eBPF для DevOps: продвинутый мониторинг и безопасность Linux-инфраструктуры в 2026 году
TL;DR
- eBPF — это геймчейнджер: Позволяет безопасно и эффективно исполнять программы в ядре Linux, открывая беспрецедентные возможности для мониторинга и безопасности.
- Глубокая видимость без накладных расходов: Предоставляет детализированную телеметрию на уровне ядра (сеть, файловая система, системные вызовы) с минимальным влиянием на производительность.
- Революция в сетевом стеке: С помощью eBPF можно реализовать высокопроизводительные сетевые функции, такие как балансировка нагрузки (XDP), фаерволы и продвинутый роутинг, прямо в ядре.
- Непревзойденная безопасность: Позволяет создавать динамические политики безопасности, обнаруживать аномалии и предотвращать атаки на уровне ядра, значительно опережая традиционные LSM.
- Интеграция со стеком DevOps: Современные eBPF-инструменты легко интегрируются с Prometheus, Grafana, OpenTelemetry, позволяя использовать привычные дашборды и алерты.
- Экосистема зреет: К 2026 году eBPF-инструментарий стал стандартом де-факто для облачных и контейнерных сред, предлагая как открытые, так и коммерческие решения.
- Маст-хэв для инфраструктуры будущего: Освоение eBPF критически важно для DevOps-инженеров, стремящихся к максимальной эффективности, безопасности и наблюдаемости своих Linux-систем.
Введение
В стремительно меняющемся ландшафте современной IT-инфраструктуры, где микросервисы, контейнеры и бессерверные архитектуры стали нормой, традиционные подходы к мониторингу и безопасности зачастую оказываются неэффективными или слишком ресурсоемкими. Старые методы, основанные на сборе логов, системных утилитах и агентах пользовательского пространства, страдают от высокого оверхеда, недостаточной детализации или задержек, критичных для высоконагруженных систем. В 2026 году, когда масштабы инфраструктуры измеряются тысячами узлов, а скорость реакции на инциденты определяет жизнеспособность бизнеса, потребность в более продвинутых решениях стала как никогда острой.
Именно здесь на сцену выходит eBPF (extended Berkeley Packet Filter) — технология, которая за последние несколько лет совершила настоящую революцию в мире Linux. Изначально задуманный как инструмент для фильтрации сетевых пакетов, eBPF эволюционировал в мощный, безопасный и высокопроизводительный механизм, позволяющий исполнять пользовательские программы прямо в ядре Linux. Это открывает беспрецедентные возможности для глубокой интроспекции, мониторинга и динамического управления поведением системы, не требуя модификации кода ядра и не добавляя значительных накладных расходов.
Почему эта тема важна именно сейчас, в 2026 году? Потому что eBPF уже вышел из фазы экспериментальных исследований и стал зрелым, широко используемым инструментом в арсенале ведущих технологических компаний. Такие проекты, как Cilium, Falco, bpftrace, продемонстрировали его огромный потенциал в области сетевой безопасности, наблюдаемости и анализа производительности. Облачные провайдеры активно интегрируют eBPF в свои платформы, а сообщество разработчиков продолжает расширять его возможности, делая его неотъемлемой частью будущих инфраструктурных решений.
Эта статья адресована широкому кругу технических специалистов: DevOps-инженерам, которые ищут способы повысить эффективность и надежность своих платформ; Backend-разработчикам на Python, Node.js, Go, PHP, которым важна глубокая диагностика и оптимизация производительности; Фаундерам SaaS-проектов, стремящимся к созданию масштабируемых и безопасных продуктов; Системным администраторам, нуждающимся в мощных инструментах для управления сложными Linux-системами; и Техническим директорам стартапов, которые формируют стратегию развития своей инфраструктуры. Мы рассмотрим, как eBPF решает ключевые проблемы, связанные с видимостью, безопасностью и производительностью, предоставим конкретные примеры и рекомендации, основанные на реальном опыте внедрения.
Наша цель — не просто рассказать о возможностях eBPF, но и предоставить практическое руководство, которое поможет вам интегрировать эту технологию в вашу инфраструктуру. Мы избежим маркетингового буллшита и сосредоточимся на конкретных данных, примерах кода и реальных кейсах, чтобы вы могли сразу применить полученные знания на практике. Приготовьтесь погрузиться в мир ядра Linux и открыть для себя новый уровень контроля и эффективности с помощью eBPF.
Основные критерии и факторы выбора eBPF-решений
Выбор и внедрение eBPF-решений — это не просто техническое решение, а стратегический шаг, который может кардинально изменить подход к мониторингу и безопасности вашей инфраструктуры. Для успешного выбора необходимо опираться на ряд ключевых критериев, которые помогут оценить применимость и эффективность различных eBPF-инструментов и подходов.
1. Глубина и гранулярность наблюдаемости (Observability Depth and Granularity)
Этот критерий определяет, насколько детальную информацию вы можете получить о работе вашей системы. eBPF позволяет «заглянуть» в ядро, предоставляя данные о сетевых соединениях, системных вызовах, файловых операциях, работе планировщика и многом другом, что недоступно традиционными методами без значительных накладных расходов. Важно оценить:
- Какие типы событий ядро может отслеживать: Kprobes, Uprobes, Tracepoints, XDP, TC.
- Насколько детальна информация: Захват аргументов системных вызовов, полные стеки вызовов, метаданные сетевых пакетов.
- Возможность агрегации и фильтрации: Можете ли вы настроить сбор только нужных данных, чтобы избежать «информационного шума» и снизить нагрузку на обработку?
Почему важен: Глубокая и гранулярная наблюдаемость критична для быстрой диагностики сложных проблем производительности, поиска узких мест и понимания истинного поведения приложений в продакшене. Без этого вы рискуете тратить часы на догадки, вместо того чтобы получить точные данные.
Как оценивать: Изучите документацию инструмента, посмотрите примеры его использования для конкретных сценариев (например, отслеживание задержек чтения с диска для определенного процесса, анализ сетевых retransmits для конкретного контейнера). Проведите пилотное тестирование на некритичной среде.
2. Производительность и накладные расходы (Performance and Overhead)
Одно из главных преимуществ eBPF — его способность работать с минимальным влиянием на производительность системы. Программы eBPF исполняются в ядре, избегая переключений контекста между ядром и пользовательским пространством, что значительно снижает оверхед по сравнению с традиционными агентами. Однако даже eBPF-программы могут быть неоптимальными. При оценке учитывайте:
- Среднее потребление CPU/RAM: Особенно под высокой нагрузкой.
- Влияние на latency: Как eBPF-мониторинг влияет на задержки сетевых запросов или системных вызовов.
- Масштабируемость: Насколько хорошо решение работает на большом количестве узлов и при высокой интенсивности событий.
Почему важен: В высоконагруженных системах даже небольшой дополнительный оверхед может привести к каскадным сбоям или деградации сервиса. eBPF должен быть вашим союзником, а не еще одним источником проблем.
Как оценивать: Обязательно проводите стресс-тесты с включенным eBPF-мониторингом. Сравнивайте метрики производительности (CPU utilization, network latency, disk I/O) до и после внедрения. Используйте бенчмаркинг-инструменты, такие как iperf3, fio, sysbench.
3. Возможности безопасности и предотвращения угроз (Security Capabilities and Threat Prevention)
eBPF предоставляет уникальные возможности для реализации динамических политик безопасности и обнаружения угроз непосредственно в ядре. Это позволяет реагировать на аномалии быстрее и эффективнее, чем традиционные IDS/IPS системы, работающие в пользовательском пространстве. Ключевые аспекты:
- Обнаружение аномалий: Способность выявлять подозрительные системные вызовы, сетевые соединения, файловые операции.
- Предотвращение угроз: Возможность блокировать или модифицировать нежелательные действия (например, запрет запуска определенных программ, модификация сетевых пакетов).
- Интеграция с SIEM/SOAR: Насколько легко eBPF-решение может отправлять данные об инцидентах в существующие системы безопасности.
- Контекстуализация событий: Возможность связывать события ядра с конкретными контейнерами, процессами, пользователями.
Почему важен: В 2026 году кибератаки становятся все более изощренными. Защита на уровне ядра — это последняя линия обороны, способная остановить атаки, которые обходят традиционные средства.
Как оценивать: Проверяйте, насколько эффективно решение обнаруживает и предотвращает известные типы атак (например, попытки эскалации привилегий, внедрение руткитов, несанкционированный доступ к файлам). Изучите набор готовых правил безопасности и возможность их кастомизации.
4. Зрелость экосистемы и сообщества (Ecosystem Maturity and Community Support)
Хотя eBPF относительно молод, его экосистема развивается с феноменальной скоростью. Выбор зрелого решения с активным сообществом гарантирует долгосрочную поддержку, наличие документации, примеров и готовых интеграций. Что учитывать:
- Активность на GitHub: Количество коммитов, звезд, контрибьюторов, открытых и закрытых issues.
- Документация: Наличие исчерпывающей и актуальной документации, туториалов.
- Поддержка: Наличие коммерческой поддержки (если это важно для вашего SLA), активные форумы, Slack-каналы.
- Интеграции: Совместимость с вашим текущим стеком мониторинга (Prometheus, Grafana, OpenTelemetry, Fluentd, Kafka).
Почему важен: Работа с новой технологией всегда сопряжена с вызовами. Сильное сообщество и хорошая документация значительно упрощают обучение, внедрение и решение возникающих проблем.
Как оценивать: Посетите репозитории проектов, проверьте даты последних коммитов, активность в дискуссиях. Попробуйте задать вопрос в сообществе и оцените скорость и качество ответа. Изучите дорожную карту проекта.
