
Gestión de infraestructura híbrida: Kubernetes en bare metal y en la nube con Rancher
TL;DR
- Kubernetes híbrido con Rancher es una elección estratégica para 2026 para empresas que buscan un equilibrio entre rendimiento, coste, seguridad y flexibilidad.
- Bare metal ofrece un rendimiento y control inigualables, mientras que la nube proporciona elasticidad y capacidad de gestión; Rancher unifica esto en un panel de control único.
- Los factores clave de éxito incluyen una arquitectura de red bien diseñada, una estrategia unificada de gestión de identidades y accesos, y un enfoque integral para la monitorización y la recuperación ante desastres.
- Evite errores comunes: subestimar la complejidad de la red y el almacenamiento de datos, la falta de un plan de DR claro y la ignorancia de los costes ocultos de transferencia de datos.
- Rancher simplifica significativamente el despliegue, la gestión y la seguridad de los clústeres de Kubernetes, tanto en servidores propios como en diversos proveedores de nube, reduciendo la carga operativa.
- El ahorro se logra mediante una distribución óptima de las cargas de trabajo: aplicaciones intensivas en recursos y sensibles a los datos en bare metal, y escalables y temporales en la nube.
- Casos reales demuestran que las soluciones híbridas permiten cumplir con estrictos requisitos regulatorios, optimizar costes y garantizar una alta disponibilidad de los servicios.
Introducción
Para 2026, el concepto de infraestructura híbrida ha dejado de ser una solución de nicho para convertirse en el enfoque dominante para la mayoría de las grandes y medianas empresas, así como para las startups ambiciosas. En un panorama de TI en constante cambio, donde la velocidad de comercialización, la optimización de costes y el cumplimiento normativo son críticos, las estrategias puramente en la nube o exclusivamente locales a menudo resultan insuficientes. El enfoque híbrido, especialmente con Kubernetes como plataforma de orquestación universal y Rancher como gestor de clústeres unificado, ofrece una potente solución a estos desafíos.
¿Por qué es tan importante este tema ahora? En primer lugar, la inestabilidad económica de los últimos años obliga a las empresas a revisar cuidadosamente sus presupuestos de TI, y los gastos en la nube, que crecen rápidamente a medida que se escala, a menudo se convierten en objeto de un escrutinio minucioso. Bare metal, con sus costes de capital predecibles y la ausencia de tarifas mensuales por recursos, vuelve a ser relevante para cargas de trabajo estables y que requieren muchos recursos. En segundo lugar, el endurecimiento de la legislación sobre protección de datos (por ejemplo, GDPR 2.0, requisitos locales de soberanía de datos) obliga a muchas organizaciones a mantener información sensible en sus propios servidores, mientras utilizan la nube para servicios menos críticos o públicos. En tercer lugar, el progreso tecnológico en el campo de las tecnologías de red (5G, edge computing) y las plataformas de gestión como Rancher ha simplificado significativamente la integración y gestión de entornos heterogéneos, haciendo que los escenarios híbridos no solo sean posibles, sino también prácticos.
Este artículo tiene como objetivo abordar una serie de problemas clave a los que se enfrentan los ingenieros y directivos modernos:
- Complejidad de la gestión: ¿Cómo gestionar eficazmente múltiples clústeres de Kubernetes desplegados en diferentes entornos (on-premise y en varias nubes)?
- Optimización de costes: ¿Cómo reducir los gastos operativos aprovechando las ventajas de bare metal para cargas estables y la nube para picos?
- Seguridad y cumplimiento: ¿Cómo garantizar políticas de seguridad unificadas y el cumplimiento normativo en una infraestructura distribuida?
- Rendimiento: ¿Cómo lograr el máximo rendimiento para aplicaciones críticas, manteniendo la flexibilidad de la nube?
- Migración y modernización: ¿Cómo migrar sin problemas las aplicaciones existentes a una plataforma de contenedores en un entorno híbrido?
Esta guía está escrita para una amplia audiencia de especialistas técnicos y directivos que toman decisiones estratégicas en el ámbito de la infraestructura: ingenieros DevOps que buscan automatizar y unificar procesos; desarrolladores Backend (Python, Node.js, Go, PHP) que necesitan una plataforma fiable y escalable para sus aplicaciones; fundadores de proyectos SaaS que buscan un equilibrio óptimo entre coste y flexibilidad; administradores de sistemas responsables de la estabilidad y seguridad de los sistemas; y, por supuesto, directores técnicos de startups que necesitan construir una infraestructura sostenible y competitiva desde cero.
Profundizaremos en los detalles, proporcionaremos ejemplos concretos, cálculos y recomendaciones prácticas basadas en la experiencia real de implementación de soluciones híbridas de Kubernetes utilizando Rancher. Nuestro objetivo es brindarle un recurso exhaustivo para tomar decisiones informadas y lograr una implementación exitosa de su estrategia híbrida.
Criterios y factores principales
Al planificar e implementar una infraestructura híbrida de Kubernetes, es necesario considerar multitud de factores que, en conjunto, determinan el éxito y la eficacia de la solución. Cada uno de estos criterios tiene su propio peso y puede ser prioritario en función de la especificidad del negocio, la naturaleza de las cargas de trabajo y los objetivos estratégicos de la empresa. Un análisis detallado de cada uno de ellos permitirá tomar decisiones ponderadas.
1. Coste total de propiedad (TCO) y eficiencia económica
Por qué es importante: El TCO va mucho más allá de los costes directos de hardware o suscripciones a la nube. Incluye los gastos de capital (CapEx) en servidores, equipos de red, almacenamiento, así como los gastos operativos (OpEx) —electricidad, refrigeración, mantenimiento, licencias de software, salarios del personal, coste del tráfico y costes ocultos como el tiempo de inactividad o la formación. Una evaluación correcta del TCO permite elegir la estrategia más rentable a largo plazo.
Cómo evaluarlo: Realice un análisis detallado de todas las partidas de gastos durante 3-5 años. Para bare metal, tenga en cuenta la amortización del equipo, los costes del centro de datos y el personal. Para la nube, los pagos mensuales por recursos (vCPU, RAM, almacenamiento), el tráfico de red (especialmente el de salida), los servicios gestionados, así como los posibles descuentos por reserva (Reserved Instances, Savings Plans). Es importante considerar que para aplicaciones estables y de alta carga, bare metal a menudo resulta más económico a largo plazo, mientras que la nube es ventajosa al principio y para cargas impredecibles.
2. Rendimiento y latencia
Por qué es importante: Algunas aplicaciones, como el trading de alta frecuencia, el análisis de IoT en el borde, los servidores de juegos o las bases de datos con escritura intensiva, dependen críticamente de una latencia mínima y un ancho de banda máximo. Bare metal a menudo gana aquí, proporcionando acceso directo al hardware sin la sobrecarga de la virtualización y las abstracciones de red de la nube.
Cómo evaluarlo: Mida la latencia de la red (RTT) entre componentes, el rendimiento de las operaciones de disco (IOPS, throughput) y el rendimiento de la CPU. Para bare metal, estos serán los valores reales del hardware. Para la nube, las características de las instancias y los tipos de almacenamiento que elija. En un entorno híbrido, la latencia entre los segmentos on-premise y en la nube es críticamente importante, y puede reducirse mediante conexiones directas (Direct Connect, ExpressRoute).
3. Seguridad y cumplimiento normativo
Por qué es importante: La protección de datos y el cumplimiento de la legislación (GDPR, HIPAA, PCI DSS, Ley Federal 152, etc.) no son solo una "buena práctica", sino una condición obligatoria para hacer negocios, especialmente en sectores como las finanzas, la atención médica o los servicios gubernamentales. Alojar datos sensibles en servidores propios otorga un control total sobre la seguridad física y el acceso, lo que simplifica la realización de auditorías.
Cómo evaluarlo: Realice una auditoría de los requisitos normativos actuales y futuros. Evalúe dónde deben almacenarse y procesarse los datos. En la nube, comparte la responsabilidad de la seguridad (Modelo de Responsabilidad Compartida), lo que requiere una configuración cuidadosa. En bare metal, toda la responsabilidad recae en usted, pero el control también es total. Rancher ayuda a unificar las políticas de seguridad y la gestión de acceso (RBAC) en todos los clústeres, independientemente de su ubicación.
4. Escalabilidad y flexibilidad
Por qué es importante: La capacidad de la infraestructura para adaptarse rápidamente a las cargas cambiantes es la base para el desarrollo exitoso de un producto. La nube ofrece una elasticidad prácticamente ilimitada, permitiendo escalar recursos instantáneamente hacia arriba o hacia abajo. Bare metal requiere planificación previa y adquisición de equipos, pero proporciona un rendimiento estable y predecible para cargas base.
Cómo evaluarlo: Determine las cargas pico y base. Evalúe el tiempo necesario para añadir nuevos recursos en cada entorno. El enfoque híbrido permite utilizar bare metal para la carga "constante" y "desbordar" (burst) las solicitudes pico a la nube, garantizando un uso óptimo de los recursos y la minimización de costes.
5. Costes de gestión y complejidad operativa
Por qué es importante: La gestión de una infraestructura distribuida puede ser extremadamente compleja sin las herramientas adecuadas. Los altos costes operativos pueden anular cualquier ahorro en hardware o recursos en la nube. Rancher juega un papel clave aquí, proporcionando un panel de control unificado para todos los clústeres de Kubernetes.
Cómo evaluarlo: Evalúe el volumen de personal necesario, su cualificación, los costes de formación, así como la complejidad de los procesos de despliegue, monitorización, actualización y resolución de problemas. Las herramientas de automatización y unificación, como Rancher, reducen significativamente esta complejidad, permitiendo gestionar decenas de clústeres con menos recursos.
