
SRE-практики для стартапов и малых SaaS-команд на VPS/Dedicated: от SLO до Post-Mortem
TL;DR
- Внедрение SRE-практик критически важно для выживания и масштабирования стартапов на VPS/Dedicated, обеспечивая стабильность и предсказуемость работы.
- Начните с определения ключевых метрик (SLI) и реалистичных целей (SLO) для ваших критических сервисов, не стремясь к идеальным "девяткам".
- Эффективный мониторинг и алертинг — основа SRE; используйте опенсорсные решения вроде Prometheus/Grafana для экономии и контроля.
- Разработайте простые, но действенные процессы реагирования на инциденты и проводите "безобвинительные" Post-Mortem для непрерывного обучения.
- Автоматизируйте рутинные задачи (развертывание, обновление, резервное копирование), чтобы сократить "toil" и минимизировать человеческий фактор.
- SRE не требует больших бюджетов; фокус на практичности, итеративном подходе и использовании доступных инструментов позволит добиться значительных результатов.
- Инвестиции в SRE окупаются снижением downtime, улучшением репутации, уменьшением стресса в команде и ускорением разработки.
Введение
В стремительно меняющемся ландшафте технологий 2026 года, где пользовательские ожидания стабильности и скорости работы сервисов достигли беспрецедентного уровня, а конкуренция среди стартапов и SaaS-проектов продолжает ужесточаться, способность поддерживать высокую доступность и производительность становится не просто преимуществом, а жизненной необходимостью. Для многих молодых компаний и небольших команд, оперирующих на VPS или выделенных серверах, внедрение сложных методологий уровня Google может казаться несбыточной мечтой. Однако, именно здесь на помощь приходят адаптированные SRE-практики (Site Reliability Engineering).
Эта статья создана, чтобы развеять миф о том, что SRE — это удел только технологических гигантов. Мы покажем, как принципы SRE, такие как определение SLI/SLO, управление бюджетом ошибок, эффективный мониторинг, оперативное реагирование на инциденты и проведение Post-Mortem, могут быть успешно применены даже в условиях ограниченных ресурсов и небольших команд. Мы сфокусируемся на практических аспектах, применимых к инфраструктуре на VPS/Dedicated, где каждый цент и каждая минута имеют значение.
Почему эта тема важна именно сейчас, в 2026 году? С одной стороны, стоимость облачных ресурсов продолжает расти, делая VPS и выделенные серверы более привлекательными с точки зрения капитальных затрат для многих стартапов. С другой стороны, сложность современных приложений не уменьшается, а ожидания пользователей от качества сервиса только возрастают. Это создает дилемму: как обеспечить надежность и масштабируемость на "железе", не имея армий инженеров и неограниченных бюджетов? SRE предлагает ответ, фокусируясь на автоматизации, измерении и культуре непрерывного улучшения.
Какие проблемы решает эта статья? Мы поможем вам:
- Преодолеть хаотичное реагирование на проблемы и перейти к проактивному управлению надежностью.
- Определить, что действительно важно для вашего бизнеса с точки зрения доступности и производительности.
- Сократить время простоя (downtime) и минимизировать его влияние на бизнес.
- Уменьшить стресс и выгорание в команде за счет автоматизации и четких процессов.
- Создать культуру обучения на ошибках, а не поиска виноватых.
- Оптимизировать затраты на инфраструктуру и инструменты, выбирая наиболее эффективные решения для вашей среды.
Для кого написано это руководство? Оно будет бесценным ресурсом для:
- DevOps-инженеров, стремящихся систематизировать свою работу и внедрить лучшие практики.
- Backend-разработчиков (на Python, Node.js, Go, PHP), которые хотят лучше понимать операционные аспекты своих приложений и участвовать в их надежности.
- Фаундеров SaaS-проектов, которым необходимо обеспечить стабильность своего продукта для удержания клиентов и роста.
- Системных администраторов, ищущих способы повышения эффективности управления серверами и приложениями.
- Технических директоров стартапов, перед которыми стоит задача построения надежной и масштабируемой инфраструктуры с ограниченными ресурсами.
Приготовьтесь к погружению в мир практического SRE, где каждый совет проверен реальным опытом и направлен на достижение ощутимых результатов.
Основные критерии и факторы SRE для малых команд
В основе любой эффективной SRE-стратегии лежит понимание ключевых метрик и принципов. Для стартапов и малых SaaS-команд на VPS/Dedicated важно не просто скопировать подходы гигантов, а адаптировать их к своим реалиям, фокусируясь на максимальной отдаче при минимальных затратах. Рассмотрим основные критерии и факторы, которые станут вашими ориентирами.
1. Service Level Indicators (SLI) – Индикаторы уровня сервиса
SLI — это количественные метрики, которые показывают, насколько хорошо работает ваш сервис. Для малых команд выбор правильных SLI критичен, поскольку их будет немного, и они должны быть максимально информативными. Почему важны: SLI служат основой для измерения производительности и надежности. Как оценивать: Они должны быть измеримы, понятны и непосредственно связаны с пользовательским опытом.
- Задержка (Latency): Время ответа от сервера на запрос пользователя. Для веб-приложений это может быть время загрузки страницы или API-ответа. Пример: 95% запросов к API должны выполняться менее чем за 300 мс.
- Частота ошибок (Error Rate): Процент запросов, завершившихся ошибкой (например, HTTP 5xx). Это прямо указывает на проблемы в работе приложения или инфраструктуры. Пример: менее 0.1% запросов к основному сервису должны возвращать ошибки 5xx.
- Доступность (Availability): Процент времени, в течение которого сервис доступен и работоспособен. Часто измеряется как (общее время - время простоя) / общее время. Пример: 99.9% доступности основного веб-сервиса.
- Пропускная способность (Throughput): Количество запросов, обработанных за единицу времени. Важно для оценки масштабируемости и производительности под нагрузкой. Пример: обработка не менее 1000 запросов/сек при пиковой нагрузке.
Наш опыт показывает, что начинать следует с 2-3 наиболее критичных SLI для вашего основного пользовательского сценария. Например, для SaaS-платформы это может быть доступность API и задержка ответа при аутентификации.
2. Service Level Objectives (SLO) – Цели уровня сервиса
SLO — это конкретные целевые значения для ваших SLI, выраженные в процентах или абсолютных числах за определенный период. Почему важны: SLO переводят абстрактные метрики в конкретные, измеримые цели, вокруг которых строится вся работа по обеспечению надежности. Они помогают команде понять, когда сервис "достаточно хорош". Как оценивать: SLO должны быть реалистичными и достижимыми, а не идеалистичными. Слишком амбициозные SLO приведут к выгоранию, слишком низкие — к недовольству пользователей.
- Пример SLO для доступности: "Доступность основного API должна быть не менее 99.9% за календарный месяц." Это означает, что допустимый простой составляет около 43 минут в месяц.
- Пример SLO для задержки: "99-й перцентиль задержки ответа для критически важных запросов базы данных должен быть менее 200 мс."
Для стартапов важно не гнаться за "пятью девятками" (99.999%), которые требуют огромных затрат. Часто 99.5% или 99.9% — это более чем достаточно, особенно на начальных этапах. Реальный кейс: Мы однажды столкнулись с тем, что команда установила SLO 99.99% для нового сервиса, работающего на одном VPS. Это привело к постоянному стрессу и переработкам, пока мы не скорректировали его до 99.5%, что оказалось вполне приемлемым для пользователей и значительно снизило нагрузку на команду.
3. Service Level Agreement (SLA) – Соглашение об уровне сервиса
SLA — это формальный договор между поставщиком услуг (вами) и клиентом, который описывает ожидаемый уровень сервиса и последствия его невыполнения (например, финансовые компенсации). Почему важны: SLA — это юридическое обязательство, которое основывается на ваших SLO. Как оценивать: Оно должно быть реалистичным и соответствовать вашим внутренним возможностям, продиктованным SLO.
Для малых SaaS-команд SLA может быть частью условий использования. Важно, чтобы SLA было менее строгим, чем ваше внутреннее SLO, чтобы у вас был "запас прочности". Например, если ваше SLO 99.9%, то SLA может быть 99.5%.
4. Error Budgets – Бюджет ошибок
Бюджет ошибок — это допустимое количество "ненадежности" или "простоя" за определенный период, которое вы готовы принять, не нарушая SLO. Если ваше SLO 99.9% доступности, то 0.1% времени (примерно 43 минуты в месяц) — это ваш бюджет ошибок. Почему важны: Бюджет ошибок — мощный инструмент для балансирования между надежностью и скоростью разработки. Если бюджет ошибок исчерпан, команда должна приостановить выпуск новых функций и сосредоточиться на повышении надежности. Как оценивать: Отслеживайте использование бюджета ошибок ежедневно или еженедельно. Когда он приближается к нулю, это сигнал к действию.
Это помогает избежать вечной дилеммы "фичи против стабильности". Реальный пример: Однажды, после серии инцидентов, наш бюджет ошибок был практически исчерпан. Мы приняли решение на две недели полностью остановить разработку новых функций, чтобы сосредоточиться на рефакторинге проблемных мест, улучшении мониторинга и автоматизации развертывания. Это позволило нам стабилизировать сервис и вернуть доверие пользователей.
5. Мониторинг и Алерт (Monitoring & Alerting)
Мониторинг — это сбор и анализ данных о состоянии вашей системы. Алерт — это уведомление о том, что что-то пошло не так или выходит за рамки допустимых значений. Почему важны: Это глаза и уши вашей SRE-практики. Без них невозможно отслеживать SLI, контролировать SLO и реагировать на проблемы. Как оценивать: Мониторинг должен быть всеобъемлющим (инфраструктура, приложение, пользовательский опыт), а алерты — действенными, не вызывающими "усталости от оповещений".
- Метрики инфраструктуры: CPU, RAM, Disk I/O, Network I/O для VPS.
- Метрики приложения: Количество запросов, задержка ответов, количество ошибок, состояние пулов соединений (БД, кэш).
- Логи: Централизованный сбор и анализ логов для быстрого поиска причин проблем.
- Трассировка (Tracing): Для распределенных систем, позволяет отследить путь запроса через разные компоненты. Для VPS это может быть сложнее, но полезно для понимания взаимодействий между вашими сервисами.
Для малых команд на VPS, самохостинг Prometheus + Grafana является золотым стандартом, предоставляя мощные возможности при минимальных затратах.