5. Простота разработки и развертывания (Ease of Development and Deployment)
Даже самая мощная технология бесполезна, если ее невозможно легко внедрить и поддерживать. eBPF-программы пишутся на C, но существуют высокоуровневые инструменты (bpftrace, BCC, libbpf), упрощающие этот процесс. Оцените:
- Порог входа для разработки: Насколько сложно написать и отладить собственную eBPF-программу.
- Инструменты для развертывания: Поддержка Kubernetes (DaemonSets, Helm charts), Ansible, Terraform.
- Управление конфигурацией: Насколько легко изменять и обновлять eBPF-политики или программы.
- Наличие готовых решений: Есть ли готовые "приложения" на eBPF, которые можно использовать "из коробки" для типовых задач.
Почему важен: Быстрое прототипирование и развертывание, а также простота поддержки, напрямую влияют на TCO (Total Cost of Ownership) и скорость реакции на бизнес-потребности.
Как оценивать: Попробуйте развернуть выбранное решение в тестовой среде. Попытайтесь создать простую кастомную eBPF-программу или модифицировать существующую. Оцените удобство использования CLI-инструментов и API.
Тщательная оценка этих критериев позволит вам выбрать eBPF-решение, которое наилучшим образом соответствует потребностям вашей инфраструктуры, обеспечивая при этом оптимальный баланс между производительностью, безопасностью и управляемостью.
Сравнительная таблица: eBPF vs. Традиционные подходы
Для лучшего понимания преимуществ eBPF, давайте сравним его с традиционными инструментами мониторинга и безопасности, которые доминировали в Linux-инфраструктурах до активного распространения eBPF. Мы сфокусируемся на ключевых характеристиках, актуальных для 2026 года, учитывая зрелость обеих категорий.
| Критерий | Традиционные Агенты (Prometheus Node Exporter, Metricbeat, Auditd, Snort) | eBPF-решения (Cilium, Falco, Tracee, bpftrace, BCC) | Комментарии (Актуально на 2026 год) |
|---|---|---|---|
| Глубина видимости | Ограничена пользовательским пространством, системными вызовами, логами. Часто требует дополнительных модулей ядра или ptrace с высоким оверхедом. |
Беспрецедентная видимость на уровне ядра: системные вызовы, сетевые пакеты, файловые операции, планировщик, без модификации ядра. | eBPF предоставляет контекст и детали, недоступные из user-space, что критично для сложных распределенных систем. |
| Накладные расходы (Overhead) | Высокий: переключение контекста между ядром и пользовательским пространством, копирование данных, парсинг логов. CPU 5-15%, RAM 100-500MB+ на агент. | Минимальный: исполнение в ядре, отсутствие переключений контекста. CPU 0.1-2%, RAM 10-100MB на узел (зависит от сложности программ). | eBPF-верификатор гарантирует безопасность и эффективность, предотвращая бесконечные циклы и доступ к несанкционированной памяти. |
| Скорость реакции на события | Задержки: события должны быть записаны, считаны агентом, обработаны и отправлены. Часто секунды, иногда десятки секунд. | Мгновенная: обработка событий прямо в ядре, возможность блокировки или модификации в реальном времени. Миллисекунды. | Критично для безопасности (предотвращение атак) и высокочастотного мониторинга (анализ сетевых микро-bursts). |
| Простота развертывания/управления | Требует установки и настройки агентов на каждом хосте, управления конфигурационными файлами. Могут быть конфликты зависимостей. | Часто развертывается как DaemonSet в Kubernetes, использует стандартные API. Единое управление политиками. | В 2026 году eBPF-инструменты имеют зрелые оркестраторы и CLI, упрощающие управление. |
| Функции безопасности | Обнаружение (IDS), аудит (Auditd), фаерволы (iptables, nftables). Часто реактивные, не превентивные на уровне ядра. | Превентивная безопасность на уровне ядра (LSM-подобные хуки), динамические политики, предотвращение атак, сетевая сегментация. | eBPF позволяет создать "умный" фаервол, работающий на XDP, или динамически блокировать подозрительные системные вызовы. |
| Сетевая функциональность | Традиционные фаерволы (iptables), маршрутизация в пользовательском пространстве. Ограничения по производительности и гибкости. | Высокопроизводительная сетевая обработка (XDP), продвинутая балансировка нагрузки, service mesh, прозрачное шифрование. | Проекты вроде Cilium полностью заменяют kube-proxy и обеспечивают Service Mesh без sidecars, значительно снижая оверхед. |
| Стоимость (TCO, 2026 год) | Лицензии на коммерческие агенты (например, Datadog, Splunk) от $100-$500/мес за узел. Высокие затраты на инженеров для поддержки. | Большинство решений Open Source. Коммерческая поддержка (Cilium Enterprise, Isovalent) от $50-$250/мес за узел (для крупных инсталляций). Ниже затраты на инженеров в долгосрочной перспективе из-за стандартизации. | TCO eBPF ниже за счет Open Source, меньших требований к ресурсам и унификации инструментов. |
| Сложность разработки кастомных решений | Требует глубоких знаний OS, C/C++, работы с системными API, поддержки различных версий ядра. | Требует понимания eBPF, C, но есть высокоуровневые обертки (bpftrace, Go/Rust с libbpf) и компиляторы (BCC) для упрощения. | Порог входа для написания простых eBPF-программ снизился благодаря инструментам, но для сложных задач все еще нужны эксперты. |
Как видно из таблицы, eBPF предлагает значительные преимущества по сравнению с традиционными подходами, особенно в части производительности, глубины видимости и скорости реакции. В 2026 году, когда инфраструктуры становятся все более динамичными и распределенными, эти преимущества становятся критически важными. Переход на eBPF-ориентированные решения позволяет не только оптимизировать затраты, но и значительно повысить надежность и безопасность всей системы.
Детальный обзор ключевых аспектов eBPF
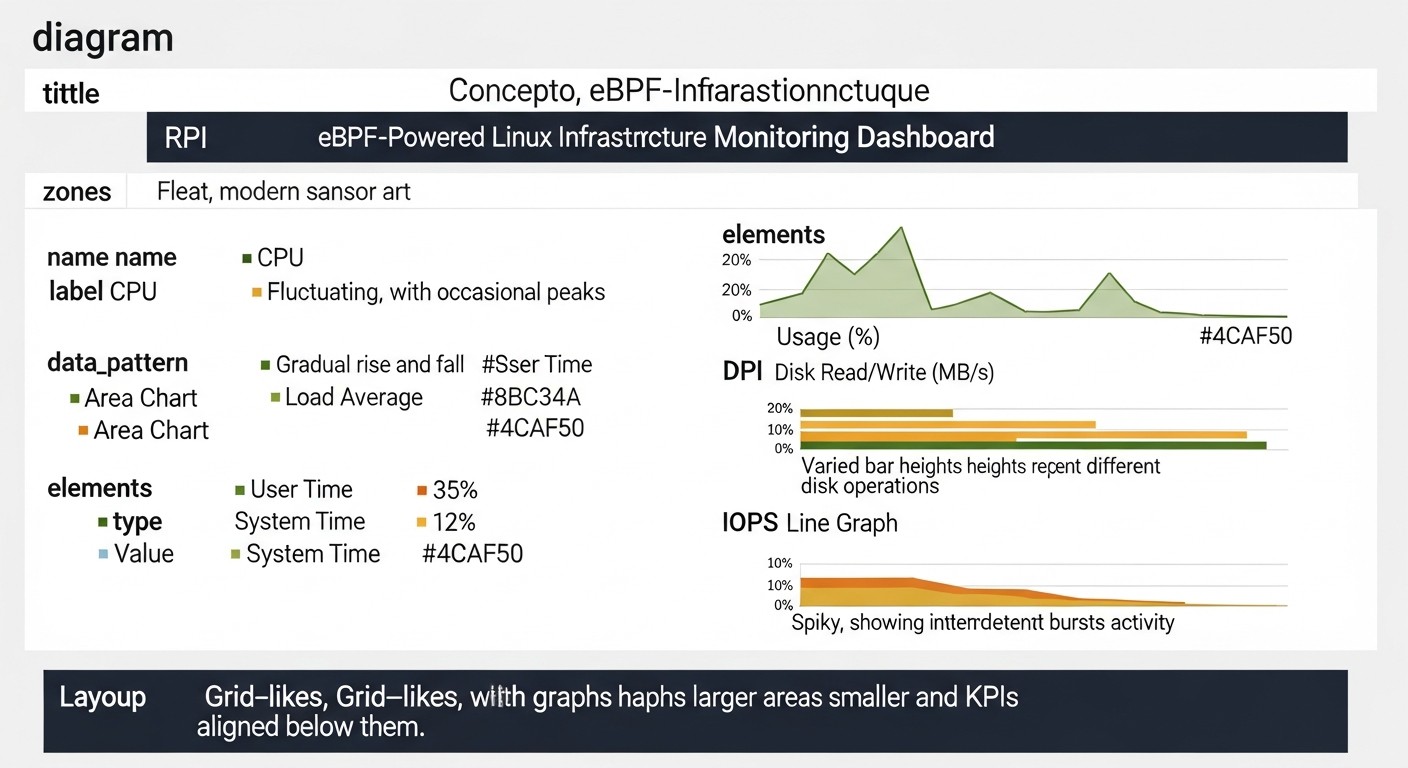
eBPF — это не просто инструмент, а целая парадигма для взаимодействия с ядром Linux. Его мощь проявляется в различных областях, от тонкого мониторинга производительности до создания продвинутых механизмов безопасности. Давайте углубимся в ключевые аспекты, которые делают eBPF столь революционным.
