Создание Высокодоступного PostgreSQL Кластера на VPS и Выделенных Серверах
TL;DR
- Высокая доступность PostgreSQL критична для непрерывности бизнеса, минимизируя простои и потери данных.
- Ключевые решения включают Patroni, pg_auto_failover и нативную потоковую репликацию с внешними инструментами.
- Выбор зависит от RPO, RTO, бюджета, сложности и уровня автоматизации, который вы готовы поддерживать.
- Автоматический failover и грамотный мониторинг — основа надежного кластера.
- Регулярное тестирование механизмов восстановления и резервного копирования абсолютно обязательно.
- Эффективное управление расходами требует оптимизации ресурсов и выбора подходящей архитектуры.
- Эта статья — ваш пошаговый гайд по проектированию, развертыванию и обслуживанию отказоустойчивого PostgreSQL.
Введение: Зачем вашему бизнесу высокодоступный PostgreSQL в 2026 году?
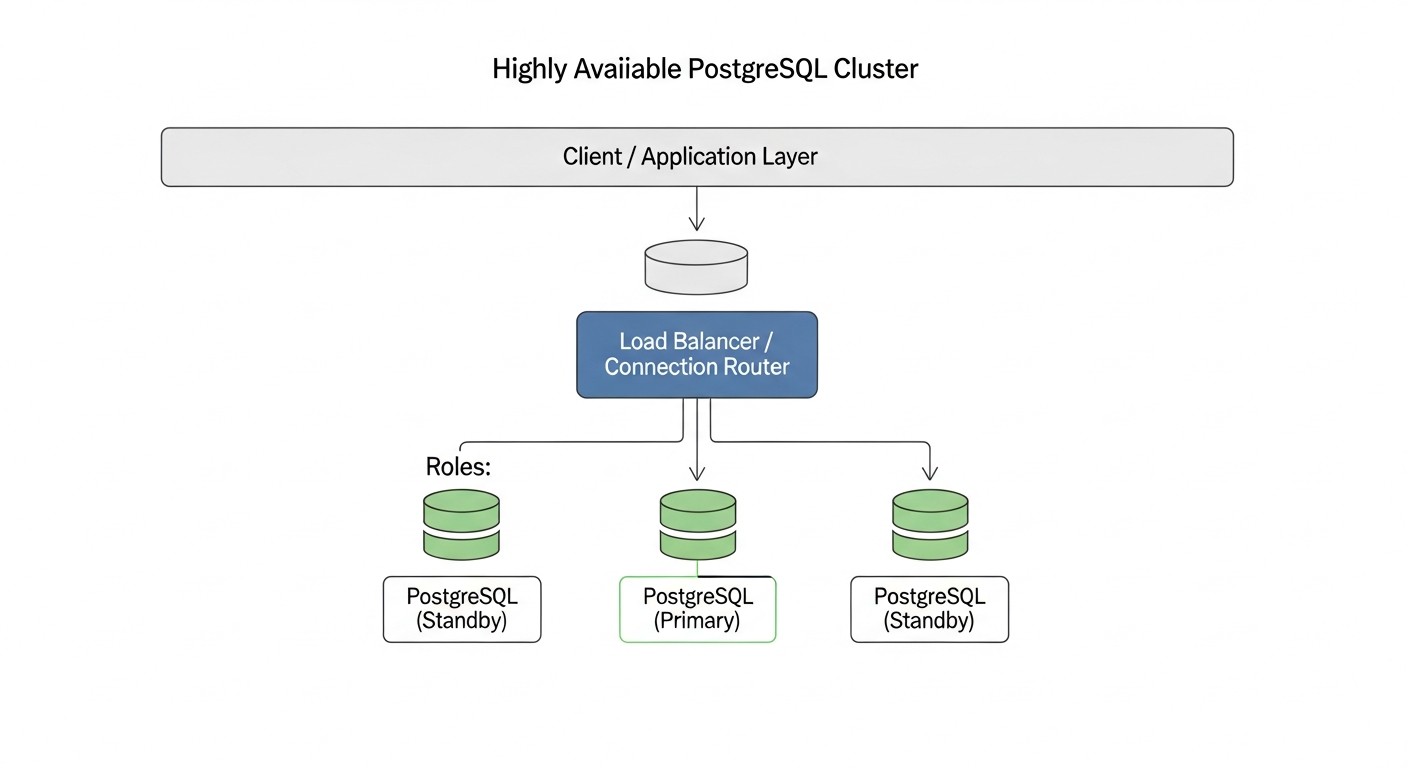
В современном мире, где цифровизация проникла во все сферы бизнеса, а пользователи ожидают круглосуточного доступа к сервисам, непрерывность работы критически важна. Простой даже на несколько минут может обернуться не только финансовыми потерями, но и серьезным ущербом для репутации компании. Особенно это актуально для проектов, где данные являются центральным активом — будь то SaaS-платформа, финансовый сервис или крупный интернет-магазин. PostgreSQL, как одна из самых надежных и функциональных реляционных баз данных, является краеугольным камнем для множества таких систем. Однако сам по себе PostgreSQL не обеспечивает высокую доступность из коробки. Отказ единственного сервера баз данных может привести к полной остановке работы приложения, что недопустимо для любого современного бизнеса.
Именно поэтому создание высокодоступного PostgreSQL кластера становится не просто "приятной опцией", а обязательным требованием. В 2026 году, на фоне постоянно растущих объемов данных, ужесточающихся требований к SLA и повсеместного распространения микросервисной архитектуры, задача обеспечения отказоустойчивости баз данных выходит на первый план. Компании, которые не уделяют этому должного внимания, рискуют потерять клиентов, доходы и конкурентные преимущества. Мы наблюдаем тренд, когда даже стартапы на ранних стадиях развития закладывают архитектуру высокой доступности, понимая, что исправление проблем "на лету" в продакшене обходится значительно дороже, чем правильное проектирование с самого начала. Более того, с увеличением сложности систем и распределенных нагрузок, ручное вмешательство в случае отказа становится все менее эффективным и более рискованным.
Эта статья призвана стать вашим исчерпывающим руководством по созданию надежного и эффективного PostgreSQL кластера на VPS и выделенных серверах. Мы рассмотрим различные подходы, инструменты и лучшие практики, актуальные на 2026 год, чтобы вы могли выбрать оптимальное решение для своих нужд. Независимо от того, являетесь ли вы DevOps-инженером, Backend-разработчиком, фаундером SaaS-проекта, системным администратором или техническим директором стартапа, здесь вы найдете практические советы и конкретные инструкции. Мы глубоко погрузимся в технические детали, разберем типовые ошибки и дадим рекомендации, основанные на реальном опыте. Наша цель — не просто рассказать "как", но и объяснить "почему", чтобы вы могли принимать обоснованные архитектурные решения и уверенно строить устойчивые системы, способные выдерживать любые испытания.
В рамках данного материала мы сфокусируемся на решениях, которые можно развернуть и контролировать самостоятельно на VPS или выделенных серверах, что особенно актуально для проектов, требующих полного контроля над инфраструктурой, оптимизации затрат или специфических требований к безопасности. Мы не будем углубляться в облачные управляемые сервисы, такие как AWS RDS/Aurora или Google Cloud SQL, так как они предоставляют HA "из коробки" и имеют свои особенности управления, отличные от подходов для самостоятельного хостинга. Вместо этого мы сосредоточимся на инструментах и методиках, которые позволяют добиться схожего уровня надежности, используя доступные и гибкие ресурсы.
Основные критерии и факторы выбора HA-решения для PostgreSQL
Выбор оптимального решения для обеспечения высокой доступности PostgreSQL — это многогранный процесс, который требует глубокого понимания как бизнес-требований, так и технических возможностей. Не существует универсального "лучшего" решения; идеальный выбор всегда является компромиссом между различными факторами. Рассмотрим ключевые критерии, которые необходимо учесть:
Recovery Point Objective (RPO) — Допустимая потеря данных
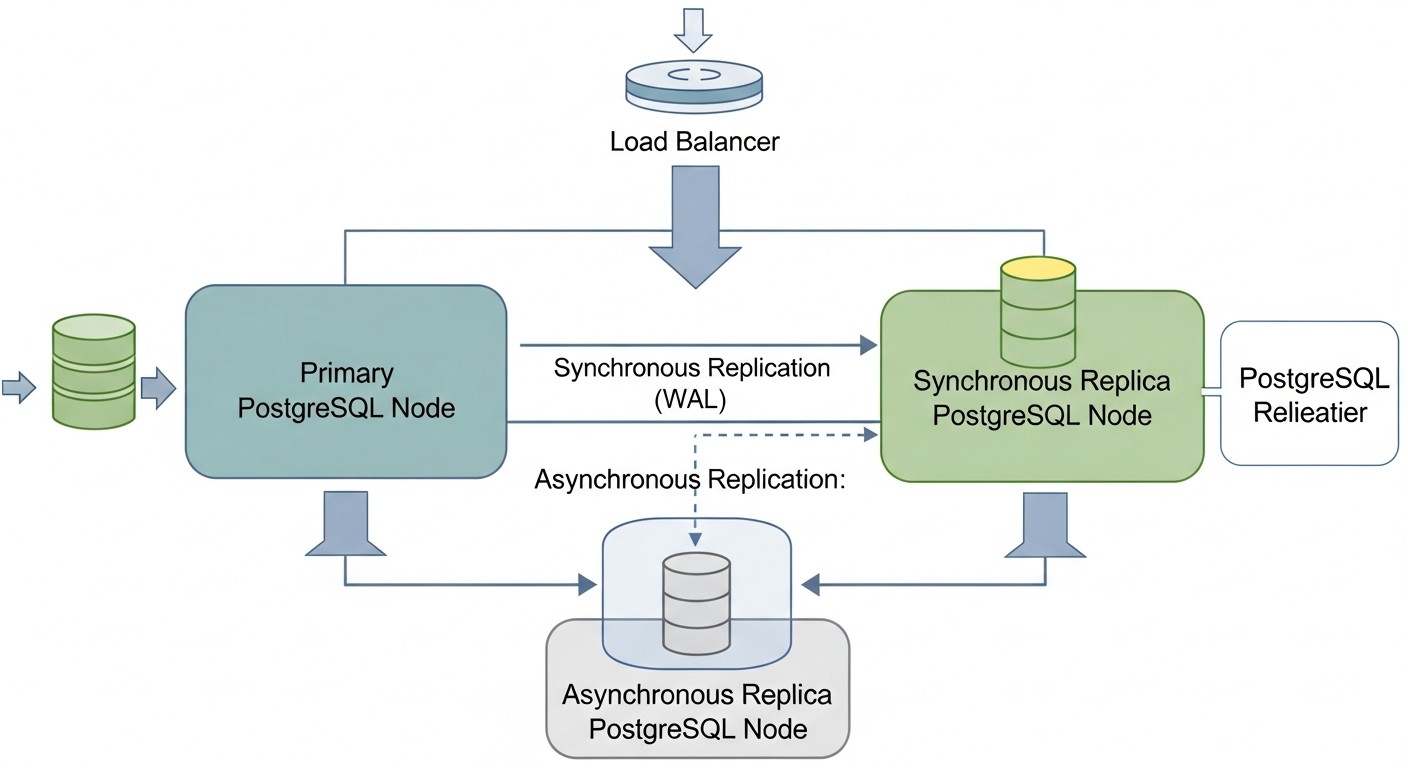
RPO определяет максимально допустимый объем данных, который может быть потерян в случае сбоя. Он измеряется во времени, например, "RPO = 5 минут" означает, что вы готовы потерять не более 5 минут последних транзакций. Для критически важных систем, таких как финансовые приложения или системы обработки платежей, RPO может быть близок к нулю (нулевая потеря данных). Это достигается с помощью синхронной репликации, где транзакция считается завершенной только после того, как она была записана и подтверждена как минимум на двух узлах. Однако синхронная репликация увеличивает задержки записи и может снижать общую производительность. Для менее критичных систем можно использовать асинхронную репликацию, которая предлагает лучшие показатели производительности, но при этом RPO будет ненулевым (обычно несколько секунд или минут, в зависимости от задержки репликации). Оценка RPO требует детального анализа бизнес-процессов и стоимости потери данных.
