Повна спостережуваність (Observability) для розподілених систем: OpenTelemetry, Loki та Tempo на VPS 2026
TL;DR
- OpenTelemetry — це стандарт 2026 року для збору телеметрії. Він уніфікує збір метрик, логів і трасувань, роблячи вашу систему готовою до майбутніх змін і уникаючи прив'язки до конкретного вендора.
- Loki — оптимальний вибір для логів на VPS. Його індекс за метаданими дозволяє ефективно зберігати та запитувати логи навіть за обмежених ресурсів, що критично для бюджетних рішень.
- Tempo — ідеальне рішення для розподілених трасувань. Він використовує об'єктне сховище, мінімізуючи вимоги до RAM і CPU, що робить його вкрай придатним для VPS-інфраструктури в 2026 році.
- Інтеграція з Grafana — ваш єдиний дашборд. Всі три компоненти легко інтегруються з Grafana, надаючи централізований інтерфейс для візуалізації та аналізу всієї телеметрії.
- Економія на VPS у 2026 році — це реально. Правильне налаштування OpenTelemetry Collector, фільтрація даних і оптимізація зберігання дозволяють значно скоротити витрати, особливо на трафік і дисковий простір.
- Практичний підхід — ключ до успіху. Почніть з малого, впроваджуйте поступово, автоматизуйте розгортання та не забувайте про регулярний аудит конфігурацій і споживання ресурсів.
- Будьте готові до масштабування. Навіть на VPS, архітектура OpenTelemetry, Loki та Tempo дозволяє відносно легко масштабуватися, переходячи на більш потужні інстанси або кластери в міру зростання проєкту.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
Вступ
 Схема: Введення
Схема: Введення
До 2026 року ландшафт розробки програмного забезпечення зазнав значних змін. Монолітні застосунки поступилися місцем розподіленим мікросервісним архітектурам, хмарні технології стали повсюдними, а концепція "серверлес" і граничних обчислень (edge computing) продовжує набирати обертів. Разом з цією еволюцією зростає і складність систем. Відмова одного з десятків або сотень мікросервісів може призвести до каскадних збоїв, а пошук кореня проблеми в заплутаній мережі взаємодій стає справжнім кошмаром без адекватних інструментів.
Саме тут на сцену виходить концепція повної спостережуваності (Observability). На відміну від традиційного моніторингу, який відповідає на питання "Що трапилось?", Observability дозволяє відповісти на питання "Чому це трапилось?", надаючи глибоке розуміння внутрішнього стану системи через три основні стовпи: метрики, логи і трасування. У 2026 році, коли час простою вимірюється не тільки грошима, а й репутацією, а користувацький досвід є ключовою конкурентною перевагою, Observability перестає бути розкішшю і стає абсолютною необхідністю.
Ця стаття присвячена побудові повноцінної системи Observability для розподілених систем, використовуючи зв'язку OpenTelemetry, Loki та Tempo, розгорнуту на віртуальному приватному сервері (VPS). Ми сфокусуємося на практичних аспектах, актуальних для 2026 року, враховуючи постійно зростаючі вимоги до продуктивності, ефективності і, звичайно ж, вартості. Ми покажемо, як, навіть за обмеженого бюджету і ресурсів VPS, можна досягти високого рівня спостережуваності, порівнянного з дорожчими хмарними рішеннями.
Для кого написана ця стаття? В першу чергу, для DevOps-інженерів і системних адміністраторів, які шукають ефективні та економічні рішення для моніторингу та діагностики. Вона буде корисна Backend-розробникам (Python, Node.js, Go, PHP), які прагнуть інтегрувати Observability в свої застосунки. Фаундери SaaS-проєктів і технічні директори стартапів знайдуть тут практичні поради щодо оптимізації витрат і підвищення надійності своїх продуктів, використовуючи передові відкриті технології.
Ми розглянемо, чому саме ця комбінація інструментів є однією з найбільш перспективних і економічно ефективних для VPS в 2026 році, як її правильно налаштувати, яких помилок уникнути і як отримати максимум користі для вашого бізнесу.
Основні критерії/фактори вибору
 Схема: Основні критерії/фактори вибору
Схема: Основні критерії/фактори вибору
Вибір правильних інструментів для Observability — це не просто слідування трендам, а стратегічне рішення, яке безпосередньо впливає на надійність, продуктивність і, в кінцевому підсумку, на бізнес-успіх проєкту. У 2026 році, коли йдеться про розподілені системи на VPS, необхідно враховувати ряд критично важливих факторів.
1. Вартість володіння (TCO)
Це, мабуть, найважливіший фактор для проєктів, що використовують VPS. TCO включає не тільки прямі витрати на сервери і сховище, а й непрямі: час інженерів на налаштування, підтримку, масштабування, а також потенційні втрати від простоїв. Рішення повинні бути ресурсоефективними, мінімізувати споживання CPU, RAM і дискового простору, а також трафіку, який часто є значною статтею витрат на VPS. Ми будемо шукати інструменти, які дозволяють зберігати великий обсяг даних за розумні гроші.
2. Простота розгортання та управління
На VPS ресурси інженерів часто обмежені. Складні в установці та налаштуванні системи можуть швидко стати тягарем. Нам потрібні рішення, які можна швидко розгорнути, легко оновити і підтримувати без необхідності глибокого занурення в їх внутрішній устрій. Документація, спільнота і наявність готових конфігурацій відіграють тут ключову роль.
3. Масштабованість і продуктивність
Навіть на VPS система повинна бути здатна обробляти зростаючий обсяг телеметрії без деградації продуктивності. Це означає ефективне використання ресурсів, горизонтальне масштабування (якщо буде потрібен перехід на декілька VPS) і здатність справлятися з піковими навантаженнями. Особливо важливо для логів і трасувань, обсяг яких може бути непередбачуваним.
4. Гнучкість і розширюваність
Світ технологій постійно змінюється. Обрані інструменти повинні бути достатньо гнучкими, щоб адаптуватися до нових джерел даних, протоколів та інтеграцій. OpenTelemetry тут є золотим стандартом, надаючи уніфікований підхід до збору даних. Можливість легко додавати нові сервіси та застосунки до системи Observability — критична.
5. Глибина і якість даних
Інструменти повинні надавати достатньо деталізовані та точні дані (метрики, логи, трасування), щоб можна було ефективно діагностувати проблеми. Можливість додавати кастомні атрибути (теги) до даних, агрегувати їх за різними вимірами та виконувати складні запити — це основа для глибокого аналізу.
6. Інтеграція з екосистемою
Система Observability не існує у вакуумі. Вона повинна легко інтегруватися з іншими інструментами у вашому стеку: системами оповіщення (Alertmanager), дашбордами (Grafana), CI/CD пайплайнами і т.д. Чим безшовніша інтеграція, тим ефективнішим стає весь процес розробки та експлуатації.
7. Відкритість і стандарти
Використання відкритих стандартів і проєктів з активною спільнотою знижує ризик прив'язки до вендора (vendor lock-in) та забезпечує довгострокову підтримку. OpenTelemetry — яскравий приклад такого підходу, ставши де-факто стандартом для телеметрії. Відкриті проєкти також часто пропонують більш гнучкі рішення та швидше адаптуються до нових вимог.
8. Безпека
Телеметрія часто містить чутливі дані. Інструменти повинні забезпечувати безпечну передачу та зберігання даних, підтримувати автентифікацію та авторизацію, а також надавати можливості для маскування або фільтрації конфіденційної інформації.
Як оцінювати кожен критерій:
- TCO: Порівнюйте не тільки вартість VPS, але й передбачуваний обсяг трафіку, дискового простору для зберігання логів/трасувань, а також прогнозований час, який інженери витратять на підтримку. Використовуйте калькулятори провайдерів і тестові розгортання.
- Простота розгортання: Оцініть кількість кроків для встановлення, складність конфігураційних файлів, наявність Docker-образів і Helm-чартів (якщо використовується Kubernetes на VPS).
- Масштабованість: Вивчіть архітектуру інструменту. Чи підтримує він горизонтальне масштабування? Які рекомендації щодо ресурсів для різних обсягів даних?
- Гнучкість: Перевірте, які протоколи підтримує інструмент для прийому даних, чи є API для розширення функціоналу, як легко додати нові джерела даних.
- Глибина даних: Подивіться приклади дашбордів і запитів. Наскільки детальну інформацію можна отримати? Чи можна фільтрувати та агрегувати дані за багатьма параметрами?
- Інтеграція: Перевірте наявність готових конекторів, плагінів і документації щодо інтеграції з Grafana, Alertmanager та іншими інструментами.
- Відкритість: Оцініть активність на GitHub, кількість контриб'юторів, частоту релізів, наявність публічної дорожньої карти.
- Безпека: Вивчіть документацію з безпеки: шифрування даних в дорозі та при зберіганні, механізми доступу.
Враховуючи ці критерії, зв'язка OpenTelemetry, Loki і Tempo на VPS у 2026 році виглядає одним з найбільш збалансованих і перспективних рішень.
Порівняльна таблиця рішень для Observability
 Схема: Порівняльна таблиця рішень для Observability
Схема: Порівняльна таблиця рішень для Observability
Для розуміння переваг обраного стеку, давайте порівняємо OpenTelemetry, Loki і Tempo з іншими популярними рішеннями, актуальними для 2026 року, особливо в контексті використання на VPS. Ми зосередимося на ключових аспектах: тип даних, вартість, складність, масштабованість та основні особливості.
