
Автоматизація розгортання та управління VPS/виділеними серверами з Terraform та Ansible у 2026 році
TL;DR
- У 2026 році Terraform та Ansible залишаються наріжними каменями для Infrastructure as Code (IaC) та Configuration Management (CM), забезпечуючи безпрецедентну швидкість та надійність розгортання серверів.
- Інтеграція цих інструментів дозволяє створити повністю автоматизований та ідемпотентний пайплайн від створення інфраструктури до її конфігурування та підтримки.
- Вибір між VPS та виділеними серверами залежить від специфічних вимог до продуктивності, безпеки та бюджету, з урахуванням нових пропозицій від провайдерів, таких як хмарні виділені сервери.
- Ключові фактори успіху включають модульність коду, грамотне управління станом Terraform, надійні Ansible-ролі, а також глибоке розуміння інструментів та хмарних платформ.
- Економія досягається не тільки за рахунок оптимізації ресурсів, але й мінімізації людських помилок, скорочення часу простою та прискорення виведення продуктів на ринок.
- Безпека автоматизації критична: використовуйте секретні менеджери, принцип найменших привілеїв та регулярно аудіюйте конфігурації.
- Очікуйте подальшої інтеграції AI для передбачуваного масштабування, оптимізації витрат та автоматичного виправлення проблем в інфраструктурі.
Потрібен виділений сервер?
Compare prices from top providers. Configure and order in minutes.
Вступ
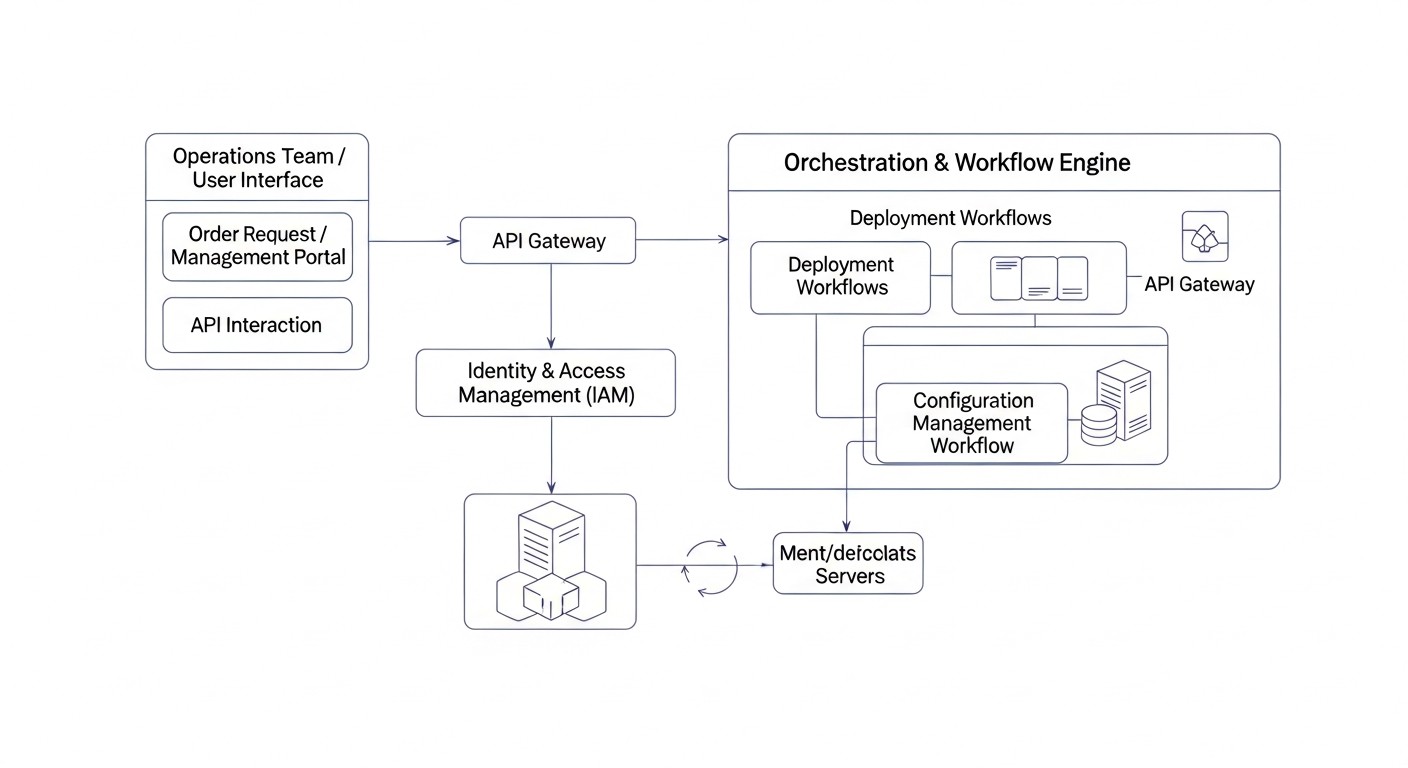
У світі, де швидкість змін та вимог до надійності систем постійно зростає, ручне управління інфраструктурою стає не просто неефективним, а небезпечним анахронізмом. До 2026 року концепція Infrastructure as Code (IaC) та автоматизація управління конфігураціями стали не просто трендом, а обов'язковим стандартом для будь-якої серйозної технологічної компанії. Особливо це стосується розгортання та управління VPS (Virtual Private Servers) та виділеними серверами, які досі складають основу для більшості критично важливих додатків та сервісів.
Чому ця тема така важлива саме зараз? По-перше, складність інфраструктур експоненціально збільшується. Мікросервіси, розподілені системи, георозподілені кластери – все це вимагає точності та повторюваності. Ручні операції неминуче призводять до "сніжинок" серверів, де кожен унікальний і невідтворюваний, що є кошмаром для підтримки та масштабування. По-друге, вартість людської помилки продовжує зростати. Неправильно налаштований сервер може призвести до багатогодинних простоїв, витоків даних або навіть до втрати репутації. По-третє, конкуренція на ринку SaaS та технологічних продуктів вимагає максимальної швидкості виведення нових функцій та оновлень, а також гнучкості в масштабуванні. Автоматизація дозволяє досягти всього цього, скорочуючи час розгортання з днів до хвилин.
У цій статті ми глибоко поринемо у світ автоматизації розгортання та управління серверами, використовуючи два найпотужніші та найпоширеніші інструменти: Terraform для управління інфраструктурою та Ansible для управління конфігураціями. Ми розглянемо, як ці інструменти працюють у зв'язці, які переваги вони дають, і як їх ефективно застосовувати в умовах 2026 року, враховуючи нові технології та підходи. Ми не будемо займатися маркетинговими гаслами, а зосередимося на конкретних практичних порадах, реальних прикладах та тонкощах, які ви зможете застосувати у своїй роботі вже сьогодні.
Ця стаття написана для широкої аудиторії технічних фахівців: DevOps-інженерів, які шукають способи оптимізувати свої пайплайни; Backend-розробників (Python, Node.js, Go, PHP), які прагнуть краще розуміти та контролювати середовище, в якому працюють їхні додатки; Фаундерів SaaS-проектів, яким критично важливо будувати масштабовану та надійну інфраструктуру з першого дня; Системних адміністраторів, які бажають перейти від ручної праці до автоматизації; та Технічних директорів стартапів, які формують стратегію розвитку інфраструктури. Якщо ви хочете будувати інфраструктуру майбутнього, ця стаття – ваш провідник.
Ми розглянемо не тільки технічні аспекти, але й економічні, а також питання безпеки, які стають все більш актуальними. Світ змінюється, і методи управління інфраструктурою повинні змінюватися разом з ним. Приготуйтеся до глибокого занурення в автоматизацію, яка зробить вашу роботу ефективнішою, а вашу інфраструктуру – надійнішою.
Основні критерії вибору та фактори успіху
Вибір правильного підходу до автоматизації розгортання та управління серверами, а також самого типу хостингу (VPS або виділений сервер), вимагає глибокого аналізу безлічі факторів. У 2026 році ці критерії стали ще більш комплексними, враховуючи появу нових технологій та посилення вимог до безпеки та продуктивності.
1. Масштабованість та гнучкість
У сучасному світі інфраструктура повинна бути здатна до швидкого масштабування як вгору (вертикальне), так і в сторони (горизонтальне). Terraform дозволяє декларативно описувати інфраструктуру, що спрощує додавання нових серверів або зміну їх характеристик. Ansible, в свою чергу, забезпечує гнучке конфігурування цих нових ресурсів. Важливо оцінити, наскільки легко ваша автоматизація зможе адаптуватися до змінюваних навантажень та вимог. Наприклад, якщо ви очікуєте пікових навантажень, автоматичне масштабування за допомогою Terraform та хмарних провайдерів буде критичним.
2. Продуктивність і тип навантаження
Різні застосунки мають різні вимоги до CPU, RAM, I/O дискової підсистеми і мережевої пропускної здатності. Для високонавантажених баз даних або обчислювально інтенсивних задач виділені сервери часто залишаються кращим вибором через гарантовану продуктивність і відсутність "сусідського шуму". VPS ж ідеально підходять для веб-серверів, мікросервісів, черг повідомлень, де важлива гнучкість і швидкий старт. У 2026 році провайдери пропонують "хмарні виділені сервери", які поєднують переваги обох світів: гарантовані ресурси з гнучкістю хмарного API. При виборі провайдера, зверніть увагу на характеристики процесорів (наприклад, Intel Xeon E5-2690 v4 або AMD EPYC 7003-ї серії), тип дисків (NVMe SSD стали стандартом), і гарантований канал зв'язку.
3. Безпека та відповідність стандартам (Compliance)
Це один з найбільш критичних факторів. Автоматизація повинна гарантувати, що всі сервери налаштовані згідно з політиками безпеки компанії і вимогам регуляторів (GDPR, HIPAA, PCI DSS і т.д.). Ansible playbooks дозволяють задати жорсткі стандарти безпеки: від встановлення міжмережевого екрану і налаштування SSH до управління користувачами і застосування патчів. Terraform може автоматично налаштовувати мережеві сегменти, групи безпеки та IAM-політики. Важливо використовувати секретні менеджери (HashiCorp Vault, AWS Secrets Manager) і принцип найменших привілеїв. Регулярний аудит конфігурацій, автоматичне застосування оновлень безпеки і моніторинг вразливостей повинні бути інтегровані в ваш CI/CD пайплайн.
4. Вартість володіння (TCO)
TCO включає не тільки прямі витрати на оренду серверів, але і вартість ліцензій, електроенергії, мережевого трафіку, а також трудовитрати на адміністрування і підтримку. Автоматизація з Terraform і Ansible значно скорочує трудовитрати, мінімізує помилки і дозволяє швидше реагувати на зміни, що в кінцевому підсумку знижує TCO. У 2026 році багато провайдерів пропонують гнучкі тарифи, а також можливості для резервування потужностей на тривалий термін зі знижками. Уважно вивчайте тарифи на вихідний трафік, так як він може стати суттєвою статтею витрат.
5. Керованість і підтримуваність
Наскільки легко буде управляти вашою інфраструктурою після розгортання? Модульна структура Terraform і Ansible-ролі значно спрощують цей процес. Документація у вигляді коду (Infrastructure as Code) дозволяє будь-якому члену команди зрозуміти стан інфраструктури. Системи моніторингу (Prometheus, Grafana) і логування (ELK Stack, Loki) повинні бути інтегровані в автоматизований пайплайн. Чим менше "магії" і більше стандартизації, тим легше підтримувати систему в довгостроковій перспективі.
