Balanceo de Carga Global y Failover DNS: Arquitectura de Aplicaciones SaaS Tolerantes a Fallos
TL;DR
- Arquitectura multirregional: la base de la tolerancia a fallos. El despliegue de aplicaciones SaaS en múltiples regiones geográficas es fundamental para minimizar el tiempo de inactividad y aumentar la disponibilidad.
- Balanceo de Carga Global (GLB): su director de tráfico. Utilice proveedores de DNS con funciones avanzadas (Route 53, Azure DNS Traffic Manager, Google Cloud DNS con GLB) para enrutar inteligentemente a los usuarios a las instancias más cercanas y saludables.
- Failover DNS: un salvavidas en caso de desastre. Conmutación automática del tráfico a una región de respaldo en caso de fallo de la principal, minimizando el RTO (Recovery Time Objective).
- Comprobaciones de salud activas (Health Checks): los ojos y oídos de su sistema. Configure comprobaciones profundas y multinivel para monitorear la disponibilidad y el rendimiento de los servicios, no solo a nivel de red.
- Estrategia de datos: la parte más compleja del rompecabezas. La replicación de bases de datos (Active-Active, Active-Passive) y la sincronización de cachés son aspectos clave para mantener la integridad de los datos durante la conmutación.
- Pruebas y automatización: no un lujo, sino una necesidad. Realice simulacros de recuperación ante desastres regularmente y automatice los procesos de conmutación para garantizar la funcionalidad de la arquitectura.
- Costo: un factor significativo que requiere optimización. La multirregionalidad aumenta los gastos, pero un sistema bien diseñado puede proporcionar un equilibrio óptimo entre disponibilidad y costos.
Introducción
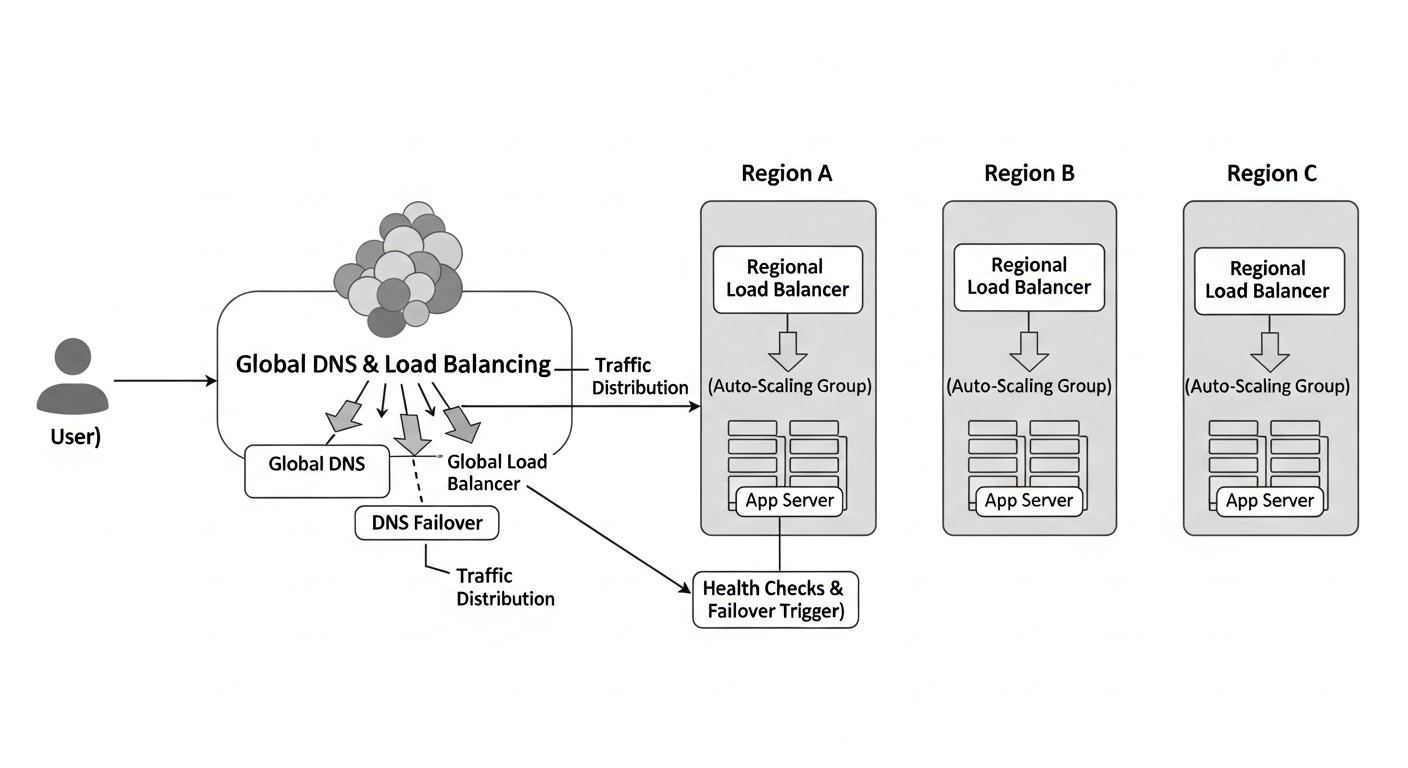 Diagrama: Introducción
Diagrama: Introducción
En el mundo moderno, donde la digitalización ha penetrado en todas las esferas de los negocios y las expectativas de los usuarios sobre la disponibilidad de los servicios se acercan al 100%, la arquitectura de aplicaciones SaaS altamente confiables ha dejado de ser una opción para convertirse en una necesidad absoluta. Para 2026, las empresas que no puedan garantizar la continuidad de sus servicios corren el riesgo de perder clientes, reputación y, en última instancia, cuota de mercado. Un tiempo de inactividad de unos pocos minutos puede resultar en pérdidas millonarias y daños irreparables para la marca.
Este artículo está dedicado a dos pilares fundamentales en la construcción de aplicaciones SaaS tolerantes a fallos: el balanceo de carga global (Global Load Balancing, GLB) y el failover DNS. Nos sumergiremos profundamente en los mecanismos que permiten distribuir el tráfico entre centros de datos geográficamente dispersos y conmutar automáticamente a sistemas de respaldo en caso de problemas. Estas no son solo conceptos técnicos; son elementos fundamentales de la estrategia de supervivencia de cualquier proyecto SaaS en un entorno de crecientes demandas de disponibilidad y rendimiento.
Examinaremos por qué estas tecnologías son importantes no solo para grandes corporaciones, sino también para startups que buscan escalar y tener una presencia global. El artículo cubre aspectos prácticos de implementación, desde la elección de proveedores adecuados hasta los matices de configuración y monitoreo. Está escrito para ingenieros DevOps, desarrolladores backend, fundadores de proyectos SaaS, administradores de sistemas y directores técnicos que enfrentan los desafíos de garantizar alta disponibilidad, resiliencia ante desastres y un rendimiento óptimo de sus aplicaciones.
El problema principal que resuelve esta guía es la construcción de una arquitectura capaz de soportar fallos regionales, problemas de red o incluso desastres completos en uno de los centros de datos, minimizando al mismo tiempo el tiempo de inactividad y la pérdida de datos. Mostraremos cómo, con la ayuda de GLB y failover DNS, no solo se pueden reducir los riesgos, sino también mejorar la experiencia del usuario, dirigiendo el tráfico a los servidores más cercanos, reduciendo así las latencias. Prepárese para una inmersión profunda en el mundo de los sistemas distribuidos, donde cada byte de datos y cada milisegundo de latencia importan.
Criterios y factores clave
Al diseñar la arquitectura de balanceo de carga global y failover DNS, es necesario considerar muchos factores que influyen directamente en la fiabilidad, el rendimiento y el costo de su plataforma SaaS. La elección de la solución correcta depende de la especificidad de su aplicación, su público objetivo y los requisitos comerciales. Examinemos los criterios clave que le ayudarán a tomar una decisión informada.
