Как эффективно управлять ресурсами виртуальных машин: оптимизация производительности
Виртуальные машины (ВМ) стали неотъемлемой частью современной IT-инфраструктуры, обеспечивая гибкость, масштабируемость и экономию ресурсов. Однако, чтобы максимально использовать их потенциал, необходимо тщательно управлять выделенными им ресурсами. В этой статье мы рассмотрим ключевые аспекты управления ресурсами виртуальных машин, с акцентом на мониторинг, оптимизацию и эффективное распределение ресурсов, чтобы обеспечить стабильную и производительную работу ваших приложений и сервисов.
Содержание
- Мониторинг производительности виртуальных машин
- Управление ресурсами CPU виртуальных машин
- Оптимизация использования памяти в виртуальных машинах
- Управление дисковым пространством и I/O в виртуальных машинах
- Оптимизация сетевых ресурсов для виртуальных машин
Мониторинг производительности виртуальных машин
Эффективное управление ресурсами начинается с непрерывного мониторинга производительности виртуальных машин. Мониторинг позволяет выявлять узкие места, прогнозировать потребности в ресурсах и оперативно реагировать на возникающие проблемы. Существует множество инструментов и методов мониторинга, как встроенных в платформы виртуализации, так и сторонних.
Инструменты мониторинга виртуальных машин
Существует широкий спектр инструментов для мониторинга виртуальных машин, каждый из которых обладает своими преимуществами и недостатками. Выбор инструмента зависит от используемой платформы виртуализации, размера инфраструктуры и требований к детализации данных.
- Встроенные инструменты виртуализации: VMware vCenter, Microsoft Hyper-V Manager, Citrix Hypervisor (XenServer) Center предоставляют базовый функционал мониторинга, включая графики загрузки CPU, использования памяти, дискового пространства и сетевой активности.
- Системы мониторинга серверов: Zabbix, Nagios, Prometheus, Grafana позволяют собирать и анализировать данные с виртуальных машин, а также устанавливать пороговые значения и получать уведомления о превышении этих значений.
- Облачные сервисы мониторинга: AWS CloudWatch, Azure Monitor, Google Cloud Monitoring предоставляют инструменты для мониторинга виртуальных машин, работающих в облаке, а также интеграцию с другими облачными сервисами.
Ключевые метрики для мониторинга
Для эффективного мониторинга необходимо отслеживать ключевые метрики, характеризующие производительность виртуальной машины. Вот некоторые из наиболее важных метрик:
- Загрузка CPU (%): Показывает, насколько загружен процессор виртуальной машины. Высокая загрузка может указывать на нехватку процессорных ресурсов.
- Использование памяти (%): Показывает, сколько памяти использует виртуальная машина. Нехватка памяти может привести к замедлению работы и использованию swap-файла, что существенно снижает производительность.
- Дисковый I/O (операции чтения/записи в секунду): Показывает интенсивность операций чтения и записи на диск. Высокие значения могут указывать на проблемы с производительностью дисковой подсистемы.
- Сетевая активность (пропускная способность, пакетная потеря): Показывает объем трафика, передаваемого и принимаемого виртуальной машиной. Высокая сетевая активность или потеря пакетов могут указывать на проблемы с сетевой инфраструктурой.
- Время отклика приложений: Показывает, сколько времени требуется приложению для обработки запроса. Этот показатель является важным индикатором производительности приложения и может быть использован для выявления проблем, связанных с ресурсами.
Пример 1: Мониторинг CPU с помощью `top` в Linux.
Команда top отображает динамическую информацию о процессах, работающих в системе, включая использование CPU. Вы можете использовать эту команду для мониторинга загрузки CPU виртуальной машины и выявления процессов, которые потребляют больше всего процессорных ресурсов.
top -n 1Вывод команды покажет общий процент использования CPU (%Cpu(s):), а также использование CPU для каждого процесса в системе. Обратите внимание на процессы, которые имеют высокие значения %CPU.
