info
¿Necesitas un servidor para esta guía? Ofrecemos servidores dedicados y VPS en más de 50 países con configuración instantánea.
Need a server for this guide?
Deploy a VPS or dedicated server in minutes.
Estrategias avanzadas de despliegue de aplicaciones Docker en VPS: Actualizaciones Blue/Green y Canary
TL;DR
- Despliegue sin interrupciones en VPS: Dominará las estrategias Blue/Green y Canary para minimizar el tiempo de inactividad y los riesgos al actualizar aplicaciones Docker en servidores virtuales.
- Blue/Green para simplicidad y seguridad: Ideal para aplicaciones donde una conmutación completa del tráfico es aceptable; proporciona una reversión rápida, pero requiere duplicar los recursos durante el despliegue.
- Canary para implementación gradual: Permite probar la nueva versión en una pequeña parte de los usuarios, minimizando el impacto de posibles errores y recopilando comentarios antes del despliegue completo.
- La automatización es clave para el éxito: Utilice pipelines CI/CD con Ansible, Jenkins, GitLab CI o GitHub Actions para automatizar todas las etapas de despliegue y monitoreo.
- El monitoreo y el registro son críticos: Implemente Prometheus, Grafana, la pila ELK o Loki/Promtail para rastrear métricas, errores y el rendimiento de ambas versiones de la aplicación en tiempo real.
- Optimización de recursos y costos: Mediante una selección inteligente de VPS, el uso de imágenes Docker eficientes y estrategias bien pensadas, se pueden reducir significativamente los costos, a pesar de la duplicación temporal de recursos.
- Ejemplos concretos y herramientas para 2026: El artículo contiene recomendaciones actualizadas para 2026 sobre herramientas, configuraciones y casos prácticos para una implementación exitosa.
1. Introducción
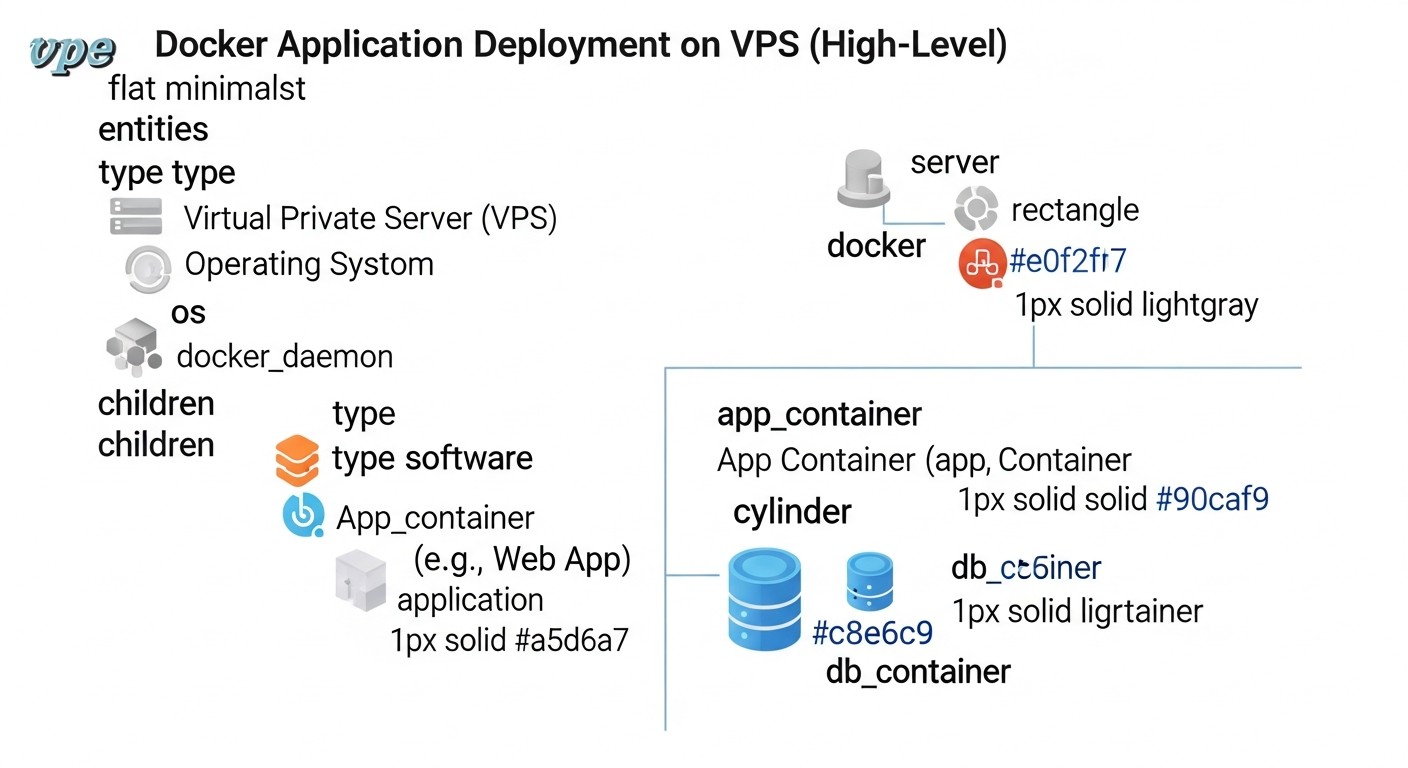 Diagrama: 1. Introducción
Diagrama: 1. Introducción
En el mundo en rápida evolución de DevOps y las tecnologías en la nube, donde cada minuto de inactividad le cuesta a las empresas miles, o incluso millones de dólares, garantizar el funcionamiento ininterrumpido de las aplicaciones se convierte no solo en un deseo, sino en una necesidad crítica. Esto es especialmente relevante para los proyectos SaaS, donde la disponibilidad del servicio afecta directamente la satisfacción del cliente, la reputación y, en última instancia, las ganancias. En 2026, cuando la arquitectura de microservicios y la contenerización con Docker se han convertido en el estándar de facto, y los alojamientos VPS ofrecen una flexibilidad y rendimiento sin precedentes a un precio asequible, la cuestión de un despliegue eficiente y seguro pasa a primer plano.
Los métodos de despliegue tradicionales, como el "rip-and-replace" (detener la versión antigua, desplegar la nueva), han demostrado su ineficacia hace mucho tiempo. Conducen a un tiempo de inactividad inevitable, un alto riesgo de errores y dificultades con la reversión en caso de problemas. Es por eso que la industria ha llegado a la necesidad de utilizar estrategias avanzadas, como las actualizaciones Blue/Green y Canary. Estos enfoques permiten minimizar o eliminar por completo el tiempo de inactividad de la aplicación, reducir significativamente los riesgos al introducir nuevas funciones y garantizar una reversión rápida y segura a la versión anterior.
Este artículo está dirigido a una amplia gama de especialistas técnicos: desde ingenieros DevOps experimentados y administradores de sistemas que buscan optimizar sus pipelines, hasta desarrolladores backend (Python, Node.js, Go, PHP) que desean comprender mejor los aspectos de infraestructura del despliegue. Los fundadores de proyectos SaaS y los directores técnicos de startups encontrarán aquí recomendaciones prácticas para reducir los riesgos operativos y aumentar la fiabilidad de sus servicios. Profundizaremos en los detalles de las estrategias Blue/Green y Canary, examinaremos sus ventajas y desventajas, proporcionaremos ejemplos concretos de implementación en VPS utilizando Docker, y discutiremos las herramientas actuales y las mejores prácticas relevantes para 2026.
No le venderemos "píldoras mágicas" ni "balas de plata". En su lugar, recibirá una guía experta y práctica, basada en la experiencia real y soluciones probadas. Analizaremos cómo estas estrategias ayudan a resolver problemas como:
- Minimización del tiempo de inactividad: Garantizar el funcionamiento continuo del servicio durante la actualización.
- Reducción de los riesgos de despliegue: Posibilidad de reversión rápida o implementación gradual de una nueva versión.
- Mejora de la calidad de los lanzamientos: Prueba de la nueva versión en un entorno de producción real con una audiencia limitada.
- Aumento de la confianza en el equipo: Demostración de la estabilidad y fiabilidad del servicio incluso con actualizaciones frecuentes.
- Optimización del uso de recursos: Gestión eficiente de la infraestructura VPS para mantener múltiples versiones de la aplicación.
Prepárese para sumergirse en el mundo de las estrategias de despliegue avanzadas que cambiarán su forma de ver cómo deben actualizarse las aplicaciones Docker en VPS. ¡Comencemos!
2. Criterios clave para elegir una estrategia de despliegue
 Diagrama: 2. Criterios clave para elegir una estrategia de despliegue
Diagrama: 2. Criterios clave para elegir una estrategia de despliegue
Elegir la estrategia de despliegue adecuada no es solo una decisión técnica, sino una elección estratégica que afecta directamente la estabilidad, fiabilidad y eficiencia económica de su aplicación. En 2026, cuando las exigencias de velocidad y calidad de los lanzamientos no hacen más que crecer, es importante considerar muchos factores. Analicemos en detalle los criterios clave que le ayudarán a determinar qué estrategia —Blue/Green o Canary— se adapta mejor a sus necesidades.
2.1. Tiempo de inactividad permitido (Downtime Tolerance)
¿Por qué es importante? Este es, quizás, el factor más obvio y crítico. Para algunos servicios (por ejemplo, sistemas bancarios, plataformas médicas, E-commerce en horas pico), cualquier tiempo de inactividad es inaceptable. Para otros (herramientas internas, blogs con tráfico no crítico), unos pocos minutos de inactividad pueden ser tolerables. El tiempo de inactividad afecta directamente la experiencia del usuario, las pérdidas financieras y la reputación de la marca. Las estrategias Blue/Green y Canary están diseñadas para minimizar o eliminar por completo el tiempo de inactividad.
Cómo evaluar: Defina el SLA (Service Level Agreement) de su aplicación. ¿Cuál es el tiempo máximo de inactividad permitido por año, mes o semana? ¿Qué pérdidas financieras y de reputación implicará el tiempo de inactividad? Si el tiempo de inactividad debe ser cero o tender a cero, entonces Blue/Green o Canary son su única opción.
2.2. Velocidad de reversión (Rollback Speed)
¿Por qué es importante? Los errores ocurren. Y cuando suceden en producción, la capacidad de volver rápidamente a una versión estable se vuelve vital. Cuanto más rápido pueda revertir, menor será el impacto en los usuarios y el negocio. Una reversión lenta puede llevar a un tiempo de inactividad prolongado y agravar los problemas.
Cómo evaluar: Mida el tiempo necesario para desplegar la versión anterior de la aplicación. Idealmente, la reversión debería tomar segundos o minutos. Blue/Green permite una reversión casi instantánea, simplemente conmutando el tráfico de vuelta al entorno "azul" (antiguo). Canary requiere una reversión más compleja, posiblemente retirando el "canario" gradualmente y devolviendo el tráfico a la versión estable.
2.3. Complejidad de implementación y sobrecarga de gestión (Implementation Complexity & Management Overhead)
¿Por qué es importante? Cada estrategia de despliegue tiene su propia curva de aprendizaje y requiere ciertas habilidades y herramientas. Una estrategia compleja puede requerir más tiempo de configuración, más recursos para el soporte y aumentar la probabilidad de errores en la gestión manual. En condiciones de recursos VPS limitados y un equipo pequeño, esto puede ser crítico.
Cómo evaluar: Evalúe el nivel de su equipo. ¿Tiene experiencia con balanceadores de carga, DNS dinámico, pipelines CI/CD? ¿Está dispuesto a invertir tiempo en aprender y configurar? Blue/Green es relativamente simple en concepto, pero requiere una gestión cuidadosa del tráfico. Canary es más complejo, ya que implica una configuración fina del enrutamiento del tráfico (usuarios, porcentaje) y un monitoreo más sofisticado.
2.4. Consumo de recursos (Resource Consumption)
¿Por qué es importante? El despliegue en VPS a menudo está asociado con recursos limitados. La estrategia Blue/Green, por su naturaleza, requiere al menos duplicar los recursos por un corto período (las versiones antigua y nueva funcionan en paralelo). Canary puede ser más económica si reemplaza gradualmente las instancias antiguas por nuevas, pero para pruebas A/B completas o el funcionamiento paralelo de dos versiones, aún se requerirán recursos adicionales.
