Глобальная балансировка нагрузки и DNS-файловер: Архитектура отказоустойчивых SaaS-приложений
TL;DR
- Мультирегиональная архитектура — основа отказоустойчивости. Развертывание SaaS-приложений в нескольких географических регионах критически важно для минимизации простоев и повышения доступности.
- Глобальная балансировка нагрузки (GLB) — ваш дирижер трафика. Используйте DNS-провайдеры с расширенными функциями (Route 53, Azure DNS Traffic Manager, Google Cloud DNS с GLB) для интеллектуальной маршрутизации пользователей к ближайшим и здоровым инстансам.
- DNS-файловер — спасательный круг в случае катастрофы. Автоматическое переключение трафика на резервный регион при сбое основного, минимизируя RTO (Recovery Time Objective).
- Активные проверки здоровья (Health Checks) — глаза и уши вашей системы. Настройте глубокие, многоуровневые проверки для мониторинга доступности и производительности сервисов, а не только сетевого уровня.
- Стратегия данных — сложнейшая часть головоломки. Репликация баз данных (Active-Active, Active-Passive) и синхронизация кэшей — ключевые аспекты для сохранения целостности данных при переключении.
- Тестирование и автоматизация — не роскошь, а необходимость. Регулярно проводите учения по аварийному восстановлению и автоматизируйте процессы переключения для уверенности в работоспособности архитектуры.
- Стоимость — значительный фактор, требующий оптимизации. Мультирегиональность увеличивает расходы, но правильно спроектированная система может обеспечить оптимальный баланс между доступностью и затратами.
Введение
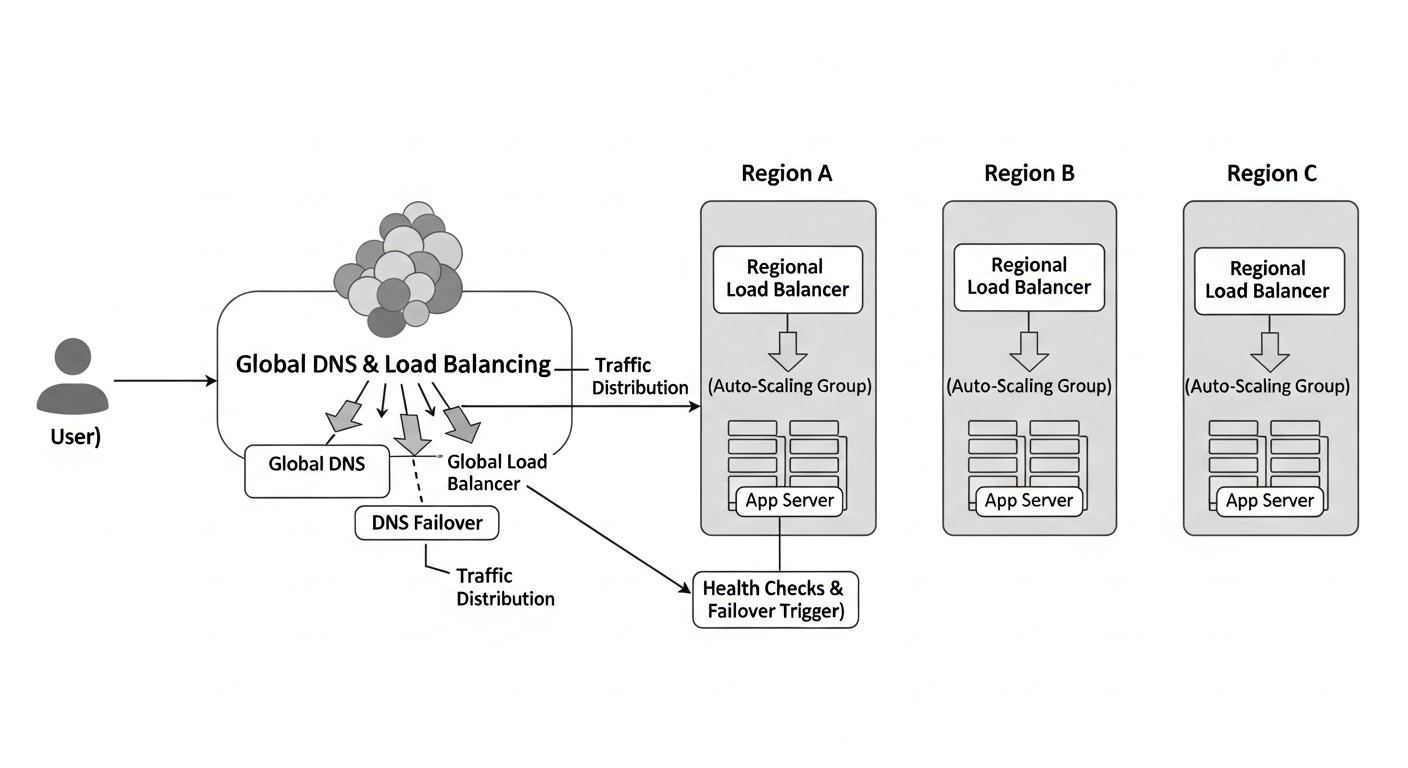 Схема: Введение
Схема: Введение
В современном мире, где цифровизация проникла во все сферы бизнеса, а ожидания пользователей от доступности сервисов стремятся к 100%, архитектура высоконадежных SaaS-приложений перестала быть опцией и превратилась в абсолютную необходимость. К 2026 году компании, которые не смогут обеспечить непрерывность работы своих сервисов, рискуют потерять клиентов, репутацию и, в конечном итоге, долю рынка. Простой в несколько минут может обернуться миллионными убытками и непоправимым ущербом для бренда.
Эта статья посвящена двум краеугольным камням построения отказоустойчивых SaaS-приложений: глобальной балансировке нагрузки (Global Load Balancing, GLB) и DNS-файловеру. Мы глубоко погрузимся в механизмы, позволяющие распределять трафик между географически разнесенными центрами обработки данных и автоматически переключаться на резервные системы в случае возникновения проблем. Это не просто технические концепции; это фундаментальные элементы стратегии выживания любого SaaS-проекта в условиях постоянно растущих требований к доступности и производительности.
Мы рассмотрим, почему эти технологии важны не только для крупных корпораций, но и для стартапов, стремящихся к масштабированию и глобальному присутствию. Статья охватывает практические аспекты реализации, начиная от выбора подходящих провайдеров и заканчивая тонкими нюансами настройки и мониторинга. Она написана для DevOps-инженеров, backend-разработчиков, фаундеров SaaS-проектов, системных администраторов и технических директоров, которые сталкиваются с вызовами обеспечения высокой доступности, катастрофоустойчивости и оптимальной производительности своих приложений.
Основная проблема, которую решает данный гайд — это построение архитектуры, способной выдержать региональные сбои, сетевые проблемы или даже целые катастрофы в одном из дата-центров, при этом минимизируя время простоя и потерю данных. Мы покажем, как с помощью GLB и DNS-файловера можно не только снизить риски, но и улучшить пользовательский опыт, направляя трафик к ближайшим серверам, тем самым уменьшая задержки. Готовьтесь к глубокому погружению в мир распределенных систем, где каждый байт данных и каждая миллисекунда задержки имеют значение.
Основные критерии и факторы
При проектировании архитектуры глобальной балансировки нагрузки и DNS-файловера необходимо учитывать множество факторов, которые напрямую влияют на надежность, производительность и стоимость вашей SaaS-платформы. Выбор правильного решения зависит от специфики вашего приложения, целевой аудитории и бизнес-требований. Давайте рассмотрим ключевые критерии, которые помогут вам принять обоснованное решение.
Это самый очевидный и, пожалуй, самый важный критерий. Доступность измеряется процентом времени, в течение которого сервис доступен для пользователей (например, 99.99% — это всего 52 минуты простоя в год). Отказоустойчивость же характеризует способность системы восстанавливаться после сбоев. Для GLB и DNS-файловера это означает способность быстро и автоматически переключать трафик на здоровые ресурсы в другом регионе при отказе основного. Важно оценить:
- RTO (Recovery Time Objective): Максимальное допустимое время простоя после сбоя. Чем ниже RTO, тем сложнее и дороже архитектура. Для критичных SaaS-приложений RTO может быть в пределах секунд или даже миллисекунд.
- RPO (Recovery Point Objective): Максимальный допустимый объем потери данных, измеряемый во времени. Для многих SaaS RPO должно стремиться к нулю, что требует синхронной или асинхронной репликации данных между регионами.
- Механизмы обнаружения сбоев: Насколько быстро и точно система GLB может обнаружить сбой в регионе или конкретном сервисе? Это включает в себя различные типы health checks (HTTP, TCP, ICMP, пользовательские скрипты).
- Скорость переключения (Failover Speed): Время, необходимое для перенаправления трафика после обнаружения сбоя. Для DNS-файловера это сильно зависит от TTL (Time To Live) DNS-записей и кэширования на стороне клиентов и провайдеров.
Пользователи ожидают быстрой работы приложений. Размещение ресурсов ближе к пользователям значительно снижает задержку. GLB может использовать гео-маршрутизацию или маршрутизацию на основе задержки, чтобы направлять запросы к ближайшему или наиболее производительному дата-центру. Оцените:
- Географическое распределение пользователей: Где находятся ваши основные пользователи? Это поможет определить оптимальное расположение регионов.
- Механизмы маршрутизации: Поддерживает ли выбранное GLB-решение маршрутизацию по географическому принципу, по задержке, по весу или комбинацию этих методов?
- Влияние на CDN: Как GLB будет взаимодействовать с вашей Content Delivery Network? Оптимизация этой связки критична для статического контента.
SaaS-приложения должны быть готовы к росту нагрузки. GLB и DNS-файловер должны позволять легко добавлять новые регионы или увеличивать ресурсы в существующих, не нарушая работу системы. Важные аспекты:
- Горизонтальная масштабируемость: Возможность легко добавлять новые инстансы или даже целые регионы.
- Интеграция с облачными сервисами: Насколько хорошо GLB-решение интегрируется с автоматическим масштабированием в облаке (Auto Scaling Groups, VM Scale Sets).
- Управление конфигурацией: Насколько просто управлять конфигурацией GLB по мере роста инфраструктуры.
Мультирегиональная архитектура по умолчанию дороже, чем однорегиональная. Важно тщательно оценить все компоненты затрат:
- Стоимость сервисов GLB/DNS: Плата за запросы, за health checks, за зоны.
- Стоимость инфраструктуры в нескольких регионах: Виртуальные машины, базы данных, хранилища, сетевые компоненты.
- Трафик между регионами (Egress/Ingress): Межрегиональный трафик часто является одним из самых дорогих пунктов в облачных счетах.
- Стоимость разработки и эксплуатации: Дополнительные часы инженеров на проектирование, внедрение и поддержку сложной архитектуры.
- Скрытые расходы: Например, лицензии на ПО, дополнительные инструменты мониторинга.