Пример 2: Мониторинг использования памяти с помощью `free -m` в Linux.
Команда free -m отображает информацию об использовании памяти в системе в мегабайтах. Вы можете использовать эту команду для мониторинга общего объема памяти, используемой памяти и доступной памяти в виртуальной машине.
free -mВывод команды покажет общий объем памяти (total), используемую память (used), свободную память (free), общую разделяемую память (shared), буферы (buff/cache) и доступную память (available).
Пример 3: Использование PowerShell для мониторинга CPU в Hyper-V.
Get-VM | Get-VMResourceMetrics | Select-Object VMName, CpuUsageAverage, MemoryDemand, MemoryAssignedЭта команда PowerShell позволяет получить информацию о загрузке CPU, необходимой памяти и выделенной памяти для всех виртуальных машин, работающих на хосте Hyper-V.
Управление ресурсами CPU виртуальных машин
Управление ресурсами CPU является критически важным для обеспечения производительности виртуальных машин. Неправильное выделение процессорных ресурсов может привести к нехватке ресурсов для одних ВМ и избыточному выделению для других, что негативно сказывается на общей производительности системы.
Методы выделения CPU виртуальным машинам
Существует несколько основных методов выделения CPU виртуальным машинам:
- Выделенное ядро: Виртуальной машине выделяется целое физическое ядро процессора. Этот метод обеспечивает максимальную производительность, но неэффективен, если ВМ не использует ядро на 100%.
- Доли CPU (CPU shares): Виртуальным машинам выделяются доли процессорного времени относительно друг друга. Например, если одной ВМ выделено 2000 долей, а другой 1000, то первая ВМ получит в два раза больше процессорного времени, если обе ВМ будут конкурировать за ресурсы.
- Ограничение использования CPU (CPU limits): Устанавливается максимальный процент использования CPU для виртуальной машины. Этот метод позволяет предотвратить ситуацию, когда одна ВМ занимает все процессорные ресурсы и мешает работе других ВМ.
Практические советы по управлению CPU
- Определите потребности каждой ВМ: Проанализируйте загрузку CPU каждой ВМ и определите, сколько процессорных ресурсов ей действительно необходимо.
- Используйте CPU shares для приоритезации: Выделите больше долей CPU для критически важных ВМ, чтобы обеспечить их высокую производительность.
- Ограничьте использование CPU для менее важных ВМ: Установите ограничения на использование CPU для ВМ, которые не требуют высокой производительности, чтобы они не мешали работе более важных ВМ.
- Настройте CPU affinity: Назначьте виртуальные машины на определенные физические ядра, чтобы минимизировать переключение контекста и повысить производительность.
Пример 1: Настройка CPU shares в VMware vSphere.
В vSphere вы можете настроить CPU shares для каждой виртуальной машины в настройках «Resource Allocation». Вы можете выбрать один из трех уровней shares: Low, Normal, High, или указать пользовательское значение. Чем выше значение shares, тем больше процессорного времени получит виртуальная машина при конкуренции за ресурсы.
Пример 2: Ограничение использования CPU в Hyper-V.
Вы можете ограничить использование CPU виртуальной машины в Hyper-V с помощью PowerShell:
Set-VMProcessor -VMName "MyVM" -MaximumPercent 50Эта команда ограничивает использование CPU виртуальной машины «MyVM» до 50% от общего количества процессорных ресурсов.
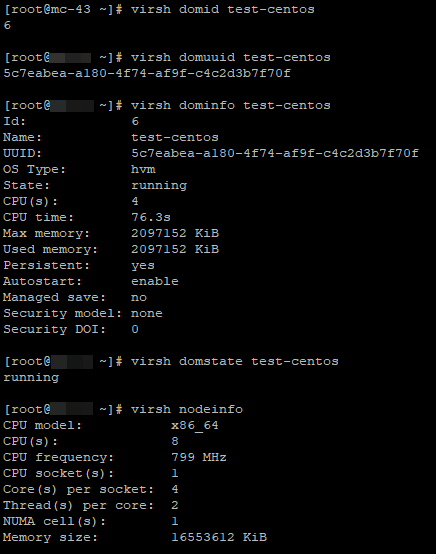
Пример 3: Настройка CPU affinity в KVM.