Este es el criterio más obvio y, quizás, el más importante. La disponibilidad se mide por el porcentaje de tiempo durante el cual el servicio está disponible para los usuarios (por ejemplo, 99.99% son solo 52 minutos de inactividad al año). La resiliencia, por su parte, caracteriza la capacidad del sistema para recuperarse después de fallos. Para GLB y failover DNS, esto significa la capacidad de conmutar el tráfico de forma rápida y automática a recursos saludables en otra región en caso de fallo de la principal. Es importante evaluar:
- RTO (Recovery Time Objective): Tiempo máximo de inactividad permitido después de un fallo. Cuanto menor sea el RTO, más compleja y costosa será la arquitectura. Para aplicaciones SaaS críticas, el RTO puede ser de segundos o incluso milisegundos.
- RPO (Recovery Point Objective): Volumen máximo permitido de pérdida de datos, medido en tiempo. Para muchas SaaS, el RPO debe tender a cero, lo que requiere replicación de datos síncrona o asíncrona entre regiones.
- Mecanismos de detección de fallos: ¿Con qué rapidez y precisión el sistema GLB puede detectar un fallo en una región o servicio específico? Esto incluye varios tipos de health checks (HTTP, TCP, ICMP, scripts personalizados).
- Velocidad de conmutación (Failover Speed): Tiempo necesario para redirigir el tráfico después de detectar un fallo. Para el failover DNS, esto depende en gran medida del TTL (Time To Live) de los registros DNS y del almacenamiento en caché por parte de los clientes y proveedores.
Los usuarios esperan que las aplicaciones funcionen rápidamente. Ubicar los recursos más cerca de los usuarios reduce significativamente la latencia. GLB puede utilizar el enrutamiento geográfico o el enrutamiento basado en latencia para dirigir las solicitudes al centro de datos más cercano o con mejor rendimiento. Evalúe:
- Distribución geográfica de usuarios: ¿Dónde se encuentran sus usuarios principales? Esto ayudará a determinar la ubicación óptima de las regiones.
- Mecanismos de enrutamiento: ¿La solución GLB elegida soporta enrutamiento geográfico, por latencia, por peso o una combinación de estos métodos?
- Impacto en la CDN: ¿Cómo interactuará GLB con su Content Delivery Network? La optimización de esta conexión es crítica para el contenido estático.
Las aplicaciones SaaS deben estar preparadas para el crecimiento de la carga. GLB y el failover DNS deben permitir añadir fácilmente nuevas regiones o aumentar los recursos en las existentes sin interrumpir el funcionamiento del sistema. Aspectos importantes:
- Escalabilidad horizontal: Capacidad de añadir fácilmente nuevas instancias o incluso regiones enteras.
- Integración con servicios en la nube: ¿Qué tan bien se integra la solución GLB con el escalado automático en la nube (Auto Scaling Groups, VM Scale Sets)?
- Gestión de la configuración: ¿Qué tan fácil es gestionar la configuración de GLB a medida que crece la infraestructura?
La arquitectura multirregional es por defecto más cara que una monorregional. Es importante evaluar cuidadosamente todos los componentes de los costos:
- Costo de los servicios GLB/DNS: Tarifa por solicitudes, por health checks, por zonas.
- Costo de la infraestructura en varias regiones: Máquinas virtuales, bases de datos, almacenamiento, componentes de red.
- Tráfico entre regiones (Egress/Ingress): El tráfico interregional suele ser uno de los elementos más caros en las facturas de la nube.
- Costo de desarrollo y operación: Horas adicionales de ingenieros para el diseño, implementación y soporte de una arquitectura compleja.
- Costos ocultos: Por ejemplo, licencias de software, herramientas de monitoreo adicionales.
Cuanto más complejo es el sistema, mayor es el riesgo de errores y más caro es su mantenimiento. La facilidad de configuración, gestión y monitoreo juega un papel importante. Evalúe:
- Curva de aprendizaje: ¿Qué tan rápido su equipo podrá dominar la solución elegida?
- Integración: ¿Qué tan fácil es integrar GLB con su CI/CD existente, sistemas de monitoreo y alerta?
- Documentación y soporte: Calidad de la documentación y disponibilidad de soporte técnico del proveedor.
El uso de servicios específicos de un único proveedor de la nube puede dificultar la migración o el uso de una estrategia multinube en el futuro. Evalúe:
- Estandarización: ¿La solución utiliza protocolos estándar (DNS) o APIs propietarias?
- Portabilidad: ¿Qué tan fácil será migrar su configuración GLB o incluso toda la aplicación a otro proveedor?
Para algunas industrias o tipos de datos, existen requisitos estrictos sobre la ubicación y el procesamiento de los datos. GLB debe permitir el cumplimiento de estos requisitos.
- Soberanía de datos: Capacidad de garantizar que los datos de los usuarios de una región específica permanezcan en esa región.
- Normas regulatorias: Cumplimiento de GDPR, HIPAA, PCI DSS y otros estándares.
Un análisis cuidadoso de estos criterios en las primeras etapas del diseño evitará errores costosos y permitirá construir una arquitectura fiable, escalable y económicamente eficiente para su aplicación SaaS.
Tabla comparativa de soluciones para GLB y DNS Failover
 Esquema: Tabla comparativa de soluciones para GLB y DNS Failover
Esquema: Tabla comparativa de soluciones para GLB y DNS Failover
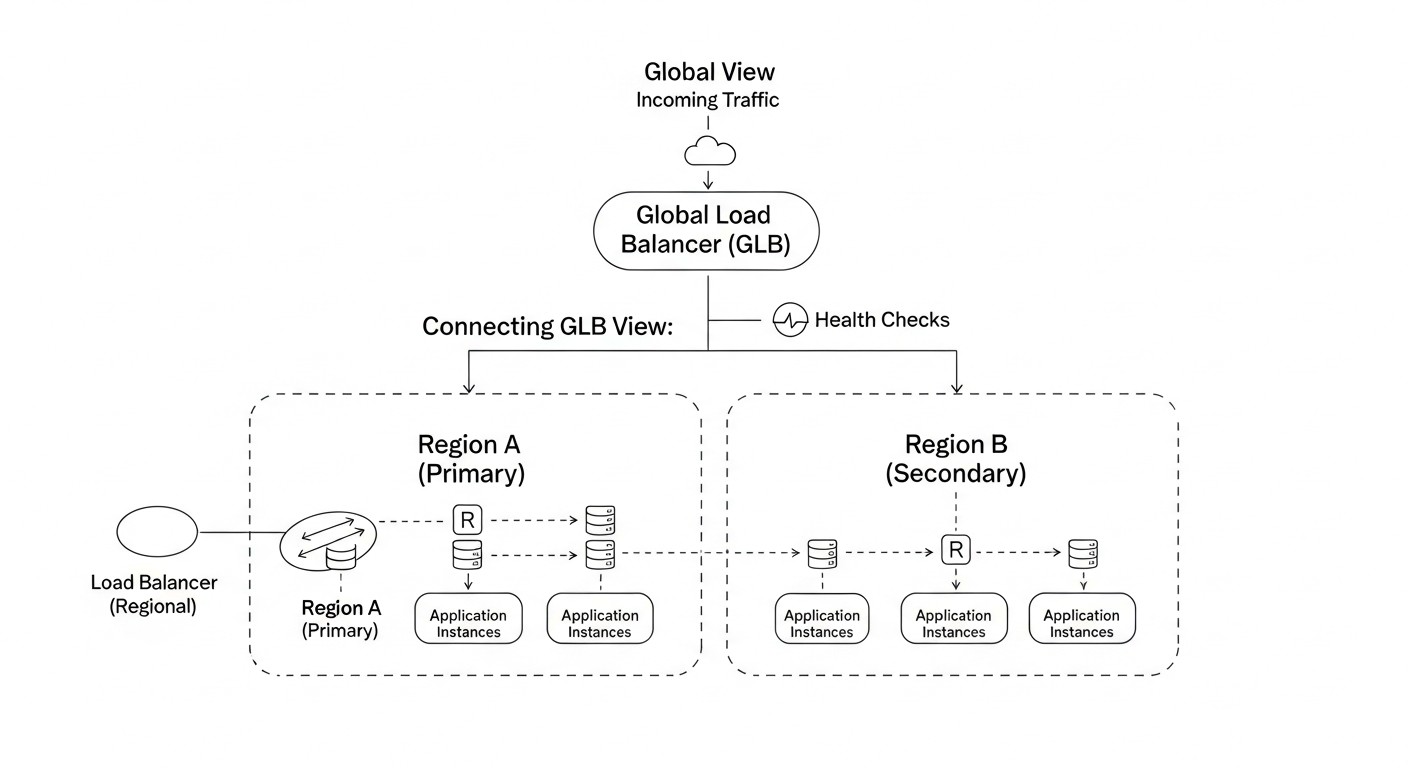
La elección de una solución específica para el balanceo de carga global y el DNS Failover depende de múltiples factores, incluyendo su presupuesto, requisitos de rendimiento, complejidad de la infraestructura y el grado de dependencia de un proveedor de la nube. En esta tabla, compararemos los enfoques y servicios más populares, relevantes para el año 2026, considerando sus capacidades, costos y aplicabilidad.
