Стратегии Disaster Recovery (DR) для SaaS-приложений на VPS и облаке: планирование, автоматизация и тестирование
TL;DR
- DR — это не просто бэкапы: Это комплексный план по восстановлению работоспособности SaaS-приложения после сбоя, минимизирующий простои и потери данных.
- RTO и RPO — ваши главные метрики: Определите целевое время восстановления (RTO) и допустимую потерю данных (RPO) на основе бизнес-требований и стоимости простоя.
- Автоматизация — ключ к успеху: Ручные процедуры DR медленны, подвержены ошибкам и не масштабируются. Инвестируйте в IaC, скрипты и оркестрацию для быстрого и надежного восстановления.
- Тестирование — не роскошь, а необходимость: Регулярно тестируйте ваш DR-план (от настольных учений до полного переключения), чтобы убедиться в его работоспособности и актуальности.
- Гибридные стратегии — оптимальный баланс: Комбинирование VPS и облачных решений часто предлагает лучший компромисс между стоимостью, производительностью и устойчивостью.
- Скрытые затраты: Учитывайте не только прямые расходы на инфраструктуру, но и стоимость простоя, потери репутации, трудозатраты на восстановление и тестирование.
- 2026 год: ИИ и ML все активнее используются для предиктивного DR, оптимизации ресурсов и автоматического анализа логов при сбоях.
Введение
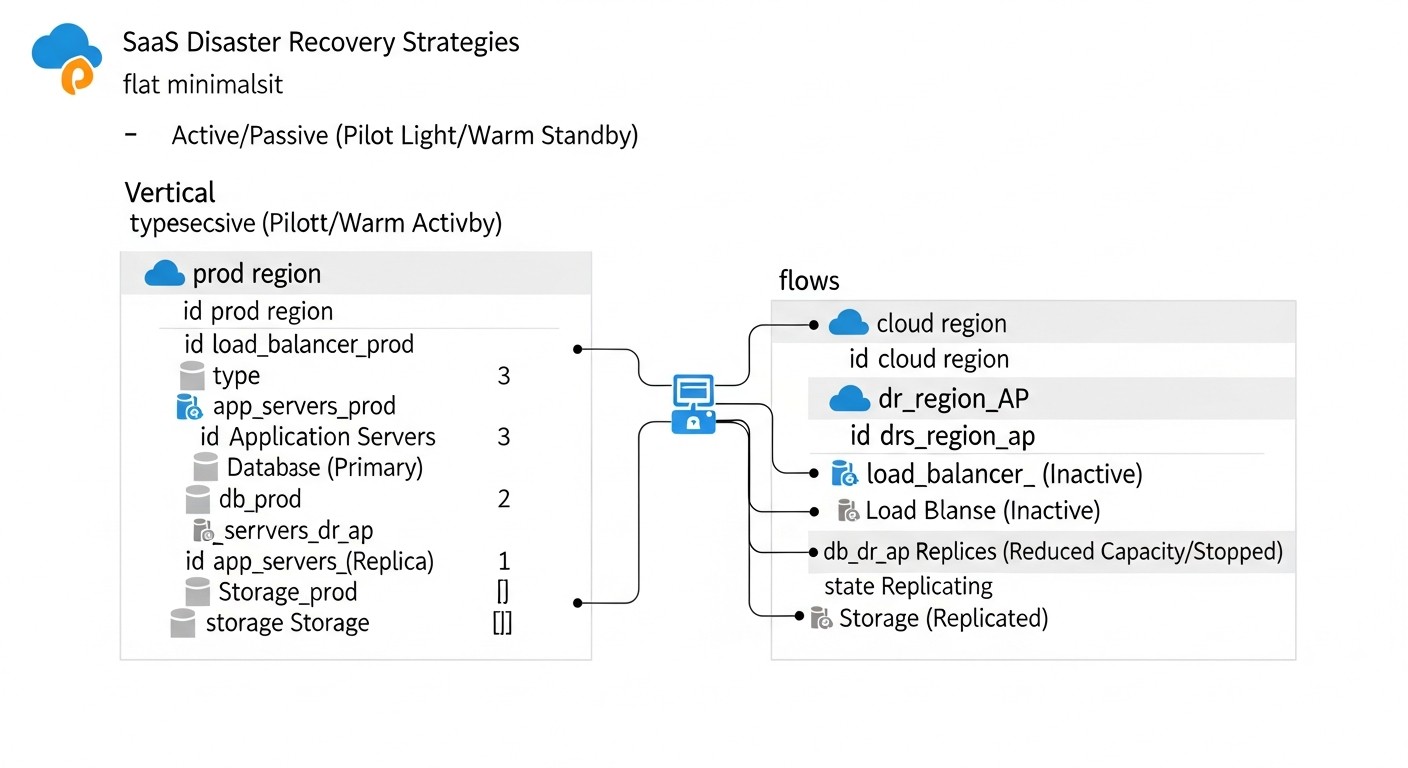 Схема: Введение
Схема: Введение
В стремительно развивающемся мире SaaS-приложений, где каждая минута простоя может стоить компании не только значительных финансовых потерь, но и невосполнимого ущерба репутации, вопрос обеспечения непрерывности бизнеса становится критически важным. К 2026 году пользователи ожидают от сервисов 24/7 доступности и мгновенного отклика, а сбои воспринимаются как прямое нарушение доверия. Кибератаки становятся всё изощреннее, инфраструктурные отказы — хоть и редки, но катастрофичны, а человеческий фактор по-прежнему остаётся одной из главных причин инцидентов.
Эта статья призвана стать исчерпывающим руководством по разработке, внедрению и тестированию стратегий Disaster Recovery (DR) для SaaS-приложений, работающих как на классических VPS, так и в современных облачных средах. Мы рассмотрим, почему DR — это не просто "хорошая практика", а жизненная необходимость, особенно для фаундеров SaaS-проектов, которые часто недооценивают его важность на ранних этапах, а также для DevOps-инженеров и системных администраторов, на чьи плечи ложится задача реализации.
В 2026 году ландшафт технологий предлагает беспрецедентные возможности для создания отказоустойчивых систем. От автоматизированных инструментов Infrastructure as Code (IaC) до интеллектуальных систем мониторинга на базе ИИ, способных предсказывать потенциальные сбои. Однако, несмотря на эти достижения, многие компании по-прежнему сталкиваются с проблемами при реализации эффективных DR-планов. Причина часто кроется в отсутствии системного подхода, недостатке тестирования и непонимании реальных бизнес-требований к восстановлению.
Данное руководство создано для того, чтобы помочь вам:
- Понять фундаментальные принципы Disaster Recovery.
- Выбрать оптимальную DR-стратегию, исходя из ваших RTO (Recovery Time Objective) и RPO (Recovery Point Objective).
- Освоить методы автоматизации DR-процессов для повышения скорости и надежности восстановления.
- Научиться эффективно тестировать ваш DR-план, выявляя и устраняя слабые места до наступления реального инцидента.
- Оценить экономическую целесообразность различных подходов к DR и оптимизировать затраты.
- Избежать распространенных ошибок, которые могут привести к провалу восстановления.
Мы будем говорить на техническом, но понятном языке, подкрепляя каждое утверждение конкретными примерами, конфигурациями и рекомендациями, основанными на реальном опыте. Приготовьтесь углубиться в мир устойчивости, где подготовка к худшему сценарию — это лучшая инвестиция в будущее вашего SaaS.
Основные критерии/факторы выбора DR-стратегии
 Схема: Основные критерии/факторы выбора DR-стратегии
Схема: Основные критерии/факторы выбора DR-стратегии
Выбор оптимальной стратегии Disaster Recovery — это не просто техническое решение, а стратегическое бизнес-решение, которое должно учитывать множество факторов. Правильное понимание и оценка этих критериев помогут вам построить DR-план, который будет соответствовать как техническим требованиям, так и финансовым возможностям вашей компании.
RTO (Recovery Time Objective) — Целевое Время Восстановления
Что это: Максимально допустимое время, в течение которого приложение или сервис может быть недоступен после сбоя. Это метрика времени простоя, которую определяет бизнес.
Почему важно: Определяет скорость, с которой ваш бизнес должен быть готов возобновить работу. Чем ниже RTO, тем дороже и сложнее DR-стратегия. Например, для финансового приложения RTO может быть 1-5 минут, для внутренней CRM — 4-8 часов.
Как оценивать: Проведите анализ влияния на бизнес (Business Impact Analysis, BIA). Оцените финансовые потери за каждый час простоя, ущерб репутации, штрафы за несоблюдение SLA. Это поможет определить, сколько вы готовы инвестировать в быстрое восстановление.
RPO (Recovery Point Objective) — Целевая Точка Восстановления
Что это: Максимально допустимый объем данных, который может быть потерян в результате сбоя. Это метрика потери данных, измеряемая во времени (например, 15 минут, 1 час).
Почему важно: Определяет частоту резервного копирования или репликации данных. Чем ниже RPO, тем чаще должны синхронизироваться данные между основной и резервной системами. Нулевое RPO означает отсутствие потери данных (требует синхронной репликации).
Как оценивать: BIA также поможет здесь. Какие данные критичны? Какова стоимость восстановления или воссоздания потерянных данных? Могут ли пользователи повторно ввести данные? Для большинства SaaS RPO 5-15 минут считается хорошим балансом.
Стоимость (Cost)
Что это: Общие затраты на реализацию и поддержание DR-стратегии. Включает прямые и скрытые расходы.
Почему важно: DR-план должен быть экономически целесообразным. Нет смысла тратить миллионы на DR, если потенциальный ущерб от простоя в десятки раз меньше. Стоимость включает: инфраструктуру (серверы, хранилища, сеть), программное обеспечение (лицензии, инструменты), персонал (разработка, поддержка), тестирование, передачу данных.
Как оценивать: Детальный расчет Total Cost of Ownership (TCO) для каждого варианта DR. Учитывайте капитальные (CAPEX) и операционные (OPEX) расходы. Не забудьте про скрытые расходы, такие как стоимость обучения персонала, время на разработку и отладку DR-скриптов, а также стоимость простоя во время тестирования.
Сложность реализации и поддержки (Complexity)
Что это: Уровень усилий, необходимых для проектирования, развертывания, настройки и последующего обслуживания DR-решения.
Почему важно: Более сложные системы требуют больше времени на разработку, более высокой квалификации персонала и более частых проверок. Высокая сложность увеличивает вероятность ошибок как при внедрении, так и при реальном восстановлении.
Как оценивать: Оцените объем работы по IaC, настройке репликации, разработке скриптов failover/failback, интеграции с мониторингом. Учитывайте доступность готовых решений и экспертизу вашей команды.
Уровень автоматизации (Automation Level)
Что это: Степень, в которой процессы резервного копирования, репликации, мониторинга, переключения (failover) и возврата (failback) выполняются без ручного вмешательства.
Почему важно: Автоматизация значительно сокращает RTO, минимизирует человеческий фактор и повышает надежность. В 2026 году ручные DR-процедуры считаются анахронизмом для критически важных систем.
Как оценивать: Разработайте сценарии DR и оцените, сколько шагов можно автоматизировать. Используйте IaC (Terraform, Ansible), CI/CD-пайплайны для развертывания DR-инфраструктуры и скрипты для оркестрации переключения.
Масштабируемость (Scalability)
Что это: Способность DR-решения адаптироваться к росту вашего SaaS-приложения (увеличение трафика, данных, пользователей) без существенного перепроектирования.
Почему важно: Ваша DR-стратегия должна расти вместе с вашим бизнесом. Немасштабируемое решение быстро устареет и станет узким местом.
Как оценивать: Рассмотрите, как DR-инфраструктура будет справляться с X2 или X10 нагрузкой. Облачные решения часто выигрывают здесь благодаря эластичности ресурсов.
Безопасность (Security)
Что это: Защита данных и инфраструктуры DR от несанкционированного доступа, компрометации и потери.
Почему важно: DR-инфраструктура содержит копии ваших критически важных данных, поэтому она является привлекательной мишенью для злоумышленников. Недостаточная безопасность DR может привести к утечке данных или их уничтожению.
Как оценивать: Применяйте те же или даже более строгие меры безопасности к DR-ресурсам: шифрование данных (в покое и в пути), управление доступом (IAM, MFA), сетевая изоляция, регулярные аудиты безопасности.
Соответствие нормативным требованиям (Compliance)
Что это: Способность DR-плана удовлетворять требованиям законодательства (GDPR, HIPAA, PCI DSS и т.д.) и отраслевых стандартов.
