
Optimización de costes en VPS en la nube y servidores dedicados: Prácticas y herramientas FinOps (relevante para 2026)
TL;DR
- FinOps no es solo ahorro, es una cultura: Integración de finanzas y operaciones para la gestión continua de los gastos en la nube, centrándose en el valor y los resultados empresariales.
- Visibilidad y control son clave: Utilice el etiquetado (tagging), informes detallados y herramientas especializadas para entender quién y por qué paga. Sin esto, la optimización es imposible.
- Rightsizing es su mejor amigo: Analice regularmente la utilización de recursos y escale los servidores (VPS/Dedicados) a tamaños óptimos. Está pagando de más por potencia no utilizada.
- Automatización y flexibilidad: Aplique autoescalado, programación de encendido/apagado, instancias Spot y capacidades reservadas para adaptarse a la carga y reducir los costes base.
- No olvide la red y el almacenamiento: El tráfico de salida (egress-traffic), los discos no utilizados y las instantáneas obsoletas pueden constituir una parte significativa de la factura. Optimícelos con la misma diligencia que la CPU/RAM.
- Cultura de colaboración: FinOps requiere interacción entre ingenieros, gerentes de producto y departamentos financieros para la toma conjunta de decisiones sobre gastos.
- Elija el tipo de servidor correcto: VPS para flexibilidad y escalabilidad, servidores dedicados para alto rendimiento y previsibilidad de la carga, contenerización y Serverless para máxima eficiencia.
3. Introducción
En el mundo de la tecnología en rápida evolución, donde la computación en la nube se ha convertido en el estándar de facto para la mayoría de las startups, proyectos SaaS e incluso grandes empresas, la gestión de los costes de la infraestructura de TI ha pasado de ser una tarea secundaria a un aspecto críticamente importante de la estrategia empresarial. Para 2026, cuando el mercado de la nube continúe su crecimiento exponencial y la competencia entre proveedores y consumidores de servicios alcance su punto máximo, la capacidad de gestionar eficazmente el presupuesto de VPS y servidores dedicados no será solo una ventaja, sino una necesidad para la supervivencia y la prosperidad.
Este artículo está dedicado a FinOps, un modelo operativo que une finanzas, tecnología y negocios para lograr el máximo valor de las inversiones en la nube. FinOps no es un evento único de reducción de costes, sino un proceso continuo, una cultura de colaboración destinada a aumentar la transparencia, la responsabilidad y la eficiencia del uso de los recursos en la nube. Examinaremos cómo las prácticas FinOps y las herramientas modernas ayudan a los ingenieros DevOps, desarrolladores backend, fundadores de SaaS, administradores de sistemas y directores técnicos de startups no solo a reducir costes, sino también a tomar decisiones estratégicas y bien fundamentadas que contribuyan al crecimiento del negocio.
¿Por qué es importante este tema precisamente en 2026? Porque la complejidad de los ecosistemas en la nube sigue creciendo. La multitud de servicios, planes de precios, modelos de tarificación (bajo demanda, instancias reservadas, instancias Spot, funciones sin servidor) crean un laberinto en el que es fácil perderse y pagar de más sin darse cuenta. Por otro lado, aparecen herramientas cada vez más sofisticadas para la monitorización, el análisis y la automatización, que permiten gestionar esta complejidad. El artículo tiene como objetivo ayudarle a navegar por este laberinto utilizando enfoques FinOps avanzados.
El artículo aborda los siguientes problemas:
- Falta de transparencia: ¿Cómo entender a dónde va el dinero y qué servicios consumen la mayor parte del presupuesto?
- Consumo excesivo: ¿Cómo evitar pagar de más por recursos no utilizados o subutilizados?
- Complejidad de la elección: ¿Cómo elegir entre VPS, servidores dedicados, contenedores o soluciones sin servidor, teniendo en cuenta el coste y el rendimiento?
- Falta de un enfoque unificado: ¿Cómo establecer la interacción entre los departamentos técnicos y financieros para una gestión eficaz de los costes?
- Escalado inteligente: ¿Cómo garantizar el crecimiento de la infraestructura sin un aumento proporcional de los gastos?
Este artículo está escrito para todos aquellos que se enfrentan a los desafíos de la gestión de costes en la nube y buscan no solo reducirlos, sino también optimizar el valor obtenido de cada dólar gastado. Proporcionaremos recomendaciones concretas y aplicables en la práctica, respaldadas por ejemplos y datos actualizados para 2026, para que pueda gestionar su infraestructura en la nube con confianza.
4. Criterios/factores principales de elección y optimización
La elección de la infraestructura óptima y su posterior optimización es un proceso multifacético que depende de numerosos factores. En el contexto de FinOps, cada uno de estos criterios influye directamente en el coste final y el valor que la empresa obtiene de las inversiones en TI. Consideremos los factores clave, relevantes para 2026.
Rendimiento y tipo de carga
Por qué es importante: Subestimar o sobrestimar el rendimiento requerido conduce a costes ineficientes. Un servidor demasiado débil no soporta la carga, causando ralentizaciones y fallos, lo que conlleva la pérdida de clientes y riesgos para la reputación. Un servidor demasiado potente es un pago directo por recursos no utilizados.
Cómo evaluar:
- Tareas intensivas en CPU: Cálculos elevados, procesamiento de grandes volúmenes de datos, aprendizaje automático, compilación. Requieren núcleos potentes y, posiblemente, procesadores especializados (GPU, TPU).
- Tareas intensivas en RAM: Bases de datos en memoria (Redis, Memcached), aplicaciones JVM con gran heap, análisis de big data, procesamiento de imágenes. Requieren un gran volumen de memoria RAM.
- Tareas intensivas en I/O: Bases de datos (PostgreSQL, MongoDB), servidores de archivos, servidores web de alta carga con gran cantidad de contenido estático. Requieren discos SSD/NVMe rápidos y un alto ancho de banda de I/O.
- Carga de red: Pasarelas API de alta carga, servicios de streaming, nodos CDN. Requieren un alto ancho de banda de red y bajas latencias.
Para 2026, están surgiendo nuevas generaciones de procesadores (por ejemplo, los procesadores ARM, como AWS Graviton, se vuelven aún más competitivos en relación precio/rendimiento), así como soluciones especializadas para IA y ML, que pueden reducir significativamente el coste de ejecutar tareas específicas.
Escalabilidad y elasticidad
Por qué es importante: La capacidad de la infraestructura para adaptarse a las cargas cambiantes sin intervención manual y con costes mínimos. Un sistema inelástico o bien no soporta los picos, o bien permanece inactivo en los períodos de baja, consumiendo recursos. FinOps busca pagar solo por los recursos realmente utilizados.
Cómo evaluar:
- Escalabilidad vertical: Aumento de los recursos (CPU, RAM) de un solo servidor. Fácil de implementar, pero tiene limitaciones físicas y requiere un reinicio.
- Escalabilidad horizontal: Adición de nuevos servidores para distribuir la carga. Más compleja de implementar (requiere aplicaciones sin estado, balanceadores de carga), pero proporciona un crecimiento casi infinito y alta disponibilidad.
- Autoescalado: Adición/eliminación automática de servidores basada en métricas (CPU, RAM, cola de solicitudes). Herramienta clave de FinOps para la optimización dinámica.
En 2026, se espera un mayor desarrollo de soluciones sin servidor (Serverless) y basadas en contenedores (Kubernetes), que ofrecen el más alto nivel de elasticidad y pago por uso real, lo que las hace extremadamente atractivas desde la perspectiva de FinOps.
Fiabilidad y disponibilidad (SLA)
Por qué es importante: El tiempo de inactividad (downtime) representa pérdidas directas e indirectas para el negocio: lucro cesante, pérdida de clientes, daño a la reputación. La alta disponibilidad suele ser más cara, por lo que es importante encontrar un equilibrio entre el nivel de SLA necesario y el presupuesto.
Cómo evaluar:
- SLA (Service Level Agreement): Porcentaje de tiempo de disponibilidad del servicio garantizado por el proveedor (por ejemplo, 99.9% o 99.99%). Cuanto mayor sea el SLA, mayor será el coste.
- Redundancia: Duplicación de componentes críticos (servidores, bases de datos, equipos de red) para evitar puntos únicos de fallo.
- Distribución geográfica: Ubicación de la infraestructura en varias regiones/zonas de disponibilidad para protegerse de fallos regionales.
- Copia de seguridad y recuperación (Backup & Recovery): Copias de seguridad regulares y planes de recuperación probados después de fallos.
El enfoque FinOps requiere una elección consciente del nivel de disponibilidad, basándose en el valor comercial de la aplicación, y no en el "máximo posible".
Seguridad y cumplimiento normativo (Compliance)
Por qué es importante: Las fugas de datos, los ciberataques, el incumplimiento de GDPR, HIPAA, PCI DSS y otras normativas pueden dar lugar a enormes multas, demandas judiciales y pérdida de confianza. Los costes de seguridad son una inversión, no un gasto.
Cómo evaluar:
- Seguridad de red: Firewalls, VPN, WAF (Web Application Firewall), protección contra DDoS.
- Seguridad de datos: Cifrado de datos en reposo y en tránsito, gestión de acceso, copia de seguridad.
- Gestión de identidad y acceso (IAM): Principio de privilegios mínimos, autenticación de dos factores.
- Cumplimiento de estándares: Certificaciones del proveedor (ISO 27001, SOC 2), cumplimiento de las normativas regionales y sectoriales.
Para 2026, aumenta el papel de las herramientas de seguridad automatizadas (DevSecOps), así como las plataformas para la gestión del cumplimiento, que ayudan a minimizar las verificaciones manuales y los costes asociados.
Modelo de precios y previsibilidad de costes
Por qué es importante: Los costes no transparentes o impredecibles dificultan la elaboración de presupuestos y la planificación. FinOps busca la máxima previsibilidad y la posibilidad de optimización.
Cómo evaluar:
- Pago por uso (Pay-as-you-go): Pago por los recursos realmente consumidos. Alta flexibilidad, pero potencialmente alta imprevisibilidad sin una monitorización adecuada.
- Instancias reservadas (Reserved Instances / Savings Plans): Descuentos por el compromiso de utilizar un volumen determinado de recursos durante un período prolongado (1-3 años). Reducen significativamente los costes base.
- Instancias Spot (Spot Instances): Instancias muy baratas, pero interrumpibles, adecuadas para tareas tolerantes a fallos y por lotes (batch).
- Coste fijo: Servidores dedicados o algunas tarifas de VPS con un pago mensual predecible. Adecuados para cargas estables y predecibles.
En 2026, los proveedores ofrecen modelos de precios aún más complejos, que requieren un análisis profundo y el uso de herramientas FinOps para elegir la opción más ventajosa.
Soporte y ecosistema
Por qué es importante: La calidad del soporte y la disponibilidad de herramientas influyen en la velocidad de resolución de problemas, el tiempo de comercialización y la eficiencia operativa general. Un soporte deficiente puede provocar largos tiempos de inactividad y costes adicionales en recursos internos.
Cómo evaluar:
- Nivel de soporte: 24/7, tiempo de respuesta, canales de comunicación (chat, teléfono, tickets).
- Documentación y comunidad: Disponibilidad de documentación exhaustiva, una comunidad activa, foros.
- Ecosistema: Disponibilidad de servicios adicionales (bases de datos, CDN, análisis), integración con otras herramientas.
- Servicios gestionados: Posibilidad de delegar parte de las tareas operativas al proveedor (por ejemplo, Managed Databases, Kubernetes as a Service).
Ubicación geográfica y latencia
Por qué es importante: La ubicación física de los servidores en relación con los usuarios finales afecta directamente a la velocidad de respuesta de la aplicación. Para los servicios globales, esto es críticamente importante. También son importantes las cuestiones de soberanía de datos y el cumplimiento de las leyes locales.
Cómo evaluar:
- Distancia a los usuarios: Elección de centros de datos lo más cercanos posible a la audiencia principal.
- CDN (Content Delivery Network): Uso de CDN para almacenar en caché el contenido más cerca de los usuarios, reduciendo la carga en el servidor principal y disminuyendo las latencias.
- Arquitectura Multi-Región/Multi-Zona: Despliegue en múltiples puntos geográficos para la tolerancia a fallos y la reducción de latencias.
- Leyes de almacenamiento de datos: Asegúrese de que los datos se almacenan de acuerdo con los requisitos de la jurisdicción donde se encuentra su audiencia.
