Estrategias de Recuperación ante Desastres (DR) para aplicaciones SaaS en VPS y la nube: planificación, automatización y pruebas
TL;DR
- DR no es solo hacer copias de seguridad: Es un plan integral para restaurar la operatividad de una aplicación SaaS después de un fallo, minimizando el tiempo de inactividad y la pérdida de datos.
- RTO y RPO son sus métricas clave: Defina el objetivo de tiempo de recuperación (RTO) y el objetivo de punto de recuperación (RPO) basándose en los requisitos del negocio y el coste del tiempo de inactividad.
- La automatización es clave para el éxito: Los procedimientos manuales de DR son lentos, propensos a errores y no escalables. Invierta en IaC, scripts y orquestación para una recuperación rápida y fiable.
- Las pruebas no son un lujo, sino una necesidad: Pruebe regularmente su plan de DR (desde ejercicios de mesa hasta una conmutación por error completa) para asegurar su operatividad y relevancia.
- Estrategias híbridas: el equilibrio óptimo: La combinación de VPS y soluciones en la nube a menudo ofrece el mejor compromiso entre coste, rendimiento y resiliencia.
- Costes ocultos: Considere no solo los costes directos de infraestructura, sino también el coste del tiempo de inactividad, la pérdida de reputación, los costes laborales de recuperación y las pruebas.
- Año 2026: La IA y el ML se utilizan cada vez más activamente para la DR predictiva, la optimización de recursos y el análisis automático de registros en caso de fallos.
Introducción
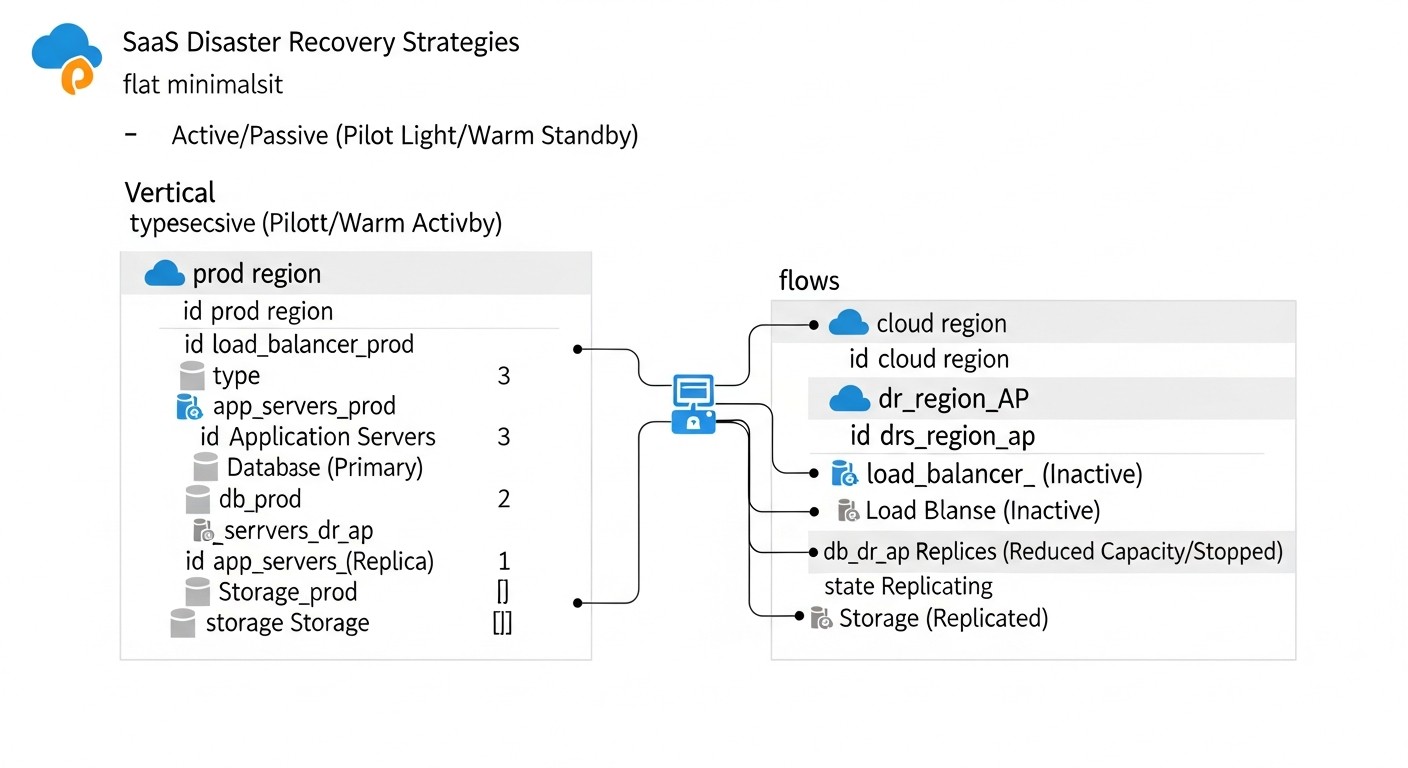 Diagrama: Introducción
Diagrama: Introducción
En el mundo en rápida evolución de las aplicaciones SaaS, donde cada minuto de inactividad puede costar a una empresa no solo pérdidas financieras significativas, sino también un daño irreparable a la reputación, la cuestión de garantizar la continuidad del negocio se vuelve críticamente importante. Para 2026, los usuarios esperan de los servicios una disponibilidad 24/7 y una respuesta instantánea, y las interrupciones se perciben como una violación directa de la confianza. Los ciberataques son cada vez más sofisticados, los fallos de infraestructura, aunque raros, son catastróficos, y el factor humano sigue siendo una de las principales causas de incidentes.
Este artículo pretende ser una guía exhaustiva para el desarrollo, implementación y prueba de estrategias de Recuperación ante Desastres (DR) para aplicaciones SaaS, que operan tanto en VPS clásicos como en entornos de nube modernos. Analizaremos por qué la DR no es solo una "buena práctica", sino una necesidad vital, especialmente para los fundadores de proyectos SaaS que a menudo subestiman su importancia en las primeras etapas, así como para los ingenieros DevOps y administradores de sistemas, sobre cuyos hombros recae la tarea de implementación.
En 2026, el panorama tecnológico ofrece oportunidades sin precedentes para crear sistemas tolerantes a fallos. Desde herramientas automatizadas de Infraestructura como Código (IaC) hasta sistemas inteligentes de monitoreo basados en IA, capaces de predecir posibles fallos. Sin embargo, a pesar de estos avances, muchas empresas aún enfrentan problemas al implementar planes de DR efectivos. La razón a menudo radica en la falta de un enfoque sistemático, la insuficiencia de pruebas y la incomprensión de los requisitos reales del negocio para la recuperación.
Esta guía ha sido creada para ayudarle a:
- Comprender los principios fundamentales de la Recuperación ante Desastres.
- Elegir la estrategia de DR óptima, basándose en sus RTO (Recovery Time Objective) y RPO (Recovery Point Objective).
- Dominar los métodos de automatización de procesos de DR para aumentar la velocidad y fiabilidad de la recuperación.
- Aprender a probar eficazmente su plan de DR, identificando y eliminando puntos débiles antes de que ocurra un incidente real.
- Evaluar la viabilidad económica de diferentes enfoques de DR y optimizar los costes.
- Evitar errores comunes que pueden llevar al fracaso de la recuperación.
Hablaremos en un lenguaje técnico pero comprensible, respaldando cada afirmación con ejemplos concretos, configuraciones y recomendaciones basadas en la experiencia real. Prepárese para sumergirse en el mundo de la resiliencia, donde la preparación para el peor escenario es la mejor inversión en el futuro de su SaaS.
Criterios/factores clave para elegir una estrategia de DR
 Diagrama: Criterios/factores clave para elegir una estrategia de DR
Diagrama: Criterios/factores clave para elegir una estrategia de DR
La elección de la estrategia óptima de Recuperación ante Desastres no es solo una decisión técnica, sino una decisión estratégica de negocio que debe considerar múltiples factores. La comprensión y evaluación correctas de estos criterios le ayudarán a construir un plan de DR que cumpla tanto con los requisitos técnicos como con las capacidades financieras de su empresa.
RTO (Recovery Time Objective) — Objetivo de Tiempo de Recuperación
¿Qué es? El tiempo máximo aceptable durante el cual una aplicación o servicio puede estar no disponible después de un fallo. Es una métrica de tiempo de inactividad definida por el negocio.
¿Por qué es importante? Determina la velocidad a la que su negocio debe estar listo para reanudar las operaciones. Cuanto menor sea el RTO, más costosa y compleja será la estrategia de DR. Por ejemplo, para una aplicación financiera, el RTO puede ser de 1 a 5 minutos; para un CRM interno, de 4 a 8 horas.
¿Cómo evaluarlo? Realice un Análisis de Impacto en el Negocio (Business Impact Analysis, BIA). Evalúe las pérdidas financieras por cada hora de inactividad, el daño a la reputación, las multas por incumplimiento de SLA. Esto le ayudará a determinar cuánto está dispuesto a invertir en una recuperación rápida.
RPO (Recovery Point Objective) — Objetivo de Punto de Recuperación
¿Qué es? La cantidad máxima aceptable de datos que se pueden perder como resultado de un fallo. Es una métrica de pérdida de datos, medida en tiempo (por ejemplo, 15 minutos, 1 hora).
¿Por qué es importante? Determina la frecuencia de las copias de seguridad o la replicación de datos. Cuanto menor sea el RPO, con mayor frecuencia deben sincronizarse los datos entre los sistemas primario y de respaldo. Un RPO cero significa que no hay pérdida de datos (requiere replicación síncrona).
¿Cómo evaluarlo? El BIA también ayudará aquí. ¿Qué datos son críticos? ¿Cuál es el coste de restaurar o recrear los datos perdidos? ¿Pueden los usuarios volver a introducir los datos? Para la mayoría de los SaaS, un RPO de 5-15 minutos se considera un buen equilibrio.
Coste (Cost)
¿Qué es? Costes totales de implementación y mantenimiento de la estrategia de DR. Incluye costes directos e indirectos.
¿Por qué es importante? El plan de DR debe ser económicamente viable. No tiene sentido gastar millones en DR si el daño potencial por el tiempo de inactividad es diez veces menor. El coste incluye: infraestructura (servidores, almacenamiento, red), software (licencias, herramientas), personal (desarrollo, soporte), pruebas, transferencia de datos.
¿Cómo evaluarlo? Cálculo detallado del Coste Total de Propiedad (TCO) para cada opción de DR. Considere los gastos de capital (CAPEX) y los gastos operativos (OPEX). No olvide los costes ocultos, como el coste de la formación del personal, el tiempo de desarrollo y depuración de los scripts de DR, y el coste del tiempo de inactividad durante las pruebas.
Complejidad de implementación y soporte (Complexity)
¿Qué es? El nivel de esfuerzo requerido para diseñar, desplegar, configurar y mantener posteriormente la solución de DR.
¿Por qué es importante? Los sistemas más complejos requieren más tiempo de desarrollo, personal más cualificado y comprobaciones más frecuentes. Una alta complejidad aumenta la probabilidad de errores tanto durante la implementación como durante la recuperación real.
¿Cómo evaluarlo? Evalúe la carga de trabajo de IaC, la configuración de la replicación, el desarrollo de scripts de failover/failback y la integración con la monitorización. Considere la disponibilidad de soluciones listas para usar y la experiencia de su equipo.
Nivel de automatización (Automation Level)
¿Qué es? El grado en que los procesos de copia de seguridad, replicación, monitoreo, conmutación por error (failover) y retorno (failback) se ejecutan sin intervención manual.
¿Por qué es importante? La automatización reduce significativamente el RTO, minimiza el factor humano y aumenta la fiabilidad. En 2026, los procedimientos manuales de DR se consideran un anacronismo para sistemas críticos.
¿Cómo evaluarlo? Desarrolle escenarios de DR y evalúe cuántos pasos se pueden automatizar. Utilice IaC (Terraform, Ansible), pipelines de CI/CD para el despliegue de la infraestructura de DR y scripts para la orquestación de la conmutación por error.
Escalabilidad (Scalability)
¿Qué es? La capacidad de la solución de DR para adaptarse al crecimiento de su aplicación SaaS (aumento de tráfico, datos, usuarios) sin un rediseño significativo.