Чем сложнее система, тем выше риск ошибок и тем дороже ее обслуживание. Простота настройки, управления и мониторинга играет большую роль. Оцените:
- Кривая обучения: Насколько быстро ваша команда сможет освоить выбранное решение.
- Интеграция: Насколько легко интегрировать GLB с существующей CI/CD, системами мониторинга и оповещения.
- Документация и поддержка: Качество документации и доступность технической поддержки от провайдера.
Использование специфических сервисов одного облачного провайдера может усложнить миграцию или использование мультиоблачной стратегии в будущем. Оцените:
- Стандартизация: Использует ли решение стандартные протоколы (DNS) или проприетарные API?
- Переносимость: Насколько легко будет перенести вашу GLB-конфигурацию или даже все приложение к другому провайдеру.
Для некоторых отраслей или типов данных существуют строгие требования к местоположению данных и обработке. GLB должно позволять соблюдать эти требования.
- Суверенитет данных: Возможность гарантировать, что данные пользователей из определенного региона остаются в этом регионе.
- Регуляторные нормы: Соответствие GDPR, HIPAA, PCI DSS и другим стандартам.
Тщательный анализ этих критериев на ранних этапах проектирования позволит избежать дорогостоящих ошибок и построить надежную, масштабируемую и экономически эффективную архитектуру для вашего SaaS-приложения.
Сравнительная таблица решений для GLB и DNS-файловера
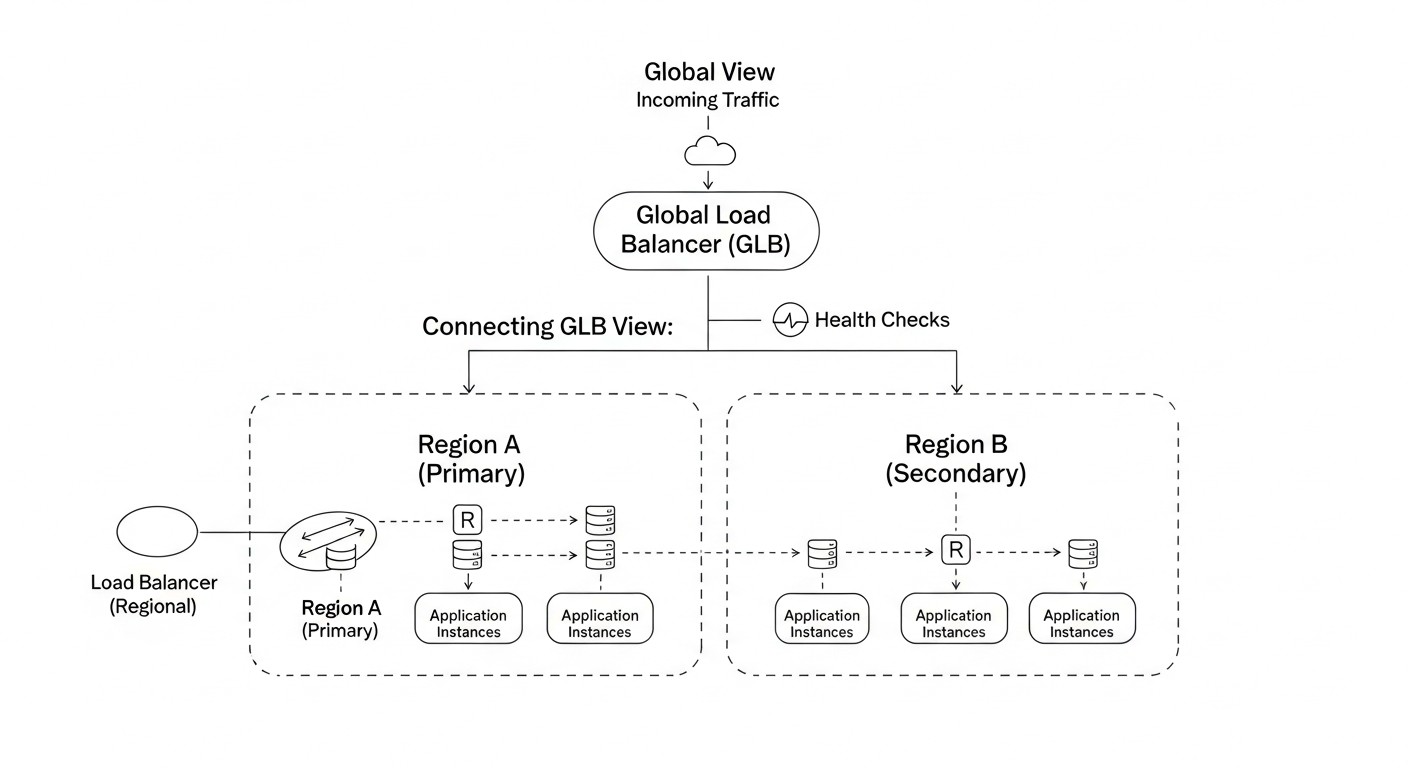 Схема: Сравнительная таблица решений для GLB и DNS-файловера
Схема: Сравнительная таблица решений для GLB и DNS-файловера
Выбор конкретного решения для глобальной балансировки нагрузки и DNS-файловера зависит от множества факторов, включая ваш бюджет, требования к производительности, сложность инфраструктуры и степень зависимости от облачного провайдера. В этой таблице мы сравним наиболее популярные подходы и сервисы, актуальные для 2026 года, с учетом их возможностей, стоимости и применимости.
| Критерий |
Управляемый DNS GLB (AWS Route 53 Traffic Flow, Azure Traffic Manager, Google Cloud DNS с Health Checks) |
CDN с GLB (Cloudflare, Akamai, AWS CloudFront с Origin Failover) |
Программный GLB (Nginx Plus, HAProxy Enterprise + Consul/Zookeeper) |
Anycast DNS (Cloudflare DNS, Google Public DNS, специализированные провайдеры) |
Мультиоблачный/Гибридный GLB (VMware NSX ALB, F5 BIG-IP DNS, NetScaler GSLB) |
| Тип решения |
Облачный сервис DNS с расширенными возможностями маршрутизации и health checks. |
Глобальная сеть доставки контента с функцией маршрутизации запросов к лучшим Origin-серверам. |
Программное обеспечение, разворачиваемое на вашей инфраструктуре (VMs, контейнеры). |
Специализированная сетевая технология маршрутизации DNS-запросов к ближайшему серверу. |
Комплексное решение для балансировки нагрузки в гибридных и мультиоблачных средах. |
| Механизм маршрутизации |
DNS-записи (A, CNAME) с гео-таргетингом, на основе задержки, взвешенные, по health check. |
HTTP(S) прокси, L7-балансировка, гео-маршрутизация, на основе производительности Origin. |
L4/L7 балансировка, гео-таргетинг (через DNS или IP-адреса), на основе health checks. |
BGP-маршрутизация IP-адресов, направляет UDP-запросы к ближайшему узлу. |
DNS-балансировка (GSLB), интеллектуальная маршрутизация, L4/L7, интеграция с облаками. |
| Скорость файловера (RTO) |
Зависит от TTL DNS-записей (от 30-60 сек до 5-10 мин). Health checks до 10-30 сек. |
Мгновенно (несколько секунд) за счет проксирования и постоянных health checks Origin-серверов. |
Мгновенно (несколько секунд) за счет локальных health checks и переключения на уровне L4/L7. |
Мгновенно на уровне DNS-запроса (не влияет на активные соединения). |
От 5 секунд (L7) до 1-2 минут (DNS GSLB) в зависимости от конфигурации. |
| RPO (потеря данных) |
Зависит от стратегии репликации баз данных, не от GLB. |
Зависит от стратегии репликации баз данных, не от CDN. |
Зависит от стратегии репликации баз данных, не от GLB. |
Зависит от стратегии репликации баз данных, не от DNS. |
Зависит от стратегии репликации баз данных, не от GSLB. |
| Примерная стоимость (2026) |
$0.50-$1.00 за зону/месяц + $0.005-$0.007 за 1M запросов + $0.70-$1.00 за health check/месяц. |
От $20/мес (Pro) до $2000+/мес (Enterprise), зависит от трафика и функций. Включает CDN. |
Лицензии от $1000-$5000+ за инстанс/год. Требуются VM/серверы. Высокие эксплуатационные расходы. |
Часто входит в базовые тарифы DNS-провайдеров (Cloudflare Free/Pro). Для крупных от $200/мес. |
Лицензии от $5000-$20000+ за устройство/год. Высокие эксплуатационные расходы. |
| Сложность внедрения |
Средняя. Требуется понимание DNS, health checks и региональных развертываний. |
Низкая-Средняя. Простая настройка DNS, но сложная оптимизация CDN и Origin. |
Высокая. Требуется глубокое знание сетевых технологий, ОС, скриптинга и кластеризации. |
Низкая. Простое изменение NS-записей. Настройка специфична для провайдера. |
Очень высокая. Требует экспертных знаний сетевых технологий, аппаратных решений и интеграции. |
| Гибкость и кастомизация |
Высокая. Гибкие политики маршрутизации, интеграция с другими облачными сервисами. |
Средняя. Кастомизация правил кэширования, WAF, но ограничена в маршрутизации Origin. |
Очень высокая. Полный контроль над логикой балансировки, скрипты, модули. |
Низкая. Фокусируется на маршрутизации DNS-запросов, не трафика приложений. |
Очень высокая. Полный контроль над всеми аспектами балансировки и маршрутизации. |
| Управление данными |
Не управляет данными, только трафиком. |
Кэширует статический контент, может влиять на динамический. |
Не управляет данными, только трафиком. |
Не управляет данными, только трафиком. |
Не управляет данными, только трафиком. |
| Сценарии использования |
Большинство SaaS-приложений, мультирегиональные развертывания, A/B-тестирование, Blue/Green деплой. |
SaaS с большим объемом статического/динамического контента, API-сервисы, защита от DDoS. |
Приложения с высокой производительностью, специфические требования к L4/L7, on-premise, гибридные облака. |
Улучшение производительности DNS-запросов, распределение низкоуровневого трафика, DDoS-защита DNS. |
Крупные предприятия, гибридные облака, мультиоблачные стратегии, комплексные требования к безопасности и производительности. |
Эта таблица дает общее представление о доступных вариантах. В 2026 году ожидается дальнейшая конвергенция этих решений, когда облачные провайдеры будут предлагать более глубокую интеграцию CDN и GLB, а программные решения станут еще более гибкими за счет контейнеризации и оркестрации.
