені.
- Команд, які цінують простоту та передбачуваність: Концепція відносно проста для розуміння та реалізації в порівнянні з Canary, особливо на VPS з використанням Docker Compose та Nginx/HAProxy.
- Проектів, здатних тимчасово виділити додаткові ресурси: Якщо ваш VPS може витримати тимчасове подвоєння навантаження або ви готові тимчасово масштабуватися.
В цілому, Blue/Green є чудовою відправною точкою для багатьох команд, які прагнуть до безшовного деплою. Він забезпечує високий рівень безпеки та надійності, при цьому залишаючись відносно керованим в реалізації на VPS.
5. Детальний огляд Canary деплою
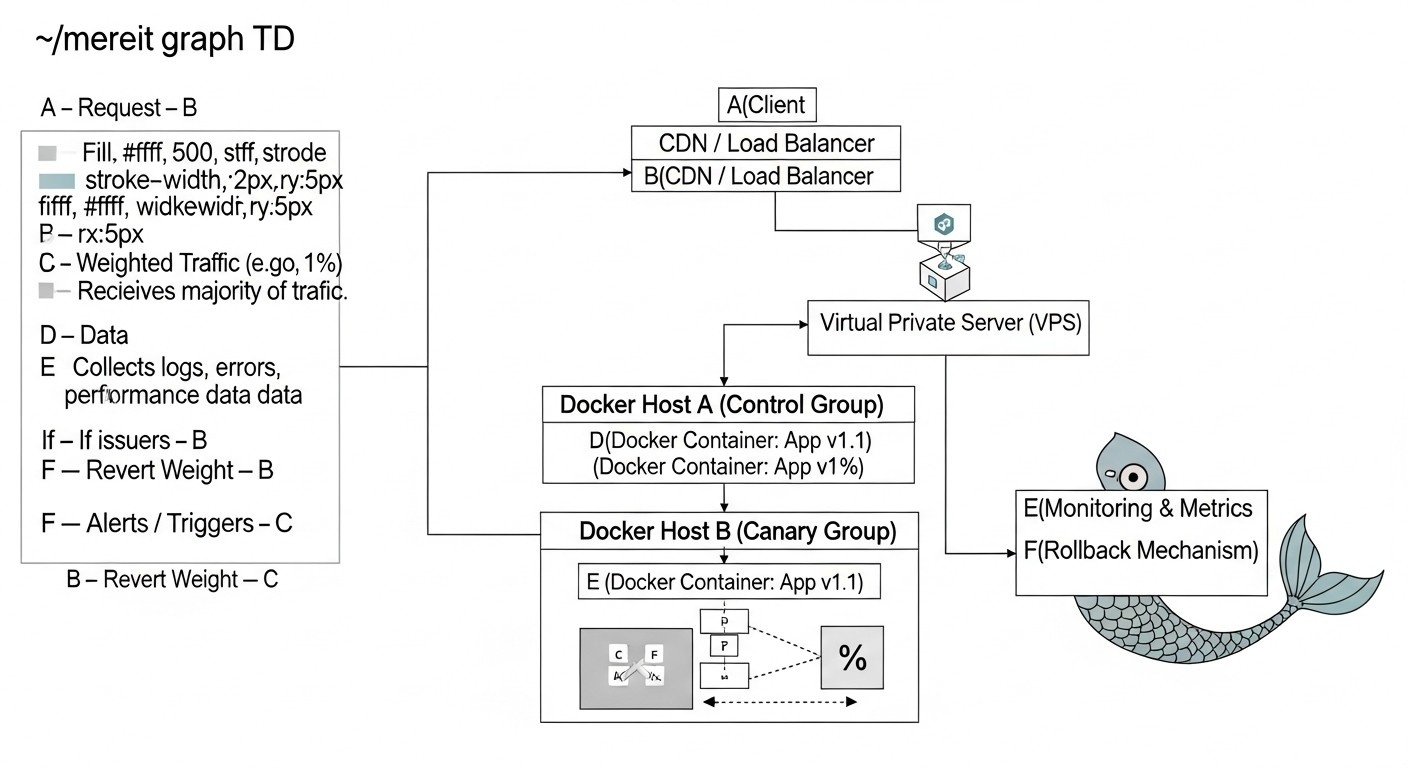 Схема: 5. Детальний огляд Canary деплою
Схема: 5. Детальний огляд Canary деплою
Canary деплой, названий на честь канарок, які використовувалися в шахтах для виявлення небезпечних газів, являє собою просунуту стратегію розгортання, яка дозволяє поступово викатувати нову версію додатку на обмежену групу користувачів. Це мінімізує потенційний вплив помилок на всю базу користувачів і дає можливість зібрати зворотний зв'язок та метрики в реальному часі, перш ніж нова версія стане загальнодоступною. У 2026 році, зі зростанням популярності A/B тестування та персоналізації, Canary стає незамінним інструментом.
5.1. Принцип роботи Canary
На відміну від Blue/Green, де трафік перемикається цілком, Canary деплой передбачає поетапне перенаправлення трафіку. Це дозволяє "перевірити воду" на невеликій, ізольованій групі користувачів.
- Розгортання "канарейки": Ви розгортаєте нову версію вашого Docker-додатку (так звану "канарейку") поруч з поточною стабільною версією на вашому VPS. Спочатку на "канарейку" не направляється трафік або направляється дуже малий відсоток.
- Перенаправлення малого відсотка трафіку: Балансувальник навантаження або API Gateway налаштовується таким чином, щоб перенаправити дуже невеликий відсоток (наприклад, 1-5%) вхідного трафіку на "канарейку". Решта трафіку продовжує обслуговуватися стабільною версією.
- Моніторинг та збір метрик: Це найкритичніший етап. Ви ретельно відстежуєте продуктивність, помилки, поведінку користувачів та бізнес-метрики для "канарейки". Важливо мати добре налаштовану систему моніторингу, яка дозволяє порівнювати показники "канарейки" зі стабільною версією.
- Поступове збільшення трафіку: Якщо "канарейка" показує стабільну роботу та хороші метрики, ви поступово збільшуєте відсоток трафіку, що направляється на неї (наприклад, до 10%, потім 25%, 50% і так далі). Кожен етап супроводжується ретельним моніторингом.
- Повний розкат: Коли "канарейка" успішно обслуговує значну частину трафіку без проблем, і ви повністю впевнені в її стабільності, ви перенаправляєте весь 100% трафік на нову версію.
- Виведення старої версії: Стара версія додатку може бути виведена з експлуатації і її ресурси звільнені.
- Відкат (Rollback): У разі виявлення проблем на будь-якому етапі, ви негайно перенаправляєте весь трафік назад на стабільну версію. Оскільки вплив було обмежено невеликою групою користувачів, збитки мінімізуються.
5.2. Переваги Canary деплою
- Мінімальний ризик: Вплив потенційних помилок обмежено невеликою частиною користувачів, що робить цю стратегію ідеальною для критично важливих систем.
- Тестування в реальному часі: Нова версія тестується на реальних користувачах в реальному виробничому середовищі, що дозволяє виявити проблеми, які могли бути пропущені при синтетичному тестуванні.
- A/B тестування: Canary деплой природним чином дозволяє проводити A/B тестування нових функцій, порівнюючи їх ефективність зі старими на основі поведінки користувачів та бізнес-метрик.
- Поступове впровадження: Можливість поступово звикати до нових функцій та збирати зворотний зв'язок, що особливо корисно для радикальних змін користувацького інтерфейсу або бізнес-логіки.
- Економія ресурсів: На початкових етапах "канарейка" може вимагати менше додаткових ресурсів у порівнянні з повним дублюванням в Blue/Green.
5.3. Недоліки Canary деплою
- Висока складність: Вимагає складного налаштування балансувальника навантаження для маршрутизації трафіку за різними критеріями (відсоток, заголовки, кукі), а також просунутої системи моніторингу та логування.
- Тривалість: Процес Canary деплою може займати значно більше часу, ніж Blue/Green, оскільки кожен етап вимагає моніторингу та прийняття рішень.
- Управління станом і базами даних: Ще більш критично, ніж у Blue/Green. Обидві версії застосунку (стабільна і "канарейка") повинні бути здатні працювати з однією і тією ж схемою бази даних і станом. Міграції повинні бути суворо зворотно сумісними.
