
Как выбрать VPS провайдера в 2026 году: практическое руководство для технических специалистов
Полное руководство по выбору VPS хостинга в 2026 году: типы виртуализации (KVM, OpenVZ, LXC), характеристики CPU и RAM, NVMe storage, сетевая инфраструктура, безопасность, ценообразование и практические сценарии использования. Для DevOps-инженеров, backend-разработчиков и системных администраторов.
Выбор VPS-провайдера — задача, которую многие недооценивают. На первый взгляд всё просто: сравниваешь цены, смотришь на характеристики, выбираешь что-то среднее по стоимости и параметрам. На практике через три месяца обнаруживаешь, что сервер стабильно деградирует под нагрузкой, поддержка отвечает сутками, а IP-адрес попал в блеклисты ещё до того, как ты начал работать.
За последние десять лет я работал с несколькими десятками хостинг-провайдеров — от бюджетных OpenVZ-хостингов за три доллара до enterprise-решений с ценником в тысячи долларов в месяц. Запускал на них всё: от pet-проектов до production-систем с миллионами запросов в сутки. И главный вывод, который сделал — между маркетинговыми обещаниями и реальностью часто лежит пропасть.
Рынок VPS в 2026 году перенасыщен предложениями. Сотни провайдеров, тысячи тарифов, бесконечные «специальные предложения» и скидки. Отличить качественный сервис от маркетинговой обёртки над перегруженным железом — задача нетривиальная. А цена ошибки — потерянное время, недовольные пользователи, потерянные данные и непредвиденные расходы на миграцию.
Типичные ошибки при выборе VPS:
- Ориентация только на цену без понимания, что именно ты покупаешь
- Игнорирование типа виртуализации и его ограничений
- Недооценка важности географии и сетевой связности
- Отсутствие проверки репутации IP-адресов
- Непонимание разницы между «гарантированными» и «выделенными» ресурсами
- Выбор провайдера без тестирования под реальной нагрузкой
Эта статья адресована тем, кто хочет разобраться в вопросе глубже, чем «посмотреть рейтинг на Trustpilot». Если ты DevOps-инженер, backend-разработчик, фаундер SaaS-проекта или системный администратор — здесь найдёшь практические критерии выбора, основанные на реальном опыте эксплуатации.
В статье разберём все ключевые аспекты выбора VPS-провайдера: от типов виртуализации и характеристик железа до репутации IP-адресов и работы с техподдержкой. Отдельно поговорим о том, как тестировать сервер перед production-использованием, что делать при типовых проблемах и как не переплачивать за ресурсы, которые не нужны.
TL;DR — ключевые выводы
- KVM-виртуализация — единственный разумный выбор для production. OpenVZ/LXC подходят только для dev-окружений с жёсткими бюджетными ограничениями
- «Неограниченные» ресурсы не существуют — всегда есть fair use policy, и она сработает в самый неподходящий момент
- Проверяй IP-адреса до покупки — запроси тестовый IP и проверь его репутацию через MXToolbox и AbuseIPDB
- Географическая близость важнее, чем кажется — 100ms latency убивает UX быстрее, чем медленный код
- SLA 99.9% — маркетинговая цифра — важно, как провайдер реагирует на инциденты и компенсирует downtime
- Тестируй IO под нагрузкой — синтетические бенчмарки не показывают поведение при конкуренции за ресурсы
- Читай AUP до покупки — многие use-cases запрещены даже у «лояльных» провайдеров
- Бэкапы храни отдельно — бэкап у того же провайдера — не бэкап
- Начинай с малого — лучше upgrade по мере роста, чем переплачивать за простаивающие ресурсы
Базовая терминология
Прежде чем углубляться в детали, убедимся, что говорим на одном языке. Хостинг-индустрия перегружена терминами, и провайдеры часто используют их по-разному.
VPS (Virtual Private Server) — виртуальный сервер, выделенная часть физического сервера с гарантированными ресурсами. У тебя root-доступ, собственный IP, полный контроль над ОС.
VDS (Virtual Dedicated Server) — по сути то же самое, что VPS. Термин чаще используется в Европе и России. Некоторые провайдеры позиционируют VDS как более «премиальный» вариант с KVM-виртуализацией, но это маркетинг.
Cloud instance / Cloud VM — VPS в облачной инфраструктуре с API-управлением, автоскейлингом и pay-per-minute биллингом. Технически тоже виртуальная машина, но с другой моделью использования.
Dedicated server — физический сервер целиком в твоём распоряжении. Никаких соседей, 100% ресурсов железа.
Colocation — ты приносишь своё железо в датацентр, они обеспечивают питание, охлаждение и сеть. Максимальный контроль, максимальная ответственность.
Bare metal — dedicated server без предустановленной ОС и гипервизора. Термин подчёркивает, что это именно физическое железо, не виртуализация.
Managed vs Unmanaged — managed означает, что провайдер берёт на себя администрирование (обновления, мониторинг, иногда настройку софта). Unmanaged — только инфраструктура, всё остальное твоя ответственность.
Hypervisor / гипервизор — софт, который создаёт и управляет виртуальными машинами. KVM, VMware ESXi, Xen, Hyper-V — примеры гипервизоров.
IOPS (Input/Output Operations Per Second) — количество операций чтения/записи на диске в секунду. Критичная метрика для баз данных и storage-intensive приложений.
Latency — задержка. Время, за которое пакет данных проходит от точки A до точки B. Измеряется в миллисекундах (ms).
Bandwidth — пропускная способность канала. Сколько данных можно передать в единицу времени (Gbps, TB/месяц).
Overselling / оверселлинг — когда провайдер продаёт больше ресурсов, чем физически существует, рассчитывая, что не все клиенты используют их одновременно.
Uptime — процент времени, когда сервис был доступен. 99.9% означает до 8.76 часов downtime в год.
SLA (Service Level Agreement) — соглашение об уровне сервиса. Формальное обязательство провайдера по uptime и компенсациям.
AUP (Acceptable Use Policy) — политика допустимого использования. Документ, определяющий, что можно и нельзя делать на сервере провайдера.
DDoS (Distributed Denial of Service) — распределённая атака на отказ в обслуживании. Попытка сделать сервис недоступным путём перегрузки запросами.
CDN (Content Delivery Network) — сеть доставки контента. Распределённая сеть серверов для ускорения доставки статического контента пользователям.
SSL/TLS — протоколы шифрования для защищённого соединения. HTTPS = HTTP + SSL/TLS.
Понимание этих терминов поможет общаться с провайдерами на одном языке, читать технические спецификации и не попадаться на маркетинговые уловки, которыми изобилует хостинг-индустрия.
Содержание
- Базовая терминология
- Кому подходит VPS, а кому нет
- Архитектура: VPS vs Dedicated vs Cloud
- Виртуализация: KVM, OpenVZ, LXC, VMware
- CPU: vCPU, overselling, NUMA
- RAM: балансировка, swap, OOM
- Storage: NVMe, SATA, RAID, Ceph, ZFS
- Сеть: bandwidth, DDoS-защита, peering
- IP-адреса, ASN и репутация
- География и latency
- SLA: что написано vs что работает
- Сравнительные таблицы
- Практические сценарии использования
- Команды для тестирования сервера
- Диагностика типовых проблем
- Безопасность, abuse и compliance
- Что изменилось в 2024–2026
- Выводы
- FAQ
Кому подходит VPS, а кому нет
VPS — не универсальное решение. Прежде чем сравнивать провайдеров, убедись, что VPS вообще подходит для твоей задачи. Ошибка на этом этапе стоит дороже всего: ты потратишь время на настройку, потом обнаружишь, что архитектура не масштабируется или требования не покрываются, и придётся переделывать.
Разберём типичные сценарии и честно оценим, где VPS работает хорошо, а где создаёт больше проблем, чем решает.
VPS подходит, если:
- Нужен полный контроль над окружением (root-доступ, произвольный софт, кастомные настройки ядра)
- Бюджет ограничен, но требуется изолированная среда
- Нагрузка предсказуема и не имеет резких пиков в 10-100x
- Проект на стадии MVP/раннего production с трафиком до нескольких миллионов запросов в сутки
- Нужен статический IP-адрес для интеграций, email-рассылок, API
- Требуется развернуть специфический стек, который не поддерживается PaaS-платформами
VPS не подходит, если:
- Нагрузка непредсказуема с пиками — облачные провайдеры с автоскейлингом будут дешевле
- Критична отказоустойчивость на уровне инфраструктуры — нужен managed Kubernetes или multi-region deployment
- Нет времени/компетенций на администрирование — managed-сервисы сэкономят больше
- Требуется compliance (PCI DSS, HIPAA, SOC2) — дешевле взять сертифицированный managed-хостинг
- Нужна GPU-ускорение для ML/AI — специализированные облака (Lambda Labs, Vast.ai) выгоднее
Серая зона:
- High-load API — VPS может работать, но требует грамотного capacity planning и готовности к вертикальному масштабированию
- E-commerce — подходит для среднего трафика, но на распродажах лучше иметь запас или CDN
- Базы данных — VPS с NVMe подходит для PostgreSQL/MySQL до определённого размера, но managed DB часто проще в обслуживании
Архитектура: VPS vs Dedicated vs Cloud
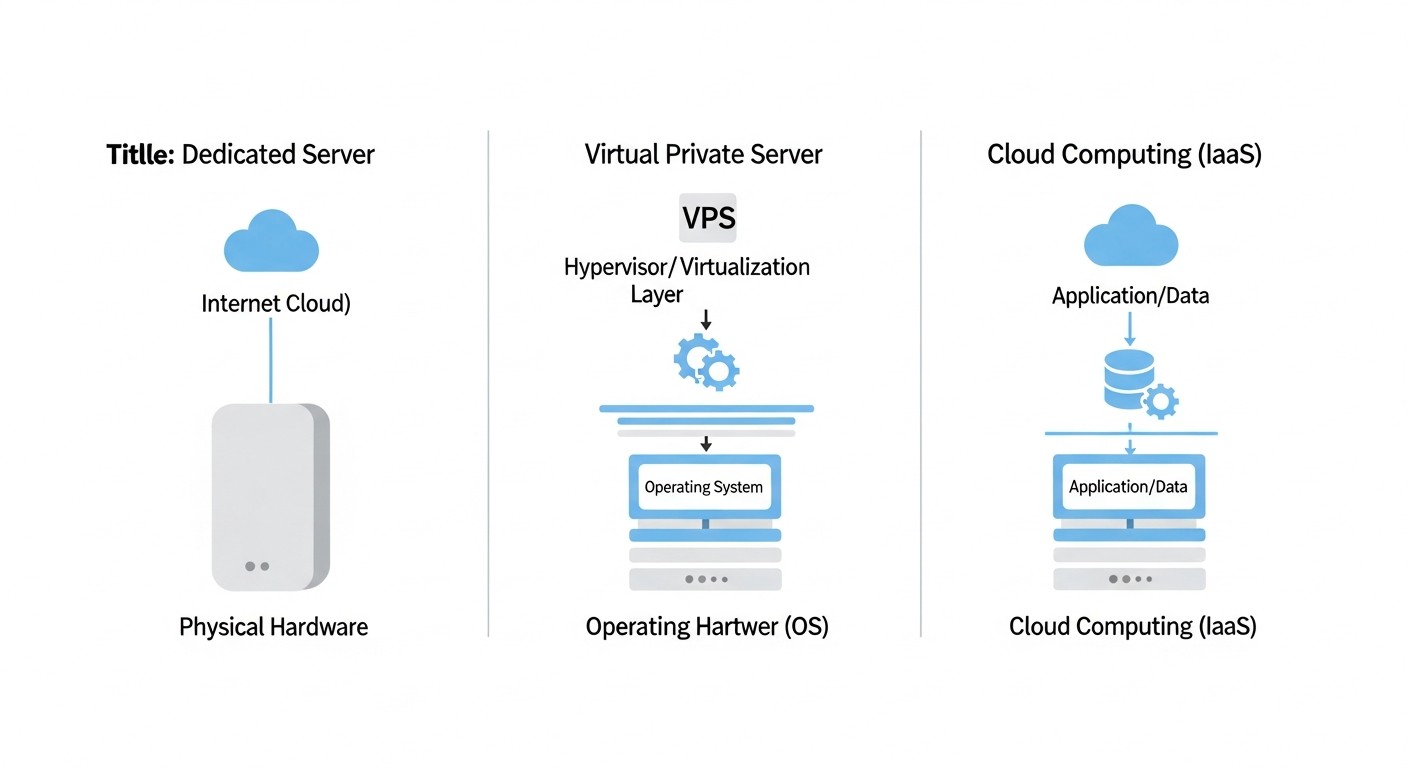
Понимание архитектурных различий — основа осознанного выбора. Маркетинговые материалы часто размывают границы между этими категориями, но технические отличия принципиальны.
VPS (Virtual Private Server)
Физический сервер делится на несколько виртуальных машин с помощью гипервизора. Каждая VM получает выделенную долю ресурсов, но они разделяются на уровне железа.
Что получаешь:
- Изолированное окружение с root-доступом
- Фиксированные лимиты на CPU/RAM/Disk
- Статический IP-адрес
- Относительно низкую стоимость за счёт разделения ресурсов
Компромиссы:
- «Шумные соседи» — другие VM на том же хосте могут влиять на производительность
- IO-производительность зависит от общей нагрузки на storage
- Лимиты сетевой полосы обычно shared
- Overselling — провайдеры часто продают больше ресурсов, чем есть физически
Dedicated Server
Физический сервер целиком в твоём распоряжении. Никаких соседей, никакого гипервизора (если сам не поставишь).
