Як обрати VPS провайдера у 2026 році: практичний посібник для технічних фахівців
Повний посібник з вибору VPS хостингу у 2026 році: типи віртуалізації (KVM, OpenVZ, LXC), характеристики CPU та RAM, NVMe storage, мережева інфраструктура, безпека, ціноутворення та практичні сценарії використання. Для DevOps-інженерів, backend-розробників та системних адміністраторів.
Вибір VPS-провайдера — задача, яку багато хто недооцінює. На перший погляд все просто: порівнюєш ціни, дивишся на характеристики, вибираєш щось середнє за вартістю та параметрами. На практиці через три місяці виявляєш, що сервер стабільно деградує під навантаженням, підтримка відповідає добами, а IP-адреса потрапила до блеклистів ще до того, як ти почав працювати.
За останні десять років я працював з декількома десятками хостинг-провайдерів — від бюджетних OpenVZ-хостингів за три долари до enterprise-рішень з цінником в тисячі доларів на місяць. Запускав на них все: від pet-проектів до production-систем з мільйонами запитів на добу. І головний висновок, який зробив — між маркетинговими обіцянками та реальністю часто лежить прірва.
Ринок VPS у 2026 році перенасичений пропозиціями. Сотні провайдерів, тисячі тарифів, нескінченні «спеціальні пропозиції» та знижки. Відрізнити якісний сервіс від маркетингової обгортки над перевантаженим залізом — задача нетривіальна. А ціна помилки — втрачений час, незадоволені користувачі, втрачені дані та непередбачені витрати на міграцію.
Типові помилки при виборі VPS:
- Орієнтація лише на ціну без розуміння, що саме ти купуєш
- Ігнорування типу віртуалізації та його обмежень
- Недооцінка важливості географії та мережевої зв'язності
- Відсутність перевірки репутації IP-адрес
- Нерозуміння різниці між «гарантованими» та «виділеними» ресурсами
- Вибір провайдера без тестування під реальним навантаженням
Ця стаття адресована тим, хто хоче розібратися в питанні глибше, ніж «подивитися рейтинг на Trustpilot». Якщо ти DevOps-інженер, backend-розробник, фаундер SaaS-проекту або системний адміністратор — тут знайдеш практичні критерії вибору, основані на реальному досвіді експлуатації.
В статті розберемо всі ключові аспекти вибору VPS-провайдера: від типів віртуалізації та характеристик заліза до репутації IP-адрес та роботи з техпідтримкою. Окремо поговоримо про те, як тестувати сервер перед production-використанням, що робити при типових проблемах та як не переплачувати за ресурси, які не потрібні.
TL;DR — ключові висновки
- KVM-віртуалізація — єдиний розумний вибір для production. OpenVZ/LXC підходять тільки для dev-оточень з жорсткими бюджетними обмеженнями
- «Необмежені» ресурси не існують — завжди є fair use policy, і вона спрацює в самий невідповідний момент
- Перевіряй IP-адреси до покупки — запроси тестовий IP та перевір його репутацію через MXToolbox та AbuseIPDB
- Географічна близькість важливіша, ніж здається — 100ms latency вбиває UX швидше, ніж повільний код
- SLA 99.9% — маркетингова цифра — важливо, як провайдер реагує на інциденти та компенсує downtime
- Тестуй IO під навантаженням — синтетичні бенчмарки не показують поведінку при конкуренції за ресурси
- Читай AUP до покупки — багато use-cases заборонені навіть у «лояльних» провайдерів
- Бекапи зберігай окремо — бекап у того ж провайдера — не бекап
- Починай з малого — краще upgrade по мірі росту, ніж переплачувати за прості ресурси
Базова термінологія
 Схема: Базова термінологія
Схема: Базова термінологія
Перш ніж заглиблюватися в деталі, переконаємося, що говоримо однією мовою. Хостинг-індустрія перевантажена термінами, і провайдери часто використовують їх по-різному.
VPS (Virtual Private Server) — віртуальний сервер, виділена частина фізичного сервера з гарантованими ресурсами. У тебе root-доступ, власний IP, повний контроль над ОС.
VDS (Virtual Dedicated Server) — по суті те ж саме, що VPS. Термін частіше використовується в Європі та Росії. Деякі провайдери позиціонують VDS як більш «преміальний» варіант з KVM-віртуалізацією, але це маркетинг.
Cloud instance / Cloud VM — VPS в хмарній інфраструктурі з API-управлінням, автоскейлінгом та pay-per-minute білінгом. Технічно теж віртуальна машина, але з іншою моделлю використання.
Dedicated server — фізичний сервер цілком в твоєму розпорядженні. Ніяких сусідів, 100% ресурсів заліза.
Colocation — ти приносиш своє залізо в датацентр, вони забезпечують живлення, охолодження та мережу. Максимальний контроль, максимальна відповідальність.
Bare metal — dedicated server без встановленої ОС та гіпервізора. Термін підкреслює, що це саме фізичне залізо, не віртуалізація.
Managed vs Unmanaged — managed означає, що провайдер бере на себе адміністрування (оновлення, моніторинг, іноді налаштування софту). Unmanaged — тільки інфраструктура, все інше твоя відповідальність.
Hypervisor / гіпервізор — софт, який створює та управляє віртуальними машинами. KVM, VMware ESXi, Xen, Hyper-V — приклади гіпервізорів.
IOPS (Input/Output Operations Per Second) — кількість операцій читання/запису на диску в секунду. Критична метрика для баз даних та storage-intensive додатків.
Latency — затримка. Час, за який пакет даних проходить від точки A до точки B. Вимірюється в мілісекундах (ms).
Bandwidth — пропускна здатність каналу. Скільки даних можна передати в одиницю часу (Gbps, TB/місяць).
Overselling / оверселінг — коли провайдер продає більше ресурсів, ніж фізично існує, розраховуючи, що не всі клієнти використовують їх одночасно.
Uptime — відсоток часу, коли сервіс був доступний. 99.9% означає до 8.76 годин downtime в рік.
SLA (Service Level Agreement) — угода про рівень сервісу. Формальне зобов'язання провайдера по uptime та компенсаціям.
AUP (Acceptable Use Policy) — політика допустимого використання. Документ, що визначає, що можна і не можна робити на сервері провайдера.
DDoS (Distributed Denial of Service) — розподілена атака на відмову в обслуговуванні. Спроба зробити сервіс недоступним шляхом перевантаження запитами.
CDN (Content Delivery Network) — мережа доставки контенту. Розподілена мережа серверів для прискорення доставки статичного контенту користувачам.
SSL/TLS — протоколи шифрування для захищеного з'єднання. HTTPS = HTTP + SSL/TLS.
Розуміння цих термінів допоможе спілкуватися з провайдерами однією мовою, читати технічні специфікації та не попадатися на маркетингові хитрощі, якими рясніє хостинг-індустрія.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
Зміст
- Базова термінологія
- Кому підходить VPS, а кому ні
- Архітектура: VPS vs Dedicated vs Cloud
- Віртуалізація: KVM, OpenVZ, LXC, VMware
- CPU: vCPU, overselling, NUMA
- RAM: балансування, swap, OOM
- Storage: NVMe, SATA, RAID, Ceph, ZFS
- Мережа: bandwidth, DDoS-захист, peering
- IP-адреси, ASN та репутація
- Географія та latency
- SLA: що написано vs що працює
- Порівняльні таблиці
- Практичні сценарії використання
- Команди для тестування сервера
- Діагностика типових проблем
- Безпека, abuse та compliance
- Що змінилось у 2024–2026
- Висновки
- FAQ
Кому підходить VPS, а кому ні
 Схема: Кому підходить VPS, а кому ні
Схема: Кому підходить VPS, а кому ні
VPS — не універсальне рішення. Перш ніж порівнювати провайдерів, переконайся, що VPS взагалі підходить для твоєї задачі. Помилка на цьому етапі коштує найдорожче: ти витратиш час на налаштування, потім виявиш, що архітектура не масштабується або вимоги не покриваються, і доведеться переробляти.
Розберемо типові сценарії та чесно оцінимо, де VPS працює добре, а де створює більше проблем, ніж вирішує.
VPS підходить, якщо:
- Потрібен повний контроль над оточенням (root-доступ, довільний софт, кастомні налаштування ядра)
- Бюджет обмежений, але потрібне ізольоване середовище
- Навантаження передбачуване і не має різких піків у 10-100x
- Проект на стадії MVP/раннього production з трафіком до декількох мільйонів запитів на добу
- Потрібна статична IP-адреса для інтеграцій, email-розсилок, API
- Потрібно розгорнути специфічний стек, який не підтримується PaaS-платформами
VPS не підходить, якщо:
- Навантаження непередбачуване з піками — хмарні провайдери з автоскейлінгом будуть дешевші
- Критична відмовостійкість на рівні інфраструктури — потрібен managed Kubernetes або multi-region deployment
- Немає часу/компетенцій на адміністрування — managed-сервіси заощадять більше
- Потрібен compliance (PCI DSS, HIPAA, SOC2) — дешевше взяти сертифікований managed-хостинг
- Потрібне GPU-прискорення для ML/AI — спеціалізовані хмари (Lambda Labs, Vast.ai) вигідніші
Сіра зона:
- High-load API — VPS може працювати, але вимагає грамотного capacity planning і готовності до вертикального масштабування
- E-commerce — підходить для середнього трафіку, але на розпродажах краще мати запас або CDN
- Бази даних — VPS з NVMe підходить для PostgreSQL/MySQL до певного розміру, але managed DB часто простіше в обслуговуванні
Архітектура: VPS vs Dedicated vs Cloud
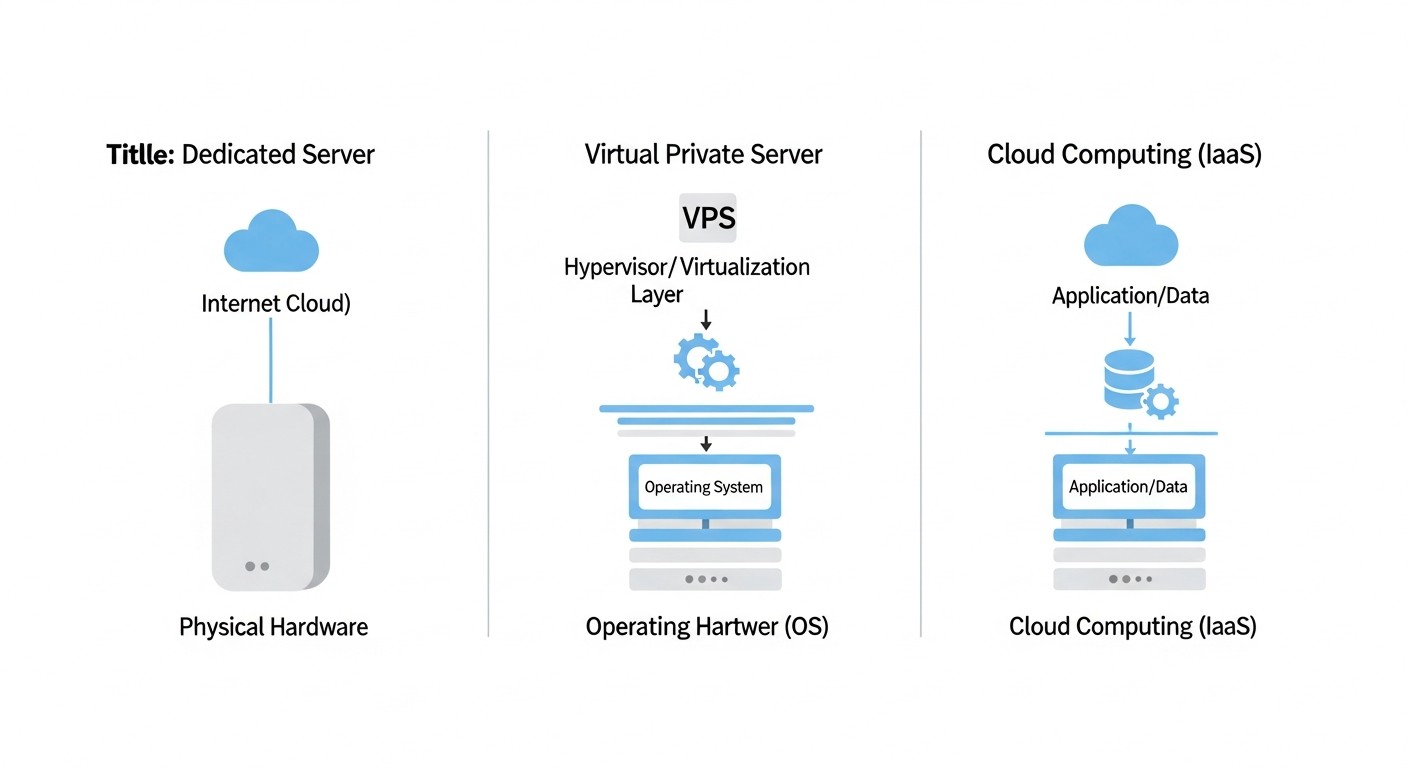 Схема: Архітектура: VPS vs Dedicated vs Cloud
Схема: Архітектура: VPS vs Dedicated vs Cloud
Розуміння архітектурних відмінностей — основа усвідомленого вибору. Маркетингові матеріали часто розмивають межі між цими категоріями, але технічні відмінності принципові.
VPS (Virtual Private Server)
Фізичний сервер ділиться на декілька віртуальних машин за допомогою гіпервізора. Кожна VM отримує виділену частку ресурсів, але вони розділяються на рівні заліза.
Що отримуєш:
- Ізольоване оточення з root-доступом
- Фіксовані ліміти на CPU/RAM/Disk
- Статичну IP-адресу
- Відносно низьку вартість за рахунок розділення ресурсів
Компроміси:
- «Шумні сусіди» — інші VM на тому ж хості можуть впливати на продуктивність
- IO-продуктивність залежить від загального навантаження на storage
- Ліміти мережевої смуги зазвичай shared
- Overselling — провайдери часто продають більше ресурсів, ніж є фізично
Dedicated Server
Фізичний сервер цілком у твоєму розпорядженні. Ніяких сусідів, ніякого гіпервізора (якщо сам не поставиш).