- Проблеми з налагоджувальною інформацією: Якщо помилка проявляється тільки на "канарейці", може бути складно зібрати достатньо інформації для налагодження, якщо трафік занадто малий.
- Потенційне погіршення користувацького досвіду: Хоча і для малої групи, деякі користувачі все ж можуть зіткнутися з помилками або регресіями.
5.4. Для кого підходить Canary
Canary деплой ідеально підходить для:
- Великих SaaS-проєктів з мільйонами користувачів: Де навіть малий відсоток помилок може зачепити значну кількість людей.
- Застосунків, де важливий безперервний збір зворотного зв'язку та метрик: Для A/B тестування нових функцій, оцінки продуктивності та реакції користувачів.
- Команд з високим рівнем автоматизації та зрілою культурою DevOps: Вимагає розвинених CI/CD пайплайнів, глибокого моніторингу та автоматичних відкотів.
- Проєктів, готових інвестувати в складну інфраструктуру: Для налаштування просунутих балансувальників (наприклад, Traefik, Nginx з Lua-скриптами), систем моніторингу та логування.
- Коли зміни можуть бути ризикованими: Наприклад, при впровадженні нової платіжної системи, зміні критично важливої бізнес-логіки або значних оновлень UI.
Canary деплой — це потужний інструмент для мінімізації ризиків і поліпшення якості релізів, але він вимагає значних інвестицій в автоматизацію, моніторинг і оркестрацію. На VPS його можна реалізувати за допомогою Docker Compose, Nginx/HAProxy і скриптів для управління трафіком, але для більш складних сценаріїв може знадобитися Kubernetes або його полегшені аналоги.
6. Практичні поради та рекомендації щодо впровадження
 Схема: 6. Практичні поради та рекомендації щодо впровадження
Схема: 6. Практичні поради та рекомендації щодо впровадження
Реалізація Blue/Green і Canary деплою на VPS вимагає не тільки розуміння концепцій, а й конкретних технічних кроків. У цьому розділі ми надамо покрокові інструкції, приклади команд і конфігурацій, а також рекомендації, засновані на реальному досвіді впровадження цих стратегій у 2026 році.
6.1. Загальні вимоги до інфраструктури VPS
- Достатні ресурси VPS: Переконайтеся, що ваш VPS має достатньо CPU, RAM і дискового простору для запуску як мінімум двох версій вашого застосунку (для Blue/Green) або стабільної версії плюс "канарейки" (для Canary). Розгляньте можливість використання VPS з можливістю швидкого вертикального масштабування або додавання тимчасових інстансів.
- Docker і Docker Compose: Встановлені та налаштовані на вашому VPS. Docker Compose буде використовуватися для оркестрації декількох контейнерів, що становлять ваш застосунок.
- Балансувальник навантаження (Reverse Proxy): Nginx, Caddy або HAProxy є відмінними кандидатами. Вони будуть відповідати за маршрутизацію трафіку до правильної версії застосунку.
- Система моніторингу та логування: Prometheus + Grafana для метрик, ELK-стек (Elasticsearch, Logstash, Kibana) або Loki + Promtail для логів. Це критично для відстеження здоров'я та продуктивності обох версій.
- CI/CD пайплайн: Автоматизація всього процесу деплою за допомогою Jenkins, GitLab CI, GitHub Actions або Ansible. Ручний деплой збільшує ризики та трудовитрати.
6.2. Реалізація Blue/Green деплою на одному VPS з Docker Compose і Nginx
Припустимо, у вас є застосунок, що складається з веб-сервера і бази даних. Для Blue/Green нам знадобляться два набори контейнерів для застосунку, але спільна база даних.
6.2.1. Структура проєкту
Створимо дві папки для різних версій застосунку, наприклад, app-blue і app-green. У кожній буде свій docker-compose.yml.
# Структура директорій
.
├── nginx.conf
├── app-blue/
│ └── docker-compose.yml
│ └── Dockerfile
│ └── app.py (version 1.0)
├── app-green/
│ └── docker-compose.yml
│ └── Dockerfile
│ └── app.py (version 2.0)
└── data/
└── db/ (для PostgreSQL/MySQL)
6.2.2. Приклад app-blue/docker-compose.yml (для версії 1.0)
version: '3.8'
services:
web:
build:
context: .
dockerfile: Dockerfile
image: myapp:1.0
container_name: myapp_blue_web
ports:
- "8080:80" # Слушаем на порту 8080
environment:
- APP_VERSION=1.0
- DATABASE_URL=postgresql://user:password@db:5432/mydatabase
volumes:
- ./app.py:/app/app.py
networks:
- app_network
db: # Общая база данных
image: postgres:14
container_name: myapp_db
environment:
POSTGRES_DB: mydatabase
POSTGRES_USER: user
POSTGRES_PASSWORD: password
volumes:
- ../data/db:/var/lib/postgresql/data
networks:
- app_network
restart: unless-stopped # Важно для общей БД
networks:
app_network:
driver: bridge
6.2.3. Приклад app-green/docker-compose.yml (для версії 2.0)
Аналогічно, але з іншим портом та ім'ям контейнера:
version: '3.8'
services:
web:
build:
context: .
dockerfile: Dockerfile
image: myapp:2.0
container_name: myapp_green_web
ports:
- "8081:80" # Слушаем на порту 8081
environment:
- APP_VERSION=2.0
- DATABASE_URL=postgresql://user:password@db:5432/mydatabase
volumes:
- ./app.py:/app/app.py
networks:
- app_network
networks:
app_network:
external: true # Используем ту же сеть, что и Blue, для доступа к общей БД
Примітка: У реальному сценарії, БД повинна бути окремим сервісом, доступним для обох середовищ, а не частиною docker-compose.yml кожного середовища. Тут для простоти вона включена в Blue, а Green підключається до неї по спільній мережі.
6.2.4. Конфігурація Nginx (nginx.conf)
Nginx буде виступати в ролі балансувальника навантаження, перемикаючи трафік між портами 8080 (Blue) і 8081 (Green).
# nginx.conf
worker_processes auto;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
upstream app_backend {
# Изначально направляем на Blue
server 127.0.0.1:8080; # Blue
# server 127.0.0.1:8081; # Green (закомментировано)
}
server {
listen 80;
server_name your_domain.com;
location / {
proxy_pass http://app_backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
}
6.2.5. Процес деплою Blue/Green
- Старт Blue (поточна версія):
cd app-blue
docker-compose up -d --build
Переконайтеся, що Nginx налаштований на порт 8080.
- Підготовка Green (нова версія):
cd app-green
docker-compose up -d --build
Це запустить нову версію на порту 8081. Проведіть тестування, звертаючись безпосередньо до http://your_vps_ip:8081.
- Перемикання трафіку:
Коли Green протестовано, оновіть nginx.conf, змінивши upstream app_backend:
upstream app_backend {
# server 127.0.0.1:8080; # Blue (закоментовано)
server 127.0.0.1:8081; # Green (активно)
}
Перезавантажте Nginx: sudo systemctl reload nginx.
- Моніторинг: Уважно стежте за логами та метриками Green.
- Очищення Blue (або підготовка до наступного деплою):
Якщо Green стабільна, зупиніть Blue:
cd app-blue
docker-compose down
- Відкат: Якщо Green викликає проблеми, негайно змініть
nginx.conf назад на server 127.0.0.1:8080; та перезавантажте Nginx.
6.3. Реалізація Canary деплою на одному VPS з Docker Compose та Nginx/Caddy
Canary складніший, оскільки вимагає динамічної маршрутизації трафіку. Nginx може це робити за допомогою Lua-скриптів або складніших конфігурацій, але для простоти ми розглянемо базовий підхід з використанням ваг або заголовків.
6.3.1. Nginx для Canary (за вагами)
Це найпростіший Canary, де трафік розподіляється за вагами.
# nginx.conf для Canary (за вагами)
upstream app_backend {
server 127.0.0.1:8080 weight=90; # Blue (стара версія, 90% трафіку)
server 127.0.0.1:8081 weight=10; # Canary (нова версія, 10% трафіку)
}
server {
listen 80;
server_name your_domain.com;
location / {
proxy_pass http://app_backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
Процес:
- Запустіть Blue на 8080.
- Запустіть Canary на 8081.
- Оновіть
nginx.conf з вагами (наприклад, 90% Blue, 10% Canary). Перезавантажте Nginx.
- Моніторинг. Якщо все добре, поступово змінюйте ваги (наприклад, 70/30, 50/50, 20/80, 0/100) та перезавантажуйте Nginx на кожному кроці.
