Полная наблюдаемость (Observability) для распределенных систем: OpenTelemetry, Loki и Tempo на VPS 2026
TL;DR
- OpenTelemetry — это стандарт 2026 года для сбора телеметрии. Он унифицирует сбор метрик, логов и трассировок, делая вашу систему готовой к будущим изменениям и избегая привязки к конкретному вендору.
- Loki — оптимальный выбор для логов на VPS. Его индекс по метаданным позволяет эффективно хранить и запрашивать логи даже при ограниченных ресурсах, что критично для бюджетных решений.
- Tempo — идеальное решение для распределенных трассировок. Он использует объектное хранилище, минимизируя требования к RAM и CPU, что делает его крайне подходящим для VPS-инфраструктуры в 2026 году.
- Интеграция с Grafana — ваш единый дашборд. Все три компонента легко интегрируются с Grafana, предоставляя централизованный интерфейс для визуализации и анализа всей телеметрии.
- Экономия на VPS в 2026 году — это реально. Правильная настройка OpenTelemetry Collector, фильтрация данных и оптимизация хранения позволяют значительно сократить расходы, особенно на трафик и дисковое пространство.
- Практический подход — ключ к успеху. Начните с малого, внедряйте постепенно, автоматизируйте развертывание и не забывайте про регулярный аудит конфигураций и потребления ресурсов.
- Будьте готовы к масштабированию. Даже на VPS, архитектура OpenTelemetry, Loki и Tempo позволяет относительно легко масштабироваться, переходя на более мощные инстансы или кластеры по мере роста проекта.
Введение
 Схема: Введение
Схема: Введение
К 2026 году ландшафт разработки программного обеспечения претерпел значительные изменения. Монолитные приложения уступили место распределенным микросервисным архитектурам, облачные технологии стали повсеместными, а концепция "серверлесс" и граничных вычислений (edge computing) продолжает набирать обороты. Вместе с этой эволюцией растет и сложность систем. Отказ одного из десятков или сотен микросервисов может привести к каскадным сбоям, а поиск корня проблемы в запутанной сети взаимодействий становится настоящим кошмаром без адекватных инструментов.
Именно здесь на сцену выходит концепция полной наблюдаемости (Observability). В отличие от традиционного мониторинга, который отвечает на вопрос "Что случилось?", Observability позволяет ответить на вопрос "Почему это случилось?", предоставляя глубокое понимание внутреннего состояния системы через три основных столпа: метрики, логи и трассировки. В 2026 году, когда время простоя измеряется не только деньгами, но и репутацией, а пользовательский опыт является ключевым конкурентным преимуществом, Observability перестает быть роскошью и становится абсолютной необходимостью.
Эта статья посвящена построению полноценной системы Observability для распределенных систем, используя связку OpenTelemetry, Loki и Tempo, развернутую на виртуальном приватном сервере (VPS). Мы сфокусируемся на практических аспектах, актуальных для 2026 года, учитывая постоянно растущие требования к производительности, эффективности и, конечно же, стоимости. Мы покажем, как, даже при ограниченном бюджете и ресурсах VPS, можно добиться высокого уровня наблюдаемости, сравнимого с более дорогими облачными решениями.
Для кого написана эта статья? В первую очередь, для DevOps-инженеров и системных администраторов, которые ищут эффективные и экономичные решения для мониторинга и диагностики. Она будет полезна Backend-разработчикам (Python, Node.js, Go, PHP), стремящимся интегрировать Observability в свои приложения. Фаундеры SaaS-проектов и технические директора стартапов найдут здесь практические советы по оптимизации затрат и повышению надежности своих продуктов, используя передовые открытые технологии.
Мы рассмотрим, почему именно эта комбинация инструментов является одной из самых перспективных и экономически эффективных для VPS в 2026 году, как ее правильно настроить, какие ошибки избежать и как извлечь максимум пользы для вашего бизнеса.
Основные критерии/факторы выбора
 Схема: Основные критерии/факторы выбора
Схема: Основные критерии/факторы выбора
Выбор правильных инструментов для Observability — это не просто следование трендам, а стратегическое решение, которое напрямую влияет на надежность, производительность и, в конечном итоге, на бизнес-успех проекта. В 2026 году, когда речь идет о распределенных системах на VPS, необходимо учитывать ряд критически важных факторов.
1. Стоимость владения (TCO)
Это, пожалуй, самый важный фактор для проектов, использующих VPS. TCO включает не только прямые расходы на серверы и хранилище, но и косвенные: время инженеров на настройку, поддержку, масштабирование, а также потенциальные потери от простоев. Решения должны быть ресурсоэффективными, минимизировать потребление CPU, RAM и дискового пространства, а также трафика, который часто является значительной статьей расходов на VPS. Мы будем искать инструменты, которые позволяют хранить большой объем данных за разумные деньги.
2. Простота развертывания и управления
На VPS ресурсы инженеров часто ограничены. Сложные в установке и настройке системы могут быстро стать обузой. Нам нужны решения, которые можно быстро развернуть, легко обновить и поддерживать без необходимости глубокого погружения в их внутреннее устройство. Документация, сообщество и наличие готовых конфигураций играют здесь ключевую роль.
3. Масштабируемость и производительность
Даже на VPS система должна быть способна обрабатывать растущий объем телеметрии без деградации производительности. Это означает эффективное использование ресурсов, горизонтальное масштабирование (если потребуется переход на несколько VPS) и способность справляться с пиковыми нагрузками. Особенно важно для логов и трассировок, объем которых может быть непредсказуемым.
4. Гибкость и расширяемость
Мир технологий постоянно меняется. Выбранные инструменты должны быть достаточно гибкими, чтобы адаптироваться к новым источникам данных, протоколам и интеграциям. OpenTelemetry здесь является золотым стандартом, предоставляя унифицированный подход к сбору данных. Возможность легко добавлять новые сервисы и приложения в систему Observability — критична.
5. Глубина и качество данных
Инструменты должны предоставлять достаточно детализированные и точные данные (метрики, логи, трассировки), чтобы можно было эффективно диагностировать проблемы. Возможность добавлять кастомные атрибуты (тэги) к данным, агрегировать их по различным измерениям и выполнять сложные запросы — это основа для глубокого анализа.
6. Интеграция с экосистемой
Система Observability не существует в вакууме. Она должна легко интегрироваться с другими инструментами в вашем стеке: системами оповещения (Alertmanager), дашбордами (Grafana), CI/CD пайплайнами и т.д. Чем бесшовнее интеграция, тем эффективнее становится весь процесс разработки и эксплуатации.
7. Открытость и стандарты
Использование открытых стандартов и проектов с активным сообществом снижает риск привязки к вендору (vendor lock-in) и обеспечивает долгосрочную поддержку. OpenTelemetry — яркий пример такого подхода, став де-факто стандартом для телеметрии. Открытые проекты также часто предлагают более гибкие решения и быстрее адаптируются к новым требованиям.
8. Безопасность
Телеметрия часто содержит чувствительные данные. Инструменты должны обеспечивать безопасную передачу и хранение данных, поддерживать аутентификацию и авторизацию, а также предоставлять возможности для маскирования или фильтрации конфиденциальной информации.
Как оценивать каждый критерий:
- TCO: Сравнивайте не только стоимость VPS, но и предполагаемый объем трафика, дискового пространства для хранения логов/трассировок, а также прогнозируемое время, которое инженеры потратят на поддержку. Используйте калькуляторы провайдеров и тестовые развертывания.
- Простота развертывания: Оцените количество шагов для установки, сложность конфигурационных файлов, наличие Docker-образов и Helm-чартов (если используется Kubernetes на VPS).
- Масштабируемость: Изучите архитектуру инструмента. Поддерживает ли он горизонтальное масштабирование? Каковы рекомендации по ресурсам для различных объемов данных?
- Гибкость: Проверьте, какие протоколы поддерживает инструмент для приема данных, есть ли API для расширения функционала, как легко добавить новые источники данных.
- Глубина данных: Посмотрите примеры дашбордов и запросов. Насколько детальную информацию можно получить? Можно ли фильтровать и агрегировать данные по многим параметрам?
- Интеграция: Проверьте наличие готовых коннекторов, плагинов и документации по интеграции с Grafana, Alertmanager и другими инструментами.
- Открытость: Оцените активность на GitHub, количество контрибьюторов, частоту релизов, наличие публичной дорожной карты.
- Безопасность: Изучите документацию по безопасности: шифрование данных в пути и при хранении, механизмы доступа.
Учитывая эти критерии, связка OpenTelemetry, Loki и Tempo на VPS в 2026 году выглядит одним из наиболее сбалансированных и перспективных решений.
