
Automatización del despliegue y gestión de servidores VPS/dedicados con Terraform y Ansible en 2026
TL;DR
- En 2026, Terraform y Ansible siguen siendo las piedras angulares para Infrastructure as Code (IaC) y Configuration Management (CM), garantizando una velocidad y fiabilidad sin precedentes en el despliegue de servidores.
- La integración de estas herramientas permite crear un pipeline completamente automatizado e idempotente, desde la creación de la infraestructura hasta su configuración y soporte.
- La elección entre servidores VPS y dedicados depende de los requisitos específicos de rendimiento, seguridad y presupuesto, considerando las nuevas ofertas de proveedores, como los servidores dedicados en la nube.
- Los factores clave de éxito incluyen la modularidad del código, una gestión adecuada del estado de Terraform, roles de Ansible fiables, así como una comprensión profunda de las herramientas y plataformas en la nube.
- El ahorro se logra no solo mediante la optimización de recursos, sino también minimizando los errores humanos, reduciendo el tiempo de inactividad y acelerando el lanzamiento de productos al mercado.
- La seguridad de la automatización es crítica: utilice gestores de secretos, el principio de mínimos privilegios y audite regularmente las configuraciones.
- Espere una mayor integración de la IA para el escalado predictivo, la optimización de costes y la corrección automática de problemas en la infraestructura.
Introducción
En un mundo donde la velocidad de los cambios y los requisitos de fiabilidad de los sistemas crecen constantemente, la gestión manual de la infraestructura se vuelve no solo ineficaz, sino un anacronismo peligroso. Para 2026, el concepto de Infrastructure as Code (IaC) y la automatización de la gestión de configuraciones se han convertido no solo en una tendencia, sino en un estándar obligatorio para cualquier empresa tecnológica seria. Esto es especialmente cierto para el despliegue y la gestión de VPS (Virtual Private Servers) y servidores dedicados, que aún constituyen la base de la mayoría de las aplicaciones y servicios críticos.
¿Por qué este tema es tan importante ahora? En primer lugar, la complejidad de las infraestructuras aumenta exponencialmente. Microservicios, sistemas distribuidos, clústeres geodistribuidos: todo esto requiere precisión y repetibilidad. Las operaciones manuales conducen inevitablemente a servidores "copo de nieve", donde cada uno es único e irreproducible, lo que es una pesadilla para el soporte y la escalabilidad. En segundo lugar, el coste del error humano sigue aumentando. Un servidor mal configurado puede provocar horas de inactividad, fugas de datos o incluso la pérdida de reputación. En tercer lugar, la competencia en el mercado de SaaS y productos tecnológicos exige la máxima velocidad en el lanzamiento de nuevas funciones y actualizaciones, así como flexibilidad en el escalado. La automatización permite lograr todo esto, reduciendo el tiempo de despliegue de días a minutos.
En este artículo, nos sumergiremos profundamente en el mundo de la automatización del despliegue y la gestión de servidores, utilizando dos de las herramientas más potentes y extendidas: Terraform para la gestión de infraestructura y Ansible para la gestión de configuraciones. Analizaremos cómo estas herramientas trabajan en conjunto, qué ventajas ofrecen y cómo aplicarlas eficazmente en las condiciones de 2026, considerando las nuevas tecnologías y enfoques. No nos centraremos en eslóganes de marketing, sino en consejos prácticos concretos, ejemplos reales y sutilezas que podrá aplicar en su trabajo hoy mismo.
Este artículo está dirigido a una amplia audiencia de especialistas técnicos: ingenieros DevOps que buscan optimizar sus pipelines; desarrolladores Backend (Python, Node.js, Go, PHP) que desean comprender y controlar mejor el entorno en el que operan sus aplicaciones; fundadores de proyectos SaaS para quienes es críticamente importante construir una infraestructura escalable y fiable desde el primer día; administradores de sistemas que desean pasar del trabajo manual a la automatización; y directores técnicos de startups que están dando forma a la estrategia de desarrollo de infraestructura. Si desea construir la infraestructura del futuro, este artículo es su guía.
No solo abordaremos los aspectos técnicos, sino también los económicos, así como las cuestiones de seguridad, que son cada vez más relevantes. El mundo está cambiando, y los métodos de gestión de infraestructura deben cambiar con él. Prepárese para una inmersión profunda en la automatización que hará su trabajo más eficiente y su infraestructura más fiable.
Criterios principales de selección y factores de éxito
La elección del enfoque correcto para la automatización del despliegue y la gestión de servidores, así como del tipo de hosting (VPS o servidor dedicado), requiere un análisis profundo de múltiples factores. En 2026, estos criterios se han vuelto aún más complejos, considerando la aparición de nuevas tecnologías y el endurecimiento de los requisitos de seguridad y rendimiento.
1. Escalabilidad y flexibilidad
En el mundo actual, la infraestructura debe ser capaz de escalar rápidamente tanto vertical como horizontalmente. Terraform permite describir la infraestructura de forma declarativa, lo que simplifica la adición de nuevos servidores o la modificación de sus características. Ansible, a su vez, proporciona una configuración flexible de estos nuevos recursos. Es importante evaluar la facilidad con la que su automatización podrá adaptarse a las cargas y requisitos cambiantes. Por ejemplo, si espera cargas pico, el escalado automático con Terraform y los proveedores de la nube será crítico.
2. Rendimiento y tipo de carga
Diferentes aplicaciones tienen distintos requisitos de CPU, RAM, E/S del subsistema de disco y ancho de banda de red. Para bases de datos de alta carga o tareas computacionalmente intensivas, los servidores dedicados suelen seguir siendo la opción preferida debido a su rendimiento garantizado y la ausencia de "ruido de vecinos". Los VPS, por otro lado, son ideales para servidores web, microservicios, colas de mensajes, donde la flexibilidad y el inicio rápido son importantes. En 2026, los proveedores ofrecen "servidores dedicados en la nube" que combinan las ventajas de ambos mundos: recursos garantizados con la flexibilidad de una API en la nube. Al elegir un proveedor, preste atención a las características del procesador (por ejemplo, Intel Xeon E5-2690 v4 o AMD EPYC serie 7003), el tipo de discos (NVMe SSD se ha convertido en el estándar) y el canal de comunicación garantizado.
3. Seguridad y cumplimiento de estándares (Compliance)
Este es uno de los factores más críticos. La automatización debe garantizar que todos los servidores estén configurados de acuerdo con las políticas de seguridad de la empresa y los requisitos regulatorios (GDPR, HIPAA, PCI DSS, etc.). Los playbooks de Ansible permiten establecer estrictos estándares de seguridad: desde la instalación de firewalls y la configuración de SSH hasta la gestión de usuarios y la aplicación de parches. Terraform puede configurar automáticamente segmentos de red, grupos de seguridad y políticas IAM. Es importante utilizar gestores de secretos (HashiCorp Vault, AWS Secrets Manager) y el principio de mínimos privilegios. La auditoría regular de las configuraciones, la aplicación automática de actualizaciones de seguridad y la monitorización de vulnerabilidades deben integrarse en su pipeline de CI/CD.
4. Coste total de propiedad (TCO)
El TCO incluye no solo los costes directos de alquiler de servidores, sino también el coste de licencias, electricidad, tráfico de red, así como los costes laborales de administración y soporte. La automatización con Terraform y Ansible reduce significativamente los costes laborales, minimiza los errores y permite reaccionar más rápidamente a los cambios, lo que en última instancia reduce el TCO. En 2026, muchos proveedores ofrecen tarifas flexibles, así como opciones para reservar capacidad a largo plazo con descuentos. Estudie cuidadosamente las tarifas de tráfico saliente, ya que puede convertirse en un gasto significativo.
5. Gestionabilidad y mantenibilidad
¿Qué tan fácil será gestionar su infraestructura después del despliegue? La estructura modular de Terraform y los roles de Ansible simplifican significativamente este proceso. La documentación en forma de código (Infrastructure as Code) permite a cualquier miembro del equipo comprender el estado de la infraestructura. Los sistemas de monitorización (Prometheus, Grafana) y de registro (ELK Stack, Loki) deben integrarse en el pipeline automatizado. Cuanta menos "magia" y más estandarización, más fácil será mantener el sistema a largo plazo.
6. Idempotencia y repetibilidad
La idempotencia significa que aplicar la misma operación varias veces producirá el mismo resultado, sin causar efectos secundarios no deseados. Esta es la piedra angular de la automatización. Terraform y Ansible son inherentemente idempotentes. Terraform garantiza que la infraestructura coincidirá con la descripción declarativa, y Ansible garantiza que el estado de configuración del servidor coincidirá con el playbook. La repetibilidad permite desplegar entornos idénticos (dev, staging, prod) y recuperarse rápidamente de fallos.
7. Ecosistema y comunidad
Una comunidad activa y un rico ecosistema alrededor de Terraform y Ansible significan acceso a una multitud de módulos, proveedores, roles y plugins listos para usar. Esto acelera el desarrollo y simplifica la búsqueda de soluciones para problemas comunes. Para 2026, ambas herramientas cuentan con una extensa documentación, cursos y un gran número de expertos, lo que reduce la barrera de entrada y los riesgos de implementación.
8. Copias de seguridad y recuperación ante desastres (DR)
La automatización debe incluir estrategias de copia de seguridad de datos y la capacidad de recuperar rápidamente toda la infraestructura en caso de desastre. Terraform puede ayudar en el despliegue de un entorno de DR, y Ansible en la restauración de configuraciones y datos. Considere el RPO (Recovery Point Objective) y el RTO (Recovery Time Objective) para cada componente de su sistema.
Tabla comparativa de soluciones de hosting (actualizada para 2026)
La elección entre VPS y servidores dedicados, así como el proveedor específico, depende de una multitud de factores, incluyendo el presupuesto, los requisitos de rendimiento, la escalabilidad y la ubicación geográfica. En 2026, el mercado de hosting continúa evolucionando, ofreciendo soluciones híbridas y características mejoradas. A continuación, se presenta una tabla comparativa de las opciones de hosting más populares, actualizadas para mediados de 2026, con precios y características aproximadas.
| Criterio | VPS en la Nube (ej., DigitalOcean Droplet / Vultr VPS) | Hetzner Cloud VPS (serie CX) | Dedicados en la Nube (ej., AWS EC2 Dedicated Host / GCP Sole-tenant node) | Servidor Dedicado Tradicional (ej., Hetzner Dedicated / OVHcloud) | Bare Metal as a Service (ej., Equinix Metal) |
|---|---|---|---|---|---|
| CPU Típica | 2-8 vCPU (Intel Xeon Platinum 84xx / AMD EPYC 9004) | 2-8 vCPU (AMD EPYC 7003/9004) | 16-64 vCPU (Intel Xeon E5-2690 v5 / AMD EPYC 9004) | 16-64 núcleos físicos (Intel Xeon E5-2699 v5 / AMD EPYC 9004) | 32-128 núcleos físicos (Intel Xeon Sapphire Rapids / AMD EPYC Genoa) |
| RAM Típica | 4-32 GB DDR5 ECC | 4-32 GB DDR5 ECC | 64-256 GB DDR5 ECC | 128-512 GB DDR5 ECC | 256 GB - 1 TB DDR5 ECC |
| E/S de Disco Típica | ~1000-2000 MB/s (NVMe SSD) | ~1500-2500 MB/s (NVMe SSD) | ~3000-5000 MB/s (NVMe SSD) | ~4000-8000 MB/s (RAID10 NVMe SSD) | ~8000-15000 MB/s (NVMe SSD Local, RAID de alta velocidad) |
| Canal de Red | 1-10 Gbps (compartido) | 1-10 Gbps (compartido, hasta 20 Gbps para tarifas altas) | 10-25 Gbps (dedicado) | 10-50 Gbps (dedicado) | 25-100 Gbps (dedicado) |
| Garantía de Recursos | No (virtualización) | No (virtualización) | Sí (núcleos físicos/RAM dedicados) | Sí (completamente) | Sí (completamente) |
| Control sobre el Hardware | No | No | Limitado | Completo | Completo |
| Precio Aproximado (mes) | $20-80 (por instancia) | €15-60 (por instancia) | $1500-5000 (por host) | €100-400 (por servidor) | $500-2000 (por servidor) |
| Escalabilidad | Alta (horizontal) | Alta (horizontal) | Media (requiere planificación) | Baja (manual) | Media (impulsada por API, pero sigue siendo física) |
| Ideal para | Servicios web, Dev/Staging, microservicios, bases de datos pequeñas | Desarrollo, servicios de producción pequeños, nodos CDN | Requisitos regulatorios, licencias por núcleo, bases de datos de alta carga | Bases de datos de alta carga, servidores de juegos, Big Data, cálculos intensivos en recursos | Cálculos de alto rendimiento, IA/ML, redes de baja latencia, nubes híbridas |
| Nivel de Gestión | API, panel de control | API, panel de control | API, panel de control, hipervisor | IPMI, KVM, consola | API, IPMI, consola |
*Los precios son orientativos y pueden variar significativamente según la configuración específica, la región, el momento y los descuentos del proveedor. Los datos son actuales para 2026 y reflejan las tendencias generales del mercado.