La optimización de los costes de red, incluido el tráfico de salida (egress-traffic), se convierte en una de las direcciones clave de FinOps para 2026, ya que los volúmenes de datos transmitidos continúan creciendo.
Bloqueo de proveedor (Vendor Lock-in)
Por qué es importante: La dependencia de un solo proveedor puede limitar las posibilidades de migración, reducir el poder de negociación y conducir a un aumento de los costes de los servicios a largo plazo. FinOps fomenta arquitecturas que minimizan la dependencia.
Cómo evaluar:
- Estandarización: Uso de estándares abiertos (Docker, Kubernetes, Terraform) y tecnologías independientes de la nube.
- Abstracción: Separación de la lógica de la aplicación de los servicios específicos de la nube.
- Estrategia multinube/híbrida: Despliegue en varias nubes o una combinación de la nube con infraestructura propia para reducir riesgos.
Para 2026, las herramientas para la gestión multinube y la abstracción de la infraestructura son cada vez más maduras, lo que permite a las empresas adoptar un enfoque más flexible en la elección de proveedores y evitar un bloqueo rígido.
5. Tabla comparativa de servidores en la nube y dedicados (2026)
En 2026, el mercado de servicios en la nube y servidores dedicados continúa evolucionando, ofreciendo una amplia gama de soluciones. A continuación se presenta una tabla comparativa que refleja las características clave y los precios orientativos para diferentes tipos de infraestructura, relevantes para 2026. Los precios son hipotéticos y pueden variar según el proveedor, la región y la configuración específica. Suponemos configuraciones medias, adecuadas para una aplicación SaaS típica o un backend.
| Criterio | VPS en la nube (CPU compartida, 8-16 GB RAM) | VPS en la nube (CPU dedicada, 16-32 GB RAM) | VPS gestionado (Managed, 16-32 GB RAM) | Servidor dedicado (Bare Metal, configuración L) | Instancia en la nube (AWS EC2/GCP Compute, m5.xlarge/e2-standard-4) | Kubernetes as a Service (EKS/GKE, 3 nodos) | Serverless (Lambda/Cloud Functions, 100M invocaciones) |
|---|---|---|---|---|---|---|---|
| CPU típica | 2-4 vCPU (compartida) | 4-8 vCPU (dedicada) | 4-8 vCPU (dedicada) | 8-16 Cores (físicos) | 4 vCPU (dedicada) | 3 x 4 vCPU (dedicada) | 0.25-1 vCPU (ráfaga) |
| RAM típica | 8-16 GB | 16-32 GB | 16-32 GB | 64-128 GB | 16 GB | 3 x 16 GB | 128-512 MB |
| Almacenamiento típico | 160-320 GB SSD | 320-640 GB NVMe | 320-640 GB NVMe | 2 x 1 TB NVMe | 300 GB GP3 SSD | 3 x 300 GB GP3 SSD | N/A (efímero) |
| Tráfico de red (entrada/salida) | 1-2 TB / 1-2 TB | 2-4 TB / 2-4 TB | 2-4 TB / 2-4 TB | 10-20 TB / 10-20 TB | Entrada gratuita, Salida 0.08-0.12 $/GB | Entrada gratuita, Salida 0.08-0.12 $/GB | Entrada gratuita, Salida 0.08-0.12 $/GB |
| Coste mensual estimado (2026, USD) | 40-80 $ | 80-180 $ | 150-300 $ | 250-500 $ (sin SO/panel) | 150-250 $ (bajo demanda) | 400-800 $ (sin Control Plane) | 50-150 $ (por 100M invocaciones) |
| Escalabilidad | Manual/Vertical | Manual/Vertical | Manual/Vertical | Manual/Vertical (actualización) | Automática (horizontal, vertical) | Automática (horizontal, pods/nodos) | Automática (bajo demanda) |
| Nivel de gestión | Bajo (solo SO) | Bajo (solo SO) | Medio (SO + Panel) | Bajo (solo Hardware) | Medio (IaaS) | Alto (PaaS) | Muy alto (FaaS) |
| Previsibilidad de costes | Alta | Alta | Alta | Muy alta | Baja (bajo demanda), Alta (RI/SP) | Media (por nodos), Baja (por tráfico) | Baja (por invocaciones/RAM/CPU) |
| Tiempo de despliegue | Minutos | Minutos | Minutos | Horas/Días | Minutos | Decenas de minutos | Segundos |
Aclaraciones a la tabla:
- VPS en la nube (CPU compartida): Servidores virtuales donde la CPU se comparte entre varios clientes. La opción más económica, pero susceptible al "vecino ruidoso". Ideal para sitios web pequeños, entornos de prueba.
- VPS en la nube (CPU dedicada): Servidores virtuales con núcleos de CPU garantizados. Rendimiento más estable, adecuado para entornos de producción con carga media.
- VPS gestionado: VPS con servicios de administración adicionales, panel de control (cPanel, Plesk), copias de seguridad del proveedor. Conveniente para quienes no tienen sus propios administradores de sistemas.
- Servidor dedicado (Bare Metal): Servidor físico, completamente a su disposición. Máximo rendimiento y control, pero requiere conocimientos profundos de administración. Económicamente ventajoso para cargas muy altas y estables.
- Instancia en la nube (AWS EC2/GCP Compute): Servicio IaaS típico de grandes proveedores de la nube. Ofrece una enorme flexibilidad, muchos tipos de instancias, opciones avanzadas de red y disco, pero requiere una gestión FinOps activa para el control de costes.
- Kubernetes as a Service: Clústeres de Kubernetes gestionados (por ejemplo, EKS, GKE, AKS). Permiten ejecutar aplicaciones en contenedores con alta escalabilidad y tolerancia a fallos. El coste incluye el pago por los nodos y, posiblemente, por la capa de control.
- Serverless (Lambda/Cloud Functions): Funciones como servicio (FaaS). El pago se realiza por el número de invocaciones y el tiempo de ejecución. Ideal para tareas basadas en eventos, poco frecuentes, microservicios. Máxima elasticidad, mínima administración, pero más difícil de predecir el coste con cargas impredecibles.
La elección entre estas opciones es siempre un compromiso entre coste, rendimiento, flexibilidad, nivel de gestión y previsibilidad. FinOps ayuda a tomar esta decisión basándose en las necesidades reales del negocio.
6. Revisión detallada de cada punto/opción

Comprender los matices de cada tipo de infraestructura es fundamental para tomar decisiones FinOps informadas. Para 2026, las diferencias entre ellos se han vuelto aún más pronunciadas, y su aplicación óptima requiere una profunda experiencia.
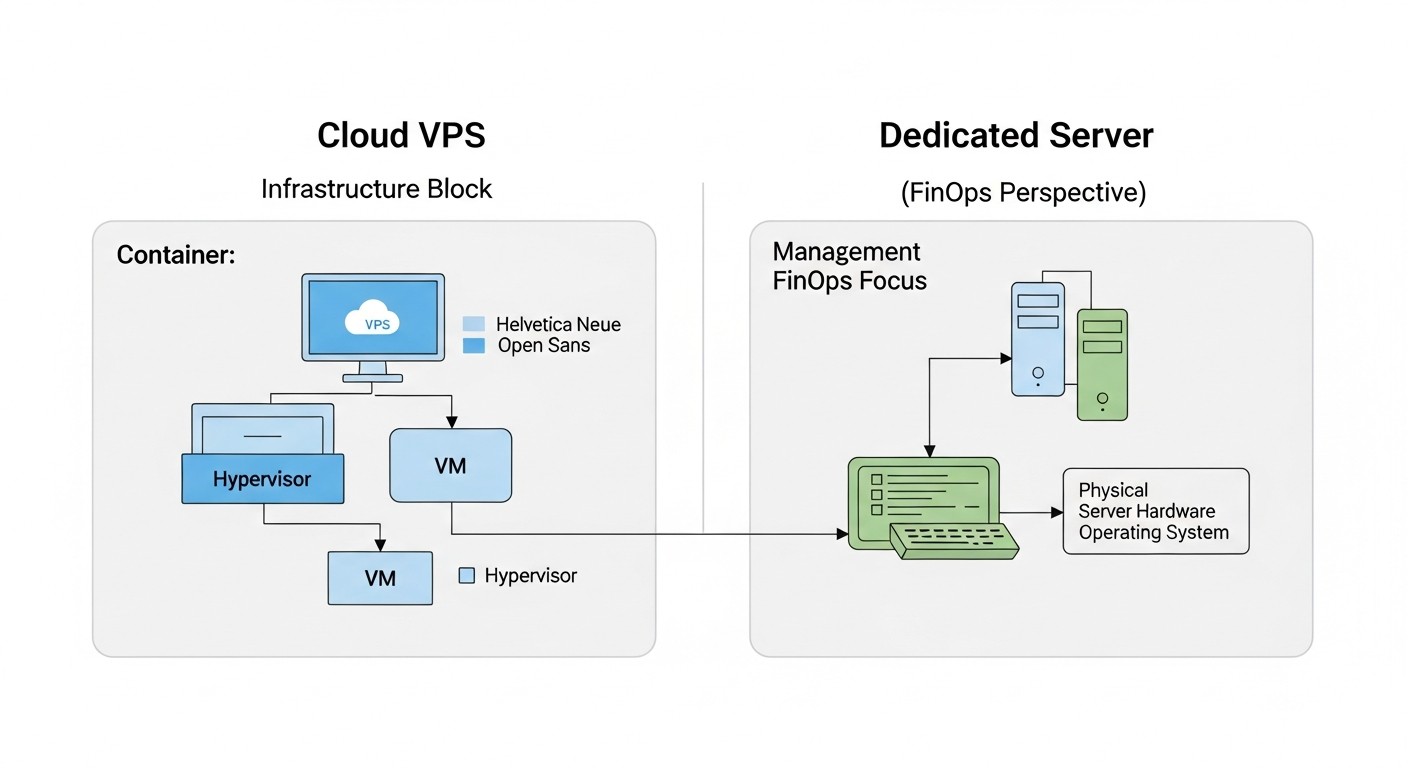
VPS en la nube (Virtual Private Servers)
Los VPS en la nube siguen siendo una de las soluciones más populares y accesibles para la mayoría de las startups y proyectos medianos. Representan una parte virtualizada de un servidor físico, donde se obtienen recursos garantizados (o recursos con overprovisioning en el caso de CPU compartida) y control total sobre el sistema operativo. Proveedores como DigitalOcean, Vultr, Hetzner, Linode, así como proveedores rusos (Yandex.Cloud, VK Cloud Solutions, Selectel) ofrecen una amplia gama de VPS.
Ventajas:
- Accesibilidad: Bajo umbral de entrada, las tarifas iniciales comienzan desde unos pocos dólares al mes.
- Flexibilidad: Fácil de escalar recursos (CPU, RAM, Almacenamiento) verticalmente (a menudo con un reinicio). Despliegue rápido.
- Control: Acceso root completo al sistema operativo, lo que permite instalar cualquier software y configurar el entorno según las necesidades.
- Previsibilidad: Generalmente una tarifa mensual fija, lo que facilita la elaboración de presupuestos.
- Amplia elección: Muchos proveedores que compiten en precio y calidad.
Desventajas:
- Escalabilidad limitada: La escalabilidad vertical tiene límites físicos. La escalabilidad horizontal requiere configuración manual o el uso de servicios adicionales (balanceadores de carga).
- Problema del "vecino ruidoso": En los VPS con CPU compartida, el rendimiento puede verse afectado por otros clientes en el mismo servidor físico.
- Falta de servicios gestionados: La mayoría de los VPS no incluyen bases de datos gestionadas, colas de mensajes y otros servicios PaaS que ofrecen los grandes proveedores de la nube.
- Administración manual: Toda la responsabilidad del SO, seguridad, actualizaciones, copias de seguridad recae en el usuario (a menos que sea un VPS gestionado).
Para quién es adecuado:
Aplicaciones web pequeñas y medianas, servicios API, blogs, entornos de prueba y desarrollo, servidores VPN, proyectos personales. Ideal para startups en etapas tempranas que necesitan flexibilidad y bajos costes iniciales. FinOps aquí se centra en la elección correcta de la tarifa, la monitorización regular de la utilización y la actualización/reducción oportuna.
Ejemplos de uso específicos:
Despliegue de un sitio web en WordPress/Laravel, una pequeña API Node.js/Python, un servidor para agentes CI/CD, un entorno de prueba para desarrolladores. Por ejemplo, una startup puede comenzar con un VPS por $20/mes, y a medida que el tráfico crece, pasar a un VPS con CPU dedicada por $80-100/mes, hasta que se requiera una arquitectura más compleja con balanceo de carga.
