Implementación de FinOps en VPS y servidores dedicados: estrategias y herramientas para el control de gastos
TL;DR
- FinOps es una cultura y un conjunto de prácticas para maximizar el valor de negocio de la infraestructura de TI, aplicables no solo a la nube, sino también a VPS/Dedicados.
- Los principios clave incluyen visibilidad completa de los gastos, rendición de cuentas de los equipos, optimización continua de los recursos y automatización.
- Para VPS y servidores dedicados, son críticamente importantes el dimensionamiento correcto, el uso de contratos a largo plazo y un monitoreo exhaustivo del rendimiento.
- La implementación de FinOps permite reducir los gastos en un 15-30% gracias a la eliminación de ineficiencias, la prevención del gasto excesivo y la mejora de la planificación.
- Utilice una combinación de herramientas de monitoreo (Prometheus, Grafana), sistemas de automatización (Ansible, Terraform) y procesos internos para alcanzar los objetivos de FinOps.
- No olvide los gastos ocultos: tráfico, licencias, copias de seguridad, costo de soporte y recursos humanos.
- La cultura FinOps requiere una interacción constante entre los equipos técnicos y financieros, así como una revisión regular de las estrategias.
Introducción
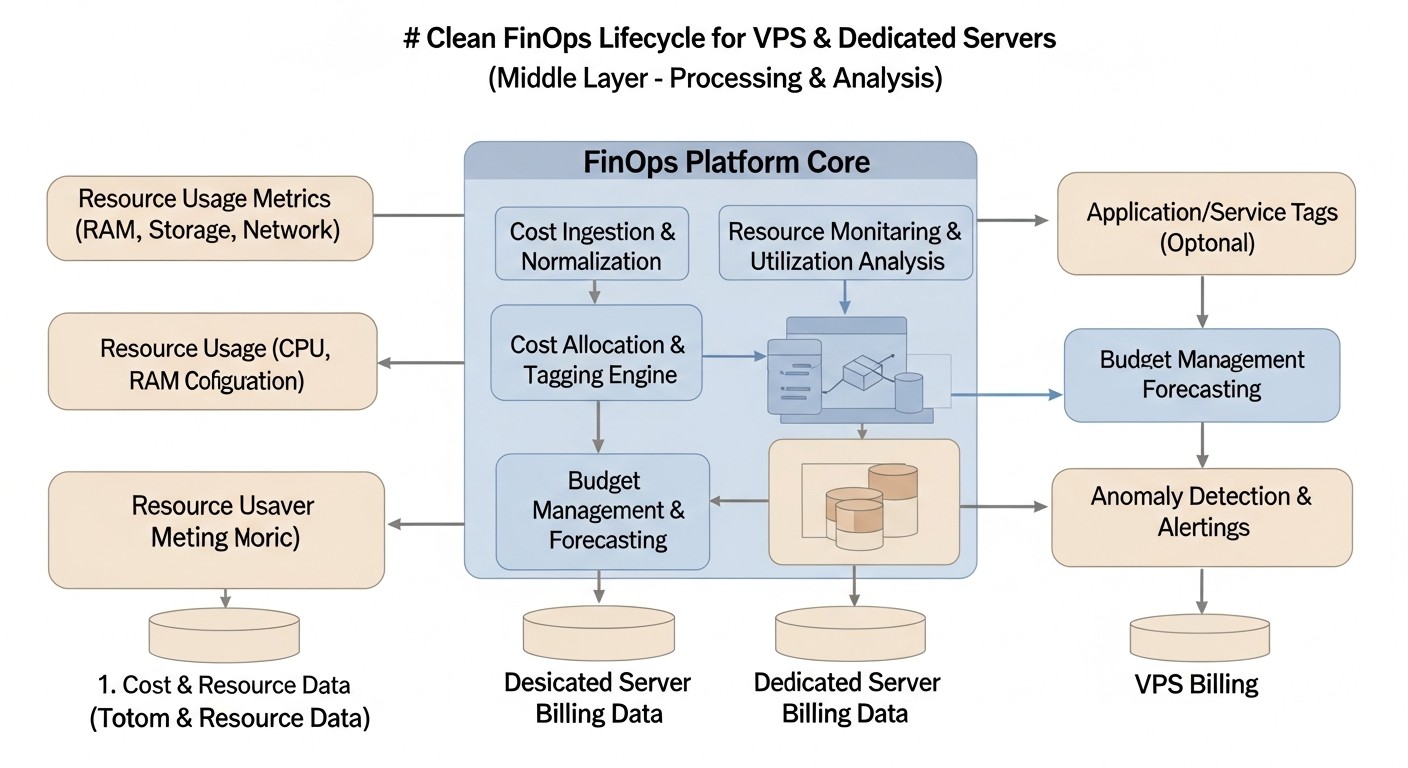 Diagrama: Introducción
Diagrama: Introducción
En 2026, el panorama de la infraestructura de TI continúa evolucionando rápidamente, ofreciendo a las empresas una amplia gama de soluciones, desde entornos completamente en la nube hasta configuraciones híbridas y servidores dedicados tradicionales. Sin embargo, independientemente de la estrategia elegida, la cuestión de la gestión eficiente de los gastos sigue siendo la piedra angular de un negocio exitoso. Si bien el concepto de FinOps ha ganado una amplia aceptación en los ecosistemas de la nube, sus principios y metodologías son igualmente, y a veces incluso más, relevantes para quienes utilizan servidores privados virtuales (VPS) y servidores dedicados. Muchos creen erróneamente que en una infraestructura fija los gastos son predecibles y no requieren una gestión activa; sin embargo, la práctica demuestra lo contrario. Los costos ocultos, el uso subóptimo de los recursos, las configuraciones obsoletas y la falta de transparencia pueden generar pérdidas financieras significativas.
Este artículo tiene como objetivo llenar el vacío en la comprensión y aplicación de FinOps para infraestructuras tradicionales e híbridas. Analizaremos por qué en 2026 FinOps se convierte no solo en una práctica deseable, sino necesaria para los propietarios de VPS y servidores dedicados. La creciente complejidad de las aplicaciones, la necesidad de alta disponibilidad, el endurecimiento de los requisitos de seguridad y la presión constante para reducir los costos operativos hacen que un enfoque sistemático de la gestión financiera de la infraestructura sea críticamente importante. Los problemas que buscamos resolver incluyen la falta de una imagen clara de los gastos por proyectos y equipos, el pago excesivo por recursos no utilizados o redundantes, las dificultades para pronosticar costos futuros y la ausencia de una estrategia de optimización unificada.
Esta guía experta está dirigida a una amplia audiencia de especialistas técnicos y gerentes que enfrentan los desafíos de la gestión de infraestructura y presupuesto. Los ingenieros de DevOps encontrarán aquí consejos prácticos sobre automatización y monitoreo, los desarrolladores de backend (ya sea en Python, Node.js, Go o PHP) aprenderán cómo sus decisiones arquitectónicas afectan los costos. Los fundadores de proyectos SaaS y los directores técnicos de startups obtendrán estrategias para escalar sin inflar el presupuesto, y los administradores de sistemas, herramientas para mejorar la eficiencia de su trabajo. Nuestro objetivo es proporcionar no solo un conjunto de recomendaciones, sino un marco práctico completo que le permita tomar el control total de los gastos de su infraestructura, aumentar su eficiencia y garantizar el desarrollo sostenible de su negocio.
En un entorno donde cada dólar cuenta, especialmente para startups y empresas de rápido crecimiento, comprender cómo utilizar eficazmente sus recursos de servidor se convierte en una ventaja competitiva directa. FinOps en VPS y servidores dedicados no se trata de recortar el presupuesto a toda costa, sino de invertir inteligentemente en infraestructura, lo que genera el máximo retorno. Mostraremos cómo, con las estrategias, herramientas y cambios culturales adecuados, se puede lograr este objetivo, transformando los gastos en inversiones estratégicas.
Criterios/factores clave de FinOps en VPS y servidores dedicados
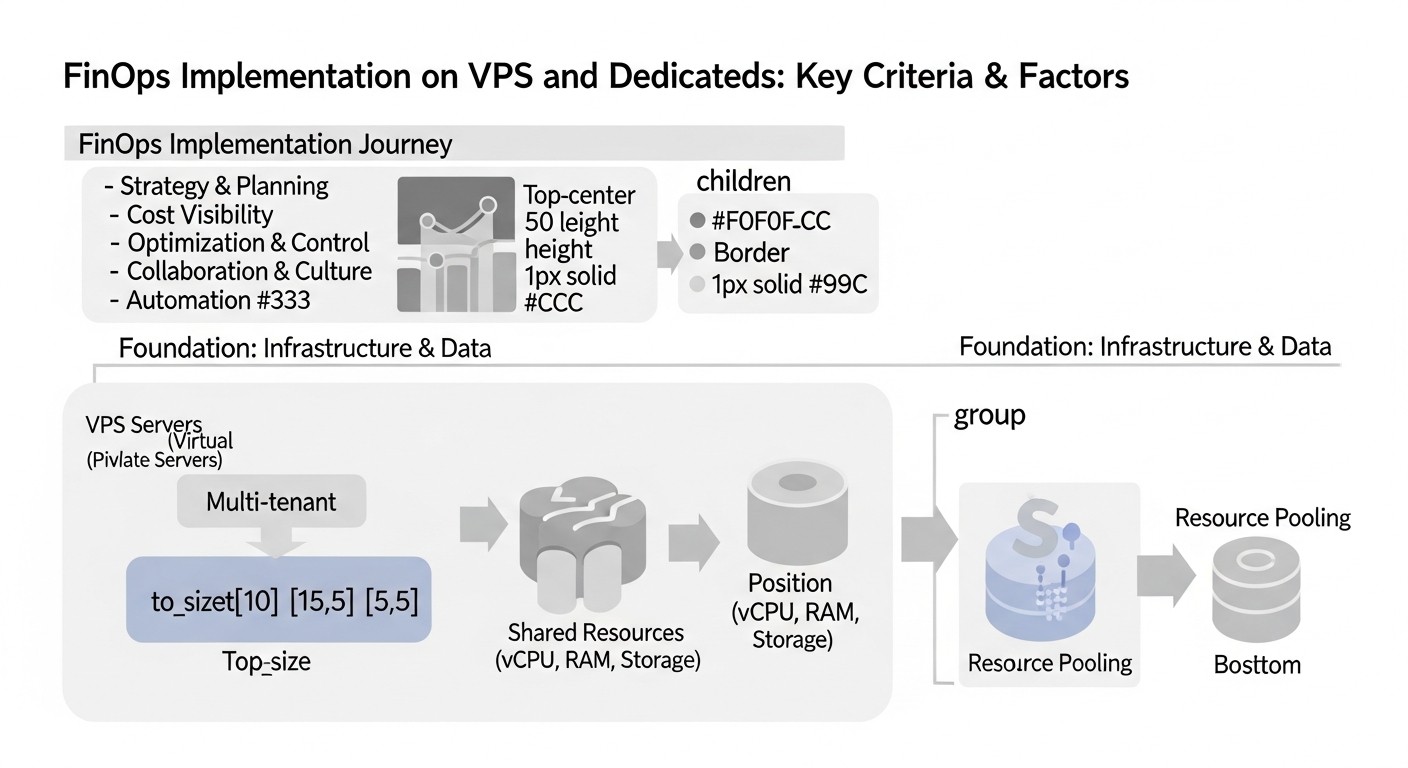 Diagrama: Criterios/factores clave de FinOps en VPS y servidores dedicados
Diagrama: Criterios/factores clave de FinOps en VPS y servidores dedicados
La implementación efectiva de FinOps en VPS y servidores dedicados requiere la comprensión y aplicación sistemática de varios factores clave. Estos criterios forman la base para la toma de decisiones informadas y garantizan la mejora continua de la eficiencia financiera de la infraestructura. Cada uno de ellos desempeña un papel en el logro de la transparencia, el control y la optimización de los gastos.