Що отримуєш:
- 100% ресурсів заліза
- Передбачувану продуктивність
- Можливість кастомної конфігурації (при замовленні)
- Доступ до IPMI/iLO/iDRAC для out-of-band management
Компроміси:
- Висока вартість (від $50-100/місяць за entry-level)
- Провізіонінг займає години або дні
- Апаратні збої — твоя проблема (якщо немає SLA на заміну)
- Немає миттєвого вертикального масштабування
Cloud (IaaS)
По суті теж віртуалізація, але з API-driven управлінням, автоскейлінгом та pay-as-you-go моделлю.
Що отримуєш:
- Миттєвий провізіонінг
- Еластичність — ресурси масштабуються за вимогою
- Багату екосистему managed-сервісів
- Глобальну інфраструктуру з multi-region deployment
Компроміси:
- Вартість вища за VPS в 2-5x при постійному навантаженні
- Vendor lock-in через пропрієтарні сервіси
- Складність ціноутворення — легко отримати несподіваний рахунок
- Менше контролю над залізом
«Premature optimization is the root of all evil. But premature infrastructure scaling is the root of all bankruptcy.»
— Адаптація висловлювання Дональда Кнута, актуальна для сучасних стартапів
Коли що вибирати
VPS — оптимальний для проектів з передбачуваним навантаженням та обмеженим бюджетом. Типові сценарії: веб-додатки, API-сервіси, CI/CD runners, dev/staging оточення.
Dedicated — коли потрібна гарантована продуктивність та передбачуваність. Бази даних з інтенсивним IO, game-сервери, рендер-ферми, highload-проекти зі стабільною нагрузкою.
Cloud — коли навантаження непередбачуване, потрібен швидкий глобальний rollout або критична інтеграція з managed-сервісами. Стартапи з невизначеним ростом, сезонні проекти, мікросервісні архітектури.
Розрахунок Total Cost of Ownership (TCO)
При порівнянні варіантів враховуй не тільки ціну сервера:
Прямі витрати:
- Вартість самого VPS/сервера
- Додаткові IP-адреси
- Бекапи (якщо платні)
- DDoS-захист
- Ліцензії (Windows, cPanel і т.д.)
- Перевищення трафіку
Приховані витрати:
- Час на адміністрування — скільки коштує твоя година?
- Час на troubleshooting при проблемах
- Втрачена вигода при даунтаймі
- Вартість міграції, якщо провайдер не підійшов
Приклад розрахунку:
VPS за $20/місяць vs managed-хостинг за $50/місяць. Здається, VPS дешевше на $360/рік. Але якщо витрачаєш 5 годин на місяць на адміністрування при ставці $50/година — це $250/місяць. Managed-хостинг виходить вигідніше.
Рахуй чесно. VPS дешевше у грошовому вираженні, але потребує компетенцій і часу.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
Віртуалізація: KVM, OpenVZ, LXC, VMware
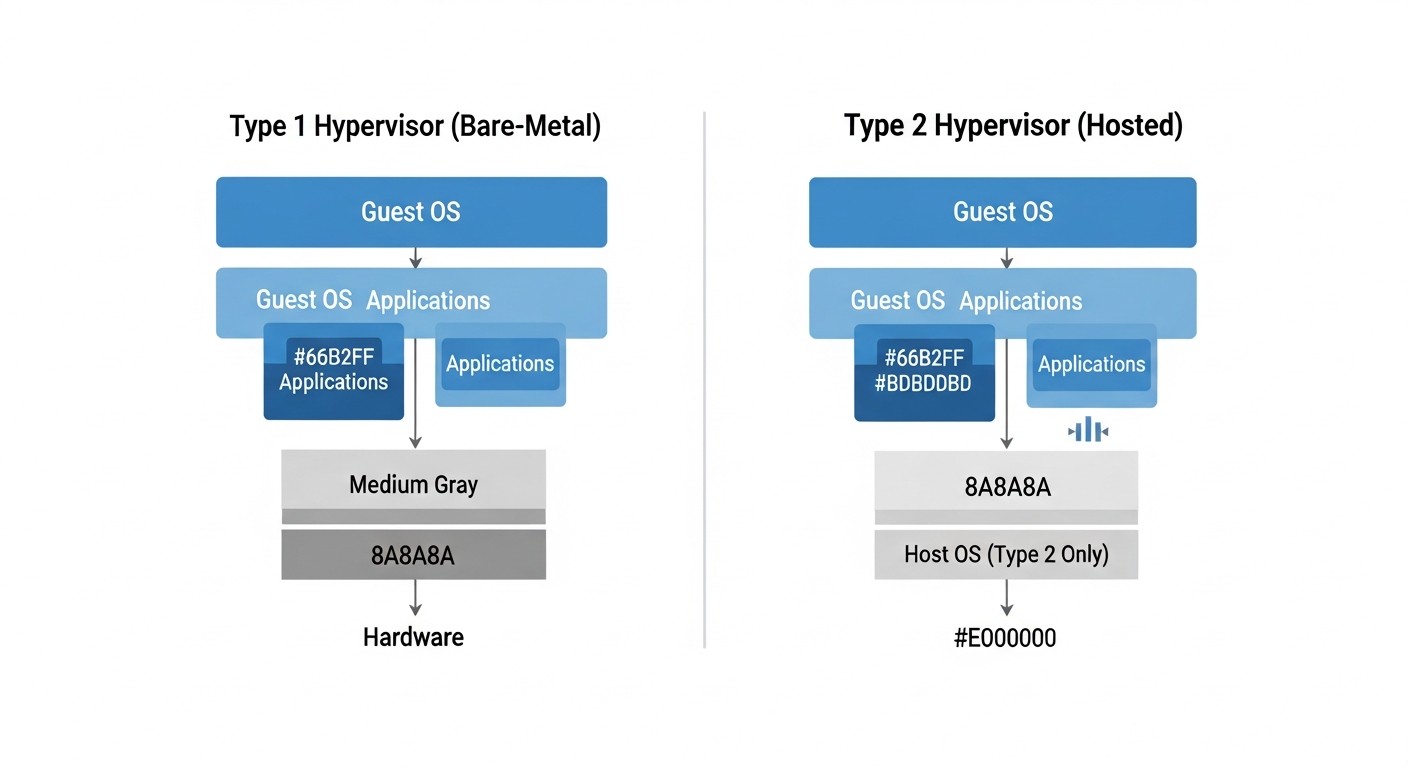 Схема: Віртуалізація: KVM, OpenVZ, LXC, VMware
Схема: Віртуалізація: KVM, OpenVZ, LXC, VMware
Тип віртуалізації — перше, що потрібно з'ясувати при виборі VPS. Від нього залежить все: продуктивність, ізоляція, сумісність софту, можливості налаштування.
KVM (Kernel-based Virtual Machine)
Повна апаратна віртуалізація на рівні ядра Linux. Кожна VM отримує власне віртуальне залізо: CPU, RAM, диск, мережеві адаптери.
Переваги:
- Повна ізоляція — VM нічого не знає про сусідів
- Можна запускати будь-яку ОС: Linux, Windows, FreeBSD, custom kernels
- Підтримка Docker, Kubernetes, вкладеної віртуалізації
- Чесні ліміти ресурсів — отримуєш те, за що платиш
- Можливість завантаження свого ISO-образу
Обмеження:
- Вищий overhead — частина ресурсів йде на гіпервізор
- Трохи повільніше, ніж контейнерна віртуалізація (на практиці різниця мінімальна)
- Потребує більше RAM для комфортної роботи (мінімум 512MB, рекомендується 1GB+)
OpenVZ
Контейнерна віртуалізація на рівні ОС. Всі контейнери розділяють одне ядро хоста.
Переваги:
- Мінімальний overhead — майже нативна продуктивність
- Низька вартість для провайдера = дешеві тарифи
- Швидкий провізіонінг
Критичні обмеження:
- Тільки Linux з ядром хоста — не можна використовувати кастомне ядро
- Docker працює з обмеженнями або не працює взагалі
- Не можна завантажити iptables-модулі, FUSE, деякі security-модулі
- «Шумні сусіди» впливають сильніше через спільне ядро
- Overselling поширений — провайдери продають 2-3x більше RAM, ніж є фізично
- OpenVZ 6 (legacy) має застаріле ядро без сучасних features
Реальність: OpenVZ у 2026 році — це legacy. OpenVZ 7 (Virtuozzo) частково вирішує проблеми, але все одно поступається KVM по ізоляції та гнучкості. Використовувати тільки для dev-оточень з мінімальним бюджетом.
Історія з практики: клієнт купив «VPS 4GB RAM» на OpenVZ за $3/місяць. Через два тижні почалися випадкові OOM-kills при використанні 2GB. Причина — провайдер oversold пам'ять, і при конкурентному навантаженні реально доступно було ~2.5GB. Після переїзду на KVM-хостинг за $8/місяць проблема зникла. Економія в $5 обійшлася в тиждень debugging і незадоволених користувачів.
LXC/LXD
Сучасна контейнерна віртуалізація, офіційно підтримувана в ядрі Linux.
Переваги:
- Продуктивність близька до нативної
- Краща ізоляція, ніж OpenVZ
- Підтримка unprivileged containers
- Активна розробка і сучасні features
Обмеження:
- Все ще спільне ядро з хостом
- Docker всередині працює, але з застереженнями
- Менше провайдерів пропонують LXC-based VPS
VMware ESXi
Enterprise-grade гіпервізор, використовується великими провайдерами і в корпоративних оточеннях.
Переваги:
- Зріла технологія з 20+ роками розвитку
- Відмінні інструменти управління (vCenter, vSphere)
- Просунуті features: vMotion, DRS, HA
- Повна ізоляція і сумісність з будь-якими ОС
Обмеження:
- Висока вартість ліцензій — провайдери перекладають на клієнтів
- Менш поширений в бюджетному сегменті
- Vendor lock-in на екосистему VMware
Proxmox VE
Популярна open-source платформа віртуалізації, підтримує і KVM, і LXC.
Переваги:
- Безкоштовна ліцензія — нижче собівартість для провайдера
- Гнучкість — можна вибирати між KVM і LXC
- Хороший веб-інтерфейс і API
- Підтримка Ceph, ZFS, кластеризації
Що важливо знати:
- Якість реалізації залежить від провайдера
- Proxmox сам по собі не гарантує хорошу продуктивність
Як дізнатися тип віртуалізації
Провайдери не завжди явно вказують тип віртуалізації. Ось як перевірити після покупки:
# Універсальний спосіб
sudo dmidecode -s system-product-name
# Для systemd-based систем
systemd-detect-virt
# Перевірка /proc
cat /proc/cpuinfo | grep -i hypervisor
cat /sys/class/dmi/id/product_name
# Для OpenVZ
cat /proc/vz/veinfo 2>/dev/null && echo "OpenVZ"
# Через virt-what (потрібно встановити)
sudo apt install virt-what && sudo virt-what
Типові результати:
kvm — KVM/QEMUvmware — VMware ESXixen — Xen HVM або PVopenvz — OpenVZlxc — LXC/LXDmicrosoft — Hyper-V
CPU: vCPU, overselling, NUMA
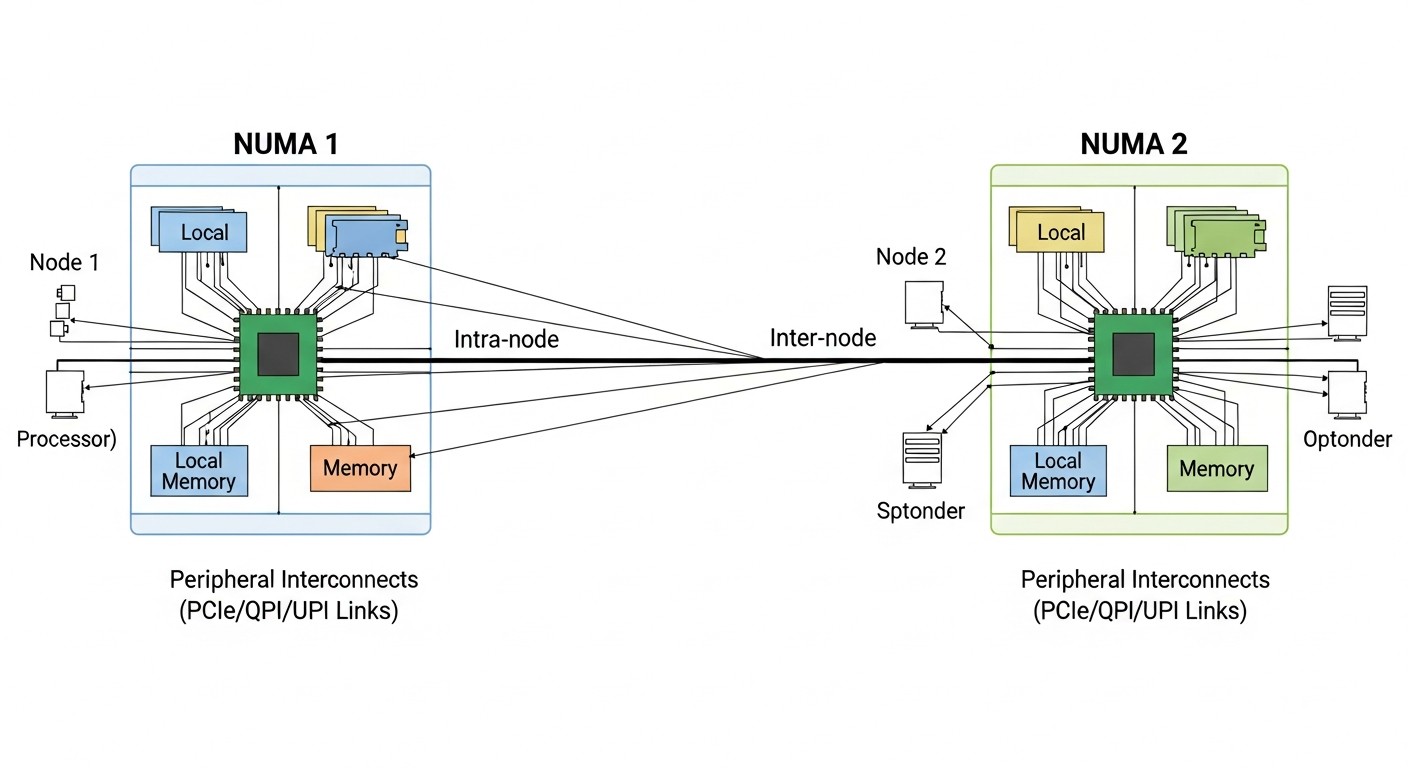 Схема: CPU: vCPU, overselling, NUMA
Схема: CPU: vCPU, overselling, NUMA
Характеристики CPU в VPS — одна з найбільш заплутаних тем. Маркетинг активно використовує терміни «vCPU», «ядра», «cores», але за ними ховаються різні реальності.