Servidores dedicados (Dedicated Servers / Bare Metal)
Un servidor dedicado le proporciona un servidor físico completo, sin virtualización (a menos que usted mismo la implemente). Esto significa acceso exclusivo a todos los recursos de hardware: CPU, RAM, discos e interfaz de red. Proveedores como Hetzner, OVHcloud, Contabo, así como los rusos Selectel, DataLine, ofrecen una amplia gama de configuraciones.
Ventajas:
- Máximo rendimiento: Ausencia de sobrecarga de virtualización, acceso completo al "hardware". Ideal para tareas que consumen muchos recursos.
- Estabilidad y previsibilidad: El rendimiento no depende de los "vecinos".
- Control total: Usted gestiona todo, desde la elección del SO hasta la configuración de bajo nivel de BIOS/UEFI.
- Seguridad: Aislamiento físico de otros clientes.
- Ahorro en grandes volúmenes: Con una carga alta y constante, un servidor dedicado puede ser más barato que una configuración equivalente en la nube (especialmente sin compromisos a largo plazo).
- Altos límites de tráfico: A menudo, los proveedores ofrecen volúmenes de tráfico muy grandes o incluso ilimitados por una tarifa fija.
Desventajas:
- Baja flexibilidad/escalabilidad: La escalabilidad vertical requiere reemplazo de hardware y tiempo de inactividad. La escalabilidad horizontal requiere la compra de nuevos servidores y configuración manual.
- Despliegue prolongado: El pedido y la preparación del servidor pueden llevar desde unas pocas horas hasta varios días.
- Alto coste de entrada: El coste de alquiler es significativamente mayor que el de un VPS.
- Altos requisitos de administración: Requiere conocimientos profundos de administración de sistemas, configuración de red, arreglos RAID, seguridad.
- Falta de servicios gestionados: Todos los servicios adicionales (bases de datos, balanceadores de carga) deben configurarse y mantenerse de forma independiente.
Para quién es adecuado:
Grandes bases de datos, servidores de juegos de alta carga, plataformas de streaming, sistemas ERP, proyectos con carga muy estable y alta, donde cada milisegundo y el máximo ancho de banda son importantes. También es adecuado para empresas que necesitan el máximo control sobre la infraestructura o requieren "hardware" específico. FinOps aquí se centra en la planificación a largo plazo, la elección correcta de la configuración y el uso eficiente de cada núcleo y gigabyte.
Ejemplos de uso específicos:
Servidores para Minecraft con cientos de jugadores, un clúster PostgreSQL de alta carga, un servidor para aprendizaje automático con GPU, un sistema corporativo 1C, una nube privada basada en Proxmox/OpenStack. Por ejemplo, un estudio de juegos para un nuevo título puede necesitar un servidor dedicado con una CPU potente y una gran cantidad de RAM, capaz de manejar una carga máxima de 5000 usuarios simultáneos, lo que costaría $400-600/mes, pero evitaría retrasos y garantizaría una experiencia de juego estable.
Instancias en la nube (IaaS de grandes proveedores: AWS EC2, GCP Compute Engine, Azure VMs)
Estos servicios proporcionan máquinas virtuales en infraestructuras de nube a gran escala, como Amazon Web Services (AWS), Google Cloud Platform (GCP) y Microsoft Azure. Ofrecen una enorme flexibilidad, escalabilidad e integración con un amplio ecosistema de servicios en la nube.
Ventajas:
- Máxima escalabilidad: Configuración sencilla de autoescalado, posibilidad de lanzar miles de instancias en cuestión de minutos.
- Flexibilidad de configuraciones: Amplia selección de tipos de instancias (optimizadas para CPU, RAM, I/O, GPU), posibilidad de configuraciones personalizadas.
- Ecosistema de servicios: Integración perfecta con bases de datos gestionadas (RDS, Cloud SQL), colas de mensajes (SQS, Pub/Sub), CDN (CloudFront, Cloud CDN), funciones sin servidor (Lambda, Cloud Functions) y una multitud de otras soluciones PaaS/SaaS.
- Alta disponibilidad: Posibilidad de despliegue en múltiples zonas de disponibilidad y regiones para una máxima tolerancia a fallos.
- Herramientas FinOps avanzadas: Herramientas integradas para monitorización de costes, facturación, presupuestos, reserva de capacidades (Reserved Instances, Savings Plans, Spot Instances).
Desventajas:
- Complejidad: La enorme cantidad de servicios y opciones puede ser abrumadora para los principiantes.
- Imprevisibilidad de costes: El modelo de pago por uso (Pay-as-you-go) puede llevar a facturas inesperadamente altas sin un control y optimización adecuados.
- Bloqueo de proveedor (Vendor Lock-in): El uso de servicios específicos de la nube puede dificultar la migración a otro proveedor.
- Costes de red: El tráfico de salida (egress-traffic) de la nube puede ser muy caro.
Para quién es adecuado:
Grandes proyectos SaaS, plataformas de comercio electrónico, servicios web de alta carga, proyectos con carga dinámica e impredecible, Big Data, proyectos de ML. Para empresas que necesitan máxima flexibilidad, escalabilidad y una amplia gama de servicios gestionados. FinOps aquí es una disciplina central, que incluye la gestión de Reserved Instances, Spot Instances, rightsizing, optimización del tráfico de red y auditorías regulares.
Ejemplos de uso específicos:
Backend para una aplicación móvil con millones de usuarios, plataforma analítica que procesa petabytes de datos, sitio web de comercio electrónico global. Por ejemplo, una empresa SaaS que proporciona un sistema CRM puede utilizar instancias EC2 para sus microservicios, RDS para la base de datos, SQS para las colas y S3 para el almacenamiento de archivos. Con una aplicación FinOps correcta, utilizando Reserved Instances para la carga base y autoescalado con Spot Instances para los picos, se pueden reducir los costes en un 30-70% en comparación con el modelo bajo demanda.
Kubernetes as a Service (EKS, GKE, AKS)
Los servicios gestionados de Kubernetes (Amazon EKS, Google GKE, Azure AKS) proporcionan clústeres de Kubernetes listos para usar, abstraendo al usuario de la gestión de los nodos maestros y su infraestructura. Esto permite centrarse en el despliegue de aplicaciones en contenedores.
Ventajas:
- Alta escalabilidad: Escalado automático de pods y nodos del clúster en función de la carga.
- Tolerancia a fallos: Mecanismos integrados de orquestación y autorrecuperación.
- Portabilidad: Los contenedores (Docker) y Kubernetes son estándares abiertos, lo que reduce el bloqueo de proveedor.
- Uso eficiente de recursos: Kubernetes permite empaquetar densamente las cargas de trabajo en los nodos, maximizando la utilización de recursos.
- Compatible con DevOps: Simplifica CI/CD y el despliegue de aplicaciones.
Desventajas:
- Complejidad: Kubernetes en sí mismo tiene un alto umbral de entrada.
- Coste de la capa de control: Algunos proveedores cobran por los nodos maestros (por ejemplo, EKS), otros lo incluyen en el coste de los nodos.
- Gastos generales: Un clúster de Kubernetes requiere más recursos para su funcionamiento en comparación con los VPS "desnudos".
- Costes de formación: Se requieren especialistas con conocimientos profundos de Kubernetes.
Para quién es adecuado:
Arquitecturas de microservicios, aplicaciones distribuidas de alta carga, plataformas SaaS que requieren un alto grado de automatización, escalabilidad y tolerancia a fallos. Empresas que ya utilizan la contenerización o planean migrar a microservicios. FinOps en Kubernetes incluye la optimización del tamaño de los pods (requests/limits), el autoescalado de nodos (Cluster Autoscaler, Karpenter), la elección de tipos de instancias óptimos para los nodos, así como la monitorización y gestión de los costes de red.
Ejemplos de uso específicos:
Despliegue de múltiples microservicios, cada uno de los cuales atiende una función separada, en un único clúster de Kubernetes. Por ejemplo, una plataforma multimedia donde cada servicio (usuarios, contenido, recomendaciones, streaming) se ejecuta en su propio pod, escalando de forma independiente. El coste de un clúster de este tipo puede comenzar en $400-500 al mes por varios nodos y la capa de control, pero permite reducir significativamente los costes operativos de administración y utilizar los recursos de manera eficiente.
Serverless (Lambda, Cloud Functions, Azure Functions)
La computación sin servidor, o "funciones como servicio" (FaaS), permite a los desarrolladores ejecutar código sin necesidad de gestionar servidores. El proveedor escala y gestiona automáticamente toda la infraestructura subyacente, y el pago se cobra solo por el tiempo de ejecución real del código y el número de invocaciones.
Ventajas:
- Máxima elasticidad: Escalado instantáneo de cero a miles de invocaciones por segundo.
- Pago por uso real: Solo paga por lo que realmente consume, sin servidores inactivos.
- Ausencia de administración: El proveedor se encarga de todas las tareas de gestión de servidores, parches, actualizaciones del SO.
- Bajos costes operativos: Reducción significativa de los esfuerzos de DevOps y administradores de sistemas.
- Tolerancia a fallos incorporada: Las funciones se duplican y se ejecutan automáticamente en diferentes zonas de disponibilidad.
Desventajas:
- Arranque en frío (Cold Start): Las primeras invocaciones de una función después de un período de inactividad pueden tardar más debido a la inicialización del entorno.
- Limitaciones: Límites en el tiempo de ejecución, volumen de memoria, tamaño del paquete de despliegue.
- Complejidad de depuración y monitorización: La naturaleza distribuida de las arquitecturas sin servidor puede complicar la depuración.
- Bloqueo de proveedor (Vendor Lock-in): Aunque el código puede ser portable, la integración con otros servicios del proveedor crea dependencia.
- Imprevisibilidad de costes: Con una carga muy alta e impredecible, el coste puede ser mayor que el de un servidor que funciona constantemente.
Para quién es adecuado:
Arquitecturas orientadas a eventos, pasarelas API, backends para aplicaciones móviles, procesamiento de archivos, procesos ETL, chatbots, webhooks, tareas en segundo plano. Ideal para aplicaciones con carga variable o esporádica. FinOps para Serverless incluye la optimización del tiempo de ejecución de las funciones, la elección del volumen de memoria óptimo, el almacenamiento en caché agresivo, así como la monitorización y el análisis de las invocaciones para identificar funciones ineficientes.
Ejemplos de uso específicos:
Procesamiento de imágenes después de subirlas a S3, envío de notificaciones por correo electrónico, autenticación de usuarios, implementación de pequeños microservicios que reaccionan a eventos en la base de datos. Por ejemplo, para procesar 100 millones de invocaciones de Lambda al mes con un tiempo de ejecución de 500 ms y 256 MB de RAM, el coste puede ser de unos $70-120 al mes, lo que para este volumen de procesamiento es extremadamente ventajoso en comparación con el mantenimiento de un servidor que funciona constantemente.
7. Consejos prácticos y recomendaciones de FinOps
La aplicación de FinOps no se limita a los conocimientos teóricos; requiere acciones y herramientas concretas. A continuación se presentan instrucciones y recomendaciones paso a paso que le ayudarán a gestionar eficazmente los costes de los VPS y servidores dedicados.
1. Implementación de una cultura de transparencia y responsabilidad (Tagging & Cost Allocation)
El primer paso hacia la optimización es comprender quién y por qué paga. Para 2026, sin un sistema adecuado de etiquetado y asignación de costes, es imposible gestionar eficazmente la nube.
Acciones:
- Desarrolle una política de etiquetado: Defina etiquetas obligatorias para todos los recursos (por ejemplo,
Project,Environment,Owner,CostCenter). - Automatice el etiquetado: Utilice Infrastructure as Code (IaC) para aplicar automáticamente etiquetas al crear recursos.
- Monitorización del cumplimiento: Verifique regularmente que todos los recursos tengan las etiquetas necesarias.
Ejemplo de política de etiquetado:
# Ejemplo de política de etiquetado para AWS/GCP/Azure
# Todos los recursos deben tener las siguientes etiquetas:
- Key: Project
Description: Nombre del proyecto o producto (e.g., "SaaS_CRM", "Analytics_Platform")
Required: true
Values: [CRM, Analytics, CoreServices, InternalTools, ... ]
- Key: Environment
Description: Entorno de despliegue (e.g., "prod", "staging", "dev", "test")
Required: true
Values: [prod, staging, dev, test]
- Key: Owner
Description: Nombre o ID del equipo/ingeniero responsable del recurso
Required: true
Values: [devops-team, backend-crm, data-eng, ... ]
- Key: CostCenter
Description: Código del centro de costes para informes financieros
Required: false # Puede ser opcional para entornos de desarrollo
Values: [CC101, CC202, ... ]
- Key: Application
Description: Nombre de la aplicación o microservicio específico
Required: false
Values: [AuthService, PaymentGateway, UserPortal, ... ]
2. Rightsizing y auditoría regular
Una de las formas más efectivas de reducir costes es ajustar el tamaño óptimo del servidor a la carga real. Muchas empresas pagan de más por recursos excesivos.