Почему важно: Несоблюдение требований может привести к огромным штрафам, потере лицензий и репутационному ущербу.
Как оценивать: Проконсультируйтесь с юристами и специалистами по комплаенсу. Убедитесь, что ваш DR-план охватывает все аспекты хранения, обработки и восстановления чувствительных данных в соответствии с регуляциями.
Частота и качество тестирования (Testing Frequency and Quality)
Что это: Регулярность проведения DR-тестов и их глубина (от настольных учений до полного переключения).
Почему важно: Непротестированный DR-план — это не план, а набор предположений. Только регулярное тестирование выявляет ошибки, узкие места и обеспечивает уверенность в работоспособности системы.
Как оценивать: Разработайте график тестирования (например, раз в квартал для полного переключения, ежемесячно для проверки бэкапов). Используйте автоматизированные фреймворки тестирования и Chaos Engineering для имитации различных сбоев.
Гравитация данных и географическое расположение (Data Gravity and Geographical Location)
Что это: Физическое расположение данных и влияние этого на задержки (latency) и стоимость передачи.
Почему важно: Для приложений с низкой RPO и высокой пропускной способностью данных, географическая близость DR-сайта к основному критична. Передача больших объемов данных между континентами может быть дорогой и медленной.
Как оценивать: Рассмотрите расположение ваших пользователей, требования к суверенитету данных (если есть), а также стоимость межрегионального трафика у провайдеров.
Тщательный анализ этих критериев позволит вам выбрать наиболее подходящую DR-стратегию, которая будет не только технически надежной, но и экономически обоснованной, а также соответствовать бизнес-целям вашего SaaS-приложения.
Сравнительная таблица DR-стратегий
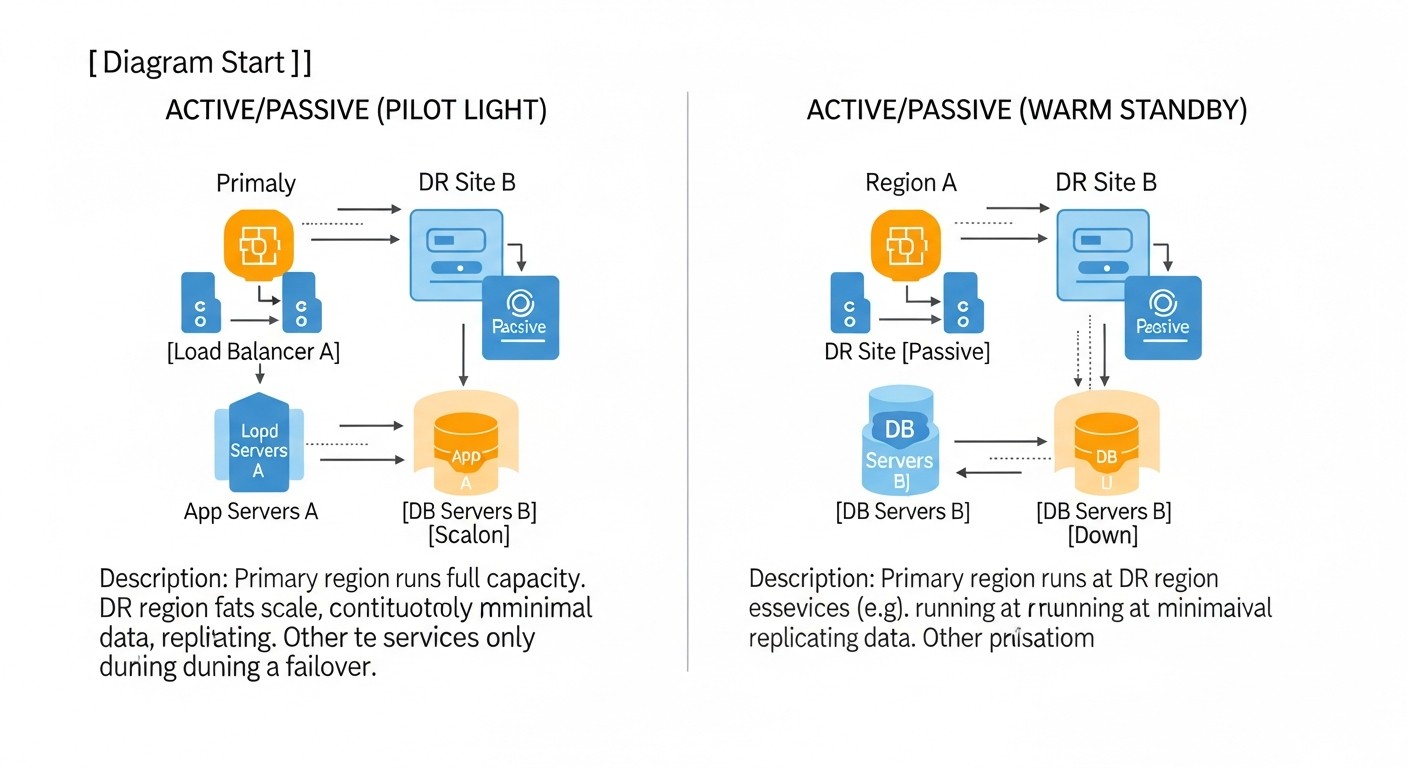 Схема: Сравнительная таблица DR-стратегий
Схема: Сравнительная таблица DR-стратегий
Выбор DR-стратегии — это всегда компромисс между стоимостью, сложностью, RTO и RPO. Ниже представлена сравнительная таблица наиболее распространенных подходов, актуальная для 2026 года, с учетом тенденций в облачных и VPS-технологиях. Цены приведены ориентировочно для среднего SaaS-приложения (например, 3-5 серверов приложений, 1-2 сервера БД, 100-500 ГБ данных), без учета стоимости персонала и лицензий специализированного ПО.
| Критерий |
Cold Standby (VPS/Облако) |
Warm Standby (VPS/Облако) |
Hot Standby (Облако/Мульти-AZ) |
Multi-Region Active/Active (Облако) |
Гибридный DR (VPS + Облако) |
| RTO (Целевое время восстановления) |
4-24 часа |
15 минут - 4 часа |
< 5 минут |
0 - несколько секунд |
30 минут - 2 часа |
| RPO (Допустимая потеря данных) |
1-24 часа (по последнему бэкапу) |
5 минут - 1 час (по последней репликации/бэкапу) |
0-5 минут (синхронная/асинхронная репликация) |
0-1 минута (практически нулевое) |
10-30 минут |
| Стоимость (ежемесячно, 2026 г., USD) |
$50 - $300 (только хранение бэкапов + минимальный VPS) |
$200 - $1000 (несколько VPS/VM + хранилище + трафик) |
$1000 - $5000+ (дублированная инфраструктура) |
$5000 - $20000+ (географически распределенная инфраструктура) |
$300 - $2000 (комбинация, зависит от используемых облачных ресурсов) |
| Сложность реализации |
Низкая (настройка бэкапов, ручной запуск) |
Средняя (настройка репликации, скрипты запуска) |
Высокая (автоматический failover, синхронизация) |
Очень высокая (глобальный балансировщик, распределенные БД) |
Средняя-Высокая (интеграция разнородных сред) |
| Уровень автоматизации |
Низкий (только бэкапы, восстановление вручную) |
Средний (автоматическая репликация, скрипты активации) |
Высокий (автоматический мониторинг, failover/failback) |
Очень высокий (полностью автоматизированное управление трафиком и данными) |
Средний (автоматизация в облачной части, ручные шаги на VPS) |
| Масштабируемость |
Низкая (требует ручного масштабирования при восстановлении) |
Средняя (можно предусмотреть шаблоны для масштабирования) |
Высокая (использует облачные возможности автомасштабирования) |
Очень высокая (глобальное автомасштабирование) |
Средняя (облачная часть масштабируема, VPS — нет) |
| Примеры технологий |
rsync, pg_dump, S3/Object Storage, Cron |
PostgreSQL Streaming Replication, MySQL GTID, rsync, DRBD, Terraform, Ansible |
AWS RDS Multi-AZ, Azure SQL Geo-replication, GCP Cloud Spanner, Kubernetes Operators, Route 53, ALB |
AWS Global Accelerator, Azure Front Door, GCP Global Load Balancer, CockroachDB, Cassandra, DynamoDB Global Tables |
VPN-туннели, rsync, S3/Object Storage, CloudFlare, Hybrid Cloud Connectors |
| Для кого подходит |
Малые стартапы, некритичные сервисы, внутренние утилиты |
Средние SaaS-проекты с умеренными требованиями к RTO/RPO |
Крупные SaaS, критически важные приложения, финансовые сервисы |
Глобальные SaaS, сервисы с крайне высокими требованиями к доступности (99.999%) |
SaaS-проекты, желающие оптимизировать затраты, но использовать преимущества облака для DR |
Эта таблица дает общее представление. Реальные цифры и сложность могут значительно варьироваться в зависимости от архитектуры вашего приложения, выбранных технологий и уровня экспертизы команды. Важно помнить, что инвестиции в DR — это страховка, которая окупается в момент катастрофы.
Детальный обзор каждой DR-стратегии
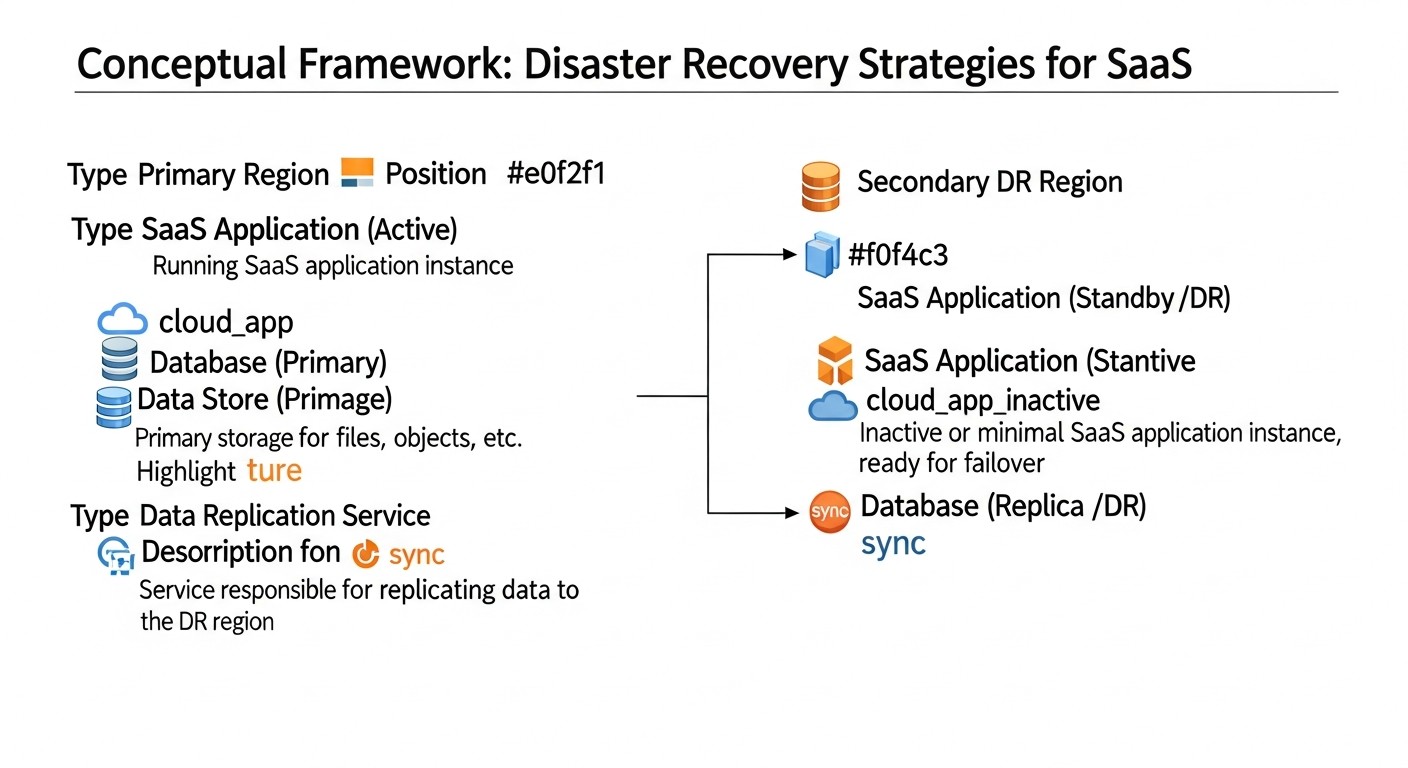 Схема: Детальный обзор каждой DR-стратегии
Схема: Детальный обзор каждой DR-стратегии
Каждая из представленных DR-стратегий имеет свои особенности, преимущества и недостатки. Выбор конкретного подхода должен основываться на тщательном анализе бизнес-требований, бюджета и технических возможностей. Рассмотрим каждую стратегию подробнее.
