
Cómo elegir un proveedor de VPS en 2026: una guía práctica para especialistas técnicos
Guía completa para elegir un hosting VPS en 2026: tipos de virtualización (KVM, OpenVZ, LXC), características de CPU y RAM, almacenamiento NVMe, infraestructura de red, seguridad, precios y escenarios de uso prácticos. Para ingenieros DevOps, desarrolladores backend y administradores de sistemas.
Elegir un proveedor de VPS es una tarea que muchos subestiman. A primera vista, todo es sencillo: comparas precios, miras las características, eliges algo de costo y parámetros medios. En la práctica, después de tres meses, descubres que el servidor se degrada constantemente bajo carga, el soporte tarda días en responder y la dirección IP ya estaba en listas negras antes de que empezaras a trabajar.
En los últimos diez años, he trabajado con varias decenas de proveedores de hosting, desde hostings OpenVZ económicos de tres dólares hasta soluciones empresariales con precios de miles de dólares al mes. He ejecutado de todo en ellos: desde proyectos personales hasta sistemas de producción con millones de solicitudes al día. Y la principal conclusión que he sacado es que a menudo hay un abismo entre las promesas de marketing y la realidad.
El mercado de VPS en 2026 está sobresaturado de ofertas. Cientos de proveedores, miles de tarifas, infinitas "ofertas especiales" y descuentos. Distinguir un servicio de calidad de un envoltorio de marketing sobre hardware sobrecargado es una tarea no trivial. Y el precio del error es tiempo perdido, usuarios insatisfechos, datos perdidos y gastos imprevistos de migración.
Errores típicos al elegir un VPS:
- Orientarse solo por el precio sin entender qué se está comprando
- Ignorar el tipo de virtualización y sus limitaciones
- Subestimar la importancia de la geografía y la conectividad de red
- No verificar la reputación de las direcciones IP
- No entender la diferencia entre recursos "garantizados" y "dedicados"
- Elegir un proveedor sin probarlo bajo carga real
Este artículo está dirigido a quienes quieren profundizar en el tema más allá de "mirar la calificación en Trustpilot". Si eres ingeniero DevOps, desarrollador backend, fundador de un proyecto SaaS o administrador de sistemas, aquí encontrarás criterios de selección prácticos basados en la experiencia operativa real.
En el artículo, analizaremos todos los aspectos clave para elegir un proveedor de VPS: desde los tipos de virtualización y las características del hardware hasta la reputación de las direcciones IP y el trabajo con el soporte técnico. Hablaremos por separado sobre cómo probar un servidor antes de usarlo en producción, qué hacer ante problemas típicos y cómo no pagar de más por recursos que no son necesarios.
TL;DR — Conclusiones clave
- Virtualización KVM — la única opción razonable para producción. OpenVZ/LXC solo son adecuados para entornos de desarrollo con restricciones presupuestarias estrictas.
- Los recursos "ilimitados" no existen — siempre hay una política de uso justo, y esta se activará en el momento más inoportuno.
- Verifica las direcciones IP antes de comprar — solicita una IP de prueba y verifica su reputación a través de MXToolbox y AbuseIPDB.
- La proximidad geográfica es más importante de lo que parece — una latencia de 100 ms mata la experiencia del usuario más rápido que un código lento.
- SLA 99.9% — una cifra de marketing — lo importante es cómo el proveedor reacciona a los incidentes y compensa el tiempo de inactividad.
- Prueba el IO bajo carga — los benchmarks sintéticos no muestran el comportamiento en la competencia por los recursos.
- Lee la PUA antes de comprar — muchos casos de uso están prohibidos incluso por proveedores "leales".
- Guarda las copias de seguridad por separado — una copia de seguridad en el mismo proveedor no es una copia de seguridad.
- Empieza con poco — es mejor actualizar a medida que creces que pagar de más por recursos inactivos.
Terminología básica
Antes de profundizar en los detalles, asegurémonos de que hablamos el mismo idioma. La industria del hosting está sobrecargada de términos, y los proveedores a menudo los usan de manera diferente.
VPS (Virtual Private Server) — servidor virtual, una parte dedicada de un servidor físico con recursos garantizados. Tienes acceso root, tu propia IP, control total sobre el SO.
VDS (Virtual Dedicated Server) — esencialmente lo mismo que un VPS. El término se usa más en Europa y Rusia. Algunos proveedores posicionan el VDS como una opción más "premium" con virtualización KVM, pero esto es marketing.
Cloud instance / Cloud VM — un VPS en una infraestructura en la nube con gestión por API, autoescalado y facturación por minuto. Técnicamente también es una máquina virtual, pero con un modelo de uso diferente.
Dedicated server — un servidor físico completamente a tu disposición. Sin vecinos, 100% de los recursos del hardware.
Colocation — traes tu propio hardware al centro de datos, ellos proporcionan energía, refrigeración y red. Máximo control, máxima responsabilidad.
Bare metal — servidor dedicado sin SO ni hipervisor preinstalados. El término enfatiza que es hardware físico, no virtualización.
Managed vs Unmanaged — gestionado significa que el proveedor se encarga de la administración (actualizaciones, monitoreo, a veces configuración de software). No gestionado — solo la infraestructura, todo lo demás es tu responsabilidad.
Hypervisor / hipervisor — software que crea y gestiona máquinas virtuales. KVM, VMware ESXi, Xen, Hyper-V son ejemplos de hipervisores.
IOPS (Input/Output Operations Per Second) — cantidad de operaciones de lectura/escritura en disco por segundo. Métrica crítica para bases de datos y aplicaciones intensivas en almacenamiento.
Latency — latencia. Tiempo que tarda un paquete de datos en ir del punto A al punto B. Se mide en milisegundos (ms).
Bandwidth — ancho de banda del canal. Cantidad de datos que se pueden transferir por unidad de tiempo (Gbps, TB/mes).
Overselling / sobreventa — cuando el proveedor vende más recursos de los que existen físicamente, esperando que no todos los clientes los usen simultáneamente.
Uptime — porcentaje de tiempo en que el servicio estuvo disponible. 99.9% significa hasta 8.76 horas de tiempo de inactividad al año.
SLA (Service Level Agreement) — acuerdo de nivel de servicio. Compromiso formal del proveedor sobre el tiempo de actividad y las compensaciones.
AUP (Acceptable Use Policy) — política de uso aceptable. Documento que define lo que se puede y no se puede hacer en el servidor del proveedor.
DDoS (Distributed Denial of Service) — ataque de denegación de servicio distribuido. Intento de hacer que un servicio no esté disponible sobrecargándolo con solicitudes.
CDN (Content Delivery Network) — red de entrega de contenido. Red distribuida de servidores para acelerar la entrega de contenido estático a los usuarios.
SSL/TLS — protocolos de cifrado para una conexión segura. HTTPS = HTTP + SSL/TLS.
Comprender estos términos te ayudará a comunicarte con los proveedores en el mismo idioma, leer especificaciones técnicas y no caer en las trampas de marketing que abundan en la industria del hosting.
Contenido
- Terminología básica
- A quién le conviene un VPS y a quién no
- Arquitectura: VPS vs Dedicado vs Nube
- Virtualización: KVM, OpenVZ, LXC, VMware
- CPU: vCPU, sobreventa, NUMA
- RAM: balanceo, swap, OOM
- Almacenamiento: NVMe, SATA, RAID, Ceph, ZFS
- Red: ancho de banda, protección DDoS, peering
- Direcciones IP, ASN y reputación
- Geografía y latencia
- SLA: lo que está escrito vs lo que funciona
- Tablas comparativas
- Escenarios de uso prácticos
- Comandos para probar el servidor
- Diagnóstico de problemas típicos
- Seguridad, abuso y cumplimiento
- Qué cambió en 2024–2026
- Conclusiones
- Preguntas frecuentes
A quién le conviene un VPS y a quién no
Un VPS no es una solución universal. Antes de comparar proveedores, asegúrate de que un VPS sea adecuado para tu tarea. Un error en esta etapa es lo más costoso: gastarás tiempo en la configuración, luego descubrirás que la arquitectura no escala o que los requisitos no se cumplen, y tendrás que rehacerlo.
Analicemos escenarios típicos y evaluemos honestamente dónde un VPS funciona bien y dónde crea más problemas de los que resuelve.
Un VPS es adecuado si:
- Necesitas control total sobre el entorno (acceso root, software arbitrario, configuraciones de kernel personalizadas)
- El presupuesto es limitado, pero se requiere un entorno aislado
- La carga es predecible y no tiene picos repentinos de 10-100x
- El proyecto está en fase MVP/producción temprana con tráfico de hasta varios millones de solicitudes al día
- Necesitas una dirección IP estática para integraciones, envíos de correo electrónico, API
- Se requiere implementar una pila específica que no es compatible con las plataformas PaaS
Un VPS no es adecuado si:
- La carga es impredecible con picos — los proveedores de la nube con autoescalado serán más económicos
- La tolerancia a fallos a nivel de infraestructura es crítica — se necesita un Kubernetes gestionado o un despliegue multirregión
- No hay tiempo/competencias para la administración — los servicios gestionados ahorrarán más
- Se requiere cumplimiento (PCI DSS, HIPAA, SOC2) — es más económico contratar un hosting gestionado certificado
- Se necesita aceleración GPU para ML/IA — las nubes especializadas (Lambda Labs, Vast.ai) son más rentables
Zona gris:
- API de alta carga — un VPS puede funcionar, pero requiere una planificación de capacidad competente y estar preparado para el escalado vertical
- Comercio electrónico — adecuado para tráfico medio, pero en ventas flash es mejor tener un colchón o una CDN
- Bases de datos — un VPS con NVMe es adecuado para PostgreSQL/MySQL hasta cierto tamaño, pero las bases de datos gestionadas suelen ser más fáciles de mantener
Arquitectura: VPS vs Dedicado vs Nube
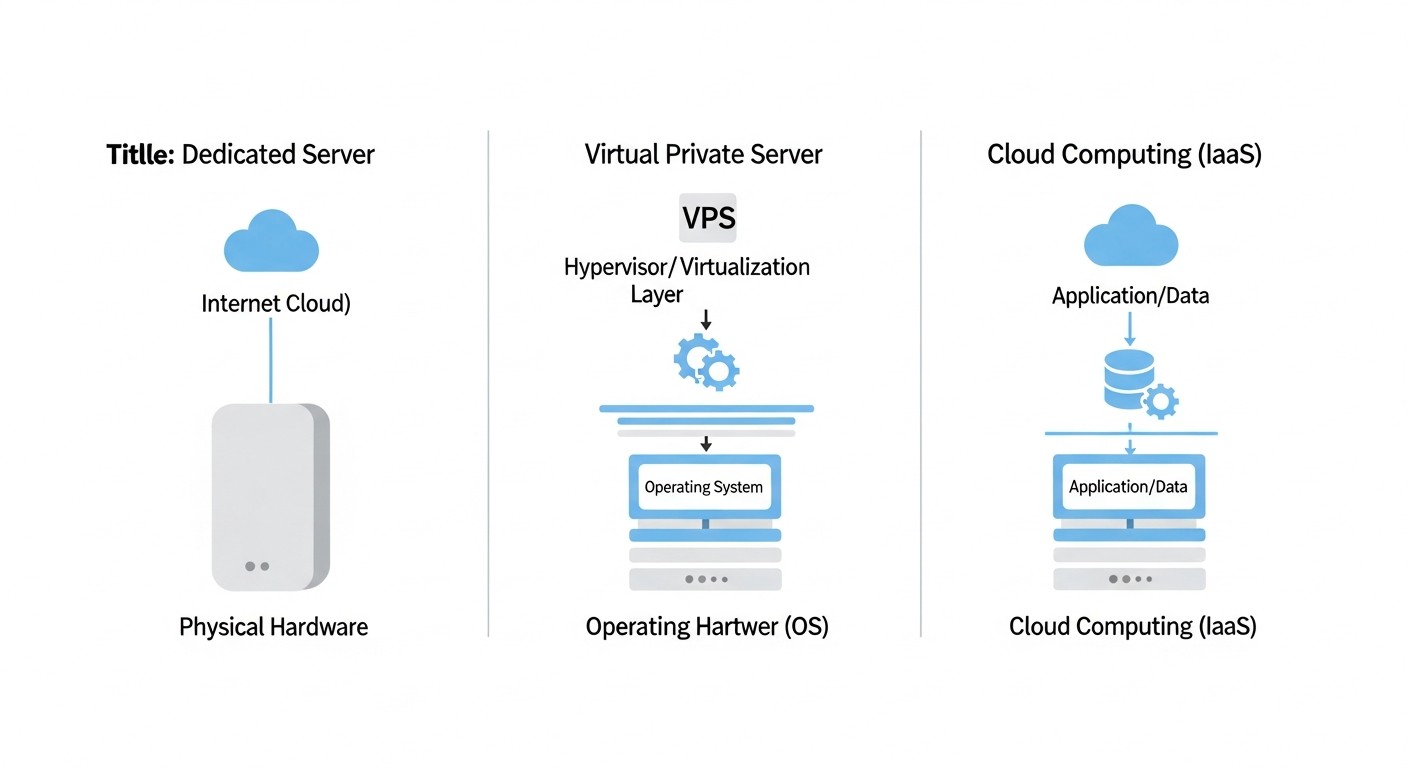
Comprender las diferencias arquitectónicas es la base de una elección informada. Los materiales de marketing a menudo difuminan las líneas entre estas categorías, pero las diferencias técnicas son fundamentales.
VPS (Servidor Privado Virtual)
Un servidor físico se divide en varias máquinas virtuales mediante un hipervisor. Cada VM recibe una parte dedicada de los recursos, pero estos se comparten a nivel de hardware.
Qué obtienes:
- Entorno aislado con acceso root
- Límites fijos de CPU/RAM/Disco
- Dirección IP estática
- Costo relativamente bajo debido a la división de recursos
Compromisos:
- "Vecinos ruidosos" — otras VM en el mismo host pueden afectar el rendimiento
- El rendimiento de IO depende de la carga general del almacenamiento
- Los límites de ancho de banda de red suelen ser compartidos
- Sobrevanta — los proveedores a menudo venden más recursos de los que existen físicamente
Servidor Dedicado
Un servidor físico completamente a tu disposición. Sin vecinos, sin hipervisor (a menos que lo instales tú mismo).
Qué obtienes:
- 100% de los recursos del hardware
- Rendimiento predecible
- Posibilidad de configuración personalizada (al realizar el pedido)
- Acceso a IPMI/iLO/iDRAC para gestión fuera de banda
Compromisos:
- Alto costo (desde $50-100/mes para nivel de entrada)
- El aprovisionamiento tarda horas o días
- Fallos de hardware — tu problema (si no hay SLA de reemplazo)
- No hay escalado vertical instantáneo
Nube (IaaS)
En esencia, también es virtualización, pero con gestión basada en API, autoescalado y un modelo de pago por uso.
Qué obtienes:
- Aprovisionamiento instantáneo
- Elasticidad — los recursos se escalan bajo demanda
- Un rico ecosistema de servicios gestionados
- Infraestructura global con despliegue multirregión
Compromisos:
- Costo 2-5 veces mayor que un VPS con carga constante
- Bloqueo de proveedor a través de servicios propietarios
- Complejidad de precios — es fácil recibir una factura inesperada
- Menos control sobre el hardware
«La optimización prematura es la raíz de todo mal. Pero el escalado prematuro de la infraestructura es la raíz de toda bancarrota.»