| Criterio |
DNS GLB Gestionado (AWS Route 53 Traffic Flow, Azure Traffic Manager, Google Cloud DNS con Health Checks) |
CDN con GLB (Cloudflare, Akamai, AWS CloudFront con Origin Failover) |
GLB por Software (Nginx Plus, HAProxy Enterprise + Consul/Zookeeper) |
Anycast DNS (Cloudflare DNS, Google Public DNS, proveedores especializados) |
GLB Multi-nube/Híbrido (VMware NSX ALB, F5 BIG-IP DNS, NetScaler GSLB) |
| Tipo de solución |
Servicio DNS en la nube con capacidades avanzadas de enrutamiento y health checks. |
Red global de entrega de contenido con función de enrutamiento de solicitudes a los mejores servidores Origin. |
Software desplegado en su infraestructura (VMs, contenedores). |
Tecnología de red especializada para enrutar solicitudes DNS al servidor más cercano. |
Solución integral para el balanceo de carga en entornos híbridos y multi-nube. |
| Mecanismo de enrutamiento |
Registros DNS (A, CNAME) con geo-targeting, basados en latencia, ponderados, por health check. |
Proxy HTTP(S), balanceo L7, geo-enrutamiento, basado en el rendimiento del Origin. |
Balanceo L4/L7, geo-targeting (a través de DNS o direcciones IP), basado en health checks. |
Enrutamiento BGP de direcciones IP, dirige solicitudes UDP al nodo más cercano. |
Balanceo DNS (GSLB), enrutamiento inteligente, L4/L7, integración con nubes. |
| Velocidad de Failover (RTO) |
Depende del TTL de los registros DNS (de 30-60 seg a 5-10 min). Health checks hasta 10-30 seg. |
Instantáneo (pocos segundos) gracias al proxy y a los health checks constantes de los servidores Origin. |
Instantáneo (pocos segundos) gracias a los health checks locales y la conmutación a nivel L4/L7. |
Instantáneo a nivel de solicitud DNS (no afecta las conexiones activas). |
De 5 segundos (L7) a 1-2 minutos (DNS GSLB) dependiendo de la configuración. |
| RPO (pérdida de datos) |
Depende de la estrategia de replicación de bases de datos, no del GLB. |
Depende de la estrategia de replicación de bases de datos, no del CDN. |
Depende de la estrategia de replicación de bases de datos, no del GLB. |
Depende de la estrategia de replicación de bases de datos, no del DNS. |
Depende de la estrategia de replicación de bases de datos, no del GSLB. |
| Costo aproximado (2026) |
$0.50-$1.00 por zona/mes + $0.005-$0.007 por 1M de solicitudes + $0.70-$1.00 por health check/mes. |
Desde $20/mes (Pro) hasta $2000+/mes (Enterprise), depende del tráfico y las funciones. Incluye CDN. |
Licencias desde $1000-$5000+ por instancia/año. Se requieren VM/servidores. Altos costos operativos. |
A menudo incluido en las tarifas básicas de los proveedores de DNS (Cloudflare Free/Pro). Para grandes volúmenes, desde $200/mes. |
Licencias desde $5000-$20000+ por dispositivo/año. Altos costos operativos. |
| Complejidad de implementación |
Media. Requiere comprensión de DNS, health checks y despliegues regionales. |
Baja-Media. Configuración DNS sencilla, pero optimización compleja de CDN y Origin. |
Alta. Requiere un conocimiento profundo de tecnologías de red, SO, scripting y clustering. |
Baja. Simple cambio de registros NS. La configuración es específica del proveedor. |
Muy alta. Requiere conocimientos expertos en tecnologías de red, soluciones de hardware e integración. |
| Flexibilidad y personalización |
Alta. Políticas de enrutamiento flexibles, integración con otros servicios en la nube. |
Media. Personalización de reglas de caché, WAF, pero limitada en el enrutamiento de Origin. |
Muy alta. Control total sobre la lógica de balanceo, scripts, módulos. |
Baja. Se enfoca en el enrutamiento de solicitudes DNS, no en el tráfico de aplicaciones. |
Muy alta. Control total sobre todos los aspectos del balanceo y enrutamiento. |
| Gestión de datos |
No gestiona datos, solo tráfico. |
Almacena en caché contenido estático, puede afectar el dinámico. |
No gestiona datos, solo tráfico. |
No gestiona datos, solo tráfico. |
No gestiona datos, solo tráfico. |
| Escenarios de uso |
La mayoría de aplicaciones SaaS, despliegues multiregionales, pruebas A/B, despliegue Blue/Green. |
SaaS con gran volumen de contenido estático/dinámico, servicios API, protección contra DDoS. |
Aplicaciones de alto rendimiento, requisitos específicos de L4/L7, on-premise, nubes híbridas. |
Mejora del rendimiento de las solicitudes DNS, distribución de tráfico de bajo nivel, protección DDoS de DNS. |
Grandes empresas, nubes híbridas, estrategias multi-nube, requisitos complejos de seguridad y rendimiento. |
Esta tabla ofrece una visión general de las opciones disponibles. En 2026, se espera una mayor convergencia de estas soluciones, donde los proveedores de la nube ofrecerán una integración más profunda de CDN y GLB, y las soluciones de software serán aún más flexibles gracias a la contenerización y orquestación.
Análisis detallado de cada punto/opción
 Esquema: Análisis detallado de cada punto/opción
Esquema: Análisis detallado de cada punto/opción
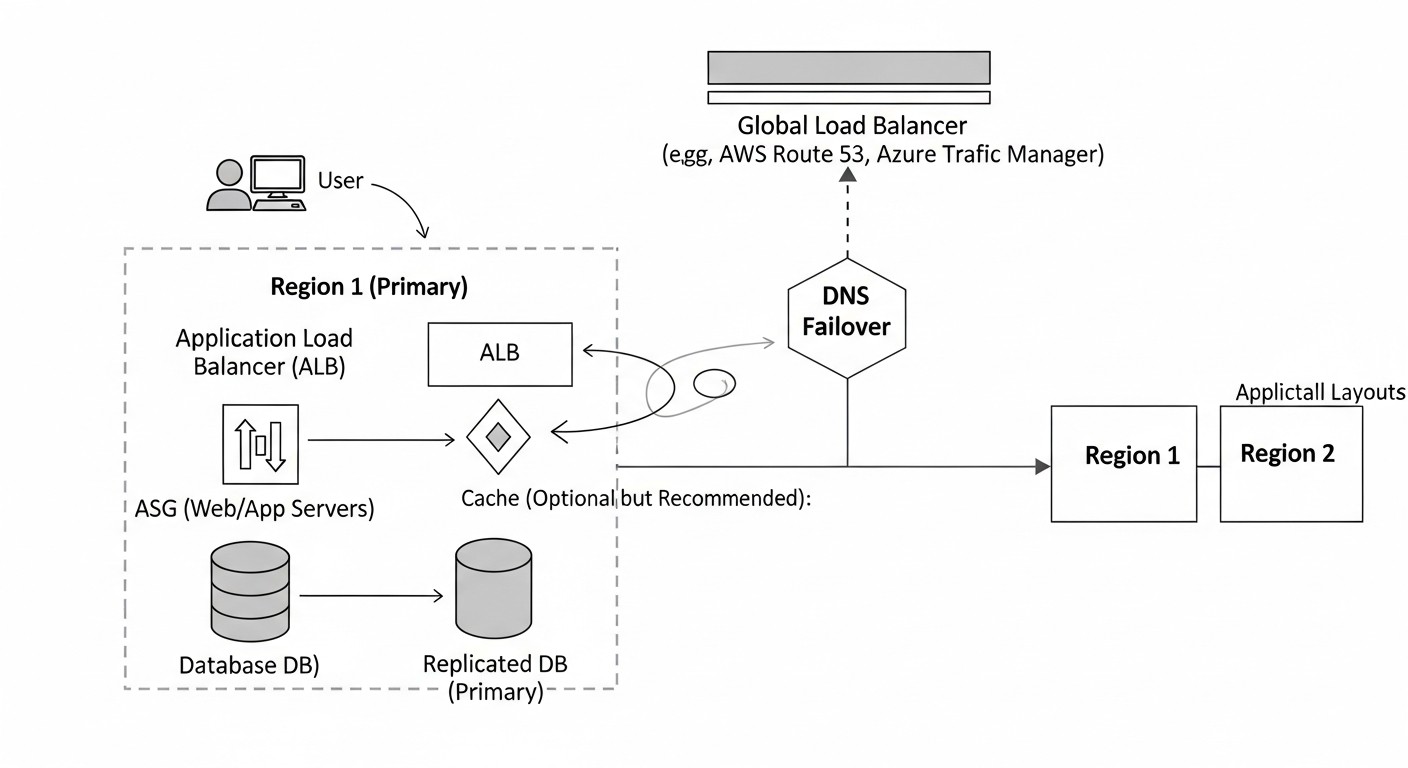
Después de una comparación general, profundicemos en los detalles de cada una de las soluciones presentadas, examinando sus características arquitectónicas, ventajas, desventajas y escenarios de uso óptimos. Comprender estos matices es fundamental para tomar una decisión informada.
