
Автоматизация развертывания и управления VPS/выделенными серверами с Terraform и Ansible в 2026 году
TL;DR
- В 2026 году Terraform и Ansible остаются краеугольными камнями для Infrastructure as Code (IaC) и Configuration Management (CM), обеспечивая беспрецедентную скорость и надежность развертывания серверов.
- Интеграция этих инструментов позволяет создать полностью автоматизированный и идемпотентный пайплайн от создания инфраструктуры до ее конфигурирования и поддержки.
- Выбор между VPS и выделенными серверами зависит от специфических требований к производительности, безопасности и бюджету, с учетом новых предложений от провайдеров, таких как облачные выделенные серверы.
- Ключевые факторы успеха включают модульность кода, грамотное управление состоянием Terraform, надежные Ansible-роли, а также глубокое понимание инструментов и облачных платформ.
- Экономия достигается не только за счет оптимизации ресурсов, но и минимизации человеческих ошибок, сокращения времени простоя и ускорения вывода продуктов на рынок.
- Безопасность автоматизации критична: используйте секретные менеджеры, принцип наименьших привилегий и регулярно аудируйте конфигурации.
- Ожидайте дальнейшей интеграции AI для предсказательного масштабирования, оптимизации затрат и автоматического исправления проблем в инфраструктуре.
Введение
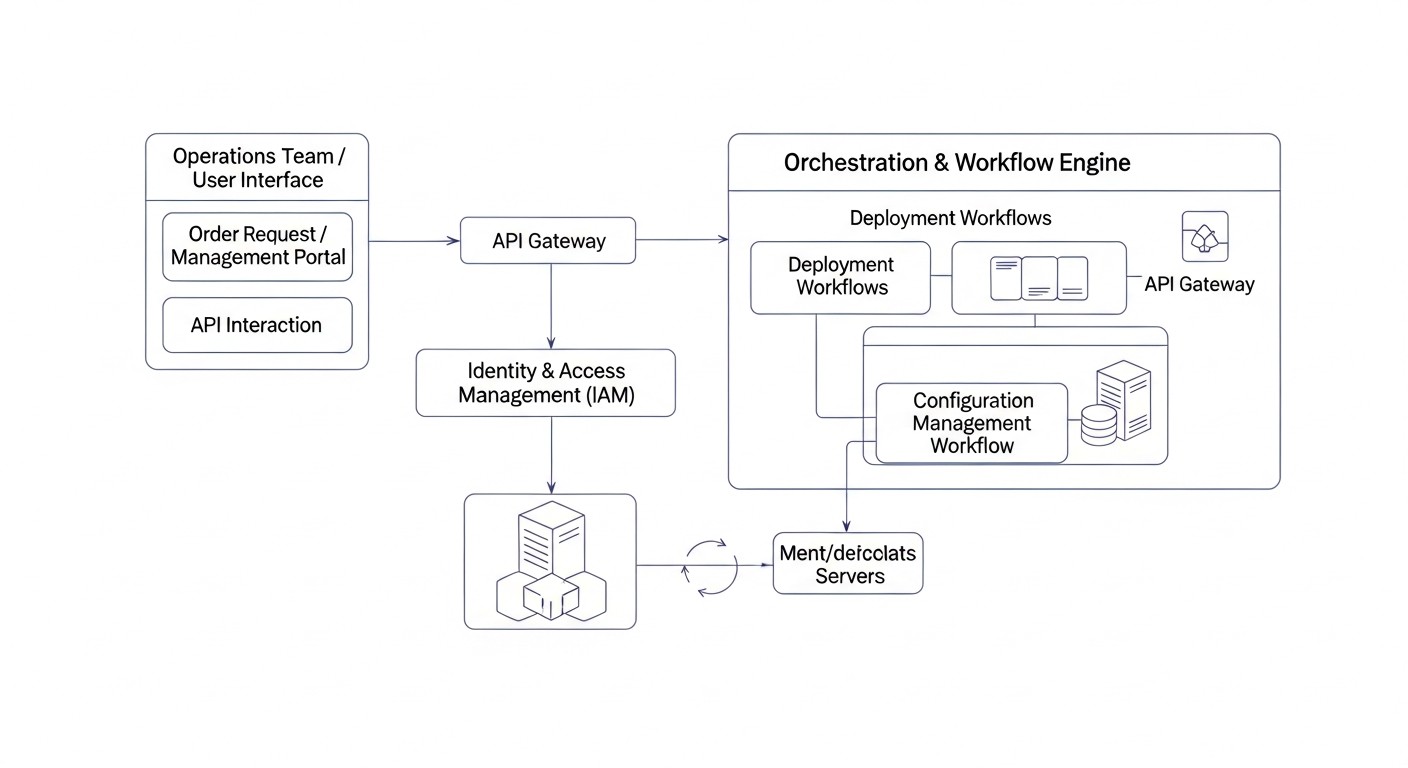
В мире, где скорость изменений и требований к надежности систем постоянно растет, ручное управление инфраструктурой становится не просто неэффективным, а опасным анахронизмом. К 2026 году концепция Infrastructure as Code (IaC) и автоматизация управления конфигурациями стали не просто трендом, а обязательным стандартом для любой серьезной технологической компании. Особенно это касается развертывания и управления VPS (Virtual Private Servers) и выделенными серверами, которые до сих пор составляют основу для большинства критически важных приложений и сервисов.
Почему эта тема так важна именно сейчас? Во-первых, сложность инфраструктур экспоненциально увеличивается. Микросервисы, распределенные системы, геораспределенные кластеры – все это требует точности и повторяемости. Ручные операции неизбежно приводят к "снежинкам" серверов, где каждый уникален и невоспроизводим, что является кошмаром для поддержки и масштабирования. Во-вторых, стоимость человеческой ошибки продолжает расти. Неправильно настроенный сервер может привести к многочасовым простоям, утечкам данных или даже к потере репутации. В-третьих, конкуренция на рынке SaaS и технологических продуктов требует максимальной скорости вывода новых функций и обновлений, а также гибкости в масштабировании. Автоматизация позволяет достичь всего этого, сокращая время развертывания с дней до минут.
В этой статье мы глубоко погрузимся в мир автоматизации развертывания и управления серверами, используя два мощнейших и наиболее распространенных инструмента: Terraform для управления инфраструктурой и Ansible для управления конфигурациями. Мы рассмотрим, как эти инструменты работают в связке, какие преимущества они дают, и как их эффективно применять в условиях 2026 года, учитывая новые технологии и подходы. Мы не будем заниматься маркетинговыми лозунгами, а сосредоточимся на конкретных практических советах, реальных примерах и тонкостях, которые вы сможете применить в своей работе уже сегодня.
Эта статья написана для широкой аудитории технических специалистов: DevOps-инженеров, которые ищут способы оптимизировать свои пайплайны; Backend-разработчиков (Python, Node.js, Go, PHP), стремящихся лучше понимать и контролировать среду, в которой работают их приложения; Фаундеров SaaS-проектов, которым критически важно строить масштабируемую и надежную инфраструктуру с первого дня; Системных администраторов, желающих перейти от ручного труда к автоматизации; и Технических директоров стартапов, которые формируют стратегию развития инфраструктуры. Если вы хотите строить инфраструктуру будущего, эта статья – ваш проводник.
Мы рассмотрим не только технические аспекты, но и экономические, а также вопросы безопасности, которые становятся все более актуальными. Мир меняется, и методы управления инфраструктурой должны меняться вместе с ним. Приготовьтесь к глубокому погружению в автоматизацию, которая сделает вашу работу эффективнее, а вашу инфраструктуру – надежнее.
Основные критерии выбора и факторы успеха
Выбор правильного подхода к автоматизации развертывания и управления серверами, а также самого типа хостинга (VPS или выделенный сервер), требует глубокого анализа множества факторов. В 2026 году эти критерии стали еще более комплексными, учитывая появление новых технологий и ужесточение требований к безопасности и производительности.
1. Масштабируемость и гибкость
В современном мире инфраструктура должна быть способна к быстрому масштабированию как вверх (вертикальное), так и в стороны (горизонтальное). Terraform позволяет декларативно описывать инфраструктуру, что упрощает добавление новых серверов или изменение их характеристик. Ansible, в свою очередь, обеспечивает гибкое конфигурирование этих новых ресурсов. Важно оценить, насколько легко ваша автоматизация сможет адаптироваться к изменяющимся нагрузкам и требованиям. Например, если вы ожидаете пиковых нагрузок, автоматическое масштабирование с помощью Terraform и облачных провайдеров будет критичным.
2. Производительность и тип нагрузки
Различные приложения имеют разные требования к CPU, RAM, I/O дисковой подсистемы и сетевой пропускной способности. Для высоконагруженных баз данных или вычислительно интенсивных задач выделенные серверы часто остаются предпочтительным выбором из-за гарантированной производительности и отсутствия "соседского шума". VPS же идеально подходят для веб-серверов, микросервисов, очередей сообщений, где важна гибкость и быстрый старт. В 2026 году провайдеры предлагают "облачные выделенные серверы", которые сочетают преимущества обоих миров: гарантированные ресурсы с гибкостью облачного API. При выборе провайдера, обратите внимание на характеристики процессоров (например, Intel Xeon E5-2690 v4 или AMD EPYC 7003-й серии), тип дисков (NVMe SSD стали стандартом), и гарантированный канал связи.
3. Безопасность и соответствие стандартам (Compliance)
Это один из наиболее критичных факторов. Автоматизация должна гарантировать, что все серверы настроены согласно политикам безопасности компании и требованиям регуляторов (GDPR, HIPAA, PCI DSS и т.д.). Ansible playbooks позволяют задать жесткие стандарты безопасности: от установки межсетевого экрана и настройки SSH до управления пользователями и применения патчей. Terraform может автоматически настраивать сетевые сегменты, группы безопасности и IAM-политики. Важно использовать секретные менеджеры (HashiCorp Vault, AWS Secrets Manager) и принцип наименьших привилегий. Регулярный аудит конфигураций, автоматическое применение обновлений безопасности и мониторинг уязвимостей должны быть интегрированы в ваш CI/CD пайплайн.
4. Стоимость владения (TCO)
TCO включает не только прямые затраты на аренду серверов, но и стоимость лицензий, электроэнергии, сетевого трафика, а также трудозатраты на администрирование и поддержку. Автоматизация с Terraform и Ansible значительно сокращает трудозатраты, минимизирует ошибки и позволяет быстрее реагировать на изменения, что в конечном итоге снижает TCO. В 2026 году многие провайдеры предлагают гибкие тарифы, а также возможности для резервирования мощностей на длительный срок со скидками. Внимательно изучайте тарифы на исходящий трафик, так как он может стать существенной статьей расходов.