1. eBPF для глубокого мониторинга производительности и наблюдаемости
Традиционные инструменты мониторинга часто ограничены тем, что они могут видеть из пользовательского пространства. Они полагаются на /proc, sysfs, strace или кастомные модули ядра, которые либо имеют высокий оверхед, либо требуют перезагрузки. eBPF кардинально меняет эту картину. Он позволяет безопасно прикреплять программы к различным точкам в ядре (kprobes, uprobes, tracepoints, perf events) и собирать данные о системных вызовах, сетевых операциях, файловом доступе, использовании CPU, блокировках и многом другом.
- Плюсы:
- Минимальный оверхед: Программы eBPF исполняются в ядре без переключения контекста, что обеспечивает сбор данных с минимальным влиянием на производительность. Это позволяет мониторить высоконагруженные системы, не опасаясь деградации.
- Непревзойденная детализация: Возможность получить полный контекст событий: кто вызвал системный вызов, с какими аргументами, какие файлы были затронуты, какой сетевой пакет был отправлен/получен.
- Динамичность: Программы можно загружать, выгружать и обновлять без перезагрузки ядра или сервисов. Это идеально для динамичных облачных сред.
- Единый источник истины: Все данные собираются непосредственно из ядра, устраняя расхождения между различными инструментами.
- Минусы:
- Высокий порог входа: Написание сложных eBPF-программ требует глубоких знаний ядра Linux, C и специфики eBPF-виртуальной машины.
- Зависимость от версии ядра: Хотя
libbpfи CO-RE (Compile Once – Run Everywhere) значительно улучшили ситуацию, некоторые программы могут требовать адаптации под конкретные версии ядра или дистрибутивы. - Обработка больших объемов данных: Глубокий мониторинг генерирует огромные объемы данных, требующие мощных систем для их хранения, обработки и анализа.
- Для кого подходит:
- DevOps-инженеры и SRE для поиска узких мест производительности в продакшене, диагностики "flapping" сервисов.
- Backend-разработчики для профилирования своих приложений, понимания взаимодействия с ОС и оптимизации системных вызовов.
- Команды, занимающиеся высокопроизводительными вычислениями и низколатентными системами.
- Конкретные примеры использования:
- Мониторинг задержек HTTP-запросов на уровне TCP/IP, выявление проблем с retransmits или slow start.
- Анализ использования CPU по стекам вызовов для каждого процесса или функции.
- Отслеживание файловых операций (read/write latency) для конкретных файлов или директорий, выявление дисковых "бутылочных горлышек".
- Диагностика проблем с планировщиком (scheduler latency) и нехваткой ресурсов.
2. eBPF для сетевой функциональности и Service Mesh
Сетевой стек Linux всегда был сложным и критически важным компонентом. eBPF радикально упрощает и ускоряет многие сетевые операции, позволяя реализовывать функциональность, которая ранее требовала сложных настроек iptables, пользовательских демонов или даже аппаратных решений.
- Плюсы:
- Высокопроизводительная обработка пакетов: С помощью XDP (eXpress Data Path) eBPF может обрабатывать сетевые пакеты на самом раннем этапе приема, до того как они попадут в традиционный сетевой стек. Это позволяет создавать сверхбыстрые фаерволы, балансировщики нагрузки и DDoS-защиту.
- Умная маршрутизация и балансировка: eBPF может динамически изменять маршрутизацию и балансировку нагрузки на основе содержимого пакетов или состояния сервисов, обходя ограничения
kube-proxyв Kubernetes и реализуя более эффективные Service Mesh без сайдкаров. - Прозрачная безопасность сети: Позволяет внедрять политики фаервола, шифрования (WireGuard) и сетевой сегментации прямо в ядре, обеспечивая безопасность на уровне L3/L4/L7 без модификации приложений.
- Упрощенный Service Mesh: Такие проекты, как Cilium, используют eBPF для создания полноценного Service Mesh, который обрабатывает трафик на уровне ядра, устраняя необходимость в прокси-сайдкарах (Envoy) и значительно снижая задержки и потребление ресурсов.
- Минусы:
- Сложность настройки для новичков: Хотя инструменты упрощают процесс, понимание сетевого стека Linux и eBPF-хуков все еще необходимо.
- Зависимость от версии ядра: Для некоторых продвинутых сетевых функций требуются относительно свежие версии ядра Linux.
- Потенциальные конфликты: Некорректно написанные eBPF-программы могут нарушить работу сети.
- Для кого подходит:
- DevOps-инженеры и SRE, управляющие крупными Kubernetes-кластерами.
- Команды, разрабатывающие высоконагруженные сетевые сервисы.
- Сетевые инженеры, ищущие более гибкие и производительные решения, чем традиционные.
- Конкретные примеры использования:
- Реализация Kubernetes Service Mesh с Cilium, обеспечивающая сетевые политики, балансировку нагрузки и наблюдаемость без сайдкаров.
- Создание высокопроизводительного фаервола для защиты от DDoS-атак с использованием XDP.
- Прозрачное шифрование трафика между сервисами в кластере с помощью eBPF и WireGuard.
- Динамическая маршрутизация трафика на основе HTTP-заголовков для A/B-тестирования или canary-деплойментов.
3. eBPF для продвинутой безопасности и предотвращения угроз
Возможность исполнять программы в ядре открывает невиданные ранее горизонты для обеспечения безопасности. eBPF может действовать как «страж», который контролирует каждый системный вызов, каждую сетевую операцию и каждое обращение к файловой системе, реагируя на подозрительные действия в реальном времени.
- Плюсы:
- Превентивная защита: eBPF может блокировать или модифицировать вредоносные действия до того, как они нанесут ущерб, в отличие от реактивных систем, которые только обнаруживают инциденты после их совершения.
- Глубокий контекст безопасности: Способность связывать действия ядра с контекстом пользовательского пространства (процессы, контейнеры, пользователи), что позволяет точно определить источник и характер угрозы.
- Обнаружение руткитов и уклонений: eBPF-программы трудно обмануть, так как они работают на том же уровне, что и ядро, и могут выявлять попытки скрытия процессов или файлов.
- Микросегментация и изоляция: Возможность создавать детализированные политики сетевой и системной безопасности для каждого приложения или контейнера, значительно снижая поверхность атаки.
- Аудит системных вызовов с низким оверхедом: Альтернатива
auditd, которая генерирует огромное количество логов и имеет высокий оверхед. eBPF позволяет собирать только нужные события с минимальным влиянием.
- Минусы:
- Сложность разработки политик: Создание эффективных и неблокирующих легитимные операции политик безопасности требует глубокого понимания как поведения системы, так и потенциальных угроз.
- Потенциал для злоупотреблений: Мощность eBPF означает, что некорректно написанные или злонамеренные программы могут нанести серьезный ущерб системе. Именно поэтому существует верификатор eBPF.
- Требует квалифицированных специалистов: Для внедрения и поддержки eBPF-решений безопасности нужны инженеры с экспертизой в области Linux-ядра и безопасности.
- Для кого подходит:
- Команды по безопасности (SecOps), ищущие передовые средства защиты.
- DevOps-инженеры, ответственные за безопасность инфраструктуры.
- Организации с высокими требованиями к комплаенсу и защите данных.
- Конкретные примеры использования:
- Использование Falco для обнаружения подозрительных системных вызовов (например, попытка изменения системных файлов из контейнера, не имеющего на это прав).
- Блокировка запуска неизвестных или несанкционированных исполняемых файлов.
- Мониторинг доступа к конфиденциальным данным и оповещение о несанкционированных попытках.
- Предотвращение атак типа "supply chain" путем контроля активности процессов, запущенных из доверенных образов.
Каждый из этих аспектов eBPF представляет собой отдельную, глубокую область знаний, но их комбинация делает eBPF универсальным инструментом для решения самых насущных проблем современных Linux-инфраструктур. В 2026 году, когда сложность систем продолжает расти, а требования к производительности и безопасности становятся все строже, eBPF становится не просто опцией, а необходимостью для тех, кто стремится к совершенству в DevOps.
Практические советы и рекомендации по внедрению eBPF
Внедрение eBPF в существующую инфраструктуру может показаться сложной задачей, но при правильном подходе и постепенной интеграции оно принесет значительные дивиденды. Ниже представлены практические советы и пошаговые инструкции, основанные на реальном опыте.
1. Начните с малого: Мониторинг и наблюдаемость
Самый безопасный и наименее рискованный способ начать работу с eBPF — это использование его для мониторинга и наблюдаемости. Это не влияет на работу системы напрямую, а лишь собирает данные.
Пошаговая инструкция: Мониторинг сетевых задержек с bpftrace
- Установите
bpftrace: Убедитесь, что ваше ядро поддерживает eBPF (Linux 4.9+). Для большинства современных дистрибутивов установка проста.# Для Ubuntu/Debian sudo apt update sudo apt install -y bpftrace # Для CentOS/RHEL sudo yum install -y bpftrace - Изучите доступные точки трассировки:
sudo bpftrace -l 'kprobe:tcp_sendmsg' sudo bpftrace -l 'tracepoint:syscalls:sys_enter_write' - Напишите простой скрипт для измерения задержек TCP-соединений: Этот скрипт будет отслеживать время между отправкой пакета и получением подтверждения (ACK) на уровне ядра.
#!/usr/local/bin/bpftrace kprobe:tcp_sendmsg { @start[comm] = nsecs; } kprobe:tcp_recvmsg /@start[comm]/ { $latency = nsecs - @start[comm]; printf("TCP Latency for %s: %d ns\n", comm, $latency); delete(@start[comm]); }Сохраните его как
tcp_latency.bt. - Запустите скрипт:
sudo bpftrace tcp_latency.btВы увидите вывод задержек для различных процессов. Это даст вам представление о том, как ваш сервис взаимодействует с сетью на низком уровне.
