Implementación de principios Zero Trust para infraestructura en VPS y servidores dedicados: Guía práctica 2026
TL;DR
- No confíe en nadie, verifique siempre: Abandone la protección perimetral en favor de la verificación de cada solicitud, usuario y dispositivo, independientemente de su ubicación.
- La microsegmentación es su mejor amigo: Divida la infraestructura en los dominios de seguridad más pequeños y aislados para limitar el movimiento lateral del atacante.
- Autenticación reforzada en todas partes: Implemente autenticación multifactor (MFA) y contraseñas sin contraseña (passwordless) para todas las cuentas, así como verificación continua de identidad.
- Principio del menor privilegio: Conceda acceso solo a los recursos necesarios y solo por el tiempo necesario, automatizando la gestión de privilegios.
- Monitoreo continuo y automatización: Implemente sistemas de monitoreo de comportamiento, detección de anomalías y respuesta automatizada a amenazas en tiempo real.
- Asuma la brecha: Diseñe sistemas asumiendo que tarde o temprano ocurrirá una brecha, y minimice sus consecuencias.
- El año 2026 exige proactividad: Dada la creciente sofisticación de los ataques de IA y la complejidad de las amenazas, Zero Trust no es una opción, sino una necesidad para la supervivencia empresarial.
Introducción: Por qué Zero Trust es crítico en 2026
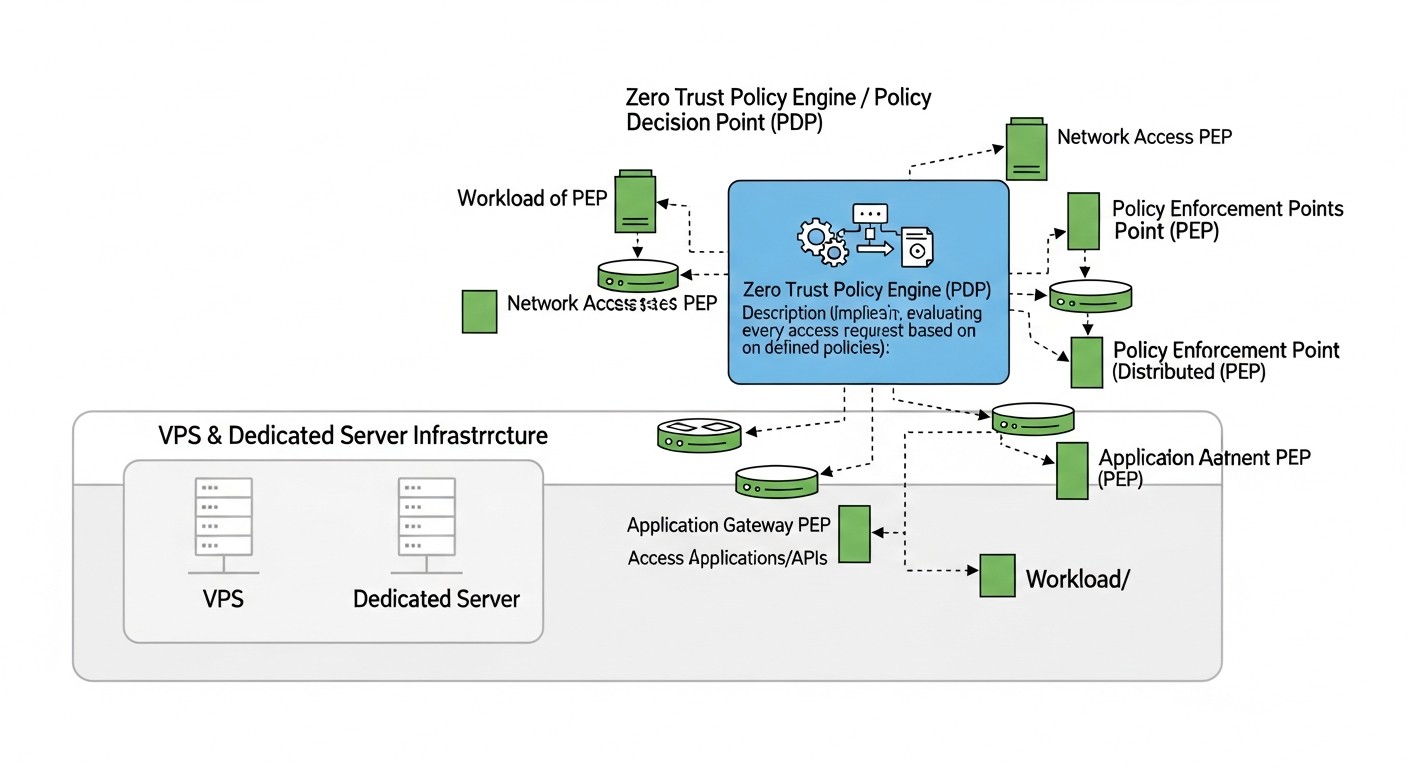 Diagrama: Introducción: Por qué Zero Trust es crítico en 2026
Diagrama: Introducción: Por qué Zero Trust es crítico en 2026
En 2026, el panorama de las ciberamenazas continúa evolucionando rápidamente, volviéndose cada vez más complejo y sofisticado. Los modelos de seguridad tradicionales, basados en el concepto de un "perímetro seguro" donde todo dentro de la red se considera confiable, han demostrado ser insostenibles frente a ataques dirigidos, amenazas internas y la creciente complejidad de los sistemas distribuidos. Los VPS individuales y los servidores dedicados, a menudo percibidos como una "isla de seguridad" debido a su relativo aislamiento, en realidad están expuestos a riesgos no menores, y a veces mayores, ya que carecen de los mecanismos de protección inherentes a los grandes proveedores de la nube.
Vivimos en una era en la que la inteligencia artificial se utiliza activamente no solo para la defensa, sino también para automatizar ataques, crear campañas de phishing convincentes y acelerar la búsqueda de vulnerabilidades. La vulneración de una cuenta o un servicio puede convertirse en un punto de entrada para un atacante, que luego se mueve libremente por la red interna "confiable". Es aquí donde entra en juego el concepto de Zero Trust — "confianza cero".
Zero Trust no es un producto o tecnología específica, sino un enfoque estratégico de seguridad basado en el principio de "no confíes en nadie, verifica siempre". Requiere una verificación estricta de cada usuario, dispositivo y aplicación que intenta acceder a los recursos, independientemente de si se encuentran dentro o fuera del perímetro de red tradicional. En el contexto de los VPS y servidores dedicados, donde no existe el concepto de "red corporativa" en el sentido tradicional, Zero Trust se vuelve aún más relevante. Permite crear un "perímetro" virtual alrededor de cada recurso, cada servicio, cada usuario.
Este artículo está dirigido a ingenieros DevOps, desarrolladores backend, fundadores de proyectos SaaS, administradores de sistemas y directores técnicos de startups que gestionan infraestructura en VPS o servidores dedicados. Exploraremos cómo aplicar los principios de Zero Trust en condiciones de recursos limitados y sin soluciones corporativas costosas. Nuestro objetivo es proporcionar una guía práctica, llena de ejemplos concretos, configuraciones y recomendaciones que le ayudarán a mejorar significativamente el nivel de seguridad de su infraestructura en 2026 y a prepararse para los desafíos del futuro. Nos sumergiremos en los detalles, mostraremos cómo evitar errores comunes y ofreceremos un plan de acción claro para crear un entorno verdaderamente seguro.
Criterios y factores clave para la implementación de Zero Trust
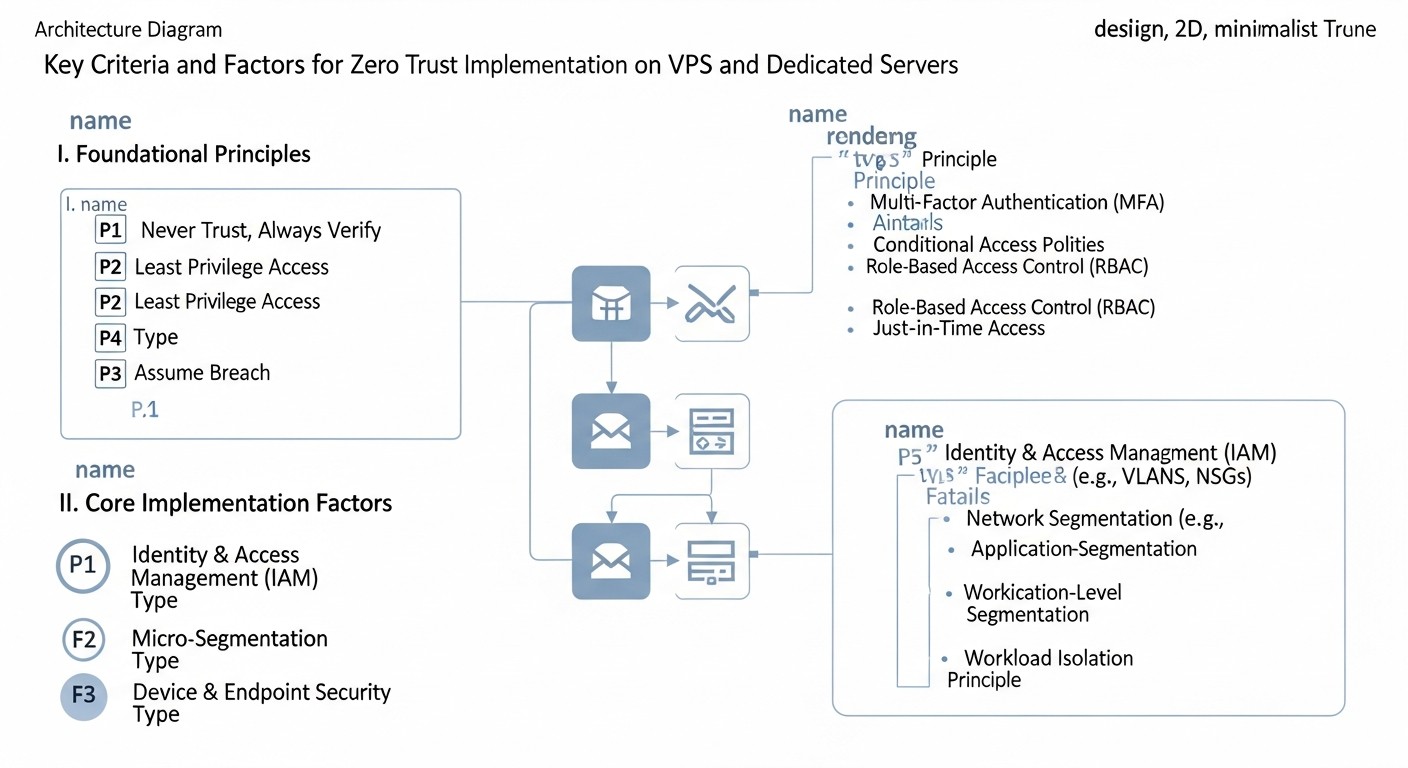 Diagrama: Criterios y factores clave para la implementación de Zero Trust
Diagrama: Criterios y factores clave para la implementación de Zero Trust
La implementación de Zero Trust en VPS y servidores dedicados requiere una comprensión profunda de los principios clave y su adaptación a su infraestructura única. Estos criterios forman la base de cualquier estrategia Zero Trust y deben ser cuidadosamente elaborados.
