info
¿Necesitas un servidor para esta guía? Ofrecemos servidores dedicados y VPS en más de 50 países con configuración instantánea.
Need a server for this guide?
Deploy a VPS or dedicated server in minutes.
Observabilidad completa (Observability) para sistemas distribuidos: OpenTelemetry, Loki y Tempo en un VPS 2026
TL;DR
- OpenTelemetry es el estándar de 2026 para la recopilación de telemetría. Unifica la recopilación de métricas, logs y trazas, preparando su sistema para futuros cambios y evitando la dependencia de un proveedor específico.
- Loki es la elección óptima para logs en un VPS. Su índice basado en metadatos permite almacenar y consultar logs de manera eficiente incluso con recursos limitados, lo cual es crítico para soluciones de bajo presupuesto.
- Tempo es la solución ideal para trazas distribuidas. Utiliza almacenamiento de objetos, minimizando los requisitos de RAM y CPU, lo que lo hace extremadamente adecuado para la infraestructura de VPS en 2026.
- Integración con Grafana — su panel de control unificado. Los tres componentes se integran fácilmente con Grafana, proporcionando una interfaz centralizada para la visualización y el análisis de toda la telemetría.
- Ahorrar en un VPS en 2026 — es una realidad. La configuración adecuada de OpenTelemetry Collector, la filtración de datos y la optimización del almacenamiento permiten reducir significativamente los costos, especialmente en tráfico y espacio en disco.
- El enfoque práctico — la clave del éxito. Empiece poco a poco, implemente gradualmente, automatice el despliegue y no olvide la auditoría regular de las configuraciones y el consumo de recursos.
- Esté preparado para escalar. Incluso en un VPS, la arquitectura de OpenTelemetry, Loki y Tempo permite una escalabilidad relativamente fácil, pasando a instancias o clústeres más potentes a medida que el proyecto crece.
Introducción
 Diagrama: Introducción
Diagrama: Introducción
Para 2026, el panorama del desarrollo de software ha experimentado cambios significativos. Las aplicaciones monolíticas han dado paso a arquitecturas de microservicios distribuidos, las tecnologías en la nube se han vuelto omnipresentes, y el concepto de "serverless" y la computación de borde (edge computing) continúan ganando impulso. Junto con esta evolución, la complejidad de los sistemas también crece. La falla de uno de decenas o cientos de microservicios puede provocar fallas en cascada, y la búsqueda de la raíz del problema en una intrincada red de interacciones se convierte en una verdadera pesadilla sin las herramientas adecuadas.
Es aquí donde entra en escena el concepto de observabilidad completa (Observability). A diferencia del monitoreo tradicional, que responde a la pregunta "¿Qué pasó?", Observability permite responder a la pregunta "¿Por qué pasó?", proporcionando una comprensión profunda del estado interno del sistema a través de tres pilares principales: métricas, logs y trazas. En 2026, cuando el tiempo de inactividad se mide no solo en dinero sino también en reputación, y la experiencia del usuario es una ventaja competitiva clave, Observability deja de ser un lujo y se convierte en una necesidad absoluta.
Este artículo está dedicado a la construcción de un sistema completo de Observability para sistemas distribuidos, utilizando la combinación de OpenTelemetry, Loki y Tempo, desplegado en un servidor privado virtual (VPS). Nos centraremos en los aspectos prácticos, relevantes para 2026, teniendo en cuenta las crecientes demandas de rendimiento, eficiencia y, por supuesto, costo. Mostraremos cómo, incluso con un presupuesto y recursos de VPS limitados, se puede lograr un alto nivel de observabilidad, comparable con soluciones en la nube más costosas.
¿Para quién está escrito este artículo? En primer lugar, para ingenieros DevOps y administradores de sistemas que buscan soluciones eficientes y económicas para el monitoreo y diagnóstico. Será útil para desarrolladores Backend (Python, Node.js, Go, PHP) que buscan integrar Observability en sus aplicaciones. Los fundadores de proyectos SaaS y los directores técnicos de startups encontrarán aquí consejos prácticos para optimizar costos y mejorar la fiabilidad de sus productos, utilizando tecnologías abiertas avanzadas.
Analizaremos por qué esta combinación de herramientas es una de las más prometedoras y económicamente eficientes para un VPS en 2026, cómo configurarla correctamente, qué errores evitar y cómo obtener el máximo beneficio para su negocio.
Criterios/factores clave de selección
 Diagrama: Criterios/factores clave de selección
Diagrama: Criterios/factores clave de selección
La elección de las herramientas adecuadas para Observability no es solo seguir tendencias, sino una decisión estratégica que influye directamente en la fiabilidad, el rendimiento y, en última instancia, en el éxito comercial del proyecto. En 2026, cuando se trata de sistemas distribuidos en un VPS, es necesario considerar una serie de factores críticamente importantes.
1. Costo total de propiedad (TCO)
Este es, quizás, el factor más importante para proyectos que utilizan un VPS. El TCO incluye no solo los costos directos de servidores y almacenamiento, sino también los indirectos: el tiempo de los ingenieros para la configuración, el soporte, la escalabilidad, así como las posibles pérdidas por tiempos de inactividad. Las soluciones deben ser eficientes en el uso de recursos, minimizando el consumo de CPU, RAM y espacio en disco, así como el tráfico, que a menudo es un elemento de gasto significativo en un VPS. Buscaremos herramientas que permitan almacenar un gran volumen de datos por un costo razonable.
2. Facilidad de despliegue y gestión
En un VPS, los recursos de los ingenieros suelen ser limitados. Los sistemas complejos de instalar y configurar pueden convertirse rápidamente en una carga. Necesitamos soluciones que puedan desplegarse rápidamente, actualizarse fácilmente y mantenerse sin necesidad de una inmersión profunda en su funcionamiento interno. La documentación, la comunidad y la disponibilidad de configuraciones predefinidas juegan un papel clave aquí.
3. Escalabilidad y rendimiento
Incluso en un VPS, el sistema debe ser capaz de procesar un volumen creciente de telemetría sin degradación del rendimiento. Esto significa un uso eficiente de los recursos, escalabilidad horizontal (si se requiere la transición a varios VPS) y la capacidad de manejar cargas pico. Es especialmente importante para los logs y las trazas, cuyo volumen puede ser impredecible.
4. Flexibilidad y extensibilidad
El mundo de la tecnología está en constante cambio. Las herramientas seleccionadas deben ser lo suficientemente flexibles para adaptarse a nuevas fuentes de datos, protocolos e integraciones. OpenTelemetry es el estándar de oro aquí, proporcionando un enfoque unificado para la recopilación de datos. La capacidad de añadir fácilmente nuevos servicios y aplicaciones al sistema de Observability es crítica.
5. Profundidad y calidad de los datos
Las herramientas deben proporcionar datos suficientemente detallados y precisos (métricas, logs, trazas) para poder diagnosticar problemas de manera efectiva. La capacidad de añadir atributos personalizados (etiquetas) a los datos, agregarlos por diferentes dimensiones y realizar consultas complejas es la base para un análisis profundo.
6. Integración con el ecosistema
Un sistema de Observability no existe en el vacío. Debe integrarse fácilmente con otras herramientas en su stack: sistemas de alerta (Alertmanager), paneles de control (Grafana), pipelines de CI/CD, etc. Cuanto más fluida sea la integración, más eficiente será todo el proceso de desarrollo y operación.
7. Apertura y estándares
El uso de estándares abiertos y proyectos con una comunidad activa reduce el riesgo de dependencia del proveedor (vendor lock-in) y garantiza un soporte a largo plazo. OpenTelemetry es un claro ejemplo de este enfoque, convirtiéndose de facto en el estándar para la telemetría. Los proyectos abiertos también suelen ofrecer soluciones más flexibles y se adaptan más rápidamente a los nuevos requisitos.
8. Seguridad
La telemetría a menudo contiene datos sensibles. Las herramientas deben garantizar la transmisión y el almacenamiento seguros de los datos, admitir la autenticación y autorización, y proporcionar capacidades para enmascarar o filtrar información confidencial.
Cómo evaluar cada criterio:
- TCO: Compare no solo el costo del VPS, sino también el volumen de tráfico estimado, el espacio en disco para almacenar logs/trazas, así como el tiempo previsto que los ingenieros dedicarán al soporte. Utilice calculadoras de proveedores y despliegues de prueba.
- Facilidad de despliegue: Evalúe el número de pasos para la instalación, la complejidad de los archivos de configuración, la disponibilidad de imágenes Docker y Helm charts (si se utiliza Kubernetes en el VPS).
- Escalabilidad: Examine la arquitectura de la herramienta. ¿Soporta escalabilidad horizontal? ¿Cuáles son las recomendaciones de recursos para diferentes volúmenes de datos?
- Flexibilidad: Verifique qué protocolos soporta la herramienta para la ingesta de datos, si hay una API para extender la funcionalidad, y qué tan fácil es añadir nuevas fuentes de datos.
- Profundidad de datos: Vea ejemplos de paneles de control y consultas. ¿Qué tan detallada es la información que se puede obtener? ¿Se pueden filtrar y agregar datos por muchos parámetros?
- Integración: Verifique la disponibilidad de conectores listos para usar, plugins y documentación para la integración con Grafana, Alertmanager y otras herramientas.
- Apertura: Evalúe la actividad en GitHub, el número de colaboradores, la frecuencia de lanzamientos, la disponibilidad de una hoja de ruta pública.
- Seguridad: Examine la documentación de seguridad: cifrado de datos en tránsito y en reposo, mecanismos de acceso.
Teniendo en cuenta estos criterios, la combinación de OpenTelemetry, Loki y Tempo en un VPS en 2026 parece ser una de las soluciones más equilibradas y prometedoras.
