
Управління гібридною інфраструктурою: Kubernetes на bare metal та в хмарі з Rancher
TL;DR
- Гібридний Kubernetes з Rancher — це стратегічний вибір 2026 року для компаній, які прагнуть до балансу між продуктивністю, вартістю, безпекою та гнучкістю.
- Bare metal пропонує неперевершену продуктивність і контроль, а хмара — еластичність і керованість, Rancher об'єднує це в єдину панель управління.
- Ключові фактори успіху включають продуману мережеву архітектуру, єдину стратегію управління ідентифікацією та доступом, а також комплексний підхід до моніторингу та аварійного відновлення.
- Уникайте типових помилок: недооцінки складності мережі та зберігання даних, відсутності чіткого плану DR та ігнорування прихованих витрат на передачу даних.
- Rancher значно спрощує розгортання, управління та забезпечення безпеки кластерів Kubernetes як на власних серверах, так і у різних хмарних провайдерів, знижуючи операційне навантаження.
- Економія досягається за рахунок оптимального розподілу робочих навантажень: ресурсоємні та чутливі до даних програми на bare metal, масштабовані та тимчасові — в хмарі.
- Реальні кейси показують, що гібридні рішення дозволяють дотримуватися суворих регуляторних вимог, оптимізувати витрати та забезпечувати високу доступність сервісів.
Потрібен виділений сервер?
Compare prices from top providers. Configure and order in minutes.
Вступ
До 2026 року концепція гібридної інфраструктури перестала бути нішевим рішенням і перетворилася на домінуючий підхід для більшості великих і середніх підприємств, а також для амбітних стартапів. В умовах постійно мінливого ландшафту IT, де швидкість виведення продуктів на ринок, оптимізація витрат і відповідність регуляторним вимогам є критично важливими, чисті хмарні або виключно локальні стратегії часто виявляються недостатніми. Гібридний підхід, особливо з використанням Kubernetes як універсальної платформи оркестрації та Rancher як уніфікованого менеджера кластерів, пропонує потужне рішення цих викликів.
Чому ця тема така важлива саме зараз? По-перше, економічна нестабільність останніх років змушує компанії ретельно переглядати свої IT-бюджети, і хмарні витрати, які швидко ростуть по мірі масштабування, часто стають предметом пильної уваги. Bare metal, з його передбачуваними капітальними витратами і відсутністю щомісячної плати за ресурси, знову набуває актуальності для стабільних, ресурсоємних робочих навантажень. По-друге, посилення законодавства про захист даних (наприклад, GDPR 2.0, локальні вимоги до суверенітету даних) змушує багато організацій тримати чутливу інформацію на власних серверах, при цьому використовуючи хмару для менш критичних або публічних сервісів. По-третє, технологічний прогрес в області мережевих технологій (5G, edge computing) і платформ управління, таких як Rancher, значно спростив інтеграцію та управління різнорідними середовищами, зробивши гібридні сценарії не тільки можливими, але і практичними.
Дана стаття покликана вирішити ряд ключових проблем, з якими стикаються сучасні інженери та керівники:
- Складність управління: Як ефективно управляти декількома кластерами Kubernetes, розгорнутими в різних середовищах (on-premise і в декількох хмарах)?
- Оптимізація витрат: Як знизити операційні витрати, використовуючи переваги bare metal для стабільних навантажень і хмари для пікових?
- Безпека та відповідність: Як забезпечити єдині політики безпеки та відповідність регуляторним вимогам у розподіленій інфраструктурі?
- Продуктивність: Як досягти максимальної продуктивності для критично важливих додатків, зберігаючи при цьому гнучкість хмари?
- Міграція та модернізація: Як плавно переводити існуючі додатки на контейнерну платформу в гібридному середовищі?
Це керівництво написано для широкої аудиторії технічних фахівців і керівників, які приймають стратегічні рішення в області інфраструктури: DevOps-інженерів, які прагнуть до автоматизації та уніфікації процесів; Backend-розробників (Python, Node.js, Go, PHP), яким потрібна надійна і масштабована платформа для своїх додатків; фаундерів SaaS-проектів, які шукають оптимальний баланс між вартістю і гнучкістю; системних адміністраторів, які відповідають за стабільність і безпеку систем; і, звичайно, технічних директорів стартапів, яким необхідно побудувати стійку і конкурентоспроможну інфраструктуру з нуля.
Ми зануримося в деталі, надамо конкретні приклади, розрахунки і практичні рекомендації, засновані на реальному досвіді впровадження гібридних Kubernetes-рішень з використанням Rancher. Наша мета — дати вам вичерпний ресурс для прийняття обґрунтованих рішень і успішної реалізації вашої гібридної стратегії.
Основні критерії та фактори
При плануванні та впровадженні гібридної Kubernetes-інфраструктури необхідно враховувати безліч факторів, які в сукупності визначають успішність і ефективність рішення. Кожен з цих критеріїв має свою вагу і може бути пріоритетним в залежності від специфіки бізнесу, характеру робочих навантажень і стратегічних цілей компанії. Детальний розбір кожного з них дозволить приймати зважені рішення.
1. Вартість володіння (TCO) та економічна ефективність
Чому це важливо: TCO виходить далеко за рамки прямих витрат на обладнання або хмарні підписки. Він включає капітальні витрати (CapEx) на сервери, мережеве обладнання, сховище, а також операційні витрати (OpEx) — електроенергію, охолодження, обслуговування, ліцензії на ПЗ, зарплату персоналу, вартість трафіку та приховані витрати, такі як вартість простою або навчання. Правильна оцінка TCO дозволяє обрати найбільш економічно вигідну стратегію на довгострокову перспективу.
Як оцінювати: Проведіть детальний аналіз всіх статей витрат за 3-5 років. Для bare metal врахуйте амортизацію обладнання, витрати на дата-центр, персонал. Для хмари — щомісячні платежі за ресурси (vCPU, RAM, сховище), мережевий трафік (особливо egress), керовані сервіси, а також потенційні знижки за резервування (Reserved Instances, Savings Plans). Важливо враховувати, що для стабільних, високонавантажених застосунків bare metal часто виявляється дешевшим на довгій дистанції, тоді як хмара виграє на старті та для непередбачуваних навантажень.
2. Продуктивність та затримка (Latency)
Чому це важливо: Деякі програми, такі як високочастотний трейдинг, IoT-аналітика на периферії, ігрові сервери або бази даних з інтенсивним записом, критично залежать від мінімальної затримки та максимальної пропускної здатності. Bare metal тут часто виграє, надаючи прямий доступ до обладнання без накладних витрат віртуалізації та мережевих абстракцій хмари.
Як оцінювати: Вимірюйте затримку мережі (RTT) між компонентами, пропускну здатність дискових операцій (IOPS, throughput) та CPU-продуктивність. Для bare metal це будуть реальні показники обладнання. Для хмари — характеристики інстансів та типи сховищ, які ви обираєте. У гібридному середовищі критично важлива затримка між on-premise та хмарними сегментами, яка може бути знижена за рахунок прямих з'єднань (Direct Connect, ExpressRoute).
3. Безпека та відповідність регуляторним вимогам
Чому це важливо: Захист даних та дотримання законодавства (GDPR, HIPAA, PCI DSS, ФЗ-152 та ін.) є не просто "хорошою практикою", а обов'язковою умовою ведення бізнесу, особливо в таких секторах, як фінанси, охорона здоров'я або державні послуги. Розміщення чутливих даних на власних серверах дає повний контроль над фізичною безпекою та доступом, що спрощує проходження аудитів.
Як оцінювати: Проведіть аудит поточних та майбутніх регуляторних вимог. Оцініть, де повинні зберігатися та оброблятися дані. У хмарі ви розділяєте відповідальність за безпеку (Shared Responsibility Model), що вимагає ретельного конфігурування. На bare metal вся відповідальність лежить на вас, але й контроль повний. Rancher допомагає уніфікувати політики безпеки та управління доступом (RBAC) по всім кластерам, незалежно від їх розташування.
4. Масштабованість та гнучкість
Чому це важливо: Здатність інфраструктури швидко адаптуватися до мінливих навантажень — це основа для успішного розвитку продукту. Хмара пропонує практично безмежну еластичність, дозволяючи миттєво масштабувати ресурси вгору або вниз. Bare metal вимагає попереднього планування та закупівлі обладнання, але надає стабільну та передбачувану продуктивність для базових навантажень.
Як оцінювати: Визначте пікові та базові навантаження. Оцініть час, необхідний для додавання нових ресурсів в кожному середовищі. Гібридний підхід дозволяє використовувати bare metal для "постійного" навантаження та "випліскувати" (burst) пікові запити в хмару, забезпечуючи оптимальне використання ресурсів та мінімізацію витрат.
5. Управлінські витрати та операційна складність
Чому це важливо: Управління розподіленою інфраструктурою може бути надзвичайно складним без правильних інструментів. Високі операційні витрати можуть нівелювати будь-яку економію на обладнанні або хмарних ресурсах. Rancher тут відіграє ключову роль, надаючи єдину панель управління для всіх Kubernetes-кластерів.
Як оцінювати: Оцініть необхідний обсяг персоналу, його кваліфікацію, витрати на навчання, а також складність процесів розгортання, моніторингу, оновлення та усунення несправностей. Інструменти автоматизації та уніфікації, такі як Rancher, значно знижують цю складність, дозволяючи управляти десятками кластерів з меншими ресурсами.
6. Залежність від постачальника (Vendor Lock-in)
Чому це важливо: Повна залежність від одного хмарного провайдера може призвести до проблем з ціноутворенням, обмеженого вибору технологій та складнощів при міграції. Гібридна стратегія, особливо з використанням Kubernetes, який є відкритим стандартом, знижує цей ризик, дозволяючи легко переміщувати робочі навантаження між різними середовищами.
Як оцінювати: Аналізуйте використовувані хмарні сервіси: наскільки вони пропрієтарні? Які зусилля знадобляться для міграції на іншого провайдера або на bare metal? Kubernetes та Rancher сприяють стандартизації, роблячи додатки більш переносними. Це дає вам важелі тиску в переговорах з постачальниками та стратегічну свободу.
7. "Гравітація" даних (Data Gravity)
Чому це важливо: Великі обсяги даних мають "гравітацію" — їх складно і дорого переміщувати. Застосунки, які інтенсивно працюють з великими базами даних або сховищами, часто вигідно розташовувати поруч з цими даними. Якщо дані знаходяться на bare metal, то і застосунки, що працюють з ними, логічно розміщувати там же для мінімізації затримок та вартості трафіку.
Як оцінювати: Визначте обсяг та інтенсивність обміну даними між компонентами вашої системи. Витрати на вихідний трафік (egress) з хмари можуть бути значними. Розміщення баз даних та аналітичних систем on-premise або на виділених серверах в хмарі, а фронтендів та API-шлюзів — в більш еластичних хмарних кластерах, може бути оптимальною стратегією.
8. Аварійне відновлення (DR) та висока доступність (HA)
Чому це важливо: Відмовостійкість інфраструктури — це критично важливий фактор для будь-якого сучасного бізнесу. Гібридне середовище пропонує унікальні можливості для побудови надійних стратегій DR, дозволяючи розподіляти ризики між різними локаціями та провайдерами.
Як оцінювати: Визначте цільові показники RTO (Recovery Time Objective) та RPO (Recovery Point Objective) для ваших додатків. Розгляньте сценарії відмови дата-центру або хмарного регіону. Гібридна стратегія дозволяє мати резервний кластер в хмарі для on-premise додатків або навпаки, забезпечуючи швидку активацію в разі збою. Rancher спрощує управління такими розподіленими кластерами, дозволяючи централізовано управляти їх конфігурацією та розгортанням.