Сравнительная таблица решений для Observability
 Схема: Сравнительная таблица решений для Observability
Схема: Сравнительная таблица решений для Observability
Для понимания преимуществ выбранного стека, давайте сравним OpenTelemetry, Loki и Tempo с другими популярными решениями, актуальными для 2026 года, особенно в контексте использования на VPS. Мы сосредоточимся на ключевых аспектах: тип данных, стоимость, сложность, масштабируемость и основные особенности.
| Критерий |
OpenTelemetry (Сбор) |
Loki (Логи) |
Tempo (Трейсы) |
Prometheus (Метрики) |
Elastic Stack (ELK) |
Jaeger (Трейсы) |
Cloud-провайдер (Managed Observability) |
| Тип данных |
Метрики, Логи, Трейсы (универсальный сборщик) |
Логи |
Трейсы |
Метрики (pull-модель) |
Логи, Метрики, Трейсы (через Filebeat, Metricbeat, APM) |
Трейсы |
Метрики, Логи, Трейсы (комплексно) |
| Стоимость (VPS, 2026) |
Низкая (только сборщик, CPU/RAM) |
Средняя (хранение на S3-совместимом, CPU/RAM для запросов) |
Низкая (хранение на S3-совместимом, минимальный CPU/RAM) |
Средняя (хранение на диске, CPU/RAM) |
Высокая (требует много RAM/CPU/диска) |
Средняя (требует Cassandra/Elasticsearch, CPU/RAM/диск) |
Высокая (по подписке, цена за объем данных) |
| Сложность развертывания |
Средняя (Collector + агенты) |
Средняя (Loki + Promtail) |
Низкая (Tempo + OpenTelemetry Collector) |
Средняя (Prometheus + Exporters) |
Высокая (Elasticsearch, Kibana, Logstash/Beats) |
Высокая (Collector, Query, Agent, Storage) |
Низкая (конфигурация через UI/API) |
| Масштабируемость на VPS |
Высокая (горизонтально Collector) |
Средняя (разделение на ingester/querier, объектное хранилище) |
Высокая (объектное хранилище, минимальные ресурсы) |
Средняя (Federation, Thanos/Cortex для кластера) |
Низкая (очень ресурсоемкий для кластера) |
Средняя (с внешней БД) |
Очень высокая (управляется провайдером) |
| Хранение данных |
Нет (только буферизация) |
Объектное хранилище (S3-совместимое), индекс по метаданным |
Объектное хранилище (S3-совместимое), индекс по ID трейса |
Локальный диск (TSDB) |
Локальный диск (Lucene/inverted index) |
Cassandra, Elasticsearch, Kafka |
Управляется провайдером (собственные решения) |
| Особенности 2026 года для VPS |
Универсальный стандарт, vendor-agnostic, активное развитие, широкая поддержка языков. |
Эффективное хранение логов, низкие требования к RAM/CPU, отличная интеграция с Grafana, поддержка Cloud Object Storage как бэкенда. |
Минимальные требования к RAM/CPU, хранение трейсов в объектном хранилище, "храни все" подход, быстрые запросы по ID трейса. |
Де-факто стандарт для метрик, pull-модель, мощный язык запросов PromQL, активное сообщество. |
Мощная аналитика, полнотекстовый поиск, но очень ресурсоемкий, что делает его дорогим для VPS. |
Открытый стандарт для трассировок, но требует мощной СУБД для хранения, что удорожает VPS. |
Удобство, отсутствие необходимости управления, но высокая стоимость за объем данных и vendor lock-in. |
| Интеграция с Grafana |
Да (через Prometheus/Loki/Tempo) |
Да (нативная) |
Да (нативная) |
Да (нативная) |
Да (через плагин) |
Да (через плагин) |
Да (часто нативная или через API) |
Из таблицы видно, что связка OpenTelemetry, Loki и Tempo предлагает уникальный баланс между функциональностью, производительностью и стоимостью, особенно для развертывания на VPS в 2026 году. Отказ от ресурсоемких баз данных для хранения логов и трассировок в пользу объектных хранилищ (S3-совместимых) является ключевым фактором, позволяющим значительно снизить TCO и упростить управление.
Prometheus остается стандартом для метрик, и его часто используют вместе с OpenTelemetry Collector для сбора и агрегации метрик. Elastic Stack, хотя и мощный, чрезмерно дорог и сложен для большинства VPS-проектов. Cloud-провайдеры предлагают удобство, но их ценовая политика за объем данных может быстро стать неподъемной для стартапов и небольших команд.
Таким образом, OpenTelemetry как универсальный сборщик, Loki для экономичного хранения логов и Tempo для трассировок на объектном хранилище, дополненные Grafana для визуализации, представляют собой оптимальное решение для Observability на VPS в 2026 году.
Детальный обзор OpenTelemetry, Loki и Tempo
 Схема: Детальный обзор OpenTelemetry, Loki и Tempo
Схема: Детальный обзор OpenTelemetry, Loki и Tempo
Для глубокого понимания того, почему именно эта связка инструментов является столь эффективной для Observability на VPS в 2026 году, рассмотрим каждый компонент подробнее.
OpenTelemetry: Универсальный сборщик телеметрии
OpenTelemetry (сокращенно OTel) — это не просто инструмент, это набор стандартов, API, SDK и инструментов, разработанных для унифицированного сбора, обработки и экспорта телеметрии (метрик, логов и трассировок) из ваших приложений и инфраструктуры. К 2026 году OTel стал де-факто стандартом в индустрии, поддерживаемым практически всеми крупными облачными провайдерами и инструментами Observability.
Плюсы:
- Vendor-agnostic: Вы не привязаны к конкретному вендору или платформе. Вы можете собирать данные один раз и отправлять их в Loki, Tempo, Prometheus, а также в любые коммерческие решения, которые поддерживают OTel. Это обеспечивает огромную гибкость и защиту инвестиций в будущем.
- Единый подход: OTel предоставляет единый API и SDK для всех трех типов телеметрии, что значительно упрощает инструментацию приложений. Разработчикам не нужно изучать разные библиотеки для метрик, логов и трассировок.
- Мощный Collector: OpenTelemetry Collector — это прокси, который может получать, обрабатывать и экспортировать телеметрию. Он позволяет фильтровать, преобразовывать, агрегировать данные прямо на границе сети, снижая нагрузку на бэкенды и экономя трафик. Это критически важно для VPS, где каждый мегабайт трафика и каждый цикл CPU на счету.
- Широкая поддержка языков: OTel имеет SDK для большинства популярных языков программирования (Python, Java, Go, Node.js, .NET, PHP, Ruby и т.д.), что делает его применимым практически в любой среде.
- Активное сообщество и развитие: Проект находится под эгидой Cloud Native Computing Foundation (CNCF) и активно развивается, постоянно добавляя новые функции и улучшая производительность.
Минусы:
- Кривая обучения: Несмотря на унификацию, освоение всех концепций OTel (трассеры, спаны, контексты, ресурсы, атрибуты, семантические конвенции) может занять некоторое время.
- Накладные расходы: Инструментация приложений и работа Collector требуют некоторого потребления CPU и RAM, хоть и оптимизированного. На очень маленьких VPS (< 1GB RAM) это может быть заметно.
Для кого подходит: Для всех, кто хочет создать гибкую, масштабируемую и vendor-agnostic систему Observability. Особенно полезен для микросервисных архитектур, где необходимо отслеживать взаимодействие между множеством компонентов.
Примеры использования: Инструментация HTTP-запросов в Go-приложении, сбор метрик из Node.js-сервиса, отправка кастомных логов из Python-скрипта. Collector может быть настроен для агрегации метрик из нескольких сервисов перед отправкой в Prometheus, или для сэмплирования трассировок, чтобы снизить объем данных, отправляемых в Tempo.
Loki: Экономичное хранилище логов
Loki, разработанный компанией Grafana Labs, позиционируется как "Prometheus для логов". Его ключевое отличие от традиционных систем управления логами (вроде Elastic Stack) заключается в том, что он индексирует только метаданные (лейблы) логов, а не их полное содержимое. Это позволяет значительно сократить объем индекса и, как следствие, требования к дисковому пространству и оперативной памяти.
Плюсы:
- Экономия ресурсов: Благодаря индексации только метаданных, Loki потребляет гораздо меньше RAM и CPU по сравнению с решениями, использующими полнотекстовый поиск. Это делает его идеальным для VPS, где ресурсы ограничены.
- Объектное хранилище: Loki может использовать S3-совместимые объектные хранилища (такие как MinIO на том же VPS, или облачные S3/Google Cloud Storage/Azure Blob Storage) для хранения самих логов. Это обеспечивает высокую масштабируемость и низкую стоимость хранения.
- Query Language (LogQL): Loki использует язык запросов, вдохновленный PromQL, что упрощает его освоение для тех, кто уже знаком с Prometheus. LogQL очень мощный и позволяет фильтровать, агрегировать и анализировать логи по их лейблам и содержимому.
- Нативная интеграция с Grafana: Loki разработан той же командой, что и Grafana, поэтому интеграция между ними безупречна. Вы можете легко создавать дашборды, исследовать логи и переходить от метрик к логам в одном интерфейсе.
- Простота развертывания: Loki относительно легко развернуть, особенно в режиме "монолита" (single binary) для небольших инсталляций на VPS.
Минусы:
- Нет полнотекстового поиска: Если вам нужен высокопроизводительный полнотекстовый поиск по всем логам без предварительного знания лейблов, Loki может быть не лучшим выбором. Однако, в 2026 году, с развитием OpenTelemetry и стандартизацией атрибутов, этот недостаток становится менее критичным.
- Зависимость от лейблов: Эффективность запросов сильно зависит от правильного выбора и использования лейблов. Неправильная стратегия лейблирования может привести к медленным запросам или "кардинальной взрыву" (high cardinality).
Для кого подходит: Для команд, которые хотят эффективно управлять большими объемами логов на ограниченных ресурсах, используя Grafana для визуализации. Идеален для SaaS-проектов, где логирование критично, но бюджет ограничен.
Примеры использования: Сбор логов веб-сервера Nginx, микросервисов на Go, логов из Docker-контейнеров, системных логов. Использование Promtail (агента Loki) или OpenTelemetry Collector для отправки логов в Loki.
Tempo: Распределенные трассировки без головной боли
Tempo — еще один проект от Grafana Labs, предназначенный для хранения и запроса распределенных трассировок. Его уникальность заключается в том, что он не строит индексы по всему содержимому трассировок. Вместо этого он хранит трассировки в S3-совместимом объектном хранилище и индексирует только их ID. Запросы к Tempo выполняются по ID трассировки, что делает его чрезвычайно эффективным и ресурсонезависимым.
Плюсы:
- Минимальные требования к ресурсам: Поскольку Tempo не индексирует содержимое трассировок, он потребляет очень мало RAM и CPU. Это позволяет развернуть его даже на самых скромных VPS.
- Масштабируемость через объектное хранилище: Подобно Loki, Tempo использует S3-совместимые хранилища для самих трассировок. Это обеспечивает практически неограниченную масштабируемость и низкую стоимость хранения данных.
- "Храни все" подход: Из-за низкой стоимости хранения и минимальных ресурсов, Tempo позволяет хранить 100% ваших трассировок, а не полагаться на сэмплирование. Это дает возможность глубокого анализа даже редких проблем.