Estos servicios ofrecen balanceo de carga global gestionado por DNS. El principio operativo principal es que los servidores DNS del proveedor responden a las solicitudes de los clientes, proporcionando las direcciones IP de los recursos más cercanos o más saludables, basándose en las políticas de enrutamiento configuradas y los resultados de las comprobaciones de estado (health checks). El navegador o la aplicación del cliente se conecta directamente a esa dirección IP.
Cómo funciona: Usted crea múltiples registros DNS (por ejemplo, registros A) para su dominio, cada uno de los cuales apunta a la dirección IP de su aplicación en diferentes regiones. Luego, aplica políticas de enrutamiento (por ejemplo, enrutamiento geográfico, enrutamiento basado en latencia, enrutamiento ponderado) y vincula comprobaciones de estado a cada registro. Cuando un usuario solicita su dominio, el proveedor de DNS verifica las políticas y los resultados de las comprobaciones de estado, y luego devuelve la dirección IP más adecuada. Si una región falla, la comprobación de estado lo detectará, y el proveedor de DNS dejará de emitir su dirección IP, redirigiendo el tráfico a una región saludable.
Ventajas:
- Simplicidad de implementación: Relativamente fácil de configurar, especialmente si ya utiliza un proveedor de la nube.
- Eficiencia de costos: Generalmente más económico que las soluciones L7 complejas, especialmente para cargas de trabajo pequeñas y medianas.
- Enrutamiento geográfico y por latencia: Permite dirigir a los usuarios a los servidores más cercanos, mejorando la experiencia del usuario.
- Integración con la infraestructura de la nube: Profunda integración con otros servicios del proveedor de la nube (EC2, Load Balancers, VMs).
Desventajas:
- Dependencia del TTL: El tiempo de conmutación por error está limitado por el TTL de los registros DNS. Si el TTL es alto (por ejemplo, 5 minutos), los clientes pueden seguir recibiendo la IP de la región defectuosa hasta que expire la caché.
- Caché DNS: Los servidores DNS intermedios y los dispositivos de usuario pueden almacenar en caché los registros, ignorando los cambios rápidos.
- Solo balanceo L4: Las soluciones DNS operan a nivel de direcciones IP. No pueden inspeccionar encabezados HTTP ni realizar un balanceo L7 complejo.
- Complejidad para escenarios multi-nube: El uso de un GLB de un solo proveedor para balancear entre diferentes nubes puede ser difícil o requerir soluciones adicionales.
Para quién es adecuado: La mayoría de las aplicaciones SaaS que desean garantizar la tolerancia a fallos multiregional y optimizar la latencia, especialmente si ya están fuertemente integradas en un único proveedor de la nube. Ideal para pruebas A/B y despliegues Blue/Green a nivel de región.
Las CDN (Content Delivery Network) están diseñadas inicialmente para el almacenamiento en caché y la entrega de contenido estático. Sin embargo, los proveedores de CDN modernos han ampliado significativamente su funcionalidad, ofreciendo capacidades avanzadas de balanceo de carga, conmutación por error y protección. Actúan como proxies inversos, aceptando todo el tráfico en sus nodos perimetrales en todo el mundo y luego redirigiéndolo a sus servidores de origen (Origin).
Cómo funciona: Usted configura su dominio para que apunte a la CDN (generalmente a través de un CNAME). La CDN, a su vez, conoce sus servidores de origen en diferentes regiones. Monitorea constantemente su estado y rendimiento. Cuando un usuario realiza una solicitud, la CDN lo dirige al nodo perimetral más cercano, que luego selecciona el servidor de origen más óptimo (por principio geográfico, latencia, carga) para obtener el contenido o procesar la solicitud dinámica. En caso de fallo de un servidor de origen, la CDN cambia instantáneamente a otro origen saludable, ya que controla todo el tráfico.
Ventajas:
- Conmutación por error instantánea: Dado que la CDN actúa como proxy, puede cambiar instantáneamente el tráfico a un origen saludable, sin esperar a que expire el TTL.
- Rendimiento mejorado: Además del GLB, la CDN almacena en caché el contenido, reduce la latencia y descarga sus servidores de origen.
- Protección DDoS: La mayoría de las CDN proporcionan una potente protección contra ataques DDoS en los nodos perimetrales.
- Balanceo L7: Posibilidad de enrutamiento basado en encabezados HTTP, rutas URL, métodos de solicitud.
- WAF (Web Application Firewall): Protección contra vulnerabilidades web comunes.
Desventajas:
- Costo: Puede ser significativamente más caro que un GLB DNS puro, especialmente con un gran volumen de tráfico.
- Complejidad de configuración: La optimización del almacenamiento en caché, las reglas de WAF y el enrutamiento de origen puede ser compleja.
- Punto único de fallo adicional: La CDN se convierte en un punto único de fallo (aunque las CDN grandes son muy fiables).
- Latencia para contenido dinámico: A pesar de las optimizaciones, el proxy a través de una CDN puede añadir una pequeña latencia para solicitudes completamente dinámicas que no se almacenan en caché.
Para quién es adecuado: Aplicaciones SaaS con alto volumen de tráfico que requieren máxima tolerancia a fallos, baja latencia para contenido estático y dinámico, así como protección integrada contra DDoS y otros ataques web. Ideal para e-commerce, plataformas de medios, servicios API.
Este enfoque implica el despliegue y la gestión de sus propios balanceadores de carga de software en cada región. Estos balanceadores pueden configurarse para operar tanto en niveles L4 como L7, y a menudo utilizan servicios externos para el descubrimiento de servicios (Service Discovery) y la gestión de la configuración.
Cómo funciona: En cada región, usted despliega un clúster de Nginx Plus o HAProxy Enterprise. Estos balanceadores están configurados para distribuir el tráfico entre las instancias internas de su aplicación. Para el balanceo global, utiliza un GLB DNS (como en la primera opción), que apunta a las direcciones IP de sus balanceadores en diferentes regiones. Dentro de cada región, los balanceadores monitorean constantemente el estado de los servidores backend. Para garantizar la tolerancia a fallos y la sincronización de la configuración entre balanceadores y regiones, a menudo se utilizan herramientas como Consul, ZooKeeper o etcd.
Ventajas:
- Control y flexibilidad totales: Máxima personalización de la lógica de balanceo, reglas de enrutamiento, procesamiento de solicitudes.
- Alto rendimiento: Posibilidad de ajuste fino para lograr el máximo rendimiento y la mínima latencia.
- Ausencia de vendor lock-in: No está atado a un proveedor de la nube específico para las funciones de GLB.
- Seguridad: Posibilidad de integración profunda con su propia estrategia de seguridad.
Desventajas:
- Alta complejidad: Requiere un esfuerzo de ingeniería significativo para el despliegue, configuración, monitoreo y soporte.
- Costos operativos: Es necesario gestionar servidores, sistemas operativos, actualizaciones, clustering.
