
Оптимизация затрат на облачные VPS и выделенные серверы: FinOps практики и инструменты (актуально для 2026 года)
TL;DR
- FinOps — это не просто экономия, а культура: Интеграция финансов и операций для постоянного управления облачными расходами, фокус на ценности и бизнес-результатах.
- Видимость и контроль — ключ: Используйте tagging, детальные отчеты и специализированные инструменты для понимания, кто и за что платит. Без этого оптимизация невозможна.
- Права сайзинг (Rightsizing) — ваш лучший друг: Регулярно анализируйте утилизацию ресурсов и масштабируйте серверы (VPS/Dedicated) до оптимальных размеров. Переплачиваете за неиспользуемую мощность.
- Автоматизация и гибкость: Применяйте автоскейлинг, планирование включений/выключений, Spot-инстансы и зарезервированные мощности для адаптации к нагрузке и снижения базовых затрат.
- Не забывайте про сеть и хранилища: Egress-трафик, неиспользуемые диски, устаревшие снапшоты могут составлять значительную часть счета. Оптимизируйте их так же тщательно, как CPU/RAM.
- Культура сотрудничества: FinOps требует взаимодействия между инженерами, менеджерами продуктов и финансовыми отделами для совместного принятия решений о расходах.
- Выбирайте правильный тип сервера: VPS для гибкости и масштабирования, выделенные серверы для высокой производительности и предсказуемости нагрузки, контейнеризация и Serverless для максимальной эффективности.
3. Введение
В стремительно развивающемся мире технологий, где облачные вычисления стали стандартом де-факто для большинства стартапов, SaaS-проектов и даже крупных предприятий, управление затратами на IT-инфраструктуру превратилось из второстепенной задачи в критически важный аспект бизнес-стратегии. К 2026 году, когда облачный рынок продолжит свой экспоненциальный рост, а конкуренция среди провайдеров и потребителей услуг достигнет пика, умение эффективно управлять бюджетом на VPS и выделенные серверы станет не просто преимуществом, а необходимостью для выживания и процветания.
Эта статья посвящена FinOps — операционной модели, которая объединяет финансы, технологии и бизнес для достижения максимальной ценности от облачных инвестиций. FinOps — это не одноразовое мероприятие по сокращению расходов, а непрерывный процесс, культура сотрудничества, направленная на повышение прозрачности, подотчетности и эффективности использования облачных ресурсов. Мы рассмотрим, как FinOps-практики и современные инструменты помогают DevOps-инженерам, backend-разработчикам, фаундерам SaaS, системным администраторам и техническим директорам стартапов не просто сокращать расходы, но и принимать обоснованные, стратегические решения, которые способствуют росту бизнеса.
Почему эта тема важна именно в 2026 году? Потому что сложность облачных экосистем продолжает расти. Множество сервисов, тарифных планов, моделей ценообразования (по запросу, зарезервированные инстансы, спотовые инстансы, бессерверные функции) создают лабиринт, в котором легко потеряться и незаметно для себя переплачивать. С другой стороны, появляются все более совершенные инструменты для мониторинга, анализа и автоматизации, которые позволяют управлять этой сложностью. Статья призвана помочь вам ориентироваться в этом лабиринте, используя передовые подходы FinOps.
Статья решает следующие проблемы:
- Отсутствие прозрачности: Как понять, куда уходят деньги и какие сервисы потребляют наибольшую часть бюджета?
- Избыточное потребление: Как избежать переплаты за неиспользуемые или недоиспользуемые ресурсы?
- Сложность выбора: Как выбрать между VPS, выделенными серверами, контейнерами или бессерверными решениями с учетом стоимости и производительности?
- Отсутствие единого подхода: Как наладить взаимодействие между техническими и финансовыми отделами для эффективного управления затратами?
- Масштабирование с умом: Как обеспечить рост инфраструктуры без пропорционального увеличения расходов?
Эта статья написана для всех, кто сталкивается с вызовами управления облачными затратами и стремится не только сократить их, но и оптимизировать ценность, получаемую от каждого потраченного доллара. Мы предоставим конкретные, применимые на практике рекомендации, подкрепленные примерами и актуальными данными на 2026 год, чтобы вы могли уверенно управлять своей облачной инфраструктурой.
4. Основные критерии/факторы выбора и оптимизации
Выбор оптимальной инфраструктуры и последующая её оптимизация — это многогранный процесс, зависящий от множества факторов. В контексте FinOps, каждый из этих критериев напрямую влияет на итоговую стоимость и ценность, которую бизнес получает от IT-инвестиций. Рассмотрим ключевые факторы, актуальные для 2026 года.
Производительность и тип нагрузки
Почему важен: Недооценка или переоценка требуемой производительности приводит к неэффективным затратам. Слишком слабый сервер не справляется с нагрузкой, вызывая замедления и отказы, что влечет потерю клиентов и репутационные риски. Слишком мощный сервер — это прямая переплата за неиспользуемые ресурсы.
Как оценивать:
- CPU-интенсивные задачи: Высокие вычисления, обработка больших объемов данных, машинное обучение, компиляция. Требуют мощных ядер и, возможно, специализированных процессоров (GPU, TPU).
- RAM-интенсивные задачи: Базы данных в памяти (Redis, Memcached), JVM-приложения с большим хипом, аналитика больших данных, обработка изображений. Требуют большого объема оперативной памяти.
- I/O-интенсивные задачи: Базы данных (PostgreSQL, MongoDB), файловые серверы, высоконагруженные веб-серверы с большим количеством статики. Требуют быстрых SSD/NVMe дисков и высокой пропускной способности I/O.
- Сетевая нагрузка: Высоконагруженные API-шлюзы, стриминговые сервисы, CDN-узлы. Требуют высокой пропускной способности сети и низких задержек.
К 2026 году появляются новые поколения процессоров (например, ARM-процессоры, такие как AWS Graviton, становятся еще более конкурентоспособными по соотношению цена/производительность), а также специализированные решения для ИИ и ML, которые могут значительно снизить стоимость выполнения специфических задач.
Масштабируемость и эластичность
Почему важен: Способность инфраструктуры адаптироваться к изменяющейся нагрузке без ручного вмешательства и с минимальными затратами. Неэластичная система либо не справляется с пиками, либо простаивает в периоды спада, потребляя ресурсы. FinOps стремится к оплате только за фактически используемые ресурсы.
Как оценивать:
- Вертикальная масштабируемость: Увеличение ресурсов (CPU, RAM) одного сервера. Проста в реализации, но имеет физические ограничения и требует перезапуска.
- Горизонтальная масштабируемость: Добавление новых серверов для распределения нагрузки. Более сложна в реализации (требует stateless-приложений, балансировщиков), но обеспечивает почти бесконечный рост и высокую доступность.
- Автоскейлинг: Автоматическое добавление/удаление серверов на основе метрик (CPU, RAM, очередь запросов). Ключевой инструмент FinOps для динамической оптимизации.
В 2026 году ожидается дальнейшее развитие бессерверных (Serverless) и контейнерных (Kubernetes) решений, которые предлагают высочайший уровень эластичности и оплаты по факту использования, что делает их крайне привлекательными с точки зрения FinOps.
Надежность и доступность (SLA)
Почему важен: Время простоя (downtime) — это прямые и косвенные потери для бизнеса: упущенная прибыль, потеря клиентов, ущерб репутации. Высокая доступность обычно стоит дороже, поэтому важно найти баланс между необходимым уровнем SLA и бюджетом.
Как оценивать:
- SLA (Service Level Agreement): Гарантированный провайдером процент времени доступности сервиса (например, 99.9% или 99.99%). Чем выше SLA, тем выше стоимость.
- Резервирование (Redundancy): Дублирование критически важных компонентов (серверы, базы данных, сетевое оборудование) для предотвращения единых точек отказа.
- Географическое распределение: Размещение инфраструктуры в нескольких регионах/зонах доступности для защиты от региональных сбоев.
- Резервное копирование и восстановление (Backup & Recovery): Регулярные бэкапы и проверенные планы восстановления после сбоев.
FinOps подход требует осознанного выбора уровня доступности, исходя из бизнес-ценности приложения, а не "максимально возможного".
Безопасность и соответствие нормативам (Compliance)
Почему важен: Утечки данных, кибератаки, несоответствие GDPR, HIPAA, PCI DSS и другим стандартам могут привести к огромным штрафам, судебным искам и потере доверия. Затраты на безопасность — это инвестиции, а не расходы.
Как оценивать:
- Сетевая безопасность: Фаерволы, VPN, WAF (Web Application Firewall), защита от DDoS.
- Безопасность данных: Шифрование данных в покое и при передаче, управление доступом, резервное копирование.
- Управление идентификацией и доступом (IAM): Принцип наименьших привилегий, двухфакторная аутентификация.
- Соответствие стандартам: Сертификации провайдера (ISO 27001, SOC 2), соответствие региональным и отраслевым нормам.
К 2026 году возрастает роль автоматизированных средств безопасности (DevSecOps), а также платформ для управления соответствием, которые помогают минимизировать ручные проверки и связанные с ними затраты.
Модель ценообразования и прогнозируемость затрат
Почему важен: Непрозрачные или непредсказуемые затраты затрудняют бюджетирование и планирование. FinOps стремится к максимальной предсказуемости и возможности оптимизации.
Как оценивать:
- Pay-as-you-go: Оплата за фактически потребленные ресурсы. Высокая гибкость, но потенциально высокая непредсказуемость без должного мониторинга.
- Зарезервированные инстансы (Reserved Instances / Savings Plans): Скидки за обязательство использовать определенный объем ресурсов на длительный срок (1-3 года). Значительно снижают базовые затраты.
- Спотовые инстансы (Spot Instances): Очень дешевые, но прерываемые инстансы, подходящие для отказоустойчивых и batch-задач.
- Фиксированная стоимость: Выделенные серверы или некоторые VPS-тарифы с предсказуемой ежемесячной оплатой. Подходят для стабильной, предсказуемой нагрузки.
В 2026 году провайдеры предлагают еще более сложные модели ценообразования, требующие глубокого анализа и использования FinOps-инструментов для выбора наиболее выгодного варианта.
Поддержка и экосистема
Почему важен: Качество поддержки и доступность инструментов влияют на скорость решения проблем, время выхода на рынок и общую операционную эффективность. Плохая поддержка может привести к длительным простоям и дополнительным расходам на внутренние ресурсы.
Как оценивать:
- Уровень поддержки: 24/7, время ответа, каналы связи (чат, телефон, тикеты).
- Документация и сообщество: Наличие исчерпывающей документации, активного сообщества, форумов.
- Экосистема: Доступность дополнительных сервисов (базы данных, CDN, аналитика), интеграция с другими инструментами.
- Управляемые сервисы: Возможность делегировать часть операционных задач провайдеру (например, Managed Databases, Kubernetes as a Service).
Географическое расположение и задержки (Latency)
Почему важен: Физическое расположение серверов относительно конечных пользователей напрямую влияет на скорость отклика приложения. Для глобальных сервисов это критически важно. Также важны вопросы суверенитета данных и соответствия местным законам.
Как оценивать:
- Расстояние до пользователей: Выбор дата-центров, максимально близких к основной аудитории.
- CDN (Content Delivery Network): Использование CDN для кэширования контента ближе к пользователям, снижая нагрузку на основной сервер и уменьшая задержки.
- Multi-Region/Multi-Zone архитектура: Развертывание в нескольких географических точках для отказоустойчивости и снижения задержек.
- Законы о хранении данных: Убедитесь, что данные хранятся в соответствии с требованиями юрисдикции, где находится ваша аудитория.
Оптимизация сетевых затрат, включая egress-трафик, становится одним из ключевых направлений FinOps к 2026 году, так как объемы передаваемых данных продолжают расти.
Вендор-лок-ин (Vendor Lock-in)
Почему важен: Зависимость от одного провайдера может ограничивать возможности миграции, снижать переговорную силу и приводить к удорожанию услуг в долгосрочной перспективе. FinOps поощряет архитектуры, которые минимизируют зависимость.
