
Управление гибридной инфраструктурой: Kubernetes на bare metal и в облаке с Rancher
TL;DR
- Гибридный Kubernetes с Rancher — это стратегический выбор 2026 года для компаний, стремящихся к балансу между производительностью, стоимостью, безопасностью и гибкостью.
- Bare metal предлагает непревзойденную производительность и контроль, а облако — эластичность и управляемость, Rancher объединяет это в единую панель управления.
- Ключевые факторы успеха включают продуманную сетевую архитектуру, единую стратегию управления идентификацией и доступом, а также комплексный подход к мониторингу и аварийному восстановлению.
- Избегайте типичных ошибок: недооценки сложности сети и хранения данных, отсутствия четкого плана DR и игнорирования скрытых затрат на передачу данных.
- Rancher значительно упрощает развертывание, управление и обеспечение безопасности кластеров Kubernetes как на собственных серверах, так и у различных облачных провайдеров, снижая операционную нагрузку.
- Экономия достигается за счет оптимального распределения рабочих нагрузок: ресурсоемкие и чувствительные к данным приложения на bare metal, масштабируемые и временные — в облаке.
- Реальные кейсы показывают, что гибридные решения позволяют соблюдать строгие регуляторные требования, оптимизировать затраты и обеспечивать высокую доступность сервисов.
Введение
К 2026 году концепция гибридной инфраструктуры перестала быть нишевым решением и превратилась в доминирующий подход для большинства крупных и средних предприятий, а также для амбициозных стартапов. В условиях постоянно меняющегося ландшафта IT, где скорость вывода продуктов на рынок, оптимизация затрат и соответствие регуляторным требованиям являются критически важными, чистые облачные или исключительно локальные стратегии часто оказываются недостаточными. Гибридный подход, особенно с использованием Kubernetes как универсальной платформы оркестрации и Rancher как унифицированного менеджера кластеров, предлагает мощное решение этих вызовов.
Почему эта тема так важна именно сейчас? Во-первых, экономическая нестабильность последних лет заставляет компании тщательно пересматривать свои IT-бюджеты, и облачные расходы, которые быстро растут по мере масштабирования, часто становятся предметом пристального внимания. Bare metal, с его предсказуемыми капитальными затратами и отсутствием ежемесячной платы за ресурсы, вновь обретает актуальность для стабильных, ресурсоемких рабочих нагрузок. Во-вторых, ужесточение законодательства о защите данных (например, GDPR 2.0, локальные требования к суверенитету данных) заставляет многие организации держать чувствительную информацию на собственных серверах, при этом используя облако для менее критичных или публичных сервисов. В-третьих, технологический прогресс в области сетевых технологий (5G, edge computing) и платформ управления, таких как Rancher, значительно упростил интеграцию и управление разнородными средами, сделав гибридные сценарии не только возможными, но и практичными.
Данная статья призвана решить ряд ключевых проблем, с которыми сталкиваются современные инженеры и руководители:
- Сложность управления: Как эффективно управлять несколькими кластерами Kubernetes, развернутыми в разных средах (on-premise и в нескольких облаках)?
- Оптимизация затрат: Как снизить операционные расходы, используя преимущества bare metal для стабильных нагрузок и облака для пиковых?
- Безопасность и соответствие: Как обеспечить единые политики безопасности и соответствие регуляторным требованиям в распределенной инфраструктуре?
- Производительность: Как достичь максимальной производительности для критически важных приложений, сохраняя при этом гибкость облака?
- Миграция и модернизация: Как плавно переводить существующие приложения на контейнерную платформу в гибридной среде?
Это руководство написано для широкой аудитории технических специалистов и руководителей, которые принимают стратегические решения в области инфраструктуры: DevOps-инженеров, стремящихся к автоматизации и унификации процессов; Backend-разработчиков (Python, Node.js, Go, PHP), которым нужна надежная и масштабируемая платформа для своих приложений; фаундеров SaaS-проектов, ищущих оптимальный баланс между стоимостью и гибкостью; системных администраторов, отвечающих за стабильность и безопасность систем; и, конечно, технических директоров стартапов, которым необходимо построить устойчивую и конкурентоспособную инфраструктуру с нуля.
Мы погрузимся в детали, предоставим конкретные примеры, расчеты и практические рекомендации, основанные на реальном опыте внедрения гибридных Kubernetes-решений с использованием Rancher. Наша цель — дать вам исчерпывающий ресурс для принятия обоснованных решений и успешной реализации вашей гибридной стратегии.
Основные критерии и факторы
При планировании и внедрении гибридной Kubernetes-инфраструктуры необходимо учитывать множество факторов, которые в совокупности определяют успешность и эффективность решения. Каждый из этих критериев имеет свой вес и может быть приоритетным в зависимости от специфики бизнеса, характера рабочих нагрузок и стратегических целей компании. Детальный разбор каждого из них позволит принимать взвешенные решения.
1. Стоимость владения (TCO) и экономическая эффективность
Почему важен: TCO выходит далеко за рамки прямых затрат на оборудование или облачные подписки. Он включает капитальные затраты (CapEx) на серверы, сетевое оборудование, хранилище, а также операционные расходы (OpEx) — электроэнергию, охлаждение, обслуживание, лицензии на ПО, зарплату персонала, стоимость трафика и скрытые расходы, такие как стоимость простоя или обучения. Правильная оценка TCO позволяет выбрать наиболее экономически выгодную стратегию на долгосрочную перспективу.
Как оценивать: Проведите детальный анализ всех статей расходов за 3-5 лет. Для bare metal учтите амортизацию оборудования, затраты на дата-центр, персонал. Для облака — ежемесячные платежи за ресурсы (vCPU, RAM, хранилище), сетевой трафик (особенно egress), управляемые сервисы, а также потенциальные скидки за резервирование (Reserved Instances, Savings Plans). Важно учитывать, что для стабильных, высоконагруженных приложений bare metal часто оказывается дешевле на длинной дистанции, тогда как облако выигрывает на старте и для непредсказуемых нагрузок.
2. Производительность и задержка (Latency)
Почему важен: Некоторые приложения, такие как высокочастотный трейдинг, IoT-аналитика на периферии, игровые серверы или базы данных с интенсивной записью, критически зависят от минимальной задержки и максимальной пропускной способности. Bare metal здесь часто выигрывает, предоставляя прямой доступ к оборудованию без накладных расходов виртуализации и сетевых абстракций облака.
Как оценивать: Измеряйте задержку сети (RTT) между компонентами, пропускную способность дисковых операций (IOPS, throughput) и CPU-производительность. Для bare metal это будут реальные показатели оборудования. Для облака — характеристики инстансов и типы хранилищ, которые вы выбираете. В гибридной среде критически важна задержка между on-premise и облачными сегментами, которая может быть снижена за счет прямых соединений (Direct Connect, ExpressRoute).
3. Безопасность и соответствие регуляторным требованиям
Почему важен: Защита данных и соблюдение законодательства (GDPR, HIPAA, PCI DSS, ФЗ-152 и др.) являются не просто "хорошей практикой", а обязательным условием ведения бизнеса, особенно в таких секторах, как финансы, здравоохранение или государственные услуги. Размещение чувствительных данных на собственных серверах дает полный контроль над физической безопасностью и доступом, что упрощает прохождение аудитов.
Как оценивать: Проведите аудит текущих и будущих регуляторных требований. Оцените, где должны храниться и обрабатываться данные. В облаке вы разделяете ответственность за безопасность (Shared Responsibility Model), что требует тщательного конфигурирования. На bare metal вся ответственность лежит на вас, но и контроль полный. Rancher помогает унифицировать политики безопасности и управления доступом (RBAC) по всем кластерам, независимо от их расположения.
4. Масштабируемость и гибкость
Почему важен: Способность инфраструктуры быстро адаптироваться к изменяющимся нагрузкам — это основа для успешного развития продукта. Облако предлагает практически безграничную эластичность, позволяя мгновенно масштабировать ресурсы вверх или вниз. Bare metal требует предварительного планирования и закупки оборудования, но предоставляет стабильную и предсказуемую производительность для базовых нагрузок.
Как оценивать: Определите пиковые и базовые нагрузки. Оцените время, необходимое для добавления новых ресурсов в каждой среде. Гибридный подход позволяет использовать bare metal для "постоянной" нагрузки и "выплескивать" (burst) пиковые запросы в облако, обеспечивая оптимальное использование ресурсов и минимизацию затрат.
5. Управленческие издержки и операционная сложность
Почему важен: Управление распределенной инфраструктурой может быть чрезвычайно сложным без правильных инструментов. Высокие операционные издержки могут нивелировать любую экономию на оборудовании или облачных ресурсах. Rancher здесь играет ключевую роль, предоставляя единую панель управления для всех Kubernetes-кластеров.
Как оценивать: Оцените необходимый объем персонала, его квалификацию, затраты на обучение, а также сложность процессов развертывания, мониторинга, обновления и устранения неполадок. Инструменты автоматизации и унификации, такие как Rancher, значительно снижают эту сложность, позволяя управлять десятками кластеров с меньшими ресурсами.
6. Зависимость от поставщика (Vendor Lock-in)
Почему важен: Полная зависимость от одного облачного провайдера может привести к проблемам с ценообразованием, ограниченному выбору технологий и сложностям при миграции. Гибридная стратегия, особенно с использованием Kubernetes, который является открытым стандартом, снижает этот риск, позволяя легко перемещать рабочие нагрузки между различными средами.
Как оценивать: Анализируйте используемые облачные сервисы: насколько они проприетарны? Какие усилия потребуются для миграции на другого провайдера или на bare metal? Kubernetes и Rancher способствуют стандартизации, делая приложения более переносимыми. Это дает вам рычаги давления в переговорах с поставщиками и стратегическую свободу.
7. "Гравитация" данных (Data Gravity)
Почему важен: Большие объемы данных имеют "гравитацию" — их сложно и дорого перемещать. Приложения, которые интенсивно работают с большими базами данных или хранилищами, часто выгодно располагать рядом с этими данными. Если данные находятся на bare metal, то и приложения, работающие с ними, логично размещать там же для минимизации задержек и стоимости трафика.
Как оценивать: Определите объем и интенсивность обмена данными между компонентами вашей системы. Расходы на исходящий трафик (egress) из облака могут быть значительными. Размещение баз данных и аналитических систем on-premise или на выделенных серверах в облаке, а фронтендов и API-шлюзов — в более эластичных облачных кластерах, может быть оптимальной стратегией.
8. Аварийное восстановление (DR) и высокая доступность (HA)
Почему важен: Отказоустойчивость инфраструктуры — это критически важный фактор для любого современного бизнеса. Гибридная среда предлагает уникальные возможности для построения надежных стратегий DR, позволяя распределять риски между разными локациями и провайдерами.
Как оценивать: Определите целевые показатели RTO (Recovery Time Objective) и RPO (Recovery Point Objective) для ваших приложений. Рассмотрите сценарии отказа дата-центра или облачного региона. Гибридная стратегия позволяет иметь резервный кластер в облаке для on-premise приложений или наоборот, обеспечивая быструю активацию в случае сбоя. Rancher упрощает управление такими распределенными кластерами, позволяя централизованно управлять их конфигурацией и развертыванием.