1. Cold Standby (Холодный резерв)
Описание: Это наименее затратная и наиболее простая стратегия. На резервном сайте (будь то другой VPS или облачная VM) нет постоянно запущенных ресурсов приложения. Вместо этого, регулярно создаются резервные копии данных (базы данных, файлы, конфигурации) с основного сайта и хранятся на удаленном, независимом хранилище (например, S3-совместимое хранилище, другой VPS с большим диском). В случае катастрофы, резервный сервер или VM разворачивается "с нуля" или из заранее подготовленного образа, на него загружаются последние резервные копии данных, и приложение запускается. DNS-записи переключаются на новый IP-адрес.
Плюсы:
- Низкая стоимость: Основные затраты связаны только с хранением резервных копий и, возможно, оплатой минимального VPS или VM, который находится в выключенном состоянии и оплачивается по факту использования (если облако).
- Простота реализации: Требует базовых навыков по настройке бэкапов и развертыванию серверов.
- Хорошо подходит для некритичных данных: Если RPO и RTO могут быть в пределах нескольких часов, это приемлемый вариант.
Минусы:
- Высокие RTO: Время восстановления может составлять от 4 до 24 часов, так как включает развертывание инфраструктуры, загрузку данных и настройку приложения.
- Высокие RPO: Потеря данных ограничена частотой создания резервных копий (например, 1-24 часа).
- Ручное вмешательство: Процесс восстановления часто требует значительного ручного вмешательства, что увеличивает вероятность ошибок.
- Не масштабируется: Быстрое восстановление большого и сложного приложения в ручном режиме практически невозможно.
Для кого подходит: Малые стартапы на ранних стадиях, внутренние инструменты, тестовые среды, некритичные SaaS-приложения, где простой в несколько часов не приводит к катастрофическим потерям. Фаундеры SaaS-проектов с ограниченным бюджетом могут начать с этого, но должны планировать переход к более надежным стратегиям по мере роста.
Примеры использования: SaaS для ведения блогов, небольшие CRM, личные кабинеты, где бизнес-процессы не страдают критически от нескольких часов простоя. Например, ваш SaaS-припроложение — это таск-трекер для фрилансеров, и потеря данных за последние 12 часов или простой на 8 часов не является фатальным для бизнеса.
2. Warm Standby (Теплый резерв)
Описание: Эта стратегия предполагает наличие резервного сайта, который частично или полностью запущен и готов к приему трафика, но не является активным. Инфраструктура (серверы, базы данных) на резервном сайте уже развернута и настроена. Данные с основного сайта регулярно реплицируются или синхронизируются на резервный сайт. При сбое на основном сайте, резервный сайт активируется, и DNS-записи переключаются. Это может включать запуск дополнительных сервисов, масштабирование мощностей и переключение балансировщиков нагрузки.
Плюсы:
- Умеренные RTO: Время восстановления значительно сокращается до 15 минут - 4 часов, так как большая часть инфраструктуры уже готова.
- Умеренные RPO: Потеря данных может быть сокращена до минут или десятков минут благодаря частой репликации.
- Баланс стоимости и надежности: Более дорогой, чем Cold Standby, но значительно дешевле Hot Standby.
- Возможность частичной автоматизации: Процессы репликации и частичного переключения могут быть автоматизированы.
Минусы:
- Требует больше ресурсов: Постоянно работающая, хотя и неполноценно загруженная, инфраструктура на резервном сайте.
- Сложность настройки: Настройка репликации баз данных и синхронизации файлов требует определенных знаний.
- Риск устаревания конфигураций: Если резервный сайт не используется активно, его конфигурации могут отставать от основного.
- Неполная автоматизация: Часто требует ручного вмешательства для финальной активации и проверки.
Для кого подходит: Растущие SaaS-проекты со средними требованиями к доступности, где простой в несколько часов уже ощутим, но не критичен. Backend-разработчики и DevOps-инженеры могут реализовать эту стратегию, используя стандартные средства репликации БД и IaC для развертывания инфраструктуры.
Примеры использования: E-commerce платформы, SaaS для управления проектами, CRM-системы, где потеря часа-двух данных или простоя на 30 минут приемлема. Например, SaaS для управления инвентаризацией, где синхронизация раз в 15 минут позволяет минимизировать потери.
3. Hot Standby (Горячий резерв) / Multi-AZ в облаке
Описание: Эта стратегия предполагает наличие полностью функционального и постоянно запущенного резервного сайта, который является зеркалом основного. Обе системы (основная и резервная) работают параллельно, и данные синхронизируются практически в реальном времени. В облачных средах это часто реализуется через Multi-AZ (Multi-Availability Zone) развертывания, где приложение и база данных дублируются в разных физически изолированных датацентрах (AZ) одного региона. Трафик направляется на активную систему, а при сбое происходит автоматическое переключение (failover) на резервную систему с минимальным или нулевым простоем.
Плюсы:
- Низкие RTO: Время восстановления составляет минуты или даже секунды, так как резервная система уже работает.
- Низкие RPO: Потеря данных минимальна или отсутствует благодаря синхронной или очень частой асинхронной репликации.
- Высокая доступность: Обеспечивает практически непрерывную работу сервиса.
- Высокая степень автоматизации: Процессы мониторинга, обнаружения сбоев и переключения полностью автоматизированы.
Минусы:
- Высокая стоимость: Требует дублирования всей производственной инфраструктуры, что значительно увеличивает затраты.
- Высокая сложность: Настройка синхронной репликации, автоматического failover, балансировки нагрузки и обеспечения консистентности данных требует высокой квалификации.
- Риск "Split-brain": Неправильная настройка может привести к ситуации, когда обе системы считают себя активными, что вызывает потерю данных.
- Не защищает от региональных сбоев: Multi-AZ защищает от сбоев в одной AZ, но не от сбоя всего региона (хотя вероятность такого события крайне мала).
Для кого подходит: Крупные SaaS-проекты, критически важные приложения, финансовые сервисы, E-commerce с высоким объемом транзакций, где каждая минута простоя обходится в огромные суммы. Системные администраторы и DevOps-инженеры с опытом работы в облаке и с распределенными системами являются ключевыми для реализации.
Примеры использования: Платежные системы, платформы онлайн-банкинга, глобальные игровые сервисы, SaaS для здравоохранения, где непрерывность и целостность данных абсолютно критичны.
4. Multi-Region Active/Active (Мультирегиональный активный/активный)
Описание: Это высший уровень DR и высокой доступности. Приложение развернуто и активно работает одновременно в нескольких географически удаленных регионах (например, в Европе и Северной Америке). Пользователи направляются в ближайший или наименее загруженный регион с помощью глобальных балансировщиков нагрузки (например, AWS Route 53, Azure Front Door, GCP Global Load Balancer). Данные реплицируются между регионами, часто с использованием распределенных баз данных, способных работать в режиме Active/Active. При отказе целого региона, трафик автоматически перенаправляется на оставшиеся регионы без какого-либо простоя для конечного пользователя.
Плюсы:
- Практически нулевые RTO и RPO: Пользователи могут не заметить сбоя, так как трафик мгновенно переключается на другой активный регион. Потеря данных минимальна или отсутствует.
- Максимальная устойчивость: Защищает от сбоев целых регионов, что крайне редко, но возможно.
- Глобальная производительность: Пользователи обслуживаются из ближайшего региона, что снижает задержки.
- Высочайший уровень доступности: Достижение 99.999% и выше.
Минусы:
- Экстремально высокая стоимость: Требует полного дублирования инфраструктуры в нескольких регионах, а также дорогостоящих глобальных сервисов и распределенных баз данных.
- Исключительно высокая сложность: Проектирование и поддержка такой системы — это сложнейшая инженерная задача. Управление консистентностью данных между регионами является серьезным вызовом.
- Проблема "Eventual Consistency": Для многих распределенных баз данных характерна eventual consistency, что может быть неприемлемо для некоторых приложений.
- Требует специализированных инструментов и экспертизы: Команда должна обладать глубокими знаниями в области распределенных систем.
Для кого подходит: Глобальные SaaS-проекты, социальные сети, критически важные сервисы с миллионами пользователей по всему миру, для которых любая минута простоя недопустима. CTO и ведущие архитекторы должны тщательно взвесить все "за" и "против", прежде чем принимать решение о такой дорогостоящей и сложной стратегии.
Примеры использования: Google, Facebook, Netflix, крупные банковские системы, глобальные SaaS-платформы, где доступность по всему миру и нулевой простой являются ключевыми для бизнеса.
5. Гибридный DR (VPS + Облако)
Описание: Эта стратегия сочетает в себе преимущества и VPS, и облачных сред. Основное приложение может работать на VPS (для контроля затрат или специфических требований), а DR-сайт разворачивается в облаке. Например, данные с VPS реплицируются в облачное хранилище (S3, GCS, Azure Blob Storage) или в облачную базу данных (RDS, Cloud SQL). При сбое основного VPS, в облаке автоматически или полуавтоматически разворачивается инфраструктура (VMs, контейнеры, бессерверные функции) из заранее подготовленных образов и конфигураций, и приложение запускается с использованием реплицированных данных. DNS-записи переключаются на облачные ресурсы.
Плюсы:
- Оптимизация стоимости: Позволяет использовать более дешевые VPS для основной работы, а платить за облачные ресурсы DR только при необходимости (модель "pay-as-you-go" для DR-инфраструктуры).
- Гибкость: Сочетает контроль и предсказуемость VPS с эластичностью и богатым набором сервисов облака.
- Умеренные RTO и RPO: В зависимости от уровня автоматизации и репликации, можно достичь RTO от 30 минут до 2 часов, и RPO от 10 до 30 минут.
- Защита от сбоев провайдера: Если основной VPS-провайдер выходит из строя, облачный DR-сайт остается доступным.
Минусы:
- Сложность интеграции: Требует настройки сетевого взаимодействия (VPN), синхронизации данных и конфигураций между двумя разными средами.
- Дополнительные инструменты: Нужны инструменты для оркестрации развертывания в облаке (IaC) и управления данными.
- Передача данных: Стоимость и задержки при передаче данных между VPS и облаком могут быть значительными.
- Требуется экспертиза в обеих средах: Команда должна разбираться как в VPS, так и в облачных технологиях.
Для кого подходит: SaaS-проекты, которые хотят получить преимущества облачного DR, не перенося всю свою основную инфраструктуру в облако. Фаундеры SaaS, которые хотят контролировать бюджет, но при этом обеспечить надежный DR. Системные администраторы и DevOps-инженеры, способные работать с обеими платформами и настраивать гибридные решения.
Примеры использования: SaaS-приложения, которые выросли на VPS, но хотят получить более надежный и автоматизированный DR, чем могут предложить другие VPS-провайдеры. Например, SaaS-платформа для бухгалтерии, которая хранит данные на VPS, но использует AWS S3 для бэкапов и AWS EC2/RDS для DR-сайта.
Выбирая стратегию, всегда начинайте с определения ваших RTO и RPO, затем оцените доступный бюджет и экспертизу команды. Помните, что DR — это эволюционный процесс, и вы можете начать с более простого решения, постепенно усложняя его по мере роста бизнеса и увеличения требований к доступности.