6. Incident Response – Реагирование на инциденты
Incident Response — это процесс, который команда использует для обнаружения, оценки, разрешения и документирования инцидентов, влияющих на сервис. Почему важны: Даже с лучшими SRE-практиками инциденты неизбежны. Эффективный процесс реагирования минимизирует время простоя (MTTR - Mean Time To Recover) и его влияние на бизнес. Как оценивать: Измеряйте MTTR и количество инцидентов. Цель — сократить MTTR и предотвратить повторение инцидентов.
Малым командам нужен четкий, но простой план: кто на дежурстве, как оповещается, где документируется, какие шаги предпринимаются. Важно иметь "runbooks" — пошаговые инструкции для решения типичных проблем.
7. Post-Mortem (Blameless) – Безобвинительный анализ инцидентов
Post-Mortem — это процесс анализа инцидента после его разрешения с целью извлечения уроков и предотвращения его повторения. "Безобвинительный" означает, что фокус делается на системных проблемах, а не на поиске виноватых. Почему важны: Это ключевой механизм для непрерывного улучшения надежности. Без Post-Mortem команда обречена наступать на одни и те же грабли. Как оценивать: Количество и качество выявленных "action items" (действий по улучшению), их выполнение и влияние на метрики надежности.
Для стартапов это может быть простое совещание на 30-60 минут после каждого серьезного инцидента, где обсуждаются: что произошло, почему, что мы сделали, чтобы исправить, что мы можем сделать, чтобы предотвратить повторение. Важно документировать выводы.
8. Автоматизация (Automation)
Автоматизация — это устранение рутинных, повторяющихся задач (toil) с помощью скриптов и инструментов. Почему важны: Автоматизация сокращает человеческие ошибки, ускоряет операции, освобождает время инженеров для более ценной работы и повышает предсказуемость системы. Как оценивать: Количество автоматизированных задач, сокращение "toil", скорость развертывания, снижение количества ошибок, связанных с ручными операциями.
Для VPS/Dedicated это может быть автоматизация развертывания (CI/CD), резервного копирования, обновления ОС и зависимостей, масштабирования (если возможно), настройки серверов (Infrastructure as Code с Ansible). Даже простые bash-скрипты могут дать огромный эффект.
9. Observability – Наблюдаемость
Наблюдаемость — это способность понять внутреннее состояние системы, просто исследуя данные, которые она генерирует (метрики, логи, трассировки). Почему важны: Observability позволяет не просто знать, что что-то сломалось, но и понять, *почему* это произошло, без необходимости дополнительного дебаггинга или доступа к машине. Как оценивать: Скорость диагностики и разрешения неизвестных проблем, глубина понимания поведения системы.
Для малых команд это может быть сложной задачей из-за ограниченности ресурсов. Начните с хорошего сбора метрик и централизованного логирования. Трассировка может быть внедрена позже, по мере роста сложности и ресурсов. Loki для логов и Tempo для трассировок (в связке с Grafana) могут быть хорошим опенсорсным выбором.
10. Capacity Planning – Планирование мощностей
Capacity Planning — это процесс прогнозирования будущих потребностей в ресурсах (CPU, RAM, диск, сеть) и соответствующего планирования инфраструктуры. Почему важны: Позволяет избежать деградации сервиса из-за нехватки ресурсов и оптимизировать затраты, покупая только необходимые мощности. Как оценивать: Точность прогнозов, отсутствие инцидентов, связанных с нехваткой ресурсов, оптимальное использование текущих мощностей.
На VPS/Dedicated это обычно сводится к мониторингу текущего использования ресурсов и прогнозированию на основе трендов роста. Если вы видите, что CPU постоянно загружен на 80-90%, это сигнал к апгрейду VPS или оптимизации приложения. Для стартапов этот процесс часто более реактивный, чем проактивный, но постоянный мониторинг позволяет принимать обоснованные решения о масштабировании.
Сравнительная таблица инструментов для SRE
Выбор правильных инструментов критически важен для эффективного внедрения SRE-практик, особенно при ограниченных бюджетах VPS/Dedicated. В 2026 году рынок предлагает как зрелые опенсорсные решения, так и коммерческие SaaS-продукты с тарифами для малых команд. Эта таблица поможет сравнить некоторые из них по ключевым параметрам.
| Критерий | Prometheus + Grafana | Zabbix | Datadog (Starter/Pro) | New Relic (Standard) | ELK Stack (self-hosted) | Loki + Grafana |
|---|---|---|---|---|---|---|
| Тип решения | Open-source, self-hosted | Open-source, self-hosted | SaaS | SaaS | Open-source, self-hosted | Open-source, self-hosted |
| Основные функции | Метрики, алерты, дашборды | Метрики, алерты, дашборды, инвентаризация | APM, инфраструктура, логи, синтетика, RUM | APM, инфраструктура, логи, синтетика, RUM | Логи, метрики, трассировки (через APM) | Логи (с метриками и трассировками через Grafana) |
| Сложность внедрения (для VPS) | Средняя (требует настройки) | Средняя (требует настройки) | Низкая (установка агента) | Низкая (установка агента) | Высокая (много компонентов) | Низкая-средняя (проще ELK) |
| Примерная стоимость (2026, $/мес) | 0 (только ресурсы VPS) | 0 (только ресурсы VPS) | $30-100+ (зависит от объема) | $25-75+ (зависит от объема) | 0 (только ресурсы VPS) | 0 (только ресурсы VPS) |
| Требования к ресурсам VPS | Средние | Средние | Низкие (агент) | Низкие (агент) | Высокие (особенно Elasticsearch) | Низкие-средние |
| Масштабируемость | Хорошая (federation) | Хорошая | Отличная (SaaS) | Отличная (SaaS) | Средняя-хорошая (кластер) | Отличная (cloud-native) |
| Идеально для | Малых команд, бюджетных проектов, гибкости | Традиционных SysOps, комплексного мониторинга инфраструктуры | Быстрого старта, комплексного APM, готовых решений | Быстрого старта, комплексного APM, готовых решений | Глубокого анализа логов, больших объемов данных | Экономичного логирования, интеграции с Grafana |
| Поддержка | Сообщество, платные вендоры | Сообщество, платные вендоры | Вендор | Вендор | Сообщество, Elastic Inc. | Сообщество, Grafana Labs |
Комментарии к таблице:
- Prometheus + Grafana: Это "золотой стандарт" для многих стартапов на VPS. Prometheus собирает метрики, Grafana визуализирует их. Оба инструмента очень мощные, гибкие и имеют огромное сообщество. Требуют некоторого времени на изучение и настройку, но окупаются полной свободой и отсутствием ежемесячных платежей за функционал.
- Zabbix: Более традиционная система мониторинга, часто используемая системными администраторами. Отлична для мониторинга серверов, сетевого оборудования, но может быть менее гибка для мониторинга современных микросервисных приложений по сравнению с Prometheus.
- Datadog / New Relic: Это мощные коммерческие платформы "всё в одном". Они предлагают APM (Application Performance Monitoring), мониторинг инфраструктуры, логи, трассировку, синтетический мониторинг и многое другое. Их главное преимущество — простота внедрения и глубокая аналитика из коробки. Однако, для стартапов на VPS их стоимость может быстро стать значительной, особенно при росте объемов данных. Для очень маленьких команд могут быть бесплатные или очень дешевые тарифы, но с ограничениями.
- ELK Stack: Elasticsearch, Logstash, Kibana — это мощный стек для сбора, хранения, анализа и визуализации логов. Он предоставляет глубокие возможности для поиска и анализа текстовых данных. Однако, Elasticsearch очень требователен к ресурсам, и его развертывание на одном VPS может быть сложным и ресурсоемким. Часто требует отдельного выделенного сервера или кластера.
- Loki + Grafana: Loki — это система агрегации логов, разработанная Grafana Labs. Она гораздо менее ресурсоемка, чем Elasticsearch, поскольку индексирует только метаданные логов, а не весь их контент. Это делает ее отличным выбором для централизованного логирования на VPS, особенно в связке с Grafana. Позволяет эффективно искать и анализировать логи, интегрируя их с метриками.
Выбор инструмента во многом зависит от ваших текущих потребностей, размера команды, бюджета и готовности инвестировать время в настройку. Для большинства стартапов на VPS/Dedicated комбинация Prometheus + Grafana для метрик и Loki + Grafana для логов является наиболее сбалансированным и экономически выгодным решением.
Детальный обзор ключевых SRE-практик
Внедрение SRE в условиях стартапа или малой команды на VPS/Dedicated требует прагматичного подхода. Здесь мы углубимся в детали каждой ключевой практики, объясняя, как ее эффективно адаптировать к вашим реалиям.
1. SLI, SLO и Бюджет ошибок для малых команд
SLI (Service Level Indicators) — это ваши глаза на состояние системы. Для начала, сосредоточьтесь на том, что непосредственно влияет на пользователя и легко измеряется. Для типичного SaaS-приложения на VPS это:
- Доступность основного API/Веб-интерфейса: Процент успешных HTTP-запросов (2xx, 3xx) от общего числа запросов. Используйте внешние пинги (UptimeRobot, Healthchecks.io) и внутренние метрики (Prometheus HTTP_exporter) для сбора.
- Задержка критических операций: Время ответа для наиболее частых или важных запросов (например, вход в систему, загрузка панели управления, сохранение данных). Отслеживайте 95-й и 99-й перцентили, чтобы понять не только среднее, но и худшие сценарии.
- Частота ошибок: Процент запросов, возвращающих HTTP 5xx. Также важно отслеживать ошибки в логах приложения, которые могут не приводить к 5xx, но влияют на функциональность.
SLO (Service Level Objectives) — это ваши обещания самим себе и пользователям. Не стремитесь к нереалистичным 99.999%. Для стартапа, начинающего с VPS, 99.5% или 99.9% доступности — это отличная цель, которая означает всего 43 минуты простоя в месяц для 99.9%. Это дает пространство для маневра, обновлений и даже небольших инцидентов. Пример: "Доступность API для клиентов должна быть ≥99.9% за последние 30 дней", "95% запросов к базе данных должны выполняться ≤100 мс". Важно, чтобы SLO были согласованы с бизнес-целями и возможностями команды.
Бюджет ошибок (Error Budget) — это ваш "кредит" на ненадежность. Если ваше SLO 99.9%, то у вас есть 0.1% от общего времени работы сервиса, которое вы можете "потратить" на инциденты, плановые работы или эксперименты. Как использовать: Если бюджет ошибок начинает быстро сокращаться, это сигнал для команды приостановить разработку новых функций и сосредоточиться на повышении надежности. Например, если за неделю вы "потратили" половину месячного бюджета ошибок, возможно, стоит отложить релиз новой фичи и провести рефакторинг проблемного компонента. Этот механизм помогает сбалансировать скорость разработки и стабильность.