Cómo evaluar: Analice la carga actual de su VPS. ¿Tiene margen de CPU, RAM, espacio en disco? ¿Está dispuesto a escalar temporalmente el VPS o usar instancias adicionales? El costo de los recursos en VPS en 2026, aunque ha disminuido, sigue siendo un factor significativo. Evalúe si puede permitirse duplicar los recursos durante 10-30 minutos durante el despliegue.
2.5. Capacidades de prueba y validación (Testing & Validation Capabilities)
¿Por qué es importante? Cuanto antes detecte un error, más barato resultará. Las estrategias de despliegue deben proporcionar oportunidades para probar la nueva versión en condiciones lo más cercanas posible a la producción, antes de que esté disponible para todos los usuarios. Esto incluye pruebas funcionales, pruebas de carga, monitoreo del rendimiento y recopilación de métricas.
Cómo evaluar: Blue/Green permite realizar pruebas completas del nuevo entorno "verde" antes de conmutar el tráfico. Canary va más allá, permitiendo probar la nueva versión con usuarios reales, recopilando métricas y comentarios, antes de desplegarla por completo. Esto es especialmente valioso para evaluar la experiencia del usuario y el rendimiento en condiciones reales.
2.6. Compatibilidad con bases de datos y migraciones (Database & Data Migration Compatibility)
¿Por qué es importante? La actualización de una aplicación a menudo implica cambios en el esquema de la base de datos. Esta es una de las partes más complejas del despliegue, ya que puede interrumpir el funcionamiento tanto de la versión antigua como de la nueva de la aplicación. Es importante asegurarse de que su estrategia de despliegue admita la compatibilidad hacia atrás y hacia adelante con los cambios de la base de datos.
Cómo evaluar: Planifique las migraciones de la base de datos de manera que no sean bloqueantes y sean compatibles con versiones anteriores. Por ejemplo, al agregar una nueva columna, primero despliegue la nueva versión de la aplicación que pueda trabajar con la nueva columna (pero no la requiera). Luego, realice la migración de la base de datos y, después de eso, cambie el tráfico. Al eliminar una columna, primero asegúrese de que todas las versiones antiguas que usan esa columna estén fuera de servicio. Esto requiere una planificación cuidadosa y, posiblemente, el uso de patrones como "Two-Phase Schema Migration".
2.7. Requisitos de tolerancia a fallos (Fault Tolerance Requirements)
¿Por qué es importante? Incluso con las estrategias mejor pensadas, pueden ocurrir fallos. Su sistema debe estar diseñado para soportar fallos de componentes individuales o de versiones completas de la aplicación. Esto incluye la detección automática de problemas, la conmutación a recursos de respaldo y el aislamiento de las partes defectuosas.
Cómo evaluar: Evalúe cuán crítico es para su negocio que el sistema siga funcionando incluso con un fallo parcial. Blue/Green proporciona una alta tolerancia a fallos en la reversión, ya que la versión antigua permanece disponible. Canary, gracias al despliegue gradual, limita el impacto de un fallo solo a una parte de los usuarios, lo que aumenta la tolerancia general a fallos del sistema durante el proceso de despliegue.
Un análisis cuidadoso de estos criterios le permitirá elegir la estrategia de despliegue más adecuada, que no solo minimice los riesgos y el tiempo de inactividad, sino que también sea económicamente viable y manejable para su equipo y la infraestructura VPS.
3. Tabla comparativa: Actualizaciones Blue/Green vs. Canary
 Esquema: 3. Tabla comparativa: Actualizaciones Blue/Green vs. Canary
Esquema: 3. Tabla comparativa: Actualizaciones Blue/Green vs. Canary
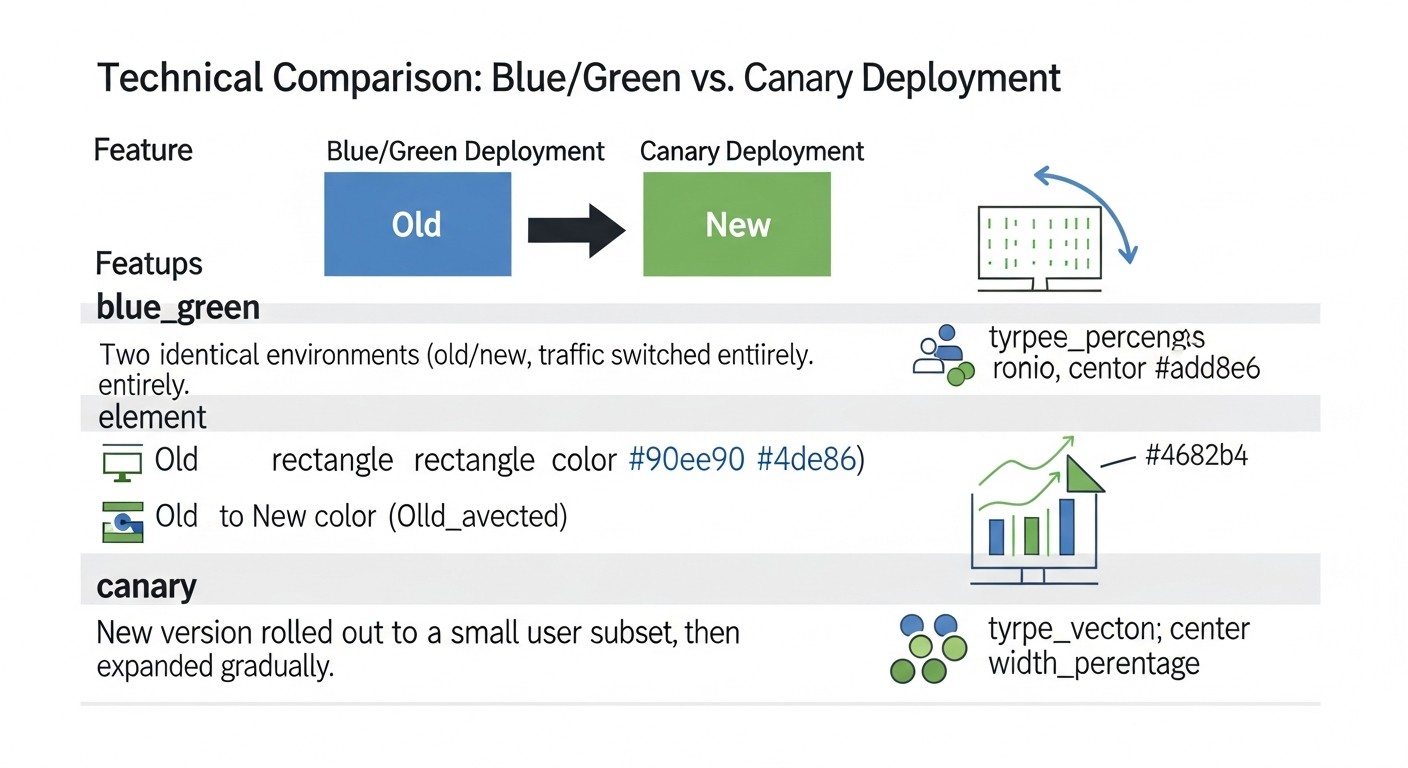
La elección entre las estrategias de despliegue Blue/Green y Canary a menudo se reduce a un compromiso entre la simplicidad, la velocidad de reversión y la capacidad de realizar pruebas con usuarios reales. En esta tabla, presentaremos una comparación detallada de ambas estrategias, considerando las realidades actuales y las expectativas para 2026, incluyendo los costos aproximados y las características técnicas.
| Criterio |
Despliegue Blue/Green |
Despliegue Canary |
| Idea principal |
Dos entornos idénticos (Blue - antiguo, Green - nuevo). El tráfico se conmuta completamente a Green después de pruebas exitosas. |
Implementación gradual de una nueva versión (Canary) para una pequeña parte de los usuarios, luego aumento del porcentaje. |
| Tiempo de inactividad durante el despliegue |
Prácticamente nulo (tiempo de conmutación del tráfico). |
Nulo, ya que la versión antigua sigue sirviendo a la mayoría de los usuarios. |
| Velocidad de reversión |
Instantánea (conmutación del tráfico de vuelta a Blue). |
Toma más tiempo, ya que es necesario retirar Canary de la operación y redirigir el tráfico. |
| Consumo de recursos (VPS) |
Duplica temporalmente el consumo (entornos Blue + Green). Por ejemplo, 2x VPS o 2x conjunto de contenedores. |
Puede ser más eficiente si Canary ocupa una pequeña parte de los recursos. En su pico, puede ser 1.1x - 1.5x de lo habitual. |
| Complejidad de implementación |
Media. Requiere la gestión de dos entornos y un balanceador de carga. |
Alta. Requiere enrutamiento de tráfico complejo, monitoreo avanzado y automatización. |
| Capacidades de prueba |
Pruebas completas de la nueva versión antes del lanzamiento. |
Pruebas con usuarios reales, pruebas A/B, recopilación de métricas de rendimiento y errores en producción. |
| Detección de errores |
Los errores se detectan antes de la conmutación del tráfico (en Green). |
Los errores se detectan en una pequeña parte de los usuarios, minimizando el impacto general. |
| Gestión de bases de datos |
Requiere una planificación cuidadosa de las migraciones con compatibilidad inversa. |
Un requisito aún más estricto de compatibilidad inversa, ya que ambas versiones pueden trabajar simultáneamente con la BD. |
| Ideal para |
Aplicaciones críticas con SLA alto, donde se requiere una reversión rápida y pruebas completas antes del lanzamiento. |
Aplicaciones donde es importante minimizar el riesgo, probar nuevas funciones con una audiencia en vivo, implementar cambios gradualmente. |
| Costos adicionales aproximados de VPS (2026) |
Corto plazo +100%: Si su servicio se ejecuta en 2 VPS a $20/mes, durante el despliegue se necesitarán 4 VPS, es decir, $80/mes en lugar de $40/mes (por unos minutos/horas). A largo plazo, esto puede ser +$5-10/mes para un VPS más potente o una instancia adicional por unas horas. |
Largo plazo +10-50%: Por ejemplo, si su servicio se ejecuta en 2 VPS a $20/mes, para Canary podría requerir 2 VPS principales + 1 VPS adicional (para Canary), o VPS más potentes para alojar más contenedores. Esto podría ser +$20/mes constantemente, si las instancias Canary funcionan durante mucho tiempo. |
| Herramientas principales (2026) |
Docker Compose, Nginx/Caddy, HAProxy, Ansible, GitLab CI/GitHub Actions, Prometheus, Grafana. |
Docker Compose, Nginx/Caddy, HAProxy, Traefik, Istio (para escenarios más complejos), Kubernetes, Ansible, GitLab CI/GitHub Actions, Prometheus, Grafana, OpenTelemetry. |
Esta tabla demuestra claramente que no existe una estrategia "mejor"; existe aquella que se adapta mejor a un escenario, presupuesto y nivel de madurez del equipo específicos. Blue/Green ofrece la simplicidad y seguridad de una conmutación completa, mientras que Canary proporciona oportunidades inigualables para la implementación gradual y las pruebas en tiempo real, pero a costa de una mayor complejidad y posibles costos de recursos permanentes.
4. Descripción detallada del despliegue Blue/Green
 Esquema: 4. Descripción detallada del despliegue Blue/Green
Esquema: 4. Descripción detallada del despliegue Blue/Green
La estrategia de despliegue Blue/Green es uno de los métodos más populares y efectivos para garantizar actualizaciones de aplicaciones sin interrupciones y con un tiempo de inactividad mínimo. Su idea clave radica en mantener dos entornos de producción idénticos, a los que llamamos convencionalmente "azul" (Blue) y "verde" (Green). En cualquier momento, solo uno de estos entornos está activo y sirve todo el tráfico de usuarios. Profundicemos en los detalles de esta estrategia.
4.1. Principio de funcionamiento de Blue/Green
Imagine que tiene dos infraestructuras o conjuntos de recursos completamente idénticos en su VPS. Una de ellas, digamos, la "azul", contiene la versión actual y estable de su aplicación Docker y sirve todo el tráfico entrante. Cuando llega el momento de actualizar la aplicación, despliega la nueva versión en el entorno "verde", que hasta ese momento estaba inactivo o contenía la versión antigua, pero sin tráfico.