1. Verificación explícita (Verify Explicitly)
Esta es la piedra angular de Zero Trust. En lugar de depender de la confianza implícita, es necesario autenticar y autorizar explícitamente a cada usuario, cada dispositivo y cada servicio en cada solicitud de acceso. En 2026, esto significa no solo verificar el nombre de usuario y la contraseña, sino también utilizar una multitud de factores contextuales.
- Identificación del usuario: No solo nombre de usuario/contraseña, sino MFA (autenticación multifactor) o incluso soluciones sin contraseña (claves FIDO2, biometría). Es importante la autenticación continua, donde el sistema verifica periódicamente la identidad del usuario durante la sesión.
- Identificación del dispositivo: Verificación del estado del dispositivo (si las actualizaciones están instaladas, si el antivirus está activo, si la configuración cumple con las políticas de seguridad). En el caso de VPS/servidores dedicados, esto puede ser la verificación de huellas dactilares de claves SSH, certificados para clientes VPN o incluso el monitoreo de la actividad de los agentes de seguridad en el propio servidor.
- Contexto de la solicitud: ¿Dónde se encuentra el usuario (geolocalización)? ¿Qué hora del día es? ¿Cuál es el comportamiento habitual de este usuario/dispositivo? ¿Hay anomalías en la solicitud? Por ejemplo, un intento de acceso a una base de datos crítica desde un nuevo país a las 3 de la mañana debería generar una mayor atención.
- Autorización por el principio de mínimos privilegios: Después de una autenticación exitosa, el sistema debe otorgar acceso solo a los recursos necesarios para completar la tarea actual y solo por un tiempo limitado.
Por qué es importante: Esto previene ataques basados en la compromiso de credenciales o dispositivos, ya que incluso si se obtiene acceso, el atacante tendrá que pasar verificaciones adicionales. Esto dificulta significativamente el movimiento lateral dentro de una red comprometida.
Cómo evaluar: La existencia de un sistema centralizado de gestión de identidades y accesos (IAM), la implementación generalizada de MFA, la presencia de políticas de acceso condicional, la capacidad del sistema para reaccionar a los cambios de contexto en tiempo real.
2. Microsegmentación de la red (Micro-segmentation)
En lugar de una gran red "interna" donde todo se comunica con todo, la microsegmentación divide su infraestructura en zonas de seguridad pequeñas y aisladas. Cada servicio, cada aplicación, cada servidor obtiene su propio "mini-perímetro".
- Aislamiento de cargas de trabajo: Separación del frontend, backend, base de datos, caché, colas de mensajes y otros componentes en segmentos lógicos o físicos separados.
- Políticas de "lista blanca": Permitir solo el tráfico explícitamente autorizado entre segmentos. Todo lo demás se bloquea por defecto. Por ejemplo, el frontend solo puede comunicarse con el servidor API, y el servidor API solo con la base de datos y la caché.
- Firewalls de host: Uso de
iptables, nftables o firewalld en cada VPS/servidor dedicado para controlar el tráfico a nivel de host.
- VLAN/subredes: Uso de la separación lógica de la red a nivel de proveedor (si está disponible) o mediante soluciones de software, como túneles VPN entre servidores.
Por qué es importante: Si un atacante compromete un segmento, no podrá moverse fácilmente a otros. Esto limita significativamente el alcance del daño potencial y da más tiempo para la detección y respuesta.
Cómo evaluar: La existencia de un mapa claro de interacciones de red, el número mínimo de reglas de firewall permitidas, el uso del principio "denegar por defecto", la auditoría regular de las reglas de seguridad de la red.
3. Principio de mínimos privilegios (Least Privilege Access)
Otorgue a los usuarios, procesos y dispositivos solo el acceso que sea absolutamente necesario para realizar sus tareas actuales, y solo por el tiempo requerido. Ni más, ni por más tiempo.
- Control de Acceso Basado en Roles (RBAC): Definición de roles y asignación de los derechos de acceso mínimos necesarios. Por ejemplo, un desarrollador puede tener acceso a servidores de prueba, pero no a producción, y un administrador de bases de datos solo a la propia BD, pero no al sistema de archivos del servidor de aplicaciones.
- Acceso Just-in-Time (JIT): Otorgamiento de privilegios elevados solo por un período de tiempo corto y estrictamente definido (por ejemplo, 30 minutos para realizar una tarea urgente), después del cual los privilegios se revocan automáticamente.
- Segregación de funciones: División de tareas críticas entre varios empleados para que ninguna persona tenga control total sobre todo el sistema.
- Automatización de la gestión de privilegios: Uso de herramientas para el otorgamiento y la revocación automáticos de acceso basados en flujos de trabajo.
Por qué es importante: Minimiza el daño potencial en caso de compromiso de una cuenta o dispositivo. Si un atacante obtiene acceso a una cuenta con privilegios limitados, no podrá realizar acciones críticas ni acceder a datos sensibles.
Cómo evaluar: La existencia de un sistema centralizado de gestión de privilegios, auditorías regulares de los derechos de acceso, la ausencia de privilegios administrativos "permanentes", la automatización de la revocación de derechos.
4. Monitoreo y análisis continuo (Continuous Monitoring & Analytics)
En Zero Trust no existe el concepto de zona "de confianza", por lo que toda la actividad debe ser monitoreada y analizada continuamente en busca de anomalías y posibles amenazas.
- Registro centralizado: Recopilación de registros de todos los servidores, aplicaciones, firewalls y sistemas de autenticación en un sistema unificado (por ejemplo, ELK Stack, Graylog, Splunk).
- Monitoreo del comportamiento de usuarios y entidades (UEBA): Análisis de patrones de acceso y actividad para identificar desviaciones de la norma. Por ejemplo, si un usuario normalmente inicia sesión desde Moscú y de repente intenta iniciar sesión desde Nueva York, esto podría ser sospechoso.
- Detección de intrusiones (IDS/IPS): Uso de sistemas basados en host (HIDS, por ejemplo, OSSEC, Wazuh) y/o de red (NIDS) para detectar y prevenir ataques.
- Análisis de vulnerabilidades: Escaneo regular del sistema en busca de vulnerabilidades conocidas y configuraciones incorrectas.
- Métricas de rendimiento y seguridad: Seguimiento de indicadores que pueden señalar un compromiso (por ejemplo, tráfico inusualmente alto, mayor carga de CPU, errores de acceso).
Por qué es importante: Permite detectar y responder rápidamente a incidentes de seguridad, incluso si un atacante logró eludir las medidas de protección iniciales. En 2026, a medida que los ataques se vuelven cada vez más sigilosos, el monitoreo continuo es la única forma de mantenerse un paso adelante.
Cómo evaluar: La existencia de un sistema SIEM operativo, alertas automatizadas sobre anomalías, informes regulares sobre el estado de la seguridad, la capacidad de responder rápidamente a los incidentes.
5. Automatización y orquestación (Automation & Orchestration)
La implementación de Zero Trust sin automatización se convierte en una tarea abrumadora. La automatización es esencial para escalar, mantener la coherencia de las políticas y responder rápidamente.
- Despliegue automático y gestión de configuraciones: Uso de Ansible, Puppet, Chef o Terraform para garantizar la uniformidad de las configuraciones de seguridad en todos los servidores.
- Gestión automática de acceso: Integración de sistemas IAM con pipelines CI/CD para el otorgamiento y la revocación automáticos de acceso.
- Respuesta automática a incidentes (SOAR): Scripts o sistemas que bloquean automáticamente el tráfico sospechoso, aíslan nodos comprometidos o notifican a los administradores al detectar una amenaza.
- Actualización y parcheo automáticos: Sistemas que garantizan la aplicación oportuna de actualizaciones de seguridad a todos los componentes de la infraestructura.