Как оценивать:
- Стандартизация: Использование открытых стандартов (Docker, Kubernetes, Terraform) и облачно-независимых технологий.
- Абстракция: Отделение логики приложения от специфических облачных сервисов.
- Мультиоблачная/Гибридная стратегия: Развертывание в нескольких облаках или комбинация облака с собственной инфраструктурой для снижения рисков.
К 2026 году инструменты для мультиоблачного управления и абстракции инфраструктуры становятся все более зрелыми, позволяя компаниям более гибко подходить к выбору провайдеров и избегать жесткого лок-ина.
5. Сравнительная таблица облачных и выделенных серверов (2026)
В 2026 году рынок облачных услуг и выделенных серверов продолжает развиваться, предлагая широкий спектр решений. Ниже представлена сравнительная таблица, отражающая ключевые характеристики и ориентировочные цены для различных типов инфраструктуры, актуальные для 2026 года. Цены являются гипотетическими и могут варьироваться в зависимости от провайдера, региона и конкретной конфигурации. Мы предполагаем средние конфигурации, подходящие для типичного SaaS-приложения или бэкенда.
| Критерий | Облачный VPS (Shared CPU, 8-16 GB RAM) | Облачный VPS (Dedicated CPU, 16-32 GB RAM) | Управляемый VPS (Managed, 16-32 GB RAM) | Выделенный Сервер (Bare Metal, L-конфигурация) | Облачный Инстанс (AWS EC2/GCP Compute, m5.xlarge/e2-standard-4) | Kubernetes as a Service (EKS/GKE, 3 узла) | Serverless (Lambda/Cloud Functions, 100M вызовов) |
|---|---|---|---|---|---|---|---|
| Типичный CPU | 2-4 vCPU (shared) | 4-8 vCPU (dedicated) | 4-8 vCPU (dedicated) | 8-16 Cores (физические) | 4 vCPU (dedicated) | 3 x 4 vCPU (dedicated) | 0.25-1 vCPU (burst) |
| Типичная RAM | 8-16 GB | 16-32 GB | 16-32 GB | 64-128 GB | 16 GB | 3 x 16 GB | 128-512 MB |
| Типичный Storage | 160-320 GB SSD | 320-640 GB NVMe | 320-640 GB NVMe | 2 x 1 TB NVMe | 300 GB GP3 SSD | 3 x 300 GB GP3 SSD | N/A (Ephemeral) |
| Сетевой трафик (входящий/исходящий) | 1-2 TB / 1-2 TB | 2-4 TB / 2-4 TB | 2-4 TB / 2-4 TB | 10-20 TB / 10-20 TB | Входящий бесплатно, Исходящий 0.08-0.12 $/GB | Входящий бесплатно, Исходящий 0.08-0.12 $/GB | Входящий бесплатно, Исходящий 0.08-0.12 $/GB |
| Ориентировочная месячная стоимость (2026, USD) | 40-80 $ | 80-180 $ | 150-300 $ | 250-500 $ (без ОС/панели) | 150-250 $ (On-Demand) | 400-800 $ (без Control Plane) | 50-150 $ (за 100М вызовов) |
| Масштабируемость | Ручная/Вертикальная | Ручная/Вертикальная | Ручная/Вертикальная | Ручная/Вертикальная (апгрейд) | Автоматическая (горизонтальная, вертикальная) | Автоматическая (горизонтальная, поды/узлы) | Автоматическая (по запросу) |
| Уровень управления | Низкий (OS Only) | Низкий (OS Only) | Средний (OS + Панель) | Низкий (Hardware Only) | Средний (IaaS) | Высокий (PaaS) | Очень высокий (FaaS) |
| Предсказуемость затрат | Высокая | Высокая | Высокая | Очень высокая | Низкая (On-Demand), Высокая (RI/SP) | Средняя (по узлам), Низкая (по трафику) | Низкая (по вызовам/RAM/CPU) |
| Время развертывания | Минуты | Минуты | Минуты | Часы/Дни | Минуты | Десятки минут | Секунды |
Пояснения к таблице:
- Облачный VPS (Shared CPU): Виртуальные серверы, где CPU делится между несколькими клиентами. Самый бюджетный вариант, но подвержен "шумному соседу". Идеален для небольших сайтов, тестовых сред.
- Облачный VPS (Dedicated CPU): Виртуальные серверы с гарантированными ядрами CPU. Более стабильная производительность, подходит для production-сред со средней нагрузкой.
- Управляемый VPS: VPS с дополнительными услугами администрирования, панелью управления (cPanel, Plesk), бэкапами от провайдера. Удобно для тех, у кого нет своих сисадминов.
- Выделенный Сервер (Bare Metal): Физический сервер, полностью в вашем распоряжении. Максимальная производительность и контроль, но требует глубоких знаний администрирования. Экономически выгоден при очень высокой и стабильной нагрузке.
- Облачный Инстанс (AWS EC2/GCP Compute): Типичный IaaS-сервис от крупных облачных провайдеров. Предлагает огромную гибкость, множество типов инстансов, продвинутые сетевые и дисковые опции, но требует активного управления FinOps для контроля затрат.
- Kubernetes as a Service: Управляемые кластеры Kubernetes (например, EKS, GKE, AKS). Позволяют запускать контейнеризированные приложения с высокой масштабируемостью и отказоустойчивостью. Стоимость включает оплату за узлы и, возможно, за управляющий слой.
- Serverless (Lambda/Cloud Functions): Функции как сервис (FaaS). Оплата идет за количество вызовов и время выполнения. Идеально для событийных, нечастых задач, микросервисов. Максимальная эластичность, минимальное администрирование, но сложнее прогнозировать стоимость при непредсказуемой нагрузке.
Выбор между этими вариантами — это всегда компромисс между стоимостью, производительностью, гибкостью, уровнем управления и предсказуемостью. FinOps помогает принять это решение, исходя из реальных потребностей бизнеса.
6. Детальный обзор каждого пункта/варианта

Понимание нюансов каждого типа инфраструктуры критически важно для принятия обоснованных FinOps-решений. К 2026 году различия между ними стали еще более выраженными, а их оптимальное применение требует глубокой экспертизы.
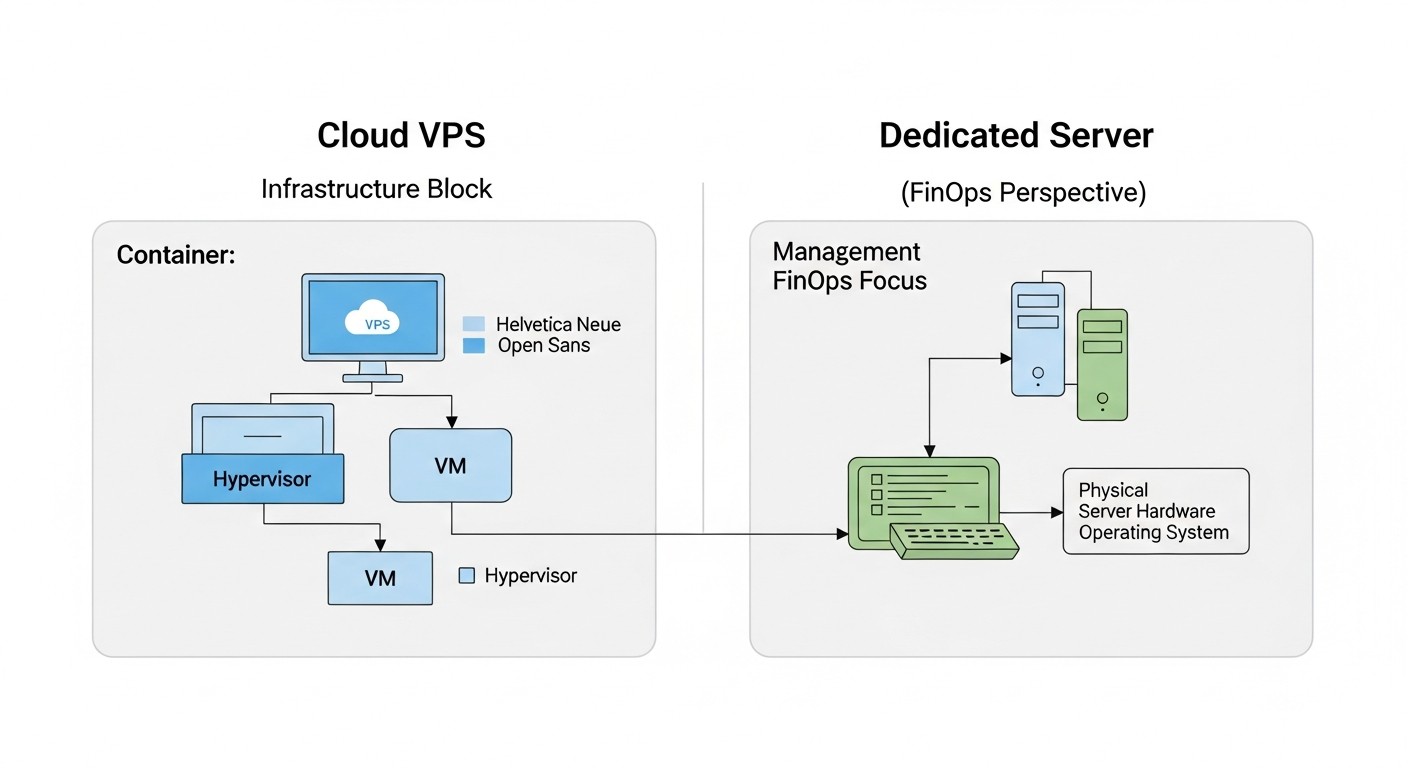
Облачные VPS (Virtual Private Servers)
Облачные VPS остаются одним из самых популярных и доступных решений для большинства стартапов и средних проектов. Они представляют собой виртуализированную часть физического сервера, где вы получаете гарантированные ресурсы (или ресурсы с оверселлингом в случае Shared CPU) и полный контроль над операционной системой. Провайдеры, такие как DigitalOcean, Vultr, Hetzner, Linode, а также российские провайдеры (Яндекс.Облако, VK Cloud Solutions, Selectel) предлагают широкий спектр VPS.
Плюсы:
- Доступность: Низкий порог входа, стартовые тарифы начинаются от нескольких долларов в месяц.
- Гибкость: Легко масштабировать ресурсы (CPU, RAM, Storage) вертикально (часто с перезагрузкой). Быстрое развертывание.
- Контроль: Полный root-доступ к операционной системе, что позволяет устанавливать любое ПО и настраивать среду под свои нужды.
- Предсказуемость: Обычно фиксированная ежемесячная плата, что облегчает бюджетирование.
- Широкий выбор: Множество провайдеров, конкурирующих по цене и качеству.
Минусы:
- Ограниченная масштабируемость: Вертикальное масштабирование имеет физические пределы. Горизонтальное масштабирование требует ручной настройки или использования дополнительных сервисов (балансировщиков).
- Проблема "шумного соседа": На Shared CPU VPS производительность может страдать из-за других клиентов на том же физическом сервере.
- Отсутствие Managed-сервисов: Большинство VPS не включают управляемые базы данных, очереди сообщений и другие PaaS-сервисы, которые есть у крупных облачных провайдеров.
- Ручное администрирование: Вся ответственность за ОС, безопасность, обновления, бэкапы лежит на пользователе (если это не Managed VPS).
Для кого подходит:
Небольшие и средние веб-приложения, API-сервисы, блоги, тестовые и dev-среды, VPN-серверы, личные проекты. Идеально для стартапов на ранних стадиях, которым нужна гибкость и низкие стартовые затраты. FinOps здесь фокусируется на правильном выборе тарифа, регулярном мониторинге утилизации и своевременном апгрейде/даунгрейде.