- Интеграция с Prometheus/Grafana: Для продакшена используйте такие инструменты, как Prometheus Node Exporter с textfile collector или специализированные eBPF-экспортеры, чтобы собирать эти метрики и визуализировать их в Grafana. Например, можно использовать скрипты BCC, которые выводят данные в формате Prometheus.
2. Используйте готовые инструменты и библиотеки
Не пытайтесь сразу писать все с нуля. Экосистема eBPF предлагает множество готовых решений и библиотек, которые значительно упрощают разработку и внедрение.
- BCC (BPF Compiler Collection): Набор инструментов и библиотек на Python/Lua для написания eBPF-программ. Идеально для быстрого прототипирования и создания кастомных инструментов.
- bpftrace: Высокоуровневый язык для трассировки, позволяющий писать мощные eBPF-скрипты в несколько строк.
- libbpf и CO-RE (Compile Once – Run Everywhere): Современный подход для создания более стабильных и переносимых eBPF-приложений, написанных на C/Go/Rust.
- Cilium/Hubble: Для сетевых задач и Service Mesh.
- Falco/Tracee: Для безопасности и аудита системных вызовов.
3. Тестируйте в изолированной среде
Перед развертыванием eBPF-решений в продакшене обязательно проводите тщательное тестирование в изолированной среде (staging, dev). Это поможет выявить потенциальные конфликты или проблемы производительности.
- Используйте виртуальные машины или контейнеры (например, с помощью Vagrant, Docker, Kind).
- Имитируйте реальную нагрузку с помощью инструментов вроде
k6,JMeter,wrk. - Мониторьте потребление ресурсов (CPU, RAM, I/O) с помощью традиционных инструментов, чтобы убедиться в минимальном оверхеде eBPF.
- Проверяйте функциональность eBPF-программ, убеждаясь, что они собирают правильные данные или применяют нужные политики.
4. Постепенное внедрение: "Canary Deployment" для eBPF
Вместо того чтобы разворачивать eBPF сразу на всей инфраструктуре, начните с небольшой части. Это минимизирует риски.
- Выбор тестовой группы: Выберите несколько некритичных серверов или небольшой кластер Kubernetes для первого развертывания.
- Мониторинг: Внимательно отслеживайте метрики производительности и стабильности этих узлов.
- Расширение: Постепенно увеличивайте количество узлов, на которых работает eBPF, пока не охватите всю инфраструктуру.
5. Интеграция с существующим стеком
eBPF не должен быть изолированным инструментом. Интегрируйте его данные в ваш текущий стек мониторинга, логирования и оповещения.
- Prometheus/Grafana: Большинство eBPF-инструментов могут экспортировать метрики в формате Prometheus.
- OpenTelemetry: Некоторые eBPF-решения уже поддерживают экспорт трассировок и метрик через OpenTelemetry.
- Fluentd/Kafka: Для потоковой передачи событий безопасности или детализированных логов.
- Alertmanager: Настраивайте алерты на основе аномалий, обнаруженных eBPF-программами.
# Пример конфигурации Prometheus для сбора метрик с eBPF-экспортера
scrape_configs:
- job_name: 'ebpf-metrics'
static_configs:
- targets: ['ebpf-exporter.monitoring.svc.cluster.local:9100']
labels:
env: production
app: ebpf-observability
relabel_configs:
- source_labels: [__address__]
regex: '(.):9100'
target_label: instance
replacement: $1
6. Обучение и обмен знаниями
eBPF — это мощная, но сложная технология. Инвестируйте в обучение команды, проводите внутренние семинары и делитесь опытом.
- Назначьте "чемпионов" по eBPF в команде, которые будут углублять свои знания и делиться ими.
- Используйте ресурсы из раздела "Инструменты и ресурсы" для самообучения.
- Участвуйте в сообществе eBPF (форумы, Slack, конференции).
7. Управление версиями ядра
Помните, что eBPF тесно связан с ядром Linux. Планируйте обновления ядра и тестируйте eBPF-решения на новых версиях.
- Используйте дистрибутивы с более предсказуемым циклом обновлений ядра (например, LTS-версии Ubuntu, RHEL).
- Внедрите автоматизированные тесты для проверки совместимости eBPF-программ после обновления ядра.
- Рассмотрите использование CO-RE (Compile Once – Run Everywhere) для создания более устойчивых к изменениям ядра программ.
Придерживаясь этих рекомендаций, вы сможете эффективно и безопасно внедрить eBPF в вашу DevOps-практику, значительно повысив уровень мониторинга, безопасности и производительности вашей Linux-инфраструктуры.
Типичные ошибки при работе с eBPF
Как и любая мощная технология, eBPF требует осторожного и продуманного подхода. Неправильное использование может привести не только к неэффективности, но и к серьезным проблемам со стабильностью и безопасностью системы. Ниже приведены наиболее распространенные ошибки, с которыми сталкиваются инженеры при внедрении eBPF.
1. Игнорирование верификатора eBPF и его ограничений
Ошибка: Попытка написать слишком сложные eBPF-программы, которые не проходят проверку верификатора, или игнорирование причин, по которым верификатор отклоняет программу.
Последствия: Программа не загружается, а разработчик тратит часы на отладку, пытаясь понять, почему "простой" код не работает. В худшем случае, попытки обойти верификатор могут привести к нестабильности ядра.
Как избежать:
- Всегда помните, что eBPF-программы должны быть детерминированными, не иметь бесконечных циклов, не обращаться к недопустимым областям памяти и завершаться за ограниченное число инструкций.
- Начните с простых программ, постепенно усложняя их.
- Внимательно читайте сообщения об ошибках верификатора – они дают четкие подсказки о проблеме (например, "program too large", "loop detected", "invalid memory access").
- Используйте высокоуровневые инструменты (
bpftrace,BCC), которые генерируют корректный eBPF-код, или современные библиотеки (libbpf) с поддержкой CO-RE, которые упрощают управление памятью и регистрами.
Реальный пример: Однажды команда пыталась написать eBPF-программу для отслеживания всех файловых операций, но забыла о максимальном размере программы. Верификатор постоянно отклонял ее с ошибкой "program too large". Пришлось перепроектировать программу, чтобы она выполняла более узкие, специализированные задачи и использовала карты eBPF для агрегации данных, вместо того чтобы пытаться обработать все в одной программе.
2. Чрезмерный сбор данных и высокий оверхед
Ошибка: Попытка собрать "все" данные из ядра, подключаясь ко всем возможным точкам трассировки и не фильтруя информацию. Это приводит к высокому оверхеду, несмотря на эффективность eBPF.
Последствия: Деградация производительности системы, переполнение буферов eBPF-карт, потеря ценных данных, высокая нагрузка на системы хранения и анализа логов/метрик.
Как избежать:
- Принцип минимальной достаточности: Собирайте только те данные, которые вам действительно нужны для решения конкретной проблемы.
- Фильтрация на уровне ядра: Используйте возможности eBPF для фильтрации событий прямо в ядре. Например, отслеживайте системные вызовы только для конкретного PID, CGroup или сетевого порта.
- Агрегация данных: Агрегируйте данные в eBPF-картах в ядре, прежде чем передавать их в пользовательское пространство. Например, вместо отправки каждого события "открытие файла", можно подсчитывать количество открытий в секунду для каждого процесса.
- Мониторинг самого eBPF: Отслеживайте метрики использования CPU и памяти eBPF-программами, чтобы оперативно реагировать на рост оверхеда.
3. Недостаточное тестирование и развертывание в продакшен без "канарейки"
Ошибка: Развертывание новых или измененных eBPF-программ непосредственно в продакшене без предварительного тестирования в изолированной среде или использования стратегии "canary deployment".
Последствия: Нестабильность системы, падение сервисов, kernel panic (хоть и редко, но возможно при очень серьезных ошибках или багах в ядре), проблемы с производительностью, которые могут затронуть весь кластер.
Как избежать:
- Всегда начинайте с тестовой среды (dev/staging), максимально приближенной к продакшену.
- Используйте стратегию "canary deployment": разверните eBPF на небольшом подмножестве узлов, внимательно мониторьте их состояние и только после этого масштабируйте.
- Проводите нагрузочное тестирование с включенными eBPF-программами, чтобы убедиться в минимальном оверхеде.
- Используйте автоматизированные тесты, которые проверяют корректность работы eBPF-программ и их влияние на систему.
4. Неправильное управление жизненным циклом eBPF-программ
Ошибка: Загрузка множества eBPF-программ, которые конкурируют за одни и те же точки трассировки, или забывание выгрузить ненужные программы.
Последствия: Конфликты между программами, непредсказуемое поведение системы, повышенное потребление ресурсов ядра, утечки памяти в ядре (при некорректной выгрузке).
Как избежать:
- Используйте централизованный подход к управлению eBPF-программами, особенно в Kubernetes (DaemonSets, операторы).
- Документируйте, какие программы загружены, к каким точкам они прикреплены и для чего используются.
- Убедитесь, что программы корректно выгружаются при остановке сервиса или при обновлении.
- Используйте инструменты, такие как
bpftool, для инспекции загруженных программ и карт eBPF:sudo bpftool prog show sudo bpftool map show
5. Игнорирование версий ядра и CO-RE
Ошибка: Разработка eBPF-программы, которая жестко привязана к конкретной версии или конфигурации ядра, что приводит к проблемам совместимости при обновлении системы.
Последствия: Программа перестает работать после обновления ядра, требуя перекомпиляции или модификации кода. Это увеличивает операционные издержки и снижает гибкость инфраструктуры.
Как избежать:
- Используйте CO-RE (Compile Once – Run Everywhere): Это современный подход, который позволяет eBPF-программам адаптироваться к различным версиям ядра без перекомпиляции, используя информацию о типах ядра.