- Коли 100% трафіку йде на Canary, зупиніть Blue.
6.3.2. Canary за заголовками/куками (для внутрішніх тестувальників)
Більш просунутий Canary може направляти трафік на нову версію лише для певних користувачів (наприклад, з певним HTTP-заголовком або кукою).
# nginx.conf для Canary (за заголовками)
upstream app_blue {
server 127.0.0.1:8080;
}
upstream app_canary {
server 127.0.0.1:8081;
}
server {
listen 80;
server_name your_domain.com;
location / {
# Якщо є заголовок "X-Canary: true", направляємо на Canary
if ($http_x_canary = "true") {
proxy_pass http://app_canary;
}
# Інакше, на Blue
proxy_pass http://app_blue;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
Процес:
- Запустіть Blue на 8080.
- Запустіть Canary на 8081.
- Оновіть
nginx.conf. Перезавантажте Nginx.
- Тестуйте Canary, відправляючи запити з заголовком
X-Canary: true.
- Коли впевнені, що Canary стабільна, змініть
nginx.conf, щоб весь трафік йшов на app_canary, або використовуйте ваги, як у попередньому прикладі, для поступового розгортання.
6.4. Автоматизація CI/CD пайплайну (на прикладі GitLab CI)
Автоматизація — це серце ефективного деплою. Ручне керування Nginx та Docker Compose швидко стає неконтрольованим.
Приклад .gitlab-ci.yml для Blue/Green:
stages:
- build
- deploy_green
- switch_traffic
- cleanup_blue
variables:
DOCKER_HOST_USER: "user"
DOCKER_HOST_IP: "your_vps_ip"
APP_DIR: "/path/to/your/app"
BLUE_PORT: "8080"
GREEN_PORT: "8081"
build:
stage: build
script:
- docker build -t myapp:$CI_COMMIT_SHORT_SHA .
- docker save myapp:$CI_COMMIT_SHORT_SHA | gzip > myapp-$CI_COMMIT_SHORT_SHA.tar.gz
- scp myapp-$CI_COMMIT_SHORT_SHA.tar.gz $DOCKER_HOST_USER@$DOCKER_HOST_IP:$APP_DIR/
tags:
- docker_builder # Пример тега для раннера
deploy_green:
stage: deploy_green
script:
- ssh $DOCKER_HOST_USER@$DOCKER_HOST_IP "
cd $APP_DIR/app-green &&
docker load < myapp-$CI_COMMIT_SHORT_SHA.tar.gz &&
docker-compose down || true && # Остановка предыдущего Green, если был
sed -i 's/image: myapp:.$/image: myapp:$CI_COMMIT_SHORT_SHA/' docker-compose.yml &&
docker-compose up -d --build &&
# Здесь можно добавить скрипты для запуска тестов на Green
# Например: curl -f http://$DOCKER_HOST_IP:$GREEN_PORT/health || exit 1
"
tags:
- deployer
allow_failure: false
switch_traffic:
stage: switch_traffic
script:
- ssh $DOCKER_HOST_USER@$DOCKER_HOST_IP "
sed -i 's/server 127.0.0.1:$BLUE_PORT;/ # server 127.0.0.1:$BLUE_PORT;/' $APP_DIR/nginx.conf &&
sed -i 's/# server 127.0.0.1:$GREEN_PORT;/ server 127.0.0.1:$GREEN_PORT;/' $APP_DIR/nginx.conf &&
sudo systemctl reload nginx
"
tags:
- deployer
when: manual # Ручное подтверждение после тестирования Green
cleanup_blue:
stage: cleanup_blue
script:
- ssh $DOCKER_HOST_USER@$DOCKER_HOST_IP "
cd $APP_DIR/app-blue &&
docker-compose down &&
rm -f myapp-$CI_COMMIT_SHORT_SHA.tar.gz
"
tags:
- deployer
when: manual # Ручное подтверждение после успешного переключения
Важливі зауваження щодо CI/CD:
- Використовуйте SSH-ключі для доступу до VPS без пароля.
- Змінні оточення для чутливих даних (паролі, ключі).
sed -i для модифікації конфігураційних файлів Nginx. У більш складних сценаріях можна використовувати Ansible шаблони.when: manual для етапів перемикання та очищення, щоб забезпечити ручну перевірку та підтвердження. В ідеалі, після автоматичних тестів на Green, можна зробити паузу для ручного смоук-тесту.- Додайте повноцінні тести (health checks, інтеграційні) в пайплайн.
- Для Canary пайплайн буде складнішим, з етапами поступового збільшення трафіку та моніторингом після кожного кроку.
6.5. Моніторинг та логування
Моніторинг — це ваші очі та вуха в продакшені. Без нього Blue/Green та Canary деплой втрачають сенс.
- Метрики: Використовуйте Prometheus для збору метрик (CPU, RAM, мережевий трафік VPS, а також метрики вашого застосунку: кількість запитів, затримки, помилки). Експортери для Docker, Node Exporter для VPS, і кастомні експортери для вашого застосунку. Grafana для візуалізації.
- Логи: Збирайте логи всіх контейнерів.
- Просте рішення: Використовувати
docker logs -f <container_name> або налаштувати log-driver Docker на json-file і збирати їх з допомогою journalctl.
- Просунуте рішення: ELK-стек (Elasticsearch, Logstash, Kibana) або Loki + Promtail. Promtail збирає логи з контейнерів Docker і відправляє їх в Loki, а Grafana використовується для запитів до Loki.
- Алерти: Налаштуйте оповіщення (через Alertmanager для Prometheus) про будь-які аномалії: зростання помилок в новій версії, деградація продуктивності, високе завантаження ресурсів.
- Трасування (Distributed Tracing): Для мікросервісних архітектур розгляньте OpenTelemetry або Jaeger/Zipkin для відстеження запитів через декілька сервісів. Це допомагає зрозуміти, де саме виникла проблема в Canary деплої.
6.6. Управління базами даних
Міграції БД — це найслабша ланка в безшовних деплоях. Завжди дотримуйтесь принципу зворотної сумісності:
- Додавання колонки: Спочатку розгорніть нову версію застосунку, яка вміє працювати з новою колонкою (але не вимагає її). Потім виконайте міграцію БД. Після цього переключіть трафік.
- Видалення колонки: Спочатку переконайтеся, що всі старі версії, які використовують цю колонку, виведені з експлуатації. Потім видаліть колонку з БД.
- Зміна типу колонки: Часто вимагає двофазної міграції: спочатку додавання нової колонки з новим типом, перенесення даних, переключення застосунку на нову колонку, потім видалення старої.
Використовуйте інструменти для міграції БД, такі як Alembic (Python), Flyway (Java), Liquibase, Knex.js (Node.js).
Впровадження цих практичних порад дозволить вам створити надійний та автоматизований процес деплою, який значно знизить ризики та підвищить стабільність ваших Docker-застосунків на VPS.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
7. Типові помилки при впровадженні Blue/Green та Canary
 Схема: 7. Типові помилки при впровадженні Blue/Green та Canary
Схема: 7. Типові помилки при впровадженні Blue/Green та Canary
Впровадження просунутих стратегій деплою, таких як Blue/Green та Canary, може значно покращити стабільність і надійність ваших релізів. Однак, як і будь-яке складне інженерне завдання, воно пов'язане з рядом типових помилок, які можуть звести нанівець всі переваги і навіть призвести до серйозних проблем. У 2026 році, коли автоматизація і швидкість стали ключовими, ці помилки можуть бути особливо дорогими.
7.1. Недостатнє тестування "зеленого" або "канареечного" середовища
Опис помилки: Це, мабуть, найпоширеніша і небезпечна помилка. Розробники або DevOps-інженери покладаються на те, що нова версія "повинна працювати", або проводять лише поверхові перевірки. Іноді через поспіх пропускаються інтеграційні або навантажувальні тести на новому середовищі, або ж тести проводяться в ізольованому тестовому середовищі, яке не повністю відповідає продакшену. У випадку Canary, це проявляється в недостатньому моніторингу на малому відсотку трафіку.