6. Ідемпотентність і повторюваність
Ідемпотентність означає, що застосування однієї і тієї ж операції кілька разів призведе до одного і того ж результату, не викликаючи небажаних побічних ефектів. Це наріжний камінь автоматизації. Terraform і Ansible за своєю природою ідемпотентні. Terraform гарантує, що інфраструктура буде відповідати декларативному опису, а Ansible – що стан конфігурації сервера буде відповідати playbook'у. Повторюваність дозволяє розгортати ідентичні середовища (dev, staging, prod) і швидко відновлюватися після збоїв.
7. Екосистема і спільнота
Активна спільнота і багата екосистема навколо Terraform і Ansible означають доступ до безлічі готових модулів, провайдерів, ролей і плагінів. Це прискорює розробку і спрощує пошук рішень для поширених проблем. До 2026 року обидва інструменти мають велику документацію, курси і велика кількість експертів, що знижує поріг входу і ризики при впровадженні.
8. Резервне копіювання і аварійне відновлення (DR)
Автоматизація повинна включати стратегії резервного копіювання даних і можливість швидкого відновлення всієї інфраструктури в разі катастрофи. Terraform може допомогти в розгортанні DR-середовища, а Ansible – у відновленні конфігурацій і даних. Продумайте RPO (Recovery Point Objective) і RTO (Recovery Time Objective) для кожного компонента вашої системи.
Порівняльна таблиця рішень для хостингу (актуально для 2026 року)
Вибір між VPS і виділеними серверами, а також конкретним провайдером, залежить від безлічі факторів, включаючи бюджет, вимоги до продуктивності, масштабованості і географічного розташування. У 2026 році ринок хостингу продовжує розвиватися, пропонуючи гібридні рішення і поліпшені характеристики. Нижче представлена порівняльна таблиця найбільш популярних варіантів хостингу, актуальна для середини 2026 року, з приблизними цінами і характеристиками.
| Критерій | Хмарний VPS (e.g., DigitalOcean Droplet / Vultr VPS) | Hetzner Cloud VPS (CX-серія) | Хмарні виділені (e.g., AWS EC2 Dedicated Host / GCP Sole-tenant node) | Традиційний виділений сервер (e.g., Hetzner Dedicated / OVHcloud) | Bare Metal as a Service (e.g., Equinix Metal) |
|---|---|---|---|---|---|
| Типовий CPU | 2-8 vCPU (Intel Xeon Platinum 84xx / AMD EPYC 9004) | 2-8 vCPU (AMD EPYC 7003/9004) | 16-64 vCPU (Intel Xeon E5-2690 v5 / AMD EPYC 9004) | 16-64 фізичних ядер (Intel Xeon E5-2699 v5 / AMD EPYC 9004) | 32-128 фізичних ядер (Intel Xeon Sapphire Rapids / AMD EPYC Genoa) |
| Типова RAM | 4-32 GB DDR5 ECC | 4-32 GB DDR5 ECC | 64-256 GB DDR5 ECC | 128-512 GB DDR5 ECC | 256 GB - 1 TB DDR5 ECC |
| Типовий Disk I/O | ~1000-2000 MB/s (NVMe SSD) | ~1500-2500 MB/s (NVMe SSD) | ~3000-5000 MB/s (NVMe SSD) | ~4000-8000 MB/s (RAID10 NVMe SSD) | ~8000-15000 MB/s (Local NVMe SSD, High-speed RAID) |
| Мережевий канал | 1-10 Gbps (shared) | 1-10 Gbps (shared, до 20 Gbps для високих тарифів) | 10-25 Gbps (dedicated) | 10-50 Gbps (dedicated) | 25-100 Gbps (dedicated) |
| Гарантія ресурсів | Ні (віртуалізація) | Ні (віртуалізація) | Так (виділені фізичні ядра/RAM) | Так (повністю) | Так (повністю) |
| Контроль над залізом | Ні | Ні | Обмежений | Повний | Повний |
| Приблизна ціна (міс.) | $20-80 (за екземпляр) | €15-60 (за екземпляр) | $1500-5000 (за хост) | €100-400 (за сервер) | $500-2000 (за сервер) |
| Масштабованість | Висока (горизонтальна) | Висока (горизонтальна) | Середня (потребує планування) | Низька (ручна) | Середня (API-driven, але все ще фізика) |
| Ідеально для | Веб-сервіси, Dev/Staging, мікросервіси, невеликі бази даних | Розробка, невеликі продакшн-сервіси, CDN-ноди | Регуляторні вимоги, ліцензії на ядро, високонавантажені БД | Високонавантажені БД, ігрові сервери, Big Data, ресурсоємні обчислення | Високопродуктивні обчислення, AI/ML, низьколатентні мережі, гібридні хмари |
| Рівень управління | API, панель управління | API, панель управління | API, панель управління, гіпервізор | IPMI, KVM, консоль | API, IPMI, консоль |
*Ціни вказані орієнтовно і можуть значно варіюватися в залежності від конкретної конфігурації, регіону, часу і знижок провайдера. Дані актуальні для 2026 року і відображають загальні тенденції ринку.
Важливо відзначити, що в 2026 році межа між "хмарним" і "традиційним" хостингом продовжує стиратися. Багато провайдерів виділених серверів пропонують API для автоматизації, а хмарні гіганти вводять опції "dedicated host" або "sole-tenant node", які по суті є виділеними серверами, але з хмарною моделлю споживання і управління. Це відкриває нові можливості для гнучкої і потужної інфраструктури, керованої через IaC.
Потрібен виділений сервер?
Compare prices from top providers. Configure and order in minutes.
Детальний огляд Terraform та Ansible
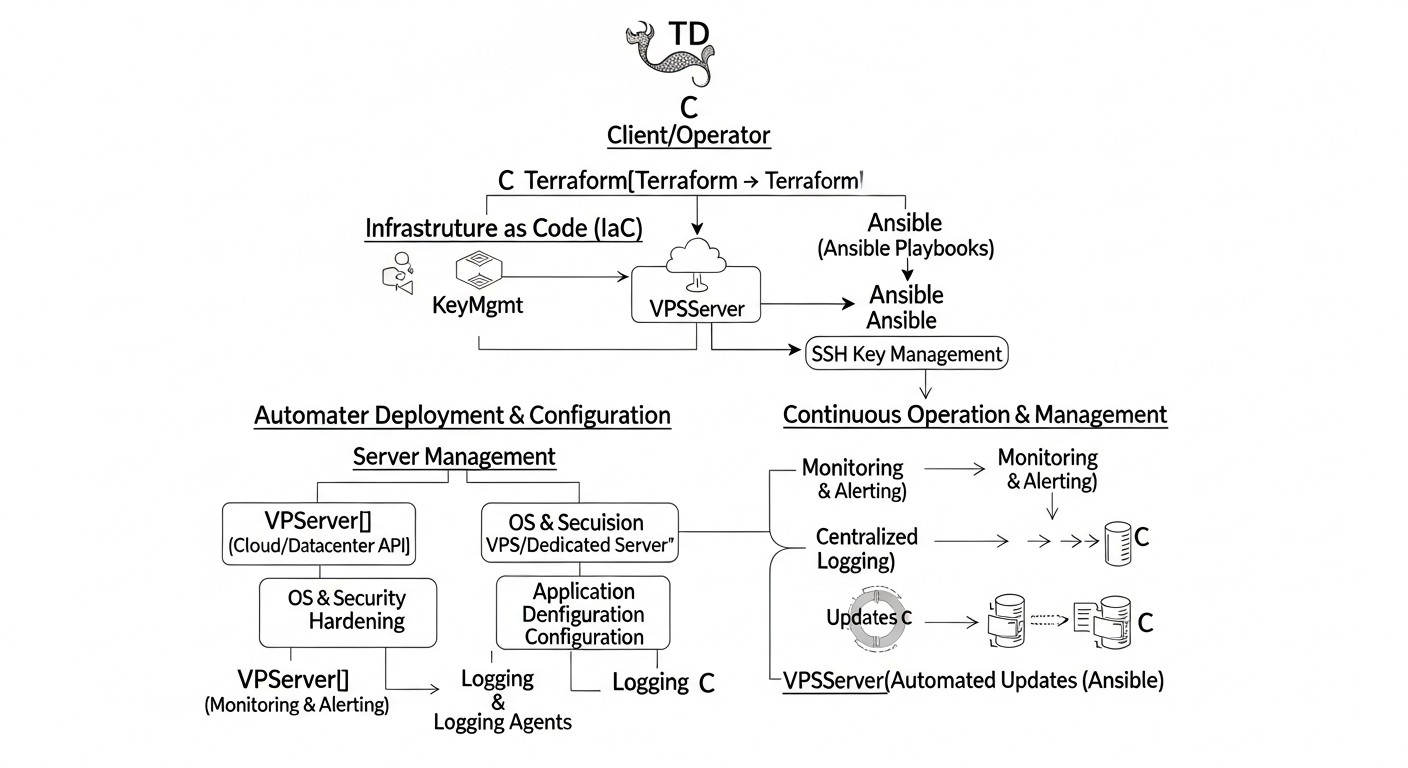
Для ефективної автоматизації розгортання та управління серверами в 2026 році ключовим є розуміння і глибоке використання двох потужних інструментів: Terraform та Ansible. Вони доповнюють один одного, вирішуючи різні, але взаємопов'язані завдання в життєвому циклі інфраструктури.
1. Terraform: Управління інфраструктурою як код (IaC)
Terraform, розроблений HashiCorp, є інструментом для декларативного створення, зміни та видалення інфраструктури. Він дозволяє описувати бажаний стан вашої інфраструктури (будь то VPS, виділені сервери, мережеві налаштування, балансувальники навантаження або бази даних) за допомогою спеціальної мови HCL (HashiCorp Configuration Language) або JSON. До 2026 року Terraform став де-факто стандартом для IaC завдяки своїй універсальності, широкій підтримці провайдерів і потужній екосистемі.
Принципи роботи та переваги:
- Декларативний підхід: Ви описуєте "що" ви хочете отримати, а не "як" цього досягти. Terraform сам визначає послідовність дій для досягнення бажаного стану.
- Провайдери: Terraform працює через "провайдери", які є плагінами для взаємодії з різними платформами (AWS, Azure, GCP, DigitalOcean, Vultr, Hetzner Cloud, VMware vSphere, OpenStack і навіть локальні провайдери для роботи з API виділених серверів). У 2026 році кількість і функціональність провайдерів значно розширилися, включаючи глибшу інтеграцію з управлінням виділеними серверами через їх API.
- Стан (State): Terraform зберігає стан вашої інфраструктури у файлі
.tfstate. Цей файл є критично важливим, оскільки він зіставляє реальні ресурси з вашою конфігурацією. У продакшені обов'язково використовується віддалене сховище стану (наприклад, S3, Azure Blob Storage, HashiCorp Consul або Terraform Cloud/Enterprise) з блокуванням для запобігання конфліктам. - Модульність: Можливість створювати модулі для повторного використання дозволяє структурувати код, підвищити його читабельність і підтримку. Ви можете створити модуль для типового VPS, який потім будете використовувати по всій організації.
- План виконання: Команда
terraform planпоказує, які зміни будуть внесені в інфраструктуру перед їх фактичним застосуванням, що значно знижує ризик помилок.
Приклад використання Terraform для розгортання VPS на DigitalOcean (2026):
Припустимо, ми хочемо розгорнути Droplet на DigitalOcean з Ubuntu 24.04.