Учет этих факторов на этапе проектирования позволит построить не просто работающую, но и эффективную, экономически выгодную и устойчивую гибридную инфраструктуру на базе Kubernetes и Rancher.
Сравнительная таблица
Для наглядности и принятия обоснованных решений представим сравнительную таблицу основных подходов к развертыванию Kubernetes, с учетом гибридной стратегии и роли Rancher. Данные актуальны для прогнозов на 2026 год, отражая тенденции в ценообразовании, производительности и операционных моделях.
| Критерий | Bare Metal (Самоуправляемый K8s) | Bare Metal (K8s с Rancher) | Public Cloud (EKS/AKS/GKE) | Гибрид (K8s с Rancher) |
|---|---|---|---|---|
| Стоимость (TCO 3 года, $K) | Высокий CapEx (~$100-500K за 10 серверов), низкий OpEx ($5-15K/мес) | Высокий CapEx (~$100-500K за 10 серверов), средний OpEx ($8-20K/мес, включая поддержку Rancher) | Низкий CapEx ($0), высокий OpEx ($15-50K/мес за эквивалент 10 серверов) | Сбалансированный CapEx/OpEx ($50-200K CapEx, $10-30K/мес OpEx) |
| Производительность CPU/RAM | ~95-98% от физического железа. Прямой доступ к ресурсам. | ~95-98% от физического железа. Незначительные накладные расходы Rancher агентов. | ~70-90% от физического железа (из-за виртуализации). Зависит от типа инстанса. | Bare Metal часть: 95-98%. Cloud часть: 70-90%. Оптимально для разных нагрузок. |
| Задержка сети (внутри кластера) | <1 мс (физическая сеть) | <1 мс (физическая сеть) | ~1-5 мс (виртуальная сеть облака) | Bare Metal: <1 мс. Cloud: 1-5 мс. Межкластерная: 10-50 мс (с Direct Connect <5 мс). |
| Масштабируемость | Ручная, медленная (закупка, установка). До нескольких недель. | Полуавтоматическая с Rancher, но ограничена физическими ресурсами. Дни/недели. | Автоматическая, быстрая (несколько минут) с Cluster Autoscaler. Практически безграничная. | Гибкая: Bare Metal для базы, Cloud для пиков (минуты). Оптимальный баланс. |
| Безопасность и контроль | Полный контроль над всей цепочкой, от железа до ПО. Высокий уровень безопасности. | Полный контроль + унифицированное управление безопасностью через Rancher. | Модель общей ответственности. Высокая безопасность провайдера, но меньше контроля. | Высокий контроль для чувствительных данных (on-prem), модель общей ответственности для облака. |
| Сложность управления | Очень высокая (ручное развертывание, обновление, мониторинг). Требует глубоких знаний. | Средняя-высокая (Rancher значительно упрощает K8s, но bare metal требует администрирования). | Средняя (управляемые сервисы, но свои нюансы провайдера). | Высокая, но снижается за счет Rancher, который унифицирует управление. Требует экспертизы. |
| Соответствие требованиям (Compliance) | Полный контроль над данными и инфраструктурой. Легче пройти аудит. | Полный контроль + унифицированные политики через Rancher. | Зависит от провайдера и региона. Shared responsibility. | Оптимально: чувствительные данные on-prem, остальное в облаке с соблюдением региональных норм. |
| Риск Vendor Lock-in | Низкий (открытый стандарт K8s). | Низкий (Rancher открыт, но есть привязка к его экосистеме управления). | Высокий (глубокая интеграция с облачными сервисами провайдера). | Низкий (возможность перемещать рабочие нагрузки, использовать разных провайдеров). |
Примечание: Цифры в таблице являются оценочными и могут варьироваться в зависимости от конкретной реализации, масштаба проекта, региона и квалификации команды. Ценовые диапазоны указаны для среднего предприятия, оперирующего эквивалентом 10-20 физических серверов.
Детальный обзор каждого пункта/варианта
Понимание сильных и слабых сторон каждого подхода к развертыванию Kubernetes критически важно для выбора оптимальной стратегии. Рассмотрим детально каждый вариант, акцентируя внимание на его применимости и особенностях в контексте 2026 года.
1. Kubernetes на Bare Metal (Самоуправляемый)
Этот подход подразумевает развертывание Kubernetes непосредственно на физических серверах без промежуточного слоя виртуализации или управляющих платформ, таких как Rancher. Вы полностью отвечаете за все аспекты: от установки ОС и настройки сети до развертывания компонентов Kubernetes (kubeadm, kops, kubespray) и последующего их обслуживания.
Плюсы:
- Максимальная производительность: Прямой доступ к аппаратным ресурсам обеспечивает минимальные накладные расходы и наивысшую производительность для CPU, RAM, дисков и сети. Это критично для высокопроизводительных вычислений (HPC), баз данных с интенсивной I/O, AI/ML-моделей и низколатентных сетевых сервисов.
- Полный контроль и кастомизация: Вы контролируете каждый аспект инфраструктуры, что позволяет тонко настраивать систему под уникальные требования. Это важно для специфических аппаратных конфигураций, специализированных сетевых решений или особых требований безопасности.
- Экономия на масштабе: Для очень больших, стабильных кластеров (сотни узлов) в долгосрочной перспективе CapEx на bare metal может быть значительно ниже, чем OpEx в облаке, особенно если у вас есть собственный дата-центр или co-location.
- Независимость от поставщика: Отсутствие привязки к облачному провайдеру или управляющей платформе.
Минусы:
- Высокая сложность и операционная нагрузка: Развертывание, обновление, мониторинг и устранение неполадок требуют глубоких знаний Kubernetes, сетевых технологий, системного администрирования. Это значительно увеличивает OpEx за счет высококвалифицированного персонала.
- Длительное время развертывания: Закупка, доставка, установка и настройка оборудования могут занимать недели или месяцы. Масштабирование также не происходит мгновенно.
- Отсутствие эластичности: Ресурсы ограничены имеющимся оборудованием. Bursting в облако невозможен без гибридной стратегии.
- Сложности с HA и DR: Построение отказоустойчивой архитектуры и плана аварийного восстановления полностью ложится на вашу команду.
Для кого подходит:
Крупные предприятия с собственными дата-центрами, которым требуется максимальная производительность и контроль, а также есть штат высококвалифицированных инженеров. Компании, работающие с очень чувствительными данными, где требуется полный контроль над физической инфраструктурой. Проекты с предсказуемой, но очень высокой нагрузкой, где облачные затраты становятся непомерными.
2. Kubernetes на Bare Metal с Rancher
Этот вариант использует преимущества bare metal, добавляя к ним мощь и удобство Rancher для управления жизненным циклом кластеров Kubernetes. Rancher позволяет развертывать, обновлять и управлять несколькими кластерами Kubernetes (RKE, K3s) на физических серверах из единой панели.
Плюсы:
- Упрощенное управление: Rancher значительно снижает операционную сложность, автоматизируя многие рутинные задачи по развертыванию и обновлению кластеров. Единый UI/API для всех кластеров.
- Консистентность операций: Rancher обеспечивает единый подход к управлению кластерами, независимо от их расположения. Это унифицирует политики безопасности, мониторинга и развертывания приложений.
- Использование преимуществ bare metal: Сохраняется высокая производительность и полный контроль над оборудованием.
- Интеграция с экосистемой: Rancher предоставляет доступ к каталогам приложений, инструментам мониторинга (Prometheus/Grafana), логирования (Fluentd/Loki), CI/CD (ArgoCD/Flux) и другим компонентам, что упрощает построение комплексного решения.
- Основа для гибрида: Rancher изначально спроектирован для управления мульти-кластерными и мульти-облачными средами, что делает его идеальным выбором для гибридной стратегии.
Минусы:
- Кривая обучения Rancher: Хотя Rancher упрощает K8s, сама платформа имеет свою кривую обучения.
- Накладные расходы Rancher: Небольшие накладные расходы на работу агентов Rancher и управляющего сервера.
- Все еще требуется администрирование bare metal: Вы по-прежнему отвечаете за физическое оборудование, его обслуживание, электропитание, охлаждение и базовую ОС.
- Ограниченная эластичность: Масштабирование bare metal кластера все еще ограничено физическими ресурсами и временем их приобретения/установки.
Для кого подходит:
Компании, которые хотят использовать bare metal для производительности и контроля, но при этом минимизировать операционную нагрузку на администрирование Kubernetes. Идеально подходит для основы гибридной инфраструктуры, где требуется централизованное управление разнородными кластерами. SaaS-проекты, достигшие масштаба, при котором облачные расходы становятся чрезмерными, но не готовы к полной ручной оркестрации K8s.
3. Kubernetes в Public Cloud (EKS/AKS/GKE)
Это самый популярный подход для многих стартапов и компаний, которые ценят скорость развертывания, эластичность и управляемые сервисы. Облачные провайдеры предлагают полностью управляемые сервисы Kubernetes (Amazon EKS, Azure AKS, Google GKE), снимая с вас большую часть забот по управлению контрольной плоскостью.
Плюсы:
- Высокая эластичность и масштабируемость: Мгновенное масштабирование вверх и вниз, автоматическое добавление/удаление узлов. Оплата по мере использования.
- Минимальные операционные издержки на K8s: Провайдер управляет мастер-узлами, их обновлением, безопасностью и доступностью. Вы фокусируетесь на приложениях.
- Широкий спектр управляемых сервисов: Легкая интеграция с базами данных, очередями сообщений, балансировщиками нагрузки, функциями бессерверных вычислений и другими сервисами облака.
- Глобальное покрытие и DR: Возможность развертывания в нескольких регионах и зонах доступности для высокой доступности и аварийного восстановления.
- Быстрый старт: Развертывание кластера занимает минуты.
Минусы:
- Высокие OpEx на масштабе: По мере роста ресурсов и сетевого трафика (особенно egress) облачные расходы могут стать очень значительными и непредсказуемыми.
- Vendor Lock-in: Глубокая интеграция с проприетарными облачными сервисами затрудняет миграцию на другого провайдера или на bare metal.
- Ограниченный контроль: Меньше контроля над базовой инфраструктурой, сетевыми настройками и некоторыми аспектами безопасности.
- Проблемы с производительностью/задержкой: Накладные расходы виртуализации и сетевых абстракций могут приводить к более высокой задержке и меньшей производительности по сравнению с bare metal.
- Сложности с соблюдением требований: Модель общей ответственности требует тщательного аудита и настройки для соответствия строгим регуляторным нормам.
Для кого подходит:
Стартапы, которые быстро растут и нуждаются в максимальной гибкости. Компании с непредсказуемыми или сильно колеблющимися нагрузками. Проекты, где скорость вывода на рынок важнее абсолютной минимизации затрат на инфраструктуру. Команды, которые хотят минимизировать административную нагрузку на инфраструктуру и сосредоточиться на разработке.
