
Оптимизация производительности I/O на Linux с io_uring для высоконагруженных приложений
TL;DR
- io_uring — это современный асинхронный I/O интерфейс ядра Linux, унифицирующий дисковые, сетевые и файловые операции, значительно превосходящий традиционные методы в высоконагруженных сценариях.
- Он устраняет накладные расходы на системные вызовы и переключения контекста, используя кольцевые буферы для обмена данными между ядром и пользовательским пространством.
- Ключевые преимущества: снижение задержек, увеличение пропускной способности, существенное уменьшение утилизации CPU для I/O-интенсивных задач.
- Актуален для 2026 года как стандарт де-факто для высокопроизводительных баз данных, прокси-серверов, игровых серверов и любых приложений с экстремальными требованиями к I/O.
- Требует глубокого понимания низкоуровневого программирования и специфики ядра Linux, но предоставляет беспрецедентный контроль и эффективность.
- Начинать использовать io_uring рекомендуется с ядра Linux 5.10+, оптимально — с версий 6.x для максимальной стабильности и функциональности.
- Экономически выгоден за счет снижения требований к аппаратным ресурсам и оптимизации облачных затрат, несмотря на более высокую начальную стоимость разработки.
Ищете сервер, который просто работает?
Valebyte VPS — NVMe, поддержка 24/7, развёртывание за 60 секунд.
1. Введение
В условиях экспоненциального роста объемов данных, повсеместного распространения микросервисной архитектуры и требований к обработке транзакций в реальном времени, производительность подсистемы ввода-вывода (I/O) становится критическим фактором успеха для любого высоконагруженного приложения. К 2026 году этот тренд только усиливается, поскольку пользователи ожидают мгновенного отклика, а бизнес-процессы требуют обработки петабайтов информации с минимальными задержками.
Традиционные подходы к управлению I/O в Linux, такие как блокирующие вызовы, select()/poll()/epoll() для сетевых операций и libaio для дисковых, демонстрируют свои ограничения. Они страдают от высоких накладных расходов на системные вызовы (syscalls), частых переключений контекста между пользовательским пространством и ядром, а также фрагментации API для разных типов I/O. Эти недостатки приводят к неэффективному использованию ресурсов CPU, увеличению задержек и ограничению масштабируемости.
Именно здесь на сцену выходит io_uring — революционный асинхронный I/O интерфейс ядра Linux, представленный в версии 5.1 ядра. io_uring призван решить фундаментальные проблемы производительности I/O, унифицируя операции с файлами, дисками и сетью под единым, высокоэффективным API. Он позволяет приложениям выполнять тысячи I/O операций без единого системного вызова после инициализации, значительно сокращая накладные расходы и высвобождая CPU для полезной работы.
Данная статья предназначена для широкого круга технических специалистов, сталкивающихся с вызовами высоконагруженных систем: DevOps-инженеров, стремящихся оптимизировать инфраструктуру; Backend-разработчиков (особенно на Python, Node.js, Go, PHP), работающих над производительностью своих сервисов; Фаундеров SaaS-проектов, которым важна экономическая эффективность и масштабируемость; Системных администраторов, отвечающих за стабильность и скорость работы серверов; и Технических директоров стартапов, принимающих архитектурные решения. Мы погрузимся в детали io_uring, рассмотрим его преимущества, недостатки, практические аспекты применения и экономическую целесообразность, чтобы помочь вам принимать обоснованные решения в мире высокопроизводительных систем 2026 года.
2. Основные критерии и факторы производительности I/O
Для эффективной оптимизации производительности I/O необходимо четко понимать, какие метрики и факторы являются ключевыми. Однобокий подход может привести к неверным выводам и неэффективным решениям. В 2026 году, когда аппаратные возможности продолжают расти, а требования к скорости обработки данных ужесточаются, детальный анализ этих критериев становится еще важнее.
2.1. Задержка (Latency)
Что это: Время, необходимое для завершения одной I/O операции, от момента запроса до момента получения результата. Измеряется в миллисекундах (мс), микросекундах (мкс) или даже наносекундах (нс) для критически важных систем. Различают среднюю задержку, а также задержки на перцентилях (P90, P99, P99.9), которые показывают, сколько времени занимает операция для 90%, 99% или 99.9% запросов соответственно. Высокие значения на P99 или P99.9 указывают на "хвостовые" задержки, которые могут сильно портить пользовательский опыт.
Почему важно: Прямо влияет на скорость отклика приложения. Для интерактивных систем (веб-серверы, базы данных, игровые серверы) низкая задержка критична для обеспечения плавного пользовательского опыта. Высокие задержки могут привести к таймаутам, снижению удовлетворенности клиентов и потере дохода.
Как оценивать: Используйте утилиты типа fio, iostat, а также специализированные инструменты мониторинга приложений и инфраструктуры, которые собирают метрики задержки. Важно измерять задержку как на уровне операционной системы, так и на уровне самого приложения.
2.2. Пропускная способность (Throughput)
Что это: Объем данных или количество операций, которые система может обработать за единицу времени. Для дисковых операций это может быть МБ/с или ГБ/с, для сетевых — пакеты/с или Гбит/с, для баз данных — IOPS (операций ввода/вывода в секунду) или транзакций/с. IOPS особенно важен для баз данных с большим количеством мелких случайных операций.
Почему важно: Определяет общую производительность системы при обработке больших объемов данных. Высокая пропускная способность позволяет обрабатывать больше запросов, сохранять лог-файлы, передавать потоковое видео или выполнять аналитические задачи быстрее.
Как оценивать: Аналогично задержке, с помощью fio, iostat, sar, а также сетевых анализаторов и мониторинга производительности баз данных. Важно различать последовательную и случайную пропускную способность, а также пропускную способность для чтения и записи.
2.3. Утилизация CPU (CPU Utilization)
Что это: Доля процессорного времени, используемая для выполнения I/O операций и связанных с ними системных вызовов, переключений контекста и обработки прерываний. Высокая утилизация CPU для I/O указывает на неэффективность.
Почему важно: Каждый цикл CPU, потраченный на обработку I/O, не может быть использован для выполнения полезной бизнес-логики. Снижение утилизации CPU для I/O позволяет приложению выполнять больше работы на том же оборудовании, уменьшая потребность в масштабировании и, как следствие, затраты.
Как оценивать: Используйте top, htop, vmstat, perf, bpftrace для детального анализа профиля CPU. Обращайте внимание на %sy (системное время) и %wa (время ожидания I/O).
2.4. Параллелизм (Concurrency)
Что это: Количество I/O операций, которые могут выполняться одновременно. Современные приложения часто обрабатывают тысячи или миллионы параллельных запросов.
Почему важно: Прямо влияет на способность системы обслуживать множество клиентов или внутренних процессов без деградации производительности. Традиционные блокирующие I/O модели плохо масштабируются по параллелизму, требуя большого количества потоков или процессов, что увеличивает накладные расходы.
Как оценивать: Нагрузочное тестирование с увеличением числа одновременных клиентов/запросов. Мониторинг количества активных соединений, потоков или запросов в ожидании.
2.5. Масштабируемость (Scalability)
Что это: Способность системы эффективно увеличивать свою производительность при добавлении дополнительных ресурсов (CPU, RAM, диски, сетевые адаптеры) или при увеличении нагрузки. Идеально, если производительность растет линейно с ресурсами.
Почему важно: Позволяет приложению расти вместе с потребностями бизнеса, избегая дорогостоящих переработок архитектуры или лимитов производительности. Хорошая масштабируемость снижает риски и обеспечивает гибкость.
Как оценивать: Проведение нагрузочного тестирования на различных конфигурациях оборудования, анализ производительности при увеличении числа узлов в кластере или ресурсов на одном узле.
2.6. Эффективность использования ресурсов (Resource Efficiency)
Что это: Насколько эффективно система использует доступные CPU, RAM, пропускную способность сети и диска. Меньше ресурсов для той же работы — выше эффективность.
Почему важно: Напрямую влияет на операционные расходы (OpEx), особенно в облачных средах, где каждый гигабайт RAM и каждый час CPU оплачиваются. Оптимизация I/O может привести к существенной экономии.
Как оценивать: Комплексный мониторинг всех системных ресурсов, сопоставление их утилизации с достигнутой пропускной способностью и задержкой.
2.7. Джиттер (Jitter)
Что это: Вариабельность или флуктуации задержки I/O операций. Даже при низкой средней задержке, высокий джиттер (большие разбросы в P99.9 по сравнению с P50) может создавать проблемы.
Почему важно: Непредсказуемость задержек может быть хуже, чем стабильно высокая задержка. Она затрудняет планирование, приводит к непредсказуемым таймаутам и может вызывать каскадные сбои в распределенных системах.
Как оценивать: Анализ перцентилей задержки (P90, P99, P99.9), построение гистограмм распределения задержек.
Понимание этих критериев позволяет не только диагностировать проблемы производительности, но и выбирать наиболее подходящие технологии и подходы, такие как io_uring, для достижения оптимальных результатов в конкретных сценариях.