2.1. Visibilidad completa de los gastos (Cost Visibility)
La visibilidad es el primer y, posiblemente, el paso más importante en FinOps. Sin una comprensión clara de a dónde va el dinero, es imposible gestionar los gastos. En VPS y servidores dedicados, esto significa no solo conocer la tarifa mensual de alquiler, sino también detallar todos los costos asociados: tráfico, licencias de software (SO, paneles de control, bases de datos), copias de seguridad, direcciones IP, servicios adicionales (protección DDoS, CDN), así como costos indirectos como salarios de ingenieros, tiempo de inactividad y soporte técnico. Es importante desglosar estos gastos por proyectos, equipos o incluso microservicios, si corresponde. Sin una visibilidad detallada, es imposible identificar áreas de gasto excesivo o ineficiencia. La visibilidad se puede evaluar por el nivel de detalle de los informes, la disponibilidad de datos para todas las partes interesadas y la capacidad de correlacionar los costos con métricas comerciales específicas.
2.2. Distribución de responsabilidades y rendición de cuentas (Accountability)
El principio de rendición de cuentas significa que cada equipo o incluso cada ingeniero debe comprender las consecuencias financieras de sus decisiones y ser responsable de los gastos que generan. En el contexto de VPS y servidores dedicados, esto puede ser más complejo que en la nube con sus etiquetas flexibles y sus informes de facturación detallados. Sin embargo, esto no hace que el principio sea menos importante. Es necesario implementar mecanismos de "showback" o "chargeback", mediante los cuales los costos de un servidor o servicio específico se vinculan al equipo o proyecto responsable. Esto incentiva a los equipos a adoptar un enfoque más responsable en el consumo de recursos. La rendición de cuentas se evalúa a través de revisiones regulares de gastos con los equipos, la existencia de métricas internas de eficiencia y el grado de participación de los desarrolladores en el proceso de optimización.
2.3. Optimización de recursos (Resource Optimization)
La optimización es un proceso continuo para alinear el consumo de recursos con las necesidades reales. En VPS y servidores dedicados, esto incluye:
- Dimensionamiento correcto (Right-sizing): Elegir un servidor con la cantidad óptima de CPU, RAM, espacio en disco y ancho de banda de red, evitando tanto el exceso como la escasez de recursos. Esto requiere un análisis profundo de la carga y el rendimiento.
- Consolidación: Combinar varios VPS menos cargados en un servidor dedicado más potente utilizando virtualización (por ejemplo, Proxmox, VMware ESXi), lo que puede reducir significativamente los costos generales de alquiler y gestión.
- Gestión automática del ciclo de vida: Automatización del desaprovisionamiento de servidores de prueba o temporales no utilizados.
- Optimización del rendimiento: Ajuste fino de sistemas operativos, bases de datos, servidores web y aplicaciones para un uso más eficiente de los recursos disponibles.
La optimización se evalúa a través de métricas de utilización de recursos (CPU, RAM, E/S), el número de servidores "ociosos" y el porcentaje de ahorro logrado mediante cambios en las configuraciones.
2.4. Automatización e Infraestructura como Código (IaC)
La automatización es el motor de la eficiencia en FinOps. La gestión manual de cientos de servidores no solo es laboriosa, sino que también está plagada de errores e ineficiencias. La implementación de Infraestructura como Código (IaC) utilizando herramientas como Ansible, Terraform o Puppet, permite estandarizar el despliegue, la actualización y el desaprovisionamiento de servidores, garantizando que los recursos se asignen de acuerdo con los parámetros definidos y no permanezcan activos más tiempo del necesario. La automatización también simplifica la recopilación de métricas y la aplicación de políticas de optimización. La automatización se evalúa por el número de operaciones manuales, el tiempo de despliegue de nuevos servicios y el porcentaje de infraestructura gestionada por IaC.
2.5. Previsión y presupuestación (Forecasting & Budgeting)
La previsión fiable de los gastos futuros y su comparación con el presupuesto es un aspecto críticamente importante de FinOps. En VPS y servidores dedicados, donde los contratos a menudo se celebran a largo plazo y la escalabilidad no siempre es instantánea, una previsión precisa ayuda a evitar sorpresas y a planificar con antelación las inversiones necesarias o las medidas de reducción de gastos. Esto incluye el análisis de datos históricos de consumo de recursos, la consideración de la estacionalidad, el crecimiento empresarial planificado y el lanzamiento de nuevos proyectos. Se evalúa la precisión de las previsiones, la puntualidad en la detección de desviaciones presupuestarias y la capacidad de tomar medidas proactivas.
2.6. Cultura de colaboración (Collaboration)
FinOps no es solo tecnología, sino también cultura. Requiere una estrecha colaboración entre los equipos técnicos (DevOps, desarrolladores, administradores de sistemas) y los departamentos financieros. Los desarrolladores deben comprender las consecuencias financieras de sus decisiones arquitectónicas, y los gerentes financieros deben tener una comprensión de los aspectos técnicos de la infraestructura para tomar decisiones presupuestarias informadas. Las reuniones regulares, los paneles de control compartidos, la capacitación y una terminología unificada contribuyen a la creación de esta cultura. La colaboración se evalúa a través de la retroalimentación de los equipos, la velocidad de las decisiones relacionadas con los gastos y el nivel de comprensión mutua entre los departamentos.
Todos estos criterios están interconectados y deben aplicarse de forma integral para lograr el máximo efecto. Ignorar cualquiera de ellos dará lugar a lagunas en la estrategia FinOps y a una reducción de su eficacia general en VPS y servidores dedicados.
Tabla comparativa: Tipos de servidores y su costo en 2026
 Diagrama: Tabla comparativa: Tipos de servidores y su costo en 2026
Diagrama: Tabla comparativa: Tipos de servidores y su costo en 2026
La elección del tipo de servidor adecuado es una de las primeras y más significativas decisiones en el contexto de FinOps. En 2026, el mercado de VPS y servidores dedicados continúa ofreciendo una amplia gama de configuraciones, capaces de satisfacer las necesidades más diversas, desde pequeños blogs hasta aplicaciones corporativas de alta carga. Sin embargo, con esta diversidad viene la complejidad de elegir la solución óptima que sea eficiente en términos de costos y rendimiento. Esta tabla presenta datos actuales y precios estimados para varios tipos de servidores disponibles en los principales proveedores, teniendo en cuenta el progreso tecnológico y las tendencias del mercado para 2026.
Los precios y las características son orientativos y pueden variar según el proveedor específico, la región, la duración del contrato y los servicios adicionales incluidos (por ejemplo, hosting administrado, protección DDoS, licencias específicas). Sin embargo, esta tabla ofrece una buena visión general de las configuraciones típicas y su rango de precios, lo que ayudará en la planificación y presupuestación preliminar.
| Parámetro |
VPS de nivel de entrada (Estándar) |
VPS de rango medio (Rendimiento) |
VPS de alto rendimiento (Optimizado) |
Servidor dedicado pequeño |
Servidor dedicado empresarial |
Servidor dedicado con GPU |
| CPU típica |
2 vCPU (Intel Xeon E3/E5, 3.0-3.2 GHz) |
4 vCPU (Intel Xeon E5/Gold, AMD EPYC, 3.5-3.8 GHz) |
8 vCPU (Intel Xeon Platinum, AMD EPYC, 4.0+ GHz) |
Intel Xeon E-2414 (4c/4t, 3.2 GHz) |
Dual AMD EPYC 9354 (64c/128t, 3.2 GHz) |
Intel Xeon E-2414 (4c/4t) + NVIDIA L40S |
| RAM (GB) |
4 GB DDR4 |
8-16 GB DDR4/DDR5 |
32-64 GB DDR5 ECC |
32 GB DDR5 ECC |
256-512 GB DDR5 ECC |
64 GB DDR5 ECC |
| Almacenamiento (Tipo/Volumen) |
80 GB NVMe SSD |
160-320 GB NVMe SSD |
640 GB - 1.2 TB NVMe SSD (RAID 1) |
2 x 1 TB NVMe SSD (RAID 1) |
4 x 3.84 TB NVMe SSD (RAID 10) |
2 x 2 TB NVMe SSD (RAID 1) |
| Interfaz de red |
1 Gbps (1-2 TB de tráfico) |
2.5 Gbps (5-10 TB de tráfico) |
5-10 Gbps (15-20 TB de tráfico) |
10 Gbps (10-20 TB de tráfico) |
2 x 25 Gbps (tráfico ilimitado) |
10 Gbps (15-20 TB de tráfico) |
| Costo mensual estimado (USD) |
$12 - $25 |
$35 - $80 |
$90 - $200 |
$110 - $180 |
$700 - $1500+ |
$400 - $1000+ |
| Características clave |
Rendimiento básico, SSD, inicio rápido |
Buen equilibrio CPU/RAM, NVMe, escalabilidad |
Alto rendimiento, baja latencia, RAM ECC |
Control total, rendimiento predecible, aislamiento |
Máximo rendimiento, redundancia, alta escalabilidad |
Alta potencia de cálculo para IA/ML, renderizado |
| Mejor escenario de uso |
Sitios web pequeños, entornos de prueba, blogs, servidores VPN |
Aplicaciones web medianas, servicios API, bases de datos pequeñas, entornos de staging |
Servidores web de alta carga, análisis, microservicios, e-commerce, servidores de juegos |
Entornos de producción, bases de datos críticas, aplicaciones de alta carga donde se requiere estabilidad |
Grandes aplicaciones corporativas, Big Data, computación de alto rendimiento, virtualización |
Aprendizaje automático, aprendizaje profundo, investigación científica, procesamiento de video, renderizado 3D |
Al elegir un servidor, es importante considerar no solo las necesidades actuales, sino también el crecimiento potencial. La transición de un VPS a un servidor dedicado o entre diferentes configuraciones puede implicar tiempos de inactividad y costos de migración, que también deben incluirse en el análisis de FinOps. Los contratos a largo plazo (de 1 a 3 años) suelen ofrecer descuentos significativos, lo que los convierte en una opción atractiva para cargas de trabajo estables en servidores dedicados. Sin embargo, esto también lo vincula a un proveedor y una configuración durante un período prolongado, lo que requiere una previsión más precisa.
Para los VPS también existen diferentes planes de tarifas, incluidos los que ofrecen facturación por hora o por minuto, aunque esto es más común en las nubes públicas. En el mercado de VPS, los proveedores suelen ofrecer pagos mensuales fijos por un conjunto determinado de recursos. En 2026, la popularidad de los "VPS en la nube" (cloud VPS) está creciendo, combinando las ventajas de los VPS (precio fijo, simplicidad) con algunos elementos de la nube (escalado rápido, API), lo que difumina las fronteras entre estos tipos de infraestructura y requiere un análisis más profundo al elegir.
Revisión detallada de las estrategias FinOps para VPS y Dedicados
 Diagrama: Revisión detallada de las estrategias FinOps para VPS y Dedicados
Diagrama: Revisión detallada de las estrategias FinOps para VPS y Dedicados
La implementación de FinOps en VPS y servidores dedicados requiere la aplicación de estrategias específicas, adaptadas a la particularidad de esta infraestructura. A diferencia de las nubes públicas con su flexibilidad y facturación granular, aquí el enfoque se desplaza hacia la maximización del uso de recursos fijos y la optimización de las inversiones a largo plazo. Analicemos las estrategias clave con más detalle.
4.1. Dimensionamiento correcto (Right-sizing) y consolidación de recursos
Esencia: Selección de la configuración óptima del servidor (CPU, RAM, disco, red) y combinación de varias cargas de trabajo en un único servidor físico para aumentar la utilización.
Ventajas:
- Reducción significativa de los costos directos de alquiler de servidores.
- Disminución de los costos operativos al reducir el número de entidades gestionadas.
- Aumento de la eficiencia general en el uso del hardware.
- Reducción del consumo de energía y, en consecuencia, de la huella ecológica.
