Продвинутые стратегии деплоя Docker-приложений на VPS: Blue/Green и Canary обновления
TL;DR
- Бесшовный деплой на VPS: Освоите стратегии Blue/Green и Canary для минимизации даунтайма и рисков при обновлении Docker-приложений на виртуальных серверах.
- Blue/Green для простоты и безопасности: Идеально для приложений, где полное переключение трафика приемлемо; обеспечивает быстрый откат, но требует удвоения ресурсов на время деплоя.
- Canary для постепенного внедрения: Позволяет тестировать новую версию на небольшой части пользователей, минимизируя влияние возможных ошибок и собирая обратную связь перед полным раскатом.
- Автоматизация — ключ к успеху: Используйте CI/CD пайплайны с Ansible, Jenkins, GitLab CI или GitHub Actions для автоматизации всех этапов деплоя и мониторинга.
- Мониторинг и логирование критичны: Внедрите Prometheus, Grafana, ELK-стек или Loki/Promtail для отслеживания метрик, ошибок и производительности обеих версий приложения в реальном времени.
- Оптимизация ресурсов и затрат: С помощью грамотного выбора VPS, использования эффективных образов Docker и продуманных стратегий, можно значительно сократить расходы, несмотря на временное удвоение ресурсов.
- Конкретные примеры и инструменты 2026 года: Статья содержит актуальные для 2026 года рекомендации по инструментам, конфигурациям и практическим кейсам для успешного внедрения.
1. Введение
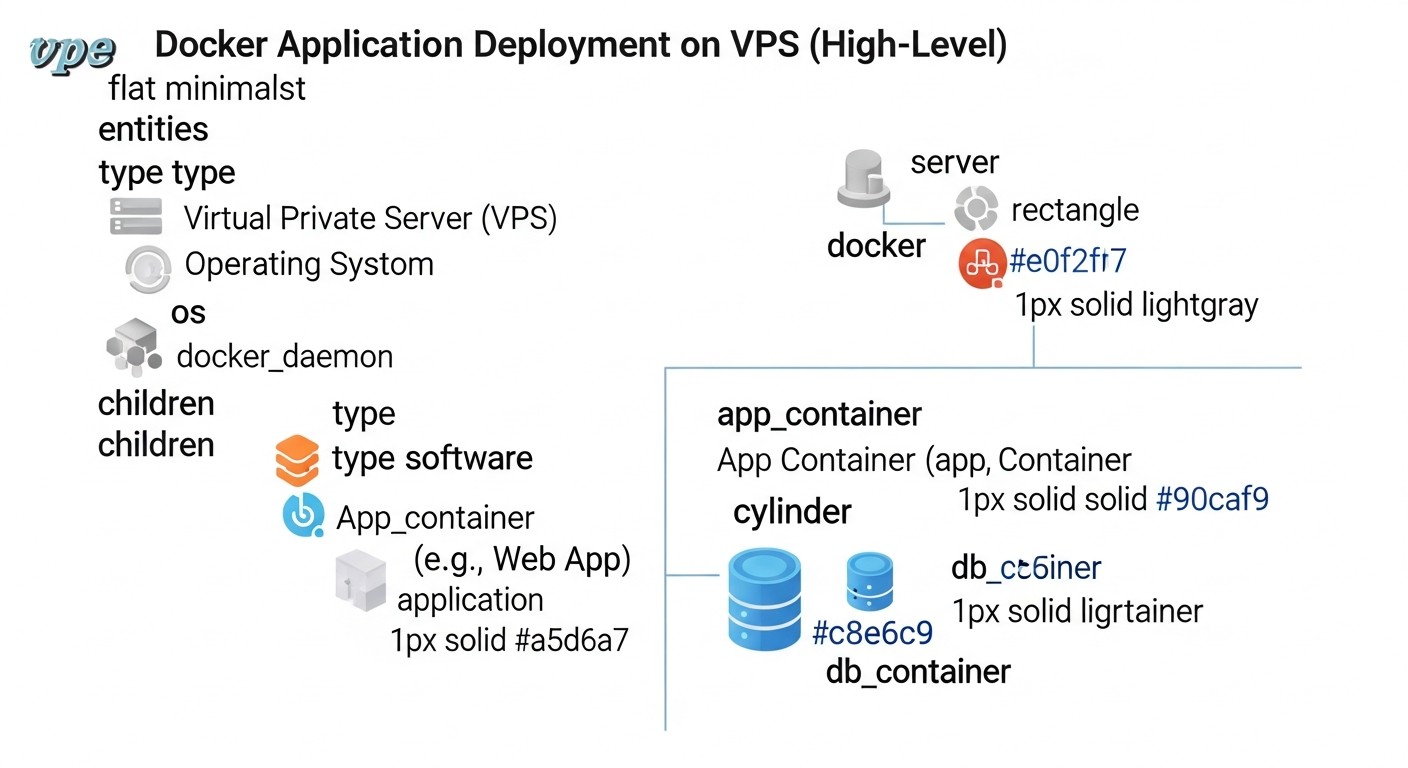 Схема: 1. Введение
Схема: 1. Введение
В стремительно развивающемся мире DevOps и облачных технологий, где каждая минута простоя обходится бизнесу в тысячи, а то и миллионы долларов, обеспечение бесперебойной работы приложений становится не просто желанием, а критической необходимостью. Особенно это актуально для SaaS-проектов, где доступность сервиса напрямую влияет на удовлетворенность клиентов, репутацию и, в конечном итоге, на прибыль. В 2026 году, когда микросервисная архитектура и контейнеризация с помощью Docker стали де-факто стандартом, а VPS-хостинги предлагают беспрецедентную гибкость и производительность по доступной цене, вопрос эффективного и безопасного деплоя выходит на первый план.
Традиционные методы деплоя, такие как "rip-and-replace" (остановка старой версии, развертывание новой), давно показали свою несостоятельность. Они приводят к неизбежному даунтайму, высокому риску ошибок и сложностям с откатом в случае проблем. Именно поэтому индустрия пришла к необходимости использования продвинутых стратегий, таких как Blue/Green и Canary обновления. Эти подходы позволяют минимизировать или полностью исключить простой приложения, значительно снизить риски при внедрении новых функций и обеспечить быстрый и безопасный откат к предыдущей версии.
Эта статья предназначена для широкого круга технических специалистов: от опытных DevOps-инженеров и системных администраторов, стремящихся оптимизировать свои пайплайны, до backend-разработчиков (Python, Node.js, Go, PHP), желающих лучше понимать инфраструктурные аспекты деплоя. Фаундеры SaaS-проектов и технические директора стартапов найдут здесь практические рекомендации по снижению операционных рисков и повышению надежности своих сервисов. Мы углубимся в детали Blue/Green и Canary стратегий, рассмотрим их преимущества и недостатки, приведем конкретные примеры реализации на VPS с использованием Docker, а также обсудим актуальные инструменты и лучшие практики, актуальные на 2026 год.
Мы не будем продавать вам "волшебные таблетки" или "серебряные пули". Вместо этого, вы получите экспертный, практичный гайд, основанный на реальном опыте и проверенных решениях. Мы разберем, как эти стратегии помогают решать такие проблемы, как:
- Минимизация даунтайма: Обеспечение непрерывной работы сервиса во время обновления.
- Снижение рисков деплоя: Возможность быстрого отката или постепенного внедрения новой версии.
- Улучшение качества релизов: Тестирование новой версии в реальной производственной среде на ограниченной аудитории.
- Повышение доверия к команде: Демонстрация стабильности и надежности сервиса даже при частых обновлениях.
- Оптимизация использования ресурсов: Эффективное управление инфраструктурой VPS для поддержания нескольких версий приложения.
Приготовьтесь к погружению в мир продвинутых стратегий деплоя, которые изменят ваше представление о том, как должны обновляться Docker-приложения на VPS. Давайте начнем.
2. Основные критерии выбора стратегии деплоя
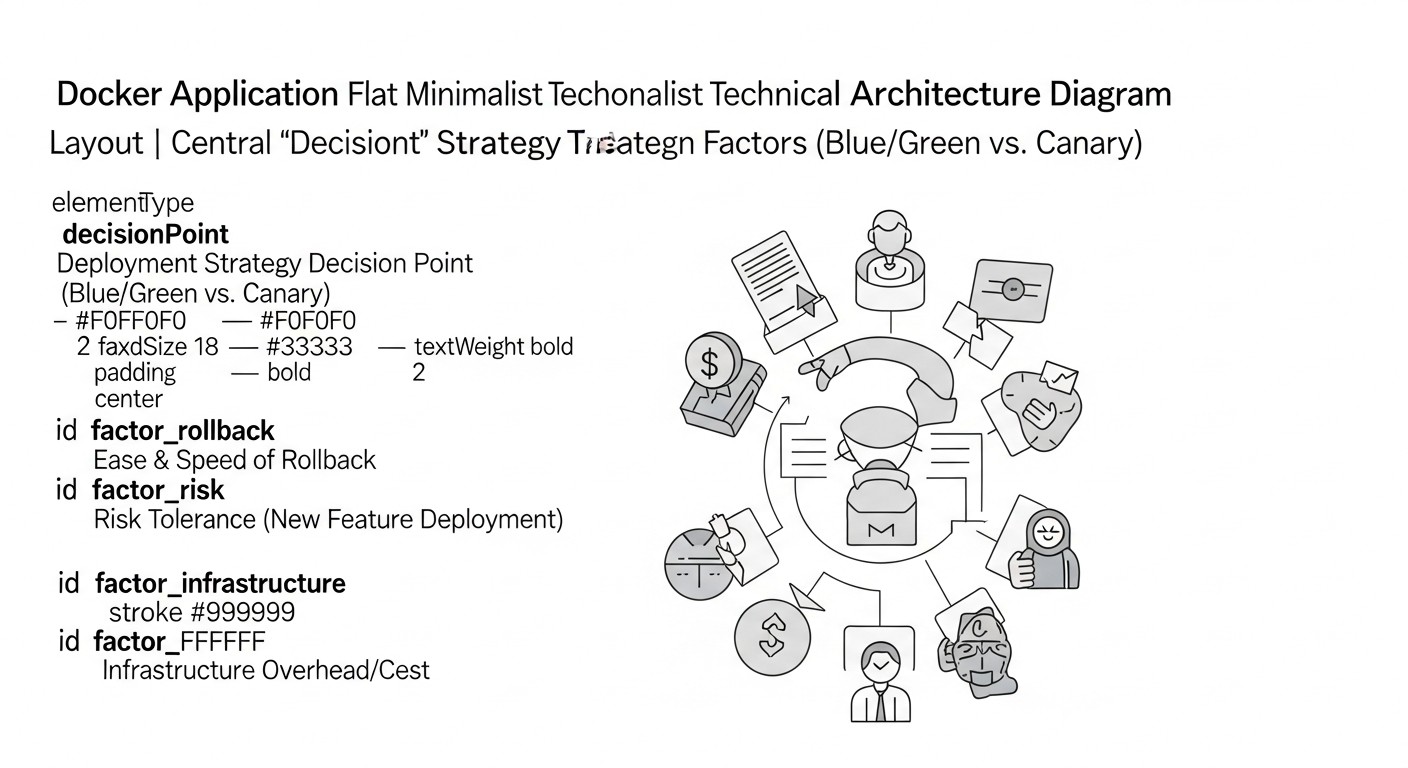 Схема: 2. Основные критерии выбора стратегии деплоя
Схема: 2. Основные критерии выбора стратегии деплоя
Выбор подходящей стратегии деплоя — это не просто техническое решение, а стратегический выбор, который напрямую влияет на стабильность, надежность и экономическую эффективность вашего приложения. В 2026 году, когда требования к скорости и качеству релизов только растут, важно учитывать множество факторов. Давайте детально разберем ключевые критерии, которые помогут вам определить, какая стратегия — Blue/Green или Canary — наилучшим образом соответствует вашим потребностям.
2.1. Допустимый даунтайм (Downtime Tolerance)
Почему важен: Это, пожалуй, самый очевидный и критичный фактор. Для некоторых сервисов (например, банковских систем, медицинских платформ, E-commerce в пиковые часы) любой простой неприемлем. Для других (внутренние инструменты, блоги с некритичным трафиком) несколько минут простоя могут быть допустимы. Даунтайм напрямую влияет на пользовательский опыт, финансовые потери и репутацию бренда. Стратегии Blue/Green и Canary созданы для минимизации или полного исключения даунтайма.
Как оценивать: Определите SLA (Service Level Agreement) вашего приложения. Каково максимально допустимое время простоя в год, месяц или неделю? Какие финансовые и репутационные потери повлечет за собой простой? Если даунтайм должен быть нулевым или стремиться к нулю, то Blue/Green или Canary — ваш единственный выбор.