3. Сравнительная таблица методов I/O
В мире Linux существует множество подходов к управлению вводом-выводом, каждый со своими сильными и слабыми сторонами. io_uring не является универсальным решением для всех задач, но в определенных сценариях он демонстрирует беспрецедентную эффективность. В этой таблице мы сравним ключевые методы I/O, актуальные на 2026 год, чтобы дать представление об их применимости и производительности.
| Критерий | Блокирующий I/O (read()/write()) |
Мультиплексирование (epoll/select) |
Linux Native AIO (libaio) |
io_uring (с SQPOLL) |
io_uring (без SQPOLL) |
|---|---|---|---|---|---|
| Год появления / Актуальность | 1970-е / Все еще базовый | 1990-е (select), 2002 (epoll) / Широко используется |
2002 / Узкоспециализированный | 2019 (Linux 5.1) / Стандарт для high-perf (2026) | 2019 (Linux 5.1) / Стандарт для high-perf (2026) |
| Сложность API | Очень низкая | Средняя | Высокая | Очень высокая | Высокая |
| Накладные расходы (syscalls на операцию) | 1-2 (ожидание + чтение/запись) | 1 (epoll_wait) + N (read/write) |
2 (io_submit, io_getevents) |
~0 (после инициализации) | 1 (io_uring_enter) на батч |
| Поддержка сетевых операций | Да | Да (основное применение) | Нет | Полная (accept, connect, recvmsg, sendmsg) |
Полная (accept, connect, recvmsg, sendmsg) |
| Поддержка дисковых операций | Да | Нет (только готовность FD) | Да (только O_DIRECT) | Полная (включая кешированный I/O) | Полная (включая кешированный I/O) |
| Поддержка файловых операций (общие) | Да | Нет | Ограниченная (open, close) |
Полная (openat, close, statx, fadvise) |
Полная (openat, close, statx, fadvise) |
| Асинхронность | Нет (блокирующий) | Псевдо-асинхронный (готовность к I/O) | Да (настоящий асинхронный) | Да (настоящий асинхронный, kernel-side polling) | Да (настоящий асинхронный, user-side polling) |
| Рекомендуемые сценарии | Простые скрипты, низконагруженные приложения | Высоконагруженные сетевые приложения (веб-серверы, прокси) | СУБД, специализированные хранилища (O_DIRECT) | Экстремально высоконагруженные приложения (СУБД, кэши, брокеры сообщений, прокси) | Высоконагруженные приложения, где SQPOLL не критичен или нежелателен |
| Типичная задержка (нс) при высокой нагрузке (P99) | 20000+ | 5000-10000 | 3000-7000 | 500-1500 | 1000-3000 |
| Макс. QPS (IOPS) на 1 ядро (K) (усл.) | 10-20 | 50-150 | 80-200 | 500-1500+ | 200-800 |
| Утилизация CPU при 100K IOPS (%) | ~50-70 | ~30-40 | ~20-30 | ~5-15 | ~15-25 |
| Стоимость разработки (условные единицы, 2026) | 1 | 2-3 | 4-5 | 8-10 | 6-8 |
Примечание: Указанные цифры являются приблизительными оценками для высоконагруженных сценариев на современном оборудовании (процессоры Intel Xeon/AMD EPYC 2024-2026 годов, NVMe SSDs, 100GbE сети) и могут сильно варьироваться в зависимости от конкретного приложения, типа I/O, размера блоков и конфигурации системы. "Стоимость разработки" отражает относительную сложность освоения и интеграции.
Ищете сервер, который просто работает?
Valebyte VPS — NVMe, поддержка 24/7, развёртывание за 60 секунд.
4. Детальный обзор каждого пункта/варианта I/O
Давайте углубимся в особенности каждого метода I/O, чтобы понять, когда и почему они используются, и почему io_uring становится предпочтительным выбором для высокопроизводительных систем.
4.1. Блокирующий I/O (read()/write())
Это самый простой и интуитивно понятный способ выполнения операций ввода-вывода. Когда приложение вызывает read() или write(), оно блокируется до тех пор, пока операция не будет завершена ядром. В это время поток, инициировавший I/O, переходит в состояние ожидания, и планировщик ядра может переключиться на другой поток или процесс. Простота API делает его идеальным для простых приложений и скриптов, где производительность I/O не является узким местом. Однако для высоконагруженных приложений такая модель приводит к серьезным проблемам масштабируемости. Каждая I/O операция требует системного вызова, переключения контекста и ожидания, что порождает огромные накладные расходы при большом количестве параллельных запросов. Для обработки параллелизма приходится запускать множество потоков или процессов, каждый из которых может быть заблокирован, что приводит к "пробуксовке" CPU на переключениях контекста и неэффективному использованию ресурсов. В 2026 году этот метод остается базовым, но абсолютно непригоден для систем, где требуется обрабатывать десятки и сотни тысяч I/O операций в секунду.
4.2. Мультиплексирование I/O (select(), poll(), epoll())
Эти механизмы были разработаны для решения проблемы блокирующего I/O в сетевых приложениях. Вместо того чтобы блокировать на каждой операции чтения/записи, приложение может "спросить" ядро, какие из множества открытых файловых дескрипторов (сокеты, пайпы) готовы к чтению или записи. select() и poll() страдают от масштабирования по количеству файловых дескрипторов (O(N) сканирование списка), тогда как epoll() (представленный в Linux 2.5.44) значительно эффективнее, работая в режиме O(1) за счет использования обратных вызовов ядра и кольцевых буферов событий. epoll позволяет приложению эффективно обрабатывать тысячи и миллионы параллельных сетевых соединений с минимальными накладными расходами. Он является краеугольным камнем большинства современных веб-серверов, прокси и брокеров сообщений. Однако epoll не является истинно асинхронным I/O для дисковых операций; он лишь уведомляет о готовности файлового дескриптора. Сами операции read()/write() после получения события все еще могут блокировать, если данные еще не готовы или буфер заполнен, или если операция выполняется с диском, а не с сетью. Это ограничивает его применение в сценариях с интенсивным дисковым I/O, таких как базы данных.
4.3. Linux Native AIO (libaio)
libaio (или Linux Native AIO) был разработан специально для решения проблем асинхронного дискового I/O, особенно для баз данных, которым требуется прямой доступ к диску (O_DIRECT) без вмешательства кеша страницы ядра. Он позволяет приложению отправлять ядру пачку I/O запросов и затем асинхронно получать уведомления об их завершении. Это устраняет блокировку вызывающего потока и позволяет эффективно использовать преимущества высокопроизводительных хранилищ (например, NVMe SSD). API libaio довольно сложен и низкоуровнев, требуя ручного управления iocb (I/O control blocks) и io_event. Основные ограничения libaio заключаются в его фокусе исключительно на дисковых операциях (и только с O_DIRECT для асинхронности) и отсутствии поддержки сетевого I/O. Кроме того, даже с libaio, каждая пачка операций требует системных вызовов io_submit() и io_getevents(), что, хотя и лучше, чем по одному вызову, все же создает накладные расходы, которые io_uring стремится устранить. К 2026 году libaio по большей части вытеснен io_uring в новых высокопроизводительных проектах, хотя все еще присутствует в старых, проверенных временем системах.
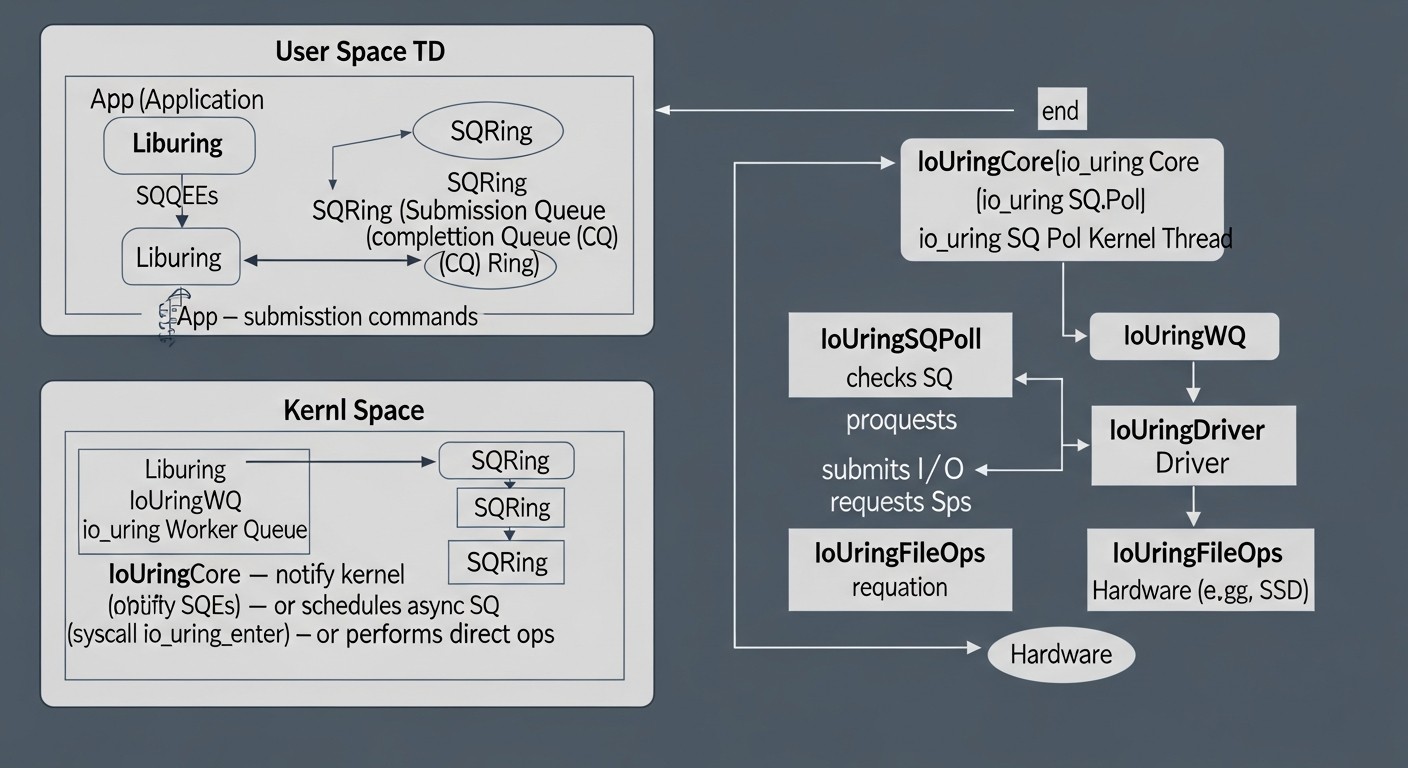
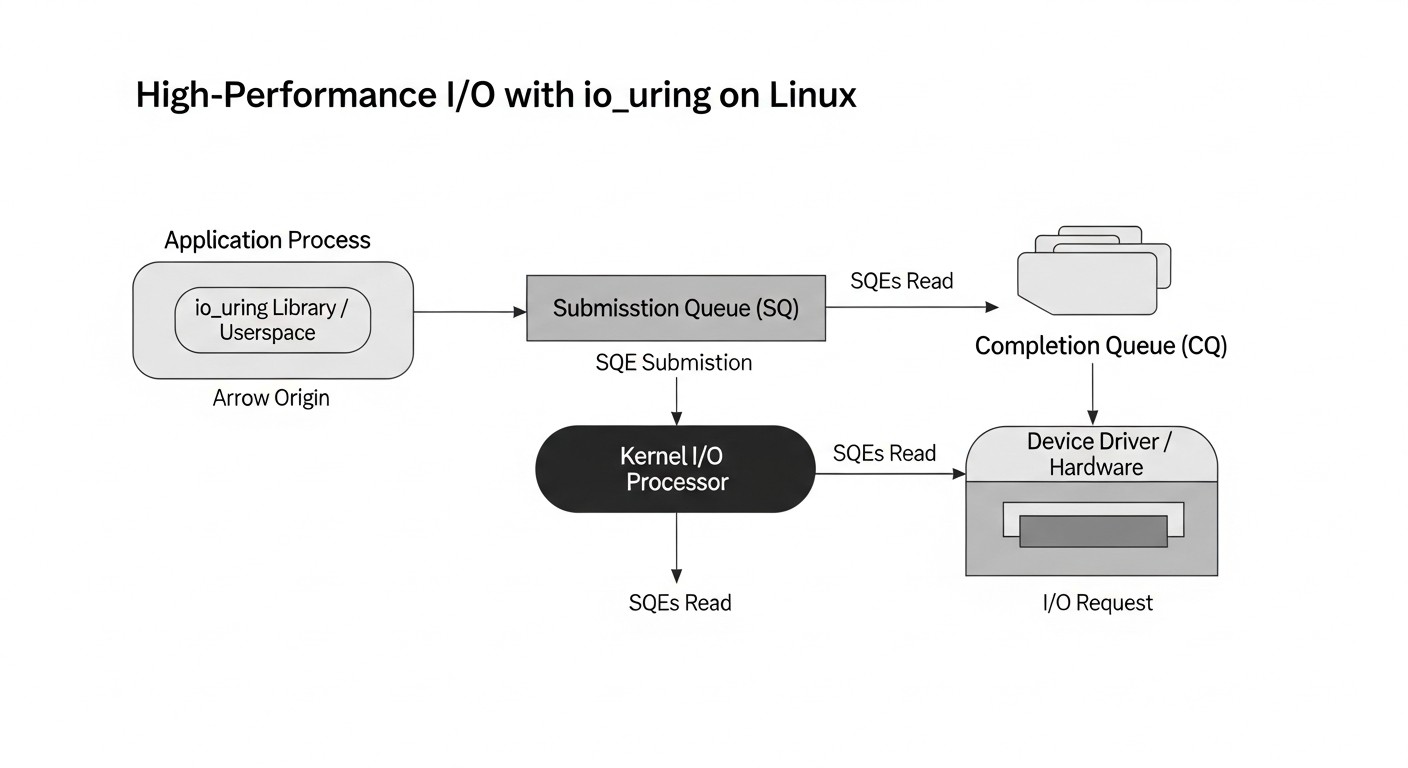
4.4. io_uring: Единый асинхронный I/O для Linux
io_uring — это кульминация десятилетий развития I/O в Linux. Его главная цель — предоставить единый, высокоэффективный, асинхронный интерфейс для всех типов I/O операций: дисковых, файловых, сетевых, а также для ряда других системных операций. В отличие от предыдущих методов, io_uring работает по принципу "запросил и забыл" с минимальным взаимодействием с ядром после первоначальной настройки.
