Gestión de recursos multi-nube e híbrida con Terraform: De VPS a Kubernetes
TL;DR
- Necesidad estratégica: Los enfoques multi-nube e híbridos se convertirán en el estándar para 2026 para garantizar la resiliencia, la optimización de costos y la reducción de los riesgos de vendor lock-in.
- Terraform como base: Terraform es el estándar de facto para Infrastructure as Code (IaC), permitiendo unificar la gestión de recursos en cualquier plataforma, desde VPS locales hasta complejos clústeres de Kubernetes en múltiples nubes.
- Beneficios clave: Despliegue acelerado, automatización de operaciones, reducción del error humano, consistencia de configuraciones y gestión eficiente del ciclo de vida de la infraestructura.
- Desafíos y soluciones: La gestión del estado, la conectividad de red, la seguridad y la optimización de costos requieren una arquitectura bien pensada, el uso de módulos, el estado remoto y herramientas como Terragrunt.
- Ahorro y eficiencia: La aplicación inteligente de Terraform en un entorno multi-nube no solo permite evitar sobrecostos, sino también proporcionar flexibilidad para una rápida escalabilidad y adaptación a los requisitos cambiantes del negocio.
- El futuro ya está aquí: La integración con GitOps, las pruebas automatizadas y la monitorización avanzada convierten a Terraform en un elemento central de la estrategia DevOps moderna.
Introducción
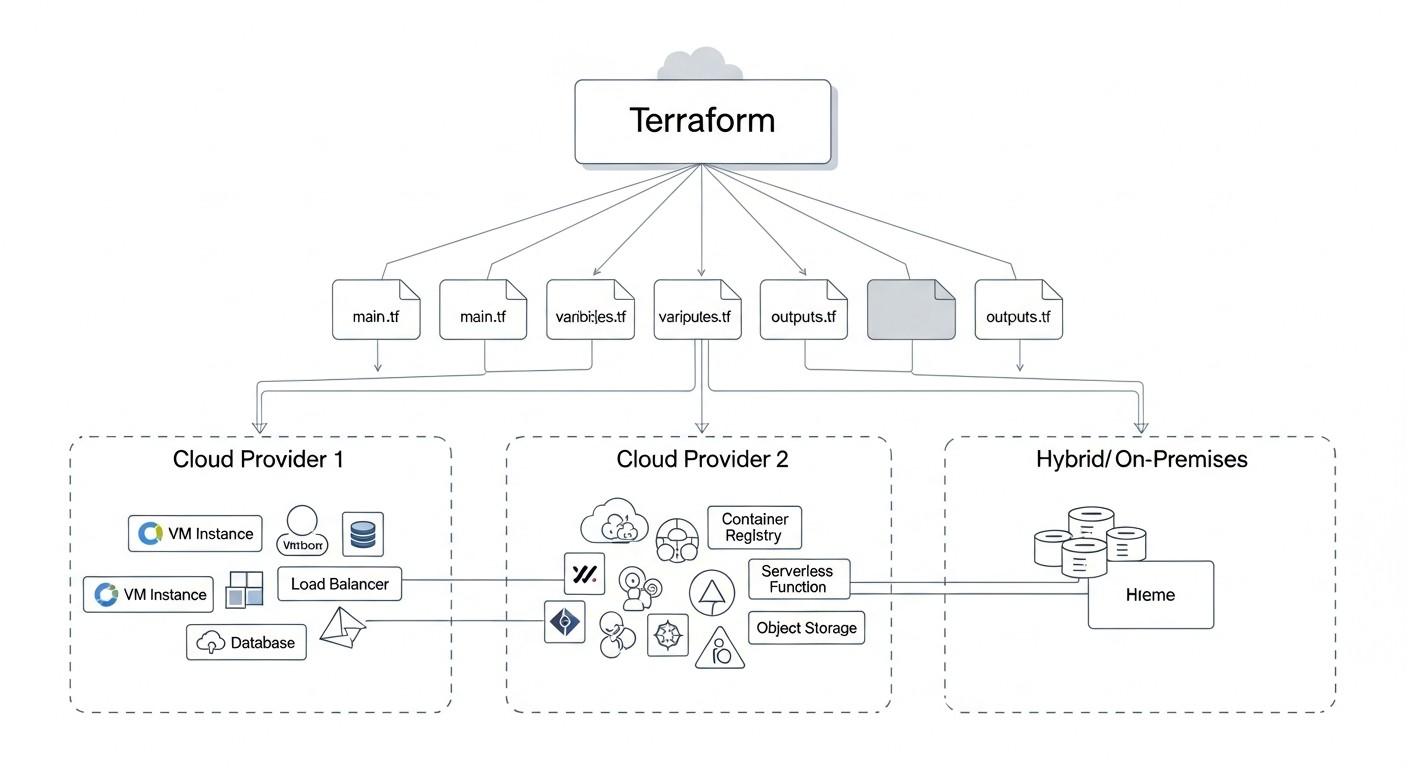 Diagrama: Introducción
Diagrama: Introducción
Para 2026, el panorama de la infraestructura de TI ha experimentado cambios significativos. Las aplicaciones monolíticas que residían en un solo servidor han dado paso a arquitecturas de microservicios distribuidas, desplegadas en la nube. Sin embargo, la simple migración a una sola nube ya no es la panacea. Las empresas exigen máxima resiliencia, flexibilidad, optimización de costos e independencia de un único proveedor. Es aquí donde entran en juego los conceptos de multi-nube e infraestructuras híbridas.
La multi-nube implica el uso de varios proveedores de nube pública (por ejemplo, AWS, Azure, Google Cloud, Yandex.Cloud) para diferentes partes de un mismo sistema o para sistemas distintos, mientras que el enfoque híbrido combina nubes públicas con infraestructura on-premise propia (nube privada o servidores tradicionales). Esto permite a las empresas aprovechar las mejores características de cada enfoque: la escalabilidad y las innovaciones de las nubes públicas en combinación con el control, la seguridad y la baja latencia de la infraestructura propia.
Sin embargo, la gestión de una infraestructura tan compleja y distribuida sin las herramientas adecuadas se convierte rápidamente en un caos. Las configuraciones manuales, las API heterogéneas, los scripts dispersos, todo esto conduce a errores, retrasos y enormes costos operativos. Aquí es donde entra en juego Infrastructure as Code (IaC), y su buque insignia, Terraform de HashiCorp.
Este artículo está dirigido a ingenieros DevOps, desarrolladores backend, fundadores de proyectos SaaS, administradores de sistemas y directores técnicos de startups que buscan gestionar eficazmente su infraestructura en 2026. Exploraremos cómo Terraform permite unificar el despliegue y la gestión de recursos en todos los niveles: desde simples servidores privados virtuales (VPS) hasta clústeres de Kubernetes de alta disponibilidad, abarcando tanto nubes públicas como privadas. Nos sumergiremos en los aspectos prácticos, analizaremos errores comunes y propondremos soluciones concretas basadas en la experiencia real.
El objetivo de este artículo no es solo hablar sobre las capacidades de Terraform, sino proporcionar una guía práctica exhaustiva que permita al lector diseñar, desplegar y mantener con confianza su infraestructura multi-nube o híbrida, minimizando riesgos y maximizando beneficios.