— Adaptación de una frase de Donald Knuth, relevante para las startups modernas
Cuándo elegir qué
VPS — óptimo para proyectos con carga predecible y presupuesto limitado. Escenarios típicos: aplicaciones web, servicios API, ejecutores de CI/CD, entornos de desarrollo/staging.
Dedicado — cuando se necesita rendimiento garantizado y previsibilidad. Bases de datos con IO intensivo, servidores de juegos, granjas de renderizado, proyectos de alta carga con carga estable.
Nube — cuando la carga es impredecible, se necesita un despliegue global rápido o la integración con servicios gestionados es crítica. Startups con crecimiento incierto, proyectos estacionales, arquitecturas de microservicios.
Cálculo del Costo Total de Propiedad (TCO)
Al comparar opciones, considera no solo el precio del servidor:
Costos directos:
- Costo del propio VPS/servidor
- Direcciones IP adicionales
- Copias de seguridad (si son de pago)
- Protección DDoS
- Licencias (Windows, cPanel, etc.)
- Exceso de tráfico
Costos ocultos:
- Tiempo de administración — ¿cuánto vale tu hora?
- Tiempo de resolución de problemas
- Pérdida de ingresos por tiempo de inactividad
- Costo de migración si el proveedor no fue adecuado
Ejemplo de cálculo:
VPS por $20/mes vs hosting gestionado por $50/mes. Parece que el VPS es $360/año más barato. Pero si dedicas 5 horas al mes a la administración con una tarifa de $50/hora, eso son $250/mes. El hosting gestionado resulta más rentable.
Calcula honestamente. Un VPS es más barato en términos monetarios, pero requiere competencias y tiempo.
Virtualización: KVM, OpenVZ, LXC, VMware
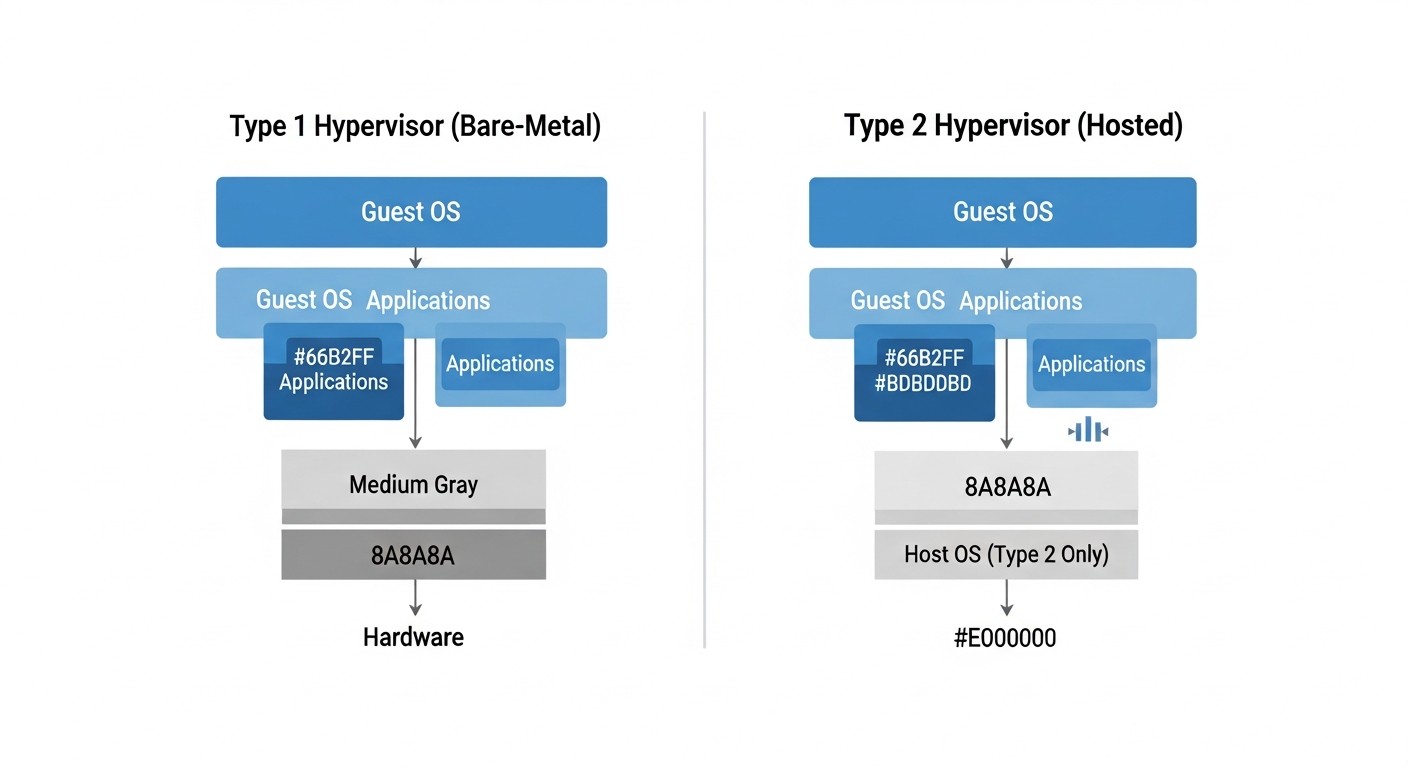
El tipo de virtualización es lo primero que debes averiguar al elegir un VPS. De ello depende todo: rendimiento, aislamiento, compatibilidad de software, posibilidades de configuración.
KVM (Kernel-based Virtual Machine)
Virtualización de hardware completa a nivel del kernel de Linux. Cada VM recibe su propio hardware virtual: CPU, RAM, disco, adaptadores de red.
Ventajas:
- Aislamiento completo — la VM no sabe nada de sus vecinos
- Puede ejecutar cualquier SO: Linux, Windows, FreeBSD, kernels personalizados
- Soporte para Docker, Kubernetes, virtualización anidada
- Límites de recursos honestos — obtienes lo que pagas
- Posibilidad de cargar tu propia imagen ISO
Limitaciones:
- Mayor sobrecarga — parte de los recursos se destina al hipervisor
- Ligeramente más lento que la virtualización de contenedores (en la práctica, la diferencia es mínima)
- Requiere más RAM para un funcionamiento cómodo (mínimo 512 MB, se recomienda 1 GB+)
OpenVZ
Virtualización de contenedores a nivel del SO. Todos los contenedores comparten un único kernel del host.
Ventajas:
- Sobrecarga mínima — rendimiento casi nativo
- Bajo costo para el proveedor = tarifas económicas
- Aprovisionamiento rápido
Limitaciones críticas:
- Solo Linux con el kernel del host — no se puede usar un kernel personalizado
- Docker funciona con limitaciones o no funciona en absoluto
- No se pueden cargar módulos iptables, FUSE, algunos módulos de seguridad
- Los "vecinos ruidosos" afectan más debido al kernel compartido
- La sobreventa es común — los proveedores venden 2-3 veces más RAM de la que existe físicamente
- OpenVZ 6 (legado) tiene un kernel obsoleto sin características modernas
Realidad: OpenVZ en 2026 es legado. OpenVZ 7 (Virtuozzo) resuelve parcialmente los problemas, pero aún así es inferior a KVM en aislamiento y flexibilidad. Úsalo solo para entornos de desarrollo con un presupuesto mínimo.
Historia de la práctica: un cliente compró un "VPS 4GB RAM" en OpenVZ por $3/mes. Dos semanas después, comenzaron a producirse OOM-kills aleatorios al usar 2GB. La razón: el proveedor sobrevendió la memoria, y bajo carga competitiva, solo estaban disponibles ~2.5GB. Después de migrar a un hosting KVM por $8/mes, el problema desapareció. Un ahorro de $5 costó una semana de depuración y usuarios insatisfechos.
LXC/LXD
Virtualización de contenedores moderna, oficialmente compatible con el kernel de Linux.
Ventajas:
- Rendimiento cercano al nativo
- Mejor aislamiento que OpenVZ
- Soporte para contenedores sin privilegios
- Desarrollo activo y características modernas
Limitaciones:
- Todavía comparte el kernel con el host
- Docker funciona dentro, pero con salvedades
- Menos proveedores ofrecen VPS basados en LXC
VMware ESXi
Hipervisor de grado empresarial, utilizado por grandes proveedores y en entornos corporativos.
Ventajas:
- Tecnología madura con más de 20 años de desarrollo
- Excelentes herramientas de gestión (vCenter, vSphere)
- Características avanzadas: vMotion, DRS, HA
- Aislamiento completo y compatibilidad con cualquier SO
Limitaciones:
- Alto costo de licencias — los proveedores lo trasladan a los clientes
- Menos común en el segmento económico
- Bloqueo de proveedor en el ecosistema VMware
Proxmox VE
Popular plataforma de virtualización de código abierto, compatible con KVM y LXC.
Ventajas:
- Licencia gratuita — menor costo para el proveedor
- Flexibilidad — se puede elegir entre KVM y LXC
- Buena interfaz web y API
- Soporte para Ceph, ZFS, clustering
Lo que es importante saber:
- La calidad de la implementación depende del proveedor
- Proxmox por sí mismo no garantiza un buen rendimiento
Cómo saber el tipo de virtualización
Los proveedores no siempre indican explícitamente el tipo de virtualización. Así es como se puede verificar después de la compra:
# Método universal
sudo dmidecode -s system-product-name
# Para sistemas basados en systemd
systemd-detect-virt
# Verificación /proc
cat /proc/cpuinfo | grep -i hypervisor
cat /sys/class/dmi/id/product_name
# Para OpenVZ
cat /proc/vz/veinfo 2>/dev/null && echo "OpenVZ"
# A través de virt-what (necesita instalación)
sudo apt install virt-what && sudo virt-what
Resultados típicos:
kvm— KVM/QEMUvmware— VMware ESXixen— Xen HVM o PVopenvz— OpenVZlxc— LXC/LXDmicrosoft— Hyper-V
CPU: vCPU, sobreventa, NUMA
Las características de la CPU en un VPS son uno de los temas más confusos. El marketing utiliza activamente los términos "vCPU", "núcleos", "cores", pero detrás de ellos se esconden diferentes realidades.
Qué es un vCPU
Un vCPU (virtual CPU) es un procesador virtual asignado a una máquina virtual. Un vCPU generalmente corresponde a un hilo (thread) de un procesador físico, pero no siempre a un solo núcleo.
Modelos típicos:
- 1 vCPU = 1 thread — con Hyper-Threading en Intel o SMT en AMD activado, 1 vCPU = 1/2 de un núcleo físico
- 1 vCPU = 1 core — asignación honesta de un núcleo completo (raramente se encuentra en el segmento económico)
- 1 vCPU = shared time — el tiempo de CPU se divide dinámicamente entre las VM
Sobrevanta de CPU
La sobreventa (overselling) es cuando un proveedor vende más vCPU de los que hay núcleos/hilos físicos. Esta es una práctica estándar, pero su grado varía.
Sobrevanta moderada (2-4x):
- Funciona si los clientes no cargan la CPU simultáneamente
- Adecuado para hosting web, donde la carga es de tipo ráfaga
- La degradación es notable bajo carga competitiva
Sobrevanta agresiva (8x+):
- Característica de proveedores ultrabaratos
- El tiempo de robo de CPU puede alcanzar el 30-50%
- Rendimiento impredecible
Tiempo de robo de CPU (CPU Steal Time)
El tiempo de robo (steal time) es el porcentaje de tiempo en que un vCPU estaba listo para ejecutar tareas, pero el hipervisor no le asignó una CPU física (porque otras VM la estaban usando).