Por qué es importante: Reduce la probabilidad de errores humanos, acelera el despliegue de configuraciones seguras, y garantiza una respuesta rápida y eficaz a los incidentes, lo cual es crucial en el entorno de amenazas de 2026, que cambia rápidamente.
Cómo evaluar: Alto nivel de automatización en la gestión de la infraestructura, existencia de playbooks para la respuesta a incidentes, número mínimo de operaciones manuales relacionadas con la seguridad.
6. Asunción de compromiso (Assume Breach)
Este principio significa que siempre debe diseñar y operar su infraestructura asumiendo que, tarde o temprano, ocurrirá un compromiso. El objetivo es minimizar las consecuencias de esta brecha.
- Aislamiento y segmentación: La microsegmentación mencionada anteriormente es un elemento clave de este principio.
- Cifrado en todas partes: Cifrado de datos en reposo (at rest) y en tránsito (in transit). Esto incluye cifrado de disco, SSL/TLS para todas las comunicaciones, cifrado de bases de datos.
- Copia de seguridad y recuperación regulares: Copias de seguridad probadas y aisladas que pueden restaurarse rápidamente en caso de compromiso o extorsión.
- Planes de respuesta a incidentes: Procedimientos claramente definidos para el caso de una brecha, incluyendo detección, contención, erradicación y recuperación.
- Pruebas de penetración (Pentesting) y Red Teaming: Simulaciones regulares de ataques para identificar debilidades y verificar la efectividad de las medidas de protección.
Por qué es importante: Permite prepararse para el peor escenario y garantizar la resiliencia del negocio incluso después de un ataque exitoso, lo cual es cada vez más relevante en 2026 con el aumento de los ciberataques dirigidos y destructivos.
Cómo evaluar: La existencia de planes de respuesta a incidentes actualizados, ejercicios regulares de recuperación ante desastres, el uso de cifrado por defecto, la realización de pentests regulares.
Tabla comparativa de enfoques de Zero Trust en servidores VPS/dedicados
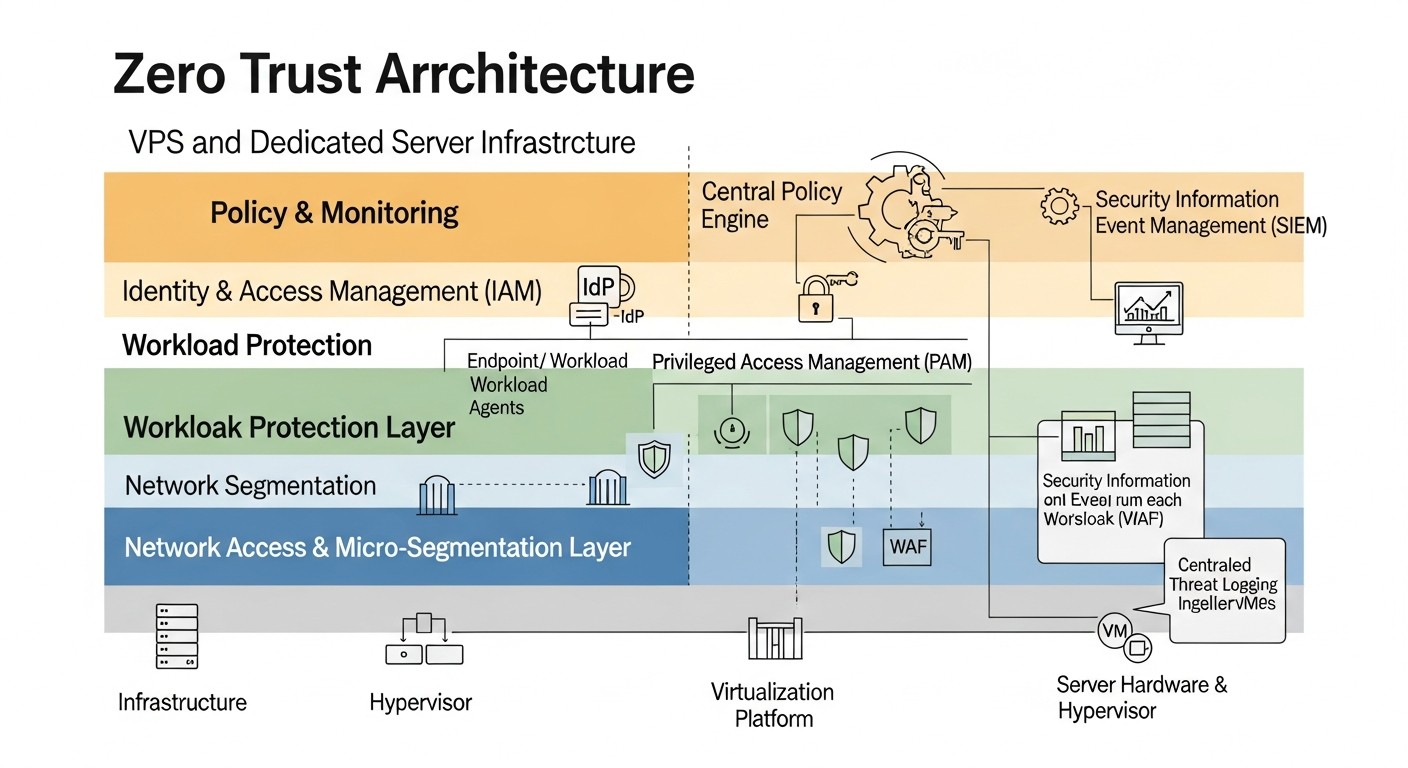 Esquema: Tabla comparativa de enfoques de Zero Trust en servidores VPS/dedicados
Esquema: Tabla comparativa de enfoques de Zero Trust en servidores VPS/dedicados
La elección de herramientas y enfoques específicos para implementar los principios de Zero Trust en servidores VPS y dedicados puede ser una tarea desafiante. En la siguiente tabla, compararemos varias estrategias y tecnologías comunes, relevantes para 2026, en términos de su aplicabilidad, costo y complejidad de implementación.
| Criterio |
Enfoque nativo (OS + Open Source) |
Zero Trust de red (SDP/ZTNA) |
Zero Trust de identidad (IAM + PAM) |
Zero Trust de contenedores/Service Mesh |
Monitoreo mejorado por IA (tendencia 2026) |
| Tecnologías / Herramientas clave |
iptables/nftables, WireGuard/OpenVPN, FreeIPA/OpenLDAP, OSSEC/Wazuh, Vault (HashiCorp), Ansible, ELK Stack. |
Cloudflare Zero Trust, Tailscale, ZeroTier, OpenZiti, Twingate. |
Keycloak, FreeIPA, HashiCorp Vault, Apache Syncope, Teleport (Proxy/PAM). |
Docker/Podman, Kubernetes (K3s), Istio/Linkerd, Cilium. |
Elastic Security (SIEM con ML), Wazuh (módulos de IA), CrowdStrike Falcon (EDR), Vectra AI, modelos de ML personalizados en logs. |
| Principio Zero Trust que refuerza |
Microsegmentación, Verificación explícita (básica), Menos privilegios (básica), Monitoreo. |
Verificación explícita, Menos privilegios, Asunción de brecha (aislamiento). |
Verificación explícita, Menos privilegios, Automatización. |
Microsegmentación, Verificación explícita (para servicios), Asunción de brecha. |
Monitoreo continuo, Automatización (respuesta), Verificación explícita (análisis de comportamiento). |
| Complejidad de implementación (1-5, 5-difícil) |
3 (requiere conocimientos profundos de OS y red) |
2 (relativamente sencillo para equipos pequeños, soluciones SaaS) |
4 (esfuerzos significativos para la integración y configuración) |
4-5 (requiere el dominio de la contenerización y orquestación) |
3-5 (depende de la profundidad de la integración y personalización de ML) |
| Costo aproximado (mensual para 5-10 servidores, 2026) |
0 - 150 USD (depende de extensiones/soporte de pago para Open Source) |
50 - 500 USD (suscripciones SaaS, depende del número de usuarios/tráfico) |
0 - 300 USD (Open Source gratuito, pero puede requerir soporte de pago/versiones comerciales) |
0 - 200 USD (Open Source gratuito, pero gastos en recursos computacionales) |
200 - 1500 USD (plataformas SaaS, licencias SIEM con ML, servicios de expertos) |
| Ventajas principales |
Control total, flexibilidad, bajos costos directos, independencia del proveedor. |
Despliegue rápido, facilidad de gestión, ocultamiento de infraestructura, acceso remoto eficiente. |
Gestión de acceso centralizada, autenticación fuerte, acceso JIT, auditoría. |
Aislamiento granular de servicios, gestión de tráfico entre microservicios, políticas de seguridad integradas. |
Detección temprana de anomalías, reducción de falsos positivos, identificación automática de amenazas complejas. |
| Desventajas principales |
Alto umbral de entrada, requiere expertos, posibles errores de configuración, escalado manual. |
Dependencia de un proveedor externo, posible latencia de tráfico, no siempre control total sobre la red. |
Complejidad de la configuración inicial, necesidad de integración con todas las aplicaciones. |
Complejidad de la arquitectura, alto umbral de entrada, gastos generales adicionales de recursos. |
Alto costo, requiere grandes volúmenes de datos para el entrenamiento, puede generar falsos positivos en la etapa inicial. |
| Para quién es adecuado |
Equipos pequeños y medianos con fuerte experiencia técnica, presupuesto limitado. |
Equipos que necesitan acceso remoto rápido y seguro, ocultamiento de servicios públicos. |
Cualquier equipo que se tome en serio la gestión de acceso e identidad. |
Proyectos que utilizan microservicios y contenerización, equipos orientados a DevOps. |
Proyectos medianos y grandes, dispuestos a invertir en monitoreo avanzado y protección proactiva. |
Análisis detallado de cada punto/opción de Zero Trust