Criterios y factores clave para la elección de una estrategia multi-nube y enfoque híbrido
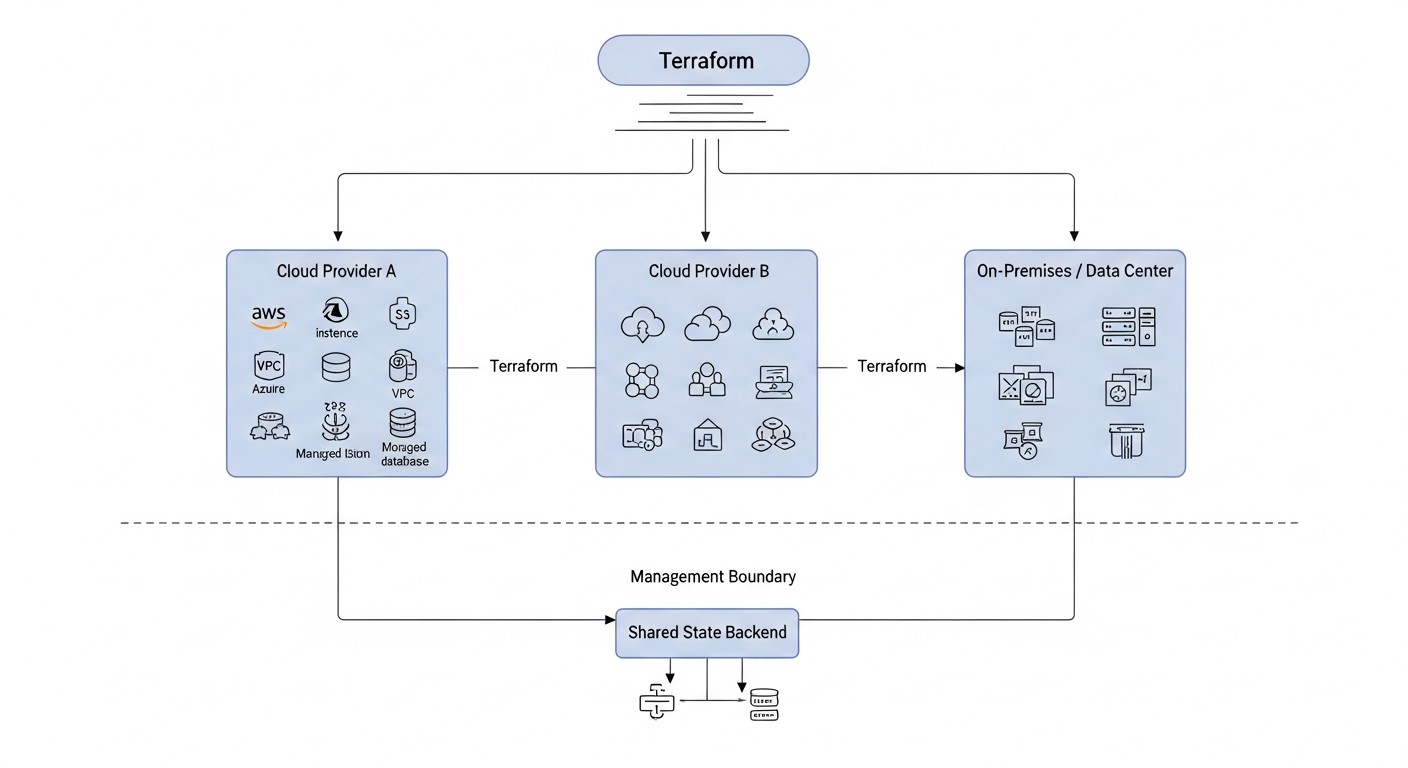 Diagrama: Criterios y factores clave para la elección de una estrategia multi-nube y enfoque híbrido
Diagrama: Criterios y factores clave para la elección de una estrategia multi-nube y enfoque híbrido
La elección de la estrategia óptima para una infraestructura multi-nube o híbrida no es solo una decisión técnica, sino estratégica. Debe estar profundamente integrada con los objetivos de negocio, los requisitos de rendimiento, seguridad y presupuesto. A continuación, se presentan los criterios clave que deben considerarse durante la planificación.
1. Reducción del vendor lock-in (Bloqueo de proveedor)
¿Por qué es importante? La dependencia de un único proveedor de nube puede generar dificultades en la migración, altos costos a largo plazo y limitaciones en el uso de servicios innovadores de otros proveedores. En 2026, cuando los mercados de la nube se han vuelto aún más competitivos, la capacidad de cambiar fácilmente entre proveedores o distribuir las cargas de trabajo es fundamental.
Cómo evaluar: Evalúe el grado de abstracción de sus aplicaciones respecto a los servicios específicos de la nube. ¿Utiliza API estándar (por ejemplo, Kubernetes, SQL) o está profundamente integrado con soluciones PaaS propietarias? Terraform, utilizando un enfoque declarativo, permite abstraerse de las API de bajo nivel de cada proveedor, pero el propio código de Terraform sigue vinculado a los proveedores. Es importante utilizar abstracciones comunes (por ejemplo, Kubernetes) y evitar una fuerte dependencia de servicios gestionados específicos.
2. Resiliencia y recuperación ante desastres (Disaster Recovery, DR)
¿Por qué es importante? Las aplicaciones críticas para el negocio deben estar disponibles 24/7. La caída de una región completa de un proveedor, aunque rara, puede tener consecuencias catastróficas. Una estrategia DR multi-nube (por ejemplo, active-passive o active-active) garantiza la continuidad operativa.
Cómo evaluar: Defina los objetivos de RTO (Recovery Time Objective) y RPO (Recovery Point Objective). ¿Cuánto tiempo de inactividad es aceptable? ¿Cuántos datos se pueden perder? Para DR active-passive, Terraform puede desplegar un conjunto mínimo de recursos en la nube de respaldo, listos para la activación. Para active-active, se requiere una sincronización de datos y un enrutamiento de tráfico más complejos.
3. Optimización de costos
¿Por qué es importante? Los precios de los recursos en la nube cambian constantemente, y los proveedores ofrecen diferentes descuentos y modelos de precios. La multi-nube permite elegir el proveedor más rentable para una carga de trabajo específica o incluso cambiar dinámicamente entre ellos. Un enfoque híbrido puede ser ventajoso para cargas de trabajo estables y predecibles en equipos propios.
Cómo evaluar: Realice un análisis detallado del TCO (Total Cost of Ownership) para cada opción. Considere no solo el costo de los recursos computacionales, sino también el tráfico de red (especialmente el saliente y entre nubes), el almacenamiento de datos, los servicios gestionados, las licencias y los gastos operativos. En 2026, el costo del tráfico saliente sigue siendo uno de los "impuestos" ocultos de la nube.
4. Rendimiento y latencia (Latency)
¿Por qué es importante? Para aplicaciones sensibles a la latencia (por ejemplo, juegos en línea, transacciones financieras, IoT), la ubicación de los recursos es de suma importancia. Colocar los servicios más cerca de los usuarios finales o de las fuentes de datos mejora la experiencia del usuario.
Cómo evaluar: Mida las latencias entre diferentes regiones y proveedores, así como entre su infraestructura on-premise y las nubes. Para escenarios híbridos, el ancho de banda y la estabilidad de las conexiones VPN/Direct Connect son críticos. Terraform puede ayudar en el despliegue de CDN o servicios Edge para minimizar las latencias.
5. Cumplimiento normativo y seguridad (Compliance & Security)
¿Por qué es importante? Los organismos reguladores (GDPR, HIPAA, PCI DSS, etc.) a menudo imponen requisitos estrictos sobre el almacenamiento y procesamiento de datos, así como sobre su ubicación geográfica. Diferentes proveedores pueden ofrecer diversas certificaciones y niveles de seguridad.
Cómo evaluar: Analice los requisitos de datos: dónde pueden almacenarse, quién tiene acceso a ellos. Evalúe las certificaciones de cada proveedor y sus capacidades para garantizar el cumplimiento. Terraform permite automatizar el despliegue de recursos con políticas de seguridad definidas (por ejemplo, IAM, reglas de red, cifrado de datos).
6. Complejidad operativa y habilidades del equipo
¿Por qué es importante? La gestión de múltiples nubes o un entorno híbrido es significativamente más compleja que la gestión de una sola nube. Se requieren conocimientos y herramientas especializadas. Subestimar este factor puede llevar a un aumento de los gastos operativos y al agotamiento del equipo.
Cómo evaluar: Evalúe el nivel actual de competencia de su equipo. ¿Tienen experiencia trabajando con múltiples nubes? ¿Están dispuestos a aprender nuevas API y herramientas? Terraform estandariza el proceso de despliegue, pero requiere una comprensión profunda de los proveedores con los que trabaja. El uso de módulos de Terraform puede reducir significativamente la complejidad.
7. Gravedad de los datos (Data Gravity)
¿Por qué es importante? Grandes volúmenes de datos tienen "gravedad": su movimiento es costoso y lento. A menudo, las aplicaciones migran hacia los datos, y no al revés. Esto es especialmente relevante para escenarios híbridos, donde los conjuntos de datos pueden permanecer on-premise.
