
Оптимізація витрат на хмарні VPS та виділені сервери: FinOps практики та інструменти (актуально для 2026 року)
TL;DR
- FinOps — це не просто економія, а культура: Інтеграція фінансів та операцій для постійного управління хмарними витратами, фокус на цінності та бізнес-результатах.
- Видимість та контроль — ключ: Використовуйте tagging, детальні звіти та спеціалізовані інструменти для розуміння, хто і за що платить. Без цього оптимізація неможлива.
- Правильний сайзинг (Rightsizing) — ваш найкращий друг: Регулярно аналізуйте утилізацію ресурсів та масштабуйте сервери (VPS/Dedicated) до оптимальних розмірів. Переплачуєте за невикористану потужність.
- Автоматизація та гнучкість: Застосовуйте автоскейлінг, планування вмикань/вимикань, Spot-інстанси та зарезервовані потужності для адаптації до навантаження та зниження базових витрат.
- Не забувайте про мережу та сховища: Egress-трафік, невикористані диски, застарілі снапшоти можуть складати значну частину рахунку. Оптимізуйте їх так само ретельно, як CPU/RAM.
- Культура співпраці: FinOps вимагає взаємодії між інженерами, менеджерами продуктів та фінансовими відділами для спільного прийняття рішень про витрати.
- Вибирайте правильний тип сервера: VPS для гнучкості та масштабування, виділені сервери для високої продуктивності та передбачуваності навантаження, контейнеризація та Serverless для максимальної ефективності.
Потрібен виділений сервер?
Compare prices from top providers. Configure and order in minutes.
3. Вступ
У світі технологій, що стрімко розвивається, де хмарні обчислення стали стандартом де-факто для більшості стартапів, SaaS-проєктів та навіть великих підприємств, управління витратами на IT-інфраструктуру перетворилося з другорядної задачі на критично важливий аспект бізнес-стратегії. До 2026 року, коли хмарний ринок продовжить своє експоненціальне зростання, а конкуренція серед провайдерів та споживачів послуг досягне піку, вміння ефективно управляти бюджетом на VPS та виділені сервери стане не просто перевагою, а необхідністю для виживання та процвітання.
Ця стаття присвячена FinOps — операційній моделі, яка об'єднує фінанси, технології та бізнес для досягнення максимальної цінності від хмарних інвестицій. FinOps — це не одноразовий захід зі скорочення витрат, а безперервний процес, культура співпраці, спрямована на підвищення прозорості, підзвітності та ефективності використання хмарних ресурсів. Ми розглянемо, як FinOps-практики та сучасні інструменти допомагають DevOps-інженерам, backend-розробникам, фаундерам SaaS, системним адміністраторам та технічним директорам стартапів не просто скорочувати витрати, а й приймати обґрунтовані, стратегічні рішення, які сприяють зростанню бізнесу.
Чому ця тема важлива саме у 2026 році? Тому що складність хмарних екосистем продовжує зростати. Безліч сервісів, тарифних планів, моделей ціноутворення (за запитом, зарезервовані інстанси, спотові інстанси, безсерверні функції) створюють лабіринт, в якому легко загубитися і непомітно для себе переплачувати. З іншого боку, з'являються все більш досконалі інструменти для моніторингу, аналізу та автоматизації, які дозволяють управляти цією складністю. Стаття покликана допомогти вам орієнтуватися в цьому лабіринті, використовуючи передові підходи FinOps.
Стаття вирішує наступні проблеми:
- Відсутність прозорості: Як зрозуміти, куди йдуть гроші і які сервіси споживають найбільшу частину бюджету?
- Надлишкове споживання: Як уникнути переплати за невикористані або недовикористані ресурси?
- Складність вибору: Як вибрати між VPS, виділеними серверами, контейнерами або безсерверними рішеннями з урахуванням вартості та продуктивності?
- Відсутність єдиного підходу: Як налагодити взаємодію між технічними та фінансовими відділами для ефективного управління витратами?
- Масштабування з розумом: Як забезпечити зростання інфраструктури без пропорційного збільшення витрат?
Ця стаття написана для всіх, хто стикається з викликами управління хмарними витратами і прагне не тільки скоротити їх, але й оптимізувати цінність, отриману від кожного витраченого долара. Ми надамо конкретні, застосовні на практиці рекомендації, підкріплені прикладами та актуальними даними на 2026 рік, щоб ви могли впевнено управляти своєю хмарною інфраструктурою.
4. Основні критерії/фактори вибору та оптимізації
Вибір оптимальної інфраструктури та подальша її оптимізація — це багатогранний процес, що залежить від безлічі факторів. У контексті FinOps, кожен з цих критеріїв безпосередньо впливає на підсумкову вартість та цінність, яку бізнес отримує від IT-інвестицій. Розглянемо ключові фактори, актуальні для 2026 року.
Продуктивність і тип навантаження
Чому це важливо: Недооцінка або переоцінка необхідної продуктивності призводить до неефективних витрат. Занадто слабкий сервер не справляється з навантаженням, викликаючи сповільнення та відмови, що тягне за собою втрату клієнтів та репутаційні ризики. Занадто потужний сервер — це пряма переплата за невикористані ресурси.
Як оцінювати:
- CPU-інтенсивні задачі: Високі обчислення, обробка великих обсягів даних, машинне навчання, компіляція. Вимагають потужних ядер і, можливо, спеціалізованих процесорів (GPU, TPU).
- RAM-інтенсивні задачі: Бази даних в пам'яті (Redis, Memcached), JVM-додатки з великим хіпом, аналітика великих даних, обробка зображень. Вимагають великого обсягу оперативної пам'яті.
- I/O-інтенсивні задачі: Бази даних (PostgreSQL, MongoDB), файлові сервери, високонавантажені веб-сервери з великою кількістю статики. Вимагають швидких SSD/NVMe дисків і високої пропускної здатності I/O.
- Мережеве навантаження: Високонавантажені API-шлюзи, стримінгові сервіси, CDN-вузли. Вимагають високої пропускної здатності мережі та низьких затримок.
До 2026 року з'являються нові покоління процесорів (наприклад, ARM-процесори, такі як AWS Graviton, стають ще більш конкурентоспроможними за співвідношенням ціна/продуктивність), а також спеціалізовані рішення для ШІ та ML, які можуть значно знизити вартість виконання специфічних задач.
Масштабованість та еластичність
Чому це важливо: Здатність інфраструктури адаптуватися до змін навантаження без ручного втручання та з мінімальними витратами. Нееластична система або не справляється з піками, або простоює в періоди спаду, споживаючи ресурси. FinOps прагне до оплати лише за фактично використані ресурси.
Як оцінювати:
- Вертикальна масштабованість: Збільшення ресурсів (CPU, RAM) одного сервера. Проста в реалізації, але має фізичні обмеження та вимагає перезапуску.
- Горизонтальна масштабованість: Додавання нових серверів для розподілу навантаження. Складніша в реалізації (вимагає stateless-додатків, балансувальників), але забезпечує майже нескінченне зростання та високу доступність.
- Автоскейлінг: Автоматичне додавання/видалення серверів на основі метрик (CPU, RAM, черга запитів). Ключовий інструмент FinOps для динамічної оптимізації.
У 2026 році очікується подальший розвиток безсерверних (Serverless) та контейнерних (Kubernetes) рішень, які пропонують найвищий рівень еластичності та оплати за фактом використання, що робить їх вкрай привабливими з точки зору FinOps.
Надійність і доступність (SLA)
Чому це важливо: Час простою (downtime) — це прямі та непрямі втрати для бізнесу: втрачений прибуток, втрата клієнтів, шкода репутації. Висока доступність зазвичай коштує дорожче, тому важливо знайти баланс між необхідним рівнем SLA та бюджетом.
Як оцінювати:
- SLA (Service Level Agreement): Гарантований провайдером відсоток часу доступності сервісу (наприклад, 99.9% або 99.99%). Чим вище SLA, тим вища вартість.
- Резервування (Redundancy): Дублювання критично важливих компонентів (сервери, бази даних, мережеве обладнання) для запобігання єдиним точкам відмови.
- Географічне розподілення: Розміщення інфраструктури в кількох регіонах/зонах доступності для захисту від регіональних збоїв.
- Резервне копіювання та відновлення (Backup & Recovery): Регулярні бекапи та перевірені плани відновлення після збоїв.
FinOps підхід вимагає усвідомленого вибору рівня доступності, виходячи з бізнес-цінності додатку, а не "максимально можливого".
Безпека та відповідність нормативам (Compliance)
Чому це важливо: Витоки даних, кібератаки, невідповідність GDPR, HIPAA, PCI DSS та іншим стандартам можуть призвести до величезних штрафів, судових позовів та втрати довіри. Витрати на безпеку — це інвестиції, а не витрати.
Як оцінювати:
- Мережева безпека: Фаєрволи, VPN, WAF (Web Application Firewall), захист від DDoS.
- Безпека даних: Шифрування даних в стані спокою та при передачі, управління доступом, резервне копіювання.
- Управління ідентифікацією та доступом (IAM): Принцип найменших привілеїв, двофакторна аутентифікація.
- Відповідність стандартам: Сертифікації провайдера (ISO 27001, SOC 2), відповідність регіональним та галузевим нормам.
До 2026 року зростає роль автоматизованих засобів безпеки (DevSecOps), а також платформ для управління відповідністю, які допомагають мінімізувати ручні перевірки та пов'язані з ними витрати.
Модель ціноутворення та прогнозованість витрат
Чому це важливо: Непрозорі або непередбачувані витрати ускладнюють бюджетування та планування. FinOps прагне до максимальної передбачуваності та можливості оптимізації.
Як оцінювати:
- Pay-as-you-go: Оплата за фактично спожиті ресурси. Висока гнучкість, але потенційно висока непередбачуваність без належного моніторингу.
- Зарезервовані інстанси (Reserved Instances / Savings Plans): Знижки за зобов'язання використовувати певний обсяг ресурсів на тривалий термін (1-3 роки). Значно знижують базові витрати.
- Спотові інстанси (Spot Instances): Дуже дешеві, але переривані інстанси, які підходять для відмовостійких та batch-задач.
- Фіксована вартість: Виділені сервери або деякі VPS-тарифи з передбачуваною щомісячною оплатою. Підходять для стабільного, передбачуваного навантаження.
У 2026 році провайдери пропонують ще більш складні моделі ціноутворення, які вимагають глибокого аналізу та використання FinOps-інструментів для вибору найбільш вигідного варіанту.
Підтримка та екосистема
Чому це важливо: Якість підтримки та доступність інструментів впливають на швидкість вирішення проблем, час виходу на ринок та загальну операційну ефективність. Погана підтримка може призвести до тривалих простоїв та додаткових витрат на внутрішні ресурси.
Як оцінювати:
- Рівень підтримки: 24/7, час відповіді, канали зв'язку (чат, телефон, тікети).
- Документація та спільнота: Наявність вичерпної документації, активної спільноти, форумів.
- Екосистема: Доступність додаткових сервісів (бази даних, CDN, аналітика), інтеграція з іншими інструментами.
- Керовані сервіси: Можливість делегувати частину операційних задач провайдеру (наприклад, Managed Databases, Kubernetes as a Service).
Географічне розташування та затримки (Latency)
Чому це важливо: Фізичне розташування серверів відносно кінцевих користувачів напряму впливає на швидкість відгуку застосунку. Для глобальних сервісів це критично важливо. Також важливі питання суверенітету даних та відповідності місцевим законам.
Як оцінювати:
- Відстань до користувачів: Вибір дата-центрів, максимально наближених до основної аудиторії.
- CDN (Content Delivery Network): Використання CDN для кешування контенту ближче до користувачів, знижуючи навантаження на основний сервер та зменшуючи затримки.
- Multi-Region/Multi-Zone архітектура: Розгортання в декількох географічних точках для відмовостійкості та зниження затримок.