- Нативная интеграция с Grafana и Prometheus: Tempo легко интегрируется с Grafana, позволяя переходить от метрик (Prometheus) или логов (Loki) к конкретным трассировкам. Также поддерживается поиск трассировок по атрибутам через Loki или Prometheus.
- Простота развертывания: Tempo, как и Loki, может быть запущен в режиме "монолита" для простых инсталляций, что упрощает его развертывание на VPS.
Минусы:
- Поиск только по ID или косвенно: Основной способ поиска трассировок — по их уникальному ID. Поиск по атрибутам (например, по имени пользователя или ID заказа) возможен, но требует интеграции с Loki (для поиска по логам, содержащим эти атрибуты и ID трассировки) или с Prometheus (для поиска по метрикам, агрегирующим атрибуты и ID трассировки).
- Нет встроенного UI: Tempo не имеет собственного пользовательского интерфейса, полностью полагаясь на Grafana для визуализации и исследования трассировок.
Для кого подходит: Для команд, которым требуется полная видимость взаимодействия между микросервисами, но при этом они ограничены в бюджете и ресурсах. Идеально для диагностики производительности, выявления узких мест и понимания потока данных в распределенных системах.
Примеры использования: Отслеживание полного пути запроса через API Gateway, несколько бэкенд-сервисов и базу данных. Диагностика задержек, вызванных внешними API-вызовами. Использование OpenTelemetry SDK в приложениях для генерации трассировок и отправки их через OpenTelemetry Collector в Tempo.
Вместе, OpenTelemetry, Loki и Tempo, интегрированные с Grafana, предоставляют мощное, экономичное и масштабируемое решение для Observability, которое идеально подходит для распределенных систем, развернутых на VPS в 2026 году.
Практические советы и рекомендации по внедрению
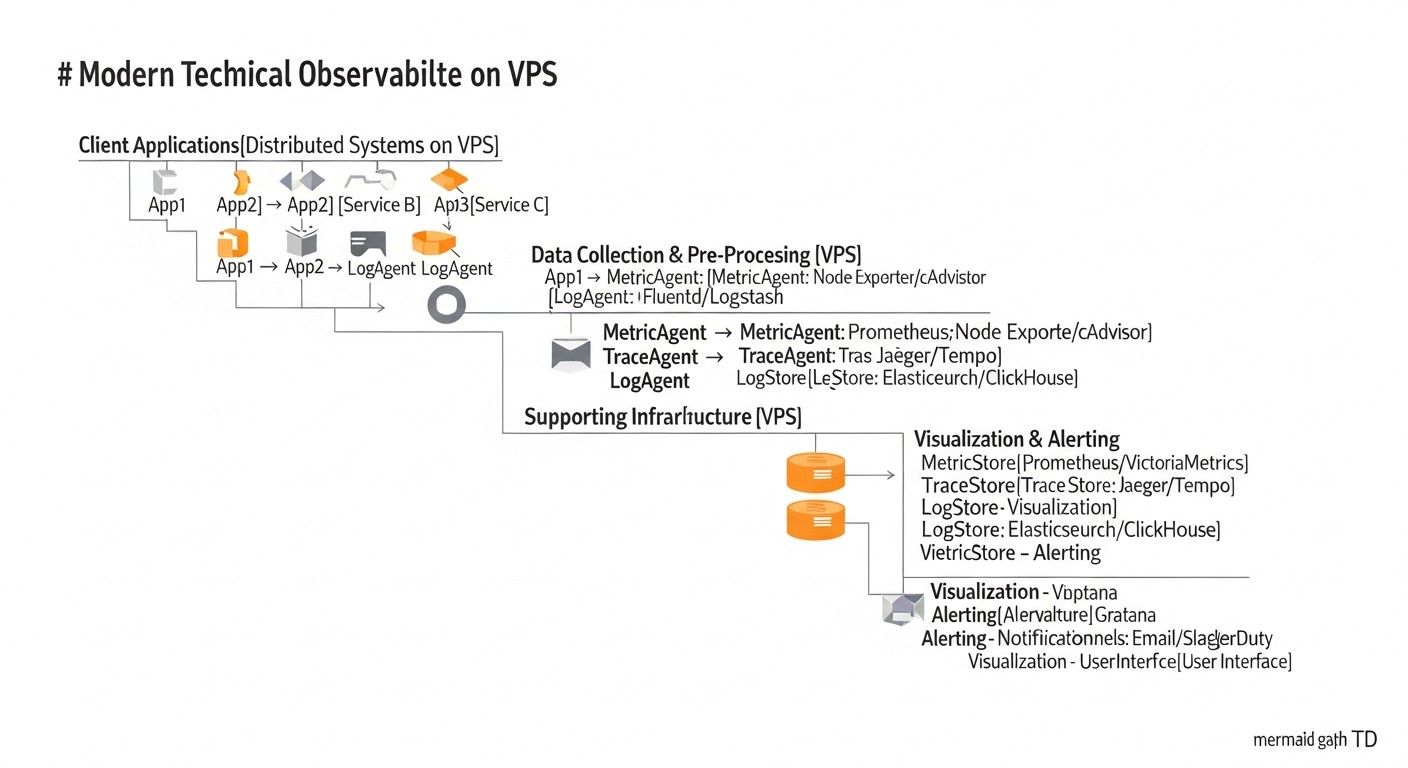 Схема: Практические советы и рекомендации по внедрению
Схема: Практические советы и рекомендации по внедрению
Внедрение полноценной системы Observability на VPS требует не только понимания инструментов, но и практического подхода. Вот пошаговые инструкции и рекомендации, основанные на реальном опыте.
1. Подготовка VPS и базовая настройка
Прежде чем что-либо устанавливать, убедитесь, что ваш VPS готов. Рекомендуется использовать свежую установку Ubuntu Server 24.04 LTS или Debian 12. Для наших целей потребуется минимум 4GB RAM и 2 CPU ядра, а также достаточно дискового пространства или возможность подключения S3-совместимого хранилища.
# Обновление системы
sudo apt update && sudo apt upgrade -y
# Установка Docker и Docker Compose (для упрощения развертывания)
sudo apt install ca-certificates curl gnupg lsb-release -y
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt update
sudo apt install docker-ce docker-ce-cli containerd.io docker-compose-plugin -y
# Добавление пользователя в группу docker
sudo usermod -aG docker $USER
# Выйдите и войдите заново, чтобы изменения вступили в силу, или выполните:
# newgrp docker
# Установка MinIO (локальное S3-совместимое хранилище для Loki и Tempo)
# Создадим директории для данных и конфигурации MinIO
sudo mkdir -p /mnt/data/minio
sudo mkdir -p /etc/minio
# Создадим файл docker-compose.yml для MinIO
# nano docker-compose.yml
Пример docker-compose.yml для MinIO:
version: '3.8'
services:
minio:
image: minio/minio:latest
container_name: minio
ports:
- "9000:9000"
- "9001:9001"
volumes:
- /mnt/data/minio:/data
- /etc/minio:/root/.minio
environment:
MINIO_ROOT_USER: minioadmin
MINIO_ROOT_PASSWORD: minioadminpassword
MINIO_BROWSER: "on"
command: server /data --console-address ":9001"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
restart: unless-stopped
# Запуск MinIO
docker compose up -d
Теперь MinIO доступен по адресу http://<ваш_ip>:9001. Создайте бакеты для Loki и Tempo, например, loki-bucket и tempo-bucket.
2. Развертывание OpenTelemetry Collector
Collector будет центральным узлом для сбора, обработки и маршрутизации телеметрии. Для VPS его можно развернуть как Docker-контейнер.
Пример otel-collector-config.yaml:
receivers:
otlp:
protocols:
grpc:
http:
processors:
batch:
send_batch_size: 1000
timeout: 10s
memory_limiter:
check_interval: 1s
limit_mib: 256 # Ограничение RAM для Collector
spike_limit_mib: 64
resource:
attributes:
- key: host.name
value: ${env:HOSTNAME}
action: upsert
- key: deployment.environment
value: production
action: insert
exporters:
loki:
endpoint: http://loki:3100/loki/api/v1/push
# auth:
# basic:
# username: ${env:LOKI_USERNAME}
# password: ${env:LOKI_PASSWORD}
tempo:
endpoint: http://tempo:4317
tls:
insecure: true # В production использовать TLS
prometheus:
endpoint: 0.0.0.0:8889
resource_to_telemetry_conversion:
enabled: true
logging:
loglevel: debug
service:
pipelines:
traces:
receivers: [otlp]
processors: [memory_limiter, batch, resource]
exporters: [tempo, logging]
metrics:
receivers: [otlp]
processors: [memory_limiter, batch, resource]
exporters: [prometheus, logging]
logs:
receivers: [otlp]
processors: [memory_limiter, batch, resource]
exporters: [loki, logging]
Запуск Collector через docker-compose.yml:
version: '3.8'
services:
otel-collector:
image: otel/opentelemetry-collector:0.96.0 # Актуальная версия на 2026 год
container_name: otel-collector
command: ["--config=/etc/otel-collector-config.yaml"]
volumes:
- ./otel-collector-config.yaml:/etc/otel-collector-config.yaml
ports:
- "4317:4317" # OTLP gRPC receiver
- "4318:4318" # OTLP HTTP receiver
- "8889:8889" # Prometheus exporter
environment:
HOSTNAME: ${HOSTNAME} # Передаем имя хоста
depends_on:
- loki
- tempo
restart: unless-stopped
3. Развертывание Loki
Для Loki также используем Docker. Нам потребуется конфигурационный файл loki-config.yaml.