6. Dependencia del proveedor (Vendor Lock-in)
Por qué es importante: La dependencia total de un único proveedor de la nube puede generar problemas de precios, una selección limitada de tecnologías y dificultades en la migración. Una estrategia híbrida, especialmente con Kubernetes, que es un estándar abierto, reduce este riesgo al permitir mover fácilmente las cargas de trabajo entre diferentes entornos.
Cómo evaluarlo: Analice los servicios en la nube utilizados: ¿cuán propietarios son? ¿Qué esfuerzos se requerirían para migrar a otro proveedor o a bare metal? Kubernetes y Rancher promueven la estandarización, haciendo que las aplicaciones sean más portátiles. Esto le otorga poder de negociación con los proveedores y libertad estratégica.
7. "Gravedad" de los datos (Data Gravity)
Por qué es importante: Grandes volúmenes de datos tienen "gravedad": son difíciles y costosos de mover. Las aplicaciones que trabajan intensivamente con grandes bases de datos o almacenamientos a menudo se benefician de estar ubicadas cerca de esos datos. Si los datos están en bare metal, es lógico ubicar las aplicaciones que trabajan con ellos en el mismo lugar para minimizar la latencia y el coste del tráfico.
Cómo evaluarlo: Determine el volumen y la intensidad del intercambio de datos entre los componentes de su sistema. Los costes del tráfico de salida (egress) desde la nube pueden ser significativos. Ubicar las bases de datos y los sistemas analíticos on-premise o en servidores dedicados en la nube, y los frontends y las pasarelas API en clústeres de nube más elásticos, puede ser una estrategia óptima.
8. Recuperación ante desastres (DR) y alta disponibilidad (HA)
Por qué es importante: La tolerancia a fallos de la infraestructura es un factor crítico para cualquier negocio moderno. Un entorno híbrido ofrece oportunidades únicas para construir estrategias de DR fiables, permitiendo distribuir los riesgos entre diferentes ubicaciones y proveedores.
Cómo evaluarlo: Defina los objetivos de RTO (Recovery Time Objective) y RPO (Recovery Point Objective) para sus aplicaciones. Considere escenarios de fallo de un centro de datos o una región de la nube. Una estrategia híbrida permite tener un clúster de respaldo en la nube para aplicaciones on-premise o viceversa, garantizando una activación rápida en caso de fallo. Rancher simplifica la gestión de estos clústeres distribuidos, permitiendo gestionar su configuración y despliegue de forma centralizada.
Considerar estos factores en la fase de diseño permitirá construir una infraestructura híbrida basada en Kubernetes y Rancher que no solo funcione, sino que sea eficiente, económicamente viable y resiliente.
Tabla comparativa
Para mayor claridad y para facilitar la toma de decisiones informadas, presentamos una tabla comparativa de los principales enfoques para el despliegue de Kubernetes, considerando la estrategia híbrida y el papel de Rancher. Los datos son relevantes para las previsiones de 2026, reflejando las tendencias en precios, rendimiento y modelos operativos.
| Criterio | Bare Metal (K8s autogestionado) | Bare Metal (K8s con Rancher) | Nube Pública (EKS/AKS/GKE) | Híbrido (K8s con Rancher) |
|---|---|---|---|---|
| Coste (TCO 3 años, $K) | CapEx alto (~$100-500K por 10 servidores), OpEx bajo ($5-15K/mes) | CapEx alto (~$100-500K por 10 servidores), OpEx medio ($8-20K/mes, incluyendo soporte Rancher) | CapEx bajo ($0), OpEx alto ($15-50K/mes por el equivalente a 10 servidores) | CapEx/OpEx equilibrado ($50-200K CapEx, $10-30K/mes OpEx) |
| Rendimiento CPU/RAM | ~95-98% del hardware físico. Acceso directo a los recursos. | ~95-98% del hardware físico. Sobrecarga insignificante de los agentes de Rancher. | ~70-90% del hardware físico (debido a la virtualización). Depende del tipo de instancia. | Parte Bare Metal: 95-98%. Parte Cloud: 70-90%. Óptimo para diferentes cargas. |
| Latencia de red (dentro del clúster) | <1 ms (red física) | <1 ms (red física) | ~1-5 ms (red virtual de la nube) | Bare Metal: <1 ms. Cloud: 1-5 ms. Interclúster: 10-50 ms (con Direct Connect <5 ms). |
| Escalabilidad | Manual, lenta (adquisición, instalación). Hasta varias semanas. | Semiautomática con Rancher, pero limitada por los recursos físicos. Días/semanas. | Automática, rápida (pocos minutos) con Cluster Autoscaler. Prácticamente ilimitada. | Flexible: Bare Metal para la base, Cloud para los picos (minutos). Equilibrio óptimo. |
| Seguridad y control | Control total sobre toda la cadena, desde el hardware hasta el software. Alto nivel de seguridad. | Control total + gestión de seguridad unificada a través de Rancher. | Modelo de responsabilidad compartida. Alta seguridad del proveedor, pero menos control. | Alto control para datos sensibles (on-prem), modelo de responsabilidad compartida para la nube. |
| Complejidad de gestión | Muy alta (despliegue manual, actualización, monitorización). Requiere conocimientos profundos. | Media-alta (Rancher simplifica significativamente K8s, pero bare metal requiere administración). | Media (servicios gestionados, pero con sus matices de proveedor). | Alta, pero se reduce gracias a Rancher, que unifica la gestión. Requiere experiencia. |
| Cumplimiento normativo (Compliance) | Control total sobre los datos y la infraestructura. Más fácil pasar auditorías. | Control total + políticas unificadas a través de Rancher. | Depende del proveedor y la región. Responsabilidad compartida. | Óptimo: datos sensibles on-prem, el resto en la nube cumpliendo con las normativas regionales. |
| Riesgo de Vendor Lock-in | Bajo (estándar abierto K8s). | Bajo (Rancher es abierto, pero hay una vinculación a su ecosistema de gestión). | Alto (integración profunda con los servicios de la nube del proveedor). | Bajo (posibilidad de mover cargas de trabajo, usar diferentes proveedores). |
Nota: Las cifras de la tabla son estimaciones y pueden variar en función de la implementación específica, la escala del proyecto, la región y la cualificación del equipo. Los rangos de precios se indican para una empresa mediana que opera el equivalente a 10-20 servidores físicos.
Revisión detallada de cada punto/opción
Comprender las fortalezas y debilidades de cada enfoque para el despliegue de Kubernetes es fundamental para elegir la estrategia óptima. Examinaremos cada opción en detalle, centrándonos en su aplicabilidad y características en el contexto de 2026.
1. Kubernetes en Bare Metal (Autogestionado)
Este enfoque implica el despliegue de Kubernetes directamente en servidores físicos sin una capa intermedia de virtualización o plataformas de gestión como Rancher. Usted es totalmente responsable de todos los aspectos: desde la instalación del SO y la configuración de la red hasta el despliegue de los componentes de Kubernetes (kubeadm, kops, kubespray) y su posterior mantenimiento.
Ventajas:
- Máximo rendimiento: El acceso directo a los recursos de hardware garantiza una sobrecarga mínima y el máximo rendimiento para CPU, RAM, discos y red. Esto es crítico para la computación de alto rendimiento (HPC), bases de datos con E/S intensiva, modelos de IA/ML y servicios de red de baja latencia.
- Control total y personalización: Usted controla cada aspecto de la infraestructura, lo que permite ajustar finamente el sistema a requisitos únicos. Esto es importante para configuraciones de hardware específicas, soluciones de red especializadas o requisitos de seguridad particulares.
- Economía de escala: Para clústeres muy grandes y estables (cientos de nodos), a largo plazo, el CapEx en bare metal puede ser significativamente menor que el OpEx en la nube, especialmente si tiene su propio centro de datos o co-location.
- Independencia del proveedor: Ausencia de vinculación a un proveedor de la nube o plataforma de gestión.
Desventajas:
- Alta complejidad y carga operativa: El despliegue, la actualización, la monitorización y la resolución de problemas requieren un conocimiento profundo de Kubernetes, tecnologías de red y administración de sistemas. Esto aumenta significativamente el OpEx debido al personal altamente cualificado.
- Tiempo de despliegue prolongado: La adquisición, entrega, instalación y configuración del hardware pueden llevar semanas o meses. El escalado tampoco es instantáneo.
- Falta de elasticidad: Los recursos están limitados por el hardware disponible. El bursting a la nube no es posible sin una estrategia híbrida.
- Dificultades con HA y DR: La construcción de una arquitectura de alta disponibilidad y un plan de recuperación ante desastres recae completamente en su equipo.
Para quién es adecuado:
Grandes empresas con centros de datos propios que requieren el máximo rendimiento y control, y que cuentan con personal de ingeniería altamente cualificado. Empresas que trabajan con datos muy sensibles, donde se requiere un control total sobre la infraestructura física. Proyectos con una carga predecible pero muy alta, donde los costes de la nube se vuelven prohibitivos.
2. Kubernetes en Bare Metal con Rancher
Esta opción aprovecha las ventajas de bare metal, añadiendo la potencia y comodidad de Rancher para gestionar el ciclo de vida de los clústeres de Kubernetes. Rancher permite desplegar, actualizar y gestionar múltiples clústeres de Kubernetes (RKE, K3s) en servidores físicos desde un único panel.
Ventajas:
- Gestión simplificada: Rancher reduce significativamente la complejidad operativa, automatizando muchas tareas rutinarias de despliegue y actualización de clústeres. Una única UI/API para todos los clústeres.
- Consistencia operativa: Rancher proporciona un enfoque unificado para la gestión de clústeres, independientemente de su ubicación. Esto unifica las políticas de seguridad, monitorización y despliegue de aplicaciones.
- Aprovechamiento de las ventajas de bare metal: Se mantiene el alto rendimiento y el control total sobre el hardware.