Es importante señalar que en 2026, la línea entre el hosting "en la nube" y el "tradicional" sigue difuminándose. Muchos proveedores de servidores dedicados ofrecen API para la automatización, y los gigantes de la nube introducen opciones de "host dedicado" o "nodo de inquilino único", que son esencialmente servidores dedicados, pero con un modelo de consumo y gestión en la nube. Esto abre nuevas oportunidades para una infraestructura flexible y potente, gestionada a través de IaC.
Visión general detallada de Terraform y Ansible
Para una automatización eficaz del despliegue y la gestión de servidores en 2026, es clave comprender y utilizar a fondo dos potentes herramientas: Terraform y Ansible. Se complementan entre sí, resolviendo tareas diferentes pero interconectadas en el ciclo de vida de la infraestructura.
1. Terraform: Gestión de infraestructura como código (IaC)
Terraform, desarrollado por HashiCorp, es una herramienta para la creación, modificación y eliminación declarativa de infraestructura. Permite describir el estado deseado de su infraestructura (ya sean VPS, servidores dedicados, configuraciones de red, balanceadores de carga o bases de datos) utilizando el lenguaje especializado HCL (HashiCorp Configuration Language) o JSON. Para 2026, Terraform se ha convertido en el estándar de facto para IaC gracias a su universalidad, amplio soporte de proveedores y potente ecosistema.
Principios de funcionamiento y ventajas:
- Enfoque declarativo: Usted describe "qué" quiere lograr, no "cómo" lograrlo. Terraform determina la secuencia de acciones para alcanzar el estado deseado.
- Proveedores: Terraform funciona a través de "proveedores", que son plugins para interactuar con diversas plataformas (AWS, Azure, GCP, DigitalOcean, Vultr, Hetzner Cloud, VMware vSphere, OpenStack e incluso proveedores locales para trabajar con la API de servidores dedicados). En 2026, la cantidad y funcionalidad de los proveedores se han expandido significativamente, incluyendo una integración más profunda con la gestión de servidores dedicados a través de su API.
- Estado (State): Terraform almacena el estado de su infraestructura en el archivo
.tfstate. Este archivo es críticamente importante, ya que mapea los recursos reales con su configuración. En producción, es obligatorio utilizar un almacenamiento de estado remoto (por ejemplo, S3, Azure Blob Storage, HashiCorp Consul o Terraform Cloud/Enterprise) con bloqueo para evitar conflictos. - Modularidad: La capacidad de crear módulos reutilizables permite estructurar el código, mejorar su legibilidad y mantenibilidad. Puede crear un módulo para un VPS típico que luego utilizará en toda la organización.
- Plan de ejecución: El comando
terraform planmuestra qué cambios se realizarán en la infraestructura antes de su aplicación real, lo que reduce significativamente el riesgo de errores.
Ejemplo de uso de Terraform para el despliegue de un VPS en DigitalOcean (2026):
Supongamos que queremos desplegar un Droplet en DigitalOcean con Ubuntu 24.04.
# main.tf
terraform {
required_providers {
digitalocean = {
source = "digitalocean/digitalocean"
version = "~> 2.0"
}
}
}
provider "digitalocean" {
token = var.do_token
}
variable "do_token" {
description = "DigitalOcean API Token"
type = string
sensitive = true
}
variable "ssh_keys" {
description = "List of SSH key IDs to add to the droplet"
type = list(string)
default = []
}
resource "digitalocean_droplet" "web_server" {
image = "ubuntu-24-04-x64" # Imagen de Ubuntu actual para 2026
name = "web-server-01"
region = "fra1"
size = "s-2vcpu-4gb" # Suponemos que es un tamaño popular en 2026
ssh_keys = var.ssh_keys
tags = ["web", "production"]
# Configuraciones adicionales para 2026:
# Posibilidad de especificar un tipo de almacenamiento NVMe o GPU concreto
# user_data = file("cloud-init.yaml") # Para la configuración inicial
}
output "web_server_ip" {
value = digitalocean_droplet.web_server.ipv4_address
}
Este código describe declarativamente un VPS. Después de terraform init y terraform apply, Terraform creará este servidor y mostrará su dirección IP. Para servidores dedicados, la lógica será similar, pero el proveedor y los recursos serán específicos de la plataforma seleccionada (por ejemplo, hetznercloud_server o aws_ec2_dedicated_host).
2. Ansible: Gestión de configuraciones y orquestación
Ansible, adquirido por Red Hat, es una herramienta para automatizar tareas de gestión de configuraciones, despliegue de aplicaciones y orquestación. A diferencia de Terraform, que se ocupa de la infraestructura, Ansible se centra en "lo que hay dentro" de esa infraestructura. Utiliza SSH para comunicarse con los nodos gestionados, sin requerir la instalación de agentes, lo que simplifica significativamente su despliegue y uso. Para 2026, Ansible sigue siendo una de las herramientas más populares y flexibles para CM, especialmente en entornos híbridos y multi-nube.
Principios de funcionamiento y ventajas:
- Sin agente: No requiere la instalación de software adicional en los servidores gestionados, utilizando SSH estándar. Esto reduce los gastos generales y simplifica la seguridad.
- Playbooks: La unidad principal de trabajo en Ansible. Los playbooks son archivos YAML que describen una secuencia de tareas a ejecutar en los hosts de destino.
- Idempotencia: Ansible está diseñado con la idempotencia en mente. Si una tarea ya se ha completado (por ejemplo, un paquete está instalado), Ansible no la ejecutará de nuevo, lo que ahorra tiempo y evita cambios no deseados.
- Módulos: Ansible viene con cientos de módulos incorporados para realizar una amplia gama de tareas: gestión de paquetes, archivos, servicios, usuarios, bases de datos, recursos en la nube y mucho más.
- Roles: Un mecanismo para organizar Playbooks, variables, plantillas y archivos en unidades estructuradas y reutilizables. Los roles simplifican significativamente la gestión de configuraciones complejas y su reutilización.
- Inventario: Una lista de hosts gestionados, agrupados por categorías lógicas. El inventario puede ser estático (archivo) o dinámico (generado a partir de una API en la nube, CMDB).
Ejemplo de uso de Ansible para configurar un VPS:
Una vez que Terraform ha desplegado el Droplet, Ansible puede configurar Nginx en él.
# playbook.yaml
---
- name: Configure Nginx web server
hosts: web_servers
become: true # Ejecutar tareas con privilegios de root
vars:
nginx_port: 80
server_name: "your-domain.com"
app_root: "/var/www/html"
tasks:
- name: Ensure Nginx package is installed
ansible.builtin.apt:
name: nginx
state: present
update_cache: yes
- name: Ensure Nginx service is running and enabled
ansible.builtin.systemd:
name: nginx
state: started
enabled: yes
- name: Create Nginx configuration directory for sites-available
ansible.builtin.file:
path: /etc/nginx/sites-available
state: directory
mode: '0755'
- name: Create Nginx configuration directory for sites-enabled
ansible.builtin.file:
path: /etc/nginx/sites-enabled
state: directory
mode: '0755'
- name: Copy Nginx default site configuration
ansible.builtin.template:
src: templates/nginx.conf.j2
dest: "/etc/nginx/sites-available/{{ server_name }}.conf"
owner: root
group: root
mode: '0644'
notify: Reload Nginx
- name: Enable Nginx default site
ansible.builtin.file:
src: "/etc/nginx/sites-available/{{ server_name }}.conf"
dest: "/etc/nginx/sites-enabled/{{ server_name }}.conf"
state: link
notify: Reload Nginx
handlers:
- name: Reload Nginx
ansible.builtin.systemd:
name: nginx
state: reloaded
Y la plantilla correspondiente templates/nginx.conf.j2:
# templates/nginx.conf.j2
server {
listen {{ nginx_port }};
server_name {{ server_name }};
root {{ app_root }};
index index.html index.htm;
location / {
try_files $uri $uri/ =404;
}
error_log /var/log/nginx/{{ server_name }}_error.log warn;
access_log /var/log/nginx/{{ server_name }}_access.log main;
}
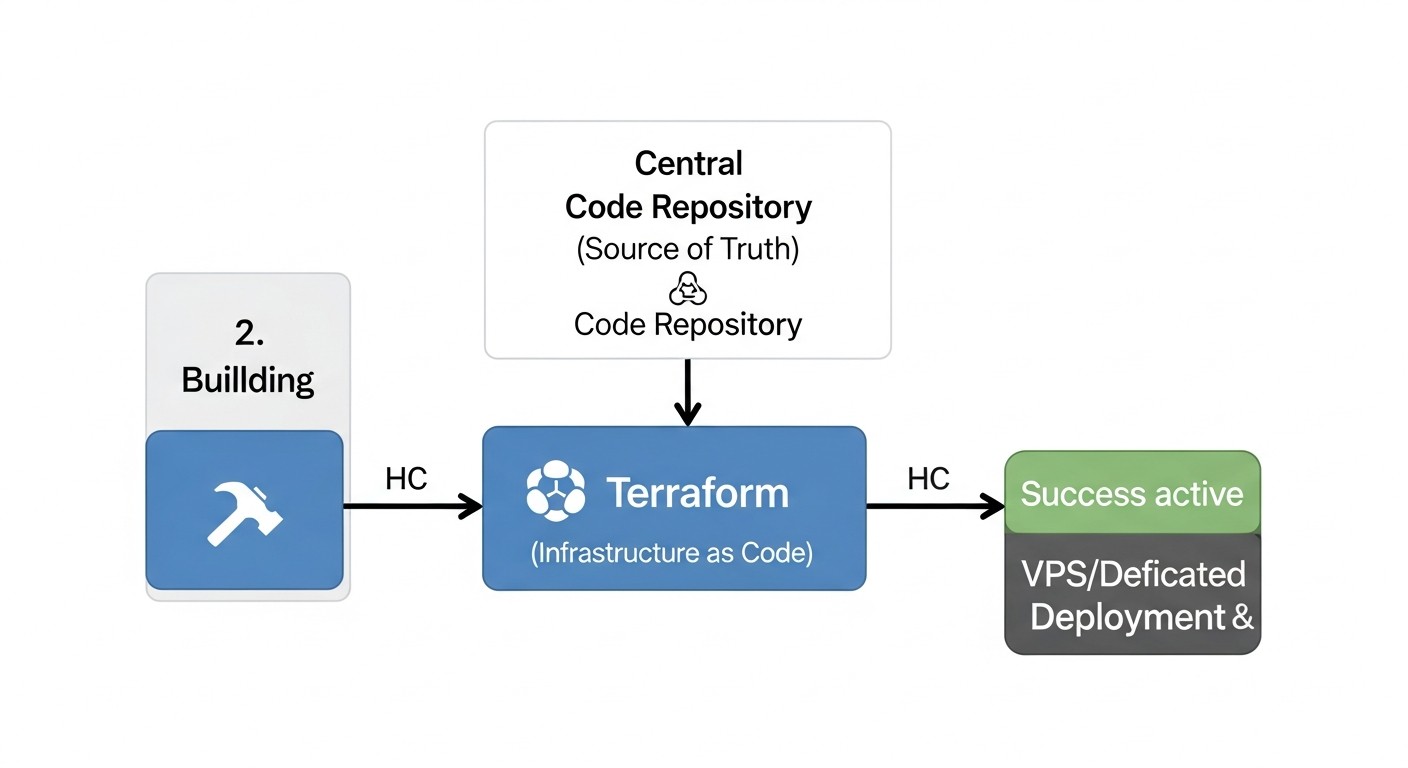
Este playbook instala Nginx, lo configura usando una plantilla y garantiza que el servicio esté en ejecución. La combinación de Terraform y Ansible permite primero crear el "hardware" y luego "llenarlo" con el software y las configuraciones necesarias, automatizando completamente el proceso de despliegue.