Практические советы и рекомендации по внедрению DR
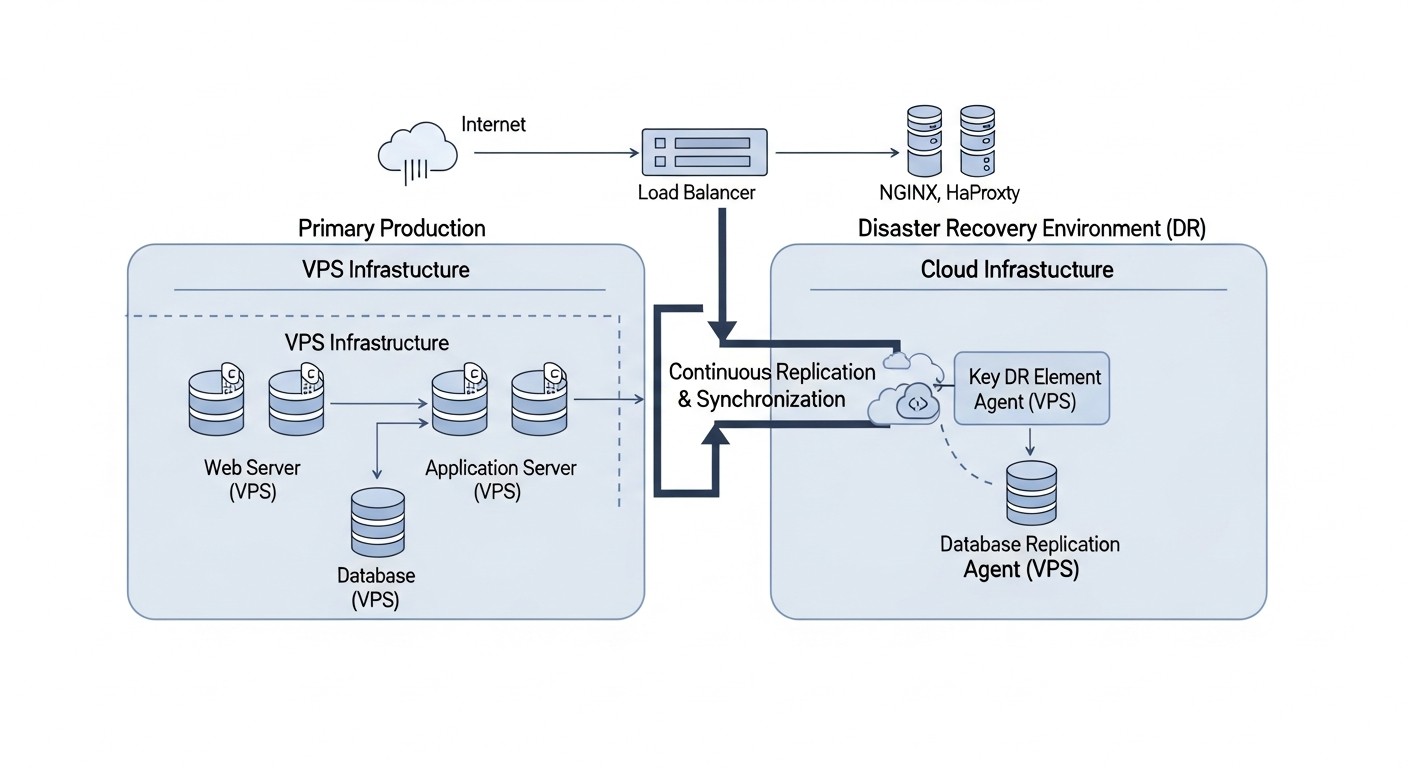 Схема: Практические советы и рекомендации по внедрению DR
Схема: Практические советы и рекомендации по внедрению DR
Внедрение эффективной стратегии Disaster Recovery требует системного подхода и внимания к деталям. Следующие практические советы и команды помогут вам в этом процессе.
1. Разработка Плана Disaster Recovery (DRP)
DRP — это не просто документ, это живое руководство к действию. Он должен быть подробным, актуальным и доступным для всех причастных. Ключевые компоненты DRP:
- Цели RTO/RPO: Четко определенные для каждого критического сервиса.
- Сценарии катастроф: Список возможных сбоев (отказ сервера, ЦОД, кибератака, человеческий фактор).
- Роли и обязанности: Кто за что отвечает во время инцидента.
- Процедуры активации DR: Пошаговые инструкции по переключению на резервный сайт.
- Процедуры Failback: Как вернуться на основной сайт после устранения проблемы.
- Контакты: Внутренние команды, внешние провайдеры, клиенты.
- Коммуникационный план: Кто, когда и как информирует заинтересованные стороны.
- Место хранения: DRP должен храниться вне основной инфраструктуры (например, в Google Docs, распечатанный экземпляр).
2. Определение RTO и RPO с Бизнес-Владельцами
Это не техническая задача, а бизнес-задача. Проведите встречи с руководителями отделов, чтобы понять, сколько времени простоя или потери данных они могут себе позволить. Используйте эти данные для выбора DR-стратегии. Например, для финансового модуля RPO может быть 1 минута, а для аналитического отчета — 4 часа.
3. Выбор Правильной Стратегии Резервного Копирования (Backup Strategy)
Бэкапы — основа любого DR. Используйте правило 3-2-1:
- 3 копии данных: Основная и две резервные.
- 2 разных носителя: Например, локальный диск и облачное хранилище.
- 1 удаленное хранилище: Географически отделенное от основного сайта.
Типы бэкапов: полные, инкрементальные, дифференциальные. Используйте снапшоты для быстрого создания точек восстановления VM и дисков.
# Пример бэкапа PostgreSQL в S3-совместимое хранилище
# Установите aws-cli или s3cmd
# pg_dump -Fc -Z9 -h localhost -U youruser yourdatabase > /tmp/yourdatabase_$(date +%F).dump
# aws s3 cp /tmp/yourdatabase_$(date +%F).dump s3://your-backup-bucket/db/
# rm /tmp/yourdatabase_$(date +%F).dump
# Пример бэкапа файлов с помощью rsync
# rsync -avz --delete /var/www/your_app/ s3://your-backup-bucket/app_files/
4. Настройка Репликации Данных
Для достижения низких RPO необходима репликация баз данных и, возможно, файловых систем.
- Базы данных:
- PostgreSQL: Используйте Streaming Replication (WAL shipping) для асинхронной или синхронной репликации.
- MySQL: Binary Log Replication (GTID-based) для асинхронной репликации.
- MongoDB: Replica Sets.
- Облачные БД: Используйте Multi-AZ или Geo-replication функции (AWS RDS, Azure SQL, GCP Cloud SQL).
- Файловые системы:
rsync для периодической синхронизации.DRBD (Distributed Replicated Block Device) для синхронной блочной репликации между двумя Linux-серверами.- Облачные решения: AWS EFS, Azure Files, GCP Filestore с репликацией или синхронизацией.
# Пример настройки PostgreSQL Streaming Replication (на мастере)
# В postgresql.conf:
# wal_level = replica
# max_wal_senders = 10
# max_replication_slots = 10
# hot_standby = on
# listen_addresses = ''
# В pg_hba.conf:
# host replication all 0.0.0.0/0 md5
# Пример создания базовой копии для реплики
# sudo -u postgres pg_basebackup -h master_ip -D /var/lib/postgresql/16/main/ -U replicator -P -R -W
5. Автоматизация DR-процессов (IaC, Скрипты, Оркестрация)
Автоматизация — это сердце современного DR. Ручные действия медленны и подвержены ошибкам.
- Infrastructure as Code (IaC): Используйте Terraform, Ansible, CloudFormation (AWS), ARM Templates (Azure), Deployment Manager (GCP) для описания всей вашей инфраструктуры (включая DR-сайт). Это позволяет быстро развернуть или восстановить окружение.
- Скрипты Failover: Напишите скрипты на Bash, Python или PowerShell для автоматического переключения. Они должны включать:
- Определение сбоя (мониторинг).
- Активация резервных ресурсов.
- Обновление DNS-записей или переключение балансировщика.
- Проверка работоспособности.
- Оповещения.
- Оркестрация контейнеров: Для приложений в Kubernetes используйте операторы (например, Velero для бэкапов, Strimzi для Kafka DR) и решения для Multi-Cluster DR.
- CI/CD для DR: Интегрируйте развертывание и тестирование DR-инфраструктуры в ваш CI/CD пайплайн.
# Пример Terraform для развертывания EC2 инстанса в AWS (DR-сайт)
resource "aws_instance" "dr_app_server" {
ami = "ami-0abcdef1234567890" # Укажите актуальный AMI
instance_type = "t3.medium"
key_name = "my-ssh-key"
vpc_security_group_ids = [aws_security_group.dr_sg.id]
subnet_id = aws_subnet.dr_subnet.id
tags = {
Name = "DR-App-Server"
Environment = "DR"
}
# ... другие настройки, например, EBS-тома для данных
}
6. Мониторинг и Оповещения
Надежный мониторинг критически важен для своевременного обнаружения сбоев и активации DR-плана. Мониторьте не только основную, но и DR-инфраструктуру.
- Метрики: CPU, RAM, Disk I/O, Network I/O, latency, health checks приложения, статусы репликации БД, доступность DNS.
- Инструменты: Prometheus/Grafana, Zabbix, Datadog, New Relic, ELK Stack.
- Оповещения: Настройте оповещения (SMS, звонки через PagerDuty, Slack, Email) для критических событий, которые требуют немедленного вмешательства или запуска DR-процедур.
7. Регулярное Тестирование DR-плана
Как уже упоминалось, непроверенный DRP бесполезен. Разработайте стратегию тестирования:
- Настольные учения (Tabletop Exercises): Обсуждение DRP с командой, проработка сценариев без реальных действий.
- Симулированные тесты: Имитация отказа компонента (например, остановка БД) без полного переключения.
- Полный Failover Test: Переключение на резервный сайт и работа с него в течение определенного времени. Это наиболее реалистичный тест, но требует тщательного планирования, чтобы не затронуть реальных пользователей.
- Failback Test: Проверка процедуры возвращения на основной сайт.
- Chaos Engineering: Используйте инструменты (Gremlin, Chaos Mesh) для контролируемого внедрения сбоев в продакшн или DR-среду, чтобы выявить слабые места.
Важно: Всегда документируйте результаты тестирования, ошибки и их решения. Обновляйте DRP после каждого теста.
8. Актуальная Документация
Подробная и актуальная документация — это ваша "спасательная шлюпка" во время катастрофы. В ней должно быть описано все: архитектура, зависимости, процедуры развертывания, настройки, процедуры DR, контакты. Храните ее в легкодоступном, но безопасном месте.
9. Управление Конфигурациями
Используйте системы управления конфигурациями (Ansible, Chef, Puppet, SaltStack) для единообразного развертывания и настройки серверов на основном и DR-сайтах. Это гарантирует, что DR-инфраструктура будет идентична основной.
10. Сетевая Изоляция и Безопасность DR-сайта
DR-сайт должен быть максимально изолирован от основной сети, но при этом иметь возможность получать данные. Используйте VPN-туннели для безопасной репликации. Применяйте строгие правила фаерволов, IAM-политики, шифрование данных в покое и в пути. Помните, что DR-сайт — это потенциальная точка входа для злоумышленников, если он не защищен должным образом.
Применяя эти рекомендации, вы сможете значительно повысить устойчивость вашего SaaS-приложения к различным видам сбоев и обеспечить непрерывность бизнеса даже в самых сложных ситуациях.