- Integración con el ecosistema: Rancher proporciona acceso a catálogos de aplicaciones, herramientas de monitorización (Prometheus/Grafana), logging (Fluentd/Loki), CI/CD (ArgoCD/Flux) y otros componentes, lo que simplifica la construcción de una solución integral.
- Base para un híbrido: Rancher está diseñado desde el principio para gestionar entornos multiclúster y multinube, lo que lo convierte en una opción ideal para una estrategia híbrida.
Desventajas:
- Curva de aprendizaje de Rancher: Aunque Rancher simplifica K8s, la plataforma en sí tiene su propia curva de aprendizaje.
- Sobrecarga de Rancher: Pequeña sobrecarga por el funcionamiento de los agentes de Rancher y el servidor de gestión.
- Todavía se requiere administración de bare metal: Usted sigue siendo responsable del hardware físico, su mantenimiento, la alimentación, la refrigeración y el SO base.
- Elasticidad limitada: El escalado de un clúster bare metal sigue estando limitado por los recursos físicos y el tiempo de adquisición/instalación.
Para quién es adecuado:
Empresas que desean utilizar bare metal para rendimiento y control, pero minimizando la carga operativa de la administración de Kubernetes. Ideal para la base de una infraestructura híbrida donde se requiere una gestión centralizada de clústeres heterogéneos. Proyectos SaaS que han alcanzado una escala en la que los costes de la nube se vuelven excesivos, pero no están preparados para una orquestación manual completa de K8s.
3. Kubernetes en la Nube Pública (EKS/AKS/GKE)
Este es el enfoque más popular para muchas startups y empresas que valoran la velocidad de despliegue, la elasticidad y los servicios gestionados. Los proveedores de la nube ofrecen servicios de Kubernetes totalmente gestionados (Amazon EKS, Azure AKS, Google GKE), liberándole de la mayor parte de las preocupaciones de gestión del plano de control.
Ventajas:
- Alta elasticidad y escalabilidad: Escalado instantáneo hacia arriba y hacia abajo, adición/eliminación automática de nodos. Pago por uso.
- Costes operativos mínimos en K8s: El proveedor gestiona los nodos maestros, su actualización, seguridad y disponibilidad. Usted se centra en las aplicaciones.
- Amplia gama de servicios gestionados: Fácil integración con bases de datos, colas de mensajes, balanceadores de carga, funciones de computación sin servidor y otros servicios de la nube.
- Cobertura global y DR: Posibilidad de despliegue en múltiples regiones y zonas de disponibilidad para alta disponibilidad y recuperación ante desastres.
- Inicio rápido: El despliegue del clúster lleva minutos.
Desventajas:
- OpEx altos a escala: A medida que aumentan los recursos y el tráfico de red (especialmente el de salida), los costes de la nube pueden volverse muy significativos e impredecibles.
- Vendor Lock-in: La profunda integración con servicios propietarios de la nube dificulta la migración a otro proveedor o a bare metal.
- Control limitado: Menos control sobre la infraestructura subyacente, la configuración de red y algunos aspectos de seguridad.
- Problemas de rendimiento/latencia: La sobrecarga de la virtualización y las abstracciones de red puede provocar una mayor latencia y un menor rendimiento en comparación con bare metal.
- Dificultades con el cumplimiento: El modelo de responsabilidad compartida requiere una auditoría y configuración cuidadosas para cumplir con estrictas normativas.
Para quién es adecuado:
Startups que crecen rápidamente y necesitan máxima flexibilidad. Empresas con cargas impredecibles o muy fluctuantes. Proyectos donde la velocidad de comercialización es más importante que la minimización absoluta de los costes de infraestructura. Equipos que desean minimizar la carga administrativa de la infraestructura y centrarse en el desarrollo.
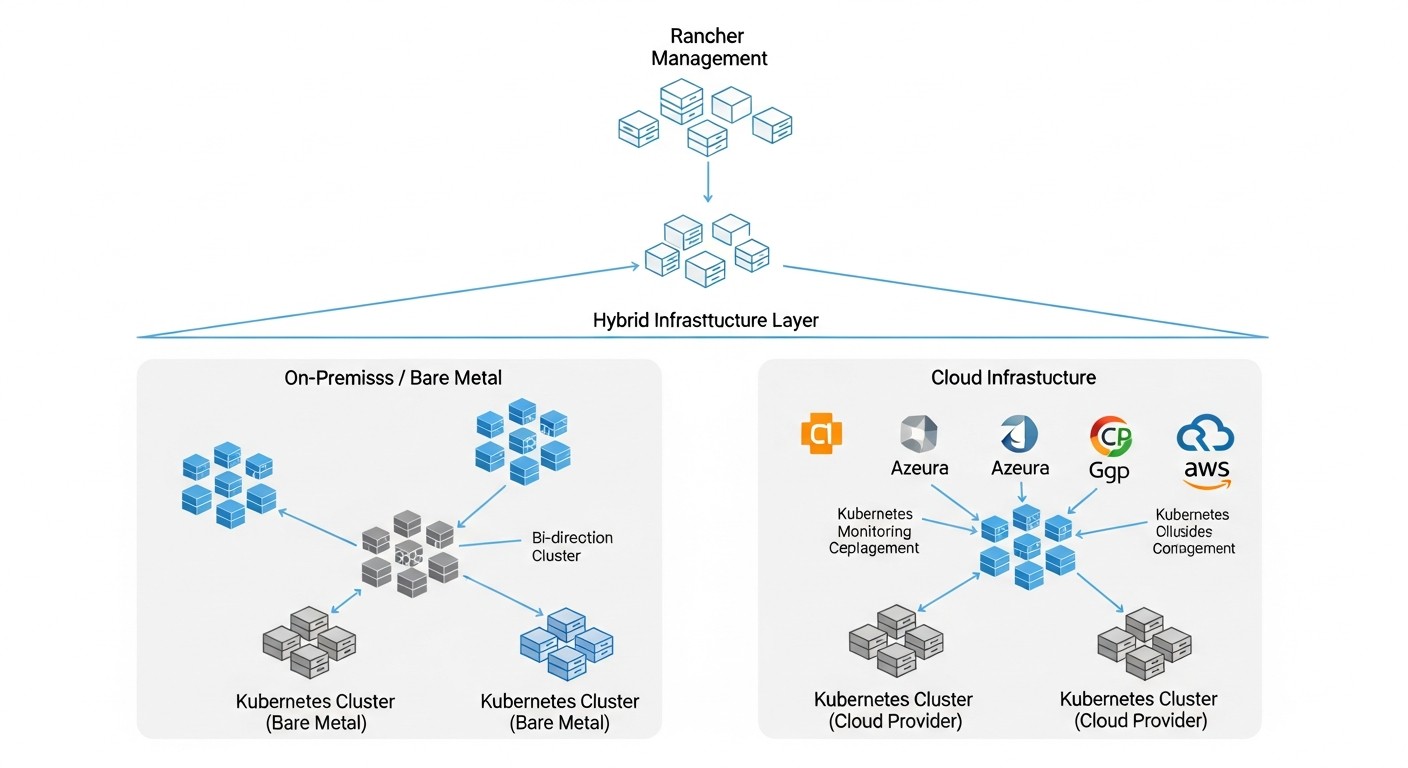
4. Kubernetes Híbrido con Rancher
Esta es una combinación de clústeres de Kubernetes en bare metal y en la nube, gestionados desde un único panel de Rancher. Este enfoque permite aprovechar las ventajas de cada entorno, minimizando sus desventajas.
Ventajas:
- Optimización de costes: Ubicación de cargas de trabajo estables y que requieren muchos recursos en bare metal (OpEx bajo a largo plazo) y uso de la nube para cargas elásticas, picos de carga o entornos temporales (Dev/Test).
- Máxima flexibilidad y escalabilidad: Combinación del rendimiento predecible de bare metal con la elasticidad ilimitada de la nube. Posibilidad de "desbordar" la carga a la nube.
- Seguridad y cumplimiento mejorados: Los datos sensibles y las aplicaciones críticas pueden permanecer en bare metal bajo control total, mientras que los servicios públicos y menos críticos se alojan en la nube. Rancher garantiza políticas de seguridad unificadas.
- Recuperación ante desastres mejorada: Posibilidad de crear arquitecturas tolerantes a fallos, donde un segmento de la infraestructura sirve como respaldo para otro (por ejemplo, un clúster on-prem como DR para uno en la nube y viceversa).
- Reducción del Vendor Lock-in: Posibilidad de utilizar múltiples proveedores de la nube (estrategia multinube) y bare metal, lo que otorga mayor libertad de elección y portabilidad de las aplicaciones.
- Gestión unificada: Rancher proporciona una interfaz única para gestionar todos los clústeres, simplificando las operaciones, la monitorización y el despliegue de aplicaciones.
Desventajas:
- Alta complejidad inicial: El diseño y despliegue de una infraestructura híbrida requiere una experiencia significativa en tecnologías de red, seguridad, almacenamiento de datos y, por supuesto, Kubernetes y Rancher.
- Dificultades con la integración de red: Garantizar una conectividad fluida y segura entre los clústeres on-premise y en la nube puede ser una tarea no trivial (VPN, Direct Connect, SD-WAN).
- Gestión de datos: Las estrategias para la sincronización, replicación y acceso a los datos entre diferentes entornos requieren una planificación cuidadosa.
- Posibles costes ocultos: Costes de tráfico de salida, conexiones directas, equipos especializados.
Para quién es adecuado:
Prácticamente para cualquier empresa que busque un equilibrio óptimo entre coste, rendimiento, seguridad y flexibilidad. Especialmente relevante para grandes empresas que necesitan modernizar una infraestructura on-premise obsoleta, cumplir con estrictos requisitos regulatorios, así como para proveedores de SaaS que desean optimizar sus costes en la nube manteniendo la elasticidad. Una elección ideal para aquellos que ya tienen inversiones significativas en bare metal y desean expandir sus capacidades a través de la nube, o viceversa, que desean devolver parte de las cargas de trabajo de la nube a sus propios servidores.