Конкретные примеры использования:
Развертывание сайта на WordPress/Laravel, небольшого Node.js/Python API, сервера для CI/CD агентов, тестовой среды для разработчиков. Например, стартап может начать с VPS за $20/месяц, а по мере роста трафика перейти на Dedicated CPU VPS за $80-100/месяц, пока не потребуется более сложная архитектура с балансировкой нагрузки.
Выделенные серверы (Dedicated Servers / Bare Metal)
Выделенный сервер предоставляет вам полный физический сервер, без виртуализации (если вы сами ее не развернете). Это означает эксклюзивный доступ ко всем аппаратным ресурсам: CPU, RAM, дискам и сетевому интерфейсу. Провайдеры, такие как Hetzner, OVHcloud, Contabo, а также российские Selectel, DataLine, предлагают широкий выбор конфигураций.
Плюсы:
- Максимальная производительность: Отсутствие оверхеда виртуализации, полный доступ к "железу". Идеально для ресурсоемких задач.
- Стабильность и предсказуемость: Производительность не зависит от "соседей".
- Полный контроль: Вы управляете всем, от выбора ОС до низкоуровневых настроек BIOS/UEFI.
- Безопасность: Физическая изоляция от других клиентов.
- Экономия на больших объемах: При высокой и постоянной нагрузке выделенный сервер может быть дешевле, чем эквивалентная конфигурация в облаке (особенно без долгосрочных обязательств).
- Высокие лимиты трафика: Часто провайдеры предлагают очень большие объемы трафика или даже неограниченный трафик за фиксированную плату.
Минусы:
- Низкая гибкость/масштабируемость: Вертикальное масштабирование требует замены оборудования и простоя. Горизонтальное масштабирование требует покупки новых серверов и ручной настройки.
- Длительное развертывание: Заказ и подготовка сервера может занимать от нескольких часов до нескольких дней.
- Высокая стоимость входа: Стоимость аренды значительно выше, чем у VPS.
- Высокие требования к администрированию: Требует глубоких знаний системного администрирования, настройки сети, RAID-массивов, безопасности.
- Отсутствие managed-сервисов: Все дополнительные сервисы (базы данных, балансировщики) нужно настраивать и поддерживать самостоятельно.
Для кого подходит:
Крупные базы данных, высоконагруженные игровые серверы, стриминговые платформы, ERP-системы, проекты с очень стабильной и высокой нагрузкой, где важна каждая миллисекунда и максимальная пропускная способность. Также подходит для компаний, которым нужен максимальный контроль над инфраструктурой или требуется специфическое "железо". FinOps здесь сосредоточен на долгосрочном планировании, правильном выборе конфигурации и эффективном использовании каждого ядра и гигабайта.
Конкретные примеры использования:
Серверы для Minecraft с сотнями игроков, высоконагруженный PostgreSQL-кластер, сервер для машинного обучения с GPU, корпоративная система 1С, частное облако на базе Proxmox/OpenStack. Например, игровой студии для нового тайтла может потребоваться выделенный сервер с мощным CPU и большим объемом RAM, способный обработать пиковую нагрузку в 5000 одновременных пользователей, что обойдется в $400-600/месяц, но позволит избежать лагов и обеспечить стабильный игровой опыт.
Облачные Инстансы (IaaS от крупных провайдеров: AWS EC2, GCP Compute Engine, Azure VMs)
Эти сервисы предоставляют виртуальные машины в крупномасштабных облачных инфраструктурах, таких как Amazon Web Services (AWS), Google Cloud Platform (GCP) и Microsoft Azure. Они предлагают огромную гибкость, масштабируемость и интеграцию с обширной экосистемой облачных сервисов.
Плюсы:
- Высочайшая масштабируемость: Простая настройка автоскейлинга, возможность запуска тысяч инстансов за считанные минуты.
- Гибкость конфигураций: Широкий выбор типов инстансов (оптимизированные для CPU, RAM, I/O, GPU), возможность кастомных конфигураций.
- Экосистема сервисов: Бесшовная интеграция с управляемыми базами данных (RDS, Cloud SQL), очередями сообщений (SQS, Pub/Sub), CDN (CloudFront, Cloud CDN), бессерверными функциями (Lambda, Cloud Functions) и множеством других PaaS/SaaS решений.
- Высокая доступность: Возможность развертывания в нескольких зонах доступности и регионах для максимальной отказоустойчивости.
- Продвинутые FinOps-инструменты: Встроенные инструменты для мониторинга затрат, биллинга, бюджетирования, резервирования мощностей (Reserved Instances, Savings Plans, Spot Instances).
Минусы:
- Сложность: Огромное количество сервисов и опций может быть ошеломляющим для новичков.
- Непредсказуемость затрат: Модель оплаты Pay-as-you-go может привести к неожиданно высоким счетам без должного контроля и оптимизации.
- Вендор-лок-ин: Использование специфических облачных сервисов может затруднить миграцию на другого провайдера.
- Сетевые затраты: Egress-трафик (исходящий трафик из облака) может быть очень дорогим.
Для кого подходит:
Крупные SaaS-проекты, e-commerce платформы, высоконагруженные веб-сервисы, проекты с динамичной и непредсказуемой нагрузкой, Big Data, ML-проекты. Для компаний, которым нужна максимальная гибкость, масштабируемость и широкий спектр управляемых сервисов. FinOps здесь — это центральная дисциплина, включающая управление Reserved Instances, Spot Instances, rightsizing, оптимизацию сетевого трафика и регулярный аудит.
Конкретные примеры использования:
Backend для мобильного приложения с миллионами пользователей, аналитическая платформа, обрабатывающая петабайты данных, глобальный e-commerce сайт. Например, SaaS-компания, предоставляющая CRM-систему, может использовать EC2 инстансы для своих микросервисов, RDS для базы данных, SQS для очередей и S3 для хранения файлов. При правильном применении FinOps, используя Reserved Instances для базовой нагрузки и автоскейлинг с Spot Instances для пиков, можно снизить затраты на 30-70% по сравнению с On-Demand.
Kubernetes as a Service (EKS, GKE, AKS)
Управляемые сервисы Kubernetes (Amazon EKS, Google GKE, Azure AKS) предоставляют готовые к использованию кластеры Kubernetes, абстрагируя пользователя от управления мастер-нодами и их инфраструктурой. Это позволяет сосредоточиться на развертывании приложений в контейнерах.
Плюсы:
- Высокая масштабируемость: Автоматическое масштабирование подов и узлов кластера в зависимости от нагрузки.
- Отказоустойчивость: Встроенные механизмы оркестрации и самовосстановления.
- Переносимость: Контейнеры (Docker) и Kubernetes являются открытыми стандартами, что снижает вендор-лок-ин.
- Эффективное использование ресурсов: Kubernetes позволяет плотно упаковывать рабочие нагрузки на узлах, максимизируя утилизацию ресурсов.
- DevOps-friendly: Упрощает CI/CD и развертывание приложений.
Минусы:
- Сложность: Kubernetes сам по себе имеет высокий порог входа.
- Стоимость управляющего слоя: Некоторые провайдеры берут плату за мастер-ноды (например, EKS), другие включают это в стоимость узлов.
- Накладные расходы: Кластер Kubernetes требует больше ресурсов для своей работы по сравнению с "голыми" VPS.
- Затраты на обучение: Требуются специалисты с глубокими знаниями Kubernetes.
Для кого подходит:
Микросервисные архитектуры, высоконагруженные распределенные приложения, SaaS-платформы, которым требуется высокая степень автоматизации, масштабируемости и отказоустойчивости. Компании, которые уже используют контейнеризацию или планируют миграцию на микросервисы. FinOps в Kubernetes включает оптимизацию размеров подов (requests/limits), автоскейлинг узлов (Cluster Autoscaler, Karpenter), выбор оптимальных типов инстансов для узлов, а также мониторинг и управление сетевыми затратами.
Конкретные примеры использования:
Развертывание множества микросервисов, каждый из которых обслуживает отдельную функцию, на едином кластере Kubernetes. Например, медиа-платформа, где каждый сервис (пользователи, контент, рекомендации, стриминг) работает в своем поде, масштабируясь независимо. Стоимость такого кластера может начинаться от $400-500 в месяц за несколько узлов и управляющий слой, но позволяет значительно сократить операционные расходы на администрирование и эффективно использовать ресурсы.
Serverless (Lambda, Cloud Functions, Azure Functions)
Serverless-вычисления, или "функции как сервис" (FaaS), позволяют разработчикам запускать код без необходимости управления серверами. Провайдер автоматически масштабирует и управляет всей базовой инфраструктурой, а оплата взимается только за фактическое время выполнения кода и количество вызовов.
Плюсы:
- Максимальная эластичность: Мгновенное масштабирование от нуля до тысяч вызовов в секунду.
- Оплата по факту использования: Вы платите только за то, что реально потребляете, без простаивающих серверов.
- Отсутствие администрирования: Провайдер берет на себя все задачи по управлению серверами, патчингу, обновлению ОС.
- Низкие операционные расходы: Значительное сокращение усилий DevOps и системных администраторов.
- Встроенная отказоустойчивость: Функции автоматически дублируются и запускаются в разных зонах доступности.
Минусы:
- Холодный старт (Cold Start): Первые вызовы функции после простоя могут занимать больше времени из-за инициализации среды.
- Ограничения: Лимиты на время выполнения, объем памяти, размер пакета развертывания.
- Сложность отладки и мониторинга: Распределенная природа Serverless-архитектур может усложнять отладку.
- Вендор-лок-ин: Хотя код может быть переносимым, интеграция с другими сервисами провайдера создает зависимость.
- Непредсказуемость затрат: При очень высокой и непредсказуемой нагрузке стоимость может быть выше, чем у постоянно работающего сервера.
Для кого подходит:
Событийно-ориентированные архитектуры, API-шлюзы, бэкенды для мобильных приложений, обработка файлов, ETL-процессы, чат-боты, webhooks, фоновые задачи. Идеально для приложений с переменной или спорадической нагрузкой. FinOps для Serverless включает оптимизацию времени выполнения функций, выбор оптимального объема памяти, агрессивное кэширование, а также мониторинг и анализ вызовов для выявления неэффективных функций.
Конкретные примеры использования:
Обработка изображений после загрузки в S3, отправка уведомлений по email, аутентификация пользователей, реализация небольших микросервисов, которые реагируют на события в базе данных. Например, для обработки 100 миллионов вызовов Lambda в месяц с временем выполнения 500 мс и 256 МБ RAM, стоимость может составить порядка $70-120 в месяц, что для такого объема обработки крайне выгодно по сравнению с поддержанием постоянно работающего сервера.
7. Практические советы и рекомендации по FinOps
Применение FinOps не ограничивается теоретическими знаниями; оно требует конкретных действий и инструментов. Ниже представлены пошаговые инструкции и рекомендации, которые помогут вам эффективно управлять затратами на VPS и выделенные серверы.
1. Внедрение культуры прозрачности и подотчетности (Tagging & Cost Allocation)
Первый шаг к оптимизации — понять, кто и за что платит. К 2026 году без адекватной системы тегирования и распределения затрат невозможно эффективно управлять облаком.
Действия:
- Разработайте политику тегирования: Определите обязательные теги для всех ресурсов (например,
Project,Environment,Owner,CostCenter). - Автоматизируйте тегирование: Используйте Infrastructure as Code (IaC) для автоматического применения тегов при создании ресурсов.
- Мониторинг соблюдения: Регулярно проверяйте, что все ресурсы имеют необходимые теги.