Детальный обзор каждого пункта/варианта
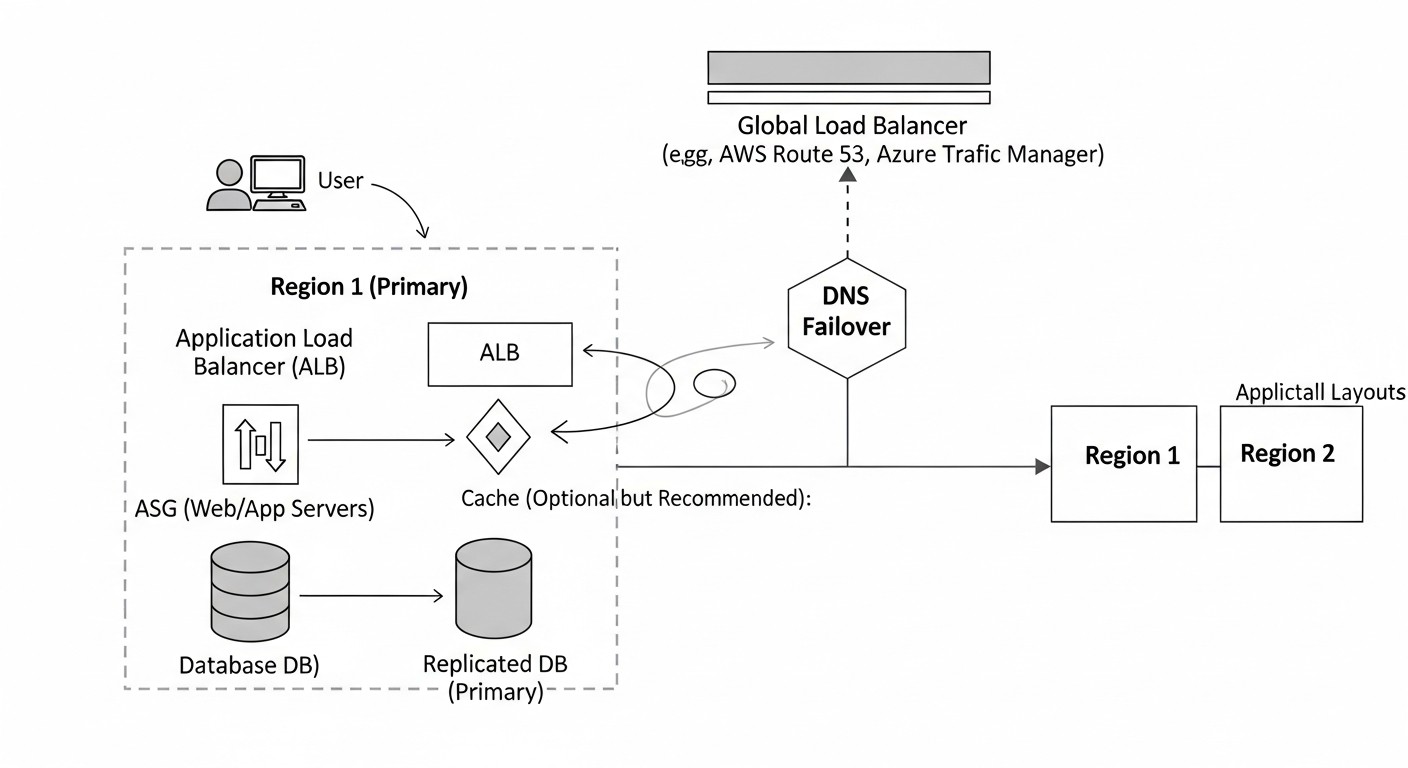 Схема: Детальный обзор каждого пункта/варианта
Схема: Детальный обзор каждого пункта/варианта
После общего сравнения, давайте углубимся в детали каждого из представленных решений, рассмотрим их архитектурные особенности, плюсы, минусы и оптимальные сценарии использования. Понимание этих нюансов критически важно для принятия обоснованного решения.
Эти сервисы предлагают DNS-управляемую глобальную балансировку нагрузки. Основной принцип работы заключается в том, что DNS-серверы провайдера отвечают на запросы клиентов, выдавая IP-адреса ближайших или наиболее здоровых ресурсов, основываясь на настроенных политиках маршрутизации и результатах health checks. Клиентский браузер или приложение затем напрямую подключается к этому IP-адресу.
Как это работает: Вы создаете несколько DNS-записей (например, A-записи) для вашего домена, каждая из которых указывает на IP-адрес вашего приложения в разных регионах. Затем вы применяете политики маршрутизации (например, гео-маршрутизация, маршрутизация на основе задержки, взвешенная маршрутизация) и привязываете к каждой записи health checks. Когда пользователь запрашивает ваш домен, DNS-провайдер проверяет политики и результаты health checks, а затем возвращает наиболее подходящий IP-адрес. Если один регион выходит из строя, health check это обнаружит, и DNS-провайдер перестанет выдавать его IP-адрес, перенаправляя трафик на здоровый регион.
Плюсы:
- Простота реализации: Относительно легко настроить, особенно если вы уже используете облачного провайдера.
- Эффективность по стоимости: Обычно дешевле, чем комплексные L7-решения, особенно для небольших и средних нагрузок.
- Гео-маршрутизация и маршрутизация по задержке: Позволяет направлять пользователей к ближайшим серверам, улучшая UX.
- Интеграция с облачной инфраструктурой: Глубокая интеграция с другими сервисами облачного провайдера (EC2, Load Balancers, VMs).
Минусы:
- Зависимость от TTL: Время переключения при файловере ограничено TTL DNS-записей. Если TTL высокий (например, 5 минут), клиенты могут продолжать получать IP неисправного региона до истечения кэша.
- Кэширование DNS: Промежуточные DNS-серверы и пользовательские устройства могут кэшировать записи, игнорируя быстрые изменения.
- Только L4-балансировка: DNS-решения работают на уровне IP-адресов. Они не могут инспектировать HTTP-заголовки или выполнять сложную L7-балансировку.
- Сложность для мультиоблачных сценариев: Использование GLB одного провайдера для балансировки между разными облаками может быть затруднительным или потребовать дополнительных решений.
Для кого подходит: Большинство SaaS-приложений, которые хотят обеспечить мультирегиональную отказоустойчивость и оптимизировать задержки, особенно если они уже плотно интегрированы в одного облачного провайдера. Идеально для A/B-тестирования и Blue/Green деплоя на уровне регионов.
CDN (Content Delivery Network) изначально предназначены для кэширования и доставки статического контента. Однако современные CDN-провайдеры значительно расширили свой функционал, предлагая продвинутые возможности балансировки нагрузки, файловера и защиты. Они действуют как обратные прокси, принимая весь трафик на свои граничные узлы по всему миру, а затем перенаправляя его к вашим Origin-серверам.
Как это работает: Вы настраиваете свой домен так, чтобы он указывал на CDN (обычно через CNAME). CDN, в свою очередь, знает о ваших Origin-серверах в разных регионах. Она постоянно проверяет их здоровье и производительность. Когда пользователь делает запрос, CDN направляет его к ближайшему граничному узлу, который затем выбирает наиболее оптимальный Origin-сервер (по гео-принципу, задержке, нагрузке) для получения контента или обработки динамического запроса. При сбое Origin-сервера CDN мгновенно переключается на другой здоровый Origin, поскольку она контролирует весь трафик.
Плюсы:
- Мгновенный файловер: Поскольку CDN выступает в роли прокси, она может мгновенно переключить трафик на здоровый Origin, не дожидаясь истечения TTL.
- Улучшенная производительность: Помимо GLB, CDN кэширует контент, снижает задержки и разгружает ваши Origin-серверы.
- DDoS-защита: Большинство CDN предоставляют мощную защиту от DDoS-атак на граничных узлах.
- L7-балансировка: Возможность маршрутизации на основе HTTP-заголовков, URL-путей, методов запроса.
- WAF (Web Application Firewall): Защита от распространенных веб-уязвимостей.
Минусы:
- Стоимость: Может быть значительно дороже, чем чистый DNS GLB, особенно при большом объеме трафика.
- Сложность настройки: Оптимизация кэширования, правил WAF и маршрутизации Origin может быть сложной.
- Дополнительная точка отказа: CDN становится единой точкой отказа (хотя крупные CDN очень надежны).
- Задержка для динамического контента: Несмотря на оптимизации, проксирование через CDN может добавить небольшую задержку для полностью динамических запросов, которые не кэшируются.
Для кого подходит: SaaS-приложения с высоким объемом трафика, требующие максимальной отказоустойчивости, низкой задержки для статического и динамического контента, а также встроенной защиты от DDoS и других веб-атак. Идеально для e-commerce, медиа-платформ, API-сервисов.
Этот подход предполагает развертывание и управление собственными программными балансировщиками нагрузки в каждом регионе. Эти балансировщики могут быть настроены для работы как на L4, так и на L7 уровнях, и часто используют внешние сервисы для обнаружения сервисов (Service Discovery) и управления конфигурацией.
Как это работает: В каждом регионе вы развертываете кластер Nginx Plus или HAProxy Enterprise. Эти балансировщики настроены для распределения трафика между внутренними инстансами вашего приложения. Для глобальной балансировки вы используете DNS GLB (как в первом варианте), который указывает на IP-адреса ваших балансировщиков в разных регионах. Внутри каждого региона балансировщики постоянно мониторят здоровье бэкенд-серверов. Для обеспечения отказоустойчивости и синхронизации конфигурации между балансировщиками и регионами часто используются такие инструменты, как Consul, ZooKeeper или etcd.
Плюсы:
- Полный контроль и гибкость: Максимальная кастомизация логики балансировки, правил маршрутизации, обработки запросов.
- Высокая производительность: Возможность тонкой настройки для достижения максимальной пропускной способности и минимальной задержки.
- Отсутствие vendor lock-in: Вы не привязаны к конкретному облачному провайдеру для GLB-функций.
- Безопасность: Возможность глубокой интеграции с вашей собственной стратегией безопасности.
Минусы:
- Высокая сложность: Требует значительных инженерных усилий для развертывания, настройки, мониторинга и поддержки.
- Эксплуатационные расходы: Необходимо управлять серверами, ОС, обновлениями, кластеризацией.
- RTO зависит от DNS: Глобальный файловер все равно будет зависеть от TTL DNS-записей, если вы используете DNS GLB для переключения между регионами.
- Сложности с гео-маршрутизацией: Самостоятельная реализация гео-маршрутизации без внешнего DNS GLB может быть очень сложной.
Для кого подходит: Крупные компании со специфическими требованиями к производительности, безопасности или функционалу, которые имеют сильные DevOps-команды и готовы инвестировать в собственную инфраструктуру. Также подходит для гибридных облаков или on-premise развертываний, где облачные GLB-сервисы не применимы.
Anycast — это сетевая технология, при которой один и тот же IP-адрес маршрутизируется в нескольких географических точках. Когда клиент отправляет пакет на Anycast IP, сетевая инфраструктура (BGP) направляет его к ближайшей точке присутствия (PoP), которая анонсирует этот IP-адрес. Anycast DNS означает, что DNS-серверы провайдера доступны по одному и тому же IP-адресу в десятках или сотнях PoP по всему миру.