2.2. Скорость отката (Rollback Speed)
Почему важен: Ошибки случаются. И когда они происходят в продакшене, способность быстро вернуться к стабильной версии становится жизненно важной. Чем быстрее вы можете откатиться, тем меньше будет воздействие на пользователей и бизнес. Медленный откат может привести к длительному простою и усугублению проблем.
Как оценивать: Измерьте время, необходимое для развертывания предыдущей версии приложения. В идеале, откат должен занимать секунды или минуты. Blue/Green позволяет выполнить откат практически мгновенно, просто переключив трафик обратно на "синюю" (старую) среду. Canary требует более сложного отката, возможно, поэтапного вывода "канарейки" из эксплуатации и возврата трафика на стабильную версию.
2.3. Сложность реализации и управления (Implementation Complexity & Management Overhead)
Почему важен: Каждая стратегия деплоя имеет свою кривую обучения и требует определенных навыков и инструментов. Сложная стратегия может потребовать больше времени на настройку, больше ресурсов для поддержки и увеличить вероятность ошибок при ручном управлении. В условиях ограниченных ресурсов VPS и небольшой команды это может быть критично.
Как оценивать: Оцените уровень вашей команды. Есть ли у вас опыт работы с балансировщиками нагрузки, динамическим DNS, CI/CD пайплайнами? Готовы ли вы инвестировать время в изучение и настройку? Blue/Green относительно прост в концепции, но требует тщательного управления трафиком. Canary сложнее, так как предполагает тонкую настройку маршрутизации трафика (пользователи, процент) и более сложный мониторинг.
2.4. Потребление ресурсов (Resource Consumption)
Почему важен: Деплой на VPS часто связан с ограниченными ресурсами. Blue/Green стратегия, по своей сути, требует как минимум удвоения ресурсов на короткий период (старая и новая версии работают параллельно). Canary может быть более экономной, если вы постепенно заменяете старые инстансы новыми, но для полноценного A/B тестирования или параллельной работы двух версий все равно потребуются дополнительные ресурсы.
Как оценивать: Проанализируйте текущую загрузку вашего VPS. Есть ли у вас запас по CPU, RAM, дисковому пространству? Готовы ли вы временно масштабировать VPS или использовать дополнительные инстансы? Стоимость ресурсов на VPS в 2026 году, хотя и снизилась, все еще является значимым фактором. Оцените, можете ли вы позволить себе удвоить ресурсы на 10-30 минут во время деплоя.
2.5. Возможности тестирования и валидации (Testing & Validation Capabilities)
Почему важен: Чем раньше вы обнаружите ошибку, тем дешевле она обойдется. Стратегии деплоя должны предоставлять возможности для тестирования новой версии в максимально приближенных к продакшену условиях, прежде чем она станет доступна всем пользователям. Это включает функциональное тестирование, нагрузочное тестирование, мониторинг производительности и сбор метрик.
Как оценивать: Blue/Green позволяет провести полное тестирование новой "зеленой" среды перед переключением трафика. Canary идет дальше, позволяя тестировать новую версию на реальных пользователях, собирая метрики и обратную связь, прежде чем полностью развернуть ее. Это особенно ценно для оценки пользовательского опыта и производительности в реальных условиях.
2.6. Совместимость с базами данных и миграциями (Database & Data Migration Compatibility)
Почему важен: Обновление приложения часто влечет за собой изменения в схеме базы данных. Это одна из самых сложных частей деплоя, поскольку она может нарушить работу как старой, так и новой версии приложения. Важно убедиться, что ваша стратегия деплоя поддерживает обратную и прямую совместимость с изменениями базы данных.
Как оценивать: Планируйте миграции базы данных так, чтобы они были неблокирующими и обратно совместимыми. Например, при добавлении новой колонки, сначала разверните новую версию приложения, которая умеет работать с новой колонкой (но не требует ее). Затем выполните миграцию БД, а после этого переключите трафик. При удалении колонки, сначала убедитесь, что все старые версии, использующие эту колонку, выведены из эксплуатации. Это требует тщательного планирования и, возможно, использования паттернов, таких как "Two-Phase Schema Migration".
2.7. Требования к отказоустойчивости (Fault Tolerance Requirements)
Почему важен: Даже при самых продуманных стратегиях, сбои могут происходить. Ваша система должна быть спроектирована так, чтобы выдерживать отказы отдельных компонентов или целых версий приложения. Это включает в себя автоматическое обнаружение проблем, переключение на резервные ресурсы и изоляцию неисправных частей.
Как оценивать: Оцените, насколько критично для вашего бизнеса, чтобы система продолжала работать даже при частичном сбое. Blue/Green обеспечивает высокую отказоустойчивость при откате, так как старая версия остается доступной. Canary, благодаря постепенному раскату, ограничивает воздействие сбоя лишь на часть пользователей, что повышает общую отказоустойчивость системы в процессе деплоя.
Тщательный анализ этих критериев позволит вам выбрать наиболее подходящую стратегию деплоя, которая не только минимизирует риски и даунтайм, но и будет экономически оправданной и управляемой для вашей команды и инфраструктуры VPS.
3. Сравнительная таблица: Blue/Green vs. Canary обновления
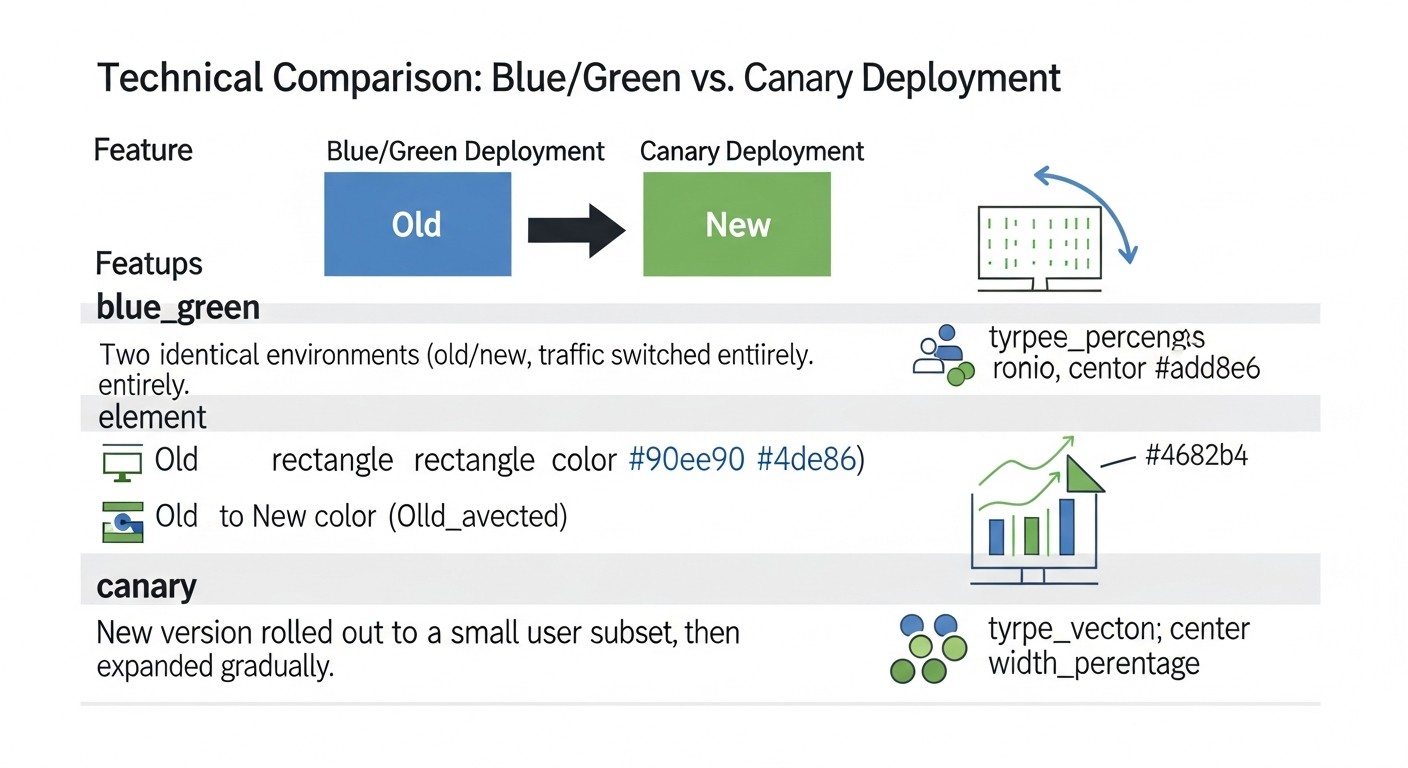 Схема: 3. Сравнительная таблица: Blue/Green vs. Canary обновления
Схема: 3. Сравнительная таблица: Blue/Green vs. Canary обновления
Выбор между Blue/Green и Canary стратегиями деплоя зачастую сводится к компромиссу между простотой, скоростью отката и возможностью тестирования на реальных пользователях. В этой таблице мы представим детальное сравнение обеих стратегий, учитывая актуальные реалии и ожидания 2026 года, включая примерные затраты и технические особенности.
| Критерий |
Blue/Green Деплой |
Canary Деплой |
| Основная идея |
Две идентичные среды (Blue - старая, Green - новая). Трафик переключается целиком на Green после успешного тестирования. |
Постепенное внедрение новой версии (Canary) для небольшой части пользователей, затем увеличение процента. |
| Даунтайм при деплое |
Практически нулевой (время переключения трафика). |
Нулевой, так как старая версия продолжает обслуживать большинство пользователей. |
| Скорость отката |
Мгновенный (переключение трафика обратно на Blue). |
Занимает больше времени, так как нужно вывести Canary из эксплуатации и перенаправить трафик. |
| Потребление ресурсов (VPS) |
Временно удваивает потребление (Blue + Green среды). Например, 2x VPS или 2x набор контейнеров. |
Может быть более эффективным, если Canary занимает небольшую часть ресурсов. На пике может быть 1.1x - 1.5x от обычного. |
| Сложность реализации |
Средняя. Требует управления двумя средами и балансировщиком нагрузки. |
Высокая. Требует сложной маршрутизации трафика, продвинутого мониторинга и автоматизации. |
| Возможности тестирования |
Полное тестирование новой версии перед запуском. |
Тестирование на реальных пользователях, A/B тестирование, сбор метрик производительности и ошибок в продакшене. |
| Выявление ошибок |
Ошибки выявляются до переключения трафика (в Green). |
Ошибки выявляются на небольшой части пользователей, минимизируя общее влияние. |
| Управление базами данных |
Требует тщательного планирования миграций с обратной совместимостью. |
Еще более строгое требование к обратной совместимости, т.к. обе версии могут одновременно работать с БД. |
| Идеально подходит для |
Критических приложений с высоким SLA, где требуется быстрый откат и полное тестирование перед релизом. |
Приложений, где важно минимизировать риск, тестировать новые функции на живой аудитории, постепенно внедрять изменения. |
| Примерные дополнительные затраты на VPS (2026) |
Кратковременно +100%: Если ваш сервис работает на 2 VPS по $20/мес, то на время деплоя потребуется 4 VPS, т.е. $80/мес вместо $40/мес (на несколько минут/часов). В долгосрочной перспективе, это может быть +$5-10/мес на более мощный VPS или дополнительный инстанс на несколько часов. |
Долговременно +10-50%: Например, если ваш сервис работает на 2 VPS по $20/мес, то для Canary может потребоваться 2 основных + 1 дополнительный VPS (для Canary), или более мощные VPS для размещения большего количества контейнеров. Это может быть +$20/мес постоянно, если Canary инстансы работают долго. |
| Основные инструменты (2026) |
Docker Compose, Nginx/Caddy, HAProxy, Ansible, GitLab CI/GitHub Actions, Prometheus, Grafana. |
Docker Compose, Nginx/Caddy, HAProxy, Traefik, Istio (для более сложных сценариев), Kubernetes, Ansible, GitLab CI/GitHub Actions, Prometheus, Grafana, OpenTelemetry. |
Эта таблица наглядно демонстрирует, что нет "лучшей" стратегии; есть та, которая лучше подходит для конкретного сценария, бюджета и уровня зрелости команды. Blue/Green обеспечивает простоту и безопасность полного переключения, в то время как Canary предлагает непревзойденные возможности для постепенного внедрения и тестирования в реальном времени, но ценой большей сложности и возможных постоянных затрат на ресурсы.