Пример политики тегирования:
# Пример политики тегирования для AWS/GCP/Azure
# Все ресурсы должны иметь следующие теги:
- Key: Project
Description: Название проекта или продукта (e.g., "SaaS_CRM", "Analytics_Platform")
Required: true
Values: [CRM, Analytics, CoreServices, InternalTools, ... ]
- Key: Environment
Description: Среда развертывания (e.g., "prod", "staging", "dev", "test")
Required: true
Values: [prod, staging, dev, test]
- Key: Owner
Description: Имя или ID команды/инженера, ответственного за ресурс
Required: true
Values: [devops-team, backend-crm, data-eng, ... ]
- Key: CostCenter
Description: Код центра затрат для финансовой отчетности
Required: false # Может быть опциональным для dev-сред
Values: [CC101, CC202, ... ]
- Key: Application
Description: Название конкретного приложения или микросервиса
Required: false
Values: [AuthService, PaymentGateway, UserPortal, ... ]
2. Права сайзинг (Rightsizing) и регулярный аудит
Один из самых эффективных способов снижения затрат — это подбор оптимального размера сервера под реальную нагрузку. Многие компании переплачивают за избыточные ресурсы.
Действия:
- Мониторинг утилизации: Собирайте метрики CPU, RAM, дискового I/O и сетевого трафика за длительный период (минимум 30-90 дней).
- Идентификация недоиспользуемых ресурсов: Ищите серверы с постоянной низкой утилизацией (например, CPU ниже 10-15%, RAM ниже 30-40%).
- Даунгрейд/Терминация: Переводите недоиспользуемые серверы на меньшие тарифы или полностью удаляйте неиспользуемые.
- Оптимизация кода: Если ресурс постоянно перегружен, вместо апгрейда сервера рассмотрите оптимизацию кода приложения.
Пример команды для проверки утилизации RAM/CPU (Linux):
# Проверка текущей утилизации CPU и RAM
top -bn1 | head -n 5 # Краткий обзор
free -h # Использование RAM
vmstat 1 10 # Мониторинг CPU, I/O, RAM в реальном времени
# Более глубокий анализ с помощью sar (System Activity Reporter)
# Установите sysstat, если его нет: sudo apt install sysstat
sar -u 1 10 # Утилизация CPU
sar -r 1 10 # Утилизация RAM
sar -b 1 10 # I/O операции
# Для просмотра истории за конкретную дату (например, 2026-03-15)
# sar -f /var/log/sysstat/sa15 # (saYY где YY - день месяца)
3. Использование моделей оплаты с обязательствами (Reserved Instances / Savings Plans)
Для предсказуемой базовой нагрузки зарезервированные мощности могут обеспечить значительную экономию.
Действия:
- Анализ стабильной нагрузки: Определите минимальное количество серверов (VPS/VMs), которые работают 24/7 в течение длительного времени.
- Выбор оптимального плана: Выберите Reserved Instances (RI) или Savings Plans (SP) на 1 или 3 года, с предоплатой или без, в зависимости от финансовой стратегии.
- Мониторинг покрытия: Регулярно проверяйте, какой процент вашей стабильной нагрузки покрывается RI/SP.
Важно: RI/SP подходят только для стабильной нагрузки. Не резервируйте то, что может быть отключено или уменьшено.
4. Автоматизация инфраструктуры и масштабирования
Автоматизация — это не только ускорение, но и значительная экономия.
Действия:
- Автоскейлинг: Настройте автоматическое добавление/удаление серверов (в облаках) или контейнеров (в Kubernetes) в зависимости от нагрузки.
- Планирование включения/выключения: Автоматически отключайте dev/test/staging среды в нерабочее время (ночью, в выходные).
- Использование Spot Instances: Для отказоустойчивых, прерываемых рабочих нагрузок (например, обработка больших данных, рендеринг, CI/CD) используйте Spot-инстансы с их огромными скидками.
- Infrastructure as Code (IaC): Используйте Terraform, Ansible, CloudFormation, Pulumi для декларативного управления инфраструктурой, что снижает ошибки и обеспечивает воспроизводимость.
Пример скрипта для остановки dev-серверов в нерабочее время (для VPS с API, например, DigitalOcean):
#!/bin/bash
# Скрипт для остановки dev-серверов DigitalOcean по тегу 'Environment:dev'
# Требуется установленный doctl и аутентификация
# doctl auth init
DO_TOKEN="YOUR_DIGITALOCEAN_API_TOKEN" # Используйте переменные окружения!
# Получаем список дроплетов с тегом 'Environment:dev'
DROPLET_IDS=$(doctl compute droplet list --format "ID,Tags" | grep "Environment:dev" | awk '{print $1}')
if [ -z "$DROPLET_IDS" ]; then
echo "Нет активных dev-дроплетов для остановки."
exit 0
fi
echo "Остановка следующих dev-дроплетов: $DROPLET_IDS"
for ID in $DROPLET_IDS; do
echo "Останавливаем дроплет ID: $ID..."
doctl compute droplet-action power-off $ID --force
if [ $? -eq 0 ]; then
echo "Дроплет $ID успешно остановлен."
else
echo "Ошибка при остановке дроплета $ID."
fi
done
echo "Процесс остановки dev-дроплетов завершен."
5. Оптимизация хранилищ и сетевого трафика
Эти компоненты часто недооцениваются, но могут составлять значительную долю счета.
Действия:
- Аудит дисков: Идентифицируйте неиспользуемые диски, устаревшие снапшоты, неактуальные образы. Удаляйте их.
- Выбор типа хранилища: Используйте S3-совместимые хранилища для статических файлов, блочные хранилища для баз данных, а холодные хранилища (Glacier, Coldline) для архивов.
- Оптимизация egress-трафика:
- Используйте CDN (Content Delivery Network) для кэширования контента ближе к пользователям, снижая нагрузку на основной сервер и уменьшая egress-трафик из облака.
- Сжимайте данные (gzip, brotli) перед отправкой.
- Минимизируйте размер изображений и видео.
- Рассмотрите размещение ресурсов в том же регионе, что и потребители, чтобы избежать межрегионального трафика.
Пример конфигурации Nginx для сжатия Gzip:
http {
# ... другие настройки ...
gzip on;
gzip_vary on;
gzip_proxied any;
gzip_comp_level 6; # Уровень сжатия: 1 (быстро) - 9 (макс. сжатие)
gzip_buffers 16 8k;
gzip_http_version 1.1;
gzip_types text/plain text/css application/json application/javascript text/xml application/xml application/xml+rss text/javascript font/truetype font/opentype application/vnd.ms-fontobject image/svg+xml;
gzip_disable "MSIE [1-6]\."; # Отключить для старых IE
server {
# ... настройки вашего сервера ...
}
}
6. Мониторинг и оповещения о затратах
Без постоянного мониторинга невозможно быстро реагировать на изменения.
Действия:
- Настройте бюджеты: Установите месячные или квартальные бюджеты для каждого проекта/отдела и настройте оповещения при превышении порогов (например, 50%, 80%, 100% бюджета).
- Отслеживайте аномалии: Используйте инструменты для выявления резких скачков затрат или необычного использования ресурсов.
- Регулярные отчеты: Предоставляйте регулярные отчеты о затратах техническим и финансовым командам.
7. Оптимизация баз данных
Базы данных часто являются одним из самых дорогих компонентов инфраструктуры.
Действия:
- Права сайзинг: Убедитесь, что тип и размер инстанса базы данных соответствуют реальной нагрузке.
- Индексирование: Оптимизируйте запросы и добавьте необходимые индексы для ускорения работы базы данных, что может снизить потребность в более мощном "железе".
- Кэширование: Используйте кэширование (Redis, Memcached) для снижения нагрузки на базу данных.
- Архивирование/Шардирование: Переносите старые данные в холодное хранилище или шардируйте базу данных для распределения нагрузки.
- Managed Databases: Используйте управляемые базы данных от облачных провайдеров, которые часто включают автоматическое масштабирование, бэкапы и патчинг, что снижает TCO (Total Cost of Ownership).
Пример SQL-запроса для поиска медленных запросов в PostgreSQL:
-- Убедитесь, что pg_stat_statements включен в postgresql.conf
-- shared_preload_libraries = 'pg_stat_statements'
-- pg_stat_statements.track = all
-- RESTART DB
SELECT
query,
calls,
total_time,
mean_time,
stddev_time,
rows,
100.0 * shared_blks_hit / (shared_blks_hit + shared_blks_read) AS hit_percent
FROM
pg_stat_statements
ORDER BY
total_time DESC
LIMIT 10;
8. Дедубликация и архивирование данных
Хранилище занимает значительную часть затрат, особенно с учетом резервных копий и снапшотов.
Действия:
- Политики жизненного цикла: Настройте автоматическое перемещение старых данных в более дешевые классы хранения (например, S3 Standard-IA, Glacier).
- Удаление устаревших бэкапов/снапшотов: Регулярно удаляйте бэкапы и снапшоты, которые вышли за рамки установленных политик хранения.
- Дедубликация: Используйте инструменты дедубликации для хранения только уникальных копий данных.
8. Типичные ошибки при оптимизации затрат
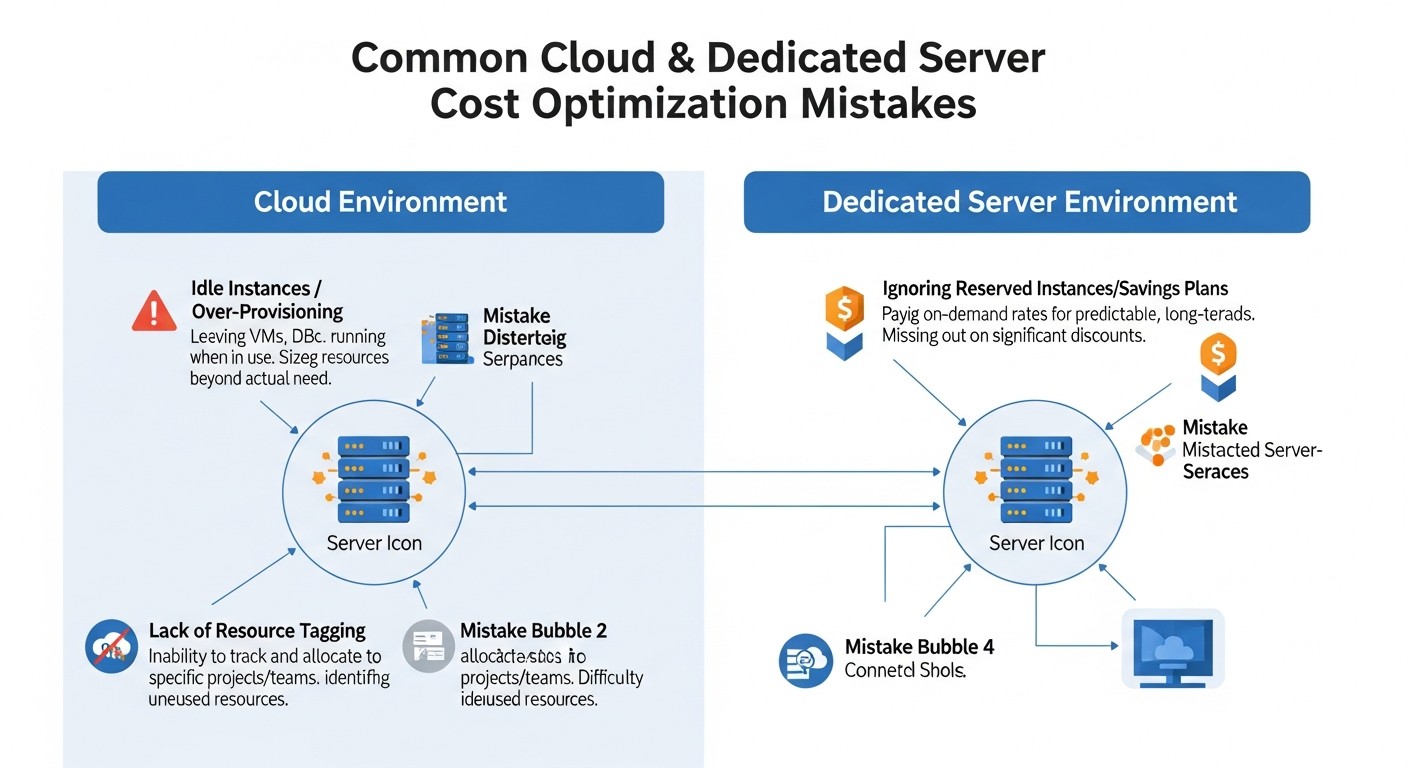
Даже опытные команды DevOps и системные администраторы могут совершать ошибки, которые приводят к переплатам. К 2026 году эти ошибки становятся еще более дорогостоящими из-за растущей сложности облачных экосистем.
