Creación de un Clúster PostgreSQL de Alta Disponibilidad en Servidores VPS y Dedicados
TL;DR
- La alta disponibilidad de PostgreSQL es crítica para la continuidad del negocio, minimizando el tiempo de inactividad y la pérdida de datos.
- Las soluciones clave incluyen Patroni, pg_auto_failover y la replicación por streaming nativa con herramientas externas.
- La elección depende del RPO, RTO, presupuesto, complejidad y nivel de automatización que esté dispuesto a mantener.
- El failover automático y una monitorización adecuada son la base de un clúster fiable.
- Las pruebas regulares de los mecanismos de recuperación y copia de seguridad son absolutamente obligatorias.
- La gestión eficiente de los costos requiere la optimización de los recursos y la elección de una arquitectura adecuada.
- Este artículo es su guía paso a paso para el diseño, despliegue y mantenimiento de un PostgreSQL tolerante a fallos.
Introducción: ¿Por qué su negocio necesita un PostgreSQL de alta disponibilidad en 2026?
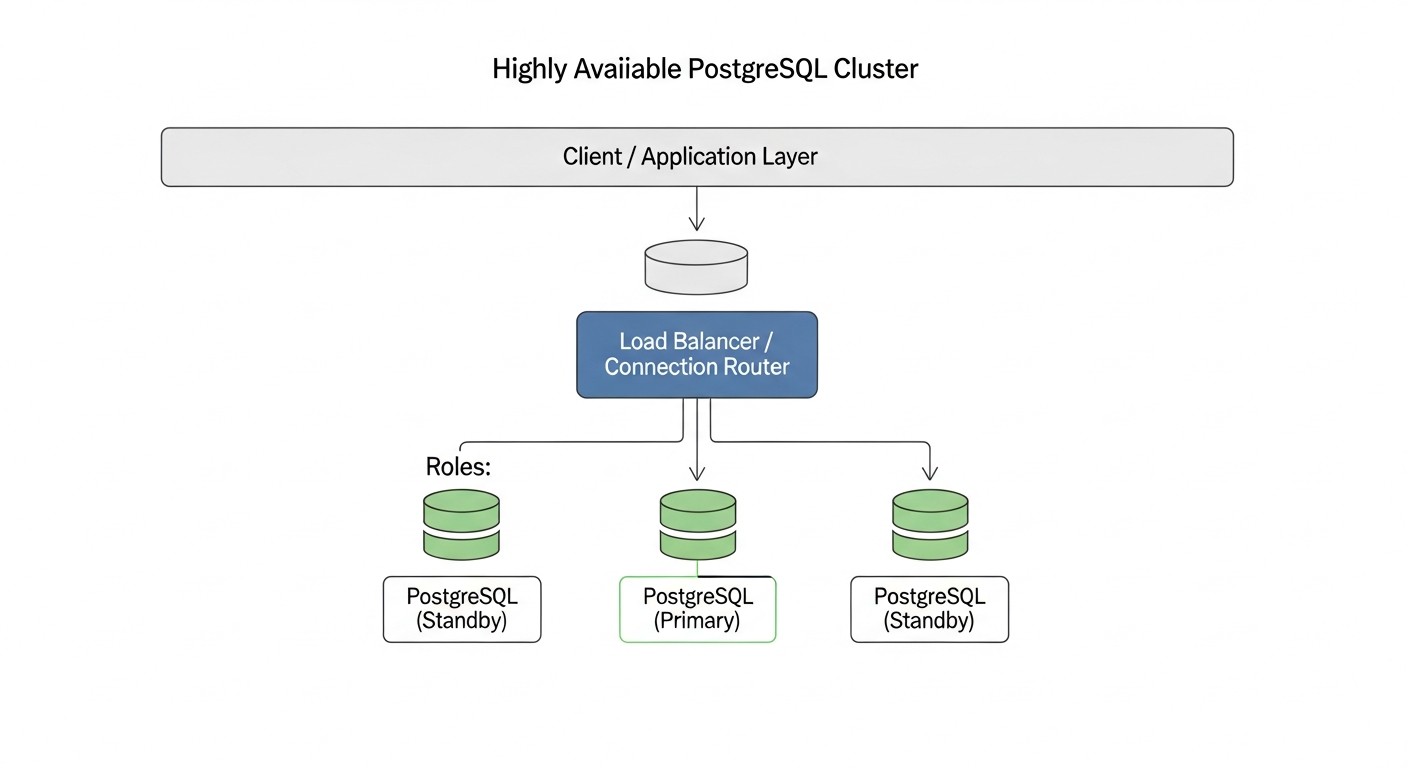
En el mundo actual, donde la digitalización ha penetrado en todas las esferas de negocio y los usuarios esperan acceso 24/7 a los servicios, la continuidad operativa es fundamental. Un tiempo de inactividad de incluso unos pocos minutos puede resultar no solo en pérdidas financieras, sino también en un daño grave a la reputación de la empresa. Esto es especialmente relevante para proyectos donde los datos son el activo central, ya sea una plataforma SaaS, un servicio financiero o una gran tienda en línea. PostgreSQL, como una de las bases de datos relacionales más fiables y funcionales, es la piedra angular de muchos de estos sistemas. Sin embargo, PostgreSQL por sí solo no proporciona alta disponibilidad de forma predeterminada. La falla de un único servidor de base de datos puede llevar a una interrupción completa de la aplicación, lo cual es inaceptable para cualquier negocio moderno.
Es por eso que la creación de un clúster PostgreSQL de alta disponibilidad se convierte no solo en una "opción agradable", sino en un requisito obligatorio. En 2026, en el contexto de volúmenes de datos en constante crecimiento, requisitos de SLA cada vez más estrictos y la proliferación generalizada de la arquitectura de microservicios, la tarea de garantizar la tolerancia a fallos de las bases de datos pasa a primer plano. Las empresas que no prestan la debida atención a esto corren el riesgo de perder clientes, ingresos y ventajas competitivas. Observamos una tendencia en la que incluso las startups en sus primeras etapas de desarrollo establecen una arquitectura de alta disponibilidad, entendiendo que corregir problemas "sobre la marcha" en producción es significativamente más costoso que un diseño adecuado desde el principio. Además, con el aumento de la complejidad de los sistemas y las cargas distribuidas, la intervención manual en caso de fallo se vuelve cada vez menos eficiente y más arriesgada.
Este artículo tiene como objetivo ser su guía completa para crear un clúster PostgreSQL fiable y eficiente en servidores VPS y dedicados. Exploraremos diferentes enfoques, herramientas y mejores prácticas, relevantes para 2026, para que pueda elegir la solución óptima para sus necesidades. Independientemente de si es un ingeniero DevOps, un desarrollador Backend, el fundador de un proyecto SaaS, un administrador de sistemas o el director técnico de una startup, aquí encontrará consejos prácticos e instrucciones específicas. Nos sumergiremos profundamente en los detalles técnicos, analizaremos errores comunes y ofreceremos recomendaciones basadas en la experiencia real. Nuestro objetivo no es solo decir "cómo", sino también explicar "por qué", para que pueda tomar decisiones arquitectónicas informadas y construir con confianza sistemas robustos capaces de soportar cualquier desafío.
Dentro de este material, nos centraremos en soluciones que se pueden desplegar y controlar de forma independiente en servidores VPS o dedicados, lo cual es especialmente relevante para proyectos que requieren control total sobre la infraestructura, optimización de costos o requisitos de seguridad específicos. No profundizaremos en servicios gestionados en la nube, como AWS RDS/Aurora o Google Cloud SQL, ya que estos proporcionan HA "de fábrica" y tienen sus propias características de gestión, diferentes de los enfoques para el autoalojamiento. En su lugar, nos concentraremos en herramientas y metodologías que permiten lograr un nivel similar de fiabilidad utilizando recursos accesibles y flexibles.
Criterios y factores clave para elegir una solución HA para PostgreSQL
La elección de la solución óptima para garantizar la alta disponibilidad de PostgreSQL es un proceso multifacético que requiere una comprensión profunda tanto de los requisitos comerciales como de las capacidades técnicas. No existe una solución "mejor" universal; la elección ideal siempre es un compromiso entre varios factores. Consideremos los criterios clave que deben tenerse en cuenta:
Recovery Point Objective (RPO) — Pérdida de datos tolerable
El RPO define la cantidad máxima tolerable de datos que se pueden perder en caso de un fallo. Se mide en tiempo, por ejemplo, "RPO = 5 minutos" significa que está dispuesto a perder no más de 5 minutos de las últimas transacciones. Para sistemas críticos, como aplicaciones financieras o sistemas de procesamiento de pagos, el RPO puede ser cercano a cero (pérdida de datos cero). Esto se logra mediante la replicación síncrona, donde una transacción se considera completa solo después de haber sido escrita y confirmada en al menos dos nodos. Sin embargo, la replicación síncrona aumenta las latencias de escritura y puede reducir el rendimiento general. Para sistemas menos críticos, se puede utilizar la replicación asíncrona, que ofrece mejores métricas de rendimiento, pero el RPO será distinto de cero (normalmente unos pocos segundos o minutos, dependiendo de la latencia de replicación). La evaluación del RPO requiere un análisis detallado de los procesos de negocio y el costo de la pérdida de datos.
Recovery Time Objective (RTO) — Tiempo de recuperación tolerable
El RTO define el tiempo máximo tolerable durante el cual un sistema puede estar no disponible después de un fallo. Por ejemplo, "RTO = 30 segundos" significa que su clúster debe recuperarse y estar listo para aceptar solicitudes en medio minuto. Cuanto menor sea el RTO, más compleja y costosa será la solución. Un failover automático con conmutación instantánea a un nodo de respaldo proporciona un RTO bajo, a menudo medido en segundos. Un failover manual, por el contrario, aumenta el RTO, ya que requiere intervención humana. Para sistemas críticos con un RTO bajo, se necesitan herramientas de detección automática de fallos y coordinación de failover, como Patroni o pg_auto_failover. Es necesario considerar no solo el tiempo de reinicio de la BD, sino también el tiempo de conmutación de direcciones de red, actualización de DNS y reconexión de aplicaciones cliente.
Escalabilidad (Scalability)
La escalabilidad se refiere a la capacidad de un sistema para manejar eficazmente volúmenes de carga crecientes. En el contexto de HA PostgreSQL, esto puede significar tanto escalado horizontal (añadir más nodos para distribuir la carga) como vertical (aumentar los recursos de un solo nodo). Para el escalado de lectura, se suelen utilizar réplicas (servidores en espera) a las que se dirigen las consultas SELECT. El escalado de escritura es más complejo y a menudo requiere soluciones más sofisticadas, como el sharding o el uso de extensiones especializadas. Es importante evaluar las necesidades de escalado actuales y futuras para elegir una solución que no se convierta en un "cuello de botella" en el futuro. Algunas soluciones HA (por ejemplo, Patroni) se integran bien con los mecanismos de escalado horizontal de lectura, permitiendo añadir nuevas réplicas fácilmente.
Consistencia de datos (Consistency)
La consistencia de datos garantiza que todos los nodos del clúster vean los mismos datos en el mismo momento. En sistemas distribuidos, lograr una consistencia estricta con alta disponibilidad y rendimiento es una tarea no trivial (teorema CAP). PostgreSQL, por defecto, proporciona una consistencia estricta en el nodo primario. Al usar replicación, es importante entender qué nivel de consistencia ofrece. La replicación asíncrona puede tener un pequeño retraso, lo que significa que la réplica puede "quedarse atrás" del maestro por unos pocos milisegundos o segundos. La replicación síncrona proporciona un nivel de consistencia más alto, pero, como se mencionó, afecta el rendimiento. Para la mayoría de las aplicaciones, se requiere una consistencia estricta para las operaciones de escritura y una consistencia aceptable (eventual consistency) para las operaciones de lectura desde las réplicas. La elección de la solución HA debe considerar cómo gestiona la consistencia de datos durante la conmutación de nodos y durante el funcionamiento normal.
Costo (Cost)
El costo incluye no solo los gastos directos en hardware o VPS, sino también licencias (aunque PostgreSQL es gratuito), costos de software (sistemas de monitorización, orquestadores), así como gastos indirectos como el tiempo de los ingenieros para el despliegue, soporte y capacitación. Para VPS y servidores dedicados, el costo dependerá del número de servidores, su configuración (CPU, RAM, SSD) y el tráfico de red. Las soluciones que requieren más nodos (por ejemplo, para el quórum) o una configuración más compleja serán más caras de operar. Es importante realizar un cálculo detallado del TCO (Costo Total de Propiedad) para varios años, considerando los costos potenciales de recuperación ante desastres y tiempos de inactividad.
Complejidad (Complexity)
La complejidad de la solución afecta el tiempo de despliegue, la probabilidad de errores y el esfuerzo de soporte. Las soluciones simples pueden configurarse fácilmente, pero pueden tener capacidades limitadas. Las soluciones complejas, como Patroni con un almacén de configuración distribuido (etcd/Consul), ofrecen más funcionalidad y automatización, pero requieren un conocimiento profundo para una configuración y depuración correctas. Es necesario evaluar el nivel de experiencia de su equipo. Si los recursos y la experiencia son escasos, vale la pena comenzar con soluciones más simples o invertir en capacitación. Una solución demasiado compleja puede convertirse en una fuente de problemas, no en su solución.