Desventajas:
- Requiere una comprensión profunda de los perfiles de carga y rendimiento de las aplicaciones.
- Riesgo de "efecto dominó": la falla de un servidor físico puede afectar a varias máquinas virtuales.
- Puede requerir inversiones en herramientas de monitoreo y virtualización.
- Dificultades con el aislamiento de recursos para aplicaciones críticas en un servidor consolidado.
Para quién es adecuado: Empresas con cargas de trabajo heterogéneas (desde servicios de baja carga hasta bases de datos de alto rendimiento), startups que buscan optimizar costos, empresas con equipos obsoletos o subutilizados.
Ejemplos de uso:
- El análisis muestra que varios VPS con 2 vCPU y 4GB de RAM se utilizan al 10-20%. Se pueden consolidar en un servidor dedicado con 16 vCPU y 64GB de RAM, utilizando contenedores (Docker/Kubernetes) o virtualización ligera (LXC).
- Una aplicación que se ejecuta en un servidor dedicado con 32GB de RAM, pero que en picos no utiliza más de 12GB, puede trasladarse a un VPS más económico con 16GB de RAM, o se puede trasladar otro servicio a este servidor.
4.2. Uso de contratos a largo plazo y reservas
Esencia: Celebrar contratos de alquiler de servidores a largo plazo (1-3 años) para obtener descuentos sustanciales.
Ventajas:
- Ahorro significativo (hasta un 30-50% del costo mensual) en comparación con el pago mensual.
- Previsibilidad de los gastos de infraestructura a largo plazo.
- Garantía de disponibilidad de recursos y ausencia de problemas de escasez de capacidad.
Desventajas:
- Requiere una previsión precisa de las necesidades de recursos durante toda la duración del contrato.
- Reduce la flexibilidad: es difícil cambiar la configuración o el proveedor antes de que finalice el contrato.
- Riesgo de pago excesivo si la necesidad de recursos disminuye.
- Requiere una inversión inicial (a veces, el pago completo por adelantado).
Para quién es adecuado: Empresas con cargas de trabajo estables y predecibles, proyectos a largo plazo, entornos de producción de alta carga donde no se planean cambios de recursos en un futuro cercano.
Ejemplos de uso:
- Un proyecto SaaS con una base de usuarios en constante crecimiento pero estable, que sabe que sus servidores de producción principales serán necesarios durante al menos 2-3 años. La celebración de un contrato de 3 años para 5 servidores dedicados ahorra a la empresa cientos de miles de dólares al año.
- Un sistema ERP corporativo que se ejecuta en un servidor dedicado, que requiere una configuración estable y no está sujeto a cambios frecuentes.
4.3. Automatización de la gestión del ciclo de vida de los recursos
Esencia: Uso de herramientas de Infraestructura como Código (IaC) y automatización para el despliegue, configuración, actualización y desaprovisionamiento de servidores.
Ventajas:
- Eliminación de errores relacionados con la configuración manual.
- Aceleración del despliegue y desaprovisionamiento de recursos.
- Garantía de conformidad de las configuraciones y seguridad.
- Apagado o eliminación automática de entornos de prueba temporales, reduciendo los gastos improductivos.
Desventajas:
- Requiere una inversión inicial en el aprendizaje e implementación de herramientas (Terraform, Ansible).
- Necesidad de mantener y actualizar el código IaC.
- Dificultades con la automatización en sistemas altamente personalizados u obsoletos.
Para quién es adecuado: Empresas con un gran número de servidores, entornos de prueba que cambian con frecuencia, equipos orientados a DevOps.
Ejemplos de uso:
- Creación de playbooks de Ansible para la instalación y configuración automática de todos los servicios necesarios en un nuevo VPS.
- Uso de Terraform para gestionar el ciclo de vida de toda la infraestructura, incluida la creación/eliminación de VPS a través de la API del proveedor (si está disponible).
- Apagado o destrucción automática de servidores de staging según un horario fuera del horario laboral.
4.4. Monitoreo y alerta de gastos y rendimiento
Esencia: Implementación de sistemas para la recopilación de métricas de rendimiento y consumo de recursos, así como alertas sobre el exceso de umbrales o anomalías en los gastos.
Ventajas:
- Detección temprana de problemas de rendimiento y posible gasto excesivo.
- Datos precisos para la toma de decisiones sobre dimensionamiento y optimización.
- Aumento de la disponibilidad de los servicios gracias a una respuesta proactiva.
- Mejor comprensión del comportamiento de los sistemas y su impacto en los costos.
Desventajas:
- Requiere la configuración y el mantenimiento de sistemas de monitoreo (Prometheus, Grafana, Zabbix).
- Riesgo de "ruido de información" por un exceso de alertas.
- Necesidad de definir métricas significativas y umbrales.
Para quién es adecuado: Todas las empresas que utilizan VPS o servidores dedicados, especialmente para entornos de producción y servicios críticos.
Ejemplos de uso:
- Configuración de paneles de control de Grafana que muestren la utilización de CPU, RAM, E/S y tráfico de red para cada servidor, con indicadores agregados por proyectos.
- Creación de alertas en Prometheus que notifiquen al equipo de DevOps si el uso de CPU en un servidor supera el 80% durante 15 minutos o si el volumen de tráfico saliente supera el límite mensual en un 70%.
4.5. Optimización de los gastos de red
Esencia: Gestión del tráfico de red entrante y saliente, que a menudo es una partida de gastos oculta pero significativa.
Ventajas:
- Reducción de los cargos por exceso de tráfico, especialmente el saliente.
- Mejora del rendimiento y la velocidad de entrega de contenido a los usuarios.
- Aumento de la tolerancia a fallos y la disponibilidad.
Desventajas:
- Requiere el análisis de patrones de red y la implementación de servicios adicionales (CDN).
- Posibilidad de aumentar la complejidad de la infraestructura.
- Costos iniciales de implementación de CDN u otras soluciones.
Para quién es adecuado: Sitios web con gran volumen de contenido estático, servicios de streaming, API con alta carga.
Ejemplos de uso:
- Integración de una CDN (Content Delivery Network) para el almacenamiento en caché de contenido estático (imágenes, videos, archivos JS/CSS). Esto permite reducir la carga en los servidores y disminuir significativamente el volumen de tráfico saliente, que se paga según las tarifas del proveedor.
- Optimización de protocolos de red y compresión de datos (gzip, Brotli) para reducir el tamaño de los datos transmitidos.
- Revisión de la arquitectura para minimizar el tráfico entre servidores, si este se factura.
4.6. Gestión de licencias y software
Esencia: Contabilidad y optimización cuidadosas de los gastos en licencias de sistemas operativos, bases de datos, paneles de control y otro software comercial.
Ventajas:
- Evitar multas por software no licenciado.
- Reducción de costos mediante la elección de modelos de licencia óptimos.
- Aumento de la seguridad y el soporte.
Desventajas:
- Requiere una auditoría regular del software utilizado.
- Dificultades para rastrear todas las licencias, especialmente en grandes infraestructuras.
- Necesidad de una comprensión profunda de los acuerdos de licencia.
Para quién es adecuado: Todas las empresas que utilizan software comercial en sus servidores.
Ejemplos de uso:
- Transición de un SGBD comercial (por ejemplo, MS SQL Server) a uno de código abierto (PostgreSQL, MySQL) donde sea posible, para ahorrar en licencias.
- Elección del sistema operativo Linux en lugar de Windows Server, si la funcionalidad lo permite, para evitar pagos mensuales de licencias.
- Uso de paneles de control gratuitos (HestiaCP, VestaCP) en lugar de comerciales (cPanel, Plesk) para VPS, donde esté justificado.
Cada una de estas estrategias requiere una planificación y ejecución detalladas. Un enfoque integral que combine soluciones técnicas con cambios organizativos y un cambio cultural es clave para el éxito de la implementación de FinOps en VPS y servidores dedicados.
Consejos prácticos y recomendaciones para la optimización
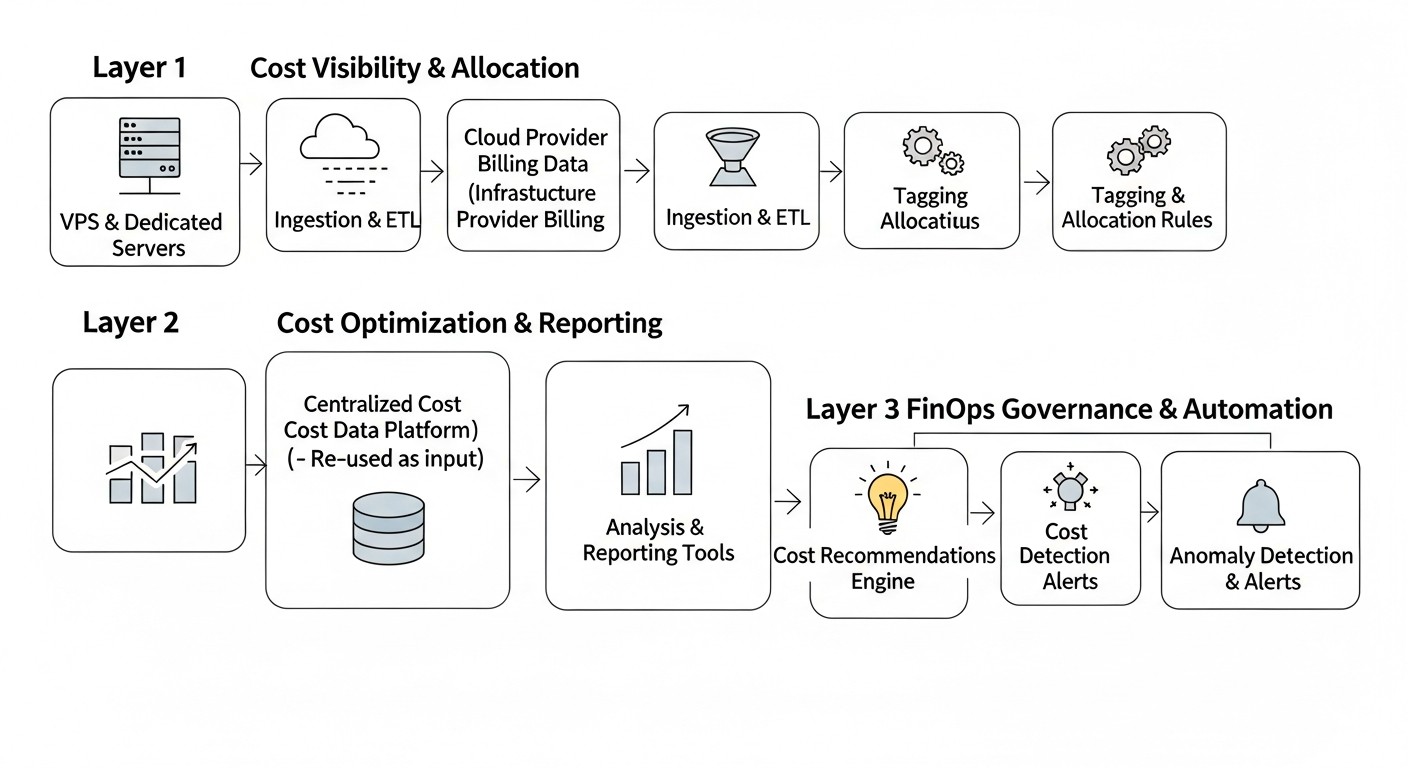 Diagrama: Consejos prácticos y recomendaciones para la optimización
Diagrama: Consejos prácticos y recomendaciones para la optimización
La implementación de FinOps es un proceso continuo que requiere acciones prácticas y una revisión regular. A continuación, se presentan pasos, comandos y configuraciones específicos que le ayudarán a optimizar los gastos en VPS y servidores dedicados.
5.1. Auditoría de la infraestructura actual y definición de la línea base
Antes de optimizar cualquier cosa, es necesario comprender el estado actual. Realice una auditoría completa de todos sus servidores, sus configuraciones, el software utilizado y la carga real.