- Preparación del entorno "verde": Despliega la nueva versión de la imagen Docker de su aplicación en la infraestructura "verde". Esto puede ser un contenedor Docker separado, un grupo de contenedores o incluso un VPS separado, configurado de manera idéntica al "azul".
- Pruebas del entorno "verde": Después de desplegar la nueva versión en el entorno "verde", realiza todas las pruebas necesarias: funcionales, de integración, de carga. Esto le da la confianza de que la nueva versión funciona correctamente en condiciones de producción, pero aún no afecta a los usuarios reales.
- Conmutación del tráfico: Si las pruebas son exitosas, conmuta todo el tráfico de usuarios entrante del entorno "azul" al "verde". Esto generalmente se hace cambiando la configuración del balanceador de carga (por ejemplo, Nginx, HAProxy, Caddy) o el registro DNS. Esta conmutación ocurre casi instantáneamente.
- Monitoreo del entorno "verde": Después de la conmutación del tráfico, monitorea cuidadosamente el funcionamiento del nuevo entorno "verde", recopilando métricas de rendimiento, errores y registros.
- Reversión (Rollback): Si se detectan problemas críticos en el entorno "verde", puede revertir instantáneamente, simplemente conmutando el tráfico de vuelta al entorno "azul" estable. Esto ocurre muy rápidamente y de forma segura, ya que el entorno "azul" permaneció intacto.
- Limpieza o reutilización: Si el entorno "verde" es estable, el entorno "azul" puede ser destruido (para ahorrar recursos) o actualizado a la nueva versión y convertirse en el siguiente entorno "verde" para futuros despliegues.
4.2. Ventajas del despliegue Blue/Green
- Tiempo de inactividad cero: La conmutación del tráfico ocurre muy rápidamente, generalmente en segundos, lo que minimiza o elimina por completo el tiempo de inactividad para los usuarios.
- Reversión rápida y segura: En caso de problemas, la vuelta a la versión estable anterior ocurre instantáneamente, simplemente conmutando el tráfico de vuelta al entorno "azul". Esto proporciona un alto grado de confianza en el proceso de despliegue.
- Simplicidad de las pruebas: La nueva versión puede ser completamente probada en el entorno de producción antes de estar disponible para los usuarios, lo que reduce el riesgo de introducir errores en producción.
- Aislamiento de entornos: Los entornos "azul" y "verde" están completamente aislados, lo que evita conflictos y simplifica la gestión.
- Confianza en los lanzamientos: La capacidad de una reversión rápida reduce el estrés y aumenta la confianza del equipo en cada nuevo lanzamiento.
4.3. Desventajas del despliegue Blue/Green
- Duplicación de recursos: Durante el despliegue, se requiere duplicar los recursos computacionales (CPU, RAM, espacio en disco), ya que ambos entornos (Blue y Green) funcionan en paralelo. En un VPS, esto puede significar un escalado temporal o el uso de un servidor más potente.
- Gestión de estado: Si la aplicación tiene estado (por ejemplo, sesiones de usuario, cachés), es necesario asegurar su correcto manejo durante la conmutación. Esto puede requerir el uso de almacenes de estado compartidos (Redis, Memcached) o un diseño cuidadoso de las sesiones.
- Migraciones de bases de datos: Los cambios en el esquema de la base de datos requieren una atención especial. Las migraciones deben ser compatibles con versiones anteriores para que ambas versiones de la aplicación (antigua y nueva) puedan trabajar con la misma base de datos durante el período de transición.
- Complejidad para aplicaciones muy grandes: Para aplicaciones monolíticas con muchas dependencias o una infraestructura muy compleja, la creación de dos entornos completamente idénticos puede ser costosa y laboriosa.
4.4. Para quién es adecuado Blue/Green
El despliegue Blue/Green es ideal para:
- Proyectos SaaS con SLA alto: Donde el tiempo de inactividad cero y la reversión rápida son críticamente importantes.
- Aplicaciones con lanzamientos frecuentes pero predecibles: Cuando está seguro de la calidad del código después de las pruebas internas, pero desea una seguridad adicional en producción.
- Equipos que valoran la simplicidad y la previsibilidad: El concepto es relativamente fácil de entender e implementar en comparación con Canary, especialmente en un VPS utilizando Docker Compose y Nginx/HAProxy.
- Proyectos capaces de asignar temporalmente recursos adicionales: Si su VPS puede soportar una duplicación temporal de la carga o está dispuesto a escalar temporalmente.
En general, Blue/Green es un excelente punto de partida para muchos equipos que buscan un despliegue sin interrupciones. Proporciona un alto nivel de seguridad y fiabilidad, al tiempo que sigue siendo relativamente manejable en su implementación en un VPS.
5. Descripción detallada del despliegue Canary
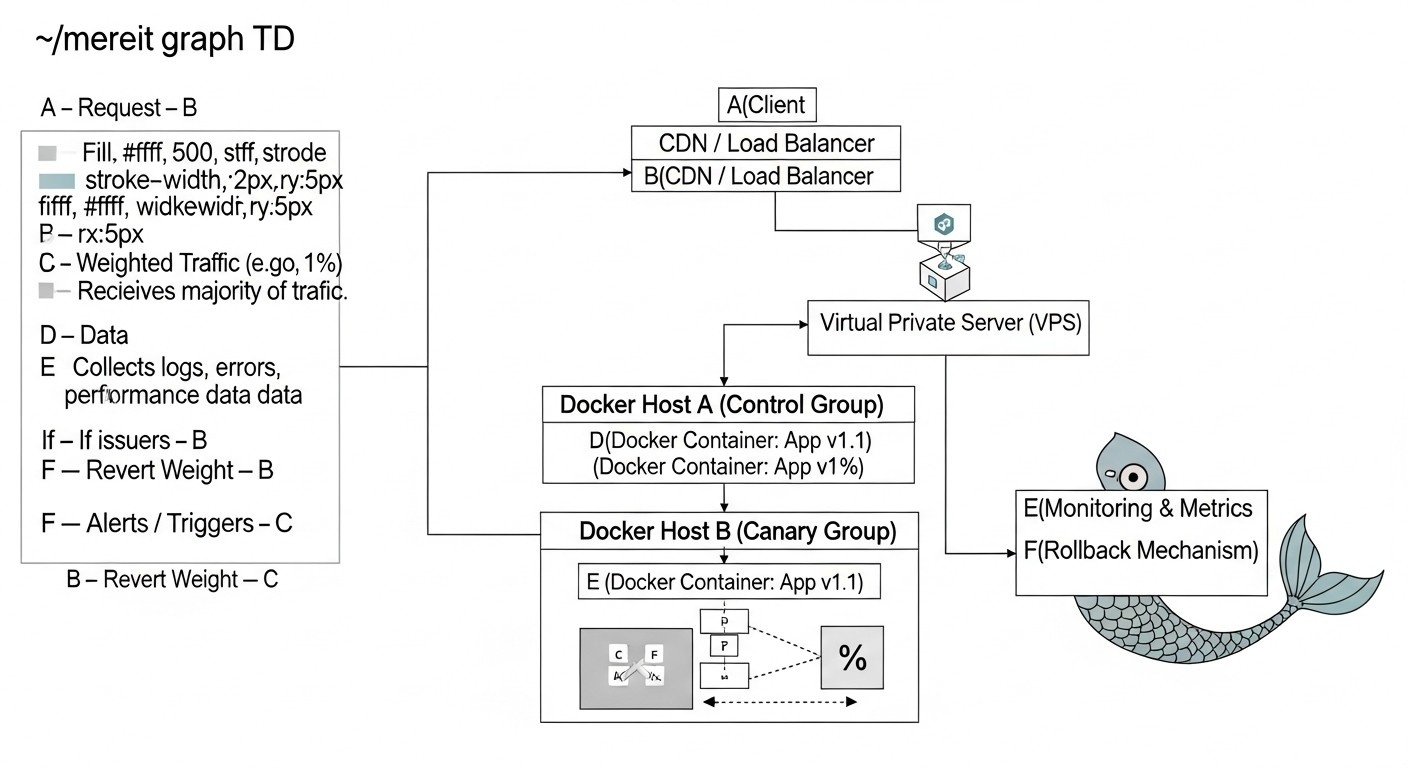 Diagrama: 5. Descripción detallada del despliegue Canary
Diagrama: 5. Descripción detallada del despliegue Canary
El despliegue Canary, llamado así por los canarios utilizados en las minas para detectar gases peligrosos, es una estrategia de despliegue avanzada que permite lanzar gradualmente una nueva versión de una aplicación a un grupo limitado de usuarios. Esto minimiza el impacto potencial de los errores en toda la base de usuarios y permite recopilar comentarios y métricas en tiempo real antes de que la nueva versión esté disponible para el público en general. En 2026, con el aumento de la popularidad de las pruebas A/B y la personalización, Canary se convierte en una herramienta indispensable.
5.1. Principio de funcionamiento de Canary
A diferencia de Blue/Green, donde el tráfico se conmuta por completo, el despliegue Canary implica una redirección gradual del tráfico. Esto permite "probar las aguas" en un grupo pequeño y aislado de usuarios.
- Despliegue del "canario": Usted despliega una nueva versión de su aplicación Docker (el llamado "canario") junto con la versión estable actual en su VPS. Inicialmente, no se dirige tráfico al "canario" o se dirige un porcentaje muy pequeño.
- Redirección de un pequeño porcentaje de tráfico: El balanceador de carga o API Gateway se configura para redirigir un porcentaje muy pequeño (por ejemplo, 1-5%) del tráfico entrante al "canario". El resto del tráfico sigue siendo atendido por la versión estable.
- Monitorización y recopilación de métricas: Esta es la etapa más crítica. Usted monitorea cuidadosamente el rendimiento, los errores, el comportamiento del usuario y las métricas de negocio para el "canario". Es importante tener un sistema de monitorización bien configurado que permita comparar los indicadores del "canario" con la versión estable.
- Aumento gradual del tráfico: Si el "canario" muestra un funcionamiento estable y buenas métricas, usted aumenta gradualmente el porcentaje de tráfico dirigido a él (por ejemplo, hasta el 10%, luego el 25%, el 50% y así sucesivamente). Cada etapa va acompañada de una monitorización cuidadosa.
- Despliegue completo: Cuando el "canario" atiende con éxito una parte significativa del tráfico sin problemas, y usted está completamente seguro de su estabilidad, redirige el 100% de todo el tráfico a la nueva versión.
- Retirada de la versión antigua: La versión antigua de la aplicación puede ser retirada de servicio y sus recursos liberados.
- Reversión (Rollback): En caso de detectar problemas en cualquier etapa, usted redirige inmediatamente todo el tráfico de vuelta a la versión estable. Dado que el impacto se limitó a un pequeño grupo de usuarios, el daño se minimiza.
5.2. Ventajas del despliegue Canary
- Riesgo mínimo: El impacto de los errores potenciales se limita a una pequeña parte de los usuarios, lo que hace que esta estrategia sea ideal para sistemas de misión crítica.
- Pruebas en tiempo real: La nueva versión se prueba con usuarios reales en un entorno de producción real, lo que permite identificar problemas que podrían haberse pasado por alto en las pruebas sintéticas.
- Pruebas A/B: El despliegue Canary permite de forma natural realizar pruebas A/B de nuevas funcionalidades, comparando su eficacia con las antiguas basándose en el comportamiento del usuario y las métricas de negocio.
- Implementación gradual: Posibilidad de acostumbrarse gradualmente a las nuevas funcionalidades y recopilar comentarios, lo cual es especialmente útil para cambios radicales en la interfaz de usuario o la lógica de negocio.
- Ahorro de recursos: En las etapas iniciales, el "canario" puede requerir menos recursos adicionales en comparación con la duplicación completa en Blue/Green.
5.3. Desventajas del despliegue Canary
- Alta complejidad: Requiere una configuración compleja del balanceador de carga para enrutar el tráfico según diversos criterios (porcentaje, encabezados, cookies), así como un sistema avanzado de monitorización y registro.
- Duración: El proceso de despliegue Canary puede llevar mucho más tiempo que Blue/Green, ya que cada etapa requiere monitorización y toma de decisiones.