5. Управляемость и поддерживаемость
Насколько легко будет управлять вашей инфраструктурой после развертывания? Модульная структура Terraform и Ansible-роли значительно упрощают этот процесс. Документация в виде кода (Infrastructure as Code) позволяет любому члену команды понять состояние инфраструктуры. Системы мониторинга (Prometheus, Grafana) и логирования (ELK Stack, Loki) должны быть интегрированы в автоматизированный пайплайн. Чем меньше "магии" и больше стандартизации, тем легче поддерживать систему в долгосрочной перспективе.
6. Идемпотентность и повторяемость
Идемпотентность означает, что применение одной и той же операции несколько раз приведет к одному и тому же результату, не вызывая нежелательных побочных эффектов. Это краеугольный камень автоматизации. Terraform и Ansible по своей природе идемпотентны. Terraform гарантирует, что инфраструктура будет соответствовать декларативному описанию, а Ansible – что состояние конфигурации сервера будет соответствовать playbook'у. Повторяемость позволяет разворачивать идентичные среды (dev, staging, prod) и быстро восстанавливаться после сбоев.
7. Экосистема и сообщество
Активное сообщество и богатая экосистема вокруг Terraform и Ansible означают доступ к множеству готовых модулей, провайдеров, ролей и плагинов. Это ускоряет разработку и упрощает поиск решений для распространенных проблем. К 2026 году оба инструмента имеют обширную документацию, курсы и большое количество экспертов, что снижает порог входа и риски при внедрении.
8. Резервное копирование и аварийное восстановление (DR)
Автоматизация должна включать стратегии резервного копирования данных и возможность быстрого восстановления всей инфраструктуры в случае катастрофы. Terraform может помочь в развертывании DR-среды, а Ansible – в восстановлении конфигураций и данных. Продумайте RPO (Recovery Point Objective) и RTO (Recovery Time Objective) для каждого компонента вашей системы.
Сравнительная таблица решений для хостинга (актуально для 2026 года)
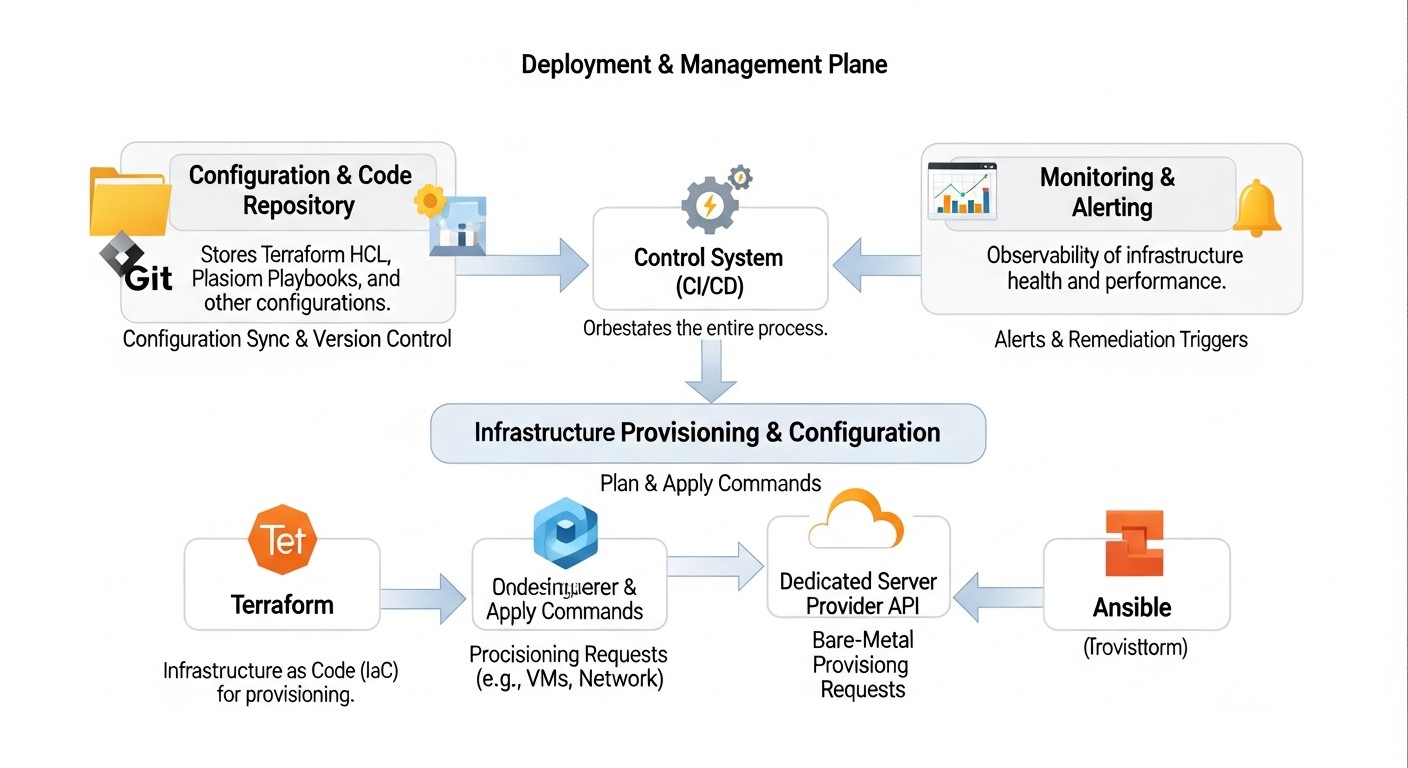
Выбор между VPS и выделенными серверами, а также конкретным провайдером, зависит от множества факторов, включая бюджет, требования к производительности, масштабируемости и географическому расположению. В 2026 году рынок хостинга продолжает развиваться, предлагая гибридные решения и улучшенные характеристики. Ниже представлена сравнительная таблица наиболее популярных вариантов хостинга, актуальная для середины 2026 года, с примерными ценами и характеристиками.
| Критерий | Облачный VPS (e.g., DigitalOcean Droplet / Vultr VPS) | Hetzner Cloud VPS (CX-серия) | Облачные выделенные (e.g., AWS EC2 Dedicated Host / GCP Sole-tenant node) | Традиционный выделенный сервер (e.g., Hetzner Dedicated / OVHcloud) | Bare Metal as a Service (e.g., Equinix Metal) |
|---|---|---|---|---|---|
| Типичный CPU | 2-8 vCPU (Intel Xeon Platinum 84xx / AMD EPYC 9004) | 2-8 vCPU (AMD EPYC 7003/9004) | 16-64 vCPU (Intel Xeon E5-2690 v5 / AMD EPYC 9004) | 16-64 физических ядер (Intel Xeon E5-2699 v5 / AMD EPYC 9004) | 32-128 физических ядер (Intel Xeon Sapphire Rapids / AMD EPYC Genoa) |
| Типичная RAM | 4-32 GB DDR5 ECC | 4-32 GB DDR5 ECC | 64-256 GB DDR5 ECC | 128-512 GB DDR5 ECC | 256 GB - 1 TB DDR5 ECC |
| Типичный Disk I/O | ~1000-2000 MB/s (NVMe SSD) | ~1500-2500 MB/s (NVMe SSD) | ~3000-5000 MB/s (NVMe SSD) | ~4000-8000 MB/s (RAID10 NVMe SSD) | ~8000-15000 MB/s (Local NVMe SSD, High-speed RAID) |
| Сетевой канал | 1-10 Gbps (shared) | 1-10 Gbps (shared, до 20 Gbps для высоких тарифов) | 10-25 Gbps (dedicated) | 10-50 Gbps (dedicated) | 25-100 Gbps (dedicated) |
| Гарантия ресурсов | Нет (виртуализация) | Нет (виртуализация) | Да (выделенные физические ядра/RAM) | Да (полностью) | Да (полностью) |
| Контроль над железом | Нет | Нет | Ограниченный | Полный | Полный |
| Примерная цена (мес.) | $20-80 (за экземпляр) | €15-60 (за экземпляр) | $1500-5000 (за хост) | €100-400 (за сервер) | $500-2000 (за сервер) |
| Масштабируемость | Высокая (горизонтальная) | Высокая (горизонтальная) | Средняя (требует планирования) | Низкая (ручная) | Средняя (API-driven, но все еще физика) |
| Идеально для | Веб-сервисы, Dev/Staging, микросервисы, небольшие базы данных | Разработка, небольшие продакшн-сервисы, CDN-ноды | Регуляторные требования, лицензии на ядро, высоконагруженные БД | Высоконагруженные БД, игровые серверы, Big Data, ресурсоемкие вычисления | Высокопроизводительные вычисления, AI/ML, низколатентные сети, гибридные облака |
| Уровень управления | API, панель управления | API, панель управления | API, панель управления, гипервизор | IPMI, KVM, консоль | API, IPMI, консоль |
*Цены указаны ориентировочно и могут значительно варьироваться в зависимости от конкретной конфигурации, региона, времени и скидок провайдера. Данные актуальны для 2026 года и отражают общие тенденции рынка.
Важно отметить, что в 2026 году граница между "облачным" и "традиционным" хостингом продолжает стираться. Многие провайдеры выделенных серверов предлагают API для автоматизации, а облачные гиганты вводят опции "dedicated host" или "sole-tenant node", которые по сути являются выделенными серверами, но с облачной моделью потребления и управления. Это открывает новые возможности для гибкой и мощной инфраструктуры, управляемой через IaC.