Вы можете настроить CPU affinity для виртуальной машины KVM с помощью команды virsh vcpupin:
virsh vcpupin MyVM 0 1Эта команда закрепляет виртуальный CPU 0 виртуальной машины «MyVM» за физическим CPU 1.
Экспертный совет:
Не перегружайте хост виртуализации слишком большим количеством виртуальных машин. Оптимальное количество виртуальных машин на хосте зависит от мощности процессора, объема памяти и дисковой подсистемы, а также от потребностей каждой ВМ. Регулярно анализируйте загрузку хоста и принимайте меры по перераспределению ВМ, если это необходимо.
Оптимизация использования памяти в виртуальных машинах
Эффективное управление памятью является важным аспектом оптимизации производительности виртуальных машин. Недостаток памяти может привести к swap-файлу, что значительно замедляет работу ВМ. Избыточное выделение памяти, напротив, приводит к неэффективному использованию ресурсов хоста виртуализации.
Техники оптимизации памяти
- Ballooning: Технология, позволяющая гипервизору забирать память у виртуальных машин, если она необходима другим ВМ или хосту. Ballooning использует специальный драйвер внутри ВМ, который выделяет и освобождает память по запросу гипервизора.
- Deduplication: Технология, позволяющая удалять дублирующиеся блоки памяти, что позволяет экономить дисковое пространство и уменьшить использование памяти.
- Page sharing: Технология, позволяющая виртуальным машинам совместно использовать одинаковые страницы памяти, что также позволяет экономить память.
- Memory Overcommitment: Выделение виртуальным машинам больше памяти, чем доступно на хосте. Эта техника позволяет повысить плотность виртуальных машин на хосте, но может привести к проблемам с производительностью, если все ВМ одновременно начнут использовать всю выделенную им память.
Практические советы по оптимизации памяти
- Определите оптимальный объем памяти для каждой ВМ: Не выделяйте ВМ больше памяти, чем ей действительно необходимо. Используйте инструменты мониторинга для определения оптимального объема памяти.
- Используйте ballooning для динамического управления памятью: Ballooning позволяет гипервизору динамически перераспределять память между ВМ, обеспечивая оптимальное использование ресурсов.
- Включите deduplication и page sharing: Эти технологии позволяют экономить память за счет удаления дублирующихся блоков памяти.
- Будьте осторожны с memory overcommitment: Memory overcommitment может быть полезен для повышения плотности виртуальных машин, но может привести к проблемам с производительностью, если все ВМ одновременно начнут использовать всю выделенную им память. Тщательно мониторьте использование памяти и избегайте чрезмерного overcommitment.
Пример 1: Настройка ballooning в VMware vSphere.
Ballooning включен по умолчанию в VMware vSphere. Убедитесь, что VMware Tools установлены внутри виртуальной машины, чтобы ballooning работал корректно.
Пример 2: Мониторинг использования swap-файла в Linux.
Вы можете мониторить использование swap-файла в Linux с помощью команды vmstat:
vmstat 1 5Эта команда отображает информацию о использовании памяти и swap-файла каждые 1 секунду в течение 5 секунд. Обратите внимание на столбцы «si» (swap in) и «so» (swap out). Высокие значения в этих столбцах указывают на то, что виртуальная машина активно использует swap-файл, что может привести к замедлению работы.
Пример 3: Определение потребления памяти отдельным процессом в Linux.
Используйте top или ps для нахождения PID процесса, а затем pmap:
pmap -p PIDЗамените PID на ID нужного процесса. Эта команда покажет карту памяти процесса, включая использованную память.