Tabla comparativa de soluciones de Observability
 Esquema: Tabla comparativa de soluciones de Observability
Esquema: Tabla comparativa de soluciones de Observability
Para comprender las ventajas de la pila seleccionada, comparemos OpenTelemetry, Loki y Tempo con otras soluciones populares, relevantes para 2026, especialmente en el contexto de su uso en un VPS. Nos centraremos en aspectos clave: tipo de datos, costo, complejidad, escalabilidad y características principales.
| Criterio |
OpenTelemetry (Recopilación) |
Loki (Logs) |
Tempo (Traces) |
Prometheus (Métricas) |
Elastic Stack (ELK) |
Jaeger (Traces) |
Proveedor de Nube (Managed Observability) |
| Tipo de datos |
Métricas, Logs, Traces (colector universal) |
Logs |
Traces |
Métricas (modelo pull) |
Logs, Métricas, Traces (a través de Filebeat, Metricbeat, APM) |
Traces |
Métricas, Logs, Traces (integralmente) |
| Costo (VPS, 2026) |
Bajo (solo colector, CPU/RAM) |
Medio (almacenamiento compatible con S3, CPU/RAM para consultas) |
Bajo (almacenamiento compatible con S3, CPU/RAM mínimo) |
Medio (almacenamiento en disco, CPU/RAM) |
Alto (requiere mucha RAM/CPU/disco) |
Medio (requiere Cassandra/Elasticsearch, CPU/RAM/disco) |
Alto (por suscripción, precio por volumen de datos) |
| Complejidad de despliegue |
Media (Collector + agentes) |
Media (Loki + Promtail) |
Baja (Tempo + OpenTelemetry Collector) |
Media (Prometheus + Exporters) |
Alta (Elasticsearch, Kibana, Logstash/Beats) |
Alta (Collector, Query, Agent, Storage) |
Baja (configuración a través de UI/API) |
| Escalabilidad en VPS |
Alta (Collector horizontalmente) |
Media (separación en ingester/querier, almacenamiento de objetos) |
Alta (almacenamiento de objetos, recursos mínimos) |
Media (Federation, Thanos/Cortex para clúster) |
Baja (muy intensivo en recursos para clúster) |
Media (con base de datos externa) |
Muy alta (gestionada por el proveedor) |
| Almacenamiento de datos |
No (solo almacenamiento en búfer) |
Almacenamiento de objetos (compatible con S3), índice por metadatos |
Almacenamiento de objetos (compatible con S3), índice por ID de trace |
Disco local (TSDB) |
Disco local (Lucene/índice invertido) |
Cassandra, Elasticsearch, Kafka |
Gestionado por el proveedor (soluciones propias) |
| Características para 2026 en VPS |
Estándar universal, vendor-agnostic, desarrollo activo, amplio soporte de idiomas. |
Almacenamiento eficiente de logs, bajos requisitos de RAM/CPU, excelente integración con Grafana, soporte de Cloud Object Storage como backend. |
Requisitos mínimos de RAM/CPU, almacenamiento de traces en almacenamiento de objetos, enfoque "almacenar todo", consultas rápidas por ID de trace. |
Estándar de facto para métricas, modelo pull, potente lenguaje de consulta PromQL, comunidad activa. |
Potente analítica, búsqueda de texto completo, pero muy intensivo en recursos, lo que lo hace costoso para VPS. |
Estándar abierto para trazas, pero requiere un potente SGBD para el almacenamiento, lo que encarece el VPS. |
Conveniencia, sin necesidad de gestión, pero alto costo por volumen de datos y vendor lock-in. |
| Integración con Grafana |
Sí (a través de Prometheus/Loki/Tempo) |
Sí (nativa) |
Sí (nativa) |
Sí (nativa) |
Sí (a través de plugin) |
Sí (a través de plugin) |
Sí (a menudo nativa o a través de API) |
De la tabla se desprende que la combinación de OpenTelemetry, Loki y Tempo ofrece un equilibrio único entre funcionalidad, rendimiento y costo, especialmente para el despliegue en un VPS en 2026. La renuncia a bases de datos intensivas en recursos para el almacenamiento de logs y traces en favor de almacenamientos de objetos (compatibles con S3) es un factor clave que permite reducir significativamente el TCO y simplificar la gestión.
Prometheus sigue siendo el estándar para métricas y a menudo se utiliza junto con OpenTelemetry Collector para la recopilación y agregación de métricas. Elastic Stack, aunque potente, es excesivamente caro y complejo para la mayoría de los proyectos VPS. Los proveedores de nube ofrecen comodidad, pero su política de precios por volumen de datos puede volverse rápidamente inasequible para startups y equipos pequeños.
Así, OpenTelemetry como colector universal, Loki para el almacenamiento económico de logs y Tempo para traces en almacenamiento de objetos, complementados con Grafana para la visualización, constituyen una solución óptima para Observability en un VPS en 2026.
Visión detallada de OpenTelemetry, Loki y Tempo
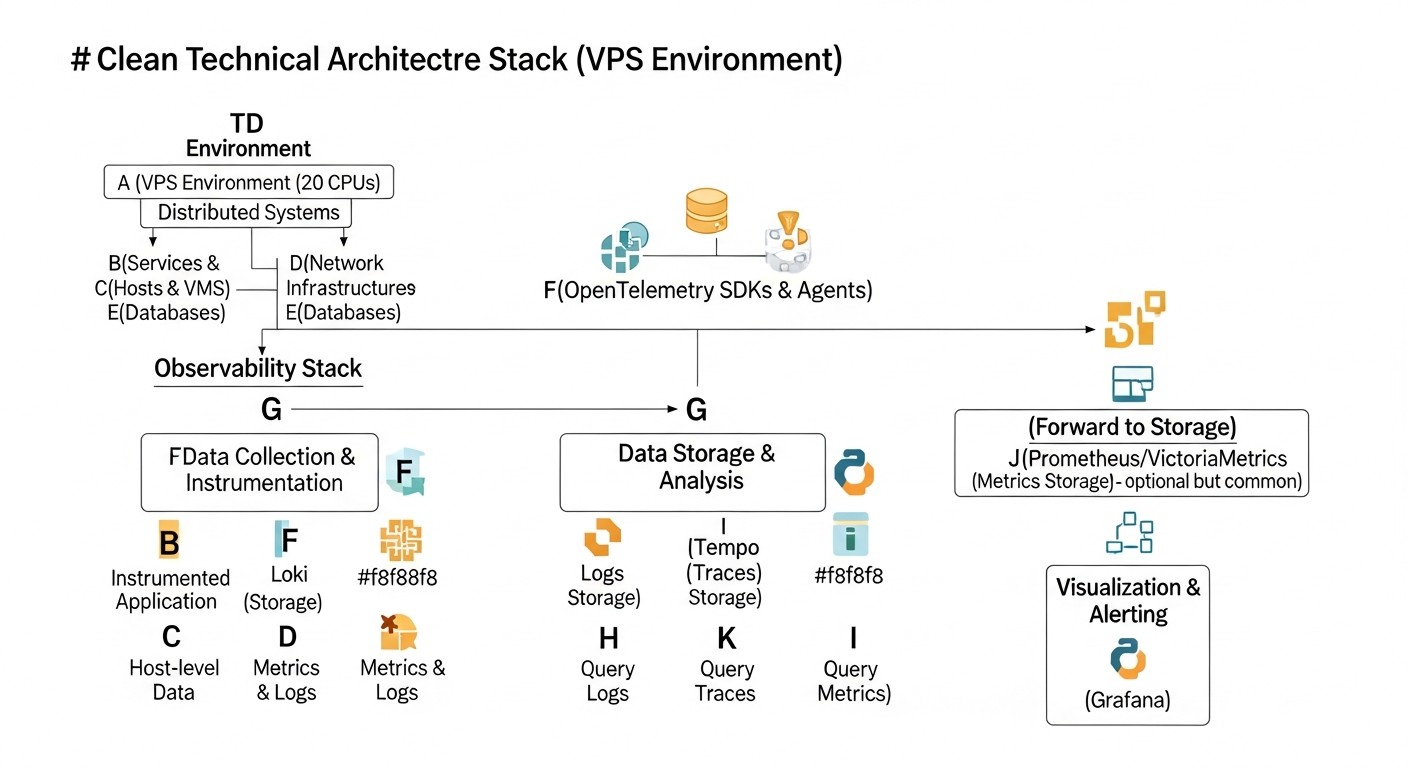 Esquema: Visión detallada de OpenTelemetry, Loki y Tempo
Esquema: Visión detallada de OpenTelemetry, Loki y Tempo
Para una comprensión profunda de por qué esta combinación de herramientas es tan efectiva para la Observabilidad en un VPS en 2026, examinemos cada componente en detalle.
OpenTelemetry: Recolector universal de telemetría
OpenTelemetry (abreviado OTel) no es solo una herramienta, es un conjunto de estándares, API, SDK e instrumentos diseñados para la recopilación, procesamiento y exportación unificada de telemetría (métricas, logs y trazas) de sus aplicaciones e infraestructura. Para 2026, OTel se ha convertido en el estándar de facto en la industria, respaldado por prácticamente todos los principales proveedores de la nube y herramientas de Observabilidad.
Ventajas:
- Independiente del proveedor: No está vinculado a un proveedor o plataforma específica. Puede recopilar datos una vez y enviarlos a Loki, Tempo, Prometheus, así como a cualquier solución comercial que admita OTel. Esto proporciona una enorme flexibilidad y protección de la inversión a futuro.
- Enfoque unificado: OTel proporciona una API y un SDK unificados para los tres tipos de telemetría, lo que simplifica enormemente la instrumentación de aplicaciones. Los desarrolladores no necesitan aprender diferentes bibliotecas para métricas, logs y trazas.
- Collector potente: OpenTelemetry Collector es un proxy que puede recibir, procesar y exportar telemetría. Permite filtrar, transformar y agregar datos directamente en el borde de la red, reduciendo la carga en los backends y ahorrando tráfico. Esto es críticamente importante para los VPS, donde cada megabyte de tráfico y cada ciclo de CPU cuentan.
- Amplio soporte de lenguajes: OTel tiene SDK para la mayoría de los lenguajes de programación populares (Python, Java, Go, Node.js, .NET, PHP, Ruby, etc.), lo que lo hace aplicable en prácticamente cualquier entorno.
- Comunidad activa y desarrollo: El proyecto está bajo el paraguas de la Cloud Native Computing Foundation (CNCF) y se desarrolla activamente, añadiendo constantemente nuevas funciones y mejorando el rendimiento.