Детальный обзор Terraform и Ansible
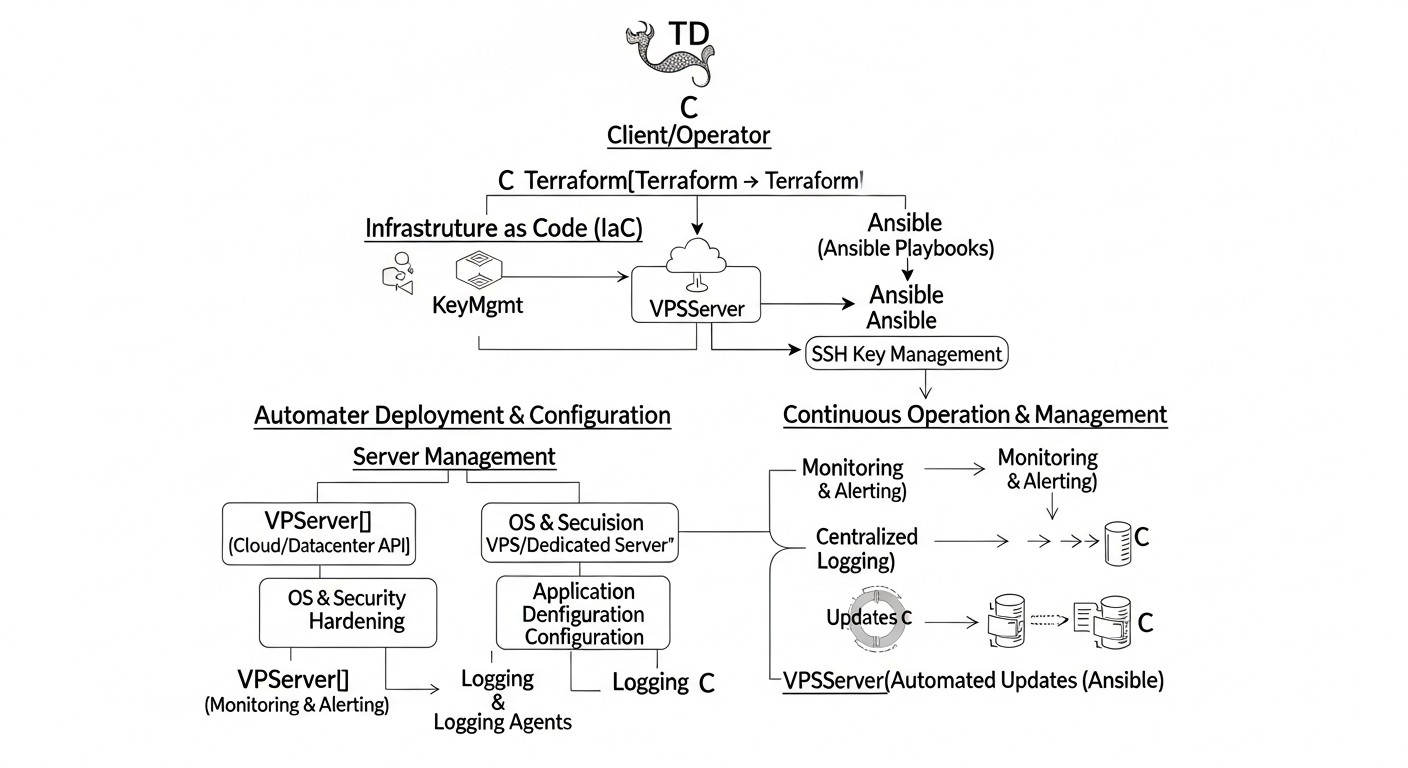
Для эффективной автоматизации развертывания и управления серверами в 2026 году ключевым является понимание и глубокое использование двух мощных инструментов: Terraform и Ansible. Они дополняют друг друга, решая разные, но взаимосвязанные задачи в жизненном цикле инфраструктуры.
1. Terraform: Управление инфраструктурой как код (IaC)
Terraform, разработанный HashiCorp, является инструментом для декларативного создания, изменения и удаления инфраструктуры. Он позволяет описывать желаемое состояние вашей инфраструктуры (будь то VPS, выделенные серверы, сетевые настройки, балансировщики нагрузки или базы данных) с помощью специального языка HCL (HashiCorp Configuration Language) или JSON. К 2026 году Terraform стал де-факто стандартом для IaC благодаря своей универсальности, широкой поддержке провайдеров и мощной экосистеме.
Принципы работы и преимущества:
- Декларативный подход: Вы описываете "что" вы хотите получить, а не "как" этого достичь. Terraform сам определяет последовательность действий для достижения желаемого состояния.
- Провайдеры: Terraform работает через "провайдеры", которые являются плагинами для взаимодействия с различными платформами (AWS, Azure, GCP, DigitalOcean, Vultr, Hetzner Cloud, VMware vSphere, OpenStack и даже локальные провайдеры для работы с API выделенных серверов). В 2026 году количество и функциональность провайдеров значительно расширились, включая более глубокую интеграцию с управлением выделенными серверами через их API.
- Состояние (State): Terraform хранит состояние вашей инфраструктуры в файле
.tfstate. Этот файл является критически важным, так как он сопоставляет реальные ресурсы с вашей конфигурацией. В продакшене обязательно используется удаленное хранилище состояния (например, S3, Azure Blob Storage, HashiCorp Consul или Terraform Cloud/Enterprise) с блокировкой для предотвращения конфликтов. - Модульность: Возможность создавать переиспользуемые модули позволяет структурировать код, повысить его читаемость и поддерживаемость. Вы можете создать модуль для типового VPS, который затем будете использовать по всей организации.
- План выполнения: Команда
terraform planпоказывает, какие изменения будут внесены в инфраструктуру перед их фактическим применением, что значительно снижает риск ошибок.
Пример использования Terraform для развертывания VPS на DigitalOcean (2026):
Допустим, мы хотим развернуть Droplet на DigitalOcean с Ubuntu 24.04.
# main.tf
terraform {
required_providers {
digitalocean = {
source = "digitalocean/digitalocean"
version = "~> 2.0"
}
}
}
provider "digitalocean" {
token = var.do_token
}
variable "do_token" {
description = "DigitalOcean API Token"
type = string
sensitive = true
}
variable "ssh_keys" {
description = "List of SSH key IDs to add to the droplet"
type = list(string)
default = []
}
resource "digitalocean_droplet" "web_server" {
image = "ubuntu-24-04-x64" # Актуальный образ Ubuntu для 2026
name = "web-server-01"
region = "fra1"
size = "s-2vcpu-4gb" # Предположим, это популярный размер в 2026
ssh_keys = var.ssh_keys
tags = ["web", "production"]
# Дополнительные настройки для 2026:
# Возможность указания конкретного типа NVMe хранилища или GPU
# user_data = file("cloud-init.yaml") # Для начальной конфигурации
}
output "web_server_ip" {
value = digitalocean_droplet.web_server.ipv4_address
}
Этот код декларативно описывает один VPS. После terraform init и terraform apply Terraform создаст этот сервер и выведет его IP-адрес. Для выделенных серверов логика будет аналогичной, но провайдер и ресурсы будут специфичными для выбранной платформы (например, `hetznercloud_server` или `aws_ec2_dedicated_host`).
2. Ansible: Управление конфигурациями и оркестрация
Ansible, приобретенный Red Hat, является инструментом для автоматизации задач управления конфигурациями, развертывания приложений и оркестрации. В отличие от Terraform, который занимается инфраструктурой, Ansible фокусируется на том, "что внутри" этой инфраструктуры. Он использует SSH для связи с управляемыми узлами, не требуя установки агентов, что значительно упрощает его развертывание и использование. К 2026 году Ansible продолжает быть одним из самых популярных и гибких инструментов для CM, особенно в гибридных и мультиоблачных средах.
Принципы работы и преимущества:
- Агентless: Не требует установки дополнительного ПО на управляемые серверы, используя стандартный SSH. Это снижает накладные расходы и упрощает безопасность.
- Playbooks: Основная единица работы в Ansible. Playbook'и – это YAML-файлы, которые описывают последовательность задач для выполнения на целевых хостах.
- Идемпотентность: Ansible разработан с учетом идемпотентности. Если задача уже выполнена (например, пакет установлен), Ansible не будет выполнять ее повторно, что экономит время и предотвращает нежелательные изменения.
- Модули: Ansible поставляется с сотнями встроенных модулей для выполнения широкого спектра задач: управление пакетами, файлами, сервисами, пользователями, базами данных, облачными ресурсами и многим другим.
- Роли (Roles): Механизм для организации Playbook'ов, переменных, шаблонов и файлов в структурированные, переиспользуемые единицы. Роли значительно упрощают управление сложными конфигурациями и их повторное использование.
- Инвентарь (Inventory): Список управляемых хостов, сгруппированных по логическим категориям. Инвентарь может быть статическим (файл) или динамическим (генерироваться из облачного API, CMDB).
Пример использования Ansible для конфигурирования VPS:
После того как Terraform развернул Droplet, Ansible может настроить на нем Nginx.
# playbook.yaml
---
- name: Configure Nginx web server
hosts: web_servers
become: true # Выполнять задачи с правами root
vars:
nginx_port: 80
server_name: "your-domain.com"
app_root: "/var/www/html"
tasks:
- name: Ensure Nginx package is installed
ansible.builtin.apt:
name: nginx
state: present
update_cache: yes
- name: Ensure Nginx service is running and enabled
ansible.builtin.systemd:
name: nginx
state: started
enabled: yes
- name: Create Nginx configuration directory for sites-available
ansible.builtin.file:
path: /etc/nginx/sites-available
state: directory
mode: '0755'
- name: Create Nginx configuration directory for sites-enabled
ansible.builtin.file:
path: /etc/nginx/sites-enabled
state: directory
mode: '0755'
- name: Copy Nginx default site configuration
ansible.builtin.template:
src: templates/nginx.conf.j2
dest: "/etc/nginx/sites-available/{{ server_name }}.conf"
owner: root
group: root
mode: '0644'
notify: Reload Nginx
- name: Enable Nginx default site
ansible.builtin.file:
src: "/etc/nginx/sites-available/{{ server_name }}.conf"
dest: "/etc/nginx/sites-enabled/{{ server_name }}.conf"
state: link
notify: Reload Nginx
handlers:
- name: Reload Nginx
ansible.builtin.systemd:
name: nginx
state: reloaded
И соответствующий шаблон templates/nginx.conf.j2:
# templates/nginx.conf.j2
server {
listen {{ nginx_port }};
server_name {{ server_name }};
root {{ app_root }};
index index.html index.htm;
location / {
try_files $uri $uri/ =404;
}
error_log /var/log/nginx/{{ server_name }}_error.log warn;
access_log /var/log/nginx/{{ server_name }}_access.log main;
}
Этот playbook устанавливает Nginx, настраивает его с использованием шаблона и гарантирует, что сервис запущен. Связка Terraform и Ansible позволяет сначала создать "железо", а затем "наполнить" его необходимым ПО и конфигурациями, полностью автоматизируя процесс развертывания.
3. Интеграция Terraform и Ansible
Сила этих инструментов раскрывается по-настоящему при их совместном использовании. Terraform создает инфраструктуру, а затем передает информацию о ней (например, IP-адреса новых серверов) Ansible, который затем конфигурирует эти серверы.
Поток работы:
- Terraform: Определяет и развертывает облачные ресурсы (VPS, выделенные серверы, сети, балансировщики и т.д.).
- Terraform Output: Извлекает важную информацию о развернутых ресурсах (например, публичные IP-адреса, имена хостов).
- Динамический инвентарь Ansible: Использует вывод Terraform для создания или обновления инвентаря Ansible. Существуют специальные скрипты и плагины для Terraform, которые могут генерировать инвентарь Ansible (например,
local-execпровайдер или просто парсингterraform output -json). - Ansible: Подключается к новым серверам, используя информацию из динамического инвентаря, и применяет playbooks для установки ПО, настройки конфигураций, развертывания приложений и обеспечения безопасности.
К 2026 году такой подход стал стандартом. Интеграция часто происходит в рамках CI/CD пайплайнов (Jenkins, GitLab CI, GitHub Actions), где Terraform `apply` запускается первым, а затем, после успешного завершения, запускается Ansible `playbook` с динамическим инвентарем. Это обеспечивает полную автоматизацию от "голого" сервера до готового к работе приложения.