Acciones:
- Monitorización de la utilización: Recopile métricas de CPU, RAM, I/O de disco y tráfico de red durante un período prolongado (mínimo 30-90 días).
- Identificación de recursos subutilizados: Busque servidores con una utilización constantemente baja (por ejemplo, CPU por debajo del 10-15%, RAM por debajo del 30-40%).
- Reducción/Terminación: Mueva los servidores subutilizados a tarifas más bajas o elimine completamente los no utilizados.
- Optimización de código: Si un recurso está constantemente sobrecargado, en lugar de actualizar el servidor, considere optimizar el código de la aplicación.
Ejemplo de comando para verificar la utilización de RAM/CPU (Linux):
# Verificación de la utilización actual de CPU y RAM
top -bn1 | head -n 5 # Resumen breve
free -h # Uso de RAM
vmstat 1 10 # Monitorización de CPU, I/O, RAM en tiempo real
# Análisis más profundo con sar (System Activity Reporter)
# Instale sysstat, si no está: sudo apt install sysstat
sar -u 1 10 # Utilización de CPU
sar -r 1 10 # Utilización de RAM
sar -b 1 10 # Operaciones de I/O
# Para ver el historial de una fecha específica (por ejemplo, 2026-03-15)
# sar -f /var/log/sysstat/sa15 # (saYY donde YY - día del mes)
3. Uso de modelos de pago con compromisos (Reserved Instances / Savings Plans)
Para una carga base predecible, las capacidades reservadas pueden proporcionar un ahorro significativo.
Acciones:
- Análisis de carga estable: Determine la cantidad mínima de servidores (VPS/VMs) que funcionan 24/7 durante un período prolongado.
- Elección del plan óptimo: Elija Reserved Instances (RI) o Savings Plans (SP) por 1 o 3 años, con o sin pago anticipado, según la estrategia financiera.
- Monitorización de la cobertura: Verifique regularmente qué porcentaje de su carga estable está cubierta por RI/SP.
Importante: RI/SP solo son adecuados para cargas estables. No reserve lo que pueda ser apagado o reducido.
4. Automatización de la infraestructura y el escalado
La automatización no solo acelera, sino que también genera un ahorro significativo.
Acciones:
- Autoescalado: Configure la adición/eliminación automática de servidores (en la nube) o contenedores (en Kubernetes) en función de la carga.
- Programación de encendido/apagado: Apague automáticamente los entornos de desarrollo/prueba/staging fuera del horario laboral (por la noche, fines de semana).
- Uso de Spot Instances: Para cargas de trabajo tolerantes a fallos e interrumpibles (por ejemplo, procesamiento de big data, renderizado, CI/CD) utilice instancias Spot con sus enormes descuentos.
- Infrastructure as Code (IaC): Utilice Terraform, Ansible, CloudFormation, Pulumi para la gestión declarativa de la infraestructura, lo que reduce errores y garantiza la reproducibilidad.
Ejemplo de script para detener servidores de desarrollo fuera del horario laboral (para VPS con API, por ejemplo, DigitalOcean):
#!/bin/bash
# Script para detener servidores de desarrollo de DigitalOcean por la etiqueta 'Environment:dev'
# Requiere doctl instalado y autenticación
# doctl auth init
DO_TOKEN="YOUR_DIGITALOCEAN_API_TOKEN" # ¡Utilice variables de entorno!
# Obtenemos la lista de droplets con la etiqueta 'Environment:dev'
DROPLET_IDS=$(doctl compute droplet list --format "ID,Tags" | grep "Environment:dev" | awk '{print $1}')
if [ -z "$DROPLET_IDS" ]; then
echo "No hay droplets de desarrollo activos para detener."
exit 0
fi
echo "Deteniendo los siguientes droplets de desarrollo: $DROPLET_IDS"
for ID in $DROPLET_IDS; do
echo "Deteniendo droplet ID: $ID..."
doctl compute droplet-action power-off $ID --force
if [ $? -eq 0 ]; then
echo "Droplet $ID detenido exitosamente."
else
echo "Error al detener el droplet $ID."
fi
done
echo "Proceso de detención de droplets de desarrollo completado."
5. Optimización de almacenamiento y tráfico de red
Estos componentes a menudo se subestiman, pero pueden representar una parte significativa de la factura.
Acciones:
- Auditoría de discos: Identifique discos no utilizados, instantáneas obsoletas, imágenes no actuales. Elimínelos.
- Elección del tipo de almacenamiento: Utilice almacenamiento compatible con S3 para archivos estáticos, almacenamiento en bloques para bases de datos y almacenamiento en frío (Glacier, Coldline) para archivos.
- Optimización del tráfico de salida (egress-traffic):
- Utilice CDN (Content Delivery Network) para almacenar en caché el contenido más cerca de los usuarios, reduciendo la carga en el servidor principal y disminuyendo el tráfico de salida de la nube.
- Comprima los datos (gzip, brotli) antes de enviarlos.
- Minimice el tamaño de las imágenes y videos.
- Considere ubicar los recursos en la misma región que los consumidores para evitar el tráfico interregional.
Ejemplo de configuración de Nginx para compresión Gzip:
http {
# ... otras configuraciones ...
gzip on;
gzip_vary on;
gzip_proxied any;
gzip_comp_level 6; # Nivel de compresión: 1 (rápido) - 9 (máx. compresión)
gzip_buffers 16 8k;
gzip_http_version 1.1;
gzip_types text/plain text/css application/json application/javascript text/xml application/xml application/xml+rss text/javascript font/truetype font/opentype application/vnd.ms-fontobject image/svg+xml;
gzip_disable "MSIE [1-6]\."; # Deshabilitar para IE antiguos
server {
# ... configuraciones de su servidor ...
}
}
6. Monitorización y alertas de costes
Sin una monitorización constante, es imposible reaccionar rápidamente a los cambios.
Acciones:
- Configure presupuestos: Establezca presupuestos mensuales o trimestrales para cada proyecto/departamento y configure alertas cuando se superen los umbrales (por ejemplo, 50%, 80%, 100% del presupuesto).
- Rastree anomalías: Utilice herramientas para detectar picos repentinos de costes o un uso inusual de recursos.
- Informes regulares: Proporcione informes regulares de costes a los equipos técnicos y financieros.
7. Optimización de bases de datos
Las bases de datos suelen ser uno de los componentes más caros de la infraestructura.
Acciones:
- Rightsizing: Asegúrese de que el tipo y tamaño de la instancia de la base de datos coincidan con la carga real.
- Indexación: Optimice las consultas y añada los índices necesarios para acelerar el funcionamiento de la base de datos, lo que puede reducir la necesidad de hardware más potente.
- Almacenamiento en caché: Utilice el almacenamiento en caché (Redis, Memcached) para reducir la carga en la base de datos.
- Archivado/Sharding: Mueva los datos antiguos a almacenamiento en frío o fragmente la base de datos para distribuir la carga.
- Bases de datos gestionadas (Managed Databases): Utilice bases de datos gestionadas de proveedores de la nube, que a menudo incluyen escalado automático, copias de seguridad y parches, lo que reduce el TCO (Total Cost of Ownership).
Ejemplo de consulta SQL para encontrar consultas lentas en PostgreSQL:
-- Asegúrese de que pg_stat_statements esté habilitado en postgresql.conf
-- shared_preload_libraries = 'pg_stat_statements'
-- pg_stat_statements.track = all
-- REINICIAR DB
SELECT
query,
calls,
total_time,
mean_time,
stddev_time,
rows,
100.0 * shared_blks_hit / (shared_blks_hit + shared_blks_read) AS hit_percent
FROM
pg_stat_statements
ORDER BY
total_time DESC
LIMIT 10;
8. Deduplicación y archivado de datos
El almacenamiento ocupa una parte significativa de los costes, especialmente teniendo en cuenta las copias de seguridad y las instantáneas.
Acciones:
- Políticas de ciclo de vida: Configure el movimiento automático de datos antiguos a clases de almacenamiento más baratas (por ejemplo, S3 Standard-IA, Glacier).
- Eliminación de copias de seguridad/instantáneas obsoletas: Elimine regularmente las copias de seguridad y las instantáneas que hayan superado las políticas de retención establecidas.
- Deduplicación: Utilice herramientas de deduplicación para almacenar solo copias únicas de los datos.
8. Errores comunes en la optimización de costes
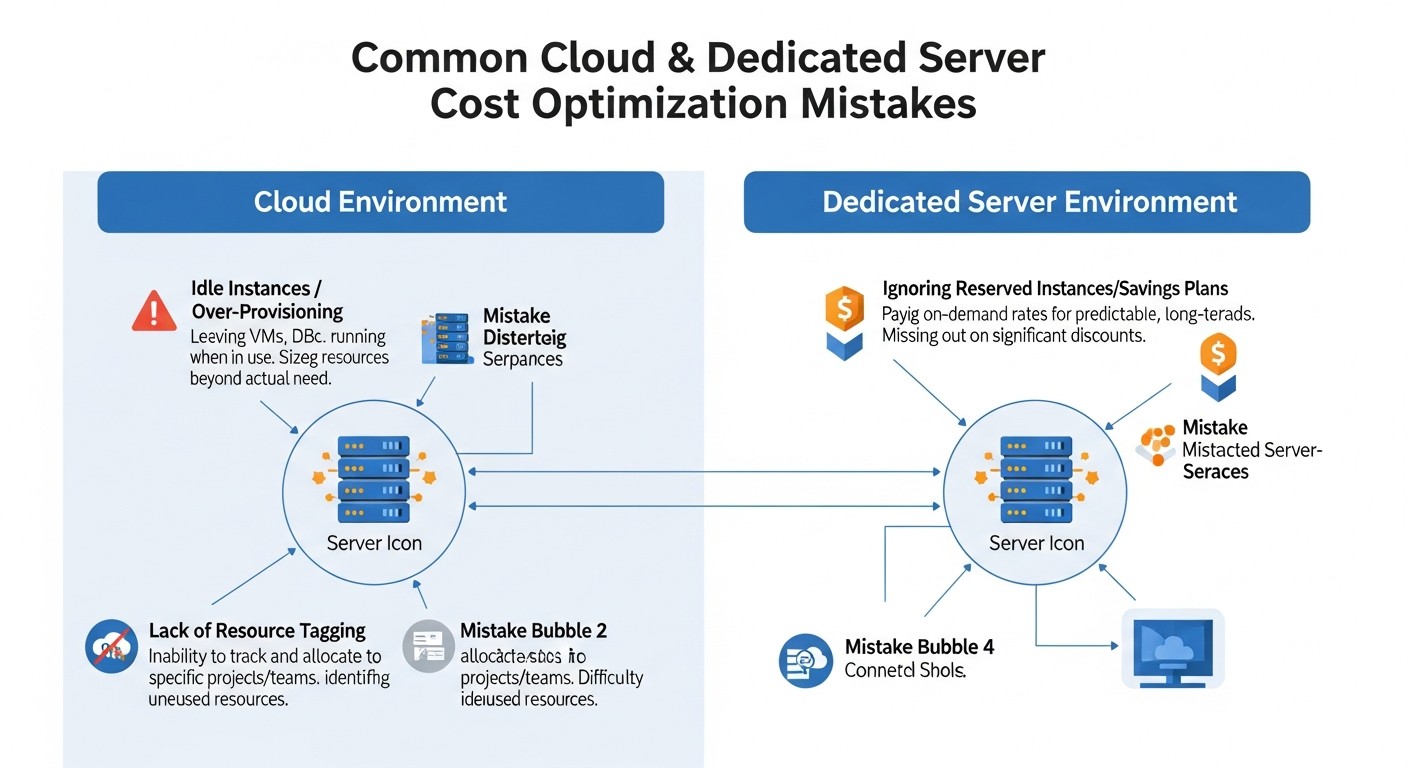
Incluso los equipos de DevOps y los administradores de sistemas experimentados pueden cometer errores que conducen a pagos excesivos. Para 2026, estos errores se vuelven aún más costosos debido a la creciente complejidad de los ecosistemas en la nube.