Як уникнути: Впровадьте комплексну стратегію тестування, що включає модульні, інтеграційні, E2E (End-to-End) і навантажувальні тести. Автоматизуйте ці тести в вашому CI/CD пайплайні. Для Blue/Green переконайтеся, що "зелене" середовище повністю працездатне і стабільне під навантаженням, перш ніж перемикати на нього трафік. Для Canary, встановіть чіткі критерії успіху і метрики, які повинні бути досягнуті, перш ніж збільшувати відсоток трафіку. Використовуйте інструменти на зразок Selenium, Cypress, JMeter, K6.
Приклад наслідків: Переключення на "зелене" середовище з критичною помилкою, яка проявляється тільки під навантаженням, призводить до повної відмови сервісу для всіх користувачів. У випадку Canary, навіть 1% користувачів може зіткнутися з фатальною помилкою, що підриває довіру і репутацію.
7.2. Відсутність або неефективний моніторинг і алертинг
Опис помилки: Деплой без надійної системи моніторингу та алертингу - це як політ наосліп. Якщо ви не знаєте, що відбувається з вашим застосунком після деплою, ви не зможете оперативно відреагувати на проблеми. Часто команди налаштовують базовий моніторинг, але не кастомні метрики застосунку, або не мають чітких порогів для алертів.
Як уникнути: Впровадьте наскрізний моніторинг: інфраструктура (CPU, RAM, диск VPS), контейнери Docker, сам застосунок (метрики запитів, помилок, затримок, бізнес-метрики). Використовуйте Prometheus + Grafana для метрик, Loki/ELK для логів. Налаштуйте Alertmanager для відправки повідомлень в Slack, PagerDuty або по email при перевищенні порогових значень помилок, затримок або недоступності. Переконайтеся, що метрики доступні для обох версій застосунку, щоб можна було порівнювати їх продуктивність.
Приклад наслідків: Нова версія застосунку починає повільно "вмирати" через витік пам'яті або занадто великої кількості запитів до БД, але команда дізнається про це тільки через годину, коли користувачі вже масово скаржаться, а відкат займає дорогоцінний час.
7.3. Неправильне управління станом і міграціями баз даних
Опис помилки: Це ахіллесова п'ята багатьох стратегій безшовного деплою. Якщо застосунок має стан (сесії, кеші) або вимагає міграції бази даних, то просте перемикання трафіку може призвести до несумісності даних, втрати сесій користувачів або пошкодження даних. Забувають про те, що обидві версії застосунку можуть одночасно працювати з однією і тією ж базою даних.
Як уникнути:
- Стан: В ідеалі, ваш застосунок повинен бути stateless. Якщо це неможливо, використовуйте зовнішні, спільні сховища стану (Redis, Memcached) або бази даних, до яких обидві версії застосунку мають доступ.
- База даних: Всі міграції повинні бути зворотно сумісними. Це означає, що нова версія застосунку повинна вміти працювати зі старою схемою БД, а стара версія повинна вміти працювати з новою схемою БД (до тих пір, поки вона не буде виведена з експлуатації). Використовуйте двофазні міграції для складних змін схеми. Завжди робіть бекапи перед міграцією.
Приклад наслідків: Після деплою Blue/Green, користувачі, які були на "синьому" середовищі, втрачають свої сесії при переключенні на "зелене". Або нова версія намагається використовувати неіснуючу колонку в БД, а стара версія не може працювати з новою схемою, що призводить до повної недоступності застосунку.
7.4. Відсутність або складність автоматизації відкату
Опис помилки: В теорії, відкат в Blue/Green і Canary простий. На практиці, якщо процес відкату не автоматизований і не протестований, він може бути повільним, схильним до помилок і призвести до додаткового даунтайму. Іноді команди зосереджуються тільки на деплої, забуваючи про важливість швидкого і надійного відкату.
Як уникнути: Включіть процес відкату у ваш CI/CD пайплайн. Він повинен бути таким же автоматизованим і протестованим, як і процес деплою. Для Blue/Green це просто перемикання балансувальника навантаження. Для Canary це може бути автоматичне зниження трафіку на "канарейку" до нуля при виявленні критичних метрик або помилок. Регулярно тестуйте процедуру відкату в тестовому середовищі.
Приклад наслідків: Виявлено критичну помилку в новій версії. Команда намагається вручну відкотити Nginx, але допускає помилку в конфігурації, що призводить до додаткового простою. Або відкат займає 15 хвилин замість 15 секунд.
7.5. Ігнорування очищення старих ресурсів
Опис помилки: Особливо актуально для Blue/Green. Після успішного деплою і переходу на "зелене" середовище, "синє" середовище часто залишається працювати, споживаючи цінні ресурси VPS. Якщо це не відстежується і не автоматизується, з часом це призводить до значних перевитрат і неефективного використання інфраструктури.
Як уникнути: Включіть етап очищення старих ресурсів (зупинку і видалення старих контейнерів/сервісів) у ваш CI/CD пайплайн. Зробіть його або автоматичним після певного періоду стабільної роботи нової версії, або ручним, але з чітким нагадуванням. Для Canary, переконайтеся, що інстанси "канарейки" виводяться з експлуатації після повного розкочування нової версії.
Приклад наслідків: Через кілька місяців з'ясовується, що на VPS працює 5-6 старих версій додатку, що споживають CPU і RAM, що призводить до уповільнення роботи активного додатку і невиправданих витрат на VPS.
7.6. Неправильна конфігурація балансувальника навантаження
Опис помилки: Балансувальник навантаження (Nginx, HAProxy, Caddy, Traefik) є ключовим компонентом обох стратегій. Помилки в його конфігурації можуть призвести до неправильної маршрутизації трафіку, витоків сесій, або навіть до DoS-атак на неактивне середовище. Наприклад, неправильне налаштування проксі-заголовків може призвести до того, що додаток не бачить реальний IP користувача.
Як уникнути: Ретельно перевірте конфігурацію вашого балансувальника навантаження. Використовуйте health checks для перевірки доступності бекендів. Переконайтеся, що sticky sessions (якщо вони потрібні) налаштовані коректно. Автоматизуйте зміну конфігурації через CI/CD. Використовуйте інструменти на кшталт nginx -t для перевірки синтаксису перед перезавантаженням.
Приклад наслідків: Користувачі бачать стару версію додатку, хоча трафік повинен бути переключений на нову. Або запити розподіляються нерівномірно, викликаючи перевантаження одного з середовищ. У Canary, неправильна маршрутизація може призвести до того, що "канарейку" побачить набагато більше користувачів, ніж планувалося, або вона не побачить трафіку зовсім.
Уникаючи цих поширених помилок, ви значно підвищите шанси на успішне впровадження і ефективне використання стратегій Blue/Green і Canary деплою, забезпечуючи стабільність і надійність ваших Docker-додатків на VPS.
8. Чекліст для практичного застосування
Перед початком впровадження або чергового деплою з використанням Blue/Green або Canary стратегій, пройдіться по цьому чеклисту. Він допоможе переконатися, що ви врахували всі критичні аспекти і мінімізували ризики. Цей чеклист актуальний для 2026 року, з урахуванням сучасних практик DevOps.
8.1. Загальна підготовка та планування
- Визначено допустимий даунтайм: Ви знаєте, який рівень простою прийнятний для вашого додатку і цільової аудиторії.
- Обрано стратегію деплою: Blue/Green або Canary, виходячи з потреб бізнесу і технічних можливостей.
- Ресурси VPS достатні: Перевірено доступність CPU, RAM, диска для одночасної роботи двох версій (Blue/Green) або стабільної і Canary версій.
- План відкату готовий і протестований: Ви знаєте, як швидко і безпечно повернутися до попередньої стабільної версії.
- План міграції БД готовий: Всі зміни в БД спроектовані з урахуванням зворотної сумісності.
- Команда проінформована: Всі учасники процесу (розробники, тестувальники, DevOps) знають свої ролі і етапи деплою.
- Графік деплою узгоджено: Обрано найменш завантажений час для деплою, щоб мінімізувати вплив на користувачів.
8.2. Підготовка інфраструктури та інструментів
- Docker і Docker Compose встановлені і налаштовані: На вашому VPS готові до роботи.
- Балансувальник навантаження налаштовано: Nginx, Caddy або HAProxy готові до управління трафіком.
- CI/CD пайплайн налаштовано: Jenkins, GitLab CI, GitHub Actions або Ansible автоматизують збірку, тестування і деплой.
- SSH доступ без пароля: Для CI/CD агента налаштовано SSH-ключ для безпечного доступу до VPS.
- Система моніторингу налаштована: Prometheus + Grafana збирають метрики інфраструктури і додатку.