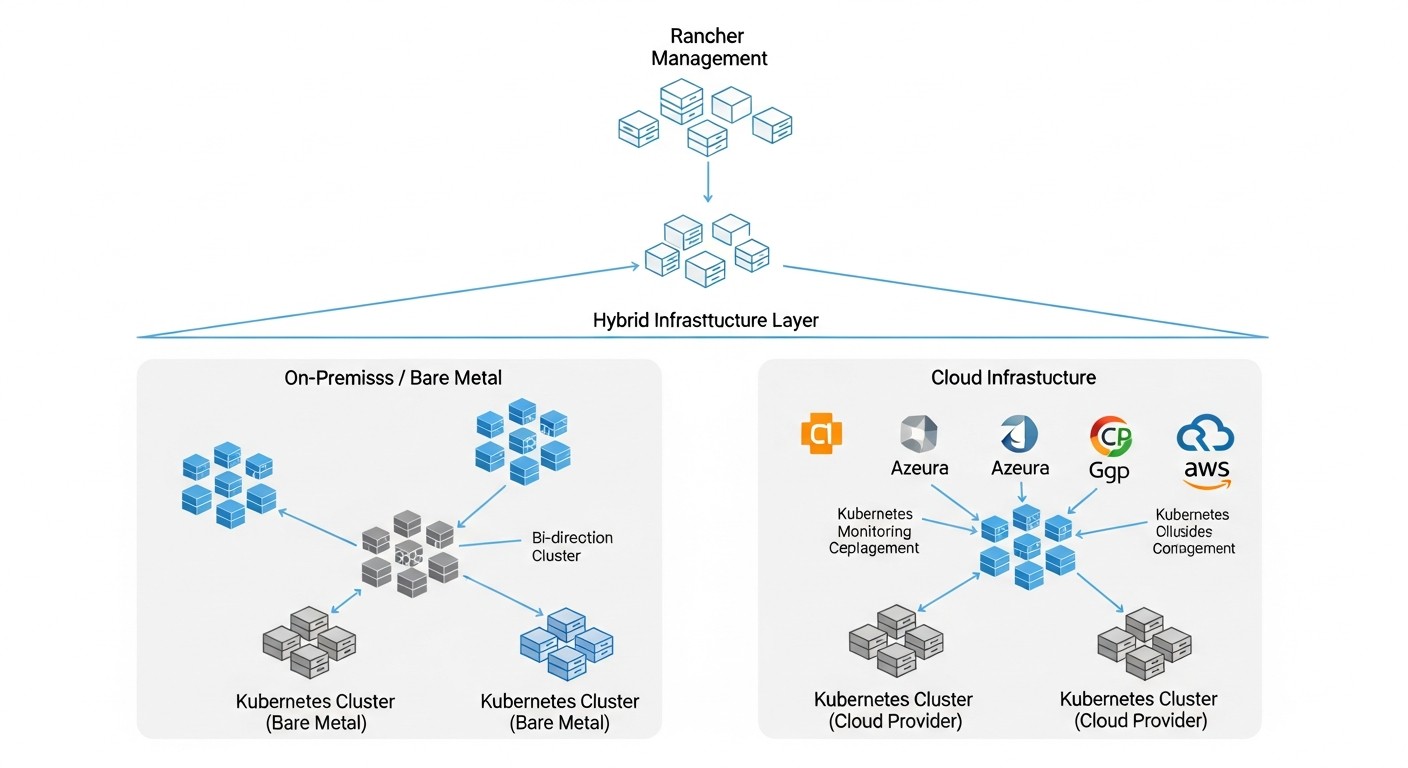
4. Гибридный Kubernetes с Rancher
Это комбинация bare metal и облачных кластеров Kubernetes, управляемых из единой панели Rancher. Этот подход позволяет извлекать выгоду из преимуществ каждой среды, минимизируя их недостатки.
Плюсы:
- Оптимизация затрат: Размещение стабильных, ресурсоемких нагрузок на bare metal (низкий OpEx в долгосрочной перспективе) и использование облака для эластичных, пиковых нагрузок или временных сред (Dev/Test).
- Максимальная гибкость и масштабируемость: Сочетание предсказуемой производительности bare metal с неограниченной эластичностью облака. Возможность "выплескивания" нагрузки в облако.
- Усиленная безопасность и соответствие: Чувствительные данные и критически важные приложения могут оставаться на bare metal под полным контролем, в то время как публичные и менее критичные сервисы размещаются в облаке. Rancher обеспечивает единые политики безопасности.
- Улучшенное аварийное восстановление: Возможность создания отказоустойчивых архитектур, где один сегмент инфраструктуры служит резервным для другого (например, on-prem кластер как DR для облачного и наоборот).
- Снижение Vendor Lock-in: Возможность использовать несколько облачных провайдеров (мульти-облачная стратегия) и bare metal, что дает большую свободу выбора и переносимость приложений.
- Унифицированное управление: Rancher предоставляет единый интерфейс для управления всеми кластерами, упрощая операции, мониторинг и развертывание приложений.
Минусы:
- Высокая начальная сложность: Проектирование и развертывание гибридной инфраструктуры требует значительной экспертизы в сетевых технологиях, безопасности, хранилищах данных и, конечно, Kubernetes и Rancher.
- Сложности с сетевой интеграцией: Обеспечение бесшовной и безопасной связи между on-premise и облачными кластерами может быть нетривиальной задачей (VPN, Direct Connect, SD-WAN).
- Управление данными: Стратегии для синхронизации, репликации и доступа к данным между разными средами требуют тщательного планирования.
- Потенциальные скрытые расходы: Затраты на egress-трафик, прямые соединения, специализированное оборудование.
Для кого подходит:
Практически для любой компании, которая стремится к оптимальному балансу между стоимостью, производительностью, безопасностью и гибкостью. Особенно актуально для крупных предприятий, которым необходимо модернизировать устаревшую on-premise инфраструктуру, соблюдать строгие регуляторные требования, а также для SaaS-провайдеров, которые хотят оптимизировать свои расходы на облако, сохраняя при этом эластичность. Идеальный выбор для тех, кто уже имеет значительные инвестиции в bare metal и хочет расширить свои возможности за счет облака, или наоборот, кто хочет вернуть часть рабочих нагрузок из облака на свои сервера.
Выбор конкретного варианта или их комбинации всегда должен основываться на глубоком анализе текущих потребностей, будущих планов развития и имеющихся ресурсов. Гибридная стратегия с Rancher предоставляет наиболее полный набор инструментов для адаптации к этим требованиям.
Практические советы и рекомендации
Успешное внедрение гибридной Kubernetes-инфраструктуры с Rancher требует не только понимания теории, но и глубокого погружения в практические аспекты. Вот ключевые рекомендации и пошаговые инструкции, основанные на реальном опыте.
1. Проектирование сетевой архитектуры
Сеть — это кровеносная система вашей гибридной инфраструктуры. Ее правильное проектирование критически важно для производительности, безопасности и доступности.
Пошаговая инструкция:
- IP-планирование: Выделите непересекающиеся диапазоны IP-адресов для каждого on-premise и облачного кластера, а также для соединений между ними. Используйте RFC1918 для приватных сетей.
- Соединение on-premise и облака:
- VPN (IPsec/OpenVPN/WireGuard): Для начала или небольших объемов трафика. Легко настраивается, но имеет ограничения по пропускной способности и задержке.
- Direct Connect (AWS)/ExpressRoute (Azure)/Cloud Interconnect (GCP): Для высокопроизводительных, низколатентных и стабильных соединений. Это выделенные линии, обеспечивающие предсказуемую производительность, но требующие значительных инвестиций.
- SD-WAN: Современное решение для управления трафиком через различные каналы, оптимизации маршрутизации и обеспечения безопасности.
- Сетевые плагины (CNI) для Kubernetes:
- Calico/Cilium: Отличный выбор для гибридных сред, так как они поддерживают сетевые политики (Network Policies), обеспечивают высокую производительность и могут работать в разных режимах (IP-in-IP, BGP). Calico также поддерживает интеграцию с BGP для bare metal кластеров.
- Flannel: Проще в настройке, но менее функционален и производителен. Хорош для простых сценариев.
- DNS-стратегия: Реализуйте единую стратегию DNS для разрешения имен между on-premise и облачными кластерами. Используйте CoreDNS в Kubernetes и настройте условные пересылки (conditional forwarders) к on-premise DNS-серверам для внутренних доменов и наоборот.
- Load Balancing:
- Bare Metal: Используйте MetalLB для предоставления LoadBalancer Service. Он распределяет IP-адреса из пула и анонсирует их по BGP или ARP.
- Cloud: Используйте нативные облачные балансировщики (AWS ELB/ALB, Azure Load Balancer, GCP GCLB).
- Ingress Controllers: NGINX Ingress Controller, Traefik, Istio Ingress Gateway для маршрутизации HTTP/S трафика.
# Пример конфигурации MetalLB (bare metal)
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: bare-metal-lb-pool
spec:
addresses:
- 192.168.100.200-192.168.100.250
---
apiVersion: metallb.io/v1beta1
kind: BGPAdvertisement
metadata:
name: bare-metal-bgp-advertisement
spec:
ipAddressPools:
- bare-metal-lb-pool
2. Стратегия хранения данных
Данные — это сердце ваших приложений. Выбор правильной стратегии хранения в гибридной среде критически важен.
Пошаговая инструкция:
- CSI (Container Storage Interface): Используйте CSI-драйверы для интеграции Kubernetes с различными типами хранилищ.
- On-premise хранилища:
- Rook (Ceph): Распределенное хранилище, создаваемое на базе локальных дисков серверов. Обеспечивает блочное, файловое и объектное хранение, высокую доступность и масштабируемость.
- Longhorn: Легковесное распределенное блочное хранилище, также построенное на базе локальных дисков, управляемое из Kubernetes. Хорошо подходит для небольших и средних кластеров.
- Внешние СХД (NFS/iSCSI): Интеграция с существующими NAS/SAN системами через соответствующие CSI-драйверы.
- Облачные хранилища:
- Managed Disks: AWS EBS, Azure Disks, GCP Persistent Disks для блочного хранения, привязанного к конкретной VM.
- Managed File Storage: AWS EFS, Azure Files, GCP Filestore для общего файлового доступа.
- Object Storage: AWS S3, Azure Blob Storage, GCP Cloud Storage для объектного хранения (часто используется для бэкапов, статических файлов).
- Стратегия репликации и бэкапов: Для критически важных данных рассмотрите репликацию между on-premise и облаком (например, синхронизация баз данных, репликация Ceph между кластерами). Используйте Velero для бэкапа и восстановления Kubernetes-ресурсов и Persistent Volumes.
# Пример PersistentVolumeClaim для Longhorn
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-app-pvc
spec:
accessModes:
- ReadWriteOnce
storageClassName: longhorn
resources:
requests:
storage: 10Gi
3. Управление идентификацией и доступом (IAM)
Единая система аутентификации и авторизации упрощает управление пользователями и обеспечивает безопасность.
Пошаговая инструкция:
- Централизованный провайдер идентичности: Интегрируйте Rancher с корпоративным LDAP/AD, Okta, Auth0 или другими SSO-решениями. Это позволит пользователям входить в Rancher с помощью своих корпоративных учетных записей.
- RBAC в Kubernetes: Настройте Role-Based Access Control (RBAC) в каждом кластере, а также глобальные роли в Rancher. Определите, кто имеет доступ к кластерам, неймспейсам и конкретным ресурсам.