- El RTO depende del DNS: La conmutación por error global seguirá dependiendo del TTL de los registros DNS si utiliza un GLB DNS para cambiar entre regiones.
- Complicaciones con el enrutamiento geográfico: La implementación independiente del enrutamiento geográfico sin un GLB DNS externo puede ser muy compleja.
Para quién es adecuado: Grandes empresas con requisitos específicos de rendimiento, seguridad o funcionalidad, que tienen equipos DevOps sólidos y están dispuestas a invertir en su propia infraestructura. También es adecuado para nubes híbridas o despliegues on-premise donde los servicios GLB en la nube no son aplicables.
Anycast es una tecnología de red en la que una misma dirección IP se enruta a múltiples puntos geográficos. Cuando un cliente envía un paquete a una IP Anycast, la infraestructura de red (BGP) lo dirige al Punto de Presencia (PoP) más cercano que anuncia esa dirección IP. Anycast DNS significa que los servidores DNS del proveedor están disponibles a través de la misma dirección IP en decenas o cientos de PoP en todo el mundo.
Cómo funciona: Su dominio se configura para usar registros NS que apuntan a las direcciones IP Anycast de los servidores DNS del proveedor. Cuando un usuario realiza una solicitud DNS, su solicitud se dirige automáticamente al PoP Anycast más cercano, que luego procesa la solicitud. Esto acelera significativamente la resolución de nombres DNS, ya que la solicitud no tiene que cruzar medio mundo. Es importante tener en cuenta que Anycast funciona a nivel de solicitudes DNS, no a nivel del tráfico de su aplicación. Acelera el proceso de obtención de una dirección IP, pero el tráfico de la aplicación seguirá la ruta normal hacia la IP obtenida.
Ventajas:
- Baja latencia en las solicitudes DNS: Acelera significativamente la resolución de nombres de dominio, ya que la solicitud es procesada por el servidor más cercano.
- Mayor disponibilidad de DNS: En caso de fallo de un PoP, las solicitudes DNS se redirigen automáticamente al siguiente PoP más cercano, lo que garantiza una alta tolerancia a fallos del propio servicio DNS.
- Protección DDoS de DNS: La naturaleza distribuida de Anycast ayuda a absorber los ataques DDoS en DNS, ya que el tráfico se dispersa entre múltiples nodos.
- Simplicidad de configuración: Generalmente se reduce a cambiar los registros NS del dominio.
Desventajas:
- Solo para DNS: Anycast DNS no balancea el tráfico de su aplicación. Solo acelera y hace más tolerante a fallos el proceso de resolución de nombres de dominio. Para balancear el tráfico de la aplicación, seguirá necesitando un GLB (GLB DNS o CDN).
- Sin funciones L7: No proporciona funcionalidad de balanceo a nivel de aplicación, WAF o almacenamiento en caché.
- Costo: Aunque algunos proveedores ofrecen Anycast DNS de forma gratuita (Cloudflare Free), para funciones más avanzadas y SLA puede ser necesaria una suscripción de pago.
Para quién es adecuado: Todas las aplicaciones SaaS para mejorar el rendimiento y la tolerancia a fallos de las solicitudes DNS. Es un excelente complemento para cualquiera de las soluciones GLB mencionadas anteriormente, pero no las reemplaza. Es esencial para proyectos SaaS globales.
Estas soluciones representan sistemas de balanceo de carga empresariales diseñados para operar en entornos complejos y heterogéneos, incluyendo infraestructuras multi-nube, híbridas y on-premise. Ofrecen gestión centralizada del balanceo de carga global, conmutación por error, así como capacidades avanzadas de balanceo L4/L7 y seguridad.
Cómo funciona: Estos sistemas se despliegan como dispositivos virtuales o de hardware en cada uno de sus centros de datos o regiones de la nube. Pueden utilizar tanto métodos DNS (GSLB – Global Server Load Balancing) como métodos de proxy directo para el enrutamiento del tráfico. Tienen sus propios mecanismos de comprobación de estado y pueden integrarse con varias API de la nube para el descubrimiento de servicios y el escalado automático. Una consola de gestión centralizada le permite definir políticas de enrutamiento, monitorear el estado de todos los recursos y gestionar la conmutación por error entre regiones y nubes.
Ventajas:
- Solución integral: Combina GLB, balanceo L4/L7, WAF, descarga SSL/TLS y otras funciones en un solo producto.
- Soporte multi-nube e híbrido: Ideal para empresas que utilizan múltiples nubes o combinan recursos en la nube y on-premise.
- Alto rendimiento y escalabilidad: Diseñados para manejar volúmenes de tráfico muy grandes.
- Gestión centralizada: Un único punto de control para toda la infraestructura de balanceo global.
- Integración profunda: Posibilidad de integración profunda con sistemas empresariales de monitoreo, seguridad y orquestación.
Desventajas:
- Costo muy elevado: Las licencias y el soporte de estos sistemas son significativamente más caros que sus equivalentes en la nube.
- Complejidad de implementación y mantenimiento: Requiere especialistas altamente cualificados y recursos de ingeniería significativos.
- Costos operativos: Además de las licencias, es necesario gestionar la propia infraestructura en la que se despliegan estas soluciones.
- Redundancia de funcionalidad: Para proyectos SaaS pequeños y medianos, la funcionalidad puede ser excesiva.
Para quién es adecuado: Grandes empresas y corporaciones con infraestructuras complejas y heterogéneas, requisitos estrictos de seguridad y rendimiento, que están dispuestas a invertir en soluciones potentes y gestionadas centralmente. Rara vez utilizado por startups o proyectos SaaS pequeños.
La elección de una solución específica debe basarse en un análisis cuidadoso de sus necesidades actuales y futuras, presupuesto y recursos de ingeniería disponibles. A menudo, el enfoque óptimo es un enfoque híbrido, por ejemplo, el uso de un GLB DNS gestionado en combinación con una CDN para el almacenamiento en caché y la protección, y Anycast DNS para acelerar las solicitudes DNS.
Consejos y recomendaciones prácticas
 Esquema: Consejos y recomendaciones prácticas
Esquema: Consejos y recomendaciones prácticas
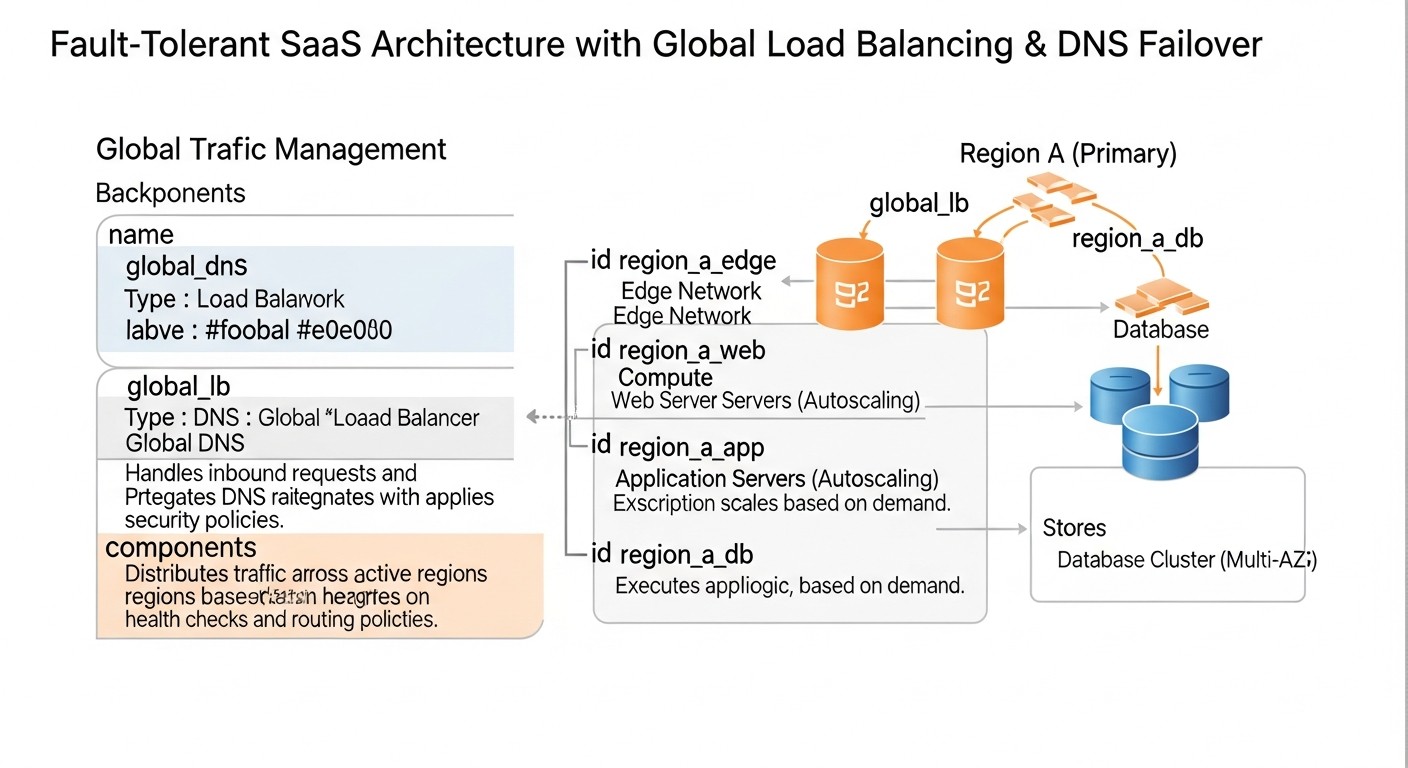
La teoría es buena, pero sin pasos prácticos es inútil. En esta sección, analizaremos recomendaciones específicas, instrucciones paso a paso y ejemplos de configuración que le ayudarán a implementar el balanceo de carga global y el failover de DNS en su aplicación SaaS.