Facilidad de gestión y monitorización (Ease of Management & Monitoring)
Una buena solución HA no solo debe ser fiable, sino también fácil de gestionar. Esto incluye herramientas para monitorizar el estado del clúster, el registro, las alertas, así como la capacidad de realizar fácilmente operaciones rutinarias como añadir nuevas réplicas, actualizar PostgreSQL o probar el failover. Las soluciones con buena documentación, una comunidad activa y utilidades CLI integradas simplifican significativamente la vida. Es importante integrar el clúster HA en el sistema de monitorización y alertas existente para reaccionar rápidamente a cualquier problema. La falta de una monitorización adecuada es un camino directo a tiempos de inactividad inesperados.
Tabla comparativa de soluciones populares para HA PostgreSQL
Existen varios enfoques maduros en el mercado para construir clústeres PostgreSQL de alta disponibilidad en servidores VPS y dedicados. Cada uno tiene sus propias características, ventajas y desventajas. En esta tabla, compararemos las soluciones más populares y probadas, relevantes para 2026, para ayudarle a tomar una decisión informada.
| Criterio | Patroni + etcd/Consul | pg_auto_failover | Replicación por streaming nativa + Keepalived/HAProxy | Pgpool-II (modo HA) |
|---|---|---|---|---|
| Tipo de solución | Orquestador basado en almacenamiento distribuido (DCS) | Herramienta integrada de failover automático | Failover manual/semiautomático con herramientas externas | Servidor proxy con funciones HA y balanceo de carga |
| RPO (Pérdida de datos tolerable) | 0-pocos segundos (depende de la sincronía de la replicación) | 0-pocos segundos (depende de la sincronía de la replicación) | Pocos segundos/minutos (replicación asíncrona) | Pocos segundos/minutos (replicación asíncrona) |
| RTO (Tiempo de recuperación tolerable) | 5-30 segundos (failover automático) | 10-60 segundos (failover automático) | 30 segundos - 5 minutos (requiere scripts/intervención manual) | 10-60 segundos (failover automático a nivel de Pgpool) |
| Complejidad de configuración | Alta (DCS, Patroni, PostgreSQL) | Media (herramienta especializada) | Media (PostgreSQL, Keepalived/HAProxy, scripts) | Media (Pgpool-II, PostgreSQL) |
| Requisitos de servidores (mín.) | 3 nodos (1 maestro, 2 réplicas) + 3 nodos para DCS (se pueden combinar) | 2 nodos (1 maestro, 1 réplica) + 1 monitor | 2 nodos (1 maestro, 1 réplica) | 2-3 nodos (1 maestro, 1-2 réplicas) + 2 nodos Pgpool-II |
| Failover automático | Sí (completamente automático, considerando el quórum) | Sí (automático, con la ayuda del monitor) | No (requiere scripts externos y Keepalived/Corosync) | Sí (a nivel de Pgpool-II, para backends) |
| Escalado de lectura | Excelentes capacidades (fácil añadir réplicas) | Buenas capacidades (fácil añadir réplicas) | Básico (gestión manual de la conexión) | Excelentes capacidades (balanceo de consultas) |
| Soporte de replicación síncrona | Sí (a través de la API de Patroni) | Sí | Sí (función nativa de PostgreSQL) | Sí |
| Costo estimado (VPS, 2026, USD/mes) | $90-150 (3 VPS x $30-50, 4vCPU/8GB RAM/160GB NVMe) | $60-100 (2 VPS x $30-50, 4vCPU/8GB RAM/160GB NVMe) | $60-100 (2 VPS x $30-50, 4vCPU/8GB RAM/160GB NVMe) | $90-150 (3 VPS x $30-50, 4vCPU/8GB RAM/160GB NVMe) |
| Características clave | Automatización completa, API, integración con DCS, autorrecuperación. | Facilidad de despliegue, monitor integrado, especializado para PostgreSQL. | Básico, control total, requiere scripts personalizados, flexibilidad. | Balanceo de carga, caché, pooling de conexiones, HA. |
| Mejor escenario de uso | Aplicaciones críticas, exigentes en RPO/RTO, equipos orientados a DevOps. | Proyectos medianos, donde se necesita simplicidad y automatización sin alta complejidad. | Proyectos pequeños, presupuesto limitado, alto nivel de control, equipo experimentado. | Proyectos con alta carga de lectura, donde se necesita pooling y caché, así como HA. |
*Nota: Los precios de los VPS son orientativos para 2026 y pueden variar según el proveedor, la región y las condiciones actuales del mercado. Las configuraciones indicadas (4vCPU/8GB RAM/160GB NVMe) asumen una carga media para un sistema de producción.
Descripción detallada de cada punto/opción de solución HA
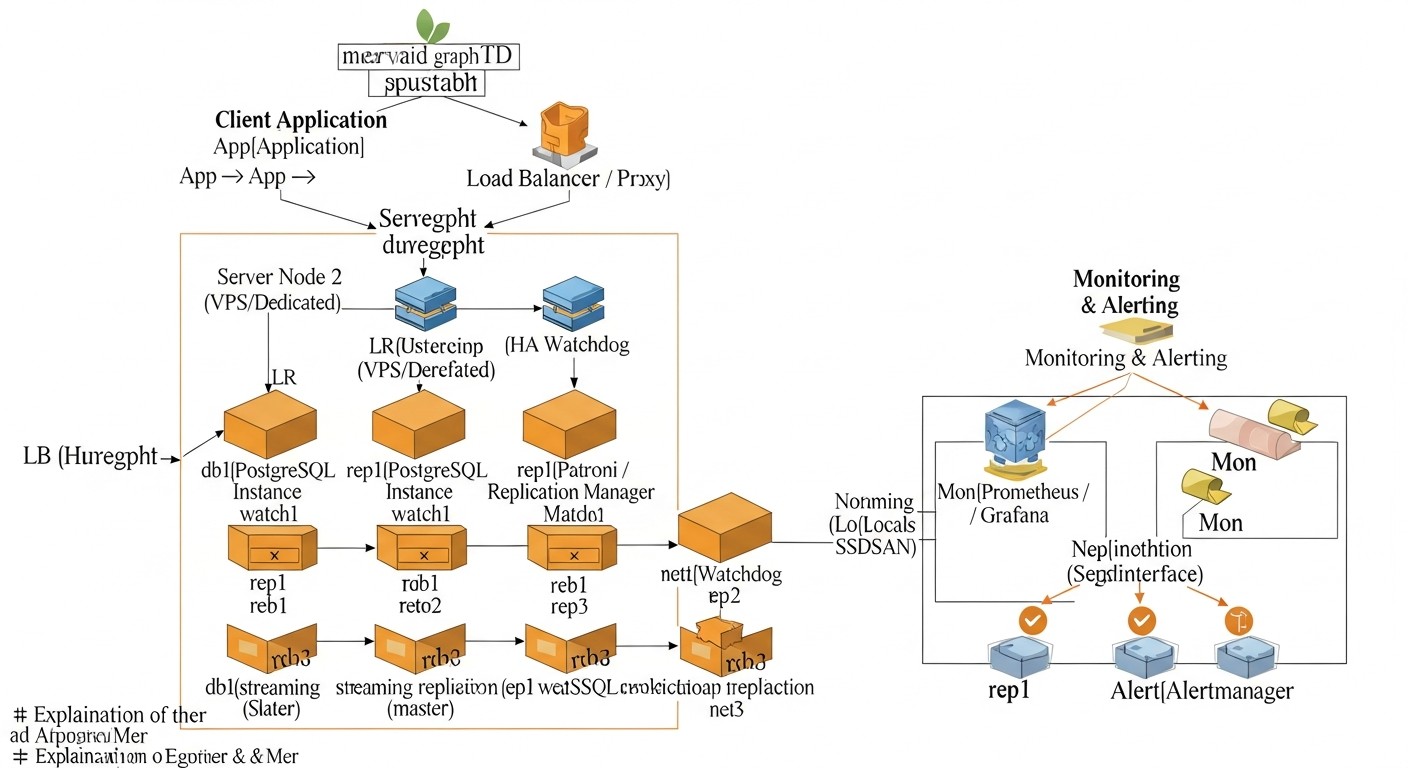
Examinemos más de cerca cada una de las soluciones mencionadas para comprender su mecánica interna, ventajas y desventajas. Esto le permitirá tomar una decisión más informada, basándose en la especificidad de su proyecto y los recursos del equipo.
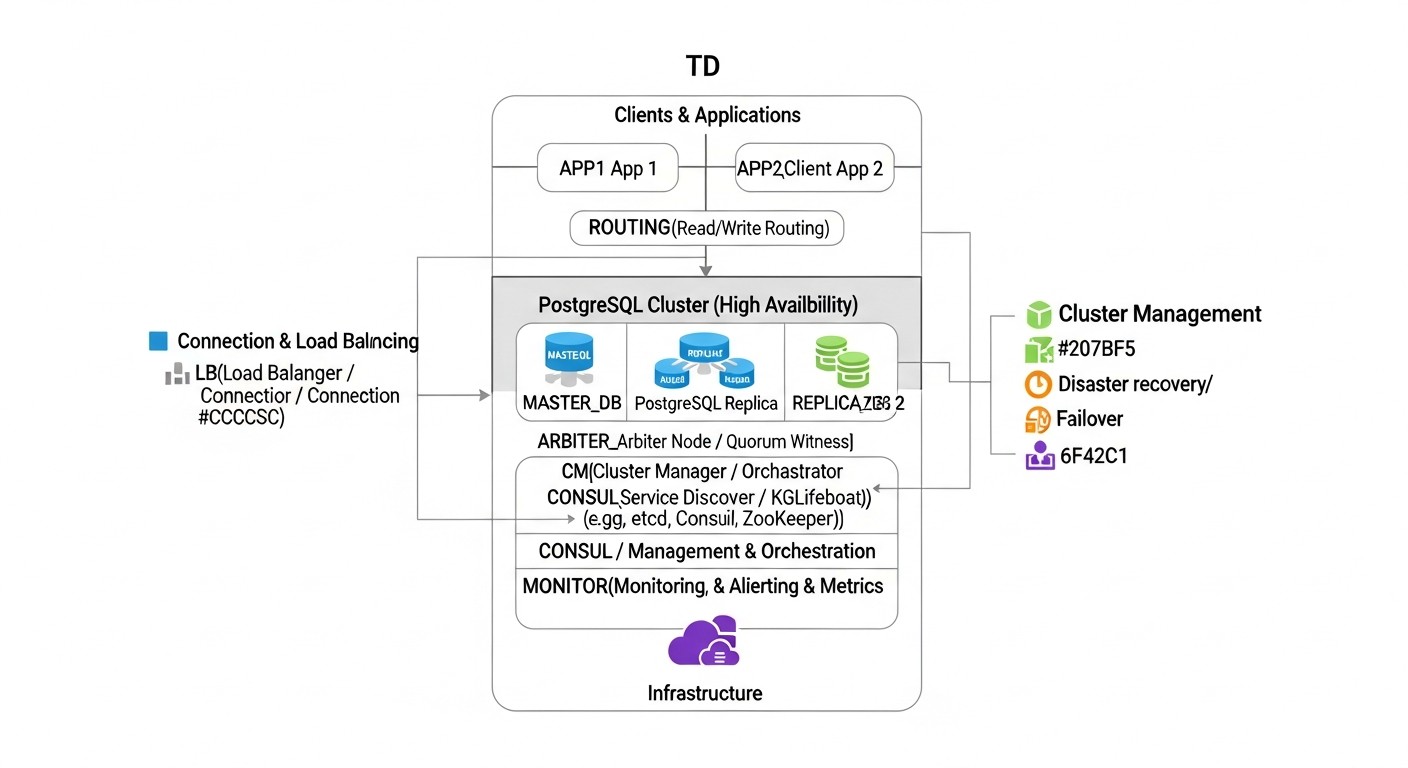
Patroni + Almacén de configuración distribuido (etcd/Consul/ZooKeeper)
Patroni es un potente demonio Python, desarrollado por Zalando, que proporciona una solución fiable y completamente automatizada para crear clústeres PostgreSQL de alta disponibilidad. Actúa como un orquestador, gestionando el ciclo de vida de las instancias de PostgreSQL, la replicación, las operaciones de failover y switchover. La característica clave de Patroni es el uso de un almacén de configuración distribuido (DCS) para almacenar el estado del clúster, como etcd, Consul o Apache ZooKeeper. El DCS actúa como la fuente de verdad para todos los nodos del clúster, asegurando la consistencia de la información sobre el maestro actual, el estado de las réplicas y la configuración.