- Принцип минимальных привилегий: Предоставляйте пользователям и приложениям только те права, которые необходимы для выполнения их задач.
4. CI/CD для гибридной среды
Автоматизация развертывания приложений в гибридной среде требует продуманного CI/CD пайплайна.
Пошаговая инструкция:
- GitOps: Используйте Git как единый источник истины для конфигурации ваших кластеров и приложений. Инструменты, такие как ArgoCD или Flux, будут синхронизировать состояние кластеров с репозиторием Git.
- Мульти-кластерное развертывание: Настройте пайплайны так, чтобы они могли разворачивать приложения в конкретные on-premise или облачные кластеры, или даже в несколько кластеров одновременно. Rancher Fleet может быть использован для централизованного развертывания и управления приложениями в большом количестве кластеров.
- Секреты: Используйте Vault от HashiCorp, External Secrets Operator или облачные менеджеры секретов для безопасного хранения и доступа к конфиденциальным данным.
# Пример ArgoCD Application для развертывания в гибридном кластере
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-hybrid-app
namespace: argocd
spec:
project: default
source:
repoURL: https://github.com/my-org/my-app-configs.git
targetRevision: HEAD
path: k8s/production/hybrid-cluster
destination:
server: https://kubernetes.default.svc # Или URL вашего кластера Rancher
namespace: my-app
syncPolicy:
automated:
prune: true
selfHeal: true
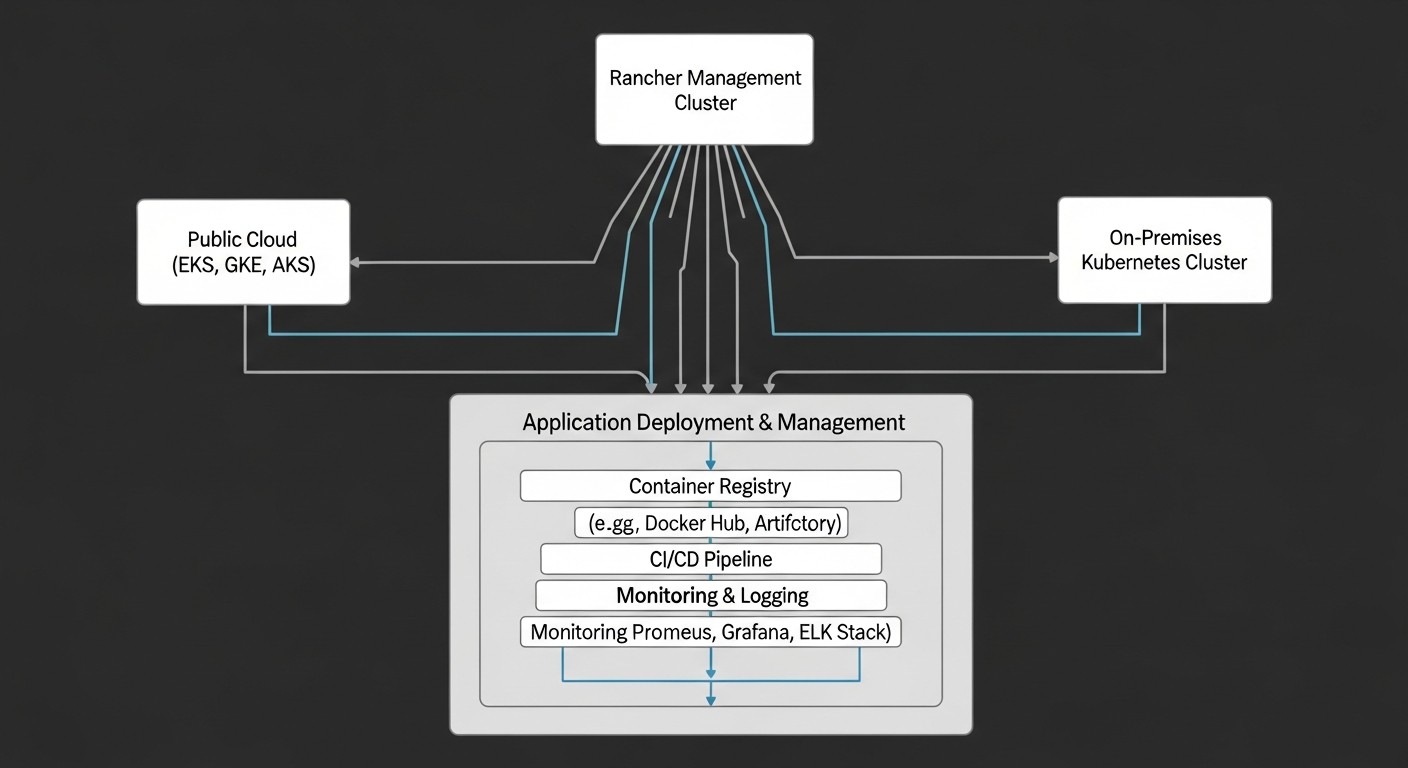
5. Мониторинг и логирование
Единая система мониторинга и логирования критична для здоровья и отладки гибридной инфраструктуры.
Пошаговая инструкция:
- Мониторинг: Разверните Prometheus и Grafana в каждом кластере или централизованно. Rancher включает встроенную интеграцию с Prometheus и Grafana, что упрощает их настройку. Собирайте метрики с узлов, подов, контейнеров, а также сетевые и дисковые метрики.
- Логирование: Используйте централизованную систему логирования, такую как ELK Stack (Elasticsearch, Logstash, Kibana) или Loki с Grafana. Настройте Fluentd/Fluent Bit в каждом кластере для сбора логов и отправки их в централизованное хранилище.
- Алерты: Настройте Alertmanager (часть Prometheus) для отправки уведомлений в Slack, PagerDuty, email при возникновении проблем.
6. Стратегия аварийного восстановления (DR)
Необходимо иметь четкий план действий на случай сбоев.
Пошаговая инструкция:
- Определение RTO/RPO: Для каждого приложения определите допустимое время восстановления (RTO) и допустимую потерю данных (RPO).
- Резервное копирование и восстановление: Используйте Velero для бэкапа и восстановления Kubernetes-ресурсов (Deployments, Services, ConfigMaps) и Persistent Volumes. Velero может сохранять бэкапы в объектное хранилище (S3-совместимое или облачное).
- Географическая распределенность: Разверните кластеры в разных географических локациях (on-premise дата-центр, разные облачные регионы) для защиты от региональных сбоев.
- Тестирование DR: Регулярно тестируйте ваш план DR, имитируя сбои и проверяя процедуры восстановления. Это единственный способ убедиться в его работоспособности.
# Пример бэкапа кластера с Velero
velero backup create my-cluster-backup --include-namespaces my-app-namespace --wait
# Пример восстановления кластера с Velero
velero restore create --from-backup my-cluster-backup --wait
7. Управление версиями Kubernetes и обновлениями
Обновление Kubernetes может быть сложным, но Rancher значительно упрощает этот процесс.
Пошаговая инструкция:
- Планирование: Следите за жизненным циклом версий Kubernetes. Планируйте обновления заранее, учитывая совместимость приложений.
- Rancher для обновлений: Rancher позволяет обновлять версии Kubernetes для управляемых кластеров через UI или API. Это значительно упрощает процесс, автоматизируя многие шаги.
- Последовательные обновления: Обновляйте кластеры не сразу, а по очереди: сначала dev/test, затем staging, и только потом production.
- Тестирование: После каждого обновления проводите тщательное регрессионное тестирование приложений.
Применяя эти практические советы, вы сможете построить надежную, эффективную и легко управляемую гибридную инфраструктуру на базе Kubernetes и Rancher, готовую к вызовам 2026 года и далее.
Типичные ошибки
Внедрение гибридной инфраструктуры — это сложный проект, и на этом пути легко совершить ошибки, которые могут привести к значительным затратам, простоям или проблемам с безопасностью. Изучение этих распространенных ошибок и знание способов их предотвращения является ключом к успешной реализации.
1. Недооценка сложности сетевой интеграции
Ошибка: Многие инженеры недооценивают, насколько сложной может быть настройка бесшовной и безопасной сети между on-premise и облачными кластерами. Проблемы с IP-планированием, маршрутизацией, DNS-разрешением и пропускной способностью часто всплывают на поздних этапах, приводя к задержкам и переработкам.
Как избежать:
- Начните с детального IP-планирования, убедитесь в отсутствии пересечений диапазонов.
- Инвестируйте в надежное межсетевое соединение (Direct Connect, ExpressRoute) для критически важных нагрузок. Для менее требовательных можно начать с VPN.
- Используйте продвинутые CNI-плагины, такие как Calico или Cilium, которые поддерживают сетевые политики и BGP.
- Реализуйте унифицированную DNS-стратегию с условной пересылкой между on-premise и облаком.
Последствия: Высокая задержка, нестабильное соединение, проблемы с разрешением имен между сервисами, что приводит к неработоспособности распределенных приложений и дорогостоящим простоям.
2. Игнорирование стратегии хранения данных и их "гравитации"
Ошибка: Разработчики часто переносят приложения в облако, не задумываясь о том, где находятся их данные. Или, наоборот, размещают базы данных on-premise, а приложения в облаке, что приводит к высоким затратам на egress-трафик и задержкам.
Как избежать:
- Проанализируйте характер данных: объем, скорость изменения, чувствительность, требования к задержке.
- Размещайте приложения максимально близко к данным, с которыми они интенсивно работают. Если данные on-premise, то и часть приложений, работающих с ними, должна быть on-premise.
- Используйте распределенные хранилища (Rook/Ceph, Longhorn) на bare metal и соответствующие облачные CSI-драйверы.
- Планируйте стратегию репликации и бэкапов данных между средами.
Последствия: Неожиданно высокие счета за облачный трафик, низкая производительность приложений из-за задержек при доступе к данным, проблемы с целостностью данных при отсутствии адекватной стратегии репликации.
3. Отсутствие единой стратегии IAM и RBAC
Ошибка: Управление пользователями и их правами доступа в каждом кластере отдельно, без централизованной системы. Это ведет к хаосу, проблемам с безопасностью и высоким операционным издержкам.
Как избежать:
- Интегрируйте Rancher с корпоративным LDAP/AD или SSO-провайдером для централизованной аутентификации.
- Используйте глобальные и кластерные роли в Rancher для унифицированного управления авторизацией.
- Применяйте принцип минимальных привилегий для всех пользователей и сервисных аккаунтов.
- Регулярно проводите аудит прав доступа.
Последствия: Несанкционированный доступ, нарушение безопасности, сложности с аудитом, высокие затраты времени на управление доступом.
4. Неадекватное планирование аварийного восстановления (DR)
Ошибка: Многие компании создают гибридную инфраструктуру, но не тестируют свои DR-планы или вообще не имеют их. Надежда на то, что "ничего не случится", приводит к катастрофическим последствиям при реальном сбое.
Как избежать:
- Определите четкие RTO и RPO для каждого критически важного сервиса.
- Разработайте подробный план DR, включающий процедуры бэкапа, восстановления, переключения на резервный кластер (failover) и возврата (failback).
- Используйте такие инструменты, как Velero, для автоматизированного бэкапа и восстановления Kubernetes-ресурсов и данных.