Как это работает: Ваш домен настраивается на использование NS-записей, которые указывают на Anycast IP-адреса DNS-серверов провайдера. Когда пользователь делает DNS-запрос, его запрос автоматически направляется к ближайшему Anycast PoP, который затем обрабатывает запрос. Это значительно ускоряет разрешение DNS-имен, так как запрос не должен пересекать полмира. Важно отметить, что Anycast работает на уровне DNS-запросов, а не на уровне трафика вашего приложения. Он ускоряет процесс получения IP-адреса, но сам трафик приложения все равно пойдет по обычному маршруту к полученному IP.
Плюсы:
- Низкая задержка DNS-запросов: Значительно ускоряет разрешение доменных имен, поскольку запрос обрабатывается ближайшим сервером.
- Повышенная доступность DNS: При отказе одного PoP, DNS-запросы автоматически перенаправляются к следующему ближайшему PoP, обеспечивая высокую отказоустойчивость самого DNS-сервиса.
- DDoS-защита DNS: Распределенная природа Anycast помогает поглощать DDoS-атаки на DNS, поскольку трафик рассеивается по множеству узлов.
- Простота настройки: Обычно сводится к изменению NS-записей домена.
Минусы:
- Только для DNS: Anycast DNS не балансирует трафик вашего приложения. Он лишь ускоряет и делает более отказоустойчивым сам процесс разрешения доменных имен. Для балансировки трафика приложения вам все равно потребуется GLB (DNS GLB или CDN).
- Нет L7-функций: Не предоставляет функционала балансировки на уровне приложений, WAF или кэширования.
- Стоимость: Хотя некоторые провайдеры предлагают Anycast DNS бесплатно (Cloudflare Free), для более продвинутых функций и SLA может потребоваться платная подписка.
Для кого подходит: Всем SaaS-приложениям для улучшения производительности и отказоустойчивости DNS-запросов. Является отличным дополнением к любому из вышеперечисленных GLB-решений, но не заменяет их. Обязателен для глобальных SaaS-проектов.
Эти решения представляют собой корпоративные системы балансировки нагрузки, которые предназначены для работы в сложных, гетерогенных средах, включая мультиоблачные, гибридные и on-premise инфраструктуры. Они предлагают централизованное управление глобальной балансировкой нагрузки, файловером, а также расширенные возможности L4/L7 балансировки и безопасности.
Как это работает: Эти системы развертываются как виртуальные или аппаратные устройства в каждом из ваших центров обработки данных или облачных регионов. Они могут использовать как DNS-методы (GSLB – Global Server Load Balancing), так и прямые прокси-методы для маршрутизации трафика. Они имеют собственные механизмы health checks и могут интегрироваться с различными облачными API для обнаружения сервисов и автоматического масштабирования. Центральная консоль управления позволяет вам определять политики маршрутизации, мониторить состояние всех ресурсов и управлять файловером между регионами и облаками.
Плюсы:
- Комплексное решение: Объединяет GLB, L4/L7 балансировку, WAF, SSL/TLS offloading и другие функции в одном продукте.
- Мультиоблачная и гибридная поддержка: Идеально подходит для компаний, использующих несколько облаков или сочетающих облачные и on-premise ресурсы.
- Высокая производительность и масштабируемость: Разработаны для работы с очень большими объемами трафика.
- Централизованное управление: Единая точка управления для всей глобальной инфраструктуры балансировки.
- Глубокая интеграция: Возможность глубокой интеграции с корпоративными системами мониторинга, безопасности и оркестрации.
Минусы:
- Очень высокая стоимость: Лицензии и поддержка этих систем значительно дороже облачных аналогов.
- Сложность внедрения и обслуживания: Требует высококвалифицированных специалистов и значительных инженерных ресурсов.
- Эксплуатационные расходы: Помимо лицензий, необходимо управлять самой инфраструктурой, на которой развернуты эти решения.
- Избыточность функционала: Для небольших и средних SaaS-проектов функционал может быть избыточным.
Для кого подходит: Крупные предприятия и корпорации с комплексными, гетерогенными инфраструктурами, строгими требованиями к безопасности и производительности, которые готовы инвестировать в мощные, централизованно управляемые решения. Редко используется стартапами или небольшими SaaS-проектами.
Выбор конкретного решения должен быть основан на тщательном анализе ваших текущих и будущих потребностей, бюджета и доступных инженерных ресурсов. Часто оптимальным является гибридный подход, например, использование управляемого DNS GLB в сочетании с CDN для кэширования и защиты, и Anycast DNS для ускорения DNS-запросов.
Практические советы и рекомендации
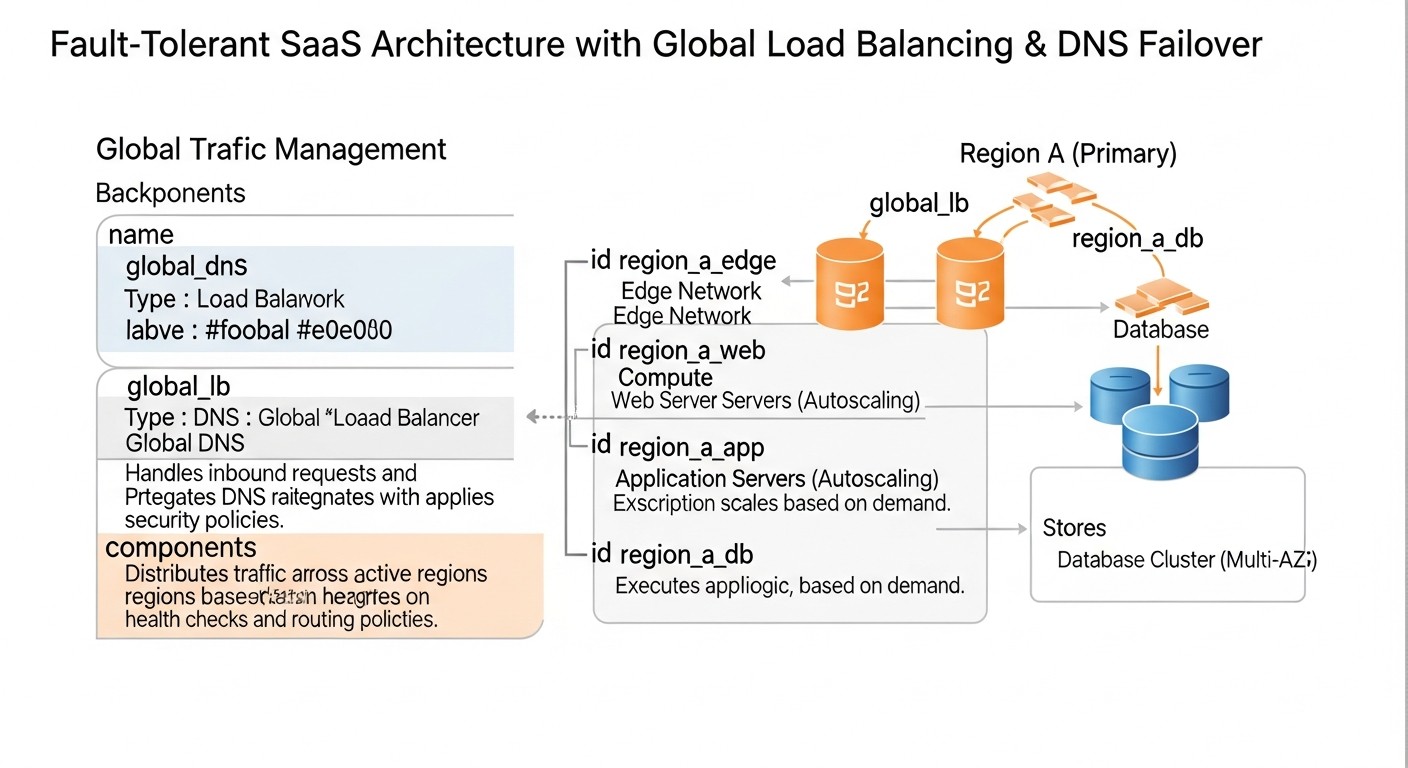 Схема: Практические советы и рекомендации
Схема: Практические советы и рекомендации
Теория — это хорошо, но без практических шагов она бесполезна. В этом разделе мы рассмотрим конкретные рекомендации, пошаговые инструкции и примеры конфигураций, которые помогут вам внедрить глобальную балансировку нагрузки и DNS-файловер в ваше SaaS-приложение.
Не пытайтесь прикрутить мультирегиональность к монолиту, изначально спроектированному для одного ЦОД. Заранее продумайте, как будут взаимодействовать компоненты в разных регионах. Это касается не только сетевого уровня, но и баз данных, очередей сообщений, кэшей и хранилищ файлов.
- Определите регионы: Выберите 2-3 региона, где сосредоточены ваши пользователи или где есть стратегические преимущества (например, соблюдение регуляторных требований). Рекомендуется выбирать регионы на разных континентах для максимальной отказоустойчивости.
- Изоляция ресурсов: Каждый регион должен быть максимально независимым. Сбой в одном регионе не должен влиять на работу другого.
- Репликация данных: Это самый сложный аспект. Для баз данных рассмотрите:
- Active-Passive: Один регион активен, другой — резервный. Данные реплицируются асинхронно или полусинхронно. Проще в реализации, но RPO > 0. Пример: PostgreSQL с WAL shipping, MySQL с репликацией.
- Active-Active: Оба региона принимают запись. Требует распределенных баз данных (Cassandra, CockroachDB, Spanner) или сложных схем разрешения конфликтов. RPO = 0, но очень высокая сложность.
- Гео-партиционирование: Данные пользователей хранятся в ближайшем к ним регионе. Упрощает репликацию, но усложняет запросы, охватывающие несколько регионов.
Используйте сервисы типа AWS Route 53 Traffic Flow, Azure Traffic Manager или Google Cloud DNS с политиками маршрутизации. Для примера рассмотрим AWS Route 53.
Шаг 1: Создайте Health Checks
Health checks должны быть максимально глубокими. Недостаточно проверять только доступность порта 80. Убедитесь, что ваше приложение способно ответить на запрос, обработать его и взаимодействовать с базой данных.
# Пример URL для Health Check, который проверяет не только доступность, но и работоспособность DB
# GET /healthz - возвращает 200 OK, если приложение и его зависимости (DB, Redis) живы.
# Создание Health Check для основного региона (например, us-east-1)
aws route53 create-health-check \
--caller-reference "my-saas-app-us-east-1-health-check-$(date +%s)" \
--health-check-config '{"IPAddress": "1.2.3.4", "Port": 80, "Type": "HTTP", "ResourcePath": "/healthz", "RequestInterval": 10, "FailureThreshold": 3}'
# Создание Health Check для резервного региона (например, eu-west-1)
aws route53 create-health-check \
--caller-reference "my-saas-app-eu-west-1-health-check-$(date +%s)" \
--health-check-config '{"IPAddress": "5.6.7.8", "Port": 80, "Type": "HTTP", "ResourcePath": "/healthz", "RequestInterval": 10, "FailureThreshold": 3}'
Шаг 2: Настройте Record Sets с политиками маршрутизации
Используйте политику Failover или Latency-based Routing для автоматического переключения.