- Inventario: Cree una lista de todos los VPS y servidores dedicados, sus direcciones IP, proveedores, fechas de inicio de alquiler, costos, propósitos (producción, staging, desarrollo, prueba) y equipos responsables.
- Recopilación de métricas: Configure sistemas de monitoreo (Prometheus + Node Exporter, Zabbix, Netdata) para recopilar datos sobre el uso de CPU, RAM, E/S de disco, tráfico de red. Recopile datos durante al menos 3-6 meses para ver las cargas máximas y mínimas, así como las fluctuaciones estacionales.
- Análisis de registros: Utilice sistemas de registro centralizados (ELK Stack, Loki + Promtail) para analizar errores, rendimiento de aplicaciones e identificar cuellos de botella.
Ejemplo de comando para una revisión rápida de recursos:
# Обзор использования CPU и RAM
top -b -n 1 | head -n 15
# Обзор использования диска
df -h
du -sh /var/log /home /opt
# Обзор сетевых подключений
netstat -tunlp
# Обзор дискового I/O (установите sysstat, если нет)
iostat -xz 1 10
Estos comandos proporcionan una instantánea, pero para un análisis a largo plazo se necesita un sistema de monitoreo.
5.2. Implementación de Right-sizing y consolidación
Basándose en los datos recopilados, identifique los servidores que están sobrecargados (requieren una actualización) o, lo que es más común, subutilizados (se pueden reducir o consolidar).
- Actualización/Reducción: Si un servidor funciona constantemente con una carga de CPU o RAM superior al 80%, considere su actualización. Si la carga es constantemente inferior al 20-30%, es posible que esté pagando de más.
- Consolidación: Para varios VPS subutilizados, considere la posibilidad de migrarlos a un servidor dedicado más potente utilizando virtualización (Proxmox, KVM) o contenerización (Docker Swarm, Kubernetes). Esto permite ahorrar significativamente en el alquiler de VPS individuales.
Caso práctico: Teníamos 5 VPS a $25/mes cada uno (2vCPU, 4GB RAM), cuya utilización no superaba el 15%. Migramos todas las aplicaciones a un servidor dedicado por $120/mes (8c/16t, 64GB RAM) con Proxmox. El ahorro total: $125 - $120 = $5/mes, pero con una reserva de recursos mucho mayor y una gestión simplificada. Además, se liberaron 4 direcciones IP, por las que dejamos de pagar.
Ejemplo de configuración para virtualización en un servidor dedicado (Proxmox):
# Установка Proxmox VE (предполагает чистую установку Debian)
echo "deb http://download.proxmox.com/debian/pve bookworm pve-no-subscription" > /etc/apt/sources.list.d/pve-no-subscription.list
wget https://enterprise.proxmox.com/debian/proxmox-release-bookworm.gpg -O /etc/apt/trusted.gpg.d/proxmox-release-bookworm.gpg
apt update && apt full-upgrade -y
apt install proxmox-ve postfix open-iscsi chrony -y
Después de instalar Proxmox, a través de la interfaz web se pueden crear y gestionar máquinas virtuales y contenedores.
5.3. Automatización del desaprovisionamiento y la gestión de entornos
Muchas empresas gastan dinero en servidores de prueba, desarrollo o staging no utilizados. Automatice su apagado o eliminación.
- Políticas de ciclo de vida: Defina reglas para entornos temporales: por ejemplo, todos los servidores de desarrollo se apagan automáticamente a las 19:00 y se encienden a las 08:00, o se eliminan después de 7 días de inactividad.
- IaC para entornos: Utilice Terraform o Ansible para desplegar y destruir entornos completos.
Ejemplo de playbook de Ansible para apagar un VPS (a través de la API del proveedor, si es compatible, o a través de SSH):
---
- name: Shutdown non-production VPS
hosts: non_prod_vps
become: yes
tasks:
- name: Check if server is running
shell: systemctl is-active --quiet
register: service_status
failed_when: service_status.rc not in [0, 3] # 0 for active, 3 for inactive
- name: Shutdown server if active
command: /sbin/shutdown -h now
when: service_status.rc == 0
ignore_errors: yes # Allow playbook to continue even if shutdown fails (e.g., already off)
Para los proveedores que ofrecen API, se pueden utilizar módulos de Terraform o scripts personalizados para gestionar los VPS.
5.4. Optimización del tráfico de red
El tráfico, especialmente el saliente (egress), puede ser costoso.
- CDN: Para aplicaciones web con gran volumen de contenido estático (imágenes, videos, CSS, JS), utilice una CDN (Cloudflare, Akamai, KeyCDN). Esto reducirá significativamente la carga en su servidor y disminuirá el volumen de tráfico facturado.
- Compresión de datos: Asegúrese de que su servidor web (Nginx, Apache) esté configurado para comprimir (gzip, Brotli) los datos transmitidos.
Ejemplo de configuración de Gzip en Nginx:
http {
gzip on;
gzip_vary on;
gzip_proxied any;
gzip_comp_level 6;
gzip_buffers 16 8k;
gzip_http_version 1.1;
gzip_types text/plain text/css application/json application/javascript text/xml application/xml application/xml+rss text/javascript;
}
5.5. Optimización de bases de datos y aplicaciones
Las consultas ineficientes a la base de datos o las secciones de código que consumen muchos recursos pueden "devorar" CPU y RAM, requiriendo servidores más potentes.
- Indexación de BD: Revise las consultas lentas y añada los índices necesarios.
- Caché: Utilice caché en todos los niveles: Redis, Memcached para datos, Varnish para respuestas HTTP, caché en la aplicación.
- Optimización de código: Perfilado y optimización regular del código de la aplicación.
Ejemplo de comando para buscar consultas lentas en PostgreSQL:
SELECT
query,
calls,
total_time,
mean_time
FROM
pg_stat_statements
ORDER BY
total_time DESC
LIMIT 10;
Para habilitar `pg_stat_statements` es necesario añadir `shared_preload_libraries = 'pg_stat_statements'` en `postgresql.conf` y reiniciar el servicio.
5.6. Implementación de Showback/Chargeback
Este es un cambio cultural, pero tiene herramientas prácticas.
- Etiquetado: Si el proveedor lo admite (algunos VPS en la nube), utilice etiquetas para los servidores (por ejemplo, `project: frontend`, `owner: dev_team_A`). Si no, lleve un registro en un CMDB o una tabla.
- Informes: Genere informes de gastos por proyectos/equipos regularmente y revíselos.
Ejemplo: Un sistema de contabilidad interno puede generar informes mensuales que muestren que el equipo "Alpha" gastó $300 en VPS para su servicio, y el equipo "Beta" – $150. Esto permite a los equipos ver sus gastos y tomar medidas para la optimización.
Al aplicar estos consejos y recomendaciones prácticas, no solo podrá reducir los gastos actuales, sino también crear una cultura sostenible de gestión financiera de la infraestructura que generará dividendos a largo plazo.
Errores comunes en la gestión de gastos y cómo evitarlos
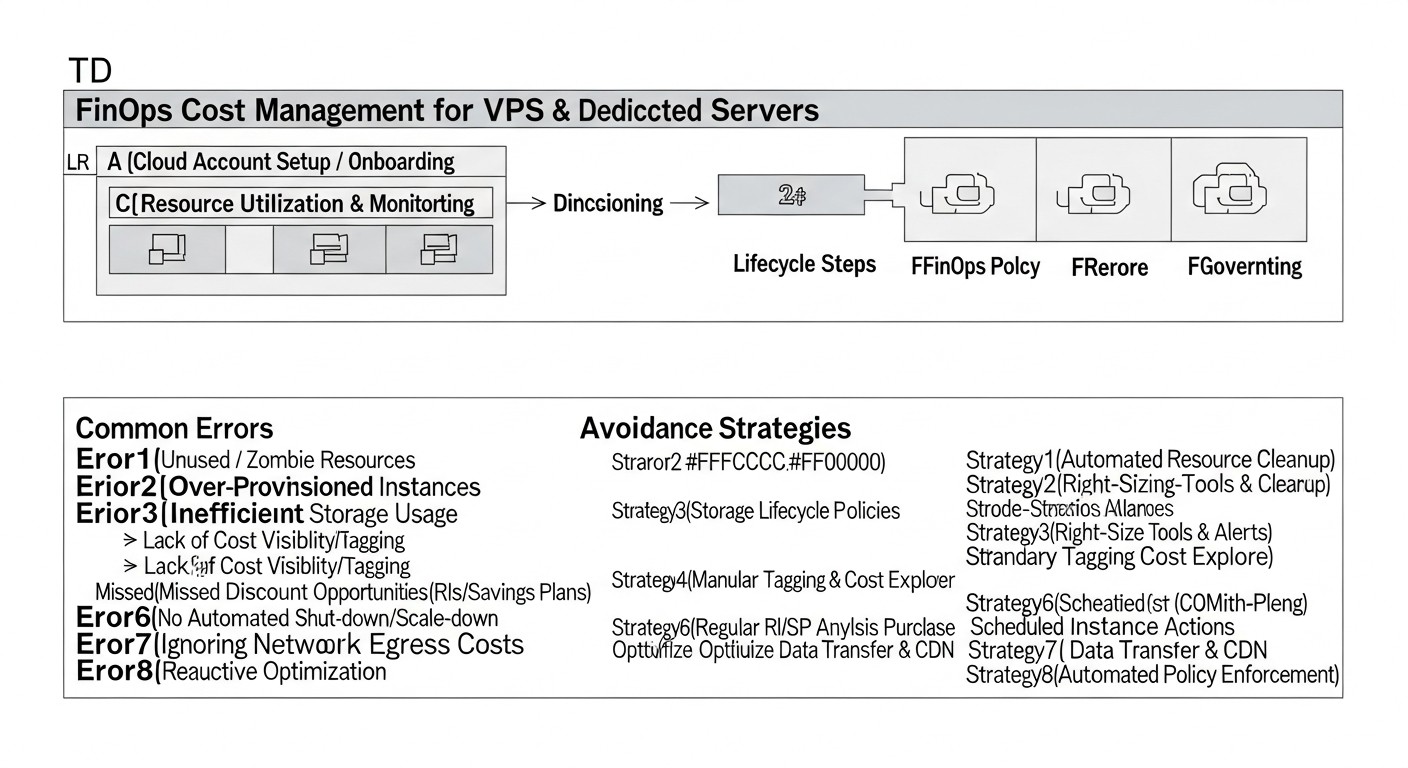 Diagrama: Errores comunes en la gestión de gastos y cómo evitarlos
Diagrama: Errores comunes en la gestión de gastos y cómo evitarlos
La gestión de gastos en VPS y servidores dedicados, a pesar de su aparente simplicidad, está asociada con una serie de errores típicos que pueden llevar a pagos excesivos significativos e ineficiencia. Comprender estas trampas y saber cómo evitarlas es un componente críticamente importante de la estrategia FinOps.
6.1. Aprovisionamiento excesivo (Over-provisioning)
Error: Asignar más recursos (CPU, RAM, disco) de los que realmente necesita la aplicación, "para crecer" o "por si acaso". Este es el error más común y costoso.
Cómo evitarlo:
- Monitoreo preciso: Implemente un sistema de monitoreo integral (Prometheus, Grafana) para recopilar y analizar datos sobre la utilización de recursos durante un período prolongado (mínimo 3-6 meses).
- Dimensionamiento correcto (Right-sizing): Revise regularmente las configuraciones de los servidores, ajustándolas a la carga real. No tema reducir la configuración de un servidor si está subutilizado.
- Escalado por etapas: Comience con la configuración mínima suficiente y escale a medida que crezcan las necesidades, no de antemano.
Ejemplo de consecuencias: Una empresa alquiló un servidor dedicado con 64GB de RAM por $250/mes, mientras que la aplicación utilizaba no más de 10GB. En un año, esto resultó en un pago excesivo de $2400 por memoria no utilizada.