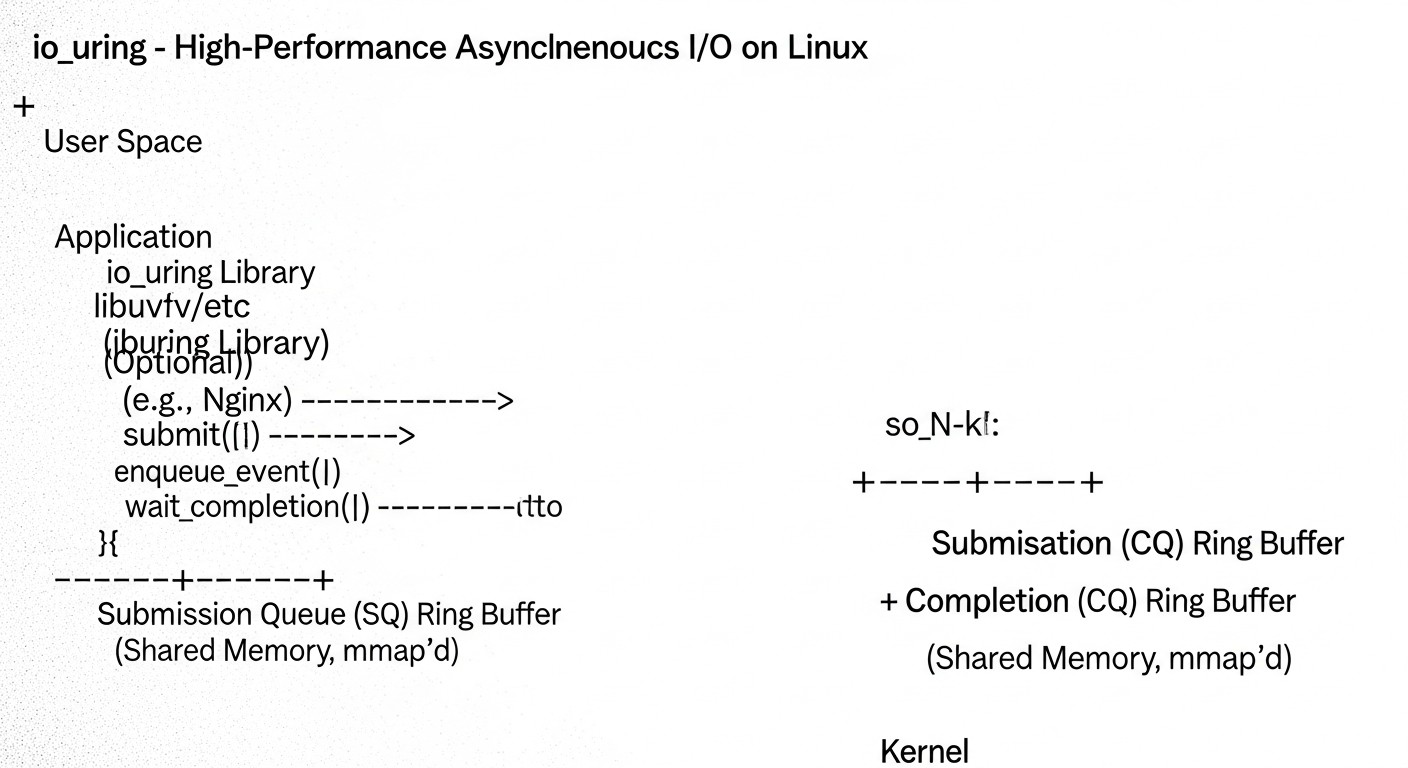
Архитектура io_uring:
- Кольцевые буферы (Ring Buffers): В основе io_uring лежат два кольцевых буфера, отображаемых в память пользовательского пространства:
- Submission Queue (SQ): Очередь запросов. Приложение помещает сюда дескрипторы операций (Submission Queue Entries, SKE), описывающие, что нужно сделать (например, прочитать файл, отправить данные по сокету).
- Completion Queue (CQ): Очередь завершений. Ядро помещает сюда результаты выполненных операций (Completion Queue Entries, CQE), уведомляя приложение о статусе и результате каждой операции.
- Минимальное количество системных вызовов: После инициализации io_uring, приложение может отправлять тысячи операций, просто записывая их в SQ. Ядро берет их из SQ и выполняет асинхронно. Когда операции завершаются, результаты помещаются в CQ. Приложение периодически проверяет CQ на наличие завершенных операций. Системный вызов
io_uring_enter()требуется только для "пробуждения" ядра, если оно неактивно, или для отправки большого батча запросов, если SQ заполнен. Это радикально сокращает накладные расходы на системные вызовы. - Унификация: io_uring поддерживает широкий спектр операций, включая:
- Дисковый/файловый I/O:
read,write,fsync,openat,close,statx,fadvise. Поддерживает как кешированный, так и прямой I/O (O_DIRECT). - Сетевой I/O:
accept,connect,recvmsg,sendmsg. Это позволяет создавать высокопроизводительные сетевые серверы, которые ранее полагались наepoll. - Другие операции:
link_timeout(асинхронные таймеры),async_cancel(отмена операций),io_uring_cmd(расширяемые команды для драйверов).
- Дисковый/файловый I/O:
- SQPOLL (Submission Queue Polling): Это опциональный режим, при котором отдельный поток ядра постоянно опрашивает SQ на наличие новых запросов. Это полностью исключает необходимость системного вызова
io_uring_enter()для отправки запросов, доводя накладные расходы до абсолютного минимума. Идеально подходит для экстремально высоких нагрузок, но потребляет одно ядро CPU для потока-опросчика. - IORING_SETUP_IOPOLL: Это режим, когда ядро не генерирует прерывания по завершению I/O, а пользовательское приложение само опрашивает CQ на предмет завершенных операций. Требует активного цикла опроса в пользовательском пространстве. Используется в сценариях с очень низкими задержками, когда даже прерывания слишком дороги.
- Регистрация ресурсов: io_uring позволяет предварительно регистрировать буферы памяти и файловые дескрипторы в ядре. Это устраняет необходимость дорогостоящих системных вызовов
mmap/munmapили проверок дескрипторов при каждой операции, дополнительно снижая накладные расходы и позволяя ядру выполнять операции более эффективно (например, избегая копирования данных между пользовательским и ядром).
Преимущества: io_uring значительно снижает задержки, увеличивает пропускную способность и уменьшает утилизацию CPU для I/O-интенсивных задач. Он позволяет обрабатывать миллионы IOPS на одном ядре CPU, что было немыслимо с предыдущими методами. Это достигается за счет минимизации системных вызовов, переключений контекста и использования ядра для выполнения асинхронных операций.
Недостатки: Сложный и низкоуровневый API, требующий глубокого понимания работы ядра и тщательного управления памятью. Высокий порог входа для разработчиков. Ошибки в работе с io_uring могут привести к труднодиагностируемым проблемам.
Для кого подходит: io_uring является идеальным решением для разработчиков высокопроизводительных баз данных, key-value хранилищ, брокеров сообщений, прокси-серверов, игровых серверов, высоконагруженных веб-серверов и любых других приложений, где I/O является узким местом и требуется максимальная эффективность использования аппаратных ресурсов. В 2026 году он становится стандартом для таких систем.