La elección de una opción específica o su combinación siempre debe basarse en un análisis profundo de las necesidades actuales, los planes de desarrollo futuros y los recursos disponibles. La estrategia híbrida con Rancher proporciona el conjunto de herramientas más completo para adaptarse a estos requisitos.
Consejos y recomendaciones prácticas
La implementación exitosa de una infraestructura híbrida de Kubernetes con Rancher requiere no solo la comprensión de la teoría, sino también una inmersión profunda en los aspectos prácticos. A continuación, se presentan las recomendaciones clave e instrucciones paso a paso, basadas en la experiencia real.
1. Diseño de la arquitectura de red
La red es el sistema circulatorio de su infraestructura híbrida. Su diseño correcto es fundamental para el rendimiento, la seguridad y la disponibilidad.
Instrucciones paso a paso:
- Planificación de IP: Asigne rangos de direcciones IP no superpuestos para cada clúster on-premise y en la nube, así como para las conexiones entre ellos. Utilice RFC1918 para redes privadas.
- Conexión on-premise y en la nube:
- VPN (IPsec/OpenVPN/WireGuard): Para empezar o para volúmenes de tráfico pequeños. Fácil de configurar, pero tiene limitaciones de ancho de banda y latencia.
- Direct Connect (AWS)/ExpressRoute (Azure)/Cloud Interconnect (GCP): Para conexiones de alto rendimiento, baja latencia y estables. Son líneas dedicadas que proporcionan un rendimiento predecible, pero requieren una inversión significativa.
- SD-WAN: Una solución moderna para gestionar el tráfico a través de diferentes canales, optimizar el enrutamiento y garantizar la seguridad.
- Plugins de red (CNI) para Kubernetes:
- Calico/Cilium: Una excelente opción para entornos híbridos, ya que admiten políticas de red (Network Policies), proporcionan un alto rendimiento y pueden operar en diferentes modos (IP-in-IP, BGP). Calico también admite la integración con BGP para clústeres bare metal.
- Flannel: Más sencillo de configurar, pero menos funcional y con menor rendimiento. Bueno para escenarios simples.
- Estrategia DNS: Implemente una estrategia DNS unificada para la resolución de nombres entre clústeres on-premise y en la nube. Utilice CoreDNS en Kubernetes y configure reenviadores condicionales (conditional forwarders) a los servidores DNS on-premise para dominios internos y viceversa.
- Balanceo de carga:
- Bare Metal: Utilice MetalLB para proporcionar un servicio LoadBalancer. Distribuye direcciones IP de un pool y las anuncia a través de BGP o ARP.
- Nube: Utilice los balanceadores de carga nativos de la nube (AWS ELB/ALB, Azure Load Balancer, GCP GCLB).
- Controladores Ingress: NGINX Ingress Controller, Traefik, Istio Ingress Gateway para el enrutamiento del tráfico HTTP/S.
# Ejemplo de configuración de MetalLB (bare metal)
apiVersion: metallb.io/v1beta1
kind: IPAddressPool
metadata:
name: bare-metal-lb-pool
spec:
addresses:
- 192.168.100.200-192.168.100.250
---
apiVersion: metallb.io/v1beta1
kind: BGPAdvertisement
metadata:
name: bare-metal-bgp-advertisement
spec:
ipAddressPools:
- bare-metal-lb-pool
2. Estrategia de almacenamiento de datos
Los datos son el corazón de sus aplicaciones. Elegir la estrategia de almacenamiento correcta en un entorno híbrido es fundamental.
Instrucciones paso a paso:
- CSI (Container Storage Interface): Utilice controladores CSI para integrar Kubernetes con diferentes tipos de almacenamiento.
- Almacenamiento on-premise:
- Rook (Ceph): Almacenamiento distribuido creado a partir de discos locales de servidores. Proporciona almacenamiento en bloque, de archivos y de objetos, alta disponibilidad y escalabilidad.
- Longhorn: Almacenamiento en bloque distribuido y ligero, también construido sobre discos locales, gestionado desde Kubernetes. Muy adecuado para clústeres pequeños y medianos.
- Almacenamiento externo (NFS/iSCSI): Integración con sistemas NAS/SAN existentes a través de los controladores CSI correspondientes.
- Almacenamiento en la nube:
- Managed Disks: AWS EBS, Azure Disks, GCP Persistent Disks para almacenamiento en bloque, vinculado a una VM específica.
- Managed File Storage: AWS EFS, Azure Files, GCP Filestore para acceso compartido a archivos.
- Object Storage: AWS S3, Azure Blob Storage, GCP Cloud Storage para almacenamiento de objetos (a menudo utilizado para copias de seguridad, archivos estáticos).
- Estrategia de replicación y copias de seguridad: Para datos críticos, considere la replicación entre on-premise y la nube (por ejemplo, sincronización de bases de datos, replicación de Ceph entre clústeres). Utilice Velero para la copia de seguridad y restauración de recursos de Kubernetes y Persistent Volumes.
# Ejemplo de PersistentVolumeClaim para Longhorn
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: my-app-pvc
spec:
accessModes:
- ReadWriteOnce
storageClassName: longhorn
resources:
requests:
storage: 10Gi
3. Gestión de identidades y accesos (IAM)
Un sistema unificado de autenticación y autorización simplifica la gestión de usuarios y garantiza la seguridad.
Instrucciones paso a paso:
- Proveedor de identidad centralizado: Integre Rancher con LDAP/AD corporativo, Okta, Auth0 u otras soluciones SSO. Esto permitirá a los usuarios iniciar sesión en Rancher utilizando sus cuentas corporativas.
- RBAC en Kubernetes: Configure el Control de Acceso Basado en Roles (RBAC) en cada clúster, así como roles globales en Rancher. Defina quién tiene acceso a los clústeres, namespaces y recursos específicos.
- Principio de mínimos privilegios: Conceda a los usuarios y aplicaciones solo los derechos necesarios para realizar sus tareas.
4. CI/CD para un entorno híbrido
La automatización del despliegue de aplicaciones en un entorno híbrido requiere un pipeline de CI/CD bien diseñado.
Instrucciones paso a paso:
- GitOps: Utilice Git como única fuente de verdad para la configuración de sus clústeres y aplicaciones. Herramientas como ArgoCD o Flux sincronizarán el estado de los clústeres con el repositorio Git.
- Despliegue multiclúster: Configure los pipelines para que puedan desplegar aplicaciones en clústeres on-premise o en la nube específicos, o incluso en varios clústeres simultáneamente. Rancher Fleet puede utilizarse para el despliegue y la gestión centralizados de aplicaciones en un gran número de clústeres.
- Secretos: Utilice Vault de HashiCorp, External Secrets Operator o gestores de secretos en la nube para el almacenamiento y acceso seguro a datos confidenciales.
# Ejemplo de ArgoCD Application para despliegue en un clúster híbrido
apiVersion: argoproj.io/v1alpha1
kind: Application
metadata:
name: my-hybrid-app
namespace: argocd
spec:
project: default
source:
repoURL: https://github.com/my-org/my-app-configs.git
targetRevision: HEAD
path: k8s/production/hybrid-cluster
destination:
server: https://kubernetes.default.svc # O la URL de su clúster Rancher
namespace: my-app
syncPolicy:
automated:
prune: true
selfHeal: true
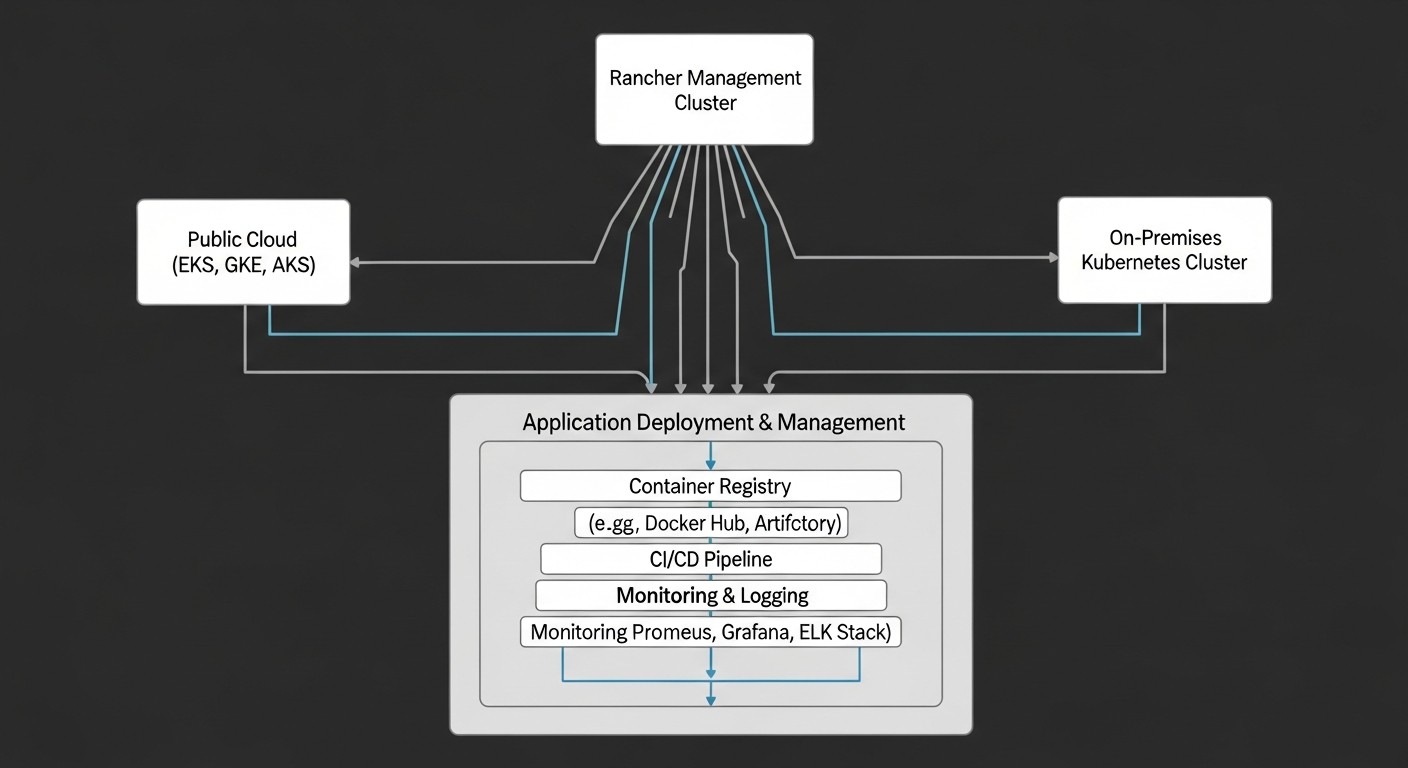
5. Monitorización y registro
Un sistema unificado de monitorización y registro es fundamental para la salud y la depuración de una infraestructura híbrida.