auth_enabled: false # Для простоты, в production использовать аутентификацию
server:
http_listen_port: 3100
grpc_listen_port: 9095
common:
path_prefix: /loki
storage:
filesystem:
directory: /tmp/loki/chunks # Только для временного хранения, затем в S3
replication_factor: 1
ring:
kvstore:
store: inmemory # Для single-node, в production использовать Consul/Etcd
instance_addr: 127.0.0.1
instance_port: 3100
schema_config:
configs:
- from: 2023-01-01
store: boltdb-shipper
object_store: s3
schema: v12
index:
prefix: index_
period: 24h
compactor:
working_directory: /tmp/loki/compactor
shared_store: s3
chunk_store_config:
max_look_back_period: 30d # Хранить чанки логов 30 дней
storage_config:
boltdb_shipper:
active_index_directory: /tmp/loki/boltdb-shipper-active
cache_location: /tmp/loki/boltdb-shipper-cache
resync_interval: 5s
shared_store: s3
s3:
endpoint: minio:9000
bucketnames: loki-bucket
access_key_id: minioadmin
secret_access_key: minioadminpassword
s3forcepathstyle: true
Добавляем Loki в docker-compose.yml:
loki:
image: grafana/loki:2.9.0 # Актуальная версия на 2026 год
container_name: loki
command: -config.file=/etc/loki/loki-config.yaml
volumes:
- ./loki-config.yaml:/etc/loki/loki-config.yaml
- /mnt/data/loki:/tmp/loki # Данные Loki
ports:
- "3100:3100"
environment:
MINIO_ENDPOINT: minio:9000 # Для Loki, чтобы мог достучаться до MinIO
depends_on:
- minio
restart: unless-stopped
4. Развертывание Tempo
Конфигурация Tempo в tempo-config.yaml:
server:
http_listen_port: 3200
grpc_listen_port: 9096
distributor:
receivers:
otlp:
protocols:
grpc:
http:
ingester:
lifecycler:
ring:
kvstore:
store: inmemory # Для single-node, в production использовать Consul/Etcd
replication_factor: 1
compactor:
compaction_interval: 10m
storage:
trace:
backend: s3
s3:
endpoint: minio:9000
bucket: tempo-bucket
access_key_id: minioadmin
secret_access_key: minioadminpassword
s3forcepathstyle: true
wal:
path: /tmp/tempo/wal # Write Ahead Log
block:
bloom_filter_false_positive_rate: 0.05
index_downsample_bytes: 1000
max_block_bytes: 5000000 # 5MB
max_block_duration: 15m
retention: 30d # Хранить трассировки 30 дней
Добавляем Tempo в docker-compose.yml:
tempo:
image: grafana/tempo:2.4.0 # Актуальная версия на 2026 год
container_name: tempo
command: -config.file=/etc/tempo/tempo-config.yaml
volumes:
- ./tempo-config.yaml:/etc/tempo/tempo-config.yaml
- /mnt/data/tempo:/tmp/tempo # Данные Tempo
ports:
- "3200:3200" # HTTP
- "9096:9096" # gRPC
- "4317" # OTLP gRPC receiver (Tempo может принимать напрямую, но лучше через Collector)
- "4318" # OTLP HTTP receiver
environment:
MINIO_ENDPOINT: minio:9000 # Для Tempo, чтобы мог достучаться до MinIO
depends_on:
- minio
restart: unless-stopped
5. Развертывание Grafana
Grafana будет вашим единым интерфейсом для всех данных Observability.
grafana:
image: grafana/grafana:10.4.0 # Актуальная версия на 2026 год
container_name: grafana
ports:
- "3000:3000"
volumes:
- /mnt/data/grafana:/var/lib/grafana # Для персистентности данных Grafana
environment:
GF_SECURITY_ADMIN_USER: admin
GF_SECURITY_ADMIN_PASSWORD: supersecretpassword # Смените на сложный пароль!
GF_AUTH_ANONYMOUS_ENABLED: "false"
GF_AUTH_DISABLE_SIGNOUT_MENU: "false"
depends_on:
- loki
- tempo
- otel-collector
restart: unless-stopped
# Запуск всех сервисов
docker compose up -d
Теперь Grafana доступна по адресу http://<ваш_ip>:3000. Войдите с логином admin и паролем supersecretpassword.
6. Настройка источников данных в Grafana
- Добавьте Loki как источник данных:
- Type: Loki
- URL:
http://loki:3100
- Добавьте Tempo как источник данных:
- Type: Tempo
- URL:
http://tempo:3200
- Для "Data Links" укажите источник Loki, чтобы можно было переходить от трассировок к логам.
- Добавьте Prometheus (OpenTelemetry Collector) как источник данных:
- Type: Prometheus
- URL:
http://otel-collector:8889
7. Инструментация приложений
Самый важный шаг — это инструментация ваших приложений с помощью OpenTelemetry SDK. Пример для Python:
import os
from opentelemetry import trace
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.instrumentation.flask import FlaskInstrumentor
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from flask import Flask
# Настройка OpenTelemetry
resource = Resource.create({
"service.name": "my-python-app",
"service.version": "1.0.0",
"deployment.environment": "production",
"host.name": os.getenv("HOSTNAME", "unknown_host")
})
trace.set_tracer_provider(TracerProvider(resource=resource))
tracer = trace.get_tracer(__name__)
# Экспорт трассировок в OpenTelemetry Collector
otlp_exporter = OTLPSpanExporter(endpoint="http://otel-collector:4317", insecure=True)
span_processor = BatchSpanProcessor(otlp_exporter)
trace.get_tracer_provider().add_span_processor(span_processor)
app = Flask(__name__)
FlaskInstrumentor().instrument_app(app)
@app.route('/')
def hello():
with tracer.start_as_current_span("hello-request"):
return "Hello, Observability!"
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
Подобные SDK доступны для всех популярных языков. Используйте их для генерации метрик, логов и трассировок, отправляя их в OpenTelemetry Collector на порты 4317 (gRPC) или 4318 (HTTP).
8. Автоматизация развертывания
В 2026 году ручное развертывание — это анахронизм. Используйте Ansible, Terraform или другие инструменты IaC (Infrastructure as Code) для автоматизации установки и настройки VPS, Docker и всех компонентов Observability. Это значительно сократит время на развертывание и снизит вероятность ошибок.
9. Мониторинг самой системы Observability
Не забывайте мониторить Loki, Tempo и OpenTelemetry Collector. Используйте их собственные метрики (которые можно собирать Prometheus'ом) для отслеживания их производительности, потребления ресурсов и объема обрабатываемых данных. Это поможет выявить узкие места до того, как они станут критическими.
Типичные ошибки при построении Observability на VPS
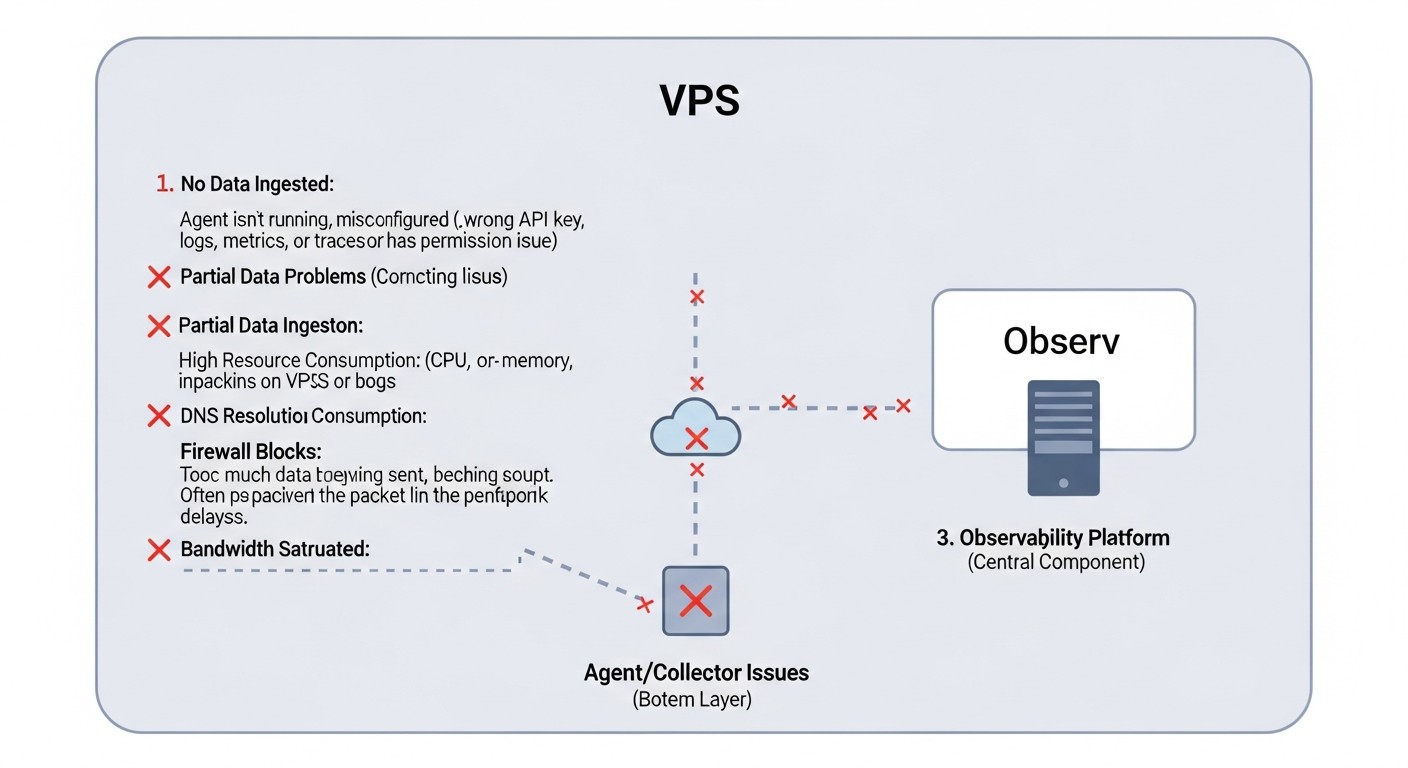 Схема: Типичные ошибки при построении Observability на VPS
Схема: Типичные ошибки при построении Observability на VPS
Даже с самыми лучшими инструментами, ошибки в реализации могут свести на нет все усилия. Вот наиболее распространенные заблуждения и промахи при построении системы Observability на VPS, актуальные для 2026 года.