4. Детальный обзор Blue/Green деплоя
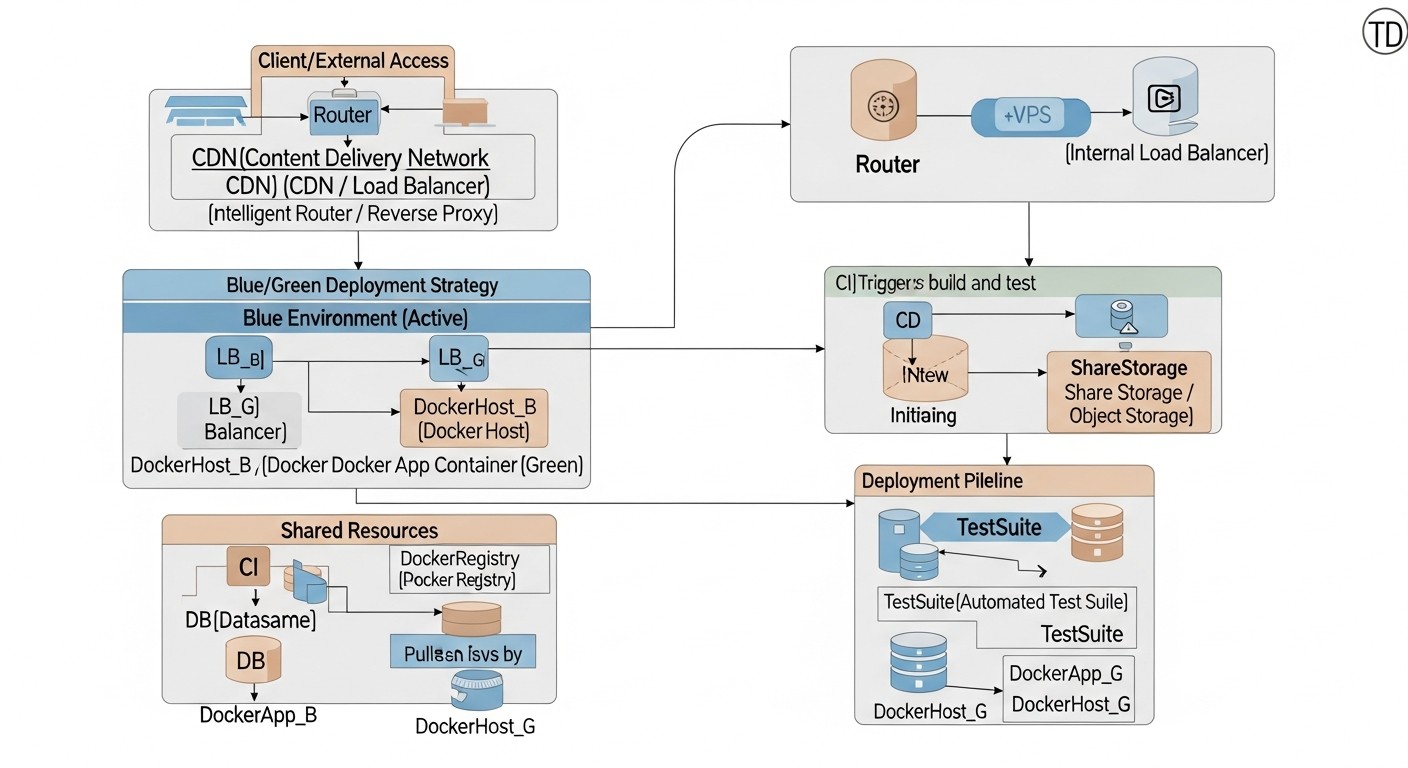 Схема: 4. Детальный обзор Blue/Green деплоя
Схема: 4. Детальный обзор Blue/Green деплоя
Стратегия Blue/Green деплоя является одним из наиболее популярных и эффективных методов обеспечения бесшовных обновлений приложений с минимальным даунтаймом. Ее ключевая идея заключается в поддержании двух идентичных производственных сред, которые мы условно называем "синей" (Blue) и "зеленой" (Green). В любой момент времени только одна из этих сред активна и обслуживает весь пользовательский трафик. Давайте углубимся в детали этой стратегии.
4.1. Принцип работы Blue/Green
Представьте, что у вас есть две полностью идентичные инфраструктуры или наборы ресурсов на вашем VPS. Одна из них, скажем, "синяя", содержит текущую, стабильную версию вашего Docker-приложения и обслуживает весь входящий трафик. Когда приходит время обновить приложение, вы разворачиваете новую версию на "зеленой" среде, которая до этого момента была неактивна или содержала старую версию, но без трафика.
- Подготовка "зеленой" среды: Вы разворачиваете новую версию Docker-образа вашего приложения на "зеленой" инфраструктуре. Это может быть отдельный Docker-контейнер, группа контейнеров, или даже отдельный VPS, настроенный идентично "синему".
- Тестирование "зеленой" среды: После развертывания новой версии на "зеленой" среде, вы проводите все необходимые тесты: функциональные, интеграционные, нагрузочные. Это дает вам уверенность, что новая версия работает корректно в производственных условиях, но еще не затрагивает реальных пользователей.
- Переключение трафика: Если тесты прошли успешно, вы переключаете весь входящий пользовательский трафик с "синей" среды на "зеленую". Это обычно делается путем изменения конфигурации балансировщика нагрузки (например, Nginx, HAProxy, Caddy) или DNS-записи. Это переключение происходит практически мгновенно.
- Мониторинг "зеленой" среды: После переключения трафика, вы внимательно отслеживаете работу новой "зеленой" среды, собирая метрики производительности, ошибки и логи.
- Откат (Rollback): Если в "зеленой" среде обнаруживаются критические проблемы, вы можете моментально откатиться, просто переключив трафик обратно на стабильную "синюю" среду. Это происходит очень быстро и безопасно, так как "синяя" среда оставалась нетронутой.
- Очистка или повторное использование: Если "зеленая" среда стабильна, "синяя" среда может быть либо уничтожена (для экономии ресурсов), либо обновлена до новой версии и стать следующей "зеленой" средой для будущего деплоя.
4.2. Преимущества Blue/Green деплоя
- Нулевой даунтайм: Переключение трафика происходит очень быстро, обычно в течение секунд, что минимизирует или полностью исключает простой для пользователей.
- Быстрый и безопасный откат: В случае проблем, возврат к предыдущей стабильной версии происходит мгновенно, просто путем переключения трафика обратно на "синюю" среду. Это дает высокую степень уверенности в процессе деплоя.
- Простота тестирования: Новая версия может быть полностью протестирована в производственной среде перед тем, как стать доступной для пользователей, что снижает риск вывода ошибок в продакшен.
- Изоляция сред: "Синяя" и "зеленая" среды полностью изолированы, что предотвращает конфликты и упрощает управление.
- Уверенность в релизах: Возможность быстрого отката снижает стресс и повышает уверенность команды в каждом новом релизе.
4.3. Недостатки Blue/Green деплоя
- Удвоение ресурсов: На время деплоя требуется удвоение вычислительных ресурсов (CPU, RAM, дисковое пространство), так как обе среды (Blue и Green) работают параллельно. На VPS это может означать временное масштабирование или использование более мощного сервера.
- Управление состоянием: Если приложение имеет состояние (например, сессии пользователей, кэши), необходимо обеспечить их корректную обработку при переключении. Это может потребовать использования общих хранилищ состояния (Redis, Memcached) или тщательного проектирования сессий.
- Миграции баз данных: Изменения в схеме базы данных требуют особого внимания. Миграции должны быть обратно совместимыми, чтобы обе версии приложения (старая и новая) могли работать с одной и той же базой данных во время переходного периода.
- Сложность для очень больших приложений: Для монолитных приложений с большим количеством зависимостей или очень сложной инфраструктурой, создание двух полностью идентичных сред может быть дорогостоящим и трудоемким.
4.4. Для кого подходит Blue/Green
Blue/Green деплой идеально подходит для:
- SaaS-проектов с высоким SLA: Где критически важен нулевой даунтайм и быстрый откат.
- Приложений с частыми, но предсказуемыми релизами: Когда вы уверены в качестве кода после внутреннего тестирования, но хотите дополнительную страховку в продакшене.
- Команд, которые ценят простоту и предсказуемость: Концепция относительно проста для понимания и реализации по сравнению с Canary, особенно на VPS с использованием Docker Compose и Nginx/HAProxy.
- Проектов, способных временно выделить дополнительные ресурсы: Если ваш VPS может выдержать временное удвоение нагрузки или вы готовы временно масштабироваться.
В целом, Blue/Green является отличной отправной точкой для многих команд, стремящихся к бесшовному деплою. Он обеспечивает высокий уровень безопасности и надежности, при этом оставаясь относительно управляемым в реализации на VPS.
5. Детальный обзор Canary деплоя
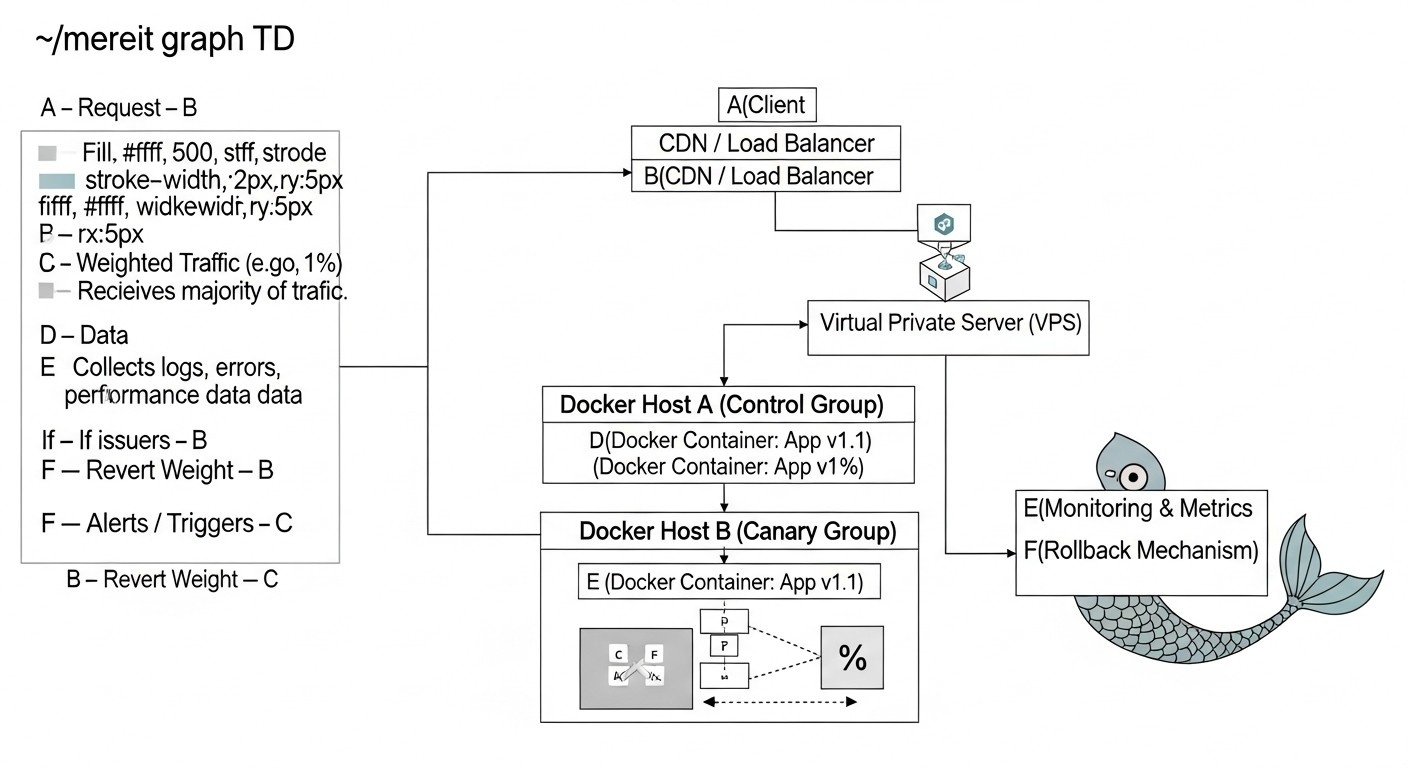 Схема: 5. Детальный обзор Canary деплоя
Схема: 5. Детальный обзор Canary деплоя
Canary деплой, названный в честь канареек, используемых в шахтах для обнаружения опасных газов, представляет собой продвинутую стратегию развертывания, которая позволяет постепенно выкатывать новую версию приложения на ограниченную группу пользователей. Это минимизирует потенциальное воздействие ошибок на всю пользовательскую базу и дает возможность собрать обратную связь и метрики в реальном времени, прежде чем новая версия станет общедоступной. В 2026 году, с ростом популярности A/B тестирования и персонализации, Canary становится незаменимым инструментом.