Врахування цих факторів на етапі проектування дозволить побудувати не просто працюючу, але й ефективну, економічно вигідну та стійку гібридну інфраструктуру на базі Kubernetes та Rancher.
Порівняльна таблиця
Для наочності та прийняття обґрунтованих рішень представимо порівняльну таблицю основних підходів до розгортання Kubernetes, з урахуванням гібридної стратегії та ролі Rancher. Дані актуальні для прогнозів на 2026 рік, відображаючи тенденції в ціноутворенні, продуктивності та операційних моделях.
| Критерій | Bare Metal (Самоврядний K8s) | Bare Metal (K8s з Rancher) | Public Cloud (EKS/AKS/GKE) | Гібрид (K8s з Rancher) |
|---|---|---|---|---|
| Вартість (TCO 3 роки, $K) | Високий CapEx (~$100-500K за 10 серверів), низький OpEx ($5-15K/міс) | Високий CapEx (~$100-500K за 10 серверів), середній OpEx ($8-20K/міс, включно з підтримкою Rancher) | Низький CapEx ($0), високий OpEx ($15-50K/міс за еквівалент 10 серверів) | Збалансований CapEx/OpEx ($50-200K CapEx, $10-30K/міс OpEx) |
| Продуктивність CPU/RAM | ~95-98% від фізичного заліза. Прямий доступ до ресурсів. | ~95-98% від фізичного заліза. Незначні накладні витрати Rancher агентів. | ~70-90% від фізичного заліза (через віртуалізацію). Залежить від типу інстанса. | Bare Metal частина: 95-98%. Cloud частина: 70-90%. Оптимально для різних навантажень. |
| Затримка мережі (всередині кластера) | <1 мс (фізична мережа) | <1 мс (фізична мережа) | ~1-5 мс (віртуальна мережа хмари) | Bare Metal: <1 мс. Cloud: 1-5 мс. Міжкластерна: 10-50 мс (з Direct Connect <5 мс). |
| Масштабованість | Ручна, повільна (закупівля, встановлення). До декількох тижнів. | Напівавтоматична з Rancher, але обмежена фізичними ресурсами. Дні/тижні. | Автоматична, швидка (кілька хвилин) з Cluster Autoscaler. Практично безмежна. | Гнучка: Bare Metal для бази, Cloud для піків (хвилини). Оптимальний баланс. |
| Безпека та контроль | Повний контроль над усім ланцюжком, від заліза до ПЗ. Високий рівень безпеки. | Повний контроль + уніфіковане управління безпекою через Rancher. | Модель спільної відповідальності. Висока безпека провайдера, але менше контролю. | Високий контроль для чутливих даних (on-prem), модель спільної відповідальності для хмари. |
| Складність управління | Дуже висока (ручне розгортання, оновлення, моніторинг). Потребує глибоких знань. | Середня-висока (Rancher значно спрощує K8s, але bare metal потребує адміністрування). | Середня (керовані сервіси, але свої нюанси провайдера). | Висока, але знижується за рахунок Rancher, який уніфікує управління. Потребує експертизи. |
| Відповідність вимогам (Compliance) | Повний контроль над даними та інфраструктурою. Легше пройти аудит. | Повний контроль + уніфіковані політики через Rancher. | Залежить від провайдера та регіону. Shared responsibility. | Оптимально: чутливі дані on-prem, решта в хмарі з дотриманням регіональних норм. |
| Ризик Vendor Lock-in | Низький (відкритий стандарт K8s). | Низький (Rancher відкритий, але є прив'язка до його екосистеми управління). | Високий (глибока інтеграція з хмарними сервісами провайдера). | Низький (можливість переміщувати робочі навантаження, використовувати різних провайдерів). |
Примітка: Цифри в таблиці є оціночними і можуть варіюватися в залежності від конкретної реалізації, масштабу проєкту, регіону та кваліфікації команди. Цінові діапазони вказані для середнього підприємства, що оперує еквівалентом 10-20 фізичних серверів.
Потрібен виділений сервер?
Compare prices from top providers. Configure and order in minutes.
Детальний огляд кожного пункту/варіанту
Розуміння сильних і слабких сторін кожного підходу до розгортання Kubernetes критично важливе для вибору оптимальної стратегії. Розглянемо детально кожен варіант, акцентуючи увагу на його застосовності та особливостях в контексті 2026 року.
```1. Kubernetes на Bare Metal (Самокерований)
Цей підхід передбачає розгортання Kubernetes безпосередньо на фізичних серверах без проміжного шару віртуалізації або керуючих платформ, таких як Rancher. Ви повністю відповідаєте за всі аспекти: від встановлення ОС і налаштування мережі до розгортання компонентів Kubernetes (kubeadm, kops, kubespray) і подальшого їх обслуговування.
Переваги:
- Максимальна продуктивність: Прямий доступ до апаратних ресурсів забезпечує мінімальні накладні витрати та найвищу продуктивність для CPU, RAM, дисків і мережі. Це критично для високопродуктивних обчислень (HPC), баз даних з інтенсивним I/O, AI/ML-моделей і низьколатентних мережевих сервісів.
- Повний контроль і кастомізація: Ви контролюєте кожен аспект інфраструктури, що дозволяє тонко налаштовувати систему під унікальні вимоги. Це важливо для специфічних апаратних конфігурацій, спеціалізованих мережевих рішень або особливих вимог безпеки.
- Економія на масштабі: Для дуже великих, стабільних кластерів (сотні вузлів) в довгостроковій перспективі CapEx на bare metal може бути значно нижчим, ніж OpEx в хмарі, особливо якщо у вас є власний дата-центр або co-location.
- Незалежність від постачальника: Відсутність прив'язки до хмарного провайдера або керуючої платформи.
Недоліки:
- Висока складність і операційне навантаження: Розгортання, оновлення, моніторинг і усунення несправностей вимагають глибоких знань Kubernetes, мережевих технологій, системного адміністрування. Це значно збільшує OpEx за рахунок висококваліфікованого персоналу.
- Тривалий час розгортання: Закупівля, доставка, встановлення та налаштування обладнання можуть займати тижні або місяці. Масштабування також не відбувається миттєво.
- Відсутність еластичності: Ресурси обмежені наявним обладнанням. Bursting в хмару неможливий без гібридної стратегії.
- Складнощі з HA і DR: Побудова відмовостійкої архітектури і плану аварійного відновлення повністю лягає на вашу команду.
Для кого підходить:
Великі підприємства з власними дата-центрами, яким потрібна максимальна продуктивність і контроль, а також є штат висококваліфікованих інженерів. Компанії, що працюють з дуже чутливими даними, де потрібен повний контроль над фізичною інфраструктурою. Проекти з передбачуваним, але дуже високим навантаженням, де хмарні витрати стають непомірними.
2. Kubernetes на Bare Metal з Rancher
Цей варіант використовує переваги bare metal, додаючи до них потужність і зручність Rancher для управління життєвим циклом кластерів Kubernetes. Rancher дозволяє розгортати, оновлювати і управляти кількома кластерами Kubernetes (RKE, K3s) на фізичних серверах з єдиної панелі.
Переваги:
- Спрощене управління: Rancher значно знижує операційну складність, автоматизуючи багато рутинних завдань з розгортання та оновлення кластерів. Єдиний UI/API для всіх кластерів.
- Консистентність операцій: Rancher забезпечує єдиний підхід до управління кластерами, незалежно від їх розташування. Це уніфікує політики безпеки, моніторингу та розгортання додатків.
- Використання переваг bare metal: Зберігається висока продуктивність і повний контроль над обладнанням.
- Інтеграція з екосистемою: Rancher надає доступ до каталогів додатків, інструментів моніторингу (Prometheus/Grafana), логування (Fluentd/Loki), CI/CD (ArgoCD/Flux) та інших компонентів, що спрощує побудову комплексного рішення.
- Основа для гібрида: Rancher спочатку спроектований для управління мульти-кластерними і мульти-хмарними середовищами, що робить його ідеальним вибором для гібридної стратегії.
Недоліки:
- Крива навчання Rancher: Хоча Rancher спрощує K8s, сама платформа має свою криву навчання.
- Накладні витрати Rancher: Невеликі накладні витрати на роботу агентів Rancher і керуючого сервера.
- Все ще потрібне адміністрування bare metal: Ви, як і раніше, відповідаєте за фізичне обладнання, його обслуговування, електроживлення, охолодження і базову ОС.
- Обмежена еластичність: Масштабування bare metal кластера все ще обмежене фізичними ресурсами і часом їх придбання/встановлення.
Для кого підходить:
Компанії, які хочуть використовувати bare metal для продуктивності і контролю, але при цьому мінімізувати операційне навантаження на адміністрування Kubernetes. Ідеально підходить для основи гібридної інфраструктури, де потрібне централізоване управління різнорідними кластерами. SaaS-проекти, що досягли масштабу, при якому хмарні витрати стають надмірними, але не готові до повної ручної оркестрації K8s.
3. Kubernetes у Public Cloud (EKS/AKS/GKE)
Це найпопулярніший підхід для багатьох стартапів і компаній, які цінують швидкість розгортання, еластичність і керовані сервіси. Хмарні провайдери пропонують повністю керовані сервіси Kubernetes (Amazon EKS, Azure AKS, Google GKE), знімаючи з вас більшу частину турбот з управління контрольною площиною.
Плюси:
- Висока еластичність і масштабованість: Миттєве масштабування вгору і вниз, автоматичне додавання/видалення вузлів. Оплата за мірою використання.
- Мінімальні операційні витрати на K8s: Провайдер управляє майстер-вузлами, їх оновленням, безпекою і доступністю. Ви фокусуєтесь на додатках.
- Широкий спектр керованих сервісів: Легка інтеграція з базами даних, чергами повідомлень, балансувальниками навантаження, функціями безсерверних обчислень та іншими сервісами хмари.
- Глобальне покриття і DR: Можливість розгортання в декількох регіонах і зонах доступності для високої доступності та аварійного відновлення.
- Швидкий старт: Розгортання кластера займає хвилини.
Мінуси:
- Високі OpEx на масштабі: Зі збільшенням ресурсів і мережевого трафіку (особливо egress) хмарні витрати можуть стати дуже значними і непередбачуваними.
- Vendor Lock-in: Глибока інтеграція з пропрієтарними хмарними сервісами ускладнює міграцію на іншого провайдера або на bare metal.
- Обмежений контроль: Менше контролю над базовою інфраструктурою, мережевими налаштуваннями і деякими аспектами безпеки.
- Проблеми з продуктивністю/затримкою: Накладні витрати віртуалізації і мережевих абстракцій можуть призводити до більш високої затримки і меншої продуктивності в порівнянні з bare metal.
- Складнощі з дотриманням вимог: Модель спільної відповідальності вимагає ретельного аудиту і налаштування для відповідності суворим регуляторним нормам.
Для кого підходить:
Стартапи, які швидко ростуть і потребують максимальної гнучкості. Компанії з непередбачуваними або сильно коливаються навантаженнями. Проєкти, де швидкість виведення на ринок важливіше абсолютної мінімізації витрат на інфраструктуру. Команди, які хочуть мінімізувати адміністративне навантаження на інфраструктуру і зосередитися на розробці.