¿Por qué es importante? Su estrategia de DR debe crecer con su negocio. Una solución no escalable quedará obsoleta rápidamente y se convertirá en un cuello de botella.
¿Cómo evaluarlo? Considere cómo la infraestructura de DR manejará una carga X2 o X10. Las soluciones en la nube a menudo ganan aquí gracias a la elasticidad de los recursos.
Seguridad (Security)
¿Qué es? Protección de los datos y la infraestructura de DR contra el acceso no autorizado, la corrupción y la pérdida.
¿Por qué es importante? La infraestructura de DR contiene copias de sus datos críticos, por lo que es un objetivo atractivo para los atacantes. Una seguridad insuficiente de la DR puede provocar la fuga o destrucción de datos.
¿Cómo evaluarlo? Aplique las mismas o incluso más estrictas medidas de seguridad a los recursos de DR: cifrado de datos (en reposo y en tránsito), gestión de acceso (IAM, MFA), aislamiento de red, auditorías de seguridad regulares.
Cumplimiento normativo (Compliance)
¿Qué es? La capacidad del plan de DR para cumplir con los requisitos legales (GDPR, HIPAA, PCI DSS, etc.) y los estándares de la industria.
¿Por qué es importante? El incumplimiento de los requisitos puede resultar en multas enormes, pérdida de licencias y daño a la reputación.
¿Cómo evaluarlo? Consulte con abogados y especialistas en cumplimiento. Asegúrese de que su plan de DR cubra todos los aspectos del almacenamiento, procesamiento y recuperación de datos sensibles de acuerdo con las regulaciones.
Frecuencia y calidad de las pruebas (Testing Frequency and Quality)
¿Qué es? La regularidad de las pruebas de DR y su profundidad (desde ejercicios de mesa hasta una conmutación por error completa).
¿Por qué es importante? Un plan de DR no probado no es un plan, sino un conjunto de suposiciones. Solo las pruebas regulares revelan errores, cuellos de botella y garantizan la operatividad del sistema.
¿Cómo evaluarlo? Desarrolle un cronograma de pruebas (por ejemplo, trimestralmente para una conmutación por error completa, mensualmente para la verificación de copias de seguridad). Utilice marcos de pruebas automatizados y Chaos Engineering para simular varios fallos.
Gravedad de los datos y ubicación geográfica (Data Gravity and Geographical Location)
¿Qué es? La ubicación física de los datos y su impacto en la latencia y el coste de la transferencia.
¿Por qué es importante? Para aplicaciones con un RPO bajo y un alto rendimiento de datos, la proximidad geográfica del sitio de DR al principal es crítica. La transferencia de grandes volúmenes de datos entre continentes puede ser costosa y lenta.
¿Cómo evaluarlo? Considere la ubicación de sus usuarios, los requisitos de soberanía de datos (si los hay) y el coste del tráfico interregional con los proveedores.
Un análisis exhaustivo de estos criterios le permitirá elegir la estrategia de DR más adecuada, que no solo sea técnicamente fiable, sino también económicamente viable y que se ajuste a los objetivos de negocio de su aplicación SaaS.
Tabla comparativa de estrategias de DR
 Esquema: Tabla comparativa de estrategias de DR
Esquema: Tabla comparativa de estrategias de DR
La elección de una estrategia de DR es siempre un compromiso entre costo, complejidad, RTO y RPO. A continuación se presenta una tabla comparativa de los enfoques más comunes, relevante para el año 2026, considerando las tendencias en tecnologías de nube y VPS. Los precios son aproximados para una aplicación SaaS promedio (por ejemplo, 3-5 servidores de aplicaciones, 1-2 servidores de bases de datos, 100-500 GB de datos), sin incluir el costo del personal ni las licencias de software especializado.
| Criterio |
Cold Standby (VPS/Nube) |
Warm Standby (VPS/Nube) |
Hot Standby (Nube/Multi-AZ) |
Multi-Region Active/Active (Nube) |
DR Híbrido (VPS + Nube) |
| RTO (Tiempo Objetivo de Recuperación) |
4-24 horas |
15 minutos - 4 horas |
< 5 minutos |
0 - varios segundos |
30 minutos - 2 horas |
| RPO (Pérdida de Datos Admisible) |
1-24 horas (según la última copia de seguridad) |
5 minutos - 1 hora (según la última replicación/copia de seguridad) |
0-5 minutos (replicación síncrona/asíncrona) |
0-1 minuto (prácticamente cero) |
10-30 minutos |
| Costo (mensual, 2026, USD) |
$50 - $300 (solo almacenamiento de copias de seguridad + VPS mínimo) |
$200 - $1000 (varios VPS/VM + almacenamiento + tráfico) |
$1000 - $5000+ (infraestructura duplicada) |
$5000 - $20000+ (infraestructura geográficamente distribuida) |
$300 - $2000 (combinación, depende de los recursos de nube utilizados) |
| Complejidad de implementación |
Baja (configuración de copias de seguridad, inicio manual) |
Media (configuración de replicación, scripts de inicio) |
Alta (failover automático, sincronización) |
Muy alta (balanceador de carga global, bases de datos distribuidas) |
Media-Alta (integración de entornos heterogéneos) |
| Nivel de automatización |
Bajo (solo copias de seguridad, recuperación manual) |
Medio (replicación automática, scripts de activación) |
Alto (monitoreo automático, failover/failback) |
Muy alto (gestión de tráfico y datos totalmente automatizada) |
Medio (automatización en la parte de la nube, pasos manuales en VPS) |
| Escalabilidad |
Baja (requiere escalado manual durante la recuperación) |
Media (se pueden prever plantillas para el escalado) |
Alta (utiliza las capacidades de autoescalado de la nube) |
Muy alta (autoescalado global) |
Media (la parte de la nube es escalable, el VPS no) |
| Ejemplos de tecnologías |
rsync, pg_dump, S3/Object Storage, Cron |
PostgreSQL Streaming Replication, MySQL GTID, rsync, DRBD, Terraform, Ansible |
AWS RDS Multi-AZ, Azure SQL Geo-replication, GCP Cloud Spanner, Kubernetes Operators, Route 53, ALB |
AWS Global Accelerator, Azure Front Door, GCP Global Load Balancer, CockroachDB, Cassandra, DynamoDB Global Tables |
Túneles VPN, rsync, S3/Object Storage, CloudFlare, Hybrid Cloud Connectors |
| Para quién es adecuado |
Pequeñas startups, servicios no críticos, utilidades internas |
Proyectos SaaS medianos con requisitos moderados de RTO/RPO |
SaaS grandes, aplicaciones críticas, servicios financieros |
SaaS globales, servicios con requisitos de disponibilidad extremadamente altos (99.999%) |
Proyectos SaaS que buscan optimizar costos, pero utilizar las ventajas de la nube para DR |
Esta tabla ofrece una visión general. Las cifras reales y la complejidad pueden variar significativamente según la arquitectura de su aplicación, las tecnologías elegidas y el nivel de experiencia del equipo. Es importante recordar que las inversiones en DR son un seguro que se amortiza en el momento de un desastre.
Descripción detallada
Análisis detallado de cada estrategia de DR
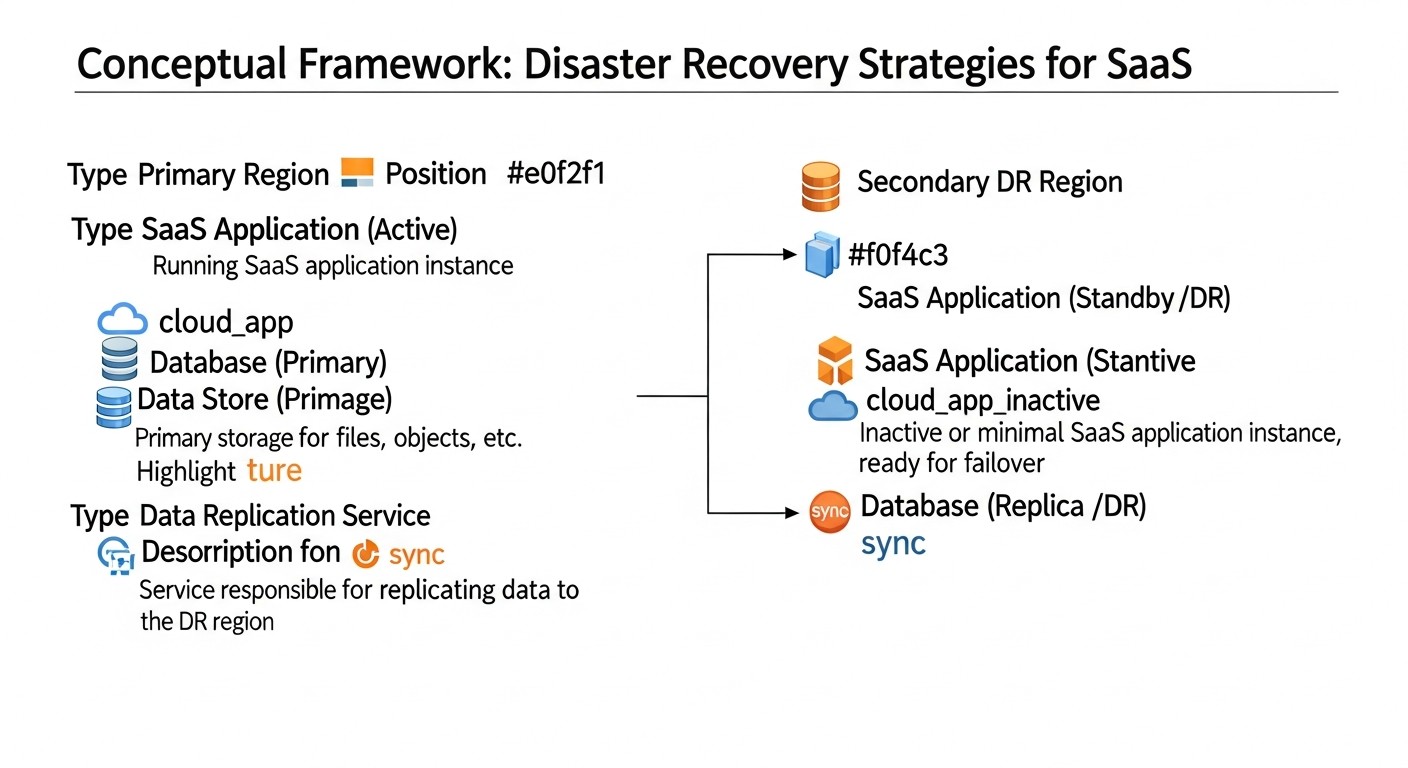 Esquema: Análisis detallado de cada estrategia de DR
Esquema: Análisis detallado de cada estrategia de DR
Cada una de las estrategias de DR presentadas tiene sus propias características, ventajas y desventajas. La elección de un enfoque específico debe basarse en un análisis cuidadoso de los requisitos comerciales, el presupuesto y las capacidades técnicas. Examinemos cada estrategia en detalle.
