
Prácticas SRE para startups y pequeños equipos SaaS en VPS/Dedicated: de SLO a Post-Mortem
TL;DR
- La implementación de prácticas SRE es fundamental para la supervivencia y escalabilidad de las startups en VPS/Dedicated, asegurando la estabilidad y previsibilidad del funcionamiento.
- Comience definiendo métricas clave (SLI) y objetivos realistas (SLO) para sus servicios críticos, sin aspirar a las "nueves" ideales.
- La monitorización y las alertas eficaces son la base de SRE; utilice soluciones de código abierto como Prometheus/Grafana para ahorrar costes y tener control.
- Desarrolle procesos sencillos pero efectivos para la respuesta a incidentes y realice Post-Mortem "sin culpa" para el aprendizaje continuo.
- Automatice las tareas rutinarias (despliegue, actualización, copia de seguridad) para reducir el "toil" y minimizar el factor humano.
- SRE no requiere grandes presupuestos; el enfoque en la practicidad, un enfoque iterativo y el uso de herramientas disponibles permitirán lograr resultados significativos.
- Las inversiones en SRE se amortizan con la reducción del tiempo de inactividad, la mejora de la reputación, la disminución del estrés en el equipo y la aceleración del desarrollo.
Introducción
En el panorama tecnológico de 2026, que cambia rápidamente, donde las expectativas de los usuarios sobre la estabilidad y la velocidad de los servicios han alcanzado un nivel sin precedentes, y la competencia entre startups y proyectos SaaS sigue intensificándose, la capacidad de mantener una alta disponibilidad y rendimiento se convierte no solo en una ventaja, sino en una necesidad vital. Para muchas empresas jóvenes y equipos pequeños que operan en VPS o servidores dedicados, la implementación de metodologías complejas a nivel de Google puede parecer un sueño inalcanzable. Sin embargo, es aquí donde las prácticas SRE (Site Reliability Engineering) adaptadas vienen al rescate.
Este artículo está diseñado para disipar el mito de que SRE es solo para gigantes tecnológicos. Mostraremos cómo los principios de SRE, como la definición de SLI/SLO, la gestión del presupuesto de errores, la monitorización efectiva, la respuesta operativa a incidentes y la realización de Post-Mortem, pueden aplicarse con éxito incluso en condiciones de recursos limitados y equipos pequeños. Nos centraremos en los aspectos prácticos, aplicables a la infraestructura en VPS/Dedicated, donde cada céntimo y cada minuto cuentan.
¿Por qué es importante este tema precisamente ahora, en 2026? Por un lado, el coste de los recursos en la nube sigue aumentando, haciendo que los VPS y los servidores dedicados sean más atractivos en términos de costes de capital para muchas startups. Por otro lado, la complejidad de las aplicaciones modernas no disminuye, y las expectativas de los usuarios sobre la calidad del servicio solo aumentan. Esto crea un dilema: ¿cómo garantizar la fiabilidad y la escalabilidad en "hardware" sin tener ejércitos de ingenieros y presupuestos ilimitados? SRE ofrece una respuesta, centrándose en la automatización, la medición y la cultura de mejora continua.
¿Qué problemas resuelve este artículo? Le ayudaremos a:
- Superar la respuesta caótica a los problemas y pasar a una gestión proactiva de la fiabilidad.
- Determinar qué es realmente importante para su negocio en términos de disponibilidad y rendimiento.
- Reducir el tiempo de inactividad (downtime) y minimizar su impacto en el negocio.
- Disminuir el estrés y el agotamiento en el equipo mediante la automatización y procesos claros.
- Crear una cultura de aprendizaje de los errores, en lugar de buscar culpables.
- Optimizar los costes de infraestructura y herramientas, eligiendo las soluciones más eficientes para su entorno.
¿Para quién está escrita esta guía? Será un recurso inestimable para:
- Ingenieros DevOps, que buscan sistematizar su trabajo e implementar las mejores prácticas.
- Desarrolladores Backend (en Python, Node.js, Go, PHP), que desean comprender mejor los aspectos operativos de sus aplicaciones y participar en su fiabilidad.
- Fundadores de proyectos SaaS, que necesitan asegurar la estabilidad de su producto para retener clientes y crecer.
- Administradores de sistemas, que buscan formas de aumentar la eficiencia en la gestión de servidores y aplicaciones.
- Directores técnicos de startups, que tienen la tarea de construir una infraestructura fiable y escalable con recursos limitados.
Prepárese para sumergirse en el mundo de SRE práctico, donde cada consejo ha sido probado con experiencia real y está dirigido a lograr resultados tangibles.
Criterios y factores clave de SRE para equipos pequeños
En el corazón de cualquier estrategia SRE efectiva se encuentra la comprensión de las métricas y principios clave. Para startups y pequeños equipos SaaS en VPS/Dedicated, es importante no solo copiar los enfoques de los gigantes, sino adaptarlos a sus realidades, centrándose en el máximo rendimiento con los mínimos costes. Consideremos los criterios y factores principales que se convertirán en sus guías.
1. Service Level Indicators (SLI) – Indicadores de nivel de servicio
Los SLI son métricas cuantitativas que muestran qué tan bien funciona su servicio. Para equipos pequeños, la elección de los SLI correctos es crítica, ya que serán pocos y deben ser lo más informativos posible. Por qué son importantes: Los SLI sirven como base para medir el rendimiento y la fiabilidad. Cómo evaluarlos: Deben ser medibles, comprensibles y directamente relacionados con la experiencia del usuario.
- Latencia: Tiempo de respuesta del servidor a una solicitud del usuario. Para aplicaciones web, puede ser el tiempo de carga de la página o la respuesta de la API. Ejemplo: El 95% de las solicitudes a la API deben completarse en menos de 300 ms.
- Tasa de errores (Error Rate): Porcentaje de solicitudes que terminaron en error (por ejemplo, HTTP 5xx). Esto indica directamente problemas en el funcionamiento de la aplicación o la infraestructura. Ejemplo: Menos del 0.1% de las solicitudes al servicio principal deben devolver errores 5xx.
- Disponibilidad (Availability): Porcentaje de tiempo durante el cual el servicio está disponible y operativo. A menudo se mide como (tiempo total - tiempo de inactividad) / tiempo total. Ejemplo: 99.9% de disponibilidad del servicio web principal.
- Rendimiento (Throughput): Número de solicitudes procesadas por unidad de tiempo. Importante para evaluar la escalabilidad y el rendimiento bajo carga. Ejemplo: Procesamiento de al menos 1000 solicitudes/segundo en el pico de carga.
Nuestra experiencia demuestra que se debe comenzar con los 2-3 SLI más críticos para su escenario de usuario principal. Por ejemplo, para una plataforma SaaS, esto podría ser la disponibilidad de la API y la latencia de respuesta durante la autenticación.
2. Service Level Objectives (SLO) – Objetivos de nivel de servicio
Los SLO son valores objetivo específicos para sus SLI, expresados en porcentajes o números absolutos durante un período determinado. Por qué son importantes: Los SLO traducen métricas abstractas en objetivos concretos y medibles, alrededor de los cuales se construye todo el trabajo para garantizar la fiabilidad. Ayudan al equipo a comprender cuándo un servicio es "suficientemente bueno". Cómo evaluarlos: Los SLO deben ser realistas y alcanzables, no idealistas. SLOs demasiado ambiciosos conducirán al agotamiento, demasiado bajos, a la insatisfacción del usuario.
- Ejemplo de SLO para disponibilidad: "La disponibilidad de la API principal debe ser de al menos el 99.9% durante un mes natural." Esto significa que el tiempo de inactividad permitido es de aproximadamente 43 minutos al mes.
- Ejemplo de SLO para latencia: "El percentil 99 de la latencia de respuesta para solicitudes críticas de la base de datos debe ser inferior a 200 ms."
Para las startups, es importante no perseguir las "cinco nueves" (99.999%), que requieren enormes costes. A menudo, el 99.5% o el 99.9% es más que suficiente, especialmente en las etapas iniciales. Caso real: Una vez nos encontramos con que el equipo estableció un SLO del 99.99% para un nuevo servicio que se ejecutaba en un solo VPS. Esto llevó a un estrés constante y a horas extras, hasta que lo ajustamos al 99.5%, lo que resultó ser bastante aceptable para los usuarios y redujo significativamente la carga de trabajo del equipo.
3. Service Level Agreement (SLA) – Acuerdo de nivel de servicio
Un SLA es un contrato formal entre el proveedor de servicios (usted) y el cliente que describe el nivel de servicio esperado y las consecuencias de su incumplimiento (por ejemplo, compensaciones financieras). Por qué son importantes: Un SLA es una obligación legal que se basa en sus SLO. Cómo evaluarlo: Debe ser realista y corresponder a sus capacidades internas, dictadas por los SLO.
Para pequeños equipos SaaS, un SLA puede ser parte de los términos de uso. Es importante que el SLA sea menos estricto que su SLO interno para que tenga un "margen de seguridad". Por ejemplo, si su SLO es del 99.9%, el SLA podría ser del 99.5%.
4. Error Budgets – Presupuesto de errores
El presupuesto de errores es la cantidad permitida de "falta de fiabilidad" o "tiempo de inactividad" durante un período determinado que está dispuesto a aceptar sin violar el SLO. Si su SLO es del 99.9% de disponibilidad, entonces el 0.1% del tiempo (aproximadamente 43 minutos al mes) es su presupuesto de errores. Por qué son importantes: El presupuesto de errores es una herramienta poderosa para equilibrar la fiabilidad y la velocidad de desarrollo. Si el presupuesto de errores se agota, el equipo debe pausar el lanzamiento de nuevas funciones y centrarse en mejorar la fiabilidad. Cómo evaluarlo: Realice un seguimiento del uso del presupuesto de errores diariamente o semanalmente. Cuando se acerca a cero, es una señal para actuar.
Esto ayuda a evitar el eterno dilema de "características versus estabilidad". Ejemplo real: Una vez, después de una serie de incidentes, nuestro presupuesto de errores estaba prácticamente agotado. Decidimos detener por completo el desarrollo de nuevas funciones durante dos semanas para centrarnos en la refactorización de puntos problemáticos, la mejora de la monitorización y la automatización del despliegue. Esto nos permitió estabilizar el servicio y recuperar la confianza de los usuarios.
5. Monitorización y Alerta (Monitoring & Alerting)
La monitorización es la recopilación y el análisis de datos sobre el estado de su sistema. La alerta es una notificación de que algo ha salido mal o está fuera de los valores permitidos. Por qué son importantes: Son los ojos y los oídos de su práctica SRE. Sin ellos, es imposible rastrear los SLI, controlar los SLO y responder a los problemas. Cómo evaluarlos: La monitorización debe ser exhaustiva (infraestructura, aplicación, experiencia del usuario), y las alertas deben ser procesables, sin causar "fatiga de alertas".
- Métricas de infraestructura: CPU, RAM, E/S de disco, E/S de red para VPS.
- Métricas de aplicación: Número de solicitudes, latencia de respuesta, número de errores, estado de los pools de conexión (BD, caché).
- Registros (Logs): Recopilación y análisis centralizados de registros para una rápida búsqueda de las causas de los problemas.