2. Практический мониторинг и алертинг
Для VPS/Dedicated, мониторинг является краеугольным камнем SRE. Ваша цель — видеть, что происходит с сервером и приложением, и получать уведомления до того, как пользователи заметят проблему.
- Мониторинг инфраструктуры: Установите Node Exporter на каждый VPS для сбора метрик CPU, RAM, диска, сети. Для контейнеров используйте cAdvisor.
- Мониторинг приложения: Интегрируйте библиотеки для экспорта метрик (например, Prometheus client libraries) в ваш код. Отслеживайте количество запросов, задержку, ошибки, состояние очереди, использование памяти JVM/Go/Node.js.
- Мониторинг логов: Используйте Loki + Promtail для сбора логов с ваших серверов и приложений. Это позволит централизованно искать и анализировать события, а также создавать алерты на основе паттернов в логах.
- Синтетический мониторинг: Используйте внешние сервисы (UptimeRobot, Healthchecks.io) или Blackbox Exporter для Prometheus, чтобы регулярно проверять доступность и корректность ответов ваших публичных эндпоинтов извне.
Алертинг: Настройте Alertmanager для обработки алертов от Prometheus. Ключевые принципы:
- Конкретика: Алерты должны быть максимально информативными: что сломалось, где, когда, и что делать.
- Действенность: Алерты должны требовать немедленного действия. Если алерт не требует действия, это шум.
- Приоритеты: Разделите алерты по критичности. Высокоприоритетные (сервис недоступен) должны будить команду. Низкоприоритетные (использование диска 80%) могут отправляться в Slack/Telegram.
- "Runbooks": К каждому алерту привяжите ссылку на "runbook" — короткую инструкцию, что делать при срабатывании этого алерта.
Реальный кейс: Мы сократили количество "ложных" алертов на 70% после того, как ввели правило: "Если алерт срабатывает больше 3 раз за неделю и не приводит к реальному инциденту, он подлежит пересмотру или отключению". Это заставило команду настраивать более точные пороги и фокусироваться на действительно важных проблемах.
3. Эффективный Incident Response для малых команд
Даже с лучшим мониторингом инциденты случаются. Ваша цель — минимизировать Mean Time To Recover (MTTR). Для небольшой команды это означает:
- Четкое дежурство (On-Call Rotation): Даже если вас всего двое, определите, кто дежурит в нерабочее время. Используйте простые инструменты: PagerDuty (есть бесплатный/дешевый тариф для малых команд), Opsgenie, или даже самописный скрипт, отправляющий уведомления в Telegram/Slack по расписанию.
- Каналы коммуникации: Выделите отдельный канал в Slack/Telegram для инцидентов. Вся коммуникация должна быть там.
- Runbooks: Это пошаговые инструкции для решения типичных проблем. Храните их в Wiki или Git-репозитории. Пример: "Сервер X не отвечает: 1) Проверить пинг. 2) Проверить SSH. 3) Перезапустить сервис Y. 4) Перезагрузить VPS."
- Инцидент-менеджер: Назначьте одного человека, который будет координировать действия во время инцидента, даже если это всего 2-3 человека. Он отвечает за коммуникацию, а не за техническое решение.
- Быстрая диагностика: Убедитесь, что у каждого дежурного есть доступ к мониторингу, логам и возможность выполнять диагностические команды на серверах.
Секрет успеха — практика. Регулярно проводите "учения", моделируя небольшие инциденты, чтобы команда знала, что делать.
4. Культура Post-Mortem (Blameless)
Post-Mortem — это не поиск виноватых, а системный анализ для предотвращения будущих проблем. Для стартапов:
- Проводите Post-Mortem для каждого значимого инцидента: Определите "значимый" как любой инцидент, нарушивший SLO или вызвавший существенное недовольство клиентов.
- Фокус на системе, а не на людях: Вопросы "Что произошло?", "Почему?", "Как мы это обнаружили?", "Что мы сделали?", "Что мы могли бы сделать лучше?", "Какие системные изменения необходимы?".
- Документируйте: Записывайте выводы, хронологию, принятые решения и, самое главное, "action items" — конкретные задачи по улучшению (например, "Добавить алерт на заполнение диска", "Обновить документацию по развертыванию", "Провести тренировку по Incident Response").
- Назначайте ответственных и сроки: Убедитесь, что у каждого "action item" есть ответственный и реалистичный срок выполнения.
- Делитесь уроками: Рассказывайте о выводах всей команде, чтобы все учились на чужих ошибках.
Это помогает создать культуру доверия и непрерывного обучения, что особенно важно в быстрорастущих командах.
5. Автоматизация рутины и Toil
Toil (рутинная, повторяющаяся, не приносящая долгосрочной пользы работа) — враг SRE. Автоматизация — ваш лучший друг на VPS/Dedicated:
- Развертывание (CI/CD): Используйте GitLab CI, GitHub Actions (с self-hosted runner на вашем VPS) или Jenkins для автоматического тестирования и развертывания кода при каждом коммите. Это уменьшает ошибки и ускоряет релизы.
- Управление конфигурацией (IaC): Используйте Ansible для автоматической настройки серверов, установки ПО, управления файлами конфигурации. Даже для одного VPS это сэкономит время и обеспечит консистентность.
- Резервное копирование: Настройте автоматическое резервное копирование базы данных и важных файлов на удаленное хранилище (S3-совместимое хранилище, Rsync.net). Используйте скрипты, cron-задания.
- Обновления: Автоматизируйте установку патчей безопасности для ОС (например, с помощью `unattended-upgrades` в Debian/Ubuntu) и зависимостей приложения.
- Проверка состояния: Скрипты, проверяющие состояние сервисов, свободное место на диске, доступность портов, и отправляющие отчеты.
Начните с малого: автоматизируйте то, что вы делаете чаще всего и что наиболее подвержено ошибкам. Например, процесс развертывания нового микросервиса или настройки нового VPS.
6. Observability на VPS/Dedicated
Даже на одном сервере, Observability позволяет глубже понять, что происходит.
- Метрики: Как уже упоминалось, Prometheus + Grafana. Собирайте метрики не только с ОС, но и из самого приложения.
- Логи: Loki + Promtail + Grafana. Убедитесь, что ваше приложение логирует достаточно информации (уровни, контекст, User ID, Request ID).
- Трассировки (Tracing): Для более сложных приложений, где есть несколько сервисов, даже на одном VPS, трассировка может быть полезной. Grafana Tempo — опенсорсное решение, которое может быть развернуто на том же VPS, что и Loki/Prometheus. Интегрируйте OpenTelemetry SDK в ваше приложение для отправки трассировок.
Начните с метрик и логов. Это даст вам 80% необходимой информации. Трассировка — это следующий шаг, когда у вас есть ресурсы и потребность в более глубоком анализе распределенных транзакций.
Практические советы и рекомендации по внедрению
Переходим от теории к конкретным шагам. Здесь вы найдете пошаговые инструкции, примеры команд и конфигураций, которые можно применить прямо сейчас.
1. Установка базового стека мониторинга (Prometheus + Grafana + Node Exporter) на VPS
Это "must-have" для любой команды на VPS. Предполагаем, что у вас есть VPS с Ubuntu 22.04.
Шаг 1: Установка Prometheus
# Создаем пользователя и директории
sudo useradd --no-create-home --shell /bin/false prometheus
sudo mkdir /etc/prometheus
sudo mkdir /var/lib/prometheus
# Скачиваем и распаковываем Prometheus (актуальная версия на 2026 год может отличаться)
wget https://github.com/prometheus/prometheus/releases/download/v2.x.x/prometheus-2.x.x.linux-amd64.tar.gz
tar xvfz prometheus-2.x.x.linux-amd64.tar.gz
cd prometheus-2.x.x.linux-amd64
# Копируем бинарники и конфиг
sudo cp prometheus /usr/local/bin/
sudo cp promtool /usr/local/bin/
sudo cp -r consoles /etc/prometheus
sudo cp -r console_libraries /etc/prometheus
sudo cp prometheus.yml /etc/prometheus/prometheus.yml # Это будет базовый конфиг
# Устанавливаем права
sudo chown -R prometheus:prometheus /etc/prometheus
sudo chown -R prometheus:prometheus /var/lib/prometheus
sudo chown prometheus:prometheus /usr/local/bin/prometheus
sudo chown prometheus:prometheus /usr/local/bin/promtool
# Создаем systemd-сервис для Prometheus
sudo nano /etc/systemd/system/prometheus.service
Содержимое файла /etc/systemd/system/prometheus.service:
[Unit]
Description=Prometheus
Wants=network-online.target
After=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/usr/local/bin/prometheus \
--config.file /etc/prometheus/prometheus.yml \
--storage.tsdb.path /var/lib/prometheus \
--web.console.templates=/etc/prometheus/consoles \
--web.console.libraries=/etc/prometheus/console_libraries \
--web.listen-address="0.0.0.0:9090" \
--storage.tsdb.retention.time=30d # Хранить данные 30 дней
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
# Перезагружаем systemd и запускаем Prometheus
sudo systemctl daemon-reload
sudo systemctl start prometheus
sudo systemctl enable prometheus
sudo systemctl status prometheus # Проверяем статус
Шаг 2: Установка Node Exporter
# Создаем пользователя
sudo useradd --no-create-home --shell /bin/false node_exporter
# Скачиваем и распаковываем Node Exporter
wget https://github.com/prometheus/node_exporter/releases/download/v1.x.x/node_exporter-1.x.x.linux-amd64.tar.gz
tar xvfz node_exporter-1.x.x.linux-amd64.tar.gz
cd node_exporter-1.x.x.linux-amd64
# Копируем бинарник
sudo cp node_exporter /usr/local/bin
sudo chown node_exporter:node_exporter /usr/local/bin/node_exporter
# Создаем systemd-сервис для Node Exporter
sudo nano /etc/systemd/system/node_exporter.service
Содержимое файла /etc/systemd/system/node_exporter.service:
[Unit]
Description=Node Exporter
Wants=network-online.target
After=network-online.target
[Service]
User=node_exporter
Group=node_exporter
Type=simple
ExecStart=/usr/local/bin/node_exporter
[Install]
WantedBy=multi-user.target
# Перезагружаем systemd и запускаем Node Exporter
sudo systemctl daemon-reload
sudo systemctl start node_exporter
sudo systemctl enable node_exporter
sudo systemctl status node_exporter
Шаг 3: Настройка Prometheus для сбора метрик с Node Exporter
Отредактируйте /etc/prometheus/prometheus.yml, добавив job для Node Exporter:
# ... (остальной конфиг)
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090'] # Сам Prometheus
- job_name: 'node_exporter'
static_configs:
- targets: ['localhost:9100'] # Node Exporter на этом же сервере
# Перезагружаем Prometheus, чтобы применить изменения
sudo systemctl reload prometheus
Шаг 4: Установка Grafana
# Добавляем ключ GPG
sudo apt install -y apt-transport-https software-properties-common wget
wget -q -O - https://apt.grafana.com/gpg.key | sudo gpg --dearmor | sudo tee /etc/apt/keyrings/grafana.gpg > /dev/null
# Добавляем репозиторий Grafana
echo "deb [signed-by=/etc/apt/keyrings/grafana.gpg] https://apt.grafana.com stable main" | sudo tee /etc/apt/sources.list.d/grafana.list
# Обновляем список пакетов и устанавливаем Grafana
sudo apt update
sudo apt install grafana -y
# Запускаем и включаем Grafana
sudo systemctl start grafana-server
sudo systemctl enable grafana-server
sudo systemctl status grafana-server
Grafana будет доступна по адресу http://ВАШ_IP:3000. Логин/пароль по умолчанию: admin/admin (смените сразу!). Добавьте Prometheus как источник данных (Data Source) и импортируйте готовые дашборды для Node Exporter (например, ID 1860, 11074).