| Критерій |
OpenTelemetry (Збір) |
Loki (Логи) |
Tempo (Трейси) |
Prometheus (Метрики) |
Elastic Stack (ELK) |
Jaeger (Трейси) |
Cloud-провайдер (Managed Observability) |
| Тип даних |
Метрики, Логи, Трейси (універсальний збирач) |
Логи |
Трейси |
Метрики (pull-модель) |
Логи, Метрики, Трейси (через Filebeat, Metricbeat, APM) |
Трейси |
Метрики, Логи, Трейси (комплексно) |
| Вартість (VPS, 2026) |
Низька (тільки збирач, CPU/RAM) |
Середня (зберігання на S3-сумісному, CPU/RAM для запитів) |
Низька (зберігання на S3-сумісному, мінімальний CPU/RAM) |
Середня (зберігання на диску, CPU/RAM) |
Висока (потребує багато RAM/CPU/диска) |
Середня (потребує Cassandra/Elasticsearch, CPU/RAM/диск) |
Висока (за підпискою, ціна за обсяг даних) |
| Складність розгортання |
Середня (Collector + агенти) |
Середня (Loki + Promtail) |
Низька (Tempo + OpenTelemetry Collector) |
Середня (Prometheus + Exporters) |
Висока (Elasticsearch, Kibana, Logstash/Beats) |
Висока (Collector, Query, Agent, Storage) |
Низька (конфігурація через UI/API) |
| Масштабованість на VPS |
Висока (горизонтально Collector) |
Середня (розділення на ingester/querier, об'єктне сховище) |
Висока (об'єктне сховище, мінімальні ресурси) |
Середня (Federation, Thanos/Cortex для кластера) |
Низька (дуже ресурсоємний для кластера) |
Середня (з зовнішньою БД) |
Дуже висока (управляється провайдером) |
| Зберігання даних |
Немає (тільки буферизація) |
Об'єктне сховище (S3-сумісне), індекс за метаданими |
Об'єктне сховище (S3-сумісне), індекс за ID трейса |
Локальний диск (TSDB) |
Локальний диск (Lucene/inverted index) |
Cassandra, Elasticsearch, Kafka |
Керується провайдером (власні рішення) |
| Особливості 2026 року для VPS |
Універсальний стандарт, vendor-agnostic, активний розвиток, широка підтримка мов. |
Ефективне зберігання логів, низькі вимоги до RAM/CPU, відмінна інтеграція з Grafana, підтримка Cloud Object Storage як бекенду. |
Мінімальні вимоги до RAM/CPU, зберігання трейсів в об'єктному сховищі, "зберігай все" підхід, швидкі запити за ID трейсу. |
Де-факто стандарт для метрик, pull-модель, потужна мова запитів PromQL, активна спільнота. |
Потужна аналітика, повнотекстовий пошук, але дуже ресурсоємний, що робить його дорогим для VPS. |
Відкритий стандарт для трасувань, але потребує потужної СУБД для зберігання, що здорожує VPS. |
Зручність, відсутність необхідності управління, але висока вартість за обсяг даних і vendor lock-in. |
| Інтеграція з Grafana |
Так (через Prometheus/Loki/Tempo) |
Так (нативна) |
Так (нативна) |
Так (нативна) |
Так (через плагін) |
Так (через плагін) |
Так (часто нативна або через API) |
З таблиці видно, що зв'язка OpenTelemetry, Loki і Tempo пропонує унікальний баланс між функціональністю, продуктивністю і вартістю, особливо для розгортання на VPS у 2026 році. Відмова від ресурсоємних баз даних для зберігання логів і трасувань на користь об'єктних сховищ (S3-сумісних) є ключовим фактором, що дозволяє значно знизити TCO і спростити управління.
Prometheus залишається стандартом для метрик, і його часто використовують разом з OpenTelemetry Collector для збору та агрегації метрик. Elastic Stack, хоча і потужний, надмірно дорогий і складний для більшості VPS-проєктів. Cloud-провайдери пропонують зручність, але їх цінова політика за обсяг даних може швидко стати непідйомною для стартапів і невеликих команд.
Таким чином, OpenTelemetry як універсальний збирач, Loki для економічного зберігання логів і Tempo для трасувань на об'єктному сховищі, доповнені Grafana для візуалізації, є оптимальним рішенням для Observability на VPS у 2026 році.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
Детальний огляд OpenTelemetry, Loki і Tempo
 Схема: Детальний огляд OpenTelemetry, Loki і Tempo
Схема: Детальний огляд OpenTelemetry, Loki і Tempo
Для глибокого розуміння того, чому саме ця зв'язка інструментів є настільки ефективною для Observability на VPS у 2026 році, розглянемо кожен компонент детальніше.
OpenTelemetry: Універсальний збирач телеметрії
OpenTelemetry (скорочено OTel) — це не просто інструмент, це набір стандартів, API, SDK і інструментів, розроблених для уніфікованого збору, обробки та експорту телеметрії (метрик, логів і трасувань) з ваших додатків та інфраструктури. До 2026 року OTel став де-факто стандартом в індустрії, підтримуваним практично всіма великими хмарними провайдерами та інструментами Observability.
Плюси:
- Vendor-agnostic: Ви не прив'язані до конкретного вендора або платформи. Ви можете збирати дані один раз і відправляти їх в Loki, Tempo, Prometheus, а також в будь-які комерційні рішення, які підтримують OTel. Це забезпечує величезну гнучкість і захист інвестицій в майбутньому.
- Єдиний підхід: OTel надає єдиний API і SDK для всіх трьох типів телеметрії, що значно спрощує інструментацію додатків. Розробникам не потрібно вивчати різні бібліотеки для метрик, логів і трасувань.
- Потужний Collector: OpenTelemetry Collector — це проксі, який може отримувати, обробляти та експортувати телеметрію. Він дозволяє фільтрувати, перетворювати, агрегувати дані прямо на кордоні мережі, знижуючи навантаження на бекенди і економлячи трафік. Це критично важливо для VPS, де кожен мегабайт трафіку і кожен цикл CPU на рахунку.
- Широка підтримка мов: OTel має SDK для більшості популярних мов програмування (Python, Java, Go, Node.js, .NET, PHP, Ruby і т.д.), що робить його застосовним практично в будь-якому середовищі.
- Активна спільнота і розвиток: Проєкт знаходиться під егідою Cloud Native Computing Foundation (CNCF) і активно розвивається, постійно додаючи нові функції і покращуючи продуктивність.
Мінуси:
- Крива навчання: Незважаючи на уніфікацію, освоєння всіх концепцій OTel (трасери, спани, контексти, ресурси, атрибути, семантичні конвенції) може зайняти деякий час.
- Накладні витрати: Інструментація додатків і робота Collector вимагають деякого споживання CPU і RAM, хоч і оптимізованого. На дуже маленьких VPS (< 1GB RAM) це може бути помітно.
Для кого підходить: Для всіх, хто хоче створити гнучку, масштабовану і vendor-agnostic систему Observability. Особливо корисний для мікросервісних архітектур, де необхідно відстежувати взаємодію між безліччю компонентів.
Приклади використання: Інструментація HTTP-запитів в Go-додатку, збір метрик з Node.js-сервісу, відправка кастомних логів з Python-скрипта. Collector може бути налаштований для агрегації метрик з декількох сервісів перед відправкою в Prometheus, або для семплювання трасувань, щоб знизити обсяг даних, що відправляються в Tempo.
Loki: Економічне сховище логів
Loki, розроблений компанією Grafana Labs, позиціонується як "Prometheus для логів". Його ключова відмінність від традиційних систем управління логами (на зразок Elastic Stack) полягає в тому, що він індексує тільки метадані (лейбли) логів, а не їх повний вміст. Це дозволяє значно скоротити обсяг індексу і, як наслідок, вимоги до дискового простору та оперативної пам'яті.
Плюси:
- Економія ресурсів: Завдяки індексації тільки метаданих, Loki споживає набагато менше RAM і CPU в порівнянні з рішеннями, що використовують повнотекстовий пошук. Це робить його ідеальним для VPS, де ресурси обмежені.
- Об'єктне сховище: Loki може використовувати S3-сумісні об'єктні сховища (такі як MinIO на тому ж VPS, або хмарні S3/Google Cloud Storage/Azure Blob Storage) для зберігання самих логів. Це забезпечує високу масштабованість і низьку вартість зберігання.
- Query Language (LogQL): Loki використовує мову запитів, натхненну PromQL, що спрощує його освоєння для тих, хто вже знайомий з Prometheus. LogQL дуже потужний і дозволяє фільтрувати, агрегувати і аналізувати логи по їх лейблам і вмісту.
- Нативна інтеграція з Grafana: Loki розроблений тією ж командою, що й Grafana, тому інтеграція між ними бездоганна. Ви можете легко створювати дашборди, досліджувати логи та переходити від метрик до логів в одному інтерфейсі.
- Простота розгортання: Loki відносно легко розгорнути, особливо в режимі "моноліту" (single binary) для невеликих інсталяцій на VPS.
Мінуси:
- Немає повнотекстового пошуку: Якщо вам потрібен високопродуктивний повнотекстовий пошук по всіх логах без попереднього знання лейблів, Loki може бути не найкращим вибором. Однак, у 2026 році, з розвитком OpenTelemetry і стандартизацією атрибутів, цей недолік стає менш критичним.
- Залежність від лейблів: Ефективність запитів сильно залежить від правильного вибору і використання лейблів. Неправильна стратегія лейблінгу може призвести до повільних запитів або "кардинального вибуху" (high cardinality).
Для кого підходить: Для команд, які хочуть ефективно керувати великими обсягами логів на обмежених ресурсах, використовуючи Grafana для візуалізації. Ідеальний для SaaS-проєктів, де логування критичне, але бюджет обмежений.
Приклади використання: Збір логів веб-сервера Nginx, мікросервісів на Go, логів з Docker-контейнерів, системних логів. Використання Promtail (агента Loki) або OpenTelemetry Collector для відправки логів в Loki.
Tempo: Розподілені трасування без головного болю
Tempo — ще один проєкт від Grafana Labs, призначений для зберігання і запиту розподілених трасувань. Його унікальність полягає в тому, що він не будує індекси по всьому вмісту трасувань. Замість цього він зберігає трасування в S3-сумісному об'єктному сховищі та індексує тільки їх ID. Запити до Tempo виконуються за ID трасування, що робить його надзвичайно ефективним і ресурсонезалежним.
Плюси:
- Мінімальні вимоги до ресурсів: Оскільки Tempo не індексує вміст трасувань, він споживає дуже мало RAM і CPU. Це дозволяє розгорнути його навіть на найскромніших VPS.
- Масштабованість через об'єктне сховище: Подібно до Loki, Tempo використовує S3-сумісні сховища для самих трасувань. Це забезпечує практично необмежену масштабованість і низьку вартість зберігання даних.
- "Зберігай все" підхід: Через низьку вартість зберігання і мінімальні ресурси, Tempo дозволяє зберігати 100% ваших трасувань, а не покладатися на семплювання. Це дає можливість глибокого аналізу навіть рідкісних проблем.
- Нативна інтеграція з Grafana і Prometheus: Tempo легко інтегрується з Grafana, дозволяючи переходити від метрик (Prometheus) або логів (Loki) до конкретних трасувань. Також підтримується пошук трасувань за атрибутами через Loki або Prometheus.
- Простота розгортання: Tempo, як і Loki, може бути запущений в режимі "моноліту" для простих інсталяцій, що спрощує його розгортання на VPS.
Мінуси:
- Пошук тільки за ID або непрямо: Основний спосіб пошуку трасувань — за їх унікальним ID. Пошук за атрибутами (наприклад, за ім'ям користувача або ID замовлення) можливий, але вимагає інтеграції з Loki (для пошуку за логами, що містять ці атрибути і ID трасування) або з Prometheus (для пошуку за метриками, що агрегують атрибути і ID трасування).
- Немає вбудованого UI: Tempo не має власного інтерфейсу користувача, повністю покладаючись на Grafana для візуалізації і дослідження трасувань.