- Trazado (Tracing): Para sistemas distribuidos, permite rastrear la ruta de una solicitud a través de diferentes componentes. Para VPS, esto puede ser más complejo, pero útil para comprender las interacciones entre sus servicios.
Para equipos pequeños en VPS, el autoalojamiento de Prometheus + Grafana es el estándar de oro, proporcionando potentes capacidades con costes mínimos.
6. Incident Response – Respuesta a incidentes
La respuesta a incidentes es el proceso que utiliza un equipo para detectar, evaluar, resolver y documentar incidentes que afectan al servicio. Por qué son importantes: Incluso con las mejores prácticas SRE, los incidentes son inevitables. Un proceso de respuesta eficaz minimiza el tiempo de inactividad (MTTR - Mean Time To Recover) y su impacto en el negocio. Cómo evaluarlo: Mida el MTTR y el número de incidentes. El objetivo es reducir el MTTR y evitar la repetición de incidentes.
Los equipos pequeños necesitan un plan claro pero sencillo: quién está de guardia, cómo se notifica, dónde se documenta, qué pasos se toman. Es importante tener "runbooks", instrucciones paso a paso para resolver problemas típicos.
7. Post-Mortem (Blameless) – Análisis de incidentes sin culpa
Un Post-Mortem es el proceso de analizar un incidente después de su resolución con el objetivo de aprender lecciones y evitar que se repita. "Sin culpa" significa que el enfoque se centra en los problemas del sistema, no en la búsqueda de culpables. Por qué son importantes: Es un mecanismo clave para la mejora continua de la fiabilidad. Sin Post-Mortem, el equipo está condenado a cometer los mismos errores. Cómo evaluarlo: El número y la calidad de los "elementos de acción" (acciones de mejora) identificados, su ejecución y su impacto en las métricas de fiabilidad.
Para las startups, esto puede ser una simple reunión de 30 a 60 minutos después de cada incidente grave, donde se discute: qué pasó, por qué, qué hicimos para solucionarlo, qué podemos hacer para evitar que se repita. Es importante documentar las conclusiones.
8. Automatización (Automation)
La automatización es la eliminación de tareas rutinarias y repetitivas (toil) mediante scripts y herramientas. Por qué son importantes: La automatización reduce los errores humanos, acelera las operaciones, libera tiempo a los ingenieros para un trabajo más valioso y aumenta la previsibilidad del sistema. Cómo evaluarlo: Número de tareas automatizadas, reducción del "toil", velocidad de despliegue, disminución del número de errores relacionados con operaciones manuales.
Para VPS/Dedicated, esto puede ser la automatización del despliegue (CI/CD), la copia de seguridad, la actualización del SO y las dependencias, la escalabilidad (si es posible), la configuración de servidores (Infrastructure as Code con Ansible). Incluso los scripts bash simples pueden tener un efecto enorme.
9. Observabilidad (Observability)
La observabilidad es la capacidad de comprender el estado interno de un sistema simplemente examinando los datos que genera (métricas, registros, trazas). Por qué son importantes: La observabilidad permite no solo saber que algo se ha roto, sino también comprender *por qué* ha ocurrido, sin necesidad de depuración adicional o acceso a la máquina. Cómo evaluarlo: Velocidad de diagnóstico y resolución de problemas desconocidos, profundidad de comprensión del comportamiento del sistema.
Para equipos pequeños, esto puede ser una tarea compleja debido a la limitación de recursos. Comience con una buena recopilación de métricas y un registro centralizado. El trazado puede implementarse más tarde, a medida que crezca la complejidad y los recursos. Loki para registros y Tempo para trazas (en combinación con Grafana) pueden ser una buena opción de código abierto.
10. Capacity Planning – Planificación de capacidades
La planificación de capacidades es el proceso de prever las necesidades futuras de recursos (CPU, RAM, disco, red) y la planificación correspondiente de la infraestructura. Por qué son importantes: Permite evitar la degradación del servicio debido a la falta de recursos y optimizar los costes, comprando solo las capacidades necesarias. Cómo evaluarlo: Precisión de las previsiones, ausencia de incidentes relacionados con la falta de recursos, uso óptimo de las capacidades actuales.
En VPS/Dedicated, esto generalmente se reduce a la monitorización del uso actual de los recursos y la previsión basada en las tendencias de crecimiento. Si ve que la CPU está constantemente cargada al 80-90%, es una señal para actualizar el VPS o optimizar la aplicación. Para las startups, este proceso suele ser más reactivo que proactivo, pero la monitorización constante permite tomar decisiones informadas sobre la escalabilidad.
Tabla comparativa de herramientas para SRE
La elección de las herramientas adecuadas es fundamental para una implementación efectiva de las prácticas SRE, especialmente con presupuestos limitados en VPS/Dedicated. En 2026, el mercado ofrece tanto soluciones de código abierto maduras como productos SaaS comerciales con tarifas para equipos pequeños. Esta tabla le ayudará a comparar algunas de ellas según parámetros clave.
| Criterio | Prometheus + Grafana | Zabbix | Datadog (Starter/Pro) | New Relic (Standard) | ELK Stack (autoalojado) | Loki + Grafana |
|---|---|---|---|---|---|---|
| Tipo de solución | Código abierto, autoalojado | Código abierto, autoalojado | SaaS | SaaS | Código abierto, autoalojado | Código abierto, autoalojado |
| Funciones principales | Métricas, alertas, paneles | Métricas, alertas, paneles, inventario | APM, infraestructura, logs, sintéticos, RUM | APM, infraestructura, logs, sintéticos, RUM | Logs, métricas, trazas (vía APM) | Logs (con métricas y trazas vía Grafana) |
| Complejidad de implementación (para VPS) | Media (requiere configuración) | Media (requiere configuración) | Baja (instalación de agente) | Baja (instalación de agente) | Alta (muchos componentes) | Baja-media (más fácil que ELK) |
| Coste aproximado (2026, $/mes) | 0 (solo recursos VPS) | 0 (solo recursos VPS) | $30-100+ (depende del volumen) | $25-75+ (depende del volumen) | 0 (solo recursos VPS) | 0 (solo recursos VPS) |
| Requisitos de recursos VPS | Medios | Medios | Bajos (agente) | Bajos (agente) | Altos (especialmente Elasticsearch) | Bajos-medios |
| Escalabilidad | Buena (federación) | Buena | Excelente (SaaS) | Excelente (SaaS) | Media-buena (clúster) | Excelente (cloud-native) |
| Ideal para | Equipos pequeños, proyectos económicos, flexibilidad | SysOps tradicionales, monitorización de infraestructura compleja | Inicio rápido, APM completo, soluciones listas para usar | Inicio rápido, APM completo, soluciones listas para usar | Análisis profundo de logs, grandes volúmenes de datos | Registro económico, integración con Grafana |
| Soporte | Comunidad, proveedores de pago | Comunidad, proveedores de pago | Proveedor | Proveedor | Comunidad, Elastic Inc. | Comunidad, Grafana Labs |
Comentarios sobre la tabla:
- Prometheus + Grafana: Este es el "estándar de oro" para muchas startups en VPS. Prometheus recopila métricas, Grafana las visualiza. Ambas herramientas son muy potentes, flexibles y tienen una enorme comunidad. Requieren algo de tiempo para aprender y configurar, pero se amortizan con total libertad y sin pagos mensuales por la funcionalidad.
- Zabbix: Un sistema de monitorización más tradicional, a menudo utilizado por administradores de sistemas. Excelente para monitorizar servidores, equipos de red, pero puede ser menos flexible para monitorizar aplicaciones de microservicios modernas en comparación con Prometheus.
- Datadog / New Relic: Son potentes plataformas comerciales "todo en uno". Ofrecen APM (Application Performance Monitoring), monitorización de infraestructura, logs, trazado, monitorización sintética y mucho más. Su principal ventaja es la facilidad de implementación y el análisis profundo de forma predeterminada. Sin embargo, para las startups en VPS, su coste puede volverse rápidamente significativo, especialmente con el crecimiento del volumen de datos. Para equipos muy pequeños, puede haber tarifas gratuitas o muy económicas, pero con limitaciones.
- ELK Stack: Elasticsearch, Logstash, Kibana: es una potente pila para la recopilación, almacenamiento, análisis y visualización de logs. Ofrece amplias capacidades para la búsqueda y el análisis de datos de texto. Sin embargo, Elasticsearch es muy exigente en cuanto a recursos, y su despliegue en un solo VPS puede ser complejo y consumir muchos recursos. A menudo requiere un servidor dedicado o un clúster separado.
- Loki + Grafana: Loki es un sistema de agregación de logs desarrollado por Grafana Labs. Es mucho menos intensivo en recursos que Elasticsearch, ya que solo indexa los metadatos de los logs, no todo su contenido. Esto lo convierte en una excelente opción para el registro centralizado en VPS, especialmente en combinación con Grafana. Permite buscar y analizar logs de manera eficiente, integrándolos con métricas.
La elección de la herramienta depende en gran medida de sus necesidades actuales, el tamaño del equipo, el presupuesto y la disposición a invertir tiempo en la configuración. Para la mayoría de las startups en VPS/Dedicated, la combinación de Prometheus + Grafana para métricas y Loki + Grafana para logs es la solución más equilibrada y rentable.
Revisión detallada de las prácticas SRE clave
La implementación de SRE en el contexto de una startup o un equipo pequeño en VPS/Dedicated requiere un enfoque pragmático. Aquí profundizaremos en los detalles de cada práctica clave, explicando cómo adaptarla eficazmente a sus realidades.
1. SLI, SLO y Presupuesto de errores para equipos pequeños
SLI (Service Level Indicators) son sus ojos sobre el estado del sistema. Para empezar, concéntrese en lo que afecta directamente al usuario y es fácil de medir. Para una aplicación SaaS típica en VPS, esto es:
- Disponibilidad de la API principal/Interfaz web: Porcentaje de solicitudes HTTP exitosas (2xx, 3xx) del número total de solicitudes. Utilice pings externos (UptimeRobot, Healthchecks.io) y métricas internas (Prometheus HTTP_exporter) para la recopilación.
- Latencia de operaciones críticas: Tiempo de respuesta para las solicitudes más frecuentes o importantes (por ejemplo, inicio de sesión, carga del panel de control, guardado de datos). Realice un seguimiento de los percentiles 95 y 99 para comprender no solo el promedio, sino también los peores escenarios.
- Tasa de errores: Porcentaje de solicitudes que devuelven HTTP 5xx. También es importante rastrear los errores en los registros de la aplicación que pueden no conducir a 5xx, pero afectan la funcionalidad.
SLO (Service Level Objectives) son sus promesas a sí mismo y a los usuarios. No aspire a un 99.999% poco realista. Para una startup que comienza con un VPS, el 99.5% o el 99.9% de disponibilidad es un excelente objetivo, lo que significa solo 43 minutos de tiempo de inactividad al mes para el 99.9%. Esto le da margen de maniobra, actualizaciones e incluso pequeños incidentes. Ejemplo: "La disponibilidad de la API para los clientes debe ser ≥99.9% en los últimos 30 días", "El 95% de las solicitudes a la base de datos deben completarse en ≤100 ms". Es importante que los SLO estén alineados con los objetivos comerciales y las capacidades del equipo.