- Gestión de estado y bases de datos: Aún más crítico que en Blue/Green. Ambas versiones de la aplicación (la estable y el "canario") deben ser capaces de funcionar con el mismo esquema de base de datos y estado. Las migraciones deben ser estrictamente retrocompatibles.
- Problemas con la información de depuración: Si un error se manifiesta solo en el "canario", puede ser difícil recopilar suficiente información para la depuración si el tráfico es demasiado pequeño.
- Potencial deterioro de la experiencia del usuario: Aunque sea para un grupo pequeño, algunos usuarios aún pueden encontrarse con errores o regresiones.
5.4. Para quién es adecuado Canary
El despliegue Canary es ideal para:
- Grandes proyectos SaaS con millones de usuarios: Donde incluso un pequeño porcentaje de errores puede afectar a un número significativo de personas.
- Aplicaciones donde es importante la recopilación continua de comentarios y métricas: Para pruebas A/B de nuevas funcionalidades, evaluación del rendimiento y la reacción de los usuarios.
- Equipos con un alto nivel de automatización y una cultura DevOps madura: Requiere pipelines CI/CD desarrollados, monitorización profunda y reversiones automáticas.
- Proyectos dispuestos a invertir en infraestructura compleja: Para configurar balanceadores avanzados (por ejemplo, Traefik, Nginx con scripts Lua), sistemas de monitorización y registro.
- Cuando los cambios pueden ser arriesgados: Por ejemplo, al implementar un nuevo sistema de pago, cambiar una lógica de negocio críticamente importante o realizar actualizaciones significativas de la UI.
El despliegue Canary es una herramienta poderosa para minimizar riesgos y mejorar la calidad de los lanzamientos, pero requiere una inversión significativa en automatización, monitorización y orquestación. En un VPS se puede implementar utilizando Docker Compose, Nginx/HAProxy y scripts para la gestión del tráfico, pero para escenarios más complejos puede ser necesario Kubernetes o sus equivalentes ligeros.
6. Consejos prácticos y recomendaciones para la implementación
 Diagrama: 6. Consejos prácticos y recomendaciones para la implementación
Diagrama: 6. Consejos prácticos y recomendaciones para la implementación
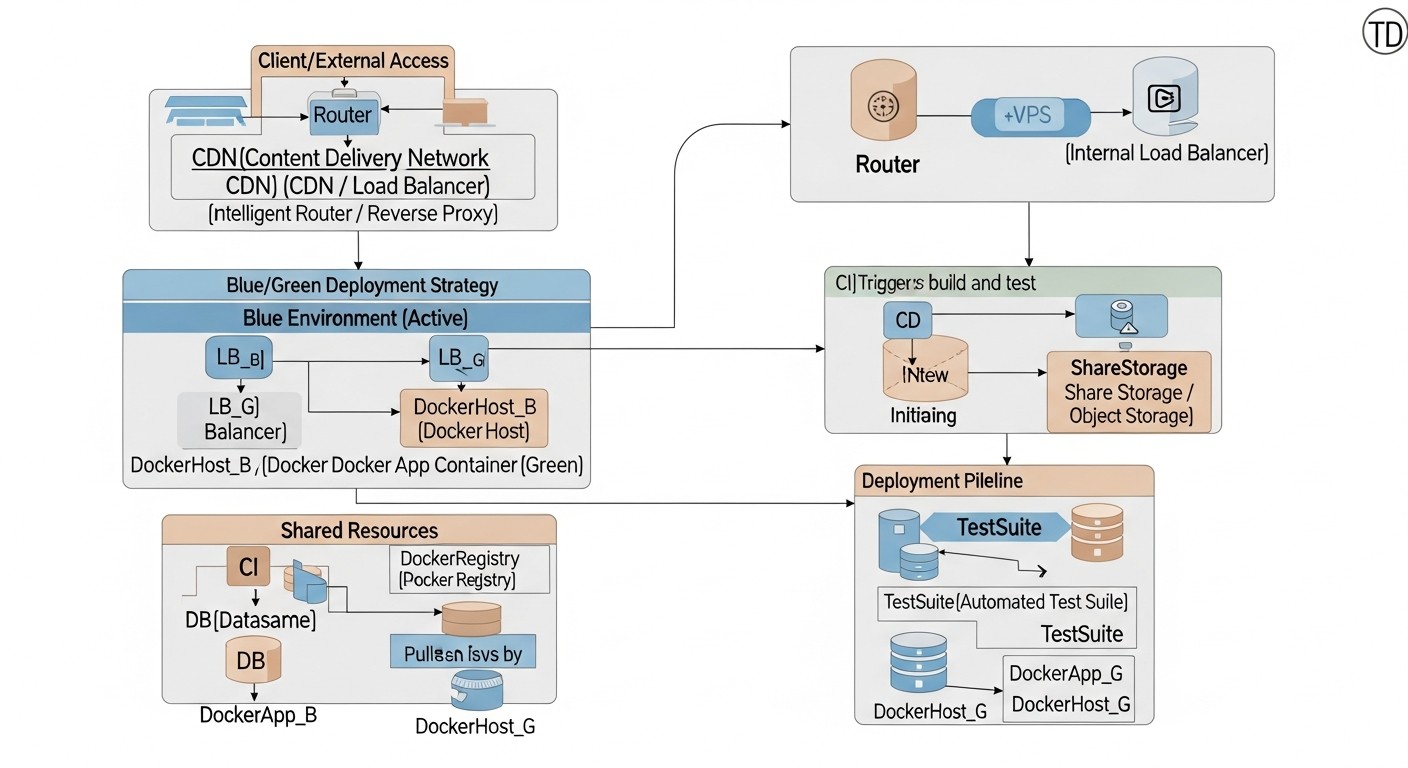
La implementación de despliegues Blue/Green y Canary en un VPS requiere no solo la comprensión de los conceptos, sino también pasos técnicos concretos. En esta sección, proporcionaremos instrucciones paso a paso, ejemplos de comandos y configuraciones, así como recomendaciones basadas en la experiencia real de implementación de estas estrategias en 2026.
6.1. Requisitos generales para la infraestructura VPS
- Recursos VPS suficientes: Asegúrese de que su VPS tenga suficiente CPU, RAM y espacio en disco para ejecutar al menos dos versiones de su aplicación (para Blue/Green) o una versión estable más la "canary" (para Canary). Considere la posibilidad de utilizar un VPS con capacidad de escalado vertical rápido o de añadir instancias temporales.
- Docker y Docker Compose: Instalados y configurados en su VPS. Docker Compose se utilizará para la orquestación de múltiples contenedores que componen su aplicación.
- Balanceador de carga (Reverse Proxy): Nginx, Caddy o HAProxy son excelentes candidatos. Serán responsables de enrutar el tráfico a la versión correcta de la aplicación.
- Sistema de monitoreo y registro: Prometheus + Grafana para métricas, ELK-stack (Elasticsearch, Logstash, Kibana) o Loki + Promtail para logs. Esto es crítico para rastrear la salud y el rendimiento de ambas versiones.
- Pipeline de CI/CD: Automatización de todo el proceso de despliegue con Jenkins, GitLab CI, GitHub Actions o Ansible. El despliegue manual aumenta los riesgos y los costos de mano de obra.
6.2. Implementación de despliegue Blue/Green en un solo VPS con Docker Compose y Nginx
Supongamos que tiene una aplicación que consta de un servidor web y una base de datos. Para Blue/Green, necesitaremos dos conjuntos de contenedores para la aplicación, pero una base de datos compartida.
6.2.1. Estructura del proyecto
Crearemos dos carpetas para diferentes versiones de la aplicación, por ejemplo, app-blue y app-green. Cada una tendrá su propio docker-compose.yml.
# Estructura de directorios
.
├── nginx.conf
├── app-blue/
│ └── docker-compose.yml
│ └── Dockerfile
│ └── app.py (version 1.0)
├── app-green/
│ └── docker-compose.yml
│ └── Dockerfile
│ └── app.py (version 2.0)
└── data/
└── db/ (para PostgreSQL/MySQL)
6.2.2. Ejemplo de app-blue/docker-compose.yml (para la versión 1.0)
version: '3.8'
services:
web:
build:
context: .
dockerfile: Dockerfile
image: myapp:1.0
container_name: myapp_blue_web
ports:
- "8080:80" # Escuchamos en el puerto 8080
environment:
- APP_VERSION=1.0
- DATABASE_URL=postgresql://user:password@db:5432/mydatabase
volumes:
- ./app.py:/app/app.py
networks:
- app_network
db: # Base de datos compartida
image: postgres:14
container_name: myapp_db
environment:
POSTGRES_DB: mydatabase
POSTGRES_USER: user
POSTGRES_PASSWORD: password
volumes:
- ../data/db:/var/lib/postgresql/data
networks:
- app_network
restart: unless-stopped # Importante para la BD compartida
networks:
app_network:
driver: bridge
6.2.3. Ejemplo de app-green/docker-compose.yml (para la versión 2.0)
De manera similar, pero con un puerto y nombre de contenedor diferentes:
version: '3.8'
services:
web:
build:
context: .
dockerfile: Dockerfile
image: myapp:2.0
container_name: myapp_green_web
ports:
- "8081:80" # Escuchamos en el puerto 8081
environment:
- APP_VERSION=2.0
- DATABASE_URL=postgresql://user:password@db:5432/mydatabase
volumes:
- ./app.py:/app/app.py
networks:
- app_network
networks:
app_network:
external: true # Usamos la misma red que Blue, para acceder a la BD compartida
Nota: En un escenario real, la BD debería ser un servicio separado, accesible para ambos entornos, y no parte del docker-compose.yml de cada entorno. Aquí, por simplicidad, se incluye en Blue, y Green se conecta a ella a través de la red compartida.
6.2.4. Configuración de Nginx (nginx.conf)
Nginx actuará como balanceador de carga, alternando el tráfico entre los puertos 8080 (Blue) y 8081 (Green).
# nginx.conf
worker_processes auto;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
keepalive_timeout 65;
upstream app_backend {
# Inicialmente, dirigimos a Blue
server 127.0.0.1:8080; # Blue
# server 127.0.0.1:8081; # Green (comentado)
}
server {
listen 80;
server_name your_domain.com;
location / {
proxy_pass http://app_backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
}
6.2.5. Proceso de despliegue Blue/Green
- Inicio de Blue (versión actual):
cd app-blue
docker-compose up -d --build
Asegúrese de que Nginx esté configurado para el puerto 8080.
- Preparación de Green (nueva versión):
cd app-green
docker-compose up -d --build
Esto iniciará la nueva versión en el puerto 8081. Realice pruebas accediendo directamente a http://your_vps_ip:8081.
- Cambio de tráfico:
Una vez que Green haya sido probada, actualice nginx.conf, modificando upstream app_backend:
upstream app_backend {
# server 127.0.0.1:8080; # Blue (comentado)
server 127.0.0.1:8081; # Green (activo)
}
Recargue Nginx: sudo systemctl reload nginx.
- Monitoreo: Monitoree cuidadosamente los logs y métricas de Green.
- Limpieza de Blue (o preparación para el próximo despliegue):
Si Green es estable, detenga Blue:
cd app-blue
docker-compose down
- Reversión: Si Green causa problemas, cambie inmediatamente
nginx.conf de nuevo a server 127.0.0.1:8080; y recargue Nginx.
6.3. Implementación de despliegue Canary en un solo VPS con Docker Compose y Nginx/Caddy
Canary es más complejo, ya que requiere un enrutamiento de tráfico dinámico. Nginx puede hacerlo con scripts Lua o configuraciones más complejas, pero para simplificar, consideraremos un enfoque básico utilizando pesos o encabezados.
6.3.1. Nginx para Canary (por pesos)
Este es el Canary más simple, donde el tráfico se distribuye por pesos.
# nginx.conf para Canary (por pesos)
upstream app_backend {
server 127.0.0.1:8080 weight=90; # Blue (versión antigua, 90% del tráfico)
server 127.0.0.1:8081 weight=10; # Canary (nueva versión, 10% del tráfico)
}
server {
listen 80;
server_name your_domain.com;
location / {
proxy_pass http://app_backend;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
Proceso:
- Inicie Blue en 8080.
- Inicie Canary en 8081.
- Actualice
nginx.conf con los pesos (por ejemplo, 90% Blue, 10% Canary). Recargue Nginx.