Cómo funciona: Cada nodo PostgreSQL gestionado por Patroni actualiza regularmente su estado en el DCS. Patroni en cada nodo monitoriza el estado de los otros nodos y del propio DCS. Si el maestro actual falla, Patroni inicia automáticamente el procedimiento de failover: selecciona un nuevo maestro de entre las réplicas saludables, utilizando un algoritmo basado en quórum y prioridades. Después de seleccionar el nuevo maestro, Patroni cambia las réplicas restantes al nuevo maestro y, si es necesario, inicia el antiguo maestro como réplica después de la recuperación. Patroni también proporciona una API REST para gestionar el clúster, monitorizar y realizar operaciones como el switchover (conmutación planificada del maestro).
Ventajas:
- Automatización completa: Failover automático, switchover, recuperación de réplicas, adición de nuevos nodos.
- Alta fiabilidad: Utiliza DCS para el quórum y la prevención de split-brain.
- Flexibilidad: Soporta varios tipos de replicación (asíncrona, síncrona), integración con proxies (HAProxy, PgBouncer).
- API y CLI: Herramientas convenientes para la gestión y la integración con otros sistemas.
- Comunidad activa: Mantenido por Zalando y una gran comunidad de desarrolladores.
Desventajas:
- Alta complejidad: Requiere comprender el funcionamiento de PostgreSQL, Patroni y DCS. La configuración puede ser laboriosa.
- Infraestructura adicional: Se necesita un clúster DCS separado (mínimo 3 nodos para etcd/Consul).
- Consumo de recursos: Patroni y DCS consumen sus propios recursos, aunque pequeños.
Para quién es adecuado: Para proyectos medianos y grandes, plataformas SaaS, donde el RPO y el RTO son críticos, y hay un equipo con experiencia en DevOps y administración de bases de datos. Ideal para aquellos que buscan una solución lo más automatizada y fiable posible.
pg_auto_failover
pg_auto_failover es una herramienta desarrollada por Citus Data (ahora parte de Microsoft) que simplifica el despliegue y la gestión de clústeres PostgreSQL de alta disponibilidad. Se centra en la facilidad de uso y la automatización, proporcionando un único binario para todos los componentes del clúster: el coordinador (monitor), el maestro y las réplicas.
Cómo funciona: pg_auto_failover crea un clúster de al menos dos nodos PostgreSQL (maestro y réplica) y un nodo monitor separado. El monitor consulta constantemente el estado de todos los nodos y toma decisiones sobre el failover. Si el maestro deja de estar disponible, el monitor inicia el failover, seleccionando una de las réplicas como nuevo maestro y conmutando las conexiones de los clientes a ella. También puede gestionar la replicación síncrona, asegurando un RPO cero en la mayoría de los casos. El monitor en sí mismo puede configurarse para alta disponibilidad, pero esto añade complejidad.
Ventajas:
- Facilidad de despliegue: Significativamente más fácil de configurar en comparación con Patroni.
- Failover automático: Detección de fallos y conmutación completamente automatizadas.
- Monitor integrado: Herramienta única para todas las funciones de HA.
- Soporte de replicación síncrona: Fácil de configurar para un RPO cero.
- Especializado para PostgreSQL: Profunda integración con las características de PostgreSQL.
Desventajas:
- Dependencia del monitor: El monitor es un punto único de fallo si no está configurado para HA.
- Menor flexibilidad: Menos opciones de ajuste fino en comparación con Patroni.
- Comunidad menos madura: Aunque es compatible con Microsoft, la comunidad es más pequeña que la de Patroni.
Para quién es adecuado: Para proyectos de tamaño mediano, startups, donde la simplicidad de despliegue y gestión es importante, pero se requiere un alto nivel de automatización y fiabilidad. Ideal para equipos que desean minimizar el tiempo de configuración de HA y centrarse en el desarrollo.
Replicación por streaming nativa de PostgreSQL + Keepalived/HAProxy
Este enfoque utiliza las capacidades integradas de PostgreSQL para la replicación por streaming en combinación con herramientas externas para la detección de fallos y la gestión de direcciones IP o el balanceo de carga. La replicación por streaming permite transferir continuamente los cambios del servidor maestro a una o varias réplicas, manteniéndolas actualizadas.
Cómo funciona: Se configura un servidor PostgreSQL como maestro y uno o varios como réplicas. Las réplicas reciben continuamente los archivos WAL (Write-Ahead Log) del maestro y los aplican. Para la detección automática de fallos y la conmutación, se utiliza Keepalived: monitoriza el estado del servidor maestro y, en caso de fallo, transfiere automáticamente la dirección IP virtual (VIP) a una de las réplicas, convirtiéndola en el nuevo maestro. HAProxy o Nginx pueden utilizarse para balancear la carga de lectura entre las réplicas y redirigir la escritura al maestro actual. Para automatizar la promoción de una réplica a maestro y la reconfiguración de las demás réplicas, se requieren scripts personalizados que serán ejecutados por Keepalived.
Ventajas:
- Control total: Usted controla completamente cada componente y script.
- Bajo costo: Utiliza solo componentes Open Source sin licencias adicionales.
- Flexibilidad: Se puede configurar para requisitos muy específicos.
- Simplicidad de la replicación básica: La configuración de la replicación por streaming es bastante sencilla.
Desventajas:
- Alta complejidad de automatización: Escribir y depurar scripts fiables para failover, switchover y recuperación es una tarea muy laboriosa y propensa a errores.
- Riesgo de split-brain: Sin un mecanismo de quórum fiable (que Keepalived por sí solo no proporciona), existe el riesgo de que varios maestros se promocionen simultáneamente.
- Alto RTO: El tiempo de recuperación puede ser mayor debido a la intervención manual/script.
- Soporte: Depende de la cualificación de su equipo, no hay soporte centralizado.
Para quién es adecuado: Para proyectos pequeños con presupuesto limitado, donde hay un equipo DBA/DevOps muy experimentado, dispuesto a dedicar tiempo al desarrollo y soporte de scripts personalizados. También puede ser una opción cuando se necesita una solución lo más "ligera" posible sin dependencias adicionales.
Pgpool-II (modo HA)
Pgpool-II es un middleware para PostgreSQL que proporciona una serie de funciones útiles, incluyendo pooling de conexiones, balanceo de carga, caché de consultas y, lo que es importante para nosotros, funciones de alta disponibilidad. Pgpool-II funciona como un proxy entre las aplicaciones cliente y los servidores PostgreSQL.
Cómo funciona: Pgpool-II se coloca delante del clúster PostgreSQL y gestiona las conexiones de los clientes. En modo de alta disponibilidad, monitoriza el estado de los servidores PostgreSQL backend. Si el servidor maestro falla, Pgpool-II puede conmutar automáticamente el tráfico a una de las réplicas, convirtiéndola en el nuevo maestro. También puede gestionar la conmutación de la dirección IP virtual mediante funciones de watchdog que se integran con herramientas como `pcp_attach_node` y `pcp_detach_node` para cambiar el estado de los nodos. Para garantizar la HA del propio Pgpool-II, normalmente se despliegan dos instancias de Pgpool-II con Keepalived para la conmutación de VIP.
Ventajas:
- Multifuncionalidad: Además de HA, proporciona pooling de conexiones, balanceo de lectura, caché.
- Mejora del rendimiento: El pooling y el caché pueden reducir significativamente la carga de la BD.
- Failover automático: Capaz de conmutar automáticamente el maestro.
- Transparencia para las aplicaciones: Las aplicaciones se conectan a Pgpool-II sin conocer la topología del clúster.
Desventajas:
- Punto único de fallo: El propio Pgpool-II puede convertirse en uno si no está configurado para HA (lo que complica la arquitectura).
- Retraso adicional: Introduce una pequeña sobrecarga debido al proxying.
- Complejidad de configuración: La configuración de Pgpool-II puede ser bastante compleja, especialmente con HA y watchdog.
- No gestiona PostgreSQL: Pgpool-II solo gestiona la conmutación, pero no orquesta el propio PostgreSQL (por ejemplo, no restaura réplicas).
Para quién es adecuado: Para proyectos donde, además de la alta disponibilidad, también se requiere optimización del rendimiento mediante el pooling de conexiones y el balanceo de lectura. Adecuado para equipos dispuestos a invertir en el aprendizaje y soporte de Pgpool-II como componente clave de la infraestructura.
Consejos prácticos y recomendaciones para la implementación de Patroni
Patroni es una de las soluciones más potentes y flexibles para HA PostgreSQL, por lo que nos centraremos en su implementación práctica. Esta sección proporcionará instrucciones paso a paso y recomendaciones basadas en la experiencia real.
1. Planificación de la infraestructura
Para un clúster HA de Patroni mínimo con un quórum fiable, necesitará al menos 3 servidores. Estos pueden ser VPS o servidores dedicados. Se recomienda la siguiente configuración:
- 3 nodos PostgreSQL: Cada nodo ejecutará Patroni y PostgreSQL. Uno será el maestro, los otros serán réplicas.
- 3 nodos para Distributed Configuration Store (DCS): etcd o Consul. En clústeres pequeños (3 nodos), el DCS se puede ubicar en los mismos servidores que PostgreSQL/Patroni. En sistemas más grandes o muy críticos, se recomienda colocar el DCS en servidores separados.
Ejemplo de configuración de VPS (año 2026):
- CPU: 4 vCPU
- RAM: 8-16 GB
- Disco: 160-320 GB NVMe SSD (para datos de PostgreSQL)
- Red: 1 Gbit/s
- SO: Ubuntu 24.04 LTS o Debian 13
Asegúrese de que todos los servidores tengan direcciones IP estáticas y los puertos necesarios abiertos (PostgreSQL: 5432, Patroni API: 8008, etcd: 2379/2380, Consul: 8300/8301/8302/8500/8600).
2. Preparación del sistema operativo
En cada uno de los tres servidores, realice la configuración básica:
# Actualización del sistema
sudo apt update && sudo apt upgrade -y
# Instalación de paquetes necesarios
sudo apt install -y python3 python3-pip python3-psycopg2 python3-yaml postgresql-client-16
# Creación del usuario postgres (si no existe o se requiere una configuración específica)
# Por defecto, PostgreSQL crea el usuario postgres, úselo.
# Configuración del firewall (ejemplo para UFW)
sudo ufw allow 22/tcp
sudo ufw allow 5432/tcp
sudo ufw allow 8008/tcp # API de Patroni
sudo ufw allow 2379/tcp # Cliente etcd
sudo ufw allow 2380/tcp # Servidor etcd
sudo ufw enable
3. Instalación y configuración de DCS (etcd)
En cada uno de los tres servidores, instale y configure etcd. En un entorno de producción, es mejor desplegar etcd en nodos dedicados, pero para empezar, se pueden combinar.
# Instalación de etcd (ejemplo para Ubuntu/Debian)
# Descargue la última versión de GitHub: https://github.com/etcd-io/etcd/releases
ETCD_VERSION="v3.5.12" # Actual para 2026, verifique
wget "https://github.com/etcd-io/etcd/releases/download/${ETCD_VERSION}/etcd-${ETCD_VERSION}-linux-amd64.tar.gz"
tar xzvf etcd-${ETCD_VERSION}-linux-amd64.tar.gz
sudo mv etcd-${ETCD_VERSION}-linux-amd64/etcd /usr/local/bin/
sudo mv etcd-${ETCD_VERSION}-linux-amd64/etcdctl /usr/local/bin/
# Creación de directorios para datos de etcd
sudo mkdir -p /var/lib/etcd
sudo mkdir -p /etc/etcd
# Creación del servicio systemd para etcd (en cada nodo)
# Reemplace las direcciones IP y los nombres de los nodos con los suyos
# NODE_1_IP, NODE_2_IP, NODE_3_IP
# NODE_1_NAME, NODE_2_NAME, NODE_3_NAME
# Ejemplo para node1:
sudo nano /etc/systemd/system/etcd.service
Contenido del archivo `/etc/systemd/system/etcd.service` para `node1` (con IP 192.168.1.1):
[Unit]
Description=etcd - Highly-available key value store
Documentation=https://github.com/etcd-io/etcd
After=network.target
[Service]
Type=notify
Restart=always
RestartSec=5s
LimitNOFILE=40000
TimeoutStartSec=0
ExecStart=/usr/local/bin/etcd \\
--name node1 \\
--data-dir /var/lib/etcd \\
--initial-advertise-peer-urls http://192.168.1.1:2380 \\
--listen-peer-urls http://192.168.1.1:2380 \\
--listen-client-urls http://192.168.1.1:2379,http://127.0.0.1:2379 \\
--advertise-client-urls http://192.168.1.1:2379 \\
--initial-cluster-token etcd-cluster-1 \\
--initial-cluster node1=http://192.168.1.1:2380,node2=http://192.168.1.2:2380,node3=http://192.168.1.3:2380 \\
--initial-cluster-state new \\
--heartbeat-interval 100 \\
--election-timeout 500
[Install]
WantedBy=multi-user.target
Repita para `node2` (192.168.1.2) y `node3` (192.168.1.3), cambiando `--name`, `--initial-advertise-peer-urls`, `--listen-peer-urls`, `--listen-client-urls`, `--advertise-client-urls` a las direcciones IP correspondientes. Después de crear el archivo en todos los nodos:
sudo systemctl daemon-reload
sudo systemctl enable etcd
sudo systemctl start etcd
# Verificación del estado del clúster etcd en cualquier nodo
etcdctl --endpoints=http://192.168.1.1:2379,http://192.168.1.2:2379,http://192.168.1.3:2379 member list
4. Instalación de Patroni
En cada nodo, instale Patroni a través de pip:
sudo pip3 install patroni[etcd]
5. Configuración de Patroni
Cree un archivo de configuración de Patroni en cada nodo. Utilice la misma plantilla, cambiando solo los nombres y las direcciones IP de escucha.