5. Практические советы и рекомендации по io_uring
Интеграция io_uring в высоконагруженное приложение — это нетривиальная задача, требующая внимательности и глубокого понимания. Вот ряд практических советов и пошаговых рекомендаций, основанных на реальном опыте.
5.1. Выбор правильной версии ядра Linux
Для полноценного использования io_uring строго рекомендуется использовать ядро Linux версии 5.10 или новее. В версиях 5.1-5.9 функциональность была ограниченной, имелись баги и отсутствовали многие важные операции (например, сетевые). Оптимальный выбор для production-среды в 2026 году — это ядра серии 6.x (например, 6.6 LTS или новее), которые предлагают максимальную стабильность, производительность и полный набор функций, включая расширенную поддержку файловых операций, таймеров и отмены запросов.
# Проверка версии ядра
uname -r
# Ожидаемый вывод: 6.6.10-amd64 или новее
5.2. Использование библиотеки liburing
Хотя можно работать с io_uring напрямую через системные вызовы, настоятельно рекомендуется использовать пользовательскую библиотеку liburing. Она предоставляет удобный и безопасный высокоуровневый API, абстрагирующий от низкоуровневых деталей работы с кольцевыми буферами и системными вызовами, значительно упрощая разработку и снижая вероятность ошибок.
# Установка liburing (пример для Debian/Ubuntu)
sudo apt update
sudo apt install liburing-dev
# Для других дистрибутивов используйте соответствующий менеджер пакетов (dnf, pacman)
5.3. Инициализация контекста io_uring
Первый шаг — создание экземпляра io_uring. Необходимо определить размер кольцевых буферов (количество записей SQE). Чем больше размер, тем больше операций можно поставить в очередь без системного вызова io_uring_enter.
#include <liburing.h>
#include <stdio.h>
#include <stdlib.h>
#define QUEUE_DEPTH 4096 // Рекомендуемая глубина очереди для высоконагруженных систем
struct io_uring ring;
int main() {
struct io_uring_params p = {};
// Можно добавить флаги, например, IORING_SETUP_SQPOLL
// p.flags |= IORING_SETUP_SQPOLL;
// p.sq_thread_cpu = 0; // Привязать SQPOLL к конкретному ядру
int ret = io_uring_queue_init_params(QUEUE_DEPTH, &ring, &p);
if (ret < 0) {
fprintf(stderr, "io_uring_queue_init: %s\n", strerror(-ret));
return 1;
}
printf("io_uring initialized successfully with queue depth %d\n", QUEUE_DEPTH);
// ... ваш код работы с io_uring ...
io_uring_queue_exit(&ring);
return 0;
}
5.4. Регистрация буферов и файловых дескрипторов
Для достижения максимальной производительности обязательно регистрируйте буферы памяти и файловые дескрипторы. Это позволяет ядру избежать дорогостоящих проверок и копирования данных, а также использовать оптимизации, такие как I/O с нулевым копированием (zero-copy) в некоторых сценариях.
// Пример регистрации буферов
char buffer_pool[NUM_BUFFERS]; // Предварительно выделенные буферы
// ... инициализация buffer_pool ...
int ret = io_uring_register_buffers(&ring, buffer_pool, NUM_BUFFERS, BUFFER_SIZE);
if (ret < 0) {
fprintf(stderr, "io_uring_register_buffers: %s\n", strerror(-ret));
// Обработка ошибки
}
// Пример регистрации файловых дескрипторов
int files[NUM_FILES]; // Массив открытых FD
// ... инициализация files ...
ret = io_uring_register_files(&ring, files, NUM_FILES);
if (ret < 0) {
fprintf(stderr, "io_uring_register_files: %s\n", strerror(-ret));
// Обработка ошибки
}
5.5. Батчинг операций (Batching)
Один из главных принципов io_uring — отправка максимально возможного количества операций за один системный вызов. Вместо того чтобы вызывать io_uring_submit() после каждой операции, накапливайте SQE в очереди и отправляйте их пачкой. Это резко сокращает количество переключений контекста.
// Пример батчинга операций чтения
for (int i = 0; i < batch_size; ++i) {
struct io_uring_sqe sqe = io_uring_get_sqe(&ring);
if (!sqe) {
// Очередь SQ заполнена, отправляем текущие и пробуем снова
io_uring_submit(&ring);
sqe = io_uring_get_sqe(&ring); // Повторная попытка
if (!sqe) {
fprintf(stderr, "Failed to get SQE even after submit\n");
break;
}
}
io_uring_prep_read(sqe, file_descriptors[i], buffers[i], BUFFER_SIZE, offsets[i]);
io_uring_sqe_set_data(sqe, (void)(long)request_id[i]); // Пользовательские данные для идентификации
}
io_uring_submit(&ring); // Отправляем оставшиеся операции
5.6. Обработка завершенных операций
После отправки запросов необходимо периодически проверять Completion Queue на наличие завершенных операций. Это можно делать как блокирующим (io_uring_wait_cqe), так и неблокирующим (io_uring_peek_cqe, io_uring_for_each_cqe) способом.
struct io_uring_cqe cqe;
unsigned head;
unsigned count = 0;
// Неблокирующий опрос CQ
io_uring_for_each_cqe(&ring, head, cqe) {
long request_id = (long)io_uring_cqe_get_data(cqe);
int res = cqe->res; // Результат операции (количество байт или код ошибки)
if (res < 0) {
fprintf(stderr, "I/O error for request %ld: %s\n", request_id, strerror(-res));
} else {
printf("Request %ld completed successfully, bytes: %d\n", request_id, res);
}
count++;
}
io_uring_cq_advance(&ring, count); // Отметить обработанные CQE
5.7. Использование IORING_SETUP_SQPOLL
Для самых экстремальных нагрузок рассмотрите использование IORING_SETUP_SQPOLL. Этот флаг при инициализации io_uring создает поток ядра, который постоянно опрашивает SQ. Это устраняет необходимость в системном вызове io_uring_enter() для отправки запросов, но потребляет одно ядро CPU. Привязка этого потока к конкретному ядру (sq_thread_cpu) может улучшить кеширование.
struct io_uring_params p = {};
p.flags |= IORING_SETUP_SQPOLL;
p.sq_thread_cpu = 0; // Привязать к CPU 0
int ret = io_uring_queue_init_params(QUEUE_DEPTH, &ring, &p);
// ...
5.8. Асинхронные сетевые операции
io_uring полностью поддерживает асинхронные сетевые операции, заменяя epoll в высокопроизводительных сетевых серверах.
// Пример асинхронного accept
struct io_uring_sqe sqe = io_uring_get_sqe(&ring);
io_uring_prep_accept(sqe, listen_fd, (struct sockaddr )&client_addr, &client_addr_len, 0);
io_uring_sqe_set_data(sqe, (void)(long)ACCEPT_REQ_ID);
io_uring_submit(&ring);
// Пример асинхронного recv
sqe = io_uring_get_sqe(&ring);
io_uring_prep_recv(sqe, client_fd, buffer, BUFFER_SIZE, 0);
io_uring_sqe_set_data(sqe, (void)(long)RECV_REQ_ID);
io_uring_submit(&ring);
5.9. Управление жизненным циклом буферов
При использовании зарегистрированных буферов, убедитесь, что они остаются валидными до тех пор, пока ядро не завершит все операции с ними. Использование "user_data" в SQE для передачи указателей на структуры запросов или идентификаторов помогает корректно управлять буферами и ресурсами после завершения операции.
5.10. Тщательное тестирование и бенчмаркинг
После внедрения io_uring, обязательно проводите нагрузочное тестирование с помощью fio (с движком io_uring), wrk, ab или специализированных бенчмарков. Сравнивайте производительность с предыдущими реализациями, анализируйте метрики задержки, пропускной способности и утилизации CPU. io_uring не всегда дает выигрыш для всех типов нагрузок, поэтому важно убедиться, что он действительно решает вашу проблему.
6. Типичные ошибки при работе с io_uring
io_uring — мощный, но сложный инструмент. Ошибки при его использовании могут привести к непредсказуемому поведению, утечкам памяти, или, что иронично, к снижению производительности. Вот наиболее распространенные ошибки, с которыми сталкиваются разработчики:
6.1. Игнорирование версии ядра Linux
Ошибка: Попытка использовать io_uring на старых ядрах (до 5.10) или ожидание полной функциональности на ранних версиях (5.1-5.9).
Последствия: Отсутствие поддержки нужных операций (например, сетевых), наличие багов, нестабильность, невозможность использования ключевых оптимизаций. Приложение может компилироваться, но падать в рантайме или работать некорректно.
Как избежать: Всегда проверяйте версию ядра с помощью uname -r. В 2026 году для серьезных проектов используйте ядра 6.x LTS. Включайте проверку версии ядра на старте приложения или в скриптах деплоя.
6.2. Отсутствие батчинга операций
Ошибка: Отправка каждого I/O запроса в ядро через io_uring_submit() (или io_uring_enter()) по отдельности, вместо объединения их в пачки.
Последствия: Снижение производительности, так как каждый вызов io_uring_submit() — это системный вызов, который влечет за собой переключение контекста. Это сводит на нет одно из главных преимуществ io_uring, делая его ненамного лучше традиционного AIO или даже epoll для большого количества мелких операций.
Как избежать: Максимально батчите запросы. Накапливайте SQE в Submission Queue до определенного порога (например, 64, 128, 256 операций) или до истечения короткого таймаута, прежде чем вызывать io_uring_submit(). Используйте флаг IOSQE_IO_DRAIN для операций, которые должны быть выполнены до последующих, но это редко нужно.
6.3. Некорректное управление жизненным циклом буферов и файловых дескрипторов
Ошибка: Освобождение буферов памяти или закрытие файловых дескрипторов до того, как ядро завершило все операции с ними. Или наоборот, не освобождение ресурсов после их использования.
Последствия: Утечки памяти, ошибки "use-after-free", краши приложения, повреждение данных. Ядро работает с указателями на ваши буферы; если они становятся недействительными, возникает неопределенное поведение.
Как избежать:
- Используйте
user_dataв SQE для связывания запроса с контекстом (например, указателем на структуру запроса, включающую буферы). - Освобождайте или переиспользуйте буферы только после получения соответствующего CQE (Completion Queue Entry) о завершении операции.