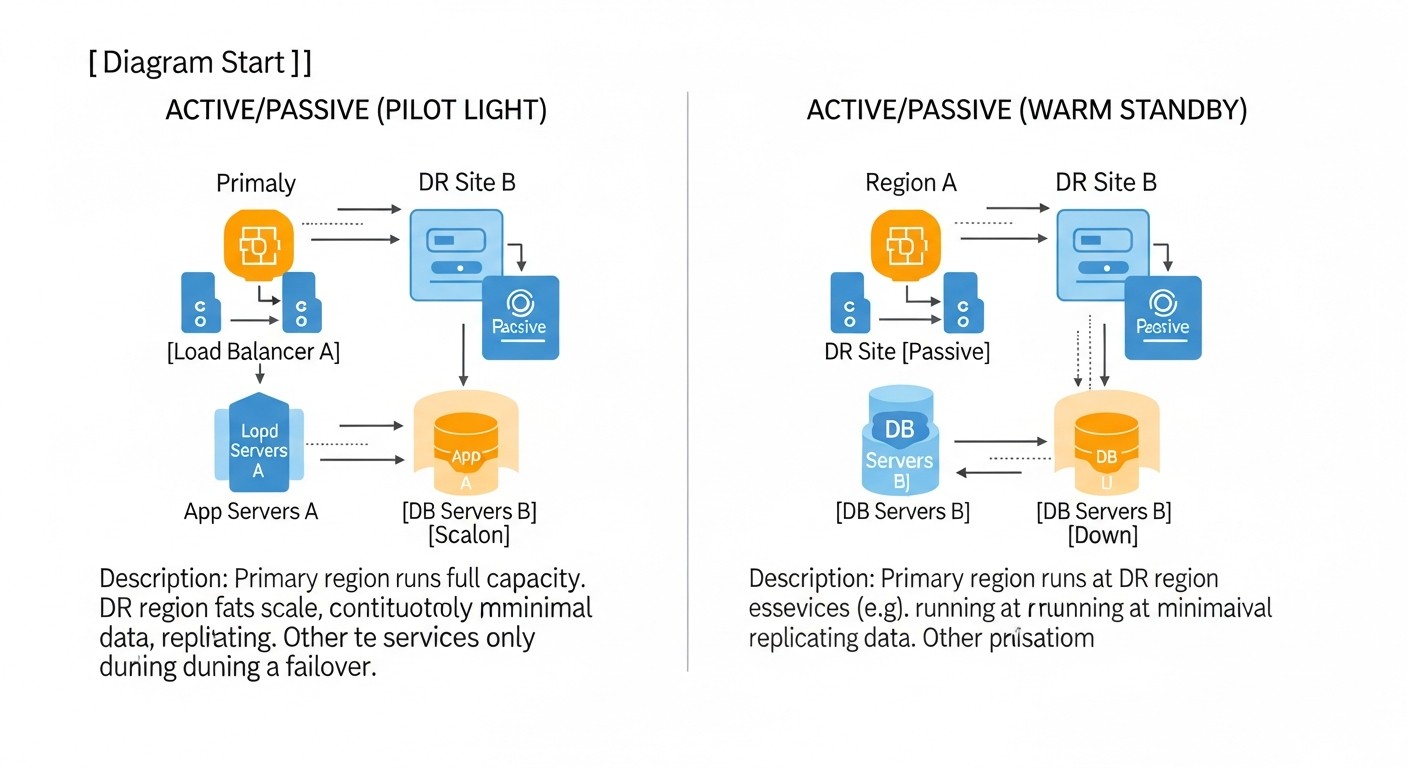
1. Cold Standby (Reserva en frío)
Descripción: Esta es la estrategia menos costosa y más sencilla. En el sitio de respaldo (ya sea otro VPS o una VM en la nube) no hay recursos de aplicación ejecutándose constantemente. En su lugar, se crean regularmente copias de seguridad de los datos (bases de datos, archivos, configuraciones) del sitio principal y se almacenan en un almacenamiento remoto e independiente (por ejemplo, almacenamiento compatible con S3, otro VPS con un disco grande). En caso de desastre, el servidor de respaldo o la VM se implementa "desde cero" o a partir de una imagen preconfigurada, se cargan las últimas copias de seguridad de los datos y se inicia la aplicación. Los registros DNS se cambian a la nueva dirección IP.
Ventajas:
- Bajo costo: Los costos principales están relacionados únicamente con el almacenamiento de las copias de seguridad y, posiblemente, el pago de un VPS o VM mínimo que se encuentra apagado y se paga según el uso (si es en la nube).
- Facilidad de implementación: Requiere habilidades básicas para configurar copias de seguridad e implementar servidores.
- Adecuado para datos no críticos: Si el RPO y el RTO pueden estar dentro de unas pocas horas, esta es una opción aceptable.
Desventajas:
- RTO altos: El tiempo de recuperación puede ser de 4 a 24 horas, ya que incluye la implementación de la infraestructura, la carga de datos y la configuración de la aplicación.
- RPO altos: La pérdida de datos está limitada por la frecuencia de las copias de seguridad (por ejemplo, 1-24 horas).
- Intervención manual: El proceso de recuperación a menudo requiere una intervención manual significativa, lo que aumenta la probabilidad de errores.
- No escalable: La recuperación rápida de una aplicación grande y compleja en modo manual es prácticamente imposible.
Para quién es adecuado: Pequeñas startups en etapas tempranas, herramientas internas, entornos de prueba, aplicaciones SaaS no críticas donde un tiempo de inactividad de varias horas no conduce a pérdidas catastróficas. Los fundadores de proyectos SaaS con un presupuesto limitado pueden comenzar con esto, pero deben planificar la transición a estrategias más robustas a medida que crecen.
Ejemplos de uso: SaaS para blogs, pequeños CRM, paneles de usuario, donde los procesos de negocio no se ven críticamente afectados por varias horas de inactividad. Por ejemplo, su aplicación SaaS es un gestor de tareas para freelancers, y la pérdida de datos de las últimas 12 horas o un tiempo de inactividad de 8 horas no es fatal para el negocio.
2. Warm Standby (Reserva en caliente)
Descripción: Esta estrategia implica tener un sitio de respaldo que está parcial o totalmente en funcionamiento y listo para recibir tráfico, pero no está activo. La infraestructura (servidores, bases de datos) en el sitio de respaldo ya está implementada y configurada. Los datos del sitio principal se replican o sincronizan regularmente con el sitio de respaldo. En caso de una falla en el sitio principal, el sitio de respaldo se activa y los registros DNS se cambian. Esto puede incluir el inicio de servicios adicionales, el escalado de capacidades y el cambio de balanceadores de carga.
Ventajas:
- RTO moderados: El tiempo de recuperación se reduce significativamente a 15 minutos - 4 horas, ya que la mayor parte de la infraestructura ya está lista.
- RPO moderados: La pérdida de datos puede reducirse a minutos o decenas de minutos gracias a la replicación frecuente.
- Equilibrio entre costo y fiabilidad: Más costoso que Cold Standby, pero significativamente más barato que Hot Standby.
- Posibilidad de automatización parcial: Los procesos de replicación y conmutación parcial pueden automatizarse.
Desventajas:
- Requiere más recursos: Infraestructura en el sitio de respaldo que funciona constantemente, aunque no esté completamente cargada.
- Complejidad de configuración: La configuración de la replicación de bases de datos y la sincronización de archivos requiere conocimientos específicos.
- Riesgo de configuraciones obsoletas: Si el sitio de respaldo no se utiliza activamente, sus configuraciones pueden quedar desactualizadas respecto al principal.
- Automatización incompleta: A menudo requiere intervención manual para la activación y verificación final.
Para quién es adecuado: Proyectos SaaS en crecimiento con requisitos de disponibilidad medios, donde un tiempo de inactividad de varias horas ya es perceptible pero no crítico. Los desarrolladores backend e ingenieros DevOps pueden implementar esta estrategia utilizando herramientas estándar de replicación de bases de datos e IaC para la implementación de la infraestructura.
Ejemplos de uso: Plataformas de E-commerce, SaaS para gestión de proyectos, sistemas CRM, donde la pérdida de una o dos horas de datos o un tiempo de inactividad de 30 minutos es aceptable. Por ejemplo, un SaaS para gestión de inventario, donde la sincronización cada 15 minutos permite minimizar las pérdidas.
3. Hot Standby (Reserva en caliente) / Multi-AZ en la nube
Descripción: Esta estrategia implica tener un sitio de respaldo completamente funcional y en funcionamiento constante, que es un espejo del principal. Ambos sistemas (principal y de respaldo) operan en paralelo, y los datos se sincronizan prácticamente en tiempo real. En entornos de nube, esto a menudo se implementa a través de despliegues Multi-AZ (Multi-Availability Zone), donde la aplicación y la base de datos se duplican en diferentes centros de datos (AZ) físicamente aislados de la misma región. El tráfico se dirige al sistema activo, y en caso de falla, se produce una conmutación automática (failover) al sistema de respaldo con un tiempo de inactividad mínimo o nulo.
Ventajas:
- RTO bajos: El tiempo de recuperación es de minutos o incluso segundos, ya que el sistema de respaldo ya está en funcionamiento.
- RPO bajos: La pérdida de datos es mínima o nula gracias a la replicación síncrona o asíncrona muy frecuente.
- Alta disponibilidad: Garantiza un funcionamiento del servicio prácticamente ininterrumpido.
- Alto grado de automatización: Los procesos de monitoreo, detección de fallas y conmutación están completamente automatizados.
Desventajas:
- Alto costo: Requiere la duplicación de toda la infraestructura de producción, lo que aumenta significativamente los costos.
- Alta complejidad: La configuración de la replicación síncrona, el failover automático, el balanceo de carga y la garantía de la consistencia de los datos requiere una alta cualificación.
- Riesgo de "Split-brain": Una configuración incorrecta puede llevar a una situación en la que ambos sistemas se consideren activos, lo que provoca la pérdida de datos.
- No protege contra fallas regionales: Multi-AZ protege contra fallas en una AZ, pero no contra la falla de toda la región (aunque la probabilidad de tal evento es extremadamente baja).
Para quién es adecuado: Grandes proyectos SaaS, aplicaciones críticas, servicios financieros, E-commerce con alto volumen de transacciones, donde cada minuto de inactividad cuesta enormes sumas. Los administradores de sistemas e ingenieros DevOps con experiencia en la nube y en sistemas distribuidos son clave para la implementación.
Ejemplos de uso: Sistemas de pago, plataformas de banca en línea, servicios de juegos globales, SaaS para el sector de la salud, donde la continuidad y la integridad de los datos son absolutamente críticas.
4. Multi-Region Active/Active (Multirregional activo/activo)
Descripción: Este es el nivel más alto de DR y alta disponibilidad. La aplicación se implementa y funciona activamente de forma simultánea en varias regiones geográficamente distantes (por ejemplo, en Europa y América del Norte). Los usuarios son dirigidos a la región más cercana o menos cargada mediante balanceadores de carga globales (por ejemplo, AWS Route 53, Azure Front Door, GCP Global Load Balancer). Los datos se replican entre regiones, a menudo utilizando bases de datos distribuidas capaces de operar en modo Activo/Activo. En caso de falla de una región completa, el tráfico se redirige automáticamente a las regiones restantes sin ningún tiempo de inactividad para el usuario final.
Ventajas:
- RTO y RPO prácticamente nulos: Los usuarios pueden no notar la falla, ya que el tráfico se conmuta instantáneamente a otra región activa. La pérdida de datos es mínima o nula.
- Máxima resiliencia: Protege contra fallas de regiones enteras, lo cual es extremadamente raro, pero posible.
- Rendimiento global: Los usuarios son atendidos desde la región más cercana, lo que reduce la latencia.
- Nivel más alto de disponibilidad: Logrando 99.999% y superior.
Desventajas:
- Costo extremadamente alto: Requiere la duplicación completa de la infraestructura en varias regiones, así como servicios globales y bases de datos distribuidas costosos.
- Complejidad excepcionalmente alta: El diseño y mantenimiento de un sistema así es una tarea de ingeniería extremadamente compleja. La gestión de la consistencia de los datos entre regiones es un desafío importante.
- Problema de "Consistencia Eventual": Muchas bases de datos distribuidas se caracterizan por la consistencia eventual, lo que puede ser inaceptable para algunas aplicaciones.
- Requiere herramientas y experiencia especializadas: El equipo debe poseer un conocimiento profundo en el campo de los sistemas distribuidos.
Para quién es adecuado: Proyectos SaaS globales, redes sociales, servicios críticos con millones de usuarios en todo el mundo, para los cuales cualquier minuto de inactividad es inaceptable. Los CTO y arquitectos principales deben sopesar cuidadosamente todos los pros y los contras antes de decidirse por una estrategia tan costosa y compleja.
Ejemplos de uso: Google, Facebook, Netflix, grandes sistemas bancarios, plataformas SaaS globales, donde la disponibilidad mundial y el tiempo de inactividad cero son clave para el negocio.