# main.tf
terraform {
required_providers {
digitalocean = {
source = "digitalocean/digitalocean"
version = "~> 2.0"
}
}
}
provider "digitalocean" {
token = var.do_token
}
variable "do_token" {
description = "DigitalOcean API Token"
type = string
sensitive = true
}
variable "ssh_keys" {
description = "List of SSH key IDs to add to the droplet"
type = list(string)
default = []
}
resource "digitalocean_droplet" "web_server" {
image = "ubuntu-24-04-x64" # Актуальний образ Ubuntu для 2026
name = "web-server-01"
region = "fra1"
size = "s-2vcpu-4gb" # Припустимо, це популярний розмір в 2026
ssh_keys = var.ssh_keys
tags = ["web", "production"]
# Додаткові налаштування для 2026:
# Можливість вказання конкретного типу NVMe сховища або GPU
# user_data = file("cloud-init.yaml") # Для початкової конфігурації
}
output "web_server_ip" {
value = digitalocean_droplet.web_server.ipv4_address
}
Цей код декларативно описує один VPS. Після terraform init і terraform apply Terraform створить цей сервер і виведе його IP-адресу. Для виділених серверів логіка буде аналогічною, але провайдер і ресурси будуть специфічними для обраної платформи (наприклад, `hetznercloud_server` або `aws_ec2_dedicated_host`).
2. Ansible: Управління конфігураціями та оркестрація
Ansible, придбаний Red Hat, є інструментом для автоматизації задач управління конфігураціями, розгортання додатків та оркестрації. На відміну від Terraform, який займається інфраструктурою, Ansible фокусується на тому, "що всередині" цієї інфраструктури. Він використовує SSH для зв'язку з керованими вузлами, не вимагаючи встановлення агентів, що значно спрощує його розгортання та використання. До 2026 року Ansible продовжує бути одним з найпопулярніших і гнучких інструментів для CM, особливо в гібридних і мультихмарних середовищах.
Принципи роботи та переваги:
- Агентless: Не вимагає встановлення додаткового ПЗ на керовані сервери, використовуючи стандартний SSH. Це знижує накладні витрати і спрощує безпеку.
- Playbooks: Основна одиниця роботи в Ansible. Playbook'и – це YAML-файли, які описують послідовність задач для виконання на цільових хостах.
- Ідемпотентність: Ansible розроблений з урахуванням ідемпотентності. Якщо задача вже виконана (наприклад, пакет встановлено), Ansible не буде виконувати її повторно, що економить час і запобігає небажаним змінам.
- Модулі: Ansible поставляється з сотнями вбудованих модулів для виконання широкого спектру задач: управління пакетами, файлами, сервісами, користувачами, базами даних, хмарними ресурсами та багатьом іншим.
- Ролі (Roles): Механізм для організації Playbook'ів, змінних, шаблонів і файлів в структуровані, одиниці, які можна повторно використовувати. Ролі значно спрощують управління складними конфігураціями та їх повторне використання.
- Інвентар (Inventory): Список керованих хостів, згрупованих за логічними категоріями. Інвентар може бути статичним (файл) або динамічним (генеруватися з хмарного API, CMDB).
Приклад використання Ansible для конфігурування VPS:
Після того як Terraform розгорнув Droplet, Ansible може налаштувати на ньому Nginx.
# playbook.yaml
---
- name: Configure Nginx web server
hosts: web_servers
become: true # Виконувати задачі з правами root
vars:
nginx_port: 80
server_name: "your-domain.com"
app_root: "/var/www/html"
tasks:
- name: Ensure Nginx package is installed
ansible.builtin.apt:
name: nginx
state: present
update_cache: yes
- name: Ensure Nginx service is running and enabled
ansible.builtin.systemd:
name: nginx
state: started
enabled: yes
- name: Create Nginx configuration directory for sites-available
ansible.builtin.file:
path: /etc/nginx/sites-available
state: directory
mode: '0755'
- name: Create Nginx configuration directory for sites-enabled
ansible.builtin.file:
path: /etc/nginx/sites-enabled
state: directory
mode: '0755'
- name: Copy Nginx default site configuration
ansible.builtin.template:
src: templates/nginx.conf.j2
dest: "/etc/nginx/sites-available/{{ server_name }}.conf"
owner: root
group: root
mode: '0644'
notify: Reload Nginx
- name: Enable Nginx default site
ansible.builtin.file:
src: "/etc/nginx/sites-available/{{ server_name }}.conf"
dest: "/etc/nginx/sites-enabled/{{ server_name }}.conf"
state: link
notify: Reload Nginx
handlers:
- name: Reload Nginx
ansible.builtin.systemd:
name: nginx
state: reloaded
І відповідний шаблон templates/nginx.conf.j2:
# templates/nginx.conf.j2
server {
listen {{ nginx_port }};
server_name {{ server_name }};
root {{ app_root }};
index index.html index.htm;
location / {
try_files $uri $uri/ =404;
}
error_log /var/log/nginx/{{ server_name }}_error.log warn;
access_log /var/log/nginx/{{ server_name }}_access.log main;
}
Цей playbook встановлює Nginx, налаштовує його з використанням шаблону і гарантує, що сервіс запущено. Зв'язка Terraform і Ansible дозволяє спочатку створити "залізо", а потім "наповнити" його необхідним ПЗ і конфігураціями, повністю автоматизуючи процес розгортання.
3. Інтеграція Terraform та Ansible
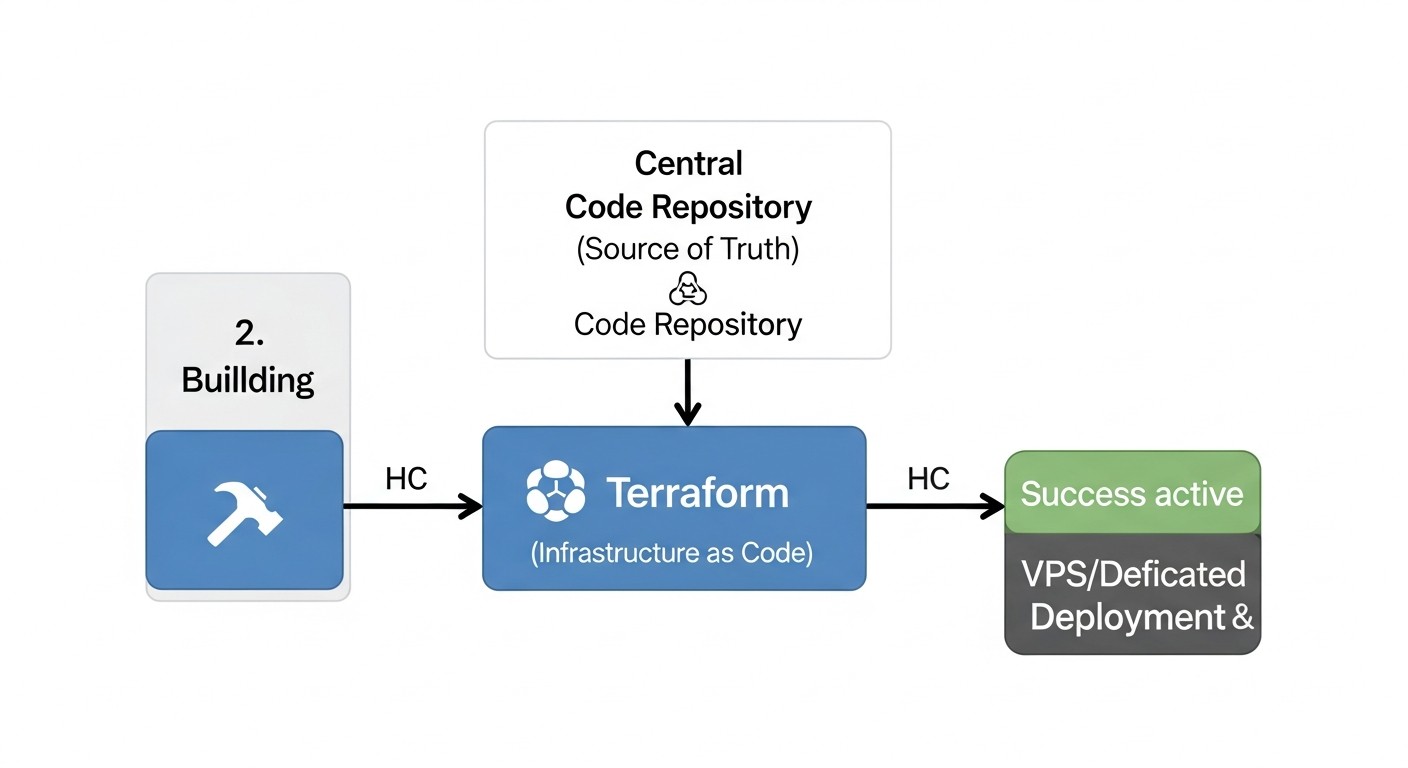
Сила цих інструментів розкривається по-справжньому при їх спільному використанні. Terraform створює інфраструктуру, а потім передає інформацію про неї (наприклад, IP-адреси нових серверів) Ansible, який потім конфігурує ці сервери.
Потік роботи:
- Terraform: Визначає та розгортає хмарні ресурси (VPS, виділені сервери, мережі, балансувальники і т.д.).
- Terraform Output: Витягує важливу інформацію про розгорнуті ресурси (наприклад, публічні IP-адреси, імена хостів).
- Динамічний інвентар Ansible: Використовує вивід Terraform для створення або оновлення інвентарю Ansible. Існують спеціальні скрипти та плагіни для Terraform, які можуть генерувати інвентар Ansible (наприклад,
local-execпровайдер або просто парсингterraform output -json). - Ansible: Підключається до нових серверів, використовуючи інформацію з динамічного інвентарю, і застосовує playbooks для встановлення ПЗ, налаштування конфігурацій, розгортання додатків та забезпечення безпеки.
До 2026 року такий підхід став стандартом. Інтеграція часто відбувається в рамках CI/CD пайплайнів (Jenkins, GitLab CI, GitHub Actions), де Terraform `apply` запускається першим, а потім, після успішного завершення, запускається Ansible `playbook` з динамічним інвентарем. Це забезпечує повну автоматизацію від "голого" сервера до готового до роботи додатку.
Практичні поради та рекомендації щодо впровадження
Впровадження автоматизації з Terraform та Ansible — це не просто освоєння синтаксису, а зміна підходу до управління інфраструктурою. Ось ряд практичних порад, заснованих на багаторічному досвіді, які допоможуть вам уникнути поширених пасток і побудувати надійний, масштабований і безпечний процес.
1. Почніть з малого, ітеруйте
Не намагайтеся автоматизувати все і відразу. Почніть з одного простого сервісу або компонента. Розгорніть один VPS, налаштуйте на ньому Nginx або Docker. Освойте базові концепції, переконайтеся, що ваш пайплайн працює. Потім поступово додавайте складності: базу даних, балансувальник, інші сервіси. Ітеративний підхід дозволяє швидко отримувати зворотний зв'язок і коригувати курс.
2. Використовуйте модулі Terraform і ролі Ansible
Модульність — ключ до підтримуваної та переиспользуемой автоматизації. Створюйте модулі Terraform для типових ресурсів (наприклад, "web-server-module", "database-module"), які інкапсулюють логіку розгортання і надають простий інтерфейс через змінні. Аналогічно, використовуйте ролі Ansible для групування пов'язаних завдань (наприклад, "nginx", "docker", "postgres"). Існують готові модулі і ролі на Terraform Registry і Ansible Galaxy – використовуйте їх як відправні точки, але завжди адаптуйте під свої потреби.