Cómo evaluar: Determine dónde se encuentran sus principales almacenes de datos y con qué frecuencia se requiere su sincronización o acceso desde diferentes entornos. Si los datos son críticamente importantes y su volumen es enorme, un enfoque híbrido que mantenga los datos on-premise o en una nube, y los recursos computacionales en otra, podría ser óptimo.
Un análisis exhaustivo de estos criterios permitirá a su equipo tomar una decisión informada sobre la elección de una estrategia multi-nube o un enfoque híbrido, y Terraform se convertirá en una herramienta poderosa para su implementación.
Tabla comparativa de estrategias de gestión multi-nube e híbrida con Terraform (Válido para 2026)
 Diagrama: Tabla comparativa de estrategias de gestión multi-nube e híbrida con Terraform (Válido para 2026)
Diagrama: Tabla comparativa de estrategias de gestión multi-nube e híbrida con Terraform (Válido para 2026)
En esta tabla, compararemos diferentes estrategias para implementar enfoques multi-nube e híbridos, evaluándolos según parámetros clave relevantes para el año 2026. Se asume que Terraform se utiliza para la gestión de la infraestructura en todos los escenarios.
| Criterio |
Nube única (para comparación) |
Multi-nube: DR activo-pasivo |
Multi-nube: Activo-activo |
Híbrido: Nube + On-premise (datos on-premise) |
Híbrido: Nube + On-premise (expansión de capacidad) |
| Reducción de la dependencia del proveedor |
Baja (alta vinculación) |
Media (posibilidad de migración) |
Alta (distribución de carga) |
Media (dependencia de on-premise) |
Media (dependencia de on-premise) |
| Tolerancia a fallos (DR) |
Baja (vulnerabilidad a fallos de región) |
Alta (conmutación a nube de respaldo) |
Muy alta (conmutación instantánea) |
Media (depende del DR on-premise) |
Media (depende del DR on-premise) |
| Optimización de costes |
Media (depende de descuentos) |
Media (recursos de respaldo) |
Alta (elección del mejor proveedor) |
Alta (cargas estables on-premise) |
Alta (escalado dinámico) |
| Rendimiento/Latencia |
Alta (dentro de la región) |
Alta (dentro de la región activa) |
Muy alta (región más cercana al usuario) |
Baja (latencias entre nubes) |
Media (latencias entre nubes) |
| Complejidad de implementación (Terraform) |
Baja |
Media (dos proveedores, sincronización) |
Alta (varios proveedores, balanceo, datos) |
Alta (integración con on-premise, red) |
Alta (autoescalado, red) |
| Gastos operativos (OpEx) |
Bajos |
Medios |
Altos (monitorización, balanceo) |
Medios (soporte on-premise) |
Medios (soporte on-premise, nube) |
| Aplicabilidad para datos |
Localmente |
Replicación a respaldo |
Bases de datos distribuidas/sincronización |
Principalmente on-premise (Data Gravity) |
Expansión de almacenamiento a la nube |
| Coste típico (unidades condicionales, 2026) |
X |
1.3X - 1.8X |
1.5X - 2.5X |
0.8X - 1.5X |
0.9X - 1.7X |
| Herramientas Terraform recomendadas |
Core, Providers |
Core, Providers, Modules, Remote State |
Core, Providers, Modules, Terragrunt, Cross-Cloud Networking |
Core, Providers (vSphere/OpenStack), VPN/Direct Connect |
Core, Providers (vSphere/OpenStack), Kubernetes Provider |
Análisis detallado de cada estrategia
 Diagrama: Análisis detallado de cada estrategia
Diagrama: Análisis detallado de cada estrategia
Cada una de las estrategias consideradas tiene sus ventajas y desventajas únicas. La elección depende de los requisitos específicos del negocio, la madurez técnica del equipo y el presupuesto. Terraform es una herramienta clave para implementar cualquiera de estas estrategias, asegurando consistencia y automatización.
1. Nube única (para comparación)
Aunque este artículo se centra en los enfoques multinube e híbridos, es importante comprender la estrategia básica de nube única para establecer un contraste. En este escenario, toda la infraestructura se despliega con un único proveedor de nube (por ejemplo, AWS, Azure, Google Cloud). Terraform se utiliza activamente para gestionar todos los recursos dentro de esta nube.
- Ventajas:
- Simplicidad: Menos proveedores, menos API, menos herramientas que aprender. El equipo se centra en un único ecosistema.
- Integración: Integración profunda entre los servicios de un mismo proveedor, a menudo con baja latencia y alto ancho de banda.
- Costo: Potencialmente menor debido a descuentos por volumen y facturación unificada, especialmente para cargas de trabajo estables.
- Desventajas:
- Bloqueo de proveedor (Vendor lock-in): Alta dependencia de un único proveedor, lo que complica la migración y limita las opciones.
- Resiliencia: Vulnerabilidad a fallos globales en la región del proveedor. La DR (Recuperación ante desastres) solo es posible dentro de la misma nube.
- Limitaciones: Imposibilidad de utilizar los mejores servicios de diferentes proveedores.
- Para quién es adecuado: Startups en etapas tempranas, proyectos pequeños con presupuesto limitado, empresas sin requisitos estrictos de DR o dispuestas a aceptar el riesgo de bloqueo de proveedor.
- Ejemplo de uso: Un proyecto SaaS desplegado completamente en AWS, utilizando EC2, RDS, S3 y EKS, gestionado a través de un único repositorio de Terraform.
2. Multinube: DR Activo-Pasivo
En esta estrategia, la carga de trabajo principal opera en una nube (activa), mientras que en otra nube (pasiva) se mantiene un conjunto mínimo de recursos, listos para activarse en caso de fallo de la principal. Los datos se replican entre las nubes.
- Ventajas:
- Alta resiliencia: Protección contra un fallo global de un proveedor de nube. Conmutación rápida (dependiendo del RTO).
- Reducción del bloqueo de proveedor (vendor lock-in): Permite migrar a la nube de respaldo o utilizarla para nuevos proyectos si es necesario.
- Costos de DR relativamente bajos: La nube pasiva contiene solo el mínimo de recursos necesarios, lo que reduce los OpEx en comparación con una configuración activo-activo.
- Desventajas:
- Complejidad de la replicación de datos: Asegurar la consistencia de los datos entre nubes puede ser una tarea compleja, especialmente para grandes volúmenes.
- Costo: A pesar de ser "pasiva", la nube de respaldo aún requiere algunos recursos y costos de replicación.
- RTO: El tiempo de conmutación puede ser significativo, dependiendo de la automatización y el volumen de recursos a desplegar.
- Para quién es adecuado: Empresas que necesitan alta resiliencia, pero sin requisitos estrictos de RTO en segundos. Aplicaciones críticas para el negocio donde son aceptables unos pocos minutos u horas de inactividad en caso de desastre.
- Ejemplo de uso: Un clúster principal de Kubernetes en GKE (Google Cloud), un conjunto de recursos de respaldo (VPC, balanceador de carga, clúster AKS vacío) en Azure, los datos se replican a través de almacenamientos compatibles con S3 o herramientas especializadas para bases de datos. Terraform despliega ambos conjuntos de recursos.
3. Multinube: Activo-Activo
En este escenario, la carga de trabajo se distribuye activamente entre varias nubes, cada una de las cuales procesa una parte del tráfico. Esto proporciona máxima resiliencia y rendimiento, pero aumenta significativamente la complejidad.
- Ventajas:
- Máxima resiliencia: El fallo de una nube no afecta la disponibilidad del servicio, ya que el tráfico simplemente se redirige a las otras nubes activas.
- Optimización del rendimiento: Ubicación de recursos más cerca de los usuarios en todo el mundo, reduciendo la latencia.
- Optimización de costos: Posibilidad de distribuir dinámicamente la carga entre proveedores, eligiendo los precios más ventajosos en un momento dado.
- Cero bloqueo de proveedor (vendor lock-in): Máxima independencia, posibilidad de cambiar fácilmente.
- Desventajas:
- Muy alta complejidad: Requiere una arquitectura muy compleja para la sincronización de datos, el balanceo de carga global, el estado distribuido y la monitorización.
- Altos costos: Mantenimiento de múltiples entornos completamente activos, así como costos de tráfico entre nubes y herramientas de sincronización.