- Регулярно (не реже раза в полгода) проводите полномасштабные учения по DR, имитируя реальные сбои.
Последствия: Длительные простои (часы или дни), потеря критически важных данных, значительный репутационный и финансовый ущерб.
5. Недооценка операционной сложности и потребности в квалифицированных кадрах
Ошибка: Полагать, что Rancher решит все проблемы, и гибридный Kubernetes можно будет управлять силами одного джуниора. Гибридная инфраструктура, даже с Rancher, требует значительной экспертизы в различных областях (Kubernetes, сети, хранилища, облачные технологии, безопасность).
Как избежать:
- Инвестируйте в обучение команды. Убедитесь, что у вас есть специалисты с опытом работы в Kubernetes, Rancher, а также в сетевых технологиях и облачных платформах.
- Начните с малого, постепенно наращивая сложность инфраструктуры и компетенции команды.
- Автоматизируйте рутинные задачи с помощью CI/CD и GitOps.
- Рассмотрите возможность использования внешней экспертизы или консультантов на начальных этапах.
Последствия: Медленное развертывание, частые инциденты, низкая эффективность использования ресурсов, выгорание команды, высокие затраты на поиск и найм высококвалифицированных специалистов.
6. Отсутствие мониторинга и алертов для гибридной среды
Ошибка: Развертывание кластеров в разных средах, но без централизованного мониторинга и логирования. Это приводит к "слепым зонам" и невозможности быстро реагировать на проблемы.
Как избежать:
- Внедрите унифицированную систему мониторинга (Prometheus/Grafana) и логирования (ELK/Loki) для всех кластеров, независимо от их расположения.
- Настройте агрегацию метрик и логов в централизованном хранилище для удобного анализа.
- Определите ключевые метрики здоровья для каждого компонента и настройте адекватные пороги для алертов.
- Убедитесь, что алерты доставляются в нужные каналы (Slack, PagerDuty, email) и по ним есть четкий план действий.
Последствия: Долгие поиски причин инцидентов, реактивный, а не проактивный подход к управлению, высокий MTTR (Mean Time To Recovery).
Избегая этих распространенных ошибок, вы значительно повысите шансы на успешное и эффективное внедрение гибридной Kubernetes-инфраструктуры с Rancher.
Чеклист для практического применения
Этот чеклист поможет вам систематизировать процесс планирования и внедрения гибридной инфраструктуры Kubernetes с Rancher. Проходите по пунктам последовательно, убеждаясь, что каждый шаг выполнен или учтен.
- Определение требований и планирование:
- [ ] Определены бизнес-цели и ожидаемые выгоды от гибридной инфраструктуры.
- [ ] Выявлены критически важные приложения и их требования к производительности, задержке, безопасности.
- [ ] Определены требования к соблюдению регуляторных норм (GDPR, HIPAA, ФЗ-152 и т.д.).
- [ ] Проанализированы текущие и прогнозируемые объемы данных и их "гравитация".
- [ ] Сформирован бюджет на CapEx (bare metal) и OpEx (облако, персонал, лицензии).
- [ ] Сформирован состав команды и оценены ее компетенции, запланировано обучение при необходимости.
- Выбор компонентов и архитектуры:
- [ ] Выбран основной облачный провайдер (AWS, Azure, GCP) для облачных кластеров.
- [ ] Определены спецификации bare metal серверов (CPU, RAM, Storage, Network) для on-premise кластеров.
- [ ] Выбран дистрибутив Kubernetes (RKE/K3s для bare metal, EKS/AKS/GKE для облака).
- [ ] Выбран CNI-плагин (Calico, Cilium) с учетом гибридной среды.
- [ ] Выбрана стратегия хранения данных (Rook/Ceph, Longhorn on-prem; облачные CSI-драйверы).
- [ ] Определена стратегия балансировки нагрузки (MetalLB on-prem, облачные ALB/NLB, Ingress Controllers).
- Проектирование сетевой инфраструктуры:
- [ ] Выделены непересекающиеся IP-диапазоны для всех кластеров и межкластерных соединений.
- [ ] Спроектировано соединение между on-premise и облаком (VPN, Direct Connect/ExpressRoute).
- [ ] Спроектирована единая DNS-стратегия с условной пересылкой.
- [ ] Настроены сетевые политики безопасности (Network Policies) для изоляции подов.
- Развертывание Rancher и кластеров:
- [ ] Развернут управляющий сервер Rancher (on-premise или в выделенном облачном кластере).
- [ ] Развернут первый bare metal Kubernetes кластер (RKE/K3s) и импортирован в Rancher.
- [ ] Развернут первый облачный Kubernetes кластер (EKS/AKS/GKE) и импортирован в Rancher.
- [ ] Настроена интеграция Rancher с провайдером идентичности (LDAP/AD, SSO).
- Настройка безопасности и IAM:
- [ ] Настроены глобальные роли и RBAC в Rancher для управления кластерами.
- [ ] Настроен RBAC в каждом кластере Kubernetes для управления ресурсами.
- [ ] Внедрен механизм управления секретами (Vault, External Secrets Operator).
- [ ] Настроены фаерволы и группы безопасности для изоляции кластеров и сервисов.
- Внедрение CI/CD и GitOps:
- [ ] Выбран инструмент GitOps (ArgoCD, Flux) и настроена его интеграция с репозиторием Git.
- [ ] Разработаны Helm-чарты или Kustomize-конфигурации для приложений.
- [ ] Настроены пайплайны CI/CD для сборки образов и их развертывания в гибридной среде.
- [ ] Внедрен Rancher Fleet для управления развертыванием приложений в масштабе (опционально).
- Мониторинг, логирование и алерты:
- [ ] Развернуты Prometheus и Grafana в каждом кластере или централизованно.
- [ ] Настроены сбор и агрегация логов (Fluentd/Fluent Bit + ELK/Loki).
- [ ] Определены ключевые метрики здоровья и настроены правила алертинга.
- [ ] Настроены каналы доставки алертов (Slack, PagerDuty, email).
- Планирование и тестирование аварийного восстановления (DR):
- [ ] Определены RTO и RPO для всех критически важных сервисов.
- [ ] Внедрен инструмент для бэкапа и восстановления Kubernetes-ресурсов и PV (Velero).
- [ ] Разработан и документирован план действий при аварии.
- [ ] Проведены регулярные учения по аварийному восстановлению.
- Оптимизация и управление расходами:
- [ ] Внедрены инструменты для мониторинга облачных расходов и использования ресурсов.
- [ ] Настроены политики автоматического масштабирования (Cluster Autoscaler, HPA) для эффективного использования облачных ресурсов.
- [ ] Регулярно проводится анализ затрат и поиск возможностей для оптимизации.
- Документация и обучение:
- [ ] Создана полная документация по архитектуре, конфигурации и процедурам эксплуатации.
- [ ] Проведено обучение команды по всем аспектам новой инфраструктуры.
- [ ] Разработаны runbooks для типовых операций и устранения неполадок.
Следуя этому чеклисту, вы сможете создать устойчивую, безопасную и эффективную гибридную инфраструктуру Kubernetes с Rancher, минимизируя риски и максимизируя отдачу от инвестиций.
Расчет стоимости / Экономика
Понимание экономики гибридной инфраструктуры критически важно для принятия стратегических решений. Расчеты могут быть сложными, поскольку включают как капитальные, так и операционные затраты, а также скрытые издержки. Мы рассмотрим примеры расчетов для разных сценариев в контексте 2026 года, учитывая инфляцию и технологические тренды.
Компоненты стоимости
- CapEx (Капитальные затраты) для Bare Metal:
- Серверы: Стоимость физических серверов (CPU, RAM, диски). В 2026 году мощные серверы с 2x 64-ядерными CPU, 512GB RAM, 8x NVMe SSD могут стоить от $15,000 до $30,000 за штуку.
- Сетевое оборудование: Коммутаторы, маршрутизаторы, кабели. От $5,000 до $50,000 в зависимости от масштаба.
- СХД: Если не используется распределенное хранилище на базе локальных дисков, то внешние СХД могут стоить от $20,000 до $100,000+.
- Стойки, PDU, KVM: Небольшие, но необходимые расходы.
- OpEx (Операционные затраты) для Bare Metal:
- Размещение (Co-location): Плата за стойко-место, электроэнергию, охлаждение, доступ в интернет. В 2026 году это может быть от $500 до $1,500 в месяц за стойку с несколькими серверами.
- Персонал: Зарплата системных администраторов, DevOps-инженеров. Это одна из самых больших статей расходов.
- Лицензии/Поддержка: Если используются коммерческие ОС, ПО или enterprise-поддержка Rancher (Rancher Prime), Red Hat OpenShift.
- Обслуживание: Замена вышедших из строя компонентов, гарантийное обслуживание.
- OpEx для Облака:
- Вычислительные ресурсы (vCPU, RAM): Стоимость инстансов (VM). В 2026 году стоимость 1 vCPU/GB RAM может незначительно снизиться, но общая стоимость будет расти с масштабом.
- Хранилище: EBS, Azure Disks, GCP Persistent Disks, S3-подобные хранилища.
- Сетевой трафик: Особенно egress (исходящий трафик). Это одна из самых коварных скрытых статей расходов.
- Управляемые сервисы: Стоимость EKS/AKS/GKE Control Plane, управляемые базы данных, очереди, балансировщики нагрузки.
- Резервирование/Скидки: Reserved Instances, Savings Plans могут значительно снизить стоимость, если нагрузка предсказуема.
- Скрытые расходы:
- Data Egress: Стоимость вывода данных из облака может быть очень высокой ($0.05 - $0.15 за GB).
- Обучение персонала: Инвестиции в повышение квалификации команды.
- Неэффективное использование ресурсов: Перепланировка или недоиспользование ресурсов.
- Простои: Потеря прибыли, репутационный ущерб.
- Безопасность: Затраты на инструменты безопасности, аудит, реагирование на инциденты.
Примеры расчетов для разных сценариев (прогноз на 2026 год)
Для примера возьмем среднюю компанию, которая оперирует нагрузкой, эквивалентной 10-15 современным физическим серверам (например, 200-300 vCPU, 1-2 TB RAM, 20-30 TB NVMe хранилища).
Сценарий 1: Чистый Bare Metal (с Rancher)
Компания инвестирует в собственное оборудование, используя Rancher для упрощения управления Kubernetes. Это выбор для максимального контроля и производительности, где CapEx высок, но OpEx ниже в долгосрочной перспективе.
- CapEx (начальные инвестиции):
- 15 серверов (2x64c/512GB/8xNVMe): 15 * $25,000 = $375,000
- Сетевое оборудование: $30,000
- Стойки, PDU: $10,000
- ИТОГО CapEx: $415,000
- OpEx (ежемесячно):
- Co-location (3 стойки): 3 * $1,000 = $3,000
- Зарплата 2 DevOps-инженеров (с учетом overhead): 2 * $12,000 = $24,000
- Enterprise поддержка Rancher Prime (опционально, $10-20K/год): ~$1,500
- Обслуживание/замена: $1,000
- ИТОГО OpEx: $29,500/месяц
- TCO за 3 года: $415,000 (CapEx) + (36 * $29,500) (OpEx) = $415,000 + $1,062,000 = $1,477,000
Сценарий 2: Чистое Облако (EKS/AKS/GKE)
Компания полностью полагается на управляемые облачные сервисы Kubernetes. Высокая гибкость, но потенциально высокие OpEx на масштабе.