Instrucciones paso a paso:
- Monitorización: Despliegue Prometheus y Grafana en cada clúster o de forma centralizada. Rancher incluye integración nativa con Prometheus y Grafana, lo que simplifica su configuración. Recopile métricas de nodos, pods, contenedores, así como métricas de red y disco.
- Registro (Logging): Utilice un sistema de registro centralizado, como ELK Stack (Elasticsearch, Logstash, Kibana) o Loki con Grafana. Configure Fluentd/Fluent Bit en cada clúster para recopilar registros y enviarlos a un almacenamiento centralizado.
- Alertas: Configure Alertmanager (parte de Prometheus) para enviar notificaciones a Slack, PagerDuty, correo electrónico cuando surjan problemas.
6. Estrategia de recuperación ante desastres (DR)
Es necesario tener un plan de acción claro en caso de fallos.
Instrucciones paso a paso:
- Definición de RTO/RPO: Para cada aplicación, defina el tiempo de recuperación objetivo (RTO) y la pérdida de datos objetivo (RPO) aceptables.
- Copia de seguridad y restauración: Utilice Velero para la copia de seguridad y restauración de recursos de Kubernetes (Deployments, Services, ConfigMaps) y Persistent Volumes. Velero puede guardar las copias de seguridad en un almacenamiento de objetos (compatible con S3 o en la nube).
- Distribución geográfica: Despliegue clústeres en diferentes ubicaciones geográficas (centro de datos on-premise, diferentes regiones de la nube) para protegerse contra fallos regionales.
- Pruebas de DR: Pruebe regularmente su plan de DR, simulando fallos y verificando los procedimientos de recuperación. Esta es la única forma de asegurar su operatividad.
# Ejemplo de copia de seguridad de un clúster con Velero
velero backup create my-cluster-backup --include-namespaces my-app-namespace --wait
# Ejemplo de restauración de un clúster con Velero
velero restore create --from-backup my-cluster-backup --wait
7. Gestión de versiones y actualizaciones de Kubernetes
Actualizar Kubernetes puede ser complejo, pero Rancher simplifica significativamente este proceso.
Instrucciones paso a paso:
- Planificación: Manténgase al tanto del ciclo de vida de las versiones de Kubernetes. Planifique las actualizaciones con antelación, considerando la compatibilidad de las aplicaciones.
- Rancher para actualizaciones: Rancher permite actualizar las versiones de Kubernetes para clústeres gestionados a través de la UI o la API. Esto simplifica significativamente el proceso, automatizando muchos pasos.
- Actualizaciones secuenciales: Actualice los clústeres no de inmediato, sino de forma secuencial: primero dev/test, luego staging, y solo después production.
- Pruebas: Después de cada actualización, realice pruebas de regresión exhaustivas de las aplicaciones.
Aplicando estos consejos prácticos, podrá construir una infraestructura híbrida fiable, eficiente y fácilmente gestionable basada en Kubernetes y Rancher, preparada para los desafíos de 2026 y más allá.
Errores comunes
La implementación de una infraestructura híbrida es un proyecto complejo, y en este camino es fácil cometer errores que pueden llevar a costes significativos, tiempos de inactividad o problemas de seguridad. Estudiar estos errores comunes y saber cómo prevenirlos es clave para una implementación exitosa.
1. Subestimación de la complejidad de la integración de red
Error: Muchos ingenieros subestiman lo compleja que puede ser la configuración de una red fluida y segura entre clústeres on-premise y en la nube. Los problemas con la planificación de IP, el enrutamiento, la resolución de DNS y el ancho de banda a menudo surgen en etapas tardías, lo que lleva a retrasos y retrabajos.
Cómo evitarlo:
- Comience con una planificación detallada de IP, asegurándose de que no haya superposiciones de rangos.
- Invierta en una interconexión de red fiable (Direct Connect, ExpressRoute) para cargas críticas. Para las menos exigentes, puede empezar con VPN.
- Utilice plugins CNI avanzados, como Calico o Cilium, que admiten políticas de red y BGP.
- Implemente una estrategia DNS unificada con reenvío condicional entre on-premise y la nube.
Consecuencias: Alta latencia, conexión inestable, problemas de resolución de nombres entre servicios, lo que lleva a la inoperatividad de las aplicaciones distribuidas y a costosos tiempos de inactividad.
2. Ignorar la estrategia de almacenamiento de datos y su "gravedad"
Error: Los desarrolladores a menudo migran aplicaciones a la nube sin considerar dónde residen sus datos. O, por el contrario, colocan bases de datos on-premise y aplicaciones en la nube, lo que genera altos costes de tráfico de salida y latencia.
Cómo evitarlo:
- Analice la naturaleza de los datos: volumen, velocidad de cambio, sensibilidad, requisitos de latencia.
- Ubique las aplicaciones lo más cerca posible de los datos con los que trabajan intensivamente. Si los datos están on-premise, una parte de las aplicaciones que trabajan con ellos también debería estar on-premise.
- Utilice almacenamiento distribuido (Rook/Ceph, Longhorn) en bare metal y los controladores CSI de la nube correspondientes.
- Planifique una estrategia de replicación y copias de seguridad de datos entre entornos.
Consecuencias: Facturas de tráfico en la nube inesperadamente altas, bajo rendimiento de las aplicaciones debido a la latencia en el acceso a los datos, problemas de integridad de los datos si no hay una estrategia de replicación adecuada.
3. Ausencia de una estrategia unificada de IAM y RBAC
Error: La gestión de usuarios y sus derechos de acceso en cada clúster por separado, sin un sistema centralizado. Esto conduce al caos, problemas de seguridad y altos costes operativos.
Cómo evitarlo:
- Integre Rancher con LDAP/AD corporativo o un proveedor SSO para una autenticación centralizada.
- Utilice roles globales y de clúster en Rancher para una gestión de autorización unificada.
- Aplique el principio de mínimos privilegios para todos los usuarios y cuentas de servicio.
- Realice auditorías periódicas de los derechos de acceso.
Consecuencias: Acceso no autorizado, violación de la seguridad, dificultades de auditoría, altos costes de tiempo en la gestión de accesos.
4. Planificación inadecuada de la recuperación ante desastres (DR)
Error: Muchas empresas crean una infraestructura híbrida, pero no prueban sus planes de DR o ni siquiera los tienen. La esperanza de que "nada sucederá" conduce a consecuencias catastróficas en caso de un fallo real.
Cómo evitarlo:
- Defina RTO y RPO claros para cada servicio crítico.
- Desarrolle un plan de DR detallado que incluya procedimientos de copia de seguridad, restauración, conmutación por error (failover) a un clúster de respaldo y reversión (failback).
- Utilice herramientas como Velero para la copia de seguridad y restauración automatizadas de recursos y datos de Kubernetes.
- Realice simulacros de DR a gran escala regularmente (al menos una vez cada seis meses), simulando fallos reales.
Consecuencias: Tiempos de inactividad prolongados (horas o días), pérdida de datos críticos, daños significativos a la reputación y financieros.
5. Subestimación de la complejidad operativa y la necesidad de personal cualificado
Error: Creer que Rancher resolverá todos los problemas y que un Kubernetes híbrido puede ser gestionado por un solo junior. Una infraestructura híbrida, incluso con Rancher, requiere una experiencia significativa en diversas áreas (Kubernetes, redes, almacenamiento, tecnologías de la nube, seguridad).
Cómo evitarlo:
- Invierta en la formación del equipo. Asegúrese de tener especialistas con experiencia en Kubernetes, Rancher, así como en tecnologías de red y plataformas en la nube.
- Comience poco a poco, aumentando gradualmente la complejidad de la infraestructura y las competencias del equipo.
- Automatice las tareas rutinarias utilizando CI/CD y GitOps.
- Considere la posibilidad de utilizar experiencia externa o consultores en las etapas iniciales.
Consecuencias: Despliegue lento, incidentes frecuentes, baja eficiencia en el uso de recursos, agotamiento del equipo, altos costes de búsqueda y contratación de especialistas altamente cualificados.
6. Ausencia de monitorización y alertas para el entorno híbrido
Error: Desplegar clústeres en diferentes entornos, pero sin monitorización y registro centralizados. Esto conduce a "puntos ciegos" y a la incapacidad de reaccionar rápidamente ante los problemas.
Cómo evitarlo:
- Implemente un sistema unificado de monitorización (Prometheus/Grafana) y registro (ELK/Loki) para todos los clústeres, independientemente de su ubicación.