Для кого підходить: Для команд, яким потрібна повна видимість взаємодії між мікросервісами, але при цьому вони обмежені в бюджеті і ресурсах. Ідеально для діагностики продуктивності, виявлення вузьких місць і розуміння потоку даних в розподілених системах.
Приклади використання: Відстеження повного шляху запиту через API Gateway, кілька бекенд-сервісів і базу даних. Діагностика затримок, викликаних зовнішніми API-викликами. Використання OpenTelemetry SDK в додатках для генерації трасувань і відправки їх через OpenTelemetry Collector в Tempo.
Разом, OpenTelemetry, Loki і Tempo, інтегровані з Grafana, надають потужне, економічне і масштабоване рішення для Observability, яке ідеально підходить для розподілених систем, розгорнутих на VPS у 2026 році.
Практичні поради та рекомендації щодо впровадження
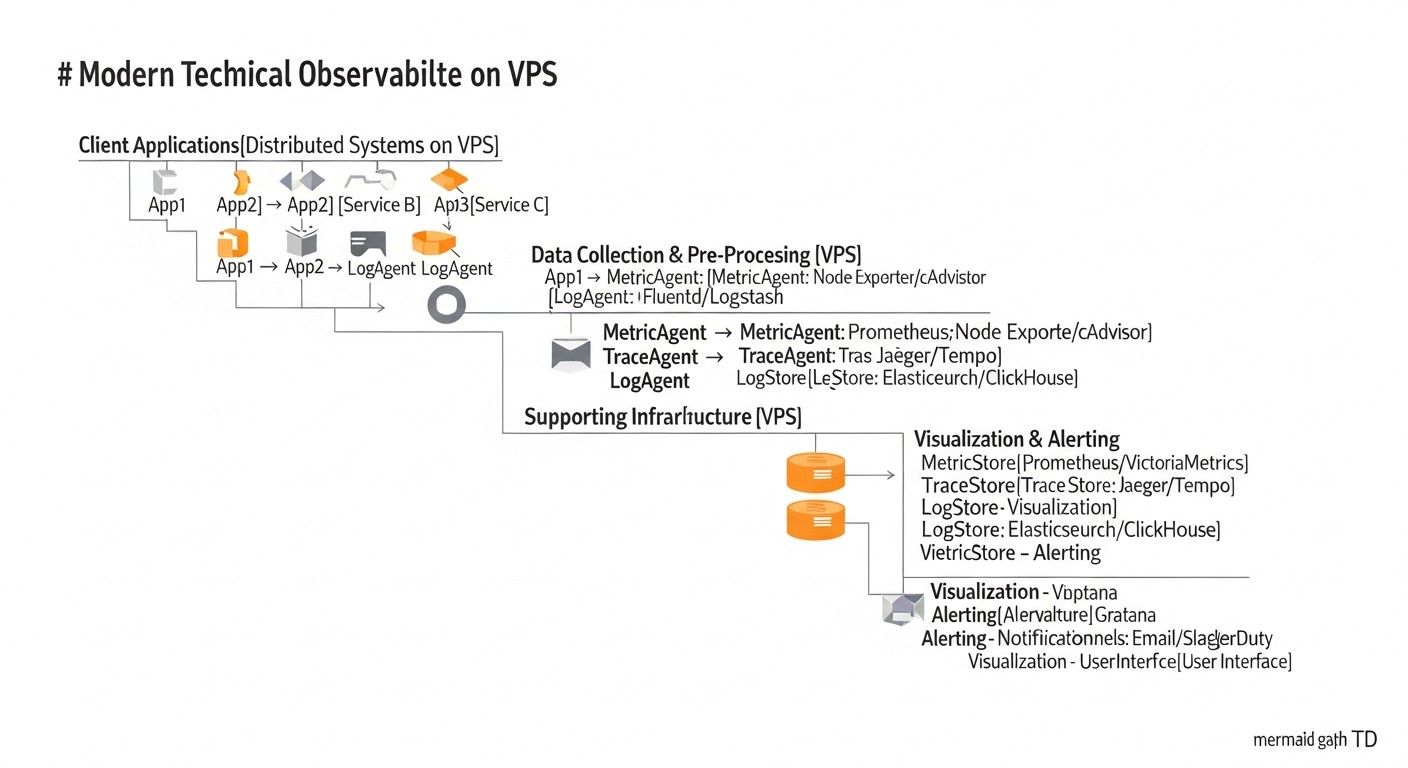 Схема: Практичні поради та рекомендації щодо впровадження
Схема: Практичні поради та рекомендації щодо впровадження
Впровадження повноцінної системи Observability на VPS вимагає не тільки розуміння інструментів, але й практичного підходу. Ось покрокові інструкції та рекомендації, засновані на реальному досвіді.
1. Підготовка VPS та базове налаштування
Перш ніж що-небудь встановлювати, переконайтеся, що ваш VPS готовий. Рекомендується використовувати свіжу установку Ubuntu Server 24.04 LTS або Debian 12. Для наших цілей потрібно мінімум 4GB RAM і 2 CPU ядра, а також достатньо дискового простору або можливість підключення S3-сумісного сховища.
# Оновлення системи
sudo apt update && sudo apt upgrade -y
# Встановлення Docker і Docker Compose (для спрощення розгортання)
sudo apt install ca-certificates curl gnupg lsb-release -y
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt update
sudo apt install docker-ce docker-ce-cli containerd.io docker-compose-plugin -y
# Додавання користувача до групи docker
sudo usermod -aG docker $USER
# Вийдіть і зайдіть знову, щоб зміни набрали чинності, або виконайте:
# newgrp docker
# Встановлення MinIO (локальне S3-сумісне сховище для Loki і Tempo)
# Створимо директорії для даних і конфігурації MinIO
sudo mkdir -p /mnt/data/minio
sudo mkdir -p /etc/minio
# Створимо файл docker-compose.yml для MinIO
# nano docker-compose.yml
Приклад docker-compose.yml для MinIO:
version: '3.8'
services:
minio:
image: minio/minio:latest
container_name: minio
ports:
- "9000:9000"
- "9001:9001"
volumes:
- /mnt/data/minio:/data
- /etc/minio:/root/.minio
environment:
MINIO_ROOT_USER: minioadmin
MINIO_ROOT_PASSWORD: minioadminpassword
MINIO_BROWSER: "on"
command: server /data --console-address ":9001"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
restart: unless-stopped
# Запуск MinIO
docker compose up -d
Тепер MinIO доступний за адресою http://<ваш_ip>:9001. Створіть бакети для Loki та Tempo, наприклад, loki-bucket та tempo-bucket.
2. Розгортання OpenTelemetry Collector
Collector буде центральним вузлом для збору, обробки та маршрутизації телеметрії. Для VPS його можна розгорнути як Docker-контейнер.
Приклад otel-collector-config.yaml:
receivers:
otlp:
protocols:
grpc:
http:
processors:
batch:
send_batch_size: 1000
timeout: 10s
memory_limiter:
check_interval: 1s
limit_mib: 256 # Обмеження RAM для Collector
spike_limit_mib: 64
resource:
attributes:
- key: host.name
value: ${env:HOSTNAME}
action: upsert
- key: deployment.environment
value: production
action: insert
exporters:
loki:
endpoint: http://loki:3100/loki/api/v1/push
# auth:
# basic:
# username: ${env:LOKI_USERNAME}
# password: ${env:LOKI_PASSWORD}
tempo:
endpoint: http://tempo:4317
tls:
insecure: true # В production використовувати TLS
prometheus:
endpoint: 0.0.0.0:8889
resource_to_telemetry_conversion:
enabled: true
logging:
loglevel: debug
service:
pipelines:
traces:
receivers: [otlp]
processors: [memory_limiter, batch, resource]
exporters: [tempo, logging]
metrics:
receivers: [otlp]
processors: [memory_limiter, batch, resource]
exporters: [prometheus, logging]
logs:
receivers: [otlp]
processors: [memory_limiter, batch, resource]
exporters: [loki, logging]
Запуск Collector через docker-compose.yml:
version: '3.8'
services:
otel-collector:
image: otel/opentelemetry-collector:0.96.0 # Актуальна версія на 2026 рік
container_name: otel-collector
command: ["--config=/etc/otel-collector-config.yaml"]
volumes:
- ./otel-collector-config.yaml:/etc/otel-collector-config.yaml
ports:
- "4317:4317" # OTLP gRPC receiver
- "4318:4318" # OTLP HTTP receiver
- "8889:8889" # Prometheus exporter
environment:
HOSTNAME: ${HOSTNAME} # Передаємо ім'я хоста
depends_on:
- loki
- tempo
restart: unless-stopped
3. Розгортання Loki
Для Loki також використовуємо Docker. Нам знадобиться конфігураційний файл loki-config.yaml.
auth_enabled: false # Для простоти, в production використовувати аутентифікацію
server:
http_listen_port: 3100
grpc_listen_port: 9095
common:
path_prefix: /loki
storage:
filesystem:
directory: /tmp/loki/chunks # Тільки для тимчасового зберігання, потім в S3
replication_factor: 1
ring:
kvstore:
store: inmemory # Для single-node, в production використовувати Consul/Etcd
instance_addr: 127.0.0.1
instance_port: 3100
schema_config:
configs:
- from: 2023-01-01
store: boltdb-shipper
object_store: s3
schema: v12
index:
prefix: index_
period: 24h
compactor:
working_directory: /tmp/loki/compactor
shared_store: s3
chunk_store_config:
max_look_back_period: 30d # Зберігати чанки логів 30 днів
storage_config:
boltdb_shipper:
active_index_directory: /tmp/loki/boltdb-shipper-active
cache_location: /tmp/loki/boltdb-shipper-cache
resync_interval: 5s
shared_store: s3
s3:
endpoint: minio:9000
bucketnames: loki-bucket
access_key_id: minioadmin
secret_access_key: minioadminpassword
s3forcepathstyle: true
Додаємо Loki в docker-compose.yml:
loki:
image: grafana/loki:2.9.0 # Актуальна версія на 2026 рік
container_name: loki
command: -config.file=/etc/loki/loki-config.yaml
volumes:
- ./loki-config.yaml:/etc/loki/loki-config.yaml
- /mnt/data/loki:/tmp/loki # Дані Loki
ports:
- "3100:3100"
environment:
MINIO_ENDPOINT: minio:9000 # Для Loki, щоб міг достукатись до MinIO
depends_on:
- minio
restart: unless-stopped
4. Розгортання Tempo
Конфігурація Tempo в tempo-config.yaml:
server:
http_listen_port: 3200
grpc_listen_port: 9096
distributor:
receivers:
otlp:
protocols:
grpc:
http:
ingester:
lifecycler:
ring:
kvstore:
store: inmemory # Для single-node, в production використовувати Consul/Etcd
replication_factor: 1
compactor:
compaction_interval: 10m
storage:
trace:
backend: s3
s3:
endpoint: minio:9000
bucket: tempo-bucket
access_key_id: minioadmin
secret_access_key: minioadminpassword
s3forcepathstyle: true
wal:
path: /tmp/tempo/wal # Write Ahead Log
block:
bloom_filter_false_positive_rate: 0.05
index_downsample_bytes: 1000
max_block_bytes: 5000000 # 5MB
max_block_duration: 15m
retention: 30d # Зберігати трасування 30 днів
Додаємо Tempo в docker-compose.yml:
tempo:
image: grafana/tempo:2.4.0 # Актуальна версія на 2026 рік
container_name: tempo
command: -config.file=/etc/tempo/tempo-config.yaml
volumes:
- ./tempo-config.yaml:/etc/tempo/tempo-config.yaml
- /mnt/data/tempo:/tmp/tempo # Дані Tempo
ports:
- "3200:3200" # HTTP
- "9096:9096" # gRPC
- "4317" # OTLP gRPC receiver (Tempo може приймати напряму, але краще через Collector)
- "4318" # OTLP HTTP receiver
environment:
MINIO_ENDPOINT: minio:9000 # Для Tempo, щоб міг достукатись до MinIO
depends_on:
- minio
restart: unless-stopped
5. Розгортання Grafana
Grafana буде вашим єдиним інтерфейсом для всіх даних Observability.