El Presupuesto de errores (Error Budget) es su "crédito" de falta de fiabilidad. Si su SLO es del 99.9%, tiene el 0.1% del tiempo total de funcionamiento del servicio que puede "gastar" en incidentes, trabajos planificados o experimentos. Cómo usarlo: Si el presupuesto de errores comienza a agotarse rápidamente, es una señal para que el equipo pause el desarrollo de nuevas funciones y se concentre en mejorar la fiabilidad. Por ejemplo, si en una semana ha "gastado" la mitad del presupuesto de errores mensual, quizás valga la pena posponer el lanzamiento de una nueva función y refactorizar un componente problemático. Este mecanismo ayuda a equilibrar la velocidad de desarrollo y la estabilidad.
2. Monitorización y alerta prácticas
Para VPS/Dedicated, la monitorización es la piedra angular de SRE. Su objetivo es ver lo que sucede con el servidor y la aplicación, y recibir notificaciones antes de que los usuarios noten un problema.
- Monitorización de infraestructura: Instale Node Exporter en cada VPS para recopilar métricas de CPU, RAM, disco, red. Para contenedores, use cAdvisor.
- Monitorización de aplicaciones: Integre bibliotecas para exportar métricas (por ejemplo, bibliotecas cliente de Prometheus) en su código. Realice un seguimiento del número de solicitudes, latencia, errores, estado de la cola, uso de memoria de JVM/Go/Node.js.
- Monitorización de logs: Use Loki + Promtail para recopilar logs de sus servidores y aplicaciones. Esto le permitirá buscar y analizar eventos de forma centralizada, así como crear alertas basadas en patrones en los logs.
- Monitorización sintética: Use servicios externos (UptimeRobot, Healthchecks.io) o Blackbox Exporter para Prometheus para verificar regularmente la disponibilidad y la corrección de las respuestas de sus puntos finales públicos desde el exterior.
Alertas: Configure Alertmanager para procesar las alertas de Prometheus. Principios clave:
- Especificidad: Las alertas deben ser lo más informativas posible: qué se rompió, dónde, cuándo y qué hacer.
- Accionabilidad: Las alertas deben requerir una acción inmediata. Si una alerta no requiere acción, es ruido.
- Prioridades: Divida las alertas por criticidad. Las de alta prioridad (servicio no disponible) deben despertar al equipo. Las de baja prioridad (uso de disco al 80%) pueden enviarse a Slack/Telegram.
- "Runbooks": A cada alerta, adjunte un enlace a un "runbook", una instrucción breve sobre qué hacer cuando se activa esa alerta.
Caso real: Redujimos el número de alertas "falsas" en un 70% después de introducir la regla: "Si una alerta se activa más de 3 veces en una semana y no conduce a un incidente real, debe ser revisada o desactivada". Esto obligó al equipo a configurar umbrales más precisos y a centrarse en problemas realmente importantes.
3. Respuesta a incidentes eficaz para equipos pequeños
Incluso con la mejor monitorización, los incidentes ocurren. Su objetivo es minimizar el tiempo medio de recuperación (MTTR). Para un equipo pequeño, esto significa:
- Rotación de guardias clara (On-Call Rotation): Incluso si solo son dos, defina quién está de guardia fuera del horario laboral. Utilice herramientas sencillas: PagerDuty (tiene una tarifa gratuita/económica para equipos pequeños), Opsgenie, o incluso un script propio que envíe notificaciones a Telegram/Slack según un horario.
- Canales de comunicación: Dedique un canal separado en Slack/Telegram para incidentes. Toda la comunicación debe estar allí.
- Runbooks: Son instrucciones paso a paso para resolver problemas típicos. Guárdelos en una Wiki o en un repositorio Git. Ejemplo: "El servidor X no responde: 1) Comprobar ping. 2) Comprobar SSH. 3) Reiniciar el servicio Y. 4) Reiniciar el VPS."
- Gestor de incidentes: Asigne a una persona para que coordine las acciones durante un incidente, incluso si solo hay 2 o 3 personas. Esta persona es responsable de la comunicación, no de la solución técnica.
- Diagnóstico rápido: Asegúrese de que cada persona de guardia tenga acceso a la monitorización, los logs y la capacidad de ejecutar comandos de diagnóstico en los servidores.
El secreto del éxito es la práctica. Realice "simulacros" regularmente, modelando pequeños incidentes, para que el equipo sepa qué hacer.
4. Cultura Post-Mortem (sin culpa)
El Post-Mortem no es una búsqueda de culpables, sino un análisis sistemático para prevenir problemas futuros. Para startups:
- Realice un Post-Mortem para cada incidente significativo: Defina "significativo" como cualquier incidente que haya violado el SLO o causado una insatisfacción sustancial en el cliente.
- Enfoque en el sistema, no en las personas: Preguntas como "¿Qué pasó?", "¿Por qué?", "¿Cómo lo descubrimos?", "¿Qué hicimos?", "¿Qué podríamos haber hecho mejor?", "¿Qué cambios sistémicos son necesarios?".
- Documente: Registre las conclusiones, la cronología, las decisiones tomadas y, lo más importante, los "elementos de acción" (tareas concretas de mejora, por ejemplo, "Añadir una alerta para el llenado del disco", "Actualizar la documentación de despliegue", "Realizar un entrenamiento de respuesta a incidentes").
- Asigne responsables y plazos: Asegúrese de que cada "elemento de acción" tenga un responsable y un plazo de ejecución realista.
- Comparta las lecciones: Comunique las conclusiones a todo el equipo para que todos aprendan de los errores de los demás.
Esto ayuda a crear una cultura de confianza y aprendizaje continuo, lo cual es especialmente importante en equipos de rápido crecimiento.
5. Automatización de la rutina y el Toil
El Toil (trabajo rutinario, repetitivo, que no aporta valor a largo plazo) es el enemigo de SRE. La automatización es su mejor amigo en VPS/Dedicated:
- Despliegue (CI/CD): Utilice GitLab CI, GitHub Actions (con un runner autoalojado en su VPS) o Jenkins para pruebas automáticas y despliegue de código en cada commit. Esto reduce errores y acelera los lanzamientos.
- Gestión de configuración (IaC): Utilice Ansible para la configuración automática de servidores, instalación de software, gestión de archivos de configuración. Incluso para un solo VPS, esto ahorrará tiempo y garantizará la coherencia.
- Copia de seguridad: Configure copias de seguridad automáticas de la base de datos y archivos importantes en un almacenamiento remoto (almacenamiento compatible con S3, Rsync.net). Utilice scripts, tareas cron.
- Actualizaciones: Automatice la instalación de parches de seguridad para el SO (por ejemplo, con `unattended-upgrades` en Debian/Ubuntu) y las dependencias de la aplicación.
- Verificación de estado: Scripts que verifican el estado de los servicios, el espacio libre en disco, la disponibilidad de puertos y envían informes.
Comience poco a poco: automatice lo que hace con más frecuencia y lo que es más propenso a errores. Por ejemplo, el proceso de despliegue de un nuevo microservicio o la configuración de un nuevo VPS.
6. Observabilidad en VPS/Dedicated
Incluso en un solo servidor, la Observabilidad permite comprender más profundamente lo que sucede.
- Métricas: Como ya se mencionó, Prometheus + Grafana. Recopile métricas no solo del SO, sino también de la propia aplicación.
- Logs: Loki + Promtail + Grafana. Asegúrese de que su aplicación registre suficiente información (niveles, contexto, ID de usuario, ID de solicitud).
- Trazas (Tracing): Para aplicaciones más complejas, donde hay varios servicios, incluso en un solo VPS, el trazado puede ser útil. Grafana Tempo es una solución de código abierto que se puede implementar en el mismo VPS que Loki/Prometheus. Integre el SDK de OpenTelemetry en su aplicación para enviar trazas.
Comience con métricas y logs. Esto le dará el 80% de la información necesaria. El trazado es el siguiente paso, cuando tenga recursos y la necesidad de un análisis más profundo de las transacciones distribuidas.
Consejos prácticos y recomendaciones para la implementación
Pasamos de la teoría a los pasos concretos. Aquí encontrará instrucciones paso a paso, ejemplos de comandos y configuraciones que puede aplicar ahora mismo.
1. Instalación de la pila básica de monitorización (Prometheus + Grafana + Node Exporter) en un VPS
Esto es un "imprescindible" para cualquier equipo en un VPS. Suponemos que tiene un VPS con Ubuntu 22.04.
Paso 1: Instalación de Prometheus
# Creamos el usuario y los directorios
sudo useradd --no-create-home --shell /bin/false prometheus
sudo mkdir /etc/prometheus
sudo mkdir /var/lib/prometheus
# Descargamos y descomprimimos Prometheus (la versión actual en 2026 puede variar)
wget https://github.com/prometheus/prometheus/releases/download/v2.x.x/prometheus-2.x.x.linux-amd64.tar.gz
tar xvfz prometheus-2.x.x.linux-amd64.tar.gz
cd prometheus-2.x.x.linux-amd64
# Copiamos los binarios y la configuración
sudo cp prometheus /usr/local/bin/
sudo cp promtool /usr/local/bin/
sudo cp -r consoles /etc/prometheus
sudo cp -r console_libraries /etc/prometheus
sudo cp prometheus.yml /etc/prometheus/prometheus.yml # Esta será la configuración base
# Establecemos los permisos
sudo chown -R prometheus:prometheus /etc/prometheus
sudo chown -R prometheus:prometheus /var/lib/prometheus
sudo chown prometheus:prometheus /usr/local/bin/prometheus
sudo chown prometheus:prometheus /usr/local/bin/promtool
# Creamos el servicio systemd para Prometheus
sudo nano /etc/systemd/system/prometheus.service
Contenido del archivo /etc/systemd/system/prometheus.service:
[Unit]
Description=Prometheus
Wants=network-online.target
After=network-online.target
[Service]
User=prometheus
Group=prometheus
Type=simple
ExecStart=/usr/local/bin/prometheus \
--config.file /etc/prometheus/prometheus.yml \
--storage.tsdb.path /var/lib/prometheus \
--web.console.templates=/etc/prometheus/consoles \
--web.console.libraries=/etc/prometheus/console_libraries \
--web.listen-address="0.0.0.0:9090" \
--storage.tsdb.retention.time=30d # Almacenar datos durante 30 días
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
[Install]
WantedBy=multi-user.target
# Recargamos systemd e iniciamos Prometheus
sudo systemctl daemon-reload
sudo systemctl start prometheus
sudo systemctl enable prometheus
sudo systemctl status prometheus # Verificamos el estado
Paso 2: Instalación de Node Exporter
# Creamos el usuario
sudo useradd --no-create-home --shell /bin/false node_exporter
# Descargamos y descomprimimos Node Exporter
wget https://github.com/prometheus/node_exporter/releases/download/v1.x.x/node_exporter-1.x.x.linux-amd64.tar.gz
tar xvfz node_exporter-1.x.x.linux-amd64.tar.gz
cd node_exporter-1.x.x.linux-amd64
# Copiamos el binario
sudo cp node_exporter /usr/local/bin
sudo chown node_exporter:node_exporter /usr/local/bin/node_exporter
# Creamos el servicio systemd para Node Exporter
sudo nano /etc/systemd/system/node_exporter.service
Contenido del archivo /etc/systemd/system/node_exporter.service:
[Unit]
Description=Node Exporter
Wants=network-online.target
After=network-online.target
[Service]
User=node_exporter
Group=node_exporter
Type=simple
ExecStart=/usr/local/bin/node_exporter
[Install]
WantedBy=multi-user.target
# Recargamos systemd e iniciamos Node Exporter
sudo systemctl daemon-reload
sudo systemctl start node_exporter
sudo systemctl enable node_exporter
sudo systemctl status node_exporter
Paso 3: Configuración de Prometheus para recopilar métricas de Node Exporter
Edite /etc/prometheus/prometheus.yml, añadiendo un trabajo para Node Exporter:
# ... (resto de la configuración)
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['localhost:9090'] # El propio Prometheus
- job_name: 'node_exporter'
static_configs:
- targets: ['localhost:9100'] # Node Exporter en el mismo servidor
# Recargamos Prometheus para aplicar los cambios
sudo systemctl reload prometheus
Paso 4: Instalación de Grafana
# Añadimos la clave GPG
sudo apt install -y apt-transport-https software-properties-common wget
wget -q -O - https://apt.grafana.com/gpg.key | sudo gpg --dearmor | sudo tee /etc/apt/keyrings/grafana.gpg > /dev/null
# Añadimos el repositorio de Grafana
echo "deb [signed-by=/etc/apt/keyrings/grafana.gpg] https://apt.grafana.com stable main" | sudo tee /etc/apt/sources.list.d/grafana.list
# Actualizamos la lista de paquetes e instalamos Grafana
sudo apt update
sudo apt install grafana -y
# Iniciamos y habilitamos Grafana
sudo systemctl start grafana-server
sudo systemctl enable grafana-server
sudo systemctl status grafana-server
Grafana estará disponible en http://SU_IP:3000. Nombre de usuario/contraseña predeterminados: admin/admin (¡cámbielos inmediatamente!). Agregue Prometheus como fuente de datos (Data Source) e importe paneles preconfigurados para Node Exporter (por ejemplo, ID 1860, 11074).