Практические советы и рекомендации по внедрению
Внедрение автоматизации с Terraform и Ansible — это не просто освоение синтаксиса, а изменение подхода к управлению инфраструктурой. Вот ряд практических советов, основанных на многолетнем опыте, которые помогут вам избежать распространенных ловушек и построить надежный, масштабируемый и безопасный процесс.
1. Начните с малого, итерируйте
Не пытайтесь автоматизировать все и сразу. Начните с одного простого сервиса или компонента. Разверните один VPS, настройте на нем Nginx или Docker. Освойте базовые концепции, убедитесь, что ваш пайплайн работает. Затем постепенно добавляйте сложности: базу данных, балансировщик, другие сервисы. Итеративный подход позволяет быстро получать обратную связь и корректировать курс.
2. Используйте модули Terraform и роли Ansible
Модульность — ключ к поддерживаемой и переиспользуемой автоматизации. Создавайте модули Terraform для типовых ресурсов (например, "web-server-module", "database-module"), которые инкапсулируют логику развертывания и предоставляют простой интерфейс через переменные. Аналогично, используйте роли Ansible для группировки связанных задач (например, "nginx", "docker", "postgres"). Существуют готовые модули и роли на Terraform Registry и Ansible Galaxy – используйте их как отправные точки, но всегда адаптируйте под свои нужды.
# Пример использования Terraform модуля
module "web_server_prod" {
source = "./modules/droplet" # Локальный путь к модулю
name_prefix = "prod-web"
count = 3
region = "fra1"
size = "s-4vcpu-8gb"
ssh_key_ids = [digitalocean_ssh_key.my_key.id]
tags = ["production", "web"]
}
# Пример использования Ansible роли
- name: Deploy web application
hosts: web_servers
become: true
roles:
- role: nginx
nginx_port: 80
server_name: "app.example.com"
- role: docker
docker_version: "25.0.3" # Актуальная версия для 2026
- role: my_app
app_version: "1.2.0"
3. Управление состоянием Terraform (Terraform State)
Никогда не храните .tfstate локально в продакшене. Используйте удаленное хранилище с блокировкой. AWS S3 с DynamoDB Lock, Azure Blob Storage, Google Cloud Storage, HashiCorp Consul или Terraform Cloud – это обязательные опции. Это предотвращает конфликты при параллельных изменениях и обеспечивает централизованное, надежное хранение состояния. Регулярно делайте бэкапы состояния.
# Пример настройки удаленного бэкенда S3 с блокировкой DynamoDB
terraform {
backend "s3" {
bucket = "my-terraform-state-bucket-2026"
key = "prod/infrastructure.tfstate"
region = "eu-central-1"
encrypt = true
dynamodb_table = "terraform-lock-table"
}
}
4. Динамический инвентарь Ansible
Не создавайте статические файлы инвентаря вручную. Используйте динамический инвентарь, который автоматически собирает информацию о ваших серверах из облачных провайдеров (DigitalOcean, AWS, GCP и т.д.) или из вывода Terraform. Это гарантирует, что Ansible всегда работает с актуальным списком хостов. Существуют готовые скрипты инвентаря для большинства облачных платформ.
# Пример запуска Ansible с динамическим инвентарем DigitalOcean
ansible-playbook -i /usr/local/bin/digital_ocean.py --private-key ~/.ssh/id_rsa playbook.yaml
Или используя вывод Terraform:
# Скрипт для генерации динамического инвентаря из Terraform output
#!/bin/bash
echo '{"_meta": {"hostvars": {}}}' > inventory.json
terraform output -json | jq -r 'to_entries | .[] | select(.key | endswith("_ip")) | .value | to_entries | .[] | .key + " ansible_host=" + .value' | while read line; do
HOST_NAME=$(echo $line | awk '{print $1}')
IP_ADDR=$(echo $line | awk '{print $2}' | cut -d'=' -f2)
jq --arg host "$HOST_NAME" --arg ip "$IP_ADDR" \
'.web_servers.hosts += [$host] | ._meta.hostvars[$host].ansible_host = $ip' \
inventory.json > tmp.$$.json && mv tmp.$$.json inventory.json
done
# Добавить группы
jq '.web_servers = {"hosts": []}' inventory.json > tmp.$$.json && mv tmp.$$.json inventory.json
ansible-playbook -i inventory.json playbook.yaml
(Примечание: приведенный скрипт является упрощенным примером и требует доработки для продакшн-использования, особенно в части группировки хостов.)
5. Управление секретами
Никогда не храните чувствительную информацию (API-ключи, пароли, приватные ключи) в открытом виде в репозитории. Используйте специализированные инструменты: HashiCorp Vault, AWS Secrets Manager, Google Secret Manager, Azure Key Vault или Ansible Vault. Для Terraform переменные могут быть помечены как sensitive = true, но это не заменяет полноценного секретного менеджера.
# Использование Ansible Vault для шифрования файлов с секретами
ansible-vault encrypt vars/secrets.yaml
ansible-playbook --ask-vault-pass playbook.yaml
6. Idempotency First
Всегда пишите Ansible playbooks таким образом, чтобы они были идемпотентны. Это означает, что повторный запуск playbook'а должен приводить к тому же состоянию, что и первый, без ошибок и нежелательных изменений. Используйте модули Ansible, которые по своей природе идемпотентны (например, apt, yum, file, service). Если вы пишете свои скрипты, проверяйте состояние перед внесением изменений.
7. Тестирование автоматизации
Ваш код инфраструктуры должен быть протестирован так же тщательно, как и код приложения. Используйте:
- `terraform validate` / `terraform plan`: для синтаксических ошибок и предварительного просмотра изменений.
- `ansible-lint`: для проверки стиля и лучших практик Ansible.
- Molecule: для тестирования Ansible ролей на различных дистрибутивах.
- Terratest / InSpec / Serverspec: для интеграционного и end-to-end тестирования развернутой инфраструктуры. Это позволяет убедиться, что серверы не только созданы, но и правильно настроены и функционируют.
8. Версионирование всего
Весь код (Terraform, Ansible playbooks, скрипты, шаблоны) должен храниться в системе контроля версий (Git). Это позволяет отслеживать изменения, откатываться к предыдущим версиям, работать в команде и проводить code review. Каждое изменение в инфраструктуре должно проходить через процесс Pull Request.
9. Интеграция с CI/CD
Полная автоматизация достигается при интеграции Terraform и Ansible в ваш CI/CD пайплайн.
- CI (Continuous Integration): Автоматический запуск `terraform validate`, `terraform plan`, `ansible-lint`, Molecule при каждом коммите.
- CD (Continuous Deployment): После успешного прохождения тестов, автоматический запуск `terraform apply` и `ansible-playbook` для развертывания или обновления инфраструктуры. Это может быть полностью автоматизировано или требовать ручного подтверждения для продакшн-среды.
10. Документация и стандарты
Хотя IaC сам по себе является формой документации, важно иметь дополнительные README-файлы, описывающие высокоуровневую архитектуру, зависимости и процесс развертывания. Установите стандарты именования ресурсов, переменных, тегов и придерживайтесь их. Чем более единообразен ваш код, тем легче его понимать и поддерживать.
11. Мониторинг и оповещения
Автоматизация развертывания должна включать автоматическую настройку мониторинга и оповещений для всех новых серверов. Ansible может развернуть агенты Prometheus Node Exporter, Grafana Agent, Datadog или New Relic. Убедитесь, что все критически важные метрики собираются, и настроены соответствующие алерты. В 2026 году AI-driven мониторинг становится стандартом, предсказывая проблемы до их возникновения.
Типичные ошибки при работе с IaC и CM
Даже опытные инженеры допускают ошибки при работе с Terraform и Ansible. Знание этих типичных ошибок поможет вам избежать дорогостоящих проблем и ускорить процесс внедрения автоматизации.
1. Игнорирование состояния Terraform (Terraform State Management)
Ошибка: Хранение файла .tfstate локально, отсутствие блокировки состояния, ручное изменение .tfstate, или потеря файла состояния.
Последствия: Конфликты при работе нескольких инженеров, рассинхронизация реальной инфраструктуры с файлом состояния, "дрейф" конфигурации, невозможность управления ресурсами, потеря инфраструктуры.
Как избежать: Всегда используйте удаленный бэкенд (S3, Azure Blob Storage, GCS, HashiCorp Consul/Cloud) с включенной блокировкой состояния. Никогда не редактируйте .tfstate вручную, используйте terraform state mv, terraform state rm, terraform import. Регулярно делайте бэкапы удаленного состояния.
2. Неидемпотентные Ansible Playbooks
Ошибка: Написание задач в Ansible, которые не являются идемпотентными, т.е. повторный запуск которых приводит к нежелательным изменениям или ошибкам. Например, скрипты, которые всегда создают файл, не проверяя его существование.
Последствия: Непредсказуемое состояние серверов, ошибки при повторном развертывании, сложность отладки, риск "снежинок" серверов.
Как избежать: Всегда используйте встроенные модули Ansible, которые по своей природе идемпотентны. Если пишете свои скрипты или используете команду shell/command, всегда добавляйте условия (`when`, `creates`, `removes`, `changed_when`) для проверки текущего состояния перед выполнением действия. Тестируйте playbooks с помощью Molecule.
3. Жесткое кодирование секретов и чувствительных данных
Ошибка: Хранение API-ключей, паролей, приватных ключей SSH, токенов в открытом виде в файлах Terraform, Ansible playbooks или в системе контроля версий (Git).
Последствия: Утечка конфиденциальных данных, компрометация инфраструктуры, нарушение безопасности и соответствия стандартам.
Как избежать: Используйте специализированные секретные менеджеры (HashiCorp Vault, AWS Secrets Manager, Azure Key Vault, Google Secret Manager) для хранения и динамической выдачи секретов. Для Ansible используйте Ansible Vault для шифрования файлов с секретами. Интегрируйте эти инструменты в ваш CI/CD пайплайн.
4. Отсутствие модульности и переиспользования
Ошибка: Создание монолитных, больших файлов Terraform и Ansible playbooks без использования модулей и ролей. Копирование и вставка кода между проектами.
Последствия: Дублирование кода, сложность вносимых изменений (приходится менять в нескольких местах), низкая читаемость, трудности в поддержке, медленная разработка новых компонентов.
Как избежать: Активно используйте модули Terraform для инкапсуляции логики развертывания ресурсов. Создавайте роли Ansible для типовых конфигураций. Размещайте модули и роли в отдельных репозиториях или в общей библиотеке для переиспользования. Используйте переменные для параметризации.
5. Ручные изменения после автоматизации ("Drift")
Ошибка: Внесение изменений на серверах вручную (например, через SSH), которые не зафиксированы в коде Terraform или Ansible.