2. Определение первых SLO и SLI
Не пытайтесь сразу охватить все. Выберите 1-2 наиболее критичных сервиса и 1-2 SLI для каждого.
- Сервис: Основной API вашего SaaS-продукта.
- SLI 1: Доступность (количество HTTP 2xx/3xx от общего количества запросов к API).
- SLO 1: 99.9% доступности за 30 дней.
- Бюджет ошибок: 0.1% от общего времени работы (примерно 43.2 минуты в месяц).
- SLI 2: Задержка ответа (95-й перцентиль для запросов типа POST /login).
- SLO 2: 95% запросов POST /login должны выполняться за менее чем 500 мс за 7 дней.
- Бюджет ошибок: 5% запросов могут превышать 500 мс.
Используйте Prometheus Alertmanager для создания алертов, которые срабатывают, когда вы приближаетесь к исчерпанию бюджета ошибок, а не только когда SLO уже нарушено. Это дает вам время на реакцию.
# Пример правила для Prometheus Alertmanager
groups:
- name: service_availability
rules:
- alert: HighAvailabilityErrorRate
expr: |
sum(rate(http_requests_total{job="my_api", status=~"5.."}[5m])) by (job) / sum(rate(http_requests_total{job="my_api"}[5m])) by (job) > 0.001
for: 5m
labels:
severity: critical
annotations:
summary: "Высокий уровень ошибок 5xx на API {{ $labels.job }}"
description: "Более 0.1% запросов к API {{ $labels.job }} возвращают 5xx ошибки в течение 5 минут. Это угрожает нашему SLO 99.9%."
runbook: "https://your-wiki.com/runbooks/api_5xx_errors"
3. Пример простого Runbook для инцидента "Высокая загрузка CPU на VPS"
Это может быть простой файл в Git-репозитории или страница в Wiki.
# Runbook: Высокая загрузка CPU на VPS
**Название инцидента:** Высокая загрузка CPU (более 90% в течение 5 минут) на VPS {{ $labels.instance }}
**Приоритет:** P1 (Критический), немедленное реагирование
**Цель:** Идентифицировать и устранить причину высокой загрузки CPU, восстановить нормальную работу.
**Ответственный:** Дежурный инженер
---
**Шаги по диагностике и устранению:**
1. **Подтверждение инцидента:**
* Проверьте текущую загрузку CPU через Grafana (дашборд Node Exporter).
* Подключитесь к VPS по SSH: `ssh user@{{ $labels.instance }}`
2. **Идентификация процесса-виновника:**
* Выполните `top` или `htop` для просмотра процессов, потребляющих больше всего CPU.
* Обратите внимание на `PID` и `COMMAND` процессов с высоким потреблением.
3. **Анализ логов:**
* Если виновник - ваше приложение, проверьте его логи на наличие ошибок или аномалий:
`journalctl -u your_app_service.service -f`
(или просмотр логов через Loki/Grafana, если настроено).
* Проверьте системные логи: `journalctl -f`
4. **Попытка восстановления (неразрушающая):**
* Если виновник - ваше приложение, попробуйте его перезапустить:
`sudo systemctl restart your_app_service.service`
* Если это известный баг или временная нагрузка, рассмотрите возможность временного масштабирования (если возможно) или снижения нагрузки.
5. **Попытка восстановления (разрушающая):**
* Если перезапуск сервиса не помог, и VPS остается перегружен, рассмотрите перезагрузку всего VPS:
`sudo reboot` (предварительно убедитесь, что это не приведет к потере данных и оповестите команду).
6. **Документирование:**
* Запишите все предпринятые шаги, найденные причины и результаты в трекер инцидентов (Jira, Notion).
* Соберите команду для Post-Mortem, если инцидент был серьезным или повторяющимся.
---
**Дополнительные команды диагностики:**
* `sudo dmesg -T` - сообщения ядра
* `free -h` - использование RAM
* `df -h` - использование диска
* `netstat -tunlp` - открытые порты и соединения
4. Пример автоматизации развертывания с GitLab CI (для VPS)
Предположим, у вас есть NodeJS приложение и вы хотите развертывать его на VPS при каждом коммите в ветку `main`.
Файл .gitlab-ci.yml в корне вашего репозитория:
stages:
- build
- deploy
variables:
# Настройте SSH-ключ для доступа к VPS в GitLab CI/CD Variables
# SSH_PRIVATE_KEY: ваш приватный ключ SSH
# SSH_USER: пользователь на VPS (например, deploy_user)
# SSH_HOST: IP или домен вашего VPS
build_job:
stage: build
image: node:18-alpine
script:
- npm install
- npm test
- npm run build # Если у вас есть этап сборки (например, для React/Vue фронтенда)
artifacts:
paths:
- node_modules/
- dist/ # Или build/
only:
- main
deploy_job:
stage: deploy
image: alpine/git # Легкий образ с Git и SSH
before_script:
- apk add openssh-client # Устанавливаем SSH-клиент
- eval $(ssh-agent -s)
- echo "$SSH_PRIVATE_KEY" | tr -d '\r' | ssh-add - # Добавляем приватный ключ
- mkdir -p ~/.ssh
- chmod 700 ~/.ssh
- ssh-keyscan -H "$SSH_HOST" >> ~/.ssh/known_hosts # Добавляем хост в known_hosts
- chmod 644 ~/.ssh/known_hosts
script:
- echo "Deploying to $SSH_USER@$SSH_HOST..."
- ssh "$SSH_USER@$SSH_HOST" "mkdir -p /var/www/my-app" # Создаем директорию, если нет
- scp -r node_modules/ "$SSH_USER@$SSH_HOST:/var/www/my-app/"
- scp -r dist/ "$SSH_USER@$SSH_HOST:/var/www/my-app/" # Копируем собранные файлы
- scp package.json "$SSH_USER@$SSH_HOST:/var/www/my-app/"
- scp app.js "$SSH_USER@$SSH_HOST:/var/www/my-app/" # Копируем основные файлы приложения
- ssh "$SSH_USER@$SSH_HOST" "cd /var/www/my-app && sudo systemctl restart my-app-service" # Перезапускаем сервис
- echo "Deployment completed!"
only:
- main
На вашем VPS должен быть пользователь (например, `deploy_user`) с SSH-доступом и настроенный `sudo` для перезапуска сервиса без пароля. Также убедитесь, что ваше приложение работает как systemd-сервис.
5. Оптимизация затрат на мониторинг
- Используйте опенсорс: Prometheus, Grafana, Loki, Alertmanager, Node Exporter — все это бесплатно. Ваши затраты — это ресурсы VPS.
- Экономьте дисковое пространство: Настройте короткий срок хранения данных в Prometheus (например, 30 дней с помощью
--storage.tsdb.retention.time=30d). Для логов в Loki также можно настроить TTL. - Ограничьте кардинальность метрик: Избегайте создания метрик с очень большим количеством уникальных лейблов (например, с User ID в качестве лейбла), это раздувает базу данных Prometheus.
- Оптимизируйте запросы: В Grafana старайтесь использовать агрегирующие функции и запросы с меньшим разрешением для длительных периодов.
- Рассмотрите небольшие VPS для мониторинга: Если ваш основной VPS уже нагружен, выделите отдельный, менее мощный VPS специально для Prometheus, Grafana и Loki. Это разнесет нагрузку и повысит отказоустойчивость самого мониторинга.
Наш опыт показывает, что даже базовый набор из Prometheus, Grafana и Loki на отдельном VPS с 2 CPU, 4GB RAM и 80GB SSD может комфортно обслуживать мониторинг и логирование для нескольких небольших SaaS-сервисов.
Типичные ошибки при внедрении SRE в стартапах
Внедрение SRE — это путь, полный подводных камней, особенно когда ресурсы ограничены. Знание типичных ошибок поможет вам избежать их и сэкономить время, нервы и деньги.
1. Игнорирование или неверное определение SLI/SLO
Ошибка: Либо не определять SLI/SLO вообще, либо копировать их у крупных компаний (например, стремиться к 99.999% доступности), либо выбирать метрики, которые не отражают реальный пользовательский опыт.
Как избежать: Начните с 1-2 самых критичных SLI, которые напрямую влияют на доход или удержание клиентов (например, доступность основного API, скорость загрузки ключевой страницы). Установите реалистичные SLO (99.5%-99.9% для начала) и регулярно пересматривайте их. Вовлекайте бизнес в процесс определения SLO, чтобы они понимали компромиссы между надежностью и скоростью разработки.
Последствия: Отсутствие четких целей приводит к хаотичным приоритетам, постоянному стрессу от "тушения пожаров" и невозможности измерить реальный прогресс в надежности. Нереалистичные SLO приводят к выгоранию команды и постоянному ощущению провала.
2. Alert Fatigue (Усталость от оповещений)
Ошибка: Настройка слишком большого количества алертов, алертов на некритичные события, алертов без четкого "runbook" или алертов, которые срабатывают слишком часто без реальной проблемы.