No intente añadir multirregionalidad a un monolito diseñado inicialmente para un solo centro de datos. Piense de antemano cómo interactuarán los componentes en diferentes regiones. Esto se aplica no solo al nivel de red, sino también a las bases de datos, colas de mensajes, cachés y almacenamiento de archivos.
- Defina las regiones: Elija 2-3 regiones donde se concentren sus usuarios o donde existan ventajas estratégicas (por ejemplo, cumplimiento normativo). Se recomienda elegir regiones en diferentes continentes para una máxima tolerancia a fallos.
- Aislamiento de recursos: Cada región debe ser lo más independiente posible. Una falla en una región no debe afectar el funcionamiento de otra.
- Replicación de datos: Este es el aspecto más complejo. Para las bases de datos, considere:
- Active-Passive: Una región está activa, la otra es de respaldo. Los datos se replican de forma asíncrona o semisíncrona. Más fácil de implementar, pero RPO > 0. Ejemplo: PostgreSQL con WAL shipping, MySQL con replicación.
- Active-Active: Ambas regiones aceptan escrituras. Requiere bases de datos distribuidas (Cassandra, CockroachDB, Spanner) o esquemas complejos de resolución de conflictos. RPO = 0, pero con una complejidad muy alta.
- Geoparticionamiento: Los datos de los usuarios se almacenan en la región más cercana a ellos. Simplifica la replicación, pero complica las consultas que abarcan varias regiones.
Utilice servicios como AWS Route 53 Traffic Flow, Azure Traffic Manager o Google Cloud DNS con políticas de enrutamiento. A modo de ejemplo, consideremos AWS Route 53.
Paso 1: Cree Health Checks
Los health checks deben ser lo más profundos posible. No basta con comprobar solo la disponibilidad del puerto 80. Asegúrese de que su aplicación sea capaz de responder a una solicitud, procesarla e interactuar con la base de datos.
# Ejemplo de URL para Health Check, que verifica no solo la disponibilidad, sino también el funcionamiento de la DB
# GET /healthz - devuelve 200 OK, si la aplicación y sus dependencias (DB, Redis) están activas.
# Creación de Health Check para la región principal (por ejemplo, us-east-1)
aws route53 create-health-check \
--caller-reference "my-saas-app-us-east-1-health-check-$(date +%s)" \
--health-check-config '{"IPAddress": "1.2.3.4", "Port": 80, "Type": "HTTP", "ResourcePath": "/healthz", "RequestInterval": 10, "FailureThreshold": 3}'
# Creación de Health Check para la región de respaldo (por ejemplo, eu-west-1)
aws route53 create-health-check \
--caller-reference "my-saas-app-eu-west-1-health-check-$(date +%s)" \
--health-check-config '{"IPAddress": "5.6.7.8", "Port": 80, "Type": "HTTP", "ResourcePath": "/healthz", "RequestInterval": 10, "FailureThreshold": 3}'
Paso 2: Configure Record Sets con políticas de enrutamiento
Utilice la política Failover o Latency-based Routing para la conmutación automática.
# Ejemplo de creación de Failover Record Set para el dominio app.example.com
# Región principal (Primary)
{
"Comment": "Primary record for app.example.com in us-east-1",
"Changes": [
{
"Action": "CREATE",
"ResourceRecordSet": {
"Name": "app.example.com",
"Type": "A",
"SetIdentifier": "us-east-1-primary",
"Failover": "PRIMARY",
"HealthCheckId": "YOUR_US_EAST_1_HEALTH_CHECK_ID",
"TTL": 60,
"ResourceRecords": [
{ "Value": "IP_OF_US_EAST_1_LOAD_BALANCER" }
]
}
}
]
}
# Región de respaldo (Secondary)
{
"Comment": "Secondary record for app.example.com in eu-west-1",
"Changes": [
{
"Action": "CREATE",
"ResourceRecordSet": {
"Name": "app.example.com",
"Type": "A",
"SetIdentifier": "eu-west-1-secondary",
"Failover": "SECONDARY",
"HealthCheckId": "YOUR_EU_WEST_1_HEALTH_CHECK_ID",
"TTL": 60,
"ResourceRecords": [
{ "Value": "IP_OF_EU_WEST_1_LOAD_BALANCER" }
]
}
}
]
}
Paso 3: Establezca un TTL bajo
Para servicios críticos, establezca el TTL en 60-300 segundos (1-5 minutos). Un TTL demasiado bajo (por ejemplo, 5 segundos) puede aumentar la carga en los servidores DNS, pero acelerará significativamente el failover. Encuentre el punto medio.
Incluso si utiliza DNS GLB, una CDN puede mejorar significativamente la experiencia del usuario y proporcionar una capa adicional de protección.
- Configure Origin Failover: En Cloudflare o AWS CloudFront, puede especificar varios servidores de origen (sus balanceadores de carga regionales) y configurar reglas de conmutación entre ellos.
- Optimice el almacenamiento en caché: Asegúrese de que el contenido estático se almacene en caché de la manera más eficiente posible.
- Habilite WAF y protección DDoS: Utilice las capacidades de la CDN para proteger su aplicación a nivel de Edge.
Debe conocer los problemas antes que sus clientes. El monitoreo debe cubrir:
- Health Checks GLB: Monitoreo del estado de sus health checks de DNS.
- Métricas de la aplicación: Latencia, errores, rendimiento, uso de CPU/RAM en cada región.
- Métricas de la base de datos: Replicación, latencias, errores, uso del disco.
- Métricas de red: Latencia entre regiones, pérdida de paquetes.
Configure alertas (Slack, PagerDuty, email) para eventos críticos, como fallas en los health checks, aumento de errores o latencia.
La única forma de asegurarse de que su arquitectura funciona es probándola regularmente. Simule fallas en una de las regiones y verifique cómo reacciona el sistema.
- Inicie una falla de Health Check: Bloquee temporalmente el acceso a
/healthz en una región o detenga el servicio para verificar cómo GLB conmuta el tráfico.
- Desactive una región: Utilice AWS Fault Injection Simulator o herramientas similares para simular una falla completa de una región.
- Documente RTO y RPO: Mida el tiempo de recuperación real y la posible pérdida de datos.
- Automatice las pruebas: Incluya la verificación de failover en sus pipelines de CI/CD.
Todas sus configuraciones de infraestructura, incluyendo GLB, DNS, health checks, deben describirse en código (Terraform, CloudFormation, Pulumi). Esto garantiza la repetibilidad, el versionado y simplifica la gestión.