1. Ignorar recursos no utilizados (Zombie Resources)
Descripción del error: Este es, quizás, el error más común y costoso. Después de pruebas, experimentos o la desactivación de servicios antiguos, a menudo quedan servidores (VPS/VM) en ejecución pero no utilizados, balanceadores de carga inactivos, direcciones IP no utilizadas, discos no utilizados, instantáneas, bases de datos y otros recursos. Estos continúan generando facturas, a veces de forma imperceptible, hasta que crecen a sumas significativas.
Cómo evitarlo:
- Implemente una política estricta para eliminar recursos después de su uso, especialmente para entornos de desarrollo/prueba.
- Automatice la limpieza de recursos mediante scripts o IaC (Infrastructure as Code) después de la finalización de proyectos o al expirar su vida útil.
- Configure auditorías regulares de los recursos en la nube utilizando herramientas especializadas (ver sección 12) para identificar "recursos zombi".
- Utilice el etiquetado (
Owner,TTL- Time To Live) para todos los recursos, a fin de identificar fácilmente a sus propietarios y su vida útil.
Ejemplo real de consecuencias: Una startup descubrió que pagaba $1500 al mes por 10 instancias EC2 que se habían utilizado para pruebas A/B hacía seis meses y se habían olvidado. El pago excesivo total fue de $9000, lo que era crítico para su modesto presupuesto.
2. Rightsizing insuficiente (Pago excesivo por potencia sobrante)
Descripción del error: A menudo, los ingenieros eligen configuraciones de servidor "con margen" o grandes estándar, sin analizar las necesidades reales de la aplicación. Como resultado, los servidores funcionan con una utilización de CPU del 5-10% y RAM del 20-30%, y la empresa paga de más por potencia no utilizada.
Cómo evitarlo:
- Implemente un sistema de monitorización que recopile métricas de utilización (CPU, RAM, I/O, Red) durante un período prolongado (mínimo 30-90 días).
- Analice regularmente estas métricas y utilice las recomendaciones del proveedor (por ejemplo, AWS Compute Optimizer) o herramientas de terceros para determinar el tamaño óptimo de la instancia.
- No tema reducir el tamaño del servidor (downgrade) si la carga lo permite. Es más fácil aumentar si es necesario.
- Considere el uso del autoescalado, que ajusta automáticamente la cantidad y el tamaño de las instancias a la carga actual.
Ejemplo real de consecuencias: Un proyecto SaaS alojaba su backend en 4 VPS de $120 cada uno, aunque la monitorización mostraba que 3 de ellos estaban constantemente cargados con menos del 15% de CPU. Después de reducir a VPS de $60 cada uno, el ahorro mensual fue de $240, o $2880 al año, sin pérdida de rendimiento.
3. Ignorar los costes de red (Egress-traffic)
Descripción del error: Muchos se centran en el coste de CPU/RAM/Almacenamiento, olvidando que el tráfico de red saliente (egress) de la nube puede ser muy caro, especialmente con grandes volúmenes de datos o transferencias interregionales. Para 2026, con el crecimiento de los volúmenes de datos y multimedia, este problema solo se agrava.
Cómo evitarlo:
- Utilice CDN (Content Delivery Network) para entregar contenido estático (imágenes, videos, JS/CSS) a los usuarios, ya que el tráfico de CDN suele ser más barato que el tráfico de salida directo de la nube.
- Comprima los datos (gzip, brotli) antes de transmitirlos por la red.
- Coloque los recursos que intercambian datos con frecuencia en la misma zona de disponibilidad o región para minimizar el tráfico interzonal/interregional.
- Optimice las solicitudes a la API para no transmitir datos excesivos.
- Almacene en caché los datos en el lado del cliente o en servicios intermedios.
Ejemplo real de consecuencias: Una plataforma multimedia se encontró con una factura de tráfico de salida de AWS CloudFront que superaba el coste de todas sus instancias EC2. La razón: imágenes y videos no optimizados que se transmitían sin la compresión y el almacenamiento en caché adecuados. Después de la optimización y la implementación de CDN, los costes de tráfico se redujeron en un 60%.
4. Falta de automatización y planificación
Descripción del error: La gestión manual de la infraestructura no solo consume tiempo, sino que también conduce a un uso ineficiente de los recursos. Entornos de prueba olvidados, ejecutándose los fines de semana, o escalados manuales que no siguen el ritmo de la carga, todo esto lleva a pagos excesivos.
Cómo evitarlo:
- Implemente Infrastructure as Code (IaC) para la gestión declarativa de recursos.
- Configure el autoescalado para cambiar dinámicamente los recursos en función de la carga.
- Utilice programadores (cronjobs, funciones en la nube) para encender/apagar automáticamente los entornos de desarrollo/prueba fuera del horario laboral.
- Automatice la eliminación de instantáneas y copias de seguridad obsoletas.
Ejemplo real de consecuencias: Un equipo de desarrolladores iniciaba y detenía manualmente los servidores de prueba. Como resultado, cada viernes olvidaban apagar 3 servidores que funcionaban todo el fin de semana. En un año, esto llevó a un pago excesivo de $3600 por horas de inactividad que podrían haberse evitado con un simple script de cron.
5. Uso ineficiente de capacidades reservadas (Reserved Instances / Savings Plans)
Descripción del error: O bien la empresa no utiliza RI/SP en absoluto, perdiendo la oportunidad de ahorrar hasta un 70% en la carga base, o los compra sin un análisis adecuado, reservando demasiados o tipos de instancias incorrectos que luego no se utilizan.
Cómo evitarlo:
- Realice un análisis exhaustivo del historial de uso de recursos para determinar la carga base estable y predecible que funciona 24/7.
- Utilice las recomendaciones de los proveedores de la nube (por ejemplo, las recomendaciones de AWS Cost Explorer RI/SP) para determinar la cantidad y los tipos óptimos de RI/SP.
- Supervise la utilización de sus RI/SP para asegurarse de que se utilizan de forma eficaz. Si es necesario, venda los RI no utilizados en los mercados (si están disponibles).
- Recuerde que RI/SP es un compromiso. No los compre para cargas de trabajo temporales o experimentales.
Ejemplo real de consecuencias: Una gran empresa compró Reserved Instances por $50 000 para sus instancias EC2, pero debido a una reestructuración repentina del proyecto y la transición a Kubernetes, el 40% de estas instancias dejaron de utilizarse. Los RI quedaron sin pagar, ya que no había forma de transferirlos o venderlos, lo que provocó pérdidas financieras significativas.
6. Falta de cultura FinOps y colaboración interfuncional
Descripción del error: Cuando los ingenieros no comprenden las implicaciones financieras de sus decisiones, y los departamentos financieros no comprenden las especificidades técnicas, se produce una brecha. Los ingenieros pueden elegir las soluciones más caras pero convenientes, y los gerentes financieros pueden exigir recortes de gastos sin comprender el impacto en el rendimiento o la estabilidad.
Cómo evitarlo:
- Implemente FinOps como una cultura, no como una herramienta. Cree un equipo interfuncional (ingenieros, finanzas, producto).
- Capacite a los ingenieros en alfabetización financiera en el contexto de la nube.
- Proporcione a los ingenieros acceso a informes de costes (por sus proyectos/servicios) y hágalos responsables del presupuesto.
- Establezca KPI que incluyan métricas técnicas (tiempo de actividad, rendimiento) y financieras (Coste por Transacción, Coste por Usuario).
- Realice reuniones periódicas donde se discutan tanto los aspectos técnicos como financieros del uso de la nube.
Ejemplo real de consecuencias: En una empresa, los desarrolladores elegían constantemente las instancias más potentes para sus bases de datos porque "así es más rápido". El departamento financiero, sin comprender el aspecto técnico, simplemente pagaba las facturas. Al final, los costes de las bases de datos representaban el 40% de todo el presupuesto de la nube, aunque la mayor parte de esa potencia no se utilizaba, y la optimización de las consultas podría haber tenido un efecto mucho mayor con menos costes.
9. Lista de verificación para la aplicación práctica de FinOps
Esta lista de verificación le ayudará a abordar sistemáticamente la optimización de costes en VPS en la nube y servidores dedicados, siguiendo los principios de FinOps. Revísela regularmente, por ejemplo, una vez al mes o al trimestre.
Fase 1: Información y Visibilidad (Inform)
- ¿Se ha implementado una política de etiquetado para todos los recursos?
- ¿Todos los recursos tienen las etiquetas obligatorias (Project, Environment, Owner, CostCenter)?
- ¿Está automatizado el etiquetado a través de IaC?
- ¿Se realiza una auditoría regular del cumplimiento de la política de etiquetado?
- ¿Están configuradas las herramientas de monitorización de costes?
- ¿Se utilizan las herramientas nativas de los proveedores de la nube (Cost Explorer, Billing Reports)?
- ¿Están integradas plataformas FinOps de terceros (CloudHealth, Apptio Cloudability, CloudZero)?
- ¿Están disponibles informes detallados de costes por proyectos, equipos, entornos?
- ¿Están configurados los presupuestos y las alertas?
- ¿Se han establecido presupuestos mensuales/trimestrales para cada proyecto/departamento?
- ¿Están configuradas las alertas cuando se superan los umbrales (50%, 80%, 100%)?
- ¿Reciben las personas responsables estas alertas?
- ¿Existe un repositorio centralizado de métricas de utilización?
- ¿Se recopilan métricas de CPU, RAM, I/O, Red de los últimos 30-90 días para todos los servidores?
- ¿Están disponibles estas métricas para análisis y elaboración de informes?
Fase 2: Optimización (Optimize)
- ¿Se ha realizado una auditoría de los recursos no utilizados ("recursos zombi")?
- ¿Se han identificado VPS/VM, discos, IP, balanceadores de carga, instantáneas no utilizados?
- ¿Se ha desarrollado un plan para su eliminación o desactivación?
- ¿Está automatizada la limpieza de recursos temporales?
- ¿Se realiza Rightsizing para todos los servidores?
- ¿Se han analizado las métricas de utilización para identificar servidores subutilizados/sobreutilizados?
- ¿Se aplican las recomendaciones para reducir/aumentar el tamaño de las instancias?
- ¿Se utilizan las recomendaciones para migrar a tipos de instancias más nuevos y económicos (por ejemplo, Graviton)?
- ¿Están optimizados los almacenamientos de datos?
- ¿Se han movido los datos poco utilizados a clases de almacenamiento más baratas (por ejemplo, Glacier, Coldline)?
- ¿Se han eliminado las copias de seguridad/instantáneas obsoletas de acuerdo con las políticas?
- ¿Se utilizan tipos de discos óptimos (GP3 en lugar de GP2, HDD en lugar de SSD para archivos)?
- ¿Se aplican modelos de pago con compromisos (RI/Savings Plans)?
- ¿Se ha determinado la carga base estable que se puede cubrir con RI/SP?
- ¿Se utilizan las recomendaciones del proveedor para la compra de RI/SP?
- ¿Se realiza un seguimiento de la utilización de RI/SP?
- ¿Se ha implementado la automatización del escalado y la gestión?
- ¿Está configurado el autoescalado para cargas de trabajo dinámicas?
- ¿Se utilizan Spot Instances para tareas tolerantes a fallos?
- ¿Están configurados los horarios automáticos de encendido/apagado para entornos de desarrollo/prueba?
- ¿Se utiliza IaC (Terraform, Ansible) para gestionar la infraestructura?
- ¿Está optimizado el tráfico de red (especialmente el de salida)?
- ¿Se utiliza CDN para contenido estático?
- ¿Se aplica compresión de datos (gzip, brotli) para el tráfico?
- ¿Se minimiza el tráfico interregional/interzonal?
- ¿Están optimizadas las bases de datos?
- ¿Se ha realizado una auditoría de consultas lentas y se han añadido los índices necesarios?
- ¿Se utiliza el almacenamiento en caché (Redis, Memcached) para reducir la carga en la BD?
- ¿Se ha considerado el uso de bases de datos gestionadas para reducir el TCO?
Fase 3: Operación y Colaboración (Operate)
- ¿Se ha implementado la cultura FinOps en el equipo?
- ¿Están los ingenieros capacitados en los fundamentos de FinOps y la alfabetización financiera?
- ¿Tienen los ingenieros acceso a informes de costes de sus servicios/proyectos?
- ¿Se han establecido KPI que incluyan métricas de costes?
- ¿Se realizan reuniones FinOps regulares?