Cómo verificar:
# Muestra el tiempo de robo en tiempo real
top
# Busca la columna %st en la línea Cpu(s)
# O a través de vmstat
vmstat 1 10
# Columna st en la sección cpu
# Estadísticas detalladas
mpstat -P ALL 1
# Columna %steal para cada vCPU
Interpretación:
- 0-2% — normal, no afecta el rendimiento
- 2-10% — sobreventa moderada, tolerable para la mayoría de las tareas
- 10-20% — degradación grave, deberías considerar cambiar de proveedor
- >20% — crítico, el proveedor abusa de la sobreventa
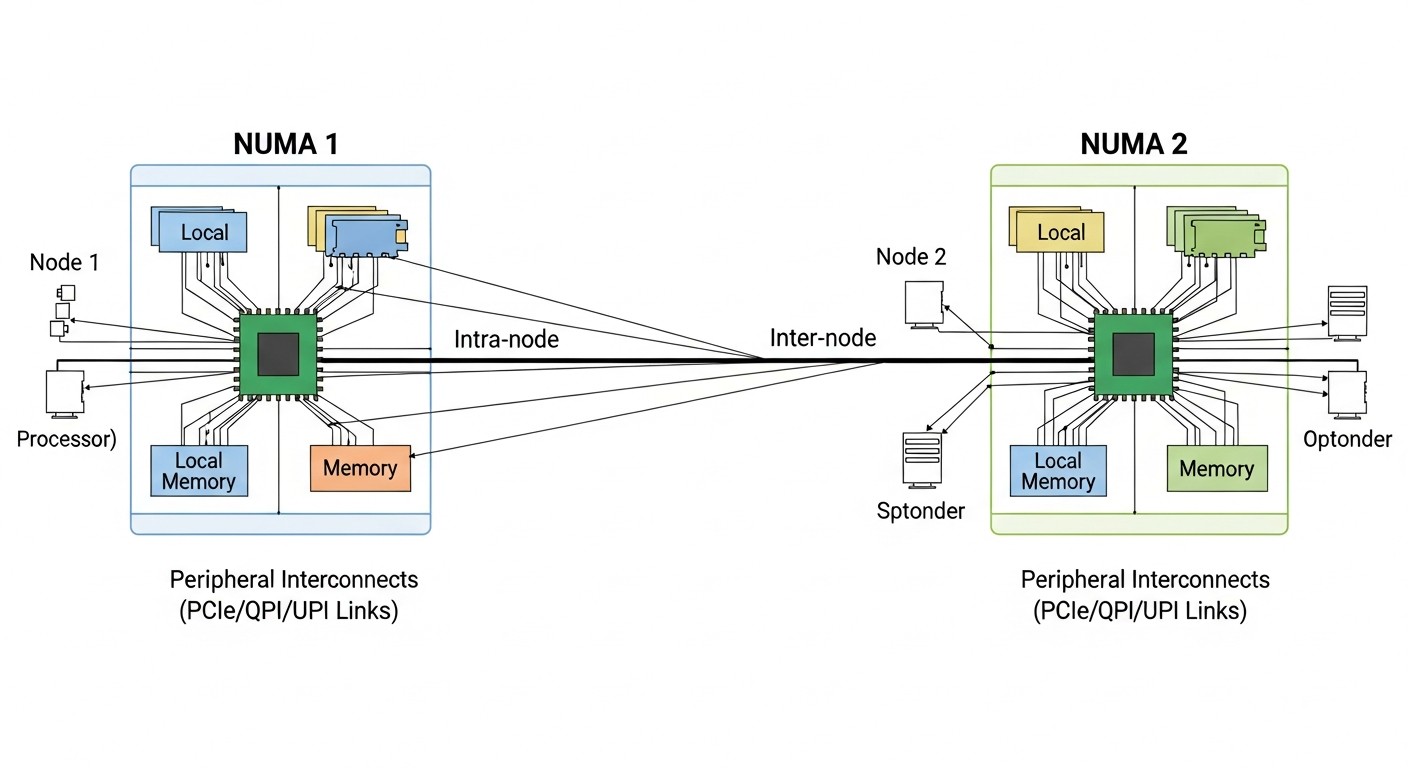
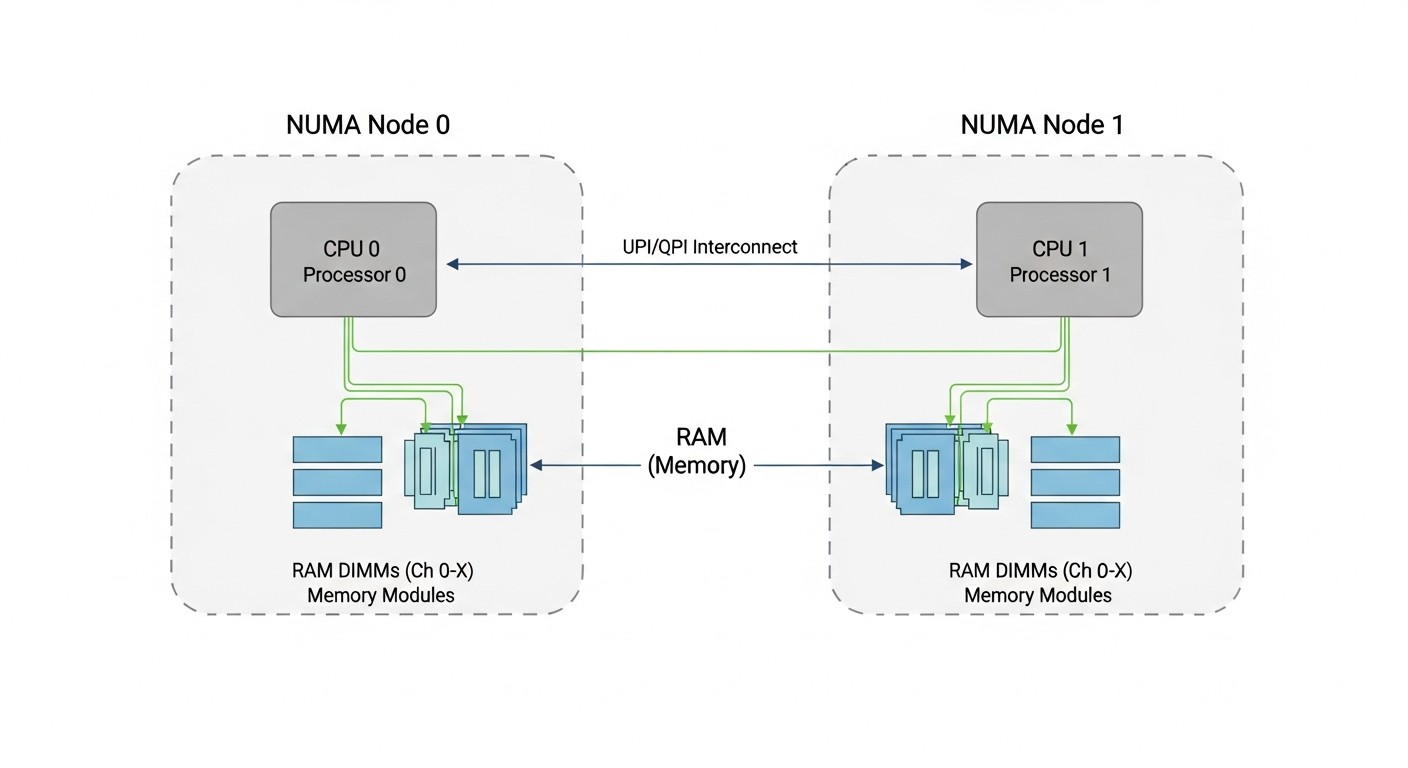
NUMA y topología de CPU
NUMA (Non-Uniform Memory Access) — arquitectura donde el acceso a diferentes secciones de memoria tiene diferente latencia. Importante para servidores con múltiples sockets.
Por qué es importante para VPS:
- Si una VM se coloca en vCPU de diferentes nodos NUMA, el acceso a la memoria es más lento
- Los buenos proveedores fijan las VM a un solo nodo NUMA
- Los malos — no, y obtienes degradación en tareas intensivas en memoria
Cómo verificar:
# Topología NUMA
numactl --hardware
# o
lscpu | grep -i numa
# Topología de CPU
lscpu -e
Modelos de procesadores
Es importante entender en qué hardware funciona tu VM. La diferencia entre generaciones de procesadores es sustancial.
# Conocer el modelo de CPU
cat /proc/cpuinfo | grep "model name" | head -1
# Información detallada
lscpu
A qué prestar atención:
- Intel Xeon E5-2600 v1/v2 — hardware legado (2012-2014), baja IPC, alto consumo de energía
- Intel Xeon E5-2600 v3/v4 — aceptable para la mayoría de las tareas
- Intel Xeon Scalable (Gold, Platinum) — hardware moderno con alta IPC
- AMD EPYC 7xx2/7xx3/9xx4 — excelente relación precio/rendimiento
Consejo práctico: AMD EPYC en 2026 a menudo ofrece el mejor rendimiento por el mismo dinero. No temas elegir un VPS basado en AMD.
Rendimiento de CPU: qué afecta la velocidad
No todos los vCPU son iguales. El rendimiento depende de muchos factores:
IPC (Instrucciones por Ciclo):
Los procesadores modernos realizan más operaciones por ciclo. Un vCPU en la serie AMD EPYC 9004 es significativamente más rápido que en un Intel Xeon E5-2670 (año 2012), incluso con la misma frecuencia.
Turbo Boost / Precision Boost:
Los procesadores aumentan automáticamente la frecuencia bajo baja carga. En un VPS, esto funciona si el hipervisor está configurado correctamente y los vecinos no cargan la CPU. La diferencia entre la frecuencia base y la de boost puede ser del 30-50%.
Caché:
La caché L3 es crítica para muchas cargas de trabajo. Con la sobreventa, varias VM compiten por la caché, lo que reduce el rendimiento. Esto no se refleja en el tiempo de robo, pero afecta la latencia.
Prueba práctica de CPU:
# Prueba de un solo hilo (importante para aplicaciones sensibles a la latencia)
sysbench cpu --cpu-max-prime=20000 --threads=1 run
# Prueba de múltiples hilos (rendimiento)
sysbench cpu --cpu-max-prime=20000 --threads=$(nproc) run
# Compara los resultados con valores de referencia
# EPYC/Xeon Gold moderno de un solo hilo: 2000-2500 eventos/seg
# Xeon E5 antiguo: 800-1200 eventos/seg
Cuando la CPU es crítica:
- Compilación de código
- Procesamiento de video/imágenes
- Terminación SSL bajo carga
- Compresión/descompresión
- Algunos tipos de cargas de trabajo de bases de datos
Cuando la CPU es menos importante:
- Sitios web simples (el cuello de botella suele ser el IO o la red)
- Proxies y balanceadores de carga
- Aplicaciones intensivas en almacenamiento
RAM: balanceo, swap, OOM
La memoria es un recurso que o está o no está. A diferencia de la CPU, donde se puede "robar" tiempo a los vecinos, la memoria es fija. ¿O no?
Memory Ballooning
Algunos hipervisores utilizan el memory ballooning — una técnica de redistribución dinámica de memoria entre las VM.
Cómo funciona:
- Se instala un controlador de balloon en la VM
- El hipervisor puede "inflar" el balloon, quitando memoria a la VM
- La memoria liberada se cede a otras VM
Problemas:
- Si el balloon se activa bajo carga, la aplicación pierde memoria
- Puede llevar a OOM sin razones aparentes
- Difícil de diagnosticar —
freemuestra menos memoria de la comprada
Cómo verificar:
# Verificar la presencia del controlador de balloon
lsmod | grep -i balloon
# Para KVM/QEMU
lsmod | grep virtio_balloon
# Si el módulo está cargado, el ballooning es posible
# Para deshabilitar (si tienes root):
rmmod virtio_balloon
# O a través de la lista negra en /etc/modprobe.d/
Swap y overcommit
Swap — espacio en disco utilizado como memoria adicional. En SSD/NVMe funciona de manera tolerable, en HDD — mata el rendimiento.
Políticas de swap:
- Algunos proveedores ofrecen swap fijo (1-2GB)
- Otros — prohíben el swap por completo
- Otros — no lo limitan, pero el swap en almacenamiento compartido = problemas
# Verificar swap
free -h
swapon --show
# Uso actual de swap
cat /proc/swaps
# Swappiness (cuán agresivamente se usa swap)
cat /proc/sys/vm/swappiness
# Se recomienda 10-30 para VPS con suficiente RAM
OOM Killer
Cuando la memoria se agota, Linux invoca al OOM Killer — un mecanismo que mata procesos para liberar memoria.
Víctimas típicas:
- Procesos con alto consumo de memoria
- Procesos recién iniciados
- Procesos sin privilegios especiales
Cómo rastrear OOM:
# Verificar los logs del kernel
dmesg | grep -i "oom\|killed"
# En los logs del sistema
journalctl -k | grep -i "oom\|killed"
# Configurar un proceso para "no matar"
echo -1000 > /proc/PID/oom_score_adj
Memory overcommit
Linux por defecto permite a los procesos solicitar más memoria de la que hay. Esto funciona porque no todas las páginas solicitadas se usan de inmediato.
# Política actual
cat /proc/sys/vm/overcommit_memory
# 0 = heurística (por defecto)
# 1 = siempre overcommit
# 2 = no overcommit
# Para producción a menudo se recomienda:
# vm.overcommit_memory = 2
# vm.overcommit_ratio = 80
Volumen real de memoria
No toda la RAM indicada en la tarifa está disponible para las aplicaciones.
# Volumen total de memoria
free -h
# Estadísticas detalladas
cat /proc/meminfo
# Memoria disponible (incluye buffers y caché)
# Ver la línea "available" en free -h
Qué consume memoria:
- Kernel — 100-300MB dependiendo de la configuración
- Systemd y servicios básicos — 100-200MB
- Daemon SSH, crond, y otros — 50-100MB
- Total: de 1GB de RAM, las aplicaciones tienen disponibles ~600-700MB
Almacenamiento: NVMe, SATA, RAID, Ceph, ZFS
El almacenamiento es a menudo el cuello de botella de un VPS. Mientras que la CPU y la RAM escalan de forma relativamente lineal, el IO se topa con las limitaciones físicas de los discos y el almacenamiento en red.
Tipos de almacenamiento en VPS
NVMe local
Los discos NVMe están conectados directamente al servidor donde se ejecuta la VM.
Características:
- IOPS: 50,000-500,000+ (depende del modelo y la división)
- Latencia: 0.1-0.5ms
- Rendimiento: 1-5+ GB/s
Ventajas:
- Latencia mínima
- Altos IOPS para acceso aleatorio
- Ideal para bases de datos
Desventajas:
- Los datos están vinculados a un servidor específico
- En caso de fallo del disco — pérdida de datos (si no hay RAID)
- La migración de VM a otro host es más compleja
SATA SSD local
SSD SATA en el servidor.
Características:
- IOPS: 10,000-80,000
- Latencia: 0.5-2ms
- Rendimiento: 400-550 MB/s
Adecuado para la mayoría de las tareas, excepto cargas de trabajo de altos IOPS.
Almacenamiento en red (Ceph, iSCSI, NFS)
Los discos se almacenan en un clúster de almacenamiento separado y se conectan a través de la red.
Características:
- IOPS: 5,000-50,000 (depende del backend y la red)
- Latencia: 1-5ms
- Rendimiento: depende de la red (1-10 GB/s)
Ventajas:
- Los datos se replican, mayor tolerancia a fallos
- Migración en vivo de VM sin tiempo de inactividad
- Escalado flexible del volumen
Desventajas:
- Mayor latencia debido a la red
- El rendimiento se comparte entre todos los clientes
- En caso de problemas de red — todas las VM sufren
HDD
Discos duros clásicos. En 2026, son raros, generalmente para almacenamiento de archivo.
Características:
- IOPS: 100-200 (¡acceso aleatorio!)
- Latencia: 5-15ms
- Rendimiento: 100-200 MB/s
Cuando es aceptable:
- Almacenamiento de copias de seguridad
- Servidores de archivos con lectura secuencial
- Logs y archivos
Cuando NO es aceptable:
- Bases de datos (excepto réplicas de solo lectura)
- Aplicaciones web con IO activo
- Todo lo que requiera capacidad de respuesta
Configuraciones RAID
| Nivel RAID | Discos | Tolerancia a fallos | Rendimiento | Eficiencia |
|---|---|---|---|---|
| RAID 0 | 2+ | No | Alta | 100% |
| RAID 1 | 2 | 1 disco | Lectura x2 | 50% |
| RAID 5 | 3+ | 1 disco | Bueno | 67-94% |
| RAID 6 | 4+ | 2 discos | Medio | 50-88% |
| RAID 10 | 4+ | 1 disco en par | Alto | 50% |
Qué usan los proveedores:
- Económicos: a menudo RAID 0 o sin RAID (JBOD)
- Medios: RAID 5/6 o RAID 10
- Empresariales: Ceph con replicación x3
Cómo probar el almacenamiento
# Instalar fio (Flexible I/O Tester)
apt install fio
# Prueba de lectura aleatoria (bloques de 4K, típico para DB)
fio --name=random-read --ioengine=libaio --iodepth=32 \
--rw=randread --bs=4k --direct=1 --size=1G \
--numjobs=4 --runtime=60 --group_reporting
# Prueba de escritura aleatoria
fio --name=random-write --ioengine=libaio --iodepth=32 \
--rw=randwrite --bs=4k --direct=1 --size=1G \
--numjobs=4 --runtime=60 --group_reporting
# Prueba de lectura secuencial (rendimiento)
fio --name=seq-read --ioengine=libaio --iodepth=16 \
--rw=read --bs=1M --direct=1 --size=1G \
--numjobs=1 --runtime=60 --group_reporting
# Prueba mixta (70% lectura, 30% escritura)
fio --name=mixed --ioengine=libaio --iodepth=32 \
--rw=randrw --rwmixread=70 --bs=4k --direct=1 --size=1G \
--numjobs=4 --runtime=60 --group_reporting
Orientaciones para VPS NVMe:
- IOPS de lectura aleatoria: 20,000+
- IOPS de escritura aleatoria: 10,000+
- Lectura secuencial: 500+ MB/s
- Escritura secuencial: 300+ MB/s
Si los indicadores son significativamente más bajos, o se utiliza SATA/HDD, o hay una fuerte sobreventa de almacenamiento, o el almacenamiento en red está bajo carga.
ZFS y otros sistemas de archivos
Algunos proveedores utilizan sistemas de archivos avanzados a nivel de host:
ZFS:
- Compresión incorporada (ahorra espacio, puede mejorar el IO)
- Snapshots y clones (copias de seguridad rápidas)
- Protección contra la corrupción de datos (checksums)
- Requiere mucha RAM en el host
Btrfs:
- Copy-on-write, snapshots
- RAID incorporado
- Menos maduro que ZFS
Para ti como cliente, esto suele ser transparente, pero si el proveedor menciona ZFS, es más bien una ventaja.