Как избежать: Следуйте принципу "каждый алерт должен требовать действия". Если алерт срабатывает, но не требует немедленного вмешательства (например, "использование диска 70%"), переведите его в информационное сообщение в Slack или измените порог срабатывания. Настройте эскалацию: сначала в общий чат, затем дежурному. Убедитесь, что каждый алерт имеет связанный "runbook".
Последствия: Команда начинает игнорировать алерты, что приводит к пропуску реальных инцидентов и увеличению времени простоя. Это также сильно подрывает моральный дух и вызывает выгорание.
3. Отсутствие или неэффективный процесс Post-Mortem
Ошибка: Не проводить Post-Mortem вообще, или проводить их с целью найти виноватого, или проводить, но не документировать выводы и не выполнять "action items".
Как избежать: Сделайте Post-Mortem обязательной практикой после каждого значимого инцидента. Подчеркивайте безобвинительный характер процесса, фокусируясь на системных причинах. Четко документируйте хронологию, причины, предпринятые шаги и, самое главное, конкретные "action items" с ответственными и сроками. Регулярно отслеживайте выполнение этих задач.
Последствия: Команда постоянно наступает на одни и те же грабли, инциденты повторяются, а культура поиска виноватых подавляет инициативу и честность, препятствуя обучению и улучшению.
4. Переусложнение и "золотая клетка"
Ошибка: Пытаться внедрить все "модные" SRE-инструменты и практики сразу, не учитывая текущий размер команды, бюджет и сложность системы. Например, внедрять полноценный распределенный трейсинг для монолита на одном VPS.
Как избежать: Начните с основ: базовый мониторинг, централизованные логи, простые SLO. Внедряйте SRE итеративно, добавляя новые практики и инструменты по мере роста потребностей и ресурсов. Фокусируйтесь на "достаточно хороших" решениях, а не на "идеальных". Используйте опенсорс и простые решения, пока не возникнет реальная потребность в коммерческих продуктах.
Последствия: Избыточная сложность приводит к медленному внедрению, высоким затратам, трудностям в поддержке и не дает реальной пользы, вызывая фрустрацию и отторжение SRE-практик.
5. Игнорирование автоматизации и технического долга
Ошибка: Откладывать автоматизацию "на потом" или считать, что "ручками быстрее". Игнорировать накопление технического долга в инфраструктуре и коде, что делает систему хрупкой и трудно поддерживаемой.
Как избежать: Выделите время на автоматизацию рутинных задач (развертывание, резервное копирование, обновление). Даже небольшие скрипты могут сэкономить часы. Включите работу с техническим долгом в регулярное планирование (например, 10-20% спринта). Используйте результаты Post-Mortem для выявления критического технического долга.
Последствия: Увеличение "toil", человеческие ошибки, медленные и непредсказуемые релизы, высокая стоимость поддержки и постоянная угроза стабильности системы. Накопленный техдолг в итоге замедляет разработку новых функций.
6. Отсутствие четкого плана реагирования на инциденты
Ошибка: Предполагать, что "кто-нибудь разберется", когда что-то сломается, или отсутствие четкой процедуры оповещения и действий.
Как избежать: Создайте простой, но четкий план Incident Response: кто дежурит, как оповещается, кто главный по инциденту, где ведется коммуникация, где хранятся "runbooks". Проводите регулярные "учения", чтобы команда знала свои роли.
Последствия: Хаос во время инцидента, паника, медленное восстановление, что приводит к длительным простоям, потере клиентов и репутационному ущербу.
7. Отсутствие резервного копирования или его неэффективность
Ошибка: Полное отсутствие резервного копирования, или наличие резервных копий, которые никогда не проверялись на работоспособность, или хранение их на том же сервере, что и основной сервис.
Как избежать: Внедрите регулярное автоматическое резервное копирование всех критически важных данных (базы данных, конфигурации, пользовательские файлы). Храните копии на удаленном, независимом хранилище (например, S3-совместимое облако). Регулярно (хотя бы раз в квартал) проверяйте работоспособность восстановления из резервных копий.
Последствия: Потеря данных в случае сбоя сервера, атаки или человеческой ошибки, что может быть катастрофическим для SaaS-бизнеса и привести к его закрытию.
Чеклист для практического применения SRE
Этот пошаговый алгоритм поможет вам систематизировать внедрение SRE-практик в вашей малой команде на VPS/Dedicated. Проходите по пунктам и отмечайте прогресс.
Фаза 1: Подготовка и планирование
- Определите критические сервисы:
- Составьте список 1-3 ключевых сервисов вашего SaaS-продукта, от которых напрямую зависит пользовательская ценность и доход.
- Пример: API бэкенда, веб-интерфейс, сервис авторизации.
- Выберите ключевые SLI:
- Для каждого критического сервиса выберите 1-2 наиболее важных SLI (доступность, задержка, частота ошибок), которые легко измерить и которые отражают пользовательский опыт.
- Пример: Доступность API, 95-й перцентиль задержки POST /login.
- Установите реалистичные SLO:
- Для каждого SLI определите реалистичную цель (например, 99.9% доступности, 95% запросов < 500мс). Обсудите и согласуйте их с командой и стейкхолдерами.
- Пример: SLO доступности API = 99.9% за 30 дней.
- Определите бюджет ошибок:
- Рассчитайте допустимое время простоя или количество ошибок, соответствующее вашим SLO.
- Пример: Бюджет ошибок для 99.9% доступности = 43.2 минуты в месяц.
- Выберите инструменты мониторинга и логирования:
- Для VPS/Dedicated рассмотрите Prometheus + Grafana для метрик и Loki + Promtail для логов.
- Пример: Решено использовать Prometheus, Grafana, Node Exporter, Loki, Promtail.
Фаза 2: Внедрение базовых практик
- Разверните стек мониторинга:
- Установите Prometheus, Node Exporter и Grafana на ваш основной или отдельный VPS.
- Настройте Prometheus для сбора метрик с Node Exporter и, при необходимости, с вашего приложения.
- Настройте централизованное логирование:
- Установите Loki и Promtail. Настройте Promtail для сбора логов вашего приложения и системных логов.
- Подключите Loki как источник данных в Grafana.
- Создайте первые дашборды:
- В Grafana импортируйте готовые дашборды для Node Exporter.
- Создайте собственные дашборды для мониторинга ваших SLI (доступность, задержка, ошибки приложения).
- Настройте базовый алертинг:
- Установите и настройте Alertmanager.
- Создайте алерты для критических событий (например, сервис недоступен, высокая частота ошибок, исчерпание бюджета ошибок).
- Настройте уведомления в Slack/Telegram или через PagerDuty/Opsgenie.
- Разработайте простые Runbooks:
- Для каждого критического алерта создайте короткую, пошаговую инструкцию по диагностике и устранению проблемы.
- Храните их в легкодоступном месте (Wiki, Git-репозиторий).
- Настройте автоматическое резервное копирование:
- Внедрите скрипты для автоматического бэкапа базы данных и важных файлов.
- Настройте хранение бэкапов на удаленном, независимом ресурсе.
- Проверьте процедуру восстановления из бэкапа.
Фаза 3: Развитие и оптимизация
- Внедрите автоматизацию развертывания (CI/CD):
- Настройте GitLab CI/GitHub Actions с self-hosted runner или Jenkins для автоматического тестирования и деплоя вашего приложения.
- Начните проводить Post-Mortem:
- После каждого значимого инцидента проводите безобвинительный Post-Mortem.
- Документируйте выводы и создавайте "action items" с ответственными и сроками.
- Оптимизируйте алерты:
- Регулярно пересматривайте алерты, устраняйте "шум", настраивайте более точные пороги.
- Убедитесь, что каждый алерт действительно требует действия.
- Документируйте инфраструктуру и процессы:
- Создайте простую схему вашей инфраструктуры.
- Опишите ключевые процессы (развертывание, реагирование на инциденты, обновление).
- Регулярно пересматривайте SLO и SLI:
- Ежеквартально или при значительных изменениях в продукте пересматривайте актуальность и достижимость ваших целей.
- Инвестируйте в обучение команды:
- Поощряйте изучение SRE-принципов и инструментов.
- Проводите внутренние "учения" по реагированию на инциденты.
Расчет стоимости / Экономика SRE

Одна из основных причин, почему стартапы и малые команды на VPS/Dedicated выбирают этот путь, — это стремление к оптимизации затрат. SRE, на первый взгляд, может показаться дополнительной статьей расходов, но на самом деле это инвестиция, которая многократно окупается. Давайте разберем экономику SRE.
1. Стоимость простоя (Cost of Downtime)
Прежде чем говорить о затратах на SRE, необходимо понять, сколько стоит отсутствие SRE. Каждый час простоя вашего SaaS-продукта — это не просто технический сбой, это прямые и косвенные потери для бизнеса.
- Прямые потери дохода: Если ваш продукт не работает, клиенты не могут им пользоваться, а значит, вы теряете потенциальные продажи, подписки, транзакции.
- Пример: SaaS-проект с 1000 активными платными пользователями, каждый из которых приносит $20/месяц. Ежедневный доход = (1000 * $20) / 30 = ~$667. Часовой доход = ~$28. Если простой длится 4 часа, прямые потери составят $112.
- Потеря репутации и доверия клиентов: Это более трудноизмеримый, но часто более разрушительный фактор. Ненадежный сервис отпугивает новых клиентов и заставляет уходить старых.
- Пример: После 4-часового простоя 5% клиентов могут отменить подписку. Это 50 клиентов * $20/месяц = $1000/месяц потерянного дохода, умноженного на срок жизни клиента.
- Штрафы по SLA: Если у вас есть SLA с клиентами, каждый час простоя может повлечь за собой финансовые компенсации.
- Пример: SLA предусматривает 10% возврат средств за месяц, если доступность падает ниже 99.5%. Один серьезный инцидент может стоить вам значительной части месячной выручки.
- Операционные издержки: Время, потраченное командой на "тушение пожара", вместо работы над новыми функциями. Это упущенная выгода и снижение производительности.
- Пример: 3 инженера потратили по 4 часа на устранение инцидента. Если средняя стоимость часа инженера $50, это $600.
Итого: Даже небольшой простой в 4 часа может стоить стартапу сотни или тысячи долларов прямых потерь, не говоря уже о долгосрочном ущербе репутации и оттоке клиентов. Инвестиции в SRE — это страховка от этих потерь.
2. Расчет затрат на SRE для VPS/Dedicated
Хорошая новость в том, что SRE-практики не обязательно дороги. Основные затраты приходятся на:
- Ресурсы VPS/Dedicated: Для хостинга SRE-инструментов (Prometheus, Grafana, Loki).
