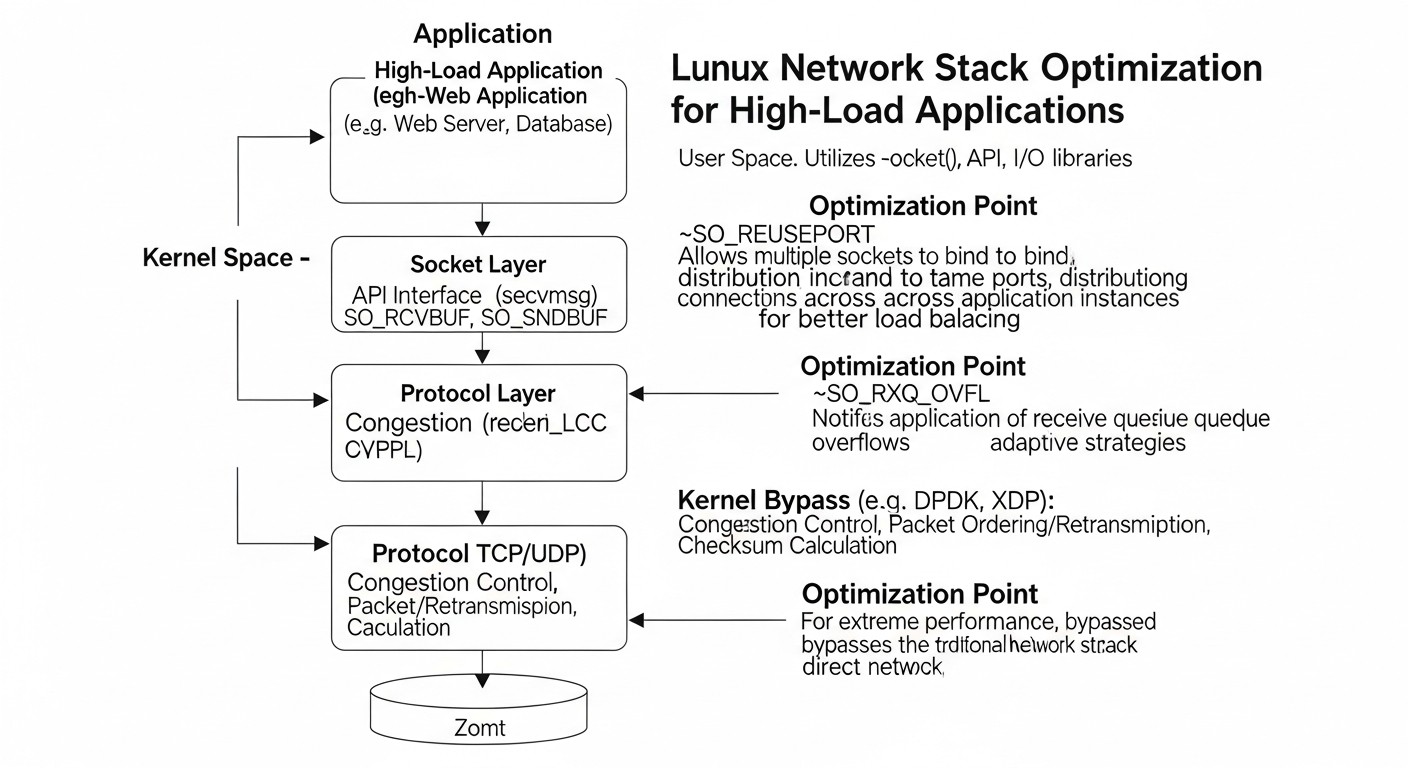
Optimización de la pila de red de Linux para aplicaciones de alta carga: del kernel a eBPF
TL;DR
Enfoque integral: La optimización de la pila de red para sistemas de alta carga requiere atención a todos los niveles, desde los controladores de tarjetas de red (NIC) y los parámetros del kernel hasta los espacios de usuario y tecnologías avanzadas como eBPF.
La medición es clave para el éxito: Antes de realizar cualquier cambio, es esencial establecer métricas de rendimiento de referencia y monitorear continuamente el impacto de las optimizaciones, utilizando herramientas como iperf3, netstat, ss, perf y bcc-tools.
Ajuste fino del kernel: Los parámetros sysctl (por ejemplo, net.core.somaxconn, net.ipv4.tcp_tw_reuse, net.ipv4.tcp_rmem/wmem) son críticamente importantes para gestionar las conexiones, los búferes y el comportamiento de TCP, pero requieren un enfoque cauteloso.
Uso de las capacidades de la NIC: Las tarjetas de red modernas ofrecen descargas de hardware (TSO, GSO, GRO, RSS, LRO) que reducen significativamente la carga de la CPU, y su activación a través de ethtool es el primer paso para mejorar el rendimiento.
eBPF como herramienta revolucionaria: Extended Berkeley Packet Filter (eBPF) permite programar la pila de red a nivel del kernel sin necesidad de recompilarlo, proporcionando capacidades sin precedentes para el filtrado de paquetes (XDP), el equilibrio de carga, la monitorización y la creación de funciones de red personalizadas con una sobrecarga mínima.
Importancia de la estrategia de congestión TCP: La elección del algoritmo de control de congestión TCP (BBR, CUBIC) puede influir significativamente en el rendimiento y la latencia, especialmente en redes con alta latencia o pérdidas.
Enfoque iterativo y pruebas: Aplique los cambios gradualmente, pruébelos bajo carga real y esté preparado para revertirlos. Una optimización incorrecta puede llevar a la inestabilidad o a una disminución del rendimiento.
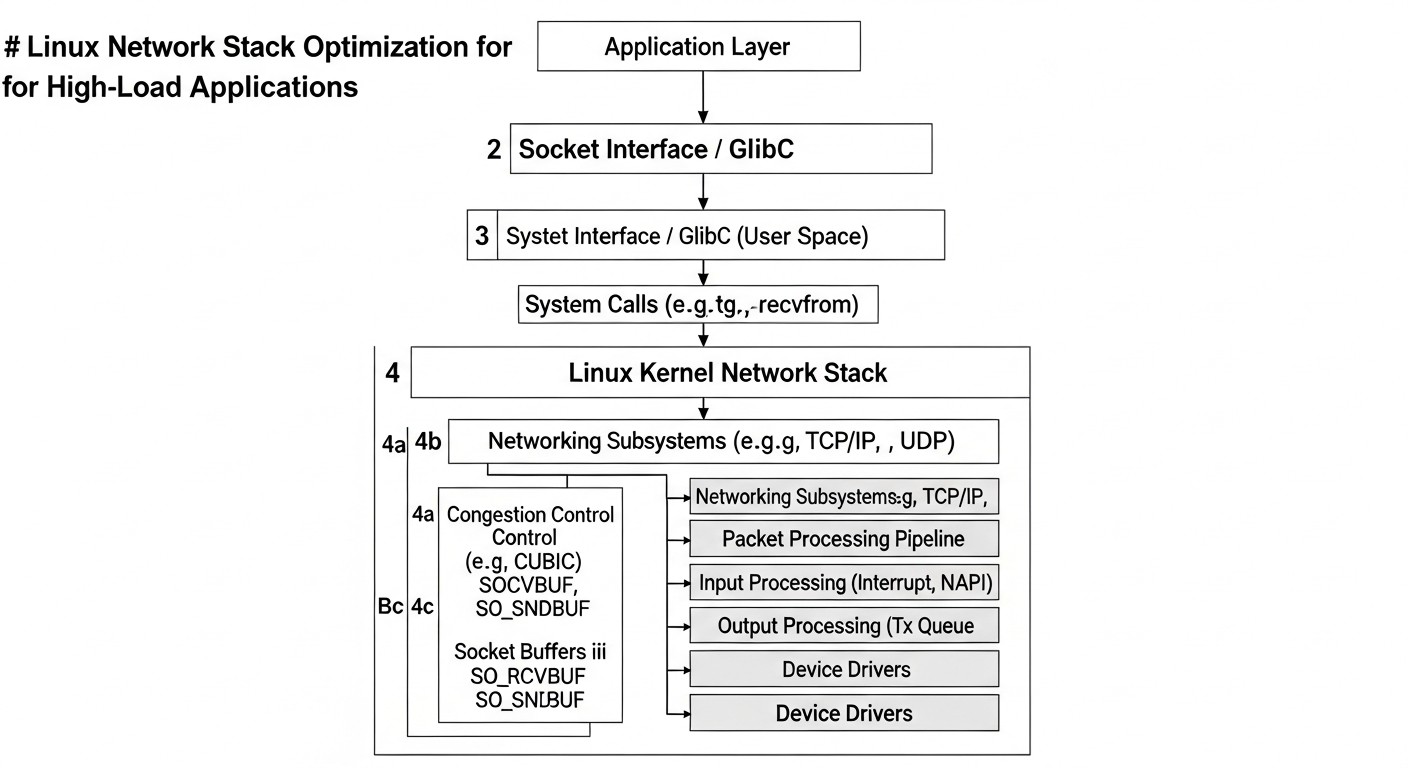
Introducción
Diagrama: Introducción
En el mundo en rápida evolución de 2026, donde dominan las tecnologías en la nube, la arquitectura de microservicios, la inteligencia artificial, el aprendizaje automático y el IoT omnipresente, el rendimiento de la pila de red de Linux se convierte no solo en un aspecto importante, sino en un factor crítico de éxito para cualquier aplicación de alta carga. La capacidad de respuesta de las pasarelas API, la velocidad de procesamiento de transacciones en sistemas financieros, la fluidez de la transmisión de datos en tiempo real, la eficiencia de las bases de datos y los sistemas distribuidos, todo esto depende directamente de la eficacia con la que Linux maneja el tráfico de red. Las configuraciones estándar del kernel, diseñadas para una amplia gama de tareas, a menudo no pueden proporcionar un rendimiento óptimo en condiciones de cargas extremas, características de los proyectos SaaS modernos, backends altamente escalables e infraestructuras DevOps.
Este artículo pretende ser una guía exhaustiva para ingenieros DevOps, desarrolladores backend, fundadores de proyectos SaaS, administradores de sistemas y directores técnicos de startups. Nos sumergiremos en las profundidades de la pila de red de Linux, comenzando con los parámetros básicos del kernel y las capacidades de hardware de las tarjetas de red (NIC), y terminando con tecnologías avanzadas como eBPF. El objetivo es proporcionar no solo un conjunto de comandos, sino una comprensión profunda de los principios de funcionamiento, ejemplos concretos, consejos prácticos y casos reales que le permitirán tomar decisiones informadas y lograr el máximo rendimiento de sus sistemas.
Examinaremos cómo diagnosticar correctamente los cuellos de botella, qué parámetros del kernel de Linux se pueden y deben ajustar, cómo utilizar las descargas de hardware de las tarjetas de red y cómo eBPF abre nuevos horizontes para la manipulación dinámica, segura y de alto rendimiento del tráfico de red directamente en el kernel. Responderemos preguntas relacionadas con la elección de estrategias de control de congestión TCP, la optimización de búferes, la escalabilidad del manejo de interrupciones y mucho más. En 2026, cuando cada milisegundo de latencia y cada porcentaje de uso de CPU pueden costar dinero real o reputación, comprender y aplicar estas técnicas no es un lujo, sino una necesidad. Prepárese para una inmersión profunda en el mundo de las redes Linux de alto rendimiento.
Criterios y factores clave de optimización
Diagrama: Criterios y factores clave de optimización
Antes de comenzar la optimización, es fundamental comprender claramente qué métricas y factores determinan el rendimiento de la pila de red y cómo evaluarlos. Sin esto, cualquier cambio será aleatorio y podría causar más daño que beneficio. En 2026, con el crecimiento exponencial de los volúmenes de datos y los requisitos de baja latencia, estos criterios se vuelven aún más relevantes.
1. Latencia (Latency)
La latencia es el tiempo que tarda un paquete de datos en viajar del remitente al receptor y viceversa (Round Trip Time, RTT) o en una sola dirección (One-Way Latency). En el contexto de la pila de red de Linux, es el tiempo que tarda el kernel en procesar un paquete entrante y enviar uno saliente. Una latencia alta afecta directamente la capacidad de respuesta de las aplicaciones, especialmente para servicios interactivos, plataformas de juegos, transacciones financieras y cualquier sistema sensible al tiempo de respuesta. Para proyectos SaaS, donde la experiencia del usuario es crucial, cada milisegundo de latencia puede llevar a la pérdida de conversiones o a la fuga de clientes. Por ejemplo, un estudio de Google demostró que un aumento de 500 ms en la latencia provoca una caída del 20% en el tráfico.