Типичные ошибки при разработке и реализации DR-плана
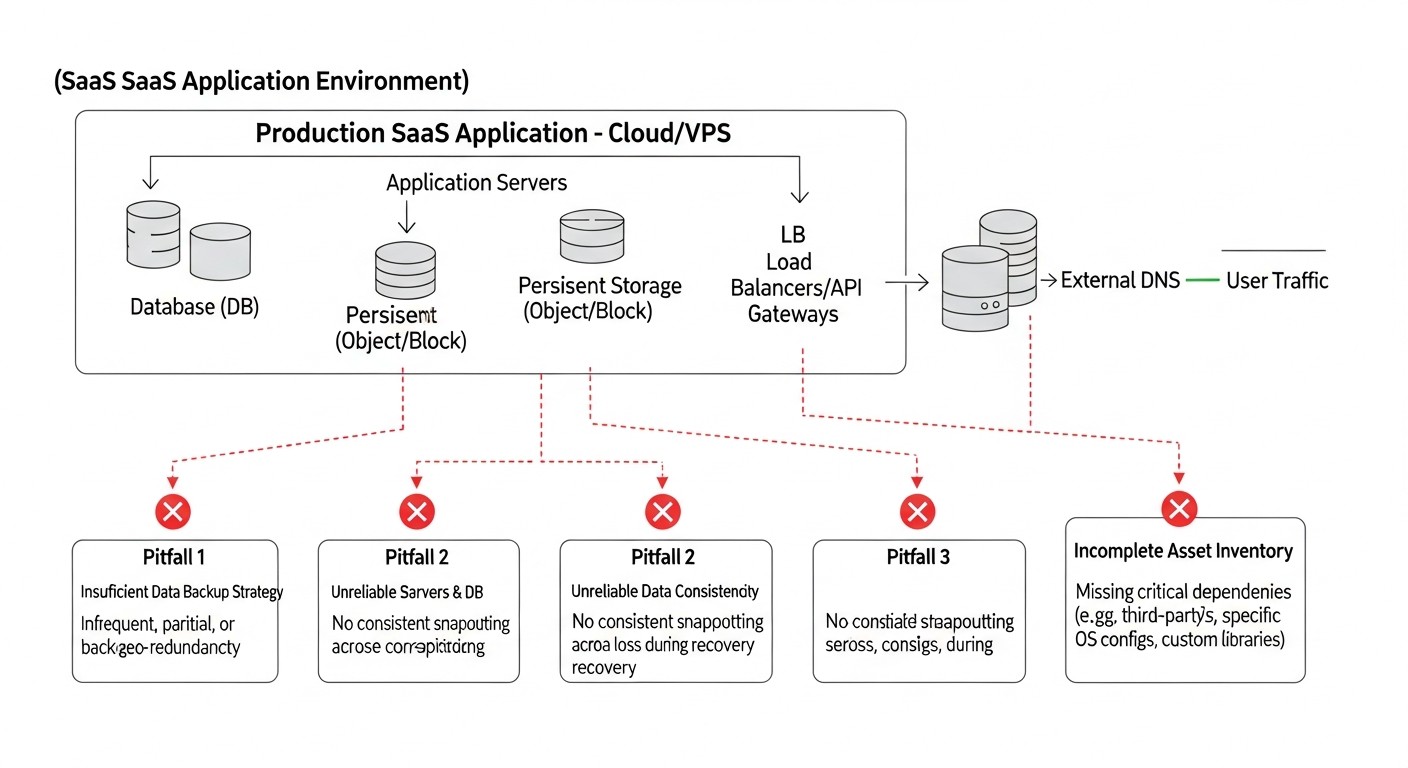 Схема: Типичные ошибки при разработке и реализации DR-плана
Схема: Типичные ошибки при разработке и реализации DR-плана
Даже самые опытные команды могут совершать ошибки при планировании и реализации Disaster Recovery. Знание этих подводных камней поможет вам избежать дорогостоящих провалов.
1. Отсутствие DR-плана или его устаревание
Ошибка: Многие компании либо вообще не имеют формализованного DRP, либо он существует "для галочки" и не обновляется годами. В условиях быстро меняющейся инфраструктуры и архитектуры SaaS, такой план быстро становится неактуальным.
Как избежать: Разработайте DRP, который включает все ключевые компоненты: RTO/RPO, сценарии, роли, пошаговые инструкции. Сделайте его живым документом, который регулярно пересматривается и обновляется (например, ежеквартально или после каждого значительного изменения архитектуры). Храните его в доступном, но защищенном месте, а также в нескольких копиях (включая оффлайн).
Реальные примеры последствий: Во время масштабного сбоя команда паникует, тратит часы на поиск актуальной информации, не может определить, кто за что отвечает, и в итоге процесс восстановления затягивается на неопределенный срок, многократно превышая допустимые RTO.
2. Непротестированные бэкапы и DR-план
Ошибка: Одна из самых распространенных и опасных ошибок. Компании настраивают бэкапы, считают, что DR "есть", но никогда не проверяют, можно ли из этих бэкапов реально восстановиться, и работает ли процедура переключения.
Как избежать: Сделайте тестирование DR обязательной и регулярной процедурой. Начните с проверки целостности бэкапов (например, попытка восстановления на тестовом сервере). Проводите полные DR-учения (failover/failback) не реже одного раза в полгода. Документируйте каждый тест, выявляйте проблемы и немедленно их устраняйте. Автоматизируйте тестирование, где это возможно.
Реальные примеры последствий: Во время реальной катастрофы выясняется, что бэкапы повреждены, неполны, или процедура восстановления содержит критические ошибки. Это приводит к полной потере данных или к невозможности восстановления сервиса в принципе, что может быть фатальным для SaaS-бизнеса.
3. Недооценка RTO и RPO
Ошибка: Технические специалисты часто устанавливают RTO и RPO, исходя из технических возможностей, а не из реальных бизнес-требований. Или, наоборот, бизнес запрашивает нулевые RTO/RPO, не понимая астрономической стоимости их реализации.
Как избежать: Проводите тщательный Business Impact Analysis (BIA) с участием всех заинтересованных сторон. Определите финансовые и репутационные потери от простоя и потери данных для каждого критического компонента. Сопоставьте эти потери с затратами на достижение различных RTO/RPO. Найдите оптимальный баланс. Документируйте принятые решения и их обоснование.
Реальные примеры последствий: При сбое выясняется, что заявленное RTO в 4 часа на самом деле является 8-12 часами, что приводит к многомиллионным потерям и разрыву клиентских договоров. Или, наоборот, компания вложила огромные средства в Hot Standby, когда Warm Standby был бы вполне достаточен и намного дешевле.
4. Игнорирование человеческого фактора
Ошибка: Предполагается, что в условиях стресса команда будет действовать идеально по написанным инструкциям. Забывается про усталость, панику, недостаток знаний у конкретного сотрудника.
Как избежать: Обучайте команду DR-процедурам. Проводите регулярные учения, чтобы каждый знал свою роль и мог действовать без паники. Автоматизируйте как можно больше шагов, чтобы минимизировать ручное вмешательство. Обеспечьте четкие каналы коммуникации. Убедитесь, что DRP понятен даже новичку. Рассмотрите возможность использования внешних экспертов для аудита или помощи при сложных инцидентах.
Реальные примеры последствий: Во время инцидента сотрудник ошибочно удаляет критически важные данные, или не может найти нужную команду в DRP, или просто паникует и бездействует, что усугубляет ситуацию и увеличивает время простоя.
5. Единая точка отказа в DR-инфраструктуре
Ошибка: При проектировании DR-решения команда может непреднамеренно создать новую единую точку отказа. Например, DR-сайт использует тот же DNS-провайдер, что и основной, или бэкапы хранятся в том же регионе облака, что и основной сервис.
Как избежать: Всегда проектируйте DR с учетом полной независимости от основной инфраструктуры. Используйте разных провайдеров (для VPS, DNS), разные регионы облака, разные аппаратные платформы. Проводите тщательный аудит архитектуры DR для выявления скрытых зависимостей. Для критически важных компонентов рассмотрите мультирегиональные решения.
Реальные примеры последствий: Отказ DNS-провайдера делает недоступными как основной, так и DR-сайт. Или региональный сбой в облаке выводит из строя обе системы, потому что DR-решение было развернуто в той же области, но в другой AZ, которая оказалась затронута общим сбоем региона.
6. Недостаточное внимание к безопасности DR-сайта
Ошибка: DR-инфраструктура часто рассматривается как "второстепенная" и получает меньше внимания к безопасности, чем основной продакшн. Однако она содержит копии всех ваших данных и может стать легкой мишенью для злоумышленников.
Как избежать: Применяйте те же или даже более строгие стандарты безопасности к DR-инфраструктуре. Шифруйте данные в покое и в пути. Используйте строгие правила контроля доступа (IAM, MFA). Регулярно проводите аудиты безопасности и пентесты для DR-сайта. Изолируйте DR-сеть от публичного доступа. Убедитесь, что резервные копии также защищены от компрометации.
Реальные примеры последствий: Злоумышленник получает доступ к DR-сайту через плохо защищенный сервис, который был развернут "на всякий случай", и уничтожает или крадет все резервные копии данных, делая восстановление невозможным.
7. Забывание о данных, не относящихся к БД
Ошибка: Часто фокус DR смещается исключительно на базу данных, забывая о файлах пользователя, логах, конфигурациях, статическом контенте, кэшах и других нереляционных данных, которые также важны для функционирования SaaS.
Как избежать: Включите в DRP все типы данных, необходимые для полного восстановления приложения. Разработайте стратегию бэкапов и репликации для каждого из них. Используйте объектные хранилища (S3) для файлов, централизованные системы логирования (ELK, Splunk) с репликацией, системы управления конфигурациями (Git) для всех настроек.
Реальные примеры последствий: После восстановления БД приложение не может запуститься, потому что отсутствуют файлы загрузок пользователей или критические конфигурационные файлы. Это приводит к дополнительному простою и усилиям по восстановлению.
Избегая этих распространенных ошибок, вы значительно повысите шансы на успешное восстановление вашего SaaS-приложения после любой катастрофы.
Чеклист для практического применения DR-стратегий
Этот чеклист поможет вам систематизировать процесс планирования, внедрения и тестирования Disaster Recovery для вашего SaaS-приложения.
-
Определение бизнес-требований:
- Проведен ли Business Impact Analysis (BIA) для всех критически важных компонентов SaaS?
- Определены ли целевые RTO (Recovery Time Objective) для каждого сервиса?
- Определены ли целевые RPO (Recovery Point Objective) для каждого сервиса?
- Согласованы ли эти метрики с бизнес-владельцами?
-
Разработка DR-плана (DRP):
- Создан ли формальный документ DRP?
- Описаны ли в DRP все сценарии катастроф?
- Четко ли определены роли и обязанности команды в случае инцидента?
- Есть ли пошаговые инструкции для активации DR и возврата (failover/failback)?
- Содержит ли DRP актуальные контактные данные всех участников и провайдеров?
- Разработан ли коммуникационный план для информирования клиентов и стейкхолдеров?
- Хранится ли DRP в безопасном, но доступном месте, отдельно от основной инфраструктуры?
-
Выбор и проектирование DR-стратегии:
- Выбрана ли оптимальная DR-стратегия (Cold/Warm/Hot Standby, Multi-Region, Hybrid), соответствующая RTO/RPO и бюджету?
- Спроектирована ли DR-архитектура, обеспечивающая независимость от основной инфраструктуры?
- Учтены ли географические факторы и требования к суверенитету данных?
- Определены ли технологии для бэкапов, репликации и автоматизации?
-
Внедрение бэкапов и репликации:
- Реализована ли стратегия резервного копирования 3-2-1 для всех критических данных?
- Настроена ли регулярная проверка целостности бэкапов?
- Настроена ли репликация баз данных (streaming replication, replica sets и т.д.)?
- Обеспечена ли синхронизация файловых систем и других нереляционных данных?
- Зашифрованы ли все резервные копии и данные в пути?
-
Автоматизация DR-процессов:
- Разработана ли инфраструктура DR с помощью IaC (Terraform, CloudFormation и т.д.)?
- Созданы ли скрипты для автоматического обнаружения сбоев и переключения (failover)?
- Автоматизирован ли процесс обновления DNS-записей или переключения балансировщиков нагрузки?
- Интегрированы ли DR-процессы в CI/CD пайплайн?
-
Мониторинг и оповещения:
- Настроен ли комплексный мониторинг основной и DR-инфраструктуры (метрики, логи, health checks)?
- Созданы ли оповещения для критических событий, требующих активации DR?
- Обеспечена ли доставка оповещений по нескольким каналам (SMS, звонки, Slack, email)?
-
Тестирование и проверка:
- Разработан ли график регулярного тестирования DR-плана?
- Проведены ли настольные учения (Tabletop Exercises) с командой?
- Выполнялись ли симулированные тесты без полного переключения?
- Проводились ли полные тесты Failover и Failback?
- Использовались ли элементы Chaos Engineering для выявления слабых мест?
- Документируются ли все результаты тестирования, выявленные проблемы и их решения?
- Обновляется ли DRP после каждого теста и выявленных изменений?
-
Безопасность и соответствие:
- Применены ли строгие меры безопасности к DR-инфраструктуре (IAM, фаерволы, шифрование)?
- Соответствует ли DR-план всем применимым нормативным требованиям (GDPR, HIPAA, PCI DSS)?
- Проводился ли аудит безопасности DR-решения?
-
Документация и обучение:
- Является ли вся документация (архитектура, конфигурации, DRP) актуальной и доступной?
- Обучена ли команда всем аспектам DR-плана и процедурам?
- Есть ли резервные сотрудники, способные выполнять DR-процедуры?
-
Оптимизация стоимости:
- Проведен ли анализ TCO для DR-решения?
- Используются ли возможности оптимизации затрат (резервные экземпляры, спотовые инстансы, tiering хранения)?
- Регулярно ли пересматриваются затраты на DR?
Следуя этому чеклисту, вы сможете построить устойчивую и надежную систему Disaster Recovery, которая защитит ваш SaaS-бизнес от непредвиденных сбоев.