- Регистрируйте буферы и файловые дескрипторы с помощью
io_uring_register_buffers()иio_uring_register_files(). Это помогает ядру более безопасно управлять ресурсами и снижает накладные расходы.
6.4. Неправильная обработка завершенных операций
Ошибка: Неправильное чтение Completion Queue (CQ) или игнорирование кодов ошибок в CQE.
Последствия: Зависания приложения (если CQ переполняется и новые операции не могут быть завершены), потеря данных, некорректное состояние приложения, пропуск ошибок I/O.
Как избежать:
- Всегда проверяйте
cqe->resна предмет ошибок (отрицательные значения). Используйтеstrerror(-cqe->res)для получения текстового описания ошибки. - Регулярно опрашивайте CQ и продвигайте указатель
headс помощьюio_uring_cq_advance()после обработки CQE. - Используйте
io_uring_wait_cqe()с осторожностью, чтобы не блокировать основной цикл обработки слишком долго, если есть другие задачи.
6.5. Неправильное использование или игнорирование IORING_SETUP_SQPOLL
Ошибка: Включение IORING_SETUP_SQPOLL без понимания его последствий (потребление ядра CPU) или его неиспользование в сценариях, где он мог бы дать значительный прирост производительности.
Последствия: Если SQPOLL включен без необходимости, вы впустую тратите ядро CPU. Если он не используется там, где нужен, приложение страдает от лишних системных вызовов io_uring_enter().
Как избежать: SQPOLL предназначен для экстремальных нагрузок, где каждый системный вызов критичен. Применяйте его только после тщательного бенчмаркинга. Убедитесь, что вы привязываете SQPOLL-поток к конкретному CPU (p.sq_thread_cpu), чтобы избежать проблем с кешированием и изоляцией.
6.6. Отсутствие обработки отмены операций
Ошибка: Неспособность отменить зависшие или неактуальные I/O операции, особенно в долгоживущих сетевых соединениях или при работе с медленными дисками.
Последствия: Зависание ресурсов, таймауты, потребление памяти и CPU ядром на операции, которые уже не нужны приложению.
Как избежать: Используйте IORING_OP_ASYNC_CANCEL. Сохраняйте user_data для каждого запроса, чтобы можно было идентифицировать и отменить конкретную операцию. Это особенно важно для сетевых операций с таймаутами или при закрытии клиентских соединений.
6.7. Недостаточное логирование и мониторинг
Ошибка: Отсутствие детального логирования ошибок и метрик производительности io_uring.
Последствия: Трудности в диагностике проблем в production-среде, невозможность выявить узкие места, неоптимальная работа системы.
Как избежать: Логируйте все ошибки, возвращаемые io_uring. Мониторьте количество SQE, CQE, задержки операций, количество системных вызовов io_uring_enter(), утилизацию CPU (особенно %sy и %wa) с помощью инструментов, таких как bpftrace, perf, iostat. Используйте /proc/sys/fs/io_uring/ для получения статистики о текущих контекстах io_uring.
Ищете сервер, который просто работает?
Valebyte VPS — NVMe, поддержка 24/7, развёртывание за 60 секунд.
7. Чеклист для практического применения io_uring
Этот чеклист поможет вам систематизировать процесс внедрения и оптимизации io_uring в вашем приложении, минимизируя риски и максимизируя производительность.
7.1. Подготовка и планирование
- Определить I/O профиль приложения:
- Какой тип I/O доминирует: дисковый (случайный/последовательный, мелкие/крупные блоки), сетевой (много соединений/мало трафика, мало соединений/много трафика)?
- Каковы текущие метрики: задержка (P99, P99.9), пропускная способность (IOPS/МБ/с), утилизация CPU?
- Какие текущие I/O методы используются?
- Проверить версию ядра Linux: Убедитесь, что используется ядро 5.10+ (рекомендуется 6.x LTS). Если нет, запланируйте обновление.
- Оценить сложность интеграции: io_uring требует значительных усилий по разработке. Оцените, оправданы ли эти усилия потенциальным приростом производительности.
7.2. Инициализация io_uring
- Использовать
liburing: Включите библиотекуliburingв ваш проект для упрощения работы с API. - Инициализировать io_uring контекст:
- Определите оптимальную глубину очереди (
QUEUE_DEPTH) для SQ и CQ, исходя из ожидаемого параллелизма. - Выберите флаги инициализации:
IORING_SETUP_SQPOLL: Если требуется экстремально низкая задержка и вы готовы пожертвовать ядром CPU. Привяжите поток SQPOLL к конкретному ядру (p.sq_thread_cpu).IORING_SETUP_IOPOLL: Для устройств, поддерживающих опрос на стороне ядра (например, NVMe).IORING_SETUP_SQ_AFF: Привязка SQ к определенному ядру.
- Определите оптимальную глубину очереди (
- Зарегистрировать ресурсы:
- Зарегистрируйте буферы памяти (
io_uring_register_buffers), если вы будете использовать фиксированные буферы. - Зарегистрируйте файловые дескрипторы (
io_uring_register_files), если вы работаете с постоянным набором файлов/сокетов. - Помните о правильном управлении жизненным циклом зарегистрированных ресурсов.
- Зарегистрируйте буферы памяти (
7.3. Реализация I/O логики
- Реализовать батчинг операций:
- Накапливайте SQE в Submission Queue.
- Вызывайте
io_uring_submit()только когда SQ заполнен или истек короткий таймаут.
- Спроектировать структуру запросов: Используйте
io_uring_sqe_set_data()для привязки пользовательских данных (указателей на буферы, идентификаторы запросов, коллбэки) к каждому SQE. - Реализовать обработку завершений:
- Периодически опрашивайте Completion Queue.
- Используйте
io_uring_for_each_cqe()для эффективной обработки всех завершенных событий. - Всегда проверяйте
cqe->resна ошибки и логируйте их. - После обработки всех CQE, продвигайте указатель
headс помощьюio_uring_cq_advance().
- Обработать отмену операций: Внедрите механизм отмены зависших или неактуальных запросов с помощью
IORING_OP_ASYNC_CANCEL.
7.4. Тестирование, мониторинг и оптимизация
- Провести бенчмаркинг:
- Используйте
fio(с движком io_uring) для дисковых операций. - Используйте
wrk,ab, или пользовательские бенчмарки для сетевых операций. - Сравните производительность с предыдущей реализацией и с другими I/O методами.
- Используйте
- Настроить мониторинг:
- Отслеживайте метрики I/O (IOPS, throughput, latency) с помощью
iostat,vmstat. - Мониторьте утилизацию CPU (
top,htop), особенно системное время и время ожидания I/O. - Используйте
bpftraceилиperfдля глубокого анализа поведения io_uring в ядре.
- Отслеживайте метрики I/O (IOPS, throughput, latency) с помощью
- Изолировать CPU: Для критически важных I/O-потоков рассмотрите изоляцию CPU с помощью параметров ядра (
isolcpus,nohz_full) и привязки процессов/потоков к конкретным ядрам (taskset). - Тонкая настройка: Экспериментируйте с размерами кольцевых буферов, количеством батчей, флагами инициализации и настройками регистрации буферов для достижения оптимальной производительности для вашего конкретного сценария.
8. Расчет стоимости / Экономика использования io_uring
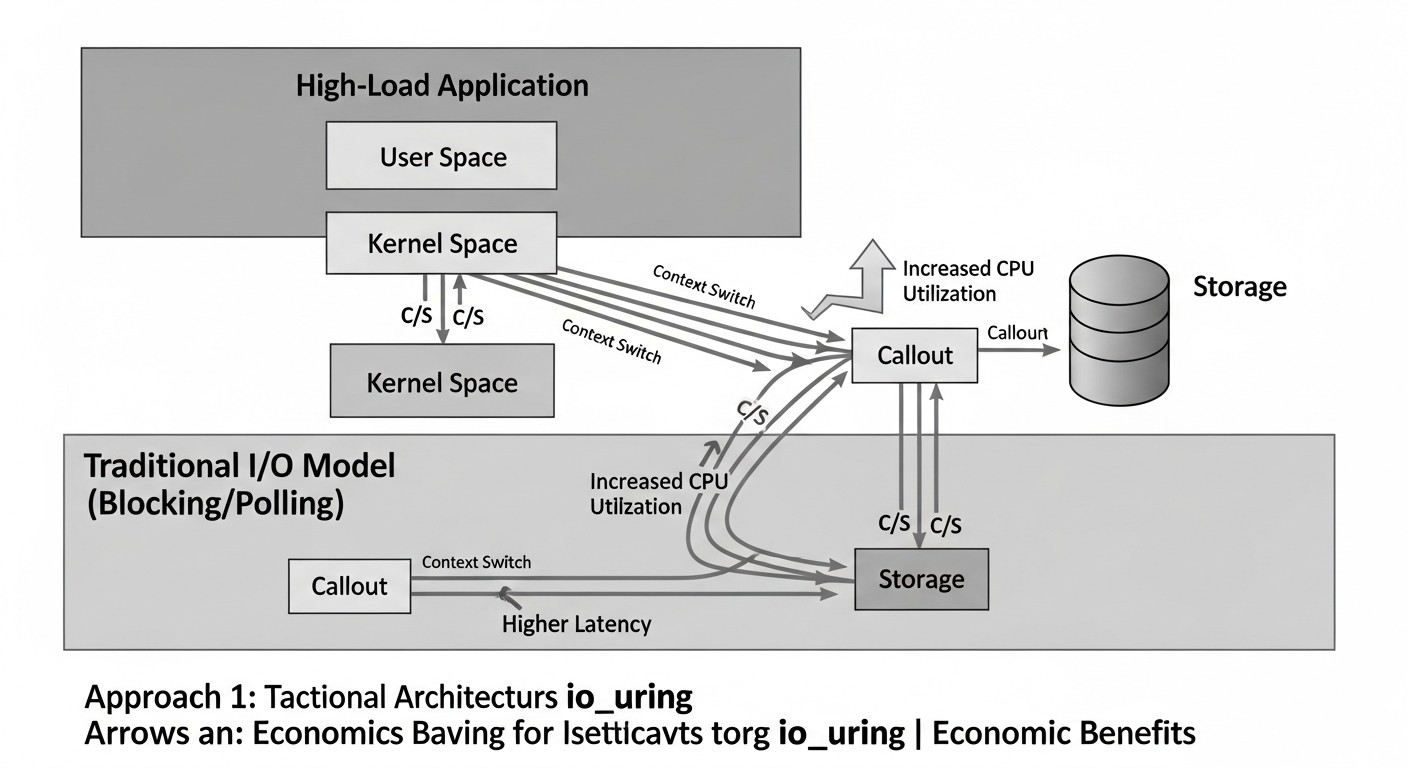
Внедрение io_uring — это инвестиция, которая окупается не только в виде прироста производительности, но и в виде значительной экономии операционных расходов (OpEx) и повышения бизнес-ценности. К 2026 году, когда облачные сервисы продолжают дорожать, а требования к эффективности растут, экономический аспект io_uring становится все более очевидным.