Последствия: "Дрейф" конфигурации (Infrastructure Drift), когда реальное состояние инфраструктуры отличается от описанного в коде. Непредсказуемое поведение системы, проблемы при повторном развертывании или масштабировании, сложности в отладке.
Как избежать: Установите строгие правила: все изменения должны проходить через IaC. Используйте `terraform plan -destroy` для выявления дрейфа в Terraform и регулярно запускайте Ansible playbooks в режиме `check` или `diff` для обнаружения изменений. Внедрите автоматизированные инструменты для обнаружения дрейфа (например, Cloud Custodian, Open Policy Agent). Рассмотрите концепцию "Immutable Infrastructure", где серверы не изменяются, а заменяются новыми.
6. Недостаточное тестирование автоматизации
Ошибка: Отсутствие автоматических тестов для Terraform конфигураций и Ansible playbooks. Запуск кода в продакшене без предварительной проверки.
Последствия: Развертывание нерабочей или небезопасной инфраструктуры, длительные простои, регрессии, потеря данных.
Как избежать: Интегрируйте `terraform validate`, `terraform plan`, `ansible-lint` в ваш CI. Используйте Molecule для тестирования ролей Ansible. Применяйте интеграционные тесты (Terratest, InSpec) для проверки развернутой инфраструктуры. Создайте отдельные среды (dev, staging) для тестирования изменений перед их внедрением в продакшн.
7. Неправильное управление доступом и привилегиями
Ошибка: Использование учетной записи с избыточными правами для Terraform и Ansible. Например, использование учетной записи администратора облака для развертывания повседневных ресурсов.
Последствия: Угрозы безопасности, возможность непреднамеренного удаления или изменения критически важных ресурсов, нарушение принципа наименьших привилегий.
Как избежать: Создавайте отдельные IAM-роли или сервисные учетные записи для Terraform и Ansible с минимально необходимыми правами доступа. Используйте временные учетные данные, где это возможно. Регулярно пересматривайте и аудируйте права доступа.
8. Отсутствие документации и стандартов
Ошибка: Полагаться только на код как на документацию, отсутствие комментариев, несоблюдение стандартов именования.
Последствия: Новым членам команды трудно разобраться в инфраструктуре, снижение скорости онбординга, ошибки из-за неправильного понимания кода, зависимость от "носителей знаний".
Как избежать: Дополняйте код README-файлами, диаграммами архитектуры. Используйте комментарии для объяснения сложных логических блоков. Разработайте и придерживайтесь строгих стандартов именования ресурсов, переменных, тегов. Проводите регулярные code review.
Чеклист для практического применения
Этот чеклист поможет вам структурировать процесс внедрения автоматизации развертывания и управления VPS/выделенными серверами с использованием Terraform и Ansible. Следуйте этим шагам, чтобы обеспечить надежность, безопасность и эффективность вашей инфраструктуры.
Этап 1: Подготовка и планирование
- Определите цели автоматизации: Четко сформулируйте, что вы хотите достичь (например, сократить время развертывания, повысить надежность, обеспечить масштабируемость).
- Выберите провайдера хостинга: Исходя из требований к производительности, бюджету и географии, выберите одного или нескольких провайдеров (DigitalOcean, Hetzner, AWS, GCP, OVHcloud, Equinix Metal и др.).
- Спроектируйте архитектуру: Нарисуйте схему вашей целевой инфраструктуры: количество серверов, их роли, сетевые настройки, базы данных, балансировщики.
- Определите структуру репозитория: Заранее продумайте, как будут организованы ваши Terraform-файлы, Ansible playbooks, роли и переменные в Git.
- Настройте систему контроля версий (Git): Создайте репозиторий для вашего IaC/CM кода.
- Установите Terraform и Ansible: Убедитесь, что у всех членов команды установлены актуальные версии инструментов.
Этап 2: Разработка Terraform (IaC)
- Настройте провайдера Terraform: Добавьте необходимый провайдер (
digitalocean,aws,hetznercloudи т.д.) в вашmain.tf. - Настройте удаленный бэкенд Terraform State: Обязательно используйте S3, GCS, Azure Blob Storage или Terraform Cloud с блокировкой состояния.
- Создайте SSH-ключи: Сгенерируйте и зарегистрируйте SSH-ключи у провайдера, которые будут использоваться для доступа к создаваемым серверам.
- Опишите ресурсы VPS/серверов: Используйте
resourceблоки для создания виртуальных машин или выделенных серверов. Укажите тип образа, размер, регион, сеть, SSH-ключи. - Добавьте сетевые ресурсы: Настройте группы безопасности, фаерволы, VPC/VNet, если это применимо.
- Используйте модули: Создайте собственные или используйте готовые модули Terraform для повторно используемых компонентов.
- Проведите
terraform init,terraform plan,terraform apply: Проверьте, что Terraform корректно развертывает инфраструктуру. - Извлеките выводы (Outputs): Используйте
outputблоки для получения IP-адресов, DNS-имен или других данных о развернутых ресурсах.
Этап 3: Разработка Ansible (CM)
- Создайте динамический инвентарь: Настройте скрипт или плагин для Ansible, который будет автоматически генерировать список хостов из вывода Terraform или API облачного провайдера.
- Организуйте Playbooks и роли: Создайте структуру каталогов для Ansible, используя роли для логического разделения задач (например,
roles/webserver,roles/database). - Настройте SSH-доступ: Убедитесь, что Ansible может подключаться к новым серверам по SSH, используя приватный ключ, соответствующий публичному ключу, добавленным Terraform.
- Напишите Playbooks для базовой конфигурации: Включите задачи по обновлению системы, установке необходимых пакетов (Python, Docker, Nginx), настройке фаервола (UFW/firewalld).
- Внедрите управление секретами: Используйте Ansible Vault для шифрования конфиденциальных данных или интегрируйтесь с внешним секретным менеджером.
- Создайте Playbooks для развертывания приложений: Настройте Nginx, разверните ваш бэкенд-сервис, настройте базу данных, если это необходимо.
- Обеспечьте идемпотентность: Убедитесь, что все задачи в Playbooks являются идемпотентными.
Этап 4: Интеграция и тестирование
- Интегрируйте в CI/CD: Настройте пайплайн (Jenkins, GitLab CI, GitHub Actions) для автоматического запуска:
- `terraform validate` и `terraform plan`
- `ansible-lint`
- Запуска Molecule для тестирования ролей Ansible
- Запуск `terraform apply` (возможно, с ручным подтверждением для продакшн)
- Запуск Ansible Playbooks с динамическим инвентарем
- Настройте мониторинг и логирование: Убедитесь, что после развертывания и конфигурирования на серверах автоматически устанавливаются агенты мониторинга (Prometheus Node Exporter, Grafana Agent, Datadog) и логирования (Fluentd, Filebeat).
- Проведите интеграционное тестирование: Используйте Terratest, InSpec или аналогичные инструменты для проверки, что развернутая инфраструктура соответствует ожиданиям и работает корректно.
- Документируйте процесс: Создайте README-файлы для ваших проектов Terraform и Ansible, описывающие их назначение, переменные, зависимости и шаги развертывания.
Этап 5: Поддержка и оптимизация
- Регулярно обновляйте инструменты: Следите за обновлениями Terraform, Ansible и их провайдеров/модулей для получения новых функций и исправлений безопасности.
- Мониторинг дрейфа конфигурации: Периодически запускайте `terraform plan` и Ansible playbooks в режиме `check` для выявления ручных изменений.
- Оптимизируйте затраты: Используйте возможности Terraform для масштабирования ресурсов вверх/вниз или их удаления, чтобы сократить расходы. Анализируйте отчеты о стоимости провайдера.
- Проводите аудит безопасности: Регулярно проверяйте конфигурации безопасности, права доступа и соответствие стандартам.
- Обучайте команду: Убедитесь, что все члены команды понимают принципы IaC и умеют работать с Terraform и Ansible.
Расчет стоимости и экономика автоматизации
В 2026 году, когда облачные ресурсы и выделенные серверы становятся все более доступными, но и более сложными в управлении, понимание истинной стоимости владения (TCO) инфраструктурой критически важно. Автоматизация с Terraform и Ansible не только повышает эффективность, но и оказывает прямое влияние на экономику проекта, часто приводя к значительной экономии в долгосрочной перспективе.
Прямые и скрытые расходы
При расчете стоимости инфраструктуры важно учитывать не только очевидные ежемесячные счета от провайдера, но и менее заметные, но существенные скрытые расходы:
- Прямые расходы:
- Аренда серверов (VPS/Выделенные): Стоимость CPU, RAM, диска, сетевого трафика. Актуальные тарифы на 2026 год показывают стабилизацию цен, но с более сложными тарифными планами за специфические ресурсы (GPU, высокопроизводительные NVMe, премиальный трафик).
- Лицензии ПО: Операционные системы (Windows Server), базы данных (Oracle, MS SQL), специализированное ПО.
- Сетевой трафик: Особенно исходящий трафик, который может быть дорогим у некоторых облачных провайдеров. В 2026 году многие провайдеры предлагают более щедрые квоты, но за их пределами стоимость остается высокой.
- Дополнительные сервисы: Балансировщики нагрузки, управляемые базы данных, CDN, фаерволы, IP-адреса.
- Скрытые расходы (значительно сокращаемые автоматизацией):
- Трудозатраты инженеров: Время, затрачиваемое на ручное развертывание, конфигурирование, исправление ошибок, поддержку. Автоматизация сокращает эти часы в разы.
- Человеческие ошибки: Стоимость простоя из-за неправильной конфигурации, утечки данных, нарушений безопасности. Один день простоя для SaaS-проекта может стоить десятки тысяч долларов.
- Время выхода на рынок (Time-to-Market): Чем дольше вы разворачиваете инфраструктуру для нового сервиса, тем дольше он не приносит доход. Автоматизация ускоряет этот процесс.
- Неэффективное использование ресурсов: Забытые или недоиспользуемые серверы, которые продолжают работать и потреблять ресурсы. IaC позволяет легко идентифицировать и удалять ненужные ресурсы.
- Обучение и адаптация: Время, необходимое новым сотрудникам для освоения уникальной инфраструктуры, созданной вручную. Стандартизированный IaC код значительно упрощает онбординг.
- Аудит и соответствие стандартам: Ручной аудит безопасности и соответствия может быть очень трудоемким. Автоматизация позволяет гарантировать соответствие через код.
Примеры расчетов для разных сценариев (2026 год)
Рассмотрим несколько гипотетических сценариев для SaaS-проекта, использующего 10 серверов, с учетом средних зарплат и стоимости услуг в 2026 году. Предположим, средняя зарплата DevOps-инженера в месяц составляет $5000.
Сценарий 1: Неавтоматизированное развертывание (ручное)
- Затраты на серверы: 10 VPS по $40/мес = $400/мес.
- Время развертывания 1 сервера: ~4 часа (установка ОС, базовое ПО, конфигурация).