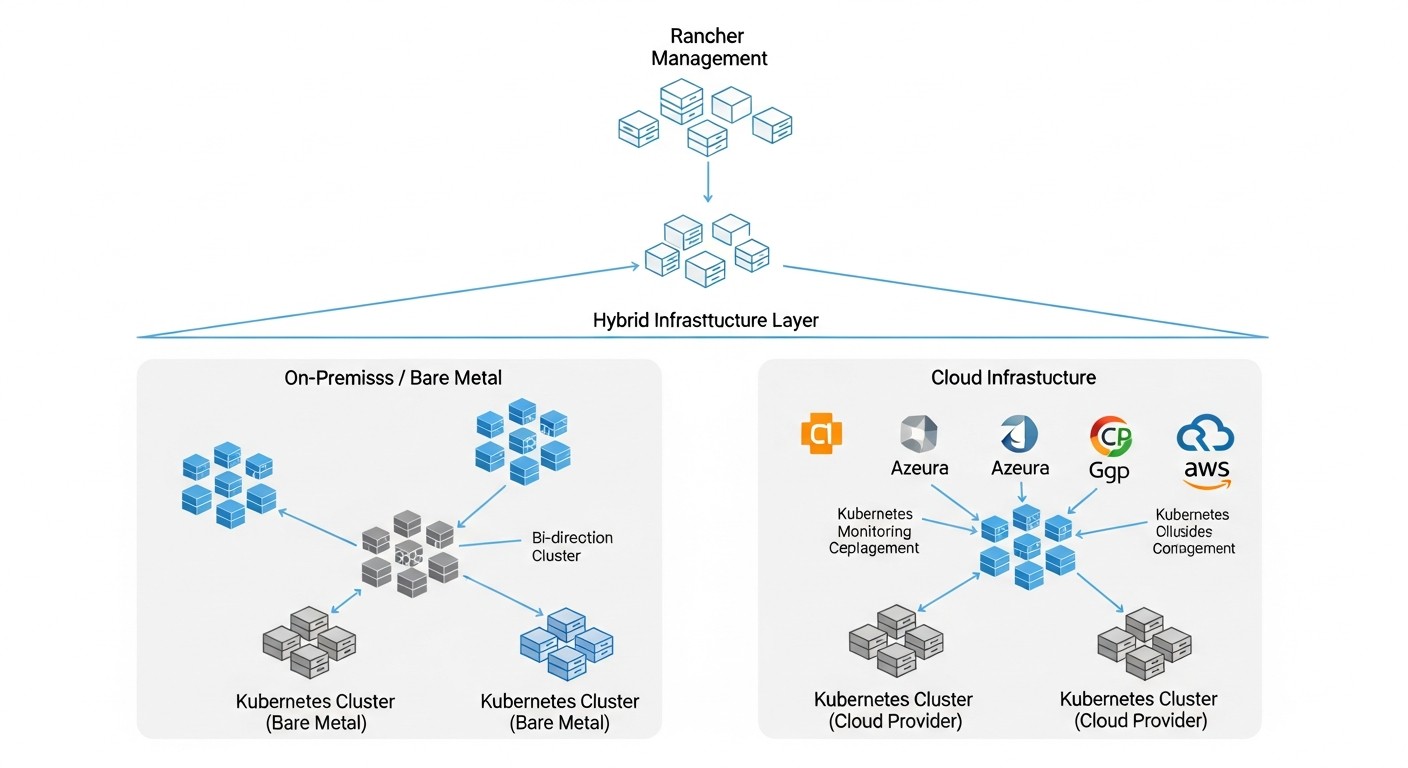
4. Гібридний Kubernetes з Rancher
Це комбінація bare metal і хмарних кластерів Kubernetes, керованих з єдиної панелі Rancher. Цей підхід дозволяє витягувати вигоду з переваг кожного середовища, мінімізуючи їх недоліки.
Плюси:
- Оптимізація витрат: Розміщення стабільних, ресурсоємних навантажень на bare metal (низький OpEx в довгостроковій перспективі) і використання хмари для еластичних, пікових навантажень або тимчасових середовищ (Dev/Test).
- Максимальна гнучкість і масштабованість: Поєднання передбачуваної продуктивності bare metal з необмеженою еластичністю хмари. Можливість "випліскування" навантаження в хмару.
- Посилена безпека і відповідність: Чутливі дані і критично важливі додатки можуть залишатися на bare metal під повним контролем, в той час як публічні і менш критичні сервіси розміщуються в хмарі. Rancher забезпечує єдині політики безпеки.
- Покращене аварійне відновлення: Можливість створення відмовостійких архітектур, де один сегмент інфраструктури служить резервним для іншого (наприклад, on-prem кластер як DR для хмарного і навпаки).
- Зниження Vendor Lock-in: Можливість використовувати кілька хмарних провайдерів (мульти-хмарна стратегія) і bare metal, що дає більшу свободу вибору і переносимість додатків.
- Уніфіковане управління: Rancher надає єдиний інтерфейс для управління всіма кластерами, спрощуючи операції, моніторинг і розгортання додатків.
Мінуси:
- Висока початкова складність: Проєктування і розгортання гібридної інфраструктури вимагає значної експертизи в мережевих технологіях, безпеці, сховищах даних і, звичайно, Kubernetes і Rancher.
- Складнощі з мережевою інтеграцією: Забезпечення безшовної і безпечного зв'язку між on-premise і хмарними кластерами може бути нетривіальним завданням (VPN, Direct Connect, SD-WAN).
- Управління даними: Стратегії для синхронізації, реплікації і доступу до даних між різними середовищами вимагають ретельного планування.
- Потенційні приховані витрати: Витрати на egress-трафік, прямі з'єднання, спеціалізоване обладнання.
Для кого підходить:
Практично для будь-якої компанії, яка прагне до оптимального балансу між вартістю, продуктивністю, безпекою і гнучкістю. Особливо актуально для великих підприємств, яким необхідно модернізувати застарілу on-premise інфраструктуру, дотримуватися суворих регуляторних вимог, а також для SaaS-провайдерів, які хочуть оптимізувати свої витрати на хмару, зберігаючи при цьому еластичність. Ідеальний вибір для тих, хто вже має значні інвестиції в bare metal і хоче розширити свої можливості за рахунок хмари, або навпаки, хто хоче повернути частину робочих навантажень з хмари на свої сервера.
Вибір конкретного варіанту або їх комбінації завжди повинен ґрунтуватися на глибокому аналізі поточних потреб, майбутніх планів розвитку і наявних ресурсів. Гібридна стратегія з Rancher надає найбільш повний набір інструментів для адаптації до цих вимог.
Практичні поради та рекомендації
Успішне впровадження гібридної Kubernetes-інфраструктури з Rancher вимагає не тільки розуміння теорії, а й глибокого занурення в практичні аспекти. Ось ключові рекомендації і покрокові інструкції, засновані на реальному досвіді.
1. Проєктування мережевої архітектури
Мережа — це кровоносна система вашої гібридної інфраструктури. Її правильне проєктування критично важливе для продуктивності, безпеки та доступності.
Покрокова інструкція:
- IP-планування: Виділіть IP-адресні діапазони, що не перетинаються, для кожного on-premise та хмарного кластера, а також для з'єднань між ними. Використовуйте RFC1918 для приватних мереж.
- З'єднання on-premise та хмари:
- VPN (IPsec/OpenVPN/WireGuard): Для початку або невеликих обсягів трафіку. Легко налаштовується, але має обмеження щодо пропускної здатності та затримки.
- Direct Connect (AWS)/ExpressRoute (Azure)/Cloud Interconnect (GCP): Для високопродуктивних, низьколатентних та стабільних з'єднань. Це виділені лінії, що забезпечують передбачувану продуктивність, але потребують значних інвестицій.
- SD-WAN: Сучасне рішення для керування трафіком через різні канали, оптимізації маршрутизації та забезпечення безпеки.
- Мережеві плагіни (CNI) для Kubernetes:
- Calico/Cilium: Чудовий вибір для гібридних середовищ, оскільки вони підтримують мережеві політики (Network Policies), забезпечують високу продуктивність і можуть працювати в різних режимах (IP-in-IP, BGP). Calico також підтримує інтеграцію з BGP для bare metal кластерів.
- Flannel: Простіший у налаштуванні, але менш функціональний та продуктивний. Хороший для простих сценаріїв.
- DNS-стратегія: Реалізуйте єдину стратегію DNS для розв'язання імен між on-premise та хмарними кластерами. Використовуйте CoreDNS у Kubernetes та налаштуйте умовні пересилання (conditional forwarders) до on-premise DNS-серверів для внутрішніх доменів і навпаки.
- Load Balancing:
- Bare Metal: Використовуйте MetalLB для надання LoadBalancer Service. Він розподіляє IP-адреси з пулу та анонсує їх за допомогою BGP або ARP.
- Cloud: Використовуйте нативні хмарні балансувальники (AWS ELB/ALB, Azure Load Balancer, GCP GCLB).
- Ingress Controllers: NGINX Ingress Controller, Traefik, Istio Ingress Gateway для маршрутизації HTTP/S трафіку.
# Пример конфигурации MetalLB (bare metal)
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: bare-metal-lb-pool
spec:
addresses:
- 192.168.100.200-192.168.100.250
---
apiVersion: metallb.io/v1beta1
kind: BGPAdvertisement
metadata:
name: bare-metal-bgp-advertisement
spec:
ipAddressPools:
- bare-metal-lb-pool
2. Стратегія зберігання даних
Дані — це серце ваших додатків. Вибір правильної стратегії зберігання в гібридному середовищі критично важливий.
Покрокова інструкція:
- CSI (Container Storage Interface): Використовуйте CSI-драйвери для інтеграції Kubernetes з різними типами сховищ.
- On-premise сховища:
- Rook (Ceph): Розподілене сховище, що створюється на базі локальних дисків серверів. Забезпечує блочне, файлове та об'єктне зберігання, високу доступність та масштабованість.
- Longhorn: Легковаге розподілене блочне сховище, також побудоване на базі локальних дисків, кероване з Kubernetes. Добре підходить для невеликих та середніх кластерів.
- Зовнішні СЗД (NFS/iSCSI): Інтеграція з існуючими NAS/SAN системами через відповідні CSI-драйвери.
- Хмарні сховища:
- Managed Disks: AWS EBS, Azure Disks, GCP Persistent Disks для блочного зберігання, прив'язаного до конкретної VM.
- Managed File Storage: AWS EFS, Azure Files, GCP Filestore для спільного файлового доступу.
- Object Storage: AWS S3, Azure Blob Storage, GCP Cloud Storage для об'єктного зберігання (часто використовується для бекапів, статичних файлів).
- Стратегія реплікації та бекапів: Для критично важливих даних розгляньте реплікацію між on-premise та хмарою (наприклад, синхронізація баз даних, реплікація Ceph між кластерами). Використовуйте Velero для бекапу та відновлення Kubernetes-ресурсів та Persistent Volumes.
# Пример PersistentVolumeClaim для Longhorn
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-app-pvc
spec:
accessModes:
- ReadWriteOnce
storageClassName: longhorn
resources:
requests:
storage: 10Gi
3. Управління ідентифікацією та доступом (IAM)
Єдина система автентифікації та авторизації спрощує управління користувачами та забезпечує безпеку.
Покрокова інструкція:
- Централізований провайдер ідентичності: Інтегруйте Rancher з корпоративним LDAP/AD, Okta, Auth0 або іншими SSO-рішеннями. Це дозволить користувачам входити в Rancher за допомогою своїх корпоративних облікових записів.
- RBAC в Kubernetes: Налаштуйте Role-Based Access Control (RBAC) у кожному кластері, а також глобальні ролі в Rancher. Визначте, хто має доступ до кластерів, неймспейсів та конкретних ресурсів.