# Пример использования Terraform модуля
module "web_server_prod" {
source = "./modules/droplet" # Локальный путь к модулю
name_prefix = "prod-web"
count = 3
region = "fra1"
size = "s-4vcpu-8gb"
ssh_key_ids = [digitalocean_ssh_key.my_key.id]
tags = ["production", "web"]
}
# Пример использования Ansible роли
- name: Deploy web application
hosts: web_servers
become: true
roles:
- role: nginx
nginx_port: 80
server_name: "app.example.com"
- role: docker
docker_version: "25.0.3" # Актуальная версия для 2026
- role: my_app
app_version: "1.2.0"
3. Управління станом Terraform (Terraform State)
Ніколи не зберігайте .tfstate локально в продакшені. Використовуйте віддалене сховище з блокуванням. AWS S3 з DynamoDB Lock, Azure Blob Storage, Google Cloud Storage, HashiCorp Consul або Terraform Cloud – це обов'язкові опції. Це запобігає конфліктам при паралельних змінах і забезпечує централізоване, надійне зберігання стану. Регулярно робіть бекапи стану.
# Пример настройки удаленного бэкенда S3 с блокировкой DynamoDB
terraform {
backend "s3" {
bucket = "my-terraform-state-bucket-2026"
key = "prod/infrastructure.tfstate"
region = "eu-central-1"
encrypt = true
dynamodb_table = "terraform-lock-table"
}
}
4. Динамічний інвентар Ansible
Не створюйте статичні файли інвентарю вручну. Використовуйте динамічний інвентар, який автоматично збирає інформацію про ваші сервери з хмарних провайдерів (DigitalOcean, AWS, GCP і т.д.) або з виводу Terraform. Це гарантує, що Ansible завжди працює з актуальним списком хостів. Існують готові скрипти інвентарю для більшості хмарних платформ.
# Пример запуска Ansible с динамическим инвентарем DigitalOcean
ansible-playbook -i /usr/local/bin/digital_ocean.py --private-key ~/.ssh/id_rsa playbook.yaml
Або використовуючи вивід Terraform:
# Скрипт для генерации динамического инвентаря из Terraform output
#!/bin/bash
echo '{"_meta": {"hostvars": {}}}' > inventory.json
terraform output -json | jq -r 'to_entries | .[] | select(.key | endswith("_ip")) | .value | to_entries | .[] | .key + " ansible_host=" + .value' | while read line; do
HOST_NAME=$(echo $line | awk '{print $1}')
IP_ADDR=$(echo $line | awk '{print $2}' | cut -d'=' -f2)
jq --arg host "$HOST_NAME" --arg ip "$IP_ADDR" \
'.web_servers.hosts += [$host] | ._meta.hostvars[$host].ansible_host = $ip' \
inventory.json > tmp.$$.json && mv tmp.$$.json inventory.json
done
# Добавить группы
jq '.web_servers = {"hosts": []}' inventory.json > tmp.$$.json && mv tmp.$$.json inventory.json
ansible-playbook -i inventory.json playbook.yaml
(Примітка: наведений скрипт є спрощеним прикладом і вимагає доопрацювання для продакшн-використання, особливо в частині групування хостів.)
5. Управління секретами
Ніколи не зберігайте чутливу інформацію (API-ключі, паролі, приватні ключі) у відкритому вигляді в репозиторії. Використовуйте спеціалізовані інструменти: HashiCorp Vault, AWS Secrets Manager, Google Secret Manager, Azure Key Vault або Ansible Vault. Для Terraform змінні можуть бути позначені як sensitive = true, але це не замінює повноцінного секретного менеджера.
# Использование Ansible Vault для шифрования файлов с секретами
ansible-vault encrypt vars/secrets.yaml
ansible-playbook --ask-vault-pass playbook.yaml
6. Idempotency First
Завжди пишіть Ansible playbooks таким чином, щоб вони були ідемпотентні. Це означає, що повторний запуск playbook'а повинен приводити до того ж стану, що й перший, без помилок і небажаних змін. Використовуйте модулі Ansible, які за своєю природою ідемпотентні (наприклад, apt, yum, file, service). Якщо ви пишете свої скрипти, перевіряйте стан перед внесенням змін.
7. Тестування автоматизації
Ваш код інфраструктури має бути протестований так само ретельно, як і код застосунку. Використовуйте:
- `terraform validate` / `terraform plan`: для синтаксичних помилок і попереднього перегляду змін.
- `ansible-lint`: для перевірки стилю та найкращих практик Ansible.
- Molecule: для тестування Ansible ролей на різних дистрибутивах.
- Terratest / InSpec / Serverspec: для інтеграційного та end-to-end тестування розгорнутої інфраструктури. Це дозволяє переконатися, що сервери не тільки створені, але й правильно налаштовані та функціонують.
8. Версіонування всього
Весь код (Terraform, Ansible playbooks, скрипти, шаблони) має зберігатися в системі контролю версій (Git). Це дозволяє відстежувати зміни, відкочуватися до попередніх версій, працювати в команді та проводити code review. Кожна зміна в інфраструктурі має проходити через процес Pull Request.
9. Інтеграція з CI/CD
Повна автоматизація досягається при інтеграції Terraform і Ansible у ваш CI/CD пайплайн.
- CI (Continuous Integration): Автоматичний запуск `terraform validate`, `terraform plan`, `ansible-lint`, Molecule при кожному коміті.
- CD (Continuous Deployment): Після успішного проходження тестів, автоматичний запуск `terraform apply` і `ansible-playbook` для розгортання або оновлення інфраструктури. Це може бути повністю автоматизовано або вимагати ручного підтвердження для продакшн-середовища.
10. Документація та стандарти
Хоча IaC сам по собі є формою документації, важливо мати додаткові README-файли, які описують високорівневу архітектуру, залежності та процес розгортання. Встановіть стандарти іменування ресурсів, змінних, тегів і дотримуйтесь їх. Чим більш однорідний ваш код, тим легше його розуміти та підтримувати.
11. Моніторинг та оповіщення
Автоматизація розгортання повинна включати автоматичне налаштування моніторингу та оповіщень для всіх нових серверів. Ansible може розгорнути агенти Prometheus Node Exporter, Grafana Agent, Datadog або New Relic. Переконайтеся, що всі критично важливі метрики збираються, і налаштовані відповідні алерти. У 2026 році AI-driven моніторинг стає стандартом, передбачаючи проблеми до їх виникнення.
Типові помилки при роботі з IaC і CM
Навіть досвідчені інженери допускають помилки при роботі з Terraform і Ansible. Знання цих типових помилок допоможе вам уникнути дорогих проблем і прискорити процес впровадження автоматизації.
1. Ігнорування стану Terraform (Terraform State Management)
Помилка: Зберігання файлу .tfstate локально, відсутність блокування стану, ручна зміна .tfstate, або втрата файлу стану.
Наслідки: Конфлікти при роботі декількох інженерів, розсинхронізація реальної інфраструктури з файлом стану, "дрейф" конфігурації, неможливість управління ресурсами, втрата інфраструктури.
Як уникнути: Завжди використовуйте віддалений бекенд (S3, Azure Blob Storage, GCS, HashiCorp Consul/Cloud) з увімкненим блокуванням стану. Ніколи не редагуйте .tfstate вручну, використовуйте terraform state mv, terraform state rm, terraform import. Регулярно робіть бекапи віддаленого стану.
2. Неідемпотентні Ansible Playbooks
Помилка: Написання задач в Ansible, які не є ідемпотентними, тобто повторний запуск яких призводить до небажаних змін або помилок. Наприклад, скрипти, які завжди створюють файл, не перевіряючи його існування.
Наслідки: Непередбачуваний стан серверів, помилки при повторному розгортанні, складність налагодження, ризик "сніжинок" серверів.
Як уникнути: Завжди використовуйте вбудовані модулі Ansible, які за своєю природою ідемпотентні. Якщо пишете свої скрипти або використовуєте команду shell/command, завжди додавайте умови (`when`, `creates`, `removes`, `changed_when`) для перевірки поточного стану перед виконанням дії. Тестуйте playbooks за допомогою Molecule.
3. Жорстке кодування секретів та чутливих даних
Помилка: Зберігання API-ключів, паролів, приватних ключів SSH, токенів у відкритому вигляді у файлах Terraform, Ansible playbooks або в системі контролю версій (Git).
Наслідки: Витік конфіденційних даних, компрометація інфраструктури, порушення безпеки та відповідності стандартам.
Як уникнути: Використовуйте спеціалізовані секретні менеджери (HashiCorp Vault, AWS Secrets Manager, Azure Key Vault, Google Secret Manager) для зберігання та динамічної видачі секретів. Для Ansible використовуйте Ansible Vault для шифрування файлів з секретами. Інтегруйте ці інструменти у ваш CI/CD пайплайн.
4. Відсутність модульності та перевикористання
Помилка: Створення монолітних, великих файлів Terraform і Ansible playbooks без використання модулів і ролей. Копіювання та вставка коду між проектами.
Наслідки: Дублювання коду, складність внесених змін (доводиться міняти в декількох місцях), низька читабельність, труднощі в підтримці, повільна розробка нових компонентів.
Як уникнути: Активно використовуйте модулі Terraform для інкапсуляції логіки розгортання ресурсів. Створюйте ролі Ansible для типових конфігурацій. Розміщуйте модулі та ролі в окремих репозиторіях або в загальній бібліотеці для перевикористання. Використовуйте змінні для параметризації.
5. Ручні зміни після автоматизації ("Drift")
Помилка: Внесення змін на серверах вручну (наприклад, через SSH), які не зафіксовані в коді Terraform або Ansible.
Наслідки: "Дрейф" конфігурації (Infrastructure Drift), коли реальний стан інфраструктури відрізняється від описаного в коді. Непередбачувана поведінка системи, проблеми при повторному розгортанні або масштабуванні, складнощі в налагодженні.
Як уникнути: Встановіть суворі правила: всі зміни повинні проходити через IaC. Використовуйте `terraform plan -destroy` для виявлення дрейфу в Terraform і регулярно запускайте Ansible playbooks в режимі `check` або `diff` для виявлення змін. Впровадьте автоматизовані інструменти для виявлення дрейфу (наприклад, Cloud Custodian, Open Policy Agent). Розгляньте концепцію "Immutable Infrastructure", де сервери не змінюються, а замінюються новими.
6. Недостатнє тестування автоматизації
Помилка: Відсутність автоматичних тестів для Terraform конфігурацій та Ansible playbooks. Запуск коду в продакшені без попередньої перевірки.
Наслідки: Розгортання неробочої або небезпечної інфраструктури, тривалі простої, регресії, втрата даних.
Як уникнути: Інтегруйте `terraform validate`, `terraform plan`, `ansible-lint` у ваш CI. Використовуйте Molecule для тестування ролей Ansible. Застосовуйте інтеграційні тести (Terratest, InSpec) для перевірки розгорнутої інфраструктури. Створіть окремі середовища (dev, staging) для тестування змін перед їх впровадженням в продакшн.
7. Неправильне управління доступом і привілеями
Помилка: Використання облікового запису з надлишковими правами для Terraform і Ansible. Наприклад, використання облікового запису адміністратора хмари для розгортання повсякденних ресурсів.
Наслідки: Загрози безпеці, можливість ненавмисного видалення або зміни критично важливих ресурсів, порушення принципу найменших привілеїв.
Як уникнути: Створюйте окремі IAM-ролі або сервісні облікові записи для Terraform і Ansible з мінімально необхідними правами доступу. Використовуйте тимчасові облікові дані, де це можливо. Регулярно переглядайте та аудіюйте права доступу.
8. Відсутність документації та стандартів
Помилка: Покладатися тільки на код як на документацію, відсутність коментарів, недотримання стандартів іменування.