Что получаешь:
- 100% ресурсов железа
- Предсказуемую производительность
- Возможность кастомной конфигурации (при заказе)
- Доступ к IPMI/iLO/iDRAC для out-of-band management
Компромиссы:
- Высокая стоимость (от $50-100/месяц за entry-level)
- Провизионинг занимает часы или дни
- Аппаратные сбои — твоя проблема (если нет SLA на замену)
- Нет мгновенного вертикального масштабирования
Cloud (IaaS)
По сути тоже виртуализация, но с API-driven управлением, автоскейлингом и pay-as-you-go моделью.
Что получаешь:
- Мгновенный провизионинг
- Эластичность — ресурсы масштабируются по требованию
- Богатую экосистему managed-сервисов
- Глобальную инфраструктуру с multi-region deployment
Компромиссы:
- Стоимость выше VPS в 2-5x при постоянной нагрузке
- Vendor lock-in через проприетарные сервисы
- Сложность ценообразования — легко получить неожиданный счёт
- Меньше контроля над железом
«Premature optimization is the root of all evil. But premature infrastructure scaling is the root of all bankruptcy.»
— Адаптация высказывания Дональда Кнута, актуальная для современных стартапов
Когда что выбирать
VPS — оптимален для проектов с предсказуемой нагрузкой и ограниченным бюджетом. Типичные сценарии: веб-приложения, API-сервисы, CI/CD runners, dev/staging окружения.
Dedicated — когда нужна гарантированная производительность и предсказуемость. Базы данных с интенсивным IO, game-серверы, рендер-фермы, highload-проекты с стабильной нагрузкой.
Cloud — когда нагрузка непредсказуема, нужен быстрый глобальный rollout или критична интеграция с managed-сервисами. Стартапы с неопределённым ростом, сезонные проекты, микросервисные архитектуры.
Расчёт Total Cost of Ownership (TCO)
При сравнении вариантов учитывай не только цену сервера:
Прямые затраты:
- Стоимость самого VPS/сервера
- Дополнительные IP-адреса
- Бэкапы (если платные)
- DDoS-защита
- Лицензии (Windows, cPanel и т.д.)
- Превышение трафика
Скрытые затраты:
- Время на администрирование — сколько стоит твой час?
- Время на troubleshooting при проблемах
- Упущенная выгода при даунтайме
- Стоимость миграции, если провайдер не подошёл
Пример расчёта:
VPS за $20/месяц vs managed-хостинг за $50/месяц. Кажется, VPS дешевле на $360/год. Но если тратишь 5 часов в месяц на администрирование при ставке $50/час — это $250/месяц. Managed-хостинг выходит выгоднее.
Считай честно. VPS дешевле в денежном выражении, но требует компетенций и времени.
Виртуализация: KVM, OpenVZ, LXC, VMware
Тип виртуализации — первое, что нужно выяснить при выборе VPS. От него зависит всё: производительность, изоляция, совместимость софта, возможности настройки.
KVM (Kernel-based Virtual Machine)
Полная аппаратная виртуализация на уровне ядра Linux. Каждая VM получает собственное виртуальное железо: CPU, RAM, диск, сетевые адаптеры.
Преимущества:
- Полная изоляция — VM ничего не знает о соседях
- Можно запускать любую ОС: Linux, Windows, FreeBSD, custom kernels
- Поддержка Docker, Kubernetes, вложенной виртуализации
- Честные лимиты ресурсов — получаешь то, за что платишь
- Возможность загрузки своего ISO-образа
Ограничения:
- Выше overhead — часть ресурсов уходит на гипервизор
- Чуть медленнее, чем контейнерная виртуализация (на практике разница минимальна)
- Требует больше RAM для комфортной работы (минимум 512MB, рекомендуется 1GB+)
OpenVZ
Контейнерная виртуализация на уровне ОС. Все контейнеры разделяют одно ядро хоста.
Преимущества:
- Минимальный overhead — почти нативная производительность
- Низкая стоимость для провайдера = дешёвые тарифы
- Быстрый провизионинг
Критические ограничения:
- Только Linux с ядром хоста — нельзя использовать кастомное ядро
- Docker работает с ограничениями или не работает вообще
- Нельзя загрузить iptables-модули, FUSE, некоторые security-модули
- «Шумные соседи» влияют сильнее из-за общего ядра
- Overselling распространён — провайдеры продают 2-3x больше RAM, чем есть физически
- OpenVZ 6 (legacy) имеет устаревшее ядро без современных features
Реальность: OpenVZ в 2026 году — это legacy. OpenVZ 7 (Virtuozzo) частично решает проблемы, но всё равно уступает KVM по изоляции и гибкости. Использовать только для dev-окружений с минимальным бюджетом.
История из практики: клиент купил «VPS 4GB RAM» на OpenVZ за $3/месяц. Через две недели начались случайные OOM-kills при использовании 2GB. Причина — провайдер oversold память, и при конкурентной нагрузке реально доступно было ~2.5GB. После переезда на KVM-хостинг за $8/месяц проблема исчезла. Экономия в $5 обошлась в неделю debugging и недовольных пользователей.
LXC/LXD
Современная контейнерная виртуализация, официально поддерживаемая в ядре Linux.
Преимущества:
- Производительность близка к нативной
- Лучшая изоляция, чем OpenVZ
- Поддержка unprivileged containers
- Активная разработка и современные features
Ограничения:
- Всё ещё общее ядро с хостом
- Docker внутри работает, но с оговорками
- Меньше провайдеров предлагают LXC-based VPS
VMware ESXi
Enterprise-grade гипервизор, используется крупными провайдерами и в корпоративных окружениях.
Преимущества:
- Зрелая технология с 20+ годами развития
- Отличные инструменты управления (vCenter, vSphere)
- Продвинутые features: vMotion, DRS, HA
- Полная изоляция и совместимость с любыми ОС
Ограничения:
- Высокая стоимость лицензий — провайдеры перекладывают на клиентов
- Менее распространён в бюджетном сегменте
- Vendor lock-in на экосистему VMware
Proxmox VE
Популярная open-source платформа виртуализации, поддерживает и KVM, и LXC.
Преимущества:
- Бесплатная лицензия — ниже себестоимость для провайдера
- Гибкость — можно выбирать между KVM и LXC
- Хороший веб-интерфейс и API
- Поддержка Ceph, ZFS, кластеризации
Что важно знать:
- Качество реализации зависит от провайдера
- Proxmox сам по себе не гарантирует хорошую производительность
Как узнать тип виртуализации
Провайдеры не всегда явно указывают тип виртуализации. Вот как проверить после покупки:
# Универсальный способ
sudo dmidecode -s system-product-name
# Для systemd-based систем
systemd-detect-virt
# Проверка /proc
cat /proc/cpuinfo | grep -i hypervisor
cat /sys/class/dmi/id/product_name
# Для OpenVZ
cat /proc/vz/veinfo 2>/dev/null && echo "OpenVZ"
# Через virt-what (нужно установить)
sudo apt install virt-what && sudo virt-what
Типичные результаты:
kvm— KVM/QEMUvmware— VMware ESXixen— Xen HVM или PVopenvz— OpenVZlxc— LXC/LXDmicrosoft— Hyper-V
CPU: vCPU, overselling, NUMA
Характеристики CPU в VPS — одна из самых запутанных тем. Маркетинг активно использует термины «vCPU», «ядра», «cores», но за ними скрываются разные реальности.
Что такое vCPU
vCPU (virtual CPU) — это виртуальный процессор, выделенный виртуальной машине. Один vCPU обычно соответствует одному потоку (thread) физического процессора, но не всегда одному ядру.
Типичные модели:
- 1 vCPU = 1 thread — при включённом Hyper-Threading на Intel или SMT на AMD, 1 vCPU = 1/2 физического ядра
- 1 vCPU = 1 core — честное выделение целого ядра (редко встречается в бюджетном сегменте)
- 1 vCPU = shared time — CPU time делится между VM динамически
Overselling CPU
Overselling — когда провайдер продаёт больше vCPU, чем есть физических ядер/потоков. Это стандартная практика, но её степень варьируется.
Умеренный overselling (2-4x):
- Работает, если клиенты не нагружают CPU одновременно
- Подходит для веб-хостинга, где нагрузка burst-характера
- Деградация заметна при конкурентной нагрузке
Агрессивный overselling (8x+):
- Характерен для ультрабюджетных провайдеров
- CPU steal time может достигать 30-50%
- Непредсказуемая производительность
CPU Steal Time
Steal time — процент времени, когда vCPU был готов выполнять задачи, но гипервизор не дал ему физический CPU (потому что его использовали другие VM).
Как проверить:
# Показывает steal time в реальном времени
top
# Смотри столбец %st в строке Cpu(s)
# Или через vmstat
vmstat 1 10
# Столбец st в секции cpu
# Детальная статистика
mpstat -P ALL 1
# Столбец %steal для каждого vCPU
Интерпретация:
- 0-2% — норма, не влияет на производительность
- 2-10% — умеренный overselling, терпимо для большинства задач
- 10-20% — серьёзная деградация, стоит задуматься о смене провайдера
- >20% — критично, провайдер злоупотребляет overselling
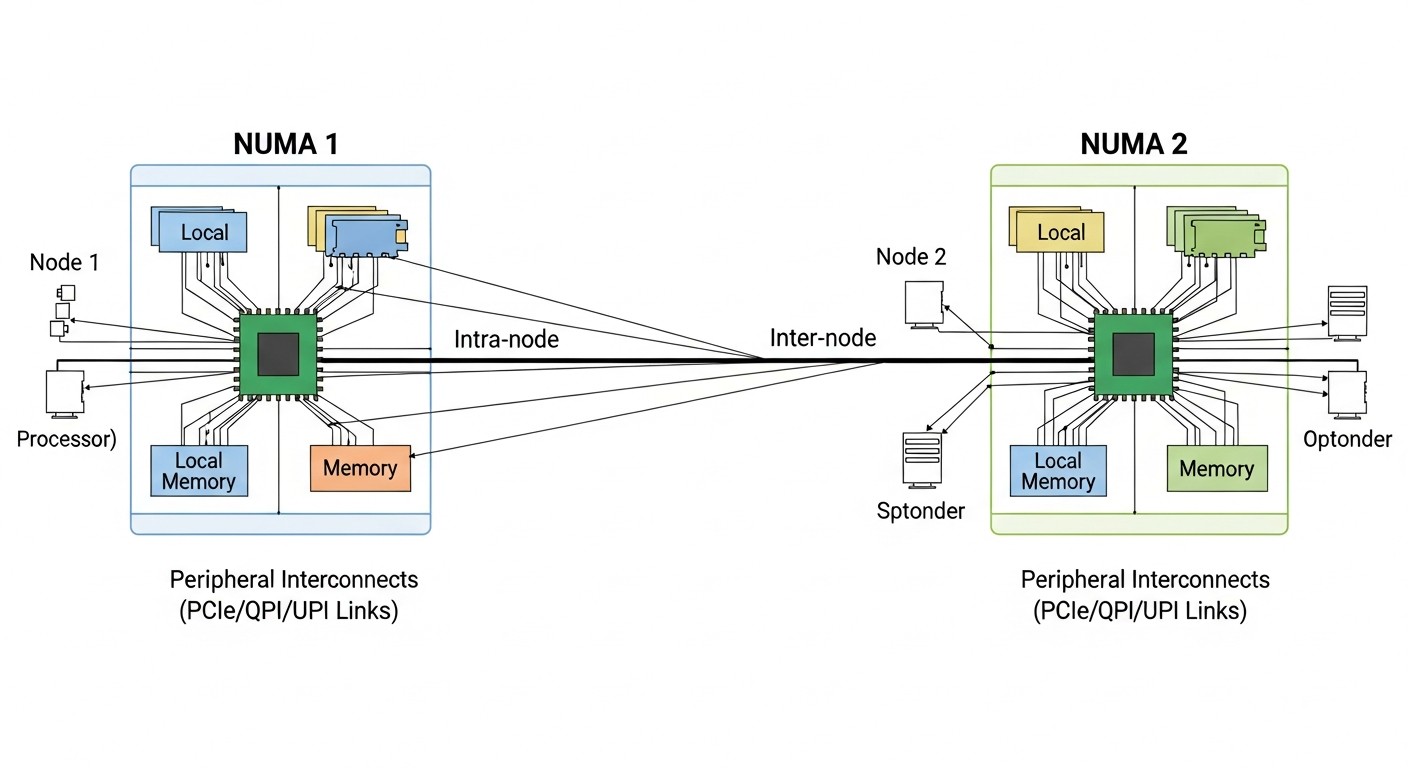
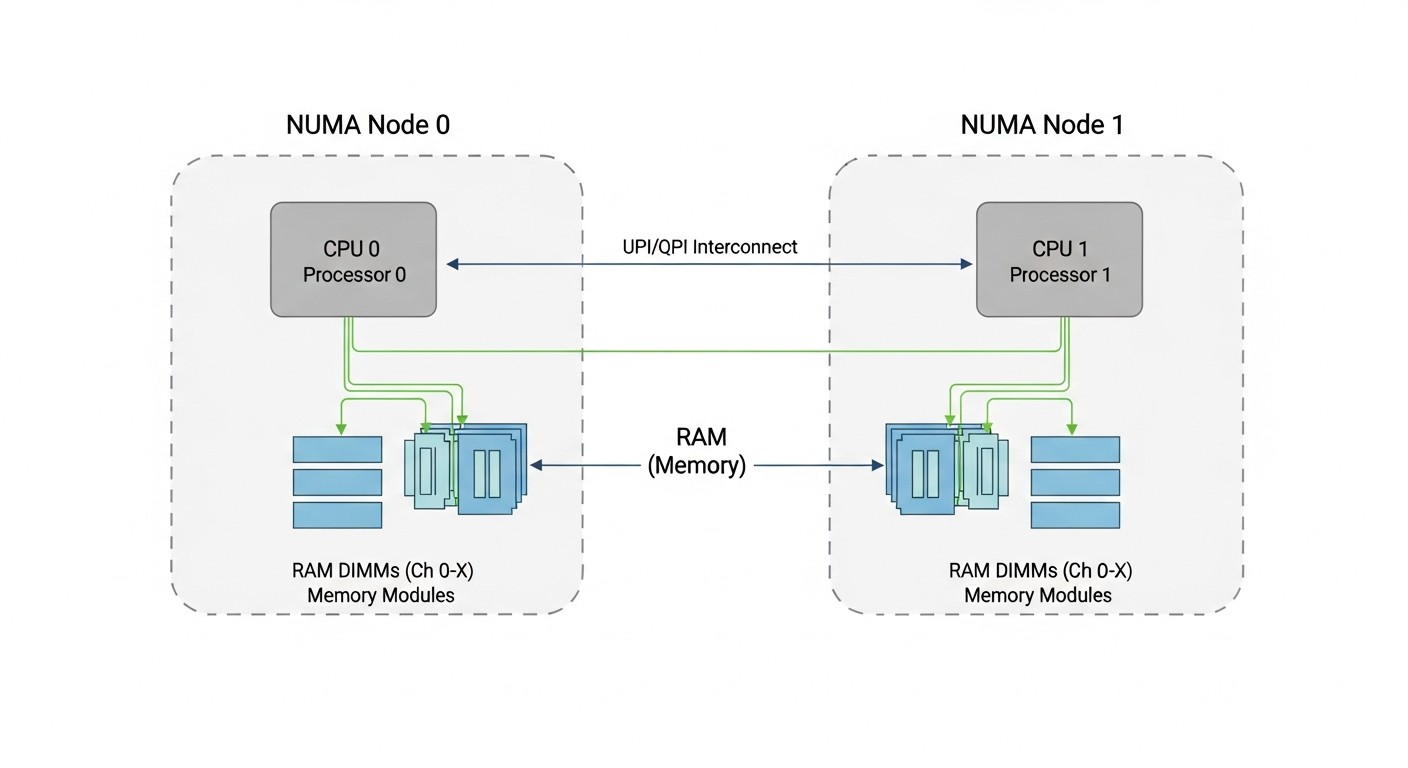
NUMA и топология CPU
NUMA (Non-Uniform Memory Access) — архитектура, где доступ к разным участкам памяти имеет разную латентность. Важно для серверов с несколькими сокетами.