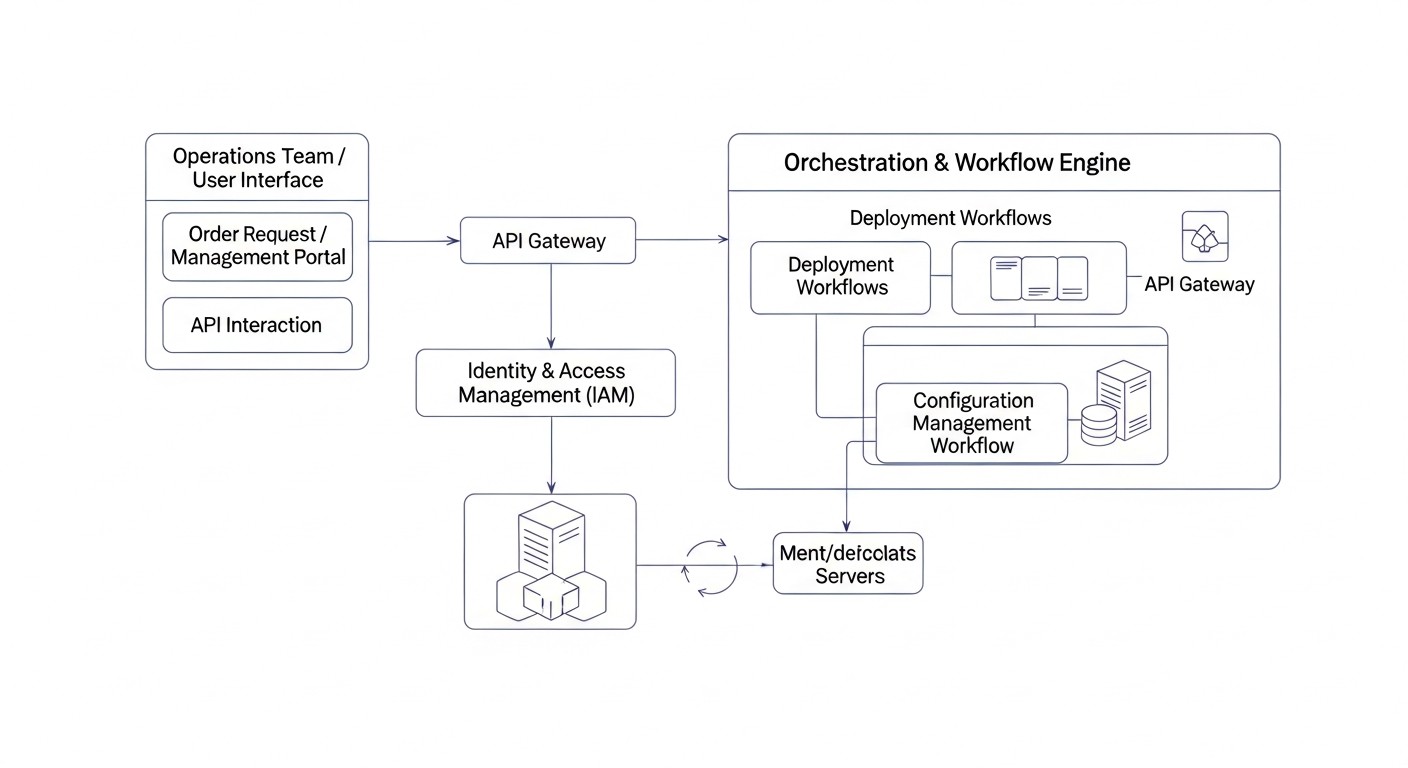
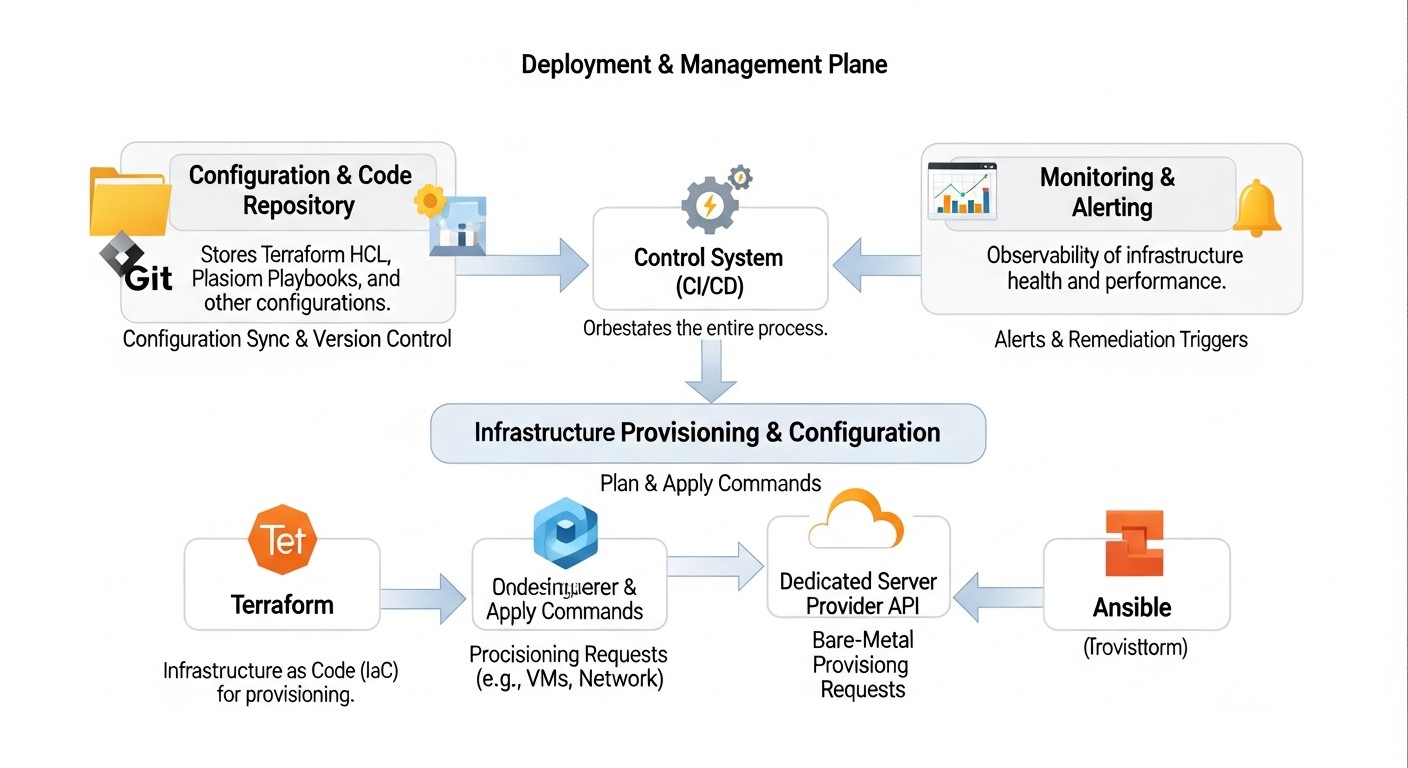
3. Integración de Terraform y Ansible
La verdadera fuerza de estas herramientas se revela cuando se utilizan juntas. Terraform crea la infraestructura y luego pasa información sobre ella (por ejemplo, las direcciones IP de los nuevos servidores) a Ansible, que luego configura esos servidores.
Flujo de trabajo:
- Terraform: Define y despliega recursos en la nube (VPS, servidores dedicados, redes, balanceadores de carga, etc.).
- Salida de Terraform: Extrae información importante sobre los recursos desplegados (por ejemplo, direcciones IP públicas, nombres de host).
- Inventario dinámico de Ansible: Utiliza la salida de Terraform para crear o actualizar el inventario de Ansible. Existen scripts y plugins especiales para Terraform que pueden generar un inventario de Ansible (por ejemplo, el proveedor
local-execo simplemente el análisis deterraform output -json). - Ansible: Se conecta a los nuevos servidores, utilizando la información del inventario dinámico, y aplica playbooks para instalar software, configurar, desplegar aplicaciones y garantizar la seguridad.
Para 2026, este enfoque se ha convertido en un estándar. La integración a menudo ocurre dentro de los pipelines de CI/CD (Jenkins, GitLab CI, GitHub Actions), donde terraform apply se ejecuta primero, y luego, después de una finalización exitosa, se ejecuta el playbook de Ansible con el inventario dinámico. Esto garantiza una automatización completa desde un servidor "bare metal" hasta una aplicación lista para usar.
Consejos prácticos y recomendaciones para la implementación
La implementación de la automatización con Terraform y Ansible no es solo dominar la sintaxis, sino cambiar el enfoque de la gestión de la infraestructura. Aquí hay una serie de consejos prácticos, basados en años de experiencia, que le ayudarán a evitar trampas comunes y a construir un proceso fiable, escalable y seguro.
1. Empiece poco a poco, itere
No intente automatizar todo a la vez. Empiece con un servicio o componente simple. Despliegue un VPS, configure Nginx o Docker en él. Domine los conceptos básicos, asegúrese de que su pipeline funciona. Luego, añada complejidad gradualmente: una base de datos, un balanceador de carga, otros servicios. Un enfoque iterativo le permite obtener retroalimentación rápidamente y corregir el rumbo.
2. Utilice módulos de Terraform y roles de Ansible
La modularidad es clave para una automatización mantenible y reutilizable. Cree módulos de Terraform para recursos típicos (por ejemplo, "web-server-module", "database-module") que encapsulen la lógica de despliegue y proporcionen una interfaz simple a través de variables. De manera similar, utilice roles de Ansible para agrupar tareas relacionadas (por ejemplo, "nginx", "docker", "postgres"). Existen módulos y roles preexistentes en Terraform Registry y Ansible Galaxy; utilícelos como puntos de partida, pero siempre adáptelos a sus necesidades.
