Як перевірити температуру обладнання сервера?
Як перевірити температуру обладнання сервера? Комплексно, з використанням програмних засобів для постійного моніторингу та періодичних фізичних інспекцій. Для нас, колег-сисадмінів, це не просто пункт у чек-листі, а наріжний камінь стабільної та довговічної роботи серверної інфраструктури. Перегрів — тихий вбивця заліза, здатний призвести до деградації продуктивності, раптових збоїв і, в гіршому випадку, до повного виходу з ладу дорогого обладнання. У цій статті ми детально розберемо, які інструменти та методи доступні для контролю температурного режиму, від програмного забезпечення до фізичного огляду та профілактичного обслуговування.
Чому моніторинг температури — це не примха, а необхідність?

Перш ніж занурюватися в технічні деталі, давайте згадаємо, чому ми так пильно стежимо за градусами Цельсія в наших серверних стійках. Висока температура — це не просто дискомфорт для обладнання, це пряма загроза його працездатності та терміну служби.
- Зниження продуктивності (Thermal Throttling): При досягненні певних температурних порогів процесор або інші компоненти починають скидати частоти, щоб уникнути перегріву. Це безпосередньо веде до уповільнення роботи сервера, що критично для високонавантажених додатків і сервісів.
- Нестабільність і збої: Перегрів може викликати помилки в роботі пам'яті, дисків, чипсетів, що призводить до зависань, "синіх екранів смерті" (BSOD) або раптових перезавантажень. Уявіть собі таку ситуацію посеред пікового навантаження!
- Скорочення терміну служби компонентів: Постійна робота при підвищених температурах прискорює деградацію напівпровідників та інших електронних елементів, значно скорочуючи загальний ресурс обладнання. Те, що могло прослужити 5-7 років, вийде з ладу за 2-3 роки.
- Ризик повної відмови та пожежі: У крайніх випадках, неконтрольований перегрів може призвести до виходу з ладу цілих модулів або навіть до загоряння. Хоча останнє трапляється рідко, ризик є, і він неприйнятний в дата-центрах.
- Збільшення TCO (Total Cost of Ownership): Позапланові простої, необхідність екстреної заміни обладнання, втрата даних — все це обертається значними фінансовими та репутаційними втратами. Запобігання цим проблемам через грамотний моніторинг і обслуговування — це інвестиція.
Тому підтримання оптимального температурного режиму — це ключовий аспект забезпечення надійності та ефективності нашої інфраструктури.
Методи контролю температури: від софту до фізичного огляду
Існує кілька підходів до перевірки температури серверного обладнання, кожен з яких має свої переваги та області застосування.
1. Програмний моніторинг: Погляд зсередини
Більшість сучасних серверів оснащені цілим арсеналом вбудованих датчиків, які надають детальну інформацію про температуру різних компонентів. Доступ до цих даних здійснюється програмно.
Вбудовані датчики температури та IPMI/BMC
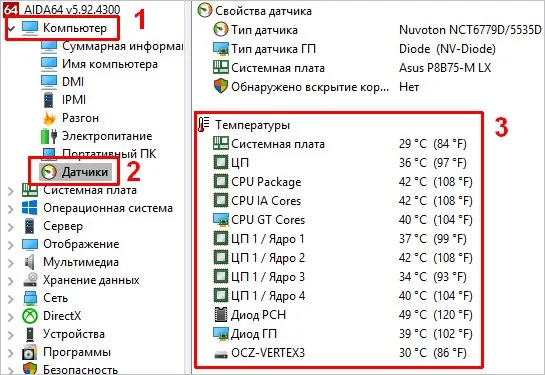
Сервери корпоративного класу практично завжди обладнані контролерами IPMI (Intelligent Platform Management Interface) або BMC (Baseboard Management Controller). Це, по суті, окремий мікрокомп'ютер всередині сервера, який працює незалежно від основної ОС і дозволяє керувати сервером віддалено, навіть якщо він вимкнений або ОС не завантажена. IPMI надає доступ до даних з безлічі датчиків, включаючи температуру процесорів, пам'яті, чипсетів, дисків, VRM (Voltage Regulator Module) та інших критично важливих зон.