- Оценка: Отдельный небольшой VPS (2 CPU, 4GB RAM, 80GB SSD) для мониторинга и логирования может стоить $15-30/месяц в 2026 году. Если размещать на основном сервере, то "стоимость" — это часть его ресурсов.
- Время команды: На внедрение, настройку и поддержку SRE-инструментов и процессов. Это самая значительная "скрытая" стоимость.
- Оценка: На начальное внедрение SRE (базовый мониторинг, алерты, Post-Mortem) может потребоваться 10-20% рабочего времени одного инженера в течение 1-2 месяцев. Далее — 5-10% времени на поддержку и улучшение.
- Платные сторонние сервисы (опционально): Для алертинга (PagerDuty, Opsgenie), внешнего мониторинга (UptimeRobot Pro), удаленного бэкапа (S3-совместимые хранилища).
- Оценка: PagerDuty/Opsgenie (Starter) $10-25/месяц, UptimeRobot Pro $10-20/месяц, S3-хранилище $5-15/месяц (зависит от объема).
Примерный расчет ежемесячных затрат для малого SaaS на VPS (2026 год):
| Категория затрат | Описание | Примерная стоимость ($/месяц) | Примечания |
|---|---|---|---|
| VPS для основного приложения | 1x VPS (4 CPU, 8GB RAM, 160GB SSD) | $40-70 | Для хостинга приложения |
| VPS для SRE-инструментов | 1x VPS (2 CPU, 4GB RAM, 80GB SSD) | $15-30 | Для Prometheus, Grafana, Loki, Alertmanager |
| Удаленное хранилище для бэкапов | S3-совместимое хранилище (500GB) | $5-15 | Важно для восстановления данных |
| Сервис оповещений (опционально) | PagerDuty/Opsgenie (Starter Plan) | $10-25 | Для on-call ротации и эскалации |
| Внешний мониторинг (опционально) | UptimeRobot Pro | $10-20 | Для проверки доступности извне |
| Время инженера (доля) | 10% времени одного инженера ($50/час * 160 часов * 0.1) | $800 | Самая большая "стоимость", но это инвестиция в стабильность |
| Итоговая примерная стоимость | $880 - $980 | Включая стоимость ресурсов и времени инженера |
Как видно, большая часть затрат приходится на время инженера. Однако, это время, которое в противном случае было бы потрачено на "тушение пожаров", рутинную работу или решение проблем, которые можно было бы предотвратить. SRE переводит эти реактивные затраты в проактивные инвестиции.
3. Как оптимизировать затраты
- Максимально используйте опенсорс: Prometheus, Grafana, Loki, Ansible, GitLab CI (self-hosted runner) — все это бесплатно.
- Консолидируйте ресурсы: Если ваш основной VPS имеет запас по ресурсам, можно разместить Prometheus, Grafana и Loki на нем же, сэкономив на отдельном VPS. Однако это снижает отказоустойчивость мониторинга.
- Итеративное внедрение: Не пытайтесь внедрить все и сразу. Начните с самых дешевых и эффективных практик (базовый мониторинг, алерты, Post-Mortem) и постепенно расширяйте.
- Автоматизация Toil: Чем больше рутинных задач вы автоматизируете, тем меньше времени инженеры тратят на "toil", освобождая его для более ценной работы.
- Обучение команды: Инвестиции в обучение команды SRE-принципам повышают их эффективность и снижают потребность в найме дорогостоящих узких специалистов.
Экономика SRE для стартапа на VPS/Dedicated заключается в том, что эти практики позволяют вам получать преимущества крупного бизнеса (стабильность, надежность, предсказуемость) при гораздо меньших затратах, предотвращая гораздо более дорогостоящие последствия простоя и потери клиентов.
Кейсы и примеры из практики
Теория важна, но реальные примеры помогают лучше понять, как SRE-практики применимы в жизни. Вот 2-3 реалистичных сценария из нашего опыта работы со стартапами и малыми SaaS-командами на VPS/Dedicated.
Кейс 1: Повышение доступности и снижение стресса в SaaS-стартапе "TaskFlow"
Проблема: "TaskFlow" — SaaS-платформа для управления проектами, работающая на одном мощном VPS. Команда из 3 разработчиков постоянно сталкивалась с непредсказуемыми простоями (2-3 раза в месяц по 1-2 часа), вызванными пиковыми нагрузками или ошибками в новых релизах. Мониторинг был минимальным (только uptime-пинги), а реагирование на инциденты — хаотичным и стрессовым. Это приводило к потере клиентов и выгоранию команды.
Решение:
- Внедрение SLI/SLO: Определили, что критическими SLI являются доступность основного API (создание/редактирование задач) и задержка ответа на главной панели. Установили SLO: 99.8% доступности API и 95% запросов к панели < 800мс.
- Стек мониторинга: Развернули Prometheus + Grafana + Node Exporter на том же VPS. Интегрировали Prometheus client library в Node.js бэкенд для сбора метрик приложения (количество запросов, ошибки, задержки).
- Алертинг: Настроили Alertmanager для отправки критических алертов в специально выделенный Telegram-канал. Алерты срабатывали, если доступность падала ниже 99.5% или задержка превышала 1.5 секунды.
- Инцидент-менеджмент: Создали простой график дежурств (по очереди на неделю). Разработали 5 базовых "runbooks" для самых частых проблем (высокий CPU, ошибка БД, недоступность сервиса).
- Post-Mortem: После каждого инцидента проводили 30-минутный "безобвинительный" Post-Mortem, документируя хронологию и "action items".
Результаты:
- Доступность: За 3 месяца доступность API выросла с 97-98% до стабильных 99.9%.
- MTTR: Среднее время восстановления сократилось с 1-2 часов до 15-30 минут.
- Снижение стресса: Команда стала чувствовать себя увереннее, имея четкий план действий. Количество ночных пробуждений из-за ложных алертов сократилось на 80%.
- Улучшение продукта: "Action items" из Post-Mortem привели к оптимизации нескольких "узких" мест в коде и настройке базы данных, что улучшило общую производительность.
Этот кейс демонстрирует, как даже на одном VPS, базовые SRE-практики могут значительно улучшить надежность и качество работы команды.
Кейс 2: Управление бюджетом ошибок и оптимизация релизного цикла в e-commerce проекте "ShopBoost"
Проблема: "ShopBoost" — малый e-commerce проект на выделенном сервере, часто выпускал новые функции. Однако, каждый новый релиз нес риск деградации производительности или появления багов, что приводило к потерям продаж. Команда разработчиков была под давлением со стороны бизнеса, требующего новых фич, но и постоянно жалующегося на нестабильность.
Решение:
- Бюджет ошибок: После определения SLO доступности (99.9%) и частоты ошибок (менее 0.2%), команда установила бюджет ошибок. Если за неделю более 50% месячного бюджета ошибок было "потрачено", новые релизы приостанавливались.
- Улучшенный мониторинг: В дополнение к Prometheus/Grafana, внедрили Loki для централизованного сбора логов приложения и веб-сервера. Это позволило быстро искать ошибки, связанные с новыми релизами.
- Автоматизация CI/CD: Настроили GitLab CI с self-hosted runner на сервере для автоматического развертывания. Каждый коммит проходил базовые тесты, а затем автоматически деплоился на staging, и после ручного тестирования — на production.
- Post-Mortem с фокусом на релизы: Каждый инцидент, связанный с релизом, тщательно анализировался. Особое внимание уделялось тому, как можно было бы предотвратить проблему на этапе разработки или тестирования.
Результаты:
- Баланс "фичи vs. стабильность": Бюджет ошибок стал четким индикатором, когда нужно "тормозить" с новыми функциями и фокусироваться на стабильности. Это снизило конфликты между разработкой и бизнесом.
- Качество релизов: Количество критических багов, попадающих в продакшн, сократилось на 60% благодаря улучшенному тестированию и контролю качества.
- Скорость развертывания: Время от коммита до продакшна сократилось с нескольких часов (ручной деплой) до 15-20 минут (автоматический деплой).
- Культура качества: Разработчики стали более внимательно относиться к тестированию и мониторингу своих изменений, понимая, что это напрямую влияет на их способность выпускать новые фичи.
Этот кейс показывает, как SRE помогает управлять рисками и оптимизировать цикл разработки, находя баланс между инновациями и стабильностью.
Кейс 3: Масштабирование и оптимизация ресурсов для аналитического сервиса "DataInsight"
Проблема: "DataInsight" — стартап, предоставляющий аналитику данных для малого бизнеса, столкнулся с проблемой роста. Их сервис, работающий на двух VPS, периодически замедлялся или падал из-за нехватки ресурсов (особенно RAM и CPU) при обработке больших отчетов. Команда не понимала, когда и какие ресурсы нужно масштабировать, и часто действовала реактивно, покупая более мощные VPS "на всякий случай".
Решение:
- Capacity Planning: Внедрен детальный мониторинг использования ресурсов (CPU, RAM, Disk I/O) с помощью Prometheus + Grafana. Метрики собирались каждые 15 секунд.
- SLI/SLO на основе ресурсов: Определили SLI для использования CPU (< 80% в течение 10 минут) и RAM (< 90% свободной памяти). Установили SLO на основе этих метрик.
- Проактивные алерты: Настроили алерты в Alertmanager, которые срабатывали, когда использование ресурсов приближалось к критическим порогам (например, CPU > 70% более 5 минут).
- Анализ трендов: Регулярно анализировали графики использования ресурсов в Grafana, чтобы прогнозировать будущие потребности. Например, если потребление RAM стабильно росло на 10% в месяц, планировали апгрейд VPS через 2-3 месяца.
- Оптимизация кода: Post-Mortem после инцидентов с нехваткой ресурсов привели к выявлению "тяжелых" запросов к БД и неэффективных алгоритмов обработки данных, которые были оптимизированы.
Результаты:
- Оптимизация затрат: Вместо реактивной покупки более мощных VPS, команда стала принимать обоснованные решения. Например, вместо апгрейда всего сервера, они смогли оптимизировать запросы к БД, что отложило необходимость покупки более дорогого оборудования на 6 месяцев, сэкономив до $300 в месяц.
- Стабильность: Количество инцидентов, связанных с нехваткой ресурсов, сократилось на 90%.
- Проактивность: Команда стала заранее планировать апгрейды или оптимизации, избегая сюрпризов.
Этот кейс подчеркивает, как SRE-подход к мониторингу и планированию мощностей позволяет стартапам эффективно масштабироваться, избегая ненужных расходов и обеспечивая стабильность сервиса.