- ¿Participan en ellas representantes de ingeniería, finanzas y producto?
- ¿Se discuten los costes actuales, los planes de optimización y los nuevos proyectos?
- ¿Existe un plan de respuesta a anomalías en los costes?
- ¿Se han definido los procedimientos para investigar y eliminar las causas de los picos repentinos de gastos?
- ¿Se realiza una revisión periódica de la estrategia del proveedor?
- ¿Se evalúan nuevas ofertas de otros proveedores de la nube o opciones con servidores dedicados?
- ¿Se analiza la posibilidad de migración para obtener mejores condiciones?
10. Cálculo de costes / Economía de servidores en la nube y dedicados
Comprender la economía de los servidores en la nube y dedicados es la base de FinOps. Los costes no se limitan solo a la tarifa mensual de CPU y RAM; existen gastos ocultos y factores que pueden influir significativamente en la factura final. Para 2026, estos factores se vuelven aún más complejos.
Componentes principales de los costes
- Recursos computacionales (Compute): CPU, RAM. El principal elemento de gasto, pero a menudo no el único.
- Almacenamiento (Storage): Discos (SSD, NVMe, HDD), almacenamiento de objetos (compatible con S3), sistemas de archivos. Dependen del volumen, tipo (rendimiento) y número de operaciones de I/O.
- Tráfico de red (Network): El tráfico entrante (ingress) suele ser gratuito, el saliente (egress) es de pago y puede ser muy caro, especialmente el interregional. También se pagan las direcciones IP, los balanceadores de carga, las pasarelas VPN.
- Bases de datos: Las bases de datos gestionadas (RDS, Cloud SQL) incluyen el coste de la instancia, el almacenamiento, las operaciones de I/O y la copia de seguridad.
- Servicios adicionales: CDN, colas de mensajes, funciones sin servidor, monitorización, registro, seguridad (WAF, protección DDoS).
- Licencias: Coste de licencias de SO (Windows Server), bases de datos (MS SQL Server), paneles de control (cPanel, Plesk) y otro software.
- Gastos operativos (OpEx): Costes de personal (DevOps, administradores de sistemas), su formación, tiempo dedicado a la gestión y depuración.
Cómo optimizar los costes
La optimización de costes no es solo una reducción, sino también la obtención del máximo valor por cada rublo/dólar gastado. Esto se logra mediante:
- Rightsizing: Ajuste constante del tamaño óptimo de los recursos.
- Automatización: Uso de autoescalado, programación de encendido/apagado.
- Modelos de pago: Aplicación de Reserved Instances, Savings Plans, Spot Instances.
- Optimización de código: Un código más eficiente requiere menos recursos.
- Soluciones arquitectónicas: Transición a microservicios, contenedores, Serverless para una mejor utilización y escalabilidad.
- Gestión de almacenamiento: Uso de almacenamiento multinivel, eliminación de datos innecesarios.
- Optimización de red: CDN, compresión de datos, minimización del tráfico interregional.
- Monitorización e informes: Análisis constante de costes e identificación de anomalías.
Gastos ocultos
Para 2026, a pesar del esfuerzo de los proveedores por la transparencia, algunos gastos siguen siendo "ocultos" o no obvios:
- Recursos inactivos: Direcciones IP, balanceadores de carga, discos no utilizados que siguen siendo facturados.
- Tráfico interzonal/interregional: Transferencia de datos entre diferentes zonas de disponibilidad o regiones dentro de un mismo proveedor.
- Operaciones de I/O de almacenamiento: En algunos modelos de pago, además del volumen de disco, se facturan las operaciones de lectura/escritura.
- Costes de registro y monitorización: La recopilación y el almacenamiento de registros y métricas pueden ser costosos para grandes volúmenes.
- Costes de soporte: El soporte premium de los proveedores de la nube puede ser caro, pero a menudo se justifica para sistemas críticos.
- Costes de migración: La transferencia de datos y aplicaciones entre proveedores o dentro de la nube puede implicar costes de tráfico y mano de obra.
- Costes de formación del personal: La necesidad de capacitar al equipo en nuevas tecnologías y prácticas FinOps.
Ejemplos de cálculos para diferentes escenarios (año 2026, precios hipotéticos)
Para mayor claridad, consideraremos tres escenarios típicos y realizaremos un cálculo de costes simplificado, demostrando la influencia de las prácticas FinOps.
Escenario 1: Pequeño proyecto SaaS (MVP al inicio)
Descripción: Pequeña aplicación web con una API básica y una base de datos simple, 1000 usuarios activos, carga máxima de 50 RPS. Se requiere alta flexibilidad y bajos costes iniciales.
| Recurso | Configuración | Coste mensual (sin FinOps) | Coste mensual (con FinOps) | Comentario |
|---|---|---|---|---|
| Backend/API | 1 x VPS con CPU dedicada (4vCPU, 8GB RAM, 160GB NVMe) | 80 $ | 40 $ | Rightsizing: 1 x VPS con CPU compartida (2vCPU, 4GB RAM, 80GB SSD) al inicio. |
| Base de datos | 1 x PostgreSQL gestionado (4vCPU, 8GB RAM, 100GB SSD) | 120 $ | 80 $ | Rightsizing: Instancia de BD más pequeña (2vCPU, 4GB RAM). |
| CDN | No | 0 $ (pero egress caro) | 15 $ | Implementación de CDN para contenido estático (500GB de tráfico). |
| Tráfico (Egress) | 1 TB | 80 $ | 20 $ | Reducción por CDN y compresión. |
| Copias de seguridad | Manuales/Básicas | 10 $ | 10 $ | Instantáneas/copias de seguridad automáticas. |
| Total: | 290 $ | 165 $ | Ahorro: 43% |
Escenario 2: Proyecto de comercio electrónico en crecimiento
Descripción: Tienda online con carga variable, picos en vacaciones y rebajas. 10 000 usuarios activos, hasta 500 RPS. Se requiere alta disponibilidad y escalabilidad.
| Recurso | Configuración | Coste mensual (sin FinOps) | Coste mensual (con FinOps) | Comentario | |
|---|---|---|---|---|---|
| Backend (EC2/Compute Engine) | 4 x m5.large (2vCPU, 8GB RAM) bajo demanda | 4 x 70 $ = 280 $ | 2 x m5.large RI + 2 x m5.large bajo demanda con autoescalado | 2 x 40 $ (RI) + 2 x 70 $ (bajo demanda) = 220 $ | RI para carga base, autoescalado para picos, ahorro del 21% |
| Base de datos (RDS/Cloud SQL) | 1 x db.m5.xlarge (4vCPU, 16GB RAM) bajo demanda | 350 $ | 1 x db.m5.large (2vCPU, 8GB RAM) RI + Réplica de lectura | 200 $ (RI) + 100 $ (Réplica) = 300 $ | Rightsizing + RI + Réplica de lectura para escalado de lectura, ahorro del 14% |
| Caché (Redis) | 1 x Elasticache m5.large (8GB RAM) | 80 $ | 1 x Elasticache m5.medium (4GB RAM) | 40 $ | Rightsizing, ahorro del 50% |
| CDN (CloudFront/Cloud CDN) | 10 TB de tráfico | 1000 $ | 600 $ | Optimización de imágenes, videos, compresión, caché, ahorro del 40% | |
| S3/Cloud Storage | 5 TB Estándar | 120 $ | 60 $ | Políticas de ciclo de vida (movimiento de datos antiguos a IA), ahorro del 50% | |
| Otros (LB, IP, Monitorización) | 50 $ | 30 $ | Eliminación de IP no utilizadas, optimización de registros, ahorro del 40% | ||
| Total: | 1880 $ | 1250 $ | Ahorro: 33.6% |
Escenario 3: Servidor de juegos de alta carga (Servidor dedicado)
Descripción: Servidor de juegos para un juego online, que requiere el máximo rendimiento de CPU y baja latencia. 5000 jugadores simultáneos. Carga estable y alta.
| Recurso | Configuración | Coste mensual (sin FinOps) | Coste mensual (con FinOps) | Comentario |
|---|---|---|---|---|
| Servidor de juegos | 1 x Servidor dedicado (16 Cores, 128GB RAM, 2x1TB NVMe) | 450 $ | 450 $ | El servidor dedicado suele ser óptimo para esta carga, aquí FinOps se centra en la utilización. |
| Base de datos | En el mismo servidor | 0 $ (pero competencia por recursos) | 80 $ | Movimiento de la BD a un VPS separado (4vCPU, 8GB RAM) para aislamiento y estabilidad. |
| CDN/Protección DDoS | Básico | 30 $ | 70 $ | Protección DDoS mejorada y CDN para la descarga de recursos del juego. Inversión en estabilidad. |
| Monitorización/Registro | Básico | 10 $ | 30 $ | Monitorización extendida (Prometheus/Grafana) y registro centralizado (ELK). Inversión en eficiencia operativa. |
| Tráfico | 20 TB incluidos | 0 $ | 0 $ | Normalmente incluido en la tarifa del servidor dedicado. |
| Licencias (SO/Panel) | Windows Server | 25 $ | 0 $ | Transición a Linux, ahorro en licencias. |
| Total: | 515 $ | 630 $ | Aumento del 22% |
Conclusión del escenario 3: En este caso, FinOps no siempre significa una reducción directa de costes. A veces significa optimización del valor, cuando un pequeño aumento de los costes en los servicios correctos (BD separada, seguridad mejorada, monitorización) conduce a una mejora significativa de la estabilidad, el rendimiento y la reducción de los riesgos operativos, lo que en última instancia genera más beneficios o previene pérdidas significativamente mayores.
11. Casos de estudio y ejemplos
Los ejemplos reales siempre demuestran mejor la eficacia de FinOps. Para 2026, las empresas siguen enfrentándose a desafíos similares, pero las soluciones son cada vez más sofisticadas gracias al desarrollo de herramientas y metodologías.
Caso 1: Plataforma SaaS para gestión de proyectos
Problema: La empresa "TaskMaster" (SaaS mediano, 50 000 usuarios activos) se enfrentaba a facturas de la nube (AWS) en constante crecimiento, que superaban los $20 000 al mes. Los costes principales correspondían a instancias EC2, RDS PostgreSQL y tráfico de salida. El equipo de DevOps estaba ocupado con nuevas funcionalidades y no tenía tiempo para una optimización profunda. El departamento financiero exigía recortes.
Solución FinOps:
- Visibilidad y etiquetado: En primer lugar, el equipo implementó una política de etiquetado estricta para todos los recursos:
Project(Backend, Frontend, Analytics),Environment(prod, staging, dev),Owner(equipo de desarrollo). Esto permitió identificar con precisión qué equipos y servicios generaban los costes principales. - Rightsizing de EC2: Con la ayuda de AWS Cost Explorer y Compute Optimizer, se realizó una auditoría de todas las instancias EC2. Se descubrió que alrededor del 30% de las instancias estaban sobredimensionadas (utilización de CPU < 15%). 10 instancias m5.xlarge se redujeron a m5.large, y 5 instancias de prueba m5.large, que funcionaban 24/7, se configuraron para apagarse automáticamente fuera del horario laboral.
- Optimización de RDS: La instancia de RDS PostgreSQL también se redimensionó de db.r5.2xlarge a db.r5.xlarge, ya que la carga máxima no alcanzaba la utilización completa de la instancia actual. Se añadieron índices para consultas lentas, lo que redujo la carga de CPU de la BD.
- Reserved Instances/Savings Plans: Después de analizar la carga base estable (alrededor del 70% de todas las instancias EC2 y RDS), la empresa adquirió Savings Plans por 1 año, lo que proporcionó un descuento de hasta el 30% en estos recursos.
- Optimización del tráfico de salida: Se observó un alto tráfico de S3 a internet. Resultó que los usuarios a menudo descargaban archivos grandes. Se implementó la integración con CloudFront para todos los archivos estáticos y el contenido descargable, y también se configuró la compresión Gzip para todas las respuestas HTTP.
Resultados:
- Los costes mensuales se redujeron de $20 000 a $13 500 (ahorro del 32.5%).
- Mejoró la transparencia de los costes, cada equipo ahora veía su "presupuesto" y estaba motivado para optimizar.
- El rendimiento de la aplicación no se vio afectado, e incluso mejoró en algunos lugares gracias a la optimización de la BD y CDN.
- FinOps se convirtió en parte de los procesos regulares, y el equipo de DevOps ahora dedica 2-3 horas a la semana a la monitorización y optimización.