Por qué es importante: Afecta la UX, el rendimiento de los sistemas distribuidos y la velocidad de las transacciones.
Cómo evaluarla: Herramientas como ping, traceroute, hping3, así como sistemas de monitoreo especializados que recopilan RTT para conexiones TCP. Es importante medir la latencia no solo a recursos externos, sino también dentro del clúster, entre microservicios.
Optimización: Minimización del procesamiento de paquetes en el kernel, uso de descargas de hardware, configuración adecuada de búferes, XDP.
2. Rendimiento (Throughput)
El rendimiento es el volumen de datos que se puede transmitir por unidad de tiempo (por ejemplo, megabits por segundo, Mbps o gigabits por segundo, Gbps). Este es un factor crítico para aplicaciones que manejan grandes volúmenes de datos: servicios de streaming, sistemas de copia de seguridad, plataformas analíticas, bases de datos. En 2026, con la aparición de tarjetas de red 400GbE e incluso 800GbE, la capacidad del kernel para procesar eficazmente estos flujos de datos se vuelve clave. Un rendimiento insuficiente puede llevar a la "inanición" de datos de las aplicaciones, al aumento del tiempo de procesamiento de tareas y a la disminución del rendimiento general del sistema.
Por qué es importante: Determina la velocidad de transmisión de grandes volúmenes de datos, afecta el tiempo de ejecución de tareas por lotes.
Cómo evaluarlo: Herramientas como iperf3, netperf, así como métricas de interfaces de red (rx_bytes_per_sec, tx_bytes_per_sec) de /proc/net/dev o sistemas de monitoreo.
Optimización: Aumento de los búferes TCP/UDP, activación de Jumbo Frames, uso de TSO/GSO/GRO, configuración adecuada del balanceo de IRQ y RSS.
3. Pérdida de paquetes (Packet Loss)
La pérdida de paquetes ocurre cuando los paquetes de datos no llegan a su destino. Esto puede ser causado por el desbordamiento de búferes, errores en la red, problemas de hardware o una configuración incorrecta. La pérdida de paquetes afecta catastróficamente el rendimiento, ya que conduce a retransmisiones de datos, lo que aumenta la latencia, reduce el rendimiento y carga la CPU. Para protocolos en tiempo real (VoIP, videoconferencias), la pérdida de paquetes deteriora la calidad de la comunicación. En escenarios de IoT o Edge Computing, donde la estabilidad de la conexión es crítica, la pérdida de paquetes puede ser inaceptable.
Por qué es importante: Provoca retransmisiones de datos, aumenta la latencia, reduce el rendimiento y carga la CPU.
Cómo evaluarla: Métricas rx_dropped, tx_dropped de /proc/net/dev, ss -s (pérdidas para TCP), netstat -s, tcpdump para el análisis de retransmisiones.
Optimización: Aumento de búferes (net.core.netdev_max_backlog, tcp_rmem/wmem), gestión de colas (QoS), XDP para el descarte rápido de tráfico no deseado.
4. Utilización de CPU (CPU Utilization)
El procesamiento del tráfico de red en Linux requiere recursos de CPU. Esto incluye el manejo de interrupciones (IRQs), la copia de datos entre el espacio de usuario y el espacio del kernel, la ejecución de protocolos de red (TCP/IP), el enrutamiento y el filtrado. Una alta carga de CPU, especialmente en el contexto de ksoftirqd o kworker, a menudo indica cuellos de botella en la pila de red. El uso excesivo de la CPU por parte de la red quita recursos a las aplicaciones, lo que reduce su rendimiento y la eficiencia general del servidor. En 2026, a medida que el costo de cada núcleo de CPU en la nube sigue aumentando, el uso eficiente de la CPU se convierte en un factor directo de ahorro.
Por qué es importante: Afecta la disponibilidad de CPU para las aplicaciones y el rendimiento general del sistema.
Cómo evaluarla: Herramientas como top, htop, perf, mpstat para monitorear el uso de la CPU, especialmente en los modos softirq y si.
Optimización: Descargas de hardware de NIC (TSO, GSO, GRO, RSS), RPS/RFS, XDP, eBPF para desplazar la lógica del espacio de usuario al kernel con una sobrecarga mínima.
5. Uso de memoria (Memory Usage)
La pila de red utiliza memoria para búferes (búferes de socket, búferes de tarjetas de red), tablas de enrutamiento, caché ARP y otras estructuras de datos. La falta de memoria para los búferes puede provocar la pérdida de paquetes, especialmente durante las cargas máximas. La asignación excesiva de memoria puede ser ineficiente, pero la mayoría de las veces el problema es la escasez. Para sistemas de alta carga con un gran número de conexiones simultáneas o un alto rendimiento, la configuración adecuada de los búferes de memoria es crítica para evitar pérdidas y mantener un rendimiento estable. En los entornos contenerizados y sin servidor de 2026, donde los recursos suelen ser limitados, la gestión eficiente de la memoria para las operaciones de red es de suma importancia.
Por qué es importante: La escasez de búferes provoca la pérdida de paquetes, el exceso, un uso ineficiente de los recursos.
Cómo evaluarla:/proc/meminfo (Buffers, Cached), métricas de sockets (ss -m), vmstat.
Optimización: Configuración de net.core.rmem_max, net.core.wmem_max, net.ipv4.tcp_rmem, net.ipv4.tcp_wmem, net.core.netdev_max_backlog.
6. Escalabilidad (Scalability)
La escalabilidad de la pila de red se refiere a su capacidad para manejar eficazmente un número creciente de conexiones, paquetes o rendimiento sin degradación del rendimiento. Esto incluye la distribución eficiente de la carga entre los núcleos de la CPU, la gestión de un gran número de descriptores de archivo y la optimización de las estructuras de datos del kernel para el procesamiento paralelo. Para las arquitecturas de microservicios modernas y los sistemas distribuidos, donde el número de interacciones de red puede ascender a millones por segundo, la escalabilidad de la pila de red es la base de la estabilidad y la capacidad de respuesta de todo el sistema. La capacidad de manejar el tráfico "explosivo" y adaptarse a las cargas cambiantes es la piedra angular de una infraestructura fiable en 2026.
Por qué es importante: Permite que el sistema maneje cargas crecientes sin degradación.
Cómo evaluarla: Pruebas de carga con un número creciente de clientes/conexiones, monitoreo de métricas de CPU, memoria y latencia a medida que aumenta la carga.
Optimización: RSS/RPS/RFS, net.core.somaxconn, net.ipv4.tcp_max_syn_backlog, net.ipv4.ip_local_port_range, eBPF para una distribución más eficiente del tráfico.
7. Jitter (Jitter)
El jitter es la variación de la latencia de los paquetes. Incluso si la latencia promedio es baja, una alta variabilidad puede ser un problema, especialmente para aplicaciones en tiempo real (VoIP, video, juegos en línea) o trading de alta frecuencia. Las latencias impredecibles pueden provocar almacenamiento en búfer, omisión de fotogramas o errores de sincronización. En 2026, con el aumento de la popularidad de las aplicaciones interactivas y AR/VR, la minimización del jitter se vuelve cada vez más crítica para garantizar una experiencia de usuario fluida.
Por qué es importante: Afecta la calidad de las aplicaciones en tiempo real y la estabilidad de los flujos de datos.
Cómo evaluarlo: Herramientas especializadas para medir el RTT con seguimiento de variaciones, análisis de la distribución de latencias.
Optimización: Priorización del tráfico (QoS), minimización de colas, estabilidad del procesamiento de interrupciones, eBPF para un control más preciso de los flujos.
8. Implicaciones de seguridad (Security Implications)
Cualquier cambio en la pila de red puede tener implicaciones de seguridad. Por ejemplo, debilitar ciertos parámetros TCP para mejorar el rendimiento puede hacer que el sistema sea más vulnerable a ataques SYN-flood u otros tipos de ataques. La activación de ciertas funciones (por ejemplo, tcp_tw_reuse sin la debida comprensión) puede llevar a consecuencias no deseadas. El uso de eBPF, aunque seguro por naturaleza (los programas son verificados por el kernel), requiere atención al escribir el código para evitar vulnerabilidades lógicas o efectos secundarios no intencionados. En 2026, a medida que las amenazas se vuelven más sofisticadas, la seguridad debe ser una parte integral de cualquier estrategia de optimización.
Por qué es importante: La optimización no debe dar lugar a la creación de nuevas vulnerabilidades.
Cómo evaluarla: Auditoría de cambios, pruebas de penetración, análisis de vectores de ataque.
Optimización: Estudio cuidadoso de la documentación, uso de prácticas probadas, eBPF para la implementación de firewalls y sistemas de detección de intrusiones a nivel del kernel.
Tabla comparativa de métodos de optimización
Esquema: Tabla comparativa de métodos de optimización
La elección del método de optimización de la pila de red de Linux adecuado depende de los requisitos específicos de la aplicación, la configuración del hardware y el presupuesto. En esta tabla, compararemos los enfoques clave, relevantes para 2026, según varios criterios importantes. Los precios y las características son orientativos y pueden variar.
Criterio
Ajuste fino de sysctl
Descargas de hardware de NIC
RSS/RPS/RFS
eBPF (XDP/TC)
Userspace Networking (DPDK)
Control de Congestión TCP (BBR)
Complejidad de implementación
Baja-Media
Baja-Media
Media
Alta
Muy Alta
Baja
Ganancia potencial de rendimiento (2026)
5-20% (depende del escenario)
10-30% reducción de la carga de CPU
Hasta 20% de aumento de PPS
Hasta 70% de reducción de CPU para L3/L4, 10-30% general
100-300% de aumento de PPS (evitando el kernel)
10-50% de aumento del ancho de banda en WAN
Impacto en la CPU
Reduce/redistribuye
Reduce significativamente
Redistribuye, reduce softirq
Reduce significativamente (especialmente XDP)
Evita completamente la CPU del kernel
Mínimo
Impacto en la latencia
Puede reducir
Reduce
Reduce
Reduce significativamente (XDP)
Reduce significativamente
Puede reducir (BBR)
Requisitos de hardware
Servidor Linux estándar
NIC moderna con soporte de descarga (offload)
CPU multinúcleo
Kernel Linux 4.x+ (mejor 5.x+), CPU moderna
NIC especializada, CPU multinúcleo, soporte IOMMU
Servidor Linux estándar
Escenarios de uso típicos
Servidores web, bases de datos, proxies
Cualquier aplicación de red de alta carga
Gateways de red de alto rendimiento, balanceadores de carga
Protección DDoS, firewalls personalizados, balanceadores de carga, monitoreo, telemetría
Telecomunicaciones, HFT, NFV, procesamiento de paquetes de alta velocidad
Optimización WAN, entornos de nube, CDN
Costo aproximado de implementación (Tiempo de desarrollo)
Bajo (horas)
Bajo (horas)
Medio (días)
Alto (semanas/meses)
Muy alto (meses)
Bajo (minutos)
Riesgos/Efectos secundarios
Una configuración incorrecta puede empeorar el rendimiento
Conflictos con controladores, incompatibilidad
Una configuración incorrecta puede causar desequilibrio
Complejidad de depuración, riesgo de inestabilidad con errores
Evita completamente el kernel, requiere aplicaciones especializadas
Puede ser agresivo en algunas redes
Análisis detallado de cada punto/opción
Diagrama: Análisis detallado de cada punto/opción
Cada método de optimización de la pila de red de Linux tiene sus propias características, ventajas y desventajas. Comprender estos matices permite seleccionar las herramientas más adecuadas para una tarea específica y lograr la máxima eficiencia.