# Пример создания Failover Record Set для домена app.example.com
# Основной регион (Primary)
{
"Comment": "Primary record for app.example.com in us-east-1",
"Changes": [
{
"Action": "CREATE",
"ResourceRecordSet": {
"Name": "app.example.com",
"Type": "A",
"SetIdentifier": "us-east-1-primary",
"Failover": "PRIMARY",
"HealthCheckId": "YOUR_US_EAST_1_HEALTH_CHECK_ID",
"TTL": 60,
"ResourceRecords": [
{ "Value": "IP_OF_US_EAST_1_LOAD_BALANCER" }
]
}
}
]
}
# Резервный регион (Secondary)
{
"Comment": "Secondary record for app.example.com in eu-west-1",
"Changes": [
{
"Action": "CREATE",
"ResourceRecordSet": {
"Name": "app.example.com",
"Type": "A",
"SetIdentifier": "eu-west-1-secondary",
"Failover": "SECONDARY",
"HealthCheckId": "YOUR_EU_WEST_1_HEALTH_CHECK_ID",
"TTL": 60,
"ResourceRecords": [
{ "Value": "IP_OF_EU_WEST_1_LOAD_BALANCER" }
]
}
}
]
}
Шаг 3: Установите низкий TTL
Для критически важных сервисов установите TTL на 60-300 секунд (1-5 минут). Слишком низкий TTL (например, 5 секунд) может увеличить нагрузку на DNS-серверы, но значительно ускорит файловер. Найдите золотую середину.
Даже если вы используете DNS GLB, CDN может значительно улучшить опыт пользователя и обеспечить дополнительный уровень защиты.
- Настройте Origin Failover: В Cloudflare или AWS CloudFront вы можете указать несколько Origin-серверов (ваших региональных балансировщиков) и настроить правила переключения между ними.
- Оптимизируйте кэширование: Убедитесь, что статический контент кэшируется максимально эффективно.
- Включите WAF и DDoS-защиту: Используйте возможности CDN для защиты вашего приложения на уровне Edge.
Вы должны знать о проблемах раньше своих клиентов. Мониторинг должен охватывать:
- Health Checks GLB: Мониторинг статуса ваших DNS health checks.
- Метрики приложения: Задержка, ошибки, пропускная способность, загрузка CPU/RAM в каждом регионе.
- Метрики базы данных: Репликация, задержки, ошибки, использование диска.
- Сетевые метрики: Задержка между регионами, потери пакетов.
Настройте оповещения (Slack, PagerDuty, email) на критические события, такие как сбой health check, увеличение ошибок или задержки.
Единственный способ убедиться, что ваша архитектура работает, — это регулярно ее тестировать. Имитируйте сбои в одном из регионов и проверяйте, как система реагирует.
- Инициируйте сбой Health Check: Временно заблокируйте доступ к
/healthz в одном регионе или остановите сервис, чтобы проверить, как GLB переключает трафик.
- Отключите регион: Используйте AWS Fault Injection Simulator или аналогичные инструменты для имитации полного сбоя региона.
- Документируйте RTO и RPO: Замеряйте фактическое время восстановления и потенциальную потерю данных.
- Автоматизируйте тестирование: Включите проверку файловера в ваши CI/CD пайплайны.
Все ваши настройки инфраструктуры, включая GLB, DNS, health checks, должны быть описаны в коде (Terraform, CloudFormation, Pulumi). Это обеспечивает повторяемость, версионирование и упрощает управление.
# Пример Terraform для AWS Route 53 Health Check
resource "aws_route53_health_check" "us_east_1_app_health" {
fqdn = "app.example.com"
port = 80
type = "HTTP"
resource_path = "/healthz"
request_interval = 10
failure_threshold = 3
tags = {
Name = "app-us-east-1-health"
}
}
# Пример Terraform для AWS Route 53 Failover A Record Set
resource "aws_route53_record" "app_primary" {
zone_id = aws_route53_zone.main.zone_id
name = "app.example.com"
type = "A"
ttl = 60
set_identifier = "us-east-1-primary"
failover_routing_policy {
type = "PRIMARY"
}
health_check_id = aws_route53_health_check.us_east_1_app_health.id
records = ["IP_OF_US_EAST_1_LOAD_BALANCER"]
}
resource "aws_route53_record" "app_secondary" {
zone_id = aws_route53_zone.main.zone_id
name = "app.example.com"
type = "A"
ttl = 60
set_identifier = "eu-west-1-secondary"
failover_routing_policy {
type = "SECONDARY"
}
health_check_id = aws_route53_health_check.eu_west_1_app_health.id # Предполагаем, что есть health check для eu-west-1
records = ["IP_OF_EU_WEST_1_LOAD_BALANCER"]
}
При файловере на другой регион, данные должны быть актуальными. Для реляционных баз данных рассмотрите:
- PostgreSQL с Logical Replication: Позволяет реплицировать данные между регионами.
- Aurora Global Database (AWS): Полностью управляемое решение для глобальной репликации PostgreSQL/MySQL.
- Cassandra/MongoDB Atlas Global Clusters: Для NoSQL баз данных, изначально разработанных для распределенных сред.
Помните о кэшах. При переключении региона, кэши в новом активном регионе могут быть холодными или содержать устаревшие данные. Продумайте стратегию инвалидации или прогрева кэша.
Если пользователи авторизованы в одном регионе, при переключении на другой регион им не должно требоваться повторная авторизация. Используйте распределенные хранилища сессий (например, Redis Cluster, DynamoDB) или JWT-токены, которые не привязаны к конкретному серверу или региону.
Типичные ошибки
 Схема: Типичные ошибки
Схема: Типичные ошибки
Внедрение глобальной балансировки нагрузки и DNS-файловера — сложный процесс, и ошибки на этом пути могут привести к длительным простоям, потере данных и значительным финансовым потерям. Знание типичных ошибок поможет вам их избежать.
Ошибка: Установка TTL (Time To Live) DNS-записей на часы или даже дни (например, 24 часа).
Последствия: При сбое основного региона, DNS-кэши по всему миру будут продолжать указывать на неработающий IP-адрес в течение всего срока TTL. Это означает, что даже после того, как ваш GLB обнаружит сбой и обновит записи, пользователи не смогут получить доступ к вашему приложению в течение длительного времени (RTO будет очень высоким). Пример: у SaaS-компании с TTL 1 день произошел сбой в AWS us-east-1. Несмотря на наличие резервного региона, пользователи не могли подключиться к сервису в течение 12-24 часов, пока их локальные DNS-кэши не обновились. Это привело к потере миллионов долларов и массовому оттоку клиентов.
Как избежать: Для критически важных записей, используемых GLB, установите TTL в диапазоне от 60 до 300 секунд (1-5 минут). Это обеспечит разумный компромисс между скоростью файловера и нагрузкой на DNS-серверы.
Ошибка: Настройка Health Checks, которые проверяют только доступность порта (например, TCP 80/443), но не работоспособность самого приложения или его зависимостей.
Последствия: Балансировщик нагрузки может считать регион здоровым, потому что веб-сервер отвечает, но на самом деле приложение может быть неработоспособным (например, из-за проблем с базой данных, Redis, внешними API). Это приводит к тому, что трафик направляется в регион, который не может обслуживать запросы, что вызывает ошибки у пользователей. Пример: Health Check проверял только Nginx. Nginx работал, но бэкенд-приложение упало из-за проблем с базой данных. GLB продолжал направлять трафик на Nginx, который возвращал 502 Bad Gateway, вместо того чтобы переключиться на резервный регион.
Как избежать: Создавайте глубокие Health Checks, которые проверяют состояние всех критически важных компонентов приложения (API, база данных, кэш, очереди). Реализуйте специальный эндпоинт /healthz или /status, который выполняет эти проверки и возвращает HTTP 200 OK только в случае полной работоспособности.
Ошибка: Развертывание архитектуры с GLB и DNS-файловером без регулярного тестирования сценариев сбоев.
Последствия: В реальной ситуации сбоя система может не сработать так, как ожидалось. Процесс переключения может быть медленным, неполным или вовсе не произойти из-за ошибок в конфигурации, забытых зависимостей или проблем с репликацией данных. Пример: Крупный банк развернул мультирегиональную архитектуру, но никогда не проводил полноценных учений. Во время регионального сбоя выяснилось, что один из критических микросервисов не был настроен на репликацию в резервный регион, и процесс восстановления занял часы вместо минут.
Как избежать: Включите регулярные учения по аварийному восстановлению (DR Drills) в свою операционную практику. Имитируйте сбои в одном регионе (отключение сервисов, изоляция сети) и проверяйте, как быстро и корректно система переключается. Автоматизируйте эти тесты, если это возможно.
Ошибка: Отсутствие или неправильная настройка репликации данных между регионами.
Последствия: При переключении на резервный регион пользователи могут столкнуться с устаревшими или отсутствующими данными. Это может привести к потере пользовательских данных, нарушению бизнес-логики и серьезным проблемам с доверием. Пример: SaaS-платформа для управления проектами использовала асинхронную репликацию базы данных. Во время файловера, последние 5 минут данных (созданные в основном регионе) были потеряны, что привело к исчезновению недавно созданных задач и комментариев у пользователей.
Как избежать: Тщательно спланируйте стратегию репликации данных. Для критически важных данных стремитесь к RPO, близкому к нулю, используя синхронную или полусинхронную репликацию (например, AWS Aurora Global Database, CockroachDB). Помните о кэшах и файловых хранилищах; они также должны быть реплицированы или иметь стратегию восстановления.
Ошибка: Недооценка стоимости трафика, передаваемого между регионами (egress/ingress).
Последствия: Мультирегиональная архитектура по умолчанию дороже, но межрегиональный трафик может стать скрытым "пожирателем" бюджета. Если ваши сервисы в разных регионах активно обмениваются данными, счета за облако могут быстро выйти из-под контроля. Пример: Стартап развернул Active-Active архитектуру с двумя регионами, но не учел, что их микросервисы постоянно обменивались большим объемом данных друг с другом, даже если пользовательский трафик шел в ближайший регион. Это привело к тому, что счет за трафик между регионами превысил стоимость всех остальных ресурсов.
Как избежать: Минимизируйте межрегиональный трафик. Проектируйте сервисы так, чтобы они были максимально автономны в рамках своего региона. Если межрегиональное взаимодействие необходимо, используйте эффективные протоколы, сжатие данных и рассмотрите возможность использования частных соединений (VPC Peering, Direct Connect) для снижения стоимости трафика.