# Ejemplo de uso de un módulo de Terraform
module "web_server_prod" {
source = "./modules/droplet" # Ruta local al módulo
name_prefix = "prod-web"
count = 3
region = "fra1"
size = "s-4vcpu-8gb"
ssh_key_ids = [digitalocean_ssh_key.my_key.id]
tags = ["production", "web"]
}
# Ejemplo de uso de un rol de Ansible
- name: Deploy web application
hosts: web_servers
become: true
roles:
- role: nginx
nginx_port: 80
server_name: "app.example.com"
- role: docker
docker_version: "25.0.3" # Versión actual para 2026
- role: my_app
app_version: "1.2.0"
3. Gestión del estado de Terraform (Terraform State)
Nunca almacene .tfstate localmente en producción. Utilice un almacenamiento remoto con bloqueo. AWS S3 con DynamoDB Lock, Azure Blob Storage, Google Cloud Storage, HashiCorp Consul o Terraform Cloud son opciones obligatorias. Esto previene conflictos durante cambios paralelos y proporciona un almacenamiento de estado centralizado y fiable. Realice copias de seguridad del estado regularmente.
# Ejemplo de configuración de un backend remoto S3 con bloqueo DynamoDB
terraform {
backend "s3" {
bucket = "my-terraform-state-bucket-2026"
key = "prod/infrastructure.tfstate"
region = "eu-central-1"
encrypt = true
dynamodb_table = "terraform-lock-table"
}
}
4. Inventario dinámico de Ansible
No cree archivos de inventario estáticos manualmente. Utilice un inventario dinámico que recopile automáticamente información sobre sus servidores de los proveedores de la nube (DigitalOcean, AWS, GCP, etc.) o de la salida de Terraform. Esto garantiza que Ansible siempre trabaje con una lista de hosts actualizada. Existen scripts de inventario listos para la mayoría de las plataformas en la nube.
# Ejemplo de ejecución de Ansible con inventario dinámico de DigitalOcean
ansible-playbook -i /usr/local/bin/digital_ocean.py --private-key ~/.ssh/id_rsa playbook.yaml
O utilizando la salida de Terraform:
# Script para generar inventario dinámico a partir de la salida de Terraform
#!/bin/bash
echo '{"_meta": {"hostvars": {}}}' > inventory.json
terraform output -json | jq -r 'to_entries | .[] | select(.key | endswith("_ip")) | .value | to_entries | .[] | .key + " ansible_host=" + .value' | while read line; do
HOST_NAME=$(echo $line | awk '{print $1}')
IP_ADDR=$(echo $line | awk '{print $2}' | cut -d'=' -f2)
jq --arg host "$HOST_NAME" --arg ip "$IP_ADDR" \
'.web_servers.hosts += [$host] | ._meta.hostvars[$host].ansible_host = $ip' \
inventory.json > tmp.$$.json && mv tmp.$$.json inventory.json
done
# Añadir grupos
jq '.web_servers = {"hosts": []}' inventory.json > tmp.$$.json && mv tmp.$$.json inventory.json
ansible-playbook -i inventory.json playbook.yaml
(Nota: el script proporcionado es un ejemplo simplificado y requiere mejoras para su uso en producción, especialmente en la parte de agrupación de hosts.)
5. Gestión de secretos
Nunca almacene información sensible (claves API, contraseñas, claves privadas SSH) en texto plano en el repositorio. Utilice herramientas especializadas: HashiCorp Vault, AWS Secrets Manager, Google Secret Manager, Azure Key Vault o Ansible Vault. Para Terraform, las variables pueden marcarse como sensitive = true, pero esto no reemplaza a un gestor de secretos completo.
# Uso de Ansible Vault para cifrar archivos con secretos
ansible-vault encrypt vars/secrets.yaml
ansible-playbook --ask-vault-pass playbook.yaml
6. Idempotencia Primero
Siempre escriba playbooks de Ansible de manera que sean idempotentes. Esto significa que la ejecución repetida de un playbook debe conducir al mismo estado que la primera, sin errores ni cambios no deseados. Utilice módulos de Ansible que son inherentemente idempotentes (por ejemplo, apt, yum, file, service). Si escribe sus propios scripts, verifique el estado antes de realizar cambios.
7. Pruebas de automatización
Su código de infraestructura debe ser probado tan rigurosamente como el código de la aplicación. Utilice:
terraform validate/terraform plan: para errores de sintaxis y vista previa de cambios.ansible-lint: para verificar el estilo y las mejores prácticas de Ansible.- Molecule: para probar roles de Ansible en diferentes distribuciones.
- Terratest / InSpec / Serverspec: para pruebas de integración y de extremo a extremo de la infraestructura desplegada. Esto permite asegurar que los servidores no solo se crean, sino que también se configuran y funcionan correctamente.
8. Versionado de todo
Todo el código (Terraform, playbooks de Ansible, scripts, plantillas) debe almacenarse en un sistema de control de versiones (Git). Esto permite rastrear los cambios, revertir a versiones anteriores, trabajar en equipo y realizar revisiones de código. Cada cambio en la infraestructura debe pasar por un proceso de Pull Request.
9. Integración con CI/CD
La automatización completa se logra al integrar Terraform y Ansible en su pipeline de CI/CD.
- CI (Integración Continua): Ejecución automática de
terraform validate,terraform plan,ansible-lint, Molecule en cada commit. - CD (Despliegue Continuo): Después de pasar las pruebas con éxito, ejecución automática de
terraform applyyansible-playbookpara desplegar o actualizar la infraestructura. Esto puede ser completamente automatizado o requerir confirmación manual para el entorno de producción.
10. Documentación y estándares
Aunque IaC es en sí mismo una forma de documentación, es importante tener archivos README adicionales que describan la arquitectura de alto nivel, las dependencias y el proceso de despliegue. Establezca estándares para nombrar recursos, variables, etiquetas y adhiérase a ellos. Cuanto más uniforme sea su código, más fácil será de entender y mantener.
11. Monitorización y alertas
La automatización del despliegue debe incluir la configuración automática de monitorización y alertas para todos los nuevos servidores. Ansible puede desplegar agentes de Prometheus Node Exporter, Grafana Agent, Datadog o New Relic. Asegúrese de que se recopilan todas las métricas críticas y de que se configuran las alertas correspondientes. En 2026, la monitorización impulsada por IA se está convirtiendo en un estándar, prediciendo problemas antes de que ocurran.
Errores comunes al trabajar con IaC y CM
Incluso los ingenieros experimentados cometen errores al trabajar con Terraform y Ansible. Conocer estos errores comunes le ayudará a evitar problemas costosos y a acelerar el proceso de implementación de la automatización.
1. Ignorar el estado de Terraform (Terraform State Management)
Error: Almacenar el archivo .tfstate localmente, falta de bloqueo de estado, modificación manual de .tfstate o pérdida del archivo de estado.
Consecuencias: Conflictos cuando varios ingenieros trabajan simultáneamente, desincronización de la infraestructura real con el archivo de estado, "deriva" de la configuración, imposibilidad de gestionar recursos, pérdida de infraestructura.
Cómo evitarlo: Utilice siempre un backend remoto (S3, Azure Blob Storage, GCS, HashiCorp Consul/Cloud) con bloqueo de estado habilitado. Nunca edite .tfstate manualmente; use terraform state mv, terraform state rm, terraform import. Realice copias de seguridad del estado remoto regularmente.
2. Playbooks de Ansible no idempotentes
Error: Escribir tareas en Ansible que no son idempotentes, es decir, cuya ejecución repetida conduce a cambios no deseados o errores. Por ejemplo, scripts que siempre crean un archivo sin verificar su existencia.
Consecuencias: Estado impredecible de los servidores, errores en el redespliegue, dificultad de depuración, riesgo de servidores "copo de nieve".
Cómo evitarlo: Utilice siempre los módulos integrados de Ansible que son inherentemente idempotentes. Si escribe sus propios scripts o utiliza el comando shell/command, añada siempre condiciones (when, creates, removes, changed_when) para verificar el estado actual antes de ejecutar la acción. Pruebe los playbooks con Molecule.
3. Codificación rígida de secretos y datos sensibles
Error: Almacenar claves API, contraseñas, claves privadas SSH, tokens en texto plano en archivos de Terraform, playbooks de Ansible o en el sistema de control de versiones (Git).
Consecuencias: Fuga de datos confidenciales, compromiso de la infraestructura, violación de la seguridad y el cumplimiento de estándares.
Cómo evitarlo: Utilice gestores de secretos especializados (HashiCorp Vault, AWS Secrets Manager, Azure Key Vault, Google Secret Manager) para almacenar y emitir secretos dinámicamente. Para Ansible, utilice Ansible Vault para cifrar archivos con secretos. Integre estas herramientas en su pipeline de CI/CD.
4. Falta de modularidad y reutilización
Error: Creación de archivos monolíticos y grandes de Terraform y playbooks de Ansible sin usar módulos y roles. Copiar y pegar código entre proyectos.
Consecuencias: Duplicación de código, dificultad para realizar cambios (hay que modificar en varios lugares), baja legibilidad, problemas de mantenimiento, desarrollo lento de nuevos componentes.
Cómo evitarlo: Utilice activamente módulos de Terraform para encapsular la lógica de despliegue de recursos. Cree roles de Ansible para configuraciones típicas. Coloque módulos y roles en repositorios separados o en una biblioteca común para su reutilización. Utilice variables para la parametrización.
5. Cambios manuales después de la automatización ("Drift")
Error: Realizar cambios en los servidores manualmente (por ejemplo, a través de SSH) que no están registrados en el código de Terraform o Ansible.
Consecuencias: "Deriva" de la configuración (Infrastructure Drift), cuando el estado real de la infraestructura difiere del descrito en el código. Comportamiento impredecible del sistema, problemas en el redespliegue o escalado, dificultades en la depuración.
Cómo evitarlo: Establezca reglas estrictas: todos los cambios deben pasar por IaC. Utilice terraform plan -destroy para detectar la deriva en Terraform y ejecute regularmente los playbooks de Ansible en modo check o diff para detectar cambios. Implemente herramientas automatizadas para la detección de deriva (por ejemplo, Cloud Custodian, Open Policy Agent). Considere el concepto de "Infraestructura Inmutable", donde los servidores nunca se modifican, sino que se reemplazan por otros nuevos.
6. Pruebas insuficientes de la automatización
Error: Ausencia de pruebas automáticas para las configuraciones de Terraform y los playbooks de Ansible. Ejecutar código en producción sin verificación previa.
Consecuencias: Despliegue de infraestructura inoperable o insegura, largos tiempos de inactividad, regresiones, pérdida de datos.
Cómo evitarlo: Integre terraform validate, terraform plan, ansible-lint en su CI. Utilice Molecule para probar los roles de Ansible. Aplique pruebas de integración (Terratest, InSpec) para verificar la infraestructura desplegada. Cree entornos separados (dev, staging) para probar los cambios antes de implementarlos en producción.
7. Gestión incorrecta de accesos y privilegios
Error: Uso de una cuenta con privilegios excesivos para Terraform y Ansible. Por ejemplo, usar una cuenta de administrador de la nube para desplegar recursos cotidianos.
Consecuencias: Amenazas de seguridad, posibilidad de eliminación o modificación involuntaria de recursos críticos, violación del principio de mínimos privilegios.
Cómo evitarlo: Cree roles IAM o cuentas de servicio separadas para Terraform y Ansible con los derechos de acceso mínimos necesarios. Utilice credenciales temporales siempre que sea posible. Revise y audite regularmente los derechos de acceso.