- Monitoreo. Si todo va bien, cambie gradualmente los pesos (por ejemplo, 70/30, 50/50, 20/80, 0/100) y recargue Nginx en cada paso.
- Cuando el 100% del tráfico vaya a Canary, detenga Blue.
6.3.2. Canary por encabezados/cookies (para testers internos)
Un Canary más avanzado puede dirigir el tráfico a la nueva versión solo para usuarios específicos (por ejemplo, con un encabezado HTTP o una cookie determinada).
# nginx.conf para Canary (por encabezados)
upstream app_blue {
server 127.0.0.1:8080;
}
upstream app_canary {
server 127.0.0.1:8081;
}
server {
listen 80;
server_name your_domain.com;
location / {
# Si existe el encabezado "X-Canary: true", dirigimos a Canary
if ($http_x_canary = "true") {
proxy_pass http://app_canary;
}
# De lo contrario, a Blue
proxy_pass http://app_blue;
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header X-Forwarded-Proto $scheme;
}
}
Proceso:
- Inicie Blue en 8080.
- Inicie Canary en 8081.
- Actualice
nginx.conf. Recargue Nginx.
- Pruebe Canary, enviando solicitudes con el encabezado
X-Canary: true.
- Cuando esté seguro de que Canary es estable, modifique
nginx.conf para que todo el tráfico vaya a app_canary, o use pesos, como en el ejemplo anterior, para un despliegue gradual.
6.4. Automatización del pipeline de CI/CD (ejemplo con GitLab CI)
La automatización es el corazón de un despliegue eficiente. La gestión manual de Nginx y Docker Compose se vuelve rápidamente incontrolable.
Ejemplo de .gitlab-ci.yml para Blue/Green:
stages:
- build
- deploy_green
- switch_traffic
- cleanup_blue
variables:
DOCKER_HOST_USER: "user"
DOCKER_HOST_IP: "your_vps_ip"
APP_DIR: "/path/to/your/app"
BLUE_PORT: "8080"
GREEN_PORT: "8081"
build:
stage: build
script:
- docker build -t myapp:$CI_COMMIT_SHORT_SHA .
- docker save myapp:$CI_COMMIT_SHORT_SHA | gzip > myapp-$CI_COMMIT_SHORT_SHA.tar.gz
- scp myapp-$CI_COMMIT_SHORT_SHA.tar.gz $DOCKER_HOST_USER@$DOCKER_HOST_IP:$APP_DIR/
tags:
- docker_builder # Ejemplo de etiqueta para el runner
deploy_green:
stage: deploy_green
script:
- ssh $DOCKER_HOST_USER@$DOCKER_HOST_IP "
cd $APP_DIR/app-green &&
docker load < myapp-$CI_COMMIT_SHORT_SHA.tar.gz &&
docker-compose down || true && # Detener el Green anterior, si existía
sed -i 's/image: myapp:.$/image: myapp:$CI_COMMIT_SHORT_SHA/' docker-compose.yml &&
docker-compose up -d --build &&
# Aquí se pueden añadir scripts para ejecutar pruebas en Green
# Por ejemplo: curl -f http://$DOCKER_HOST_IP:$GREEN_PORT/health || exit 1
"
tags:
- deployer
allow_failure: false
switch_traffic:
stage: switch_traffic
script:
- ssh $DOCKER_HOST_USER@$DOCKER_HOST_IP "
sed -i 's/server 127.0.0.1:$BLUE_PORT;/ # server 127.0.0.1:$BLUE_PORT;/' $APP_DIR/nginx.conf &&
sed -i 's/# server 127.0.0.1:$GREEN_PORT;/ server 127.0.0.1:$GREEN_PORT;/' $APP_DIR/nginx.conf &&
sudo systemctl reload nginx
"
tags:
- deployer
when: manual # Confirmación manual después de probar Green
cleanup_blue:
stage: cleanup_blue
script:
- ssh $DOCKER_HOST_USER@$DOCKER_HOST_IP "
cd $APP_DIR/app-blue &&
docker-compose down &&
rm -f myapp-$CI_COMMIT_SHORT_SHA.tar.gz
"
tags:
- deployer
when: manual # Confirmación manual después de un cambio exitoso
Notas importantes sobre CI/CD:
- Utilice claves SSH para acceder al VPS sin contraseña.
- Variables de entorno para datos sensibles (contraseñas, claves).
sed -i para modificar archivos de configuración de Nginx. En escenarios más complejos, se pueden usar plantillas de Ansible.when: manual para las etapas de cambio y limpieza, para asegurar una verificación y confirmación manual. Idealmente, después de las pruebas automáticas en Green, se puede hacer una pausa para una prueba de humo manual.- Añada pruebas completas (health checks, integración) al pipeline.
- Para Canary, el pipeline será más complejo, con etapas de aumento gradual del tráfico y monitoreo después de cada paso.
6.5. Monitoreo y registro
El monitoreo es sus ojos y oídos en producción. Sin él, los despliegues Blue/Green y Canary pierden sentido.
- Métricas: Utilice Prometheus para recopilar métricas (CPU, RAM, tráfico de red del VPS, así como métricas de su aplicación: número de solicitudes, latencias, errores). Exportadores para Docker, Node Exporter para VPS, y exportadores personalizados para su aplicación. Grafana para la visualización.
- Logs: Recopile los logs de todos los contenedores.
- Solución simple: Utilizar
docker logs -f <container_name> o configurar el log-driver de Docker a json-file y recopilarlos con journalctl.
- Solución avanzada: ELK-stack (Elasticsearch, Logstash, Kibana) o Loki + Promtail. Promtail recopila logs de los contenedores Docker y los envía a Loki, y Grafana se utiliza para consultar Loki.
- Alertas: Configure alertas (a través de Alertmanager para Prometheus) sobre cualquier anomalía: aumento de errores en la nueva versión, degradación del rendimiento, alta carga de recursos.
- Trazabilidad (Distributed Tracing): Para arquitecturas de microservicios, considere OpenTelemetry o Jaeger/Zipkin para rastrear solicitudes a través de múltiples servicios. Esto ayuda a comprender dónde surgió exactamente el problema en el despliegue Canary.
6.6. Gestión de bases de datos
Las migraciones de BD son el eslabón más débil en los despliegues sin interrupciones. Siga siempre el principio de compatibilidad inversa:
- Adición de una columna: Primero, despliegue la nueva versión de la aplicación que pueda trabajar con la nueva columna (pero no la requiera). Luego, realice la migración de la BD. Después de esto, cambie el tráfico.
- Eliminación de una columna: Primero, asegúrese de que todas las versiones antiguas que utilizan esta columna estén fuera de servicio. Luego, elimine la columna de la BD.
- Cambio de tipo de columna: A menudo requiere una migración de dos fases: primero, añadir una nueva columna con el nuevo tipo, transferir los datos, cambiar la aplicación a la nueva columna y luego eliminar la antigua.
Utilice herramientas para la migración de BD, como Alembic (Python), Flyway (Java), Liquibase, Knex.js (Node.js).
La implementación de estos consejos prácticos le permitirá crear un proceso de despliegue fiable y automatizado que reducirá significativamente los riesgos y aumentará la estabilidad de sus aplicaciones Docker en un VPS.
7. Errores comunes al implementar Blue/Green y Canary
 Diagrama: 7. Errores comunes al implementar Blue/Green y Canary
Diagrama: 7. Errores comunes al implementar Blue/Green y Canary
La implementación de estrategias de despliegue avanzadas, como Blue/Green y Canary, puede mejorar significativamente la estabilidad y fiabilidad de sus lanzamientos. Sin embargo, como cualquier tarea de ingeniería compleja, conlleva una serie de errores comunes que pueden anular todos los beneficios e incluso provocar problemas graves. En 2026, cuando la automatización y la velocidad se han vuelto clave, estos errores pueden ser especialmente costosos.
7.1. Pruebas insuficientes del entorno "verde" o "canario"
Descripción del error: Este es, quizás, el error más común y peligroso. Los desarrolladores o ingenieros de DevOps confían en que la nueva versión "debe funcionar" o realizan solo verificaciones superficiales. A veces, debido a la prisa, se omiten las pruebas de integración o de carga en el nuevo entorno, o las pruebas se realizan en un entorno de prueba aislado que no se corresponde completamente con la producción. En el caso de Canary, esto se manifiesta en una monitorización insuficiente de un pequeño porcentaje del tráfico.
Cómo evitarlo: Implemente una estrategia de pruebas integral que incluya pruebas unitarias, de integración, E2E (End-to-End) y de carga. Automatice estas pruebas en su pipeline de CI/CD. Para Blue/Green, asegúrese de que el entorno "verde" sea completamente funcional y estable bajo carga antes de cambiar el tráfico a él. Para Canary, establezca criterios de éxito y métricas claras que deben alcanzarse antes de aumentar el porcentaje de tráfico. Utilice herramientas como Selenium, Cypress, JMeter, K6.
Ejemplo de consecuencias: Cambiar a un entorno "verde" con un error crítico que solo se manifiesta bajo carga, provoca una falla total del servicio para todos los usuarios. En el caso de Canary, incluso el 1% de los usuarios puede encontrarse con un error fatal, lo que socava la confianza y la reputación.
7.2. Ausencia o monitorización y alertado ineficaces
Descripción del error: Un despliegue sin un sistema fiable de monitorización y alertado es como volar a ciegas. Si no sabe lo que sucede con su aplicación después del despliegue, no podrá reaccionar rápidamente a los problemas. A menudo, los equipos configuran una monitorización básica, pero no métricas de aplicación personalizadas, o no tienen umbrales claros para las alertas.
Cómo evitarlo: Implemente una monitorización de extremo a extremo: infraestructura (CPU, RAM, disco VPS), contenedores Docker, la propia aplicación (métricas de solicitudes, errores, latencias, métricas de negocio). Utilice Prometheus + Grafana para las métricas, Loki/ELK para los logs. Configure Alertmanager para enviar notificaciones a Slack, PagerDuty o por correo electrónico cuando se superen los umbrales de errores, latencias o indisponibilidad. Asegúrese de que las métricas estén disponibles para ambas versiones de la aplicación para poder comparar su rendimiento.
Ejemplo de consecuencias: Una nueva versión de la aplicación comienza a "morir" lentamente debido a una fuga de memoria o a un número excesivo de solicitudes a la base de datos, pero el equipo se entera de esto solo una hora después, cuando los usuarios ya se están quejando masivamente y la reversión toma un tiempo precioso.
7.3. Gestión incorrecta del estado y las migraciones de bases de datos
Descripción del error: Este es el talón de Aquiles de muchas estrategias de despliegue sin interrupciones. Si la aplicación tiene estado (sesiones, cachés) o requiere migraciones de base de datos, un simple cambio de tráfico puede provocar incompatibilidad de datos, pérdida de sesiones de usuario o corrupción de datos. Se olvida que ambas versiones de la aplicación pueden operar simultáneamente con la misma base de datos.
Cómo evitarlo:
- Estado: Idealmente, su aplicación debería ser sin estado (stateless). Si esto no es posible, utilice almacenes de estado externos y compartidos (Redis, Memcached) o bases de datos a las que ambas versiones de la aplicación tengan acceso.
- Base de datos: Todas las migraciones deben ser retrocompatibles. Esto significa que la nueva versión de la aplicación debe poder trabajar con el esquema de base de datos antiguo, y la versión antigua debe poder trabajar con el esquema de base de datos nuevo (hasta que sea retirada). Utilice migraciones de dos fases para cambios de esquema complejos. Siempre realice copias de seguridad antes de la migración.
Ejemplo de consecuencias: Después de un despliegue Blue/Green, los usuarios que estaban en el entorno "azul" pierden sus sesiones al cambiar al "verde". O la nueva versión intenta usar una columna inexistente en la base de datos, y la versión antigua no puede trabajar con el nuevo esquema, lo que lleva a la indisponibilidad total de la aplicación.
7.4. Ausencia o complejidad de la automatización de la reversión
Descripción del error: En teoría, la reversión en Blue/Green y Canary es sencilla. En la práctica, si el proceso de reversión no está automatizado y probado, puede ser lento, propenso a errores y provocar un tiempo de inactividad adicional. A veces, los equipos se centran solo en el despliegue, olvidando la importancia de una reversión rápida y fiable.