6.2. Ignorar los gastos de red (Egress Traffic)
Error: Centrarse solo en el costo del servidor, ignorando el costo del tráfico saliente, que puede ser una partida de gastos significativa, especialmente para servicios multimedia o API con un gran número de solicitudes.
Cómo evitarlo:
- Análisis de tráfico: Incluya el monitoreo del tráfico de red en su sistema FinOps. Realice un seguimiento de los volúmenes de tráfico entrante y saliente por cada servidor.
- Uso de CDN: Para la entrega de contenido estático, utilice redes de entrega de contenido (CDN).
- Optimización de datos: Aplique compresión (gzip, Brotli) para las respuestas HTTP y otros datos transmitidos. Minimice el tamaño de las respuestas de la API.
- Elección del proveedor: Al elegir un proveedor de VPS/Dedicado, estudie cuidadosamente las tarifas de tráfico, especialmente después de exceder el volumen incluido.
Ejemplo de consecuencias: Un proyecto SaaS que olvidó configurar una CDN para sus imágenes recibió una factura de tráfico que triplicaba el costo del alquiler del servidor. El pago excesivo mensual fue de $400.
6.3. Falta de automatización del desaprovisionamiento
Error: Servidores de prueba/desarrollo olvidados o no utilizados que continúan consumiendo recursos y dinero. La gestión manual del ciclo de vida de los recursos conduce a "servidores zombi".
Cómo evitarlo:
- Políticas de ciclo de vida: Implemente políticas claras para todos los entornos temporales (por ejemplo, "todos los servidores de desarrollo se eliminan después de 3 días de inactividad").
- Automatización IaC: Utilice Terraform o Ansible para la creación y destrucción automática de entornos según un horario o un disparador.
- Auditoría regular: Realice una auditoría semanal o mensual de todos los servidores en ejecución y sus propósitos.
Ejemplo de consecuencias: Una gran empresa descubrió 15 VPS no utilizados que se habían lanzado para pruebas a corto plazo un año antes. El costo total de los recursos perdidos superó los $3000 al año.
6.4. Ignorar los contratos a largo plazo y los descuentos
Error: Pago constante de servidores con tarifa mensual, incluso si su necesidad es predecible y a largo plazo.
Cómo evitarlo:
- Previsión: Analice los planes de desarrollo empresarial a largo plazo y las necesidades de infraestructura.
- Fijación de la carga: Para servidores de producción estables, cuya carga es predecible, celebre contratos de 1 a 3 años.
- Negociaciones con el proveedor: No dude en negociar y solicitar condiciones individuales, especialmente si tiene un gran volumen de consumo.
Ejemplo de consecuencias: Una startup alquiló 10 VPS a $50/mes cada uno durante dos años. Si hubieran celebrado un contrato de 2 años, podrían haber obtenido un descuento del 20%, lo que les habría ahorrado $2400 en dos años.
6.5. Falta de transparencia en los gastos y rendición de cuentas
Error: Ausencia de una imagen clara de quién paga qué. Los gastos de infraestructura se perciben como una partida presupuestaria única e intransparente, sin vinculación a proyectos o equipos específicos.
Cómo evitarlo:
- Sistema de contabilidad: Implemente un sistema de contabilidad de gastos por proyectos, equipos o unidades de negocio (por ejemplo, a través de un CMDB interno o software especializado).
- Showback/Chargeback: Implemente mecanismos de "showback" (simplemente informar sobre los gastos) o "chargeback" (facturación real dentro de la empresa).
- Capacitación de equipos: Realice sesiones regulares para desarrolladores e ingenieros de DevOps, explicándoles las consecuencias financieras de sus decisiones.
- Terminología unificada: Cree un lenguaje común para los equipos técnicos y financieros.
Ejemplo de consecuencias: Los desarrolladores lanzaban nuevos servidores de prueba sin previo aviso, sin conocer su costo. El departamento financiero solo veía el monto total de la factura, sin comprender su estructura. Esto conducía a un constante exceso de presupuesto y a la imposibilidad de identificar la fuente del gasto excesivo.
6.6. Monitoreo insuficiente del rendimiento y los recursos
Error: Ausencia de herramientas adecuadas para el monitoreo o recopilación de una cantidad insuficiente de métricas, lo que lleva a una gestión ciega y a la imposibilidad de identificar problemas antes de su manifestación crítica.
Cómo evitarlo:
- Monitoreo integral: Implemente sistemas de monitoreo que recopilen métricas de CPU, RAM, E/S, tráfico de red, así como métricas de aplicaciones (solicitudes por segundo, tiempo de respuesta, número de errores).
- Paneles de control y alertas: Cree paneles de control informativos para una visión rápida del estado de la infraestructura y configure alertas para el consumo anómalo de recursos o el exceso de umbrales.
- Análisis regular: Realice un análisis regular de los datos recopilados para identificar tendencias y problemas potenciales.
Ejemplo de consecuencias: Un servidor de base de datos comenzó a funcionar lentamente, pero el equipo no pudo entender la causa, ya que el monitoreo era básico. Después de una semana de inactividad y depuración manual, se descubrió que se había agotado el espacio en disco debido a registros no optimizados, lo que provocó una pérdida de rendimiento y, finalmente, costos por una actualización de emergencia.
Al evitar estos errores comunes, las empresas pueden aumentar significativamente la eficiencia de sus inversiones en VPS y servidores dedicados, garantizando la estabilidad y la previsibilidad de los gastos.
Lista de verificación para la aplicación práctica de FinOps
Para una implementación exitosa de FinOps en VPS y servidores dedicados, se requiere un enfoque sistemático. Esta lista de verificación le ayudará a estructurar el trabajo y asegurarse de no omitir ningún paso importante.
- Realice un inventario completo de todos los servidores:
- Elabore una lista de todos los VPS y servidores dedicados (IP, proveedor, configuración).
- Indique el propósito de cada servidor (prod, dev, staging, test) y los equipos/proyectos responsables.
- Registre los costos mensuales/anuales actuales de cada servidor y de todos los servicios asociados (tráfico, licencias, copias de seguridad, direcciones IP).
- Implemente un sistema de monitoreo integral:
- Instale agentes de monitoreo (Node Exporter para Prometheus, agentes Zabbix) en todos los servidores.
- Configure la recopilación de métricas de CPU, RAM, E/S de disco, tráfico de red (entrada/salida), así como métricas de aplicaciones (si corresponde).
- Despliegue un sistema centralizado de monitoreo y visualización (Prometheus + Grafana, Zabbix).
- Recopile datos durante al menos 3-6 meses para analizar tendencias.
- Defina la línea base de gastos y las métricas clave (KPI):
- Calcule los costos totales actuales de la infraestructura.
- Defina métricas como "costo por solicitud", "costo por usuario", "costo por terabyte de datos", "utilización de CPU/RAM".
- Establezca objetivos para la reducción de costos o el aumento de la eficiencia.
- Realice un análisis de dimensionamiento correcto (Right-sizing) y consolidación:
- Utilizando los datos de monitoreo, identifique los servidores sobrecargados (más del 80% de utilización) y subutilizados (menos del 20-30% de utilización).
- Desarrolle un plan para la reducción o actualización de las configuraciones.
- Identifique oportunidades para consolidar varios VPS subutilizados en un servidor dedicado con virtualización o contenerización.
- Optimice el uso de contratos a largo plazo:
- Identifique cargas de trabajo estables que no se planean cambiar en 1-3 años.
- Explore las ofertas de los proveedores para contratos a largo plazo y reservas.
- Celebre contratos a largo plazo para los servidores adecuados para obtener descuentos.
- Implemente la automatización de la gestión de recursos (IaC):
- Utilice Terraform para gestionar el ciclo de vida (creación/eliminación) de los VPS a través de la API del proveedor (si está disponible).
- Aplique Ansible, Puppet o Chef para la configuración automática, el despliegue de aplicaciones y la gestión de configuraciones de servidores.
- Automatice el apagado/eliminación de entornos temporales de desarrollo/staging según un horario o después de un período determinado de inactividad.
- Optimice los gastos de red:
- Analice los volúmenes de tráfico saliente por cada servidor.
- Implemente una CDN para la entrega de contenido estático.
- Asegúrese de que los servidores web estén configurados para la compresión de datos (gzip/Brotli).
- Gestione licencias y software:
- Realice una auditoría de todo el software comercial utilizado en los servidores.
- Considere la posibilidad de migrar a software de código abierto (Linux, PostgreSQL, Nginx) para ahorrar en licencias.
- Revise regularmente los acuerdos de licencia y elija los modelos óptimos.
- Implemente Showback/Chargeback y una cultura de rendición de cuentas:
- Cree un sistema interno para vincular los gastos de los servidores a proyectos o equipos específicos.
- Genere informes de gastos regularmente para cada equipo y realice revisiones.
- Capacite a los equipos técnicos sobre los aspectos financieros de sus decisiones.
- Realice revisiones FinOps regulares:
- Mensual o trimestralmente, reúna a los equipos de DevOps, desarrollo y finanzas para analizar los gastos actuales, discutir estrategias de optimización y pronosticar necesidades futuras.
- Ajuste las estrategias de FinOps en función de los datos obtenidos y la retroalimentación.
- Desarrolle un plan de respuesta a incidentes relacionados con los gastos:
- Configure alertas para el crecimiento anómalo de los gastos o el exceso de límites de tráfico.
- Defina procedimientos de respuesta rápida para tales incidentes.
- Documente todos los procesos y decisiones:
- Cree una base de conocimientos sobre prácticas FinOps, estándares de configuración y procedimientos de optimización.
- Actualice la documentación a medida que cambien la infraestructura o las estrategias.
Siguiendo esta lista de verificación, podrá implementar gradualmente la cultura FinOps en su organización, garantizando la transparencia, el control y la optimización constante de los gastos en VPS y servidores dedicados.
Cálculo de costos / Economía de FinOps
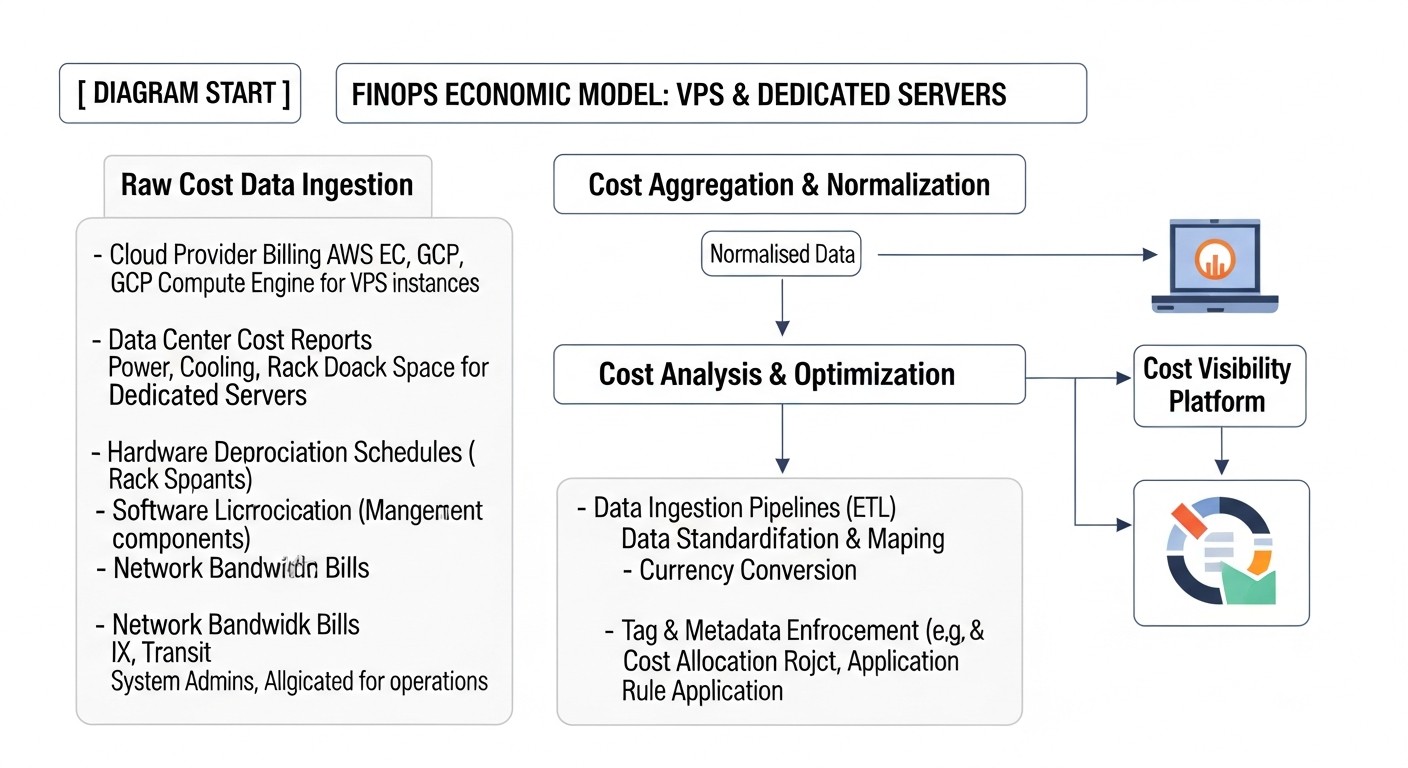 Diagrama: Cálculo de costos / Economía de FinOps
Diagrama: Cálculo de costos / Economía de FinOps
Comprender la economía de FinOps en VPS y servidores dedicados va más allá de una simple comparación de precios. Incluye un análisis detallado de los costos directos y ocultos, así como una evaluación del ahorro potencial de la implementación de estrategias de optimización. Aquí examinaremos ejemplos de cálculos para diferentes escenarios e identificaremos gastos que a menudo se pasan por alto.