- Система логування налаштована: ELK-стек або Loki + Promtail збирають і агрегують логи з усіх контейнерів.
- Алерти налаштовані і протестовані: Сповіщення про критичні проблеми приходять в реальному часі.
- Бекапи БД виконані: Свіжі бекапи бази даних зроблені перед початком деплою.
8.3. Підготовка додатку і коду
- Docker-образ додатку оптимізовано: Мінімальний розмір, багатошаровий кеш, відсутність непотрібних залежностей.
- Health checks реалізовано: Додаток надає endpoint (наприклад,
/health), який балансувальник навантаження може використовувати для перевірки його працездатності.
- Метрики додатку експонуються: Додаток надає метрики для Prometheus (наприклад, через клієнтську бібліотеку).
- Логування стандартизовано: Додаток логує в stdout/stderr в форматі, зручному для парсингу (наприклад, JSON).
- Конфігурація додатку параметризована: Всі чутливі дані і специфічні для середовища параметри завантажуються з змінних оточення або файлів конфігурації, а не зашиті в образ.
- Тести пройдено: Всі автоматичні тести (юніт, інтеграційні, E2E) успішно пройдені в тестовому середовищі.
- Зворотна сумісність API/контрактів: Переконайтеся, що нова версія не порушує роботу клієнтів, які використовують старе API.
8.4. Етапи деплою
- Стара версія (Blue) працює стабільно: Перевірено стан поточної версії додатку.
- Нова версія (Green/Canary) розгорнута: Контейнери нової версії успішно запущені на VPS, але трафік на них ще не направлено.
- Тестування нової версії (до перемикання трафіку): Виконано ручні та автоматичні тести на Green/Canary без впливу на основних користувачів.
- Перемикання трафіку:
- Blue/Green: Балансувальник навантаження перемкнено на Green.
- Canary: Балансувальник навантаження починає направляти малий відсоток трафіку на Canary.
- Моніторинг після перемикання: Активно відстежуються метрики та логи нової версії.
- Прийняття рішення:
- Blue/Green: Якщо Green стабільна, Blue може бути зупинена. Якщо проблеми, відкат на Blue.
- Canary: Якщо Canary стабільна, поступово збільшується відсоток трафіку. Якщо проблеми, відкат Canary.
- Очищення ресурсів: Старі контейнери та образи видалені для звільнення ресурсів VPS.
Дотримуючись цього чеклисту, ви значно підвищите ймовірність успішного та безпроблемного деплою, забезпечуючи високу доступність та надійність ваших Docker-додатків.
9. Розрахунок вартості / Економіка впровадження
 Схема: 9. Розрахунок вартості / Економіка впровадження
Схема: 9. Розрахунок вартості / Економіка впровадження
Впровадження просунутих стратегій деплою, таких як Blue/Green і Canary, на VPS завжди пов'язане з певними витратами. Важливо розуміти, що ці витрати не обмежуються лише вартістю самого VPS, але включають в себе також приховані витрати і потенційну економію. У 2026 році, коли вартість хмарних ресурсів продовжує оптимізуватися, а автоматизація стає більш доступною, правильний розрахунок економіки може дати значну конкурентну перевагу.
9.1. Прямі витрати на VPS
Основна стаття витрат - це сам віртуальний сервер. Ціни на VPS в 2026 році продовжують знижуватися, особливо для стандартних конфігурацій. Для Docker-додатків на VPS середньої потужності (4 vCPU, 8GB RAM, 160GB SSD) можна орієнтуватися на наступні приблизні місячні тарифи від провідних провайдерів (DigitalOcean, Vultr, Hetzner, Linode):
- Базовий VPS: $15 - $25 / місяць
- Середній VPS: $30 - $50 / місяць
- Потужний VPS: $60 - $100+ / місяць
9.1.1. Сценарій Blue/Green: Тимчасове подвоєння ресурсів
Для Blue/Green стратегії вам буде потрібно тимчасово подвоїти ресурси. Якщо ваш додаток зазвичай працює на одному VPS за $40/місяць, то на час деплою вам буде потрібно другий такий самий VPS (або його еквівалент за ресурсами). Припустимо, деплой займає 30 хвилин.
- Місячна вартість одного VPS: $40
- Вартість години роботи VPS: $40 / (30 днів * 24 години) = ~$0.055 / година
- Додаткові витрати на деплой (30 хвилин): $0.055 / 2 = ~$0.0275 за один деплой.
- Якщо ви деплоїте 4 рази на місяць: 4 * $0.0275 = ~$0.11
Як бачите, прямі додаткові витрати на VPS для Blue/Green вкрай малі, якщо ви використовуєте тимчасове масштабування або у вас є запас ресурсів на існуючому сервері. Основне, на що потрібно звернути увагу, це помилка ігнорування очищення старих ресурсів, яка може призвести до постійних зайвих витрат.
9.1.2. Сценарій Canary: Постійно підвищені ресурси
Для Canary деплою ви часто тримаєте "канареечні" інстанси постійно, навіть якщо вони обслуговують невеликий відсоток трафіку. Це може означати, що вам постійно потрібно на 10-50% більше ресурсів, ніж для однієї стабільної версії.
- Місячна вартість одного VPS: $40
- Додаткові ресурси для Canary: Наприклад, 20% від одного VPS.
- Постійні додаткові витрати: $40 * 0.20 = $8/місяць.
Ці витрати можуть бути вище, якщо Canary-інстанси вимагають окремого VPS або ви використовуєте більш складну маршрутизацію, яка може споживати додаткові ресурси балансувальника навантаження.
9.2. Приховані витрати
Крім прямих витрат на VPS, існують приховані витрати, які часто упускаються з виду, але можуть бути досить значними.
- Час інженерів: Найбільша прихована вартість. Налаштування та підтримка CI/CD пайплайнів, систем моніторингу, налагодження проблем. У 2026 році середня ставка DevOps-інженера становить $80-150/година. Якщо налаштування займає 80 годин: 80 * $100 = $8000.
- Вартість інструментів: Хоча багато інструментів (Docker, Nginx, Prometheus, Grafana) безкоштовні, деякі можуть мати платні версії або вимагати платних хостингів (наприклад, GitLab EE, хмарні рішення для логування).
- Навчання команди: Інвестиції в навчання інженерів новим стратегіям та інструментам.
- Потенційні втрати від помилок: Незважаючи на зниження ризиків, помилки все одно можуть статися. Втрата клієнтів, репутаційний збиток, штрафи за порушення SLA.
9.3. Як оптимізувати витрати
- Ефективне використання ресурсів VPS:
- Оптимізація Docker-образів: Зменшення розміру образів, використання multi-stage builds.
- Оптимізація Docker Compose: Використання зовнішніх мереж, грамотне управління томами.
- Моніторинг завантаження: Вибір VPS, який точно відповідає вашим потребам, а не "з запасом".
- Автоматизація: Інвестиції в CI/CD пайплайни скорочують ручну працю і мінімізують помилки, що в довгостроковій перспективі економить час інженерів.
- Ретельне планування БД: Мінімізація складних міграцій, які можуть призвести до простоїв або необхідності ручного втручання.
- Використання безкоштовних і Open-Source інструментів: Максимальне використання екосистеми Open-Source (Nginx, Docker, Prometheus, Grafana, Ansible, GitLab CE/GitHub Actions).
- Регулярний аудит ресурсів: Періодично перевіряйте, які контейнери та сервіси запущені на вашому VPS, і видаляйте невикористовувані.