8.1. Снижение требований к аппаратным ресурсам
Главное экономическое преимущество io_uring заключается в его способности выполнять гораздо больший объем I/O операций с меньшим количеством ресурсов CPU. Это означает, что для той же рабочей нагрузки вам потребуется:
- Меньше CPU-ядер: io_uring значительно сокращает системные вызовы и переключения контекста, освобождая CPU для полезной работы приложения. Это позволяет обслуживать ту же нагрузку на серверах с меньшим количеством ядер или на меньшем количестве инстансов в облаке.
- Меньше RAM: Хотя io_uring сам по себе может требовать выделения буферов, общая эффективность может позволить сократить объем RAM, необходимый для поддержания большого количества потоков или процессов, каждый из которых требует своего стека и контекста.
- Меньше серверов/инстансов: Если одна машина может обрабатывать в 2-3 раза больше I/O, вы можете сократить количество физических серверов или облачных инстансов, необходимых для кластера.
8.2. Оптимизация облачных затрат
В облачных средах (AWS, GCP, Azure), где стоимость инстансов напрямую зависит от количества vCPU и объема RAM, экономия может быть драматической. Например, переход с инстансов типа m6a.xlarge на m6a.large или даже m6a.medium для той же I/O-интенсивной задачи может сократить ежемесячные счета на десятки процентов. Кроме того, меньшее количество инстансов означает меньшие затраты на сетевой трафик (ingress/egress), IP-адреса и управление.
8.3. Повышение бизнес-ценности
- Улучшенный пользовательский опыт: Снижение задержек I/O напрямую ведет к более быстрому отклику приложения, что повышает удовлетворенность клиентов, снижает отток и способствует росту бизнеса.
- Увеличение пропускной способности: Возможность обрабатывать больше запросов или данных за единицу времени позволяет расширять функциональность, внедрять новые сервисы и поддерживать больший объем бизнеса без перепроектирования инфраструктуры.
- Конкурентное преимущество: Приложения, использующие io_uring, могут превосходить конкурентов по производительности и стоимости, что является критически важным фактором на высококонкурентных рынках SaaS и онлайн-сервисов.
8.4. Скрытые расходы
- Высокая стоимость разработки: API io_uring сложен и низкоуровнев. Разработчикам потребуется значительное время на изучение и интеграцию, что увеличивает начальные затраты на разработку. Требуются высококвалифицированные специалисты.
- Сложность отладки: Ошибки в работе с io_uring могут быть труднодиагностируемыми, что увеличивает время на поиск и устранение проблем.
- Зависимость от версии ядра: Требование к новой версии ядра Linux может быть проблемой для компаний с консервативной политикой обновлений.
- Потребление CPU для SQPOLL: Если используется
IORING_SETUP_SQPOLL, одно ядро CPU будет постоянно занято потоком ядра, что может быть неэффективно для низконагруженных систем.
8.5. Таблица с примерами расчетов для разных сценариев (2026 год)
Предположим, у нас есть SaaS-приложение, которому требуется обрабатывать 1 миллион IOPS для своей основной базы данных или кэша.
| Параметр | Традиционный I/O (epoll + блокирующий read/write) |
io_uring (без SQPOLL) |
io_uring (с SQPOLL) |
|---|---|---|---|
| Требуемое количество CPU-ядер (для 1M IOPS) | ~16-24 ядра | ~4-8 ядер | ~2-4 ядра (+1 ядро для SQPOLL) |
| Требуемый объем RAM (для 1M IOPS) | ~64-128 GB | ~32-64 GB | ~32-64 GB |
| Тип инстанса (пример, 2026) | 2 x m7g.8xlarge (16 vCPU, 64GB RAM) |
1 x m7g.4xlarge (8 vCPU, 32GB RAM) |
1 x m7g.2xlarge (4 vCPU, 16GB RAM) + 1 ядро для SQPOLL |
| Стоимость инстансов (мес, 2026, усл.) | ~$2000 - $3000 | ~$500 - $800 | ~$250 - $400 |
| Энергопотребление (кВт/ч, мес) | ~1000 кВт/ч | ~300 кВт/ч | ~150 кВт/ч |
| Стоимость разработки (условные единицы, 2026) | 10 | 25 | 30 |
| Стоимость поддержки (условные единицы, 2026) | 5 | 8 | 10 |
| Общая TCO за 3 года (условные единицы) | ~1000 | ~400 | ~300 |
Примечание: Условные единицы и цены инстансов являются гипотетическими для 2026 года и служат для иллюстрации относительной экономии. Реальные цифры будут зависеть от конкретного провайдера, региона, скидок и рабочей нагрузки. TCO (Total Cost of Ownership) включает разработку, поддержку и 3 года эксплуатации.
Как видно из таблицы, несмотря на более высокие начальные затраты на разработку, io_uring обеспечивает значительную экономию на операционных расходах в долгосрочной перспективе, особенно для высоконагруженных систем. Это делает его крайне привлекательной инвестицией для SaaS-проектов и других I/O-интенсивных приложений.
9. Кейсы и примеры внедрения io_uring
io_uring уже зарекомендовал себя в реальных высоконагруженных проектах. Приведем несколько реалистичных сценариев, демонстрирующих его трансформационный потенциал.
9.1. Кейс 1: Высокопроизводительная Key-Value база данных (аналог Redis/Memcached)
Проблема: Стартап разрабатывал распределенную Key-Value базу данных с низкими задержками для игровых приложений. Изначально использовался epoll для сетевого I/O и libaio для сохранения данных на NVMe SSD (с O_DIRECT). При достижении 500 000 IOPS на одном узле, утилизация CPU достигала 70-80%, а P99 задержка операций записи возрастала до 10-15 мс из-за частых системных вызовов и переключений контекста между сетевым и дисковым I/O. Масштабирование требовало добавления большого количества узлов, что приводило к высоким облачным затратам.
Решение с io_uring: Команда переписала I/O-подсистему, полностью перейдя на io_uring. Все сетевые операции (accept, recvmsg, sendmsg) и дисковые операции (read, write, fsync) были унифицированы под единый цикл обработки io_uring. Были внедрены следующие оптимизации:
- Использование
IORING_SETUP_SQPOLL, привязанного к отдельному ядру CPU. - Регистрация буферов памяти для избежания копирования данных.
- Регистрация файловых дескрипторов для открытых файлов данных.
- Агрессивный батчинг операций (до 256 SQE за один
io_uring_submit(), при необходимости).
Результаты:
- Пропускная способность: Увеличилась до 1.5 миллиона IOPS на одном узле (300% прирост).
- Задержка (P99): Снизилась с 10-15 мс до 1.5-3 мс для операций записи.
- Утилизация CPU: При 1 миллионе IOPS снизилась с 70-80% до 20-25% (включая ядро для SQPOLL).
- Экономия: Количество требуемых облачных инстансов сократилось в 3 раза, что привело к экономии более 60% на ежемесячных операционных расходах инфраструктуры.
Этот кейс показал, как io_uring позволил стартапу достигнуть производительности, ранее доступной только с очень дорогим аппаратным обеспечением или сложными специализированными решениями.
9.2. Кейс 2: Высоконагруженный Прокси-сервер / Балансировщик нагрузки
Проблема: Крупный онлайн-сервис использовал NGINX в качестве основного прокси-сервера и балансировщика нагрузки. В пиковые часы, при обработке миллионов активных TCP-соединений и тысяч запросов в секунду, NGINX (на основе epoll) начинал потреблять значительные ресурсы CPU, а задержки проксирования возрастали. Это требовало масштабирования путем добавления множества прокси-инстансов, что увеличивало стоимость и сложность управления.
Решение с io_uring: Команда решила разработать кастомный, легковесный прокси-сервер на C++ с использованием io_uring. Целью было не заменить NGINX полностью, а создать специализированный компонент для наиболее критичных путей данных. Были использованы асинхронные accept, connect, recvmsg, sendmsg операции io_uring. Основной акцент был сделан на минимизации копирования данных.
- Использование зарегистрированных буферов для входящих и исходящих данных, чтобы избежать
memcpyмежду пользовательским пространством и ядром. - Применение
IORING_OP_SPLICEдля прямого копирования данных между сокетами без копирования в пользовательское пространство (zero-copy). - Оптимизация цикла обработки CQ для мгновенной реакции на сетевые события.
Результаты:
- Обработка соединений: Кастомный прокси смог обрабатывать в 2-2.5 раза больше активных TCP-соединений на одном ядре CPU по сравнению с NGINX.
- Задержка (P99): Средняя задержка проксирования снизилась на 30-40% при высоких нагрузках.
- Утилизация CPU: Для того же объема трафика утилизация CPU снизилась на 50-60%.
- Экономия: Позволило сократить количество прокси-инстансов на 40%, значительно уменьшив облачные затраты и упростив архитектуру.
Этот кейс подчеркивает эффективность io_uring в сетевых сценариях, особенно когда требуется обработка огромного количества соединений и минимизация задержек.
9.3. Кейс 3: Система логирования и сбора метрик
Проблема: Крупная система мониторинга и сбора логов сталкивалась с проблемой записи огромных объемов данных на диск. Серверы агрегации логов постоянно работали с высокой нагрузкой I/O, что приводило к высоким задержкам записи, переполнению буферов и потере некоторых логов в пиковые моменты. Использовались стандартные блокирующие вызовы write() с периодическим fsync().
Решение с io_uring: Разработчики переработали компонент записи логов, используя io_uring для всех дисковых операций. Они реализовали механизм асинхронной записи и асинхронной синхронизации (IORING_OP_FSYNC).
- Пул предварительно выделенных и зарегистрированных буферов для входящих логов.