sudo mkdir -p /etc/patroni
sudo nano /etc/patroni/patroni.yml
Ejemplo del archivo `patroni.yml` para `node1`:
scope: my_pg_cluster
name: node1 # Nombre único para cada nodo
restapi:
listen: 0.0.0.0:8008
connect_address: 192.168.1.1:8008 # Dirección IP del nodo actual
etcd:
host: 192.168.1.1:2379,192.168.1.2:2379,192.168.1.3:2379
postgresql:
listen: 0.0.0.0:5432
connect_address: 192.168.1.1:5432 # Dirección IP del nodo actual
data_dir: /var/lib/postgresql/data # Ruta a los datos de PG
bin_dir: /usr/lib/postgresql/16/bin # Ruta a los binarios de PG (verifique la versión)
authentication:
replication:
username: repl_user
password: repl_password
superuser:
username: postgres
password: superuser_password
parameters:
wal_level: replica
hot_standby: on
max_wal_senders: 10
max_replication_slots: 10
archive_mode: on
archive_command: 'cd . && test ! -f %p && cp %p %l' # Ejemplo, para producción se necesita un sistema de archivado
log_destination: stderr
logging_collector: on
log_directory: pg_log
log_filename: 'postgresql-%Y-%m-%d_%H%M%S.log'
log_file_mode: 0600
log_truncate_on_rotation: on
log_rotation_age: 1d
log_rotation_size: 10MB
max_connections: 100
# Configuración para la recuperación automática
bootstrap:
dcs:
ttl: 30 # Time-to-live para las claves en DCS
loop_wait: 10 # Retraso entre las iteraciones de Patroni
retry_timeout: 10 # Tiempo de espera para reintentos
maximum_lag_on_failover: 1048576 # Retraso máximo de replicación para failover (1MB)
initdb:
- encoding: UTF8
- locale: en_US.UTF-8
- data-checksums
pg_hba:
- host replication repl_user 0.0.0.0/0 md5
- host all all 0.0.0.0/0 md5
- host all all ::/0 md5
users:
admin_user:
password: admin_password
options:
- createrole
- createdb
repl_user:
password: repl_password
options:
- replication
- bypassrls
Importante:
- Reemplace `192.168.1.1`, `192.168.1.2`, `192.168.1.3` con las direcciones IP actuales de sus servidores.
- Especifique el `bin_dir` correcto para su versión de PostgreSQL (por ejemplo, `/usr/lib/postgresql/16/bin`).
- Establezca contraseñas seguras para `repl_user`, `postgres` y `admin_user`.
- El parámetro `archive_command` en un entorno de producción debe configurarse para un sistema de archivado WAL real (por ejemplo, S3, NFS), no para una copia local.
6. Creación del servicio systemd para Patroni
Cree un archivo de unidad para Patroni en cada nodo:
sudo nano /etc/systemd/system/patroni.service
Contenido de `patroni.service`:
[Unit]
Description=Patroni - A Template for PostgreSQL High Availability
After=network.target etcd.service # Agregue etcd.service si etcd está en el mismo nodo
[Service]
Type=simple
User=postgres
Group=postgres
ExecStart=/usr/bin/python3 -m patroni -c /etc/patroni/patroni.yml
Restart=on-failure
TimeoutStopSec=60
LimitNOFILE=131072
[Install]
WantedBy=multi-user.target
Después de crear el archivo en todos los nodos:
sudo systemctl daemon-reload
sudo systemctl enable patroni
sudo systemctl start patroni
7. Inicialización del clúster
Patroni inicializará automáticamente PostgreSQL en el primer nodo iniciado, que se convertirá en el maestro. Los nodos restantes se unirán a él como réplicas. Espere unos minutos hasta que todos los nodos se inicien y sincronicen.
8. Verificación del estado del clúster
Utilice la utilidad `patronictl` para verificar el estado del clúster en cualquier nodo:
patronictl -c /etc/patroni/patroni.yml list
La salida debería mostrar un maestro y dos réplicas. Ejemplo:
+ Cluster: my_pg_cluster (6909873467941793393) ---+----+-----------+----+-----------+
| Member | Host | Role | State | Lag in MB |
+--------+--------------+---------+----------+-----------+
| node1 | 192.168.1.1 | Leader | running | 0 |
| node2 | 192.168.1.2 | Replica | running | 0 |
| node3 | 192.168.1.3 | Replica | running | 0 |
+--------+--------------+---------+----------+-----------+
9. Prueba de Failover
Este es un paso crítico. Debe probar el failover regularmente para asegurarse de que el clúster funciona como se espera. La forma más sencilla es detener Patroni en el maestro actual:
# En el nodo maestro actual
sudo systemctl stop patroni
Patroni en los nodos restantes detectará que el maestro no está disponible e iniciará el failover. En 5-30 segundos, una de las réplicas debería convertirse en el nuevo maestro. Verifique esto con `patronictl list` en otro nodo. Luego, inicie Patroni en el antiguo maestro, y debería unirse como réplica.
10. Configuración del balanceador de carga (HAProxy)
Para las aplicaciones cliente, se recomienda utilizar un balanceador de carga (por ejemplo, HAProxy) que dirigirá las solicitudes de escritura al maestro actual y las solicitudes de lectura a las réplicas. HAProxy se puede configurar para monitorizar la API de Patroni y determinar el rol de cada nodo.
Ejemplo de configuración de HAProxy (en un servidor separado, o en cada nodo si se utiliza Keepalived para HAProxy):
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats socket /run/haproxy/admin.sock mode 660 level admin expose-fd listeners
stats timeout 30s
user haproxy
group haproxy
daemon
defaults
log global
mode tcp
option tcplog
option dontlognull
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
listen stats
bind *:8080
mode http
stats enable
stats uri /haproxy_stats
stats refresh 10s
stats auth admin:password
listen postgres_primary
bind *:5432
mode tcp
option httpchk GET /primary # Utilizamos la API de Patroni para verificar el rol
balance roundrobin
server node1 192.168.1.1:5432 check port 8008 inter 1s fall 3 rise 2 weight 10 on-marked-down shutdown-sessions
server node2 192.168.1.2:5432 check port 8008 inter 1s fall 3 rise 2 weight 10 on-marked-down shutdown-sessions
server node3 192.168.1.3:5432 check port 8008 inter 1s fall 3 rise 2 weight 10 on-marked-down shutdown-sessions
listen postgres_replicas
bind *:5433 # Puerto separado para lectura desde réplicas
mode tcp
option httpchk GET /replica # Utilizamos la API de Patroni para verificar el rol
balance leastconn
server node1 192.168.1.1:5432 check port 8008 inter 1s fall 3 rise 2 weight 10 on-marked-down shutdown-sessions
server node2 192.168.1.2:5432 check port 8008 inter 1s fall 3 rise 2 weight 10 on-marked-down shutdown-sessions
server node3 192.168.1.3:5432 check port 8008 inter 1s fall 3 rise 2 weight 10 on-marked-down shutdown-sessions
En este ejemplo, HAProxy dirigirá el tráfico al puerto 5432 solo al nodo que Patroni haya identificado como maestro (`/primary`). Al puerto 5433, dirigirá las solicitudes de lectura a todos los nodos que Patroni haya identificado como réplicas (`/replica`), incluyendo el maestro (que también puede procesar solicitudes de lectura).
Estos consejos prácticos le ayudarán a desplegar y configurar con éxito un clúster HA de PostgreSQL básico utilizando Patroni. Recuerde que cada paso requiere atención, y las pruebas son la clave para la confianza en el funcionamiento de su sistema.
Errores comunes al construir un clúster HA de PostgreSQL

Incluso los ingenieros experimentados pueden cometer errores al diseñar y desplegar sistemas de alta disponibilidad. Comprender estos problemas comunes le ayudará a evitar costosos tiempos de inactividad y dolores de cabeza. Aquí están los cinco errores más frecuentes:
1. Quórum insuficiente o mal configurado (Split-Brain)
Descripción: El quórum es el número mínimo de nodos que deben estar disponibles para tomar decisiones en un clúster. Si el quórum no está configurado o está mal configurado, en caso de una partición de red (network partition), dos o más nodos pueden decidir que son maestros. Este estado se denomina "split-brain" y conduce a la desincronización de datos, donde cada "maestro" acepta escrituras de forma independiente, lo que hace que la recuperación sea muy compleja y propensa a la pérdida de datos.
Cómo evitarlo: Utilice siempre un número impar de nodos para su DCS (Distributed Configuration Store), por ejemplo, 3 o 5. Esto garantiza que, en caso de fallo de uno o dos nodos, siempre habrá una mayoría capaz de decidir la elección del maestro. Patroni y pg_auto_failover utilizan mecanismos de quórum por defecto. Asegúrese de que la configuración del DCS (etcd/Consul) sea correcta y resistente a fallos. Verifique regularmente el estado del quórum.
Consecuencias reales: "En una empresa, debido a una configuración incorrecta del clúster etcd, durante un fallo temporal de la red, dos nodos se consideraron maestros. Las aplicaciones continuaron escribiendo datos en ambos nodos. Cuando la red se restauró, los datos se habían desincronizado. La recuperación tardó más de 12 horas, requirió un análisis manual de los logs y la elección del maestro 'correcto', lo que resultó en la pérdida de parte de las transacciones y graves costos reputacionales."
2. Falta o insuficiencia de pruebas de Failover y Recovery
Descripción: Muchos ingenieros despliegan un clúster HA, ven que funciona y se dan por satisfechos. Sin embargo, los mecanismos de failover y recovery pueden ser complejos, y su comportamiento en condiciones reales (por ejemplo, con un tipo de fallo específico o bajo carga) puede diferir de lo esperado. Un failover no probado no es un failover que funcione.
Cómo evitarlo: Realice "simulacros" de recuperación ante desastres regularmente, al menos una vez por trimestre. Esto incluye la desconexión artificial del nodo maestro, la simulación de problemas de red y la detención completa del DCS. Mida el RTO y verifique la integridad de los datos después de la recuperación. Automatice estas pruebas si es posible. Asegúrese de que su equipo sepa cómo actuar en caso de un fallo real.
Consecuencias reales: "Una vez, en una startup donde yo asesoraba, el clúster Patroni había sido configurado hacía más de un año. Durante el primer fallo real, resultó que debido a una actualización del sistema operativo, las rutas a los binarios de PostgreSQL habían cambiado, y Patroni no pudo iniciar correctamente el nuevo maestro. El tiempo de inactividad se prolongó durante varias horas mientras los ingenieros investigaban la causa y ajustaban manualmente la configuración. Si hubieran probado el failover regularmente, este problema se habría detectado mucho antes de la producción."
3. Ignorar la monitorización y las alertas
Descripción: Los clústeres HA son inherentemente más complejos que los servidores individuales. Sin una monitorización adecuada, es imposible detectar rápidamente problemas como el retraso de la replicación, el agotamiento del espacio en disco, la alta carga en el DCS o problemas de red. La falta de alertas significa que solo se enterará del problema cuando ya haya provocado un tiempo de inactividad.
Cómo evitarlo: Implemente un sistema de monitorización integral (Prometheus+Grafana, Zabbix, Datadog) para todos los componentes del clúster: PostgreSQL (métricas, replicación, WAL), Patroni (API), DCS (etcd/Consul), sistema operativo (CPU, RAM, disco, red). Configure alertas (Alertmanager, Slack, Telegram, PagerDuty) para métricas críticas: RPO > X segundos, espacio en disco < Y%, número de nodos en el clúster < Z, indisponibilidad de la API de Patroni. Revise regularmente los umbrales de las alertas.
Consecuencias reales: "Un cliente tenía Patroni configurado, pero la monitorización de la replicación era básica. Debido a un error de red entre los centros de datos, la replicación comenzó a retrasarse varias horas. No hubo alertas, ya que los umbrales eran demasiado altos. Cuando el maestro falló, el failover se realizó, pero el nuevo maestro tenía datos con un retraso de 3 horas, lo que llevó a la reversión de parte de las transacciones y a tener que restaurar los datos desde una copia de seguridad, lo que tardó casi un día."
4. Configuración incorrecta de red y DNS
Descripción: La red es la base de cualquier clúster distribuido. Una configuración incorrecta de DNS, problemas de resolución de nombres, reglas de firewall erróneas y enrutamiento asimétrico pueden provocar que los nodos no puedan "verse" entre sí, o que las aplicaciones no puedan conectarse al maestro actual después de un failover.