1. Ajuste fino de los parámetros del kernel (sysctl)
Los parámetros del kernel de Linux, accesibles a través de la interfaz sysctl, son el primer y más accesible nivel de optimización. Permiten configurar el comportamiento de la pila de red, controlando los tamaños de los búferes, los tiempos de espera, los mecanismos de control de congestión y otros aspectos. A pesar de su aparente simplicidad, su configuración requiere una comprensión profunda, ya que valores incorrectos pueden llevar a una degradación del rendimiento o incluso a la inestabilidad del sistema. En 2026, cuando la mayoría de los sistemas operan en contenedores o máquinas virtuales, estos parámetros siguen siendo relevantes, aunque algunos de ellos pueden estar limitados por el entorno.
net.core.somaxconn: Define el número máximo de conexiones que pueden estar en el estado LISTEN-backlog. Para servidores web de alta carga o balanceadores de carga que manejan miles de nuevas conexiones por segundo, el valor predeterminado (normalmente 128) a menudo es insuficiente. Aumentarlo a 4096 o incluso 65535 puede reducir significativamente el número de conexiones rechazadas (connection refused) bajo carga máxima. Por ejemplo, para una puerta de enlace API que recibe 10 000 RPS, aumentar somaxconn de 128 a 8192 puede prevenir hasta un 5% de errores de conexión en los momentos pico, mejorando la experiencia del usuario y la estabilidad del servicio.
net.ipv4.tcp_tw_reuse y net.ipv4.tcp_fin_timeout:tcp_tw_reuse permite reutilizar sockets en estado TIME_WAIT para nuevas conexiones salientes. Esto es críticamente importante para clientes que abren y cierran rápidamente muchas conexiones. En combinación con tcp_fin_timeout (reducción del tiempo en estado FIN_WAIT2), ayuda a prevenir el agotamiento de puertos y reduce la carga del sistema durante la creación/cierre intensivo de conexiones. Sin embargo, tcp_tw_reuse debe usarse con precaución en servidores, ya que puede causar problemas al interactuar con algunos dispositivos NAT que envían paquetes con números de secuencia obsoletos. Para proxies salientes o microservicios que inician muchas solicitudes, la activación de tcp_tw_reuse puede reducir el número de puertos en estado TIME_WAIT en un 30-50%, liberando recursos.
net.core.rmem_max / net.core.wmem_max y net.ipv4.tcp_rmem / net.ipv4.tcp_wmem: Estos parámetros controlan los tamaños máximos de los búferes de recepción y envío para todos los sockets (net.core.) y para los sockets TCP (net.ipv4.tcp_). Aumentar estos valores permite que las ventanas TCP sean más grandes, lo cual es especialmente importante para redes de alta velocidad con gran latencia (High-Bandwidth Delay Product, BDP). Para servidores que transfieren archivos grandes o trabajan con bases de datos de alta velocidad, aumentar los búferes a 16MB (16777216) o incluso 32MB puede aumentar significativamente el rendimiento, reduciendo el número de retransmisiones y mejorando la eficiencia del uso del canal. Por ejemplo, en un canal de 10 Gbit/s con un RTT de 50 ms, el tamaño óptimo del búfer es de aproximadamente 625 KB. Si el búfer es menor, el canal estará subutilizado.
net.ipv4.tcp_max_syn_backlog: Número máximo de conexiones TCP para las cuales se han recibido paquetes SYN, pero el handshake de tres vías aún no se ha completado. Aumentar este valor (por ejemplo, a 8192 o 16384) ayuda a proteger contra ataques de SYN flood y previene la pérdida de conexiones bajo una alta carga de establecimiento de conexiones.
net.ipv4.tcp_timestamps: La habilitación de las marcas de tiempo TCP (RFC 1323) ayuda al kernel a medir el RTT con mayor precisión y protege contra segmentos obsoletos, pero añade 12 bytes a cada encabezado TCP. Para LAN de alta velocidad con un gran número de paquetes pequeños, esto puede ser una sobrecarga. En la mayoría de los casos, para WAN, debe dejarse habilitado.
Ventajas: Facilidad de aplicación, no requiere cambios en el código de la aplicación, versatilidad. Desventajas: Requiere un reinicio para algunos parámetros, puede llevar a inestabilidad si se configura incorrectamente, no resuelve problemas fundamentales de rendimiento en cargas muy altas. Para quién es adecuado: La mayoría de los servidores donde se requiere una optimización general del rendimiento de la red sin cambios profundos en la arquitectura. Ejemplos: Aumento de somaxconn para servidores web, configuración de búferes para servidores de archivos, optimización de tcp_tw_reuse para aplicaciones cliente o proxies.
2. Descargas de hardware de tarjetas de red (NIC Offloads)
Las tarjetas de red (NIC) modernas no son solo transceptores, sino potentes coprocesadores capaces de realizar parte del procesamiento de red que tradicionalmente recae en la CPU del kernel. El uso de estas descargas de hardware (offloads) permite reducir significativamente la carga sobre la CPU, liberándola para tareas de aplicación y, por lo tanto, aumentando el rendimiento general del sistema. En 2026, con la proliferación de NIC de 10/25/40/100GbE, la activación de estas funciones es un primer paso obligatorio.
TSO (TCP Segmentation Offload) / GSO (Generic Segmentation Offload): Permiten al kernel enviar segmentos TCP muy grandes (hasta 64 KB) al controlador de la NIC, que luego los divide de forma independiente en paquetes que se ajustan al MTU de la red. Esto reduce significativamente el número de operaciones realizadas por la CPU, ya que el kernel procesa menos paquetes, pero más datos a la vez. Especialmente útil para la transferencia de archivos grandes a alta velocidad.
GRO (Generic Receive Offload) / LRO (Large Receive Offload): La otra cara de TSO/GSO. La NIC o el controlador combinan varios paquetes entrantes en un gran segmento antes de pasarlos al kernel. Esto reduce el número de interrupciones y el número de paquetes que el kernel debe procesar, disminuyendo así la carga de la CPU. GRO es una versión más universal de LRO y es preferible.
RSS (Receive Side Scaling): Permite distribuir el procesamiento de interrupciones de red y paquetes entrantes entre múltiples núcleos de CPU. La NIC utiliza una función hash para determinar qué núcleo debe procesar un paquete específico, evitando así la sobrecarga de un solo núcleo y aumentando el rendimiento general. Para sistemas multinúcleo con NIC de alta velocidad, esto es críticamente importante. Por ejemplo, una NIC de 100GbE sin RSS puede resultar en que un solo núcleo de CPU esté completamente cargado con el procesamiento del tráfico de red, mientras que los demás están inactivos.
RPS (Receive Packet Steering) / RFS (Receive Flow Steering): Implementaciones de software de RSS, cuando la NIC no soporta RSS por hardware o cuando se requiere un control más fino. RPS distribuye los paquetes entre los núcleos de la CPU después de que han sido recibidos por la NIC. RFS intenta adicionalmente dirigir los paquetes al núcleo donde se ejecuta la aplicación que los procesará, mejorando la eficiencia de la caché.
SR-IOV (Single Root I/O Virtualization): Tecnología de virtualización que permite a las máquinas virtuales acceder directamente a las funciones de hardware de la NIC, omitiendo el hipervisor. Esto proporciona un rendimiento de red casi nativo para las VM, reduciendo significativamente la latencia y aumentando el rendimiento. Críticamente importante para NFV (Network Function Virtualization) e instancias de nube de alto rendimiento.
Ventajas: Reducción significativa de la carga de la CPU, aumento del rendimiento y disminución de la latencia, no requiere cambios en el código de la aplicación. Desventajas: Depende del soporte de hardware de la NIC y de los controladores, puede ser complejo de configurar (especialmente SR-IOV), a veces puede causar problemas de compatibilidad o depuración. Para quién es adecuado: Cualquier servidor de alta carga, especialmente con NIC de 10GbE+, entornos virtualizados. Ejemplos: Activación de TSO/GSO/GRO para servidores de archivos, configuración de RSS para balanceadores de carga, uso de SR-IOV para funciones de red virtuales.
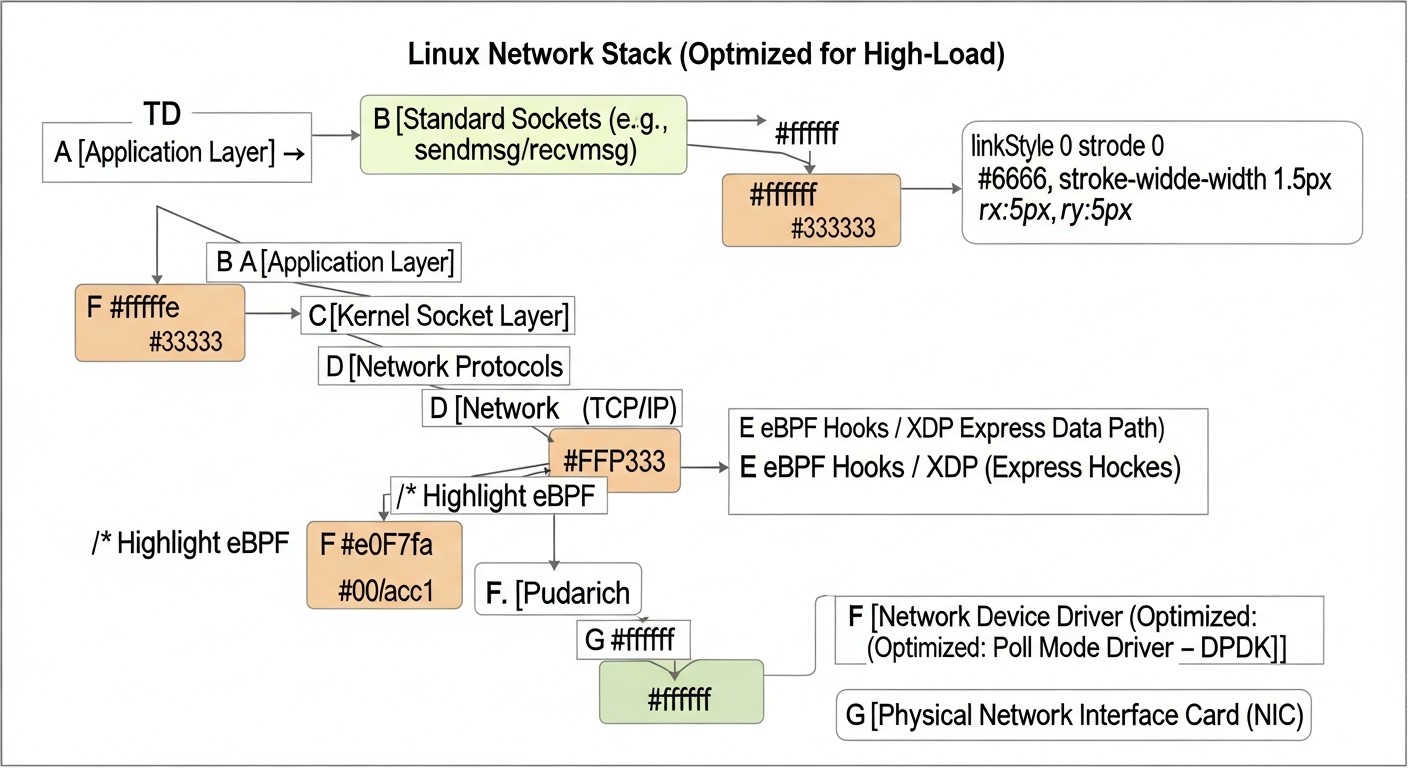
3. eBPF (Extended Berkeley Packet Filter)
eBPF es una tecnología revolucionaria que permite ejecutar programas a nivel del kernel de Linux sin necesidad de recompilarlo o cargar módulos. Estos programas, escritos en un subconjunto limitado de C y compilados a bytecode, son verificados por el kernel en cuanto a seguridad y luego se ejecutan en un entorno aislado (sandbox). eBPF ofrece capacidades sin precedentes para monitoreo, trazado, seguridad y, lo que es especialmente importante para nosotros, para el procesamiento de red de alto rendimiento. En 2026, eBPF es una de las herramientas más potentes para optimizar la pila de red, permitiendo implementar lógica que antes solo era posible en el espacio de usuario o requería modificar el kernel.
XDP (eXpress Data Path): La ruta más rápida para el procesamiento de paquetes en Linux. Los programas XDP se ejecutan directamente en el controlador de la tarjeta de red, antes de que el paquete ingrese a la pila de red normal. Esto permite realizar operaciones como filtrado de tráfico DDoS, balanceo de carga, enrutamiento rápido o redirección de paquetes con una latencia y carga de CPU mínimas. XDP permite descartar tráfico no deseado o redirigirlo a otras interfaces/CPU antes de que sea completamente procesado por el kernel. En casos reales, XDP puede procesar millones de paquetes por segundo en un solo núcleo de CPU, reduciendo la carga de la CPU en un 50-70% en comparación con los métodos tradicionales para ciertas tareas.