- Configure la agregación de métricas y registros en un almacenamiento centralizado para un análisis conveniente.
- Defina métricas clave de salud para cada componente y configure umbrales adecuados para las alertas.
- Asegúrese de que las alertas se entreguen a los canales correctos (Slack, PagerDuty, correo electrónico) y de que exista un plan de acción claro para ellas.
Consecuencias: Largas búsquedas de las causas de los incidentes, un enfoque reactivo en lugar de proactivo de la gestión, un MTTR (Tiempo Medio de Recuperación) alto.
Evitando estos errores comunes, aumentará significativamente las posibilidades de una implementación exitosa y eficiente de una infraestructura híbrida de Kubernetes con Rancher.
Checklist para aplicación práctica
Este checklist le ayudará a sistematizar el proceso de planificación e implementación de una infraestructura híbrida de Kubernetes con Rancher. Revise los puntos secuencialmente, asegurándose de que cada paso se haya completado o considerado.
- Definición de requisitos y planificación:
- [ ] Se han definido los objetivos de negocio y los beneficios esperados de la infraestructura híbrida.
- [ ] Se han identificado las aplicaciones críticas y sus requisitos de rendimiento, latencia y seguridad.
- [ ] Se han definido los requisitos de cumplimiento normativo (GDPR, HIPAA, Ley Federal 152, etc.).
- [ ] Se han analizado los volúmenes de datos actuales y previstos y su "gravedad".
- [ ] Se ha elaborado el presupuesto para CapEx (bare metal) y OpEx (nube, personal, licencias).
- [ ] Se ha formado el equipo y se han evaluado sus competencias, y se ha planificado la formación si es necesario.
- Selección de componentes y arquitectura:
- [ ] Se ha seleccionado el proveedor de nube principal (AWS, Azure, GCP) para los clústeres en la nube.
- [ ] Se han definido las especificaciones de los servidores bare metal (CPU, RAM, Almacenamiento, Red) para los clústeres on-premise.
- [ ] Se ha seleccionado la distribución de Kubernetes (RKE/K3s para bare metal, EKS/AKS/GKE para la nube).
- [ ] Se ha seleccionado el plugin CNI (Calico, Cilium) considerando el entorno híbrido.
- [ ] Se ha elegido la estrategia de almacenamiento de datos (Rook/Ceph, Longhorn on-prem; controladores CSI en la nube).
- [ ] Se ha definido la estrategia de balanceo de carga (MetalLB on-prem, ALB/NLB en la nube, Controladores Ingress).
- Diseño de la infraestructura de red:
- [ ] Se han asignado rangos de IP no superpuestos para todos los clústeres y conexiones interclúster.
- [ ] Se ha diseñado la conexión entre on-premise y la nube (VPN, Direct Connect/ExpressRoute).
- [ ] Se ha diseñado una estrategia DNS unificada con reenvío condicional.
- [ ] Se han configurado políticas de seguridad de red (Network Policies) para el aislamiento de pods.
- Despliegue de Rancher y clústeres:
- [ ] Se ha desplegado el servidor de gestión de Rancher (on-premise o en un clúster de nube dedicado).
- [ ] Se ha desplegado el primer clúster de Kubernetes bare metal (RKE/K3s) y se ha importado a Rancher.
- [ ] Se ha desplegado el primer clúster de Kubernetes en la nube (EKS/AKS/GKE) y se ha importado a Rancher.
- [ ] Se ha configurado la integración de Rancher con el proveedor de identidad (LDAP/AD, SSO).
- Configuración de seguridad e IAM:
- [ ] Se han configurado roles globales y RBAC en Rancher para la gestión de clústeres.
- [ ] Se ha configurado RBAC en cada clúster de Kubernetes para la gestión de recursos.
- [ ] Se ha implementado un mecanismo de gestión de secretos (Vault, External Secrets Operator).
- [ ] Se han configurado firewalls y grupos de seguridad para el aislamiento de clústeres y servicios.
- Implementación de CI/CD y GitOps:
- [ ] Se ha seleccionado la herramienta GitOps (ArgoCD, Flux) y se ha configurado su integración con el repositorio Git.
- [ ] Se han desarrollado Helm charts o configuraciones Kustomize para las aplicaciones.
- [ ] Se han configurado pipelines de CI/CD para la construcción de imágenes y su despliegue en el entorno híbrido.
- [ ] Se ha implementado Rancher Fleet para gestionar el despliegue de aplicaciones a escala (opcional).
- Monitorización, registro y alertas:
- [ ] Se han desplegado Prometheus y Grafana en cada clúster o de forma centralizada.
- [ ] Se ha configurado la recopilación y agregación de registros (Fluentd/Fluent Bit + ELK/Loki).
- [ ] Se han definido métricas clave de salud y se han configurado reglas de alerta.
- [ ] Se han configurado canales de entrega de alertas (Slack, PagerDuty, correo electrónico).
- Planificación y pruebas de recuperación ante desastres (DR):
- [ ] Se han definido RTO y RPO para todos los servicios críticos.
- [ ] Se ha implementado una herramienta para la copia de seguridad y restauración de recursos de Kubernetes y PV (Velero).
- [ ] Se ha desarrollado y documentado un plan de acción en caso de desastre.
- [ ] Se han realizado simulacros regulares de recuperación ante desastres.
- Optimización y gestión de costes:
- [ ] Se han implementado herramientas para la monitorización de los costes en la nube y el uso de recursos.
- [ ] Se han configurado políticas de escalado automático (Cluster Autoscaler, HPA) para un uso eficiente de los recursos en la nube.
- [ ] Se realiza un análisis periódico de los costes y se buscan oportunidades de optimización.
- Documentación y formación:
- [ ] Se ha creado una documentación completa sobre la arquitectura, configuración y procedimientos operativos.
- [ ] Se ha impartido formación al equipo sobre todos los aspectos de la nueva infraestructura.
- [ ] Se han desarrollado runbooks para operaciones estándar y resolución de problemas.
Siguiendo este checklist, podrá crear una infraestructura híbrida de Kubernetes con Rancher robusta, segura y eficiente, minimizando los riesgos y maximizando el retorno de la inversión.
Cálculo de costes / Economía
Comprender la economía de una infraestructura híbrida es fundamental para tomar decisiones estratégicas. Los cálculos pueden ser complejos, ya que incluyen tanto gastos de capital como operativos, así como costes ocultos. Examinaremos ejemplos de cálculos para diferentes escenarios en el contexto de 2026, teniendo en cuenta la inflación y las tendencias tecnológicas.
Componentes del coste
- CapEx (Gastos de capital) para Bare Metal:
- Servidores: Coste de los servidores físicos (CPU, RAM, discos). En 2026, servidores potentes con 2x CPU de 64 núcleos, 512GB de RAM, 8x NVMe SSD pueden costar entre $15,000 y $30,000 por unidad.
- Equipos de red: Switches, routers, cables. Desde $5,000 hasta $50,000 dependiendo de la escala.
- Almacenamiento: Si no se utiliza almacenamiento distribuido basado en discos locales, el almacenamiento externo puede costar entre $20,000 y $100,000+.
- Racks, PDUs, KVM: Gastos pequeños pero necesarios.
- OpEx (Gastos operativos) para Bare Metal:
- Colocación (Co-location): Tarifa por espacio en rack, electricidad, refrigeración, acceso a internet. En 2026, esto puede ser de $500 a $1,500 al mes por un rack con varios servidores.
- Personal: Salario de administradores de sistemas, ingenieros DevOps. Esta es una de las mayores partidas de gastos.
- Licencias/Soporte: Si se utilizan sistemas operativos comerciales, software o soporte empresarial de Rancher (Rancher Prime), Red Hat OpenShift.
- Mantenimiento: Reemplazo de componentes defectuosos, servicio de garantía.
- OpEx para la Nube:
- Recursos de cómputo (vCPU, RAM): Coste de las instancias (VM). En 2026, el coste de 1 vCPU/GB de RAM puede disminuir ligeramente, pero el coste total aumentará con la escala.
- Almacenamiento: EBS, Azure Disks, GCP Persistent Disks, almacenamiento tipo S3.
- Tráfico de red: Especialmente el de salida (tráfico saliente). Esta es una de las partidas de gastos ocultos más insidiosas.
- Servicios gestionados: Coste del Control Plane de EKS/AKS/GKE, bases de datos gestionadas, colas, balanceadores de carga.
- Reservas/Descuentos: Reserved Instances, Savings Plans pueden reducir significativamente el coste si la carga es predecible.
- Costes ocultos:
- Salida de datos (Data Egress): El coste de sacar datos de la nube puede ser muy alto ($0.05 - $0.15 por GB).
- Formación del personal: Inversiones en la mejora de las cualificaciones del equipo.
- Uso ineficiente de los recursos: Sobreaprovisionamiento o subutilización de los recursos.
- Tiempos de inactividad: Pérdida de beneficios, daño a la reputación.
- Seguridad: Costes de herramientas de seguridad, auditorías, respuesta a incidentes.
Ejemplos de cálculos para diferentes escenarios (previsión para 2026)
A modo de ejemplo, tomemos una empresa mediana que opera una carga equivalente a 10-15 servidores físicos modernos (por ejemplo, 200-300 vCPU, 1-2 TB de RAM, 20-30 TB de almacenamiento NVMe).
Escenario 1: Bare Metal puro (con Rancher)
La empresa invierte en su propio equipo, utilizando Rancher para simplificar la gestión de Kubernetes. Esta es la elección para el máximo control y rendimiento, donde el CapEx es alto, pero el OpEx es menor a largo plazo.