- Закони про зберігання даних: Переконайтеся, що дані зберігаються у відповідності до вимог юрисдикції, де знаходиться ваша аудиторія.
Оптимізація мережевих витрат, включаючи egress-трафік, стає одним з ключових напрямків FinOps до 2026 року, оскільки обсяги даних, що передаються, продовжують зростати.
Вендор-лок-ін (Vendor Lock-in)
Чому це важливо: Залежність від одного провайдера може обмежувати можливості міграції, знижувати переговорну силу та призводити до здорожчання послуг у довгостроковій перспективі. FinOps заохочує архітектури, які мінімізують залежність.
Як оцінювати:
- Стандартизація: Використання відкритих стандартів (Docker, Kubernetes, Terraform) та хмарно-незалежних технологій.
- Абстракція: Відокремлення логіки застосунку від специфічних хмарних сервісів.
- Мультихмарна/Гібридна стратегія: Розгортання в декількох хмарах або комбінація хмари з власною інфраструктурою для зниження ризиків.
До 2026 року інструменти для мультихмарного управління та абстракції інфраструктури стають все більш зрілими, дозволяючи компаніям більш гнучко підходити до вибору провайдерів та уникати жорсткого лок-іну.
5. Порівняльна таблиця хмарних та виділених серверів (2026)
У 2026 році ринок хмарних послуг та виділених серверів продовжує розвиватися, пропонуючи широкий спектр рішень. Нижче представлена порівняльна таблиця, що відображає ключові характеристики та орієнтовні ціни для різних типів інфраструктури, актуальні для 2026 року. Ціни є гіпотетичними та можуть варіюватися в залежності від провайдера, регіону та конкретної конфігурації. Ми припускаємо середні конфігурації, що підходять для типового SaaS-застосунку або бекенду.
| Критерій | Хмарний VPS (Shared CPU, 8-16 GB RAM) | Хмарний VPS (Dedicated CPU, 16-32 GB RAM) | Керований VPS (Managed, 16-32 GB RAM) | Виділений Сервер (Bare Metal, L-конфігурація) | Хмарний Інстанс (AWS EC2/GCP Compute, m5.xlarge/e2-standard-4) | Kubernetes as a Service (EKS/GKE, 3 вузли) | Serverless (Lambda/Cloud Functions, 100M викликів) |
|---|---|---|---|---|---|---|---|
| Типовий CPU | 2-4 vCPU (shared) | 4-8 vCPU (dedicated) | 4-8 vCPU (dedicated) | 8-16 Cores (фізичні) | 4 vCPU (dedicated) | 3 x 4 vCPU (dedicated) | 0.25-1 vCPU (burst) |
| Типова RAM | 8-16 GB | 16-32 GB | 16-32 GB | 64-128 GB | 16 GB | 3 x 16 GB | 128-512 MB |
| Типовий Storage | 160-320 GB SSD | 320-640 GB NVMe | 320-640 GB NVMe | 2 x 1 TB NVMe | 300 GB GP3 SSD | 3 x 300 GB GP3 SSD | N/A (Ephemeral) |
| Мережевий трафік (вхідний/вихідний) | 1-2 TB / 1-2 TB | 2-4 TB / 2-4 TB | 2-4 TB / 2-4 TB | 10-20 TB / 10-20 TB | Вхідний безкоштовно, Вихідний 0.08-0.12 $/GB | Вхідний безкоштовно, Вихідний 0.08-0.12 $/GB | Вхідний безкоштовно, Вихідний 0.08-0.12 $/GB |
| Орієнтовна місячна вартість (2026, USD) | 40-80 $ | 80-180 $ | 150-300 $ | 250-500 $ (без ОС/панелі) | 150-250 $ (On-Demand) | 400-800 $ (без Control Plane) | 50-150 $ (за 100М викликів) |
| Масштабованість | Ручна/Вертикальна | Ручна/Вертикальна | Ручна/Вертикальна | Ручна/Вертикальна (апгрейд) | Автоматична (горизонтальна, вертикальна) | Автоматична (горизонтальна, поди/вузли) | Автоматична (за запитом) |
| Рівень управління | Низький (OS Only) | Низький (OS Only) | Середній (OS + Панель) | Низький (Hardware Only) | Середній (IaaS) | Високий (PaaS) | Дуже високий (FaaS) |
| Передбачуваність витрат | Висока | Висока | Висока | Дуже висока | Низька (On-Demand), Висока (RI/SP) | Середня (по вузлах), Низька (по трафіку) | Низька (по викликах/RAM/CPU) |
| Час розгортання | Хвилини | Хвилини | Хвилини | Години/Дні | Хвилини | Десятки хвилин | Секунди |
Пояснення до таблиці:
- Хмарний VPS (Shared CPU): Віртуальні сервери, де CPU ділиться між кількома клієнтами. Найдешевший варіант, але схильний до "галасливого сусіда". Ідеальний для невеликих сайтів, тестових середовищ.
- Хмарний VPS (Dedicated CPU): Віртуальні сервери з гарантованими ядрами CPU. Більш стабільна продуктивність, підходить для production-середовищ з середнім навантаженням.
- Керований VPS: VPS з додатковими послугами адміністрування, панеллю управління (cPanel, Plesk), бекапами від провайдера. Зручно для тих, у кого немає своїх сисадмінів.
- Виділений Сервер (Bare Metal): Фізичний сервер, повністю у вашому розпорядженні. Максимальна продуктивність і контроль, але вимагає глибоких знань адміністрування. Економічно вигідний при дуже високому і стабільному навантаженні.
- Хмарний Інстанс (AWS EC2/GCP Compute): Типовий IaaS-сервіс від великих хмарних провайдерів. Пропонує величезну гнучкість, безліч типів інстансів, просунуті мережеві та дискові опції, але вимагає активного управління FinOps для контролю витрат.
- Kubernetes as a Service: Керовані кластери Kubernetes (наприклад, EKS, GKE, AKS). Дозволяють запускати контейнеризовані додатки з високою масштабованістю і відмовостійкістю. Вартість включає оплату за вузли і, можливо, за керуючий шар.
- Serverless (Lambda/Cloud Functions): Функції як сервіс (FaaS). Оплата йде за кількість викликів і час виконання. Ідеально для подійних, нечастих задач, мікросервісів. Максимальна еластичність, мінімальне адміністрування, але складніше прогнозувати вартість при непередбачуваному навантаженні.
Вибір між цими варіантами — це завжди компроміс між вартістю, продуктивністю, гнучкістю, рівнем управління і передбачуваністю. FinOps допомагає прийняти це рішення, виходячи з реальних потреб бізнесу.
Потрібен виділений сервер?
Compare prices from top providers. Configure and order in minutes.
6. Детальний огляд кожного пункту/варіанту

Розуміння нюансів кожного типу інфраструктури критично важливе для прийняття обґрунтованих FinOps-рішень. До 2026 року відмінності між ними стали ще більш вираженими, а їх оптимальне застосування вимагає глибокої експертизи.
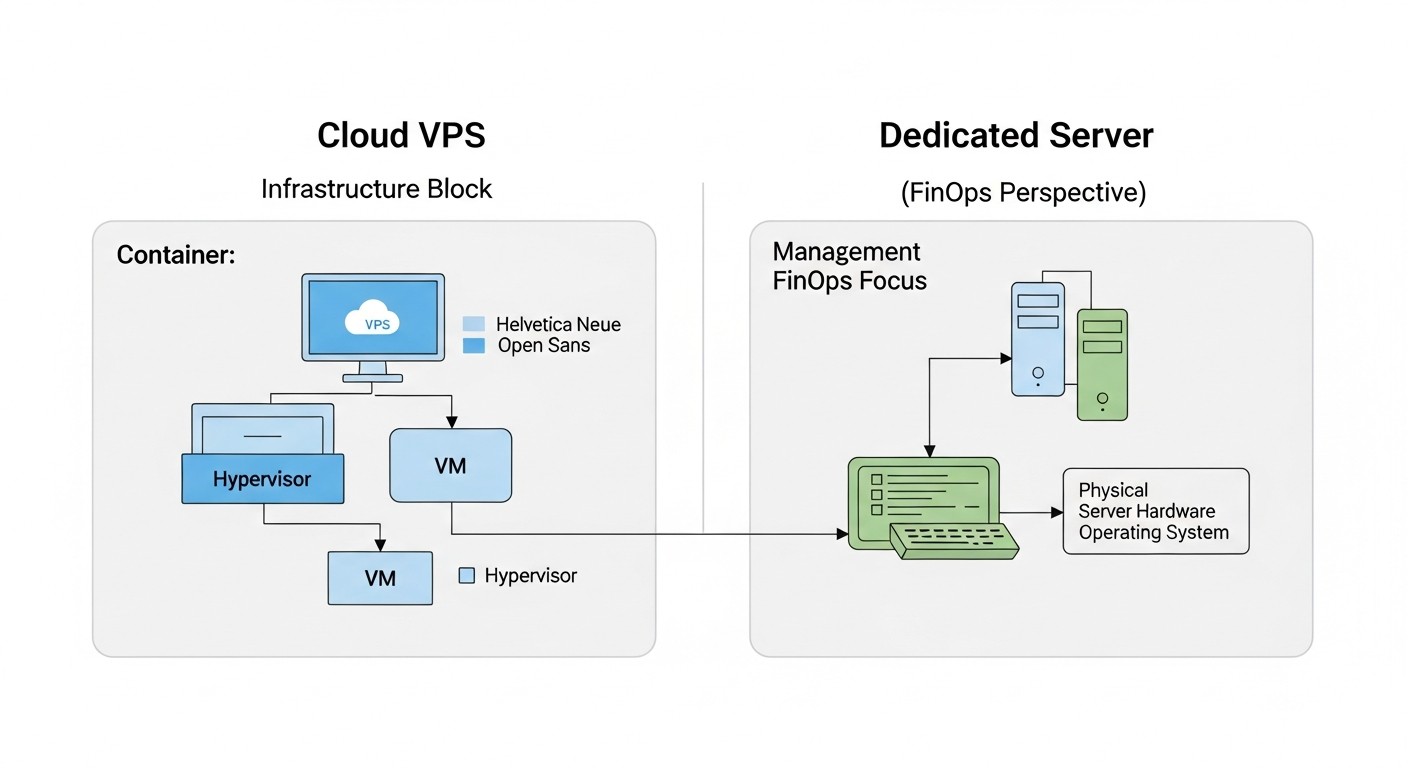
Хмарні VPS (Virtual Private Servers)
Хмарні VPS залишаються одним з найпопулярніших та доступних рішень для більшості стартапів та середніх проєктів. Вони представляють собою віртуалізовану частину фізичного сервера, де ви отримуєте гарантовані ресурси (або ресурси з оверселінгом у випадку Shared CPU) та повний контроль над операційною системою. Провайдери, такі як DigitalOcean, Vultr, Hetzner, Linode, а також російські провайдери (Яндекс.Облако, VK Cloud Solutions, Selectel) пропонують широкий спектр VPS.
Плюси:
- Доступність: Низький поріг входу, стартові тарифи починаються від декількох доларів на місяць.
- Гнучкість: Легко масштабувати ресурси (CPU, RAM, Storage) вертикально (часто з перезавантаженням). Швидке розгортання.
- Контроль: Повний root-доступ до операційної системи, що дозволяє встановлювати будь-яке ПЗ та налаштовувати середовище під свої потреби.
- Передбачуваність: Зазвичай фіксована щомісячна плата, що полегшує бюджетування.
- Широкий вибір: Безліч провайдерів, які конкурують за ціною та якістю.
Мінуси:
- Обмежена масштабованість: Вертикальне масштабування має фізичні межі. Горизонтальне масштабування вимагає ручного налаштування або використання додаткових сервісів (балансувальників).