TC eBPF (Traffic Control eBPF): Programas eBPF que se adjuntan a los puntos de entrada en el subsistema de control de tráfico de Linux. Permiten implementar políticas más complejas de filtrado, clasificación y modificación de paquetes que XDP, pero con una latencia ligeramente mayor, ya que operan más profundamente en la pila. TC eBPF se utiliza para crear firewalls avanzados, políticas de QoS, funciones de red como proxy o tunelización, e incluso para implementar parte de los controladores SDN.
Socket Filters: Programas eBPF que se adjuntan a los sockets. Permiten filtrar los paquetes entrantes antes de que sean entregados a la aplicación. Esto puede utilizarse para implementar protocolos personalizados, optimizar el procesamiento de tráfico específico o para una seguridad más granular a nivel de aplicación.
Cilium, Calico y otros: En 2026, eBPF se utiliza activamente en entornos de nube y contenedores para implementar políticas de red, balanceo de carga y seguridad. Proyectos como Cilium se han reconstruido completamente sobre eBPF, proporcionando una red de alto rendimiento y segura para Kubernetes.
Ventajas: Rendimiento y flexibilidad sin precedentes, ejecución de código a nivel del kernel sin modificarlo, seguridad (verificador del kernel), potentes capacidades de monitoreo y depuración, desarrollo activo por la comunidad. Desventajas: Alto umbral de entrada (requiere conocimientos de C, API específica de eBPF), complejidad de depuración, no todos los controladores de NIC soportan XDP, los programas están limitados en tamaño y complejidad. Para quién es adecuado: Ingenieros y desarrolladores DevOps que trabajan con cargas extremadamente altas, que requieren lógica personalizada de procesamiento de paquetes, protección DDoS, balanceo de carga de alto rendimiento, monitoreo avanzado. Ejemplos: XDP para descartar tráfico DDoS, TC eBPF para crear balanceadores de carga L4 personalizados, eBPF para telemetría profunda del tráfico de red.
4. Espacio de usuario (Userspace Networking - DPDK)
Para las cargas más extremas, cuando incluso XDP no es suficiente, existen soluciones que evitan completamente la pila de red del kernel y procesan los paquetes directamente en el espacio de usuario. La más conocida de ellas es DPDK (Data Plane Development Kit). DPDK proporciona un conjunto de bibliotecas y controladores que permiten a las aplicaciones interactuar directamente con la tarjeta de red, omitiendo el kernel de Linux. Esto se logra mediante el uso del modo "poll mode driver" (PMD), donde la CPU consulta constantemente la NIC en busca de nuevos paquetes, evitando la sobrecarga de las interrupciones. DPDK requiere la asignación de núcleos de CPU y páginas de memoria grandes, pero a cambio ofrece un rendimiento medido en decenas de millones de paquetes por segundo (Mpps) en un solo núcleo.
Principio de funcionamiento: Las aplicaciones DPDK obtienen acceso exclusivo a la NIC. Los controladores DPDK operan en el espacio de usuario y consultan constantemente las colas de la NIC en busca de paquetes. Esto elimina los cambios de contexto, la copia de datos entre el kernel y el espacio de usuario, así como el procesamiento de interrupciones, que son las principales fuentes de sobrecarga en la pila de red tradicional.
Aplicación: Se utiliza en la industria de las telecomunicaciones (NFV), trading de alta frecuencia (HFT), routers especializados, firewalls, sistemas IDS/IPS, donde se requiere el máximo rendimiento y la mínima latencia.
Ventajas: Máximo rendimiento (decenas de Mpps), latencia mínima, control total sobre el procesamiento de paquetes. Desventajas: Extremadamente alta complejidad de desarrollo e implementación (requiere reescribir o adaptar aplicaciones), bypass completo de la pila de red del kernel (se pierden las funciones estándar de Linux), requiere núcleos de CPU dedicados y una configuración específica, no hay utilidades estándar. Para quién es adecuado: Solo para los escenarios más exigentes, donde la pila de red estándar (incluso con eBPF) no es suficiente, y hay recursos para un desarrollo profundo. Ejemplos: Soluciones NFV comerciales (routers virtuales, firewalls), plataformas HFT, dispositivos de red especializados.
5. Algoritmos de control de congestión TCP
El algoritmo de control de congestión TCP determina cómo una conexión TCP reacciona a la congestión de la red, controlando el tamaño de la ventana de congestión. La elección del algoritmo correcto puede afectar significativamente el rendimiento, la latencia y la equidad en la distribución del ancho de banda. En 2026, a medida que las redes se vuelven cada vez más diversas (desde centros de datos de alta velocidad hasta canales satelitales), la elección del algoritmo tiene una gran importancia.
CUBIC: Algoritmo predeterminado en la mayoría de los kernels de Linux modernos. Funciona bien en redes de alta velocidad con alta latencia, pero puede ser menos agresivo y reaccionar más lentamente a los cambios que otros algoritmos.
BBR (Bottleneck Bandwidth and RTT): Desarrollado por Google, BBR se enfoca en medir el ancho de banda del "cuello de botella" y la latencia mínima de RTT para determinar la ventana de congestión óptima. A diferencia de CUBIC, que reacciona a la pérdida de paquetes (lo que a menudo es un indicador tardío de congestión), BBR busca activamente el ancho de banda disponible, lo que a menudo resulta en un aumento significativo del rendimiento y una reducción de la latencia, especialmente en canales con alta latencia y/o pérdidas. Para entornos de nube, conexiones interregionales y CDN, BBR a menudo demuestra resultados superiores. Su uso puede aumentar el rendimiento en un 10-50% y reducir la latencia en un 5-10% en ciertos escenarios.
Reno/NewReno: Algoritmos más antiguos que todavía se utilizan, pero que generalmente son inferiores a CUBIC y BBR en las redes modernas de alta velocidad.
Ventajas: Fácil de configurar (sysctl), aumento significativo del rendimiento para BBR en redes WAN. Desventajas: BBR puede ser demasiado agresivo en algunas redes, lo que puede llevar al desplazamiento del tráfico que utiliza otros algoritmos. Para quién es adecuado: Todos los servidores, especialmente aquellos que interactúan a través de WAN o redes en la nube. BBR se recomienda para la mayoría de los escenarios. Ejemplos: Activación de BBR para servidores web, nodos CDN, servidores de archivos que operan a través de Internet.
6. Balanceo de interrupciones (IRQ Balancing)
Las tarjetas de red generan interrupciones (IRQs) para cada paquete recibido o enviado. En NIC de alta velocidad, el número de interrupciones puede ser enorme, lo que resulta en una carga significativa para la CPU si todas son procesadas por un solo núcleo. El balanceo de interrupciones distribuye estas IRQs entre varios núcleos de CPU, lo que permite procesar el tráfico de red en paralelo y prevenir la sobrecarga de núcleos individuales.
irqbalance: Demonio que distribuye automáticamente las IRQs entre los núcleos de CPU disponibles. Es una solución sencilla para la mayoría de los sistemas.
Configuración manual de /proc/irq/<IRQ_NUMBER>/smp_affinity: Para un rendimiento y predictibilidad máximos, especialmente en sistemas dedicados, se pueden vincular manualmente las IRQs de las tarjetas de red a núcleos de CPU específicos. Esto permite evitar la competencia con otros procesos y optimizar la eficiencia de la caché. Por ejemplo, para una NIC de 100GbE con 16 colas, se puede vincular cada cola a un núcleo de CPU separado, asegurando la máxima paralelización.
Ventajas: Reduce la carga de la CPU, mejora la escalabilidad y el rendimiento. Desventajas: La configuración manual puede ser compleja, requiere comprender la topología NUMA. Para quién es adecuado: Cualquier servidor multinúcleo con NIC de alta velocidad, especialmente gateways de red y balanceadores de carga. Ejemplos: Configuración de irqbalance en servidores estándar, vinculación manual de IRQs para dispositivos de red de alto rendimiento.
Consejos y recomendaciones prácticas
Diagrama: Consejos y recomendaciones prácticas
La aplicación de conocimientos teóricos en la práctica requiere pasos y comandos específicos. A continuación, se presentan instrucciones paso a paso y ejemplos de configuraciones que le ayudarán a optimizar la pila de red de Linux en condiciones reales para el año 2026.
1. Establecimiento de métricas base y monitoreo
Antes de cambiar cualquier cosa, mida el rendimiento actual. Esto le permitirá evaluar el efecto de los cambios realizados.
Uso de iperf3 para medir el ancho de banda:
# En el servidor (lado receptor)
iperf3 -s
# En el cliente (lado emisor)
iperf3 -c <server_ip> -t 60 -P 10 # 60 segundos, 10 flujos paralelos
Monitoreo de métricas de red:
# Estadísticas generales de interfaces de red
ip -s link show eth0
# Estadísticas de sockets TCP/UDP
ss -s
# Estadísticas detalladas por protocolos de red
netstat -s
# Monitoreo del uso de CPU, especialmente softirq
mpstat -P ALL 1
# Verificación de paquetes descartados en el controlador NIC
ethtool -S eth0 | grep "drop"
2. Configuración de parámetros del kernel (sysctl)
Los cambios a través de sysctl se aplican inmediatamente, pero no se guardan después de un reinicio. Para que sean permanentes, deben agregarse a /etc/sysctl.conf o a los archivos en /etc/sysctl.d/.
Ejemplo de configuración de /etc/sysctl.d/99-network-optimizations.conf:
# Aumentamos el backlog para sockets LISTEN
net.core.somaxconn = 65535
net.ipv4.tcp_max_syn_backlog = 16384
# Aumentamos los tamaños de búfer para todos los sockets
net.core.rmem_max = 33554432
net.core.wmem_max = 33554432
net.core.rmem_default = 16777216
net.core.wmem_default = 16777216
# Aumentamos los tamaños de búfer para sockets TCP
# Formato: min default max
net.ipv4.tcp_rmem = 4096 87380 33554432
net.ipv4.tcp_wmem = 4096 65536 33554432
# Permitimos la reutilización de sockets en estado TIME_WAIT
net.ipv4.tcp_tw_reuse = 1
# Reducimos el tiempo de espera para FIN-WAIT2
net.ipv4.tcp_fin_timeout = 30
# Usamos el algoritmo de control de congestión BBR
net.ipv4.tcp_congestion_control = bbr
# Aumentamos el número máximo de puertos para conexiones salientes
net.ipv4.ip_local_port_range = 1024 65535
# Deshabilitamos SACK (Selective Acknowledgement) - puede ser útil en algunos casos, pero a menudo es mejor dejarlo habilitado
# net.ipv4.tcp_sack = 0
# Deshabilitamos TCP Slow Start después de la inactividad (puede ser útil para conexiones cortas)
net.ipv4.tcp_slow_start_after_idle = 0
# Aumentamos la cola de paquetes entrantes a nivel del controlador
net.core.netdev_max_backlog = 16384
Use ethtool para verificar y configurar las capacidades de su tarjeta de red. Reemplace eth0 con el nombre de su interfaz.
Verificación de las capacidades actuales:
sudo ethtool -k eth0
Habilitación de todas las descargas compatibles (si están deshabilitadas):
sudo ethtool -K eth0 rx on tx on sg on tso on gso on gro on lro off
# lro a menudo entra en conflicto con gro, por lo que es mejor dejar gro
Configuración de colas RSS (Receive Side Scaling):
# Verificar el número de colas y su distribución
sudo ethtool -l eth0
# Establecer el número máximo de colas RX/TX disponibles para la NIC (si la NIC lo soporta)
sudo ethtool -L eth0 rx 16 tx 16
Configuración del balanceo de IRQ:
Para el balanceo automático de IRQs, asegúrese de que el servicio irqbalance esté en ejecución:
Para la vinculación manual de IRQs (para escenarios avanzados):
# Determinar los números de IRQ para eth0
grep eth0 /proc/interrupts
# Ejemplo: vincular IRQ 123 (primera cola de eth0) a la CPU 1
echo 2 > /proc/irq/123/smp_affinity_list
# (2 en la máscara de bits corresponde a la CPU 1. Para la CPU 0 es 1, para la CPU 0 y 1 es 3, etc.)
4. Configuración de eBPF (XDP)
La configuración de eBPF generalmente implica escribir un programa en C y cargarlo en el kernel usando utilidades de bcc-tools o libbpf. Este es un proceso más complejo.