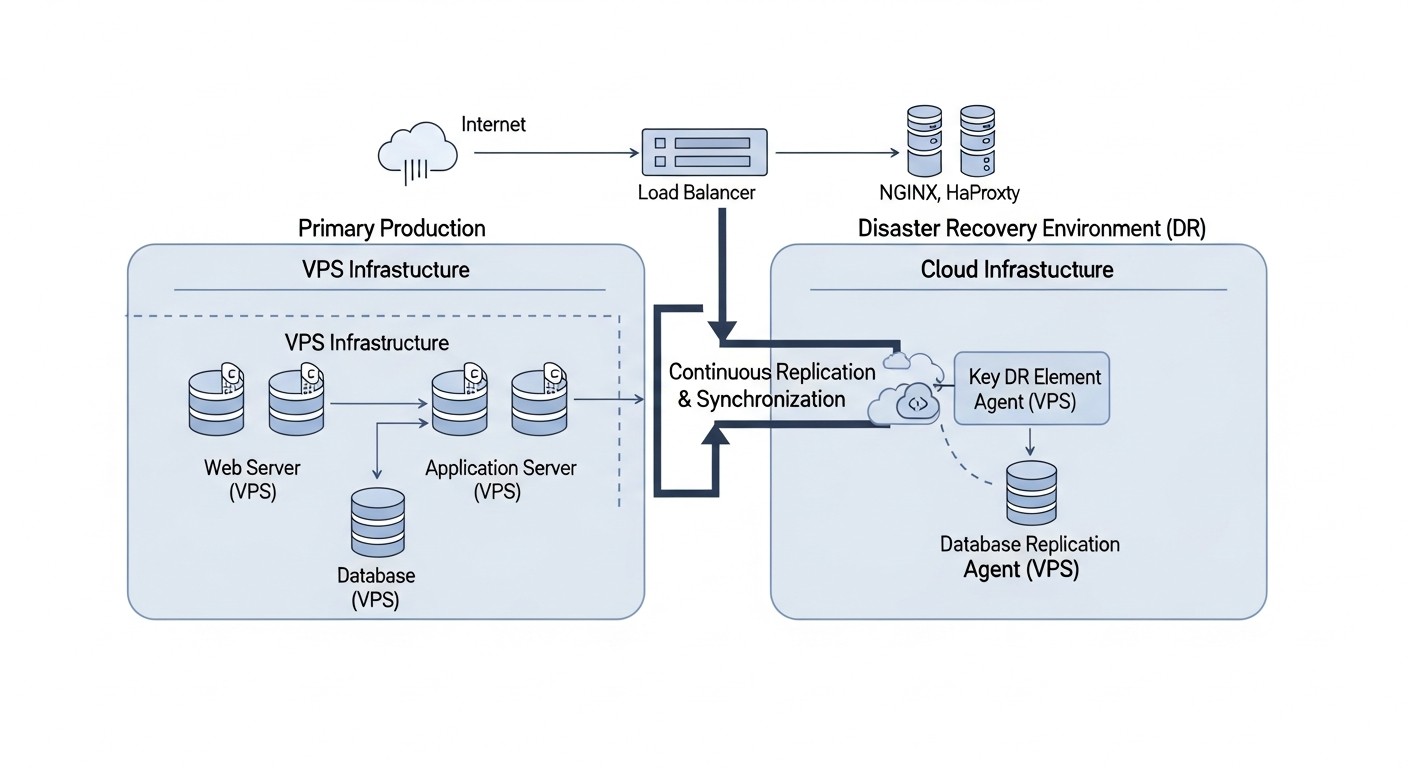
5. DR Híbrido (VPS + Nube)
Descripción: Esta estrategia combina las ventajas de los entornos VPS y de la nube. La aplicación principal puede ejecutarse en un VPS (para control de costos o requisitos específicos), mientras que el sitio de DR se implementa en la nube. Por ejemplo, los datos del VPS se replican en un almacenamiento en la nube (S3, GCS, Azure Blob Storage) o en una base de datos en la nube (RDS, Cloud SQL). En caso de falla del VPS principal, la infraestructura (VMs, contenedores, funciones sin servidor) se implementa de forma automática o semiautomática en la nube a partir de imágenes y configuraciones preestablecidas, y la aplicación se inicia utilizando los datos replicados. Los registros DNS se cambian a los recursos de la nube.
Ventajas:
- Optimización de costos: Permite utilizar VPS más económicos para el funcionamiento principal y pagar por los recursos de DR en la nube solo cuando sea necesario (modelo "pay-as-you-go" para la infraestructura de DR).
- Flexibilidad: Combina el control y la previsibilidad del VPS con la elasticidad y la rica variedad de servicios de la nube.
- RTO y RPO moderados: Dependiendo del nivel de automatización y replicación, se pueden lograr RTO de 30 minutos a 2 horas, y RPO de 10 a 30 minutos.
- Protección contra fallas del proveedor: Si el proveedor de VPS principal falla, el sitio de DR en la nube permanece disponible.
Desventajas:
- Complejidad de integración: Requiere la configuración de la interacción de red (VPN), la sincronización de datos y configuraciones entre dos entornos diferentes.
- Herramientas adicionales: Se necesitan herramientas para la orquestación de la implementación en la nube (IaC) y la gestión de datos.
- Transferencia de datos: El costo y las latencias en la transferencia de datos entre el VPS y la nube pueden ser significativos.
- Se requiere experiencia en ambos entornos: El equipo debe comprender tanto las tecnologías VPS como las de la nube.
Para quién es adecuado: Proyectos SaaS que desean obtener las ventajas de la DR en la nube sin trasladar toda su infraestructura principal a la nube. Fundadores de SaaS que desean controlar el presupuesto, pero al mismo tiempo garantizar una DR fiable. Administradores de sistemas e ingenieros DevOps capaces de trabajar con ambas plataformas y configurar soluciones híbridas.
Ejemplos de uso: Aplicaciones SaaS que crecieron en VPS, pero desean obtener una DR más fiable y automatizada de lo que otros proveedores de VPS pueden ofrecer. Por ejemplo, una plataforma SaaS para contabilidad que almacena datos en un VPS, pero utiliza AWS S3 para copias de seguridad y AWS EC2/RDS para el sitio de DR.
Al elegir una estrategia, siempre comience por definir sus RTO y RPO, luego evalúe el presupuesto disponible y la experiencia del equipo. Recuerde que la DR es un proceso evolutivo, y puede comenzar con una solución más simple, complicándola gradualmente a medida que el negocio crece y aumentan los requisitos de disponibilidad.
Consejos prácticos y recomendaciones para la implementación de DR
 Esquema: Consejos prácticos y recomendaciones para la implementación de DR
Esquema: Consejos prácticos y recomendaciones para la implementación de DR
La implementación de una estrategia efectiva de Disaster Recovery requiere un enfoque sistemático y atención a los detalles. Los siguientes consejos prácticos y comandos le ayudarán en este proceso.
1. Desarrollo de un Plan de Recuperación ante Desastres (DRP)
Un DRP no es solo un documento, es una guía de acción viva. Debe ser detallado, actualizado y accesible para todos los involucrados. Componentes clave de un DRP:
- Objetivos RTO/RPO: Claramente definidos para cada servicio crítico.
- Escenarios de desastre: Lista de posibles fallas (falla de servidor, centro de datos, ciberataque, factor humano).
- Roles y responsabilidades: Quién es responsable de qué durante un incidente.
- Procedimientos de activación de DR: Instrucciones paso a paso para la conmutación al sitio de respaldo.
- Procedimientos de Failback: Cómo regresar al sitio principal después de resolver el problema.
- Contactos: Equipos internos, proveedores externos, clientes.
- Plan de comunicación: Quién, cuándo y cómo informa a las partes interesadas.
- Ubicación de almacenamiento: El DRP debe almacenarse fuera de la infraestructura principal (por ejemplo, en Google Docs, una copia impresa).
2. Definición de RTO y RPO con los Propietarios del Negocio
Esta no es una tarea técnica, sino una tarea de negocio. Realice reuniones con los jefes de departamento para comprender cuánto tiempo de inactividad o pérdida de datos pueden permitirse. Utilice estos datos para elegir la estrategia de DR. Por ejemplo, para un módulo financiero, el RPO puede ser de 1 minuto, y para un informe analítico, de 4 horas.
3. Elección de la Estrategia Correcta de Copia de Seguridad (Backup Strategy)
Las copias de seguridad son la base de cualquier DR. Utilice la regla 3-2-1:
- 3 copias de datos: Una principal y dos de respaldo.
- 2 medios diferentes: Por ejemplo, un disco local y un almacenamiento en la nube.
- 1 almacenamiento remoto: Geográficamente separado del sitio principal.
Tipos de copias de seguridad: completas, incrementales, diferenciales. Utilice instantáneas para crear rápidamente puntos de restauración de VM y discos.
# Ejemplo de copia de seguridad de PostgreSQL en almacenamiento compatible con S3
# Instale aws-cli o s3cmd
# pg_dump -Fc -Z9 -h localhost -U youruser yourdatabase > /tmp/yourdatabase_$(date +%F).dump
# aws s3 cp /tmp/yourdatabase_$(date +%F).dump s3://your-backup-bucket/db/
# rm /tmp/yourdatabase_$(date +%F).dump
# Ejemplo de copia de seguridad de archivos usando rsync
# rsync -avz --delete /var/www/your_app/ s3://your-backup-bucket/app_files/
4. Configuración de la Replicación de Datos
Para lograr RPO bajos, es necesaria la replicación de bases de datos y, posiblemente, de sistemas de archivos.
- Bases de datos:
- PostgreSQL: Utilice Streaming Replication (WAL shipping) para replicación asíncrona o síncrona.
- MySQL: Binary Log Replication (basada en GTID) para replicación asíncrona.
- MongoDB: Replica Sets.
- Bases de datos en la nube: Utilice funciones Multi-AZ o Geo-replication (AWS RDS, Azure SQL, GCP Cloud SQL).
- Sistemas de archivos:
rsync para sincronización periódica.DRBD (Distributed Replicated Block Device) para replicación de bloques síncrona entre dos servidores Linux.- Soluciones en la nube: AWS EFS, Azure Files, GCP Filestore con replicación o sincronización.
# Ejemplo de configuración de PostgreSQL Streaming Replication (en el maestro)
# En postgresql.conf:
# wal_level = replica
# max_wal_senders = 10
# max_replication_slots = 10
# hot_standby = on
# listen_addresses = ''
# En pg_hba.conf:
# host replication all 0.0.0.0/0 md5
# Ejemplo de creación de una copia base para la réplica
# sudo -u postgres pg_basebackup -h master_ip -D /var/lib/postgresql/16/main/ -U replicator -P -R -W
5. Automatización de Procesos de DR (IaC, Scripts, Orquestación)
La automatización es el corazón del DR moderno. Las acciones manuales son lentas y propensas a errores.
- Infrastructure as Code (IaC): Utilice Terraform, Ansible, CloudFormation (AWS), ARM Templates (Azure), Deployment Manager (GCP) para describir toda su infraestructura (incluido el sitio de DR). Esto permite desplegar o restaurar rápidamente el entorno.
- Scripts de Failover: Escriba scripts en Bash, Python o PowerShell para la conmutación automática. Deben incluir:
- Detección de fallas (monitoreo).
- Activación de recursos de respaldo.
- Actualización de registros DNS o conmutación del balanceador.
- Verificación de la operatividad.
- Alertas.
- Orquestación de contenedores: Para aplicaciones en Kubernetes, utilice operadores (por ejemplo, Velero para copias de seguridad, Strimzi para Kafka DR) y soluciones para Multi-Cluster DR.
- CI/CD para DR: Integre el despliegue y las pruebas de la infraestructura de DR en su pipeline de CI/CD.
# Ejemplo de Terraform para desplegar una instancia EC2 en AWS (sitio de DR)
resource "aws_instance" "dr_app_server" {
ami = "ami-0abcdef1234567890" # Especifique un AMI actualizado
instance_type = "t3.medium"
key_name = "my-ssh-key"
vpc_security_group_ids = [aws_security_group.dr_sg.id]
subnet_id = aws_subnet.dr_subnet.id
tags = {
Name = "DR-App-Server"
Environment = "DR"
}
# ... otras configuraciones, por ejemplo, volúmenes EBS para datos
}
6. Monitoreo y Alertas
Un monitoreo confiable es crucial para la detección oportuna de fallas y la activación del plan de DR. Monitoree no solo la infraestructura principal, sino también la de DR.
- Métricas: CPU, RAM, Disk I/O, Network I/O, latencia, health checks de la aplicación, estados de replicación de la BD, disponibilidad de DNS.
- Herramientas: Prometheus/Grafana, Zabbix, Datadog, New Relic, ELK Stack.
- Alertas: Configure alertas (SMS, llamadas a través de PagerDuty, Slack, Email) para eventos críticos que requieran intervención inmediata o el inicio de procedimientos de DR.
7. Pruebas Regulares del Plan de DR
Como se mencionó, un DRP no probado es inútil. Desarrolle una estrategia de prueba:
- Ejercicios de mesa (Tabletop Exercises): Discusión del DRP con el equipo, elaboración de escenarios sin acciones reales.
- Pruebas simuladas: Simulación de la falla de un componente (por ejemplo, detención de la BD) sin una conmutación completa.