Почему это важно для VPS:
- Если VM размещена на vCPU из разных NUMA-нод, доступ к памяти медленнее
- Хорошие провайдеры пинят VM к одной NUMA-ноде
- Плохие — нет, и ты получаешь деградацию на memory-intensive задачах
Как проверить:
# Топология NUMA
numactl --hardware
# или
lscpu | grep -i numa
# CPU topology
lscpu -e
Модели процессоров
Важно понимать, на каком железе работает твоя VM. Разница между поколениями процессоров существенна.
# Узнать модель CPU
cat /proc/cpuinfo | grep "model name" | head -1
# Детальная информация
lscpu
На что обращать внимание:
- Intel Xeon E5-2600 v1/v2 — legacy железо (2012-2014), низкая IPC, высокое энергопотребление
- Intel Xeon E5-2600 v3/v4 — приемлемо для большинства задач
- Intel Xeon Scalable (Gold, Platinum) — современное железо с высокой IPC
- AMD EPYC 7xx2/7xx3/9xx4 — отличное соотношение цена/производительность
Практический совет: AMD EPYC в 2026 году часто предлагает лучшую производительность за те же деньги. Не бойся выбирать AMD-based VPS.
CPU Performance: что влияет на скорость
Не все vCPU равны. Производительность зависит от множества факторов:
IPC (Instructions Per Clock):
Современные процессоры выполняют больше операций за такт. Один vCPU на AMD EPYC 9004 series значительно быстрее, чем на Intel Xeon E5-2670 (2012 год), даже при одинаковой частоте.
Turbo Boost / Precision Boost:
Процессоры автоматически повышают частоту при низкой нагрузке. На VPS это работает, если гипервизор настроен правильно и соседи не грузят CPU. Разница между base clock и boost может быть 30-50%.
Кэш:
L3 кэш критичен для многих workloads. При overselling несколько VM конкурируют за кэш, что снижает производительность. Это не отображается в steal time, но влияет на latency.
Практический тест CPU:
# Тест single-threaded (важен для latency-sensitive приложений)
sysbench cpu --cpu-max-prime=20000 --threads=1 run
# Тест multi-threaded (throughput)
sysbench cpu --cpu-max-prime=20000 --threads=$(nproc) run
# Сравни результаты с референсными значениями
# Modern EPYC/Xeon Gold single-thread: 2000-2500 events/sec
# Old Xeon E5: 800-1200 events/sec
Когда CPU critical:
- Компиляция кода
- Обработка видео/изображений
- SSL-терминация под нагрузкой
- Сжатие/распаковка
- Некоторые типы database workloads
Когда CPU менее важен:
- Простые веб-сайты (bottleneck обычно IO или сеть)
- Proxy и load balancers
- Storage-intensive приложения
RAM: балансировка, swap, OOM
Память — ресурс, который либо есть, либо нет. В отличие от CPU, где можно «занять» время у соседей, память фиксированная. Или нет?
Memory Ballooning
Некоторые гипервизоры используют memory ballooning — технику динамического перераспределения памяти между VM.
Как работает:
- В VM устанавливается balloon driver
- Гипервизор может «надуть» balloon, забирая память у VM
- Освободившаяся память отдаётся другим VM
Проблемы:
- Если balloon активируется под нагрузкой, приложение теряет память
- Может привести к OOM без явных причин
- Сложно диагностировать —
freeпоказывает меньше памяти, чем куплено
Как проверить:
# Проверить наличие balloon driver
lsmod | grep -i balloon
# Для KVM/QEMU
lsmod | grep virtio_balloon
# Если модуль загружен, ballooning возможен
# Чтобы отключить (если есть root):
rmmod virtio_balloon
# Или через blacklist в /etc/modprobe.d/
Swap и overcommit
Swap — дисковое пространство, используемое как дополнительная память. На SSD/NVMe работает терпимо, на HDD — убивает производительность.
Политики swap:
- Некоторые провайдеры дают фиксированный swap (1-2GB)
- Другие — запрещают swap полностью
- Третьи — не ограничивают, но swap на shared storage = проблемы
# Проверить swap
free -h
swapon --show
# Текущее использование swap
cat /proc/swaps
# Swappiness (насколько агрессивно используется swap)
cat /proc/sys/vm/swappiness
# Рекомендуется 10-30 для VPS с достаточной RAM
OOM Killer
Когда память заканчивается, Linux вызывает OOM Killer — механизм, убивающий процессы для освобождения памяти.
Типичные жертвы:
- Процессы с высоким потреблением памяти
- Недавно запущенные процессы
- Процессы без особых привилегий
Как отследить OOM:
# Проверить логи ядра
dmesg | grep -i "oom\|killed"
# В системных логах
journalctl -k | grep -i "oom\|killed"
# Настроить процесс как «не убивать»
echo -1000 > /proc/PID/oom_score_adj
Memory overcommit
Linux по умолчанию разрешает процессам запрашивать больше памяти, чем есть. Это работает, потому что не все запрошенные страницы используются сразу.
# Текущая политика
cat /proc/sys/vm/overcommit_memory
# 0 = heuristic (default)
# 1 = always overcommit
# 2 = don't overcommit
# Для production часто рекомендуется:
# vm.overcommit_memory = 2
# vm.overcommit_ratio = 80
Реальный объём памяти
Не вся RAM, указанная в тарифе, доступна приложениям.
# Общий объём памяти
free -h
# Детальная статистика
cat /proc/meminfo
# Доступная память (учитывает буферы и кэш)
# Смотри строку "available" в free -h
Что съедает память:
- Ядро — 100-300MB в зависимости от конфигурации
- Systemd и базовые сервисы — 100-200MB
- SSH daemon, crond, и прочее — 50-100MB
- Итого: из 1GB RAM приложениям доступно ~600-700MB
Storage: NVMe, SATA, RAID, Ceph, ZFS
Storage — часто узкое место VPS. Пока CPU и RAM масштабируются относительно линейно, IO упирается в физические ограничения дисков и сетевого storage.
Типы storage в VPS
Local NVMe
Диски NVMe подключены напрямую к серверу, на котором работает VM.
Характеристики:
- IOPS: 50,000-500,000+ (зависит от модели и разделения)
- Latency: 0.1-0.5ms
- Throughput: 1-5+ GB/s
Плюсы:
- Минимальная латентность
- Высокие IOPS для случайного доступа
- Идеально для баз данных
Минусы:
- Данные привязаны к конкретному серверу
- При смерти диска — потеря данных (если нет RAID)
- Миграция VM на другой хост сложнее
Local SATA SSD
SATA SSD на сервере.
Характеристики:
- IOPS: 10,000-80,000
- Latency: 0.5-2ms
- Throughput: 400-550 MB/s
Подходит для большинства задач, кроме high-IOPS workloads.
Network Storage (Ceph, iSCSI, NFS)
Диски хранятся на отдельном кластере storage и подключаются по сети.
Характеристики:
- IOPS: 5,000-50,000 (зависит от backend и сети)
- Latency: 1-5ms
- Throughput: зависит от сети (1-10 GB/s)
Плюсы:
- Данные реплицируются, выше отказоустойчивость
- Live migration VM без простоя
- Гибкое масштабирование объёма
Минусы:
- Выше латентность из-за сети
- Производительность делится между всеми клиентами
- При проблемах с сетью — все VM страдают
HDD
Классические жёсткие диски. В 2026 году встречаются редко, обычно для архивного storage.
Характеристики:
- IOPS: 100-200 (случайный доступ!)
- Latency: 5-15ms
- Throughput: 100-200 MB/s
Когда допустимо:
- Хранение бэкапов
- Файловые серверы с последовательным чтением
- Логи и архивы
Когда НЕ допустимо:
- Базы данных (кроме read-only реплик)
- Веб-приложения с активным IO
- Всё, где важна отзывчивость
RAID конфигурации
| RAID Level | Диски | Отказоустойчивость | Производительность | Эффективность |
|---|---|---|---|---|
| RAID 0 | 2+ | Нет | Высокая | 100% |
| RAID 1 | 2 | 1 диск | Чтение x2 | 50% |
| RAID 5 | 3+ | 1 диск | Хорошая | 67-94% |
| RAID 6 | 4+ | 2 диска | Средняя | 50-88% |
| RAID 10 | 4+ | 1 диск в паре | Высокая | 50% |
Что используют провайдеры:
- Бюджетные: часто RAID 0 или без RAID (JBOD)
- Средние: RAID 5/6 или RAID 10
- Enterprise: Ceph с репликацией x3
Как тестировать storage
# Установить fio (Flexible I/O Tester)
apt install fio
# Тест случайного чтения (4K блоки, типично для БД)
fio --name=random-read --ioengine=libaio --iodepth=32 \
--rw=randread --bs=4k --direct=1 --size=1G \
--numjobs=4 --runtime=60 --group_reporting
# Тест случайной записи
fio --name=random-write --ioengine=libaio --iodepth=32 \
--rw=randwrite --bs=4k --direct=1 --size=1G \
--numjobs=4 --runtime=60 --group_reporting
# Тест последовательного чтения (throughput)
fio --name=seq-read --ioengine=libaio --iodepth=16 \
--rw=read --bs=1M --direct=1 --size=1G \
--numjobs=1 --runtime=60 --group_reporting
# Смешанный тест (70% read, 30% write)
fio --name=mixed --ioengine=libaio --iodepth=32 \
--rw=randrw --rwmixread=70 --bs=4k --direct=1 --size=1G \
--numjobs=4 --runtime=60 --group_reporting
Ориентиры для NVMe VPS:
- Random Read IOPS: 20,000+
- Random Write IOPS: 10,000+
- Sequential Read: 500+ MB/s
- Sequential Write: 300+ MB/s
Если показатели значительно ниже — либо используется SATA/HDD, либо сильный overselling storage, либо network storage под нагрузкой.