Desgaste de SSD y TRIM
Los SSD tienen un número limitado de ciclos de escritura. En un hosting compartido, la escritura intensiva de un cliente puede acelerar el desgaste del disco.
Qué significa esto:
- Los proveedores de calidad utilizan SSD de grado empresarial (mayor número de ciclos)
- TRIM debe estar habilitado para mantener el rendimiento
- Los proveedores económicos pueden usar SSD de consumo con menor vida útil
Cómo verificar la compatibilidad con TRIM:
# En Linux (si el disco se ve como /dev/vda o /dev/sda)
lsblk --discard
# Valores no nulos en DISC-GRAN y DISC-MAX significan compatibilidad con TRIM
# Ejecutar TRIM manualmente (requiere root)
fstrim -v /
Red: ancho de banda, protección DDoS, peering
Las características de red de un VPS a menudo se ignoran al elegir, aunque para muchas tareas son más críticas que la CPU o la RAM.
Ancho de banda: lo que venden y lo que obtienes
Velocidad de puerto vs Ancho de banda
- Velocidad de puerto — velocidad física del puerto (1Gbps, 10Gbps)
- Ancho de banda — volumen de tráfico por mes (1TB, 5TB, ilimitado)
- Ráfaga (Burst) — superación temporal del límite de velocidad
Modelos típicos:
- 1Gbps compartido, 1TB/mes — estándar para VPS económicos
- 1Gbps sin medidor (unmetered) — sin límite de tráfico, pero la velocidad es compartida
- Puerto de 10Gbps, 10TB/mes — para proyectos de alto ancho de banda
Qué significa "sin medidor" (unmetered)
Sin medidor ≠ ilimitado. El proveedor siempre tiene una política de uso justo:
- Límite en la velocidad media durante un período
- Restricción en el uso pico
- Prohibición de ciertos tipos de tráfico (P2P, streaming)
¡Lee la PUA! "1Gbps sin medidor" puede significar "hasta 1Gbps, si el puerto no está ocupado por otros clientes, y no más de 50TB/mes".
Ancho de banda compartido vs dedicado
Compartido (sobreventa):
- Varios VPS comparten un único enlace ascendente (uplink)
- En el pico, los 10 clientes quieren 1Gbps, y el uplink también es de 1Gbps
- Resultado: cada uno obtiene ~100Mbps
Dedicado:
- Ancho de banda garantizado para tu VM
- Más caro, pero predecible
- Generalmente disponible en servidores dedicados o VPS premium
Protección DDoS
Los ataques DDoS son una realidad del internet moderno. Incluso un sitio pequeño puede ser víctima.
Tipos de protección:
Null-routing:
- En caso de ataque, todo el tráfico a la IP se bloquea
- El sitio no está disponible, pero otros clientes están protegidos
- Gratuito, pero inútil para ti
Mitigación de Capa 3/4:
- Filtrado de ataques volumétricos (SYN flood, UDP flood)
- Funciona a nivel de red
- Estándar para proveedores decentes
Mitigación de Capa 7:
- Filtrado de ataques a nivel de aplicación (HTTP flood, slowloris)
- Requiere análisis de tráfico
- Generalmente una opción de pago o a través de CDN (Cloudflare, etc.)
Qué buscar:
- Volumen de protección (Gbps/Tbps)
- Tiempo de reacción al ataque
- Si la protección está incluida en la tarifa o es un extra
- Si hay protección de Capa 7
Peering y conectividad
La calidad de la red se determina no solo por la velocidad del puerto, sino también por el enrutamiento del tráfico.
Factores de calidad:
- Número de puntos de peering — cuantos más, más cortas las rutas
- Tránsito Tier-1 — conexión a grandes proveedores troncales
- Peering local — conexiones directas con ISP locales
- IX (Internet Exchange) — participación en puntos de intercambio de tráfico
Cómo verificar:
# Traceroute a tus usuarios
traceroute -n target.com
mtr -n target.com
# Información sobre el ASN del proveedor
# A través de bgp.he.net o bgpview.io
whois AS12345
# Prueba de velocidad a diferentes regiones
iperf3 -c iperf.server.com
Pruebas de rendimiento de red
# Instalar speedtest-cli
apt install speedtest-cli
speedtest-cli
# O a través de curl (estimación aproximada)
curl -o /dev/null -w "%{speed_download}\n" \
http://speedtest.tele2.net/100MB.zip
# iperf3 para mediciones precisas
# En el servidor remoto:
iperf3 -s
# En el VPS:
iperf3 -c remote.server.ip -t 30
# Prueba de latencia
ping -c 100 target.com | tail -1
# Muestra min/avg/max/mdev
BGP y enrutamiento
Para usuarios avanzados: la calidad de la red se determina no solo por la velocidad del puerto, sino también por el enrutamiento del tráfico a través de Internet.
Qué es BGP:
BGP (Border Gateway Protocol) — protocolo que define cómo el tráfico se mueve entre redes. Los proveedores con buena conectividad BGP tienen rutas cortas a la mayoría de los destinos.
Qué buscar:
- Número de proveedores upstream: más = mejor redundancia y elección de rutas
- Conectividad Tier-1: conexiones directas con las principales troncales
- Participación en IX: Internet Exchange Points para peering local
- Looking glass: herramienta para ver las rutas BGP del proveedor
Cómo verificar:
- bgp.he.net — información sobre ASN, peerings, upstream
- Looking glass del proveedor (si lo hay)
- traceroute/mtr a puntos clave
Cuando esto es importante:
- Servicios globales con usuarios en todo el mundo
- Servidores de juegos (la latencia es crítica)
- VoIP y videoconferencias
- Aplicaciones financieras
Para la mayoría de los proyectos web, es suficiente verificar la latencia a las regiones principales mediante ping/mtr.
Direcciones IP, ASN y reputación
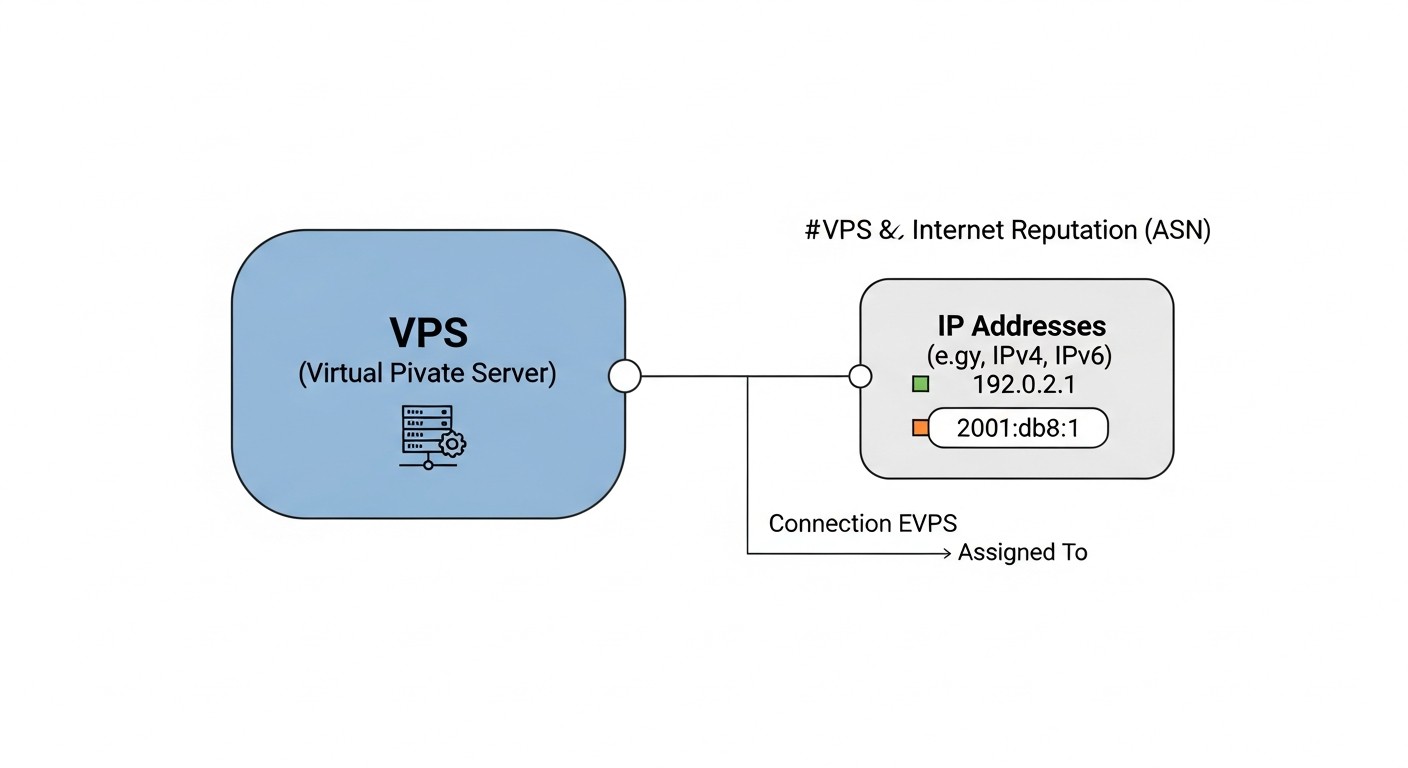
La dirección IP de tu VPS es su "pasaporte" en internet. La reputación de la IP afecta la entregabilidad del correo electrónico, el acceso a la API e incluso la indexación por parte de los motores de búsqueda.
Por qué la reputación de la IP es importante
- Correo electrónico: los correos de una IP "sucia" terminan en spam o son rechazados
- API: muchos servicios bloquean IP de rangos "malos"
- CDN: Cloudflare y otros pueden requerir CAPTCHA para el tráfico de IP sospechosas
- SEO: los motores de búsqueda consideran la reputación de la IP al evaluar un sitio
De dónde vienen los problemas
- Propietarios anteriores: la IP fue utilizada para spam, escaneo, botnets
- Vecinos de subred: todo el bloque /24 o /16 terminó en una lista de bloqueo debido a otros clientes
- ASN del proveedor: la reputación de todo el sistema autónomo es baja
- Región: algunos países y centros de datos tienen mala reputación por defecto
Cómo verificar la reputación de una IP
Antes de comprar:
- Solicita una IP de prueba al proveedor
- Algunos proveedores ofrecen una IP de prueba o un período de prueba
Servicios para verificar:
- MXToolbox: mxtoolbox.com/blacklists.aspx
- Spamhaus: check.spamhaus.org
- AbuseIPDB: abuseipdb.com
- VirusTotal: virustotal.com
- IPQualityScore: ipqualityscore.com
- Talos Intelligence: talosintelligence.com/reputation_center
# Verificación en las principales listas de bloqueo a través de DNS
# Spamhaus ZEN
dig +short $(echo YOUR_IP | awk -F. '{print $4"."$3"."$2"."$1}').zen.spamhaus.org
# Si devuelve una IP (127.0.0.x) — está en la lista
# Si NXDOMAIN — está limpia
ASN y su influencia
ASN (Autonomous System Number) — identificador de la red del proveedor. La reputación del ASN afecta a todas las IP en sus rangos.
Categorías de ASN problemáticas:
- Hostings "a prueba de balas" (toleran el abuso)
- Proveedores offshore baratos
- Centros de datos en países con alto nivel de ciberdelincuencia
Cómo verificar el ASN:
# Conocer el ASN de tu IP
whois YOUR_IP | grep -i origin
# Información sobre el ASN
# En bgp.he.net:
# https://bgp.he.net/ASXXXXX
# A través de la línea de comandos
whois -h whois.radb.net AS12345
Qué hacer con una mala reputación
- Solicitar un cambio de IP — la mayoría de los proveedores permiten cambiarla
- Eliminación de la lista (Delisting): para correo electrónico — solicitar la eliminación de la lista de bloqueo (largo, no siempre exitoso)
- Usar un relay: para correo electrónico — enviar a través de un servicio como SendGrid, Mailgun
- Cambiar de proveedor: si el problema es sistémico (ASN malo)
Geografía y latencia

La ubicación física del servidor influye directamente en la experiencia del usuario. La velocidad de la luz es una limitación estricta que no se puede eludir con código.
Latencia: por qué es importante
Orientaciones aproximadas (tiempo de ida y vuelta):
- Dentro de la región (Moscú-Moscú): 1-5ms
- Entre ciudades (Moscú-San Petersburgo): 10-20ms
- Entre países (Moscú-Fráncfort): 30-50ms
- Entre continentes (Moscú-Nueva York): 100-150ms
- A través del océano (Europa-Asia): 150-300ms
Impacto en las aplicaciones:
- Cada solicitud HTTP incluye al menos 1 RTT (a menudo 2-3)
- Una página con 50 recursos × 100ms RTT = ralentización notable
- Las API con solicitudes secuenciales se degradan linealmente
- Las aplicaciones en tiempo real (chats, juegos) requieren <50ms
Cómo elegir la ubicación
La regla es simple: el servidor debe estar cerca de los usuarios.
Escenarios típicos:
- Audiencia rusa: Moscú, San Petersburgo, Fráncfort (buen peering con RU)
- Audiencia europea: Fráncfort, Ámsterdam, Londres, París
- EE. UU.: Ashburn (Virginia), Chicago, Los Ángeles
- Asia: Singapur, Tokio, Hong Kong
- Audiencia global: CDN + varios puntos de presencia
Verificación de latencia antes de la compra
Muchos proveedores ofrecen looking glass o IP de prueba:
# Ping a la IP de prueba del proveedor
ping -c 100 test.ip.provider.com
# MTR para análisis de ruta
mtr -r -c 100 test.ip.provider.com
# Verificar dónde se encuentra la IP
curl ipinfo.io/YOUR_TEST_IP
Aspectos legales
La geografía influye en la jurisdicción:
- UE: el GDPR es obligatorio para los datos de los europeos
- EE. UU.: CLOUD Act — posible acceso de las autoridades
- Offshore (BVI, Panamá): menos regulación, pero peor reputación
- Rusia: requisitos de localización de datos (Ley Federal 152)
Consejos para la elección
- Determina dónde se encuentra la mayoría de tus usuarios 2. Prueba la latencia desde los puntos de presencia de los usuarios 3. Considera los requisitos legales 4. Para proyectos globales, el CDN es obligatorio; el servidor puede estar en cualquier lugar
SLA: lo que está escrito vs lo que funciona
SLA (Service Level Agreement) — una promesa formal del proveedor sobre la disponibilidad. Pero entre el 99.9% en papel y el 99.9% en la realidad, hay un abismo.
Qué significan los números
| SLA | Tiempo de inactividad/año | Tiempo de inactividad/mes | Realidad |
|---|---|---|---|
| 99% | 3.65 días | 7.3 horas | Inaceptable para producción |
| 99.9% | 8.76 horas | 43 minutos | Estándar para la mayoría |
| 99.95% | 4.38 horas | 22 minutos | Nivel empresarial |
| 99.99% | 52 minutos | 4.3 minutos | Requiere redundancia |
Qué NO suele incluirse en el SLA
- Trabajos planificados: las ventanas de mantenimiento no se consideran tiempo de inactividad
- Ataques DDoS: a menudo excluidos o con salvedades
- Problemas del cliente: OOM, kernel panic por tu culpa
- Problemas de red fuera del centro de datos: proveedores troncales
- Fuerza mayor: incendios, inundaciones, cortes de electricidad
Compensaciones
Compensación típica: crédito para futuros servicios.