Расчет стоимости / Экономика Disaster Recovery
 Схема: Расчет стоимости / Экономика Disaster Recovery
Схема: Расчет стоимости / Экономика Disaster Recovery
Экономика Disaster Recovery — это не только прямые затраты на инфраструктуру, но и скрытые расходы, а также стоимость потенциальных потерь от сбоев. Правильный расчет TCO (Total Cost of Ownership) и ROI (Return on Investment) DR-решения критически важен для принятия обоснованных решений.
Компоненты стоимости DR
- Инфраструктура:
- Вычислительные ресурсы: VPS, облачные VM (EC2, Azure VMs, GCP Compute Engine), контейнеры, бессерверные функции. Стоимость зависит от выбранной стратегии (Cold/Warm/Hot Standby).
- Хранение данных: Диски (EBS, Azure Disks, GCP Persistent Disks), объектное хранилище (S3, Azure Blob, GCS) для бэкапов и холодных данных. Стоимость зависит от объема, типа хранения (Standard, Infrequent Access, Archive).
- Сетевые ресурсы: Трафик на репликацию данных, исходящий трафик при переключении, VPN-туннели, балансировщики нагрузки, DNS-сервисы. Межрегиональный трафик может быть дорогим.
- Управляемые сервисы: Управляемые базы данных (RDS, Azure SQL, Cloud SQL), очереди сообщений, кэши, CDN.
- Программное обеспечение:
- Лицензии на специализированное DR-ПО (Veeam, Zerto).
- Лицензии на ОС и другое ПО (если не используются open-source или бесплатные версии).
- Персонал:
- Время инженеров на проектирование, реализацию, тестирование и поддержку DR-решения.
- Обучение команды.
- Время на реальное восстановление при инциденте.
- Тестирование:
- Ресурсы, выделяемые для DR-тестов (временное развертывание тестовых сред).
- Трудозатраты команды на планирование и проведение тестов.
- Скрытые расходы и потери:
- Потеря дохода: Прямые финансовые потери от недоступности сервиса.
- Потеря производительности: Сотрудники не могут работать из-за недоступности внутренних инструментов.
- Ущерб репутации: Потеря доверия клиентов, негативные отзывы, отток пользователей.
- Штрафы: За несоблюдение SLA или регуляторных требований.
- Стоимость восстановления данных: Если данные были утеряны и их нужно воссоздавать вручную.
- Юридические издержки: Судебные иски от пострадавших клиентов.
Примеры расчетов для разных сценариев (ориентировочные цены 2026 г.)
Предположим, у нас SaaS-приложение с 3 серверами приложений (CPU, RAM), 1 сервером БД (PostgreSQL), 200 ГБ данных, 500 ГБ файлов, 1 ТБ ежемесячного трафика.
Сценарий 1: Малый SaaS (Warm Standby на VPS)
- Основная инфраструктура: 3 x VPS (4vCPU, 8GB RAM, 100GB SSD) + 1 x VPS (8vCPU, 16GB RAM, 200GB SSD) = $200/мес.
- DR-инфраструктура (Warm Standby):
- 1 x VPS (2vCPU, 4GB RAM, 50GB SSD) для реплики БД: $30/мес.
- 2 x VPS (2vCPU, 4GB RAM, 50GB SSD) в выключенном состоянии (оплата за хранение диска): $20/мес.
- Объектное хранилище (S3-совместимое) для бэкапов (1 ТБ): $20/мес.
- Трафик на репликацию и бэкапы (500 ГБ): $25/мес.
- Управляемый DNS (например, Cloudflare): $5/мес.
- Итого прямые DR-затраты: ~$100/мес.
- Трудозатраты (инженер 0.1 FTE): $500/мес.
- Общий TCO DR: ~$600/мес.
- Потенциальный ущерб от простоя (12 часов, $1000/час): $12000. DR окупается, если предотвращает 1-2 крупных простоя в год.
Сценарий 2: Средний SaaS (Hot Standby в облаке, Multi-AZ)
- Основная инфраструктура (AWS):
- 3 x EC2 (t3.medium) = $150/мес.
- 1 x RDS PostgreSQL (db.t3.large, Multi-AZ) = $200/мес.
- S3 (500GB) + EBS (200GB) = $40/мес.
- ALB, Route 53, VPC, трафик = $100/мес.
- Итого основная: ~$490/мес.
- DR-инфраструктура (почти зеркало, Multi-AZ):
- RDS Multi-AZ уже включен в стоимость, обеспечивает DR для БД.
- EC2 (Auto Scaling Group в 2 AZ) = $150/мес.
- S3 для бэкапов (1 ТБ) = $20/мес.
- EBS для EC2 (200GB) = $20/мес.
- ALB, Route 53, VPC, трафик (включая меж-AZ) = $120/мес.
- Итого прямые DR-затраты: ~$310/мес (поверх базовой инфраструктуры, которая уже отказоустойчива в рамках AZ).
- Трудозатраты (инженер 0.2 FTE): $1000/мес.
- Общий TCO DR: ~$1310/мес.
- Потенциальный ущерб от простоя (1 час, $5000/час): $5000. DR окупается, предотвращая 3-4 крупных простоя в год.
Сценарий 3: Крупный SaaS (Multi-Region Active/Active в облаке)
Здесь стоимость значительно возрастает из-за полного дублирования инфраструктуры в нескольких регионах и использования глобальных сервисов. Основная инфраструктура умножается на количество регионов, добавляются затраты на межрегиональную репликацию данных и глобальный балансировщик.
- Два полноценных региона (например, US-East и EU-West): Удваивает стоимость основной инфраструктуры, плюс дополнительные затраты.
- Инфраструктура в каждом регионе: ~$490/мес 2 = $980/мес.
- Межрегиональная репликация данных: Для 200 ГБ БД и 500 ГБ файлов, при активном использовании, трафик может быть 1-2 ТБ/мес, плюс стоимость чтения/записи. Ориентировочно: $200-$500/мес.
- Глобальный балансировщик (AWS Global Accelerator/Route 53): ~$100/мес.
- Итого прямые DR-затраты: ~$500/мес (поверх стоимости дублирования инфраструктуры).
- Трудозатраты (инженер 0.5 FTE): $2500/мес.
- Общий TCO DR: ~$3980/мес ($980 + $500 + $2500).
- Потенциальный ущерб от простоя (10 минут, $20000/минута): $200000. DR критически важен и окупается при предотвращении даже одного такого инцидента.
Таблица с примерами расчетов (усредненные значения для 2026 г.)
| Компонент / Стратегия |
Cold Standby (VPS) |
Warm Standby (VPS/Cloud) |
Hot Standby (Cloud Multi-AZ) |
Multi-Region A/A (Cloud) |
| Инфраструктура DR (мес.) |
$50 - $150 |
$150 - $500 |
$300 - $1000 |
$1000 - $5000+ |
| Хранение бэкапов (мес.) |
$10 - $30 |
$15 - $50 |
$20 - $70 |
$50 - $200 |
| Трафик репликации/бэкапов (мес.) |
$5 - $20 |
$20 - $100 |
$50 - $200 |
$200 - $1000+ |
| Лицензии ПО (мес.) |
$0 - $50 |
$0 - $100 |
$0 - $200 |
$0 - $500+ |
| Трудозатраты инженеров (мес.) |
$200 - $500 |
$500 - $1500 |
$1000 - $3000 |
$2000 - $5000+ |
| Итого TCO DR (мес.) |
$265 - $750 |
$685 - $2150 |
$1370 - $4470 |
$3250 - $11700+ |
| Потенциальный ущерб от 1 часа простоя |
$500 - $5000 |
$2000 - $15000 |
$10000 - $50000 |
$50000 - $500000+ |
Как оптимизировать затраты
- Резервные экземпляры (Reserved Instances) / Сберегательные планы (Savings Plans): Для стабильной части DR-инфраструктуры в облаке можно значительно снизить стоимость.
- Спотовые инстансы (Spot Instances): Могут использоваться для некритичных частей DR-инфраструктуры или для временных тестовых развертываний, но требуют устойчивости к прерываниям.
- Тиринг хранения данных (Storage Tiering): Перемещайте старые бэкапы в более дешевые архивные классы хранения (Glacier, Deep Archive).
- Open-source инструменты: Используйте бесплатные и мощные open-source решения для бэкапов, репликации и автоматизации, чтобы избежать лицензионных платежей.
- Автоматическое выключение/включение: Для Warm Standby можно выключать неактивные ресурсы DR-сайта в нерабочее время (если RTO позволяет).
- Оптимизация трафика: Компрессия данных перед передачей, использование частных сетей (VPN) для репликации, выбор провайдера с выгодными тарифами на исходящий трафик.
- DR-as-a-Service: Рассмотрите сторонние решения DRaaS, которые могут быть более экономичными для некоторых компаний, чем создание собственного DR-центра.
Экономика DR — это постоянный процесс оценки и оптимизации. Важно не просто сокращать расходы, а находить оптимальный баланс между стоимостью, надежностью и соответствием бизнес-требованиям.
Кейсы и примеры внедрения DR
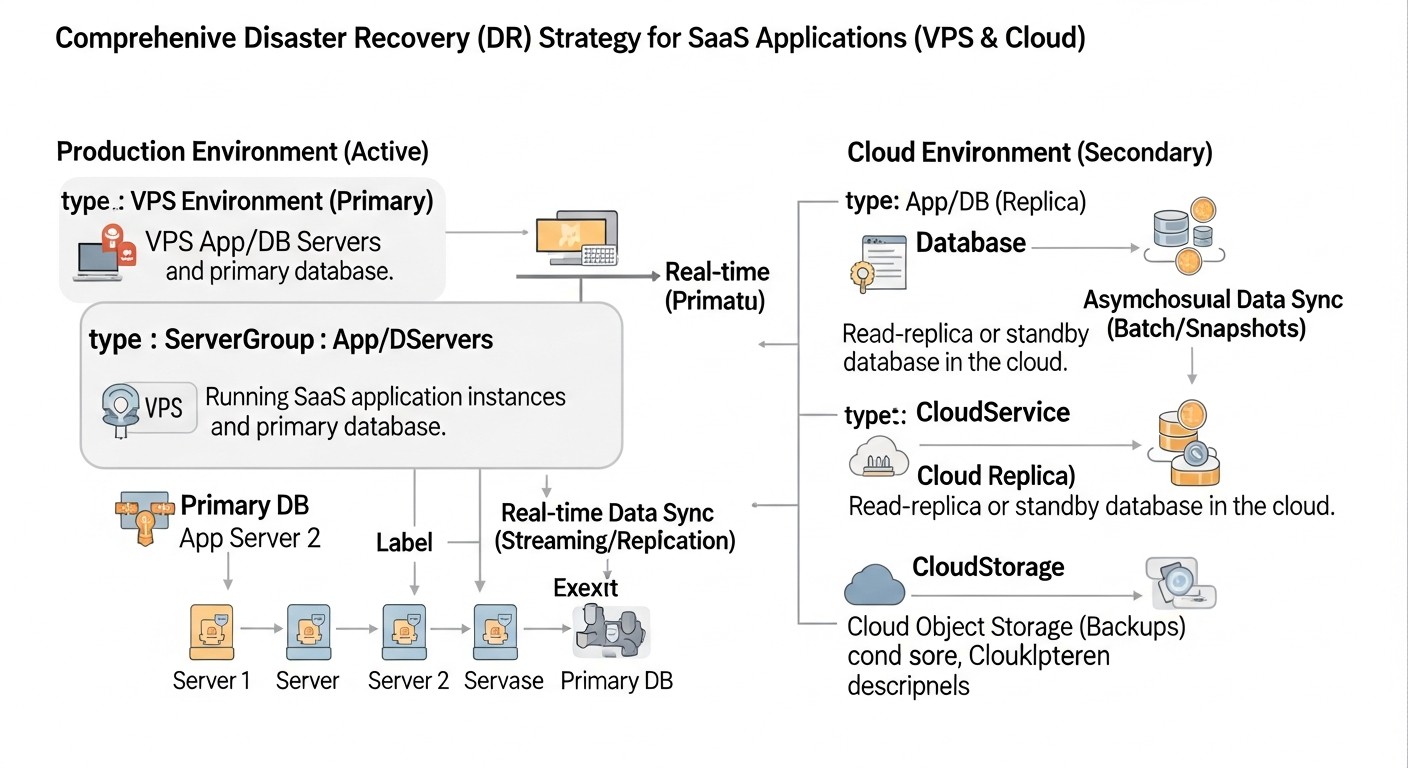 Схема: Кейсы и примеры внедрения DR
Схема: Кейсы и примеры внедрения DR
Реальные примеры помогут лучше понять, как различные стратегии DR применяются на практике и какие результаты они приносят.