ZFS и другие файловые системы
Некоторые провайдеры используют продвинутые файловые системы на хост-уровне:
ZFS:
- Встроенное сжатие (экономит место, может улучшить IO)
- Snapshots и clones (быстрые бэкапы)
- Защита от повреждения данных (checksums)
- Требует много RAM на хосте
Btrfs:
- Copy-on-write, snapshots
- Встроенный RAID
- Менее зрелый, чем ZFS
Для тебя как клиента это обычно прозрачно, но если провайдер упоминает ZFS — это скорее плюс.
SSD Wear и TRIM
SSD имеют ограниченное количество циклов записи. На shared-хостинге интенсивная запись одного клиента может ускорить износ диска.
Что это значит:
- Качественные провайдеры используют enterprise-grade SSD (большее количество циклов)
- TRIM должен быть включён для поддержания производительности
- Бюджетные провайдеры могут использовать consumer SSD с меньшим ресурсом
Как проверить поддержку TRIM:
# На Linux (если диск виден как /dev/vda или /dev/sda)
lsblk --discard
# Non-zero значения в DISC-GRAN и DISC-MAX означают поддержку TRIM
# Вручную запустить TRIM (требует root)
fstrim -v /
Сеть: bandwidth, DDoS-защита, peering
Сетевые характеристики VPS часто игнорируются при выборе, хотя для многих задач они критичнее CPU или RAM.
Bandwidth: что продают и что получаешь
Port Speed vs Bandwidth
- Port speed — физическая скорость порта (1Gbps, 10Gbps)
- Bandwidth — объём трафика в месяц (1TB, 5TB, unlimited)
- Burst — временное превышение лимита скорости
Типичные модели:
- 1Gbps shared, 1TB/месяц — стандарт для бюджетных VPS
- 1Gbps unmetered — без лимита трафика, но скорость shared
- 10Gbps port, 10TB/месяц — для high-bandwidth проектов
Что значит «unmetered»
Unmetered ≠ unlimited. У провайдера всегда есть fair use policy:
- Лимит на среднюю скорость за период
- Ограничение на пиковое использование
- Запрет определённых типов трафика (P2P, streaming)
Читай AUP! «Unmetered 1Gbps» может означать «до 1Gbps, если порт не занят другими клиентами, и не более 50TB/месяц».
Shared vs Dedicated bandwidth
Shared (оверселлинг):
- Несколько VPS делят один uplink
- В пике все 10 клиентов хотят 1Gbps, а uplink — тоже 1Gbps
- Результат: каждый получает ~100Mbps
Dedicated:
- Гарантированная полоса для твоей VM
- Дороже, но предсказуемо
- Обычно доступно на dedicated серверах или premium VPS
DDoS-защита
DDoS-атаки — реальность современного интернета. Даже небольшой сайт может стать жертвой.
Типы защиты:
Null-routing:
- При атаке весь трафик на IP блокируется
- Сайт недоступен, но другие клиенты защищены
- Бесплатно, но бесполезно для тебя
Layer 3/4 mitigation:
- Фильтрация volumetric-атак (SYN flood, UDP flood)
- Работает на уровне сети
- Стандарт для приличных провайдеров
Layer 7 mitigation:
- Фильтрация application-layer атак (HTTP flood, slowloris)
- Требует анализа трафика
- Обычно платная опция или через CDN (Cloudflare, etc.)
На что смотреть:
- Объём защиты (Gbps/Tbps)
- Время реакции на атаку
- Включена ли защита в тариф или за доплату
- Есть ли Layer 7 защита
Peering и connectivity
Качество сети определяется не только скоростью порта, но и маршрутизацией трафика.
Факторы качества:
- Количество пиринговых точек — чем больше, тем короче маршруты
- Tier-1 transit — подключение к крупным магистральным провайдерам
- Local peering — прямые соединения с локальными ISP
- IX (Internet Exchange) — участие в точках обмена трафиком
Как проверить:
# Traceroute до своих пользователей
traceroute -n target.com
mtr -n target.com
# Информация об ASN провайдера
# Через bgp.he.net или bgpview.io
whois AS12345
# Тест скорости до разных регионов
iperf3 -c iperf.server.com
Тестирование сетевой производительности
# Установить speedtest-cli
apt install speedtest-cli
speedtest-cli
# Или через curl (грубая оценка)
curl -o /dev/null -w "%{speed_download}\n" \
http://speedtest.tele2.net/100MB.zip
# iperf3 для точных измерений
# На удалённом сервере:
iperf3 -s
# На VPS:
iperf3 -c remote.server.ip -t 30
# Тест latency
ping -c 100 target.com | tail -1
# Показывает min/avg/max/mdev
BGP и маршрутизация
Для продвинутых пользователей: качество сети определяется не только скоростью порта, но и маршрутизацией трафика через интернет.
Что такое BGP:
BGP (Border Gateway Protocol) — протокол, определяющий, как трафик идёт между сетями. Провайдеры с хорошим BGP-connectivity имеют короткие маршруты до большинства destination.
На что смотреть:
- Количество upstream-провайдеров: больше = лучшая redundancy и выбор маршрутов
- Tier-1 connectivity: прямые соединения с крупнейшими магистралями
- Участие в IX: Internet Exchange Points для локального peering
- Looking glass: инструмент для просмотра BGP-маршрутов провайдера
Как проверить:
- bgp.he.net — информация об ASN, пирингах, upstream
- Looking glass провайдера (если есть)
- traceroute/mtr до ключевых точек
Когда это важно:
- Глобальные сервисы с пользователями по всему миру
- Игровые серверы (критична латентность)
- VoIP и видеоконференции
- Финансовые приложения
Для большинства веб-проектов достаточно проверить latency до основных регионов через ping/mtr.
IP-адреса, ASN и репутация
IP-адрес твоего VPS — это его «паспорт» в интернете. Репутация IP влияет на доставляемость email, доступ к API, и даже на индексацию поисковиками.
Почему репутация IP важна
- Email: письма с «грязного» IP попадают в спам или отклоняются
- API: многие сервисы блокируют IP из «плохих» диапазонов
- CDN: Cloudflare и другие могут требовать CAPTCHA для трафика с подозрительных IP
- SEO: поисковики учитывают репутацию IP при оценке сайта
Откуда берутся проблемы
- Предыдущие владельцы: IP использовался для спама, сканирования, ботнетов
- Соседи по подсети: весь /24 или /16 блок попал в blocklist из-за других клиентов
- ASN провайдера: репутация всей автономной системы низкая
- Регион: некоторые страны и датацентры имеют плохую репутацию по умолчанию
Как проверить репутацию IP
До покупки:
- Запроси тестовый IP у провайдера
- Некоторые провайдеры дают test IP или trial
Сервисы для проверки:
- MXToolbox: mxtoolbox.com/blacklists.aspx
- Spamhaus: check.spamhaus.org
- AbuseIPDB: abuseipdb.com
- VirusTotal: virustotal.com
- IPQualityScore: ipqualityscore.com
- Talos Intelligence: talosintelligence.com/reputation_center
# Проверка в основных blocklists через DNS
# Spamhaus ZEN
dig +short $(echo YOUR_IP | awk -F. '{print $4"."$3"."$2"."$1}').zen.spamhaus.org
# Если возвращает IP (127.0.0.x) — в списке
# Если NXDOMAIN — чисто
ASN и его влияние
ASN (Autonomous System Number) — идентификатор сети провайдера. Репутация ASN влияет на все IP в его диапазонах.
Проблемные категории ASN:
- Bullet-proof хостинги (терпят abuse)
- Дешёвые offshore провайдеры
- Датацентры в странах с высоким уровнем киберпреступности
Как проверить ASN:
# Узнать ASN своего IP
whois YOUR_IP | grep -i origin
# Информация об ASN
# На bgp.he.net:
# https://bgp.he.net/ASXXXXX
# Через командную строку
whois -h whois.radb.net AS12345
Что делать с плохой репутацией
- Запросить смену IP — у большинства провайдеров можно поменять
- Delisting: для email — запросить удаление из blocklist (долго, не всегда успешно)
- Использовать relay: для email — отправлять через сервис типа SendGrid, Mailgun
- Сменить провайдера: если проблема системная (плохой ASN)
География и latency

Физическое расположение сервера напрямую влияет на user experience. Скорость света — жёсткое ограничение, которое не обойти кодом.
Latency: почему важна
Грубые ориентиры (round-trip time):
- Внутри региона (Москва-Москва): 1-5ms
- Между городами (Москва-Петербург): 10-20ms
- Между странами (Москва-Франкфурт): 30-50ms
- Между континентами (Москва-Нью-Йорк): 100-150ms
- Через океан (Европа-Азия): 150-300ms
Влияние на приложения:
- Каждый HTTP-запрос включает минимум 1 RTT (часто 2-3)
- Страница с 50 ресурсами × 100ms RTT = заметное торможение
- API с последовательными запросами деградирует линейно
- Realtime-приложения (чаты, игры) требуют <50ms
Как выбирать локацию
Правило простое: сервер должен быть близко к пользователям.
Типичные сценарии:
- Российская аудитория: Москва, Санкт-Петербург, Франкфурт (хороший peering с RU)
- Европейская аудитория: Франкфурт, Амстердам, Лондон, Париж
- США: Эшберн (Virginia), Чикаго, Лос-Анджелес
- Азия: Сингапур, Токио, Гонконг
- Глобальная аудитория: CDN + несколько точек присутствия
Проверка latency до покупки
Многие провайдеры предоставляют looking glass или test IP:
# Ping до тестового IP провайдера
ping -c 100 test.ip.provider.com
# MTR для анализа маршрута
mtr -r -c 100 test.ip.provider.com
# Проверить, где находится IP
curl ipinfo.io/YOUR_TEST_IP
Юридические аспекты
География влияет на юридикцию:
- EU: GDPR обязателен для данных европейцев
- US: CLOUD Act — возможен доступ властей
- Offshore (BVI, Panama): меньше регуляции, но хуже репутация
- Russia: требования по локализации данных (ФЗ-152)
Советы по выбору
- Определи, где большинство твоих пользователей
- Тестируй latency из точек присутствия пользователей
- Учитывай юридические требования
- Для глобальных проектов — CDN обязателен, сервер может быть где угодно
SLA: что написано vs что работает
SLA (Service Level Agreement) — формальное обещание провайдера по доступности. Но между 99.9% на бумаге и 99.9% в реальности — пропасть.
Что значат цифры
| SLA | Downtime/год | Downtime/месяц | Реальность |
|---|---|---|---|
| 99% | 3.65 дня | 7.3 часа | Неприемлемо для production |
| 99.9% | 8.76 часа | 43 минуты | Стандарт для большинства |
| 99.95% | 4.38 часа | 22 минуты | Enterprise-уровень |
| 99.99% | 52 минуты | 4.3 минуты | Требует redundancy |
Что обычно НЕ входит в SLA
- Плановые работы: maintenance windows не считаются downtime
- DDoS-атаки: часто исключены или с оговорками
- Проблемы клиента: OOM, kernel panic по твоей вине
- Сетевые проблемы за пределами датацентра: магистральные провайдеры
- Force majeure: пожары, наводнения, отключения электричества
Компенсации
Типичная компенсация: credit на будущие услуги.
Пример:
- <99.9% → 10% credit
- <99.5% → 25% credit
- <99% → 50% credit
Реальность: credit за $5 VPS после 2 часов даунтайма — $0.50. Твои убытки от недоступности сервиса — несопоставимо больше.
На что смотреть
- Как измеряется downtime: внутренний мониторинг провайдера vs внешний
- Процедура claim: нужно ли самому заявлять о даунтайме
- Исключения: читай мелкий шрифт
- История инцидентов: status page, форумы, Reddit
- Реакция на инциденты: как быстро отвечают, как коммуницируют
Практический подход
SLA — это baseline, не гарантия. Строй архитектуру, которая переживёт даунтайм провайдера:
- Регулярные бэкапы в другое место
- Готовность развернуть сервис у другого провайдера
- Мониторинг с внешних точек
- CDN для кэширования статики
Оценка качества поддержки
Качество техподдержки критично. Проблемы случаются, и от скорости реакции зависит многое.
До покупки:
- Посмотри отзывы о поддержке (не о сервисе в целом)
- Задай pre-sales вопрос и оцени время и качество ответа
- Проверь наличие status page с историей инцидентов
Каналы поддержки (от лучшего к худшему):
- Live chat с техническими специалистами — быстро и эффективно
- Телефон — для срочных вопросов, но не все провайдеры предлагают
- Ticket system — стандарт, время ответа варьируется от минут до дней
- Email — обычно медленнее, чем тикеты
- Только форум/KB — минимальная поддержка, проблемы решаешь сам
Red flags в поддержке:
- Шаблонные ответы, не относящиеся к вопросу
- Время ответа более 24 часов на простые вопросы
- Отсутствие технической компетенции (рекомендуют перезагрузить на любой вопрос)
- Агрессивный upselling вместо решения проблемы
- Нет эскалации для сложных проблем
Тест поддержки:
После покупки открой тикет с техническим вопросом средней сложности (не «как изменить пароль», но и не «помогите настроить кластер»). Оцени время ответа, понимание вопроса и качество решения. Это покажет, чего ожидать при реальных проблемах.