Desventajas:
- Curva de aprendizaje: A pesar de la unificación, dominar todos los conceptos de OTel (trazadores, spans, contextos, recursos, atributos, convenciones semánticas) puede llevar algún tiempo.
- Sobrecarga: La instrumentación de aplicaciones y el funcionamiento del Collector requieren cierto consumo de CPU y RAM, aunque optimizado. En VPS muy pequeños (< 1GB RAM) esto puede ser notable.
Para quién es adecuado: Para todos aquellos que deseen crear un sistema de Observabilidad flexible, escalable e independiente del proveedor. Especialmente útil para arquitecturas de microservicios, donde es necesario rastrear la interacción entre múltiples componentes.
Ejemplos de uso: Instrumentación de solicitudes HTTP en una aplicación Go, recopilación de métricas de un servicio Node.js, envío de logs personalizados desde un script Python. El Collector puede configurarse para agregar métricas de varios servicios antes de enviarlas a Prometheus, o para muestrear trazas para reducir el volumen de datos enviados a Tempo.
Loki: Almacenamiento de logs económico
Loki, desarrollado por Grafana Labs, se posiciona como el "Prometheus para logs". Su diferencia clave con los sistemas de gestión de logs tradicionales (como Elastic Stack) radica en que solo indexa los metadatos (etiquetas) de los logs, y no su contenido completo. Esto permite reducir significativamente el volumen del índice y, en consecuencia, los requisitos de espacio en disco y memoria RAM.
Ventajas:
- Ahorro de recursos: Gracias a la indexación de solo metadatos, Loki consume mucha menos RAM y CPU en comparación con las soluciones que utilizan búsqueda de texto completo. Esto lo hace ideal para VPS, donde los recursos son limitados.
- Almacenamiento de objetos: Loki puede utilizar almacenamientos de objetos compatibles con S3 (como MinIO en el mismo VPS, o S3/Google Cloud Storage/Azure Blob Storage en la nube) para almacenar los logs. Esto proporciona alta escalabilidad y bajo costo de almacenamiento.
- Lenguaje de consulta (LogQL): Loki utiliza un lenguaje de consulta inspirado en PromQL, lo que simplifica su aprendizaje para quienes ya están familiarizados con Prometheus. LogQL es muy potente y permite filtrar, agregar y analizar logs por sus etiquetas y contenido.
- Integración nativa con Grafana: Loki fue desarrollado por el mismo equipo que Grafana, por lo que la integración entre ellos es impecable. Puede crear fácilmente dashboards, explorar logs y pasar de métricas a logs en una sola interfaz.
- Facilidad de despliegue: Loki es relativamente fácil de desplegar, especialmente en modo "monolito" (binario único) para instalaciones pequeñas en un VPS.
Desventajas:
- Sin búsqueda de texto completo: Si necesita una búsqueda de texto completo de alto rendimiento en todos los logs sin conocimiento previo de las etiquetas, Loki podría no ser la mejor opción. Sin embargo, en 2026, con el desarrollo de OpenTelemetry y la estandarización de atributos, esta desventaja se vuelve menos crítica.
- Dependencia de las etiquetas: La eficiencia de las consultas depende en gran medida de la correcta elección y uso de las etiquetas. Una estrategia de etiquetado incorrecta puede llevar a consultas lentas o a una "explosión de cardinalidad" (high cardinality).
Para quién es adecuado: Para equipos que desean gestionar eficazmente grandes volúmenes de logs con recursos limitados, utilizando Grafana para la visualización. Ideal para proyectos SaaS donde el logging es crítico, pero el presupuesto es limitado.
Ejemplos de uso: Recopilación de logs de un servidor web Nginx, microservicios en Go, logs de contenedores Docker, logs del sistema. Uso de Promtail (agente de Loki) o OpenTelemetry Collector para enviar logs a Loki.
Tempo: Trazas distribuidas sin dolores de cabeza
Tempo es otro proyecto de Grafana Labs, diseñado para almacenar y consultar trazas distribuidas. Su singularidad radica en que no construye índices sobre todo el contenido de las trazas. En su lugar, almacena las trazas en un almacenamiento de objetos compatible con S3 e indexa solo sus ID. Las consultas a Tempo se realizan por ID de traza, lo que lo hace extremadamente eficiente e independiente de los recursos.
Ventajas:
- Requisitos mínimos de recursos: Dado que Tempo no indexa el contenido de las trazas, consume muy poca RAM y CPU. Esto permite desplegarlo incluso en los VPS más modestos.
- Escalabilidad a través de almacenamiento de objetos: Al igual que Loki, Tempo utiliza almacenamientos compatibles con S3 para las trazas. Esto proporciona una escalabilidad prácticamente ilimitada y un bajo costo de almacenamiento de datos.
- Enfoque de "almacenar todo": Debido al bajo costo de almacenamiento y los recursos mínimos, Tempo permite almacenar el 100% de sus trazas, en lugar de depender del muestreo. Esto permite un análisis profundo incluso de problemas raros.
- Integración nativa con Grafana y Prometheus: Tempo se integra fácilmente con Grafana, permitiendo pasar de métricas (Prometheus) o logs (Loki) a trazas específicas. También se admite la búsqueda de trazas por atributos a través de Loki o Prometheus.
- Facilidad de despliegue: Tempo, al igual que Loki, puede ejecutarse en modo "monolito" para instalaciones sencillas, lo que simplifica su despliegue en un VPS.
Desventajas:
- Búsqueda solo por ID o indirectamente: La forma principal de buscar trazas es por su ID único. La búsqueda por atributos (por ejemplo, por nombre de usuario o ID de pedido) es posible, pero requiere integración con Loki (para buscar en logs que contengan estos atributos y el ID de traza) o con Prometheus (para buscar en métricas que agreguen atributos y el ID de traza).
- Sin UI integrado: Tempo no tiene su propia interfaz de usuario, dependiendo completamente de Grafana para la visualización y exploración de trazas.
Para quién es adecuado: Para equipos que requieren visibilidad completa de la interacción entre microservicios, pero están limitados en presupuesto y recursos. Ideal para diagnosticar el rendimiento, identificar cuellos de botella y comprender el flujo de datos en sistemas distribuidos.
Ejemplos de uso: Seguimiento de la ruta completa de una solicitud a través de un API Gateway, varios servicios de backend y una base de datos. Diagnóstico de latencias causadas por llamadas a API externas. Uso del SDK de OpenTelemetry en aplicaciones para generar trazas y enviarlas a Tempo a través del OpenTelemetry Collector.
Juntos, OpenTelemetry, Loki y Tempo, integrados con Grafana, proporcionan una solución de Observabilidad potente, económica y escalable, ideal para sistemas distribuidos desplegados en un VPS en 2026.
Consejos prácticos y recomendaciones para la implementación
 Diagrama: Consejos prácticos y recomendaciones para la implementación
Diagrama: Consejos prácticos y recomendaciones para la implementación
La implementación de un sistema de Observabilidad completo en un VPS requiere no solo la comprensión de las herramientas, sino también un enfoque práctico. Aquí se presentan instrucciones paso a paso y recomendaciones basadas en la experiencia real.
1. Preparación del VPS y configuración básica
Antes de instalar cualquier cosa, asegúrese de que su VPS esté listo. Se recomienda utilizar una instalación nueva de Ubuntu Server 24.04 LTS o Debian 12. Para nuestros propósitos, se requerirá un mínimo de 4GB de RAM y 2 núcleos de CPU, así como suficiente espacio en disco o la posibilidad de conectar un almacenamiento compatible con S3.
# Обновление системы
sudo apt update && sudo apt upgrade -y
# Установка Docker и Docker Compose (для упрощения развертывания)
sudo apt install ca-certificates curl gnupg lsb-release -y
sudo mkdir -p /etc/apt/keyrings
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
echo "deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
sudo apt update
sudo apt install docker-ce docker-ce-cli containerd.io docker-compose-plugin -y
# Добавление пользователя в группу docker
sudo usermod -aG docker $USER
# Выйдите и войдите заново, чтобы изменения вступили в силу, или выполните:
# newgrp docker
# Установка MinIO (локальное S3-совместимое хранилище для Loki и Tempo)
# Создадим директории для данных и конфигурации MinIO
sudo mkdir -p /mnt/data/minio
sudo mkdir -p /etc/minio
# Создадим файл docker-compose.yml для MinIO
# nano docker-compose.yml
Ejemplo de docker-compose.yml para MinIO:
version: '3.8'
services:
minio:
image: minio/minio:latest
container_name: minio
ports:
- "9000:9000"
- "9001:9001"
volumes:
- /mnt/data/minio:/data
- /etc/minio:/root/.minio
environment:
MINIO_ROOT_USER: minioadmin
MINIO_ROOT_PASSWORD: minioadminpassword
MINIO_BROWSER: "on"
command: server /data --console-address ":9001"
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
restart: unless-stopped
# Запуск MinIO
docker compose up -d
Ahora MinIO está disponible en http://<ваш_ip>:9001. Cree buckets para Loki y Tempo, por ejemplo, loki-bucket y tempo-bucket.
2. Despliegue de OpenTelemetry Collector
El Collector será el nodo central para la recopilación, procesamiento y enrutamiento de telemetría. Para un VPS, se puede desplegar como un contenedor Docker.