- Принцип мінімальних привілеїв: Надавайте користувачам та додаткам тільки ті права, які необхідні для виконання їхніх задач.
4. CI/CD для гібридного середовища
Автоматизація розгортання додатків у гібридному середовищі вимагає продуманого CI/CD пайплайну.
Покрокова інструкція:
- GitOps: Використовуйте Git як єдине джерело істини для конфігурації ваших кластерів та додатків. Інструменти, такі як ArgoCD або Flux, будуть синхронізувати стан кластерів з репозиторієм Git.
- Мульти-кластерне розгортання: Налаштуйте пайплайни так, щоб вони могли розгортати додатки в конкретні on-premise або хмарні кластери, або навіть у кілька кластерів одночасно. Rancher Fleet може бути використаний для централізованого розгортання та управління додатками у великій кількості кластерів.
- Секрети: Використовуйте Vault від HashiCorp, External Secrets Operator або хмарні менеджери секретів для безпечного зберігання та доступу до конфіденційних даних.
# Пример ArgoCD Application для развертывания в гибридном кластере
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-hybrid-app
namespace: argocd
spec:
project: default
source:
repoURL: https://github.com/my-org/my-app-configs.git
targetRevision: HEAD
path: k8s/production/hybrid-cluster
destination:
server: https://kubernetes.default.svc # Или URL вашего кластера Rancher
namespace: my-app
syncPolicy:
automated:
prune: true
selfHeal: true
5. Моніторинг та логування
Єдина система моніторингу та логування критична для здоров'я та налагодження гібридної інфраструктури.
Покрокова інструкція:
- Моніторинг: Розгорніть Prometheus та Grafana в кожному кластері або централізовано. Rancher включає вбудовану інтеграцію з Prometheus та Grafana, що спрощує їх налаштування. Збирайте метрики з вузлів, подів, контейнерів, а також мережеві та дискові метрики.
- Логування: Використовуйте централізовану систему логування, таку як ELK Stack (Elasticsearch, Logstash, Kibana) або Loki з Grafana. Налаштуйте Fluentd/Fluent Bit в кожному кластері для збору логів та відправки їх в централізоване сховище.
- Алерти: Налаштуйте Alertmanager (частина Prometheus) для відправки повідомлень в Slack, PagerDuty, email при виникненні проблем.
6. Стратегія аварійного відновлення (DR)
Необхідно мати чіткий план дій на випадок збоїв.
Покрокова інструкція:
- Визначення RTO/RPO: Для кожного застосунку визначте допустимий час відновлення (RTO) та допустиму втрату даних (RPO).
- Резервне копіювання та відновлення: Використовуйте Velero для бекапу та відновлення Kubernetes-ресурсів (Deployments, Services, ConfigMaps) і Persistent Volumes. Velero може зберігати бекапи в об'єктне сховище (S3-сумісне або хмарне).
- Географічна розподіленість: Розгорніть кластери в різних географічних локаціях (on-premise дата-центр, різні хмарні регіони) для захисту від регіональних збоїв.
- Тестування DR: Регулярно тестуйте ваш план DR, імітуючи збої та перевіряючи процедури відновлення. Це єдиний спосіб переконатися в його працездатності.
# Пример бэкапа кластера с Velero
velero backup create my-cluster-backup --include-namespaces my-app-namespace --wait
# Пример восстановления кластера с Velero
velero restore create --from-backup my-cluster-backup --wait
7. Управління версіями Kubernetes та оновленнями
Оновлення Kubernetes може бути складним, але Rancher значно спрощує цей процес.
Покрокова інструкція:
- Планування: Слідкуйте за життєвим циклом версій Kubernetes. Плануйте оновлення заздалегідь, враховуючи сумісність застосунків.
- Rancher для оновлень: Rancher дозволяє оновлювати версії Kubernetes для керованих кластерів через UI або API. Це значно спрощує процес, автоматизуючи багато кроків.
- Послідовні оновлення: Оновлюйте кластери не відразу, а по черзі: спочатку dev/test, потім staging, і тільки потім production.
- Тестування: Після кожного оновлення проводьте ретельне регресійне тестування застосунків.
Застосовуючи ці практичні поради, ви зможете побудувати надійну, ефективну та легко керовану гібридну інфраструктуру на базі Kubernetes і Rancher, готову до викликів 2026 року і далі.
Типові помилки
Впровадження гібридної інфраструктури — це складний проєкт, і на цьому шляху легко зробити помилки, які можуть призвести до значних витрат, простоїв або проблем з безпекою. Вивчення цих поширених помилок і знання способів їх запобігання є ключем до успішної реалізації.
1. Недооцінка складності мережевої інтеграції
Помилка: Багато інженерів недооцінюють, наскільки складним може бути налаштування безшовної та безпечної мережі між on-premise та хмарними кластерами. Проблеми з IP-плануванням, маршрутизацією, DNS-розрішенням і пропускною здатністю часто виринають на пізніх етапах, призводячи до затримок і переробок.
Як уникнути:
- Почніть з детального IP-планування, переконайтеся у відсутності перетинів діапазонів.
- Інвестуйте в надійне міжмережеве з'єднання (Direct Connect, ExpressRoute) для критично важливих навантажень. Для менш вимогливих можна почати з VPN.
- Використовуйте просунуті CNI-плагіни, такі як Calico або Cilium, які підтримують мережеві політики та BGP.
- Реалізуйте уніфіковану DNS-стратегію з умовною пересилкою між on-premise та хмарою.
Наслідки: Висока затримка, нестабільне з'єднання, проблеми з розрішенням імен між сервісами, що призводить до непрацездатності розподілених застосунків і дорогих простоїв.
2. Ігнорування стратегії зберігання даних та їхньої "гравітації"
Помилка: Розробники часто переносять застосунки в хмару, не замислюючись про те, де знаходяться їхні дані. Або, навпаки, розміщують бази даних on-premise, а застосунки в хмарі, що призводить до високих витрат на egress-трафік і затримки.
Як уникнути:
- Проаналізуйте характер даних: обсяг, швидкість зміни, чутливість, вимоги до затримки.
- Розміщуйте застосунки максимально близько до даних, з якими вони інтенсивно працюють. Якщо дані on-premise, то і частина застосунків, що працюють з ними, має бути on-premise.
- Використовуйте розподілені сховища (Rook/Ceph, Longhorn) на bare metal і відповідні хмарні CSI-драйвери.
- Плануйте стратегію реплікації та бекапів даних між середовищами.
Наслідки: Несподівано високі рахунки за хмарний трафік, низька продуктивність застосунків через затримки при доступі до даних, проблеми з цілісністю даних при відсутності адекватної стратегії реплікації.
3. Відсутність єдиної стратегії IAM та RBAC
Помилка: Управління користувачами та їхніми правами доступу в кожному кластері окремо, без централізованої системи. Це веде до хаосу, проблем з безпекою і високих операційних витрат.
Як уникнути:
- Інтегруйте Rancher з корпоративним LDAP/AD або SSO-провайдером для централізованої аутентифікації.
- Використовуйте глобальні та кластерні ролі в Rancher для уніфікованого управління авторизацією.
- Застосовуйте принцип мінімальних привілеїв для всіх користувачів і сервісних акаунтів.
- Регулярно проводьте аудит прав доступу.
Наслідки: Несанкціонований доступ, порушення безпеки, складнощі з аудитом, високі витрати часу на управління доступом.
4. Неадекватне планування аварійного відновлення (DR)
Помилка: Багато компаній створюють гібридну інфраструктуру, але не тестують свої DR-плани або взагалі їх не мають. Сподівання на те, що "нічого не трапиться", призводить до катастрофічних наслідків при реальному збої.
Як уникнути:
- Визначте чіткі RTO та RPO для кожного критично важливого сервісу.
- Розробіть детальний план DR, що включає процедури бекапу, відновлення, перемикання на резервний кластер (failover) та повернення (failback).
- Використовуйте такі інструменти, як Velero, для автоматизованого бекапу та відновлення Kubernetes-ресурсів та даних.
- Регулярно (не рідше разу на пів року) проводьте повномасштабні навчання з DR, імітуючи реальні збої.
Наслідки: Тривалі простої (години або дні), втрата критично важливих даних, значна репутаційна та фінансова шкода.
5. Недооцінка операційної складності та потреби в кваліфікованих кадрах
Помилка: Вважати, що Rancher вирішить всі проблеми, і гібридним Kubernetes можна буде керувати силами одного джуніора. Гібридна інфраструктура, навіть з Rancher, вимагає значної експертизи в різних областях (Kubernetes, мережі, сховища, хмарні технології, безпека).
Як уникнути:
- Інвестуйте в навчання команди. Переконайтеся, що у вас є фахівці з досвідом роботи в Kubernetes, Rancher, а також в мережевих технологіях і хмарних платформах.
- Почніть з малого, поступово нарощуючи складність інфраструктури та компетенції команди.
- Автоматизуйте рутинні завдання за допомогою CI/CD та GitOps.
- Розгляньте можливість використання зовнішньої експертизи або консультантів на початкових етапах.
Наслідки: Повільне розгортання, часті інциденти, низька ефективність використання ресурсів, вигорання команди, високі витрати на пошук і найм висококваліфікованих фахівців.
6. Відсутність моніторингу та алертів для гібридного середовища
Помилка: Розгортання кластерів в різних середовищах, але без централізованого моніторингу та логування. Це призводить до "сліпих зон" і неможливості швидко реагувати на проблеми.
Як уникнути:
- Впровадьте уніфіковану систему моніторингу (Prometheus/Grafana) та логування (ELK/Loki) для всіх кластерів, незалежно від їх розташування.
- Налаштуйте агрегацію метрик і логів в централізованому сховищі для зручного аналізу.
- Визначте ключові метрики здоров'я для кожного компонента і налаштуйте адекватні пороги для алертів.
- Переконайтеся, що алерти доставляються в потрібні канали (Slack, PagerDuty, email) і по ним є чіткий план дій.
Наслідки: Довгі пошуки причин інцидентів, реактивний, а не проактивний підхід до управління, високий MTTR (Mean Time To Recovery).
Уникаючи цих поширених помилок, ви значно підвищите шанси на успішне та ефективне впровадження гібридної Kubernetes-інфраструктури з Rancher.
Потрібен виділений сервер?
Compare prices from top providers. Configure and order in minutes.
Чекліст для практичного застосування
Цей чекліст допоможе вам систематизувати процес планування та впровадження гібридної інфраструктури Kubernetes з Rancher. Проходьте по пунктах послідовно, переконуючись, що кожен крок виконано або враховано.
- Визначення вимог та планування:
- [ ] Визначено бізнес-цілі та очікувані вигоди від гібридної інфраструктури.
- [ ] Виявлено критично важливі програми та їх вимоги до продуктивності, затримки, безпеки.
- [ ] Визначено вимоги до дотримання регуляторних норм (GDPR, HIPAA, ФЗ-152 і т.д.).
- [ ] Проаналізовано поточні та прогнозовані обсяги даних та їх "гравітація".
- [ ] Сформовано бюджет на CapEx (bare metal) та OpEx (хмара, персонал, ліцензії).
- [ ] Сформовано склад команди та оцінено її компетенції, заплановано навчання при необхідності.
- Вибір компонентів та архітектури:
- [ ] Вибрано основного хмарного провайдера (AWS, Azure, GCP) для хмарних кластерів.
- [ ] Визначено специфікації bare metal серверів (CPU, RAM, Storage, Network) для on-premise кластерів.