Cómo evitarlo: Asegúrese de que todos los nodos puedan comunicarse entre sí a través de todos los puertos necesarios. Utilice direcciones IP estáticas. Configure el DNS de manera que el nombre de host de su clúster (por ejemplo, `pg-cluster.mydomain.com`) siempre apunte al maestro actual (a través de un balanceador de carga o una actualización dinámica de DNS). Verifique las reglas del firewall en cada nodo. Utilice redes internas para el tráfico de replicación y DCS, si es posible.
Consecuencias reales: "En un proyecto, después de un failover automático, las aplicaciones no pudieron conectarse al nuevo maestro. El problema resultó ser el almacenamiento en caché de DNS en el lado del cliente y un TTL demasiado largo para el registro A. Tuvimos que borrar manualmente las cachés y reiniciar las aplicaciones, lo que aumentó el RTO varias veces. Desde entonces, utilizamos un TTL muy bajo para los registros DNS del clúster y recomendamos usar un balanceador de carga con comprobación de estado de los nodos."
5. Descuidar las copias de seguridad y sus pruebas
Descripción: La alta disponibilidad protege contra el tiempo de inactividad, pero no contra la pérdida de datos debido a errores lógicos (por ejemplo, la eliminación accidental de una tabla) o fallos catastróficos (por ejemplo, la falla simultánea de todos los nodos en un centro de datos). Las copias de seguridad son su última línea de defensa. Si las copias de seguridad no se realizan regularmente, no se almacenan de forma segura o, lo que es peor, no se prueban para su recuperación, son inútiles.
Cómo evitarlo: Implemente una estrategia de copia de seguridad fiable (por ejemplo, con pgBackRest o Barman) con copias de seguridad completas e incrementales regulares. Almacene las copias de seguridad en un almacenamiento remoto y geográficamente distribuido (por ejemplo, almacenamiento compatible con S3). Lo más importante: restaure regularmente las copias de seguridad en un entorno de prueba para verificar su integridad y funcionalidad. Esta es la única forma de asegurarse de que, en caso de necesidad, realmente podrá recuperar los datos.
Consecuencias reales: "En una empresa, se produjo un error lógico en la aplicación que provocó la eliminación masiva de datos. El clúster HA siguió funcionando, pero los datos se perdieron. Cuando se intentó restaurar desde una copia de seguridad, se descubrió que, debido a un error de configuración, las copias de seguridad de los últimos 3 meses estaban dañadas y no se podían restaurar. La empresa tuvo que restaurar los datos de copias de seguridad más antiguas y transferir manualmente parte de la información, lo que resultó en pérdidas significativas y multas de los reguladores."
Checklist para la aplicación práctica: Despliegue de HA PostgreSQL
Esta lista de verificación paso a paso le ayudará a sistematizar el proceso de despliegue de un clúster PostgreSQL de alta disponibilidad, minimizando la probabilidad de errores y garantizando un enfoque integral.
Fase 1: Planificación y Diseño
- Definición de requisitos RPO y RTO: Establezca claramente cuántos datos está dispuesto a perder y con qué rapidez debe recuperarse después de un fallo. Estos son parámetros clave para la elección de la arquitectura.
- Elección de la solución HA: Basándose en el RPO, RTO, presupuesto, complejidad y experiencia del equipo, elija la solución óptima (Patroni, pg_auto_failover, replicación nativa + scripts, Pgpool-II).
- Diseño de la arquitectura del clúster:
- Defina el número de nodos (mínimo 3 para Patroni/etcd, 2+monitor para pg_auto_failover).
- Distribuya los nodos en diferentes centros de datos/racks/proveedores para aumentar la resiliencia (si el presupuesto lo permite).
- Planifique la ubicación del DCS (etcd/Consul) — junto con la BD o en nodos separados.
- Evaluación de recursos de servidores: Determine la configuración necesaria de CPU, RAM, SSD y recursos de red para cada nodo, basándose en la carga esperada.
- Planificación de la infraestructura de red:
- Asigne direcciones IP estáticas para todos los nodos.
- Defina los puertos para PostgreSQL (5432), Patroni API (8008), DCS (etcd: 2379/2380, Consul: 8500), balanceador de carga (5432, 5433).
- Configure las reglas del firewall (UFW, firewalld, ACL de red del proveedor) para permitir el tráfico necesario.
- Desarrollo de la estrategia de copia de seguridad y recuperación: Elija la herramienta (pgBackRest, Barman), defina la frecuencia, el lugar de almacenamiento (remoto, geográficamente distribuido) y los procedimientos de recuperación.
- Planificación de la monitorización y las alertas: Elija las herramientas (Prometheus, Grafana, Alertmanager) y defina las métricas clave y los umbrales para las alertas.
- Documentación: Cree una documentación detallada sobre la arquitectura, configuración, procedimientos de failover/switchover y recuperación ante desastres.
Fase 2: Preparación de la Infraestructura
- Pedido/asignación de servidores: Despliegue el número necesario de VPS o servidores dedicados.
- Configuración básica del SO: Instale el SO elegido (Ubuntu LTS, Debian), actualice el sistema, configure el acceso SSH, la zona horaria, NTP.
- Instalación de PostgreSQL: Instale PostgreSQL en todos los nodos, pero no lo inicialice manualmente (Patroni/pg_auto_failover lo hará).
- Instalación de dependencias: Instale Python, pip, psycopg2, PyYAML y otras dependencias para Patroni/pg_auto_failover.
- Configuración del firewall: Abra los puertos necesarios en cada nodo.
- Configuración de DNS: Asegúrese de que los nombres de host se resuelvan correctamente y, si es necesario, configure la actualización dinámica de DNS o utilice un balanceador de carga.
Fase 3: Despliegue de la solución HA
- Instalación y configuración del DCS (si es necesario): Despliegue etcd/Consul en todos los nodos, asegúrese de que el clúster DCS funcione correctamente.
- Instalación y configuración de Patroni/pg_auto_failover:
- Instale la herramienta elegida.
- Cree archivos de configuración en cada nodo, adaptándolos a las especificidades de cada servidor (nombre, direcciones IP).
- Configure los parámetros de PostgreSQL en la configuración de la herramienta HA (wal_level, max_wal_senders, etc.).
- Configure los usuarios para la replicación y el superusuario con contraseñas seguras.
- Creación de servicios systemd: Cree y configure los servicios systemd para Patroni/pg_auto_failover en cada nodo.
- Inicio del clúster: Inicie los servicios DCS (si son separados), luego Patroni/pg_auto_failover en todos los nodos.
- Inicialización del clúster: Espere a la inicialización automática del maestro y la unión de las réplicas.
- Verificación del estado del clúster: Utilice `patronictl list` o `pg_auto_failover show state` para confirmar el funcionamiento correcto.
Fase 4: Pruebas y Monitorización
- Configuración del balanceador de carga: Despliegue y configure HAProxy/PgBouncer para enrutar el tráfico al maestro y a las réplicas.
- Configuración de la monitorización: Integre el clúster en su sistema de monitorización, configure la recopilación de métricas y las alertas.
- Prueba de Failover: Inicie un fallo artificial del maestro y verifique la conmutación automática a la réplica, mida el RTO.
- Prueba de Switchover: Realice una conmutación planificada del maestro a una réplica.
- Prueba de recuperación desde copia de seguridad: Restaure una base de datos de prueba desde una copia de seguridad en un entorno separado.
- Prueba de rendimiento: Realice pruebas de carga del clúster en diferentes escenarios.
- Actualización de la documentación: Actualice toda la documentación después del despliegue y las pruebas.
Fase 5: Operación y Mantenimiento
- Monitorización regular: Supervise constantemente el estado del clúster, responda a las alertas.
- Pruebas regulares: Continúe probando periódicamente el failover y la recuperación de copias de seguridad.
- Actualización de software: Planifique y realice actualizaciones de PostgreSQL, Patroni/pg_auto_failover, DCS y el SO de acuerdo con las mejores prácticas para sistemas HA.
- Análisis de logs: Revise regularmente los logs de PostgreSQL, Patroni y DCS para identificar posibles problemas.
- Optimización: Analice el rendimiento y, si es necesario, optimice la configuración de PostgreSQL y la solución HA.
Cálculo de costos / Economía de un clúster PostgreSQL de alta disponibilidad
La creación y el mantenimiento de un clúster PostgreSQL de alta disponibilidad en servidores VPS o dedicados conllevan ciertos costos. Es importante comprender no solo los gastos directos, sino también los ocultos, para obtener una visión completa del TCO (Costo Total de Propiedad) y gestionar eficazmente el presupuesto. Las cifras que se presentan a continuación son orientativas para el año 2026 y pueden variar según el proveedor, la región y los requisitos específicos.
Principales partidas de gastos
- Costo de los servidores (VPS/Dedicados): Esta es la partida de gastos principal y más obvia. Para un clúster HA se requieren al menos 3 nodos para garantizar el quórum y la tolerancia a fallos (por ejemplo, 1 maestro, 2 réplicas).
- VPS: Más flexibles, escalables y a menudo más baratos para cargas pequeñas y medianas. El costo depende de vCPU, RAM, SSD y tráfico de red.
- Servidores dedicados: Ofrecen el máximo rendimiento y control, pero son más caros y requieren más esfuerzo de gestión.
- Costo de almacenamiento de datos (Storage): Además del disco básico del SO, necesitará un almacenamiento lo suficientemente rápido y voluminoso para los datos de PostgreSQL (logs WAL, bases de datos). Los SSD NVMe son el estándar para sistemas de producción.
- Tráfico de red: El tráfico entrante suele ser gratuito, pero el saliente puede tener un costo, especialmente con grandes volúmenes de replicación entre centros de datos o con copias de seguridad frecuentes en almacenamiento en la nube.
- Sistemas de monitorización y registro: Aunque muchas soluciones son de código abierto (Prometheus, Grafana, ELK), su despliegue y soporte requieren recursos. Las soluciones comerciales (Datadog, New Relic) simplifican significativamente la vida, pero tienen su propio costo.
- Copia de seguridad y DR: Almacenamiento de copias de seguridad (almacenamientos compatibles con S3, NFS), así como costos de entornos de prueba para la recuperación.
- Tiempo de ingeniería (Capital Humano): Esta es a menudo una de las partidas de gastos más significativas y subestimadas. Tiempo de los ingenieros para el diseño, despliegue, configuración, pruebas, monitorización, mantenimiento, resolución de problemas y capacitación. Los sistemas HA son más complejos que los servidores individuales y requieren una mayor cualificación.
- Licencias de software: PostgreSQL y la mayoría de las herramientas HA (Patroni, pg_auto_failover, HAProxy, etcd, Consul) son de código abierto y gratuitas. Sin embargo, si utiliza sistemas operativos comerciales o software especializado, puede haber tarifas de licencia.
Costos ocultos
- Tiempos de inactividad: El costo del tiempo de inactividad puede ser enorme (pérdida de ingresos, daño a la reputación, multas por SLA). Las inversiones en HA son un seguro contra estas pérdidas.
- Pérdida de ingresos: Una base de datos lenta o fallos frecuentes pueden ahuyentar a los clientes, reducir la conversión e impedir el crecimiento del negocio.
- Capacitación del equipo: Mantener la cualificación de los ingenieros para trabajar con sistemas HA complejos.
- Escalabilidad: Una arquitectura mal elegida puede requerir un rediseño completo a medida que crece la carga.
- Deuda técnica: La falta de atención a la HA en las primeras etapas conduce a la acumulación de deuda técnica, que luego será más costosa.
Cómo optimizar los costos
- Elección óptima de VPS/servidores: No pague de más por recursos excesivos, pero tampoco escatime en componentes críticos (SSD, RAM). Comience con una configuración mínimamente suficiente y escale a medida que crezca.
- Uso de Open Source: Utilice al máximo las soluciones Open Source gratuitas para todos los componentes (SO, BD, herramientas HA, monitorización).
- Automatización: Invierta en la automatización del despliegue (Ansible, Terraform) y las operaciones. Esto reducirá los costos de tiempo de ingeniería a largo plazo.
- Monitorización inteligente: La detección temprana de problemas previene costosos tiempos de inactividad.
- Estrategia de copia de seguridad eficiente: Utilice copias de seguridad incrementales, compresión y almacene solo la cantidad necesaria de copias para reducir los costos de almacenamiento.
- Arquitectura de red: Utilice las redes internas del proveedor para el tráfico de replicación y DCS para evitar cargos por tráfico saliente.
- Capacitación y documentación: Las inversiones en el conocimiento del equipo y una buena documentación reducen los riesgos y el tiempo de resolución de problemas.