- Prueba de Failover Completo: Conmutación al sitio de respaldo y operación desde este durante un período determinado. Esta es la prueba más realista, pero requiere una planificación cuidadosa para no afectar a los usuarios reales.
- Prueba de Failback: Verificación del procedimiento para regresar al sitio principal.
- Chaos Engineering: Utilice herramientas (Gremlin, Chaos Mesh) para la introducción controlada de fallas en el entorno de producción o DR, con el fin de identificar puntos débiles.
Importante: Siempre documente los resultados de las pruebas, los errores y sus soluciones. Actualice el DRP después de cada prueba.
8. Documentación Actualizada
Una documentación detallada y actualizada es su "bote salvavidas" durante un desastre. Debe describir todo: arquitectura, dependencias, procedimientos de despliegue, configuraciones, procedimientos de DR, contactos. Guárdela en un lugar de fácil acceso pero seguro.
9. Gestión de Configuraciones
Utilice sistemas de gestión de configuraciones (Ansible, Chef, Puppet, SaltStack) para el despliegue y la configuración uniformes de los servidores en los sitios principal y de DR. Esto garantiza que la infraestructura de DR sea idéntica a la principal.
10. Aislamiento de Red y Seguridad del Sitio de DR
El sitio de DR debe estar lo más aislado posible de la red principal, pero al mismo tiempo debe poder recibir datos. Utilice túneles VPN para una replicación segura. Aplique reglas estrictas de firewall, políticas IAM, cifrado de datos en reposo y en tránsito. Recuerde que el sitio de DR es un punto de entrada potencial para los atacantes si no está debidamente protegido.
Al aplicar estas recomendaciones, podrá aumentar significativamente la resiliencia de su aplicación SaaS a diversos tipos de fallas y garantizar la continuidad del negocio incluso en las situaciones más complejas.
Errores comunes en el desarrollo e implementación de un plan de DR
 Diagrama: Errores comunes en el desarrollo e implementación de un plan de DR
Diagrama: Errores comunes en el desarrollo e implementación de un plan de DR
Incluso los equipos más experimentados pueden cometer errores al planificar e implementar la Recuperación ante Desastres. Conocer estos escollos le ayudará a evitar fallos costosos.
1. Ausencia o obsolescencia del plan de DR
Error: Muchas empresas o bien no tienen un DRP formalizado en absoluto, o existe "por cumplir" y no se actualiza durante años. En un entorno de infraestructura y arquitectura SaaS que cambia rápidamente, dicho plan se vuelve obsoleto rápidamente.
Cómo evitarlo: Desarrolle un DRP que incluya todos los componentes clave: RTO/RPO, escenarios, roles, instrucciones paso a paso. Conviértalo en un documento vivo que se revise y actualice regularmente (por ejemplo, trimestralmente o después de cada cambio significativo en la arquitectura). Guárdelo en un lugar accesible pero seguro, y también en varias copias (incluyendo offline).
Ejemplos reales de consecuencias: Durante una falla a gran escala, el equipo entra en pánico, dedica horas a buscar información actualizada, no puede determinar quién es responsable de qué, y al final el proceso de recuperación se prolonga indefinidamente, superando con creces los RTO permitidos.
2. Copias de seguridad y plan de DR no probados
Error: Uno de los errores más comunes y peligrosos. Las empresas configuran las copias de seguridad, asumen que la DR "existe", pero nunca verifican si es posible recuperarse realmente de esas copias de seguridad y si el procedimiento de conmutación por error funciona.
Cómo evitarlo: Haga del testing de DR un procedimiento obligatorio y regular. Comience con la verificación de la integridad de las copias de seguridad (por ejemplo, intentando una recuperación en un servidor de prueba). Realice simulacros completos de DR (failover/failback) al menos una vez cada seis meses. Documente cada prueba, identifique los problemas y corríjalos de inmediato. Automatice las pruebas siempre que sea posible.
Ejemplos reales de consecuencias: Durante un desastre real, se descubre que las copias de seguridad están dañadas, incompletas o que el procedimiento de recuperación contiene errores críticos. Esto lleva a una pérdida total de datos o a la imposibilidad de restaurar el servicio en absoluto, lo que puede ser fatal para un negocio SaaS.
3. Subestimación de RTO y RPO
Error: Los especialistas técnicos a menudo establecen RTO y RPO basándose en las capacidades técnicas, y no en los requisitos reales del negocio. O, por el contrario, el negocio solicita RTO/RPO cero sin comprender el costo astronómico de su implementación.
Cómo evitarlo: Realice un Análisis de Impacto en el Negocio (BIA) exhaustivo con la participación de todas las partes interesadas. Determine las pérdidas financieras y de reputación por el tiempo de inactividad y la pérdida de datos para cada componente crítico. Compare estas pérdidas con los costos de lograr diferentes RTO/RPO. Encuentre el equilibrio óptimo. Documente las decisiones tomadas y su justificación.
Ejemplos reales de consecuencias: En caso de una falla, se descubre que el RTO declarado de 4 horas es en realidad de 8 a 12 horas, lo que resulta en pérdidas multimillonarias y la rescisión de contratos con clientes. O, por el contrario, la empresa invirtió enormes sumas en Hot Standby, cuando Warm Standby habría sido suficiente y mucho más económico.
4. Ignorar el factor humano
Error: Se asume que, bajo estrés, el equipo actuará perfectamente según las instrucciones escritas. Se olvida la fatiga, el pánico, la falta de conocimiento de un empleado específico.
Cómo evitarlo: Capacite al equipo en los procedimientos de DR. Realice simulacros regulares para que todos conozcan su rol y puedan actuar sin pánico. Automatice tantos pasos como sea posible para minimizar la intervención manual. Asegure canales de comunicación claros. Asegúrese de que el DRP sea comprensible incluso para un novato. Considere la posibilidad de utilizar expertos externos para auditorías o asistencia en incidentes complejos.
Ejemplos reales de consecuencias: Durante un incidente, un empleado elimina por error datos críticos, o no puede encontrar el comando correcto en el DRP, o simplemente entra en pánico y no actúa, lo que agrava la situación y aumenta el tiempo de inactividad.
5. Punto único de fallo en la infraestructura de DR
Error: Al diseñar una solución de DR, el equipo puede crear inadvertidamente un nuevo punto único de fallo. Por ejemplo, el sitio de DR utiliza el mismo proveedor de DNS que el principal, o las copias de seguridad se almacenan en la misma región de la nube que el servicio principal.
Cómo evitarlo: Siempre diseñe la DR teniendo en cuenta la independencia total de la infraestructura principal. Utilice diferentes proveedores (para VPS, DNS), diferentes regiones de la nube, diferentes plataformas de hardware. Realice una auditoría exhaustiva de la arquitectura de DR para identificar dependencias ocultas. Para componentes críticos, considere soluciones multiregionales.
Ejemplos reales de consecuencias: Una falla del proveedor de DNS deja inaccesibles tanto el sitio principal como el de DR. O una falla regional en la nube inutiliza ambos sistemas porque la solución de DR se implementó en la misma área, pero en otra AZ que se vio afectada por la falla general de la región.
6. Atención insuficiente a la seguridad del sitio de DR
Error: La infraestructura de DR a menudo se considera "secundaria" y recibe menos atención en seguridad que la producción principal. Sin embargo, contiene copias de todos sus datos y puede convertirse en un blanco fácil para los atacantes.
Cómo evitarlo: Aplique los mismos o incluso más estrictos estándares de seguridad a la infraestructura de DR. Cifre los datos en reposo y en tránsito. Utilice reglas estrictas de control de acceso (IAM, MFA). Realice auditorías de seguridad y pruebas de penetración (pentests) regularmente para el sitio de DR. Aísle la red de DR del acceso público. Asegúrese de que las copias de seguridad también estén protegidas contra la compromiso.
Ejemplos reales de consecuencias: Un atacante obtiene acceso al sitio de DR a través de un servicio mal protegido que se implementó "por si acaso", y destruye o roba todas las copias de seguridad de los datos, haciendo imposible la recuperación.
7. Olvido de datos no relacionados con la BD
Error: A menudo, el enfoque de la DR se desplaza exclusivamente a la base de datos, olvidando los archivos de usuario, los logs, las configuraciones, el contenido estático, las cachés y otros datos no relacionales que también son importantes para el funcionamiento de SaaS.
Cómo evitarlo: Incluya en el DRP todos los tipos de datos necesarios para la recuperación completa de la aplicación. Desarrolle una estrategia de copias de seguridad y replicación para cada uno de ellos. Utilice almacenamiento de objetos (S3) para archivos, sistemas de registro centralizados (ELK, Splunk) con replicación, sistemas de gestión de configuraciones (Git) para todas las configuraciones.
Ejemplos reales de consecuencias: Después de restaurar la BD, la aplicación no puede iniciarse porque faltan archivos de carga de usuarios o archivos de configuración críticos. Esto conduce a un tiempo de inactividad adicional y a esfuerzos de recuperación.
Al evitar estos errores comunes, aumentará significativamente las posibilidades de una recuperación exitosa de su aplicación SaaS después de cualquier desastre.
Lista de verificación para la aplicación práctica de estrategias de DR
Esta lista de verificación le ayudará a sistematizar el proceso de planificación, implementación y prueba de la Recuperación ante Desastres para su aplicación SaaS.
-
Definición de requisitos de negocio:
- ¿Se ha realizado un Análisis de Impacto en el Negocio (BIA) para todos los componentes críticos de SaaS?
- ¿Se han definido los RTO (Recovery Time Objective) objetivo para cada servicio?
- ¿Se han definido los RPO (Recovery Point Objective) objetivo para cada servicio?
- ¿Se han acordado estas métricas con los propietarios del negocio?
-
Desarrollo del plan de DR (DRP):
- ¿Se ha creado un documento DRP formal?
- ¿Se describen en el DRP todos los escenarios de desastre?
- ¿Se han definido claramente los roles y responsabilidades del equipo en caso de un incidente?
- ¿Existen instrucciones paso a paso para la activación de la DR y el retorno (failover/failback)?
- ¿Contiene el DRP datos de contacto actualizados de todos los participantes y proveedores?
- ¿Se ha desarrollado un plan de comunicación para informar a clientes y stakeholders?
- ¿Se almacena el DRP en un lugar seguro pero accesible, separado de la infraestructura principal?
-
Selección y diseño de la estrategia de DR:
- ¿Se ha seleccionado la estrategia de DR óptima (Cold/Warm/Hot Standby, Multi-Region, Hybrid) que se ajuste a los RTO/RPO y al presupuesto?
- ¿Se ha diseñado la arquitectura de DR para garantizar la independencia de la infraestructura principal?
- ¿Se han tenido en cuenta los factores geográficos y los requisitos de soberanía de datos?
- ¿Se han definido las tecnologías para copias de seguridad, replicación y automatización?
-
Implementación de copias de seguridad y replicación:
- ¿Se ha implementado la estrategia de copia de seguridad 3-2-1 para todos los datos críticos?
- ¿Se ha configurado la verificación regular de la integridad de las copias de seguridad?
- ¿Se ha configurado la replicación de bases de datos (streaming replication, replica sets, etc.)?
- ¿Se ha asegurado la sincronización de sistemas de archivos y otros datos no relacionales?
- ¿Están cifradas todas las copias de seguridad y los datos en tránsito?
-
Automatización de procesos de DR:
- ¿Se ha desarrollado la infraestructura de DR utilizando IaC (Terraform, CloudFormation, etc.)?
- ¿Se han creado scripts para la detección automática de fallos y la conmutación por error (failover)?
- ¿Se ha automatizado el proceso de actualización de registros DNS o la conmutación de balanceadores de carga?
- ¿Se han integrado los procesos de DR en el pipeline de CI/CD?
-
Monitorización y alertas:
- ¿Se ha configurado una monitorización integral de la infraestructura principal y de DR (métricas, logs, health checks)?
- ¿Se han creado alertas para eventos críticos que requieran la activación de la DR?
- ¿Se ha asegurado la entrega de alertas a través de múltiples canales (SMS, llamadas, Slack, email)?
-
Pruebas y verificación:
- ¿Se ha desarrollado un calendario de pruebas regulares del plan de DR?
- ¿Se han realizado ejercicios de mesa (Tabletop Exercises) con el equipo?
- ¿Se han realizado pruebas simuladas sin una conmutación por error completa?
- ¿Se han realizado pruebas completas de Failover y Failback?
- ¿Se han utilizado elementos de Chaos Engineering para identificar puntos débiles?