grafana:
image: grafana/grafana:10.4.0 # Актуальна версія на 2026 рік
container_name: grafana
ports:
- "3000:3000"
volumes:
- /mnt/data/grafana:/var/lib/grafana # Для персистентності даних Grafana
environment:
GF_SECURITY_ADMIN_USER: admin
GF_SECURITY_ADMIN_PASSWORD: supersecretpassword # Змініть на складний пароль!
GF_AUTH_ANONYMOUS_ENABLED: "false"
GF_AUTH_DISABLE_SIGNOUT_MENU: "false"
depends_on:
- loki
- tempo
- otel-collector
restart: unless-stopped
# Запуск всіх сервісів
docker compose up -d
Тепер Grafana доступна за адресою http://<ваш_ip>:3000. Увійдіть з логіном admin та паролем supersecretpassword.
6. Налаштування джерел даних в Grafana
- Додайте Loki як джерело даних:
- Type: Loki
- URL:
http://loki:3100
- Додайте Tempo як джерело даних:
- Type: Tempo
- URL:
http://tempo:3200
- Для "Data Links" вкажіть джерело Loki, щоб можна було переходити від трасувань до логів.
- Додайте Prometheus (OpenTelemetry Collector) як джерело даних:
- Type: Prometheus
- URL:
http://otel-collector:8889
7. Інструментація застосунків
Найважливіший крок — це інструментація ваших застосунків за допомогою OpenTelemetry SDK. Приклад для Python:
import os
```html
from opentelemetry import trace
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.instrumentation.flask import FlaskInstrumentor
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from flask import Flask
# Налаштування OpenTelemetry
resource = Resource.create({
"service.name": "my-python-app",
"service.version": "1.0.0",
"deployment.environment": "production",
"host.name": os.getenv("HOSTNAME", "unknown_host")
})
trace.set_tracer_provider(TracerProvider(resource=resource))
tracer = trace.get_tracer(__name__)
# Експорт трасувань в OpenTelemetry Collector
otlp_exporter = OTLPSpanExporter(endpoint="http://otel-collector:4317", insecure=True)
span_processor = BatchSpanProcessor(otlp_exporter)
trace.get_tracer_provider().add_span_processor(span_processor)
app = Flask(__name__)
FlaskInstrumentor().instrument_app(app)
@app.route('/')
def hello():
with tracer.start_as_current_span("hello-request"):
return "Hello, Observability!"
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
```
Подібні SDK доступні для всіх популярних мов. Використовуйте їх для генерації метрик, логів і трасувань, відправляючи їх в OpenTelemetry Collector на порти 4317 (gRPC) або 4318 (HTTP).
8. Автоматизація розгортання
У 2026 році ручне розгортання — це анахронізм. Використовуйте Ansible, Terraform або інші інструменти IaC (Infrastructure as Code) для автоматизації установки та налаштування VPS, Docker і всіх компонентів Observability. Це значно скоротить час на розгортання і знизить ймовірність помилок.
9. Моніторинг самої системи Observability
Не забувайте моніторити Loki, Tempo і OpenTelemetry Collector. Використовуйте їх власні метрики (які можна збирати Prometheus'ом) для відстеження їх продуктивності, споживання ресурсів і обсягу оброблюваних даних. Це допоможе виявити вузькі місця до того, як вони стануть критичними.
Типові помилки при побудові Observability на VPS
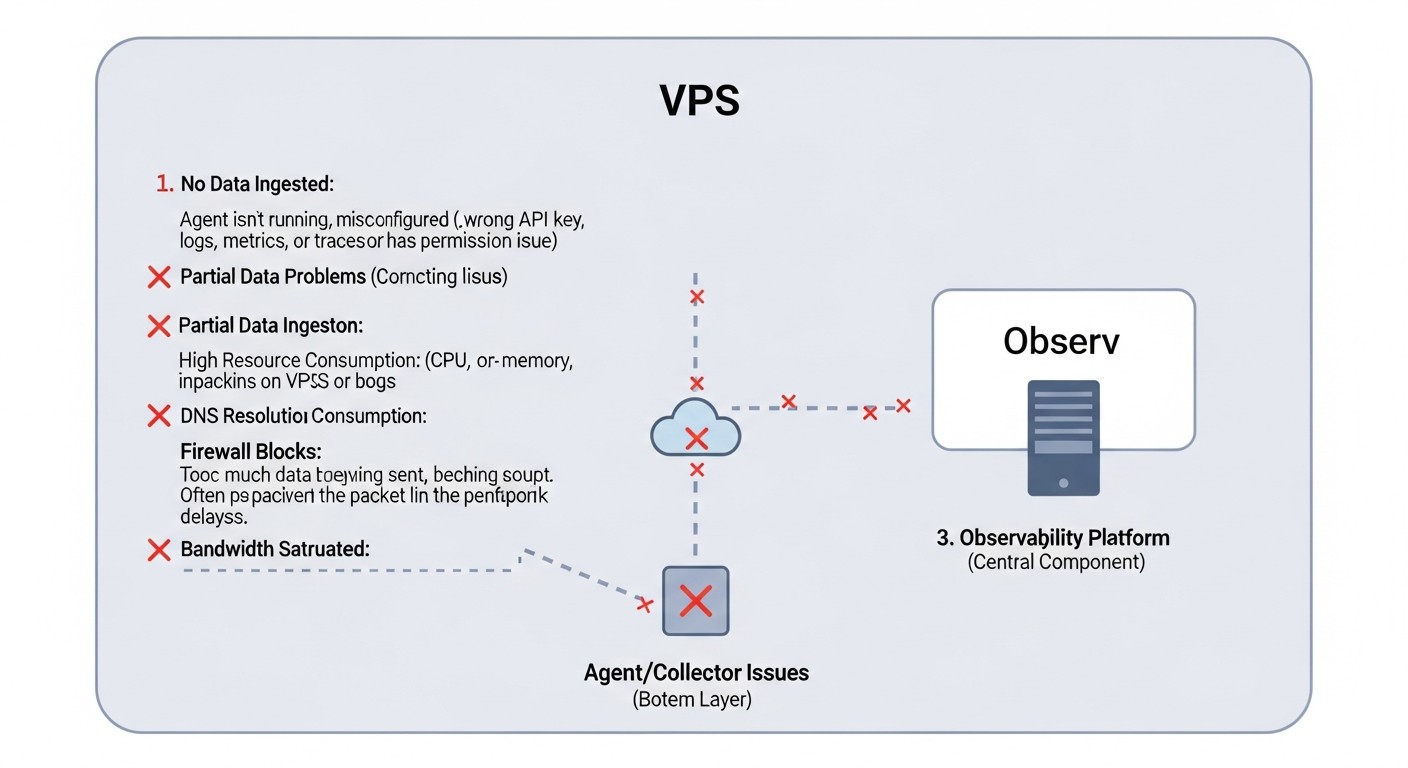 Схема: Типові помилки при побудові Observability на VPS
Схема: Типові помилки при побудові Observability на VPS
Навіть з найкращими інструментами, помилки в реалізації можуть звести нанівець всі зусилля. Ось найбільш поширені помилки та промахи при побудові системи Observability на VPS, актуальні для 2026 року.
1. Ігнорування OpenTelemetry Collector як проксі
Помилка: Відправлення телеметрії безпосередньо з додатків в Loki, Tempo або Prometheus без використання OpenTelemetry Collector. Або використання Collector, але без ефективних процесорів (наприклад, батчінг, фільтрація, семплювання).
Як уникнути: Завжди використовуйте OpenTelemetry Collector як центральний хаб. Він створений для того, щоб бути буфером, проксі і процесором. Налаштуйте його на батчінг (об'єднання даних в пакети), фільтрацію непотрібних даних, агрегацію метрик і семплювання трасувань (особливо для високонавантажених систем). Це значно знижує навантаження на бекенди (Loki, Tempo) і економить трафік, що критично для VPS.
Реальний приклад наслідків: Сервіс з високою частотою запитів генерує величезну кількість коротких трасувань. Якщо відправляти їх безпосередньо в Tempo, кожен "спан" буде окремим HTTP-запитом, що призведе до перевантаження мережі і Tempo-інгесторів, швидко вичерпавши ресурси VPS і перевищивши ліміти трафіку.
2. Неправильне використання лейблів в Loki (High Cardinality)
Помилка: Використання висококардинальних даних (наприклад, унікальних ID сесій, ID користувачів, повних URL-шляхів з параметрами) в якості лейблів для логів в Loki. Це призводить до роздування індексу і уповільнення запитів.
Як уникнути: Лейбли в Loki повинні бути низькокардинальними (наприклад, ім'я сервісу, версія, хост, рівень лога, HTTP-метод, статус-код). Висококардинальні дані слід залишати в тілі лога, де їх можна шукати за допомогою регулярних виразів, але не індексувати. У 2026 році з розвитком LogQL і можливістю парсингу логів на льоту, це стає ще більш актуальним.
Реальний приклад наслідків: Розробник додає user_id в якості лейбла до кожного логу. Якщо у вас 100 000 активних користувачів, це створить 100 000 унікальних комбінацій лейблів, що в рази збільшить розмір індексу Loki, сповільнить всі запити і швидко заповнить дисковий простір, навіть при використанні об'єктного сховища.