Чеклист для практического применения
Этот чеклист поможет вам систематизировать процесс проектирования и внедрения глобальной балансировки нагрузки и DNS-файловера для вашего SaaS-приложения. Пройдитесь по каждому пункту, чтобы убедиться, что вы ничего не упустили.
- Определение требований:
- Определен ли целевой RTO (Recovery Time Objective) для вашего приложения (например, 30 секунд, 5 минут)?
- Определен ли целевой RPO (Recovery Point Objective) для вашего приложения (например, 0 секунд, 1 минута)?
- Определены ли ключевые регионы, где будут размещены ресурсы, исходя из географии пользователей и регуляторных требований?
- Проведен ли анализ критических компонентов приложения, которые требуют максимальной отказоустойчивости?
- Архитектурное проектирование:
- Выбрана ли стратегия репликации данных (Active-Passive, Active-Active, гео-партиционирование) и соответствующие технологии баз данных?
- Спроектирована ли архитектура приложения с учетом отсутствия состояния (stateless) для легкой переносимости между регионами?
- Разработана ли стратегия для кэшей и хранилищ файлов (например, S3 Cross-Region Replication)?
- Продумано ли, как будут обрабатываться пользовательские сессии и аутентификация при переключении между регионами?
- Выбор и настройка GLB/DNS:
- Выбран ли основной GLB/DNS-провайдер (AWS Route 53, Azure Traffic Manager, Google Cloud DNS) или CDN с GLB (Cloudflare, Akamai)?
- Настроены ли NS-записи вашего домена для использования выбранного DNS-провайдера?
- Созданы ли Health Checks для каждого региона, проверяющие глубокую работоспособность приложения и его зависимостей (HTTP
/healthz)?
- Настроены ли DNS-записи (A/CNAME) с соответствующими политиками маршрутизации (Failover, Latency, Geo) и привязаны ли к ним Health Checks?
- Установлен ли оптимальный TTL (например, 60-300 секунд) для критически важных DNS-записей?
- (Опционально) Интегрирована ли CDN для кэширования, DDoS-защиты и дополнительного уровня файловера?
- (Опционально) Используется ли Anycast DNS для повышения отказоустойчивости и скорости разрешения DNS-запросов?
- Внедрение инфраструктуры:
- Развернута ли идентичная (или максимально похожая) инфраструктура в каждом из выбранных регионов?
- Настроена ли репликация баз данных и других постоянных хранилищ между регионами?
- Используется ли Infrastructure as Code (Terraform, CloudFormation) для управления всей инфраструктурой, включая GLB и DNS?
- Настроены ли региональные балансировщики нагрузки (ALB, Nginx) для распределения трафика внутри каждого региона?
- Мониторинг и оповещения:
- Настроен ли мониторинг статуса GLB Health Checks и метрик переключения?
- Настроен ли мониторинг ключевых метрик приложения (ошибки, задержки, пропускная способность) в каждом регионе?
- Настроен ли мониторинг состояния репликации данных между регионами?
- Настроены ли оповещения для ключевых событий (сбой Health Check, региональный сбой, проблемы с репликацией)?
- Тестирование и оптимизация:
- Проведены ли учения по аварийному восстановлению (DR Drills) с имитацией сбоя основного региона?
- Измерены ли фактические RTO и RPO во время учений?
- Оптимизированы ли затраты на межрегиональный трафик и ресурсы в резервных регионах?
- Документированы ли все процедуры файловера и восстановления?
- Включено ли тестирование файловера в CI/CD пайплайн, где это применимо?
Расчет стоимости / Экономика
 Схема: Расчет стоимости / Экономика
Схема: Расчет стоимости / Экономика
Внедрение глобальной балансировки нагрузки и DNS-файловера значительно увеличивает отказоустойчивость, но также существенно влияет на бюджет. Важно понимать, из чего складываются затраты и как их оптимизировать. Рассмотрим примеры расчетов для различных сценариев, актуальные для 2026 года.
- GLB/DNS-сервисы: Плата за DNS-зоны, запросы, Health Checks.
- AWS Route 53: $0.50/зона/мес, $0.005/1M запросов, $0.70/Health Check/мес.
- Azure Traffic Manager: $0.50/1M DNS-запросов, $1.00/Health Check/мес.
- Google Cloud DNS: $0.20/зона/мес, $0.40/1M запросов. Health checks интегрированы с Cloud Load Balancing.
- Инфраструктура в резервном регионе:
- Active-Passive: Резервный регион работает в "горячем" (всегда включенном), "теплом" (включены только критические компоненты) или "холодном" (развертывание по требованию) режиме. Стоимость зависит от выбранного режима.
- Active-Active: Полная инфраструктура в каждом регионе.
- Виртуальные машины/контейнеры, базы данных, хранилища, балансировщики нагрузки.
- Трафик между регионами:
- Межрегиональная репликация данных (баз данных, хранилищ).
- Межсервисное взаимодействие.
- Часто это самый дорогой компонент, например, $0.02-$0.09 за ГБ.
- CDN: Если используется, то плата за трафик, запросы, WAF, DDoS-защиту.
- Разработка и эксплуатация: Зарплаты инженеров, время на проектирование, внедрение, тестирование, мониторинг и поддержку.
- Лицензии: Если используются сторонние программные GLB или корпоративные решения.
Предположим, у нас есть SaaS-приложение с 100 000 активных пользователей, генерирующее 500 млн DNS-запросов в месяц и 10 ТБ исходящего трафика в месяц (без CDN). База данных генерирует 500 ГБ репликационного трафика между регионами в месяц.
Сценарий 1: Active-Passive с AWS Route 53 (2 региона)
Основной регион (us-east-1) работает на полную мощность, резервный (eu-west-1) в "горячем" режиме (т.е. вся инфраструктура запущена, но простаивает или обслуживает минимальный трафик).
- AWS Route 53:
- 1 Hosted Zone: $0.50
- 500 млн DNS-запросов: 500 $0.005 = $2500
- 2 Health Checks: 2 $0.70 = $1.40
- Итого Route 53: ~$2502
- Инфраструктура:
- Основной регион: $5000/мес (виртуальные машины, базы данных, балансировщики)
- Резервный регион (горячий): $5000/мес (полностью дублирующая инфраструктура)
- Итого инфраструктура: ~$10000
- Трафик:
- 10 ТБ исходящего трафика (из основного региона): $0.05/ГБ 10240 ГБ = $512
- 500 ГБ межрегионального трафика (репликация DB): $0.02/ГБ 500 ГБ = $10
- Итого трафик: ~$522
- Общая ориентировочная стоимость: ~$13024/мес
Сценарий 2: Active-Active с Cloudflare и AWS Route 53 (2 региона)
Оба региона обслуживают трафик. Cloudflare выступает как основной GLB и CDN, Route 53 используется для DNS-разрешения домена Cloudflare.
- Cloudflare (Enterprise): Ориентировочно $2000/мес (включает CDN, WAF, GLB, 50 ТБ трафика).
- AWS Route 53:
- 1 Hosted Zone: $0.50
- 500 млн DNS-запросов (к Cloudflare): $2500 (если Route 53 используется для балансировки DNS-запросов к Cloudflare, но обычно Cloudflare берет на себя DNS). Если Cloudflare DNS, то $0.
- 2 Health Checks (для Origin-серверов Cloudflare): 2 $0.70 = $1.40
- Итого Route 53: ~$1.90 (если Cloudflare DNS) или ~$2502 (если Route 53 DNS)
- Инфраструктура:
- Основной регион: $5000/мес
- Второй активный регион: $5000/мес
- Итого инфраструктура: ~$10000
- Трафик:
- Трафик от Cloudflare к Origin (10 ТБ): $0.01/ГБ 10240 ГБ = $102.40 (Cloudflare обычно имеет более низкие цены на egress к Origin).
- 500 ГБ межрегионального трафика (репликация DB): $0.02/ГБ * 500 ГБ = $10
- Итого трафик: ~$112.40
- Общая ориентировочная стоимость: ~$12114/мес (с Cloudflare DNS) или ~$14614/мес (с Route 53 DNS)
- Неэффективное использование ресурсов: Запуск полной инфраструктуры в резервном регионе, которая не используется (в Active-Passive).
- Data Transfer Out (Egress): Передача данных из облака всегда самая дорогая. Межрегиональный трафик может быть в несколько раз дороже, чем внутрирегиональный.
- Сложность управления: Дополнительные часы инженеров на настройку, мониторинг, тестирование и устранение проблем в более сложной системе.
- Лицензии на стороннее ПО: Если вы используете Nginx Plus, HAProxy Enterprise или другие коммерческие решения.
- Аудит и комплаенс: Для обеспечения соответствия регуляторным требованиям в разных регионах.
- Оптимизация режима резервного региона: Вместо "горячего" Active-Passive рассмотрите "теплый" (запущены только минимальные сервисы, масштабирование по требованию) или "холодный" (развертывание инфраструктуры с нуля при сбое) режимы. Это снижает затраты на простаивающие ресурсы, но увеличивает RTO.
- Минимизация межрегионального трафика:
- Размещайте данные и сервисы рядом с пользователями (гео-партиционирование).
- Используйте сжатие данных при передаче.
- Оптимизируйте протоколы взаимодействия.
- Используйте частные соединения (VPC Peering, Direct Connect) для снижения стоимости трафика между облачными аккаунтами или регионами.
- Использование Spot Instances/Preemptible VMs: Для некритичных или масштабируемых рабочих нагрузок в резервном регионе можно использовать более дешевые инстансы, которые могут быть прерваны.
- Резервирование (Reserved Instances/Savings Plans): Если вы уверены в долгосрочном использовании ресурсов, покупка Reserved Instances или Savings Plans может значительно снизить стоимость виртуальных машин и баз данных.
- Эффективное использование CDN: Максимально кэшируйте статический контент, чтобы снизить нагрузку и трафик на ваши Origin-серверы.
- Автоматизация: Автоматизируйте развертывание, масштабирование и файловер, чтобы снизить операционные расходы.
Таблица с примерами расчетов для различных режимов резервирования (на базе сценария 1, инфраструктура):
| Режим резервного региона |
Описание |
Ориентировочные затраты на инфраструктуру (2 региона) |
Ориентировочный RTO |
Примеры использования |
| Горячий (Hot Standby) |
Полностью развернутая и работающая инфраструктура в резервном регионе. |
$10000/мес (2 x $5000) |
Секунды-Минуты |
Критически важные SaaS с низким RTO, финансовые, медицинские приложения. |
| Теплый (Warm Standby) |
Минимальный набор ресурсов запущен в резервном регионе, масштабирование по требованию. |
$6000-$8000/мес (1 x $5000 + 1 x $1000-$3000) |
Минуты-Десятки минут |
Большинство SaaS, где допустим небольшой простой. |
| Холодный (Cold Standby) |
Инфраструктура разворачивается с нуля или из образов при сбое. |
$5000-$5500/мес (1 x $5000 + хранение образов) |
Часы |
Некритические приложения, где высокий RTO допустим. |
Экономика мультирегиональной архитектуры — это баланс между доступностью, производительностью и стоимостью. Тщательное планирование и постоянная оптимизация необходимы для достижения наилучшего результата.