2. Definición de los primeros SLO y SLI
No intente abarcarlo todo de inmediato. Elija 1-2 servicios más críticos y 1-2 SLI para cada uno.
- Servicio: La API principal de su producto SaaS.
- SLI 1: Disponibilidad (número de HTTP 2xx/3xx del número total de solicitudes a la API).
- SLO 1: 99.9% de disponibilidad en 30 días.
- Presupuesto de errores: 0.1% del tiempo total de funcionamiento (aproximadamente 43.2 minutos al mes).
- SLI 2: Latencia de respuesta (percentil 95 para solicitudes de tipo POST /login).
- SLO 2: El 95% de las solicitudes POST /login deben completarse en menos de 500 ms en 7 días.
- Presupuesto de errores: El 5% de las solicitudes pueden superar los 500 ms.
Utilice Prometheus Alertmanager para crear alertas que se activen cuando se acerque al agotamiento del presupuesto de errores, y no solo cuando el SLO ya se haya violado. Esto le da tiempo para reaccionar.
# Ejemplo de regla para Prometheus Alertmanager
groups:
- name: service_availability
rules:
- alert: HighAvailabilityErrorRate
expr: |
sum(rate(http_requests_total{job="my_api", status=~"5.."}[5m])) by (job) / sum(rate(http_requests_total{job="my_api"}[5m])) by (job) > 0.001
for: 5m
labels:
severity: critical
annotations:
summary: "Alta tasa de errores 5xx en la API {{ $labels.job }}"
description: "Más del 0.1% de las solicitudes a la API {{ $labels.job }} devuelven errores 5xx en 5 minutos. Esto amenaza nuestro SLO del 99.9%."
runbook: "https://your-wiki.com/runbooks/api_5xx_errors"
3. Ejemplo de un Runbook sencillo para el incidente "Alta carga de CPU en VPS"
Esto puede ser un archivo simple en un repositorio Git o una página en una Wiki.
# Runbook: Alta carga de CPU en VPS
**Nombre del incidente:** Alta carga de CPU (más del 90% durante 5 minutos) en VPS {{ $labels.instance }}
**Prioridad:** P1 (Crítico), respuesta inmediata
**Objetivo:** Identificar y eliminar la causa de la alta carga de CPU, restaurar el funcionamiento normal.
**Responsable:** Ingeniero de guardia
---
**Pasos para el diagnóstico y la resolución:**
1. **Confirmación del incidente:**
* Verifique la carga actual de la CPU a través de Grafana (panel de Node Exporter).
* Conéctese al VPS por SSH: `ssh user@{{ $labels.instance }}`
2. **Identificación del proceso culpable:**
* Ejecute `top` o `htop` para ver los procesos que consumen más CPU.
* Preste atención al `PID` y `COMMAND` de los procesos con alto consumo.
3. **Análisis de logs:**
* Si el culpable es su aplicación, revise sus logs en busca de errores o anomalías:
`journalctl -u your_app_service.service -f`
(o vea los logs a través de Loki/Grafana, si está configurado).
* Revise los logs del sistema: `journalctl -f`
4. **Intento de recuperación (no destructivo):**
* Si el culpable es su aplicación, intente reiniciarla:
`sudo systemctl restart your_app_service.service`
* Si es un error conocido o una carga temporal, considere la posibilidad de escalar temporalmente (si es posible) o reducir la carga.
5. **Intento de recuperación (destructivo):**
* Si el reinicio del servicio no ayudó y el VPS sigue sobrecargado, considere reiniciar todo el VPS:
`sudo reboot` (asegúrese previamente de que esto no provocará pérdida de datos y notifique al equipo).
6. **Documentación:**
* Registre todos los pasos tomados, las causas encontradas y los resultados en el rastreador de incidentes (Jira, Notion).
* Reúna al equipo para un Post-Mortem si el incidente fue grave o recurrente.
---
**Comandos de diagnóstico adicionales:**
* `sudo dmesg -T` - mensajes del kernel
* `free -h` - uso de RAM
* `df -h` - uso de disco
* `netstat -tunlp` - puertos y conexiones abiertas
4. Ejemplo de automatización de despliegue con GitLab CI (para VPS)
Supongamos que tiene una aplicación NodeJS y desea desplegarla en un VPS en cada commit a la rama `main`.
Archivo .gitlab-ci.yml en la raíz de su repositorio:
stages:
- build
- deploy
variables:
# Configure la clave SSH para acceder al VPS en GitLab CI/CD Variables
# SSH_PRIVATE_KEY: su clave privada SSH
# SSH_USER: usuario en el VPS (por ejemplo, deploy_user)
# SSH_HOST: IP o dominio de su VPS
build_job:
stage: build
image: node:18-alpine
script:
- npm install
- npm test
- npm run build # Si tiene una etapa de compilación (por ejemplo, para frontend de React/Vue)
artifacts:
paths:
- node_modules/
- dist/ # O build/
only:
- main
deploy_job:
stage: deploy
image: alpine/git # Imagen ligera con Git y SSH
before_script:
- apk add openssh-client # Instalamos el cliente SSH
- eval $(ssh-agent -s)
- echo "$SSH_PRIVATE_KEY" | tr -d '\r' | ssh-add - # Añadimos la clave privada
- mkdir -p ~/.ssh
- chmod 700 ~/.ssh
- ssh-keyscan -H "$SSH_HOST" >> ~/.ssh/known_hosts # Añadimos el host a known_hosts
- chmod 644 ~/.ssh/known_hosts
script:
- echo "Deploying to $SSH_USER@$SSH_HOST..."
- ssh "$SSH_USER@$SSH_HOST" "mkdir -p /var/www/my-app" # Creamos el directorio, si no existe
- scp -r node_modules/ "$SSH_USER@$SSH_HOST:/var/www/my-app/"
- scp -r dist/ "$SSH_USER@$SSH_HOST:/var/www/my-app/" # Copiamos los archivos compilados
- scp package.json "$SSH_USER@$SSH_HOST:/var/www/my-app/"
- scp app.js "$SSH_USER@$SSH_HOST:/var/www/my-app/" # Copiamos los archivos principales de la aplicación
- ssh "$SSH_USER@$SSH_HOST" "cd /var/www/my-app && sudo systemctl restart my-app-service" # Reiniciamos el servicio
- echo "Deployment completed!"
only:
- main
En su VPS debe haber un usuario (por ejemplo, `deploy_user`) con acceso SSH y `sudo` configurado para reiniciar el servicio sin contraseña. También asegúrese de que su aplicación se ejecute como un servicio systemd.
5. Optimización de costes de monitorización
- Utilice código abierto: Prometheus, Grafana, Loki, Alertmanager, Node Exporter, todo es gratuito. Sus costes son los recursos del VPS.
- Ahorre espacio en disco: Configure un período de retención de datos corto en Prometheus (por ejemplo, 30 días con `--storage.tsdb.retention.time=30d`). Para los logs en Loki también se puede configurar un TTL.
- Limite la cardinalidad de las métricas: Evite crear métricas con un número muy grande de etiquetas únicas (por ejemplo, con el ID de usuario como etiqueta), esto infla la base de datos de Prometheus.
- Optimice las consultas: En Grafana, intente utilizar funciones de agregación y consultas con menor resolución para períodos largos.
- Considere VPS pequeños para la monitorización: Si su VPS principal ya está cargado, asigne un VPS separado, menos potente, específicamente para Prometheus, Grafana y Loki. Esto distribuirá la carga y aumentará la tolerancia a fallos de la propia monitorización.
Nuestra experiencia demuestra que incluso un conjunto básico de Prometheus, Grafana y Loki en un VPS separado con 2 CPU, 4 GB de RAM y 80 GB de SSD puede atender cómodamente la monitorización y el registro de varios servicios SaaS pequeños.
Errores comunes al implementar SRE en startups
La implementación de SRE es un camino lleno de trampas, especialmente cuando los recursos son limitados. Conocer los errores típicos le ayudará a evitarlos y a ahorrar tiempo, nervios y dinero.
1. Ignorar o definir incorrectamente los SLI/SLO
Error: O no definir SLI/SLO en absoluto, o copiarlos de grandes empresas (por ejemplo, aspirar a un 99.999% de disponibilidad), o elegir métricas que no reflejan la experiencia real del usuario.
Cómo evitarlo: Comience con 1-2 SLI más críticos que afecten directamente los ingresos o la retención de clientes (por ejemplo, la disponibilidad de la API principal, la velocidad de carga de la página clave). Establezca SLO realistas (99.5%-99.9% para empezar) y revíselos regularmente. Involucre al negocio en el proceso de definición de los SLO para que comprendan las compensaciones entre la fiabilidad y la velocidad de desarrollo.
Consecuencias: La falta de objetivos claros conduce a prioridades caóticas, estrés constante por "apagar incendios" y la imposibilidad de medir el progreso real en la fiabilidad. Los SLO poco realistas conducen al agotamiento del equipo y a una sensación constante de fracaso.
2. Fatiga de alertas (Alert Fatigue)
Error: Configurar demasiadas alertas, alertas para eventos no críticos, alertas sin un "runbook" claro o alertas que se activan con demasiada frecuencia sin un problema real.