Внешняя ссылка:
Подробнее о ballooning можно прочитать в документации VMware: VMware Documentation (Найти раздел про memory management).
Управление дисковым пространством и I/O в виртуальных машинах
Эффективное управление дисковым пространством и I/O является критически важным для обеспечения производительности виртуальных машин. Медленная дисковая подсистема может стать узким местом и замедлить работу всех ВМ, использующих эту подсистему. Недостаток дискового пространства может привести к невозможности запуска ВМ или потере данных.
Типы дисковых систем
- Локальный диск: Виртуальная машина использует дисковое пространство, расположенное непосредственно на хосте виртуализации. Этот метод прост в настройке, но не обеспечивает высокой доступности и масштабируемости.
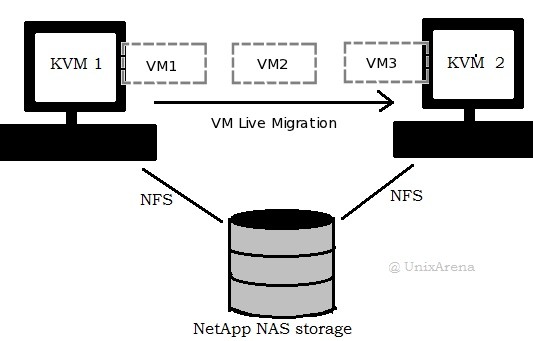
- NAS (Network Attached Storage): Виртуальная машина использует дисковое пространство, расположенное на сетевом хранилище NAS. NAS обеспечивает более высокую доступность и масштабируемость, чем локальный диск, но может быть медленнее из-за сетевой задержки.
- SAN (Storage Area Network): Виртуальная машина использует дисковое пространство, расположенное на сети хранения данных SAN. SAN обеспечивает высокую производительность, доступность и масштабируемость, но является более сложной и дорогой в настройке, чем NAS.
Практические советы по управлению дисковым пространством и I/O
- Используйте быстрые диски: Для виртуальных машин, требующих высокой производительности дисковой подсистемы, используйте быстрые диски, такие как SSD.
- Разделите дисковую подсистему: Разделите дисковую подсистему на несколько томов, чтобы уменьшить конкуренцию за ресурсы. Например, можно выделить отдельный том для операционной системы, приложений и данных.
- Используйте правильный тип дисков для каждой ВМ: Для ВМ, которые не требуют высокой производительности, можно использовать более медленные и дешевые диски, такие как HDD.
- Мониторьте дисковый I/O: Регулярно мониторьте дисковый I/O каждой ВМ и выявляйте ВМ, которые испытывают проблемы с производительностью дисковой подсистемы.
- Используйте thin provisioning: Thin provisioning позволяет выделять виртуальным дискам больше дискового пространства, чем они фактически используют. Это позволяет экономить дисковое пространство, но может привести к проблемам, если все ВМ одновременно начнут использовать все выделенное им дисковое пространство.
Пример 1: Мониторинг дискового I/O с помощью `iostat` в Linux.
Команда iostat отображает информацию об использовании дисковой подсистемы. Вы можете использовать эту команду для мониторинга количества операций чтения и записи, пропускной способности и времени отклика дисков.
iostat -x 1 5Эта команда отображает расширенную статистику I/O каждые 1 секунду в течение 5 секунд. Обратите внимание на столбцы «rrqm/s» (количество запросов чтения, объединенных в секунду), «wrqm/s» (количество запросов записи, объединенных в секунду), «r/s» (количество операций чтения в секунду), «w/s» (количество операций записи в секунду), «rsec/s» (количество секторов, прочитанных в секунду), «wsec/s» (количество секторов, записанных в секунду), «await» (среднее время ожидания запроса I/O) и «%util» (процент времени, в течение которого диск был занят обработкой запросов I/O).