8. Falta de documentación y estándares
Error: Confiar únicamente en el código como documentación, ausencia de comentarios, incumplimiento de los estándares de nomenclatura.
Consecuencias: Dificultad para los nuevos miembros del equipo para comprender la infraestructura, menor velocidad de incorporación, errores debido a una comprensión incorrecta del código, dependencia de "portadores de conocimiento".
Cómo evitarlo: Complemente el código con archivos README, diagramas de arquitectura. Utilice comentarios para explicar bloques lógicos complejos. Desarrolle y adhiera a estrictos estándares de nomenclatura para recursos, variables y etiquetas. Realice revisiones de código regularmente.
Checklist para la aplicación práctica
Este checklist le ayudará a estructurar el proceso de implementación de la automatización del despliegue y la gestión de servidores VPS/dedicados utilizando Terraform y Ansible. Siga estos pasos para garantizar la fiabilidad, seguridad y eficiencia de su infraestructura.
Etapa 1: Preparación y planificación
- Defina los objetivos de la automatización: Formule claramente lo que desea lograr (por ejemplo, reducir el tiempo de despliegue, aumentar la fiabilidad, garantizar la escalabilidad).
- Elija el proveedor de hosting: Basándose en los requisitos de rendimiento, presupuesto y geografía, seleccione uno o varios proveedores (DigitalOcean, Hetzner, AWS, GCP, OVHcloud, Equinix Metal, etc.).
- Diseñe la arquitectura: Dibuje un esquema de su infraestructura objetivo: número de servidores, sus roles, configuraciones de red, bases de datos, balanceadores de carga.
- Defina la estructura del repositorio: Piense de antemano cómo se organizarán sus archivos de Terraform, playbooks de Ansible, roles y variables en Git.
- Configure el sistema de control de versiones (Git): Cree un repositorio para su código IaC/CM.
- Instale Terraform y Ansible: Asegúrese de que todos los miembros del equipo tienen instaladas las versiones actuales de las herramientas.
Etapa 2: Desarrollo de Terraform (IaC)
- Configure el proveedor de Terraform: Añada el proveedor necesario (
digitalocean,aws,hetznercloud, etc.) a sumain.tf. - Configure el backend remoto de Terraform State: Es obligatorio utilizar S3, GCS, Azure Blob Storage o Terraform Cloud con bloqueo de estado.
- Cree claves SSH: Genere y registre las claves SSH con el proveedor, que se utilizarán para acceder a los servidores que se creen.
- Describa los recursos de VPS/servidores: Utilice bloques
resourcepara crear máquinas virtuales o servidores dedicados. Especifique el tipo de imagen, tamaño, región, red, claves SSH. - Añada recursos de red: Configure grupos de seguridad, firewalls, VPC/VNet, si es aplicable.
- Utilice módulos: Cree sus propios módulos o utilice módulos de Terraform preexistentes para componentes reutilizables.
- Ejecute
terraform init,terraform plan,terraform apply: Verifique que Terraform despliega la infraestructura correctamente. - Extraiga salidas (Outputs): Utilice bloques
outputpara obtener direcciones IP, nombres DNS u otros datos sobre los recursos desplegados.
Etapa 3: Desarrollo de Ansible (CM)
- Cree un inventario dinámico: Configure un script o plugin para Ansible que genere automáticamente una lista de hosts a partir de la salida de Terraform o de la API del proveedor de la nube.
- Organice Playbooks y roles: Cree una estructura de directorios para Ansible, utilizando roles para la separación lógica de tareas (por ejemplo,
roles/webserver,roles/database). - Configure el acceso SSH: Asegúrese de que Ansible puede conectarse a los nuevos servidores por SSH, utilizando la clave privada correspondiente a la clave pública añadida por Terraform.
- Escriba Playbooks para la configuración básica: Incluya tareas para actualizar el sistema, instalar los paquetes necesarios (Python, Docker, Nginx), configurar el firewall (UFW/firewalld).
- Implemente la gestión de secretos: Utilice Ansible Vault para cifrar datos confidenciales o intégrese con un gestor de secretos externo.
- Cree Playbooks para el despliegue de aplicaciones: Configure Nginx, despliegue su servicio backend, configure la base de datos, si es necesario.
- Garantice la idempotencia: Asegúrese de que todas las tareas en los Playbooks son idempotentes.
Etapa 4: Integración y pruebas
- Integre en CI/CD: Configure un pipeline (Jenkins, GitLab CI, GitHub Actions) para la ejecución automática de:
terraform validateyterraform planansible-lint- Ejecución de Molecule para probar roles de Ansible
- Ejecución de
terraform apply(posiblemente con confirmación manual para producción) - Ejecución de Playbooks de Ansible con inventario dinámico
- Configure la monitorización y el registro: Asegúrese de que, después del despliegue y la configuración, se instalen automáticamente agentes de monitorización (Prometheus Node Exporter, Grafana Agent, Datadog) y de registro (Fluentd, Filebeat) en los servidores.
- Realice pruebas de integración: Utilice Terratest, InSpec o herramientas similares para verificar que la infraestructura desplegada cumple con las expectativas y funciona correctamente.
- Documente el proceso: Cree archivos README para sus proyectos de Terraform y Ansible, describiendo su propósito, variables, dependencias y pasos de despliegue.
Etapa 5: Soporte y optimización
- Actualice las herramientas regularmente: Esté atento a las actualizaciones de Terraform, Ansible y sus proveedores/módulos para obtener nuevas funciones y correcciones de seguridad.
- Monitorización de la deriva de configuración: Ejecute periódicamente
terraform plany los playbooks de Ansible en modocheckpara detectar cambios manuales. - Optimice los costes: Utilice las capacidades de Terraform para escalar recursos hacia arriba/abajo o eliminarlos, a fin de reducir gastos. Analice los informes de costes del proveedor.
- Realice auditorías de seguridad: Verifique regularmente las configuraciones de seguridad, los derechos de acceso y el cumplimiento de los estándares.
- Capacite al equipo: Asegúrese de que todos los miembros del equipo comprenden los principios de IaC y saben cómo trabajar con Terraform y Ansible.
Cálculo de costes y economía de la automatización
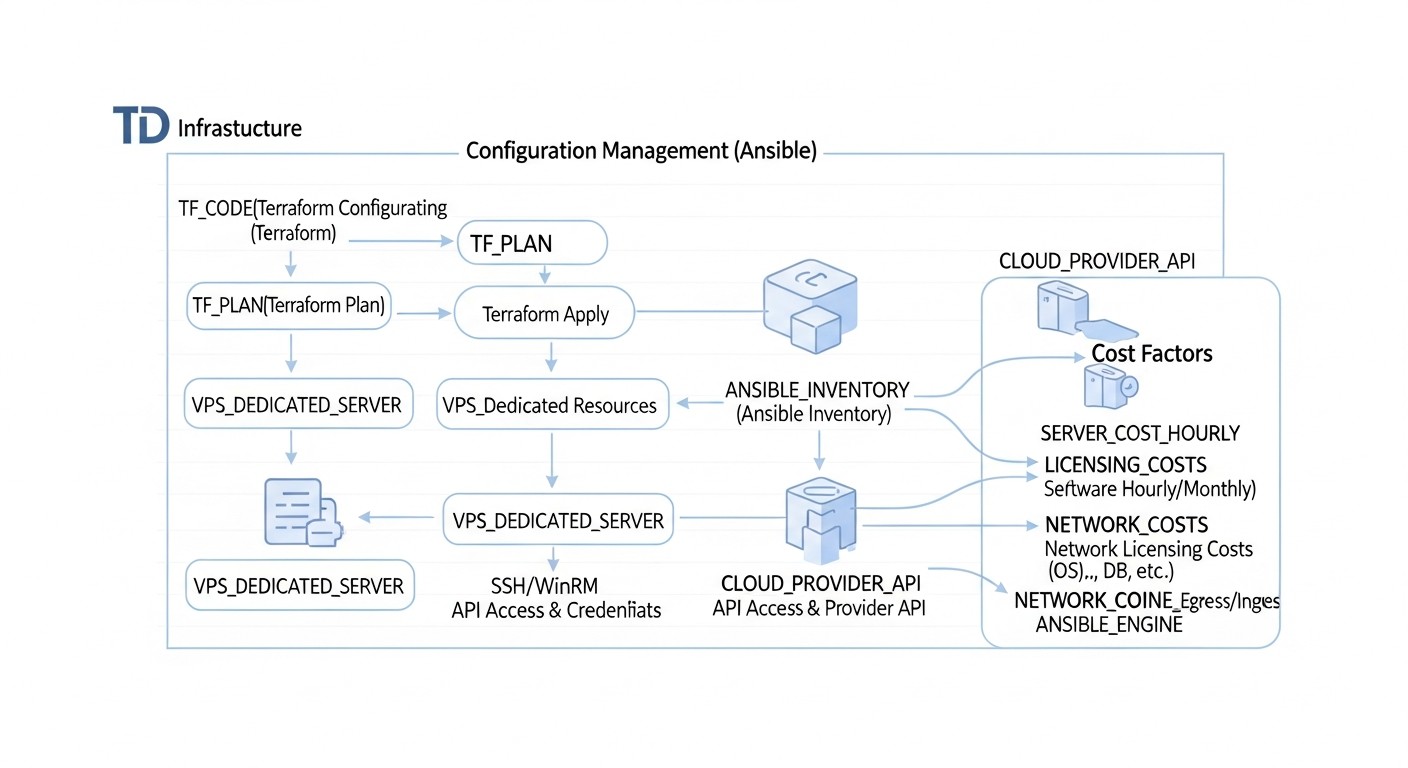
En 2026, cuando los recursos en la nube y los servidores dedicados son cada vez más accesibles, pero también más complejos de gestionar, comprender el verdadero coste total de propiedad (TCO) de la infraestructura es críticamente importante. La automatización con Terraform y Ansible no solo aumenta la eficiencia, sino que también tiene un impacto directo en la economía del proyecto, a menudo conduciendo a un ahorro significativo a largo plazo.
Costes directos e indirectos
Al calcular el coste de la infraestructura, es importante considerar no solo las facturas mensuales obvias del proveedor, sino también los costes ocultos menos visibles pero sustanciales:
- Costes directos:
- Alquiler de servidores (VPS/Dedicados): Coste de CPU, RAM, disco, tráfico de red. Las tarifas actuales para 2026 muestran una estabilización de precios, pero con planes tarifarios más complejos para recursos específicos (GPU, NVMe de alto rendimiento, tráfico premium).
- Licencias de software: Sistemas operativos (Windows Server), bases de datos (Oracle, MS SQL), software especializado.
- Tráfico de red: Especialmente el tráfico saliente, que puede ser costoso en algunos proveedores de la nube. En 2026, muchos proveedores ofrecen cuotas más generosas, pero más allá de ellas el coste sigue siendo alto.
- Servicios adicionales: Balanceadores de carga, bases de datos gestionadas, CDN, firewalls, direcciones IP.
- Costes indirectos (significativamente reducidos por la automatización):
- Costes laborales de los ingenieros: Tiempo dedicado al despliegue manual, configuración, corrección de errores, soporte. La automatización reduce estas horas drásticamente.
- Errores humanos: Coste del tiempo de inactividad debido a una configuración incorrecta, fugas de datos, violaciones de seguridad. Un día de inactividad para un proyecto SaaS puede costar decenas de miles de dólares.
- Tiempo de salida al mercado (Time-to-Market): Cuanto más tiempo tarde en desplegar la infraestructura para un nuevo servicio, más tiempo tardará en generar ingresos. La automatización acelera este proceso.