- Проблема "шумного сусіда": На Shared CPU VPS продуктивність може страждати через інших клієнтів на тому ж фізичному сервері.
- Відсутність Managed-сервісів: Більшість VPS не включають керовані бази даних, черги повідомлень та інші PaaS-сервіси, які є у великих хмарних провайдерів.
- Ручне адміністрування: Вся відповідальність за ОС, безпеку, оновлення, бекапи лежить на користувачеві (якщо це не Managed VPS).
Для кого підходить:
Невеликі та середні веб-застосунки, API-сервіси, блоги, тестові та dev-середовища, VPN-сервери, особисті проєкти. Ідеально для стартапів на ранніх стадіях, яким потрібна гнучкість та низькі стартові витрати. FinOps тут фокусується на правильному виборі тарифу, регулярному моніторингу утилізації та своєчасному апгрейді/даунгрейді.
Конкретні приклади використання:
Розгортання сайту на WordPress/Laravel, невеликого Node.js/Python API, сервера для CI/CD агентів, тестового середовища для розробників. Наприклад, стартап може почати з VPS за $20/місяць, а по мірі зростання трафіку перейти на Dedicated CPU VPS за $80-100/місяць, поки не знадобиться більш складна архітектура з балансуванням навантаження.
Виділені сервери (Dedicated Servers / Bare Metal)
Виділений сервер надає вам повний фізичний сервер, без віртуалізації (якщо ви самі її не розгорнете). Це означає ексклюзивний доступ до всіх апаратних ресурсів: CPU, RAM, дисків та мережевого інтерфейсу. Провайдери, такі як Hetzner, OVHcloud, Contabo, а також російські Selectel, DataLine, пропонують широкий вибір конфігурацій.
Плюси:
- Максимальна продуктивність: Відсутність оверхеду віртуалізації, повний доступ до "заліза". Ідеально для ресурсоємних задач.
- Стабільність та передбачуваність: Продуктивність не залежить від "сусідів".
- Повний контроль: Ви керуєте всім, від вибору ОС до низькорівневих налаштувань BIOS/UEFI.
- Безпека: Фізична ізоляція від інших клієнтів.
- Економія на великих обсягах: При високому та постійному навантаженні виділений сервер може бути дешевшим, ніж еквівалентна конфігурація в хмарі (особливо без довгострокових зобов'язань).
- Високі ліміти трафіку: Часто провайдери пропонують дуже великі обсяги трафіку або навіть необмежений трафік за фіксовану плату.
Мінуси:
- Низька гнучкість/масштабованість: Вертикальне масштабування вимагає заміни обладнання та простою. Горизонтальне масштабування вимагає покупки нових серверів та ручного налаштування.
- Тривале розгортання: Замовлення та підготовка сервера може займати від декількох годин до декількох днів.
- Висока вартість входу: Вартість оренди значно вища, ніж у VPS.
- Високі вимоги до адміністрування: Вимагає глибоких знань системного адміністрування, налаштування мережі, RAID-масивів, безпеки.
- Відсутність managed-сервісів: Всі додаткові сервіси (бази даних, балансувальники) потрібно налаштовувати та підтримувати самостійно.
Для кого підходить:
Великі бази даних, високонавантажені ігрові сервери, стрімінгові платформи, ERP-системи, проєкти з дуже стабільним та високим навантаженням, де важлива кожна мілісекунда та максимальна пропускна здатність. Також підходить для компаній, яким потрібен максимальний контроль над інфраструктурою або потрібне специфічне "залізо". FinOps тут зосереджений на довгостроковому плануванні, правильному виборі конфігурації та ефективному використанні кожного ядра та гігабайта.
Конкретні приклади використання:
Сервери для Minecraft з сотнями гравців, високонавантажений PostgreSQL-кластер, сервер для машинного навчання з GPU, корпоративна система 1С, приватна хмара на базі Proxmox/OpenStack. Наприклад, ігровій студії для нового тайтлу може знадобитися виділений сервер з потужним CPU та великим обсягом RAM, здатний обробити пікове навантаження в 5000 одночасних користувачів, що обійдеться в $400-600/місяць, але дозволить уникнути лагів та забезпечити стабільний ігровий досвід.
Хмарні інстанси (IaaS від великих провайдерів: AWS EC2, GCP Compute Engine, Azure VMs)
Ці сервіси надають віртуальні машини у великомасштабних хмарних інфраструктурах, таких як Amazon Web Services (AWS), Google Cloud Platform (GCP) та Microsoft Azure. Вони пропонують величезну гнучкість, масштабованість та інтеграцію з великою екосистемою хмарних сервісів.
Плюси:
- Найвища масштабованість: Просте налаштування автоскейлінгу, можливість запуску тисяч інстансів за лічені хвилини.
- Гнучкість конфігурацій: Широкий вибір типів інстансів (оптимізовані для CPU, RAM, I/O, GPU), можливість кастомних конфігурацій.
- Екосистема сервісів: Безшовна інтеграція з керованими базами даних (RDS, Cloud SQL), чергами повідомлень (SQS, Pub/Sub), CDN (CloudFront, Cloud CDN), безсерверними функціями (Lambda, Cloud Functions) та безліччю інших PaaS/SaaS рішень.
- Висока доступність: Можливість розгортання в кількох зонах доступності та регіонах для максимальної відмовостійкості.
- Просунуті FinOps-інструменти: Вбудовані інструменти для моніторингу витрат, білінгу, бюджетування, резервування потужностей (Reserved Instances, Savings Plans, Spot Instances).
Мінуси:
- Складність: Величезна кількість сервісів та опцій може бути приголомшливою для новачків.
- Непередбачуваність витрат: Модель оплати Pay-as-you-go може призвести до несподівано високих рахунків без належного контролю та оптимізації.
- Вендор-лок-ін: Використання специфічних хмарних сервісів може ускладнити міграцію на іншого провайдера.
- Мережеві витрати: Egress-трафік (вихідний трафік з хмари) може бути дуже дорогим.
Для кого підходить:
Великі SaaS-проєкти, e-commerce платформи, високонавантажені веб-сервіси, проєкти з динамічним та непередбачуваним навантаженням, Big Data, ML-проєкти. Для компаній, яким потрібна максимальна гнучкість, масштабованість та широкий спектр керованих сервісів. FinOps тут — це центральна дисципліна, що включає управління Reserved Instances, Spot Instances, rightsizing, оптимізацію мережевого трафіку та регулярний аудит.
Конкретні приклади використання:
Backend для мобільного додатку з мільйонами користувачів, аналітична платформа, що обробляє петабайти даних, глобальний e-commerce сайт. Наприклад, SaaS-компанія, що надає CRM-систему, може використовувати EC2 інстанси для своїх мікросервісів, RDS для бази даних, SQS для черг та S3 для зберігання файлів. За правильного застосування FinOps, використовуючи Reserved Instances для базового навантаження та автоскейлінг зі Spot Instances для піків, можна знизити витрати на 30-70% у порівнянні з On-Demand.
Kubernetes as a Service (EKS, GKE, AKS)
Керовані сервіси Kubernetes (Amazon EKS, Google GKE, Azure AKS) надають готові до використання кластери Kubernetes, абстрагуючи користувача від управління майстер-нодами та їх інфраструктурою. Це дозволяє зосередитись на розгортанні додатків у контейнерах.
Плюси:
- Висока масштабованість: Автоматичне масштабування подів та вузлів кластера в залежності від навантаження.
- Відмовостійкість: Вбудовані механізми оркестрації та самовідновлення.
- Переносність: Контейнери (Docker) та Kubernetes є відкритими стандартами, що знижує вендор-лок-ін.
- Ефективне використання ресурсів: Kubernetes дозволяє щільно запаковувати робочі навантаження на вузлах, максимізуючи утилізацію ресурсів.
- DevOps-friendly: Спрощує CI/CD та розгортання додатків.
Мінуси:
- Складність: Kubernetes сам по собі має високий поріг входу.
- Вартість керуючого шару: Деякі провайдери беруть плату за майстер-ноди (наприклад, EKS), інші включають це у вартість вузлів.
- Накладні витрати: Кластер Kubernetes потребує більше ресурсів для своєї роботи у порівнянні з "голими" VPS.
- Витрати на навчання: Потрібні спеціалісти з глибокими знаннями Kubernetes.
Для кого підходить:
Мікросервісні архітектури, високонавантажені розподілені додатки, SaaS-платформи, яким потрібна висока ступінь автоматизації, масштабованості та відмовостійкості. Компанії, які вже використовують контейнеризацію або планують міграцію на мікросервіси. FinOps в Kubernetes включає оптимізацію розмірів подів (requests/limits), автоскейлінг вузлів (Cluster Autoscaler, Karpenter), вибір оптимальних типів інстансів для вузлів, а також моніторинг та управління мережевими витратами.
Конкретні приклади використання:
Розгортання безлічі мікросервісів, кожен з яких обслуговує окрему функцію, на єдиному кластері Kubernetes. Наприклад, медіа-платформа, де кожен сервіс (користувачі, контент, рекомендації, стримінг) працює у своєму поді, масштабуючись незалежно. Вартість такого кластера може починатися від $400-500 на місяць за декілька вузлів та керуючий шар, але дозволяє значно скоротити операційні витрати на адміністрування та ефективно використовувати ресурси.
Serverless (Lambda, Cloud Functions, Azure Functions)
Serverless-обчислення, або "функції як сервіс" (FaaS), дозволяють розробникам запускати код без необхідності керування серверами. Провайдер автоматично масштабує та управляє всією базовою інфраструктурою, а оплата стягується лише за фактичний час виконання коду та кількість викликів.
Плюси:
- Максимальна еластичність: Миттєве масштабування від нуля до тисяч викликів на секунду.
- Оплата за фактом використання: Ви платите тільки за те, що реально споживаєте, без простоюючих серверів.
- Відсутність адміністрування: Провайдер бере на себе всі задачі з управління серверами, патчингу, оновлення ОС.
- Низькі операційні витрати: Значне скорочення зусиль DevOps та системних адміністраторів.
- Вбудована відмовостійкість: Функції автоматично дублюються та запускаються в різних зонах доступності.
Мінуси:
- Холодний старт (Cold Start): Перші виклики функції після простою можуть займати більше часу через ініціалізацію середовища.
- Обмеження: Ліміти на час виконання, обсяг пам'яті, розмір пакета розгортання.
- Складність налагодження та моніторингу: Розподілена природа Serverless-архітектур може ускладнювати налагодження.
- Вендор-лок-ін: Хоча код може бути переносним, інтеграція з іншими сервісами провайдера створює залежність.
- Непередбачуваність витрат: При дуже високому та непередбачуваному навантаженні вартість може бути вищою, ніж у постійно працюючого сервера.
Для кого підходить:
С подійно-орієнтовані архітектури, API-шлюзи, бекенди для мобільних додатків, обробка файлів, ETL-процеси, чат-боти, webhooks, фонові задачі. Ідеально для додатків зі змінним або спорадичним навантаженням. FinOps для Serverless включає оптимізацію часу виконання функцій, вибір оптимального обсягу пам'яті, агресивне кешування, а також моніторинг та аналіз викликів для виявлення неефективних функцій.
Конкретні приклади використання:
Обробка зображень після завантаження в S3, відправка повідомлень по email, аутентифікація користувачів, реалізація невеликих мікросервісів, які реагують на події в базі даних. Наприклад, для обробки 100 мільйонів викликів Lambda в місяць з часом виконання 500 мс та 256 МБ RAM, вартість може скласти близько $70-120 в місяць, що для такого обсягу обробки вкрай вигідно в порівнянні з підтримкою постійно працюючого сервера.
7. Практичні поради та рекомендації щодо FinOps
Застосування FinOps не обмежується теоретичними знаннями; воно вимагає конкретних дій та інструментів. Нижче представлені покрокові інструкції та рекомендації, які допоможуть вам ефективно управляти витратами на VPS та виділені сервери.