8.1. Costos directos y ocultos
Costos directos:
- Alquiler de servidor/VPS: Partida principal, a menudo fija mensualmente.
- Direcciones IP adicionales: Cada IP adicional suele tener un costo.
- Tráfico: Cargo por exceder el volumen incluido, especialmente el saliente (egress).
- Licencias de software: Sistemas operativos (Windows Server), paneles de control (cPanel, Plesk), SGBD comerciales (MS SQL Server), antivirus.
- Servicios adicionales del proveedor: Protección DDoS, copias de seguridad, servicios gestionados, acceso KVM.
Costos ocultos:
- Recursos humanos: Tiempo de los ingenieros para el despliegue, configuración, monitoreo, resolución de problemas. Esta es una de las partidas ocultas más significativas. La automatización reduce estos costos.
- Consumo de energía (para co-location): Si tiene su propio servidor en un centro de datos, paga por la electricidad.
- Tiempo de inactividad (Downtime): Pérdida de beneficios, daño a la reputación debido a la indisponibilidad de los servicios.
- Multas por incumplimiento de licencias: Si utiliza software no licenciado.
- Hardware obsoleto: Si posee servidores, el hardware antiguo requiere más energía, se avería con más frecuencia y es menos productivo.
- Costo de migración: El traslado entre proveedores o servidores requiere tiempo y puede provocar tiempos de inactividad.
- Capacitación: Costos de capacitación del personal en nuevas herramientas y prácticas FinOps.
8.2. Ejemplos de cálculos para diferentes escenarios
Consideremos varios escenarios para ilustrar cómo FinOps puede influir en la economía.
Escenario 1: Pequeño proyecto SaaS (hasta 5000 usuarios activos)
Situación inicial:
- 2 x VPS de rango medio (4 vCPU, 8GB RAM, 160GB NVMe) a $50/mes cada uno = $100/mes.
- 1 x VPS de nivel de entrada (2 vCPU, 4GB RAM, 80GB NVMe) para staging/dev a $20/mes.
- Gastos directos totales: $120/mes.
- El monitoreo muestra que los VPS de producción están cargados al 20-30% en horario normal, y hasta el 60% en picos. El VPS de staging se utiliza 2-3 veces por semana.
- Costo inicial: $120/mes = $1440/año.
Optimización FinOps:
- Dimensionamiento correcto (Right-sizing): El análisis mostró que un VPS de alto rendimiento (8 vCPU, 32GB RAM, 640GB NVMe) por $100/mes puede manejar ambas cargas de producción con margen.
- Automatización: El VPS de staging se configura para apagarse automáticamente fuera del horario laboral (ahorro del 50% de $20 = $10/mes).
- Contrato a largo plazo: El VPS de producción se traslada a un contrato de 1 año con un descuento del 10% ($100 -> $90/mes).
Situación final:
- 1 x VPS de alto rendimiento (prod) a $90/mes.
- 1 x VPS de nivel de entrada (staging/dev) a $10/mes.
- Gastos directos totales: $100/mes.
Ahorro: $120 - $100 = $20/mes, o $240/año (16.7%).
Escenario 2: Proyecto de e-commerce en crecimiento (hasta 50 000 visitantes únicos al día)
Situación inicial:
- 3 x VPS de alto rendimiento (8 vCPU, 32GB RAM) para servidores web a $100/mes = $300/mes.
- 1 x VPS de alto rendimiento (8 vCPU, 64GB RAM) para SGBD a $150/mes.
- Tráfico adicional: $50/mes (después de exceder el límite incluido).
- Gastos directos totales: $500/mes.
- Costo inicial: $500/mes = $6000/año.
Optimización FinOps:
- Consolidación: En lugar de 4 VPS, la empresa pasa a 2 servidores dedicados pequeños (Xeon E-2414, 32GB RAM, 2x1TB NVMe) a $120/mes cada uno = $240/mes. En uno se alojan los servidores web, en el otro, el SGBD y las copias de seguridad. Esto proporciona más recursos y aislamiento.
- CDN: Implementación de CDN para contenido estático, lo que elimina por completo el pago excesivo por tráfico (ahorro de $50/mes).
- Contrato a largo plazo: Se celebra un contrato de 2 años para los servidores dedicados con un descuento del 15% ($240 -> $204/mes).
Situación final:
- 2 x servidores dedicados pequeños a $102/mes cada uno = $204/mes.
- Gastos de tráfico: $0/mes.
- Gastos directos totales: $204/mes.
Ahorro: $500 - $204 = $296/mes, o $3552/año (59.2%).
8.3. Tabla con ejemplos de cálculos
Esta tabla demuestra el ahorro potencial al pasar del pago mensual a contratos a largo plazo para un servidor dedicado típico.
| Parámetro |
Pago mensual (USD) |
Contrato de 1 año (USD/mes) |
Contrato de 2 años (USD/mes) |
Contrato de 3 años (USD/mes) |
| Servidor dedicado estándar (por ejemplo, Small Dedicated) |
$120 |
$108 (10% de descuento) |
$96 (20% de descuento) |
$84 (30% de descuento) |
| Gastos anuales (sin descuento) |
$1440 |
$1296 |
$1152 |
$1008 |
| Ahorro total en 3 años |
- |
$432 (12%) |
$864 (24%) |
$1296 (36%) |
Como se desprende de la tabla, los contratos a largo plazo pueden generar un ahorro significativo, especialmente cuando existen cargas de trabajo estables. Sin embargo, es importante recordar que esto requiere una previsión precisa y la disposición a asumir compromisos a largo plazo.
La economía de FinOps en VPS y servidores dedicados no se trata solo de un ahorro directo. También se trata de aumentar la eficiencia en el uso de los recursos, reducir riesgos, mejorar el rendimiento y, en última instancia, maximizar el valor de negocio de la infraestructura de TI. Las inversiones en prácticas FinOps se amortizan mediante la reducción de costos y un enfoque más estratégico en la asignación de recursos.
Casos y ejemplos de implementación de FinOps
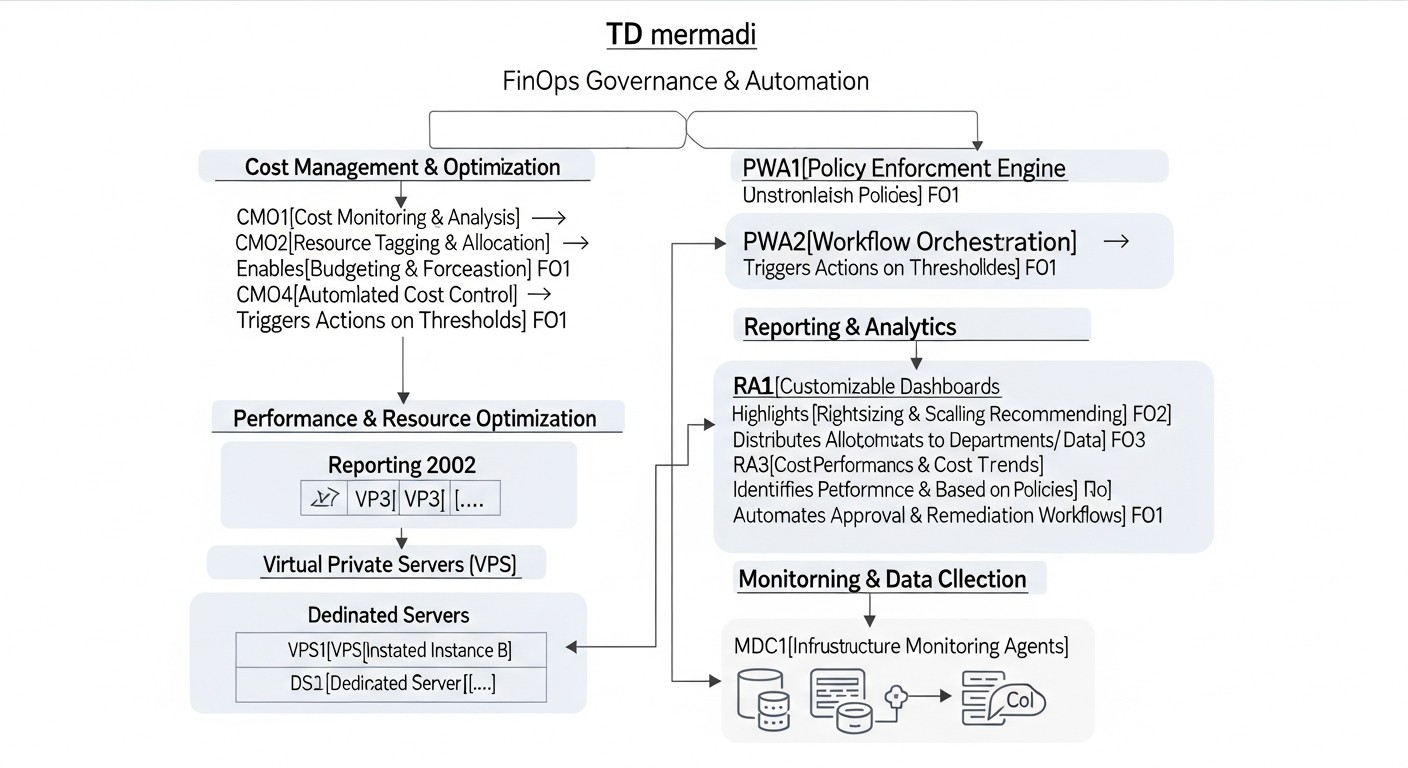 Diagrama: Casos y ejemplos de implementación de FinOps
Diagrama: Casos y ejemplos de implementación de FinOps
Los casos reales demuestran mejor la eficacia del enfoque FinOps. Aquí examinaremos varios escenarios hipotéticos, pero realistas, basados en problemas típicos que enfrentan las empresas que utilizan VPS y servidores dedicados.