- Uso ineficiente de recursos: Servidores olvidados o subutilizados que siguen funcionando y consumiendo recursos. IaC permite identificar y eliminar fácilmente los recursos innecesarios.
- Formación y adaptación: Tiempo necesario para que los nuevos empleados dominen una infraestructura única creada manualmente. El código IaC estandarizado simplifica significativamente la incorporación.
- Auditoría y cumplimiento de estándares: La auditoría manual de seguridad y cumplimiento puede ser muy laboriosa. La automatización permite garantizar el cumplimiento a través del código.
Ejemplos de cálculos para diferentes escenarios (año 2026)
Consideremos varios escenarios hipotéticos para un proyecto SaaS que utiliza 10 servidores, teniendo en cuenta los salarios promedio y el coste de los servicios en 2026. Supongamos que el salario promedio de un ingeniero DevOps al mes es de $5000.
Escenario 1: Despliegue no automatizado (manual)
- Coste de servidores: 10 VPS a $40/mes = $400/mes.
- Tiempo de despliegue de 1 servidor: ~4 horas (instalación de SO, software básico, configuración).
- Tiempo de despliegue de 10 servidores: 40 horas = 1 semana laboral de un ingeniero.
- Coste de despliegue (mano de obra): $5000/mes * (40 horas / 160 horas laborales) = $1250.
- Tiempo para soporte/actualizaciones mensuales: ~2 horas por servidor * 10 servidores = 20 horas.
- Coste de soporte: $5000/mes * (20 horas / 160 horas laborales) = $625.
- Tiempos de inactividad/errores: Supongamos 1 incidente mayor al año debido a un error manual, coste $10,000. Mensual $833.
- TOTAL (mes): $400 (servidores) + $1250 (despliegue inicial, amortización) + $625 (soporte) + $833 (errores) = $3108 / mes.
- TOTAL (año): $37,296.
Escenario 2: Despliegue automatizado con Terraform y Ansible
- Coste de servidores: 10 VPS a $40/mes = $400/mes. (sin cambios)
- Tiempo de desarrollo de IaC/CM (inicial): 80 horas (2 semanas de ingeniero).
- Coste de desarrollo (inicial): $5000/mes * (80 horas / 160 horas laborales) = $2500. (Costes únicos, amortizados en 2 años: $104/mes)
- Tiempo de despliegue de 10 servidores: ~10-20 minutos (ejecución de script). Coste laboral: $5000/mes * (0.25 horas / 160 horas laborales) = ~$8.
- Tiempo para soporte/actualizaciones mensuales: ~2 horas (actualización de playbooks/módulos, ejecución). Coste laboral: $5000/mes * (2 horas / 160 horas laborales) = $62.5.
- Tiempos de inactividad/errores: Reducción del 90% a 1 incidente menor, coste $1,000/año. Mensual $83.
- TOTAL (mes): $400 (servidores) + $104 (amortización de desarrollo) + $8 (despliegue) + $62.5 (soporte) + $83 (errores) = $657.5 / mes.
- TOTAL (año): $7,890.
Ahorro: $3108 - $657.5 = $2450.5 / mes. o $29,406 / año.
Como se desprende de los cálculos, incluso con un número relativamente pequeño de servidores, la automatización se amortiza en unos pocos meses y luego genera un ahorro significativo. Cuanto mayor sea la infraestructura, mayor será el efecto económico.
Tabla con ejemplos de cálculos para diferentes escenarios
Supongamos que el "Coste por hora de ingeniero" = $31.25 (con un salario de $5000/mes por 160 horas).
| Parámetro | Despliegue manual (10 VPS) | Despliegue automatizado (10 VPS) | Despliegue automatizado (50 VPS) |
|---|---|---|---|
| Coste de servidores (mes) | $400 | $400 | $2000 |
| Desarrollo inicial de IaC/CM (horas) | 0 | 80 | 120 |
| Desarrollo inicial de IaC/CM (coste, amortización en 2 años) | $0 | $104 | $156 |
| Tiempo de despliegue (horas/mes) | 40 | 0.25 | 0.5 |
| Coste de despliegue (mes) | $1250 | $8 | $16 |
| Tiempo de soporte/actualizaciones (horas/mes) | 20 | 2 | 5 |
| Coste de soporte (mes) | $625 | $62.5 | $156.25 |
| Coste de tiempos de inactividad/errores (mes) | $833 | $83 | $200 |
| TOTAL (mes) | $3108 | $657.5 | $2528.25 |
| TOTAL (año) | $37,296 | $7,890 | $30,339 |
Cómo optimizar los costes
- Gestión automática del ciclo de vida de los recursos: Utilice Terraform para crear y eliminar recursos automáticamente según un horario o evento. Por ejemplo, los entornos de prueba pueden ser destruidos al final del día laboral.
- Elección correcta de instancias: Terraform permite cambiar fácilmente los tipos de instancias. Analice las métricas de uso de recursos y elija los tamaños óptimos de VPS/servidores. No pague de más por capacidades excesivas.
- Reserva de capacidad: Para cargas estables, utilice instancias reservadas (Reserved Instances) o contratos de servidores dedicados que ofrecen descuentos significativos.
- Monitorización y alertas de gastos: Integre la monitorización de gastos en su pipeline. Establezca alertas cuando los gastos superen ciertos umbrales.
- Uso de Spot Instances (para cargas tolerantes a fallos): En la nube, para cargas interrumpibles pero tolerantes a fallos, se pueden utilizar Spot Instances con Terraform, lo que reduce significativamente el coste.
- Optimización del tráfico de red: Utilice CDN para contenido estático, almacenamiento en caché, compresión de datos para reducir el volumen de tráfico saliente.
- Minimización de operaciones manuales: Cuantas menos acciones manuales, menor la probabilidad de errores costosos y mayor la eficiencia de los ingenieros.
En última instancia, la automatización con Terraform y Ansible es una inversión estratégica que no solo aumenta la madurez técnica del proyecto, sino que también proporciona un retorno financiero significativo, permitiendo a su equipo centrarse en la creación de valor en lugar de en la rutina.
Casos de estudio y ejemplos de la práctica real
Para comprender mejor cómo se aplican Terraform y Ansible en la práctica, consideremos varios escenarios realistas del mundo de DevOps y SaaS en 2026.
Caso 1: Despliegue de una plataforma SaaS escalable en DigitalOcean
Problema:
La joven startup SaaS "CloudSync" se enfrentó a un rápido crecimiento del número de usuarios y a la necesidad de escalar su plataforma. Inicialmente, la infraestructura se desplegaba manualmente en varios VPS, lo que provocaba servidores "copo de nieve", largos tiempos de inactividad durante las actualizaciones y la incapacidad de reaccionar rápidamente a las cargas pico. El equipo dedicaba hasta el 30% de su tiempo a la gestión manual de la infraestructura.
Solución con Terraform y Ansible:
El equipo de CloudSync decidió migrar completamente a IaC. Eligieron DigitalOcean por su facilidad de uso y su buena API.
- Terraform para la infraestructura:
- Se creó un proyecto de Terraform que describía toda la infraestructura: 3 balanceadores de carga (DigitalOcean Load Balancers), 10-50 Droplets para servidores web (Ubuntu 24.04, s-4vcpu-8gb), 3 Droplets para un clúster de PostgreSQL (s-8vcpu-16gb), 2 Droplets para un clúster de Redis (s-2vcpu-4gb), así como todos los firewalls y redes privadas necesarios.
- Se utilizaron módulos de Terraform para cada tipo de recurso (
droplet-module,loadbalancer-module,database-cluster-module), lo que garantizó la reutilización y la estandarización. - Se configuró un backend remoto S3 para almacenar el estado de Terraform, integrado con GitLab CI.
- Ansible para configuración y despliegue:
- Después del despliegue de la infraestructura por Terraform, GitLab CI ejecutaba automáticamente los Playbooks de Ansible.
- Ansible utilizó un inventario dinámico, generado a partir de la salida de Terraform, para obtener las direcciones IP actualizadas de los Droplets.
- Se desarrollaron roles de Ansible:
webserver(instalación de Nginx, PHP-FPM, configuración),postgresql(instalación de clúster, copias de seguridad),redis(configuración de clúster),app-deploy(despliegue de la aplicación desde una imagen Docker). - Ansible también fue responsable de la instalación de agentes de monitorización (Prometheus Node Exporter) y de registro (Fluentd) en todos los servidores.
- Pipeline de CI/CD:
- Cualquier cambio en el código de la infraestructura o la aplicación iniciaba el pipeline en GitLab CI.
terraform planse ejecutaba automáticamente para verificar los cambios.- Después de la confirmación manual (para producción),
terraform applyactualizaba la infraestructura. - Luego, los Playbooks de Ansible se aplicaban para configurar los servidores y desplegar el nuevo código de la aplicación.
Resultados:
- Reducción del tiempo de despliegue: Despliegue de un nuevo entorno o escalado de un clúster de 30 minutos a 5-7 minutos.
- Reducción del número de errores: Eliminación casi completa del factor humano en el despliegue y la configuración.
- Escalabilidad mejorada: Capacidad de añadir o eliminar Droplets rápidamente según la carga.
- Ahorro de costes: Reducción del 70% en los costes laborales de los ingenieros DevOps, lo que les permitió centrarse en tareas más estratégicas.
- Mayor fiabilidad: Fácil recuperación de la infraestructura después de fallos gracias a IaC.
Caso 2: Gestión de infraestructura híbrida con servidores dedicados y VPS
Problema:
El gran estudio de juegos "PixelForge" utilizaba una infraestructura híbrida: servidores dedicados de alto rendimiento (Hetzner Dedicated) para servidores de juegos y bases de datos, y VPS en la nube (AWS EC2) para el sitio web, la API y la analítica. La gestión de esta infraestructura heterogénea era extremadamente compleja y requería diferentes enfoques para cada tipo de servidor.
Solución con Terraform y Ansible:
PixelForge implementó un enfoque de gestión unificado utilizando Terraform y Ansible.
- Terraform para infraestructura heterogénea:
- Para AWS EC2, se utilizó el proveedor oficial de AWS Terraform para el despliegue de instancias, VPC, Security Groups, Load Balancers.
- Para los servidores dedicados de Hetzner, se utilizó un proveedor de Terraform personalizado (o scripts invocados a través de
local-exec) que interactuaba con la API de Hetzner Robot para solicitar, reinstalar el SO y obtener las direcciones IP de los servidores dedicados. - Todos los recursos (tanto en la nube como dedicados) se describieron en Terraform, lo que permitió tener un "mapa" unificado de toda la infraestructura.
- Terraform generaba las direcciones IP de todos los servidores, que luego eran utilizadas por el inventario dinámico de Ansible.
- Ansible para configuración unificada:
- Ansible utilizó el mismo conjunto de roles para la configuración básica (SSH, firewall, usuarios, monitorización) tanto para AWS EC2 como para Hetzner Dedicated.
- Las configuraciones específicas para cada tipo de servidor (por ejemplo, la configuración del sistema de archivos para servidores de juegos en Hetzner) se implementaron a través de operadores condicionales (
when) en los Playbooks o mediante diferentes variables para distintos grupos de inventario. - Ansible fue responsable del despliegue de servidores de juegos (SteamCMD, configuración del motor), bases de datos (PostgreSQL Master-Replica), servidores web (Nginx, Node.js) y herramientas analíticas.
- CI/CD Centralizado:
- Jenkins se configuró para orquestar todo el proceso.
- El pipeline ejecutaba Terraform para crear/actualizar recursos en ambas plataformas.