1. Впровадження культури прозорості та підзвітності (Tagging & Cost Allocation)
Перший крок до оптимізації — зрозуміти, хто і за що платить. До 2026 року без адекватної системи тегування та розподілу витрат неможливо ефективно управляти хмарою.
Дії:
- Розробіть політику тегування: Визначте обов'язкові теги для всіх ресурсів (наприклад,
Project,Environment,Owner,CostCenter). - Автоматизуйте тегування: Використовуйте Infrastructure as Code (IaC) для автоматичного застосування тегів при створенні ресурсів.
- Моніторинг дотримання: Регулярно перевіряйте, що всі ресурси мають необхідні теги.
Приклад політики тегування:
# Приклад політики тегування для AWS/GCP/Azure
# Всі ресурси повинні мати наступні теги:
- Key: Project
Description: Назва проекту або продукту (e.g., "SaaS_CRM", "Analytics_Platform")
Required: true
Values: [CRM, Analytics, CoreServices, InternalTools, ... ]
- Key: Environment
Description: Середовище розгортання (e.g., "prod", "staging", "dev", "test")
Required: true
Values: [prod, staging, dev, test]
- Key: Owner
Description: Ім'я або ID команди/інженера, відповідального за ресурс
Required: true
Values: [devops-team, backend-crm, data-eng, ... ]
- Key: CostCenter
Description: Код центру витрат для фінансової звітності
Required: false # Може бути опціональним для dev-середовищ
Values: [CC101, CC202, ... ]
- Key: Application
Description: Назва конкретного додатка або мікросервісу
Required: false
Values: [AuthService, PaymentGateway, UserPortal, ... ]
2. Правий сайзинг (Rightsizing) та регулярний аудит
Один з найефективніших способів зниження витрат — це підбір оптимального розміру сервера під реальне навантаження. Багато компаній переплачують за надлишкові ресурси.
Дії:
- Моніторинг утилізації: Збирайте метрики CPU, RAM, дискового I/O та мережевого трафіку за тривалий період (мінімум 30-90 днів).
- Ідентифікація недовикористаних ресурсів: Шукайте сервери з постійно низькою утилізацією (наприклад, CPU нижче 10-15%, RAM нижче 30-40%).
- Даунгрейд/Термінація: Переводьте недовикористані сервери на менші тарифи або повністю видаляйте невикористані.
- Оптимізація коду: Якщо ресурс постійно перевантажений, замість апгрейду сервера розгляньте оптимізацію коду програми.
Приклад команди для перевірки утилізації RAM/CPU (Linux):
# Перевірка поточної утилізації CPU та RAM
top -bn1 | head -n 5 # Короткий огляд
free -h # Використання RAM
vmstat 1 10 # Моніторинг CPU, I/O, RAM в реальному часі
# Більш глибокий аналіз за допомогою sar (System Activity Reporter)
# Встановіть sysstat, якщо його немає: sudo apt install sysstat
sar -u 1 10 # Утилізація CPU
sar -r 1 10 # Утилізація RAM
sar -b 1 10 # I/O операції
# Для перегляду історії за конкретну дату (наприклад, 2026-03-15)
# sar -f /var/log/sysstat/sa15 # (saYY де YY - день місяця)
3. Використання моделей оплати з зобов'язаннями (Reserved Instances / Savings Plans)
Для передбачуваного базового навантаження зарезервовані потужності можуть забезпечити значну економію.
Дії:
- Аналіз стабільного навантаження: Визначте мінімальну кількість серверів (VPS/VMs), які працюють 24/7 протягом тривалого часу.
- Вибір оптимального плану: Виберіть Reserved Instances (RI) або Savings Plans (SP) на 1 або 3 роки, з передоплатою або без, залежно від фінансової стратегії.
- Моніторинг покриття: Регулярно перевіряйте, який відсоток вашого стабільного навантаження покривається RI/SP.
Важливо: RI/SP підходять тільки для стабільного навантаження. Не резервуйте те, що може бути вимкнено або зменшено.
4. Автоматизація інфраструктури та масштабування
Автоматизація — це не тільки прискорення, але й значна економія.
Дії:
- Автоскейлінг: Налаштуйте автоматичне додавання/видалення серверів (у хмарах) або контейнерів (у Kubernetes) в залежності від навантаження.
- Планування ввімкнення/вимкнення: Автоматично вимикайте dev/test/staging середовища в неробочий час (вночі, у вихідні).
- Використання Spot Instances: Для відмовостійких, переривчастих робочих навантажень (наприклад, обробка великих даних, рендеринг, CI/CD) використовуйте Spot-інстанси з їхніми величезними знижками.
- Infrastructure as Code (IaC): Використовуйте Terraform, Ansible, CloudFormation, Pulumi для декларативного управління інфраструктурою, що знижує помилки та забезпечує відтворюваність.
Приклад скрипту для зупинки dev-серверів у неробочий час (для VPS з API, наприклад, DigitalOcean):
#!/bin/bash
# Скрипт для зупинки dev-серверів DigitalOcean за тегом 'Environment:dev'
# Потрібен встановлений doctl та аутентифікація
# doctl auth init
DO_TOKEN="YOUR_DIGITALOCEAN_API_TOKEN" # Використовуйте змінні середовища!
# Отримуємо список дроплетів з тегом 'Environment:dev'
DROPLET_IDS=$(doctl compute droplet list --format "ID,Tags" | grep "Environment:dev" | awk '{print $1}')
if [ -z "$DROPLET_IDS" ]; then
echo "Немає активних dev-дроплетів для зупинки."
exit 0
fi
echo "Зупинка наступних dev-дроплетів: $DROPLET_IDS"
for ID in $DROPLET_IDS; do
echo "Зупиняємо дроплет ID: $ID..."
doctl compute droplet-action power-off $ID --force
if [ $? -eq 0 ]; then
echo "Дроплет $ID успішно зупинений."
else
echo "Помилка при зупинці дроплета $ID."
fi
done
echo "Процес зупинки dev-дроплетів завершено."
5. Оптимізація сховищ та мережевого трафіку
Ці компоненти часто недооцінюються, але можуть становити значну частку рахунку.
Дії:
- Аудит дисків: Ідентифікуйте невикористовувані диски, застарілі снапшоти, неактуальні образи. Видаляйте їх.
- Вибір типу сховища: Використовуйте S3-сумісні сховища для статичних файлів, блокові сховища для баз даних, а холодні сховища (Glacier, Coldline) для архівів.
- Оптимізація egress-трафіку:
- Використовуйте CDN (Content Delivery Network) для кешування контенту ближче до користувачів, знижуючи навантаження на основний сервер і зменшуючи egress-трафік з хмари.
- Стискайте дані (gzip, brotli) перед відправкою.
- Мінімізуйте розмір зображень та відео.
- Розгляньте розміщення ресурсів в тому ж регіоні, що й споживачі, щоб уникнути міжрегіонального трафіку.
Приклад конфігурації Nginx для стиснення Gzip:
http {
# ... інші налаштування ...
gzip on;
gzip_vary on;
gzip_proxied any;
gzip_comp_level 6; # Рівень стиснення: 1 (швидко) - 9 (макс. стиснення)
gzip_buffers 16 8k;
gzip_http_version 1.1;
gzip_types text/plain text/css application/json application/javascript text/xml application/xml application/xml+rss text/javascript font/truetype font/opentype application/vnd.ms-fontobject image/svg+xml;
gzip_disable "MSIE [1-6]\."; # Відключити для старих IE
server {
# ... налаштування вашого сервера ...
}
}
6. Моніторинг та оповіщення про витрати
Без постійного моніторингу неможливо швидко реагувати на зміни.
Дії:
- Налаштуйте бюджети: Встановіть місячні або квартальні бюджети для кожного проєкту/відділу та налаштуйте оповіщення при перевищенні порогів (наприклад, 50%, 80%, 100% бюджету).
- Відстежуйте аномалії: Використовуйте інструменти для виявлення різких стрибків витрат або незвичайного використання ресурсів.
- Регулярні звіти: Надавайте регулярні звіти про витрати технічним та фінансовим командам.
7. Оптимізація баз даних
Бази даних часто є одним з найдорожчих компонентів інфраструктури.
Дії:
- Правильний сайзинг: Переконайтеся, що тип і розмір інстанса бази даних відповідають реальному навантаженню.
- Індексування: Оптимізуйте запити та додайте необхідні індекси для прискорення роботи бази даних, що може знизити потребу в більш потужному "залізі".
- Кешування: Використовуйте кешування (Redis, Memcached) для зниження навантаження на базу даних.
- Архівування/Шардування: Переносьте старі дані в холодне сховище або шадруйте базу даних для розподілу навантаження.
- Managed Databases: Використовуйте керовані бази даних від хмарних провайдерів, які часто включають автоматичне масштабування, бекапи та патчінг, що знижує TCO (Total Cost of Ownership).
Приклад SQL-запиту для пошуку повільних запитів в PostgreSQL:
-- Переконайтеся, що pg_stat_statements включений в postgresql.conf
-- shared_preload_libraries = 'pg_stat_statements'
-- pg_stat_statements.track = all
-- RESTART DB
SELECT
query,
calls,
total_time,
mean_time,
stddev_time,
rows,
100.0 * shared_blks_hit / (shared_blks_hit + shared_blks_read) AS hit_percent
FROM
pg_stat_statements
ORDER BY
total_time DESC
LIMIT 10;
8. Дедублікація та архівування даних
Сховище займає значну частину витрат, особливо з урахуванням резервних копій та снапшотів.
Дії:
- Політики життєвого циклу: Налаштуйте автоматичне переміщення старих даних в дешевші класи зберігання (наприклад, S3 Standard-IA, Glacier).
- Видалення застарілих бекапів/снапшотів: Регулярно видаляйте бекапи та снапшоти, які вийшли за рамки встановлених політик зберігання.
- Дедублікація: Використовуйте інструменти дедублікації для зберігання тільки унікальних копій даних.
8. Типові помилки при оптимізації витрат
Навіть досвідчені команди DevOps і системні адміністратори можуть робити помилки, які призводять до переплат. До 2026 року ці помилки стають ще дорожчими через зростаючу складність хмарних екосистем.
1. Ігнорування невикористаних ресурсів (Zombie Resources)
Опис помилки: Це, мабуть, найпоширеніша і найдорожча помилка. Після тестування, експериментів або деактивації старих сервісів часто залишаються запущені, але невикористані сервери (VPS/VM), неактивні балансувальники, невикористані IP-адреси, невикористані диски, снапшоти, бази даних та інші ресурси. Вони продовжують генерувати рахунки, іноді непомітно, поки не виростуть до значних сум.
Як уникнути:
- Впровадьте сувору політику з видалення ресурсів після використання, особливо для dev/test середовищ.
- Автоматизуйте очищення ресурсів за допомогою скриптів або IaC (Infrastructure as Code) після завершення проєктів або після закінчення терміну життя.
- Налаштуйте регулярні аудити хмарних ресурсів за допомогою спеціалізованих інструментів (див. розділ 12) для виявлення "зомбі-ресурсів".
- Використовуйте тегування (
Owner,TTL- Time To Live) для всіх ресурсів, щоб легко ідентифікувати їхніх власників і термін життя.
Реальний приклад наслідків: Один зі стартапів виявив, що платить $1500 на місяць за 10 EC2-інстансів, які використовувалися для A/B тестування пів року тому і були забуті. Загальна переплата склала $9000, що було критично для їхнього скромного бюджету.
2. Недостатній Rightsizing (Переплата за надлишкову потужність)
Опис помилки: Часто інженери вибирають "з запасом" або стандартні великі конфігурації для серверів, не аналізуючи реальні потреби програми. В результаті, сервери працюють з утилізацією CPU 5-10% і RAM 20-30%, а компанія переплачує за невикористану потужність.