3. Відсутність семплювання трасувань для високонавантажених систем
Помилка: Спроба збирати 100% трасувань з усіх сервісів у високонавантаженій розподіленій системі, що працює на VPS.
Як уникнути: Для production-систем на VPS обов'язково налаштуйте семплювання трасувань в OpenTelemetry Collector. Ви можете використовувати Head-based семплювання (рішення про семплювання приймається на початку трасування) або Tail-based семплювання (рішення приймається після завершення трасування, що дозволяє семплювати по помилках або тривалості). Типові стратегії: семплювати 1 з 1000 запитів, але 100% запитів з помилками або запитів, що перевищують певний поріг затримки. Tempo спроектований для зберігання 100% трасувань, але якщо у вас дуже великий обсяг, семплювання на Collector може бути необхідно для економії ресурсів і трафіку.
Реальний приклад наслідків: 100% семплювання на сервісі, що обробляє 1000 запитів в секунду, призведе до генерації десятків тисяч спанів в секунду. Це швидко перевантажить Collector, заб'є чергу на відправку в Tempo і, ймовірно, перевищить ліміти на запис в об'єктне сховище, приводячи до втрати даних і нестабільності всієї системи Observability.
4. Недооцінка вартості зберігання даних і трафіку
Помилка: Припущення, що об'єктне сховище (навіть S3-сумісне на VPS) або хмарне S3 буде "безкоштовним" або дуже дешевим при великих обсягах даних. Ігнорування вартості вихідного трафіку.
Як уникнути: Завжди плануйте обсяги даних, які будуть генерувати ваші програми. Прогнозуйте зростання і регулярно переглядайте політику зберігання (retention policy) для Loki і Tempo. Використовуйте OpenTelemetry Collector для попередньої фільтрації і агрегації даних, щоб відправляти тільки найважливіше. Якщо використовуєте хмарне S3, будьте особливо уважні до вартості вихідного трафіку при запитах даних з Loki/Tempo на вашому VPS. Розміщення MinIO на тому ж VPS, що і Loki/Tempo, виключає витрати на трафік між ними.
Реальний приклад наслідків: Проект запускається з 30-денним терміном зберігання логів і трасувань. Через кілька місяців обсяг даних виростає до терабайтів, а щомісячний рахунок за зберігання і, що більш критично, за запити до S3 з Loki/Tempo на VPS (вихідний трафік), стає непідйомним, перевищуючи вартість самого VPS.
5. Відсутність моніторингу самої системи Observability
Помилка: Розгортання Loki, Tempo, OpenTelemetry Collector і відсутність моніторингу їх власного стану і продуктивності.
```
Як уникнути: Розглядайте вашу систему Observability як будь-який інший критично важливий сервіс. Збирайте метрики з Loki (/metrics), Tempo (/metrics) та OpenTelemetry Collector (/metrics). Додайте їх до вашого Prometheus-експортера (який в нашому випадку є частиною Collector). Створіть дашборди в Grafana для моніторингу їх CPU, RAM, дискового простору, кількості оброблюваних даних, затримок при записі/читанні. Налаштуйте alerts на критичні пороги.
Реальний приклад наслідків: Loki починає повільно індексувати логи через нестачу RAM, але ніхто цього не помічає. Через декілька днів запити до логів стають неможливими, а нові логи перестають записуватись, що робить діагностику будь-яких проблем з основним додатком сліпою.
6. Недостатня або надмірна інструментація
Помилка: Або інструментація додатків дуже поверхнева (немає достатніх даних для діагностики), або надмірна (генерується занадто багато нерелевантної телеметрії).
Як уникнути: Почніть з базової інструментації: HTTP-запити (вхідні/вихідні), виклики до баз даних, критичні бізнес-операції. Поступово додавайте більш детальну телеметрію по мірі виявлення вузьких місць або при появі нових вимог. Використовуйте семантичні конвенції OpenTelemetry для стандартизації імен метрик, спанів та атрибутів. Навчіть розробників, які дані важливі, а які — ні. У 2026 році, коли AI-асистенти можуть допомогти в аналізі, якість та консистентність інструментації стає ще більш важливою.
Реальний приклад наслідків:
- Недостатня: У додатку виникає помилка, але логи містять тільки "Internal Server Error", а трасування обривається на середині, не даючи ніякого контексту, що призвело до багатогодинного пошуку проблеми.
- Надмірна: Кожен виклик до внутрішнього кешу генерує новий спан, хоча це не критична операція. Це призводить до роздування трасувань, збільшення обсягу даних та складності читання.
7. Ігнорування безпеки
Помилка: Відсутність аутентифікації та авторизації для доступу до Loki, Tempo, Grafana, MinIO. Передача чутливих даних в логах або трасуваннях без маскування.
Як уникнути: Завжди налаштовуйте аутентифікацію (наприклад, базову HTTP-аутентифікацію для MinIO, Grafana, Loki) та використовуйте TLS для шифрування трафіку між компонентами. В OpenTelemetry Collector є процесори для маскування чутливих даних. Регулярно проводьте аудит того, які дані потрапляють у вашу систему Observability.
Реальний приклад наслідків: Конфігурація Loki або Tempo доступна без пароля. Зловмисник отримує доступ до логів та трасувань, що містять персональні дані користувачів або конфіденційну бізнес-інформацію, що призводить до витоку даних та серйозних наслідків для репутації та юридичних проблем.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
Чекліст для практичного застосування
Цей чекліст допоможе вам послідовно впровадити та підтримувати систему Observability на базі OpenTelemetry, Loki та Tempo на вашому VPS у 2026 році.
- Планування ресурсів VPS:
- [ ] Вибрано VPS з достатнім обсягом RAM (мінімум 4GB), CPU (мінімум 2 ядра) та дискового простору (почати з 100GB, планувати зростання).
- [ ] Визначено провайдера S3-сумісного сховища або виділено місце для локального MinIO на VPS.
- [ ] Прогнозовано обсяги логів та трасувань, розраховано приблизні витрати на зберігання та трафік.
- Базове налаштування VPS:
- [ ] VPS оновлено та захищено (брандмауер, SSH-ключі).
- [ ] Встановлено Docker та Docker Compose (або Kubernetes, якщо застосовно).
- [ ] Створено директорії для персистентних даних MinIO, Loki, Tempo, Grafana.
- Розгортання MinIO (або підключення до S3):
- [ ] MinIO запущено та доступно (або налаштовано креди для хмарного S3).
- [ ] Створено окремі бакети для Loki (наприклад,
loki-bucket) та Tempo (наприклад, tempo-bucket).
- [ ] Налаштовано облікові дані для доступу до MinIO/S3.
- Розгортання OpenTelemetry Collector:
- [ ] Collector розгорнуто як Docker-контейнер.
- [ ] Конфігурація
otel-collector-config.yaml налаштована для прийому OTLP.
- [ ] Налаштовано процесори:
batch, memory_limiter, resource (з додаванням імені хоста, оточення).
- [ ] Експортери налаштовані для Loki, Tempo та Prometheus (для метрик Collector).
- [ ] Collector налаштовано на відправку логів в Loki, трасувань в Tempo, метрик в Prometheus.
- Розгортання Loki:
- [ ] Loki розгорнуто як Docker-контейнер.
- [ ] Конфігурація
loki-config.yaml налаштована для використання S3-сумісного сховища (MinIO).
- [ ] Встановлено розумну політику зберігання (
chunk_store_config.max_look_back_period, schema_config.configs.period).
- [ ] Налаштовано аутентифікацію, якщо Loki доступний ззовні (в production).
- Розгортання Tempo:
- [ ] Tempo розгорнуто як Docker-контейнер.
- [ ] Конфігурація
tempo-config.yaml налаштована для використання S3-сумісного сховища (MinIO).
- [ ] Встановлено розумну політику зберігання (
storage.trace.retention).
- [ ] Налаштовано аутентифікацію, якщо Tempo доступний ззовні (в production).
- Розгортання Grafana:
- [ ] Grafana розгорнуто як Docker-контейнер.
- [ ] Встановлено складний пароль для адміністратора Grafana.
- [ ] Додано джерела даних: Loki (
http://loki:3100), Tempo (http://tempo:3200), Prometheus (http://otel-collector:8889).
- [ ] В Tempo джерелі даних налаштовано зв'язок з Loki для пошуку логів по трасуваннях.
- Інструментація додатків:
- [ ] Додатки інструментовані за допомогою OpenTelemetry SDK.
- [ ] Налаштовано відправку метрик, логів та трасувань в OpenTelemetry Collector (
http://otel-collector:4317 або 4318).
- [ ] Використовуються семантичні конвенції OpenTelemetry для імен та атрибутів.
- [ ] Реалізовано семплювання трасувань для високонавантажених сервісів.
- [ ] Перевірено, що чутливі дані не потрапляють в телеметрію без маскування.
- Створення дашбордів та алертів:
- [ ] Створено базові дашборди в Grafana для моніторингу ключових метрик додатків, логів та трасувань.
- [ ] Налаштовані алерти на критичні події та пороги продуктивності.
- [ ] Створені дашборди для моніторингу самої системи Observability (Loki, Tempo, Collector).
- Автоматизація та підтримка:
- [ ] Розгортання всіх компонентів автоматизовано з використанням IaC (Ansible, Terraform).
- [ ] Налаштовано автоматичне резервне копіювання важливих конфігураційних файлів.
- [ ] Розроблено план регулярного оновлення компонентів Observability.
- [ ] Проведена оцінка та оптимізація витрат на зберігання та трафік.
Розрахунок вартості / Економіка Observability на VPS
 Схема: Розрахунок вартості / Економіка Observability на VPS
Схема: Розрахунок вартості / Економіка Observability на VPS
Економіка Observability на VPS у 2026 році — це не тільки прямі витрати на сервер, а й ретельно сплановані витрати на зберігання даних, трафік і, що не менш важливо, час інженерів. Правильний вибір стеку OpenTelemetry, Loki та Tempo дозволяє значно оптимізувати ці витрати.
Основні статті витрат на VPS у 2026 році:
- VPS-інстанс: CPU, RAM, базова дискова підсистема.
- Зберігання даних: Для логів (Loki), трасування (Tempo) та метрик (Prometheus). Може бути локальним на VPS або зовнішнім (S3-сумісне об'єктне сховище).
- Трафік: Вхідний (від додатків до Collector) і вихідний (від Collector до бекендів, від Loki/Tempo до Grafana, від Grafana до користувачів, а також між VPS та S3-сховищем, якщо воно зовнішнє).
- Час інженерів: Налаштування, підтримка, оптимізація, усунення проблем.