Що таке vCPU
vCPU (virtual CPU) — це віртуальний процесор, виділений віртуальній машині. Один vCPU зазвичай відповідає одному потоку (thread) фізичного процесора, але не завжди одному ядру.
Типові моделі:
- 1 vCPU = 1 thread — при включеному Hyper-Threading на Intel або SMT на AMD, 1 vCPU = 1/2 фізичного ядра
- 1 vCPU = 1 core — чесне виділення цілого ядра (рідко зустрічається в бюджетному сегменті)
- 1 vCPU = shared time — CPU time ділиться між VM динамічно
Overselling CPU
Overselling — коли провайдер продає більше vCPU, ніж є фізичних ядер/потоків. Це стандартна практика, але її ступінь варіюється.
Помірний overselling (2-4x):
- Працює, якщо клієнти не навантажують CPU одночасно
- Підходить для веб-хостингу, де навантаження burst-характера
- Деградація помітна при конкурентному навантаженні
Агресивний overselling (8x+):
- Характерний для ультрабюджетних провайдерів
- CPU steal time може досягати 30-50%
- Непередбачувана продуктивність
CPU Steal Time
Steal time — відсоток часу, коли vCPU був готовий виконувати завдання, але гіпервізор не надав йому фізичний CPU (тому що його використовували інші VM).
Як перевірити:
# Показує steal time в реальному часі
top
# Дивись стовпець %st в рядку Cpu(s)
# Або через vmstat
vmstat 1 10
# Стовпець st в секції cpu
# Детальна статистика
mpstat -P ALL 1
# Стовпець %steal для кожного vCPU
Інтерпретація:
- 0-2% — норма, не впливає на продуктивність
- 2-10% — помірний overselling, терпимо для більшості задач
- 10-20% — серйозна деградація, варто задуматися про зміну провайдера
- >20% — критично, провайдер зловживає overselling
NUMA і топологія CPU
NUMA (Non-Uniform Memory Access) — архітектура, де доступ до різних ділянок пам'яті має різну латентність. Важливо для серверів з кількома сокетами.
Чому це важливо для VPS:
- Якщо VM розміщена на vCPU з різних NUMA-нод, доступ до пам'яті повільніший
- Хороші провайдери піннять VM до однієї NUMA-ноди
- Погані — ні, і ти отримуєш деградацію на memory-intensive задачах
Як перевірити:
# Топологія NUMA
numactl --hardware
# або
lscpu | grep -i numa
# CPU topology
lscpu -e
Моделі процесорів
Важливо розуміти, на якому залізі працює твоя VM. Різниця між поколіннями процесорів суттєва.
# Дізнатися модель CPU
cat /proc/cpuinfo | grep "model name" | head -1
# Детальна інформація
lscpu
На що звертати увагу:
- Intel Xeon E5-2600 v1/v2 — legacy залізо (2012-2014), низька IPC, високе енергоспоживання
- Intel Xeon E5-2600 v3/v4 — прийнятно для більшості задач
- Intel Xeon Scalable (Gold, Platinum) — сучасне залізо з високою IPC
- AMD EPYC 7xx2/7xx3/9xx4 — відмінне співвідношення ціна/продуктивність
Практична порада: AMD EPYC в 2026 році часто пропонує кращу продуктивність за ті ж гроші. Не бійся вибирати AMD-based VPS.
CPU Performance: що впливає на швидкість
Не всі vCPU рівні. Продуктивність залежить від багатьох факторів:
IPC (Instructions Per Clock):
Сучасні процесори виконують більше операцій за такт. Один vCPU на AMD EPYC 9004 series значно швидший, ніж на Intel Xeon E5-2670 (2012 рік), навіть при однаковій частоті.
Turbo Boost / Precision Boost:
Процесори автоматично підвищують частоту при низькому навантаженні. На VPS це працює, якщо гіпервізор налаштовано правильно і сусіди не навантажують CPU. Різниця між base clock і boost може бути 30-50%.
Кеш:
L3 кеш критичний для багатьох workloads. При overselling декілька VM конкурують за кеш, що знижує продуктивність. Це не відображається в steal time, але впливає на latency.
Практичний тест CPU:
# Тест single-threaded (важливий для latency-sensitive додатків)
sysbench cpu --cpu-max-prime=20000 --threads=1 run
# Тест multi-threaded (throughput)
sysbench cpu --cpu-max-prime=20000 --threads=$(nproc) run
# Порівняй результати з референсними значеннями
# Modern EPYC/Xeon Gold single-thread: 2000-2500 events/sec
# Old Xeon E5: 800-1200 events/sec
Коли CPU critical:
- Компіляція коду
- Обробка відео/зображень
- SSL-термінація під навантаженням
- Стиснення/розпакування
- Деякі типи database workloads
Коли CPU менш важливий:
- Прості веб-сайти (bottleneck зазвичай IO або мережа)
- Proxy і load balancers
- Storage-intensive додатки
RAM: балансування, swap, OOM
 Схема: RAM: балансування, swap, OOM
Схема: RAM: балансування, swap, OOM
Пам'ять — ресурс, який або є, або немає. На відміну від CPU, де можна «позичити» час у сусідів, пам'ять фіксована. Чи ні?
Memory Ballooning
Деякі гіпервізори використовують memory ballooning — техніку динамічного перерозподілу пам'яті між VM.
Як працює:
- У VM встановлюється balloon driver
- Гіпервізор може «надути» balloon, забираючи пам'ять у VM
- Звільнена пам'ять віддається іншим VM
Проблеми:
- Якщо balloon активується під навантаженням, додаток втрачає пам'ять
- Може призвести до OOM без явних причин
- Складно діагностувати —
free показує менше пам'яті, ніж куплено
Як перевірити:
# Перевірити наявність balloon driver
lsmod | grep -i balloon
# Для KVM/QEMU
lsmod | grep virtio_balloon
# Якщо модуль завантажено, ballooning можливий
# Щоб вимкнути (якщо є root):
rmmod virtio_balloon
# Або через blacklist в /etc/modprobe.d/
Swap і overcommit
Swap — дисковий простір, який використовується як додаткова пам'ять. На SSD/NVMe працює терпимо, на HDD — вбиває продуктивність.
Політики swap:
- Деякі провайдери дають фіксований swap (1-2GB)
- Інші — забороняють swap повністю
- Треті — не обмежують, але swap на shared storage = проблеми
# Перевірити swap
free -h
swapon --show
# Поточне використання swap
cat /proc/swaps
# Swappiness (наскільки агресивно використовується swap)
cat /proc/sys/vm/swappiness
# Рекомендується 10-30 для VPS з достатньою RAM
OOM Killer
Коли пам'ять закінчується, Linux викликає OOM Killer — механізм, який вбиває процеси для звільнення пам'яті.
Типові жертви:
- Процеси з високим споживанням пам'яті
- Нещодавно запущені процеси
- Процеси без особливих привілеїв
Як відстежити OOM:
# Перевірити логи ядра
dmesg | grep -i "oom\|killed"
# В системних логах
journalctl -k | grep -i "oom\|killed"
# Налаштувати процес як «не вбивати»
echo -1000 > /proc/PID/oom_score_adj
Memory overcommit
Linux за замовчуванням дозволяє процесам запитувати більше пам'яті, ніж є. Це працює, тому що не всі запитані сторінки використовуються відразу.
# Поточна політика
cat /proc/sys/vm/overcommit_memory
# 0 = heuristic (default)
# 1 = always overcommit
# 2 = don't overcommit
# Для production часто рекомендується:
# vm.overcommit_memory = 2
# vm.overcommit_ratio = 80
Реальний обсяг пам'яті
Не вся RAM, вказана в тарифі, доступна додаткам.
# Загальний обсяг пам'яті
free -h
# Детальна статистика
cat /proc/meminfo
# Доступна пам'ять (враховує буфери і кеш)
# Дивись рядок "available" в free -h
Що з'їдає пам'ять:
- Ядро — 100-300MB в залежності від конфігурації
- Systemd та базові сервіси — 100-200MB
- SSH daemon, crond, та інше — 50-100MB
- Разом: з 1GB RAM додаткам доступно ~600-700MB
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
Storage: NVMe, SATA, RAID, Ceph, ZFS
 Схема: Storage: NVMe, SATA, RAID, Ceph, ZFS
Схема: Storage: NVMe, SATA, RAID, Ceph, ZFS
Storage — часто вузьке місце VPS. Поки CPU та RAM масштабуються відносно лінійно, IO впирається у фізичні обмеження дисків та мережевого storage.
Типи storage в VPS
Local NVMe
Диски NVMe підключені безпосередньо до сервера, на якому працює VM.
Характеристики:
- IOPS: 50,000-500,000+ (залежить від моделі та розподілу)
- Latency: 0.1-0.5ms
- Throughput: 1-5+ GB/s
Плюси:
- Мінімальна латентність
- Високі IOPS для випадкового доступу
- Ідеально для баз даних
Мінуси:
- Дані прив'язані до конкретного сервера
- При смерті диска — втрата даних (якщо немає RAID)
- Міграція VM на інший хост складніша
Local SATA SSD
SATA SSD на сервері.
Характеристики:
- IOPS: 10,000-80,000
- Latency: 0.5-2ms
- Throughput: 400-550 MB/s
Підходить для більшості задач, окрім high-IOPS workloads.
Network Storage (Ceph, iSCSI, NFS)
Диски зберігаються на окремому кластері storage та підключаються по мережі.
Характеристики:
- IOPS: 5,000-50,000 (залежить від backend та мережі)
- Latency: 1-5ms
- Throughput: залежить від мережі (1-10 GB/s)
Плюси:
- Дані реплікуються, вища відмовостійкість
- Live migration VM без простою
- Гнучке масштабування об'єму
Мінуси:
- Вища латентність через мережу
- Продуктивність ділиться між усіма клієнтами
- При проблемах з мережею — всі VM страждають
HDD
Класичні жорсткі диски. У 2026 році зустрічаються рідко, зазвичай для архівного storage.
Характеристики:
- IOPS: 100-200 (випадковий доступ!)
- Latency: 5-15ms
- Throughput: 100-200 MB/s
Коли допустимо:
- Зберігання бекапів
- Файлові сервери з послідовним читанням
- Логи та архіви
Коли НЕ допустимо:
- Бази даних (окрім read-only реплік)
- Веб-додатки з активним IO
- Все, де важлива чуйність
RAID конфігурації
| RAID Level |
Диски |
Відмовостійкість |
Продуктивність |
Ефективність |
| RAID 0 |
2+ |
Немає |
Висока |
100% |
| RAID 1 |
2 |
1 диск |
Читання x2 |
50% |
| RAID 5 |
3+ |
1 диск |
Хороша |
67-94% |
| RAID 6 |
4+ |
2 диска |
Середня |
50-88% |
| RAID 10 |
4+ |
1 диск в парі |
Висока |
50% |
Що використовують провайдери:
- Бюджетні: часто RAID 0 або без RAID (JBOD)
- Середні: RAID 5/6 або RAID 10
- Enterprise: Ceph з реплікацією x3
Як тестувати storage
# Встановити fio (Flexible I/O Tester)
apt install fio
# Тест випадкового читання (4K блоки, типово для БД)
fio --name=random-read --ioengine=libaio --iodepth=32 \
--rw=randread --bs=4k --direct=1 --size=1G \
--numjobs=4 --runtime=60 --group_reporting
# Тест випадкового запису
fio --name=random-write --ioengine=libaio --iodepth=32 \
--rw=randwrite --bs=4k --direct=1 --size=1G \
--numjobs=4 --runtime=60 --group_reporting
# Тест послідовного читання (throughput)
fio --name=seq-read --ioengine=libaio --iodepth=16 \
--rw=read --bs=1M --direct=1 --size=1G \
--numjobs=1 --runtime=60 --group_reporting
# Змішаний тест (70% read, 30% write)
fio --name=mixed --ioengine=libaio --iodepth=32 \
--rw=randrw --rwmixread=70 --bs=4k --direct=1 --size=1G \
--numjobs=4 --runtime=60 --group_reporting
Орієнтири для NVMe VPS:
- Random Read IOPS: 20,000+
- Random Write IOPS: 10,000+
- Sequential Read: 500+ MB/s
- Sequential Write: 300+ MB/s
Якщо показники значно нижчі — або використовується SATA/HDD, або сильний overselling storage, або network storage під навантаженням.
ZFS та інші файлові системи
Деякі провайдери використовують просунуті файлові системи на хост-рівні:
ZFS:
- Вбудоване стиснення (економить місце, може покращити IO)
- Snapshots та clones (швидкі бекапи)
- Захист від пошкодження даних (checksums)
- Потребує багато RAM на хості
Btrfs:
- Copy-on-write, snapshots
- Вбудований RAID
- Менш зрілий, ніж ZFS
Для тебе як клієнта це зазвичай прозоро, але якщо провайдер згадує ZFS — це скоріше плюс.
SSD Wear та TRIM
SSD мають обмежену кількість циклів запису. На shared-хостингу інтенсивний запис одного клієнта може прискорити знос диска.
Що це значить:
- Якісні провайдери використовують enterprise-grade SSD (більша кількість циклів)
- TRIM повинен бути включений для підтримки продуктивності
- Бюджетні провайдери можуть використовувати consumer SSD з меншим ресурсом
Як перевірити підтримку TRIM:
# На Linux (якщо диск видно як /dev/vda або /dev/sda)
lsblk --discard
# Non-zero значення в DISC-GRAN та DISC-MAX означають підтримку TRIM
# Вручну запустити TRIM (требує root)
fstrim -v /
Мережа: bandwidth, DDoS-захист, peering
 Схема: Мережа: bandwidth, DDoS-захист, peering
Схема: Мережа: bandwidth, DDoS-захист, peering
Мережеві характеристики VPS часто ігноруються при виборі, хоча для багатьох задач вони критичніші за CPU або RAM.