Recovery Time Objective (RTO) — Допустимое время восстановления
RTO определяет максимально допустимое время, в течение которого система может быть недоступна после сбоя. Например, "RTO = 30 секунд" означает, что ваш кластер должен восстановиться и быть готовым принимать запросы в течение полуминуты. Чем ниже RTO, тем сложнее и дороже решение. Автоматический failover с мгновенным переключением на резервный узел обеспечивает низкий RTO, часто измеряемый секундами. Ручной failover, напротив, увеличивает RTO, так как требует человеческого вмешательства. Для критичных систем с низким RTO необходимы инструменты автоматического обнаружения сбоев и координации failover, такие как Patroni или pg_auto_failover. Необходимо учитывать не только время перезапуска БД, но и время переключения сетевых адресов, обновления DNS и переподключения клиентских приложений.
Масштабируемость (Scalability)
Масштабируемость относится к способности системы эффективно обрабатывать растущие объемы нагрузки. В контексте HA PostgreSQL это может означать как горизонтальное масштабирование (добавление большего количества узлов для распределения нагрузки), так и вертикальное (увеличение ресурсов одного узла). Для масштабирования чтения обычно используются реплики (standby servers), на которые направляются запросы SELECT. Масштабирование записи сложнее и часто требует более сложных решений, таких как шардирование или использование специализированных расширений. Важно оценить текущие и прогнозируемые потребности в масштабировании, чтобы выбрать решение, которое не станет "бутылочным горлышком" в будущем. Некоторые HA-решения (например, Patroni) изначально хорошо интегрируются с механизмами горизонтального масштабирования чтения, позволяя легко добавлять новые реплики.
Согласованность данных (Consistency)
Согласованность данных гарантирует, что все узлы кластера видят одни и те же данные в один и тот же момент времени. В распределенных системах достичь строгой согласованности при высокой доступности и производительности — задача нетривиальная (CAP-теорема). PostgreSQL по умолчанию обеспечивает строгую согласованность на основном узле. При использовании репликации важно понимать, какой уровень согласованности она предоставляет. Асинхронная репликация может иметь небольшую задержку, что означает, что реплика может "отставать" от мастера на несколько миллисекунд или секунд. Синхронная репликация обеспечивает более высокий уровень согласованности, но, как уже упоминалось, влияет на производительность. Для большинства приложений требуется строгая согласованность для операций записи и приемлемая (eventual consistency) для операций чтения с реплик. Выбор HA-решения должен учитывать, как оно управляет согласованностью данных при переключении узлов и при обычной работе.
Стоимость (Cost)
Стоимость включает в себя не только прямые расходы на оборудование или VPS, но и лицензии (хотя PostgreSQL бесплатен), затраты на софт (системы мониторинга, оркестраторы), а также косвенные расходы, такие как время инженеров на развертывание, поддержку и обучение. Для VPS и выделенных серверов стоимость будет зависеть от количества серверов, их конфигурации (CPU, RAM, SSD) и сетевого трафика. Решения, требующие большего количества узлов (например, для кворума), или более сложной настройки, будут дороже в эксплуатации. Важно провести детальный расчет TCO (Total Cost of Ownership) на несколько лет вперед, учитывая потенциальные затраты на аварийное восстановление и простои.
Сложность (Complexity)
Сложность решения влияет на время развертывания, вероятность ошибок и трудозатраты на поддержку. Простые решения могут быть легко настроены, но могут иметь ограниченные возможности. Сложные решения, такие как Patroni с распределенным хранилищем конфигурации (etcd/Consul), предлагают больше функциональности и автоматизации, но требуют глубоких знаний для правильной настройки и отладки. Необходимо оценить уровень экспертизы вашей команды. Если ресурсов и опыта мало, стоит начать с более простых решений или инвестировать в обучение. Слишком сложное решение может стать источником проблем, а не их решением.
Простота управления и мониторинга (Ease of Management & Monitoring)
Хорошее HA-решение должно быть не только надежным, но и удобным в управлении. Это включает в себя инструменты для мониторинга состояния кластера, логирования, оповещений, а также возможность легко выполнять рутинные операции, такие как добавление новых реплик, обновление PostgreSQL или тестирование failover. Решения с хорошей документацией, активным сообществом и встроенными CLI-утилитами значительно упрощают жизнь. Важно интегрировать HA-кластер в существующую систему мониторинга и оповещений, чтобы оперативно реагировать на любые проблемы. Отсутствие адекватного мониторинга — прямой путь к неожиданным простоям.
Сравнительная таблица популярных решений для HA PostgreSQL
На рынке существует несколько зрелых подходов к построению высокодоступных PostgreSQL кластеров на VPS и выделенных серверах. Каждый из них имеет свои особенности, преимущества и недостатки. В этой таблице мы сравним наиболее популярные и проверенные решения, актуальные для 2026 года, чтобы помочь вам сделать информированный выбор.
| Критерий | Patroni + etcd/Consul | pg_auto_failover | Нативная потоковая репликация + Keepalived/HAProxy | Pgpool-II (HA-режим) |
|---|---|---|---|---|
| Тип решения | Оркестратор на базе распределенного хранилища (DCS) | Интегрированный инструмент автоматического failover | Ручной/полуавтоматический failover с внешними инструментами | Прокси-сервер с функциями HA и балансировки |
| RPO (Допустимая потеря данных) | 0-несколько секунд (зависит от синхронности репликации) | 0-несколько секунд (зависит от синхронности репликации) | Несколько секунд/минут (асинхронная репликация) | Несколько секунд/минут (асинхронная репликация) |
| RTO (Допустимое время восстановления) | 5-30 секунд (автоматический failover) | 10-60 секунд (автоматический failover) | 30 секунд - 5 минут (требует скриптов/ручного вмешательства) | 10-60 секунд (автоматический failover на уровне Pgpool) |
| Сложность настройки | Высокая (DCS, Patroni, PostgreSQL) | Средняя (специализированный инструмент) | Средняя (PostgreSQL, Keepalived/HAProxy, скрипты) | Средняя (Pgpool-II, PostgreSQL) |
| Требования к серверам (мин.) | 3 узла (1 мастер, 2 реплики) + 3 узла для DCS (можно совмещать) | 2 узла (1 мастер, 1 реплика) + 1 монитор | 2 узла (1 мастер, 1 реплика) | 2-3 узла (1 мастер, 1-2 реплики) + 2 узла Pgpool-II |
| Автоматический Failover | Да (полностью автоматический, с учетом кворума) | Да (автоматический, с помощью монитора) | Нет (требует внешних скриптов и Keepalived/Corosync) | Да (на уровне Pgpool-II, для бэкендов) |
| Масштабирование чтения | Отличные возможности (легко добавлять реплики) | Хорошие возможности (легко добавлять реплики) | Базовое (ручное управление подключением) | Отличные возможности (балансировка запросов) |
| Поддержка синхронной репликации | Да (через Patroni API) | Да | Да (нативная функция PostgreSQL) | Да |
| Ориентировочная стоимость (VPS, 2026, USD/мес) | $90-150 (3 VPS x $30-50, 4vCPU/8GB RAM/160GB NVMe) | $60-100 (2 VPS x $30-50, 4vCPU/8GB RAM/160GB NVMe) | $60-100 (2 VPS x $30-50, 4vCPU/8GB RAM/160GB NVMe) | $90-150 (3 VPS x $30-50, 4vCPU/8GB RAM/160GB NVMe) |
| Ключевые особенности | Полная автоматизация, API, интеграция с DCS, самовосстановление. | Простота развертывания, встроенный монитор, специализирован для PostgreSQL. | Базовое, полный контроль, требует кастомных скриптов, гибкость. | Балансировка нагрузки, кэширование, пулинг соединений, HA. |
| Лучший сценарий использования | Критические приложения, требовательные к RPO/RTO, DevOps-ориентированные команды. | Средние проекты, где нужна простота и автоматизация без высокой сложности. | Небольшие проекты, ограниченный бюджет, высокий уровень контроля, опытная команда. | Проекты с высокой нагрузкой чтения, где нужен пулинг и кэширование, а также HA. |
*Примечание: Цены на VPS являются ориентировочными для 2026 года и могут варьироваться в зависимости от провайдера, региона и текущих рыночных условий. Указанные конфигурации (4vCPU/8GB RAM/160GB NVMe) предполагают среднюю нагрузку для продакшн-системы.
Детальный обзор каждого пункта/варианта HA-решения
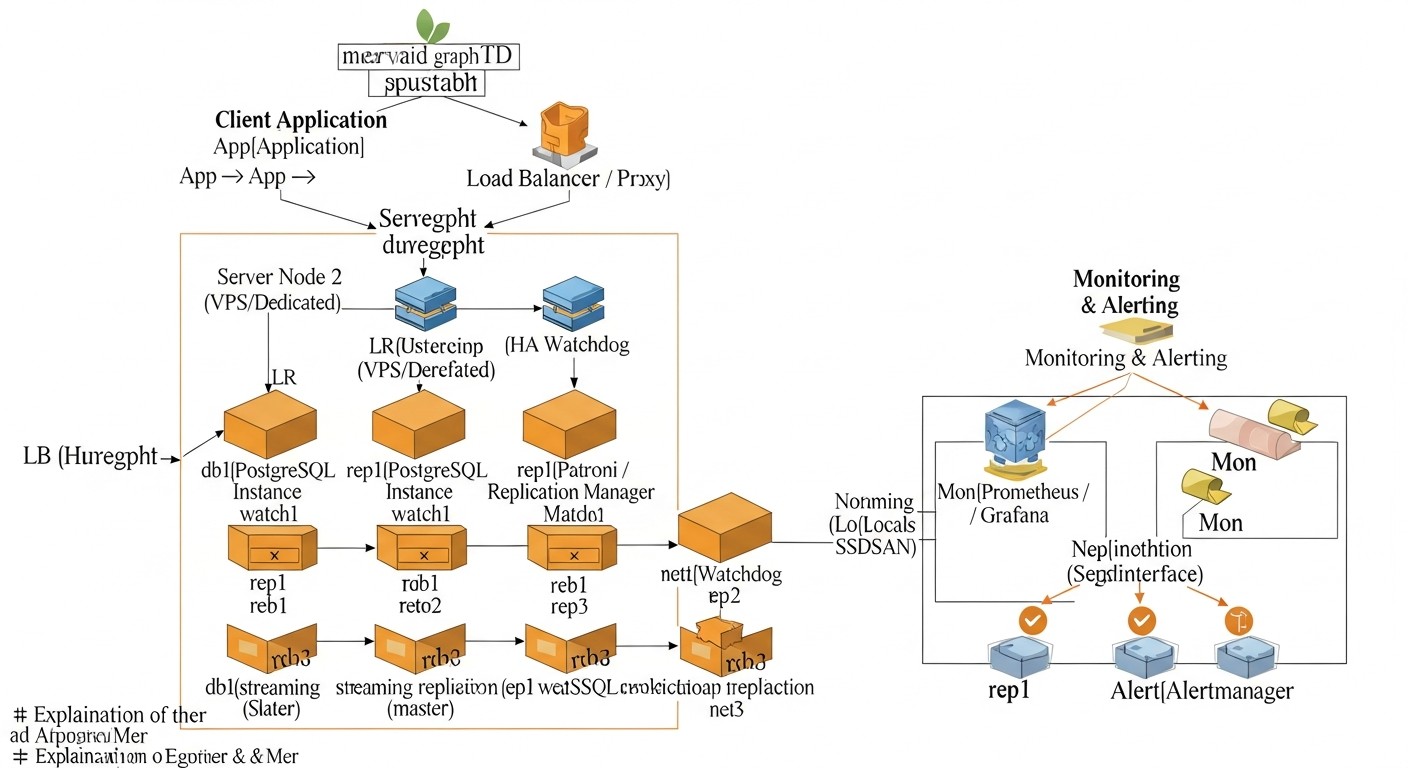
Давайте подробнее рассмотрим каждое из упомянутых решений, чтобы понять их внутреннюю механику, преимущества и недостатки. Это позволит вам принять более обоснованное решение, исходя из специфики вашего проекта и ресурсов команды.