Переваги IPMI:
- Out-of-band management: Моніторинг і управління без залежності від операційної системи.
- Логування подій: Запис температурних порогів, помилок вентиляторів та інших критичних подій.
- Сповіщення: Можливість налаштування автоматичних оповіщень по SNMP, email при перевищенні порогів.
Для роботи з IPMI в Linux часто використовується утиліта ipmitool. Приклад отримання даних про датчики:
# apt install ipmitool (або yum install OpenIPMI ipmitool)
# ipmitool sensor
Ця команда виведе список всіх доступних датчиків і їх поточні значення, включаючи температуру, напругу, обороти вентиляторів і т.д.
# Пример вывода ipmitool sensor:
CPU1 Temp | 45.000 | C | ok | 0.000 | 0.000 | 0.000 | 80.000 | 85.000 | 90.000
CPU2 Temp | 43.000 | C | ok | 0.000 | 0.000 | 0.000 | 80.000 | 85.000 | 90.000
FAN1 | 1500.000 | RPM | ok | 0.000 | 0.000 | 0.000 | 1000.000 | 8000.000 | 9000.000
...
Операційна система та утиліти
Всередині операційної системи також доступні інструменти для моніторингу температури:
- Linux:
lm_sensors: Основний інструмент для читання даних з апаратних датчиків, доступних через ядро Linux. Після установки пакетаlm_sensorsі запускуsensors-detectдля визначення чипсетів, командаsensorsвиведе поточні температури CPU, материнської плати, VRM та інших компонентів.
# apt install lm-sensors # sensors-detect (відповідаємо 'yes' на більшість питань) # sensorsПриклад виводу
sensors:# coretemp-isa-0000 # Adapter: ISA adapter # Package id 0: +48.0°C (high = +80.0°C, crit = +100.0°C) # Core 0: +47.0°C (high = +80.0°C, crit = +100.0°C) # Core 1: +48.0°C (high = +80.0°C, crit = +100.0°C) # # nct6775-isa-0290 # Adapter: ISA adapter # CPU Fan: 1200 RPM (min = 100 RPM) # System Fan: 1500 RPM (min = 100 RPM) # intrusion0: OK # temp1: +35.0°C (high = +60.0°C, hyst = +55.0°C) # temp2: +40.0°C (high = +60.0°C, hyst = +55.0°C) hddtempабоsmartctl: Для моніторингу температури жорстких дисків і SSD.smartctl(з пакетаsmartmontools) також надає доступ до S.M.A.R.T.-даних, що вкрай корисно для оцінки стану накопичувачів.
# smartctl -a /dev/sda | grep Temperature_Celsius
- Open Hardware Monitor, HWMonitor, SpeedFan: Популярні утиліти, які надають графічний інтерфейс для моніторингу різних датчиків в системі. Вони зручні для швидкого перегляду, але для серверного використання переважніше консольні або централізовані рішення.
Системи централізованого моніторингу
Для серйозних інфраструктур ручний запуск команд — це не варіант. Тут на допомогу приходять системи централізованого моніторингу, такі як Zabbix, Prometheus + Grafana, Nagios, PRTG та інші. Вони дозволяють:
- Автоматичний збір даних: Через агентів, SNMP, IPMI-інтерфейси або спеціальні плагіни.
- Агрегація та візуалізація: Всі дані збираються в єдиному інтерфейсі, будуються графіки, тренди.
- Налаштування порогів і оповіщень: Можливість задати пороги для кожного датчика і отримувати повідомлення по email, SMS, Telegram, Slack і т.д. при їх перевищенні.