Як уникнути:
- Впровадьте систему моніторингу, яка збирає метрики утилізації (CPU, RAM, I/O, Network) за тривалий період (мінімум 30-90 днів).
- Регулярно аналізуйте ці метрики і використовуйте рекомендації провайдера (наприклад, AWS Compute Optimizer) або сторонні інструменти для визначення оптимального розміру інстанса.
- Не бійтеся зменшувати розмір сервера (даунгрейд), якщо це дозволяє навантаження. Легше збільшити, якщо буде потрібно.
- Розгляньте використання автоскейлінгу, який автоматично підлаштовує кількість і розмір інстансів під поточне навантаження.
Реальний приклад наслідків: SaaS-проєкт розміщував свій backend на 4 VPS по $120 кожен, хоча моніторинг показував, що 3 з них постійно завантажені менш ніж на 15% CPU. Після даунгрейду до VPS по $60 кожен, щомісячна економія склала $240, або $2880 на рік, без втрати продуктивності.
3. Ігнорування мережевих витрат (Egress-трафік)
Опис помилки: Багато хто зосереджується на вартості CPU/RAM/Storage, забуваючи, що вихідний мережевий трафік (egress) з хмари може бути дуже дорогим, особливо при великих обсягах даних або міжрегіональних передачах. До 2026 року, зі зростанням обсягів даних і мультимедіа, ця проблема тільки посилюється.
Як уникнути:
- Використовуйте CDN (Content Delivery Network) для доставки статичного контенту (зображення, відео, JS/CSS) користувачам, оскільки CDN-трафік часто дешевший, ніж прямий egress з хмари.
- Стискайте дані (gzip, brotli) перед передаванням мережею.
- Розміщуйте ресурси, які часто обмінюються даними, в одній зоні доступності або регіоні, щоб мінімізувати міжзональний/міжрегіональний трафік.
- Оптимізуйте запити до API, щоб не передавати надлишкові дані.
- Кешуйте дані на стороні клієнта або в проміжних сервісах.
Реальний приклад наслідків: Одна медіа-платформа зіткнулася з рахунком за egress-трафік AWS CloudFront, який перевищував вартість всіх їхніх EC2 інстансів. Причина: неоптимізовані зображення і відео, які передавалися без належного стиснення і кешування. Після оптимізації та впровадження CDN, витрати на трафік скоротилися на 60%.
4. Відсутність автоматизації та планування
Опис помилки: Ручне управління інфраструктурою не тільки забирає час, але й призводить до неефективного використання ресурсів. Забуті тестові середовища, запущені у вихідні, або ручні масштабування, які не встигають за навантаженням, — все це веде до переплат.
Як уникнути:
- Впровадьте Infrastructure as Code (IaC) для декларативного управління ресурсами.
- Налаштуйте автоскейлінг для динамічної зміни ресурсів в залежності від навантаження.
- Використовуйте планувальники (cronjobs, хмарні функції) для автоматичного включення/виключення dev/test середовищ в неробочий час.
- Автоматизуйте видалення застарілих снапшотів і бекапів.
Реальний приклад наслідків: Команда розробників вручну запускала і зупиняла тестові сервери. В результаті, щоп'ятниці забували вимкнути 3 сервери, які працювали всі вихідні. За рік це призвело до переплати в $3600 за години простою, яких можна було уникнути за допомогою простого cron-скрипта.
5. Неефективне використання зарезервованих потужностей (Reserved Instances / Savings Plans)
Опис помилки: Або компанія взагалі не використовує RI/SP, втрачаючи можливість заощадити до 70% на базовому навантаженні, або купує їх без належного аналізу, резервуючи занадто багато або не ті типи інстансів, які потім не використовуються.
Як уникнути:
- Проводьте ретельний аналіз історії використання ресурсів, щоб визначити стабільне, передбачуване базове навантаження, яке працює 24/7.
- Використовуйте рекомендації хмарних провайдерів (наприклад, AWS Cost Explorer RI/SP recommendations) для визначення оптимальної кількості і типів RI/SP.
- Моніторте утилізацію ваших RI/SP, щоб переконатися, що вони використовуються ефективно. За потреби продавайте невикористані RI на маркетплейсах (якщо доступно).
- Пам'ятайте, що RI/SP — це зобов'язання. Не купуйте їх для тимчасових або експериментальних робочих навантажень.
Реальний приклад наслідків: Велика компанія купила Reserved Instances на $50 000 для своїх EC2-інстансів, але через раптову реструктуризацію проєкту і перехід на Kubernetes, 40% цих інстансів перестали використовуватися. RI залишилися неоплаченими, оскільки не було можливості їх перенести або продати, що призвело до значних фінансових втрат.
6. Відсутність FinOps-культури та міжфункціональної співпраці
Опис помилки: Коли інженери не розуміють фінансові наслідки своїх рішень, а фінансові відділи не розуміють технічну специфіку, виникає розрив. Інженери можуть вибирати найдорожчі, але зручні рішення, а фінансові менеджери можуть вимагати скорочення витрат без розуміння впливу на продуктивність або стабільність.
Як уникнути:
- Впроваджуйте FinOps як культуру, а не як інструмент. Створіть міжфункціональну команду (інженери, фінанси, продукт).
- Навчайте інженерів фінансової грамотності в контексті хмари.
- Надавайте інженерам доступ до звітів про витрати (за їхніми проєктами/сервісами) і зробіть їх відповідальними за бюджет.
- Встановіть KPI, які включають як технічні метрики (uptime, продуктивність), так і фінансові (Cost per Transaction, Cost per User).
- Регулярно проводьте зустрічі, де обговорюються як технічні, так і фінансові аспекти використання хмари.
Реальний приклад наслідків: В одній компанії розробники постійно вибирали найпотужніші інстанси для своїх баз даних, тому що "так швидше". Фінансовий відділ, не розуміючи технічної сторони, просто оплачував рахунки. В результаті, витрати на бази даних складали 40% від усього хмарного бюджету, хоча велика частина цієї потужності не використовувалася, а оптимізація запитів могла б дати набагато більший ефект при менших витратах.
Потрібен виділений сервер?
Compare prices from top providers. Configure and order in minutes.
9. Чекліст для практичного застосування FinOps
Цей чекліст допоможе вам систематично підходити до оптимізації витрат на хмарні VPS та виділені сервери, дотримуючись принципів FinOps. Проходьте по ньому регулярно, наприклад, раз на місяць або квартал.
Фаза 1: Інформування та Видимість (Inform)
- Чи впроваджена політика тегування для всіх ресурсів?
- Чи всі ресурси мають обов'язкові теги (Project, Environment, Owner, CostCenter)?
- Чи автоматизовано тегування через IaC?
- Чи проводиться регулярний аудит дотримання політики тегування?
- Чи налаштовані інструменти моніторингу витрат?
- Чи використовуються вбудовані засоби хмарних провайдерів (Cost Explorer, Billing Reports)?
- Чи інтегровані сторонні FinOps-платформи (CloudHealth, Apptio Cloudability, CloudZero)?
- Чи доступні деталізовані звіти про витрати за проєктами, командами, середовищами?
- Чи налаштовані бюджети та сповіщення?
- Чи встановлені місячні/квартальні бюджети для кожного проєкту/відділу?
- Чи налаштовані сповіщення при перевищенні порогів (50%, 80%, 100%)?
- Чи отримують відповідальні особи ці сповіщення?
- Чи є централізоване сховище метрик утилізації?
- Чи збираються метрики CPU, RAM, I/O, Network за останні 30-90 днів для всіх серверів?
- Чи доступні ці метрики для аналізу та побудови звітів?
Фаза 2: Оптимізація (Optimize)
- Чи проведено аудит невикористовуваних ресурсів ("зомбі-ресурсів")?
- Чи ідентифіковані невикористовувані VPS/VM, диски, IP, балансувальники, снапшоти?
- Чи розроблено план щодо їх видалення або деактивації?
- Чи автоматизовано очищення тимчасових ресурсів?
- Чи виконується Rightsizing для всіх серверів?
- Чи проаналізовані метрики утилізації для виявлення недовикористовуваних/перевикористовуваних серверів?
- Чи застосовуються рекомендації щодо зменшення/збільшення розміру інстансів?
- Чи використовуються рекомендації щодо переходу на новіші, економічні типи інстансів (наприклад, Graviton)?
- Чи оптимізовані сховища даних?
- Чи переміщені рідко використовувані дані в дешевші класи зберігання (наприклад, Glacier, Coldline)?
- Чи видалені застарілі бекапи/снапшоти відповідно до політик?
- Чи використовуються оптимальні типи дисків (GP3 замість GP2, HDD замість SSD для архівів)?
- Чи застосовуються моделі оплати з зобов'язаннями (RI/Savings Plans)?
- Чи визначено стабільне базове навантаження, яке можна покрити RI/SP?
- Чи використовуються рекомендації провайдера для купівлі RI/SP?
- Чи відстежується утилізація RI/SP?
- Чи впроваджена автоматизація масштабування та управління?
- Чи налаштовано автоскейлінг для динамічних робочих навантажень?
- Чи використовуються Spot Instances для відмовостійких завдань?
- Чи налаштовані автоматичні розклади ввімкнення/вимкнення для dev/test середовищ?
- Чи використовується IaC (Terraform, Ansible) для управління інфраструктурою?
- Чи оптимізовано мережевий трафік (особливо egress)?
- Чи використовується CDN для статичного контенту?
- Чи застосовується стиснення даних (gzip, brotli) для трафіку?
- Чи мінімізується міжрегіональний/міжзональний трафік?
- Чи оптимізовані бази даних?
- Чи проведено аудит повільних запитів і чи додано необхідні індекси?
- Чи використовується кешування (Redis, Memcached) для зниження навантаження на БД?
- Чи розглянуто використання керованих баз даних для зниження TCO?
Фаза 3: Експлуатація та Співпраця (Operate)
- Чи впроваджена FinOps-культура в команді?
- Чи навчені інженери основам FinOps та фінансовій грамотності?
- Чи є у інженерів доступ до звітів про витрати за їхніми сервісами/проєктами?
- Чи встановлені KPI, що включають метрики вартості?
- Чи проводяться регулярні зустрічі FinOps?
- Чи беруть участь у них представники інженерії, фінансів та продукту?
- Чи обговорюються поточні витрати, плани з оптимізації та нові проєкти?
- Чи є план реагування на аномалії у витратах?
- Чи визначені процедури розслідування та усунення причин різких стрибків витрат?
- Чи проводиться періодичний перегляд стратегії провайдера?
- Чи оцінюються нові пропозиції від інших хмарних провайдерів або варіанти з виділеними серверами?
- Чи аналізується можливість міграції для отримання кращих умов?
10. Розрахунок вартості / Економіка хмарних та виділених серверів
Розуміння економіки хмарних та виділених серверів — це основа FinOps. Витрати не обмежуються лише щомісячною платою за CPU та RAM; існують приховані витрати та фактори, які можуть значно вплинути на підсумковий рахунок. До 2026 року ці фактори стають ще більш комплексними.
Основні компоненти витрат
- Обчислювальні ресурси (Compute): CPU, RAM. Основна стаття витрат, але часто не єдина.
- Сховище (Storage): Диски (SSD, NVMe, HDD), об'єктні сховища (S3-сумісні), файлові системи. Залежать від обсягу, типу (продуктивність) та кількості I/O операцій.
- Мережевий трафік (Network): Вхідний (ingress) зазвичай безкоштовний, вихідний (egress) — платний і може бути дуже дорогим, особливо міжрегіональний. Також оплачуються IP-адреси, балансувальники, VPN-шлюзи.
- Бази даних: Керовані бази даних (RDS, Cloud SQL) включають вартість інстансу, сховища, I/O та резервного копіювання.
- Додаткові сервіси: CDN, черги повідомлень, безсерверні функції, моніторинг, логування, безпека (WAF, DDoS-захист).