1. Игнорирование неиспользуемых ресурсов (Zombie Resources)
Описание ошибки: Это, пожалуй, самая распространенная и дорогостоящая ошибка. После тестирования, экспериментов или деактивации старых сервисов часто остаются запущенные, но неиспользуемые серверы (VPS/VM), неактивные балансировщики, неиспользуемые IP-адреса, неиспользуемые диски, снапшоты, базы данных и другие ресурсы. Они продолжают генерировать счета, иногда незаметно, пока не вырастут до значительных сумм.
Как избежать:
- Внедрите строгую политику по удалению ресурсов после использования, особенно для dev/test сред.
- Автоматизируйте очистку ресурсов с помощью скриптов или IaC (Infrastructure as Code) после завершения проектов или по истечении срока жизни.
- Настройте регулярные аудиты облачных ресурсов с помощью специализированных инструментов (см. раздел 12) для выявления "зомби-ресурсов".
- Используйте тегирование (
Owner,TTL- Time To Live) для всех ресурсов, чтобы легко идентифицировать их владельцев и срок жизни.
Реальный пример последствий: Один из стартапов обнаружил, что платит $1500 в месяц за 10 EC2-инстансов, которые использовались для A/B тестирования полгода назад и были забыты. Общая переплата составила $9000, что было критично для их скромного бюджета.
2. Недостаточный Rightsizing (Переплата за избыточную мощность)
Описание ошибки: Часто инженеры выбирают "с запасом" или стандартные большие конфигурации для серверов, не анализируя реальные потребности приложения. В результате, серверы работают с утилизацией CPU 5-10% и RAM 20-30%, а компания переплачивает за неиспользуемую мощность.
Как избежать:
- Внедрите систему мониторинга, которая собирает метрики утилизации (CPU, RAM, I/O, Network) за длительный период (минимум 30-90 дней).
- Регулярно анализируйте эти метрики и используйте рекомендации провайдера (например, AWS Compute Optimizer) или сторонние инструменты для определения оптимального размера инстанса.
- Не бойтесь уменьшать размер сервера (даунгрейд), если это позволяет нагрузка. Легче увеличить, если потребуется.
- Рассмотрите использование автоскейлинга, который автоматически подстраивает количество и размер инстансов под текущую нагрузку.
Реальный пример последствий: SaaS-проект размещал свой backend на 4 VPS по $120 каждый, хотя мониторинг показывал, что 3 из них постоянно загружены менее чем на 15% CPU. После даунгрейда до VPS по $60 каждый, ежемесячная экономия составила $240, или $2880 в год, без потери производительности.
3. Игнорирование сетевых затрат (Egress-трафик)
Описание ошибки: Многие сосредотачиваются на стоимости CPU/RAM/Storage, забывая, что исходящий сетевой трафик (egress) из облака может быть очень дорогим, особенно при больших объемах данных или межрегиональных передачах. К 2026 году, с ростом объемов данных и мультимедиа, эта проблема только усугубляется.
Как избежать:
- Используйте CDN (Content Delivery Network) для доставки статического контента (изображения, видео, JS/CSS) пользователям, так как CDN-трафик часто дешевле, чем прямой egress из облака.
- Сжимайте данные (gzip, brotli) перед передачей по сети.
- Размещайте ресурсы, которые часто обмениваются данными, в одной зоне доступности или регионе, чтобы минимизировать межзональный/межрегиональный трафик.
- Оптимизируйте запросы к API, чтобы не передавать избыточные данные.
- Кэшируйте данные на стороне клиента или в промежуточных сервисах.
Реальный пример последствий: Одна медиа-платформа столкнулась со счетом за egress-трафик AWS CloudFront, который превышал стоимость всех их EC2 инстансов. Причина: неоптимизированные изображения и видео, которые передавались без должного сжатия и кэширования. После оптимизации и внедрения CDN, затраты на трафик сократились на 60%.
4. Отсутствие автоматизации и планирования
Описание ошибки: Ручное управление инфраструктурой не только отнимает время, но и приводит к неэффективному использованию ресурсов. Забытые тестовые среды, запущенные по выходным, или ручные масштабирования, которые не успевают за нагрузкой, — все это ведет к переплатам.
Как избежать:
- Внедрите Infrastructure as Code (IaC) для декларативного управления ресурсами.
- Настройте автоскейлинг для динамического изменения ресурсов в зависимости от нагрузки.
- Используйте планировщики (cronjobs, облачные функции) для автоматического включения/выключения dev/test сред в нерабочее время.
- Автоматизируйте удаление устаревших снапшотов и бэкапов.
Реальный пример последствий: Команда разработчиков вручную запускала и останавливала тестовые серверы. В результате, каждую пятницу забывали выключить 3 сервера, которые работали все выходные. За год это привело к переплате в $3600 за часы простоя, которые можно было избежать с помощью простого cron-скрипта.
5. Неэффективное использование зарезервированных мощностей (Reserved Instances / Savings Plans)
Описание ошибки: Либо компания вообще не использует RI/SP, теряя возможность сэкономить до 70% на базовой нагрузке, либо покупает их без должного анализа, резервируя слишком много или не те типы инстансов, которые потом не используются.
Как избежать:
- Проводите тщательный анализ истории использования ресурсов, чтобы определить стабильную, предсказуемую базовую нагрузку, которая работает 24/7.
- Используйте рекомендации облачных провайдеров (например, AWS Cost Explorer RI/SP recommendations) для определения оптимального количества и типов RI/SP.
- Мониторьте утилизацию ваших RI/SP, чтобы убедиться, что они используются эффективно. При необходимости продавайте неиспользуемые RI на маркетплейсах (если доступно).
- Помните, что RI/SP — это обязательство. Не покупайте их для временных или экспериментальных рабочих нагрузок.
Реальный пример последствий: Крупная компания купила Reserved Instances на $50 000 для своих EC2-инстансов, но из-за внезапной реструктуризации проекта и перехода на Kubernetes, 40% этих инстансов перестали использоваться. RI остались неоплаченными, так как не было возможности их перенести или продать, что привело к значительным финансовым потерям.
6. Отсутствие FinOps-культуры и межфункционального сотрудничества
Описание ошибки: Когда инженеры не понимают финансовые последствия своих решений, а финансовые отделы не понимают техническую специфику, возникает разрыв. Инженеры могут выбирать самые дорогие, но удобные решения, а финансовые менеджеры могут требовать сокращения расходов без понимания влияния на производительность или стабильность.
Как избежать:
- Внедрите FinOps как культуру, а не как инструмент. Создайте межфункциональную команду (инженеры, финансы, продукт).
- Обучайте инженеров финансовой грамотности в контексте облака.
- Предоставляйте инженерам доступ к отчетам о затратах (по их проектам/сервисам) и сделайте их ответственными за бюджет.
- Установите KPI, которые включают как технические метрики (uptime, производительность), так и финансовые (Cost per Transaction, Cost per User).
- Регулярно проводите встречи, где обсуждаются как технические, так и финансовые аспекты использования облака.
Реальный пример последствий: В одной компании разработчики постоянно выбирали самые мощные инстансы для своих баз данных, потому что "так быстрее". Финансовый отдел, не понимая технической стороны, просто оплачивал счета. В итоге, затраты на базы данных составляли 40% от всего облачного бюджета, хотя большая часть этой мощности не использовалась, а оптимизация запросов могла бы дать гораздо больший эффект при меньших затратах.
9. Чеклист для практического применения FinOps
Этот чеклист поможет вам систематически подходить к оптимизации затрат на облачные VPS и выделенные серверы, следуя принципам FinOps. Проходите по нему регулярно, например, раз в месяц или квартал.
Фаза 1: Информирование и Видимость (Inform)
- Внедрена ли политика тегирования для всех ресурсов?
- Все ли ресурсы имеют обязательные теги (Project, Environment, Owner, CostCenter)?
- Автоматизировано ли тегирование через IaC?
- Проводится ли регулярный аудит соблюдения политики тегирования?
- Настроены ли инструменты мониторинга затрат?
- Используются ли встроенные средства облачных провайдеров (Cost Explorer, Billing Reports)?
- Интегрированы ли сторонние FinOps-платформы (CloudHealth, Apptio Cloudability, CloudZero)?
- Доступны ли детализированные отчеты о затратах по проектам, командам, средам?
- Настроены ли бюджеты и оповещения?
- Установлены ли месячные/квартальные бюджеты для каждого проекта/отдела?
- Настроены ли оповещения при превышении порогов (50%, 80%, 100%)?
- Получают ли ответственные лица эти оповещения?
- Есть ли централизованное хранилище метрик утилизации?
- Собираются ли метрики CPU, RAM, I/O, Network за последние 30-90 дней для всех серверов?
- Доступны ли эти метрики для анализа и построения отчетов?
Фаза 2: Оптимизация (Optimize)
- Проведен ли аудит неиспользуемых ресурсов ("зомби-ресурсов")?
- Идентифицированы ли неиспользуемые VPS/VM, диски, IP, балансировщики, снапшоты?
- Разработан ли план по их удалению или деактивации?
- Автоматизирована ли очистка временных ресурсов?
- Выполняется ли Rightsizing для всех серверов?
- Проанализированы ли метрики утилизации для выявления недоиспользуемых/переиспользуемых серверов?
- Применяются ли рекомендации по уменьшению/увеличению размера инстансов?
- Используются ли рекомендации по переходу на более новые, экономичные типы инстансов (например, Graviton)?
- Оптимизированы ли хранилища данных?
- Перемещены ли редко используемые данные в более дешевые классы хранения (например, Glacier, Coldline)?
- Удалены ли устаревшие бэкапы/снапшоты в соответствии с политиками?
- Используются ли оптимальные типы дисков (GP3 вместо GP2, HDD вместо SSD для архивов)?
- Применяются ли модели оплаты с обязательствами (RI/Savings Plans)?
- Определена ли стабильная базовая нагрузка, которую можно покрыть RI/SP?
- Используются ли рекомендации провайдера для покупки RI/SP?
- Отслеживается ли утилизация RI/SP?
- Внедрена ли автоматизация масштабирования и управления?
- Настроен ли автоскейлинг для динамических рабочих нагрузок?
- Используются ли Spot Instances для отказоустойчивых задач?
- Настроены ли автоматические расписания включения/выключения для dev/test сред?
- Используется ли IaC (Terraform, Ansible) для управления инфраструктурой?
- Оптимизирован ли сетевой трафик (особенно egress)?
- Используется ли CDN для статического контента?
- Применяется ли сжатие данных (gzip, brotli) для трафика?
- Минимизируется ли межрегиональный/межзональный трафик?
- Оптимизированы ли базы данных?
- Проведен ли аудит медленных запросов и добавлены ли необходимые индексы?
- Используется ли кэширование (Redis, Memcached) для снижения нагрузки на БД?
- Рассмотрено ли использование управляемых баз данных для снижения TCO?
Фаза 3: Эксплуатация и Сотрудничество (Operate)
- Внедрена ли FinOps-культура в команде?
- Обучены ли инженеры основам FinOps и финансовой грамотности?
- Есть ли у инженеров доступ к отчетам о затратах по их сервисам/проектам?
- Установлены ли KPI, включающие метрики стоимости?
- Проводятся ли регулярные встречи FinOps?
- Участвуют ли в них представители инженерии, финансов и продукта?
- Обсуждаются ли текущие затраты, планы по оптимизации и новые проекты?