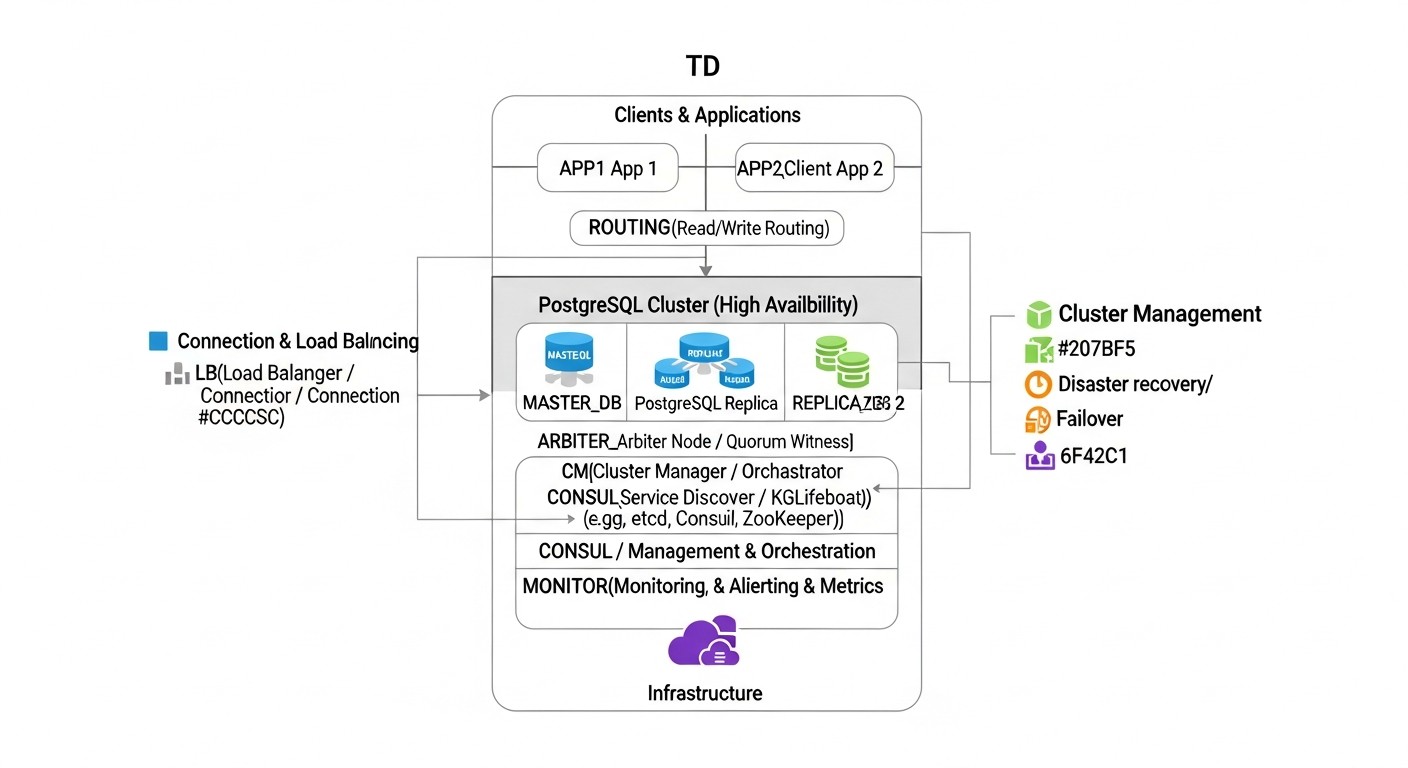
Patroni + Распределенное хранилище конфигурации (etcd/Consul/ZooKeeper)
Patroni — это мощный Python-демон, разработанный компанией Zalando, который предоставляет надежное и полностью автоматизированное решение для создания высокодоступных кластеров PostgreSQL. Он действует как оркестратор, управляя жизненным циклом экземпляров PostgreSQL, репликацией, failover и switchover операциями. Ключевая особенность Patroni — использование распределенного хранилища конфигурации (DCS) для хранения состояния кластера, такой как etcd, Consul или Apache ZooKeeper. DCS играет роль источника истины для всех узлов кластера, обеспечивая консистентность информации о текущем мастере, статусе реплик и настройках.
Как это работает: Каждый узел PostgreSQL, управляемый Patroni, регулярно обновляет свой статус в DCS. Patroni на каждом узле мониторит состояние других узлов и самого DCS. Если текущий мастер падает, Patroni автоматически инициирует процедуру failover: он выбирает нового мастера из числа здоровых реплик, используя алгоритм на основе кворума и приоритетов. После выбора нового мастера, Patroni переключает остальные реплики на нового мастера и, при необходимости, запускает старый мастер как реплику после восстановления. Patroni также предоставляет REST API для управления кластером, мониторинга и выполнения операций, таких как switchover (плановое переключение мастера).
Плюсы:
- Полная автоматизация: Автоматический failover, switchover, восстановление реплик, добавление новых узлов.
- Высокая надежность: Использует DCS для кворума и предотвращения split-brain.
- Гибкость: Поддерживает различные типы репликации (асинхронная, синхронная), интеграцию с прокси (HAProxy, PgBouncer).
- API и CLI: Удобные инструменты для управления и интеграции с другими системами.
- Активное сообщество: Поддерживается Zalando и большим сообществом разработчиков.
Минусы:
- Высокая сложность: Требует понимания работы PostgreSQL, Patroni и DCS. Настройка может быть трудоемкой.
- Дополнительная инфраструктура: Необходим отдельный кластер DCS (минимум 3 узла для etcd/Consul).
- Потребление ресурсов: Patroni и DCS потребляют свои ресурсы, хоть и небольшие.
Для кого подходит: Для средних и крупных проектов, SaaS-платформ, где критичны RPO и RTO, и есть команда с опытом в DevOps и администрировании баз данных. Идеально для тех, кто ищет максимально автоматизированное и надежное решение.
pg_auto_failover
pg_auto_failover — это инструмент, разработанный компанией Citus Data (теперь часть Microsoft), который упрощает развертывание и управление высокодоступными кластерами PostgreSQL. Он фокусируется на простоте использования и автоматизации, предоставляя единый бинарник для всех компонентов кластера: координатора (монитора), мастера и реплик.
Как это работает: pg_auto_failover создает кластер из как минимум двух узлов PostgreSQL (мастер и реплика) и отдельного узла-монитора. Монитор постоянно опрашивает состояние всех узлов и принимает решения о failover. Если мастер становится недоступным, монитор инициирует failover, выбирая одну из реплик в качестве нового мастера и переключая на нее клиентские соединения. Он также может управлять синхронной репликацией, обеспечивая нулевой RPO в большинстве случаев. Монитор сам по себе может быть настроен на высокую доступность, но это добавляет сложности.
Плюсы:
- Простота развертывания: Значительно проще в настройке по сравнению с Patroni.
- Автоматический Failover: Полностью автоматизированное обнаружение сбоев и переключение.
- Встроенный монитор: Единый инструмент для всех функций HA.
- Поддержка синхронной репликации: Легко настраивается для нулевого RPO.
- Специализирован для PostgreSQL: Глубокая интеграция с особенностями PostgreSQL.
Минусы:
- Зависимость от монитора: Монитор является единой точкой отказа, если не настроен на HA.
- Меньшая гибкость: Меньше возможностей для тонкой настройки по сравнению с Patroni.
- Менее зрелое сообщество: Хотя поддерживается Microsoft, сообщество меньше, чем у Patroni.
Для кого подходит: Для проектов среднего размера, стартапов, где важна простота развертывания и управления, но при этом требуется высокий уровень автоматизации и надежности. Отлично подходит для команд, которые хотят минимизировать время на настройку HA и сосредоточиться на разработке.
Нативная потоковая репликация PostgreSQL + Keepalived/HAProxy
Этот подход использует встроенные возможности PostgreSQL для потоковой репликации (streaming replication) в сочетании с внешними инструментами для обнаружения сбоев и управления IP-адресами или балансировкой нагрузки. Потоковая репликация позволяет постоянно передавать изменения с мастер-сервера на один или несколько реплик, поддерживая их в актуальном состоянии.
Как это работает: Вы настраиваете один PostgreSQL сервер как мастер и один или несколько как реплики. Реплики постоянно получают WAL-файлы (Write-Ahead Log) от мастера и применяют их. Для автоматического обнаружения сбоев и переключения используется Keepalived: он мониторит состояние мастер-сервера и, в случае его отказа, автоматически переносит виртуальный IP-адрес (VIP) на одну из реплик, делая ее новым мастером. HAProxy или Nginx могут использоваться для балансировки нагрузки чтения между репликами и перенаправления записи на текущий мастер. Для автоматизации промоута реплики в мастер и перенастройки остальных реплик требуются кастомные скрипты, которые будут запускаться Keepalived.
Плюсы:
- Полный контроль: Вы полностью контролируете каждый компонент и скрипт.
- Низкая стоимость: Использует только Open Source компоненты без дополнительных лицензий.
- Гибкость: Можно настроить под очень специфические требования.
- Простота базовой репликации: Настройка потоковой репликации достаточно проста.
Минусы:
- Высокая сложность автоматизации: Написание и отладка надежных скриптов для failover, switchover и восстановления — очень трудоемкая задача, склонная к ошибкам.
- Риск split-brain: Без надежного механизма кворума (который Keepalived сам по себе не предоставляет) есть риск одновременного промоута нескольких мастеров.
- Высокий RTO: Время восстановления может быть выше из-за ручного/скриптового вмешательства.
- Поддержка: Зависит от квалификации вашей команды, нет централизованной поддержки.
Для кого подходит: Для небольших проектов с ограниченным бюджетом, где есть очень опытная команда DBA/DevOps, готовая потратить время на разработку и поддержку кастомных скриптов. Также может быть вариантом, когда нужно максимально "облегченное" решение без дополнительных зависимостей.
Pgpool-II (HA-режим)
Pgpool-II — это промежуточное ПО (middleware) для PostgreSQL, которое предоставляет ряд полезных функций, включая пулинг соединений, балансировку нагрузки, кэширование запросов и, что важно для нас, функции высокой доступности. Pgpool-II работает как прокси между клиентскими приложениями и серверами PostgreSQL.
Как это работает: Pgpool-II размещается перед кластером PostgreSQL и управляет соединениями клиентов. В режиме высокой доступности он мониторит состояние бэкенд-серверов PostgreSQL. Если мастер-сервер выходит из строя, Pgpool-II может автоматически переключить трафик на одну из реплик, сделав ее новым мастером. Он также может управлять переключением виртуального IP-адреса с помощью watchdog-функций, которые интегрируются с такими инструментами, как `pcp_attach_node` и `pcp_detach_node` для изменения состояния узлов. Для обеспечения HA самого Pgpool-II обычно разворачивают два экземпляра Pgpool-II с Keepalived для переключения VIP.
Плюсы:
- Многофункциональность: Кроме HA, предоставляет пулинг соединений, балансировку чтения, кэширование.
- Улучшение производительности: Пулинг и кэширование могут значительно снизить нагрузку на БД.
- Автоматический Failover: Способен автоматически переключать мастер.
- Прозрачность для приложений: Приложения подключаются к Pgpool-II, не зная о топологии кластера.
Минусы:
- Единая точка отказа: Сам Pgpool-II может стать ей, если не настроен на HA (что усложняет архитектуру).
- Дополнительная задержка: Вносит небольшой оверхед из-за проксирования.
- Сложность настройки: Конфигурация Pgpool-II может быть довольно сложной, особенно с HA и watchdog.
- Не управляет PostgreSQL: Pgpool-II управляет только переключением, но не оркестрирует сам PostgreSQL (например, не восстанавливает реплики).
Для кого подходит: Для проектов, где помимо высокой доступности требуется также оптимизация производительности за счет пулинга соединений и балансировки чтения. Подходит для команд, готовых инвестировать в изучение и поддержку Pgpool-II как ключевого компонента инфраструктуры.
Практические советы и рекомендации по внедрению Patroni
Patroni является одним из самых мощных и гибких решений для HA PostgreSQL, поэтому мы сосредоточимся на его практическом внедрении. Данный раздел предоставит пошаговые инструкции и рекомендации, основанные на реальном опыте.
1. Планирование инфраструктуры
Для минимального HA-кластера Patroni с надежным кворумом вам потребуется как минимум 3 сервера. Это могут быть VPS или выделенные серверы. Рекомендуется следующая конфигурация:
- 3 узла PostgreSQL: Каждый узел будет запускать Patroni и PostgreSQL. Один будет мастером, остальные — репликами.
- 3 узла для Distributed Configuration Store (DCS): etcd или Consul. В небольших кластерах (3 узла) DCS можно разместить на тех же серверах, что и PostgreSQL/Patroni. В более крупных или очень критичных системах рекомендуется выносить DCS на отдельные серверы.