- Історичні дані: Аналіз температурних режимів за тривалі періоди для виявлення проблемних тенденцій.
Наприклад, в Zabbix можна налаштувати item-и для читання даних з lm_sensors або безпосередньо через IPMI-інтерфейс сервера, а потім створити тригери, які будуть спрацьовувати, якщо температура CPU перевищить 75°C.
2. Фізичний контроль: Коли софт не всесильний
Не завжди програмні методи дають повну картину. Іноді необхідно "помацати" ситуацію руками, особливо при діагностиці або після внесення змін в конфігурацію.
Термоіндикатори та тепловізори
- Термоіндикатори (термостикери): Це прості, недорогі наклейки, які змінюють колір при досягненні певної температури. Їх можна розмістити на компонентах, де немає вбудованих датчиків (наприклад, на VRM старих материнських плат, на чипсетах, на окремих конденсаторах). Вони дають лише бінарну інформацію ("було гаряче/ні"), але можуть бути корисні для виявлення локальних гарячих точок.
- Тепловізори: Більш професійний інструмент. Тепловізійна камера дозволяє отримати візуальну карту розподілу температур по поверхні обладнання. Це безцінно для:
- Виявлення заблокованих повітряних потоків.
- Діагностики несправних компонентів, які гріються сильніше норми.
- Оцінки ефективності системи охолодження в цілому.
- Перевірки рівномірності нагріву в стійці.
Використання тепловізора вимагає фізичної присутності і є скоріше інструментом для аудиту або глибокої діагностики, ніж для повсякденного моніторингу.
Візуальна перевірка та аудит повітряних потоків
Банальна, але дуже ефективна міра. Регулярний візуальний огляд може виявити безліч проблем:
- Пил і бруд: Головний ворог будь-якого заліза. Скупчення пилу на радіаторах і вентиляторах різко знижують ефективність охолодження. Перевіряйте вентиляційні решітки та нутрощі сервера.
- Стан вентиляторів: Чи всі вентилятори крутяться? Чи немає сторонніх шумів? Чи правильний напрямок повітряного потоку? (В серверних стійках зазвичай стандартизовано: холодне повітря спереду, гаряче ззаду).
- Кабель-менеджмент: Безлад з кабелів всередині сервера або в стійці може створювати серйозні перешкоди для циркуляції повітря. Акуратне укладання кабелів — це не тільки естетика, але і функціональність.
- Заглушки в стійці (Панелі-заглушки): Порожні простори в стійці між серверами обов'язково повинні бути закриті заглушками. Це запобігає рециркуляції гарячого повітря з задньої частини стійки в передню, забезпечуючи проходження холодного повітря через обладнання, а не навколо нього.
- Гарячі та холодні коридори (Hot/Cold Aisle Containment): У великих ЦОД це стандарт. Переконайтеся, що ваш сервер знаходиться в правильному коридорі і не отримує гаряче повітря від сусідніх стійок.
3. Регулярне обслуговування: Профілактика краще лікування
Найкращий моніторинг марний, якщо не проводити профілактичні роботи.
Потрібен надійний сервер для оптимальної температури?
Забезпечте стабільну роботу вашого обладнання. Наші виділені сервери пропонують ідеальні умови для підтримання оптимальної температури. — from €5.99/mo.
Вибрати сервер →- Чистка від пилу: Регулярна (раз в 3-6 місяців, в залежності від умов) чистка внутрішніх компонентів сервера стисненим повітрям або спеціалізованим пилососом. Особлива увага — радіаторам CPU, GPU (якщо є) і блокам живлення.
- Заміна термопасти/термопрокладок: Термопаста на CPU і GPU з часом висихає і втрачає свої теплопровідні властивості. Рекомендується міняти її раз в 2-3 роки або при значному підвищенні температур. Термопрокладки на чипсетах і VRM також можуть вимагати заміни. Вибирайте якісні термоінтерфейси, призначені для тривалої роботи.