- ¿Se documentan todos los resultados de las pruebas, los problemas identificados y sus soluciones?
- ¿Se actualiza el DRP después de cada prueba y de los cambios identificados?
-
Seguridad y cumplimiento:
- ¿Se han aplicado medidas de seguridad estrictas a la infraestructura de DR (IAM, firewalls, cifrado)?
- ¿Cumple el plan de DR con todos los requisitos normativos aplicables (GDPR, HIPAA, PCI DSS)?
- ¿Se ha realizado una auditoría de seguridad de la solución de DR?
-
Documentación y formación:
- ¿Está toda la documentación (arquitectura, configuraciones, DRP) actualizada y disponible?
- ¿Está el equipo capacitado en todos los aspectos del plan y procedimientos de DR?
- ¿Hay personal de respaldo capaz de realizar los procedimientos de DR?
-
Optimización de costes:
- ¿Se ha realizado un análisis de TCO para la solución de DR?
- ¿Se utilizan las oportunidades de optimización de costes (instancias reservadas, instancias spot, tiering de almacenamiento)?
- ¿Se revisan regularmente los costes de DR?
Siguiendo esta lista de verificación, podrá construir un sistema de Recuperación ante Desastres robusto y fiable que protegerá su negocio SaaS de fallos imprevistos.
Cálculo de Costos / Economía de la Recuperación ante Desastres
 Diagrama: Cálculo de Costos / Economía de la Recuperación ante Desastres
Diagrama: Cálculo de Costos / Economía de la Recuperación ante Desastres
La economía de la Recuperación ante Desastres no solo incluye los costos directos de infraestructura, sino también los gastos ocultos y el costo de las pérdidas potenciales por interrupciones. Un cálculo correcto del TCO (Total Cost of Ownership) y el ROI (Return on Investment) de una solución de DR es crucial para tomar decisiones informadas.
Componentes del costo de DR
- Infraestructura:
- Recursos de cómputo: VPS, VM en la nube (EC2, Azure VMs, GCP Compute Engine), contenedores, funciones sin servidor. El costo depende de la estrategia elegida (Cold/Warm/Hot Standby).
- Almacenamiento de datos: Discos (EBS, Azure Disks, GCP Persistent Disks), almacenamiento de objetos (S3, Azure Blob, GCS) para copias de seguridad y datos fríos. El costo depende del volumen, tipo de almacenamiento (Standard, Infrequent Access, Archive).
- Recursos de red: Tráfico para replicación de datos, tráfico saliente durante la conmutación por error, túneles VPN, balanceadores de carga, servicios DNS. El tráfico interregional puede ser costoso.
- Servicios gestionados: Bases de datos gestionadas (RDS, Azure SQL, Cloud SQL), colas de mensajes, cachés, CDN.
- Software:
- Licencias para software de DR especializado (Veeam, Zerto).
- Licencias de SO y otro software (si no se utilizan versiones de código abierto o gratuitas).
- Personal:
- Tiempo de los ingenieros para el diseño, implementación, pruebas y soporte de la solución de DR.
- Capacitación del equipo.
- Tiempo para la recuperación real en caso de un incidente.
- Pruebas:
- Recursos asignados para pruebas de DR (implementación temporal de entornos de prueba).
- Esfuerzo del equipo para planificar y ejecutar las pruebas.
- Costos ocultos y pérdidas:
- Pérdida de ingresos: Pérdidas financieras directas por la indisponibilidad del servicio.
- Pérdida de productividad: Los empleados no pueden trabajar debido a la indisponibilidad de herramientas internas.
- Daño a la reputación: Pérdida de confianza de los clientes, reseñas negativas, fuga de usuarios.
- Multas: Por incumplimiento de SLA o requisitos regulatorios.
- Costo de recuperación de datos: Si los datos se perdieron y necesitan ser recreados manualmente.
- Costos legales: Demandas judiciales de clientes afectados.
Ejemplos de cálculos para diferentes escenarios (precios estimados para 2026)
Supongamos que tenemos una aplicación SaaS con 3 servidores de aplicaciones (CPU, RAM), 1 servidor de BD (PostgreSQL), 200 GB de datos, 500 GB de archivos, 1 TB de tráfico mensual.
Escenario 1: SaaS Pequeño (Warm Standby en VPS)
- Infraestructura principal: 3 x VPS (4vCPU, 8GB RAM, 100GB SSD) + 1 x VPS (8vCPU, 16GB RAM, 200GB SSD) = $200/mes.
- Infraestructura de DR (Warm Standby):
- 1 x VPS (2vCPU, 4GB RAM, 50GB SSD) para réplica de BD: $30/mes.
- 2 x VPS (2vCPU, 4GB RAM, 50GB SSD) en estado apagado (pago por almacenamiento en disco): $20/mes.
- Almacenamiento de objetos (compatible con S3) para copias de seguridad (1 TB): $20/mes.
- Tráfico para replicación y copias de seguridad (500 GB): $25/mes.
- DNS gestionado (por ejemplo, Cloudflare): $5/mes.
- Total costos directos de DR: ~$100/mes.
- Costo de mano de obra (ingeniero 0.1 FTE): $500/mes.
- TCO total de DR: ~$600/mes.
- Daño potencial por tiempo de inactividad (12 horas, $1000/hora): $12000. DR se amortiza si previene 1-2 interrupciones importantes al año.
Escenario 2: SaaS Mediano (Hot Standby en la nube, Multi-AZ)
- Infraestructura principal (AWS):
- 3 x EC2 (t3.medium) = $150/mes.
- 1 x RDS PostgreSQL (db.t3.large, Multi-AZ) = $200/mes.
- S3 (500GB) + EBS (200GB) = $40/mes.
- ALB, Route 53, VPC, tráfico = $100/mes.
- Total principal: ~$490/mes.
- Infraestructura de DR (casi un espejo, Multi-AZ):
- RDS Multi-AZ ya está incluido en el costo, proporciona DR para la BD.
- EC2 (Auto Scaling Group en 2 AZ) = $150/mes.
- S3 para copias de seguridad (1 TB) = $20/mes.
- EBS para EC2 (200GB) = $20/mes.
- ALB, Route 53, VPC, tráfico (incluido entre AZ) = $120/mes.
- Total costos directos de DR: ~$310/mes (adicional a la infraestructura base, que ya es tolerante a fallos dentro de la AZ).
- Costo de mano de obra (ingeniero 0.2 FTE): $1000/mes.
- TCO total de DR: ~$1310/mes.
- Daño potencial por tiempo de inactividad (1 hora, $5000/hora): $5000. DR se amortiza previniendo 3-4 interrupciones importantes al año.
Escenario 3: SaaS Grande (Multi-Region Active/Active en la nube)
Aquí el costo aumenta significativamente debido a la duplicación completa de la infraestructura en varias regiones y el uso de servicios globales. La infraestructura principal se multiplica por el número de regiones, y se añaden los costos de replicación de datos interregional y el balanceador de carga global.
- Dos regiones completas (por ejemplo, US-East y EU-West): Duplica el costo de la infraestructura principal, más costos adicionales.
- Infraestructura en cada región: ~$490/mes 2 = $980/mes.
- Replicación de datos interregional: Para 200 GB de BD y 500 GB de archivos, con uso activo, el tráfico puede ser de 1-2 TB/mes, más el costo de lectura/escritura. Aproximadamente: $200-$500/mes.
- Balanceador de carga global (AWS Global Accelerator/Route 53): ~$100/mes.
- Total costos directos de DR: ~$500/mes (adicional al costo de duplicación de infraestructura).
- Costo de mano de obra (ingeniero 0.5 FTE): $2500/mes.
- TCO total de DR: ~$3980/mes ($980 + $500 + $2500).
- Daño potencial por tiempo de inactividad (10 minutos, $20000/minuto): $200000. DR es críticamente importante y se amortiza al prevenir incluso un solo incidente de este tipo.
Tabla con ejemplos de cálculos (valores promedio para 2026)
| Componente / Estrategia |
Cold Standby (VPS) |
Warm Standby (VPS/Nube) |
Hot Standby (Nube Multi-AZ) |
Multi-Region A/A (Nube) |
| Infraestructura DR (mes) |
$50 - $150 |
$150 - $500 |
$300 - $1000 |
$1000 - $5000+ |
| Almacenamiento de copias de seguridad (mes) |
$10 - $30 |
$15 - $50 |
$20 - $70 |
$50 - $200 |
| Tráfico de replicación/copias de seguridad (mes) |
$5 - $20 |
$20 - $100 |
$50 - $200 |
$200 - $1000+ |
| Licencias de software (mes) |
$0 - $50 |
$0 - $100 |
$0 - $200 |
$0 - $500+ |
| Costo de mano de obra de ingenieros (mes) |
$200 - $500 |
$500 - $1500 |
$1000 - $3000 |
$2000 - $5000+ |
| TCO Total DR (mes) |
$265 - $750 |
$685 - $2150 |
$1370 - $4470 |
$3250 - $11700+ |
| Daño potencial por 1 hora de inactividad |
$500 - $5000 |
$2000 - $15000 |
$10000 - $50000 |
$50000 - $500000+ |
Cómo optimizar los costos
- Instancias reservadas (Reserved Instances) / Planes de ahorro (Savings Plans): Para la parte estable de la infraestructura de DR en la nube, se puede reducir significativamente el costo.
- Instancias Spot (Spot Instances): Pueden utilizarse para partes no críticas de la infraestructura de DR o para implementaciones de prueba temporales, pero requieren resistencia a las interrupciones.
- Clasificación por niveles de almacenamiento (Storage Tiering): Mueva las copias de seguridad antiguas a clases de almacenamiento de archivo más baratas (Glacier, Deep Archive).
- Herramientas de código abierto (Open-source): Utilice soluciones de código abierto gratuitas y potentes para copias de seguridad, replicación y automatización para evitar pagos de licencias.
- Apagado/encendido automático: Para Warm Standby, se pueden apagar los recursos inactivos del sitio de DR fuera del horario laboral (si el RTO lo permite).
- Optimización del tráfico: Compresión de datos antes de la transmisión, uso de redes privadas (VPN) para la replicación, elección de un proveedor con tarifas favorables para el tráfico saliente.
- DR-as-a-Service: Considere soluciones DRaaS de terceros, que pueden ser más económicas para algunas empresas que construir su propio centro de DR.
La economía de DR es un proceso continuo de evaluación y optimización. Es importante no solo reducir los costos, sino encontrar el equilibrio óptimo entre costo, fiabilidad y cumplimiento de los requisitos empresariales.
Casos y ejemplos de implementación de DR
 Esquema: Casos y ejemplos de implementación de DR
Esquema: Casos y ejemplos de implementación de DR
Ejemplos reales ayudarán a comprender mejor cómo se aplican las diferentes estrategias de DR en la práctica y qué resultados ofrecen.
Caso 1: Proyecto SaaS pequeño en VPS — "TaskFlow" (Warm Standby)
Proyecto: "TaskFlow" — SaaS para la gestión de tareas y proyectos para equipos pequeños. Basado en Python/Django con PostgreSQL, desplegado en 3 VPS de un mismo proveedor.
Problema: Riesgos crecientes de pérdida de datos y tiempo de inactividad prolongado. RTO = 3 horas, RPO = 15 minutos.
Solución: Implementación de una estrategia Warm Standby utilizando un segundo proveedor de VPS y almacenamiento en la nube.
- Base de datos (PostgreSQL): En el VPS principal se configuró una replicación en streaming asíncrona (streaming replication) a un VPS separado y en funcionamiento constante de otro proveedor. Los logs WAL se copian cada 5 minutos a un almacenamiento de objetos (compatible con S3).
- Archivos de la aplicación y estáticos: Sincronización horaria de todos los archivos de usuario (cargas, adjuntos) y estáticos desde el VPS principal a un almacenamiento de objetos utilizando
rsync.
- Código y configuraciones: Se almacenan en un repositorio Git.
- Sitio DR: En el segundo proveedor, se preinstalaron imágenes de VPS con el sistema operativo y el software básico. En caso de fallo del principal, se activan dos nuevos VPS a partir de las imágenes (para la aplicación y para la BD, si la réplica no puede ser promovida a maestro), se cargan los últimos archivos de S3 y se inicia la aplicación.
- Automatización: Se desarrollaron scripts Bash para monitorear el estado del servidor principal, conmutar los registros DNS (a través de la API del proveedor de DNS) e iniciar la aplicación en el sitio DR. El proceso de activación es semiautomático y requiere la confirmación de un ingeniero.