5.1. Принцип работы Canary
В отличие от Blue/Green, где трафик переключается целиком, Canary деплой предполагает поэтапное перенаправление трафика. Это позволяет "проверить воду" на небольшой, изолированной группе пользователей.
- Развертывание "канарейки": Вы разворачиваете новую версию вашего Docker-приложения (так называемую "канарейку") рядом с текущей стабильной версией на вашем VPS. Изначально на "канарейку" не направляется трафик или направляется очень малый процент.
- Перенаправление малого процента трафика: Балансировщик нагрузки или API Gateway настраивается таким образом, чтобы перенаправить очень небольшой процент (например, 1-5%) входящего трафика на "канарейку". Остальной трафик продолжает обслуживаться стабильной версией.
- Мониторинг и сбор метрик: Это самый критичный этап. Вы тщательно отслеживаете производительность, ошибки, пользовательское поведение и бизнес-метрики для "канарейки". Важно иметь хорошо настроенную систему мониторинга, которая позволяет сравнивать показатели "канарейки" со стабильной версией.
- Постепенное увеличение трафика: Если "канарейка" показывает стабильную работу и хорошие метрики, вы постепенно увеличиваете процент трафика, направляемого на нее (например, до 10%, затем 25%, 50% и так далее). Каждый этап сопровождается тщательным мониторингом.
- Полный раскат: Когда "канарейка" успешно обслуживает значительную часть трафика без проблем, и вы полностью уверены в ее стабильности, вы перенаправляете весь 100% трафик на новую версию.
- Вывод старой версии: Старая версия приложения может быть выведена из эксплуатации и ее ресурсы освобождены.
- Откат (Rollback): В случае обнаружения проблем на любом этапе, вы немедленно перенаправляете весь трафик обратно на стабильную версию. Поскольку воздействие было ограничено небольшой группой пользователей, ущерб минимизируется.
5.2. Преимущества Canary деплоя
- Минимальный риск: Воздействие потенциальных ошибок ограничено небольшой частью пользователей, что делает эту стратегию идеальной для критически важных систем.
- Тестирование в реальном времени: Новая версия тестируется на реальных пользователях в реальной производственной среде, что позволяет выявить проблемы, которые могли быть упущены при синтетическом тестировании.
- A/B тестирование: Canary деплой естественным образом позволяет проводить A/B тестирование новых функций, сравнивая их эффективность со старыми на основе пользовательского поведения и бизнес-метрик.
- Постепенное внедрение: Возможность постепенно привыкать к новым функциям и собирать обратную связь, что особенно полезно для радикальных изменений пользовательского интерфейса или бизнес-логики.
- Экономия ресурсов: На начальных этапах "канарейка" может требовать меньше дополнительных ресурсов по сравнению с полным дублированием в Blue/Green.
5.3. Недостатки Canary деплоя
- Высокая сложность: Требует сложной настройки балансировщика нагрузки для маршрутизации трафика по различным критериям (процент, заголовки, куки), а также продвинутой системы мониторинга и логирования.
- Продолжительность: Процесс Canary деплоя может занимать значительно больше времени, чем Blue/Green, так как каждый этап требует мониторинга и принятия решений.
- Управление состоянием и базами данных: Еще более критично, чем в Blue/Green. Обе версии приложения (стабильная и "канарейка") должны быть способны работать с одной и той же схемой базы данных и состоянием. Миграции должны быть строго обратно совместимыми.
- Проблемы с отладочной информацией: Если ошибка проявляется только на "канарейке", может быть сложно собрать достаточную информацию для отладки, если трафик слишком мал.
- Потенциальное ухудшение пользовательского опыта: Хотя и для малой группы, некоторые пользователи все же могут столкнуться с ошибками или регрессиями.
5.4. Для кого подходит Canary
Canary деплой идеально подходит для:
- Крупных SaaS-проектов с миллионами пользователей: Где даже малый процент ошибок может затронуть значительное количество людей.
- Приложений, где важен непрерывный сбор обратной связи и метрик: Для A/B тестирования новых функций, оценки производительности и реакции пользователей.
- Команд с высоким уровнем автоматизации и зрелой культурой DevOps: Требует развитых CI/CD пайплайнов, глубокого мониторинга и автоматических откатов.
- Проектов, готовых инвестировать в сложную инфраструктуру: Для настройки продвинутых балансировщиков (например, Traefik, Nginx с Lua-скриптами), систем мониторинга и логирования.
- Когда изменения могут быть рискованными: Например, при внедрении новой платежной системы, изменении критически важной бизнес-логики или значительных обновлений UI.
Canary деплой — это мощный инструмент для минимизации рисков и улучшения качества релизов, но он требует значительных инвестиций в автоматизацию, мониторинг и оркестрацию. На VPS его можно реализовать с помощью Docker Compose, Nginx/HAProxy и скриптов для управления трафиком, но для более сложных сценариев может потребоваться Kubernetes или его легковесные аналоги.
6. Практические советы и рекомендации по внедрению
 Схема: 6. Практические советы и рекомендации по внедрению
Схема: 6. Практические советы и рекомендации по внедрению
Реализация Blue/Green и Canary деплоя на VPS требует не только понимания концепций, но и конкретных технических шагов. В этом разделе мы предоставим пошаговые инструкции, примеры команд и конфигураций, а также рекомендации, основанные на реальном опыте внедрения этих стратегий в 2026 году.
6.1. Общие требования к инфраструктуре VPS
- Достаточные ресурсы VPS: Убедитесь, что ваш VPS имеет достаточно CPU, RAM и дискового пространства для запуска как минимум двух версий вашего приложения (для Blue/Green) или стабильной версии плюс "канарейки" (для Canary). Рассмотрите возможность использования VPS с возможностью быстрого вертикального масштабирования или добавления временных инстансов.
- Docker и Docker Compose: Установлены и настроены на вашем VPS. Docker Compose будет использоваться для оркестрации нескольких контейнеров, составляющих ваше приложение.
- Балансировщик нагрузки (Reverse Proxy): Nginx, Caddy или HAProxy являются отличными кандидатами. Они будут отвечать за маршрутизацию трафика к правильной версии приложения.
- Система мониторинга и логирования: Prometheus + Grafana для метрик, ELK-стек (Elasticsearch, Logstash, Kibana) или Loki + Promtail для логов. Это критично для отслеживания здоровья и производительности обеих версий.
- CI/CD пайплайн: Автоматизация всего процесса деплоя с помощью Jenkins, GitLab CI, GitHub Actions или Ansible. Ручной деплой увеличивает риски и трудозатраты.
6.2. Реализация Blue/Green деплоя на одном VPS с Docker Compose и Nginx
Предположим, у вас есть приложение, состоящее из веб-сервера и базы данных. Для Blue/Green нам понадобятся два набора контейнеров для приложения, но общая база данных.
6.2.1. Структура проекта
Создадим две папки для разных версий приложения, например, app-blue и app-green. В каждой будет свой docker-compose.yml.
# Структура директорий
.
├── nginx.conf
├── app-blue/
│ └── docker-compose.yml
│ └── Dockerfile
│ └── app.py (version 1.0)
├── app-green/
│ └── docker-compose.yml
│ └── Dockerfile
│ └── app.py (version 2.0)
└── data/
└── db/ (для PostgreSQL/MySQL)
6.2.2. Пример app-blue/docker-compose.yml (для версии 1.0)
version: '3.8'
services:
web:
build:
context: .
dockerfile: Dockerfile
image: myapp:1.0
container_name: myapp_blue_web
ports:
- "8080:80" # Слушаем на порту 8080
environment:
- APP_VERSION=1.0
- DATABASE_URL=postgresql://user:password@db:5432/mydatabase
volumes:
- ./app.py:/app/app.py
networks:
- app_network
db: # Общая база данных
image: postgres:14
container_name: myapp_db
environment:
POSTGRES_DB: mydatabase
POSTGRES_USER: user
POSTGRES_PASSWORD: password
volumes:
- ../data/db:/var/lib/postgresql/data
networks:
- app_network
restart: unless-stopped # Важно для общей БД
networks:
app_network:
driver: bridge
6.2.3. Пример app-green/docker-compose.yml (для версии 2.0)
Аналогично, но с другим портом и именем контейнера:
version: '3.8'
services:
web:
build:
context: .
dockerfile: Dockerfile
image: myapp:2.0
container_name: myapp_green_web
ports:
- "8081:80" # Слушаем на порту 8081
environment:
- APP_VERSION=2.0
- DATABASE_URL=postgresql://user:password@db:5432/mydatabase
volumes:
- ./app.py:/app/app.py
networks:
- app_network
networks:
app_network:
external: true # Используем ту же сеть, что и Blue, для доступа к общей БД
Примечание: В реальном сценарии, БД должна быть отдельным сервисом, доступным для обеих сред, а не частью docker-compose.yml каждой среды. Здесь для простоты она включена в Blue, а Green подключается к ней по общей сети.
6.2.4. Конфигурация Nginx (nginx.conf)
Nginx будет выступать в роли балансировщика нагрузки, переключая трафик между портами 8080 (Blue) и 8081 (Green).
# nginx.conf
worker_processes auto;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
upstream app_backend {
# Изначально направляем на Blue
server 127.0.0.1:8080; # Blue
# server 127.0.0.1:8081; # Green (закомментировано)
}
server {
listen 80;
server_name your_domain.com;
location / {
proxy_pass http://app_backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
}
6.2.5. Процесс деплоя Blue/Green
- Старт Blue (текущая версия):
cd app-blue
docker-compose up -d --build
Убедитесь, что Nginx настроен на порт 8080.
- Подготовка Green (новая версия):
cd app-green
docker-compose up -d --build
Это запустит новую версию на порту 8081. Проведите тестирование, обращаясь напрямую к http://your_vps_ip:8081.
- Переключение трафика:
Когда Green протестирована, обновите nginx.conf, изменив upstream app_backend:
upstream app_backend {
# server 127.0.0.1:8080; # Blue (закомментировано)
server 127.0.0.1:8081; # Green (активно)
}
Перезагрузите Nginx: sudo systemctl reload nginx.
- Мониторинг: Внимательно следите за логами и метриками Green.
- Очистка Blue (или подготовка к следующему деплою):
Если Green стабильна, остановите Blue:
cd app-blue
docker-compose down
- Откат: Если Green вызывает проблемы, немедленно измените
nginx.conf обратно на server 127.0.0.1:8080; и перезагрузите Nginx.
6.3. Реализация Canary деплоя на одном VPS с Docker Compose и Nginx/Caddy
Canary сложнее, так как требует динамической маршрутизации трафика. Nginx может это делать с помощью Lua-скриптов или более сложных конфигураций, но для простоты мы рассмотрим базовый подход с использованием весов или заголовков.
6.3.1. Nginx для Canary (по весам)
Это простейший Canary, где трафик распределяется по весам.
# nginx.conf для Canary (по весам)
upstream app_backend {
server 127.0.0.1:8080 weight=90; # Blue (старая версия, 90% трафика)
server 127.0.0.1:8081 weight=10; # Canary (новая версия, 10% трафика)
}
server {
listen 80;
server_name your_domain.com;
location / {
proxy_pass http://app_backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
Процесс:
- Запустите Blue на 8080.
- Запустите Canary на 8081.
- Обновите
nginx.conf с весами (например, 90% Blue, 10% Canary). Перезагрузите Nginx.
- Мониторинг. Если все хорошо, постепенно меняйте веса (например, 70/30, 50/50, 20/80, 0/100) и перезагружайте Nginx на каждом шаге.
- Когда 100% трафика идет на Canary, остановите Blue.
6.3.2. Canary по заголовкам/кукам (для внутренних тестеров)
Более продвинутый Canary может направлять трафик на новую версию только для определенных пользователей (например, с определенным HTTP-заголовком или кукой).
# nginx.conf для Canary (по заголовкам)
upstream app_blue {
server 127.0.0.1:8080;
}
upstream app_canary {
server 127.0.0.1:8081;
}
server {
listen 80;
server_name your_domain.com;
location / {
# Если есть заголовок "X-Canary: true", направляем на Canary
if ($http_x_canary = "true") {
proxy_pass http://app_canary;
}
# Иначе, на Blue
proxy_pass http://app_blue;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
Процесс:
- Запустите Blue на 8080.
- Запустите Canary на 8081.
- Обновите
nginx.conf. Перезагрузите Nginx.
- Тестируйте Canary, отправляя запросы с заголовком
X-Canary: true.
- Когда уверены, что Canary стабильна, измените
nginx.conf, чтобы весь трафик шел на app_canary, или используйте веса, как в предыдущем примере, для постепенного раската.
6.4. Автоматизация CI/CD пайплайна (на примере GitLab CI)
Автоматизация — это сердце эффективного деплоя. Ручное управление Nginx и Docker Compose быстро становится неконтролируемым.