- Батчинг операций
IORING_OP_WRITEдля записи нескольких блоков логов за один раз. - Использование
IORING_OP_FSYNCдля асинхронной принудительной записи данных на диск через определенные интервалы или после накопления определенного объема данных.
Результаты:
- Пропускная способность записи: Увеличилась на 50-70%, позволяя системе обрабатывать пиковые нагрузки без потери данных.
- Задержка записи (P99): Снизилась на 20-30%, обеспечивая более стабильную работу.
- Утилизация CPU: Затраты CPU на операции записи значительно сократились, высвобождая ресурсы для обработки и фильтрации логов.
- Надежность: Система стала более устойчивой к пиковым нагрузкам I/O, уменьшилось количество случаев "backpressure" и потери данных.
Этот пример показывает, что io_uring полезен не только для баз данных, но и для любых систем, где требуется эффективная и надежная запись больших объемов данных на диск.
Ищете сервер, который просто работает?
Valebyte VPS — NVMe, поддержка 24/7, развёртывание за 60 секунд.
10. Инструменты и ресурсы для работы с io_uring
Работа с io_uring требует не только понимания концепций, но и умения использовать правильные инструменты для разработки, тестирования и мониторинга. К 2026 году экосистема вокруг io_uring значительно расширилась, предоставляя разработчикам мощные средства.
10.1. Библиотеки и фреймворки
liburing(официальная пользовательская библиотека):- Описание: Стандартная, поддерживаемая ядром библиотека, предоставляющая высокоуровневый C API для io_uring. Значительно упрощает взаимодействие с кольцевыми буферами и системными вызовами io_uring. Это ваш основной инструмент для разработки на C/C++.
- Ссылка: https://github.com/axboe/liburing
- Языковые биндинги:
- Go: Проект iouring-go и другие.
- Rust: Проект io-uring (часть экосистемы Tokio).
- Python: Биндинги через
ctypesили специализированные библиотеки. - Node.js: Экспериментальные биндинги.
- Описание: Позволяют использовать io_uring из высокоуровневых языков программирования, хотя и с небольшими накладными расходами по сравнению с C/C++.
iouring-by-example:- Описание: Отличный ресурс с набором простых, но показательных примеров использования различных функций io_uring. Незаменим для изучения.
- Ссылка: https://unixism.net/loti/
10.2. Утилиты для тестирования и бенчмаркинга I/O
fio(Flexible I/O Tester):- Описание: Промышленный стандарт для тестирования производительности I/O. Поддерживает движок
io_uring, позволяя бенчмаркать дисковые операции с его использованием. - Использование:
fio --name=test --ioengine=iouring --direct=1 --rw=randread --bs=4k --size=1G --numjobs=1 --iodepth=64 - Ссылка: https://github.com/axboe/fio
- Описание: Промышленный стандарт для тестирования производительности I/O. Поддерживает движок
wrk/ab(HTTP Benchmarking tools):- Описание: Для тестирования сетевых приложений, использующих io_uring для HTTP-серверов или прокси.
- Использование:
wrk -t4 -c100 -d30s http://localhost:8080/
10.3. Инструменты мониторинга и отладки
perf(Linux Performance Tools):- Описание: Мощный инструмент для профилирования ядра и пользовательского пространства. Позволяет анализировать системные вызовы, прерывания, кеширование CPU и многое другое, что критично для выявления узких мест I/O.
- Использование:
perf record -g -F 99 -a sleep 10, затемperf report
bpftrace/bcc-tools(eBPF-based tools):- Описание: Предоставляют беспрецедентный уровень видимости в работу ядра Linux без модификации кода. Позволяют трассировать системные вызовы io_uring, анализировать поведение кольцевых буферов, отслеживать задержки I/O и многое другое.
- Примеры:
bpftrace -e 'tracepoint:io_uring:* { @[probe] = count(); }' - Ссылка: https://github.com/iovisor/bpftrace, https://github.com/iovisor/bcc
iostat/vmstat/sar:- Описание: Стандартные утилиты Linux для мониторинга I/O и системных ресурсов. Помогают оценить общую загрузку дисков, сети и CPU.
- Использование:
iostat -xz 1,vmstat 1,sar -d 1
strace:- Описание: Хотя
straceне показывает детали работы внутри io_uring (так как операции выполняются без системных вызовов), он полезен для отладки инициализации io_uring контекста и системных вызововio_uring_enter(). - Использование:
strace -f -e io_uring_enter,io_uring_setup ./your_app
- Описание: Хотя
10.4. Полезные ссылки и документация
- Официальная документация ядра Linux по io_uring:
- Описание: Самый авторитетный источник информации. Содержит подробное описание системных вызовов, флагов и операций.
- Ссылка: https://www.kernel.org/doc/html/latest/core-api/io_uring.html
- Блог и презентации Йенса Аксбо (Jens Axboe):
- Описание: Йенс Аксбо — основной разработчик io_uring. Его статьи и презентации содержат ценные инсайты и практические советы.
- Ссылка: Поиск по "Jens Axboe io_uring" на конференциях (например, FOSDEM, Linux Plumbers Conference) и в его блоге.
- Статьи и гайды от сообщества:
- Описание: Множество технических блогов и статей от инженеров, использующих io_uring в продакшене.
- Поиск: Используйте поисковые запросы типа "io_uring performance", "io_uring tutorial", "io_uring examples".
Вооружившись этими инструментами и ресурсами, вы сможете эффективно разрабатывать, отлаживать, тестировать и мониторить приложения, использующие io_uring, максимально раскрывая его потенциал.
11. Troubleshooting: Решение проблем с io_uring
Несмотря на свою мощь, io_uring может быть источником сложных проблем, требующих глубокого понимания системы. Вот типичные проблемы и подходы к их решению.
11.1. Проблемы с инициализацией io_uring
Симптомы: io_uring_queue_init() или io_uring_queue_init_params() возвращает отрицательное значение (код ошибки).
- Ошибка
-EPERM(Operation not permitted) или-EINVAL(Invalid argument):- Причина 1: Слишком старая версия ядра Linux. io_uring требует ядро 5.1+, а для полной функциональности 5.10+ (оптимально 6.x).
- Решение: Обновите ядро.
- Причина 2: Попытка использовать флаги инициализации (например,
IORING_SETUP_SQPOLL), которые не поддерживаются вашей версией ядра или несовместимы с текущей конфигурацией. - Решение: Проверьте документацию ядра для вашей версии. Уберите флаги по одному, чтобы определить проблемный.
- Причина 3: Недостаточные права. Хотя io_uring обычно не требует root-прав, некоторые флаги или операции могут быть ограничены.
- Решение: Попробуйте запустить приложение с
sudoдля диагностики. Если это работает, возможно, требуется настроить возможности (capabilities) или использовать флаги, не требующие повышенных привилегий.
- Ошибка
-ENOMEM(Out of memory):- Причина: Слишком большая глубина очереди (
queue_depth) или система испытывает нехватку памяти. - Решение: Уменьшите
queue_depth. Проверьте свободную память в системе.
- Причина: Слишком большая глубина очереди (
11.2. Операции io_uring зависают или не завершаются
Симптомы: Запросы отправляются в SQ, но соответствующие CQE никогда не появляются. Приложение блокируется или зависает.
- Причина 1: Недостаточный или отсутствующий вызов
io_uring_submit()(илиio_uring_enter()). Ядро не знает, что в SQ появились новые запросы. - Решение: Убедитесь, что вы регулярно вызываете
io_uring_submit()после добавления SQE. Если вы используетеIORING_SETUP_SQPOLL, убедитесь, что поток SQPOLL активен и не заблокирован. - Причина 2: Ошибки в SQE (некорректные файловые дескрипторы, буферы, смещения). Ядро может молча игнорировать некорректные запросы или возвращать ошибки, которые вы не обрабатываете.
- Решение: Внимательно проверяйте параметры каждого SQE. Используйте
io_uring_sqe_set_data()для привязки контекста и отладочной информации к каждому запросу, чтобы при получении CQE можно было понять, какой запрос завис. - Причина 3: Неправильное управление буферами или файловыми дескрипторами (см. раздел "Типичные ошибки").
- Решение: Убедитесь, что буферы и FD остаются валидными на протяжении всей операции. Используйте зарегистрированные буферы/FD.
- Причина 4: Зависание или блокировка на уровне ядра/драйвера.
- Решение: Проверьте
dmesgна наличие ошибок ядра. Используйтеbpftraceдля трассировки системных вызовов io_uring и связанных с ними функций ядра, чтобы увидеть, где происходит задержка.
11.3. Плохая производительность или высокая утилизация CPU
Симптомы: Приложение использует io_uring, но производительность не улучшается или даже ухудшается по сравнению с предыдущими методами. Утилизация CPU остается высокой.
- Причина 1: Отсутствие батчинга операций. Слишком частые вызовы
io_uring_submit(). - Решение: Внедрите эффективный батчинг (см. раздел "Практические советы").
- Причина 2: Неиспользование зарегистрированных буферов/файловых дескрипторов. Ядро тратит время на проверку и копирование данных.
- Решение: Зарегистрируйте буферы и FD, если это возможно для вашего сценария.
- Причина 3: Неправильное использование
IORING_SETUP_SQPOLL. Например, если нагрузка низкая, поток SQPOLL может впустую потреблять ядро CPU. - Решение: Отключите SQPOLL для низконагруженных сценариев. Убедитесь, что поток SQPOLL привязан к изолированному ядру CPU, чтобы минимизировать влияние на другие процессы.
- Причина 4: Неэффективный цикл обработки завершений (CQ). Например, блокирующий вызов
io_uring_wait_cqe(), когда ожидается много событий, или слишком частые неблокирующие опросы. - Решение: Оптимизируйте цикл обработки CQ. Используйте
io_uring_for_each_cqe()для обработки пачки событий. - Причина 5: Проблема не в I/O. io_uring оптимизирует I/O, но если узкое место в другом месте (например, CPU-интенсивные вычисления, блокировки мьютексов, неэффективные алгоритмы), то io_uring не поможет.
- Решение: Проведите полное профилирование приложения с помощью
perfилиbpftrace, чтобы определить истинное узкое место.
11.4. Утечки памяти
Симптомы: Потребление памяти приложением постоянно растет.
- Причина: Неправильное управление буферами памяти или контекстами запросов после завершения операций.