Cómo evitarlo: Siga el principio de que "cada alerta debe requerir una acción". Si una alerta se activa pero no requiere una intervención inmediata (por ejemplo, "uso de disco al 70%"), conviértala en un mensaje informativo en Slack o cambie el umbral de activación. Configure la escalada: primero a un chat general, luego al ingeniero de guardia. Asegúrese de que cada alerta tenga un "runbook" asociado.
Consecuencias: El equipo comienza a ignorar las alertas, lo que lleva a la pérdida de incidentes reales y al aumento del tiempo de inactividad. Esto también socava gravemente la moral y causa agotamiento.
3. Ausencia o ineficacia del proceso Post-Mortem
Error: No realizar Post-Mortem en absoluto, o realizarlos con el objetivo de encontrar un culpable, o realizarlos pero no documentar las conclusiones y no ejecutar los "elementos de acción".
Cómo evitarlo: Haga del Post-Mortem una práctica obligatoria después de cada incidente significativo. Enfatice la naturaleza sin culpa del proceso, centrándose en las causas sistémicas. Documente claramente la cronología, las causas, los pasos tomados y, lo más importante, los "elementos de acción" concretos con responsables y plazos. Realice un seguimiento regular de la ejecución de estas tareas.
Consecuencias: El equipo comete constantemente los mismos errores, los incidentes se repiten y la cultura de búsqueda de culpables suprime la iniciativa y la honestidad, impidiendo el aprendizaje y la mejora.
4. Sobrecarga y "jaula de oro"
Error: Intentar implementar todas las herramientas y prácticas SRE "de moda" a la vez, sin tener en cuenta el tamaño actual del equipo, el presupuesto y la complejidad del sistema. Por ejemplo, implementar un trazado distribuido completo para un monolito en un solo VPS.
Cómo evitarlo: Comience con lo básico: monitorización básica, logs centralizados, SLO sencillos. Implemente SRE de forma iterativa, añadiendo nuevas prácticas y herramientas a medida que crezcan las necesidades y los recursos. Concéntrese en soluciones "suficientemente buenas", no en las "ideales". Utilice código abierto y soluciones sencillas hasta que surja una necesidad real de productos comerciales.
Consecuencias: La complejidad excesiva conduce a una implementación lenta, altos costes, dificultades de soporte y no proporciona beneficios reales, causando frustración y rechazo de las prácticas SRE.
5. Ignorar la automatización y la deuda técnica
Error: Posponer la automatización "para más tarde" o creer que "manualmente es más rápido". Ignorar la acumulación de deuda técnica en la infraestructura y el código, lo que hace que el sistema sea frágil y difícil de mantener.
Cómo evitarlo: Dedique tiempo a automatizar tareas rutinarias (despliegue, copia de seguridad, actualización). Incluso pequeños scripts pueden ahorrar horas. Incluya el trabajo con la deuda técnica en la planificación regular (por ejemplo, 10-20% del sprint). Utilice los resultados de los Post-Mortem para identificar la deuda técnica crítica.
Consecuencias: Aumento del "toil", errores humanos, lanzamientos lentos e impredecibles, alto coste de soporte y una amenaza constante a la estabilidad del sistema. La deuda técnica acumulada finalmente ralentiza el desarrollo de nuevas funciones.
6. Falta de un plan claro de respuesta a incidentes
Error: Suponer que "alguien se encargará" cuando algo falle, o la ausencia de un procedimiento claro de notificación y acción.
Cómo evitarlo: Cree un plan de respuesta a incidentes sencillo pero claro: quién está de guardia, cómo se notifica, quién es el responsable del incidente, dónde se lleva a cabo la comunicación, dónde se guardan los "runbooks". Realice "simulacros" regulares para que el equipo conozca sus roles.
Consecuencias: Caos durante el incidente, pánico, recuperación lenta, lo que lleva a largos tiempos de inactividad, pérdida de clientes y daños a la reputación.
7. Ausencia de copias de seguridad o su ineficacia
Error: Ausencia total de copias de seguridad, o existencia de copias de seguridad que nunca se han probado para verificar su funcionamiento, o su almacenamiento en el mismo servidor que el servicio principal.
Cómo evitarlo: Implemente copias de seguridad automáticas regulares de todos los datos críticos (bases de datos, configuraciones, archivos de usuario). Almacene las copias en un almacenamiento remoto e independiente (por ejemplo, una nube compatible con S3). Verifique regularmente (al menos una vez al trimestre) la capacidad de recuperación a partir de las copias de seguridad.
Consecuencias: Pérdida de datos en caso de fallo del servidor, ataque o error humano, lo que puede ser catastrófico para un negocio SaaS y llevar a su cierre.
Lista de verificación para la aplicación práctica de SRE
Este algoritmo paso a paso le ayudará a sistematizar la implementación de prácticas SRE en su pequeño equipo en VPS/Dedicated. Revise los puntos y marque el progreso.
Fase 1: Preparación y planificación
- Defina los servicios críticos:
- Haga una lista de 1-3 servicios clave de su producto SaaS de los que dependan directamente el valor para el usuario y los ingresos.
- Ejemplo: API de backend, interfaz web, servicio de autorización.
- Elija los SLI clave:
- Para cada servicio crítico, elija 1-2 SLI más importantes (disponibilidad, latencia, tasa de errores) que sean fáciles de medir y que reflejen la experiencia del usuario.
- Ejemplo: Disponibilidad de la API, percentil 95 de latencia POST /login.
- Establezca SLO realistas:
- Para cada SLI, defina un objetivo realista (por ejemplo, 99.9% de disponibilidad, 95% de solicitudes < 500ms). Discuta y acuerde estos objetivos con el equipo y los stakeholders.
- Ejemplo: SLO de disponibilidad de la API = 99.9% en 30 días.
- Defina el presupuesto de errores:
- Calcule el tiempo de inactividad o la cantidad de errores permitidos que corresponden a sus SLO.
- Ejemplo: Presupuesto de errores para el 99.9% de disponibilidad = 43.2 minutos al mes.
- Elija las herramientas de monitorización y registro:
- Para VPS/Dedicated, considere Prometheus + Grafana para métricas y Loki + Promtail para logs.
- Ejemplo: Se decidió usar Prometheus, Grafana, Node Exporter, Loki, Promtail.
Fase 2: Implementación de prácticas básicas
- Despliegue la pila de monitorización:
- Instale Prometheus, Node Exporter y Grafana en su VPS principal o en uno separado.
- Configure Prometheus para recopilar métricas de Node Exporter y, si es necesario, de su aplicación.
- Configure el registro centralizado:
- Instale Loki y Promtail. Configure Promtail para recopilar los logs de su aplicación y los logs del sistema.
- Conecte Loki como fuente de datos en Grafana.
- Cree los primeros paneles:
- En Grafana, importe paneles preconfigurados para Node Exporter.
- Cree sus propios paneles para monitorizar sus SLI (disponibilidad, latencia, errores de la aplicación).
- Configure las alertas básicas:
- Instale y configure Alertmanager.
- Cree alertas para eventos críticos (por ejemplo, servicio no disponible, alta tasa de errores, agotamiento del presupuesto de errores).
- Configure las notificaciones en Slack/Telegram o a través de PagerDuty/Opsgenie.
- Desarrolle Runbooks sencillos:
- Para cada alerta crítica, cree una instrucción corta y paso a paso para diagnosticar y resolver el problema.
- Guárdelos en un lugar de fácil acceso (Wiki, repositorio Git).
- Configure la copia de seguridad automática:
- Implemente scripts para la copia de seguridad automática de la base de datos y archivos importantes.
- Configure el almacenamiento de las copias de seguridad en un recurso remoto e independiente.
- Verifique el procedimiento de restauración a partir de la copia de seguridad.
Fase 3: Desarrollo y optimización
- Implemente la automatización del despliegue (CI/CD):
- Configure GitLab CI/GitHub Actions con un runner autoalojado o Jenkins para pruebas automáticas y despliegue de su aplicación.
- Comience a realizar Post-Mortem:
- Después de cada incidente significativo, realice un Post-Mortem sin culpa.
- Documente las conclusiones y cree "elementos de acción" con responsables y plazos.
- Optimice las alertas:
- Revise regularmente las alertas, elimine el "ruido", configure umbrales más precisos.
- Asegúrese de que cada alerta realmente requiera una acción.
- Documente la infraestructura y los procesos:
- Cree un esquema sencillo de su infraestructura.
- Describa los procesos clave (despliegue, respuesta a incidentes, actualización).
- Revise regularmente los SLO y SLI:
- Trimestralmente o ante cambios significativos en el producto, revise la relevancia y la alcanzabilidad de sus objetivos.
- Invierta en la formación del equipo:
- Fomente el estudio de los principios y herramientas de SRE.
- Realice "simulacros" internos de respuesta a incidentes.
Cálculo de costes / Economía de SRE

Una de las principales razones por las que las startups y los equipos pequeños en VPS/Dedicated eligen este camino es el deseo de optimizar los costes. SRE, a primera vista, puede parecer un gasto adicional, pero en realidad es una inversión que se amortiza muchas veces. Analicemos la economía de SRE.
1. Coste del tiempo de inactividad (Cost of Downtime)
Antes de hablar de los costes de SRE, es necesario comprender cuánto cuesta la ausencia de SRE. Cada hora de inactividad de su producto SaaS no es solo un fallo técnico, son pérdidas directas e indirectas para el negocio.
- Pérdidas directas de ingresos: Si su producto no funciona, los clientes no pueden usarlo, lo que significa que pierde ventas potenciales, suscripciones, transacciones.
- Ejemplo: Un proyecto SaaS con 1000 usuarios activos de pago, cada uno de los cuales aporta $20/mes. Ingresos diarios = (1000 * $20) / 30 = ~$667. Ingresos por hora = ~$28. Si el tiempo de inactividad dura 4 horas, las pérdidas directas serán de $112.
- Pérdida de reputación y confianza del cliente: Este es un factor más difícil de medir, pero a menudo más destructivo. Un servicio poco fiable ahuyenta a los nuevos clientes y hace que los antiguos se vayan.
- Ejemplo: Después de 4 horas de inactividad, el 5% de los clientes pueden cancelar su suscripción. Esto es 50 clientes * $20/mes = $1000/mes de ingresos perdidos, multiplicado por la vida útil del cliente.
- Penalizaciones por SLA: Si tiene un SLA con los clientes, cada hora de inactividad puede conllevar compensaciones económicas.
- Ejemplo: El SLA prevé un reembolso del 10% de los fondos por mes si la disponibilidad cae por debajo del 99.5%. Un incidente grave puede costarle una parte significativa de los ingresos mensuales.
- Costes operativos: Tiempo que el equipo dedica a "apagar incendios", en lugar de trabajar en nuevas funciones. Esto es una pérdida de beneficios y una reducción de la productividad.
- Ejemplo: 3 ingenieros dedicaron 4 horas cada uno a resolver un incidente. Si el coste medio por hora de un ingeniero es de $50, esto es $600.
Total: Incluso un pequeño tiempo de inactividad de 4 horas puede costarle a una startup cientos o miles de dólares en pérdidas directas, sin mencionar el daño a largo plazo a la reputación y la rotación de clientes. Las inversiones en SRE son un seguro contra estas pérdidas.