Bandwidth: що продають і що отримуєш
Port Speed vs Bandwidth
- Port speed — фізична швидкість порту (1Gbps, 10Gbps)
- Bandwidth — об'єм трафіку в місяць (1TB, 5TB, unlimited)
- Burst — тимчасове перевищення ліміту швидкості
Типові моделі:
- 1Gbps shared, 1TB/місяць — стандарт для бюджетних VPS
- 1Gbps unmetered — без ліміту трафіку, але швидкість shared
- 10Gbps port, 10TB/місяць — для high-bandwidth проектів
Що означає «unmetered»
Unmetered ≠ unlimited. У провайдера завжди є fair use policy:
- Ліміт на середню швидкість за період
- Обмеження на пікове використання
- Заборона певних типів трафіку (P2P, streaming)
Читай AUP! «Unmetered 1Gbps» може означати «до 1Gbps, якщо порт не зайнятий іншими клієнтами, і не більше 50TB/місяць».
Shared vs Dedicated bandwidth
Shared (оверселінг):
- Кілька VPS ділять один uplink
- В піку всі 10 клієнтів хочуть 1Gbps, а uplink — теж 1Gbps
- Результат: кожен отримує ~100Mbps
Dedicated:
- Гарантована полоса для твоєї VM
- Дорожче, але передбачувано
- Зазвичай доступно на dedicated серверах або premium VPS
DDoS-захист
DDoS-атаки — реальність сучасного інтернету. Навіть невеликий сайт може стати жертвою.
Типи захисту:
Null-routing:
- При атаці весь трафік на IP блокується
- Сайт недоступний, але інші клієнти захищені
- Безкоштовно, але даремно для тебе
Layer 3/4 mitigation:
- Фільтрація volumetric-атак (SYN flood, UDP flood)
- Працює на рівні мережі
- Стандарт для пристойних провайдерів
Layer 7 mitigation:
- Фільтрація application-layer атак (HTTP flood, slowloris)
- Вимагає аналізу трафіку
- Зазвичай платна опція або через CDN (Cloudflare, etc.)
На що дивитися:
- Об'єм захисту (Gbps/Tbps)
- Час реакції на атаку
- Чи включений захист в тариф, чи за доплату
- Чи є Layer 7 захист
Peering і connectivity
Якість мережі визначається не тільки швидкістю порту, але й маршрутизацією трафіку.
Фактори якості:
- Кількість пірингових точок — чим більше, тим коротші маршрути
- Tier-1 transit — підключення до великих магістральних провайдерів
- Local peering — прямі з'єднання з локальними ISP
- IX (Internet Exchange) — участь в точках обміну трафіком
Як перевірити:
# Traceroute до своїх користувачів
traceroute -n target.com
mtr -n target.com
# Інформація об ASN провайдера
# Через bgp.he.net або bgpview.io
whois AS12345
# Тест швидкості до різних регіонів
iperf3 -c iperf.server.com
Тестування мережевої продуктивності
# Встановити speedtest-cli
apt install speedtest-cli
speedtest-cli
# Або через curl (груба оцінка)
curl -o /dev/null -w "%{speed_download}\n" \
http://speedtest.tele2.net/100MB.zip
# iperf3 для точних вимірювань
# На віддаленому сервері:
iperf3 -s
# На VPS:
iperf3 -c remote.server.ip -t 30
# Тест latency
ping -c 100 target.com | tail -1
# Показує min/avg/max/mdev
BGP і маршрутизація
Для просунутих користувачів: якість мережі визначається не тільки швидкістю порту, але й маршрутизацією трафіку через інтернет.
Що таке BGP:
BGP (Border Gateway Protocol) — протокол, який визначає, як трафік іде між мережами. Провайдери з хорошим BGP-connectivity мають короткі маршрути до більшості destination.
На що дивитися:
- Кількість upstream-провайдерів: більше = краща redundancy і вибір маршрутів
- Tier-1 connectivity: прямі з'єднання з найбільшими магістралями
- Участь в IX: Internet Exchange Points для локального peering
- Looking glass: інструмент для перегляду BGP-маршрутів провайдера
Як перевірити:
- bgp.he.net — інформація об ASN, пірингах, upstream
- Looking glass провайдера (якщо є)
- traceroute/mtr до ключових точок
Коли це важливо:
- Глобальні сервіси з користувачами по всьому світу
- Ігрові сервери (критична латентність)
- VoIP і відеоконференції
- Фінансові додатки
Для більшості веб-проєктів достатньо перевірити latency до основних регіонів через ping/mtr.
IP-адреси, ASN і репутація
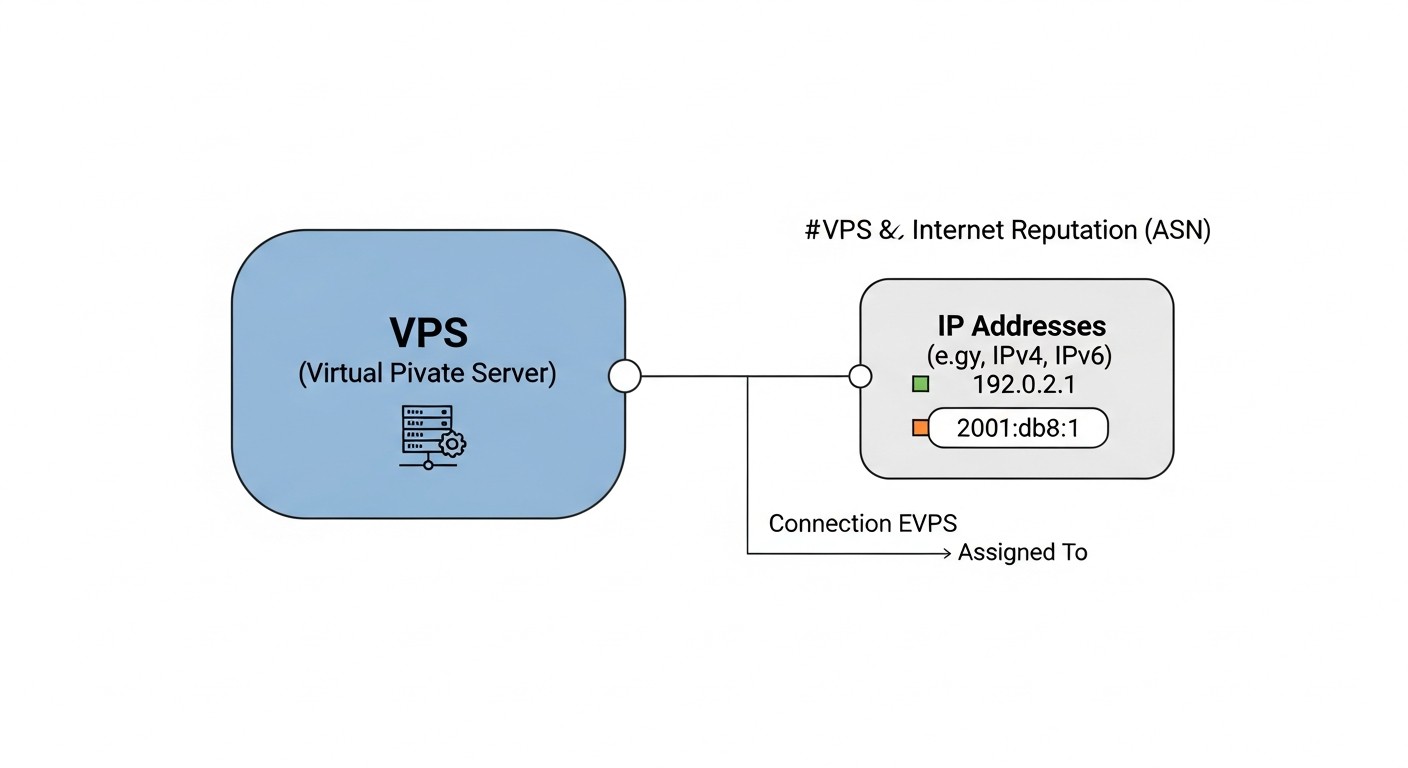 Схема: IP-адреси, ASN і репутація
Схема: IP-адреси, ASN і репутація
IP-адреса твого VPS — це його «паспорт» в інтернеті. Репутація IP впливає на доставляємість email, доступ до API, і навіть на індексацію пошуковими системами.
Чому репутація IP важлива
- Email: листи з «брудного» IP потрапляють в спам або відхиляються
- API: багато сервісів блокують IP з «поганих» діапазонів
- CDN: Cloudflare та інші можуть вимагати CAPTCHA для трафіку з підозрілих IP
- SEO: пошуковики враховують репутацію IP при оцінці сайту
Звідки беруться проблеми
- Попередні власники: IP використовувався для спаму, сканування, ботнетів
- Сусіди по підмережі: весь /24 або /16 блок потрапив в blocklist через інших клієнтів
- ASN провайдера: репутація всієї автономної системи низька
- Регіон: деякі країни і датацентри мають погану репутацію за замовчуванням
Як перевірити репутацію IP
До покупки:
- Запитай тестовий IP у провайдера
- Деякі провайдери дають test IP або trial
Сервіси для перевірки:
- MXToolbox: mxtoolbox.com/blacklists.aspx
- Spamhaus: check.spamhaus.org
- AbuseIPDB: abuseipdb.com
- VirusTotal: virustotal.com
- IPQualityScore: ipqualityscore.com
- Talos Intelligence: talosintelligence.com/reputation_center
# Перевірка в основних blocklists через DNS
# Spamhaus ZEN
dig +short $(echo YOUR_IP | awk -F. '{print $4"."$3"."$2"."$1}').zen.spamhaus.org
# Якщо повертає IP (127.0.0.x) — в списку
# Якщо NXDOMAIN — чисто
ASN і його вплив
ASN (Autonomous System Number) — ідентифікатор мережі провайдера. Репутація ASN впливає на всі IP в його діапазонах.
Проблемні категорії ASN:
- Bullet-proof хостинги (терплять abuse)
- Дешеві offshore провайдери
- Датацентри в країнах з високим рівнем кіберзлочинності
Як перевірити ASN:
# Дізнатись ASN свого IP
whois YOUR_IP | grep -i origin
# Інформація об ASN
# На bgp.he.net:
# https://bgp.he.net/ASXXXXX
# Через командну строку
whois -h whois.radb.net AS12345
Що робити з поганою репутацією
- Запросити зміну IP — у більшості провайдерів можна поміняти
- Delisting: для email — запросити видалення з blocklist (довго, не завжди успішно)
- Використовувати relay: для email — відправляти через сервіс типу SendGrid, Mailgun
- Змінити провайдера: якщо проблема системна (поганий ASN)
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
Географія та latency
 Схема: Географія та latency
Схема: Географія та latency
Фізичне розташування сервера напряму впливає на user experience. Швидкість світла — жорстке обмеження, яке не обійти кодом.
Latency: чому важлива
Грубі орієнтири (round-trip time):
- Всередині регіону (Москва-Москва): 1-5ms
- Між містами (Москва-Санкт-Петербург): 10-20ms
- Між країнами (Москва-Франкфурт): 30-50ms
- Між континентами (Москва-Нью-Йорк): 100-150ms
- Через океан (Європа-Азія): 150-300ms
Вплив на додатки:
- Кожен HTTP-запит включає мінімум 1 RTT (часто 2-3)
- Сторінка з 50 ресурсами × 100ms RTT = помітне гальмування
- API з послідовними запитами деградує лінійно
- Realtime-додатки (чати, ігри) вимагають <50ms
Як обирати локацію
Правило просте: сервер повинен бути близько до користувачів.
Типові сценарії:
- Російська аудиторія: Москва, Санкт-Петербург, Франкфурт (хороший peering з RU)
- Європейська аудиторія: Франкфурт, Амстердам, Лондон, Париж
- США: Ешберн (Virginia), Чикаго, Лос-Анджелес
- Азія: Сінгапур, Токіо, Гонконг
- Глобальна аудиторія: CDN + декілька точок присутності
Перевірка latency до покупки
Багато провайдерів надають looking glass або test IP:
# Ping до тестового IP провайдера
ping -c 100 test.ip.provider.com
# MTR для аналізу маршруту
mtr -r -c 100 test.ip.provider.com
# Проверить, где находится IP
curl ipinfo.io/YOUR_TEST_IP
Юридичні аспекти
Географія впливає на юрисдикцію:
- EU: GDPR обов'язковий для даних європейців
- US: CLOUD Act — можливий доступ влади
- Offshore (BVI, Panama): менше регуляції, але гірша репутація
- Russia: вимоги щодо локалізації даних (ФЗ-152)
Поради щодо вибору
- Визнач, де більшість твоїх користувачів
- Тестуй latency з точок присутності користувачів
- Враховуй юридичні вимоги
- Для глобальних проєктів — CDN обов'язковий, сервер може бути де завгодно
SLA: що написано vs що працює
 Схема: SLA: що написано vs що працює
Схема: SLA: що написано vs що працює
SLA (Service Level Agreement) — формальна обіцянка провайдера щодо доступності. Але між 99.9% на папері та 99.9% в реальності — прірва.
Що значать цифри
| SLA |
Downtime/рік |
Downtime/місяць |
Реальність |
| 99% |
3.65 дні |
7.3 години |
Неприйнятно для production |
| 99.9% |
8.76 години |
43 хвилини |
Стандарт для більшості |
| 99.95% |
4.38 години |
22 хвилини |
Enterprise-рівень |
| 99.99% |
52 хвилини |
4.3 хвилини |
Вимагає redundancy |
Що зазвичай НЕ входить в SLA
- Планові роботи: maintenance windows не вважаються downtime
- DDoS-атаки: часто виключені або з застереженнями
- Проблеми клієнта: OOM, kernel panic з твоєї вини
- Мережеві проблеми за межами датацентру: магістральні провайдери
- Force majeure: пожежі, повені, відключення електрики
Компенсації
Типова компенсація: credit на майбутні послуги.
Приклад:
- <99.9% → 10% credit
- <99.5% → 25% credit
- <99% → 50% credit
Реальність: credit за $5 VPS після 2 годин даунтайму — $0.50. Твої збитки від недоступності сервісу — непорівнянно більші.