- Зависимость от
libbpf: Используйтеlibbpfв качестве основы для ваших eBPF-приложений, так как она предоставляет надежную абстракцию над низкоуровневыми вызовами ядра. - Тестирование на разных ядрах: Если ваша инфраструктура неоднородна, тестируйте eBPF-программы на разных версиях ядра, которые используются в вашей среде.
- Обоснованное обновление ядра: Планируйте и тестируйте обновления ядра, учитывая их влияние на eBPF-программы.
Избегая этих распространенных ошибок, вы сможете максимально эффективно использовать потенциал eBPF, минимизируя риски и обеспечивая стабильную и безопасную работу вашей Linux-инфраструктуры.
Чеклист для практического применения eBPF
Этот чеклист поможет вам структурировать процесс внедрения и использования eBPF в вашей DevOps-практике, обеспечивая систематический подход и минимизируя риски.
Фаза 1: Планирование и Подготовка
- Определите конкретные цели: Четко сформулируйте, какие проблемы вы хотите решить с помощью eBPF (например, "снизить время отклика сервиса X на 15%", "обнаруживать несанкционированный доступ к файлам Y").
- Оцените текущую инфраструктуру:
- Версия ядра Linux на ваших серверах (минимум 4.9 для базовых функций, 5.x+ для продвинутых).
- Используемый дистрибутив (наличие необходимых пакетов, компиляторов).
- Наличие Kubernetes-кластера (если планируется использование eBPF в контейнерах).
- Выберите целевые области: Мониторинг производительности, сетевая безопасность, аудит системных вызовов, Service Mesh. Не пытайтесь охватить все сразу.
- Исследуйте готовые решения: Изучите существующие eBPF-инструменты (Cilium, Falco, Tracee, bpftrace, BCC) и выберите те, которые наилучшим образом подходят для ваших целей.
- Оцените ресурсы команды: Есть ли в команде специалисты с опытом работы с Linux-ядром, C/Go/Rust, или готовы ли вы инвестировать в обучение?
- Выделите тестовую среду: Подготовьте изолированную среду (VM, dev-кластер Kubernetes) для экспериментов и тестирования.
Фаза 2: Внедрение и Тестирование
- Установите необходимые инструменты: Разверните выбранные eBPF-решения (например, Cilium как CNI в Kubernetes, Falco как DaemonSet).
# Пример установки Cilium в Kubernetes helm repo add cilium https://helm.cilium.io/ helm install cilium cilium/cilium --version 1.15.5 \ --namespace kube-system \ --set kubeProxyReplacement=strict \ --set hubble.enabled=true \ --set hubble.ui.enabled=true - Начните с мониторинга (read-only): Сначала используйте eBPF-инструменты только для сбора данных, без активного воздействия на систему (например,
bpftraceскрипты, Hubble для сетевой видимости). - Проведите нагрузочное тестирование: Запустите тесты производительности с включенными eBPF-программами, чтобы оценить их реальное влияние на систему (CPU, RAM, latency).
- Мониторинг стабильности: Внимательно отслеживайте логи ядра (
dmesg), системные метрики и стабильность приложений в тестовой среде. - Настройте интеграции: Подключите eBPF-метрики и события к вашей существующей системе мониторинга (Prometheus, Grafana), логирования (Fluentd, ELK) и оповещения (Alertmanager).
# Пример: Hubble UI kubectl port-forward -n kube-system svc/hubble-ui 8080:80 # Откройте http://localhost:8080 в браузере - Используйте "Canary Deployment": Разверните eBPF на небольшом сегменте продакшен-инфраструктуры, постоянно отслеживая его поведение.
Фаза 3: Оптимизация и Масштабирование
- Оптимизируйте eBPF-программы: Пересмотрите свои кастомные скрипты и конфигурации для минимизации оверхеда, используя фильтрацию и агрегацию данных на уровне ядра.
- Разработайте политики безопасности: Начните с простых, неблокирующих политик (например, с
Falcoв режиме аудита), затем постепенно переходите к превентивным мерам. - Документируйте внедрение: Создайте документацию по архитектуре eBPF-решений, их конфигурации, процессам развертывания и устранения неполадок.
- Обучите команду: Проведите внутренние тренинги и семинары для команды DevOps и разработчиков по работе с eBPF.
- Планируйте обновления ядра: Учитывайте eBPF-совместимость при планировании обновлений ядра Linux. Используйте CO-RE для обеспечения переносимости.
- Автоматизируйте: Интегрируйте развертывание и управление eBPF-решениями в ваш CI/CD-пайплайн (например, с помощью Helm, Terraform, Ansible).
- Регулярный аудит: Периодически пересматривайте eBPF-политики и программы, чтобы убедиться в их актуальности и эффективности.
- Взаимодействуйте с сообществом: Участвуйте в дискуссиях, задавайте вопросы и делитесь своим опытом с eBPF-сообществом.
Расчет стоимости / Экономика внедрения eBPF
Оценка экономической эффективности внедрения eBPF — это комплексный процесс, который выходит за рамки прямых затрат на лицензии. В большинстве случаев eBPF-инструменты являются Open Source, но это не означает отсутствие TCO (Total Cost of Ownership). Необходимо учитывать скрытые расходы, потенциальную экономию и возврат инвестиций (ROI).
Примеры расчетов для разных сценариев (2026 год)
Сценарий 1: Малый стартап (10-20 серверов/виртуальных машин, Kubernetes-кластер на 5-10 узлов)
- Цель: Улучшить наблюдаемость и базовую безопасность.
- Используемые инструменты:
bpftraceдля ad-hoc трассировки,Falcoдля безопасности,Ciliumдля CNI и сетевых политик в Kubernetes. Все Open Source. - Прямые затраты: ~$0 на лицензии.
- Скрытые расходы:
- Инженерное время на изучение и внедрение: 1-2 инженера 2-4 недели (обучение, пилот, настройка). Ориентировочно $10,000 - $20,000 (при средней зарплате $2000-2500/неделя).
- Инфраструктура для сбора/анализа данных: Увеличение объема данных для Prometheus/Grafana, ELK. Дополнительные $50-$150/мес на облачные ресурсы.
- Поддержка: Время на решение проблем, обновление. 0.5 инженера 1 неделя/мес = $1,000/мес.
- Общий TCO (первый год): ~$22,000 - $35,000 (включая первоначальное внедрение и 10 месяцев поддержки).
- Экономия/ROI:
- Сокращение времени на диагностику проблем (MTTR) на 20-30%.
- Повышение безопасности, снижение рисков инцидентов.
- Отсутствие необходимости в коммерческих агентах мониторинга (экономия $500-$1000/мес).
Сценарий 2: Средняя компания (100-200 серверов/VM, Kubernetes-кластер на 30-50 узлов)
- Цель: Полная миграция на eBPF-ориентированный Service Mesh, продвинутая безопасность, централизованный мониторинг.
- Используемые инструменты:
Cilium Enterprise(для коммерческой поддержки и расширенных функций),Falcoс кастомными правилами,OpenTelemetry+ eBPF-экспортеры. - Прямые затраты:
- Лицензии Cilium Enterprise (например, Isovalent): $100-$150/узел/мес 50 узлов = $5,000-$7,500/мес, или $60,000-$90,000/год.
- Возможно, платные курсы/консалтинг: $5,000-$15,000.
- Скрытые расходы:
- Инженерное время на изучение и внедрение: 2-3 инженера 1-2 месяца. Ориентировочно $16,000 - $48,000.
- Инфраструктура для сбора/анализа данных: Значительное увеличение, $500-$1500/мес на облачные ресурсы.
- Поддержка: 1 инженер 1 неделя/мес = $2,000/мес.
- Общий TCO (первый год): ~$100,000 - $180,000.
- Экономия/ROI:
- Снижение MTTR на 30-50%.
- Устранение необходимости в Sidecar-прокси (Envoy) для Service Mesh (экономия CPU/RAM на каждом поде, до 15-20% ресурсов кластера).
- Замена дорогостоящих коммерческих агентов мониторинга/безопасности (экономия $5,000-$15,000/мес).
- Значительное повышение уровня безопасности и соответствия требованиям (compliance).
Скрытые расходы
- Время инженеров: Самая большая статья расходов. Обучение, разработка кастомных eBPF-программ, настройка, отладка, поддержка.
- Инфраструктура для данных: eBPF генерирует много высокогранулярных данных. Их нужно хранить, обрабатывать и визуализировать. Это требует дополнительных ресурсов для Prometheus, Grafana, Loki, ClickHouse, ELK-стека.
- Консалтинг и обучение: Для сложных внедрений может потребоваться внешняя экспертиза или специализированные курсы.
- Поддержка ядра: Обеспечение актуальной версии ядра Linux и тестирование eBPF-решений после его обновлений.
- Инструменты CI/CD: Интеграция eBPF-программ и политик в автоматизированные пайплайны.
Как оптимизировать затраты
- Начните с Open Source: Используйте открытые решения (Cilium, Falco, bpftrace) до тех пор, пока не возникнет реальная потребность в коммерческой поддержке или расширенных функциях.
- Постепенное внедрение: Начните с малого, решайте конкретные проблемы. Это позволит вашей команде постепенно осваивать технологию и сократит первоначальные инвестиции.
- Обучайте команду: Инвестиции в знания внутри команды окупятся быстрее, чем постоянное привлечение внешних консультантов.
- Оптимизация сбора данных: Используйте фильтрацию и агрегацию на уровне ядра, чтобы не собирать избыточные данные. Это снизит нагрузку на бэкенды мониторинга и хранения.
- Используйте готовые решения: Не пишите все с нуля. Используйте готовые eBPF-приложения и библиотеки.
- Автоматизация: Автоматизируйте развертывание, обновление и управление eBPF-решениями, чтобы сократить ручной труд.