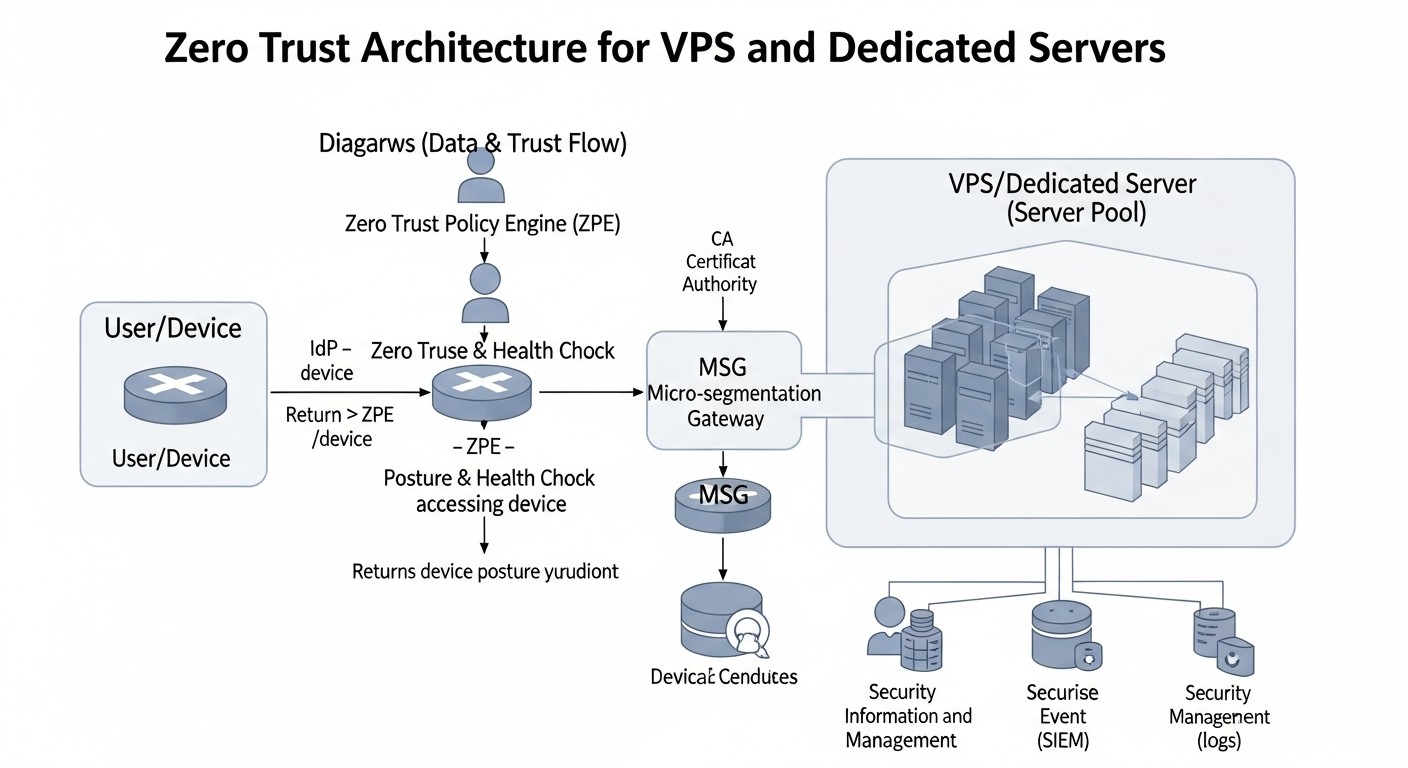 Diagrama: Análisis detallado de cada punto/opción de Zero Trust
Diagrama: Análisis detallado de cada punto/opción de Zero Trust
Profundicemos en cada uno de los enfoques presentados en la tabla comparativa para comprender sus fortalezas y debilidades, así como los escenarios de aplicación en 2026.
1. Enfoque nativo (OS + Open Source)
Este enfoque implica el uso de mecanismos integrados del sistema operativo (Linux) y soluciones Open Source maduras. Proporciona el máximo control y flexibilidad, pero requiere conocimientos profundos y un esfuerzo considerable en configuración y soporte.
Ventajas: Independencia total de los proveedores y sus políticas de licencia. Ausencia de costos directos de licencia. Máxima personalización para requisitos específicos. Alto rendimiento, ya que no hay abstracciones innecesarias. Comprensión profunda del funcionamiento del sistema a bajo nivel, lo que contribuye a una resolución de problemas más eficaz. En 2026, muchos proyectos Open Source han alcanzado la madurez y ofrecen soluciones estables y seguras, activamente respaldadas por la comunidad. Esto permite crear sistemas de seguridad verdaderamente robustos si el equipo cuenta con la experiencia suficiente.
Desventajas: Alta barrera de entrada. Requiere un equipo con conocimientos profundos de Linux, tecnologías de red, criptografía y seguridad. La gestión manual puede dar lugar a errores de configuración, especialmente en ausencia de automatización. La escalabilidad requiere un esfuerzo considerable de automatización (por ejemplo, con Ansible). El tiempo de implementación y configuración es significativamente mayor que con las soluciones SaaS. El soporte y la actualización de todos los componentes recaen en el equipo, lo que puede ser intensivo en recursos.
Para quién es adecuado: Startups pequeñas y medianas con un equipo DevOps/SysAdmin fuerte, dispuestas a invertir tiempo en aprendizaje y configuración. Proyectos con datos muy sensibles que requieren un control total sobre cada aspecto de la seguridad. Empresas que desean evitar la dependencia de proveedores de la nube o soluciones comerciales. Por ejemplo, si está desarrollando su propio SaaS y desea tener el máximo control sobre su infraestructura con costos operativos mínimos en servicios de terceros, este enfoque puede ser ideal.
Ejemplos de uso:
- Uso de
nftables para microsegmentación entre servicios en un mismo servidor o entre varios VPS.
- Configuración de WireGuard VPN para un acceso seguro a la red interna de servidores.
- Implementación de FreeIPA para la gestión centralizada de usuarios y claves SSH.
- Despliegue de HashiCorp Vault para la gestión de secretos y credenciales dinámicas.
- Recopilación de logs con
rsyslog y su agregación en ELK Stack para monitorización.
2. Zero Trust de red (SDP/ZTNA)
Software-Defined Perimeter (SDP) o Zero Trust Network Access (ZTNA) es un enfoque en el que el acceso a los recursos se concede solo después de una autenticación estricta del usuario y del dispositivo, y solo a aplicaciones específicas, no a toda la red. La infraestructura se vuelve "invisible" para los usuarios no autorizados.
Ventajas: Simplifica significativamente el acceso remoto y lo hace más seguro que las VPN tradicionales. Oculta la infraestructura de internet público, reduciendo la superficie de ataque. Despliegue rápido (especialmente con proveedores SaaS). Gestión centralizada de políticas de acceso. Soporte para acceso condicional (por ejemplo, acceso solo desde dispositivos corporativos). En 2026, estas soluciones han madurado aún más, ofreciendo una profunda integración con sistemas IAM y EDR, así como un rendimiento mejorado.
Desventajas: Dependencia de un proveedor externo (si es una solución SaaS), lo que puede plantear preguntas sobre la privacidad de los datos y la disponibilidad del servicio. Posibles latencias de tráfico debido al paso por los servidores proxy del proveedor. Puede ser más costoso que las soluciones Open Source, especialmente con un gran número de usuarios o un alto volumen de tráfico. No siempre proporciona un control total sobre la capa de red, lo que puede ser una limitación para configuraciones muy específicas. Algunas soluciones pueden ser menos flexibles en la integración con sistemas internos únicos.
Para quién es adecuado: Equipos con empleados distribuidos que necesitan acceso seguro a recursos internos. Proyectos SaaS que desean ocultar al máximo su infraestructura de internet público y simplificar la gestión de accesos. Empresas que desean implementar rápidamente Zero Trust sin grandes inversiones en desarrollo y soporte propios. Por ejemplo, una startup que contrata activamente empleados remotos en todo el mundo puede usar Cloudflare Zero Trust para garantizar un acceso seguro a sus servidores y herramientas internas, sin preocuparse por la configuración y el soporte de una infraestructura VPN compleja.
Ejemplos de uso:
- Uso de Cloudflare Zero Trust Tunnel para conectar servidores a la red de Cloudflare y proporcionar acceso a ellos a través del navegador o SSH después de la autenticación.
- Implementación de Tailscale para crear una red mesh entre todos los VPS, desarrolladores e incluso dispositivos móviles, utilizando WireGuard.
- Uso de Twingate para crear un acceso seguro a aplicaciones internas sin necesidad de abrir puertos a internet.
3. Zero Trust de identidad (IAM + PAM)
Este enfoque se centra en la gestión de identidades y accesos (IAM) y la gestión de accesos privilegiados (PAM). Garantiza que solo los usuarios autorizados puedan acceder a recursos críticos, y solo con los privilegios mínimos necesarios.
Ventajas: Gestión centralizada de todas las cuentas y derechos de acceso, lo que simplifica significativamente la auditoría y el cumplimiento. Aplicación forzada de políticas estrictas de contraseñas, MFA y acceso JIT. Reducción del riesgo de abuso de privilegios. Mayor seguridad para las cuentas administrativas. En 2026, los sistemas IAM/PAM ofrecen funciones avanzadas, como autenticación adaptativa basada en riesgos, integración con análisis de comportamiento y gestión automática del ciclo de vida de las cuentas.