- Después de esto, los Playbooks de Ansible se aplicaban a los grupos de servidores correspondientes.
Resultados:
- Unificación de la gestión: Un enfoque unificado para la gestión de infraestructura híbrida, a pesar de su heterogeneidad.
- Aceleración significativa del despliegue: Los nuevos servidores de juegos podían iniciarse en 15 minutos, y la infraestructura web actualizada, en 5 minutos.
- Mayor fiabilidad: Reducción de errores relacionados con la configuración manual y la capacidad de recuperación rápida.
- Optimización de costes: Uso más eficiente de servidores dedicados para cargas críticas y escalado flexible de recursos en la nube para cargas variables.
- Seguridad mejorada: Configuraciones de seguridad estandarizadas, aplicadas automáticamente a toda la infraestructura.
Herramientas y recursos para un trabajo eficaz
La automatización del despliegue y la gestión de servidores con Terraform y Ansible no son solo estas herramientas en sí mismas, sino todo un ecosistema de utilidades, plataformas y recursos auxiliares. En 2026, este conjunto se ha vuelto aún más extenso e integrado.
1. Herramientas principales
- Terraform (HashiCorp): Su herramienta principal para IaC.
- Sitio web oficial de Terraform
- Terraform Registry (para buscar proveedores y módulos)
- Ansible (Red Hat): Su herramienta principal para la gestión de configuraciones.
- Sitio web oficial de Ansible
- Ansible Galaxy (para buscar roles y colecciones)
- Git (sistema de control de versiones): Para el versionado de todo su código de infraestructura.
- Sitio web oficial de Git
- Plataformas: GitHub, GitLab, Bitbucket
- Cliente SSH: Para conectarse a los servidores y ejecutar comandos de Ansible.
2. Gestión de secretos
Críticamente importante para la seguridad de su automatización.
- HashiCorp Vault: Solución universal para el almacenamiento y la gestión centralizada de secretos. Se integra con Terraform y Ansible.
- Gestores de secretos en la nube:
- AWS Secrets Manager
- Azure Key Vault
- Google Secret Manager
- Ansible Vault: Herramienta integrada para cifrar datos sensibles en Playbooks y archivos de variables de Ansible.
3. Plataformas CI/CD
Para automatizar la ejecución de pipelines de IaC y CM.
- GitLab CI/CD: Integrado en GitLab. Excelente opción para el ciclo completo de desarrollo y despliegue.
- GitHub Actions: Solución flexible, integrada con GitHub.
- Jenkins: Uno de los servidores CI/CD más antiguos y flexibles, requiere más configuración.
- CircleCI, Travis CI, Argo CD: Otras soluciones populares.
4. Monitorización y registro
Para observar su infraestructura y su rendimiento.
- Prometheus + Grafana: Soluciones de código abierto para la recopilación de métricas y visualización. Ansible puede desplegar Prometheus Node Exporter en cada servidor.
- ELK Stack (Elasticsearch, Logstash, Kibana): Un potente stack para la recopilación, análisis y visualización centralizada de logs.
- Loki + Grafana: Solución ligera para logs, inspirada en Prometheus.
- Soluciones comerciales: Datadog, New Relic, Splunk (a menudo tienen roles de Ansible listos para la instalación de agentes).
5. Pruebas de infraestructura como código
Para garantizar la calidad y fiabilidad de su automatización.
terraform validateyterraform plan: Comandos integrados para verificar la sintaxis y previsualizar los cambios.ansible-lint: Analizador estático para Playbooks de Ansible, que verifica el cumplimiento de las mejores prácticas.- Molecule: Framework para probar roles de Ansible, soporta varios drivers (Docker, Vagrant).
- Terratest (Go): Framework para escribir pruebas automatizadas para infraestructura desplegada con Terraform.
- InSpec (Chef): Framework para auditar y probar el cumplimiento de las configuraciones.
- Serverspec (Ruby): Herramienta para probar el estado de los servidores.
6. Utilidades y conceptos adicionales
- Cloud-init: Forma estándar de ejecutar scripts en el primer arranque de instancias en la nube. A menudo utilizado por Terraform para la configuración inicial antes de que Ansible tome el control.
- Vagrant (HashiCorp): Para crear y gestionar entornos de desarrollo ligeros y portátiles. Útil para pruebas locales de roles de Ansible.
- Docker: Para la contenerización de aplicaciones. Ansible puede desplegar Docker Engine y ejecutar contenedores.
- Packer (HashiCorp): Para crear imágenes de máquinas (AMI, VMDK, OVF) a partir de un único archivo fuente. Permite crear imágenes "doradas" con software preinstalado, lo que acelera el despliegue y reduce la carga de Ansible.
- Open Policy Agent (OPA): Para implementar políticas de "Infrastructure as Code" y garantizar el cumplimiento de los estándares de seguridad.
7. Enlaces útiles y documentación
- Documentación de proveedores de Terraform: Para cada proveedor de la nube o hosting, existe su propia documentación de Terraform (por ejemplo, DigitalOcean Terraform Provider).
- Documentación oficial de Ansible: Guías detalladas sobre módulos, roles y Playbooks.
- Blogs y comunidades: Blogs de DevOps (por ejemplo, HashiCorp Blog, Red Hat Blog), Stack Overflow, Reddit (r/devops, r/terraform, r/ansible).
- Cursos y certificaciones: Coursera, Udemy, Linux Academy, HashiCorp Certified: Terraform Associate, Red Hat Certified Specialist in Ansible Automation.
El uso de este conjunto de herramientas y recursos le permitirá crear un proceso de automatización altamente eficiente, fiable y escalable, que seguirá siendo relevante en 2026.
Troubleshooting: resolución de problemas de automatización
Incluso con la preparación más minuciosa, pueden surgir problemas durante el proceso de automatización con Terraform y Ansible. La capacidad de diagnosticarlos y resolverlos rápidamente es una habilidad clave. Aquí hay una lista de problemas típicos y enfoques para su solución.
1. Problemas con Terraform
1.1. Errores al ejecutar terraform plan o terraform apply:
- Síntoma: Errores de sintaxis HCL, problemas de autenticación del proveedor, parámetros de recursos incorrectos.
Diagnóstico: Lea atentamente la salida de Terraform. Suele ser muy informativa e indica la línea específica y la causa del error. Verifique su token API o claves de acceso, y sus permisos. - Síntoma: "Resource already exists" o "Resource not found" al ejecutar
applyrepetidamente.
Diagnóstico: Verifique el archivo de estado (.tfstate). Es posible que el recurso haya sido creado manualmente o que su estado se haya desincronizado.
Solución: Utiliceterraform importpara añadir un recurso existente al estado, oterraform state rmpara eliminar una entrada del estado (si el recurso ha sido realmente eliminado). ¡Tenga extrema precaución conterraform state rm! - Síntoma:
terraform applyse cuelga o la operación agota el tiempo de espera.
Diagnóstico: Generalmente relacionado con problemas de red, límites del proveedor u operaciones muy largas. Verifique los logs del proveedor (por ejemplo, AWS CloudTrail, DigitalOcean Activity Log).
Solución: Aumente los tiempos de espera en la configuración de Terraform, si es posible. Verifique las cuotas y límites de su proveedor.
1.2. Problemas con el estado de Terraform:
- Síntoma: "State file locked" o conflictos en ejecuciones paralelas.
Diagnóstico: Asegúrese de que está utilizando un backend remoto con bloqueo.
Solución: Si el bloqueo se ha atascado (raro), puede forzar su liberación (terraform force-unlock <LOCK_ID>), pero solo si está seguro de que nadie más está trabajando con el estado. - Síntoma: Deriva de configuración (Drift) – la infraestructura real difiere del estado.
Diagnóstico: Ejecuteterraform plan. Mostrará todas las diferencias.
Solución: Si la deriva es causada por cambios manuales, apliqueterraform applypara volver al código, o actualice el código de Terraform para que coincida con los cambios manuales. Idealmente, los cambios manuales deberían estar prohibidos.
Comandos de diagnóstico de Terraform:
terraform validate # Verificación de sintaxis
terraform plan # Vista previa de cambios
terraform apply # Aplicación de cambios
terraform state list # Lista de recursos en el estado
terraform state show <RESOURCE_ADDRESS> # Información detallada sobre el recurso
terraform output -json # Salida de todas las variables de output en formato JSON
TF_LOG=TRACE terraform apply # Logs muy detallados para depuración
2. Problemas con Ansible
2.1. Problemas de conexión a los hosts:
- Síntoma: "Unreachable", "Authentication failed", "Permission denied (publickey)".
Diagnóstico:- Verifique que la clave SSH (
-i ~/.ssh/id_rsa) esté especificada correctamente y tenga los permisos adecuados (chmod 400). - Asegúrese de que la dirección IP o el nombre de host en el inventario son correctos.
- Verifique que el servidor SSH en el host de destino esté en ejecución y accesible (
ssh user@ip). - Verifique la configuración del firewall en el host de destino y en la nube (grupos de seguridad).
- Asegúrese de que el usuario con el que Ansible intenta conectarse existe en el servidor remoto y tiene permisos para conectarse por SSH.
- Verifique que la clave SSH (
- Síntoma: "Host key checking failed".
Diagnóstico: Esto significa que la huella digital de la clave del host no coincide o falta enknown_hosts.
Solución: Si es un servidor nuevo, puede deshabilitar temporalmente la verificación de claves (-o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null) para la primera ejecución, pero esto es altamente desaconsejable en producción. Es mejor añadir la clave aknown_hostsmanualmente o usarssh-keyscan.
2.2. Errores de ejecución de Playbooks:
- Síntoma: La tarea finaliza con un error, mensaje de error del módulo.
Diagnóstico: Lea atentamente el mensaje de error. Generalmente indica el módulo específico y la causa (por ejemplo, "package not found", "file permissions error").
Solución: Verifique la sintaxis YAML, las variables, los permisos de archivos/directorios en el host de destino. Ejecute el playbook con mayor verbosidad (-vvv). - Síntoma: El playbook se "cuelga" o se ejecuta durante mucho tiempo.
Diagnóstico: Puede estar relacionado con la espera de entrada, comandos largos o tiempos de espera de red.
Solución: Verifique si hay comandos interactivos. Asegúrese de que los comandos no estén bloqueados por el firewall. - Síntoma: No idempotencia – la ejecución repetida del Playbook cambia el estado o causa errores.
Diagnóstico: Ejecute conansible-playbook --check --diff. Esto mostrará qué cambios se realizarán sin aplicación real.
Solución: Reescriba las tareas utilizando módulos y condiciones idempotentes.
Comandos de diagnóstico de Ansible:
ansible all -i inventory.ini -m ping # Verificación de accesibilidad de hosts
ansible-playbook -i inventory.ini playbook.yaml # Ejecución de playbook
ansible-playbook -i inventory.ini playbook.yaml -vvv # Salida detallada para depuración
ansible-playbook -i inventory.ini playbook.yaml --check --diff # Vista previa de cambios
ansible-inventory -i inventory.ini --list # Vista del inventario
ansible-lint <PLAYBOOK_FILE> # Verificación de estilo y mejores prácticas
3. Problemas comunes
- Problemas de red: Puertos inaccesibles, enrutamiento incorrecto, bloqueos por firewall.
Solución: Verifique las reglas del firewall en la nube (Security Groups), en el servidor (UFW, firewalld). Utiliceping,traceroute,telnet,ncpara diagnosticar la conectividad de red. - Problemas de permisos: Permisos de usuario insuficientes para realizar operaciones.