На що дивитися
- Як вимірюється downtime: внутрішній моніторинг провайдера vs зовнішній
- Процедура claim: чи потрібно самому заявляти про даунтайм
- Винятки: читай дрібний шрифт
- Історія інцидентів: status page, форуми, Reddit
- Реакція на інциденти: як швидко відповідають, як комунікують
Практичний підхід
SLA — це baseline, не гарантія. Будуй архітектуру, яка переживе даунтайм провайдера:
- Регулярні бекапи в інше місце
- Готовність розгорнути сервіс в іншого провайдера
- Моніторинг з зовнішніх точок
- CDN для кешування статики
Оцінка якості підтримки
Якість техпідтримки критична. Проблеми трапляються, і від швидкості реакції залежить багато чого.
До покупки:
- Подивись відгуки про підтримку (не про сервіс в цілому)
- Постав pre-sales питання і оціни час та якість відповіді
- Перевір наявність status page з історією інцидентів
Канали підтримки (від кращого до гіршого):
- Live chat з технічними спеціалістами — швидко та ефективно
- Телефон — для термінових питань, але не всі провайдери пропонують
- Ticket system — стандарт, час відповіді варіюється від хвилин до днів
- Email — зазвичай повільніше, ніж тікети
- Тільки форум/KB — мінімальна підтримка, проблеми вирішуєш сам
Red flags в підтримці:
- Шаблонні відповіді, які не відносяться до питання
- Час відповіді більше 24 годин на прості питання
- Відсутність технічної компетенції (рекомендують перезавантажити на будь-яке питання)
- Агресивний upselling замість вирішення проблеми
- Немає ескалації для складних проблем
Тест підтримки:
Після покупки відкрий тікет з технічним питанням середньої складності (не «як змінити пароль», але й не «допоможіть налаштувати кластер»). Оціни час відповіді, розуміння питання та якість рішення. Це покаже, чого очікувати при реальних проблемах.
Порівняльні таблиці
 Схема: Порівняльні таблиці
Схема: Порівняльні таблиці
VPS vs Dedicated vs Cloud
| Критерій |
VPS |
Dedicated |
Cloud (AWS/GCP/Azure) |
| Вартість (базова) |
$5-50/міс |
$50-500/міс |
$20-200/міс |
| Провізіонінг |
Хвилини |
Години-дні |
Секунди-хвилини |
| Ізоляція |
Віртуальна |
Фізична |
Віртуальна |
| Масштабування |
Вертикальне |
Обмежено |
Авто-скейлінг |
| Передбачуваність ціни |
Висока |
Висока |
Низька |
| Продуктивність |
Змінна |
Стабільна |
Змінна |
| Кастомізація заліза |
Ні |
Так |
Обмежена |
| Managed сервіси |
Мінімум |
Мінімум |
Багаті |
KVM vs OpenVZ vs LXC
| Критерій |
KVM |
OpenVZ 7 |
LXC/LXD |
| Тип віртуалізації |
Повна |
Контейнерна |
Контейнерна |
| Ізоляція |
Висока |
Середня |
Середня-висока |
| Підтримка ОС |
Будь-яка |
Тільки Linux |
Тільки Linux |
| Custom kernel |
Так |
Ні |
Ні |
| Docker |
Повна |
Обмежена |
Так |
| Overhead |
2-5% |
<1% |
<1% |
| Типова ціна |
$5-10+ |
$2-5 |
$3-8 |
| Production-ready |
Так |
Умовно |
Так |
Managed vs Unmanaged
| Критерій |
Unmanaged |
Managed |
| Встановлення ОС |
Ти |
Провайдер |
| Оновлення безпеки |
Ти |
Провайдер |
| Моніторинг |
Ти |
Провайдер |
| Бекапи |
Ти |
Часто включені |
| Техпідтримка |
Тільки інфра |
Інфра + софт |
| Ціна |
Нижче |
Вище 2-5x |
| Для кого |
DevOps, sysadmins |
Немає часу на ops |
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
Практичні сценарії використання
Сценарій 1: SaaS MVP
Контекст: Стартап запускає MVP SaaS-продукту. Бюджет обмежений, команда з 2-3 розробників, очікуване навантаження — кілька сотень активних користувачів.
Вимоги:
- Web-додаток на Node.js/Python/Ruby
- PostgreSQL database
- Redis для сесій і кешу
- Background workers
- SSL, static files через CDN
Рекомендована конфігурація:
- VPS: KVM, 4 vCPU, 8GB RAM, 100GB NVMe
- Локація: ближче до цільової аудиторії
- Бюджет: $20-50/місяць
Архітектура:
# Все на одному сервері (monolith deployment)
├── nginx (reverse proxy, SSL termination)
├── app (Node.js/Python/Ruby)
├── PostgreSQL
├── Redis
└── background workers (Sidekiq/Celery)
# Docker Compose для управління
docker-compose up -d
Чого уникати:
- Передчасного розділення на мікросервіси
- Kubernetes на одному сервері (overhead не виправданий)
- Managed DB за $50+/місяць, коли traffic мінімальний
Сценарій 2: High-load API
Контекст: API-сервіс обробляє 10M+ запитів на добу. Критична латентність і стабільність.
Вимоги:
- Sub-100ms response time (p99)
- Обробка 500+ RPS постійно, піки до 2000 RPS
- Висока доступність
- Можливість масштабування
Рекомендована конфігурація (варіант 1 — VPS):
- Application servers: 2-4 × KVM, 8 vCPU, 16GB RAM, NVMe
- Database: Dedicated server або managed DB
- Load balancer: HAProxy/nginx на окремій VM або managed LB
- Бюджет: $200-500/місяць
Рекомендована конфігурація (варіант 2 — Hybrid):
- Application: Cloud (auto-scaling)
- Database: Dedicated server з NVMe RAID
- Cache: Managed Redis або self-hosted cluster
Архітектура:
┌─────────────────┐
│ Load Balancer │
└────────┬────────┘
│
┌───────────────────┼───────────────────┐
▼ ▼ ▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ App Server 1 │ │ App Server 2 │ │ App Server N │
└────────┬────────┘ └────────┬────────┘ └────────┬────────┘
│ │ │
└───────────────────┴───────────────────┘
│
┌───────────────────┴───────────────────┐
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ Redis Cluster │ │ PostgreSQL (HA)│
└─────────────────┘ └─────────────────┘
Ключові метрики для моніторингу:
- Request latency (p50, p95, p99)
- Error rate
- CPU steal time на кожному node
- Database connections і query time
- Memory pressure
Сценарій 3: Scanner / Crawler / Worker nodes
Контекст: Система для сканування web-ресурсів, парсингу даних або background processing. Потрібно багато outbound з'єднань.
Вимоги:
- Багато вихідного трафіку
- Безліч одночасних з'єднань
- Стійкість до блокувань
- Мінімальна вартість за одиницю роботи
Специфічні ризики:
- IP можуть потрапити в blocklist
- Провайдер може розцінити активність як abuse
- Rate limiting на target-ресурсах
Рекомендований підхід:
- Багато дрібних VPS: 5-10 × 1 vCPU, 1GB RAM замість одного великого
- Різні провайдери/ASN: знижує ризик одночасного блокування
- Proxy rotation: residential або datacenter proxies
- Бюджет: $5-10 × кількість nodes
Архітектура:
┌─────────────────┐
│ Control Plane │ (координація, черги)
│ (1 VPS) │
└────────┬────────┘
│
│ Redis/RabbitMQ
│
┌────────┴────────┐
│ │
▼ ▼
┌─────────┐ ┌─────────┐ ┌─────────┐
│ Worker 1│ │ Worker 2│ │ Worker N│ (різні провайдери/регіони)
│(VPS #1) │ │(VPS #2) │ │(VPS #N) │
└─────────┘ └─────────┘ └─────────┘
Важливо: уважно читай AUP провайдера. Багато хто забороняє scanning/scraping в будь-якій формі.
Сценарій 4: E-commerce магазин
Контекст: інтернет-магазин на WooCommerce/Magento/OpenCart з каталогом 5000+ товарів і трафіком 1000-5000 відвідувачів в день.
Вимоги:
- Стабільна робота під постійним навантаженням
- Швидке завантаження сторінок товарів
- Обробка платежів (критична безпека)
- Пікові навантаження при розпродажах
- SSL обов'язковий
Рекомендована конфігурація:
- VPS: 4 vCPU, 8GB RAM, 100GB NVMe
- Stack: nginx + PHP-FPM + MySQL/MariaDB + Redis
- CDN: Cloudflare для статики та захисту
- Бюджет: $30-60/місяць за VPS + CDN (безкоштовний план достатній)
Критичні оптимізації:
- OPcache для PHP
- Redis для сесій та object cache
- Оптимізація зображень
- Database indexing
- Lazy loading для каталогу
На розпродажі:
- Тимчасовий upgrade VPS (якщо провайдер дозволяє)
- Або підключення додаткового сервера з load balancing
- Aggressive caching для сторінок категорій
Сценарій 5: Telegram/Discord бот
Контекст: бот для месенджера з базою користувачів до 10K активних.
Вимоги:
- Робота 24/7 без перерв
- Швидка відповідь на команди
- Зберігання даних користувачів
- Мінімальний бюджет
Рекомендована конфігурація:
- VPS: 1 vCPU, 1GB RAM, 20GB SSD
- Stack: Python/Node.js + SQLite або PostgreSQL
- Бюджет: $5-10/місяць
Особливості:
- Боти зазвичай легкі, не вимагають багато ресурсів
- Важлива стабільність, а не продуктивність
- Systemd для автозапуску та перезапуску при падіннях
- Найпростіший моніторинг (перевірка процесу)
# /etc/systemd/system/mybot.service
[Unit]
Description=Telegram Bot
After=network.target
[Service]
Type=simple
User=botuser
WorkingDirectory=/home/botuser/bot
ExecStart=/usr/bin/python3 bot.py
Restart=always
RestartSec=10
[Install]
WantedBy=multi-user.target
Сценарій 6: CI/CD Runner
Контекст: self-hosted runner для GitHub Actions/GitLab CI для економії на платних хвилинах.
Вимоги:
- Швидка збірка проєктів
- Docker для контейнерних білдів
- Достатньо місця для кешу
- Ізоляція між білдами
Рекомендована конфігурація:
- VPS: 4+ vCPU, 8GB+ RAM, 100GB+ NVMe (для кешу)
- Обов'язково: KVM-віртуалізація (Docker вимагає)
- Бюджет: $20-50/місяць
Розрахунок окупності:
GitHub Actions коштує $0.008/хвилина для Linux-раннерів. VPS за $30/місяць окупається при використанні більше 3750 хвилин/місяць (62 години). Якщо білдиш часто — self-hosted вигідніше.
Налаштування:
# Установити Docker
curl -fsSL https://get.docker.com | sh
usermod -aG docker gitlab-runner
# Установити GitLab Runner
curl -L https://packages.gitlab.com/install/repositories/runner/gitlab-runner/script.deb.sh | bash
apt install gitlab-runner
# Зареєструвати runner
gitlab-runner register
Команди для тестування сервера
Після отримання доступу до VPS — перш за все протестуй його. Ось набір команд для всебічної перевірки.
Базова інформація про систему
# Інформація про CPU
lscpu
# Модель процесора
cat /proc/cpuinfo | grep "model name" | head -1
# Об'єм пам'яті
free -h
# Інформація про диски
lsblk
df -h
# Тип віртуалізації
systemd-detect-virt
# Версія ядра
uname -r
# Інформація про ОС
cat /etc/os-release
CPU Benchmark
# Установити sysbench
apt install sysbench
# Тест CPU (single-threaded)
sysbench cpu --cpu-max-prime=20000 run
# Тест CPU (multi-threaded, всі ядра)
sysbench cpu --cpu-max-prime=20000 --threads=$(nproc) run
# Перевірка steal time під навантаженням
# В одному терміналі:
sysbench cpu --cpu-max-prime=50000 --threads=$(nproc) --time=60 run
# В іншому:
vmstat 1
# Дивись стовпець st
Орієнтири (events per second, single thread):
- Modern Xeon/EPYC: 1500-2500
- Old Xeon (E5 v2): 800-1200
- Якщо значно нижче — або старе залізо, або сильний overselling
Memory Benchmark
# Тест пам'яті (sysbench)
sysbench memory --memory-block-size=1K --memory-total-size=10G run
sysbench memory --memory-block-size=1M --memory-total-size=10G run
# Або через dd (груба оцінка)
dd if=/dev/zero of=/dev/null bs=1M count=10000
Disk I/O Benchmark
# Установити fio
apt install fio
# Швидкий тест (створить файл test.fio)
# Random read (типово для БД)
fio --name=randread --ioengine=libaio --iodepth=16 \
--rw=randread --bs=4k --direct=1 --size=256M \
--numjobs=4 --runtime=30 --group_reporting --filename=test.fio
# Random write
fio --name=randwrite --ioengine=libaio --iodepth=16 \
--rw=randwrite --bs=4k --direct=1 --size=256M \
--numjobs=4 --runtime=30 --group_reporting --filename=test.fio
# Sequential read (throughput)
fio --name=seqread --ioengine=libaio --iodepth=16 \
--rw=read --bs=1M --direct=1 --size=1G \
--numjobs=1 --runtime=30 --group_reporting --filename=test.fio
# Видалити тестовий файл
rm test.fio
# Простий тест через dd
# Write
dd if=/dev/zero of=testfile bs=1M count=1024 conv=fdatasync
# Read
dd if=testfile of=/dev/null bs=1M
rm testfile
Network Benchmark
# Speedtest
apt install speedtest-cli
speedtest-cli
# Або через curl
# Download speed
curl -o /dev/null http://speedtest.tele2.net/1GB.zip
# Latency до ключових точок
ping -c 20 8.8.8.8
ping -c 20 1.1.1.1
# MTR для аналізу маршрутів
apt install mtr
mtr -r -c 100 google.com
# iperf3 (якщо є другий сервер)
# На сервері: iperf3 -s
# На VPS: iperf3 -c server.ip -t 30
Комплексний скрипт перевірки
#!/bin/bash
# vps-benchmark.sh
echo "=== System Info ==="
echo "CPU: $(grep "model name" /proc/cpuinfo | head -1 | cut -d: -f2)"
echo "Cores: $(nproc)"
echo "RAM: $(free -h | grep Mem | awk '{print $2}')"
echo "Disk: $(df -h / | tail -1 | awk '{print $2}')"
echo "Virtualization: $(systemd-detect-virt)"
echo "Kernel: $(uname -r)"
echo ""
echo "=== CPU Steal Time (10 sec) ==="
vmstat 1 10 | tail -9 | awk '{sum+=$16} END {print "Avg steal: " sum/9 "%"}'
echo ""
echo "=== Quick Disk Test ==="
dd if=/dev/zero of=testfile bs=1M count=256 conv=fdatasync 2>&1 | tail -1
rm testfile
echo ""
echo "=== Memory ==="
free -h
echo ""
echo "=== Network Latency ==="
ping -c 10 8.8.8.8 | tail -1
Діагностика типових проблем
Проблема: «VPS гальмує»
Найчастіша скарга. Причин може бути десяток.