- Время развертывания 10 серверов: 40 часов = 1 рабочая неделя одного инженера.
- Стоимость развертывания (трудозатраты): $5000/мес * (40 часов / 160 рабочих часов) = $1250.
- Время на ежемесячную поддержку/обновления: ~2 часа на сервер * 10 серверов = 20 часов.
- Стоимость поддержки: $5000/мес * (20 часов / 160 рабочих часов) = $625.
- Простои/ошибки: Предположим, 1 крупный инцидент в год из-за ручной ошибки, стоимость $10,000. Ежемесячно $833.
- ИТОГО (месяц): $400 (серверы) + $1250 (первичное развертывание, амортизация) + $625 (поддержка) + $833 (ошибки) = $3108 / мес.
- ИТОГО (год): $37,296.
Сценарий 2: Автоматизированное развертывание с Terraform и Ansible
- Затраты на серверы: 10 VPS по $40/мес = $400/мес. (без изменений)
- Время на разработку IaC/CM (первично): 80 часов (2 недели инженера).
- Стоимость разработки (первично): $5000/мес * (80 часов / 160 рабочих часов) = $2500. (Единовременные затраты, амортизируем на 2 года: $104/мес)
- Время развертывания 10 серверов: ~10-20 минут (запуск скрипта). Трудозатраты: $5000/мес * (0.25 часа / 160 рабочих часов) = ~$8.
- Время на ежемесячную поддержку/обновления: ~2 часа (обновление playbooks/модулей, запуск). Трудозатраты: $5000/мес * (2 часа / 160 рабочих часов) = $62.5.
- Простои/ошибки: Снижение на 90% до 1 незначительного инцидента, стоимость $1,000/год. Ежемесячно $83.
- ИТОГО (месяц): $400 (серверы) + $104 (амортизация разработки) + $8 (развертывание) + $62.5 (поддержка) + $83 (ошибки) = $657.5 / мес.
- ИТОГО (год): $7,890.
Экономия: $3108 - $657.5 = $2450.5 / мес. или $29,406 / год.
Как видно из расчетов, даже при относительно небольшом количестве серверов, автоматизация окупается в течение нескольких месяцев и затем приносит значительную экономию. Чем больше инфраструктура, тем выше экономический эффект.
Таблица с примерами расчетов для разных сценариев
Предположим, что "Стоимость часа инженера" = $31.25 (при зарплате $5000/мес за 160 часов).
| Параметр | Ручное развертывание (10 VPS) | Автоматизированное развертывание (10 VPS) | Автоматизированное развертывание (50 VPS) |
|---|---|---|---|
| Стоимость серверов (мес.) | $400 | $400 | $2000 |
| Первичная разработка IaC/CM (часы) | 0 | 80 | 120 |
| Первичная разработка IaC/CM (стоимость, амортизация на 2 года) | $0 | $104 | $156 |
| Время развертывания (часы/мес.) | 40 | 0.25 | 0.5 |
| Стоимость развертывания (мес.) | $1250 | $8 | $16 |
| Время поддержки/обновлений (часы/мес.) | 20 | 2 | 5 |
| Стоимость поддержки (мес.) | $625 | $62.5 | $156.25 |
| Стоимость простоев/ошибок (мес.) | $833 | $83 | $200 |
| ИТОГО (месяц) | $3108 | $657.5 | $2528.25 |
| ИТОГО (год) | $37,296 | $7,890 | $30,339 |
Как оптимизировать затраты
- Автоматическое управление жизненным циклом ресурсов: Используйте Terraform для автоматического создания и удаления ресурсов по расписанию или событию. Например, тестовые среды могут быть уничтожены по окончании рабочего дня.
- Правильный выбор инстансов: Terraform позволяет легко менять типы инстансов. Анализируйте метрики использования ресурсов и выбирайте оптимальные размеры VPS/серверов. Не переплачивайте за избыточные мощности.
- Резервирование мощностей: Для стабильных нагрузок используйте зарезервированные экземпляры (Reserved Instances) или контракты на выделенные серверы, которые предлагают значительные скидки.
- Мониторинг и оповещения о расходах: Интегрируйте мониторинг расходов в ваш пайплайн. Установите алерты, когда расходы превышают определенные пороги.
- Использование Spot Instances (для отказоустойчивых нагрузок): В облаке, для прерываемых, но отказоустойчивых нагрузок можно использовать Spot Instances с Terraform, что значительно снижает стоимость.
- Оптимизация сетевого трафика: Используйте CDN для статического контента, кэширование, сжатие данных, чтобы уменьшить объем исходящего трафика.
- Минимизация ручных операций: Чем меньше ручных действий, тем меньше вероятность дорогостоящих ошибок и тем выше эффективность инженеров.
В конечном итоге, автоматизация с Terraform и Ansible является стратегической инвестицией, которая не только повышает техническую зрелость проекта, но и обеспечивает значительную финансовую отдачу, позволяя вашей команде сосредоточиться на создании ценности, а не на рутине.
Кейсы и примеры из реальной практики
Чтобы лучше понять, как Terraform и Ansible применяются на практике, рассмотрим несколько реалистичных сценариев из мира DevOps и SaaS в 2026 году.
Кейс 1: Развертывание масштабируемой SaaS-платформы на DigitalOcean
Проблема:
Молодой SaaS-стартап "CloudSync" столкнулся с быстрым ростом числа пользователей и необходимостью масштабирования своей платформы. Изначально инфраструктура развертывалась вручную на нескольких VPS, что приводило к "снежинкам" серверов, долгим простоям при обновлениях и невозможности быстро реагировать на пиковые нагрузки. Команда тратила до 30% времени на ручное управление инфраструктурой.
Решение с Terraform и Ansible:
Команда CloudSync приняла решение полностью перейти на IaC. Они выбрали DigitalOcean из-за простоты использования и хорошего API.
- Terraform для инфраструктуры:
- Был создан Terraform-проект, который описывал всю инфраструктуру: 3 балансировщика нагрузки (DigitalOcean Load Balancers), 10-50 Droplet'ов для веб-серверов (Ubuntu 24.04, s-4vcpu-8gb), 3 Droplet'а для кластера PostgreSQL (s-8vcpu-16gb), 2 Droplet'а для кластера Redis (s-2vcpu-4gb), а также все необходимые фаерволы и приватные сети.
- Использовались Terraform-модули для каждого типа ресурса (
droplet-module,loadbalancer-module,database-cluster-module), что обеспечило переиспользование и стандартизацию. - Настроен удаленный бэкенд S3 для хранения состояния Terraform, интегрированный с GitLab CI.
- Ansible для конфигурации и развертывания:
- После развертывания инфраструктуры Terraform, GitLab CI автоматически запускал Ansible Playbooks.
- Ansible использовал динамический инвентарь, генерируемый из вывода Terraform, чтобы получить актуальные IP-адреса Droplet'ов.
- Были разработаны Ansible-роли:
webserver(установка Nginx, PHP-FPM, настройка),postgresql(установка кластера, бэкапы),redis(настройка кластера),app-deploy(развертывание приложения из Docker-образа). - Ansible также отвечал за установку агентов мониторинга (Prometheus Node Exporter) и логирования (Fluentd) на все серверы.
- CI/CD пайплайн:
- Любое изменение в коде инфраструктуры или приложения инициировало пайплайн в GitLab CI.
- Terraform `plan` запускался автоматически для проверки изменений.
- После ручного подтверждения (для продакшн), `terraform apply` обновлял инфраструктуру.
- Затем Ansible Playbooks применялись для конфигурирования серверов и развертывания нового кода приложения.
Результаты:
- Сокращение времени развертывания: Развертывание новой среды или масштабирование кластера с 30 минут до 5-7 минут.
- Снижение количества ошибок: Практически полное исключение человеческого фактора при развертывании и конфигурировании.
- Улучшенная масштабируемость: Возможность быстро добавлять или удалять Droplet'ы в зависимости от нагрузки.
- Экономия затрат: Сокращение трудозатрат DevOps-инженеров на 70%, что позволило им сосредоточиться на более стратегических задачах.
- Повышение надежности: Легкое восстановление инфраструктуры после сбоев благодаря IaC.
Кейс 2: Управление гибридной инфраструктурой с выделенными серверами и VPS
Проблема:
Крупная игровая студия "PixelForge" использовала гибридную инфраструктуру: высокопроизводительные выделенные серверы (Hetzner Dedicated) для игровых серверов и баз данных, и облачные VPS (AWS EC2) для веб-сайта, API и аналитики. Управление этой разнородной инфраструктурой было крайне сложным и требовало разных подходов для каждого типа сервера.
Решение с Terraform и Ansible:
PixelForge внедрила унифицированный подход к управлению с помощью Terraform и Ansible.
- Terraform для разнородной инфраструктуры:
- Для AWS EC2 использовался официальный AWS-провайдер Terraform для развертывания инстансов, VPC, Security Groups, Load Balancers.
- Для Hetzner Dedicated Servers использовался кастомный провайдер Terraform (или скрипты, вызываемые через `local-exec`), который взаимодействовал с Hetzner Robot API для заказа, переустановки ОС и получения IP-адресов выделенных серверов.
- Все ресурсы (как облачные, так и выделенные) были описаны в Terraform, что позволило иметь единую "карту" всей инфраструктуры.
- Terraform выводил IP-адреса всех серверов, которые затем использовались динамическим инвентарем Ansible.
- Ansible для унифицированного конфигурирования:
- Ansible использовал один и тот же набор ролей для базовой конфигурации (SSH, фаервол, пользователи, мониторинг) как для AWS EC2, так и для Hetzner Dedicated.
- Специфичные для каждого типа сервера конфигурации (например, настройка файловой системы для игровых серверов на Hetzner) были реализованы через условные операторы (`when`) в Playbooks или через разные переменные для разных групп инвентаря.
- Ansible отвечал за развертывание игровых серверов (SteamCMD, настройка движка), баз данных (PostgreSQL Master-Replica), веб-серверов (Nginx, Node.js) и аналитических инструментов.
- Централизованный CI/CD:
- Jenkins был настроен для оркестрации всего процесса.
- Пайплайн запускал Terraform для создания/обновления ресурсов на обеих платформах.
- После этого Ansible Playbooks применялись к соответствующим группам серверов.
Результаты:
- Унификация управления: Единый подход к управлению гибридной инфраструктурой, несмотря на ее разнородность.
- Значительное ускорение развертывания: Новые игровые серверы могли быть запущены в течение 15 минут, а обновленная веб-инфраструктура – за 5 минут.
- Повышение надежности: Уменьшение ошибок, связанных с ручным конфигурированием, и возможность быстрого восстановления.
- Оптимизация затрат: Более эффективное использование выделенных серверов для критических нагрузок и гибкое масштабирование облачных ресурсов для переменных нагрузок.
- Улучшенная безопасность: Стандартизированные конфигурации безопасности, автоматически применяемые ко всей инфраструктуре.