Кейсы и примеры
 Схема: Кейсы и примеры
Схема: Кейсы и примеры
Чтобы лучше понять, как глобальная балансировка нагрузки и DNS-файловер работают на практике, рассмотрим несколько реалистичных сценариев из опыта SaaS-компаний.
Проблема: Крупная e-commerce платформа, работающая на мировом рынке, сталкивалась с двумя основными проблемами: высокой задержкой для пользователей, находящихся далеко от основного ЦОД в США, и риском полного простоя во время крупных распродаж (например, Черная пятница) из-за региональных сбоев. Требовалось обеспечить RTO менее 5 минут и RPO, близкое к нулю, для транзакционных данных.
Решение:
- Мультирегиональная архитектура Active-Active: Платформа была развернута в трех регионах AWS:
us-east-1 (Северная Америка), eu-central-1 (Европа) и ap-southeast-2 (Азия/Тихий океан). В каждом регионе развернуты полные стеки приложения (веб-серверы, API-сервисы, кэши).
- AWS Route 53 с Latency-based Routing и Failover:
- Для домена
shop.example.com были настроены A-записи, указывающие на региональные Application Load Balancers (ALB) в каждом из трех регионов.
- Использовалась политика маршрутизации Latency-based Routing, чтобы направлять пользователей к региону с наименьшей задержкой.
- К каждой A-записи был привязан Health Check, который проверял доступность и работоспособность не только ALB, но и ключевых API-сервисов и соединения с базой данных в каждом регионе (через эндпоинт
/healthz-deep).
- TTL для A-записей был установлен на 60 секунд.
- Дополнительно, для критических внутренних сервисов, были настроены Failover Routing Policies, где один регион был Primary, а два других Secondary.
- Cloudflare CDN и WAF: Весь пользовательский трафик проходил через Cloudflare для кэширования статического контента, снижения задержек, DDoS-защиты и использования WAF. Cloudflare был настроен с несколькими Origin-серверами (региональными ALB) и функцией Origin Failover, что обеспечивало мгновенное переключение на уровне L7.
- База данных: Использовалась AWS Aurora Global Database (PostgreSQL-совместимая), которая обеспечивала асинхронную репликацию с низкой задержкой между всеми тремя регионами. В каждом регионе был свой кластер Aurora, при этом один регион был Primary (для записи), а остальные Secondary (для чтения и быстрого продвижения до Primary при файловере). Механизм Aurora Global Database обеспечивал RPO < 5 секунд.
- Сессии и кэши: Сессии хранились в распределенном Redis Cluster, развернутом в каждом регионе, с асинхронной репликацией между регионами для минимизации потери сессий при файловере. Кэши были региональными, с возможностью быстрого прогрева при переключении.
Результаты:
- Значительное снижение задержки для пользователей по всему миру (на 30-50% в зависимости от региона).
- Во время крупного сбоя в
us-east-1, система автоматически переключила весь трафик Северной Америки на eu-central-1 в течение 90 секунд. Пользователи испытали кратковременные проблемы, но сервис остался доступным. Потеря данных составила менее 5 секунд (RPO).
- Платформа успешно выдерживала пиковые нагрузки, распределяя их между регионами.
- Значительное повышение безопасности благодаря Cloudflare WAF и DDoS-защите.
Проблема: SaaS-компания предоставляла платформу для аналитики финансовых данных, что требовало строгих требований к суверенитету данных (данные европейских клиентов должны оставаться в Европе) и высокой доступности (RTO < 10 минут, RPO < 1 минута). В основном ЦОД (eu-west-1) произошел серьезный сбой, и компания понесла убытки.
Решение:
- Гео-партиционированная архитектура Active-Passive: Были созданы два независимых "стека" приложения: один в
eu-west-1 (Ирландия) для европейских клиентов и один в us-east-1 (США) для американских клиентов. Каждый стек был Active-Passive в рамках своего региона, но глобально они работали как Active-Active для разных групп пользователей.
- Azure Traffic Manager с Geo-routing и Priority Failover:
- Для домена
app.example.com были настроены профили Traffic Manager.
- Использовалась политика Geographic Routing, чтобы направлять европейских пользователей на
eu-west-1, а американских — на us-east-1.
- Внутри каждого географического профиля была настроена политика Priority Failover:
eu-west-1 был Primary, а eu-west-2 (Лондон) был Secondary для европейских клиентов. Аналогично для США.
- Endpoint Monitoring проверял доступность и работоспособность региональных Application Gateways (L7-балансировщиков) и ключевых API.
- TTL для DNS-записей был установлен на 120 секунд.
- База данных: Использовалась PostgreSQL с Logical Replication для асинхронной репликации данных между
eu-west-1 и eu-west-2 (и аналогично для США). Для каждого клиента данные хранились только в его географическом регионе, обеспечивая суверенитет данных. RPO был настроен на 30 секунд.
- Файловое хранилище: Azure Blob Storage с гео-избыточностью (GRS) в рамках каждого географического кластера.
Результаты:
- Полное соответствие требованиям суверенитета данных.
- Во время имитации сбоя в
eu-west-1, Traffic Manager успешно переключил европейский трафик на eu-west-2 в течение 5 минут. Потеря данных составила менее 30 секунд.
- Значительно улучшена производительность для европейских и американских пользователей за счет локализации данных и сервисов.
- Снижены риски глобальных сбоев, так как проблемы в одном географическом кластере не влияют на другой.
Проблема: IoT-платформа собирала данные с тысяч устройств по всему миру. Важно было обеспечить максимально низкую задержку для приема данных и высокую доступность для API управления устройствами. Сбои в передаче данных или недоступность API могли привести к потере критически важных показаний.
Решение:
- Распределенная микросервисная архитектура с Edge Computing: Основные хабы обработки данных были развернуты в трех регионах GCP:
us-central1, europe-west1, asia-east1. В каждом регионе работали микросервисы для приема, обработки и хранения данных.
- Google Cloud Load Balancer (Global External HTTP(S) Load Balancer) с Cross-Region Failover:
- Это L7-балансировщик, который предоставляет единый глобальный IP-адрес. Он автоматически направляет трафик к ближайшему бэкенд-сервису.
- Для API управления устройствами был настроен Global External HTTP(S) Load Balancer, указывающий на группы инстансов (Managed Instance Groups) в каждом регионе.
- GCP Load Balancer сам выполняет Health Checks для групп инстансов и автоматически исключает неисправные инстансы или даже целые регионы из пула.
- Автоматическое переключение происходит мгновенно на уровне L7, без зависимости от TTL DNS.
- Google Cloud DNS с Anycast: Использовался для быстрого разрешения имен для IoT-устройств, хотя основную балансировку выполнял Global Load Balancer.
- База данных: Использовалась Google Cloud Spanner — глобально распределенная, горизонтально масштабируемая реляционная база данных, обеспечивающая сильную консистентность и RPO=0 в нескольких регионах.
- Очереди сообщений: Google Cloud Pub/Sub для приема данных с устройств, обеспечивающий глобальную доступность и высокую пропускную способность.
Результаты:
- Максимально низкая задержка для IoT-устройств, поскольку трафик всегда направлялся к ближайшему хабу.
- Высокая доступность API управления устройствами с мгновенным файловером при сбоях в регионах.
- RPO=0 благодаря Cloud Spanner, что исключило потерю данных устройств.
- Система легко масштабировалась для обработки растущего числа устройств и объемов данных.
Troubleshooting (решение проблем)
 Схема: Troubleshooting (решение проблем)
Схема: Troubleshooting (решение проблем)
Даже с самой продуманной архитектурой, проблемы неизбежны. Умение быстро диагностировать и устранять сбои в системе глобальной балансировки нагрузки и DNS-файловера является критически важным навыком. Ниже описаны типичные проблемы и подходы к их решению.
Описание проблемы: Основной регион вышел из строя, но пользователи по-прежнему направляются туда, или переключение происходит очень медленно.
Диагностика:
- Проверьте Health Checks: Убедитесь, что ваш GLB-провайдер (Route 53, Traffic Manager) действительно видит основной регион как "нездоровый".
# AWS Route 53: Проверить статус Health Check
aws route53 list-health-checks --query "HealthChecks[?Id=='YOUR_HEALTH_CHECK_ID'].HealthCheckObservations"
Проверьте логи Health Check (если доступны), чтобы понять, почему он считает регион нездоровым. Возможно, проблема глубже, чем кажется.
- Проверьте TTL DNS-записей: Используйте
dig или онлайн-инструменты (dnschecker.org) для проверки текущего TTL и IP-адресов, которые выдает ваш DNS-сервер. Возможно, клиенты или промежуточные DNS-серверы кэшируют старые записи.
dig +trace app.example.com
- Проверьте конфигурацию GLB: Убедитесь, что политики маршрутизации (Failover, Latency) настроены корректно и привязаны к правильным Health Checks. Иногда бывает, что Health Check настроен, но не привязан к DNS-записи.
- Проверьте сетевое взаимодействие: Убедитесь, что Health Check-серверы GLB-провайдера могут достучаться до вашего эндпоинта. Возможно, есть проблемы с сетевыми ACL, фаерволами или группами безопасности.
Решение: Снизить TTL для критических записей (если он был высоким). Исправить ошибки в конфигурации Health Checks или политик маршрутизации. Открыть необходимые порты/IP-адреса для Health Check-серверов.
Описание проблемы: После переключения на резервный регион, пользователи видят старые данные или сталкиваются с ошибками, связанными с отсутствием данных.
Диагностика:
- Проверьте статус репликации базы данных: Убедитесь, что репликация работает и отставание минимально.
-- Пример для PostgreSQL: проверить WAL replay lag
SELECT pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn(), (pg_last_wal_receive_lsn() - pg_last_wal_replay_lsn()) AS replay_lag;
Для облачных баз данных используйте их нативные метрики репликации (например, Aurora Global Database Lag).
- Проверьте кэши: Возможно, кэши в новом активном регионе "холодные" или содержат устаревшие данные.
- Проверьте файловые хранилища: Если используются S3, Azure Blob Storage или Google Cloud Storage, убедитесь, что файлы реплицированы между регионами (например, S3 Cross-Region Replication).
Решение: Оптимизировать репликацию базы данных (возможно, перейти на более производительный тип репликации или увеличить пропускную способность сети). Реализовать стратегию прогрева кэша после файловера или использовать распределенные кэши. Убедиться в корректной настройке репликации файловых хранилищ.
Описание проблемы: Сервис доступен, но работает медленнее, чем обычно, после переключения региона.
Диагностика:
- Проверьте ресурсы резервного региона: Достаточно ли мощности (CPU, RAM, IOPS) у виртуальных машин и баз данных в резервном регионе, чтобы принять всю нагрузку? Возможно, он был настроен как "теплый" стендбай с меньшим количеством ресурсов.