- CapEx (inversión inicial):
- 15 servidores (2x64c/512GB/8xNVMe): 15 * $25,000 = $375,000
- Equipos de red: $30,000
- Racks, PDUs: $10,000
- TOTAL CapEx: $415,000
- OpEx (mensual):
- Colocación (3 racks): 3 * $1,000 = $3,000
- Salario de 2 ingenieros DevOps (incluyendo gastos generales): 2 * $12,000 = $24,000
- Soporte Enterprise Rancher Prime (opcional, $10-20K/año): ~$1,500
- Mantenimiento/reemplazo: $1,000
- TOTAL OpEx: $29,500/mes
- TCO a 3 años: $415,000 (CapEx) + (36 * $29,500) (OpEx) = $415,000 + $1,062,000 = $1,477,000
Escenario 2: Nube Pura (EKS/AKS/GKE)
La empresa depende completamente de los servicios gestionados de Kubernetes en la nube. Alta flexibilidad, pero OpEx potencialmente altos a escala.
- CapEx: $0
- OpEx (mensual, sin RI/Savings Plans):
- 15 instancias (equivalente a 2x64c/512GB): 15 * $1,500 (por ejemplo, m6i.16xlarge) = $22,500
- Almacenamiento (30TB GP3): $1,500
- EKS Control Plane: $730
- Tráfico de red (salida, 10TB/mes): 10,000 * $0.08 = $800
- Otros servicios gestionados (DB, Load Balancer, Monitoring): $3,000
- Salario de 2 ingenieros DevOps (menos administración, más automatización): 2 * $11,000 = $22,000
- TOTAL OpEx: $50,530/mes
- TCO a 3 años: 36 * $50,530 = $1,819,080
- Con Reserved Instances/Savings Plans (30-50% de ahorro): $1,273,356 - $909,540
Escenario 3: Infraestructura Híbrida (con Rancher)
La empresa distribuye el 60% de la carga en bare metal (servicios estables y de alto consumo de recursos) y el 40% en la nube (elásticos y temporales). Todo se gestiona a través de Rancher.
- CapEx (inversión inicial para 60% bare metal):
- 9 servidores: 9 * $25,000 = $225,000
- Equipos de red: $20,000
- Racks, PDUs: $5,000
- TOTAL CapEx: $250,000
- OpEx (mensual):
- Colocación (2 racks): 2 * $1,000 = $2,000 (parte bare metal)
- Recursos en la nube (40% del escenario 2, con RI/SP): $50,530 * 0.4 * 0.7 = $14,148 (parte en la nube)
- Salario de 2 ingenieros DevOps (se requiere mayor cualificación): 2 * $13,000 = $26,000
- Soporte Enterprise Rancher Prime: ~$1,500
- Mantenimiento bare metal: $600
- Direct Connect/ExpressRoute (para conectividad): $1,000
- TOTAL OpEx: $45,248/mes
- TCO a 3 años: $250,000 (CapEx) + (36 * $45,248) (OpEx) = $250,000 + $1,628,928 = $1,878,928
- Nota: El TCO de un híbrido puede ser superior al de una nube pura con RI, pero ofrece más control, seguridad y flexibilidad. Además, el OpEx en un híbrido incluye el salario de ingenieros más cualificados. Si la parte de la nube es más dinámica y no utiliza RI, el híbrido será significativamente más barato.
Cómo optimizar los costes
- Resource Rightsizing: Analice regularmente el consumo de recursos de sus pods y nodos. Utilice VPA (Vertical Pod Autoscaler) y HPA (Horizontal Pod Autoscaler) para el escalado automático. No pague de más por recursos no utilizados.
- Reserved Instances / Savings Plans: Si tiene una carga base predecible en la nube, utilice estos mecanismos para un ahorro significativo (hasta el 70%).
- Spot Instances: Para cargas de trabajo no críticas e interrumpibles, utilice instancias Spot en la nube para un ahorro máximo (hasta el 90%).
- Optimización del tráfico de red: Minimice el tráfico de salida. Utilice CDN, almacenamiento en caché, compresión de datos. Ubique los datos cerca de las aplicaciones.
- Uso eficiente de Bare Metal: Utilice Kubernetes para maximizar la utilización de recursos en servidores físicos. Consolide las cargas de trabajo.
- Soluciones Open Source: Utilice al máximo las herramientas open-source gratuitas (Rancher, Prometheus, Grafana, Velero, Longhorn) para evitar pagos de licencias.
- Automatización: Invierta en automatización (GitOps, CI/CD) para reducir los costes laborales y minimizar los errores humanos.
Tabla con ejemplos de cálculos (TCO a 3 años)
| Escenario | CapEx inicial (Bare Metal) | OpEx mensual | TCO a 3 años | Principales ventajas |
|---|---|---|---|---|
| Bare Metal puro (con Rancher) | ~$415,000 | ~$29,500 | ~$1,477,000 | Alto rendimiento, control total, ahorro a largo plazo para cargas estables. |
| Nube Pura (EKS/AKS/GKE) | $0 | ~$50,530 (sin RI/SP) | ~$1,819,080 | Máxima elasticidad, inicio rápido, administración mínima de K8s. |
| (Nube con RI/SP) | $0 | ~$35,000 | ~$1,260,000 | Ahorro de OpEx con carga de nube predecible. |
| Híbrido (K8s con Rancher) | ~$250,000 | ~$45,248 | ~$1,878,928 | Equilibrio de control, rendimiento y elasticidad. Seguridad de datos, DR. |
Nota: Estos cálculos son estimaciones simplificadas. Las cifras reales pueden variar significativamente en función de los requisitos específicos, los descuentos, los precios regionales y la eficiencia operativa. La conclusión clave es que una estrategia híbrida no siempre es la más barata en términos de TCO, pero ofrece un equilibrio óptimo entre todos los factores críticos, lo que en última instancia puede proporcionar un mayor valor para el negocio.
Casos de estudio y ejemplos
La teoría es importante, pero los ejemplos reales de uso de infraestructura híbrida con Kubernetes y Rancher ofrecen la visión más completa de sus ventajas y desafíos. Examinemos algunos escenarios realistas de diversas industrias.
Caso 1: Startup Fintech con trading de alta frecuencia y analítica
Problema:
Una startup fintech joven y de rápido crecimiento desarrolló una plataforma innovadora para el trading de alta frecuencia (HFT) y el análisis predictivo. El componente HFT requería una latencia mínima (menos de 1 ms) para la ejecución de órdenes, así como un ancho de banda máximo para procesar datos de mercado. Al mismo tiempo, el bloque analítico, que procesaba enormes volúmenes de datos históricos y ejecutaba modelos de ML que consumían muchos recursos, tenía cargas pico impredecibles y requería elasticidad. Los requisitos regulatorios obligaban a almacenar todos los datos transaccionales dentro del país.
Solución con Rancher:
La empresa decidió crear una infraestructura híbrida basada en Kubernetes, gestionada por Rancher.
- Clúster on-premise (Bare Metal): Se desplegó un clúster de Kubernetes en servidores bare metal dedicados en su propio centro de datos. Este clúster se utilizó para aplicaciones HFT, bases de datos de transacciones y el almacenamiento primario de datos financieros sensibles. Se utilizó RKE (Rancher Kubernetes Engine) para el despliegue de K8s, MetalLB para el Load Balancer y Calico para el CNI. Para el almacenamiento de datos se eligió Rook/Ceph, que proporciona alto rendimiento y tolerancia a fallos.
- Clúster en la nube (AWS EKS): En AWS se desplegó un clúster EKS para servicios analíticos, entrenamientos de ML y APIs públicas. Este clúster utilizó Cluster Autoscaler para el escalado automático de nodos en función de la carga.
- Conectividad de red: Entre el centro de datos on-premise y AWS se configuró AWS Direct Connect para proporcionar una conexión de baja latencia y alta velocidad. Esto permitió a los servicios analíticos acceder de forma segura a los datos transaccionales con una latencia mínima, así como transferir datos agregados a la nube.
- Gestión con Rancher: Ambos clústeres fueron importados y gestionados a través de la interfaz unificada de Rancher. Esto permitió al equipo de DevOps unificar el despliegue (a través de GitOps con ArgoCD), la monitorización (Prometheus/Grafana) y la gestión de acceso (integración con SSO corporativo) para ambos entornos. Rancher Fleet se utilizó para el despliegue y la actualización centralizados de componentes base y aplicaciones en ambos clústeres.
Resultados:
- Optimización del rendimiento: Las aplicaciones HFT lograron la latencia requerida de <1 ms, proporcionando una ventaja competitiva.
- Elasticidad y ahorro: Las cargas analíticas se escalaron eficazmente en la nube, pagando solo por los recursos utilizados, lo que evitó inversiones excesivas en bare metal para los picos.
- Cumplimiento normativo: Los datos transaccionales sensibles permanecieron en servidores propios, cumpliendo plenamente con los requisitos locales de soberanía de datos.
- Gestión simplificada: Rancher redujo significativamente la carga operativa, proporcionando un único punto de control sobre un entorno híbrido complejo.
- DR mejorada: Las copias de seguridad de datos críticos de bare metal se replicaron en un almacenamiento compatible con S3 en AWS, proporcionando un plan de recuperación ante desastres fiable.
Caso 2: Gran institución médica con sistema EHR
Problema:
Una gran red de clínicas utilizaba un sistema monolítico obsoleto de registros médicos electrónicos (EHR) en servidores on-premise. El sistema era crítico, requería alta disponibilidad y cumplía con los estrictos requisitos de HIPAA y otros estándares médicos. La clínica también quería desarrollar nuevos servicios de acceso público (portal de pacientes, telemedicina) utilizando tecnologías modernas, pero no podía arriesgar la seguridad de los datos sensibles.
Solución con Rancher:
Se eligió una estrategia de modernización gradual y despliegue híbrido.