- [ ] Вибрано дистрибутив Kubernetes (RKE/K3s для bare metal, EKS/AKS/GKE для хмари).
- [ ] Вибрано CNI-плагін (Calico, Cilium) з урахуванням гібридного середовища.
- [ ] Вибрано стратегію зберігання даних (Rook/Ceph, Longhorn on-prem; хмарні CSI-драйвери).
- [ ] Визначено стратегію балансування навантаження (MetalLB on-prem, хмарні ALB/NLB, Ingress Controllers).
- Проектування мережевої інфраструктури:
- [ ] Виділено IP-діапазони, що не перетинаються, для всіх кластерів та міжкластерних з'єднань.
- [ ] Спроектовано з'єднання між on-premise та хмарою (VPN, Direct Connect/ExpressRoute).
- [ ] Спроектовано єдину DNS-стратегію з умовною пересилкою.
- [ ] Налаштовано мережеві політики безпеки (Network Policies) для ізоляції подів.
- Розгортання Rancher та кластерів:
- [ ] Розгорнуто керуючий сервер Rancher (on-premise або у виділеному хмарному кластері).
- [ ] Розгорнуто перший bare metal Kubernetes кластер (RKE/K3s) та імпортовано в Rancher.
- [ ] Розгорнуто перший хмарний Kubernetes кластер (EKS/AKS/GKE) та імпортовано в Rancher.
- [ ] Налаштовано інтеграцію Rancher з провайдером ідентичності (LDAP/AD, SSO).
- Налаштування безпеки та IAM:
- [ ] Налаштовано глобальні ролі та RBAC в Rancher для управління кластерами.
- [ ] Налаштовано RBAC у кожному кластері Kubernetes для управління ресурсами.
- [ ] Впроваджено механізм управління секретами (Vault, External Secrets Operator).
- [ ] Налаштовано фаєрволи та групи безпеки для ізоляції кластерів та сервісів.
- Впровадження CI/CD та GitOps:
- [ ] Вибрано інструмент GitOps (ArgoCD, Flux) та налаштовано його інтеграцію з репозиторієм Git.
- [ ] Розроблено Helm-чарти або Kustomize-конфігурації для програм.
- [ ] Налаштовано пайплайни CI/CD для збирання образів та їх розгортання у гібридному середовищі.
- [ ] Впроваджено Rancher Fleet для управління розгортанням програм у масштабі (опціонально).
- Моніторинг, логування та алерти:
- [ ] Розгорнуто Prometheus та Grafana у кожному кластері або централізовано.
- [ ] Налаштовано збір та агрегація логів (Fluentd/Fluent Bit + ELK/Loki).
- [ ] Визначено ключові метрики здоров'я та налаштовано правила алертингу.
- [ ] Налаштовано канали доставки алертів (Slack, PagerDuty, email).
- Планування та тестування аварійного відновлення (DR):
- [ ] Визначено RTO та RPO для всіх критично важливих сервісів.
- [ ] Впроваджено інструмент для бекапу та відновлення Kubernetes-ресурсів та PV (Velero).
- [ ] Розроблено та документовано план дій при аварії.
- [ ] Проведено регулярні навчання з аварійного відновлення.
- Оптимізація та управління витратами:
- [ ] Впроваджено інструменти для моніторингу хмарних витрат та використання ресурсів.
- [ ] Налаштовано політики автоматичного масштабування (Cluster Autoscaler, HPA) для ефективного використання хмарних ресурсів.
- [ ] Регулярно проводиться аналіз витрат та пошук можливостей для оптимізації.
- Документація та навчання:
- [ ] Створено повну документацію з архітектури, конфігурації та процедур експлуатації.
- [ ] Проведено навчання команди з усіх аспектів нової інфраструктури.
- [ ] Розроблено runbooks для типових операцій та усунення неполадок.
Дотримуючись цього чекліста, ви зможете створити стійку, безпечну та ефективну гібридну інфраструктуру Kubernetes з Rancher, мінімізуючи ризики та максимізуючи віддачу від інвестицій.
Розрахунок вартості / Економіка
Розуміння економіки гібридної інфраструктури критично важливе для прийняття стратегічних рішень. Розрахунки можуть бути складними, оскільки включають як капітальні, так і операційні витрати, а також приховані витрати. Ми розглянемо приклади розрахунків для різних сценаріїв у контексті 2026 року, враховуючи інфляцію та технологічні тренди.
Компоненти вартості
- CapEx (Капітальні витрати) для Bare Metal:
- Сервери: Вартість фізичних серверів (CPU, RAM, диски). У 2026 році потужні сервери з 2x 64-ядерними CPU, 512GB RAM, 8x NVMe SSD можуть коштувати від $15,000 до $30,000 за штуку.
- Мережеве обладнання: Комутатори, маршрутизатори, кабелі. Від $5,000 до $50,000 в залежності від масштабу.
- СЗД: Якщо не використовується розподілене сховище на базі локальних дисків, то зовнішні СЗД можуть коштувати від $20,000 до $100,000+.
- Стійки, PDU, KVM: Невеликі, але необхідні витрати.
- OpEx (Операційні витрати) для Bare Metal:
- Розміщення (Co-location): Плата за стійко-місце, електроенергію, охолодження, доступ в інтернет. У 2026 році це може бути від $500 до $1,500 в місяць за стійку з кількома серверами.
- Персонал: Зарплата системних адміністраторів, DevOps-інженерів. Це одна з найбільших статей витрат.
- Ліцензії/Підтримка: Якщо використовуються комерційні ОС, ПЗ або enterprise-підтримка Rancher (Rancher Prime), Red Hat OpenShift.
- Обслуговування: Заміна компонентів, що вийшли з ладу, гарантійне обслуговування.
- OpEx для Хмари:
- Обчислювальні ресурси (vCPU, RAM): Вартість інстансів (VM). У 2026 році вартість 1 vCPU/GB RAM може незначно знизитися, але загальна вартість буде рости з масштабом.
- Сховище: EBS, Azure Disks, GCP Persistent Disks, S3-подібні сховища.
- Мережевий трафік: Особливо egress (вихідний трафік). Це одна з найбільш підступних прихованих статей витрат.
- Керовані сервіси: Вартість EKS/AKS/GKE Control Plane, керовані бази даних, черги, балансувальники навантаження.
- Резервування/Знижки: Reserved Instances, Savings Plans можуть значно знизити вартість, якщо навантаження передбачуване.
- Приховані витрати:
- Data Egress: Вартість виведення даних з хмари може бути дуже високою ($0.05 - $0.15 за GB).
- Навчання персоналу: Інвестиції в підвищення кваліфікації команди.
- Неефективне використання ресурсів: Перепланування або недовикористання ресурсів.
- Простої: Втрата прибутку, репутаційний збиток.
- Безпека: Витрати на інструменти безпеки, аудит, реагування на інциденти.
Приклади розрахунків для різних сценаріїв (прогноз на 2026 рік)
Для прикладу візьмемо середню компанію, яка оперує навантаженням, еквівалентним 10-15 сучасним фізичним серверам (наприклад, 200-300 vCPU, 1-2 TB RAM, 20-30 TB NVMe сховища).
Сценарій 1: Чистий Bare Metal (з Rancher)
Компанія інвестує у власне обладнання, використовуючи Rancher для спрощення управління Kubernetes. Це вибір для максимального контролю та продуктивності, де CapEx високий, але OpEx нижчий у довгостроковій перспективі.
- CapEx (початкові інвестиції):
- 15 серверів (2x64c/512GB/8xNVMe): 15 * $25,000 = $375,000
- Мережеве обладнання: $30,000
- Стійки, PDU: $10,000
- РАЗОМ CapEx: $415,000
- OpEx (щомісячно):
- Co-location (3 стійки): 3 * $1,000 = $3,000
- Зарплата 2 DevOps-інженерів (з урахуванням overhead): 2 * $12,000 = $24,000
- Enterprise підтримка Rancher Prime (опціонально, $10-20K/рік): ~$1,500
- Обслуговування/заміна: $1,000
- РАЗОМ OpEx: $29,500/місяць
- TCO за 3 роки: $415,000 (CapEx) + (36 * $29,500) (OpEx) = $415,000 + $1,062,000 = $1,477,000
Сценарій 2: Чиста Хмара (EKS/AKS/GKE)
Компанія повністю покладається на керовані хмарні сервіси Kubernetes. Висока гнучкість, але потенційно високі OpEx на масштабі.
- CapEx: $0
- OpEx (щомісячно, без RI/Savings Plans):
- 15 інстансів (еквівалент 2x64c/512GB): 15 * $1,500 (наприклад, m6i.16xlarge) = $22,500
- Сховище (30TB GP3): $1,500
- EKS Control Plane: $730
- Мережевий трафік (egress, 10TB/міс): 10,000 * $0.08 = $800
- Інші керовані сервіси (DB, Load Balancer, Monitoring): $3,000
- Зарплата 2 DevOps-інженерів (менше адміністрування, більше автоматизації): 2 * $11,000 = $22,000
- РАЗОМ OpEx: $50,530/місяць
- TCO за 3 роки: 36 * $50,530 = $1,819,080
- З урахуванням Reserved Instances/Savings Plans (30-50% економії): $1,273,356 - $909,540
Сценарій 3: Гібридна Інфраструктура (з Rancher)
Компанія розміщує 60% навантаження на bare metal (стабільні, ресурсоємні сервіси) і 40% в хмарі (еластичні, тимчасові). Все управляється через Rancher.
- CapEx (початкові інвестиції для 60% bare metal):
- 9 серверів: 9 * $25,000 = $225,000
- Мережеве обладнання: $20,000
- Стійки, PDU: $5,000
- РАЗОМ CapEx: $250,000
- OpEx (щомісячно):
- Co-location (2 стійки): 2 * $1,000 = $2,000 (bare metal частина)
- Хмарні ресурси (40% від сценарію 2, з урахуванням RI/SP): $50,530 * 0.4 * 0.7 = $14,148 (хмарна частина)
- Зарплата 2 DevOps-інженерів (потрібна більш висока кваліфікація): 2 * $13,000 = $26,000
- Enterprise підтримка Rancher Prime: ~$1,500
- Обслуговування bare metal: $600
- Direct Connect/ExpressRoute (для зв'язку): $1,000
- РАЗОМ OpEx: $45,248/місяць
- TCO за 3 роки: $250,000 (CapEx) + (36 * $45,248) (OpEx) = $250,000 + $1,628,928 = $1,878,928
- Примітка: TCO гібрида може бути вище, ніж чистої хмари з RI, але дає більше контролю, безпеки та гнучкості. Також OpEx в гібриді включає зарплату більш кваліфікованих інженерів. Якщо хмарна частина більш динамічна і не використовує RI, то гібрид буде значно дешевшим.
Як оптимізувати витрати
- Resource Rightsizing: Регулярно аналізуйте споживання ресурсів вашими подами та вузлами. Використовуйте VPA (Vertical Pod Autoscaler) та HPA (Horizontal Pod Autoscaler) для автоматичного масштабування. Не переплачуйте за невикористовувані ресурси.
- Reserved Instances / Savings Plans: Якщо у вас є передбачуване базове навантаження в хмарі, використовуйте ці механізми для значної економії (до 70%).
- Spot Instances: Для некритичних, перериваних робочих навантажень використовуйте Spot-інстанси в хмарі для максимальної економії (до 90%).
- Оптимізація мережевого трафіку: Мінімізуйте egress-трафік. Використовуйте CDN, кешування, стиснення даних. Розміщуйте дані поруч із застосунками.