Сравнительные таблицы
VPS vs Dedicated vs Cloud
| Критерий | VPS | Dedicated | Cloud (AWS/GCP/Azure) |
|---|---|---|---|
| Стоимость (базовая) | $5-50/мес | $50-500/мес | $20-200/мес |
| Провизионинг | Минуты | Часы-дни | Секунды-минуты |
| Изоляция | Виртуальная | Физическая | Виртуальная |
| Масштабирование | Вертикальное | Ограничено | Авто-скейлинг |
| Предсказуемость цены | Высокая | Высокая | Низкая |
| Производительность | Переменная | Стабильная | Переменная |
| Кастомизация железа | Нет | Да | Ограничена |
| Managed сервисы | Минимум | Минимум | Богатые |
KVM vs OpenVZ vs LXC
| Критерий | KVM | OpenVZ 7 | LXC/LXD |
|---|---|---|---|
| Тип виртуализации | Полная | Контейнерная | Контейнерная |
| Изоляция | Высокая | Средняя | Средняя-высокая |
| Поддержка ОС | Любая | Только Linux | Только Linux |
| Custom kernel | Да | Нет | Нет |
| Docker | Полная | Ограничена | Да |
| Overhead | 2-5% | <1% | <1% |
| Типичная цена | $5-10+ | $2-5 | $3-8 |
| Production-ready | Да | Условно | Да |
Managed vs Unmanaged
| Критерий | Unmanaged | Managed |
|---|---|---|
| Установка ОС | Ты | Провайдер |
| Обновления безопасности | Ты | Провайдер |
| Мониторинг | Ты | Провайдер |
| Бэкапы | Ты | Часто включены |
| Техподдержка | Только инфра | Инфра + софт |
| Цена | Ниже | Выше 2-5x |
| Для кого | DevOps, sysadmins | Нет времени на ops |
Практические сценарии использования
Сценарий 1: SaaS MVP
Контекст: Стартап запускает MVP SaaS-продукта. Бюджет ограничен, команда из 2-3 разработчиков, ожидаемая нагрузка — несколько сотен активных пользователей.
Требования:
- Web-приложение на Node.js/Python/Ruby
- PostgreSQL database
- Redis для сессий и кэша
- Background workers
- SSL, static files через CDN
Рекомендуемая конфигурация:
- VPS: KVM, 4 vCPU, 8GB RAM, 100GB NVMe
- Локация: ближе к целевой аудитории
- Бюджет: $20-50/месяц
Архитектура:
# Всё на одном сервере (monolith deployment)
├── nginx (reverse proxy, SSL termination)
├── app (Node.js/Python/Ruby)
├── PostgreSQL
├── Redis
└── background workers (Sidekiq/Celery)
# Docker Compose для управления
docker-compose up -d
Чего избегать:
- Преждевременного разделения на микросервисы
- Kubernetes на одном сервере (overhead не оправдан)
- Managed DB за $50+/месяц, когда traffic минимален
Сценарий 2: High-load API
Контекст: API-сервис обрабатывает 10M+ запросов в сутки. Критична латентность и стабильность.
Требования:
- Sub-100ms response time (p99)
- Обработка 500+ RPS постоянно, пики до 2000 RPS
- Высокая доступность
- Возможность масштабирования
Рекомендуемая конфигурация (вариант 1 — VPS):
- Application servers: 2-4 × KVM, 8 vCPU, 16GB RAM, NVMe
- Database: Dedicated server или managed DB
- Load balancer: HAProxy/nginx на отдельной VM или managed LB
- Бюджет: $200-500/месяц
Рекомендуемая конфигурация (вариант 2 — Hybrid):
- Application: Cloud (auto-scaling)
- Database: Dedicated server с NVMe RAID
- Cache: Managed Redis или self-hosted cluster
Архитектура:
┌─────────────────┐
│ Load Balancer │
└────────┬────────┘
│
┌───────────────────┼───────────────────┐
▼ ▼ ▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ App Server 1 │ │ App Server 2 │ │ App Server N │
└────────┬────────┘ └────────┬────────┘ └────────┬────────┘
│ │ │
└───────────────────┴───────────────────┘
│
┌───────────────────┴───────────────────┐
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ Redis Cluster │ │ PostgreSQL (HA)│
└─────────────────┘ └─────────────────┘
Ключевые метрики для мониторинга:
- Request latency (p50, p95, p99)
- Error rate
- CPU steal time на каждом node
- Database connections и query time
- Memory pressure
Сценарий 3: Scanner / Crawler / Worker nodes
Контекст: Система для сканирования web-ресурсов, парсинга данных или background processing. Нужно много outbound соединений.
Требования:
- Много исходящего трафика
- Множество одновременных соединений
- Устойчивость к блокировкам
- Минимальная стоимость за единицу работы
Специфические риски:
- IP могут попасть в blocklist
- Провайдер может расценить активность как abuse
- Rate limiting на target-ресурсах
Рекомендуемый подход:
- Много мелких VPS: 5-10 × 1 vCPU, 1GB RAM вместо одного большого
- Разные провайдеры/ASN: снижает риск одновременной блокировки
- Proxy rotation: residential или datacenter proxies
- Бюджет: $5-10 × количество nodes
Архитектура:
┌─────────────────┐
│ Control Plane │ (координация, очереди)
│ (1 VPS) │
└────────┬────────┘
│
│ Redis/RabbitMQ
│
┌────────┴────────┐
│ │
▼ ▼
┌─────────┐ ┌─────────┐ ┌─────────┐
│ Worker 1│ │ Worker 2│ │ Worker N│ (разные провайдеры/регионы)
│(VPS #1) │ │(VPS #2) │ │(VPS #N) │
└─────────┘ └─────────┘ └─────────┘
Важно: внимательно читай AUP провайдера. Многие запрещают scanning/scraping в любой форме.
Сценарий 4: E-commerce магазин
Контекст: интернет-магазин на WooCommerce/Magento/OpenCart с каталогом 5000+ товаров и трафиком 1000-5000 посетителей в день.
Требования:
- Стабильная работа под постоянной нагрузкой
- Быстрая загрузка страниц товаров
- Обработка платежей (критична безопасность)
- Пиковые нагрузки при распродажах
- SSL обязателен
Рекомендуемая конфигурация:
- VPS: 4 vCPU, 8GB RAM, 100GB NVMe
- Stack: nginx + PHP-FPM + MySQL/MariaDB + Redis
- CDN: Cloudflare для статики и защиты
- Бюджет: $30-60/месяц за VPS + CDN (бесплатный план достаточен)
Критичные оптимизации:
- OPcache для PHP
- Redis для сессий и object cache
- Оптимизация изображений
- Database indexing
- Lazy loading для каталога
На распродажи:
- Временный upgrade VPS (если провайдер позволяет)
- Или подключение дополнительного сервера с load balancing
- Aggressive caching для страниц категорий
Сценарий 5: Telegram/Discord бот
Контекст: бот для мессенджера с базой пользователей до 10K активных.
Требования:
- Работа 24/7 без перерывов
- Быстрый отклик на команды
- Хранение данных пользователей
- Минимальный бюджет
Рекомендуемая конфигурация:
- VPS: 1 vCPU, 1GB RAM, 20GB SSD
- Stack: Python/Node.js + SQLite или PostgreSQL
- Бюджет: $5-10/месяц
Особенности:
- Боты обычно легковесные, не требуют много ресурсов
- Важна стабильность, а не производительность
- Systemd для автозапуска и перезапуска при падениях
- Простейший мониторинг (проверка процесса)
# /etc/systemd/system/mybot.service
[Unit]
Description=Telegram Bot
After=network.target
[Service]
Type=simple
User=botuser
WorkingDirectory=/home/botuser/bot
ExecStart=/usr/bin/python3 bot.py
Restart=always
RestartSec=10
[Install]
WantedBy=multi-user.target
Сценарий 6: CI/CD Runner
Контекст: self-hosted runner для GitHub Actions/GitLab CI для экономии на платных минутах.
Требования:
- Быстрая сборка проектов
- Docker для контейнерных билдов
- Достаточно места для кэша
- Изоляция между билдами
Рекомендуемая конфигурация:
- VPS: 4+ vCPU, 8GB+ RAM, 100GB+ NVMe (для кэша)
- Обязательно: KVM-виртуализация (Docker требует)
- Бюджет: $20-50/месяц
Расчёт окупаемости:
GitHub Actions стоит $0.008/минута для Linux-раннеров. VPS за $30/месяц окупается при использовании более 3750 минут/месяц (62 часа). Если билдишь часто — self-hosted выгоднее.
Настройка:
# Установить Docker
curl -fsSL https://get.docker.com | sh
usermod -aG docker gitlab-runner
# Установить GitLab Runner
curl -L https://packages.gitlab.com/install/repositories/runner/gitlab-runner/script.deb.sh | bash
apt install gitlab-runner
# Зарегистрировать runner
gitlab-runner register
Команды для тестирования сервера
После получения доступа к VPS — первым делом протестируй его. Вот набор команд для всесторонней проверки.
Базовая информация о системе
# Информация о CPU
lscpu
# Модель процессора
cat /proc/cpuinfo | grep "model name" | head -1
# Объём памяти
free -h
# Информация о дисках
lsblk
df -h
# Тип виртуализации
systemd-detect-virt
# Версия ядра
uname -r
# Информация об ОС
cat /etc/os-release
CPU Benchmark
# Установить sysbench
apt install sysbench
# Тест CPU (single-threaded)
sysbench cpu --cpu-max-prime=20000 run
# Тест CPU (multi-threaded, все ядра)
sysbench cpu --cpu-max-prime=20000 --threads=$(nproc) run
# Проверка steal time под нагрузкой
# В одном терминале:
sysbench cpu --cpu-max-prime=50000 --threads=$(nproc) --time=60 run
# В другом:
vmstat 1
# Смотри столбец st
Ориентиры (events per second, single thread):
- Modern Xeon/EPYC: 1500-2500
- Old Xeon (E5 v2): 800-1200
- Если значительно ниже — либо старое железо, либо сильный overselling
Memory Benchmark
# Тест памяти (sysbench)
sysbench memory --memory-block-size=1K --memory-total-size=10G run
sysbench memory --memory-block-size=1M --memory-total-size=10G run
# Или через dd (грубая оценка)
dd if=/dev/zero of=/dev/null bs=1M count=10000
Disk I/O Benchmark
# Установить fio
apt install fio
# Быстрый тест (создаст файл test.fio)
# Random read (типично для БД)
fio --name=randread --ioengine=libaio --iodepth=16 \
--rw=randread --bs=4k --direct=1 --size=256M \
--numjobs=4 --runtime=30 --group_reporting --filename=test.fio
# Random write
fio --name=randwrite --ioengine=libaio --iodepth=16 \
--rw=randwrite --bs=4k --direct=1 --size=256M \
--numjobs=4 --runtime=30 --group_reporting --filename=test.fio
# Sequential read (throughput)
fio --name=seqread --ioengine=libaio --iodepth=16 \
--rw=read --bs=1M --direct=1 --size=1G \
--numjobs=1 --runtime=30 --group_reporting --filename=test.fio
# Удалить тестовый файл
rm test.fio
# Простой тест через dd
# Write
dd if=/dev/zero of=testfile bs=1M count=1024 conv=fdatasync
# Read
dd if=testfile of=/dev/null bs=1M
rm testfile
Network Benchmark
# Speedtest
apt install speedtest-cli
speedtest-cli
# Или через curl
# Download speed
curl -o /dev/null http://speedtest.tele2.net/1GB.zip
# Latency до ключевых точек
ping -c 20 8.8.8.8
ping -c 20 1.1.1.1
# MTR для анализа маршрутов
apt install mtr
mtr -r -c 100 google.com
# iperf3 (если есть второй сервер)
# На сервере: iperf3 -s
# На VPS: iperf3 -c server.ip -t 30
Комплексный скрипт проверки
#!/bin/bash
# vps-benchmark.sh
echo "=== System Info ==="
echo "CPU: $(grep "model name" /proc/cpuinfo | head -1 | cut -d: -f2)"
echo "Cores: $(nproc)"
echo "RAM: $(free -h | grep Mem | awk '{print $2}')"
echo "Disk: $(df -h / | tail -1 | awk '{print $2}')"
echo "Virtualization: $(systemd-detect-virt)"
echo "Kernel: $(uname -r)"
echo ""
echo "=== CPU Steal Time (10 sec) ==="
vmstat 1 10 | tail -9 | awk '{sum+=$16} END {print "Avg steal: " sum/9 "%"}'
echo ""
echo "=== Quick Disk Test ==="
dd if=/dev/zero of=testfile bs=1M count=256 conv=fdatasync 2>&1 | tail -1
rm testfile
echo ""
echo "=== Memory ==="
free -h
echo ""
echo "=== Network Latency ==="
ping -c 10 8.8.8.8 | tail -1
Диагностика типовых проблем
Проблема: «VPS тормозит»
Самая частая жалоба. Причин может быть десяток.