Ejemplo de otel-collector-config.yaml:
receivers:
otlp:
protocols:
grpc:
http:
processors:
batch:
send_batch_size: 1000
timeout: 10s
memory_limiter:
check_interval: 1s
limit_mib: 256 # Ограничение RAM для Collector
spike_limit_mib: 64
resource:
attributes:
- key: host.name
value: ${env:HOSTNAME}
action: upsert
- key: deployment.environment
value: production
action: insert
exporters:
loki:
endpoint: http://loki:3100/loki/api/v1/push
# auth:
# basic:
# username: ${env:LOKI_USERNAME}
# password: ${env:LOKI_PASSWORD}
tempo:
endpoint: http://tempo:4317
tls:
insecure: true # В production использовать TLS
prometheus:
endpoint: 0.0.0.0:8889
resource_to_telemetry_conversion:
enabled: true
logging:
loglevel: debug
service:
pipelines:
traces:
receivers: [otlp]
processors: [memory_limiter, batch, resource]
exporters: [tempo, logging]
metrics:
receivers: [otlp]
processors: [memory_limiter, batch, resource]
exporters: [prometheus, logging]
logs:
receivers: [otlp]
processors: [memory_limiter, batch, resource]
exporters: [loki, logging]
Inicio del Collector mediante docker-compose.yml:
version: '3.8'
services:
otel-collector:
image: otel/opentelemetry-collector:0.96.0 # Актуальная версия на 2026 год
container_name: otel-collector
command: ["--config=/etc/otel-collector-config.yaml"]
volumes:
- ./otel-collector-config.yaml:/etc/otel-collector-config.yaml
ports:
- "4317:4317" # OTLP gRPC receiver
- "4318:4318" # OTLP HTTP receiver
- "8889:8889" # Prometheus exporter
environment:
HOSTNAME: ${HOSTNAME} # Передаем имя хоста
depends_on:
- loki
- tempo
restart: unless-stopped
3. Despliegue de Loki
Para Loki, también usamos Docker. Necesitaremos el archivo de configuración loki-config.yaml.
auth_enabled: false # Для простоты, в production использовать аутентификацию
server:
http_listen_port: 3100
grpc_listen_port: 9095
common:
path_prefix: /loki
storage:
filesystem:
directory: /tmp/loki/chunks # Только для временного хранения, затем в S3
replication_factor: 1
ring:
kvstore:
store: inmemory # Для single-node, в production использовать Consul/Etcd
instance_addr: 127.0.0.1
instance_port: 3100
schema_config:
configs:
- from: 2023-01-01
store: boltdb-shipper
object_store: s3
schema: v12
index:
prefix: index_
period: 24h
compactor:
working_directory: /tmp/loki/compactor
shared_store: s3
chunk_store_config:
max_look_back_period: 30d # Хранить чанки логов 30 дней
storage_config:
boltdb_shipper:
active_index_directory: /tmp/loki/boltdb-shipper-active
cache_location: /tmp/loki/boltdb-shipper-cache
resync_interval: 5s
shared_store: s3
s3:
endpoint: minio:9000
bucketnames: loki-bucket
access_key_id: minioadmin
secret_access_key: minioadminpassword
s3forcepathstyle: true
Añadimos Loki a docker-compose.yml:
loki:
image: grafana/loki:2.9.0 # Актуальная версия на 2026 год
container_name: loki
command: -config.file=/etc/loki/loki-config.yaml
volumes:
- ./loki-config.yaml:/etc/loki/loki-config.yaml
- /mnt/data/loki:/tmp/loki # Данные Loki
ports:
- "3100:3100"
environment:
MINIO_ENDPOINT: minio:9000 # Для Loki, чтобы мог достучаться до MinIO
depends_on:
- minio
restart: unless-stopped
4. Despliegue de Tempo
Configuración de Tempo en tempo-config.yaml:
server:
http_listen_port: 3200
grpc_listen_port: 9096
distributor:
receivers:
otlp:
protocols:
grpc:
http:
ingester:
lifecycler:
ring:
kvstore:
store: inmemory # Для single-node, в production использовать Consul/Etcd
replication_factor: 1
compactor:
compaction_interval: 10m
storage:
trace:
backend: s3
s3:
endpoint: minio:9000
bucket: tempo-bucket
access_key_id: minioadmin
secret_access_key: minioadminpassword
s3forcepathstyle: true
wal:
path: /tmp/tempo/wal # Write Ahead Log
block:
bloom_filter_false_positive_rate: 0.05
index_downsample_bytes: 1000
max_block_bytes: 5000000 # 5MB
max_block_duration: 15m
retention: 30d # Хранить трассировки 30 дней
Añadimos Tempo a docker-compose.yml:
tempo:
image: grafana/tempo:2.4.0 # Актуальная версия на 2026 год
container_name: tempo
command: -config.file=/etc/tempo/tempo-config.yaml
volumes:
- ./tempo-config.yaml:/etc/tempo/tempo-config.yaml
- /mnt/data/tempo:/tmp/tempo # Данные Tempo
ports:
- "3200:3200" # HTTP
- "9096:9096" # gRPC
- "4317" # OTLP gRPC receiver (Tempo может принимать напрямую, но лучше через Collector)
- "4318" # OTLP HTTP receiver
environment:
MINIO_ENDPOINT: minio:9000 # Для Tempo, чтобы мог достучаться до MinIO
depends_on:
- minio
restart: unless-stopped
5. Despliegue de Grafana
Grafana será su interfaz unificada para todos los datos de Observabilidad.
grafana:
image: grafana/grafana:10.4.0 # Актуальная версия на 2026 год
container_name: grafana
ports:
- "3000:3000"
volumes:
- /mnt/data/grafana:/var/lib/grafana # Для персистентности данных Grafana
environment:
GF_SECURITY_ADMIN_USER: admin
GF_SECURITY_ADMIN_PASSWORD: supersecretpassword # Смените на сложный пароль!
GF_AUTH_ANONYMOUS_ENABLED: "false"
GF_AUTH_DISABLE_SIGNOUT_MENU: "false"
depends_on:
- loki
- tempo
- otel-collector
restart: unless-stopped
# Запуск всех сервисов
docker compose up -d
Ahora Grafana está disponible en http://<ваш_ip>:3000. Inicie sesión con el usuario admin y la contraseña supersecretpassword.
6. Configuración de fuentes de datos en Grafana
- Añada Loki como fuente de datos:
- Type: Loki
- URL:
http://loki:3100
- Añada Tempo como fuente de datos:
- Type: Tempo
- URL:
http://tempo:3200
- Para "Data Links", especifique la fuente Loki para poder navegar de las trazas a los logs.
- Añada Prometheus (OpenTelemetry Collector) como fuente de datos:
- Type: Prometheus
- URL:
http://otel-collector:8889
7. Instrumentación de aplicaciones
El paso más importante es la instrumentación de sus aplicaciones utilizando el SDK de OpenTelemetry. Ejemplo para Python:
import os
from opentelemetry import trace
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.instrumentation.flask import FlaskInstrumentor
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from flask import Flask
# Настройка OpenTelemetry
resource = Resource.create({
"service.name": "my-python-app",
"service.version": "1.0.0",
"deployment.environment": "production",
"host.name": os.getenv("HOSTNAME", "unknown_host")
})
trace.set_tracer_provider(TracerProvider(resource=resource))
tracer = trace.get_tracer(__name__)
# Экспорт трассировок в OpenTelemetry Collector
otlp_exporter = OTLPSpanExporter(endpoint="http://otel-collector:4317", insecure=True)
span_processor = BatchSpanProcessor(otlp_exporter)
trace.get_tracer_provider().add_span_processor(span_processor)
app = Flask(__name__)
FlaskInstrumentor().instrument_app(app)
@app.route('/')
def hello():
with tracer.start_as_current_span("hello-request"):
return "Hello, Observability!"
if __name__ == '__main__':
app.run(host='0.0.0.0', port=5000)
SDK similares están disponibles para todos los lenguajes populares. Úselos para generar métricas, logs y trazas, enviándolos al OpenTelemetry Collector en los puertos 4317 (gRPC) o 4318 (HTTP).
8. Automatización del despliegue
En 2026, el despliegue manual es un anacronismo. Utilice Ansible, Terraform u otras herramientas de IaC (Infrastructure as Code) para automatizar la instalación y configuración del VPS, Docker y todos los componentes de Observabilidad. Esto reducirá significativamente el tiempo de despliegue y la probabilidad de errores.
9. Monitorización del propio sistema de Observabilidad
No olvide monitorizar Loki, Tempo y OpenTelemetry Collector. Utilice sus propias métricas (que pueden ser recopiladas por Prometheus) para rastrear su rendimiento, consumo de recursos y volumen de datos procesados. Esto ayudará a identificar cuellos de botella antes de que se vuelvan críticos.
Errores comunes al construir Observability en un VPS
 Diagrama: Errores comunes al construir Observability en un VPS
Diagrama: Errores comunes al construir Observability en un VPS
Incluso con las mejores herramientas, los errores en la implementación pueden anular todos los esfuerzos. Aquí están los conceptos erróneos y fallos más comunes al construir un sistema de Observability en un VPS, relevantes para 2026.
1. Ignorar OpenTelemetry Collector como proxy
Error: Envío de telemetría directamente desde las aplicaciones a Loki, Tempo o Prometheus sin usar OpenTelemetry Collector. O usar Collector, pero sin procesadores eficientes (por ejemplo, batching, filtrado, muestreo).
Cómo evitarlo: Utilice siempre OpenTelemetry Collector como un hub central. Está diseñado para ser un búfer, proxy y procesador. Configúrelo para batching (agrupación de datos en paquetes), filtrado de datos innecesarios, agregación de métricas y muestreo de trazas (especialmente para sistemas de alta carga). Esto reduce significativamente la carga en los backends (Loki, Tempo) y ahorra tráfico, lo cual es crítico para un VPS.
Ejemplo real de consecuencias: Un servicio con alta frecuencia de solicitudes genera una enorme cantidad de trazas cortas. Si se envían directamente a Tempo, cada "span" será una solicitud HTTP separada, lo que provocará una sobrecarga de la red y de los ingesters de Tempo, agotando rápidamente los recursos del VPS y excediendo los límites de tráfico.
2. Uso incorrecto de etiquetas en Loki (High Cardinality)
Error: Uso de datos de alta cardinalidad (por ejemplo, IDs de sesión únicos, IDs de usuario, rutas URL completas con parámetros) como etiquetas para los logs en Loki. Esto conduce a la hinchazón del índice y a la ralentización de las consultas.
Cómo evitarlo: Las etiquetas en Loki deben ser de baja cardinalidad (por ejemplo, nombre del servicio, versión, host, nivel de log, método HTTP, código de estado). Los datos de alta cardinalidad deben dejarse en el cuerpo del log, donde se pueden buscar con expresiones regulares, pero no indexar. En 2026, con el desarrollo de LogQL y la capacidad de parsear logs sobre la marcha, esto se vuelve aún más relevante.