2. Cálculo de costes de SRE para VPS/Dedicated
La buena noticia es que las prácticas SRE no son necesariamente caras. Los costes principales se destinan a:
- Recursos de VPS/Dedicated: Para alojar herramientas SRE (Prometheus, Grafana, Loki).
- Estimación: Un VPS pequeño separado (2 CPU, 4 GB de RAM, 80 GB de SSD) para monitorización y registro puede costar entre $15 y $30 al mes en 2026. Si se aloja en el servidor principal, el "coste" es una parte de sus recursos.
- Tiempo del equipo: Para la implementación, configuración y soporte de herramientas y procesos SRE. Este es el "coste oculto" más significativo.
- Estimación: La implementación inicial de SRE (monitorización básica, alertas, Post-Mortem) puede requerir del 10 al 20% del tiempo de trabajo de un ingeniero durante 1-2 meses. Posteriormente, del 5 al 10% del tiempo para soporte y mejora.
- Servicios de terceros de pago (opcional): Para alertas (PagerDuty, Opsgenie), monitorización externa (UptimeRobot Pro), copia de seguridad remota (almacenamientos compatibles con S3).
- Estimación: PagerDuty/Opsgenie (Starter) $10-25/mes, UptimeRobot Pro $10-20/mes, almacenamiento S3 $5-15/mes (depende del volumen).
Cálculo aproximado de costes mensuales para un pequeño SaaS en VPS (año 2026):
| Categoría de costes | Descripción | Coste aproximado ($/mes) | Notas |
|---|---|---|---|
| VPS para la aplicación principal | 1x VPS (4 CPU, 8GB RAM, 160GB SSD) | $40-70 | Para el alojamiento de la aplicación |
| VPS para herramientas SRE | 1x VPS (2 CPU, 4GB RAM, 80GB SSD) | $15-30 | Para Prometheus, Grafana, Loki, Alertmanager |
| Almacenamiento remoto para copias de seguridad | Almacenamiento compatible con S3 (500GB) | $5-15 | Importante para la recuperación de datos |
| Servicio de alertas (opcional) | PagerDuty/Opsgenie (Plan Starter) | $10-25 | Para rotación de guardias y escalada |
| Monitorización externa (opcional) | UptimeRobot Pro | $10-20 | Para verificar la disponibilidad desde el exterior |
| Tiempo del ingeniero (parte) | 10% del tiempo de un ingeniero ($50/hora * 160 horas * 0.1) | $800 | El "coste" más grande, pero es una inversión en estabilidad |
| Coste aproximado total | $880 - $980 | Incluye el coste de los recursos y el tiempo del ingeniero |
Como se puede ver, la mayor parte de los costes recae en el tiempo del ingeniero. Sin embargo, este es un tiempo que de otro modo se gastaría en "apagar incendios", trabajo rutinario o resolver problemas que podrían haberse evitado. SRE convierte estos costes reactivos en inversiones proactivas.
3. Cómo optimizar los costes
- Maximice el uso de código abierto: Prometheus, Grafana, Loki, Ansible, GitLab CI (runner autoalojado), todo esto es gratuito.
- Consolide recursos: Si su VPS principal tiene recursos de sobra, puede alojar Prometheus, Grafana y Loki en él, ahorrando en un VPS separado. Sin embargo, esto reduce la tolerancia a fallos de la monitorización.
- Implementación iterativa: No intente implementarlo todo a la vez. Comience con las prácticas más económicas y eficaces (monitorización básica, alertas, Post-Mortem) y expanda gradualmente.
- Automatización del Toil: Cuantas más tareas rutinarias automatice, menos tiempo dedicarán los ingenieros al "toil", liberándolo para un trabajo más valioso.
- Formación del equipo: Las inversiones en la formación del equipo en los principios de SRE aumentan su eficiencia y reducen la necesidad de contratar especialistas caros y altamente especializados.
La economía de SRE para una startup en VPS/Dedicated radica en que estas prácticas le permiten obtener las ventajas de una gran empresa (estabilidad, fiabilidad, previsibilidad) con costes mucho menores, evitando consecuencias mucho más costosas de tiempo de inactividad y pérdida de clientes.
Casos de estudio y ejemplos prácticos
La teoría es importante, pero los ejemplos reales ayudan a comprender mejor cómo se aplican las prácticas SRE en la vida. Aquí hay 2-3 escenarios realistas de nuestra experiencia trabajando con startups y pequeños equipos SaaS en VPS/Dedicated.
Caso 1: Aumento de la disponibilidad y reducción del estrés en la startup SaaS "TaskFlow"
Problema: "TaskFlow", una plataforma SaaS para la gestión de proyectos, que operaba en un único y potente VPS. El equipo de 3 desarrolladores se enfrentaba constantemente a tiempos de inactividad impredecibles (2-3 veces al mes durante 1-2 horas), causados por picos de carga o errores en nuevas versiones. La monitorización era mínima (solo pings de tiempo de actividad), y la respuesta a incidentes, caótica y estresante. Esto provocaba la pérdida de clientes y el agotamiento del equipo.
Solución:
- Implementación de SLI/SLO: Se determinó que los SLI críticos eran la disponibilidad de la API principal (creación/edición de tareas) y la latencia de respuesta en el panel principal. Se estableció un SLO: 99.8% de disponibilidad de la API y 95% de solicitudes al panel < 800ms.
- Pila de monitorización: Se desplegó Prometheus + Grafana + Node Exporter en el mismo VPS. Se integró la biblioteca cliente de Prometheus en el backend de Node.js para recopilar métricas de la aplicación (número de solicitudes, errores, latencias).
- Alertas: Se configuró Alertmanager para enviar alertas críticas a un canal de Telegram especialmente dedicado. Las alertas se activaban si la disponibilidad caía por debajo del 99.5% o la latencia superaba 1.5 segundos.
- Gestión de incidentes: Se creó un sencillo horario de guardias (por turnos semanales). Se desarrollaron 5 "runbooks" básicos para los problemas más frecuentes (CPU alta, error de BD, servicio no disponible).
- Post-Mortem: Después de cada incidente, se realizaba un Post-Mortem "sin culpa" de 30 minutos, documentando la cronología y los "elementos de acción".
Resultados:
- Disponibilidad: En 3 meses, la disponibilidad de la API aumentó del 97-98% a un estable 99.9%.
- MTTR: El tiempo medio de recuperación se redujo de 1-2 horas a 15-30 minutos.
- Reducción del estrés: El equipo se sintió más seguro al tener un plan de acción claro. El número de despertares nocturnos debido a falsas alertas se redujo en un 80%.
- Mejora del producto: Los "elementos de acción" del Post-Mortem llevaron a la optimización de varios "cuellos de botella" en el código y la configuración de la base de datos, lo que mejoró el rendimiento general.
Este caso demuestra cómo, incluso en un solo VPS, las prácticas SRE básicas pueden mejorar significativamente la fiabilidad y la calidad del trabajo del equipo.
Caso 2: Gestión del presupuesto de errores y optimización del ciclo de lanzamiento en el proyecto de e-commerce "ShopBoost"
Problema: "ShopBoost", un pequeño proyecto de e-commerce en un servidor dedicado, lanzaba nuevas funciones con frecuencia. Sin embargo, cada nuevo lanzamiento conllevaba el riesgo de degradación del rendimiento o aparición de errores, lo que provocaba pérdidas de ventas. El equipo de desarrolladores estaba bajo presión del negocio, que exigía nuevas funciones, pero también se quejaba constantemente de la inestabilidad.
Solución:
- Presupuesto de errores: Después de definir el SLO de disponibilidad (99.9%) y la tasa de errores (menos del 0.2%), el equipo estableció un presupuesto de errores. Si en una semana se había "gastado" más del 50% del presupuesto de errores mensual, se suspendían los nuevos lanzamientos.
- Monitorización mejorada: Además de Prometheus/Grafana, se implementó Loki para la recopilación centralizada de logs de la aplicación y del servidor web. Esto permitió buscar rápidamente errores relacionados con los nuevos lanzamientos.
- Automatización CI/CD: Se configuró GitLab CI con un runner autoalojado en el servidor para el despliegue automático. Cada commit pasaba por pruebas básicas y luego se desplegaba automáticamente en staging, y después de las pruebas manuales, en producción.
- Post-Mortem con enfoque en los lanzamientos: Cada incidente relacionado con un lanzamiento se analizaba cuidadosamente. Se prestaba especial atención a cómo se podría haber prevenido el problema en la etapa de desarrollo o prueba.
Resultados:
- Equilibrio "características vs. estabilidad": El presupuesto de errores se convirtió en un indicador claro de cuándo era necesario "frenar" con las nuevas funciones y centrarse en la estabilidad. Esto redujo los conflictos entre desarrollo y negocio.
- Calidad de los lanzamientos: El número de errores críticos que llegaban a producción se redujo en un 60% gracias a la mejora de las pruebas y el control de calidad.
- Velocidad de despliegue: El tiempo desde el commit hasta la producción se redujo de varias horas (despliegue manual) a 15-20 minutos (despliegue automático).
- Cultura de calidad: Los desarrolladores comenzaron a prestar más atención a las pruebas y la monitorización de sus cambios, comprendiendo que esto afectaba directamente su capacidad para lanzar nuevas funciones.
Este caso muestra cómo SRE ayuda a gestionar riesgos y optimizar el ciclo de desarrollo, encontrando un equilibrio entre innovación y estabilidad.
Caso 3: Escalado y optimización de recursos para el servicio analítico "DataInsight"
Problema: "DataInsight", una startup que proporciona análisis de datos para pequeñas empresas, se enfrentó a un problema de crecimiento. Su servicio, que se ejecutaba en dos VPS, se ralentizaba o caía periódicamente debido a la falta de recursos (especialmente RAM y CPU) al procesar informes grandes. El equipo no entendía cuándo y qué recursos escalar, y a menudo actuaba de forma reactiva, comprando VPS más potentes "por si acaso".
Solución:
- Planificación de capacidad: Se implementó una monitorización detallada del uso de recursos (CPU, RAM, E/S de disco) utilizando Prometheus + Grafana. Las métricas se recopilaban cada 15 segundos.
- SLI/SLO basados en recursos: Se definieron SLI para el uso de CPU (< 80% durante 10 minutos) y RAM (< 90% de memoria libre). Se establecieron SLO basados en estas métricas.
- Alertas proactivas: Se configuraron alertas en Alertmanager que se activaban cuando el uso de recursos se acercaba a umbrales críticos (por ejemplo, CPU > 70% durante más de 5 minutos).
- Análisis de tendencias: Se analizaban regularmente los gráficos de uso de recursos en Grafana para prever necesidades futuras. Por ejemplo, si el consumo de RAM crecía constantemente un 10% al mes, se planificaba una actualización del VPS en 2-3 meses.
- Optimización del código: Los Post-Mortem después de incidentes con escasez de recursos llevaron a la identificación de consultas "pesadas" a la base de datos y algoritmos ineficientes de procesamiento de datos, que fueron optimizados.