Приклади розрахунків для різних сценаріїв (ілюстративно, ціни 2026 року):
Припустимо, що середня вартість VPS у 2026 році:
- Малий VPS (2 CPU, 4GB RAM, 100GB SSD): 15-25 USD/міс
- Середній VPS (4 CPU, 8GB RAM, 200GB SSD): 30-50 USD/міс
- Об'єктне сховище (S3-сумісне): 0.01-0.02 USD/GB/міс
- Вихідний трафік: 0.05-0.10 USD/GB
Сценарій 1: Невеликий стартап (1-3 мікросервіси, ~500 RPS)
- VPS: 1x Середній VPS (4 CPU, 8GB RAM, 200GB SSD) для всіх компонентів (OpenTelemetry Collector, Loki, Tempo, Grafana, MinIO).
- Вартість VPS: ~40 USD/міс.
- Обсяг даних:
- Логи: 50 GB/міс (30-денне зберігання)
- Трасування: 20 GB/міс (30-денне зберігання, семплювання 1:100)
- Метрики: 5 GB/міс
- Зберігання (MinIO на тому ж VPS):
- Дисковий простір: 50 GB (Loki) + 20 GB (Tempo) + 5 GB (Prometheus) + 10 GB (Grafana, OS) = ~85 GB. Це вкладається в 200GB SSD VPS.
- Вартість: Включена у VPS.
- Трафік:
- Вхідний (від додатків до Collector): 100 GB/міс
- Вихідний (від Collector до Loki/Tempo/Prometheus, внутрішній): 0 USD (всередині VPS).
- Вихідний (від Grafana до користувачів): 20 GB/міс
- Загальний платний трафік: ~120 GB/міс.
- Вартість трафіку: 120 GB 0.07 USD/GB = 8.4 USD/міс.
- Підсумкова приблизна вартість: 40 USD (VPS) + 8.4 USD (трафік) = ~48.4 USD/міс.
Сценарій 2: Зростаючий SaaS-проект (5-10 мікросервісів, ~5000 RPS)
- VPS:
- 1x Середній VPS (4 CPU, 8GB RAM, 200GB SSD) для OpenTelemetry Collector, Prometheus, Grafana. (~40 USD/міс)
- 1x Малий VPS (2 CPU, 4GB RAM, 100GB SSD) для Loki та Tempo (розділення навантаження). (~20 USD/міс)
- Обсяг даних:
- Логи: 500 GB/міс (30-денне зберігання)
- Трасування: 200 GB/міс (30-денне зберігання, семплювання 1:50)
- Метрики: 50 GB/міс
- Зберігання (хмарне S3):
- Загальний обсяг: 500 GB (Loki) + 200 GB (Tempo) = 700 GB.
- Вартість S3: 700 GB 0.015 USD/GB = 10.5 USD/міс.
- Трафік:
- Вхідний (від додатків до Collector): 1 TB/міс
- Вихідний (від Collector до Loki/Tempo/Prometheus): 1 TB/міс (частина внутрішня, частина на S3).
- Вихідний (від Loki/Tempo до S3): 700 GB/міс (запис)
- Вихідний (від S3 до Loki/Tempo на VPS при запитах): 100 GB/міс (дуже активні запити)
- Вихідний (від Grafana до користувачів): 50 GB/міс
- Загальний платний трафік (включаючи S3): ~100 GB (S3 retrieval) + 50 GB (Grafana) + 1 TB (Collector -> S3) = ~1.15 TB/міс.
- Вартість трафіку: 1150 GB 0.07 USD/GB = 80.5 USD/міс.
- Підсумкова приблизна вартість: 40 USD (VPS1) + 20 USD (VPS2) + 10.5 USD (S3) + 80.5 USD (трафік) = ~151 USD/міс.
Приховані витрати та як їх оптимізувати:
- Вихідний трафік: Це найбільш підступна витрата.
- Оптимізація: Максимально використовуйте OpenTelemetry Collector для фільтрації, агрегації та семплювання даних ДО їх відправки. Якщо можливо, розміщуйте S3-сумісне сховище на тому ж VPS або в тій самій мережі, щоб мінімізувати платний трафік.
- Накладні витрати на CPU/RAM: Неефективні запити до Loki або Tempo, занадто велика кількість лейблів, відсутність батчингу можуть швидко вичерпати ресурси VPS.
- Оптимізація: Налаштовуйте
memory_limiter в Collector. Оптимізуйте запити LogQL і PromQL. Регулярно аналізуйте метрики самого Observability стека, щоб виявити вузькі місця.
- Час інженерів: Ручне налаштування, дебагінг, оновлення.
- Оптимізація: Інвестуйте в Infrastructure as Code (Docker Compose, Ansible). Створюйте стандартизовані конфігурації та шаблони. Навчайте команду використанню інструментів Observability.
- Довгострокове зберігання: Якщо вам потрібно зберігати дані довше 30-90 днів, вартість буде рости.
- Оптимізація: Розробіть стратегію архівування. Для дуже старих логів і трасувань можна переносити їх у дешевші "холодні" S3-класи або повністю видаляти, якщо вони не потрібні для аудиту.
Таблиця з прикладами розрахунків для різних сценаріїв (узагальнено):
| Параметр |
Малий проєкт (500 RPS) |
Середній проєкт (5000 RPS) |
Великий проєкт (20000+ RPS) |
| Кількість VPS |
1 (середній) |
2 (1 середній, 1 малий) |
3+ (кластер Loki/Tempo) |
| Вартість VPS/міс |
~40 USD |
~60 USD |
~150-300 USD+ |
| Обсяг логів/міс |
50 GB |
500 GB |
2 TB+ |
| Обсяг трасувань/міс |
20 GB |
200 GB |
800 GB+ |
| Вартість зберігання S3/міс |
0 USD (локально) |
~10.5 USD |
~40-100 USD+ |
| Вартість трафіку/міс |
~8.4 USD |
~80.5 USD |
~300-600 USD+ |
| Підсумкова вартість/міс |
~48.4 USD |
~151 USD |
~490-1000 USD+ |
| Рекомендації |
MinIO на тому ж VPS, агресивне семплювання/фільтрація |
Розділення Loki/Tempo на окремий VPS, хмарне S3, активна оптимізація Collector |
Кластерна версія Loki/Tempo (наприклад, на K8s), виділені інстанси, багатозонне S3, глибока оптимізація |
Як видно, навіть для проєктів, що ростуть, зв'язка OpenTelemetry, Loki і Tempo на VPS залишається значно економічнішою, ніж більшість комерційних або повністю хмарних рішень, особливо коли йдеться про контроль над трафіком та ефективне використання об'єктного сховища.
Кейси та приклади використання
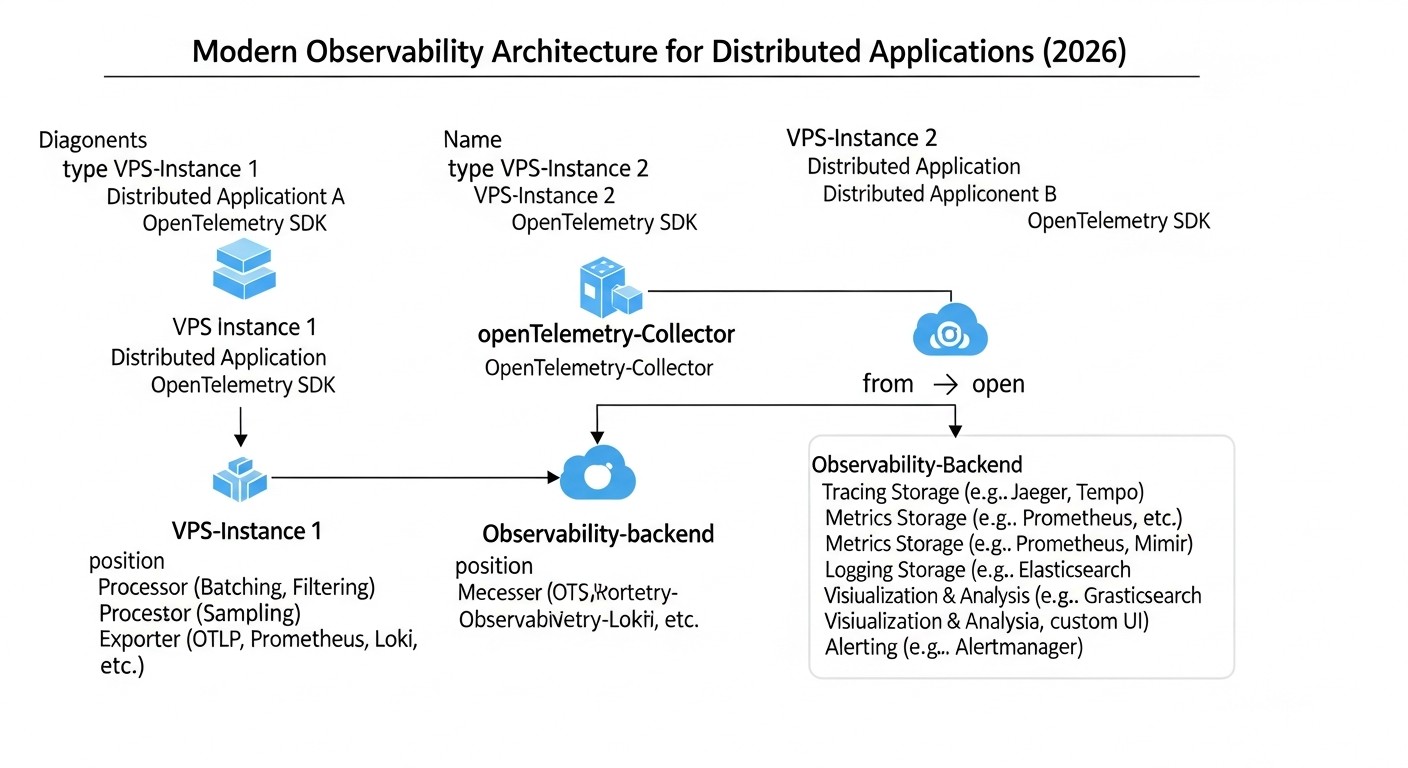 Схема: Кейси та приклади використання
Схема: Кейси та приклади використання
Розглянемо кілька реалістичних сценаріїв, що демонструють ефективність зв'язки OpenTelemetry, Loki та Tempo на VPS у 2026 році.
Кейс 1: Діагностика повільних запитів у e-commerce API
Проблема: Користувачі скаржаться на випадкові, але помітні затримки під час оформлення замовлення в невеликому інтернет-магазині, що працює на 5 мікросервісах (Go, Python) на одному середньому VPS. Традиційний моніторинг показує лише загальне завантаження CPU та RAM, але не дає розуміння, де саме відбувається затримка.