Таблица с примерами расчетов (условные значения на 2026 год)
| Статья расходов/экономии | Малый стартап (до 20 узлов) | Средняя компания (до 50 узлов) | Крупное предприятие (100+ узлов) |
|---|---|---|---|
| Лицензии eBPF-решений (год) | $0 (Open Source) | $60,000 - $90,000 (Cilium Enterprise) | $150,000 - $300,000+ |
| Инженерное время (внедрение, 1 раз) | $10,000 - $20,000 | $16,000 - $48,000 | $50,000 - $150,000 |
| Инженерное время (поддержка, год) | $10,000 - $15,000 | $24,000 - $36,000 | $50,000 - $100,000 |
| Инфраструктура для данных (год) | $600 - $1,800 | $6,000 - $18,000 | $12,000 - $60,000 |
| Консалтинг/Обучение (1 раз) | $0 - $2,000 | $5,000 - $15,000 | $10,000 - $30,000 |
| ИТОГО TCO (1-й год) | $20,600 - $38,800 | $111,000 - $207,000 | $272,000 - $640,000+ |
| Потенциальная экономия (год) | $6,000 - $12,000 (агенты) | $60,000 - $180,000 (агенты, ресурсы Service Mesh) | $120,000 - $500,000+ |
| Нематериальная выгода | Снижение MTTR, повышение безопасности, комплаенс, конкурентное преимущество, инновации. | ||
Внедрение eBPF — это инвестиция, которая, хоть и требует первоначальных затрат на обучение и интеграцию, в долгосрочной перспективе приносит значительную экономию за счет оптимизации ресурсов, снижения операционных издержек, повышения безопасности и ускорения реакции на инциденты. Для крупных инфраструктур, где стоимость каждого процента CPU или RAM исчисляется десятками тысяч долларов в год, eBPF может обеспечить ROI, измеряемый сотнями процентов.
Кейсы и примеры использования eBPF в реальных проектах
Теория — это хорошо, но реальные примеры использования eBPF демонстрируют его истинную мощь и применимость в различных сценариях. Ниже представлены несколько реалистичных кейсов, вдохновленных опытом компаний, активно использующих eBPF в 2026 году.
Кейс 1: Оптимизация сетевой производительности и безопасности в Kubernetes-кластере крупного e-commerce
Проблема: Крупный e-commerce-проект столкнулся с проблемами сетевой производительности и безопасности в своем Kubernetes-кластере, состоящем из 500+ узлов. Традиционный kube-proxy вызывал значительные задержки из-за iptables, а sidecar-прокси для Service Mesh (на основе Envoy) потребляли до 25% ресурсов CPU и RAM в подах, что приводило к высоким операционным расходам и сложности управления. Кроме того, требовалась более гранулярная сетевая безопасность между микросервисами.
Решение с eBPF: Команда DevOps решила внедрить Cilium в качестве CNI и Service Mesh. Cilium, полностью построенный на eBPF, заменил kube-proxy и устранил необходимость в sidecar-прокси Envoy.
- Замена
kube-proxy: Cilium сkubeProxyReplacement=strictвзял на себя обработку сервисного трафика, используя eBPF-карты для маршрутизации и балансировки нагрузки прямо в ядре. Это устранило bottleneckiptables. - Service Mesh без сайдкаров: Cilium Layer 7 Policy Enforcement и Observability позволили реализовать Service Mesh функциональность (балансировка нагрузки, политики, метрики, трассировка) без развертывания дополнительных контейнеров в каждом поде.
- Продвинутые сетевые политики: Использовались Cilium Network Policies для микросегментации, контролируя трафик между тысячами микросервисов на основе их идентификаторов (Service Identity) и меток Kubernetes. Были настроены политики, запрещающие прямое обращение из публичных сервисов к базам данных, минуя API-шлюзы.
- Наблюдаемость с Hubble: Инструмент Hubble (на основе eBPF, часть Cilium) предоставил детальную видимость сетевого трафика в реальном времени, включая метрики latency, пропускной способности и ошибок на уровне L3/L4/L7. Это позволило быстро диагностировать проблемы сетевого взаимодействия между микросервисами.
Результаты:
- Снижение затрат: Сокращение потребления CPU и RAM в кластере на 18% за счет устранения Envoy sidecar-ов, что привело к годовой экономии в размере около $150,000 на облачных ресурсах.
- Повышение производительности: Среднее время отклика сети снизилось на 10-12% из-за более эффективной обработки пакетов в ядре.
- Усиление безопасности: Реализована строгая микросегментация, значительно снизившая поверхность атаки и риски горизонтального перемещения злоумышленников внутри кластера.
- Улучшение MTTR: Благодаря Hubble, время на диагностику сетевых проблем сократилось с часов до минут.
Кейс 2: Обнаружение аномалий и предотвращение угроз в критической инфраструктуре финтех-компании
Проблема: Финтех-компания, работающая с конфиденциальными данными, нуждалась в усиленной защите своих Linux-серверов от продвинутых угроз, включая руткиты, эксплойты нулевого дня и несанкционированный доступ к данным. Традиционные HIDS (Host Intrusion Detection Systems) и auditd имели высокий оверхед и часто пропускали тонкие аномалии, генерируя слишком много логов для эффективного анализа.
Решение с eBPF: Было принято решение внедрить Falco для мониторинга системных вызовов и Tracee для более глубокой интроспекции и аудита.
- Falco для обнаружения угроз: Falco был развернут как DaemonSet на всех узлах Kubernetes и напрямую взаимодействовал с ядром через eBPF. Были настроены кастомные правила для обнаружения:
- Попыток изменения системных файлов (
/etc/passwd,/bin) процессами, не имеющими на это прав. - Запуска исполняемых файлов из подозрительных директорий (например,
/tmp) или с необычными аргументами. - Несанкционированного доступа к конфиденциальным файлам (например, ключи API, данные клиентов).
- Создания сетевых соединений из контейнеров, которым это не разрешено политиками.
- Попыток изменения системных файлов (
- Tracee для глубокого аудита и forensics: Tracee использовался для записи детализированных трассировок системных вызовов в случае срабатывания алертов Falco. Это позволяло проводить пост-инцидентный анализ с полным контекстом, включая аргументы вызовов, стеки вызовов и метаданные процессов.
- Интеграция с SIEM: События Falco и Tracee отправлялись в централизованную SIEM-систему (Splunk), где анализировались и коррелировались с другими источниками данных.
Результаты:
- Высокая точность обнаружения: Falco смог выявить несколько попыток несанкционированного доступа и подозрительной активности, которые были пропущены предыдущими HIDS.
- Снижение ложного срабатывания: Благодаря гранулярности eBPF и возможности фильтрации на уровне ядра, количество ложных срабатываний значительно сократилось, что позволило команде безопасности сосредоточиться на реальных угрозах.
- Быстрая реакция: Алерты Falco срабатывали в миллисекунды, позволяя оперативно реагировать на инциденты.
- Глубокий forensics: Tracee предоставил исчерпывающую информацию для анализа корневых причин инцидентов, что значительно ускорило расследования.
- Минимальный оверхед: Оба инструмента работали с минимальным влиянием на производительность серверов (менее 1% CPU).
Кейс 3: Диагностика "плавающих" проблем производительности в SaaS-платформе
Проблема: SaaS-платформа на Go и Node.js время от времени сталкивалась с "плавающими" проблемами производительности: случайные задержки в API, медленные ответы баз данных, которые было крайне сложно диагностировать. Традиционные APM-инструменты показывали общую картину, но не давали достаточно глубокого контекста на уровне ядра, чтобы понять, почему конкретный запрос иногда "зависал".
Решение с eBPF: Команда SRE решила использовать BCC (BPF Compiler Collection) и bpftrace для динамической трассировки и профилирования.
- Динамическое профилирование CPU: С помощью инструмента
profileиз BCC были получены стеки вызовов ядра и пользовательского пространства, что позволило выявить функции, потребляющие наибольшее количество CPU во время пиковых нагрузок.sudo /usr/share/bcc/tools/profile -F 99 -f -p $(pgrep node) 10Это помогло обнаружить неожиданные блокировки в ядре, вызванные неоптимальным I/O.
- Мониторинг задержек системных вызовов: Скрипты
execsnoop,opensnoop,writesnoopиз BCC использовались для отслеживания задержек в системных вызовах, связанных с файловыми операциями и запуском процессов. Было выявлено, что один из микросервисов генерировал слишком много маленьких файлов, что приводило к высокому I/O-оверхеду.sudo /usr/share/bcc/tools/opensnoop -T -n node - Трассировка сетевых задержек: С помощью
tcplifeи кастомныхbpftraceскриптов отслеживались задержки на уровне TCP для конкретных сетевых соединений, что помогло выявить проблемы с сетевым оборудованием или конфигурацией, проявляющиеся только под определенной нагрузкой. - Кастомная трассировка: Для Go-приложений были написаны
uprobesсbpftrace, чтобы отслеживать вызовы конкретных функций внутри приложения и связывать их с активностью ядра. Это позволило понять, как внутренние проблемы Go-рантайма (например, GC-паузы) коррелируют с системными событиями.
Результаты:
- Точная диагностика: Были выявлены и устранены несколько "плавающих" проблем, которые ранее были невидимы для APM-инструментов, включая неоптимальные файловые операции и сетевые блокировки.
- Оптимизация кода: Разработчики смогли оптимизировать код приложений, снизив количество ненужных системных вызовов и улучшив взаимодействие с ядром.
- Снижение MTTR: Время на диагностику и устранение сложных проблем производительности сократилось в среднем на 50%.
- Проактивное выявление: Команда теперь использует eBPF-инструменты для регулярного аудита производительности, выявляя потенциальные проблемы до того, как они станут критическими.