- CapEx: $0
- OpEx (ежемесячно, без RI/Savings Plans):
- 15 инстансов (эквивалент 2x64c/512GB): 15 * $1,500 (например, m6i.16xlarge) = $22,500
- Хранилище (30TB GP3): $1,500
- EKS Control Plane: $730
- Сетевой трафик (egress, 10TB/мес): 10,000 * $0.08 = $800
- Прочие управляемые сервисы (DB, Load Balancer, Monitoring): $3,000
- Зарплата 2 DevOps-инженеров (меньше администрирования, больше автоматизации): 2 * $11,000 = $22,000
- ИТОГО OpEx: $50,530/месяц
- TCO за 3 года: 36 * $50,530 = $1,819,080
- С учетом Reserved Instances/Savings Plans (30-50% экономии): $1,273,356 - $909,540
Сценарий 3: Гибридная Инфраструктура (с Rancher)
Компания размещает 60% нагрузки на bare metal (стабильные, ресурсоемкие сервисы) и 40% в облаке (эластичные, временные). Все управляется через Rancher.
- CapEx (начальные инвестиции для 60% bare metal):
- 9 серверов: 9 * $25,000 = $225,000
- Сетевое оборудование: $20,000
- Стойки, PDU: $5,000
- ИТОГО CapEx: $250,000
- OpEx (ежемесячно):
- Co-location (2 стойки): 2 * $1,000 = $2,000 (bare metal часть)
- Облачные ресурсы (40% от сценария 2, с учетом RI/SP): $50,530 * 0.4 * 0.7 = $14,148 (облачная часть)
- Зарплата 2 DevOps-инженеров (требуется более высокая квалификация): 2 * $13,000 = $26,000
- Enterprise поддержка Rancher Prime: ~$1,500
- Обслуживание bare metal: $600
- Direct Connect/ExpressRoute (для связи): $1,000
- ИТОГО OpEx: $45,248/месяц
- TCO за 3 года: $250,000 (CapEx) + (36 * $45,248) (OpEx) = $250,000 + $1,628,928 = $1,878,928
- Примечание: TCO гибрида может быть выше, чем чистого облака с RI, но дает больше контроля, безопасности и гибкости. Также OpEx в гибриде включает зарплату более квалифицированных инженеров. Если облачная часть более динамична и не использует RI, то гибрид будет значительно дешевле.
Как оптимизировать затраты
- Resource Rightsizing: Регулярно анализируйте потребление ресурсов вашими подами и узлами. Используйте VPA (Vertical Pod Autoscaler) и HPA (Horizontal Pod Autoscaler) для автоматического масштабирования. Не переплачивайте за неиспользуемые ресурсы.
- Reserved Instances / Savings Plans: Если у вас есть предсказуемая базовая нагрузка в облаке, используйте эти механизмы для значительной экономии (до 70%).
- Spot Instances: Для некритичных, прерываемых рабочих нагрузок используйте Spot-инстансы в облаке для максимальной экономии (до 90%).
- Оптимизация сетевого трафика: Минимизируйте egress-трафик. Используйте CDN, кэширование, сжатие данных. Размещайте данные рядом с приложениями.
- Эффективное использование Bare Metal: Используйте Kubernetes для максимальной утилизации ресурсов на физических серверах. Консолидируйте рабочие нагрузки.
- Open Source решения: Максимально используйте бесплатные open-source инструменты (Rancher, Prometheus, Grafana, Velero, Longhorn), чтобы избежать лицензионных платежей.
- Автоматизация: Инвестируйте в автоматизацию (GitOps, CI/CD) для снижения трудозатрат и минимизации человеческих ошибок.
Таблица с примерами расчетов (3-летний TCO)
| Сценарий | Начальный CapEx (Bare Metal) | Ежемесячный OpEx | 3-летний TCO | Основные преимущества |
|---|---|---|---|---|
| Чистый Bare Metal (с Rancher) | ~$415,000 | ~$29,500 | ~$1,477,000 | Высокая производительность, полный контроль, долгосрочная экономия для стабильных нагрузок. |
| Чистое Облако (EKS/AKS/GKE) | $0 | ~$50,530 (без RI/SP) | ~$1,819,080 | Максимальная эластичность, быстрый старт, минимальное администрирование K8s. |
| (Облако с RI/SP) | $0 | ~$35,000 | ~$1,260,000 | Экономия OpEx при предсказуемой облачной нагрузке. |
| Гибрид (K8s с Rancher) | ~$250,000 | ~$45,248 | ~$1,878,928 | Баланс контроля, производительности и эластичности. Безопасность данных, DR. |
Примечание: Эти расчеты являются упрощенными оценками. Реальные цифры могут сильно отличаться в зависимости от конкретных требований, скидок, региональных цен и эффективности эксплуатации. Ключевой вывод: гибридная стратегия не всегда является самой дешевой по TCO, но предлагает оптимальный баланс между всеми критически важными факторами, что в конечном итоге может обеспечить большую ценность для бизнеса.
Кейсы и примеры
Теория важна, но реальные примеры использования гибридной инфраструктуры с Kubernetes и Rancher дают наиболее полное представление о ее преимуществах и вызовах. Рассмотрим несколько реалистичных сценариев из различных индустрий.
Кейс 1: Финтех-стартап с высокочастотным трейдингом и аналитикой
Проблема:
Молодой, быстрорастущий финтех-стартап разработал инновационную платформу для высокочастотного трейдинга (HFT) и предиктивной аналитики. HFT-компонент требовал минимальной задержки (менее 1 мс) для исполнения ордеров, а также максимальной пропускной способности для обработки рыночных данных. При этом аналитический блок, который обрабатывал огромные объемы исторических данных и запускал ресурсоемкие ML-модели, имел непредсказуемые пиковые нагрузки и требовал эластичности. Регуляторные требования обязывали хранить все транзакционные данные на территории страны.
Решение с Rancher:
Компания приняла решение о создании гибридной инфраструктуры на базе Kubernetes, управляемой Rancher.
- On-premise кластер (Bare Metal): Был развернут кластер Kubernetes на выделенных bare metal серверах в собственном дата-центре. Этот кластер использовался для HFT-приложений, баз данных транзакций и первичного хранения чувствительных финансовых данных. Использовался RKE (Rancher Kubernetes Engine) для развертывания K8s, MetalLB для Load Balancer и Calico для CNI. Для хранения данных был выбран Rook/Ceph, обеспечивающий высокую производительность и отказоустойчивость.
- Облачный кластер (AWS EKS): В AWS был развернут кластер EKS для аналитических сервисов, ML-тренировок и публичных API. Этот кластер использовал Cluster Autoscaler для автоматического масштабирования узлов в зависимости от нагрузки.
- Сетевая связность: Между on-premise дата-центром и AWS был настроен AWS Direct Connect для обеспечения низколатентного и высокоскоростного соединения. Это позволяло аналитическим сервисам безопасно обращаться к транзакционным данным с минимальной задержкой, а также передавать агрегированные данные в облако.
- Управление с Rancher: Оба кластера были импортированы и управлялись через единый интерфейс Rancher. Это позволило команде DevOps унифицировать развертывание (через GitOps с ArgoCD), мониторинг (Prometheus/Grafana) и управление доступом (интеграция с корпоративным SSO) для обеих сред. Rancher Fleet использовался для централизованного развертывания и обновления базовых компонентов и приложений в обоих кластерах.
Результаты:
- Оптимизация производительности: HFT-приложения достигли требуемой задержки <1 мс, обеспечивая конкурентное преимущество.
- Эластичность и экономия: Аналитические нагрузки эффективно масштабировались в облаке, оплачивались только используемые ресурсы, что позволило избежать избыточных инвестиций в bare metal для пиков.
- Соответствие регулятору: Чувствительные транзакционные данные оставались на собственных серверах, полностью соответствуя локальным требованиям к суверенитету данных.
- Упрощенное управление: Rancher значительно снизил операционную нагрузку, предоставив единую точку контроля над сложной гибридной средой.
- Улучшенная DR: Бэкапы критически важных данных с bare metal реплицировались в S3-совместимое хранилище в AWS, обеспечивая надежный план аварийного восстановления.
Кейс 2: Крупное медицинское учреждение с EHR-системой
Проблема:
Крупная сеть клиник использовала устаревшую монолитную систему электронных медицинских карт (EHR) на on-premise серверах. Система была критически важна, требовала высокой доступности и соответствовала строгим требованиям HIPAA и другим медицинским стандартам. Клиника также хотела разработать новые, публично доступные сервисы (портал пациентов, телемедицина) с использованием современных технологий, но не могла рисковать безопасностью чувствительных данных.
Решение с Rancher:
Была выбрана стратегия постепенной модернизации и гибридного развертывания.
- On-premise кластер (Bare Metal): Существующие физические серверы были модернизированы и на них развернут кластер Kubernetes (RKE) для хостинга EHR-системы и связанных с ней баз данных. Это обеспечило максимальный контроль над данными пациентов и соответствие HIPAA. Для миграции монолита на контейнеры использовались техники "lift-and-shift" и постепенная декомпозиция на микросервисы.
- Облачный кластер (Azure AKS): В Azure был развернут кластер AKS для новых публичных сервисов (портал пациентов, телемедицинские API, мобильные бэкенды). Эти сервисы не хранили чувствительные данные напрямую, а обращались к EHR-системе через защищенные API.
- Сетевая связность и безопасность: Между on-premise дата-центром и Azure был настроен Azure ExpressRoute для безопасного и высокопроизводительного соединения. Были реализованы строгие сетевые политики и фаерволы, а также OPA Gatekeeper для enforcement'а политик безопасности в Kubernetes.
- Управление с Rancher: Rancher использовался для управления обоими кластерами. Это позволило команде ИТ применять единые политики RBAC, управлять жизненным циклом кластеров и развертывать приложения с использованием GitOps. Особое внимание уделялось мониторингу (Prometheus/Grafana) и аудиту (Fluentd/Loki) для обеспечения соответствия регуляторным требованиям.
Результаты:
- Соответствие и безопасность: Чувствительные данные пациентов оставались под полным контролем on-premise, обеспечивая соответствие HIPAA. Публичные сервисы были изолированы в облаке.
- Модернизация: Клиника смогла модернизировать свою устаревшую EHR-систему, постепенно переводя ее на микросервисную архитектуру, не прерывая работу критически важных сервисов.
- Инновации: Была получена возможность быстро разворачивать новые сервисы для пациентов в облаке, используя современные технологии и гибкость.
- Высокая доступность: On-premise кластер был настроен с избыточностью, а облачный кластер обеспечивал DR для публичных сервисов.
Кейс 3: SaaS-провайдер с целью оптимизации расходов
Проблема:
Средний SaaS-провайдер, предоставляющий B2B-решения, полностью работал в AWS на EKS. По мере роста клиентской базы и увеличения объемов данных, ежемесячные счета за облачные ресурсы (особенно за базы данных, хранилище и egress-трафик) росли экспоненциально, угрожая маржинальности бизнеса. Также наблюдались проблемы с производительностью для некоторых ресурсоемких аналитических отчетов.