Tabla con ejemplos de cálculos para diferentes escenarios (año 2026, USD/mes)
Se asume el uso de 3 nodos VPS para el clúster PostgreSQL (Patroni + etcd) y un VPS para el balanceador de carga HAProxy/PgBouncer, así como almacenamiento remoto para las copias de seguridad.
| Partida de gastos | Proyecto pequeño (3 VPS x 2vCPU/4GB RAM/80GB NVMe) | Proyecto mediano (3 VPS x 4vCPU/8GB RAM/160GB NVMe) | Proyecto grande (3 VPS x 8vCPU/16GB RAM/320GB NVMe) |
|---|---|---|---|
| VPS para PostgreSQL (3 unidades) | 3 x $15 = $45 | 3 x $35 = $105 | 3 x $70 = $210 |
| VPS para HAProxy/PgBouncer (1 unidad) | 1 x $10 = $10 | 1 x $15 = $15 | 1 x $20 = $20 |
| Almacenamiento remoto para copias de seguridad (compatible con S3) | $5 (500 GB) | $10 (1 TB) | $25 (2.5 TB) |
| Tráfico de red (saliente) | $5 | $10 | $25 |
| Monitorización (Open Source, costos de VPS) | $0 (совместно с HAProxy) | $10 (VPS separado) | $20 (VPS separado) |
| TOTAL gastos directos (USD/mes) | $65 | $150 | $300 |
| Tiempo de ingeniería (estimado, USD/mes)* | $200-500 | $500-1500 | $1500-3000+ |
| TOTAL TCO (directos + tiempo de ing.) | $265-565 | $650-1650 | $1800-3300+ |
*Nota sobre el tiempo de ingeniería: Esta es una estimación muy aproximada, que depende en gran medida de la cualificación del equipo, el nivel de automatización y la complejidad del proyecto. Incluye el tiempo de despliegue, soporte, monitorización, resolución de problemas y pruebas. Al inicio del proyecto, los costos de tiempo de ingeniería serán significativamente mayores.
Como se puede ver en la tabla, los costos directos de infraestructura para un clúster HA son bastante asequibles incluso para proyectos pequeños. Sin embargo, una partida de gastos mucho más significativa es el tiempo de ingeniería, especialmente en la fase de implementación y con un bajo nivel de automatización. La elección correcta de la solución y la inversión en automatización se amortizan al reducir el TCO a largo plazo y aumentar la fiabilidad del sistema.
Casos de estudio y ejemplos de implementaciones reales de HA PostgreSQL
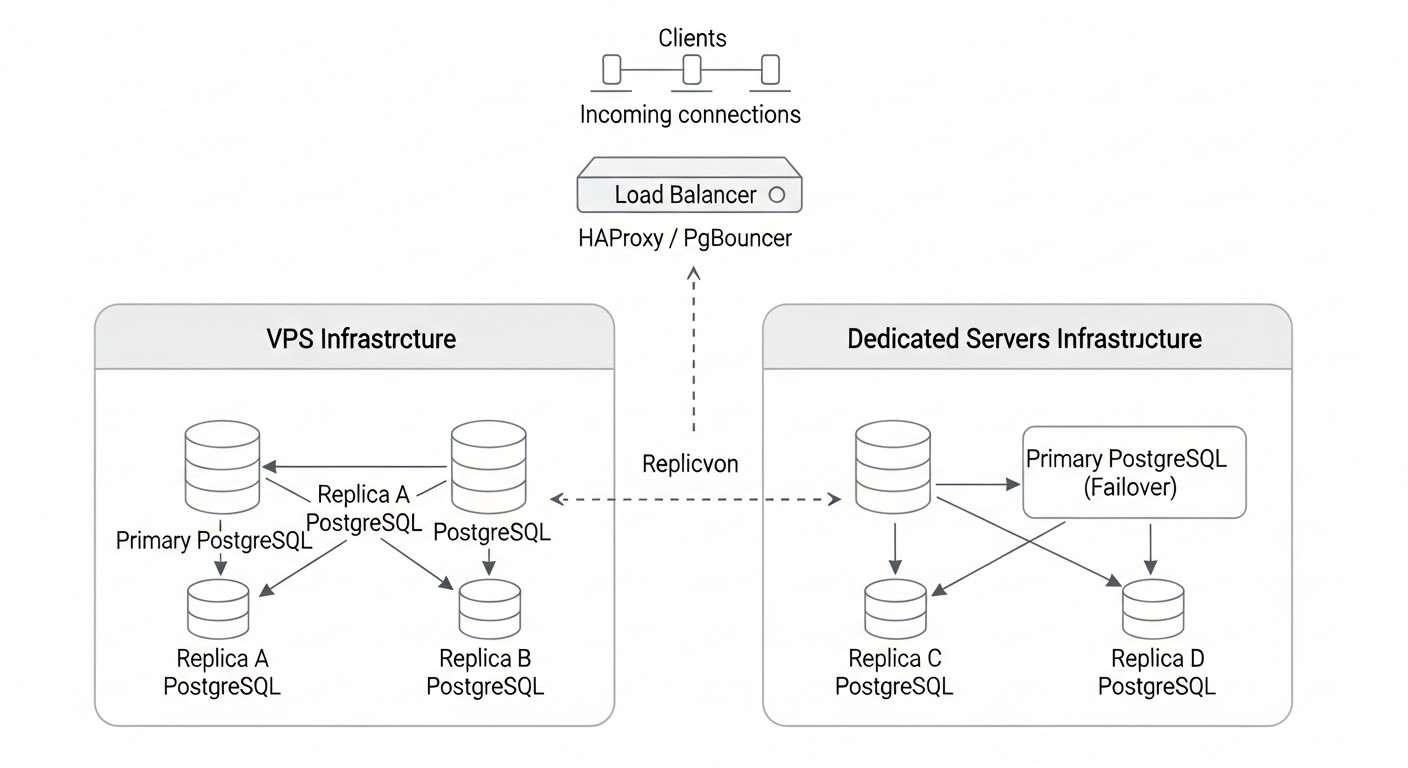
La teoría es importante, pero los casos reales ofrecen una mejor comprensión de cómo funcionan las soluciones HA en la práctica y qué desafíos ayudan a superar. Aquí hay algunos escenarios de nuestra práctica y la experiencia de colegas.
Caso 1: Plataforma SaaS para la gestión de proyectos (Patroni + etcd)
Problema: Una joven empresa SaaS estaba creciendo activamente, y su única instancia de PostgreSQL en un servidor dedicado se convirtió en un punto crítico de fallo. Cualquier tiempo de inactividad resultaba en la indisponibilidad del servicio para miles de clientes, lo que afectaba directamente la reputación y los ingresos. El RPO se estableció en 0 segundos (replicación síncrona), el RTO, en no más de 30 segundos.
Solución: Se decidió desplegar un clúster Patroni con etcd.
- Arquitectura: 3 servidores dedicados (8vCPU, 32GB RAM, 500GB NVMe SSD) en un mismo centro de datos, pero en diferentes racks, para minimizar los riesgos de fallo de hardware. Cada servidor ejecutaba PostgreSQL 16, Patroni y etcd.
- Configuración de Patroni: Se configuró la replicación síncrona con un `synchronous_standby_names`, lo que garantizaba un RPO cero. Se utilizó HAProxy en un VPS separado para enrutar el tráfico: escritura al maestro (puerto 5432), lectura a las réplicas (puerto 5433).
- Monitorización: Prometheus con `postgres_exporter` y `patroni_exporter`, Grafana para visualización, Alertmanager para alertas en Slack y PagerDuty.
- Copias de seguridad: pgBackRest para copias de seguridad incrementales en almacenamiento compatible con S3.
Resultados:
- RTO 15 segundos: Al simular un fallo del maestro (apagado del servidor), Patroni conmutaba automáticamente el rol a una réplica en 15-20 segundos.
- RPO cero: Gracias a la replicación síncrona, no se registró pérdida de datos en caso de fallos.
- Mejora del SLA: La empresa pudo garantizar a sus clientes una disponibilidad del servicio del 99.99%.
- Reducción del estrés operativo: La automatización del failover permitió al equipo de DevOps centrarse en el desarrollo, en lugar de la recuperación manual.
Caso 2: Plataforma de E-commerce con alta carga de lectura (pg_auto_failover + PgBouncer)
Problema: Una gran tienda en línea experimentaba picos de carga durante las ventas, lo que provocaba una degradación del rendimiento de la BD y, en ocasiones, tiempos de inactividad breves. El problema principal era la escalabilidad de lectura y la necesidad de una recuperación rápida después de los fallos. El RPO era aceptable en unos pocos segundos, el RTO, hasta 1 minuto.
Solución: Implementación de pg_auto_failover en combinación con PgBouncer para el pooling de conexiones y HAProxy para el balanceo de carga.
- Arquitectura: 2 servidores dedicados (16vCPU, 64GB RAM, 1TB NVMe SSD) para PostgreSQL (maestro y réplica) y 1 VPS para el monitor pg_auto_failover. Adicionalmente, 2 VPS para PgBouncer y HAProxy en modo activo/pasivo con Keepalived.
- Configuración de pg_auto_failover: Replicación asíncrona para un mejor rendimiento, pero con configuraciones de `wal_level = replica` y `hot_standby = on`. El monitor pg_auto_failover se ubicó en un nodo separado para aumentar la fiabilidad.
- PgBouncer: Desplegado en dos nodos (HAProxy delante de ellos) para gestionar cientos de miles de conexiones de clientes, reduciendo la carga en PostgreSQL.
- HAProxy: Configurado para dirigir las solicitudes de escritura al maestro actual (a través de PgBouncer) y balancear las solicitudes de lectura entre el maestro y la réplica (también a través de PgBouncer).
- Copias de seguridad: Barman para copias de seguridad por streaming y recuperación a un punto en el tiempo.
Resultados:
- RTO ~45 segundos: En caso de fallo del maestro, pg_auto_failover conmutaba con éxito, y HAProxy y PgBouncer redirigían rápidamente el tráfico.
- Escalado de lectura: PgBouncer y HAProxy distribuían eficazmente la carga de lectura, permitiendo al clúster soportar picos de hasta 100.000 RPS.
- Estabilidad: Se redujo significativamente el número de tiempos de inactividad y degradaciones del rendimiento durante las cargas altas.
- Gestión simplificada: pg_auto_failover simplificó las tareas de gestión de HA en comparación con scripts personalizados.
Caso 3: Startup con arquitectura de microservicios (Patroni en contenedores en VPS)
Problema: Una pequeña startup estaba desarrollando una nueva plataforma de microservicios y necesitaba una BD de alta disponibilidad que se integrara fácilmente con un entorno de contenedores (Docker/Kubernetes). El presupuesto era limitado, por lo que se utilizaron VPS. Se requería un failover rápido y flexibilidad en la gestión.
Solución: Despliegue de Patroni en contenedores Docker en 3 VPS con etcd, también ejecutado en contenedores.
- Arquitectura: 3 VPS (4vCPU, 8GB RAM, 160GB NVMe SSD). Docker se ejecutaba en cada VPS. En cada VPS se ejecutaban contenedores para PostgreSQL, Patroni y etcd.
- Configuración: Se utilizaron imágenes oficiales de Docker de PostgreSQL y Patroni. La configuración de Patroni se adaptó para funcionar en contenedores, con el montaje de volúmenes para los datos de PostgreSQL y etcd. La red de contenedores se configuró para interactuar a través de las direcciones IP internas de los VPS.
- Interacción con microservicios: Los microservicios se conectaban al clúster a través de HAProxy, ejecutado en un VPS separado, que monitorizaba la API de Patroni para determinar el maestro.
- CICD: El despliegue y la actualización del clúster Patroni se automatizaron utilizando GitLab CI/CD y Ansible.
Resultados:
- Despliegue rápido: Gracias a la contenerización y la automatización, el despliegue de un nuevo clúster tomaba solo unos minutos.
- Alta disponibilidad: El clúster sobrevivió con éxito a fallos de VPS individuales, conmutando automáticamente el maestro.
- Rentabilidad: El uso de VPS y soluciones de código abierto permitió ajustarse a un presupuesto limitado.
- Flexibilidad: Fácil escalado del clúster añadiendo nuevos VPS y ejecutando contenedores en ellos.
Estos casos demuestran que, con la elección correcta de herramientas y un enfoque adecuado, se puede lograr un alto nivel de disponibilidad de PostgreSQL incluso en servidores VPS y dedicados relativamente económicos, satisfaciendo diversas necesidades comerciales.
Herramientas y recursos para la gestión de un clúster HA PostgreSQL
El despliegue y mantenimiento exitosos de un clúster PostgreSQL de alta disponibilidad son imposibles sin el conjunto adecuado de herramientas. Aquí enumeramos las utilidades y recursos clave que le ayudarán en cada etapa.
1. Herramientas para la creación de clústeres HA
- Patroni: (Zalando) — Orquestador para PostgreSQL, que utiliza DCS para la coordinación de HA. Imprescindible para clústeres automatizados y fiables.
- pg_auto_failover: (Citus Data / Microsoft) — Solución simplificada para failover automático, integrada con PostgreSQL.
- Pgpool-II: Servidor proxy con pooling de conexiones, balanceo de carga y funciones HA.
2. Almacenes de configuración distribuidos (DCS)
Necesarios para Patroni, proporcionan quórum y almacenan el estado del clúster.