Пример .gitlab-ci.yml для Blue/Green:
stages:
- build
- deploy_green
- switch_traffic
- cleanup_blue
variables:
DOCKER_HOST_USER: "user"
DOCKER_HOST_IP: "your_vps_ip"
APP_DIR: "/path/to/your/app"
BLUE_PORT: "8080"
GREEN_PORT: "8081"
build:
stage: build
script:
- docker build -t myapp:$CI_COMMIT_SHORT_SHA .
- docker save myapp:$CI_COMMIT_SHORT_SHA | gzip > myapp-$CI_COMMIT_SHORT_SHA.tar.gz
- scp myapp-$CI_COMMIT_SHORT_SHA.tar.gz $DOCKER_HOST_USER@$DOCKER_HOST_IP:$APP_DIR/
tags:
- docker_builder # Пример тега для раннера
deploy_green:
stage: deploy_green
script:
- ssh $DOCKER_HOST_USER@$DOCKER_HOST_IP "
cd $APP_DIR/app-green &&
docker load < myapp-$CI_COMMIT_SHORT_SHA.tar.gz &&
docker-compose down || true && # Остановка предыдущего Green, если был
sed -i 's/image: myapp:.$/image: myapp:$CI_COMMIT_SHORT_SHA/' docker-compose.yml &&
docker-compose up -d --build &&
# Здесь можно добавить скрипты для запуска тестов на Green
# Например: curl -f http://$DOCKER_HOST_IP:$GREEN_PORT/health || exit 1
"
tags:
- deployer
allow_failure: false
switch_traffic:
stage: switch_traffic
script:
- ssh $DOCKER_HOST_USER@$DOCKER_HOST_IP "
sed -i 's/server 127.0.0.1:$BLUE_PORT;/ # server 127.0.0.1:$BLUE_PORT;/' $APP_DIR/nginx.conf &&
sed -i 's/# server 127.0.0.1:$GREEN_PORT;/ server 127.0.0.1:$GREEN_PORT;/' $APP_DIR/nginx.conf &&
sudo systemctl reload nginx
"
tags:
- deployer
when: manual # Ручное подтверждение после тестирования Green
cleanup_blue:
stage: cleanup_blue
script:
- ssh $DOCKER_HOST_USER@$DOCKER_HOST_IP "
cd $APP_DIR/app-blue &&
docker-compose down &&
rm -f myapp-$CI_COMMIT_SHORT_SHA.tar.gz
"
tags:
- deployer
when: manual # Ручное подтверждение после успешного переключения
Важные замечания по CI/CD:
- Используйте SSH-ключи для доступа к VPS без пароля.
- Переменные окружения для чувствительных данных (пароли, ключи).
sed -i для модификации конфигурационных файлов Nginx. В более сложных сценариях можно использовать Ansible шаблоны.when: manual для этапов переключения и очистки, чтобы обеспечить ручную проверку и подтверждение. В идеале, после автоматических тестов на Green, можно сделать паузу для ручного смоук-теста.- Добавьте полноценные тесты (health checks, интеграционные) в пайплайн.
- Для Canary пайплайн будет сложнее, с этапами постепенного увеличения трафика и мониторингом после каждого шага.
6.5. Мониторинг и логирование
Мониторинг — это ваши глаза и уши в продакшене. Без него Blue/Green и Canary деплой теряют смысл.
- Метрики: Используйте Prometheus для сбора метрик (CPU, RAM, сетевой трафик VPS, а также метрики вашего приложения: количество запросов, задержки, ошибки). Экспортеры для Docker, Node Exporter для VPS, и кастомные экспортеры для вашего приложения. Grafana для визуализации.
- Логи: Собирайте логи всех контейнеров.
- Простое решение: Использовать
docker logs -f <container_name> или настроить log-driver Docker на json-file и собирать их с помощью journalctl.
- Продвинутое решение: ELK-стек (Elasticsearch, Logstash, Kibana) или Loki + Promtail. Promtail собирает логи с контейнеров Docker и отправляет их в Loki, а Grafana используется для запросов к Loki.
- Алерты: Настройте оповещения (через Alertmanager для Prometheus) о любых аномалиях: рост ошибок в новой версии, деградация производительности, высокая загрузка ресурсов.
- Трассировка (Distributed Tracing): Для микросервисных архитектур рассмотрите OpenTelemetry или Jaeger/Zipkin для отслеживания запросов через несколько сервисов. Это помогает понять, где именно возникла проблема в Canary деплое.
6.6. Управление базами данных
Миграции БД — это самое слабое звено в бесшовных деплоях. Всегда следуйте принципу обратной совместимости:
- Добавление колонки: Сначала разверните новую версию приложения, которая умеет работать с новой колонкой (но не требует ее). Затем выполните миграцию БД. После этого переключите трафик.
- Удаление колонки: Сначала убедитесь, что все старые версии, использующие эту колонку, выведены из эксплуатации. Затем удалите колонку из БД.
- Изменение типа колонки: Часто требует двухфазной миграции: сначала добавление новой колонки с новым типом, перенос данных, переключение приложения на новую колонку, затем удаление старой.
Используйте инструменты для миграции БД, такие как Alembic (Python), Flyway (Java), Liquibase, Knex.js (Node.js).
Внедрение этих практических советов позволит вам создать надежный и автоматизированный процесс деплоя, который значительно снизит риски и повысит стабильность ваших Docker-приложений на VPS.
7. Типичные ошибки при внедрении Blue/Green и Canary
 Схема: 7. Типичные ошибки при внедрении Blue/Green и Canary
Схема: 7. Типичные ошибки при внедрении Blue/Green и Canary
Внедрение продвинутых стратегий деплоя, таких как Blue/Green и Canary, может значительно улучшить стабильность и надежность ваших релизов. Однако, как и любая сложная инженерная задача, оно сопряжено с рядом типичных ошибок, которые могут свести на нет все преимущества и даже привести к серьезным проблемам. В 2026 году, когда автоматизация и скорость стали ключевыми, эти ошибки могут быть особенно дорогостоящими.
7.1. Недостаточное тестирование "зеленой" или "канареечной" среды
Описание ошибки: Это, пожалуй, самая распространенная и опасная ошибка. Разработчики или DevOps-инженеры полагаются на то, что новая версия "должна работать", или проводят лишь поверхностные проверки. Иногда из-за спешки пропускаются интеграционные или нагрузочные тесты на новой среде, или же тесты проводятся в изолированной тестовой среде, которая не полностью соответствует продакшену. В случае Canary, это проявляется в недостаточном мониторинге на малом проценте трафика.
Как избежать: Внедрите комплексную стратегию тестирования, включающую модульные, интеграционные, E2E (End-to-End) и нагрузочные тесты. Автоматизируйте эти тесты в вашем CI/CD пайплайне. Для Blue/Green убедитесь, что "зеленая" среда полностью работоспособна и стабильна под нагрузкой, прежде чем переключать на нее трафик. Для Canary, установите четкие критерии успеха и метрики, которые должны быть достигнуты, прежде чем увеличивать процент трафика. Используйте инструменты вроде Selenium, Cypress, JMeter, K6.
Пример последствий: Переключение на "зеленую" среду с критической ошибкой, которая проявляется только под нагрузкой, приводит к полному отказу сервиса для всех пользователей. В случае Canary, даже 1% пользователей может столкнуться с фатальной ошибкой, что подрывает доверие и репутацию.
7.2. Отсутствие или неэффективный мониторинг и алертинг
Описание ошибки: Деплой без надежной системы мониторинга и алертинга — это как полет вслепую. Если вы не знаете, что происходит с вашим приложением после деплоя, вы не сможете оперативно отреагировать на проблемы. Часто команды настраивают базовый мониторинг, но не кастомные метрики приложения, или не имеют четких порогов для алертов.
Как избежать: Внедрите сквозной мониторинг: инфраструктура (CPU, RAM, диск VPS), контейнеры Docker, само приложение (метрики запросов, ошибок, задержек, бизнес-метрики). Используйте Prometheus + Grafana для метрик, Loki/ELK для логов. Настройте Alertmanager для отправки уведомлений в Slack, PagerDuty или по email при превышении пороговых значений ошибок, задержек или недоступности. Убедитесь, что метрики доступны для обеих версий приложения, чтобы можно было сравнивать их производительность.
Пример последствий: Новая версия приложения начинает медленно "умирать" из-за утечки памяти или слишком большого количества запросов к БД, но команда узнает об этом только через час, когда пользователи уже массово жалуются, а откат занимает драгоценное время.
7.3. Неправильное управление состоянием и миграциями баз данных
Описание ошибки: Это ахиллесова пята многих стратегий бесшовного деплоя. Если приложение имеет состояние (сессии, кэши) или требует миграции базы данных, то простое переключение трафика может привести к несовместимости данных, потере сессий пользователей или повреждению данных. Забывают о том, что обе версии приложения могут одновременно работать с одной и той же базой данных.
Как избежать:
- Состояние: В идеале, ваше приложение должно быть stateless. Если это невозможно, используйте внешние, общие хранилища состояния (Redis, Memcached) или базы данных, к которым обе версии приложения имеют доступ.
- База данных: Все миграции должны быть обратно совместимыми. Это означает, что новая версия приложения должна уметь работать со старой схемой БД, а старая версия должна уметь работать с новой схемой БД (до тех пор, пока она не будет выведена из эксплуатации). Используйте двухфазные миграции для сложных изменений схемы. Всегда делайте бэкапы перед миграцией.
Пример последствий: После деплоя Blue/Green, пользователи, которые были на "синей" среде, теряют свои сессии при переключении на "зеленую". Или новая версия пытается использовать несуществующую колонку в БД, а старая версия не может работать с новой схемой, что приводит к полной недоступности приложения.
7.4. Отсутствие или сложность автоматизации отката
Описание ошибки: В теории, откат в Blue/Green и Canary прост. На практике, если процесс отката не автоматизирован и не протестирован, он может быть медленным, подверженным ошибкам и привести к дополнительному даунтайму. Иногда команды сосредотачиваются только на деплое, забывая о важности быстрого и надежного отката.
Как избежать: Включите процесс отката в ваш CI/CD пайплайн. Он должен быть таким же автоматизированным и протестированным, как и процесс деплоя. Для Blue/Green это просто переключение балансировщика нагрузки. Для Canary это может быть автоматическое снижение трафика на "канарейку" до нуля при обнаружении критических метрик или ошибок. Регулярно тестируйте процедуру отката в тестовой среде.
Пример последствий: Обнаружена критическая ошибка в новой версии. Команда пытается вручную откатить Nginx, но допускает ошибку в конфигурации, что приводит к дополнительному простою. Или откат занимает 15 минут вместо 15 секунд.
7.5. Игнорирование очистки старых ресурсов
Описание ошибки: Особенно актуально для Blue/Green. После успешного деплоя и перехода на "зеленую" среду, "синяя" среда часто остается работать, потребляя ценные ресурсы VPS. Если это не отслеживается и не автоматизируется, со временем это приводит к значительным перерасходам и неэффективному использованию инфраструктуры.
Как избежать: Включите этап очистки старых ресурсов (остановку и удаление старых контейнеров/сервисов) в ваш CI/CD пайплайн. Сделайте его либо автоматическим после определенного периода стабильной работы новой версии, либо ручным, но с четким напоминанием. Для Canary, убедитесь, что инстансы "канарейки" выводятся из эксплуатации после полного раската новой версии.
Пример последствий: Через несколько месяцев выясняется, что на VPS работает 5-6 старых версий приложения, потребляющих CPU и RAM, что приводит к замедлению работы активного приложения и неоправданным затратам на VPS.
7.6. Неправильная конфигурация балансировщика нагрузки
Описание ошибки: Балансировщик нагрузки (Nginx, HAProxy, Caddy, Traefik) является ключевым компонентом обеих стратегий. Ошибки в его конфигурации могут привести к неправильной маршрутизации трафика, утечкам сессий, или даже к DoS-атакам на неактивную среду. Например, неправильная настройка прокси-заголовков может привести к тому, что приложение не видит реальный IP пользователя.
Как избежать: Тщательно проверьте конфигурацию вашего балансировщика нагрузки. Используйте health checks для проверки доступности бэкендов. Убедитесь, что sticky sessions (если они нужны) настроены корректно. Автоматизируйте изменение конфигурации через CI/CD. Используйте инструменты вроде nginx -t для проверки синтаксиса перед перезагрузкой.
Пример последствий: Пользователи видят старую версию приложения, хотя трафик должен быть переключен на новую. Или запросы распределяются неравномерно, вызывая перегрузку одной из сред. В Canary, неправильная маршрутизация может привести к тому, что "канарейку" увидит гораздо больше пользователей, чем планировалось, или она не увидит трафика вовсе.