Наслідки: Новим членам команди важко розібратися в інфраструктурі, зниження швидкості онбордингу, помилки через неправильне розуміння коду, залежність від "носіїв знань".
Як уникнути: Доповнюйте код README-файлами, діаграмами архітектури. Використовуйте коментарі для пояснення складних логічних блоків. Розробіть і дотримуйтеся суворих стандартів іменування ресурсів, змінних, тегів. Проводьте регулярні code review.
Потрібен виділений сервер?
Compare prices from top providers. Configure and order in minutes.
Чекліст для практичного застосування
Цей чекліст допоможе вам структурувати процес впровадження автоматизації розгортання та управління VPS/виділеними серверами з використанням Terraform та Ansible. Дотримуйтеся цих кроків, щоб забезпечити надійність, безпеку та ефективність вашої інфраструктури.
Етап 1: Підготовка та планування
- Визначте цілі автоматизації: Чітко сформулюйте, що ви хочете досягти (наприклад, скоротити час розгортання, підвищити надійність, забезпечити масштабованість).
- Виберіть провайдера хостингу: Виходячи з вимог до продуктивності, бюджету та географії, виберіть одного або кількох провайдерів (DigitalOcean, Hetzner, AWS, GCP, OVHcloud, Equinix Metal та ін.).
- Спроектуйте архітектуру: Намалюйте схему вашої цільової інфраструктури: кількість серверів, їх ролі, мережеві налаштування, бази даних, балансувальники.
- Визначте структуру репозиторію: Заздалегідь продумайте, як будуть організовані ваші Terraform-файли, Ansible playbooks, ролі та змінні в Git.
- Налаштуйте систему контролю версій (Git): Створіть репозиторій для вашого IaC/CM коду.
- Встановіть Terraform та Ansible: Переконайтеся, що у всіх членів команди встановлені актуальні версії інструментів.
Етап 2: Розробка Terraform (IaC)
- Налаштуйте провайдера Terraform: Додайте необхідний провайдер (
digitalocean,aws,hetznercloudі т.д.) у вашmain.tf. - Налаштуйте віддалений бекенд Terraform State: Обов'язково використовуйте S3, GCS, Azure Blob Storage або Terraform Cloud з блокуванням стану.
- Створіть SSH-ключі: Згенеруйте та зареєструйте SSH-ключі у провайдера, які будуть використовуватися для доступу до створюваних серверів.
- Опишіть ресурси VPS/серверів: Використовуйте
resourceблоки для створення віртуальних машин або виділених серверів. Вкажіть тип образу, розмір, регіон, мережу, SSH-ключі. - Додайте мережеві ресурси: Налаштуйте групи безпеки, фаєрволи, VPC/VNet, якщо це применимо.
- Використовуйте модулі: Створіть власні або використовуйте готові модулі Terraform для повторно використовуваних компонентів.
- Проведіть
terraform init,terraform plan,terraform apply: Перевірте, що Terraform коректно розгортає інфраструктуру. - Вийміть висновки (Outputs): Використовуйте
outputблоки для отримання IP-адрес, DNS-імен або інших даних про розгорнуті ресурси.
Етап 3: Розробка Ansible (CM)
- Створіть динамічний інвентар: Налаштуйте скрипт або плагін для Ansible, який буде автоматично генерувати список хостів з виводу Terraform або API хмарного провайдера.
- Організуйте Playbooks та ролі: Створіть структуру каталогів для Ansible, використовуючи ролі для логічного розділення задач (наприклад,
roles/webserver,roles/database). - Налаштуйте SSH-доступ: Переконайтеся, що Ansible може підключатися до нових серверів по SSH, використовуючи приватний ключ, що відповідає публічному ключу, доданим Terraform.
- Напишіть Playbooks для базової конфігурації: Включіть завдання по оновленню системи, встановленню необхідних пакетів (Python, Docker, Nginx), налаштуванню фаєрвола (UFW/firewalld).
- Впровадьте управління секретами: Використовуйте Ansible Vault для шифрування конфіденційних даних або інтегруйтеся з зовнішнім секретним менеджером.
- Створіть Playbooks для розгортання додатків: Налаштуйте Nginx, розгорніть ваш бекенд-сервіс, налаштуйте базу даних, якщо це необхідно.
- Забезпечте ідемпотентність: Переконайтеся, що всі завдання в Playbooks є ідемпотентними.
Етап 4: Інтеграція та тестування
- Інтегруйте в CI/CD: Налаштуйте пайплайн (Jenkins, GitLab CI, GitHub Actions) для автоматичного запуску:
- `terraform validate` і `terraform plan`
- `ansible-lint`
- Запускайте Molecule для тестування ролей Ansible
- Запуск `terraform apply` (можливо, з ручним підтвердженням для продакшн)
- Запуск Ansible Playbooks з динамічним інвентарем
- Налаштуйте моніторинг і логування: Переконайтеся, що після розгортання і конфігурування на серверах автоматично встановлюються агенти моніторингу (Prometheus Node Exporter, Grafana Agent, Datadog) і логування (Fluentd, Filebeat).
- Проведіть інтеграційне тестування: Використовуйте Terratest, InSpec або аналогічні інструменти для перевірки, що розгорнута інфраструктура відповідає очікуванням і працює коректно.
- Документуйте процес: Створіть README-файли для ваших проектів Terraform і Ansible, що описують їх призначення, змінні, залежності та кроки розгортання.
Етап 5: Підтримка та оптимізація
- Регулярно оновлюйте інструменти: Слідкуйте за оновленнями Terraform, Ansible та їхніх провайдерів/модулів для отримання нових функцій і виправлень безпеки.
- Моніторинг дрейфу конфігурації: Періодично запускайте `terraform plan` і Ansible playbooks в режимі `check` для виявлення ручних змін.
- Оптимізуйте витрати: Використовуйте можливості Terraform для масштабування ресурсів вгору/вниз або їх видалення, щоб скоротити витрати. Аналізуйте звіти про вартість провайдера.
- Проводьте аудит безпеки: Регулярно перевіряйте конфігурації безпеки, права доступу та відповідність стандартам.
- Навчайте команду: Переконайтеся, що всі члени команди розуміють принципи IaC і вміють працювати з Terraform і Ansible.
Розрахунок вартості та економіка автоматизації
У 2026 році, коли хмарні ресурси та виділені сервери стають все більш доступними, але й більш складними в управлінні, розуміння істинної вартості володіння (TCO) інфраструктурою критично важливе. Автоматизація з Terraform і Ansible не тільки підвищує ефективність, але й має прямий вплив на економіку проекту, часто призводячи до значної економії в довгостроковій перспективі.
Прямі та приховані витрати
При розрахунку вартості інфраструктури важливо враховувати не тільки очевидні щомісячні рахунки від провайдера, але й менш помітні, але суттєві приховані витрати:
- Прямі витрати:
- Оренда серверів (VPS/Виділені): Вартість CPU, RAM, диска, мережевого трафіку. Актуальні тарифи на 2026 рік показують стабілізацію цін, але зі складнішими тарифними планами за специфічні ресурси (GPU, високопродуктивні NVMe, преміальний трафік).
- Ліцензії ПЗ: Операційні системи (Windows Server), бази даних (Oracle, MS SQL), спеціалізоване ПЗ.
- Мережевий трафік: Особливо вихідний трафік, який може бути дорогим у деяких хмарних провайдерів. У 2026 році багато провайдерів пропонують більш щедрі квоти, але за їх межами вартість залишається високою.
- Додаткові сервіси: Балансувальники навантаження, керовані бази даних, CDN, фаєрволи, IP-адреси.
- Приховані витрати (значно скорочувані автоматизацією):
- Трудовитрати інженерів: Час, що витрачається на ручне розгортання, конфігурування, виправлення помилок, підтримку. Автоматизація скорочує ці години в рази.
- Людські помилки: Вартість простою через неправильну конфігурацію, витоки даних, порушення безпеки. Один день простою для SaaS-проекту може коштувати десятки тисяч доларів.
- Час виходу на ринок (Time-to-Market): Чим довше ви розгортаєте інфраструктуру для нового сервісу, тим довше він не приносить дохід. Автоматизація прискорює цей процес.
- Неефективне використання ресурсів: Забуті або недовикористані сервери, які продовжують працювати і споживати ресурси. IaC дозволяє легко ідентифікувати і видаляти непотрібні ресурси.
- Навчання та адаптація: Час, необхідний новим співробітникам для освоєння унікальної інфраструктури, створеної вручну. Стандартизований IaC код значно спрощує онбординг.
- Аудит і відповідність стандартам: Ручний аудит безпеки та відповідності може бути дуже трудомістким. Автоматизація дозволяє гарантувати відповідність через код.
Приклади розрахунків для різних сценаріїв (2026 рік)
Розглянемо кілька гіпотетичних сценаріїв для SaaS-проекту, що використовує 10 серверів, з урахуванням середніх зарплат і вартості послуг в 2026 році. Припустимо, середня зарплата DevOps-інженера в місяць становить $5000.
Сценарій 1: Неавтоматизоване розгортання (ручне)
- Витрати на сервери: 10 VPS по $40/міс = $400/міс.
- Час розгортання 1 сервера: ~4 години (встановлення ОС, базове ПЗ, конфігурація).
- Час розгортання 10 серверів: 40 годин = 1 робочий тиждень одного інженера.
- Вартість розгортання (трудовитрати): $5000/міс * (40 годин / 160 робочих годин) = $1250.
- Час на щомісячну підтримку/оновлення: ~2 години на сервер * 10 серверів = 20 годин.
- Вартість підтримки: $5000/міс * (20 годин / 160 робочих годин) = $625.
- Простої/помилки: Припустимо, 1 великий інцидент на рік через ручну помилку, вартість $10,000. Щомісячно $833.
- РАЗОМ (місяць): $400 (сервери) + $1250 (первинне розгортання, амортизація) + $625 (підтримка) + $833 (помилки) = $3108 / міс.
- РАЗОМ (рік): $37,296.
Сценарій 2: Автоматизоване розгортання з Terraform та Ansible
- Витрати на сервери: 10 VPS по $40/міс = $400/міс. (без змін)
- Час на розробку IaC/CM (первинно): 80 годин (2 тижні інженера).
- Вартість розробки (первинно): $5000/міс * (80 годин / 160 робочих годин) = $2500. (Одноразові витрати, амортизуємо на 2 роки: $104/міс)
- Час розгортання 10 серверів: ~10-20 хвилин (запуск скрипта). Трудовитрати: $5000/міс * (0.25 години / 160 робочих годин) = ~$8.
- Час на щомісячну підтримку/оновлення: ~2 години (оновлення playbooks/модулів, запуск). Трудовитрати: $5000/міс * (2 години / 160 робочих годин) = $62.5.
- Простої/помилки: Зниження на 90% до 1 незначного інциденту, вартість $1,000/рік. Щомісячно $83.
- РАЗОМ (місяць): $400 (сервери) + $104 (амортизація розробки) + $8 (розгортання) + $62.5 (підтримка) + $83 (помилки) = $657.5 / міс.
- РАЗОМ (рік): $7,890.
Економія: $3108 - $657.5 = $2450.5 / міс. або $29,406 / рік.
Як видно з розрахунків, навіть при відносно невеликій кількості серверів, автоматизація окупається протягом декількох місяців і потім приносить значну економію. Чим більша інфраструктура, тим вищий економічний ефект.