- Complejidad de desarrollo: Las aplicaciones deben diseñarse para operar en un entorno distribuido, considerando la eventual consistency y otros patrones.
- Para quién es adecuado: Plataformas SaaS globales, servicios de alta carga que requieren máxima disponibilidad y mínima latencia, sistemas financieros, e-commerce con audiencia internacional.
- Ejemplo de uso: Un sistema distribuido global donde el frontend y los microservicios sin estado se despliegan en EKS (AWS) y GKE (Google Cloud), y los datos se sincronizan a través de una base de datos distribuida (por ejemplo, CockroachDB o Cassandra). El balanceo de carga global se realiza a través de DNS (Route 53, Cloud DNS) o servicios especializados. Terraform gestiona todos los componentes en ambas nubes.
4. Híbrido: Nube + On-premise (datos on-premise)
Esta estrategia implica alojar datos sensibles o sistemas heredados en la propia infraestructura on-premise, mientras que los recursos computacionales o aplicaciones menos sensibles se despliegan en la nube pública. La nube se utiliza como una extensión del centro de datos.
- Ventajas:
- Cumplimiento normativo: Ideal para empresas con requisitos regulatorios estrictos sobre el almacenamiento de datos (por ejemplo, agencias gubernamentales, bancos).
- Control: Control total sobre los datos y la infraestructura on-premise.
- Uso de sistemas heredados: Permite modernizar gradualmente la infraestructura sin migrar todos los "monolitos" a la nube de inmediato.
- Reducción de costos: Para cargas de trabajo estables y predecibles, on-premise puede ser más económico que la nube a largo plazo.
- Desventajas:
- Complejidad de integración: Asegurar una conexión de red fiable y segura (VPN, Direct Connect) entre la nube y on-premise.
- Latencia: Alta latencia al acceder aplicaciones en la nube a datos on-premise.
- Gestión: Requiere la gestión de dos entornos diferentes con distintos conjuntos de herramientas (aunque Terraform puede ayudar).
- Para quién es adecuado: Grandes empresas, organizaciones financieras, entidades gubernamentales, empresas con grandes volúmenes de datos que no pueden ser fácilmente trasladados a la nube.
- Ejemplo de uso: Un sistema ERP corporativo y bases de datos permanecen en servidores on-premise, mientras que nuevos microservicios y API se despliegan en una nube pública (por ejemplo, Yandex.Cloud) y acceden a los datos a través de una conexión VPN segura. Terraform gestiona la parte de la infraestructura en la nube y la configuración de las pasarelas VPN.
5. Híbrido: Nube + On-premise (expansión de capacidad)
Este enfoque utiliza la nube pública para "extender" la infraestructura on-premise cuando se requiere potencia computacional adicional para cargas de trabajo pico (bursting) o para el despliegue de nuevos servicios no críticos. La nube actúa como un centro de datos "externo".
- Ventajas:
- Flexibilidad de escalado: Posibilidad de escalar rápidamente los recursos computacionales en la nube para manejar cargas pico, sin invertir en hardware on-premise excesivo.
- Ahorro: Pago de recursos en la nube solo por el uso real, lo que reduce los gastos de capital.
- Despliegue rápido: Los nuevos proyectos se pueden lanzar rápidamente en la nube, sin esperar la adquisición de hardware.
- Desventajas:
- Complejidad de gestión: Es necesario gestionar eficazmente la distribución de la carga entre on-premise y la nube, así como la conectividad de red.
- Costos de tráfico: Pueden ser significativos con la transferencia frecuente de datos entre on-premise y la nube.
- Consistencia: Mantenimiento de un entorno de desarrollo y despliegue unificado entre ambas plataformas.
- Para quién es adecuado: Empresas con cargas de trabajo variables e impredecibles, empresas de medios, minoristas (para ventas), desarrolladores de juegos.
- Ejemplo de uso: Un clúster de Kubernetes on-premise se utiliza para la carga base, y cuando el tráfico aumenta, se escala automáticamente a un EKS/AKS/GKE en la nube utilizando Kubernetes Federation o tecnologías similares. Terraform gestiona el despliegue de los clústeres en ambos entornos y su integración.
Consejos prácticos y recomendaciones para trabajar con Terraform en entornos multi-nube e híbridos
 Esquema: Consejos prácticos y recomendaciones para trabajar con Terraform en entornos multi-nube e híbridos
Esquema: Consejos prácticos y recomendaciones para trabajar con Terraform en entornos multi-nube e híbridos
El uso eficaz de Terraform en arquitecturas complejas requiere no solo el conocimiento de la sintaxis, sino también la comprensión de las mejores prácticas. A continuación, se presentan recomendaciones específicas, respaldadas por ejemplos de código, que le ayudarán a evitar trampas comunes.
1. Utilice módulos para la abstracción y la reutilización
Los módulos son la piedra angular de un Terraform eficaz. Permiten encapsular configuraciones de recursos, creando bloques reutilizables. En un entorno multi-nube, esto es fundamental para garantizar la coherencia y reducir la duplicación de código.
Consejo: Cree módulos que abstraigan las especificidades del proveedor de la nube. Por ejemplo, un módulo network puede aceptar parámetros para crear una VPC en AWS o una VNet en Azure, y utilizar el proveedor correspondiente internamente.
# modules/vpc_network/main.tf
variable "cloud_provider" {
description = "Proveedor de la nube (aws, azure, gcp)"
type = string
}
variable "region" {
description = "Región de la nube"
type = string
}
variable "cidr_block" {
description = "Bloque CIDR para la red"
type = string
}
variable "name_prefix" {
description = "Prefijo para nombres de recursos"
type = string
}
# AWS VPC
resource "aws_vpc" "main" {
count = var.cloud_provider == "aws" ? 1 : 0
cidr_block = var.cidr_block
tags = {
Name = "${var.name_prefix}-vpc-aws"
}
}
# Azure VNet
resource "azurerm_virtual_network" "main" {
count = var.cloud_provider == "azure" ? 1 : 0
name = "${var.name_prefix}-vnet-azure"
address_space = [var.cidr_block]
location = var.region
resource_group_name = "rg-${var.name_prefix}" # Asumimos que el RG ya está creado o se creará por separado
}
output "vpc_id" {
value = var.cloud_provider == "aws" ? aws_vpc.main[0].id : (var.cloud_provider == "azure" ? azurerm_virtual_network.main[0].id : null)
}
Luego puede invocar este módulo para diferentes nubes:
# main.tf (para AWS)
module "aws_network" {
source = "./modules/vpc_network"
cloud_provider = "aws"
region = "eu-central-1"
cidr_block = "10.0.0.0/16"
name_prefix = "prod"
}
# main.tf (para Azure)
module "azure_network" {
source = "./modules/vpc_network"
cloud_provider = "azure"
region = "West Europe"
cidr_block = "10.1.0.0/16"
name_prefix = "prod"
}
2. Utilice el estado remoto (Remote State)
El almacenamiento local del estado de Terraform en un entorno multi-nube es una receta para el desastre. El estado remoto permite la colaboración, el bloqueo de estado y el historial de cambios.
Consejo: Utilice siempre el estado remoto. S3 para AWS, Azure Blob Storage para Azure, GCS para Google Cloud o Terraform Cloud/Enterprise para una gestión centralizada. En 2026, Terraform Cloud/Enterprise ofrecen las funciones más avanzadas para el trabajo en equipo y la gestión de políticas.
# backend.tf (para S3)
terraform {
backend "s3" {
bucket = "my-tf-state-bucket-prod"
key = "prod/network.tfstate"
region = "eu-central-1"
encrypt = true
dynamodb_table = "my-tf-state-lock" # Para el bloqueo de estado
}
}
# backend.tf (para Azure Blob Storage)
terraform {
backend "azurerm" {
resource_group_name = "tfstate-rg"
storage_account_name = "tfstatesa2026"
container_name = "tfstate"
key = "prod/network.tfstate"
}
}
3. Organice el código con Workspaces o Terragrunt
La gestión de diferentes entornos (dev, staging, prod) y nubes requiere una estructura clara. Los workspaces de Terraform pueden ayudar, pero Terragrunt ofrece capacidades más potentes para DRY (Don't Repeat Yourself) y una organización jerárquica.