Cómo evitarlo: Incluya el proceso de reversión en su pipeline de CI/CD. Debe ser tan automatizado y probado como el proceso de despliegue. Para Blue/Green, es simplemente un cambio en el balanceador de carga. Para Canary, puede ser una reducción automática del tráfico al "canario" a cero al detectar métricas o errores críticos. Pruebe regularmente el procedimiento de reversión en un entorno de prueba.
Ejemplo de consecuencias: Se detecta un error crítico en la nueva versión. El equipo intenta revertir Nginx manualmente, pero comete un error en la configuración, lo que provoca un tiempo de inactividad adicional. O la reversión tarda 15 minutos en lugar de 15 segundos.
7.5. Ignorar la limpieza de recursos antiguos
Descripción del error: Especialmente relevante para Blue/Green. Después de un despliegue exitoso y el cambio al entorno "verde", el entorno "azul" a menudo sigue funcionando, consumiendo valiosos recursos de VPS. Si esto no se monitorea y automatiza, con el tiempo conduce a gastos excesivos significativos y a un uso ineficiente de la infraestructura.
Cómo evitarlo: Incluya la etapa de limpieza de recursos antiguos (detención y eliminación de contenedores/servicios antiguos) en su pipeline de CI/CD. Hágalo automático después de un período determinado de funcionamiento estable de la nueva versión, o manual, pero con un recordatorio claro. Para Canary, asegúrese de que las instancias "canario" se retiren después del despliegue completo de la nueva versión.
Ejemplo de consecuencias: Después de varios meses, se descubre que 5-6 versiones antiguas de la aplicación están funcionando en el VPS, consumiendo CPU y RAM, lo que ralentiza la aplicación activa y genera costos de VPS injustificados.
7.6. Configuración incorrecta del balanceador de carga
Descripción del error: El balanceador de carga (Nginx, HAProxy, Caddy, Traefik) es un componente clave de ambas estrategias. Los errores en su configuración pueden llevar a un enrutamiento incorrecto del tráfico, fugas de sesiones o incluso a ataques DoS en un entorno inactivo. Por ejemplo, una configuración incorrecta de los encabezados de proxy puede hacer que la aplicación no vea la IP real del usuario.
Cómo evitarlo: Revise cuidadosamente la configuración de su balanceador de carga. Utilice health checks para verificar la disponibilidad de los backends. Asegúrese de que las sticky sessions (si son necesarias) estén configuradas correctamente. Automatice el cambio de configuración a través de CI/CD. Utilice herramientas como nginx -t para verificar la sintaxis antes de reiniciar.
Ejemplo de consecuencias: Los usuarios ven la versión antigua de la aplicación, aunque el tráfico debería haberse cambiado a la nueva. O las solicitudes se distribuyen de manera desigual, causando una sobrecarga en uno de los entornos. En Canary, un enrutamiento incorrecto puede hacer que el "canario" sea visto por muchos más usuarios de lo previsto, o que no reciba tráfico en absoluto.
Al evitar estos errores comunes, aumentará significativamente las posibilidades de una implementación exitosa y un uso eficaz de las estrategias de despliegue Blue/Green y Canary, garantizando la estabilidad y fiabilidad de sus aplicaciones Docker en un VPS.
8. Lista de verificación para la aplicación práctica
Antes de comenzar la implementación o un nuevo despliegue utilizando las estrategias Blue/Green o Canary, revise esta lista de verificación. Le ayudará a asegurarse de que ha considerado todos los aspectos críticos y ha minimizado los riesgos. Esta lista de verificación es relevante para 2026, teniendo en cuenta las prácticas modernas de DevOps.
8.1. Preparación y planificación general
- Tiempo de inactividad permitido definido: Sabe qué nivel de inactividad es aceptable para su aplicación y público objetivo.
- Estrategia de despliegue seleccionada: Blue/Green o Canary, según las necesidades del negocio y las capacidades técnicas.
- Recursos de VPS suficientes: Verificada la disponibilidad de CPU, RAM, disco para el funcionamiento simultáneo de dos versiones (Blue/Green) o versiones estable y Canary.
- Plan de reversión listo y probado: Sabe cómo volver rápida y seguramente a la versión estable anterior.
- Plan de migración de BD listo: Todos los cambios en la BD están diseñados teniendo en cuenta la retrocompatibilidad.
- Equipo informado: Todos los participantes del proceso (desarrolladores, testers, DevOps) conocen sus roles y las etapas del despliegue.
- Calendario de despliegue acordado: Se ha elegido el momento de menor carga para el despliegue, a fin de minimizar el impacto en los usuarios.
8.2. Preparación de infraestructura y herramientas
- Docker y Docker Compose instalados y configurados: Listos para funcionar en su VPS.
- Balanceador de carga configurado: Nginx, Caddy o HAProxy listos para gestionar el tráfico.
- Pipeline de CI/CD configurado: Jenkins, GitLab CI, GitHub Actions o Ansible automatizan la compilación, las pruebas y el despliegue.
- Acceso SSH sin contraseña: Clave SSH configurada para el agente de CI/CD para un acceso seguro al VPS.
- Sistema de monitorización configurado: Prometheus + Grafana recopilan métricas de infraestructura y aplicación.
- Sistema de registro configurado: ELK stack o Loki + Promtail recopilan y agregan logs de todos los contenedores.
- Alertas configuradas y probadas: Las notificaciones de problemas críticos llegan en tiempo real.
- Copias de seguridad de la BD realizadas: Se han realizado copias de seguridad recientes de la base de datos antes de iniciar el despliegue.
8.3. Preparación de la aplicación y el código
- Imagen Docker de la aplicación optimizada: Tamaño mínimo, caché multicapa, ausencia de dependencias innecesarias.
- Health checks implementados: La aplicación proporciona un endpoint (por ejemplo,
/health) que el balanceador de carga puede usar para verificar su operatividad.
- Métricas de la aplicación expuestas: La aplicación proporciona métricas para Prometheus (por ejemplo, a través de una biblioteca cliente).
- Registro estandarizado: La aplicación registra en stdout/stderr en un formato fácil de analizar (por ejemplo, JSON).
- Configuración de la aplicación parametrizada: Todos los datos sensibles y los parámetros específicos del entorno se cargan desde variables de entorno o archivos de configuración, y no están codificados en la imagen.
- Pruebas superadas: Todas las pruebas automáticas (unitarias, de integración, E2E) se han superado con éxito en el entorno de prueba.
- Retrocompatibilidad de API/contratos: Asegúrese de que la nueva versión no interrumpa el funcionamiento de los clientes que utilizan la API antigua.
8.4. Etapas del despliegue
- Versión antigua (Blue) funciona de forma estable: Se ha verificado el estado de la versión actual de la aplicación.
- Nueva versión (Green/Canary) desplegada: Los contenedores de la nueva versión se han iniciado con éxito en el VPS, pero el tráfico aún no se ha dirigido a ellos.
- Pruebas de la nueva versión (antes del cambio de tráfico): Se han realizado pruebas manuales y automáticas en Green/Canary sin afectar a los usuarios principales.
- Cambio de tráfico:
- Blue/Green: Balanceador de carga cambiado a Green.
- Canary: El balanceador de carga comienza a dirigir un pequeño porcentaje de tráfico a Canary.
- Monitorización después del cambio: Las métricas y los logs de la nueva versión se monitorean activamente.
- Toma de decisiones:
- Blue/Green: Si Green es estable, Blue puede ser detenida. Si hay problemas, reversión a Blue.
- Canary: Si Canary es estable, el porcentaje de tráfico se aumenta gradualmente. Si hay problemas, reversión de Canary.
- Limpieza de recursos: Contenedores e imágenes antiguos eliminados para liberar recursos del VPS.
Siguiendo esta lista de verificación, aumentará significativamente la probabilidad de un despliegue exitoso y sin problemas, garantizando una alta disponibilidad y fiabilidad de sus aplicaciones Docker.
9. Cálculo de costos / Economía de la implementación
 Esquema: 9. Cálculo de costos / Economía de la implementación
Esquema: 9. Cálculo de costos / Economía de la implementación
La implementación de estrategias avanzadas de despliegue, como Blue/Green y Canary, en un VPS siempre conlleva ciertos costos. Es importante entender que estos costos no se limitan únicamente al precio del propio VPS, sino que también incluyen gastos ocultos y ahorros potenciales. En 2026, cuando el costo de los recursos en la nube continúa optimizándose y la automatización se vuelve más accesible, un cálculo económico correcto puede proporcionar una ventaja competitiva significativa.
9.1. Costos directos del VPS
El principal elemento de gasto es el propio servidor virtual. Los precios de los VPS en 2026 continúan disminuyendo, especialmente para configuraciones estándar. Para aplicaciones Docker en un VPS de potencia media (4 vCPU, 8GB RAM, 160GB SSD), se pueden considerar las siguientes tarifas mensuales aproximadas de los principales proveedores (DigitalOcean, Vultr, Hetzner, Linode):
- VPS Básico: $15 - $25 / mes
- VPS Medio: $30 - $50 / mes
- VPS Potente: $60 - $100+ / mes
9.1.1. Escenario Blue/Green: Duplicación temporal de recursos
Para la estrategia Blue/Green, necesitará duplicar temporalmente los recursos. Si su aplicación normalmente funciona en un VPS por $40/mes, durante el despliegue necesitará un segundo VPS idéntico (o su equivalente en recursos). Supongamos que el despliegue toma 30 minutos.
- Costo mensual de un VPS: $40
- Costo por hora de funcionamiento del VPS: $40 / (30 días * 24 horas) = ~$0.055 / hora
- Gastos adicionales por despliegue (30 minutos): $0.055 / 2 = ~$0.0275 por un despliegue.
- Si despliega 4 veces al mes: 4 * $0.0275 = ~$0.11
Como puede ver, los costos directos adicionales del VPS para Blue/Green son extremadamente bajos si utiliza el escalado temporal o si tiene un excedente de recursos en su servidor existente. Lo principal a lo que debe prestar atención es el error de ignorar la limpieza de recursos antiguos, lo que puede llevar a gastos innecesarios constantes.
9.1.2. Escenario Canary: Recursos permanentemente aumentados
Para el despliegue Canary, a menudo mantiene instancias "canary" de forma permanente, incluso si atienden un pequeño porcentaje del tráfico. Esto puede significar que necesita constantemente entre un 10% y un 50% más de recursos que para una versión estable.
- Costo mensual de un VPS: $40
- Recursos adicionales para Canary: Por ejemplo, 20% de un VPS.
- Gastos adicionales permanentes: $40 * 0.20 = $8/mes.
Estos costos pueden ser más altos si las instancias Canary requieren un VPS separado o si utiliza un enrutamiento más complejo que puede consumir recursos adicionales del balanceador de carga.
9.2. Costos ocultos
Además de los costos directos del VPS, existen costos ocultos que a menudo se pasan por alto, pero que pueden ser muy significativos.
- Tiempo de los ingenieros: El mayor costo oculto. Configuración y soporte de pipelines CI/CD, sistemas de monitoreo, depuración de problemas. En 2026, la tarifa promedio de un ingeniero DevOps es de $80-150/hora. Si la configuración toma 80 horas: 80 * $100 = $8000.
- Costo de las herramientas: Aunque muchas herramientas (Docker, Nginx, Prometheus, Grafana) son gratuitas, algunas pueden tener versiones de pago o requerir alojamiento de pago (por ejemplo, GitLab EE, soluciones de registro en la nube).
- Capacitación del equipo: Inversión en la capacitación de ingenieros en nuevas estrategias y herramientas.
- Pérdidas potenciales por errores: A pesar de la reducción de riesgos, los errores aún pueden ocurrir. Pérdida de clientes, daño a la reputación, multas por incumplimiento de SLA.
9.3. Cómo optimizar los costos
- Uso eficiente de los recursos del VPS:
- Optimización de imágenes Docker: Reducción del tamaño de las imágenes, uso de multi-stage builds.
- Optimización de Docker Compose: Uso de redes externas, gestión inteligente de volúmenes.
- Monitoreo de carga: Elección de un VPS que se ajuste exactamente a sus necesidades, y no "con margen".
- Automatización: Las inversiones en pipelines CI/CD reducen el trabajo manual y minimizan los errores, lo que a largo plazo ahorra tiempo a los ingenieros.