Инструменты и ресурсы
Для успешного внедрения SRE-практик, даже на VPS/Dedicated, вам понадобится арсенал надежных и эффективных инструментов. Мы сосредоточимся на решениях, которые доказали свою ценность для малых команд, предлагая отличный баланс функциональности и стоимости.
1. Мониторинг и визуализация метрик
- Prometheus: Система сбора и хранения временных рядов метрик. Является стандартом де-факто для облачного и контейнерного мониторинга, но прекрасно подходит и для VPS.
- Grafana: Мощная платформа для визуализации метрик. Позволяет создавать информативные дашборды, настраивать алерты и исследовать данные из различных источников (Prometheus, Loki, базы данных).
- Node Exporter: Экспортер метрик для Prometheus, собирающий данные о состоянии операционной системы (CPU, RAM, диск, сеть). Должен быть установлен на каждом VPS.
- cAdvisor: Экспортер метрик для Prometheus, собирающий данные о контейнерах (Docker). Полезно, если ваше приложение работает в контейнерах на VPS.
- Blackbox Exporter: Экспортер для Prometheus, который позволяет проверять доступность и корректность HTTP/HTTPS, TCP, ICMP эндпоинтов изнутри вашей инфраструктуры.
- UptimeRobot / Healthchecks.io: Внешние сервисы для мониторинга доступности ваших публичных эндпоинтов из разных географических точек. У UptimeRobot есть щедрый бесплатный тариф.
2. Логирование и трассировка
- Loki: Система агрегации логов, разработанная Grafana Labs. Менее ресурсоемкая, чем Elasticsearch, так как индексирует только метаданные логов. Отлично интегрируется с Grafana.
- Promtail: Агент для Loki, который собирает логи с ваших серверов и отправляет их в Loki.
- Grafana Tempo: Распределенная система трассировки, также от Grafana Labs. Позволяет собирать и хранить трассировки OpenTelemetry, интегрируясь с метриками и логами в Grafana.
- OpenTelemetry: Набор инструментов, API и SDK для инструментирования вашего приложения, позволяющий генерировать метрики, логи и трассировки в едином формате.
3. Алерт-менеджмент и On-Call
- Alertmanager: Компонент Prometheus, который обрабатывает алерты, дедуплицирует их, группирует и отправляет в нужные каналы (Slack, Telegram, PagerDuty, email).
- PagerDuty / Opsgenie: Профессиональные сервисы для управления on-call ротациями, эскалацией алертов и планированием дежурств. Предлагают бесплатные или недорогие тарифы для малых команд.
- Telegram / Slack: Простые и бесплатные каналы для отправки алертов. Alertmanager легко интегрируется с ними.
4. Автоматизация и Infrastructure as Code (IaC)
- Ansible: Простой, но мощный инструмент для управления конфигурацией, развертывания приложений и оркестрации задач. Не требует агентов на управляемых серверах. Идеален для VPS/Dedicated.
- GitLab CI / GitHub Actions: Системы непрерывной интеграции/непрерывного развертывания (CI/CD). Позволяют автоматизировать тестирование и деплой кода. Могут использовать self-hosted runner на вашем VPS.
- Bash / Python скрипты: Недооцененные, но чрезвычайно мощные инструменты для автоматизации специфических задач на VPS.
5. Документация и управление знаниями
- Wiki (Confluence, Notion, DokuWiki): Для хранения runbooks, Post-Mortem отчетов, документации по инфраструктуре и процессам.
- Git-репозитории: Для хранения конфигураций (IaC), скриптов, runbooks в виде Markdown-файлов.
6. Полезные книги и ресурсы
- "Site Reliability Engineering: How Google Runs Production Systems" и "The Site Reliability Workbook": Классические книги от Google, хотя и ориентированы на масштабные системы, базовые принципы применимы везде.
- Блоги Grafana Labs, Prometheus, Incident.io: Регулярно публикуют полезные статьи и кейсы.
- Сообщества DevOps и SRE: Telegram-чаты, Discord-серверы, Stack Overflow.
Начните с освоения Prometheus и Grafana, затем добавьте Loki. Постепенно внедряйте автоматизацию с Ansible и CI/CD. Помните, что инструменты — это лишь средства; главное — принципы и культура SRE.
Troubleshooting: решение типичных проблем
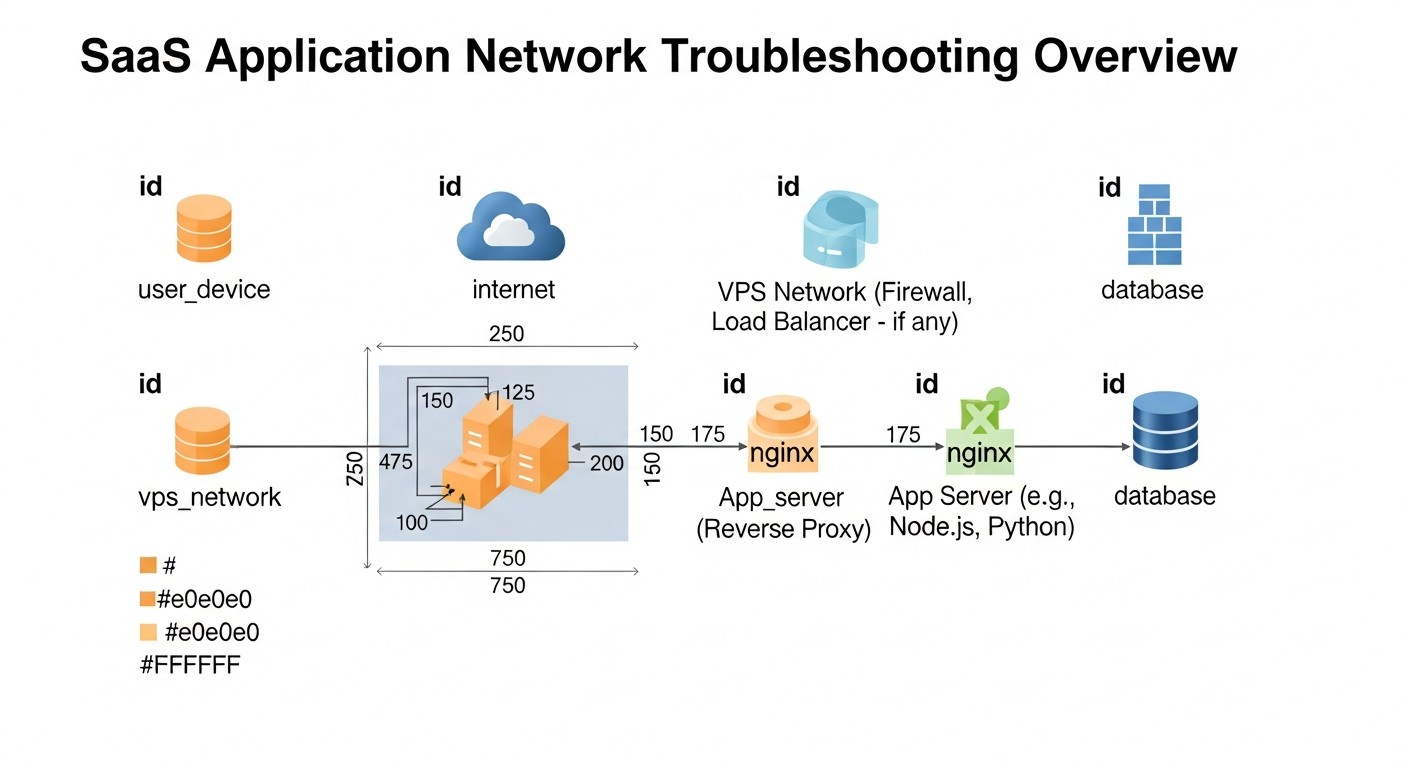
Даже с лучшими SRE-практиками, проблемы в продакшене неизбежны. Умение быстро диагностировать и устранять их — ключевой навык. Ниже представлены типичные проблемы, с которыми сталкиваются малые SaaS-команды на VPS/Dedicated, и практические команды для их решения.
1. Высокая загрузка CPU
Симптомы: Медленная работа приложения, задержки в ответах, алерты о высоком CPU.
Диагностика:
topилиhtop: Показывает процессы, отсортированные по потреблению CPU. Ищите процессы, потребляющие >80-90% CPU.uptime: Показывает среднюю загрузку системы за 1, 5 и 15 минут. Если load average выше количества ядер CPU, система перегружена.- Grafana (Node Exporter dashboard): Визуальный анализ трендов CPU-использования.
- Логи приложения: Ищите ошибки, "тяжелые" запросы к БД, бесконечные циклы или ресурсоемкие операции.
Решение:
- Если виновник — ваше приложение:
- Перезапустите сервис:
sudo systemctl restart your_app_service.service - Если это временный пик, возможно, стоит оптимизировать код или базу данных.
- Если проблема постоянная, рассмотрите апгрейд VPS или масштабирование на несколько серверов.
- Перезапустите сервис:
- Если виновник — другой процесс (например, какой-то скрипт, cron-задача):
- Идентифицируйте, что это за процесс, и почему он потребляет много ресурсов.
- Оптимизируйте скрипт или измените расписание его запуска.
2. Нехватка оперативной памяти (RAM)
Симптомы: Приложение "падает" с ошибками Out Of Memory, медленная работа, активное использование swap-раздела.
Диагностика:
free -h: Показывает общее количество RAM, использованное и свободное, а также использование swap.htop: Показывает потребление RAM каждым процессом.- Grafana (Node Exporter dashboard): Мониторинг использования RAM и swap.
- Логи приложения: Ищите ошибки Out Of Memory.
Решение:
- Если ваше приложение потребляет слишком много RAM:
- Оптимизируйте код (например, избегайте загрузки больших объемов данных в память, используйте потоковую обработку).
- Увеличьте лимиты памяти для вашего приложения (если это возможно, например, JVM-параметры).
- Рассмотрите апгрейд VPS с большим объемом RAM.
- Если другие процессы потребляют RAM:
- Остановите ненужные сервисы.
- Оптимизируйте конфигурацию других сервисов (например, уменьшите количество worker-процессов веб-сервера).
3. Заполнение дискового пространства
Симптомы: Ошибки записи файлов, сбои приложений, невозможность установки новых пакетов.