- Есть ли план реагирования на аномалии в затратах?
- Определены ли процедуры расследования и устранения причин резких скачков расходов?
- Проводится ли периодический пересмотр стратегии провайдера?
- Оцениваются ли новые предложения от других облачных провайдеров или варианты с выделенными серверами?
- Анализируется ли возможность миграции для получения лучших условий?
10. Расчет стоимости / Экономика облачных и выделенных серверов
Понимание экономики облачных и выделенных серверов — это основа FinOps. Затраты не ограничиваются только ежемесячной платой за CPU и RAM; существуют скрытые расходы и факторы, которые могут значительно повлиять на итоговый счет. К 2026 году эти факторы становятся еще более комплексными.
Основные компоненты затрат
- Вычислительные ресурсы (Compute): CPU, RAM. Основная статья расходов, но часто не единственная.
- Хранилище (Storage): Диски (SSD, NVMe, HDD), объектные хранилища (S3-совместимые), файловые системы. Зависят от объема, типа (производительность) и количества I/O операций.
- Сетевой трафик (Network): Входящий (ingress) обычно бесплатен, исходящий (egress) — платный и может быть очень дорогим, особенно межрегиональный. Также оплачиваются IP-адреса, балансировщики, VPN-шлюзы.
- Базы данных: Управляемые базы данных (RDS, Cloud SQL) включают стоимость инстанса, хранилища, I/O и резервного копирования.
- Дополнительные сервисы: CDN, очереди сообщений, бессерверные функции, мониторинг, логирование, безопасность (WAF, DDoS-защита).
- Лицензии: Стоимость лицензий на ОС (Windows Server), базы данных (MS SQL Server), панели управления (cPanel, Plesk) и другое ПО.
- Операционные расходы (OpEx): Затраты на персонал (DevOps, сисадмины), их обучение, время, потраченное на управление и отладку.
Как оптимизировать затраты
Оптимизация затрат — это не только сокращение, но и получение максимальной ценности за каждый потраченный рубль/доллар. Это достигается за счет:
- Rightsizing: Постоянный подбор оптимального размера ресурсов.
- Автоматизация: Использование автоскейлинга, планирования включения/выключения.
- Модели оплаты: Применение Reserved Instances, Savings Plans, Spot Instances.
- Оптимизация кода: Более эффективный код требует меньше ресурсов.
- Архитектурные решения: Переход на микросервисы, контейнеры, Serverless для лучшей утилизации и масштабируемости.
- Управление хранилищем: Использование многоуровневого хранения, удаление ненужных данных.
- Оптимизация сети: CDN, сжатие данных, минимизация межрегионального трафика.
- Мониторинг и отчетность: Постоянный анализ затрат и выявление аномалий.
Скрытые расходы
К 2026 году, несмотря на стремление провайдеров к прозрачности, некоторые расходы остаются "скрытыми" или неочевидными:
- Неактивные ресурсы: Неиспользуемые IP-адреса, балансировщики, диски, которые продолжают тарифицироваться.
- Межзональный/межрегиональный трафик: Передача данных между разными зонами доступности или регионами внутри одного провайдера.
- I/O операции хранилища: В некоторых моделях оплаты, помимо объема диска, тарифицируются операции чтения/записи.
- Затраты на логирование и мониторинг: Сбор и хранение логов, метрик могут быть дорогими при больших объемах.
- Затраты на поддержку: Премиум-поддержка от облачных провайдеров может быть дорогой, но часто оправдана для критически важных систем.
- Затраты на миграцию: Перенос данных и приложений между провайдерами или внутри облака может повлечь затраты на трафик и трудозатраты.
- Затраты на обучение персонала: Необходимость обучать команду новым технологиям и FinOps-практикам.
Примеры расчетов для разных сценариев (2026 год, гипотетические цены)
Для наглядности рассмотрим три типовых сценария и проведем упрощенный расчет стоимости, демонстрирующий влияние FinOps-практик.
Сценарий 1: Малый SaaS-проект (MVP на старте)
Описание: Небольшое веб-приложение с базовым API и простой базой данных, 1000 активных пользователей, пиковая нагрузка 50 RPS. Требуется высокая гибкость и низкие стартовые затраты.
| Ресурс | Конфигурация | Ежемесячная стоимость (без FinOps) | Ежемесячная стоимость (с FinOps) | Комментарий |
|---|---|---|---|---|
| Backend/API | 1 x Dedicated CPU VPS (4vCPU, 8GB RAM, 160GB NVMe) | 80 $ | 40 $ | Rightsizing: 1 x Shared CPU VPS (2vCPU, 4GB RAM, 80GB SSD) на старте. |
| База данных | 1 x Managed PostgreSQL (4vCPU, 8GB RAM, 100GB SSD) | 120 $ | 80 $ | Rightsizing: Меньший инстанс БД (2vCPU, 4GB RAM). |
| CDN | Нет | 0 $ (но дорогой egress) | 15 $ | Внедрение CDN для статики (500GB трафика). |
| Трафик (Egress) | 1 TB | 80 $ | 20 $ | Снижение за счет CDN и сжатия. |
| Бэкапы | Ручные/Базовые | 10 $ | 10 $ | Автоматические снапшоты/бэкапы. |
| Итого: | 290 $ | 165 $ | Экономия: 43% |
Сценарий 2: Растущий e-commerce проект
Описание: Интернет-магазин с переменной нагрузкой, пики в праздники и распродажи. 10 000 активных пользователей, до 500 RPS. Требуется высокая доступность и масштабируемость.
| Ресурс | Конфигурация | Ежемесячная стоимость (без FinOps) | Ежемесячная стоимость (с FinOps) | Комментарий | |
|---|---|---|---|---|---|
| Backend (EC2/Compute Engine) | 4 x m5.large (2vCPU, 8GB RAM) On-Demand | 4 x 70 $ = 280 $ | 2 x m5.large RI + 2 x m5.large On-Demand с автоскейлингом | 2 x 40 $ (RI) + 2 x 70 $ (On-Demand) = 220 $ | RI для базовой нагрузки, автоскейлинг для пиков, экономия 21% |
| База данных (RDS/Cloud SQL) | 1 x db.m5.xlarge (4vCPU, 16GB RAM) On-Demand | 350 $ | 1 x db.m5.large (2vCPU, 8GB RAM) RI + Read Replica | 200 $ (RI) + 100 $ (Replica) = 300 $ | Rightsizing + RI + Read Replica для масштабирования чтения, экономия 14% |
| Кэш (Redis) | 1 x Elasticache m5.large (8GB RAM) | 80 $ | 1 x Elasticache m5.medium (4GB RAM) | 40 $ | Rightsizing, экономия 50% |
| CDN (CloudFront/Cloud CDN) | 10 TB трафика | 1000 $ | 600 $ | Оптимизация изображений, видео, сжатие, кэширование, экономия 40% | |
| S3/Cloud Storage | 5 TB Standard | 120 $ | 60 $ | Политики жизненного цикла (перенос старых данных в IA), экономия 50% | |
| Прочее (LB, IP, Monitoring) | 50 $ | 30 $ | Удаление неиспользуемых IP, оптимизация логов, экономия 40% | ||
| Итого: | 1880 $ | 1250 $ | Экономия: 33.6% |
Сценарий 3: Высоконагруженный игровой сервер (Dedicated Server)
Описание: Игровой сервер для онлайн-игры, требующий максимальной производительности CPU и низкой задержки. 5000 одновременных игроков. Стабильная, высокая нагрузка.
| Ресурс | Конфигурация | Ежемесячная стоимость (без FinOps) | Ежемесячная стоимость (с FinOps) | Комментарий |
|---|---|---|---|---|
| Игровой сервер | 1 x Dedicated Server (16 Cores, 128GB RAM, 2x1TB NVMe) | 450 $ | 450 $ | Выделенный сервер часто оптимален для такой нагрузки, здесь FinOps фокусируется на утилизации. |
| База данных | На том же сервере | 0 $ (но конкуренция за ресурсы) | 80 $ | Вынесение БД на отдельный VPS (4vCPU, 8GB RAM) для изоляции и стабильности. |
| CDN/Защита от DDoS | Базовый | 30 $ | 70 $ | Усиленная DDoS-защита и CDN для загрузки игровых ресурсов. Инвестиции в стабильность. |
| Мониторинг/Логирование | Базовый | 10 $ | 30 $ | Расширенный мониторинг (Prometheus/Grafana) и централизованное логирование (ELK). Инвестиции в операционную эффективность. |
| Трафик | 20 TB включено | 0 $ | 0 $ | Обычно включено в тариф выделенного сервера. |
| Лицензии (ОС/Панель) | Windows Server | 25 $ | 0 $ | Переход на Linux, экономия на лицензиях. |
| Итого: | 515 $ | 630 $ | Увеличение на 22% |
Вывод по сценарию 3: В этом случае FinOps не всегда означает прямое сокращение расходов. Иногда это означает оптимизацию ценности, когда небольшое увеличение затрат на правильные сервисы (отдельная БД, усиленная безопасность, мониторинг) приводит к значительному улучшению стабильности, производительности и снижению операционных рисков, что в итоге приносит больше прибыли или предотвращает значительно большие потери.
11. Кейсы и примеры
Реальные примеры всегда лучше демонстрируют эффективность FinOps. К 2026 году компании продолжают сталкиваться со схожими вызовами, но решения становятся более изощренными благодаря развитию инструментов и методологий.
Кейс 1: SaaS-платформа для управления проектами
Проблема: Компания "TaskMaster" (средний SaaS, 50 000 активных пользователей) столкнулась с постоянно растущими облачными счетами (AWS), которые превышали $20 000 в месяц. Основные затраты приходились на EC2-инстансы, RDS PostgreSQL и исходящий трафик. Команда DevOps была загружена новыми фичами, и времени на глубокую оптимизацию не хватало. Финансовый отдел требовал сокращений.
Решение FinOps:
- Видимость и тегирование: В первую очередь, команда внедрила строгую политику тегирования для всех ресурсов:
Project(Backend, Frontend, Analytics),Environment(prod, staging, dev),Owner(команда разработки). Это позволило точно определить, какие команды и сервисы генерируют основные затраты. - Rightsizing EC2: С помощью AWS Cost Explorer и Compute Optimizer был проведен аудит всех EC2-инстансов. Выяснилось, что около 30% инстансов были переразмерены (CPU utilization < 15%). 10 инстансов m5.xlarge были уменьшены до m5.large, а 5 тестовых инстансов m5.large, работающих 24/7, были настроены на автоматическое выключение в нерабочее время.
- Оптимизация RDS: Инстанс RDS PostgreSQL был также переразмерен с db.r5.2xlarge до db.r5.xlarge, так как пиковая нагрузка не достигала полной утилизации текущего инстанса. Были добавлены индексы для медленных запросов, что снизило нагрузку на CPU БД.
- Reserved Instances/Savings Plans: После анализа стабильной базовой нагрузки (около 70% от всех EC2 и RDS инстансов), компания приобрела Savings Plans на 1 год, что дало скидку до 30% на эти ресурсы.
- Оптимизация egress-трафика: Заметили высокий трафик из S3 в интернет. Оказалось, что пользователи часто загружали большие файлы. Была внедрена интеграция с CloudFront для всех статических файлов и загружаемого контента, а также настроено сжатие Gzip для всех HTTP-ответов.
Результаты:
- Ежемесячные затраты сократились с $20 000 до $13 500 (экономия 32.5%).
- Улучшилась прозрачность затрат, каждая команда теперь видела свой "бюджет" и была мотивирована к оптимизации.
- Производительность приложения не пострадала, а в некоторых местах даже улучшилась за счет оптимизации БД и CDN.
- FinOps стал частью регулярных процессов, и команда DevOps теперь тратит 2-3 часа в неделю на мониторинг и оптимизацию.