Caso 2: Desarrollo de un nuevo producto de IA en servidores dedicados
Problema: La startup "VisionAI" estaba desarrollando un nuevo producto para el procesamiento de imágenes utilizando aprendizaje automático. Para entrenar modelos, se requerían servidores potentes con GPU. Alquilaron 3 servidores dedicados a Hetzner con GPU NVIDIA A100, cada uno con un coste de alrededor de $1500 al mes. El problema era que el entrenamiento de modelos no se realizaba 24/7, pero los servidores funcionaban constantemente, y también surgían dificultades con la gestión de dependencias y el escalado para diferentes etapas de desarrollo.
Solución FinOps:
- Enfoque híbrido: Se decidió no renunciar a los servidores dedicados (debido al alto coste de las GPU en la nube), sino complementarlos con soluciones en la nube para mayor flexibilidad.
- Optimización del uso de servidores GPU:
- En lugar de un funcionamiento constante, los servidores GPU se configuraron para encenderse solo bajo demanda (a través de la API de Hetzner) o según un horario para entrenamientos nocturnos.
- Se implementó un sistema de colas (Kubernetes con un planificador de GPU o simplemente Celery/RQ) para cargar al máximo los servidores GPU cuando estaban activos.
- Se utilizaron contenedores Docker para aislar los entornos de entrenamiento, lo que permitió ejecutar diferentes experimentos en un mismo servidor sin conflictos.
- Migración de tareas no relacionadas con GPU a la nube:
- El preprocesamiento de datos, el almacenamiento de conjuntos de datos, el alojamiento de API para inferencia (después del entrenamiento) se migraron a AWS.
- Para el preprocesamiento se utilizaron instancias EC2 Spot (para tareas por lotes) y AWS Lambda (para pequeñas transformaciones).
- Para el almacenamiento de conjuntos de datos se utilizó S3 con políticas de ciclo de vida (movimiento de datos antiguos a Glacier).
- La API para inferencia se desplegó en EKS con autoescalado, utilizando instancias más baratas sin GPU.
- Monitorización y métricas: Se configuró la monitorización de la utilización de GPU en los servidores dedicados y métricas de costes en AWS para ver la eficiencia con la que se utilizaban los recursos.
Resultados:
- Los costes de los servidores GPU se redujeron en un 40% (de $4500 a $2700 al mes) gracias a su encendido solo bajo demanda y la máxima utilización durante el funcionamiento.
- Los costes generales de la infraestructura se volvieron más flexibles y predecibles.
- El proceso de desarrollo se aceleró significativamente: los ingenieros podían lanzar rápidamente experimentos en Spot Instances o Serverless sin esperar a que los servidores GPU estuvieran libres.
- Mejoró la escalabilidad del servicio de inferencia, que ahora podía manejar automáticamente las cargas máximas.
- El valor total de la infraestructura aumentó significativamente, mientras que la empresa obtuvo ahorros en los componentes más caros.
Caso 3: Migración de un sistema ERP obsoleto
Problema: Una gran empresa manufacturera "GlobalProd" utilizaba un sistema ERP obsoleto basado en MS SQL Server, que funcionaba en un servidor físico dedicado en un centro de datos local. El servidor había sido comprado hace 5 años, estaba moralmente obsoleto, su mantenimiento era costoso y carecía de escalabilidad. Los gastos operativos mensuales (electricidad, refrigeración, administración, licencias) ascendían a unos $1000, sin contar el CAPEX para la compra de un nuevo servidor.
Solución FinOps:
- Evaluación del TCO (Total Cost of Ownership): Se realizó un análisis detallado de todos los costes, incluyendo el CAPEX para la actualización del equipo, el OpEx para el mantenimiento, las licencias, así como los riesgos de inactividad. Se descubrió que el TCO actual era significativamente mayor de lo que parecía.
- Migración a la nube: Se tomó la decisión de migrar el sistema ERP a la nube para aprovechar las ventajas de los servicios gestionados y la flexibilidad. Se eligió Azure, ya que ya existían licencias de MS SQL Server y experiencia en .NET.
- Elección de servicios óptimos:
- Para MS SQL Server se eligió Azure SQL Database (Managed Instance), lo que permitió utilizar las licencias existentes (Azure Hybrid Benefit) y liberarse de la carga de la administración de la BD.
- Para la parte del servidor del ERP (API, interfaz web) se utilizaron Azure Virtual Machines.
- Para el almacenamiento de archivos (informes, documentos) se utilizó Azure Files.
- Optimización de costes en la nube:
- Después de la migración y la monitorización, las Azure Virtual Machines se redimensionaron a configuraciones óptimas.
- Se adquirieron Azure Reserved VM Instances por 3 años para la carga base, lo que proporcionó un descuento de hasta el 72%.
- Se configuró el escalado automático para los servidores web durante los picos (fin de mes, período de informes).
- Se implementaron políticas de ciclo de vida para Azure Files, moviendo documentos antiguos a almacenamiento en frío.
Resultados:
- Reducción del OpEx de $1000 a $450 al mes (ahorro del 55%), incluyendo licencias de SQL Server (gracias a Azure Hybrid Benefit) e Managed Instance.
- Ausencia total de CAPEX para la actualización del equipo.
- Aumento significativo de la fiabilidad y disponibilidad del sistema (SLA de Azure).
- Reducción de la carga del departamento de TI, que ahora podía centrarse en el desarrollo en lugar de en el mantenimiento de hardware obsoleto.
- El sistema ERP se volvió más flexible y capaz de escalar según las necesidades del negocio.
Estos casos demuestran que FinOps no es una solución universal "talla única", sino un enfoque adaptable que requiere una comprensión profunda tanto de los aspectos técnicos como financieros, así como la disposición a cambiar la arquitectura y los procesos.
12. Herramientas y recursos
La aplicación efectiva de FinOps es imposible sin las herramientas adecuadas. Para 2026, el ecosistema de herramientas FinOps se ha vuelto aún más maduro, ofreciendo soluciones para cada aspecto de la gestión de costes en la nube.
Herramientas para trabajar con FinOps y análisis de costes
- Proveedores de la nube (Native Tools):
- AWS Cost Explorer & AWS Budgets: Permiten analizar gastos, obtener recomendaciones sobre RI/SP, crear presupuestos y alertas.
- Google Cloud Billing & Cost Management: Herramientas similares para GCP, incluyendo informes de costes, presupuestos y exportación de datos a BigQuery para un análisis profundo.
- Azure Cost Management + Billing: Proporciona análisis de costes, la capacidad de crear presupuestos, exportar datos, recomendaciones de optimización.
- Yandex.Cloud Cost & Usage Reports: Informes detallados sobre consumo y costes.
- Plataformas FinOps de terceros:
- CloudHealth by VMware: Plataforma integral para la gestión de costes, seguridad, rendimiento y cumplimiento normativo en entornos multinube.
- Apptio Cloudability: Se especializa en la gestión financiera de la nube, proporciona análisis profundo, optimización de costes, presupuestos y pronósticos.
- CloudZero: Se centra en vincular los costes con las métricas de negocio (Coste por Cliente, Coste por Característica), ayudando a los ingenieros a comprender el impacto financiero de sus decisiones.
- Flexera (RightScale): Gestión de la nube y FinOps para entornos híbridos y multinube.
- Kubecost: Herramienta para la monitorización y optimización de costes en Kubernetes, permite distribuir costes a pods, namespaces, equipos.
- Herramientas para la monitorización de la utilización y el rendimiento:
- Prometheus & Grafana: Soluciones de código abierto para la recopilación de métricas y la visualización de datos. Permiten rastrear la utilización de CPU, RAM, I/O y otros recursos.
- Datadog, New Relic, Dynatrace: Plataformas comerciales de APM (Application Performance Monitoring) y monitorización de infraestructura, que proporcionan métricas detalladas y capacidades para el análisis del rendimiento y los costes asociados.
- Zabbix / Icinga: Sistemas de monitorización tradicionales para VPS y servidores dedicados.
- Herramientas Infrastructure as Code (IaC):
- Terraform: Gestión declarativa de la infraestructura en cualquier nube o en servidores dedicados. Ayuda a automatizar el despliegue y el etiquetado, reduciendo errores manuales.
- Ansible: Herramienta para la automatización de la configuración y el despliegue de software en servidores.
- CloudFormation (AWS), Deployment Manager (GCP), ARM Templates (Azure): Herramientas IaC nativas de los proveedores de la nube.
- Herramientas para la automatización y scripting:
- Python Boto3 (AWS), Google Cloud Client Libraries, Azure SDK: Bibliotecas para interactuar con las API de la nube, permiten crear scripts personalizados para automatizar tareas de FinOps (por ejemplo, detener instancias, eliminar instantáneas).
- Bash / PowerShell: Para scripts de automatización simples en VPS y servidores dedicados.
Enlaces y documentación útiles
- FinOps Foundation: finops.org - Sitio web oficial de FinOps Foundation, contiene guías, mejores prácticas, certificaciones.
- AWS Well-Architected Framework (Cost Optimization Pillar): aws.amazon.com/architecture/well-architected/cost-optimization/ - Recomendaciones detalladas para la optimización de costes en AWS. Existen frameworks similares para GCP y Azure.
- Blogs y artículos de proveedores: Lea regularmente los blogs de AWS, Google Cloud, Azure, DigitalOcean, Hetzner, ya que publican nuevas funciones, descuentos y mejores prácticas.
- Stack Overflow, Reddit (r/devops, r/cloud, r/finops): Excelente lugar para buscar soluciones a problemas específicos e intercambiar experiencias con la comunidad.
- Documentación de herramientas específicas: Consulte siempre la documentación oficial de Terraform, Kubernetes, Prometheus y otras herramientas para obtener información actualizada.
13. Troubleshooting (resolución de problemas)
Incluso con las prácticas FinOps más cuidadosamente planificadas, pueden surgir problemas inesperados con los costes. La capacidad de diagnosticarlos y resolverlos rápidamente es una habilidad clave.
Problemas típicos y sus soluciones
Problema 1: Aumento repentino y drástico de la factura de la nube
Posibles causas:
- Recursos olvidados: Instancias de prueba en ejecución, bases de datos no utilizadas, balanceadores de carga antiguos.
- Autoescalado incontrolado: Configuración errónea del autoescalado, que lleva al lanzamiento de demasiadas instancias.
- Pico de tráfico: Ataque DDoS, contenido viral, solicitud no optimizada, descarga masiva de archivos grandes.
- Cambios en la política de precios del proveedor: Raro, pero posible.
- Errores en la aplicación: Bucles infinitos, fugas de memoria, consultas ineficientes a la BD, que generan una carga excesiva y, en consecuencia, consumo de recursos.
Solución:
- Verifique las alertas: Lo primero es comprobar si se activaron las alertas de presupuesto.
- Análisis de informes de costes: Utilice AWS Cost Explorer, GCP Billing Reports o Azure Cost Management para determinar qué categoría de servicios (Compute, Network, Storage, Database) o qué proyecto/servicio causó el pico.
- Auditoría de recursos: Verifique los recursos creados o modificados recientemente. Busque "recursos zombi".
- Monitorización del tráfico: Si el problema es el tráfico, revise los registros de los servidores web/balanceadores de carga/CDN en busca de actividad anómala.
- Monitorización del rendimiento de la aplicación: Utilice herramientas APM (Datadog, New Relic) o registros para identificar errores en la aplicación que puedan estar causando una carga excesiva.
- Reversión de cambios: Si el aumento está relacionado con un despliegue reciente, considere revertir a la versión anterior.
Problema 2: Factura constantemente alta con baja utilización de recursos
Posibles causas:
- Rightsizing excesivo: Los servidores son demasiado grandes para la carga actual.
- Reserved Instances/Savings Plans no utilizados: Comprados, pero no utilizados o utilizados de forma ineficiente.
- Servicios gestionados caros: Uso de configuraciones caras de servicios gestionados (bases de datos, colas) con baja carga.
- Altos costes de licencias: Uso de SO o software de pago.
- Gastos ocultos: IP no utilizadas, balanceadores de carga, instantáneas, tráfico interzonal.
Solución:
- Rightsizing detallado: Realice un análisis profundo de las métricas de utilización (CPU, RAM, I/O) durante 30-90 días y redimensione todas las instancias y servicios gestionados.
- Auditoría de RI/SP: Verifique la utilización de sus Reserved Instances o Savings Plans. Si están subutilizados, considere la posibilidad de venderlos (si hay un mercado) o ajustar futuras compras.
- Optimización de licencias: Considere la transición a alternativas de código abierto o el uso de Linux en lugar de Windows.