Ejemplo de programa XDP más simple (descarte de todo el tráfico):
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
SEC("xdp")
int xdp_drop_all(struct xdp_md *ctx)
{
// Este programa simplemente descarta todos los paquetes entrantes
// Los programas XDP reales tienen una lógica de filtrado compleja
return XDP_DROP;
}
char _license[] SEC("license") = "GPL";
Carga del programa XDP (usando ip link):
# Compilar el código C en un archivo objeto (requiere clang y llvm)
clang -O2 -target bpf -c xdp_drop_all.c -o xdp_drop_all.o
# Cargar el programa XDP en la interfaz eth0
sudo ip link set dev eth0 xdp obj xdp_drop_all.o section xdp
# Verificar el estado de XDP
sudo ip link show dev eth0
# Deshabilitar XDP
sudo ip link set dev eth0 xdp off
Nota: El uso de eBPF requiere una comprensión profunda y precaución. Comience estudiando bcc-tools y los ejemplos en GitHub bcc y XDP Tutorial.
5. Configuración de Jumbo Frames
Si toda su red (NIC, conmutadores, enrutadores) soporta Jumbo Frames (MTU > 1500), su activación puede aumentar significativamente el ancho de banda al reducir el número de paquetes. Un valor típico para Jumbo Frames es 9000 bytes.
Cambio de MTU:
sudo ip link set dev eth0 mtu 9000
Importante: Todos los dispositivos en la ruta deben soportar y estar configurados para usar Jumbo Frames. De lo contrario, esto resultará en fragmentación y una reducción del rendimiento.
6. Recomendaciones para la elección de la pila TCP/IP
IPv6 First: En 2026, IPv6 se convierte en el estándar. Asegúrese de que sus aplicaciones e infraestructura soporten completamente IPv6. A veces, esto puede ofrecer pequeñas ventajas de rendimiento debido a un enrutamiento más eficiente y la ausencia de NAT.
TCP Fast Open (TFO): Para conexiones TCP cortas y frecuentes, TFO puede reducir significativamente la latencia al permitir el envío de datos en el primer paquete SYN. Actívelo en el servidor y el cliente:
net.ipv4.tcp_fastopen = 3 # 1 para el cliente, 2 para el servidor, 3 para ambos
Aplique estas recomendaciones y comandos gradualmente, probando cada paso y observando las métricas de rendimiento. Documente todos los cambios y esté preparado para revertir si algo sale mal.
Errores comunes al optimizar la pila de red
Diagrama: Errores comunes al optimizar la pila de red
La optimización de la pila de red es un arte delicado, y los errores pueden ser costosos. En 2026, a medida que los sistemas se vuelven más complejos e interconectados, las consecuencias de una configuración incorrecta pueden ser catastróficas. Aquí hay cinco de los errores más comunes que deben evitarse:
1. Optimización sin medición y benchmarking previos
Error: Aplicar recomendaciones de optimización "generales" (por ejemplo, de un artículo en internet o de un colega) sin comprender los cuellos de botella actuales y sin medir el rendimiento base.
Cómo evitarlo: Siempre comience con un diagnóstico exhaustivo. Use iperf3, netstat, ss, mpstat, ethtool para recopilar métricas antes de cualquier cambio. Cree pruebas de carga que simulen el comportamiento real de su aplicación. Solo así podrá determinar con precisión qué necesita optimización y evaluar la efectividad de sus acciones. Sin métricas base, no podrá demostrar que la optimización funcionó o comprender que empeoró la situación.
Ejemplo de consecuencias: Aumentar net.core.somaxconn a 65535 en un servidor que nunca experimentó problemas con el backlog de LISTEN no aportará ningún beneficio, pero puede crear una falsa sensación de optimización. Al mismo tiempo, si el problema real es la falta de búferes TCP y usted configura irqbalance, no solo no resolverá el problema, sino que también perderá el tiempo.
2. Copia ciega de configuraciones sin comprender el contexto
Error: Aplicar configuraciones encontradas en internet o utilizadas en otro sistema sin tener en cuenta las especificidades de su infraestructura, aplicación y hardware.
Cómo evitarlo: Comprenda lo que hace cada parámetro. Los parámetros óptimos para un tipo de carga (por ejemplo, transferencia de archivos de alta velocidad) pueden ser completamente ineficaces o incluso perjudiciales para otro (por ejemplo, muchas solicitudes HTTP cortas). Considere el tipo de NIC, el número de núcleos de CPU, la topología NUMA, la versión del kernel de Linux y las especificidades del entorno de red (LAN/WAN).
Ejemplo de consecuencias: La activación de tcp_tw_reuse en un servidor público sin comprender su interacción con los dispositivos NAT de los clientes puede llevar a la recepción errónea de paquetes "antiguos" y a la inestabilidad de las conexiones para algunos usuarios. O, por ejemplo, deshabilitar tcp_timestamps para "ahorrar" 12 bytes de encabezado puede afectar negativamente la precisión de la medición de RTT y la protección contra segmentos obsoletos, lo cual es más crítico para las conexiones WAN.
3. Ignorar las capacidades de hardware de la NIC
Error: Intentar optimizar la pila de red exclusivamente con métodos de software, ignorando las descargas de hardware proporcionadas por una tarjeta de red moderna.
Cómo evitarlo: Siempre verifique las capacidades de su NIC usando ethtool -k <interface> y ethtool -S <interface>. Asegúrese de que TSO, GSO, GRO, RSS y otras descargas compatibles estén activadas. Para NIC de alta velocidad (10GbE y superiores), esto es críticamente importante.
Ejemplo de consecuencias: Carga de CPU al 50% debido al procesamiento de interrupciones de red en una NIC de 25GbE, mientras que el RSS de hardware está deshabilitado. La activación de RSS podría reducir esta carga al 5-10%, liberando la CPU para las aplicaciones y aumentando significativamente el ancho de banda sin ningún cambio en el kernel o la aplicación.
4. Pruebas insuficientes bajo carga y falta de monitoreo después de los cambios
Error: Realizar cambios en producción sin pruebas previas en un entorno de prueba que simule la carga real, o la ausencia de monitoreo constante después de implementar los cambios.
Cómo evitarlo: Siempre pruebe los cambios en un entorno aislado que sea lo más parecido posible a producción. Utilice herramientas de prueba de carga (wrk, locust, JMeter) y asegúrese de que el sistema sea estable y el rendimiento haya mejorado. Después de la implementación en producción, monitoree cuidadosamente las métricas clave (CPU, memoria, latencia, pérdida de paquetes, errores) utilizando sistemas de monitoreo (Prometheus, Grafana, ELK).
Ejemplo de consecuencias: Cambiar el parámetro net.ipv4.tcp_max_orphans a un valor muy grande puede hacer que el sistema mantenga demasiados sockets "huérfanos", lo que eventualmente puede agotar la memoria y causar la caída del servidor bajo ciertas cargas pico que no fueron consideradas en el entorno de prueba.
5. Ignorar el impacto en la seguridad y la estabilidad
Error: Centrarse exclusivamente en el rendimiento, olvidando los riesgos potenciales para la seguridad y la estabilidad general del sistema.
Cómo evitarlo: Algunas optimizaciones pueden debilitar los mecanismos de seguridad del kernel. Por ejemplo, algunos parámetros destinados a reducir los tiempos de espera o la reutilización de conexiones pueden ser explotados por atacantes. Siempre evalúe los riesgos de seguridad. Al trabajar con eBPF, asegúrese de que los programas estén minuciosamente probados y verificados para evitar errores o vulnerabilidades no intencionadas. Siempre planifique una estrategia de reversión.
Ejemplo de consecuencias: Deshabilitar SYN Cookies (net.ipv4.tcp_syncookies = 0) para mejorar el rendimiento del establecimiento de conexiones bajo una carga muy alta puede hacer que el servidor sea extremadamente vulnerable a ataques de inundación SYN, lo que resultaría en la inaccesibilidad total del servicio.
Lista de verificación para la aplicación práctica
Esta lista de verificación paso a paso le ayudará a sistematizar el proceso de optimización de la pila de red de Linux para sus aplicaciones de alta carga. Sígala para garantizar un enfoque integral y seguro.
Defina el objetivo de la optimización:
¿Qué es exactamente lo que quiere mejorar? (¿Reducir la latencia, aumentar el ancho de banda, disminuir el uso de CPU, prevenir la pérdida de paquetes, mejorar la escalabilidad?)
¿Cuáles son sus límites y cuellos de botella actuales?
Establezca métricas de rendimiento de referencia:
Realice pruebas de carga con la configuración actual.
Registre los indicadores clave: RTT, ancho de banda (iperf3), PPS (pktgen), uso de CPU (mpstat, top), errores y caídas de paquetes (netstat -s, ss -s, ethtool -S).
Cree gráficos en su sistema de monitoreo (Prometheus/Grafana) para rastrear estas métricas.
Verifique las capacidades de hardware de la NIC:
Ejecute sudo ethtool -k <interface> y sudo ethtool -l <interface>.
Asegúrese de que TSO, GSO, GRO, RSS estén activados, si son compatibles.
Configure el número máximo de colas RX/TX, si es aplicable (sudo ethtool -L <interface> rx <N> tx <N>).
Considere el uso de Jumbo Frames, si toda la red lo soporta (sudo ip link set dev <interface> mtu 9000).
Optimice los parámetros del kernel (sysctl):
Cree o edite el archivo /etc/sysctl.d/99-network-optimizations.conf.
Establezca valores adecuados para net.core.somaxconn, net.ipv4.tcp_max_syn_backlog, net.core.rmem_max, net.core.wmem_max, net.ipv4.tcp_rmem, net.ipv4.tcp_wmem.
Habilite net.ipv4.tcp_tw_reuse = 1 (si es aplicable para su rol de servidor).
Establezca net.ipv4.tcp_congestion_control = bbr.
Aplique los cambios: sudo sysctl -p /etc/sysctl.d/99-network-optimizations.conf.
Configure el balanceo de interrupciones (IRQ Balancing):
Asegúrese de que el servicio irqbalance esté en ejecución y activo.
Para cargas extremas, considere la asignación manual de IRQs a la CPU (/proc/irq/<IRQ_NUMBER>/smp_affinity_list), especialmente para sistemas NUMA.
Considere la aplicación de eBPF:
Explore las capacidades de XDP para el filtrado DDoS, enrutamiento rápido o balanceo de carga.
Utilice bcc-tools para monitorear y rastrear la pila de red.
Si se requiere lógica personalizada, desarrolle y pruebe programas eBPF.
Realice pruebas después de cada etapa de optimización:
Repita las pruebas de carga y compare los resultados con las métricas de referencia.
Evalúe el impacto en la CPU, memoria, latencia y ancho de banda.
Asegúrese de la estabilidad del sistema.
Verifique el impacto en la seguridad:
Asegúrese de que las optimizaciones no hayan abierto nuevos vectores de ataque ni debilitado las protecciones existentes.
Realice una auditoría de los cambios, especialmente si afectan al firewall o a las políticas de red.
Documente todos los cambios:
Registre todos los cambios realizados, su justificación y los resultados.
Guarde las configuraciones en un sistema de control de versiones.
Planifique una estrategia de reversión:
Siempre tenga un plan de acción claro en caso de que las optimizaciones causen problemas.
Asegúrese de poder volver rápidamente a la configuración operativa anterior.