Крок 1: Визначити, що саме гальмує
# Загальна картина
top
htop
# Load average
uptime
# Якщо load > кількість CPU — система перевантажена
# Що займає CPU
ps aux --sort=-%cpu | head -10
# Що займає пам'ять
ps aux --sort=-%mem | head -10
Крок 2: Перевірити CPU steal time
vmstat 1 10
# Стовпець st > 10% — проблема на стороні хостера
Крок 3: Перевірити IO
iostat -x 1 10
# %util близько до 100% — диск перевантажений
# await > 10ms на SSD — проблема
# Який процес вантажить диск
iotop
Крок 4: Перевірити пам'ять
free -h
# Якщо available близько до 0 і swap використовується активно — OOM скоро
dmesg | grep -i oom
# Якщо є записи — OOM killer працював
Можливі рішення:
- High steal → скарга провайдеру або зміна тарифу/провайдера
- High IO → оптимізація застосунку, додавання RAM для кешу, upgrade на NVMe
- High CPU → профілювання коду, масштабування
- High memory → оптимізація, збільшення RAM
Проблема: «Диск повільний»
Діагностика:
# Поточне навантаження на диск
iostat -x 1
# IOPS та latency
# await — середній час відгуку
# r_await, w_await — окремо читання/запис
# Якщо await високий:
# - На SSD > 5ms — проблема
# - На HDD > 20ms — очікувано під навантаженням
# Перевірити, хто навантажує
iotop -o
# Тест продуктивності
fio --name=test --rw=randread --bs=4k --direct=1 \
--size=256M --numjobs=4 --runtime=30 --group_reporting
Часті причини:
- Network storage під навантаженням
- Сусіди по хосту навантажують shared storage
- HDD замість заявленого SSD
- Застосунок робить надмірні IO (логіювання, sync)
Проблема: «Packet loss»
Діагностика:
# Базовий тест
ping -c 100 8.8.8.8
# Дивись % packet loss та mdev (jitter)
# Детальний аналіз маршруту
mtr -r -c 100 problem-host.com
# Дивись Loss% на кожному хопі
# Traceroute
traceroute -n problem-host.com
Інтерпретація MTR:
- Loss на проміжних хопах може бути нормою (ICMP rate limiting)
- Loss на кінцевому хості — реальна проблема
- Loss починається з певного хопу і продовжується — проблема на цій ділянці
Дії:
- Loss всередині мережі провайдера → тікет в підтримку
- Loss на магістралях → мало що можеш зробити, спробувати Cloudflare/CDN
- Loss тільки до певних destination → проблема на їх стороні
Проблема: «Сервер заблокували»
Раптове відключення сервера без попередження.
Часті причини:
- Abuse report (скарга на спам, сканування, атаки)
- Порушення AUP (prohibited content, services)
- Неоплата
- Compromised сервер (входить в ботнет)
Що робити:
- Перевірити email — зазвичай приходить повідомлення
- Зайти в панель керування — там може бути інформація
- Відкрити тікет в підтримку
- Не панікувати — часто можна відновити доступ після пояснень
Профілактика:
- Оновлювати софт (уникати компрометації)
- Не запускати нічого, що може згенерувати abuse reports
- Читати і дотримуватись AUP
- Тримати бекапи в іншому місці
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
Безпека, abuse та compliance
Розуміння правил гри — критично. Провайдер може відключити сервер за порушення, і формально буде правий.
Acceptable Use Policy (AUP)
AUP — документ, який визначає, що можна і не можна робити на сервері.
Типово заборонено всюди:
- Поширення malware
- DDoS-атаки
- Спам
- Хостинг нелегального контенту (CP, тероризм)
- Порушення авторських прав (піратство)
Часто заборонено:
- Port scanning (навіть «безпечний»)
- Torrent trackers / seedboxes
- Cryptocurrency mining
- Mass mailing (навіть opt-in)
- Open resolvers / open relays
- Adult content (у деяких провайдерів)
Сіра зона:
- Web scraping / crawling
- VPN / proxy для третіх осіб
- Tor exit nodes
- IRC bouncers
Abuse Reports
Abuse report — скарга на активність з твого IP.
Як приходять:
- Автоматично (fail2ban, DDoS detection)
- Від інших провайдерів
- Від правовласників (DMCA)
- Від користувачів (спам, атаки)
Що відбувається:
- Провайдер отримує скаргу
- Пересилає тобі з вимогою відповісти
- Ти повинен пояснити і усунути причину
- При ігноруванні або повторних порушеннях — відключення
Як реагувати:
- Відповідати швидко (24-48 годин)
- Розслідувати реальну причину
- Усунути і повідомити про вжиті заходи
- Якщо скарга неправдива — пояснити з доказами
DMCA
DMCA (Digital Millennium Copyright Act) — американський закон про копірайт, але застосовується глобально через хостинг-провайдерів.
Типовий процес:
- Правовласник знаходить порушення
- Відправляє DMCA notice провайдеру
- Провайдер зобов'язаний прибрати контент або переслати тобі
- Ти можеш подати counter-notice, якщо вважаєш скаргу необґрунтованою
Практика:
- Більшість провайдерів видаляють контент без розглядів
- Повторні DMCA → відключення аккаунта
- Offshore-хостинги часто ігнорують DMCA (але мають інші проблеми)
Compliance (GDPR, etc.)
GDPR (EU):
- Якщо обробляєш дані громадян EU — GDPR обов'язковий
- Хостинг в EU спрощує compliance, але не гарантує його
- Потрібен DPA (Data Processing Agreement) з провайдером
Вимоги по локалізації (Росія, Китай, etc.):
- Деякі країни вимагають зберігати дані громадян всередині країни
- Перевіряй застосовність до твого сервісу
Рекомендації з безпеки VPS
# Базова настройка після отримання сервера
# 1. Оновити систему
apt update && apt upgrade -y
# 2. Створити non-root користувача
adduser myuser
usermod -aG sudo myuser
# 3. Налаштувати SSH
# В /etc/ssh/sshd_config:
# PermitRootLogin no
# PasswordAuthentication no
# Port 2222 (опціонально, змінити порт)
# 4. Налаштувати firewall
ufw default deny incoming
ufw default allow outgoing
ufw allow 2222/tcp # SSH
ufw allow 80/tcp
ufw allow 443/tcp
ufw enable
# 5. Встановити fail2ban
apt install fail2ban
systemctl enable fail2ban
# 6. Налаштувати автоматичні оновлення безпеки
apt install unattended-upgrades
dpkg-reconfigure -plow unattended-upgrades
Розширені заходи безпеки
Базова настройка — це мінімум. Для production-серверів рекомендуються додаткові заходи.
SSH hardening:
# /etc/ssh/sshd_config додаткові налаштування
MaxAuthTries 3
ClientAliveInterval 300
ClientAliveCountMax 2
AllowUsers myuser
Protocol 2
Моніторинг змін файлів:
# Встановити AIDE (Advanced Intrusion Detection Environment)
apt install aide
aideinit
# Перевірка змін
aide --check
Ліміти на ресурси:
# /etc/security/limits.conf
# Обмежити кількість процесів для користувача
* soft nproc 1000
* hard nproc 2000
Логіювання:
- Налаштуй централізований збір логів (rsyslog, Loki)
- Логи повинні зберігатися окремо від сервера (на випадок компрометації)
- Налаштуй алерти на підозрілі події (невдалі логіни, sudo використання)
Регулярні задачі:
- Щотижня перевіряти оновлення безпеки
- Щомісяця рев'юїти відкриті порти і сервіси
- Періодично перевіряти логи на аномалії
- Тестувати відновлення з бекапів
Що змінилося в 2024–2026
Хостинг-індустрія не стоїть на місці. Кілька трендів, які варто враховувати.
Зростання популярності ARM
ARM-сервери (Ampere Altra, AWS Graviton) стають mainstream:
- Краще співвідношення продуктивність/ват
- Дешевше при comparable workloads
- Більшість софту вже підтримує ARM64
Практична порада: якщо твій стек сумісний з ARM — розглянь ARM-based VPS. Часто на 20-30% дешевше при тій же продуктивності.
NVMe став стандартом
SATA SSD в нових пропозиціях зустрічається все рідше. NVMe — новий baseline.
Що це значить: якщо провайдер досі продає «SSD VPS» без уточнення — ймовірно, це SATA. Запитуй явно.
Консолідація ринку
Великі гравці скуповують дрібних провайдерів. Це не добре і не погано, але впливає на:
- Якість підтримки (може погіршитися)
- Цінову політику
- AUP та умови обслуговування
Зростання цін на енергоносії
Енергетична криза 2022-2023 призвела до підвищення цін на хостинг в Європі. Тренд частково зберігається:
- EU-хостинги дорожчають
- Датацентри в регіонах з дешевою енергією (Скандинавія, US) стають привабливішими
IPv4 вичерпання
IPv4-адреси продовжують дорожчати:
- Багато провайдерів беруть доплату за додаткові IPv4
- Деякі пропонують NAT IPv4 + публічний IPv6
- IPv6-only хостинг стає реальністю для деяких use-cases
Практична порада: якщо твій сервіс не потребує IPv4 (наприклад, бекенд за CDN) — IPv6-only може заощадити гроші.
AI/ML workloads
Попит на GPU-сервери зріс експоненціально:
- Дефіцит потужностей
- Високі ціни
- Поява спеціалізованих провайдерів (Lambda Labs, Vast.ai, RunPod)
Примітка: інформація про ціни та доступність GPU змінюється швидко. Перевіряй актуальність на момент читання.
Посилення регуляції
Регуляторний тиск на хостинг-індустрію зростає:
- Посилення вимог по KYC (Know Your Customer) — анонімні VPS стають рідкістю
- Відповідальність провайдерів за контент клієнтів
- Санкційний тиск — деякі регіони обмежені
- Вимоги по локалізації даних в різних країнах
Практичний висновок: заздалегідь перевіряй, чи зможеш оплатити послуги і чи буде твій use-case дозволено в обраній юрисдикції.
Containerization як стандарт
Docker і контейнери стали mainstream:
- Більшість сучасних додатків поширюються як Docker images
- Deployment через docker-compose став стандартом для невеликих проектів
- Це робить KVM-віртуалізацію ще більш кращою (Docker нормально працює тільки на KVM)
Serverless і VPS
Serverless не вбив VPS, а зайняв свою нішу:
- Serverless хороший для event-driven, спорадичних задач
- VPS залишається кращим для постійних workloads
- Гібридні архітектури: core на VPS + serverless для peaks
Висновки
Вибір VPS провайдера — рішення, яке буде впливати на твій проект місяці або роки. Декілька фінальних рекомендацій.
Чого навчилися
- Віртуалізація має значення. KVM — розумний вибір для production. OpenVZ/LXC — тільки для dev або при жорстких бюджетних обмеженнях.
- Характеристики на папері ≠ реальність. 4 vCPU при 20% steal time — це не 4 vCPU. 100GB SSD на перевантаженому Ceph — це не швидкий storage.
- Репутація IP критична для email, API-інтеграцій і багато чого іншого. Перевіряй до покупки.
- Географія визначає latency. Ніяка оптимізація коду не компенсує 200ms до сервера.
- SLA — це minimum, не гарантія. Будуй архітектуру, яка виживе при даунтаймі провайдера.
- Читай AUP. Те, що здається тобі невинним, може бути заборонено.
Розумний підхід до вибору
- Визнач вимоги: CPU, RAM, storage type, bandwidth, latency, uptime
- Відфільтруй по типу віртуалізації: KVM для production
- Вибери географію: близько до користувачів
- Перевір репутацію: IP, ASN, відгуки
- Протестуй: використовуй trial або найдешевший тариф для тестів
- Масштабуйся поступово: почни з малого, upgrade по мірі росту
Де найчастіше помиляються
- Вибирають по ціні, ігноруючи все інше
- Не тестують перед production deployment
- Не читають AUP і отримують блокування
- Не роблять бекапи в інше місце
- Переплачують за ресурси, які не використовуються
- Недоплачують і отримують unstable service
- Оптимізують infrastructure замість коду
- Не моніторять і дізнаються про проблеми від користувачів
- Ігнорують безпеку до першого взлому
- Не документують налаштування і забувають через місяць
Типова еволюція інфраструктури
Більшість проектів проходять схожий шлях:
Стадія 1: Старт
- Shared-хостинг або найдешевший VPS
- Все на одному сервері
- Мінімальне налаштування
- Бекапи? Які бекапи?
Стадія 2: Зростання
- Upgrade до більш потужного VPS
- З'являється моніторинг
- Налаштовуються бекапи
- Оптимізація бази даних і кешування
Стадія 3: Масштабування
- Відділення бази даних на окремий сервер
- CDN для статики
- Можливо, кілька app-серверів з load balancer
- Більш серйозний моніторинг і алертинг
Стадія 4: Enterprise
- Multi-region deployment
- Kubernetes або аналог
- Managed services де виправдано
- Виділені команди для ops
Не стрибай через стадії. Kubernetes для MVP з 100 користувачами — overkill. Один VPS для сервісу з мільйоном DAU — проблема. Рости разом з проектом.