9.1. Caso 1: Startup "PixelPulse" – Optimización de gastos en desarrollo y pruebas
Problema: "PixelPulse", una startup de rápido crecimiento en diseño gráfico y herramientas en la nube, utilizaba más de 20 VPS para diferentes entornos de desarrollo, pruebas y demostraciones a clientes. Los VPS se lanzaban a petición de los desarrolladores y a menudo permanecían activos después de finalizar el trabajo. Los gastos mensuales de infraestructura superaban los $600, lo cual era crítico para una startup joven. Faltaba transparencia sobre quién pagaba qué.
Solución FinOps:
- Inventario y monitoreo: Se implementó un sistema de monitoreo (Netdata + Prometheus) para recopilar datos sobre la utilización de recursos de todos los VPS. Se descubrió que el 70% de los VPS de desarrollo/prueba se utilizaban menos del 20% del tiempo.
- Automatización del desaprovisionamiento: Se desarrollaron playbooks de Ansible para apagar automáticamente todos los VPS de desarrollo/prueba a las 19:00 hora local y encenderlos a las 08:00. Para los entornos de demostración temporales, se configuró un disparador para su eliminación 24 horas después del último uso.
- Consolidación: Varios VPS de baja carga se migraron a un VPS más potente utilizando contenedores Docker, lo que permitió reducir el número de máquinas activas.
- Showback: Se implementó un sistema simple de "showback", donde cada VPS se etiquetaba con el nombre del equipo propietario, y semanalmente se generaba un informe de gastos por equipos.
Resultados:
- Reducción de gastos: Los gastos mensuales en VPS se redujeron de $600 a $380 (ahorro del 36.7%).
- Aumento de la eficiencia: Los equipos adoptaron un enfoque más responsable en el uso de los recursos, participando activamente en la optimización.
- Transparencia: Los desarrolladores obtuvieron una comprensión clara del costo de sus entornos, lo que llevó a decisiones arquitectónicas más reflexivas.
9.2. Caso 2: "DataVault Solutions" – Optimización de servidores dedicados para Big Data
Problema: "DataVault Solutions", una empresa que ofrece servicios de procesamiento de big data, utilizaba 10 servidores dedicados para un clúster de Apache Kafka y Apache Spark. Los servidores se alquilaban mensualmente, lo que impedía obtener descuentos. Debido a las cargas máximas y las consultas no optimizadas a la base de datos, el equipo se enfrentaba periódicamente a problemas de rendimiento, que requerían optimización manual y, en consecuencia, costosas actualizaciones de emergencia. Los gastos totales ascendían a unos $1500/mes.
Solución FinOps:
- Monitoreo detallado y análisis de carga: Se implementó un monitoreo integral con Prometheus, Grafana y exportadores JMX para Kafka/Spark. Se identificaron puntos críticos en el clúster y trabajos de Spark ineficientes.
- Optimización del rendimiento: Los analistas de datos y los ingenieros de DevOps trabajaron en conjunto para optimizar las consultas SQL y las aplicaciones Spark, lo que permitió reducir la carga máxima en un 20%.
- Contratos a largo plazo: Después de estabilizar la carga y confirmar la necesidad a largo plazo de la configuración actual, la empresa celebró contratos de 2 años para los 10 servidores, obteniendo un descuento del 20%.
- Automatización del escalado (parcial): Se implementaron playbooks de Ansible para el despliegue rápido de nuevos nodos del clúster en caso de necesidad (aunque eran servidores dedicados, el proceso de despliegue se estandarizó).
Resultados:
- Reducción de gastos: Los gastos mensuales en servidores disminuyeron de $1500 a $1200 (ahorro del 20%) gracias al descuento por contratos a largo plazo.
- Aumento de la estabilidad: La optimización de las aplicaciones y el monitoreo permitieron evitar costosas actualizaciones de emergencia y mejorar la estabilidad del clúster.
- Mejor planificación: Se logró la previsibilidad de los gastos de infraestructura para los próximos dos años, lo que simplificó la presupuestación.
9.3. Caso 3: "GlobalConnect" – Gestión de infraestructura híbrida y gastos de red
Problema: "GlobalConnect", una empresa de logística internacional, utilizaba una infraestructura híbrida: parte de los servicios se ejecutaban en la nube pública, y los sistemas ERP y bases de datos críticamente importantes se alojaban en 5 servidores dedicados en su propio centro de datos (co-location). El problema principal eran los gastos incontrolados de tráfico saliente entre el centro de datos y la nube, así como el uso ineficiente del espacio en disco en los servidores dedicados debido a una política de copias de seguridad obsoleta. Los gastos totales de co-location y tráfico ascendían a unos $2000/mes.
Solución FinOps:
- Análisis del tráfico de red: Se implementó un monitoreo NetFlow para analizar el tráfico entre redes. Se descubrió que se transfería un gran volumen de datos entre la nube y el entorno local para análisis que podrían haberse realizado más cerca de la fuente de datos.
- Optimización de la arquitectura: Parte de los servicios analíticos se trasladaron al centro de datos para procesar los datos localmente, minimizando el tráfico saliente a la nube. Para los datos críticamente importantes transferidos a la nube, se implementó compresión y deduplicación.
- Optimización del almacenamiento y las copias de seguridad: Se revisó la política de copias de seguridad en los servidores dedicados. En lugar de una copia de seguridad diaria completa, se implementaron copias de seguridad incrementales y el archivo de datos antiguos en almacenamientos más económicos. Los datos obsoletos que se almacenaban "por si acaso" se eliminaron.
- Gestión de licencias: Se realizó una auditoría de las licencias de SGBD (MS SQL Server) en los servidores dedicados. Se descubrió que en uno de los servidores se utilizaba una licencia excesivamente cara, que fue reemplazada por una versión más adecuada.
Resultados:
- Reducción de gastos de red: Los gastos de tráfico saliente entre el centro de datos y la nube se redujeron en un 40%, lo que representó $300/mes.
- Optimización del almacenamiento: Se liberaron 15TB de espacio en disco, lo que permitió posponer la compra de nuevo equipo de almacenamiento durante 1.5 años (ahorro de $5000).
- Reducción de costos de licencias: El reemplazo de una licencia de MS SQL Server ahorró $150/mes.
- Ahorro total: Más de $450/mes en gastos directos y un aplazamiento significativo de los gastos de capital.
Estos casos demuestran que FinOps no es una solución universal, pero sus principios – visibilidad, rendición de cuentas, optimización y automatización – son aplicables en una amplia variedad de escenarios y aportan beneficios financieros tangibles, incluso en infraestructuras tradicionales.
Herramientas y recursos para FinOps en VPS/Dedicados
 Diagrama: Herramientas y recursos para FinOps en VPS/Dedicados
Diagrama: Herramientas y recursos para FinOps en VPS/Dedicados
La implementación efectiva de FinOps en VPS y servidores dedicados es imposible sin el uso de las herramientas adecuadas. A diferencia de las plataformas en la nube, donde muchas herramientas FinOps están integradas en el ecosistema del proveedor, para entornos on-prem e híbridos a menudo se requiere la integración de diversas soluciones. A continuación, se presenta una lista de herramientas clave y recursos útiles.
10.1. Utilidades para monitoreo y recopilación de métricas
La base de FinOps son los datos. Sin un monitoreo detallado, es imposible tomar decisiones informadas sobre la optimización.
10.2. Herramientas para automatización e Infraestructura como Código (IaC)
La automatización es clave para reducir el trabajo manual y aumentar la eficiencia.
10.3. Herramientas para inventario y CMDB
Para entender qué posee y quién es responsable de ello.
- NetBox: Sistema de código abierto para IPAM (Gestión de Direcciones IP) y DCIM (Gestión de Infraestructura de Centro de Datos). Permite llevar un registro detallado de servidores, equipos de red, direcciones IP, máquinas virtuales y sus relaciones.
- GLPI: Sistema integral de gestión de activos de TI y Service Desk. Ayuda a rastrear todos los activos de TI, incluyendo hardware y software.
- Custom Spreadsheets/Databases: Para empresas pequeñas, una hoja de cálculo simple en Google Sheets o Excel, así como una base de datos (PostgreSQL, MySQL) con una interfaz personalizada, puede ser suficiente para el seguimiento de activos y gastos.
10.4. Herramientas para el análisis de costos y la elaboración de informes
Dado que los proveedores de VPS/Dedicados no tienen informes FinOps integrados, a menudo se requieren soluciones personalizadas.
- Custom Scripts: Scripts en Python, Go o Bash para recopilar datos de las API de facturación de los proveedores (si las hay), datos de monitoreo y CMDB, y luego agregarlos y generar informes.
- Business Intelligence (BI) Tools: Tableau, Power BI, Metabase (código abierto) para crear paneles de control e informes de gastos personalizados, combinando datos de diferentes fuentes.
- Infracost: Herramienta que se integra con Terraform y muestra los costos estimados de la infraestructura antes de su despliegue. Aunque está más orientada a la nube, sus principios pueden adaptarse para evaluar los costos de VPS/Dedicados si tiene sus propios módulos Terraform para estos recursos.
10.5. Enlaces útiles y documentación
- FinOps Foundation: https://www.finops.org/ – el recurso principal sobre prácticas FinOps. Aunque muchos materiales se centran en la nube, los principios son universales.
- Documentación de los proveedores: Estudie cuidadosamente la documentación de sus proveedores de hosting, especialmente las secciones relativas a la API (si la hay), la tarificación del tráfico y los servicios adicionales.
- Comunidades de código abierto: Los foros y comunidades de Prometheus, Grafana, Ansible, Terraform son valiosas fuentes de conocimiento y soluciones listas para usar.
La elección de las herramientas depende de la escala de su infraestructura, la complejidad de las tareas y los recursos disponibles. Comience con el monitoreo y la automatización básicos, ampliando gradualmente el conjunto de herramientas a medida que se desarrolla su cultura FinOps.
Troubleshooting: Resolución de problemas, relacionados con gastos y rendimiento
 Diagrama: Troubleshooting: Resolución de problemas, relacionados con gastos y rendimiento
Diagrama: Troubleshooting: Resolución de problemas, relacionados con gastos y rendimiento
Los problemas de rendimiento en un VPS o servidor dedicado casi siempre conducen directa o indirectamente a un aumento de los gastos. Esto puede ser un gasto excesivo directo (por ejemplo, debido a la necesidad de una actualización) o indirecto (pérdidas por tiempo de inactividad, tiempo de los ingenieros para la depuración). La resolución eficaz de problemas es un elemento clave de FinOps.
11.1. Problemas típicos y sus soluciones
11.1.1. Alta utilización de CPU
Problema: El servidor funciona constantemente con un alto uso de CPU (más del 80%), lo que provoca una ralentización de las aplicaciones, un aumento del tiempo de respuesta y posibles errores.
Diagnóstico:
- `top` o `htop`: Identificar los procesos que consumen más CPU.
- `perf`, `strace`: Para un análisis profundo de las llamadas al sistema y la creación de perfiles de aplicaciones.
- Métricas de CPU en Grafana/Prometheus: Consultar datos históricos y tendencias.
Soluciones:
- Optimización de código: Si el problema está en una aplicación específica, perfile su código y optimice las secciones que consumen muchos recursos.
- Optimización de la base de datos: Las consultas SQL lentas pueden cargar mucho la CPU. Utilice índices, optimice las consultas.
- Caché: Implemente caché a nivel de aplicación, Redis/Memcached, Varnish.
- Escalado: Si la optimización no ayuda, considere actualizar el VPS/servidor a una configuración más potente o el escalado horizontal (añadir otro servidor y equilibrar la carga).
11.1.2. Falta de memoria RAM (OOM - Out Of Memory)
Problema: El servidor experimenta una escasez de RAM, lo que lleva al uso de la partición de intercambio (ralentiza mucho el trabajo), la terminación forzada de procesos (OOM Killer) y la inestabilidad del sistema.
Diagnóstico:
- `free -h`: Mostrar el uso actual de RAM y swap.
- `top` o `htop`: Identificar los procesos que consumen más memoria.
- `dmesg | grep -i oom`: Revisar los registros del kernel en busca de mensajes de OOM Killer.