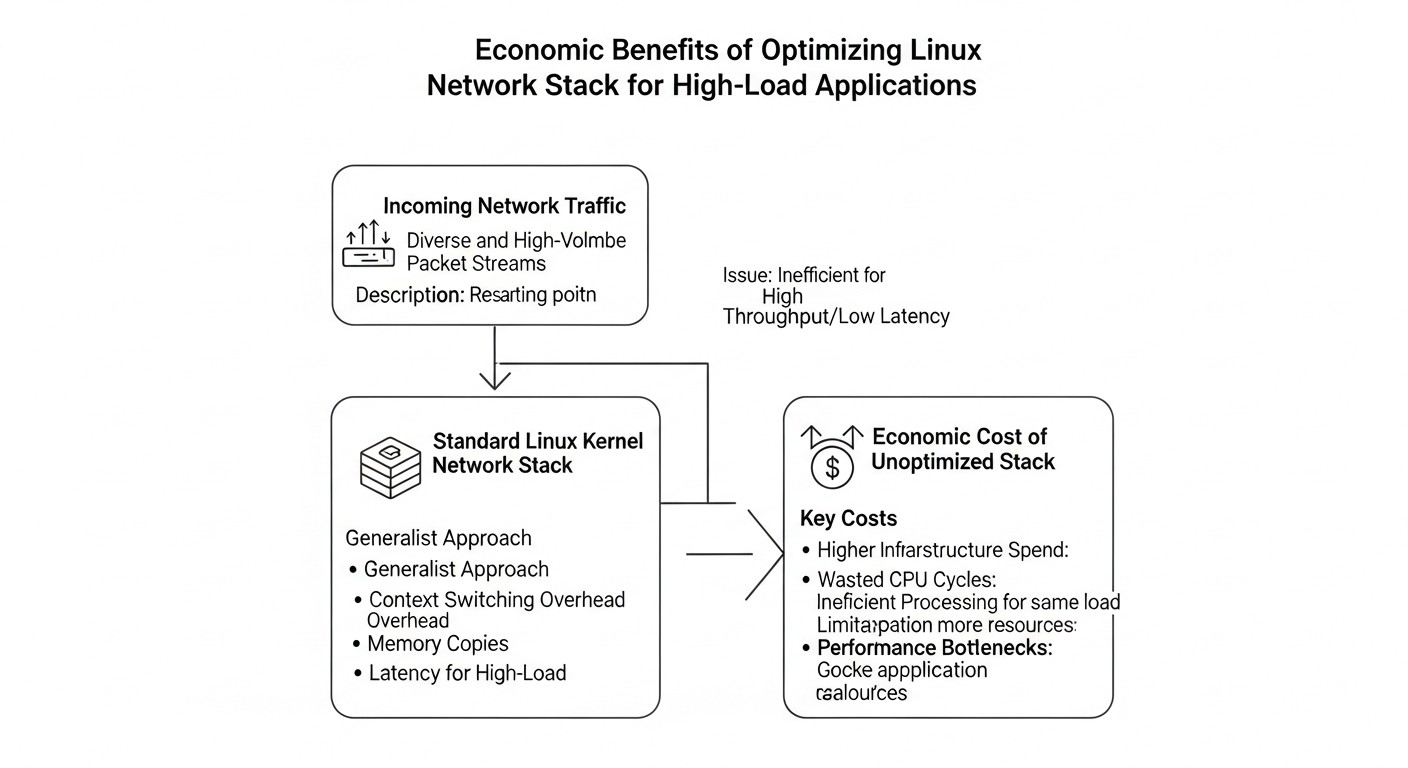
Cálculo de costos / Economía de la optimización
Diagrama: Cálculo de costos / Economía de la optimización
La optimización de la pila de red de Linux no es solo una tarea técnica, sino también una decisión económica. En 2026, a medida que los recursos en la nube se vuelven más caros y las demandas de rendimiento aumentan, una optimización adecuada puede generar ahorros sustanciales y mejorar la competitividad. Sin embargo, también requiere inversión. Veamos los principales aspectos económicos.
Costos directos y ocultos
Costo del hardware:
NIC con descargas avanzadas: Las NIC modernas de 25/50/100GbE con soporte SR-IOV, funciones de descarga extendidas y un hashing de hardware más potente pueden costar entre $300 y $2000+ por tarjeta. Estas son inversiones significativas, pero se amortizan al reducir la carga de la CPU.
CPU: A veces, para manejar PPS muy altos, se requiere una CPU más potente o un servidor con más núcleos. Sin embargo, el objetivo de la optimización a menudo es evitar la compra de una CPU más potente mediante el uso eficiente de la existente.
Costo del tiempo de ingeniería:
Estudio y planificación: Tiempo dedicado al estudio de la documentación, benchmarking, análisis de cuellos de botella.
Implementación y pruebas: Configuración de sysctl, ethtool, escritura y depuración de programas eBPF, realización de pruebas de carga. Esto puede variar desde unas pocas horas para configuraciones básicas hasta varias semanas o incluso meses para soluciones eBPF complejas o DPDK.
Soporte y monitoreo: Monitoreo continuo del rendimiento y adaptación de las configuraciones a las cargas cambiantes.
Costo de las herramientas:
La mayoría de las herramientas (iperf3, netstat, bcc-tools) son gratuitas y de código abierto.
Los sistemas de monitoreo (Prometheus, Grafana) también son gratuitos, pero su despliegue y soporte requieren recursos.
Costos ocultos de un sistema no optimizado:
Facturas de la nube aumentadas: El uso ineficiente de la CPU debido a la pila de red significa que paga por capacidad no utilizada o se ve obligado a escalar instancias antes de lo necesario. Por ejemplo, si la pila de red consume el 30% de la CPU, esto equivale a un 30% de sobrepago por la CPU.
Pérdida de ingresos debido al bajo rendimiento: La alta latencia o el bajo ancho de banda pueden llevar a una mala experiencia de usuario, abandono de clientes, menor conversión o oportunidades de negocio perdidas (por ejemplo, en HFT).
Pérdidas por inestabilidad: Las sobrecargas, la pérdida de paquetes y las caídas de servicios debido a una red no optimizada provocan tiempos de inactividad y pérdidas de reputación.
Costos adicionales de software: A veces, una pila de red no optimizada obliga a comprar licencias más caras para software de red o balanceadores de carga que podrían ser reemplazados por soluciones eBPF.
Ejemplos de cálculos para diferentes escenarios (2026)
Supongamos que el costo por hora de un ingeniero DevOps cualificado es de $100.
Escenario
Método de optimización
Inversión (Tiempo de Desarrollo)
Inversión (Hardware)
Ahorro/Beneficio potencial
ROI (Retorno de la Inversión)
SaaS Pequeño (1000 RPS)
sysctl básico, BBR, verificación de offloads
4-8 horas ($400-$800)
$0 (uso de NIC actuales)
Reducción de CPU del 5-10%, ahorro de $50-$100/mes en la nube, mejora de UX.
1-2 meses
Backend Mediano (100k RPS)
sysctl avanzado, RSS/RPS, ethtool, irqbalance
20-40 horas ($2000-$4000)
$0-$600 (actualización de NIC)
Reducción de CPU del 10-20%, ahorro de $200-$500/mes en la nube, aumento de la estabilidad.
2-6 meses
Centro de Datos Grande (1M+ PPS)
eBPF (XDP/TC), SR-IOV, DPDK (si es necesario), ajuste profundo del kernel
80-320 horas ($8000-$32000)
$1000-$5000 (NIC de alto rendimiento)
Reducción de CPU del 20-50%, posibilidad de consolidación de servidores (ahorro de $1000-$5000/mes), nuevas capacidades (protección DDoS, LB personalizado).
3-12 meses (depende de la complejidad)
HFT/Tiempo real (microsegundos)
DPDK, NIC especializadas, CPU affinity, kernel bypass
Empiece por lo simple: Primero aplique los métodos más baratos y sencillos (sysctl, ethtool). A menudo, estos proporcionan un aumento significativo.
Utilice Open Source: La mayoría de las herramientas y tecnologías (Linux, eBPF, Prometheus, Grafana) son gratuitas, lo que reduce el costo del software.
Implementación gradual: No intente implementar todo a la vez. Un enfoque iterativo con monitoreo constante ayuda a evitar errores costosos.
Capacitación del equipo: Las inversiones en la capacitación de ingenieros en eBPF y en una comprensión profunda de la pila de red se amortizarán muchas veces, reduciendo la dependencia de consultores externos.
Automatización: Utilice Ansible, Terraform u otras herramientas de IaC para automatizar el despliegue y la gestión de configuraciones, lo que reduce los errores manuales y el tiempo de implementación.
La economía de la optimización de la pila de red es un equilibrio entre la inversión en tiempo de ingeniería y hardware, y el ahorro potencial en recursos de la nube, el aumento de ingresos gracias a una mejor UX y la reducción de los riesgos de inactividad. En 2026, este equilibrio se inclina cada vez más hacia la optimización activa, ya que el costo de la ineficiencia aumenta.
Casos y ejemplos de la práctica real
Diagrama: Casos y ejemplos de la práctica real
La teoría es importante, pero los ejemplos reales de aplicación de optimizaciones demuestran su verdadero valor. Aquí hay algunos escenarios de la práctica de 2026 que muestran cómo diferentes enfoques para la optimización de la pila de red de Linux ayudan a resolver problemas de negocio específicos.
Caso 1: Optimización de la pasarela API para un servicio SaaS en la nube
Problema: Un gran servicio SaaS, que proporciona API para aplicaciones móviles y web, experimentó una alta latencia y errores aleatorios de Connection Refused bajo carga máxima (hasta 50 000 RPS). El monitoreo mostró que la CPU de las pasarelas API (basadas en Nginx y Envoy) estaba cargada entre un 70 y un 80%, y los registros del kernel mostraban mensajes de desbordamiento de LISTEN-backlog. Los servidores funcionaban en instancias AWS c5n.xlarge (4 vCPU, 10 Gbps NIC).
Solución:
Configuración de sysctl:
Se aumentó net.core.somaxconn de 128 a 16384, y net.ipv4.tcp_max_syn_backlog de 1024 a 8192. Esto permitió al kernel manejar más intentos de conexión simultáneos.
Se activó net.ipv4.tcp_tw_reuse = 1 y se redujo net.ipv4.tcp_fin_timeout = 30 para liberar puertos más rápidamente después de conexiones HTTP cortas.
Se estableció net.ipv4.tcp_congestion_control = bbr para un mejor rendimiento a través de WAN.
Descargas de hardware de NIC:
Se verificaron y activaron TSO, GSO, GRO usando ethtool -K eth0 rx on tx on sg on tso on gso on gro on. Esto redujo significativamente la carga de la CPU relacionada con la segmentación y el ensamblaje de paquetes.
Se configuró el balanceo de IRQ con irqbalance y, adicionalmente, se vincularon manualmente las colas RSS a diferentes vCPU para distribuir uniformemente el procesamiento de interrupciones.
XDP para protección DDoS:
Se implementó un programa XDP simple que, a nivel del controlador de NIC, descarta paquetes con firmas conocidas de ataques DDoS (por ejemplo, SYN-flood con banderas o fuentes anómalas) antes de que lleguen a la pila de red principal y a Nginx.
Resultados:
Los errores de Connection Refused desaparecieron por completo.
La latencia promedio de la API se redujo en un 15% (de 40 ms a 34 ms).
El uso de CPU en las pasarelas API disminuyó del 70-80% al 40-50% bajo la misma carga, lo que permitió procesar un 30% más de RPS en una sola instancia.
El ahorro en recursos de la nube fue de aproximadamente $1500 al mes debido a la reducción del número de instancias necesarias.
Caso 2: Optimización de la plataforma para el procesamiento de datos en tiempo real
Problema: Una empresa dedicada al análisis de datos financieros en tiempo real utilizaba un clúster de Kafka para la ingesta y el procesamiento de enormes volúmenes de datos (hasta 20 Gbps de tráfico entrante por nodo). Surgieron problemas de pérdida de paquetes, lo que provocaba retrasos en el procesamiento e imprecisiones en la analítica. El monitoreo mostraba altos valores de rx_dropped y desbordamientos de net.core.netdev_max_backlog.
Solución:
Aumento de los búferes del kernel:
Se aumentaron significativamente net.core.netdev_max_backlog a 65535, así como net.core.rmem_max y net.ipv4.tcp_rmem a 32 MB. Esto permitió al kernel almacenar en búfer más paquetes entrantes en momentos pico, evitando su pérdida.
Se configuró net.ipv4.tcp_wmem para los productores de Kafka para una transmisión más eficiente.
Optimización de NIC:
Se utilizaron NIC de 100GbE con soporte SR-IOV para las máquinas virtuales donde operaban los brokers de Kafka, lo que proporcionó un rendimiento de red casi nativo.
Se configuraron las colas RSS al número máximo correspondiente al número de núcleos de CPU, y se vincularon manualmente las IRQ para evitar la contención.
eBPF para enrutamiento personalizado:
Se desarrolló un programa TC eBPF que, basándose en los encabezados de los mensajes de Kafka (u otros metadatos), redirigía ciertos flujos de datos a temas de Kafka especializados o incluso a otros nodos del clúster, omitiendo el enrutamiento estándar del kernel para datos "calientes". Esto permitió reducir la carga de la CPU de la pila de red estándar y proporcionar una ruta más directa para el tráfico crítico.
Resultados:
La pérdida de paquetes se redujo prácticamente a cero.
El rendimiento del clúster aumentó en un 25%, lo que permitió manejar cargas pico sin degradación.
La latencia de procesamiento de datos se redujo en un 10%, lo cual es crítico para aplicaciones financieras.
Se redujo el número de retransmisiones TCP, lo que disminuyó la carga de la CPU de los brokers de Kafka.