Desventajas: Complejidad de la configuración inicial e integración con todas las aplicaciones y servicios existentes. Requiere cambios en los flujos de trabajo para utilizar el acceso JIT y otras funciones. Puede ser costoso si se utilizan soluciones comerciales. Mantener la relevancia de los roles y privilegios requiere un esfuerzo constante. Si el sistema IAM/PAM se ve comprometido, esto puede tener consecuencias catastróficas, por lo que su protección debe ser una prioridad.
Para quién es adecuado: Cualquier empresa que se tome en serio la gestión de accesos y quiera minimizar los riesgos asociados con las cuentas privilegiadas. Especialmente relevante para equipos con un gran número de empleados o contratistas que requieren acceso a sistemas sensibles. Ejemplo: Una empresa SaaS con varias decenas de desarrolladores y administradores de sistemas que necesitan acceso a servidores de producción, bases de datos y herramientas de monitorización. La implementación de Keycloak para SSO y autenticación centralizada, así como HashiCorp Vault para la gestión de secretos y credenciales dinámicas, aumentará significativamente la seguridad.
Ejemplos de uso:
- Uso de Keycloak como IdP centralizado para todas las aplicaciones internas y externas, con soporte para MFA.
- Implementación de FreeIPA para la gestión centralizada de claves SSH, autenticación LDAP para servicios y Kerberos para autenticación entre servicios.
- Uso de Teleport para proporcionar acceso Just-in-Time a servidores, bases de datos y clústeres de Kubernetes con auditoría completa de sesiones.
- Configuración de HashiCorp Vault para la emisión de certificados SSH temporales y credenciales dinámicas para bases de datos.
4. Zero Trust de Contenedores/Service Mesh
Este enfoque está orientado a arquitecturas de microservicios desplegadas en contenedores (Docker, Podman) y gestionadas por orquestadores (Kubernetes, K3s). Service Mesh (Istio, Linkerd) añade una capa de gestión de tráfico y seguridad entre los servicios.
Ventajas: Microsegmentación muy granular a nivel de microservicios individuales. Cifrado TLS mutuo automático entre servicios (mTLS). Gestión centralizada de políticas de tráfico y seguridad. Capacidades integradas para la observabilidad (métricas, logs, trazado). Simplificación de la implementación de políticas de "lista blanca" para la interacción entre servicios. En 2026, la contenerización y la orquestación se han convertido en un estándar, y las soluciones Service Mesh ofrecen funciones de seguridad más maduras y de mayor rendimiento, incluyendo la aplicación automática de políticas Zero Trust.
Desventajas: Alta complejidad arquitectónica y una barrera de entrada significativa. Requiere el dominio de Kubernetes y del Service Mesh elegido. Añade sobrecarga de recursos (memoria, CPU) debido a los contenedores proxy (sidecars). La resolución de problemas puede ser compleja debido a las múltiples capas de abstracción. No siempre es aplicable a aplicaciones "monolíticas" o VPS simples donde no se necesita orquestación. Para VPS y servidores dedicados, esto generalmente significa desplegar un clúster de Kubernetes ligero, como K3s.
Para quién es adecuado: Equipos que desarrollan y despliegan microservicios. Proyectos que ya utilizan la contenerización y están considerando la transición a Kubernetes (o ya lo utilizan). Empresas que necesitan una seguridad muy granular a nivel de servicios individuales. Ejemplo: Un proyecto SaaS que está migrando de una arquitectura monolítica a una de microservicios, desplegada en varios VPS con K3s. La implementación de Linkerd permitirá una interacción mTLS segura entre todos los microservicios, garantizando que solo los servicios autorizados puedan comunicarse entre sí.
Ejemplos de uso:
- Despliegue de K3s en varios VPS para crear un clúster de Kubernetes ligero.
- Implementación de Linkerd para mTLS automático entre microservicios y aplicación de políticas de autorización.
- Uso de Cilium para políticas de red a nivel de CNI, proporcionando microsegmentación granular basada en identificadores de servicio.
- Configuración de Docker/Podman con políticas de seguridad estrictas (AppArmor/SELinux) para el aislamiento de contenedores.
5. Monitorización potenciada por IA (tendencia 2026)
Este enfoque utiliza las capacidades de la inteligencia artificial y el aprendizaje automático para analizar enormes volúmenes de datos de seguridad (logs, métricas, tráfico de red) con el fin de identificar anomalías, amenazas y comportamientos sospechosos que podrían pasar desapercibidos para un humano o las reglas tradicionales.
Ventajas: Aumenta significativamente la eficacia en la detección de ataques complejos y de "día cero". Reduce el número de falsos positivos gracias al entrenamiento con datos reales. Automatiza el análisis y la correlación de eventos, lo que acorta el tiempo de detección y respuesta. Permite identificar patrones de comportamiento ocultos de los atacantes. En 2026, los sistemas de monitorización con IA se han vuelto más accesibles y precisos, capaces de analizar anomalías de comportamiento de usuarios y sistemas en tiempo real, prediciendo posibles amenazas antes de su desarrollo completo.
Desventajas: Alto costo de implementación y soporte, especialmente para soluciones comerciales. Requiere grandes volúmenes de datos de calidad para entrenar los modelos. Puede generar falsos positivos en las etapas iniciales o cuando el comportamiento normal del sistema cambia. Requiere expertos para la configuración, calibración e interpretación de los resultados. Complejidad de integración con la infraestructura existente. Dependencia de la calidad de los datos de entrada — "basura entra, basura sale".
Para quién es adecuado: Proyectos medianos y grandes con un alto volumen de tráfico y una infraestructura compleja, que estén dispuestos a invertir en herramientas de protección avanzadas. Empresas que se enfrentan a ataques altamente cualificados y dirigidos. Para proyectos SaaS cuya reputación y datos de clientes son críticos. Ejemplo: Una plataforma SaaS que procesa datos financieros sensibles de clientes utiliza Elastic Security con módulos de aprendizaje automático para analizar logs e identificar anomalías en el comportamiento de usuarios y sistemas. Esto ayuda a detectar amenazas internas o intentos de eludir la protección que no serían detectados por las reglas estándar.
Ejemplos de uso:
- Uso de Elastic Security (u otro SIEM con módulos de ML) para analizar logs y tráfico de red en busca de anomalías.
- Integración de Wazuh HIDS con análisis de comportamiento para detectar desviaciones en la actividad de los hosts.
- Desarrollo de modelos de ML propios para analizar logs específicos de la aplicación e identificar comportamientos anómalos en las solicitudes API.
- Aplicación de soluciones EDR (Endpoint Detection and Response) con funciones de IA, como CrowdStrike Falcon, para una monitorización profunda y respuesta a amenazas a nivel de cada servidor.
Consejos prácticos y recomendaciones para implementar Zero Trust
 Esquema: Consejos prácticos y recomendaciones para implementar Zero Trust
Esquema: Consejos prácticos y recomendaciones para implementar Zero Trust
La implementación de Zero Trust no es un proyecto único, sino un proceso continuo. Aquí tiene instrucciones paso a paso, comandos y ejemplos de configuración que le ayudarán a empezar.
1. Inventario y mapeo
Antes de cambiar nada, debe saber exactamente qué tiene.
Paso 1: Cree una lista completa de todos los servidores, servicios, aplicaciones, bases de datos, cuentas y sus interrelaciones.
Paso 2: Determine qué datos se almacenan en cada servidor y cuál es su sensibilidad.
Paso 3: Dibuje un mapa de los flujos de datos y las interacciones de red. Esto es fundamental para la planificación de la microsegmentación.
# Ejemplo de comando para inventariar puertos abiertos en Linux
sudo netstat -tulpn | grep LISTEN
# o
sudo ss -tulpn | grep LISTEN
# Ejemplo para ver los paquetes instalados
dpkg -l # Debian/Ubuntu
rpm -qa # CentOS/RHEL
Ejemplo práctico: Utilice herramientas como nmap para escanear su propia infraestructura desde fuera y desde dentro, para entender qué puertos están realmente abiertos. Documente cada servicio, su propósito y quién accede a él.
2. Refuerzo de la autenticación y autorización
La implementación de MFA y políticas de acceso estrictas es el primer y más importante paso.
Paso 1: Habilite MFA para todas las cuentas con acceso a servidores (SSH, panel de control de VPS, repositorios Git, CI/CD).
Paso 2: Utilice claves SSH en lugar de contraseñas para acceder a los servidores. Proteja las claves con una frase de contraseña.
Paso 3: Configure un sistema centralizado de gestión de identidades (IAM) para todos los usuarios y servicios. FreeIPA o Keycloak son excelentes opciones de código abierto.
# Ejemplo de configuración de SSH para deshabilitar la autenticación por contraseña
# Edite /etc/ssh/sshd_config
PasswordAuthentication no
ChallengeResponseAuthentication no
UsePAM yes # Si usa PAM para MFA
AuthenticationMethods publickey,keyboard-interactive # publickey O keyboard-interactive (para MFA)
KbdInteractiveAuthentication yes # Para MFA basado en PAM
# Reinicie el servicio SSH
sudo systemctl restart sshd
Ejemplo práctico: Integre Google Authenticator (o FreeOTP) con PAM para el acceso SSH. Instale libpam-google-authenticator y configúrelo para cada usuario. Esto proporcionará autenticación de dos factores al iniciar sesión por SSH.
3. Microsegmentación con firewalls
Divida su red en segmentos lógicos y aplique reglas estrictas de firewall.