Рішення з Observability:
- Інструментація: Усі мікросервіси було інструментовано за допомогою OpenTelemetry SDK. Кожен HTTP-запит, виклик до бази даних, запит до зовнішнього платіжного шлюзу та внутрішні виклики між сервісами генерують спани. Логи кожного сервісу також надсилаються через OpenTelemetry Collector до Loki.
- Налаштування Collector: OpenTelemetry Collector налаштовано на збір усіх трасувань, метрик та логів, а потім надсилає їх до Tempo, Loki та Prometheus (для метрик). Було увімкнено семплювання трасувань 1:100, але 100% трасувань з помилками або тривалістю понад 500 мс.
- Графана: У Grafana створено дашборди, що показують загальну латентність API, кількість помилок та завантаження ресурсів. Додано "Service Graph" на основі трасувань, що показує взаємозв'язки між сервісами.
- Діагностика:
- Інженер помічає на дашборді Grafana пік латентності для ендпоінта
/checkout.
- З дашборда метрик він переходить до трасувань у Tempo, використовуючи "Trace ID" з логів або просто клікаючи на "Explore traces" для даного часового інтервалу.
- У Tempo він знаходить трасування, що відповідає повільному запиту. Візуалізація трасування показує, що більша частина затримки відбувається в сервісі
payment-gateway-service під час виклику зовнішнього API.
- З спана виклику зовнішнього API він клікає на "Logs" (інтеграція Tempo-Loki) і бачить логи з
payment-gateway-service для даного trace_id. У логах виявляється повторюване повідомлення про помилку тайм-ауту під час з'єднання із зовнішнім платіжним шлюзом.
Результат: Замість багатогодинного дебагінгу та перебору логів, проблему було локалізовано за 15 хвилин. З'ясувалося, що зовнішній платіжний шлюз має проблеми з продуктивністю. Команда змогла оперативно зв'язатися з провайдером шлюзу та переключитися на резервний варіант, мінімізувавши втрати.
Кейс 2: Оптимізація споживання ресурсів та вартості для стартапу з IoT-пристроями
Проблема: Стартап розробляє платформу для моніторингу IoT-пристроїв. Кожен пристрій надсилає телеметрію кожні 10 секунд. Кількість пристроїв швидко зростає, і поточна система на базі Elastic Stack на VPS стає непомірно дорогою через величезний обсяг логів та метрик, а також високі вимоги до RAM/CPU для Elasticsearch.
Рішення з Observability:
- Перехід на OpenTelemetry, Loki, Tempo: Було прийнято рішення перейти на більш ресурсоефективний стек.
- Інструментація IoT-агентів: Агенти на IoT-пристроях налаштовано на надсилання метрик та логів через OpenTelemetry Protocol (OTLP) до OpenTelemetry Collector на центральному VPS. Трасування для IoT-пристроїв було визнано надлишковими для даної задачі та відключено для економії.
- Налаштування Collector: OpenTelemetry Collector на VPS налаштовано на:
- Агрегацію метрик (наприклад, середнє значення за 1 хвилину замість кожної точки).
- Фільтрацію логів: відкидання інформаційних логів, збереження лише попереджень та помилок.
- Додавання атрибутів
device_id, device_type, location до кожного логу та метрики.
- Loki та Tempo: Loki використовується для зберігання відфільтрованих логів. Tempo розгорнуто, але використовується лише для трасувань бекенд-сервісів, що обробляють дані з IoT-пристроїв, а не для самих пристроїв. MinIO розгорнуто на тому ж VPS для зберігання даних Loki та Tempo.
- Графана: Дашборди показують агреговані метрики за типами пристроїв, локаціями, а також попередження та помилки, відфільтровані за тими ж атрибутами.
Результат:
- Зниження витрат на VPS: Вимоги до RAM/CPU для Loki виявилися в 3-5 разів нижчими, ніж для Elasticsearch, що дозволило використовувати дешевший VPS.
- Економія на зберіганні: Завдяки фільтрації логів та індексації лише метаданих у Loki, обсяг логів, що зберігаються, скоротився на 70%, а вартість зберігання даних у MinIO була значно нижчою, ніж у Elastic.
- Контроль над трафіком: Агрегація та фільтрація в Collector скоротили обсяг вхідного трафіку на 50%, що безпосередньо позначилося на рахунках від провайдера VPS.
- Покращена діагностика: Незважаючи на агрегацію, важливі метрики та помилки стало легше знаходити завдяки правильному лейблюванню та ефективним запитам у Grafana.
Ці кейси демонструють, як OpenTelemetry, Loki та Tempo можуть бути ефективно використані для вирішення реальних бізнес-задач, забезпечуючи глибоку спостережуваність при збереженні контролю над витратами на VPS.
Troubleshooting (вирішення проблем)
 Схема: Troubleshooting (вирішення проблем)
Схема: Troubleshooting (вирішення проблем)
Навіть при найретельнішому налаштуванні, в процесі експлуатації системи Observability можуть виникати проблеми. Нижче перелічені типові неполадки та методи їх діагностики і усунення для OpenTelemetry, Loki та Tempo на VPS.
1. Немає даних в Grafana (метрики, логи, трасування)
Можливі причини:
- Застосунок не відправляє дані в Collector.
- Collector не отримує дані або не може їх експортувати.
- Loki/Tempo не отримує дані від Collector або не може їх записати в сховище.
- Grafana не може підключитися до Loki/Tempo/Collector.
- Проблеми з мережею/файрволом.
Діагностичні команди та кроки:
- Перевірте логи застосунків: Переконайтеся, що OpenTelemetry SDK ініціалізовано і не видає помилок при відправці даних. Перевірте, що ендпоінт Collector вказано правильно (наприклад,
http://otel-collector:4317).
- Перевірте логи OpenTelemetry Collector:
docker logs otel-collector
# Або якщо Collector працює як systemd сервіс
sudo journalctl -u otel-collector -f
Шукайте помилки підключення до Loki/Tempo, помилки парсингу даних, повідомлення про переповнення буфера. Переконайтеся, що Collector слухає на потрібних портах.
sudo netstat -tulnp | grep 4317 # Перевірити, чи слухає Collector порт OTLP gRPC
sudo netstat -tulnp | grep 4318 # Перевірити, чи слухає Collector порт OTLP HTTP
- Перевірте логи Loki та Tempo:
docker logs loki
docker logs tempo
Шукайте помилки запису в S3/MinIO, помилки аутентифікації, проблеми з дисковим простором. Переконайтеся, що Loki та Tempo слухають на своїх портах (3100 та 3200 відповідно).
- Перевірте підключення Grafana: В Grafana перейдіть в "Configuration" -> "Data Sources". Для кожного джерела даних натисніть "Save & Test". Переконайтеся, що статус "Data source is working". Якщо ні, перевірте URL-и (наприклад,
http://loki:3100), налаштування файрвола на VPS.
- Перевірте файрвол: Переконайтеся, що порти (4317, 4318, 3100, 3200, 3000) відкриті на VPS, якщо до них має бути зовнішній доступ, і між Docker-контейнерами.
2. Повільні запити в Grafana (до Loki або Tempo)
Можливі причини:
- Висока кардинальність лейблів в Loki.
- Занадто великий діапазон часу для запиту.
- Неефективні запити LogQL/PromQL.
- Брак ресурсів (CPU/RAM) у Loki/Tempo.
- Повільне S3-сумісне сховище або висока затримка мережі до нього.
Діагностичні команди та кроки:
- Перевірте кардинальність лейблів в Loki: Використовуйте запит
sum by (label_name) (count_over_time({job="your-app"}[1h])) для виявлення висококардинальних лейблів. Уникайте використання унікальних ID в лейблах.
- Оптимізуйте запити:
- Для Loki: Починайте запити з фільтрації за низькокардинальними лейблами, потім використовуйте повнотекстовий пошук або регулярні вирази. Використовуйте
line_format для вилучення потрібних даних.
- Для Tempo: Запити за ID трасування завжди найшвидші. Якщо шукаєте за атрибутами, переконайтеся, що ви використовуєте інтеграцію з Loki/Prometheus, і що запити до них ефективні.
- Моніторинг ресурсів Loki/Tempo: Використовуйте дашборди Grafana для моніторингу CPU, RAM, дискового I/O Loki та Tempo. Зверніть увагу на метрики
loki_ingester_chunk_age_seconds (затримка запису чанків) та tempo_ingester_blocks_created_total.
- Перевірте продуктивність сховища: Якщо використовуєте зовнішнє S3, перевірте затримку мережі. Якщо MinIO на тому ж VPS, переконайтеся, що диск не перевантажений.
- Збільште ресурси: Якщо всі оптимізації зроблені, але запити все ще повільні, можливо, час збільшити CPU/RAM для Loki/Tempo або розглянути горизонтальне масштабування.
3. Переповнення диска на VPS
Можливі причини:
- Занадто великий обсяг логів/трасувань для локального MinIO.
- Неправильне налаштування політики зберігання (retention policy) в Loki/Tempo.
- Накопичення WAL-файлів Tempo або тимчасових файлів Loki.
- Проблеми з ротацією логів Docker.
Діагностичні команди та кроки:
- Перевірте використання диска:
df -h
du -sh /mnt/data/
Визначте, яка директорія займає найбільше місця.
- Перевірте політики зберігання: Переконайтеся, що в
loki-config.yaml (chunk_store_config.max_look_back_period) та tempo-config.yaml (storage.trace.retention) встановлені розумні терміни зберігання. Переконайтеся, що вони застосовуються.Перевірте логи Docker-контейнерів: Логи Docker можуть швидко заповнювати диск. Налаштуйте ротацію логів для Docker Daemon.
# /etc/docker/daemon.json
{
"log-driver": "json-file",
"log-opts": {
"max-size": "10m",
"max-file": "3"
}
}
Після зміни перезапустіть Docker: sudo systemctl restart docker.
- Очищення тимчасових файлів: Іноді тимчасові директорії Loki (
/tmp/loki/boltdb-shipper-cache, /tmp/loki/compactor) або Tempo (/tmp/tempo/wal) можуть розростатися. Переконайтеся, що компресор і шиппер працюють коректно.
4. OpenTelemetry Collector споживає занадто багато ресурсів
Можливі причини:
- Занадто великий обсяг вхідних даних.
- Неефективні процесори (наприклад, занадто багато складних перетворень).
- Відсутність батчингу.
Діагностичні команди та кроки:
- Моніторинг Collector: Використовуйте метрики самого Collector (доступні через Prometheus-експортер на
:8889) для відстеження його CPU, RAM, кількості прийнятих/відправлених спанів/логів/метрик.
- Оптимізуйте конфігурацію:
- Переконайтеся, що
batch процесор включено та налаштовано.
- Використовуйте
memory_limiter для обмеження споживання RAM.