- Clúster on-premise (Bare Metal): Los servidores físicos existentes se modernizaron y se desplegó un clúster de Kubernetes (RKE) en ellos para alojar el sistema EHR y sus bases de datos asociadas. Esto garantizó el máximo control sobre los datos de los pacientes y el cumplimiento de HIPAA. Para la migración del monolito a contenedores se utilizaron técnicas de "lift-and-shift" y una descomposición gradual en microservicios.
- Clúster en la nube (Azure AKS): En Azure se desplegó un clúster AKS para nuevos servicios públicos (portal de pacientes, APIs de telemedicina, backends móviles). Estos servicios no almacenaban datos sensibles directamente, sino que accedían al sistema EHR a través de APIs seguras.
- Conectividad de red y seguridad: Entre el centro de datos on-premise y Azure se configuró Azure ExpressRoute para una conexión segura y de alto rendimiento. Se implementaron estrictas políticas de red y firewalls, así como OPA Gatekeeper para la aplicación de políticas de seguridad en Kubernetes.
- Gestión con Rancher: Rancher se utilizó para gestionar ambos clústeres. Esto permitió al equipo de TI aplicar políticas RBAC unificadas, gestionar el ciclo de vida de los clústeres y desplegar aplicaciones utilizando GitOps. Se prestó especial atención a la monitorización (Prometheus/Grafana) y la auditoría (Fluentd/Loki) para garantizar el cumplimiento normativo.
Resultados:
- Cumplimiento y seguridad: Los datos sensibles de los pacientes permanecieron bajo control total on-premise, garantizando el cumplimiento de HIPAA. Los servicios públicos se aislaron en la nube.
- Modernización: La clínica pudo modernizar su sistema EHR obsoleto, migrándolo gradualmente a una arquitectura de microservicios sin interrumpir el funcionamiento de los servicios críticos.
- Innovación: Se obtuvo la capacidad de desplegar rápidamente nuevos servicios para pacientes en la nube, utilizando tecnologías modernas y flexibilidad.
- Alta disponibilidad: El clúster on-premise se configuró con redundancia, y el clúster en la nube proporcionó DR para los servicios públicos.
Caso 3: Proveedor de SaaS con el objetivo de optimizar costes
Problema:
Un proveedor de SaaS mediano, que ofrecía soluciones B2B, operaba completamente en AWS con EKS. A medida que crecía la base de clientes y aumentaban los volúmenes de datos, las facturas mensuales por recursos en la nube (especialmente por bases de datos, almacenamiento y tráfico de salida) crecían exponencialmente, amenazando la rentabilidad del negocio. También se observaron problemas de rendimiento para algunos informes analíticos que consumían muchos recursos.
Solución con Rancher:
La empresa decidió migrar parte de sus cargas de trabajo a bare metal, creando una infraestructura híbrida.
- Clúster on-premise (Bare Metal): La empresa alquiló varios racks en un centro de co-location y desplegó un clúster de Kubernetes (RKE) en servidores bare metal. Aquí se migraron las bases de datos principales (PostgreSQL, ClickHouse), así como los servicios que generaban grandes volúmenes de datos y requerían alto rendimiento para el análisis. Se eligió Longhorn para el almacenamiento.
- Clúster en la nube (AWS EKS): En AWS se mantuvo un clúster EKS, donde se alojaron las aplicaciones frontend, las pasarelas API, los microservicios que tenían una carga muy fluctuante y requerían una rápida escalabilidad.
- Conectividad de red: Se configuró AWS Direct Connect entre el centro de co-location y AWS para proporcionar una conexión rápida y económica entre los microservicios en la nube y las bases de datos on-premise.
- Gestión con Rancher: Rancher se desplegó como un nodo de gestión central en un clúster separado y pequeño en AWS. Se utilizó para la gestión unificada de ambos clústeres, el despliegue de aplicaciones a través de GitOps (ArgoCD) y la monitorización centralizada.
Resultados:
- Ahorro significativo: La migración de bases de datos y backends de alta carga a bare metal redujo los OpEx mensuales en un 35-40%, especialmente al reducir los costes de bases de datos en la nube y el tráfico de salida.
- Rendimiento mejorado: Los informes analíticos se generaron más rápido gracias al acceso directo a potentes equipos bare metal.
- Mantenimiento de la flexibilidad: Los frontends y las pasarelas API continuaron escalando en la nube, garantizando alta disponibilidad y capacidad de respuesta para los usuarios.
- Reducción del Vendor Lock-in: La empresa obtuvo la capacidad de utilizar diferentes proveedores de la nube en el futuro y no depender completamente de AWS.
Estos casos demuestran que una infraestructura híbrida con Kubernetes y Rancher es una herramienta potente para resolver una amplia gama de problemas de negocio, desde la optimización del rendimiento y el cumplimiento normativo hasta un ahorro significativo de costes y una mayor flexibilidad.
Herramientas y recursos
Para construir y gestionar con éxito una infraestructura híbrida de Kubernetes con Rancher, se requiere un conjunto de herramientas probadas y acceso a recursos actualizados. A continuación, se presenta una lista de categorías clave y ejemplos específicos, relevantes para 2026.
1. Plataformas principales
- Rancher: Sitio web oficial
Plataforma central para gestionar múltiples clústeres de Kubernetes desplegados en cualquier lugar: en bare metal, en máquinas virtuales, en nubes privadas y públicas. Proporciona una UI, API y CLI unificadas para gestionar el ciclo de vida de los clústeres, el despliegue de aplicaciones y la seguridad.
- Kubernetes (K8s): Sitio web oficial
Plataforma de código abierto para la automatización del despliegue, escalado y gestión de aplicaciones en contenedores. La base de toda la estrategia híbrida.
- RKE (Rancher Kubernetes Engine): Documentación oficial
Distribución certificada de Kubernetes de Rancher, ideal para el despliegue en bare metal y máquinas virtuales, así como para escenarios edge.
- K3s: Sitio web oficial
Kubernetes ligero y certificado, optimizado para entornos edge, IoT y bare metal con recursos limitados. Gestionado por Rancher.
- Servicios K8s en la nube:
- Amazon EKS: Sitio web oficial
- Azure AKS: Sitio web oficial
- Google GKE: Sitio web oficial
Servicios gestionados de Kubernetes de los principales proveedores de la nube.
2. Herramientas de red (CNI, Balanceador de carga, Conectividad)
- Calico: Sitio web oficial
Un popular plugin CNI para Kubernetes, que proporciona conectividad de red, políticas de seguridad y soporte BGP, lo que lo convierte en una excelente opción para entornos híbridos y bare metal.
- Cilium: Sitio web oficial
Otro CNI avanzado basado en eBPF, que ofrece alto rendimiento, políticas de red avanzadas y observabilidad.
- MetalLB: Sitio web oficial
Implementación de un balanceador de carga para clústeres de Kubernetes bare metal, que utiliza protocolos de enrutamiento estándar (ARP, BGP).
- Controladores Ingress (NGINX, Traefik, Istio Ingress Gateway):
- NGINX Ingress Controller: GitHub oficial
- Traefik: Sitio web oficial
- Istio: Sitio web oficial (como parte de una malla de servicios)
Para el enrutamiento del tráfico HTTP/S externo a los servicios dentro del clúster.
- Herramientas para la interconexión de red:
- OpenVPN / WireGuard: Para crear túneles seguros entre on-premise y la nube.
- AWS Direct Connect / Azure ExpressRoute / Google Cloud Interconnect: Conexiones de red dedicadas para alto rendimiento y seguridad.
3. Sistemas de almacenamiento de datos (CSI)
- Rook (Ceph): Sitio web oficial
Operador de Kubernetes que despliega y gestiona el almacenamiento distribuido Ceph, transformando un clúster de Kubernetes en un sistema de almacenamiento autoescalable y autorreparable (bloque, archivo, objeto).
- Longhorn: Sitio web oficial
Almacenamiento en bloque distribuido para Kubernetes de Rancher, fácil de desplegar y gestionar, ideal para bare metal y edge.
- Controladores CSI en la nube:
Controladores para integrar Kubernetes con el almacenamiento nativo de la nube.
4. CI/CD y GitOps
- ArgoCD: Sitio web oficial
Herramienta de entrega continua declarativa y orientada a GitOps para Kubernetes. Excelente para gestionar despliegues en entornos multiclúster.
- Flux: Sitio web oficial
Otro popular operador GitOps que proporciona entrega continua y sincronización del estado del clúster con un repositorio Git.
- Rancher Fleet: Sitio web oficial
Herramienta para la gestión centralizada de una flota de miles de clústeres de Kubernetes, el despliegue de aplicaciones y la gestión de configuraciones a escala.
- Jenkins / GitLab CI / GitHub Actions:
Herramientas de CI tradicionales para construir imágenes, ejecutar pruebas y lanzar pipelines de GitOps.
5. Monitorización, registro y alertas
- Prometheus: Sitio web oficial
Sistema de monitorización y alertas de código abierto, el estándar de facto para la monitorización de Kubernetes.
- Grafana: Sitio web oficial
Plataforma para la visualización de métricas agregadas por Prometheus, así como registros de Loki.
- Loki: Sitio web oficial
Sistema de agregación de registros, optimizado para Kubernetes, funciona según el principio de "métricas para registros".
- ELK Stack (Elasticsearch, Logstash, Kibana): Sitio web oficial
Potente stack para la recopilación, análisis y visualización de registros a escala.
- Fluentd / Fluent Bit: Sitio web oficial / Sitio web oficial
Agentes ligeros para recopilar registros de contenedores y enviarlos a un almacenamiento centralizado.
6. Seguridad y gestión de secretos
- Vault (HashiCorp): Sitio web oficial
Herramienta para el almacenamiento y la gestión seguros de secretos, claves API, tokens y otros datos confidenciales.
- OPA Gatekeeper:
¿Te fue útil esta guía?