Эти кейсы демонстрируют, как eBPF позволяет решать широкий спектр задач, от повышения эффективности инфраструктуры до усиления безопасности, предоставляя инженерам беспрецедентный контроль и видимость на самом низком уровне системы.
Инструменты и ресурсы для работы с eBPF
Экосистема eBPF активно развивается, и к 2026 году существует множество зрелых инструментов, библиотек и ресурсов, которые значительно упрощают разработку, развертывание и использование eBPF-приложений.
1. Основные утилиты и библиотеки
- BCC (BPF Compiler Collection):
- Описание: Набор инструментов и библиотек, позволяющий писать eBPF-программы на Python и Lua. Включает в себя готовые утилиты для трассировки (
execsnoop,opensnoop,biolatency,tcplifeи многие другие). - Для кого: Идеально для быстрого прототипирования, ad-hoc анализа и создания собственных простых инструментов мониторинга.
- Ссылка: https://github.com/iovisor/bcc
- Описание: Набор инструментов и библиотек, позволяющий писать eBPF-программы на Python и Lua. Включает в себя готовые утилиты для трассировки (
- bpftrace:
- Описание: Высокоуровневый язык трассировки, вдохновленный DTrace и SystemTap. Позволяет писать мощные eBPF-скрипты в несколько строк для диагностики производительности и безопасности.
- Для кого: SRE, DevOps-инженеры, разработчики, которым нужна быстрая и гибкая диагностика без глубокого погружения в C-код eBPF.
- Ссылка: https://github.com/iovisor/bpftrace
- libbpf & BPF CO-RE (Compile Once – Run Everywhere):
- Описание: Низкоуровневая библиотека для работы с eBPF, предоставляющая стабильный API для загрузки, управления и взаимодействия с eBPF-программами. CO-RE позволяет создавать eBPF-приложения, которые работают на разных версиях ядра без перекомпиляции.
- Для кого: Разработчики, создающие продакшен-готовые eBPF-приложения на C/C++, Go, Rust.
- Ссылки: https://github.com/libbpf/libbpf, https://nakryiko.com/posts/bpf-core-link/
- bpftool:
- Описание: Официальная утилита командной строки для инспекции и управления eBPF-программами и картами, загруженными в ядро. Входит в состав ядра Linux.
- Для кого: Все, кто работает с eBPF, для отладки и понимания состояния eBPF-подсистемы.
- Ссылка: Обычно устанавливается с ядром, документация доступна через
man bpftool.
2. Инструменты для мониторинга и тестирования на базе eBPF
- Cilium & Hubble:
- Описание: Cilium — это CNI (Container Network Interface) для Kubernetes, обеспечивающий сетевую безопасность, наблюдаемость и Service Mesh на основе eBPF. Hubble — это платформа наблюдаемости для Cilium, предоставляющая глубокую видимость сетевого трафика.
- Для кого: DevOps-инженеры, SRE, сетевые инженеры, работающие с Kubernetes.
- Ссылка: https://cilium.io/
- Falco:
- Описание: Инструмент для обнаружения угроз безопасности в реальном времени, использующий eBPF для мониторинга системных вызовов. Позволяет определять подозрительную активность и генерировать алерты.
- Для кого: Команды по безопасности (SecOps), DevOps-инженеры, системные администраторы.
- Ссылка: https://falco.org/
- Tracee:
- Описание: Инструмент для аудита и трассировки системных событий Linux в реальном времени. Использует eBPF для сбора данных о системных вызовах, сетевых событиях, файловых операциях и многом другом.
- Для кого: SecOps, исследователи безопасности, для forensics и глубокого аудита.
- Ссылка: https://github.com/aquasecurity/tracee
- Pixie:
- Описание: Kubernetes-нативная платформа наблюдаемости, использующая eBPF для автоматического сбора телеметрии (метрики, логи, трассировки) без изменения кода приложений.
- Для кого: Разработчики, DevOps-инженеры, SRE, которым нужна "из коробки" наблюдаемость для микросервисов.
- Ссылка: https://pixie.ai/
- Parca:
- Описание: Профилировщик непрерывного действия на основе eBPF, собирающий данные о потреблении CPU и памяти для всей системы с минимальным оверхедом.
- Для кого: Разработчики, SRE, для оптимизации производительности приложений и инфраструктуры.
- Ссылка: https://www.parca.dev/
3. Полезные ссылки и документация
- eBPF.io:
- Описание: Официальный сайт eBPF, содержащий обширную документацию, туториалы, новости и список проектов.
- Ссылка: https://ebpf.io/
- Awesome eBPF:
- Описание: Курируемый список eBPF-ресурсов, проектов, примеров и статей.
- Ссылка: https://github.com/zoidbergwill/awesome-ebpf
- Linux Kernel Documentation (eBPF):
- Описание: Официальная документация ядра Linux по eBPF, содержит низкоуровневые детали реализации и API.
- Ссылка: https://www.kernel.org/doc/html/latest/bpf/index.html
- Курсы и книги:
- "Learning eBPF" от O'Reilly (2023-2024 год): Отличное введение в eBPF для практиков.
- "BPF Performance Tools" от Brendan Gregg (2019): Хотя книга и старше, она содержит фундаментальные концепции и примеры использования BCC.
- Онлайн-курсы от Linux Foundation, Isovalent, Aquasec по eBPF и его применению.
- Блоги и сообщества:
- Блог Cilium (Isovalent): Регулярные обновления и глубокие статьи по eBPF в Kubernetes.
- Блог Brendan Gregg: Пионер в области трассировки производительности, много статей по eBPF.
- eBPF Slack-канал: Активное сообщество для обсуждения вопросов и получения помощи.
Используя этот обширный набор инструментов и ресурсов, вы сможете эффективно освоить eBPF, внедрить его в свою инфраструктуру и решать самые сложные задачи мониторинга, безопасности и оптимизации.
Troubleshooting: решение типичных проблем с eBPF
Работа с eBPF, особенно на ранних этапах, может сопровождаться рядом специфических проблем. Знание типичных ошибок и методов их диагностики поможет вам быстро находить решения и поддерживать стабильность системы.
1. Программы eBPF не загружаются или не работают
Проблема: Вы пытаетесь загрузить eBPF-программу, но получаете ошибку или программа просто не производит никакого вывода.
Диагностические команды:
- Проверка версии ядра: eBPF требует Linux-ядра версии 4.9+ для базовых функций и 5.x+ для более продвинутых.
uname -r - Проверка включения eBPF в ядре: Убедитесь, что ядро скомпилировано с поддержкой BPF.
grep -i bpf /boot/config-$(uname -r) # Ожидаемый вывод: CONFIG_BPF=y, CONFIG_BPF_SYSCALL=y, CONFIG_BPF_JIT=y и т.д. - Сообщения верификатора: Если программа не загружается, верификатор eBPF в ядре выводит сообщение об ошибке. Обычно это видно в
dmesgили в выводе утилиты, которую вы используете для загрузки (например,bpftrace,bcc).sudo dmesg | grep -i bpfИщите сообщения типа "bpf: failed to load program", "bpf: R0 invalid mem access", "bpf: loop detected".
- Проверка прав: Загрузка eBPF-программ требует либо
CAP_BPF, либоCAP_SYS_ADMIN. Убедитесь, что ваша утилита или контейнер имеет необходимые привилегии.# Для контейнера в Kubernetes apiVersion: v1 kind: Pod metadata: name: ebpf-privileged spec: containers: - name: ebpf-app image: your-ebpf-image securityContext: privileged: true # Или использовать capabilities CAP_BPF, CAP_SYS_ADMIN - Использование
bpftool: Проверьте, загружены ли программы и карты.sudo bpftool prog show sudo bpftool map show
Решение: Обновите ядро, скорректируйте код eBPF-программы согласно требованиям верификатора, убедитесь в наличии необходимых прав.
2. Высокий оверхед или деградация производительности
Проблема: После активации eBPF-мониторинга или политик вы замечаете рост потребления CPU, памяти или увеличение задержек.
Диагностические команды:
- Мониторинг системных метрик: Используйте стандартные инструменты (
top,htop, Prometheus) для мониторинга CPU, RAM, I/O. - Проверка интенсивности событий: eBPF-программа может генерировать слишком много событий, перегружая буферы или пользовательское пространство.
- Анализ кода eBPF: Проверьте, нет ли в программе неэффективных циклов (хотя верификатор должен их ловить), слишком частых обращений к картам или избыточного копирования данных в user-space.
Решение:
- Фильтрация на уровне ядра: Уточните условия фильтрации в eBPF-программе, чтобы собирать только релевантные данные.
- Агрегация в картах: Используйте eBPF-карты для агрегации данных в ядре, вместо отправки каждого события в пользовательское пространство.
- Ограничение частоты: Для некоторых типов событий можно реализовать rate limiting прямо в eBPF-программе.
- Оптимизация кода: Перепишите неэффективные участки eBPF-кода.
- Изменение точек присоединения: Иногда переключение на другую точку трассировки (например, с kprobe на tracepoint) может снизить оверхед.
3. Конфликты между eBPF-программами или с другими инструментами
Проблема: Несколько eBPF-программ, прикрепленных к одной и той же точке, могут конфликтовать, или eBPF-решение конфликтует с существующими инструментами (например, iptables, другими CNI).
Диагностические команды:
- Проверка загруженных программ:
sudo bpftool prog showОбратите внимание на
attach_typeиattach_point. Если несколько программ прикреплены к одной точке, это может быть источником конфликта. - Логи приложений: Проверьте логи eBPF-инструментов (Cilium, Falco) на наличие ошибок или предупреждений о конфликтах.
dmesg: Сообщения ядра могут указывать на проблемы.
Решение:
- Приоритизация: Некоторые точки присоединения (например, XDP) позволяют указывать приоритет для программ.