Ejemplo real de consecuencias: Un desarrollador añade user_id como etiqueta a cada log. Si tiene 100.000 usuarios activos, esto creará 100.000 combinaciones únicas de etiquetas, lo que aumentará drásticamente el tamaño del índice de Loki, ralentizará todas las consultas y llenará rápidamente el espacio en disco, incluso utilizando almacenamiento de objetos.
3. Falta de muestreo de trazas para sistemas de alta carga
Error: Intentar recopilar el 100% de las trazas de todos los servicios en un sistema distribuido de alta carga que se ejecuta en un VPS.
Cómo evitarlo: Para sistemas en producción en un VPS, es imprescindible configurar el muestreo de trazas en OpenTelemetry Collector. Puede utilizar el muestreo Head-based (la decisión de muestreo se toma al inicio de la traza) o el muestreo Tail-based (la decisión se toma después de que la traza ha finalizado, lo que permite muestrear por errores o duración). Estrategias típicas: muestrear 1 de cada 1000 solicitudes, pero el 100% de las solicitudes con errores o las que superan un umbral de latencia determinado. Tempo está diseñado para almacenar el 100% de las trazas, pero si tiene un volumen muy grande, el muestreo en el Collector puede ser necesario para ahorrar recursos y tráfico.
Ejemplo real de consecuencias: El muestreo del 100% en un servicio que procesa 1000 solicitudes por segundo generará decenas de miles de spans por segundo. Esto sobrecargará rápidamente el Collector, saturará la cola de envío a Tempo y, probablemente, excederá los límites de escritura en el almacenamiento de objetos, lo que provocará la pérdida de datos y la inestabilidad de todo el sistema de Observability.
4. Subestimación del costo de almacenamiento de datos y tráfico
Error: Asumir que el almacenamiento de objetos (incluso compatible con S3 en un VPS) o S3 en la nube será "gratis" o muy barato con grandes volúmenes de datos. Ignorar el costo del tráfico saliente.
Cómo evitarlo: Siempre planifique los volúmenes de datos que generarán sus aplicaciones. Pronostique el crecimiento y revise regularmente la política de retención (retention policy) para Loki y Tempo. Utilice OpenTelemetry Collector para el filtrado y la agregación previa de datos, enviando solo lo más importante. Si utiliza S3 en la nube, preste especial atención al costo del tráfico saliente al solicitar datos de Loki/Tempo en su VPS. Alojar MinIO en el mismo VPS que Loki/Tempo elimina los costos de tráfico entre ellos.
Ejemplo real de consecuencias: Un proyecto se lanza con un período de retención de logs y trazas de 30 días. Después de unos meses, el volumen de datos crece a terabytes, y la factura mensual por almacenamiento y, lo que es más crítico, por las solicitudes a S3 desde Loki/Tempo en el VPS (tráfico saliente), se vuelve insostenible, superando el costo del propio VPS.
5. Falta de monitoreo del propio sistema de Observability
Error: Desplegar Loki, Tempo, OpenTelemetry Collector y no monitorear su propio estado y rendimiento.
Cómo evitarlo: Considere su sistema de Observability como cualquier otro servicio crítico. Recopile métricas de Loki (/metrics), Tempo (/metrics) y OpenTelemetry Collector (/metrics). Agréguelas a su exportador de Prometheus (que en nuestro caso es parte del Collector). Cree dashboards en Grafana para monitorear su CPU, RAM, espacio en disco, cantidad de datos procesados, latencias de escritura/lectura. Configure alertas para umbrales críticos.
Ejemplo real de consecuencias: Loki comienza a indexar logs lentamente debido a la falta de RAM, pero nadie lo nota. Después de unos días, las consultas a los logs se vuelven imposibles y los nuevos logs dejan de registrarse, lo que deja ciega la capacidad de diagnosticar cualquier problema con la aplicación principal.
6. Instrumentación insuficiente o excesiva
Error: La instrumentación de las aplicaciones es muy superficial (no hay datos suficientes para el diagnóstico), o es excesiva (se genera demasiada telemetría irrelevante).
Cómo evitarlo: Comience con la instrumentación básica: solicitudes HTTP (entrantes/salientes), llamadas a bases de datos, operaciones comerciales críticas. Añada gradualmente telemetría más detallada a medida que identifique cuellos de botella o surjan nuevos requisitos. Utilice las convenciones semánticas de OpenTelemetry para estandarizar los nombres de métricas, spans y atributos. Capacite a los desarrolladores sobre qué datos son importantes y cuáles no. En 2026, cuando los asistentes de IA pueden ayudar en el análisis, la calidad y la consistencia de la instrumentación se vuelven aún más importantes.
Ejemplo real de consecuencias:
- Insuficiente: En la aplicación ocurre un error, pero los logs solo contienen "Internal Server Error", y las trazas se cortan a la mitad, sin proporcionar ningún contexto, lo que llevó a horas de búsqueda del problema.
- Excesiva: Cada llamada a la caché interna genera un nuevo span, aunque no es una operación crítica. Esto provoca una hinchazón de las trazas, un aumento del volumen de datos y una dificultad de lectura.
7. Ignorar la seguridad
Error: Falta de autenticación y autorización para acceder a Loki, Tempo, Grafana, MinIO. Transmisión de datos sensibles en logs o trazas sin enmascaramiento.
Cómo evitarlo: Siempre configure la autenticación (por ejemplo, autenticación HTTP básica para MinIO, Grafana, Loki) y utilice TLS para cifrar el tráfico entre componentes. OpenTelemetry Collector tiene procesadores para enmascarar datos sensibles. Realice auditorías regulares sobre qué datos entran en su sistema de Observability.
Ejemplo real de consecuencias: La configuración de Loki o Tempo está accesible sin contraseña. Un atacante obtiene acceso a logs y trazas que contienen datos personales de usuarios o información comercial confidencial, lo que lleva a una fuga de datos y graves consecuencias para la reputación y problemas legales.
Lista de verificación para la aplicación práctica
Esta lista de verificación le ayudará a implementar y mantener sistemáticamente un sistema de Observability basado en OpenTelemetry, Loki y Tempo en su VPS en 2026.
- Planificación de recursos del VPS:
- [ ] VPS seleccionado con suficiente RAM (mínimo 4GB), CPU (mínimo 2 núcleos) y espacio en disco (comenzar con 100GB, planificar el crecimiento).
- [ ] Proveedor de almacenamiento compatible con S3 definido o espacio asignado para MinIO local en el VPS.
- [ ] Volúmenes de logs y trazas pronosticados, costos aproximados de almacenamiento y tráfico calculados.
- Configuración básica del VPS:
- [ ] VPS actualizado y protegido (firewall, claves SSH).
- [ ] Docker y Docker Compose instalados (o Kubernetes, si aplica).
- [ ] Directorios creados para datos persistentes de MinIO, Loki, Tempo, Grafana.
- Despliegue de MinIO (o conexión a S3):
- [ ] MinIO iniciado y accesible (o credenciales configuradas para S3 en la nube).
- [ ] Buckets separados creados para Loki (por ejemplo,
loki-bucket) y Tempo (por ejemplo, tempo-bucket).
- [ ] Credenciales de acceso a MinIO/S3 configuradas.
- Despliegue de OpenTelemetry Collector:
- [ ] Collector desplegado como contenedor Docker.
- [ ] Configuración de
otel-collector-config.yaml ajustada para la recepción de OTLP.
- [ ] Procesadores configurados:
batch, memory_limiter, resource (con adición de nombre de host, entorno).
- [ ] Exportadores configurados para Loki, Tempo y Prometheus (para métricas del Collector).
- [ ] Collector configurado para enviar logs a Loki, trazas a Tempo, métricas a Prometheus.
- Despliegue de Loki:
- [ ] Loki desplegado como contenedor Docker.
- [ ] Configuración de
loki-config.yaml ajustada para usar almacenamiento compatible con S3 (MinIO).
- [ ] Política de retención razonable establecida (
chunk_store_config.max_look_back_period, schema_config.configs.period).
- [ ] Autenticación configurada si Loki es accesible desde el exterior (en producción).
- Despliegue de Tempo:
- [ ] Tempo desplegado como contenedor Docker.
- [ ] Configuración de
tempo-config.yaml ajustada para usar almacenamiento compatible con S3 (MinIO).
- [ ] Política de retención razonable establecida (
storage.trace.retention).
- [ ] Autenticación configurada si Tempo es accesible desde el exterior (en producción).
- Despliegue de Grafana:
- [ ] Grafana desplegada como contenedor Docker.
- [ ] Contraseña segura establecida para el administrador de Grafana.
- [ ] Fuentes de datos añadidas: Loki (
http://loki:3100), Tempo (http://tempo:3200), Prometheus (http://otel-collector:8889).
- [ ] En la fuente de datos de Tempo, la conexión con Loki está configurada para buscar logs por trazas.
- Instrumentación de aplicaciones:
- [ ] Aplicaciones instrumentadas con OpenTelemetry SDK.
- [ ] Envío de métricas, logs y trazas configurado a OpenTelemetry Collector (
http://otel-collector:4317 o 4318).
- [ ] Convenciones semánticas de OpenTelemetry utilizadas para nombres y atributos.
- [ ] Muestreo de trazas implementado para servicios de alta carga.
- [ ] Verificado que los datos sensibles no se envían a la telemetría sin enmascaramiento.
- Creación de dashboards y alertas:
- [ ] Dashboards básicos creados en Grafana para monitorear métricas clave de aplicaciones, logs y trazas.
- [ ] Alertas configuradas para eventos críticos y umbrales de rendimiento.
- [ ] Dashboards creados para monitorear el propio sistema de Observability (Loki, Tempo, Collector).
- Automatización y soporte:
- [ ] Despliegue de todos los componentes automatizado usando IaC (Ansible, Terraform).
- [ ] Copia de seguridad automática de archivos de configuración importantes configurada.
- [ ] Plan de actualización regular de componentes de Observability desarrollado.
- [ ] Evaluación y optimización de costos de almacenamiento y tráfico realizada.