Consejo: Para proyectos sencillos, puede utilizar los workspaces de Terraform. Para escenarios complejos multi-nube/híbridos con muchos entornos y módulos, Terragrunt es la mejor opción.
# Ejemplo de uso de Terraform Workspaces
terraform workspace new prod
terraform workspace select prod
terraform apply
# Ejemplo de estructura con Terragrunt
# live/prod/aws/eu-central-1/network/terragrunt.hcl
# live/prod/azure/west-europe/network/terragrunt.hcl
# live/dev/aws/eu-west-1/network/terragrunt.hcl
# terragrunt.hcl
include {
path = find_in_parent_folders()
}
terraform {
source = "../../modules/vpc_network" # Ruta a su módulo
}
inputs = {
cloud_provider = "aws" # o "azure"
region = "eu-central-1"
cidr_block = "10.0.0.0/16"
name_prefix = "prod"
}
4. Diseñe la conectividad de red entre nubes e híbrida
La conectividad de red es una de las partes más complejas de una arquitectura multi-nube e híbrida. Utilice VPN, Direct Connect/ExpressRoute/Cloud Interconnect para garantizar una conexión segura y de alto rendimiento.
Consejo: Utilice siempre direcciones IP privadas para la comunicación interna. Evite el internet público para el tráfico entre nubes. Terraform permite automatizar la creación de gateways VPN y conexiones de peering.
# Ejemplo de creación de VPN entre AWS y Azure (simplificado)
resource "aws_vpn_connection" "main" {
customer_gateway_id = aws_customer_gateway.main.id
transit_gateway_id = aws_ec2_transit_gateway.main.id # Si se utiliza TGW
type = "ipsec.1"
static_routes_only = true
tunnel1_inside_cidr = "169.254.10.0/30"
tunnel2_inside_cidr = "169.254.11.0/30"
}
resource "azurerm_vpn_gateway" "main" {
name = "my-vpngw"
location = azurerm_resource_group.main.location
resource_group_name = azurerm_resource_group.main.name
virtual_network_id = azurerm_virtual_network.main.id
sku = "VpnGw1"
}
5. Gestión segura de secretos
Nunca almacene secretos (contraseñas, claves API) en el código de Terraform o en los archivos de estado. Utilice herramientas especializadas.
Consejo: Integre Terraform con sistemas de gestión de secretos como HashiCorp Vault, AWS Secrets Manager, Azure Key Vault, Google Secret Manager. Utilice variables de entorno para pasar datos sensibles durante la ejecución de Terraform.
# Obtención de un secreto de AWS Secrets Manager
data "aws_secretsmanager_secret" "db_password" {
name = "prod/db/password"
}
resource "aws_db_instance" "main" {
# ...
password = data.aws_secretsmanager_secret.db_password.secret_string
}
6. Gestión de Kubernetes con Terraform
Terraform puede gestionar directamente los recursos de Kubernetes utilizando el proveedor de Kubernetes. Esto es especialmente útil para desplegar componentes básicos del clúster (por ejemplo, controladores Ingress, CRD, namespaces) o para garantizar la coherencia de los despliegues entre diferentes clústeres.
Consejo: Utilice el proveedor de Kubernetes para los componentes de infraestructura de K8s, y Helm/GitOps (FluxCD, ArgoCD) para el despliegue de aplicaciones. Esta separación de responsabilidades hace que el sistema sea más manejable.
# main.tf (dentro del módulo para el clúster de Kubernetes)
resource "kubernetes_namespace" "app_ns" {
metadata {
name = "my-application"
}
}
resource "kubernetes_deployment" "nginx" {
metadata {
name = "nginx-deployment"
namespace = kubernetes_namespace.app_ns.metadata[0].name
}
spec {
replicas = 3
selector {
match_labels = {
app = "nginx"
}
}
template {
metadata {
labels = {
app = "nginx"
}
}
spec {
container {
name = "nginx"
image = "nginx:1.21"
port {
container_port = 80
}
}
}
}
}
}
7. Integración con CI/CD
Automatice la ejecución de Terraform a través de pipelines de CI/CD (GitHub Actions, GitLab CI, Jenkins, Azure DevOps). Esto garantiza la coherencia, la seguridad y acelera el despliegue.
Consejo: Implemente terraform plan en la etapa de Pull Request para verificar los cambios. terraform apply solo debe ejecutarse después de la revisión y aprobación. Utilice herramientas especializadas, como Atlantis, para gestionar Terraform a través de Pull Requests.
# .github/workflows/terraform.yml
name: 'Terraform CI/CD'
on:
push:
branches:
- main
pull_request:
jobs:
terraform:
name: 'Terraform'
runs-on: ubuntu-latest
steps:
- name: Checkout
uses: actions/checkout@v3
- name: Setup Terraform
uses: hashicorp/setup-terraform@v2
with:
terraform_version: 1.5.7 # Versión actual para 2026
- name: Terraform Init
run: terraform init
- name: Terraform Format
run: terraform fmt -check
- name: Terraform Plan
if: github.event_name == 'pull_request'
run: terraform plan -no-color
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
- name: Terraform Apply
if: github.ref == 'refs/heads/main' && github.event_name == 'push'
run: terraform apply -auto-approve
env:
AWS_ACCESS_KEY_ID: ${{ secrets.AWS_ACCESS_KEY_ID }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
Estas recomendaciones le ayudarán a construir una infraestructura robusta, escalable y manejable, utilizando Terraform en los escenarios multi-nube e híbridos más complejos.
Errores comunes al implementar entornos multi-nube e híbridos con Terraform
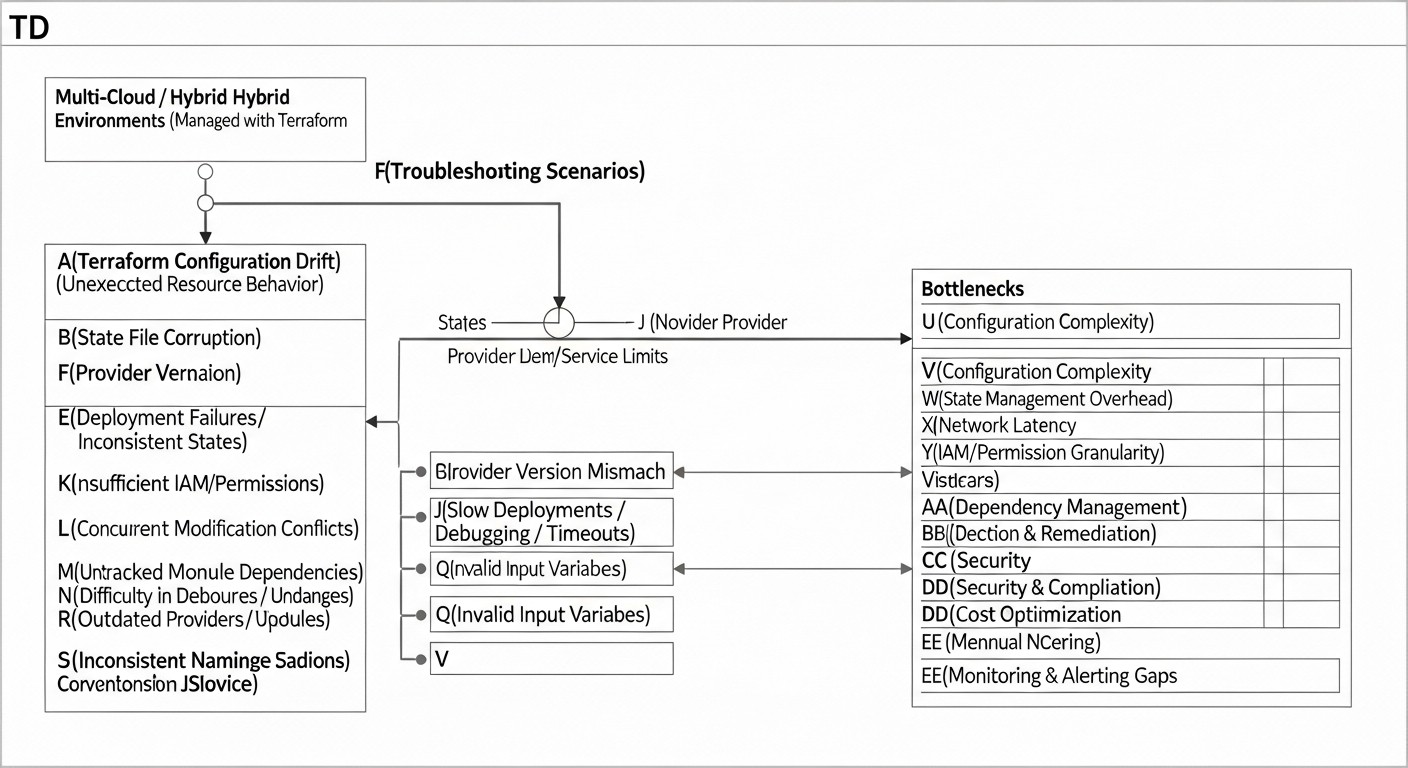 Diagrama: Errores comunes al implementar entornos multi-nube e híbridos con Terraform
Diagrama: Errores comunes al implementar entornos multi-nube e híbridos con Terraform
La implementación de soluciones de infraestructura complejas siempre conlleva riesgos. Los enfoques multi-nube e híbridos, a pesar de todas sus ventajas, pueden convertirse en una fuente de dolores de cabeza si no se tienen en cuenta los errores típicos. Aquí están los más comunes, con consejos para prevenirlos.