- Решение: Убедитесь, что каждый буфер или структура запроса, выделенная для SQE, освобождается или переиспользуется ровно один раз после получения соответствующего CQE. Используйте инструменты вроде Valgrind для обнаружения утечек.
11.5. Диагностические команды
dmesg: Проверяйте логи ядра на наличие ошибок, связанных с io_uring или дисковой подсистемой./proc/sys/fs/io_uring/: В этой директории находятся файлы с информацией о текущих активных контекстах io_uring, их параметрах и статистике. Например,/proc/sys/fs/io_uring/max_filesили/proc/sys/fs/io_uring/max_sq_entries.bpftrace: Создавайте собственные скрипты для трассировки конкретных функций ядра, связанных с io_uring, и анализа их поведения.perf: Профилирование приложения и ядра для выявления горячих точек CPU.strace -e trace=io_uring ./app: Поможет увидеть системные вызовыio_uring_setupиio_uring_enter, но не внутренние операции.
11.6. Когда обращаться в поддержку или к сообществу
Если вы исчерпали все возможности самостоятельной диагностики и уверены, что проблема связана с ядром Linux или спецификой io_uring, не стесняйтесь обращаться:
- Linux Kernel Mailing List (LKML): Для сообщений о потенциальных багах в ядре или запросов на новые функции io_uring.
- GitHub репозиторий
liburing: Для вопросов, связанных с использованием библиотеки. - Специализированные форумы и сообщества: Stack Overflow, Reddit (r/linux, r/kernel, r/programming), или сообщества вашего языка программирования.
Предоставляйте максимально подробную информацию: версия ядра, код, шаги для воспроизведения, логи ошибок, результаты бенчмарков и профилирования.
12. FAQ: Часто задаваемые вопросы об io_uring
1. Является ли io_uring всегда быстрее, чем традиционные методы I/O?
Ответ: Нет, не всегда. io_uring разработан для высоконагруженных асинхронных I/O-интенсивных задач, где он значительно снижает накладные расходы на системные вызовы и переключения контекста. Для простых, низконагруженных или преимущественно CPU-интенсивных приложений, накладные расходы на более сложный API io_uring могут перевесить потенциальные выгоды, и традиционные блокирующие вызовы или epoll могут быть более подходящими или даже немного быстрее из-за своей простоты.
2. Какая минимальная версия ядра Linux требуется для io_uring?
Ответ: io_uring был представлен в ядре Linux 5.1. Однако для полноценного использования всех функций, включая сетевые операции и множество оптимизаций, настоятельно рекомендуется использовать ядро Linux 5.10 или новее. Оптимальным выбором для production-среды в 2026 году являются ядра серии 6.x LTS, которые обеспечивают максимальную стабильность и производительность.
3. io_uring предназначен только для дискового I/O или для сетевого тоже?
Ответ: io_uring унифицирует оба типа I/O. Он предоставляет асинхронный интерфейс как для дисковых и файловых операций (read, write, fsync, openat), так и для сетевых операций (accept, connect, recvmsg, sendmsg). Это одно из его ключевых преимуществ, позволяющее создавать высокопроизводительные системы, обрабатывающие все виды I/O под единым API.
4. Насколько сложно освоить и использовать io_uring?
Ответ: io_uring имеет довольно крутую кривую обучения. Его API низкоуровневый и требует глубокого понимания принципов работы ядра Linux, управления памятью и асинхронного программирования. Он значительно сложнее, чем epoll или libaio. Однако использование пользовательской библиотеки liburing значительно упрощает процесс, абстрагируя от многих низкоуровневых деталей.
5. Могу ли я использовать io_uring с высокоуровневыми языками, такими как Python, Node.js, Go или Rust?
Ответ: Да, это возможно. Для Go и Rust существуют достаточно зрелые биндинги и библиотеки, интегрирующие io_uring в их асинхронные рантаймы (например, io-uring для Rust/Tokio). Для Python и Node.js существуют экспериментальные биндинги, обычно использующие FFI (Foreign Function Interface) для взаимодействия с liburing. Однако накладные расходы на FFI могут снизить часть преимуществ io_uring, и полный потенциал раскрывается в C/C++.
6. Является ли epoll устаревшим теперь, когда есть io_uring?
Ответ: Нет, epoll не устарел. Он остается эффективным и широко используемым механизмом для событийного сетевого I/O. io_uring является более мощной и универсальной заменой, особенно для сценариев, требующих максимальной производительности и унификации дискового и сетевого I/O. Для многих приложений, где epoll уже работает хорошо, переход на io_uring может быть излишним, учитывая его сложность.
7. Поддерживает ли io_uring zero-copy I/O?
Ответ: Да, io_uring разработан с учетом оптимизаций zero-copy. Путем регистрации буферов памяти (io_uring_register_buffers) ядро может выполнять операции I/O напрямую в эти буферы, минуя копирование данных между пространством ядра и пользовательским пространством. Кроме того, операции вроде IORING_OP_SPLICE позволяют напрямую передавать данные между файловыми дескрипторами (например, сокетами), также без копирования в пользовательский буфер.
8. Что такое SQPOLL и когда его следует использовать?
Ответ: SQPOLL (Submission Queue Polling) — это опциональный режим io_uring, активируемый флагом IORING_SETUP_SQPOLL при инициализации. В этом режиме ядро создает специальный поток, который постоянно опрашивает Submission Queue на наличие новых запросов. Это полностью исключает необходимость системного вызова io_uring_enter() для отправки запросов, что снижает накладные расходы до абсолютного минимума. Его следует использовать только в экстремально высоконагруженных сценариях, где каждый системный вызов критичен, так как SQPOLL потребляет одно ядро CPU.
9. В каких случаях не стоит использовать io_uring?
Ответ: io_uring не рекомендуется для:
- Низконагруженных приложений, где I/O не является узким местом.
- Проектов с жесткими временными рамками и ограниченными ресурсами на разработку.
- Приложений, где основное узкое место находится в CPU-интенсивных вычислениях, а не в I/O.
- Систем, работающих на очень старых версиях ядра Linux без возможности обновления.
В этих случаях сложность io_uring может принести больше проблем, чем пользы.
10. Как io_uring соотносится с DPDK?
Ответ: io_uring и DPDK (Data Plane Development Kit) решают схожие проблемы производительности I/O, но на разных уровнях и с разными подходами. io_uring — это интерфейс ядра Linux, который предоставляет асинхронный I/O с минимальными накладными расходами, оставаясь при этом в рамках стандартной сетевой и дисковой подсистемы ядра. DPDK, в свою очередь, является пользовательским фреймворком, который "обходит" ядро Linux, напрямую управляя сетевыми картами и обрабатывая пакеты в пользовательском пространстве. DPDK обеспечивает еще более низкие задержки и более высокую пропускную способность для сетевых задач, но требует специализированного оборудования, более сложной архитектуры и не поддерживает дисковый I/O. io_uring более универсален и интегрирован в ядро, тогда как DPDK — это нишевое решение для самых требовательных сетевых задач.
Ищете сервер, который просто работает?
Valebyte VPS — NVMe, поддержка 24/7, развёртывание за 60 секунд.
13. Заключение
io_uring — это не просто очередное обновление в ядре Linux; это фундаментальный сдвиг в парадигме асинхронного ввода-вывода, который к 2026 году становится де-факто стандартом для высоконагруженных приложений. Он предоставляет беспрецедентный уровень контроля и эффективности, позволяя приложениям достигать миллионов I/O операций в секунду с минимальной утилизацией CPU.
Мы рассмотрели, как io_uring решает болевые точки традиционных I/O методов, унифицируя дисковые, файловые и сетевые операции под единым, высокоэффективным API. Его ключевые особенности — кольцевые буферы, минимизация системных вызовов, поддержка SQPOLL и регистрация ресурсов — открывают путь к созданию систем с экстремально низкими задержками и колоссальной пропускной способностью.
Экономический анализ показал, что, несмотря на более высокую начальную стоимость разработки из-за сложности API, io_uring обеспечивает значительную долгосрочную экономию. Сокращение требований к аппаратным ресурсам напрямую транслируется в уменьшение облачных затрат и повышение конкурентоспособности продукта на рынке. Реальные кейсы подтверждают эти выводы, демонстрируя впечатляющие приросты производительности в базах данных, прокси-серверах и системах логирования.
Однако, как и любой мощный инструмент, io_uring требует глубокого понимания и осторожности. Типичные ошибки, такие как отсутствие батчинга, неправильное управление буферами или игнорирование версии ядра, могут свести на нет все его преимущества. Использование библиотеки liburing, тщательное тестирование, мониторинг с помощью perf и bpftrace, а также следование лучшим практикам являются ключом к успешному внедрению.
Итоговые рекомендации:
- Оцените вашу нагрузку: Если ваше приложение испытывает I/O-узкие места, а требования к задержкам и пропускной способности высоки, io_uring — ваш кандидат №1.
- Обновите ядро: Убедитесь, что ваша система работает на Linux 5.10+ (идеально 6.x LTS).
- Используйте
liburing: Начните с этой библиотеки, чтобы упростить разработку. - Батчите операции: Это критически важно для производительности io_uring.
- Регистрируйте ресурсы: Для максимальной эффективности используйте зарегистрированные буферы и файловые дескрипторы.
- Тщательно тестируйте и мониторьте: Измеряйте реальные метрики и профилируйте ваше приложение.
Следующие шаги для читателя:
Если вы дочитали до этого момента, значит, вы готовы к глубокому погружению в io_uring. Ваши следующие шаги должны включать:
- Изучение
iouring-by-example: Проработайте примеры, чтобы получить практический опыт. - Эксперименты с
fio: Проведите бенчмаркинг вашей текущей системы сfio, а затем попробуйте использовать движокio_uring. - Пилотный проект: Начните с небольшого, но I/O-интенсивного компонента вашего приложения, чтобы оценить сложность и потенциальные выгоды в вашей среде.
- Глубокое изучение документации: Регулярно обращайтесь к официальной документации ядра Linux и статьям Йенса Аксбо.
В мире, где данные — это новая нефть, а скорость — это валюта, io_uring предоставляет вам инструменты для создания по-настоящему конкурентоспособных и эффективных высоконагруженных приложений. Освойте его, и вы откроете новые горизонты производительности для ваших проектов в 2026 году и далее.