Решение с Rancher:
Компания решила перенести часть своих рабочих нагрузок на bare metal, создав гибридную инфраструктуру.
- On-premise кластер (Bare Metal): Компания арендовала несколько стоек в co-location центре и развернула кластер Kubernetes (RKE) на bare metal серверах. Сюда были перенесены основные базы данных (PostgreSQL, ClickHouse), а также сервисы, генерирующие большие объемы данных и требующие высокой производительности для аналитики. Для хранения был выбран Longhorn.
- Облачный кластер (AWS EKS): В AWS остался кластер EKS, где размещались фронтенд-приложения, API-шлюзы, микросервисы, которые имели сильно колеблющуюся нагрузку и требовали быстрой масштабируемости.
- Сетевая связность: Был настроен AWS Direct Connect между co-location центром и AWS, чтобы обеспечить быстрое и экономичное соединение между облачными микросервисами и on-premise базами данных.
- Управление с Rancher: Rancher был развернут как центральный управляющий узел в отдельном, небольшом кластере в AWS. Он использовался для унифицированного управления обоими кластерами, развертывания приложений через GitOps (ArgoCD) и централизованного мониторинга.
Результаты:
- Значительная экономия: Перенос баз данных и высоконагруженных бэкендов на bare metal снизил ежемесячные OpEx на 35-40%, особенно за счет сокращения затрат на облачные базы данных и egress-трафик.
- Улучшенная производительность: Аналитические отчеты стали генерироваться быстрее благодаря прямому доступу к мощному bare metal оборудованию.
- Сохранение гибкости: Фронтенды и API-шлюзы продолжали масштабироваться в облаке, обеспечивая высокую доступность и отзывчивость для пользователей.
- Снижение Vendor Lock-in: Компания получила возможность использовать различные облачные провайдеры в будущем и не зависеть полностью от AWS.
Эти кейсы демонстрируют, что гибридная инфраструктура с Kubernetes и Rancher является мощным инструментом для решения широкого круга бизнес-задач, от оптимизации производительности и соблюдения регуляторных требований до значительной экономии затрат и повышения гибкости.
Инструменты и ресурсы
Для успешного построения и управления гибридной инфраструктурой Kubernetes с Rancher требуется набор проверенных инструментов и доступ к актуальным ресурсам. Вот список ключевых категорий и конкретных примеров, актуальных для 2026 года.
1. Основные платформы
- Rancher: Official Website
Центральная платформа для управления несколькими Kubernetes-кластерами, развернутыми где угодно: на bare metal, в виртуальных машинах, в частных и публичных облаках. Предоставляет унифицированный UI, API и CLI для управления жизненным циклом кластеров, развертывания приложений и обеспечения безопасности.
- Kubernetes (K8s): Official Website
Открытая платформа для автоматизации развертывания, масштабирования и управления контейнеризированными приложениями. Основа всей гибридной стратегии.
- RKE (Rancher Kubernetes Engine): Official Documentation
Сертифицированный дистрибутив Kubernetes от Rancher, идеально подходящий для развертывания на bare metal и в виртуальных машинах, а также для edge-сценариев.
- K3s: Official Website
Легковесный, сертифицированный Kubernetes, оптимизированный для edge, IoT и bare metal окружений с ограниченными ресурсами. Управляется Rancher.
- Облачные K8s-сервисы:
- Amazon EKS: Official Website
- Azure AKS: Official Website
- Google GKE: Official Website
Управляемые сервисы Kubernetes от ведущих облачных провайдеров.
2. Сетевые инструменты (CNI, Load Balancer, Connectivity)
- Calico: Official Website
Популярный CNI-плагин для Kubernetes, обеспечивающий сетевую связанность, политики безопасности и поддержку BGP, что делает его отличным выбором для гибридных и bare metal сред.
- Cilium: Official Website
Еще один продвинутый CNI на базе eBPF, предлагающий высокую производительность, продвинутые сетевые политики и observability.
- MetalLB: Official Website
Реализация балансировщика нагрузки для bare metal Kubernetes кластеров, использующая стандартные протоколы маршрутизации (ARP, BGP).
- Ingress Controllers (NGINX, Traefik, Istio Ingress Gateway):
- NGINX Ingress Controller: Official GitHub
- Traefik: Official Website
- Istio: Official Website (как часть сервис-меша)
Для маршрутизации внешнего HTTP/S трафика к сервисам внутри кластера.
- Инструменты для межсетевого соединения:
- OpenVPN / WireGuard: Для создания безопасных туннелей между on-premise и облаком.
- AWS Direct Connect / Azure ExpressRoute / Google Cloud Interconnect: Выделенные сетевые соединения для высокой производительности и безопасности.
3. Системы хранения данных (CSI)
- Rook (Ceph): Official Website
Оператор Kubernetes, который развертывает и управляет распределенным хранилищем Ceph, превращая кластер Kubernetes в самомасштабируемую, самовосстанавливающуюся систему хранения (блочное, файловое, объектное).
- Longhorn: Official Website
Распределенное блочное хранилище для Kubernetes от Rancher, простое в развертывании и управлении, идеально подходит для bare metal и edge.
- Cloud CSI Drivers:
Драйверы для интеграции Kubernetes с нативными облачными хранилищами.
4. CI/CD и GitOps
- ArgoCD: Official Website
Декларативный, GitOps-ориентированный инструмент непрерывной доставки для Kubernetes. Отлично подходит для управления развертываниями в мульти-кластерных средах.
- Flux: Official Website
Другой популярный GitOps-оператор, который обеспечивает непрерывную доставку и синхронизацию состояния кластера с Git-репозиторием.
- Rancher Fleet: Official Website
Инструмент для централизованного управления флотом из тысяч Kubernetes-кластеров, развертывания приложений и управления конфигурациями в масштабе.
- Jenkins / GitLab CI / GitHub Actions:
Традиционные CI-инструменты для сборки образов, выполнения тестов и запуска GitOps-пайплайнов.
5. Мониторинг, логирование и алертинг
- Prometheus: Official Website
Система мониторинга и алертинга с открытым исходным кодом, де-факто стандарт для мониторинга Kubernetes.
- Grafana: Official Website
Платформа для визуализации метрик, агрегированных Prometheus, а также логов из Loki.
- Loki: Official Website
Система агрегации логов, оптимизированная для Kubernetes, работает по принципу "метрики для логов".
- ELK Stack (Elasticsearch, Logstash, Kibana): Official Website
Мощный стек для сбора, анализа и визуализации логов в масштабе.
- Fluentd / Fluent Bit: Official Website / Official Website
Легковесные агенты для сбора логов из контейнеров и отправки их в централизованное хранилище.
6. Безопасность и управление секретами
- Vault (HashiCorp): Official Website
Инструмент для безопасного хранения и управления секретами, API-ключами, токенами и другими конфиденциальными данными.
- OPA Gatekeeper: Official GitHub
Оператор Kubernetes, который применяет политики Open Policy Agent (OPA) для обеспечения соответствия кластера заданным правилам (например, запрет на запуск привилегированных контейнеров).
- Falco: Official Website
Инструмент для обнаружения угроз безопасности в реальном времени для Kubernetes и контейнеров.
7. Аварийное восстановление (DR)
- Velero: Official Website
Инструмент с открытым исходным кодом для безопасного резервного копирования и восстановления ресурсов Kubernetes и постоянных томов.
8. Полезные ссылки и документация
- Официальная документация Kubernetes: kubernetes.io/docs/
- Официальная документация Rancher: rancher.com/docs/
- CNCF Landscape: landscape.cncf.io
Интерактивная карта проектов Cloud Native Computing Foundation, полезная для поиска инструментов.
- Блоги и сообщества:
- Kubernetes Blog
- Rancher Blog
- Stack Overflow (теги kubernetes, rancher)
- Reddit (r/kubernetes, r/devops)
Использование этого набора инструментов и постоянное обращение к актуальным ресурсам позволит вашей команде эффективно строить, поддерживать и развивать гибридную Kubernetes-инфраструктуру с Rancher.
Troubleshooting (решение проблем)
Даже в самой тщательно спроектированной гибридной инфраструктуре возникают проблемы. Важно иметь четкий алгоритм диагностики и устранения неполадок. Rancher, благодаря своей централизованной панели, часто помогает быстро локализовать источник проблемы, но глубокое понимание Kubernetes и базовой инфраструктуры остается ключевым.
1. Общие проблемы кластера Kubernetes
Проблема: Узел (Node) не готов (NotReady)
Диагностика:
kubectl get nodes
kubectl describe node <node-name>
journalctl -u kubelet -f # На проблемном узле
- Проверьте сетевое подключение узла.
- Убедитесь, что kubelet запущен и не выдает ошибок.
- Проверьте использование ресурсов (CPU, RAM, дисковое пространство) на узле. Возможно, узел перегружен.
- Проверьте CNI-плагин: корректно ли он работает на узле?
Проблема: Под (Pod) находится в состоянии Pending, CrashLoopBackOff, ImagePullBackOff
Диагностика:
kubectl get pods -o wide # Чтобы увидеть на каком узле под
kubectl describe pod <pod-name> -n <namespace>
kubectl logs <pod-name> -n <namespace> # Для CrashLoopBackOff
- Pending: Проверьте ресурсы узлов (CPU/RAM). Убедитесь, что есть доступные узлы с достаточными ресурсами. Проверьте
Eventsвkubectl describe podна наличие проблем с VolumeMounts или Network. - CrashLoopBackOff: Проблема в приложении. Проверьте логи пода. Возможно, некорректная конфигурация, ошибка в коде или нехватка ресурсов.
- ImagePullBackOff: Проблема с доступом к реестру образов. Проверьте имя образа, доступность реестра и учетные данные (ImagePullSecrets).
2. Сетевые проблемы
Проблема: Сервис недоступен извне или между подами
Диагностика:
kubectl get svc <service-name> -n <namespace>
kubectl get ep <service-name> -n <namespace> # Проверить наличие Endpoint'ов
kubectl get networkpolicy -n <namespace> # Если используется CNI с NetworkPolicy
ip route show # На узле, где запущен под
- Проверьте, что у сервиса есть Endpoint'ы (поды, которые он обслуживает, должны быть запущены и здоровы).
- Убедитесь, что Network Policies не блокируют трафик.
- Проверьте настройки Load Balancer (MetalLB on-prem, облачный LB) или Ingress Controller.
- Для межподового взаимодействия: проверьте CNI-плагин и его логи.
- Для межкластерного взаимодействия в гибриде: проверьте VPN/Direct Connect, маршрутизацию, фаерволы.
Проблема: Проблемы с DNS-разрешением между on-premise и облачными кластерами
Диагностика:
kubectl exec -it <pod-name> -n <namespace> -- nslookup <hostname>
- Проверьте конфигурацию CoreDNS в Kubernetes (ConfigMap).
- Убедитесь, что условные пересылки (conditional forwarders) настроены корректно на CoreDNS и на ваших on-premise DNS-серверах.
- Проверьте доступность DNS-серверов через VPN/Direct Connect.