Cálculo de costos / Economía de la Observabilidad en VPS
 Esquema: Cálculo de costos / Economía de la Observabilidad en VPS
Esquema: Cálculo de costos / Economía de la Observabilidad en VPS
La economía de la Observabilidad en VPS en 2026 no se trata solo de los costos directos del servidor, sino también de gastos cuidadosamente planificados en almacenamiento de datos, tráfico y, no menos importante, el tiempo de los ingenieros. La elección correcta de la pila OpenTelemetry, Loki y Tempo permite optimizar significativamente estos costos.
Principales partidas de gastos en VPS en 2026:
- Instancia de VPS: CPU, RAM, subsistema de disco básico.
- Almacenamiento de datos: Para logs (Loki), trazas (Tempo) y métricas (Prometheus). Puede ser local en el VPS o externo (almacenamiento de objetos compatible con S3).
- Tráfico: Entrante (de las aplicaciones al Collector) y saliente (del Collector a los backends, de Loki/Tempo a Grafana, de Grafana a los usuarios, y también entre el VPS y el almacenamiento S3, si es externo).
- Tiempo de los ingenieros: Configuración, soporte, optimización, resolución de problemas.
Ejemplos de cálculos para diferentes escenarios (ilustrativo, precios de 2026):
Supongamos que el costo promedio de un VPS en 2026 es:
- VPS pequeño (2 CPU, 4GB RAM, 100GB SSD): 15-25 USD/mes
- VPS mediano (4 CPU, 8GB RAM, 200GB SSD): 30-50 USD/mes
- Almacenamiento de objetos (compatible con S3): 0.01-0.02 USD/GB/mes
- Tráfico saliente: 0.05-0.10 USD/GB
Escenario 1: Pequeña startup (1-3 microservicios, ~500 RPS)
- VPS: 1x VPS mediano (4 CPU, 8GB RAM, 200GB SSD) para todos los componentes (OpenTelemetry Collector, Loki, Tempo, Grafana, MinIO).
- Costo del VPS: ~40 USD/mes.
- Volumen de datos:
- Logs: 50 GB/mes (almacenamiento de 30 días)
- Trazas: 20 GB/mes (almacenamiento de 30 días, muestreo 1:100)
- Métricas: 5 GB/mes
- Almacenamiento (MinIO en el mismo VPS):
- Espacio en disco: 50 GB (Loki) + 20 GB (Tempo) + 5 GB (Prometheus) + 10 GB (Grafana, OS) = ~85 GB. Esto cabe en el VPS SSD de 200GB.
- Costo: Incluido en el VPS.
- Tráfico:
- Entrante (de las aplicaciones al Collector): 100 GB/mes
- Saliente (del Collector a Loki/Tempo/Prometheus, interno): 0 USD (dentro del VPS).
- Saliente (de Grafana a los usuarios): 20 GB/mes
- Tráfico total de pago: ~120 GB/mes.
- Costo del tráfico: 120 GB * 0.07 USD/GB = 8.4 USD/mes.
- Costo total aproximado: 40 USD (VPS) + 8.4 USD (tráfico) = ~48.4 USD/mes.
Escenario 2: Proyecto SaaS en crecimiento (5-10 microservicios, ~5000 RPS)
- VPS:
- 1x VPS mediano (4 CPU, 8GB RAM, 200GB SSD) para OpenTelemetry Collector, Prometheus, Grafana. (~40 USD/mes)
- 1x VPS pequeño (2 CPU, 4GB RAM, 100GB SSD) para Loki y Tempo (separación de carga). (~20 USD/mes)
- Volumen de datos:
- Logs: 500 GB/mes (almacenamiento de 30 días)
- Trazas: 200 GB/mes (almacenamiento de 30 días, muestreo 1:50)
- Métricas: 50 GB/mes
- Almacenamiento (S3 en la nube):
- Volumen total: 500 GB (Loki) + 200 GB (Tempo) = 700 GB.
- Costo de S3: 700 GB * 0.015 USD/GB = 10.5 USD/mes.
- Tráfico:
- Entrante (de las aplicaciones al Collector): 1 TB/mes
- Saliente (del Collector a Loki/Tempo/Prometheus): 1 TB/mes (parte interna, parte a S3).
- Saliente (de Loki/Tempo a S3): 700 GB/mes (escritura)
- Saliente (de S3 a Loki/Tempo en el VPS para consultas): 100 GB/mes (consultas muy activas)
- Saliente (de Grafana a los usuarios): 50 GB/mes
- Tráfico total de pago (incluyendo S3): ~100 GB (recuperación de S3) + 50 GB (Grafana) + 1 TB (Collector -> S3) = ~1.15 TB/mes.
- Costo del tráfico: 1150 GB * 0.07 USD/GB = 80.5 USD/mes.
- Costo total aproximado: 40 USD (VPS1) + 20 USD (VPS2) + 10.5 USD (S3) + 80.5 USD (tráfico) = ~151 USD/mes.
Costos ocultos y cómo optimizarlos:
- Tráfico saliente: Este es el gasto más insidioso.
- Optimización: Utilice OpenTelemetry Collector al máximo para filtrar, agregar y muestrear datos ANTES de enviarlos. Si es posible, coloque el almacenamiento compatible con S3 en el mismo VPS o en la misma red para minimizar el tráfico de pago.
- Sobrecarga de CPU/RAM: Consultas ineficientes a Loki o Tempo, un número excesivo de etiquetas, la falta de procesamiento por lotes pueden agotar rápidamente los recursos del VPS.
- Optimización: Configure
memory_limiter en el Collector. Optimice las consultas LogQL y PromQL. Analice regularmente las métricas de la propia pila de Observabilidad para identificar cuellos de botella.
- Tiempo de los ingenieros: Configuración manual, depuración, actualización.
- Optimización: Invierta en Infrastructure as Code (Docker Compose, Ansible). Cree configuraciones y plantillas estandarizadas. Capacite al equipo en el uso de herramientas de Observabilidad.
- Almacenamiento a largo plazo: Si necesita almacenar datos por más de 30-90 días, el costo aumentará.
- Optimización: Desarrolle una estrategia de archivado. Para logs y trazas muy antiguas, se pueden mover a clases S3 "frías" más baratas o eliminarlas por completo si no son necesarias para auditorías.
Tabla con ejemplos de cálculos para diferentes escenarios (generalizado):
| Parámetro |
Proyecto pequeño (500 RPS) |
Proyecto mediano (5000 RPS) |
Proyecto grande (20000+ RPS) |
| Cantidad de VPS |
1 (mediano) |
2 (1 mediano, 1 pequeño) |
3+ (clúster Loki/Tempo) |
| Costo de VPS/mes |
~40 USD |
~60 USD |
~150-300 USD+ |
| Volumen de logs/mes |
50 GB |
500 GB |
2 TB+ |
| Volumen de trazas/mes |
20 GB |
200 GB |
800 GB+ |
| Costo de almacenamiento S3/mes |
0 USD (local) |
~10.5 USD |
~40-100 USD+ |
| Costo de tráfico/mes |
~8.4 USD |
~80.5 USD |
~300-600 USD+ |
| Costo total/mes |
~48.4 USD |
~151 USD |
~490-1000 USD+ |
| Recomendaciones |
MinIO en el mismo VPS, muestreo/filtrado agresivo |
Separación de Loki/Tempo en un VPS separado, S3 en la nube, optimización activa del Collector |
Versión en clúster de Loki/Tempo (por ejemplo, en K8s), instancias dedicadas, S3 multizona, optimización profunda |
Como se puede ver, incluso para proyectos en crecimiento, la combinación de OpenTelemetry, Loki y Tempo en un VPS sigue siendo significativamente más económica que la mayoría de las soluciones comerciales o totalmente en la nube, especialmente cuando se trata del control del tráfico y el uso eficiente del almacenamiento de objetos.
Casos y ejemplos de uso
 Diagrama: Casos y ejemplos de uso
Diagrama: Casos y ejemplos de uso
Consideremos varios escenarios realistas que demuestran la eficacia de la combinación de OpenTelemetry, Loki y Tempo en un VPS en 2026.
Caso 1: Diagnóstico de solicitudes lentas en una API de e-commerce
Problema: Los usuarios se quejan de retrasos aleatorios pero notables al realizar pedidos en una pequeña tienda online que funciona con 5 microservicios (Go, Python) en un VPS de tamaño medio. El monitoreo tradicional solo muestra la carga general de CPU y RAM, pero no proporciona información sobre dónde se produce exactamente el retraso.
Solución con Observabilidad:
- Instrumentación: Todos los microservicios fueron instrumentados utilizando el SDK de OpenTelemetry. Cada solicitud HTTP, llamada a la base de datos, solicitud a una pasarela de pago externa y llamadas internas entre servicios generan spans. Los logs de cada servicio también se envían a través del OpenTelemetry Collector a Loki.
- Configuración del Collector: El OpenTelemetry Collector está configurado para recopilar todas las trazas, métricas y logs, y luego enviarlos a Tempo, Loki y Prometheus (para métricas). Se habilitó un muestreo de trazas de 1:100, pero el 100% de las trazas con errores o con una duración superior a 500ms.
- Grafana: En Grafana se crearon dashboards que muestran la latencia general de la API, el número de errores y la carga de recursos. Se añadió un "Service Graph" basado en trazas, que muestra las interconexiones entre los servicios.
- Diagnóstico:
- El ingeniero observa en el dashboard de Grafana un pico de latencia para el endpoint
/checkout.
- Desde el dashboard de métricas, navega a las trazas en Tempo, utilizando el "Trace ID" de los logs o simplemente haciendo clic en "Explore traces" para ese intervalo de tiempo.
- En Tempo, encuentra la traza correspondiente a la solicitud lenta. La visualización de la traza muestra que la mayor parte del retraso ocurre en el servicio
payment-gateway-service al llamar a una API externa.
- Desde el span de la llamada a la API externa, hace clic en "Logs" (integración Tempo-Loki) y ve los logs de
payment-gateway-service para ese trace_id. En los logs se encuentra un mensaje de error recurrente sobre un timeout al conectar con la pasarela de pago externa.