Пример конфигурации VPS (2026 год):
- CPU: 4 vCPU
- RAM: 8-16 GB
- Диск: 160-320 GB NVMe SSD (для данных PostgreSQL)
- Сеть: 1 Гбит/с
- ОС: Ubuntu 24.04 LTS или Debian 13
Убедитесь, что у всех серверов есть статические IP-адреса и открыты необходимые порты (PostgreSQL: 5432, Patroni API: 8008, etcd: 2379/2380, Consul: 8300/8301/8302/8500/8600).
2. Подготовка операционной системы
На каждом из трех серверов выполните базовую настройку:
# Обновление системы
sudo apt update && sudo apt upgrade -y
# Установка необходимых пакетов
sudo apt install -y python3 python3-pip python3-psycopg2 python3-yaml postgresql-client-16
# Создание пользователя postgres (если его нет или требуется специфическая настройка)
# По умолчанию PostgreSQL создает пользователя postgres, используйте его.
# Настройка файрвола (пример для UFW)
sudo ufw allow 22/tcp
sudo ufw allow 5432/tcp
sudo ufw allow 8008/tcp # Patroni API
sudo ufw allow 2379/tcp # etcd client
sudo ufw allow 2380/tcp # etcd server
sudo ufw enable
3. Установка и настройка DCS (etcd)
На каждом из трех серверов установите и настройте etcd. В production-среде etcd лучше разворачивать на выделенных узлах, но для начала можно совместить.
# Установка etcd (пример для Ubuntu/Debian)
# Скачайте последний релиз с GitHub: https://github.com/etcd-io/etcd/releases
ETCD_VERSION="v3.5.12" # Актуально на 2026 год, проверьте
wget "https://github.com/etcd-io/etcd/releases/download/${ETCD_VERSION}/etcd-${ETCD_VERSION}-linux-amd64.tar.gz"
tar xzvf etcd-${ETCD_VERSION}-linux-amd64.tar.gz
sudo mv etcd-${ETCD_VERSION}-linux-amd64/etcd /usr/local/bin/
sudo mv etcd-${ETCD_VERSION}-linux-amd64/etcdctl /usr/local/bin/
# Создание директорий для данных etcd
sudo mkdir -p /var/lib/etcd
sudo mkdir -p /etc/etcd
# Создание systemd-сервиса для etcd (на каждом узле)
# Замените IP-адреса и имена узлов на свои
# NODE_1_IP, NODE_2_IP, NODE_3_IP
# NODE_1_NAME, NODE_2_NAME, NODE_3_NAME
# Пример для node1:
sudo nano /etc/systemd/system/etcd.service
Содержимое файла `/etc/systemd/system/etcd.service` для `node1` (с IP 192.168.1.1):
[Unit]
Description=etcd - Highly-available key value store
Documentation=https://github.com/etcd-io/etcd
After=network.target
[Service]
Type=notify
Restart=always
RestartSec=5s
LimitNOFILE=40000
TimeoutStartSec=0
ExecStart=/usr/local/bin/etcd \\
--name node1 \\
--data-dir /var/lib/etcd \\
--initial-advertise-peer-urls http://192.168.1.1:2380 \\
--listen-peer-urls http://192.168.1.1:2380 \\
--listen-client-urls http://192.168.1.1:2379,http://127.0.0.1:2379 \\
--advertise-client-urls http://192.168.1.1:2379 \\
--initial-cluster-token etcd-cluster-1 \\
--initial-cluster node1=http://192.168.1.1:2380,node2=http://192.168.1.2:2380,node3=http://192.168.1.3:2380 \\
--initial-cluster-state new \\
--heartbeat-interval 100 \\
--election-timeout 500
[Install]
WantedBy=multi-user.target
Повторите для `node2` (192.168.1.2) и `node3` (192.168.1.3), изменяя `--name`, `--initial-advertise-peer-urls`, `--listen-peer-urls`, `--listen-client-urls`, `--advertise-client-urls` на соответствующие IP-адреса. После создания файла на всех узлах:
sudo systemctl daemon-reload
sudo systemctl enable etcd
sudo systemctl start etcd
# Проверка статуса кластера etcd на любом узле
etcdctl --endpoints=http://192.168.1.1:2379,http://192.168.1.2:2379,http://192.168.1.3:2379 member list
4. Установка Patroni
На каждом узле установите Patroni через pip:
sudo pip3 install patroni[etcd]
5. Настройка Patroni
Создайте конфигурационный файл Patroni на каждом узле. Используйте один и тот же шаблон, изменяя только `name` и `listen` IP-адреса.
sudo mkdir -p /etc/patroni
sudo nano /etc/patroni/patroni.yml
Пример файла `patroni.yml` для `node1`:
scope: my_pg_cluster
name: node1 # Уникальное имя для каждого узла
restapi:
listen: 0.0.0.0:8008
connect_address: 192.168.1.1:8008 # IP-адрес текущего узла
etcd:
host: 192.168.1.1:2379,192.168.1.2:2379,192.168.1.3:2379
postgresql:
listen: 0.0.0.0:5432
connect_address: 192.168.1.1:5432 # IP-адрес текущего узла
data_dir: /var/lib/postgresql/data # Путь к данным PG
bin_dir: /usr/lib/postgresql/16/bin # Путь к бинарникам PG (проверьте версию)
authentication:
replication:
username: repl_user
password: repl_password
superuser:
username: postgres
password: superuser_password
parameters:
wal_level: replica
hot_standby: on
max_wal_senders: 10
max_replication_slots: 10
archive_mode: on
archive_command: 'cd . && test ! -f %p && cp %p %l' # Пример, для продакшена нужна система архивации
log_destination: stderr
logging_collector: on
log_directory: pg_log
log_filename: 'postgresql-%Y-%m-%d_%H%M%S.log'
log_file_mode: 0600
log_truncate_on_rotation: on
log_rotation_age: 1d
log_rotation_size: 10MB
max_connections: 100
# Настройки для автоматического восстановления
bootstrap:
dcs:
ttl: 30 # Time-to-live для ключей в DCS
loop_wait: 10 # Задержка между итерациями Patroni
retry_timeout: 10 # Таймаут для повторных попыток
maximum_lag_on_failover: 1048576 # Максимальный лаг репликации для failover (1MB)
initdb:
- encoding: UTF8
- locale: en_US.UTF-8
- data-checksums
pg_hba:
- host replication repl_user 0.0.0.0/0 md5
- host all all 0.0.0.0/0 md5
- host all all ::/0 md5
users:
admin_user:
password: admin_password
options:
- createrole
- createdb
repl_user:
password: repl_password
options:
- replication
- bypassrls
Важно:
- Замените `192.168.1.1`, `192.168.1.2`, `192.168.1.3` на актуальные IP-адреса ваших серверов.
- Укажите корректный `bin_dir` для вашей версии PostgreSQL (например, `/usr/lib/postgresql/16/bin`).
- Установите надежные пароли для `repl_user`, `postgres` и `admin_user`.
- Параметр `archive_command` в production-среде должен быть настроен на реальную систему архивации WAL (например, S3, NFS), а не на локальное копирование.
6. Создание systemd-сервиса для Patroni
Создайте unit-файл для Patroni на каждом узле:
sudo nano /etc/systemd/system/patroni.service
Содержимое `patroni.service`:
[Unit]
Description=Patroni - A Template for PostgreSQL High Availability
After=network.target etcd.service # Добавьте etcd.service если etcd на том же узле
[Service]
Type=simple
User=postgres
Group=postgres
ExecStart=/usr/bin/python3 -m patroni -c /etc/patroni/patroni.yml
Restart=on-failure
TimeoutStopSec=60
LimitNOFILE=131072
[Install]
WantedBy=multi-user.target
После создания файла на всех узлах:
sudo systemctl daemon-reload
sudo systemctl enable patroni
sudo systemctl start patroni
7. Инициализация кластера
Patroni автоматически инициализирует PostgreSQL на первом запущенном узле, который станет мастером. Остальные узлы присоединятся к нему как реплики. Подождите несколько минут, пока все узлы запустятся и синхронизируются.
8. Проверка состояния кластера
Используйте утилиту `patronictl` для проверки состояния кластера на любом узле:
patronictl -c /etc/patroni/patroni.yml list
Вывод должен показать один мастер и две реплики. Пример:
+ Cluster: my_pg_cluster (6909873467941793393) ---+----+-----------+----+-----------+
| Member | Host | Role | State | Lag in MB |
+--------+--------------+---------+----------+-----------+
| node1 | 192.168.1.1 | Leader | running | 0 |
| node2 | 192.168.1.2 | Replica | running | 0 |
| node3 | 192.168.1.3 | Replica | running | 0 |
+--------+--------------+---------+----------+-----------+
9. Тестирование Failover
Это критически важный шаг. Вы должны регулярно тестировать failover, чтобы убедиться, что кластер работает, как ожидается. Самый простой способ — остановить Patroni на текущем мастере:
# На текущем мастер-узле
sudo systemctl stop patroni
Patroni на оставшихся узлах обнаружит, что мастер недоступен, и инициирует failover. Через 5-30 секунд один из реплик должен стать новым мастером. Проверьте это с помощью `patronictl list` на другом узле. Затем запустите Patroni на старом мастере, и он должен присоединиться как реплика.
10. Настройка балансировщика нагрузки (HAProxy)
Для клиентских приложений рекомендуется использовать балансировщик нагрузки (например, HAProxy), который будет направлять запросы записи на текущий мастер, а запросы чтения — на реплики. HAProxy может быть настроен на мониторинг Patroni API для определения роли каждого узла.
Пример конфигурации HAProxy (на отдельном сервере, или на каждом узле, если используется Keepalived для HAProxy):
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats socket /run/haproxy/admin.sock mode 660 level admin expose-fd listeners
stats timeout 30s
user haproxy
group haproxy
daemon
defaults
log global
mode tcp
option tcplog
option dontlognull
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
listen stats
bind *:8080
mode http
stats enable
stats uri /haproxy_stats
stats refresh 10s
stats auth admin:password
listen postgres_primary
bind *:5432
mode tcp
option httpchk GET /primary # Используем Patroni API для проверки роли
balance roundrobin
server node1 192.168.1.1:5432 check port 8008 inter 1s fall 3 rise 2 weight 10 on-marked-down shutdown-sessions
server node2 192.168.1.2:5432 check port 8008 inter 1s fall 3 rise 2 weight 10 on-marked-down shutdown-sessions
server node3 192.168.1.3:5432 check port 8008 inter 1s fall 3 rise 2 weight 10 on-marked-down shutdown-sessions
listen postgres_replicas
bind *:5433 # Отдельный порт для чтения с реплик
mode tcp
option httpchk GET /replica # Используем Patroni API для проверки роли
balance leastconn
server node1 192.168.1.1:5432 check port 8008 inter 1s fall 3 rise 2 weight 10 on-marked-down shutdown-sessions
server node2 192.168.1.2:5432 check port 8008 inter 1s fall 3 rise 2 weight 10 on-marked-down shutdown-sessions
server node3 192.168.1.3:5432 check port 8008 inter 1s fall 3 rise 2 weight 10 on-marked-down shutdown-sessions
В этом примере HAProxy будет направлять трафик на порт 5432 только на тот узел, который Patroni определил как мастер (`/primary`). На порт 5433 он будет направлять запросы на чтения на все узлы, которые Patroni определил как реплики (`/replica`), включая мастера (который также может обрабатывать запросы чтения).
Эти практические советы помогут вам успешно развернуть и настроить базовый HA-кластер PostgreSQL с использованием Patroni. Помните, что каждый шаг требует внимательности, а тестирование — это ключ к уверенности в работе вашей системы.
Типичные ошибки при построении HA кластера PostgreSQL

Даже опытные инженеры могут допускать ошибки при проектировании и развертывании высокодоступных систем. Понимание этих распространенных проблем поможет вам избежать дорогостоящих простоев и головной боли. Вот пять наиболее частых ошибок:
1. Недостаточный или неправильно настроенный кворум (Split-Brain)
Описание: Кворум — это минимальное количество узлов, которое должно быть доступно для принятия решений в кластере. Если кворум не настроен или настроен неправильно, в случае сетевого разделения (network partition) два или более узла могут решить, что они являются мастерами. Это состояние называется "split-brain" и приводит к рассинхронизации данных, когда каждый "мастер" принимает записи независимо, что делает восстановление очень сложным и чреватым потерей данных.