- etcd: Almacén clave/valor distribuido de alta disponibilidad, a menudo utilizado en Kubernetes.
- Consul: Service mesh y almacén clave/valor distribuido de HashiCorp.
- Apache ZooKeeper: Otra solución madura para la coordinación distribuida.
3. Balanceadores de carga y proxies
- HAProxy: Balanceador de carga TCP/HTTP de alto rendimiento. Ideal para distribuir las solicitudes de los clientes entre el maestro y las réplicas.
- PgBouncer: Pooler de conexiones ligero para PostgreSQL. Reduce la carga en el servidor de BD de un gran número de conexiones de clientes.
- Keepalived: Se utiliza para garantizar la alta disponibilidad de direcciones IP (IP Virtual) y servicios mediante el protocolo VRRP. A menudo se utiliza con HAProxy.
4. Herramientas de copia de seguridad y recuperación
- pgBackRest: Herramienta potente y flexible para la copia de seguridad y recuperación de PostgreSQL, compatible con copias de seguridad incrementales, compresión y almacenamiento remoto.
- Barman: (Backup and Recovery Manager) — Otra herramienta popular para la gestión centralizada de copias de seguridad de PostgreSQL, incluyendo la recuperación a un punto en el tiempo.
5. Herramientas de monitorización y registro
- Prometheus: Sistema de monitorización y alertas con un potente lenguaje de consulta PromQL.
- Grafana: Plataforma para la visualización de datos de monitorización.
- postgres_exporter: Exportador de métricas de PostgreSQL para Prometheus.
- patroni_exporter: Exportador de métricas de Patroni para Prometheus.
- pgBadger: Potente analizador de logs de PostgreSQL, que genera informes HTML detallados.
- ELK Stack (Elasticsearch, Logstash, Kibana): Para la recopilación, almacenamiento, indexación y visualización centralizada de logs.
6. Automatización del despliegue
- Ansible: Herramienta para la automatización de la configuración y el despliegue de software. Ideal para la gestión de la configuración del clúster.
- Terraform: Herramienta para la gestión de infraestructura como código (IaC). Permite automatizar la creación de VPS y su configuración básica.
7. Enlaces y documentación útiles
- Documentación oficial de PostgreSQL — Fuente de información siempre actualizada y completa sobre el propio SGBD.
- PostgreSQL Wiki: High Availability and Load Balancing — Resumen de diversas soluciones y enfoques de HA.
- Blogs y comunidades: Planet PostgreSQL, PostgreSQL.ru, Habr, varios canales de Telegram sobre PostgreSQL y DevOps — excelentes fuentes para estudiar casos y resolver problemas.
Troubleshooting: Solución de problemas comunes en HA PostgreSQL
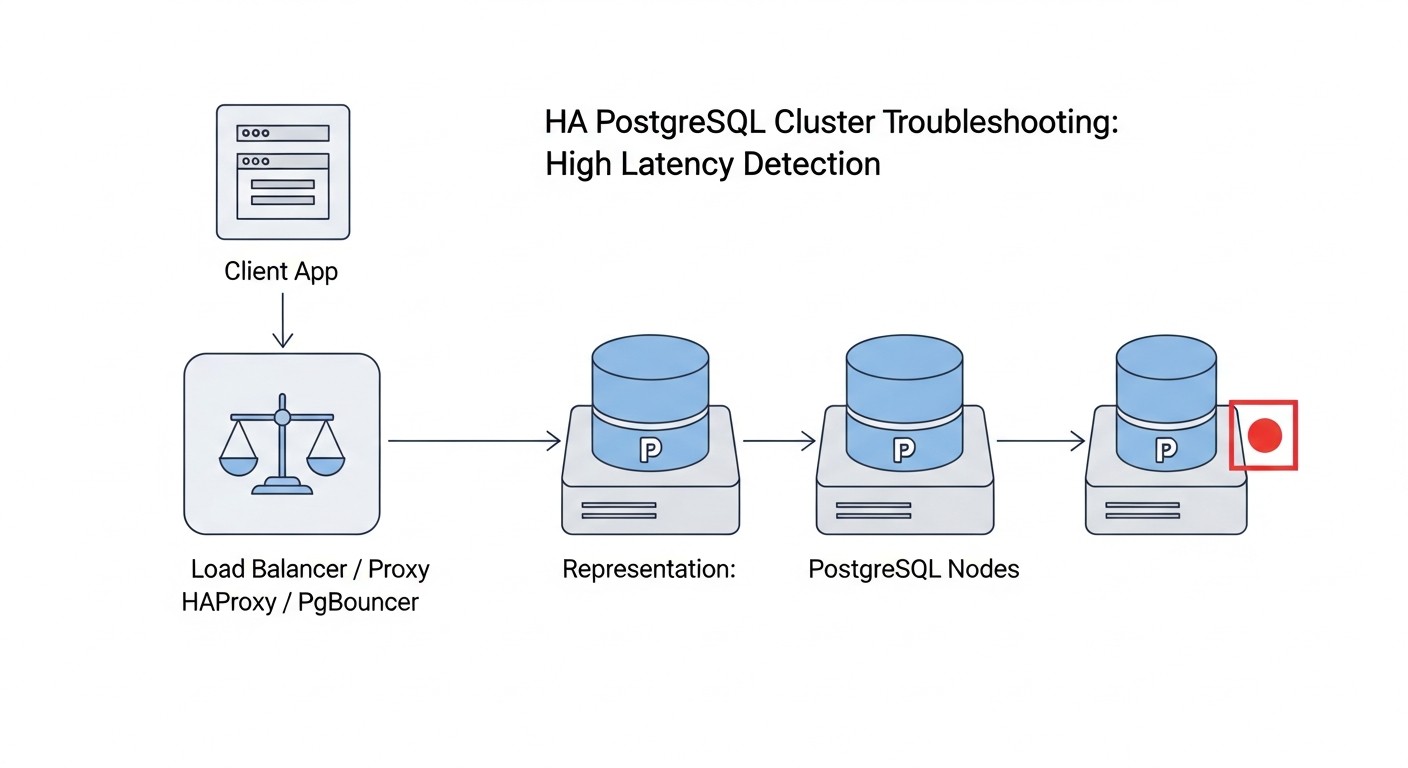
Incluso con la configuración más meticulosa, pueden surgir problemas en los sistemas de alta disponibilidad. Es importante saber cómo diagnosticarlos y resolverlos rápidamente. Aquí se presentan algunos problemas típicos y enfoques para su solución.
1. Problemas de replicación (Replication Lag)
Síntomas: Las réplicas se retrasan significativamente con respecto al maestro, lo que se observa en las métricas de monitorización o en las consultas.
Diagnóstico:
-- En el maestro
SELECT client_addr, state, sync_state, pg_wal_lsn_diff(pg_current_wal_lsn(), replay_lsn) AS lag_bytes
FROM pg_stat_replication;
-- En la réplica
SELECT pg_wal_lsn_diff(pg_last_wal_receive_lsn(), pg_last_wal_replay_lsn()); -- Lag en bytes
Posibles causas y soluciones:
- Problemas de red: Conexión de red lenta o inestable entre el maestro y la réplica.
- Solución: Verifique el ancho de banda (`iperf3`) y la latencia (`ping`, `mtr`) entre los nodos. Asegúrese de que no haya pérdida de paquetes. Es posible que sea necesario optimizar la infraestructura de red o utilizar VPS/servidores dedicados más rápidos.
- Carga en la réplica: La réplica está sobrecargada con solicitudes de lectura, lo que impide la aplicación de los archivos WAL.
- Solución: Optimice las solicitudes de lectura, añada más réplicas para distribuir la carga, considere el uso de PgBouncer para una gestión eficiente de las conexiones.
- Disco lento en la réplica: El subsistema de disco de la réplica no puede manejar la escritura de los archivos WAL.
- Solución: Verifique las métricas de E/S (iostat, fio). Es posible que se necesite un SSD más rápido (NVMe) o la optimización del subsistema de disco.
- Recursos insuficientes en el maestro: El maestro no puede generar archivos WAL lo suficientemente rápido o tiene pocos `wal_senders`.
- Solución: Aumente `max_wal_senders` y verifique los recursos generales del maestro.
2. Problemas con el Failover (Patroni/pg_auto_failover no conmuta el maestro)
Síntomas: El maestro no está disponible, pero el failover automático no ocurre o tarda demasiado.
Diagnóstico:
# Para Patroni
patronictl -c /etc/patroni/patroni.yml list
# Verifique los logs de Patroni en todos los nodos
sudo journalctl -u patroni -f
# Para pg_auto_failover
pg_auto_failover show state
# Verifique los logs del monitor pg_auto_failover y de los nodos
sudo journalctl -u pg_auto_failover_monitor -f
sudo journalctl -u pg_auto_failover_node -f
Posibles causas y soluciones:
- Problemas con el DCS (etcd/Consul): El DCS no está disponible o no tiene quórum. Patroni no puede actualizar el estado.
- Solución: Verifique el estado del DCS (`etcdctl member list`). Asegúrese de que todos los nodos del DCS estén funcionando y tengan quórum. Es posible que sea necesario reiniciar el DCS o restaurar el quórum manualmente.
- Problemas de red: Los nodos de Patroni/pg_auto_failover no pueden "verse" entre sí o al DCS.
- Solución: Verifique la conectividad de red (ping, telnet a los puertos) entre todos los nodos y el DCS. Asegúrese de que los firewalls funcionen correctamente.
- Configuración incorrecta de Patroni/pg_auto_failover: Errores en `patroni.yml` o en la configuración de pg_auto_failover.
- Solución: Revise cuidadosamente los archivos de configuración en todos los nodos. Especialmente los parámetros `ttl`, `loop_wait`, `retry_timeout`, `maximum_lag_on_failover`.
- Problemas de recursos: Los nodos están sobrecargados (CPU, RAM), lo que impide el funcionamiento normal de Patroni/pg_auto_failover.
- Solución: Verifique la utilización de recursos en todos los nodos. Es posible que sea necesario aumentar los recursos u optimizar la carga.
- Replication Lag demasiado grande: Si `maximum_lag_on_failover` es demasiado bajo y la réplica está retrasada, Patroni puede no seleccionarla como candidata a maestro.
- Solución: Aumente el valor de `maximum_lag_on_failover` o elimine la causa del retraso de la replicación.
3. Problemas de conexión de clientes después del Failover
Síntomas: Después de un failover exitoso, las aplicaciones cliente no pueden conectarse al nuevo maestro.
Diagnóstico:
- Verifique a dónde apunta el registro DNS de su clúster.
- Verifique el estado del balanceador de carga (HAProxy) y sus backends.
- Intente conectarse al nuevo maestro directamente desde el host cliente (`psql -h
-p 5432 -U `).
Posibles causas y soluciones:
- Almacenamiento en caché de DNS: Las aplicaciones cliente o el SO almacenan en caché el registro DNS antiguo.
- Solución: Utilice un TTL bajo para el registro DNS del clúster (por ejemplo, 30-60 segundos). Se recomienda utilizar un balanceador de carga que no dependa de las conmutaciones de DNS.
- El balanceador de carga no actualizó el estado: HAProxy u otro balanceador de carga no conmutó el tráfico al nuevo maestro.
- Solución: Verifique los logs de HAProxy, asegúrese de que sus comprobaciones de salud funcionen correctamente con la API de Patroni (`/primary`, `/replica`). Reinicie HAProxy si es necesario.
- Firewall: El firewall bloquea las conexiones al nuevo maestro.
- Solución: Asegúrese de que el puerto 5432 esté abierto en el nuevo nodo maestro para las conexiones de los clientes.
4. Problemas de rendimiento
Síntomas: Consultas lentas, alta utilización de CPU/RAM/IO, transacciones largas.
Diagnóstico:
-- Verificación de consultas activas
SELECT pid, usename, client_addr, application_name, backend_start, state, query_start, query
FROM pg_stat_activity
WHERE state != 'idle' ORDER BY query_start;
-- Verificación de consultas lentas (si log_min_duration_statement está habilitado)
-- Análisis de logs de PostgreSQL a través de pgBadger
-- Monitorización de recursos del SO
top, htop, iostat, vmstat, netstat
Posibles causas y soluciones:
- Consultas no optimizadas: Consultas mal escritas, falta de índices.
- Solución: Utilice `EXPLAIN ANALYZE` para analizar consultas, cree los índices necesarios, optimice el esquema de la BD.
- Recursos insuficientes: Falta de CPU, RAM o disco lento.
- Solución: Aumente los recursos del VPS/servidor dedicado.
- Configuración incorrecta de PostgreSQL: Valores no óptimos de `work_mem`, `shared_buffers`, `effective_cache_size`, etc.
- Solución: Configure los parámetros de PostgreSQL de acuerdo con las recomendaciones para su carga y los recursos disponibles.
- Bloqueos: Transacciones largas o bloqueos que impiden otras consultas.
- Solución: Identifique y elimine la fuente de los bloqueos. Optimice las transacciones.