Resultados:
- Optimización de costes: En lugar de comprar reactivamente VPS más potentes, el equipo comenzó a tomar decisiones informadas. Por ejemplo, en lugar de actualizar todo el servidor, pudieron optimizar las consultas a la base de datos, lo que pospuso la necesidad de comprar hardware más caro durante 6 meses, ahorrando hasta $300 al mes.
- Estabilidad: El número de incidentes relacionados con la falta de recursos se redujo en un 90%.
- Proactividad: El equipo comenzó a planificar actualizaciones u optimizaciones con antelación, evitando sorpresas.
Este caso destaca cómo el enfoque SRE en la monitorización y la planificación de capacidades permite a las startups escalar de manera eficiente, evitando gastos innecesarios y garantizando la estabilidad del servicio.
Herramientas y recursos
Para una implementación exitosa de las prácticas SRE, incluso en VPS/Dedicated, necesitará un arsenal de herramientas fiables y eficientes. Nos centraremos en soluciones que han demostrado su valor para equipos pequeños, ofreciendo un excelente equilibrio entre funcionalidad y coste.
1. Monitorización y visualización de métricas
- Prometheus: Sistema de recopilación y almacenamiento de series temporales de métricas. Es el estándar de facto para la monitorización en la nube y de contenedores, pero también es perfectamente adecuado para VPS.
- Grafana: Potente plataforma para la visualización de métricas. Permite crear paneles informativos, configurar alertas e investigar datos de diversas fuentes (Prometheus, Loki, bases de datos).
- Node Exporter: Exportador de métricas para Prometheus, que recopila datos sobre el estado del sistema operativo (CPU, RAM, disco, red). Debe instalarse en cada VPS.
- cAdvisor: Exportador de métricas para Prometheus, que recopila datos sobre contenedores (Docker). Útil si su aplicación se ejecuta en contenedores en un VPS.
- Blackbox Exporter: Exportador para Prometheus que permite verificar la disponibilidad y la corrección de los puntos finales HTTP/HTTPS, TCP, ICMP desde dentro de su infraestructura.
- UptimeRobot / Healthchecks.io: Servicios externos para monitorizar la disponibilidad de sus puntos finales públicos desde diferentes ubicaciones geográficas. UptimeRobot tiene un generoso plan gratuito.
2. Registro y trazado
- Loki: Sistema de agregación de logs, desarrollado por Grafana Labs. Menos intensivo en recursos que Elasticsearch, ya que solo indexa los metadatos de los logs. Se integra perfectamente con Grafana.
- Promtail: Agente para Loki, que recopila logs de sus servidores y los envía a Loki.
- Grafana Tempo: Sistema de trazado distribuido, también de Grafana Labs. Permite recopilar y almacenar trazas de OpenTelemetry, integrándose con métricas y logs en Grafana.
- OpenTelemetry: Conjunto de herramientas, API y SDK para instrumentar su aplicación, permitiendo generar métricas, logs y trazas en un formato unificado.
3. Gestión de alertas y On-Call
- Alertmanager: Componente de Prometheus que procesa las alertas, las deduplica, las agrupa y las envía a los canales adecuados (Slack, Telegram, PagerDuty, correo electrónico).
- PagerDuty / Opsgenie: Servicios profesionales para la gestión de rotaciones de guardia, escalada de alertas y planificación de turnos. Ofrecen tarifas gratuitas o económicas para equipos pequeños.
- Telegram / Slack: Canales sencillos y gratuitos para el envío de alertas. Alertmanager se integra fácilmente con ellos.
4. Automatización e Infraestructura como Código (IaC)
- Ansible: Herramienta sencilla pero potente para la gestión de configuración, el despliegue de aplicaciones y la orquestación de tareas. No requiere agentes en los servidores gestionados. Ideal para VPS/Dedicated.
- GitLab CI / GitHub Actions: Sistemas de integración continua/despliegue continuo (CI/CD). Permiten automatizar las pruebas y el despliegue de código. Pueden utilizar un runner autoalojado en su VPS.
- Scripts Bash / Python: Herramientas subestimadas pero extremadamente potentes para automatizar tareas específicas en un VPS.
5. Documentación y gestión del conocimiento
- Wiki (Confluence, Notion, DokuWiki): Para almacenar runbooks, informes Post-Mortem, documentación de infraestructura y procesos.
- Repositorios Git: Para almacenar configuraciones (IaC), scripts, runbooks en formato Markdown.
6. Libros y recursos útiles
- "Site Reliability Engineering: How Google Runs Production Systems" y "The Site Reliability Workbook": Libros clásicos de Google, aunque orientados a sistemas a gran escala, los principios básicos son aplicables en todas partes.
- Blogs de Grafana Labs, Prometheus, Incident.io: Publican regularmente artículos y casos de estudio útiles.
- Comunidades DevOps y SRE: Chats de Telegram, servidores de Discord, Stack Overflow.
Comience dominando Prometheus y Grafana, luego agregue Loki. Implemente gradualmente la automatización con Ansible y CI/CD. Recuerde que las herramientas son solo medios; lo principal son los principios y la cultura SRE.
Troubleshooting: resolución de problemas típicos
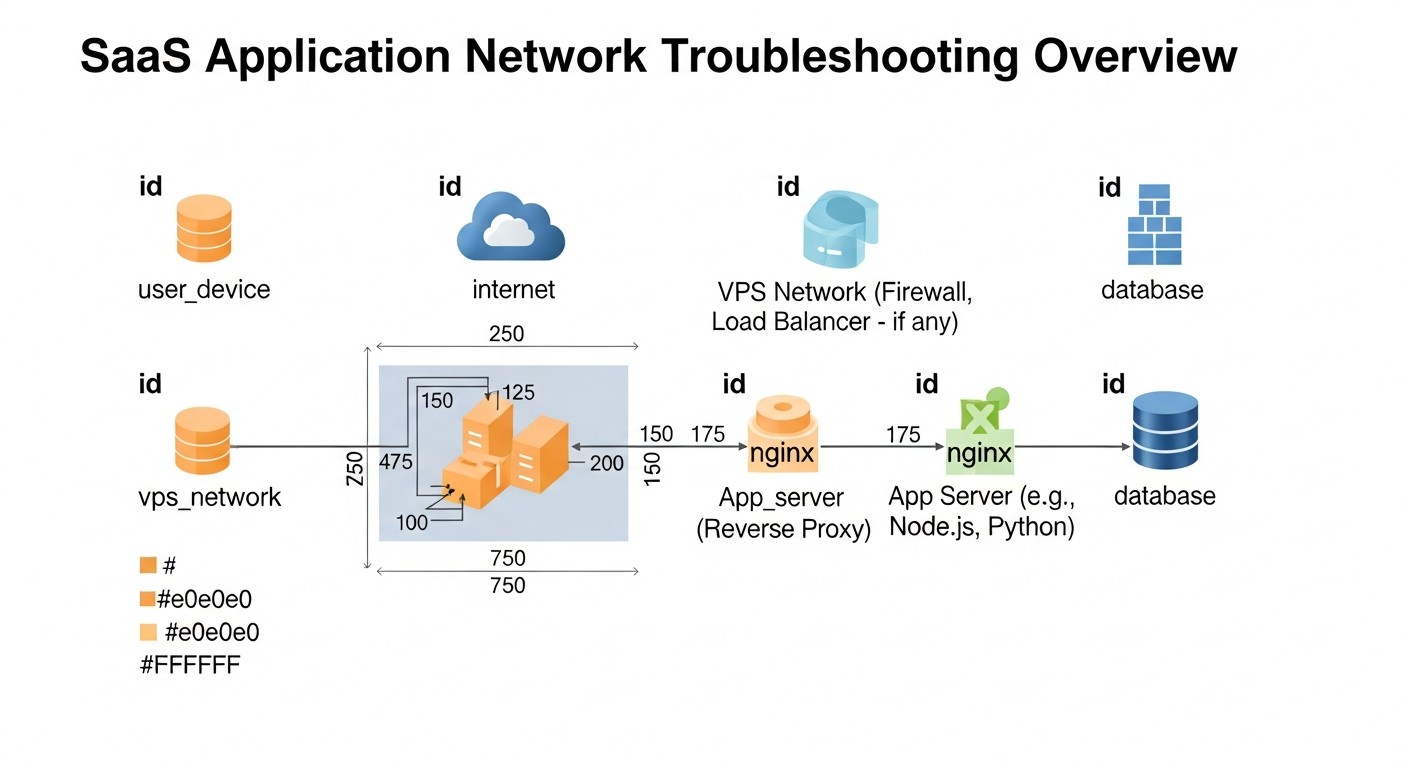
Incluso con las mejores prácticas SRE, los problemas en producción son inevitables. La capacidad de diagnosticarlos y resolverlos rápidamente es una habilidad clave. A continuación se presentan problemas típicos que enfrentan los pequeños equipos SaaS en VPS/Dedicated, y comandos prácticos para su resolución.
1. Alta carga de CPU
Síntomas: Funcionamiento lento de la aplicación, retrasos en las respuestas, alertas de CPU alta.
Diagnóstico:
topohtop: Muestra los procesos ordenados por consumo de CPU. Busque procesos que consuman >80-90% de CPU.uptime: Muestra la carga promedio del sistema durante 1, 5 y 15 minutos. Si la carga promedio es superior al número de núcleos de CPU, el sistema está sobrecargado.- Grafana (panel de Node Exporter): Análisis visual de las tendencias de uso de CPU.
- Logs de la aplicación: Busque errores, consultas "pesadas" a la base de datos, bucles infinitos u operaciones que consuman muchos recursos.
Solución:
- Si el culpable es su aplicación:
- Reinicie el servicio:
sudo systemctl restart your_app_service.service - Si es un pico temporal, quizás valga la pena optimizar el código o la base de datos.
- Si el problema es constante, considere actualizar el VPS o escalar a varios servidores.
- Reinicie el servicio:
- Si el culpable es otro proceso (por ejemplo, algún script, tarea cron):
- Identifique qué proceso es y por qué consume muchos recursos.
- Optimice el script o cambie su horario de ejecución.
2. Falta de memoria RAM
Síntomas: La aplicación "se cae" con errores de Out Of Memory, funcionamiento lento, uso activo de la partición swap.
Diagnóstico:
free -h: Muestra la cantidad total de RAM, utilizada y libre, así como el uso de swap.htop: Muestra el consumo de RAM de cada proceso.- Grafana (panel de Node Exporter): Monitorización del uso de RAM y swap.
- Logs de la aplicación: Busque errores de Out Of Memory.
Solución:
- Si su aplicación consume demasiada RAM:
- Optimice el código (por ejemplo, evite cargar grandes volúmenes de datos en memoria, utilice procesamiento por streaming).
- Aumente los límites de memoria para su aplicación (si es posible, por ejemplo, parámetros de JVM).
- Considere actualizar el VPS con una mayor cantidad de RAM.
- Si otros procesos consumen RAM:
- Detenga los servicios innecesarios.
- Optimice la configuración de otros servicios (por ejemplo, reduzca el número de procesos worker del servidor web).
3. Llenado del espacio en disco
Síntomas: Errores de escritura de archivos, fallos de aplicaciones, imposibilidad de instalar nuevos paquetes.