9.4. Таблиця з прикладами розрахунків для різних сценаріїв (2026 рік)
Припустимо, що базовий VPS, достатній для однієї версії додатка, коштує $40/місяць.
| Параметр |
Сценарій 1: Blue/Green (1 деплой/тиждень) |
Сценарій 2: Canary (постійно 20% трафіку на Canary) |
Сценарій 3: Без просунутих стратегій (простий деплой з 5 хв даунтайму) |
| Прямі витрати на VPS |
$40 (основний) + $0.11 (дод.години) = $40.11/міс |
$40 (основний) + $8 (доп. ресурси) = $48/міс |
$40/міс |
| Вартість часу інженерів (налаштування) |
~80 годин $100 = $8000 (одноразово) |
~120 годин $100 = $12000 (одноразово) |
~20 годин $100 = $2000 (одноразово) |
| Вартість часу інженерів (підтримка) |
~5 годин/міс $100 = $500/міс |
~8 годин/міс $100 = $800/міс |
~2 години/міс $100 = $200/міс |
| Втрати від даунтайму (приклад) |
$0 (майже нульовий) |
$0 (майже нульовий) |
$100/хв 5 хв 4 деплої = $2000/міс |
| Ризик репутаційних втрат |
Низький |
Дуже низький (обмежена аудиторія) |
Високий |
| Загальна "вартість володіння" (TCO) за рік |
$8000 (налаштування) + $40.1112 (VPS) + $50012 (підтримка) = ~$14500 |
$12000 (налаштування) + $4812 (VPS) + $80012 (підтримка) = ~$22600 |
$2000 (налаштування) + $4012 (VPS) + $20012 (підтримка) + $200012 (втрати) = ~$29000 |
Ця таблиця наочно демонструє, що, хоча початкові інвестиції в Blue/Green і Canary деплой вищі, вони окупаються за рахунок зниження втрат від даунтайму, зменшення ручних операцій і підвищення надійності. Для критично важливих додатків, де кожна хвилина простою коштує грошей, ці просунуті стратегії є не просто бажаними, а економічно обґрунтованими інвестиціями.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
10. Кейси та приклади з реальної практики
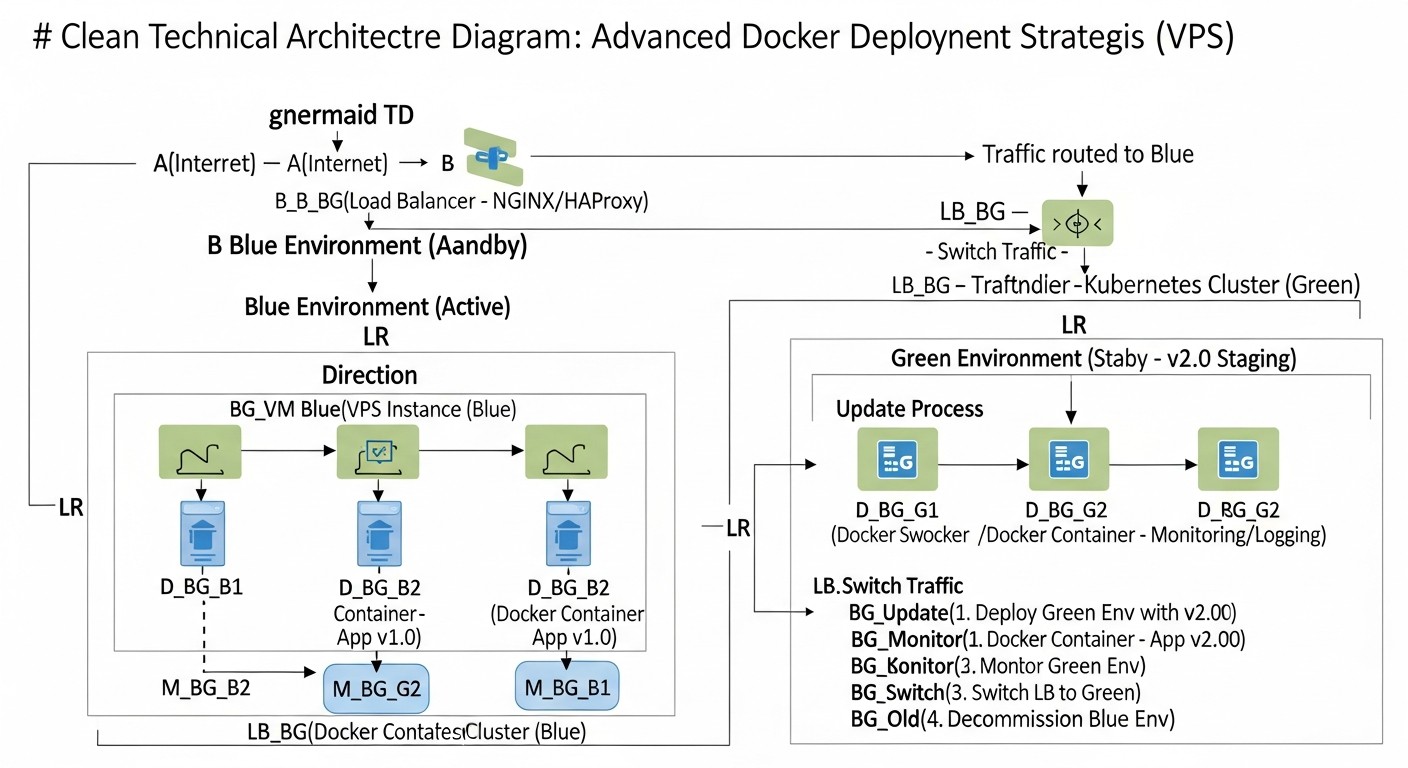 Схема: 10. Кейси та приклади з реальної практики
Схема: 10. Кейси та приклади з реальної практики
Щоб краще зрозуміти, як Blue/Green і Canary деплой застосовуються на практиці, розглянемо кілька реалістичних сценаріїв. Ці кейси демонструють, як різні компанії можуть використовувати ці стратегії для вирішення своїх унікальних задач на VPS.
10.1. Кейс 1: SaaS-платформа для управління проєктами (Blue/Green)
Сценарій
Невелика, але швидкозростаюча SaaS-компанія "TaskFlow" надає платформу для управління проєктами. У них близько 5000 активних клієнтів, які використовують сервіс 24/7. Команда розробників (4 бекенда на Node.js) випускає нові фічі і виправлення помилок щотижня. Простій сервісу навіть на 5 хвилин призводить до скарг клієнтів і потенційної втрати підписок. Інфраструктура складається з одного потужного VPS (8 vCPU, 16GB RAM) з Docker Compose, Nginx в якості реверс-проксі і PostgreSQL.
Проблема
Традиційний деплой "зупини-заміни-запусти" призводив до 2-5 хвилин простою щотижня. Це викликало невдоволення клієнтів, особливо з інших часових поясів, і збільшувало навантаження на підтримку.
Рішення: Впровадження Blue/Green деплою
- Дублювання контейнерів: Замість одного набору контейнерів для Node.js додатку, було створено два набори:
taskflow-blue і taskflow-green, кожен на своєму порту (наприклад, 3000 і 3001).
- Спільна база даних: PostgreSQL залишилася єдиною, але міграції БД були ретельно спроєктовані для зворотної сумісності.
- Nginx як комутатор: Nginx було налаштовано для маршрутизації всього трафіку на порт 3000 (Blue).
- CI/CD пайплайн: Був налаштований GitLab CI, який:
- Збирав новий Docker-образ.
- Розгортав нову версію на порт 3001 (Green).
- Запускав автоматичні інтеграційні тести проти Green-середовища.
- Після успішного тестування, очікував ручного підтвердження.
- За командою інженера автоматично змінював конфігурацію Nginx для перемикання трафіку на порт 3001 і перезавантажував Nginx.
- Після підтвердження стабільності Green, зупиняв і видаляв контейнери Blue.
- Моніторинг: Prometheus і Grafana були налаштовані для відстеження метрик обох середовищ, з алертингом на Slack при зростанні помилок або затримок.
Результати
- Нульовий даунтайм: Час перемикання трафіку скоротився до 1-2 секунд, повністю виключивши простій.
- Швидкий відкат: У разі проблем, відкат займав менше 10 секунд.
- Підвищення довіри клієнтів: Кількість скарг на недоступність сервісу різко скоротилася.
- Впевненість команди: Розробники стали більш сміливо випускати нові функції, знаючи, що ризик мінімальний.
- Додаткові витрати: Мінімальні, оскільки VPS мав достатній запас ресурсів для тимчасового подвоєння навантаження, а час інженерів на налаштування окупився за 3 місяці за рахунок скорочення ручних операцій і простою.
10.2. Кейс 2: E-commerce платформа з високим навантаженням (Canary)
Сценарій
Велика E-commerce платформа "ShopSphere" (на PHP/Laravel) має десятки тисяч активних користувачів щодня. Їх VPS-інфраструктура складається з декількох потужних серверів, об'єднаних в кластер з HAProxy в якості балансувальника навантаження. Впровадження нових функцій, особливо в платіжній системі або кошику, несе високі ризики. Навіть 0.1% помилок може призвести до значних фінансових втрат. Команда хоче тестувати нові функції на реальних користувачах, перш ніж викатувати їх всім.