Paso 1: Determine qué servicios deben comunicarse entre sí.
Paso 2: Configure nftables o iptables en cada servidor, permitiendo solo el tráfico necesario.
# Ejemplo de reglas de nftables para microsegmentación
# Supongamos que tiene un servidor web (80/443) que se comunica con una base de datos (3306)
# y un servidor de base de datos que solo acepta conexiones del servidor web.
# En el servidor web:
sudo nft add table ip filter
sudo nft add chain ip filter input { type filter hook input priority 0; policy drop; }
sudo nft add chain ip filter output { type filter hook output priority 0; policy accept; } # Abrimos el tráfico saliente
sudo nft add rule ip filter input ip saddr { 127.0.0.1/8, } accept
sudo nft add rule ip filter input tcp dport { 80, 443 } accept # Permitimos HTTP/HTTPS desde el exterior
sudo nft add rule ip filter input ct state established,related accept # Permitimos respuestas a conexiones salientes
sudo nft add rule ip filter input drop # Todo lo demás se descarta
# En el servidor de base de datos (supongamos que la IP del servidor web es 192.168.1.10):
sudo nft add table ip filter
sudo nft add chain ip filter input { type filter hook input priority 0; policy drop; }
sudo nft add chain ip filter output { type filter hook output priority 0; policy accept; }
sudo nft add rule ip filter input ip saddr { 127.0.0.1/8, } accept
sudo nft add rule ip filter input ip saddr 192.168.1.10 tcp dport 3306 accept # Permitimos solo desde el servidor web
sudo nft add rule ip filter input ct state established,related accept
sudo nft add rule ip filter input drop
Ejemplo práctico: Utilice Ansible para desplegar y gestionar automáticamente las reglas de nftables en todos sus servidores, asegurando la consistencia y reduciendo el riesgo de errores.
4. Implementación del principio de mínimos privilegios
No conceda a nadie más derechos de los que necesita.
Paso 1: Cree usuarios de sistema separados para cada aplicación/servicio.
Paso 2: Utilice sudo con los derechos mínimos necesarios en lugar de usar root directamente.
Paso 3: Configure el acceso JIT para tareas administrativas, utilizando, por ejemplo, Teleport o HashiCorp Vault.
# Ejemplo de configuración de sudoers para acceso JIT (parte del archivo /etc/sudoers.d/devops)
# Permite al usuario 'devops_user' ejecutar service restart para nginx sin contraseña
devops_user ALL=(ALL) NOPASSWD: /usr/sbin/service nginx restart
# Enfoque más seguro usando Teleport (a través de proxy)
# El usuario solicita acceso al servidor a través de Teleport,
# Teleport emite un certificado SSH temporal con derechos limitados.
tsh login --proxy=teleport.example.com --auth=github
tsh ssh --request-roles=admin-role web-01.example.com # Solicitar rol de administrador
Ejemplo práctico: Para las bases de datos, cree cuentas separadas para cada microservicio con derechos solo sobre las tablas con las que trabaja. Por ejemplo, el microservicio "Pedidos" tiene acceso solo a las tablas orders y order_items, y no a toda la base de datos.
5. Monitorización y registro continuos
Recopile, analice y reaccione a todos los eventos de seguridad.
Paso 1: Implemente un sistema de registro centralizado (ELK Stack, Graylog).
Paso 2: Utilice HIDS (OSSEC, Wazuh) para monitorear la integridad de los archivos, las llamadas al sistema y la actividad de los usuarios en cada servidor.
Paso 3: Configure alertas para eventos críticos (intentos de inicio de sesión desde IP desconocidas, cambio de archivos críticos, tráfico de red inusual).
# Ejemplo de configuración de rsyslog para enviar registros a un servidor central
# Edite /etc/rsyslog.conf en cada cliente
. @192.168.1.20:514 # Envía todos los registros al servidor SIEM 192.168.1.20 por UDP 514
# Ejemplo de instalación del Agente Wazuh
# Descargue e instale el agente según la documentación de Wazuh para su SO
# Después de la instalación, edite /var/ossec/etc/ossec.conf
192.168.1.20 # IP de su Wazuh Manager
# Reinicie el Agente Wazuh
sudo systemctl restart wazuh-agent
Ejemplo práctico: Configure Grafana para visualizar métricas de seguridad (intentos de inicio de sesión, paquetes bloqueados por el firewall) e intégrelo con Prometheus. Cree paneles que muestren anomalías en tiempo real.
6. Cifrado de datos
Cifre todo: datos en reposo y en tránsito.
Paso 1: Utilice HTTPS (Let's Encrypt) para todos los servicios web.
Paso 2: Cifre los discos en los servidores (LUKS).
Paso 3: Utilice mTLS para la comunicación entre servicios, si es posible (por ejemplo, con Service Mesh).
# Ejemplo de comando para cifrar una partición de disco con LUKS (durante la instalación o con precaución en un sistema en vivo)
# Esto es un ejemplo, requiere comprensión del trabajo con discos
sudo cryptsetup luksFormat /dev/vdb1 # Formateo de la partición
sudo cryptsetup luksOpen /dev/vdb1 my_encrypted_data # Apertura de la partición
sudo mkfs.ext4 /dev/mapper/my_encrypted_data # Creación del sistema de archivos
sudo mount /dev/mapper/my_encrypted_data /mnt/data # Montaje
# Ejemplo de obtención de certificado Let's Encrypt con certbot
sudo apt install certbot python3-certbot-nginx # Instalación para Nginx
sudo certbot --nginx -d yourdomain.com -d www.yourdomain.com # Obtención y configuración
Ejemplo práctico: Al desplegar un nuevo VPS, elija siempre la opción de cifrado de disco si está disponible. Si no, considere usar dm-crypt/LUKS para cifrar los datos antes de escribirlos en el disco, especialmente para datos críticos y bases de datos.
7. Automatización e Infraestructura como Código (IaC)
Automatice todo lo posible para garantizar la consistencia y la velocidad.
Paso 1: Utilice Ansible, Terraform o Puppet para gestionar las configuraciones de los servidores y el despliegue de aplicaciones.
Paso 2: Implemente pipelines de CI/CD para la prueba y el despliegue automático de código.
Paso 3: Automatice la actualización de paquetes y la aplicación de parches de seguridad.
# Ejemplo de playbook de Ansible para configurar el firewall
# file: firewall.yml
- name: Configure nftables for web server
hosts: webservers
become: yes
tasks:
- name: Ensure nftables is installed
ansible.builtin.apt:
name: nftables
state: present
- name: Copy nftables configuration
ansible.builtin.copy:
src: files/nftables.conf
dest: /etc/nftables.conf
mode: '0640'
notify: Restart nftables
- name: Enable and start nftables service
ansible.builtin.service:
name: nftables
state: started
enabled: yes
handlers:
- name: Restart nftables
ansible.builtin.service:
name: nftables
state: restarted
Ejemplo práctico: Utilice Terraform para describir su infraestructura (VPS, reglas de red del proveedor) y Ansible para la configuración del sistema operativo y la instalación de aplicaciones. Esto garantiza que cada nuevo servidor se despliegue con las mismas políticas de seguridad.
Errores comunes al implementar Zero Trust
 Diagrama: Errores comunes al implementar Zero Trust
Diagrama: Errores comunes al implementar Zero Trust
La implementación de Zero Trust es un proceso complejo, y en el camino es fácil cometer errores que pueden socavar todos los esfuerzos para mejorar la seguridad. A continuación, se presentan al menos 5 errores comunes y cómo evitarlos.
1. Enfoque "todo o nada"
Error: Intentar implementar todos los principios de Zero Trust a la vez en toda la infraestructura. Esto lleva a la sobrecarga del equipo, largos tiempos de inactividad, conflictos y, en última instancia, al fracaso del proyecto debido a su complejidad.
Cómo evitarlo: Adopte un enfoque iterativo. Comience con los activos más críticos o con los componentes menos complejos de implementar. Por ejemplo, primero implemente MFA para el acceso administrativo, luego la microsegmentación para un servicio crítico, y después el acceso JIT. Divida el proyecto en etapas pequeñas y manejables. Celebre las pequeñas victorias y expanda gradualmente el alcance. En 2026, este enfoque se ha vuelto aún más relevante, ya que la complejidad de los sistemas crece y las implementaciones de "big bang" casi siempre están destinadas al fracaso.
Ejemplo real de consecuencias: Una empresa SaaS intentó implementar un Zero Trust completo con Service Mesh, un nuevo IAM y microsegmentación total en 6 meses. El proyecto se extendió a 1,5 años, causó agotamiento del equipo, numerosos fallos en producción debido a una configuración incorrecta y finalmente fue descontinuado sin alcanzar todos sus objetivos. Como resultado, volvieron a etapas menos ambiciosas pero más manejables.
2. Olvidar la inventariación y el mapeo
Error: Comenzar la implementación de Zero Trust sin una comprensión completa del estado actual de la infraestructura, todos los activos, sus interrelaciones y flujos de datos. Esto lleva a la creación de "puntos ciegos", políticas de seguridad incorrectas y posibles brechas.
Cómo evitarlo: Realice una inventariación exhaustiva de todos los activos (servidores, aplicaciones, bases de datos, API, cuentas), sus roles, propietarios y la sensibilidad de los datos. Cree mapas detallados de las interacciones de red y los flujos de datos. Utilice herramientas automatizadas para el descubrimiento de activos y dependencias. Actualice esta documentación regularmente. En 2026, existen muchas herramientas para el descubrimiento y mapeo automático de dependencias en entornos dinámicos.
