Мониторинг доступности нескольких серверов – это не просто задача, а краеугольный камень стабильности вашей IT-инфраструктуры. Для эффективного отслеживания работоспособности парка машин существует спектр решений: от простых облачных сервисов, которые быстро разворачиваются и не требуют глубоких технических знаний, до мощных саморазворачиваемых платформ, предоставляющих полный контроль и глубокую кастомизацию, а также кастомных скриптов для специфических нужд. Выбор подходящего инструмента зависит от масштаба вашей инфраструктуры, бюджета, требований к гибкости и компетенций вашей команды. Главная цель – обеспечить своевременное обнаружение проблем и минимизацию простоя, чтобы вы могли спать спокойно, зная, что ваша система под присмотром.
Почему мониторинг доступности – это не роскошь, а необходимость?

В современном мире, где любая задержка или сбой могут обернуться значительными репутационными и финансовыми потерями, надежный мониторинг доступности серверов является критически важным. Давайте разберемся, почему это так:
- Быстрое обнаружение проблем: Чем быстрее вы узнаете о сбое, тем оперативнее сможете отреагировать. Мониторинг позволяет перейти от реактивного исправления к проактивному управлению инцидентами.
- Минимизация простоя и финансовых потерь: Каждый час простоя веб-сервера, базы данных или другого критически важного сервиса может стоить компании тысяч, а то и миллионов рублей. Своевременное оповещение помогает сократить время восстановления.
- Улучшение пользовательского опыта: Доступность ваших сервисов напрямую влияет на удовлетворенность конечных пользователей или клиентов. Стабильная работа – залог лояльности.
- Планирование ресурсов и масштабирование: Хотя мониторинг доступности в первую очередь касается статуса "жив/мертв", многие инструменты предоставляют и метрики производительности. Анализируя их, можно предсказывать потенциальные проблемы с ресурсами и планировать масштабирование.
- Соблюдение SLA: Для многих компаний, особенно работающих по контрактам с клиентами, соблюдение соглашений об уровне обслуживания (SLA) является обязательным. Мониторинг предоставляет данные для подтверждения соответствия этим требованиям.
Основные подходы к мониторингу доступности нескольких серверов
Разнообразие инфраструктур и бизнес-потребностей привело к появлению нескольких ключевых подходов к мониторингу. Рассмотрим их подробнее.
1. Готовые облачные сервисы (SaaS-решения)
Эти сервисы предлагают "мониторинг как услугу", позволяя вам быстро настроить проверки без необходимости разворачивать собственную инфраструктуру. Они идеально подходят для стартапов, малого и среднего бизнеса, а также для внешнего мониторинга критически важных веб-сервисов.
Популярные примеры: Pingdom, UptimeRobot, StatusCake, Site24x7, Freshping.
Как это работает?
Вы регистрируетесь на платформе, добавляете IP-адреса или доменные имена ваших серверов, указываете порты или URL-адреса для проверки. Сервис с определенной периодичностью (например, каждые 1-5 минут) отправляет запросы к вашим серверам из разных географических точек и при обнаружении недоступности отправляет уведомление.
Преимущества:
- Быстрый старт: Настройка занимает считанные минуты.
- Простота использования: Интуитивно понятные интерфейсы, не требуют глубоких технических знаний.
- Глобальные точки проверки: Мониторинг осуществляется из разных стран, что позволяет оценить доступность для разных регионов и выявить проблемы с маршрутизацией.
- Минимум обслуживания: Вся инфраструктура и поддержка на стороне провайдера.
- Разнообразие методов проверки: ICMP (ping), HTTP/HTTPS (статус кода, содержимое страницы), TCP-порты, DNS, SMTP/POP3/IMAP, FTP.
Недостатки:
- Стоимость: Обычно зависит от количества мониторов и интервалов проверок, может расти с масштабом.
- Ограниченная кастомизация: Вы ограничены функционалом, предоставляемым сервисом.
- Зависимость от провайдера: Доступность вашей системы мониторинга зависит от доступности облачного сервиса.
Пример настройки HTTP-мониторинга в UptimeRobot:
Тип: HTTP(s)
URL: https://ваш-сервер.ru/health
Интервал: 1 минута
Таймаут: 30 секунд
Ключевое слово: "OK" (необязательно, для проверки содержимого страницы)2. Самостоятельно разворачиваемые платформы (Self-Hosted)
Если вам нужен полный контроль, глубокая интеграция и максимальная гибкость, то самостоятельное развертывание платформы мониторинга – ваш выбор. Это требует больше усилий на старте, но окупается в долгосрочной перспективе для крупных и сложных инфраструктур.
Популярные примеры: Zabbix, Nagios (и его форки, такие как Icinga), Prometheus + Grafana.