- Planificación cuidadosa de la BD: Minimización de migraciones complejas que pueden provocar tiempos de inactividad o la necesidad de intervención manual.
- Uso de herramientas gratuitas y de código abierto: Máximo aprovechamiento del ecosistema de código abierto (Nginx, Docker, Prometheus, Grafana, Ansible, GitLab CE/GitHub Actions).
- Auditoría regular de recursos: Verifique periódicamente qué contenedores y servicios se están ejecutando en su VPS y elimine los que no se utilicen.
9.4. Tabla con ejemplos de cálculos para diferentes escenarios (año 2026)
Supongamos que un VPS básico, suficiente para una versión de la aplicación, cuesta $40/mes.
| Parámetro |
Escenario 1: Blue/Green (1 despliegue/semana) |
Escenario 2: Canary (20% de tráfico constante en Canary) |
Escenario 3: Sin estrategias avanzadas (despliegue simple con 5 min de inactividad) |
| Costos directos del VPS |
$40 (principal) + $0.11 (horas adicionales) = $40.11/mes |
$40 (principal) + $8 (recursos adicionales) = $48/mes |
$40/mes |
| Costo del tiempo de los ingenieros (configuración) |
~80 horas * $100 = $8000 (una sola vez) |
~120 horas * $100 = $12000 (una sola vez) |
~20 horas * $100 = $2000 (una sola vez) |
| Costo del tiempo de los ingenieros (soporte) |
~5 horas/mes * $100 = $500/mes |
~8 horas/mes * $100 = $800/mes |
~2 horas/mes * $100 = $200/mes |
| Pérdidas por tiempo de inactividad (ejemplo) |
$0 (casi nulo) |
$0 (casi nulo) |
$100/min * 5 min * 4 despliegues = $2000/mes |
| Riesgo de pérdidas de reputación |
Bajo |
Muy bajo (audiencia limitada) |
Alto |
| Costo total de propiedad (TCO) por año |
$8000 (configuración) + $40.11*12 (VPS) + $500*12 (soporte) = ~$14500 |
$12000 (configuración) + $48*12 (VPS) + $800*12 (soporte) = ~$22600 |
$2000 (configuración) + $40*12 (VPS) + $200*12 (soporte) + $2000*12 (pérdidas) = ~$29000 |
Esta tabla demuestra claramente que, aunque las inversiones iniciales en el despliegue Blue/Green y Canary son mayores, se amortizan gracias a la reducción de las pérdidas por tiempo de inactividad, la disminución de las operaciones manuales y el aumento de la fiabilidad. Para aplicaciones de misión crítica, donde cada minuto de inactividad cuesta dinero, estas estrategias avanzadas no son solo deseables, sino inversiones económicamente justificadas.
10. Casos y ejemplos de la práctica real
 Esquema: 10. Casos y ejemplos de la práctica real
Esquema: 10. Casos y ejemplos de la práctica real
Para comprender mejor cómo se aplican en la práctica las implementaciones Blue/Green y Canary, examinemos varios escenarios realistas. Estos casos demuestran cómo diferentes empresas pueden utilizar estas estrategias para resolver sus desafíos únicos en un VPS.
10.1. Caso 1: Plataforma SaaS para la gestión de proyectos (Blue/Green)
Escenario
Una pequeña pero creciente empresa SaaS, "TaskFlow", ofrece una plataforma para la gestión de proyectos. Tienen alrededor de 5000 clientes activos que utilizan el servicio 24/7. El equipo de desarrollo (4 backends en Node.js) lanza nuevas características y correcciones de errores semanalmente. Un tiempo de inactividad del servicio, incluso de 5 minutos, provoca quejas de los clientes y una posible pérdida de suscripciones. La infraestructura consta de un potente VPS (8 vCPU, 16GB RAM) con Docker Compose, Nginx como proxy inverso y PostgreSQL.
Problema
La implementación tradicional de "detener-reemplazar-iniciar" provocaba de 2 a 5 minutos de inactividad cada semana. Esto generaba insatisfacción en los clientes, especialmente en otras zonas horarias, y aumentaba la carga de trabajo del soporte.
Solución: Implementación de Blue/Green
- Duplicación de contenedores: En lugar de un único conjunto de contenedores para la aplicación Node.js, se crearon dos conjuntos:
taskflow-blue y taskflow-green, cada uno en su propio puerto (por ejemplo, 3000 y 3001).
- Base de datos compartida: PostgreSQL se mantuvo unificada, pero las migraciones de la base de datos fueron cuidadosamente diseñadas para la compatibilidad con versiones anteriores.
- Nginx como conmutador: Nginx se configuró para enrutar todo el tráfico al puerto 3000 (Blue).
- Pipeline de CI/CD: Se configuró GitLab CI, que:
- Compilaba una nueva imagen de Docker.
- Desplegaba la nueva versión en el puerto 3001 (Green).
- Ejecutaba pruebas de integración automáticas contra el entorno Green.
- Después de pruebas exitosas, esperaba la confirmación manual.
- Por orden del ingeniero, cambiaba automáticamente la configuración de Nginx para conmutar el tráfico al puerto 3001 y reiniciaba Nginx.
- Después de confirmar la estabilidad de Green, detenía y eliminaba los contenedores Blue.
- Monitorización: Prometheus y Grafana se configuraron para monitorear las métricas de ambos entornos, con alertas en Slack en caso de aumento de errores o latencias.
Resultados
- Tiempo de inactividad cero: El tiempo de conmutación del tráfico se redujo a 1-2 segundos, eliminando completamente el tiempo de inactividad.
- Rollback rápido: En caso de problemas, el rollback tomaba menos de 10 segundos.
- Aumento de la confianza del cliente: El número de quejas por indisponibilidad del servicio se redujo drásticamente.
- Confianza del equipo: Los desarrolladores se atrevieron más a lanzar nuevas funciones, sabiendo que el riesgo era mínimo.
- Costos adicionales: Mínimos, ya que el VPS tenía suficientes recursos de sobra para duplicar temporalmente la carga, y el tiempo de los ingenieros para la configuración se amortizó en 3 meses gracias a la reducción de operaciones manuales y tiempos de inactividad.
10.2. Caso 2: Plataforma de E-commerce con alta carga (Canary)
Escenario
La gran plataforma de E-commerce "ShopSphere" (en PHP/Laravel) tiene decenas de miles de usuarios activos diariamente. Su infraestructura VPS consta de varios servidores potentes, agrupados en un clúster con HAProxy como balanceador de carga. La implementación de nuevas funciones, especialmente en el sistema de pago o el carrito de compras, conlleva altos riesgos. Incluso un 0.1% de errores puede resultar en pérdidas financieras significativas. El equipo desea probar las nuevas funciones con usuarios reales antes de lanzarlas a todos.
Problema
Blue/Green era bueno para el tiempo de inactividad, pero no permitía probar nuevas funciones en una muestra pequeña y representativa de usuarios reales. A veces, las nuevas características funcionaban perfectamente en el entorno de prueba, pero causaban un comportamiento inesperado o errores en producción debido a la especificidad de los datos de usuario o los patrones de uso.
Solución: Implementación de Canary
- Asignación de instancias Canary: En uno de los VPS se asignaron recursos para ejecutar la versión "canary" de la aplicación (
shopsphere-canary).
- HAProxy para el enrutamiento del tráfico: HAProxy se configuró para redirigir el tráfico:
- Inicialmente, el 99.5% del tráfico se dirigía a las instancias estables (Blue).
- El 0.5% del tráfico se dirigía a la instancia Canary. Esto se implementó mediante pesos en la configuración de HAProxy.
- Para los testers internos, se previó un enrutamiento mediante una cabecera HTTP especial
X-Test-Version: canary.
- Monitorización avanzada: Además de Prometheus/Grafana, se implementó una pila ELK para un análisis profundo de los logs. Se prestó especial atención a las métricas de negocio (conversión, ticket promedio) para el grupo Canary en comparación con el grupo Blue.
- Pipeline automatizado con pasos manuales: GitLab CI se configuró para:
- Compilar y desplegar la versión Canary.
- Ejecutar automáticamente pruebas de humo (smoke tests).
- Una etapa manual de "Evaluación Canary 0.5%": el equipo analizaba métricas y logs durante 4-6 horas.
- Si todo iba bien, un paso manual de "Aumentar al 5%".
- Repetición de la monitorización y el aumento (25%, 50%, 100%).
- Rollback automático de Canary al detectar anomalías críticas (por ejemplo, un aumento brusco de errores 5xx, caída de la conversión).
Resultados
- Riesgo mínimo: Los errores críticos se detectaban en una muestra muy pequeña de usuarios, previniendo problemas masivos.
- Calidad de los lanzamientos: Las nuevas funciones se verificaban meticulosamente en condiciones reales, lo que mejoró significativamente la calidad y estabilidad de los lanzamientos.
- Optimización de la experiencia del usuario: Posibilidad de realizar pruebas A/B de nuevas funciones y cambios de UI en una pequeña audiencia, recopilando feedback real.
- Costos adicionales: Uso constante de un VPS adicional para instancias Canary ($40/mes) e inversiones significativas en la configuración y el soporte de un pipeline y monitorización complejos (aproximadamente 120 horas de ingeniero). Sin embargo, estos costos están completamente justificados por la prevención de pérdidas multimillonarias debido a errores en el E-commerce.
Estos casos demuestran que las implementaciones Blue/Green y Canary no son solo conceptos teóricos, sino estrategias potentes y probadas en la práctica, capaces de mejorar significativamente el proceso de desarrollo y operación de aplicaciones en un VPS, garantizando al mismo tiempo una alta disponibilidad y calidad del servicio.
12. Troubleshooting: solución de problemas típicos
 Diagrama: 12. Troubleshooting: solución de problemas típicos
Diagrama: 12. Troubleshooting: solución de problemas típicos
Incluso con la preparación más meticulosa y el uso de estrategias de despliegue avanzadas, pueden surgir problemas en producción. La capacidad de diagnosticarlos y resolverlos rápidamente es una habilidad clave para cualquier ingeniero DevOps. En esta sección, examinaremos los problemas típicos que pueden surgir con el despliegue Blue/Green y Canary en un VPS con Docker, y ofreceremos pasos concretos para su solución.
12.1. Problema: La nueva versión de la aplicación (Green/Canary) no se inicia o falla inmediatamente después del arranque
Síntomas
- El contenedor no se inicia o se reinicia constantemente.
- Errores en los logs de Docker o de la aplicación.
- El endpoint de health check no está disponible.
Comandos de diagnóstico
# Проверить статус контейнера
docker ps -a | grep
# Просмотреть логи контейнера
docker logs
# Зайти внутрь контейнера для ручной проверки
docker exec -it /bin/bash
Soluciones
- Verifique los logs: Lo primero y más importante. Busque mensajes de error, excepciones, problemas con dependencias, variables de entorno, conexión a la base de datos o servicios externos.
- Falta de recursos: Verifique la carga de CPU/RAM en el VPS. Es posible que la nueva versión consuma más recursos de lo esperado y Docker no pueda asignar los suficientes.
htop # Или top, free -h
docker stats
- Problemas de configuración: Asegúrese de que todas las variables de entorno, archivos de configuración y volúmenes montados sean correctos para la nueva versión.
- Puertos ocupados: Asegúrese de que el puerto en el que debe ejecutarse la nueva versión no esté ocupado por otro proceso.
sudo netstat -tulnp | grep
- Errores en Dockerfile/imagen: Si la nueva versión no se compila o no se ejecuta correctamente, revise el
Dockerfile y el proceso de compilación.
12.2. Problema: El tráfico no se cambia a la nueva versión o se cambia incorrectamente
Síntomas
- Los usuarios siguen viendo la versión antigua, aunque lógicamente el tráfico debería haberse cambiado.
- Parte de los usuarios ve la versión antigua, parte la nueva (para Blue/Green).
- Para Canary: el porcentaje de tráfico no coincide con las expectativas.
Comandos de diagnóstico
# Проверить конфигурацию Nginx
sudo nginx -t
sudo cat /etc/nginx/nginx.conf
# Проверить логи Nginx
sudo tail -f /var/log/nginx/access.log
sudo tail -f /var/log/nginx/error.log
# Проверить доступность портов приложения
curl http://127.0.0.1:8080/health # Blue
curl http://127.0.0.1:8081/health # Green/Canary
Soluciones
- Verifique la configuración del balanceador: Asegúrese de que los cambios en
nginx.conf (o Caddyfile/HAProxy) se hayan aplicado y que la sintaxis sea correcta. Recargue o relea la configuración.
