Привет, коллега! Замучился бороться с медленным VPS хостинг и загадочными ошибками? Устал тратить часы на поиск узких мест? Тогда ты попал по адресу! В этой статье мы разберем, как эффективно мониторить ресурсы твоего виртуального сервера, избегая головной боли и нервотрепки. Поверь мне, я сам прошел через это… много раз. Здесь ты найдешь практические советы, реальные команды, и даже немного юмора (потому что без него никак!). Готовься, будет жарко!
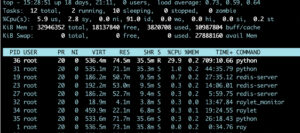
CPU – сердце твоего VPS. Если оно барахлит, всё остальное работает с трудом. Вот несколько способов проверить загрузку процессора. Проще всего – использовать команду top. Запусти её в терминале, и ты увидишь реальную картину в динамике. Круто, правда?
top
Обрати внимание на столбец «%CPU». Если значение постоянно держится на уровне 90% и выше, пора бить тревогу! Ты явно перегрузил сервер. Чтобы понять, какой процесс жрет ресурсы, используй htop – это более удобная интерактивная версия top. Там можно даже процессы убивать прям из интерфейса!
sudo apt update && sudo apt install htop
htop
Ещё один полезный инструмент – mpstat. Он предоставляет более подробную статистику по каждому ядру процессора. Это особенно важно, если у тебя многоядерный VPS.
sudo apt install sysstat
sudo mpstat -P ALL 1 5
(Команда выведет статистику за 5 секунд с интервалом в 1 секунду для всех процессорных ядер). Если видишь, что какое-то ядро постоянно загружено на 100%, значит, там есть какой-то ресурсоемкий процесс, который нужно оптимизировать или, в крайнем случае, прибить.
Pro tip: Не забывай про iostat для мониторинга дисковой подсистемы, она тоже может сильно влиять на производительность процессора!
Мониторинг памяти (RAM)
RAM – это оперативная память, и её нехватка – это как бесконечная загрузка в браузере. Бесконечно долгая и мучительно раздражающая. Для мониторинга RAM используй команду free -h. Она покажет тебе общее количество памяти, сколько занято, сколько свободно, и сколько используется под кэш.
free -h
Обращай внимание на `used` и `cache`. Если `used` близка к `total`, то памяти мало. Если `cache` очень велика, то система эффективно использует кэш, и это нормально. Но если `used` + `cache` близки к `total`, то мало свободной памяти.
Для более подробного анализа можно использовать top или htop – они тоже показывают использование памяти процессами. Иногда приходится искать утечки памяти в приложениях – это может быть очень больно, знаю по собственному опыту…
Еще одна полезная команда — vmstat. Она показывает статистику по виртуальной памяти, свопингу и другим параметрам, помогая выявить проблемы с памятью, связанные со свопингом (когда система начинает использовать жесткий диск как оперативную память — очень медленно!).
vmstat 1 5
(Выводит статистику 5 раз с интервалом в 1 секунду). Обращайте внимание на столбцы si (swap in) и so (swap out). Высокие значения говорят о проблемах со свопингом.
Мониторинг дискового пространства
Заполненный диск – это катастрофа. Сервер может внезапно перестать работать, и ты будешь сидеть и кусать локти. Поэтому регулярный мониторинг – это must have. Самая простая команда – df -h. Она покажет тебе использование дискового пространства на всех разделах.
df -h
Если видишь, что какой-то раздел почти полон, немедленно найди виновника! Это могут быть логи, временные файлы, или что-то ещё. Команда du -sh * в нужной директории поможет определить, что занимает больше всего места.
du -sh *
А вот и мой любимый трюк: ncdu – интерактивный инструмент для визуализации использования дискового пространства. Он показывает иерархическую структуру директорий и помогает быстро найти «большие» файлы и папки. Установи его – не пожалеешь!
sudo apt install ncdu
ncdu
Не забывай про регулярное очищение логов! logrotate – твой друг. Настройте его правильно – и проблем с заполнением диска будет меньше.
Мониторинг сетевого трафика
Сетевой трафик – это кровь твоего сервера. Если он забит, всё работает медленно. Для мониторинга используй iftop. Это крутая интерактивная программа, которая показывает в реальном времени, кто и сколько трафика пересылает.
sudo apt install iftop
sudo iftop
Эта команда показывает активность сетевых интерфейсов. Если замечаешь подозрительную активность или большой объем трафика от неизвестных источников, это повод насторожиться. Возможно, есть DDoS-атака или вредоносная программа.
Для более глубокого анализа можно использовать tcpdump, но с ним нужно обращаться осторожно, иначе можно заполнить диск логамаи нужно разбираться в пакетах. Он позволяет захватывать и анализировать сетевой трафик на низком уровне.
sudo tcpdump -i eth0 -nn -s 0 -w traffic.pcap
(Запись трафика на интерфейсе eth0 в файл traffic.pcap. Замените eth0 на имя вашего интерфейса.)
ss – ещё одна полезная команда. Она показывает состояние сетевых соединений. Можно увидеть, какие порты используются и кто с кем связывается. Это пригодится при диагностике проблем с сетью и обнаружении подозрительных подключений.
ss -tulnp
Использование специализированных инструментов
Вручную мониторить всё – это утомительно и неэффективно. Есть куча крутых инструментов, которые делают это за тебя! Например, Zabbix, Nagios, Prometheus, Grafana. Они позволяют строить красивые графики, настраивать сигналы оповещения, и в целом упрощают жизнь.
Например, Grafana – это дашборд для визуализации данных. Она работает с разными источниками данных, включая Prometheus. Этот стек *просто огонь*! Ты можешь создавать кастомные дашборды, отслеживающие все важные метрики твоего VPS.
Установка и настройка таких инструментов может потребовать определенных знаний и времени, но поверьте, это того стоит. Однажды потратив время на настройку, вы сэкономите его в десятки раз в будущем.
Реактивное мониторинг – это не тот подход. Проактивный – вот что нужно! Настройте сигналы оповещения – и вы будете знать о проблемах сразу, а не когда уже поздно. Это может быть email, SMS, или Telegram.
Большинство инструментов мониторинга (Zabbix, Nagios, и т.д.) позволяют настраивать условия оповещения. Например, можно настроить уведомление, если загрузка CPU превысит 80%, или если дисковое пространство опустится ниже 10%.
Вот пример конфигурации уведомлений через email (это зависит от конкретного инструмента). В этом примере мы предположим, что вы используете `monit`:
set mailserver localhost
set mailfrom monit@example.com
set auth-method simple
set smtp-port 25
set smtp-username my_user
set smtp-password my_password
Remember to replace `localhost`, `monit@example.com`, `my_user`, and `my_password` with your actual mail server settings. Yeah, this part always trips people up, trust me on this one…
Проверяйте настройки регулярно! Ничего не работает без тестирования. Запустите тестовое оповещение, чтобы убедиться, что все работает как задумано. Boom! That’s it!
В заключение скажу: мониторинг VPS – это не разовая процедура, а непрерывный процесс. Регулярно проверяйте ресурсы, настраивайте сигналы оповещения, и ваш сервер будет работать стабильно и надежно. No cap!