Ejemplo:
- <99.9% → 10% de crédito
- <99.5% → 25% de crédito
- <99% → 50% de crédito
Realidad: un crédito por un VPS de $5 después de 2 horas de inactividad es $0.50. Tus pérdidas por la indisponibilidad del servicio son incomparablemente mayores.
Qué buscar
- Cómo se mide el tiempo de inactividad: monitoreo interno del proveedor vs. externo
- Procedimiento de reclamación: ¿es necesario informar tú mismo sobre el tiempo de inactividad?
- Excepciones: lee la letra pequeña
- Historial de incidentes: página de estado, foros, Reddit
- Reacción a los incidentes: con qué rapidez responden, cómo se comunican
Enfoque práctico
El SLA es una base, no una garantía. Construye una arquitectura que sobreviva al tiempo de inactividad del proveedor:
- Copias de seguridad regulares en otro lugar
- Disposición para desplegar el servicio en otro proveedor
- Monitoreo desde puntos externos
- CDN para el almacenamiento en caché de contenido estático
Evaluación de la calidad del soporte
La calidad del soporte técnico es crítica. Los problemas ocurren, y la velocidad de reacción es muy importante.
Antes de comprar:
- Busca opiniones sobre el soporte (no sobre el servicio en general)
- Haz una pregunta de preventa y evalúa el tiempo y la calidad de la respuesta
- Verifica la existencia de una página de estado con el historial de incidentes
Canales de soporte (de mejor a peor):
- Chat en vivo con especialistas técnicos — rápido y eficiente
- Teléfono — para preguntas urgentes, pero no todos los proveedores lo ofrecen
- Sistema de tickets — estándar, el tiempo de respuesta varía de minutos a días
- Correo electrónico — generalmente más lento que los tickets
- Solo foro/base de conocimientos — soporte mínimo, resuelves los problemas tú mismo
Señales de alerta en el soporte:
- Respuestas genéricas que no se relacionan con la pregunta
- Tiempo de respuesta superior a 24 horas para preguntas sencillas
- Falta de competencia técnica (recomiendan reiniciar ante cualquier pregunta)
- Venta agresiva en lugar de resolver el problema
- No hay escalada para problemas complejos
Prueba de soporte:
Después de la compra, abre un ticket con una pregunta técnica de dificultad media (no "cómo cambiar la contraseña", pero tampoco "ayúdame a configurar un clúster"). Evalúa el tiempo de respuesta, la comprensión de la pregunta y la calidad de la solución. Esto te mostrará qué esperar ante problemas reales.
Tablas comparativas
VPS vs Dedicado vs Nube
| Criterio | VPS | Dedicado | Nube (AWS/GCP/Azure) |
|---|---|---|---|
| Costo (básico) | $5-50/mes | $50-500/mes | $20-200/mes |
| Aprovisionamiento | Minutos | Horas-días | Segundos-minutos |
| Aislamiento | Virtual | Físico | Virtual |
| Escalado | Vertical | Limitado | Autoescalado |
| Previsibilidad del precio | Alta | Alta | Baja |
| Rendimiento | Variable | Estable | Variable |
| Personalización de hardware | No | Sí | Limitada |
| Servicios gestionados | Mínimo | Mínimo | Abundantes |
KVM vs OpenVZ vs LXC
| Criterio | KVM | OpenVZ 7 | LXC/LXD |
|---|---|---|---|
| Tipo de virtualización | Completa | Contenedores | Contenedores |
| Aislamiento | Alto | Medio | Medio-alto |
| Soporte de SO | Cualquiera | Solo Linux | Solo Linux |
| Kernel personalizado | Sí | No | No |
| Docker | Completo | Limitado | Sí |
| Sobrecarga | 2-5% | <1% | <1% |
| Precio típico | $5-10+ | $2-5 | $3-8 |
| Listo para producción | Sí | Condicionalmente | Sí |
Gestionado vs No gestionado
| Criterio | No gestionado | Gestionado |
|---|---|---|
| Instalación de SO | Tú | Proveedor |
| Actualizaciones de seguridad | Tú | Proveedor |
| Monitoreo | Tú | Proveedor |
| Copias de seguridad | Tú | A menudo incluidas |
| Soporte técnico | Solo infraestructura | Infraestructura + software |
| Precio | Más bajo | Más alto 2-5x |
| Para quién | DevOps, sysadmins | Sin tiempo para operaciones |
Escenarios de uso prácticos
Escenario 1: SaaS MVP
Contexto: Una startup lanza un MVP de un producto SaaS. El presupuesto es limitado, el equipo es de 2-3 desarrolladores, la carga esperada es de varios cientos de usuarios activos.
Requisitos:
- Aplicación web en Node.js/Python/Ruby
- Base de datos PostgreSQL
- Redis para sesiones y caché
- Workers en segundo plano
- SSL, archivos estáticos a través de CDN
Configuración recomendada:
- VPS: KVM, 4 vCPU, 8GB RAM, 100GB NVMe
- Ubicación: más cerca de la audiencia objetivo
- Presupuesto: $20-50/mes
Arquitectura:
# Todo en un solo servidor (despliegue monolítico)
├── nginx (proxy inverso, terminación SSL)
├── app (Node.js/Python/Ruby)
├── PostgreSQL
├── Redis
└── background workers (Sidekiq/Celery)
# Docker Compose para la gestión
docker-compose up -d
Qué evitar:
- Separación prematura en microservicios
- Kubernetes en un solo servidor (la sobrecarga no se justifica)
- Base de datos gestionada por $50+/mes cuando el tráfico es mínimo
Escenario 2: API de alta carga
Contexto: Un servicio API procesa más de 10 millones de solicitudes al día. La latencia y la estabilidad son críticas.
Requisitos:
- Tiempo de respuesta inferior a 100 ms (p99)
- Procesamiento constante de más de 500 RPS, picos de hasta 2000 RPS
- Alta disponibilidad
- Capacidad de escalado
Configuración recomendada (opción 1 — VPS):
- Servidores de aplicaciones: 2-4 × KVM, 8 vCPU, 16GB RAM, NVMe
- Base de datos: Servidor dedicado o base de datos gestionada
- Balanceador de carga: HAProxy/nginx en una VM separada o LB gestionado
- Presupuesto: $200-500/mes
Configuración recomendada (opción 2 — Híbrida):
- Aplicación: Nube (autoescalado)
- Base de datos: Servidor dedicado con RAID NVMe
- Caché: Redis gestionado o clúster autoalojado
Arquitectura:
┌─────────────────┐
│ Load Balancer │
└────────┬────────┘
│
┌───────────────────┼───────────────────┐
▼ ▼ ▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ App Server 1 │ │ App Server 2 │ │ App Server N │
└────────┬────────┘ └────────┬────────┘ └────────┬────────┘
│ │ │
└───────────────────┴───────────────────┘
│
┌───────────────────┴───────────────────┐
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ Redis Cluster │ │ PostgreSQL (HA)│
└─────────────────┘ └─────────────────┘
Métricas clave para el monitoreo:
- Latencia de solicitud (p50, p95, p99)
- Tasa de errores
- Tiempo de robo de CPU en cada nodo
- Conexiones de base de datos y tiempo de consulta
- Presión de memoria
Escenario 3: Nodos de escáner / rastreador / worker
Contexto: Sistema para escanear recursos web, analizar datos o procesamiento en segundo plano. Se necesitan muchas conexiones salientes.
Requisitos:
- Mucho tráfico saliente
- Múltiples conexiones simultáneas
- Resistencia a bloqueos
- Costo mínimo por unidad de trabajo
Riesgos específicos:
- Las IP pueden terminar en listas negras
- El proveedor puede considerar la actividad como abuso
- Limitación de velocidad en los recursos objetivo
Enfoque recomendado:
- Muchos VPS pequeños: 5-10 × 1 vCPU, 1GB RAM en lugar de uno grande
- Diferentes proveedores/ASN: reduce el riesgo de bloqueo simultáneo
- Rotación de proxies: proxies residenciales o de centro de datos
- Presupuesto: $5-10 × número de nodos
Arquitectura:
┌─────────────────┐
│ Control Plane │ (coordinación, colas)
│ (1 VPS) │
└────────┬────────┘
│
│ Redis/RabbitMQ
│
┌────────┴────────┐
│ │
▼ ▼
┌─────────┐ ┌─────────┐ ┌─────────┐
│ Worker 1│ │ Worker 2│ │ Worker N│ (diferentes proveedores/regiones)
│(VPS #1) │ │(VPS #2) │ │(VPS #N) │
└─────────┘ └─────────┘ └─────────┘
Importante: lee atentamente la PUA del proveedor. Muchos prohíben el escaneo/scraping en cualquier forma.
Escenario 4: Tienda de comercio electrónico
Contexto: Tienda en línea con WooCommerce/Magento/OpenCart con un catálogo de más de 5000 productos y un tráfico de 1000-5000 visitantes al día.
Requisitos:
- Funcionamiento estable bajo carga constante
- Carga rápida de páginas de productos
- Procesamiento de pagos (la seguridad es crítica)
- Picos de carga durante las ventas flash
- SSL obligatorio
Configuración recomendada:
- VPS: 4 vCPU, 8GB RAM, 100GB NVMe
- Pila: nginx + PHP-FPM + MySQL/MariaDB + Redis
- CDN: Cloudflare para estáticos y protección
- Presupuesto: $30-60/mes para VPS + CDN (el plan gratuito es suficiente)
Optimizaciones críticas:
- OPcache para PHP
- Redis para sesiones y caché de objetos
- Optimización de imágenes
- Indexación de bases de datos
- Carga diferida (Lazy loading) para el catálogo
Para ventas flash:
- Actualización temporal del VPS (si el proveedor lo permite)
- O conexión de un servidor adicional con balanceo de carga
- Caché agresivo para páginas de categorías
Escenario 5: Bot de Telegram/Discord
Contexto: Bot para mensajería con una base de hasta 10K usuarios activos.
Requisitos:
- Funcionamiento 24/7 sin interrupciones
- Respuesta rápida a los comandos
- Almacenamiento de datos de usuario
- Presupuesto mínimo
Configuración recomendada:
- VPS: 1 vCPU, 1GB RAM, 20GB SSD
- Pila: Python/Node.js + SQLite o PostgreSQL
- Presupuesto: $5-10/mes
Características:
- Los bots suelen ser ligeros, no requieren muchos recursos
- La estabilidad es importante, no el rendimiento
- Systemd para el inicio automático y el reinicio en caso de fallos
- Monitoreo básico (verificación de procesos)
# /etc/systemd/system/mybot.service
[Unit]
Description=Telegram Bot
After=network.target
[Service]
Type=simple
User=botuser
WorkingDirectory=/home/botuser/bot
ExecStart=/usr/bin/python3 bot.py
Restart=always
RestartSec=10
[Install]
WantedBy=multi-user.target
Escenario 6: CI/CD Runner
Contexto: Runner autoalojado para GitHub Actions/GitLab CI para ahorrar en minutos de pago.
Requisitos:
- Construcción rápida de proyectos
- Docker para compilaciones en contenedores
- Suficiente espacio para la caché
- Aislamiento entre compilaciones
Configuración recomendada:
- VPS: 4+ vCPU, 8GB+ RAM, 100GB+ NVMe (para caché)
- Obligatorio: virtualización KVM (Docker lo requiere)
- Presupuesto: $20-50/mes
Cálculo de rentabilidad:
GitHub Actions cuesta $0.008/minuto para runners de Linux. Un VPS por $30/mes se amortiza con más de 3750 minutos/mes (62 horas) de uso. Si compilas a menudo, el autoalojado es más rentable.
Configuración:
# Instalar Docker
curl -fsSL https://get.docker.com | sh
usermod -aG docker gitlab-runner
# Instalar GitLab Runner
curl -L https://packages.gitlab.com/install/repositories/runner/gitlab-runner/script.deb.sh | bash
apt install gitlab-runner
# Registrar runner
gitlab-runner register
Comandos para probar el servidor
Después de obtener acceso al VPS, lo primero es probarlo. Aquí tienes un conjunto de comandos para una verificación exhaustiva.
Información básica del sistema
# Información de la CPU
lscpu
# Modelo de procesador
cat /proc/cpuinfo | grep "model name" | head -1
# Cantidad de memoria
free -h
# Información de los discos
lsblk
df -h
# Tipo de virtualización
systemd-detect-virt
# Versión del kernel
uname -r
# Información del SO
cat /etc/os-release
Benchmark de CPU
# Instalar sysbench
apt install sysbench
# Prueba de CPU (un solo hilo)
sysbench cpu --cpu-max-prime=20000 run
# Prueba de CPU (múltiples hilos, todos los núcleos)
sysbench cpu --cpu-max-prime=20000 --threads=$(nproc) run
# Verificación del tiempo de robo bajo carga
# En una terminal:
sysbench cpu --cpu-max-prime=50000 --threads=$(nproc) --time=60 run
# En otra:
vmstat 1
# Busca la columna st
Orientaciones (eventos por segundo, un solo hilo):
- Xeon/EPYC moderno: 1500-2500
- Xeon antiguo (E5 v2): 800-1200
- Si es significativamente menor, o es hardware antiguo o hay una fuerte sobreventa
Benchmark de Memoria
# Prueba de memoria (sysbench)
sysbench memory --memory-block-size=1K --memory-total-size=10G run
sysbench memory --memory-block-size=1M --memory-total-size=10G run
# O a través de dd (estimación aproximada)
dd if=/dev/zero of=/dev/null bs=1M count=10000
Benchmark de E/S de Disco
# Instalar fio
apt install fio
# Prueba rápida (creará el archivo test.fio)
# Lectura aleatoria (típica para DB)
fio --name=randread --ioengine=libaio --iodepth=16 \
--rw=randread --bs=4k --direct=1 --size=256M \
--numjobs=4 --runtime=30 --group_reporting --filename=test.fio
# Escritura aleatoria
fio --name=randwrite --ioengine=libaio --iodepth=16 \
--rw=randwrite --bs=4k --direct=1 --size=256M \
--numjobs=4 --runtime=30 --group_reporting --filename=test.fio
# Lectura secuencial (rendimiento)
fio --name=seqread --ioengine=libaio --iodepth=16 \
--rw=read --bs=1M --direct=1 --size=1G \
--numjobs=1 --runtime=30 --group_reporting --filename=test.fio
# Eliminar el archivo de prueba
rm test.fio
# Prueba simple con dd
# Escritura
dd if=/dev/zero of=testfile bs=1M count=1024 conv=fdatasync
# Lectura
dd if=testfile of=/dev/null bs=1M
rm testfile
Benchmark de Red
# Speedtest
apt install speedtest-cli
speedtest-cli
# O a través de curl
# Velocidad de descarga
curl -o /dev/null http://speedtest.tele2.net/1GB.zip
# Latencia a puntos clave
ping -c 20 8.8.8.8
ping -c 20 1.1.1.1
# MTR para análisis de rutas
apt install mtr
mtr -r -c 100 google.com
# iperf3 (si hay un segundo servidor)
# En el servidor: iperf3 -s
# En el VPS: iperf3 -c server.ip -t 30
Script de verificación completo
#!/bin/bash
# vps-benchmark.sh
echo "=== Información del Sistema ==="
echo "CPU: $(grep "model name" /proc/cpuinfo | head -1 | cut -d: -f2)"
echo "Núcleos: $(nproc)"
echo "RAM: $(free -h | grep Mem | awk '{print $2}')"
echo "Disco: $(df -h / | tail -1 | awk '{print $2}')"
echo "Virtualización: $(systemd-detect-virt)"
echo "Kernel: $(uname -r)"
echo ""
echo "=== Tiempo de Robo de CPU (10 seg) ==="
vmstat 1 10 | tail -9 | awk '{sum+=$16} END {print "Robo promedio: " sum/9 "%"}'
echo ""
echo "=== Prueba Rápida de Disco ==="
dd if=/dev/zero of=testfile bs=1M count=256 conv=fdatasync 2>&1 | tail -1
rm testfile
echo ""
echo "=== Memoria ==="
free -h
echo ""
echo "=== Latencia de Red ==="
ping -c 10 8.8.8.8 | tail -1
Diagnóstico de problemas típicos
Problema: "El VPS está lento"
La queja más frecuente. Las causas pueden ser una docena.