Ознаки хорошого провайдера
На що звертати увагу при оцінці:
- Прозорість: чітко вказані характеристики заліза, тип віртуалізації, умови SLA
- Status page: публічна історія інцидентів показує зрілість процесів
- Документація: якісна KB і tutorials
- Технічний блог: показує експертизу і культуру компанії
- Адекватна підтримка: технічно грамотні відповіді в розумні терміни
- Стабільні ціни: часті «знижки 90%» — ознака проблем
- Вік: провайдери, що працюють 5+ років, зазвичай надійніші новачків
- Спільнота: активні форуми, Discord, Telegram — ознака живого сервісу і зацікавленості в клієнтах
Мислення при виборі інфраструктури
Інфраструктура — це trade-off між вартістю, продуктивністю, надійністю і зручністю.
- Вартість: скільки готовий платити?
- Продуктивність: які метрики критичні?
- Надійність: що трапиться при даунтаймі?
- Зручність: скільки часу готовий витрачати на ops?
Ідеального рішення не існує. Є рішення, оптимальне для твоєї конкретної ситуації. І воно може змінитися по мірі росту проекту.
Фінальний чеклист перед вибором
Перед прийняттям рішення дай собі відповідь на ці питання:
- Що за проект? Web-сайт, API, бот, game-сервер, щось специфічне?
- Де користувачі? Визначає вибір географії.
- Яке навантаження? Поточне і очікуване через 6-12 місяців.
- Який бюджет? Включаючи приховані витрати на адміністрування.
- Які компетенції? Сам управляєш або потрібен managed?
- Які ризики? Що трапиться при даунтаймі? Втраті даних?
- Які вимоги compliance? GDPR, локалізація даних, etc.
- Який запас потрібен? На ріст, на піки, на форс-мажор.
З відповідями на ці питання вибір стає значно простішим і усвідомленішим. Ти зможеш відфільтрувати 90% варіантів відразу, а ті, що залишилися — протестувати на практиці.
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
FAQ
Який VPS краще для початківців?
KVM-based VPS з managed control panel (типу SolusVM, Virtualizor) і адекватною підтримкою. Не женіться за ціною — $5-10/місяць за 2GB RAM, 2 vCPU, 40GB SSD — розумний старт для більшості проєктів.
Чим відрізняється VPS від VDS?
Маркетинговими термінами. Технічно обидва терміни означають віртуальний сервер. Деякі провайдери використовують VDS для позначення KVM-віртуалізації, VPS — для OpenVZ. Але це не стандарт. Завжди уточнюйте тип віртуалізації.
Чи можна запускати Docker на VPS?
На KVM — так, без обмежень. На OpenVZ — з застереженнями (залежить від версії і налаштувань хоста). На LXC — зазвичай так, але перевіряйте.
Скільки RAM потрібно для веб-сервера?
Залежить від стека і навантаження. Мінімум для комфортної роботи: 1GB для простого сайту, 2-4GB для застосунку з БД, 4-8GB для навантаженого сервісу. Краще почати з меншого і моніторити використання.
Що таке overselling і як його виявити?
Overselling — продаж більше ресурсів, ніж є фізично. Ознаки: високий CPU steal time (>5%), непередбачувана продуктивність IO, деградація під навантаженням. Тестуйте в пікові години.
Як перевірити швидкість VPS?
CPU: sysbench cpu. Storage: fio або dd. Network: speedtest-cli, iperf3. Memory: sysbench memory. Не забувайте перевіряти steal time через vmstat.
Що робити, якщо IP в блеклісті?
Запросити зміну IP у провайдера. Якщо це системна проблема (весь ASN в blocklist) — розглянути зміну провайдера. Для email використовувати relay-сервіси (SendGrid, Mailgun).
VPS або хмара для стартапу?
Для MVP з передбачуваним навантаженням — VPS дешевше і простіше. Для продукту з непередбачуваним ростом або який потребує managed-сервісів — хмара може бути виправдана, незважаючи на більш високу вартість.
Як часто потрібно робити бекапи VPS?
Залежить від RPO (Recovery Point Objective). Для більшості проєктів: щоденні бекапи БД, щотижневі повні бекапи. Критичні дані — частіше. Зберігайте бекапи в іншому місці, не у того ж провайдера.
Чи можна довіряти «безлімітному» трафіку?
Ні. Завжди є fair use policy. Типово «безлімітний» означає 10-50TB/місяць при average usage. Читай AUP і ToS.
Панелі управління VPS: що вибрати
Панель управління — інтерфейс між тобою і сервером. Вибір залежить від задач, бюджету і рівня технічної підготовки.
Панелі від провайдера (клієнтські)
Більшість VPS-провайдерів надають власну панель або стандартні рішення:
SolusVM
Класична панель для VPS-хостингу, досі широко використовується.
- Управління VM: start/stop/reboot/reinstall
- VNC/noVNC консоль для аварійного доступу
- Статистика використання ресурсів
- Управління ISO-образами (на KVM)
Virtualizor
Сучасна альтернатива SolusVM з кращим інтерфейсом.
- Підтримка KVM, Xen, OpenVZ, LXC
- API для автоматизації
- Вбудовані бекапи
- Більш дружній UI
Пропрієтарні панелі
Багато великих провайдерів розробляють власні рішення. Якість варіюється від відмінної до жахливої. Дивись скриншоти і відгуки перед покупкою.
Серверні панелі (ставляться на VPS)
Якщо провайдер дає тільки SSH-доступ, можна встановити панель самостійно.
Безкоштовні варіанти
HestiaCP — форк VestaCP, активно розвивається.
- Web-сервер (nginx/Apache)
- Поштовий сервер
- DNS
- Бази даних (MySQL/PostgreSQL)
- Управління доменами і SSL
- Споживання: ~200-300MB RAM
# Установка HestiaCP
wget https://raw.githubusercontent.com/hestiacp/hestiacp/release/install/hst-install.sh
bash hst-install.sh
Webmin/Virtualmin — класика, працює стабільно.
- Універсальне управління Linux-сервером
- Virtualmin додає хостинг-функції
- Модульна архітектура
- Споживання: ~100-200MB RAM
CyberPanel — панель на базі OpenLiteSpeed.
- Висока продуктивність веб-сервера
- Вбудований LSCache
- Email, DNS, FTP
- Docker-інтеграція
Платні варіанти
cPanel/WHM — індустріальний стандарт.
- Повний набір функцій для хостингу
- Величезна екосистема плагінів
- Відмінна документація
- Ціна: від $15/місяць (після безкоштовного періоду)
- Споживання: 1-2GB RAM мінімум
Plesk — основний конкурент cPanel.
- Підтримка Windows і Linux
- Сучасний інтерфейс
- WordPress Toolkit
- Ціна: від $10/місяць
DirectAdmin — легковажна альтернатива.
- Менше споживання ресурсів
- Простий інтерфейс
- Ціна: від $5/місяць
Коли панель не потрібна
Для багатьох задач панель управління — зайвий overhead:
- API-сервери і backend-сервіси
- Docker/Kubernetes deployments
- Спеціалізовані застосунки
- Коли є CI/CD і Infrastructure as Code
В цих випадках достатньо SSH + базове налаштування.
Порівняння панелей управління
| Панель |
Ціна |
RAM вимоги |
Для кого |
| HestiaCP |
Безкоштовно |
~300MB |
Невеликі проєкти, веб-хостинг |
| Webmin |
Безкоштовно |
~150MB |
Універсальне управління Linux |
| CyberPanel |
Безкоштовно |
~400MB |
Високопродуктивний веб-хостинг |
| cPanel |
від $15/міс |
~1.5GB |
Професійний хостинг |
| Plesk |
від $10/міс |
~1GB |
Windows/Linux хостинг |
| DirectAdmin |
від $5/міс |
~500MB |
Легка альтернатива cPanel |
Рекомендація: для VPS з 2GB RAM і менше — HestiaCP або Webmin. Для 4GB+ можна розглядати cPanel/Plesk, якщо функціонал виправданий.
Бекапи і Disaster Recovery
Бекапи — єдиний захист від втрати даних. Надіятись на провайдера — помилка.
Правило 3-2-1
Класична стратегія бекапів:
- 3 копії даних
- 2 різних типи носіїв
- 1 копія offsite (в іншому місці)
Для VPS це означає:
- Дані на сервері (primary)
- Локальні бекапи на тому ж VPS або у провайдера
- Зовнішні бекапи (інший провайдер, S3, Backblaze)
Що бекапити
Критично:
- Бази даних (MySQL, PostgreSQL, MongoDB)
- Користувацькі дані і uploads
- Конфігураційні файли
- SSL-сертифікати і ключі
- Crontab і scheduled tasks
Бажано:
- Логи (для розслідувань)
- Email (якщо хостиш сам)
- Custom-скрипти
Не потрібно:
- Системні файли (можна відновити з образу)
- Кеші і тимчасові файли
- Package managers cache
Інструменти для бекапів
Для баз даних
# MySQL/MariaDB
mysqldump -u root -p --all-databases --single-transaction > all_databases.sql
# З компресією
mysqldump -u root -p dbname | gzip > backup_$(date +%Y%m%d).sql.gz
# PostgreSQL
pg_dumpall -U postgres > all_databases.sql
# Одна база
pg_dump -U postgres dbname > dbname.sql
Для файлів
# rsync на віддалений сервер
rsync -avz --delete /var/www/ backup@remote:/backups/www/
# З SSH
rsync -avz -e ssh /data/ user@backup-server:/backups/
# tar архів
tar -czvf backup_$(date +%Y%m%d).tar.gz /var/www /etc/nginx /etc/letsencrypt
Спеціалізовані інструменти
restic — сучасний інструмент з дедуплікацією та шифруванням.
# Ініціалізація репозиторію
restic init --repo /backup/restic
# Бекап
restic -r /backup/restic backup /var/www /etc
# Відновлення
restic -r /backup/restic restore latest --target /restore
borgbackup — схожий на restic, ефективна дедуплікація.
# Ініціалізація
borg init --encryption=repokey /backup/borg
# Бекап
borg create /backup/borg::backup-{now} /var/www /etc
# Список архівів
borg list /backup/borg
Хмарні сховища
# rclone — універсальний інструмент для хмар
# Підтримує S3, Backblaze B2, Google Drive, і десятки інших
# Налаштування
rclone config
# Синхронізація
rclone sync /backup/ remote:bucket-name/
# Копіювання з прогресом
rclone copy --progress /data/ remote:bucket/data/
Автоматизація бекапів
# /etc/cron.d/backup
# Щоденний бекап о 3:00
0 3 * * * root /usr/local/bin/backup.sh >> /var/log/backup.log 2>&1
# Приклад скрипта /usr/local/bin/backup.sh
#!/bin/bash
set -e
DATE=$(date +%Y%m%d)
BACKUP_DIR=/backup
# Бекап MySQL
mysqldump --all-databases | gzip > $BACKUP_DIR/mysql_$DATE.sql.gz
# Бекап файлів
tar -czf $BACKUP_DIR/www_$DATE.tar.gz /var/www
# Відправка в хмару
rclone copy $BACKUP_DIR remote:backups/
# Видалення старих локальних бекапів (старше 7 днів)
find $BACKUP_DIR -type f -mtime +7 -delete
echo "Backup completed: $DATE"
Перевірка бекапів
Бекап, який не перевірено — не бекап. Регулярно тестуй відновлення:
- Розгортай на тестовому сервері
- Перевіряй цілісність архівів
- Переконайся, що додаток працює після відновлення
- Вимірюй RTO (час відновлення)
Disaster Recovery Plan
Документ, що описує що робити при різних сценаріях:
- Збій додатку — перезапуск, відкат до попередньої версії
- Збій бази даних — відновлення з бекапу, point-in-time recovery
- Збій VPS — розгортання на новому сервері
- Збій провайдера — переїзд до альтернативного провайдера
Для кожного сценарію:
- Послідовність дій
- Контакти відповідальних
- Доступи та credentials (в захищеному місці)
- Очікуваний час відновлення
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
Моніторинг VPS
Без моніторингу ти дізнаєшся про проблеми від користувачів. З моніторингом — раніше.
Що моніторити
Системні метрики
- CPU: використання, load average, steal time
- Memory: used, available, swap usage
- Disk: використання, IOPS, latency
- Network: bandwidth in/out, packet loss, latency
Метрики додатків
- Web-сервер: requests/sec, response time, error rate
- База даних: queries/sec, slow queries, connections
- Додаток: специфічні метрики (черги, jobs, etc.)
Доступність (Uptime)
- HTTP(S) endpoints
- TCP-порти
- SSL-сертифікати (термін дії)
- DNS
Інструменти моніторингу
Зовнішній моніторинг (SaaS)
UptimeRobot — безкоштовний для базових перевірок.
- До 50 моніторів безкоштовно
- HTTP, Ping, Port, Keyword
- Сповіщення: email, Slack, Telegram
BetterUptime, Pingdom, StatusCake — більш просунуті платні варіанти.
Self-hosted моніторинг
Netdata — real-time моніторинг з мінімальним налаштуванням.
# Встановлення
bash <(curl -Ss https://my-netdata.io/kickstart.sh)
# Доступ на http://server:19999
Prometheus + Grafana — стек для серйозного моніторингу.
- Prometheus збирає метрики
- Grafana візуалізує
- Alertmanager відправляє сповіщення
- Потребує 512MB-1GB RAM
Zabbix — enterprise-рішення.
- Повнофункціональний моніторинг
- Автовиявлення
- Складніше в налаштуванні
- Потребує PostgreSQL/MySQL
Мінімальний моніторинг через CLI
# Простий скрипт перевірки (додати в cron)
#!/bin/bash
# Перевірка HTTP
STATUS=$(curl -s -o /dev/null -w "%{http_code}" https://mysite.com)
if [ "$STATUS" != "200" ]; then
echo "Site down! Status: $STATUS" | mail -s "Alert" [email protected]
fi
# Перевірка диска
DISK_USAGE=$(df / | tail -1 | awk '{print $5}' | sed 's/%//')
if [ "$DISK_USAGE" -gt 90 ]; then
echo "Disk usage: $DISK_USAGE%" | mail -s "Disk Alert" [email protected]
fi
# Перевірка пам'яті
MEM_AVAILABLE=$(free -m | grep Mem | awk '{print $7}')
if [ "$MEM_AVAILABLE" -lt 200 ]; then
echo "Low memory: ${MEM_AVAILABLE}MB available" | mail -s "Memory Alert" [email protected]
fi
Налаштування алертів
Алерти повинні бути actionable — якщо отримав алерт, повинен знати що робити.