- Verifique los health checks: El balanceador de carga podría haber marcado la nueva versión como "no saludable" y no dirigir tráfico hacia ella. Revise los logs del balanceador.
- Caché DNS: Si está cambiando el tráfico a través de DNS, los cambios pueden propagarse lentamente debido al almacenamiento en caché. Esto no aplica a Nginx/HAProxy, que operan a nivel L7.
- Sticky sessions: Si se utilizan sticky sessions, asegúrese de que estén configuradas correctamente y no interfieran con el cambio de tráfico.
12.3. Problema: La nueva versión funciona más lento o genera más errores
Síntomas
- Aumento de las métricas de error (5xx) en Prometheus/Grafana para la nueva versión.
- Aumento de la latencia de respuesta.
- Aumento del consumo de CPU/RAM para los contenedores de la nueva versión.
- Quejas de los usuarios sobre un rendimiento lento o inaccesibilidad.
Comandos de diagnóstico
# Мониторинг метрик в Grafana
# Анализ логов в Loki/Kibana
docker stats # Сравнить с docker stats
Soluciones
- Monitoreo y logs: Este es su principal punto de apoyo. Compare las métricas y los logs de la versión nueva y la antigua. Busque anomalías: nuevos tipos de errores, aumento del tiempo de ejecución de consultas a la base de datos, APIs externas.
- Recursos: Asegúrese de que la nueva versión no esté alcanzando los límites de CPU/RAM en el VPS. Es posible que requiera más recursos.
- Problemas con la base de datos: Verifique las consultas lentas a la base de datos, problemas con índices o bloqueos causados por cambios en la nueva versión.
- Dependencias externas: La nueva versión puede tener problemas para conectarse a servicios externos, cachés, colas de mensajes.
- Rollback: Si el problema es crítico y no se encuentra una solución rápida, realice inmediatamente un rollback a la versión estable anterior.
12.4. Problema: Problemas con la migración de bases de datos
Síntomas
- Errores de la aplicación relacionados con el acceso a la base de datos (por ejemplo, "column not found", "table not found").
- Corrupción de datos o inconsistencia.
Comandos de diagnóstico
# Проверить логи миграций
# Подключиться к БД и проверить схему
psql -U user -d mydatabase -h db -c "\dt"
psql -U user -d mydatabase -h db -c "\d "
Soluciones
- Compatibilidad inversa: Asegúrese de que las migraciones se hayan diseñado teniendo en cuenta la compatibilidad inversa. Ambas versiones de la aplicación (antigua y nueva) deben poder trabajar con la base de datos durante el período de transición.
- Orden de las migraciones: Asegúrese de que las migraciones se ejecuten en el orden correcto: primero los cambios compatibles con la versión antigua, luego el despliegue de la nueva versión, y luego, si es necesario, la eliminación de elementos antiguos.
- Copias de seguridad: Siempre realice copias de seguridad de la base de datos antes del despliegue y la migración. En caso de problemas graves, esto permitirá restaurar los datos.
- Prueba de migraciones: Pruebe las migraciones no solo con datos de prueba, sino también con una copia de la base de datos de producción.
12.5. Cuándo contactar al soporte
Si se encuentra con problemas que no puede resolver por sí mismo, o si tiene dificultades con la propia infraestructura del VPS:
- Problemas con el VPS: Indisponibilidad del servidor, problemas de red, problemas de disco que no están relacionados con su aplicación.
- Problemas con el proveedor: Si sospecha que el problema está del lado del proveedor de hosting (por ejemplo, indisponibilidad general de la región, problemas de red).
- Errores desconocidos: Si los logs no proporcionan una comprensión clara del problema, y todos los pasos de diagnóstico estándar no han dado resultado.
Proporcione al soporte la información más completa posible: la hora exacta en que ocurrió el problema, logs, métricas, los pasos de diagnóstico realizados, así como cualquier cambio que haya realizado antes de que surgiera el problema.
13. FAQ: Preguntas frecuentes
¿Qué es el despliegue Blue/Green?
El despliegue Blue/Green es una estrategia de implementación en la que se mantienen dos entornos de producción idénticos: el "azul" (Blue) con la versión estable actual de la aplicación y el "verde" (Green) para la nueva versión. Todo el tráfico de usuarios se dirige a uno de ellos. Al actualizar, la nueva versión se despliega en el entorno "verde", se prueba, y luego el tráfico se cambia instantáneamente del "azul" al "verde". Esto garantiza un tiempo de inactividad prácticamente nulo y una rápida reversión.
¿Cuál es la principal diferencia entre el despliegue Blue/Green y Canary?
La principal diferencia radica en la forma de cambiar el tráfico. Blue/Green cambia todo el tráfico a la nueva versión de una sola vez después de una prueba completa. El despliegue Canary, por el contrario, dirige gradualmente un pequeño porcentaje del tráfico a la nueva versión, permitiendo probarla con usuarios reales y recopilar métricas antes de implementarla por completo. Canary minimiza los riesgos, pero es más complejo de implementar y lleva más tiempo.
¿Se puede implementar Blue/Green o Canary en un solo VPS?
Sí, es totalmente posible, especialmente para aplicaciones de complejidad media. Esto requiere una reserva suficiente de recursos en el VPS (CPU, RAM) para ejecutar varias versiones de su aplicación Docker simultáneamente. Se utilizan diferentes puertos para cada versión y un balanceador de carga (Nginx, HAProxy) para enrutar el tráfico. Docker Compose ayuda a gestionar múltiples conjuntos de contenedores en un mismo host.
¿Qué herramientas son necesarias para Blue/Green/Canary en un VPS?
Necesitará: Docker y Docker Compose para la contenerización y orquestación, un balanceador de carga (Nginx, Caddy, HAProxy) para el enrutamiento del tráfico, un sistema CI/CD (GitLab CI, GitHub Actions, Jenkins, Ansible) para la automatización del despliegue, así como sistemas de monitoreo (Prometheus, Grafana) y registro (Loki, Promtail, ELK-stack) para controlar el estado de ambas versiones de la aplicación.
¿Cómo manejar las bases de datos y sus migraciones con este tipo de despliegue?
La gestión de bases de datos es un aspecto crítico. Todas las migraciones de la base de datos deben ser compatibles con versiones anteriores, de modo que tanto la versión antigua como la nueva de la aplicación puedan trabajar con el mismo esquema de base de datos durante el período de transición. Utilice migraciones de dos fases para cambios complejos. Siempre realice copias de seguridad antes de la migración. Idealmente, la aplicación debe diseñarse de manera que los cambios en el esquema de la base de datos sean mínimos y no bloqueantes.
¿Cuánto aumentan los costos del VPS al usar estas estrategias?
Para Blue/Green, los costos del VPS aumentan temporalmente (durante el despliegue) por el costo de duplicar los recursos. Si tiene recursos de sobra en el VPS, esto puede ser muy económico. Para Canary, pueden ser necesarios recursos adicionales de forma constante (por ejemplo, del 10 al 50% de la carga actual) para mantener las instancias Canary. Sin embargo, estos costos directos a menudo se compensan con la reducción de pérdidas por tiempo de inactividad y errores, lo que en última instancia hace que estas estrategias sean económicamente ventajosas.
¿Qué riesgos están asociados con el despliegue Blue/Green?
Los principales riesgos incluyen: la necesidad de duplicar recursos durante el despliegue, la complejidad de gestionar el estado de la aplicación (sesiones, cachés) durante el cambio, y la necesidad de una planificación cuidadosa de las migraciones de bases de datos. Si el entorno "verde" no está bien probado, el cambio a este puede resultar en una falla completa del servicio para todos los usuarios.
¿Qué riesgos están asociados con el despliegue Canary?
El despliegue Canary es más complejo de implementar, requiere un sistema avanzado de monitoreo y enrutamiento de tráfico. Existe el riesgo de que un pequeño grupo de usuarios encuentre errores antes de que se detecte el problema. El proceso de despliegue puede llevar más tiempo. La gestión del estado y de la base de datos es aún más crítica, ya que ambas versiones de la aplicación funcionan en paralelo durante un período prolongado.
¿Cómo automatizar el cambio de tráfico para Blue/Green/Canary?
La automatización del cambio de tráfico se realiza generalmente a través de un pipeline CI/CD. Los scripts (por ejemplo, Ansible, scripts Bash invocados desde GitLab CI/GitHub Actions) pueden modificar la configuración del balanceador de carga (Nginx, HAProxy), reiniciarlo o actualizar los registros DNS. Para Canary, esto puede implicar un cambio gradual de los pesos en la configuración del balanceador.
¿Qué es un Health Check y por qué es importante?
Un Health Check es un endpoint especial (por ejemplo, /health) en su aplicación que el balanceador de carga o el sistema de monitoreo consulta regularmente. Si el endpoint devuelve un código 200 OK, la aplicación se considera saludable; de lo contrario, no saludable. El Health Check es críticamente importante, ya que permite al balanceador excluir automáticamente las instancias defectuosas del pool y garantizar que el tráfico se dirija solo a las versiones de la aplicación que funcionan correctamente.
14. Conclusión
En un mundo donde la velocidad de los cambios y la disponibilidad continua de los servicios se han convertido no solo en una ventaja competitiva, sino en un requisito básico, los enfoques tradicionales para el despliegue de aplicaciones Docker en un VPS ya no son suficientes. Las estrategias de actualización Blue/Green y Canary ofrecen soluciones potentes para estos desafíos, permitiendo minimizar el tiempo de inactividad (downtime), reducir los riesgos y mejorar significativamente la calidad de sus lanzamientos.
Hemos examinado en detalle ambas estrategias, sus principios de funcionamiento, ventajas y desventajas, así como ejemplos concretos de implementación utilizando las herramientas actuales de 2026. El despliegue Blue/Green es ideal para proyectos donde el tiempo de inactividad cero (zero downtime) y la reversión rápida son críticos, y la duplicación temporal de recursos es aceptable. Es relativamente sencillo de aprender e implementar en un VPS con Docker Compose y Nginx. El despliegue Canary, aunque más complejo, ofrece oportunidades sin precedentes para probar nuevas funciones con usuarios reales, minimizando los riesgos al mínimo absoluto, lo cual es especialmente valioso para proyectos SaaS grandes y críticos.
Independientemente de la estrategia elegida, los factores clave para el éxito son:
- Automatización: Un pipeline CI/CD de extremo a extremo que automatice la construcción, las pruebas, el despliegue y la reversión.
- Monitorización y registro (logging): Una comprensión profunda del estado de su aplicación e infraestructura en tiempo real.
- Planificación meticulosa: Atención especial a las migraciones de bases de datos, la gestión de estados y las pruebas.
- Cultura DevOps: Interacción entre desarrolladores e ingenieros de operaciones para garantizar un funcionamiento ininterrumpido.
Próximos pasos para el lector
- Evalúe sus necesidades actuales: Analice el tiempo de inactividad (downtime) permitido, los riesgos y los recursos de su proyecto.
- Empiece poco a poco: Si es nuevo en esto, intente implementar un despliegue Blue/Green básico en un VPS de prueba con una aplicación Docker sencilla.
- Invierta en automatización: Comience configurando un pipeline CI/CD simple para la construcción y el despliegue.
- Implemente la monitorización: Incluso un Prometheus y Grafana básicos le proporcionarán información inestimable.
- Estudie las herramientas: Profundice en la documentación de Nginx/HAProxy, Ansible, GitLab CI/GitHub Actions.
- Practique: La experiencia viene con la práctica. No tema experimentar en un entorno controlado.
La implementación de estas estrategias avanzadas no es solo un ejercicio técnico, sino una inversión en la estabilidad, fiabilidad y competitividad de su producto. En 2026, esto ya no es un lujo, sino una necesidad para cualquier proyecto SaaS serio o servicio en línea que aspire a la excelencia.
¿Te fue útil esta guía?
Estrategias avanzadas de despliegue de aplicaciones Docker en VPS: actualizaciones blue/
support_agent
Valebyte Support
Usually replies within minutes
Hi there!
Send us a message and we'll reply as soon as possible.