Solución: Asegúrese de que el usuario tiene los permisos necesarios (por ejemplo,sudo). Para Ansible, usebecome: true. - Problemas de versiones: Incompatibilidad de versiones de Terraform, Ansible, proveedores o sistemas operativos.
Solución: Utilice siempre versiones fijas de proveedores en Terraform (version = "~> 2.0"). Verifique la compatibilidad de los roles de Ansible con las versiones del SO. - Recursos insuficientes: Los servidores no pueden iniciarse debido a la falta de RAM, CPU o espacio en disco.
Solución: Verifique los logs del proveedor. Aumente el tamaño de la instancia o del disco.
Recuerde que los logs son su mejor amigo. Siempre empiece por examinar la salida de los comandos y los logs del sistema. No tema experimentar en un entorno de prueba y utilizar los modos check y diff antes de aplicar cambios en producción.
FAQ: Preguntas frecuentes
1. ¿Por qué debería usar Terraform Y Ansible, si puedo usar solo uno de ellos?
Terraform y Ansible resuelven tareas diferentes pero complementarias. Terraform se centra en la gestión declarativa de la infraestructura (IaC) – creación, modificación y eliminación de recursos (VPS, redes, balanceadores de carga). Ansible se enfoca en la gestión de configuraciones (CM) – instalación de software, configuración de servicios, despliegue de aplicaciones DENTRO de esos recursos. El uso de ambas herramientas en conjunto proporciona una automatización completa desde el hardware "bare metal" hasta una aplicación en funcionamiento, dividiendo las áreas de responsabilidad y haciendo el proceso más fiable y escalable.
2. ¿Qué proveedor es mejor para VPS/servidores dedicados en 2026?
El mejor proveedor depende de sus necesidades específicas. DigitalOcean y Vultr siguen siendo excelentes opciones para startups y proyectos pequeños gracias a su facilidad de uso y buena relación precio/rendimiento. Hetzner Cloud ofrece precios muy competitivos y potentes servidores dedicados. AWS, Azure y GCP son adecuados para grandes empresas con requisitos complejos y un gran presupuesto, ofreciendo una amplia gama de servicios. Equinix Metal es una buena opción para Bare Metal as a Service. Evalúe según el rendimiento, la geografía, el precio, la API para la automatización y la calidad del soporte.
3. ¿Qué tan difícil es aprender Terraform y Ansible?
Ambas herramientas tienen una curva de aprendizaje relativamente baja, especialmente para aquellos que ya están familiarizados con la línea de comandos y los conceptos de Linux. Terraform utiliza HCL, que es intuitivo. Ansible utiliza YAML, que también es fácil de leer. La principal dificultad radica en comprender los conceptos de IaC, la idempotencia, la gestión del estado y el diseño de una arquitectura modular. Con una comunidad activa y una extensa documentación, el aprendizaje básico lleva unas pocas semanas, y el nivel experto, varios meses de práctica.
4. ¿Cómo garantizar la seguridad de los secretos (contraseñas, claves API) en la automatización?
Nunca almacene secretos en texto plano en repositorios Git. Utilice herramientas especializadas: HashiCorp Vault, AWS Secrets Manager, Azure Key Vault, Google Secret Manager. Para Ansible, utilice Ansible Vault para cifrar archivos con datos sensibles. Integre estos gestores de secretos en su pipeline de CI/CD para que proporcionen dinámicamente los secretos solo durante la ejecución de las tareas, utilizando el principio de mínimos privilegios.
5. ¿Qué es el "Infrastructure Drift" y cómo combatirlo?
Infrastructure Drift (deriva de la configuración) es una situación en la que el estado real de su infraestructura difiere de lo descrito en su código IaC (Terraform). Esto a menudo ocurre debido a cambios manuales realizados directamente en los servidores. Para combatir la deriva, ejecute regularmente terraform plan (idealmente en CI/CD) para detectarla. Implemente políticas estrictas que prohíban los cambios manuales. Considere el uso de "Infraestructura Inmutable", donde los servidores nunca se modifican, sino que se reemplazan por otros nuevos.
6. ¿Puedo usar Terraform para gestionar servidores dedicados sin API?
Directamente, no. Terraform funciona a través de las API de los proveedores. Si su proveedor de servidores dedicados no ofrece una API, no podrá usar Terraform para su despliegue o gestión directa (por ejemplo, reinstalación del SO). Sin embargo, puede usar Terraform para gestionar registros DNS, configuraciones de red u otros componentes en la nube relacionados con sus servidores dedicados. Para los servidores sin API, tendrá que recurrir a operaciones manuales o a Ansible para configurar máquinas ya existentes.
7. ¿Cuáles son las mejores prácticas para estructurar proyectos de Terraform y Ansible?
Para Terraform: utilice módulos para componentes reutilizables, separe las configuraciones por entornos (dev, staging, prod) y por componentes (network, compute, database). Para Ansible: utilice roles para agrupar lógicamente tareas, variables y plantillas. Separe las variables por grupos de hosts y entornos. Almacene todo el código en Git, utilice nombres y comentarios claros. Siga el principio DRY (Don't Repeat Yourself).
8. ¿Cómo probar mi código de infraestructura?
Las pruebas de IaC son tan importantes como las pruebas del código de la aplicación. Para Terraform, utilice terraform validate y terraform plan. Para Ansible, ansible-lint y Molecule para probar roles en entornos aislados. Para pruebas de integración de la infraestructura desplegada, utilice frameworks como Terratest, InSpec o Serverspec. Incluya estas pruebas en su pipeline de CI/CD.
9. ¿Qué hacer si Terraform o Ansible causan un error en producción?
Primero, no entre en pánico. Segundo, revierta inmediatamente los últimos cambios si es posible (por ejemplo, terraform destroy para un recurso recién creado o un rollback de un commit de Git). Tercero, examine cuidadosamente los logs (con TF_LOG=TRACE para Terraform, -vvv para Ansible). Utilice el modo plan o check para el diagnóstico. Si el problema está relacionado con un servicio externo, verifique su estado. Tenga un plan claro de reversión y recuperación.
10. ¿Qué pasa con Kubernetes? ¿Reemplazará a los servidores VPS/dedicados?
Kubernetes (K8s) es una potente plataforma para la orquestación de contenedores, que sigue evolucionando activamente en 2026. No reemplaza directamente a los servidores VPS/dedicados, sino que los abstrae. K8s en sí mismo funciona SOBRE servidores (virtuales o dedicados). Terraform puede desplegar clústeres de K8s (por ejemplo, EKS, GKE, AKS o K3s en VPS), y Ansible puede usarse para la configuración inicial de esos nodos o el despliegue de un clúster de K8s en Bare Metal. Para muchas aplicaciones, especialmente las de microservicios, K8s es una excelente opción, pero para aplicaciones monolíticas, bases de datos de alta carga o servidores de juegos específicos, los VPS y los servidores dedicados siguen siendo relevantes y más sencillos de gestionar.
11. ¿Cómo actualizo una infraestructura existente, creada manualmente, a IaC?
Esto se denomina despliegue "adoption" o "brownfield". Pasos: 1) Importe los recursos existentes al estado de Terraform utilizando terraform import. Esto permite a Terraform tomar el control de los recursos ya creados. 2) Cree Playbooks de Ansible para configurar los servidores existentes y estandarizar su estado. 3) Aplique los cambios gradualmente, primero en un entorno de prueba. Este es un proceso laborioso pero necesario para la transición a la automatización.
12. ¿Cuáles son las tendencias en la automatización de infraestructura para los próximos años?
En 2026 y más allá, veremos un mayor desarrollo de:
- Operaciones impulsadas por IA/ML (AIOps): Uso de IA para el escalado predictivo, la corrección automática de problemas, la optimización de costes y la detección de anomalías.
- GitOps: Gestión de infraestructura y aplicaciones a través de un repositorio Git como única fuente de verdad, con sincronización automática.
- Serverless y Function as a Service (FaaS): Continuación de la tendencia hacia la abstracción de los servidores para ciertos tipos de cargas.
- Security as Code: Integración de políticas de seguridad directamente en el código de la infraestructura y automatización de su aplicación y auditoría.
- Platform Engineering: Creación de plataformas internas que abstraen la complejidad de la infraestructura subyacente para los desarrolladores, utilizando IaC y CM como base.
Conclusión
En 2026, la automatización del despliegue y la gestión de servidores VPS y dedicados con Terraform y Ansible no es solo un "lujo", sino una necesidad absoluta para cualquier organización que aspire a la eficiencia, fiabilidad y competitividad. Hemos visto cómo estas dos potentes herramientas, trabajando en conjunto, permiten crear, configurar y mantener la infraestructura con una velocidad y precisión sin precedentes. Desde la descripción declarativa de recursos con Terraform hasta la gestión idempotente de configuraciones con Ansible, cada paso en el ciclo de vida de un servidor puede ser automatizado y registrado en código.
Hemos examinado los criterios clave de selección, estudiado en detalle los principios de funcionamiento de Terraform y Ansible, compartido consejos prácticos para la implementación, y analizado los errores típicos y cómo evitarlos. Los cálculos económicos han demostrado claramente que la inversión en automatización se amortiza muchas veces, reduciendo los costes laborales, minimizando los tiempos de inactividad y acelerando el lanzamiento de productos al mercado. Los casos de estudio de la práctica real han confirmado la universalidad y eficacia de este enfoque tanto para plataformas SaaS escalables como para infraestructuras híbridas complejas.
El mundo de la infraestructura cambia constantemente, pero los principios de IaC y CM permanecen inquebrantables. Las herramientas y tecnologías evolucionarán, surgirán nuevos proveedores y capacidades, pero la idea fundamental de gestionar la infraestructura como código solo se fortalecerá. La integración con CI/CD, el refuerzo de la seguridad a través de gestores de secretos y Security as Code, así como la implementación de monitorización y pruebas avanzadas, son todos componentes de una estrategia de automatización exitosa.
Recomendaciones finales:
- Invierta en formación: Asegúrese de que su equipo comprende profundamente Terraform, Ansible y los conceptos relacionados.
- Empiece poco a poco: La implementación gradual de la automatización reduce los riesgos y permite obtener resultados rápidamente.
- Aplique la modularidad: Utilice módulos de Terraform y roles de Ansible para crear componentes reutilizables y mantenibles.
- Versionado de todo: Git es su mejor amigo. Todos los cambios en la infraestructura deben pasar por control de versiones y revisión de código.
- Pruebe sin piedad: Su código de infraestructura debe ser probado tanto como el código de la aplicación.
- Gestione los secretos: Utilice herramientas especializadas para almacenar y acceder a datos confidenciales.
- Evite los cambios manuales: Procure que toda la infraestructura se gestione exclusivamente a través del código.
- Integre en CI/CD: La automatización completa libera todo el potencial de IaC y CM.
Próximos pasos para el lector:
Si ha llegado hasta aquí, significa que está listo para actuar. No lo posponga.
- Elija un proyecto piloto: Identifique un componente pequeño pero significativo de su infraestructura para la primera automatización.
- Estudie la documentación: Sumérjase profundamente en las guías oficiales de Terraform y Ansible.
- Empiece a escribir código: Cree su primer
main.tfyplaybook.yaml. Despliegue un VPS de prueba. - Utilice la comunidad: Haga preguntas en Stack Overflow, Reddit, participe en debates.
- Construya su pipeline de CI/CD: Integre sus scripts de Terraform y Ansible en un proceso automatizado.
La automatización no es un objetivo final, sino un proceso continuo de mejora. Aplicando los principios y herramientas descritos en este artículo, podrá construir una infraestructura fiable, escalable y eficiente, preparada para los desafíos de 2026 y más allá. ¡Mucha suerte en su viaje de automatización!