Как избежать: Всегда используйте нечетное количество узлов для вашего DCS (Distributed Configuration Store), например, 3 или 5. Это гарантирует, что при отказе одного или двух узлов всегда будет большинство, способное принять решение о выборе мастера. Patroni и pg_auto_failover по умолчанию используют механизмы кворума. Убедитесь, что конфигурация DCS (etcd/Consul) корректна и устойчива к отказам. Регулярно проверяйте состояние кворума.
Реальные последствия: "В одной компании, из-за неправильной настройки etcd-кластера, при временном сбое сети два узла посчитали себя мастерами. Приложения продолжали писать данные на оба узла. Когда сеть восстановилась, данные разошлись. Восстановление заняло более 12 часов, потребовало ручного анализа логов и выбора 'правильного' мастера, что привело к потере части транзакций и серьезным репутационным издержкам."
2. Отсутствие или недостаточное тестирование Failover и Recovery
Описание: Многие инженеры разворачивают HA-кластер, видят, что он работает, и на этом успокаиваются. Однако механизмы failover и recovery могут быть сложными, и их поведение в реальных условиях (например, при специфическом типе сбоя или под нагрузкой) может отличаться от ожидаемого. Непроверенный failover — это не работающий failover.
Как избежать: Регулярно, как минимум раз в квартал, проводите "учения" по аварийному восстановлению. Это включает в себя искусственное отключение мастер-узла, имитацию сетевых проблем, полную остановку DCS. Замеряйте RTO, проверяйте целостность данных после восстановления. Автоматизируйте эти тесты, если это возможно. Убедитесь, что ваша команда знает, как действовать в случае реального сбоя.
Реальные последствия: "Однажды в стартапе, где я консультировал, кластер Patroni был настроен более года назад. При первом реальном сбое оказалось, что из-за обновления операционной системы изменились пути к бинарникам PostgreSQL, и Patroni не мог корректно запустить новый мастер. Простой продлился несколько часов, пока инженеры выясняли причину и вручную корректировали конфигурацию. Если бы они регулярно тестировали failover, эта проблема была бы обнаружена задолго до продакшена."
3. Игнорирование мониторинга и оповещений
Описание: HA-кластеры по своей природе более сложны, чем одиночные серверы. Без адекватного мониторинга невозможно оперативно узнать о проблемах, таких как отставание репликации, исчерпание дискового пространства, высокая нагрузка на DCS или проблемы с сетью. Отсутствие оповещений означает, что вы узнаете о проблеме только тогда, когда она уже привела к простою.
Как избежать: Внедрите комплексную систему мониторинга (Prometheus+Grafana, Zabbix, Datadog) для всех компонентов кластера: PostgreSQL (метрики, репликация, WAL), Patroni (API), DCS (etcd/Consul), операционная система (CPU, RAM, диск, сеть). Настройте оповещения (Alertmanager, Slack, Telegram, PagerDuty) на критические метрики: RPO > X секунд, дисковое пространство < Y%, количество узлов в кластере < Z, недоступность Patroni API. Регулярно пересматривайте пороги оповещений.
Реальные последствия: "У клиента был настроен Patroni, но мониторинг репликации был базовым. Из-за ошибки в сети между дата-центрами репликация начала отставать на несколько часов. Никаких оповещений не было, так как пороги были слишком высоки. Когда произошел сбой мастера, failover прошел, но новый мастер имел данные, отстающие на 3 часа, что привело к откату части транзакций и пришлось восстанавливать данные из бэкапа, что заняло почти сутки."
4. Неправильная конфигурация сети и DNS
Описание: Сеть является основой любого распределенного кластера. Некорректная настройка DNS, проблемы с разрешением имен, неправильные правила файрвола, а также асимметричная маршрутизация могут привести к тому, что узлы не смогут "видеть" друг друга, или приложения не смогут подключиться к актуальному мастеру после failover.
Как избежать: Убедитесь, что все узлы могут обращаться друг к другу по всем необходимым портам. Используйте статические IP-адреса. Настройте DNS таким образом, чтобы имя хоста вашего кластера (например, `pg-cluster.mydomain.com`) всегда указывало на актуальный мастер (через балансировщик или динамическое обновление DNS). Проверяйте правила файрвола на каждом узле. Используйте внутренние сети для трафика репликации и DCS, если это возможно.
Реальные последствия: "В одном проекте, после автоматического failover, приложения не могли подключиться к новому мастеру. Проблема оказалась в кэшировании DNS на клиентской стороне и слишком долгом TTL для записи A-записи. Пришлось вручную очищать кэши и перезапускать приложения, что увеличило RTO в несколько раз. С тех пор мы используем очень низкий TTL для DNS-записей кластера и рекомендуем использовать балансировщик нагрузки с проверкой здоровья узлов."
5. Пренебрежение бэкапами и их тестированием
Описание: Высокая доступность защищает от простоев, но не от потери данных из-за логических ошибок (например, случайное удаление таблицы) или катастрофических сбоев (например, одновременный отказ всех узлов в дата-центре). Бэкапы — это ваша последняя линия обороны. Если бэкапы не делаются регулярно, не хранятся безопасно или, что еще хуже, не тестируются на возможность восстановления, они бесполезны.
Как избежать: Внедрите надежную стратегию резервного копирования (например, с помощью pgBackRest или Barman) с регулярным полным и инкрементальным резервированием. Храните бэкапы в удаленном, географически распределенном хранилище (например, S3-совместимое хранилище). Самое главное: регулярно восстанавливайте бэкапы на тестовом стенде, чтобы убедиться в их целостности и работоспособности. Это единственный способ убедиться, что в случае чего вы действительно сможете восстановить данные.
Реальные последствия: "В одной компании произошла логическая ошибка в приложении, которая привела к массовому удалению данных. HA-кластер продолжал работать, но данные были утеряны. Когда попытались восстановиться из бэкапа, выяснилось, что из-за ошибки конфигурации последние 3 месяца бэкапы были повреждены и не подлежали восстановлению. Компании пришлось восстанавливать данные из более старых бэкапов и вручную переносить часть информации, что привело к значительным потерям и штрафам от регуляторов."
Чеклист для практического применения: Развертывание HA PostgreSQL
Этот пошаговый чеклист поможет вам систематизировать процесс развертывания высокодоступного PostgreSQL кластера, минимизируя вероятность ошибок и обеспечивая комплексный подход.
Фаза 1: Планирование и Проектирование
- Определение требований RPO и RTO: Четко установите, сколько данных вы готовы потерять и как быстро должны восстановиться после сбоя. Это ключевые параметры для выбора архитектуры.
- Выбор HA-решения: На основе RPO, RTO, бюджета, сложности и экспертизы команды выберите оптимальное решение (Patroni, pg_auto_failover, нативная репликация + скрипты, Pgpool-II).
- Проектирование архитектуры кластера:
- Определите количество узлов (минимум 3 для Patroni/etcd, 2+монитор для pg_auto_failover).
- Распределите узлы по разным дата-центрам/стойкам/провайдерам для повышения устойчивости (если позволяет бюджет).
- Спланируйте размещение DCS (etcd/Consul) — совместно с БД или на отдельных узлах.
- Оценка ресурсов серверов: Определите необходимую конфигурацию CPU, RAM, SSD и сетевых ресурсов для каждого узла, исходя из ожидаемой нагрузки.
- Планирование сетевой инфраструктуры:
- Назначьте статические IP-адреса для всех узлов.
- Определите порты для PostgreSQL (5432), Patroni API (8008), DCS (etcd: 2379/2380, Consul: 8500), балансировщика (5432, 5433).
- Настройте правила файрвола (UFW, firewalld, сетевые ACL провайдера) для разрешения необходимого трафика.
- Разработка стратегии резервного копирования и восстановления: Выберите инструмент (pgBackRest, Barman), определите частоту, место хранения (удаленное, географически распределенное) и процедуры восстановления.
- Планирование мониторинга и оповещений: Выберите инструменты (Prometheus, Grafana, Alertmanager) и определите ключевые метрики и пороги для оповещений.
- Документация: Создайте подробную документацию по архитектуре, настройке, процедурам failover/switchover и аварийному восстановлению.
Фаза 2: Подготовка Инфраструктуры
- Заказ/выделение серверов: Разверните необходимое количество VPS или выделенных серверов.
- Базовая настройка ОС: Установите выбранную ОС (Ubuntu LTS, Debian), обновите систему, настройте SSH-доступ, часовой пояс, NTP.
- Установка PostgreSQL: Установите PostgreSQL на всех узлах, но не инициализируйте его вручную (это сделает Patroni/pg_auto_failover).
- Установка зависимостей: Установите Python, pip, psycopg2, PyYAML и другие зависимости для Patroni/pg_auto_failover.
- Настройка файрвола: Откройте необходимые порты на каждом узле.
- Настройка DNS: Убедитесь, что имена хостов разрешаются корректно и, при необходимости, настройте динамическое обновление DNS или используйте балансировщик.
Фаза 3: Развертывание HA-решения
- Установка и настройка DCS (если требуется): Разверните etcd/Consul на всех узлах, убедитесь в работоспособности кластера DCS.
- Установка и настройка Patroni/pg_auto_failover:
- Установите выбранный инструмент.
- Создайте конфигурационные файлы на каждом узле, адаптируя под специфику каждого сервера (имя, IP-адреса).
- Настройте параметры PostgreSQL в конфигурации HA-инструмента (wal_level, max_wal_senders и т.д.).
- Настройте пользователей для репликации и суперпользователя с надежными паролями.
- Создание systemd-сервисов: Создайте и настройте systemd-сервисы для Patroni/pg_auto_failover на каждом узле.
- Запуск кластера: Запустите сервисы DCS (если отдельные), затем Patroni/pg_auto_failover на всех узлах.
- Инициализация кластера: Дождитесь автоматической инициализации мастера и присоединения реплик.
- Проверка состояния кластера: Используйте `patronictl list` или `pg_auto_failover show state` для подтверждения корректной работы.
Фаза 4: Тестирование и Мониторинг
- Настройка балансировщика нагрузки: Разверните и настройте HAProxy/PgBouncer для маршрутизации трафика к мастеру и репликам.
- Настройка мониторинга: Интегрируйте кластер в вашу систему мониторинга, настройте сбор метрик и оповещения.
- Тестирование Failover: Инициируйте искусственный отказ мастера и проверьте автоматическое переключение на реплику, измерьте RTO.
- Тестирование Switchover: Проведите плановое переключение мастера на реплику.
- Тестирование восстановления из бэкапа: Восстановите тестовую БД из бэкапа на отдельном стенде.
- Тестирование производительности: Проведите нагрузочное тестирование кластера в различных сценариях.
- Обновление документации: Актуализируйте всю документацию после развертывания и тестирования.
Фаза 5: Эксплуатация и Обслуживание
- Регулярный мониторинг: Постоянно следите за состоянием кластера, реагируйте на оповещения.
- Регулярное тестирование: Продолжайте периодически тестировать failover и восстановление бэкапов.
- Обновление ПО: Планируйте и выполняйте обновления PostgreSQL, Patroni/pg_auto_failover, DCS и ОС в соответствии с best practices для HA-систем.
- Анализ логов: Регулярно просматривайте логи PostgreSQL, Patroni и DCS для выявления потенциальных проблем.
- Оптимизация: Анализируйте производительность и при необходимости оптимизируйте конфигурацию PostgreSQL и HA-решения.
Расчет стоимости / Экономика высокодоступного PostgreSQL кластера
Создание и поддержание высокодоступного PostgreSQL кластера на VPS или выделенных серверах влечет за собой определенные затраты. Важно понимать не только прямые, но и скрытые расходы, чтобы получить полное представление о TCO (Total Cost of Ownership) и эффективно управлять бюджетом. Приведенные ниже цифры являются ориентировочными для 2026 года и могут варьироваться в зависимости от провайдера, региона и конкретных требований.