1. Игнорирование OpenTelemetry Collector как прокси
Ошибка: Отправка телеметрии напрямую из приложений в Loki, Tempo или Prometheus без использования OpenTelemetry Collector. Или использование Collector, но без эффективных процессоров (например, батчинг, фильтрация, сэмплирование).
Как избежать: Всегда используйте OpenTelemetry Collector как центральный хаб. Он создан для того, чтобы быть буфером, прокси и процессором. Настройте его на батчинг (объединение данных в пакеты), фильтрацию ненужных данных, агрегацию метрик и сэмплирование трассировок (особенно для высоконагруженных систем). Это значительно снижает нагрузку на бэкенды (Loki, Tempo) и экономит трафик, что критично для VPS.
Реальный пример последствий: Сервис с высокой частотой запросов генерирует огромное количество коротких трассировок. Если отправлять их напрямую в Tempo, каждый "спан" будет отдельным HTTP-запросом, что приведет к перегрузке сети и Tempo-ингестеров, быстро исчерпав ресурсы VPS и превысив лимиты трафика.
2. Неправильное использование лейблов в Loki (High Cardinality)
Ошибка: Использование высококардинальных данных (например, уникальных ID сессий, ID пользователей, полных URL-путей с параметрами) в качестве лейблов для логов в Loki. Это приводит к раздуванию индекса и замедлению запросов.
Как избежать: Лейблы в Loki должны быть низкокардинальными (например, имя сервиса, версия, хост, уровень лога, HTTP-метод, статус-код). Высококардинальные данные следует оставлять в теле лога, где их можно искать с помощью регулярных выражений, но не индексировать. В 2026 году с развитием LogQL и возможностью парсинга логов на лету, это становится еще более актуальным.
Реальный пример последствий: Разработчик добавляет user_id в качестве лейбла к каждому логу. Если у вас 100 000 активных пользователей, это создаст 100 000 уникальных комбинаций лейблов, что в разы увеличит размер индекса Loki, замедлит все запросы и быстро заполнит дисковое пространство, даже при использовании объектного хранилища.
3. Отсутствие сэмплирования трассировок для высоконагруженных систем
Ошибка: Попытка собирать 100% трассировок со всех сервисов в высоконагруженной распределенной системе, работающей на VPS.
Как избежать: Для production-систем на VPS обязательно настройте сэмплирование трассировок в OpenTelemetry Collector. Вы можете использовать Head-based сэмплирование (решение о сэмплировании принимается в начале трассировки) или Tail-based сэмплирование (решение принимается после завершения трассировки, что позволяет сэмплировать по ошибкам или длительности). Типичные стратегии: сэмплировать 1 из 1000 запросов, но 100% запросов с ошибками или запросов, превышающих определенный порог задержки. Tempo спроектирован для хранения 100% трассировок, но если у вас очень большой объем, сэмплирование на Collector может быть необходимо для экономии ресурсов и трафика.
Реальный пример последствий: 100% сэмплирование на сервисе, обрабатывающем 1000 запросов в секунду, приведет к генерации десятков тысяч спанов в секунду. Это быстро перегрузит Collector, забьет очередь на отправку в Tempo и, вероятно, превысит лимиты на запись в объектное хранилище, приводя к потере данных и нестабильности всей системы Observability.
4. Недооценка стоимости хранения данных и трафика
Ошибка: Предположение, что объектное хранилище (даже S3-совместимое на VPS) или облачное S3 будет "бесплатным" или очень дешевым при больших объемах данных. Игнорирование стоимости исходящего трафика.
Как избежать: Всегда планируйте объемы данных, которые будут генерировать ваши приложения. Прогнозируйте рост и регулярно пересматривайте политику хранения (retention policy) для Loki и Tempo. Используйте OpenTelemetry Collector для предварительной фильтрации и агрегации данных, чтобы отправлять только самое важное. Если используете облачное S3, будьте особенно внимательны к стоимости исходящего трафика при запросах данных из Loki/Tempo на вашем VPS. Размещение MinIO на том же VPS, что и Loki/Tempo, исключает затраты на трафик между ними.
Реальный пример последствий: Проект запускается с 30-дневным сроком хранения логов и трассировок. Через несколько месяцев объем данных вырастает до терабайтов, а ежемесячный счет за хранение и, что более критично, за запросы к S3 из Loki/Tempo на VPS (исходящий трафик), становится неподъемным, превышая стоимость самого VPS.
5. Отсутствие мониторинга самой системы Observability
Ошибка: Развертывание Loki, Tempo, OpenTelemetry Collector и отсутствие мониторинга их собственного состояния и производительности.
Как избежать: Рассматривайте вашу систему Observability как любой другой критически важный сервис. Собирайте метрики с Loki (/metrics), Tempo (/metrics) и OpenTelemetry Collector (/metrics). Добавьте их в ваш Prometheus-экспортер (который в нашем случае является частью Collector). Создайте дашборды в Grafana для мониторинга их CPU, RAM, дискового пространства, количества обрабатываемых данных, задержек при записи/чтении. Настройте алерты на критические пороги.
Реальный пример последствий: Loki начинает медленно индексировать логи из-за нехватки RAM, но никто этого не замечает. Через несколько дней запросы к логам становятся невозможными, а новые логи перестают записываться, что делает диагностику любых проблем с основным приложением слепым.
6. Недостаточная или избыточная инструментация
Ошибка: Либо инструментация приложений очень поверхностная (нет достаточных данных для диагностики), либо избыточная (генерируется слишком много нерелевантной телеметрии).
Как избежать: Начните с базовой инструментации: HTTP-запросы (входящие/исходящие), вызовы к базам данных, критические бизнес-операции. Постепенно добавляйте более детальную телеметрию по мере выявления узких мест или при появлении новых требований. Используйте семантические конвенции OpenTelemetry для стандартизации имен метрик, спанов и атрибутов. Обучите разработчиков, какие данные важны, а какие — нет. В 2026 году, когда AI-ассистенты могут помочь в анализе, качество и консистентность инструментации становится еще более важным.
Реальный пример последствий:
- Недостаточная: В приложении возникает ошибка, но логи содержат только "Internal Server Error", а трассировки обрываются на середине, не давая никакого контекста, что привело к многочасовому поиску проблемы.
- Избыточная: Каждый вызов к внутреннему кэшу генерирует новый спан, хотя это не критичная операция. Это приводит к раздуванию трассировок, увеличению объема данных и сложности чтения.
7. Игнорирование безопасности
Ошибка: Отсутствие аутентификации и авторизации для доступа к Loki, Tempo, Grafana, MinIO. Передача чувствительных данных в логах или трассировках без маскирования.
Как избежать: Всегда настраивайте аутентификацию (например, базовую HTTP-аутентификацию для MinIO, Grafana, Loki) и используйте TLS для шифрования трафика между компонентами. В OpenTelemetry Collector есть процессоры для маскирования чувствительных данных. Регулярно проводите аудит того, какие данные попадают в вашу систему Observability.
Реальный пример последствий: Конфигурация Loki или Tempo доступна без пароля. Злоумышленник получает доступ к логам и трассировкам, содержащим персональные данные пользователей или конфиденциальную бизнес-информацию, что приводит к утечке данных и серьезным последствиям для репутации и юридическим проблемам.
Чеклист для практического применения
Этот чеклист поможет вам последовательно внедрить и поддерживать систему Observability на базе OpenTelemetry, Loki и Tempo на вашем VPS в 2026 году.
- Планирование ресурсов VPS:
- [ ] Выбран VPS с достаточным объемом RAM (минимум 4GB), CPU (минимум 2 ядра) и дискового пространства (начать с 100GB, планировать рост).
- [ ] Определен провайдер S3-совместимого хранилища или выделено место для локального MinIO на VPS.
- [ ] Прогнозированы объемы логов и трассировок, рассчитаны примерные затраты на хранение и трафик.
- Базовая настройка VPS:
- [ ] VPS обновлен и защищен (брандмауэр, SSH-ключи).
- [ ] Установлен Docker и Docker Compose (или Kubernetes, если применимо).
- [ ] Созданы директории для персистентных данных MinIO, Loki, Tempo, Grafana.
- Развертывание MinIO (или подключение к S3):
- [ ] MinIO запущен и доступен (или настроены креды для облачного S3).
- [ ] Созданы отдельные бакеты для Loki (например,
loki-bucket) и Tempo (например, tempo-bucket).
- [ ] Настроены учетные данные для доступа к MinIO/S3.
- Развертывание OpenTelemetry Collector:
- [ ] Collector развернут как Docker-контейнер.
- [ ] Конфигурация
otel-collector-config.yaml настроена для приема OTLP.
- [ ] Настроены процессоры:
batch, memory_limiter, resource (с добавлением имени хоста, окружения).
- [ ] Экспортеры настроены для Loki, Tempo и Prometheus (для метрик Collector).
- [ ] Collector настроен на отправку логов в Loki, трассировок в Tempo, метрик в Prometheus.
- Развертывание Loki:
- [ ] Loki развернут как Docker-контейнер.
- [ ] Конфигурация
loki-config.yaml настроена для использования S3-совместимого хранилища (MinIO).
- [ ] Установлена разумная политика хранения (
chunk_store_config.max_look_back_period, schema_config.configs.period).
- [ ] Настроена аутентификация, если Loki доступен извне (в production).
- Развертывание Tempo:
- [ ] Tempo развернут как Docker-контейнер.
- [ ] Конфигурация
tempo-config.yaml настроена для использования S3-совместимого хранилища (MinIO).
- [ ] Установлена разумная политика хранения (
storage.trace.retention).
- [ ] Настроена аутентификация, если Tempo доступен извне (в production).
- Развертывание Grafana:
- [ ] Grafana развернута как Docker-контейнер.
- [ ] Установлен сложный пароль для администратора Grafana.
- [ ] Добавлены источники данных: Loki (
http://loki:3100), Tempo (http://tempo:3200), Prometheus (http://otel-collector:8889).
- [ ] В Tempo источнике данных настроена связь с Loki для поиска логов по трассировкам.