Resultado: En lugar de horas de depuración y revisión de logs, el problema se localizó en 15 minutos. Se descubrió que la pasarela de pago externa estaba experimentando problemas de rendimiento. El equipo pudo contactar rápidamente con el proveedor de la pasarela y cambiar a una opción de respaldo, minimizando las pérdidas.
Caso 2: Optimización del consumo de recursos y costes para una startup con dispositivos IoT
Problema: Una startup está desarrollando una plataforma para monitorear dispositivos IoT. Cada dispositivo envía telemetría cada 10 segundos. El número de dispositivos crece rápidamente, y el sistema actual basado en Elastic Stack en un VPS se vuelve prohibitivamente caro debido al enorme volumen de logs y métricas, así como a los altos requisitos de RAM/CPU para Elasticsearch.
Solución con Observabilidad:
- Transición a OpenTelemetry, Loki, Tempo: Se decidió migrar a una pila más eficiente en recursos.
- Instrumentación de agentes IoT: Los agentes en los dispositivos IoT están configurados para enviar métricas y logs a través del OpenTelemetry Protocol (OTLP) al OpenTelemetry Collector en el VPS central. Las trazas para los dispositivos IoT se consideraron redundantes para esta tarea y se deshabilitaron para ahorrar costes.
- Configuración del Collector: El OpenTelemetry Collector en el VPS está configurado para:
- Agregación de métricas (por ejemplo, valor promedio durante 1 minuto en lugar de cada punto).
- Filtrado de logs: descartar logs informativos, conservar solo advertencias y errores.
- Adición de atributos
device_id, device_type, location a cada log y métrica.
- Loki y Tempo: Loki se utiliza para almacenar logs filtrados. Tempo está desplegado, pero se usa solo para trazas de servicios de backend que procesan datos de dispositivos IoT, no para los propios dispositivos. MinIO está desplegado en el mismo VPS para almacenar datos de Loki y Tempo.
- Grafana: Los dashboards muestran métricas agregadas por tipo de dispositivo, ubicación, así como advertencias y errores, filtrados por los mismos atributos.
Resultado:
- Reducción de costes del VPS: Los requisitos de RAM/CPU para Loki resultaron ser de 3 a 5 veces menores que para Elasticsearch, lo que permitió utilizar un VPS más económico.
- Ahorro en almacenamiento: Gracias al filtrado de logs y la indexación solo de metadatos en Loki, el volumen de logs almacenados se redujo en un 70%, y el coste de almacenamiento de datos en MinIO fue significativamente menor que el de Elastic.
- Control del tráfico: La agregación y el filtrado en el Collector redujeron el volumen de tráfico entrante en un 50%, lo que impactó directamente en las facturas del proveedor de VPS.
- Diagnóstico mejorado: A pesar de la agregación, las métricas y errores importantes se volvieron más fáciles de encontrar gracias al etiquetado correcto y a las consultas eficientes en Grafana.
Estos casos demuestran cómo OpenTelemetry, Loki y Tempo pueden utilizarse eficazmente para resolver problemas empresariales reales, proporcionando una observabilidad profunda mientras se mantiene el control sobre los costes del VPS.
Solución de problemas (troubleshooting)
 Diagrama: Solución de problemas (troubleshooting)
Diagrama: Solución de problemas (troubleshooting)
Incluso con la configuración más cuidadosa, pueden surgir problemas durante la operación de un sistema de Observabilidad. A continuación se enumeran los problemas típicos y los métodos para su diagnóstico y resolución para OpenTelemetry, Loki y Tempo en un VPS.
1. No hay datos en Grafana (métricas, logs, trazas)
Posibles causas:
- La aplicación no envía datos al Collector.
- El Collector no recibe datos o no puede exportarlos.
- Loki/Tempo no recibe datos del Collector o no puede escribirlos en el almacenamiento.
- Grafana no puede conectarse a Loki/Tempo/Collector.
- Problemas de red/firewall.
Comandos y pasos de diagnóstico:
- Verifique los logs de las aplicaciones: Asegúrese de que el SDK de OpenTelemetry esté inicializado y no genere errores al enviar datos. Verifique que el endpoint del Collector esté especificado correctamente (por ejemplo,
http://otel-collector:4317).
- Verifique los logs del OpenTelemetry Collector:
docker logs otel-collector
# O si el Collector se ejecuta como un servicio systemd
sudo journalctl -u otel-collector -f
Busque errores de conexión a Loki/Tempo, errores de análisis de datos, mensajes de desbordamiento de búfer. Asegúrese de que el Collector esté escuchando en los puertos correctos.
sudo netstat -tulnp | grep 4317 # Verificar si el Collector está escuchando en el puerto OTLP gRPC
sudo netstat -tulnp | grep 4318 # Verificar si el Collector está escuchando en el puerto OTLP HTTP
- Verifique los logs de Loki y Tempo:
docker logs loki
docker logs tempo
Busque errores de escritura en S3/MinIO, errores de autenticación, problemas de espacio en disco. Asegúrese de que Loki y Tempo estén escuchando en sus puertos (3100 y 3200 respectivamente).
- Verifique la conexión de Grafana: En Grafana, vaya a "Configuration" -> "Data Sources". Para cada fuente de datos, haga clic en "Save & Test". Asegúrese de que el estado sea "Data source is working". Si no, verifique las URLs (por ejemplo,
http://loki:3100), la configuración del firewall en el VPS.
- Verifique el firewall: Asegúrese de que los puertos (4317, 4318, 3100, 3200, 3000) estén abiertos en el VPS, si deben tener acceso externo, y entre los contenedores Docker.
2. Consultas lentas en Grafana (a Loki o Tempo)
Posibles causas:
- Alta cardinalidad de etiquetas en Loki.
- Rango de tiempo demasiado amplio para la consulta.
- Consultas LogQL/PromQL ineficientes.
- Falta de recursos (CPU/RAM) en Loki/Tempo.
- Almacenamiento compatible con S3 lento o alta latencia de red hacia él.
Comandos y pasos de diagnóstico:
- Verifique la cardinalidad de las etiquetas en Loki: Utilice la consulta
sum by (label_name) (count_over_time({job="your-app"}[1h])) para identificar etiquetas de alta cardinalidad. Evite usar IDs únicos en las etiquetas.
- Optimice las consultas:
- Para Loki: Comience las consultas filtrando por etiquetas de baja cardinalidad, luego use la búsqueda de texto completo o expresiones regulares. Utilice
line_format para extraer los datos necesarios.
- Para Tempo: Las consultas por ID de traza son siempre las más rápidas. Si busca por atributos, asegúrese de que está utilizando la integración con Loki/Prometheus y de que las consultas a estos son eficientes.
- Monitoreo de recursos de Loki/Tempo: Utilice los dashboards de Grafana para monitorear CPU, RAM, I/O de disco de Loki y Tempo. Preste atención a las métricas
loki_ingester_chunk_age_seconds (latencia de escritura de chunks) y tempo_ingester_blocks_created_total.
- Verifique el rendimiento del almacenamiento: Si utiliza S3 externo, verifique la latencia de la red. Si MinIO está en el mismo VPS, asegúrese de que el disco no esté sobrecargado.
- Aumente los recursos: Si todas las optimizaciones se han realizado, pero las consultas siguen siendo lentas, puede que sea el momento de aumentar la CPU/RAM para Loki/Tempo o considerar el escalado horizontal.
3. Desbordamiento de disco en el VPS
Posibles causas:
- Demasiado volumen de logs/trazas para MinIO local.
- Configuración incorrecta de la política de retención (retention policy) en Loki/Tempo.
- Acumulación de archivos WAL de Tempo o archivos temporales de Loki.
- Problemas con la rotación de logs de Docker.
Comandos y pasos de diagnóstico:
- Verifique el uso del disco:
df -h
du -sh /mnt/data/
Determine qué directorio ocupa más espacio.
- Verifique las políticas de retención: Asegúrese de que en
loki-config.yaml (chunk_store_config.max_look_back_period) y tempo-config.yaml (storage.trace.retention) se hayan establecido períodos de retención razonables. Asegúrese de que se apliquen.
- Verifique MinIO: Si MinIO almacena datos localmente, asegúrese de que sus buckets no crezcan indefinidamente.
- Verifique los logs de los contenedores Docker: Los logs de Docker pueden llenar rápidamente el disco. Configure la rotación de logs para el Daemon de Docker.
# /etc/docker/daemon.json
{
"log-driver": "json-file",
"log-opts": {
"max-size": "10m",
"max-file": "3"
}
}
Después de los cambios, reinicie Docker: sudo systemctl restart docker.
- Limpieza de archivos temporales: A veces, los directorios temporales de Loki (
/tmp/loki/boltdb-shipper-cache, /tmp/loki/compactor) o Tempo (/tmp/tempo/wal) pueden crecer excesivamente. Asegúrese de que el compresor y el shipper funcionen correctamente.
4. OpenTelemetry Collector consume demasiados recursos
Posibles causas:
- Demasiado volumen de datos entrantes.
- Procesadores ineficientes (por ejemplo, demasiadas transformaciones complejas).
- Falta de procesamiento por lotes (batching).
Comandos y pasos de diagnóstico:
- Monitoreo del Collector: Utilice las métricas del propio Collector (disponibles a través del exportador de Prometheus en
:8889) para monitorear su CPU, RAM, cantidad de spans/logs/métricas recibidos/enviados.
- Optimice la configuración:
- Asegúrese de que el procesador
batch esté habilitado y configurado.
- Utilice
memory_limiter para limitar el consumo de RAM.
- Revise los procesadores: si hay operaciones complejas, como
transform o filter, asegúrese de que sean eficientes. Quizás parte del filtrado debería hacerse a nivel de aplicación.
- Considere el muestreo de trazas en el Collector.
- Reduzca el volumen de datos entrantes: Si las aplicaciones generan demasiado ruido, configúrelas para que envíen solo la telemetría relevante.
Cuándo contactar al soporte:
- Proveedor de VPS: Si hay sospechas de problemas de hardware con el VPS (disco, red, CPU), o si no puede acceder al servidor por SSH.
- Comunidades de OpenTelemetry, Loki, Tempo: Si encuentra errores que parecen ser bugs en el propio software, o si no puede encontrar una solución al problema en la documentación. Utilice GitHub Issues, canales de Discord o foros.