Основные статьи расходов
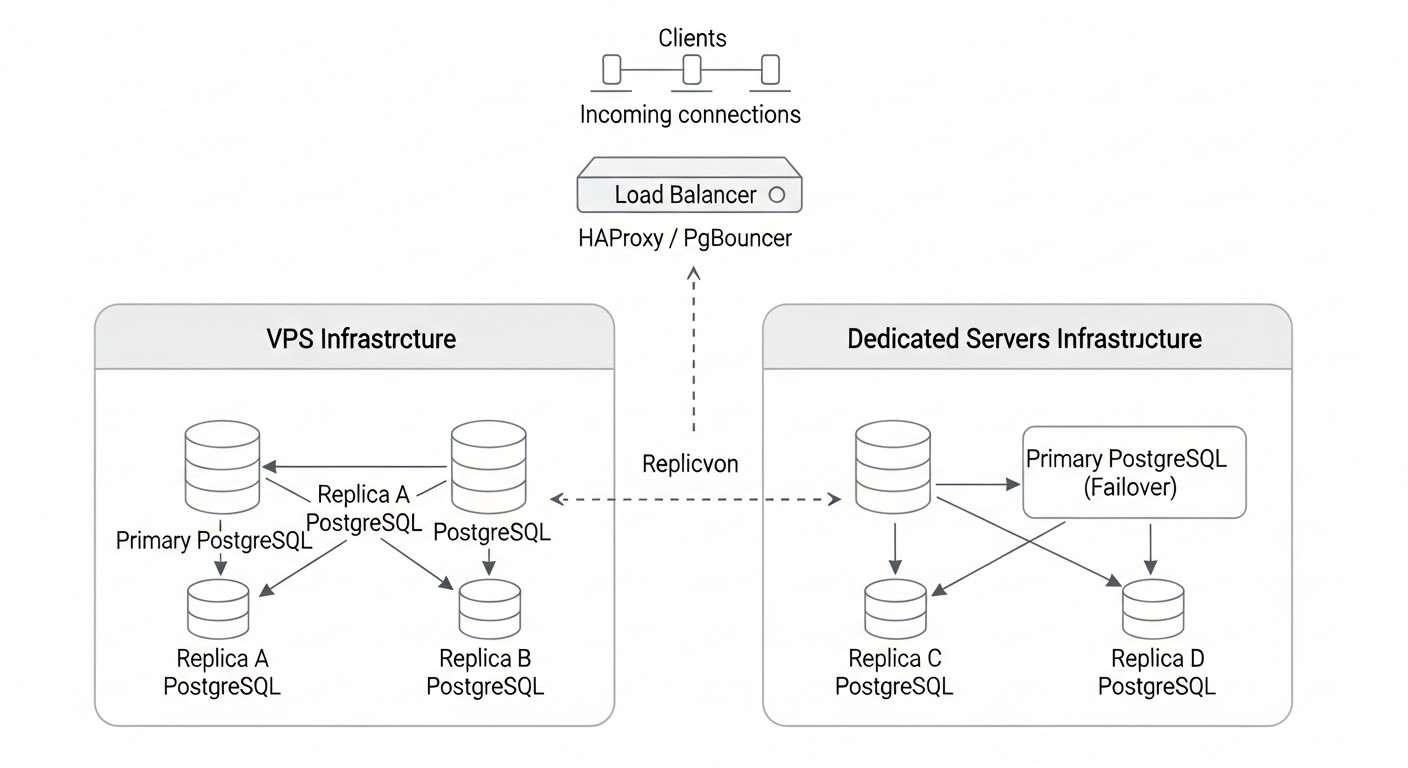
- Стоимость серверов (VPS/Dedicated): Это основная и наиболее очевидная статья расходов. Для HA-кластера требуется минимум 3 узла для обеспечения кворума и отказоустойчивости (например, 1 мастер, 2 реплики).
- VPS: Более гибкие, масштабируемые и часто дешевле для небольших и средних нагрузок. Стоимость зависит от vCPU, RAM, SSD и сетевого трафика.
- Выделенные серверы: Обеспечивают максимальную производительность и контроль, но дороже и требуют больше усилий по управлению.
- Стоимость хранения данных (Storage): Помимо базового диска ОС, вам потребуется достаточно быстрое и объемное хранилище для данных PostgreSQL (WAL-логи, базы данных). NVMe SSD являются стандартом для продакшн-систем.
- Сетевой трафик: Входящий трафик обычно бесплатен, но исходящий может тарифицироваться, особенно при больших объемах репликации между дата-центрами или при частых бэкапах в облачное хранилище.
- Системы мониторинга и логирования: Хотя многие решения Open Source (Prometheus, Grafana, ELK), их развертывание и поддержка требуют ресурсов. Коммерческие решения (Datadog, New Relic) значительно упрощают жизнь, но имеют свою стоимость.
- Резервное копирование и DR: Хранение бэкапов (S3-совместимые хранилища, NFS), а также затраты на тестовые стенды для восстановления.
- Инженерное время (Human Capital): Это часто недооцениваемая, но одна из самых значительных статей расходов. Время инженеров на проектирование, развертывание, настройку, тестирование, мониторинг, обслуживание, устранение проблем и обучение. HA-системы сложнее, чем одиночные серверы, и требуют более высокой квалификации.
- Лицензии ПО: PostgreSQL и большинство HA-инструментов (Patroni, pg_auto_failover, HAProxy, etcd, Consul) являются Open Source и бесплатны. Однако, если вы используете коммерческие ОС или специализированное ПО, могут быть лицензионные сборы.
Скрытые расходы
- Простои: Стоимость простоя может быть огромной (потеря дохода, репутационный ущерб, штрафы по SLA). Инвестиции в HA — это страховка от этих потерь.
- Упущенная выгода: Медленная БД или частые сбои могут отпугивать клиентов, снижать конверсию и мешать росту бизнеса.
- Обучение команды: Поддержание квалификации инженеров для работы со сложными HA-системами.
- Масштабирование: Неудачно выбранная архитектура может потребовать полного перепроектирования при росте нагрузки.
- Технический долг: Недостаточное внимание к HA на ранних этапах приводит к накоплению технического долга, который потом будет стоить дороже.
Как оптимизировать затраты
- Оптимальный выбор VPS/серверов: Не переплачивайте за избыточные ресурсы, но и не экономьте на критически важных компонентах (SSD, RAM). Начните с минимально достаточной конфигурации и масштабируйте по мере роста.
- Использование Open Source: Максимально используйте бесплатные Open Source решения для всех компонентов (ОС, БД, HA-инструменты, мониторинг).
- Автоматизация: Инвестируйте в автоматизацию развертывания (Ansible, Terraform) и операций. Это снизит затраты на инженерное время в долгосрочной перспективе.
- Грамотный мониторинг: Раннее обнаружение проблем предотвращает дорогостоящие простои.
- Эффективная стратегия бэкапа: Используйте инкрементальные бэкапы, сжатие, и храните только необходимое количество копий, чтобы снизить расходы на хранение.
- Сетевая архитектура: Используйте внутренние сети провайдера для трафика репликации и DCS, чтобы избежать платы за исходящий трафик.
- Обучение и документация: Инвестиции в знания команды и хорошую документацию снижают риски и время на решение проблем.
Таблица с примерами расчетов для разных сценариев (2026 год, USD/месяц)
Предполагается использование 3-х VPS узлов для кластера PostgreSQL (Patroni + etcd) и одного VPS для балансировщика HAProxy/PgBouncer, а также удаленного хранилища для бэкапов.
| Статья расходов | Малый проект (3 VPS x 2vCPU/4GB RAM/80GB NVMe) | Средний проект (3 VPS x 4vCPU/8GB RAM/160GB NVMe) | Крупный проект (3 VPS x 8vCPU/16GB RAM/320GB NVMe) |
|---|---|---|---|
| VPS для PostgreSQL (3 шт) | 3 x $15 = $45 | 3 x $35 = $105 | 3 x $70 = $210 |
| VPS для HAProxy/PgBouncer (1 шт) | 1 x $10 = $10 | 1 x $15 = $15 | 1 x $20 = $20 |
| Удаленное хранилище для бэкапов (S3-совместимое) | $5 (500 GB) | $10 (1 TB) | $25 (2.5 TB) |
| Сетевой трафик (исходящий) | $5 | $10 | $25 |
| Мониторинг (Open Source, затраты на VPS) | $0 (совместно с HAProxy) | $10 (отдельный VPS) | $20 (отдельный VPS) |
| ИТОГО прямые расходы (USD/мес) | $65 | $150 | $300 |
| Инженерное время (ориентировочно, USD/мес)* | $200-500 | $500-1500 | $1500-3000+ |
| ИТОГО TCO (прямые + инж. время) | $265-565 | $650-1650 | $1800-3300+ |
*Примечание по инженерному времени: Это очень приблизительная оценка, сильно зависящая от квалификации команды, уровня автоматизации и сложности проекта. Она включает время на развертывание, поддержку, мониторинг, устранение проблем и тестирование. В начале проекта затраты на инженерное время будут значительно выше.
Как видно из таблицы, прямые расходы на инфраструктуру для HA-кластера вполне доступны даже для небольших проектов. Однако, гораздо более значительной статьей расходов является инженерное время, особенно на этапе внедрения и при низком уровне автоматизации. Правильный выбор решения и инвестиции в автоматизацию окупаются за счет снижения TCO в долгосрочной перспективе и повышения надежности системы.
Кейсы и примеры реальных внедрений HA PostgreSQL
Теория важна, но реальные кейсы дают лучшее понимание того, как HA-решения работают на практике и какие вызовы они помогают преодолеть. Вот несколько сценариев из нашей практики и опыта коллег.
Кейс 1: SaaS-платформа для управления проектами (Patroni + etcd)
Проблема: Молодая SaaS-компания активно росла, и их единственная инстанция PostgreSQL на выделенном сервере стала критической точкой отказа. Любой простой приводил к недоступности сервиса для тысяч клиентов, что напрямую влияло на репутацию и доходы. RPO был установлен в 0 секунд (синхронная репликация), RTO — не более 30 секунд.
Решение: Было принято решение развернуть кластер Patroni с etcd.
- Архитектура: 3 выделенных сервера (8vCPU, 32GB RAM, 500GB NVMe SSD) в одном дата-центре, но в разных стойках, чтобы минимизировать риски отказа оборудования. Каждый сервер запускал PostgreSQL 16, Patroni и etcd.
- Конфигурация Patroni: Настроена синхронная репликация с одним `synchronous_standby_names`, что обеспечивало нулевой RPO. Использовался HAProxy на отдельном VPS для маршрутизации трафика: запись на мастер (порт 5432), чтение на реплики (порт 5433).
- Мониторинг: Prometheus с `postgres_exporter` и `patroni_exporter`, Grafana для визуализации, Alertmanager для оповещений в Slack и PagerDuty.
- Бэкапы: pgBackRest для инкрементальных бэкапов в S3-совместимое хранилище.
Результаты:
- RTO 15 секунд: При имитации отказа мастера (выключение сервера) Patroni автоматически переключал роль на реплику за 15-20 секунд.
- Нулевой RPO: Благодаря синхронной репликации не было зафиксировано потери данных при сбоях.
- Улучшение SLA: Компания смогла гарантировать клиентам 99.99% доступности сервиса.
- Снижение операционного стресса: Автоматизация failover позволила команде DevOps сосредоточиться на развитии, а не на ручном восстановлении.
Кейс 2: E-commerce платформа с высокой нагрузкой чтения (pg_auto_failover + PgBouncer)
Проблема: Крупный интернет-магазин испытывал пиковые нагрузки во время распродаж, что приводило к деградации производительности БД и иногда к кратковременным простоям. Основная проблема была в масштабировании чтения и необходимости быстрого восстановления после сбоев. RPO был приемлем в несколько секунд, RTO — до 1 минуты.
Решение: Внедрение pg_auto_failover в сочетании с PgBouncer для пулинга соединений и HAProxy для балансировки.
- Архитектура: 2 выделенных сервера (16vCPU, 64GB RAM, 1TB NVMe SSD) для PostgreSQL (мастер и реплика) и 1 VPS для монитора pg_auto_failover. Дополнительно 2 VPS для PgBouncer и HAProxy в режиме active/passive с Keepalived.
- Конфигурация pg_auto_failover: Асинхронная репликация для лучшей производительности, но с настройками `wal_level = replica` и `hot_standby = on`. Монитор pg_auto_failover размещен на отдельном узле для повышения надежности.
- PgBouncer: Развернут на двух узлах (HAProxy перед ними), чтобы управлять сотнями тысяч клиентских соединений, снижая нагрузку на PostgreSQL.