Кейс 2: Разработка нового ИИ-продукта на выделенных серверах
Проблема: Стартап "VisionAI" разрабатывал новый продукт для обработки изображений с использованием машинного обучения. Для обучения моделей требовались мощные серверы с GPU. Они арендовали 3 выделенных сервера у Hetzner с NVIDIA A100 GPU, каждый стоимостью около $1500 в месяц. Проблема была в том, что обучение моделей не шло 24/7, но серверы работали постоянно, а также возникали сложности с управлением зависимостями и масштабированием для разных этапов разработки.
Решение FinOps:
- Гибридный подход: Решили не отказываться от выделенных серверов (из-за высокой стоимости GPU в облаке), но дополнить их облачными решениями для гибкости.
- Оптимизация использования GPU-серверов:
- Вместо постоянной работы, GPU-серверы были настроены на включение только по требованию (через API Hetzner) или по расписанию для ночных тренировок.
- Внедрена система очередей (Kubernetes с GPU-планировщиком или просто Celery/RQ), чтобы максимально загрузить GPU-серверы, когда они активны.
- Использовали Docker-контейнеры для изоляции сред обучения, что позволило запускать разные эксперименты на одном сервере без конфликтов.
- Перенос не-GPU задач в облако:
- Препроцессинг данных, хранение датасетов, хостинг API для инференса (после обучения) были перенесены на AWS.
- Для препроцессинга использовались EC2 Spot Instances (для batch-задач) и AWS Lambda (для небольших трансформаций).
- Для хранения датасетов использовался S3 с политиками жизненного цикла (перенос старых данных в Glacier).
- API для инференса развернули на EKS с автоскейлингом, используя более дешевые инстансы без GPU.
- Мониторинг и метрики: Настроили мониторинг утилизации GPU на выделенных серверах и метрики стоимости в AWS, чтобы видеть, насколько эффективно используются ресурсы.
Результаты:
- Затраты на GPU-серверы сократились на 40% (с $4500 до $2700 в месяц) за счет их включения только по требованию и максимальной утилизации во время работы.
- Общие затраты на инфраструктуру стали более гибкими и предсказуемыми.
- Значительно ускорился процесс разработки: инженеры могли быстро запускать эксперименты на Spot Instances или Serverless без ожидания свободных GPU-серверов.
- Улучшилась масштабируемость инференс-сервиса, который теперь мог автоматически обрабатывать пиковые нагрузки.
- Общая ценность от инфраструктуры значительно возросла, при этом компания получила экономию на самых дорогих компонентах.
Кейс 3: Миграция устаревшей ERP-системы
Проблема: Крупная производственная компания "GlobalProd" использовала устаревшую ERP-систему на базе MS SQL Server, работающую на физическом выделенном сервере в локальном дата-центре. Сервер был куплен 5 лет назад, морально устарел, его обслуживание обходилось дорого, а масштабируемость отсутствовала. Ежемесячные OpEx (электричество, охлаждение, администрирование, лицензии) составляли около $1000, не считая CAPEX на покупку нового сервера.
Решение FinOps:
- Оценка TCO (Total Cost of Ownership): Провели детальный анализ всех затрат, включая CAPEX на обновление оборудования, OpEx на обслуживание, лицензии, а также риски простоя. Выяснилось, что текущий TCO был значительно выше, чем казалось.
- Миграция в облако: Было принято решение о миграции ERP-системы в облако, чтобы воспользоваться преимуществами управляемых сервисов и гибкости. Выбрали Azure, так как уже были лицензии MS SQL Server и экспертиза по .NET.
- Выбор оптимальных сервисов:
- Для MS SQL Server выбрали Azure SQL Database (Managed Instance) — это позволило использовать существующие лицензии (Azure Hybrid Benefit) и снять с себя бремя администрирования БД.
- Для серверной части ERP (API, веб-интерфейс) использовали Azure Virtual Machines.
- Для файлового хранилища (отчеты, документы) — Azure Files.
- Оптимизация затрат в облаке:
- После миграции и мониторинга, Azure Virtual Machines были переразмерены до оптимальных конфигураций.
- Приобрели Azure Reserved VM Instances на 3 года для базовой нагрузки, что дало скидку до 72%.
- Настроили автоматическое масштабирование для веб-серверов во время пиков (конец месяца, отчетный период).
- Внедрили политики жизненного цикла для Azure Files, перемещая старые документы в холодное хранилище.
Результаты:
- Снижение OpEx с $1000 до $450 в месяц (экономия 55%), включая лицензии на SQL Server (за счет Azure Hybrid Benefit) и Managed Instance.
- Полное отсутствие CAPEX на обновление оборудования.
- Значительное повышение надежности и доступности системы (SLA от Azure).
- Снижение нагрузки на IT-отдел, который теперь мог сосредоточиться на развитии, а не на обслуживании устаревшего "железа".
- ERP-система стала более гибкой и способной к масштабированию в соответствии с потребностями бизнеса.
Эти кейсы демонстрируют, что FinOps — это не универсальное решение "один размер для всех", а адаптивный подход, который требует глубокого понимания как технических, так и финансовых аспектов, а также готовности к изменению архитектуры и процессов.
12. Инструменты и ресурсы
Эффективное применение FinOps невозможно без правильных инструментов. К 2026 году экосистема FinOps-инструментов стала еще более зрелой, предлагая решения для каждого аспекта управления облачными затратами.
Инструменты для работы с FinOps и анализом затрат
- Облачные провайдеры (Native Tools):
- AWS Cost Explorer & AWS Budgets: Позволяют анализировать расходы, получать рекомендации по RI/SP, создавать бюджеты и оповещения.
- Google Cloud Billing & Cost Management: Аналогичные инструменты для GCP, включая отчеты по затратам, бюджеты и экспорт данных в BigQuery для глубокого анализа.
- Azure Cost Management + Billing: Предоставляет аналитику затрат, возможность создания бюджетов, экспорт данных, рекомендации по оптимизации.
- Яндекс.Облако Cost & Usage Reports: Детализированные отчеты по потреблению и затратам.
- Сторонние FinOps-платформы:
- CloudHealth by VMware: Комплексная платформа для управления облачными расходами, безопасностью, производительностью и соответствием нормативам в мультиоблачных средах.
- Apptio Cloudability: Специализируется на финансовом управлении облаком, предоставляет глубокую аналитику, оптимизацию затрат, бюджетирование и прогнозирование.
- CloudZero: Фокусируется на связывании затрат с бизнес-метриками (Cost per Customer, Cost per Feature), помогая инженерам понимать финансовое влияние их решений.
- Flexera (RightScale): Управление облаком и FinOps для гибридных и мультиоблачных сред.
- Kubecost: Инструмент для мониторинга и оптимизации затрат в Kubernetes, позволяет распределять затраты на поды, namespaces, команды.
- Инструменты для мониторинга утилизации и производительности:
- Prometheus & Grafana: Открытые решения для сбора метрик и визуализации данных. Позволяют отслеживать утилизацию CPU, RAM, I/O и других ресурсов.
- Datadog, New Relic, Dynatrace: Коммерческие APM (Application Performance Monitoring) и инфраструктурные мониторинговые платформы, предоставляющие детальные метрики и возможности для анализа производительности и связанных с ней затрат.
- Zabbix / Icinga: Традиционные системы мониторинга для VPS и выделенных серверов.
- Инструменты Infrastructure as Code (IaC):
- Terraform: Декларативное управление инфраструктурой в любом облаке или на выделенных серверах. Помогает автоматизировать развертывание и тегирование, снижая ручные ошибки.
- Ansible: Инструмент для автоматизации настройки и развертывания ПО на серверах.
- CloudFormation (AWS), Deployment Manager (GCP), ARM Templates (Azure): Нативные IaC-инструменты облачных провайдеров.
- Инструменты для автоматизации и скриптинга:
- Python Boto3 (AWS), Google Cloud Client Libraries, Azure SDK: Библиотеки для взаимодействия с облачными API, позволяют создавать кастомные скрипты для автоматизации задач FinOps (например, остановка инстансов, удаление снапшотов).
- Bash / PowerShell: Для простых скриптов автоматизации на VPS и выделенных серверах.
Полезные ссылки и документация
- FinOps Foundation: finops.org - Официальный сайт FinOps Foundation, содержит гайды, лучшие практики, сертификации.
- AWS Well-Architected Framework (Cost Optimization Pillar): aws.amazon.com/architecture/well-architected/cost-optimization/ - Подробные рекомендации по оптимизации затрат в AWS. Аналогичные фреймворки есть у GCP и Azure.
- Блоги и статьи провайдеров: Регулярно читайте блоги AWS, Google Cloud, Azure, DigitalOcean, Hetzner, так как они публикуют новые функции, скидки и лучшие практики.
- Stack Overflow, Reddit (r/devops, r/cloud, r/finops): Отличное место для поиска решений конкретных проблем и обмена опытом с сообществом.
- Документация по конкретным инструментам: Всегда обращайтесь к официальной документации Terraform, Kubernetes, Prometheus и других инструментов для получения актуальной информации.
13. Troubleshooting (решение проблем)
Даже при самых продуманных FinOps-практиках могут возникать неожиданные проблемы с затратами. Умение быстро диагностировать и решать их — ключевой навык.
Типичные проблемы и их решения
Проблема 1: Внезапный резкий рост облачного счета
Возможные причины:
- Забытые ресурсы: Запущенные тестовые инстансы, неиспользуемые базы данных, старые балансировщики.
- Неконтролируемый автоскейлинг: Ошибочная конфигурация автоскейлинга, приводящая к запуску слишком большого количества инстансов.
- Скачок трафика: DDoS-атака, вирусный контент, неоптимизированный запрос, массовая загрузка больших файлов.
- Изменения в ценовой политике провайдера: Редкое, но возможное.
- Ошибки в приложении: Бесконечные циклы, утечки памяти, неэффективные запросы к БД, генерирующие избыточную нагрузку и, как следствие, потребление ресурсов.
Решение:
- Проверьте оповещения: Первым делом, проверьте, сработали ли бюджетные оповещения.
- Анализ отчетов о затратах: Используйте AWS Cost Explorer, GCP Billing Reports или Azure Cost Management, чтобы определить, какая категория сервисов (Compute, Network, Storage, Database) или какой проект/сервис стал причиной скачка.
- Аудит ресурсов: Проверьте недавно созданные или измененные ресурсы. Ищите "зомби-ресурсы".
- Мониторинг трафика: Если проблема в трафике, проверьте логи веб-серверов/балансировщиков/CDN на предмет аномальной активности.
- Мониторинг производительности приложения: Используйте APM-инструменты (Datadog, New Relic) или логи, чтобы выявить ошибки в приложении, которые могут вызывать избыточную нагрузку.
- Откат изменений: Если рост связан с недавним развертыванием, рассмотрите откат к предыдущей версии.
Проблема 2: Постоянно высокий счет при низкой утилизации ресурсов
Возможные причины:
- Избыточный Rightsizing: Серверы слишком большие для текущей нагрузки.
- Неиспользуемые Reserved Instances/Savings Plans: Куплены, но не используются или используются неэффективно.
- Дорогие Managed-сервисы: Использование дорогих конфигураций управляемых сервисов (базы данных, очереди) при низкой нагрузке.
- Высокие лицензионные расходы: Использование платных ОС или ПО.
- Скрытые расходы: Неиспользуемые IP, балансировщики, снапшоты, межзональный трафик.
Решение:
- Детальный Rightsizing: Проведите глубокий анализ метрик утилизации (CPU, RAM, I/O) за 30-90 дней и переразмерьте все инстансы и управляемые сервисы.
- Аудит RI/SP: Проверьте утилизацию ваших Reserved Instances или Savings Plans. Если они недоиспользуются, рассмотрите возможность их продажи (если есть маркетплейс) или корректировки будущих покупок.
- Оптимизация лицензий: Рассмотрите переход на Open-Source альтернативы или использование Linux вместо Windows.
- Поиск скрытых расходов: Проведите аудит всех ресурсов через консоль провайдера или с помощью скриптов, ищите неиспользуемые компоненты.