Шаг 1: Определить, что именно тормозит
# Общая картина
top
htop
# Load average
uptime
# Если load > количество CPU — система перегружена
# Что занимает CPU
ps aux --sort=-%cpu | head -10
# Что занимает память
ps aux --sort=-%mem | head -10
Шаг 2: Проверить CPU steal time
vmstat 1 10
# Столбец st > 10% — проблема на стороне хостера
Шаг 3: Проверить IO
iostat -x 1 10
# %util близко к 100% — диск перегружен
# await > 10ms на SSD — проблема
# Какой процесс грузит диск
iotop
Шаг 4: Проверить память
free -h
# Если available близко к 0 и swap используется активно — OOM скоро
dmesg | grep -i oom
# Если есть записи — OOM killer работал
Возможные решения:
- High steal → жалоба провайдеру или смена тарифа/провайдера
- High IO → оптимизация приложения, добавление RAM для кэша, upgrade на NVMe
- High CPU → профилирование кода, масштабирование
- High memory → оптимизация, увеличение RAM
Проблема: «Диск медленный»
Диагностика:
# Текущая нагрузка на диск
iostat -x 1
# IOPS и latency
# await — среднее время отклика
# r_await, w_await — отдельно чтение/запись
# Если await высокий:
# - На SSD > 5ms — проблема
# - На HDD > 20ms — ожидаемо под нагрузкой
# Проверить, кто грузит
iotop -o
# Тест производительности
fio --name=test --rw=randread --bs=4k --direct=1 \
--size=256M --numjobs=4 --runtime=30 --group_reporting
Частые причины:
- Network storage под нагрузкой
- Соседи по хосту грузят shared storage
- HDD вместо заявленного SSD
- Приложение делает избыточные IO (логирование, sync)
Проблема: «Packet loss»
Диагностика:
# Базовый тест
ping -c 100 8.8.8.8
# Смотри % packet loss и mdev (jitter)
# Детальный анализ маршрута
mtr -r -c 100 problem-host.com
# Смотри Loss% на каждом хопе
# Traceroute
traceroute -n problem-host.com
Интерпретация MTR:
- Loss на промежуточных хопах может быть нормой (ICMP rate limiting)
- Loss на конечном хосте — реальная проблема
- Loss начинается с определённого хопа и продолжается — проблема на этом участке
Действия:
- Loss внутри сети провайдера → тикет в поддержку
- Loss на магистралях → мало что можешь сделать, попробовать Cloudflare/CDN
- Loss только до определённых destination → проблема на их стороне
Проблема: «Сервер заблокировали»
Внезапное отключение сервера без предупреждения.
Частые причины:
- Abuse report (жалоба на спам, сканирование, атаки)
- Нарушение AUP (prohibited content, services)
- Неоплата
- Compromised сервер (входит в ботнет)
Что делать:
- Проверить email — обычно приходит уведомление
- Зайти в панель управления — там может быть информация
- Открыть тикет в поддержку
- Не паниковать — часто можно восстановить доступ после объяснений
Профилактика:
- Обновлять софт (избегать компрометации)
- Не запускать ничего, что может сгенерировать abuse reports
- Читать и соблюдать AUP
- Держать бэкапы в другом месте
Безопасность, abuse и compliance
Понимание правил игры — критично. Провайдер может отключить сервер за нарушения, и формально будет прав.
Acceptable Use Policy (AUP)
AUP — документ, определяющий, что можно и нельзя делать на сервере.
Типично запрещено везде:
- Распространение malware
- DDoS-атаки
- Спам
- Хостинг нелегального контента (CP, терроризм)
- Нарушение авторских прав (пиратство)
Часто запрещено:
- Port scanning (даже «безобидный»)
- Torrent trackers / seedboxes
- Cryptocurrency mining
- Mass mailing (даже opt-in)
- Open resolvers / open relays
- Adult content (у некоторых провайдеров)
Серая зона:
- Web scraping / crawling
- VPN / proxy для третьих лиц
- Tor exit nodes
- IRC bouncers
Abuse Reports
Abuse report — жалоба на активность с твоего IP.
Как приходят:
- Автоматически (fail2ban, DDoS detection)
- От других провайдеров
- От правообладателей (DMCA)
- От пользователей (спам, атаки)
Что происходит:
- Провайдер получает жалобу
- Пересылает тебе с требованием ответить
- Ты должен объяснить и устранить причину
- При игнорировании или повторных нарушениях — отключение
Как реагировать:
- Отвечать быстро (24-48 часов)
- Расследовать реальную причину
- Устранить и сообщить о принятых мерах
- Если жалоба ложная — объяснить с доказательствами
DMCA
DMCA (Digital Millennium Copyright Act) — американский закон о копирайте, но применяется глобально через хостинг-провайдеров.
Типичный процесс:
- Правообладатель находит нарушение
- Отправляет DMCA notice провайдеру
- Провайдер обязан убрать контент или переслать тебе
- Ты можешь подать counter-notice, если считаешь жалобу необоснованной
Практика:
- Большинство провайдеров удаляют контент без разбирательств
- Повторные DMCA → отключение аккаунта
- Offshore-хостинги часто игнорируют DMCA (но имеют другие проблемы)
Compliance (GDPR, etc.)
GDPR (EU):
- Если обрабатываешь данные граждан EU — GDPR обязателен
- Хостинг в EU упрощает compliance, но не гарантирует его
- Нужен DPA (Data Processing Agreement) с провайдером
Требования по локализации (Россия, Китай, etc.):
- Некоторые страны требуют хранить данные граждан внутри страны
- Проверяй применимость к твоему сервису
Рекомендации по безопасности VPS
# Базовая настройка после получения сервера
# 1. Обновить систему
apt update && apt upgrade -y
# 2. Создать non-root пользователя
adduser myuser
usermod -aG sudo myuser
# 3. Настроить SSH
# В /etc/ssh/sshd_config:
# PermitRootLogin no
# PasswordAuthentication no
# Port 2222 (опционально, изменить порт)
# 4. Настроить firewall
ufw default deny incoming
ufw default allow outgoing
ufw allow 2222/tcp # SSH
ufw allow 80/tcp
ufw allow 443/tcp
ufw enable
# 5. Установить fail2ban
apt install fail2ban
systemctl enable fail2ban
# 6. Настроить автоматические обновления безопасности
apt install unattended-upgrades
dpkg-reconfigure -plow unattended-upgrades
Расширенные меры безопасности
Базовая настройка — это минимум. Для production-серверов рекомендуются дополнительные меры.
SSH hardening:
# /etc/ssh/sshd_config дополнительные настройки
MaxAuthTries 3
ClientAliveInterval 300
ClientAliveCountMax 2
AllowUsers myuser
Protocol 2
Мониторинг изменений файлов:
# Установить AIDE (Advanced Intrusion Detection Environment)
apt install aide
aideinit
# Проверка изменений
aide --check
Лимиты на ресурсы:
# /etc/security/limits.conf
# Ограничить количество процессов для пользователя
* soft nproc 1000
* hard nproc 2000
Логирование:
- Настрой централизованный сбор логов (rsyslog, Loki)
- Логи должны храниться отдельно от сервера (на случай компрометации)
- Настрой алерты на подозрительные события (неудачные логины, sudo использование)
Регулярные задачи:
- Еженедельно проверять обновления безопасности
- Ежемесячно ревьюить открытые порты и сервисы
- Периодически проверять логи на аномалии
- Тестировать восстановление из бэкапов
Что изменилось в 2024–2026
Хостинг-индустрия не стоит на месте. Несколько трендов, которые стоит учитывать.
Рост популярности ARM
ARM-серверы (Ampere Altra, AWS Graviton) становятся mainstream:
- Лучшее соотношение производительность/ватт
- Дешевле при comparable workloads
- Большинство софта уже поддерживает ARM64
Практический совет: если твой стек совместим с ARM — рассмотри ARM-based VPS. Часто на 20-30% дешевле при той же производительности.
NVMe стал стандартом
SATA SSD в новых предложениях встречается всё реже. NVMe — новый baseline.
Что это значит: если провайдер до сих пор продаёт «SSD VPS» без уточнения — вероятно, это SATA. Спрашивай явно.
Консолидация рынка
Крупные игроки скупают мелких провайдеров. Это не хорошо и не плохо, но влияет на:
- Качество поддержки (может ухудшиться)
- Ценовую политику
- AUP и условия обслуживания
Рост цен на энергоносители
Энергетический кризис 2022-2023 привёл к повышению цен на хостинг в Европе. Тренд частично сохраняется:
- EU-хостинги дорожают
- Датацентры в регионах с дешёвой энергией (Скандинавия, US) становятся привлекательнее
IPv4 исчерпание
IPv4-адреса продолжают дорожать:
- Многие провайдеры берут доплату за дополнительные IPv4
- Некоторые предлагают NAT IPv4 + публичный IPv6
- IPv6-only хостинг становится реальностью для некоторых use-cases
Практический совет: если твой сервис не требует IPv4 (например, бэкенд за CDN) — IPv6-only может сэкономить деньги.
AI/ML workloads
Спрос на GPU-серверы вырос экспоненциально:
- Дефицит мощностей
- Высокие цены
- Появление специализированных провайдеров (Lambda Labs, Vast.ai, RunPod)
Примечание: информация о ценах и доступности GPU меняется быстро. Проверяй актуальность на момент чтения.
Усиление регуляции
Регуляторное давление на хостинг-индустрию растёт:
- Усиление требований по KYC (Know Your Customer) — анонимные VPS становятся редкостью
- Ответственность провайдеров за контент клиентов
- Санкционное давление — некоторые регионы ограничены
- Требования по локализации данных в разных странах
Практический вывод: заранее проверяй, сможешь ли оплатить услуги и будет ли твой use-case разрешён в выбранной юрисдикции.
Containerization как стандарт
Docker и контейнеры стали mainstream:
- Большинство современных приложений распространяются как Docker images
- Deployment через docker-compose стал стандартом для небольших проектов
- Это делает KVM-виртуализацию ещё более предпочтительной (Docker нормально работает только на KVM)
Serverless и VPS
Serverless не убил VPS, а занял свою нишу:
- Serverless хорош для event-driven, спорадических задач
- VPS остаётся предпочтительным для постоянных workloads
- Гибридные архитектуры: core на VPS + serverless для peaks
Выводы
Выбор VPS провайдера — решение, которое будет влиять на твой проект месяцы или годы. Несколько финальных рекомендаций.
Чему научились
- Виртуализация имеет значение. KVM — разумный выбор для production. OpenVZ/LXC — только для dev или при жёстких бюджетных ограничениях.
- Характеристики на бумаге ≠ реальность. 4 vCPU при 20% steal time — это не 4 vCPU. 100GB SSD на перегруженном Ceph — это не быстрый storage.
- Репутация IP критична для email, API-интеграций и многого другого. Проверяй до покупки.
- География определяет latency. Никакая оптимизация кода не компенсирует 200ms до сервера.
- SLA — это minimum, не гарантия. Строй архитектуру, которая выживет при даунтайме провайдера.
- Читай AUP. То, что кажется тебе безобидным, может быть запрещено.
Разумный подход к выбору
- Определи требования: CPU, RAM, storage type, bandwidth, latency, uptime
- Отфильтруй по типу виртуализации: KVM для production
- Выбери географию: близко к пользователям
- Проверь репутацию: IP, ASN, отзывы
- Протестируй: используй trial или самый дешёвый тариф для тестов
- Масштабируйся постепенно: начни с малого, upgrade по мере роста
Где чаще всего ошибаются
- Выбирают по цене, игнорируя всё остальное
- Не тестируют перед production deployment
- Не читают AUP и получают блокировку
- Не делают бэкапы в другое место
- Переплачивают за ресурсы, которые не используются
- Недоплачивают и получают unstable service
- Оптимизируют infrastructure вместо кода
- Не мониторят и узнают о проблемах от пользователей
- Игнорируют безопасность до первого взлома
- Не документируют настройки и забывают через месяц
Типичная эволюция инфраструктуры
Большинство проектов проходят похожий путь:
Стадия 1: Старт
- Shared-хостинг или самый дешёвый VPS
- Всё на одном сервере
- Минимальная настройка
- Бэкапы? Какие бэкапы?
Стадия 2: Рост
- Upgrade до более мощного VPS
- Появляется мониторинг
- Настраиваются бэкапы
- Оптимизация базы данных и кэширование
Стадия 3: Масштабирование
- Отделение базы данных на отдельный сервер
- CDN для статики
- Возможно, несколько app-серверов с load balancer
- Более серьёзный мониторинг и алертинг
Стадия 4: Enterprise
- Multi-region deployment
- Kubernetes или аналог
- Managed services где оправдано
- Выделенные команды для ops
Не прыгай через стадии. Kubernetes для MVP с 100 пользователями — overkill. Один VPS для сервиса с миллионом DAU — проблема. Расти вместе с проектом.
Признаки хорошего провайдера
На что обращать внимание при оценке:
- Прозрачность: чётко указаны характеристики железа, тип виртуализации, условия SLA
- Status page: публичная история инцидентов показывает зрелость процессов
- Документация: качественная KB и tutorials
- Технический блог: показывает экспертизу и культуру компании
- Адекватная поддержка: технически грамотные ответы в разумные сроки
- Стабильные цены: частые «скидки 90%» — признак проблем
- Возраст: провайдеры, работающие 5+ лет, обычно надёжнее новичков
- Сообщество: активные форумы, Discord, Telegram — признак живого сервиса и заинтересованности в клиентах
Мышление при выборе инфраструктуры
Инфраструктура — это trade-off между стоимостью, производительностью, надёжностью и удобством.
- Стоимость: сколько готов платить?
- Производительность: какие метрики критичны?
- Надёжность: что случится при даунтайме?
- Удобство: сколько времени готов тратить на ops?
Идеального решения не существует. Есть решение, оптимальное для твоей конкретной ситуации. И оно может измениться по мере роста проекта.