Кейс 1: Малый SaaS-проект на VPS — "TaskFlow" (Warm Standby)
Проект: "TaskFlow" — SaaS для управления задачами и проектами для небольших команд. Основан на Python/Django с PostgreSQL, развернут на 3 VPS у одного провайдера.
Проблема: Возрастающие риски потери данных и длительного простоя. RTO = 3 часа, RPO = 15 минут.
Решение: Внедрение стратегии Warm Standby с использованием второго VPS-провайдера и облачного хранилища.
- База данных (PostgreSQL): На основном VPS настроена асинхронная потоковая репликация (streaming replication) на отдельный, постоянно работающий VPS у другого провайдера. WAL-логи копируются каждые 5 минут в объектное хранилище (S3-совместимое).
- Файлы приложения и статика: Ежечасная синхронизация всех пользовательских файлов (загрузки, вложения) и статики с основного VPS в объектное хранилище с помощью
rsync.
- Код и конфигурации: Хранятся в Git-репозитории.
- DR-сайт: У второго провайдера предустановлены образы VPS с операционной системой и базовым ПО. При сбое основного, активируются два новых VPS из образов (для приложения и для БД, если реплика не может быть повышена до мастера), на них загружаются последние файлы из S3, и приложение запускается.
- Автоматизация: Разработаны Bash-скрипты для мониторинга состояния основного сервера, переключения DNS-записей (через API DNS-провайдера) и запуска приложения на DR-сайте. Процесс активации полуавтоматический, требует подтверждения инженера.
- Тестирование: Полный Failover Test проводится раз в 3 месяца в нерабочее время.
Результаты:
- RTO: Сокращено до 45-60 минут (включая ручное подтверждение и проверку).
- RPO: До 5-15 минут благодаря потоковой репликации и частой синхронизации WAL-логов.
- Стоимость: Дополнительные ~$150/мес на DR-VPS, хранилище и трафик, что было приемлемо для бюджета.
- Значительно повышена устойчивость к сбоям одного VPS-провайдера.
Кейс 2: Средний SaaS-проект в AWS — "AnalyticsPro" (Hot Standby Multi-AZ)
Проект: "AnalyticsPro" — SaaS-платформа для глубокой аналитики данных, развернутая в AWS. Использует Node.js на EC2 (в Auto Scaling Group), MongoDB Atlas (managed service) и S3 для хранения сырых данных.
Проблема: Высокие требования к доступности (99.99%) и минимальная потеря данных (RPO < 1 минута). Простой в 15 минут уже критичен.
Решение: Внедрение стратегии Hot Standby с использованием AWS Multi-AZ возможностей и MongoDB Atlas.
- База данных (MongoDB Atlas): Используется Multi-Region Replica Set, который по сути является Active/Passive DR-решением в рамках провайдера. MongoDB Atlas автоматически управляет репликацией и failover между AZ.
- Приложение (Node.js на EC2): Развернуто в Auto Scaling Group, которая распределяет инстансы по двум Availability Zones (AZ) в одном регионе. Перед ASG стоит Application Load Balancer (ALB), также работающий в нескольких AZ.
- Хранилище данных (S3): S3 по своей природе является высокодоступным и гео-реплицируемым внутри региона.
- Автоматизация:
- Инфраструктура описана с помощью AWS CloudFormation.
- Health checks на ALB и в ASG автоматически обнаруживают неработоспособные инстансы и заменяют их.
- DNS-записи (Route 53) указывают на ALB, который сам управляет трафиком между AZ.
- Lambda-функции мониторят состояние репликации MongoDB и отправляют оповещения.
- Тестирование: Регулярно проводятся имитации сбоев AZ (например, остановка инстансов в одной AZ) для проверки автоматического переключения.
Результаты:
- RTO: Менее 1-2 минут (время переключения ALB и запуска новых инстансов ASG). Для БД практически нулевое.
- RPO: Практически нулевое для всех критических данных.
- Стоимость: Увеличилась примерно на 40-50% по сравнению с однозонным развертыванием, но это было оправдано бизнес-требованиями и предотвращенным ущербом.
- Обеспечена высокая доступность и устойчивость к сбоям на уровне AZ.
Кейс 3: Крупный SaaS-проект с гибридной инфраструктурой — "EnterpriseConnect" (Hybrid DR)
Проект: "EnterpriseConnect" — SaaS для управления корпоративными коммуникациями, изначально развернутый в собственном датацентре (On-Premise) из-за требований к суверенитету данных и высокой производительности. Часть сервисов (например, аналитика, отчетность) уже вынесена в облако.
Проблема: Высокие RTO (8-12 часов) и RPO (4 часа) для критически важных компонентов в собственном ЦОД. Необходимо обеспечить более низкие RTO/RPO без полного переноса в облако.
Решение: Внедрение гибридной DR-стратегии с использованием публичного облака (Azure) как резервного сайта.
- База данных (SQL Server): Настроена Geo-replication в Azure SQL Database. Локальная БД постоянно реплицируется в облачную управляемую БД.
- Файловые серверы: Критически важные файлы синхронизируются в Azure Blob Storage.
- Приложение (ASP.NET Core): Образы VM с приложением и базовым ПО хранятся в Azure Image Gallery. Конфигурации хранятся в Azure Key Vault.
- DR-сайт в Azure:
- Настроен VPN-туннель между локальным ЦОД и Azure VNet.
- В Azure VNet заранее подготовлены подсети, группы безопасности, балансировщики нагрузки (Azure Application Gateway).
- Развернуты минимальные, но постоянно работающие VM для мониторинга и поддержки VPN-туннеля.
- Автоматизация:
- Вся DR-инфраструктура в Azure описана с помощью Azure Resource Manager (ARM) шаблонов.
- Разработаны PowerShell скрипты для автоматической активации DR: запуск VM из образов, подключение дисков, настройка приложения, переключение DNS-записей (через Azure DNS).
- Мониторинг основного ЦОД настроен в Azure Monitor, который при обнаружении сбоя запускает оповещение и инициирует скрипт активации DR.
- Тестирование: Ежеквартальный полный Failover Test с переключением части трафика на Azure.
Результаты:
- RTO: Сокращено до 1-2 часов.
- RPO: Сокращено до 15-30 минут для БД и файлов.
- Стоимость: Значительные инвестиции в разработку и поддержку, но операционные расходы на облачную инфраструктуру в режиме "standby" были оптимизированы.
- Обеспечена надежная защита от сбоев всего локального датацентра.
Эти кейсы демонстрируют, что эффективная стратегия DR не является универсальным решением, а требует индивидуального подхода, основанного на специфике проекта, его требованиях и доступных ресурсах.
Troubleshooting: Решение типовых проблем DR
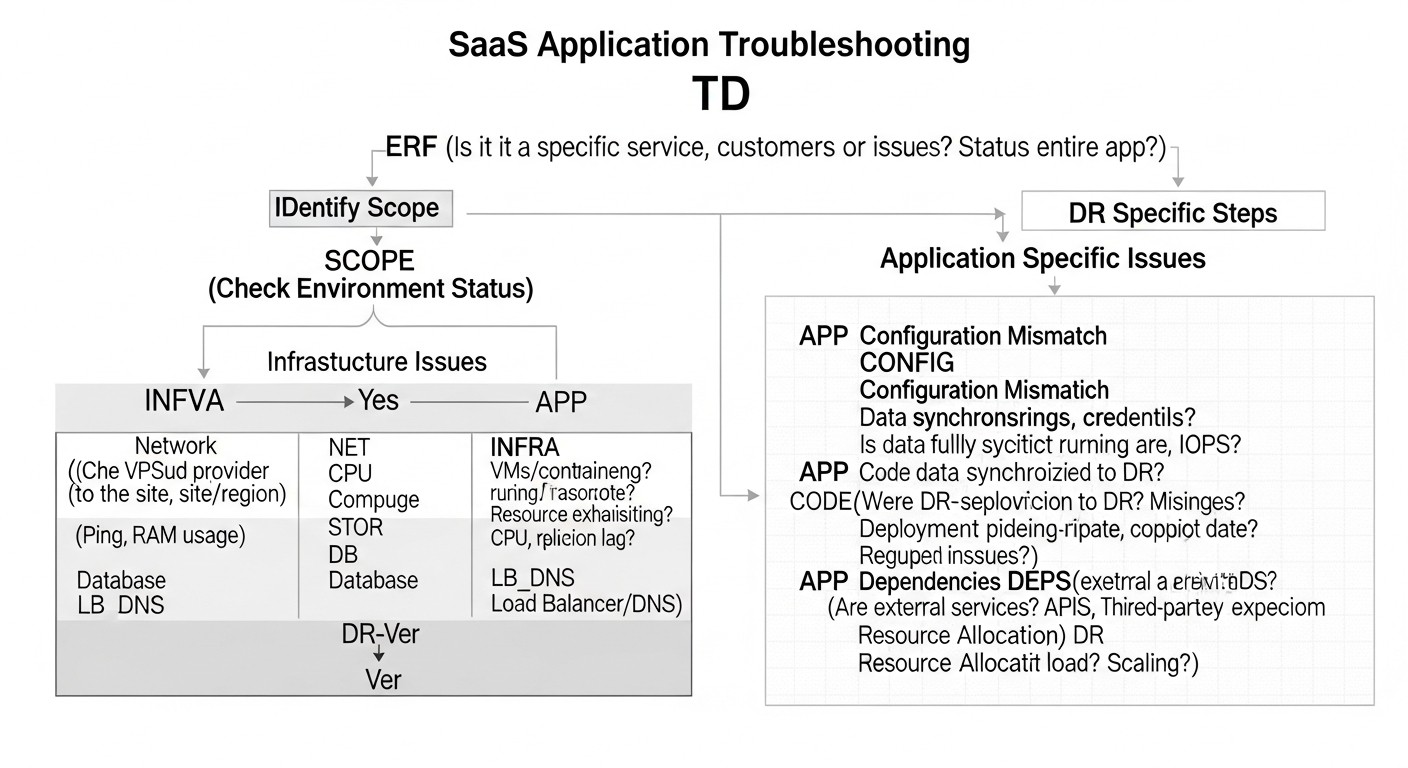 Схема: Troubleshooting: Решение типовых проблем DR
Схема: Troubleshooting: Решение типовых проблем DR
Даже при самом тщательном планировании и автоматизации, в процессе Disaster Recovery могут возникать проблемы. Знание типичных сценариев и подходов к их решению значительно сокращает время восстановления.
1. Проблема: Сбои резервного копирования или репликации
Симптомы: Отсутствие свежих бэкапов, отставание реплики БД, ошибки в логах бэкап-скриптов.
Диагностика:
- Проверьте логи бэкап-процессов и сервисов репликации (например,
tail -f /var/log/syslog, логи PostgreSQL/MySQL).
- Проверьте дисковое пространство на серверах и в целевом хранилище (
df -h, мониторинг облачного хранилища).
- Проверьте сетевое соединение между основным и резервным сайтами (
ping, traceroute, netstat -tulnp).
- Проверьте права доступа пользователя, от имени которого запускаются бэкапы/репликация.
- Для баз данных:
- PostgreSQL:
SELECT * FROM pg_stat_replication; на мастере, SELECT pg_is_in_recovery(); на реплике.
- MySQL:
SHOW SLAVE STATUS\G; на реплике.
Решение:
- Устраните проблемы с дисковым пространством, сетью или правами.
- Перезапустите сервисы репликации.
- При значительном отставании реплики, возможно, потребуется пересоздать ее с нуля (
pg_basebackup для PostgreSQL, mysqldump с последующим импортом для MySQL, rsync для файловых систем).
- Настройте агрессивный мониторинг и оповещения о сбоях бэкапов/репликации.
2. Проблема: Несогласованность данных после failover
Симптомы: Часть данных отсутствует, транзакции потеряны, приложение ведет себя непредсказуемо после переключения на DR-сайт.
Диагностика:
- Проверьте RPO, которое было достигнуто на момент сбоя. Соответствует ли оно ожиданиям?
- Сравните контрольные суммы файлов или количество записей в таблицах БД между основным и DR-сайтами (если возможно).
- Проанализируйте логи репликации на предмет ошибок или пропущенных транзакций.
- Проверьте настройки репликации: была ли она синхронной или асинхронной?
Решение:
- Если RPO было нарушено, и данные действительно потеряны, оцените возможность восстановления из более старых бэкапов (если это допустимо) или ручного восстановления данных.