Избегая этих распространенных ошибок, вы значительно повысите шансы на успешное внедрение и эффективное использование стратегий Blue/Green и Canary деплоя, обеспечивая стабильность и надежность ваших Docker-приложений на VPS.
8. Чеклист для практического применения
Перед началом внедрения или очередного деплоя с использованием Blue/Green или Canary стратегий, пройдитесь по этому чеклисту. Он поможет убедиться, что вы учли все критические аспекты и минимизировали риски. Этот чеклист актуален для 2026 года, с учетом современных практик DevOps.
8.1. Общая подготовка и планирование
- Определен допустимый даунтайм: Вы знаете, какой уровень простоя приемлем для вашего приложения и целевой аудитории.
- Выбрана стратегия деплоя: Blue/Green или Canary, исходя из потребностей бизнеса и технических возможностей.
- Ресурсы VPS достаточны: Проверена доступность CPU, RAM, диска для одновременной работы двух версий (Blue/Green) или стабильной и Canary версий.
- План отката готов и протестирован: Вы знаете, как быстро и безопасно вернуться к предыдущей стабильной версии.
- План миграции БД готов: Все изменения в БД спроектированы с учетом обратной совместимости.
- Команда проинформирована: Все участники процесса (разработчики, тестировщики, DevOps) знают свои роли и этапы деплоя.
- График деплоя согласован: Выбрано наименее загруженное время для деплоя, чтобы минимизировать влияние на пользователей.
8.2. Подготовка инфраструктуры и инструментов
- Docker и Docker Compose установлены и настроены: На вашем VPS готовы к работе.
- Балансировщик нагрузки настроен: Nginx, Caddy или HAProxy готовы к управлению трафиком.
- CI/CD пайплайн настроен: Jenkins, GitLab CI, GitHub Actions или Ansible автоматизируют сборку, тестирование и деплой.
- SSH доступ без пароля: Для CI/CD агента настроен SSH-ключ для безопасного доступа к VPS.
- Система мониторинга настроена: Prometheus + Grafana собирают метрики инфраструктуры и приложения.
- Система логирования настроена: ELK-стек или Loki + Promtail собирают и агрегируют логи со всех контейнеров.
- Алерты настроены и протестированы: Уведомления о критических проблемах приходят в реальном времени.
- Бэкапы БД выполнены: Свежие бэкапы базы данных сделаны перед началом деплоя.
8.3. Подготовка приложения и кода
- Docker-образ приложения оптимизирован: Минимальный размер, многослойный кэш, отсутствие ненужных зависимостей.
- Health checks реализованы: Приложение предоставляет endpoint (например,
/health), который балансировщик нагрузки может использовать для проверки его работоспособности.
- Метрики приложения экспонируются: Приложение предоставляет метрики для Prometheus (например, через клиентскую библиотеку).
- Логирование стандартизировано: Приложение логирует в stdout/stderr в формате, удобном для парсинга (например, JSON).
- Конфигурация приложения параметризована: Все чувствительные данные и специфичные для среды параметры загружаются из переменных окружения или файлов конфигурации, а не зашиты в образ.
- Тесты пройдены: Все автоматические тесты (юнит, интеграционные, E2E) успешно пройдены в тестовой среде.
- Обратная совместимость API/контрактов: Убедитесь, что новая версия не нарушает работу клиентов, использующих старое API.
8.4. Этапы деплоя
- Старая версия (Blue) работает стабильно: Проверено состояние текущей версии приложения.
- Новая версия (Green/Canary) развернута: Контейнеры новой версии успешно запущены на VPS, но трафик на них еще не направлен.
- Тестирование новой версии (до переключения трафика): Выполнены ручные и автоматические тесты на Green/Canary без воздействия на основных пользователей.
- Переключение трафика:
- Blue/Green: Балансировщик нагрузки переключен на Green.
- Canary: Балансировщик нагрузки начинает направлять малый процент трафика на Canary.
- Мониторинг после переключения: Активно отслеживаются метрики и логи новой версии.
- Принятие решения:
- Blue/Green: Если Green стабильна, Blue может быть остановлена. Если проблемы, откат на Blue.
- Canary: Если Canary стабильна, постепенно увеличивается процент трафика. Если проблемы, откат Canary.
- Очистка ресурсов: Старые контейнеры и образы удалены для освобождения ресурсов VPS.
Следуя этому чеклисту, вы значительно повысите вероятность успешного и беспроблемного деплоя, обеспечивая высокую доступность и надежность ваших Docker-приложений.
9. Расчет стоимости / Экономика внедрения
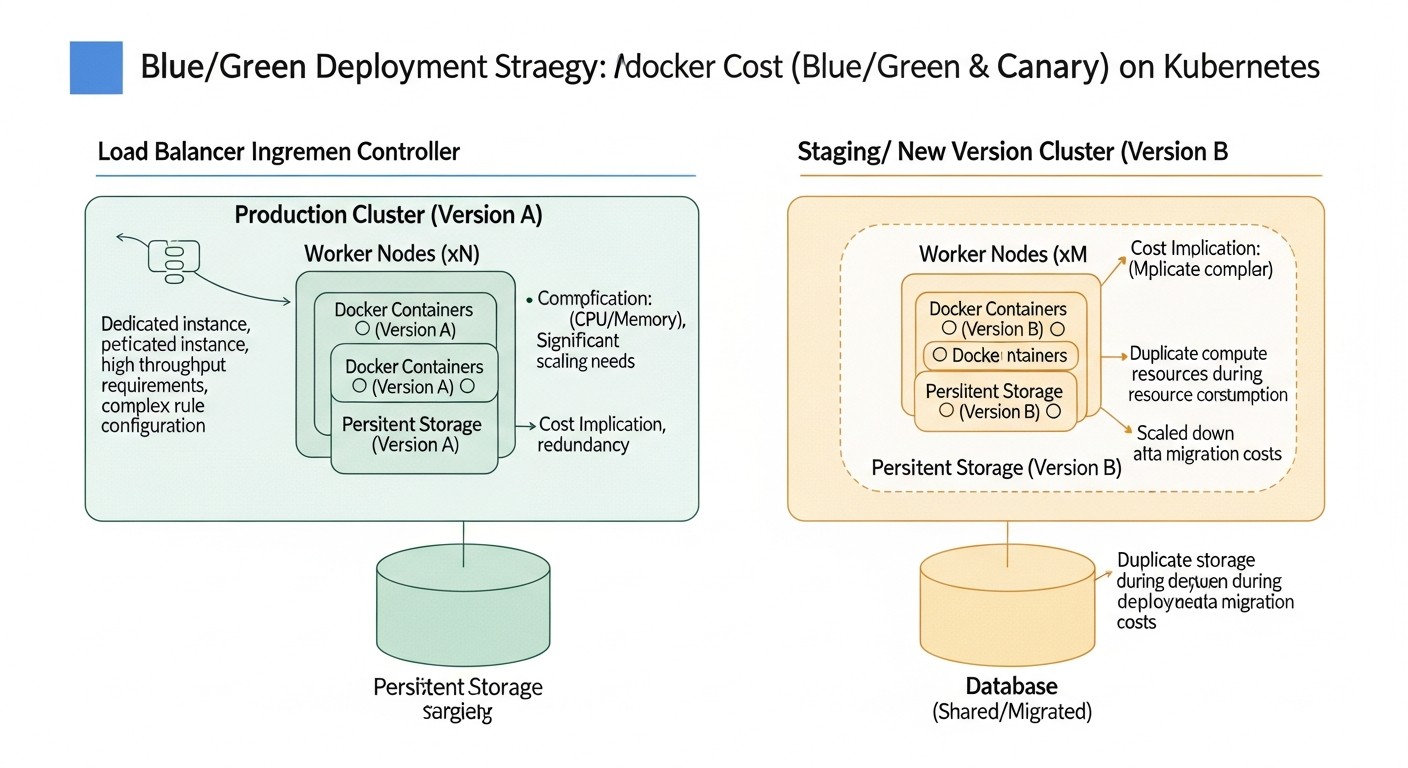 Схема: 9. Расчет стоимости / Экономика внедрения
Схема: 9. Расчет стоимости / Экономика внедрения
Внедрение продвинутых стратегий деплоя, таких как Blue/Green и Canary, на VPS всегда сопряжено с определенными затратами. Важно понимать, что эти затраты не ограничиваются только стоимостью самого VPS, но включают в себя также скрытые расходы и потенциальную экономию. В 2026 году, когда стоимость облачных ресурсов продолжает оптимизироваться, а автоматизация становится более доступной, правильный расчет экономики может дать значительное конкурентное преимущество.
9.1. Прямые затраты на VPS
Основная статья расходов — это сам виртуальный сервер. Цены на VPS в 2026 году продолжают снижаться, особенно для стандартных конфигураций. Для Docker-приложений на VPS средней мощности (4 vCPU, 8GB RAM, 160GB SSD) можно ориентироваться на следующие примерные месячные тарифы от ведущих провайдеров (DigitalOcean, Vultr, Hetzner, Linode):
- Базовый VPS: $15 - $25 / месяц
- Средний VPS: $30 - $50 / месяц
- Мощный VPS: $60 - $100+ / месяц
9.1.1. Сценарий Blue/Green: Временное удвоение ресурсов
Для Blue/Green стратегии вам потребуется временно удвоить ресурсы. Если ваше приложение обычно работает на одном VPS за $40/месяц, то на время деплоя вам потребуется второй такой же VPS (или его эквивалент по ресурсам). Допустим, деплой занимает 30 минут.
- Месячная стоимость одного VPS: $40
- Стоимость часа работы VPS: $40 / (30 дней 24 часа) = ~$0.055 / час
- Дополнительные расходы на деплой (30 минут): $0.055 / 2 = ~$0.0275 за один деплой.
- Если вы деплоите 4 раза в месяц: 4 $0.0275 = ~$0.11
Как видите, прямые дополнительные затраты на VPS для Blue/Green крайне малы, если вы используете временное масштабирование или у вас есть запас ресурсов на существующем сервере. Основное, на что нужно обратить внимание, это ошибка игнорирования очистки старых ресурсов, которая может привести к постоянным лишним тратам.
9.1.2. Сценарий Canary: Постоянно повышенные ресурсы
Для Canary деплоя вы часто держите "канареечные" инстансы постоянно, даже если они обслуживают небольшой процент трафика. Это может означать, что вам постоянно требуется на 10-50% больше ресурсов, чем для одной стабильной версии.
- Месячная стоимость одного VPS: $40
- Дополнительные ресурсы для Canary: Например, 20% от одного VPS.
- Постоянные дополнительные расходы: $40 0.20 = $8/месяц.
Эти затраты могут быть выше, если Canary-инстансы требуют отдельного VPS или вы используете более сложную маршрутизацию, которая может потреблять дополнительные ресурсы балансировщика нагрузки.
9.2. Скрытые расходы
Помимо прямых затрат на VPS, существуют скрытые расходы, которые часто упускаются из виду, но могут быть весьма значительными.
- Время инженеров: Самая большая скрытая стоимость. Настройка и поддержка CI/CD пайплайнов, систем мониторинга, отладка проблем. В 2026 году средняя ставка DevOps-инженера составляет $80-150/час. Если настройка занимает 80 часов: 80 $100 = $8000.
- Стоимость инструментов: Хотя многие инструменты (Docker, Nginx, Prometheus, Grafana) бесплатны, некоторые могут иметь платные версии или требовать платных хостингов (например, GitLab EE, облачные решения для логирования).
- Обучение команды: Инвестиции в обучение инженеров новым стратегиям и инструментам.
- Потенциальные потери от ошибок: Несмотря на снижение рисков, ошибки все равно могут произойти. Потеря клиентов, репутационный ущерб, штрафы за нарушение SLA.
9.3. Как оптимизировать затраты
- Эффективное использование ресурсов VPS:
- Оптимизация Docker-образов: Уменьшение размера образов, использование multi-stage builds.
- Оптимизация Docker Compose: Использование внешних сетей, грамотное управление томами.
- Мониторинг загрузки: Выбор VPS, который точно соответствует вашим потребностям, а не "с запасом".
- Автоматизация: Инвестиции в CI/CD пайплайны сокращают ручной труд и минимизируют ошибки, что в долгосрочной перспективе экономит время инженеров.
- Тщательное планирование БД: Минимизация сложных миграций, которые могут привести к простоям или необходимости ручного вмешательства.
- Использование бесплатных и Open-Source инструментов: Максимальное использование экосистемы Open-Source (Nginx, Docker, Prometheus, Grafana, Ansible, GitLab CE/GitHub Actions).