- Инструментация приложений:
- [ ] Приложения инструментированы с помощью OpenTelemetry SDK.
- [ ] Настроена отправка метрик, логов и трассировок в OpenTelemetry Collector (
http://otel-collector:4317 или 4318).
- [ ] Используются семантические конвенции OpenTelemetry для имен и атрибутов.
- [ ] Реализовано сэмплирование трассировок для высоконагруженных сервисов.
- [ ] Проверено, что чувствительные данные не попадают в телеметрию без маскирования.
- Создание дашбордов и алертов:
- [ ] Созданы базовые дашборды в Grafana для мониторинга ключевых метрик приложений, логов и трассировок.
- [ ] Настроены алерты на критические события и пороги производительности.
- [ ] Созданы дашборды для мониторинга самой системы Observability (Loki, Tempo, Collector).
- Автоматизация и поддержка:
- [ ] Развертывание всех компонентов автоматизировано с использованием IaC (Ansible, Terraform).
- [ ] Настроено автоматическое резервное копирование важных конфигурационных файлов.
- [ ] Разработан план регулярного обновления компонентов Observability.
- [ ] Проведена оценка и оптимизация затрат на хранение и трафик.
Расчет стоимости / Экономика Observability на VPS
 Схема: Расчет стоимости / Экономика Observability на VPS
Схема: Расчет стоимости / Экономика Observability на VPS
Экономика Observability на VPS в 2026 году — это не только прямые затраты на сервер, но и тщательно спланированные расходы на хранение данных, трафик и, что не менее важно, время инженеров. Правильный выбор стека OpenTelemetry, Loki и Tempo позволяет значительно оптимизировать эти затраты.
Основные статьи расходов на VPS в 2026 году:
- VPS-инстанс: CPU, RAM, базовая дисковая подсистема.
- Хранение данных: Для логов (Loki), трассировок (Tempo) и метрик (Prometheus). Может быть локальным на VPS или внешним (S3-совместимое объектное хранилище).
- Трафик: Входящий (от приложений к Collector) и исходящий (от Collector к бэкендам, от Loki/Tempo к Grafana, от Grafana к пользователям, а также между VPS и S3-хранилищем, если оно внешнее).
- Время инженеров: Настройка, поддержка, оптимизация, устранение проблем.
Примеры расчетов для разных сценариев (иллюстративно, цены 2026 года):
Предположим, что средняя стоимость VPS в 2026 году:
- Малый VPS (2 CPU, 4GB RAM, 100GB SSD): 15-25 USD/мес
- Средний VPS (4 CPU, 8GB RAM, 200GB SSD): 30-50 USD/мес
- Объектное хранилище (S3-совместимое): 0.01-0.02 USD/GB/мес
- Исходящий трафик: 0.05-0.10 USD/GB
Сценарий 1: Небольшой стартап (1-3 микросервиса, ~500 RPS)
- VPS: 1x Средний VPS (4 CPU, 8GB RAM, 200GB SSD) для всех компонентов (OpenTelemetry Collector, Loki, Tempo, Grafana, MinIO).
- Стоимость VPS: ~40 USD/мес.
- Объем данных:
- Логи: 50 GB/мес (30-дневное хранение)
- Трассировки: 20 GB/мес (30-дневное хранение, сэмплирование 1:100)
- Метрики: 5 GB/мес
- Хранение (MinIO на том же VPS):
- Дисковое пространство: 50 GB (Loki) + 20 GB (Tempo) + 5 GB (Prometheus) + 10 GB (Grafana, OS) = ~85 GB. Это укладывается в 200GB SSD VPS.
- Стоимость: Включена в VPS.
- Трафик:
- Входящий (от приложений к Collector): 100 GB/мес
- Исходящий (от Collector к Loki/Tempo/Prometheus, внутренний): 0 USD (внутри VPS).
- Исходящий (от Grafana к пользователям): 20 GB/мес
- Общий платный трафик: ~120 GB/мес.
- Стоимость трафика: 120 GB 0.07 USD/GB = 8.4 USD/мес.
- Итоговая примерная стоимость: 40 USD (VPS) + 8.4 USD (трафик) = ~48.4 USD/мес.
Сценарий 2: Растущий SaaS-проект (5-10 микросервисов, ~5000 RPS)
- VPS:
- 1x Средний VPS (4 CPU, 8GB RAM, 200GB SSD) для OpenTelemetry Collector, Prometheus, Grafana. (~40 USD/мес)
- 1x Малый VPS (2 CPU, 4GB RAM, 100GB SSD) для Loki и Tempo (разделение нагрузки). (~20 USD/мес)
- Объем данных:
- Логи: 500 GB/мес (30-дневное хранение)
- Трассировки: 200 GB/мес (30-дневное хранение, сэмплирование 1:50)
- Метрики: 50 GB/мес
- Хранение (облачное S3):
- Общий объем: 500 GB (Loki) + 200 GB (Tempo) = 700 GB.
- Стоимость S3: 700 GB 0.015 USD/GB = 10.5 USD/мес.
- Трафик:
- Входящий (от приложений к Collector): 1 TB/мес
- Исходящий (от Collector к Loki/Tempo/Prometheus): 1 TB/мес (часть внутренняя, часть на S3).
- Исходящий (от Loki/Tempo к S3): 700 GB/мес (запись)
- Исходящий (от S3 к Loki/Tempo на VPS при запросах): 100 GB/мес (очень активные запросы)
- Исходящий (от Grafana к пользователям): 50 GB/мес
- Общий платный трафик (включая S3): ~100 GB (S3 retrieval) + 50 GB (Grafana) + 1 TB (Collector -> S3) = ~1.15 TB/мес.
- Стоимость трафика: 1150 GB 0.07 USD/GB = 80.5 USD/мес.
- Итоговая примерная стоимость: 40 USD (VPS1) + 20 USD (VPS2) + 10.5 USD (S3) + 80.5 USD (трафик) = ~151 USD/мес.
Скрытые расходы и как их оптимизировать:
- Исходящий трафик: Это самый коварный расход.
- Оптимизация: Максимально используйте OpenTelemetry Collector для фильтрации, агрегации и сэмплирования данных ДО их отправки. Если возможно, размещайте S3-совместимое хранилище на том же VPS или в той же сети, чтобы минимизировать платный трафик.
- Накладные расходы на CPU/RAM: Неэффективные запросы к Loki или Tempo, слишком большое количество лейблов, отсутствие батчинга могут быстро исчерпать ресурсы VPS.
- Оптимизация: Настраивайте
memory_limiter в Collector. Оптимизируйте запросы LogQL и PromQL. Регулярно анализируйте метрики самого Observability стека, чтобы выявить узкие места.
- Время инженеров: Ручная настройка, дебаггинг, обновление.
- Оптимизация: Инвестируйте в Infrastructure as Code (Docker Compose, Ansible). Создавайте стандартизированные конфигурации и шаблоны. Обучайте команду использованию инструментов Observability.
- Долгосрочное хранение: Если вам нужно хранить данные дольше 30-90 дней, стоимость будет расти.
- Оптимизация: Разработайте стратегию архивирования. Для очень старых логов и трассировок можно переносить их в более дешевые "холодные" S3-классы или полностью удалять, если они не требуются для аудита.
Таблица с примерами расчетов для разных сценариев (обобщенно):
| Параметр |
Малый проект (500 RPS) |
Средний проект (5000 RPS) |
Крупный проект (20000+ RPS) |
| Количество VPS |
1 (средний) |
2 (1 средний, 1 малый) |
3+ (кластер Loki/Tempo) |
| Стоимость VPS/мес |
~40 USD |
~60 USD |
~150-300 USD+ |
| Объем логов/мес |
50 GB |
500 GB |
2 TB+ |
| Объем трассировок/мес |
20 GB |
200 GB |
800 GB+ |
| Стоимость хранения S3/мес |
0 USD (локально) |
~10.5 USD |
~40-100 USD+ |
| Стоимость трафика/мес |
~8.4 USD |
~80.5 USD |
~300-600 USD+ |
| Итоговая стоимость/мес |
~48.4 USD |
~151 USD |
~490-1000 USD+ |
| Рекомендации |
MinIO на том же VPS, агрессивное сэмплирование/фильтрация |
Разделение Loki/Tempo на отдельный VPS, облачное S3, активная оптимизация Collector |
Кластерная версия Loki/Tempo (например, на K8s), выделенные инстансы, многозонное S3, глубокая оптимизация |
Как видно, даже для растущих проектов, связка OpenTelemetry, Loki и Tempo на VPS остается значительно более экономичной, чем большинство коммерческих или полностью облачных решений, особенно когда речь идет о контроле над трафиком и эффективном использовании объектного хранилища.
Кейсы и примеры использования
 Схема: Кейсы и примеры использования
Схема: Кейсы и примеры использования
Рассмотрим несколько реалистичных сценариев, демонстрирующих эффективность связки OpenTelemetry, Loki и Tempo на VPS в 2026 году.
Кейс 1: Диагностика медленных запросов в e-commerce API
Проблема: Пользователи жалуются на случайные, но заметные задержки при оформлении заказа в небольшом интернет-магазине, работающем на 5 микросервисах (Go, Python) на одном среднем VPS. Традиционный мониторинг показывает лишь общую загрузку CPU и RAM, но не дает понимания, где именно происходит задержка.
Решение с Observability:
- Инструментация: Все микросервисы были инструментированы с помощью OpenTelemetry SDK. Каждый HTTP-запрос, вызов к базе данных, запрос к внешнему платежному шлюзу и внутренние вызовы между сервисами генерируют спаны. Логи каждого сервиса также отправляются через OpenTelemetry Collector в Loki.
- Настройка Collector: OpenTelemetry Collector настроен на сбор всех трассировок, метрик и логов, а затем отправляет их в Tempo, Loki и Prometheus (для метрик). Было включено сэмплирование трассировок 1:100, но 100% трассировок с ошибками или длительностью более 500мс.