- Для будущих инцидентов: пересмотрите RPO и стратегию репликации. Возможно, требуется более строгая синхронная репликация или использование распределенных баз данных с гарантированной консистентностью.
- Внедрите дополнительные проверки консистентности данных в DR-план.
3. Проблема: Медленное или неудачное переключение (Failover)
Симптомы: DR-сайт активируется дольше, чем ожидалось, скрипты failover зависают, приложение не запускается корректно на DR-сайте.
Диагностика:
- Проверьте логи скриптов failover. На каком шаге произошла задержка или ошибка?
- Проверьте доступность внешних сервисов, от которых зависит DR-сайт (DNS-провайдер, облачные API).
- Проверьте состояние ресурсов на DR-сайте: достаточно ли CPU/RAM/IOPS? Не "замерзли" ли VM?
- Проверьте сетевые настройки на DR-сайте (фаерволы, маршрутизация).
- Убедитесь, что все зависимости приложения (очереди, кэши, сторонние API) доступны или правильно сконфигурированы на DR-сайте.
Решение:
- Оптимизируйте скрипты failover: сделайте их более робастными, добавьте таймауты и повторные попытки.
- Предварительно "разогрейте" (pre-warm) инстансы на DR-сайте, если это Warm Standby, чтобы сократить время загрузки.
- Устраните сетевые проблемы.
- Актуализируйте конфигурации DR-сайта. Он должен быть идентичен основному.
- Проведите тщательное тестирование failover, чтобы выявить все узкие места.
4. Проблема: Ошибки при возврате (Failback)
Симптомы: Невозможно переключиться обратно на основной сайт, данные на основном сайте устарели, возникают конфликты данных.
Диагностика:
- Проверьте, был ли основной сайт полностью восстановлен и готов к приему трафика.
- Убедитесь, что данные с DR-сайта были корректно реплицированы обратно на основной сайт.
- Проверьте логи failback-скриптов.
- Оцените, есть ли конфликты данных, которые могли возникнуть в процессе работы DR-сайта.
Решение:
- Процедура failback часто сложнее, чем failover, и требует еще более тщательного планирования.
- Обеспечьте полную синхронизацию данных с DR-сайта на основной перед переключением.
- Разработайте стратегию разрешения конфликтов данных, если они возникли.
- Тестируйте failback так же тщательно, как и failover.
5. Проблема: Человеческий фактор
Симптомы: Ошибки при выполнении ручных шагов DR, паника, отсутствие четкого понимания ролей.
Диагностика:
- Анализ инцидента: какой шаг был выполнен неправильно, почему?
- Оценка уровня стресса и усталости команды.
- Проверка актуальности и понятности DRP.
Решение:
- Максимально автоматизируйте все возможные шаги.
- Проводите регулярные тренировки и учения, чтобы команда привыкла к процедурам.
- Улучшите DRP, сделайте его более детализированным и понятным.
- Обеспечьте наличие нескольких обученных сотрудников, способных выполнить DR-процедуры.
- Внедрите чек-листы для критических ручных операций.
Когда обращаться в поддержку
- Проблемы с базовой инфраструктурой: Если вы уверены, что проблема не в вашей конфигурации, а в работе VPS-провайдера или облачной платформы (недоступность сети, сбои дисков, недоступность региона).
- Сложные проблемы с управляемыми сервисами: Если управляемая база данных или другой облачный сервис ведет себя непредсказуемо, и документация не помогает.
- Невозможность восстановления: Если, несмотря на все усилия, вы не можете восстановить данные или запустить приложение, и все внутренние ресурсы исчерпаны.
- Вопросы безопасности: Если вы подозреваете компрометацию DR-инфраструктуры или данных.
Всегда имейте под рукой контакты службы поддержки ваших провайдеров и SLA с ними.
FAQ: Часто задаваемые вопросы о Disaster Recovery
Что такое RTO и RPO и почему они так важны?
RTO (Recovery Time Objective) — это максимально допустимое время, в течение которого ваше SaaS-приложение может быть недоступно после сбоя. RPO (Recovery Point Objective) — это максимально допустимый объем данных, который может быть потерян в результате сбоя, измеряемый во времени. Эти метрики критически важны, потому что они определяют, насколько быстро и с какой степенью полноты ваш бизнес должен восстановиться. Они являются основой для выбора DR-стратегии и напрямую влияют на ее стоимость и сложность.
Чем отличается Disaster Recovery от простого резервного копирования (бэкапов)?
Резервное копирование — это лишь один из компонентов Disaster Recovery. Бэкапы позволяют восстановить данные до определенной точки во времени. DR — это комплексный план, который включает не только бэкапы, но и механизмы репликации данных, автоматизацию развертывания инфраструктуры, процедуры переключения на резервный сайт (failover), восстановления работы (failback), мониторинг, оповещения и регулярное тестирование. DR направлен на полное восстановление работоспособности всего приложения, а не только данных.
Нужен ли DR для малого SaaS-проекта с небольшим бюджетом?
Да, абсолютно. Даже для малого SaaS-проекта потеря данных или длительный простой может быть катастрофическим. Начать можно с базовой, но эффективной стратегии Cold Standby, которая относительно недорога. Главное — это иметь план, регулярно делать бэкапы и тестировать возможность восстановления из них. По мере роста проекта и увеличения требований к доступности, можно постепенно переходить к более сложным и дорогим стратегиям DR.
Как часто нужно тестировать DR-план?
Частота тестирования зависит от критичности вашего SaaS-приложения и скорости изменений в инфраструктуре. Для критически важных систем рекомендуется проводить полный Failover Test не реже одного раза в квартал. Проверку целостности бэкапов и репликации следует выполнять еженедельно или ежедневно. Настольные учения (Tabletop Exercises) можно проводить ежемесячно. Главное правило: тестируйте ваш DR-план так часто, чтобы быть уверенным в его работоспособности, и всегда после значительных изменений в архитектуре или конфигурации.
Какие основные типы DR-стратегий существуют?
Основные типы DR-стратегий включают: Cold Standby (холодный резерв, самый дешевый, высокие RTO/RPO), Warm Standby (теплый резерв, умеренные RTO/RPO), Hot Standby (горячий резерв, низкие RTO/RPO, дорогой), Multi-Region Active/Active (высочайшая доступность, очень дорогой и сложный), и Гибридный DR (сочетание VPS и облака для оптимизации). Выбор зависит от ваших RTO, RPO, бюджета и сложности приложения.
Можно ли автоматизировать весь процесс Disaster Recovery?
Для большинства современных SaaS-приложений, особенно тех, что развернуты в облаке, значительную часть DR-процессов можно и нужно автоматизировать. С помощью Infrastructure as Code (IaC), скриптов, CI/CD пайплайнов, облачных сервисов и инструментов оркестрации можно автоматизировать обнаружение сбоев, развертывание ресурсов, переключение DNS и запуск приложения. Однако, полностью исключить человеческое участие, особенно на этапе принятия решений и контроля, пока сложно, хотя ИИ и ML активно развиваются в этом направлении.
Какие облачные сервисы помогают с Disaster Recovery?
Практически все крупные облачные провайдеры (AWS, Azure, Google Cloud) предлагают широкий спектр сервисов для DR: Multi-AZ/Multi-Region развертывания для VM и БД, управляемые базы данных (RDS, Azure SQL, Cloud SQL) со встроенной репликацией, объектные хранилища (S3, Blob Storage, GCS) для бэкапов, IaC-инструменты (CloudFormation, ARM Templates, Deployment Manager), DNS-сервисы (Route 53, Azure DNS, Cloud DNS) с функциями failover, глобальные балансировщики нагрузки (Global Accelerator, Front Door, Global Load Balancer) и сервисы мониторинга и оповещения (CloudWatch, Azure Monitor, Cloud Monitoring).
Как выбрать между VPS и облаком для DR?
Выбор зависит от вашего бюджета, RTO/RPO и экспертизы команды. VPS может быть дешевле для Cold/Warm Standby, особенно если у вас уже есть инфраструктура на VPS и вы хотите сохранить контроль. Однако масштабируемость и автоматизация на VPS часто сложнее. Облако предлагает высокую гибкость, эластичность, богатый набор DR-сервисов и более легкую автоматизацию, но может быть дороже, особенно для Hot Standby и Multi-Region решений. Гибридный подход (VPS для основной работы, облако для DR) часто является хорошим компромиссом.
Что такое Chaos Engineering и как он связан с DR?
Chaos Engineering — это практика контролируемого внедрения сбоев в распределенные системы с целью выявления слабых мест и проверки устойчивости. Он напрямую связан с DR, потому что позволяет активно тестировать ваш DR-план в реальных условиях, имитируя отказы серверов, сети, баз данных или даже целых AZ. Это помогает выявить скрытые зависимости и узкие места, которые могут привести к провалу DR, прежде чем они произойдут в реальной катастрофе.
Какова роль ИИ в DR 2026 года?
В 2026 году ИИ и машинное обучение играют все более важную роль в DR. Они используются для предиктивного анализа: ИИ может анализировать паттерны в логах и метриках, чтобы предсказывать потенциальные сбои до их возникновения. Также ИИ помогает в автоматическом анализе инцидентов, быстро выявляя первопричины проблем. В будущем можно ожидать автоматизированного принятия решений о failover на основе ИИ, который будет учитывать множество факторов, минимизируя человеческое вмешательство и сокращая RTO.
Заключение
Disaster Recovery — это не просто техническая задача, а фундаментальная составляющая устойчивости любого SaaS-бизнеса в 2026 году. В условиях постоянно растущих ожиданий пользователей, ужесточения регуляторных требований и увеличения сложности инфраструктур, эффективный DR-план становится не роскошью, а критической необходимостью. Отсутствие такого плана или его неэффективность может привести к катастрофическим финансовым потерям, необратимому ущербу репутации и потере доверия клиентов.
Мы рассмотрели широкий спектр стратегий — от бюджетного Cold Standby для небольших проектов до сложных Multi-Region Active/Active систем для глобальных SaaS-гигантов. Ключевым выводом является то, что не существует универсального решения. Выбор оптимальной стратегии всегда должен основываться на тщательном анализе ваших RTO (целевого времени восстановления) и RPO (допустимой потери данных), которые, в свою очередь, определяются бизнес-требованиями и стоимостью простоя для вашей компании.
Главные рекомендации, которые вы должны вынести из этой статьи:
- Планируйте системно: Разработайте подробный и актуальный Disaster Recovery Plan (DRP), который охватывает все аспекты: от сценариев сбоев до коммуникационного плана.
- Автоматизируйте максимально: Используйте Infrastructure as Code (IaC), скрипты и инструменты оркестрации для минимизации ручного труда, сокращения RTO и исключения человеческого фактора.
- Тестируйте безжалостно: Непротестированный DR-план — это иллюзия безопасности. Регулярно проводите учения и тесты, вплоть до полного переключения, чтобы выявить и устранить все слабые места.
- Инвестируйте в правильные инструменты: Современные облачные сервисы и open-source инструменты предлагают мощные возможности для построения отказоустойчивых систем.
- Учитывайте экономику: Всегда сопоставляйте затраты на DR с потенциальным ущербом от сбоя. Ищите оптимальный баланс, используя возможности оптимизации стоимости.
- Обучайте команду: Ваши инженеры должны быть хорошо знакомы с DRP и процедурами, чтобы действовать эффективно в условиях стресса.
- Будьте готовы к гибридности: Комбинирование VPS и облачных решений часто дает наилучший результат по соотношению "цена/качество" для многих SaaS-проектов.
Следующие шаги для читателя:
- Начните с BIA: Определите критичность ваших сервисов и установите реалистичные RTO и RPO.
- Разработайте или обновите DRP: Формализуйте ваш план.
- Внедрите базовые бэкапы: Убедитесь, что все критические данные регулярно бэкапятся и хранятся по правилу 3-2-1.
- Проведите первый тест: Попробуйте восстановить данные из бэкапов на тестовом сервере. Это даст вам бесценный опыт.
- Постепенно автоматизируйте: Начните с автоматизации бэкапов, затем переходите к развертыванию инфраструктуры с помощью IaC.
Помните, что Disaster Recovery — это непрерывный процесс. Ваша инфраструктура меняется, бизнес-требования эволюционируют, и ваш DR-план должен развиваться вместе с ними. Инвестиции в DR — это инвестиции в стабильность, доверие клиентов и долгосрочный успех вашего SaaS-проекта.