Cuándo contactar al soporte
Si ha agotado todas las posibilidades de diagnóstico y resolución del problema, o si el problema es crítico y causa un tiempo de inactividad prolongado, no dude en buscar ayuda:
- Comunidad PostgreSQL: Foros, listas de correo, chats de Telegram.
- Desarrolladores de Patroni/pg_auto_failover: GitHub Issues o canales especializados.
- Soporte profesional: Empresas especializadas en PostgreSQL o consultoría DevOps.
Es importante proporcionar la información más completa posible: logs, archivos de configuración, métricas de monitorización, pasos para reproducir el problema.
FAQ: Preguntas frecuentes sobre PostgreSQL de alta disponibilidad
¿Puedo usar solo dos nodos para HA PostgreSQL?
Teóricamente, sí, pero es altamente desaconsejable para un entorno de producción. Con dos nodos, no podrá garantizar un quórum. En caso de una partición de red (network split-brain), ambos nodos podrían decidir que el otro nodo no está disponible, y cada uno intentaría convertirse en maestro, lo que llevaría a una desincronización de datos. Para un quórum fiable y para prevenir el split-brain, utilice siempre un número impar de nodos (mínimo tres) para la votación o para su almacén de configuración distribuido (etcd/Consul).
¿Cómo actualizar PostgreSQL en un clúster HA sin tiempo de inactividad?
Para actualizar PostgreSQL en un clúster HA, se recomienda utilizar el método de "actualización continua" (rolling upgrade). Primero, actualice las réplicas, una por una, luego realice un switchover planificado (conmutación del maestro) a una de las réplicas actualizadas. Después de esto, actualice el antiguo maestro restante. Patroni proporciona herramientas convenientes para realizar el switchover. Es importante probar a fondo el proceso de actualización en un entorno de prueba antes de aplicarlo en producción.
¿Qué pasa con las copias de seguridad? ¿Siguen siendo necesarias si tengo HA?
¡Absolutamente! La alta disponibilidad protege contra el tiempo de inactividad, pero no contra la pérdida de datos debido a errores lógicos (por ejemplo, la eliminación accidental de datos por parte de la aplicación), fallos de hardware de todos los nodos simultáneamente (por ejemplo, un incendio en un centro de datos) o errores humanos. Las copias de seguridad son su última línea de defensa. Realice siempre copias de seguridad regulares y probadas, y almacénelas de forma remota del clúster principal.
¿Cómo escalar la lectura en un clúster HA?
El escalado de lectura en un clúster HA de PostgreSQL se logra añadiendo réplicas adicionales. Puede dirigir las consultas SELECT a estas réplicas utilizando un balanceador de carga (por ejemplo, HAProxy, Pgpool-II) que distribuirá el tráfico. Patroni y pg_auto_failover permiten añadir fácilmente nuevas réplicas al clúster. Asegúrese de que su aplicación separe correctamente las solicitudes de lectura y escritura.
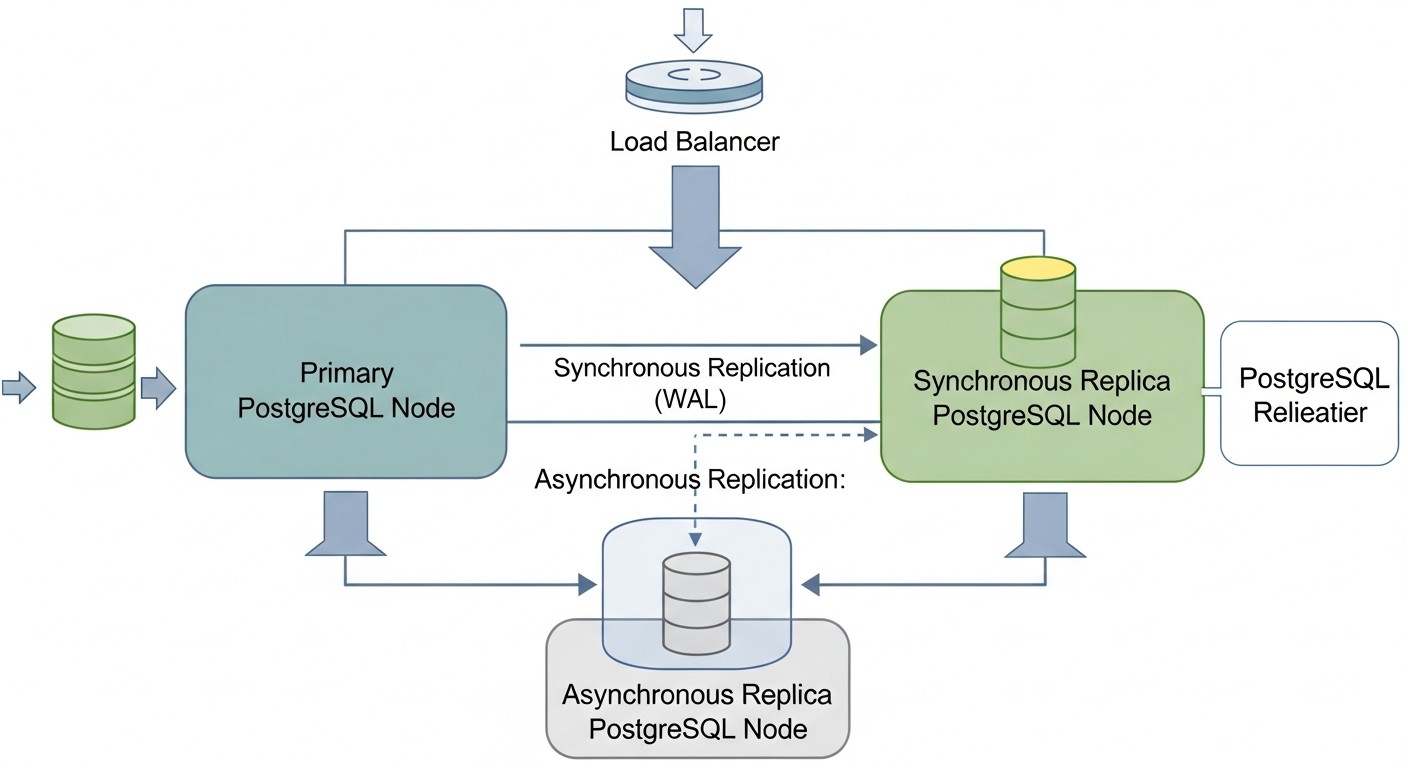
¿Cuál es la diferencia entre replicación síncrona y asíncrona?
En la replicación asíncrona, el servidor maestro confirma la transacción al cliente inmediatamente después de que se ha escrito en el WAL del maestro, sin esperar la confirmación de la réplica. Esto proporciona un alto rendimiento, pero en caso de fallo del maestro, puede perder las últimas transacciones que aún no se habían transmitido o aplicado en la réplica (RPO distinto de cero). En la replicación síncrona, el maestro espera la confirmación de una o varias réplicas de que la transacción se ha escrito correctamente en sus discos, antes de confirmarla al cliente. Esto garantiza un RPO cero (sin pérdida de datos), pero aumenta la latencia de escritura y reduce el rendimiento.
¿Qué es el "quórum" en el contexto de HA PostgreSQL?
El quórum es el número mínimo de nodos que deben estar disponibles y ser unánimes en su decisión para realizar una operación específica (por ejemplo, elegir un nuevo maestro o confirmar una transacción). En sistemas distribuidos, el quórum previene el escenario de split-brain. Por ejemplo, en un clúster de 3 nodos, el quórum suele ser de 2 nodos. Si 2 nodos se ven entre sí, pero no ven al tercero, pueden tomar una decisión sobre la elección del maestro. Sin embargo, si cada uno de los dos nodos solo se ve a sí mismo, no se alcanza el quórum, y ninguno de ellos se convertirá en maestro, evitando el conflicto.
¿Cómo manejar las particiones de red (Network Partitions) en un clúster?
Las particiones de red son escenarios en los que una parte de los nodos del clúster pierde la comunicación con otra parte. Un mecanismo de quórum correctamente configurado (por ejemplo, a través de etcd/Consul en Patroni) es clave. Garantiza que solo la mayoría de los nodos (que tienen quórum) pueda continuar funcionando como maestro, mientras que la minoría pasará a modo de espera o se detendrá por completo para evitar el split-brain. Es importante planificar cuidadosamente la ubicación de los nodos (por ejemplo, en diferentes racks o incluso centros de datos) y tener una monitorización de red fiable.
¿Se pueden mezclar VPS y servidores dedicados en un mismo clúster HA?
Técnicamente es posible, pero no se recomienda para sistemas críticos. Diferentes tipos de servidores pueden tener diferente rendimiento, latencia de red y fiabilidad, lo que complica la predicción del comportamiento del clúster y puede llevar a problemas asimétricos. Si aún así decide hacerlo, asegúrese de que el componente más lento no se convierta en un "cuello de botella" y de que tiene una estrategia clara para gestionar la heterogeneidad.
¿Qué es Point-in-Time Recovery (PITR) y cómo se relaciona con HA?
Point-in-Time Recovery (PITR) es la capacidad de restaurar una base de datos a cualquier momento en el pasado (dentro de los límites de las copias de seguridad y los archivos WAL disponibles). Esta es una función críticamente importante para la recuperación después de errores lógicos o corrupción de datos. Aunque PITR no es parte de una solución HA directamente, complementa la HA al proporcionar una recuperación completa de datos en casos en los que la HA no puede ayudar (por ejemplo, después de un DELETE accidental). Herramientas como pgBackRest y Barman proporcionan capacidades de PITR.
¿Existe una solución completamente gratuita para HA PostgreSQL?
Sí, la mayoría de las soluciones mencionadas, como Patroni, pg_auto_failover, Pgpool-II, así como el propio PostgreSQL, son de código abierto y gratuitas. Sin embargo, la "gratuidad" se refiere solo al costo de las licencias. Todavía tendrá que pagar por la infraestructura (VPS/servidores), así como por el tiempo de ingeniería para el diseño, despliegue, configuración, monitorización y soporte, lo cual es una parte sustancial de los costos totales.
Conclusión: Su camino hacia un PostgreSQL fiable
La creación de un clúster PostgreSQL de alta disponibilidad en servidores VPS o dedicados no es solo una tarea técnica, sino una decisión estratégica que afecta directamente la continuidad de su negocio, su reputación y sus ingresos. En 2026, cuando el tiempo de inactividad es inaceptable y los datos son oro, la inversión en una base de datos tolerante a fallos se amortiza muchas veces.
Hemos examinado diferentes enfoques, desde el potente orquestador Patroni hasta el más simple pg_auto_failover y las soluciones manuales con replicación nativa. Cada uno tiene sus fortalezas y debilidades, y la elección siempre debe basarse en un análisis cuidadoso de sus requisitos de RPO y RTO, el presupuesto disponible y el nivel de experiencia de su equipo. Recuerde que no existe una solución universal que se adapte a todos. Su tarea es encontrar el equilibrio entre la complejidad, el costo y el nivel de fiabilidad que se alinee con sus objetivos comerciales.
Conclusiones clave que debe extraer de esta guía maestra:
- Planificación — lo es todo: El diseño detallado de la arquitectura, la evaluación de los recursos y la definición clara de los requisitos comerciales son la base del éxito.
- Pruebas — su seguro: Las pruebas regulares de los mecanismos de failover, switchover y recuperación desde copias de seguridad son absolutamente críticas. Un sistema HA no probado es una ilusión de seguridad.
- Monitorización — sus ojos y oídos: Sin una monitorización integral de todos los componentes del clúster, estará ciego a los problemas potenciales. Configure alertas para métricas críticas.
- Automatización — su mejor amigo: Invierta en la automatización del despliegue y las operaciones rutinarias. Esto reducirá el riesgo de errores humanos y liberará tiempo a los ingenieros para tareas más complejas.
- Copias de seguridad — última línea de defensa: Nunca olvide las copias de seguridad fiables y probadas, que complementan la estrategia HA y protegen contra errores lógicos y fallos catastróficos.
La construcción de un clúster PostgreSQL HA fiable es un proceso continuo que requiere atención constante, aprendizaje y adaptación a las condiciones cambiantes. Pero con las herramientas, el conocimiento y el enfoque adecuados, su base de datos se convertirá no solo en un almacén de datos, sino en el corazón fiable y robusto de su infraestructura digital.
Próximos pasos para el lector:
- Elija una solución: Decida la solución HA que mejor se adapte a sus necesidades.
- Desarrolle un proyecto piloto: Comience con un pequeño clúster de prueba en varios VPS para dominar la herramienta elegida y practicar todos los pasos.
- Automatice: Utilice Ansible o Terraform para crear un proceso de despliegue repetible.
- Implemente la monitorización: Configure Prometheus/Grafana para rastrear el estado de su clúster.
- Practique: Realice regularmente simulacros de recuperación ante desastres y pruebe el failover.
- Continúe aprendiendo: Participe activamente en la comunidad de PostgreSQL, lea blogs y documentación para estar al tanto de los últimos desarrollos y mejores prácticas.
¡Que su clúster PostgreSQL esté siempre disponible y sea fiable!