- Графана: В Grafana созданы дашборды, показывающие общую латентность API, количество ошибок и загрузку ресурсов. Добавлен "Service Graph" на основе трассировок, показывающий взаимосвязи между сервисами.
- Диагностика:
- Инженер замечает на дашборде Grafana пик латентности для эндпоинта
/checkout.
- Из дашборда метрик, он переходит к трассировкам в Tempo, используя "Trace ID" из логов или просто кликая на "Explore traces" для данного временного интервала.
- В Tempo он находит трассировку, соответствующую медленному запросу. Визуализация трассировки показывает, что большая часть задержки происходит в сервисе
payment-gateway-service при вызове внешнего API.
- Из спана вызова внешнего API он кликает на "Logs" (интеграция Tempo-Loki) и видит логи из
payment-gateway-service для данного trace_id. В логах обнаруживается повторяющееся сообщение об ошибке таймаута при соединении с внешним платежным шлюзом.
Результат: Вместо многочасового дебаггинга и перебора логов, проблема была локализована за 15 минут. Выяснилось, что внешний платежный шлюз испытывает проблемы с производительностью. Команда смогла оперативно связаться с провайдером шлюза и переключиться на резервный вариант, минимизировав потери.
Кейс 2: Оптимизация потребления ресурсов и стоимости для стартапа с IoT-устройствами
Проблема: Стартап разрабатывает платформу для мониторинга IoT-устройств. Каждое устройство отправляет телеметрию каждые 10 секунд. Количество устройств быстро растет, и текущая система на базе Elastic Stack на VPS становится непомерно дорогой из-за огромного объема логов и метрик, а также высоких требований к RAM/CPU для Elasticsearch.
Решение с Observability:
- Переход на OpenTelemetry, Loki, Tempo: Было принято решение перейти на более ресурсоэффективный стек.
- Инструментация IoT-агентов: Агенты на IoT-устройствах настроены на отправку метрик и логов через OpenTelemetry Protocol (OTLP) в OpenTelemetry Collector на центральном VPS. Трассировки для IoT-устройств были сочтены избыточными для данной задачи и отключены для экономии.
- Настройка Collector: OpenTelemetry Collector на VPS настроен на:
- Агрегацию метрик (например, среднее значение за 1 минуту вместо каждой точки).
- Фильтрацию логов: отбрасывание информационных логов, сохранение только предупреждений и ошибок.
- Добавление атрибутов
device_id, device_type, location к каждому логу и метрике.
- Loki и Tempo: Loki используется для хранения отфильтрованных логов. Tempo развернут, но используется только для трассировок бэкенд-сервисов, обрабатывающих данные с IoT-устройств, а не для самих устройств. MinIO развернут на том же VPS для хранения данных Loki и Tempo.
- Графана: Дашборды показывают агрегированные метрики по типам устройств, локациям, а также предупреждения и ошибки, отфильтрованные по тем же атрибутам.
Результат:
- Снижение затрат на VPS: Требования к RAM/CPU для Loki оказались в 3-5 раз ниже, чем для Elasticsearch, что позволило использовать более дешевый VPS.
- Экономия на хранении: Благодаря фильтрации логов и индексации только метаданных в Loki, объем хранимых логов сократился на 70%, а стоимость хранения данных в MinIO была значительно ниже, чем у Elastic.
- Контроль над трафиком: Агрегация и фильтрация в Collector сократили объем входящего трафика на 50%, что напрямую сказалось на счетах от провайдера VPS.
- Улучшенная диагностика: Несмотря на агрегацию, важные метрики и ошибки стали легче находить благодаря правильному лейблированию и эффективным запросам в Grafana.
Эти кейсы демонстрируют, как OpenTelemetry, Loki и Tempo могут быть эффективно использованы для решения реальных бизнес-задач, обеспечивая глубокую наблюдаемость при сохранении контроля над расходами на VPS.
Troubleshooting (решение проблем)
 Схема: Troubleshooting (решение проблем)
Схема: Troubleshooting (решение проблем)
Даже при самой тщательной настройке, в процессе эксплуатации системы Observability могут возникать проблемы. Ниже перечислены типичные неполадки и методы их диагностики и устранения для OpenTelemetry, Loki и Tempo на VPS.
1. Нет данных в Grafana (метрики, логи, трассировки)
Возможные причины:
- Приложение не отправляет данные в Collector.
- Collector не получает данные или не может их экспортировать.
- Loki/Tempo не получает данные от Collector или не может их записать в хранилище.
- Grafana не может подключиться к Loki/Tempo/Collector.
- Проблемы с сетью/файрволом.
Диагностические команды и шаги:
- Проверьте логи приложений: Убедитесь, что OpenTelemetry SDK инициализирован и не выдает ошибок при отправке данных. Проверьте, что эндпоинт Collector указан правильно (например,
http://otel-collector:4317).
- Проверьте логи OpenTelemetry Collector:
docker logs otel-collector
# Или если Collector работает как systemd сервис
sudo journalctl -u otel-collector -f
Ищите ошибки подключения к Loki/Tempo, ошибки парсинга данных, сообщения о переполнении буфера. Убедитесь, что Collector слушает на нужных портах.
sudo netstat -tulnp | grep 4317 # Проверить, слушает ли Collector порт OTLP gRPC
sudo netstat -tulnp | grep 4318 # Проверить, слушает ли Collector порт OTLP HTTP
- Проверьте логи Loki и Tempo:
docker logs loki
docker logs tempo
Ищите ошибки записи в S3/MinIO, ошибки аутентификации, проблемы с дисковым пространством. Убедитесь, что Loki и Tempo слушают на своих портах (3100 и 3200 соответственно).
- Проверьте подключение Grafana: В Grafana перейдите в "Configuration" -> "Data Sources". Для каждого источника данных нажмите "Save & Test". Убедитесь, что статус "Data source is working". Если нет, проверьте URL-ы (например,
http://loki:3100), настройки файрвола на VPS.
- Проверьте файрвол: Убедитесь, что порты (4317, 4318, 3100, 3200, 3000) открыты на VPS, если к ним должен быть внешний доступ, и между Docker-контейнерами.
2. Медленные запросы в Grafana (к Loki или Tempo)
Возможные причины:
- Высокая кардинальность лейблов в Loki.
- Слишком большой диапазон времени для запроса.
- Неэффективные запросы LogQL/PromQL.
- Нехватка ресурсов (CPU/RAM) у Loki/Tempo.
- Медленное S3-совместимое хранилище или высокая задержка сети до него.
Диагностические команды и шаги:
- Проверьте кардинальность лейблов в Loki: Используйте запрос
sum by (label_name) (count_over_time({job="your-app"}[1h])) для выявления высококардинальных лейблов. Избегайте использования уникальных ID в лейблах.
- Оптимизируйте запросы:
- Для Loki: Начинайте запросы с фильтрации по низкокардинальным лейблам, затем используйте полнотекстовый поиск или регулярные выражения. Используйте
line_format для извлечения нужных данных.
- Для Tempo: Запросы по ID трассировки всегда самые быстрые. Если ищете по атрибутам, убедитесь, что вы используете интеграцию с Loki/Prometheus, и что запросы к ним эффективны.
- Мониторинг ресурсов Loki/Tempo: Используйте дашборды Grafana для мониторинга CPU, RAM, дискового I/O Loki и Tempo. Обратите внимание на метрики
loki_ingester_chunk_age_seconds (задержка записи чанков) и tempo_ingester_blocks_created_total.
- Проверьте производительность хранилища: Если используете внешнее S3, проверьте задержку сети. Если MinIO на том же VPS, убедитесь, что диск не перегружен.
- Увеличьте ресурсы: Если все оптимизации сделаны, но запросы все еще медленные, возможно, пора увеличить CPU/RAM для Loki/Tempo или рассмотреть горизонтальное масштабирование.
3. Переполнение диска на VPS
Возможные причины:
- Слишком большой объем логов/трассировок для локального MinIO.
- Неправильная настройка политики хранения (retention policy) в Loki/Tempo.
- Накопление WAL-файлов Tempo или временных файлов Loki.
- Проблемы с ротацией логов Docker.
Диагностические команды и шаги:
- Проверьте использование диска:
df -h
du -sh /mnt/data/
Определите, какая директория занимает больше всего места.
- Проверьте политики хранения: Убедитесь, что в
loki-config.yaml (chunk_store_config.max_look_back_period) и tempo-config.yaml (storage.trace.retention) установлены разумные сроки хранения. Убедитесь, что они применяются.
- Проверьте MinIO: Если MinIO хранит данные локально, убедитесь, что его бакеты не растут бесконечно.
- Проверьте логи Docker-контейнеров: Логи Docker могут быстро заполнять диск. Настройте ротацию логов для Docker Daemon.
# /etc/docker/daemon.json
{
"log-driver": "json-file",
"log-opts": {
"max-size": "10m",
"max-file": "3"
}
}
После изменения перезапустите Docker: sudo systemctl restart docker.
- Очистка временных файлов: Иногда временные директории Loki (
/tmp/loki/boltdb-shipper-cache, /tmp/loki/compactor) или Tempo (/tmp/tempo/wal) могут разрастаться. Убедитесь, что компрессор и шиппер работают корректно.
4. OpenTelemetry Collector потребляет слишком много ресурсов
Возможные причины:
- Слишком большой объем входящих данных.
- Неэффективные процессоры (например, слишком много сложных преобразований).
- Отсутствие батчинга.
Диагностические команды и шаги:
- Мониторинг Collector: Используйте метрики самого Collector (доступны через Prometheus-экспортер на
:8889) для отслеживания его CPU, RAM, количества принятых/отправленных спанов/логов/метрик.
- Оптимизируйте конфигурацию:
- Убедитесь, что
batch процессор включен и настроен.
- Используйте
memory_limiter для ограничения потребления RAM.
- Пересмотрите процессоры: если есть сложные операции, такие как
transform или filter, убедитесь, что они эффективны. Возможно, часть фильтрации стоит делать на уровне приложения.
- Рассмотрите сэмплирование трассировок на Collector.