Пример 2: Мониторинг дискового пространства с помощью `df -h` в Linux.
Команда df -h отображает информацию об использовании дискового пространства в удобочитаемом формате.
df -hВывод команды покажет общий объем дискового пространства (Size), используемое дисковое пространство (Used), доступное дисковое пространство (Avail) и процент использования дискового пространства (Use%) для каждого раздела.
Пример 3: Thin provisioning в VMware vSphere.
При создании виртуального диска в vSphere вы можете выбрать тип выделения дискового пространства: Thick Provision Eager Zeroed, Thick Provision Lazy Zeroed или Thin Provision. Выберите Thin Provision, чтобы создать тонкий диск.
Оптимизация сетевых ресурсов для виртуальных машин
Оптимизация сетевых ресурсов является важным аспектом управления виртуальными машинами, особенно в средах с высокой сетевой нагрузкой. Неправильная настройка сетевых параметров может привести к задержкам, потере пакетов и снижению производительности приложений.
Ключевые факторы оптимизации сетевых ресурсов
- Выбор правильного типа виртуального коммутатора: Существуют различные типы виртуальных коммутаторов, такие как стандартные виртуальные коммутаторы, распределенные виртуальные коммутаторы и Open vSwitch. Каждый тип имеет свои преимущества и недостатки, и выбор зависит от требований к производительности, безопасности и масштабируемости.
- Использование VLAN: VLAN позволяют сегментировать сеть и изолировать трафик между различными виртуальными машинами. Это повышает безопасность и улучшает производительность сети.
- QoS (Quality of Service): QoS позволяет приоритизировать сетевой трафик для критически важных приложений. Это гарантирует, что важные приложения получат достаточную полосу пропускания, даже при высокой сетевой нагрузке.
- Offload-технологии: Использование аппаратных offload-технологий, таких как TCP Segmentation Offload (TSO) и Large Receive Offload (LRO), позволяет разгрузить процессор хоста виртуализации и повысить производительность сети.
Практические советы по оптимизации сетевых ресурсов
- Мониторьте сетевую активность: Регулярно мониторьте сетевую активность виртуальных машин и выявляйте ВМ, которые потребляют больше всего сетевых ресурсов.
- Используйте jumbo frames: Jumbo frames позволяют увеличить размер пакета, что снижает нагрузку на процессор и повышает пропускную способность сети.
- Настройте сетевой bonding: Сетевой bonding позволяет объединить несколько сетевых интерфейсов в один логический интерфейс, что повышает доступность и пропускную способность сети.
- Используйте SR-IOV (Single Root I/O Virtualization): SR-IOV позволяет виртуальным машинам напрямую обращаться к сетевой карте, минуя виртуальный коммутатор. Это значительно повышает производительность сети, но требует поддержки со стороны сетевой карты и хоста виртуализации.
Пример 1: Мониторинг сетевой активности с помощью `iftop` в Linux.
Команда iftop отображает информацию о сетевой активности в режиме реального времени. Вы можете использовать эту команду для мониторинга пропускной способности сети, используемой каждой виртуальной машиной.
iftop -i eth0Эта команда отображает сетевую активность на интерфейсе eth0. Обратите внимание на IP-адреса и пропускную способность, используемую каждой ВМ.
Пример 2: Настройка VLAN в VMware vSphere.
Вы можете настроить VLAN для виртуальной машины в vSphere в настройках «Port Group». Укажите VLAN ID для порта группы, чтобы назначить виртуальную машину в VLAN.
Пример 3: Использование `ethtool` для просмотра настроек сетевой карты и включения jumbo frames в Linux.
Сначала просмотрите текущие настройки:
ethtool eth0Затем, если поддерживается, включите jumbo frames (MTU 9000):
ip link set mtu 9000 dev eth0Важно: Убедитесь, что всё сетевое оборудование поддерживает jumbo frames, прежде чем включать их.