- HAProxy: Настроен для направления запросов записи на текущий мастер (через PgBouncer) и балансировки запросов чтения между мастером и репликой (также через PgBouncer).
- Бэкапы: Barman для потоковых бэкапов и point-in-time recovery.
Результаты:
- RTO ~45 секунд: При сбое мастера pg_auto_failover успешно переключался, а HAProxy и PgBouncer быстро перенаправляли трафик.
- Масштабирование чтения: PgBouncer и HAProxy эффективно распределяли нагрузку чтения, позволяя кластеру выдерживать пики до 100 000 RPS.
- Стабильность: Значительно сократилось количество простоев и деградаций производительности во время высоких нагрузок.
- Упрощенное управление: pg_auto_failover упростил задачи по управлению HA по сравнению с кастомными скриптами.
Кейс 3: Стартап с микросервисной архитектурой (Patroni в контейнерах на VPS)
Проблема: Небольшой стартап разрабатывал новую микросервисную платформу и нуждался в высокодоступной БД, которая легко интегрировалась бы с контейнерной средой (Docker/Kubernetes). Бюджет был ограничен, поэтому использовались VPS. Требовался быстрый failover и гибкость в управлении.
Решение: Развертывание Patroni в Docker-контейнерах на 3 VPS с etcd, также запущенным в контейнерах.
- Архитектура: 3 VPS (4vCPU, 8GB RAM, 160GB NVMe SSD). На каждом VPS запущен Docker. В каждом VPS запущены контейнеры для PostgreSQL, Patroni и etcd.
- Конфигурация: Использовались официальные Docker-образы PostgreSQL и Patroni. Конфигурация Patroni была адаптирована для работы в контейнерах, с монтированием томов для данных PostgreSQL и etcd. Сеть контейнеров настроена для взаимодействия через внутренние IP-адреса VPS.
- Взаимодействие с микросервисами: Микросервисы подключались к кластеру через HAProxy, запущенный на отдельном VPS, который мониторил Patroni API для определения мастера.
- CICD: Развертывание и обновление кластера Patroni было автоматизировано с помощью GitLab CI/CD и Ansible.
Результаты:
- Быстрое развертывание: Благодаря контейнеризации и автоматизации, развертывание нового кластера занимало считанные минуты.
- Высокая доступность: Кластер успешно переживал отказы отдельных VPS, автоматически переключая мастера.
- Экономичность: Использование VPS и Open Source решений позволило уложиться в ограниченный бюджет.
- Гибкость: Легко масштабировать кластер, добавляя новые VPS и запуская на них контейнеры.
Эти кейсы демонстрируют, что с правильным выбором инструментов и подходом, можно достичь высокого уровня доступности PostgreSQL даже на относительно недорогих VPS и выделенных серверах, удовлетворяя различные бизнес-требования.
Инструменты и ресурсы для управления HA PostgreSQL кластером
Успешное развертывание и поддержание высокодоступного PostgreSQL кластера невозможно без правильного набора инструментов. Здесь мы перечислим ключевые утилиты и ресурсы, которые помогут вам на каждом этапе.
1. Инструменты для создания HA-кластера
- Patroni: (Zalando) — Оркестратор для PostgreSQL, использующий DCS для координации HA. Must-have для автоматизированных и надежных кластеров.
- pg_auto_failover: (Citus Data / Microsoft) — Упрощенное решение для автоматического failover, интегрированное с PostgreSQL.
- Pgpool-II: Прокси-сервер с пулингом соединений, балансировкой нагрузки и функциями HA.
2. Распределенные хранилища конфигурации (DCS)
Необходимы для Patroni, обеспечивают кворум и хранят состояние кластера.
- etcd: Высокодоступное распределенное хранилище ключ/значение, часто используемое в Kubernetes.
- Consul: Сервис-меш и распределенное хранилище ключ/значение от HashiCorp.
- Apache ZooKeeper: Еще одно зрелое решение для распределенной координации.
3. Балансировщики нагрузки и прокси
- HAProxy: Высокопроизводительный TCP/HTTP балансировщик нагрузки. Идеален для распределения клиентских запросов между мастером и репликами.
- PgBouncer: Легковесный пулер соединений для PostgreSQL. Уменьшает нагрузку на сервер БД от большого количества клиентских соединений.
- Keepalived: Используется для обеспечения высокой доступности IP-адресов (Virtual IP) и сервисов с помощью протокола VRRP. Часто используется с HAProxy.
4. Инструменты резервного копирования и восстановления
- pgBackRest: Мощный и гибкий инструмент для резервного копирования и восстановления PostgreSQL, поддерживающий инкрементальные бэкапы, сжатие и удаленное хранение.
- Barman: (Backup and Recovery Manager) — Еще один популярный инструмент для централизованного управления бэкапами PostgreSQL, включая Point-in-Time Recovery.
5. Инструменты мониторинга и логирования
- Prometheus: Система мониторинга и оповещений с мощным языком запросов PromQL.
- Grafana: Платформа для визуализации данных мониторинга.
- postgres_exporter: Экспортер метрик PostgreSQL для Prometheus.
- patroni_exporter: Экспортер метрик Patroni для Prometheus.
- pgBadger: Мощный анализатор логов PostgreSQL, генерирующий подробные HTML-отчеты.
- ELK Stack (Elasticsearch, Logstash, Kibana): Для централизованного сбора, хранения, индексации и визуализации логов.
6. Автоматизация развертывания
- Ansible: Инструмент для автоматизации настройки и развертывания ПО. Идеален для управления конфигурацией кластера.
- Terraform: Инструмент для управления инфраструктурой как кодом (IaC). Позволяет автоматизировать создание VPS и их базовую настройку.
7. Полезные ссылки и документация
- Официальная документация PostgreSQL — Всегда актуальный и полный источник информации о самой СУБД.
- PostgreSQL Wiki: High Availability and Load Balancing — Обзор различных HA-решений и подходов.
- Блоги и сообщества: Planet PostgreSQL, PostgreSQL.ru, Хабр, различные Telegram-каналы по PostgreSQL и DevOps — отличные источники для изучения кейсов и решения проблем.
Troubleshooting: Решение типовых проблем в HA PostgreSQL
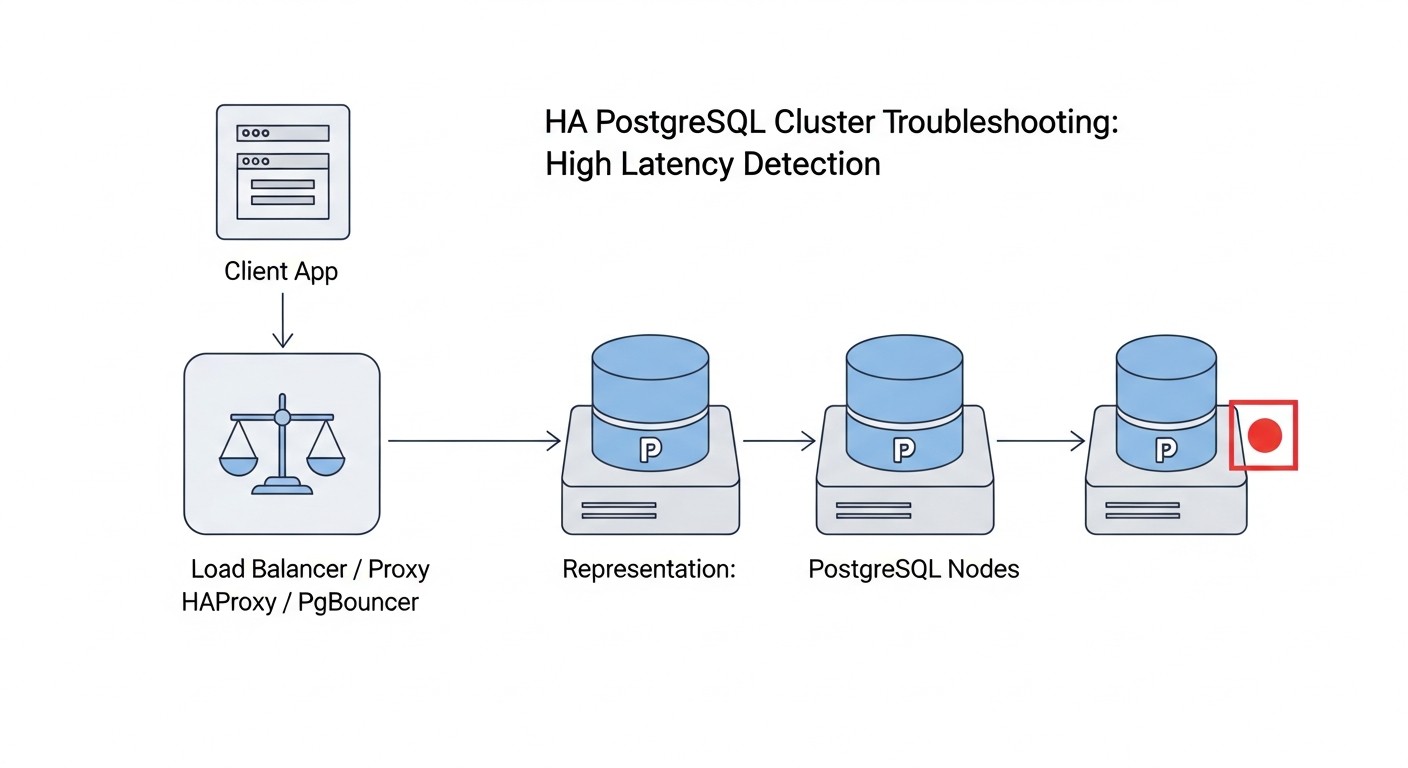
Даже при самой тщательной настройке в высокодоступных системах могут возникать проблемы. Важно уметь быстро диагностировать и устранять их. Вот некоторые типичные проблемы и подходы к их решению.
1. Проблемы с репликацией (Replication Lag)
Симптомы: Реплики значительно отстают от мастера, что видно по метрикам мониторинга или по запросам.
Диагностика:
-- На мастере
SELECT client_addr, state, sync_state, pg_wal_lsn_diff(pg_current_wal_lsn(), replay_lsn) AS lag_bytes
FROM pg_stat_replication;
-- На реплике
SELECT pg_wal_lsn_diff(pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn()); -- Lag в байтах
Возможные причины и решения:
- Сетевые проблемы: Медленное или нестабильное сетевое соединение между мастером и репликой.
- Решение: Проверьте пропускную способность (`iperf3`) и задержку (`ping`, `mtr`) между узлами. Убедитесь, что нет потери пакетов. Возможно, потребуется оптимизировать сетевую инфраструктуру или использовать более быстрые VPS/выделенные серверы.
- Нагрузка на реплику: Реплика перегружена запросами чтения, что мешает применению WAL-файлов.
- Решение: Оптимизируйте запросы чтения, добавьте больше реплик для распределения нагрузки, рассмотрите использование PgBouncer для эффективного управления соединениями.
- Медленный диск на реплике: Дисковая подсистема реплики не справляется с записью WAL-файлов.
- Решение: Проверьте метрики I/O (iostat, fio). Возможно, потребуется более быстрый SSD (NVMe) или оптимизация дисковой подсистемы.
- Недостаточные ресурсы на мастере: Мастер не успевает генерировать WAL-файлы или у него мало `wal_senders`.
- Решение: Увеличьте `max_wal_senders` и проверьте общие ресурсы мастера.
2. Проблемы с Failover (Patroni/pg_auto_failover не переключает мастера)
Симптомы: Мастер недоступен, но автоматический failover не происходит или занимает слишком много времени.
Диагностика:
# Для Patroni
patronictl -c /etc/patroni/patroni.yml list
# Проверьте логи Patroni на всех узлах
sudo journalctl -u patroni -f
# Для pg_auto_failover
pg_auto_failover show state
# Проверьте логи pg_auto_failover monitor и узлов
sudo journalctl -u pg_auto_failover_monitor -f
sudo journalctl -u pg_auto_failover_node -f
Возможные причины и решения:
- Проблемы с DCS (etcd/Consul): DCS недоступен или не имеет кворума. Patroni не может обновить состояние.
- Решение: Проверьте статус DCS (`etcdctl member list`). Убедитесь, что все узлы DCS работают и имеют кворум. Возможно, потребуется перезапустить DCS или вручную восстановить кворум.
- Сетевые проблемы: Узлы Patroni/pg_auto_failover не могут "видеть" друг друга или DCS.