- Ефективне використання Bare Metal: Використовуйте Kubernetes для максимальної утилізації ресурсів на фізичних серверах. Консолідуйте робочі навантаження.
- Open Source рішення: Максимально використовуйте безкоштовні open-source інструменти (Rancher, Prometheus, Grafana, Velero, Longhorn), щоб уникнути ліцензійних платежів.
- Автоматизація: Інвестуйте в автоматизацію (GitOps, CI/CD) для зниження трудовитрат і мінімізації людських помилок.
Таблиця з прикладами розрахунків (3-річний TCO)
| Сценарій | Початковий CapEx (Bare Metal) | Щомісячний OpEx | 3-річний TCO | Основні переваги |
|---|---|---|---|---|
| Чистий Bare Metal (з Rancher) | ~$415,000 | ~$29,500 | ~$1,477,000 | Висока продуктивність, повний контроль, довгострокова економія для стабільних навантажень. |
| Чиста Хмара (EKS/AKS/GKE) | $0 | ~$50,530 (без RI/SP) | ~$1,819,080 | Максимальна еластичність, швидкий старт, мінімальне адміністрування K8s. |
| (Хмара з RI/SP) | $0 | ~$35,000 | ~$1,260,000 | Економія OpEx при передбачуваному хмарному навантаженні. |
| Гібрид (K8s з Rancher) | ~$250,000 | ~$45,248 | ~$1,878,928 | Баланс контролю, продуктивності та еластичності. Безпека даних, DR. |
Примітка: Ці розрахунки є спрощеними оцінками. Реальні цифри можуть сильно відрізнятися в залежності від конкретних вимог, знижок, регіональних цін і ефективності експлуатації. Ключовий висновок: гібридна стратегія не завжди є найдешевшою за TCO, але пропонує оптимальний баланс між усіма критично важливими факторами, що в кінцевому підсумку може забезпечити більшу цінність для бізнесу.
Кейси та приклади
Теорія важлива, але реальні приклади використання гібридної інфраструктури з Kubernetes і Rancher дають найбільш повне уявлення про її переваги та виклики. Розглянемо кілька реалістичних сценаріїв з різних індустрій.
Кейс 1: Фінтех-стартап з високочастотним трейдингом і аналітикою
Проблема:
Молодий, швидкозростаючий фінтех-стартап розробив інноваційну платформу для високочастотного трейдингу (HFT) і предиктивної аналітики. HFT-компонент вимагав мінімальної затримки (менше 1 мс) для виконання ордерів, а також максимальної пропускної здатності для обробки ринкових даних. При цьому аналітичний блок, який обробляв величезні обсяги історичних даних і запускав ресурсоємні ML-моделі, мав непередбачувані пікові навантаження і вимагав еластичності. Регуляторні вимоги зобов'язували зберігати всі транзакційні дані на території країни.
Рішення з Rancher:
Компанія прийняла рішення про створення гібридної інфраструктури на базі Kubernetes, керованої Rancher.
- On-premise кластер (Bare Metal): Був розгорнутий кластер Kubernetes на виділених bare metal серверах у власному дата-центрі. Цей кластер використовувався для HFT-застосунків, баз даних транзакцій і первинного зберігання чутливих фінансових даних. Використовувався RKE (Rancher Kubernetes Engine) для розгортання K8s, MetalLB для Load Balancer і Calico для CNI. Для зберігання даних був обраний Rook/Ceph, що забезпечує високу продуктивність і відмовостійкість.
- Облачний кластер (AWS EKS): В AWS був розгорнутий кластер EKS для аналітичних сервісів, ML-тренувань і публічних API. Цей кластер використовував Cluster Autoscaler для автоматичного масштабування вузлів в залежності від навантаження.
- Мережева зв'язність: Між on-premise дата-центром і AWS був налаштований AWS Direct Connect для забезпечення низьколатентного і високошвидкісного з'єднання. Це дозволяло аналітичним сервісам безпечно звертатися до транзакційних даних з мінімальною затримкою, а також передавати агреговані дані в хмару.
- Управління з Rancher: Обидва кластери були імпортовані і управлялися через єдиний інтерфейс Rancher. Це дозволило команді DevOps уніфікувати розгортання (через GitOps з ArgoCD), моніторинг (Prometheus/Grafana) і управління доступом (інтеграція з корпоративним SSO) для обох середовищ. Rancher Fleet використовувався для централізованого розгортання і оновлення базових компонентів і застосунків в обох кластерах.
Результати:
- Оптимізація продуктивності: HFT-застосунки досягли необхідної затримки <1 мс, забезпечуючи конкурентну перевагу.
- Еластичність і економія: Аналітичні навантаження ефективно масштабувалися в хмарі, оплачувалися тільки використовувані ресурси, що дозволило уникнути надлишкових інвестицій в bare metal для піків.
- Відповідність регулятору: Чутливі транзакційні дані залишалися на власних серверах, повністю відповідаючи локальним вимогам до суверенітету даних.
- Спрощене управління: Rancher значно знизив операційне навантаження, надавши єдину точку контролю над складним гібридним середовищем.
- Покращена DR: Бекапи критично важливих даних з bare metal реплікувалися в S3-сумісне сховище в AWS, забезпечуючи надійний план аварійного відновлення.
Кейс 2: Великий медичний заклад з EHR-системою
Проблема:
Велика мережа клінік використовувала застарілу монолітну систему електронних медичних карт (EHR) на on-premise серверах. Система була критично важлива, вимагала високої доступності та відповідала суворим вимогам HIPAA та іншим медичним стандартам. Клініка також хотіла розробити нові, публічно доступні сервіси (портал пацієнтів, телемедицина) з використанням сучасних технологій, але не могла ризикувати безпекою чутливих даних.
Рішення з Rancher:
Була обрана стратегія поступової модернізації та гібридного розгортання.
- On-premise кластер (Bare Metal): Існуючі фізичні сервери були модернізовані і на них розгорнуто кластер Kubernetes (RKE) для хостингу EHR-системи та пов'язаних з нею баз даних. Це забезпечило максимальний контроль над даними пацієнтів і відповідність HIPAA. Для міграції моноліту на контейнери використовувалися техніки "lift-and-shift" і поступова декомпозиція на мікросервіси.
- Хмарний кластер (Azure AKS): В Azure був розгорнутий кластер AKS для нових публічних сервісів (портал пацієнтів, телемедичні API, мобільні бекенди). Ці сервіси не зберігали чутливі дані напряму, а зверталися до EHR-системи через захищені API.
- Мережева зв'язність і безпека: Між on-premise дата-центром і Azure був налаштований Azure ExpressRoute для безпечного і високопродуктивного з'єднання. Були реалізовані суворі мережеві політики і фаєрволи, а також OPA Gatekeeper для enforcement'а політик безпеки в Kubernetes.
- Управління з Rancher: Rancher використовувався для управління обома кластерами. Це дозволило команді ІТ застосовувати єдині політики RBAC, управляти життєвим циклом кластерів і розгортати додатки з використанням GitOps. Особлива увага приділялася моніторингу (Prometheus/Grafana) і аудиту (Fluentd/Loki) для забезпечення відповідності регуляторним вимогам.
Результати:
- Відповідність і безпека: Чутливі дані пацієнтів залишалися під повним контролем on-premise, забезпечуючи відповідність HIPAA. Публічні сервіси були ізольовані в хмарі.
- Модернізація: Клініка змогла модернізувати свою застарілу EHR-систему, поступово переводячи її на мікросервісну архітектуру, не перериваючи роботу критично важливих сервісів.
- Інновації: Була отримана можливість швидко розгортати нові сервіси для пацієнтів в хмарі, використовуючи сучасні технології і гнучкість.
- Висока доступність: On-premise кластер був налаштований з надмірністю, а хмарний кластер забезпечував DR для публічних сервісів.
Кейс 3: SaaS-провайдер з метою оптимізації витрат
Проблема:
Середній SaaS-провайдер, що надає B2B-рішення, повністю працював в AWS на EKS. По мірі зростання клієнтської бази і збільшення обсягів даних, щомісячні рахунки за хмарні ресурси (особливо за бази даних, сховище і egress-трафік) росли експоненціально, загрожуючи маржинальності бізнесу. Також спостерігалися проблеми з продуктивністю для деяких ресурсоємних аналітичних звітів.
Рішення з Rancher:
Компанія вирішила перенести частину своїх робочих навантажень на bare metal, створивши гібридну інфраструктуру.
- On-premise кластер (Bare Metal): Компанія орендувала кілька стійок в co-location центрі і розгорнула кластер Kubernetes (RKE) на bare metal серверах. Сюди були перенесені основні бази даних (PostgreSQL, ClickHouse), а також сервіси, що генерують великі обсяги даних і вимагають високої продуктивності для аналітики. Для зберігання був обраний Longhorn.
- Хмарний кластер (AWS EKS): В AWS залишився кластер EKS, де розміщувалися фронтенд-додатки, API-шлюзи, мікросервіси, які мали сильно коливальну навантаження і вимагали швидкої масштабованості.
- Мережева зв'язність: Був налаштований AWS Direct Connect між co-location центром і AWS, щоб забезпечити швидке і економічне з'єднання між хмарними мікросервісами і on-premise базами даних.
- Управління з Rancher: Rancher був розгорнутий як центральний керуючий вузол в окремому, невеликому кластері в AWS. Він використовувався для уніфікованого управління обома кластерами, розгортання додатків через GitOps (ArgoCD) і централізованого моніторингу.
Результати:
- Значна економія: Перенесення баз даних і високонавантажених бекендів на bare metal знизило щомісячні OpEx на 35-40%, особливо за рахунок скорочення витрат на хмарні бази даних і egress-трафік.
- Покращена продуктивність: Аналітичні звіти стали генеруватися швидше завдяки прямому доступу до потужного bare metal обладнання.
- Збереження гнучкості: Фронтенди і API-шлюзи продовжували масштабуватися в хмарі, забезпечуючи високу доступність і чуйність для користувачів.
- Зниження Vendor Lock-in: Компанія отримала можливість використовувати різні хмарні провайдери в майбутньому і не залежати повністю від AWS.
Ці кейси демонструють, що гібридна інфраструктура з Kubernetes і Rancher є потужним інструментом для вирішення широкого кола бізнес-задач, від оптимізації продуктивності і дотримання регуляторних вимог до значної економії витрат і підвищення гнучкості.
Потрібен виділений сервер?
Compare prices from top providers. Configure and order in minutes.