Diagnóstico:
df -h: Muestra el uso del espacio en disco por particiones. Busque particiones llenas al 90% o más.du -sh /ruta/al/directorio: Muestra el tamaño de un directorio específico. Úselo para buscar directorios "pesados" (por ejemplo,/var/log,/var/lib/docker,/tmp).- Grafana (panel de Node Exporter): Monitorización del uso del disco.
Solución:
- Limpieza de logs:
sudo journalctl --vacuum-size=1G(para systemd journal)- Elimine manualmente los logs antiguos de su aplicación o configure logrotate.
- Limpieza de cachés:
sudo apt clean(para Debian/Ubuntu)- Limpie las cachés de su aplicación.
- Eliminación de archivos innecesarios:
- Copias de seguridad antiguas, archivos temporales, imágenes Docker no utilizadas.
- Si el problema es constante, considere actualizar el disco del VPS o mover grandes datos a un almacenamiento externo.
4. Problemas de red
Síntomas: Conexiones lentas, errores de tiempo de espera, imposibilidad de conectar a servicios.
Diagnóstico:
ping google.com: Comprueba la disponibilidad de recursos externos.ping localhost: Comprueba la tarjeta de red.netstat -tunlp: Muestra los puertos abiertos y las conexiones activas. Asegúrese de que su aplicación escucha en el puerto correcto.ss -tulpn: Alternativa a netstat, a menudo más rápida.ip a: Muestra las interfaces de red y sus direcciones IP.traceroute example.com: Rastrea la ruta a un host remoto.- Grafana (panel de Node Exporter): Monitorización del tráfico de red.
Solución:
- Verifique el firewall (
sudo ufw statuso reglas de iptables). - Asegúrese de que la aplicación escucha en
0.0.0.0o en la IP correcta, si debe ser accesible desde el exterior. - Verifique la configuración de DNS (
cat /etc/resolv.conf). - Si el problema está en el lado del proveedor de VPS, póngase en contacto con su soporte.
5. Fallos de la aplicación / Errores HTTP 5xx
Síntomas: Los usuarios ven páginas de error, la API devuelve 5xx, la aplicación no se inicia.
Diagnóstico:
- Logs de la aplicación: Esta es su principal fuente de información. Busque trazas de pila, mensajes de error, advertencias. Utilice Loki/Grafana para una búsqueda rápida.
sudo systemctl status your_app_service.service: Comprueba el estado del servicio systemd.sudo journalctl -u your_app_service.service -f: Muestra los logs de su servicio en tiempo real.- Monitorización de métricas: Anomalías en el número de solicitudes, latencia, errores.
Solución:
- Reinicie el servicio:
sudo systemctl restart your_app_service.service. - Si el problema se repite, analice los logs para encontrar la causa raíz (error en el código, problema con la base de datos, servicio externo).
- Verifique los archivos de configuración de la aplicación.
- Vuelva a la versión estable anterior si el problema apareció después de un lanzamiento.
Cuándo contactar con el soporte del proveedor de VPS
No dude en ponerse en contacto con el soporte si:
- No puede conectarse al VPS por SSH, y el problema no está en su configuración de red.
- Su VPS no responde a los pings, pero la aplicación debería estar funcionando.
- Se observan problemas de red que claramente no están relacionados con su configuración (por ejemplo, pérdida de paquetes a su VPS).
- El hardware (disco, RAM) muestra signos de fallo físico.
- Su VPS ha sido atacado o incluido en una lista negra.
Siempre proporcione al proveedor la máxima información: hora exacta de inicio del problema, síntomas observados, resultados de sus comandos de diagnóstico.
Preguntas frecuentes (FAQ)
¿Necesito un ingeniero SRE a tiempo completo en una startup?
En la etapa inicial, cuando el equipo consta de unas pocas personas, un ingeniero SRE dedicado probablemente no sea necesario. Las funciones de SRE pueden ser realizadas por ingenieros DevOps o incluso desarrolladores backend con una inclinación operativa. Es importante que los principios de SRE estén integrados en la cultura del equipo, y que cada uno asuma la responsabilidad de la fiabilidad. Un ingeniero SRE a tiempo completo se vuelve relevante cuando el equipo crece a más de 10-15 personas y la complejidad del sistema aumenta significativamente.
¿Cómo elegir los primeros SLI/SLO?
Comience con lo que es más crítico para su negocio y afecta directamente al usuario. Para la mayoría de los SaaS, esto es la disponibilidad de la API principal/interfaz web y la latencia de las operaciones clave del usuario (por ejemplo, inicio de sesión, guardado de datos). Establezca SLO realistas (por ejemplo, 99.9% de disponibilidad), no los "cinco nueves" ideales, que requerirán esfuerzos y costes injustificados.
¿Cuánto cuesta implementar SRE?
Los costes directos de SRE para VPS/Dedicated pueden ser mínimos si se utilizan herramientas de código abierto (Prometheus, Grafana, Loki). El "coste" principal es el tiempo de su equipo para implementar y mantener estas prácticas. Es una inversión que se amortiza con la reducción del tiempo de inactividad, la mejora de la reputación y la prevención de la pérdida de clientes. Para una pila básica de monitorización en un VPS separado, se puede mantener dentro de $15-30/mes por el propio servidor, más una parte del salario del ingeniero.
¿Se puede prescindir de herramientas de pago?
Absolutamente. Para startups en VPS/Dedicated, las soluciones de código abierto (Prometheus, Grafana, Loki, Ansible) son una opción ideal. Ofrecen una potente funcionalidad, flexibilidad y no requieren pagos mensuales. Los servicios de pago (por ejemplo, PagerDuty, Datadog) pueden simplificar algunos aspectos, pero no son obligatorios para empezar.
¿Cómo combatir la 'fatiga de alertas'?
La clave para combatir la 'fatiga de alertas' es la calidad, no la cantidad de alertas. Cada alerta debe ser accionable, requerir una intervención inmediata y tener un "runbook" claro. Revise regularmente las alertas, desactive las que no aporten valor y configure umbrales más precisos. Utilice diferentes canales para alertas de diferente criticidad (por ejemplo, PagerDuty para críticas, Slack para informativas).
¿En qué se diferencia SRE de DevOps?
DevOps es una filosofía cultural y metodológica más amplia, orientada a mejorar la colaboración entre desarrollo y operaciones. SRE es una implementación específica de los principios de DevOps, centrada en la aplicación de enfoques de ingeniería a los problemas de operación. SRE utiliza métricas, automatización y gestión de riesgos para lograr objetivos de fiabilidad específicos (SLO), mientras que DevOps abarca todo el ciclo de vida de desarrollo y despliegue.
¿Qué hacer si solo tengo un servidor?
Incluso para un solo servidor, las prácticas SRE son muy útiles. Comience con la monitorización básica (Prometheus + Node Exporter + Grafana en el mismo servidor), el registro centralizado (Loki + Promtail), la copia de seguridad automática y SLO sencillos. Esto le ayudará a comprender mejor el estado del servidor, reaccionar rápidamente a los problemas y prevenirlos. Tener un solo servidor hace que SRE sea aún más crítico, ya que no hay redundancia.
¿Cómo convencer al equipo de dedicar tiempo a SRE?
Muestre al equipo el beneficio directo: menos "incendios", menos despertares nocturnos, un producto más estable que gusta a los clientes. Explique que SRE no es un trabajo adicional, sino la sistematización y automatización de lo que ya hacen, pero de forma más eficiente. Involucre al equipo en la definición de los SLO y los Post-Mortem para que sientan su implicación y vean los resultados.
¿Qué métricas son las más importantes para SaaS?
Para SaaS, las métricas más importantes son las directamente relacionadas con la experiencia del usuario y los objetivos comerciales:
- Disponibilidad (el servicio funciona y está accesible).
- Latencia (velocidad de respuesta de la aplicación).
- Tasa de errores (cantidad de errores visibles para los usuarios).
- Rendimiento (capacidad para manejar la carga).
- Métricas de recursos (CPU, RAM, disco) para la planificación de capacidades.
¿Con qué frecuencia se deben realizar los Post-Mortem?
Los Post-Mortem deben realizarse después de cada incidente que haya violado su SLO o causado una insatisfacción significativa en el cliente. Para una startup, esto puede ser 1-2 veces al mes, y a veces incluso con más frecuencia. Lo más importante no es la frecuencia, sino la calidad: céntrese en extraer lecciones y crear "elementos de acción" concretos que se ejecutarán.
¿Cómo empezar la automatización?
Comience con las tareas más rutinarias y propensas a errores. Esto puede ser la automatización del despliegue de código (CI/CD), la copia de seguridad, la instalación de actualizaciones o la configuración de un nuevo servidor. Utilice herramientas sencillas, como scripts Bash o Ansible. Automatice gradualmente más procesos, liberando tiempo para trabajos más complejos.
Conclusión
La implementación de prácticas SRE para startups y pequeños equipos SaaS en VPS/Dedicated no es un lujo, sino una necesidad estratégica en el actual mercado altamente competitivo de 2026. Hemos comprobado que los principios de Site Reliability Engineering, desarrollados inicialmente para la escala de Google, pueden adaptarse y aplicarse con éxito incluso con recursos limitados, aportando beneficios significativos.
Las conclusiones clave que debe extraer de este artículo son:
- El pragmatismo es su mejor amigo: No aspire a la perfección de inmediato. Comience poco a poco, elija 1-2 SLI críticos y SLO realistas, ampliando gradualmente la cobertura.
- La monitorización es la base de todo: Sin una monitorización fiable, estará "apagando incendios" a ciegas. Las soluciones de código abierto como Prometheus y Grafana ofrecen potentes capacidades con costes mínimos.
- La automatización es el camino hacia la eficiencia: Reduzca el "toil" (trabajo rutinario) con scripts, Ansible y CI/CD. Esto liberará tiempo a los ingenieros y reducirá el número de errores humanos.
- Cultura de aprendizaje, no de culpa: Los Post-Mortem sin culpa son una herramienta poderosa para la mejora continua y la prevención de la repetición de incidentes.
- SRE es una inversión: El tiempo y los recursos invertidos en SRE se amortizan con la reducción del tiempo de inactividad, la mejora de la reputación, la disminución del estrés en el equipo y la aceleración del desarrollo de nuevas funciones.
Próximos pasos para el lector:
- Evalúe el estado actual: Realice una auditoría de su infraestructura y procesos actuales. ¿Dónde están los "cuellos de botella"? ¿Qué problemas surgen con más frecuencia?
- Elija el primer servicio "piloto": Comience con el servicio más crítico o el más problemático.
- Defina los primeros SLI y SLO: Acuérdelos con el equipo y el negocio.
- Implemente la pila básica de monitorización: Instale Prometheus, Node Exporter, Grafana y Loki. Configure los paneles para sus SLI.
- Configure las alertas: Cree varias alertas críticas que se activen antes de que se viole el SLO.
- Desarrolle el primer Runbook: Para una de sus alertas críticas.
- Realice el primer Post-Mortem: Después del siguiente incidente significativo, incluso si es pequeño.
- Automatice una tarea rutinaria: Por ejemplo, la copia de seguridad o el despliegue.
Recuerde, SRE no es un proyecto único, sino un proceso continuo de mejora. Comience poco a poco, mejore de forma iterativa y verá cómo su startup se vuelve más fiable, predecible y exitosa. ¡Buena suerte!
¿Te fue útil esta guía?