- Ліцензії: Вартість ліцензій на ОС (Windows Server), бази даних (MS SQL Server), панелі керування (cPanel, Plesk) та інше ПЗ.
- Операційні витрати (OpEx): Витрати на персонал (DevOps, сисадміни), їх навчання, час, витрачений на управління та налагодження.
Як оптимізувати витрати
Оптимізація витрат — це не тільки скорочення, але й отримання максимальної цінності за кожен витрачений рубль/долар. Це досягається за рахунок:
- Rightsizing: Постійний підбір оптимального розміру ресурсів.
- Автоматизація: Використання автоскейлінгу, планування увімкнення/вимкнення.
- Моделі оплати: Застосування Reserved Instances, Savings Plans, Spot Instances.
- Оптимізація коду: Більш ефективний код потребує менше ресурсів.
- Архітектурні рішення: Перехід на мікросервіси, контейнери, Serverless для кращої утилізації та масштабованості.
- Управління сховищем: Використання багаторівневого зберігання, видалення непотрібних даних.
- Оптимізація мережі: CDN, стиснення даних, мінімізація міжрегіонального трафіку.
- Моніторинг та звітність: Постійний аналіз витрат та виявлення аномалій.
Приховані витрати
До 2026 року, незважаючи на прагнення провайдерів до прозорості, деякі витрати залишаються "прихованими" або неочевидними:
- Неактивні ресурси: IP-адреси, балансувальники, диски, які не використовуються, але продовжують тарифікуватися.
- Міжзональний/міжрегіональний трафік: Передача даних між різними зонами доступності або регіонами всередині одного провайдера.
- I/O операції сховища: У деяких моделях оплати, крім обсягу диска, тарифікуються операції читання/запису.
- Витрати на логування та моніторинг: Збір та зберігання логів, метрик можуть бути дорогими при великих обсягах.
- Витрати на підтримку: Преміум-підтримка від хмарних провайдерів може бути дорогою, але часто виправдана для критично важливих систем.
- Витрати на міграцію: Перенесення даних та додатків між провайдерами або всередині хмари може спричинити витрати на трафік та трудовитрати.
- Витрати на навчання персоналу: Необхідність навчати команду новим технологіям та FinOps-практикам.
Приклади розрахунків для різних сценаріїв (2026 рік, гіпотетичні ціни)
Для наочності розглянемо три типових сценарії та проведемо спрощений розрахунок вартості, що демонструє вплив FinOps-практик.
Сценарій 1: Малий SaaS-проект (MVP на старті)
Опис: Невеликий веб-додаток з базовим API та простою базою даних, 1000 активних користувачів, пікове навантаження 50 RPS. Потрібна висока гнучкість та низькі стартові витрати.
| Ресурс | Конфігурація | Щомісячна вартість (без FinOps) | Щомісячна вартість (з FinOps) | Коментар |
|---|---|---|---|---|
| Backend/API | 1 x Dedicated CPU VPS (4vCPU, 8GB RAM, 160GB NVMe) | 80 $ | 40 $ | Rightsizing: 1 x Shared CPU VPS (2vCPU, 4GB RAM, 80GB SSD) на старті. |
| База даних | 1 x Managed PostgreSQL (4vCPU, 8GB RAM, 100GB SSD) | 120 $ | 80 $ | Rightsizing: Менший інстанс БД (2vCPU, 4GB RAM). |
| CDN | Немає | 0 $ (але дорогий egress) | 15 $ | Впровадження CDN для статики (500GB трафіку). |
| Трафік (Egress) | 1 TB | 80 $ | 20 $ | Зниження за рахунок CDN та стиснення. |
| Бекапи | Ручні/Базові | 10 $ | 10 $ | Автоматичні снапшоти/бекапи. |
| Разом: | 290 $ | 165 $ | Економія: 43% |
Сценарій 2: Зростаючий e-commerce проєкт
Опис: Інтернет-магазин зі змінним навантаженням, піки у свята та розпродажі. 10 000 активних користувачів, до 500 RPS. Потрібна висока доступність та масштабованість.
| Ресурс | Конфігурація | Щомісячна вартість (без FinOps) | Щомісячна вартість (з FinOps) | Коментар | |
|---|---|---|---|---|---|
| Backend (EC2/Compute Engine) | 4 x m5.large (2vCPU, 8GB RAM) On-Demand | 4 x 70 $ = 280 $ | 2 x m5.large RI + 2 x m5.large On-Demand з автоскейлінгом | 2 x 40 $ (RI) + 2 x 70 $ (On-Demand) = 220 $ | RI для базового навантаження, автоскейлінг для піків, економія 21% |
| База даних (RDS/Cloud SQL) | 1 x db.m5.xlarge (4vCPU, 16GB RAM) On-Demand | 350 $ | 1 x db.m5.large (2vCPU, 8GB RAM) RI + Read Replica | 200 $ (RI) + 100 $ (Replica) = 300 $ | Rightsizing + RI + Read Replica для масштабування читання, економія 14% |
| Кеш (Redis) | 1 x Elasticache m5.large (8GB RAM) | 80 $ | 1 x Elasticache m5.medium (4GB RAM) | 40 $ | Rightsizing, економія 50% |
| CDN (CloudFront/Cloud CDN) | 10 TB трафіку | 1000 $ | 600 $ | Оптимізація зображень, відео, стиснення, кешування, економія 40% | |
| S3/Cloud Storage | 5 TB Standard | 120 $ | 60 $ | Політики життєвого циклу (перенесення старих даних в IA), економія 50% | |
| Інше (LB, IP, Monitoring) | 50 $ | 30 $ | Видалення невикористовуваних IP, оптимізація логів, економія 40% | ||
| Разом: | 1880 $ | 1250 $ | Економія: 33.6% |
Сценарій 3: Високонавантажений ігровий сервер (Dedicated Server)
Опис: Ігровий сервер для онлайн-гри, що вимагає максимальної продуктивності CPU та низької затримки. 5000 одночасних гравців. Стабільне, високе навантаження.
| Ресурс | Конфігурація | Щомісячна вартість (без FinOps) | Щомісячна вартість (з FinOps) | Коментар |
|---|---|---|---|---|
| Ігровий сервер | 1 x Dedicated Server (16 Cores, 128GB RAM, 2x1TB NVMe) | 450 $ | 450 $ | Виділений сервер часто оптимальний для такого навантаження, тут FinOps фокусується на утилізації. |
| База даних | На тому ж самому сервері | 0 $ (але конкуренція за ресурси) | 80 $ | Винесення БД на окремий VPS (4vCPU, 8GB RAM) для ізоляції та стабільності. |
| CDN/Захист від DDoS | Базовий | 30 $ | 70 $ | Посилений DDoS-захист та CDN для завантаження ігрових ресурсів. Інвестиції в стабільність. |
| Моніторинг/Логування | Базовий | 10 $ | 30 $ | Розширений моніторинг (Prometheus/Grafana) та централізоване логування (ELK). Інвестиції в операційну ефективність. |
| Трафік | 20 TB включено | 0 $ | 0 $ | Зазвичай включено в тариф виділеного сервера. |
| Ліцензії (ОС/Панель) | Windows Server | 25 $ | 0 $ | Перехід на Linux, економія на ліцензіях. |
| Разом: | 515 $ | 630 $ | Збільшення на 22% |
Висновок за сценарієм 3: У цьому випадку FinOps не завжди означає пряме скорочення витрат. Іноді це означає оптимізацію цінності, коли невелике збільшення витрат на правильні сервіси (окрема БД, посилена безпека, моніторинг) призводить до значного поліпшення стабільності, продуктивності та зниження операційних ризиків, що в результаті приносить більше прибутку або запобігає значно більшим втратам.
11. Кейси та приклади
Реальні приклади завжди краще демонструють ефективність FinOps. До 2026 року компанії продовжують стикатися зі схожими викликами, але рішення стають більш витонченими завдяки розвитку інструментів та методологій.
Кейс 1: SaaS-платформа для управління проєктами
Проблема: Компанія "TaskMaster" (середній SaaS, 50 000 активних користувачів) зіткнулася з постійно зростаючими хмарними рахунками (AWS), які перевищували $20 000 на місяць. Основні витрати припадали на EC2-інстанси, RDS PostgreSQL та вихідний трафік. Команда DevOps була завантажена новими фічами, і часу на глибоку оптимізацію не вистачало. Фінансовий відділ вимагав скорочень.
Рішення FinOps:
- Видимість і тегування: В першу чергу, команда впровадила строгу політику тегування для всіх ресурсів:
Project(Backend, Frontend, Analytics),Environment(prod, staging, dev),Owner(команда розробки). Це дозволило точно визначити, які команди та сервіси генерують основні витрати. - Rightsizing EC2: За допомогою AWS Cost Explorer та Compute Optimizer було проведено аудит всіх EC2-інстансів. З'ясувалося, що близько 30% інстансів були перерозмірені (CPU utilization < 15%). 10 інстансів m5.xlarge були зменшені до m5.large, а 5 тестових інстансів m5.large, що працювали 24/7, були налаштовані на автоматичне вимкнення в неробочий час.
- Оптимізація RDS: Інстанс RDS PostgreSQL був також перерозмірений з db.r5.2xlarge до db.r5.xlarge, оскільки пікове навантаження не досягало повної утилізації поточного інстанса. Були додані індекси для повільних запитів, що знизило навантаження на CPU БД.
- Reserved Instances/Savings Plans: Після аналізу стабільного базового навантаження (близько 70% від всіх EC2 і RDS інстансів), компанія придбала Savings Plans на 1 рік, що дало знижку до 30% на ці ресурси.
- Оптимізація egress-трафіку: Помітили високий трафік з S3 в інтернет. Виявилося, що користувачі часто завантажували великі файли. Була впроваджена інтеграція з CloudFront для всіх статичних файлів і контенту, що завантажується, а також налаштовано стиснення Gzip для всіх HTTP-відповідей.
Результати:
- Щомісячні витрати скоротилися з $20 000 до $13 500 (економія 32.5%).
- Покращилась прозорість витрат, кожна команда тепер бачила свій "бюджет" і була мотивована до оптимізації.
- Продуктивність застосунку не постраждала, а в деяких місцях навіть покращилась за рахунок оптимізації БД та CDN.
- FinOps став частиною регулярних процесів, і команда DevOps тепер витрачає 2-3 години на тиждень на моніторинг та оптимізацію.
Кейс 2: Розробка нового ІІ-продукту на виділених серверах
Проблема: Стартап "VisionAI" розробляв новий продукт для обробки зображень з використанням машинного навчання. Для навчання моделей потрібні були потужні сервери з GPU. Вони орендували 3 виділені сервери у Hetzner з NVIDIA A100 GPU, кожен вартістю близько $1500 на місяць. Проблема була в тому, що навчання моделей не відбувалося 24/7, але сервери працювали постійно, а також виникали складнощі з управлінням залежностями та масштабуванням для різних етапів розробки.
Рішення FinOps:
- Гібридний підхід: Вирішили не відмовлятися від виділених серверів (через високу вартість GPU в хмарі), але доповнити їх хмарними рішеннями для гнучкості.
- Оптимізація використання GPU-серверів:
- Замість постійної роботи, GPU-сервери були налаштовані на включення тільки за вимогою (через API Hetzner) або за розкладом для нічних тренувань.
- Впроваджена система черг (Kubernetes з GPU-планувальником або просто Celery/RQ), щоб максимально завантажити GPU-сервери, коли вони активні.
- Використовували Docker-контейнери для ізоляції середовищ навчання, що дозволило запускати різні експерименти на одному сервері без конфліктів.
- Перенесення не-GPU задач в хмару:
- Препроцесинг даних, зберігання датасетів, хостинг API для інференсу (після навчання) були перенесені на AWS.