- Перегляньте процесори: якщо є складні операції, такі як
transform або filter, переконайтеся, що вони ефективні. Можливо, частину фільтрації варто робити на рівні застосунку.
- Розгляньте семплювання трасувань на Collector.
- Зменште обсяг вхідних даних: Якщо програми генерують занадто багато шуму, налаштуйте їх так, щоб вони надсилали лише релевантну телеметрію.
Коли звертатися до підтримки:
- Провайдер VPS: Якщо є підозри на апаратні проблеми з VPS (диск, мережа, CPU), або якщо ви не можете отримати доступ до сервера через SSH.
- Спільноти OpenTelemetry, Loki, Tempo: Якщо ви зіткнулися з помилками, які здаються багами в самому ПЗ, або якщо ви не можете знайти рішення проблеми в документації. Використовуйте GitHub Issues, Discord-канали або форуми.
- Власна команда: Якщо проблема пов'язана з інструментарієм застосунків або бізнес-логікою.
FAQ: Часті запитання
Що таке Observability і чим вона відрізняється від моніторингу в 2026 році?
У 2026 році різниця між Observability і моніторингом стала ще більш критичною. Моніторинг, по суті, відповідає на питання "Що сталося?", стежачи за заздалегідь відомими метриками та станами (наприклад, "CPU вище 80%"). Observability ж дозволяє відповісти на питання "Чому це сталося?", надаючи глибоке розуміння внутрішнього стану системи через метрики, логи та трасування, дозволяючи досліджувати невідомі раніше проблеми та поведінку системи.
Чому саме OpenTelemetry, Loki і Tempo, а не Elastic Stack або Jaeger?
OpenTelemetry, Loki і Tempo обрані для VPS-середовища в 2026 році через їх виняткову ресурсоефективність і гнучкість. Elastic Stack (Elasticsearch, Kibana, Logstash) вимагає значно більше RAM і CPU, що робить його дорогим для VPS. Jaeger, хоча і є відмінним інструментом для трасувань, часто вимагає потужної СУБД (Cassandra або Elasticsearch) для зберігання, що також збільшує витрати. Loki і Tempo спроектовані для роботи з об'єктним сховищем, мінімізуючи вимоги до RAM/CPU і роблячи їх ідеальними для бюджетних VPS-рішень.
Чи можна використовувати OpenTelemetry тільки для частини телеметрії (наприклад, тільки для трасувань)?
Так, OpenTelemetry є модульним. Ви можете використовувати його SDK тільки для трасувань, тільки для метрик або тільки для логів, або для будь-якої їх комбінації. OpenTelemetry Collector також може бути налаштований на обробку тільки певних типів телеметрії та маршрутизацію їх у відповідні бекенди. Це дозволяє впроваджувати Observability поступово, крок за кроком.
Наскільки безпечно зберігати логи і трасування в MinIO на тому ж VPS?
Зберігання даних в MinIO на тому ж VPS безпечне за умови, що VPS надійно захищений (файрвол, SSH-ключі, регулярні оновлення). Однак, для критично важливих даних і високої доступності, рекомендується використовувати хмарне S3-сумісне сховище (AWS S3, Google Cloud Storage, Azure Blob Storage) або виділений кластер MinIO. Для більшості стартапів і середніх проєктів на VPS локальний MinIO є прийнятним компромісом між безпекою, продуктивністю і вартістю.
Як довго рекомендується зберігати логи і трасування?
Термін зберігання залежить від вимог бізнесу, регуляторних норм і вартості. Для оперативної діагностики зазвичай достатньо 7-30 днів. Для аудиту і аналізу довгострокових трендів може знадобитися 90 днів і більше. Loki і Tempo дозволяють гнучко налаштовувати політику зберігання. У 2026 році, зі зростанням обсягів даних, все частіше застосовуються багаторівневі стратегії зберігання (гаряче, холодне, архівне).
Чи потрібно семплювати трасування, якщо Tempo спроектований для "зберігай все"?
Tempo дійсно спроектований для ефективного зберігання 100% трасувань завдяки своїй архітектурі. Однак, "зберігай все" відноситься до бекенду. Якщо ваш застосунок генерує дуже великий обсяг трасувань (наприклад, десятки тисяч спанів в секунду), то навантаження на OpenTelemetry Collector і мережевий трафік можуть стати вузьким місцем. У таких випадках семплювання на OpenTelemetry Collector (наприклад, Head-based семплювання) допоможе знизити навантаження і контролювати витрати, зберігаючи при цьому цінні трасування (наприклад, з помилками).
Чи може OpenTelemetry Collector виступати в ролі Prometheus-сервера?
Ні, OpenTelemetry Collector не є повноцінним Prometheus-сервером. Він може приймати метрики у форматі OTLP, перетворювати їх і експортувати в Prometheus-сумісний формат, а також скрейпити метрики з інших експортерів (як Prometheus). У нашому стеку Collector виступає як експортер для метрик, а Grafana безпосередньо читає ці метрики з Collector. Для повноцінного довгострокового зберігання метрик і складних запитів PromQL зазвичай використовують окремий Prometheus-сервер або його кластерні варіанти (Thanos, Cortex).
Як контролювати витрати на трафік при використанні Observability на VPS?
Контроль трафіку — ключовий фактор на VPS. Використовуйте OpenTelemetry Collector для максимальної фільтрації, агрегації і семплювання телеметрії до її відправки. Розміщуйте MinIO (або інший S3-сумісний сервіс) на тому ж VPS, що і Loki/Tempo, щоб уникнути платного вихідного трафіку між ними. Мінімізуйте кількість вихідних запитів з Grafana до Loki/Tempo, якщо вони розміщені в іншому ЦОД або хмарі.
Що робити, якщо VPS перестає справлятися з навантаженням?
Якщо ваш VPS починає відчувати нестачу ресурсів, розгляньте наступні кроки: 1) Оптимізуйте конфігурації Collector, Loki, Tempo (більш агресивне семплювання/фільтрація, оптимізація запитів). 2) Збільште ресурси VPS (CPU, RAM). 3) Розділіть компоненти на декілька VPS (наприклад, один для Collector/Prometheus/Grafana, інший для Loki/Tempo). 4) Розгляньте перехід на керований Kubernetes-кластер, де Loki і Tempo можуть бути розгорнуті у високодоступній та масштабованій конфігурації.
Чи можна інтегрувати існуючі логи з OpenTelemetry?
Так, OpenTelemetry Collector має різні приймачі (receivers), які можуть збирати логи з різних джерел, включаючи файли (filelog receiver), системний журнал (journald receiver), Docker-контейнери. Ви також можете використовувати Promtail для збору логів і відправки їх в Loki, а потім вже зв'язувати їх з трасуваннями OpenTelemetry через спільні атрибути (trace_id).
Які переваги дає використання семантичних конвенцій OpenTelemetry?
Семантичні конвенції OpenTelemetry надають стандартизовані імена та значення для атрибутів (тегів) трасувань, метрик і логів (наприклад, http.method, db.statement, service.name). Це значно покращує читабельність, переносимість та аналізованість телеметрії, полегшуючи створення дашбордів, алертів та запитів, а також інтеграцію з різними інструментами Observability.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
Висновок
У 2026 році, коли розподілені системи стали нормою, а складність інфраструктури продовжує зростати, повна спостережуваність (Observability) є не просто бажаною функцією, а критично важливим компонентом для стабільності, продуктивності та успішності будь-якого IT-проєкту. Ми показали, що навіть за обмежених ресурсів віртуального приватного сервера (VPS) можна побудувати потужну, гнучку та економічно ефективну систему Observability.
Зв'язка OpenTelemetry, Loki і Tempo, інтегрована з Grafana, пропонує унікальний баланс між функціональністю та вартістю. OpenTelemetry виступає як універсальний стандарт для збору всіх видів телеметрії, забезпечуючи vendor-agnostic підхід та гнучкість. Loki надає економічне та масштабоване рішення для зберігання логів, використовуючи об'єктне сховище та індексацію за метаданими. Tempo революціонізує підхід до розподілених трасувань, пропонуючи "зберігай все" модель з мінімальними вимогами до ресурсів, також використовуючи об'єктне сховище.
Ключовими факторами успіху при впровадженні цієї зв'язки на VPS є: ретельне планування ресурсів, ефективне використання OpenTelemetry Collector для фільтрації, агрегації та семплювання даних, правильне лейблювання в Loki для уникнення проблем з кардинальністю, а також постійний моніторинг самої системи Observability. Не варто забувати і про автоматизацію розгортання за допомогою інструментів Infrastructure as Code, що значно скорочує час і знижує ймовірність помилок.
Підсумкові рекомендації:
- Почніть з OpenTelemetry: Інструментуйте свої застосунки за допомогою OpenTelemetry SDK. Це інвестиція в майбутнє, яка окупиться багаторазово.
- Використовуйте Collector ефективно: OpenTelemetry Collector — ваш найкращий друг на VPS. Налаштовуйте його для оптимізації трафіку та навантаження на бекенди.
- Обирайте сховище з розумом: Для VPS MinIO на тому ж сервері або недороге хмарне S3-сумісне сховище є оптимальним вибором для Loki і Tempo.
- Моніторте та оптимізуйте: Регулярно перевіряйте споживання ресурсів вашими компонентами Observability та оптимізуйте конфігурації, щоб уникнути прихованих витрат.
- Автоматизуйте: Ручне управління швидко стане вузьким місцем. Автоматизуйте розгортання та налаштування.
- Навчайте команду: Чим краще ваша команда розуміє та використовує інструменти Observability, тим швидше будуть вирішуватися проблеми і тим вище буде стабільність ваших систем.
Наступні кроки для читача:
- Проведіть пілотне розгортання: Почніть з невеликого VPS і кількох тестових сервісів, щоб на практиці освоїти налаштування OpenTelemetry, Loki і Tempo.
- Вивчіть документацію: Заглибтесь в документацію по кожному з компонентів, особливо в розділ "Configuration" і "Troubleshooting".
- Приєднайтеся до спільноти: Активна участь в спільнотах OpenTelemetry, Grafana Labs (Loki, Tempo) дозволить вам бути в курсі останніх оновлень і отримувати допомогу від досвідчених інженерів.
- Розробіть стратегію інструментації: Визначте, які метрики, логи та трасування найбільш важливі для ваших застосунків, і як їх ефективно збирати.
Впровадження повної спостережуваності — це не одноразове завдання, а безперервний процес вдосконалення. Але з правильним стеком інструментів і методичним підходом, ви зможете забезпечити надійну роботу ваших розподілених систем на VPS, випереджаючи конкурентів в динамічному світі 2026 року.
Поділитися цим записом:
полная наблюдаемость (observability) для распределенных систем: opentelemetry, loki и tempo на vps 2026