Инструменты и ресурсы для эффективной работы
Автоматизация развертывания и управления серверами с Terraform и Ansible – это не только сами эти инструменты, но и целая экосистема вспомогательных утилит, платформ и ресурсов. В 2026 году этот набор стал еще более обширным и интегрированным.
1. Основные инструменты
- Terraform (HashiCorp): Ваш основной инструмент для IaC.
- Официальный сайт Terraform
- Terraform Registry (для поиска провайдеров и модулей)
- Ansible (Red Hat): Ваш основной инструмент для управления конфигурациями.
- Официальный сайт Ansible
- Ansible Galaxy (для поиска ролей и коллекций)
- Git (система контроля версий): Для версионирования всего вашего кода инфраструктуры.
- Официальный сайт Git
- Платформы: GitHub, GitLab, Bitbucket
- SSH-клиент: Для подключения к серверам и выполнения команд Ansible.
2. Управление секретами
Критически важно для безопасности вашей автоматизации.
- HashiCorp Vault: Универсальное решение для централизованного хранения и управления секретами. Интегрируется с Terraform и Ansible.
- Облачные секретные менеджеры:
- AWS Secrets Manager
- Azure Key Vault
- Google Secret Manager
- Ansible Vault: Встроенный инструмент для шифрования чувствительных данных в Ansible Playbooks и файлах переменных.
3. CI/CD платформы
Для автоматизации запуска пайплайнов IaC и CM.
- GitLab CI/CD: Встроенный в GitLab. Отличный выбор для полного цикла разработки и развертывания.
- GitHub Actions: Гибкое решение, интегрированное с GitHub.
- Jenkins: Один из старейших и наиболее гибких CI/CD серверов, требует больше настроек.
- CircleCI, Travis CI, Argo CD: Другие популярные решения.
4. Мониторинг и логирование
Для наблюдения за вашей инфраструктурой и ее производительностью.
- Prometheus + Grafana: Открытые решения для сбора метрик и визуализации. Ansible может развернуть Prometheus Node Exporter на каждом сервере.
- ELK Stack (Elasticsearch, Logstash, Kibana): Мощный стек для централизованного сбора, анализа и визуализации логов.
- Loki + Grafana: Легковесное решение для логов, вдохновленное Prometheus.
- Коммерческие решения: Datadog, New Relic, Splunk (часто имеют готовые Ansible-роли для установки агентов).
5. Тестирование инфраструктуры как кода
Для обеспечения качества и надежности вашей автоматизации.
- `terraform validate` и `terraform plan`: Встроенные команды для проверки синтаксиса и просмотра предстоящих изменений.
- `ansible-lint`: Статический анализатор для Ansible Playbooks, который проверяет на соответствие лучшим практикам.
- Molecule: Фреймворк для тестирования Ansible ролей, поддерживает различные драйверы (Docker, Vagrant).
- Terratest (Go): Фреймворк для написания автоматизированных тестов для инфраструктуры, развернутой с помощью Terraform.
- InSpec (Chef): Фреймворк для аудита и тестирования соответствия конфигураций.
- Serverspec (Ruby): Инструмент для тестирования состояния серверов.
6. Дополнительные утилиты и концепции
- Cloud-init: Стандартный способ для выполнения скриптов при первом запуске облачных инстансов. Часто используется Terraform для начальной настройки перед тем, как Ansible возьмет управление на себя.
- Vagrant (HashiCorp): Для создания и управления легкими, переносимыми средами разработки. Полезно для локального тестирования Ansible ролей.
- Docker: Для контейнеризации приложений. Ansible может развертывать Docker Engine и запускать контейнеры.
- Packer (HashiCorp): Для создания образов машин (AMI, VMDK, OVF) из единого исходного файла. Позволяет создавать "золотые" образы с уже предустановленным ПО, что ускоряет развертывание и снижает нагрузку на Ansible.
- Open Policy Agent (OPA): Для внедрения политик "Infrastructure as Code" и обеспечения соответствия стандартам безопасности.
7. Полезные ссылки и документация
- Документация провайдеров Terraform: Для каждого облачного провайдера или хостинга есть своя документация по Terraform (например, DigitalOcean Terraform Provider).
- Официальная документация Ansible: Подробные руководства по модулям, ролям и Playbooks.
- Блоги и сообщества: DevOps-блоги (например, HashiCorp Blog, Red Hat Blog), Stack Overflow, Reddit (r/devops, r/terraform, r/ansible).
- Курсы и сертификации: Coursera, Udemy, Linux Academy, HashiCorp Certified: Terraform Associate, Red Hat Certified Specialist in Ansible Automation.
Использование этого набора инструментов и ресурсов позволит вам создать высокоэффективный, надежный и масштабируемый процесс автоматизации, который будет актуален и в 2026 году.
Troubleshooting: решение проблем автоматизации
Даже при самой тщательной подготовке, в процессе автоматизации с Terraform и Ansible могут возникать проблемы. Умение быстро диагностировать и устранять их – ключевой навык. Вот список типичных проблем и подходов к их решению.
1. Проблемы с Terraform
1.1. Ошибки при terraform plan или terraform apply:
- Симптом: Синтаксические ошибки HCL, проблемы с аутентификацией провайдера, некорректные параметры ресурсов.
Диагностика: Внимательно читайте вывод Terraform. Он обычно очень информативен и указывает на конкретную строку и причину ошибки. Проверьте ваш API-токен или ключи доступа, их права. - Симптом: "Resource already exists" или "Resource not found" при повторном `apply`.
Диагностика: Проверьте файл состояния (`.tfstate`). Возможно, ресурс был создан вручную или его состояние рассинхронизировалось.
Решение: Используйте `terraform import` для добавления существующего ресурса в состояние, или `terraform state rm` для удаления записи из состояния (если ресурс действительно удален). Будьте крайне осторожны с `terraform state rm`! - Симптом: Зависание `terraform apply` или таймаут операции.
Диагностика: Обычно связано с сетевыми проблемами, лимитами провайдера или очень долгими операциями. Проверьте логи провайдера (например, AWS CloudTrail, DigitalOcean Activity Log).
Решение: Увеличьте таймауты в конфигурации Terraform, если это возможно. Проверьте квоты и лимиты у вашего провайдера.
1.2. Проблемы с Terraform State:
- Симптом: "State file locked" или конфликты при параллельных запусках.
Диагностика: Убедитесь, что вы используете удаленный бэкенд с блокировкой.
Решение: Если блокировка застряла (редко), можно принудительно снять ее (`terraform force-unlock`), но только если вы уверены, что никто другой не работает с состоянием. - Симптом: Дрейф конфигурации (Drift) – реальная инфраструктура отличается от состояния.
Диагностика: Запустите `terraform plan`. Он покажет все различия.
Решение: Если дрейф вызван ручными изменениями, либо примените `terraform apply` для возврата к коду, либо обновите код Terraform, чтобы он соответствовал ручным изменениям. В идеале, ручные изменения должны быть запрещены.
Диагностические команды Terraform:
terraform validate # Проверка синтаксиса
terraform plan # Предварительный просмотр изменений
terraform apply # Применение изменений
terraform state list # Список ресурсов в состоянии
terraform state show # Подробная информация о ресурсе
terraform output -json # Вывод всех output переменных в JSON формате
TF_LOG=TRACE terraform apply # Очень подробные логи для отладки
2. Проблемы с Ansible
2.1. Проблемы подключения к хостам:
- Симптом: "Unreachable", "Authentication failed", "Permission denied (publickey)".
Диагностика:- Проверьте, что SSH-ключ (`-i ~/.ssh/id_rsa`) указан верно и имеет правильные права (`chmod 400`).
- Убедитесь, что IP-адрес или имя хоста в инвентаре верны.
- Проверьте, что SSH-сервер на целевом хосте запущен и доступен (
ssh user@ip). - Проверьте настройки фаервола на целевом хосте и в облаке (группы безопасности).
- Убедитесь, что пользователь, под которым Ansible пытается подключиться, существует на удаленном сервере и имеет права на подключение по SSH.
- Симптом: "Host key checking failed".
Диагностика: Это означает, что отпечаток ключа хоста не совпадает или отсутствует вknown_hosts.
Решение: Если это новый сервер, вы можете временно отключить проверку ключей (-o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null) для первого запуска, но в продакшене это крайне не рекомендуется. Лучше добавить ключ вknown_hostsвручную или использовать `ssh-keyscan`.
2.2. Ошибки выполнения Playbook'ов:
- Симптом: Задача завершается с ошибкой, сообщение об ошибке модуля.
Диагностика: Внимательно читайте сообщение об ошибке. Оно обычно указывает на конкретный модуль и причину (например, "package not found", "file permissions error").
Решение: Проверьте синтаксис YAML, переменные, права файлов/каталогов на целевом хосте. Запустите playbook с повышенной детализацией (`-vvv`). - Симптом: Playbook "зависает" или выполняется очень долго.
Диагностика: Может быть связано с ожиданием ввода, долгими командами или сетевыми таймаутами.
Решение: Проверьте, нет ли интерактивных команд. Убедитесь, что команды не блокируются фаерволом. - Симптом: Неидемпотентность – повторный запуск Playbook'а меняет состояние или вызывает ошибки.
Диагностика: Запустите с `ansible-playbook --check --diff`. Это покажет, какие изменения будут внесены без фактического применения.
Решение: Перепишите задачи, используя идемпотентные модули и условия.
Диагностические команды Ansible:
ansible all -i inventory.ini -m ping # Проверка доступности хостов
ansible-playbook -i inventory.ini playbook.yaml # Запуск playbook
ansible-playbook -i inventory.ini playbook.yaml -vvv # Подробный вывод для отладки
ansible-playbook -i inventory.ini playbook.yaml --check --diff # Предпросмотр изменений
ansible-inventory -i inventory.ini --list # Просмотр инвентаря
ansible-lint # Проверка на соответствие стилю и лучшим практикам
3. Общие проблемы
- Сетевые проблемы: Недоступность портов, неправильная маршрутизация, блокировки фаерволом.
Решение: Проверьте правила фаервола в облаке (Security Groups), на сервере (UFW, firewalld). Используйте `ping`, `traceroute`, `telnet`, `nc` для диагностики сетевого подключения. - Проблемы с правами: Недостаточные права пользователя для выполнения операций.
Решение: Убедитесь, что пользователь имеет необходимые права (например, `sudo`). Для Ansible используйте `become: true`. - Проблемы с версиями: Несовместимость версий Terraform, Ansible, провайдеров или операционных систем.
Решение: Всегда используйте фиксированные версии провайдеров в Terraform (`version = "~> 2.0"`). Проверяйте совместимость Ansible-ролей с версиями ОС. - Недостаточно ресурсов: Серверы не могут запуститься из-за нехватки RAM, CPU или дискового пространства.