- Pruebas: Se realiza una prueba completa de Failover cada 3 meses fuera del horario laboral.
Resultados:
- RTO: Reducido a 45-60 minutos (incluyendo confirmación y verificación manual).
- RPO: Hasta 5-15 minutos gracias a la replicación en streaming y la sincronización frecuente de los logs WAL.
- Costo: Adicionales ~$150/mes en DR-VPS, almacenamiento y tráfico, lo cual fue aceptable para el presupuesto.
- Se mejoró significativamente la resiliencia ante fallos de un único proveedor de VPS.
Caso 2: Proyecto SaaS mediano en AWS — "AnalyticsPro" (Hot Standby Multi-AZ)
Proyecto: "AnalyticsPro" — Plataforma SaaS para análisis de datos profundos, desplegada en AWS. Utiliza Node.js en EC2 (en un Auto Scaling Group), MongoDB Atlas (servicio gestionado) y S3 para almacenar datos brutos.
Problema: Altos requisitos de disponibilidad (99.99%) y mínima pérdida de datos (RPO < 1 minuto). Un tiempo de inactividad de 15 minutos ya es crítico.
Solución: Implementación de una estrategia Hot Standby utilizando las capacidades Multi-AZ de AWS y MongoDB Atlas.
- Base de datos (MongoDB Atlas): Se utiliza un Multi-Region Replica Set, que es esencialmente una solución DR Active/Passive dentro del proveedor. MongoDB Atlas gestiona automáticamente la replicación y el failover entre AZ.
- Aplicación (Node.js en EC2): Desplegada en un Auto Scaling Group, que distribuye las instancias en dos Availability Zones (AZ) dentro de una misma región. Delante del ASG se encuentra un Application Load Balancer (ALB), que también opera en varias AZ.
- Almacenamiento de datos (S3): S3 es por naturaleza altamente disponible y geo-replicable dentro de la región.
- Automatización:
- La infraestructura se describe mediante AWS CloudFormation.
- Los health checks en el ALB y en el ASG detectan automáticamente las instancias no operativas y las reemplazan.
- Los registros DNS (Route 53) apuntan al ALB, que gestiona el tráfico entre AZ.
- Las funciones Lambda monitorean el estado de la replicación de MongoDB y envían alertas.
- Pruebas: Se realizan regularmente simulaciones de fallos de AZ (por ejemplo, detención de instancias en una AZ) para verificar la conmutación automática.
Resultados:
- RTO: Menos de 1-2 minutos (tiempo de conmutación del ALB e inicio de nuevas instancias de ASG). Para la BD, es prácticamente nulo.
- RPO: Prácticamente nulo para todos los datos críticos.
- Costo: Aumentó aproximadamente un 40-50% en comparación con un despliegue de una sola zona, pero esto se justificó por los requisitos del negocio y el daño evitado.
- Se garantizó alta disponibilidad y resiliencia ante fallos a nivel de AZ.
Caso 3: Proyecto SaaS grande con infraestructura híbrida — "EnterpriseConnect" (DR Híbrido)
Proyecto: "EnterpriseConnect" — SaaS para la gestión de comunicaciones corporativas, inicialmente desplegado en un centro de datos propio (On-Premise) debido a los requisitos de soberanía de datos y alto rendimiento. Parte de los servicios (por ejemplo, análisis, informes) ya se han trasladado a la nube.
Problema: Altos RTO (8-12 horas) y RPO (4 horas) para componentes críticos en el centro de datos propio. Es necesario asegurar RTO/RPO más bajos sin una migración completa a la nube.
Solución: Implementación de una estrategia DR híbrida utilizando la nube pública (Azure) como sitio de respaldo.
- Base de datos (SQL Server): Se configuró la Geo-replication en Azure SQL Database. La BD local se replica constantemente en la BD gestionada en la nube.
- Servidores de archivos: Los archivos críticos se sincronizan con Azure Blob Storage.
- Aplicación (ASP.NET Core): Las imágenes de VM con la aplicación y el software básico se almacenan en Azure Image Gallery. Las configuraciones se guardan en Azure Key Vault.
- Sitio DR en Azure:
- Se configuró un túnel VPN entre el centro de datos local y Azure VNet.
- En Azure VNet se prepararon previamente subredes, grupos de seguridad, balanceadores de carga (Azure Application Gateway).
- Se desplegaron VM mínimas, pero en funcionamiento constante, para monitorear y mantener el túnel VPN.
- Automatización:
- Toda la infraestructura DR en Azure se describe mediante plantillas de Azure Resource Manager (ARM).
- Se desarrollaron scripts de PowerShell para la activación automática de DR: inicio de VM desde imágenes, conexión de discos, configuración de la aplicación, conmutación de registros DNS (a través de Azure DNS).
- El monitoreo del centro de datos principal se configuró en Azure Monitor, que al detectar un fallo, activa una alerta e inicia el script de activación de DR.
- Pruebas: Prueba completa de Failover trimestral con conmutación de parte del tráfico a Azure.
Resultados:
- RTO: Reducido a 1-2 horas.
- RPO: Reducido a 15-30 minutos para la BD y los archivos.
- Costo: Inversiones significativas en desarrollo y soporte, pero los gastos operativos de la infraestructura en la nube en modo "standby" se optimizaron.
- Se garantizó una protección fiable contra fallos de todo el centro de datos local.
Estos casos demuestran que una estrategia DR efectiva no es una solución universal, sino que requiere un enfoque individualizado, basado en la especificidad del proyecto, sus requisitos y los recursos disponibles.
Resolución de problemas: Solución de problemas comunes de DR
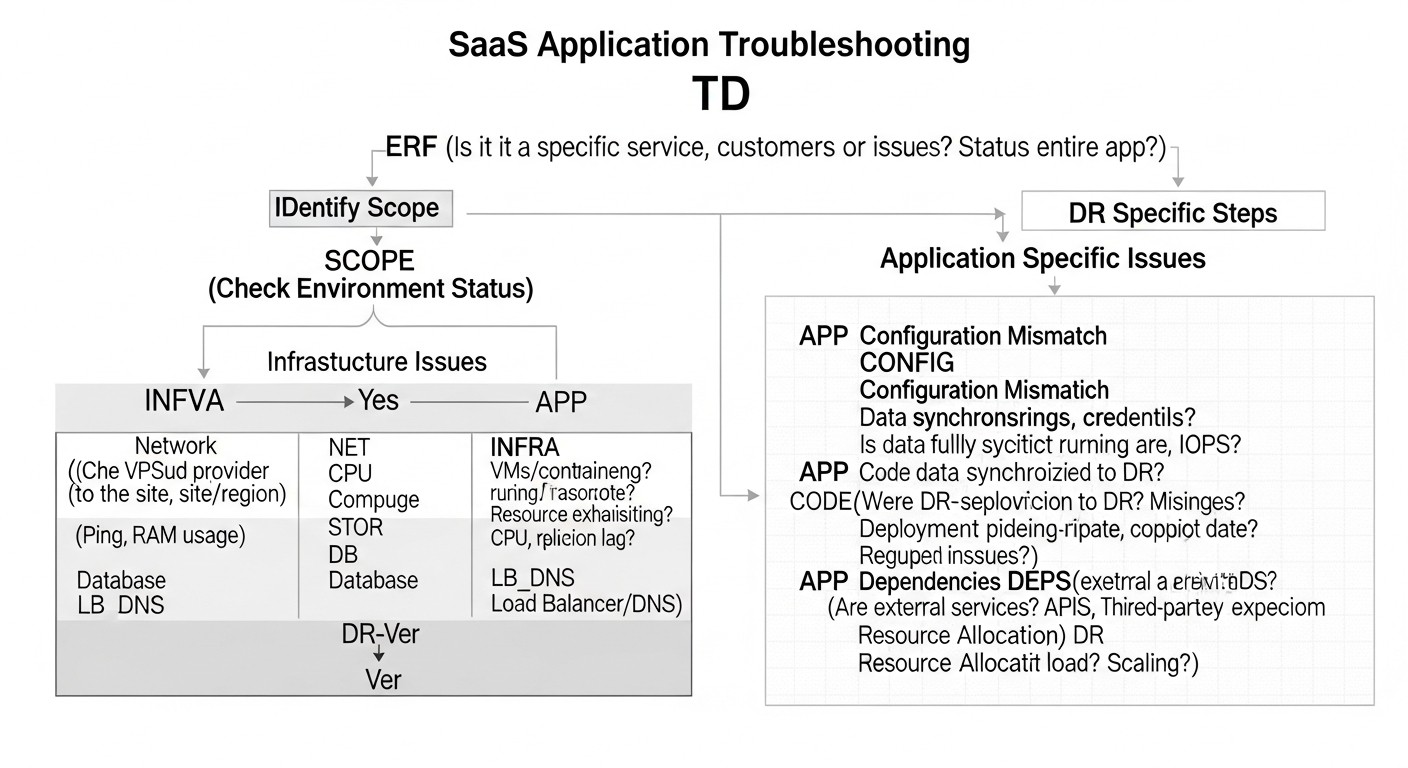 Diagrama: Resolución de problemas: Solución de problemas comunes de DR
Diagrama: Resolución de problemas: Solución de problemas comunes de DR
Incluso con la planificación y automatización más meticulosas, pueden surgir problemas durante el proceso de Disaster Recovery. Conocer los escenarios típicos y los enfoques para resolverlos reduce significativamente el tiempo de recuperación.
1. Problema: Fallos en la copia de seguridad o replicación
Síntomas: Ausencia de copias de seguridad recientes, retraso en la réplica de la BD, errores en los registros de los scripts de copia de seguridad.
Diagnóstico:
- Verifique los registros de los procesos de copia de seguridad y los servicios de replicación (por ejemplo,
tail -f /var/log/syslog, registros de PostgreSQL/MySQL).
- Verifique el espacio en disco en los servidores y en el almacenamiento de destino (
df -h, monitoreo del almacenamiento en la nube).
- Verifique la conexión de red entre los sitios principal y de respaldo (
ping, traceroute, netstat -tulnp).
- Verifique los permisos de acceso del usuario bajo el cual se ejecutan las copias de seguridad/replicación.
- Para bases de datos:
- PostgreSQL:
SELECT * FROM pg_stat_replication; en el maestro, SELECT pg_is_in_recovery(); en la réplica.
- MySQL:
SHOW SLAVE STATUS\G; en la réplica.
Solución:
- Resuelva los problemas de espacio en disco, red o permisos.
- Reinicie los servicios de replicación.
- Si la réplica está significativamente atrasada, es posible que deba recrearla desde cero (
pg_basebackup para PostgreSQL, mysqldump con importación posterior para MySQL, rsync para sistemas de archivos).
- Configure un monitoreo agresivo y alertas sobre fallos de copia de seguridad/replicación.
2. Problema: Inconsistencia de datos después de un failover
Síntomas: Parte de los datos faltan, transacciones perdidas, la aplicación se comporta de manera impredecible después de cambiar al sitio de DR.
Diagnóstico:
- Verifique el RPO que se logró en el momento del fallo. ¿Coincide con las expectativas?
- Compare las sumas de verificación de archivos o el número de registros en las tablas de la BD entre los sitios principal y de DR (si es posible).
- Analice los registros de replicación en busca de errores o transacciones omitidas.
- Verifique la configuración de replicación: ¿era síncrona o asíncrona?
Solución:
- Si el RPO se ha violado y los datos se han perdido realmente, evalúe la posibilidad de restaurar desde copias de seguridad más antiguas (si es permisible) o la recuperación manual de datos.
- Para futuros incidentes: revise el RPO y la estrategia de replicación. Es posible que se requiera una replicación síncrona más estricta o el uso de bases de datos distribuidas con consistencia garantizada.
- Implemente verificaciones adicionales de consistencia de datos en el plan de DR.
3. Problema: Failover lento o fallido
Síntomas: El sitio de DR se activa más lentamente de lo esperado, los scripts de failover se cuelgan, la aplicación no se inicia correctamente en el sitio de DR.
Diagnóstico:
- Verifique los registros de los scripts de failover. ¿En qué paso ocurrió el retraso o el error?
- Verifique la disponibilidad de los servicios externos de los que depende el sitio de DR (proveedor de DNS, API de la nube).
- Verifique el estado de los recursos en el sitio de DR: ¿hay suficiente CPU/RAM/IOPS? ¿Las VM no están "congeladas"?