3. Проблемы с хранилищем
Проблема: PersistentVolumeClaim (PVC) завис в состоянии Pending
Диагностика:
kubectl get pvc <pvc-name> -n <namespace>
kubectl describe pvc <pvc-name> -n <namespace>
kubectl get storageclass
- Проверьте, существует ли StorageClass, указанный в PVC.
- Убедитесь, что CSI-драйвер для этого StorageClass развернут и работает в кластере.
- Проверьте логи CSI-контроллера (например,
kubectl logs -f <csi-driver-pod> -n <csi-namespace>). - Для Rook/Ceph или Longhorn: проверьте статус оператора и его подов.
- Для облачных PV: проверьте квоты и доступность облачного хранилища.
4. Проблемы с Rancher
Проблема: Кластер не импортируется или находится в состоянии "Unavailable"
Диагностика:
- Проверьте логи Rancher Server (
kubectl logs -f <rancher-pod> -n cattle-system). - На проблемном кластере: проверьте логи Rancher Agent (
kubectl logs -f <cattle-cluster-agent-pod> -n cattle-system). - Убедитесь в сетевой связанности между Rancher Server и проблемным кластером (порт 443).
- Проверьте, что Rancher Agent имеет достаточные права (RBAC) в кластере.
- Устраните сетевые проблемы.
- Перезапустите Rancher Agent на проблемном кластере.
- В крайнем случае, удалите Rancher Agent с кластера и попробуйте импортировать его заново.
5. Проблемы гибридной среды
Проблема: Задержки или потеря пакетов между on-premise и облачным кластерами
Диагностика:
ping <ip-address-in-other-cluster>
traceroute <ip-address-in-other-cluster>
# На сетевом оборудовании: проверка статистики Direct Connect/ExpressRoute, логов VPN-туннеля.
- Проверьте состояние Direct Connect/ExpressRoute или VPN-туннеля.
- Убедитесь, что фаерволы и группы безопасности (в облаке) не блокируют трафик.
- Проверьте таблицы маршрутизации на всех промежуточных устройствах.
- Оцените пропускную способность соединения. Возможно, она недостаточна для текущей нагрузки.
Когда обращаться в поддержку
- Неустранимые критические сбои: Если кластер полностью неработоспособен, и вы исчерпали все свои диагностические возможности.
- Проблемы с базовым оборудованием: Сбои сервера, сетевого оборудования, СХД на bare metal.
- Проблемы с управляемыми облачными сервисами: Если EKS/AKS/GKE Control Plane ведет себя некорректно, или есть сбои в облачной сети/хранилище.
- Проблемы с Rancher Enterprise Prime: Если у вас есть коммерческая поддержка Rancher, обращайтесь при проблемах с самой платформой Rancher.
- Отсутствие экспертизы: Если проблема выходит за рамки компетенции вашей команды.
Систематический подход к устранению неполадок, хорошая документация и развитые навыки команды DevOps являются основой для поддержания стабильности любой, а тем более гибридной, инфраструктуры.
FAQ
Зачем мне гибридная инфраструктура, если я могу использовать только облако?
Чистое облако отлично подходит для быстрого старта и высокой эластичности, но с ростом масштаба оно может стать очень дорогим, особенно для стабильных, ресурсоемких нагрузок и исходящего трафика. Гибрид позволяет оптимизировать затраты, размещая предсказуемые и критичные к производительности сервисы на своих серверах (bare metal), а эластичные и временные — в облаке. Это также дает больше контроля над данными и облегчает соблюдение регуляторных требований.
Можно ли обойтись без Rancher при управлении гибридным Kubernetes?
Теоретически да, но на практике это крайне сложно. Без Rancher вам придется управлять каждым кластером Kubernetes по отдельности, используя нативные инструменты провайдера или kubectl. Это приведет к значительной операционной нагрузке, рассинхронизации конфигураций, усложнению мониторинга и безопасности. Rancher унифицирует управление, предоставляя единую панель для всех кластеров, независимо от их расположения, что значительно снижает сложность и OpEx.
Какие CNI-плагины лучше всего подходят для гибридных Kubernetes-кластеров?
Для гибридных сред отлично подходят CNI-плагины, поддерживающие сетевые политики и обеспечивающие высокую производительность. Calico и Cilium являются лидерами в этой области. Они могут работать в различных режимах, поддерживают BGP для интеграции с bare metal сетями и позволяют создавать сложные сетевые политики для изоляции трафика между подами, что критично для безопасности в распределенной среде.
Как обеспечить безопасность чувствительных данных в гибридной инфраструктуре?
Ключ к безопасности — это сегментация и контроль. Размещайте самые чувствительные данные и приложения на bare metal серверах, где у вас есть полный контроль над физической и логической безопасностью. Используйте строгие сетевые политики, шифрование данных в покое и при передаче, централизованное управление идентификацией (IAM) через Rancher. Регулярно проводите аудиты и используйте инструменты вроде OPA Gatekeeper для enforcement'а политик безопасности в Kubernetes.
В чем разница между Bare Metal и виртуальными машинами на своем железе?
Bare metal — это использование физических серверов напрямую, без слоя виртуализации. Это обеспечивает максимальную производительность, так как нет накладных расходов гипервизора. Виртуальные машины (VM) на своем железе подразумевают наличие гипервизора (например, VMware vSphere, KVM), который создает виртуальные машины. VM дают большую гибкость в управлении ресурсами, но добавляют небольшие накладные расходы. Для Kubernetes bare metal часто выбирают для самых требовательных к производительности нагрузок.
Как управлять обновлениями Kubernetes в гибридной среде?
Rancher значительно упрощает управление обновлениями. Вы можете использовать Rancher для оркестрации обновлений RKE или K3s кластеров на bare metal, а также для управляемых облачных кластеров (EKS/AKS/GKE). Рекомендуется иметь четкий процесс: сначала обновить dev/test кластеры, провести регрессионное тестирование, затем staging и только потом production. Rancher предоставляет удобный UI для этого, минимизируя ручные операции.
Какие риски существуют при переходе на гибридную инфраструктуру?
Основные риски включают: высокую начальную сложность проектирования и внедрения, значительные инвестиции в квалифицированный персонал, потенциальные проблемы с сетевой интеграцией и управлением данными, а также скрытые затраты на межоблачный трафик. Однако эти риски можно минимизировать тщательным планированием, поэтапным внедрением, использованием надежных инструментов вроде Rancher и обучением команды.
Можно ли использовать разные версии Kubernetes в разных кластерах гибридной среды?
Да, это одна из сильных сторон гибридного подхода с Rancher. Rancher позволяет управлять кластерами с разными версиями Kubernetes. Это полезно для тестирования новых версий, постепенного обновления или поддержания совместимости с устаревшими приложениями. Однако для критически важных приложений рекомендуется стремиться к единообразию версий для упрощения управления и снижения рисков совместимости.
Как масштабировать кластеры на bare metal?
Масштабирование bare metal кластеров требует добавления физических серверов. Это не происходит мгновенно, как в облаке. Процесс включает закупку, установку, настройку ОС и добавление узлов в кластер Kubernetes. Rancher упрощает последний шаг, позволяя легко добавлять новые узлы в существующий RKE/K3s кластер. Для эффективного масштабирования на bare metal требуется тщательное планирование мощностей и автоматизация процесса развертывания новых серверов (например, с помощью PXE-загрузки и Ansible).
Насколько сложна миграция существующих приложений на гибридный Kubernetes?
Сложность миграции зависит от архитектуры приложения. Монолитные приложения могут потребовать значительных усилий для контейнеризации и декомпозиции на микросервисы. Облачно-нативные приложения мигрировать проще. Rancher и Kubernetes предоставляют платформу, но сама миграция требует анализа зависимостей, переписывания конфигураций и тщательного тестирования. Рекомендуется начинать с "lift-and-shift" для простых приложений, а затем постепенно модернизировать их.
Заключение
В 2026 году управление гибридной инфраструктурой, особенно с использованием Kubernetes на bare metal и в облаке в связке с Rancher, является не просто техническим выбором, а стратегической необходимостью для многих организаций. Мы подробно рассмотрели ключевые факторы, такие как стоимость, производительность, безопасность, масштабируемость и управленческие издержки, показав, как гибридный подход позволяет достичь оптимального баланса между ними.
Bare metal предоставляет непревзойденную производительность и полный контроль для критически важных и ресурсоемких рабочих нагрузок, а облако предлагает беспрецедентную эластичность и скорость развертывания для динамичных и масштабируемых сервисов. Rancher выступает в роли связующего звена, унифицируя управление, мониторинг и обеспечение безопасности этих разнородных сред. Это позволяет DevOps-инженерам, разработчикам и техническим директорам сосредоточиться на создании ценности для бизнеса, а не на борьбе со сложностью инфраструктуры.
Мы подчеркнули важность детального планирования сетевой архитектуры, стратегии хранения данных, централизованного IAM, надежного CI/CD и комплексного подхода к аварийному восстановлению. Избегание типичных ошибок, таких как недооценка сложности сети или отсутствие адекватного DR-плана, является залогом успеха. Примеры расчетов TCO показали, что, хотя гибридная инфраструктура может иметь более высокие начальные CapEx, она часто обеспечивает лучшую долгосрочную экономию и стратегическую гибкость по сравнению с чистыми облачными решениями, особенно при наличии стабильных, высоконагруженных компонентов.
Реальные кейсы из финтеха, медицины и SaaS-сектора продемонстрировали, как компании используют гибрид с Rancher для решения конкретных бизнес-задач: от обеспечения низкой задержки для HFT и соблюдения строгих регуляторных требований до значительной оптимизации облачных расходов.
Итоговые рекомендации:
- Планируйте тщательно: Начните с глубокого анализа ваших бизнес-потребностей, требований к производительности, безопасности и бюджета.
- Начните с малого: Не пытайтесь перенести всю инфраструктуру сразу. Выберите пилотный проект или некритичное приложение для начала, чтобы набраться опыта.
- Инвестируйте в команду: Гибридная инфраструктура требует высококвалифицированных специалистов. Обеспечьте обучение и развитие компетенций вашей команды.
- Автоматизируйте все: Используйте GitOps и CI/CD для максимальной автоматизации развертывания, управления и мониторинга.
- Не забывайте о безопасности и DR: Это не опции, а обязательные компоненты вашей стратегии. Регулярно тестируйте свои планы.
- Используйте Rancher: Это критически важный инструмент для унификации управления и снижения операционной нагрузки в гибридной среде.
Следующие шаги для читателя:
- Проведите внутренний аудит вашей текущей инфраструктуры и бизнес-требований.
- Изучите документацию Rancher и Kubernetes, поэкспериментируйте с развертыванием небольшого кластера RKE или K3s.
- Постройте пилотный гибридный сценарий, например, развернув несколько микросервисов в облаке и базу данных на bare metal, управляя ими через Rancher.
- Начните планировать детальную сетевую архитектуру и стратегию хранения данных для вашей будущей гибридной инфраструктуры.
Гибридная инфраструктура с Kubernetes и Rancher — это мощный фундамент для построения гибкой, устойчивой и экономически эффективной IT-среды, способной адаптироваться к быстро меняющимся требованиям современного цифрового мира.