Таблиця з прикладами розрахунків для різних сценаріїв
Припустимо, що "Вартість години інженера" = $31.25 (при зарплаті $5000/міс за 160 годин).
| Параметр | Ручне розгортання (10 VPS) | Автоматизоване розгортання (10 VPS) | Автоматизоване розгортання (50 VPS) |
|---|---|---|---|
| Вартість серверів (міс.) | $400 | $400 | $2000 |
| Первинна розробка IaC/CM (години) | 0 | 80 | 120 |
| Первинна розробка IaC/CM (вартість, амортизація на 2 роки) | $0 | $104 | $156 |
| Час розгортання (години/міс.) | 40 | 0.25 | 0.5 |
| Вартість розгортання (міс.) | $1250 | $8 | $16 |
| Час підтримки/оновлень (години/міс.) | 20 | 2 | 5 |
| Вартість підтримки (міс.) | $625 | $62.5 | $156.25 |
| Вартість простоїв/помилок (міс.) | $833 | $83 | $200 |
| РАЗОМ (місяць) | $3108 | $657.5 | $2528.25 |
| РАЗОМ (рік) | $37,296 | $7,890 | $30,339 |
Як оптимізувати витрати
- Автоматичне управління життєвим циклом ресурсів: Використовуйте Terraform для автоматичного створення та видалення ресурсів за розкладом або подією. Наприклад, тестові середовища можуть бути знищені після закінчення робочого дня.
- Правильний вибір інстансів: Terraform дозволяє легко змінювати типи інстансів. Аналізуйте метрики використання ресурсів та обирайте оптимальні розміри VPS/серверів. Не переплачуйте за надлишкові потужності.
- Резервування потужностей: Для стабільних навантажень використовуйте зарезервовані екземпляри (Reserved Instances) або контракти на виділені сервери, які пропонують значні знижки.
- Моніторинг та оповіщення про витрати: Інтегруйте моніторинг витрат у ваш пайплайн. Встановіть алерти, коли витрати перевищують певні пороги.
- Використання Spot Instances (для відмовостійких навантажень): У хмарі, для переривчастих, але відмовостійких навантажень можна використовувати Spot Instances з Terraform, що значно знижує вартість.
- Оптимізація мережевого трафіку: Використовуйте CDN для статичного контенту, кешування, стиснення даних, щоб зменшити обсяг вихідного трафіку.
- Мінімізація ручних операцій: Чим менше ручних дій, тим менша ймовірність дорогих помилок і тим вища ефективність інженерів.
В кінцевому підсумку, автоматизація з Terraform та Ansible є стратегічною інвестицією, яка не тільки підвищує технічну зрілість проєкту, але й забезпечує значну фінансову віддачу, дозволяючи вашій команді зосередитися на створенні цінності, а не на рутині.
Кейси та приклади з реальної практики
Щоб краще зрозуміти, як Terraform та Ansible застосовуються на практиці, розглянемо декілька реалістичних сценаріїв зі світу DevOps та SaaS у 2026 році.
Кейс 1: Розгортання масштабованої SaaS-платформи на DigitalOcean
Проблема:
Молодий SaaS-стартап "CloudSync" зіткнувся зі швидким зростанням числа користувачів і необхідністю масштабування своєї платформи. Спочатку інфраструктура розгорталася вручну на кількох VPS, що призводило до "сніжинок" серверів, довгих простоїв при оновленнях і неможливості швидко реагувати на пікові навантаження. Команда витрачала до 30% часу на ручне управління інфраструктурою.
Рішення з Terraform і Ansible:
Команда CloudSync прийняла рішення повністю перейти на IaC. Вони обрали DigitalOcean через простоту використання і хороший API.
- Terraform для інфраструктури:
- Був створений Terraform-проект, який описував всю інфраструктуру: 3 балансувальники навантаження (DigitalOcean Load Balancers), 10-50 Droplet'ів для веб-серверів (Ubuntu 24.04, s-4vcpu-8gb), 3 Droplet'а для кластера PostgreSQL (s-8vcpu-16gb), 2 Droplet'а для кластера Redis (s-2vcpu-4gb), а також всі необхідні фаєрволи і приватні мережі.
- Використовувалися Terraform-модулі для кожного типу ресурсу (
droplet-module,loadbalancer-module,database-cluster-module), що забезпечило перевикористання і стандартизацію. - Налаштовано віддалений бекенд S3 для зберігання стану Terraform, інтегрований з GitLab CI.
- Ansible для конфігурації і розгортання:
- Після розгортання інфраструктури Terraform, GitLab CI автоматично запускав Ansible Playbooks.
- Ansible використовував динамічний інвентар, що генерувався з виводу Terraform, щоб отримати актуальні IP-адреси Droplet'ів.
- Були розроблені Ansible-ролі:
webserver(встановлення Nginx, PHP-FPM, налаштування),postgresql(встановлення кластера, бекапи),redis(налаштування кластера),app-deploy(розгортання програми з Docker-образу). - Ansible також відповідав за встановлення агентів моніторингу (Prometheus Node Exporter) і логування (Fluentd) на всі сервери.
- CI/CD пайплайн:
- Будь-яка зміна в коді інфраструктури або програми ініціювала пайплайн в GitLab CI.
- Terraform `plan` запускався автоматично для перевірки змін.
- Після ручного підтвердження (для продакшн), `terraform apply` оновлював інфраструктуру.
- Потім Ansible Playbooks застосовувалися для конфігурування серверів і розгортання нового коду програми.
Результати:
- Скорочення часу розгортання: Розгортання нового середовища або масштабування кластера з 30 хвилин до 5-7 хвилин.
- Зниження кількості помилок: Практично повне виключення людського фактора при розгортанні і конфігуруванні.
- Покращена масштабованість: Можливість швидко додавати або видаляти Droplet'и в залежності від навантаження.
- Економія витрат: Скорочення трудозатрат DevOps-інженерів на 70%, що дозволило їм зосередитися на більш стратегічних задачах.
- Підвищення надійності: Легке відновлення інфраструктури після збоїв завдяки IaC.
Кейс 2: Управління гібридною інфраструктурою з виділеними серверами і VPS
Проблема:
Велика ігрова студія "PixelForge" використовувала гібридну інфраструктуру: високопродуктивні виділені сервери (Hetzner Dedicated) для ігрових серверів і баз даних, і хмарні VPS (AWS EC2) для веб-сайту, API і аналітики. Управління цією різнорідною інфраструктурою було вкрай складним і вимагало різних підходів для кожного типу сервера.
Рішення з Terraform і Ansible:
PixelForge впровадила уніфікований підхід до управління за допомогою Terraform і Ansible.
- Terraform для різнорідної інфраструктури:
- Для AWS EC2 використовувався офіційний AWS-провайдер Terraform для розгортання інстансів, VPC, Security Groups, Load Balancers.
- Для Hetzner Dedicated Servers використовувався кастомний провайдер Terraform (або скрипти, що викликаються через `local-exec`), який взаємодіяв з Hetzner Robot API для замовлення, перевстановлення ОС і отримання IP-адрес виділених серверів.
- Всі ресурси (як хмарні, так і виділені) були описані в Terraform, що дозволило мати єдину "карту" всієї інфраструктури.
- Terraform виводив IP-адреси всіх серверів, які потім використовувалися динамічним інвентарем Ansible.
- Ansible для уніфікованого конфігурування:
- Ansible використовував один і той же набір ролей для базової конфігурації (SSH, фаєрвол, користувачі, моніторинг) як для AWS EC2, так і для Hetzner Dedicated.
- Специфічні для кожного типу сервера конфігурації (наприклад, налаштування файлової системи для ігрових серверів на Hetzner) були реалізовані через умовні оператори (`when`) в Playbooks або через різні змінні для різних груп інвентарю.
- Ansible відповідав за розгортання ігрових серверів (SteamCMD, налаштування движка), баз даних (PostgreSQL Master-Replica), веб-серверів (Nginx, Node.js) і аналітичних інструментів.
- Централізований CI/CD:
- Jenkins був налаштований для оркестрації всього процесу.
- Пайплайн запускав Terraform для створення/оновлення ресурсів на обох платформах.
- Після цього Ansible Playbooks застосовувалися до відповідних груп серверів.
Результати:
- Уніфікація управління: Єдиний підхід до управління гібридною інфраструктурою, незважаючи на її різнорідність.
- Значне прискорення розгортання: Нові ігрові сервери могли бути запущені протягом 15 хвилин, а оновлена веб-інфраструктура – за 5 хвилин.
- Підвищення надійності: Зменшення помилок, пов'язаних з ручним конфігуруванням, і можливість швидкого відновлення.
- Оптимізація витрат: Більш ефективне використання виділених серверів для критичних навантажень і гнучке масштабування хмарних ресурсів для змінних навантажень.
- Покращена безпека: Стандартизовані конфігурації безпеки, автоматично застосовуються до всієї інфраструктури.
Потрібен виділений сервер?
Compare prices from top providers. Configure and order in minutes.
Інструменти та ресурси для ефективної роботи
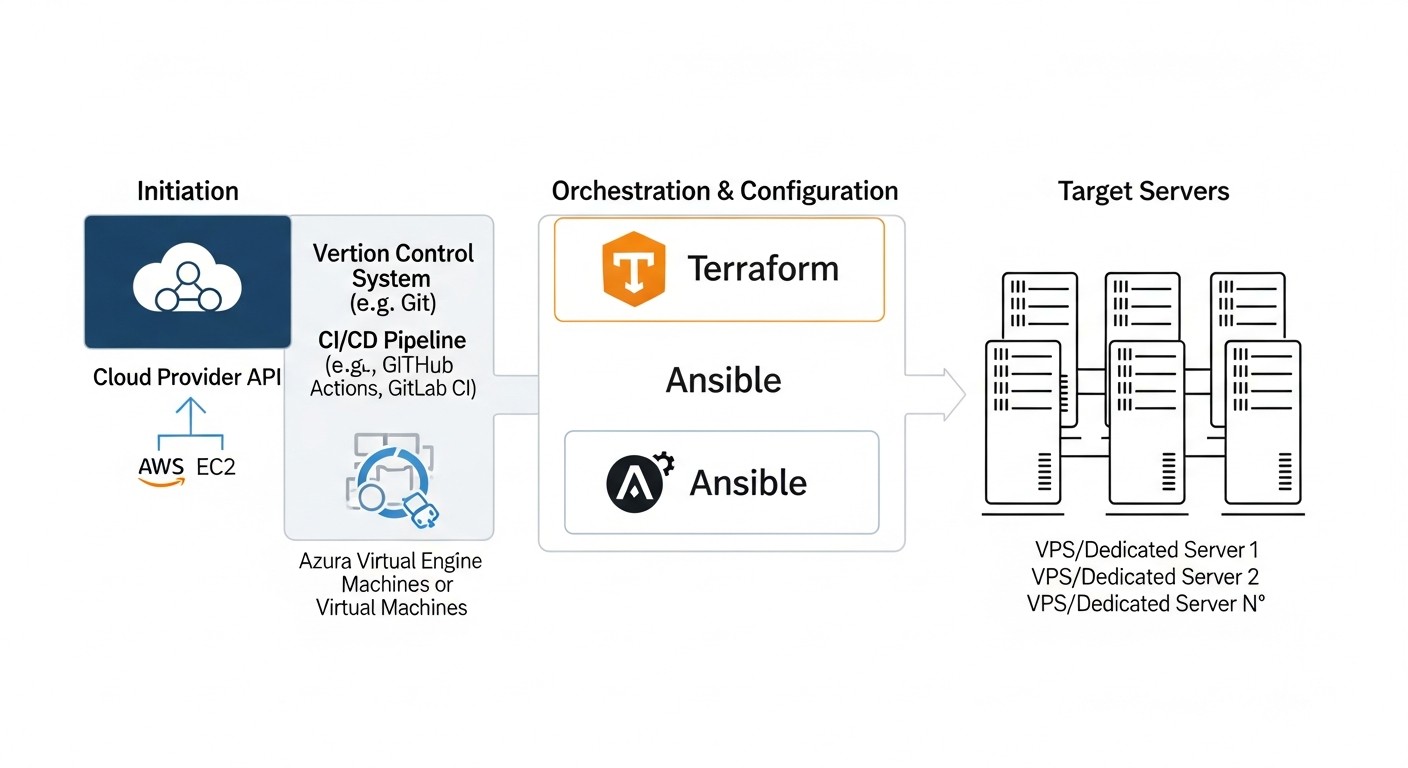
Автоматизація розгортання та управління серверами з Terraform і Ansible – це не тільки самі ці інструменти, а й ціла екосистема допоміжних утиліт, платформ і ресурсів. У 2026 році цей набір став ще більш великим та інтегрованим.