- Регулярный аудит ресурсов: Периодически проверяйте, какие контейнеры и сервисы запущены на вашем VPS, и удаляйте неиспользуемые.
9.4. Таблица с примерами расчетов для разных сценариев (2026 год)
Предположим, что базовый VPS, достаточный для одной версии приложения, стоит $40/месяц.
| Параметр |
Сценарий 1: Blue/Green (1 деплой/неделя) |
Сценарий 2: Canary (постоянно 20% трафика на Canary) |
Сценарий 3: Без продвинутых стратегий (простой деплой с 5 мин даунтайма) |
| Прямые затраты на VPS |
$40 (основной) + $0.11 (доп.часы) = $40.11/мес |
$40 (основной) + $8 (доп. ресурсы) = $48/мес |
$40/мес |
| Стоимость времени инженеров (настройка) |
~80 часов $100 = $8000 (единовременно) |
~120 часов $100 = $12000 (единовременно) |
~20 часов $100 = $2000 (единовременно) |
| Стоимость времени инженеров (поддержка) |
~5 часов/мес $100 = $500/мес |
~8 часов/мес $100 = $800/мес |
~2 часов/мес $100 = $200/мес |
| Потери от даунтайма (пример) |
$0 (почти нулевой) |
$0 (почти нулевой) |
$100/мин 5 мин 4 деплоя = $2000/мес |
| Риск репутационных потерь |
Низкий |
Очень низкий (ограниченная аудитория) |
Высокий |
| Общая "стоимость владения" (TCO) за год |
$8000 (настройка) + $40.1112 (VPS) + $50012 (поддержка) = ~$14500 |
$12000 (настройка) + $4812 (VPS) + $80012 (поддержка) = ~$22600 |
$2000 (настройка) + $4012 (VPS) + $20012 (поддержка) + $200012 (потери) = ~$29000 |
Эта таблица наглядно демонстрирует, что, хотя начальные инвестиции в Blue/Green и Canary деплой выше, они окупаются за счет снижения потерь от даунтайма, уменьшения ручных операций и повышения надежности. Для критически важных приложений, где каждая минута простоя стоит денег, эти продвинутые стратегии являются не просто желательными, а экономически обоснованными инвестициями.
10. Кейсы и примеры из реальной практики
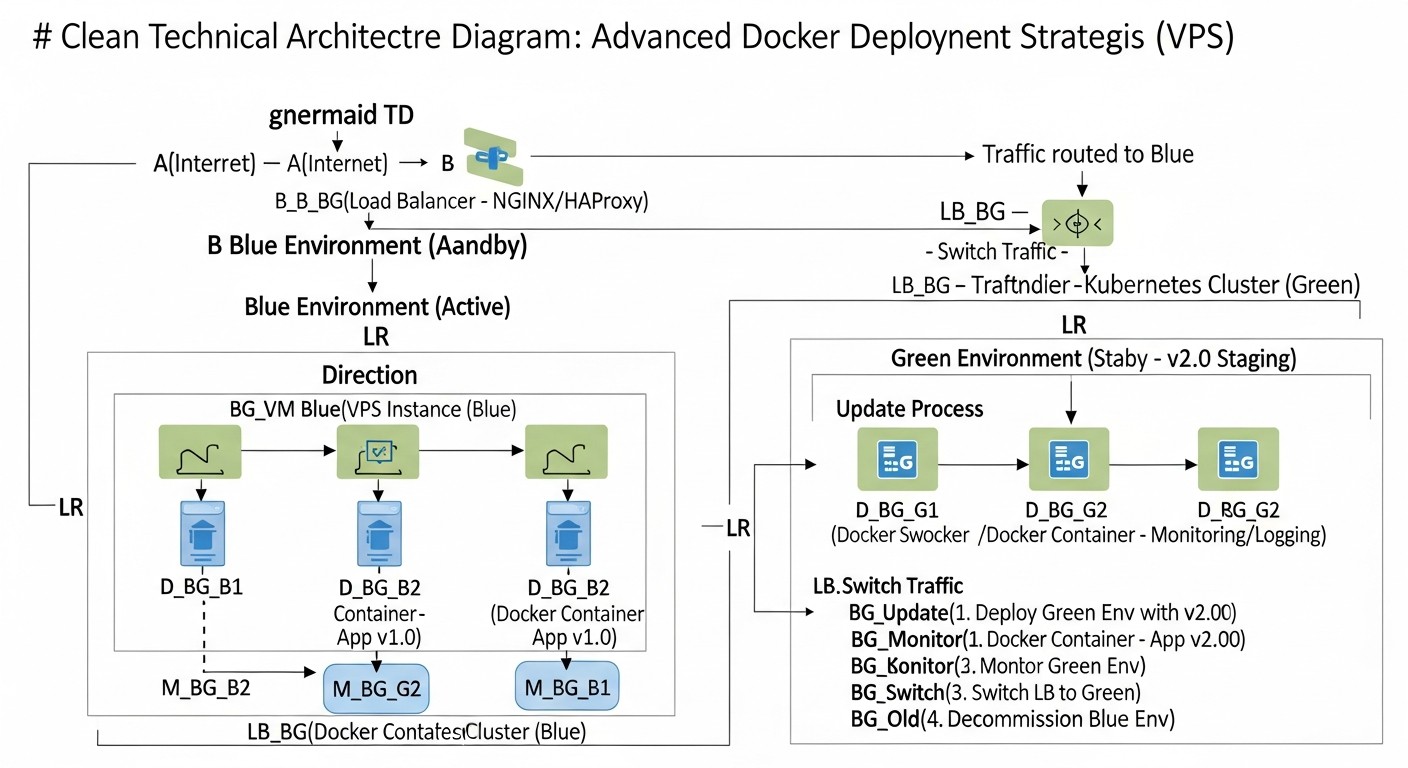 Схема: 10. Кейсы и примеры из реальной практики
Схема: 10. Кейсы и примеры из реальной практики
Чтобы лучше понять, как Blue/Green и Canary деплой применяются на практике, рассмотрим несколько реалистичных сценариев. Эти кейсы демонстрируют, как различные компании могут использовать эти стратегии для решения своих уникальных задач на VPS.
10.1. Кейс 1: SaaS-платформа для управления проектами (Blue/Green)
Сценарий
Небольшая, но быстрорастущая SaaS-компания "TaskFlow" предоставляет платформу для управления проектами. У них около 5000 активных клиентов, которые используют сервис 24/7. Команда разработчиков (4 бэкенда на Node.js) выпускает новые фичи и исправления ошибок еженедельно. Простой сервиса даже на 5 минут приводит к жалобам клиентов и потенциальной потере подписок. Инфраструктура состоит из одного мощного VPS (8 vCPU, 16GB RAM) с Docker Compose, Nginx в качестве реверс-прокси и PostgreSQL.
Проблема
Традиционный деплой "останови-замени-запусти" приводил к 2-5 минутам простоя каждую неделю. Это вызывало недовольство клиентов, особенно из других часовых поясов, и увеличивало нагрузку на поддержку.
Решение: Внедрение Blue/Green деплоя
- Дублирование контейнеров: Вместо одного набора контейнеров для Node.js приложения, были созданы два набора:
taskflow-blue и taskflow-green, каждый на своем порту (например, 3000 и 3001).
- Общая база данных: PostgreSQL осталась единой, но миграции БД были тщательно спроектированы для обратной совместимости.
- Nginx как коммутатор: Nginx был настроен для маршрутизации всего трафика на порт 3000 (Blue).
- CI/CD пайплайн: Был настроен GitLab CI, который:
- Собирал новый Docker-образ.
- Разворачивал новую версию на порт 3001 (Green).
- Запускал автоматические интеграционные тесты против Green-среды.
- После успешного тестирования, ожидал ручного подтверждения.
- По команде инженера автоматически изменял конфигурацию Nginx для переключения трафика на порт 3001 и перезагружал Nginx.
- После подтверждения стабильности Green, останавливал и удалял контейнеры Blue.
- Мониторинг: Prometheus и Grafana были настроены для отслеживания метрик обеих сред, с алертингом на Slack при росте ошибок или задержек.
Результаты
- Нулевой даунтайм: Время переключения трафика сократилось до 1-2 секунд, полностью исключив простой.
- Быстрый откат: В случае проблем, откат занимал менее 10 секунд.
- Повышение доверия клиентов: Количество жалоб на недоступность сервиса резко сократилось.
- Уверенность команды: Разработчики стали более смело выпускать новые функции, зная, что риск минимален.
- Дополнительные затраты: Минимальны, так как VPS имел достаточный запас ресурсов для временного удвоения нагрузки, а время инженеров на настройку окупилось за 3 месяца за счет сокращения ручных операций и простоя.
10.2. Кейс 2: E-commerce платформа с высокой нагрузкой (Canary)
Сценарий
Крупная E-commerce платформа "ShopSphere" (на PHP/Laravel) имеет десятки тысяч активных пользователей ежедневно. Их VPS-инфраструктура состоит из нескольких мощных серверов, объединенных в кластер с HAProxy в качестве балансировщика нагрузки. Внедрение новых функций, особенно в платежной системе или корзине, несет высокие риски. Даже 0.1% ошибок может привести к значительным финансовым потерям. Команда хочет тестировать новые функции на реальных пользователях, прежде чем выкатывать их всем.
Проблема
Blue/Green был хорош для даунтайма, но не давал возможности протестировать новые функции на небольшой, репрезентативной выборке реальных пользователей. Иногда новые фичи работали идеально в тестовой среде, но вызывали неожиданное поведение или ошибки в продакшене из-за специфики пользовательских данных или паттернов использования.
Решение: Внедрение Canary деплоя
- Выделение Canary-инстансов: На одном из VPS были выделены ресурсы для запуска "канареечной" версии приложения (
shopsphere-canary).
- HAProxy для маршрутизации трафика: HAProxy был настроен для перенаправления трафика:
- Изначально 99.5% трафика шло на стабильные (Blue) инстансы.
- 0.5% трафика направлялось на Canary-инстанс. Это было реализовано с помощью весов в конфигурации HAProxy.
- Для внутренних тестеров была предусмотрена маршрутизация по специальному HTTP-заголовку
X-Test-Version: canary.
- Продвинутый мониторинг: Помимо Prometheus/Grafana, был внедрен ELK-стек для глубокого анализа логов. Особое внимание уделялось бизнес-метрикам (конверсия, средний чек) для Canary-группы по сравнению с Blue-группой.
- Автоматизированный пайплайн с ручными шагами: GitLab CI был настроен для:
- Сборки и развертывания Canary-версии.
- Автоматического запуска смоук-тестов.
- Ручного этапа "Оценка Canary 0.5%": команда анализировала метрики и логи в течение 4-6 часов.
- Если все хорошо, ручной шаг "Увеличить до 5%".
- Повторение мониторинга и увеличения (25%, 50%, 100%).
- Автоматический откат Canary при обнаружении критических аномалий (например, резкий рост ошибок 5xx, падение конверсии).
Результаты
- Минимальный риск: Критические ошибки выявлялись на очень малой выборке пользователей, предотвращая массовые проблемы.
- Качество релизов: Новые функции тщательно проверялись в реальных условиях, что значительно повысило качество и стабильность релизов.
- Оптимизация пользовательского опыта: Возможность проводить A/B тестирование новых функций и UI-изменений на небольшой аудитории, собирая реальную обратную связь.
- Дополнительные затраты: Постоянное использование одного дополнительного VPS для Canary инстансов ($40/мес) и значительные инвестиции в настройку и поддержку сложного пайплайна и мониторинга (около 120 часов инженера). Однако эти затраты полностью оправданы предотвращением многомиллионных потерь от ошибок в E-commerce.
Эти кейсы показывают, что Blue/Green и Canary деплой — это не просто теоретические концепции, а мощные, проверенные на практике стратегии, способные значительно улучшить процесс разработки и эксплуатации приложений на VPS, обеспечивая при этом высокую доступность и качество сервиса.
12. Troubleshooting: решение типичных проблем
 Схема: 12. Troubleshooting: решение типичных проблем
Схема: 12. Troubleshooting: решение типичных проблем
Даже при самой тщательной подготовке и использовании продвинутых стратегий деплоя, проблемы в продакшене могут возникнуть. Умение быстро диагностировать и устранять их — ключевой навык для любого DevOps-инженера. В этом разделе мы рассмотрим типичные проблемы, которые могут возникнуть при Blue/Green и Canary деплое на VPS с Docker, и предложим конкретные шаги для их решения.
12.1. Проблема: Новая версия приложения (Green/Canary) не запускается или падает сразу после старта
Симптомы
- Контейнер не стартует или постоянно перезапускается.
- Ошибки в логах Docker или приложения.
- Health check endpoint недоступен.