# Ejemplo de Terraform para AWS Route 53 Health Check
resource "aws_route53_health_check" "us_east_1_app_health" {
fqdn = "app.example.com"
port = 80
type = "HTTP"
resource_path = "/healthz"
request_interval = 10
failure_threshold = 3
tags = {
Name = "app-us-east-1-health"
}
}
# Ejemplo de Terraform para AWS Route 53 Failover A Record Set
resource "aws_route53_record" "app_primary" {
zone_id = aws_route53_zone.main.zone_id
name = "app.example.com"
type = "A"
ttl = 60
set_identifier = "us-east-1-primary"
failover_routing_policy {
type = "PRIMARY"
}
health_check_id = aws_route53_health_check.us_east_1_app_health.id
records = ["IP_OF_US_EAST_1_LOAD_BALANCER"]
}
resource "aws_route53_record" "app_secondary" {
zone_id = aws_route53_zone.main.zone_id
name = "app.example.com"
type = "A"
ttl = 60
set_identifier = "eu-west-1-secondary"
failover_routing_policy {
type = "SECONDARY"
}
health_check_id = aws_route53_health_check.eu_west_1_app_health.id # Suponemos que existe un health check para eu-west-1
records = ["IP_OF_EU_WEST_1_LOAD_BALANCER"]
}
En caso de failover a otra región, los datos deben estar actualizados. Para bases de datos relacionales, considere:
- PostgreSQL con Logical Replication: Permite replicar datos entre regiones.
- Aurora Global Database (AWS): Una solución completamente administrada para la replicación global de PostgreSQL/MySQL.
- Cassandra/MongoDB Atlas Global Clusters: Para bases de datos NoSQL, diseñadas inicialmente para entornos distribuidos.
Recuerde las cachés. Al cambiar de región, las cachés en la nueva región activa pueden estar frías o contener datos obsoletos. Piense en una estrategia de invalidación o calentamiento de la caché.
Si los usuarios están autorizados en una región, al cambiar a otra región no se les debe exigir una nueva autorización. Utilice almacenes de sesiones distribuidos (por ejemplo, Redis Cluster, DynamoDB) o tokens JWT que no estén vinculados a un servidor o región específica.
Errores comunes
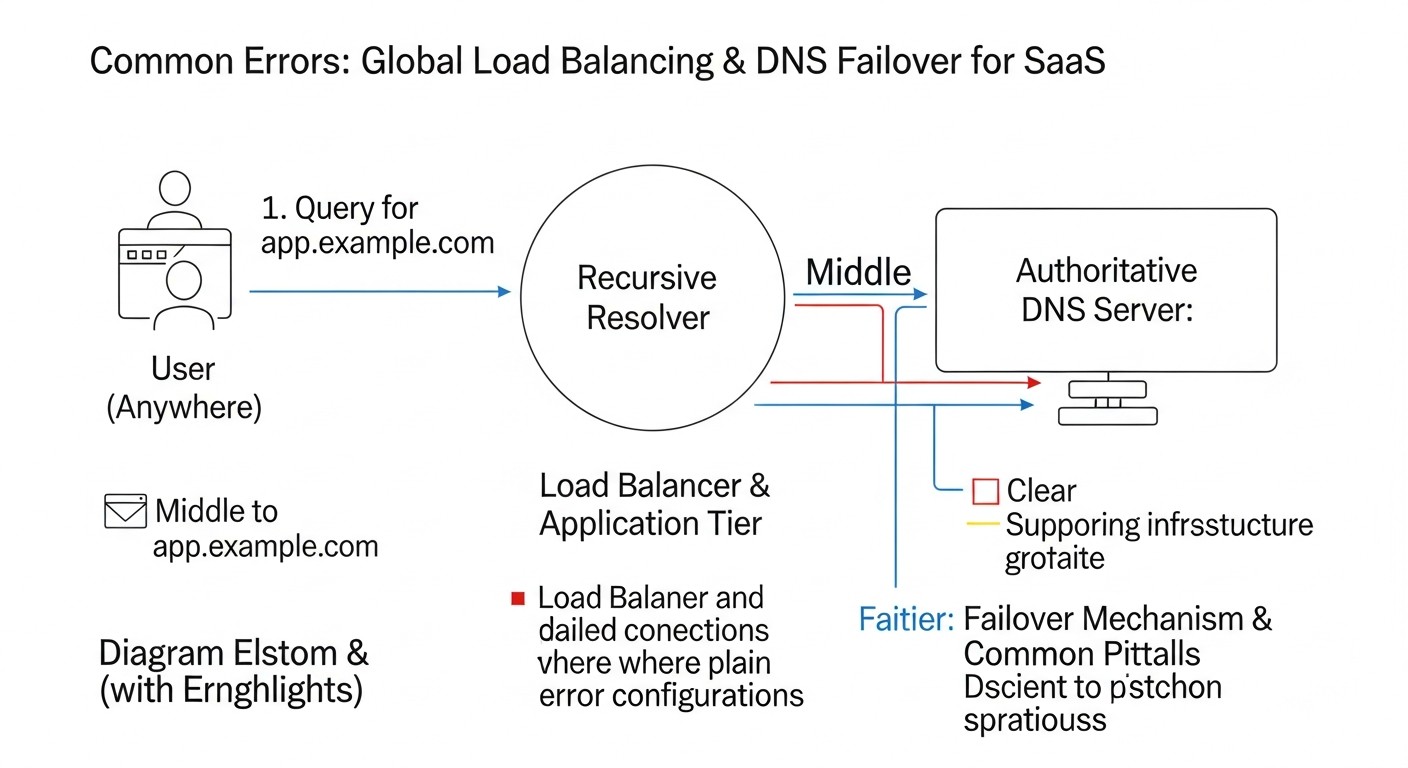 Esquema: Errores comunes
Esquema: Errores comunes
La implementación del balanceo de carga global y el failover de DNS es un proceso complejo, y los errores en el camino pueden llevar a largos tiempos de inactividad, pérdida de datos y pérdidas financieras significativas. Conocer los errores comunes le ayudará a evitarlos.
Error: Establecer el TTL (Time To Live) de los registros DNS en horas o incluso días (por ejemplo, 24 horas).
Consecuencias: En caso de fallo de la región principal, las cachés de DNS en todo el mundo seguirán apuntando a una dirección IP inoperativa durante todo el período de TTL. Esto significa que incluso después de que su GLB detecte el fallo y actualice los registros, los usuarios no podrán acceder a su aplicación durante un largo período (el RTO será muy alto). Ejemplo: una empresa SaaS con un TTL de 1 día experimentó un fallo en AWS us-east-1. A pesar de tener una región de respaldo, los usuarios no pudieron conectarse al servicio durante 12-24 horas hasta que sus cachés de DNS locales se actualizaron. Esto resultó en la pérdida de millones de dólares y una fuga masiva de clientes.
Cómo evitarlo: Para registros críticos utilizados por GLB, establezca el TTL en un rango de 60 a 300 segundos (1-5 minutos). Esto proporcionará un compromiso razonable entre la velocidad de failover y la carga en los servidores DNS.
Error: Configurar Health Checks que solo verifican la disponibilidad del puerto (por ejemplo, TCP 80/443), pero no la operatividad de la aplicación en sí o sus dependencias.
Consecuencias: El balanceador de carga puede considerar que una región está saludable porque el servidor web responde, pero en realidad la aplicación puede estar inoperativa (por ejemplo, debido a problemas con la base de datos, Redis, API externas). Esto lleva a que el tráfico se dirija a una región que no puede atender las solicitudes, lo que provoca errores en los usuarios. Ejemplo: El Health Check solo verificaba Nginx. Nginx funcionaba, pero la aplicación de backend se cayó debido a problemas con la base de datos. El GLB continuó dirigiendo el tráfico a Nginx, que devolvía 502 Bad Gateway, en lugar de cambiar a la región de respaldo.
Cómo evitarlo: Cree Health Checks profundos que verifiquen el estado de todos los componentes críticos de la aplicación (API, base de datos, caché, colas). Implemente un endpoint especial /healthz o /status que realice estas verificaciones y devuelva HTTP 200 OK solo si la operatividad es completa.
Error: Desplegar una arquitectura con GLB y failover de DNS sin probar regularmente los escenarios de fallo.