Хороші алерти:
- Диск заповнений на 90%+ → очистити або розширити
- Сайт недоступний → перевірити сервер, перезапустити сервіси
- CPU steal > 15% → скарга провайдеру
Погані алерти:
- CPU 80% (якщо це нормально для твого навантаження)
- 100 помилок 404 (якщо це боти сканують)
- Будь-який алерт, який ігноруєш
Чек-лист вибору VPS-провайдера
Використовуй цей чек-лист при оцінці провайдерів.
Технічні характеристики
| Критерій |
Питання |
Червоний прапор |
| Віртуалізація |
KVM, OpenVZ, LXC, VMware? |
OpenVZ 6, не вказано тип |
| CPU |
Модель процесора? Dedicated або shared? |
Не вказана модель, старі Xeon E5 v1/v2 |
| Storage |
NVMe, SSD, HDD? RAID? Local або network? |
«SSD» без уточнення, HDD для production |
| Мережа |
Port speed? Bandwidth limit? DDoS захист? |
100Mbps порт, жорсткі ліміти |
| IP |
IPv4/IPv6? Додаткові IP? |
Тільки IPv6, висока доплата за IPv4 |
Надійність та підтримка
| Критерій |
Питання |
Червоний прапор |
| SLA |
Який SLA? Що включено? |
Немає SLA, багато виключень |
| Підтримка |
Канали? Час відповіді? 24/7? |
Тільки тікети, відповідь >24г |
| Історія |
Скільки років працюють? Відгуки? |
Новий провайдер, багато негативних відгуків |
| Датацентр |
Де фізично? Tier? Сертифікації? |
Невідома локація, немає інформації |
Умови та обмеження
| Критерій |
Питання |
Червоний прапор |
| AUP |
Що заборонено? Дозволено твій use-case? |
Заборонено потрібний функціонал |
| Бекапи |
Включені? Частота? Вартість? |
Немає бекапів взагалі |
| Масштабування |
Чи можна upgrade без перевстановлення? |
Тільки перевстановлення |
| Оплата |
Методи? Refund policy? |
Тільки криптовалюта, немає refund |
Тестування
Перед production-використанням:
- Замов мінімальний тариф або trial
- Перевір CPU steal time під навантаженням
- Протестуй IO (fio)
- Перевір мережеву зв'язність до твоїх користувачів
- Перевір IP-репутацію
- Відкрий тікет в підтримку — оціни час та якість відповіді
- Спробуй встановити потрібний софт
Прикладний алгоритм вибору
Якщо складно визначитися, використовуй цей алгоритм:
- Визнач критичний фактор: ціна, продуктивність, географія, підтримка?
- Відсічи невідповідних: за типом віртуалізації, географією, AUP
- Склади шортліст: 3-5 провайдерів, що відповідають вимогам
- Перевір відгуки: Reddit, Trustpilot, профільні форуми — шукай конкретику, а не емоції
- Протестуй 2-3 варіанти: замов мінімальні тарифи, прожени бенчмарки
- Вибери найкращий за співвідношенням: продуктивність + стабільність + підтримка / ціна
Не поспішай з остаточним вибором провайдера. Зайвий день на тестування заощадить тижні проблем в production.
Міграція між провайдерами
Рано чи пізно доведеться переїжджати. Підготуйся заздалегідь.
Підготовка до міграції
- Документація — зафіксуй поточну конфігурацію
- Бекапи — свіжий повний бекап
- DNS — знизь TTL заздалегідь (до 300-600 секунд)
- Тестування — розгорни копію на новому сервері, перевір
Стратегії міграції
Повна міграція (big bang)
- Зупиняєш старий сервер
- Переносиш дані
- Запускаєш на новому
- Перемикаєш DNS
Підходить для невеликих проєктів з допустимим даунтаймом.
Паралельна робота
- Підіймаєш новий сервер
- Синхронізуєш дані в реальному часі
- Перемикаєш трафік поступово
- Вимикаєш старий після стабілізації
Мінімізує ризик, потребує більше ресурсів.
Інструменти
# Синхронізація файлів з rsync
rsync -avz --progress root@old-server:/var/www/ /var/www/
# Реплікація MySQL
# На старому сервері налаштувати master
# На новому — slave, потім promote
# Синхронізація PostgreSQL
pg_basebackup -h old-server -D /var/lib/postgresql/data -P
Після міграції
- Перевір роботу всіх функцій
- Монітор помилки в логах
- Стеж за продуктивністю
- Не видаляй старий сервер одразу — тримай тиждень на випадок проблем
- Поверни TTL DNS до нормальних значень
Checklist міграції
Використовуй цей чекліст при переїзді:
До міграції:
- ☐ Повний бекап даних (перевірений!)
- ☐ Список всіх сервісів і конфігурацій
- ☐ DNS TTL знижено до 300-600 сек
- ☐ Новий сервер розгорнуто і протестовано
- ☐ SSL-сертифікати готові для нового сервера
- ☐ Cron-завдання задокументовані
- ☐ Час міграції узгоджено (низький трафік)
Під час міграції:
- ☐ Повідомити користувачів про можливі перебої
- ☐ Зупинити записи в БД на старому сервері
- ☐ Фінальна синхронізація даних
- ☐ Переключити DNS
- ☐ Перевірити роботу основних функцій
Після міграції:
- ☐ Моніторинг помилок 24-48 годин
- ☐ Перевірка всіх інтеграцій
- ☐ Тестування email-відправки
- ☐ Перевірка бекапів на новому сервері
- ☐ Оновити документацію
- ☐ Через тиждень: видалити старий сервер
rocket_launch
Quick pick
Looking for a server that just works?
Valebyte VPS — NVMe, 24/7 support, deploy in 60 seconds.
View VPS plans
arrow_forward
Оптимізація вартості VPS
Переплачувати — нерозумно, недоплачувати — небезпечно. Ось як знайти баланс.
Правильний розмір (Right-sizing)
Типова помилка — брати з запасом «на всякий випадок». В результаті 70% ресурсів простоюють.
Як визначити потрібний розмір:
- Запусти на мінімальному тарифі
- Монітор використання 1-2 тижні
- Оціни пікові та середні значення
- Додай 20-30% запасу від піку
# Середній CPU за останню годину
sar -u 1 3600 | tail -1
# Максимальне використання пам'яті
# (потребує збір статистики)
cat /var/log/sysstat/sa* | sar -r | sort -k4 -n | tail -1
# Реальне використання диску
df -h | grep -v tmpfs
Резервування vs Pay-as-you-go
Багато провайдерів пропонують знижки за передоплату:
- Місячна оплата: базова ціна
- Річна оплата: знижка 10-20%
- 2-3 роки: знижка до 40%
Коли брати тривалий термін:
- Стабільний проєкт з передбачуваними вимогами
- Провайдер перевірений на практиці
- Є фінансовий запас
Коли НЕ брати:
- Новий проєкт з невизначеним майбутнім
- Новий провайдер (не перевірений)
- Швидкозростаючий проєкт (доведеться upgrade)
Альтернативи стандартним VPS
Spot/Preemptible instances
Хмарні провайдери продають надлишкові потужності зі знижкою 60-90%, але можуть відкликати з попередженням 30 сек — 2 хв.
Підходить для: batch processing, CI/CD runners, stateless workers.
Auction servers
Деякі провайдери (Hetzner) продають dedicated сервери на аукціоні — вживане залізо за зниженими цінами.
Community/Reseller хостинг
Дрібні провайдери, що перепродають потужності великих. Іноді дешевше, але вищі ризики.
Що не економить гроші
- Занадто дешевий провайдер — втратиш час на проблеми
- Oversized VPS «про запас» — краще масштабуватися по мірі росту
- Ігнорування managed-сервісів — час DevOps теж коштує грошей
Додаткові питання
Як захистити VPS від взлому?
Базові міри: вимкнути root-логін по паролю, використовувати SSH-ключі, налаштувати firewall (ufw/iptables), встановити fail2ban, регулярно оновлювати систему, не запускати зайві сервіси, використовувати складні паролі для всіх сервісів.
Що краще: один потужний VPS чи декілька маленьких?
Залежить від задачі. Один VPS простіше в управлінні. Декілька — вища відмовостійкість і можливість розподілити навантаження. Для більшості проєктів до 10K DAU достатньо одного правильно налаштованого VPS.
Як перенести сайт з shared-хостингу на VPS?
Експортувати файли (FTP/SSH), експортувати БД (phpMyAdmin або mysqldump), встановити на VPS веб-сервер і PHP потрібної версії, імпортувати дані, налаштувати віртуальний хост, перевірити роботу, переключити DNS.
Чи можна використовувати VPS як VPN?
Так, але перевір AUP провайдера. Багато хто дозволяє особистий VPN, але забороняє комерційні VPN-сервіси. Популярні рішення: WireGuard, OpenVPN, Outline.
Як дізнатися, що сусід по хосту навантажує сервер?
Високий CPU steal time при низькому власному навантаженні. Непередбачувана деградація IO. Періодичні «зависання» без видимих причин. Все це — ознаки «шумних сусідів» або overselling.
Чи варто брати VPS з Windows?
Тільки якщо потрібен специфічний Windows-софт (.NET Framework, MSSQL). Windows VPS дорожче (ліцензія), потребує більше ресурсів, складніше в автоматизації. Для більшості задач Linux кращий.
Як вибрати між Ubuntu, Debian, CentOS?
Ubuntu — найпопулярніший, багато документації та прикладів. Debian — стабільний і легкий. CentOS Stream/AlmaLinux/Rocky — для enterprise-оточень. Для VPS найчастіше підходить Ubuntu LTS або Debian stable.
Що робити при DDoS-атаці?
Якщо провайдер має захист — він має спрацювати автоматично. Якщо ні — включити Cloudflare або аналог. В крайньому випадку — попросити провайдера тимчасово null-route IP (сайт буде недоступний, але атака припиниться).
Як перевірити, чи не зламаний VPS?
Перевірити незвичайні процеси (ps aux), мережеві з'єднання (netstat -tulpn), останні логіни (last, lastb), crontab всіх користувачів, зміни в системних файлах. Використовувати rkhunter, chkrootkit для пошуку руткітів.
Чи можна майнити криптовалюту на VPS?
Технічно — так, практично — майже всюди заборонено в AUP. Майнінг створює постійне 100% навантаження на CPU, що впливає на сусідів. За це відключають без попередження.
Як вибрати між Європою та США для хостингу?
Залежить від аудиторії та регуляторних вимог. Для російської аудиторії Європа (особливо Франкфурт, Амстердам) зазвичай має кращу зв'язність. Для глобальних проектів — залежить від розподілу користувачів. США дешевше для compute, але GDPR може вимагати хостингу в EU для європейських даних.
Що робити, якщо провайдер закрився?
Якщо є бекапи — розгорнути в іншого провайдера. Якщо немає — молитися. Саме тому бекапи повинні зберігатися в незалежному місці. Ознаки проблем провайдера: затримки з відповідями, почастішали інциденти, звільнення ключових співробітників, фінансові проблеми в новинах.
Чи потрібен виділений IP для SEO?
Для SEO сам по собі shared IP не проблема — Google це підтверджував неодноразово. Виділений IP потрібен для: SSL-сертифікатів (хоча SNI вирішує це), email-розсилок (критично), деяких API-інтеграцій і якщо сусіди по IP займаються спамом.
Як зрозуміти, що пора переїжджати на dedicated?
Коли вартість кількох потужних VPS наближається до dedicated. Коли критична стабільна продуктивність без сусідів. Коли потрібні специфічні конфігурації заліза. Коли потрібен повний контроль аж до BIOS/IPMI. Типово це відбувається при витратах $150-200+/місяць на VPS.
Чому VPS дешевше, ніж хмара при тій же конфігурації?
Хмарні провайдери (AWS, GCP, Azure) включають в ціну: global infrastructure, managed services ecosystem, enterprise support, compliance сертифікації, R&D вартість. VPS-провайдери продають тільки compute — без екосистеми. Якщо тобі потрібен тільки сервер — VPS вигідніше. Якщо потрібна екосистема — хмара окупається.
Які метрики моніторити в першу чергу?
Для початку достатньо базових: uptime (доступність сервісу), response time (час відгуку), CPU і RAM usage, disk space. По мірі росту додавай application-specific метрики: queries per second для БД, requests per second для веб-сервера, error rate. Головне правило: монітор то, на що можеш зреагувати.
Чи варто використовувати кілька VPS-провайдерів одночасно?
Для критичних проектів — так, це розумна стратегія. Primary в одного провайдера, бекапи і failover — в іншого. Для невеликих проектів зазвичай достатньо одного провайдера з зовнішніми бекапами. Multi-cloud додає складності в управлінні, використовуй коли виправдано бізнес-вимогами.
Як оцінити реальну вартість VPS?
Базова ціна — це початок. Додай: вартість додаткових IP, бекапів, перевищення трафіку, ліцензій софту (Windows, панелі), DDoS-захисту якщо платна. Врахуй свій час на адміністрування за ринковою ставкою. Реальна вартість часто в 1.5-2 рази вище заявленої.
Пов'язані матеріали для додаткового вивчення
Для більш глибокого занурення в окремі теми та питання, порушені в цьому керівництві, рекомендуємо ознайомитися з наступними корисними матеріалами:
- Налаштування безпеки Linux-сервера після встановлення: hardening, firewall, моніторинг загроз
- Порівняння панелей управління сервером: cPanel vs Plesk vs HestiaCP vs DirectAdmin
- Оптимізація продуктивності веб-сервера на VPS: nginx, PHP-FPM, Redis і кешування
- Автоматизація бекапів для VPS: налаштування restic, borgbackup, rclone з хмарним сховищем
- Моніторинг серверів: від простих перевірок uptime до повноцінної observability
- Docker на VPS: практичний посібник з контейнеризації додатків
- Вибір між shared-хостингом і VPS: коли пора переходити на власний віртуальний сервер
Стаття оновлена: січень 2026. Інформація актуальна на момент публікації, проте рекомендуємо перевіряти поточні умови провайдерів перед прийняттям остаточного рішення про покупку.