- Verifique la configuración de red en el sitio de DR (firewalls, enrutamiento).
- Asegúrese de que todas las dependencias de la aplicación (colas, cachés, API de terceros) estén disponibles o configuradas correctamente en el sitio de DR.
Solución:
- Optimice los scripts de failover: hágalos más robustos, agregue tiempos de espera y reintentos.
- "Precaliente" (pre-warm) las instancias en el sitio de DR, si es Warm Standby, para reducir el tiempo de carga.
- Resuelva los problemas de red.
- Actualice las configuraciones del sitio de DR. Debe ser idéntico al principal.
- Realice pruebas exhaustivas de failover para identificar todos los cuellos de botella.
4. Problema: Errores durante el failback
Síntomas: Imposibilidad de volver al sitio principal, los datos en el sitio principal están desactualizados, surgen conflictos de datos.
Diagnóstico:
- Verifique si el sitio principal ha sido completamente restaurado y está listo para recibir tráfico.
- Asegúrese de que los datos del sitio de DR se hayan replicado correctamente de vuelta al sitio principal.
- Verifique los registros de los scripts de failback.
- Evalúe si hay conflictos de datos que podrían haber surgido durante la operación del sitio de DR.
Solución:
- El procedimiento de failback es a menudo más complejo que el de failover y requiere una planificación aún más meticulosa.
- Asegure la sincronización completa de los datos del sitio de DR al principal antes de la conmutación.
- Desarrolle una estrategia para resolver conflictos de datos, si surgieran.
- Pruebe el failback con la misma minuciosidad que el failover.
5. Problema: Factor humano
Síntomas: Errores al realizar pasos manuales de DR, pánico, falta de comprensión clara de los roles.
Diagnóstico:
- Análisis del incidente: ¿qué paso se realizó incorrectamente, por qué?
- Evaluación del nivel de estrés y fatiga del equipo.
- Verificación de la actualidad y claridad del DRP.
Solución:
- Automatice al máximo todos los pasos posibles.
- Realice entrenamientos y simulacros regulares para que el equipo se acostumbre a los procedimientos.
- Mejore el DRP, hágalo más detallado y comprensible.
- Asegure la disponibilidad de varios empleados capacitados capaces de ejecutar los procedimientos de DR.
- Implemente listas de verificación para operaciones manuales críticas.
Cuándo contactar con soporte
- Problemas con la infraestructura básica: Si está seguro de que el problema no está en su configuración, sino en el funcionamiento del proveedor de VPS o la plataforma en la nube (indisponibilidad de red, fallos de disco, indisponibilidad de la región).
- Problemas complejos con servicios gestionados: Si una base de datos gestionada u otro servicio en la nube se comporta de manera impredecible y la documentación no ayuda.
- Imposibilidad de recuperación: Si, a pesar de todos los esfuerzos, no puede recuperar datos o iniciar la aplicación, y todos los recursos internos se han agotado.
- Cuestiones de seguridad: Si sospecha de una compromiso de la infraestructura o los datos de DR.
Tenga siempre a mano los contactos del servicio de soporte de sus proveedores y los SLA correspondientes.
FAQ: Preguntas frecuentes sobre Disaster Recovery
¿Qué son RTO y RPO y por qué son tan importantes?
RTO (Recovery Time Objective) es el tiempo máximo permitido durante el cual su aplicación SaaS puede estar no disponible después de un fallo. RPO (Recovery Point Objective) es el volumen máximo permitido de datos que se pueden perder como resultado de un fallo, medido en tiempo. Estas métricas son críticamente importantes porque determinan qué tan rápido y con qué grado de integridad debe recuperarse su negocio. Son la base para elegir una estrategia de DR e influyen directamente en su costo y complejidad.
¿En qué se diferencia Disaster Recovery de una simple copia de seguridad (backups)?
La copia de seguridad es solo uno de los componentes de Disaster Recovery. Las copias de seguridad permiten restaurar datos hasta un punto específico en el tiempo. DR es un plan integral que incluye no solo copias de seguridad, sino también mecanismos de replicación de datos, automatización del despliegue de infraestructura, procedimientos de conmutación al sitio de respaldo (failover), restauración de operaciones (failback), monitoreo, alertas y pruebas regulares. DR tiene como objetivo la recuperación completa de la funcionalidad de toda la aplicación, no solo de los datos.
¿Es necesario DR para un pequeño proyecto SaaS con un presupuesto limitado?
Sí, absolutamente. Incluso para un pequeño proyecto SaaS, la pérdida de datos o un tiempo de inactividad prolongado puede ser catastrófico. Se puede empezar con una estrategia básica pero efectiva de Cold Standby, que es relativamente económica. Lo principal es tener un plan, realizar copias de seguridad regularmente y probar la capacidad de recuperación a partir de ellas. A medida que el proyecto crece y aumentan los requisitos de disponibilidad, se puede pasar gradualmente a estrategias de DR más complejas y costosas.
¿Con qué frecuencia se debe probar el plan de DR?
La frecuencia de las pruebas depende de la criticidad de su aplicación SaaS y de la velocidad de los cambios en la infraestructura. Para sistemas críticamente importantes, se recomienda realizar una prueba completa de Failover al menos una vez por trimestre. La verificación de la integridad de las copias de seguridad y la replicación debe realizarse semanal o diariamente. Los ejercicios de mesa (Tabletop Exercises) se pueden realizar mensualmente. La regla principal: pruebe su plan de DR con la frecuencia necesaria para asegurarse de su operatividad, y siempre después de cambios significativos en la arquitectura o configuración.
¿Cuáles son los principales tipos de estrategias de DR que existen?
Los principales tipos de estrategias de DR incluyen: Cold Standby (reserva fría, la más barata, RTO/RPO altos), Warm Standby (reserva caliente, RTO/RPO moderados), Hot Standby (reserva caliente, RTO/RPO bajos, cara), Multi-Region Active/Active (la más alta disponibilidad, muy cara y compleja), y DR Híbrido (combinación de VPS y nube para optimización). La elección depende de sus RTO, RPO, presupuesto y complejidad de la aplicación.
¿Se puede automatizar todo el proceso de Disaster Recovery?
Para la mayoría de las aplicaciones SaaS modernas, especialmente aquellas desplegadas en la nube, una parte significativa de los procesos de DR puede y debe automatizarse. Con la ayuda de Infrastructure as Code (IaC), scripts, pipelines de CI/CD, servicios en la nube y herramientas de orquestación, se puede automatizar la detección de fallos, el despliegue de recursos, la conmutación de DNS y el inicio de la aplicación. Sin embargo, eliminar completamente la participación humana, especialmente en la etapa de toma de decisiones y control, sigue siendo difícil, aunque la IA y el ML se están desarrollando activamente en esta dirección.
¿Qué servicios en la nube ayudan con Disaster Recovery?
Prácticamente todos los grandes proveedores de la nube (AWS, Azure, Google Cloud) ofrecen una amplia gama de servicios para DR: despliegues Multi-AZ/Multi-Region para VM y BD, bases de datos gestionadas (RDS, Azure SQL, Cloud SQL) con replicación integrada, almacenamiento de objetos (S3, Blob Storage, GCS) para copias de seguridad, herramientas de IaC (CloudFormation, ARM Templates, Deployment Manager), servicios de DNS (Route 53, Azure DNS, Cloud DNS) con funciones de failover, balanceadores de carga globales (Global Accelerator, Front Door, Global Load Balancer) y servicios de monitoreo y alerta (CloudWatch, Azure Monitor, Cloud Monitoring).
¿Cómo elegir entre VPS y la nube para DR?
La elección depende de su presupuesto, RTO/RPO y la experiencia del equipo. VPS puede ser más barato para Cold/Warm Standby, especialmente si ya tiene infraestructura en VPS y desea mantener el control. Sin embargo, la escalabilidad y la automatización en VPS suelen ser más complejas. La nube ofrece alta flexibilidad, elasticidad, un rico conjunto de servicios de DR y una automatización más sencilla, pero puede ser más cara, especialmente para soluciones Hot Standby y Multi-Region. Un enfoque híbrido (VPS para el trabajo principal, nube para DR) suele ser un buen compromiso.
¿Qué es Chaos Engineering y cómo se relaciona con DR?
Chaos Engineering es la práctica de introducir fallos controlados en sistemas distribuidos con el objetivo de identificar puntos débiles y verificar la resiliencia. Se relaciona directamente con DR porque permite probar activamente su plan de DR en condiciones reales, simulando fallos de servidores, redes, bases de datos o incluso AZ completas. Esto ayuda a identificar dependencias ocultas y cuellos de botella que podrían llevar al fracaso de DR, antes de que ocurran en una catástrofe real.
¿Cuál es el papel de la IA en la DR de 2026?
En 2026, la IA y el aprendizaje automático desempeñan un papel cada vez más importante en la DR. Se utilizan para el análisis predictivo: la IA puede analizar patrones en los registros y métricas para predecir posibles fallos antes de que ocurran. La IA también ayuda en el análisis automático de incidentes, identificando rápidamente las causas raíz de los problemas. En el futuro, se puede esperar una toma de decisiones automatizada sobre el failover basada en IA, que tendrá en cuenta múltiples factores, minimizando la intervención humana y reduciendo el RTO.
Conclusión
Disaster Recovery no es solo una tarea técnica, sino un componente fundamental de la resiliencia de cualquier negocio SaaS en 2026. En un entorno de expectativas de usuario en constante crecimiento, requisitos regulatorios más estrictos y una complejidad de infraestructura creciente, un plan de DR eficaz se convierte no en un lujo, sino en una necesidad crítica. La ausencia de dicho plan o su ineficacia puede llevar a pérdidas financieras catastróficas, un daño irreversible a la reputación y la pérdida de la confianza de los clientes.
Hemos examinado una amplia gama de estrategias, desde el económico Cold Standby para proyectos pequeños hasta complejos sistemas Multi-Region Active/Active para gigantes globales de SaaS. La conclusión clave es que no existe una solución universal. La elección de la estrategia óptima siempre debe basarse en un análisis cuidadoso de sus RTO (Objetivo de Tiempo de Recuperación) y RPO (Objetivo de Punto de Recuperación), que, a su vez, se determinan por los requisitos del negocio y el costo del tiempo de inactividad para su empresa.
Principales recomendaciones que debe extraer de este artículo:
- Planifique sistemáticamente: Desarrolle un Plan de Recuperación ante Desastres (DRP) detallado y actualizado que cubra todos los aspectos: desde escenarios de fallos hasta un plan de comunicación.
- Automatice al máximo: Utilice Infrastructure as Code (IaC), scripts y herramientas de orquestación para minimizar el trabajo manual, reducir el RTO y eliminar el factor humano.
- Pruebe sin piedad: Un plan de DR no probado es una ilusión de seguridad. Realice simulacros y pruebas regularmente, hasta una conmutación completa, para identificar y eliminar todas las debilidades.
- Invierta en las herramientas adecuadas: Los servicios en la nube modernos y las herramientas open-source ofrecen potentes capacidades para construir sistemas tolerantes a fallos.
- Considere la economía: Siempre compare los costos de DR con el daño potencial de una interrupción. Busque el equilibrio óptimo, utilizando las oportunidades de optimización de costos.
- Capacite al equipo: Sus ingenieros deben estar familiarizados con el DRP y los procedimientos para actuar eficazmente bajo estrés.
- Esté preparado para la hibridez: La combinación de VPS y soluciones en la nube a menudo ofrece el mejor resultado en términos de relación "precio/calidad" para muchos proyectos SaaS.
Próximos pasos para el lector:
- Comience con un BIA: Determine la criticidad de sus servicios y establezca RTO y RPO realistas.
- Desarrolle o actualice el DRP: Formalice su plan.
- Implemente copias de seguridad básicas: Asegúrese de que todos los datos críticos se respalden regularmente y se almacenen según la regla 3-2-1.
- Realice la primera prueba: Intente restaurar datos de las copias de seguridad en un servidor de prueba. Esto le proporcionará una experiencia invaluable.
- Automatice gradualmente: Comience con la automatización de las copias de seguridad, luego pase al despliegue de infraestructura utilizando IaC.
Recuerde que Disaster Recovery es un proceso continuo. Su infraestructura cambia, los requisitos del negocio evolucionan, y su plan de DR debe desarrollarse junto con ellos. Las inversiones en DR son inversiones en estabilidad, confianza del cliente y el éxito a largo plazo de su proyecto SaaS.