Paso 1: Identificar qué es lo que está lento
# Panorama general
top
htop
# Carga promedio (Load average)
uptime
# Si la carga > número de CPU — el sistema está sobrecargado
# Qué está ocupando la CPU
ps aux --sort=-%cpu | head -10
# Qué está ocupando la memoria
ps aux --sort=-%mem | head -10
Paso 2: Verificar el tiempo de robo de CPU (CPU steal time)
vmstat 1 10
# Columna st > 10% — problema del proveedor
Paso 3: Verificar el IO
iostat -x 1 10
# %util cerca del 100% — el disco está sobrecargado
# await > 10ms en SSD — problema
# Qué proceso está cargando el disco
iotop
Paso 4: Verificar la memoria
free -h
# Si available está cerca de 0 y el swap se usa activamente — OOM pronto
dmesg | grep -i oom
# Si hay entradas — OOM killer funcionó
Posibles soluciones:
- Alto steal → queja al proveedor o cambio de plan/proveedor
- Alto IO → optimización de la aplicación, adición de RAM para caché, actualización a NVMe
- Alta CPU → perfilado de código, escalado
- Alta memoria → optimización, aumento de RAM
Problema: "El disco es lento"
Diagnóstico:
# Carga actual del disco
iostat -x 1
# IOPS y latencia
# await — tiempo de respuesta promedio
# r_await, w_await — lectura/escritura por separado
# Si await es alto:
# - En SSD > 5ms — problema
# - En HDD > 20ms — esperado bajo carga
# Verificar quién está cargando
iotop -o
# Prueba de rendimiento
fio --name=test --rw=randread --bs=4k --direct=1 \
--size=256M --numjobs=4 --runtime=30 --group_reporting
Causas frecuentes:
- Almacenamiento en red bajo carga
- Vecinos del host cargando el almacenamiento compartido
- HDD en lugar de SSD declarado
- La aplicación realiza IO excesivo (registro, sincronización)
Problema: "Pérdida de paquetes" (Packet loss)
Diagnóstico:
# Prueba básica
ping -c 100 8.8.8.8
# Busca % de pérdida de paquetes y mdev (jitter)
# Análisis detallado de la ruta
mtr -r -c 100 problem-host.com
# Busca Loss% en cada salto
# Traceroute
traceroute -n problem-host.com
Interpretación de MTR:
- La pérdida en saltos intermedios puede ser normal (limitación de velocidad de ICMP)
- La pérdida en el host final es un problema real
- La pérdida comienza en un salto específico y continúa — problema en esa sección
Acciones:
- Pérdida dentro de la red del proveedor → ticket de soporte
- Pérdida en las troncales → poco puedes hacer, prueba Cloudflare/CDN
- Pérdida solo a destinos específicos → problema en su lado
Problema: "El servidor fue bloqueado"
Apagado repentino del servidor sin previo aviso.
Causas frecuentes:
- Reporte de abuso (queja por spam, escaneo, ataques)
- Violación de la PUA (contenido, servicios prohibidos)
- Falta de pago
- Servidor comprometido (parte de una botnet)
Qué hacer:
- Revisar el correo electrónico — generalmente llega una notificación
- Acceder al panel de control — puede haber información allí
- Abrir un ticket de soporte
- No entrar en pánico — a menudo se puede restaurar el acceso después de las explicaciones
Prevención:
- Actualizar el software (evitar compromisos)
- No ejecutar nada que pueda generar reportes de abuso
- Leer y cumplir la PUA
- Mantener copias de seguridad en otro lugar
Seguridad, abuso y cumplimiento
Comprender las reglas del juego es fundamental. El proveedor puede desactivar el servidor por infracciones, y formalmente tendrá razón.
Política de Uso Aceptable (PUA)
La PUA es un documento que define lo que se puede y no se puede hacer en el servidor.
Típicamente prohibido en todas partes:
- Distribución de malware
- Ataques DDoS
- Spam
- Alojamiento de contenido ilegal (CP, terrorismo)
- Violación de derechos de autor (piratería)
A menudo prohibido:
- Escaneo de puertos (incluso "inofensivo")
- Rastreadores de torrents / seedboxes
- Minería de criptomonedas
- Envío masivo de correos (incluso opt-in)
- Resolvers abiertos / relays abiertos
- Contenido para adultos (en algunos proveedores)
Zona gris:
- Web scraping / crawling
- VPN / proxy para terceros
- Nodos de salida de Tor
- IRC bouncers
Reportes de Abuso
Un reporte de abuso es una queja sobre la actividad de tu IP.
Cómo llegan:
- Automáticamente (fail2ban, detección de DDoS)
- De otros proveedores
- De titulares de derechos de autor (DMCA)
- De usuarios (spam, ataques)
Qué sucede:
- El proveedor recibe la queja
- Te la reenvía con la demanda de respuesta
- Debes explicar y eliminar la causa
- Si se ignora o hay violaciones repetidas — desconexión
Cómo reaccionar:
- Responder rápidamente (24-48 horas)
- Investigar la causa real
- Eliminarla e informar sobre las medidas tomadas
- Si la queja es falsa — explicar con pruebas
DMCA
DMCA (Digital Millennium Copyright Act) — ley de derechos de autor estadounidense, pero se aplica globalmente a través de los proveedores de hosting.
Proceso típico:
- El titular de los derechos de autor encuentra una infracción
- Envía una notificación DMCA al proveedor
- El proveedor está obligado a eliminar el contenido o reenviártelo
- Puedes presentar una contra-notificación si consideras que la queja es infundada
Práctica:
- La mayoría de los proveedores eliminan el contenido sin investigar
- DMCA repetidos → desactivación de la cuenta
- Los hostings offshore a menudo ignoran el DMCA (pero tienen otros problemas)
Cumplimiento (GDPR, etc.)
GDPR (UE):
- Si procesas datos de ciudadanos de la UE, el GDPR es obligatorio
- El hosting en la UE simplifica el cumplimiento, pero no lo garantiza
- Se necesita un DPA (Acuerdo de Procesamiento de Datos) con el proveedor
Requisitos de localización (Rusia, China, etc.):
- Algunos países exigen almacenar los datos de los ciudadanos dentro del país
- Verifica la aplicabilidad a tu servicio
Recomendaciones de seguridad para VPS
# Configuración básica después de obtener el servidor
# 1. Actualizar el sistema
apt update && apt upgrade -y
# 2. Crear un usuario no root
adduser myuser
usermod -aG sudo myuser
# 3. Configurar SSH
# En /etc/ssh/sshd_config:
# PermitRootLogin no
# PasswordAuthentication no
# Port 2222 (opcional, cambiar puerto)
# 4. Configurar el firewall
ufw default deny incoming
ufw default allow outgoing
ufw allow 2222/tcp # SSH
ufw allow 80/tcp
ufw allow 443/tcp
ufw enable
# 5. Instalar fail2ban
apt install fail2ban
systemctl enable fail2ban
# 6. Configurar actualizaciones de seguridad automáticas
apt install unattended-upgrades
dpkg-reconfigure -plow unattended-upgrades
Medidas de seguridad avanzadas
La configuración básica es el mínimo. Para servidores de producción se recomiendan medidas adicionales.
Reforzamiento de SSH:
# /etc/ssh/sshd_config configuraciones adicionales
MaxAuthTries 3
ClientAliveInterval 300
ClientAliveCountMax 2
AllowUsers myuser
Protocol 2
Monitoreo de cambios de archivos:
# Instalar AIDE (Advanced Intrusion Detection Environment)
apt install aide
aideinit
# Verificación de cambios
aide --check
Límites de recursos:
# /etc/security/limits.conf
# Limitar el número de procesos para un usuario
* soft nproc 1000
* hard nproc 2000
Registro (Logging):
- Configura la recopilación centralizada de logs (rsyslog, Loki)
- Los logs deben almacenarse por separado del servidor (en caso de compromiso)
- Configura alertas para eventos sospechosos (inicios de sesión fallidos, uso de sudo)
Tareas regulares:
- Verificar semanalmente las actualizaciones de seguridad
- Revisar mensualmente los puertos y servicios abiertos
- Verificar periódicamente los logs en busca de anomalías
- Probar la recuperación a partir de las copias de seguridad
Qué cambió en 2024–2026
La industria del hosting no se detiene. Varias tendencias a tener en cuenta.
Crecimiento de la popularidad de ARM
Los servidores ARM (Ampere Altra, AWS Graviton) se están volviendo mainstream:
- Mejor relación rendimiento/vatio
- Más económicos para cargas de trabajo comparables
- La mayoría del software ya es compatible con ARM64
Consejo práctico: si tu pila es compatible con ARM, considera un VPS basado en ARM. A menudo es un 20-30% más barato con el mismo rendimiento.
NVMe se convirtió en estándar
Los SSD SATA en las nuevas ofertas son cada vez menos comunes. NVMe es el nuevo punto de referencia.
Qué significa esto: si un proveedor todavía vende "SSD VPS" sin especificar, probablemente sea SATA. Pregunta explícitamente.
Consolidación del mercado
Los grandes actores están comprando a los proveedores más pequeños. Esto no es ni bueno ni malo, pero afecta a:
- La calidad del soporte (puede empeorar)
- La política de precios
- La PUA y las condiciones de servicio
Aumento de los precios de la energía
La crisis energética de 2022-2023 provocó un aumento de los precios del hosting en Europa. La tendencia se mantiene parcialmente:
- Los hostings de la UE se encarecen
- Los centros de datos en regiones con energía barata (Escandinavia, EE. UU.) se vuelven más atractivos
Agotamiento de IPv4
Las direcciones IPv4 siguen encareciéndose:
- Muchos proveedores cobran un extra por IPv4 adicionales
- Algunos ofrecen NAT IPv4 + IPv6 público
- El hosting solo IPv6 se está convirtiendo en una realidad para algunos casos de uso
Consejo práctico: si tu servicio no requiere IPv4 (por ejemplo, un backend detrás de una CDN), el IPv6-only puede ahorrarte dinero.
Cargas de trabajo de IA/ML
La demanda de servidores GPU ha crecido exponencialmente:
- Escasez de capacidad
- Precios altos
- Aparición de proveedores especializados (Lambda Labs, Vast.ai, RunPod)
Nota: la información sobre precios y disponibilidad de GPU cambia rápidamente. Verifica la actualidad en el momento de la lectura.
Reforzamiento de la regulación
La presión regulatoria sobre la industria del hosting está creciendo:
- Refuerzo de los requisitos de KYC (Know Your Customer) — los VPS anónimos son cada vez más raros
- Responsabilidad de los proveedores por el contenido de los clientes
- Presión de sanciones — algunas regiones están restringidas
- Requisitos de localización de datos en diferentes países
Conclusión práctica: verifica de antemano si podrás pagar los servicios y si tu caso de uso estará permitido en la jurisdicción elegida.
La contenerización como estándar
Docker y los contenedores se han vuelto mainstream:
- La mayoría de las aplicaciones modernas se distribuyen como imágenes Docker
- El despliegue a través de docker-compose se ha convertido en el estándar para proyectos pequeños
- Esto hace que la virtualización KVM sea aún más preferible (Docker funciona correctamente solo en KVM)
Serverless y VPS
Serverless no mató a los VPS, sino que ocupó su propio nicho:
- Serverless es bueno para tareas esporádicas y basadas en eventos
- Los VPS siguen siendo preferibles para cargas de trabajo constantes
- Arquitecturas híbridas: núcleo en VPS + serverless para picos
Conclusiones
Elegir un proveedor de VPS es una decisión que afectará a tu proyecto durante meses o años. Algunas recomendaciones finales.
Qué hemos aprendido
- La virtualización importa. KVM es una elección sensata para producción. OpenVZ/LXC, solo para desarrollo o con restricciones presupuestarias estrictas.
- Las características en papel ≠ realidad. 4 vCPU con un 20% de tiempo de robo no son 4 vCPU. 100GB de SSD en un Ceph sobrecargado no es almacenamiento rápido.
- La reputación de la IP es crítica para el correo electrónico, las integraciones de API y mucho más. Verifícala antes de comprar.
- La geografía determina la latencia. Ninguna optimización de código compensará 200 ms hasta el servidor.
- El SLA es un mínimo, no una garantía. Construye una arquitectura que sobreviva al tiempo de inactividad del proveedor.
- Lee la PUA. Lo que te parece inofensivo puede estar prohibido.
Enfoque sensato para la elección
- Define los requisitos: CPU, RAM, tipo de almacenamiento, ancho de banda, latencia, tiempo de actividad
- Filtra por tipo de virtualización: KVM para producción
- Elige la geografía: cerca de los usuarios
- Verifica la reputación: IP, ASN, opiniones
- Prueba: utiliza una prueba o la tarifa más barata para las pruebas
- Escala gradualmente: empieza con poco, actualiza a medida que creces
Dónde se cometen más errores
- Eligen por precio, ignorando todo lo demás
- No prueban antes del despliegue en producción
- No leen la PUA y son bloqueados
- No hacen copias de seguridad en otro lugar
- Pagan de más por recursos que no se utilizan
- Pagan de menos y obtienen un servicio inestable
- Optimizan la infraestructura en lugar del código
- No monitorean y se enteran de los problemas por los usuarios
- Ignoran la seguridad hasta el primer hackeo
- No documentan las configuraciones y las olvidan al mes
Evolución típica de la infraestructura
La mayoría de los proyectos siguen un camino similar:
Etapa 1: Inicio
- Shared-hosting o el VPS más barato
- Todo en un solo servidor
- Configuración mínima
- ¿Copias de seguridad? ¿Qué copias de seguridad?
Etapa 2: Crecimiento
- Actualización a un VPS más potente
- Aparece el monitoreo
- Se configuran las copias de seguridad
- Optimización de la base de datos y caché
Etapa 3: Escalado
- Separación de la base de datos en un servidor aparte
- CDN para contenido estático
- Posiblemente, varios servidores de aplicaciones con balanceador de carga
- Monitoreo y alertas más serios
Etapa 4: Empresarial
- Despliegue multirregión
- Kubernetes o similar
- Servicios gestionados donde se justifique
- Equipos dedicados para operaciones
No saltes etapas. Kubernetes para un MVP con 100 usuarios es excesivo. Un solo VPS para un servicio con un millón de DAU es un problema. Crece junto con el proyecto.