Zabbix
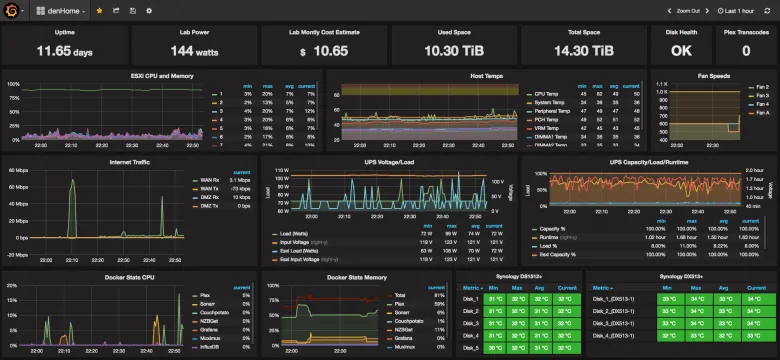
Мощная и гибкая платформа, поддерживающая как агентный, так и безагентный мониторинг. Позволяет собирать тысячи метрик с серверов, сетевого оборудования, приложений и баз данных. Обладает развитой системой триггеров, шаблонов и визуализации.
- Плюсы: Крайне гибкий, масштабируемый, большое сообщество, богатый функционал оповещений и визуализации.
- Минусы: Довольно сложен в освоении и первоначальной настройке, требует значительных ресурсов для больших инсталляций.
Пример проверки доступности порта 22 (SSH) через Zabbix Agent (UserParameter):
UserParameter=ssh.port.check,nc -z -w 1 localhost 22 &>/dev/null; echo $?Этот параметр можно добавить в конфигурацию агента Zabbix, после чего на сервере Zabbix создать элемент данных, который будет опрашивать этот UserParameter и триггер, срабатывающий, если значение будет равно 1 (порт недоступен).
Nagios / Icinga
Одни из старейших и проверенных временем систем мониторинга. Nagios Core послужил основой для множества других проектов, включая Icinga, которая активно развивается и предлагает более современный интерфейс и функционал. Они используют плагины для проверок, что делает их очень расширяемыми.
- Плюсы: Стабильность, огромное количество готовых плагинов, надежность.
- Минусы: Интерфейс может показаться устаревшим (особенно у Nagios Core), конфигурация в текстовых файлах может быть сложной для больших систем.
Prometheus + Grafana
Prometheus – это система мониторинга с открытым исходным кодом, ориентированная на метрики. Она использует pull-модель (Prometheus сам забирает метрики с целевых систем) и идеально подходит для динамических сред, таких как контейнеры и микросервисы. В паре с Grafana (мощным инструментом для визуализации данных) создает очень эффективную и современную систему мониторинга.
- Плюсы: Отлично подходит для метрического мониторинга, мощный язык запросов (PromQL), высокая масштабируемость, великолепная визуализация с Grafana.
- Минусы: Не является полноценным решением для логирования или распределенной трассировки, требует освоения специфичного подхода.
3. Облачные платформы мониторинга (Cloud-Native)
Если ваша инфраструктура полностью или преимущественно развернута в публичном облаке (AWS, Azure, Google Cloud), то использование нативных инструментов мониторинга может быть наиболее эффективным.
Примеры: AWS CloudWatch, Azure Monitor, Google Cloud Monitoring.
Преимущества:
- Глубокая интеграция: Автоматическое обнаружение ресурсов, сбор метрик "из коробки" для всех облачных сервисов.
- Масштабируемость: Разработаны для работы с динамическими и крупными облачными средами.
- Единая панель управления: Централизованный мониторинг всей облачной инфраструктуры.
Недостатки:
- Привязка к конкретному облаку: Менее удобны для гибридных или мультиоблачных сред.
- Стоимость: Может быстро расти в зависимости от объема собираемых данных и количества оповещений.
4. Скриптовый мониторинг (Custom Scripts)
Для очень специфических задач, быстрых проверок или интеграции с уникальными системами, написание собственных скриптов остается актуальным и мощным инструментом. Это позволяет контролировать каждый аспект проверки.
Когда использовать:
- Проверка доступности специфического внутреннего API.
- Мониторинг очень редких или уникальных состояний.
- Легковесные проверки на небольшом количестве серверов.
- Интеграция с существующими внутренними системами оповещения.
Языки: Bash, Python, Perl, PowerShell.
Как это работает?
Вы пишете скрипт, который выполняет нужную проверку (например, пытается подключиться к порту, делает HTTP-запрос, проверяет наличие процесса). Скрипт возвращает код успеха/ошибки или выводит сообщение. Затем вы настраиваете его запуск по расписанию (например, через cron в Linux или Task Scheduler в Windows) и обрабатываете результат, отправляя уведомление при необходимости.