- Для препроцесингу використовувалися EC2 Spot Instances (для batch-задач) та AWS Lambda (для невеликих трансформацій).
- Для зберігання датасетів використовувався S3 з політиками життєвого циклу (перенесення старих даних в Glacier).
- API для інференсу розгорнули на EKS з автоскейлінгом, використовуючи дешевші інстанси без GPU.
- Моніторинг і метрики: Налаштували моніторинг утилізації GPU на виділених серверах та метрики вартості в AWS, щоб бачити, наскільки ефективно використовуються ресурси.
Результати:
- Витрати на GPU-сервери скоротилися на 40% (з $4500 до $2700 на місяць) за рахунок їх включення тільки за вимогою та максимальної утилізації під час роботи.
- Загальні витрати на інфраструктуру стали більш гнучкими та передбачуваними.
- Значно пришвидшився процес розробки: інженери могли швидко запускати експерименти на Spot Instances або Serverless без очікування вільних GPU-серверів.
- Покращилась масштабованість інференс-сервісу, який тепер міг автоматично обробляти пікові навантаження.
- Загальна цінність від інфраструктури значно зросла, при цьому компанія отримала економію на найдорожчих компонентах.
Кейс 3: Міграція застарілої ERP-системи
Проблема: Велика виробнича компанія "GlobalProd" використовувала застарілу ERP-систему на базі MS SQL Server, що працювала на фізичному виділеному сервері в локальному дата-центрі. Сервер був куплений 5 років тому, морально застарів, його обслуговування обходилося дорого, а масштабованість була відсутня. Щомісячні OpEx (електрика, охолодження, адміністрування, ліцензії) складали близько $1000, не враховуючи CAPEX на покупку нового сервера.
Рішення FinOps:
- Оцінка TCO (Total Cost of Ownership): Провели детальний аналіз всіх витрат, включаючи CAPEX на оновлення обладнання, OpEx на обслуговування, ліцензії, а також ризики простою. З'ясувалося, що поточний TCO був значно вищим, ніж здавалося.
- Міграція в хмару: Було прийнято рішення про міграцію ERP-системи в хмару, щоб скористатися перевагами керованих сервісів та гнучкості. Обрали Azure, оскільки вже були ліцензії MS SQL Server та експертиза по .NET.
- Вибір оптимальних сервісів:
- Для MS SQL Server обрали Azure SQL Database (Managed Instance) — це дозволило використовувати існуючі ліцензії (Azure Hybrid Benefit) та зняти з себе тягар адміністрування БД.
- Для серверної частини ERP (API, веб-інтерфейс) використовували Azure Virtual Machines.
- Для файлового сховища (звіти, документи) — Azure Files.
- Оптимізація витрат у хмарі:
- Після міграції та моніторингу, Azure Virtual Machines були перерозмірені до оптимальних конфігурацій.
- Придбали Azure Reserved VM Instances на 3 роки для базового навантаження, що дало знижку до 72%.
- Налаштували автоматичне масштабування для веб-серверів під час піків (кінець місяця, звітний період).
- Впровадили політики життєвого циклу для Azure Files, переміщуючи старі документи в холодне сховище.
Результати:
- Зниження OpEx з $1000 до $450 на місяць (економія 55%), включаючи ліцензії на SQL Server (за рахунок Azure Hybrid Benefit) та Managed Instance.
- Повна відсутність CAPEX на оновлення обладнання.
- Значне підвищення надійності та доступності системи (SLA від Azure).
- Зниження навантаження на IT-відділ, який тепер міг зосередитися на розвитку, а не на обслуговуванні застарілого "заліза".
- ERP-система стала більш гнучкою та здатною до масштабування відповідно до потреб бізнесу.
Ці кейси демонструють, що FinOps — це не універсальне рішення "один розмір для всіх", а адаптивний підхід, який вимагає глибокого розуміння як технічних, так і фінансових аспектів, а також готовності до зміни архітектури та процесів.
Потрібен виділений сервер?
Compare prices from top providers. Configure and order in minutes.
12. Інструменти та ресурси
Ефективне застосування FinOps неможливе без правильних інструментів. До 2026 року екосистема FinOps-інструментів стала ще більш зрілою, пропонуючи рішення для кожного аспекту управління хмарними витратами.
Інструменти для роботи з FinOps та аналізом витрат
- Хмарні провайдери (Native Tools):
- AWS Cost Explorer & AWS Budgets: Дозволяють аналізувати витрати, отримувати рекомендації по RI/SP, створювати бюджети та оповіщення.
- Google Cloud Billing & Cost Management: Аналогічні інструменти для GCP, включаючи звіти по витратах, бюджети та експорт даних в BigQuery для глибокого аналізу.
- Azure Cost Management + Billing: Надає аналітику витрат, можливість створення бюджетів, експорт даних, рекомендації по оптимізації.
- Яндекс.Облако Cost & Usage Reports: Деталізовані звіти по споживанню та витратах.
- Сторонні FinOps-платформи:
- CloudHealth by VMware: Комплексна платформа для управління хмарними витратами, безпекою, продуктивністю та відповідністю нормативам в мультихмарних середовищах.
- Apptio Cloudability: Спеціалізується на фінансовому управлінні хмарою, надає глибоку аналітику, оптимізацію витрат, бюджетування та прогнозування.
- CloudZero: Фокусується на зв'язуванні витрат з бізнес-метриками (Cost per Customer, Cost per Feature), допомагаючи інженерам розуміти фінансовий вплив їхніх рішень.
- Flexera (RightScale): Управління хмарою та FinOps для гібридних та мультихмарних середовищ.
- Kubecost: Інструмент для моніторингу та оптимізації витрат в Kubernetes, дозволяє розподіляти витрати на поди, namespaces, команди.
- Інструменти для моніторингу утилізації та продуктивності:
- Prometheus & Grafana: Відкриті рішення для збору метрик та візуалізації даних. Дозволяють відстежувати утилізацію CPU, RAM, I/O та інших ресурсів.
- Datadog, New Relic, Dynatrace: Комерційні APM (Application Performance Monitoring) та інфраструктурні моніторингові платформи, що надають детальні метрики та можливості для аналізу продуктивності та пов'язаних з нею витрат.
- Zabbix / Icinga: Традиційні системи моніторингу для VPS та виділених серверів.
- Інструменти Infrastructure as Code (IaC):
- Terraform: Декларативне управління інфраструктурою в будь-якій хмарі або на виділених серверах. Допомагає автоматизувати розгортання та тегування, знижуючи ручні помилки.
- Ansible: Інструмент для автоматизації налаштування та розгортання ПЗ на серверах.
- CloudFormation (AWS), Deployment Manager (GCP), ARM Templates (Azure): Нативні IaC-інструменти хмарних провайдерів.
- Інструменти для автоматизації та скриптингу:
- Python Boto3 (AWS), Google Cloud Client Libraries, Azure SDK: Бібліотеки для взаємодії з хмарними API, дозволяють створювати кастомні скрипти для автоматизації задач FinOps (наприклад, зупинка інстансів, видалення снапшотів).
- Bash / PowerShell: Для простих скриптів автоматизації на VPS та виділених серверах.
Корисні посилання та документація
- FinOps Foundation: finops.org - Офіційний сайт FinOps Foundation, містить гайди, кращі практики, сертифікації.
- AWS Well-Architected Framework (Cost Optimization Pillar): aws.amazon.com/architecture/well-architected/cost-optimization/ - Детальні рекомендації з оптимізації витрат в AWS. Аналогічні фреймворки є у GCP та Azure.
- Блоги та статті провайдерів: Регулярно читайте блоги AWS, Google Cloud, Azure, DigitalOcean, Hetzner, оскільки вони публікують нові функції, знижки та кращі практики.
- Stack Overflow, Reddit (r/devops, r/cloud, r/finops): Відмінне місце для пошуку рішень конкретних проблем та обміну досвідом зі спільнотою.
- Документація по конкретним інструментам: Завжди звертайтесь до офіційної документації Terraform, Kubernetes, Prometheus та інших інструментів для отримання актуальної інформації.
13. Troubleshooting (вирішення проблем)
Навіть при найбільш продуманих FinOps-практиках можуть виникати несподівані проблеми з витратами. Вміння швидко діагностувати та вирішувати їх — ключова навичка.
Типові проблеми та їх вирішення
Проблема 1: Раптове різке зростання хмарного рахунку
Можливі причини:
- Забуті ресурси: Запущені тестові інстанси, невикористовувані бази даних, старі балансувальники.
- Неконтрольований автоскейлінг: Помилкова конфігурація автоскейлінгу, що призводить до запуску занадто великої кількості інстансів.
- Стрибок трафіку: DDoS-атака, вірусний контент, неоптимізований запит, масове завантаження великих файлів.
- Зміни в ціновій політиці провайдера: Рідкісне, але можливе.
- Помилки в додатку: Нескінченні цикли, витоки пам'яті, неефективні запити до БД, що генерують надлишкове навантаження і, як наслідок, споживання ресурсів.
Рішення:
- Перевірте сповіщення: Насамперед, перевірте, чи спрацювали бюджетні сповіщення.
- Аналіз звітів про витрати: Використовуйте AWS Cost Explorer, GCP Billing Reports або Azure Cost Management, щоб визначити, яка категорія сервісів (Compute, Network, Storage, Database) або який проект/сервіс став причиною стрибка.
- Аудит ресурсів: Перевірте нещодавно створені або змінені ресурси. Шукайте "зомбі-ресурси".
- Моніторинг трафіку: Якщо проблема в трафіку, перевірте логи веб-серверів/балансувальників/CDN на предмет аномальної активності.
- Моніторинг продуктивності програми: Використовуйте APM-інструменти (Datadog, New Relic) або логи, щоб виявити помилки в додатку, які можуть викликати надлишкове навантаження.
- Відкат змін: Якщо зростання пов'язане з нещодавнім розгортанням, розгляньте відкат до попередньої версії.
Проблема 2: Постійно високий рахунок при низькій утилізації ресурсів
Можливі причини:
- Надмірний Rightsizing: Сервери занадто великі для поточного навантаження.
- Невикористовувані Reserved Instances/Savings Plans: Куплені, але не використовуються або використовуються неефективно.
- Дорогі Managed-сервіси: Використання дорогих конфігурацій керованих сервісів (бази даних, черги) при низькому навантаженні.
- Високі ліцензійні витрати: Використання платних ОС або ПЗ.
- Приховані витрати: Невикористовувані IP, балансувальники, снапшоти, міжзональний трафік.
Рішення:
- Детальний Rightsizing: Проведіть глибокий аналіз метрик утилізації (CPU, RAM, I/O) за 30-90 днів і перерозмірте всі інстанси та керовані сервіси.
- Аудит RI/SP: Перевірте утилізацію ваших Reserved Instances або Savings Plans. Якщо вони недовикористовуються, розгляньте можливість їх продажу (якщо є маркетплейс) або коригування майбутніх покупок.
- Оптимізація ліцензій: Розгляньте перехід на Open-Source альтернативи або використання Linux замість Windows.
- Пошук прихованих витрат: Проведіть аудит всіх ресурсів через консоль провайдера або за допомогою скриптів, шукайте невикористовувані компоненти.
- Впровадження автоскейлінгу: Якщо навантаження змінне, налаштуйте автоскейлінг для динамічної адаптації.
Проблема 3: Довгий "холодний старт" Serverless-функцій
Можливі причини:
- Великий розмір пакету: Чим більший код функції та її залежності, тим довше ініціалізація.
- Складна логіка ініціалізації: Довге завантаження бібліотек, підключення до БД, ініціалізація зовнішніх сервісів.
- Рідкісні виклики: Функція рідко викликається, і провайдер "вивантажує" її з пам'яті.
Рішення:
- Оптимізація коду: Зменште розмір пакету функції, видаліть невикористовувані залежності.