- Проверьте сетевую задержку: Возможно, новый активный регион находится дальше от большинства пользователей, что увеличивает сетевую задержку. Используйте
traceroute.
- Проверьте "холодные" кэши: Если кэши в новом регионе были пусты, это может привести к дополнительной нагрузке на базу данных и замедлению работы.
Решение: Увеличить ресурсы в резервном регионе. Оптимизировать масштабирование. Разработать стратегию "прогрева" кэшей. Рассмотреть гео-маршрутизацию или Anycast DNS для минимизации сетевой задержки для пользователей.
Описание проблемы: Оба региона считают себя "активными" и пытаются принимать запросы на запись, что приводит к конфликтам данных и непредсказуемому поведению.
Диагностика:
- Проверьте логи GLB: Убедитесь, что GLB корректно исключил неисправный регион.
- Проверьте состояние баз данных: Убедитесь, что только один регион считается Primary для записи.
- Мониторинг конфликтов: Отслеживайте метрики конфликтов записи в вашей базе данных.
Решение: Это серьезная проблема, требующая тщательного проектирования. Используйте кворумные механизмы (например, в распределенных базах данных) или строгие правила для определения "Primary" региона. В Active-Passive архитектурах убедитесь, что резервный регион никогда не становится Primary, пока основной явно не будет объявлен мертвым или не будет произведено ручное переключение. Автоматизация файловера должна быть очень хорошо протестирована, чтобы избежать этой ситуации.
Описание проблемы: Ваше приложение подвергается DDoS-атаке, которая перегружает GLB или DNS-серверы, делая сервис недоступным.
Диагностика:
- Мониторинг DNS-запросов: Внезапный всплеск DNS-запросов или запросов к GLB.
- Мониторинг трафика: Аномальный объем трафика.
Решение: Используйте CDN-провайдеров (Cloudflare, Akamai) с встроенной DDoS-защитой, которые могут поглощать атаки на уровне Edge. Используйте Anycast DNS для распределения нагрузки DNS-запросов. Включите нативные облачные сервисы DDoS-защиты (AWS Shield Advanced, Azure DDoS Protection, Google Cloud Armor).
- Если вы подозреваете глобальный сбой на стороне вашего облачного провайдера (проверьте страницы статуса).
- Если Health Checks показывают, что ваш ресурс "нездоров", но вы уверены, что он работает (возможно, проблема в самом Health Check-сервисе).
- Если вы столкнулись с проблемами, связанными с маршрутизацией BGP или Anycast, которые находятся вне вашего контроля.
- Если вы не можете понять причину аномального поведения GLB или DNS, несмотря на все внутренние проверки.
Главное в troubleshooting — это систематический подход, использование всех доступных инструментов мониторинга и логирования, а также хорошо документированные процедуры.
FAQ
Региональный балансировщик нагрузки (например, AWS ALB, Azure Application Gateway) распределяет трафик только внутри одного региона или зоны доступности. Глобальная балансировка нагрузки (GLB) работает на более высоком уровне, направляя пользователей в наиболее подходящий географический регион. Она обеспечивает отказоустойчивость на уровне региона, переключая трафик на другой регион в случае сбоя, и оптимизирует задержку, направляя пользователей к ближайшему доступному ЦОД. Это два разных, но взаимодополняющих уровня балансировки.
Выбор TTL — это компромисс между скоростью файловера и нагрузкой на DNS-серверы. Для критически важных записей, используемых в GLB-архитектуре, рекомендуется устанавливать TTL в диапазоне от 60 до 300 секунд (1-5 минут). Это достаточно низко, чтобы обеспечить относительно быстрый файловер (в пределах нескольких минут), но не настолько низко, чтобы вызвать чрезмерную нагрузку на DNS-инфраструктуру. Для записей, которые редко меняются (например, NS-записи), можно использовать более высокий TTL (1 час и более).
Active-Active: Оба (или все) региона активно обслуживают трафик. Преимущества: высокая доступность, низкие задержки, эффективное использование ресурсов. Недостатки: высокая сложность управления данными (требуется распределенная база данных с разрешением конфликтов), выше стоимость.
Active-Passive: Один регион активен, другой (или другие) находится в режиме ожидания. Преимущества: проще в реализации, легче управлять данными. Недостатки: простаивающие ресурсы в резервном регионе, потенциально более высокий RTO и RPO. Выбор зависит от требований к RTO/RPO и бюджета.
Это одна из самых сложных задач. Для реляционных баз данных можно использовать асинхронную репликацию (например, PostgreSQL Logical Replication, MySQL Replication) для Active-Passive, или специализированные глобальные базы данных (AWS Aurora Global Database, Google Cloud Spanner) для Active-Active с сильной консистентностью. Для NoSQL баз данных (Cassandra, MongoDB) используйте их встроенные механизмы распределения данных. Важно также продумать репликацию файловых хранилищ (S3 Cross-Region Replication) и управление распределенными кэшами.
Современные CDN (например, Cloudflare, Akamai) предлагают мощные функции GLB на уровне L7 (HTTP/HTTPS), включая маршрутизацию по гео-принципу, задержке и файловеру. Для многих SaaS-приложений CDN может выполнять функции GLB, особенно если основной трафик — HTTP/HTTPS. Однако, если у вас есть трафик, не относящийся к HTTP (например, TCP, UDP), или вам нужен более низкоуровневый контроль на уровне DNS, то чистый DNS GLB (Route 53, Traffic Manager) или гибридный подход с использованием обоих решений будет более подходящим.
Глубокие Health Checks не просто проверяют доступность порта или базовый HTTP 200 OK. Они должны имитировать реальный пользовательский запрос или проверять работоспособность всех критических зависимостей приложения. Например, эндпоинт /healthz может попытаться подключиться к базе данных, запросить данные из кэша, проверить доступность внешних API и только после успешного выполнения всех этих шагов вернуть HTTP 200 OK. Это гарантирует, что GLB переключит трафик только тогда, когда приложение действительно готово обслуживать запросы.
Рекомендуется проводить учения по аварийному восстановлению (DR Drills) не реже одного раза в квартал, а для критически важных систем — ежемесячно. Это позволяет выявлять ошибки в конфигурации, проблемы с репликацией и другие неожиданные нюансы до того, как они приведут к реальному простою. Автоматизированные тесты файловера можно запускать еще чаще, например, как часть CI/CD пайплайна при каждом значительном изменении инфраструктуры.
Основные способы:
- Использовать "теплый" или "холодный" режим резервного региона вместо "горячего" для экономии на простаивающих ресурсах.
- Минимизировать межрегиональный трафик, оптимизируя архитектуру сервисов и репликации данных.
- Использовать резервирование (Reserved Instances, Savings Plans) для стабильных нагрузок.
- Максимально использовать CDN для кэширования и снижения нагрузки на Origin-серверы.
- Оптимизировать Health Checks, чтобы они не генерировали избыточных запросов.
Локальное кэширование DNS на клиентских устройствах и промежуточных DNS-серверах (провайдеров) является основной причиной медленного файловера при использовании DNS GLB. Полностью избежать его невозможно, но можно минимизировать эффект:
- Установить низкий TTL (60-300 секунд) для критических DNS-записей.
- Использовать CDN: CDN выступает в роли прокси, и переключение на уровне CDN происходит мгновенно, поскольку клиенты взаимодействуют только с CDN, а не напрямую с вашими Origin-серверами.
- Обучить пользователей сбрасывать DNS-кэш на своих устройствах (хотя это не всегда практично).
Мультиоблачная стратегия (размещение приложения в нескольких разных облаках) может повысить отказоустойчивость, защитив от сбоев целого облачного провайдера. Однако она значительно увеличивает сложность, стоимость и операционную нагрузку. Для большинства SaaS-проектов достаточно мультирегионального развертывания в одном облаке. Мультиоблако стоит рассматривать только при очень строгих требованиях к доступности (например, 5 девяток), жестких регуляторных нормах или для избежания vendor lock-in. В этом случае потребуются специализированные мультиоблачные GLB-решения.
Заключение
Построение отказоустойчивой архитектуры для SaaS-приложений с использованием глобальной балансировки нагрузки и DNS-файловера — это не просто набор технических решений, а стратегический императив для любого бизнеса, стремящегося к успеху в цифровой экономике 2026 года. Мы рассмотрели, как эти концепции позволяют не только минимизировать время простоя и потерю данных в случае катастроф, но и значительно улучшить пользовательский опыт за счет снижения задержек и повышения производительности.
Ключевые выводы, которые мы можем сделать из этого глубокого погружения, сводятся к нескольким фундаментальным принципам:
- Планирование — это половина успеха: Начинайте проектирование с учетом мультирегиональности, продумывая не только сетевой уровень, но и стратегии работы с данными, сессиями и кэшами.
- Глубокие Health Checks спасают жизнь: Не полагайтесь на поверхностные проверки. Убедитесь, что ваш GLB видит реальное состояние приложения и его зависимостей.
- Данные — ваш главный актив: Выберите и настройте стратегию репликации данных, которая соответствует вашим RPO-требованиям, помня о балансе между консистентностью и производительностью.
- Тестирование — ваша страховка: Регулярные учения по аварийному восстановлению и автоматизированные тесты файловера — единственный способ убедиться, что ваша система работает так, как задумано.
- Оптимизация затрат — постоянный процесс: Мультирегиональность дорога, но правильный выбор архитектуры, режима резервирования и минимизация межрегионального трафика помогут удержать бюджет в разумных рамках.
- Инструменты ускоряют работу: Используйте IaC для автоматизации, мощные системы мониторинга для контроля и специализированные инструменты для диагностики.
Мир SaaS постоянно меняется, и требования к доступности будут только расти. Инвестиции в надежную архитектуру сегодня окупятся сторицей, защищая вашу репутацию, лояльность клиентов и, в конечном итоге, ваш доход. Пусть эти знания станут вашим компасом в создании архитектуры, которая не просто выживает, но и процветает в условиях любых вызовов.
Следующие шаги для читателя:
- Проведите аудит текущей архитектуры: Оцените ее уязвимости и соответствие требованиям RTO/RPO.
- Выберите стратегию: Определите, какой подход к GLB и репликации данных лучше всего подходит для вашего SaaS.
- Начните с малого: Если вы только начинаете, рассмотрите Active-Passive в двух регионах как отправную точку, постепенно усложняя архитектуру.
- Автоматизируйте: Переведите все настройки GLB, DNS и инфраструктуры в Infrastructure as Code.
- Практикуйтесь: Запланируйте и проведите свои первые учения по аварийному восстановлению.
- Мониторьте и оптимизируйте: Постоянно отслеживайте производительность, доступность и затраты, вносите корректировки.
Успехов в построении вашей глобально распределенной и отказоустойчивой SaaS-платформы!