Consecuencias: En una situación de fallo real, el sistema puede no funcionar como se esperaba. El proceso de conmutación puede ser lento, incompleto o no ocurrir en absoluto debido a errores de configuración, dependencias olvidadas o problemas de replicación de datos. Ejemplo: Un banco importante desplegó una arquitectura multiregional, pero nunca realizó simulacros completos. Durante un fallo regional, se descubrió que uno de los microservicios críticos no estaba configurado para la replicación en la región de respaldo, y el proceso de recuperación tardó horas en lugar de minutos.
Cómo evitarlo: Incluya simulacros regulares de recuperación ante desastres (DR Drills) en su práctica operativa. Simule fallos en una región (apagado de servicios, aislamiento de red) y verifique qué tan rápido y correctamente se conmuta el sistema. Automatice estas pruebas, si es posible.
Error: Ausencia o configuración incorrecta de la replicación de datos entre regiones.
Consecuencias: Al cambiar a la región de respaldo, los usuarios pueden encontrar datos obsoletos o faltantes. Esto puede llevar a la pérdida de datos de usuario, interrupción de la lógica de negocio y problemas graves de confianza. Ejemplo: Una plataforma SaaS para la gestión de proyectos utilizaba replicación asíncrona de la base de datos. Durante el failover, se perdieron los últimos 5 minutos de datos (creados en la región principal), lo que resultó en la desaparición de tareas y comentarios recién creados para los usuarios.
Cómo evitarlo: Planifique cuidadosamente la estrategia de replicación de datos. Para datos críticos, busque un RPO cercano a cero utilizando replicación síncrona o semisíncrona (por ejemplo, AWS Aurora Global Database, CockroachDB). Tenga en cuenta las cachés y los almacenamientos de archivos; también deben replicarse o tener una estrategia de recuperación.
Error: Subestimar el costo del tráfico transferido entre regiones (egress/ingress).
Consecuencias: Una arquitectura multiregional es más cara por defecto, pero el tráfico interregional puede convertirse en un "devorador" de presupuesto oculto. Si sus servicios en diferentes regiones intercambian datos activamente, las facturas de la nube pueden salirse rápidamente de control. Ejemplo: Una startup desplegó una arquitectura Active-Active con dos regiones, pero no tuvo en cuenta que sus microservicios intercambiaban constantemente un gran volumen de datos entre sí, incluso si el tráfico de usuarios iba a la región más cercana. Esto llevó a que la factura por el tráfico entre regiones superara el costo de todos los demás recursos.
Cómo evitarlo: Minimice el tráfico interregional. Diseñe los servicios para que sean lo más autónomos posible dentro de su región. Si la interacción interregional es necesaria, utilice protocolos eficientes, compresión de datos y considere el uso de conexiones privadas (VPC Peering, Direct Connect) para reducir el costo del tráfico.
Preguntas Frecuentes
Un balanceador de carga regional (por ejemplo, AWS ALB, Azure Application Gateway) distribuye el tráfico solo dentro de una región o zona de disponibilidad. El balanceo de carga global (GLB) opera a un nivel superior, dirigiendo a los usuarios a la región geográfica más adecuada. Proporciona tolerancia a fallos a nivel regional, desviando el tráfico a otra región en caso de un fallo, y optimiza la latencia al dirigir a los usuarios al centro de datos disponible más cercano. Estos son dos niveles de balanceo diferentes pero complementarios.
La elección del TTL es un compromiso entre la velocidad de la conmutación por error (failover) y la carga en los servidores DNS. Para registros críticos utilizados en una arquitectura GLB, se recomienda establecer un TTL en el rango de 60 a 300 segundos (1-5 minutos). Esto es lo suficientemente bajo para asegurar una conmutación por error relativamente rápida (en cuestión de minutos), pero no tan bajo como para causar una carga excesiva en la infraestructura DNS. Para registros que rara vez cambian (por ejemplo, registros NS), se puede usar un TTL más alto (1 hora o más).
Active-Active: Ambas (o todas) las regiones sirven activamente el tráfico. Ventajas: alta disponibilidad, baja latencia, uso eficiente de los recursos. Desventajas: alta complejidad en la gestión de datos (requiere una base de datos distribuida con resolución de conflictos), mayor costo.
Active-Passive: Una región está activa, la otra (o las otras) está en modo de espera. Ventajas: más sencilla de implementar, más fácil de gestionar los datos. Desventajas: recursos inactivos en la región de respaldo, RTO y RPO potencialmente más altos. La elección depende de los requisitos de RTO/RPO y del presupuesto.
Esta es una de las tareas más complejas. Para bases de datos relacionales, se puede usar replicación asíncrona (por ejemplo, PostgreSQL Logical Replication, MySQL Replication) para Active-Passive, o bases de datos globales especializadas (AWS Aurora Global Database, Google Cloud Spanner) para Active-Active con consistencia fuerte. Para bases de datos NoSQL (Cassandra, MongoDB), use sus mecanismos integrados de distribución de datos. También es importante considerar la replicación de almacenamiento de archivos (S3 Cross-Region Replication) y la gestión de cachés distribuidas.
Las CDN modernas (por ejemplo, Cloudflare, Akamai) ofrecen potentes funciones GLB a nivel L7 (HTTP/HTTPS), incluyendo enrutamiento basado en geografía, latencia y conmutación por error. Para muchas aplicaciones SaaS, una CDN puede realizar funciones de GLB, especialmente si el tráfico principal es HTTP/HTTPS. Sin embargo, si tiene tráfico no HTTP (por ejemplo, TCP, UDP), o necesita un control de nivel inferior a nivel de DNS, entonces un GLB DNS puro (Route 53, Traffic Manager) o un enfoque híbrido que utilice ambas soluciones será más adecuado.
Los Health Checks profundos no solo verifican la disponibilidad de un puerto o un HTTP 200 OK básico. Deben simular una solicitud de usuario real o verificar la operatividad de todas las dependencias críticas de la aplicación. Por ejemplo, un endpoint /healthz puede intentar conectarse a la base de datos, solicitar datos de la caché, verificar la disponibilidad de APIs externas y solo después de completar con éxito todos estos pasos, devolver un HTTP 200 OK. Esto garantiza que el GLB solo conmutará el tráfico cuando la aplicación esté realmente lista para atender solicitudes.
Se recomienda realizar simulacros de recuperación ante desastres (DR Drills) al menos una vez por trimestre, y para sistemas críticos, mensualmente. Esto permite identificar errores de configuración, problemas de replicación y otros matices inesperados antes de que provoquen un tiempo de inactividad real. Las pruebas automatizadas de conmutación por error se pueden ejecutar con mayor frecuencia, por ejemplo, como parte del pipeline de CI/CD con cada cambio significativo en la infraestructura.
Formas principales:
- Utilizar un modo "cálido" o "frío" para la región de respaldo en lugar de "caliente" para ahorrar en recursos inactivos.
- Minimizar el tráfico interregional optimizando la arquitectura de los servicios y la replicación de datos.
- Utilizar reservas (Reserved Instances, Savings Plans) para cargas estables.
- Maximizar el uso de CDN para el almacenamiento en caché y la reducción de la carga en los servidores de origen.
- Optimizar los Health Checks para que no generen solicitudes excesivas.
El almacenamiento en caché local de DNS en los dispositivos del cliente y en los servidores DNS intermedios (de los proveedores) es la principal causa de la lentitud en la conmutación por error (failover) cuando se utiliza DNS GLB. Es imposible evitarlo por completo, pero se puede minimizar el efecto:
- Establecer un TTL bajo (60-300 segundos) para los registros DNS críticos.
- Utilizar una CDN: la CDN actúa como un proxy, y la conmutación a nivel de CDN ocurre instantáneamente, ya que los clientes interactúan solo con la CDN y no directamente con sus servidores de origen.
- Educar a los usuarios para que borren la caché DNS en sus dispositivos (aunque esto no siempre es práctico).
Una estrategia multi-nube (alojar la aplicación en varias nubes diferentes) puede aumentar la tolerancia a fallos, protegiendo contra fallos de un proveedor de nube completo. Sin embargo, aumenta significativamente la complejidad, el costo y la carga operativa. Para la mayoría de los proyectos SaaS, un despliegue multirregional en una sola nube es suficiente. La multi-nube solo debe considerarse para requisitos de disponibilidad muy estrictos (por ejemplo, cinco nueves), regulaciones estrictas o para evitar el vendor lock-in. En este caso, se requerirán soluciones GLB multi-nube especializadas.