1. Основні інструменти
- Terraform (HashiCorp): Ваш основний інструмент для IaC.
- Офіційний сайт Terraform
- Terraform Registry (для пошуку провайдерів і модулів)
- Ansible (Red Hat): Ваш основний інструмент для управління конфігураціями.
- Офіційний сайт Ansible
- Ansible Galaxy (для пошуку ролей і колекцій)
- Git (система контролю версій): Для версіонування всього вашого коду інфраструктури.
- Офіційний сайт Git
- Платформи: GitHub, GitLab, Bitbucket
- SSH-клієнт: Для підключення до серверів і виконання команд Ansible.
2. Управління секретами
Критично важливо для безпеки вашої автоматизації.
- HashiCorp Vault: Універсальне рішення для централізованого зберігання та управління секретами. Інтегрується з Terraform і Ansible.
- Облачні секретні менеджери:
- AWS Secrets Manager
- Azure Key Vault
- Google Secret Manager
- Ansible Vault: Вбудований інструмент для шифрування чутливих даних в Ansible Playbooks і файлах змінних.
3. CI/CD платформи
Для автоматизації запуску пайплайнів IaC і CM.
- GitLab CI/CD: Вбудований в GitLab. Відмінний вибір для повного циклу розробки та розгортання.
- GitHub Actions: Гнучке рішення, інтегроване з GitHub.
- Jenkins: Один з найстаріших і найбільш гнучких CI/CD серверів, вимагає більше налаштувань.
- CircleCI, Travis CI, Argo CD: Інші популярні рішення.
4. Моніторинг і логування
Для спостереження за вашою інфраструктурою та її продуктивністю.
- Prometheus + Grafana: Відкриті рішення для збору метрик і візуалізації. Ansible може розгорнути Prometheus Node Exporter на кожному сервері.
- ELK Stack (Elasticsearch, Logstash, Kibana): Потужний стек для централізованого збору, аналізу та візуалізації логів.
- Loki + Grafana: Легковажне рішення для логів, натхненне Prometheus.
- Комерційні рішення: Datadog, New Relic, Splunk (часто мають готові Ansible-ролі для встановлення агентів).
5. Тестування інфраструктури як коду
Для забезпечення якості та надійності вашої автоматизації.
- `terraform validate` і `terraform plan`: Вбудовані команди для перевірки синтаксису та перегляду майбутніх змін.
- `ansible-lint`: Статичний аналізатор для Ansible Playbooks, який перевіряє на відповідність кращим практикам.
- Molecule: Фреймворк для тестування Ansible ролей, підтримує різні драйвери (Docker, Vagrant).
- Terratest (Go): Фреймворк для написання автоматизованих тестів для інфраструктури, розгорнутої за допомогою Terraform.
- InSpec (Chef): Фреймворк для аудиту та тестування відповідності конфігурацій.
- Serverspec (Ruby): Інструмент для тестування стану серверів.
6. Додаткові утиліти та концепції
- Cloud-init: Стандартний спосіб для виконання скриптів при першому запуску хмарних інстансів. Часто використовується Terraform для початкового налаштування перед тим, як Ansible візьме управління на себе.
- Vagrant (HashiCorp): Для створення та управління легкими, переносними середовищами розробки. Корисно для локального тестування Ansible ролей.
- Docker: Для контейнеризації додатків. Ansible може розгортати Docker Engine і запускати контейнери.
- Packer (HashiCorp): Для створення образів машин (AMI, VMDK, OVF) з єдиного вихідного файлу. Дозволяє створювати "золоті" образи з уже встановленим ПЗ, що прискорює розгортання і знижує навантаження на Ansible.
- Open Policy Agent (OPA): Для впровадження політик "Infrastructure as Code" і забезпечення відповідності стандартам безпеки.
7. Корисні посилання та документація
- Документація провайдерів Terraform: Для кожного хмарного провайдера або хостингу є своя документація по Terraform (наприклад, DigitalOcean Terraform Provider).
- Офіційна документація Ansible: Детальні керівництва по модулям, ролям і Playbooks.
- Блоги та спільноти: DevOps-блоги (наприклад, HashiCorp Blog, Red Hat Blog), Stack Overflow, Reddit (r/devops, r/terraform, r/ansible).
- Курси та сертифікації: Coursera, Udemy, Linux Academy, HashiCorp Certified: Terraform Associate, Red Hat Certified Specialist in Ansible Automation.
Використання цього набору інструментів і ресурсів дозволить вам створити високоефективний, надійний і масштабований процес автоматизації, який буде актуальним і в 2026 році.
Troubleshooting: вирішення проблем автоматизації
Навіть при самій ретельній підготовці, в процесі автоматизації з Terraform і Ansible можуть виникати проблеми. Уміння швидко діагностувати та усувати їх – ключова навичка. Ось список типових проблем і підходів до їх вирішення.
1. Проблеми з Terraform
1.1. Помилки при terraform plan або terraform apply:
- Симптом: Синтаксичні помилки HCL, проблеми з аутентифікацією провайдера, некоректні параметри ресурсів.
Діагностика: Уважно читайте вивід Terraform. Він зазвичай дуже інформативний і вказує на конкретний рядок та причину помилки. Перевірте ваш API-токен або ключі доступу, їх права. - Симптом: "Resource already exists" або "Resource not found" при повторному `apply`.
Діагностика: Перевірте файл стану (`.tfstate`). Можливо, ресурс було створено вручну або його стан розсинхронізувався.
Рішення: Використовуйте `terraform import` для додавання існуючого ресурсу в стан, або `terraform state rm` для видалення запису зі стану (якщо ресурс дійсно видалено). Будьте вкрай обережні з `terraform state rm`! - Симптом: Зависання `terraform apply` або таймаут операції.
Діагностика: Зазвичай пов'язано з мережевими проблемами, лімітами провайдера або дуже довгими операціями. Перевірте логи провайдера (наприклад, AWS CloudTrail, DigitalOcean Activity Log).
Рішення: Збільште таймаути в конфігурації Terraform, якщо це можливо. Перевірте квоти та ліміти у вашого провайдера.
1.2. Проблеми з Terraform State:
- Симптом: "State file locked" або конфлікти при паралельних запусках.
Діагностика: Переконайтеся, що ви використовуєте віддалений бекенд з блокуванням.
Рішення: Якщо блокування застрягло (рідко), можна примусово зняти його (`terraform force-unlock`), але тільки якщо ви впевнені, що ніхто інший не працює зі станом. - Симптом: Дрейф конфігурації (Drift) – реальна інфраструктура відрізняється від стану.
Діагностика: Запустіть `terraform plan`. Він покаже всі відмінності.
Рішення: Якщо дрейф викликаний ручними змінами, або застосуйте `terraform apply` для повернення до коду, або оновіть код Terraform, щоб він відповідав ручним змінам. В ідеалі, ручні зміни повинні бути заборонені.
Діагностичні команди Terraform:
terraform validate # Перевірка синтаксису
terraform plan # Попередній перегляд змін
terraform apply # Застосування змін
terraform state list # Список ресурсів у стані
terraform state show # Детальна інформація про ресурс
terraform output -json # Вивід всіх output змінних в JSON форматі
TF_LOG=TRACE terraform apply # Дуже детальні логи для відладки
2. Проблеми з Ansible
2.1. Проблеми підключення до хостів:
- Симптом: "Unreachable", "Authentication failed", "Permission denied (publickey)".
Діагностика:- Перевірте, що SSH-ключ (`-i ~/.ssh/id_rsa`) вказаний вірно і має правильні права (`chmod 400`).
- Переконайтеся, що IP-адреса або ім'я хоста в інвентарі вірні.
- Перевірте, що SSH-сервер на цільовому хості запущений і доступний (
ssh user@ip). - Перевірте налаштування фаєрвола на цільовому хості і в хмарі (групи безпеки).
- Переконайтеся, що користувач, під яким Ansible намагається підключитися, існує на віддаленому сервері і має права на підключення по SSH.
- Симптом: "Host key checking failed".
Діагностика: Це означає, що відбиток ключа хоста не співпадає або відсутній вknown_hosts.
Рішення: Якщо це новий сервер, ви можете тимчасово відключити перевірку ключів (-o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null) для першого запуску, але в продакшені це вкрай не рекомендується. Краще додати ключ вknown_hostsвручну або використовувати `ssh-keyscan`.
2.2. Помилки виконання Playbook'ів:
- Симптом: Задача завершується з помилкою, повідомлення про помилку модуля.
Діагностика: Уважно читайте повідомлення про помилку. Воно зазвичай вказує на конкретний модуль і причину (наприклад, "package not found", "file permissions error").
Рішення: Перевірте синтаксис YAML, змінні, права файлів/каталогів на цільовому хості. Запустіть playbook з підвищеною деталізацією (`-vvv`). - Симптом: Playbook "зависає" або виконується дуже довго.
Діагностика: Може бути пов'язано з очікуванням вводу, довгими командами або мережевими таймаутами.
Рішення: Перевірте, чи немає інтерактивних команд. Переконайтеся, що команди не блокуються фаєрволом. - Симптом: Неідемпотентність – повторний запуск Playbook'а змінює стан або викликає помилки.
Діагностика: Запустіть з `ansible-playbook --check --diff`. Це покаже, які зміни будуть внесені без фактичного застосування.
Рішення: Перепишіть задачі, використовуючи ідемпотентні модулі і умови.
Діагностичні команди Ansible:
ansible all -i inventory.ini -m ping # Перевірка доступності хостів
ansible-playbook -i inventory.ini playbook.yaml # Запуск playbook
ansible-playbook -i inventory.ini playbook.yaml -vvv # Детальний вивід для відладки
ansible-playbook -i inventory.ini playbook.yaml --check --diff # Передперегляд змін
ansible-inventory -i inventory.ini --list # Перегляд інвентаря
ansible-lint # Перевірка на відповідність стилю і кращим практикам
3. Загальні проблеми
- Мережеві проблеми: Недоступність портів, неправильна маршрутизація, блокування фаєрволом.
Рішення: Перевірте правила фаєрвола в хмарі (Security Groups), на сервері (UFW, firewalld). Використовуйте `ping`, `traceroute`, `telnet`, `nc` для діагностики мережевого підключення. - Проблеми з правами: Недостатні права користувача для виконання операцій.
Рішення: Переконайтеся, що користувач має необхідні права (наприклад, `sudo`). Для Ansible використовуйте `become: true`. - Проблеми з версіями: Несумісність версій Terraform, Ansible, провайдерів або операційних систем.