Caso 3: Reducción del coste de infraestructura para un proveedor de CDN
Problema: Un gran proveedor de CDN se enfrentó a costes de infraestructura en constante aumento debido a la necesidad de escalar el número de servidores para atender el tráfico pico. La carga principal era la entrega de contenido estático (vídeos, imágenes), lo que requería un alto ancho de banda y un uso eficiente de la CPU para manejar un gran número de conexiones simultáneas.
Solución:
Elección del algoritmo de control de congestión TCP:
Se activó net.ipv4.tcp_congestion_control = bbr en todos los nodos CDN. Esto permitió mejorar significativamente el rendimiento y reducir la latencia para clientes ubicados a grandes distancias o que utilizan redes con alta latencia, lo cual es especialmente importante para un CDN.
Optimización de búferes y TIME_WAIT:
Los búferes TCP se configuraron con valores óptimos para cada tipo de servidor (grandes para servidores de archivos, medianos para proxies).
net.ipv4.tcp_tw_reuse = 1 se activó en todos los servidores proxy y servidores de origen para evitar el agotamiento de puertos.
Jumbo Frames:
Dentro del centro de datos, donde fue posible, se configuraron Jumbo Frames (MTU 9000) en todas las interfaces de red y conmutadores. Esto permitió transmitir más datos en un solo paquete, reduciendo la sobrecarga de encabezados y el número de paquetes procesados por la CPU.
eBPF para balanceo de carga L4:
En lugar de utilizar costosos balanceadores de carga de hardware o soluciones de software más intensivas en recursos basadas en Nginx, se desarrolló un programa XDP para el balanceo de carga L4 del tráfico entrante. Este programa, que opera en los enrutadores de borde, distribuía las conexiones entrantes a los nodos CDN internos con una sobrecarga y latencia mínimas.
Resultados:
El rendimiento total del CDN aumentó entre un 20 y un 30% sin añadir nuevos servidores.
El número de servidores necesarios para atender la carga máxima se redujo en un 15%, lo que resultó en un ahorro directo en costes de nube/colocación de $5000-$8000 al mes.
La latencia promedio de entrega de contenido para los usuarios finales disminuyó.
La carga de la CPU en los servidores de borde que utilizan el balanceo XDP se redujo significativamente.
Estos casos demuestran que un enfoque integral para la optimización de la pila de red de Linux, que incluye la configuración del kernel, el uso de descargas de hardware y la aplicación de eBPF, puede conducir a mejoras significativas en el rendimiento y a un ahorro sustancial de recursos en una amplia variedad de escenarios.
Herramientas y recursos para la optimización y monitorización
Diagrama: Herramientas y recursos para la optimización y monitorización
Para una optimización exitosa de la pila de red de Linux, se requiere el conjunto adecuado de herramientas para diagnóstico, pruebas, monitorización y depuración. En 2026, existen muchas utilidades potentes, muchas de las cuales forman parte de la distribución estándar de Linux o están disponibles como proyectos de código abierto.
Utilidades para diagnóstico y configuración
ip (iproute2): Un reemplazo moderno para ifconfig y route. Permite gestionar interfaces de red, rutas, tablas ARP y ver estadísticas detalladas.
ip a show eth0 # Mostrar información sobre la interfaz
ip -s link show eth0 # Mostrar estadísticas de la interfaz (errores, caídas)
ip route show # Mostrar la tabla de enrutamiento
ss (socket statistics): Un reemplazo más rápido y potente para netstat para ver información sobre sockets.
ss -s # Estadísticas generales de sockets
ss -tuna # Todos los sockets TCP/UDP, escuchando y establecidos
ss -tuna | grep ESTAB # Solo conexiones TCP establecidas
ss -tuna | grep TIME-WAIT # Sockets en estado TIME_WAIT
ss -m # Mostrar estadísticas de memoria utilizada por los sockets
netstat: Herramienta clásica para estadísticas de red. Aunque ss es preferible para sistemas nuevos, netstat -s proporciona estadísticas extensas por protocolo (TCP, UDP, IP).
netstat -s # Estadísticas generales por protocolo
ethtool: Utilidad para gestionar parámetros de tarjetas de red, incluyendo descargas de hardware, velocidad, dúplex, RSS y otros.
ethtool eth0 # Información general sobre la NIC
ethtool -k eth0 # Estado de las descargas de hardware
ethtool -S eth0 # Estadísticas del controlador de la NIC (incluyendo errores y caídas)
ethtool -L eth0 # Número de colas RX/TX
sysctl: Utilidad para ver y modificar parámetros del kernel de Linux.
sysctl -a | grep net.ipv4 # Todos los parámetros net.ipv4
sysctl -w net.core.somaxconn=4096 # Establecer un parámetro
mpstat / top / htop: Para monitorizar el uso de CPU, especialmente las categorías softirq (si) y system, que a menudo indican actividad de red del kernel.
mpstat -P ALL 1 # Uso de CPU por núcleo, cada segundo
tcpdump / wireshark: Para la captura y análisis de tráfico de red a nivel de paquete. Indispensables para un diagnóstico profundo.
tcpdump -i eth0 -n -s 0 -w capture.pcap # Captura de todo el tráfico en eth0
Herramientas para monitorización y pruebas
iperf3: Estándar para medir el ancho de banda TCP y UDP. Permite probar el rendimiento entre dos puntos.
netperf: Una herramienta más avanzada para medir el rendimiento de la red, incluyendo solicitudes/respuestas, transacciones, etc.
wrk / locust / JMeter: Herramientas para pruebas de carga de aplicaciones web y API. Ayudan a simular carga real e identificar cuellos de botella.
hping3: Herramienta para crear y analizar paquetes TCP/IP, útil para probar firewalls, escanear puertos y medir la latencia.
Prometheus + Grafana: Combinación estándar para la recopilación, almacenamiento y visualización de métricas. Con la ayuda de node_exporter se pueden recopilar todas las métricas del sistema, incluidas las de red.
ELK Stack (Elasticsearch, Logstash, Kibana): Para la recopilación, análisis y visualización de logs, lo que ayuda a identificar errores y anomalías de red.
Herramientas para eBPF
bcc-tools (BPF Compiler Collection): Conjunto de potentes herramientas basadas en eBPF para el rastreo, monitorización y depuración del kernel de Linux, incluida la pila de red. Permite ver qué sucede con los paquetes en diferentes niveles.
tcplife: Muestra la vida útil de las conexiones TCP.
tcpconnect/tcpaccept: Rastrea el establecimiento de conexiones TCP.
dropwatch: Rastrea dónde el kernel descarta paquetes.
xdp_stats: Estadísticas de programas XDP.
bpftool: Utilidad oficial para gestionar programas, mapas y objetos eBPF. Permite cargar, descargar programas, ver su estado y obtener estadísticas.
bpftool prog show # Mostrar todos los programas eBPF cargados
bpftool map show # Mostrar todos los mapas eBPF
libbpf: Biblioteca para el desarrollo de aplicaciones eBPF, simplifica la interacción con el kernel.
LWN.net: Un excelente recurso para artículos técnicos profundos sobre el desarrollo del kernel de Linux, incluyendo la pila de red y eBPF.
TCP Documentation: Información detallada sobre los parámetros TCP en el kernel.
DPDK.org: Sitio web oficial de Data Plane Development Kit.
El uso de estas herramientas y recursos le permitirá no solo optimizar eficazmente la pila de red, sino también comprender profundamente su comportamiento, lo cual es críticamente importante para mantener sistemas de alto rendimiento en 2026.
Troubleshooting: solución de problemas típicos
Diagrama: Troubleshooting: solución de problemas típicos
Incluso con las configuraciones más meticulosas, pueden surgir problemas en la pila de red. La capacidad de diagnosticarlos y resolverlos rápidamente es una habilidad crucial. En esta sección, exploraremos problemas comunes y ofreceremos comandos de diagnóstico y soluciones relevantes para el año 2026.
1. Alta carga de CPU (ksoftirqd / softirq)
Descripción: Si top o mpstat muestran una alta carga de CPU en la categoría si (softirq) o el proceso ksoftirqd consume muchos recursos, esto a menudo indica que el kernel dedica mucho tiempo a procesar interrupciones de red.
Diagnóstico:
mpstat -P ALL 1: Ver la carga de softirq por cada núcleo. Si un núcleo está muy sobrecargado, esto puede indicar un problema con el balanceo de IRQ.
/proc/interrupts: Ver la distribución de IRQ por núcleos. Busque IRQ relacionados con su NIC.
ethtool -S <interface> | grep rx_queue: Verificar el número de paquetes recibidos por cada cola RX. Si una cola recibe significativamente más paquetes, esto es un problema.
Solución:
Active RSS/RPS/RFS: Asegúrese de que el RSS de hardware esté habilitado en la NIC (ethtool -k <interface>). Si no, o adicionalmente, configure RPS/RFS (/sys/class/net/<interface>/queues/rx-<N>/rps_cpus).
Configure irqbalance: Asegúrese de que el servicio irqbalance esté en ejecución. Para un control más preciso, considere la afinidad manual de IRQ a la CPU.
Verifique los offloads: Asegúrese de que TSO, GSO, GRO estén habilitados (ethtool -k <interface>).
Considere XDP: Para PPS muy altos, XDP puede reducir significativamente la carga de CPU, descartando o redirigiendo el tráfico en una etapa temprana.
2. Pérdida de paquetes (Packet Drops)
Descripción: Las aplicaciones informan de tiempos de espera, rendimiento lento, o netstat -s muestra contadores crecientes de packet receive errors, dropped, overruns.
Diagnóstico:
ip -s link show <interface>: Verificar los contadores rx_dropped, tx_dropped, overruns.
netstat -s: Verificar las estadísticas de TCP (segments retransmited), UDP (packet receive errors).
ss -s: Verificar recv-Q y send-Q para los sockets, así como los contadores globales.
ethtool -S <interface>: Verificar los contadores de errores y descartes a nivel del controlador de la NIC (por ejemplo, rx_dropped_by_nic, rx_fifo_errors).
dmesg | grep "tx ring": Buscar mensajes sobre el desbordamiento de los búferes de la NIC.
Solución:
Aumente los búferes del kernel:net.core.netdev_max_backlog, net.core.rmem_max, net.ipv4.tcp_rmem, net.ipv4.tcp_wmem.
Aumente la cola TX de la NIC:ip link set dev <interface> txqueuelen <value> (por ejemplo, 10000).
Verifique la capa física: Un cable defectuoso, un puerto de switch o una incompatibilidad de velocidad/dúplex pueden causar descartes.
Elimine la sobrecarga de CPU: Si los descartes están relacionados con una alta carga de CPU, aplique las soluciones del punto 1.
XDP para descarte temprano: Si los descartes son causados por tráfico no deseado (DDoS), XDP puede descartarlo antes de que los búferes se desborden.
3. Conexiones lentas o alta latencia
Descripción: Las aplicaciones responden lentamente, ping muestra un RTT alto, traceroute revela latencias en la ruta de red.
Diagnóstico:
ping <destination>: Mida el RTT.
traceroute <destination>: Determine en qué host/enrutador se produce la latencia.
ss -tin: Verificar el RTT para las conexiones TCP establecidas.
netstat -s | grep "retransmited": Un alto número de retransmisiones indica pérdida de paquetes, lo que aumenta la latencia.
Solución:
Verifique el algoritmo de control de congestión: Establezca net.ipv4.tcp_congestion_control = bbr, especialmente para conexiones WAN.
Configure los búferes: Asegúrese de que tcp_rmem y tcp_wmem sean lo suficientemente grandes para su ancho de banda y latencia.
Habilite TCP Fast Open:net.ipv4.tcp_fastopen = 3 para reducir la latencia de establecimiento de conexiones.
Elimine la pérdida de paquetes: Si la latencia es causada por retransmisiones, resuelva el problema de pérdida de paquetes.
Verifique el MTU: Un MTU inconsistente puede llevar a la fragmentación y a una reducción del rendimiento.
4. "Connection refused" o "Too many open files"
Descripción: Las aplicaciones no pueden establecer nuevas conexiones, los servidores se niegan a aceptar conexiones.
Diagnóstico:
ss -s | grep -i "listen": Verificar el número de sockets en estado LISTEN y su backlog.
dmesg | grep "TCP: request_sock_TCP: dropped": Mensajes sobre paquetes SYN descartados.
ulimit -n: Verificar el límite de descriptores de archivo abiertos para el proceso.
cat /proc/sys/fs/file-nr: Número total de descriptores de archivo abiertos en el sistema.