Señales de un buen proveedor
A qué prestar atención al evaluar:
- Transparencia: características de hardware, tipo de virtualización, condiciones del SLA claramente indicadas
- Página de estado: un historial público de incidentes muestra la madurez de los procesos
- Documentación: KB y tutoriales de calidad
- Blog técnico: muestra la experiencia y la cultura de la empresa
- Soporte adecuado: respuestas técnicamente competentes en un tiempo razonable
- Precios estables: los "descuentos del 90%" frecuentes son una señal de problemas
- Antigüedad: los proveedores que llevan 5+ años suelen ser más fiables que los nuevos
- Comunidad: foros activos, Discord, Telegram — señal de un servicio vivo e interés en los clientes
Mentalidad al elegir la infraestructura
La infraestructura es un compromiso entre costo, rendimiento, fiabilidad y comodidad.
- Costo: ¿cuánto estás dispuesto a pagar?
- Rendimiento: ¿qué métricas son críticas?
- Fiabilidad: ¿qué pasaría en caso de tiempo de inactividad?
- Comodidad: ¿cuánto tiempo estás dispuesto a dedicar a las operaciones?
No existe una solución ideal. Existe una solución óptima para tu situación específica. Y puede cambiar a medida que el proyecto crece.
Lista de verificación final antes de elegir
Antes de tomar una decisión, respóndete a estas preguntas:
- ¿Qué tipo de proyecto es? ¿Sitio web, API, bot, servidor de juegos, algo específico?
- ¿Dónde están los usuarios? Esto determina la elección de la geografía.
- ¿Cuál es la carga? Actual y esperada en 6-12 meses.
- ¿Cuál es el presupuesto? Incluyendo los costos ocultos de administración.
- ¿Qué competencias tienes? ¿Lo gestionas tú mismo o necesitas un servicio gestionado?
- ¿Cuáles son los riesgos? ¿Qué pasaría en caso de tiempo de inactividad? ¿Pérdida de datos?
- ¿Qué requisitos de cumplimiento? GDPR, localización de datos, etc.
- ¿Qué margen necesitas? Para el crecimiento, para los picos, para fuerza mayor.
Con las respuestas a estas preguntas, la elección se vuelve mucho más sencilla y consciente. Podrás filtrar el 90% de las opciones de inmediato, y las restantes, probarlas en la práctica.
Preguntas frecuentes
¿Qué VPS es mejor para principiantes?
Un VPS basado en KVM con un panel de control gestionado (tipo SolusVM, Virtualizor) y soporte adecuado. No te dejes llevar por el precio: $5-10/mes por 2GB RAM, 2 vCPU, 40GB SSD es un buen comienzo para la mayoría de los proyectos.
¿En qué se diferencia un VPS de un VDS?
En términos de marketing. Técnicamente, ambos términos significan un servidor virtual. Algunos proveedores usan VDS para referirse a la virtualización KVM, y VPS para OpenVZ. Pero esto no es un estándar. Siempre aclara el tipo de virtualización.
¿Se puede ejecutar Docker en un VPS?
En KVM, sí, sin restricciones. En OpenVZ, con salvedades (depende de la versión y la configuración del host). En LXC, generalmente sí, pero verifica.
¿Cuánta RAM se necesita para un servidor web?
Depende de la pila y la carga. Mínimo para un funcionamiento cómodo: 1GB para un sitio simple, 2-4GB para una aplicación con base de datos, 4-8GB para un servicio con mucha carga. Es mejor empezar con menos y monitorear el uso.
¿Qué es la sobreventa (overselling) y cómo detectarla?
La sobreventa es la venta de más recursos de los que existen físicamente. Señales: alto tiempo de robo de CPU (>5%), rendimiento de IO impredecible, degradación bajo carga. Prueba en horas pico.
¿Cómo verificar la velocidad de un VPS?
CPU: sysbench cpu. Almacenamiento: fio o dd. Red: speedtest-cli, iperf3. Memoria: sysbench memory. No olvides verificar el tiempo de robo a través de vmstat.
¿Qué hacer si la IP está en una lista negra?
Solicitar un cambio de IP al proveedor. Si es un problema sistémico (todo el ASN está en la lista de bloqueo), considera cambiar de proveedor. Para el correo electrónico, utiliza servicios de retransmisión (SendGrid, Mailgun).
¿VPS o nube para una startup?
Para un MVP con carga predecible, un VPS es más económico y sencillo. Para un producto con crecimiento impredecible o que necesita servicios gestionados, la nube puede justificarse, a pesar de su mayor costo.
¿Con qué frecuencia se deben hacer copias de seguridad de un VPS?
Depende del RPO (Recovery Point Objective). Para la mayoría de los proyectos: copias de seguridad diarias de la base de datos, copias de seguridad completas semanales. Datos críticos, con mayor frecuencia. Guarda las copias de seguridad en otro lugar, no en el mismo proveedor.
¿Se puede confiar en el tráfico "ilimitado"?
No. Siempre hay una política de uso justo. Típicamente, "ilimitado" significa 10-50TB/mes con un uso promedio. Lee la PUA y los Términos de Servicio.
Paneles de control de VPS: qué elegir
El panel de control es la interfaz entre tú y el servidor. La elección depende de las tareas, el presupuesto y el nivel de preparación técnica.
Paneles del proveedor (de cliente)
La mayoría de los proveedores de VPS ofrecen su propio panel o soluciones estándar:
SolusVM
Panel clásico para hosting VPS, todavía muy utilizado.
- Gestión de VM: iniciar/detener/reiniciar/reinstalar
- Consola VNC/noVNC para acceso de emergencia
- Estadísticas de uso de recursos
- Gestión de imágenes ISO (en KVM)
Virtualizor
Alternativa moderna a SolusVM con una mejor interfaz.
- Soporte para KVM, Xen, OpenVZ, LXC
- API para automatización
- Copias de seguridad integradas
- Interfaz de usuario más amigable
Paneles propietarios
Muchos grandes proveedores desarrollan sus propias soluciones. La calidad varía de excelente a terrible. Mira capturas de pantalla y opiniones antes de comprar.
Paneles de servidor (se instalan en el VPS)
Si el proveedor solo da acceso SSH, puedes instalar un panel por tu cuenta.
Opciones gratuitas
HestiaCP — un fork de VestaCP, en desarrollo activo.
- Servidor web (nginx/Apache)
- Servidor de correo
- DNS
- Bases de datos (MySQL/PostgreSQL)
- Gestión de dominios y SSL
- Consumo: ~200-300MB RAM
# Instalación de HestiaCP
wget https://raw.githubusercontent.com/hestiacp/hestiacp/release/install/hst-install.sh
bash hst-install.sh
Webmin/Virtualmin — un clásico, funciona de forma estable.
- Gestión universal de servidores Linux
- Virtualmin añade funciones de hosting
- Arquitectura modular
- Consumo: ~100-200MB RAM
CyberPanel — panel basado en OpenLiteSpeed.
- Alto rendimiento del servidor web
- LSCache integrado
- Correo electrónico, DNS, FTP
- Integración con Docker
Opciones de pago
cPanel/WHM — el estándar de la industria.
- Conjunto completo de funciones para hosting
- Enorme ecosistema de plugins
- Excelente documentación
- Precio: desde $15/mes (después del período gratuito)
- Consumo: 1-2GB RAM mínimo
Plesk — el principal competidor de cPanel.
- Soporte para Windows y Linux
- Interfaz moderna
- WordPress Toolkit
- Precio: desde $10/mes
DirectAdmin — una alternativa ligera.
- Menor consumo de recursos
- Interfaz sencilla
- Precio: desde $5/mes
Cuando no se necesita un panel
Para muchas tareas, un panel de control es una sobrecarga innecesaria:
- Servidores API y servicios backend
- Despliegues de Docker/Kubernetes
- Aplicaciones especializadas
- Cuando hay CI/CD e Infraestructura como Código
En estos casos, basta con SSH + configuración básica.
Comparación de paneles de control
| Panel | Precio | Requisitos de RAM | Para quién |
|---|---|---|---|
| HestiaCP | Gratis | ~300MB | Proyectos pequeños, hosting web |
| Webmin | Gratis | ~150MB | Gestión universal de Linux |
| CyberPanel | Gratis | ~400MB | Hosting web de alto rendimiento |
| cPanel | desde $15/mes | ~1.5GB | Hosting profesional |
| Plesk | desde $10/mes | ~1GB | Hosting Windows/Linux |
| DirectAdmin | desde $5/mes | ~500MB | Alternativa ligera a cPanel |
Recomendación: para VPS con 2GB de RAM o menos — HestiaCP o Webmin. Para 4GB+ se puede considerar cPanel/Plesk, si la funcionalidad lo justifica.
Copias de seguridad y Recuperación ante Desastres
Las copias de seguridad son la única protección contra la pérdida de datos. Confiar en el proveedor es un error.
Regla 3-2-1
Estrategia clásica de copias de seguridad:
- 3 copias de los datos
- 2 tipos diferentes de medios
- 1 copia offsite (en otro lugar)
Para un VPS, esto significa:
- Datos en el servidor (principal)
- Copias de seguridad locales en el mismo VPS o en el proveedor
- Copias de seguridad externas (otro proveedor, S3, Backblaze)
Qué respaldar
Crítico:
- Bases de datos (MySQL, PostgreSQL, MongoDB)
- Datos de usuario y cargas (uploads)
- Archivos de configuración
- Certificados y claves SSL
- Crontab y tareas programadas
Deseable:
- Logs (para investigaciones)
- Correo electrónico (si lo alojas tú mismo)
- Scripts personalizados
No es necesario:
- Archivos del sistema (se pueden restaurar desde una imagen)
- Cachés y archivos temporales
- Caché de gestores de paquetes
Herramientas para copias de seguridad
Para bases de datos
# MySQL/MariaDB
mysqldump -u root -p --all-databases --single-transaction > all_databases.sql
# Con compresión
mysqldump -u root -p dbname | gzip > backup_$(date +%Y%m%d).sql.gz
# PostgreSQL
pg_dumpall -U postgres > all_databases.sql
# Una base de datos
pg_dump -U postgres dbname > dbname.sql
Para archivos
# rsync a un servidor remoto
rsync -avz --delete /var/www/ backup@remote:/backups/www/
# Con SSH
rsync -avz -e ssh /data/ user@backup-server:/backups/
# Archivo tar
tar -czvf backup_$(date +%Y%m%d).tar.gz /var/www /etc/nginx /etc/letsencrypt
Herramientas especializadas
restic — herramienta moderna con deduplicación y cifrado.
# Inicialización del repositorio
restic init --repo /backup/restic
# Copia de seguridad
restic -r /backup/restic backup /var/www /etc
# Restauración
restic -r /backup/restic restore latest --target /restore
borgbackup — similar a restic, deduplicación eficiente.
# Inicialización
borg init --encryption=repokey /backup/borg
# Copia de seguridad
borg create /backup/borg::backup-{now} /var/www /etc
# Lista de archivos
borg list /backup/borg
Almacenamiento en la nube
# rclone — herramienta universal para la nube
# Soporta S3, Backblaze B2, Google Drive, y decenas de otros
# Configuración
rclone config
# Sincronización
rclone sync /backup/ remote:bucket-name/
# Copia con progreso
rclone copy --progress /data/ remote:bucket/data/
Automatización de copias de seguridad
# /etc/cron.d/backup
# Copia de seguridad diaria a las 3:00
0 3 * * * root /usr/local/bin/backup.sh >> /var/log/backup.log 2>&1
# Ejemplo de script /usr/local/bin/backup.sh
#!/bin/bash
set -e
DATE=$(date +%Y%m%d)
BACKUP_DIR=/backup
# Copia de seguridad de MySQL
mysqldump --all-databases | gzip > $BACKUP_DIR/mysql_$DATE.sql.gz
# Copia de seguridad de archivos
tar -czf $BACKUP_DIR/www_$DATE.tar.gz /var/www
# Envío a la nube
rclone copy $BACKUP_DIR remote:backups/
# Eliminación de copias de seguridad locales antiguas (más de 7 días)
find $BACKUP_DIR -type f -mtime +7 -delete
echo "Copia de seguridad completada: $DATE"
Verificación de copias de seguridad
Una copia de seguridad que no ha sido verificada no es una copia de seguridad. Prueba la restauración regularmente:
- Despliega en un servidor de prueba
- Verifica la integridad de los archivos
- Asegúrate de que la aplicación funciona después de la restauración
- Mide el RTO (tiempo de recuperación)
Plan de Recuperación ante Desastres
Documento que describe qué hacer en diferentes escenarios:
- Fallo de la aplicación — reinicio, reversión a la versión anterior
- Fallo de la base de datos — restauración desde copia de seguridad, recuperación a un punto en el tiempo
- Fallo del VPS — despliegue en un nuevo servidor
- Fallo del proveedor — migración a un proveedor alternativo
Para cada escenario:
- Secuencia de acciones
- Contactos de los responsables
- Accesos y credenciales (en un lugar seguro)
- Tiempo de recuperación esperado
Monitoreo de VPS
Sin monitoreo, te enteras de los problemas por los usuarios. Con monitoreo, antes.
Qué monitorear
Métricas del sistema
- CPU: uso, carga promedio, tiempo de robo
- Memoria: usada, disponible, uso de swap
- Disco: uso, IOPS, latencia
- Red: ancho de banda de entrada/salida, pérdida de paquetes, latencia
Métricas de la aplicación
- Servidor web: solicitudes/seg, tiempo de respuesta, tasa de errores
- Base de datos: consultas/seg, consultas lentas, conexiones
- Aplicación: métricas específicas (colas, trabajos, etc.)
Disponibilidad (Uptime)
- Endpoints HTTP(S)
- Puertos TCP
- Certificados SSL (fecha de caducidad)
- DNS
Herramientas de monitoreo
Monitoreo externo (SaaS)
UptimeRobot — gratuito para verificaciones básicas.
- Hasta 50 monitores gratis
- HTTP, Ping, Puerto, Palabra clave
- Notificaciones: correo electrónico, Slack, Telegram
BetterUptime, Pingdom, StatusCake — opciones de pago más avanzadas.
Monitoreo autoalojado
Netdata — monitoreo en tiempo real con configuración mínima.
# Instalación
bash <(curl -Ss https://my-netdata.io/kickstart.sh)
# Acceso en http://server:19999
Prometheus + Grafana — pila para monitoreo serio.
- Prometheus recopila métricas
- Grafana las visualiza
- Alertmanager envía notificaciones
- Requiere 512MB-1GB RAM
Zabbix — solución empresarial.
- Monitoreo completo
- Autodescubrimiento
- Más complejo de configurar
- Requiere PostgreSQL/MySQL
Monitoreo mínimo a través de CLI
# Script simple de verificación (añadir a cron)
#!/bin/bash
# Verificación HTTP
STATUS=$(curl -s -o /dev/null -w "%{http_code}" https://mysite.com)
if [ "$STATUS" != "200" ]; then
echo "¡Sitio caído! Estado: $STATUS" | mail -s "Alerta" admin@example.com
fi
# Verificación de disco
DISK_USAGE=$(df / | tail -1 | awk '{print $5}' | sed 's/%//')
if [ "$DISK_USAGE" -gt 90 ]; then
echo "Uso de disco: $DISK_USAGE%" | mail -s "Alerta de Disco" admin@example.com
fi
# Verificación de memoria
MEM_AVAILABLE=$(free -m | grep Mem | awk '{print $7}')
if [ "$MEM_AVAILABLE" -lt 200 ]; then
echo "Poca memoria: ${MEM_AVAILABLE}MB disponibles" | mail -s "Alerta de Memoria" admin@example.com
fi
Configuración de alertas
Las alertas deben ser accionables — si recibes una alerta, debes saber qué hacer.