Проблема
Blue/Green був хороший для даунтайму, але не давав можливості протестувати нові функції на невеликій, репрезентативній вибірці реальних користувачів. Іноді нові фічі працювали ідеально в тестовому середовищі, але викликали несподівану поведінку або помилки в продакшені через специфіку користувацьких даних або патернів використання.
Рішення: Впровадження Canary деплою
- Виділення Canary-інстансів: На одному з VPS були виділені ресурси для запуску "канареєчної" версії додатку (
shopsphere-canary).
- HAProxy для маршрутизації трафіку: HAProxy було налаштовано для перенаправлення трафіку:
- Спочатку 99.5% трафіку йшло на стабільні (Blue) інстанси.
- 0.5% трафіку направлялося на Canary-інстанс. Це було реалізовано за допомогою ваг в конфігурації HAProxy.
- Для внутрішніх тестерів була передбачена маршрутизація за спеціальним HTTP-заголовком
X-Test-Version: canary.
- Продвинутий моніторинг: Крім Prometheus/Grafana, було впроваджено ELK-стек для глибокого аналізу логів. Особлива увага приділялася бізнес-метрикам (конверсія, середній чек) для Canary-групи в порівнянні з Blue-групою.
- Автоматизований пайплайн з ручними кроками: GitLab CI було налаштовано для:
- Збірки та розгортання Canary-версії.
- Автоматичного запуску смоук-тестів.
- Ручного етапу "Оцінка Canary 0.5%": команда аналізувала метрики та логи протягом 4-6 годин.
- Якщо все добре, ручний крок "Збільшити до 5%".
- Повторення моніторингу та збільшення (25%, 50%, 100%).
- Автоматичного відкату Canary при виявленні критичних аномалій (наприклад, різке зростання помилок 5xx, падіння конверсії).
Результати
- Мінімальний ризик: Критичні помилки виявлялися на дуже малій вибірці користувачів, запобігаючи масовим проблемам.
- Якість релізів: Нові функції ретельно перевірялися в реальних умовах, що значно підвищило якість і стабільність релізів.
- Оптимізація користувацького досвіду: Можливість проводити A/B тестування нових функцій і UI-змін на невеликій аудиторії, збираючи реальний зворотний зв'язок.
- Додаткові витрати: Постійне використання одного додаткового VPS для Canary інстансів ($40/міс) і значні інвестиції в налаштування та підтримку складного пайплайну і моніторингу (близько 120 годин інженера). Однак ці витрати повністю виправдані запобіганням багатомільйонним втратам від помилок в E-commerce.
Ці кейси показують, що Blue/Green і Canary деплой — це не просто теоретичні концепції, а потужні, перевірені на практиці стратегії, здатні значно поліпшити процес розробки та експлуатації додатків на VPS, забезпечуючи при цьому високу доступність і якість сервісу.
12. Troubleshooting: вирішення типових проблем
 Схема: 12. Troubleshooting: решение типичных проблем
Схема: 12. Troubleshooting: решение типичных проблем
Навіть при найретельнішій підготовці та використанні просунутих стратегій деплою, проблеми в продакшені можуть виникнути. Вміння швидко діагностувати та усувати їх — ключова навичка для будь-якого DevOps-інженера. У цьому розділі ми розглянемо типові проблеми, які можуть виникнути при Blue/Green та Canary деплої на VPS з Docker, та запропонуємо конкретні кроки для їх вирішення.
12.1. Проблема: Нова версія застосунку (Green/Canary) не запускається або падає відразу після старту
Симптоми
- Контейнер не стартує або постійно перезапускається.
- Помилки в логах Docker або застосунку.
- Health check endpoint недоступний.
Діагностичні команди
# Проверить статус контейнера
docker ps -a | grep
# Просмотреть логи контейнера
docker logs
# Зайти внутрь контейнера для ручной проверки
docker exec -it /bin/bash
Рішення
- Перевірте логи: Найперше і головне. Шукайте повідомлення про помилки, винятки, проблеми із залежностями, змінними оточення, підключенням до БД або зовнішніх сервісів.
- Брак ресурсів: Перевірте завантаження CPU/RAM на VPS. Можливо, нова версія споживає більше ресурсів, ніж очікувалось, і Docker не може виділити достатньо.
htop # Или top, free -h
docker stats
- Проблеми з конфігурацією: Переконайтеся, що всі змінні оточення, файли конфігурації та томи, які монтуються, коректні для нової версії.
- Порти зайняті: Переконайтеся, що порт, на якому має працювати нова версія, не зайнятий іншим процесом.
sudo netstat -tulnp | grep
- Помилки в Dockerfile/образі: Якщо нова версія не збирається або запускається некоректно, перевірте
Dockerfile та процес збірки.
12.2. Проблема: Трафік не перемикається на нову версію або перемикається некоректно
Симптоми
- Користувачі продовжують бачити стару версію, хоча за логікою трафік має бути переключено.
- Частина користувачів бачить стару, частина — нову (для Blue/Green).
- Для Canary: відсоток трафіку не відповідає очікуванням.
Діагностичні команди
# Проверить конфигурацию Nginx
sudo nginx -t
sudo cat /etc/nginx/nginx.conf
# Проверить логи Nginx
sudo tail -f /var/log/nginx/access.log
sudo tail -f /var/log/nginx/error.log
# Проверить доступность портов приложения
curl http://127.0.0.1:8080/health # Blue
curl http://127.0.0.1:8081/health # Green/Canary
Рішення
- Перевірте конфігурацію балансувальника: Переконайтеся, що зміни в
nginx.conf (або Caddyfile/HAProxy) були застосовані і синтаксис коректний. Перезавантажте або перечитайте конфігурацію.
- Перевірте health checks: Балансувальник навантаження міг позначити нову версію як "нездорову" і не направляти на неї трафік. Перевірте логи балансувальника.
- DNS-кешування: Якщо ви перемикаєте трафік через DNS, зміни можуть поширюватися повільно через кешування. Це не відноситься до Nginx/HAProxy, які працюють на рівні L7.
- Sticky sessions: Якщо використовуються sticky sessions, переконайтеся, що вони коректно налаштовані і не заважають перемиканню трафіку.
12.3. Проблема: Нова версія працює повільніше або генерує більше помилок
Симптоми
- Зростання метрик помилок (5xx) в Prometheus/Grafana для нової версії.
- Збільшення затримок відповіді (latency).
- Зростання споживання CPU/RAM для контейнерів нової версії.
- Скарги користувачів на повільну роботу або недоступність.
Діагностичні команди
# Моніторинг метрик в Grafana
# Аналіз логів в Loki/Kibana
docker stats # Порівняти з docker stats
Рішення
- Моніторинг і логи: Це ваша основна точка опори. Порівняйте метрики та логи нової і старої версії. Шукайте аномалії: нові типи помилок, збільшення часу виконання запитів до БД, зовнішніх API.
- Ресурси: Переконайтеся, що нова версія не впирається в ліміти по CPU/RAM на VPS. Можливо, вона потребує більше ресурсів.
- Проблеми з БД: Перевірте повільні запити до бази даних, проблеми з індексами або блокуваннями, викликані змінами в новій версії.
- Зовнішні залежності: Нова версія може мати проблеми з підключенням до зовнішніх сервісів, кешів, черг повідомлень.
- Відкат: Якщо проблема критична і швидке рішення не знайдено, негайно виконайте відкат до попередньої стабільної версії.
12.4. Проблема: Проблеми з міграцією баз даних
Симптоми
- Помилки програми, пов'язані з доступом до БД (наприклад, "column not found", "table not found").
- Пошкодження даних або неконсистентність.
Діагностичні команди
# Перевірити логи міграцій
# Підключитися до БД і перевірити схему
psql -U user -d mydatabase -h db -c "\dt"
psql -U user -d mydatabase -h db -c "\d "
Рішення
- Зворотна сумісність: Переконайтеся, що міграції були спроектовані з урахуванням зворотної сумісності. Обидві версії програми (стара і нова) повинні вміти працювати з БД в перехідний період.
- Порядок міграцій: Переконайтеся, що міграції виконуються в правильному порядку: спочатку зміни, сумісні зі старою версією, потім деплой нової версії, потім, якщо необхідно, видалення старих елементів.
- Бекапи: Завжди робіть бекапи БД перед деплоєм і міграцією. У разі серйозних проблем, це дозволить відновити дані.