1. Gestión incorrecta del estado de Terraform
Error: Almacenar el archivo .tfstate localmente, falta de bloqueo de estado, usar un solo archivo de estado para una infraestructura demasiado grande o heterogénea.
Consecuencias: Conflictos al trabajar varios ingenieros en paralelo, pérdida de datos de estado, imposibilidad de recuperar la infraestructura después de un fallo, dificultades al escalar equipos.
Cómo evitarlo:
- Utilice siempre un almacenamiento de estado remoto (S3, Azure Blob, GCS, Terraform Cloud).
- Configure el bloqueo de estado (DynamoDB para S3, mecanismos integrados para Azure/GCS/Terraform Cloud).
- Divida el estado por límites lógicos (por ejemplo, un estado separado para la red, para las bases de datos, para el clúster de Kubernetes). Utilice Terragrunt o módulos para gestionar múltiples archivos de estado pequeños.
- Realice copias de seguridad del estado regularmente (la mayoría de los backends remotos lo hacen automáticamente, pero verifique).
2. Ignorar la seguridad y la gestión de secretos
Error: Hardcoding de contraseñas, claves API, tokens en el código HCL o en variables de Terraform. Falta de una gestión adecuada del acceso al estado de Terraform.
Consecuencias: Fuga de datos confidenciales, acceso no autorizado a la infraestructura, compromiso de sistemas, incumplimiento de los requisitos de seguridad y cumplimiento.
Cómo evitarlo:
- Utilice sistemas especializados de gestión de secretos (Vault, AWS Secrets Manager, Azure Key Vault, Google Secret Manager).
- Pase los secretos a Terraform a través de variables de entorno u obténgalos dinámicamente de los sistemas de gestión de secretos.
- Restrinja el acceso a los archivos de estado de Terraform (mediante políticas IAM para almacenamientos en la nube, RBAC para Terraform Cloud).
- Implemente el principio de privilegios mínimos para las cuentas utilizadas por Terraform.
3. Subestimar la complejidad de la integración de red
Error: Planificación incorrecta de direcciones IP, falta de consideración del tráfico y las latencias entre nubes, ignorar los problemas de enrutamiento entre nubes y on-premise.
Consecuencias: Problemas de comunicación entre servicios, altos costos de tráfico saliente, bajo rendimiento de las aplicaciones, dificultades para la resolución de problemas.
Cómo evitarlo:
- Planifique cuidadosamente los bloques CIDR para cada nube y on-premise, evite superposiciones.
- Utilice conexiones privadas (VPN, Direct Connect/ExpressRoute/Cloud Interconnect) para el tráfico inter-nube/híbrido crítico.
- Optimice el enrutamiento: utilice Transit Gateway, Virtual WAN o soluciones similares para la gestión centralizada de la red.
- Monitoree regularmente el tráfico de red y las latencias.
4. Ausencia o uso incorrecto de módulos de Terraform
Error: Copiar y pegar código de Terraform, crear configuraciones monolíticas, falta de abstracción para recursos reutilizables.
Consecuencias: Duplicación de código, dificultades de mantenimiento y actualización, alto riesgo de errores, despliegue lento, inconsistencia de la infraestructura entre entornos.
Cómo evitarlo:
- Cree módulos para cualquier bloque de infraestructura repetitivo (VPC, clúster de Kubernetes, base de datos, grupo de seguridad).
- Haga que los módulos sean lo más flexibles posible a través de variables, pero con valores predeterminados razonables.
- Utilice un registro de módulos (público o privado) para el almacenamiento centralizado y la gestión de versiones.
- Siga los principios DRY.
5. Ausencia de CI/CD para Terraform
Error: Ejecución manual de terraform apply desde la máquina local del ingeniero, falta de revisión de los cambios en la infraestructura.
Consecuencias: Errores humanos, inconsistencia de entornos, falta de auditoría de cambios, despliegue lento, imposibilidad de revertir a una versión anterior.
Cómo evitarlo:
- Implemente un pipeline de CI/CD para cada repositorio de Terraform.
- Automatice
terraform plan en la etapa de Pull Request/Merge Request.
- Requiera aprobación para
terraform apply, especialmente para entornos de producción.
- Utilice herramientas especiales para el enfoque GitOps en Terraform, como Atlantis o la integración con Terraform Cloud/Enterprise.
- Asegúrese de que los agentes de CI/CD tengan los derechos de acceso necesarios y utilicen métodos de autenticación seguros.
6. Desatención de los costos y la economía inter-nube
Error: Centrarse solo en el costo de los recursos computacionales, ignorar los costos de tráfico saliente, servicios gestionados, licencias, así como los gastos operativos para mantener un entorno complejo.
Consecuencias: Facturas de servicios en la nube inesperadamente altas, superación del presupuesto, reducción de la rentabilidad del proyecto, dificultades para justificar las inversiones en multi-nube.
Cómo evitarlo:
- Realice un análisis TCO exhaustivo para cada escenario, incluyendo todos los componentes: cómputo, almacenamiento, red, servicios gestionados, licencias, soporte.
- Preste especial atención al costo del tráfico saliente entre nubes, esto puede ser una partida de gastos significativa.
- Utilice herramientas en la nube para el monitoreo de costos y la presupuestación.
- Implemente políticas para el apagado automático de recursos no utilizados (por ejemplo, entornos de desarrollo fuera del horario laboral).
- Revise y optimice regularmente sus gastos en la nube.
Lista de verificación para la aplicación práctica de la gestión multi-nube e híbrida con Terraform
Esta lista de verificación le ayudará a estructurar el proceso de implementación y a asegurarse de que ha tenido en cuenta todos los aspectos importantes al trabajar con Terraform en entornos multi-nube e híbridos.
- Definición de estrategia y requisitos:
- ¿Ha definido los objetivos de negocio para la multi-nube/híbrido (DR, Optimización de Costos, Cumplimiento, Rendimiento)?
- ¿Ha analizado los requisitos de RTO/RPO para aplicaciones críticas?
- ¿Ha evaluado las habilidades actuales del equipo y su disposición a la formación?
- ¿Ha seleccionado proveedores de nube específicos y/o plataformas on-premise?
- Diseño de la arquitectura:
- ¿Ha diseñado la topología de red (CIDR, VPN/Direct Connect, enrutamiento) para todos los entornos?
- ¿Ha determinado qué aplicaciones/servicios se alojarán en cada nube/on-premise?
- ¿Ha desarrollado una estrategia de replicación/sincronización de datos entre entornos?
- ¿Ha determinado qué servicios se utilizarán (K8s Gestionado, PaaS, IaaS)?
- Preparación del repositorio de Terraform:
- ¿Ha creado la estructura del repositorio (por ejemplo, por nubes, por entornos, por componentes)?
- ¿Ha configurado el almacenamiento de estado remoto de Terraform con bloqueo?
- ¿Ha implementado Terragrunt para DRY y la gestión de múltiples archivos de estado?