- Búsqueda de gastos ocultos: Realice una auditoría de todos los recursos a través de la consola del proveedor o mediante scripts, buscando componentes no utilizados.
- Implementación de autoescalado: Si la carga es variable, configure el autoescalado para una adaptación dinámica.
Problema 3: Largo "arranque en frío" de las funciones Serverless
Posibles causas:
- Gran tamaño del paquete: Cuanto mayor sea el código de la función y sus dependencias, más larga será la inicialización.
- Lógica de inicialización compleja: Larga carga de bibliotecas, conexión a la BD, inicialización de servicios externos.
- Invocaciones poco frecuentes: La función se invoca raramente y el proveedor la "descarga" de la memoria.
Solución:
- Optimización de código: Reduzca el tamaño del paquete de la función, elimine dependencias no utilizadas.
- "Calentamiento" de funciones: Utilice servicios especiales o configure invocaciones "en vacío" regulares de la función para mantenerla en estado "caliente".
- Aumento de memoria: En algunos casos, aumentar la memoria asignada a la función puede acelerar su inicialización.
- Uso de Provisioned Concurrency: Configure instancias de función preasignadas que siempre estén listas para funcionar (de pago, pero elimina los arranques en frío).
Comandos y enfoques de diagnóstico
Para diagnosticar problemas en VPS y servidores dedicados:
- Monitorización del sistema:
# Información general del sistema y procesos top # Monitor interactivo de procesos htop # top mejorado free -h # Uso de RAM df -h # Uso del espacio en disco iostat -x 1 # I/O de disco (requiere el paquete sysstat) netstat -tunap # Conexiones de red - Análisis de registros:
# Visualización de registros del sistema journalctl -xe # Para sistemas systemd tail -f /var/log/syslog # Registros generales del sistema tail -f /var/log/nginx/access.log # Registros del servidor web tail -f /var/log/mysql/error.log # Registros de la base de datos - Verificación de problemas de red:
ping google.com # Verificación de la accesibilidad de recursos externos traceroute google.com # Seguimiento de la ruta de los paquetes iperf3 -c <server_ip> # Medición del ancho de banda de la red - Verificación de recursos en la consola de la nube: Revise regularmente la consola de gestión del proveedor. Busque:
- Instancias en ejecución que deberían estar detenidas.
- Discos o direcciones IP no adjuntos.
- Configuraciones de autoescalado.
- Detalles de facturación por cada servicio.
Cuándo contactar al soporte
No dude en contactar al soporte del proveedor en los siguientes casos:
- Cargos inexplicables: Si no puede encontrar la causa del aumento de la factura y todos sus recursos están contabilizados y optimizados.
- Problemas con la infraestructura del proveedor: Si sospecha que el problema no está en su aplicación, sino en la red, el hardware o los servicios del proveedor (por ejemplo, latencias de red, fallos en el centro de datos).
- Problemas técnicos con servicios gestionados: Si una base de datos gestionada u otro servicio PaaS no funciona correctamente.
- Preguntas sobre precios: Si tiene preguntas específicas sobre planes de tarifas, descuentos o modelos de pago.
- Ataques DDoS: Si se enfrenta a un ataque DDoS a gran escala, el soporte del proveedor puede ofrecer soluciones especializadas.
Al contactar al soporte, siempre proporcione la información más completa posible: ID de recursos, plazos del problema, capturas de pantalla, registros y los pasos que ya ha tomado para el diagnóstico.
14. FAQ (mínimo 10 preguntas)
¿Qué es FinOps y en qué se diferencia de la simple reducción de costes?
FinOps es un modelo operativo y una práctica cultural que une a los equipos financieros, operativos y de ingeniería para lograr el máximo valor empresarial de las inversiones en la nube. A diferencia de la simple reducción de costes, FinOps es un proceso continuo destinado a aumentar la transparencia, la responsabilidad y la eficiencia del uso de los recursos en la nube. Se centra no solo en la reducción de costes, sino también en la optimización del valor que la empresa obtiene por cada dólar gastado, garantizando al mismo tiempo el rendimiento y la escalabilidad necesarios.
¿Puede FinOps ser útil para una pequeña startup con un presupuesto limitado?
Sí, FinOps es extremadamente útil para las startups. Para ellas, cada céntimo cuenta, y el uso ineficiente de la nube puede agotar rápidamente el presupuesto. FinOps ayuda a las startups a establecer desde el principio una cultura adecuada de gestión de costes, evitar pagos excesivos por recursos no utilizados, elegir tarifas óptimas y escalar la infraestructura de forma inteligente, lo cual es fundamental para la supervivencia y el crecimiento.
¿Qué métricas principales se deben seguir para FinOps?
Las métricas principales para FinOps incluyen: gastos totales en la nube, gastos por proyectos/equipos/entornos, utilización de CPU, RAM, I/O de disco, tráfico de red (especialmente el de salida), cobertura de Reserved Instances/Savings Plans, así como métricas de negocio como Coste por Cliente (CPC), Coste por Transacción (CPT), Coste por Característica. Estas últimas ayudan a vincular los gastos técnicos con el valor real para el negocio.
¿Con qué frecuencia se debe realizar la auditoría y optimización de costes?
FinOps es un proceso continuo. La monitorización de costes y la utilización de recursos debe ser constante. Se recomienda realizar una auditoría detallada y una revisión de la estrategia de optimización mensualmente o trimestralmente, dependiendo del ritmo de crecimiento de su infraestructura y de los cambios en la aplicación. Para grandes empresas con una infraestructura dinámica, los equipos FinOps pueden realizar reuniones "stand-up" semanales o incluso diarias para discutir anomalías y planes.
¿Cuál es la diferencia entre Reserved Instances y Savings Plans?
Ambos mecanismos ofrecen descuentos por el compromiso de utilizar recursos en la nube durante un período prolongado (1 o 3 años). Las Reserved Instances (RI) están vinculadas a parámetros específicos de la instancia (tipo, región, SO). Los Savings Plans (SP) son más flexibles: ofrecen un descuento sobre un volumen determinado de recursos computacionales (por ejemplo, $10/hora) independientemente del tipo de instancia, región o SO. Los SP son más fáciles de gestionar y son más adecuados para cargas dinámicas, permitiendo cambiar el tipo de instancias sin perder el descuento, si se mantiene dentro del compromiso.
¿Debería migrar a Serverless para todas las aplicaciones en aras del ahorro?
No, Serverless no es una solución universal. Aunque ofrece la máxima elasticidad y pago por uso real, tiene sus limitaciones, como los "arranques en frío", límites de tiempo de ejecución y memoria, así como la complejidad de depurar sistemas distribuidos. Serverless es ideal para tareas basadas en eventos, poco frecuentes, microservicios con carga variable. Para aplicaciones con carga constante y alta o tiempos de ejecución prolongados, los VPS tradicionales, las instancias EC2 o Kubernetes pueden ser más rentables y adecuados.
¿Cómo evitar el bloqueo de proveedor (vendor lock-in) al elegir un proveedor de la nube?
Evitar un bloqueo de proveedor completo es difícil, pero se puede minimizar. Utilice estándares abiertos (Docker, Kubernetes, Terraform) y tecnologías independientes de la nube. Evite una integración demasiado profunda con servicios propietarios del proveedor donde existan alternativas abiertas o gestionadas (por ejemplo, en lugar de DynamoDB, considere PostgreSQL o MongoDB). Desarrolle la arquitectura teniendo en cuenta la posibilidad de migración, abstraendo la lógica de negocio de las especificidades de la nube. Considere una estrategia multinube o híbrida.
¿Cuál es el papel de un ingeniero DevOps en FinOps?
El papel del ingeniero DevOps en FinOps es central. Son ellos quienes se encargan de implementar las soluciones técnicas que conducen a la optimización: implementación de IaC, configuración de autoescalado, rightsizing, optimización de código y arquitectura, elección de tipos de instancias óptimos, monitorización de la utilización y los costes. Los ingenieros DevOps deben comprender las implicaciones financieras de sus decisiones técnicas y colaborar activamente con los equipos financieros y de producto.
¿Se pueden utilizar servidores dedicados en lugar de VPS en la nube para ahorrar?
Sí, para ciertos escenarios, los servidores dedicados pueden ser más rentables que los VPS en la nube, especialmente con cargas muy altas, estables y predecibles. Los servidores dedicados ofrecen el máximo rendimiento por una tarifa fija, a menudo con volúmenes de tráfico muy grandes. Sin embargo, requieren conocimientos más profundos en administración y tienen una baja flexibilidad de escalado. FinOps ayudará a evaluar el TCO (Total Cost of Ownership) y a determinar qué opción será óptima para su caso específico.
¿Cómo empezar a implementar FinOps en mi empresa?
Empiece poco a poco: 1) Transparencia: Implemente una política de etiquetado para todos los recursos y configure informes básicos de costes. 2) Responsabilidad: Asigne responsables de los presupuestos por proyectos. 3) Optimización: Realice una auditoría de "recursos zombi" y comience con el Rightsizing de las instancias más caras. 4) Colaboración: Organice reuniones regulares entre los ingenieros y los departamentos financieros. Expanda gradualmente las prácticas, implementando la automatización y herramientas más sofisticadas. Lo principal es empezar y hacer de FinOps parte de la cultura corporativa.
15. Conclusión
En un panorama tecnológico que cambia rápidamente y con costes en la nube en constante aumento, FinOps se convierte no solo en una palabra de moda, sino en una disciplina vital para cualquiera que gestione infraestructuras de TI. Para 2026, cuando la complejidad de los ecosistemas en la nube ha alcanzado nuevas alturas y la competencia exige la máxima eficiencia, la capacidad de transformar los gastos en la nube en inversiones estratégicas es un factor clave de éxito.
Hemos examinado cómo las prácticas FinOps y las herramientas modernas permiten a los ingenieros DevOps, desarrolladores backend, fundadores de SaaS, administradores de sistemas y directores técnicos de startups no solo reducir los costes de los VPS y servidores dedicados, sino también tomar decisiones informadas y proactivas. Desde la implementación de la transparencia a través del etiquetado y los informes detallados hasta la automatización del escalado, el rightsizing, el uso de capacidades reservadas y la optimización de todos los aspectos de la infraestructura, cada paso en FinOps está dirigido a maximizar el valor.
La conclusión clave es que FinOps no es una tarea técnica o financiera, sino una transformación cultural. Requiere la colaboración entre todas las partes interesadas, el aprendizaje y la adaptación constantes. Solo cuando los ingenieros comprenden las implicaciones financieras de sus decisiones y los especialistas financieros tienen suficiente comprensión técnica, es posible lograr una verdadera eficiencia.
Recomendaciones finales:
- Empiece ahora: No posponga la implementación de FinOps. Incluso pequeños pasos para aumentar la transparencia y eliminar recursos no utilizados pueden generar ahorros significativos.
- Colabore: Rompa los "silos" entre equipos. FinOps prospera en un entorno donde ingenieros, gerentes de producto y especialistas financieros trabajan juntos.
- Automatice: Utilice IaC, autoescalado y scripts para automatizar tareas rutinarias y garantizar la adaptación dinámica de la infraestructura.
- Monitorice y analice: Realice un seguimiento constante de las métricas de costes y utilización, busque anomalías y oportunidades de optimización.
- Optimice constantemente: FinOps es una maratón, no un sprint. El entorno de la nube cambia constantemente, y su estrategia de optimización debe cambiar con él.
Próximos pasos para el lector:
- Realice una auditoría: Comience con una auditoría de su infraestructura actual en la nube. Utilice la lista de verificación de este artículo para identificar recursos no utilizados y servidores sobredimensionados.
- Implemente el etiquetado: Si aún no tiene una política de etiquetado, desarróllela y comience a aplicarla a todos los recursos nuevos.
- Configure presupuestos y alertas: Establezca presupuestos para sus cuentas en la nube y configure alertas para estar al tanto de los gastos actuales.
- Explore herramientas: Familiarícese con las herramientas nativas de su proveedor de la nube para la gestión de costes y considere la posibilidad de utilizar plataformas FinOps de terceros.
- Fórmese: Continúe aprendiendo las prácticas FinOps, siga las noticias y actualizaciones de los proveedores de la nube, e intercambie experiencias con la comunidad.
Recuerde que la gestión eficaz de los costes en VPS en la nube y servidores dedicados no es solo una forma de ahorrar dinero, sino también una ventaja estratégica que permite a su negocio ser más flexible, escalable y competitivo en el mundo de la tecnología en constante cambio.