Финальный чеклист перед выбором
Перед принятием решения ответь себе на эти вопросы:
- Что за проект? Web-сайт, API, бот, game-сервер, что-то специфичное?
- Где пользователи? Определяет выбор географии.
- Какая нагрузка? Текущая и ожидаемая через 6-12 месяцев.
- Какой бюджет? Включая скрытые расходы на администрирование.
- Какие компетенции? Сам управляешь или нужен managed?
- Какие риски? Что случится при даунтайме? Потере данных?
- Какие требования compliance? GDPR, локализация данных, etc.
- Какой запас нужен? На рост, на пики, на форс-мажор.
С ответами на эти вопросы выбор становится значительно проще и осознаннее. Ты сможешь отфильтровать 90% вариантов сразу, а оставшиеся — протестировать на практике.
FAQ
Какой VPS лучше для начинающих?
KVM-based VPS с managed control panel (типа SolusVM, Virtualizor) и адекватной поддержкой. Не гонись за ценой — $5-10/месяц за 2GB RAM, 2 vCPU, 40GB SSD — разумный старт для большинства проектов.
Чем отличается VPS от VDS?
Маркетинговыми терминами. Технически оба термина означают виртуальный сервер. Некоторые провайдеры используют VDS для обозначения KVM-виртуализации, VPS — для OpenVZ. Но это не стандарт. Всегда уточняй тип виртуализации.
Можно ли запускать Docker на VPS?
На KVM — да, без ограничений. На OpenVZ — с оговорками (зависит от версии и настроек хоста). На LXC — обычно да, но проверяй.
Сколько RAM нужно для веб-сервера?
Зависит от стека и нагрузки. Минимум для комфортной работы: 1GB для простого сайта, 2-4GB для приложения с БД, 4-8GB для нагруженного сервиса. Лучше начать с меньшего и мониторить использование.
Что такое overselling и как его обнаружить?
Overselling — продажа больше ресурсов, чем есть физически. Признаки: высокий CPU steal time (>5%), непредсказуемая производительность IO, деградация под нагрузкой. Тестируй в пиковые часы.
Как проверить скорость VPS?
CPU: sysbench cpu. Storage: fio или dd. Network: speedtest-cli, iperf3. Memory: sysbench memory. Не забывай проверять steal time через vmstat.
Что делать, если IP в блеклисте?
Запросить смену IP у провайдера. Если это системная проблема (весь ASN в blocklist) — рассмотреть смену провайдера. Для email использовать relay-сервисы (SendGrid, Mailgun).
VPS или облако для стартапа?
Для MVP с предсказуемой нагрузкой — VPS дешевле и проще. Для продукта с непредсказуемым ростом или нуждающегося в managed-сервисах — облако может быть оправдано, несмотря на более высокую стоимость.
Как часто нужно делать бэкапы VPS?
Зависит от RPO (Recovery Point Objective). Для большинства проектов: ежедневные бэкапы БД, еженедельные полные бэкапы. Критичные данные — чаще. Храни бэкапы в другом месте, не у того же провайдера.
Можно ли доверять «безлимитному» трафику?
Нет. Всегда есть fair use policy. Типично «безлимитный» означает 10-50TB/месяц при average usage. Читай AUP и ToS.
Панели управления VPS: что выбрать
Панель управления — интерфейс между тобой и сервером. Выбор зависит от задач, бюджета и уровня технической подготовки.
Панели от провайдера (клиентские)
Большинство VPS-провайдеров предоставляют собственную панель или стандартные решения:
SolusVM
Классическая панель для VPS-хостинга, до сих пор широко используется.
- Управление VM: start/stop/reboot/reinstall
- VNC/noVNC консоль для аварийного доступа
- Статистика использования ресурсов
- Управление ISO-образами (на KVM)
Virtualizor
Современная альтернатива SolusVM с лучшим интерфейсом.
- Поддержка KVM, Xen, OpenVZ, LXC
- API для автоматизации
- Встроенные бэкапы
- Более дружелюбный UI
Проприетарные панели
Многие крупные провайдеры разрабатывают собственные решения. Качество варьируется от отличного до ужасного. Смотри скриншоты и отзывы перед покупкой.
Серверные панели (ставятся на VPS)
Если провайдер даёт только SSH-доступ, можно установить панель самостоятельно.
Бесплатные варианты
HestiaCP — форк VestaCP, активно развивается.
- Web-сервер (nginx/Apache)
- Почтовый сервер
- DNS
- Базы данных (MySQL/PostgreSQL)
- Управление доменами и SSL
- Потребление: ~200-300MB RAM
# Установка HestiaCP
wget https://raw.githubusercontent.com/hestiacp/hestiacp/release/install/hst-install.sh
bash hst-install.sh
Webmin/Virtualmin — классика, работает стабильно.
- Универсальное управление Linux-сервером
- Virtualmin добавляет хостинг-функции
- Модульная архитектура
- Потребление: ~100-200MB RAM
CyberPanel — панель на базе OpenLiteSpeed.
- Высокая производительность веб-сервера
- Встроенный LSCache
- Email, DNS, FTP
- Docker-интеграция
Платные варианты
cPanel/WHM — индустриальный стандарт.
- Полный набор функций для хостинга
- Огромная экосистема плагинов
- Отличная документация
- Цена: от $15/месяц (после бесплатного периода)
- Потребление: 1-2GB RAM минимум
Plesk — основной конкурент cPanel.
- Поддержка Windows и Linux
- Современный интерфейс
- WordPress Toolkit
- Цена: от $10/месяц
DirectAdmin — легковесная альтернатива.
- Меньше потребление ресурсов
- Простой интерфейс
- Цена: от $5/месяц
Когда панель не нужна
Для многих задач панель управления — лишний overhead:
- API-серверы и backend-сервисы
- Docker/Kubernetes deployments
- Специализированные приложения
- Когда есть CI/CD и Infrastructure as Code
В этих случаях достаточно SSH + базовая настройка.
Сравнение панелей управления
| Панель | Цена | RAM требования | Для кого |
|---|---|---|---|
| HestiaCP | Бесплатно | ~300MB | Небольшие проекты, веб-хостинг |
| Webmin | Бесплатно | ~150MB | Универсальное управление Linux |
| CyberPanel | Бесплатно | ~400MB | Высокопроизводительный веб-хостинг |
| cPanel | от $15/мес | ~1.5GB | Профессиональный хостинг |
| Plesk | от $10/мес | ~1GB | Windows/Linux хостинг |
| DirectAdmin | от $5/мес | ~500MB | Лёгкая альтернатива cPanel |
Рекомендация: для VPS с 2GB RAM и меньше — HestiaCP или Webmin. Для 4GB+ можно рассматривать cPanel/Plesk, если функционал оправдан.
Бэкапы и Disaster Recovery
Бэкапы — единственная защита от потери данных. Надеяться на провайдера — ошибка.
Правило 3-2-1
Классическая стратегия бэкапов:
- 3 копии данных
- 2 разных типа носителей
- 1 копия offsite (в другом месте)
Для VPS это означает:
- Данные на сервере (primary)
- Локальные бэкапы на том же VPS или у провайдера
- Внешние бэкапы (другой провайдер, S3, Backblaze)
Что бэкапить
Критично:
- Базы данных (MySQL, PostgreSQL, MongoDB)
- Пользовательские данные и uploads
- Конфигурационные файлы
- SSL-сертификаты и ключи
- Crontab и scheduled tasks
Желательно:
- Логи (для расследований)
- Email (если хостишь сам)
- Custom-скрипты
Не нужно:
- Системные файлы (можно восстановить из образа)
- Кэши и временные файлы
- Package managers cache
Инструменты для бэкапов
Для баз данных
# MySQL/MariaDB
mysqldump -u root -p --all-databases --single-transaction > all_databases.sql
# С компрессией
mysqldump -u root -p dbname | gzip > backup_$(date +%Y%m%d).sql.gz
# PostgreSQL
pg_dumpall -U postgres > all_databases.sql
# Одна база
pg_dump -U postgres dbname > dbname.sql
Для файлов
# rsync на удалённый сервер
rsync -avz --delete /var/www/ backup@remote:/backups/www/
# С SSH
rsync -avz -e ssh /data/ user@backup-server:/backups/
# tar архив
tar -czvf backup_$(date +%Y%m%d).tar.gz /var/www /etc/nginx /etc/letsencrypt
Специализированные инструменты
restic — современный инструмент с дедупликацией и шифрованием.
# Инициализация репозитория
restic init --repo /backup/restic
# Бэкап
restic -r /backup/restic backup /var/www /etc
# Восстановление
restic -r /backup/restic restore latest --target /restore
borgbackup — похож на restic, эффективная дедупликация.
# Инициализация
borg init --encryption=repokey /backup/borg
# Бэкап
borg create /backup/borg::backup-{now} /var/www /etc
# Список архивов
borg list /backup/borg
Облачные хранилища
# rclone — универсальный инструмент для облаков
# Поддерживает S3, Backblaze B2, Google Drive, и десятки других
# Настройка
rclone config
# Синхронизация
rclone sync /backup/ remote:bucket-name/
# Копирование с прогрессом
rclone copy --progress /data/ remote:bucket/data/
Автоматизация бэкапов
# /etc/cron.d/backup
# Ежедневный бэкап в 3:00
0 3 * * * root /usr/local/bin/backup.sh >> /var/log/backup.log 2>&1
# Пример скрипта /usr/local/bin/backup.sh
#!/bin/bash
set -e
DATE=$(date +%Y%m%d)
BACKUP_DIR=/backup
# Бэкап MySQL
mysqldump --all-databases | gzip > $BACKUP_DIR/mysql_$DATE.sql.gz
# Бэкап файлов
tar -czf $BACKUP_DIR/www_$DATE.tar.gz /var/www
# Отправка в облако
rclone copy $BACKUP_DIR remote:backups/
# Удаление старых локальных бэкапов (старше 7 дней)
find $BACKUP_DIR -type f -mtime +7 -delete
echo "Backup completed: $DATE"
Проверка бэкапов
Бэкап, который не проверен — не бэкап. Регулярно тестируй восстановление:
- Разворачивай на тестовом сервере
- Проверяй целостность архивов
- Убедись, что приложение работает после восстановления
- Измеряй RTO (время восстановления)
Disaster Recovery Plan
Документ, описывающий что делать при различных сценариях:
- Сбой приложения — перезапуск, откат до предыдущей версии
- Сбой базы данных — восстановление из бэкапа, point-in-time recovery
- Сбой VPS — развёртывание на новом сервере
- Сбой провайдера — переезд к альтернативному провайдеру
Для каждого сценария:
- Последовательность действий
- Контакты ответственных
- Доступы и credentials (в защищённом месте)
- Ожидаемое время восстановления
Мониторинг VPS
Без мониторинга ты узнаёшь о проблемах от пользователей. С мониторингом — раньше.
Что мониторить
Системные метрики
- CPU: использование, load average, steal time
- Memory: used, available, swap usage
- Disk: использование, IOPS, latency
- Network: bandwidth in/out, packet loss, latency
Метрики приложений
- Web-сервер: requests/sec, response time, error rate
- База данных: queries/sec, slow queries, connections
- Приложение: специфичные метрики (очереди, jobs, etc.)
Доступность (Uptime)
- HTTP(S) endpoints
- TCP-порты
- SSL-сертификаты (срок действия)
- DNS
Инструменты мониторинга
Внешний мониторинг (SaaS)
UptimeRobot — бесплатный для базовых проверок.
- До 50 мониторов бесплатно
- HTTP, Ping, Port, Keyword
- Уведомления: email, Slack, Telegram
BetterUptime, Pingdom, StatusCake — более продвинутые платные варианты.
Self-hosted мониторинг
Netdata — real-time мониторинг с минимальной настройкой.
# Установка
bash <(curl -Ss https://my-netdata.io/kickstart.sh)
# Доступ на http://server:19999
Prometheus + Grafana — стек для серьёзного мониторинга.
- Prometheus собирает метрики
- Grafana визуализирует
- Alertmanager отправляет уведомления
- Требует 512MB-1GB RAM
Zabbix — enterprise-решение.
- Полнофункциональный мониторинг
- Автообнаружение
- Сложнее в настройке
- Требует PostgreSQL/MySQL
Минимальный мониторинг через CLI
# Простой скрипт проверки (добавить в cron)
#!/bin/bash
# Проверка HTTP
STATUS=$(curl -s -o /dev/null -w "%{http_code}" https://mysite.com)
if [ "$STATUS" != "200" ]; then
echo "Site down! Status: $STATUS" | mail -s "Alert" admin@example.com
fi
# Проверка диска
DISK_USAGE=$(df / | tail -1 | awk '{print $5}' | sed 's/%//')
if [ "$DISK_USAGE" -gt 90 ]; then
echo "Disk usage: $DISK_USAGE%" | mail -s "Disk Alert" admin@example.com
fi
# Проверка памяти
MEM_AVAILABLE=$(free -m | grep Mem | awk '{print $7}')
if [ "$MEM_AVAILABLE" -lt 200 ]; then
echo "Low memory: ${MEM_AVAILABLE}MB available" | mail -s "Memory Alert" admin@example.com
fi
Настройка алертов
Алерты должны быть actionable — если получил алерт, должен знать что делать.