- Координация: Если вы используете несколько eBPF-решений, убедитесь, что они совместимы и не конкурируют за одни и те же ресурсы. Например, Cilium может заменять
kube-proxy, поэтому не стоит запускать его одновременно с другими решениями, пытающимися управлятьiptables. - Изоляция: Если возможно, используйте Cgroups или namespaces для изоляции eBPF-программ.
- Обновление: Убедитесь, что все компоненты (ядро, eBPF-инструменты) имеют актуальные версии, так как баги совместимости часто исправляются.
4. Проблемы с сетевой связностью при использовании eBPF CNI (Cilium)
Проблема: После развертывания Cilium, поды не могут общаться друг с другом или с внешними сервисами.
Диагностические команды:
- Статус Cilium:
cilium statusПроверьте статус агентов, версии, состояние endpoint'ов.
- Логи Cilium:
kubectl logs -n kube-system -l k8s-app=cilium --tail 100Ищите ошибки, связанные с eBPF, сетевыми политиками, kube-proxy replacement.
cilium endpoint get: Проверьте состояние сетевых endpoint'ов для подов.cilium endpoint getcilium monitor/hubble observe: Используйте для трассировки сетевого трафика в реальном времени.cilium monitor --type drop hubble observe --follow --type l3 l4 --podЭто покажет, какие пакеты дропаются и по какой причине (например, из-за сетевой политики).
- Проверка сетевых политик: Убедитесь, что ваши CiliumNetworkPolicies не блокируют легитимный трафик.
kubectl get cnp kubectl describe cnp
Решение:
- Отключение политик: Временно отключите сетевые политики, чтобы проверить, является ли проблема в них.
- Режим отладки: Включите более подробное логирование для Cilium.
- Проверка конфигурации
kubeProxyReplacement: Убедитесь, что она соответствует вашим требованиям и не конфликтует с другими компонентами. - Обновление: Убедитесь, что Cilium и ядро Linux имеют совместимые версии.
Когда обращаться в поддержку
Не стесняйтесь обращаться за помощью к сообществу или коммерческой поддержке в следующих случаях:
- Вы исчерпали все известные методы диагностики и не можете найти причину проблемы.
- Проблема связана с глубокими багами в ядре Linux или в самом eBPF-фреймворке.
- Проблема вызывает критическую деградацию сервиса в продакшене, и у вас нет времени на самостоятельное исследование.
- Вам нужна помощь с оптимизацией eBPF-программ для специфических, высоконагруженных сценариев.
Активные сообщества (Slack, GitHub Issues) для Cilium, Falco, bpftrace и других eBPF-проектов обычно очень отзывчивы и могут предложить ценные советы.
FAQ: Часто задаваемые вопросы по eBPF
Что такое eBPF простыми словами?
eBPF (extended Berkeley Packet Filter) — это технология в ядре Linux, которая позволяет безопасно запускать пользовательские программы прямо в ядре. Представьте, что у вас есть "суперсила" для наблюдения и управления всем, что происходит в операционной системе, без необходимости перезагружать ее или менять исходный код ядра. Это делает eBPF невероятно мощным для мониторинга, безопасности и сетевых функций.
Насколько безопасно запускать программы в ядре с помощью eBPF?
eBPF очень безопасен. Каждая eBPF-программа перед загрузкой проходит строгую проверку специальным "верификатором" ядра. Верификатор гарантирует, что программа не содержит бесконечных циклов, не обращается к недопустимым областям памяти и не вызовет сбой ядра. Это ключевое отличие eBPF от традиционных модулей ядра, которые могут быть опасны при некорректном написании.
Нужно ли перекомпилировать ядро для использования eBPF?
Нет, в подавляющем большинстве случаев перекомпилировать ядро не нужно. Поддержка eBPF встроена в стандартные ядра Linux, начиная с версии 4.9. Для использования eBPF достаточно иметь современное ядро и установить необходимые утилиты пользовательского пространства.
Какие языки программирования используются для написания eBPF-программ?
Сами eBPF-программы пишутся на подмножестве C и компилируются в байт-код eBPF. Однако существуют высокоуровневые инструменты и библиотеки, которые значительно упрощают этот процесс. Например, BCC позволяет писать программы на Python, а bpftrace использует свой собственный, более простой язык. Современные фреймворки с libbpf поддерживают Go, Rust, C/C++.
Может ли eBPF заменить традиционные агенты мониторинга?
Во многих случаях — да. eBPF может собирать метрики и события с гораздо меньшим оверхедом и большей детализацией, чем агенты, работающие в пользовательском пространстве. Он не заменяет полностью APM-инструменты для мониторинга бизнес-логики, но становится их мощным дополнением, предоставляя глубокий контекст на уровне инфраструктуры. Многие современные APM-решения уже используют eBPF.
Можно ли использовать eBPF для предотвращения атак, а не только для обнаружения?
Да, это одно из ключевых преимуществ eBPF. Он может не только обнаруживать подозрительную активность, но и активно предотвращать ее, блокируя нежелательные системные вызовы, модифицируя сетевые пакеты или ограничивая доступ к ресурсам. Это позволяет создавать динамические и высокоэффективные политики безопасности.
Как eBPF влияет на Service Mesh в Kubernetes?
eBPF революционизирует Service Mesh, позволяя реализовать его функциональность (маршрутизация, балансировка, политики, наблюдаемость) без использования традиционных sidecar-прокси (как Envoy). Такие решения, как Cilium, используют eBPF для обработки трафика на уровне ядра, значительно снижая задержки и потребление ресурсов кластера, упрощая управление и деплоймент.
Каков порог входа для освоения eBPF?
Для базового использования готовых eBPF-инструментов (например, bpftrace, Falco) порог входа относительно низкий. Для написания собственных, сложных eBPF-программ требуется глубокое понимание ядра Linux, C и специфики eBPF-виртуальной машины, что является более высоким порогом. Однако с развитием библиотек и фреймворков этот порог постоянно снижается.
Как eBPF взаимодействует с Prometheus и Grafana?
eBPF-инструменты часто предоставляют экспортеры, которые преобразуют собранные eBPF-данные в формат метрик Prometheus. Эти метрики затем могут быть визуализированы в Grafana, позволяя использовать привычные дашборды для отображения глубокой телеметрии из ядра.
Какие риски связаны с использованием eBPF?
Основные риски связаны с некорректным написанием или конфигурацией eBPF-программ, что может привести к высокому оверхеду, конфликтам с другими системными компонентами или даже (в редких случаях, при багах в ядре) к нестабильности системы. Однако благодаря верификатору eBPF и зрелости инструментов эти риски значительно ниже, чем при использовании традиционных модулей ядра.
Заключение
К 2026 году eBPF окончательно закрепился в статусе одной из ключевых технологий, определяющих будущее Linux-инфраструктур. Мы увидели, как эта мощная и гибкая платформа трансформирует подходы к мониторингу, безопасности и сетевому взаимодействию, предлагая беспрецедентный уровень видимости и контроля на уровне ядра, при этом сохраняя минимальный оверхед и высокую степень безопасности.
eBPF — это не просто эволюционный шаг, а фундаментальный сдвиг в парадигме работы с операционной системой. Он позволяет DevOps-инженерам, разработчикам и системным администраторам решать самые сложные задачи, которые ранее казались неразрешимыми или требовали компромиссов между производительностью и функциональностью. От глубокой диагностики "плавающих" проблем до создания ультра-быстрых сетевых фаерволов и Service Mesh без сайдкаров, eBPF предоставляет инструментарий, который становится критически важным для любой современной облачной или контейнерной среды.
Мы рассмотрели ключевые критерии выбора eBPF-решений, сравнили их с традиционными подходами, углубились в детали его применения для мониторинга, сети и безопасности, а также предоставили практические советы и чеклисты для внедрения. Расчет экономики показал, что, несмотря на первоначальные инвестиции в обучение и интеграцию, eBPF приносит значительный ROI за счет оптимизации ресурсов, снижения операционных издержек и повышения устойчивости инфраструктуры к угрозам.
Итоговые рекомендации
- Не игнорируйте eBPF: Если вы работаете с Linux-инфраструктурой, eBPF должен стать частью вашего технологического стека. Изучайте его возможности и следите за развитием экосистемы.
- Начните с малого: Не пытайтесь перестроить всю инфраструктуру за один день. Начните с использования готовых eBPF-инструментов для мониторинга и диагностики, затем постепенно расширяйте область применения.
- Инвестируйте в знания: eBPF — это глубокая тема. Обучение команды, изучение документации и участие в сообществе окупятся сторицей.
- Используйте готовые решения: Для большинства задач существуют зрелые Open Source проекты (Cilium, Falco, bpftrace), которые значительно упрощают внедрение. Кастомные программы пишите только для уникальных потребностей.
- Тестируйте тщательно: Всегда проводите тщательное тестирование eBPF-решений в изолированной среде, прежде чем развертывать их в продакшене.
Следующие шаги для читателя
- Посетите ebpf.io: Это ваш центральный ресурс для изучения eBPF.
- Установите
bpftrace: Начните с экспериментов на своей локальной машине или тестовой VM. Это самый быстрый способ получить практический опыт. - Разверните
CiliumилиFalco: Если у вас есть Kubernetes-кластер, попробуйте развернуть Cilium в качестве CNI или Falco для базовой безопасности. - Присоединяйтесь к сообществу: Активное участие в eBPF-сообществе поможет вам быстрее освоить технологию и быть в курсе последних разработок.
Будущее Linux-инфраструктуры неразрывно связано с eBPF. Освоив эту технологию, вы не только повысите свою профессиональную ценность, но и сможете создавать более эффективные, безопасные и наблюдаемые системы, готовые к вызовам завтрашнего дня.