- Métricas de RAM en Grafana/Prometheus: Rastrear el consumo de memoria a lo largo del tiempo.
Soluciones:
- Optimización de aplicaciones: Reduzca el consumo de memoria de las aplicaciones (por ejemplo, configure el pool de hilos, los límites de memoria para los contenedores).
- Optimización de la base de datos: Configure los búferes y cachés de la base de datos para que no consuman toda la memoria disponible.
- Reducción del número de servicios: Desactive o elimine los servicios no utilizados.
- Actualización de RAM: Si todas las optimizaciones se han agotado, es necesario aumentar la cantidad de memoria RAM del servidor.
11.1.3. Problemas con la E/S de disco
Problema: Funcionamiento lento del subsistema de disco, lo que provoca cargas prolongadas, retrasos en el funcionamiento de las aplicaciones, especialmente las bases de datos.
Diagnóstico:
- `iostat -xz 1`: Mostrar la utilización del disco, la cola promedio de solicitudes (avgqu-sz), el tiempo de espera (await).
- `iotop`: Mostrar los procesos que generan la mayor E/S de disco.
- `df -h`: Comprobar el espacio libre en disco.
- Métricas de E/S en Grafana/Prometheus.
Soluciones:
- Optimización de la base de datos: Asegúrese de que la base de datos esté configurada para un uso máximo eficiente del disco (por ejemplo, ubicación correcta de los registros, datos, archivos temporales).
- Caché: Implemente caché para reducir el número de accesos al disco.
- Transición a NVMe: Si se utilizan SATA SSD o HDD, considere la actualización a discos NVMe, que ofrecen un rendimiento significativamente mayor.
- Optimización del sistema de archivos: Configuración de opciones de montaje (por ejemplo, `noatime`).
- Distribución de la carga: Si es posible, distribuya la carga de disco entre varios discos o servidores.
11.1.4. Problemas de red / Alto tráfico
Problema: Alta latencia de red, pérdida de paquetes o consumo excesivo de tráfico saliente, lo que lleva a pagos excesivos.
Diagnóstico:
- `ping`, `traceroute`: Comprobar la conectividad y las latencias a recursos externos.
- `netstat -tunlp`: Mostrar puertos abiertos y conexiones de red activas.
- `iftop`, `nload`: Monitoreo del tráfico de red en tiempo real.
- Métricas de tráfico de red en Grafana/Prometheus: Rastrear el volumen de tráfico entrante/saliente.
- Informes de facturación del proveedor: Comprobar el detalle del tráfico.
Soluciones:
- Optimización de aplicaciones: Reduzca el tamaño de los datos transmitidos (compresión, optimización de API).
- CDN: Para contenido estático, utilice una red de entrega de contenido.
- Limitación de velocidad: Si algún servicio genera tráfico excesivo, considere limitar su actividad de red.
- Verificación de DDoS: Un aumento inesperado del tráfico puede ser un ataque DDoS, contacte a su proveedor para activar la protección.
- Cambio de tarifa: Si el consumo de tráfico excede constantemente los límites, puede ser más económico cambiar a una tarifa con un volumen incluido mayor o tráfico ilimitado.
11.2. Cuándo contactar al soporte del proveedor
Algunos problemas están fuera de su competencia y requieren la intervención del proveedor de hosting. Contacte al soporte si:
- Fallos de hardware: El servidor no enciende, los discos fallan (aunque los sistemas de monitoreo modernos pueden predecirlo), problemas con la RAM, fallos en la tarjeta de red.
- Problemas con la red del centro de datos: Problemas de red globales, inaccesibilidad del servidor desde el exterior, alta latencia al centro de datos no causada por su configuración.
- Ataques DDoS: Si su servidor está siendo objeto de un ataque DDoS a gran escala que supera las capacidades de su protección.
- Problemas de seguridad física: Por ejemplo, acceso al servidor o al rack.
- Cuestiones de facturación: Errores en las facturas, preguntas sobre las tarifas.
- Problemas con KVM/IPMI: Si necesita acceso a la consola del servidor y KVM/IPMI no funciona.
Antes de contactar al soporte, siempre recopile la máxima información: hora exacta del problema, registros, capturas de pantalla, resultados de comandos de diagnóstico. Esto acelerará significativamente el proceso de resolución.
FAQ: Preguntas frecuentes sobre FinOps en VPS y servidores dedicados
¿Qué es FinOps aplicado a VPS y servidores dedicados?
FinOps en VPS y servidores dedicados es una metodología operativa que une a los equipos financieros y de ingeniería para gestionar y optimizar los costos de la infraestructura no-cloud. Se enfoca en aumentar la transparencia de los gastos, distribuir la responsabilidad, optimizar continuamente los recursos y automatizar los procesos para maximizar el valor de negocio de cada dólar gastado en recursos de servidor.
¿Cómo empezar a implementar FinOps en mi empresa si solo tenemos VPS?
Empiece poco a poco:
- Realice un inventario completo de todos sus VPS y sus propósitos.
- Implemente un monitoreo básico (Prometheus/Grafana) para recopilar métricas de CPU, RAM, E/S.
- Identifique 2-3 de los VPS más subutilizados e intente optimizarlos (dimensionamiento correcto, consolidación).
- Comience a discutir los gastos con los equipos que utilizan estos VPS.
Esto le permitirá obtener victorias rápidas y demostrar el valor de FinOps.
¿Qué métricas son las más importantes para FinOps en VPS/Dedicados?
Las métricas clave incluyen: utilización de CPU, RAM, E/S de disco, volumen de tráfico de red entrante y saliente, número de servidores activos e inactivos, costo por unidad de métrica de negocio (por ejemplo, costo por usuario activo, costo por transacción), así como el porcentaje de ahorro por optimización.
¿Se puede automatizar FinOps en servidores dedicados?
Sí, la automatización es la piedra angular de FinOps. Con herramientas IaC (Ansible, Terraform) se puede automatizar el despliegue, la configuración y el desaprovisionamiento de servidores. Los sistemas de monitoreo (Prometheus) pueden generar automáticamente alertas sobre posibles problemas de gastos o rendimiento. Los scripts pueden agregar datos de facturación y generar informes.
¿Cuál es la diferencia entre FinOps y la gestión tradicional del presupuesto de TI?
La gestión tradicional del presupuesto suele ser estática y reactiva, centrándose en la aprobación y el control de los gastos por partidas. FinOps es dinámico, proactivo y centrado en la cultura. Implica una colaboración constante entre finanzas e ingeniería, la toma de decisiones operativas basadas en datos en tiempo real y el objetivo no solo de reducir los gastos, sino de maximizar el valor de negocio de las inversiones en TI.
¿Cómo evitar el vendor lock-in al elegir un proveedor de VPS/Dedicado?
Elija proveedores que ofrezcan sistemas operativos estándar (Linux), API abiertas (si las hay), así como la posibilidad de exportar datos. Utilice IaC (Terraform, Ansible) para gestionar la infraestructura, lo que la hace más portable. Evite soluciones altamente personalizadas o software propietario que pueda ser difícil de migrar.
¿Cómo tener en cuenta los recursos humanos en FinOps?
Los recursos humanos son una partida de gastos oculta pero significativa. Evalúe el tiempo que dedican los ingenieros a operaciones rutinarias, la depuración de problemas relacionados con la ineficiencia, y compare esto con el costo de implementar la automatización. El objetivo de FinOps no es reducir el personal, sino redirigir sus esfuerzos hacia tareas de mayor valor, automatizando la rutina.
¿Qué hacer con el equipo obsoleto en servidores dedicados?
El equipo obsoleto puede ser ineficiente. Evalúe su rendimiento, consumo de energía y costo de mantenimiento. Si no puede manejar la carga, requiere un mantenimiento costoso o consume demasiada energía, considere reemplazarlo por equipo más nuevo y eficiente o migrar a VPS más potentes. A veces, la venta o el desguace de hardware antiguo es económicamente más ventajoso que su uso continuado.
¿Cómo afecta FinOps a la seguridad?
FinOps mejora indirectamente la seguridad. La optimización de recursos significa que usted comprende mejor su infraestructura. La automatización reduce el número de errores manuales que pueden conducir a vulnerabilidades. La eliminación de servidores no utilizados reduce la superficie de ataque. Sin embargo, FinOps no reemplaza las prácticas de seguridad especializadas, sino que las complementa.
¿Cuáles son los escollos al hacer la transición a FinOps?
Los principales escollos son: resistencia al cambio en los equipos, falta de apoyo de la dirección, escasez de datos para la toma de decisiones, centrarse únicamente en la reducción de gastos sin tener en cuenta el valor de negocio, y el intento de implementar todo a la vez en lugar de un enfoque gradual.
¿Se puede aplicar FinOps en entornos híbridos (parte en la nube, parte on-prem)?
Sí, FinOps es ideal para entornos híbridos. Ayuda a unificar el enfoque de la gestión de gastos en toda la infraestructura, garantizando la transparencia y la optimización tanto para los recursos en la nube como para los recursos on-prem. Esto permite tomar decisiones informadas sobre dónde alojar mejor las diferentes cargas de trabajo.
Conclusión
La implementación de FinOps en VPS y servidores dedicados no es solo una tendencia de moda, sino una necesidad estratégica en el cambiante panorama de la infraestructura de TI de 2026. Hemos visto que los principios de FinOps, originalmente desarrollados para entornos en la nube, no solo son aplicables, sino también críticamente importantes para quienes gestionan infraestructuras tradicionales o híbridas. La falta de flexibilidad y la facturación granular, características de las nubes públicas, en realidad hacen que FinOps sea aún más significativo, requiriendo un análisis más profundo, una planificación cuidadosa y una gestión proactiva.
Hemos examinado en detalle los criterios clave de FinOps —visibilidad, rendición de cuentas, optimización, automatización, previsión y colaboración— y hemos comprobado que cada uno de ellos desempeña un papel crucial en la configuración de una estrategia eficaz. Desde el dimensionamiento correcto y la consolidación de recursos hasta el uso de contratos a largo plazo y la optimización de los gastos de red, cada medida, respaldada por datos de monitoreo y automatización, contribuye a una reducción significativa de los costos y a un aumento de la eficiencia general de la infraestructura.
Los consejos prácticos, los ejemplos de comandos, los cálculos económicos y los casos reales han demostrado que FinOps no es un concepto abstracto, sino un conjunto de acciones concretas y aplicables en la práctica. Al evitar errores típicos, como el aprovisionamiento excesivo o la ignorancia de los costos ocultos, las empresas no solo pueden reducir sus costos operativos en un 15-30% o más, sino también transformar sus gastos de TI de una partida de gastos pasiva en una inversión estratégica que genera el máximo valor de negocio.
Recomendaciones finales:
- Empiece por la visibilidad: Sin comprender a dónde va el dinero, es imposible gestionar los gastos. Implemente un monitoreo integral y un inventario.
- Cultive la colaboración: FinOps es un trabajo en equipo. Establezca un diálogo entre los equipos técnicos y financieros.
- Automatice la rutina: Utilice IaC y scripts para automatizar el despliegue, la configuración y el desaprovisionamiento, liberando a los ingenieros para tareas más complejas.
- Optimice constantemente: FinOps es un ciclo continuo. Analice regularmente los datos, revise las configuraciones y busque nuevas oportunidades de optimización.
- Tome decisiones basadas en datos: Abandone las conjeturas. Utilice métricas e informes para justificar cada decisión.
Próximos pasos para el lector:
No posponga la implementación de FinOps. Empiece poco a poco: elija un proyecto o varios VPS, realice una auditoría, implemente el monitoreo e intente aplicar una de las estrategias de optimización. Los resultados obtenidos serán la mejor prueba del valor de FinOps y darán impulso para escalar estas prácticas a toda su infraestructura. Recuerde que el camino hacia la transparencia financiera total y la eficiencia de la infraestructura de TI es una maratón, no un sprint. Pero cada paso dado le acerca a un futuro más sostenible y rentable para su negocio.