Решение: Проверьте логи провайдера. Увеличьте размер инстанса или диска.
Помните, что логи – ваш лучший друг. Всегда начинайте с изучения вывода команд и логов системы. Не бойтесь экспериментировать в тестовой среде и использовать режимы `check` и `diff` перед применением изменений в продакшене.
FAQ: Часто задаваемые вопросы
1. Зачем мне использовать Terraform И Ansible, если я могу использовать только один из них?
Terraform и Ansible решают разные, но комплементарные задачи. Terraform фокусируется на декларативном управлении инфраструктурой (IaC) – создании, изменении и удалении ресурсов (VPS, сети, балансировщики). Ansible – на управлении конфигурациями (CM) – установке ПО, настройке сервисов, развертывании приложений ВНУТРИ этих ресурсов. Использование обоих инструментов в связке обеспечивает полную автоматизацию от "голого" железа до работающего приложения, разделяя зоны ответственности и делая процесс более надежным и масштабируемым.
2. Какой провайдер лучше для VPS/выделенных серверов в 2026 году?
Лучший провайдер зависит от ваших конкретных потребностей. DigitalOcean и Vultr остаются отличным выбором для стартапов и небольших проектов благодаря простоте использования и хорошей цене/производительности. Hetzner Cloud предлагает очень конкурентные цены и мощные выделенные серверы. AWS, Azure и GCP подходят для крупных предприятий с комплексными требованиями и большим бюджетом, предлагая широкий спектр сервисов. Equinix Metal — хороший выбор для Bare Metal as a Service. Оценивайте по производительности, географии, цене, API для автоматизации и качеству поддержки.
3. Насколько сложно освоить Terraform и Ansible?
Оба инструмента имеют относительно низкий порог входа, особенно для тех, кто уже знаком с командной строкой и концепциями Linux. Terraform использует HCL, который интуитивно понятен. Ansible использует YAML, который также прост для чтения. Основная сложность заключается в понимании концепций IaC, идемпотентности, управления состоянием и проектировании модульной архитектуры. С активным сообществом и обширной документацией, базовое освоение занимает несколько недель, а экспертный уровень — несколько месяцев практики.
4. Как обеспечить безопасность секретов (паролей, ключей API) в автоматизации?
Никогда не храните секреты в открытом виде в Git-репозиториях. Используйте специализированные инструменты: HashiCorp Vault, AWS Secrets Manager, Azure Key Vault, Google Secret Manager. Для Ansible используйте Ansible Vault для шифрования файлов с чувствительными данными. Интегрируйте эти секретные менеджеры в ваш CI/CD пайплайн, чтобы они динамически предоставляли секреты только во время выполнения задач, используя принцип наименьших привилегий.
5. Что такое "Infrastructure Drift" и как с ним бороться?
Infrastructure Drift (дрейф конфигурации) – это ситуация, когда фактическое состояние вашей инфраструктуры отличается от того, что описано в вашем коде IaC (Terraform). Это часто происходит из-за ручных изменений, внесенных напрямую на серверах. Чтобы бороться с дрейфом, регулярно запускайте terraform plan (в идеале в CI/CD) для его обнаружения. Внедрите строгие политики, запрещающие ручные изменения. Рассмотрите использование "Immutable Infrastructure", где серверы никогда не изменяются, а заменяются новыми.
6. Могу ли я использовать Terraform для управления выделенными серверами без API?
Напрямую — нет. Terraform работает через API провайдеров. Если ваш провайдер выделенных серверов не предоставляет API, вы не сможете использовать Terraform для их непосредственного развертывания или управления (например, переустановки ОС). Однако вы можете использовать Terraform для управления DNS-записями, сетевыми настройками или другими облачными компонентами, связанными с вашими выделенными серверами. Для самих серверов без API придется использовать ручные операции или Ansible для конфигурации уже существующих машин.
7. Какие лучшие практики для структурирования Terraform и Ansible проектов?
Для Terraform: используйте модули для повторно используемых компонентов, разделяйте конфигурации по средам (dev, staging, prod) и по компонентам (network, compute, database). Для Ansible: используйте роли для логической группировки задач, переменных и шаблонов. Разделяйте переменные по группам хостов и средам. Храните весь код в Git, используйте понятные имена и комментарии. Следуйте принципу DRY (Don't Repeat Yourself).
8. Как тестировать мой код инфраструктуры?
Тестирование IaC так же важно, как и тестирование кода приложения. Для Terraform используйте terraform validate и terraform plan. Для Ansible – ansible-lint и Molecule для тестирования ролей в изолированных средах. Для интеграционного тестирования развернутой инфраструктуры используйте фреймворки типа Terratest, InSpec или Serverspec. Включайте эти тесты в ваш CI/CD пайплайн.
9. Что делать, если Terraform или Ansible вызывают ошибку в продакшене?
Во-первых, не паникуйте. Во-вторых, немедленно откатите последние изменения, если это возможно (например, terraform destroy для недавно созданного ресурса или откат Git-коммита). В-третьих, тщательно изучите логи (с `TF_LOG=TRACE` для Terraform, `-vvv` для Ansible). Используйте режим `plan` или `check` для диагностики. Если проблема связана с внешним сервисом, проверьте его статус. Имейте четкий план отката и восстановления.
10. Как насчет Kubernetes? Заменит ли он VPS/выделенные серверы?
Kubernetes (K8s) — мощная платформа для оркестрации контейнеров, которая активно развивается и в 2026 году. Он не заменяет VPS/выделенные серверы напрямую, а скорее абстрагирует их. K8s сам по себе работает НА серверах (виртуальных или выделенных). Terraform может развертывать кластеры K8s (например, EKS, GKE, AKS или K3s на VPS), а Ansible может использоваться для начальной конфигурации этих узлов или развертывания K8s-кластера на Bare Metal. Для многих приложений, особенно микросервисных, K8s является отличным выбором, но для монолитных приложений, высоконагруженных баз данных или специфических игровых серверов VPS и выделенные серверы по-прежнему остаются актуальными и более простыми в управлении.
11. Как мне обновить существующую инфраструктуру, созданную вручную, на IaC?
Это называется "adoption" или "brownfield" развертывание. Шаги: 1) Импортируйте существующие ресурсы в Terraform State с помощью terraform import. Это позволяет Terraform взять на себя управление уже созданными ресурсами. 2) Создайте Ansible Playbooks для конфигурирования существующих серверов, чтобы стандартизировать их состояние. 3) Применяйте изменения постепенно, сначала в тестовой среде. Это трудоемкий, но необходимый процесс для перехода к автоматизации.
12. Каковы тенденции в автоматизации инфраструктуры на ближайшие годы?
В 2026 году и далее мы увидим дальнейшее развитие:
- AI/ML-Driven Operations (AIOps): Использование ИИ для предсказательного масштабирования, автоматического исправления проблем, оптимизации затрат и обнаружения аномалий.
- GitOps: Управление инфраструктурой и приложениями через Git-репозиторий как единственный источник истины, с автоматической синхронизацией.
- Serverless и Function as a Service (FaaS): Продолжение тренда на абстракцию от серверов для определенных типов нагрузок.
- Security as Code: Интеграция политик безопасности непосредственно в код инфраструктуры и автоматизация их применения и аудита.
- Platform Engineering: Создание внутренних платформ, которые абстрагируют сложность нижележащей инфраструктуры для разработчиков, используя IaC и CM как фундамент.
Заключение
В 2026 году автоматизация развертывания и управления VPS и выделенными серверами с помощью Terraform и Ansible – это не просто "приятно иметь", а абсолютная необходимость для любой организации, стремящейся к эффективности, надежности и конкурентоспособности. Мы увидели, как эти два мощных инструмента, работая в связке, позволяют создавать, конфигурировать и поддерживать инфраструктуру с невиданной ранее скоростью и точностью. От декларативного описания ресурсов с Terraform до идемпотентного управления конфигурациями с Ansible – каждый шаг в жизненном цикле сервера может быть автоматизирован и зафиксирован в коде.
Мы рассмотрели ключевые критерии выбора, детально изучили принципы работы Terraform и Ansible, поделились практическими советами по внедрению, а также проанализировали типичные ошибки и способы их избежать. Экономические расчеты наглядно продемонстрировали, что инвестиции в автоматизацию окупаются многократно, сокращая трудозатраты, минимизируя простои и ускоряя вывод продуктов на рынок. Кейсы из реальной практики подтвердили универсальность и эффективность такого подхода как для масштабируемых SaaS-платформ, так и для сложных гибридных инфраструктур.
Мир инфраструктуры постоянно меняется, но принципы IaC и CM остаются незыблемыми. Инструменты и технологии будут развиваться, появятся новые провайдеры и возможности, но фундаментальная идея управления инфраструктурой как кодом будет только укрепляться. Интеграция с CI/CD, усиление безопасности через секретные менеджеры и Security as Code, а также внедрение продвинутого мониторинга и тестирования – все это компоненты успешной стратегии автоматизации.
Итоговые рекомендации:
- Инвестируйте в обучение: Убедитесь, что ваша команда глубоко понимает Terraform, Ansible и связанные концепции.
- Начните с малого: Постепенное внедрение автоматизации снижает риски и позволяет быстро получить первые результаты.
- Применяйте модульность: Используйте модули Terraform и роли Ansible для создания переиспользуемых и поддерживаемых компонентов.
- Версионируйте все: Git – ваш лучший друг. Все изменения в инфраструктуре должны проходить через контроль версий и code review.
- Тестируйте безжалостно: Ваш код инфраструктуры должен быть протестирован не меньше, чем код приложения.
- Управляйте секретами: Используйте специализированные инструменты для хранения и доступа к конфиденциальным данным.
- Избегайте ручных изменений: Стремитесь к тому, чтобы вся инфраструктура управлялась исключительно через код.
- Интегрируйте в CI/CD: Полная автоматизация раскрывает весь потенциал IaC и CM.
Следующие шаги для читателя:
Если вы дочитали до этого момента, значит, вы готовы к действиям. Не откладывайте.
- Выберите пилотный проект: Определите небольшой, но значимый компонент вашей инфраструктуры для первой автоматизации.
- Изучите документацию: Глубоко погрузитесь в официальные руководства Terraform и Ansible.
- Начните писать код: Создайте свой первый
main.tfиplaybook.yaml. Разверните тестовый VPS. - Используйте сообщество: Задавайте вопросы на Stack Overflow, Reddit, участвуйте в обсуждениях.
- Постройте свой CI/CD пайплайн: Интегрируйте ваши Terraform и Ansible скрипты в автоматический процесс.
Автоматизация – это не конечная цель, а непрерывный процесс совершенствования. Применяя принципы и инструменты, описанные в этой статье, вы сможете построить надежную, масштабируемую и эффективную инфраструктуру, готовую к вызовам 2026 года и далее. Удачи в вашем путешествии по автоматизации!