- Внедрение автоскейлинга: Если нагрузка переменная, настройте автоскейлинг для динамической адаптации.
Проблема 3: Долгий "холодный старт" Serverless-функций
Возможные причины:
- Большой размер пакета: Чем больше код функции и ее зависимости, тем дольше инициализация.
- Сложная логика инициализации: Долгая загрузка библиотек, подключение к БД, инициализация внешних сервисов.
- Редкие вызовы: Функция редко вызывается, и провайдер "выгружает" ее из памяти.
Решение:
- Оптимизация кода: Уменьшите размер пакета функции, удалите неиспользуемые зависимости.
- "Прогрев" функций: Используйте специальные сервисы или настройте регулярные "холостые" вызовы функции, чтобы поддерживать ее в "горячем" состоянии.
- Увеличение памяти: В некоторых случаях увеличение выделенной памяти для функции может ускорить ее инициализацию.
- Использование Provisioned Concurrency: Настройте заранее выделенные экземпляры функции, которые всегда готовы к работе (платно, но устраняет холодные старты).
Диагностические команды и подходы
Для диагностики проблем на VPS и выделенных серверах:
- Мониторинг системы:
# Общая информация о системе и процессах top # Интерактивный монитор процессов htop # Улучшенный top free -h # Использование RAM df -h # Использование дискового пространства iostat -x 1 # Дисковый I/O (требует пакета sysstat) netstat -tunap # Сетевые соединения - Анализ логов:
# Просмотр системных логов journalctl -xe # Для systemd-систем tail -f /var/log/syslog # Общие системные логи tail -f /var/log/nginx/access.log # Логи веб-сервера tail -f /var/log/mysql/error.log # Логи базы данных - Проверка сетевых проблем:
ping google.com # Проверка доступности внешних ресурсов traceroute google.com # Отслеживание маршрута пакетов iperf3 -c <server_ip> # Измерение пропускной способности сети - Проверка ресурсов в облачной консоли: Регулярно просматривайте консоль управления провайдера. Ищите:
- Запущенные инстансы, которые должны быть остановлены.
- Неприкрепленные диски или IP-адреса.
- Настройки автоскейлинга.
- Детализацию биллинга по каждому сервису.
Когда обращаться в поддержку
Не стесняйтесь обращаться в поддержку провайдера в следующих случаях:
- Необъяснимые начисления: Если вы не можете найти причину роста счета, а все ваши ресурсы учтены и оптимизированы.
- Проблемы с инфраструктурой провайдера: Если подозреваете, что проблема не в вашем приложении, а в сети, оборудовании или сервисах провайдера (например, сетевые задержки, сбои в дата-центре).
- Технические проблемы с управляемыми сервисами: Если управляемая база данных или другой PaaS-сервис работает некорректно.
- Вопросы по ценообразованию: Если у вас есть специфические вопросы по тарифным планам, скидкам или моделям оплаты.
- DDoS-атаки: Если вы столкнулись с масштабной DDoS-атакой, поддержка провайдера может предложить специализированные решения.
При обращении в поддержку всегда предоставляйте максимально полную информацию: ID ресурсов, временные рамки проблемы, скриншоты, логи и шаги, которые вы уже предприняли для диагностики.
14. FAQ (минимум 10 вопросов)
Что такое FinOps и чем он отличается от простого сокращения расходов?
FinOps — это операционная модель и культурная практика, которая объединяет финансовые, операционные и инженерные команды для достижения максимальной ценности бизнеса от облачных инвестиций. В отличие от простого сокращения расходов, FinOps — это непрерывный процесс, направленный на повышение прозрачности, подотчетности и эффективности использования облачных ресурсов. Он фокусируется не только на снижении затрат, но и на оптимизации ценности, которую бизнес получает за каждый потраченный доллар, обеспечивая при этом необходимую производительность и масштабируемость.
Может ли FinOps быть полезен для небольшого стартапа с ограниченным бюджетом?
Да, FinOps крайне полезен для стартапов. Для них каждая копейка на счету, и неэффективное использование облака может быстро привести к исчерпанию бюджета. FinOps помогает стартапам с самого начала выстроить правильную культуру управления затратами, избежать переплат за неиспользуемые ресурсы, выбрать оптимальные тарифы и масштабировать инфраструктуру с умом, что критически важно для выживания и роста.
Какие основные метрики следует отслеживать для FinOps?
Основные метрики для FinOps включают: общие облачные расходы, расходы по проектам/командам/средам, утилизация CPU, RAM, дискового I/O, сетевого трафика (особенно egress), покрытие Reserved Instances/Savings Plans, а также бизнес-метрики, такие как Cost per Customer (CPC), Cost per Transaction (CPT), Cost per Feature. Последние помогают связать технические расходы с реальной ценностью для бизнеса.
Как часто нужно проводить аудит и оптимизацию затрат?
FinOps — это непрерывный процесс. Мониторинг затрат и утилизации ресурсов должен быть постоянным. Детальный аудит и пересмотр стратегии оптимизации рекомендуется проводить ежемесячно или ежеквартально, в зависимости от темпов роста вашей инфраструктуры и изменений в приложении. Для крупных компаний с динамичной инфраструктурой FinOps-команды могут проводить еженедельные или даже ежедневные "stand-up" встречи для обсуждения аномалий и планов.
В чем разница между Reserved Instances и Savings Plans?
Оба механизма предоставляют скидки за обязательство использовать облачные ресурсы в течение длительного срока (1 или 3 года). Reserved Instances (RI) привязаны к конкретным параметрам инстанса (тип, регион, ОС). Savings Plans (SP) более гибкие: они предоставляют скидку на определенный объем вычислительных ресурсов (например, $10/час) независимо от типа инстанса, региона или ОС. SP проще управлять и они лучше подходят для динамических нагрузок, позволяя менять тип инстансов без потери скидки, если вы остаетесь в рамках обязательства.
Стоит ли переходить на Serverless для всех приложений ради экономии?
Нет, Serverless не является универсальным решением. Хотя он предлагает максимальную эластичность и оплату по факту использования, он имеет свои ограничения, такие как "холодные старты", лимиты на время выполнения и память, а также сложность отладки распределенных систем. Serverless идеально подходит для событийных, нечастых задач, микросервисов с переменной нагрузкой. Для приложений с постоянной, высокой нагрузкой или долгим временем выполнения традиционные VPS, EC2-инстансы или Kubernetes могут быть более экономически выгодными и подходящими.
Как избежать вендор-лок-ина при выборе облачного провайдера?
Избежать полного вендор-лок-ина сложно, но можно минимизировать. Используйте открытые стандарты (Docker, Kubernetes, Terraform) и облачно-независимые технологии. Избегайте слишком глубокой интеграции с проприетарными сервисами провайдера там, где есть открытые или управляемые альтернативы (например, вместо DynamoDB рассмотрите PostgreSQL или MongoDB). Разрабатывайте архитектуру с учетом возможности миграции, абстрагируя бизнес-логику от специфики облака. Рассмотрите мультиоблачную или гибридную стратегию.
Какова роль DevOps-инженера в FinOps?
Роль DevOps-инженера в FinOps является центральной. Именно они отвечают за реализацию технических решений, которые приводят к оптимизации: внедрение IaC, настройка автоскейлинга, права сайзинг, оптимизация кода и архитектуры, выбор оптимальных типов инстансов, мониторинг утилизации и затрат. DevOps-инженеры должны понимать финансовые последствия своих технических решений и активно сотрудничать с финансовыми и продуктовыми командами.
Можно ли использовать выделенные серверы вместо облачных VPS для экономии?
Да, для определенных сценариев выделенные серверы могут быть более экономически выгодными, чем облачные VPS, особенно при очень высокой, стабильной и предсказуемой нагрузке. Выделенные серверы предлагают максимальную производительность за фиксированную плату, часто с очень большими объемами трафика. Однако они требуют более глубоких знаний в администрировании и имеют низкую гибкость масштабирования. FinOps поможет оценить TCO (Total Cost of Ownership) и определить, какой вариант будет оптимальным для вашего конкретного случая.
Как начать внедрять FinOps в своей компании?
Начните с малого: 1) Прозрачность: Внедрите политику тегирования для всех ресурсов и настройте базовые отчеты о затратах. 2) Подотчетность: Назначьте ответственных за бюджеты по проектам. 3) Оптимизация: Проведите аудит "зомби-ресурсов" и начните с Rightsizing самых дорогих инстансов. 4) Сотрудничество: Организуйте регулярные встречи между инженерами и финансовыми отделами. Постепенно расширяйте практики, внедряя автоматизацию и более сложные инструменты. Главное — начать и сделать FinOps частью корпоративной культуры.
15. Заключение
В условиях быстро меняющегося технологического ландшафта и постоянно растущих облачных затрат, FinOps становится не просто модным словом, а жизненно важной дисциплиной для каждого, кто управляет IT-инфраструктурой. К 2026 году, когда сложность облачных экосистем достигла новых высот, а конкуренция требует максимальной эффективности, умение превращать облачные расходы в стратегические инвестиции является ключевым фактором успеха.
Мы рассмотрели, как FinOps-практики и современные инструменты позволяют DevOps-инженерам, backend-разработчикам, фаундерам SaaS, системным администраторам и техническим директорам стартапов не только сокращать затраты на VPS и выделенные серверы, но и принимать обоснованные, проактивные решения. От внедрения прозрачности через тегирование и детальные отчеты до автоматизации масштабирования, прав сайзинга, использования зарезервированных мощностей и оптимизации всех аспектов инфраструктуры — каждый шаг в FinOps направлен на максимизацию ценности.
Ключевой вывод заключается в том, что FinOps — это не техническая или финансовая задача, а культурная трансформация. Это требует сотрудничества между всеми заинтересованными сторонами, постоянного обучения и адаптации. Только когда инженеры понимают финансовые последствия своих решений, а финансовые специалисты обладают достаточным техническим пониманием, возможно достижение истинной эффективности.
Итоговые рекомендации:
- Начните сейчас: Не откладывайте внедрение FinOps. Даже небольшие шаги по повышению прозрачности и удалению неиспользуемых ресурсов могут принести значительную экономию.
- Сотрудничайте: Разрушайте "силосы" между командами. FinOps процветает в среде, где инженеры, менеджеры по продукту и финансовые специалисты работают вместе.
- Автоматизируйте: Используйте IaC, автоскейлинг и скрипты для автоматизации рутинных задач и обеспечения динамической адаптации инфраструктуры.
- Мониторьте и анализируйте: Постоянно отслеживайте метрики затрат и утилизации, ищите аномалии и возможности для оптимизации.
- Оптимизируйте постоянно: FinOps — это марафон, а не спринт. Облачная среда постоянно меняется, и ваша стратегия оптимизации должна меняться вместе с ней.
Следующие шаги для читателя:
- Проведите аудит: Начните с аудита вашей текущей облачной инфраструктуры. Используйте чеклист из этой статьи, чтобы выявить неиспользуемые ресурсы и переразмеренные серверы.
- Внедрите тегирование: Если у вас еще нет политики тегирования, разработайте ее и начните применять ко всем новым ресурсам.
- Настройте бюджеты и оповещения: Установите бюджеты для ваших облачных аккаунтов и настройте оповещения, чтобы быть в курсе текущих расходов.
- Изучите инструменты: Ознакомьтесь с нативными инструментами вашего облачного провайдера для управления затратами и рассмотрите возможность использования сторонних FinOps-платформ.
- Обучайтесь: Продолжайте изучать FinOps-практики, следите за новостями и обновлениями от облачных провайдеров, обменивайтесь опытом с сообществом.
Помните, что эффективное управление затратами на облачные VPS и выделенные серверы — это не просто способ сэкономить деньги, но и стратегическое преимущество, которое позволяет вашему бизнесу быть более гибким, масштабируемым и конкурентоспособным в постоянно меняющемся мире технологий.