- Equipo propio: Si el problema está relacionado con la instrumentación de las aplicaciones o la lógica de negocio.
FAQ: Preguntas frecuentes
¿Qué es Observability y en qué se diferencia del monitoreo en 2026?
En 2026, la diferencia entre Observability y monitoreo se ha vuelto aún más crítica. El monitoreo, en esencia, responde a la pregunta "¿Qué pasó?", siguiendo métricas y estados preestablecidos (por ejemplo, "CPU por encima del 80%"). Observability, por su parte, permite responder a la pregunta "¿Por qué pasó?", proporcionando una comprensión profunda del estado interno del sistema a través de métricas, logs y trazas, permitiendo investigar problemas y comportamientos del sistema previamente desconocidos.
¿Por qué OpenTelemetry, Loki y Tempo, y no Elastic Stack o Jaeger?
OpenTelemetry, Loki y Tempo han sido elegidos para entornos VPS en 2026 debido a su excepcional eficiencia de recursos y flexibilidad. Elastic Stack (Elasticsearch, Kibana, Logstash) requiere significativamente más RAM y CPU, lo que lo hace costoso para un VPS. Jaeger, aunque es una excelente herramienta para trazas, a menudo requiere un potente SGBD (Cassandra o Elasticsearch) para el almacenamiento, lo que también aumenta los costos. Loki y Tempo están diseñados para trabajar con almacenamiento de objetos, minimizando los requisitos de RAM/CPU y haciéndolos ideales para soluciones VPS de bajo presupuesto.
¿Se puede usar OpenTelemetry solo para una parte de la telemetría (por ejemplo, solo para trazas)?
Sí, OpenTelemetry es modular. Puede usar su SDK solo para trazas, solo para métricas o solo para logs, o para cualquier combinación de ellos. OpenTelemetry Collector también se puede configurar para procesar solo ciertos tipos de telemetría y enrutarlos a los backends correspondientes. Esto permite implementar Observability gradualmente, paso a paso.
¿Qué tan seguro es almacenar logs y trazas en MinIO en el mismo VPS?
Almacenar datos en MinIO en el mismo VPS es seguro siempre que el VPS esté protegido de manera fiable (firewall, claves SSH, actualizaciones regulares). Sin embargo, para datos críticos y alta disponibilidad, se recomienda utilizar un almacenamiento compatible con S3 en la nube (AWS S3, Google Cloud Storage, Azure Blob Storage) o un clúster MinIO dedicado. Para la mayoría de las startups y proyectos medianos en un VPS, MinIO local es un compromiso aceptable entre seguridad, rendimiento y costo.
¿Cuánto tiempo se recomienda almacenar logs y trazas?
El período de retención depende de los requisitos del negocio, las normativas y el costo. Para el diagnóstico operativo, generalmente son suficientes 7-30 días. Para auditorías y análisis de tendencias a largo plazo, pueden ser necesarios 90 días o más. Loki y Tempo permiten configurar de forma flexible la política de retención. En 2026, con el crecimiento del volumen de datos, se aplican cada vez más estrategias de almacenamiento multinivel (caliente, frío, archivo).
¿Es necesario muestrear las trazas si Tempo está diseñado para "almacenar todo"?
Tempo está realmente diseñado para almacenar eficientemente el 100% de las trazas gracias a su arquitectura. Sin embargo, "almacenar todo" se refiere al backend. Si su aplicación genera un volumen muy grande de trazas (por ejemplo, decenas de miles de spans por segundo), la carga en OpenTelemetry Collector y el tráfico de red pueden convertirse en un cuello de botella. En tales casos, el muestreo en OpenTelemetry Collector (por ejemplo, muestreo basado en cabecera) ayudará a reducir la carga y controlar los costos, conservando al mismo tiempo las trazas valiosas (por ejemplo, las que tienen errores).
¿Puede OpenTelemetry Collector actuar como un servidor Prometheus?
No, OpenTelemetry Collector no es un servidor Prometheus completo. Puede recibir métricas en formato OTLP, transformarlas y exportarlas a un formato compatible con Prometheus, así como extraer métricas de otros exportadores (como Prometheus). En nuestra pila, el Collector actúa como un exportador de métricas, y Grafana lee directamente esas métricas del Collector. Para un almacenamiento completo a largo plazo de métricas y consultas PromQL complejas, generalmente se utiliza un servidor Prometheus separado o sus variantes de clúster (Thanos, Cortex).
¿Cómo controlar los costos de tráfico al usar Observability en un VPS?
El control del tráfico es un factor clave en un VPS. Utilice OpenTelemetry Collector para la máxima filtración, agregación y muestreo de la telemetría antes de enviarla. Coloque MinIO (u otro servicio compatible con S3) en el mismo VPS que Loki/Tempo para evitar el tráfico saliente de pago entre ellos. Minimice la cantidad de solicitudes salientes de Grafana a Loki/Tempo si están alojados en otro centro de datos o en la nube.
¿Qué hacer si el VPS deja de soportar la carga?
Si su VPS comienza a experimentar escasez de recursos, considere los siguientes pasos: 1) Optimice las configuraciones de Collector, Loki, Tempo (muestreo/filtrado más agresivo, optimización de consultas). 2) Aumente los recursos del VPS (CPU, RAM). 3) Divida los componentes en varios VPS (por ejemplo, uno para Collector/Prometheus/Grafana, otro para Loki/Tempo). 4) Considere la transición a un clúster de Kubernetes gestionado, donde Loki y Tempo pueden implementarse en una configuración de alta disponibilidad y escalable.
¿Se pueden integrar los logs existentes con OpenTelemetry?
Sí, OpenTelemetry Collector tiene varios receptores (receivers) que pueden recopilar logs de diferentes fuentes, incluyendo archivos (filelog receiver), el registro del sistema (journald receiver), contenedores Docker. También puede usar Promtail para recopilar logs y enviarlos a Loki, y luego vincularlos con las trazas de OpenTelemetry a través de atributos comunes (trace_id).
¿Qué ventajas ofrece el uso de las convenciones semánticas de OpenTelemetry?
Las convenciones semánticas de OpenTelemetry proporcionan nombres y valores estandarizados para los atributos (etiquetas) de trazas, métricas y logs (por ejemplo, http.method, db.statement, service.name). Esto mejora significativamente la legibilidad, portabilidad y capacidad de análisis de la telemetría, facilitando la creación de dashboards, alertas y consultas, así como la integración con diversas herramientas de Observability.
Conclusión
En 2026, cuando los sistemas distribuidos se han convertido en la norma y la complejidad de la infraestructura sigue creciendo, la observabilidad completa (Observability) no es solo una característica deseable, sino un componente crítico para la estabilidad, el rendimiento y el éxito de cualquier proyecto de TI. Hemos demostrado que incluso con recursos limitados de un servidor privado virtual (VPS) se puede construir un sistema de Observability potente, flexible y económicamente eficiente.
La combinación de OpenTelemetry, Loki y Tempo, integrada con Grafana, ofrece un equilibrio único entre funcionalidad y costo. OpenTelemetry actúa como un estándar universal para la recopilación de todo tipo de telemetría, proporcionando un enfoque vendor-agnostic y flexibilidad. Loki ofrece una solución económica y escalable para el almacenamiento de logs, utilizando almacenamiento de objetos e indexación por metadatos. Tempo revoluciona el enfoque de las trazas distribuidas, ofreciendo un modelo de "almacenar todo" con requisitos mínimos de recursos, también utilizando almacenamiento de objetos.
Los factores clave de éxito al implementar esta combinación en un VPS son: una planificación cuidadosa de los recursos, el uso eficiente de OpenTelemetry Collector para el filtrado, agregación y muestreo de datos, el etiquetado correcto en Loki para evitar problemas de cardinalidad, y el monitoreo constante del propio sistema de Observability. No hay que olvidar la automatización del despliegue mediante herramientas de Infrastructure as Code, lo que reduce significativamente el tiempo y la probabilidad de errores.
Recomendaciones finales:
- Comience con OpenTelemetry: Instrumente sus aplicaciones utilizando el SDK de OpenTelemetry. Es una inversión en el futuro que se amortizará muchas veces.
- Use el Collector de manera eficiente: OpenTelemetry Collector es su mejor amigo en un VPS. Configúrelo para optimizar el tráfico y la carga en los backends.
- Elija el almacenamiento sabiamente: Para un VPS, MinIO en el mismo servidor o un almacenamiento en la nube compatible con S3 de bajo costo es la opción óptima para Loki y Tempo.
- Monitoree y optimice: Revise regularmente el consumo de recursos de sus componentes de Observability y optimice las configuraciones para evitar costos ocultos.
- Automatice: La gestión manual se convertirá rápidamente en un cuello de botella. Automatice el despliegue y la configuración.
- Capacite al equipo: Cuanto mejor comprenda y utilice su equipo las herramientas de Observability, más rápido se resolverán los problemas y mayor será la estabilidad de sus sistemas.
Próximos pasos para el lector:
- Realice un despliegue piloto: Comience con un VPS pequeño y varios servicios de prueba para dominar la configuración de OpenTelemetry, Loki y Tempo en la práctica.
- Estudie la documentación: Profundice en la documentación de cada componente, especialmente en las secciones "Configuration" y "Troubleshooting".
- Únase a la comunidad: La participación activa en las comunidades de OpenTelemetry, Grafana Labs (Loki, Tempo) le permitirá estar al tanto de las últimas actualizaciones y obtener ayuda de ingenieros experimentados.
- Desarrolle una estrategia de instrumentación: Determine qué métricas, logs y trazas son más importantes para sus aplicaciones y cómo recopilarlos de manera eficiente.
La implementación de la observabilidad completa no es una tarea única, sino un proceso de mejora continua. Pero con la pila de herramientas adecuada y un enfoque metódico, podrá garantizar el funcionamiento fiable de sus sistemas distribuidos en un VPS, superando a la competencia en el dinámico mundo de 2026.
¿Te fue útil esta guía?
Observabilidad completa para sistemas distribuidos: opentelemetry, loki y tempo en VPS