- ¿Ha configurado los proveedores de Terraform para todas las nubes/plataformas de destino?
- Desarrollo de módulos de Terraform:
- ¿Ha desarrollado módulos reutilizables para componentes comunes (VPC, K8s, DB, Grupos de Seguridad)?
- ¿Ha abstraído la especificidad de los proveedores dentro de los módulos, donde sea posible?
- ¿Ha asegurado el versionado de los módulos?
- ¿Ha documentado las variables y salidas de los módulos?
- Gestión de secretos y seguridad:
- ¿Ha integrado Terraform con un sistema de gestión de secretos (Vault, Secrets Manager, Key Vault)?
- ¿Aplica el principio de privilegios mínimos para las cuentas de Terraform?
- ¿Ha configurado políticas de seguridad (IAM, Firewall, Security Groups) a través de Terraform?
- ¿Está habilitado el cifrado de datos en reposo y en tránsito?
- Implementación de CI/CD:
- ¿Ha configurado pipelines de CI/CD para la ejecución automática de
terraform plan y apply?
- ¿Ha incluido la verificación de formato y el linting del código de Terraform?
- ¿Ha configurado la revisión y aprobación de cambios antes de
apply?
- ¿Utiliza herramientas para el enfoque GitOps en IaC (Atlantis, Terraform Cloud)?
- Monitoreo y alertas:
- ¿Ha configurado un sistema de monitoreo unificado para todas las nubes y on-premise?
- ¿Ha creado dashboards para el seguimiento del estado de la infraestructura y las aplicaciones?
- ¿Ha configurado alertas para eventos críticos y anomalías?
- ¿Monitorea los costos y el consumo de recursos?
- Pruebas y validación:
- ¿Ha desarrollado una estrategia de prueba de infraestructura (unitarias, integración, de extremo a extremo)?
- ¿Realiza simulacros regulares de recuperación ante desastres (DR drills)?
- ¿Prueba el rendimiento y la escalabilidad en el entorno multi-nube/híbrido?
- Documentación y formación:
- ¿Ha creado documentación detallada sobre la arquitectura y los procesos?
- ¿Ha capacitado al equipo en el uso de nuevas herramientas y procedimientos?
- ¿Ha incluido Terraform en la incorporación de nuevos empleados?
- Optimización y refactorización:
- ¿Planea auditorías regulares y optimización de costos?
- ¿Tiene un proceso para refactorizar el código de Terraform y actualizar las versiones de proveedores/módulos?
- ¿Recopila comentarios de los equipos de desarrollo y operaciones para mejorar la infraestructura?
Cálculo de costos / Economía de soluciones multi-nube e híbridas con Terraform
 Esquema: Cálculo de costos / Economía de soluciones multi-nube e híbridas con Terraform
Esquema: Cálculo de costos / Economía de soluciones multi-nube e híbridas con Terraform
La economía de las soluciones multi-nube e híbridas es significativamente más compleja de lo que parece a primera vista. Además de los costos obvios de los recursos computacionales, existen gastos ocultos que pueden afectar significativamente el presupuesto final. En 2026, los proveedores de la nube continúan mejorando sus modelos de precios, pero los principios fundamentales permanecen inalterados.
Ejemplos de cálculos para diferentes escenarios (cifras hipotéticas de 2026)
Supongamos que tenemos una aplicación SaaS promedio que se ejecuta en 10 instancias de K8s (4 vCPU, 16 GB RAM cada una) y una base de datos administrada (16 vCPU, 64 GB RAM, 1TB SSD). El tráfico de salida mensual es de 5TB.
Escenario 1: Nube única (AWS, región eu-central-1)
- Managed Kubernetes (EKS): 10 instancias a $180/mes = $1800
- Managed DB (RDS PostgreSQL): $1500/mes
- Tráfico de salida (5TB): $0.08/GB * 5000 GB = $400
- Balanceador, Storage, Monitoring: $300
- Costo mensual total: $1800 + $1500 + $400 + $300 = $4000
Escenario 2: Multi-nube DR Activo-Pasivo (AWS + Azure)
La carga principal en AWS. En Azure se ha implementado un DR "frío": un clúster K8s mínimo (2 instancias), una DB mínima (sin replicación activa, solo almacenamiento de copias de seguridad), infraestructura de red. Replicación diaria de 100GB de datos entre nubes.
- AWS (principal): $4000 (como en el Escenario 1)
- Azure (de respaldo):
- Managed Kubernetes (AKS): 2 instancias a $150/mes = $300
- Managed DB (Azure Database for PostgreSQL): $400/mes (solo almacenamiento)
- Infraestructura de red, Load Balancer: $100
- Tráfico entre nubes (replicación 100GB * 30 días = 3TB): $0.10/GB * 3000 GB = $300
- Costo mensual total: $4000 + $300 + $400 + $100 + $300 = $5100 (+27.5% a la nube única)
Escenario 3: Híbrido (On-premise + Yandex.Cloud)
Carga base (5 instancias K8s, DB) on-premise. Carga pico (5 instancias K8s adicionales) en Yandex.Cloud. 2TB de tráfico de salida on-premise, 3TB desde la nube. Conexión VPN.
- On-premise (base):
- Amortización de equipos, electricidad, soporte (equivalente a 5 instancias K8s + DB): $2500/mes (a largo plazo puede ser menor)
- Tráfico de salida (2TB): $0
- Yandex.Cloud (pico):
- Managed Kubernetes: 5 instancias a $160/mes = $800
- Managed DB (Yandex Managed Service for PostgreSQL): $700/mes (solo réplica)
- Tráfico de salida (3TB): $0.06/GB * 3000 GB = $180
- Gateway VPN y tráfico: $100
- Costo mensual total: $2500 + $800 + $700 + $180 + $100 = $4280 (+7% a la nube única)
Costos ocultos
- Tráfico entre nubes/de salida: A menudo subestimado. Los proveedores cobran por el tráfico de salida, así como por el tráfico entre regiones. En 2026, sigue siendo una partida de gastos significativa.
- Gastos operativos (OpEx): La gestión de un entorno más complejo requiere más tiempo y cualificación del equipo. Herramientas de monitoreo, seguridad, CI/CD, así como la formación del personal, todo esto es OpEx.
- Licencias: Algunos servicios PaaS o software especializado pueden tener cargos de licencia adicionales.
- Herramientas: Costo de Terraform Cloud/Enterprise, Terragrunt, sistemas de gestión de secretos, sistemas de monitoreo avanzados.
- Complejidad de la migración de datos: Mover grandes volúmenes de datos entre nubes o on-premise puede ser costoso y consumir mucho tiempo.
- Utilización de recursos: En un entorno multi-nube es más difícil rastrear y optimizar los recursos no utilizados.
Cómo optimizar los costos
- Planificación cuidadosa de la arquitectura: Minimice el tráfico entre nubes colocando los servicios relacionados cerca.
- Uso de instancias reservadas/planes de ahorro: Para cargas de trabajo predecibles, compre instancias reservadas o utilice planes de ahorro (Savings Plans), lo que puede reducir el costo hasta en un 60%.
- Escalado automático: Utilice el autoescalado (HPA, Cluster Autoscaler) para K8s para pagar solo por los recursos necesarios.
- Monitoreo y optimización: Analice regularmente el consumo de recursos y los costos. Apague los entornos no utilizados (dev/staging) fuera del horario laboral.
- Uso de instancias Spot: Para cargas de trabajo tolerantes a fallos y no críticas, se pueden utilizar instancias Spot (hasta un 90% más baratas).
- Compresión de datos: Reduzca los volúmenes de datos transferidos utilizando compresión.
- CDN: Utilice Content Delivery Networks para almacenar en caché contenido estático más cerca de los usuarios, reduciendo la carga en las nubes principales y el tráfico de salida.
- Terraform para políticas: Utilice Sentinel (Terraform Enterprise) u Open Policy Agent para implementar políticas que impidan el despliegue de recursos costosos o subóptimos.