Ejemplo real de consecuencias: Una startup implementó microsegmentación sin saber de la existencia de un antiguo servidor API poco utilizado que se comunicaba con la base de datos a través de un puerto no estándar. Este servidor quedó sin protección, se convirtió en un punto de entrada para los atacantes y provocó una fuga de datos, a pesar de todos los esfuerzos por proteger la infraestructura principal.
3. Ignorar la experiencia del usuario
Error: Implementar políticas de seguridad estrictas (por ejemplo, reautenticación frecuente, MFA complejo, acceso JIT) sin tener en cuenta la comodidad para los usuarios finales (desarrolladores, administradores de sistemas). Esto lleva a la elusión de políticas, el uso de métodos de acceso "en la sombra" y resistencia al cambio.
Cómo evitarlo: Involucre a los usuarios en el proceso de diseño. Explíqueles los beneficios de Zero Trust. Busque un equilibrio entre seguridad y comodidad. Utilice soluciones MFA modernas y fáciles de usar (por ejemplo, claves FIDO2, biometría). Automatice los procesos para minimizar las acciones manuales. En 2026, las soluciones de autenticación sin contraseña y acceso adaptativo se han vuelto mucho más maduras, lo que permite mejorar la UX sin comprometer la seguridad.
Ejemplo real de consecuencias: El equipo de DevOps implementó MFA para SSH, que requería ingresar un código largo desde el teléfono cada 15 minutos. Los desarrolladores, cansados de las interrupciones constantes, comenzaron a intercambiar claves SSH o a usar VNC para el acceso remoto, eludiendo por completo las nuevas políticas y creando riesgos de seguridad aún mayores.
4. Monitoreo y registro insuficientes
Error: Implementar Zero Trust sin sistemas adecuados de monitoreo, agregación de registros y análisis. Sin esto, es imposible detectar anomalías, evaluar la efectividad de las políticas o responder rápidamente a los incidentes. Zero Trust no es solo prevención, sino también detección rápida.
Cómo evitarlo: Desde el principio, planifique el registro centralizado de todas las fuentes (firewalls, sistemas de autenticación, aplicaciones, OS). Implemente un sistema SIEM (Elastic Security, Graylog, Splunk) y configure alertas para eventos clave y anomalías. Utilice HIDS/NIDS para una capa adicional de detección. Revise regularmente los registros e informes. En 2026, utilice activamente AI/ML para el análisis de registros y así identificar amenazas ocultas que el ojo humano o las reglas simples no detectarían.
Ejemplo real de consecuencias: Una empresa implementó microsegmentación y políticas de acceso estrictas, pero no configuró un monitoreo adecuado. Cuando uno de los servidores fue comprometido a través de una vulnerabilidad en un software antiguo, el atacante pudo moverse por el segmento restringido durante mucho tiempo antes de ser descubierto, porque nadie estaba rastreando las conexiones de red anómalas desde dentro del segmento.
5. Falta de automatización y políticas obsoletas
Error: Gestión manual de políticas Zero Trust, configuraciones de firewalls y privilegios. En un entorno dinámico, esto lleva a la rápida obsolescencia de las políticas, errores y "deriva de configuración", donde el estado real difiere del deseado.
Cómo evitarlo: Implemente Infrastructure as Code (IaC) utilizando Terraform, Ansible o Puppet para gestionar toda la infraestructura y las políticas de seguridad. Automatice el despliegue, la actualización y la revocación de privilegios. Integre las políticas de seguridad en los pipelines de CI/CD. Realice auditorías regulares de conformidad de las configuraciones. Utilice herramientas automatizadas para verificar la actualidad de las políticas. En 2026, la gestión manual de la infraestructura y la seguridad se considera un antipatrón.
Ejemplo real de consecuencias: En una de las empresas, las reglas del firewall en 50 VPS se gestionaban manualmente. Cuando fue necesario abrir un nuevo puerto para un nuevo servicio, el administrador olvidó cerrarlo después de la prueba. Más tarde, cuando el servicio se desplegó en otro puerto, la regla antigua nunca se eliminó, dejando una vulnerabilidad abierta que fue utilizada para un ataque DDoS.
La implementación de Zero Trust, especialmente en VPS y servidores dedicados, a menudo se percibe como una empresa costosa. Sin embargo, en 2026, el costo de la inacción frente a las ciberamenazas supera significativamente la inversión en seguridad. Es importante entender que el "costo" incluye no solo los gastos financieros directos, sino también el tiempo, los recursos del equipo y los posibles gastos ocultos.
Las cifras presentadas son estimaciones y pueden variar significativamente según los requisitos específicos, los proveedores seleccionados y la cualificación del equipo.
Como se desprende de la tabla, los costos directos de las licencias pueden ser bajos en el escenario de código abierto, pero esto se compensa con la alta carga de trabajo del equipo. Las soluciones comerciales reducen la carga del equipo, pero aumentan los pagos directos. La elección óptima depende del tamaño de su equipo, su cualificación y su presupuesto.
Troubleshooting: Solución de problemas comunes de Zero Trust
La implementación de Zero Trust puede conllevar diversos desafíos. A continuación, se presentan escenarios típicos y enfoques para su resolución.
1. Problemas de acceso después de configurar firewalls (microsegmentación)
Síntoma: Los servicios no pueden comunicarse entre sí, los usuarios no pueden conectarse a los servidores después de configurar nftables/iptables.
Diagnóstico:
- Verifique los registros del firewall: Asegúrese de que el firewall registre los paquetes descartados. Si no es así, agregue temporalmente reglas de registro (por ejemplo,
nft add rule ip filter input drop counter log prefix "NFT_DROP: ").
- Verifique el estado del firewall:
sudo nft list ruleset # Para nftables
sudo iptables -nvL # Para iptables
- Use
tcpdump: Ejecute tcpdump en ambos nodos (origen y destino) para analizar el tráfico.
sudo tcpdump -i any host <IP_другого_сервера> and port <PORT> -vn
- Verifique la conectividad de red: Use
ping, telnet o nc para verificar la conectividad de red básica antes de aplicar el firewall o con reglas mínimas.
telnet <IP_сервера> <PORT>
nc -vz <IP_сервера> <PORT>
Solución:
- Debilite temporalmente las reglas: Para el diagnóstico, puede permitir temporalmente todo el tráfico entre los dos nodos problemáticos para asegurarse de que el problema radica en el firewall. Luego, restrinja gradualmente las reglas.
- Verifique el orden de las reglas: En los firewalls, las reglas se procesan secuencialmente. Asegúrese de que las reglas de permiso estén antes que las de bloqueo.
- Considere
RELATED,ESTABLISHED: No olvide permitir el tráfico entrante para las conexiones ya establecidas (ct state established,related accept en nftables o -m state --state RELATED,ESTABLISHED -j ACCEPT en iptables).
- Verifique ambas direcciones: El firewall funciona en ambas direcciones. Asegúrese de que el tráfico tanto entrante como saliente esté permitido para los puertos necesarios.
2. Problemas con MFA/acceso JIT (autenticación)
Síntoma: Los usuarios no pueden autenticarse con MFA, el acceso JIT no funciona o no se emiten certificados temporales.
Diagnóstico:
- Verifique los registros del sistema: Los registros
auth.log, syslog, los registros de PAM (/var/log/auth.log en Debian/Ubuntu, /var/log/secure en CentOS/RHEL) pueden contener mensajes de error de autenticación.
- Verifique los registros del sistema IAM/PAM: Keycloak, FreeIPA, Teleport tienen sus propios registros que pueden indicar la causa de la falla.
- Verifique la sincronización de la hora: Los tokens MFA basados en el tiempo (TOTP) son muy sensibles a la sincronización de la hora entre el cliente y el servidor.
timedatectl # Проверить время на сервере
- Verifique la configuración de PAM: Asegúrese de que los módulos PAM estén configurados correctamente (por ejemplo,
/etc/pam.d/sshd para SSH).
Solución:
- Sincronice la hora: Configure la sincronización NTP en todos los servidores.
- Verifique los secretos de MFA: Asegúrese de que el secreto de MFA se haya ingresado correctamente en el cliente (por ejemplo, en Google Authenticator) y que coincida con el del servidor.
- Revise las políticas: Si el acceso JIT no se emite, asegúrese de que las políticas de autorización en Teleport o Vault estén configuradas correctamente y que el usuario tenga derecho a solicitar dicho rol/certificado.
- Pruebe con configuraciones mínimas: Deshabilite temporalmente uno de los factores de MFA para aislar el problema.
3. Problemas de rendimiento después de la implementación de Zero Trust
Síntoma: Disminución notable del rendimiento de las aplicaciones, alta carga de CPU/memoria en los servidores después de implementar nuevos componentes de Zero Trust (por ejemplo, Service Mesh, agentes SIEM).
Diagnóstico:
- Monitoreo de recursos: Use
top, htop, Prometheus/Grafana para identificar los procesos que consumen más recursos.
- Verifique los registros: La alta actividad de registro puede sobrecargar el disco y la CPU.
- Pruebas con componentes deshabilitados: Intente deshabilitar temporalmente uno de los nuevos componentes de Zero Trust (por ejemplo, el agente HIDS, el sidecar de Service Mesh) para determinar la fuente del problema.
- Analice las latencias de red: Use
mtr o traceroute para identificar cuellos de botella en la red, especialmente si se utiliza una solución ZTNA.
Solución:
- Optimice la configuración: Para los agentes HIDS, reduzca la frecuencia de escaneo o excluya rutas no críticas. Para Service Mesh, verifique la configuración de los servidores proxy.