- Решение: Проверьте сетевую связность (ping, telnet на порты) между всеми узлами и DCS. Убедитесь в корректной работе файрволов.
- Неправильная конфигурация Patroni/pg_auto_failover: Ошибки в `patroni.yml` или в настройках pg_auto_failover.
- Решение: Внимательно проверьте конфигурационные файлы на всех узлах. Особенно параметры `ttl`, `loop_wait`, `retry_timeout`, `maximum_lag_on_failover`.
- Проблемы с ресурсами: Узлы перегружены (CPU, RAM), что мешает нормальной работе Patroni/pg_auto_failover.
- Решение: Проверьте утилизацию ресурсов на всех узлах. Возможно, потребуется увеличить ресурсы или оптимизировать нагрузку.
- Replication Lag слишком велик: Если `maximum_lag_on_failover` слишком низкий, а реплика отстает, Patroni может не выбрать ее как кандидата на мастера.
- Решение: Увеличьте значение `maximum_lag_on_failover` или устраните причину отставания репликации.
3. Проблемы с подключением клиентов после Failover
Симптомы: После успешного failover клиентские приложения не могут подключиться к новому мастеру.
Диагностика:
- Проверьте, куда указывает DNS-запись для вашего кластера.
- Проверьте статус балансировщика нагрузки (HAProxy) и его бэкендов.
- Попробуйте подключиться к новому мастеру напрямую с клиентского хоста (`psql -h
-p 5432 -U `).
Возможные причины и решения:
- Кэширование DNS: Клиентские приложения или ОС кэшируют старую DNS-запись.
- Решение: Используйте низкий TTL для DNS-записи кластера (например, 30-60 секунд). Рекомендуется использовать балансировщик нагрузки, который не зависит от DNS-переключений.
- Балансировщик нагрузки не обновил состояние: HAProxy или другой балансировщик не переключил трафик на новый мастер.
- Решение: Проверьте логи HAProxy, убедитесь, что его health checks корректно работают с Patroni API (`/primary`, `/replica`). Перезапустите HAProxy, если необходимо.
- Файрвол: Файрвол блокирует подключения к новому мастеру.
- Решение: Убедитесь, что порт 5432 открыт на новом мастер-узле для клиентских подключений.
4. Проблемы с производительностью
Симптомы: Медленные запросы, высокая загрузка CPU/RAM/IO, долгие транзакции.
Диагностика:
-- Проверка активных запросов
SELECT pid, usename, client_addr, application_name, backend_start, state, query_start, query
FROM pg_stat_activity
WHERE state != 'idle' ORDER BY query_start;
-- Проверка медленных запросов (если включен log_min_duration_statement)
-- Анализ логов PostgreSQL через pgBadger
-- Мониторинг ресурсов ОС
top, htop, iostat, vmstat, netstat
Возможные причины и решения:
- Неоптимизированные запросы: Плохо написанные запросы, отсутствие индексов.
- Решение: Используйте `EXPLAIN ANALYZE` для анализа запросов, создайте необходимые индексы, оптимизируйте схему БД.
- Недостаточно ресурсов: Нехватка CPU, RAM или медленный диск.
- Решение: Увеличьте ресурсы VPS/выделенного сервера.
- Неправильная конфигурация PostgreSQL: Неоптимальные значения `work_mem`, `shared_buffers`, `effective_cache_size` и т.д.
- Решение: Настройте параметры PostgreSQL в соответствии с рекомендациями для вашей нагрузки и доступными ресурсами.
- Блокировки: Долгие транзакции или блокировки, мешающие другим запросам.
- Решение: Идентифицируйте и устраните источник блокировок. Оптимизируйте транзакции.
Когда обращаться в поддержку
Если вы исчерпали все возможности по диагностике и устранению проблемы, или если проблема критична и вызывает длительный простой, не стесняйтесь обращаться за помощью:
- Сообщество PostgreSQL: Форумы, mailing lists, Telegram-чаты.
- Разработчики Patroni/pg_auto_failover: GitHub Issues или специализированные каналы.
- Профессиональная поддержка: Компании, специализирующиеся на PostgreSQL или DevOps-консалтинге.
Важно предоставить максимально полную информацию: логи, конфигурационные файлы, метрики мониторинга, шаги по воспроизведению проблемы.
FAQ: Часто задаваемые вопросы о высокодоступном PostgreSQL
Могу ли я использовать только два узла для HA PostgreSQL?
Теоретически, да, но это крайне не рекомендуется для продакшн-среды. С двумя узлами вы не сможете обеспечить кворум. В случае сетевого разделения (network split-brain) оба узла могут решить, что другой узел недоступен, и каждый попытается стать мастером, что приведет к рассинхронизации данных. Для надежного кворума и предотвращения split-brain всегда используйте нечетное количество узлов (минимум три) для голосования или для вашего распределенного хранилища конфигурации (etcd/Consul).
Как обновить PostgreSQL в HA кластере без простоя?
Для обновления PostgreSQL в HA-кластере рекомендуется использовать метод "rolling upgrade". Сначала обновите реплики, по одной, затем выполните плановый switchover (переключение мастера) на одну из обновленных реплик. После этого обновите оставшийся старый мастер. Patroni предоставляет удобные инструменты для выполнения switchover. Важно тщательно протестировать процесс обновления на тестовом стенде перед применением в продакшене.
Что насчет бэкапов? Они по-прежнему нужны, если у меня есть HA?
Абсолютно! Высокая доступность защищает от простоев, но не от потери данных из-за логических ошибок (например, случайное удаление данных приложением), аппаратных сбоев всех узлов одновременно (например, пожар в дата-центре) или человеческих ошибок. Бэкапы — это ваша последняя линия обороны. Всегда делайте регулярные, тестируемые бэкапы и храните их удаленно от основного кластера.
Как масштабировать чтение в HA кластере?
Масштабирование чтения в HA кластере PostgreSQL достигается путем добавления дополнительных реплик. Вы можете направлять запросы SELECT на эти реплики, используя балансировщик нагрузки (например, HAProxy, Pgpool-II), который будет распределять трафик. Patroni и pg_auto_failover позволяют легко добавлять новые реплики в кластер. Убедитесь, что ваше приложение корректно разделяет запросы чтения и записи.
В чем разница между синхронной и асинхронной репликацией?
При асинхронной репликации мастер-сервер подтверждает транзакцию клиенту сразу после того, как она записана в WAL на мастере, не дожидаясь подтверждения от реплики. Это обеспечивает высокую производительность, но в случае сбоя мастера вы можете потерять последние транзакции, которые еще не были переданы или применены на реплике (ненулевой RPO). При синхронной репликации мастер ждет подтверждения от одной или нескольких реплик о том, что транзакция успешно записана на их диски, прежде чем подтвердить ее клиенту. Это гарантирует нулевой RPO (нет потери данных), но увеличивает задержку записи и снижает производительность.
Что такое "кворум" в контексте HA PostgreSQL?
Кворум — это минимальное количество узлов, которое должно быть доступно и единогласно в своем решении для выполнения определенной операции (например, выбора нового мастера или подтверждения транзакции). В распределенных системах кворум предотвращает сценарий split-brain. Например, в кластере из 3 узлов кворум обычно составляет 2 узла. Если 2 узла видят друг друга, но не видят третий, они могут принять решение о выборе мастера. Если же каждый из двух узлов видит только себя, кворум не достигается, и ни один из них не станет мастером, предотвращая конфликт.
Как справиться с сетевыми разделами (Network Partitions) в кластере?
Сетевые разделы — это сценарии, когда часть узлов кластера теряет связь с другой частью. Правильно настроенный механизм кворума (например, через etcd/Consul в Patroni) является ключевым. Он гарантирует, что только большинство узлов (имеющих кворум) сможет продолжить работу как мастер, в то время как меньшинство перейдет в режим ожидания или полностью остановится, чтобы предотвратить split-brain. Важно тщательно планировать размещение узлов (например, в разных стойках или даже дата-центрах) и иметь надежный мониторинг сети.
Можно ли смешивать VPS и выделенные серверы в одном HA кластере?
Технически это возможно, но не рекомендуется для критически важных систем. Разные типы серверов могут иметь разную производительность, задержки сети и надежность, что усложняет прогнозирование поведения кластера и может привести к асимметричным проблемам. Если вы все же решите это сделать, убедитесь, что самый медленный компонент не станет "бутылочным горлышком" и что у вас есть четкая стратегия управления неоднородностью.
Что такое Point-in-Time Recovery (PITR) и как оно связано с HA?
Point-in-Time Recovery (PITR) — это возможность восстановить базу данных до любого момента времени в прошлом (в пределах доступных бэкапов и WAL-файлов). Это критически важная функция для восстановления после логических ошибок или повреждения данных. Хотя PITR не является частью HA-решения напрямую, оно дополняет HA, обеспечивая полное восстановление данных в случаях, когда HA не может помочь (например, после случайного DELETE). Инструменты вроде pgBackRest и Barman предоставляют возможности PITR.
Есть ли полностью бесплатное решение для HA PostgreSQL?
Да, большинство упомянутых решений, таких как Patroni, pg_auto_failover, Pgpool-II, а также сам PostgreSQL, являются Open Source и бесплатны. Однако "бесплатность" относится только к стоимости лицензий. Вам все равно придется платить за инфраструктуру (VPS/серверы), а также за инженерное время на проектирование, развертывание, настройку, мониторинг и поддержку, что является существенной частью общих затрат.
Заключение: Ваш путь к надежному PostgreSQL
Создание высокодоступного PostgreSQL кластера на VPS или выделенных серверах — это не просто техническая задача, а стратегическое решение, которое напрямую влияет на непрерывность вашего бизнеса, репутацию и доходы. В 2026 году, когда простои недопустимы, а данные являются золотом, инвестиции в отказоустойчивую базу данных окупаются многократно.
Мы рассмотрели различные подходы, от мощного оркестратора Patroni до более простого pg_auto_failover и ручных решений с нативной репликацией. Каждый из них имеет свои сильные и слабые стороны, и выбор всегда должен основываться на тщательном анализе ваших требований к RPO и RTO, доступного бюджета и уровня экспертизы вашей команды. Помните, что не существует универсального решения, подходящего всем. Ваша задача — найти баланс между сложностью, стоимостью и уровнем надежности, который соответствует вашим бизнес-целям.
Ключевые выводы, которые вы должны вынести из этого мастер-промпта:
- Планирование — это все: Детальное проектирование архитектуры, оценка ресурсов и четкое определение бизнес-требований — фундамент успеха.
- Тестирование — ваша страховка: Регулярное тестирование механизмов failover, switchover и восстановления из бэкапов абсолютно критично. Непроверенная HA-система — это иллюзия безопасности.
- Мониторинг — ваши глаза и уши: Без всестороннего мониторинга всех компонентов кластера вы будете слепы к потенциальным проблемам. Настройте оповещения на критические метрики.
- Автоматизация — ваш лучший друг: Инвестируйте в автоматизацию развертывания и рутинных операций. Это снизит риск человеческих ошибок и освободит время инженеров для более сложных задач.
- Бэкапы — последняя линия обороны: Никогда не забывайте о надежных, тестируемых бэкапах, которые дополняют HA-стратегию и защищают от логических ошибок и катастрофических сбоев.
Построение надежного HA-кластера PostgreSQL — это непрерывный процесс, требующий постоянного внимания, обучения и адаптации к меняющимся условиям. Но с правильными инструментами, знаниями и подходом ваша база данных станет не просто хранилищем данных, а надежным и устойчивым сердцем вашей цифровой инфраструктуры.
Следующие шаги для читателя:
- Выберите решение: Определитесь с HA-решением, которое наилучшим образом соответствует вашим потребностям.
- Разработайте пилотный проект: Начните с небольшого тестового кластера на нескольких VPS, чтобы освоить выбранный инструмент и отработать все шаги.
- Автоматизируйте: Используйте Ansible или Terraform для создания повторяемого процесса развертывания.
- Внедрите мониторинг: Настройте Prometheus/Grafana для отслеживания состояния вашего кластера.
- Тренируйтесь: Регулярно проводите учения по аварийному восстановлению и тестируйте failover.
- Продолжайте учиться: Активно участвуйте в сообществе PostgreSQL, читайте блоги и документацию, чтобы быть в курсе последних разработок и лучших практик.
Пусть ваш PostgreSQL кластер будет всегда доступен и надежен!