Рішення: Завжди використовуйте фіксовані версії провайдерів в Terraform (`version = "~> 2.0"`). Перевіряйте сумісність Ansible-ролей з версіями ОС. - Недостатньо ресурсів: Сервери не можуть запуститися через нестачу RAM, CPU або дискового простору.
Рішення: Перевірте логи провайдера. Збільште розмір інстанса або диска.
Пам'ятайте, що логи – ваш найкращий друг. Завжди починайте з вивчення виводу команд і логів системи. Не бійтеся експериментувати в тестовому середовищі і використовувати режими `check` і `diff` перед застосуванням змін в продакшені.
FAQ: Часті запитання
1. Навіщо мені використовувати Terraform та Ansible, якщо я можу використовувати лише один з них?
Terraform та Ansible вирішують різні, але комплементарні завдання. Terraform фокусується на декларативному управлінні інфраструктурою (IaC) – створенні, зміні та видаленні ресурсів (VPS, мережі, балансувальники). Ansible – на управлінні конфігураціями (CM) – встановленні ПЗ, налаштуванні сервісів, розгортанні застосунків ВСЕРЕДИНІ цих ресурсів. Використання обох інструментів у зв'язці забезпечує повну автоматизацію від "голого" заліза до працюючого застосунку, розділяючи зони відповідальності та роблячи процес більш надійним і масштабованим.
2. Який провайдер кращий для VPS/виділених серверів у 2026 році?
Найкращий провайдер залежить від ваших конкретних потреб. DigitalOcean та Vultr залишаються відмінним вибором для стартапів та невеликих проєктів завдяки простоті використання та гарній ціні/продуктивності. Hetzner Cloud пропонує дуже конкурентні ціни та потужні виділені сервери. AWS, Azure та GCP підходять для великих підприємств з комплексними вимогами та великим бюджетом, пропонуючи широкий спектр сервісів. Equinix Metal — хороший вибір для Bare Metal as a Service. Оцінюйте за продуктивністю, географією, ціною, API для автоматизації та якістю підтримки.
3. Наскільки складно освоїти Terraform та Ansible?
Обидва інструменти мають відносно низький поріг входу, особливо для тих, хто вже знайомий з командним рядком та концепціями Linux. Terraform використовує HCL, який інтуїтивно зрозумілий. Ansible використовує YAML, який також простий для читання. Основна складність полягає в розумінні концепцій IaC, ідемпотентності, управління станом та проєктуванні модульної архітектури. З активною спільнотою та великою документацією, базове освоєння займає кілька тижнів, а експертний рівень — кілька місяців практики.
4. Як забезпечити безпеку секретів (паролів, ключів API) в автоматизації?
Ніколи не зберігайте секрети у відкритому вигляді в Git-репозиторіях. Використовуйте спеціалізовані інструменти: HashiCorp Vault, AWS Secrets Manager, Azure Key Vault, Google Secret Manager. Для Ansible використовуйте Ansible Vault для шифрування файлів з чутливими даними. Інтегруйте ці секретні менеджери у ваш CI/CD пайплайн, щоб вони динамічно надавали секрети лише під час виконання задач, використовуючи принцип найменших привілеїв.
5. Що таке "Infrastructure Drift" і як з ним боротися?
Infrastructure Drift (дрейф конфігурації) – це ситуація, коли фактичний стан вашої інфраструктури відрізняється від того, що описано у вашому коді IaC (Terraform). Це часто відбувається через ручні зміни, внесені безпосередньо на серверах. Щоб боротися з дрейфом, регулярно запускайте terraform plan (в ідеалі в CI/CD) для його виявлення. Впровадьте строгі політики, що забороняють ручні зміни. Розгляньте використання "Immutable Infrastructure", де сервери ніколи не змінюються, а замінюються новими.
6. Чи можу я використовувати Terraform для управління виділеними серверами без API?
Напряму — ні. Terraform працює через API провайдерів. Якщо ваш провайдер виділених серверів не надає API, ви не зможете використовувати Terraform для їх безпосереднього розгортання або управління (наприклад, перевстановлення ОС). Однак ви можете використовувати Terraform для управління DNS-записами, мережевими налаштуваннями або іншими хмарними компонентами, пов'язаними з вашими виділеними серверами. Для самих серверів без API доведеться використовувати ручні операції або Ansible для конфігурації вже існуючих машин.
7. Які найкращі практики для структурування Terraform та Ansible проєктів?
Для Terraform: використовуйте модулі для повторно використовуваних компонентів, розділяйте конфігурації по середовищах (dev, staging, prod) та по компонентах (network, compute, database). Для Ansible: використовуйте ролі для логічного групування задач, змінних та шаблонів. Розділяйте змінні по групах хостів та середовищах. Зберігайте весь код в Git, використовуйте зрозумілі імена та коментарі. Дотримуйтесь принципу DRY (Don't Repeat Yourself).
8. Як тестувати мій код інфраструктури?
Тестування IaC так само важливо, як і тестування коду застосунку. Для Terraform використовуйте terraform validate та terraform plan. Для Ansible – ansible-lint та Molecule для тестування ролей в ізольованих середовищах. Для інтеграційного тестування розгорнутої інфраструктури використовуйте фреймворки типу Terratest, InSpec або Serverspec. Включайте ці тести у ваш CI/CD пайплайн.
9. Що робити, якщо Terraform або Ansible викликають помилку в продакшені?
По-перше, не панікуйте. По-друге, негайно відкотіть останні зміни, якщо це можливо (наприклад, terraform destroy для нещодавно створеного ресурсу або відкат Git-комміта). По-третє, ретельно вивчіть логи (з `TF_LOG=TRACE` для Terraform, `-vvv` для Ansible). Використовуйте режим `plan` або `check` для діагностики. Якщо проблема пов'язана з зовнішнім сервісом, перевірте його статус. Майте чіткий план відкату та відновлення.
10. Як щодо Kubernetes? Чи замінить він VPS/виділені сервери?
Kubernetes (K8s) — потужна платформа для оркестрації контейнерів, яка активно розвивається і в 2026 році. Він не замінює VPS/виділені сервери напряму, а скоріше абстрагує їх. K8s сам по собі працює НА серверах (віртуальних або виділених). Terraform може розгортати кластери K8s (наприклад, EKS, GKE, AKS або K3s на VPS), а Ansible може використовуватися для початкової конфігурації цих вузлів або розгортання K8s-кластера на Bare Metal. Для багатьох застосунків, особливо мікросервісних, K8s є відмінним вибором, але для монолітних застосунків, високонавантажених баз даних або специфічних ігрових серверів VPS та виділені сервери, як і раніше, залишаються актуальними і більш простими в управлінні.
11. Як мені оновити існуючу інфраструктуру, створену вручну, на IaC?
Це називається "adoption" або "brownfield" розгортання. Кроки: 1) Імпортуйте існуючі ресурси в Terraform State за допомогою terraform import. Це дозволяє Terraform взяти на себе управління вже створеними ресурсами. 2) Створіть Ansible Playbooks для конфігурування існуючих серверів, щоб стандартизувати їх стан. 3) Застосовуйте зміни поступово, спочатку в тестовому середовищі. Це трудомісткий, але необхідний процес для переходу до автоматизації.
12. Які тенденції в автоматизації інфраструктури на найближчі роки?
У 2026 році і далі ми побачимо подальший розвиток:
- AI/ML-Driven Operations (AIOps): Використання ШІ для передбачувального масштабування, автоматичного виправлення проблем, оптимізації витрат та виявлення аномалій.
- GitOps: Управління інфраструктурою та застосунками через Git-репозиторій як єдине джерело істини, з автоматичною синхронізацією.
- Serverless та Function as a Service (FaaS): Продовження тренду на абстракцію від серверів для певних типів навантажень.
- Security as Code: Інтеграція політик безпеки безпосередньо в код інфраструктури та автоматизація їх застосування та аудиту.
- Platform Engineering: Створення внутрішніх платформ, які абстрагують складність нижньої інфраструктури для розробників, використовуючи IaC та CM як фундамент.
Потрібен виділений сервер?
Compare prices from top providers. Configure and order in minutes.
Висновок
У 2026 році автоматизація розгортання та керування VPS і виділеними серверами за допомогою Terraform та Ansible – це не просто "приємно мати", а абсолютна необхідність для будь-якої організації, яка прагне до ефективності, надійності та конкурентоспроможності. Ми побачили, як ці два потужні інструменти, працюючи у зв'язці, дозволяють створювати, конфігурувати та підтримувати інфраструктуру з небаченою раніше швидкістю та точністю. Від декларативного опису ресурсів з Terraform до ідемпотентного управління конфігураціями з Ansible – кожен крок у життєвому циклі сервера може бути автоматизований та зафіксований у коді.
Ми розглянули ключові критерії вибору, детально вивчили принципи роботи Terraform та Ansible, поділилися практичними порадами щодо впровадження, а також проаналізували типові помилки та способи їх уникнути. Економічні розрахунки наочно продемонстрували, що інвестиції в автоматизацію окупаються багаторазово, скорочуючи трудовитрати, мінімізуючи простої та прискорюючи виведення продуктів на ринок. Кейси з реальної практики підтвердили універсальність та ефективність такого підходу як для масштабованих SaaS-платформ, так і для складних гібридних інфраструктур.
Світ інфраструктури постійно змінюється, але принципи IaC та CM залишаються непорушними. Інструменти та технології будуть розвиватися, з'являться нові провайдери та можливості, але фундаментальна ідея управління інфраструктурою як кодом буде тільки зміцнюватися. Інтеграція з CI/CD, посилення безпеки через секретні менеджери та Security as Code, а також впровадження просунутого моніторингу та тестування – все це компоненти успішної стратегії автоматизації.
Підсумкові рекомендації:
- Інвестуйте в навчання: Переконайтеся, що ваша команда глибоко розуміє Terraform, Ansible та пов'язані концепції.
- Почніть з малого: Поступове впровадження автоматизації знижує ризики та дозволяє швидко отримати перші результати.
- Застосовуйте модульність: Використовуйте модулі Terraform та ролі Ansible для створення компонентів, які можна повторно використовувати та підтримувати.
- Версіоніруйте все: Git – ваш найкращий друг. Всі зміни в інфраструктурі повинні проходити через контроль версій та code review.
- Тестуйте безжально: Ваш код інфраструктури повинен бути протестований не менше, ніж код програми.
- Керуйте секретами: Використовуйте спеціалізовані інструменти для зберігання та доступу до конфіденційних даних.
- Уникайте ручних змін: Прагніть до того, щоб вся інфраструктура керувалася виключно через код.
- Інтегруйте в CI/CD: Повна автоматизація розкриває весь потенціал IaC та CM.
Наступні кроки для читача:
Якщо ви дочитали до цього моменту, значить, ви готові до дій. Не відкладайте.
- Виберіть пілотний проект: Визначте невеликий, але значущий компонент вашої інфраструктури для першої автоматизації.
- Вивчіть документацію: Глибоко пориньте в офіційні керівництва Terraform та Ansible.
- Почніть писати код: Створіть свій перший
main.tfтаplaybook.yaml. Розгорніть тестовий VPS. - Використовуйте спільноту: Задавайте питання на Stack Overflow, Reddit, беріть участь в обговореннях.
- Побудуйте свій CI/CD пайплайн: Інтегруйте ваші Terraform та Ansible скрипти в автоматичний процес.
Автоматизація – це не кінцева мета, а безперервний процес вдосконалення. Застосовуючи принципи та інструменти, описані в цій статті, ви зможете побудувати надійну, масштабовану та ефективну інфраструктуру, готову до викликів 2026 року та далі. Удачі у вашій подорожі з автоматизації!