- "Прогрів" функцій: Використовуйте спеціальні сервіси або налаштуйте регулярні "холості" виклики функції, щоб підтримувати її в "гарячому" стані.
- Збільшення пам'яті: У деяких випадках збільшення виділеної пам'яті для функції може прискорити її ініціалізацію.
- Використання Provisioned Concurrency: Налаштуйте заздалегідь виділені екземпляри функції, які завжди готові до роботи (платно, але усуває холодні старти).
Діагностичні команди та підходи
Для діагностики проблем на VPS та виділених серверах:
- Моніторинг системи:
# Загальна інформація про систему та процеси top # Інтерактивний монітор процесів htop # Покращений top free -h # Використання RAM df -h # Використання дискового простору iostat -x 1 # Дисковий I/O (потребує пакета sysstat) netstat -tunap # Мережеві з'єднання - Аналіз логів:
# Перегляд системних логів journalctl -xe # Для systemd-систем tail -f /var/log/syslog # Загальні системні логи tail -f /var/log/nginx/access.log # Логи веб-сервера tail -f /var/log/mysql/error.log # Логи бази даних - Перевірка мережевих проблем:
ping google.com # Перевірка доступності зовнішніх ресурсів traceroute google.com # Відстеження маршруту пакетів iperf3 -c <server_ip> # Вимірювання пропускної здатності мережі - Перевірка ресурсів у хмарній консолі: Регулярно переглядайте консоль управління провайдера. Шукайте:
- Запущені інстанси, які повинні бути зупинені.
- Неприкріплені диски або IP-адреси.
- Налаштування автоскейлінгу.
- Деталізацію білінгу по кожному сервісу.
Коли звертатися до підтримки
Не соромтеся звертатися до підтримки провайдера у наступних випадках:
- Непояснювані нарахування: Якщо ви не можете знайти причину зростання рахунку, а всі ваші ресурси враховані та оптимізовані.
- Проблеми з інфраструктурою провайдера: Якщо підозрюєте, що проблема не у вашому застосунку, а в мережі, обладнанні або сервісах провайдера (наприклад, мережеві затримки, збої в дата-центрі).
- Технічні проблеми з керованими сервісами: Якщо керована база даних або інший PaaS-сервіс працює некоректно.
- Питання щодо ціноутворення: Якщо у вас є специфічні питання щодо тарифних планів, знижок або моделей оплати.
- DDoS-атаки: Якщо ви зіткнулися з масштабною DDoS-атакою, підтримка провайдера може запропонувати спеціалізовані рішення.
При зверненні до підтримки завжди надавайте максимально повну інформацію: ID ресурсів, часові рамки проблеми, скріншоти, логи та кроки, які ви вже зробили для діагностики.
14. FAQ (мінімум 10 питань)
Що таке FinOps і чим він відрізняється від простого скорочення витрат?
FinOps — це операційна модель і культурна практика, яка об'єднує фінансові, операційні та інженерні команди для досягнення максимальної цінності бізнесу від хмарних інвестицій. На відміну від простого скорочення витрат, FinOps — це безперервний процес, спрямований на підвищення прозорості, підзвітності та ефективності використання хмарних ресурсів. Він фокусується не тільки на зниженні витрат, але й на оптимізації цінності, яку бізнес отримує за кожен витрачений долар, забезпечуючи при цьому необхідну продуктивність і масштабованість.
Чи може FinOps бути корисним для невеликого стартапу з обмеженим бюджетом?
Так, FinOps вкрай корисний для стартапів. Для них кожна копійка на рахунку, і неефективне використання хмари може швидко призвести до вичерпання бюджету. FinOps допомагає стартапам з самого початку вибудувати правильну культуру управління витратами, уникнути переплат за невикористовувані ресурси, вибрати оптимальні тарифи і масштабувати інфраструктуру з розумом, що критично важливо для виживання і зростання.
Які основні метрики слід відстежувати для FinOps?
Основні метрики для FinOps включають: загальні хмарні витрати, витрати по проектам/командам/середовищам, утилізація CPU, RAM, дискового I/O, мережевого трафіку (особливо egress), покриття Reserved Instances/Savings Plans, а також бізнес-метрики, такі як Cost per Customer (CPC), Cost per Transaction (CPT), Cost per Feature. Останні допомагають зв'язати технічні витрати з реальною цінністю для бізнесу.
Як часто потрібно проводити аудит та оптимізацію витрат?
FinOps — це безперервний процес. Моніторинг витрат і утилізації ресурсів повинен бути постійним. Детальний аудит і перегляд стратегії оптимізації рекомендується проводити щомісяця або щокварталу, в залежності від темпів зростання вашої інфраструктури і змін у застосунку. Для великих компаній з динамічною інфраструктурою FinOps-команди можуть проводити щотижневі або навіть щоденні "stand-up" зустрічі для обговорення аномалій і планів.
В чому різниця між Reserved Instances та Savings Plans?
Обидва механізми надають знижки за зобов'язання використовувати хмарні ресурси протягом тривалого терміну (1 або 3 роки). Reserved Instances (RI) прив'язані до конкретних параметрів інстанса (тип, регіон, ОС). Savings Plans (SP) більш гнучкі: вони надають знижку на певний обсяг обчислювальних ресурсів (наприклад, $10/годину) незалежно від типу інстанса, регіону або ОС. SP простіше управляти і вони краще підходять для динамічних навантажень, дозволяючи змінювати тип інстансів без втрати знижки, якщо ви залишаєтесь в рамках зобов'язання.
Чи варто переходити на Serverless для всіх застосунків заради економії?
Ні, Serverless не є універсальним рішенням. Хоча він пропонує максимальну еластичність і оплату за фактом використання, він має свої обмеження, такі як "холодні старти", ліміти на час виконання і пам'ять, а також складність налагодження розподілених систем. Serverless ідеально підходить для подійних, нечастих завдань, мікросервісів з перемінним навантаженням. Для застосунків з постійним, високим навантаженням або довгим часом виконання традиційні VPS, EC2-інстанси або Kubernetes можуть бути більш економічно вигідними і придатними.
Як уникнути вендор-лок-іну при виборі хмарного провайдера?
Уникнути повного вендор-лок-іну складно, але можна мінімізувати. Використовуйте відкриті стандарти (Docker, Kubernetes, Terraform) і хмарно-незалежні технології. Уникайте занадто глибокої інтеграції з пропрієтарними сервісами провайдера там, де є відкриті або керовані альтернативи (наприклад, замість DynamoDB розгляньте PostgreSQL або MongoDB). Розробляйте архітектуру з урахуванням можливості міграції, абстрагуючи бізнес-логіку від специфіки хмари. Розгляньте мультихмарну або гібридну стратегію.
Яка роль DevOps-інженера в FinOps?
Роль DevOps-інженера в FinOps є центральною. Саме вони відповідають за реалізацію технічних рішень, які призводять до оптимізації: впровадження IaC, налаштування автоскейлінгу, права сайзінг, оптимізація коду і архітектури, вибір оптимальних типів інстансів, моніторинг утилізації і витрат. DevOps-інженери повинні розуміти фінансові наслідки своїх технічних рішень і активно співпрацювати з фінансовими та продуктовими командами.
Чи можна використовувати виділені сервери замість хмарних VPS для економії?
Так, для певних сценаріїв виділені сервери можуть бути більш економічно вигідними, ніж хмарні VPS, особливо при дуже високому, стабільному і передбачуваному навантаженні. Виділені сервери пропонують максимальну продуктивність за фіксовану плату, часто з дуже великими обсягами трафіку. Однак вони вимагають більш глибоких знань в адмініструванні і мають низьку гнучкість масштабування. FinOps допоможе оцінити TCO (Total Cost of Ownership) і визначити, який варіант буде оптимальним для вашого конкретного випадку.
Як почати впроваджувати FinOps у своїй компанії?
Почніть з малого: 1) Прозорість: Впровадьте політику тегування для всіх ресурсів і налаштуйте базові звіти про витрати. 2) Підзвітність: Призначте відповідальних за бюджети по проектам. 3) Оптимізація: Проведіть аудит "зомбі-ресурсів" і почніть з Rightsizing найдорожчих інстансів. 4) Співпраця: Організуйте регулярні зустрічі між інженерами і фінансовими відділами. Поступово розширюйте практики, впроваджуючи автоматизацію і більш складні інструменти. Головне — почати і зробити FinOps частиною корпоративної культури.
Потрібен виділений сервер?
Compare prices from top providers. Configure and order in minutes.
15. Висновок
В умовах технологічного ландшафту, що швидко змінюється, і постійно зростаючих хмарних витрат, FinOps стає не просто модним словом, а життєво важливою дисципліною для кожного, хто управляє IT-інфраструктурою. До 2026 року, коли складність хмарних екосистем досягла нових висот, а конкуренція вимагає максимальної ефективності, вміння перетворювати хмарні витрати на стратегічні інвестиції є ключовим фактором успіху.
Ми розглянули, як FinOps-практики та сучасні інструменти дозволяють DevOps-інженерам, backend-розробникам, фаундерам SaaS, системним адміністраторам і технічним директорам стартапів не тільки скорочувати витрати на VPS і виділені сервери, а й приймати обґрунтовані, проактивні рішення. Від впровадження прозорості через тегування та детальні звіти до автоматизації масштабування, прав сайзингу, використання зарезервованих потужностей і оптимізації всіх аспектів інфраструктури — кожен крок у FinOps спрямований на максимізацію цінності.
Ключовий висновок полягає в тому, що FinOps — це не технічне чи фінансове завдання, а культурна трансформація. Це вимагає співпраці між усіма зацікавленими сторонами, постійного навчання та адаптації. Тільки коли інженери розуміють фінансові наслідки своїх рішень, а фінансові фахівці володіють достатнім технічним розумінням, можливо досягнення справжньої ефективності.
Підсумкові рекомендації:
- Почніть зараз: Не відкладайте впровадження FinOps. Навіть невеликі кроки з підвищення прозорості та видалення невикористовуваних ресурсів можуть принести значну економію.
- Співпрацюйте: Руйнуйте "силоси" між командами. FinOps процвітає в середовищі, де інженери, менеджери з продукту та фінансові фахівці працюють разом.
- Автоматизуйте: Використовуйте IaC, автоскейлінг і скрипти для автоматизації рутинних завдань і забезпечення динамічної адаптації інфраструктури.
- Моніторте та аналізуйте: Постійно відстежуйте метрики витрат і утилізації, шукайте аномалії та можливості для оптимізації.
- Оптимізуйте постійно: FinOps — це марафон, а не спринт. Хмарне середовище постійно змінюється, і ваша стратегія оптимізації повинна змінюватися разом з ним.
Наступні кроки для читача:
- Проведіть аудит: Почніть з аудиту вашої поточної хмарної інфраструктури. Використовуйте чекліст з цієї статті, щоб виявити невикористовувані ресурси та перерозмірені сервери.
- Впровадьте тегування: Якщо у вас ще немає політики тегування, розробіть її та почніть застосовувати до всіх нових ресурсів.
- Налаштуйте бюджети та сповіщення: Встановіть бюджети для ваших хмарних облікових записів і налаштуйте сповіщення, щоб бути в курсі поточних витрат.
- Вивчіть інструменти: Ознайомтеся з нативними інструментами вашого хмарного провайдера для управління витратами та розгляньте можливість використання сторонніх FinOps-платформ.
- Навчайтесь: Продовжуйте вивчати FinOps-практики, стежте за новинами та оновленнями від хмарних провайдерів, обмінюйтеся досвідом зі спільнотою.
Пам'ятайте, що ефективне управління витратами на хмарні VPS і виділені сервери — це не просто спосіб заощадити гроші, а й стратегічна перевага, яка дозволяє вашому бізнесу бути більш гнучким, масштабованим і конкурентоспроможним у світі технологій, що постійно змінюється.
Чи був цей гайд корисним?
Ваш відгук допомагає нам покращувати гайди.