Диагностика:
df -h: Показывает использование дискового пространства по разделам. Ищите разделы, заполненные на 90% и более.du -sh /path/to/directory: Показывает размер конкретной директории. Используйте это для поиска "тяжелых" директорий (например,/var/log,/var/lib/docker,/tmp).- Grafana (Node Exporter dashboard): Мониторинг использования диска.
Решение:
- Очистка логов:
sudo journalctl --vacuum-size=1G(для systemd journal)- Вручную удалите старые логи вашего приложения или настройте logrotate.
- Очистка кэшей:
sudo apt clean(для Debian/Ubuntu)- Очистите кэши вашего приложения.
- Удаление ненужных файлов:
- Старые резервные копии, временные файлы, неиспользуемые образы Docker.
- Если проблема постоянна, рассмотрите апгрейд диска VPS или перенос больших данных на внешнее хранилище.
4. Проблемы с сетью
Симптомы: Медленные соединения, ошибки таймаута, невозможность подключения к сервисам.
Диагностика:
ping google.com: Проверка доступности внешних ресурсов.ping localhost: Проверка сетевой карты.netstat -tunlp: Показывает открытые порты и активные соединения. Убедитесь, что ваше приложение слушает нужный порт.ss -tulpn: Аналог netstat, часто быстрее.ip a: Показывает сетевые интерфейсы и их IP-адреса.traceroute example.com: Отслеживание маршрута до удаленного хоста.- Grafana (Node Exporter dashboard): Мониторинг сетевого трафика.
Решение:
- Проверьте фаервол (
sudo ufw statusили правила iptables). - Убедитесь, что приложение слушает на
0.0.0.0или правильном IP, если оно должно быть доступно извне. - Проверьте конфигурацию DNS (
cat /etc/resolv.conf). - Если проблема на стороне VPS-провайдера, свяжитесь с их поддержкой.
5. Сбои приложения / Ошибки HTTP 5xx
Симптомы: Пользователи видят страницы ошибок, API возвращает 5xx, приложение не запускается.
Диагностика:
- Логи приложения: Это ваш основной источник информации. Ищите трассировки стека, сообщения об ошибках, предупреждения. Используйте Loki/Grafana для быстрого поиска.
sudo systemctl status your_app_service.service: Проверяет статус systemd-сервиса.sudo journalctl -u your_app_service.service -f: Показывает логи вашего сервиса в реальном времени.- Мониторинг метрик: Аномалии в количестве запросов, задержке, ошибках.
Решение:
- Перезапустите сервис:
sudo systemctl restart your_app_service.service. - Если проблема повторяется, проанализируйте логи, чтобы найти корневую причину (баг в коде, проблема с БД, внешним сервисом).
- Проверьте конфигурационные файлы приложения.
- Откатитесь к предыдущей стабильной версии, если проблема появилась после релиза.
Когда обращаться в поддержку VPS-провайдера
Не стесняйтесь обращаться в поддержку, если:
- Вы не можете подключиться к VPS по SSH, и проблема не в ваших сетевых настройках.
- Ваш VPS не отвечает на пинги, но приложение должно быть запущено.
- Наблюдаются проблемы с сетью, которые явно не связаны с вашей конфигурацией (например, потеря пакетов до вашего VPS).
- Оборудование (диск, RAM) показывает признаки физического сбоя.
- Ваш VPS был атакован или попал в черный список.
Всегда предоставляйте провайдеру максимум информации: точное время начала проблемы, наблюдаемые симптомы, результаты ваших диагностических команд.
Часто задаваемые вопросы (FAQ)
Нужен ли мне полноценный SRE-инженер в стартапе?
На начальном этапе, когда команда состоит из нескольких человек, выделенный SRE-инженер, скорее всего, не нужен. Функции SRE могут выполнять DevOps-инженеры или даже бэкенд-разработчики с операционным уклоном. Важно, чтобы принципы SRE были интегрированы в культуру команды, и каждый нес ответственность за надежность. Полноценный SRE-инженер становится актуальным, когда команда растет до 10-15+ человек, а сложность системы значительно увеличивается.
Как выбрать первые SLI/SLO?
Начните с того, что наиболее критично для вашего бизнеса и напрямую влияет на пользователя. Для большинства SaaS это доступность основного API/веб-интерфейса и задержка ключевых пользовательских операций (например, вход, сохранение данных). Установите реалистичные SLO (например, 99.9% доступности), а не идеальные "пять девяток", которые будут требовать неоправданных усилий и затрат.
Сколько стоит внедрение SRE?
Прямые затраты на SRE для VPS/Dedicated могут быть минимальными, если использовать опенсорсные инструменты (Prometheus, Grafana, Loki). Основная "стоимость" — это время вашей команды на внедрение и поддержку этих практик. Это инвестиция, которая окупается снижением простоя, улучшением репутации и предотвращением потери клиентов. Для базового стека мониторинга на отдельном VPS можно уложиться в $15-30/месяц за сам сервер, плюс доля зарплаты инженера.
Можно ли обойтись без платных инструментов?
Абсолютно. Для стартапов на VPS/Dedicated опенсорсные решения (Prometheus, Grafana, Loki, Ansible) являются идеальным выбором. Они предоставляют мощный функционал, гибкость и не требуют ежемесячных платежей. Платные сервисы (например, PagerDuty, Datadog) могут упростить некоторые аспекты, но не являются обязательными для начала.
Как бороться с 'alert fatigue'?
Ключ к борьбе с 'alert fatigue' — это качество, а не количество алертов. Каждый алерт должен быть действенным, требовать немедленного вмешательства и иметь четкий "runbook". Регулярно пересматривайте алерты, отключайте те, которые не приносят пользы, и настраивайте более точные пороги. Используйте разные каналы для алертов разной критичности (например, PagerDuty для критических, Slack для информационных).
Чем отличается SRE от DevOps?
DevOps — это более широкая культурная и методологическая философия, направленная на улучшение сотрудничества между разработкой и операциями. SRE — это конкретная реализация принципов DevOps, сфокусированная на применении инженерных подходов к проблемам эксплуатации. SRE использует метрики, автоматизацию и управление рисками для достижения определенных целей надежности (SLO), тогда как DevOps охватывает весь жизненный цикл разработки и развертывания.
Что делать, если у меня всего один сервер?
Даже для одного сервера SRE-практики очень полезны. Начните с базового мониторинга (Prometheus + Node Exporter + Grafana на том же сервере), централизованного логирования (Loki + Promtail), автоматического резервного копирования и простых SLO. Это поможет вам лучше понимать состояние сервера, быстро реагировать на проблемы и предотвращать их. Наличие одного сервера делает SRE еще более критичным, так как нет избыточности.
Как убедить команду тратить время на SRE?
Покажите команде прямую выгоду: меньше "пожаров", меньше ночных пробуждений, более стабильный продукт, который нравится клиентам. Объясните, что SRE — это не дополнительная работа, а систематизация и автоматизация того, что они уже делают, но более эффективно. Вовлекайте команду в определение SLO и Post-Mortem, чтобы они чувствовали свою причастность и видели результаты.
Какие метрики самые важные для SaaS?
Для SaaS наиболее важны метрики, напрямую связанные с пользовательским опытом и бизнес-целями:
- Доступность (сервис работает и доступен).
- Задержка (скорость ответа приложения).
- Частота ошибок (количество ошибок, видимых пользователям).
- Пропускная способность (способность обрабатывать нагрузку).
- Метрики ресурсов (CPU, RAM, диск) для планирования мощностей.
Как часто проводить Post-Mortem?
Post-Mortem следует проводить после каждого инцидента, который нарушил ваше SLO или вызвал значительное недовольство клиентов. Для стартапа это может быть 1-2 раза в месяц, а иногда и чаще. Важнее не частота, а качество: фокусируйтесь на извлечении уроков и создании конкретных "action items", которые будут выполнены.
Как начать автоматизацию?
Начните с самых рутинных и подверженных ошибкам задач. Это может быть автоматизация развертывания кода (CI/CD), резервного копирования, установки обновлений или настройки нового сервера. Используйте простые инструменты, такие как Bash-скрипты или Ansible. Постепенно автоматизируйте больше процессов, освобождая время для более сложной работы.
Заключение
Внедрение SRE-практик для стартапов и малых SaaS-команд на VPS/Dedicated — это не роскошь, а стратегическая необходимость в условиях современного высококонкурентного рынка 2026 года. Мы убедились, что принципы Site Reliability Engineering, изначально разработанные для масштабов Google, могут быть успешно адаптированы и применены даже при ограниченных ресурсах, принося значительные выгоды.
Ключевые выводы, которые вы должны унести из этой статьи:
- Прагматизм — ваш лучший друг: Не стремитесь к идеалу сразу. Начните с малого, выберите 1-2 критичных SLI и реалистичных SLO, постепенно расширяя охват.
- Мониторинг — основа всего: Без надежного мониторинга вы будете "тушить пожары" вслепую. Опенсорсные решения вроде Prometheus и Grafana предоставляют мощные возможности при минимальных затратах.
- Автоматизация — путь к эффективности: Сокращайте "toil" (рутинную работу) с помощью скриптов, Ansible и CI/CD. Это освободит время инженеров и уменьшит количество человеческих ошибок.
- Культура обучения, а не обвинения: Безобвинительные Post-Mortem являются мощным инструментом для непрерывного улучшения и предотвращения повторения инцидентов.
- SRE — это инвестиция: Время и ресурсы, вложенные в SRE, окупаются снижением downtime, улучшением репутации, уменьшением стресса в команде и ускорением разработки новых функций.
Следующие шаги для читателя:
- Оцените текущее состояние: Проведите аудит вашей текущей инфраструктуры и процессов. Где "узкие места"? Какие проблемы возникают чаще всего?
- Выберите первый "пилотный" сервис: Начните с самого критичного или самого проблемного сервиса.
- Определите первые SLI и SLO: Согласуйте их с командой и бизнесом.
- Внедрите базовый стек мониторинга: Установите Prometheus, Node Exporter, Grafana и Loki. Настройте дашборды для ваших SLI.
- Настройте алерты: Создайте несколько критических алертов, которые будут срабатывать до того, как SLO будет нарушено.
- Разработайте первый Runbook: Для одного из ваших критических алертов.
- Проведите первый Post-Mortem: После следующего значимого инцидента, даже если он небольшой.
- Автоматизируйте одну рутинную задачу: Например, резервное копирование или деплой.
Помните, SRE — это не одноразовый проект, а непрерывный процесс совершенствования. Начните с малого, итеративно улучшайте, и вы увидите, как ваш стартап становится более надежным, предсказуемым и успешным. Удачи!
Was this guide helpful?