Хорошие алерты:
- Диск заполнен на 90%+ → очистить или расширить
- Сайт недоступен → проверить сервер, перезапустить сервисы
- CPU steal > 15% → жалоба провайдеру
Плохие алерты:
- CPU 80% (если это нормально для твоей нагрузки)
- 100 ошибок 404 (если это боты сканируют)
- Любой алерт, который игнорируешь
Чек-лист выбора VPS-провайдера
Используй этот чек-лист при оценке провайдеров.
Технические характеристики
| Критерий | Вопрос | Красный флаг |
|---|---|---|
| Виртуализация | KVM, OpenVZ, LXC, VMware? | OpenVZ 6, не указан тип |
| CPU | Модель процессора? Dedicated или shared? | Не указана модель, старые Xeon E5 v1/v2 |
| Storage | NVMe, SSD, HDD? RAID? Local или network? | «SSD» без уточнения, HDD для production |
| Сеть | Port speed? Bandwidth limit? DDoS защита? | 100Mbps порт, жёсткие лимиты |
| IP | IPv4/IPv6? Дополнительные IP? | Только IPv6, высокая доплата за IPv4 |
Надёжность и поддержка
| Критерий | Вопрос | Красный флаг |
|---|---|---|
| SLA | Какой SLA? Что включено? | Нет SLA, много исключений |
| Поддержка | Каналы? Время ответа? 24/7? | Только тикеты, ответ >24ч |
| История | Сколько лет работают? Отзывы? | Новый провайдер, много негативных отзывов |
| Датацентр | Где физически? Tier? Сертификации? | Неизвестная локация, нет информации |
Условия и ограничения
| Критерий | Вопрос | Красный флаг |
|---|---|---|
| AUP | Что запрещено? Разрешён твой use-case? | Запрещён нужный функционал |
| Бэкапы | Включены? Частота? Стоимость? | Нет бэкапов вообще |
| Масштабирование | Можно ли upgrade без переустановки? | Только переустановка |
| Оплата | Методы? Refund policy? | Только криптовалюта, нет refund |
Тестирование
Перед production-использованием:
- Закажи минимальный тариф или trial
- Проверь CPU steal time под нагрузкой
- Протестируй IO (fio)
- Проверь сетевую связность до твоих пользователей
- Проверь IP-репутацию
- Открой тикет в поддержку — оцени время и качество ответа
- Попробуй установить нужный софт
Примерный алгоритм выбора
Если сложно определиться, используй этот алгоритм:
- Определи критичный фактор: цена, производительность, география, поддержка?
- Отсеки неподходящих: по типу виртуализации, географии, AUP
- Составь шортлист: 3-5 провайдеров, соответствующих требованиям
- Проверь отзывы: Reddit, Trustpilot, профильные форумы — ищи конкретику, а не эмоции
- Протестируй 2-3 варианта: закажи минимальные тарифы, прогони бенчмарки
- Выбери лучший по соотношению: производительность + стабильность + поддержка / цена
Не торопись с окончательным выбором провайдера. Лишний день на тестирование сэкономит недели проблем в production.
Миграция между провайдерами
Рано или поздно придётся переезжать. Подготовься заранее.
Подготовка к миграции
- Документация — зафиксируй текущую конфигурацию
- Бэкапы — свежий полный бэкап
- DNS — понизь TTL заранее (до 300-600 секунд)
- Тестирование — разверни копию на новом сервере, проверь
Стратегии миграции
Полная миграция (big bang)
- Останавливаешь старый сервер
- Переносишь данные
- Запускаешь на новом
- Переключаешь DNS
Подходит для небольших проектов с допустимым даунтаймом.
Параллельная работа
- Поднимаешь новый сервер
- Синхронизируешь данные в реальном времени
- Переключаешь трафик постепенно
- Выключаешь старый после стабилизации
Минимизирует риск, требует больше ресурсов.
Инструменты
# Синхронизация файлов с rsync
rsync -avz --progress root@old-server:/var/www/ /var/www/
# Репликация MySQL
# На старом сервере настроить master
# На новом — slave, затем promote
# Синхронизация PostgreSQL
pg_basebackup -h old-server -D /var/lib/postgresql/data -P
После миграции
- Проверь работу всех функций
- Мониторь ошибки в логах
- Следи за производительностью
- Не удаляй старый сервер сразу — держи неделю на случай проблем
- Верни TTL DNS к нормальным значениям
Checklist миграции
Используй этот чеклист при переезде:
До миграции:
- ☐ Полный бэкап данных (проверенный!)
- ☐ Список всех сервисов и конфигураций
- ☐ DNS TTL снижен до 300-600 сек
- ☐ Новый сервер развёрнут и протестирован
- ☐ SSL-сертификаты готовы для нового сервера
- ☐ Cron-задачи задокументированы
- ☐ Время миграции согласовано (низкий трафик)
Во время миграции:
- ☐ Уведомить пользователей о возможных перебоях
- ☐ Остановить записи в БД на старом сервере
- ☐ Финальная синхронизация данных
- ☐ Переключить DNS
- ☐ Проверить работу основных функций
После миграции:
- ☐ Мониторинг ошибок 24-48 часов
- ☐ Проверка всех интеграций
- ☐ Тестирование email-отправки
- ☐ Проверка бэкапов на новом сервере
- ☐ Обновить документацию
- ☐ Через неделю: удалить старый сервер
Оптимизация стоимости VPS
Переплачивать — глупо, недоплачивать — опасно. Вот как найти баланс.
Правильный размер (Right-sizing)
Типичная ошибка — брать с запасом «на всякий случай». В результате 70% ресурсов простаивают.
Как определить нужный размер:
- Запусти на минимальном тарифе
- Мониторь использование 1-2 недели
- Оцени пиковые и средние значения
- Добавь 20-30% запаса от пика
# Средний CPU за последний час
sar -u 1 3600 | tail -1
# Максимальное использование памяти
# (требует сбор статистики)
cat /var/log/sysstat/sa* | sar -r | sort -k4 -n | tail -1
# Реальное использование диска
df -h | grep -v tmpfs
Резервирование vs Pay-as-you-go
Многие провайдеры предлагают скидки за предоплату:
- Месячная оплата: базовая цена
- Годовая оплата: скидка 10-20%
- 2-3 года: скидка до 40%
Когда брать длительный срок:
- Стабильный проект с предсказуемыми требованиями
- Провайдер проверен на практике
- Есть финансовый запас
Когда НЕ брать:
- Новый проект с неопределённым будущим
- Новый провайдер (не проверен)
- Быстрорастущий проект (придётся upgrade)
Альтернативы стандартным VPS
Spot/Preemptible instances
Облачные провайдеры продают избыточные мощности со скидкой 60-90%, но могут отозвать с предупреждением 30 сек — 2 мин.
Подходит для: batch processing, CI/CD runners, stateless workers.
Auction servers
Некоторые провайдеры (Hetzner) продают dedicated серверы на аукционе — бывшее в употреблении железо по сниженным ценам.
Community/Reseller хостинг
Мелкие провайдеры, перепродающие мощности крупных. Иногда дешевле, но выше риски.
Что не экономит деньги
- Слишком дешёвый провайдер — потеряешь время на проблемы
- Oversized VPS «про запас» — лучше масштабироваться по мере роста
- Игнорирование managed-сервисов — время DevOps тоже стоит денег
Дополнительные вопросы
Как защитить VPS от взлома?
Базовые меры: отключить root-логин по паролю, использовать SSH-ключи, настроить firewall (ufw/iptables), установить fail2ban, регулярно обновлять систему, не запускать лишние сервисы, использовать сложные пароли для всех сервисов.
Что лучше: один мощный VPS или несколько маленьких?
Зависит от задачи. Один VPS проще в управлении. Несколько — выше отказоустойчивость и возможность распределить нагрузку. Для большинства проектов до 10K DAU достаточно одного правильно настроенного VPS.
Как перенести сайт с shared-хостинга на VPS?
Экспортировать файлы (FTP/SSH), экспортировать БД (phpMyAdmin или mysqldump), установить на VPS веб-сервер и PHP нужной версии, импортировать данные, настроить виртуальный хост, проверить работу, переключить DNS.
Можно ли использовать VPS как VPN?
Да, но проверь AUP провайдера. Многие разрешают личный VPN, но запрещают коммерческие VPN-сервисы. Популярные решения: WireGuard, OpenVPN, Outline.
Как узнать, что сосед по хосту нагружает сервер?
Высокий CPU steal time при низкой собственной нагрузке. Непредсказуемая деградация IO. Периодические «зависания» без видимых причин. Всё это — признаки «шумных соседей» или overselling.
Стоит ли брать VPS с Windows?
Только если нужен специфический Windows-софт (.NET Framework, MSSQL). Windows VPS дороже (лицензия), требует больше ресурсов, сложнее в автоматизации. Для большинства задач Linux предпочтительнее.
Как выбрать между Ubuntu, Debian, CentOS?
Ubuntu — самый популярный, много документации и примеров. Debian — стабильный и легковесный. CentOS Stream/AlmaLinux/Rocky — для enterprise-окружений. Для VPS чаще всего подходит Ubuntu LTS или Debian stable.
Что делать при DDoS-атаке?
Если провайдер имеет защиту — она должна сработать автоматически. Если нет — включить Cloudflare или аналог. В крайнем случае — попросить провайдера временно null-route IP (сайт будет недоступен, но атака прекратится).
Как проверить, не взломан ли VPS?
Проверить необычные процессы (ps aux), сетевые соединения (netstat -tulpn), последние логины (last, lastb), crontab всех пользователей, изменения в системных файлах. Использовать rkhunter, chkrootkit для поиска руткитов.
Можно ли майнить криптовалюту на VPS?
Технически — да, практически — почти везде запрещено в AUP. Майнинг создаёт постоянную 100% нагрузку на CPU, что влияет на соседей. За это отключают без предупреждения.
Как выбрать между Европой и США для хостинга?
Зависит от аудитории и регуляторных требований. Для российской аудитории Европа (особенно Франкфурт, Амстердам) обычно имеет лучшую связность. Для глобальных проектов — зависит от распределения пользователей. США дешевле для compute, но GDPR может требовать хостинга в EU для европейских данных.
Что делать, если провайдер закрылся?
Если есть бэкапы — развернуть у другого провайдера. Если нет — молиться. Именно поэтому бэкапы должны храниться в независимом месте. Признаки проблем провайдера: задержки с ответами, участившиеся инциденты, увольнения ключевых сотрудников, финансовые проблемы в новостях.
Нужен ли выделенный IP для SEO?
Для SEO сам по себе shared IP не проблема — Google это подтверждал неоднократно. Выделенный IP нужен для: SSL-сертификатов (хотя SNI решает это), email-рассылок (критично), некоторых API-интеграций и если соседи по IP занимаются спамом.
Как понять, что пора переезжать на dedicated?
Когда стоимость нескольких мощных VPS приближается к dedicated. Когда критична стабильная производительность без соседей. Когда нужны специфические конфигурации железа. Когда требуется полный контроль вплоть до BIOS/IPMI. Типично это происходит при затратах $150-200+/месяц на VPS.
Почему VPS дешевле, чем облако при той же конфигурации?
Облачные провайдеры (AWS, GCP, Azure) включают в цену: global infrastructure, managed services ecosystem, enterprise support, compliance сертификации, R&D стоимость. VPS-провайдеры продают только compute — без экосистемы. Если тебе нужен только сервер — VPS выгоднее. Если нужна экосистема — облако окупается.
Какие метрики мониторить в первую очередь?
Для начала достаточно базовых: uptime (доступность сервиса), response time (время отклика), CPU и RAM usage, disk space. По мере роста добавляй application-specific метрики: queries per second для БД, requests per second для веб-сервера, error rate. Главное правило: мониторь то, на что можешь среагировать.
Стоит ли использовать несколько VPS-провайдеров одновременно?
Для критичных проектов — да, это разумная стратегия. Primary у одного провайдера, бэкапы и failover — у другого. Для небольших проектов обычно достаточно одного провайдера с внешними бэкапами. Multi-cloud добавляет сложности в управлении, используй когда оправдано бизнес-требованиями.
Как оценить реальную стоимость VPS?
Базовая цена — это начало. Добавь: стоимость дополнительных IP, бэкапов, превышения трафика, лицензий софта (Windows, панели), DDoS-защиты если платная. Учти своё время на администрирование по рыночной ставке. Реальная стоимость часто в 1.5-2 раза выше заявленной.
Связанные материалы для дополнительного изучения
Для более глубокого погружения в отдельные темы и вопросы, затронутые в этом руководстве, рекомендуем ознакомиться со следующими полезными материалами:
- Настройка безопасности Linux-сервера после установки: hardening, firewall, мониторинг угроз
- Сравнение панелей управления сервером: cPanel vs Plesk vs HestiaCP vs DirectAdmin
- Оптимизация производительности веб-сервера на VPS: nginx, PHP-FPM, Redis и кэширование
- Автоматизация бэкапов для VPS: настройка restic, borgbackup, rclone с облачным хранилищем
- Мониторинг серверов: от простых проверок uptime к полноценной observability
- Docker на VPS: практическое руководство по контейнеризации приложений
- Выбор между shared-хостингом и VPS: когда пора переходить на собственный виртуальный сервер
Статья обновлена: январь 2026. Информация актуальна на момент публикации, однако рекомендуем проверять текущие условия провайдеров перед принятием окончательного решения о покупке.