Інструменти та ресурси
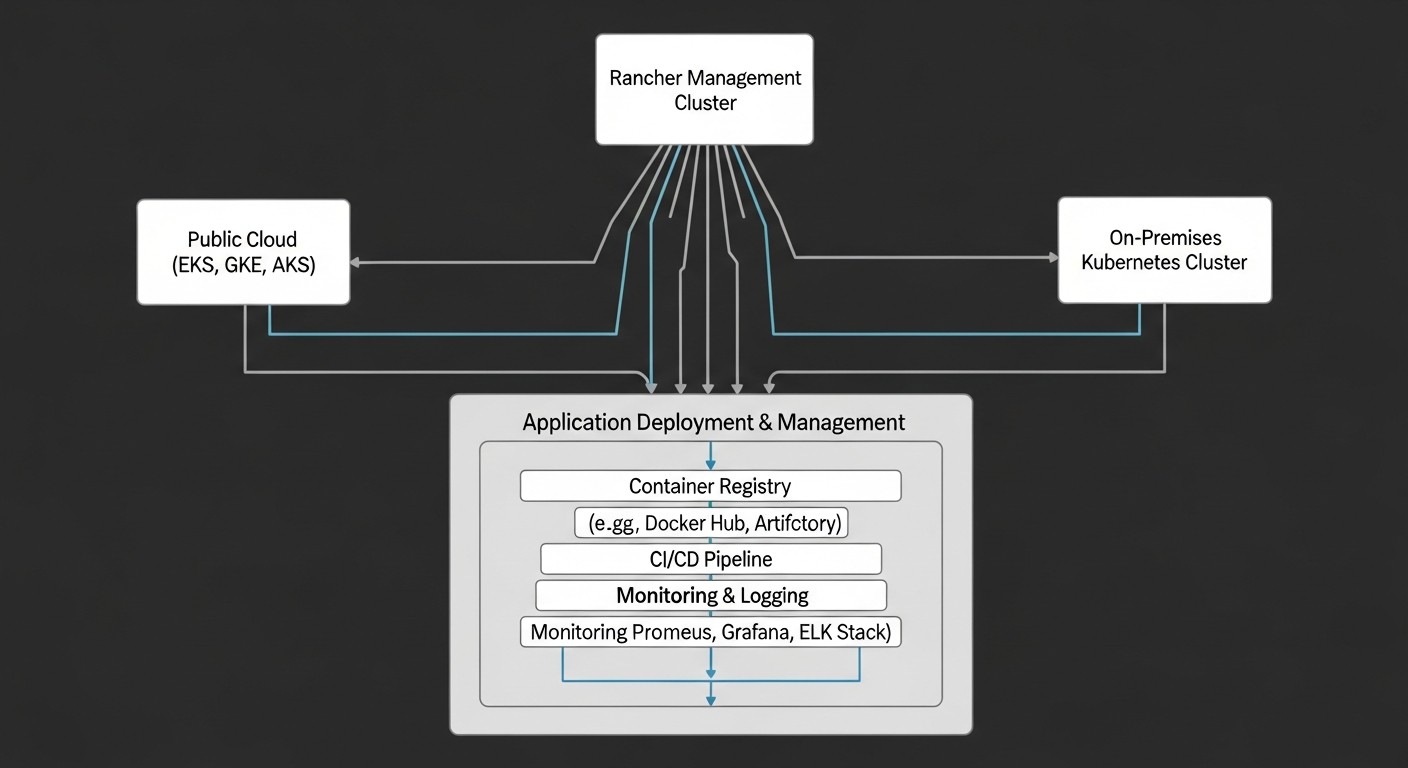
Для успішної побудови та управління гібридною інфраструктурою Kubernetes з Rancher потрібен набір перевірених інструментів і доступ до актуальних ресурсів. Ось список ключових категорій і конкретних прикладів, актуальних для 2026 року.
1. Основні платформи
- Rancher: Official Website
Центральна платформа для управління кількома Kubernetes-кластерами, розгорнутими будь-де: на bare metal, у віртуальних машинах, у приватних і публічних хмарах. Надає уніфікований UI, API і CLI для управління життєвим циклом кластерів, розгортання застосунків і забезпечення безпеки.
- Kubernetes (K8s): Official Website
Відкрита платформа для автоматизації розгортання, масштабування та управління контейнеризованими застосунками. Основа всієї гібридної стратегії.
- RKE (Rancher Kubernetes Engine): Official Documentation
Сертифікований дистрибутив Kubernetes від Rancher, ідеально підходить для розгортання на bare metal і у віртуальних машинах, а також для edge-сценаріїв.
- K3s: Official Website
Легкий, сертифікований Kubernetes, оптимізований для edge, IoT і bare metal середовищ з обмеженими ресурсами. Управляється Rancher.
- Хмарні K8s-сервіси:
- Amazon EKS: Official Website
- Azure AKS: Official Website
- Google GKE: Official Website
Керовані сервіси Kubernetes від провідних хмарних провайдерів.
2. Мережеві інструменти (CNI, Load Balancer, Connectivity)
- Calico: Official Website
Популярний CNI-плагін для Kubernetes, що забезпечує мережеву зв'язність, політики безпеки та підтримку BGP, що робить його чудовим вибором для гібридних і bare metal середовищ.
- Cilium: Official Website
Ще один просунутий CNI на базі eBPF, що пропонує високу продуктивність, просунуті мережеві політики та observability.
- MetalLB: Official Website
Реалізація балансувальника навантаження для bare metal Kubernetes кластерів, що використовує стандартні протоколи маршрутизації (ARP, BGP).
- Ingress Controllers (NGINX, Traefik, Istio Ingress Gateway):
- NGINX Ingress Controller: Official GitHub
- Traefik: Official Website
- Istio: Official Website (як частина сервіс-меші)
Для маршрутизації зовнішнього HTTP/S трафіку до сервісів всередині кластера.
- Інструменти для міжмережевого з'єднання:
- OpenVPN / WireGuard: Для створення безпечних тунелів між on-premise і хмарою.
- AWS Direct Connect / Azure ExpressRoute / Google Cloud Interconnect: Виділені мережеві з'єднання для високої продуктивності та безпеки.
3. Системи зберігання даних (CSI)
- Rook (Ceph): Official Website
Оператор Kubernetes, який розгортає та управляє розподіленим сховищем Ceph, перетворюючи кластер Kubernetes на самомасштабовану, самовідновлювальну систему зберігання (блочне, файлове, об'єктне).
- Longhorn: Official Website
Розподілене блочне сховище для Kubernetes від Rancher, просте в розгортанні та управлінні, ідеально підходить для bare metal і edge.
- Cloud CSI Drivers:
Драйвери для інтеграції Kubernetes з нативними хмарними сховищами.
4. CI/CD та GitOps
- ArgoCD: Official Website
Декларативний, GitOps-орієнтований інструмент безперервної доставки для Kubernetes. Відмінно підходить для управління розгортаннями в мульти-кластерних середовищах.
- Flux: Official Website
Інший популярний GitOps-оператор, який забезпечує безперервну доставку та синхронізацію стану кластера з Git-репозиторієм.
- Rancher Fleet: Official Website
Інструмент для централізованого управління флотом з тисяч Kubernetes-кластерів, розгортання застосунків і управління конфігураціями в масштабі.
- Jenkins / GitLab CI / GitHub Actions:
Традиційні CI-інструменти для збірки образів, виконання тестів і запуску GitOps-пайплайнів.
5. Моніторинг, логування та алертинг
- Prometheus: Official Website
Система моніторингу та алертингу з відкритим вихідним кодом, де-факто стандарт для моніторингу Kubernetes.
- Grafana: Official Website
Платформа для візуалізації метрик, агрегованих Prometheus, а також логів з Loki.
- Loki: Official Website
Система агрегації логів, оптимізована для Kubernetes, працює за принципом "метрики для логів".
- ELK Stack (Elasticsearch, Logstash, Kibana): Official Website
Потужний стек для збору, аналізу та візуалізації логів в масштабі.
- Fluentd / Fluent Bit: Official Website / Official Website
Легкі агенти для збору логів з контейнерів і відправки їх в централізоване сховище.
6. Безпека та управління секретами
- Vault (HashiCorp): Official Website
Інструмент для безпечного зберігання та управління секретами, API-ключами, токенами та іншими конфіденційними даними.
- OPA Gatekeeper: Official GitHub
Оператор Kubernetes, який застосовує політики Open Policy Agent (OPA) для забезпечення відповідності кластера заданим правилам (наприклад, заборона на запуск привілейованих контейнерів).
- Falco: Official Website
Інструмент для виявлення загроз безпеці в реальному часі для Kubernetes та контейнерів.
7. Аварійне відновлення (DR)
- Velero: Official Website
Інструмент з відкритим вихідним кодом для безпечного резервного копіювання та відновлення ресурсів Kubernetes та постійних томів.
8. Корисні посилання та документація
- Офіційна документація Kubernetes: kubernetes.io/docs/
- Офіційна документація Rancher: rancher.com/docs/
- CNCF Landscape: landscape.cncf.io
Інтерактивна карта проектів Cloud Native Computing Foundation, корисна для пошуку інструментів.
- Блоги та спільноти:
- Kubernetes Blog
- Rancher Blog
- Stack Overflow (теги kubernetes, rancher)
- Reddit (r/kubernetes, r/devops)
Використання цього набору інструментів та постійне звернення до актуальних ресурсів дозволить вашій команді ефективно будувати, підтримувати та розвивати гібридну Kubernetes-інфраструктуру з Rancher.
Troubleshooting (вирішення проблем)
Навіть у найретельніше спроектованій гібридній інфраструктурі виникають проблеми. Важливо мати чіткий алгоритм діагностики та усунення несправностей. Rancher, завдяки своїй централізованій панелі, часто допомагає швидко локалізувати джерело проблеми, але глибоке розуміння Kubernetes та базової інфраструктури залишається ключовим.
1. Загальні проблеми кластера Kubernetes
Проблема: Вузол (Node) не готовий (NotReady)
Діагностика:
kubectl get nodes
kubectl describe node <node-name>
journalctl -u kubelet -f # На проблемному вузлі
- Перевірте мережеве підключення вузла.
- Переконайтеся, що kubelet запущений і не видає помилок.
- Перевірте використання ресурсів (CPU, RAM, дисковий простір) на вузлі. Можливо, вузол перевантажений.
- Перевірте CNI-плагін: чи коректно він працює на вузлі?
Проблема: Під (Pod) знаходиться в стані Pending, CrashLoopBackOff, ImagePullBackOff
Діагностика:
kubectl get pods -o wide # Щоб побачити на якому вузлі під
kubectl describe pod <pod-name> -n <namespace>
kubectl logs <pod-name> -n <namespace> # Для CrashLoopBackOff
- Pending: Перевірте ресурси вузлів (CPU/RAM). Переконайтеся, що є доступні вузли з достатніми ресурсами. Перевірте
Eventsвkubectl describe podна наявність проблем з VolumeMounts або Network. - CrashLoopBackOff: Проблема в додатку. Перевірте логи поду. Можливо, некоректна конфігурація, помилка в коді або нестача ресурсів.
- ImagePullBackOff: Проблема з доступом до реєстру образів. Перевірте ім'я образу, доступність реєстру та облікові дані (ImagePullSecrets).
2. Мережеві проблеми
Проблема: Сервіс недоступний ззовні або між подами
Діагностика:
kubectl get svc <service-name> -n <namespace>
kubectl get ep <service-name> -n <namespace> # Перевірити наявність Endpoint'ів
kubectl get networkpolicy -n <namespace> # Якщо використовується CNI з NetworkPolicy
ip route show # На вузлі, де запущений под
- Перевірте, що у сервіса є Endpoint'и (поди, які він обслуговує, повинні бути запущені та здорові).
- Переконайтеся, що Network Policies не блокують трафік.
- Перевірте налаштування Load Balancer (MetalLB on-prem, хмарний LB) або Ingress Controller.
- Для міжподової взаємодії: перевірте CNI-плагін та його логи.
- Для міжкластерної взаємодії в гібриді: перевірте VPN/Direct Connect, маршрутизацію, фаєрволи.
Проблема: Проблеми з DNS-розрішенням між on-premise та хмарними кластерами
Діагностика:
kubectl exec -it <pod-name> -n <namespace> -- nslookup <hostname>
- Перевірте конфігурацію CoreDNS в Kubernetes (ConfigMap).
- Переконайтеся, що умовні пересилання (conditional forwarders) налаштовані коректно на CoreDNS та на ваших on-premise DNS-серверах.
- Перевірте доступність DNS-серверів через VPN/Direct Connect.