Tabla con ejemplos de cálculos (valores hipotéticos)
| Componente de costo |
Nube única ($/mes) |
Multi-nube DR ($/mes) |
Híbrido ($/mes) |
Comentario |
| Cómputo (K8s/VMs) |
1800 |
1800 (principal) + 300 (respaldo) |
800 (nube) + 1500 (on-premise) |
Principal partida de gastos, depende del tamaño y número de instancias. |
| Bases de datos (Managed DB) |
1500 |
1500 (principal) + 400 (respaldo) |
700 (nube) + 1000 (on-premise) |
Costo de licencias, almacenamiento, replicación. |
| Tráfico de red (Salida) |
400 |
400 (principal) + 300 (entre nubes) |
180 (nube) + 0 (on-premise) |
Una de las partidas más insidiosas, especialmente el tráfico entre nubes. |
| Infraestructura de red (LB, VPN) |
100 |
100 (principal) + 100 (respaldo) |
100 (nube) + 50 (on-premise) |
Balanceadores, gateways, peerings. |
| Almacenamiento de datos (S3/Blob) |
50 |
50 (principal) + 20 (respaldo) |
20 (nube) + 30 (on-premise) |
Copias de seguridad, archivos estáticos. |
| Monitoreo/Registro |
100 |
150 |
120 |
Sistema de monitoreo unificado para todos los entornos. |
| Herramientas de CI/CD e IaC |
50 |
80 |
80 |
Terraform Cloud, Atlantis, CI-runners. |
| TOTAL (mes) |
4000 |
4300 + 1270 = 5570 |
2000 + 2500 = 4500 |
|
Nota: Los costos on-premise de "cómputo" y "bases de datos" incluyen la amortización de equipos, electricidad y mantenimiento. Pueden ser significativamente más bajos que los de la nube para cargas estables y a largo plazo, pero requieren un CAPEX mayor.
FAQ (Preguntas Frecuentes)
P1: ¿Es obligatorio usar Terraform para entornos multi-nube/híbridos?
R1: Estrictamente hablando, no. Se pueden usar CloudFormation, ARM Templates, Cloud Deployment Manager o incluso scripts manuales. Sin embargo, Terraform es el estándar de facto para IaC en entornos multi-nube gracias a su versatilidad y soporte para una gran cantidad de proveedores. Proporciona un lenguaje unificado para describir la infraestructura, lo que reduce significativamente la complejidad y acelera el despliegue.
P2: ¿Qué tan difícil es migrar una infraestructura existente a Terraform?
R2: Puede ser un proceso bastante laborioso, especialmente para sistemas grandes y complejos. Terraform proporciona el comando terraform import, que permite importar recursos existentes al estado de Terraform. Sin embargo, después de la importación, aún tendrá que escribir manualmente el código HCL correspondiente a los recursos importados. Se recomienda comenzar con proyectos nuevos o componentes pequeños y aislados.
P3: ¿Cómo gestionar secretos en Terraform sin codificarlos directamente (hardcoding)?
R3: Nunca codifique directamente (hardcode) los secretos. Utilice sistemas especializados de gestión de secretos, como HashiCorp Vault, AWS Secrets Manager, Azure Key Vault o Google Secret Manager. Terraform puede obtener secretos dinámicamente de estos sistemas durante la ejecución, o pueden pasarse a través de variables de entorno del pipeline de CI/CD. Es importante que el acceso a estos sistemas también esté estrictamente controlado.
P4: ¿Se puede usar un solo archivo de estado de Terraform para toda la infraestructura multi-nube?
R4: Rotundamente no se recomienda. Un solo archivo de estado para toda la infraestructura resultará en tamaños enormes, rendimiento lento, conflictos frecuentes en el trabajo colaborativo y un alto riesgo de errores. La mejor práctica es dividir el estado por límites lógicos: por nubes, por regiones, por entornos (dev/prod), por componentes (red, K8s, BD). Terragrunt es de gran ayuda en esto.
P5: ¿Cómo asegurar la consistencia de las configuraciones entre diferentes nubes?
R5: La forma principal es el uso de módulos de Terraform. Cree módulos que abstraigan la especificidad del proveedor y le permitan definir una lógica común (por ejemplo, "crear VPC", "desplegar clúster K8s"). Estos módulos pueden luego ser invocados con diferentes parámetros para cada nube. También ayudan herramientas como Terragrunt, que permiten reutilizar el código de los módulos con una duplicación mínima.
P6: ¿Qué es la "gravedad de los datos" y cómo influye en la elección de la estrategia?
R6: La gravedad de los datos es un concepto según el cual grandes volúmenes de datos atraen aplicaciones y servicios hacia sí mismos, porque mover estos datos entre diferentes ubicaciones (por ejemplo, entre nubes o on-premise) es costoso, lento y complejo. Si tiene bases de datos masivas que no pueden replicarse o moverse fácilmente, estas pueden dictar dónde se alojará su carga de trabajo principal, lo que a menudo conduce a escenarios híbridos.
P7: ¿Qué riesgos están asociados con el uso de la multi-nube?
R7: Los riesgos principales incluyen: aumento de la complejidad operativa, costos potencialmente más altos (especialmente por el tráfico saliente y las herramientas), dificultad para garantizar una seguridad y cumplimiento unificados, y la necesidad de un equipo altamente cualificado. Sin embargo, estos riesgos pueden minimizarse con una planificación cuidadosa y el uso de las herramientas adecuadas, como Terraform.
P8: ¿Cómo ayuda Terraform en la gestión de Kubernetes en la multi-nube?
R8: Terraform puede desplegar los propios clústeres de Kubernetes (EKS, AKS, GKE) utilizando los proveedores de nube correspondientes. Luego, utilizando el proveedor de Kubernetes, Terraform puede gestionar los recursos básicos dentro del clúster (namespaces, service accounts, CRD, ingress controllers). Esto permite unificar el despliegue de clústeres y sus componentes principales, asegurando la consistencia entre diferentes nubes.
P9: ¿Qué es el "Infrastructure as Code Drift" y cómo prevenirlo?
R9: IaC Drift (desfase del estado de IaC) es una situación en la que el estado real de la infraestructura difiere de lo descrito en su código IaC (Terraform). Esto ocurre debido a cambios manuales realizados fuera de Terraform. Se puede prevenir estableciendo políticas estrictas (por ejemplo, a través de IAM) que prohíban los cambios manuales y utilizando pipelines de CI/CD que garanticen que todos los cambios pasen por Terraform. Los terraform plan regulares también ayudan a detectar el desfase.
P10: ¿Cómo gestionar las versiones del código de Terraform y de los proveedores?
R10: Siempre use un sistema de control de versiones (Git) para su código Terraform. En el archivo versions.tf (o main.tf) especifique explícitamente las versiones requeridas de Terraform Core y de cada proveedor. Por ejemplo, required_version = "~> 1.5" y version = "~> 4.0" para el proveedor. Esto previene cambios inesperados en el comportamiento al actualizar y asegura la reproducibilidad de los despliegues.
En 2026, las estrategias multi-nube e híbridas dejaron de ser una excentricidad y se convirtieron en una parte integral de la arquitectura de la mayoría de las empresas maduras. Ofrecen un nivel sin precedentes de tolerancia a fallos, flexibilidad y optimización de costes, pero al mismo tiempo introducen una complejidad significativa en la gestión de la infraestructura. Es aquí donde Terraform demuestra ser una herramienta indispensable.
Nuestro viaje desde VPS hasta Kubernetes a través de diversas nubes y entornos on-premise ha demostrado que Terraform es capaz de unificar la gestión de cualquier recurso. Gracias a su enfoque declarativo, un potente ecosistema de proveedores, módulos e integración con CI/CD, permite a los equipos desplegar, escalar y mantener de manera eficiente una infraestructura compleja y distribuida. Hemos revisado los criterios clave de selección, analizado en detalle diversas estrategias, ofrecido consejos prácticos, señalado errores comunes y propuesto formas de optimizar los costes.
Recuerde que el éxito en un entorno multi-nube e híbrido no solo depende de las herramientas, sino también de la cultura de su equipo. Los principios de Infrastructure as Code, GitOps, automatización y aprendizaje continuo deben estar profundamente integrados en sus flujos de trabajo. Las tecnologías evolucionan, y Terraform no se detiene, ofreciendo constantemente nuevas capacidades para gestionar sistemas cada vez más complejos.
El futuro multi-nube e híbrido ya está aquí. Con Terraform en su arsenal, estará preparado para sus desafíos y oportunidades.