- Тестування міграцій: Тестуйте міграції не тільки на тестових даних, але і на копії продакшен-БД.
12.5. Коли звертатися в підтримку
Якщо ви зіткнулися з проблемами, які не можете вирішити самостійно, або у вас виникли складності з самою інфраструктурою VPS:
- Проблеми з VPS: Недоступність сервера, мережеві проблеми, проблеми з диском, які не пов'язані з вашим додатком.
- Проблеми з провайдером: Якщо ви підозрюєте, що проблема на стороні хостинг-провайдера (наприклад, загальна недоступність регіону, проблеми з мережею).
- Невідомі помилки: Якщо логи не дають чіткого розуміння проблеми, а всі стандартні кроки по діагностиці не привели до результату.
Надайте підтримці максимально повну інформацію: точний час виникнення проблеми, логи, метрики, виконані діагностичні кроки, а також будь-які зміни, які ви вносили перед виникненням проблеми.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
13. FAQ: Найчастіші запитання
Що таке Blue/Green деплой?
Blue/Green деплой — це стратегія розгортання, при якій підтримуються два ідентичні виробничі середовища: "синя" (Blue) з поточною стабільною версією програми і "зелена" (Green) для нової версії. Весь користувацький трафік направляється на одне з них. При оновленні нова версія розгортається на "зеленому" середовищі, тестується, і потім трафік миттєво перемикається з "синьої" на "зелену". Це забезпечує практично нульовий даунтайм і швидкий відкат.
В чому основна відмінність Blue/Green від Canary деплою?
Основна відмінність полягає у способі перемикання трафіку. Blue/Green перемикає весь трафік на нову версію одномоментно після повного тестування. Canary деплой, навпаки, поступово направляє невеликий відсоток трафіку на нову версію, дозволяючи тестувати її на реальних користувачах і збирати метрики, перш ніж повністю розкотити. Canary мінімізує ризики, але складніший в реалізації і довший за часом.
Чи можна реалізувати Blue/Green або Canary на одному VPS?
Так, цілком можливо, особливо для додатків середньої складності. Для цього потрібен достатній запас ресурсів на VPS (CPU, RAM) для одночасного запуску декількох версій вашого Docker-додатка. Використовуються різні порти для кожної версії і балансувальник навантаження (Nginx, HAProxy) для маршрутизації трафіку. Docker Compose допомагає управляти декількома наборами контейнерів на одному хості.
Які інструменти необхідні для Blue/Green/Canary на VPS?
Вам знадобляться: Docker і Docker Compose для контейнеризації і оркестрації, балансувальник навантаження (Nginx, Caddy, HAProxy) для маршрутизації трафіку, CI/CD система (GitLab CI, GitHub Actions, Jenkins, Ansible) для автоматизації деплою, а також системи моніторингу (Prometheus, Grafana) і логування (Loki, Promtail, ELK-стек) для контролю за станом обох версій програми.
Як бути з базами даних і їх міграціями при такому деплої?
Управління базами даних — критичний аспект. Всі міграції БД повинні бути зворотно сумісними, щоб як стара, так і нова версії програми могли працювати з однією і тією ж схемою БД в перехідний період. Використовуйте двофазні міграції для складних змін. Завжди робіть бекапи перед міграцією. В ідеалі, програма повинна бути спроектована так, щоб зміни схеми БД були мінімальними і не блокуючими.
Наскільки зростають витрати на VPS при використанні цих стратегій?
Для Blue/Green витрати на VPS збільшуються тимчасово (на час деплою) на вартість дублювання ресурсів. Якщо у вас є запас на VPS, це може бути дуже дешево. Для Canary можуть знадобитися постійно додаткові ресурси (наприклад, 10-50% від поточного навантаження) для підтримки Canary-інстансів. Однак, ці прямі витрати часто компенсуються зниженням втрат від даунтайму і помилок, що в підсумку робить ці стратегії економічно вигідними.
Які ризики пов'язані з Blue/Green деплоєм?
Основні ризики включають: необхідність подвоєння ресурсів на час деплою, складність управління станом програми (сесії, кеші) при перемиканні, а також необхідність ретельного планування міграцій баз даних. Якщо "зелене" середовище погано протестоване, то перемикання на нього може призвести до повної відмови сервісу для всіх користувачів.
Які ризики пов'язані з Canary деплоєм?
Canary деплой складніший у реалізації, вимагає просунутої системи моніторингу та маршрутизації трафіку. Є ризик, що невелика група користувачів зіткнеться з помилками, перш ніж проблема буде виявлена. Процес розгортання може займати більше часу. Управління станом та БД ще більш критичне, оскільки обидві версії програми працюють паралельно протягом тривалого часу.
Як автоматизувати перемикання трафіку для Blue/Green/Canary?
Автоматизація перемикання трафіку зазвичай здійснюється через CI/CD пайплайн. Скрипти (наприклад, Ansible, Bash-скрипти, що викликаються з GitLab CI/GitHub Actions) можуть змінювати конфігурацію балансувальника навантаження (Nginx, HAProxy), перезавантажувати його, або оновлювати DNS-записи. Для Canary це може бути поступова зміна ваг у конфігурації балансувальника.
Що таке Health Check і чому він важливий?
Health Check — це спеціальний endpoint (наприклад, /health) у вашому додатку, який балансувальник навантаження або система моніторингу регулярно опитує. Якщо endpoint повертає код 200 OK, додаток вважається здоровим; інакше — нездоровим. Health Check критично важливий, оскільки він дозволяє балансувальнику автоматично виключати несправні інстанси з пулу та гарантувати, що трафік направляється тільки на працюючі версії програми.
14. Висновок
У світі, де швидкість змін і безперервна доступність сервісів стали не просто конкурентною перевагою, а базовою вимогою, традиційні підходи до деплою Docker-додатків на VPS вже не справляються. Стратегії Blue/Green і Canary оновлень пропонують потужні рішення для цих викликів, дозволяючи мінімізувати даунтайм, знизити ризики і значно підвищити якість ваших релізів.
Ми детально розглянули обидві стратегії, їхні принципи роботи, переваги та недоліки, а також конкретні приклади реалізації з використанням актуальних інструментів 2026 року. Blue/Green деплой ідеально підходить для проєктів, де критичний нульовий даунтайм і швидкий відкат, а тимчасове подвоєння ресурсів прийнятне. Він відносно простий в освоєнні та реалізації на VPS за допомогою Docker Compose і Nginx. Canary деплой, хоч і складніший, надає безпрецедентні можливості для тестування нових функцій на реальних користувачах, мінімізуючи ризики до абсолютного мінімуму, що особливо цінно для великих і критично важливих SaaS-проєктів.
Незалежно від обраної стратегії, ключовими факторами успіху є:
- Автоматизація: Наскрізний CI/CD пайплайн, що автоматизує збірку, тестування, деплой і відкат.
- Моніторинг і логування: Глибоке розуміння стану вашого додатка та інфраструктури в реальному часі.
- Ретельне планування: Особлива увага до міграцій баз даних, управління станом і тестування.
- Культура DevOps: Взаємодія між розробниками та операційними інженерами для забезпечення безперебійної роботи.
Наступні кроки для читача
- Оцініть свої поточні потреби: Проаналізуйте допустимий даунтайм, ризики та ресурси вашого проєкту.
- Почніть з малого: Якщо ви новачок, спробуйте реалізувати базовий Blue/Green деплой на тестовому VPS з простим Docker-додатком.
- Інвестуйте в автоматизацію: Почніть з налаштування простого CI/CD пайплайна для збірки та деплою.
- Впровадьте моніторинг: Навіть базовий Prometheus і Grafana дадуть вам безцінну інформацію.
- Вивчайте інструменти: Глибше пориньте в документацію Nginx/HAProxy, Ansible, GitLab CI/GitHub Actions.
- Практикуйтеся: Досвід приходить з практикою. Не бійтеся експериментувати в контрольованому середовищі.
Впровадження цих просунутих стратегій — це не просто технічна вправа, а інвестиція в стабільність, надійність і конкурентоспроможність вашого продукту. У 2026 році це вже не розкіш, а необхідність для будь-якого серйозного SaaS-проєкту або онлайн-сервісу, який прагне до досконалості.
Поділитися цим записом:
продвинутые стратегии деплоя docker-приложений на vps: blue/green и canary обновления
support_agent
Valebyte Support
Usually replies within minutes
Hi there!
Send us a message and we'll reply as soon as possible.