- Aumente los recursos: Si uno de los componentes (por ejemplo, Elasticsearch en ELK Stack) consume constantemente muchos recursos, es posible que necesite más CPU, memoria o un disco más rápido.
- Optimice el registro: Filtre los registros menos importantes, agréguelos, use protocolos de transporte más eficientes (por ejemplo, UDP para syslog, si las pérdidas no son críticas).
- Elija alternativas más ligeras: Si una solución comercial es demasiado intensiva en recursos, considere alternativas de código abierto.
4. "Deriva de configuración" y políticas desactualizadas
Síntoma: Las configuraciones de los servidores o las reglas de seguridad difieren de lo esperado, las políticas se vuelven obsoletas, aparecen cambios no documentados.
Diagnóstico:
- Auditoría de configuraciones: Use Ansible (modo
--check) u otras herramientas de IaC para verificar regularmente la conformidad del estado real con el deseado.
- Monitoreo de cambios de archivos: Los sistemas HIDS (Wazuh, OSSEC) pueden rastrear cambios en archivos de configuración críticos.
- Escaneos regulares: Los escáneres de vulnerabilidades y configuraciones pueden detectar desviaciones de las líneas base de seguridad.
Solución:
- Implemente IaC: Use Terraform/Ansible para gestionar todos los aspectos de la infraestructura.
- Automatice la aplicación de políticas: Configure CI/CD para aplicar automáticamente los cambios de configuración.
- Auditoría regular: Programe auditorías de cumplimiento automáticas o manuales, al menos trimestralmente.
- Capacite al equipo: Asegúrese de que todos los ingenieros sigan los principios de IaC y no realicen cambios manualmente sin registrarlos en el sistema de control de versiones.
Cuándo contactar al soporte o a expertos:
- Si después de todos los pasos de diagnóstico no puede determinar la causa del problema.
- Si el problema afecta a un sistema crítico y causa un tiempo de inactividad prolongado.
- Si sospecha un ataque activo o una compromiso, y su equipo no tiene suficiente experiencia en la respuesta a incidentes.
- Al implementar componentes complejos (por ejemplo, configuración de Service Mesh, políticas IAM personalizadas) sin suficiente experiencia interna.
- Para realizar una auditoría de seguridad independiente o un pentest, para obtener una perspectiva externa.
FAQ: Preguntas frecuentes sobre Zero Trust
¿Qué es Zero Trust y en qué se diferencia de la seguridad tradicional?
Zero Trust es un enfoque estratégico de seguridad basado en el principio de "no confiar en nadie, verificar siempre". A diferencia del modelo tradicional, que confía en todo lo que está dentro del perímetro de la red, Zero Trust verifica explícitamente a cada usuario, dispositivo y solicitud de acceso, independientemente de su ubicación. Esto significa que incluso si un usuario está "dentro" de su red, su acceso será estrictamente controlado y verificado.
¿Se puede implementar Zero Trust en un solo VPS o es solo para grandes empresas?
Sí, absolutamente. Zero Trust son principios que se aplican a cualquier infraestructura. Incluso en un solo VPS se puede implementar microsegmentación con nftables, fortalecer la autenticación SSH con MFA, usar HashiCorp Vault para secretos y configurar el registro centralizado. La escala de implementación será menor, pero los principios siguen siendo los mismos, y su implementación aumentará significativamente la seguridad.
¿Cuáles son los primeros pasos para implementar Zero Trust?
Comience con un inventario de todos sus activos y sus interrelaciones. Luego, concéntrese en fortalecer la autenticación: implemente MFA para todas las cuentas administrativas y use claves SSH. Paralelamente, comience con la microsegmentación de los servicios más críticos, aplicando políticas de "denegar por defecto" a nivel de firewalls de host.
¿Es necesario abandonar completamente las VPN al pasar a Zero Trust?
No necesariamente. Las VPN tradicionales, que proporcionan un amplio acceso a la red, pueden ser reemplazadas por soluciones ZTNA que otorgan acceso solo a aplicaciones específicas. Sin embargo, WireGuard u OpenVPN pueden usarse para crear túneles seguros entre servidores o para establecer una red base sobre la cual se construirán las políticas de acceso a aplicaciones de Zero Trust.
¿Cómo ayuda Zero Trust en la lucha contra las amenazas internas?
Zero Trust combate eficazmente las amenazas internas, ya que no confía en los usuarios o sistemas "internos" por defecto. El principio de privilegio mínimo, el acceso JIT, la microsegmentación y el monitoreo continuo garantizan que incluso una cuenta interna comprometida o un insider malintencionado tendrá acceso limitado y sus acciones serán detectadas rápidamente.
¿Qué herramientas de código abierto son más útiles para Zero Trust?
Para IAM: Keycloak, FreeIPA. Para la gestión de secretos: HashiCorp Vault. Para la seguridad de red: nftables/iptables, WireGuard. Para el monitoreo: ELK Stack, Graylog, Wazuh, Prometheus/Grafana. Para la automatización: Ansible, Terraform. Estas herramientas permiten construir una potente infraestructura Zero Trust con costos directos mínimos.
¿Cuánto tiempo lleva implementar Zero Trust?
La implementación de Zero Trust es un proceso continuo, no un proyecto único. Los primeros resultados significativos (por ejemplo, MFA para SSH y microsegmentación básica) pueden lograrse en 3-6 meses. La transformación completa de la infraestructura puede llevar de 1 a 3 años, dependiendo del tamaño y la complejidad de su sistema, así como de los recursos del equipo.
¿Es necesario reescribir todas las aplicaciones para Zero Trust?
No, no es necesario. Muchos principios de Zero Trust (MFA, firewalls, monitoreo) pueden aplicarse a nivel de infraestructura sin cambiar el código de las aplicaciones. Sin embargo, para lograr el máximo efecto (por ejemplo, para una autorización granular a nivel de API o mTLS para microservicios), puede ser necesaria alguna adaptación o el uso de Service Mesh, lo que podría requerir cambios en la implementación de las aplicaciones.
¿Cómo medir la eficacia de la implementación de Zero Trust?
La eficacia se puede medir mediante varios indicadores: reducción del número de incidentes de seguridad, disminución del tiempo de detección y respuesta a amenazas (MTTD/MTTR), reducción de la superficie de ataque, éxito en auditorías y pentests, y mejora del cumplimiento normativo. Es importante monitorear métricas como el número de ataques bloqueados por el firewall, el número de intentos de acceso no autorizado y la actividad de los HIDS.
¿Cuál es el papel de la IA y el ML en Zero Trust en 2026?
En 2026, la IA y el ML desempeñan un papel críticamente importante en Zero Trust, especialmente en el monitoreo continuo y la detección de amenazas. Se utilizan para analizar enormes volúmenes de registros y tráfico de red, identificar anomalías en el comportamiento de usuarios y sistemas, predecir amenazas y automatizar la respuesta. La IA ayuda a encontrar ataques ocultos que no pueden ser detectados por métodos tradicionales basados en firmas, haciendo la protección más proactiva y adaptativa.
Conclusión: Próximos pasos hacia un futuro seguro
En 2026, el concepto de Zero Trust ha dejado de ser una simple palabra de moda para convertirse en una necesidad absoluta para cualquier infraestructura, especialmente para aquellos que gestionan VPS y servidores dedicados. Dado el crecimiento exponencial de la complejidad de las ciberamenazas, potenciado por las capacidades de la inteligencia artificial, los enfoques de seguridad tradicionales ya no son capaces de proporcionar una protección adecuada. Los principios de "nunca confíes, siempre verifica", la microsegmentación, el principio de mínimo privilegio, el monitoreo continuo y la automatización no son solo las mejores prácticas, son la base para construir un entorno digital resiliente y seguro.
Hemos explorado cómo aplicar estos principios en entornos con recursos limitados, aprovechando el poder de las soluciones Open Source e implementando estratégicamente productos comerciales donde esté justificado. La conclusión clave es que Zero Trust no es un producto que se pueda comprar e instalar, sino un enfoque estratégico que requiere cambios en la mentalidad, los procesos y la arquitectura. Es un viaje continuo que exige adaptación y mejora constantes.
Próximos pasos para el lector:
- Comience con una auditoría: Utilice nuestra lista de verificación para evaluar el estado actual de su infraestructura. Identifique los activos más críticos y las brechas de seguridad más obvias.
- Priorice la MFA: Es la forma más rápida y efectiva de mejorar significativamente la seguridad. Implemente la autenticación multifactor para todas las cuentas administrativas y, si es posible, para todos los usuarios.
- Planifique la microsegmentación: Comience mapeando las interacciones de red e implemente gradualmente firewalls basados en host con una política de "deny by default" para aislar los servicios críticos.
- Invierta en automatización: Utilice herramientas de IaC, como Ansible y Terraform, para gestionar configuraciones y despliegues. Esto no solo mejorará la seguridad, sino que también simplificará significativamente las operaciones.
- Implemente un monitoreo centralizado: Configure ELK Stack o Wazuh para recopilar y analizar registros de todos sus servidores. Configure alertas para anomalías. Sin monitoreo, Zero Trust estará incompleto.
- Capacite a su equipo: Sus ingenieros son su primera línea de defensa. Invierta en su formación sobre los principios de Zero Trust y el uso de las herramientas pertinentes.
- Realice auditorías y pentests regulares: Solo una perspectiva externa o una simulación de ataque puede revelar las debilidades reales de su sistema.
Recuerde que el camino hacia la implementación completa de Zero Trust puede ser largo, pero cada paso que dé le acercará a una infraestructura más segura y resiliente. En el panorama de amenazas en constante evolución de 2026, invertir en Zero Trust es invertir en el futuro de su negocio.