Простой Bash-скрипт для проверки доступности HTTP:
#!/bin/bash
# Скрипт для проверки доступности HTTP-сервиса и логирования
URL="https://ваш-сервер.ru/health"
LOG_FILE="/var/log/http_monitor.log"
ALERT_EMAIL="admin@example.com"
# Получаем HTTP-код ответа
STATUS=$(curl -s -o /dev/null -w "%{http_code}" $URL)
if [ "$STATUS" -ne "200" ]; then
MESSAGE="$(date '+%Y-%m-%d %H:%M:%S') - ERROR: $URL вернул статус $STATUS"
echo "$MESSAGE" >> "$LOG_FILE"
# Отправка уведомления по почте
echo "$MESSAGE" | mail -s "ВНИМАНИЕ! Проблема с доступностью $URL" "$ALERT_EMAIL"
else
echo "$(date '+%Y-%m-%d %H:%M:%S') - INFO: $URL доступен, статус $STATUS" >> "$LOG_FILE"
fi
Этот скрипт можно запускать каждые 5 минут через cron. Он будет записывать статус в лог-файл и отправлять письмо, если сервер недоступен.
Нужен надежный хостинг для ваших серверов?
Обеспечьте бесперебойную работу ваших проектов с нашими мощными VPS-серверами. Идеально для стабильного мониторинга. — from €4.49/mo.
Выбрать VPS →Сравнение подходов: SaaS vs. Self-Hosted
Для наглядности сведем ключевые различия в таблицу, чтобы помочь вам сделать информированный выбор.
| Критерий | SaaS-решения (Pingdom, UptimeRobot) | Self-Hosted платформы (Zabbix, Prometheus) |
|---|---|---|
| Скорость запуска | Очень высокая (часы) | Низкая/Средняя (дни/недели) |
| Сложность настройки | Низкая (через веб-интерфейс) | Высокая (установка, конфигурация агентов, базы данных) |
| Гибкость/Кастомизация | Ограниченная (рамками сервиса) | Высокая (полный контроль над логикой и данными) |
| Стоимость | Абонентская плата (растет с масштабом) | Затраты на инфраструктуру и обслуживание (персонал) |
| Масштабируемость | Автоматическая (на стороне провайдера) | Требует планирования, ресурсов и усилий команды |
| Контроль данных | Ограниченный (данные хранятся у провайдера) | Полный контроль (данные на вашей инфраструктуре) |
| Требования к админам | Минимальные (управление через UI) | Значительные (установка, настройка, поддержка, устранение проблем) |
Лучшие практики мониторинга доступности
Независимо от выбранного инструмента, есть общие принципы, которые помогут вам построить эффективную систему мониторинга:
- Мониторинг извне и изнутри: Используйте SaaS-решения для внешнего мониторинга (как видят пользователи) и Self-Hosted/скрипты для внутреннего (состояние служб, ресурсов).
- Гранулярность и интервалы: Не перегружайте систему мониторинга слишком частыми проверками, но и не делайте их слишком редкими. Оптимально – 1-5 минут для критичных сервисов.
- Пороговые значения и триггеры: Не просто "up/down". Настраивайте триггеры на основе пороговых значений (например, "время ответа более 500 мс в течение 3 минут").
- Система оповещений:
- Избегайте "alert fatigue": Настройте уведомления так, чтобы они были значимыми. Не оповещайте о каждой мелочи, фокусируйтесь на том, что требует немедленного внимания.
- Эскалация: Настройте уровни оповещений. Сначала email, затем SMS/мессенджер, затем звонок (например, через PagerDuty или Opsgenie) для самых критичных случаев.
- Интегрируйте с вашими рабочими инструментами: Slack, Telegram, Microsoft Teams – чем быстрее команда увидит оповещение, тем лучше.
"Хороший мониторинг — это тот, который будит тебя только по делу, но будит всегда."
- Документирование: Что мониторится, почему, какие действия предпринимать при срабатывании оповещения. Это бесценно для новых сотрудников или при работе в условиях стресса.
- Регулярный аудит: Периодически пересматривайте свою систему мониторинга. Актуальны ли все проверки? Нет ли "мертвых" мониторов?
- Проактивность: Используйте мониторинг не только для реакции на инциденты, но и для анализа трендов. Рост времени ответа или уменьшение свободного места могут быть предвестниками будущих проблем.
Выводы
Мониторинг доступности нескольких серверов – это не одноразовая настройка, а непрерывный процесс, требующий внимания и адаптации. Это инвестиция в стабильность и надежность вашей IT-инфраструктуры, которая окупается спокойствием вашей команды и лояльностью ваших пользователей.
Выбор подходящего инструмента или комбинации инструментов зависит от множества факторов: размера вашей инфраструктуры, бюджета, требований к гибкости и глубине контроля, а также от компетенций вашей команды. Начните с простого, будь то облачный сервис или несколько скриптов, и постепенно масштабируйте и усложняйте систему по мере роста ваших потребностей.
Помните, что лучший мониторинг – это тот, который работает для вас, своевременно информирует о реальных проблемах и позволяет сосредоточиться на развитии, а не на тушении пожаров.
Масштабируйте мониторинг с гибкими облачными решениями
Получите максимальную производительность и гибкость для ваших задач мониторинга. Наши облачные инстансы готовы к росту.
Начать с облака →