3. Проблеми зі сховищем
Проблема: PersistentVolumeClaim (PVC) завис в стані Pending
Діагностика:
kubectl get pvc <pvc-name> -n <namespace>
kubectl describe pvc <pvc-name> -n <namespace>
kubectl get storageclass
- Перевірте, чи існує StorageClass, вказаний в PVC.
- Переконайтеся, що CSI-драйвер для цього StorageClass розгорнутий та працює в кластері.
- Перевірте логи CSI-контролера (наприклад,
kubectl logs -f <csi-driver-pod> -n <csi-namespace>). - Для Rook/Ceph або Longhorn: перевірте статус оператора та його подів.
- Для хмарних PV: перевірте квоти та доступність хмарного сховища.
4. Проблеми з Rancher
Проблема: Кластер не імпортується або знаходиться в стані "Unavailable"
Діагностика:
- Перевірте логи Rancher Server (
kubectl logs -f <rancher-pod> -n cattle-system). - На проблемному кластері: перевірте логи Rancher Agent (
kubectl logs -f <cattle-cluster-agent-pod> -n cattle-system). - Переконайтеся в мережевій зв'язності між Rancher Server та проблемним кластером (порт 443).
- Перевірте, що Rancher Agent має достатні права (RBAC) в кластері.
- Усуньте мережеві проблеми.
- Перезапустіть Rancher Agent на проблемному кластері.
- В крайньому випадку, видаліть Rancher Agent з кластера і спробуйте імпортувати його заново.
5. Проблеми гібридного середовища
Проблема: Затримки або втрата пакетів між on-premise та хмарними кластерами
Діагностика:
ping <ip-address-in-other-cluster>
traceroute <ip-address-in-other-cluster>
# На мережевому обладнанні: перевірка статистики Direct Connect/ExpressRoute, логів VPN-тунелю.
- Перевірте стан Direct Connect/ExpressRoute або VPN-тунелю.
- Переконайтеся, що фаєрволи та групи безпеки (у хмарі) не блокують трафік.
- Перевірте таблиці маршрутизації на всіх проміжних пристроях.
- Оцініть пропускну здатність з'єднання. Можливо, її недостатньо для поточного навантаження.
Коли звертатися до підтримки
- Нездоланні критичні збої: Якщо кластер повністю непрацездатний, і ви вичерпали всі свої діагностичні можливості.
- Проблеми з базовим обладнанням: Збої сервера, мережевого обладнання, СЗД на bare metal.
- Проблеми з керованими хмарними сервісами: Якщо EKS/AKS/GKE Control Plane поводиться некоректно, або є збої в хмарній мережі/сховищі.
- Проблеми з Rancher Enterprise Prime: Якщо у вас є комерційна підтримка Rancher, звертайтеся при проблемах з самою платформою Rancher.
- Відсутність експертизи: Якщо проблема виходить за рамки компетенції вашої команди.
Систематичний підхід до усунення несправностей, хороша документація та розвинені навички команди DevOps є основою для підтримки стабільності будь-якої, а тим більше гібридної, інфраструктури.
FAQ
Навіщо мені гібридна інфраструктура, якщо я можу використовувати тільки хмару?
Чиста хмара відмінно підходить для швидкого старту та високої еластичності, але зі зростанням масштабу вона може стати дуже дорогою, особливо для стабільних, ресурсоємних навантажень і вихідного трафіку. Гібрид дозволяє оптимізувати витрати, розміщуючи передбачувані та критичні до продуктивності сервіси на своїх серверах (bare metal), а еластичні та тимчасові — в хмарі. Це також дає більше контролю над даними та полегшує дотримання регуляторних вимог.
Чи можна обійтися без Rancher при управлінні гібридним Kubernetes?
Теоретично так, але на практиці це вкрай складно. Без Rancher вам доведеться управляти кожним кластером Kubernetes окремо, використовуючи нативні інструменти провайдера або kubectl. Це призведе до значного операційного навантаження, розсинхронізації конфігурацій, ускладнення моніторингу та безпеки. Rancher уніфікує управління, надаючи єдину панель для всіх кластерів, незалежно від їх розташування, що значно знижує складність і OpEx.
Які CNI-плагіни найкраще підходять для гібридних Kubernetes-кластерів?
Для гібридних середовищ відмінно підходять CNI-плагіни, що підтримують мережеві політики та забезпечують високу продуктивність. Calico і Cilium є лідерами в цій області. Вони можуть працювати в різних режимах, підтримують BGP для інтеграції з bare metal мережами і дозволяють створювати складні мережеві політики для ізоляції трафіку між подами, що критично для безпеки в розподіленому середовищі.
Як забезпечити безпеку чутливих даних в гібридній інфраструктурі?
Ключ до безпеки — це сегментація та контроль. Розміщуйте найчутливіші дані та додатки на bare metal серверах, де у вас є повний контроль над фізичною та логічною безпекою. Використовуйте суворі мережеві політики, шифрування даних у стані спокою і при передачі, централізоване управління ідентифікацією (IAM) через Rancher. Регулярно проводьте аудит і використовуйте інструменти на кшталт OPA Gatekeeper для enforcement'а політик безпеки в Kubernetes.
В чому різниця між Bare Metal і віртуальними машинами на своєму залізі?
Bare metal — це використання фізичних серверів безпосередньо, без шару віртуалізації. Це забезпечує максимальну продуктивність, оскільки немає накладних витрат гіпервізора. Віртуальні машини (VM) на своєму залізі мають на увазі наявність гіпервізора (наприклад, VMware vSphere, KVM), який створює віртуальні машини. VM дають більшу гнучкість в управлінні ресурсами, але додають невеликі накладні витрати. Для Kubernetes bare metal часто вибирають для найбільш вимогливих до продуктивності навантажень.
Як управляти оновленнями Kubernetes в гібридному середовищі?
Rancher значно спрощує управління оновленнями. Ви можете використовувати Rancher для оркестрації оновлень RKE або K3s кластерів на bare metal, а також для керованих хмарних кластерів (EKS/AKS/GKE). Рекомендується мати чіткий процес: спочатку оновити dev/test кластери, провести регресійне тестування, потім staging і тільки потім production. Rancher надає зручний UI для цього, мінімізуючи ручні операції.
Які ризики існують при переході на гібридну інфраструктуру?
Основні ризики включають: високу початкову складність проектування і впровадження, значні інвестиції в кваліфікований персонал, потенційні проблеми з мережевою інтеграцією та управлінням даними, а також приховані витрати на міжхмарний трафік. Однак ці ризики можна мінімізувати ретельним плануванням, поетапним впровадженням, використанням надійних інструментів на кшталт Rancher і навчанням команди.
Чи можна використовувати різні версії Kubernetes в різних кластерах гібридного середовища?
Так, це одна з сильних сторін гібридного підходу з Rancher. Rancher дозволяє управляти кластерами з різними версіями Kubernetes. Це корисно для тестування нових версій, поступового оновлення або підтримки сумісності з застарілими додатками. Однак для критично важливих додатків рекомендується прагнути до одноманітності версій для спрощення управління і зниження ризиків сумісності.
Як масштабувати кластери на bare metal?
Масштабування bare metal кластерів вимагає додавання фізичних серверів. Це не відбувається миттєво, як в хмарі. Процес включає закупівлю, установку, налаштування ОС і додавання вузлів в кластер Kubernetes. Rancher спрощує останній крок, дозволяючи легко додавати нові вузли в існуючий RKE/K3s кластер. Для ефективного масштабування на bare metal потрібне ретельне планування потужностей і автоматизація процесу розгортання нових серверів (наприклад, за допомогою PXE-завантаження і Ansible).
Наскільки складна міграція існуючих додатків на гібридний Kubernetes?
Складність міграції залежить від архітектури програми. Монолітні програми можуть вимагати значних зусиль для контейнеризації та декомпозиції на мікросервіси. Хмарно-нативні додатки мігрувати простіше. Rancher і Kubernetes надають платформу, але сама міграція вимагає аналізу залежностей, переписування конфігурацій і ретельного тестування. Рекомендується починати з "lift-and-shift" для простих додатків, а потім поступово модернізувати їх.
Потрібен виділений сервер?
Compare prices from top providers. Configure and order in minutes.
Висновок
У 2026 році управління гібридною інфраструктурою, особливо з використанням Kubernetes на bare metal і в хмарі у зв'язці з Rancher, є не просто технічним вибором, а стратегічною необхідністю для багатьох організацій. Ми детально розглянули ключові фактори, такі як вартість, продуктивність, безпека, масштабованість та управлінські витрати, показавши, як гібридний підхід дозволяє досягти оптимального балансу між ними.
Bare metal надає неперевершену продуктивність і повний контроль для критично важливих і ресурсоємних робочих навантажень, а хмара пропонує безпрецедентну еластичність і швидкість розгортання для динамічних і масштабованих сервісів. Rancher виступає в ролі сполучної ланки, уніфікуючи управління, моніторинг і забезпечення безпеки цих різнорідних середовищ. Це дозволяє DevOps-інженерам, розробникам і технічним директорам зосередитися на створенні цінності для бізнесу, а не на боротьбі зі складністю інфраструктури.
Ми підкреслили важливість детального планування мережевої архітектури, стратегії зберігання даних, централізованого IAM, надійного CI/CD і комплексного підходу до аварійного відновлення. Уникнення типових помилок, таких як недооцінка складності мережі або відсутність адекватного DR-плану, є запорукою успіху. Приклади розрахунків TCO показали, що, хоча гібридна інфраструктура може мати вищі початкові CapEx, вона часто забезпечує кращу довгострокову економію і стратегічну гнучкість в порівнянні з чистими хмарними рішеннями, особливо при наявності стабільних, високонавантажених компонентів.
Реальні кейси з фінтеху, медицини і SaaS-сектору продемонстрували, як компанії використовують гібрид з Rancher для вирішення конкретних бізнес-задач: від забезпечення низької затримки для HFT і дотримання суворих регуляторних вимог до значної оптимізації хмарних витрат.
Підсумкові рекомендації:
- Плануйте ретельно: Почніть з глибокого аналізу ваших бізнес-потреб, вимог до продуктивності, безпеки і бюджету.
- Почніть з малого: Не намагайтеся перенести всю інфраструктуру відразу. Виберіть пілотний проект або некритичний додаток для початку, щоб набратися досвіду.
- Інвестуйте в команду: Гібридна інфраструктура вимагає висококваліфікованих фахівців. Забезпечте навчання і розвиток компетенцій вашої команди.
- Автоматизуйте все: Використовуйте GitOps і CI/CD для максимальної автоматизації розгортання, управління і моніторингу.
- Не забувайте про безпеку і DR: Це не опції, а обов'язкові компоненти вашої стратегії. Регулярно тестуйте свої плани.
- Використовуйте Rancher: Це критично важливий інструмент для уніфікації управління і зниження операційного навантаження в гібридному середовищі.
Наступні кроки для читача:
- Проведіть внутрішній аудит вашої поточної інфраструктури і бізнес-вимог.
- Вивчіть документацію Rancher і Kubernetes, поекспериментуйте з розгортанням невеликого кластера RKE або K3s.
- Побудуйте пілотний гібридний сценарій, наприклад, розгорнувши кілька мікросервісів в хмарі і базу даних на bare metal, управляючи ними через Rancher.
- Почніть планувати детальну мережеву архітектуру і стратегію зберігання даних для вашої майбутньої гібридної інфраструктури.
Гібридна інфраструктура з Kubernetes і Rancher — це потужний фундамент для побудови гнучкого, стійкого і економічно ефективного IT-середовища, здатного адаптуватися до швидко мінливих вимог сучасного цифрового світу.