Solución:
Aumente somaxconn y tcp_max_syn_backlog:net.core.somaxconn, net.ipv4.tcp_max_syn_backlog.
Aumente el límite de descriptores de archivo: Configure ulimit -n para el usuario/aplicación y el límite del sistema fs.file-max en sysctl.
Verifique los sockets TIME_WAIT: Si hay muchos sockets en TIME_WAIT, active net.ipv4.tcp_tw_reuse = 1.
Verifique el firewall: Asegúrese de que el firewall (iptables, nftables) no esté bloqueando las conexiones entrantes.
5. Uso ineficiente de CPU en sistemas NUMA
Descripción: En servidores con arquitectura NUMA (Non-Uniform Memory Access), se observa una carga de CPU desigual, o las aplicaciones experimentan latencias al acceder a la memoria, aunque la carga general de CPU no sea alta.
Diagnóstico:
numactl --hardware: Verificar la topología NUMA.
numastat: Estadísticas de uso de memoria por nodos NUMA.
mpstat -N ALL: Carga de CPU por nodos NUMA.
Solución:
Afinidad de IRQ a nodos NUMA: Asigne los IRQ de la tarjeta de red a las CPU que se encuentran en el mismo nodo NUMA que la NIC.
Afinidad de procesos a nodos NUMA: Utilice numactl --cpunodebind=<node> --membind=<node> <command> para ejecutar aplicaciones de red en el mismo nodo NUMA que la NIC correspondiente.
Configuración de RPS/RFS con consideración NUMA: Al configurar RPS/RFS, asegúrese de que los paquetes se dirijan a las CPU que se encuentran en el mismo nodo NUMA que el manejador de la aplicación.
Cuándo contactar al soporte:
Si los problemas surgen después de una actualización del kernel o del controlador de la NIC, y no puede encontrar una solución.
Si sospecha de una falla de hardware de la NIC, pero no puede confirmarla.
Si experimenta caídas o bloqueos inexplicables del sistema relacionados con la pila de red.
Si no puede alcanzar el rendimiento esperado después de todas las optimizaciones aplicadas y ha agotado sus conocimientos.
FAQ: Preguntas frecuentes
1. ¿Es eBPF siempre la mejor solución para la optimización de red?
No, no siempre. eBPF es una herramienta potente que ofrece una flexibilidad y un rendimiento sin precedentes para tareas específicas, como la protección contra DDoS, el balanceo de carga personalizado o la monitorización avanzada. Sin embargo, su implementación requiere alta cualificación y un esfuerzo de ingeniería considerable. Para la mayoría de las aplicaciones estándar de alta carga, como servidores web o bases de datos, serán suficientes y más fáciles de implementar un ajuste fino de sysctl, la activación de descargas de hardware de NIC y la elección correcta del algoritmo de congestión TCP. eBPF debe considerarse cuando otros métodos se han agotado o se requiere una lógica de procesamiento de paquetes muy específica y de bajo nivel.
2. ¿Conviene desactivar todas las marcas de tiempo TCP (tcp_timestamps) para mejorar el rendimiento?
En la mayoría de los casos, no. Aunque desactivar tcp_timestamps ahorra 12 bytes en cada encabezado TCP, este ahorro es insignificante para las redes modernas de alta velocidad. Las marcas de tiempo juegan un papel importante en la protección contra segmentos obsoletos (PAWS - Protection Against Wrapped Sequence numbers) y en una medición más precisa del RTT. Su desactivación puede provocar problemas de estabilidad en las conexiones, especialmente en redes con alta latencia o con una creación/cierre de conexiones muy rápida. Se recomienda dejarlas activadas a menos que haya pruebas concretas de que están causando problemas.
3. ¿Con qué frecuencia se deben revisar las configuraciones de la pila de red?
Las configuraciones de la pila de red no son estáticas. Deben revisarse ante cambios significativos:
Actualización del kernel de Linux: Las nuevas versiones pueden introducir nuevos parámetros o cambiar el comportamiento de los existentes.
Actualización de hardware: Las nuevas NIC pueden tener diferentes capacidades de descarga.
Cambio en el perfil de carga de la aplicación: Aumento del tráfico, cambio en los tipos de solicitudes, incremento en el número de conexiones.
Aparición de nuevos problemas de red: Pérdida de paquetes, alta latencia, sobrecarga de CPU.
Por lo general, se recomienda realizar una auditoría de las configuraciones al menos una vez cada 6-12 meses o después de cada cambio importante en la infraestructura o la aplicación.
4. ¿Cuál es el impacto de tcp_tw_reuse en la seguridad?
tcp_tw_reuse permite reutilizar sockets en estado TIME_WAIT para nuevas conexiones salientes. Esto es seguro para clientes o proxies que inician muchas conexiones. Sin embargo, en un servidor que acepta conexiones entrantes, la activación de tcp_tw_reuse puede ser arriesgada si este servidor se encuentra detrás de un NAT que no cumple con RFC 1323 (TCP Timestamps). En tal caso, el servidor podría aceptar un paquete con un número de secuencia obsoleto de una nueva conexión, confundiéndolo erróneamente con parte de una conexión antigua, lo que podría llevar a la corrupción de datos o inestabilidad. Por lo tanto, tcp_tw_reuse generalmente se recomienda activar solo en máquinas cliente o en servidores que no están detrás de un NAT y no aceptan conexiones entrantes.
5. ¿Pueden estas optimizaciones interrumpir el funcionamiento de mi aplicación?
Sí, una optimización incorrecta puede llevar a inestabilidad, reducción del rendimiento o incluso a la caída del sistema. Por ejemplo, búferes demasiado grandes pueden causar un aumento de la latencia (bufferbloat), mientras que búferes demasiado pequeños pueden provocar pérdida de paquetes. Una configuración incorrecta de IRQ o RSS puede causar un desequilibrio en la carga de la CPU. Por eso es crucial un enfoque iterativo: realice los cambios uno por uno, pruébelos en un entorno controlado, supervise el efecto y esté preparado para revertirlos. Nunca aplique cambios en producción sin pruebas previas.
6. ¿Cuál es el papel de systemd-networkd y NetworkManager en el contexto de estas optimizaciones?
systemd-networkd y NetworkManager son servicios que gestionan las interfaces de red y su configuración a un nivel superior. Son responsables de la asignación de direcciones IP, la configuración de DNS, el enrutamiento y otros parámetros de red básicos. La mayoría de las optimizaciones descritas aquí (sysctl, ethtool) operan a un nivel inferior del kernel o del controlador de la NIC y, por lo general, no entran en conflicto con estos servicios. Sin embargo, es importante asegurarse de que estos servicios no sobrescriban sus configuraciones manuales (por ejemplo, MTU, o algunos parámetros de ethtool). Para preservar las configuraciones de ethtool después de un reinicio, a menudo se requieren scripts adicionales o archivos de configuración específicos para su sistema de inicialización.
7. ¿Cómo afectan los entornos de nube a estas optimizaciones?
En entornos de nube (AWS, GCP, Azure), se trabaja con hardware virtualizado. Algunas descargas de hardware de NIC (por ejemplo, SR-IOV) pueden estar disponibles solo en ciertos tipos de instancias. Las capacidades de configuración del kernel permanecen, pero puede haber limitaciones para cambiar algunos parámetros en entornos de contenedores (por ejemplo, en Kubernetes, donde algunos sysctl pueden estar bloqueados). A menudo, los proveedores de la nube ya aplican optimizaciones básicas a nivel de hipervisor. Es importante consultar la documentación de su proveedor de la nube con respecto a las funciones de red disponibles y las recomendaciones de optimización para su plataforma.
8. ¿Cuándo se debe considerar el espacio de usuario (DPDK) en lugar de eBPF?
DPDK debe considerarse solo en los escenarios más extremos, cuando incluso las optimizaciones XDP no proporcionan el rendimiento requerido. Esto generalmente se aplica a sistemas de telecomunicaciones, trading de alta frecuencia (HFT), routers/firewalls especializados y NFV, donde se requiere el procesamiento de decenas de millones de paquetes por segundo con latencias de microsegundos. La implementación de DPDK requiere una omisión completa de la pila de red del kernel, lo que significa que su aplicación debe ser escrita o reescrita para trabajar con las bibliotecas DPDK. Esto aumenta significativamente la complejidad del desarrollo, el soporte y se pierden las ventajas de las utilidades de red estándar de Linux.
9. ¿Cuál es el futuro de la optimización de red más allá de eBPF?
El futuro de la optimización de red en 2026 y más allá promete ser emocionante. Continuará el desarrollo de eBPF, aparecerán nuevos tipos de programas y puntos de conexión, y se expandirán las capacidades de descarga de hardware. Veremos una mayor integración con inteligencia artificial y aprendizaje automático para la optimización adaptativa de la red en tiempo real, la predicción de congestiones y la aplicación automática de configuraciones. También se desarrollarán tecnologías como las SmartNICs (tarjetas de red programables con sus propias CPU/FPGA), que asumirán aún más lógica de red. Las redes cuánticas y los nuevos protocolos también pueden introducir sus ajustes, pero los principios básicos del procesamiento eficiente de paquetes seguirán siendo relevantes.
10. ¿Es seguro usar BBR en producción?
Sí, BBR se considera seguro para usar en producción y a menudo se recomienda. Fue desarrollado por Google y es ampliamente utilizado en su infraestructura, así como en muchas CDN y servicios en la nube. BBR generalmente proporciona un mejor rendimiento y menor latencia en comparación con CUBIC, especialmente en conexiones WAN. Sin embargo, como cualquier algoritmo de control de congestión, BBR puede ser más agresivo en ciertas condiciones de red, lo que potencialmente podría desplazar el tráfico que utiliza algoritmos más antiguos. En la mayoría de los casos, esto no es un problema, pero en redes muy específicas y altamente congestionadas con tráfico heterogéneo, podría ser necesario un monitoreo adicional.
Conclusión
En un contexto de crecientes demandas de rendimiento y escalabilidad de las aplicaciones modernas, la optimización de la pila de red de Linux ha dejado de ser una tarea opcional para convertirse en un elemento crítico de una infraestructura exitosa. En 2026, cuando cada milisegundo de latencia y cada porcentaje de uso de CPU pueden influir directamente en las métricas de negocio, una comprensión profunda y una aplicación hábil de las técnicas de optimización son una ventaja competitiva.
Hemos recorrido el camino desde las configuraciones básicas del kernel mediante sysctl, que siguen siendo la base para la mayoría de los sistemas, hasta el uso de descargas de hardware avanzadas en tarjetas de red, capaces de reducir significativamente la carga de la CPU. Se prestó especial atención a eBPF, una tecnología que está revolucionando el procesamiento de red, proporcionando capacidades sin precedentes para programar el kernel sin modificarlo, abriendo las puertas a firewalls de alto rendimiento, balanceadores de carga y sistemas de monitorización que operan a velocidad de línea. También hemos considerado soluciones extremas, como DPDK, para los escenarios más exigentes.
Conclusiones clave que debe asimilar:
La medición lo es todo: Nunca optimice a ciegas. Siempre comience con el benchmarking y monitoree constantemente el impacto de los cambios.
Enfoque integral: La optimización es un proceso multinivel que afecta al kernel, los controladores, el hardware e incluso las aplicaciones.
Iteración y precaución: Realice los cambios gradualmente, pruebe en un entorno aislado y siempre tenga un plan de reversión.
Comprensión del contexto: No existen configuraciones "mejores" universales. La configuración óptima depende de su carga específica, hardware y entorno de red.
eBPF: el futuro, pero no una panacea: Una herramienta potente que requiere conocimientos profundos, pero no siempre necesaria. Comience con métodos más sencillos.
Próximos pasos para el lector:
Comience auditando su infraestructura actual. Identifique los cuellos de botella utilizando las herramientas de diagnóstico descritas en este artículo. Luego, aplicando la lista de verificación, comience con las configuraciones básicas de sysctl y ethtool. Mida y compare los resultados constantemente. A medida que profundice en los problemas de rendimiento, considere métodos más avanzados, como eBPF. Invierta en la capacitación de su equipo para que puedan utilizar eficazmente estas potentes herramientas.
El mundo de las tecnologías de red de Linux está en constante evolución. Manténgase curioso, experimente y no tema sumergirse en las profundidades del kernel. Solo así podrá construir sistemas verdaderamente de alto rendimiento y tolerantes a fallos, capaces de soportar cualquier carga en 2026 y más allá.