Buenas alertas:
- Disco lleno al 90%+ → limpiar o expandir
- Sitio no disponible → verificar servidor, reiniciar servicios
- Tiempo de robo de CPU > 15% → queja al proveedor
Malas alertas:
- CPU 80% (si es normal para tu carga)
- 100 errores 404 (si son bots escaneando)
- Cualquier alerta que ignores
Lista de verificación para elegir un proveedor de VPS
Utiliza esta lista de verificación al evaluar proveedores.
Características técnicas
| Criterio | Pregunta | Bandera roja |
|---|---|---|
| Virtualización | ¿KVM, OpenVZ, LXC, VMware? | OpenVZ 6, tipo no especificado |
| CPU | ¿Modelo de procesador? ¿Dedicado o compartido? | Modelo no especificado, Xeon E5 v1/v2 antiguos |
| Almacenamiento | ¿NVMe, SSD, HDD? ¿RAID? ¿Local o en red? | "SSD" sin especificar, HDD para producción |
| Red | ¿Velocidad de puerto? ¿Límite de ancho de banda? ¿Protección DDoS? | Puerto de 100Mbps, límites estrictos |
| IP | ¿IPv4/IPv6? ¿IPs adicionales? | Solo IPv6, alto recargo por IPv4 |
Fiabilidad y soporte
| Criterio | Pregunta | Bandera roja |
|---|---|---|
| SLA | ¿Qué SLA? ¿Qué incluye? | Sin SLA, muchas exclusiones |
| Soporte | ¿Canales? ¿Tiempo de respuesta? ¿24/7? | Solo tickets, respuesta >24h |
| Historial | ¿Cuántos años llevan operando? ¿Opiniones? | Proveedor nuevo, muchas opiniones negativas |
| Centro de datos | ¿Dónde físicamente? ¿Tier? ¿Certificaciones? | Ubicación desconocida, sin información |
Condiciones y limitaciones
| Criterio | Pregunta | Bandera roja |
|---|---|---|
| PUA | ¿Qué está prohibido? ¿Tu caso de uso está permitido? | Funcionalidad necesaria prohibida |
| Copias de seguridad | ¿Incluidas? ¿Frecuencia? ¿Costo? | No hay copias de seguridad en absoluto |
| Escalado | ¿Se puede actualizar sin reinstalar? | Solo reinstalación |
| Pago | ¿Métodos? ¿Política de reembolso? | Solo criptomoneda, sin reembolso |
Pruebas
Antes de usar en producción:
- Contrata la tarifa mínima o una prueba
- Verifica el tiempo de robo de CPU bajo carga
- Prueba el IO (fio)
- Verifica la conectividad de red con tus usuarios
- Verifica la reputación de la IP
- Abre un ticket de soporte — evalúa el tiempo y la calidad de la respuesta
- Intenta instalar el software necesario
Algoritmo de elección aproximado
Si te resulta difícil decidir, utiliza este algoritmo:
- Define el factor crítico: ¿precio, rendimiento, geografía, soporte?
- Descarta los inadecuados: por tipo de virtualización, geografía, PUA
- Crea una lista corta: 3-5 proveedores que cumplan los requisitos
- Verifica las opiniones: Reddit, Trustpilot, foros especializados — busca detalles, no emociones
- Prueba 2-3 opciones: contrata las tarifas mínimas, ejecuta benchmarks
- Elige el mejor en relación: rendimiento + estabilidad + soporte / precio
No te apresures con la elección final del proveedor. Un día extra de pruebas te ahorrará semanas de problemas en producción.
Migración entre proveedores
Tarde o temprano, tendrás que mudarte. Prepárate con antelación.
Preparación para la migración
- Documentación — registra la configuración actual
- Copias de seguridad — una copia de seguridad completa reciente
- DNS — reduce el TTL con antelación (a 300-600 segundos)
- Pruebas — despliega una copia en el nuevo servidor, verifica
Estrategias de migración
Migración completa (big bang)
- Detienes el servidor antiguo
- Transfieres los datos
- Inicias en el nuevo
- Cambias el DNS
Adecuado para proyectos pequeños con tiempo de inactividad aceptable.
Funcionamiento en paralelo
- Levantas el nuevo servidor
- Sincronizas los datos en tiempo real
- Cambias el tráfico gradualmente
- Apagas el antiguo después de la estabilización
Minimiza el riesgo, requiere más recursos.
Herramientas
# Sincronización de archivos con rsync
rsync -avz --progress root@old-server:/var/www/ /var/www/
# Replicación de MySQL
# En el servidor antiguo configurar como master
# En el nuevo — como slave, luego promover
# Sincronización de PostgreSQL
pg_basebackup -h old-server -D /var/lib/postgresql/data -P
Después de la migración
- Verifica el funcionamiento de todas las funciones
- Monitorea errores en los logs
- Vigila el rendimiento
- No elimines el servidor antiguo de inmediato — mantenlo una semana por si hay problemas
- Vuelve a establecer el TTL de DNS a valores normales
Lista de verificación de migración
Utiliza esta lista de verificación al mudarte:
Antes de la migración:
- ☐ Copia de seguridad completa de los datos (¡verificada!)
- ☐ Lista de todos los servicios y configuraciones
- ☐ TTL de DNS reducido a 300-600 segundos
- ☐ Nuevo servidor desplegado y probado
- ☐ Certificados SSL listos para el nuevo servidor
- ☐ Tareas Cron documentadas
- ☐ Tiempo de migración acordado (tráfico bajo)
Durante la migración:
- ☐ Notificar a los usuarios sobre posibles interrupciones
- ☐ Detener escrituras en la base de datos en el servidor antiguo
- ☐ Sincronización final de datos
- ☐ Cambiar DNS
- ☐ Verificar el funcionamiento de las funciones principales
Después de la migración:
- ☐ Monitoreo de errores durante 24-48 horas
- ☐ Verificación de todas las integraciones
- ☐ Prueba de envío de correo electrónico
- ☐ Verificación de copias de seguridad en el nuevo servidor
- ☐ Actualizar la documentación
- ☐ Después de una semana: eliminar el servidor antiguo
Optimización de costos de VPS
Pagar de más es una tontería, pagar de menos es peligroso. Así es como se encuentra el equilibrio.
Tamaño correcto (Right-sizing)
Un error típico es tomar con margen "por si acaso". Como resultado, el 70% de los recursos están inactivos.
Cómo determinar el tamaño necesario:
- Ejecuta en la tarifa mínima
- Monitorea el uso durante 1-2 semanas
- Evalúa los valores pico y promedio
- Añade un 20-30% de margen sobre el pico
# CPU promedio de la última hora
sar -u 1 3600 | tail -1
# Uso máximo de memoria
# (requiere recopilación de estadísticas)
cat /var/log/sysstat/sa* | sar -r | sort -k4 -n | tail -1
# Uso real del disco
df -h | grep -v tmpfs
Reserva vs Pago por uso
Muchos proveedores ofrecen descuentos por pago anticipado:
- Pago mensual: precio base
- Pago anual: descuento del 10-20%
- 2-3 años: descuento de hasta el 40%
Cuándo contratar a largo plazo:
- Proyecto estable con requisitos predecibles
- Proveedor probado en la práctica
- Hay un colchón financiero
Cuándo NO contratar:
- Proyecto nuevo con futuro incierto
- Proveedor nuevo (no probado)
- Proyecto de rápido crecimiento (habrá que actualizar)
Alternativas a los VPS estándar
Instancias Spot/Preemptibles
Los proveedores de la nube venden capacidad excedente con un descuento del 60-90%, pero pueden retirarla con un aviso de 30 segundos a 2 minutos.
Adecuado para: procesamiento por lotes, ejecutores de CI/CD, workers sin estado.
Servidores de subasta
Algunos proveedores (Hetzner) venden servidores dedicados en subasta — hardware usado a precios reducidos.
Hosting comunitario/revendedor
Pequeños proveedores que revenden capacidad de grandes. A veces más barato, pero con mayores riesgos.
Lo que no ahorra dinero
- Proveedor demasiado barato — perderás tiempo en problemas
- VPS sobredimensionado "por si acaso" — es mejor escalar a medida que creces
- Ignorar los servicios gestionados — el tiempo de DevOps también cuesta dinero
Preguntas adicionales
¿Cómo proteger un VPS de un hackeo?
Medidas básicas: deshabilitar el inicio de sesión root por contraseña, usar claves SSH, configurar un firewall (ufw/iptables), instalar fail2ban, actualizar el sistema regularmente, no ejecutar servicios innecesarios, usar contraseñas complejas para todos los servicios.
¿Qué es mejor: un VPS potente o varios pequeños?
Depende de la tarea. Un VPS es más fácil de gestionar. Varios, mayor tolerancia a fallos y posibilidad de distribuir la carga. Para la mayoría de los proyectos de hasta 10K DAU, un VPS correctamente configurado es suficiente.
¿Cómo migrar un sitio de shared-hosting a un VPS?
Exportar archivos (FTP/SSH), exportar la base de datos (phpMyAdmin o mysqldump), instalar en el VPS un servidor web y PHP de la versión necesaria, importar los datos, configurar el host virtual, verificar el funcionamiento, cambiar el DNS.
¿Se puede usar un VPS como VPN?
Sí, pero verifica la PUA del proveedor. Muchos permiten VPN personal, pero prohíben servicios VPN comerciales. Soluciones populares: WireGuard, OpenVPN, Outline.
¿Cómo saber si un vecino de host está sobrecargando el servidor?
Alto tiempo de robo de CPU con baja carga propia. Degradación impredecible de IO. "Congelamientos" periódicos sin causas aparentes. Todo esto son signos de "vecinos ruidosos" o sobreventa.
¿Vale la pena contratar un VPS con Windows?
Solo si necesitas software específico de Windows (.NET Framework, MSSQL). Un VPS con Windows es más caro (licencia), requiere más recursos, es más complejo de automatizar. Para la mayoría de las tareas, Linux es preferible.
¿Cómo elegir entre Ubuntu, Debian, CentOS?
Ubuntu — el más popular, mucha documentación y ejemplos. Debian — estable y ligero. CentOS Stream/AlmaLinux/Rocky — para entornos empresariales. Para VPS, Ubuntu LTS o Debian stable suelen ser los más adecuados.
¿Qué hacer en caso de un ataque DDoS?
Si el proveedor tiene protección, debería activarse automáticamente. Si no, activar Cloudflare o similar. En casos extremos, pedir al proveedor que anule temporalmente la ruta de la IP (el sitio no estará disponible, pero el ataque cesará).
¿Cómo saber si un VPS ha sido comprometido?
Verificar procesos inusuales (ps aux), conexiones de red (netstat -tulpn), últimos inicios de sesión (last, lastb), crontab de todos los usuarios, cambios en archivos del sistema. Usar rkhunter, chkrootkit para buscar rootkits.
¿Se puede minar criptomonedas en un VPS?
Técnicamente, sí, prácticamente, casi siempre está prohibido en la PUA. La minería crea una carga constante del 100% en la CPU, lo que afecta a los vecinos. Por esto, se desconecta sin previo aviso.
¿Cómo elegir entre Europa y EE. UU. para el hosting?
Depende de la audiencia y los requisitos regulatorios. Para la audiencia rusa, Europa (especialmente Fráncfort, Ámsterdam) suele tener mejor conectividad. Para proyectos globales, depende de la distribución de usuarios. EE. UU. es más barato para el cómputo, pero el GDPR puede requerir hosting en la UE para datos europeos.
¿Qué hacer si el proveedor cierra?
Si tienes copias de seguridad, despliégalas en otro proveedor. Si no, reza. Por eso las copias de seguridad deben almacenarse en un lugar independiente. Señales de problemas del proveedor: retrasos en las respuestas, incidentes más frecuentes, despidos de personal clave, problemas financieros en las noticias.
¿Se necesita una IP dedicada para SEO?
Para SEO, una IP compartida por sí misma no es un problema — Google lo ha confirmado repetidamente. Una IP dedicada es necesaria para: certificados SSL (aunque SNI lo resuelve), envíos de correo electrónico (crítico), algunas integraciones de API y si los vecinos de IP se dedican al spam.
¿Cómo saber cuándo es hora de migrar a un servidor dedicado?
Cuando el costo de varios VPS potentes se acerca al de un dedicado. Cuando el rendimiento estable sin vecinos es crítico. Cuando se necesitan configuraciones de hardware específicas. Cuando se requiere control total hasta el BIOS/IPMI. Típicamente esto ocurre con gastos de $150-200+/mes en VPS.
¿Por qué un VPS es más barato que la nube con la misma configuración?
Los proveedores de la nube (AWS, GCP, Azure) incluyen en el precio: infraestructura global, ecosistema de servicios gestionados, soporte empresarial, certificaciones de cumplimiento, costo de I+D. Los proveedores de VPS solo venden cómputo, sin ecosistema. Si solo necesitas un servidor, un VPS es más rentable. Si necesitas el ecosistema, la nube se amortiza.
¿Qué métricas monitorear primero?
Para empezar, las básicas son suficientes: tiempo de actividad (disponibilidad del servicio), tiempo de respuesta, uso de CPU y RAM, espacio en disco. A medida que creces, añade métricas específicas de la aplicación: consultas por segundo para la base de datos, solicitudes por segundo para el servidor web, tasa de errores. La regla principal: monitorea aquello a lo que puedas reaccionar.
¿Vale la pena usar varios proveedores de VPS simultáneamente?
Para proyectos críticos, sí, es una estrategia sensata. El primario con un proveedor, las copias de seguridad y la conmutación por error con otro. Para proyectos pequeños, un solo proveedor con copias de seguridad externas suele ser suficiente. La multi-nube añade complejidad a la gestión, úsala cuando esté justificado por los requisitos del negocio.
¿Cómo estimar el costo real de un VPS?
El precio base es solo el comienzo. Añade: el costo de IPs adicionales, copias de seguridad, exceso de tráfico, licencias de software (Windows, paneles), protección DDoS si es de pago. Considera tu tiempo de administración a la tarifa de mercado. El costo real suele ser 1.5-2 veces mayor que el declarado.
Materiales relacionados para estudio adicional
Para una inmersión más profunda en temas y preguntas específicas abordadas en esta guía, recomendamos consultar los siguientes materiales útiles:
- Configuración de seguridad de un servidor Linux después de la instalación: hardening, firewall, monitoreo de amenazas
- Comparación de paneles de control de servidor: cPanel vs Plesk vs HestiaCP vs DirectAdmin
- Optimización del rendimiento del servidor web en VPS: nginx, PHP-FPM, Redis y caché
- Automatización de copias de seguridad para VPS: configuración de restic, borgbackup, rclone con almacenamiento en la nube
- Monitoreo de servidores: desde simples verificaciones de tiempo de actividad hasta una observabilidad completa
- Docker en VPS: guía práctica para la contenerización de aplicaciones
- Elección entre shared-hosting y VPS: cuándo es hora de pasar a tu propio servidor virtual
Artículo actualizado: enero de 2026. La información es actual en el momento de la publicación, sin embargo, recomendamos verificar las condiciones actuales de los proveedores antes de tomar una decisión final de compra.