Диагностические команды
# Проверить статус контейнера
docker ps -a | grep
# Просмотреть логи контейнера
docker logs
# Зайти внутрь контейнера для ручной проверки
docker exec -it /bin/bash
Решения
- Проверьте логи: Самое первое и главное. Ищите сообщения об ошибках, исключения, проблемы с зависимостями, переменными окружения, подключением к БД или внешним сервисам.
- Нехватка ресурсов: Проверьте загрузку CPU/RAM на VPS. Возможно, новая версия потребляет больше ресурсов, чем ожидалось, и Docker не может выделить достаточно.
htop # Или top, free -h
docker stats
- Проблемы с конфигурацией: Убедитесь, что все переменные окружения, файлы конфигурации и монтируемые тома корректны для новой версии.
- Порты заняты: Убедитесь, что порт, на котором должна работать новая версия, не занят другим процессом.
sudo netstat -tulnp | grep
- Ошибки в Dockerfile/образе: Если новая версия не собирается или запускается некорректно, проверьте
Dockerfile и процесс сборки.
12.2. Проблема: Трафик не переключается на новую версию или переключается некорректно
Симптомы
- Пользователи продолжают видеть старую версию, хотя по логике трафик должен быть переключен.
- Часть пользователей видит старую, часть — новую (для Blue/Green).
- Для Canary: процент трафика не соответствует ожиданиям.
Диагностические команды
# Проверить конфигурацию Nginx
sudo nginx -t
sudo cat /etc/nginx/nginx.conf
# Проверить логи Nginx
sudo tail -f /var/log/nginx/access.log
sudo tail -f /var/log/nginx/error.log
# Проверить доступность портов приложения
curl http://127.0.0.1:8080/health # Blue
curl http://127.0.0.1:8081/health # Green/Canary
Решения
- Проверьте конфигурацию балансировщика: Убедитесь, что изменения в
nginx.conf (или Caddyfile/HAProxy) были применены и синтаксис корректен. Перезагрузите или перечитайте конфигурацию.
- Проверьте health checks: Балансировщик нагрузки мог пометить новую версию как "нездоровую" и не направлять на нее трафик. Проверьте логи балансировщика.
- DNS-кэширование: Если вы переключаете трафик через DNS, изменения могут распространяться медленно из-за кэширования. Это не относится к Nginx/HAProxy, которые работают на уровне L7.
- Sticky sessions: Если используются sticky sessions, убедитесь, что они корректно настроены и не мешают переключению трафика.
12.3. Проблема: Новая версия работает медленнее или генерирует больше ошибок
Симптомы
- Рост метрик ошибок (5xx) в Prometheus/Grafana для новой версии.
- Увеличение задержек ответа (latency).
- Рост потребления CPU/RAM для контейнеров новой версии.
- Жалобы пользователей на медленную работу или недоступность.
Диагностические команды
# Мониторинг метрик в Grafana
# Анализ логов в Loki/Kibana
docker stats # Сравнить с docker stats
Решения
- Мониторинг и логи: Это ваша основная точка опоры. Сравните метрики и логи новой и старой версии. Ищите аномалии: новые типы ошибок, увеличение времени выполнения запросов к БД, внешним API.
- Ресурсы: Убедитесь, что новая версия не упирается в лимиты по CPU/RAM на VPS. Возможно, она требует больше ресурсов.
- Проблемы с БД: Проверьте медленные запросы к базе данных, проблемы с индексами или блокировками, вызванные изменениями в новой версии.
- Внешние зависимости: Новая версия может иметь проблемы с подключением к внешним сервисам, кэшам, очередям сообщений.
- Откат: Если проблема критична и быстрое решение не найдено, немедленно выполните откат к предыдущей стабильной версии.
12.4. Проблема: Проблемы с миграцией баз данных
Симптомы
- Ошибки приложения, связанные с доступом к БД (например, "column not found", "table not found").
- Повреждение данных или неконсистентность.
Диагностические команды
# Проверить логи миграций
# Подключиться к БД и проверить схему
psql -U user -d mydatabase -h db -c "\dt"
psql -U user -d mydatabase -h db -c "\d "
Решения
- Обратная совместимость: Убедитесь, что миграции были спроектированы с учетом обратной совместимости. Обе версии приложения (старая и новая) должны уметь работать с БД в переходный период.
- Порядок миграций: Убедитесь, что миграции выполняются в правильном порядке: сначала изменения, совместимые со старой версией, затем деплой новой версии, затем, если необходимо, удаление старых элементов.
- Бэкапы: Всегда делайте бэкапы БД перед деплоем и миграцией. В случае серьезных проблем, это позволит восстановить данные.
- Тестирование миграций: Тестируйте миграции не только на тестовых данных, но и на копии продакшен-БД.
12.5. Когда обращаться в поддержку
Если вы столкнулись с проблемами, которые не можете решить самостоятельно, или у вас возникли сложности с самой инфраструктурой VPS:
- Проблемы с VPS: Недоступность сервера, сетевые проблемы, проблемы с диском, которые не связаны с вашим приложением.
- Проблемы с провайдером: Если вы подозреваете, что проблема на стороне хостинг-провайдера (например, общая недоступность региона, проблемы с сетью).
- Неизвестные ошибки: Если логи не дают четкого понимания проблемы, а все стандартные шаги по диагностике не привели к результату.
Предоставьте поддержке максимально полную информацию: точное время возникновения проблемы, логи, метрики, выполненные диагностические шаги, а также любые изменения, которые вы вносили перед возникновением проблемы.
13. FAQ: Часто задаваемые вопросы
Что такое Blue/Green деплой?
Blue/Green деплой — это стратегия развертывания, при которой поддерживаются две идентичные производственные среды: "синяя" (Blue) с текущей стабильной версией приложения и "зеленая" (Green) для новой версии. Весь пользовательский трафик направляется на одну из них. При обновлении новая версия разворачивается на "зеленой" среде, тестируется, и затем трафик мгновенно переключается с "синей" на "зеленую". Это обеспечивает практически нулевой даунтайм и быстрый откат.
В чем основное отличие Blue/Green от Canary деплоя?
Основное отличие заключается в способе переключения трафика. Blue/Green переключает весь трафик на новую версию одномоментно после полного тестирования. Canary деплой, напротив, постепенно направляет небольшой процент трафика на новую версию, позволяя тестировать ее на реальных пользователях и собирать метрики, прежде чем полностью раскатать. Canary минимизирует риски, но сложнее в реализации и дольше по времени.
Можно ли реализовать Blue/Green или Canary на одном VPS?
Да, вполне возможно, особенно для приложений средней сложности. Для этого требуется достаточный запас ресурсов на VPS (CPU, RAM) для одновременного запуска нескольких версий вашего Docker-приложения. Используются разные порты для каждой версии и балансировщик нагрузки (Nginx, HAProxy) для маршрутизации трафика. Docker Compose помогает управлять несколькими наборами контейнеров на одном хосте.
Какие инструменты необходимы для Blue/Green/Canary на VPS?
Вам понадобятся: Docker и Docker Compose для контейнеризации и оркестрации, балансировщик нагрузки (Nginx, Caddy, HAProxy) для маршрутизации трафика, CI/CD система (GitLab CI, GitHub Actions, Jenkins, Ansible) для автоматизации деплоя, а также системы мониторинга (Prometheus, Grafana) и логирования (Loki, Promtail, ELK-стек) для контроля за состоянием обеих версий приложения.
Как быть с базами данных и их миграциями при таком деплое?
Управление базами данных — критический аспект. Все миграции БД должны быть обратно совместимыми, чтобы как старая, так и новая версии приложения могли работать с одной и той же схемой БД в переходный период. Используйте двухфазные миграции для сложных изменений. Всегда делайте бэкапы перед миграцией. В идеале, приложение должно быть спроектировано так, чтобы изменения схемы БД были минимальными и не блокирующими.
Насколько возрастают затраты на VPS при использовании этих стратегий?
Для Blue/Green затраты на VPS увеличиваются временно (на время деплоя) на стоимость дублирования ресурсов. Если у вас есть запас на VPS, это может быть очень дешево. Для Canary могут потребоваться постоянно дополнительные ресурсы (например, 10-50% от текущей нагрузки) для поддержания Canary-инстансов. Однако, эти прямые затраты часто компенсируются снижением потерь от даунтайма и ошибок, что в итоге делает эти стратегии экономически выгодными.
Какие риски связаны с Blue/Green деплоем?
Основные риски включают: необходимость удвоения ресурсов на время деплоя, сложность управления состоянием приложения (сессии, кэши) при переключении, а также необходимость тщательного планирования миграций баз данных. Если "зеленая" среда плохо протестирована, то переключение на нее может привести к полному отказу сервиса для всех пользователей.
Какие риски связаны с Canary деплоем?
Canary деплой сложнее в реализации, требует продвинутой системы мониторинга и маршрутизации трафика. Есть риск, что небольшая группа пользователей столкнется с ошибками, прежде чем проблема будет обнаружена. Процесс развертывания может занимать больше времени. Управление состоянием и БД еще более критично, так как обе версии приложения работают параллельно в течение длительного времени.
Как автоматизировать переключение трафика для Blue/Green/Canary?
Автоматизация переключения трафика обычно осуществляется через CI/CD пайплайн. Скрипты (например, Ansible, Bash-скрипты, вызываемые из GitLab CI/GitHub Actions) могут изменять конфигурацию балансировщика нагрузки (Nginx, HAProxy), перезагружать его, или обновлять DNS-записи. Для Canary это может быть постепенное изменение весов в конфигурации балансировщика.
Что такое Health Check и почему он важен?
Health Check — это специальный endpoint (например, /health) в вашем приложении, который балансировщик нагрузки или система мониторинга регулярно опрашивает. Если endpoint возвращает код 200 OK, приложение считается здоровым; иначе — нездоровым. Health Check критически важен, так как он позволяет балансировщику автоматически исключать неисправные инстансы из пула и гарантировать, что трафик направляется только на работающие версии приложения.
14. Заключение
В мире, где скорость изменений и непрерывная доступность сервисов стали не просто конкурентным преимуществом, а базовым требованием, традиционные подходы к деплою Docker-приложений на VPS уже не справляются. Стратегии Blue/Green и Canary обновлений предлагают мощные решения для этих вызовов, позволяя минимизировать даунтайм, снизить риски и значительно повысить качество ваших релизов.
Мы детально рассмотрели обе стратегии, их принципы работы, преимущества и недостатки, а также конкретные примеры реализации с использованием актуальных инструментов 2026 года. Blue/Green деплой идеально подходит для проектов, где критичен нулевой даунтайм и быстрый откат, а временное удвоение ресурсов приемлемо. Он относительно прост в освоении и реализации на VPS с помощью Docker Compose и Nginx. Canary деплой, хоть и более сложен, предоставляет беспрецедентные возможности для тестирования новых функций на реальных пользователях, минимизируя риски до абсолютного минимума, что особенно ценно для крупных и критически важных SaaS-проектов.
Независимо от выбранной стратегии, ключевыми факторами успеха являются:
- Автоматизация: Сквозной CI/CD пайплайн, автоматизирующий сборку, тестирование, деплой и откат.
- Мониторинг и логирование: Глубокое понимание состояния вашего приложения и инфраструктуры в реальном времени.
- Тщательное планирование: Особое внимание к миграциям баз данных, управлению состоянием и тестированию.
- Культура DevOps: Взаимодействие между разработчиками и операционными инженерами для обеспечения бесперебойной работы.
Следующие шаги для читателя
- Оцените свои текущие потребности: Проанализируйте допустимый даунтайм, риски и ресурсы вашего проекта.
- Начните с малого: Если вы новичок, попробуйте реализовать базовый Blue/Green деплой на тестовом VPS с простым Docker-приложением.
- Инвестируйте в автоматизацию: Начните с настройки простого CI/CD пайплайна для сборки и деплоя.
- Внедрите мониторинг: Даже базовый Prometheus и Grafana дадут вам бесценную информацию.
- Изучайте инструменты: Глубже погрузитесь в документацию Nginx/HAProxy, Ansible, GitLab CI/GitHub Actions.
- Практикуйтесь: Опыт приходит с практикой. Не бойтесь экспериментировать в контролируемой среде.
Внедрение этих продвинутых стратегий — это не просто техническое упражнение, а инвестиция в стабильность, надежность и конкурентоспособность вашего продукта. В 2026 году это уже не роскошь, а необходимость для любого серьезного SaaS-проекта или онлайн-сервиса, стремящегося к совершенству.
Was this guide helpful?
продвинутые стратегии деплоя docker-приложений на vps: blue/green и canary обновления
support_agent
Valebyte Support
Usually replies within minutes
Hi there!
Send us a message and we'll reply as soon as possible.