- Перевірка вентиляторів: Вентилятори — це витратний матеріал. Перевіряйте їх на знос підшипників (сторонній шум, вібрація) і деградацію продуктивності. У разі сумнівів — краще замінити.
- Оновлення прошивок (Firmware): Виробники обладнання регулярно випускають оновлення BIOS/UEFI, прошивок для IPMI/BMC, RAID-контролерів та інших компонентів. Ці оновлення часто містять поліпшення в алгоритмах управління охолодженням, що може позитивно позначитися на температурному режимі.
- Аналіз логів: Періодично переглядайте системні журнали ОС, а також логи IPMI/BMC на предмет попереджень про температуру або збої вентиляторів.
Шукаєте сервер, який просто працює?
Valebyte VPS — NVMe, підтримка 24/7, розгортання за 60 секунд.
Визначення порогових значень і реагування
Отже, ми знаємо, як отримати дані про температуру. Але що вважати нормою, а що — тривожним сигналом?
- Нормальні температури: Вони сильно залежать від компонента, його навантаження і виробника.
- CPU: У простої 30-45°C, під навантаженням 60-75°C. Максимально допустимі температури (TjMax) зазвичай становлять 90-105°C, але прагнути до них не варто.
- HDD: Оптимально 30-45°C. Вище 50°C — вже привід для занепокоєння, так як це значно скорочує термін служби.
- SSD: Зазвичай до 60-70°C. Багато NVMe SSD можуть працювати і при більш високих температурах (до 80°C), але краще тримати їх ближче до 50-60°C.
- Чипсети, VRM: Можуть бути гарячіше, до 80-90°C під навантаженням, але стабільна робота при таких значеннях залежить від конкретної моделі і ефективності охолодження.
- Пороги оповіщення і критичні пороги: Завжди встановлюйте два пороги:
- Попередження (Warning): Наприклад, 70°C для CPU. Це сигнал, що потрібно звернути увагу, перевірити навантаження, вентиляцію.
- Критичний (Critical): Наприклад, 80°C для CPU. Це означає, що потрібно негайно вживати заходів, можливо, знижувати навантаження, або навіть тимчасово відключати сервер, якщо температура продовжує рости.
Дії при перевищенні порогів:
- Перевірте навантаження: Можливо, аномально високе навантаження є причиною.
- Візуальний огляд: Пил, непрацюючі вентилятори, заблоковані повітряні потоки.
- Поліпшите вентиляцію: Перевірте заглушки, кабель-менеджмент, температуру в приміщенні.
- Знизьте навантаження: Якщо проблема не вирішується швидко, тимчасово мігруйте сервіси або зменште навантаження.
- Діагностика компонентів: Якщо температура постійно висока для одного компонента, можливо, він несправний або його система охолодження не справляється.
Висновки
Моніторинг температури обладнання сервера — це не разовий захід, а безперервний процес, що вимагає системного підходу. Він включає в себе постійний програмний контроль з використанням вбудованих датчиків і централізованих систем моніторингу, періодичні фізичні інспекції для виявлення неочевидних проблем і, звичайно ж, регулярне профілактичне обслуговування.
Інвестиції часу і ресурсів в підтримання оптимального температурного режиму окупляться сторицею: це забезпечить стабільну роботу вашої інфраструктури, продовжить термін служби дорогого обладнання і мінімізує ризики позапланових простоїв. Пам'ятайте, що кожен градус Цельсія важливий, і турбота про "здоров'я" ваших серверів — це запорука успішної роботи всього бізнесу. Так що, колеги, тримаємо руку на пульсі... точніше, на термодатчиках!
Шукаєте максимальну продуктивність і надійність?
Наші NVMe виділені сервери забезпечують чудову швидкість і стабільність, мінімізуючи ризики перегріву. Інвестуйте в майбутнє вашого бізнесу.
Замовити NVMe сервер →