- Уменьшите объем входящих данных: Если приложения генерируют слишком много шума, настройте их так, чтобы они отправляли только релевантную телеметрию.
Когда обращаться в поддержку:
- Провайдер VPS: Если есть подозрения на аппаратные проблемы с VPS (диск, сеть, CPU), или если вы не можете получить доступ к серверу по SSH.
- Сообщества OpenTelemetry, Loki, Tempo: Если вы столкнулись с ошибками, которые кажутся багами в самом ПО, или если вы не можете найти решение проблемы в документации. Используйте GitHub Issues, Discord-каналы или форумы.
- Собственная команда: Если проблема связана с инструментацией приложений или бизнес-логикой.
FAQ: Часто задаваемые вопросы
Что такое Observability и чем она отличается от мониторинга в 2026 году?
В 2026 году разница между Observability и мониторингом стала еще более критичной. Мониторинг, по сути, отвечает на вопрос "Что случилось?", следя за заранее известными метриками и состояниями (например, "CPU выше 80%"). Observability же позволяет ответить на вопрос "Почему это случилось?", предоставляя глубокое понимание внутреннего состояния системы через метрики, логи и трассировки, позволяя исследовать неизвестные ранее проблемы и поведение системы.
Почему именно OpenTelemetry, Loki и Tempo, а не Elastic Stack или Jaeger?
OpenTelemetry, Loki и Tempo выбраны для VPS-среды в 2026 году из-за их исключительной ресурсоэффективности и гибкости. Elastic Stack (Elasticsearch, Kibana, Logstash) требует значительно больше RAM и CPU, что делает его дорогим для VPS. Jaeger, хотя и является отличным инструментом для трассировок, часто требует мощной СУБД (Cassandra или Elasticsearch) для хранения, что также увеличивает затраты. Loki и Tempo спроектированы для работы с объектным хранилищем, минимизируя требования к RAM/CPU и делая их идеальными для бюджетных VPS-решений.
Можно ли использовать OpenTelemetry только для части телеметрии (например, только для трассировок)?
Да, OpenTelemetry является модульным. Вы можете использовать его SDK только для трассировок, только для метрик или только для логов, или для любой их комбинации. OpenTelemetry Collector также может быть настроен на обработку только определенных типов телеметрии и маршрутизацию их в соответствующие бэкенды. Это позволяет внедрять Observability постепенно, шаг за шагом.
Насколько безопасно хранить логи и трассировки в MinIO на том же VPS?
Хранение данных в MinIO на том же VPS безопасно при условии, что VPS надежно защищен (файрвол, SSH-ключи, регулярные обновления). Однако, для критически важных данных и высокой доступности, рекомендуется использовать облачное S3-совместимое хранилище (AWS S3, Google Cloud Storage, Azure Blob Storage) или выделенный кластер MinIO. Для большинства стартапов и средних проектов на VPS локальный MinIO является приемлемым компромиссом между безопасностью, производительностью и стоимостью.
Как долго рекомендуется хранить логи и трассировки?
Срок хранения зависит от требований бизнеса, регуляторных норм и стоимости. Для оперативной диагностики обычно достаточно 7-30 дней. Для аудита и анализа долгосрочных трендов может потребоваться 90 дней и более. Loki и Tempo позволяют гибко настраивать политику хранения. В 2026 году, с ростом объемов данных, все чаще применяются многоуровневые стратегии хранения (горячее, холодное, архивное).
Нужно ли сэмплировать трассировки, если Tempo спроектирован для "храни все"?
Tempo действительно спроектирован для эффективного хранения 100% трассировок благодаря своей архитектуре. Однако, "храни все" относится к бэкенду. Если ваше приложение генерирует очень большой объем трассировок (например, десятки тысяч спанов в секунду), то нагрузка на OpenTelemetry Collector и сетевой трафик могут стать узким местом. В таких случаях сэмплирование на OpenTelemetry Collector (например, Head-based сэмплирование) поможет снизить нагрузку и контролировать расходы, сохраняя при этом ценные трассировки (например, с ошибками).
Может ли OpenTelemetry Collector выступать в роли Prometheus-сервера?
Нет, OpenTelemetry Collector не является полноценным Prometheus-сервером. Он может принимать метрики в формате OTLP, преобразовывать их и экспортировать в Prometheus-совместимый формат, а также скрейпить метрики с других экспортеров (как Prometheus). В нашем стеке Collector выступает как экспортер для метрик, а Grafana напрямую читает эти метрики с Collector. Для полноценного долгосрочного хранения метрик и сложных запросов PromQL обычно используют отдельный Prometheus-сервер или его кластерные варианты (Thanos, Cortex).
Как контролировать затраты на трафик при использовании Observability на VPS?
Контроль трафика — ключевой фактор на VPS. Используйте OpenTelemetry Collector для максимальной фильтрации, агрегации и сэмплирования телеметрии до ее отправки. Размещайте MinIO (или другой S3-совместимый сервис) на том же VPS, что и Loki/Tempo, чтобы избежать платного исходящего трафика между ними. Минимизируйте количество исходящих запросов из Grafana к Loki/Tempo, если они размещены в другом ЦОД или облаке.
Что делать, если VPS перестает справляться с нагрузкой?
Если ваш VPS начинает испытывать нехватку ресурсов, рассмотрите следующие шаги: 1) Оптимизируйте конфигурации Collector, Loki, Tempo (более агрессивное сэмплирование/фильтрация, оптимизация запросов). 2) Увеличьте ресурсы VPS (CPU, RAM). 3) Разделите компоненты на несколько VPS (например, один для Collector/Prometheus/Grafana, другой для Loki/Tempo). 4) Рассмотрите переход на управляемый Kubernetes-кластер, где Loki и Tempo могут быть развернуты в высокодоступной и масштабируемой конфигурации.
Можно ли интегрировать существующие логи с OpenTelemetry?
Да, OpenTelemetry Collector имеет различные приемники (receivers), которые могут собирать логи из разных источников, включая файлы (filelog receiver), системный журнал (journald receiver), Docker-контейнеры. Вы также можете использовать Promtail для сбора логов и отправки их в Loki, а затем уже связывать их с трассировками OpenTelemetry через общие атрибуты (trace_id).
Какие преимущества дает использование семантических конвенций OpenTelemetry?
Семантические конвенции OpenTelemetry предоставляют стандартизированные имена и значения для атрибутов (тегов) трассировок, метрик и логов (например, http.method, db.statement, service.name). Это значительно улучшает читаемость, переносимость и анализируемость телеметрии, облегчая создание дашбордов, алертов и запросов, а также интеграцию с различными инструментами Observability.
Заключение
В 2026 году, когда распределенные системы стали нормой, а сложность инфраструктуры продолжает расти, полная наблюдаемость (Observability) является не просто желательной функцией, а критически важным компонентом для стабильности, производительности и успешности любого IT-проекта. Мы показали, что даже при ограниченных ресурсах виртуального приватного сервера (VPS) можно построить мощную, гибкую и экономически эффективную систему Observability.
Связка OpenTelemetry, Loki и Tempo, интегрированная с Grafana, предлагает уникальный баланс между функциональностью и стоимостью. OpenTelemetry выступает как универсальный стандарт для сбора всех видов телеметрии, обеспечивая vendor-agnostic подход и гибкость. Loki предоставляет экономичное и масштабируемое решение для хранения логов, используя объектное хранилище и индексацию по метаданным. Tempo революционизирует подход к распределенным трассировкам, предлагая "храни все" модель с минимальными требованиями к ресурсам, также используя объектное хранилище.
Ключевыми факторами успеха при внедрении этой связки на VPS являются: тщательное планирование ресурсов, эффективное использование OpenTelemetry Collector для фильтрации, агрегации и сэмплирования данных, правильное лейблирование в Loki для избежания проблем с кардинальностью, а также постоянный мониторинг самой системы Observability. Не стоит забывать и про автоматизацию развертывания с помощью инструментов Infrastructure as Code, что значительно сокращает время и снижает вероятность ошибок.
Итоговые рекомендации:
- Начните с OpenTelemetry: Инструментируйте свои приложения с помощью OpenTelemetry SDK. Это инвестиция в будущее, которая окупится многократно.
- Используйте Collector эффективно: OpenTelemetry Collector — ваш лучший друг на VPS. Настраивайте его для оптимизации трафика и нагрузки на бэкенды.
- Выбирайте хранилище с умом: Для VPS MinIO на том же сервере или недорогое облачное S3-совместимое хранилище является оптимальным выбором для Loki и Tempo.
- Мониторьте и оптимизируйте: Регулярно проверяйте потребление ресурсов вашими компонентами Observability и оптимизируйте конфигурации, чтобы избежать скрытых затрат.
- Автоматизируйте: Ручное управление быстро станет узким местом. Автоматизируйте развертывание и настройку.
- Обучайте команду: Чем лучше ваша команда понимает и использует инструменты Observability, тем быстрее будут решаться проблемы и тем выше будет стабильность ваших систем.
Следующие шаги для читателя:
- Проведите пилотное развертывание: Начните с небольшого VPS и нескольких тестовых сервисов, чтобы на практике освоить настройку OpenTelemetry, Loki и Tempo.
- Изучите документацию: Углубитесь в документацию по каждому из компонентов, особенно в раздел "Configuration" и "Troubleshooting".
- Присоединитесь к сообществу: Активное участие в сообществах OpenTelemetry, Grafana Labs (Loki, Tempo) позволит вам быть в курсе последних обновлений и получать помощь от опытных инженеров.
- Разработайте стратегию инструментации: Определите, какие метрики, логи и трассировки наиболее важны для ваших приложений, и как их эффективно собирать.
Внедрение полной наблюдаемости — это не одноразовая задача, а непрерывный процесс совершенствования. Но с правильным стеком инструментов и методическим подходом, вы сможете обеспечить надежную работу ваших распределенных систем на VPS, опережая конкурентов в динамичном мире 2026 года.
Was this guide helpful?
полная наблюдаемость (observability) для распределенных систем: opentelemetry, loki и tempo на vps 2026